一、MIND[2019](用于召回)
天猫是中国最大的
Business-To-Customer: B2C电商平台,它在线提供十亿规模的商品,服务于十亿规模的用户。2018年11月11日,著名的天猫全球购物节,商品交易总额Gross Merchandise Volume: GMV大约为2130亿元,较2017年同期增长26.9%。随着用户和商品的不断增长,帮助每个用户找到他 / 她可能感兴趣的商品变得越来越重要。近年来,天猫在开发个性化推荐系统方面付出了巨大的努力,极大地促进了用户体验的优化以及商业价值的提升。例如,占天猫总流量一半左右的移动天猫App首页(如下图左图所示),就部署了推荐系统来展示个性化商品,从而满足客户的个性化需求。由于拥有十亿规模的用户和
item,天猫的推荐流程分为matching阶段和ranking阶段两个阶段。matching阶段负责检索与用户兴趣相关的数千个候选item,然后ranking阶段负责预测用户与这些候选item交互的精确概率。对于这两个阶段,为了支持对满足用户兴趣的item的高效检索,建模用户兴趣并得到捕获用户兴趣的用户representation至关重要。然而,由于用户兴趣的多样性diversity,在天猫上建模用户兴趣并非易事。平均而言,十亿级用户访问天猫,每个用户每天与数百种商品进行交互。交互的商品往往隶属不同的类目,暗示了用户兴趣的多样性。例如,如下图右图所示,不同用户的兴趣是不同的,同一用户也可能对不同的item感兴趣。因此,捕获用户多样化兴趣diverse interests的能力对天猫的推荐系统而言至关重要。注:下图中,左图的虚线矩形区域是天猫的十亿规模用户的个性化区域;右图是两个用户和不同类目商品的交互。

现有的推荐算法以不同的方式建模和表示用户兴趣:
基于协同过滤的方法通过历史交互
item或潜在因子来表示用户兴趣,这些方法存在数据稀疏问题、或者计算复杂度太高的问题。基于深度学习的方法通常用低维
embedding向量表示用户兴趣。例如,为YouTube视频推荐提出的深度神经网络(YouTubeDNN)通过一个固定长度的向量来表示每个用户,该向量是由用户历史行为转换而来。这可能是建模多样化兴趣的瓶颈,因为它的维度必须很高,从而表达天猫上的、大量的兴趣画像。深度兴趣网络
Deep Interest Network: DIN通过注意力机制来捕获用户兴趣的多样性,使得用户在不同目标item上的用户representation不同。然而,注意力机制的采纳也使得具有十亿级item的大规模应用在计算上受到限制,因为它需要重新计算每个目标item的用户representation,使得DIN仅适用于ranking阶段。
论文
《Multi-Interest Network with Dynamic Routing for Recommendation at Tmall》关注于在matching阶段对用户的多样化兴趣进行建模的问题。为了克服现有方法的局限性,论文提出了具有动态路由的多兴趣网络Multi-Interest Network with Dynamic routing: MIND。MIND用于工业级推荐系统在matching阶段学习反映用户的多样化兴趣的representation。为了推断用户
representation向量,论文设计了一个称为多兴趣提取器层multi-interest extractor layer,它利用动态路由将用户的历史行为自适应地聚合到用户representation中。动态路由的过程可以视为软聚类soft-clustering,它将用户的历史行为分为几个簇。每个历史行为簇进一步用于推断对应于一个特定兴趣的用户representation向量。这样,对于特定的用户,MIND输出多个represenation向量,它们共同代表了用户的多样化兴趣。用户representation向量只需要计算一次,就可以用于matching阶段从而在十亿级item中检索相关item。总而言之,这项工作的主要贡献:- 为了从用户行为中捕获用户的不同兴趣,论文设计了多兴趣提取器层,该层利用动态路由自适应地将用户的历史行为聚合为用户
representation向量。
通过使用多兴趣提取器层、以及新提出的标签感知注意力层
label-aware attention layer所产出的用户representation向量,论文为个性化推荐任务构建了一个深度神经网络。与现有的方法相比,MIND在多个公共数据集和一个来自天猫的工业数据集上表现出优越的性能。- 为了在天猫部署
MIND从而服务于十亿级用户,论文构建了一个系统来实现数据集采集、模型训练、以及在线serving的整个pipeline。部署的系统显著提高了移动天猫App首页的点击率click-through rate: CTR。目前MIND已经在Mobile Tmall App首页上部署从而处理主要的在线流量。
- 为了在天猫部署
相关工作:
深度学习推荐:受深度学习在计算机视觉和自然语言处理中成功应用的启发,人们投入了大量努力来开发基于深度学习的推荐算法。除了
《Deep neural networks for youtube recommendations》和《Deep interest network for click-through rate prediction》之外,各种类型的深度模型也得到了极大的关注。- 神经协同过滤
Neural Collaborative Filtering: NCF、DeepFM、和深度矩阵分解Deep Matrix Factorization Model: DMF构建了一个由若干MLP组成的神经网络,从而对用户和item之间的交互进行建模。 《Personalized top-n sequential recommendation via convolutional sequence embedding》通过提供一个统一且灵活的网络来捕获更多特征,为top-N序列推荐提供了一个新颖的解决方案。
- 神经协同过滤
用户
Representation:将用户表示为向量是推荐系统中常见的做法。传统方法将用户感兴趣的
item、用户感兴趣的关键词、用户感兴趣的主题拼接起来,从而构成用户偏好向量。随着distributed representation learning的出现,通过神经网络获取user embedding得到了广泛的应用。《Learning user and product distributed representations using a sequence model for sentiment analysis》使用RNN-GRU从时间有序的review documents中学习user embedding。《User embedding for scholarly microblog recommendation》从word embedding向量中学习user embedding向量,并将其应用于推荐学术微博scholarly microblog。《Modelling Context with User Embeddings for Sarcasm Detection in Social Media》提出了一种新的、基于卷积神经网络的模型,该模型显式地学习和利用user embedding以及从话语utterances中获得的特征。
胶囊网络
Capsule Network:”胶囊” 的概念表示一组神经元组装而成的向量,它由Hinton在2011年首次提出。动态路由dynamic routing用于学习胶囊之间连接的权重,该学习方法不是基于反向传播,而是基于Expectation-Maximization: EM算法,从而克服几个缺陷并获得更好的准确性。与传统神经网络的这两个主要区别(由一组神经元组成、通过EM算法学习)使得胶囊网络能够对部分和整体之间的关系进行编码,这在计算机视觉和自然语言处理方面是先进的。SegCaps证明,胶囊可以比传统的CNN更好地建模对象的空间关系。《Investigating Capsule Networks with Dynamic Routing for Text Classification》研究了用于文本分类的胶囊网络,并提出了三种提高性能的策略。
1.1 模型
工业推荐系统
matching阶段的目标是为每个用户 从十亿规模的item库 中检索仅包含数千个item的item子集,其中该子集中每个item都和用户的兴趣相关。为了实现该目标,我们收集用户历史行为数据从而构建
matching模型。具体而言,每个样本都可以用一个元组 ,其中:表示用户 交互的
item集合,也称作用户行为。为用户 的基础画像,如性别、年龄。
为
target item的特征,如item id、category id。注意:
target item不一定隶属于 ,即用户 不一定在target item上有过互动行为。
MIND的核心任务是学习将原始特征映射到用户representation的函数,即:其中 为用户 的 个
representation向量,向量维度为 。当 时,每个用户仅使用单个representation向量,就像YouTube DNN一样。此外,通过
embedding函数获得target item的representation向量为:其中 表示
item的representation向量。 的详细信息在后文说明。当学习了用户
representation向量、item representation向量之后,在线serving时根据评分函数检索top N候选item:其中 时在
matching阶段要检索的、预定义的item数。注意: 仅用于serving阶段,而不用于训练阶段。如下图所示,
MIND将用户行为序列、用户画像、label item等特征作为输入,然后输出用户representation从而用于推荐系统的matching阶段来检索item。MIND主要由以下部分组成:Embedding&Pooling Layer:来自输入层的id特征通过embedding层转换为embedding,然后每个item的各种id embedding由池化层进一步取平均。Multi-Interest Extractor Layer:用户行为embedding被馈入多兴趣提取器层从而产生兴趣胶囊。通过将兴趣胶囊和用户画像embedding拼接,然后经过几个ReLU的全连接层进行转换,可以得到用户representation向量。Label-aware Attention Layer:在训练过程中引入一个额外的标签感知注意力层,从而指导训练过程。
最后在
serving过程中,用户的多个representation向量用于通过最近邻检索来检索item。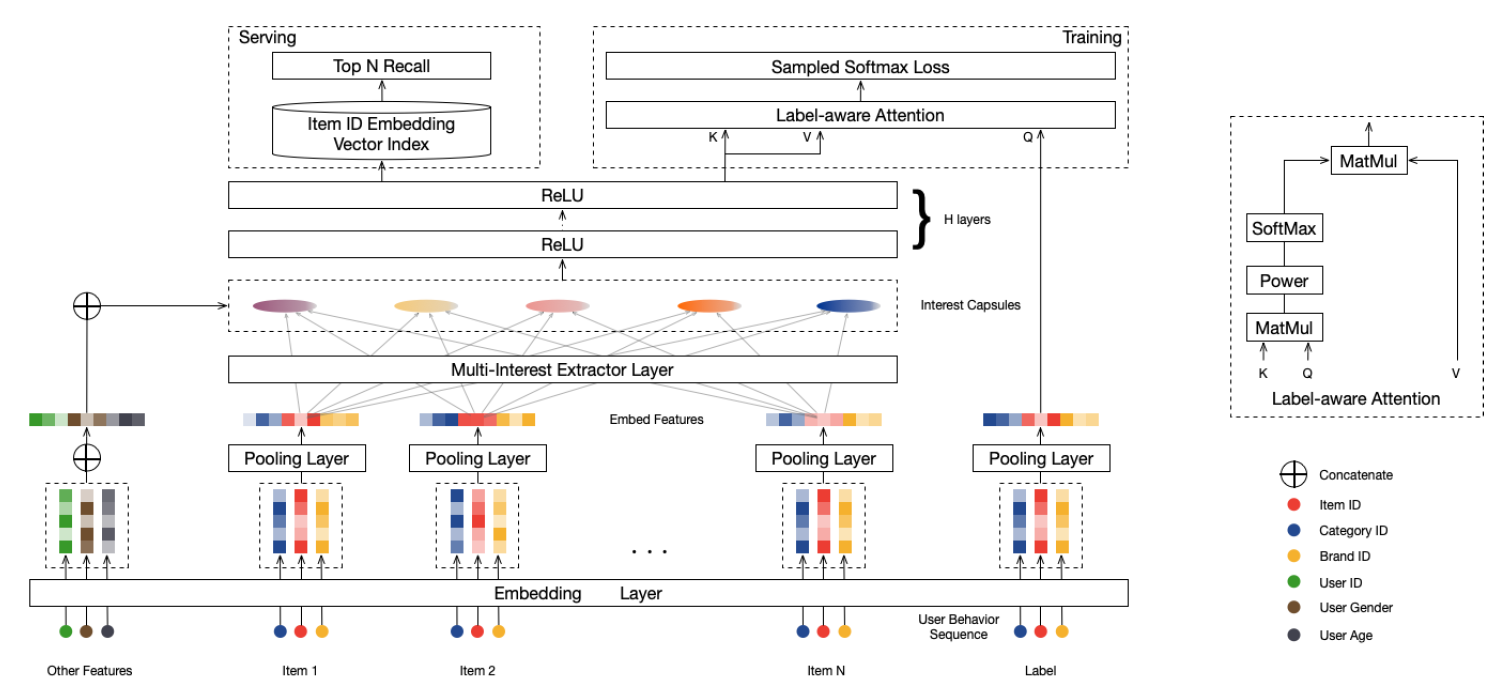
Embedding&Pooling Layer:MIND的输入包含三组:用户画像 、用户行为 、label item,每组输入包含几个具有极高维数的categorical id特征。例如,item id的数量约为数十亿个,因此我们采用了广泛使用的embedding技术将这些ID特征嵌入到低维稠密向量(也称作embedding向量)中,从而显著减少了参数数量并简化了学习过程。- 对于来自用户画像 的
id特征(性别、年龄等),对相应的embedding进行拼接从而构成用户画像embedding。 - 对于
item的item id以及其它categorical id(如品牌id、店铺id等),这些id被证明有助于label item的冷启动,相应的embedding会进一步通过均值池化层从而形成label item embedding,即 函数。 - 对于来自用户行为 的
item,收集相应的item embedding从而形成用户行为embedding,这些embedding构成了用户行为embedding矩阵 。
- 对于来自用户画像 的
1.1.1 Multi-Interest Extractor Layer
我们认为,用一个
representation向量表示用户兴趣可能是捕获用户的多样化兴趣的瓶颈,因为我们必须将与用户的多样化兴趣相关的所有信息压缩到一个representation向量中。因此,关于用户的不同兴趣的所有信息都被混合在一起,从而导致在matching阶段的item检索不准确。相反,我们采用多个
representation向量分别表达用户的不同兴趣。通过这种方式,我们可以在matching阶段分别考虑用户的多样化兴趣,从而可以更准确地检索各个方面的兴趣。为了学习多个
representation向量,我们利用聚类过程将用户的历史行为分组为几个簇cluster。我们预期来自同一个簇的item将密切相关,并且共同代表了用户在某个特定方面的兴趣。这里,我们设计了多兴趣提取器层multi-interest extractor layer,从而用于聚类历史行为,并得到结果聚类的representation向量。由于多兴趣提取器层的设计受到最近提出的、用于胶囊网络
capsule network中表示学习representation learning的动态路由dynamic routing的启发,因此我们首先回顾基础知识。动态路由
Dynamic Routing:我们简单介绍用于胶囊网络表示学习的动态路由,这是一种以向量表示的、新型的神经元。假设我们有两层胶囊,分别将第一层胶囊和第二层胶囊称作低层胶囊
low-level capsule、高层胶囊high-level capsule。动态路由的目标是以迭代的方式在给定低层胶囊值的情况下计算高层胶囊值。在每次迭代中,给定低层胶囊 对应的值 、以及高层胶囊 对应的值 ,其中 , 分别为低层
value vector和高层value vector的维度。则低层胶囊 和高层胶囊 之间的
routing logit为:其中 为待学习的双线性映射矩阵。
当计算好
routing logit之后,高层胶囊 的value vector更新为:其中:
- 为所有低层胶囊值向量的加权和。加权和的权重 表示低层胶囊 和高层胶囊 的权重,是通过对
routing logit进行softmax来计算的。 - 非线性的
squash函数用于获得高层胶囊的值向量。
另外, 的值将被初始化为零。
整个路由过程通常需要
3轮迭代才会收敛。路由结束后,高层胶囊的值向量 通常会固定不变,并且可以用于下一层layer的输入。- 为所有低层胶囊值向量的加权和。加权和的权重 表示低层胶囊 和高层胶囊 的权重,是通过对
B2I动态路由:简而言之胶囊是一种由向量表示的神经元,而不是普通神经网络中标量表示的神经元。我们期待基于向量的胶囊能够代表实体的不同属性,其中向量的方向代表一种属性、向量的长度代表该属性存在的概率。相应地,多兴趣提取器层的目标是学习用于表达用户兴趣、以及是否存在相应兴趣的
representation。胶囊和兴趣representation之间的语义联系促使我们将行为/兴趣representation视为行为/兴趣胶囊,并采用动态路由从行为胶囊behavior capsule中学习兴趣胶囊interest capsule。然而,针对图像数据提出的原始路由算法并不能用于直接处理用户行为数据。因此,我们提出了
Behavior-to-Interest:B2I动态路由,用于将用户的行为自适应地聚合到兴趣representation向量中,这和原始路由算法在三个方面有所不同:共享双线性映射矩阵:基于两方面的考虑,我们将每对低层胶囊和高层胶囊
pair对之间使用固定的双线性映射矩阵 ,而不是在原始动态路由中独立的双线性映射矩阵:- 一方面,用户行为序列的长度是可变的,天猫用户的行为序列长度从几十到几百,因此使用共享的双线性映射矩阵更为泛化
generalizable。 - 另一方面,我们希望兴趣胶囊位于相同的向量空间中,而不同的双线性映射矩阵会将兴趣胶囊映射到不同的向量空间中。
因此,
routing logit计算为:其中:
- 为
behavior item的embedding。 - 为
interest capsule的向量,一共有 个兴趣。 - 双线性映射矩阵 在每对行为胶囊和兴趣胶囊
pair对之间共享。
- 一方面,用户行为序列的长度是可变的,天猫用户的行为序列长度从几十到几百,因此使用共享的双线性映射矩阵更为泛化
随机初始化
routing logit:由于使用了共享的双线性映射矩阵 ,将routing logit初始化为零导致所有用户具有相同的初始兴趣胶囊。然后在随后的每一轮迭代中,不同用户之间在当前轮次具有相同的兴趣胶囊。(注:不同迭代步之间的取值不同,但是同一迭代步之内的取值都相同)。为了缓解这种现象,我们从高斯分布 中抽样一个随机矩阵作为初始
routing logit,使得初始兴趣胶囊彼此不同。这和著名的K-Means聚类算法的随机初始化类似。动态兴趣数量:由于不同用户的兴趣数量可能不同,因此我们引入了一种启发式规则,用于针对不同用户自适应地调整 的值。
具体而言,用户 的 值通过以下公式计算:
这种调整兴趣数量的策略可以为那些兴趣较少的用户节省一些资源,包括计算资源、内存资源。
B2I Dynamic Routing算法:输入:
- 用户 的行为
embedding集合 - 迭代轮次
- 兴趣胶囊数量
- 用户 的行为
输出:用户 的兴趣胶囊集合
算法步骤:
计算自适应的兴趣胶囊数量:
对于所有的行为胶囊 和兴趣胶囊 ,随机初始化
迭代 ,迭代步骤为:
- 对于所有行为胶囊 :
- 对于所有兴趣胶囊 :
- 对于所有兴趣胶囊 :
- 对于所有的行为胶囊 和兴趣胶囊 :
返回
注:本质上它是在给定 行为胶囊的前提下找到 个兴趣胶囊,使得:
a. 兴趣胶囊 是所有行为胶囊的加权和。
b. 行为胶囊 对所有兴趣胶囊的权重是由兴趣胶囊进行
softmax得到。这类似于二部图上的消息传递机制,因此迭代若干轮之后就会收敛。
这里 的选择是个难点:太小则不足以捕获用户多样化兴趣,太大则计算复杂度太高并引入噪音的兴趣胶囊。
注二:这里使用胶囊网络来进行聚类,本质是一个聚类过程。
1.1.2 Label-aware Attention Layer
通过多兴趣抽取层,我们从用户的行为
embedding中生成了多个兴趣胶囊。不同的兴趣胶囊代表了用户兴趣的不同方面,而且相关的兴趣胶囊用于评估用户对特定item的偏好。因此,在训练过程中我们基于scaled dot-product attention设计了标签感知注意力层label-aware attention layer。具体而言,对于一个目标
item:- 首先,我们计算每个兴趣胶囊和目标
item embedding之间的相似性。 - 然后,我们计算兴趣胶囊的加权和作为针对目标
item的用户representation向量,其中每个兴趣胶囊的权重由相应的相似性来确定。
- 首先,我们计算每个兴趣胶囊和目标
在标签感知注意力层中,
label item是query,兴趣胶囊同时作为key和value。用户 关于item的representation为:其中:
pow()函数表示逐元素的指数函数。p是一个超参数作为指数函数的指数项,它用于调整注意力分布:当 接近于零时,每个兴趣胶囊倾向于收到均匀分布的注意力。
当 大于
1时,随着 的增加,具有较大dot-product的兴趣胶囊将获得越来越大的权重。考虑极端情况下当 为正无穷时,注意力机制将成为一种硬注意力
hard attention:选择注意力最大的兴趣胶囊并忽略其它兴趣胶囊。这意味着挑选和目标
item最相似的兴趣来作为标签感知的兴趣representation。此时无需进行复杂的attention计算,直接利用最近邻检索来获取。
在我们的实验中,我们发现
hard attention可以加快收敛速度。
1.1.3 其它
Training:得到用户representation向量 以及label item embedding之后,我们计算用户 和label item交互的概率为:训练
MIND的目标函数为:其中 是包含所有
user-item交互的训练数据的集合。注意,这里通过
softmax函数变为一个多分类问题,因此没有负样本的概率。在多分类问题中,不存在负样本,只有二分类问题存在负样本。由于
item规模在数十亿级,因此 的分母计算量太大导致无法实现,因此我们采用采样的softmax技术sampled softmax technique。我们使用
Adam优化器来训练MIND。Serving:除了标签感知注意力层之外的MIND网络即为用户representation映射函数 。在serving期间:- 用户的行为序列和用户画像馈入 函数,从而为每个用户生成多个
representation向量。 - 然后,我们使用这些
representation向量通过最近邻方法检索top N个item,从而构成推荐系统matching阶段的最终候选item集。
注意:
- 当用户有新的行为时,这将改变用户的行为序列以及相应的用户
representation向量,因此MIND对于mathcing阶段拥有实时个性化的能力。 - 每个用户有 个兴趣胶囊, ,这里会针对每个兴趣胶囊进行检索然后合并。
- 用户的行为序列和用户画像馈入 函数,从而为每个用户生成多个
部署:天猫上
MIND的实现和部署如下所示:当用户启动天猫
APP时,推荐请求发送到天猫个性化平台Tmall Personality Platform,该服务器集群集成了很多插件模块并提供天猫在线推荐服务。天猫个性化平台检索用户的近期行为,并将其发送到用户兴趣提取器
User Interest Extractor,后者是实现MIND的主要模块,用于将用户行为转换为多用户兴趣multiple user interest。随后,召回引擎
Recall Engine将搜索和用户兴趣的embedding向量最邻近的item。由不同兴趣触发的item将融合为候选item,并根据它们与用户兴趣的相似性进行排序。由于基于
MIND服务的有效性,通过用户兴趣提取器和召回引擎从数十亿个item库中选择数千个候选item的整个过程可以在不到15ms的时间内完成。Ranking Service对这些候选item中的top 1000个item进行打分(在item数量和延迟时间之间进行权衡),该服务通过一系列特征来预测CTR。最后天猫个性化平台完成推荐列表,并向用户展示推荐结果。
用户兴趣提取器和
Ranking Service都是在Model Training Platform上使用100个GPU进行训练,训练可以在8个小时内完成。得益于Model Training Platform的出色性能,深度模型天级更新。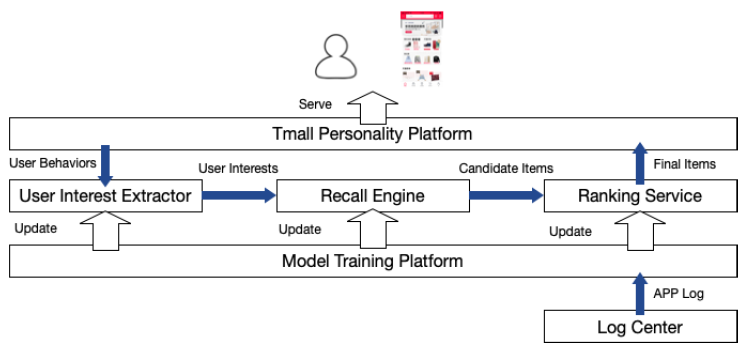
这里我们对
MIND和两种现有方法之间的关系做一些说明,说明它们的相似之处和不同之处。YouTube DNN:MIND和YouTube DNN都利用深度神经网络对行为数据进行建模从而生成用户representation。这些representation用于工业推荐系统matching阶段的大规模item检索。但是,
YouTube DNN使用一个向量来代表用户,而MIND使用多个向量。当用户兴趣数量K=1时,MIND会退化为YouTube DNN,因此MIND可以视为YouTube DNN的推广。DIN:在捕获用户的多样化兴趣方面,MIND和DIN具有相同的目标。但是,这两种方法在实现目标的方式和适用性方面有所不同。- 为了处理多样化兴趣,
DIN在item-level应用了注意力机制;而MIND使用动态路由生成兴趣胶囊,并在interest-level考虑了多样性。(interest比item更高一个level)。 - 此外,
DIN重点聚焦于ranking阶段,因为它处理上千个item;而MIND作用于matching阶段,处理数十亿个item。
- 为了处理多样化兴趣,
未来方向:
- 第一个方向是融合有关用户行为序列的更多信息,如行为时间等。
- 第二个方向是优化动态路由的初始化方案,参考
K-means++初始化方案,从而实现更好的用户representation。
1.2 实验
1.2.1 离线评估
这里我们在多个数据集上离线评估了
MIND和现有方法的推荐准确率。数据集:
Amazon Books数据集:它是电商推荐领域中使用最广的公共数据集之一。我们仅保留至少评论10次的item、以及至少评论10个item的用户。Tmall Data数据集:它是从Mobile Tmall App中随机采样的200万天猫用户,并获得这些用户在10天内的历史行为。我们保留至少600个用户点击的item。
这些数据集的统计信息如下表所示:

评估指标:我们选择
next item prediction问题(即预测用户的下一个交互)来评估方法的性能,因为这是推荐系统mathcing阶段的核心任务。我们将每个数据集的
user-item交互数据按照19:1的比例随机划分为训练集、测试集。然后对于每个用户,我们将用户交互的、测试集中的item作为目标item,该item之前所有交互的item作为用户历史行为。我们根据用户历史行为来预测目标item。我们采用命中率
hit rate作为衡量推荐效果的主要指标,定义为:其中:
- 表示由用户和
target item组成的测试集。 - 为示性函数, 。
target item occurs in top N表示目标item是否在预估多分类概率中的top N。由于模型采用softmax输出层,因此可以考虑目标item的输出概率在所有item输出概率中的位置。
我们在每个数据集上对
embedding向量维度 、用户兴趣数 进行超参数调优,并使用最佳超参数对每种方法进行测试以便进行公平的比较。- 表示由用户和
baseline方法:WALS:即加权最小二乘法Weighted Alternating Least Square。它是一种经典的矩阵分解算法,用于将user-item交互矩阵分解为用户的隐藏因子hidden factor和item的隐藏因子 。然后基于用户的隐藏因子和target item的隐藏因子之间的相似性进行推荐。YouTube DNN:它是用于工业推荐系统的最成功的深度学习方法之一。MaxMF:它引入了一种高度可扩展的方法来学习非线性潜在因子分解,从而对用户的多个兴趣进行建模。
实验结果如下表所示,我们给出了不同方法在两个数据集上
N=10,50,100的命中率结果。其中:黑体表示最佳性能;HP表示性能最佳的超参数,K表示兴趣数量,d表示embedding维度;括号中的百分比表示相对于YouTube DNN的相对提升。可以看到:
矩阵分解方法
WALS被其它方法击败,这表明深度学习方法对于改进推荐系统mathcing阶段的强大作用。但是,即使没有使用深度学习方法,
MaxMF的性能也要比WALS好得多。这可以用以下事实来解释:MaxMF将标准MF泛化为非线性模型,并对于每个用户采用了多个representation向量。可以观察到:采用用户的多个
representation向量的方法(MaxMF-K-interest、MIND-K-interest) 通常要比其它方法(WALS、YouTube DNN、MIND-1-interest)表现更好。因此,事实证明:使用用户的多个
representation向量是一种对用户的不同兴趣进行建模、并提高推荐准确性的有效方法。此外,我们可以观察到,由于天猫的用户倾向于表现出更多的兴趣,因此由于用户的多个
representation向量引入的改善对于TmallData更为显著。多样性的增加也可以通过每个数据集的最佳
K值来反映,其中TmallData的最佳K大于Amazon Books的最佳K值。
和
YouTube DNN相比,MIND-1-interest的提高表明:动态路由是一种比均值池化更好的池化策略。对比
MaxMF和MIND-K-interest的结果,这验证了通过动态路由从用户行为中提取多个兴趣优于在MaxMF中使用非线性建模策略。这可以归结于两点:- 多兴趣提取器层利用聚类过程生成兴趣的
representation,从而实现用户的更精确的representation。 - 标签感知注意力层使
target item在用户的多个representation向量上分配注意力,从而使得用户兴趣和target item之间的匹配更加准确。
- 多兴趣提取器层利用聚类过程生成兴趣的

这里我们在
Amazon Books上进行两个实验,从而研究多兴趣提取器层和标签感知注意力层中超参数的影响。routing logit的初始化:多兴趣提取器层采用的routing logit的随机初始化和K-means质心的初始化相似,其中初始聚类中心的分布对于最终聚类结果的影响很大。由于routing logit是根据高斯分布 初始化的,因此我们担心 的不同取值可能导致不同的收敛性从而影响性能。为了研究 的影响,我们使用了三个不同的 (0.1, 1, 5)来初始化routing logit。实验结果如下图所示。可以看到:不同 的每条曲线几乎都重叠。该结果表明:
MIND对于 的取值具有鲁棒性。因此我们在实际应用中选择 是合理的。
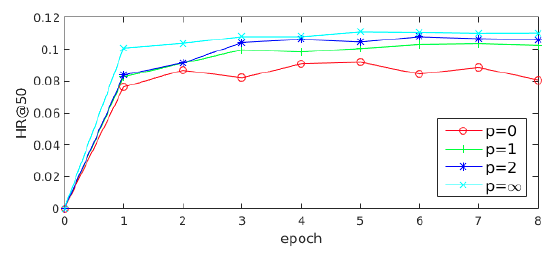
标签感知注意力层的幂次:如前所示,标签感知注意力中的幂次 控制每个兴趣在组合的标签感知兴趣表示
label-aware interest representation中所占的比例。为了研究 的影响,我们比较了 当 从 时MIND的性能变化。实验结果如下图所示。可以看到:
p=0时的性能相对而言要差很多。原因是当 时每个兴趣都具有相同的注意力,因此组合的兴趣表示combined interest representation等于没有参考label时的兴趣representation均值。- 当 时,注意力得分与兴趣
representation向量和目标item的embedding之间相似度成比例,这使得组合的兴趣representation为所有兴趣representation的加权和。 - 另外,随着 的增加性能会变得更好,因为和目标
item相似度更高的兴趣representation获得了更大的注意力。 - 最后,当 时变成了
hard attention scheme。此时和目标item最相似的兴趣representation将主导组合的兴趣representation,从而使得MIND收敛得更快并且表现最好。
1.2.2 在线评估
我们在线部署
MIND来处理天猫首页上的实际流量从而进行在线实验,为期一周。为了公平地进行比较,在matching阶段部署的所有方法后续都使用相同的ranking过程。我们评估指标是最终的CTR效果指标。baseline方法:item-based CF:它是服务于在线主流量的基本matching方法。YouTube DNN:它是著名的基于深度学习的matching方法。
我们将所有对比方法部署在
A/B test框架中,每种方法检索一千个候选item,然后将候选item送入ranking阶段以进行最终推荐。实验结果如下图所示,我们得出以下结论:
MIND优于item-based CF和YouTube DNN,这表明MIND产生了更好的用户representation。通过长期的实践优化,
item-based CF的效果要比YouTube DNN更好,而MIND-1-interest也超越了YouTube DNN。一个非常明显的趋势是:随着兴趣数量从
1增加到5,MIND的性能会变好。当兴趣数量达到5时,MIND性能达到峰值,随后继续增加K值则CTR保持不变。例如,K=7相对于K=5带来的提升几乎可以忽略。因此对于天猫用户来讲,最佳的用户兴趣数量是
5~7,这表明了用户兴趣的平均多样化程度。具有动态兴趣数的
MIND与K=7的MIND性能相当。因此动态兴趣数机制不会带来CTR收益,但是在实验过程中我们发现该方案可以降低serving的成本,这有利于大规模的service(如天猫),并且在实践中更易于采用。
总而言之,在线实验证明了
MIND可以实现更好的解决方案,从而为具有不同兴趣的用户建模,并且可以显著提高整个推荐系统的效果。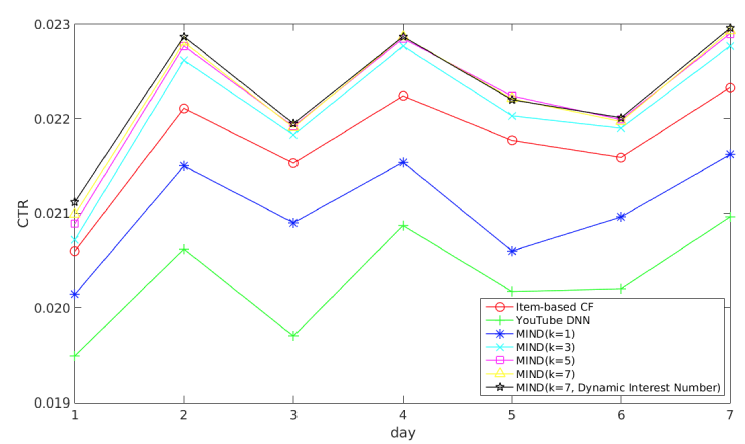
1.2.3 Case Study
耦合系数
coupling coefficient:行为胶囊和兴趣胶囊之间的耦合系数可以衡量行为对于兴趣的隶属程度。这里我们将这些耦合系数可视化,从而表明兴趣提取过程是可解释的。下图给出了从天猫每日活跃用户中随机选择的两个用户相关的耦合系数,每一行对应一个兴趣胶囊、每一列对应一个行为。每一类行为在相应的兴趣上具有最大的耦合系数。注意:这两个用户具有不同粒度的兴趣。
可以看到:
- 用户
C(上部)已经和4类商品(耳机、小吃、手提包、衣服)进行了交互,每类商品在一个兴趣胶囊上具有最大的耦合系数,并形成了相应的兴趣。 - 用户
D(下部)仅对衣服感兴趣,但是可以从行为中解析到3个细粒度的兴趣(毛衣、大衣、羽绒服)。
从这些结果中我们可以看到:用户行为的每个类别被聚类在一起,并形成了相应的兴趣
representation向量。
- 用户
item分布:在serving阶段,和用户兴趣相似的item将通过最近邻搜索来被检索到。我们根据兴趣检索的item和对应兴趣的相似度,从而可视化相似度的分布。下图给出了用户
C检索的item的结果。其中:上面的四个轴显示了基于MIND的四个兴趣召回的item;最下面的轴显示了基于YouTube DNN召回的item。item根据它们和兴趣的相似性在轴的相应位置上。我们已经通过min-max归一化将相似性缩放到0.0 ~1.0之间,并四舍五入到最近的0.05。图中每个点都是由该区域内
item组成,因此每个点的大小表示具有相应相似度的item数。 我们还给出了从所有候选item中随机选择的一些item。不出所料:
MIND召回的item和相应的兴趣密切相关;而YouTube DNN召回的item类别相差很大,并且与用户行为的相似性较低。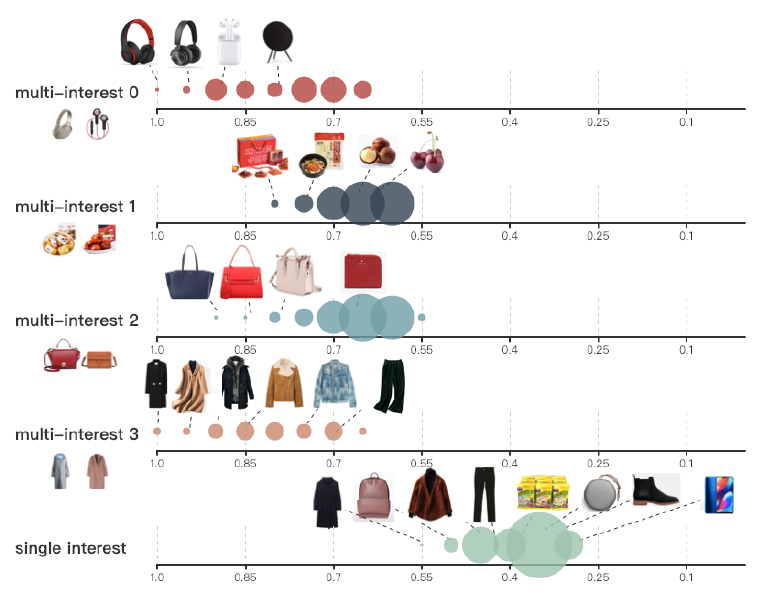
二、DNN For YouTube[2016]
YouTube是全球最大的创建creating、分享sharing和发现discovering视频内容平台。YouTube的推荐可以帮助超过十亿用户从不断增长的视频库video corpus中发现个性化内容,是现有规模最大、最复杂的工业推荐系统之一。推荐
YouTube视频在三个方面具有极大挑战:规模
scale:实践证明,现有的很多推荐算法在小规模问题上都能很好地发挥作用,但是在YouTube规模的问题上无法应用。高度专业化的分布式学习算法
highly specialized distributed learning algorithms和高效的服务系统efficient serving system对于处理YouTube庞大的用户基数和视频库至关重要。新鲜性
freshness:YouTube视频库非常活跃dynamic,每秒钟都会上传大量的视频。推荐系统应该具有足够的响应能力responsive,从而建模新上传的内容、以及建模用户的最新行为action。新内容和学习成熟的
well-established视频之间的平衡从某种角度可以视为探索和利用exploration/exploitation。噪音
noise:由于稀疏性sparsity和各种不可观察的外部因素,YouTube上的用户历史行为固有地inherently难以预测。我们几乎无法获取用户满意度的
ground truth,事实上我们是对带噪音的隐式反馈信号noisy implicit feedback signal进行建模。此外,内容关联的元数据metadata结构化较差,没有定义良好的本体ontology。因此,我们的算法需要对训练数据的这些特点具有鲁棒性
robust。
与谷歌的其它产品领域
product areas相结合,YouTube经历了根本性的范式paradigm转变,转向使用深度学习作为几乎所有学习问题的通用解决方案。YouTube的推荐系统建立在Google Bran(其开源版本即著名的TensorFlow)上。YouTube推荐的深度学习模型大约包含10亿级参数,并且使用千亿级的训练样本。与被大量研究的矩阵分解方法相比,使用深度神经网络进行推荐系统的工作相对较少。
- 神经网络在
《Personalized news recommendation using classi ed keywords to capture user preference》中用于推荐新闻、在《A neural probabilistic model for context based citation recommendation》中用于推荐ciatations、在《User modeling with neural network for review rating prediction》中用于推荐评论的评分。 - 协同过滤在
《Collaborative deep learning for recommender systems》中被表述为深度神经网络,在《Autoencoders meet collaborative fi ltering》中被表述为自编码器。 《A multi-view deep learning approach for cross domain user modeling in recommendation systems》使用深度学习进行跨域的用户建模。- 在
content-based推荐中,《Deep content-based music recommendation》使用深度神经网络进行音乐推荐。
在论文
《Deep Neural Networks for YouTube Recommendations》中,作者从从较高的视角high level描述了该系统,并聚焦于深度学习带来的显著性能提升。论文根据经典的两阶段信息检索二分法retrieval dichotomy分为两部分:首先论文详细介绍了一个深度候选生成Candidate Generation模型(即召回模型),然后论文详细介绍了一个独立的深度排序Ranking模型。论文还提供了有关设计、迭代、维护一个庞大推荐系统的实践经验教训和洞察。
2.1 Overview
我们的推荐系统由两个神经网络组成:一个用于候选生成
candidate generation、一个用于排序ranking。总体架构如下图所示。候选生成网络:从用户的
YouTube历史行为记录中获取事件event作为输入,并从大型视频库中检索一小部分(数百个)视频。这些候选视频倾向于和用户高度相关。候选生成网络仅通过协同过滤提供广泛
broad的个性化。用户之间的相似性是通过粗粒度coarse-level的特征来表示的,如观看视频video watch的ID、搜索query的token、人口统计学特征demographic。排序网络:根据一个细粒度
fine-level的representation来区分召回的候选视频之间的相对重要性,从而提供一些 “最佳” 推荐最终构成推荐列表。排序网络通过使用描述视频和用户的一组丰富的特征,并根据期望的目标函数
desired objective function,从而为每个视频分配一个score来完成该任务。候选视频根据它们的score进行排序,得分最高的候选视频被呈现给用户。
这种两阶段方法允许我们从非常大的视频库(数百万)中进行推荐,同时仍然可以确保呈现给用户的少量视频对于用户来说是个性化的
personalized和吸引人的engaging。此外,这种设计能够融合其它来源生成的候选(
other candidate sources,即其它召回通路)。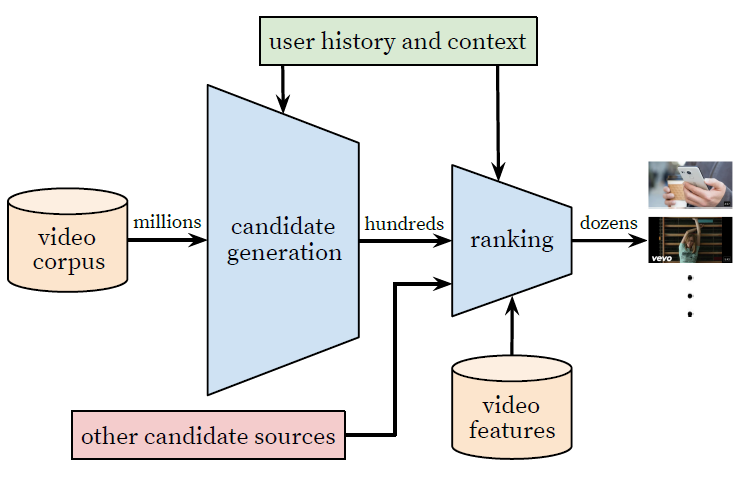
在开发过程中,我们广泛使用离线指标(精度
precision、召回率recall、ranking loss等)来指导系统的迭代改进。然后,为了最终确定算法或模型的有效性,我们依靠在线实验live experiment进行A/B test。在在线实验中,我们可以衡量
click-through rate: CTR、观看时长watch time、以及其它衡量用户互动user engagement指标的细微变化。这一点很重要,因为在线A/B test结果并不总是和离线实验正相关。
2.2 Candidate Generation
在候选生成
candidate generation过程中,我们从庞大的YouTube视频库中筛选可能与用户有关的数百个视频。这里描述的推荐器
recommender的前身predecessor是在rank loss下训练的矩阵分解matrix factorization方法。我们神经网络模型的早期迭代通过浅层网络模仿了这种分解行为,该浅层网络仅嵌入了用户历史观看的视频。从这个角度来看,我们的方法可以视为矩阵分解技术的非线性推广。作为分类任务的推荐
Recommendation as Classification:我们提出将推荐视作极端的多分类任务,其中预测问题变为:基于用户 和上下文 在时刻 从视频库 的数百万个视频(类别)中准确地分类特定的视频观看video watch为类别 (即视频库 中的第 个视频)的概率。 即:其中: 为
(user,context) pair对的embedding向量; 为每个候选视频的embedding向量; 为embedding维度。在这种
setting下,embedding只是将稀疏实体(单个视频、用户等)映射到 中的稠密向量。深度神经网络的任务是学习用户embedding作为用户历史行为和上下文的函数,这对于使用softmax分类器在视频之间进行区分discriminating是很有用的。尽管
YouTube存在明确的反馈机制(加赞thumbs up、减赞thumbs down、产品内调查等),但是我们使用视频观看video watch的隐式反馈implicit feedback来训练模型,其中用户完成视频观看就是一个正样本。这种选择是基于大规模可用的隐式用户行为历史记录,从而允许我们可以在显式反馈explicit feedback极其稀疏的长尾提供推荐。为了有效地训练具有数百万个类别的模型,我们依靠负采样技术从背景分布
background distribution中采样负样本(候选采样candidate sampling),然后通过重要性加权对这些负样本进行校正。对于每个正样本,我们最小化true label和采样的负类之间的交叉熵。- 在实践中,我们对每个正样本随机采样几千个负样本,这相当于传统
softmax的100多倍的加速。 - 一种流行的替代方法是分层
softmax(hierarchical softmax),但是它无法达到相当的准确性。在分层softmax中涉及把原本可能不相关的样本归结到同一个中间节点,这使得分类问题更加困难并降低了性能。
在
serving阶段,我们需要计算最有可能的N个类别(视频),以便选择要呈现给用户的top-N个类别。在数十毫秒的严格serving延迟时间下对数百万个item进行打分,需要一种近似的、与类别数量亚线性的评分方案。YouTube以前的系统依赖于哈希,而这里的分类器使用类似的方法。由于在serving时不需要来自softmax输出层的、经过校准的likelihood,因此评分问题简化为内积空间中的最近邻检索nearest neighbor search问题,而这可以通过通用的library来解决。我们发现A/B test结果对于最近邻检索算法的选择不是特别敏感。- 在实践中,我们对每个正样本随机采样几千个负样本,这相当于传统
模型架构:受连续的
bag-of-word语言模型的启发,我们在固定的词典vocabulary中学习每个视频的embedding,并将这些embedding馈入前馈神经网络。用户的观看历史由可变长度的视频
ID序列来表示,该序列通过embedding映射为稠密的向量representation。由于前馈神经网络需要固定尺寸的稠密输入,因此我们对embedding序列进行均值池化从而聚合为固定尺寸的向量。在所有聚合策略中(sum池化、最大池化、均值池化),均值池化效果最好。重要的是,
embedding与所有其它模型参数是通过常规的梯度下降来联合学习的。下图给出了
candidate generation网络的架构:特征被拼接称宽wide的第一层,接着是几层带ReLU激活函数的全连接层FC layer。其中:- 嵌入的稀疏特征和稠密特征进行拼接。 特征拼接之前先对
embedding序列进行均值池化,从而将可变大小的稀疏ID序列转换为适合输入到隐层hidden layer的固定尺寸的向量。 - 所有隐层都使用全连接。
- 训练过程中,通过对
softmax输出进行负采样来进行梯度下降,从而最小化交叉熵损失。 serving过程中,执行近似的最近邻检索从而生成数百个候选视频。
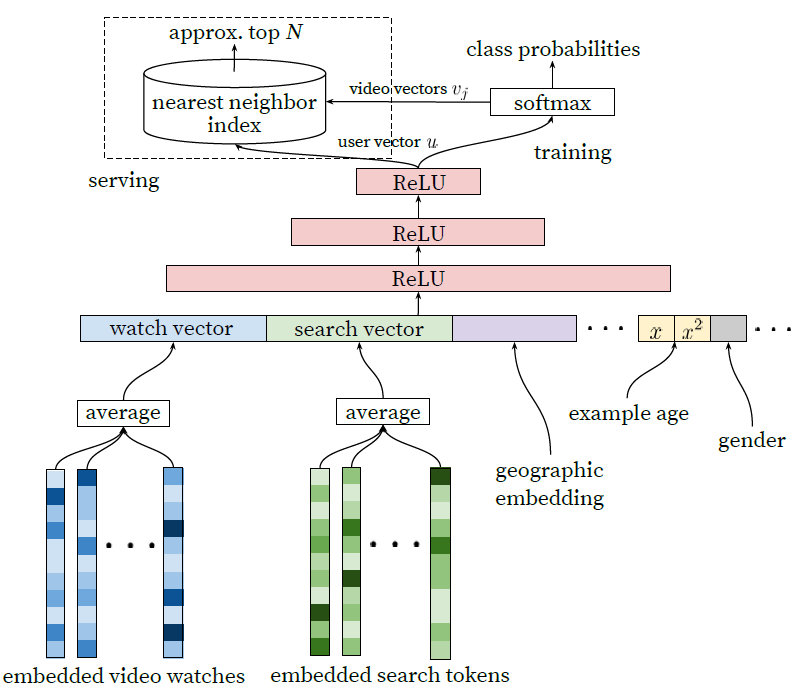
- 嵌入的稀疏特征和稠密特征进行拼接。 特征拼接之前先对
特征体系:深度神经网络作为矩阵分解的推广的一个关键优势是,可以轻松地将任意连续特征和离散特征添加到模型中。
搜索历史记录
search history和观看历史记录watch history的处理方式相似:每个query被tokenize为unigram和bigram,并且每个token都被嵌入。然后我们将所有的token的embedding均值池化。池化后的稠密向量就代表了用户的搜索历史记录。人口统计特征
demographic feature对于提供先验知识prior很重要,这样对新用户的推荐就能合理地进行。用户的地理区域
geographic region和设备分别被嵌入,然后进行拼接。简单的二元特征和连续特征(如用户性别、登录状态、用户年龄)将被直接输入到网络,其中实数值将被标准化为
[0.0, 1.0]之间。example age特征:每秒都有大量的视频上传到YouTube。因此对于YouTube产品而言,推荐最新上传(fresh) 的内容非常重要。我们始终观察到:在不牺牲相关性的前提下,用户更喜欢新鲜的内容
fresh content。除了简单地推荐用户想看的新视频这个一阶效应first-order effect之外,还有一个关键的次级现象:自举和传播病毒内容bootstrapping and propagating viral content。机器学习系统经常表现出对过去
past的隐性bias,因为它们被训练为通过历史样本来预测未来的行为。视频热度popularity的分布非常不稳定,但是我们推荐器recommender产生的视频库上的多项式分布将反映几周训练窗口中的平均观看可能性likelihood。即:我们模型学到的是过去一段时间平均的热度,而不是当前时刻的热度。而平均热度和当前热度差异很大。
为解决这个问题,我们在训练过程中以训练样本的
age作为特征,它是训练时刻减去创建日志的时刻。在serving阶段,这个特征被设为零(或者略微为负),从而表示采用最近的热度。一种朴素的方法是,将训练样本根据发生时刻进行加权:距离训练时刻越近则权重越大、距离训练时刻越久则权重越小。这种方式使得近期发生的模式更重要。这种方式的缺点是:难以确定合适的时间衰减加权方式。而
YouTube DNN中的方法是:将样本age作为特征,由模型自动根据该特征来学习模式随时间变化的规律。下图给出了这种方法在任意挑选的一个视频上的效果。可以看到:
- 添加了样本
age特征之后,模型能够准确地表示数据中观察到的上传时间和依赖于时间的热度。 - 如果没有该特征,则模型将预估为:近似于训练窗口内的平均观看可能性
likelihood。

- 添加了样本
需要强调的是,推荐通常涉及解决一个代理问题
surrogate problem,然后将结果迁移到特定的上下文context。一个经典的例子是,我们假设准确地预估收视率会带来有效的电影推荐。我们已经发现,这个代理学习问题的选择对A/B test的性能有着极其重要的影响,但是很难用离线实现来衡量。例如,离线优化的是点击率,但是在线需要优化的是
GMV,二者之间存在一定的gap。训练样本是从所有
YouTube观看记录(甚至是从其它网站内嵌的观看记录)生成的,而不仅仅是我们产生的推荐结果的观看记录。否则,新内容将很难出现,推荐器将过度倾向于利用exploitation。如果用户通过我们推荐以外的方式发现视频,我们希望能够通过协同过滤将这一发现快速传播给其他人。提升实时
metric的另一个关键洞察是:为每个用户生成固定数量的训练样本,这等效于在损失函数中认为所有用户同等重要。这防止了一小批高度活跃的用户来统治了损失函数。这里值得商榷:a. 是否活跃的用户更重要?这个问题不同的场景有不同的答案。 b. 每个用户生成固定数量的训练样本,必然会丢弃活跃用户的大量样本,这降低了训练数据量,降低模型效果。
虽然有点违背直觉,但是针对分类器的保留信息
withhold information(如hold out验证集或测试集)必须非常小心,从而防止模型利用网站的结构structure从而对代理问题过拟合。考虑这样的一个例子,用户刚刚提交了对
taylor swift的搜索query。由于我们的问题是预测下一个观看的视频,给定该搜索信息的分类器将预测最可能观看的视频是那些出现在taylor swift搜索结果页面上的视频。毫不意外的是,将用户上一次搜索页重新作为主页推荐列表,效果很差。通过丢弃序列信息,并用无序的
bag of token来表示搜索query,分类器将不再直接感知label的来源。视频的自然消费模式通常会导致非常不对称的
co-watch概率。例如:- 情景剧系列
episodic series通常是按顺序观看的。用户先看第一集、再看第二集的概率,远大于先看第二集、再看第一集。 - 用户通常会发现最流行流派
genre的艺术家,然后再关注较小的领域,而不是相反。
因此,我们发现预测用户的下一个观看
next watch要比预测一个随机hold-out(即,留一法)观看hold-out watch表现好得多。而很多协同过滤系统通过hold out一个随机item,然后从用户剩余的历史行为的其它item来预测这个item,从而隐式地选择label和上下文,如下图(a)所示。这会泄露未来的信息,并且会忽略任何非对称的消费模式asymmetric consumption pattern。相比值下,我们通过随机选择一个观看
watch,并且仅选择用户在这个hold out label之前的用户行为作为输入,从而rollback用户的历史行为记录。如下图(b)所示。如下图所示,选择模型的
label和input context对于离线评估具有挑战性,并且对于在线性能有很大影响。这里,实心事件event是网络的输入特征,而空心事件 不是网络的输入特征。我们发现:预测未来的观看(b) 在A/B test中表现更好。b中的example age表示为 ,其中 为训练数据中观察到的最大时刻。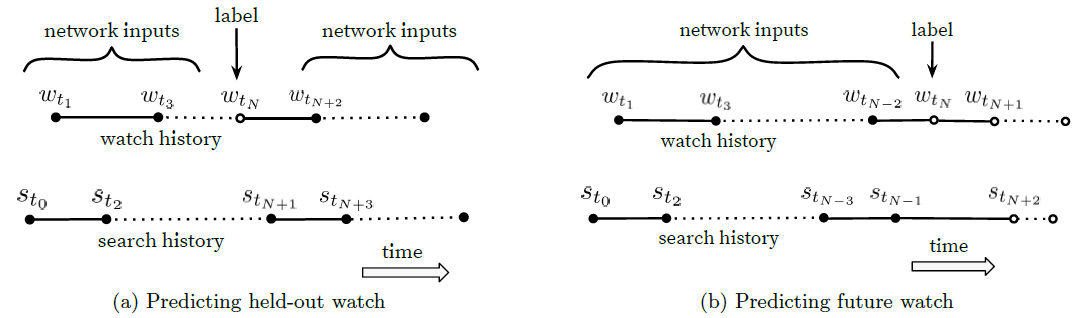
- 情景剧系列
实验结果:添加更多特征、加深模型深度显著提升了
hold out预估的精度precision,如下图所示。所谓
hold out预估指的是:label为hold out数据,特征为label之前的历史数据(如上图的b图所示)。实验中,包含
100万视频和100万搜索token的词典vocabulary被嵌入为256维的embedding向量。每个用户样本最多50个最近的观看,以及最多50个最近的搜索。softmax层输出在相同的100万个视频类别上的多项式分布,output向量的维度为256维(这可以被认为是一个独立的output video embedding)。这些模型在所有
YouTube用户上训练若干个epoch,直到收敛。网络结构遵循常见的
tower模式,其中网络的底部最宽、然后每个连续的隐层将神经元数量减半。我们进行了四组实验,深度不断增加,直到增加的收益减少并且收敛变得困难。depth 0:一个线性层,它仅仅转换这个concatenation layer来匹配softmax的维度256维。零深度的网络实际上是一种线性分解方案,它和先前
predecessor的系统非常相似。depth 1:256 ReLU。depth 2:512 ReLU --> 256 ReLU。depth 3:1024 ReLU --> 512 ReLU --> 256 ReLU。depth 4:2048 ReLU --> 1024 ReLU --> 512 ReLU --> 256 ReLU。
可以看到:特征越多,
holdout预估的Mean Average Precision: MAP越高;层的深度越深,MAP越高。因为更深的模型提升了表达能力,使得模型能够有效建模特征之间的交互。precision-k为top-k列表的推荐精准度,MAP@k为所有用户AP@k的平均。由于这里是留一法评估,因此k=1。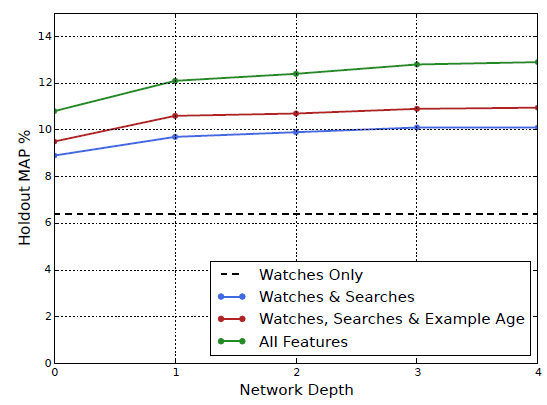
2.3 Ranking
Ranking的主要作用是使用曝光数据impression data来专门化specialize和校准calibrate特定用户界面particular user interface的候选预测。例如,用户通常可能以高概率观看给定的视频,但是由于缩略图thumbnail image的选择 ,因此不太可能点击给定的首页曝光homepage impression。在
ranking期间,我们可以访问更多的特征来描述视频、以及用户和视频之间的关系。因为只有数百个视频被评分,而不是对数百万个视频进行评分(在candidate generation中才需要对数百万个视频进行评分)。此外,
ranking对于集成ensembling来自不同候选源(每个候选源代表了一路召回通路)也至关重要,这些候选源之间的score不能直接比较(跨召回通路之间的召回score不是直接可比较的,但是召回通路内部的score是可以直接比较的)。我们使用和
candidate generation模型类似的深层神经网络,使用逻辑回归为每个视频曝光分配一个独立的score,如下图所示。然后视频列表根据这个分数排序并返回top-n视频给到用户。我们最终的
ranking目标是根据在线A/B test结果不断调整的, 但是通常是每个曝光的期望观看时长的简单函数。按点击率排名通常会鼓励用户观看一些未完成的欺骗性deceptive视频(点击诱饵clickbait),而观看时长可以更好地捕获用户的互动engagement。下图为
Ranking的深度网络体系架构,它描述了具有共享embedding的离散特征(单值univalent和多值multivalent),以及幂次power的归一化连续特征。所有的layer都是全连接的。实际上,数以百计的特征被馈入到网络中。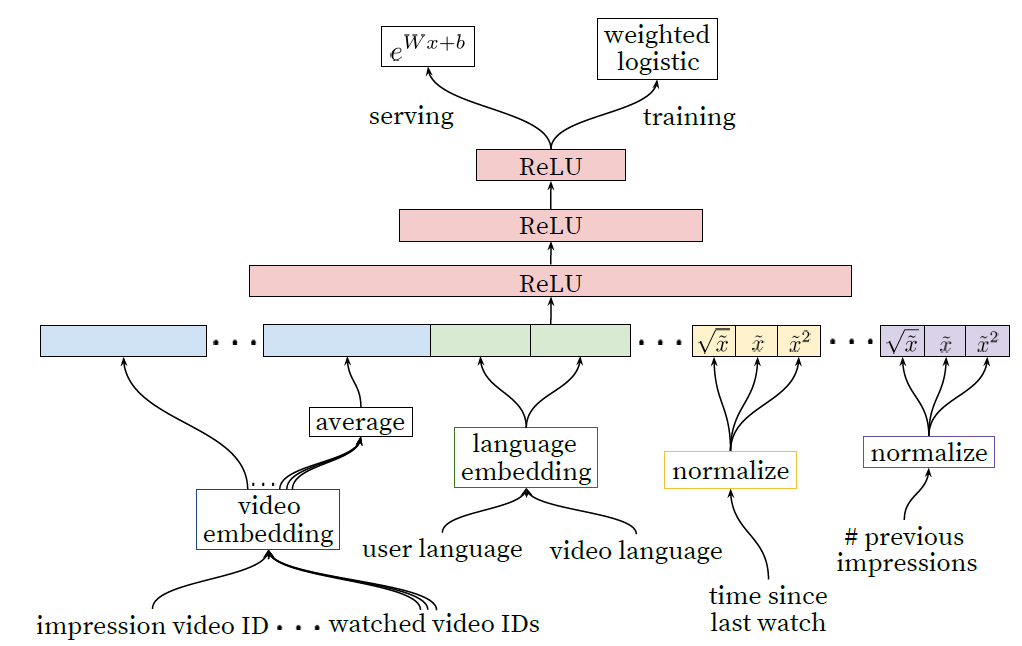
我们的特征与传统的离散特征、连续/常规特征这种分类体系不同。我们使用的离散特征的基数
cardinality差异很大:有些离散特征是二元的(如用户是否已登录),而另一些离散特征则具有数百万个可能的值(如用户上一次的搜索query)。我们将特征根据是仅贡献单个值(单值
univalent特征)、还是贡献一组值(多值multivalent特征)来进一步细分。单值离散特征的典型例子是被评分的曝光
impression的video ID。而相应的一个多值特征是用户最近观看的N个视频的video ID列表。我们还根据特征是描述
item(曝光impression)的属性,还是描述用户/上下文(query)的属性,来对特征进行分类。query特征针对每次请求request执行计算(即请求粒度),而曝光impression特征对每个被评分的item进行计算(即item粒度)。
特征工程:我们通常在
ranking模型中使用数百个特征,其中离散特征和连续特征大体上各占一半。尽管深度学习有望缓解手工特征工程的负担,但是原始数据的特性
nature不容易直接输入到前馈神经网络。我们仍然花费大量的工程资源将用户和视频数据转换为有用的特征。主要挑战在于如何表达用户行为的时间序列a temporal sequence of user action,以及这些行为如何与被评分的视频曝光video impression相关联。我们观察到,最重要的信号是那些描述用户之前与
item本身、以及其它类似item之间的交互interaction。这借鉴了其它工作在广告ranking上的经验。例如,考虑用户和需要评分的视频的频道
channel的历史记录:用户在这个频道观看了多少视频?用户最近一次看这个频道的视频是什么时候?这些描述用户过去在相关
item上的行为的连续特征是特别强大的,因为它们可以很好地在不同的item之间进行泛化。我们还发现:以特征的形式将
candidate generation中的信息传播到ranking过程中,这至关重要。例如,这个候选视频从哪个通路召回?这个候选视频的召回分是多少?
描述过去视频曝光
impression频率的特征对于在推荐中引入 “变动”churn也是至关重要的(连续的请求不会返回相同的推荐列表)。如果一个用户最近被推荐了一个视频,但是没有看,那么模型自然会在下一次页面加载
page load时剔除这个曝光impression。即剔除已经曝光过的
item(新鲜度过滤)。serving最新的曝光impression和观看历史是一个工程问题,这超出了本文的范围,但是对于产生响应性responsive推荐至关重要。
离散特征
embedding:和candidate generation模型类似,我们使用emebdding将稀疏离散特征映射到适用于神经网络的稠密representation。每个
unique的ID空间(vocabulary)都有一个独立的、待学习的embedding,其维度大约是和unique值数量的对数成正比。这些词典是简单的look-up table,通过在训练之前将数据传输一次来建立。非常大
cardinality的ID空间(如视频ID、搜索query的term)根据点击频次对top N进行截断。out-of-vocabulary取值简单地映射到全零的embedding。截断的原因是低频
ID出现次数太少,导致embedding学不好。实际上有更好的做法:进行hash映射。一方面hash映射不会对结果产生太大影响,另一方面它能自适应低频ID出现增量更新的情况。和
candidate generation一样,在多值离散特征embedding馈入网络之前,先对它们均值池化。重要的是,相同
ID空间中的离散特征共享底层的embedding。例如,我们有一个全局的视频
ID的embedding,所有用到视频ID的特征都将使用它(如曝光impression的视频ID、用户最近观看视频的视频ID等等)。尽管是共享的
embedding,但是每个特征都被独立地馈入到网络中,因此后续的layer可以学到每个特征的专门的representation。embedding共享对于提高泛化能力、加快训练速度、降低内存需求非常重要。
绝大多数模型参数都位于这些高基数
high-cardinality的embedding空间中。例如,一百万个ID映射到32维空间中,这比2048个神经元的全连接层的参数多7倍。归一化连续特征:众所周知,神经网络对于输入的缩放
scaling和分布distribution非常敏感,而诸如决策树集成ensemble模型之类的替代方法则对于特征的scaling是不变的。我们发现连续特征的适当归一化对于模型收敛至关重要。假设连续特征 的分布为 ,我们使用累积分布
cumulative distribution,通过缩放取值从而将该特征转换为 ,其中 在[0~1]之间均匀分布。在训练开始之前,通过对数据进行单次遍历来对特征取值的分位数进行线性插值,可以近似得到该积分。这种归一化实际上是
ranking归一化:即某个特征X的取值 在所有样本中X的所有取值的排名。实际上还有更简单的做法:在input层之后紧跟着一个BatchNormalization层。除了原始归一化特征 之外,我们还输入了幂次特征 ,使得网络能够轻松地构成特征的超线性函数、亚线性函数,从而赋予网络更强的表达能力。实验发现,向模型馈入幂次特征可以提高离线准确率。
建模期望观看时长
Expected Watch Time:我们的优化目标是在给定的训练样本(要么是点击样本、要么是未被点击)的情况下,预估期望观看时长expected watch time。其中,正样本带有用户观看视频所花费的时长。为了预估期望观看时长,我们使用了专门为该目标而开发的加权逻辑回归
weighted logistic regression。该模型以交叉熵损失为目标函数来训练逻辑回归,但是正样本(点击样本)会根据视频上的观看时长来加权,而所有的负样本(未点击样本)都采用单位权重。假设样本 的点击率为 ,则逻辑回归学到的几率为:
由于这里对正样本进行加权,则加权逻辑回归学到的几率为:
其中 为正样本的观看时长。考虑到 通常是一个很小的值,使得 ,因此有:
注:样本加权的方式有两种:
- 采样加权:对一条样本重复 次,其中 为加权的权重。
- 梯度加权:对样本的梯度乘以 。
从效率上看,第二种方式的计算量更小、计算效率更高。
从效果上看,如果没有随机混洗则二者效果相同(都是基于当前梯度之上的 个梯度的累加),否则二者效果不同(第一种方式中,每个样本的当前梯度都不同)。
在推断期间,我们有:
因此推断期我们使用指数函数 作为最终的激活函数,从而产生接近于预估的期望观看时长的几率。然后我们根据预估期望观看时长来进行排序。
注:由于 为单调递增函数,因此根据 排序等价于根据 排序。
表面上看,推断时没有进行样本加权,但是观看时长更长的视频预估的 更大。
实验结果:下表展示了我们在具有不同隐层配置下的、
next-day holdout数据上的实验结果。每个配置的取值(weighted, per-user loss)通过考虑为单个用户在单个页面上同时考虑正样本(点击的)、负样本(未点击的)的曝光impression来获取的。首先通过我们的模型来为这两种曝光
impression打分。如果负样本得分高于正样本,则我们认为正样本的观看时长是错误预测的观看时长。weighted per-user loss是在heldout数据上,所有错误预测的观看时长占总观看时长上的比例。可以看到:
增加隐层的宽度和深度都可以改善结果,但是代价就是推断期间所需的服务器
CPU时间。1024ReLU-512ReLU-256ReLU的配置获得了最佳的效果,同时使得我们能够保持在serving的CPU预算之内。- 对于
1024ReLU-512ReLU-256ReLU模型,我们尝试仅提供归一化的连续特征,而没有幂次特征,这会使得loss增加0.2%。 - 对于
1024ReLU-512ReLU-256ReLU模型,我们也尝试将正样本和负样本都是相等权重(相当于无加权)。毫无意外地,这使得观看时长的weighted loss显著增加了4.1%。
- 对于

2.4 总结
我们描述了推荐
YouTube视频的深度神经网络架构,分为两个不同的问题:candidate generation、ranking。candidate generation:我们的深度协同过滤deep collaborative filtering模型能够有效地吸收很多信号,并用深度网络对它们的交互进行建模,这优于以前在YouTube上使用的矩阵分解方法。- 在选择推荐的代理问题
surrogate problem方面,艺术多于科学。我们发现通过捕获不对称的co-watch行为和防止未来信息泄露,对未来观看future watch进行分类可以在在线指标上表现良好。 - 分类器中的
withholding discrimative signal(即label)对于获得好的结果也至关重要--否则模型会过拟合代理问题,并且不能很好地迁移到主页上。 - 我们证明了使用训练样本的
age作为输入特征消除了对过去past的固有偏见,并允许模型表示流行视频的时间依赖行为。这提高了离线holdout precision结果,并在A/B test中显著增加了最近上传的视频的观看时长。
- 在选择推荐的代理问题
ranking:ranking是一个更经典的机器学习问题,但是我们的深度学习方法优于以前的、用于观看时长预测的线性模型和基于树的模型。- 推荐系统尤其受益于历史用户行为(用户在
item上的行为)的专门特征。深度神经网络需要离散和连续特征的特殊表示,其中我们分别用embedding和分位数归一化来转换它们。深度的layer被证明能够有效地建模数百个特征之间的非线性相互作用。 - 逻辑回归被修改为通过正样本的观看时长来加权,而负样本的加权系数固定为单位权重。这允许我们学习与期望观看时长接近的几率
odds模型 。和直接预估点击率CTR相比,这种方法在观看时长加权的ranking评估指标上表现更好。
- 推荐系统尤其受益于历史用户行为(用户在
三、Recommending What Video to Watch Next[2019]
论文
《Recommending What Video to Watch Next: A Multitask Ranking System》描述了一个大规模的视频推荐排序系统ranking system。也就是说,给定用户当前正在观看的视频,推荐用户可能观看和喜欢的下一个视频。典型的推荐系统遵循两阶段设计,包括候选生成
candidate generation和排序ranking。本文重点研究排序阶段。在这个阶段,推荐器recommender从候选生成(如矩阵分解、或神经网络模型)中检索出几百个候选者,并应用复杂的、大容量的模型来对最有希望的item进行排序。我们展示了在大型工业视频发布和共享平台上构建这样一个排序系统的实验和经验教训。设计和开发一个真实世界的大规模视频推荐系统充满了挑战,其中包括:
我们想优化的目标
objective通常有所不同,有时甚至是相互竞争competing的。例如,我们可能想推荐用户评价高、并且分享(除了自己观看之外)给他们好友的视频。系统中经常存在隐性偏差
implicit bias。例如,用户点击并观看一个视频,可能仅仅是因为它排名最靠前,而不是因为用户最喜欢它。因此,使用当前系统生成的数据来训练的模型会有偏差
bias,导致反馈回路效应feedback loop effect。如何有效地学习降低这种bias是一个悬而未决的问题。
为应对这些挑战,我们为排序系统提出了一个高效的多任务神经网络架构,如下图所示。它通过采用
Multi-gate Mixture-of-Experts:MMoE来扩展了Wide&Deep框架,从而进行多任务学习。此外,它还引入了一个shallow tower来建模和消除选择偏差selection bias。我们将该架构应用于视频推荐来作为案例研究case study:给定用户当前正在观看的内容,推荐下一个要观看的视频recommend the next video to watch。我们在一个工业大型视频发布和共享平台上对我们提出的排序系统进行了实验。实验结果表明:我们提出的系统带来显著的提升。排序框架使用用户日志作为训练数据,并构建
Mixture-of-Experts layer来预估两类用户行为:互动engagement(如点赞、评论、分享、@好友等)、满意度satisfaction。它用侧塔side-tower修正了排序的选择偏差selection bias。最重要的是,多个预测结果被组合成一个最终的排序分ranking score。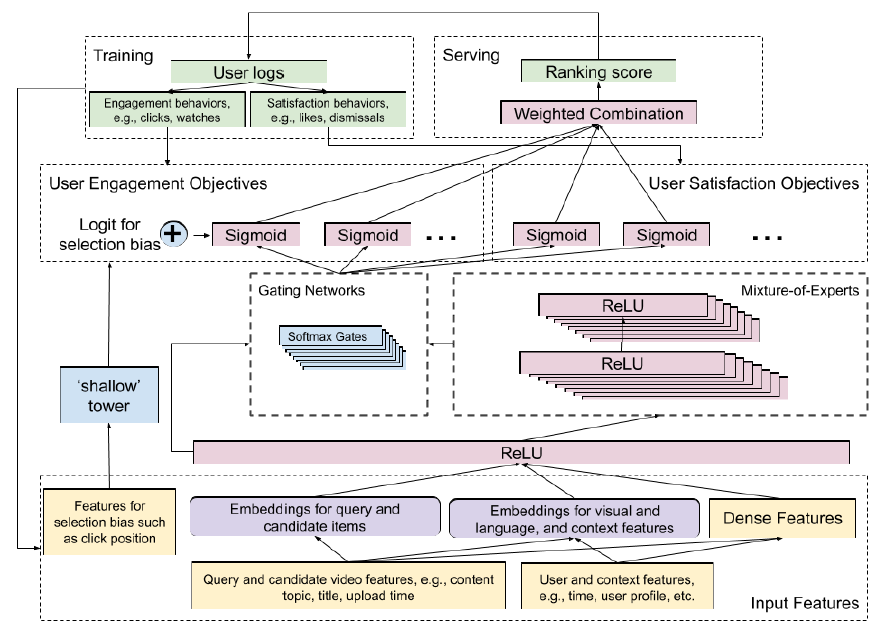
我们首先将我们的多个目标分为两类:
- 互动目标
engagement objective,如用户点击click、推荐视频的互动程度degree of engagement。 - 满意度目标
satisfaction objective,如用户喜欢YouTube上推荐的某个视频从而对推荐进行评分。
为了学习和评估多种类型的用户行为,我们使用
MMoE来自动学习参数,以便在潜在冲突的conficting目标之间共享。Mixture-of-Experts架构将输入层模块化为专家experts,每个专家聚焦于输入的不同方面aspect。这改善了来自多模态生成的复杂特征空间中学到的表示representation。然后,通过利用多个门控网络gating networks,每个目标可以选择和其它目标共享、或不共享专家。- 互动目标
为了从有偏差的训练数据中建模并减少选择偏差(如位置偏差
position bias),我们提出在主模型中添加一个shallow tower,如上图左侧所示。shallow tower接受与选择偏差相关的输入,例如当前系统决定的排序顺序ranking order,并输出标量作为主模型的最终预测的偏差项bias term。排序架构将训练数据中的
label分解为两部分:从主模型中学习的无偏用户效用unbiased user utility,以及从shallow tower中学习的估计倾向分estimated propensity score。我们提出的模型架构可以视为
Wide&Deep模型的扩展extension,其中shallow tower代表wide部分。通过与主模型一起直接学习shallow tower,我们受益于选择偏差的学习,而无需借助随机实验来获得倾向分propensity score。为评估我们提出的排序系统,我们设计并进行了一系列的在离线和在线实验,从而验证以下方法的有效性:多任务学习
multitask learning、消除一种常见的选择偏差(即,位置偏差)。和
state-of-the-art的baseline方法相比,我们提出的框架有显著的提升。我们使用最大的视频共享平台之一YouTube来进行我们的实验。总之,我们的主要贡献:
- 我们为视频推荐引入了端到端的排序系统。
- 我们将排序问题形式化为一个多目标学习问题,并扩展了
MMOE架构,从而提高所有目标的性能。 - 我们在真实世界的大规模视频推荐系统上评估了我们的方法,结果展示了显著的提升。
3.1 模型
3.1.1 相关工作
工业推荐系统:为设计和研发一个由机器学习模型支持的、成功的排序系统,我们需要的大量的训练数据。最近的大多数工业推荐系统在很大程度上依赖于大量的用户日志来构建它们的模型。
一种选择是直接询问用户对于
item效用utility的显式反馈explicit feedback。然而,由于成本太高,显式反馈的数量难以扩大scale up。因此,排序系统通常利用隐式反馈implicit feedback,例如对被推荐的item的点击和互动engagement。大多数推荐系统包含两个阶段:
候选生成
candidate generation:在candidate generation阶段,通常会使用多种信号源signal source和模型。例如,使用item之间的共现co-occurrence、使用协同过滤collaborative fltering、使用图上的随机游走random walk(它也代表了一种共现)、使用内容的representation来过滤等等。排序
ranking:在ranking阶段,广泛使用learning-to-rank框架的机器学习算法。例如,- 有的方法使用线性模型以及
tree-based模型探索了point-wise和pair-wise的learning to rank框架 。 - 有的方法使用
Gradient Boosted Decision Tree: GBDT用于point-wise排序目标ranking objective。 - 还有的方法使用以
point-wise ranking objective的神经网络来预估加权点击weighted click。
- 有的方法使用线性模型以及
这些工业推荐系统的一个主要挑战是可扩展性。因此,它们通常采用基础设施改进
infrastructure improvement和高效机器学习算法的结合。为了在模型质量和效率之间的权衡,一种流行的选择是使用基于深度神经网络的point-wise ranking模型。本文中,我们首先确定了工业排序系统中的一个关键问题:在被推荐的
item上,用户隐式反馈和真实用户效用true user utility之间的不一致性misalignment。随后,我们引入了基于深度神经网络的
ranking模型,该模型使用多任务学习技术multi-task learning technique来支持多个排序目标ranking objective,每个目标对应于一种类型的用户反馈。推荐系统的多目标学习:从训练数据中学习和预测用户行为具有挑战性。有不同类型的用户行为,如点击、评分
rating、评论commenting等。然而,每种类型的用户行为都不能独立地反映真实的用户效用。例如,用户可以点击一个item,但最终不喜欢它;用户可能仅仅为点击的item和互动的item提供评分。我们的排序系统需要能够有效地学习和评估多种类型的用户行为和效用
utility,并随后结合这些评估来计算ranking的最终效用分utility score。关于行为感知
behavior aware和多目标推荐的现有工作,要么只能在候选生成candidate generation阶段应用,要么不适合大规模在线ranking。例如,一些推荐系统扩展了协同过滤或者content-based系统,以从多个用户信号中学习user-item相似性。这些系统有效地用于候选生成,但是与基于深度神经网络的ranking模型相比,它们在提供最终推荐效果方面并不那么有效。另一方面,很多现有的多目标排序系统是为特定类型的特征和应用而设计的,例如文本
text和视觉vision。扩展这些系统以支持来自多模态的特征空间feature space(例如来自视频的标题文本、来自缩略图的视觉特征)将是具有挑战性的。同时,其他多目标排序系统(这些系统考虑了输入特征的多模态)无法扩展scale up,因为它们在有效共享多目标模型参数方面存在局限性。在推荐系统的研究领域之外,基于深度神经网络的多任务学习已经在许多传统的机器学习应用中进行了广泛的研究和探索,例如自然语言处理
nlp、计算机视觉computer vision。虽然很多为representation learning提出的多任务学习multi-task learning技术对于构建排序系统并不实用,但它们的一些构件building block启发了我们的设计。在本文中,我们描述了一个基于DNN的排序系统,该系统是为真实世界的推荐而设计的,并应用了Mixture-of-Experts layer来支持多任务学习。训练数据中
bias的理解和建模:用户日志用作我们的训练数据,它捕获当前生产系统production system中用户对于推荐的行为behavior和反映response。用户和当前系统之间的交互
interaction会在反馈feedback中产生选择偏差selection bias。例如,用户可能已经点击了一个item,仅仅是因为该item是当前系统选出来展现给用户的,而不是因为该item是整个语料库corpus中用户最喜欢的那个。因此,根据当前系统生成的数据之上而训练的新模型将偏向于当前系统,导致反馈回路效应feedback loop effect。如何有效和高效地学习减少系统的这种bias是一个悬而未决的问题。《Evaluating the accuracy of implicit feedback from clicks and query reformulations in web search》首先分析了隐式反馈数据中的位置偏差position bias和表示偏差presentation bias,从而训练learning to rank模型。通过比较点击数据和显式反馈之间的相关性,他们发现在点击数据中存在位置偏差,并可以显著地影响用于估计query和document之间相关性的learning to rank模型。根据这一发现,已经提出了很多方法来消除这种选择偏差,尤其是位置偏差。一种常用的做法是在模型训练中注入位置作为输入特征,然后在
serving阶段通过消融ablation来消除偏差 。在概率点击模型中,位置用于学习 。一种消除位置偏差的方法受到
《A dynamic bayesian network click model for web search ranking》的启发,他们使用 来推断CTR模型,并假设position = 1的推断没有没有位置偏差效应。随后,为了消除位置偏差,我们可以使用位置作为输入特征来训练模型,并通过将位置特征设为1(或者其他固定值,如缺失值)来做线上serving。其他方法试图从位置中学习一个偏差项
bias term,并将其作为一个归一化器normalizer或者正则化器regularizer。通常,要学习一个bias term,需要一些不考虑相关性的随机数据来推断这个bias项(也称作全局bias、或者倾向性propensity)。
在现实世界中的推荐系统中,尤其是像
Twitter, YouTube这样的社交媒体平台,用户行为和item流行度popularity每天都会发生显著变化。因此,当我们在训练ranking模型时需要一种有效的方法来适应训练数据分布的变化从而建模选择偏差。
3.1.2 系统概览
除了上述针对建立具有隐式反馈训练的排序系统的挑战之外,现实世界中的大规模视频推荐问题还需要考虑以下其他因素:
多模态特征空间
multimodal feature space:在上下文感知context-aware的个性化推荐系统中,我们需要学习候选视频的用户效用user utility,其中候选视频的特征空间是从多个模态生成的,例如视频内容、缩略图、音频、标题和描述description、用户人口统计特征user demographics。和其它机器学习应用相比,从多模态特征空间学习
representation以进行推荐具有独特的挑战性。它具有两个难点:- 从低级
low-level的内容中学习语义,以进行内容过滤content fltering。 - 从
item的稀疏分布中学习相似性,以进行协同过滤collaborative fltering。
- 从低级
可扩展性
scalability:可扩展性非常重要,因为我们正在为数十亿用户和视频构建一个推荐系统。模型必须能够有效地训练并高效地serving。尽管排序系统在每个
query仅对数百个候选视频评分,但现实中通常要求实时评分,因为一些query和上下文信息只能在线获取。因此,ranking sytem不仅需要学习数十亿个item和用户的representation,还需要在serving过程中保持高效。
回想一下,我们推荐系统的目标是在给定当前观看的视频和上下文的情况下,提供视频的排序列表
ranked list。为了处理多模态的特征空间,对于每个视频我们抽取诸如视频元数据meta-data、以及视频内容信号video content signal之类的特征作为视频的representation。对于上下文,我们使用诸如用户人口统计demographics、设备、时间、地理位置等特征。为了处理可扩展性,我们的推荐系统有两个阶段,即候选生成和排序。在候选生成阶段,我们从一个巨大的视频库中检索出几百个候选
item。我们的排序系统为每个候选视频提供一个分数,并生成最终排序列表。候选生成
candidate generation:我们的视频推荐算法使用多种候选生成算法,每种算法都捕获query video和候选视频之间相似性的一个方面。例如,一种算法通过召回
query video的主题来生成候选视频,另一种算法基于视频和query video共同观看的频率来检索候选视频。我们构建了一个类似于
《Deep neural networks for YouTube Recommendations》的序列模型,用于在给定用户历史记录的情况下生成个性化候选视频。最后,所有候选视频被聚集成一个
set,然后由排序系统来评分。排序
ranking:我们的排序系统会从数百名候选视频中生成排序列表ranked list。候选生成阶段试图过滤大多数
item,并只保留相关的item。和候选生成不同的是,排序系统旨在提供一个排序列表,以便对用户具有最高效用utility的item将显示在列表的头部。因此,我们在排序系统中应用最先进的机器学习技术(即一个神经网络架构),以便模型具有足够的表达能力来学习特征的关联、以及特征和效用的关系。我们的排序系统从两种类型的用户反馈中学习:互动行为
engagement behavior,如点击、观看;满意度行为satisfaction behavior,如喜欢like、拒绝dismissal。给定每个候选视频,排序系统使用候选视频的特征、
query和上下文作为输入,然后学习预测多种用户行为。对于问题的形式化,我们采用了
learning-to-rank框架。我们将排序问题建模为多目标分类问题和多目标回归问题的组合。给定query、候选视频、以及上下文,排序模型预测用户采取行为(如点击、观看、喜欢、拒绝)的概率。这种对每个候选视频进行预测的方法是一种
point-wise方法。相反,pair-wise或者list-wise方法对两个或者多个候选视频的排序进行预测。pair-wise或者list-wise方法可以用于潜在地提高推荐的多样性。然而,我们选择使用point-wise排序主要是基于serving的考虑。在serving阶段,point-wise排序简单有效,且可以扩展scale到大量候选视频。相比之下,pair-wise或者list-wise方法需要对pair对或者列表进行多次评分,从而在给定一组候选视频的情况下找到最有排序列表ranked list,这限制了它们的可扩展性。
3.1.3 排序目标
我们使用用户行为作为训练
label。由于用户可以对推荐的item具有不同类型的行为,我们设计了排序系统来支持多个目标。每个目标是预测一种与用户效用相关的用户行为。为了便于说明,在下文中我们将我们的目标分为两类:
- 互动目标
engagement objective:互动目标捕获用户的点击、观看等行为。我们将这些行为的预测形式化为两种类型的任务:针对诸如点击等行为的二元分类任务、以及针对观看时长等相关行为的回归任务。 - 满意度目标
satisfaction objective:满意度目标捕获用户点赞、点不喜欢等行为。我们将这些行为的预测形式化为二元分类任务或回归任务。例如,对视频点击 “喜欢” 这种行为被形式化为二元分类任务,而像评分行为被形式化为回归任务。
对于二元分类任务,我们计算交叉熵损失。对于回归任务,我们计算平方损失。
- 互动目标
一旦确定了多个排序目标
ranking objective及其问题类型,我们就会为这些预测任务训练一个多任务排序模型multitask ranking model。对于每个候选视频,我们采用这些多个预测的输入,并使用加权乘法形式的组合函数输出组合分数。加权的权重是手动调优的,从而在用户互动和用户满意度上同时达到最佳性能。
3.1.4 MMoE
多目标排序系统通常使用共享底部
shared-bottom的模型架构(如下图(a)所示)。然而,当任务之间的相关性较低时,这种硬参数共享hard-parameter sharing技术有时会损害多个目标的学习。为了缓解多目标的冲突conflict,我们采用并扩展了最近发布的Multi-gate Mixture-of-Experts: MMoE模型架构。MMoE是一种软参数共享soft-parameter sharing的模型架构,旨在对任务冲突和任务联系进行建模。它采用Mixture-of-Experts: MoE的结构,通过让专家experts在所有任务之间共享来进行多任务学习,同时还为每个任务训练了一个门控网络gating network。MMoE layer旨在捕获任务差异,而不需要比shared-bottom模型多得多的模型参数。它的关键思想是用MoE layer代替共享的ReLU layer,并为每个任务添加一个独立的门控网络。对于我们的排序系统,我们提出在共享的
hidden layer之上添加专家,如下图(b)所示。这是因为MoE layer能够帮助从它的输入中学习模块化信息modularized information。当直接在输入层或更低层的hidden layer之上使用时,它可以更好地建模多模态特征空间。然而,直接在输入层应用MoE layer将显著增加模型训练和serving成本。这是因为通常输入层的维度要比hidden layer的维度高得多。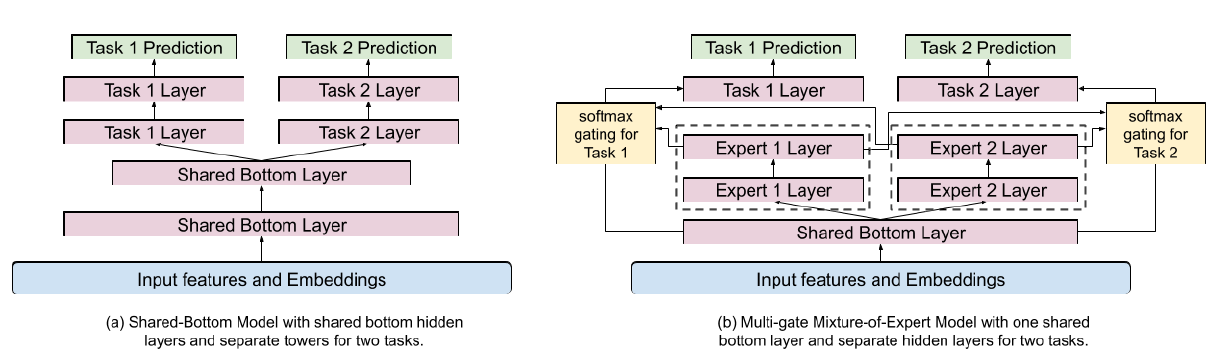
我们的专家网络
expert network的实现和采用ReLU激活函数的多层感知机相同。对于任务 ,假设最后一层的
hidden layer(即上图(b)中的Task k Layer)的函数为 ,则带 个专家的MMoE layer对于任务 的输出为:其中:
- 为低层的共享
hidden embedding。 - 为任务 的门控网络,而 为 的第 项,对应于任务 中第 个专家的权重。
- 为第 个专家,一共有 个专家。
- 为所有 个专家在任务 上的加权和,它是
Task k Layer的输入。
- 为低层的共享
门控网络只是对输入线性变换然后通过一个
softmax层:其中 是任务 门控网络的、线性变换的参数。
在论文
《Outrageously large neural networks: The sparsely-gated mixture-of-experts layer》的稀疏门控网络中,专家的数量很大,并且每个训练样本进使用表现最好的专家。与之相反,我们使用相对较少的专家。这是为了鼓励通过多个门控网络共享专家并提高训练效率。
3.1.5 选择偏差
隐式反馈已被广泛用于训练
learning-to-rank模型。可以通过从用户日志中提取大量的隐式反馈来训练复杂的深度神经网络模型。然而,由于隐式反馈是从现有的排序系统生成的,因此存在偏差
bias。位置偏差position bias以及很多其他类型的选择偏差被证明存在于不同的排序问题ranking problem中。在我们的排序系统中,
query是当前正在观看的视频,候选是相关的视频。通常,用户倾向于点击并观看更靠近列表头部展示的视频,而不管它们的的实际用户效用--无论是与观看视频的相关性还是用户的偏好。我们的目标是从排序模型中消除这种位置偏差。在我们训练数据中或者在模型训练期间建模和减少选择偏差可以导致模型质量的提高,并打破由选择偏差导致的反馈环路
feedback loop。我们提出的模型架构类似于
Wide&Deep模型架构。我们将模型预测分解为两个部分:主tower的用户效用部分user-utility component、和shallow tower的的偏差部分bias component。具体而言,我们训练一个
shallow tower,它采用有助于选择偏差的特征,如针对位置偏差的位置特征position feature。然后将shallow tower添加到主模型的最终logit中去,如下图所示。- 在训练阶段我们使用所有曝光的位置,并使用
10%的位置特征drop-out rate从而防止我们的模型过度依赖位置特征。 - 在
serving阶段,位置特征被视为缺失。
注意:我们将位置特征和设备特征交叉的原因是:在不同类型的设备上会观察到不同的位置偏差。因为不同设备的屏幕大小不同,导致呈现的
item列表有所差异。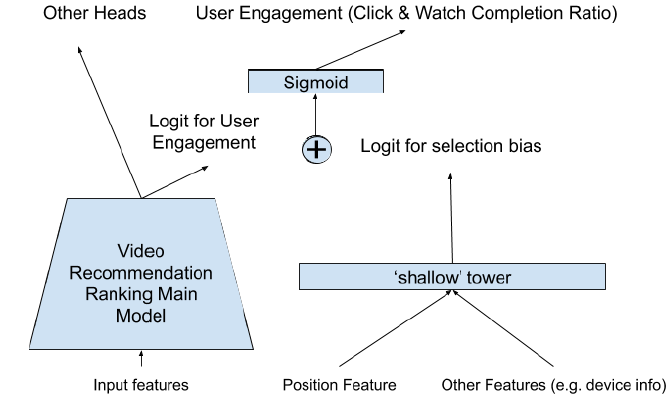
- 在训练阶段我们使用所有曝光的位置,并使用
3.1.6 讨论
这里我们讨论一些洞察和局限性,这些都是我们从开发和实验我们的排序系统的过程中学到的。
推荐和排序任务的神经网络模型架构:很多推荐系统领域的研究论文扩展了最初为传统机器学习应用程序设计的模型架构,如用于
natural language processing: NLP的multi-headed attention、用于计算机视觉的CNN。然而,我们发现这些模型体系架构中的很多仅适用于特定领域的representation learning,并不直接适用于我们的需求。这是因为:- 多模态
Multimodal特征空间:我们的排序系统依赖于多个特征源source,例如来自于query和item的内容特征、上下文特征。这些特征从稀疏的离散空间sparse categorical space、到自然语言、到图像等等。从混合特征空间中学习是一项挑战。 - 可扩展性
scalability和多个排序目标:许多模型架构被设计为捕获一种类型的信息,如特征交叉feature cros或序列信息sequential information。它们通常会提升一种排序目标,但是可能会损害其他排序目标。此外,在推荐系统中应用复杂模型架构的组合几乎无法扩展。 - 带噪音
noisy的和局部稀疏locally sparse的训练数据:我们的系统需要为item和query训练embedding向量。然而,我们的大多数稀疏特征遵循幂律分布power-law distribution,并且对于用户反馈有很大的分布差异。例如,在上下文稍有不同的情况下,即使给定相同的query,用户可能点击也可能不点击推荐的item。而这在我们的系统中是无法捕获的。这给优化长尾的尾部item的embedding空间带来了很大的困难。 mini-batch随机梯度下降的分布式训练:我们依靠一个具有强大表达能力的大型神经网络模型来找出特征关联feature association。由于我们的模型消耗了大量的训练数据,我们不得不使用分布式训练,这本身就带来了固有intrinsic的挑战。
- 多模态
效果
efectiveness和效率eficiency之间的平衡tradeoff:对于现实世界的排序系统,效率不仅影响serving成本,还影响用户体验。过于复杂的模型会显著增加生成推荐item的延时latency,从而降低用户满意度和在线指标。因此,我们通常更喜欢更简单、更直接straight-forward的模型架构。训练数据中的
biases:除了位置偏差之外,还有许多其他类型的偏差。其中一些偏差可能是未知和不可预测的。例如,由于我们的系统在获取训练数据方面的局限性(对于未曝光的item,我们压根不知道用户对它们是否会发生行为)。如何自动学习和捕获训练数据中已知和未知的偏差是一个长期的挑战,需要做更多的研究。
评估方法
evaluation的挑战:由于我们的排序系统主要使用了用户的隐式反馈,离线评估得到的效果提升结论并不一定会转化为在线性能提升。事实上,我们经常观察到离线和在线指标之间的不一致misalignment。因此,最好选择一个总体上更简单的模型,以便可以更好地泛化到在线性能。未来方向:除了
MMoE和消除位置偏差之外,我们正在沿着以下方向改进我们的排序系统:探索用于多目标排序的、新的模型架构,该架构平衡了稳定性
stability、可训练性trainability和表达能力expressiveness。我们注意到,
MMoE通过灵活地选择共享哪些专家从而提高多任务排序性能。最近的一些工作在不损害预测性能的情况下进一步提高了模型的稳定性。理解并学习分解
factorize。为了对已知和未知的偏差进行建模,我们希望探索模型架构和目标,这些架构和目标能够从训练数据中自动识别潜在偏差、并学会减少这些偏差。模型压缩
compression:出于降低serving成本的需要,我们正在探索用于排序和推荐模型的、不同类型的模型压缩技术。
3.2 实验
利用
YouTube提供的用户隐式反馈,我们训练了我们的排序模型,并进行了离线和在线的实验。YouTube的规模和复杂性使其成为我们排序系统的完美测试平台。YouTube的最大的视频分享平台,月活用户19亿。该网站每天创建了千亿级的用户日志,其中记录了用户和推荐结果之间的互动。YouTube的一个关键产品提供了在给定观看视频的情况下推荐下一个观看视频的功能(what video to watch next),如下图所示。它的用户界面为用户提供了多种与推荐视频交互的方式,如点击、观看、喜欢、拒绝dismissal。
实验配置:如前所述,我们的排序系统从多个候选生成算法中召回了几百个候选视频。我们使用
TensorFlow构建模型并训练和serving。具体而言,我们使用Tensor Processing Unit: TPU来训练我们的模型,并使用TFX Servo来serve。我们对提出的模型和
baseline模型都是串行sequentially地训练。这意味着我们根据时间顺序来组织训练数据从而训练我们的模型,并持续训练模型以消耗新到达的训练数据。通过这种方式,我们的模型适应了最新的数据。这对于很多现实世界的推荐应用程序application而言是至关重要的,在这些应用程序中,数据分布和用户模式会随着时间动态变化。对于离线实验,我们评估分类任务的
AUC和回归任务的平方误差。对于在线实验,我们进行了与生产系统production system相比较的A/B test实验。我们使用离线和在线指标来调整超参数,如学习率。我们检查了多个互动指标
engagement metric(诸如在YouTube上花费的时长等),以及满意度指标(如拒绝率dismissal rate、用户调查回访user survey response等)。除了在线指标之外,我们还关注模型在
serving时的计算成本,因为YouTube每秒都需要响应大量的query。
3.2.1 MMoE
为了评估采用
MMoE进行多任务排序的性能,我们与baseline方法进行了比较,并在YouTube上进行了在线实验。baseline方法:我们的baseline方法采用共享底部模型架构shared-bottom model architecture。我们以每个模型体系架构内的乘法数量来衡量模型的复杂度,因为这是模型
serving的主要计算成本。当比较
MMoE模型和baseline模型时,我们使用相同的模型复杂度。出于效率的考虑,我们的MMoE layer只有一层底部共享hidden layer,它使用比输入层更低的维度。YouTube上的在线实验结果如下表所示,其中MMoE模型使用4个专家或8个专家。我们报告了互动指标和满意度指标的结果。互动指标给出用户在观看推荐视频上所花的时长,满意度指标给出用户在调查回访中的评分。
可以看到:在相同模型复杂度的情况下,
MMoE显著提升了互动和满意度指标。
门控网络的分布
Gating Network Distribution:为进一步了解MMoE如何帮助多目标优化multi-objective optimization,我们绘制了softmax门控网络中每个专家上每个任务的累计概率accumulated probability,如下图所示。可以看到:一些互动任务
engagement task和其它互动任务共享多位专家,而满意度任务satisfaction task倾向于共享一小部分高效用high utilization的专家 ,这是通过使用这些专家的累计概率来衡量的。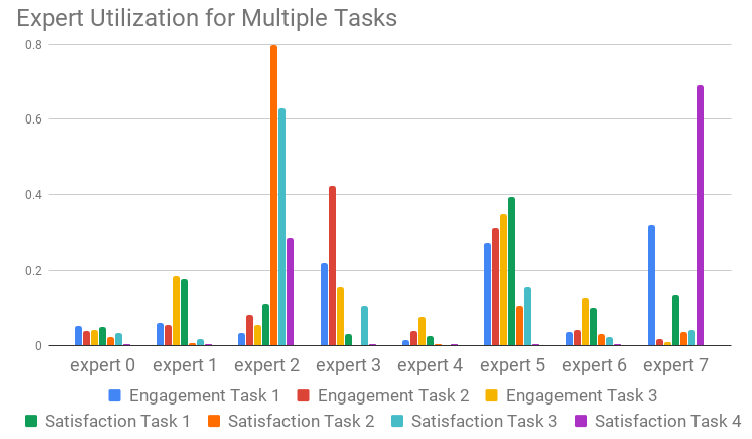
如前所述,我们的
MMoE layer共享一个bottom hidden layer,它的门控网络从共享的隐层获取输入。与直接从输入层构造MMoE layer相比,这可能使MMoE layer更难于模块化modularize输入信息。或者,我们让门控网络直接从输入层而不是共享隐层获取输入,以便让输入特征可以直接用于选择专家。然而,在线实验结果显示这种变体没有显著差异。因此,门控网络从共享隐层获取输入可以有效地将输入信息模块化到专家中,从而建模任务关系和任务冲突
conflict。门控网络稳定性
Gating Network Stability:当使用多台机器训练神经网络模型时,分布式训练策略会导致模型经常发散diverge(即不收敛)。发散的一个例子是ReLU死亡。在
MMoE中,据报道softmax门控网络具有不平衡的专家分布问题imbalanced expert distribution problem,其中门控网络收敛到绝大多数专家的效用为零zero-utilization。通过分布式训练,我们观察到在我们的模型中有20%的机会出现这种门控网络的极化问题polarization issue。门控网络的极化会损害使用该门控网络的模型的性能。为解决这个问题,我们在门控网络上应用了
drop-out。通过采用dropout rate = 10%,以及re-normalizing重新标准化softmax输出,我们消除了所有门控网络的极化。
3.2.2 Position Bias
使用用户隐式反馈作为训练数据的一个主要挑战是难以建模隐式反馈和真实用户效用之间的差距
gap。使用多种类型的隐式反馈信号和多个排序目标,我们可以在
serving阶段进行更多手段的调优tune,从而在item推荐中捕获模型预估到用户效用之间的转换。但是,我们仍然需要建模和减少隐式反馈中普遍存在的偏差,例如,由用户和当前推荐系统之间的交互引起的选择偏差。在这里,我们评估如何使用我们提出的轻量级模型架构
light-weight model architecture来建模和减少位置偏差position bias(一种类型的选择偏差)。我们的解决方案避免了随机实验或者复杂计算的代价。用户隐式反馈的分析:为了验证我们的训练数据中是否存在位置偏差,我们对不同位置的点击率
click through rate: CTR进行了分析。下图给出了位置1 ~ 9的相对CTR( 进行了同比例缩放)。正如预期所示,随着位置越来越低,点击率将显著降低。较高位置的点击率较高,这是由于推荐了更相关的
item、以及位置偏差的综合效果。使用我们提出的
shallow tower方法,我们在下面证明了该方法可以将用户效用的学习和位置偏差的学习分开。
baseline方法:为了评估我们提出的模型架构,我们将它与下面的baseline方法进行比较。直接使用位置特征作为输入特征:这种简单的方法已经在工业推荐系统中广泛使用,从而消除位置偏差。该方法用于线性的
learning-to-rank模型。对抗学习:受到领域适配
domain adaptation和机器学习公平性machine learning fairness中广泛采用的对抗学习的启发,我们使用类似的技术来引入辅助任务,该辅助任务可以预测训练数据中的位置position。随后,在反向传播阶段,我们将传递给主模型的梯度取反,确保主模型的预测不依赖于位置特征。
下表给出了我们提出的方法和
baseline方法的在线实验结果。可以看到:我们提出的方法通过建模和减少位置偏差,显著提升了互动指标。
下图显示了每个位置学到的位置偏差。可以看到:对于较低的位置,学到的偏差较小。
学到的偏差是通过有偏差的隐式反馈来得到的倾向分
propensity score的估计。使用足够的训练数据进行模型训练,我们可以有效地减少位置偏差。
四、ESAM[2020]
排序模型
ranking model的典型公式formulation是:在给定query的情况下提供item的一个排序列表rank list。它具有广泛的应用,包括推荐系统、搜索系统等。排序模型可以形式化为: ,其中:- 是
query,例如推荐系统中的用户画像和用户行为历史、个性化搜索系统中的用户画像和关键词keyword,这取决于特定的排序应用。 - 代表基于 检索的相关
item,例如文本文档、item、问题答案answer。 - 由 和整个
item空间中每个item之间的相关性得分 组成, 为item的总数。
简而言之,排序模型旨在选择与
query相关性最高的top K个item作为最终的排序结果。目前,基于深度学习的方法广泛应用于排序模型,这些方法显示出比传统算法更好的排序性能。然而,这些模型主要是使用曝光
item的隐式反馈(如点击click、购买purchase)来训练,但是在提供serving服务时被用来在包含曝光item和未曝光item的整个item空间中检索item。我们根据曝光频率将整个
item空间分为热门item和long-tail长尾item。通过分析两个公共数据集(MovieLens和CIKM Cup 2016),我们发现:82%的曝光item是热门item,而85%的非曝光item是长尾item。因此,如下图所示,样本选择偏差sample selection bias: SSB的存在会导致模型对曝光item(大部分是热门item)过拟合,并且无法准确预测长尾item。图(b)给出了CIKM Cup 2016数据集上的SSB问题:由于SSB问题导致长尾性能很差。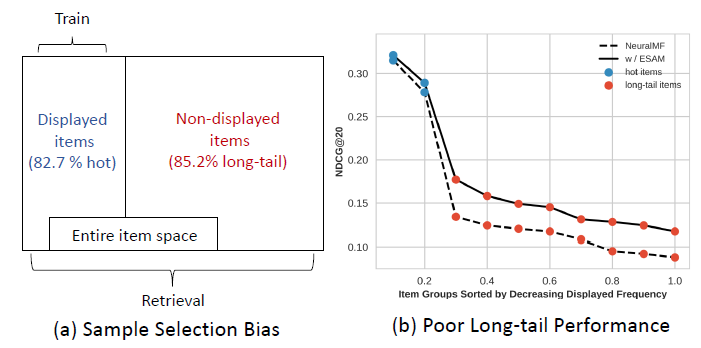
更糟糕的是:这种训练策略将使得模型偏向于热门
item。这意味着这些模型通常会检索热门item,而忽略那些更合适的长尾item,尤其是那些新上架的item。这种现象被称作 “马太效应”Matthew Effect。我们认为造成这种现象的原因是
SSB导致长尾item缺乏记录(即反馈)来获得良好的特征representation,即数据稀疏data sparsity和冷启动cold start问题。因此和拥有足够记录的热门item相比,长尾item的特征具有不一致inconsistent的分布。如下图所示,领域漂移domain shift的存在意味着这些排序模型很难检索长尾item,因为它们总是过拟合热门item。下图中,蓝色为曝光item、红色为未曝光item,不同形状(三角形、圆形、方形)表示不同反馈类型,十字星表示query,黄色阴影表示query覆盖的item。
为了提高排序模型的长尾性能并增加检索结果的多样性,现有方法利用了不容易获取的辅助信息
auxiliary information或者辅助域auxiliary domain。遵循一些过去的工作,论文《ESAM: Discriminative Domain Adaptation with Non-Displayed Items to Improve Long-Tail Performance》强调了学习未曝光item的良好特征representation的重要性。为了实现这一点,考虑到曝光item和未曝光item之间的领域漂移导致的长尾性能不佳、以及未曝光item是未标记样本,我们采用了无监督unsupervised领域自适应domain adaptation: DA技术,将曝光item视为源域source domain、将未曝光item视为目标域target domain。领域自适应方法允许将带标签的源域训练的模型应用到带很少标签或者缺失标签的目标域。以前的
DA-based工作通过最小化一些分布度量来减少领域漂移,如最大平均差异maximum mean discrepancy: MMD,或者对抗训练。对于排序任务,我们提出了一种新的DA方法,称作属性相关性对齐attribute correlation alignment: ACA。无论一个item是否曝光,其属性之间的相关性都遵循相同的规则(即知识knowledge)。例如在电商中,一个item的品牌越豪华luxurious,其售价就越高(品牌brand和价格都是item的属性)。该规则对于曝光item和未曝光item都相同。在一个排序模型中,每个item都会通过特征提取器feature extractor表示为一个特征representation,特征的每个维度都可以看做是item的一个高级属性high-level attribute。因此,我们认为高级属性之间的相关性在曝光空间和未曝光空间中都应该遵循相同的规则。然而由于缺乏
label信息,模型不能很好地获得未曝光item的特征。这导致曝光item和未曝光item的特征分布之间的不一致inconsistency,使得上述范式paradigm难以成立。因此,我们设计了属性相关一致性attribute correlation congruence: A2C来利用高级属性之间的成对相关性pair-wise correlation作为分布(从而增加分布一致性的约束)。虽然前面提到的
ACA算法可以解决分布不一致的问题,但是有两个关键的限制:使用
point-wise交叉熵的学习会忽略空间结构信息,从而导致特征空间中的邻域关系较差。如下图所示:尽管领域偏移得到缓解,但是较差的邻域关系使得模型很容易检索到异常值outlier。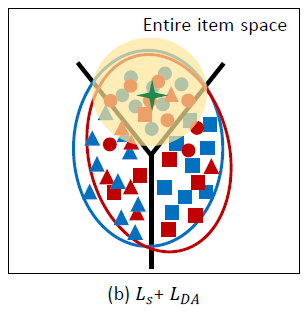
未曝光
item的target label不可用,这可能在盲目地对齐分布aligning distribution时容易导致负向迁移negative transfer。负向迁移指的是迁移模型transfer model比非自适应模型non-adaptation model更差的窘境。如下图所示:类别无关的
ACA可能导致负向迁移,如一些target域(红色)的圆形和source域(蓝色)的三角形对齐。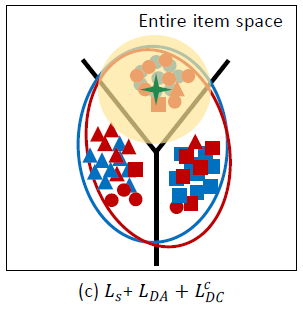
为了克服这两个困难,我们提出了两个新的正则化策略:中心聚类
center-wise clustering和自训练self-training,从而增强DA过程。- 中心聚类:我们观察到:对于同一个
query,具有相同反馈的item是相似的、具有不同反馈的item是不相似的。例如,在电商中,当向用户曝光各种手机时,用户可能点击所有的iPhone而忽略其它手机。因此,对于每个query,我们可以根据反馈类型对曝光的item进行分类categorize。我们提出的中心聚类是为了使相似的item紧密地结合在一起,而不相似的item相互分离。这种约束可以为DA提供进一步的指导,导致更好的排序性能。 - 自训练:对于
target label的缺失,我们给target item分配高置信度的伪标签pseudo-label,并通过自训练self-training使模型拟合这些item。此外,当在执行对齐alignment时考虑这些伪标签时,模型可以逐渐正确地预测更复杂的item。
综上所述,本文的主要贡献:
提出了一种通用的全空间自适应模型
entire space adaptation model: ESAM,该模型利用属性相关对齐attribute correlation alignment: ACA的领域自适应domain adaptation: DA来提高长尾性能。ESAM可以很容易地融入大多数现有的排序框架。引入两种新颖而有效的正则化策略来优化邻域关系和处理
target label缺失,从而实现有区分性discriminative的领域自适应。在
item推荐系统和个性化搜索系统这两个典型的排序应用中实现了ESAM,并在两个公开数据集、一个淘宝工业数据集上的实验结果证明了ESAM的有效性。另外,我们将
ESAM部署到淘宝搜索引擎上,通过在线A/B test测试,结果表明ESAM产生更好的性能。
- 是
在不需要任何辅助信息
auxiliary information和辅助领域auxiliary domain的情况下,ESAM将知识从曝光item迁移到未曝光item,从而缓解曝光item和未曝光item的分布不一致性distribution inconsistency。下图为
ESAM的基本思想,其中:三种形状代表三种反馈,蓝色代表源域(曝光item空间),红色代表目标域(未曝光item空间),星星代表query,带阴影的星星代表一个query及其检索范围。- 图
(a):曝光item特征和未曝光item特征之间的领域漂移。 - 图
(b):我们提出的属性相关性对齐的领域自适应可以有效缓解领域漂移。虽然领域漂移得到缓解,但是较差的邻域关系使得模型很容易检索到异常点outlier(簇内有不相似的item)。 - 图
(c):我们提出的中心聚类鼓励更好的流形结构manifold structure。但是,类别无关class-agnostic的ACA可能会导致负向迁移,如某些目标域的圆形和源域的三角形对齐。 - 图
(d):ESAM抽取了最佳的item特征representation。
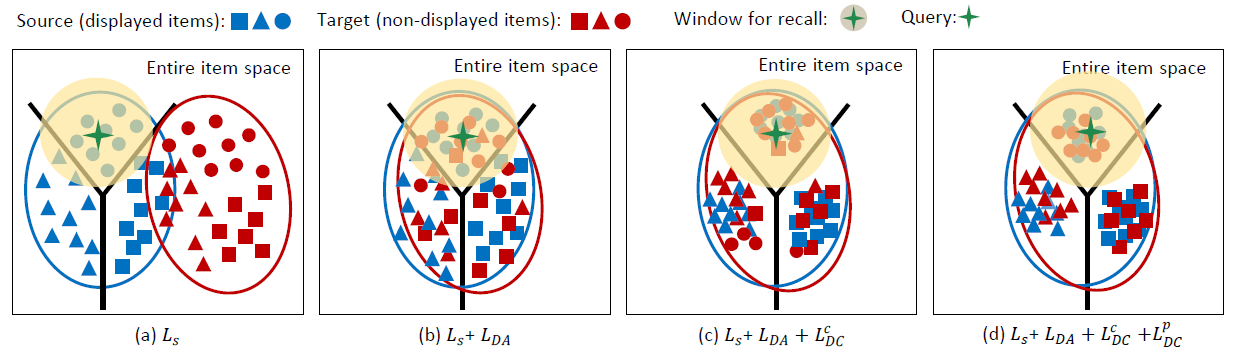
- 图
相关工作:
基于神经网络的排序模型:最近,很多工作使用神经网络来完成排序任务。排序模型的一个重要发展是深度的
learning to rank: LTR。为了解决这个问题,一些方法利用领域自适应技术,如最大均值差异
maximum mean discrepancy: MMD(《Domain Adaptation for Enterprise Email Search》)、对抗训练(《An Adversarial Approach to Improve Long-Tail Performance in Neural Collaborative Filtering》),从而缓解源域和目标域的不一致分布。此外,一些方法(
《Causal embeddings for recommendation》,《Improving Ad Click Prediction by Considering Non-displayed Events》)引入了无偏系统(即,为一个query从整个item池中随机选择item)获得的无偏数据集来训练无偏模型。此外,还有一些方法引入辅助信息(
《Improving Ad Click Prediction by Considering Non-displayed Events》,《DARec: Deep Domain Adaptation for Cross-Domain Recommendation via Transferring Rating Patterns》)或辅助域(《Cross-domain Recommendation Without Sharing User-relevant Data》,《Cross-Domain Recommendation: An Embedding and Mapping Approach》)从而获得更多的长尾信息。与之前的方法不同,
ESAM结合领域自适应和未曝光item来提高长尾性能,无需任何辅助信息和辅助域。此外,我们设计了一种新颖的领域自适应技术,称作属性相关性对齐,将item高级属性之间的相关性视为要传递的知识。区分性的领域自适应
Discriminative Domain Adaption:领域自适应将知识从大量标记的源样本迁移到具有缺失或有限标签的目标样本,从而提高目标样本性能。领域自适应最近得到了广泛研究。这些领域自适应方法通过嵌入用于矩匹配
moment matching的自适应层adaptation layer来学习领域不变性domain-invariant feature,例如:- 最大平均差异
maximum mean discrepancy: MMD(《Deep joint two-stream Wasserstein auto-encoder and selective attention alignment for unsupervised domain adaptation》)。 - 相关性对齐
correlation alignment: CORAL。 - 中心矩差异
center moment discrepancy: CMD(《Central moment discrepancy (cmd) for domaininvariant representation learning》)。
也有一些领域自适应方法集成领域判别器
domain discriminator进进行对抗训练,如领域对抗神经网络domain adversarial neural network: DANN(《Domain-adversarial training of neural networks》)和对抗判别领域适应adversarial discriminative domain adaptation: ADDA(《Adversarial discriminative domain adaptation》)。还有一些方法努力学习更多的判别特征从而提高性能,例如对比损失
contrastive loss(《Dimensionality reduction by learning an invariant mapping》) 和中心损失(《Large-margin softmax loss for convolutional neural networks》)。这些方法已经在很多应用中被采纳,例如人脸识别和person re-identification。受到上述方法的启发,我们提出对整个空间具有更好判别力的
item特征进行领域自适应。- 最大平均差异
4.1 模型
我们首先介绍了名为
BaseModel的基本排序框架,然后包括A2C和两个正则化策略的ESAM被集成到BaseModel中,以便在整个空间中更好地学习item特征representation。下图给出了ESAM的总体框架。我们将剔除未曝光
item(未曝光的item同时也是无标签的) 输入流input stream的ESAM视为BaseModel。下图中红色箭头为未标记的未曝光item,BaseModel即为剔除红色的部分。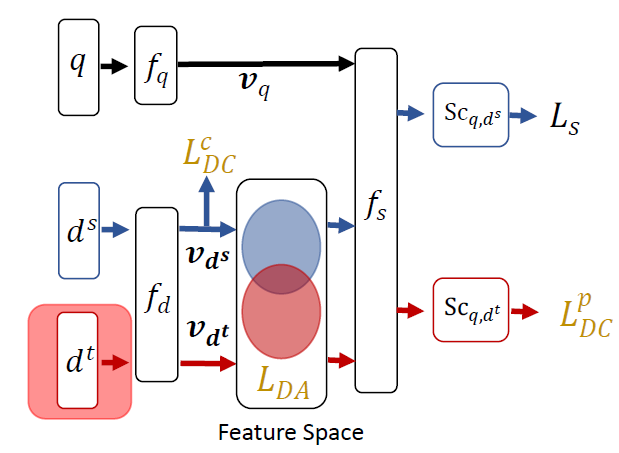
本文中,源域
source domain(曝光item)记作 ,目标域target domain(未曝光item)记作 ,整体item空间记作 。源域和目标域共享相同的query集合 。从一个query到一个item的反馈集合记作 ,其中:- 为特定的
query,如关键词keyword、用户画像user profile、问题question等等。 - 为一个
item,如文本文档、item、问题答案answer等等。 - 为一个隐式反馈,如是否点击、是否收藏等等。
对于每个
query:- 我们分配一个标记的
source item集合 ,它们的反馈是可用的。其中 为对query有反馈的item的数量, 为对应的反馈类型、 为对应的反馈item。 - 我们也分配一个未标记的
target item集合 ,它们是从未曝光item中随机选择的。其中 为随机采样的item的数量, 为采样到的item。
对于每个
query,排序模型的目标是从 中检索一个排序的item集合 ,从而最大化query的满意度satisfaction。- 为特定的
4.1.1 BaseModel
从下图可以看到:排序模型主要由
query side和item side来组成。排序模型的核心任务是:将一个query和一个item分别通过 和 映射成一个query特征 和一个item特征 。这可以公式化为:当获得
query和item的特征之后,我们利用评分函数 来计算query和item的相关性得分relevance score:然后:
在训练阶段,可以通过使用隐式反馈来训练排序模型,其中模型的损失函数为 (例如,
point-wise目标函数、pair-wise目标函数、list-wise目标函数)。注意,隐式反馈在大多数现实应用中可用,因此
point-wise目标损失被广泛用于模型训练。在
serving阶段,相关性得分最高的top-K个item组成的排序列表rank list可以作为检索结果。
最近,很多工作设计了新的 和 来抽取更好的特征。例如:
- 神经矩阵分解
neural matrix factorization: NeuralMF:采用MLP作为 和 来分别抽取query特征和item特征。 - 深度兴趣演化网络
deep interest evolution network: DIN:在 和 之间引入注意力机制。 - 行为序列
transformerbehavior sequence transformer: BST:在 中引入transformer模块来捕获query的短期兴趣。
然而,大多数方法都忽略了对未曝光
item的处理,因此这些体系架构解决方案可能无法很好地泛化generalize(到长尾item)。- 神经矩阵分解
4.1.2 ESAM
ESAM的思想是:通过抑制曝光item和未曝光item之间的分布不一致inconsistent distribution从而提高长尾性能。实现该思想的方法是:利用未曝光
item的有区分性的领域自适应discriminative domain adaptation从而在整个item空间中抽取更好的item特征。ESAM主要聚焦于item侧 的改进。具体而言,如上图所示,ESAM另外引入了一个未曝光item(未曝光的同时也是无label的)输入流input flow,它对BaseModel的 有三个约束:属性相关性对齐的领域自适应Domain Adaptation with Attribute Correlation Alignment、面向源聚类的中心聚类Center-Wise Clustering for Source Clustering、面向目标聚类的自训练Self-Training for Target Clustering。注:如何选择未曝光
item也是一个问题。由于真实世界中,item集合非常庞大,因此选择所有的未曝光item是不现实的。实验中,作者选择曝光item相似的item作为目标集合。“相似” 包括:相似的类型、相似的价格等等。属性相关性对齐的领域自适应:由于曝光
item和未曝光item之间存在领域漂移,因此我们利用领域自适应技术来提高整个item空间的检索质量。假设 表示针对
source item集合 的source item特征矩阵, 表示针对target item集合 的target item特征矩阵。其中:其中:
- 为了便于讨论,我们假设
source item集合和target item集合的规模相同,即: 。 - 分别表示
source item特征和target item特征,并且由item侧 生成。 表示item特征的维度。
从另一个角度来看,这两个矩阵也可以看做是一个
source高级属性high-level attribute矩阵 以及一个target高级属性矩阵 。其中: 分别表示源item矩阵和目标item矩阵中的第 个高级属性。我们认为:曝光
item的低级属性low-level attribute(如价格、品牌)之间的相关性,与非曝光item一致consistent。如下图所示,在电商中,品牌属性和价格属性具有高度相关性,而品牌属性和材料属性之间的相关性较低。这些知识在源域和目标域中是一致的。因此,我们认为:高级属性也应该具有和低级属性相同的相关一致性correlation consistency。基于这样的约束,我们认为:当源域中item高级属性向量之间的相关性和目标域一致时,源域和目标域的分布distribution是对齐的aligned。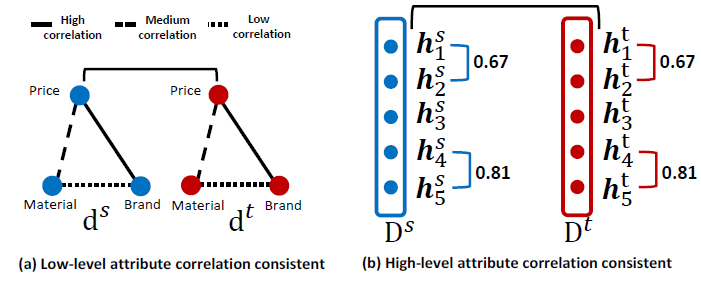
因此,我们将
item高级属性向量之间的相关性矩阵correlation matrix定义为分布distribution。具体而言,我们提出属性相关一致性attribute correlation congruence:A2C作为分布的度量。我们减少分布之间的距离,从而确保高级属性之间的相关性在源域和目标域是一致的。A2C的数学描述为:其中:
- 为矩阵的
Frobenius范数的平方。 - 为源域高级属性的协方差矩阵
covariance matrice, 为目标域高级属性的协方差矩阵。协方差矩阵中第 项表示 和 之间的相关系数 。
我们从源域抽取两个
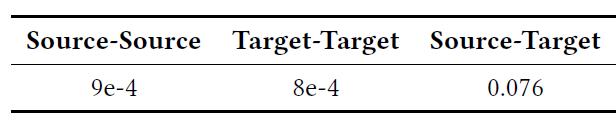
batch的样本、从目标域抽取两个batch的样本,并计算由BaseModel抽取的高级属性中每两个协方差矩阵的 。如下表所示(工业数据集),源域和目标域之间的 远大于相同域内的 ,这表明确实存在分布漂移distribution shift。下表中:
Source-Source表示 ,Target-Target表示 ,Srouce-Target表示 。其中下标1表示第一个batch、2表示第二个batch、1,2表示融合两个batch。注: 本质上是刻画两组样本之间特征相关性的距离。这两组样本可以来自于不同的
domain,也可以来自于相同的domain。注二:这是建模了特征之间的关系:即曝光数据集上的特征关系、未曝光数据集上的特征关系是相同的。这本质上是一种半监督学习:损失函数 = 监督损失 + 无监督的分布损失。
- 为了便于讨论,我们假设
面向源聚类的中心聚类:大多数
BaseModel只优化 ,而 对特征空间中的空间结构不敏感,并使得模型无法学习可区分性的特征discriminative feature。在我们的初步研究中,我们注意到:对于同一个query,具有相同反馈的item是相似的、具有不同反馈的item是不相似的。为此,我们提出一个中心聚类center-wise clustering来鼓励具有相同反馈的item的特征彼此靠近,而具有不同反馈的item的特征彼此远离。每个
query的hinge-based中心聚类可以形式化为:其中:
- 假设有 种不同的反馈类型 ,如非点击
non-click、点击、购买等等。 表示第 种反馈类型。 - 表示在 上的反馈类型。
- 表示由
query得到类型为 反馈的所有item的特征的簇中心。它就是类型 反馈的item特征归一化之后的均值向量。 - 和 是两个距离约束
margin。 - 表示如果条件满足则返回
1。
的物理意义为:
- 第一项要求每个
item的特征向量尽可能靠近它所在的簇中心,因此强制簇内(具有相同反馈的item)的紧凑性compactness。 - 第二项要求不同簇中心之间尽可能远离,因此强制簇间(具有不同反馈的
item)的可分离性separability。
由于 的存在,源域和目标域高度相关。因此,使源
item特征空间更有可区分性discriminative是合理的(通过 使得源特征空间更有区分性),这使得目标item特征空间通过优化 而变得有可区分性。从这个意义上讲,排序模型可以提取更好的item特征来提高领域自适应性,从而获得更好的长尾性能。- 假设有 种不同的反馈类型 ,如非点击
面向目标聚类的自训练:对于一个
query,我们可以为每个未曝光的item分配一个target伪标签pseudo-label(正样本或负样本)。目前为止,
ESAM可以被视为类别无关class-agnostic的领域自适应方法,该方法在对齐aligning时会忽略目标标签target label信息,并且可能将目标item映射到错误的位置(如,将目标正样本target positive sample匹配match到源负样本source negative sample)。带有伪标签的目标样本在对齐时将为模型提供目标区分性
target-discriminative的信息。因此,我们使用带有伪标签的样本进行自训练self-training,来缓解负向迁移。具体而言,最小化熵正则化 有利于类别之间的低密度分离low-density separation,并增加目标的区分度target discrimination。我们根据 来计算
query和未曝光item之间的相关性得分,然后归一化为[0.0 ~ 1.0]之间(例如通过sigmoid函数)。这个归一化的得分可以作为目标item是该query的正样本的概率。例如,对于点击反馈,这个得分表示query点击这个未曝光item的概率。如下图所示,通过梯度下降优化熵正则化会强制使得归一化得分数小于
0.4并逐渐接近0(负样本)、归一化得分数大于0.4并逐渐接近1(正样本)。因此,这种正则化可以被视为一种自训练的方式,它增强了未曝光item之间的区分能力discriminative power。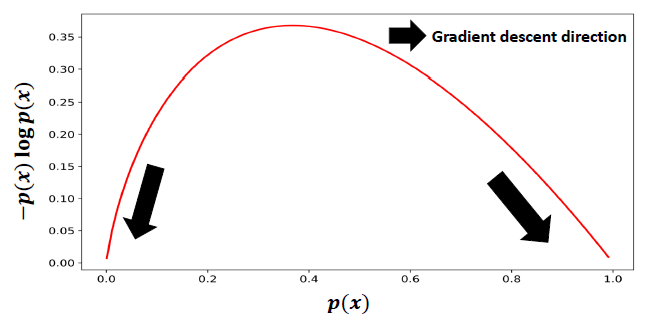
但是,当直接使用正则化时,由于在早期训练中曝光
item和未曝光item之间存在较大的领域漂移,因此排序模型无法正确预测未曝光item,尤其是对于归一化得分在[0.4,0.6]之间的item。 因此,目标样本target sample很容易被分配错误的标签,并陷入错误的反馈中。为此,我们采用带约束的熵正则化来选择可靠的目标样本进行自训练:其中:
- 为两个置信度阈值,用于选择带有置信度伪标签的可靠样本。
- 是 和 之间的相关性得分,并归一化为
[0.0,1.0]之间。 - ,如果条件
a或者条件b满足。
通过优化 ,模型可以使用 小于 的负
target item、或者 大于 的正target item进行自训练。这种带有约束的熵正则化保证了target label的正确性,从而避免了负向迁移。此外,基于课程学习curriculum learning,该模型可以从可靠样本reliable sample中学习目标有区分性target-discriminative的信息,从而将更多样本转化为可靠样本。个人认为这里的自训练的目的是提高未曝光
item预估概率的可区分性。对于未曝光item,模型预估结果倾向于集中在概率均值附近(熵值较大),使得正负样本之间区分性不大。而对于曝光item,由于有真实反馈信息,模型预估结果趋向于两端(熵值较小),使得正负样本之间区分性较大。因此,如果对未曝光
item预估概率为0.55,则它可能是一个正样本;如果对曝光item预估概率为0.55,则它可能是一个负样本。本质原因是因为未曝光item预估概率分布和曝光item预估概率分布的不一致性,后者的熵更小、更具区分性。为此,这里的自训练通过最小化未曝光
item预估结果的熵值,使得未曝光item预估概率分布尽可能有区分度。最终
ESAM总的损失函数为:其中 为超参数,分别控制对应项的重要性。
4.2 应用
这里我们将
ESAM应用于两个特定的排序场景:item推荐、个性化搜索。Item推荐:Item推荐是一个典型的排序问题。推荐系统最重要的方法之一是协同过滤,它探索了潜在的user-item相似性。推荐系统主要包括四个组成部分:特征组成
Feature Composition、特征抽取Feature Extract、评分函数Scoring Function、损失函数Loss Function。特征组成:我们在
item推荐中主要采用三组特征:用户画像特征、用户行为特征、item画像特征。每组特征由一系列的稀疏特征组成:- 用户画像
user profile特征:包括用户ID、年龄、性别等等。 - 用户行为
user behavior特征:包括用户最近交互的item id。 item画像item profile特征:包括item id、品牌、类目等等。
模型使用哪些特征组
feature group、以及使用特征组内哪些稀疏特征取决于特征提取器extractor的设计。- 用户画像
特征提取器
Feature Extractor:基于神经网络的推荐系统的基础basic特征提取器是MLP。目前设计了各种新颖的模块来增强特征抽取,如注意力机制attention mechanism、transformer模块。在我们的实验中,我们将
ESAM集成到多种提取器中,以证明它是一个提高长尾性能的通用框架。评分函数:我们定义评分函数为:
其中:
- 为针对
item的bias项。 - 为从 抽取的、用户 的特征。
- 为从 抽取的、
item的特征。
- 为针对
损失函数:我们将点击视为反馈,因此对于一个
query,一个item是否会被点击可以认为是一个二分类问题。我们应用point-wise交叉熵目标函数:其中:
- 为一个二元标签,它指示
query是否在item上产生点击。 - 是
query所有曝光的item的数量。
- 为一个二元标签,它指示
上述模型仅使用 进行训练,而 仅考虑曝光的
item。为了缓解领域偏移以提高模型的性能,我们在每个训练epoch随机地将未曝光item分配给每个query,并且通过在item侧 的三个约束来引入额外的未曝光item输入流input stream,从而将ESAM集成到模型中。在推荐场景中,面向源聚类的中心聚类是个难点。论文假设对于给定的
query,相同反馈的item是相似的。但是在这里,用户相同反馈(如点击或购买)的item不一定相似,因为用户的兴趣是多样化的。个性化搜索:这里的个性化搜索系统是根据用户发出的关键字
keyword来识别用户可能感兴趣的所有可能item。因此,ESAM的集成、特征提取器、损失函数和item推荐场景相同,只是特征组成、评分函数有所不同。特征组成:个性化搜索系统引入了额外的关键词特征组
feature group。通过对关键词的word vector求平均,将关键词转换为向量。评分函数:我们定义评分函数为余弦相似度:
为什么推荐任务中使用
sigmoid而搜索任务中使用余弦相似度?这里没有讲清楚。
4.3 实验
我们对
ESAM进行了item推荐实验和个性化搜索实验。数据集:
Item推荐:MovieLens-1M:该数据集由超过数千部电影和用户的一百万条电影评分记录组成。我们首先将评分二值化binarize来模拟CTR预估任务:评分大于3分的为正样本、评分小于等于3分的为负样本。这是常见的解决该问题的方法。我们使用的特征是
query侧的用户ID、年龄、性别、用户职业,以及item侧的电影ID、发行年份、电影流派genres。在每个训练
epoch,我们随机添加10部与曝光item相似的未曝光电影(即 ) 。相似的电影是那些流派与曝光电影相同的未曝光电影。如何定义相似?这是一个问题。
我们按照
8:1:1的比例将数据随机划分为训练集、验证集、测试集。
个性化搜索:
CIKM Cup 2016 Personalized E-Commerce Search:个性化电商搜索挑战赛发布了DIGINETICA提供的数据集。每个
item包含了item ID、类目ID、标题、描述文本。每个query由用户id、年龄、历史行为、提交的关键词ID(由单词列表转换而来)组成。每条记录都包含一个query,以及该query相关的10个曝光item、以及该query点击的item。我们采用
MovieLens-1M相同的策略为每条记录分配未曝光的item。我们按照8:1:1的比例将数据随机划分为训练集、验证集、测试集。Industrial Dataset of Taobao:我们收集了2019年6月淘宝一周的日志。在这个数据集中,所有使用的特征、获取未曝光item的方式,以及记录的组织方式都与CIKM Cup 2016数据集相同。我们将第一天到第五天的记录作为训练集、第六天的数据作为验证集、第七天的数据作为测试集。
这些数据集的统计信息如下表所示。
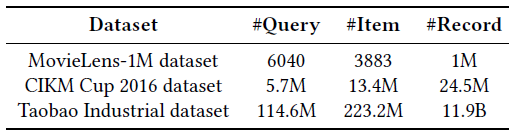
baseline方法:为了验证ESAM是一个通用框架,我们将其集成到基于神经网络的一些单域single-domain排序方法中。注意:特征提取器 ( 和 )在个性化搜索和推荐应用程序中是一致的,只有特征组成( 和 )、以及评分函数 ()取决于具体应用。
我们还比较了一些
DA-based排序方法,以及一些missing not random方法(仅考虑曝光item而不考虑未曝光item),从而显示我们提出的ESAM的优势。具体而言,
baseline方法包括:单域方法:
NeuralMF、RALM、YoutubeNet、BST。DA-based方法:DARec、DA learning to rank framework: DALRF。注意:对于
DA-based方法,我们仅将原始DA约束替换为ESAM,并保持其他模块不变以进行比较。missing not random方法:unbiased imputation model: UIM。注意:
missing not random方法需要无偏数据集unbiased dataset。这里无偏数据集是通过对一小部分在线流量部署一个统一策略uniform policy而收集的。为了公平地比较,我们仅将使用无偏数据集的约束替换为ESAM。
评估指标:我们使用三个标准评估指标来比较性能:
Normalized Discounted Cumulative Gain: NDCG、Recall、Mean Average Precision: MAP。所有方法进行了五次训练,并报告平均结果。
配置:
所有方法均由
TensorFlow实现,并使用Adam优化器进行训练。超参数:
- 对于超参数 ,我们从
{0.01, 0.1,0.3,0.5,0.7,1,10}中搜索最佳的值,并设置 。 - 对于其它超参数,我们设置学习率为 、
batch size = 256、特征维度 、距离约束 、置信阈值 。 - 对于
baseline方法的超参数,我们使用基于验证集性能的网格搜索。
- 对于超参数 ,我们从
我们为每个
query分配了10个源item、10个目标item,即 。根据曝光频率,我们将整个
item空间划分为热门item和长尾item:我们将top 20%的item定义为热门item、剩余item定义为长尾item。
公共数据集:下表分别给出了
Movielens-1M数据集和CIKM Cup 2016数据集上不带ESAM和带ESAM的性能。Hot代表测试集中的热门item、Long-tail代表测试集中的长尾item、Entire代表测试集中的所有item。上图为Movielens-1M数据集的结果,下图为CIKM Cup 2016数据集的结果。w/o ESAM表示不带ESAM,w/ESAM表示集成了ESAM。最佳结果用黑体突出显示。可以看到:
各模型对于热门
item的性能总是远远高于长尾item,这表明热门item和长尾item的分布是不一致的。带
ESAM的单域baseline优于不带ESAM的单域baseline。- 对于个性化搜索,在
NDCG@20/Recall@20/MAP指标上,带ESAM的baseline相比不带ESAM的baseline:在热门item空间中分别绝对提升1.4%/2.1%/1.5%,在长尾item空间中分别绝对提升3.3%/3.4%/2.5%,在整个item空间中分别绝对提升2.3%/2.8%/2.3%。 - 对于
item推荐,在NDCG@20/Recall@20/MAP指标上,带ESAM的baseline相比不带ESAM的baseline:在热门item空间中分别绝对提升1.3%/1.4%/1.2%,在长尾item空间中分别绝对提升2.7%/2.0%/2.2%,在整个item空间中分别绝对提升1.8%/1.9%/1.7%。
长尾空间中的显著改善证明了
ESAM能够有效缓解长尾item的领域漂移问题,使得模型为不同的数据集和application在整个item空间中学到更好的特征。- 对于个性化搜索,在
我们发现
ESAM优于其它DA-based方法(如DALRF, DARec)。结果表明,我们设计的有区分性的领域自适应考虑了高级属性之间的相关性,并采用中心聚类和自训练来改善源区分性source discrimination和目标区分性target discrimination,从而可以有效地迁移更多的有区分性的知识discriminative knowledge。


冷启动性能
Cold-Start Performance:我们随机选择测试集中20%的记录,并从训练集中删除曝光item包含所选测试记录的所有训练记录。我们使用BST作为BaseModel,因为它在公共数据集上具有最佳性能。实验结果如下所示,可以看到:
- 由于曝光
item空间中缺少这些item,BST很难解决冷启动问题。 ESAM可以显著提升冷启动性能,因为它引入了包含冷启动item的非曝光item,从而增强特征学习。

- 由于曝光
淘宝工业数据集
Industrial Dataset of Taobao:由于淘宝工业数据集非常大,我们采用Recall@1k和Recall@3k作为度量指标,并使用公共数据集上表现最好的BST作为消融研究的BaseModel。实验结果如下表所示,可以看到:
比较不带 和带 的方法(如
BM和 ,或者不带 的ESAM和ESAM),我们发现:A2C可以大幅度提高模型在长尾空间的性能(如平均绝对增益为+2.73%或+3.05%),这表明通过对齐aligning源域和目标域的分布可以解决长尾性能差的问题。和不带 的模型(如不带 的
ESAM)相比,采用 的模型(如ESAM)通过采用 优化源空间结构,从而在热门空间的性能尤为突出(如平均绝对增益为+0.6%或+0.7%)。此外, 使目标空间结构具有更好的簇内紧凑性
intra-class compactness和簇间可分性inter-class separability,从而提高了长尾性能(例如,平均绝对增益为+0.5%或+1.8%)。这三个约束条件的组合(即
ESAM)产生了最佳性能,这表明我们设计的三个正则项的必要性。ESAM的性能优于UIM,这表明ESAM可以抑制 ”马太效应“ 来提高长尾性能。
特征分布可视化
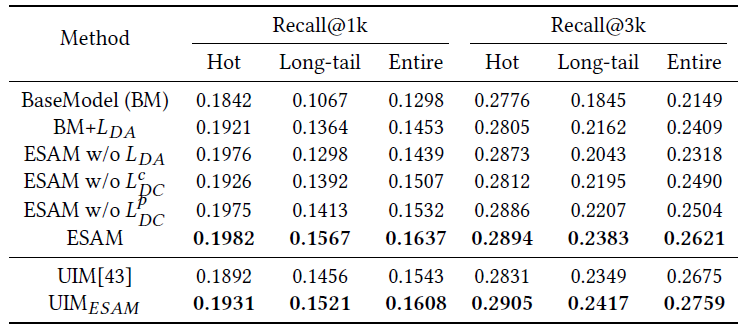
Feature Distribution Visualization:为了说明领域漂移的存在、以及我们提出的ESAM的有效性,我们随机选择了淘宝工业数据集上的2000个item,并使用t-SNE可视化了从 输出的特征。结果如下图所示,红色点代表target item、蓝色点代表source item。可以看到:- 如图
(a)所示,在源特征分布和目标特征分布之间存在domain gap。这种gap使得基于源item训练的模型无法应用于具有大量未曝光item的整个空间。 - 如图
(b)所示,我们发现 的集成可以显著降低分布之间的gap,这证明item高级属性之间的相关性可以很好地反映领域domain的分布。 - 如图
(c)所示,采用区分性的聚类discriminative clustering,特征空间将具有更好的流形结构manifold structure。 通过更好的簇内紧凑性intra-class compactness和簇间可分性inter-class separability来增强共享特征空间。 - 如图
(d)所示, 鼓励进一步的有区分性的对齐discriminative alignment。和图(c)相比,图(d)横坐标扩展为[-60,80]、纵坐标扩展为[-80, 80]。
总之,
ESAM通过区分性的领域自适应来提取领域不变的domain-invariant和有区分性的特征,使得该模型对长尾item具有鲁棒性,并且能够为用户检索更加个性化和多样化的item。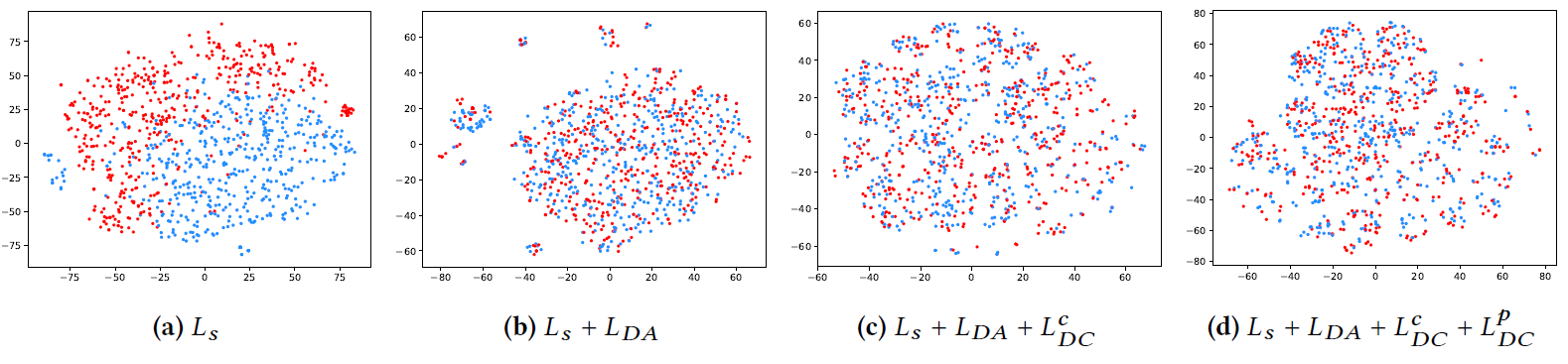
- 如图
评分的分布
Score Distribution:为进一步说明ESAM可以有效优化长尾性能,我们分别从淘宝工业数据集的源域和目标域中随机各选择500个 的组合,从而可视化评分的分布。如下图所示,横坐标分数,纵坐标为评分在区间内的样本数。可以看到:根据图
(a),模型倾向于对未曝光的item给出更低的分数,使得这些item难以被检索。根据图
(b),引入 之后模型鼓励源域和目标域具有相同的分数分布,这增加了长尾item的曝光概率。但是,对齐后的分数分布过于集中,这可能导致检索不相关的
item。为了解决这个问题,我们提出的区分性的聚类鼓励分数分布具有更好的区分性对齐(图(c)和图(d))。- 如图
(c)所示,target曲线具有一个异常尖峰(在score = 0.15附近),我们认为这是由于在对齐过程中忽略了目标label从而导致了负向迁移。 - 如图
(d)所示,使用目标可靠target reliable的伪标签进行自训练可以一定程度上解决这个负向迁移问题。
- 如图
相似度矩阵
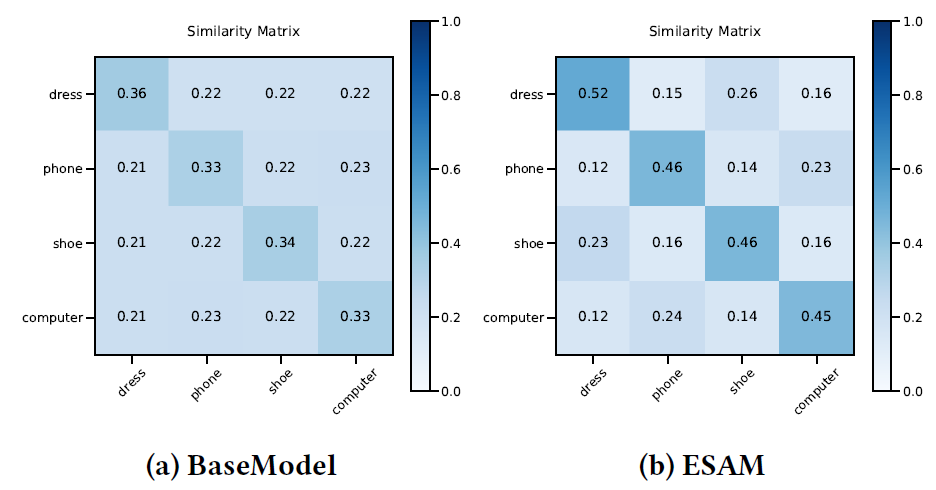
Similarity Matrix:为了证明ESAM可以学到更好的item特征representation,我们在淘宝工业数据集的整个item空间中,从每个类目(服装、电话、鞋子、计算机)中随机选择了1000个item。我们将每个类目的item平均分为两组,每组500个item。对于每一组,我们将类目中心计算为item representation的均值。然后,我们可以通过每一对中心的余弦相似度来获得相似度矩阵。结果如下图所示。可以看到:- 和
BaseModel相比,ESAM具有更大的簇内相似度和更小的簇间相似度,这表明ESAM具有更具可区分 的邻域关系。 - 此外,
ESAM抽取的相似度矩阵能够更好地反映实际情况,即服装dress和鞋子shoe的相似度高于服装dress和手机phone的相似度,而这在BaseModel中是无法体现出来的。
- 和
参数敏感性
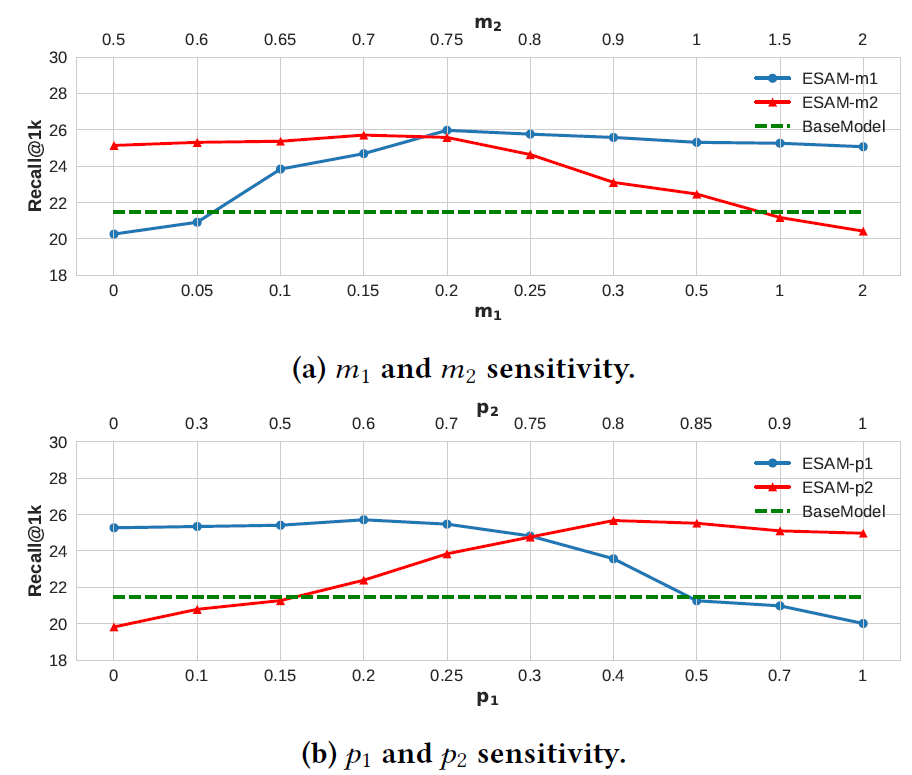
Parameter Sensitivity:为了研究 的距离约束 的影响,我们考虑 以及 时,模型效果的影响。结果如下图
(a)所示。可以看到:适当的簇内和簇间距离约束可以有效地优化邻域关系,从而提高检索性能。
对于 的置信阈值 和 ,如图
(b)所示,我们发现:为低置信度样本(如 太大或 太小)分配伪标签用于自训练将会导致模型崩溃,因为大量的标签是假的。而增加置信度阈值可以提高模型的性能。这表明:带有适当约束的熵正则化可以有效地选择可靠的目标样本,从而获得更好的领域自适应性和最终性能。
在线实验
Online Experiment:我们将ESAM用于淘宝搜索引擎进行个性化搜索,并进行了在线A/B test实验。为了公平地进行比较,除了模型是否与ESAM集成以外,其他所有变量都是一致的。和
BaseModel相比,在7天内ESAM获得了0.85%的CTR增益、0.63%的collection rate(collection表示加购物车的行为)增益、0.24%的CVR增益、0.4%的GMV增益。注意,由于淘宝中的搜索引擎服务于数十亿用户,每天产生超过一千万的GMV,因此这里的性能提升对于我们的业务来说已经足够显著了。我们将其归因于通过引入未标记的未曝光输入流
input stream来减少曝光item和未曝光item之间的分布差异,从而提高了对长尾item的检索能力。总之,在线实验验证了
ESAM可以显著提升整个搜索引擎的效率。
五、Facebook Embedding Based Retrieval[2020](用于检索)
搜索引擎已经成为帮助人们在线获取海量信息的重要工具。在过去的几十年里,已经开发了各种技术来提高搜索质量,特别是在包括
Bing和Google在内的互联网搜索引擎中。由于很难从query文本中准确地计算搜索意图search intent,也很难表达文档document的语义semantic meaning,因此搜索技术大多数基于各种term匹配技术,这对于关键词keyword匹配可以解决的情况表现良好。语义匹配仍然是一个具有挑战性的问题:需要解决与
query文本不完全匹配、但是能够满足用户搜索意图的预期结果desired result。在过去几年中,深度学习在语音识别、计算机视觉、自然语言理解方面取得了重大进展。其中
embedding(也被称作representation learning)已被证明是有助于成功的技术。本质上,embedding是将id的稀疏向量表示为稠密特征向量的一种方式,这种方式也被称作语义embedding(semantic embedding),因为它通常可以学习语义semantics。一旦学到了embedding,就可以将其用作query和文档的representation,从而应用于搜索引擎的各个阶段stages。由于该技术在包括计算机视觉和推荐系统在内的其它领域获得巨大成功,因此作为下一代搜索技术,它已经成为信息检索information retrieval社区和搜索引擎行业search engine industry的一个活跃研究课题。一般而言,搜索引擎包括:
- 召回层
recall layer:旨在以低延迟low latency和低计算量low computational cost来检索一组相关relevant的文档。这也被称作检索retrieval。 - 精确层
precision layer:旨在以更复杂的算法或模型将最想要的文档排在最前面。这也被称作排序ranking。
尽管可以将
embedding应用于检索和排序,但是通常更多地利用检索层中的emebdding,因为检索层位于系统的底部,并且通常是系统的瓶颈。embedding在检索中的应用称作基于embedding的检索embedding-based retrieval: EBR。简而言之,EBR是一种使用embedding来表示query和文档,然后将检索问题转换为embedding空间中的最近邻nearest neighbor: NN搜索问题的技术。- 由于要考虑的数据规模巨大,因此
EBR在搜索引擎中是一个具有挑战性的问题。不同于通常每个session仅考虑数百个文档的排序层,检索层需要在搜索引擎的索引中处理数十亿或者数万亿个文档。巨大的规模对于embedding的训练以及embedding的serving提出了挑战。 - 其次,与计算机视觉任务中基于
embedding的检索不同,搜索引擎通常需要将基于embedding的检索和基于term匹配的检索term matching based retrieval结合起来,从而在检索层中对文档进行评分。
Facebook搜索作为一个社交搜索引擎,它与传统搜索引擎相比有着独特的挑战。在Facebook搜索中,搜索意图不仅取决于query文本,而且还受到发出query的用户、以及该用户所处上下文的严重影响。例如,searcher的社交图social graph就是上下文的组成部分,并且是Facebook搜索的一个特有方面unique aspect。因此,正如信息检索社区IR community中积极研究的那样,在Facebook搜索中基于embedding的检索不是文本embedding问题。相反,它是一个更复杂的问题,需要完全理解文本、用户、以及上下文。为了在
Facebook搜索中部署EBR,论文《Embedding-based Retrieval in Facebook Search》开发了一些方法来解决建模modeling、serving、和全栈full-stack优化方面的挑战。在建模中,我们提出了统一嵌入
unified embedding的方法。该模型是一种two side模型,其中一个side是包含query文本、搜索用户searcher、上下文的搜索请求search request,另一个side是文档。为了有效地训练模型,我们开发了从搜索日志中挖掘训练数据,并从搜索用户、
query、上下文和文档中抽取特征的方法。为了快速进行模型迭代,我们在离线评估集合中采用召回recall指标来比较模型。为搜索引擎构建检索模型有着独特的挑战,例如如何为模型构建具有代表性
representative的训练任务,以使其有效effectively和高效efficiently地学习。我们研究了两个不同的方向:hard mining以解决有效地effectively表示representing和学习learning检索任务。ensemble embedding以将模型划分为多个阶段stage,其中每个阶段都有不同的召回率recall和精确率precision的tradeoff。
在模型开发完成之后,我们需要开发一些方法来高效
efficiently、有效effectively地serve检索stack中的模型。虽然构建一个结合现有检索(即基于term匹配的检索)和embedding KNN的系统很简单,但是由于以下几个原因,我们发现这是次优suboptimal的:- 从我们最初的实验来看,它具有巨大的性能代价
performance cost(延迟方面)。 - 双套索引(即一套为基于
term matching、一套基于embedding)导致维护成本较高。 - 现有检索的候选
item和embedding kNN的候选item可能有很大的重叠,这使得整体效率较低。
因此,我们开发了一种混合检索框架
hybrid retrieval framework,将embedding KNN和布尔匹配Boolean Matching集成integrate在一起,从而对文档打分以进行检索。为此,我们使用Faiss库来用于embedding向量的量化quantization,并将其与基于倒排索引inverted index based的检索相集成,从而构建一个混合检索系统hybrid retrieval system。除了解决上述挑战之外,该系统还具有两个主要优点:- 它可以实现
embedding和term matching的联合优化,从而解决搜索的检索问题。 - 它支持受
term matching约束的embedding KNN,这不仅有助于解决系统性能代价system performance cost问题,而且还提升了embedding KNN结果的precision。
- 从我们最初的实验来看,它具有巨大的性能代价
搜索是一个多阶段的排序系统
multi-stage ranking system,其中检索是第一阶段,然后是排序模型ranking models和过滤模型filtering models等各阶段。为了全局优化系统以最终返回那些新的好结果new good results并抑制新的坏结果new bad results,我们执行了后期优化later-stage optimization。具体而言,我们将embedding融合到排序层中,并建立了训练数据的反馈循环feedback loop,从而主动学习识别EBR中好的结果和坏的结果。下图中给出了EBR系统的说明。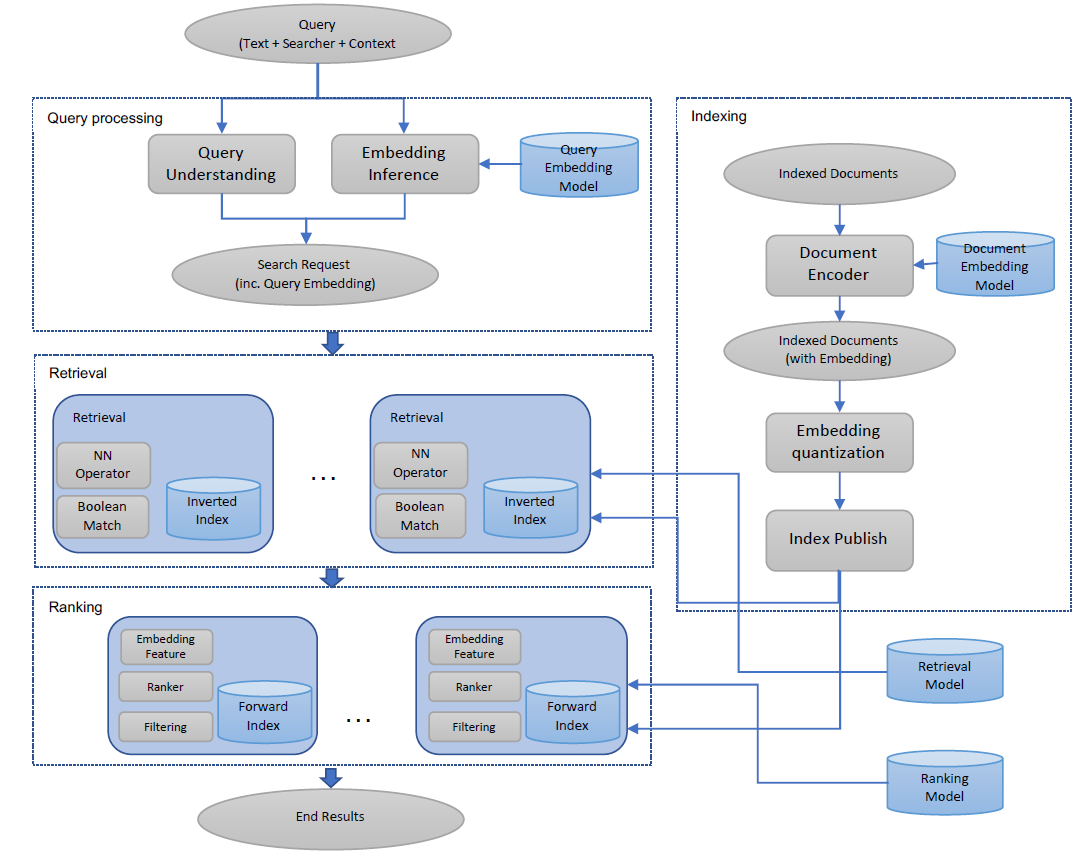
我们使用在线
A/B test对Facebook Search的垂直领域verticals评估了EBR,并观察到显著的指标增长。我们相信本文将提供有用的洞察和经验,从而帮助人们开发搜索引擎中基于embedding的检索系统。注:搜索的垂直领域
verticals指的是哪种类型的搜索,比如搜索某个人people、某个页面page、某个群组group等。- 召回层
5.1 模型
我们将搜索的检索任务形式化为召回优化
recall optimization问题。具体而言,给定一个搜索query以及target结果集合 ,我们的目标是模型返回的top-K结果 的recall召回率最大化:其中:
target结果是基于某些准则criteria下的、与给定query相关的文档(即label)。例如,它可能是用户点击的结果,或者是基于人类评分得到的相关的文档。 为target结果集合的规模。我们将召回优化问题形式化为:基于
query和文档之间计算的距离的排序问题ranking problem。query和文档被神经网络模型编码为稠密向量dense vector,在此基础上我们使用余弦相似度作为距离度量。我们提出使用
triplet loss来逼近召回目标函数recall objective,从而学习神经网络编码器(也被称作embedding模型)。尽管
semantic embedding语义embedding通常被表述为信息检索中的文本embedding问题,但是对于Facebook搜索而言这是不够的。Facebook搜索是一种个性化的搜索引擎,它不仅考虑文本query,而且还考虑searcher的信息以及搜索任务中的上下文,从而满足用户的个性化信息需求。以人物搜索people search为例,虽然Facebook可能有成千上万个名为John Smith的用户资料,但是用户通过query "John Smith"搜索的实际目标人物可能是他们的朋友或熟人。为了对这个问题进行建模,我们提出了
unified embedding,该embedding不仅考虑了文本、还考虑用户和上下文信息。
5.1.1 评估指标
虽然我们的最终目标是通过在线
A/B test实现端到端的质量提升,但重要的是开发离线指标,以便在在线实验之前快速评估模型质量,并从复杂的在线实验配置中隔离isolate问题。我们提出在整个索引中运行
KNN搜索,然后使用 作为模型评估指标。具体而言,我们采样了10000个搜索session从而收集评估集合的query和target result的pair对。然后我们报告这10000个搜索session的平均recall@K指标。
5.1.2 损失函数
给定一个三元组 ,其中 是一个
query的representation, 为对应的positive文档的representation、 为对应的negative文档的representation。triplet loss定义为:其中:
- 为两个向量 和 之间的距离。
- 为
margin超参数,它是正pair对和负pair对之间的边距margin。 - 为训练集中所有的
triplet数量。
这个损失函数的直觉是:将正
pair对和负pair对分开一段距离(由 超参数指定)。我们发现调整
margin值 非常重要:最佳 值在不同训练任务中变化很大,不同的 值会导致5 ~ 10%的KNN recall方差。我们认为,使用随机样本形成负
pair对的triplet loss可以逼近召回优化任务。 理由如下:如果我们为训练数据中每个
postive样本随机采样 个negative样本,那么当候选池candidate pool大小为 时,模型将优化最头部位置的top-1召回。候选池为
n,假设池子中每个样本都是随机选择的,则候选池中有1个positive样本。假设实际
serving的候选池大小为 ,我们将优化最前面的 位置的top-K召回。候选池为
N,假设池子中每个样本都是随机选择的,则候选池中有 个postive样本。
在后续我们将验证该假设,并提供不同正、负标签定义的比较。
5.1.3 Unified Embedding Model
为了从优化
triples loss中学习embedding,我们的模型包括三个主要组件:- 一个
query encoder, 它用于根据query产生query embedding。 - 一个
document encoder,它用于根据文档D产生 文档embedding。 - 一个相似度函数
similarity function,它用于产生query和文档 之间的得分score。
下图给出了我们的
unified embedding模型架构,其中有关特征工程将在后续讨论。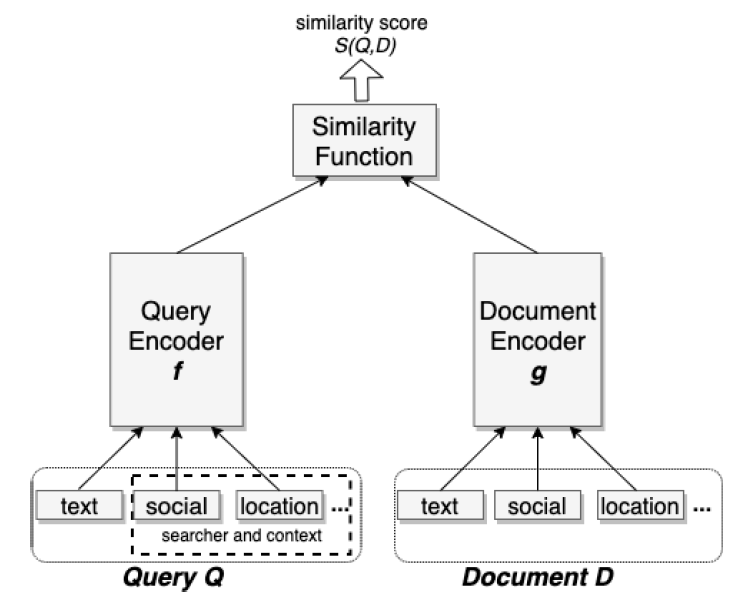
- 一个
编码器
encoder是一种神经网络,可以将输入转换为低维稠密向量,也称作embedding。在我们的模型中,这两个编码器 默认是两个独立的网络,但是可以选择共享部分参数。对于相似度函数,我们选择余弦相似度,因为它是
embedding学习中常用的方法之一:因此在
triplet loss函数中定义的距离函数为:因此如果 和 相似,则它们的相似性得分较高(由余弦相似度刻画)、距离较近。可以看到 为一个
0~2之间的正数。编码器的输入是
unified embedding模型区别于传统文本embedding模型的地方。unified embedding模型编码文本特征、社交特征、以及其他有意义的上下文特征来分别表征query和文档 。例如:- 在
query side,我们可以包括searcher location以及他们的社交关系。 - 在文档侧
document side,以group搜索为例,我们可以包含有关Facebook group的聚合location以及社交群social cluster。
大多数特征都是高基数
high cardinality的离散特征,可以是one-hot或者multi-hot向量。- 对于每个离散特征,在输入编码器之前插入一个
embedding look-up layer从而学习和输出其稠密向量的representation。 - 对于
multi-hot向量,将多个embedding的加权组合从而得到最终的feature-level embedding。
- 在
5.1.4 Training Data Mining
在搜索排序系统
search ranking system中为检索任务定义positive label和negative label是一个非常重要的问题。这里我们根据模型召回率指标比较了几种选择。对于负样本,我们在初始研究中尝试了以下两种负样本选择,同时将click作为正样本:- 随机选择:对于每个
query,我们从文档库中随机采样文档作为负样本。 non-click曝光:对于每个query,我们随机采样那些在同一个session中曝光、但是未被点击的文档作为负样本。
和使用随机负样本相比,使用
non-click曝光的负样本训练的模型具有更差的模型召回率:对于people搜索的embedding模型,召回率下降了55%(绝对值,而不是相对比例)。我们认为这是因为
non-click曝光负样本倾向于hard case(可能在一个或者多个因子factor上匹配了query),而倒排索引中的大多数文档都是easy case(根本不可能匹配上query)。将所有负样本都设为hard case会改变训练数据对于真实检索任务的表示性representativeness,这可能会对学到的embedding施加不小的bias。所谓的
easy case指的是文档和query压根无关,模型很容易学到是负样本;hard case指的是文档和query有一定相关性,模型需要努力学习才知道是不是负样本。- 随机选择:对于每个
我们还尝试了多种挖掘正样本的不同方法,并有如下有趣的发现:
click:将点击的结果作为正样本是很直观的,因为点击表明用户对结果的反馈:可能与用户的搜索意图相匹配。impression曝光:我们的想法是将检索视为ranker的近似函数,但可以更快地执行。然后,我们希望设计检索模型来学习ranker相同的结果集合以及结果排列顺序。从这个意义上讲,所有用户的曝光结果对于检索模型都是正样本。即用
matching模型去逼近ranking模型:认为曝光的item都是相关的item。
我们的实验结果表明:两种定义均有效。在给定相同数据量的情况下,使用点击的模型和使用曝光的模型产生了相似的召回率。
此外,我们还尝试了使用
impression-based的数据来扩充click-based的训练数据,但是我们并未观察到相比于click-based模型的更多增益。结果表明:增加曝光数据不能提供额外的价值,模型也不能从增加的训练数据中获益。我们的上述研究表明:使用点击作为正样本、以及使用随机采样的负样本可以提供合理的模型性能。此外,我们还进一步探索了
hard mining策略,从而提高模型区分相似结果的能力。
5.2 特征工程
unified embedding模型的优点之一是它可以融合文本之外的各种特征,从而提高模型性能。我们在不同的垂直领域vertical观察到,unified embedding比文本embedding更有效。例如,将文本embedding切换为unified embedding之后,事件搜索events search的召回率提高了18%、群组搜索group search的召回率提高了16%。unified embedding的有效性很大程度上取决于识别和构建有信息量informative的特征的成功。下表展示了通过将每个新特征添加到group embedding模型(以文本特征为baseline)而实现的增量提升。其中Abs.Recall Gain表示绝对的召回率增益。
接下来,我们将讨论有助于提升模型效果的几个重要特征。
文本特征:字符的
n-gram是用于文本embedding的表示文本的常用方法。和单词n-gram相比,它有两个优势:- 首先,由于字符
n-gram的词典规模vocabulary size有限,因此embedding lookup table规模较小,在训练过程中可以更有效地学习。 - 其次,
subword representation对于我们在query侧(例如拼写变化或错误)和文档侧(由于Facebook中的大量内容库存content inventory)遇到的out-of-vocabulary问题是鲁棒robust的。
我们比较了使用字符
n-gram训练的模型以及使用单词n-gram训练的模型,发现前者可以产生更好的模型。但是,在字符3-gram模型的基础上,包含单词n-gram representation额外提供了较小、但是一致的模型提升(+1.5%的召回率提升)。注意,由于单词
n-gram的基数cardinality通常非常高(例如,352M的query 3-gram),因此需要哈希hashing来减少embedding lookup table的规模。但是,即使有哈希冲突的缺点,添加单词n-gram仍然提供了额外的增益。对于
Facebook实体entity,抽取文本特征的主要字段是人物实体people entity的名字、非人物实体non-people entity的标题。和布尔term匹配技术相比,我们发现使用纯文本特征训练(即没有位置特征、社交特征等非文本特征)的embedding特别擅长处理以下两种情况:- 模糊文本匹配
fuzzy text match:例如,该模型能够学习在query "kacis creations"和"Kasie’s creations"网页之间进行匹配,而基于term的匹配则无法实现。 - 可选
optionalization:在query "mini cooper nw"的情况下,模型可以通过删除"nw"以获得可选的term匹配,从而学习检索预期的、Mini cooper owner/drivers club的group。
- 首先,由于字符
位置特征
location feature:位置匹配在很多搜索场景中是有利的,例如本地商业local business、本地群组local groups、本地事件local events。为了使得embedding模型在生成输出embedding时考虑位置信息,我们在query侧和文档侧的特征中都添加了位置特征。- 在
query侧,我们抽取了searcher的城市city、地区region、国家country、以及语言language。 - 在文档侧,我们添加了公开可用的信息,例如由管理员
admin打标tag的、显示的群组位置group location。
结合文本特征,该模型能够成功学习
query和结果之间的隐式位置匹配location match。下表比较了文本
embedding模型和文本+位置embedding模型返回的、用于group搜索的最相似的文档。可以看到:具有位置特征的模型可以学习将位置信号融合到embedding中,将与来自Louisville、Kentucky的searcher位置相同的文档排序到更高的position。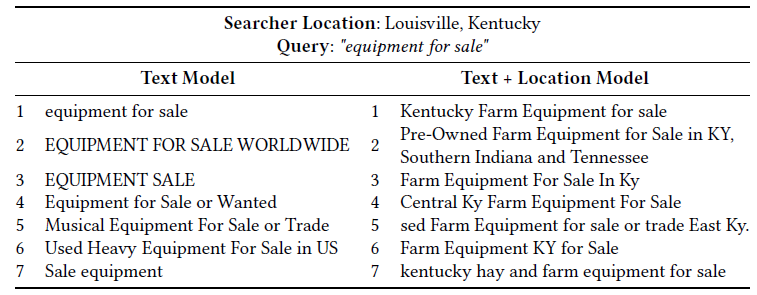
- 在
社交
embedding特征:为了利用丰富的Facebook社交图来改善unified embedding模型,我们基于社交图训练了一个单独的embedding模型来嵌入用户和实体。这有助于将综合社交图comprehensive social graph融合到unified embedding模型,否则该模型可能没有完整的社交图信息。
5.3 Serving
5.3.1 ANN
我们在系统中部署了基于倒排索引的
ANN(近似近邻approximate near neighbor)搜索算法,因为它具有以下优点:- 首先,由于
embedding向量的量化quantization,它具有较小的存储成本。 - 其次,更容易集成
integrate到现有的、基于倒排索引inverted index的检索系统中。
- 首先,由于
我们使用
Faiss library来量化向量,然后在我们现有的倒排表inverted table扫描系统scanning system中实现高效的最近邻搜索。embedding量化有两个主要组成部分:- 一个是粗量化
coarse quantization,它通常使用K-means算法将embedding向量量化为粗粒度的簇cluster。 - 一个是乘积量化
product quantization,它执行细粒度量化以实现embedding距离的有效计算。
- 一个是粗量化
我们需要调优几个重要参数:
粗量化
coarse quantization:粗量化有不同的算法,例如IMI和IVF算法。而且重要的是调整簇的数量num_cluster,这会影响性能和召回率。乘积量化
product quantization:乘积量化算法有多重变体,包括原始PQ、QPQ、带PCA变换的PQ。PQ的字节数pq_bytes是要调优的重要参数。乘积量化的思想是将向量空间(假设为 维)划分为 个(即
pq_bytes参数)子空间,每个子空间的维度为 。然后我们在每个子空间上聚类。假设每个子空间聚类的类别数都是 ,则每个原始向量将由 个整数来表示(称作codebook),每个整数代表某个子空间中的聚类类别。nprobe:该参数用于确定每个query embedding需要召回多少个簇,它进一步决定将扫描多少个粗簇。该参数会影响性能和召回率。
我们构建了一个离线
pipeline来有效地调优这些超参数。此外,我们需要进行在线实验,根据离线调优结果从选定的候选配置中确定最终配置。下面我们将分享从ANN调优中获得的经验和技巧:基于扫描的文档数量调优召回率。最初,我们比较了相同
num_cluster和相同nprobe下,不同粗量化算法的召回率。但是,通过更多的数据分析我们发现:簇
cluster是不平衡的imbalanced,特别是对于IMI算法而言大约一半的簇仅有几个样本。对于相同num_cluster和相同nprobe的配置下,这将导致扫描文档的数量不同。因此,我们将扫文档数量(而不是簇的数量)作为更好的指标来近似approximateANN调优中的性能影响,如下图所示。我们使用
1-recall@10来度量ANN的准确率accuracy,这是根据准确的KNN搜索的top结果在ANN搜索top-10结果中的召回率。即:
KNN搜索得到top-1结果,然后看这个top-1结果是否在ANN搜索的top-10列表中。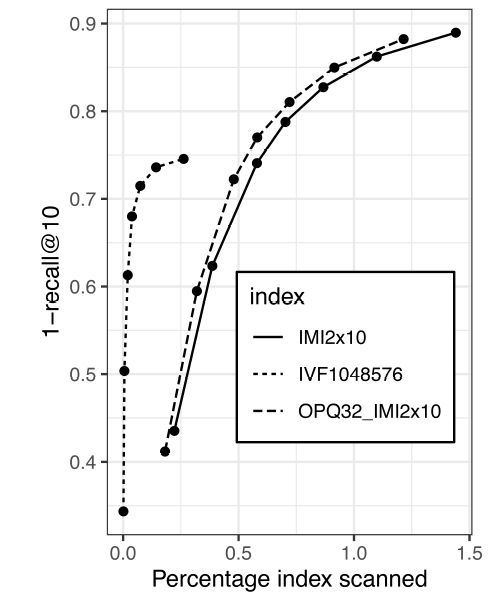
当模型发生重大变化时,调优
ANN的超参数。我们观察到,ANN的性能和模型特性characteristics有关。例如,当我们将集成技术ensemble technique用于non-click曝光训练的模型时,我们发现:虽然模型显示出比baseline更好的召回率,但是在对两者应用量化之后,模型召回率比baseline更差。当模型训练任务发生重大变化时,例如增加更多的
hard负样本,应该始终考虑调优ANN超参数。始终尝试
OPQ。在应用量化之前对数据进行转换通常很有用。我们用PCA和OPQ对数据进行了转换,发现OPQ通常更有效,如下表和下图所示,其中采用128维的embedding。OPQ的一个警告是:由于OPQ应用了embedding的旋转,我们可能还需要重新调优num_cluster和nprobe才能有类似的文档扫描。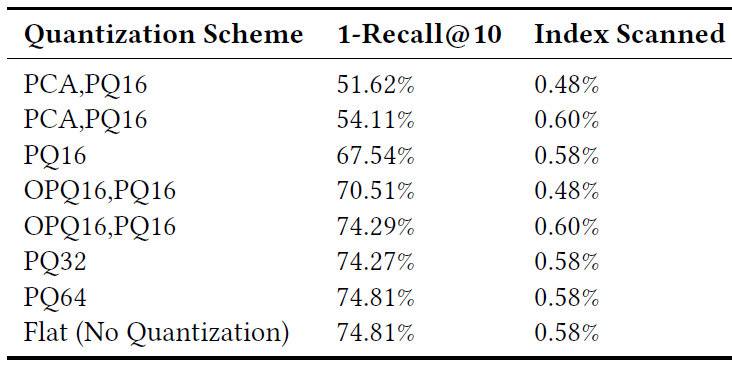
选择
pq_bytes为d/4。乘积量化器product quantizer将向量压缩为 个字节码。对于 的选择,它与embedding向量的维度 有关: 越大,搜索准确率search accuracy越高,但代价是内存和延迟的增加。从经验结果来看,我们发现 之后,准确率提升有限。在线调优
nprobe, num_clusters, py_bytes以了解实际的性能影响。虽然离线调优ANN算法和参数以合理了解性能和召回率之间的tradeoff很重要,但是我们发现同样很重要的一点是:在线部署ANN算法和参数的若干个配置,从而更好地了解从embedding-based检索、到实际系统的性能影响。这对于确定容量预算capacity budget,并减少离线调优中的参数搜索范围非常重要。
5.3.2 系统实现
为了将
EBR集成integrate到我们的serving stack中,我们在Unicorn中实现了对最近邻搜索的first-class支持。Unicorn是为Facebook上大多数搜索产品提供支持的检索引擎retrieval engine。Unicorn将每个文档表示为bag of terms,这些term是表示文档二元属性binary property的任意字符串,通常使用属性的语义来命名。例如:居住在西雅图的用户John的term为:text:john和location:seattle。term可以附加有效载荷payload。query可以是term的任何布尔表达式。例如,以下query将返回名字中有john和smithe、并且居住在Seattle(西雅图)或者Menlo Park(门罗公园)的人:1(and (or (term location:seattle)2(term location:menlo_park))3(and (term text:john)4(term text:smithe))5)为了支持最近邻,我们扩展了
document representation从而包括文档embedding。每个文档embedding都有一个预先固定的字符串关键字,并在query侧添加了一个nn<key>: radius <radius>的query operator。这个query operator匹配<key> embedding在query embedding指定半径内的所有文档。其中<key>就是预先固定的字符串关键字,如model-141795009(模型版本号)。在索引时,每个文档
embedding被量化并转换成一个term(针对粗聚类)和一个有效载荷(针对量化的残差)。在查询时,
(nn)在内部被重写为term之间的(or)的规则。这些term关联那些与query embedding最接近的coarse clusters(即(probes))。然后对于匹配的文档, 检索term的playload以验证半径约束。probes的数量可以用一个额外的属性来指定:: nprobe。
通过根据已经存在的原语
primitives实现最近邻支持,而不是编写一个单独的系统,我们继承了现有系统的所有功能,例如实时更新、高效的查询计划query planning和执行、以及对multi-hop query的支持。multi-hop query使我们能够支持基于top-K的最近邻query,其中我们只选择最接近query的K个文档,而不是通过半径进行匹配。然后评估query的剩余部分。然而,从我们的实验研究中我们发现:半径模式可以更好地权衡
tradeoff系统性能和结果质量。一个可能的原因是:半径模式支持受约束的最近邻搜索(受匹配表达式的其它部分约束),但是top K模式提供了更宽松的操作more relaxed operation,该操作需要扫描整个索引来获得top K的结果。因此,我们在当前产品中使用基于半径的匹配。混合检索
Hybrid Retrieval:通过将(nn) operator作为布尔查询语言的一部分,我们现在可以支持混合检索表达式,将embedding和term任意组合。这可用于基于模型的模糊匹配fuzzy matching,该模型可以改善拼写变体spelling variation、可选化optionalization等情况,并且重用和受益于检索表达式的其它部分。例如,假设一个拼写错误的
query "john smithe"意图寻找一个位于Seattle或者Menlo Park的、名叫john smith的用户,那么检索表达式类似于上面的表达式。该表达式将无法检索目标用户,因为termtext:smithe和该文档不匹配。我们可以通过(nn) operator为该表达式添加模糊匹配:xxxxxxxxxx61(and (or (term location:seattle)2(term location:menlo_park))3(or (and (term text:john)4(term text:smithe)))5(nn model-141795009 :radius 0.24 :nprobe 16))6)其中,
model-141795009是embedding的键。在这种情况下,如果
query "john smithe"的embedding与文档"john smith"的embedding之间余弦距离小于0.24,则目标用户将被检索。Model Serving:我们通过以下方式来serve embedding模型。在训练好two-sidedembedding模型之后,我们将该模型分解为query embedding模型和document embedding模型,然后分别独立地serve这两个模型。- 对于
query embedding,我们将模型部署在online embedding inference service从而进行实时推断。 - 对于
document embedding,我们使用Spark在离线状态下batch地进行模型推断,然后将生成的embedding内容与其它元数据metadata一起发布到正排索引forward index中。
我们还进行了额外的
embedding量化,包括粗量化和PQ,并将其发布到倒排索引inverted index中。- 对于
5.3.3 Query and Index Selection
为了提高
EBR的效率和质量,我们执行了query和索引选择query and index selection。在
query选择方面:我们应用query选择技术来克服诸如过度触发over-triggering、巨大的容量成本capacity cost、以及垃圾增加junkiness increase等问题。我们并未针对某些
query触发EBR,因为EBR在这些query上的优势很弱,并且无法提供任何额外的价值。例如考虑以下两类场景:searcher正在搜索之前已经被搜索过的、或者点击过的特定目标。query意图和embedding模型训练的意图明显不同的情况。
在索引选择方面:我们进行了索引选择,从而加快索引速度。例如,我们仅选择每月活跃用户、最近事件
event、热门页面page、热门的group。
5.4 后期优化
Facebook的搜索排序是一个复杂的多阶段排序系统multi-stage ranking system,其中每个阶段逐步精细化refine前一阶段的结果。该stack的最底部是检索层retrieval layer,这里应用了EBR。检索层的结果随后被一组ranking layer进行排序和过滤。每个阶段的模型都应该针对前一层返回的结果的分布进行优化。然而,由于当前的排序阶段是为现有检索场景设计的,这可能导致从
EBR返回的新结果被现有的ranker进行次优sub-optimally排序。为了解决这个问题,我们提出了两种方法:embedding作为ranking特征:沿着漏斗funnel进一步传播embedding similarity不仅有助于ranker从EBR中识别新结果,还为所有结果提供了通用的语义相似性度量。我们探索了几种基于
embedding的特征抽取选择,包括query和结果embedding之间的余弦相似度、Hadamard积、原始embedding。从我们的实验研究来看,余弦相似度特征始终表现出比其他选择更好的性能。训练数据反馈环
feedback loop:尽管EBR可以改善检索的召回率,但是和term matching相比,其precision可能更低。为了解决
precision问题,我们建立了一个基于人工评分pipeline的闭环反馈closed feedback loop。具体而言,在启用EBR之后,我们记录了结果,然后将这些结果发送给评估者以标记query和检索结果之间是否相关。我们使用这些人工评估的数据来重新训练相关性模型relevance model,以便模型可以学会过滤这些不相关的结果、保留相关的结果。事实证明,这是一种在
EBR中提高召回率、并达到高precision的技术。
5.5 高级主题
EBR需要广泛的研究来继续提高性能。我们研究了embedding建模的两个重要领域:hard mining和embedding ensemble,以继续推进EBR方案的state-of-the-art。
5.5.1 Hard Mining
用于检索任务的数据空间在文本匹配程度、语义匹配程度、社交匹配程度上具有不同的数据分布,并且重要的是:为
embedding模型设计训练数据集,以便在这种空间上能够有效地学习。为了解决这个问题,
hard mining是一个主要的方向,也是embedding learning的活跃研究领域。但是,大多数研究来自于计算机视觉领域,并且用于分类任务。而搜索的检索任务没有class的概念,因此是一个现有技术不一定能解决的独特unique的问题。在这个方向上,我们将解决方案分为两部分:hard negative mining: HNM、hard positive mining: HPM。hard negative mining:在分析我们的embedding模型以进行people search时,我们发现:在给定query的情况下,embedding的top K个结果通常具有相同的名称name,并且该模型并不总是将target结果排名高于其它结果,即使存在社交特征。这促使我们相信该模型尚不能正确利用社交特征,这可能是因为负的训练数据太容易了,因为它们是随机负样本,通常使用不同的名称name。因为负样本通常都是和
target结果name不同的,因此模型简单地认为:和target结果同名的文档就是正样本。为了使得模型更好地区分相似结果,我们可以使用
embedding空间中更接近正样本的样本作为训练中的hard负样本。在线
hard negative mining:由于模型训练是基于mini-batch更新的,因此可以在每个batch中以动态dynamic而有效efficient的方式选择hard负样本。假设每个
batch包含 个正positive的pair对 。然后对于每个query,我们使用所有其它的positive document构成一个小的document pool,并选择相似度得分similarity score最高的文档作为hardest负样本,从而创建训练triplet。使用在线
hard negative mining是我们改进模型的主要贡献之一。它在所有垂直领域verticals都显著提高了embedding模型的质量:对于people search,召回率+8.38%;对于groups search,召回率+7%;对于events search,召回率+5.33%。我们还观察到,最佳设置是每个正样本使用最多两个
hard负样本。使用两个以上的hard负样本将开始降低模型质量。在线
hard negative mining的一个局限性在于:从随机样本中获得任何hard负样本的概率很低,因此无法产生足够hard的负样本。接下来,我们研究如何基于整个结果池来生成更hard的负样本,即离线hard negative mining。离线
hard negative mining:离线hard negative mining的过程如下:- 首先为每个
query生成top K个结果。 - 然后根据
hard选择策略hard selection strategy来选择hard负样本。 - 接着使用新生成的
triplet来重新训练embedding模型。 - 上述过程可以反复迭代。
我们进行了广泛的实验,从而比较离线
hard negative mining和在线hard negative mining。一个可能首先看起来违反直觉的发现是:简单地使用hard负样本训练的模型无法胜过使用随机负样本训练的模型。进一步的分析表明:相比较于easy模型(即使用随机负样本训练的模型),hard模型对非文本non-text特征赋予了更多的权重,但是在文本匹配上表现更差。因此,我们调整了采样策略,最终产生了一个可以超越在线hard negative mining的模型。- 第一个洞察是关于
hard选择策略。我们发现使用最hard的样本不是最好的策略。我们比较了来自不同排序位置rank position的采样,发现排序101~500之间的采样实现了最佳的模型召回率。 - 第二个洞察是关于检索任务优化。我们的假设是:仍然需要在训练数据中包含
easy负样本。因为检索模型要在整个输入空间中进行操作,而输入空间包含各种hard级别(从最hard到最easy)的数据,并且输入空间中的大多数数据都是非常easy的负样本。
因此,我们探索了将随机负样本和
hard负样本结合在一起的方法,包括从easy模型中进行迁移学习transfer learning。根据我们的经验研究,以下两种技术显示出最高的有效性effectiveness:- 混合
easy/hard训练:在训练中混合easy负样本和hard负样本是有利的。增加easy负样本的比例(相比较于hard负样本)会持续改善模型的召回率,并且在easy : hard = 100 : 1时达到饱和。 - 从
hard模型到easy模型的迁移学习:虽然从easy模型迁移到hard模型不能产生更好的模型,但是从hard模型迁移到easy模型却进一步改善了模型召回率。
最后但同样重要的是,为训练数据中的每个数据点进行详尽地
KNN计算非常耗时,并且由于有限的计算资源,总的模型训练时间将变得不切实际。对于离线hard negative mining算法而言,有效的top K结果生成很重要。在这里,近似的近邻搜索是一种实用的解决方案,可以显著减少总的计算时间。另外,在一个随机分片shard上执行近似的近邻搜索足以生成有效的hard负样本,因为我们在训练期间仅依赖于semi-hard负样本(即排序101~500之间的)。- 首先为每个
hard positive mining:我们的baseline模型使用点击或者曝光作为正样本,这是现有产品product已经能够获取的。为了通过EBR来最大化互补增益complementary gain,一个方向是识别尚未被产品成功检索、但是仍然为正postive的结果。为此,我们从
searcher的活动日志activity log中为失败的搜索session挖掘潜在的target结果来作为正样本(怎么挖?)。我们发现以这种方式挖掘的正样本可以有效地帮助模型训练。单独使用hard正样本训练的模型就可以达到与点击训练数据相似的模型召回水平,而数据量仅为点击训练数据的4%。通过将hard正样本和曝光数据结合起来作为训练数据,可以进一步提高模型的召回率。
5.5.2 Embedding Ensemble
我们从
hard negative mining实验中了解到:easy负样本和hard负样本对于EBR模型训练都很重要。我们需要hard负样本以提高模型的precision,但是easy负样本对于表征represent检索空间也很重要。- 使用随机负样本训练的模型模拟了检索数据的分布,并对于非常大的
K是较优的,但是当K较小时,在top K处的precision较低。 - 另一方面,被训练来优化
precision的模型,例如使用non-click曝光作为负样本、或者使用离线hard negative mining来训练的模型,擅长为较小的候选集合进行排序,但是对于检索任务却失败了。
因此,我们提出通过多阶段方法
multi-stage approach将训练有不同hard级别levels of hardness的模型组合起来,其中第一阶段模型侧重于recall、第二阶段模型专门区分由第一阶段模型返回的、更相似的结果。我们使用
《Hard-Aware Deeply Cascaded Embedding》相同的级联embedding训练cascaded embedding training的思想,它以级联cascaded的方式集成ensemble了一组以不同hard水平训练的模型。我们探索了不同形式的
ensemble embedding,包括加权拼接weighted concatenation、级联模型cascade model,并且发现两者都是有效的。- 使用随机负样本训练的模型模拟了检索数据的分布,并对于非常大的
加权拼接
Weighted Concatenation:由于不同的模型为(query,document)的pair对提供了不同的余弦相似度评分,因此我们使用加权的余弦相似度作为度量来定义pair对的相似性。具体而言,对于任何
query和文档 ,给定一组模型 以及模型相应的权重 ,我们定义 和 之间的加权集成相似度weighted ensemble similarity为:其中:
- 为模型 对
query学到的embedding向量。 - 为模型 对文档 学到的
embedding向量。
出于
serving的目的,在query侧和document侧,我们需要将多个embedding向量集成ensemble到单个representation中。并且ensemble之后的query embedding向量和文档embedding之间的相似性要和 成正比。我们没有直接使用 ,一是因为它的取值范围超出了
[0,1]之间;二是它的计算在线比较复杂,需要计算 对embedding向量的相似性。我们可以证明:在
query侧(或者document侧)应用加权的归一化可以满足需求。具体而言,我们通过以下方式构造了query向量和document向量:可以看到 和 之间的余弦相似度正比于 :
我们以
5.3节所描述的相同方式为ensemble embedding执行serve。模型权重 的选择是经验性的,可以基于验证集的性能进行选择。
另外我们探索了第二阶段
embedding模型的几种选择。实验表明:使用non-click曝光训练的模型获得了最佳的KNN召回率(和baseline模型相比,召回率提升了4.39%)。但是,当应用
embedding量化时,和单个模型single model相比,ensemble model遭受了更多的准确率accuracy损失。因此,当提供在线serving时,其实际的收益会减少。我们发现,为了在
embedding量化后具有最佳召回率,最佳策略是:将相对easier的模型和离线hard negative mining模型集成ensemble,其中这些模型修改和调优了训练负样本的hard级别。这个集成ensemble模型的离线提升略低,但是能够实现在线的显著的召回率提升。
- 为模型 对
级联模型
Cascade Model:和加权ensemble中的并行组合parallel combination不同,级联模型以串行方式在第一阶段模型的输出上运行第二级模型。我们比较了不同的第二阶段的选择。我们发现:使用
non-click曝光训练的模型不是一个很好地选择。总体提升远小于加权ensemble方法。此外,随着第二阶段模型要重新排序rerank的结果数量的增加,收益会降低。但是,在第二阶段使用离线hard负样本模型可以比baseline召回率提高3.4%。这是一个更适合级联的候选模型,因为离线hard negative mining构建的训练数据完全基于第一阶段模型的输出。此外,我们探索了另一种级联模型的组成。我们观察到,尽管和文本
embedding相比,unified embedding总体上具有更大的模型召回率,但是由于它将焦点转移到了社交匹配social match和位置匹配position match上,因此产生了新的文本匹配text match失败。为了提高模型的文本匹配能力,进而提高模型precision,我们采用了级联策略:使用文本embedding来预选择pre-select文本匹配的候选文档,然后使用unified embedding模型对结果进行重排rerank以返回最终的top候选文档。和仅使用unified embedding相比,它实现了显著的在线效果提升。
六、Airbnb Search Ranking[2018]
在过去的十年中,典型的基于传统信息检索的搜索体系架构中,已经看到机器学习在其各种组件中的出现越来越多。尤其是在搜索排序
Search Ranking中,根据搜索的内容类型,搜索排序通常具有挑战性的目标。这种趋势背后的主要原因是可以收集和分析的搜索数据量的增加。大量收集的数据为使用机器学习根据历史搜索,从而为用户个性化搜索结果、并向用户推荐最近消费内容相似的内容提供了可能性。任何搜索算法的目标都可能因为当前平台的不同而有所不同,不存在一刀切
one-size-fits-all的解决方案。尽管某些平台旨在提高网站的互动engagement(如在搜索到的新闻文字上的点击click、消费时间time spent),而另一些平台则旨在最大化转化conversion(如,购买搜索到的商品或者服务)。而在双边市场two-sided marketplace的情况下,我们通常需要优化市场双方(即卖方seller和买方buyer)的搜索结果。双边市场已经成为很多现实世界应用
application中可行的商业模式。特别是,我们已经从社交网络范式social network paradigm转变为一个由两种不同类型的参与者participant(分别代表供给和需求supply and demand)组成的网络。对于Airbnb而言,它是一个双边市场two-sided marketplace,其中需要同时优化房东host和租客guest的偏好preference。实际上,用户很少两次消费相同的item,而一个listing在某个日期只能接受一个租客(电商领域一个listing表示一个商品详情页)。这意味着给定一个带有位置location和行程日期trip date的输入query:- 对于位置
location、价格price、风格style、评论review等等对租客有吸引力的listing,我们需要给该listing一个比较高的排名ranking。 - 与此同时,对于租客的行程持续时间
trip duration和提前天数lead days方面很好地匹配了房东偏好的listing,我们需要给该listing一个比较高的排名。 - 此外,我们需要检测可能因为差评
bad review、宠物pet、逗留时间、团体人数、或任何其它因素而可能拒绝租客的listing,并将这些listing的排名降低。
为了实现这一目标,论文
《Real-time Personalization using Embeddings for Search Ranking at Airbnb》求助于使用Learning to Rank。 具体而言,我们将问题形式化为pairwise regression,其中正效用positive utility用于预定booking、负效用negative utility用于拒绝rejection。我们使用Lambda Rank模型的修改版本对问题进行优化,该模型共同优化了市场双方的排名。由于租客通常会在预定之前进行多次搜索,即在他们的搜索
session中点击多个listing并联系多个房东。因此我们可以使用这些session中的信号(即点击click、房东联系host contact等等)从而进行实时个性化Real-time Personalization,目的是向租客展示更多的listing。这些推荐的listing相似于similar to我们认为从搜索session开始以来租客喜欢的那些listing。与此同时,我们可以利用负向信号negative signal(如用户跳过排名比较top的listing、反而选择了排名较bottom的listing)从而向租客少展示一些相似于similar to我们认为租客不喜欢的listing。为了能够计算租客互动的
listing和待排序的候选listing之间的相似性,我们提出使用list embedding,一个从搜索session中学到的低维向量representation。我们利用这些相似性为我们的搜索排序模型Search Ranking Model创建个性化特征,并为我们的相似listing推荐Similar Listing Recommendation提供支持。搜索排序Search Ranking和Similar Listing Recommendation这两个渠道在Airbnb带来了99%的转化conversion。使用了即时
immediate的用户行为(如点击)的实时个性化Real-time Personalization可以作为短期用户兴趣short-term user interest的代理信号proxy signal。除此之外我们还引入了另一种类型的embedding。这种embedding通过预定booking数据来训练,从而能够捕获用户的长期兴趣long-term interest。由于旅游业务
travel business的特性nature,用户平均每年旅行1~2次,因此预定是一个稀疏的信号,并且也是长尾long tail的信号(大多数用户只有单次预定)。为了解决这个问题,我们提出在用户类型级别level of user type、而不是在特定的user id上训练embedding。其中用户类型user type是使用many-to-one的、基于规则的映射来确定的类型。这些规则利用了已知的用户属性attribute。同时,我们在于user type embedding相同的向量空间中学习listing type embedding。这使得我们能够计算正在进行搜索的用户的user type embedding,和需要排序的候选listing的list type embedding之间的相似性。和之前发表的、互联网个性化
embedding的工作相比,本文的创新之处在于:实时个性化
Real-time Personalization:之前关于使用embedding的个性化推荐和item推荐的大多数工作都是通过离线创建user-item和item-item推荐表recommendation table,然后在推荐时从它们中读取而部署到生产环境中的。我们实现了一种解决方案,其中用户最近交互
item的embedding以在线方式进行组合,以计算与待排序的item的相似性。针对聚集搜索的适配训练
Adapting Training for Congregated Search:和互联网搜索web search不同,旅游平台travel platform上的搜索通常是聚集的congregated。用户通常仅在特定市场market(例如巴黎)内进行搜索,而很少在不同的市场之间搜索。我们调整了
embedding训练算法,以便在进行负采样时考虑到这一点,从而可以更好地捕获市场内within-market的listing的相似性。利用转化作为全局上下文
Leveraging Conversions as Global Context:在我们的预定案例中,我们认识到以预定结束的click session(即booked listing)的重要性。在学习
listing embedding时,我们将booked listing视为全局上下文global context。当滑动窗口在session中移动时,始终会对booked listing进行预测。用户类型
embeddingUser Type Embeddings:先前关于训练用户embedding以捕获其长期兴趣的工作为每个用户训练了一个单独的embedding。当目标信号target signal稀疏时,没有足够的数据来训练每个用户的良好embedding representation。更不用说为每个用户存储embedding以执行在线计算将需要大量内存。因此,我们提出在每个用户类型级别上训练
embedding,其中具有相同类型的用户组user group将具有相同的embedding。拒绝作为显式的负样本
Rejections as Explicit Negatives:为了减少会导致拒绝rejection的推荐,我们在训练过程中将房东拒绝host rejection视为显式的负样本,从而在user type embedding和listing type embedding中编码房东偏好。
对于短期兴趣个性化
short-term interest personalization,我们使用超过8亿次搜索click session来训练listing embedding,从而获得了高质量的listing embedding representation。我们对真实的搜索流量进行了广泛的离线和在线评估。结果表明:在排序模型中添加emebdding特征可以显著提高预定booking增益。除了搜索排序算法之外,listing embedding还成功地测试并发布于相似listing推荐similar listing recommendation,其效果比现有算法的点击率click-through rate: CTR高出20%。对于长期兴趣个性化
long-term interest personalization,我们使用5000万用户的booked listing序列来训练user type embedding和listing type embedding。user type embedding和listing type embedding都是在相同的向量空间中学习的,这样我们就可以计算出user type和待排序listing的listing type之间的相似性。这个似性被用作搜索排序模型的附加特征,并且也成功进行了测试和发布。- 对于位置
相关工作:
在很多自然语言处理
Natural Language Processing:NLP应用application中,经典的、将单词表示为高维稀疏向量的语言建模方法已经被神经语言模型Neural Language model所取代。神经语言模型通过使用神经网络来学习单词embedding,即单词的低维representation。这些神经网络是通过直接考虑单词顺序、以及单词之间的共现co-occurrence来训练的,基于这样的假设:句子中经常一起出现的单词也共享更多的统计依赖性statistical dependence。随着用于单词
representation learning的高度可扩展的continuous bag-of-words:CBOW语言模型和skip-gram:SG语言模型的发展,embedding模型已经被证明在大规模文本数据上训练之后,在许多传统语言任务language task上获得了state-of-the-art的性能。最近,
embedding的概念已经从word representation扩展到了NLP领域之外的其它应用程序application。来自互联网搜索Web Search、电商E-commerce、市场Marketplace等领域的研究人员很快意识到:就像可以通过将句子中的单词序列视为上下文来训练word embedding一样,也可以通过将用户行为序列视为上下文来训练用户行为的embedding。这些用户行为包括用户点击或购买的item、query以及被点击的广告。从那以后,我们看到embedding被用于互联网上的各种类型的推荐,包括音乐推荐music recommendation、求职搜索job search、应用推荐app recommendation、电影推荐movie recommendation等等。此外,已经表明:可以利用用户交互的
item来直接学习用户embedding,其中用户embedding和item embedding位于相同的向量空间。通过这种方式可以做出直接的user-item推荐。对于冷启动推荐
cold-start recommendation特别有用的另一种方法是:仍然使用文本embedding,并利用item和/或user元数据(如标题、详情description)来计算它们的embedding。最后,已经为社交网络分析
Social Network analysis提出了embedding方法的类似扩展,其中图上的随机游走random walk可用于学习图结构中定点的embedding。
embedding方法在学术界和工业界都产生了重大影响。最近的行业会议出版物和讨论表明,embedding方法已经成功地部署在各大互联网公司的各种个性化、推荐和排序引擎中。
6.1 模型
下面我们介绍用于
Airbnb上搜索的、针对listing recommendation任务和listing ranking任务提出的方法。我们描述了两种不同的方法,即:用于短期实时个性化
short-term real-time personalization的listing embedding,用于长期个性化long-term personalization的user-type embedding & listing type embedding。
6.1.1 Listing Embedding
假设给定一组从 个用户获得的 个
click session的集合 ,其中每个session定义为用户点击的 个listing id的不间断序列uninterrupted sequence。每当两次连续用户点击之间的时间间隔超过30分钟时,我们认为就开始新的session。给定这个数据集,我们的目标是学习每个
unique listing的 维实值real-valued的representation,使得相似的listing在embedding空间中距离较近。更正式地说,该模型的目标是通过在整个
click session集合 上,通过最大化目标函数 来使用skip-gram模型从而学习listing representation。即:其中概率 表示从点击的
listing的上下文邻域中观察到listing的概率,其定义为:其中:
- 和 分别表示
listing的input vector representation和output vector representation。 - 超参数 定义为点击
listing的上下文窗口的长度。 - 是数据集中
unique listing id组成的词汇表vocabulary。
从上式可以看到:我们提出的方法对点击
listing序列的时间上下文temporal context进行建模,其中具有相似上下文的listing(如,在click session中具有相似的邻域listing)将具有相似的representation。这里的
listing embedding没有考虑到listing的属性信息,仅考虑了listing id。- 和 分别表示
计算上述目标函数的梯度 所需的时间和词表大小 成正比,这对于具有数百万个
listing id的大规模词表是不可行的。作为替代方案,我们使用了负采样方法,该方法大大降低了计算复杂度。 负采样方法具体做法为:首先生成由点击
listing和它的上下文 (即,在长度为 的窗口内,同一个用户在点击listing之前、之后点击的其它listing)组成的正的pair对 所构成的集合 。然后生成由点击
listing和整个词表 中随机抽取的 个listing组成的负的pair对 所构成的集合 。其中这里的 为负采样的listing,而不是上下文listing。最后,优化的目标函数为:
其中 为模型参数。
然后我们通过随机梯度下降来最优化该目标函数。
预定的
listing作为全局上下文Booked Listing as Global Context:我们可以将click session集合 细分为:booked session:即以用户预定了一个listing作为结束的click session。注意,这涉及到预定之后的点击如何处理。如果预定之后立即跟随一个点击(
30分钟内),那么这个点击应该直接丢弃掉。exploratory session:即不是以用户预定作为结束的click session,用户仅仅只是在浏览。
从捕获上下文相似性的角度来看,这两者都是有用的。但是
booked session可以用于适配性adapt优化,使得在每个step中,我们不仅可以预测相邻的点击listing,还可以预测最终的预定listing。这种适配可以通过将预定的listing添加为全局上下文来实现,这样无论它是否位于上下文窗口内,都将始终对其进行预测。因此,对于booked session,embedding更新规则调整为:其中:
- 为预定
listing, 为预定listing的output vector representation。 - 对于
exploratory session,因为没有预定listing,因为它的目标函数没有最后一项。
下图显示了如何使用 的滑动窗口从
booked session中使用skip-gram模型来学习list embedding。- 该窗口从第一次点击的
listing滑动到预定的listing(booked session以预定作为结束)。 - 在每个
step,正中central的listing的embedding被更新,使得它预测来自 的上下文listing的embedding、以及全局上下文预定listing的embedding。 - 随着窗口的滑动,一些
listing进入或移出上下文集合,而预定的listing始终作为全局上下文被保留(虚线)。
针对聚集搜索适配的训练
Adapting Training for Congregated Search:在线旅游预定网站online travel booking site的用户通常只在一个市场market内搜索,即他们想去的地方。结果, 很可能仅包含来自同一个市场的listing。另一方面,由于随机的负样本采样,因此 很可能包含大多数不是位于相同市场的listing, 这与 不同。在每个
step,对于给定的central listing,正的上下文positive context主要由与 相同市场中的listing组成,而负的上下文negative contex主要由与 不同市场中的listing组成。我们发现这种不平衡会导致学到次优sub-optimal的市场内within-market相似性。为了解决这个问题,我们提出添加一组从central listing相同市场内随机采样的负样本 。此时目标函数为:
这里是不是应该去掉 比较好?感觉 是
easy负样本,因为是跨市场的,所以用户大概率对这些负样本不感兴趣。另外,这意味着非均匀的负采样:
hard负样本vseasy负样本。listing embedding的冷启动Cold start listing embeddings:房东每天都会创建新的listing,并在Airbnb上发布。此时,这些listing没有embedding,因为它们没有出现在click session训练数据中。为了为新listing创建embedding,我们提出利用现有的listing embedding。创建
listing后,房东需要提供有关listing的信息,例如位置location、价格price、listing type等等。我们使用新listing的元数据meta-data来查找3个具有embedding的已有的listing,其中已有的listing需要满足以下条件:- 和新
listing距离很近(距离半径在10英里以内)。 - 和新
listing具有相同的listing type(如,Private Room)。 - 和新
listing具有相同的价格区间(如$20 ~ $25一晚)。
接下来我们使用这
3个识别到的embedding的向量均值,从而作为新listing的embedding。使用这种技术,我们可以覆盖超过98%的新listing。基于
listing embedding我们可以找到相似的listing pair。反之,基于相似的listing embedding我们也可以得到listing embedding。- 和新
listing embedding检查Examining Listing Embedding:为了评估通过embedding捕获了listing的哪些特征,我们检查了在8亿次click session中训练的 维embedding。首先,通过对学习的
embedding执行k-means聚类,我们评估是否对地理位置相似性geographical similarity进行了编码。下图展示了加利福利亚州的
100个簇的结果,证明了来自相似位置similar location的listing是聚集在一起clustered together的。我们发现这些簇对于重新评估re-evaluating我们的旅游市场的定义非常有用。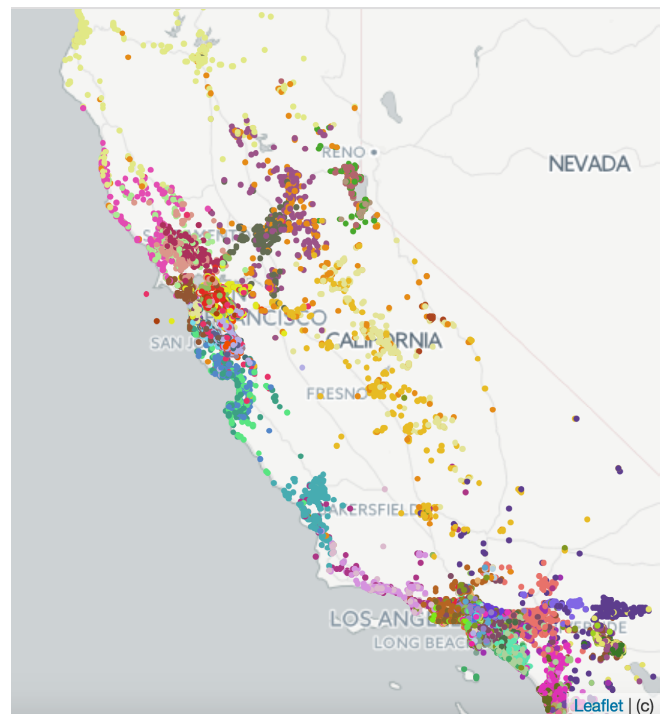
接下来,我们评估洛杉矶不同类型的
listing之间的平均余弦相似度(表1所示),以及不同不同价格范围的listing之间的平均余弦相似度(表2所示)。从这些表中可以看出:与不同类型、不同价格范围的
listing之间的相似度相比,相同类型、相同价格范围的listing之间的余弦相似度要高得多。因此,我们可以得出结论:这两个
listing特性characteristics在学到的embedding中也得到了很好地编码。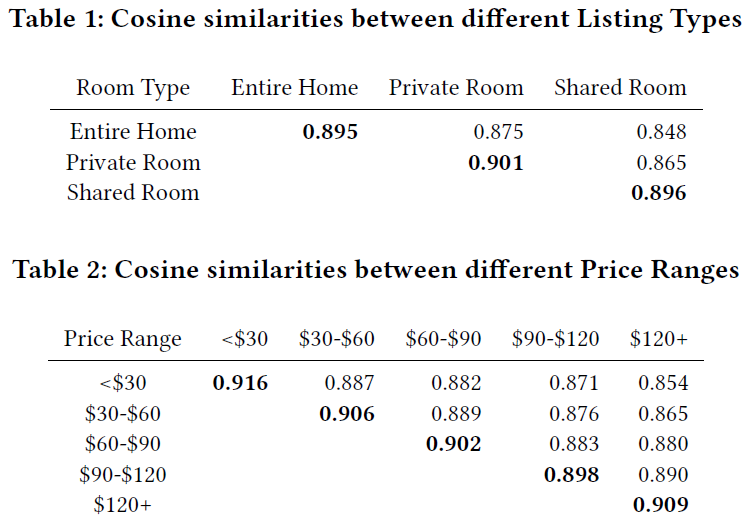
虽然有些
listing特性(例如价格)不需要学习,因为它们可以从listing meta-data中直接获取,但是其它类型的listing characteristics(如结构architecture、风格style、体验feel)则很难抽取为listing特征。为了评估这些特性是否被
embedding捕获,我们可以检查listing embedding空间中不同architecture listing的k近邻k-nearest neighbor。下图给出了这样的一个例子,其中对于左侧的
listing,右侧给出了具有相同风格和结构的、最相似的listing。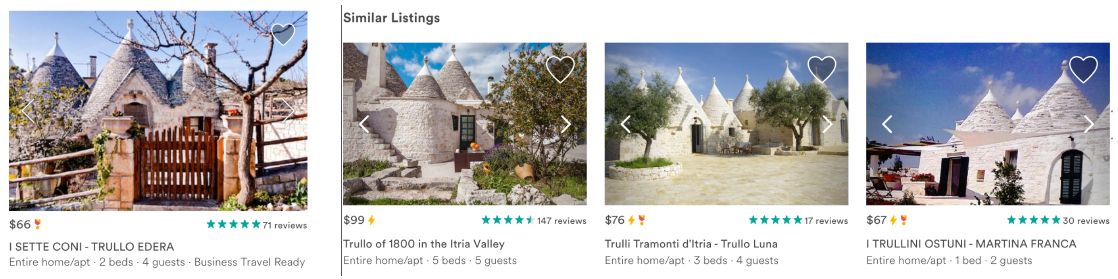
为了能够在
listing embedding空间中进行快速、简单的搜索,我们开发了一个内部的相似度探索工具Similarity Exploration Tool,如下图所示。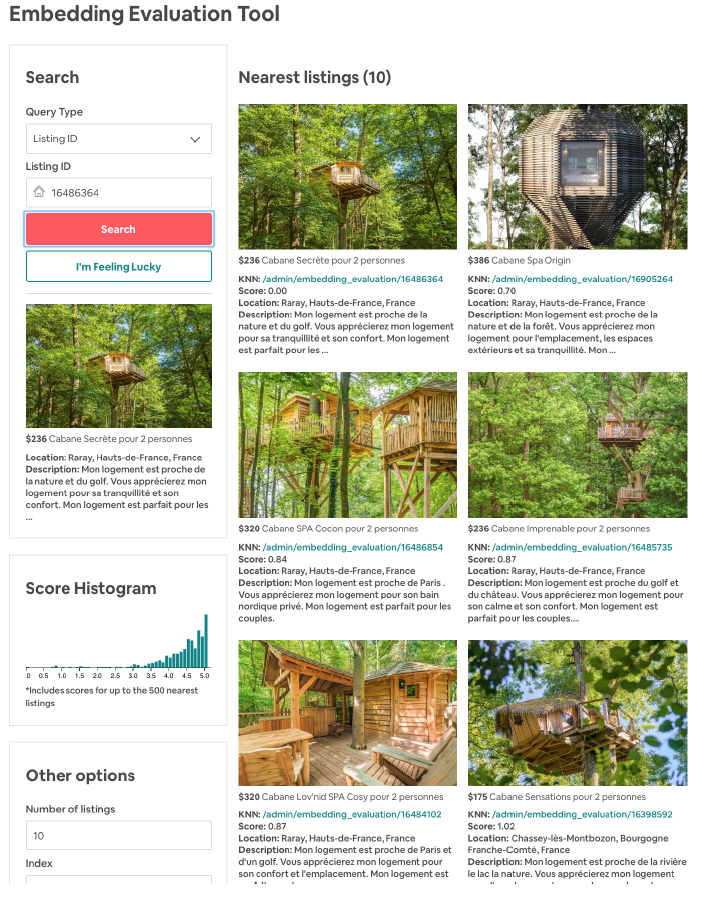
6.1.2 User-type Embedding & Listing-type Embedding
前面介绍的
listing embedding使用click session来训练,并非常善于寻找同一市场的listing之间的相似性。因此,它们适用于短期的short-term、session内的in-session个性化,目的是在即时搜索会话immanent search session期间向用户展示与他们点击的listing相似的listing。然而,除了
in-session个性化(它基于同一session内刚刚发生的信号)之外,根据用户的长期历史记录中的信号进行个性化搜索也会很有用。例如,假设某个用户当前正在搜索洛杉矶的listing,并且历史上曾经发过纽约和伦敦的预定 ,那么推荐与先前预定listing相似的listing将很有用。点击个性化是短期的、基于点击的、单个市场的个性化,预定个性化是长期的、基于预定的、跨市场的个性化。
虽然一些跨市场
cross-market相似性在使用点击训练的listing embedding中被捕获,但是学习这种cross-market相似性的更主要方式是给定用户的、随时间的预定listing所构建的session中学习。具体而言,假设给定从 个用户获得的
booking session集合 ,其中每个booking session被定义为用户 按时间顺序的一个预定listing序列。尝试使用这种类型的数据来学习每个
listing_id的embedding在很多方面都具有挑战性:- 首先,
booking session数据 比click session数据 小得多,因为预定不是太频繁的事件。 - 其次,很多用户历史上仅预定了一个
listing,而我们无法从长度为1的session中学习。 - 第三,要从上下文信息中为任何实体
entity学习有意义的embedding,数据中至少需要该实体出现5~10次。而平台上的很多listing_id被预定的次数少于5~10次。 - 最后,用户的两个连续预定之间可能会间隔很长的时间。在此期间,用户的偏好(例如价格
price)可能会发生变化,例如由于用户的职业发生变化。
为了在实践中解决这些非常常见的市场问题
marketplace problem,我们建议在listing_type级别、而不是listing_id级别学习embedding。给定某个
listing_id可用的元数据meta_data(例如位置location、价格price、listing类型listing type、容量capacity、床位数number of beds等 ),我们使用下表中定义的、基于规则的映射来确定其listing_type(注:listing type表示整租合租等固有属性,listing_type是人工映射得到的)。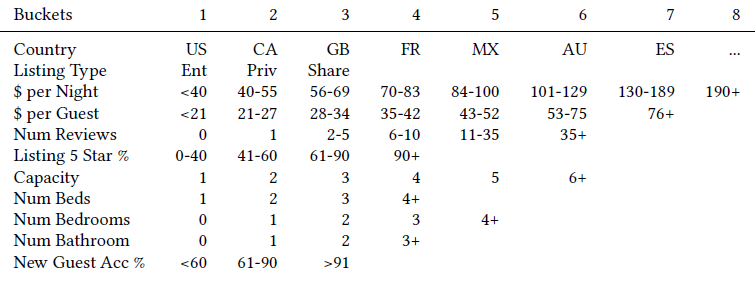
例如,来自
US的一个整租Entire Home的listing,它具有:2个人的capacity、1张床、1间卧室和1间浴室、每晚平均价格为60.8$、每位租客每晚平均价格为29.3$、5条评论、五星占比100%、100%的新客接受率New Guest Accept Rate。因此这个
listing将被映射到 :buckets以数据驱动的方式来确定,从而最大化每个listing_type bucket的覆盖范围。从
listing_id到listing_type的映射是多对一manty-to-one的映射,这意味着许多listing将映射到相同的listing_type。这里通过人工规则对
listing进行了聚类:具有相同属性的listing被划分到同一个簇cluster,然后模型下一步学习cluster id的embedding。这里的规则由业务专家来指定,事关任务成败。- 首先,
为了解决用户随时间变化的偏好,我们提出在与
listing_type embedding相同的向量空间中学习user_type embedding。user_type的确定方法与listing_type类似,即通过利用下表中定义的、有关用户及其历史预定的元数据metadata来确定。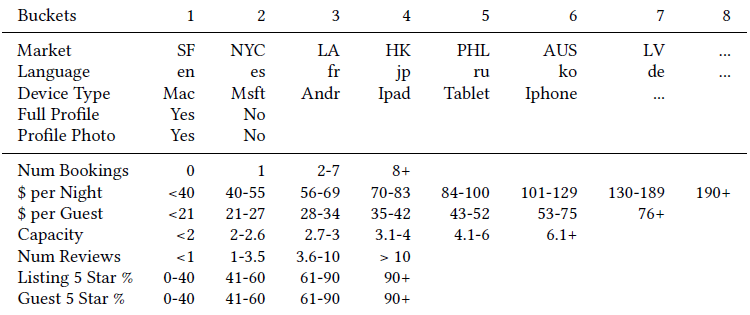
例如,对于来自旧金山的、使用
MacBook笔记本电脑的用户,他使用英文配置setting、带有用户照片的完整资料、来自房东的平均83.4%的租客五星好评级Guest 5 star rating。用户历史进行了3次预定,这些预定的平均统计数据为:52.52$每晚、31.85$每个租客每晚、2.33容量capacity、8.24个评论、76.1%的listing五星好评Listing 5 star rating。最终这个用户的user_type为:在生成用于训练
embedding的booking session时,我们会计算user_type直到最近一次预定。 对于正在进行首次预定的用户,user_type是基于上表的前5行计算的,因为在预定时我们没有关于历史预定的先验信息。这很方便,因为基于前5行的user_type学到的embedding可以用于注销logged-out用户、以及没有历史预定的新用户的冷启动个性化cold-start personalization。同样地,这里也是通过人工规则对用户进行了聚类,这里的规则由业务专家来指定,事关任务成败。
训练过程
Training Procedure:为了在同一个向量空间中学习user_type和listing_type的embedding,我们将user_type融合到booking session中。具体而言,我们使用来自 个用户的 个
booking session构成集合 ,其中每个session定义为booking event(即(user_type, listing_type)元组)按时间顺序的序列 。注意,每个
session都是由同一个user_id进行预定,但是对于同一个user_id,其user_type可能会随时间的推移而变化。这类似于同一个listing的listing_type也会随着时间的推移而变化,因为它们会收到更多的预定。目标函数类似于
listing embedding的目标函数,其中需要更新的center item不是listing,而是user_type或listing_type,具体取决于滑动窗口中捕获的是哪一个。如果需要更新
user_type的center_item,则我们优化以下目标函数:其中:
- 包含来自用户历史记录中、距离
center item窗口内的user_type和listing_type,具体而言是关于center item时间戳的最近过去near past、最近将来near future的用户预定 。 - 包含作为负样本的随机采样的
user_type或者listing_type。
- 包含来自用户历史记录中、距离
类似的,如果
central item是listing_type,则我们优化以下目标函数:
更新
user_type和更新listing_type有两点不同:a.
input/output representation不同:更新user_type时,user_type embedding采用input representation的格式,而listing_type embedding采用output representation的格式。更新listing_type时,刚好相反。b. 负样本不同:更新
user_type需要采样负的listing,更新listing_type需要采样负的user。由于根据定义的
booking session主要包含来自不同市场market的listing,因此没有必要从相同市场的预定listing中额外负采样(就像Adapting Training for Congregated Search那样) 。下图给出了这个模型的图形化表示,其中
central item表示user_type,并对其进行更新。
针对拒绝
Rejection的显式负样本Explicit Negatives for Rejections:与只反映房客偏好的点击不同,预定也反映了房东的偏好,因为房东会以接受房客预定、或者拒绝房客预定的形式给出明确的反馈。房东拒绝的原因包括:房客的guest star rating较差、房客资料不完整或者为空、房客资料中没有照片等。这些特性是user_type定义的一部分。除了房客偏好信号之外,可以在训练期间利用房东拒绝
host rejection来将房东的偏好信号编码到embedding空间中。纳入拒绝信号的整体目的是:一些listing_type对没有预定 、个人资料不完整、guest star rating低于平均水平的user_type不太敏感,我们希望这些listing_type的embedding和user_type的embedding在向量空间中更为紧密。这样,基于embedding相似性的推荐除了最大化预定机会之外,还可以减少将来的拒绝future rejection。我们通过下面的方式将拒绝的使用形式化为显式的负样本。除了集合 和 之外,我们还生成了一个涉及拒绝事件
rejection event的user_type或者listing_type的pair对 组成的集合 。如下图所示,我们特别关注这样的情况:同一个用户在房东拒绝(以减号标记)之后,成功
booking了另外一个listing(以加号标记)。注意:我们仅仅把这类有
-有+的房东拒绝作为显式负样本。新的优化目标可以表述为:
在
central item为user_type的情况下,优化目标为:在
central item为listing_type的情况下,优化目标为:
给定所有
user_type和listing_type学到的embedding,我们可以根据用户当前的user_type embedding和候选listing的listing_type embedding之间的余弦相似度,向用户推荐最相关的listing。例如,在下表中,我们展示了
user_type为 和美国的几种不同listing_type之间的余弦相似性,其中这种类型的用户通常会预定高质量、宽敞、并且有很多好评的listing。可以看到:- 最匹配这些用户偏好的
listing type(即整租entire home、很多好评、价格高于平均水平)具有较高的余弦相似性。 - 而不匹配这些用户偏好的
listing type(即空间较小less space、较低价格、较少评论)具有较低的余弦相似性。

- 最匹配这些用户偏好的
6.2 实验
这里我们首先介绍训练
Listing Embedding以及其离线评估Offline Evaluation的细节。然后,我们在
Listing Page上显示了将Listing Embedding用于相似Listing推荐Similar Listing Recommendation的在线实验结果Online Experiment Result。最后,我们给出我们搜索排序模型
Search Ranking Model的背景知识,并描述如何使用Listing Embedding和Listing Type & User Type Embedding来实现搜索中的实时个性化Real-time Personalization特征。embedding的两个应用(相似Listing推荐、搜索排序)都已经成功地投入生产。
6.2.1 Training Listing Embedding
对于
listing embedding的训练:- 我们从登录用户中获取所有的搜索,然后以
user id为单位,将该用户点击的所有listing id按时间顺序排序 。最终我们获得了8亿次click session。 - 随后,根据
30分钟的不活跃规则(即,如果用户两个相邻点击间隔超过30分钟,则我们认为这是两个session),我们将一个较大的listing id的序列拆分为多个序列。 - 接下来,我们删除了偶发的和短暂的点击,即用户在
listing页停留不到30秒的点击,并且仅保留由2次或者更多次点击组成的session。 - 最后,通过删除用户
id列来匿名化session。
如前所述,
click session由探索session(exploratory session) 和booked session组成。根据离线评估结果,我们在训练数据中对booked session进行了5倍的过采样,从而得到了表现最佳的listing embedding。过采样等价于
booked session的样本进行加权。- 我们从登录用户中获取所有的搜索,然后以
日常
Daily训练的配置:我们学习了
450万个Airbnb的listing的listing embedding,并使用下面介绍的离线评估技术调整了我们的训练数据实用性practicality和参数。我们的训练数据在几个月内以滑动窗口的方式天级更新,方法是处理最近一天的
search session,并将它们添加到数据集中,并从数据集中丢弃最早一天的search session。我们为每个
listing_id训练embedding,在训练之前随机初始化向量(每次使用相同的随机数种子)。我们发现,如果我们每天从头开始重新训练
listing embedding,而不是在现有向量上增量地连续训练,我们会获得更好的离线性能。天级别的
day-to-day向量差异不会在我们的模型中造成不一致discrepancy,因为在我们的应用中,我们使用余弦相似性作为主要信号,而不是实际的向量本身。即使向量随着时间变化,余弦相似性度量的含义及其范围也不会改变。listing embedding的维度设置为 ,因为我们发现:要在离线性能、以及为实时相似性计算目的而将向量存储在RAM中所需内存之间进行tradeoff。上下文窗口大小设置为 。我们对训练数据执行了
10轮迭代。为了实现算法的聚集搜索的修改
change,我们修改了原始的word2vec代码。训练使用了
MapReduce,其中300个mapper读取数据,而单个reducer以多线程方式训练模型。端到端的天级数据生成和训练
pipeline是使用Airflow(Airbnb的开源调度平台) 来实现的。
6.2.2 Offline Evaluation of Listing Embeddings
为了能够对优化函数、训练数据构造、超参数等方面的不同想法做出快速决策,我们需要一种快速比较不同
embedding的方法。评估训练好的
embedding的一种方法是:根据用户最近的点击来预测embedding在推荐用户想要预定的listing方面有多好。更具体而言,假设我们得到了最近点击的listing和需要排序的候选listing,候选中包含用户最终的预定listing。通过计算点击listing和候选listing的embedding之间的余弦相似度,我们可以对候选listing进行排序,并观察预定listing的排序位置rank position。出于评估的目的,我们的baseline由Search Ranking model(它是采用embedding方案之前的线上模型,从而作为对比)给出的排名,如下图的Search Ranking曲线所示。注:这里评估的是预订
listing在所有候选listing中的排序位置。如何生成候选listing,论文并未给出。常见的做法是在全局listing中随机负采样,也可以在同一市场内的listing中随机负采样。下图我们展示了离线评估的结果。我们比较了 的
embedding的几个版本,看它们如何根据之前的点击来对预定listing进行排序。预定listing的排名是针对导致预定的每次点击进行平均的,从预定前的17次点击到预定前的最后一次点击,较低的值意味着较高的排名、较小的点击意味着较长的点击序列(last表示预定前的所有点击,16表示仅使用最久远的那个点击)。我们比较的
embedding版本为:d32:使用原始负采样训练的embedding。
d32 book:在负采样中使用预定作为全局上下文来训练的embedding。d32 book+neg:在负采样中使用预定作为全局上下文、并在相同市场显式负采样来训练的embedding。
可以看到:
- 由于使用记忆特征
memorization feature,随着点击次数的增加Search Ranking模型效果更好。 - 基于
embedding相似性对listing进行重排re-ranking是很有用的,尤其是在搜索漏斗search funnel的早期阶段early stage。 d32 book + neg优于其它两个embedding版本。
最终这一类的实验结果图被用于做出关于超参数、数据构造等等的决策。
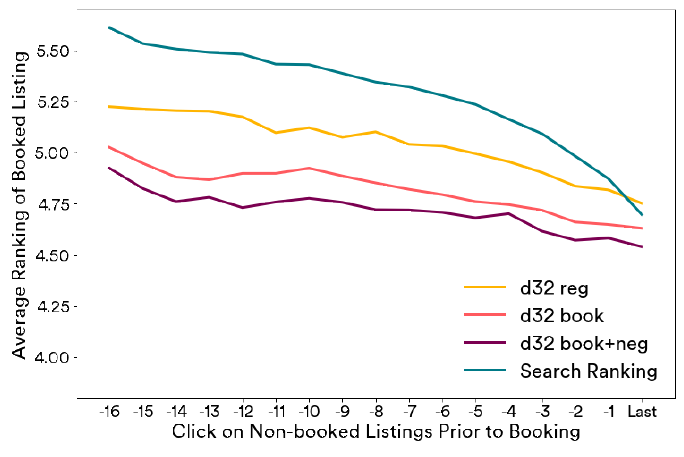
6.2.3 Similar Listings using Embeddings
每个
Aribnb主页listing page包含Similar Listing轮播,该轮播会推荐相似的、且相同日期可用的listing。在我们进行测试时,Similar Listing轮播的现有算法是在给定listing的相同location调用主搜索排序模型main Search Ranking model,然后根据可用性availability、给定listing的价格范围和listing type来过滤。我们进行了
A/B test,将现有的相似listing算法和基于embedding的解决方案进行了比较。在基于embedding的解决方案中,相似listing是通过在listing embedding空间中找到k个最近邻k-nearest neighbor来生成的。给定学到的
listing embedding,通过计算给定listing与可用于同一日期(如果入住check-in日期、退房check-out日期已确定)的、同一市场内的所有listing的向量 的余弦相似度,可以找到listing的相似listing。相似度最高的k个listing被检索为相似listing。计算是在线执行的,并使用我们的分片架构sharded architecture并行进行,其中部分embedding存储在每台搜索机器search machine上。A/B test表明:基于embedding的解决方案导致Similar Listing轮播的点击率CTR提高了21%(如果listing page输入了日期,则为23%;如果未输入日期,则为20%)。并且在Similar Listing轮播中找到他们最终预定的listing的租客增加了4.9%。根据这些结果,我们将基于
embedding的Similar Listing部署到生产环境中。
6.2.4 Real time personalization in Search Ranking using Embeddings
背景:为了正式描述我们的搜索排序模型
Search Ranking Model,这里介绍下背景。假设我们获得了有关每个搜索的训练数据 ,其中:
为搜索返回的
listing数量。为第 个结果
listing的特征向量。第 个
listing结果的特征向量 由listing特征、用户特征、query特征、以及交叉特征组成。listing特征是与listing本身相关的特征,如每晚价格、listing type、房屋数量、拒绝率rejection rate等。query特征是与发出的query相关的特征,如租客数量、停留时间length of stay、提前多少天lead days等。用户特征是与进行搜索的用户相关的特征,例如平均预定价格、租客评级等等。
交叉特征是从以下两个或多个特征源
feature source(listing, user, query)中导出的特征。这类特征的例子包括:query listing distance:query location和listing location之间的距离。capacity fit:query的租客数量和listing capacity之间的差异。price difference:listing价格和租客历史预定均价之间的差异。rejection probability:房东拒绝这些query参数的概率。- 点击百分比
click percentage:实时的memorization特征,它跟踪租客在特定listing上的点击比例。注意,它不是点击率,而是点击分布。
这里使用人工交叉特征,理论上
DNN模型也能够自动学习这类交叉特征。但是人工交叉特征相当于提供了先验知识,有助于模型的泛化和更快的收敛。
该模型使用大约
100个特征。为简明起见,我们不一一列举。为第 个结果
listing分配的标签label。为了将标签分配给搜索结果中的特定
listing,我们会在搜索发生后等待1周以观察最终结果:- 如果
listing被预定,则 。 - 如果租客和房东联系单没有预定,则 。
- 如果房东拒绝了租客,则 。
- 如果租客点击了
listing,则 。 - 如果租客仅是查看但未点击,则 。
这里的
label配置相当tricky,并没有理论指导,需要根据实验效果来调优。- 如果
经过
1周的等待之后,集合 也被缩短从而仅保留直到用户点击 的最新结果的搜索结果。即 之后的搜索结果直接丢弃,(防止被窗口截断)。最后,为了形成数据集 ,我们仅保留包含至少一个
booking label的 集合。每次我们训练一个新的排序模型,我们都使用最近30天的数据。接下来,我们将问题形式化为
pairwise回归regression问题,以搜索标签search label作为工具,并使用数据集 来训练GBDT模型,而且使用经过修改以支持Lambda Rank的package。我们将 的80%用于训练、20%用于测试,并在测试机上使用NDCG(一个标准的排序指标)来离线评估不同的模型。最后,一旦模型被训练好,它就被用于搜索
listing的在线评分。用户 执行的搜索query返回的每个listing的特征向量 所需的信号都是在线计算的,并且使用我们的分片架构sharded architecture进行评分。给定所有分数,listing以预估效用predicted utility的降序向用户展示。Listing Embedding Features:向我们的搜索排序模型添加embedding特征的第一步是将450万个embedding加载到我们的搜索后端search backend,以便可以实时访问它们以进行特征计算和模型打分model scoring。接下来,我们引入了几个用户短期
short-term历史行为记录,其中包括了最近两周的用户行为信息,并随着新的用户行为发生而实时更新。该逻辑是使用Kafka实现的。具体而言,对于每个user_id,我们收集并维度(定期更新)以下listing id的集合:-
clicked listing_ids:用户在过去两周内点击的listing。 -
long-clicked listing_ids:用户在过去两周内点击、且在listing page上停留了60秒以上的listing。 -
skipped listing_ids:用户在过去两周内跳过这些listing而点击了更低位置lower positioned的listing。(因此这些listing可以视为负样本)。 -
wishlisted listing_ids:用户在过去两周内添加到愿望清单wishlist中的listing。 -
inquired listing_ids:用户在过去两周内联系、但是没有预定的listing。 -
booked listing_ids:用户在过去两周内预定的listing。
这些
listing_id都是用户历史行为记录。我们进一步将每个短期历史行为记录 划分为多个子集,每个子集包含来自同一个市场的
listing。例如,如果用户点击了纽约和洛杉矶的listing,则他们的 集合将进一步划分为 和 。最后,我们定义
embedding特征,这些特征利用上述定义的集合和已经学到的listing embedding为每个候选listing产生得分score。下表总结了这些特征(搜索排序中的embedding特征)。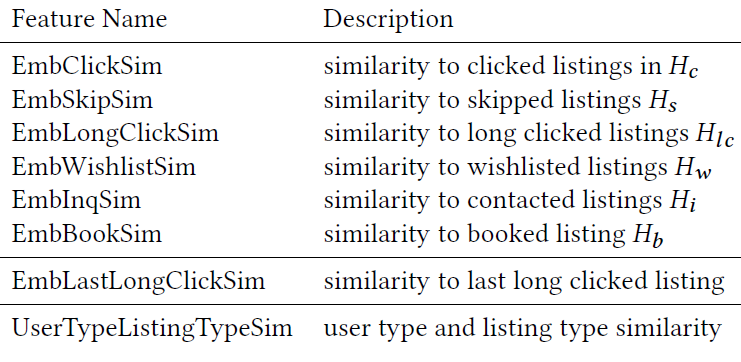
我们描述如何使用 来计算
EmbClickSim特征。使用相应的用户短期历史行为记录 ,我们以相同的方式计算上表顶部各行中的其它特征。这里计算的是:候选
listing和用户历史行为的相似性。为了计算候选
listing的EmbClickSim特征,我们需要计算它的listing embedding和 中listing的embedding之间的余弦相似度。为此,我们首先计算 的市场级别中心market-level centroid的embedding。为了说明这一点,我们假设 包含5个来自纽约的listing、以及3个来自洛杉矶的listing。这将需要通过平均每个市场的listing id的embedding来计算两个market-level centroid embedding,一个用于纽约、一个用于洛杉矶。然后,EmbClickSim被计算为listing embedding和 的market-level centroid embedding之间的两个相似性中的最大值。具体而言,EmbClickSim可以表述为:其中:
- 为用户点击
listing所属的市场的集合(去重)。 - 为用户在城市 点击
listing的集合。
除了与所有用户点击的相似性之外,我们还添加了一个特征,用于衡量与最近一次长点击的相似性,即
EmbLastLongClickSim。对于候选listing,通过找到其embedding和来自 的最近长点击listing的embedding之间的余弦相似度,我们得到:-
User-type & Listing-type Embedding Features:我们遵循类似的过程来引入基于user type embedding的特征和list type embedding的特征。我们使用
5000万个用户booking session,为50万个user type和50万个list type训练了embedding。embedding的维度是 维的,并且在booking session上使用 的滑动窗口来训练。user type embedding和list type embedding被加载到搜索机器search machine的内存中,这样我们就可以在线计算type相似性。为了计算候选
listing的UserTypeListingTypeSim特征,我们简单地查找 的当前listing type,以及执行搜索的用户的当前user type,并计算它们的embedding之间的余弦相似度:上述表格中的所有特征都记录了
30天,因此可以将其添加到搜索排序训练集合 中。特征的覆盖率(即具有特定特征的样本在 中的占比)在下表中进行了报告。观察到基于用户点击的特征和基于用户skip的特征具有最高的特征覆盖率。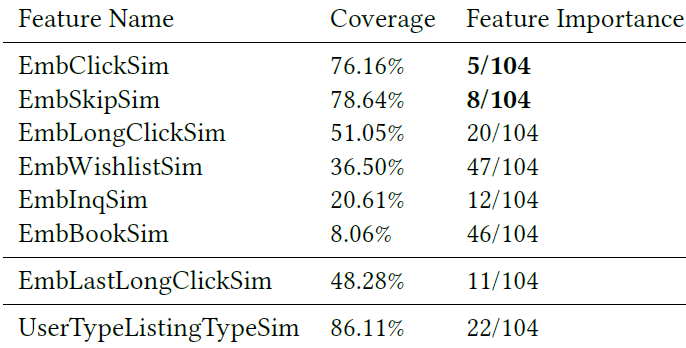
最后,我们训练了一个新的、添加了
embedding特征的GBDT搜索排序模型。表中显示了embedding特征的重要性(在104个特征中的排名)。排名靠前的特征是:- 与用户点击
listing的相似性(EmbClickSim特征,总体排名第5)。 - 与用户
skip listing的相似性(EmbSkipSim特征,总体排名第8)。
前
20个特征中有5个embedding特征。不出所料,长期long-term特征UserTypeListingTypeSim(它使用所有历史的用户预定)的排名要好于短期short-term特征EmbBookSim(仅考虑最近2周的预定)。这也表明:基于历史预定的推荐更适合使用历史booking session训练的embedding,而不是使用历史click session训练的embedding。这里将
Embedding和GBDT结合,事实上可以直接进行端到端的DNN学习。Embedding + GBDT的优势是可解释性强。- 与用户点击
为了评估模型是否学会了按照我们的意图使用特征,我们绘制了
3个embedding特征的部分依赖性partial dependency:EmbClickSim、EmbSkipSim、UserTypeListTypeSim。这些图给出了:如果我们固定目标特征(我们正在检查的特征)之外的所有特征的值,那么会对listing的排序分ranking score产生什么样的影响。- 在左侧的子图中,可以看到较大的
EmbClickSim值(表示该listing和用户最近点击的listing更相似)会导致较高的模型得分。 - 在中间的子图中,可以看到较大的
EmbSkipSim值(表示该listing和用户最近跳过的listing更相似)会导致更低的模型得分。 - 在右侧的子图中,可以看到较大的
UserTypeListingTypeSim值(表示该listing的listing type和user type相似)会导致更高的模型得分。
- 在左侧的子图中,可以看到较大的
在线实验结果
Online Experiment Results Summary:我们进行了离线和在线的实验(A/B test)。首先我们比较了在相同数据上训练的两个搜索排序模型,它们分别带有
embedding和特征、以及不具备embedding特征。在下表中,我们根据每个效用(曝光、点击、拒绝、预定)的贴现累计效用Discounted Cumulative Utility: DCU和总体归一化的贴现累计效用Normalized Discounted Cumulative Utility:NDCU来给出结果。可以看到:- 对于
NDCU,添加embedding特征导致了2.27%的提升。 - 对于预定的
DCU,添加embedding特征导致了2.58%的提升。 这意味着预定listing在测试集中排名更高。 - 对于拒绝的
DCU,添加embedding没有任何下降(DCU-0.4持平),这意味着拒绝listing没有比对照组(不带embedding特征的模型)的排名更高。
从下表中观察到的事实、以及前述表格中
embedding特征在GBDT特征重要性中排名较高的事实、以及上图中发现的特征行为与我们直观预期相匹配的事实,足以让我们做出继续进行在线实验的决定。在在线实验中,我们看到了具有统计意义的预定增益
booking gain,并且embedding特征也在投入到生产环境中。几个月后,我们进行了一次反向测试,其中我们试图移除embedding特征,结果导致负向的预定结果,这是实时embedding特征有效的另一个证明。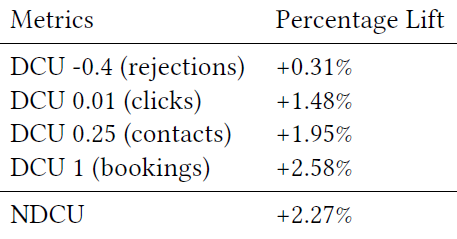
- 对于
七、MOBIUS[2019](用于召回)
百度搜索作为中国最大的商业搜索引擎
commercial search engine,每天为数亿在线用户提供服务,以响应各种各样的搜索query。众所周知,广告一直是世界上所有主要商业搜索引擎公司的主要收入来源。论文
《MOBIUS: Towards the Next Generation of Query-Ad Matching in Baidu’s Sponsored Search》重点解释百度搜索广告系统(在百度内部通常称为 “凤巢”Phoenix Nest)最近的一些令人振奋的发展development和发明invention。下图是手机上百度搜索结果的屏幕截图,它给出了一个搜索
query“阿拉斯加的旅游” 的搜索结果。我们的sponsored搜索引擎负责在自然organic的搜索结果之前,在每个page上提供有用的广告。
凤巢在检索与用户
query相关的广告以吸引用户点击方面起着至关重要的作用,因为广告主advertiser在广告被点击时付费。百度sponsored搜索系统的目标是在线用户online user、广告主advertiser、以及sponsored搜索平台platform之间形成和培育nourish一个良性的循环。传统的
sponsored搜索引擎通常通过两步来展示广告:第一步是检索给定query的相关广告,第二步是根据预测的用户互动user engagement对这些广告进行排序。作为百度商业上使用的高效sponsored搜索引擎,我们曾经采用三层漏斗形funnel-shaped的结构(如下图所示),从数十亿个候选广告中筛选和排序数百个广告,以满足低响应延迟response latency和低计算资源computing resource限制的要求。如下图所示,给定用户query和丰富的用户画像user profile,最top的matching layer负责向下一层提供语义相关的候选广告,而最bottom的排序层ranking layer更关心这些广告的业务指标(如CPM,ROI等)。这样从数十亿个候选广告中检索数百个相关的、高CPM的广告是非常高效的。为了覆盖更多语义相关的广告,大多数情况下都利用query expansion和natural language processing: NLP技术。底部的ranking layer更多地关注经过前一层过滤后的广告的业务指标,比如cost per mile:CPM(CPM = CTR x bid)、return on investment: ROI等等。
然而,由于各种原因,
matching目标和ranking目标之间的这种分离separation/不同distinction导致了较低的商业回报lower commercial return。给定一个用户query,我们必须使用复杂的模型,并花费大量的计算资源来对数百、甚至数千个候选广告进行排序。但令人失望的是:ranking模型报告说,很多相关的relevant广告并没有高CPM,因此不会被曝光。为了解决这个问题,百度搜索广告设立了Mobius项目,该项目的目的是在百度sponsored搜索中研发下一代query-ad matching系统。该项目有望将不同的学习目标(包括query-ad相关性、以及很多其他业务指标)统一在一起,同时降低响应延迟、降低计算资源的限制,并最多仅对用户体验user experience产生的很小的负面影响。在本文中,我们将介绍
Mobius-V1,这是我们首次尝试在matching layer中将CPM(训练CTR从而得到CPM)作为除了query-ad相关性relevance之外的其它优化目标。换句话讲,Mobius-V1能够准确、快速地预测数十亿user query & adpair对的点击率。为了实现这一目标,我们必须解决以下主要问题:- 不足
insufficient的点击历史:ranking layer采用的原始的神经点击模型neural click model是通过高频的广告和用户query来训练的。一旦出现高频广告或者高频query,即使query-adpair对的相关性很低,模型也倾向于以更高的点击率CTR来预估它们。
- 不足
模型对高频广告或者高频
query的记忆性太强,形成了固有的bias。这种bias可能是有利的,也可能是不利的,取决于具体的任务和场景。
- 高的计算成本/存储成本:
Mobius有望预测数十亿的user query & ad pair对的多个指标(包括相关性、CTR、ROI等),它自然面临着更大的计算资源消耗的挑战。
为了解决上述问题,我们首先设计了一个 teacher-student 框架,该框架受主动学习active learning 思想的启发,以增强augment 我们大规模神经点击模型large-scale neural click model 的训练数据,从而预测数十亿 user query & ad pair 对的点击率。
具体而言:
离线数据生成器
offline data generator负责在给定数十亿user query和候选广告的情况下,构造人工合成的syntheticquery-ad pair对。这些
query-ad pair对由一个teacher agent不断地进行判断,其中该teacher agent是从原始matching layer派生的、并且擅长度量query-ad pair对的语义相关性semantic relevance。它可以帮助检测合成的
query-ad pair对中的不良情况(即高pCTR但是低相关性relevance)。出现高
pCTR但是低相关性的原因:粗排模型认为相关性较低,但是由于存在热门query或者热门广告,精排模型得到的pCTR较高。- 作为
student,我们的神经点击模型是通过额外的bad case来提高对尾部query和广告的泛化能力。
为了节省计算资源并满足低响应延迟
response latency的要求,我们进一步采用最新的state-of-the-art近似最近邻搜索approximate nearest neighbor:ANN和最大内积搜索Maximum Inner Product Search: MIPS技术来更有效地索引indexing和检索retrieving大量广告。为了应对上述挑战,作为我们下一代
query-admatching系统的第一个版本,Mobius-V1是上述解决方案的集成,并已在百度sponsored搜索引擎中部署。- 作为
7.1 百度 SPONSORED 搜索
长期以来,漏斗形
funnel-shaped结构是sponsored搜索引擎的经典架构。主要组件包括query-ad matching和query-ad reanking。query-ad matching通常是一个轻量级模块,它度量用户query和数十亿个广告之间的语义相关性semantic relevance。- 相比之下,
query-ad ranking模块应该关注更多的业务指标,如CPM, ROI等,并使用复杂的神经网络模型对数百个候选广告进行排序sort以进行展示display。
这种解耦
decoupled的结构是在早期节省昂贵计算资源的明智选择。此外,它还可以促进科学研究和软件工程,因为这两个模块可以分配给不同的研究/开发团队,以最大限度地实现各自模块的目标。百度
sponsored搜索曾经采用三层漏斗形结构,如下图所示。顶部
matching layer的优化目标(以 来表示)是最大化所有query-ad pair对之间的平均相关性得分relevance score。但是,根据我们对百度
sponsored搜索引擎性能的长期分析,我们发现matching目标和ranking目标之间的分离separation/不同distinction往往会导致更低的CPM。而CPM是商业搜索引擎的关键业务指标之一。当ranking layer中的模型报告matching layer提供的许多相关广告不会展示在搜索结果中的时候,这是让人不满意的unsatisfactory,因为这些广告的预估CPM(由ranking layer预估)较低。随着计算资源的快速增长,百度搜索广告团队(即“凤巢”)最近建立了
Mobius项目,该项目的目标是在百度sponsored搜索中实现下一代query-ad matching系统。如下图所示,该项目的蓝图
blueprint预期将多个学习目标(包括query-ad相关性relevance,以及很多其他业务指标)统一到百度sponsored搜索的单个模块中,从而降低响应延迟、降低计算资源的限制,并最多对用户体验user experience产生很小的负面影响。本文将报告
Mobius的第一个版本,即Mobius-V1。这是我们首次尝试将CPM作为除query-ad相关性之外的其它优化目标来训练matching layer。这里我们将Mobius-V1的目标形式化为:因此,如何准确预测
Mobius-V1中数十亿对user query和候选广告之间pair对的点击率成为一个挑战。在本文的其余部分,我们将详细描述我们如何设计、实现和部署Mobius-V1。目前,我们已经部署了
Mobius的第一个版本(Mobius-V1),它可以更准确地预估数十亿user query & ad pair对之间的点击率。
7.2 模型
Mobius是这个项目在百度内部的代码。无独有偶,著名的莫比乌斯环Mobius Loop也是北京百度科技园的鸟瞰图。Mobius-V1是我们首次尝试(已经成功部署)将我们的神经点击模型迁移到直接面对数十亿用户query和广告的matching layer。随着输入数据规模的急剧增加,我们需要离线重新训练我们的神经点击模型,并更新广告索引indexing和广告检索retrieving技术。
7.2.1 主动学习的 CTR 模型
六年多以来,百度
sponsored搜索引擎一直使用深度神经网络DNN作为CTR模型(规模巨大)。最近,Mobius-V1采用了一种创新的新架构。构建
Mobius-V1模型的一个直观而简单的方法是重用ranking layer的原始CTR模型。这是一个大规模的、稀疏的、有利于记忆memorization的深度神经网络DNN。然而,它在长尾的用户query或长尾的广告上的点击率预估存在严重的bias。如下图所示,考虑同一个用户在搜索日志中请求的两个query:Tesla Model 3、White Rose。
对于过去采用的漏斗形结构,
queryTesla Model 3和广告Mercedes-Benz(梅赛德斯奔驰)的相关性首先由matching layer来保证。这里相关性得分是如何得到的?论文并没有给出具体的方案。
然后,我们在
ranking layer的神经点击模型往往会在query-ad pair对上预测较高的点击率,因为Tesla Model 3是一个高频query,并在我们的搜索日志中留下了关于广告Mercedes-Benz的丰富点击历史。但是在
Mobius-V1中,我们尝试使用我们的神经点击网络来直接处理数十亿个缺乏相关性保证的query-ad pair对。很自然地会出现很多不相关的query-ad pair对,如图中的queryWhite Rose和广告Mercedes-Benz。然而,我们已经发现:我们的神经点击模型仍然倾向于为那些不相关的query-ad pair对预测更高的点击率。这是一个典型的
bad case。由于ranking layer采用的神经点击模型最初是由高频的广告和高频的query训练的,因此一旦出现高频广告(例如,本例中的Mercedes-Benz),模型往往会以更高的点击率来预估一对query-ad pair对,尽管White Rose和Mercedes-Benz没有什么相关性。这个现象的本质是:
ranking layer的样本都是(经过matching layer筛选之后的)高相关性的query-ad pair。如果将ranking layer直接处理全部样本空间(包含大量不相关的query-ad pair),则训练空间和预测空间不一致。
为解决这个问题,我们提出使用
matching layer中的原始相关性判断器judger作为teacher,以使得我们的神经点击模型意识到低相关性low relevance的query-ad pair对。作为student,我们的神经点击模型以主动学习的方式从增强的augmentedbad case中获得额外的、关于相关性的知识knowledge on relevance。下图给出了利用增强数据
augmented data主动训练我们神经点击模型的流程图,其中分为两个阶段:数据增强data augmentation,以及CTR模型学习。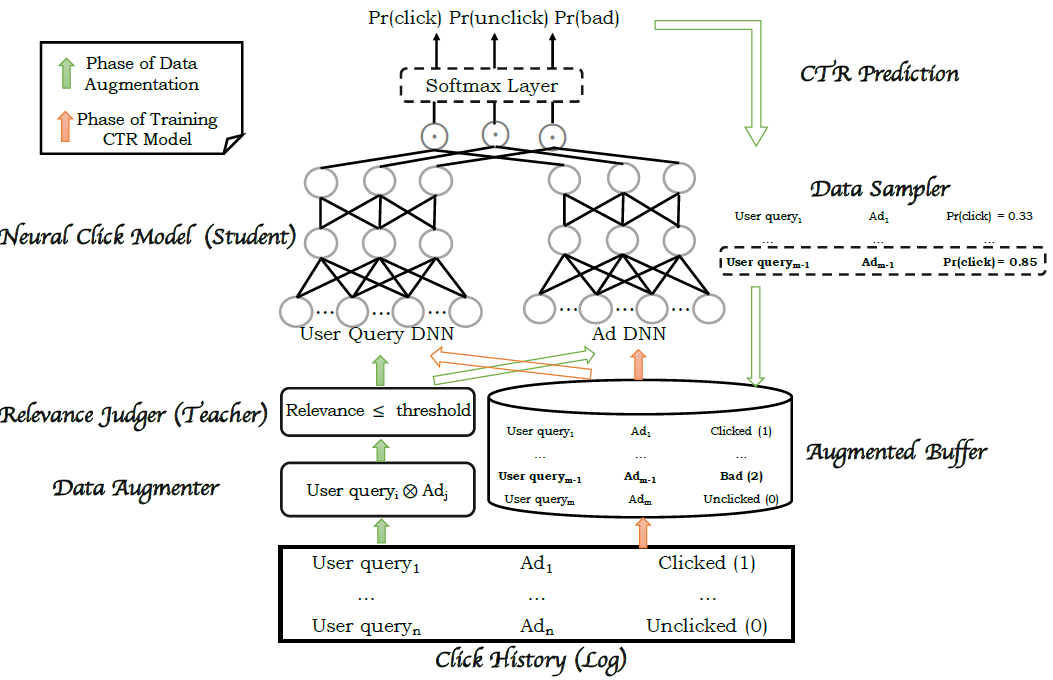
数据增强
data augmentation阶段:从将query日志中的一个batch的点击历史记录(即user query& ad pair对)加载到数据增强器data augmenter开始。每当数据增强器接收到
query-ad pair对时,它将将pair对分为两个集合:一个query集合、一个ad集合。然后我们计算这两个集合的笛卡尔积,以构造更多的user query & ad pair对(即使这些pair对没有出现在点击历史记录中)。假设在一个batch的点击历史记录中有 个query和 个广告,那么数据增强器可以帮助生成 个人工合成的query-ad pair对。在列出所有可能的
query-ad pair对之后,相关性判断器relevance judger(即原始的matching模型作为teacher)介入并负责对这些pair的相关性进行评分。由于我们想发现低相关性的query-ad pair对,因此设置了一个阈值以将这些pair对保留为候选教材candidate teaching materials。这些低相关性的query-ad pair对作为教材,首次被输入到我们的神经点击模型(作为student)中,并且每个pair对都被分配上一轮迭代更新模型预估的CTR。核心问题:
teacher模型(原始matching模型)怎么训练?个人猜测很多是基于相似性或者相关性得到的,如item-2-item、term match等方式。为了教我们
3-class(即click、unclick、bad)的神经点击模型学会识别 “低相关性但是高点击率” 的query-ad pair对,我们可以直觉地intuitively设置另一个阈值来过滤掉大多数低点击率的query-ad pair对。然而,我们考虑一个更好的选择来平衡对于增强数据augmented data的探索exploration和利用exploitation:我们使用数据采样器data sampler,根据人工合成的query-ad pair对上的预估CTR来计算采样率,从而选择和标记label增强数据。一旦一个query-ad pair对被采样为我们的神经点击网络的bad case,该pair对就被标记为一个bad类别。阈值过滤是硬过滤,数据采样是软过滤。
CTR模型学习阶段:click/unclick历史记录,以及标记的bad case都被作为训练数据添加到augmented buffer中。我们的神经点击网络是一个大规模的多层稀疏
DNN模型,它由两个子网组成,即user query DNN和ad DNN。左侧的
user query DNN将丰富的用户画像和query作为输入,而右侧的ad DNN将广告embedding视为特征。两个子网都产生一个
96维的分布式representation,每个representation向量被分段为3个向量(96 = 3 x 32)。我们对
user query DNN和ad DNN之间的三对向量应用三次内积运算,并采用softmax layer进行CTR预估。三次内积运算分别计算:非归一化的
click概率、非归一化的unclick概率、非归一化的bad概率。
一旦
buffer中的增强数据augmented data被使用,我们就清空buffer,等待加载下一个batch的点击历史记录。总体而言,我们贡献了一种学习范式,在百度
sponsored搜索引擎中离线训练我们的神经点击模型。为了提高模型对长尾数十亿个query-ad pair对的CTR预估的泛化能力,神经点击模型(student)可以主动向相关性模型(teacher) 询问query标签label。这种类型的迭代式监督学习被称为主动学习active learning。这种方式将相关性知识迁移到
CTR预估模型中。 另外,这里创新性的将label分为三类:点击、不点击、badcase,这相比传统的点击/不点击更符合业务需求。badcase是从当前训练batch中人工构造的,依赖于相关性判断器relevance judger来判断相关性、前一轮CTR预估模型来预估点击率。算法:用于训练神经点击模型以预测数十亿个
query-ad pair对的点击率的主动学习过程active learning procedure:输入:
- 历史点击信息
Click_History - 相关性判断器
Relevance_Judger(Teacher) - 神经点击模型
Neural_Click_Model(Student) - 最大迭代
epoch - 收敛误差阈值
- 历史点击信息
输出:训练好的神经点击模型
步骤:
while迭代 或者do:加载一个
batch的Click_History:构建
query集合、广告集合:生成增强数据
augmented data:获取低相关性
low-relevance的增强数据:获得低相关性增强数据的预估
CTR:根据预估
CTR从低相关性增强数据中采样bad case(低相关性且高pCTR):将
bad case添加到Click_History的训练buffer中:基于训练
buffer中的数据来更新Neural_Click_Model的模型参数:
7.2.2 快速广告检索
在百度的
sponsored搜索引擎中,我们一直在使用上图所示的深度神经网络(即user query DNN和ad DNN)来分别获取query和广告的embedding。给定一个
query embedding,Mobius必须从数十亿个候选广告中检索最相关most relevant和CPM最高的广告。当然,尽管从理论上讲暴力搜索brute-force search可以发现我们要找的所有广告(即100%的广告召回率),为每个query穷尽计算是不切实际的。在线服务通常有受限的延迟限制,并且广告检索必须在短时间内完成。因此,我们必须利用近似最近邻搜索approximate nearest neighbor:ANN技术来加快检索过程,如下图所示。下图为快速广告检索框架
fast ad retrieval framework。user query embedding和ad embedding首先被压缩以节省内存空间,然后可以采用两种策略:- 通过余弦相似度进行
ANN搜索,然后根据业务相关的权重business related weight: BRW进行重排re-rank。 - 利用权重进行排序,这是一个最大内积搜索
Maximum Inner Product Search:MIPS问题。
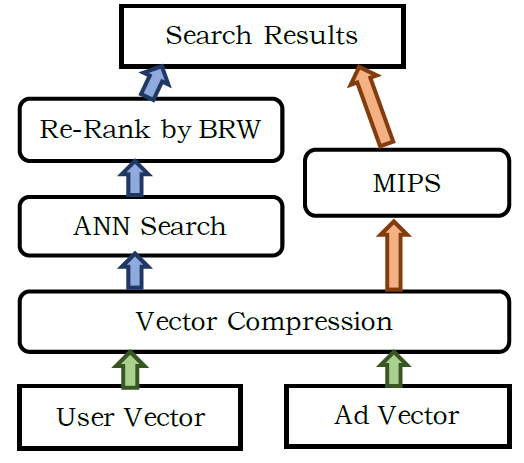
- 通过余弦相似度进行
ANN搜索:映射函数通过余弦相似度将用户向量和广告向量组合在一起,然后余弦值通过softmax layer产生最终的点击率。这样,余弦值和CTR是单调相关的。在模型训练之后,就会清楚余弦值和CTR是正相关还是负相关。如果是负相关,我们可以通过对广告向量乘以-1,从而很容易将它转换为正相关。这样,我们把CTR排序问题简化为余弦相似度排序问题,这是一个典型的ANN搜索setting。近似最近邻
ANN搜索的目标是:对于给定的query对象,通过只扫描语料库中的一小部分对象,从大的语料库中检索most similar的对象集合。这是一个基础fundamental的问题,从计算机科学早期就开始积极研究。通常,
ANN的流行算法是基于空间划分的思想,包括tree-based方法、随机哈希random hashing方法、quantization-based方法、随机划分树random partition tree方法等等。对于这个特殊的问题(处理稠密的、相对较短的向量),我们发现随机划分树方法相当有效。除了其它变体之外,还有一种叫做ANNOY的随机划分树的已知实现。最大内积搜索
MIPS:在上述解决方案中,在用户向量和广告向量matching之后,需要考虑业务相关的权重。实际上,这个权重在广告排序中至关重要。为了在排序中更早地考虑权重信息,我们通过加权余弦问题将快速ranking过程形式化为:其中:
- 为业务相关的权重。
- 为
user-query embedding向量。 - 为广告
embedding向量。
注意,加权余弦构成了内积搜索问题,通常称作最大内积搜索
Maximum Inner Product Search: MIPS。在这项工作中,可以应用多个框架来快速搜索内积。基于内积的搜索要比基于模型(如
XGB模型、DNN模型)的搜索要快得多,这也是为什么主流的召回阶段采用基于内积的搜索的主要原因。向量压缩:为数十亿个广告中的每一个存储一个高维浮点特征向量将会占用大量的磁盘空间。如果这些特征需要在内存中进行快速
ranking,则会带来更多的问题。一个通用的解决方案是将浮点特征向量压缩为随机的二进制
binary(或者整数)的哈希码hash code或者量化码quantized code。压缩过程可能会一定程度上降低检索召回率,但是它可能会带来显著的存储优势。对于当前的实现,我们采用了一种基于量化
quantization-based的方法(类似于K-Means来聚类我们的索引向量),而不是对索引中的所有广告进行排序。当query到来时,我们首先找到query向量被分配到的簇cluster,然后从索引中获取属于同一个簇的广告。乘积量化
product quantization: PQ的思想更进了一步,将单个向量划分为几个子向量,并分别对每个子向量进行了聚类。在我们的CTR模型中,我们将query embedding和ad embedding分割为三个子向量。然后,可以将每个向量分配三个cluster质心centroid,每个质心对应于一个子向量空间的聚类。例如,如果我们为每组子向量聚类到 个质心,则可以利用 个可能的cluster centroid,这对于十亿规模的广告multi-index需求来说是足够的。在Mobius-V1中,我们采用了一种称作Optimized Product Quantization: OPQ的变体算法。
7.3 实验
在将
Mobius-V1集成到百度sponsored搜索引擎之前,我们进行了彻底的实验。具体而言:- 我们首先需要对我们的点击率预估模型和新的广告索引
indexing方法进行离线评估。我们需要确保我们的CTR模型和检索广告的新方法能够发现更多相关性、更高CPM的广告。 - 然后我们尝试在线部署,处理百度搜索中的一部分
query流。
Mobius-V1在通过线下评估和在线A/B test之后,我们在多个平台上启动了它,并监控了CPM、CTR、ACP(平均点击价格average click price) 等统计信息。- 我们首先需要对我们的点击率预估模型和新的广告索引
离线评估:我们加载了搜索日志来收集
click/unclick历史记录,并构建了一个包含800亿个样本的训练集。我们还使用搜索日志来构建测试集,该测试集包含100亿条广告click/unclick历史记录。我们比较了我们主动学习的
CTR模型和两种baseline方法的有效性。一种方法是原始
ranking layer采用的2-class的CTR模型,该模型仅由点击历史记录来训练而不使用任何增强数据augmented data。另一种方法是一个
3-class的CTR模型,它使用随机的增强数据训练,其中增强数据不使用相关性模型(teacher)来判断。增强型数据随机被标记为
bad。
如下表所示,我们的模型可以保持与原始
ranking模型相当的AUC,但是显著提高了相关性模型得分relevance model score(这个得分是通过我们的相关性模型来度量):得分从0.312提升到0.575。换句话讲,在Mobius-V1模型中,低相关性但是高CPM的query-ad pair对被我们的新的CTR模型成功地识别为bad case。此外,我们将每种方法预测的点击率最高的
top 100000个query-ad pair对交付给百度的众包团队,以便由人类专家对query-ad pair对的相关性进行人工评分,评分范围从0~4(0表示无相关性,4表示非常相关)。人工评分的报告还表明:我们Mobius-V1中的点击率模型在发现相关的query-ad pair对上表现良好。下表中,
REL(Relevance Model)表示由原始的matching模型评估的、测试集query-ad pari对之间的平均相关性得分;REL(Human Experts)表示人类专家手工评分的、测试集query-ad pari对之间的平均相关性得分。
此外,对于相同的给定的广告集合,我们使用两个广告索引系统
indexing system来检索广告:随机划分树random partition tree(ANN+Re-Rank)驱动、OPQ(Compressed Code+MIPS)驱动。下表显式,OPQ将广告覆盖率Ad Coverage Rate提升了33.2%。
在线评估:在线
A/B test是从平均响应时间Avg Response Time和内存使用率Memory Usage的角度来看Mobius-V1的两种不同广告检索策略之间的差异。下表显式了OPQ可以提供比随机划分树方法低得多的延迟,并将平均响应时间减少58ms/query。此外,我们检查了
top 3%的高CPM广告的平均响应时间,这些广告具有更大的商业价值,但是需要更多的计算资源。数据表明:OPQ减少了75%的query延迟(从120ms降低到30ms),并大大节省了内存消耗。系统发布:在
Mobius-V1成功地通过离线评估和在线A/B test之后,我们决定在百度内部和外部的多个平台上启动它。这些平台包括手机版的Baidu App、PC版的Baidu Search、以及我们sponsored搜索引擎服务的许多其他关联网站和app。根据我们对整个在线流量的7天监控,下表给出了CPM, CTR, ACP的统计数据。CPM是评估sponsored搜索引擎性能的主要指标。和以前的系统相比,Baidu App的CPM显著提高了3.8%、Baidu Search的CPM显著提高了3.5%。其中Baidu Search是我们sponsored搜索引擎的主要门户网站。
八、TDM[2018](用于检索)
推荐已经被各种内容提供商
content provider广泛使用。基于用户的历史行为或相似偏好的用户来推断出用户兴趣的个性化推荐方法,已经在YouTube和Amazon中被证明是有效的。设计这样的推荐模型来为每个用户从整个语料库中预测最佳候选集合candidate set有很多挑战:在拥有大量语料库的系统中,一些表现良好
well-performed的推荐算法可能无法从整个语料库中进行预测。相对于语料库大小的线性预测复杂度是不可接受的。部署这样的大规模推荐系统需要限制单个用户的计算量。假设用户有
10亿,而item有1亿,如果是语料库的线性复杂度则需要10亿亿次,现有算力难以支持。如果是语料库的对数复杂度,则需要270亿次,现有算力可以接受。而且除了精确性
preciseness之外,也需要推荐项目的新颖性novelty从而维护用户体验user experience。我们不希望推荐结果仅包含用户历史行为的同质化homogeneous的item。
为了减少计算量并处理庞大的语料库,基于内存的协同过滤
memory-based collaborative filtering方法被广泛应用于工业界。作为协同过滤家族中的一种代表性方法,item-based协同过滤可以用相对少得多的计算从非常大的语料库中进行推荐。具体而言:- 首先预先计算的
item pair对之间的相似性。 - 然后使用用户的历史行为作为触发器
trigger来召回那些最相似的item。
然而,候选集的范围是有限制的,即,并不是所有的
item、而是只有和trigger相似的item才能被最终推荐。这种直觉阻止了推荐系统跳出历史行为来探索潜在的用户兴趣,这限制了召回结果的准确性accuracy。而且在实践中,这种方法也限制了召回结果的新颖性novelty。减少计算的另一种方法是进行粗粒度推荐
coarsegrained recommendation。例如,系统为用户推荐少量的item类目category,并选择这些类目下对应的所有item。然后这些item进入ranking阶段。但是对于大型语料库,计算问题仍然没有解决。- 如果类目数量很大,那么类目推荐本身也会遇到计算障碍。
- 如果类目数量很小,那么某些类目将必然包含非常多的
item,使得接下来的ranking阶段的计算不可行。
此外,所使用的类目体系通常不是为推荐问题而设计的,这可能会严重损害推荐的准确性
accuracy。在推荐系统的文献中,基于模型的方法是一个活跃的话题。例如:
- 矩阵分解
matrix factorization: MF等模型试图将pairwise的user-item偏好(例如评分rating)分解成用户因子user factor和item因子item factor,然后向每个用户推荐其最喜欢的item。 - 因子分解机
factorization machine:FM进一步提出了一个统一的模型,它可以用任何类型的输入数据模拟不同的因子分解模型factorization model。 - 在一些没有显式偏好而只有隐式用户反馈(例如,像点击或者购买这样的用户行为)的现实场景中,
bayesian personalized ranking: BPR给出了一种以partial order的三元组来表达偏好的解决方案,并将其应用于MF模型。 - 在工业上,
YouTube使用深度神经网络来学习用户embedding和item embedding,其中两种embedding分别由它们相应的特征生成。
在上述各种方法中,
user-item pair对的偏好可以表示为用户向量representation和item向量representation的内积。因此,预测阶段相当于检索用户向量在内积空间中的最近邻居nearest neighbor。对于向量搜索问题,针对近似k近邻approximate k-nearest neighbor的索引哈希index hashing或索引量化index quantization可以保证检索的效率。但是,用户向量
representation和item向量representation之间的内积,这样一种交互形式interaction form严重限制了模型的能力。还有许多其他类型的、更具有表达能力的交互形式,如,用户历史行为和候选item之间的叉积特征cross-product feature被广泛用于点击率预测。最近的工作提出了一种神经协同过滤方法,其中使用神经网络而不是内积来建模用户向量representation和item向量representation之间交互。实验结果表明,多层前馈神经网络比固定内积的方法具有更好的性能。deep interest network:DIN指出,用户的兴趣是多样的,类似注意力的网络结构可以根据不同的候选item生成不同的用户向量。除了上述工作之外,product neural network:PNN等其它方法也证明了高级advanced神经网络的有效性。然而,由于这些模型不能被规则化
regulated为用户向量和item向量之间的内积形式从而有效利用近似kNN搜索,因此它们不能被用在大规模推荐系统中召回候选item。如何克服计算障碍,使得任意高级神经网络在大规模推荐中可行是一个难题。为了解决上述挑战,论文
《Learning Tree-based Deep Model for Recommender Systems》提出了一种新的、基于树tree-based的深度推荐模型tree-based deep recommendation model: TDM。在多类分类问题中,人们研究了树方法以及
tree-based方法。其中,通常使用树来划分样本空间或label空间以减少计算成本。然而,研究人员很少涉足使用树结构作为检索索引的推荐系统。事实上,信息的层级结构hierarchical structure普遍存在于很多领域。例如在电商场景中,iPhone是细粒度的item,而智能手机是iPhone所属的粗粒度概念。TDM方法利用信息的层级结构,将推荐问题转化为一系列的层级分类问题hierarchical classification problem。通过解决从容易到困难的问题,TDM可以同时提高准确率accuracy和效率efficiency。论文的主要贡献:
据我们所知,在从大型语料库中生成推荐时,
TDM是第一种使得任意高级模型成为可能的方法。得益于层级树搜索
hierarchical tree search,TDM在进行预测时实现了相对于语料库大小对数复杂度的计算。TDM可以帮助更精确precisely地找到新颖novel、但有效effective的推荐结果,因为整个语料库都被探索,并且更有效的深度模型也有助于找到潜在的兴趣。除了更高级的模型之外,
TDM还通过层级搜索hierarchical search提高推荐的准确性accuracy,其中层级搜索将一个大问题分解为多个小问题,并从易到难依次解决。作为一种索引,树结构
tree structure还可以学习,从而获得item和概念concept的最佳层级optimal hierarchy,以便更有效地检索。而这反过来又有助于模型训练。我们采用一种
tree learning方法,该方法可以对神经网络和树结构进行联合训练。我们在两个大规模真实世界数据集上进行了广泛的实验。结果表明:
TDM的性能明显优于现有方法。淘宝display广告平台的在线A/B test结果也验证了该方法在生产环境中的有效性。
值得一提的是,
tree-based方法也在语言模型的工作hierarchical softmax中进行了研究。但是hierarchical softmax和我们提出的TDM不仅在动机上、而且在公式上都不相同。在
next-word prediction问题中,传统的softmax必须计算归一化的term才能获得任何单个word的概率,这非常耗时。hierarchical softmax使用树结构,next-word的概率被转换为沿着树路径tree path的节点概率的乘积。这种公式将next-word概率的计算复杂度降低到语料库大小的对数量级。然而,在推荐问题中,目标是在整个语料库中搜索那些最喜欢的
item,这是一个检索问题。在hierarchical softmax中,父节点的最优不能保证全局最优的叶节点位于该父节点的后代中,并且仍然需要遍历所有item从而找到最优叶节点。因此,hierarchical softmax不适合这样的检索问题。为了解决检索问题,我们提出了一种类似于最大堆
max-heap like的树公式tree formulation,并引入了深度神经网络对树进行建模,从而形成了一种有效的大规模推荐方法。此外,
hierarchical softmax采用单隐层网络single hidden layer network来处理特定的nlp问题,而我们提出的TDM方法适用于任何神经网络结构。
8.1 模型
首先我们介绍淘宝展示广告推荐系统
Taobao display advertising recommender system的架构,如下图所示。- 在收到来自用户的页面浏览请求
page view request之后,系统使用用户特征、上下文特征、item特征作为输入,从matching server的整个语料库(数亿)中生成相对小得多的候选item集合(通常是数百个)。tree-based推荐模型在此阶段需要付出努力,将候选集合的大小缩小了几个数量级。 - 对于这数百个候选
item,实时预估server使用更具有表达能力的、同时也是更耗时的模型来预估点击率或转化率等指标。 - 在经过策略排序
ranking by strategy之后,最终会有若干个item曝光给用户。
如前所述,我们提出的推荐模型旨在构建具有数百个
item的候选集合。这个阶段是必不可少的,也是困难的。用户是否对生成的候选item感兴趣,这决定了曝光质量impression quality的上限。如何从整个语料库中抽取候选item,并平衡效率efficiency和效果effectiveness是一个问题。
- 在收到来自用户的页面浏览请求
然后我们介绍
TDM模型。- 首先我们介绍
tree-based模型中使用的树结构tree structure,从而给出一个总体概念。 - 然后我们引入
hierarchical softmax来说明为什么它的公式不适合推荐。 - 接着我们给出了一个新颖的、类似于最大堆的树公式
tree formulation,并展示了如何训练tree-based模型。 - 接着我们介绍了深度神经网络体系架构。
- 接着我们展示了如何在
tree-based模型中构造和学习树。 - 最后我们介绍了在线
serving系统。
- 首先我们介绍
8.1.1 推荐树
推荐树
recommendation tree由节点集合 组成,其中 代表 个非叶节点或叶节点。除了根节点之外, 中的每个节点都有一个父节点和任意数量的子节点。具体而言,语料库 中的每个
item对应于、且仅对应于树中的一个叶节点,而那些非叶节点是粗粒度的概念coarse-grained concept。不失一般性,我们假设节点 始终是根节点。下图显示了一个示例的树,其中每个圆代表一个节点,节点编号
node number是它在树中的索引。该树总共有8个叶节点,每个叶节点对应于语料库中的一个item。值得一提的是,虽然给定的例子是一棵完整的二叉树
complete binary tree,但是我们并没有对模型中的树的类型施加完整complete、或者二叉binary的限制。
8.1.2 Hierarchical Softmax
在树形结构
tree structure中,我们首先介绍相关的工作hierarchical softmax,从而帮助了解它与我们的TDM之间的差异。在
hierarchical softmax中,树中的每个叶节点 具有从根节点到该叶节点的唯一编码。例如,如果我们将1编码为选择左分支、将0编码为选择右分支,那么上图中的叶节点 在树中的编码为110、 在树中的编码为000。令 为叶节点 在
level j中的编码。在hierarchical softmax中,给定上下文的next-word概率为:其中:
- 为叶节点 的编码长度。
- 为叶节点 在
level j的祖先。
这样,
hierarchical softmax通过避免常规softmax中的归一化项(需要遍历语料库中的每个word)来解决概率计算问题。然而,为了找到最可能的叶节点,模型仍然必须遍历整个语料库。因为沿着树路径
tree path自上而下遍历每一层最可能的节点并不能保证成功地检索到最优的叶节点。因此,hierarchical softmax公式不适用于大规模检索问题。此外,根据上式,树中的每个非叶节点被训练为
binary分类器,以区分其两个子节点。但是,如果这两个子节点是树中的邻居,它们很可能是相似的。在推荐场景中,用户很可能对这两个子节点都感兴趣。hierarchical softmax模型侧重于区分最优选择optimal choice和次优选择suboptimal choice,这可能会失去从全局角度进行区分的能力。即,对于某个非叶节点的两个子节点,
hierarchical softmax只能选择其中一个(最优选择),而无法同时选择二者。另外,如果使用贪婪的
beam search来检索那些最可能的叶节点,一旦在树的较高level做出了错误的决定,那么该模型可能无法在较低level的那些低质量候选中找到相对较好的结果。YouTube的工作报告说:他们已经尝试了hierarchical softmax来学习用户embedding和item embedding,而它的性能要比sampled-softmax方式更差。鉴于
hierarchical softmax的公式不适合大规模推荐,我们在下面的部分提出了一个新树模型公式。
8.1.3 Tree-based 模型公式
为了解决最喜欢
item的高效top-k检索问题,我们提出了类似于最大堆max-heap like的树概率公式tree probability formulation。max-heap like tree是一种树结构,其中对于每个用户 ,level j的每个非叶节点 满足以下方程:其中:
- 是用户 对 感兴趣的
ground truth。 - 是
level j的layer-specific归一化项,以确保level j中的概率之和为1.0。
上式表明:父节点的
ground truth偏好等于其子节点的最大偏好,然后再除以归一化项。这类似于最大池化,即 “粗粒度概念”偏好为 “细粒度概念”偏好的最大值。
注意,我们稍微混用了符号,让 表示特定的用户状态。换句话讲,一旦用户具有新的行为,特定的用户状态 可能迁移到另一个状态 。
- 是用户 对 感兴趣的
我们的目标是找到偏好概率
largest preference probability最大的 个叶节点。假设我们在树中有每个节点 的
ground truth,我们可以逐层layer-wise检索偏好概率最大的 个节点,只需要探索每个level的top k个子节点。通过这种方式,最终可以检索到top k个叶节点。实际上,我们不需要知道每个节点的确切
ground truth probability。 我们只需要每个level中,节点概率的相对顺序(layer-wise的顺序),从而帮助找到该level的top k个节点。基于这一观察,我们使用用户的隐式反馈数据implicit feedback data和神经网络来训练每个level的判别器discriminator,该判别器可以区分偏好概率preference probability的顺序。每个
level代表该level粒度的概念,因此对于每个level选择top k偏好的粒度即可。例如:假设k=2,level 1选择(图书, 数码),level2选择(科技图书, 育儿图书, 笔记本电脑, 手机),... 。实际上,这里每个
level代表的物理意义可能并不是具体的类目体系,而是比较抽象的概念。假设用户 和叶节点 有交互,即 是 的正样本节点
positive sample node。这意味着一个排序:其中 为叶节点的
level, 为任意其它叶节点。这里假设只有一个正样本节点。如果有多个正样本节点,则可以在正样本节点和负样本节点之间比较。正样本节点
A和正样本节点B之间无法比较。在任意
level j,令 表示为 在level j的祖先。根据树公式 的定义,我们可以得到:其中 为在
level j中除 之外的其它任意节点。在上述分析的基础上,我们可以使用负采样
negative sampling来训练每个level的顺序判别器order discriminator。具体而言:- 与 有交互的叶节点及其祖先节点构成了 的每个
level的正样本集合。 - 在每个
level中,除了正样本节点之外随机采样的节点构成了负样本集合。
下图中的绿色节点和红色节点给出了采样示例。假设给定一个用户及其状态,目标节点是 。那么 的祖先节点就是正样本,每个
level随机抽样的那些红色节点就是负样本。然后,这些样本被输入到 二元概率模型
binary probability models中,从而获得level顺序判别器。我们使用一个具有不同输入的全局深度神经网络二元模型binary model作为所有level的顺序判别器。可以使用任意高级神经网络来提高模型能力。- 与 有交互的叶节点及其祖先节点构成了 的每个
定义 分别为用户 的正样本节点集合、负样本节点集合。那么似然函数
likelihood function为:其中:
- 为给定 的情况下,对于节点 的预估
label。 - 是二元概率模型的输出,它以用户状态 和采样的节点 作为输入。
对应的损失函数为:
其中 为给定 的情况下,节点 的
ground truth label。关于如何根据损失函数训练模型的详细信息,参考后面的内容。注意:这里预估的是排序关系,而不是
ctr;这里的节点集合不仅包含叶节点,也包含非叶节点。- 为给定 的情况下,对于节点 的预估
注意,我们提出的采样方法和
hierarchical softmax中的采样方法有很大不同。和
hierarchical softmax中使用的方法(该方法使模型能够区分最优optimal结果和次优suboptimal结果)相比,我们为每个正样本节点随机选择相同level的负样本。这种方法使得每个level的判别器都是一个level内intra-level的全局判别器。每个level的全局判别器可以独立地做出精确precise的决策,而不依赖于上层决策的好坏。这种全局判别能力对于层级推荐
hierarchical recommendation方法非常重要。它确保即使模型做出错误的决策,并且低质量的节点泄露到上层的候选集合中,模型也可以在接下来的level中选择那些相对较好的节点,而不是非常差的节点。层级预测算法
hierarchical prediction algorithm:输入:
- 用户状态
- 推荐树
recommendation tree - 需要检索的
item数量 - 训练好的二元预估模型
输出:推荐的 个叶节点集合
算法步骤:
初始化:设置结果集合 ,设置候选集合 。
迭代直到 为空集。迭代步骤为:
- 如果 中有任何叶节点,则从 中移除这些叶节点,并将这些叶节点加入到集合 中。
- 对于 中剩下的每个节点 ,计算 。
- 对 中的节点按照 进行降序排列,选择其中的
top k个节点集合,记作 。 - 设置为 中节点的子节点集合: 。
中始终保持相同
level的节点,因此每次选择同level中的top k节点。对于top k叶节点,根据树公式 的定义,在每个level中它们的祖先节点也是top k的。根据 的排序来选择集合 中的
top k个item。
预测阶段的层级预测算法
hierarchical prediction algorithm中,检索过程是layer-wise和自上而下的top-down。假设期望的候选
item数量为 ,对于大小为 的语料库 ,最多遍历 个节点就可以得到一个完整二叉树中的最终推荐集合。需要遍历的节点数量和语料库大小成对数关系,这使得可以采用高级的二元概率模型。前面的图例假设每个叶节点的路径长度相同。实际上每个叶节点的长度可以不同,比如有的叶节点
level较小(到根节点较短)、有的叶节点level较大(到根节点较长),树模型的训练算法、预测算法仍然成立。我们提出的
TDM方法不仅减少了预测时的计算量,并且与在所有叶节点中进行暴力搜索brute-force search相比也可能提高推荐质量。在没有树的情况下,训练模型以直接找到最优
item是一个困难的问题,因为语料库太大。利用树的层级结构,一个大规模的推荐问题被分解为许多小问题。在树的高
level只存在几个节点,因此判别问题discrimination problem更容易。而高level做出的决策精化refine了候选集,这可能有助于低level做出更好的判断。后面的实验结果将表明:我们提出的层级检索
hierarchical retrieval方法比直接暴力搜索性能更好。
8.1.4 深度模型
这里介绍我们使用的深度模型,整个模型如下图所示。为了简单起见,我们仅在下图中说明了用户行为特征的使用。而其它特征,如用户画像特征、上下文特征在实践中可以毫无障碍地使用。
受点击率预估工作的启发,我们学习树中每个节点的低维
embedding,并使用attention模块来软性softly搜索相关的行为,从而获得更好的用户representation。每个节点视为一个
target item。为了利用包含时间戳信息的用户行为,我们设计了
block-wise的input layer来区分不同时间窗口中的行为。历史行为记录可以沿着时间线
timeline被划分为不同的时间窗口。通过时间窗口来捕获时间效应,这使得距离当前不同天数的用户历史行为被聚合到不同的
embedding。另外一种简单做法是:在attention中加入时间距离embedding(例如:距离现在7天时,time span = 7的embedding)。每个时间窗口内的
item embedding被加权平均,权重来自于激活单元activation unit。
激活单元的输入分为三部分:用户侧的历史互动
item的embedding、目标节点embedding、以及这两个embedding的element-wise乘积(捕获二阶交互)。- 每个时间窗口的输出以及目标节点的
embedding被拼接作为神经网络的输入。 - 在三个全连接层(具有
PReLU激活以及batch normalization)之后,使用binary softmax来产生用户是否对候选节点感兴趣的概率。 - 每个
item及其对应的叶节点共享相同的embedding。 - 所有
embedding都是随机初始化的。 attention模块和后续的网络极大地增强了模型的容量capability,也使得用户对候选item的偏好无法被标准化为内积的形式。- 树节点的
embedding和树结构本身也是模型的一部分。为了最小化损失函数 ,我们使用采样的节点和相应的特征来训练网络。
这里无法引入
item侧的特征,每个item视为一个节点,节点只有节点embedding而没有辅助信息(例如属性)。这种方式会大大扩充样本数量(正样本扩充且负样本扩充)。

8.1.5 树的构建和学习
推荐树
recommendation tree是tree-based的深度推荐模型的基础部分。与多类别
multi-class分类以及多标签multi-label分类工作不同,其中树用于划分样本空间或label空间,我们的推荐树为要检索的item建立索引。在hierarchical softmax中,单词的层级hierarchy是根据WordNet的专家知识expert knowledge建立的。在推荐场景中,并不是每个语料库都能提供具体的专家知识。一种直观的替代方法是:基于从数据集抽取的
item共现concurrence或者item相似性similarity,使用层级聚类hierarchical clustering方法构建树。但是聚类树可能非常不平衡,这对于训练和检索是不利的。给定pair-wise的item相似性,文献《Label embedding trees for largemulti-class tasks》中的算法提供了一种通过谱聚类spectral clustering从而将item递归地分割成子集的方法。然而,谱聚类对于大型语料库是无法scalable的(它是语料库大小的三次方时间复杂度)。在这里,我们重点介绍合理、可行的树构造
tree construction和树学习tree learning方法。树初始化
tree initialization:由于我们假设树代表了用户兴趣的层级信息hierarchical information,所以很自然地以相似的item被组织在相近的位置close position的方式来构建树。鉴于类目信息category information在许多领域中广泛可用,我们直观地提出了一种利用item的类目信息来构建初始树initial tree。不失一般性,这里以二叉树为例。
首先,我们对所有类目进行随机排序,并将属于同一类目的
item以类目内随机顺序放在一起。如果一个item属于一个以上的类目,则出于唯一性uniqueness,该item被随机分配给它所属的某个类目。通过这种方式,我们就可以得到一个ranked item列表(基于类目的排序)。其次,这些
ranked item被递归地划分为两个相等的部分,直到当前集合仅包含一个item为止。这可以自顶向下构建一个近似完全的二叉树near-complete binary tree。这使得在树靠近根节点的
level中,相似的item(即相同类目)位于相近的位置。
在我们的实验中,上述基于类目的初始化可以获得比完全随机的树
complete random tree更好的层级hierarchy和结果。树结构学习
tree learning:作为模型的一部分,每个叶节点的embedding可以在模型训练后学到。然后,我们可以使用学到的叶节点的embedding向量来聚类一棵新的树。考虑到语料库的规模,我们使用
k-means聚类算法,因为它具有良好的可扩展性scalability。在每个聚类step,根据item的embedding向量将item分为两个子集。注意,为了得到更平衡的树,这两个子集被调整为相同规模。当仅剩下一个item时,递归就停止。通过这种方法可以自顶向下地构建二叉树。在我们的实验中,当语料库大小约为
400万时,使用单台机器构建一个聚类树cluster tree大约需要一个小时。后面的实验结果将显示tree learning算法的有效性。深度模型
deep model和树结构tree structure以交替方式联合学习:- 构建初始树并训练模型直到收敛。
- 在训练好的叶节点
embedding的基础上,通过聚类得到新的树结构。 - 用所学到的新树再次训练模型。
8.1.6 在线 Serving
TDM在线Serving系统如下图所示。输入特征组装assembling和item检索被划分为两个异步阶段:- 包括点击、购买、加购物车在内的每个用户行为都会触发实时特征服务器
real-time feature server从而组装assemble新的输入特征。 - 一旦收到页面查看请求
page view request,user targeting server将使用预组装pre-assembled的特征从树中检索候选item。
如
hierarchical prediction algorithm所述,检索是layer-wise进行的,并且训练好的神经网络用于计算给定输入特征的情况下节点是否是用户喜欢preferred的节点的概率。
- 包括点击、购买、加购物车在内的每个用户行为都会触发实时特征服务器
预测效率
prediction efficiency:TDM使得高级神经网络在大规模推荐中对user和item进行交互成为可能,这为推荐系统开辟了一个新的视角。值得一提的是,虽然高级神经网络在推断时需要更多的计算,但是整个预测过程的复杂度不会大于 ,其中 为所需的结果集合大小, 为语料库大小, 为网络单次前向传播的复杂度。在当前
CPU/GPU硬件条件下,该复杂度上限是可接受的,并且用户侧特征在一次检索中跨不同的节点共享,而一些计算可以根据模型设计进行共享。在淘宝展示广告系统
Taobao display advertising system中,实际部署的TDM DNN模型平均需要6ms左右才能推荐一次。这样的运行时间比后续的点击率预估模型要短,并且不是系统的瓶颈。
8.2 实验
这里我们研究了
TDM的性能,并给出在MovieLens-20M和淘宝广告数据集UserBehavior上的实验结果。数据集:实验是在两个带时间戳的大规模真实世界数据集上进行的,来自于
MovieLens数据集的用户观看电影数据、来自于淘宝的user-item行为数据(称作UserBehavior数据集)。MovieLens-20M数据集:该数据集包含带时间戳的user-movie评级数据。当我们处理隐式反馈问题时,通过将评分为
4分(满分5分)或者4分以上的评分作为正label、4分以下的评分作为负label来二元化binarize。这是其它工作中常用的方式。此外,只有看过至少
10部电影的用户才会被保留。我们随机抽取了
1000个用户作为测试集,另外随机抽取了1000个用户作为验证集,剩余用户作为训练集。对于验证集和测试集,user-movie观看记录中,沿着timeline的前半部分作为预测后半部分的已知行为known behavior。UserBehavior数据集:该数据集是淘宝用户行为数据集的子集。我们随机挑选了大约
100万名用户,然后给出了他们在2017-11-25 ~ 2017-12-03期间的行为(包括点击、购买、加购物车)。数据的组织形式和MovieLens-20M非常相似,即:一个user-item行为由user ID、item ID、item类目ID、行为类型behavior type、时间戳组成。item的类目是从淘宝当前商品分类法commodity taxonomy的bottom level开始的。就像我们在
MovieLens-20M中做的那样,只有至少10个行为的用户才会被保留。我们随机选择
10000个用户作为测试集,另外随机选择10000个用户作为验证集,剩余用户作为训练集。
下表总结了预处理后上述两个数据集的主要统计信息。
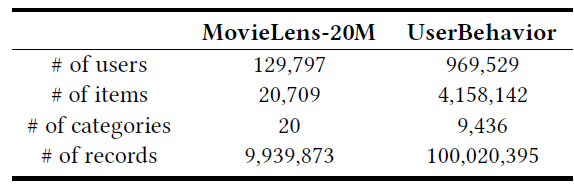
评估指标:我们使用
Precision@M、Recall@M、F-Measure@M等指标。令用户 召回的
item集合为 (其中 ),用户的ground truth集合为 。Precision@M定义为:Recall@M定义为:F-Measure@M定义为:正如我们所强调的,推荐结果的新颖性
novelty决定了用户体验。现有工作给出了几种方法来衡量推荐item列表的新颖性。根据其中的一个定义,我们定义Novelty@M为:其中 是用户 有历史交互的
item集合。
我们在测试集上计算所有用户上述四个指标的均值,从而作为每个方法的评估指标。
baseline方法:FM:FM是因子分解任务的框架。我们使用xLearn项目提供的FM实现。BPR-MF:我们使用矩阵分解形式进行隐式反馈推荐。我们使用
《MyMediaLite: A free recommender system library》提供的BPR-MF的实现。Item-CF:基于item的协同过滤是大规模语料库在生产环境中最广泛使用的个性化推荐方法之一,这也是淘宝上主要的候选item生成方法之一。我们使用阿里巴巴机器学习平台提供的
Item-CF的实现。YouTube product-DNN:是YouTube提出的深度推荐方法。在训练中使用了sampled-softmax,用户embedding和item embedding的内积反映了偏好。我们在阿里巴巴深度学习平台上实现了
YouTube product-DNN,其输入特征和我们提出的模型相同。预测阶段采用内积空间的精确kNN搜索。TDM attention-DNN: tree-based deep model using attention network:是我们提出的方法。树以前文所述的类目信息初始化,并在实验过程中保持不变。
实验配置:
对于
FM, BPR-MF, Item-CF,我们根据验证集调优几个最重要的超参数,即FM和BPR-MF中的因子数、迭代数,以及Item-CF中的邻居数。FM和BPR-MF要求测试集或验证集中的用户在训练集中也有反馈。因此,我们将测试集和验证集的timeline中,各自的前半部分的user-item交互记录都加入到训练集中。对于
YouTube product-DNN和TDM attention-DNN,node embedding维度设为24,因为在我们的实验中,更高的维度不会表现得更好。TDM attention-DNN三个全连接层的隐单元数量分别为128、64、24。根据时间戳,用户行为分为10个窗口。在
YouTube product-DNN和TDM attention-DNN中:- 对于
MovieLens-200M数据集,每个隐式反馈我们随机选择100个负样本。 - 对于
UserBehavior数据集,每个隐式反馈我们随机选择600个负样本。
注意,
TDM的负样本数是所有level负样本之和。由于树的性质,我们在接近叶节点的level采样了更多的负样本。- 对于
8.2.1 离线实验
不同方法比较结果如下表的虚线上方所示,每个指标都是测试集中所有用户的均值,并且每种配置我们运行五次并报告五次结果的均值和方差。其中在
MovieLens-20中以@10评估指标,在UserBehavior中以@200评估指标。结论:
我们提出的
TDM attention-DNN在两个数据集上的大多数指标都显著优于所有baseline。和排名第二的
YouTube product-DNN方法相比,在没有过滤的情况下(用户历史互动item过滤条件Filtering=None),TDM attention-DNN在两个数据集上的召回率分别提高了21.1%和42.6%。该结果证明了TDM attention-DNN采用的高级神经网络和hierarchical tree search的有效性。在以内积形式对用户偏好进行建模的方法中,
YouTube product-DNN超越了BPR-MF和FM,因为前者使用了神经网络。广泛使用的
Item-CF方法具有最差的新颖性novelty结果,因为它对用户已经交互的item具有很强的记忆性memory。
为了提高新颖性,实践中常用的方法是过滤推荐集合中已经交互的
item。也就是说,最终只能推荐那些新颖的item。因此,在一个完全新颖的结果集合中比较accuracy是非常重要的。在本实验中,如果过滤后结果集合的大小小于 ,则结果集合的大小将补充到 。结果表明(Filtering = Interacted items):在过滤掉历史已经交互的item之后,TDM attention-DNN在大大超越了所有baseline。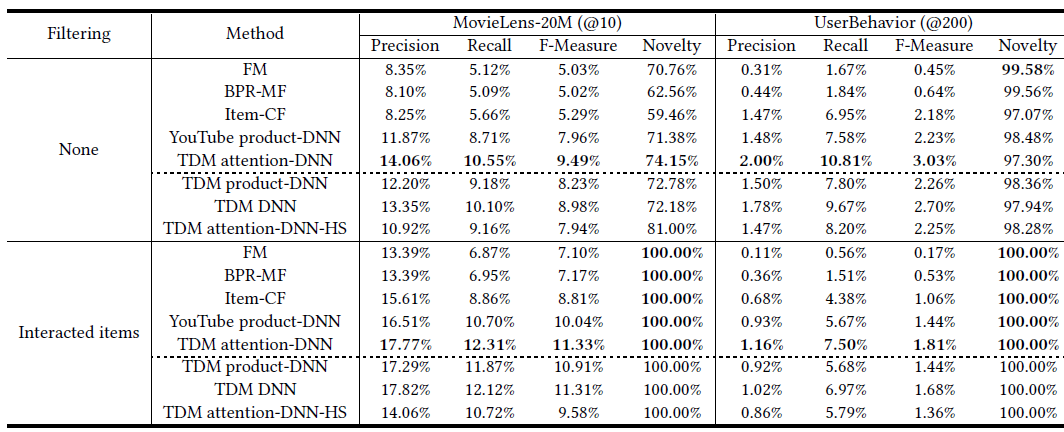
为了进一步评估不同方法的探索能力
exploration ability,我们通过从推荐结果中排出那些已经历史交互的类目category来进行实验。每种方法的结果也被要求补足结果集合大小为 的要求。事实上,类目新颖性category-level novelty是目前淘宝推荐系统中最重要的新颖性指标,因为我们希望减少和用户历史交互item相似的推荐item的数量。由于
MovieLens20M总共只有20个类目,因此该实验仅在UserBehavior数据集上进行,结果如下表所示。以召回率指标为例,可以看到:Item-CF的召回率只有1.06%,因为它的推荐结果很难跳出用户的历史行为记录。- 和
Item-CF相比,YouTube product-DNN获得了更好的结果,因为它可以从整个语料库中探索用户的潜在兴趣。 - 我们提出的
TDM attention-DNN在召回率方面比YouTube product-DNN高34.3%。这种巨大的提升对于推荐系统而言是非常有意义的,它证明了更高级的模型对于推荐问题来说是一个巨大的差异enormous difference。
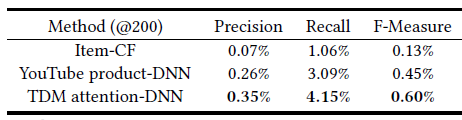
8.2.2 实证研究
TDM变体:为了理解所提出的TDM方法本身,我们评估了TDM的几种变体:TDM product-DNN:为了证明高级神经网络是否可以使TDM结果受益,我们测试了TDM的变体TDM product-DNN。TDM product-DNN使用YouTube product-DNN相同的内积方式。具体而言,TDM attention-DNN中的attention模块被删除,并且node embedding项也从网络输入中删除。node embedding和第三个全连接层的输出(没有PReLU和BN)的内积、以及sigmoid激活函数构成了新的binary分类器。TDM DNN:为了进一步验证TDM attention-DNN模型中attention模块带来的增益,我们测试了仅去除激活单元activation unit的变体TDM DNN,即,TDM attention-DNN中所有item的权重都是1.0。TDM attention-DNN-HS:如前所述,hierarchical softmax: HS方法不适合推荐。我们测试了TDM attention-DNN-HS变体,它使用positive node的邻居作为negative样本,而不是随机选择负样本。相应地,在hierarchical prediction algorithm的检索中,ranking indicator将从从单个节点的 变化为 。另外,attention-DNN作为网络结构。
上述变体在两个数据集上的实验结果如下表的虚线下方所示。结论:
相比于
TDM DNN,TDM attention-DNN在UserBehavior数据集上召回率提升了将近10%, 这表明attention模块做出了显著的贡献。相比于
TDM DNN和TDM attention-DNN,TDM product-DNN表现更差,因为内积方式远不如神经网络交互形式那么强大。这些结果表明:在
TDM中引入高级模型可以显著提高推荐性能。相比于
TDM attention-DNN,TDM attention-DNN-HS效果更差,因为hierarchical softmax的公式不适合推荐问题。
树的作用
role:树是我们提出的TDM方法的关键组成部分,它不仅作为检索中使用的索引,而且以从粗粒度到细粒度的层级hierarchy对语料库进行建模。在前文中我们提出,直接进行细粒度推荐比层级化
hierarchical的方式更困难。我们进行实验来证明这个观点。下图说明了
hierarchical tree search(即hierarchical prediction algorithm算法)和暴力搜索(遍历相应level的所有节点)的layer-wise的Recall@200。实验是在UserBehavior数据集上使用TDM-product-DNN模型进行的,因为这是唯一一种可以使用暴力搜索的变体。测试集中的ground truth可追溯到每个节点的祖先,直到根节点为止。可以看到:
暴力搜索在高
level(level 8, 9) 稍微优于tree search,因为那里的节点数很少。暴力搜索是基于节点
embedding的相似度进行检索的。而tree search是基于 进行检索的。另外,这里是预测阶段的性能比较。二者都是训练好的同一个
TDM-product-DNN模型。一旦一个
level中的节点数增加,tree search就比暴力搜索获得更好的召回结果,因为tree search可以在高level中排出那些低质量的结果,这降低了低level问题的难度。越靠近叶节点则噪音越大,基于暴力搜索得到的
top k节点越容易陷入过拟合。
这些结果表明:树结构中包含的层级信息有助于提高推荐的精确性
preciseness。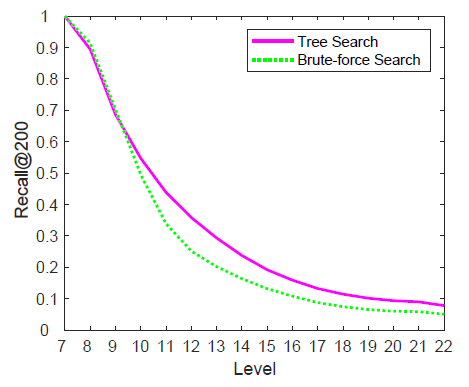
树学习
tree learning:前面我们提出了树初始化tree initialization和树学习tree learning算法。下表给出了初始树initial tree和学习树learnt tree之间的比较结果。这是TDM attention-DNN模型在 (@200)UserBehavior数据集上的不同树结构的比较结果。初始树:树被初始化之后,树结构后续不再变化;学习树:树被初始化之后,反复迭代从而学习树结构。
可以看到:学习树结构
learnt tree structure的模型显著优于初始树结构initial tree structure的模型。在过滤交互类目的实验中,和初始树相比,学习树的召回率从4.15%提升到4.82%,大大超越了YouTube product-DNN的3.09%和Item-CF的1.06%。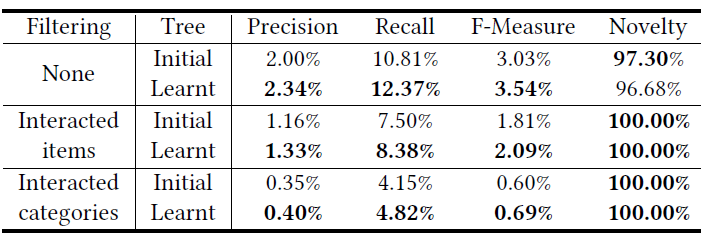
为了进一步比较这两种树,我们在下图中展示了
UserBehavior数据集上对初始树和学习树得到的测试集损失曲线和测试集Recall@200曲线 。下图表明:使用学习树,模型收敛到更好的结果。以上结果证明,树学习算法能够改善
item的层级结构hierarchy,从而进一步促进训练和预测。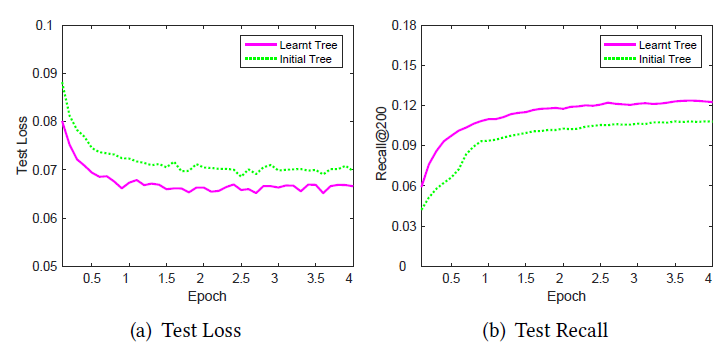
8.2.3 在线实验
我们在真实流量的淘宝展示广告平台
Taobao display advertising platform上对提出的TDM方法进行了评估。实验在淘宝App首页的 “猜你喜欢” 栏目进行,时间为2018-01-22 ~ 2018-01-28连续一周。我们使用两个在线指标online metric来评估效果:- 点击率
click-through rate: CTR:CTR= 点击量/曝光量。 - 每千次曝光收入
revenue per mille: RPM:RPM= 广告收入Ad revenue/ 曝光量 *1000。
在我们的广告系统中,广告主对一些给定的
ad cluster竞价。大约有140万个cluster,并且每个ad cluster包含数百或者数千个类似的广告。实验在ad cluster粒度上进行的,从而与现有系统保持一致。对比的方法是逻辑回归的混合
mixture,它用于从那些相互作用的cluster中挑选出更好的结果。这是一个很强的baseline。由于系统中有很多阶段
stage,如CTR预估、ranking,因此在线部署和评估提出的TDM方法是一个庞大的工程,涉及整个系统的链接和优化。目前为止,我们已经完成了TDM DNN第一版的部署,并在线评估了其效果提升。每个比较的bucket都有5%的在线流量。值得一提的是,有几种在线同时运行的推荐方法。它们从不同的角度进行努力,并且推荐结果被合并在一起从而用于后续阶段。
TDM只替换其中最有效的一个,同时保持其他模块不变。下表列出了采用TDM所在的测试bucket的指标平均提升比例。可以看到:
TDM方法的点击率提升了2.1%。这一提升表明,所提出的方法可以为用户召回更准确accurate的结果。TDM方法的RPM指标提升了6.4%,这意味着TDM方法也可以为淘宝广告平台Taobao advertising platform带来更多的收入。
目前
TDM已经部署到主要的在线流量中,我们认为上述改进只是一个大型项目的初步结果,还有进一步改进的空间。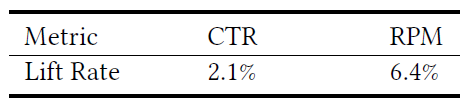
- 点击率
九、DR[2020](用于检索)
推荐系统数十年来在各种商业应用中都取得了巨大的成功。推荐系统的目标是基于用户特征和历史行为从庞大的语料库中检索相关候选
item。在移动互联网时代,来自内容提供商content provider的候选item数量、以及活跃用户数量都迅速增长到数千万甚至数亿,这使得设计准确的推荐系统accurate recommendation system变得更加具有挑战性。算法的可扩展性scalability和效率efficiency是现代推荐系统面临的主要挑战。大规模推荐的核心问题之一是准确accurately、高效地efficiently检索出最相关的候选item,最好是在亚线性sub-linear时间内。推荐系统早期的成功技术之一是协同过滤
collaborative filtering: CF,它基于相似用户可能更喜欢相似item的简单想法进行预测。基于item的协同过滤item-based collaborative filtering: Item-CF通过考虑item和item之间的相似性扩展了这一思想,后来为Amazon的推荐系统奠定了基础。最近,基于向量的推荐
vector-based recommendation算法已经被广泛采用。主要思想是将用户和item嵌入到相同的潜在向量空间latent vector space中,用向量的内积来表示用户和item之间的偏好。向量embedding方法的典型代表有:矩阵分解matrix factorization: MF、因子分解机factorization machines: FM、DeepFM、Field-aware FM: FFM等等。然而,当
item数量很大时,对所有item计算内积的计算复杂度是不可行的。因此,当语料库较大时,通常使用最大内积搜索maximum inner product search: MIPS、或者近似最近邻approximate nearest neighbor: ANN算法来检索item。高效的MIPS或ANN算法包括基于树tree-based的算法、局部敏感哈希locality sensitive hashing: LSH、乘积量化product quantization: PQ、hierarchical navigable small world graphs: HNSW等方法。尽管在实际应用中取得了成功,但是基于向量的算法有两个主要缺陷:
- 学习向量
representation和学习良好的MIPS结构,二者目标并不完全一致。 - 用户
embedding和item embedding内积的形式限制了模型的能力capability。
为了打破这些限制,人们已经提出了基于树
tree-based的模型。这些方法使用树作为索引indices,并将每个item映射为树的一个叶节点。模型参数和树结构的学习目标可以很好地对齐aligned,从而提高准确性accuracy。然而,树结构本身是很难学习的:叶子level的可用数据可能很少,并且可能无法提供足够的信号来学习在该level上表现良好的树。论文
《Deep Retrieval: An End-to-End Learnable Structure Model for Large-Scale Recommendations》提出了一种端到端的可训练结构模型trainable structure model--Deep Retrieval: DR。受到
《Learning k-way d-dimensional discrete codes for compact embedding representations》的启发,我们提出使用如下图所示的 矩阵来索引indexing。每个item由一个或者多个长度为 、取值范围在 的编码code(或者也称路径path)来索引indexing。如下图所示为一个宽度为 、深度为 的结构。假设和巧克力相关的一个
item由长度 的向量[36, 27, 20](称作code或者path)进行编码。该路径表示该item已经分配了 的(1,36), (2,27), (3,20)索引indices。图中,相同颜色的箭头形成一条路径,不同的路径可以通过在某一层layer共享相同的索引从而彼此相交。一共有 条可能的路径,并且每条路径可以解释为一族
cluster的item:每条路径可以包含多个item、每个item也可以属于多条路径。如果添加一个虚拟的
root节点,那么DR就成为一棵高度为 的树。和TDM不同的是:DR中每个level都有 个节点,父节点可以有多个子节点,父节点之间可以共享子节点,叶子节点不是代表一个item而是代表一组item。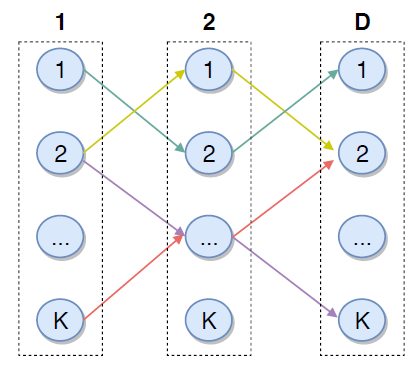
DR有两个的优点:在训练中,可以使用
expectation-maximization: EM类型的算法将item path和结构模型structure model的神经网络参数一起学习。因此,整个训练过程是端到端的,可以轻松部署到深度学习平台上。结构模型包含 层
layer、每层有 个节点。关于结构模型我们在下面重点描述。就模型能力
model capability方面,多对多multiple-to-multiple编码方案使得DR能够学习用户和item之间更复杂的关系。实验表明了学习这种复杂关系的好处。
- 学习向量
DR将所有候选item编码为离散的潜在空间。这些候选item的潜在码latent code是模型参数,将和其它神经网络参数一起学习从而最大化相同的目标函数。在模型学习之后,我们对
latent code进行beam search,从而检索最佳候选item。实验表明,DR具有亚线性的计算复杂度,并且可以达到和暴力搜索基线brute-force baseline几乎相同的准确性accuracy。
9.1 模型
9.1.1 结构模型
这里我们详细介绍
DR中的结构模型structure model。首先,在给定模型参数 的情况下,我们构建用户 (即用户输入特征向量)选择路径 的概率,并给出训练目标。
是一个长度为 的向量,每个元素 。
然后,我们引入一个多路径机制
multi-path mechanism,使得模型能够捕获item的多方面属性multi-aspect properties。在推断阶段,我们引入一种
beam search算法,根据用户embedding选择候选路径。
结构目标函数
Structure Objective Function:结构模型structure model包含 层layer,每层有 个节点。- 每层是一个带跳跃连接
skip connection和softmax输出的多层感知机multi-layer perceptron: MLP。 - 每层输入一个
input vector,并基于参数 输出在 上的概率分布。
令 为所有
item的索引集合, 为单个code取值集合, 令 为item到路径的映射。这里我们假设 是已知的(即给定item,对应的路径是已知的),并将在后文介绍共同学习 和 的算法。给定一对训练样本 ,它表示在用户 和
item之间的一个positive交互(如点击、转化、喜欢like等等),以及给定item关联的路径 ,其中 ,概率 是按照如下方式逐层构建的(如下图(b)所示)。第一层以用户
embedding作为输入,基于参数 输出在所有 个节点上的概率分布 。即:已知用户
embedding的条件下,第一层选择 的概率。从第二层开始,我们将用户
embedding和所有先前层的embedding(称作path embedding)拼接起来作为MLP的输入,并基于参数 输出layer d上 个节点的概率 。即:已知用户
embedding、以及前 层选择 的条件下,第 层选择 的概率。概率 是所有层的概率的乘积:
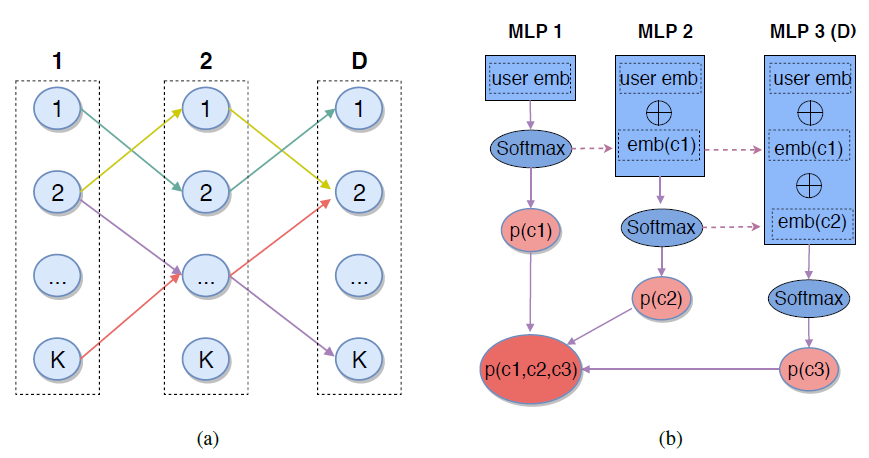
给定 个训练样本的集合 ,我们最大化结构模型
structure model的对数似然函数:注意:
- 这里的目标函数只有
positive交互,而没有negative交互。但是通过softmax函数可以引入负样本信息。 - 这里没有使用
item的特征,仅仅将item作为一个label。
感觉这是一种聚类算法,基于路径来将不同的
item进行聚类,召回时仅需要召回相应的路径即可。layer d的输入向量的尺寸是embedding向量尺寸乘以 (因为 个embedding向量的拼接),输出向量尺寸是 ,因此layer d的参数数量为 。参数 包含所有层的参数 ,以及path embedding。整个模型中的参数数量大概在 的量级,这明显小于所有可能的路径的数量 (当 时)。这个结构模型和典型的
DNN推荐模型不同,该模型更偏向于GNN图神经网络。- 每层是一个带跳跃连接
多路径结构目标
Multi-path Structure Objective:在tree-based深度模型以及我们之前介绍的结构模型structure model中,每个item只属于一个cluster,这限制了模型在真实数据中表达多方面信息multi-aspect information的能力。例如,一个与烤串
kebab相关的item应该属于一个与食物food相关的cluster。一个和鲜花flower相关的item应该属于和礼物gift有关的cluster。然而,与巧克力chocolate或者蛋糕cake相关的item应该同时属于食物和礼物两个cluster,以便推荐给对食物或礼物感兴趣的用户。在现实世界的推荐系统中,一个
cluster可能没有明确的含义,比如食物或礼物,但是这个示例促使我们将每个item分配给多个cluster。在DR中,我们允许每个item被分配到 个不同的路径 。 令 为item到multiple paths的映射,则multiple path结构目标定义为:这里将多个路径的概率相加,是否取
max可能更有意义?取sum表示用户对单个item背后的多个概念偏好的总和,取max表示用户对单个item背后的多个概念偏好的最大值。针对推断的
beam search:在推断阶段,给定用户embedding为输入,我们希望从结构模型中检索item。为此,我们利用beam search算法来检索多个path,并将检索到的path中的item合并。- 首先,在第一层挑选
top B节点。 - 然后,在前一层所有节点的后续节点
successors中挑选top B节点。 - 最后一层输出最终的 个节点。
算法如下所示。在每一层中,从 个候选节点中选择
top B节点的算法复杂度为 。总的算法复杂度为 ,它相对于item的数量是亚线性sub-linear的。- 首先,在第一层挑选
beam search算法:输入:
- 用户特征
- 参数 的结构模型
beam size
输出: 条路径的集合 。
算法步骤:
基于 中的
top B项挑选 。迭代, :
基于以下顺序,从 集合中节点的所有后继
successors中挑选top B项:然后得到集合:
因为 一共 项,每项有 个后继,所以需要从 项中挑选
top B项。如果采用最大堆,则算法复杂度为 。返回 。
9.1.2 学习
前面我们介绍了
DR中的结构模型structure model和要优化的结构目标structure objective。目标函数相对于参数是完全连续的,因此可以通过任何基于梯度的优化器进行优化。但是,目标函数涉及从item到path的映射,这是离散的,无法通过基于梯度的优化器来优化。这种映射充当
item的 "clustering" ,这促使我们使用EM风格的算法来联合优化离散的映射和连续的参数。在本节中,我们将详细描述EM算法,并引入惩罚项来防止过拟合。针对联合训练的
EM算法EM Algorithm for Joint Training:给定训练集中的一个user-item的pair对 ,令item关联的path为 为EM算法中的潜在数据latent data。连同连续参数 ,目标函数由下式给出:其中第二个等式是将训练集中
item = v的所有item聚集在一起。我们在所有可能的映射 上最大化目标函数。然而,存在 条可能的
path,因此我们无法在所有的 上最大化目标函数。相反,我们仅使用beam search来记录top path的值,而剩下的path为零分。不幸的是,由于上式中存在 ,这使得函数的数值不稳定。为了解决这个问题,我们使用上限 来近似目标函数,从而得到:
其中: 为
item出现在训练集中的次数,它独立于映射 。因为 是我们最大化的真实目标 的上限,因此无法保证前者的最大化来得到后者的最大化。但是,在实践中我们发现这种近似的做法表现良好。
要使得 最大,则我们需要使得每个
item的项 最大。为简单起见,我们记得分score。在实践中不可能保留所有的得分,因为路径 的可能的数量是指数级的,所以我们通过beam search来仅仅保留得分最大的 条path的子集。的物理意义为:所有目标
item为 的、路径为 的概率之和。这里有两点注意:- 路径为 的、目标
item为 的路径概率之间可能不相等,因为用户特征 可能不同。 - 同一个用户、目标
item为 的路径概率之间也可能不等,因为存在 条不同的路径 。
在
M-step,我们简单地在每个 上最大化 ,这相当于在来自beam search的top path中挑选 个最高的 分。- 路径为 的、目标
结构学习
structure learning的EM算法:输入:
- 训练集
- 预定义的
epoch数量
输出: 条路径
算法步骤:
随机初始化 和 。
迭代, :
固定 ,使用基于梯度的优化器优化参数 ,以最大化结构目标函数
structure objective。:
- 针对
beam search得到的top path计算得分 。 - 令 为 中的
top个得分。
- 针对
返回 条路径
path size的惩罚Penalization on Size of Paths: 如果我们不对上述EM算法进行任何惩罚,那么很可能发生过拟合。假设结构模型
structure model发生过拟合,并且对于任何输入,特定的path (0,0,0)都有非常高的概率。那么在M-step中,所有的item都将分配给路径(0,0,0),使得模型无法对item进行cluster。即单条路径上路径上分配了所有的
item。为了防止过拟合,我们对
path size引入了一个罚项。引入惩罚的 函数定义为:其中:
- 为惩罚因子。
- 表示路径 中的
item数量。 - 为一个递增的凸函数。二次函数 控制
path的平均size。更高阶的多项式在更大的path上惩罚更多。在我们的实验中,我们使用 。
值得一提的是,罚项仅适用于
M-step,而不适用于训练连续参数 。针对路径分配的坐标下降算法
coordinate descent algorithm for path assignment:在所有路径分配path assignment上联合优化带惩罚的目标函数 是困难的,因为罚项不能被分解为每个item项的求和。所以我们在M-step中使用坐标下降coordinate descent算法。当优化item的路径分配 时,我们固定所有其它item的路径分配。注意,项 和 无关,因此可以删掉。对每个
item,部分的partial目标函数可以重写为:因为不同
item的目标函数之间是相互独立的,因此可以拆分为每个item的目标函数最大化。坐标下降算法如下,其时间复杂度为 ,其中 为候选路径的
pool size。在实践中,3到5次迭代足以确保算法收敛。coordinate descent algorithm for penalized path assignment算法:输入:
- 评分函数
- 迭代次数
输出:路径分配
算法步骤:
对所有路径 初始化 。
迭代, :
对每个
item迭代:sum设置为0。sum存放 条路径的累计评分 。迭代, :
如果 ,则更新 。
对
item的所有候选路径 ,且 ,计算penalized score:更新:
输出
带
softmax模型的多任务学习和排序Multi-task Learning and Reranking with Softmax Models:基于我们在本文中进行的实验,我们发现联合训练DR和softmax分类模型大大提高了性能。softmax分类模型:给定用户特征 ,用户选择item的概率为:其中 为
item的embedding。我们推测这是因为:
item的路径在开始时是随机分配assignment的,导致优化难度增加。通过与容易训练的softmax模型共享输入,我们能够在优化方向optimization direction上提升结构模型structure model。所以我们最大化的最终目标final objective是:这里是用两路并行模型,将它们的损失函数按照
1:1相加。一路模型是DR模型、另一路模型是简单的softmax输出的DNN模型,它们共享用户特征 。在使用
beam search算法执行beam search以检索一组候选item之后,我们使用softmax模型(即 )来重新排列这些候选item,从而获得最终的top候选item。这种多任务的方式是否表明
DR模型还不够完善,需要依赖于传统的DNN模型。那么DR模型的价值体现在哪里?实验部分也没有给出明确的回答。算法复杂度分析:我们将
DR中每个阶段的时间复杂度总结如下。- 推断阶段的时间复杂度是每个样本 的复杂度,相对于
item数量而言是亚线性sub-linear的。 - 训练连续参数 的时间复杂度是 ,其中 是一个
epoch中训练样本的数量, 是路径的多重性multiplicity。 - 通过坐标下降算法进行路径分配的时间复杂度为 ,其中 是语料库大小, 为候选
path的pool size。
- 推断阶段的时间复杂度是每个样本 的复杂度,相对于
未来研究方向:
- 首先,结构模型仅基于用户侧信息定义路径上的概率分布。一个有用的想法是如何将
item侧信息更直接地整合到DR模型中。 - 其次,我们仅利用
user-item之间的positive互动(如点击、转化、喜欢like)。在将来的工作中,也应该考虑诸如non-click、dislike、取消关注unfollow之类的negative互动,从而改善模型性能。 - 最后,当前的
DR仍然使用softmax模型作为reranker,这可能受到softmax模型的性能限制。我们也在积极努力解决这个问题。
- 首先,结构模型仅基于用户侧信息定义路径上的概率分布。一个有用的想法是如何将
人们普遍认为:推荐系统不仅反映了用户的偏好,而且随着时间的推移,它们往往会重塑
reshape用户的偏好(即,影响用户)。由于系统中的连续反馈回路continuous feedback loop,这可能导致用户决策或用户行为的潜在bias。我们提出的方法更多地是从改进核心机器学习技术的角度出发,基于用户历史行为数据更好地检索出最相关的候选item。我们的方法是否放大、还是减缓了实际推荐系统中的现有bias,这还需要进一步研究。读者注:
DR算法本质上和TDM算法是相同的。DR训练算法是最大化路径的概率,如果用负采样来代替softmax,则它就和TDM思想一致。不同点:
TDM模型使用attention等复杂结构,而DR模型仅用简单的softmax;TDM的负样本是每个level中所有正样本共享的,而DR的负样本是每个正样本独立采样的。DR预测算法是对每一层进行beam search,这和TDM思想一致。不同点:二者的
score不同。TDM采用当前层每个节点的当前选中概率,DR使用当前层每个节点的累积选中概率。DR结构学习算法和TDM不同。TDM采用迭代来优化树结构,而DR采用EM算法来优化树结构。DR采用多任务来共同学习用户representation。
9.2 实验
这里我们研究了
DR在两个公共推荐数据集上的性能:MovieLens-20M和Amazon books。我们将
DR算法和暴力搜索brute-force算法、以及其它一些推荐baseline算法(包括tree-based算法TDM和JTM)。最后,我们研究了重要的超参数在
DR中的作用。数据集:
MovieLens-20M:该数据集包含来自一个叫做MovieLens的电影推荐服务中的评分rating和自由文本标记free-text tagging活动。我们使用
1995年到2015年之间138493名用户的行为创建的20M子集。每个user-movie交互都包含一个user-id、一个movie-id、一个1.0~5.0之间的评级、以及一个时间戳。为了公平地进行比较,我们严格遵循和
TDM相同的数据预处理过程。我们仅保留评级大于等于4.0的记录、仅保留至少十条评论的用户。经过预处理之后,数据集包含129797名用户、20709部电影、以及9939873条交互记录。然后我们随机抽取
1000个用户和相应的交互记录来构造验证集,另外随机抽取1000个用户和相应的交互记录来构造测试集,剩余用户及其交互记录作为训练集。对于每个用户,根据时间戳将前半部分评级作为历史行为特征,后半部分评级作为待预测的ground truth。Amazon books:该数据集包含用户对Amazon的books的评论,其中每个user-book交互都包含一个user-id、一个item-id、以及相应的时间戳。类似于
MovieLens-20M,我们遵循和JTM相同的预处理过程。数据集包含294739名用户、1477922个item、以及8654619条交互记录。注意,和Movielens-20M相比,Amazon books数据集具有更多的item,但是交互更少。我们随机抽取
5000名用户及其相应的交互记录作为测试集,另外随机抽取5000名用户及其相应的交互记录作为验证集,剩余用户及其相应的交互记录作为训练集。对于每个用户,根据时间戳将前半部分评级作为历史行为特征,后半部分评级作为待预测的ground truth。
评估指标:我们使用
precision, recall, F-measure作为指标来评估每个算法的性能。我们强调,这些指标是为每个用户分别计算的,并按照
TDM和JTM相同的设置,在没有用户权重的情况下对所有用户进行平均。我们通过检索
MovieLens-20M数据集中每个用户的top 10的item来计算指标、通过检索Amazon books数据集中每个用户的top 200的item来计算指标。训练配置:这里我们提供一些关于实验中的模型和训练过程的一些细节。
由于数据集是以这样的方式进行拆分的:即训练集、验证集、测试集中的用户是不相交的,所以我们删除
user-id,仅使用行为序列作为DR的输入。如果行为序列长于
69,则将其长度截断为69;如果行为序列长度短于69,则将其长度用占位符填充到69。我们使用一个
GRU的递归神经网络,来将行为序列映射到一个固定维度的embedding上,从而作为DR的输入。我们采用多任务学习框架
multi-task learning framework,并且通过softmax reranker对召回路径中的item进行rerank。我们在前两个
epoch共同训练DR和softmax的embedding,然后在接下来的两个epoch中冻结softmax的embedding并训练DR的embedding。原因是为了防止softmax模型的过拟合。在推断阶段,由于
path size的差异,beam search检索到的item数量并不固定,但是方差并不太大。根据经验,我们控制beam size,使得beam search的item数量是最终检索item数量的5 ~ 10倍。
实验结果:我们将
DR的性能和以下算法进行比较:Item-CF、YouTube product DNN、TDM、JTM。我们直接使用来自
TDM和JTM论文的Item-CF、YouTube product DNN、TDM、JTM结果进行公平地比较。在不同的TDM变体中,我们选择了性能最佳的一种来比较。JTM的结果仅适用于Amazon books。我们还将
DR和暴力brute-force检索算法进行了比较,后者直接计算用户embedding和所有item embedding之间的内积(这些embedding都是从softmax模型学到),从而返回top K item。在实际的大型推荐系统中,暴力算法通常在计算上是不可行的,但是在小型数据集上可以作为基于内积模型的上限。下表分别给出了
MovieLens-20M、Amazon books数据集上DR方法和其它方法的比较结果。对于DR和暴力方法,我们独立地训练同一个模型5次,并计算每个指标的均值和标准差。可以看到:DR相比包括tree-based的检索算法(如TDM和JTM)在内的所有其它方法表现更好。DR的性能相比暴力法的性能非常接近或者不相上下。
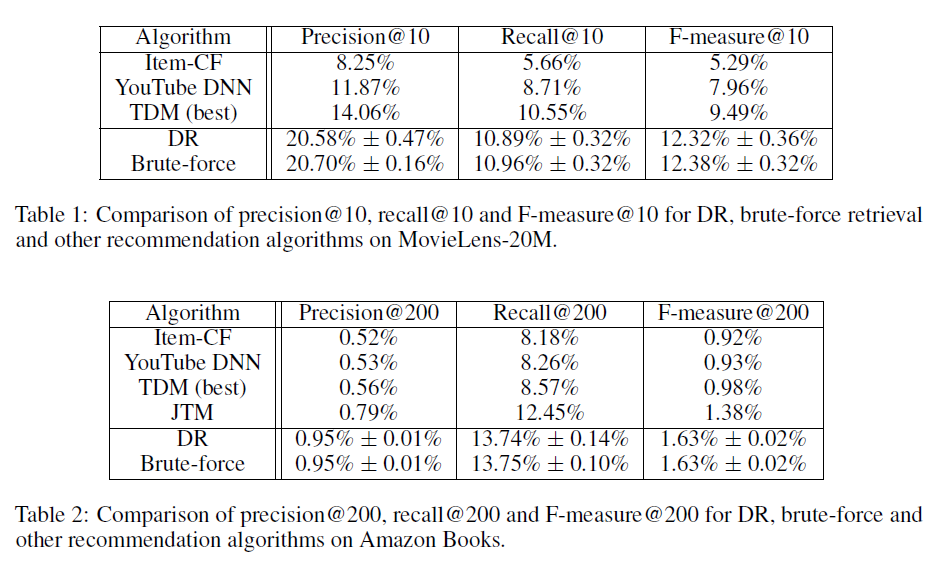
参数敏感性:
DR引入了一些可能显著影响性能的关键超参数,包括结构模型structure model的宽度 、多路径multiple path数量 、beam size、以及惩罚因子 。在
MovieLens-20M的实验中,我们选择 ;在Amazon books的实验中,我们选择 。我们在
Amazon books数据集研究了这些超参数的使用,并观察它们如何影响性能。我们在下图中展示了当这些超参数变化时,recall@200指标是如何变化的(我们以recall@200为例,precision@200和F-measure@200也遵循类似的趋势)。当改变一个超参数时,我们不改变其它超参数的值。模型宽度 : 控制了结构模型的整体容量。
- 如果 太小,那么对于所有
item而言,cluster的数量太小。 - 如果 太大,那么训练和推断的时间复杂度随着 线性增加。而且 太大可能会增加过拟合的可能性。
应该根据语料库的大小选择合适的 。
- 如果 太小,那么对于所有
路径数量 : 使模型能够表达
item的多方面信息multi-aspect information。时性能最差,并随着 的增加而不断增加。较大的 可能不会影响性能,但是训练的时间复杂度随着 的增加而线性增加。实际上建议选择 在
3到5之间。beam size: 控制召回的候选路径的数量。较大的 导致更好的性能,但是也会带来推断阶段更大的计算量。
惩罚因子 : 控制每个路径中的
item数量。当 值落在一定范围内时,性能最佳。较小的 导致较大的
path size(如下表所示为包含最多item的path(称作top path)的path size和惩罚因子的关系),因此在reranking阶段计算量较大。beam size和惩罚因子 应该适当选择,从而在模型性能和推断速度之间进行权衡trade-off。
总体而言,我们可以看到
DR对于超参数是相当稳定的,因为超参数的范围很广wide range,这导致了接近最优near-optimal的性能。
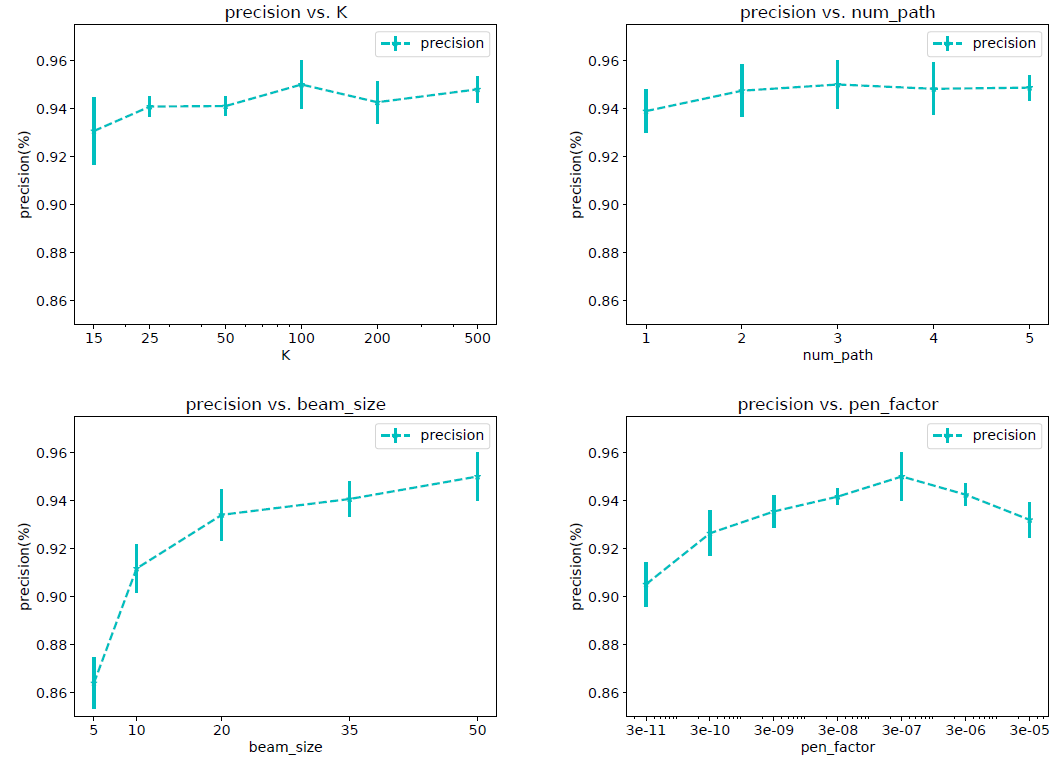
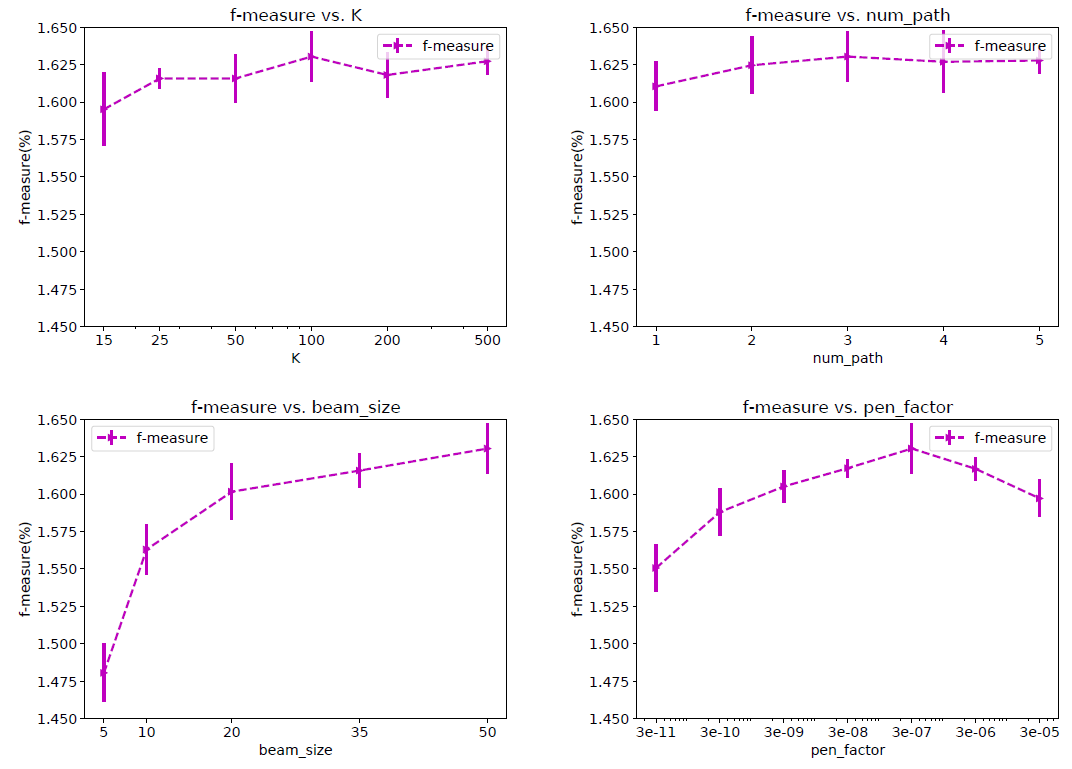
十、JTM[2019](用于检索)
推荐问题
recommendation problem本质上是从整个语料库中为每个用户请求检索一组最相关most relevant或者最喜欢most preferred的item。在大规模推荐的实践中,算法设计需要在准确性accuracy和效率efficiency之间取得平衡。在拥有数千万或数亿个item的语料库中,需要为每个用户请求user request线性扫描每个item的偏好分preference score,这在计算上是难以实现的。为了解决这个问题,通常使用索引结构
index structure来加速检索过程。在早期的推荐系统中,item-based协同过滤item-based collaborative filtering: Item-CF和倒排索引inverted index是一种克服计算障碍的流行解决方案。然而,候选集合的范围scope是有限的,因为最终只能推荐那些与用户历史行为相似的item。近年来,向量表示学习
vector representation learning方法得到了积极的研究。这种方法可以学习用户向量representation和item向量representation,然后向量的内积表示user-item偏好。对于使用vector representation-based方法的系统,推荐集合生成generation等价于k近邻搜索问题k-nearest neighbor: kNN serach problem。用于近似kNN搜索的quantization-based索引被广泛用于加速检索过程。然而,在上述解决方案中,向量表示学习和kNN搜索索引构造search index construction分别针对不同的目标进行优化。目标差异objective divergence导致次优sub-optimal的向量表示和索引结构。一个更重要的问题是,向量kNN搜索索引依赖于用户偏好建模的内积形式,而这种内积形式限制了模型的能力。像Deep Interest Network: DIN、Deep Interest Evolution Network: DIEN、xDeepFM这样的模型已经被证明在用户偏好预测方面是有效的,但是不能用于生成推荐候选集合。为了打破内积形式的限制,使得任意高级的用户偏好模型在计算上能够易于处理,从而可以从整个语料库中检索候选
item,之前的工作Tree-based Deep Model: TDM创新性地使用树结构作为索引,并大大提高了推荐的准确性accuracy。TDM使用一个树索引tree index来组织item,树中的每个叶节点对应于一个item。像最大堆max-heap,TDM假设每个user-node偏好等价于该用户在该节点的所有子节点上最大偏好。- 在训练阶段,训练
user-node偏好预测模型从而拟合max-heap like的偏好分布。不同于基于向量kNN搜索的方法,其中索引结构要求用户偏好建模的内积形式,在TDM中对偏好模型的形式没有限制。 - 在预测阶段,由训练模型给出的偏好分
preference score被用于在树索引中执行layer-wise的beam search从而检索候选item。
树索引中的
beam search的时间复杂度相对于语料库大小是对数的,并且对模型结构没有限制,这是使得高级的用户偏好模型在推荐中检索候选item可行的先决条件。索引结构在基于
kNN搜索的方法和基于树的方法中扮演不同的角色。- 在基于
kNN搜索的方法中,首先学习用户的向量表示和item的向量表示,然后建立向量搜索索引vector search index。 - 在基于树的方法中,树索引的层级
hierarchy也会影响检索模型的训练,二者相互依赖。因此,如何联合学习树索引和用户偏好模型是一个重要的问题
基于树的方法也是极端分类
extreme classification的文献中的一个活跃的研究主题,而极端分类有时也被认为是一种推荐。在现有的基于树的方法中,树结构被学习从而为了在样本空间或label空间中有更好的层级hierarchy。然而,树学习阶段的样本划分任务或label划分任务的目标并不完全符合最终目标,即准确地推荐。索引学习index learning和预测模型训练之间的目标不一致导致整个系统处于次优sub-optimal状态。为了应对这一挑战,并促进树索引和用户偏好预测模型的更好协作,论文
《Joint Optimization of Tree-based Index and Deep Model for Recommender Systems》开发了一种通过优化统一性能指标来同时学习树索引和用户偏好预测模型的方法。论文的主要贡献:- 提出了一个联合优化框架
joint optimization framework来学习tree-based推荐中的树索引和用户偏好预测模型,其中优化了统一的性能指标,即用户偏好预测的准确性accuracy。 - 证明了所提出的树学习算法等价于二部图
bipartite graph的加权最大匹配weighted maximum matching问题,并给出了树学习的近似算法。 - 提出了一种新的方法,该方法可以更好地利用树索引生成层级
hierarchical的用户representation,有助于学习更准确accurate的用户偏好预测模型。 - 证明了树索引学习和层级用户表示都可以提高推荐准确性
accuracy,并且这两个模块甚至可以相互促进,从而实现更显著的性能提升。
在两个大规模的真实世界数据集上进行的实验评估表明,论文的方法可以显著提高推荐的准确性
accuracy。在展示广告平台display advertising platform上的在线A/B test结果也证明了论文的方法在生产环境中的有效性。- 在训练阶段,训练
10.1 模型
我们首先简要回顾
TDM,然后我们提出了tree-based索引和深度模型的联合学习框架。最后,我们介绍了模型训练中使用的层级用户偏好表示hierarchical user preference representation。改进点:直接优化损失函数的树学习算法;用户历史行为的
item在不同level使用不同的representation。
10.1.1 TDM
在大规模语料库的推荐系统中,如何有效地检索候选
item是一个具有挑战性的问题。Tree-based Deep RecommendationModel: TDM使用一棵树作为索引,并在树中提出了一个max-heap like的概率公式。其中,在level中每个非叶节点 的用户偏好为:其中:
- 为用户 对节点 偏好的
ground truth概率。 - 为
level的归一化项,使得 。
上述公式意味着:节点 的
ground truth的user-node概率,等于节点 的所有子节点中的user-node概率最大值除以归一化项。因此:level的top-k节点必须包含在level的top-k节点的子节点中。- 对
top-k叶节点的检索可以严格限制为自顶向下地、递归地检索每个level的top-k节点,而不会损失准确性accuracy。
有鉴于此,
TDM将推荐任务转变为分层检索问题hierarchical retrieval problem,从粗粒度到细粒度逐步地选择候选item。- 为用户 对节点 偏好的
TDM的候选生成过程candidate generating process如下图所示。其中:图
(a)表示用户偏好预估模型user preference prediction model。首先将用户行为在相应
level进行分层抽象hierarchically abstract,得到层级的表示 。然后,层级的表示和目标节点以及其它特征(如用户画像)被用作模型的输入。图
(b)表示树层级tree hierarchy。首先将每个
item分配给具有映射函数 的不同叶节点。在检索阶段,在leaf level分配了红色节点的item被选择为候选集。
候选生成过程首先将每个
item分配给树层级tree hierarchy中的叶节点leaf node,然后执行图(b)所示的layer-wise的beam search策略:对于level,仅对level中具有top-k概率的节点的子节点进行评分和排序,从而选择level中的top-k候选节点。这个过程一直持续直到达到top-k叶节点为止。通过树索引,用户请求的整体检索复杂度从相对于语料库大小的线性降低到对数,并且对偏好模型结构
preference model structure没有任何限制。这使得TDM打破了向量kNN搜索索引带来的用户偏好建模内积形式的限制,并使得任意高级深度模型能够从整个语料库中检索候选item,大大提高了推荐准确性accuracy。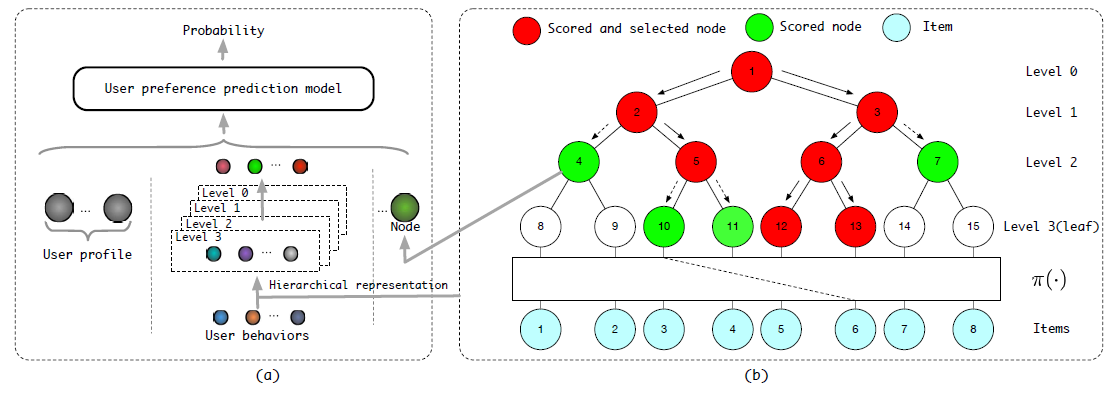
10.1.2 联合优化框架
假设包含 个样本的训练集为 ,其中第 个样本 表示用户 对
target item感兴趣。对样本 ,树层级tree hierarchy决定了预估模型 为用户 选择的、到达item的路径。我们提出在全局损失函数下共同学习 和 。正如我们将在实验中看到的那样,共同优化 和 可以提高最终推荐的准确性
accuracy。给定一个
user-item的pair对 ,令 表示用户 对于叶节点 的偏好概率。其中 是一个映射函数,它将一个item映射到 中的叶节点。注意: 完全决定了树层级 ,并且优化 实际上是在优化 。模型 在给定模型参数 的情况下预估
user-node偏好 。如果pair对是一个正样本,那么我们有ground truth。根据最大堆max-heap的属性,所有 的祖先节点的用户偏好概率(即 )也应该是1。其中 为一个映射函数,它将一个节点映射到level的祖先节点, 为 中的最大level。这里假设每个用户仅有一个互动
item。如果有多个互动item,实际上由于level的归一化项 的存在,子节点 但是祖先节点的 不一定为1。只能保证祖先节点的 。为了拟合这样的
user-node偏好分布,全局损失函数公式化为:这里我们将所有正样本(即 )和它们的祖先
user-node pair对上的预估user-node偏好概率的负对数之和作为全局经验损失global empirical loss。优化 是一个组合优化问题,很难同时与 使用基于梯度的算法进行优化。为了解决这个问题,我们提出了一种联合学习框架
joint learning framework,它交替地针对用户偏好模型以及树层级来优化全局损失函数 。模型训练和树学习tree learning中训练损失的一致性促进了框架的收敛。实际上,由于 是一个递减序列并且下界为0,因此模型训练和树学习都可以减小 的值,联合训练算法肯定会收敛。在模型训练中, 就是学习一个适用于所有
level的user-node偏好模型,这个模型可以通过神经网络的流行优化算法(如SGD, Adam等)来求解。在标准化的
normalized用户偏好设置中,由于节点数量随着level呈指数增长,因此噪声对比估计Noise-contrastive estimation是估计 的替代方法,以避免通过采样策略来计算归一化项。树学习的任务是在给定 的条件下求解 。 等价于二部图
bipartite graph的最大加权匹配问题maximum weighted matching problem,其中二部图由语料库 和 的叶节点组成。补充材料显示了详细的证明。
树索引和深度模型的联合学习框架:
输入:
- 损失函数
- 深度模型
- 树
输出:训练好的模型 、训练好的树
算法步骤:
迭代 :
- 通过优化 来求解 。
- 通过使用树学习算法
tree learning algorithm优化树层级来求解 。
输出 。
诸如经典的匈牙利算法
Hungarian algorithm之类的用于分配问题assignment problem的传统算法由于其高度复杂性而难以应用于大型语料库。即使是贪心的选择权重最大的未赋值边unassigned edge的朴素贪心算法naive greedy algorithm,也需要预先计算并存储一个大的权重矩阵,这是无法接受的。为了解决这个问题,我们提出了一种分段树学习算法segmented tree learning algorithm。我们不是直接将
item分配给叶节点,而是从根节点到leaf level一级一级地实现achieve。给定一个映射 以及语料库中的第 个item,令:其中:
- 为
target item为 的训练样本集合。 - 为
start level, 为end level。
我们首先针对 来最大化 ,这等效于将所有
item分配给level中的节点。对于最大level为 的完全二叉树 ,level中的每个节点被分配了不超过 个item。注意:根节点的
level最高,为 。叶节点的level最低,为1。这也是可以通过贪心算法
greedy algorithm有效解决的最大匹配问题,因为如果很好地选择了 ,则每个item的可能位置的数量大大减少了。例如,对于 ,数量为 ,即item可能的位置为它后代的128个叶节点之一。将这一步找到的最佳映射记作 。然后我们接下来在约束 的条件下最大化 。这意味着在
level中保持每个item的相应祖先节点不变。一直递归,直到每个item都分配给叶节点。- 为
树学习算法
tree learning algorithm:输入:
gap- 最大的树
level - 原始
original的映射
输出:优化的映射
算法步骤:
设置当前的
level,初始化 。迭代 :
对于
level中的每个节点 ,迭代:记 为在 中 的所有后继子孙节点。即 。
寻找 ,使得:
这里我们使用一个带有重新平衡策略
rebalance strategy的贪心算法greedy algorithm来解决这个子问题。每个item首先以最大权重 分配给 在level的子节点。然后,应用重新平衡过程以确保每个子节点被分配不超过 个item。更新 :
更新 :
更新 :
返回 。
10.1.3 层级的用户偏好表示
如前所述,
TDM是一个层级的检索模型hierarchical retrieval model,用于从粗粒度到细粒度逐层地生成候选item。在检索中,用户偏好预测模型 通过树索引执行layer-wise的自上而下的beam search。因此, 在每个level的任务都是异质的heterogeneous。有鉴于此,必须提供level-specific输入从而提高 的推荐准确性accuracy。一系列相关工作表明:用户的历史行为在预测用户兴趣方面起着关键作用。然而,在我们的
tree-based方法中,我们甚至可以以新颖novel和有效effective的方式扩大这个关键作用key role。给定用户行为序列 ,其中 是用户交互的第 个
item,我们提出使用 作为level中的用户行为特征。 和目标节点以及其它可能的特征(如用户画像)一起被用作level中的 的输入,从而预测user-node偏好。另外,由于每个节点或
item都是一个one-hot ID特征,我们按照常见的方式将它们嵌入到连续的特征空间中。这样,用户交互的item的祖先节点被用作层级的用户偏好表示hierarchical user preference representation。一般而言,层级的表示带来两个主要好处:
level独立level independence:与通常的方式一样,在不同level之间共享item embedding会在训练用户偏好预测模型 时带来噪声,因为不同level的target不同。一种显式的解决方案是为每个
level为item附加一个独立的embedding。但是,这将大大增加参数的数量,并使得系统难以优化和应用。我们提出的层级的表示
hierarchical representation使用相应level中的node embedding作为 的输入,从而在不增加参数数量的情况下实现了训练的level independence。精确描述
precise description: 通过树来分层地生成候选item。随着检索level的增加,每个level中的候选节点将从粗粒度到细粒度描述最终推荐的item,直到达到leaf level。我们提出的层级的用户偏好表示抓住了检索过程的本质,并给出了用户行为的精确描述,其中节点位于相应的
level。通过减少过于详细或过于粗糙的描述所带来的混乱,这种方法提高了用户偏好的可预测性。例如,在训练和预测中, 在
upper level的任务是粗略地选择一个候选集合,并且在相同的upper level中用户行为用同质的homogeneous节点embedding也是粗略地描述的。
10.2 实验
这里我们将研究所提出方法的离线性能和在线性能。
- 我们首先将所提出的方法的整体性能和其它
baseline进行对比。 - 然后我们进行实验来验证各部分的贡献和框架的收敛性。
- 最后我们在具有真实流量的在线展示广告平台
online display advertising platform上验证该方法的性能。
- 我们首先将所提出的方法的整体性能和其它
数据集:
Amazon Books:来自于Amazon的产品评论组成的user-book评论数据集。这里我们使用最大的子集Books。UserBehavior:这是淘宝用户行为数据的子集。
这两个数据集均包含数百万个
item,并且数据以user-item交互的形式进行组成。每个user-item交互包含用户ID、item ID、category ID、以及时间戳。对于上述两个数据集,我们仅保留互动次数不少于
10的用户。baseline方法:为了评估我们提出框架的性能,我们对比了以下方法:Item-CF:一种basic的协同过滤方法,广泛用于个性化推荐,尤其是大规模语料库。YouTube product-DNN:是YouTube视频推荐中使用的一种实用方法,这是基于向量kNN搜索方法的代表性工作。学到的用户向量表示和item向量表示之间的内积反映了偏好。我们使用精确的
kNN搜索来检索预估中的候选item。HSM:是分层的softmax模型。它采用layer-wise条件概率的乘积来获得归一化的item偏好概率。TDM:是tree-based的深度推荐模型。它允许任意高级模型使用树索引来检索用户兴趣。我们使用
TDM的basic DNN版本,没有tree learning、没有attention。DNN:是没有树索引tree index的TDM的变体。唯一区别是在于,它可以直接学习user-item偏好模型,并且线性扫描所有item,以检索预估中的top-k候选item。在在线系统中,这在计算上是不可行的。但是在离线比较中,这是一个很强的
baseline。JTM:是树索引和用户偏好预测模型的联合学习框架。JTM-J和JTM-H是两个变体:JTM-J:联合优化了树索引和用户偏好预测模型,但是没有采用层级的用户偏好表示。JTM-H:采用了层级的用户偏好表示,但是使用固定的初始树索引fixed initial tree index,而没有tree learning。
配置:
遵循
TDM,我们将用户拆分为训练集、验证集、测试集。- 训练集中的每个
user-item交互都是一个训练样本,交互前的用户行为就是对应的特征。 - 对于验证集和测试集中的每个用户,我们将沿时间线将前一半行为作为已知特征、后一半行为作为
ground truth。
- 训练集中的每个
利用
TDM的开源工作,我们在阿里巴巴的深度学习平台X-DeepLearning: XDL中实现了所有方法。HSM,DNN,JTM,TDM采用相同的用户偏好预测模型。我们为
Item-CF以外的所有方法都采用负采样,并使用相同的负采样率。对于每个训练样本,Amazon Books中负采样100个负item、UserBehavior中负采样200个负item。HSM,TDM,JTM在训练过程之前需要一颗初始树。遵从TDM的工作,我们使用类目信息category information来初始化树结构,其中来自相同类目的item在leaf level进行聚合。
补充材料中列出了更多关于数据预处理和训练的细节和代码。
评估指标:我们采用
Precision, Recall, F-Measure来评估不同方法的性能。令用户 召回的
item集合为 (其中 ),用户的ground truth集合为 。Precision@M定义为:Recall@M定义为:F-Measure@M定义为:
每个指标在测试集中对所有用户取平均,并且每个实验执行五次取均值。
下表给出了两个数据集上所有方法的结果,其中 。可以看到:我们提出的
JTM在所有指标上均优于其它baseline。和两个数据集上最佳的DNN模型相比,JTM在Amazon books和UserBehavior上的召回率分别提升了45.3%和9.4%。如前所述,虽然在线系统上计算量难以实现,但是
DNN是离线比较的一个非常强的baseline。DNN和其它方法的比较结果给出了许多方面的洞察insight。首先,
YouTube product-DNN和DNN之间的差距显示了内积形式的局限性。这两种方法的唯一区别是:
YouTube product-DNN使用用户向量和item向量的内积来计算偏好分,而DNN使用全连接网络来计算偏好分。这种变化带来了显著的提升,验证了高级神经网络相比于内积形式的有效性。其次,采用普通
ordinary但是未优化的树层级tree hierarch的情况下,TDM性能比DNN更差。树层级在训练和预测过程中都起作用。
user-node样本沿着树生成从而拟合max-heap like的偏好分布,并且在预测时在树索引中部署layer-wise beam search。如果没有一个定义良好的树层级,用户偏好预测模型可能会收敛到一个次优sub-optimal版本,其中生成的样本是混乱的confused,并且可能丢失non-leaf level中的target,从而可能返回不正确的候选集。特别是在像
Amazon Books这样的稀疏数据集中,树层级中每个节点学到的embedding没有足够的可区分性distinguishable,因此TDM的性能不如其它baseline。这个现象说明了树的影响、以及
tree learning的必要性。此外,
HSM的结果比TDM差很多。这与TDM报告的一致。当处理大型语料库时,由于layer-wise概率乘积和beam search的结果,HSM无法保证最终召回的集合是最优的。
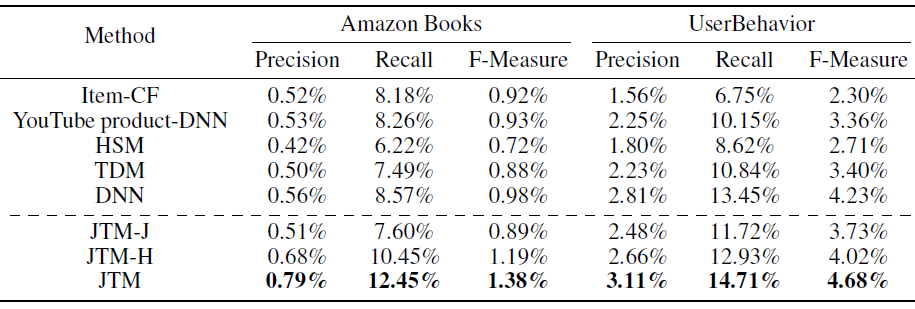
通过联合学习树索引和用户偏好模型,
JTM在两个数据集中的所有指标上均优于DNN,而检索复杂度要低得多。在JTM中可以获得更精确precise的用户偏好预测模型和更好的树层级,从而可以实现更好的item集合的选择。- 层级的用户偏好表示缓解了
upper level的数据稀疏性问题,因为在具有相同样本数的情况下,upper level用户行为特征的特征空间要小得多。并且它有助于以layer-wise的方式进行模型训练,从而减少噪声在各个level之间的传播。 - 此外,树层级学习使得相似的
item在leaf level上聚合,从而使得内部的level model可以获得分布更加一致consistent的、明确unambiguous的训练样本。
得益于上述两个原因,
JTM提供了比DNN更好的结果。上表中虚线下方的结果表明了各部分的贡献及其在
JTM中的联合性能。以召回率指标为例:在UserBehavior数据集中,和TDM相比,树学习和用户偏好的层级表示分别带来了0.88%和2.09%的绝对增益。此外,在一个统一的目标下,两种优化的组合实现了3.87%的绝对召回率提升。Amazon Books也观察到了类似的收益。以上结果清楚地表明了层级表示和树学习以及联合学习框架的有效性。
- 层级的用户偏好表示缓解了
迭代联合学习的收敛性
Convergence of Iterative Joint Learning:树层级决定了样本的生成和搜索路径,一棵合适的树将极大地有利于模型训练和推断。下图给出了在
TDM中提出的基于聚类的树学习算法,以及我们提出的联合学习方法的比较。为了公平起见,这两种方法都采用层级的用户表示。其中 ,(a),(b),(c)为Amazon Books数据集的结果,(d),(e),(f)为UserBehavior数据集的结果。横轴表示迭代次数。TDM树学习算法是基于聚类来实现的,其目标是聚类间距离。JTM树学习算法是逐级分段优化目标函数来实现,其目标是最小化损失。由于我们提出的树学习算法与用户偏好预测模型具有相同的目标,因此从结果来看,这具有两个优点:能够稳定低收敛到最优树;最终推荐准确性
accuracy高于基于聚类的方法。从下图中我们可以看到:所有三个指标的结果都在不断地增加。此外,模型在两个数据集上均稳定地收敛,而基于聚类的方法最终会过拟合。以上结果从经验上证明了迭代联合学习的有效性
effectiveness和收敛性convergence。一些细心的读者可能已经注意到:在最初的几轮迭代中,聚类算法的性能优于
JTM。原因是JTM的树学习算法涉及一种惰性策略lazy strategy,即尝试减少每次迭代中树结构修改的程度(详细内容在补充材料中给出)。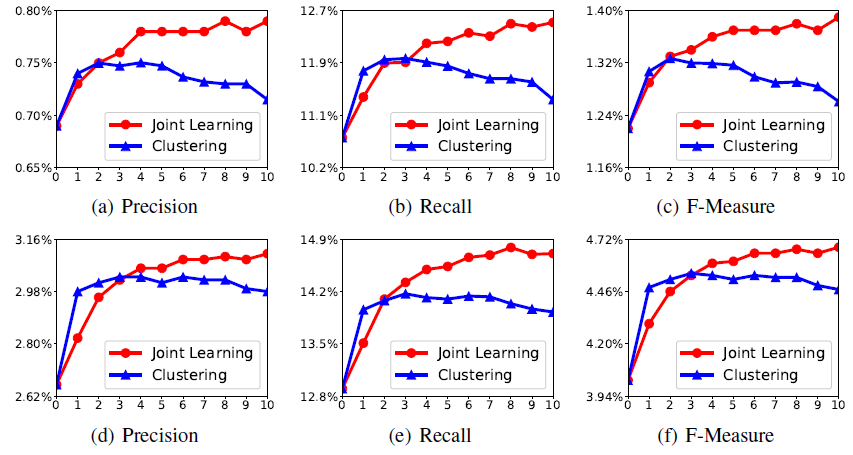
在线结果:我们还在生产环境中评估了
JTM,其中生产环境为淘宝App首页的“猜你喜欢”栏目的展示广告display advertising场景。我们使用
click-through rate: CTR和revenue per mille: RPM来衡量效果,这是关键的效果指标。其中CTR定义为:点击量/曝光量。RPM定义为:广告收入/曝光量 *1000。在广告平台,广告主可以对大量的粒度进行出价,如
ad cluster、item、shop等等。所有粒度中,几个同时运行的推荐方法产生候选集合,它们的组合会被传递到后续阶段,如CTR预估、ranking等等。比较的baseline是所有运行的推荐方法得到的这种组合。为了评估
JTM的有效性,我们部署了JTM来替代Item-CF,这是平台中item粒度的主要候选生成方法之一。TDM的评估方法和JTM相同。要处理的语料库包含数千万个item。每个比较的bucket都有2%的在线流量,考虑到整体页面请求量,这已经足够大了。下表给出了两个主要在线指标的提升情况。
CTR增长了11.3%,这表明JTM推荐了更精准precise的商品。RPM提高了12.9%,这表明JTM可以为平台带来更多收入。