十一、Pinterest Recommender System[2017]
虽然已经有很多关于高级推荐系统及其实际应用的论文发表,但是通常不可能直接构建
state-of-the-art的推荐系统。最初的产品initial product必须用一个小的工程团队、有限的计算资源、以及缺乏训练数据来构建,直到推荐系统被启用bootstrapped。工业级的推荐系统通常处理包含数十亿个item的Web-scale数据。由于内容是通过用户隐式反馈implicit user feedback收集的,因此内容通常标记不佳并且有很大噪音noisy。因此,很多从业者在构建初始系统时选择使用临时的启发式方法heuristics来trade-off。但是,系统的进一步增长grow会使得系统迅速复杂化,从而难以应对接下来的变化。在论文
《Related Pins at Pinterest: The Evolution of a Real-World Recommender System》中,作者给出了在Related Pins背景下以独特的机会在三年的时间范围内观察这些问题。Related Pins的初始版本是在2013年推出的,是Pinterest首次进入推荐系统的尝试之一。尽管在改善内容发现content discovery取得了成功,但是Related Pins最初在工程上受到的关注很少。2014年,Pinterest上大约10%的pins saved是通过Related Pins发现discovered的。2015年,一个小团队开始迭代并进一步开发Related Pins。现在,Related Pins通过多个产品界面product surfaces推动了超过40%的保存save和曝光impression,并且是Pinterest上的主要发现机制primary discovery mechanisms之一。论文通过对Related Pins的纵向研究,探索了现实世界中推荐系统的挑战。在描述Pinterest系统的逐步演变时,作者提出了应对这些挑战的解决方案、trade-off的理由、以及学到的关键洞察key insights。现实世界的推荐系统已经作为音乐推荐
music suggestion、图像搜索image search、视频发现video discovery、电影发现movie discovery。其中很多论文描述了final system,然而并没有描述如何逐步增量地incrementally构建系统。《Hidden technical debt in machine learning systems》描述了现实世界推荐系统面临的很多挑战,我们提供了在Related Pins中这些挑战的具体例子,并提出了独特的解决方案。- 对于
Related Pins,我们首先考虑最简单、性价比最高highest-leverage的产品,从而达到增量式的里程碑incremental milestones并证明可行性viability。我们最初的推荐算法由一个简单的候选生成器candidate generator以及很多启发式规则heuristic rules组成。尽管它仅在三周内建成,但是它利用了user-curated boards中的强烈信号strong signal。我们继续添加更多的候选源candidate sources,因为我们发现了覆盖率coverage和召回率recall之间的gap。 - 随着时间的推移,我们引入了
memorization layer来提高热门的结果popular results。Memboost在工程复杂度和计算强度方面都是轻量级的,但是它能显著地利用大量的用户反馈user feedback。我们不得不考虑位置偏差position bias,并以反馈回路feedback loops的形式处理复杂性complexity,但是发现付出的代价是值得的。 - 接下来我们添加了一个机器学习的
ranking组件,因为我们认为它具有最大的影响潜力。我们从只有九个特征的基础线性模型开始。当我们发现模型和训练方法的缺点时,我们开始尝试使用更高级的方法。
每个组件最初都是在工程和计算资源上有很多限制的情况下构建的,因此我们优先考虑了最简单和最高效的解决方案。我们展示了有机增长
organic growth如何导致一个复杂的系统,以及我们如何管理这种复杂性。- 对于
11.1 系统介绍
Pinterest是用于保存saving和发现discovering内容content的可视化发现工具visual discovery tool。用户将他们在Web上找到的内容另存为pins,并在boards上创建这些pins的集合。Related Pins利用这些人类收藏的human-curated内容基于给定的query pin来提供个性化的pin推荐。下图给出了pin特写视图pin closeup view。Pinterest其它几个部分也包含Related Pins推荐,包括主页feed流home feed、访客(身份未验证的访问者)的pin page、相关想法related ideas的instant ideas按钮、电子邮件email、通知notification、搜索结果search result、浏览选项卡Explore tab。
Pinterest上的用户互动user engagement通过以下操作来定义:- 用户通过点击来查看有关
pin的更多详细信息从而特写closeup这个pin。 - 然后,用户可以点击从而访问关联的
Web链接。如果用户长时间off-site,那么被视为长按long click。 - 最后,用户可以将
pin保存到自己的board上。
我们对推动相关
pin的保存倾向Related Pins Save Propensity很感兴趣,它的定义是:保存Related Pins推荐的pin的数量除以用户看到的Related Pins推荐的pin的数量。- 用户通过点击来查看有关
在
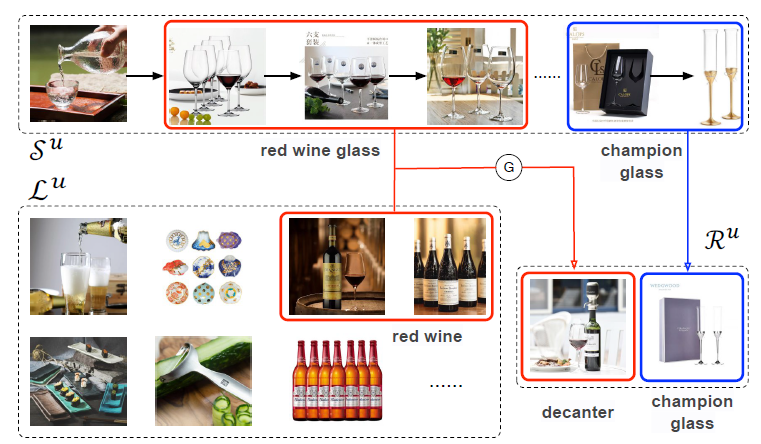
Pinterest数据模型data model中,每个pin都是一个带链接link和描述文本description的图像实例image instance,其中图像是通过一个图像签名signature来唯一标识的。尽管每个pin位于单个board上,但是同一个图像可以用于不同board上的很多pin:当pin保持到一个新的board上时,会创建该pin的拷贝。pin信息通常在image signature level上进行汇总,从而提供了比单个pin实例相比更丰富的元数据meta-data(比如pin粒度的点击量、保存量)。为方便起见,将来对query pin和result pin的引用实际上指的是pin的集合,该集合中的pin具有相同image signature。Related Pins系统包含以下三个主要组件components。随着时间的推移,这些组件已经被陆续引入到系统中,并且每个组件以各自的方式发生了巨大的演变 。下图给出了我们体系结构的各种快照snapshots,说明了整个系统以及三个组件的演变evolution。本文后续部分将更详细地探讨它们的发展。Candidate Generation组件:我们首先将候选集合candidate set(符合Related Pin推荐的pin集合)的范围从数十亿缩小到大约1000个可能和query pin相关related的pin。我们已经开发并迭代了几种不同的候选生成器
candidate generators来做到这一点。Memboost组件:我们系统的一部分会记住历史上特定query和result的pair对上的互动。我们描述了在使用历史数据时,如何通过使用点击除以期望点击的方式来解决位置偏见position bias问题。引入记忆会增加带有反馈回路
feedback loops系统的复杂性,但是会显著提高互动engagement。Ranking组件:我们应用一个机器学习的ranking model到pin上,对这些pin排序从而最大化我们的Save Propensity的目标互动指标target engagement metric。该模型结合了query特征、candidate pins特征、用户画像特征、session上下文特征、Memboost信号等特征的组合。我们采用了
learning-to-rank技术,采用历史用户互动user engagement来训练系统。

11.2 Candidate Generation 的演变
最初的
Related Pins系统仅包含一种形式的候选生成candidate generation:通过抽取经常共现co-occurring的pins来利用pin-board graph。这些候选pins作为推荐直接显示给用户(上图的(a))。后来我们引入了
Memboost和machine-learned ranking时,候选生成的问题从precision转移到了recall:生成和query pin相关的各种各样diverse的pins集合。由于我们发现了覆盖率coverage和召回率recall方面的差距,这导致我们添加了新的候选源candidate sources(上图的(d))。
11.2.1 Board 共现
我们主要的候选生成器
candidate generator是基于用户收藏的user-curatedboards和pins的graph,但是随着时间的推移我们改变了这个方法从而产生更相关relevant的结果并覆盖更多的query pins。启发式候选
Heuristic Candidates:原始的Related pins是在离线Hadoop Map/Reduce作业中计算的。我们输入boards的集合,输出在同一个board上共现的pin pair对。由于有太多的pin pair对,因此对于每个pin query我们随机采样这些pair对从而为每个pin query产生大致相同数量的候选。随机采样时,共现次数越高的
pin pair对被采样到的可能性越高,因此相当于选择top共现次数的pin pair。但是基于采样的方法避免了对pin pair的共现计数、以及对计数结果的排序。我们还基于粗略
rough的文本和类目category匹配来添加启发式的相关性得分heuristic relevance score。这个相关性得分是通过检查示例结果example results来手动调优hand-tuned的。我们选择该方法是因为它很简单。由于工程资源有限,该方法是由两名工程师在短短三周内实现的。另外,由于人类收藏
human-curatedboard graph已经是非常强烈的信号,因此该方法被证明是一种相当有效的方法。在线随机游走
Online Random Walk:我们发现:board共现co-occurrence越高候选item质量越好,如下图所示。然而,原始的方法主要是基于启发式得分
heuristic score,它并没有试图最大化board共现。我们还注意到,罕见
rare的pin(仅出现在少量board上)没有太多的候选item。
为了解决这些局限性,我们通过在线遍历
board-to-pin graph,在serving time生成候选item。现在我们使用一个叫做
Pixie的随机游走服务random walk service来生成候选item。Pixie完整的描述不在本文讨论范围之内,但是从广义上讲,Pixie将pins & boards二部图bipartite graph加载到一台具有大存储容量的机器上。二部图的边代表一个board关联了一个pin。我们根据一些启发式规则heuristic rules裁剪该二部图,从而在board上删除high-degree节点和low-relevance节点。Pixie从query pin开始在二部图上进行多次随机游走(大约100,000步),并在游走的每一步都有reset概率,最终汇总pin的访问次数。这样可以有效地计算出二部图上query pin的Personalized PageRank。该系统可以更有效地利用
board的共现,因为高度相关联highly connected的pins更可能被随机游走访问到。它还可以增加罕见pins的候选覆盖率candidate coverage,因为它可以检索距离query pin好几个hops的候选item。pins的共现代表了pin-board-pin的二阶邻近性,而随机游走方法可以检索pin-board-pin-board-pin这类的高阶邻近性从而提高罕见pins的候选覆盖率。
11.2.2 Session 共现
board共现在生成候选集时提供了良好的召回recall,但是死板rigid的、基于board的分组具有固有的缺陷inherent disadvantages。boards通常过于宽松broad,因此board上的任何pin pair对可能仅仅是很微弱地相关。对于生命周期很长的boards而言尤其如此,因为board的主题topic会随着用户的兴趣而漂移drift。boards也可能过于狭窄narrow。例如,威士忌和用威士忌调制的鸡尾酒可能被安排在不同的、但是相邻的boards上。
这两个缺点可以通过结合用户行为的时间维度
temporal dimension来解决:在同一个会话session期间保存的pins通常以某种方式关联。我们建立了一个名为Pin2Vec的额外侯选源candidate source,从而利用这些session共现co-occurrence信号。Pin2Vec是在d维空间中嵌入N个最热门的pins的一种学习方法,目标是将同一个session中保存的pins之间的距离最小化。Pin2Vec神经网络的架构类似于Word2Vec。学习问题learning problem被表述为N路分类问题,其中输入和输出均为N个pins之一,如下图所示。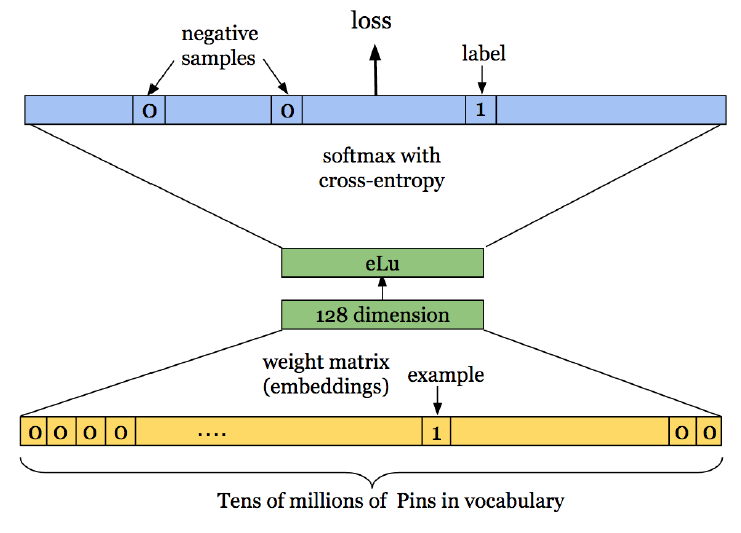
为了产生训练数据,我们认为同一个用户在特定时间窗口内保存的
pins是相关的。每个训练样本都是这样的一对pins。给定
pin pair对的其中一个pin作为输入,一个embedding matrix将pin ID映射到d维向量,然后一个softmax layer将embedding向量映射回预测的输出pin ID。这个pair对的另一个pin作为预期的输出,然后我们通过最小化网络的交叉熵损失来训练embedding。我们还使用负样本采样从而使得训练过程更简单。- 模型是通过
TensorFlow来构建和训练的,结果得到了N个pins中每个pin的d维embedding。 - 在
serving时,当用户query了N个pins中的某个时,我们通过在embedding空间中查找query pin最近的邻居来生成候选集。 - 我们发现,
session-based候选集和board-based候选集结合起来会大大提高相关性relevance。从概念上讲,session-based方法以紧凑compact的向量representation捕获了大量用户行为。
- 模型是通过
11.2.3 补充的候选
在取得上述进展的同时,出于两个原因,我们开始开发新的候选生成技术:
- 首先,我们想解决冷启动问题:罕见
pins没有很多候选,因为它们没有出现在很多boards上。 - 其次,在添加了
Ranking模块之后,我们希望在结果的多样性diversity带来更多互动engagement的情况下扩大我们的候选集。
出于这些原因,我们开始利用其它的
Pinterest discovery技术。- 首先,我们想解决冷启动问题:罕见
基于搜索的候选
search-based candidates:我们利用Pinterest的text-based search来生成候选,其中使用query pin的注释annotations(来自于web link或者描述descriptioin的单词)作为query tokens。每个热门的search query都有Pinterest Search提供的预计算的pin集合来支持。这些基于搜索的候选相对于基于
board共现的候选而言相关性较低,但是从探索exploration的角度来看,这是一个不错的折衷trade-off方案:基于搜索的候选产生了更多样化diverse的pin集合,而且这些pin集合仍然和query pin具有相关性。视觉相似的候选
visually similar candidates:我们有两个视觉候选源。- 如果某个
image和query image是几乎重复near-duplicate的,那么我们将该image添加到Related Pins推荐结果中。 - 如果没有和
query image几乎重复的image,那么我们使用Visual Search后端基于query image embedding向量的最近邻查找lookup来返回视觉相似的image。
- 如果某个
11.2.4 分区的候选
最后我们要解决内容激活问题
content activation problem:罕见的pins不会作为候选pins出现,因为它们不会出现在很多board上。当
Pinterest开始专注于国际化时,我们希望向国际用户展示更多的以他们自己语言的结果。大部分内容是来自美国的英语。尽管确实存在本地化内容local content,但是这些内容不是很热门,也没有链接到热门的pins,因此不会被其它侯选源来生成。为了解决这个问题,我们为上述许多生成技术生成了按本地化分区
segmented by locale的附加additional候选集。例如,对于board共现,我们将board-pin graph的输入集合过滤为仅包含本地化locale的pins。这种方法也可以扩展到存在内容激活问题的其它维度,例如特定于性别
gender-speci fic的内容或者新鲜fresh的内容。
11.3 Memboost 的演变
最初的
Related Pins版本已经获得了大量的互动engagement。作为从大量互动日志中学习的第一步,我们构建了Memboost来记住每个query的最佳pins结果。我们选择在尝试全面学习之前实现Memboost,因为它更轻量级lightweight,并且我们直觉上相信它会有效。我们最初只是想简单地合并每个结果的历史点击率
historical click-through rate。但是,日志数据容易受到位置偏见position bias的影响:显示在更前面位置的item更容易被点击。下图说明了每个平台platform上不同rank的全局点击率的bias(排名越小则显示越靠前)。为解决这个问题,我们选择了计算clicks over expected clicks: COEC。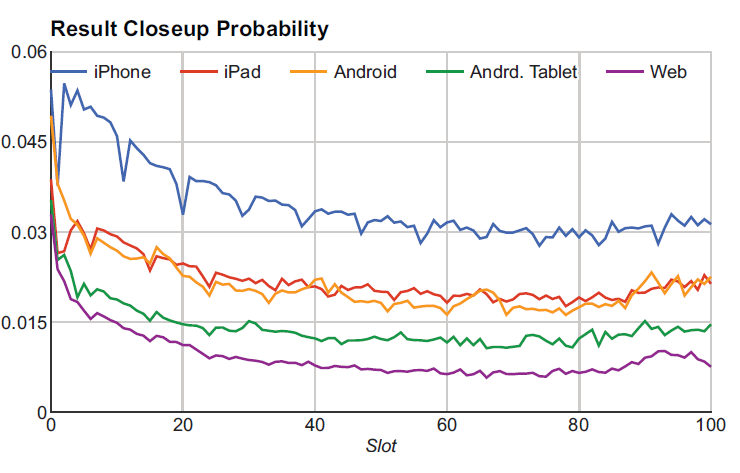
COEC:令 为result pin r在query pin q上获得的总点击量。令 为平台 、rank上result pin r在query pin q上获得的总曝光量。每个曝光贡献了一定比例的期望点击expected clicks。result pin r在query pin q上的期望点击量为:其中 为平台 、
rank的全局先验global prior的点击率。这里面的 是根据统计数据计算而来。上面公式的物理意义为:点击 = 曝光 x
ctr,但是对platform和rank求积分。我们将这些定义扩展到其它互动行为(不仅仅是点击),将这些互动行为的权重设为 :
现在 为对所有互动行为泛化的
COEC。Memboost score:为了获得一个zero-centered score,其中正值和负值分别表示结果比期望多互动多少和少互动多少,我们使用COEC的对数。另外我们还引入平滑来处理低互动或低曝光的
item。因此,总体的Memboost score为:Memboost score用于调整现有的pin score,并根据调整后的score来排序得到最终结果:历史上,
Memboost权重 通过A/B test来人工调优hand-tuned,从而最大化互动engagement。然而,这种做法会给评分函数带来不良的耦合影响:尝试使用新的ranker或者改变评分函数可能会产生更大或更小的初始得分initial scores,从而无意中改变了Memboost权重的相对大小。人工调优的权重对于新的条件condition(系统改变、不同的时间段等等)不再是最优的。每次改变 时,都需要重新调优
Memboost的超参数。为了消除这种耦合,我们现在在改变模型时共同训练
Memboost参数。我们将Memboost作为特征,Memboost的临时变量取值(clicks、Eclicks等等)作为特征馈入到基于机器学习的ranker中。Memboost Insertion:有时,已知某些item是好的(基于它们的Memboost scores),但是由于候选生成器和ranking sytem等上游的变化,这些item不再出现在候选结果中。为了处理这些情况,我们设计了一个
Memboost insertion算法。该算法将Memboost score最高的top-n item插入到候选结果中,如果这些item并未出现在候选结果中。将
Memboost结果作为一路召回。Memboost本质上就是记忆性memorization,它会记住历史上表现好的(query pin q, result pin r)。由于模型通常综合考虑了memorization和generization,因此一些历史表现好的pair可能会被稀释掉。Memboost作为一个整体,通过在系统中添加反馈回路feedback loops,显著增加了系统的复杂性。从理论上讲,它可以破坏corrupting或者稀释diluting实验结果:例如,实验中的正样本可能被挑选出来并泄漏到控制组和对照组(因为控制组和对照组都收到了反馈回流的Memboost数据)。重新评估历史的实验(例如添加了新的模型特征)变得更加困难,因为这些实验的结果可能已经被记住了。这些问题存在于任何基于记忆
memorization-based的系统中,但是Memboost具有显著的正向效果,因此我们也就接受了这些潜在的不足。我们目前正在实验替代
Memboost insertion的方法。Memboost insertion会减缓开发速度development velocity,因为有害harm结果的实验可能不再显示为负向的A/B test结果。而且新的ranking方法的试验效果可能被稀释,因为top结果可能被Memboost insertion所主导。Memboost insertion也可以无限期地维持候选items,即使候选生成器不再生成这批候选items(这批候选items由Memboost insertion产生,并始终在线上生效)。一种常见的替代
memorization方法是将item id作为ranking特征。但是,这需要一个大的模型(模型规模和被记忆的item数量呈线性关系),因此需要大量的训练数据来学习这些参数。这样的大型模型通常需要分布式训练技术。取而代之的是,Memboost预先聚合了每个result的互动统计量engagement statistics,这使得我们能够在单台机器上训练主力ranking模型。
11.4 Ranking 的演变
在引入
Ranking之前,Candidate Generation和Memboost已经工作了相当长的一段时间。我们假设下一个最大的潜在提升potential improvement将来自于我们在系统中添加一个ranking组件,并应用learning-to-rank技术。第一个
learning-to-rank模型大幅度提升了Related Pins的互动engagement,使得用户保存save和点击click结果提升了30%以上。在我们的
application中,ranker在特定query的上下文中对候选pins进行重新排序re-order。其中query包括query pin、浏览的用户、以及用户上下文user context。这些query部分和候选pin各自贡献了一些异质heterogeneous的、结构化structured的原始数据,例如注释annotations、类目categories、或者最近的用户活动user activity。如下表所示,给出了ranking feature extractor中样本可用的原始数据。我们定义了很多特征抽取器
feature extractors,这些特征抽取器输入原始数据并生成单个特征向量 。- 某些特征抽取器直接将原始数据拷贝到特征向量中,例如
topic向量和category向量。 - 另一些特征抽取器则计算原始数据的变换,如
Memboost数据的归一化normalized或者re-scaled的版本。 - 一些特征抽取器将
one-hot encoding应用于离散字段categorical fields,例如性别、国家。 - 最后,一些特征抽取器计算匹配分
match scores,例如query pin和candidate pin之间的类目向量category vector的余弦相似度,或者query image和candidate image之间的embedding距离。
ranking模型 输入特征向量并产生最终的ranking score。这个ranking模型是从训练数据中学习的,其中训练数据在后文中描述。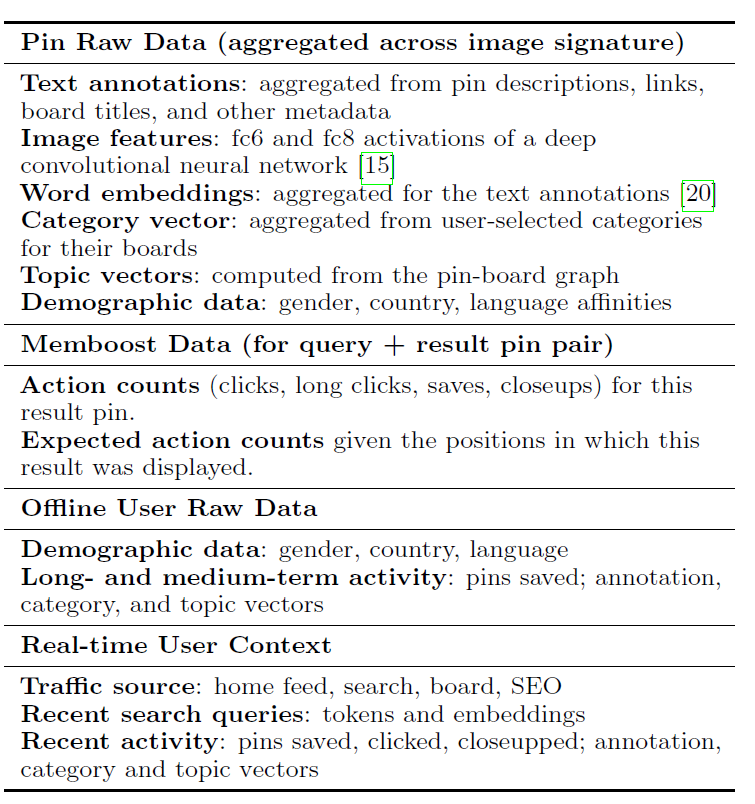
- 某些特征抽取器直接将原始数据拷贝到特征向量中,例如
我们的第一个
ranking系统仅使用pin原始数据。随着我们获得了额外的工程能力来构建必要的基础架构,我们将更多数据(如Memboost数据和用户数据)引入到ranking系统。我们还引入了从用户最近活动recent activities中抽取的个性化特征,如用户最近的search query。
11.4.1 选择
在构建
ranking系统时,我们面临三个重大largely的正交orthogonal的决策:- 训练数据集收集方法
training data collection method。 - 学习目标函数
learning objective。 - 模型类型
model type。
正交指的是决策之间互不影响。
- 训练数据集收集方法
训练数据集收集:我们探索了训练数据的两个主要数据源:
Memboost scores作为训练数据。从概念上讲,在没有足够日志数据来进行可靠的Memboost估计estimate的情况下,ranker可以学习预测query-result pair对的Memboost scores。即,对于无法从日志数据计算
Memboost scores的query-result pair对,可以通过模型来预测。单个
Related Pins session: 会话session定义为单个用户以单个query pin和Related Pins进行交互的结果。我们可以将这些交互直接作为训练数据的样本。
模型目标函数:在
《Learning to rank for information retrieval》中,learning-to-rank方法大致可以分为point-wise方法、pair-wise方法、list-wise方法。这些方法之间的主要区别在于:损失函数是一次考虑一个候选item、两个候选item、还是多个候选item。在我们的工作中,我们探索了
point-wise方法和pair-wise方法,如下表所示。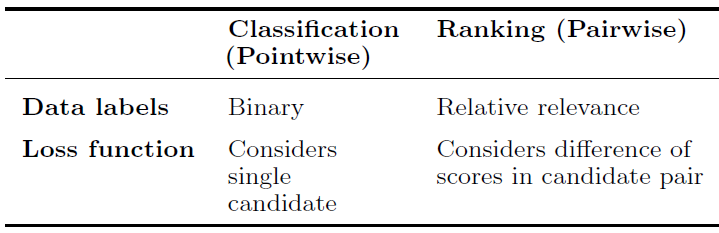
模型形式
formulation:模型的精确precise形式form决定了模型来描述特征和score之间复杂关系的能力。下表比较了我们使用的两种模型类型model types。
11.4.2 决策演变
下表给出了我们在
Related Pins Ranking中探索的训练数据、目标函数以及模型的各种组合。
第一版
V1:Memboost训练数据、相关性pair标签relevance pair labels、pair-wise损失函数、线性RankSVM模型。在我们的第一版中,我们选择使用
Memboost数据,因为我们发现Memboost数据是高质量的信号:它是在很长一段时间内数百万用户行为的聚合。我们为每个
query显式采样pair对 ,其中:- 是针对
query pin的Memboost scores最高pin。 - 是针对
query pin的Memboost scores最低pin。 - 是从
Pinterest随机采样的一个热门的pin,用于稳定排名(如论文《Optimizing search engines using clickthrough data》所示)。
我们认为,由于候选生成器提供了一定程度的相关性
relevance,因此具有较低Memboost scores的pin仍然比随机pin更相关relevant。当我们从
Memboost数据中人工检查pair对时,我们发现大约70%的时间可以猜测哪个pin的Memboost score更高。这表明训练数据是相当干净clean的 。相比之下,从每个user session中采样的pair对的噪声很大,我们无法确定用户保存了两个pin中的哪一个。因此,我们可以使用一个小得多的语料库,并且在几分钟之内在单台机器上训练一个模型。
- 是针对
第二版
V2:转向单个individual的Related Pins sessions。我们希望使用用户特征和上下文特征,但是使用
Memboost数据固有地inherently会排除个性化,因为Memboost数据是在很多用户上聚合的,从而失去了与单个用户以及session上下文的关联。此外,我们发现只有热门的内容才具有足够的交互,从而提供可靠的Memboost数据。这些局限性促使我们转向单个Related Pins sessions。每个记录
logged的session均由query pin、浏览的用户、最近的动作上下文action context、result pins列表a list of result pins来组成。每个result pin还具有一个对应的互动标签engagement label(可以为以下之一:仅仅曝光impression、特写closeup、点击click、长点击long click、保存save)。出于训练的目的,我们裁剪记录
logged的pin集合,按照rank order取每个互动的pin以及紧紧排在它前面的两个前序的pins。我们假设用户可能看到了紧紧排在互动pin之间的前序pins。在
V2版中,我们继续使用pair-wise损失,但是pin relevance pairs由动作的相对顺序来定义:save > long click > click > closeup > impression only。第三版
V3:转向一个RankNet GBDT模型。我们发现,简单的线性模型能够从
ranking中获得大部分的互动增益engagement gain。但是,线性模型有几个缺点:首先,它迫使
score和每个特征的依赖关系为线性的。为了让模型表达更复杂的关系,工程师必须人工添加这些特征的转换(分桶bucketizing、分区间percentile、数学转换mathematical transformations、归一化normalization)。其次,线性模型无法添加仅依赖于
query pin而不依赖于候选pin的特征。例如,假设特征 代表一个类似于query category = Art的特征,每个候选pin将具有相同的特征(因为query是同一个),所以对于ranking结果毫无影响。query-specific特征必须和候选pin的特征进行手动交叉,例如添加一个特征来表示query pin category + candidate pin category。设计这些交叉特征费时费力。
为避免这些缺点,我们转向梯度提升决策树
gradient-boosted decision trees: GBDT。除了允许对单个特征进行非线性响应外,决策树还固有地考虑了特征之间的交互,这对应于树的深度。例如,可以对推理
reasoning进行编码,如 “如果query pin category为Art,那么视觉相似性应该是更强的相关性信号relevance signal” 。通过自动学习特征交互feature interactions,我们消除了执行人工特征交叉的需要manual feature crosses,加快了开发速度。第四版
V4:转向point-wise分类损失、二元标签binary label、逻辑回归GBDT模型。尽管我们最初选择了
pair-wise learning,但是我们也已经在point-wise learning中取得了良好的结果。由于我们在线实验的主要目标指标target metric是用户保存result pin的倾向propensity,因此使用包含closeups和clicks的训练样本似乎会适得其反,因为这些动作可能不会影响保存倾向save propensity。我们发现给样本提供简单的
binary标签(saved或者not saved),并且重新加权reweighting正样本来对抗类别不平衡,这在增加保存倾向方面被证明是有效的。将来,我们仍然可以使用不同的pair采样策略来实验pair-wise ranking loss。
11.4.3 Previous-Model Bias
在我们努力改进
ranking的过程中,我们遇到了一个重大的挑战。因为互动日志engagement logs用于训练,所以我们引入了直接反馈环direct feedback loop,如论文《Hidden technical debt in machine learning systems》所述:当前部署currently deployed的模型极大地影响了为将来模型future models生成的训练样本。我们直接观察到了这个反馈环的负面影响
negative impact。当我们训练第一个ranking model时,日志反映了用户对仅由候选生成器排序的结果的互动。所学的模型被用于对这批候选进行排序。在接下来的几个月里,训练数据只反映了现有模型中排序较高的pins的互动(如下图(a)所示)。当我们尝试使用相同的特征和最近的互动数据来训练一个模型时,我们无法击败已经部署的模型。我们认为反馈环带来了一个问题,即训练时
pin分布和serving时的pin分布不再匹配。训练时的
pin分布:由老模型产生;serving时的pin分布:由新模型产生(由新模型排序并截断)。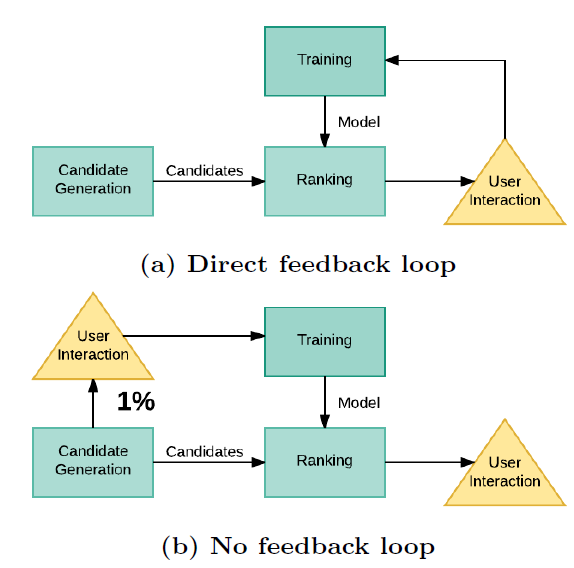
为了缓解训练数据中的
previous-model bias,我们为unbiased data collection分配了一小部分流量:对于这些请求,我们显示了来自所有候选来源的随机样本,并且没有ranking而随机排序。这将训练数据和之前的模型隔离开来(如上图(b)所示)。虽然未排序
unranked的result质量较低,但是它们为训练新的ranking model提供了有价值的数据。为了避免过多降低任何特定用户的体验,每个用户只在一小部分随机query中获取未排序的pins。尽管训练数据的数量被限制在总流量的这一小部分,但是最终得到的模型要比用有偏的数据biased data训练的模型表现得更好。仅用这
1%的随机流量来训练模型,会不会因为数据量太低而降低模型效果?一种方法是:将这1%流量的样本加权(比如加权10倍),然后和剩余99%流量的样本一起训练。
11.4.4 衡量指标
能够探索这些不同选项的一个重要
step是能够快速迭代。测试变更效果的金标准gold standard是在线A/B test实验,其中我们主要根据save propensity来评估ranking。所有的变更都要经过在线实验,但是在线
A/B test通常需要几天或者几周的时间来收集数据。我们认为,通过离线评估来马上测试变更效果从而近似approximate不同模型的性能是有帮助的。在这个过程中,我们重复使用了很多训练数据生成器来采样每个Related Pins sessions(即,生成训练集),但是选择了一个紧跟着训练日期的不同日期范围、以及一个和训练采样策略稍微不同的采样策略(即,生成测试集)。对于每个session,我们使用被测模型对用户实际看到的pins(即,label)进行重新打分rescore(即,预测),然后评估预测的score和记录的用户行为之间的一致性。我们已经尝试了多种度量方法,包括
normalized discounted cumulative gain: NDCG、PR AUC。为了确定这些离线指标在多大程度上预测了在线
A/B test影响,我们检查了我们过去几次ranking model变更的结果。我们检查了通过离线评估预测差异(即新模型和baseline模型在测试集评估指标上的差异)的方向和大小,并将其与实际实验结果进行比较。我们发现:PR AUC指标对于A/B test实验中的closeups和click-throughs具有极强的预测性,但是我们很难用离线评估来预测save行为。目前,我们将离线指标用作健全性检查
sanity check和潜在影响potential impact的粗略估计rough estimation。
11.4.5 Serving 架构
Related Pins在峰值负载下每秒可以处理数万个query。为了处理这种规模,我们利用了几个现有的Pinterest系统。我们的第一版
pin ranking是在离线的Map-Reduce作业中预计算pre-computed的,并由Terrapin提供服务(这是一个不可变的key-value的lookup service)。这需要大量的Map-Reduce作业来为每个query和candidate来join原始数据、计算特征、并对item进行打分。由于集群的限制,我们一次只能对几百万个
query进行rank,从而覆盖了50%的用户query。我们通过一次在不同的segments上运行reranking作业并合并结果来scale up,但是这种方法本质上inherently无法在合理reasonable的时间内提供完全覆盖。离线排序也显著降低了开发速度:每个变更模型的实验(特征开发、训练数据变更)都需要离线重新排序
reranking所有的query,这是一个耗时的过程。为此,我们转向在线
ranking serving system。pin的原始数据存储在叫做RealPin的分片sharded的key-value store中,通过image signature作为key。为了执行
ranking,我们将一个请求request和计算特征和score所需的候选pins列表、其它原始数据组装assemble在一起:query pin原始数据(从RealPin检索到)、离线的用户原始数据(从Terrapin而来)、最近的用户活动(从一个叫做UserContextService的service而来)。RealPin root server将请求复制到RealPin leaves server,将合适的候选子集路由到每个leaf server。leaf server在本地检索pin原始数据,并调用我们自定义的特征抽取器custom feature extractor和scorer。注意:
leaf server存储了pin的原始数据。leaf server发送top候选以及相应的score给root server,然后由root server收集并返回全局的top候选集。
我们选择了这种
serving架构来提高数据局部性data locality。基于Hadoop的系统在每次query时都需要传输大量的pin原始数据。我们还看到,由于pin原始数据的传输,其它的online pin scoring系统受到网络的限制。通过将计算下推到存储候选pin原始数据的节点,可以避免大量的数据传输。
11.5 挑战
Changing Anything Changes Everything:根据《Hidden technical debt in machine learning systems》,机器学习系统固有地会纠缠信号tangle signals。输入从来都不是真正独立的,这就产生了Changing Anything Changes Everything: CACE原则:系统的一个组件可以针对系统的现有状态进行高度优化。改进另一个组件可能会导致整体性能下降。这是一个system-level的局部最优点local optimum,可能会使得进一步的进展变得困难。我们的通用解决方案是为每个实验联合train/automate尽可能多的系统。我们提供了一些例子,这些例子说明了在我们的简单推荐系统中出现的这一特殊挑战,以及我们的缓解措施。
例子一:在我们的推荐系统
pipeline的各个阶段中使用了很多超参数。回想一下,我们使用手动调优hand-tuned的权重对Memboost进行调优,并通过耗时耗力的A/B test来进行优化。随着系统其它部分的改变,这些很快就过时了。联合训练Memboost权重避免了这个问题。同样地,ranking learner也有需要调优的超参数。为了避免导致超参数变得次优
sub-optimal的其它变更,我们实现了一个用于自动调参automated hyperparameter tuning的并行系统。因此,我们现在可以在每次变更模型时调优超参数。例子二:对原始数据的 “改进” 可能会损害我们的结果,因为我们的下游模型是基于旧的特征定义进行训练的。即使修复了一个
bug(例如在计算pin的类目向量时),我们现有的模型将依赖于有缺陷的特征定义,因此这个fix可能会对我们的系统产生负面影响。如果变更来自于另一个团队,这尤其会成为问题。在《Hidden technical debt in machine learning systems》中,这被称作不稳定的数据依赖unstable data dependency。目前,我们必须使用更新后的原始数据手动重新训练我们的模型,同时将新模型和更新后的原始数据部署到生产环境中(因为在线部署时需要获取样本特征,所以要将原始数据部署到线上)。除了耗时之外,这个解决方案也不太理想,因为它需要我们了解上游的变化。理想情况下,我们将自动对我们的模型进行连续的再训练
continual retraining,从而将上游数据upstream data的任何变化考虑进来。例子三:最后,我们经历了
candidate generation和ranking之间复杂的相互依赖关系。模型变得和训练数据的特点相协调。例如,变更或引入一个candidate generator会导致ranker的恶化,因为训练数据的分布不再和serving时的ranking数据的分布相匹配。这是我们在训练数据收集中看到的一个问题。如果引入一个
candidate generator无法提高性能,那么如何确定这是由于candidate generator性能较差、还是由于ranker并没有针对这个candidate generator的候选上训练过?我们目前的解决方案是:在用新训练的模型运行实验之前,将
candidate generator得到的候选插入训练集一段时间。这种方案一次改变一个变量:先固定
ranking模型,仅改变candidate generator;然后固定candidate generator,重新训练ranking模型。这个问题强调了尽可能简化系统的必要性,因为可能的非预期交互
unintended interactions的数量随着系统组件的数量而迅速增加。
内容激活:有大量的内容没有互动量,但是这些内容可能是潜在相关
potentially relevant的和高质量high quality的。每天都有数百万张新图像上传到Pinterest。此外还有大量的dark内容,这些dark内容是高质量的,但是很少出现。平衡
fresh or dark内容和完善的、高质量的内容,这代表了经典的探索和利用问题explore vs exploit problem。这是Pinterest的一个开放问题。我们深入探讨了如何针对本地化localization的情况解决内容激活content activation问题。由于
Pinterest是一种日益国际化的产品,因此我们特别努力确保国际用户能够看到他们自己语言的内容。出于两个主要原因,使得Related Pins本地化很困难:- 首先,一开始就没有多少本地化的候选,因为这些本地化内容并没有出现在很多
board上。 - 其次,本地化内容的历史互动要少得多,这导致我们的模型对本地化内容的排名更低,即使我们确实有本地化的候选。(即数据稀疏导致的冷启动问题)
我们尝试了几种方法来解决这些问题,最终能够将本地化
result的占比从9%增加到54%,如下图所示。Local pin swap:对于我们生成的每个相关related的pin,我们检查是否存在具有相同图像的本地化替代local alternative。如果存在,那么我们将result pin换本地化替代的pin。结果,我们增加了本地化的
pin曝光、以及本地化的pin save,而不会改变结果的相关性。Local pin boost:当返回的候选集中存在和浏览者相同语言的pin(即本地化的pin)时,我们试图人为地将本地化的pin的排名提升到result set中更高的位置。事实上证明这并不是特别有效,因为此时的候选集并没有包含很多本地化的
pin,因此该解决方案的覆盖率coverage较低。Localizing candidate sets:我们修改了board-based的候选生成方法,从而在pin采样之前对语言进行过滤,并生成针对每种语言的segmented corpus。此外,为了增加对这些本地化的
pin的曝光,我们选择以不同的比例将本地化的候选混合到result中。
这些手段都是基于业务策略的方法,而不是基于模型的方法。基于模型的方法是后验的、数据驱动的,基于策略的方法是先验的、规则驱动的。当冷启动或其它数据稀疏场景时,策略方法要优于模型方法。
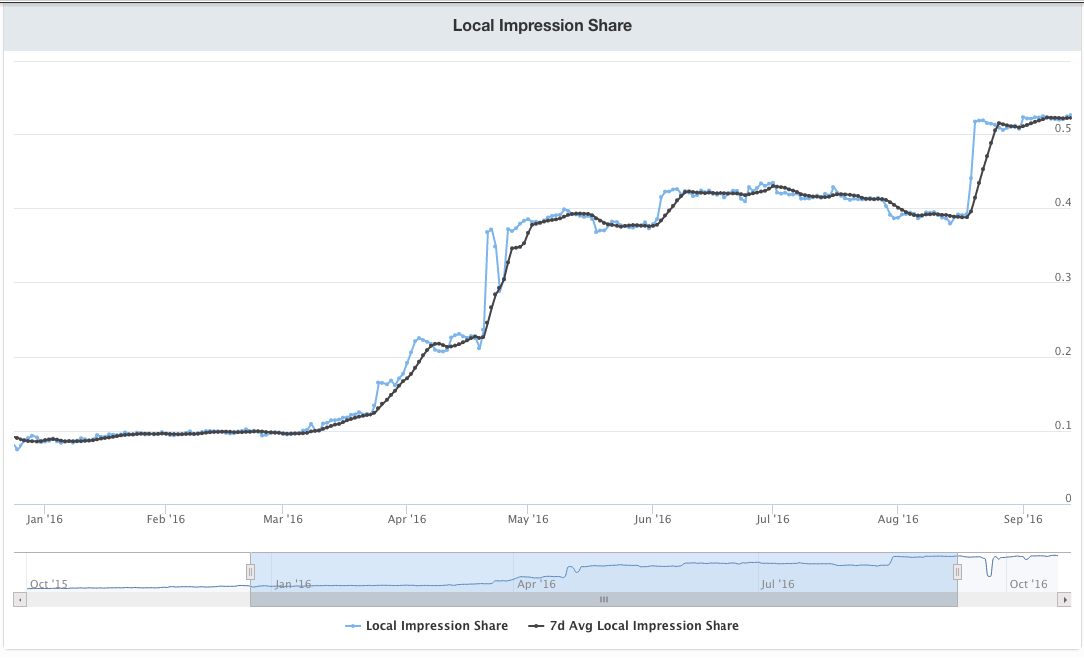
- 首先,一开始就没有多少本地化的候选,因为这些本地化内容并没有出现在很多
十二、DLRM[2019]
个性化
personalization和推荐系统recommendation systems目前已经被部署在大型互联网公司的各种任务中,包括广告点击率预估CTR prediction和排序ranking。尽管这些方法已经有很长的历史,但是直到最近这些方法才包含神经网络。有两个基本观点primary perspectives有助于个性化和推荐的深度学习模型的架构设计architectural design。第一种观点来自推荐系统。这些系统最初采用内容过滤
content filtering,其中一群专家将产品划分为不同的类目categories,用户选择他们喜欢的类目,而系统根据用户的偏好进行匹配。该领域随后发展为使用协同过滤
collaborative filtering,其中推荐是基于用户历史的行为,例如对item的历史评分。邻域
neighborhood方法通过将用户和item一起进行分组grouping从而提供推荐。潜在因子
latent factor方法通过矩阵分解技术从而使用某些潜在因子来刻画用户和item。这些方法后来都取得了成功。
第二种观点来自预测分析
predictive analytics,它依靠统计模型根据给定的数据对事件的概率进行分类classify或预测predict。预测模型从简单模型(例如线性模型和逻辑回归)转变为包含深度网络的模型。为了处理离散数据
categorical data,这些模型采用了embedding技术从而将one-hot向量和multi-hot向量转换为抽象空间abstract space中的稠密表示dense representation。这个抽象空间可以解释为推荐系统发现的潜在因子空间space of the latent factors。
在论文
《Deep Learning Recommendation Model for Personalization and Recommendation Systems》中,论文介绍了一个由上述两种观点结合而成的个性化模型。该模型使用embedding来处理代表离散数据的稀疏特征sparse features、使用多层感知机multilayer perceptron: MLP来处理稠密特征dense features,然后使用《Factorization machines》中提出的统计技术显式的交互interacts这些特征。最后,模型通过另一个MLP对交互作用进行后处理post-processing从而找到事件的概率。作者将这个模型称作深度学习推荐模型
deep learning recommendation model: DLRM,如下图所示。该模型的PyTorch和Caffe2的实现已经发布。此外,作者还设计了一种特殊的并行化方案,该方案利用
embedding tables上的模型并行性model parallelism来缓解内存限制memory constraints,同时利用数据并行性data parallelism从全连接层扩展scale-out计算。作者将DLRM与现有的推荐模型进行了比较,并在Big Basin AI平台上实验了DLRM的性能,证明了它作为未来算法实验algorithmic experimentation、以及系统协同设计system co-design的benchmark的有效性。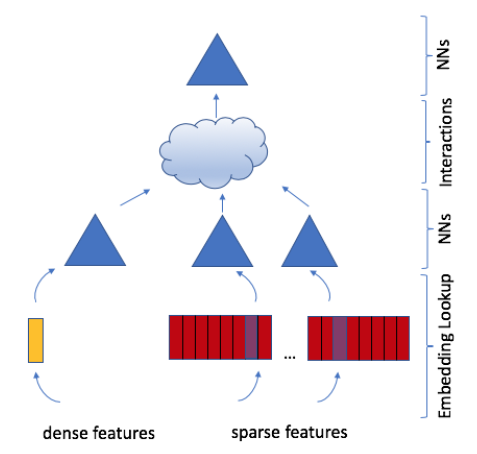
12.1 模型设计和架构
这里我们将描述
DLRM的设计。我们将从网络的高级组件high level components开始,并说明如何以及为什么将它们以特定方式组装assembled在一起,以及对未来的模型设计产生的影响。然后我们描述组成模型的低级算子
low level operators和原语primitives,以及对未来的硬件和系统设计产生的影响。
12.1.1 DLRM 组件
通过回顾早期模型,我们可以更容易理解
DLRM的高级组件。我们避免全面的科学文献综述,而将重点几种在早期模型中使用的四种技术上,这些技术可以被解释为DLRM的重要高级组件。Embedding:为了处理离散数据,embedding将每个类目category映射到抽象空间abstract space中的稠密表示dense representation。具体而言,每个
embedding lookup可以被解释为使用一个one-hot向量 (第 位为1、其它位为0,索引 代表了第 个类目 )来获得embedding table中的相应行向量row vector:其中 为类目总数, 为抽象空间的维度。
在更复杂的场景中,
embedding也可以表示多个item的加权组合,其中包含一个multi-hot向量的权重:其中 : 代表对应的
item; 代表这些item的权重。包含 个
embedding lookup的mini-batch可以写作:其中 为一个稀疏矩阵。
DLRM利用embedding tables将离散特征映射到稠密表示。然而,即使设计了这些有意义的embedding之后,如何利用它们来生成准确的预测?为了回答这个问题,我们回到潜在因子方法latent factor methods。矩阵分解
Matrix Factorization:回忆一下,在推荐问题的典型公式中,我们得到了对某些item进行评分的某些用户的集合 。其中,集合 由元组 索引组成,表示第 个用户在第 个item上已经评分。我们用向量 来表示represent第 个item、用向量 来表示第 个用户,从而找到所有评分ratings。矩阵分解方法通过最小化以下公式来求解这个问题:
其中 为第 个用户在第 个
item上的评分。令 、 ,我们可以将完整的评级矩阵 近似为矩阵乘积:
其中 为总的
item数量, 为总的用户数量。注意: 和 可以解释为两个
embedding tables,其中每一行代表潜在因子空间latent factor space中的user/item。这些embedding向量的内积可以得出对评级有意义的后续预测,这是因子分解机factorization machines和DLRM设计的关键观察。因子分解机
Factorization Machine:在分类问题中,我们要定义一个从输入数据点 到target label的预测函数 。例如,我们可以通过定义 来预测点击率click-through rate: CTR,其中+1表示点击label、-1表示未点击label。因子分解机
Factorization machines: FM通过以下定义形式的模型,将二阶交互second-order interactions融合到带有离散数据的线性模型中:其中:
- 为模型参数,且 。
upper(.)函数严格选择矩阵的上三角部分。
FM和多项式核polynomial kernel的支持向量机SVM显著不同,因为FM像矩阵分解一样将二阶交互矩阵分解为潜在因子latent factor(或embedding向量),从而更有效地处理稀疏数据。通过仅捕获不同
embedding向量pair对之间的交互,FM显著降低了二阶交互的复杂度,从而产生线性计算复杂度。根据原始公式,
FM的算法复杂度为 ,但是经过数学转换之后,计算复杂度降低到 。多层感知机
Multilayer Perceptrons:最近机器学习的成功很大程度上归功于深度学习的兴起。其中,最基本的模型是多层感知机multilayer perceptron: MLP,它是一个由全连接层fully connected layers: FC和激活函数 交替组成的预测函数prediction function:其中权重矩阵 ,
bias向量 , 。这些方法被用来捕获更复杂的交互
interactions。例如,已经表明:给定足够的参数、具有足够深度depth和宽度width的MLP能够以任何精度precistion拟合数据。这些方法的变体已经广泛应用于各种
application,包括计算机视觉和NLP。一个具体的例子是神经协同过滤Neural Collaborative Filtering: NCF被用作MLPerf benchmark的一部分,它使用MLP而不是内积来计算矩阵分解中embedding之间的交互。
12.1.2 DLRM 架构
目前为止,我们已经描述了推荐系统和预测分析中使用的不同模型。现在,让我们结合它们的直觉
intuitions来构建state-of-the-art的个性化模型。令用户和
item使用很多连续continuous的、离散categorical的特征来描述。- 为了处理离散特征,每个离散特征将由相同维度的
embedding向量来表示,从而推广了矩阵分解中潜在因子的概念。 - 为了处理连续特征,所有的连续特征整体上将被一个
MLP转换(这个MLP我们称之为bottom MLP或者dense MLP),这将产生和embedding向量相同维度的dense representation。
注意:每个离散特征会得到一个
embedding,而所有连续特征整体才能得到一个embedding。我们将根据
FM处理稀疏数据的直觉,通过MLP来显式计算不同特征的二阶交互。这是通过获取所有representation向量(包括每个离散特征的embedding向量、连续特征整体的representation向量)之间的pair对的内积来实现的。这些内积和连续特征
representation(即经过原始连续特征经过bottom MLP之后得到的)拼接起来,馈入另一个MLP(我们称之为top MLP或者output MLP)。最终这个MLP的输出馈入到一个sigmoid函数从而得到概率。我们将这个模型称作
DLRM。top MLP的特征有:显式二阶交互特征、连续representation特征。这里并没有馈入一阶embedding特征。- 为了处理离散特征,每个离散特征将由相同维度的
和早期模型的比较:许多基于深度学习的推荐模型使用类似的基本思想来生成高阶项
term从而处理稀疏特征。例如:Wide and Deep、Deep and Cross、DeepFM、xDeepFM网络等等,它们设计了专用网络specialized networks来系统地构建高阶交互higher-order interactions。然后,这些网络将它们专用网络和MLP的结果相加,并通过线性层和sigmoid激活函数产生最终的概率。DLRM特别地模仿因子分解机,以结构化方式与embedding交互,从而在最终MLP中仅考虑embedding pair对之间的内积所产生的的交叉term,从而显著降低了模型的维度。我们认为,在其他网络中发现的、超过二阶的更高阶交互可能不一定值得额外的计算代价和内存代价。DLRM和其它网络之间的主要区别在于:网络如何处理embedding特征向量及其交叉项cross-term。具体而言:DLRM(以及xDeepFM)将每个embedding向量解释为表示单个类目category的单元unit,交叉项仅在类目之间产生。像
Deep and Cross这样的网络将embedding向量中的每个元素视为单元,交叉项在元素之间产生。因此,
Deep and Cross不仅会像DLRM那样通过内积在不同embedding向量的元素之间产生交叉项,而且会在同一个embedding向量内的元素之间产生交叉项,从而导致更高的维度。
12.2 并行性
现代的个性化和推荐系统需要大型复杂的模型来利用大量的数据。
DLRM尤其包含大量参数,比其它常见的深度学习模型(例如CNN、RNN、GAN)多几个数量级。这导致训练时间长达数周或者更长。因此,更重要的是有效地并行化这些模型,以便在实际数据规模上解决这些问题。如前所述,
DLRM以耦合的方式coupled manner处理离散特征(通过embedding)和连续特征(通过bottom MLP)。embedding贡献了大部分参数,每个lookup table都需要超过几个GB的内存,使得DLRM的内存容量和带宽bandwidth代价昂贵。- 由于
embedding太大,因此无法使用数据并行data parallelism,因为数据并行需要在每个设备上拷贝超大的embedding。在很多情况下,这种内存限制需要将模型分布在多个设备上,从而满足内存容量要求。 - 另一方面,
MLP参数在内存中较小,但是却有相当可观的计算量。因此,对于MLP而言,数据并行是首选的,因为这样可以在不同的设备上同时处理样本,并且仅在累计更新accumulating updates时才需要通信。
我们的并行化
DLRM联合使用模型并行model parallelism和数据并行data parallelism:针对embedding使用模型并行、针对MLP使用数据并行,从而缓解embedding产生的内存瓶颈memory bottleneck,同时并行化MLP上的前向传播和反向传播计算。由于
DLRM的体系结构和较大的模型尺寸,因此将模型并行和数据并行相结合是DLRM的独特要求。Caffe2或PyTorch(以及其它流行的深度学习框架)均不支持这种组合并行性,因此我们设计了一个自定义的实现。我们计划在未来的工作中提供其详细的性能研究。- 由于
在我们的设置
setup中,top MLP和交互算子interaction operator要求从bottom MLP和所有embedding中访问部分mini-batch。由于模型并行已用于在设备之间分布embedding,因此这需要个性化的all-to-all通信。在
embedding lookup的最后,每个设备都针对mibi-batch中的所有样本,将对应的embedding table中的embedding向量驻留在这些设备上。需要驻留的embedding向量需要沿着mibi-batch维度分割,并传送到适当的设备,如下图所示(如黄色embedding向量都传送到Device 3)。PyTorch和Caffe2都不提供对模型并行的原生支持,因此我们通过将embedding算子显式映射到不同的设备来实现它。然后使用butterfly shuffle算子实现个性化的all-to-all通信,该算子将生成的embedding向量适当的分片slice,并将其传输到目标设备target device。在当前版本中,这些传输是显式拷贝,但是我们打算使用可用的通信原语(如all-gather和send-recv)进一步优化这一点。下图为用于
all-to-all通信的butterfly shuffle。注意,目前
pytorch.distributed package已经支持模型并行、数据并行,也支持个性化的all-to-all通信。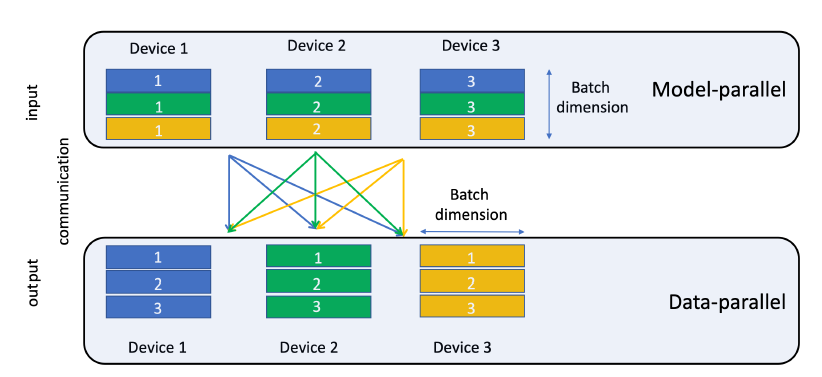
我们注意到,对于数据并行
MLP,反向传播中的参数更新以allreduce进行积累accumulated,并以同步synchronous的方式应用于每个设备上的拷贝参数replicated parameters,从而确保每个设备上的更新参数updated parameters在每次迭代之前都是一致consistent的。- 在
PyTorch中,通过nn.DistributedDataParallel和nn.DataParallel模块启用数据并行,这些模块在每个设备上拷贝模型并插入allreduce以及必要的依赖。 - 在
Caffe2中,我们在梯度更新之前人工插入allreduce。
- 在
1.3 实验
为了衡量模型的准确性
accuracy、测试模型的整体性能、并描述各个算子operator的特征,我们需要为DLRM创建或获取一个数据集。我们提供了三种类型的数据集:随机数据集
random dataset、人工合成数据集synthetic dataset、公共数据集public dataset。从系统的角度来看,前两个数据集可用于试验模型。具体而言,它允许我们通过动态生成的数据来试验不同的硬件属性和瓶颈,同时消除对数据存储系统的依赖。后者允许我们对真实数据集进行实验,并度量模型的的准确性accuracy。随机数据集:回忆一下,
DLRM接受连续continuous特征和离散categorical特征作为输入。对于连续特征,可以通过使用
numpy.random package的rand或者randn调用具有默认参数的均匀分布或正态分布(高斯分布)生成随机向量来建模。 然后可以通过生成一个矩阵来获得一个mini-batch的输入,其中矩阵的每一行代表mini-batch中的一个样本。对于离散特征,我们需要确定给定的的
multi-hot向量中有多少个非零元素。benchmark允许非零元素数量是固定的、或者是1~k范围内的一个随机数。然后,我们生成相应数量的整数索引,数量范围在
1~m范围内,其中m为embedding矩阵 的行数。最后,为了创建一个
mini-batch的lookup,我们拼接上述索引,并用lengths(Caffe中的SparseLengthsSum)、或者offsets(PyTorch中的nn.EmbeddingBag)来描述每个单独的lookup。
人工合成数据集:有很多理由支持对应于离散特征的索引的自定义生成。例如,如果我们的
application使用一个特定的数据集,但出于隐私的目的我们不愿意共享它,那么我们可以选择通过索引分布来表达离散特征。这可能会替代联邦学习federated learning等应用于application中的隐私保护技术。此外,如果我们想要测试系统组件system components,例如研究内存行为memory behavior,我们可能希望在合成的trace中捕获原始trace访问的基本局部性fundamental locality。让我们说明如何使用合成数据集。假设我们有索引的
trace,这些索引对应于某个离散特征的所有embedding lookup轨迹。我们可以在这个trace中记录去重访问unique accesses和重复访问repeated accesses之间的距离频次,然后生成合成trace。具体生成算法参考原始论文。公共数据集:
Criteo AI Labs Ad Kaggle和Criteo AI Labs Ad Terabyte数据集是公开的数据集,由用于广告点击率预测的点击日志组成。每个数据集包含
13个连续特征和26个离散特征。通常,连续特征使用简单的对数变换log(1+x)进行预处理。离散特征映射到相应的embedding index,而未标记的离散特征映射到0或者NULL。Criteo Ad Kaggle数据集包含7天内的4500万个样本,每天的样本量大致相等。在实验中,通常将第7天拆分为验证集和测试集,而前面6天用作训练集。Criteo Ad Terabyte数据集包含24天的样本,其中第24天分为验证集和测试集,前面23天用作训练集。每天的样本量大致相等。
模型配置:
DLRM模型在PyTorch和Caffe2框架中实现,可以在Github上获得。模型分别使用fp32浮点数作为模型参数,以及int32(Caffe2)/int64(PyTorch)作为模型索引。实验是在BigBasin平台进行的,该平台具有双路Intel Xeon 6138 CPU @ 2.00GHz以及8个Nvidia Tesla V100 16GB GPUs。我们在
Criteo Ad Kaggle数据集上评估了模型的准确性accuracy,并将DLRM和Deep and Cross network: DCN的性能进行了比较,后者没有进行额外的调优。我们和DCN进行比较,因为它是在相同数据集上具有综合结果comprehensive results的少数模型之一。DLRM既包含用于处理连续特征的bottom MLP(该bottom MLP分别由具有512/256/64个节点的三个隐层组成),又包括top MLP(该top MLP分别由具有512/256个节点的两个隐层组成)。DCN由六个cross layer和一个具有512/256个节点的深度网络组成。embedding的维度为16。
这样产生的
DLRM和DCN两者都具有大约540M的参数。我们使用
SGD和Adagrad优化器绘制了两个模型在完整的单个epoch内的训练准确率(实线)、验证准确率(虚线)。我们没有使用正则化。可以看到:
DLRM获得了稍高的训练准确率和验证准确率,如下图所示。我们强调,这没有对模型的超参数进行大量的调优。DLRM和DCN都没有经过超参数调优,因此实验结果的对比没有任何意义。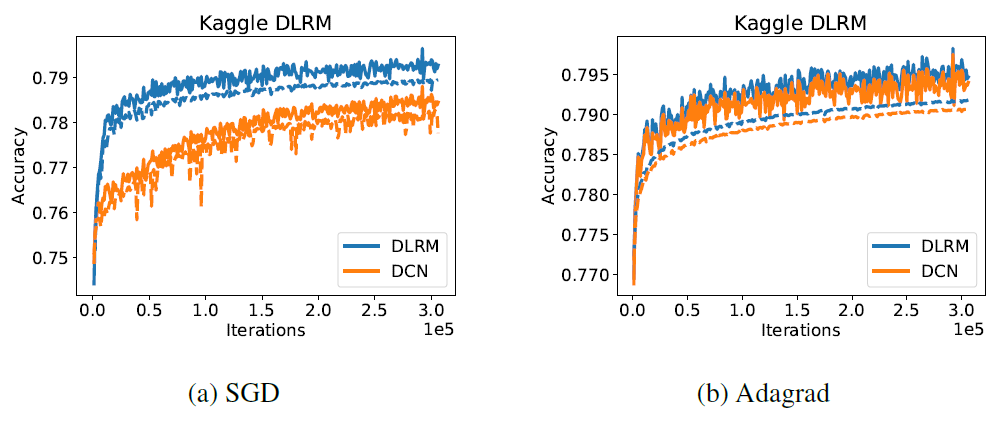
为了分析我们模型在单设备上的性能,我们考虑了一个具有
8个离散特征、512个连续特征的模型。每个离散特征都通过一个包含1M个向量的embedding table(即类目总数有1M)进行处理,向量维度为64。而连续特征被组装assembled为一个512维的向量。bottom MLP有两层,而top MLP有四层。我们让具有2048K个随机生成样本的数据集上分析了该模型,其中mini-batch的batch size = 1K。Caffe2中的这个模型实现在CPU上运行大约256秒,在GPU上运行大约62秒,每个算子的分析如下图所示。正如预期所示:大部分时间都花在了执行embedding lookup和全连接层上。在CPU上,全连接层占了很大一部分计算,而GPU上全连接层的计算几乎可以忽略不计。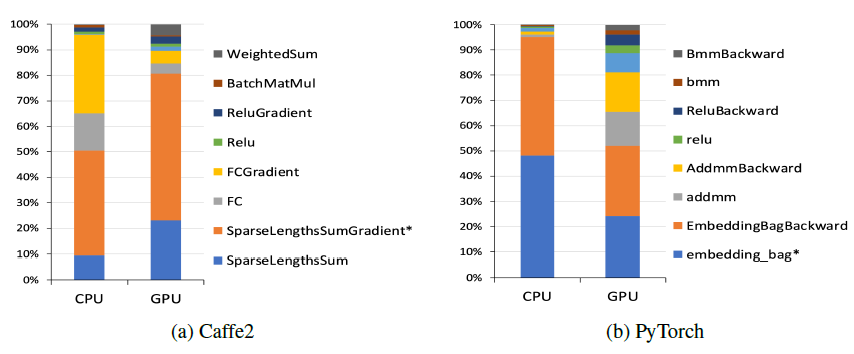
十三、Applying Deep Learning To Airbnb Search[2018]
Airbnb的home sharing platform是一个双边市场,其中房东host可以出租他们的空间(称作listings),以供来自世界各地的潜在租客guest预订。典型的预订开始于租客在airbnb.com上搜索特定地理位置的房屋。search ranking任务是从库存中的成千上万个listing中挑选一个有序的listing列表来响应租客。search ranking的第一个实现是手动制作的评分函数scoring function。用梯度提升决策树gradient boosted decision tree: GBDT模型代替手动评分函数是Airbnb历史上房屋预订量方面最大的改进之一,随后还有多次成功的迭代。在线预订量的收益最终饱和,其中很长一段时间的实验都是中性的(即没有提升)。这为尝试对系统进行全面改造提供了时机。从这一背景出发,论文
《Applying Deep Learning To Airbnb Search》讨论了作者将互联网上的一个大规模搜索引擎之一切换为深度学习的经验。本文针对是拥有机器学习系统、并开始考虑神经网络的团队。论文的目的并不是推进前沿的、新的建模技术,而是讲述了如何将神经网络应用于现实产品。- 首先,论文对模型体系结构随着时间的演变进行了总结。
- 然后,论文给出了特征工程
feature engineering和系统工程system engineering的注意事项。 - 最后,论文描述了一些工具和超参数探索。
Airbnb的search ranking模型是模型生态系统的一部分,所有这些模型都有助于决定向租客展示哪些listing。这些模型包括:预测房东接受租客预订请求可能性的模型、预测租客将旅行体验评为五星好评5-star的概率的模型等等。论文目前的讨论集中在这个生态系统中的一个特定模型上,并且被认为是排序难题ranking puzzle中最复杂的一块。这个模型负责根据租客预订的可能性来对可用的listing进行排序。典型的租客搜索会话
search session如下图所示。- 租客通常会进行多次搜索,点击一些
listing从而查看它们的详情页。 - 成功的
session以租客预订一个listing而结束。
租客的搜索以及他们和产品的交互被作为日志而记录下来。在训练期间,新模型可以访问交互日志,也可以访问产品中之前使用的模型。新模型被训练从而学习一个评分函数,该函数将曝光日志中预订
listing分配到尽可能高的排名。然后,新模型在
A/B test框架中进行在线测试,从而查看新模型和当前模型的对比,看看新模型是否可以实现统计意义上显著的预订量提升。
- 租客通常会进行多次搜索,点击一些
13.1 模型演变
我们向深度学习的转变不是原子
atomic操作的结果,而是一系列迭代改进的最终结果。- 下图
(a)显示了我们的主要离线指标normalized discounted cumulative gain: NDCG的相对提升,其中预订listing的曝光impression被分配为相关性1.0、其它listing的曝光被分配为相关性0.0。X轴描述了模型及其投入生产的时间。 - 下图
(b)显示了模型在线预订量的相对增长。
总体而言,这代表了
Airbnb上最有影响力的机器学习应用之一。以下各节简要描述了每个模型。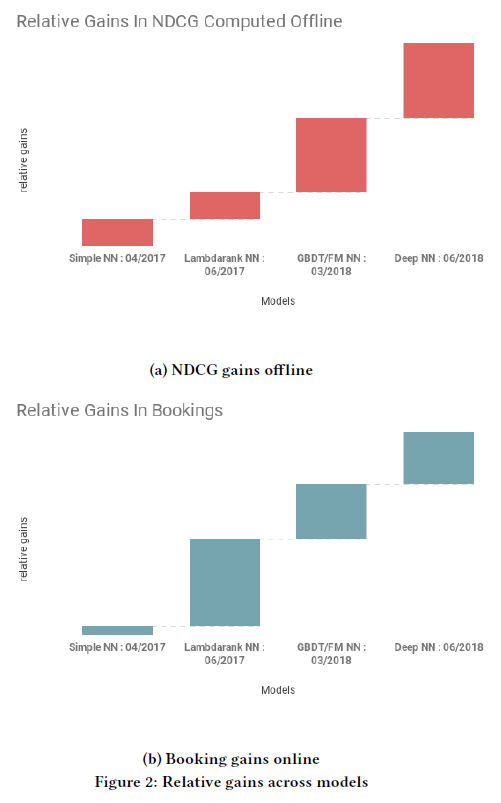
- 下图
Simple NN:Andrej Karpathy对模型架构有一些建议:不要成为英雄don’t be a hero。在 “我们为什么不能成为英雄?” 的驱动下,我们从一些复杂的自定义架构开始,结果却被它们的复杂性淹没,最终浪费了很多时间。我们最终想方设法上线的第一个体系架构是具有
ReLU激活的、简单的单隐层(32个神经元)神经网络NN。事实证明该神经网络和GBDT相比,预订量指标是中性neutral的(即效果既不正向、也不负向)。NN和GBDT模型具有相同的特征,其训练目标也和GBDT保持不变:最小化L2回归损失regression loss,其中预订listing的效用utility分配为1.0、未预订listing的效用分配为0.0。整个练习
exercise的价值在于,它验证了整个NN pipeline已经准备就绪,并且能够为实时流量提供服务。稍后在特征工程和系统工程部分讨论该pipeline的具体细节。Lambdarank NN:不是英雄not being a hero让我们有了一个开始,但没有走很远。最终我们及时的将Karpathy的建议调整为:在开始的时候不要成为英雄don’t be a hero, in the beginning。我们的第一个突破是将
Simple NN和Lambdarank思想相结合。在离线时,我们使用NDCG作为主要指标。Lambdarank为我们提供了一种直接针对NDCG优化NN的方法。这涉及为Simple NN的regression based公式的两个关键改进:转向
pairwise偏好公式,其中预订者看到的listing被用于构建pairwise的{booked listing, not-booked listing},从而作为训练样本。在训练期间,我们将预订listing和未预订listing之间得分差异的交叉熵损失最小化。即:预订
listing和未预订listing之间差异尽可能大。通过交换组成该
pair对的两个listing的位置position而导致的NDCG差异,从而加权每个pairwise损失。这使得预订listing的排名优化rank optimization朝向搜索结果列表的头部,而不是底部。例如,把预订listing的排名从位置2提升到1,将优于把预订listing的排名从位置10提升到9。即:预订
listing位置尽可能靠前。
下面给出了
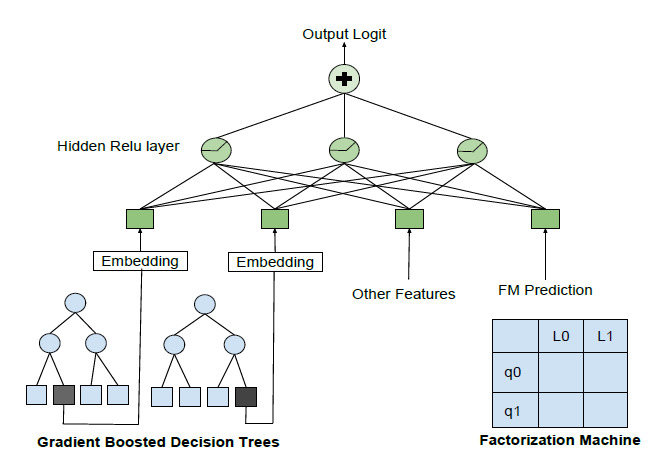
TensorFlow中的部分实现,尤其是如何对paiwise loss进行加权:x1def apply_discount(x):2'''3计算位置折扣曲线 positional discount curve4'''5return np.log(2.0)/np.log(2.0 + x)6def compute_weights(logit_op, session):7'''8根据 ndcg 的差异来计算损失的加权系数.9logit_op 是一个形状为 [BATCH_SIZE, NUM_SAMPLES] 的张量,对应于网络的输出层。每一行代表一个搜索,每一列代表搜索结果中的一个 listing。列 0 表示预订的 listing,剩余的 NUM_SAMPLES-1 列表示未预订的 listing。10'''11logit_vals = session.run(logit_op)12ranks = NUM_SAMPLES - 1 - logit_vals.argsort(axis=1).argsort(axis=1)13discounted_non_booking = apply_discount(ranks[:, 1:])14discounted_booking = apply_discount(np.expand_dims(ranks[:, 0], axis=1))15discounted_weights = np.abs(discounted_booking - discounted_non_booking)16return discounted_weight1718# 计算 pairwise loss19pairwise_loss = tf.nn.sigmoid_cross_entropy_with_logits(20targets=tf.ones_like(logit_op[:, 0]),21logits=logit_op[:, 0] - logit_op[:, i:] )22# 计算基于 ndcg 加权的 lambdarank 权重23weights = compute_weights(logit_op, session)24# 计算 lambdarank 权重加权的 pairwise loss25loss = tf.reduce_mean(tf.multiply(pairwise_loss, weights))Decision Tree/Factorization Machine NN:虽然目前服务于生产流量的主力排序模型是神经网络,但是我们仍然在研究其它模型。值得一提的模型有:GBDT模型,其中使用使用替代方法对搜索进行采样从而来构建训练数据。- 因子分解机
factorization machine:FM模型,它通过将listing和query都映射到一个32维的空间,从而预测一个listing在给定query的情况下被预订的概率。
这些研究
search ranking问题的新方法揭露了一些有趣的东西:尽管这些模型在测试数据上的性能和神经网络相当,但是它们排名靠前upranked的listing却大不相同。受到
《Deep & Cross Network for Ad Click Predictions》这样的神经网络体系架构的启发,新模型试图结合所有三种模型(GBDT模型、FM模型、NN模型)的优势:- 对于
FM模型,我们将最终预测作为特征纳入NN模型。 - 对于
GBDT模型,我们将每棵树激活的叶节点的索引作为离散特征纳入NN模型。
下图给出了一个概览。
Deep NN:Deep NN模型的复杂性是惊人的,而且《Hidden Technical Debt in Machine Learning Systems》中提到的一些问题开始出现。在我们的最后一次飞跃中,我们能够通过简单地将训练数据扩展10倍,并切换到具有两层隐层的DNN来消除所有这些复杂性。Deep NN网络的典型配置:- 一个输入层
input layer。其中,在将离散特征扩展到embedding之后,输入一共有195个特征。 - 第一个隐层
hidden layer。其中,该层具有127个全连接的ReLU激活的神经元。 - 第二个隐层
hidden layer。其中,该层具有83个全连接的ReLU激活的神经元。
馈入
DNN的特征大部分是简单的listing属性,诸如价格、设施amenities、历史预订量等等。这些特征通过最少的特征工程来提供。除此之外,还包括从其它模型输出的特征:- 启用了智能定价
Smart Pricing功能的listing价格,该特征由专门的模型提供。 - 候选
listing和用户历史查看listing的相似度similarity,这是基于co-view embedding来计算得到。
这些模型利用了不直接隶属于
search ranking训练样本的数据,为DNN提供了额外的信息。为了更深入地了解
DNN,我们在下图中绘制了它的学习曲线learning curve。我们在训练集和测试集上对比了NDCG,其中训练集有17亿的pair对。可以看到:我们能够弥合
close训练集和测试集之间的泛化距离generalization gap。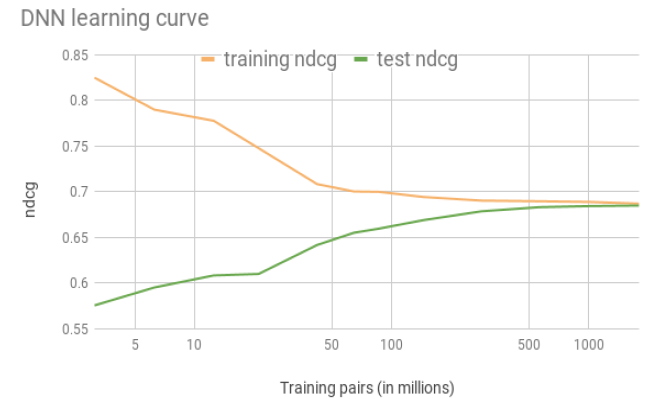
- 一个输入层
我们能否跳过演变
evolution的所有阶段直接启用DNN?我们试图在追溯部分中回答这一问题。顺便说一句,虽然
DNN在某些图像应用上取得了人类水平的性能,但我们很难判断我们在类似的比较中处于什么位置。问题的部分原因是,目前尚不清楚在search ranking问题中如何定义人类水平的性能。通过浏览日志信息,我们很难准确地判断哪些listing将会被预订。我们在日志中找不到客观的事实,只能根据租客的预算budget和口味tastes进行tradeoff,而租客的口味大多数情况下还是看不到的。一些学者指出,即使是对于熟悉的shopping items,也很难进行人工评估。对于我们的application,由于库存的新颖性novelty,这些困难将进一步加剧。说到困难,接下来我们讨论一些鲜为人知的事情:失败的尝试。
13.2 失败的模型
上一节中介绍的一个成功的
launch后又接着另一个成功的launch的叙述并没有讲出完整的故事。现实中失败的尝试比成功的尝试更多。复述每一次失败的尝试比较耗时,所以我们选择了两个特别有趣的失败来讲述。这些模型很有趣,因为它们说明了一些外部非常有效和受欢迎的技术,但是内部使用时可能会失效。Listing ID:Airbnb上的每个listing都有相应的唯一ID。NN提供的一个令人兴奋的新能力是使用这些listing id作为特征。想法是使用listing id作为embedding的索引index,这使得我们能够学习每个listing的向量representation,从而编码listing独有的属性property。我们之所以兴奋,是因为其它
application已成功地将如此高基数cardinality的离散特征映射到embedding,例如在NLP application中学习word embedding、在推荐系统中学习video id embedding和user id embedding。但是,在我们尝试的不同变体中,
listing id大多数会导致过拟合。下图绘制了一次这类尝试的学习曲线,我们看到NDCG在训练集上有显著提升,但是在测试集上却没有任何改善。这种成熟的技术在
Airbnb上失败的原因是由于底层市场underlying marketplace的某些独特属性property。embedding需要每个item有大量数据才能收敛到合理的值。- 当
item可以无限地重复时,例如在线视频或语言中的单词,那么item拥有的用户交互数量也没有限制。为item兴趣获取大量的数据相对容易。 - 另一方面,
listing受到物理世界的限制。即使是最受欢迎的listing,一年最多也就可以预订365次。平均每个listing的预订量要少得多。这一基础限制fundamental limitation生成的数据在listing-level非常稀疏。过拟合就是这种限制的直接后果。
如果
item id频次太少,则很难学到有意义的embedding。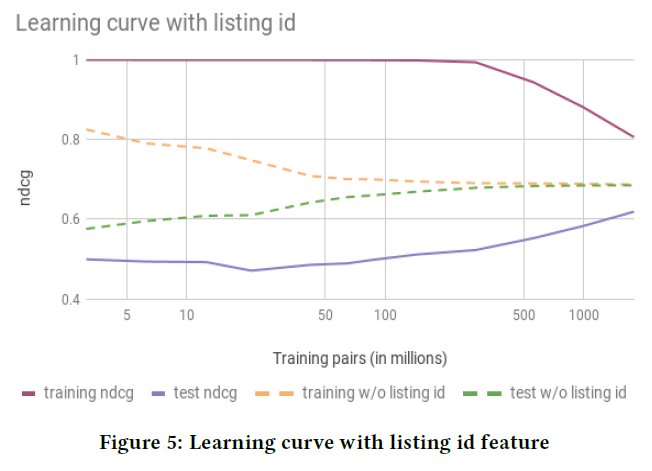
- 当
多任务学习
Multi-task Learning:虽然预订有物理限制,但是用户对listing详情页的查看并没有物理限制。下图显示了listing的详情页查看量和预订量的比例的分布,预订量通常比查看量稀疏了几个数量级(横轴为查看量和预订量之比,纵轴为listing数量)。更进一步,我们发现,不出所料,对listing详情页的长时间观看long view和预订相关。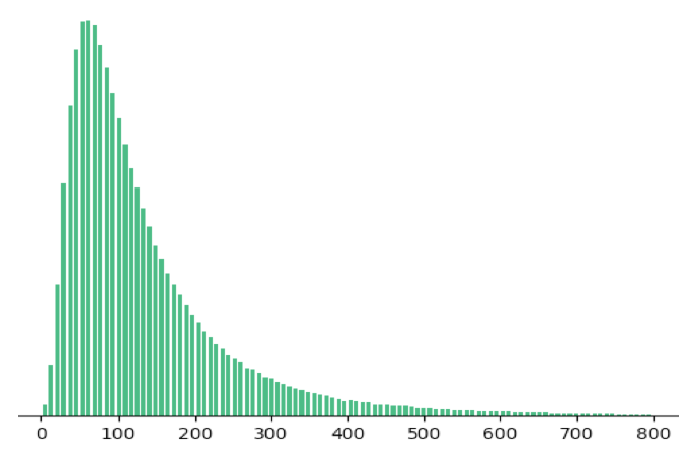
为了解决
listing id过拟合的问题,我们建立了一个多任务学习模型。该模型使用两个独立的输出层同时预测预订概率和long view的概率:- 一个以预订
listing作为正样本来优化损失,从而预测预订概率。 - 另一个以
long view listing作为正样本来优化损失,从而预测long view概率。
两个输出层共享一个公共的隐层,如下图所示。更重要的是,
listing id embedding是共享的。背后的想法是,模型能够将long view中学到的知识迁移到预订任务中,从而避免过拟合。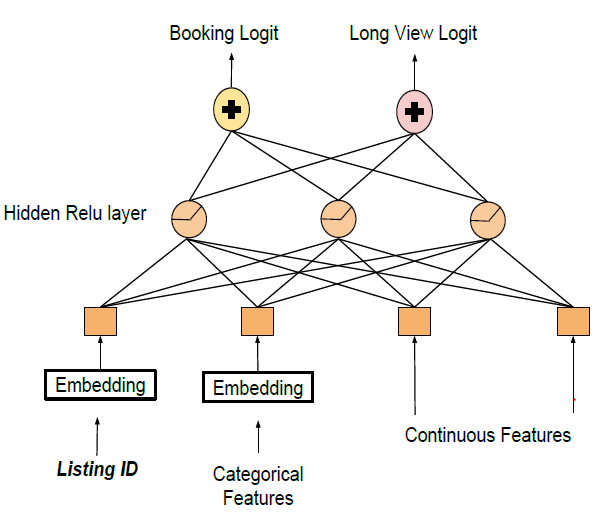
由于
long view标签的数量比预订标签的数量多几个数量级,因此对预订损失施加了较高的补偿权重,从而保持对预订目标的关注。如
《Beyond Clicks: Dwell Time for Personalization》所建议的,每个long view标签的损失进一步由log(view_duration)进行缩放。最终在线
listing评分时,我们仅使用预订预测booking prediction。但是当在线测试时,该模型大幅增加了
long view,而预订量保持不变。人工检查了具有较高long view的listing,我们发现了可能导致这种gap的几种原因:- 这种
long view可能是由于高端的、但价格昂贵的listing所驱动(所以用户会停留一段时间来慎重考虑)。 listing的描述太长,且难以阅读。- 极其独特、且有时很幽默的
listing。 - 还有一些其它原因。
同样,正是
Airbnb市场的独特性,使得long view和预订相关,但是也有很大的正交部分(即不相关的部分),这使得基于long view来预测预订具有挑战性。更好地理解listing view仍然是我们研究的主题。注:笔者在
ctr和cvr多任务建模过程中也发现类似的规律。即希望丰富的点击样本能够有助于迁移学习到转化预估任务。但是结果发现,ctr预估任务效果很好,但是cvr预估任务效果持平或略有下降。- 一个以预订
13.3 特征工程
我们开始的
baseline GBDT pipeline具有广泛的特征工程。典型的变换包括计算比率ratio、窗口平均等等。这些特征工程技巧是经过多年实验积累的。然而,目前还不清楚这些特征是否是最好的,或者是否随着市场动态变化而更新。NN的一大吸引力在于引入了特征自动化feature automation:馈入原始数据并让特征工程在以数据驱动的NN的隐单元中自动进行。然而,本节内容是专门针对特征工程的,因为我们发现让
NN有效工作不仅仅是提供原始数据,也需要特征工程。这种特征工程不同于传统的特征工程:在将特征输入到模型之前,无需人工对特征执行数学计算,而是将重点转移到确保特征符合某些属性properties,以便神经网络可以自己有效地进行数学计算。特征归一化
Feature Normalization:在我们第一次训练NN的尝试中,我们简单地将所有用于训练GBDT模型的特征输入到神经网络中。这种情况非常糟糕,损失函数在训练过程中达到饱和,后续的step没有任何效果。我们将问题追溯到以下事实:特征未能正确地归一化。- 对于决策树,只要特征的相对顺序有意义,那么特征的确切数值几乎无关紧要。
- 神经网络对于特征的数值非常敏感。超出正常特征范围的馈入值可能会导致较大梯度的反向传播。由于梯度消失,这可以使得
ReLU这类激活函数永久死亡。
为了避免这种情况,我们确保将所有特征限制在较小的取值范围内,并且大部分分布在
[-1,1]区间、均值映射到0。总的来说,这涉及检查特征,并应用以下两种转换中的任何一种:如果特征分布类似于正态分布,我们将其变换为:
其中 为特征均值, 为特征标准差。
如果特征分布类似于幂律分布
power law distribution,我们将其变换为:其中
median为特征的中位数。
另一种简单的选择是采用
BN Layer。特征分布
Feature Distribution:除了将特征映射到有限的数值范围,我们还确保大多数特征都具有平滑的分布。为什么要纠结于分布的平滑性smoothness?以下是我们的一些理由。发现错误
spotting bugs:在处理上亿个特征样本时,如何验证其中一小部分没有bug?范围检查很有用,但是很有限。我们发现分布的平滑性是发现错误的宝贵工具,因为错误的分布通常和典型的分布形成鲜明对比。举个例子,我们在某些地区记录的价格中发现了
bug。对于超过28天的区间,记录的价格是每月价格、而不是每日价格。这些错误在原始分布图上显示为尖峰。促进泛化
facilitating generalization:确切回答为什么DNN善于泛化是研究前沿的一个复杂课题。同时,我们的工作知识working knowledge是基于以下观察:在为我们的application构建的DNN中,各层的输出在其分布方面变得越来越平滑。下图显示了来自一些样本的最终输出层分布、以及隐层分布。为了绘制隐层的分布,零值被省略,并且应用了log(1 + relu_output)转换。
这些图激发了我们的直觉:为什么
DNN可以很好地泛化到我们的application中。当建立一个基于数百个特征的模型时,所有特征取值的组合空间非常庞大,并且在训练过程中常常会覆盖一定比例特征组合。来自较低层的平滑分布确保了较高层可以正确地对未看过unseen的值进行插值。将这种直觉一直扩展到输入层,我们尽力确保输入特征具有平滑的分布。这里有个平滑性假设:假设相似的特征带来相似的
label。我们如何测试模型是否在样本上良好地泛化?真正的测试当然是模型的在线性能,但是我们发现以下技术可以作为完整性检查
sanity check:将测试集中给定特征上所有的值都缩放(例如将price特征缩放为2倍或者3倍或者4倍),然后观察NDCG的变化。我们发现,在这些从未见过的price取值上,该模型的性能是非常稳定的。对特征的取值缩放可能会破坏样本的完整性。例如:对于郊区的、单个房间的
listing,如果price缩放4倍会导致一个奇怪的listing,看起来应该很便宜的listing但是标价很高。在调试
debugged并应用适当的归一化之后,大多数特征都获得了平滑分布。但是,有少数几个特征,我们不得不进行专门的特征工程。一个例子是listing的地理位置geo-location,以经度和纬度来表示。下图(a)和(b)显示了原始经纬度的分布。为了使得分布更加平滑,我们计算的是距展示给用户的地图的中心点的偏移量。如下图(c)所示,质量似乎集中在中心,因为地图的尾部被zoomed out了很多。因此,我们使用经度/纬度偏移量的log(),从而得到了下图(d)的分布。这使得我们能够构造两个平滑分布的特征,如下图(e)和(f)所示。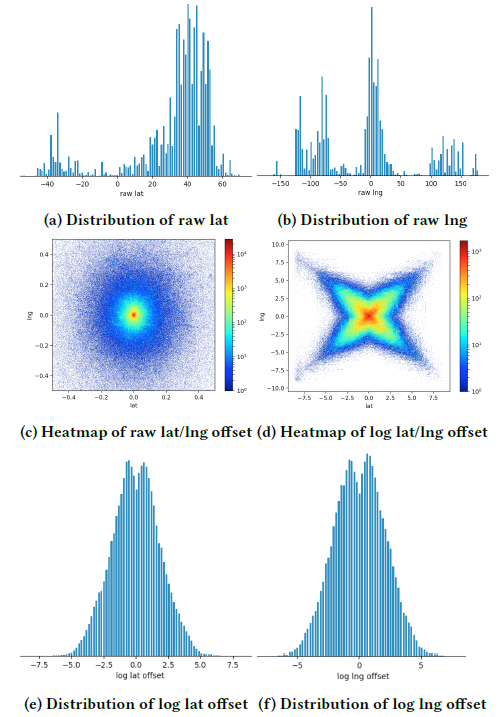
需要明确的是,原始经度/纬度到地图中心的距离变换是有损的多对一函数
many-to-one function。因为它可以将多个经度/纬度转换为相同的偏移量。这使得模型可以基于距离属性而不是特定的地理位置属性来学习全局属性。要学习特定于局部地理位置的属性,我们使用了稍后描述的高基数high cardinali离散特征。检查特征完整性
checking feature completeness:在某些情况下,调查某些特征缺乏平滑性会导致发现模型缺失missing的特征。例如,我们有一个
listing未来已预订天数占available days的比例作为一个特征(即占用率occupancy),这个特征是listing质量的信号。背后的直觉是:高质量的listing会提前售罄。但是,由于缺乏平滑性,占用率的分布却令人困惑,如下图(a)所示。经过调查,我们发现了另一个影响占用率的因素:
listing有不同的最低住宿时间minimum required stay要求,有的会要求最低住宿几个月。因此这些listing得到了不同的占用率。但是,我们没有在模型中添加最低住宿时间作为特征,因为它取决于日历并且被认为过于复杂。但是在查看了占用率分布之后,我们增加了listing的平均住宿时间作为一个特征。在占用率通过平均住宿时间归一化之后,我们可以看到下图
(b)中的分布。在一个维度中缺乏平滑性的特征可能在较高维度上变得平滑。这有助于我们思考这些维度是否可以应用在我们的模型中。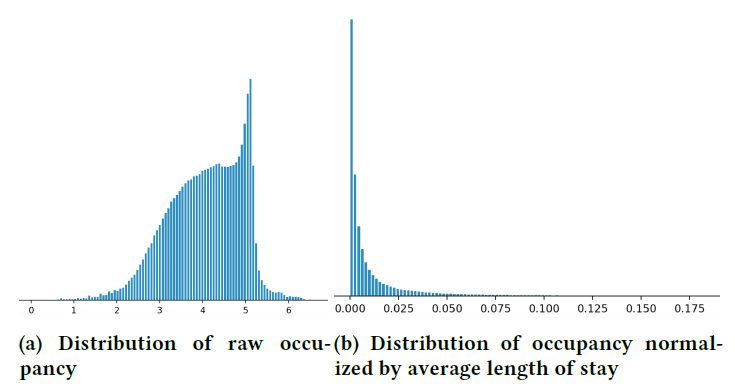
高基数离散特征
High Cardinality Categorical Features:过拟合的listing id并不是我们尝试的唯一高基数离散特征。还有其它尝试,如NN的承诺所言,我们用很少的特征工程就取得了很高的回报。一个具体的例子最能说明这一点。租客对于城市各个街区
neighborhoods的偏好是一个重要的位置信号location signal。对于GBDT模型,该信息是由一个精心设计的pipeline提供的,该pipeline跟踪了各个街区和城市的层级分布hierarchical distribution。建立和维护该pipeline的工作量很大,而且它也没有考虑诸如预订listing价格之类的关键因素。在
NN的世界中,处理这类信息本身就是简单的。我们基于query中指定的城市、以及对应于listing的level 12 S2 cell创建的一个新的离散特征,然后使用哈希函数将这二者整体映射到一个整数。例如,给定query“旧金山” 以及位于Embarcadero附近的listing,我们选择listing所在的S2 cell(539058204),然后将将{"San Francisco", 539058204}哈希映射到71829521从而建立我们的离散特征。然后该离散特征被映射到一个embedding,接着馈入NN。在训练期间,该模型通过反向传播来学习embedding,该embedding编码了在给定城市query的情况下由S2 cell代表的街区的位置偏好location preference。即将地域划分为一个个的网格,然后学习每个网格的
grid id embedding。下图可视化了为
query“旧金山” 学到的各街区的embedding(通过t-SNE)。这符合我们对该地区的直觉理解:embedding值不仅突出了该城市的主要points of interest: poi,它还表明了人们更喜欢位于西湾west bay以南一点的位置,而不是靠近主要交通拥堵桥梁的位置。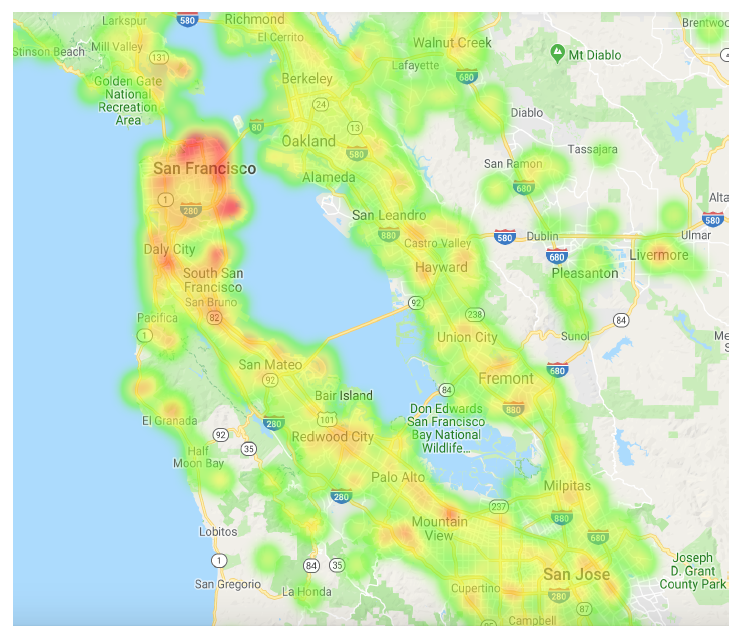
13.4 系统工程
这部分是关于加速训练
training和加速打分scoring。我们pipeline的一个quick summary:- 来自租客的搜索
query命中了一个进行检索retrieval和评分scoring的Java server。 - 这个
server还生成日志,这些日志存储为序列化的Thrift实例。 - 日志使用
Spark pipeline来处理从而创建训练数据。 - 使用
TensorFlow来训练模型。 - 使用
Scala和Java编写的各种工具用于评估模型和计算离线指标。 - 模型上传到执行检索和评分的
Java server。
所有这些组件都在
AWS实例上运行。- 来自租客的搜索
Protobufs and Datasets:GBDT模型是以CSV格式来提供训练数据的,并且我们重复使用这个pipeline的大部分,从而使用feed dict馈入TensorFlow模型。乍一看,这似乎不是一个机器学习的问题,并且在我们的优先级清单中是相当低的。但是当我们发现
GPU利用率接近25%时,我们马上警醒了。大部分训练时间都花在解析CSV和通过feed dict拷贝数据上。我们实际上是在用骡子拖着一辆法拉利。重构
pipeline以产生Protobufs训练数据,并使用Dataset可以将训练速度提高17倍,并将GPU利用率提高到大约90%。这最终允许我们将训练数据从几周扩展到几个月。重构静态特征
refactoring static features:我们的很多特征都是很少变化的listing属性。例如,地理位置location、卧室数量、便利设施amenities、租客规则guest fules等等。将所有这些特征作为训练样本的一部分将产生输入瓶颈input bottleneck。为了消除这种磁盘流量,我们仅使用
listing id作为离散特征。所有静态特征都被打包为由listing id索引的、不可训练non-trainable的embedding。对于在训练期间发生突变的特征,这需要在少量噪声和训练速度之间进行trade-off。注意:这个
embedding就是这些静态特征拼接而成的,因此是不可训练的。是否对这些属性进行embedding训练会更好?论文并未讨论这一点。这个
embedding常驻在GPU内存,消除了每个训练样本数千KB的数据,这些数据通常是通过CPU从磁盘加载的。这种效率使得探索全新类型的模型成为可能,该模型考虑了用户历史交互的数十个listing的详细信息。Java NN library:在2017年初,当我们开始将Tensorflow模型投入生产时,我们发现没有有效的解决方案可以在Java stack中对模型进行评分scoring。 通常需要在Java和另一种语言之间来回转换数据,这个过程中引入的延迟latency对我们而言是一个障碍。为了满足严格的搜索延迟要求,我们在
Java中创建了一个自定义的神经网络评分库。虽然到目前为止这对我们很有帮助,但是我们希望重新讨论这个问题,看看有没有最新的替代方案。
13.5 超参数
尽管在
GBDT世界中有一些超参数,如树的数量、正则化等,但是NN却将超参数的规模提升到一个新的高度。在最初的迭代中,我们花了大量时间探索超参数世界。调研所有选项和试验组合上的努力并没有给我们带来任何有意义的改进。但是,这个练习exercise确实让我们对我们的选择有了一些信息,我们将在下面描述。dropout:我们最初的印象是,dropout和神经网络的正则化相对应,因此必不可少。然而对于我们的application,我们尝试了不同的dropout形式,所有这些都会导致离线指标略有下降。为了理解
dropout和我们的失败,我们目前对dropout的解释更接近于一种数据增强技术。当随机性的引入模拟了有效的场景时,这种技术是有效的。对于我们的情况,随机性只能产生无效的场景。作为替代方案,我们在考虑特定特征的分布的情况下,添加了人工制作的噪声,从而使得离线
NDCG降低了大约1%。但是我们在在线性能方面没有取得任何统计意思上的显著提升。初始化
initialization:出于纯粹的习惯,我们通过将所有权重和embedding初始化为零来开始我们的第一个模型,结果发现这是开始训练神经网络的最差的方法。在研究了不同的技术之后,我们目前的选择是对网络权重使用Xavier初始化,对embedding使用{-1 ~ +1}范围内的均匀随机初始化。学习率
learning rate:这里面临着各种各样的策略,但是对于我们的application,我们发现很难使用默认的设置来改善Adam的性能。当前,我们使用了LazyAdamOptimizer变体,我们发现使用large embedding训练时该变体会更快。batch size:batch size的变化对于训练速度有着显著影响,但是对于模型本身的确切影响却难以把握。我们发现最有用的指南是《Don’t Decay the Learning Rate, Increase the Batch Size》。但是我们并没有完全遵守该论文的建议。在LazyAdamOptimizer解决了学习率问题之后,我们选择了200的固定batch size,这似乎对当前模型有效。
13.6 特征重要性
一般来说,特征重要性的估计和模型的可解释性
interpretability是神经网络不擅长的一个领域。评估特征的重要性对于确定工程工作的优先级和指导模型迭代是至关重要的。NN的优势在于找到特征之间的非线性相互作用。当理解特定特征扮演了什么角色时,这也是一个弱点,因为非线性相互作用使得很难孤立地研究任何特征。接下来,我们讲述解释神经网络的一些尝试。分数分解
Score Decomposition:在NN的世界中,试图了解单个特征的重要性只会导致混乱。我们第一个朴素的尝试是获取网络产生的最终得分,然后尝试将其分解为来自每个输入节点input node的贡献。在查看了结果之后,我们意识到这个想法存在概念上的错误:没有一种干净
clean的方法来区分一个特定的输入节点对像ReLU这样的非线性激活的影响。消融测试
Ablation Test:这是对这个问题的又一次简单的尝试。这里的想法是一次移除一个特征,重新训练模型并观察性能的差异。然后,我们可以将这些特征的重要性与移除它们所导致的性能下降成正比。然而这里的困难在于,通过移除一个特征获得的任何性能差异都类似于在重新训练模型时观察到的离线指标中的典型噪声。这可能是因为我们的特征集合中存在大量的冗余,模型似乎能够从剩余的特征中弥补一个缺失的特征。
这导致了忒休斯之船悖论
Ship-of-Theseus paradox:你能一次从模型中删除一个特征,声称该模型没有显著的性能下降吗?忒修斯悖论:如果忒修斯的船上的木头被逐渐替换,直到所有的木头都不是原来的木头,那这艘船还是原来的那艘船吗?
即:假定某物体的构成要素被置换后,但它依旧是原来的物体吗?
排列测试
Permutation Test:在接下来的尝试中,我们从针对随机森林提出的排列特征重要性permutation feature importance中得到启发。我们在测试中随机排列了特征在各个样本中的取值之后,在测试集上观察了模型的性能。我们的期望是,特征越重要,扰动它导致的模型退化degradation就越大。但是,该操作会导致有些荒谬的结果。原因是在一次排列
permuting一个特征时,我们假设不同特征之间彼此独立,这是错误的。例如,预测预订概率的最重要特征之一就是listing中的房间数。而房间数量和价格、住宿人数、便利设施等特征息息相关。对特征进行独立排列会创建在现实生活中从未发生过的样本,并且特征在无效空间invalid space中的重要性使我们误入歧途。但是,该测试在确定没有发挥作用的特征方面有些用处。如果随机排列特征完全不影响模型性能,则可以很好地表明模型可能不依赖于该特征。
TopBot Analysis:有一个自主开发的工具旨在解释这些特征,并且不会以任何方式干扰它们。这个工具叫做TopBot,它提供了一些有趣的洞察insight。TopBot是自上而下分析器top-bottom analyzer的缩写,它将一个测试集作为输入,并使用模型对每个测试query的listing进行排序。然后它为每个query从排名在top的listing生成特征取值的分布图,并将该分布图和排名在bottom的listing生成特征取值的分布图进行比较。这个比较comparison表明了模型是如何利用不同取值范围内的特征。下图显示了一个例子。排名最高的
listing的价格分布偏向于较低的值,这表明模型对于价格的敏感性sensitivity。但是,当比较排名top和排名bottom的listing的评论数量的分布时,这两个分布看起来非常相似,表明这个版本的模型未按预期使用评论,从而为下一步研究提供了方向。还可以细化下:针对不同的细分市场(或者不同类型的
listing)来可视化。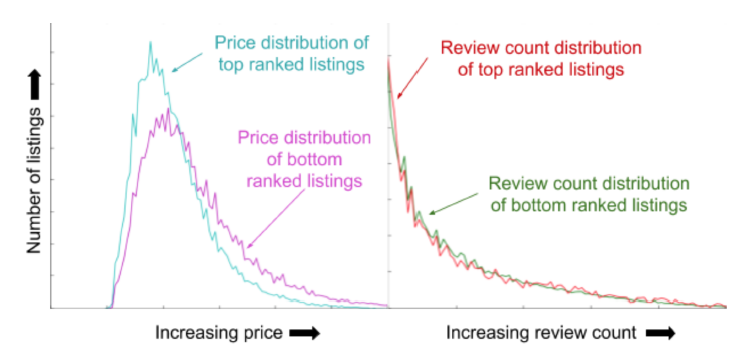
13.7 回顾
下图总结了目前为止的深度学习之旅。
- 根据无处不在的深度学习成功案例,我们从乐观主义的顶峰开始,认为深度学习将取代
GBDT模型,并为我们带来惊人的收益。 - 许多最初的讨论集中在保持其他一切不变,用神经网络替代当前的模型,看看我们能够得到什么收益。当最初没有实现这些收益时,这让我们陷入了绝望的深渊。
- 随着时间的推移,我们意识到转向深度学习根本不是一个简单的模型替代,更确切的说这是关于系统扩展
sytem scaling。因此,它需要重新思考围绕模型的整个系统。
如果仅局限于较小的规模,像
GBDT这样的模型在性能上可以说是同等水平并且更易于处理,我们继续使用GBDT来解决中等规模的问题。那么,我们会向其他人推荐深度学习吗?答案是Yes。这不仅是因为深度学习模型的在线性能大幅提升。还有部分原因是与深度学习如何改变了我们未来的roadmap有关。早期机器学习的重点主要放在特征工程上,但是在转向深度学习之后,试图手动特征工程已经失去了前景。这让我们可以在更高的层次上研究问题。比如,如何改进我们的优化目标?我们是否准确地代表了所有的用户?在迈出将神经网络应用于search ranking第一步的两年之后,我们觉得我们才刚刚开始。- 根据无处不在的深度学习成功案例,我们从乐观主义的顶峰开始,认为深度学习将取代
十四、Improving Deep Learning For Airbnb Search[2020]
Airbnb是一个双边市场,汇集了拥有出租房屋的房东hosts、以及来自世界各地的潜在租客guests。Airbnb的search ranking问题是对住宿地点(称为listing)进行排名,从而响应用户的query。这些query通常包括位置location、客人数量、入住/退房日期checkin/checkout dates。过度到深度学习是
Airbnb search ranking发展过程中的一个重要里程碑。我们在《Applying Deep Learning to Airbnb Search》对旅程(指的是超越之旅journey beyond)的描述让我们和许多行业从业人员进行了交谈,使得我们能够交换见解insights和批评critiques。此类对话中经常出现的一个问题是:下一步是什么?我们试图在论文《Improving Deep Learning For Airbnb Search》中回答这个问题。用于
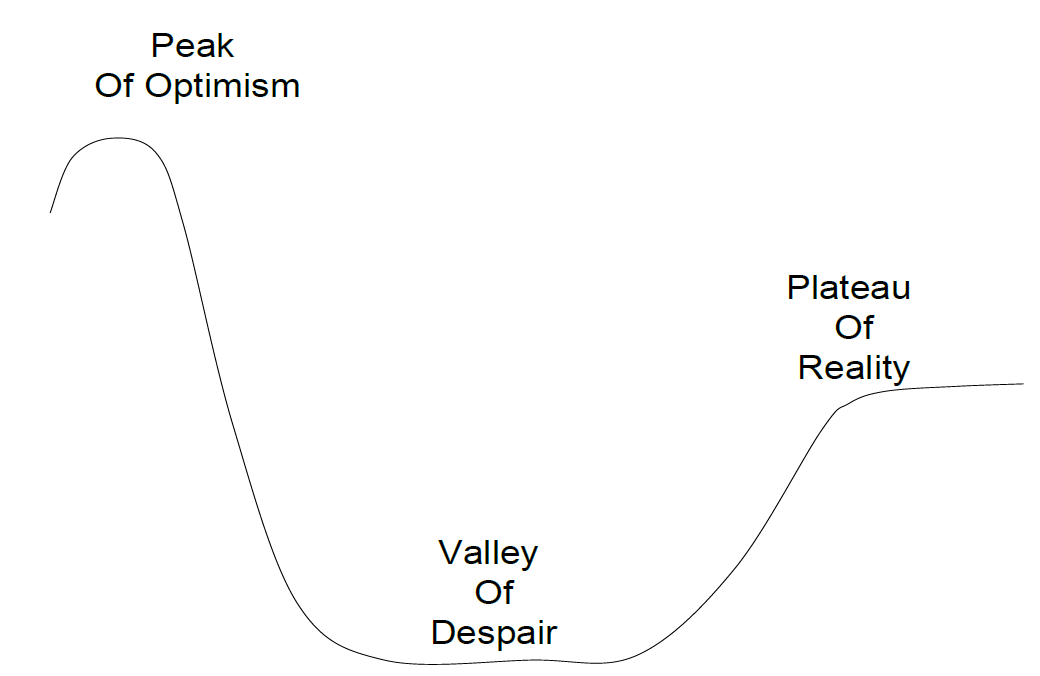
ranking的深度学习的推出引起了很多庆祝,不仅因为它带来的预订量增益,还因为它给我们未来的路线图roadmap带来了变化。最初的看法是,在深度学习上的Airbnb ranking使我们能够接触到这个巨大的机器学习思想宝库,这个宝库似乎每天都在增长。我们可以简单地从文献综述中挑选出最好的想法,一个接一个地推出,从此过上幸福的生活。但是事实证明,这是乐观情绪的山峰
the peak of optimism。熟悉的、陷入绝望之谷valley of despair的模式很快就出现了:在其他地方取得了令人印象深刻的、成功的技术在我们自己的application中证明是非常中性neutral的。这导致了我们在第一次launch之后对如何迭代深度学习的策略进行了全面修订。在论文
《Improving Deep Learning For Airbnb Search》中,我们描述了在《Applying Deep Learning to Airbnb Search》推出之后的主要改进。除了深入研究核心机器学习技术本身,我们还关注导致突破的过程process和缘由reasoning。现在从更大的角度来看,我们更重视在如何迭代DNN方面的经验教训,而不是任何单独的技术。我们希望那些专注于在工业环境中应用深度学习的人会发现我们的经验很有价值。我们通过回顾我们为改进
DNN架构所作的努力来展开讨论。- 对于架构,我们描述了一个新的
ranking神经网络,重点关注于将我们现有的DNN发展到两层全连接网络之外的过程。 - 在处理
ranking中的位置偏差positional bias时,我们描述了一种新颖的方法,该方法在处理库存inventory方面取得了显著的提升。 - 为了解决冷启动问题,我们描述了我们对问题的看法,以及我们为改善平台上新
listing的处理所做的改变。
- 对于架构,我们描述了一个新的
14.1 架构优化
什么是深度学习?嗯,添加更多的
layer。至少,在回顾了引领当前深度学习时代的一系列进展之后,这是我们朴素的解读。但是,当我们试图复制《Revisiting Unreasonable Effectiveness of Data in Deep Learning Era》中总结的scaling数据和添加更多layer的好处时,我们遇到的只是中性的测试结果。为了解释为什么增加
layer没有显示任何收益,我们从文献中借用了更多的想法,例如应用残差学习residual learning、batch normalization等等。尽管如此,NDCG在离线测试中仍然没有提升。我们从这些练习
exercise中得出的结论是:增加layer是convolutional neural networks: CNN卷积神经网络中的有效技术,但是不一定适用于所有DNN。对于像我们这样的全连接网络fully connected networks: FCN,两个隐层就足够了,模型容量不是我们的问题。如果更深的网络不适合我们的架构,那么我么假设:更专业的网络可能适合我们的架构。因此,我们尝试了可以显式处理
query和listing之间交互的架构,例如Deep and Wide,其中query-listing的特征交叉添加到wide部分。接下来是《Attention is All you Need》中基于attention的网络变体。这样做的目的是使得从query特征派生的隐层将注意力集中在从listing特征派生的隐层的某些部分上。这些努力的简短总结是,它们也未能改变现状。在尝试将成功的深度学习架构引入
product application时,在翻译任务translation中经常忽略的是:一个体系架构的成功和它的应用上下文application context有着错综复杂的联系。人们报告的架构性能提升来自于解决与它进行比较的baseline的某些缺点。由于深度学习普遍缺乏可解释性explainability,因此很难准确推断出新架构正在解决什么缺点、以及如何解决这些缺点。因此,确定这些缺点是否也同样困扰着自家产品,就变成了一种猜测。为了提高我们成功的几率,我们放弃了 “下载论文 --> 实现 -->
A/B test” 的循环。相反,我们决定基于一个非常简单的原则来推动这个过程:用户主导、模型跟随users lead, model follows。问题驱动,而不是模型驱动。
用户主导、模型跟随
Users Lead, Model Follows:这里的想法是:首先量化一个用户问题user problem,随后调整模型以响应用户问题。沿着这些思路,我们观察到
《Applying Deep Learning to Airbnb Search》中描述的一系列成功的ranking模型不仅与预订量的增加有关,而且还与搜索结果的平均listing价格降低有关。这表明模型迭代越来越接近租客的价格偏好price preference,其中每轮迭代时平均价格低于前面模型的平均价格。我们怀疑,即使在连续降价之后,模型的价格选择和租客的价格偏好之间也可能存在
gap。为了量化这种gap,我们观察了每个租客看到的搜索结果的价格中位数、以及该租客预订listing的价格之间的gap的分布。由于价格服从对数正态分布log-normal distribution,因此在对价格取对数之后计算差异。下图给出了差异的分布情况。X轴显示了预订价格和搜索结果中间价median price的对数偏移,Y轴是这个对数偏移对应的用户数。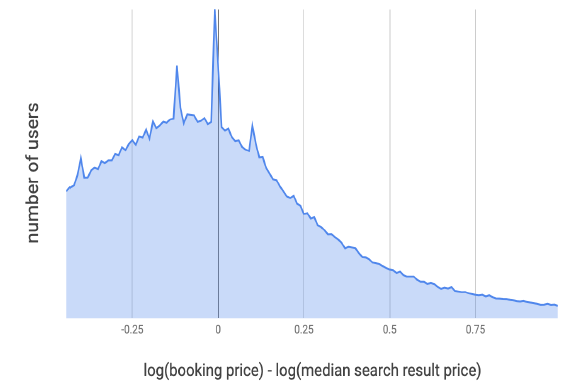
我们预期的是:预订价格将围绕着搜索结果的中间价对称分布,并且类似于以零点为中心的正态分布。实际上相反,这个分布在负向侧
negative side更大,表明租客更偏好较低的价格。这给了我们一个具体的用户问题来调查:是否需要将更接近租客价格偏好的低价listing排名更高。假设有两个普通的
listing,它们除了价格在其它方面都相同,我们的直觉理解是租客更喜欢更便宜的listing。我们的ranking模型是否真正理解了cheaper is better的原则?我们并不完全确定。cheaper is better是一个先验知识,因此希望模型能够学到这一先验知识。Enforcing Cheaper Is Better强迫cheaper is better:我们不清楚模型如何解释listing价格的原因是:模型是一个DNN。一些熟悉的工具,如检查逻辑回归模型中相应权重、或者GBDT模型中的部分依赖图partial dependence graphs,在DNN环境中都不再有效。为了使得价格更可解释
interpretable,我们对模型架构进行了以下更改:从
DNN的输入特征中移除价格。我们将这个修改的DNN模型记作 ,其中 为DNN模型参数, 为用户特征, 为query特征, 为移除了价格的listing特征。模型的最终输出修改为:
其中 为待学习的参数, 定义为:
其中
price为原始的价格特征,而 为根据日志的listing价格的中位数计算得出的常数。
-tanh(.)项允许我们通过相对于价格单调递减的output score来强制执行cheaper is better。易于解释的 和 参数使得我们能够准确描绘出价格的精确影响。通过训练数据我们学习到参数取值为: 。我们在下图中绘制了在
ranking过程中, 遇到的典型取值所对应tanh(.)项的结果。X轴表示归一化的价格( 值),Y轴表示tanh(.)项的结果。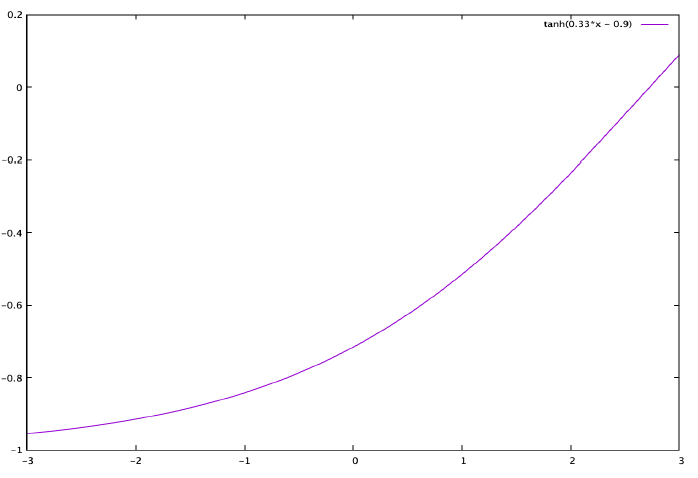
当对
《Applying Deep Learning to Airbnb Search》中的带两个隐层的DNN进行在线A/B test时,搜索结果的平均价格下降了-5.7%,这与离线分析相一致。但是价格的可解释性付出了沉重的代价,因为预订量下降了-1.5%。我们猜想背后的原因是:价格和其它特征密切相关,将价格从模型中分离出来导致欠拟合。
NDCG在训练集和测试集上都下降了,该事实支持这一假设。广义单调性
Generalized Monotonicity:为了在模型中保留cheaper is better的直觉,但是允许价格和其它特征相互作用,我们开始研究在某些输入特征方面是单调monotonic的DNN架构。lattice networks为这个问题提供了一个优雅的解决方案。但是,将我们的整个系统切换到lattice networks是一个巨大的挑战,我们寻求一种破坏性较小的机制。因此,我们构建了下图中所示的架构,除Tensorflow中原生节点之外,该架构不依赖于任何专门的计算节点。我们讨论架构的逐步构建,确保从输入价格节点到最终输出的所有路径在价格方面都是单调的:
我们将 作为
DNN的输入,该输入相对于价格单调递减。在
input layer,我们没有将 乘以权重参数,而是将它乘以权重参数的平方。因为在任何 参数(都是实数)的情况下, 都是相对于价格单调递减的。因此第一层隐层的输入对于价格也是单调递减的。对于隐层,我们使用 作为激活函数,该激活函数保持了单调性。
给定相对于 单调递减的两个函数 ,那么 也是相对于 单调递减的。其中 可以为任意实数。
我们在第二个隐层和输出层使用这个属性,所有权重都是平方的。在下图中,这在第二个隐层和输出层用粗实线表示。即:粗实线表示平方权重,虚线表示常规的权重。
添加一个既没有价格作为输入、也没有任何单调性约束的子网
subnet,从而允许其它特征之间的不受约束的交互。
尽管比
Enforcing Cheaper Is Better中描述的架构更加灵活,但是在线测试的结果非常相似:预订量下降了-1.6%。与
Enforcing Cheaper Is Better中描述的架构一样,该架构强制模型在任何情况下的输出都是相对于价格单调递减的。这种架构的失败表明:价格的单调性是一个过于严格的约束。
软单调性
Soft Monotonicity:虽然前面描述的架构揭示了DNN在支持模型约束方面的能力,但是它也教会了我们DNN的另一个特点:它们的行为就像团队中的一位明星工程师star engineer。给定一个问题,让他自己解决,他通常会想出一个合理的解决方案。但是强迫他往某个方向走,灾难很快就会随之而来。所以在我们的下一次迭代中,我们决定通过配置上下文
setting context来管理DNN,而不是通过控制control来管理DNN。我们没有强制要求模型的输出是价格的单调函数,而是添加了一个软提示soft hint:cheaper was better。通常,每个训练样本包含一对
listing,一个是预订的listing、另一个是未预订的listing。将DNN应用于这两个listing的特征并产生对应的logits,并且定义损失函数为:xxxxxxxxxx91# tensorflow 代码定义的 pairwise booking loss2def get_loss_op(positive_logits, negative_logits):3logit_diffs = positive_logits - negative_logits4xentropy = tf.nn.sigmoid_cross_entropy_with_logits(5labels = tf.ones_like(logit_diffs),6logits = logit_diffs7)8loss = tf.reduce_mean(xentropy)9return loss为了添加价格提示
price hint,我们为每个训练样本引入了第二个label,指示两个listing中哪个价格更低、哪个价格更高。然后我们修改损失函数如下:xxxxxxxxxx151# tensorflow 代码定义的 pairwise booking loss2def get_loss_op(positive_logits, negative_logits):3logit_diffs = positive_logits - negative_logits4xentropy = tf.nn.sigmoid_cross_entropy_with_logits(5labels = tf.ones_like(logit_diffs),6logits = logit_diffs7)8loss = tf.reduce_mean(xentropy)9return loss10# booked listing 为正样本、not booked listing 为负样本11booking_loss = get_loss_op(booked_logits, not_booked_logits)12# 低价 listing 为正样本、高价 listing 为负样本13price_loss = get_loss_op(lower_price_logits, higher_price_logits)14# alpha 为超参数15loss = alpha * booking_loss + (1 - alpha) * price_lossalpha超参数提供了一种方法来控制:结果是按照相关性relevance排序还是按照价格price排序。将价格约束作为一种正则化,使得模型倾向于选择低价的
listing。为了测试这个想法,我们将
alpha超参数调整到最小值,这样在离线测试中,我们得到了和baseline模型相同的NDCG。这使得我们能够在不损害相关性的情况下尽可能地推动cheaper is better的直觉,至少在离线指标上是这样的。在在线
A/B test中,我们观察到搜索结果的平均价格下降了-3.3%,但是预订量也下降了-0.67%。离线分析的局限性在于:它仅对日志中可用的、
reranking中的top结果(因为这些日志是reranking模块胜出的流量)进行评估。在在线测试期间,将新训练的模型应用于整个库存inventory空间揭示了将价格损失作为训练目标的一部分的真实代价。离线评估样本分布和在线样本分布不同,因此即使离线
auc相同的情况下,在线a/b test表现也不相同。执行个体条件期望
Putting Some ICE:降价实验带来的灾难让我们处于一种矛盾的状态:搜索结果中的listing价格似乎高于房客偏好价格,但是压低价格却让房客不高兴。为了了解新模型的不足之处,有必要比较
baseline模型是如何利用价格特征的,但是这被全连接DNN缺乏可解释性所掩盖。如前所述,像部分依赖图partial dependence plots这样的概念没有用,因为这种方式依赖于给定的特征对模型的影响独立于其它特征的假设。试图给出价格的部分依赖图会产生平缓倾斜sloping straight的直线,这表明DNN对价格有一些轻微的线性依赖,这与我们所知道的相矛盾。为了取得进展,我们缩小
scaled down了DNN可解释性的问题。我们没有试图对价格如何影响DNN做一般性的陈述statement,而是聚焦于一次解释单个搜索结果。借用《Peeking Inside the Black Box: Visualizing Statistical Learning With Plots of Individual Conditional Expectation》中的个体条件期望individual conditional expectation:ICE图plots的想法,我们从单个搜索结果中获取listing,在保持所有其它特征不变的情况下对价格选取一定的范围,并构建模型得分的plot。下面给出了一个示例。图中
x轴为价格、y轴为模型预估的listing score。每条曲线代表了单次搜索结果中的一个lising(在多个价格上的score)。因为单次搜索返回多个listing结果,所以下图中有多条曲线。该图表明,
《Applying Deep Learning to Airbnb Search》中的两层全连接层DNN已经理解了cheaper was better。对日志中随机选择的搜索集合重复ICE分析进一步加强了这个结论。失败的架构通过试图进一步压低价格从而影响了模型质量。
双塔架构
Two Tower Architecture:回到下图,租客显然是在通过这个plot传递一个信息。但是,那些致力于用相关性relevance换取价格price的架构错误地解释了这个信息。需要对下图进行重新解释,这个解释必须和价格保持一致,也必须和相关性保持一致。即不能用相关性的降低来换取价格的降低,应该在保持相关性的同时降低价格。
当我们计算租客搜索结果的中间价与其预订价格之间的差异,并计算按城市分组的均值时,就出现了上图的替代解释
alternate explanation。正如预期的那样,各城市之间存在差异。但是和头部城市相比,尾部城市的差异要大得多。尾部城市也通常位于发展中市场developing markets。下图展示了某些选定城市的搜索结果中间价和预订价格之间的差异的平均值。
这就产生了一个假设,即:搜索结果中间价与其预订价格之间差异
plot背后的DNN正遭受多数暴政tyranny of the majority,它聚焦于针对统治了预订量的热门区域调优的price-quality tradeoff。将这个trade-off推广到长尾的query效果不佳,并且该模型也不适应本地条件(即长尾城市)。该假设与馈入
DNN特征的另一个观察相吻合。鉴于DNN是使用pairwise损失训练的,pair对的两个listing中有差异的特征似乎具有最大影响力。query特征,这对于pair对的两个listing都是公共的,似乎没有什么影响,并且删除query特征对于NDCG的影响非常微小。新的想法是,该模型充分理解了
cheaper is better,但它缺少的是合适价格right price的概念。理解这一概念需要密切关注query特征,如位置location,而不是纯粹基于listing特征进行区分。这启发了该架构的下一次修订,新架构由双塔two towers组成。- 第一个塔由
query特征和用户特征馈入,生成了一个100维的向量,该向量从概念上代表了query-user组合的ideal理想listing。 - 第二个塔根据
listing特征构建了一个100维的向量。两个塔输出向量之间的欧氏距离用于衡量给定listing和query-user的理想listing之间的距离。
训练样本由
listing pair对组成:一个已预订listing、一个未预订listing。损失函数的定义是:和已预订
listing相比,未预订listing与理想情况的接近程度。因此,对这个双塔模型进行训练可以使得pair对中的预订listing更接近理想listing、同时将未预订listing远离理想listing。这类似于《A Unified Embedding for Face Recognition and Clustering》中引入的triplet loss。这里的主要区别在于:我们没有在三元组triples上训练,而是只有listing pair,并且三元组中缺失的anchor listing是由query-user塔来自动学习。query和listing的pairwise training如下图所示。
Tensorflow代码如下所示,实际实现可能略有不同从而优化训练速度:xxxxxxxxxx291import tensorflow as tf2def get_tower(features, w0, b0, w1, b1):3# 两层全连接层,用于产生一个 100 维向量4h1 = tf.nn.tanh(tf.matmul(features, w0) + b0)5h2 = tf.nn.tanh(tf.matmul(h1, w1) + b1)6return h27def get_distance_to_ideal(query_vec, listing_vec):8# 计算 listing hidden layer 和 query hidden layer 之间的欧式距离9sqdiff = tf.math.squared_difference(query_vec, listing_vec)10logits = tf.math.reduce_sum(sqdiff, axis=1)11return logits12def pairwise_loss(query_features, booked_listing_features,13not_booked_listing_features ) :14qvec = get_tower(query_features, query_w0,15query_b0, query_w1, query_b1)16booked_vec = get_tower(booked_listing_features, listing_w0,17listing_b0, listing_w1, listing_b1)18not_booked_vec = get_tower(listing_features, listing_w0,19listing_b0, listing_w1, listing_b1)20booked_distance = get_distance_to_ideal(qvec, booked_vec)21not_booked_distance = get_distance_to_ideal(qvec, not_booked_vec)22distance_diff = not_booked_distance - booked_distance23# 通过增加二者之间的相对距离,将未预定 listing 推离理想 listing,24# 将预定 listing 推近理想 listing25xentropy = tf.nn.sigmoid_cross_entropy_with_logits(26labels = tf.ones_like(logit_diffs),27logits = logit_diffs)28loss = tf.reduce_mean(xentropy)29return loss- 第一个塔由
测试结果:当进行线上
A/B test时,其中baseline为《Applying Deep Learning to Airbnb Search》中的两层全连接层的DNN,双塔架构的预订量增加了+0.6%。这一增长是由搜索便利性ease of search的提高所推动的,因为在线NDCG提高了0.7%。尽管这个双塔架构的目标不是直接降低价格,但是我们观察到搜索结果的平均价格降低了-2.3%,这是相关性增加的副作用side effect。预订量的增加抵消了价格下降对于收入的影响,整体收入增加了+0.75%。搜索便利性:搜索结果中,目标
listing排名更靠前因此有利于用户预订。除了提高搜索结果的质量之外,双塔架构还允许我们优化在线
DNN的scoring延迟。对于全连接架构,评估第一个隐层贡献了
scoring延迟的最大部分。评估第一个隐层的计算复杂度可以表示为 ,其中 是和listing无关的query和user特征的数量, 为listing特征的数量, 为第一层的隐单元数量。为了评估包含 个
listing的结果集(该结果集对应于单个query的搜索结果),总的算法复杂为 。在新架构的双塔中,
query塔独立于listing。这允许在整个搜索结果集针对该塔仅评分一次,并且仅评估每个listing的listing dependent tower。第一个隐层的计算复杂度降低到 ,其中 和 为listing塔和query塔的隐层神经元数量。当在线测试时,这导致
99th百分位数的scoring延迟降低了-33%。
架构回顾:就在我们庆祝成功的时候,随着
DNN迭代的启动,疑虑也悄然而至。架构是否按预期工作?或者DNN是否偶然发现了其它意外情况?过去,
DNN的不可解释的性质使得回答此类疑问变得极其困难。但是考虑到双塔架构的直觉是针对用户问题user problem而开发的,我们现在可以使用这些直觉来更好地了解DNN的运作方式。重温价格的
ICE图,我们看到了一个显著的变化。如下图所示,我们看到分数在某些价格附近达到峰值,而不是总是向下倾斜(对应于cheaper is better)。这更接近right price for the trip(旅行的正确价格) 的解释。在这种情况下,一个经常被提出的问题是,低质量的
listing是否可以通过简单地降低价格从而在新模型中提升排名。仔细检查ICE曲线发现,某些价格附近的分数峰值仅发生在高质量listing中,这些listing通常一开始就排名靠前。对于大多数listing,该图仍然保持着与价格相关的单调递减曲线。
正确价格
right price、理想listing这些概念的核心是query塔生成的向量,因此自然而然的后续工作是准确地研究这些向量到底是什么样子的。为了进行分析,我们随机采样了一批搜索来运行了双塔DNN,并收集了query塔的输出向量。由于100维向量对于人类是不可解释的,因此我们应用t-SNE将这些向量降维到2维空间,如下图所示。图中标出了部分城市对应的query,每个点代表一个query。某些query标记有city/guest-count/trip-length信息。点的颜色代表query的预订订单价格,越便宜颜色越绿、越贵颜色越蓝。令人欣慰的是,租客数量guest count和行程长度trip length等参数相似的值形成了大的簇clusters。在大的簇内部,直觉上感觉相似的城市(比如都是发达市场或者发展中市场)被放置在彼此相对接近的地方。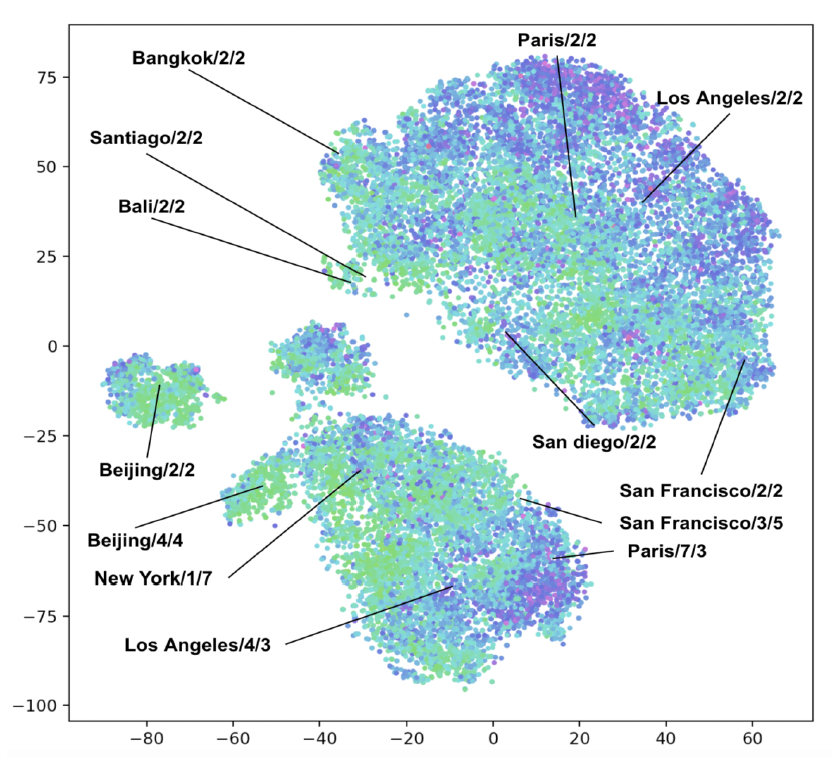
值得强调的是,簇不仅仅是价格簇
price clusters。和query对应的预订listing的价格由点的颜色来表示,我们看到簇具有所有范围all range的颜色。虽然莫斯科通常比巴黎更便宜,但是莫斯科的预订价格很容易超过巴黎的预订价格,这取决于租客数量、停留时间duration of stay、离旅游景点的距离、周末vs工作日、以及许多其他因素。价格与所有其它维度有着千丝万缕的联系,掌握旅行的正确价格意味着同时掌握所有其它因素。我们所作的分析都不能作为双塔架构确实发展出这种掌握
grasp的有力证据。但是,针对价格的ICE图、query塔输出的t-SNE可视化、以及对跨城市price movements的额外分析给了我们足够的信息,让我们相信这一机制正在按预期发挥作用。放下一系列的架构操作,接下来我们继续解决
ranking的挑战,该挑战不仅影响房客,也影响Airbnb社区的另一半,即房东。
14.2 冷启动改善
在旅游领域的机器学习
application中,任何时候都有很大一部分用户是新用户,或者在很长一段时间后才使用该产品。此时用户处于连续冷启动状态continuous cold start。处理
user level冷启动是核心排序公式core ranking formulation本身的一部分。所以在提到冷启动问题时,我们把注意力集中在item level冷启动上(即如何处理新item的排名)。和前面改进DNN架构的情况一样,我们探索的起点不是文献综述,而是对用户问题user problem的观察。使用
NDCG来量化预订listing在搜索结果中的位置,这对我们来说是衡量模型性能最可靠的方法。因此,调查用户问题的一个自然的地方是:寻找NDCG低于NDCG整体水平的细分市场。考虑平台上新
listing、老listing中,预定listing的在线NDCG之间的差异,我们观察到了-6%的差距。而模型预估的NDCG和在线预定的NDCG之间的差异只有0.7%。这表明该模型让房客更难发现值得预订的新listing。为了更好地理解这一点,我们从
DNN中移除了所有的、listing上基于房客历史互动生成的输入特征,例如一个listing的历史预订量。删除这些互动特征engagement features导致离线NDCG下降了-4.5%。显然,DNN非常依赖于互动特征。由于新listing没有这些互动特征,因此DNN被迫根据剩余特征做出宽泛broad的判断,从而接近新listing的平均表现。冷启动方法视为
Explore-Exploit:冷启动问题的一个可能的框架是将它视为探索和利用explore-exploit之间的tradeoff。排序策略可以通过利用
exploiting当前库存inventory的知识来短期地专门优化预订量,并且只押注那些有良好记录的listing。但是为了市场的长期成功,它需要支付一些成本来探索explore新的库存。这种
tradeoff可以作为新listing的显式排名提升boost来实现,它为新listing分配更高的排名(相比较于DNN所确定的排名)。这允许新listing以较低的预订代价cost收集租客的反馈。这种通用的方式在电商排序application中很流行,例如在《Re-ranking results in a search》中。这种boost可以通过曝光次数限制、或者引入时间衰减来进一步细化refined。即,给新
listing预估的得分提供一个大于1的权重,该权重可以随着时间衰减到1.0、或者随着新listing曝光次数增加而衰减到1.0。我们的第一次迭代是为了测试这种
boost。通过在线A/B test,与没有boost相比,boost并没有带来新listing的预订量的提升或下降(效果中性),并且为新listing带来了+8.5%的首页曝光次数。但是,
explore-exploit范式带来了严峻的挑战:新
listing的ranking boost被两种相反的力量拉向不同的方向:- 由于搜索结果相关性
relevance降低,短期内用户体验user experience下降。我们可以准确地衡量这一影响(通过点击率或预订量)。 - 由于库存增加,长期来看用户体验有所改善。我们发现这种影响很难量化。
缺乏对最佳
boost值的明确和客观的定义导致了激烈的内部辩论,没有一个解决方案让每个团队都满意。- 由于搜索结果相关性
即使能够确定探索
exploration成本的总体预算,很明显,预算的正确使用取决于特定地域location的供需supply and demand情况。- 当需求量
demand很大时,探索的容忍度就很高。当需求量很少时,探索的容忍度就没那么高。
即流量充裕的时候,适当的探索可以接受;但是流量稀缺的时候,探索代价较大。
在商品供给受到限制的区域,探索和扩大库存的需求很高。当大量优质
listing空置时,几乎没有动力承担探索成本。即供给稀缺的时候,很有必要进行探索;但是供给充裕的时候,没动力进行探索。
供需反过来又受到位置
location、季节性seasonality、租客容量capacity等参数的影响。因此,为了最优地使用全局探索预算,需要数千个局部参数localizing parameters,这是一项无法手动完成的任务。- 当需求量
预估将来的用户互动
User Engagement:为了让系统更易于管理,我们退了一步,开始问:是什么让一个新的listing与众不同?答案当然是缺乏用户产生的互动特征
engagement features,例如预订量、点击量、评论量等等。价格、位置location、遍历设施amenities等其它属性,新listing和其它listing一样。理论上,如果我们有一个预言机可以100%准确预测新listing的互动特征,那么它可以最佳地解决冷启动问题。因此,我们没有将冷启动视为
explore-exploit tradeoff,而是将其重新定义为一个评估新listing互动值engagement values的问题。问题的重新定义揭示了一些重要的东西:它允许我们为问题定义一个客观的理想objective ideal,并不断地朝着它努力。为了解决冷启动问题,我们引入了一个新的组件
component来为DNN提供数据,该组件在训练和评估时预测新listing的用户互动特征。为了衡量估计器estimator的准确性accuracy,我们采用了以下步骤:从日志中采样 个搜索结果。对于每个搜索结果,从
top 100个位置随机抽取一个listing。这些代表了受到租客充分关注的listing样本,因此它们的互动特征已经充分融合converged。令 表示从日志中获取的抽样
listing的排名。我们将排名表示为real,从而表示listing的互动特征是真实租客互动的结果。从排名中,我们计算real discounted rank为:为什么采用这种形式的
DR指标?论文未给出解释。该指标的性质:真实排名越靠前,指标越大;指标最大值为1.0(当真实排第一名时)、最小值趋近于零。接下来,对于每个抽样的
listing,我们删除所有互动特征,并用被estimator预测的互动特征来代替它们。我们使用预估的互动特征对listing进行评分,在相应的日志搜索结果中找到它的新排名,然后从中计算discounted rank。我们用 来表示。对于每个抽样的
listing,我们计算互动估计中的误差为 。为了获取整体误差,我们对所有抽样的
listing的互动估计误差engagement estimation error进行平均。
理想的互动估计器会产生零误差。要在两个估计器之间取舍,可以选择误差较小的估计器。
为了验证,我们对比了两种估计方法:
baseline是生产中使用的系统,它为缺失的特征分配默认值,包括新listing的互动特征默认值。默认值是通过手动分析相应特征而创建的常量。我们对比了一个
estimator,这个estimator通过新listing地理位置附近的其它listing的互动特征均值来估计了新listing的互动特征。为了提高准确性
accuracy,它只考虑和新listing的房客容量capacity相匹配的相邻listing,并计算滑动时间窗口的均值从而考虑季节性seasonality。这本质上是一种缺失值填充策略:使用相似样本在该特征上取值的均值来进行填充。但是这种方式只能填充单值型的缺失值,难以处理序列型的缺失值。
例如,为了估计一个容纳两人的新
listing的预订量,我们选取了新listing的很小半径内的、容量为两人的所有listing的平均预订量。这在概念上类似于朴素贝叶斯推荐器
Naive Bayes recommender(它使用生成式方法generative method来估计缺失信息)。
测试结果:
- 在离线分析中,与使用默认值相比,上述互动估计器将互动估计误差降低了
-42%。 - 在在线
A/B test中,我们观察到新listing的预订量提高了+14%,同时新listing的首页曝光量增加了+14%。除了对新listing的影响之外,整体预订量增加了+0.38%,表明用户体验的整体改善。
- 在离线分析中,与使用默认值相比,上述互动估计器将互动估计误差降低了
14.3 Positional Bias
我们研究位置偏差
positional bias的出发点是完全不相关unrelated的。与新listing的NDCG较低的观察结果类似,另一个表现低于预期的细分市场是精品酒店boutique hotels和传统住宿加早餐酒店traditional bed and breakfasts。这个细分市场作为库存的一部分正在迅速增长。从观察中得出的一个假设是:由于位置偏差,在训练数据中未充分表达
under-represented的库存没有得到最佳排名。但是和新listing表现与冷启动之间的联系不同,没有充分理由相信位置偏差是这个case的唯一罪魁祸首。还有多个其它假设。虽然我们发现关注用户问题
user problem要比简单地从文献综述中引入想法要好得多,但是用户问题并不是万灵药。在用户问题和模型缺陷之间建立因果关系远远不是简单直接的。在目前的场景中,我们是在黑暗中射击shooting in the dark。但是与此同时,我们决定寻找模型中的最大
gap来解释观察结果。文献综述对于确定我们模型中潜在的主要gap至关重要。相关工作:给定用户 发出的
query,用户从搜索结果中预订listing的概率可以分解为两个因素:listing和用户相关relevant的概率。这个概率可以表示为 ,从而明确它和listing、用户、query的依赖关系。给定
listing在搜索结果中的位置 的条件下,用户检查examined该listing的概率。这可能取决于用户(例如,移动设备上的用户可能对top结果有更高的bias)或query(例如,提前期lead days较短的用户可能不太关注底部结果)。我们将这个概率表示为 ,它独立于
listing。即,用户看到这个
listing的概率,它和设备相关(如,PC端还是手机端,以及手机型号)、和用户紧迫程度有关(如,是今天就想入住,还是三个月之后入住)。
使用
《Click Models for Web Search》中描述的position based模型的简化建设,我们将用户预订listing的概率简单地表示为两个分解概率的乘积:通过直接训练一个模型来预测预订,该模型学会预测了依赖于 的 。这反过来又取决于位置 ,这是先前
previous的ranking模型做出的决定。因此,当前的模型变得依赖于先前的模型(指的是模型的前一个版本)。理想情况下,我们希望模型专注于 ,并仅按照相关性
relevance对listing进行排序。为了实现这一点,《Unbiased Learning-to-Rank with Biased Feedback》描述了一种具有两个关键概念的方法:- 一个预测 的倾向性模型
propensity model。 - 用预测的倾向的倒数来加权每个训练样本。
虽然构建倾向性模型通常涉及扰乱
perturbing搜索结果从而收集反事实counterfactuals的样本,但是《Estimating Position Bias Without Intrusive Interventions》描述了在没有额外干扰的情况下构建倾向模型的方法。位置作为控制变量
Position As Control Variable:我们的解决方案有两个关键亮点。首先,它是非侵入式
non-intrusive的,不需要对搜索结果进行任何随机化。我们依赖
Airbnb搜索结果的一些独特属性,这些属性使得listing即使在排序分不变的情况下也可能出现在不同的位置:listing代表给定日期范围内只能预订一次的物理实体physical entities。随着listing被预订并从搜索结果中消失,这会改变剩余listing的position。在
Airbnb中,每个item的库存只有一个,这和电商(每个item库存很多个)、新闻(每个item库存无限)不同。每个
listing都有自己独特的日历可用性unique calendar availability,因此对于跨日期范围的相似query,不同的listing会出现在不同的position。
其次,我们没有明确建立一个倾向模型。相反,我们在
DNN中引入位置position作为特征,并通过dropout进行正则化。在评分过程中,我们将position特征设置为零。
接下来我们描述为什么这种方法有效的直觉
intuition。我们以前面描述的DNN为基础,将query特征、用户特征、listing特征作为输入。利用符号 (query特征)、 (用户特征)、 (listing特征)、(DNN参数),我们将DNN的输出表示为:这反映了
《Click Models for Web Search》中position based模型所作的假设,其中:- 估计了 ,我们称之为相关性预测
relevance prediction。 - 预估 ,我们称之为位置偏差预测
positional bias prediction。
很明显 缺少
listing的位置 作为输入,而它试图估计的量依赖于 。因此,我们的第一步是将 作为输入特征添加到DNN。因为相关性预测和位置偏差预测都是由DNN的输入馈送fed的,因此向输入中添加 会将我们的DNN变为:假设 独立于
listing,位置偏差预测对 的任何依赖性dependence都可以被视为误差error。我们假设有足够数量的训练数据,待学习的参数 能够最小化该误差。我们将这个假设理解为:其中从 中移除 。
评分时,我们将位置特征 设置为零。在给定的
query中, 和 在DNN评分的listing中是不变的。我们使用 和 来表示给定搜索的query特征和用户特征。因此,位置偏差预测变为 ,它是对给定搜索结果中所有listing不变invariant的,我们将其记作 。那么DNN的评分变为:这使得两个
listing得分的比较独立于位置偏差positional bias,并且仅依赖于listing相关性relevance。本质上,我们在排序模型中添加了position作为控制变量control variable。对于给定的 和 (因此 是固定的),我们需要对所有的
listing进行位置无关的排序。则 的排序等价于 的排序。Position Dropout:在position based模型的假设下,增加position作为控制变量有效地消除了listing排序中的位置偏差预测,但是它引入了一个新的问题:相关性预测现在依赖于位置特征position feature。这使得DNN在训练期间依赖位置特征来预测相关性,但是在评分期间无法利用学到的、位置相关的知识(因为评分期间位置特征总是为零)。将具有位置特征的
DNN和没有位置特征的baseline进行比较,我们可以看到离线NDCG下降了大约-1.3%。因此,直接将位置作为控制变量引入模型似乎会损害相关性预测。为了减少相关性预测对于位置特征的依赖项,我们使用dropout对其进行正则化。在训练期间,我们随机性地将listing的position设为0,这个概率由dropout rate来控制。dropout rate在无噪声noise-free地访问位置特征从而准确地推断位置偏差vs有噪声noisy地访问位置特征从而远离相关性预测之间进行tradeoff。我们尝试通过以下步骤找到平衡的tradeoff:扫描一个范围内的
dropout rate,并在测试集上计算两种NDCG。- 第一个是在测试期间将
position为零,这衡量了相关性预测并表示为 。 - 第二个通过保留位置特征来衡量相关性和位置偏差组合在一起的预测,记作 。
- 第一个是在测试期间将
从而获得位置偏差预测。这里的直觉是:通过比较有位置输入和没有位置输入的排序质量,我们可以估计位置对于排序的贡献。
我们得到了 针对位置偏差预测的曲线,如下图所示。
Y轴为 ,X轴为位置偏差预测。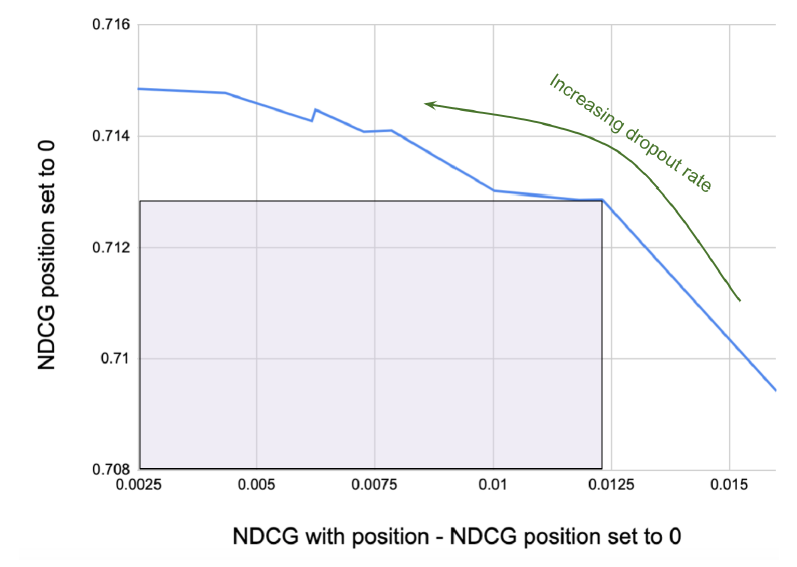
为了在相关性预测和位置偏差预测之间取得平衡,我们在曲线上选择一个点,该点在
X轴上的位置偏差预测足够先进advanced,而且不会导致Y轴上的相关性预测下降太多。
通过这个练习
exercise,我们最终选择了0.15的dropout rate。测试结果:我们通过在线
A/B test测试了这个想法,其中:对照组是没有位置偏差的DNN;实验组是相同的DNN,但是使用位置作为特征进行训练,并以0.15的dropout rate进行正则化。在在线测试中,我们观察到预订量增加了0.7%。除了预订量增加之外,收入增长
1.8%也是一个惊喜。收入增长这个副作用说明了位置偏差是如何在模型的多次迭代中累计起来的。对于排序模型来说,了解价格的影响相对容易,因为价格是一个非常清晰的特征,并且数据强烈表明人们更喜欢较低的价格。质量
quality、地域location等平衡力量balancing forces更难学习。因此,最初的简单模型严重依赖较低的价格。经过多次模型迭代,我们提高了对质量和地域的理解,但那时对更便宜的价格的
bias已经在训练数据中根深蒂固。这种黏性使得接下来的模型高估了对较低价格的偏好。消除positional bias使得模型更接近客人的真实偏好,并在价格、质量、地域之间取得更好的平衡。观察到的收入增长是其直接后果。最后,我们观察到精品酒店的预订量增加了
1.1%。
十五、HOP-Rec[2018]
推荐系统在现代无处不在,并且已经广泛应用于推荐音乐、书籍、电影等
item的服务。真实世界的推荐系统包括很多有利于推荐的user-item交互,包括播放时间、喜欢、分享、以及贴标签tag。协同过滤collaborative filtering: CF通常用于利用这种交互数据进行推荐,因为CF在各种推荐策略之间性能表现较好,并且不需要领域知识domain knowledge。有两种主流的
CF模型:潜在因子模型latent factor model和基于图的模型graph-based model。潜在因子模型通过分解
user-item矩阵来发现user-item交互背后的共享潜在因子shared latent factor。矩阵分解matrix factorization: MF是此类方法的典型代表。此外,最近的文献更多地关注从隐式数据优化
item排序,而不是预测显式的item score。大多数此类方法假设用户对未观察到的item不太感兴趣,因此这些方法旨在区分观察到的item(positive)和未观察到的item(negative)。总而言之,潜在因子模型通过分解观察到的用户和
item之间的直接交互来捕获用户偏好。基于图的模型探索了由用户、
item、及其交互构建的简单user-item二部图bipartite graph中固有的inherent、顶点之间的高阶邻近性high-order proximity。在某种程度上,这种基于图的方法放松了基于因子分解的模型所做出的假设(即:假设用户对未观察到的
item不太感兴趣),因为它们显式地对user-item交互二部图中的用户和item之间的高阶邻近性进行建模。总而言之,基于图的模型从由
user-item交互构建的图中捕获用户间接偏好。
在论文
《HOP-Rec: High-Order Proximity for Implicit Recommendation》中,作者提出了高阶临近性增强推荐模型high-order proximity augmented recommendation: HOP-Rec,这是一个结合了这两种隐式推荐方法(潜在因子模型和基于图的模型)的、统一而有效的方法。HOP-Rec通过在user-item二部图上进行随机游走,从而为每个用户发现邻域item的高阶间接信息high-order indirect information。通过对游走路径中不同阶数使用置信参数confidence parameter,HOP-Rec在分解用户偏好的潜在因子时同时考虑item的不同阶数。下图说明了在观察到的交互中对用户和
item之间的高阶邻近性建模的思想。- 图
(a)表示由观察到的user-item交互构建的二部图。 - 图
(b)给出了一条从源顶点 到目标顶点 的路径。 - 图
(c)以矩阵的形式记录了用户和item之间的直接交互(一阶邻近性)。 - 图
(d)以矩阵的形式显示了用户和item之间的高阶关系(高阶邻近性)。
具体而言,用户 的潜在偏好
item按照它们在图(b)中的路径中出现的阶数进行排序。例如,观察到的item和用户 具有一阶关系,未观察到的item和用户 具有二阶关系。HOP-Rec显式地建模这种高阶间接偏好信息high-order indirect preference information。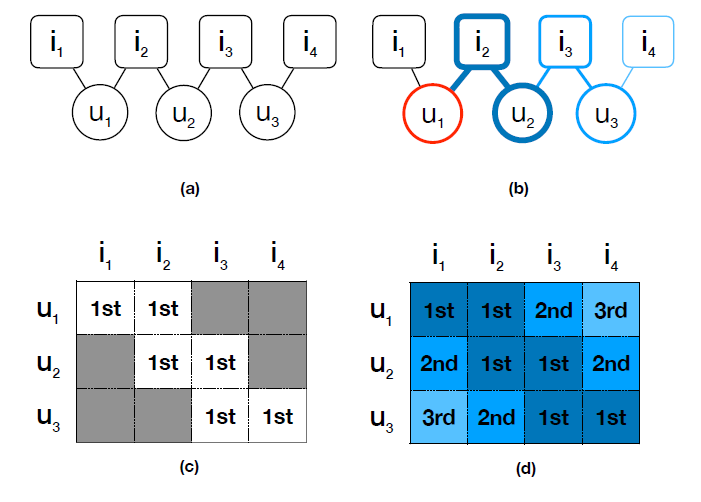
在真实世界四个大规模数据集上的实验结果表明,
HOP-Rec显著优于几种state-of-the-art的推荐算法,并表明将高阶邻近性和因子分解模型相结合对于一般的top-N隐式推荐问题很有帮助。
15.1 模型
15.1.1 因子分解模型和图模型
交互图
Interaction Graph的定义:user-item交互由一个二元邻接矩阵 来表示,二部交互图bipartite interaction graph基于二元邻接矩阵 来构建。其中:- 为用户集合, 为
item集合, 为顶点集合。 - 表示是否存在交互,边集合 。
- 为用户集合, 为
k阶邻近性k-order Proximity的定义:给定一个交互图 ,顶点 之间的k阶邻近性由它们在图上随机游走生成的序列中的转移概率来定义,其中 。具体而言,令 表示从源顶点 开始的随机游走序列,其中 和 分别表示顶点 的第 个邻居用户和第 个邻居
item。源顶点 与其第 个邻居item之间的k阶邻近性定义为 ,其中:- 表示从 到 的
k阶转移概率。 - 是
k阶衰减因子decay factor。例如 。
如果从 到 不存在可行的路径,则
k阶邻近性为零。- 表示从 到 的
Factorization Model: FM模型:因子分解模型的目标是估计以下两个潜在因子集合:,其中:- 为用户潜在因子集合, 为
item潜在因子集合, 为潜在因子空间的维度。 - 为 的超集,由我们模型中的所有参数组成。
令 表示用户 在 中的行向量, 表示
item在 中的行向量,则MF针对隐式反馈数据集的目标函数为:其中:
- , 为置信度水平
confidence level。通常选择 ,即观察到交互的user-item置信度高于未观察到交互的user-item。 - 为二元变量表示在邻接矩阵 中观察到的用户 和
item是否有交互。 - 正则化参数 是防止观测值过拟合的超参数。
在各种基于因子分解的模型中,基于排序
ranking-based的模型在top-N推荐问题中表现突出。基于排序的模型如BPR和WARP已经从传统的point-wise方法(绝对关系)转变为pairwise方法(相对关系),其中排序损失ranking loss可以定义为:其中:
- 表示用户 观察到的
item(positive), 表示用户 未观察到的item(negative), 。 - 函数 表示
item排序问题的通用目标函数。具体而言,在BPR中, 是由logistic sigmoid函数、对数函数、示性函数组成的排序函数。在WARP中, 由权重近似的排序函数和一个示性函数组成。
基于排序的模型假设用户更喜欢观察到的
item而不是未观察到的item,因此其目标是从每对item pair中区分出偏好的item。- 为用户潜在因子集合, 为
Graph Model模型:除了通常研究的基于因子分解的模型之外,人们还提出了几个基于图的模型,这些模型利用随机游走来对推荐的item进行排序。具体而言,这类模型的主要思想是将user-item交互矩阵 视为交互图,并在图上使用随机游走从而引入间接偏好信息来提供推荐。
15.1.2 HOP-Rec 模型
尽管基于因子分解的模型隐式地推断用户对未观测
item的偏好,但是最近的研究表明显式地建模此类潜在偏好potential preference可以提高推荐系统的性能。受到因子分解模型和图模型的启发,我们提出了HOP-Rec。这是一个统一的框架:HOP-Rec在给定的user-item交互矩阵中捕获高阶偏好信息。HOP-Rec通过在相应的交互图上使用随机游走来扩展scale到大规模的真实世界数据集。
HOP-Rec的目标函数定义为:其中:
- 表示从随机游走序列 中采样
item的k阶概率分布(即前面定义的 )。 - 表示从所有
item的集合中采样item的均匀分布。 - 表示在我们的方法中建模的最大阶数。
上述物理含义是:以概率 随机采样 的
k阶邻居item作为正样本、以均匀随机采样item作为负样本,然后对它们的pairwise loss进行衰减降权(由 指定衰减因子)。注意:每个正样本采样 个负样本, 为超参数。从另一个角度来看,我们通过从
user-item交互中推断高阶邻近性来丰富最初的稀疏图。它的本质是:数据集增强技术。即利用二部图来增强正样本(同时对每个正样本负采样 个负样本),另外对增强的样本赋予一个小于
1的权重。- 表示从随机游走序列 中采样
HOP-Rec方法背后的主要思想是:通过随机游走来近似高阶概率矩阵分解,其中随机游走具有一个置信权重confidence weighting的衰减因子, 。引入置信度加权参数 来区分不同邻近性之间的强度。具体而言,我们选择 作为衰减因子。注意,我们没有通过矩阵运算直接分解转移概率矩阵矩阵,这对于大规模数据集是不可行的。而随机游走近似矩阵分解已经被证明是有效和准确的。
通过这种方式,我们不仅通过引入高阶偏好信息来平滑观察的
item和未观察的item之间的严格边界(“非此即彼”的边界),而且使得我们的方法可以扩展到大规模的现实世界数据集。具体而言,我们首先引入随机游走从而为每个用户 在交互图上探索。给定从 开始的随机游走序列 ,我们采样用户 的
k阶潜在偏好的item(即用户 的k阶邻居item)。此外,在现实世界的数据集中,用户集合 和
item集合 的degree分布通常呈现幂律分布power-law distribution。如果我们使用均匀采样,那么大多数采样路径都是低degree的用户顶点和item顶点。考虑到这一点,我们在随机游走过程中使用了degree采样,即:对于随机游走采样的每一个step,我们分别以正比于deg(u)的概率对用户 采样、以正比于deg(i)的概率对item采样。如何采样正样本很关键,不同的采样方式产生不同的结果。
我们定义 函数为:
其中:
- 为示性函数,当条件
B为真时返回1、为假时返回0。上式中仅当 才考虑损失(即负样本的偏好分更高)。 - 为阶数相关的阈值参数,设置为 。这是因为阶数越高, 和 的偏好分越低,则阈值也需要越小。
注意,
item是从所有item的集合中均匀采样的,因为我们对用户不喜欢的item采用假设的均匀分布 。这个假设是合理的,因为在很多真实场景中,对每个用户来讲,喜欢的item(观察到的item)通常远远少于不喜欢的item(未观察到的item)。- 为示性函数,当条件
HOP-Rec模型的目标函数可以通过异步随机梯度下降asynchronous stochastic gradient descent: ASGD来优化。
15.2 实验
数据集:为了验证
HOP-Rec的能力和可扩展性,我们在四个公共数据集上进行了实验,这些数据集在领域domain、规模、稀疏性方面各不相同,如下表所示。对于每个数据集,我们丢弃那些交互少于
5个的用户和item。此外,我们对每个数据集的交互记录进行预处理,从而模拟用户的隐式二元反馈:- 对于包含显式评分记录的
Amazon-book和MovieLens数据集,我们将所有>=4分的评分记录转换为label = 1、将<4分的评分记录转换为label = 0。 - 对于
CiteUlike数据集,不进行任何转换,因为它本身就是一个二元偏好数据集。
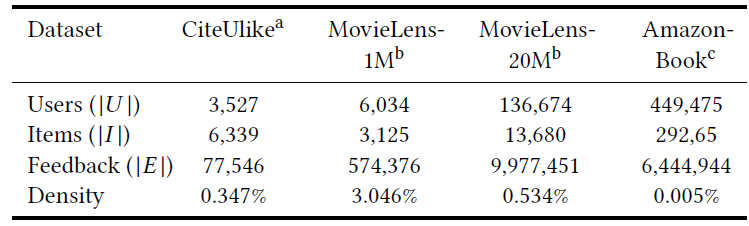
- 对于包含显式评分记录的
baseline方法:矩阵分解
Matrix Factorization: MF:MF是一种成熟且常用的user-item推荐技术。在实验中我们使用implicit library,它用交替最小二乘法alternating least-square: ALS实现了MF。贝叶斯个性化排序
Bayesian Personalized Ranking: BPR:BPR扩展了MF的pointwise方法,并引入pairwise ranking loss来进行个性化推荐。Weighted Approximate-Rank Pairwise: WARP损失:WARP是一种有效估计排序函数的近似方法,其主要思想是根据它们在排序列表中的位置来加权pairwise违规violation。K-Order Statistic: K-OS损失:K-OS通过在优化过程中考虑正样本集合来扩展WARP,其中K表示考虑的正样本数量。注意,当K=1时K-OS退化为WARP。对于
BPR, WARP, K-OS三种方法,我们使用lightfm library进行实验。Popularity-based Re-ranking: RP3(β):该方法作为各种graph-based方法的一个强基线。该方法通过调节热门item的权重重新加权ranking score,这个ranking score是基于随机游走而得到。该方法的评估时用原始作者提供的library进行的。
实验配置:
- 对于
top-N推荐,我们使用了以下三个常见的评估指标:precision@N、recall@N、MAP@N。 - 对于每个数据集,我们将二元交互矩阵随机分为两个部分:
80%作为训练集、20%作为测试集。报告的性能取20次实验的测试集均值。 - 所有基于分解的方法以及提出的
HOP-Rec都使用两个潜在因子的内积作为评分函数。 - 除了
RP3(β)这种以转移概率为排序分的纯图方法之外,其它方法的潜在因子 的维度固定为120。除了 之外,所有其它超参数都是在第一次评估时使用网格搜索和测试集基于MAP来选择。 - 对于
HOP-Rec,我们搜索了从1 ~3的最佳阶数K,以及针对不同规模数据集的采样倍数N(对于CiteUlike/MovieLens- 1M/MovieLens-20M/Amazon-Book数据集,最佳采样倍数分别为90/60/300/800)。 - 对于
HOP-Rec, 都是在 范围内随机均匀初始化,并且 。
- 对于
HOP-Rec和其它五种baseline方法的性能比较如下表所示,其中:*表示相对于所有baseline方法在 (成对t检验)时的统计显著性;%Improv表示相对于最佳baseline的性能提升比例。注意,原始library的资源限制阻碍了我们在Amazon-Book上进行PR3(β)实验。可以看到:
WARP,K-OS,PR3(β)是很强的baseline方法,因为它们和其它两种方法MF,BPR之间存在显著的性能差距。HOP-Rec通常产生优于或者相当与五种baseline方法的性能。
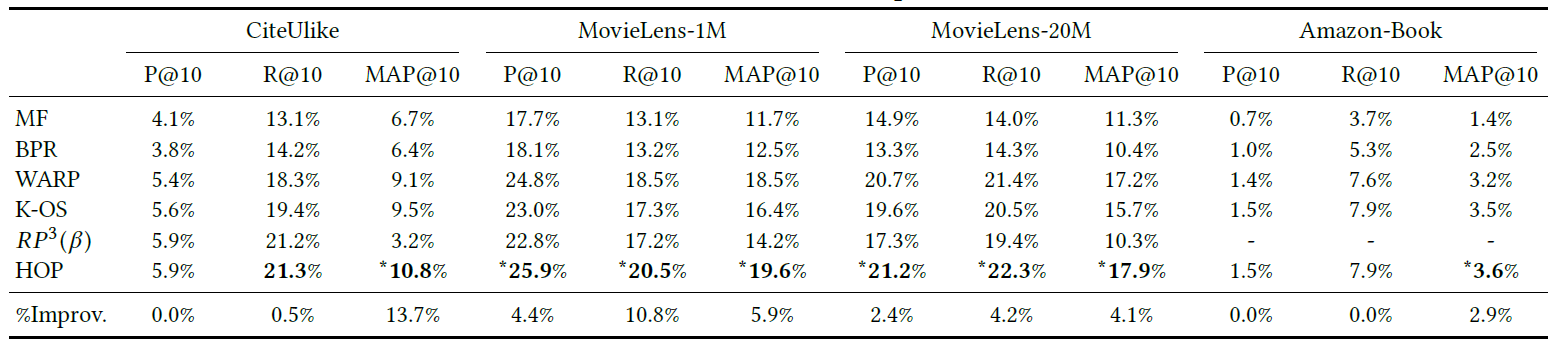
为进一步检查
HOP-Rec中建模高阶邻近性的有效性,我们评估了关于参数K的性能,结果如下图所示。可以看到:融合高阶邻近性可以提升HOP-Rec的性能,但是对于最大的数据集Amazon-Book,当K=3时性能下降。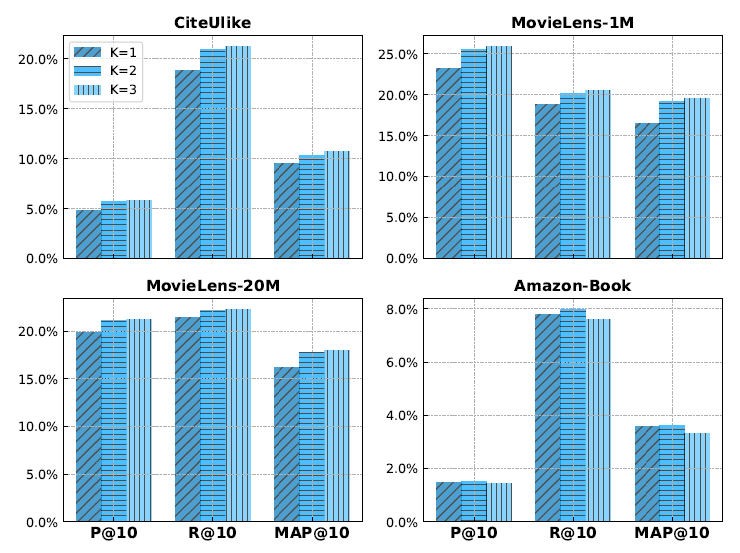
十六、NCF[2017]
在信息爆炸的时代,推荐系统在缓解信息过载
information overload方面发挥着举足轻重的作用,并且已经被许多在线服务广泛采用,包括电商、在线新闻、社交媒体网站。个性化推荐系统的关键在于根据用户历史交互(例如评分、点击)对user-item的偏好进行建模,这就是所谓的协同过滤collaborative filtering。在各种协同过滤技术中,矩阵分解
matrix factorization: MF是最流行的一种,它将用户和item投影到共享的潜在空间latent space中,使用潜在特征向量来表示用户和item。此后,用户对item的交互被建模为它们潜在向量latent vector的内积。通过Netflix Prize的推广,MF已经成为基于潜在因子模型latent factor model-based的推荐的事实上的方法。许多研究工作致力于增强
MF,例如将其与基于邻域的模型neighbor-based model相结合、将其与item内容的主题模型topic model相结合、将其扩展到分解机factorization machine从而进行特征的通用建模。尽管
MF对于协同过滤很有效,但是众所周知,它的性能可能会受到简单选择“内积” 作为交互函数的阻碍。例如,对于基于显式反馈的评分预测任务,众所周知,可以通过将user bias项和item bias项添加到交互函数中从而提高MF模型的性能。虽然这对于内积算子而言似乎只是一个微不足道的调整,但是它指出了设计一个更好的、专用的交互函数来建模用户和item之间潜在特征交互的积极效果。内积算子,它仅仅简单地线性组合多个潜在特征latent feature的乘法,可能不足以捕获用户交互数据的复杂结构。在论文
《Neural Collaborative Filtering》中,作者探讨了使用深度神经网络从数据中学习交互函数,而不是像以前许多工作那样人工设计交互函数。神经网络已经被证明能够逼近任何连续函数,而且最近发现神经网络deep neural networks: DNNs在多个领域都有效 ,从计算机视觉、语音识别到文本处理。然而,与大量关于MF方法的文献相比,使用DNN进行推荐的工作相对较少。尽管最近的一些进展已经将DNN应用于推荐任务并显示出有希望的结果,但是它们主要使用DNN来建模辅助信息auxiliary information,例如item的文本描述、音乐的音频特征、图像的视觉特征。在建模关键的协同过滤效果方面,他们仍然采用MF,使用内积来结合用户潜在特征和item潜在特征。论文通过形式化formalize用于协同过滤的神经网络建模方法来解决上述研究问题(利用神经网络来建模交互函数)。通过采用可以从数据中学习任意函数的神经网络架构代替内积,论文提出了一个名为Neural Network-based Collaborative Filtering: NCF的通用框架。论文聚焦于隐式反馈
implicit feedback,隐式反馈通过视频观看、商品购买、item点击等行为间接反映了用户的偏好。和显式反馈explicit feedback(即显式评分rating和评论review)相比,隐式反馈可以自动跟踪,因此更容易被内容提供商content provider所收集。然而,隐式反馈的使用更具有挑战性,因为无法观察到用户满意度user satisfaction,并且负反馈negative feedback天然的稀疏性。在本文中,作者探讨了如何利用DNN对包含噪音的隐式反馈信号进行建模。论文的主要贡献:
- 论文提出了一个神经网络架构来对用户和
item的潜在特征进行建模,并设计了一个基于神经网络的协同过滤通用框架NCF。 - 论文表明:
MF可以被解释为NCF的特殊情况,并利用多层感知机赋予NCF模型高度的非线性。 - 论文在两个真实数据集上进行了大量的实验,从而证明
NCF方法的有效性,以及深度学习在协同过滤方面的前景。
- 论文提出了一个神经网络架构来对用户和
相关工作:
隐式反馈:虽然关于推荐的早期文献主要集中在显式反馈,但最近人们越来越关注隐式数据。具有隐式反馈的协同过滤
collaborative filtering: CF任务通常被形式化为item推荐问题,其目的是向用户推荐一个简短的item列表。和显式反馈工作广泛解决的评分预测相比,解决item推荐问题更实用但更具有挑战性。一个关键的洞察insight是对缺失数据进行建模,而这些缺失数据总是被显式反馈的工作所忽略。为了使用隐式反馈为
item推荐定制tailor潜在因子模型,早期工作应用了两种均匀加权策略:将所有缺失数据视为负样本,或者从缺失数据中均匀采样负样本。最近,《Fast matrix factorization for online recommendation with implicit feedback》和《Modeling user exposure in recommendation》提出了专门的模型来对缺失数据进行加权。《A generic coordinate descent framework for learning from implicit feedback》为基于特征的分解模型开发了一种隐式坐标下降implicit coordinate descent: iCD解决方案,实现了state-of-the-art的item推荐性能。基于神经网络的推荐:早期先驱工作
《Restricted boltzmann machines for collaborative filtering》提出了一种两层受限玻尔兹曼机Restricted Boltzmann Machine: RBM来建模用户对item的显式评分。《Ordinal boltzmann machines for collaborative filtering》扩展了该工作从而对评分的保序性质ordinal nature进行建模。最近,自编码器已经成为构建推荐系统的流行选择。
《Autorec: Autoencoders meet collaborative filtering》提出了基于用户的AutoRec,其思想是学习隐藏的结构hidden structure,这些结构可以根据用户的历史评分作为输入从而重构用户的评分。在用户个性化方面,该方法与item-item模型(将用户表示为他/她的历史评分item)具有相似的精神。为了避免自编码器学习恒等函数
identity function从而无法泛化到未见unseen的数据,降噪自编码器denoising autoencoder: DAE应用于从故意损坏的输入中学习。最近
《A neural autoregressive approach to collaborative fi ltering》提出了一种用于CF的神经自回归方法。虽然这些工作为神经网络解决
CF的有效性提供了支持,但是其中大多数都专注于显式评分,并仅对观察到的数据进行建模。结果,对于从只有正样本的隐式数据中学习的任务,它们很容易失败。神经网络用于隐式反馈的推荐:最近的一些工作探索了基于隐式反馈的深度学习模型来进行推荐,但是他们主要使用
DNN对辅助信息进行建模,例如item的文本描述、音乐的声学特征、用户的跨域行为、以及知识库中的丰富信息。然后,将DNN学到的特征与用于协同过滤的MF集成。与我们的工作最相关的工作是
《Collaborative denoising auto-encoders for top-n recommender systems》,它为CF提供了一个带有隐式反馈的协同降噪自编码器collaborative denoising autoencoder: CDAE。 和DAE-based CF相比,CDAE额外地将一个用户节点插入到自编码器的输入中从而重建用户的评分。如作者所示,当应用恒等映射作为CDAE的隐层激活函数时,CDAE等效于SVD++模型。这意味着虽然CDAE是一种用于CF的神经网络建模方法,但是它仍然应用线性核linear kernel(即内积)来对user-item交互进行建模。这可以部分解释为什么CDAE使用更深的层不会提高性能。与
CDAE不同,我们的NCF采用双路架构,使用多层前馈神经网络对user-item交互进行建模。这允许NCF从数据中学习任意函数,比固定的内积函数更强大、更具表达能力。其它工作:沿着类似的路线,在知识图谱文献中已经深入研究了学习两个实体之间的关系。已有很多关系型机器学习
relational machine learning method方法被提出。与我们的方法最相似的一个是神经张量网络Neural Tensor Network: NTN,它使用神经网络来学习两个实体的交互并展示层强大的性能。在这里,我们关注协同过滤的不同problem setting。虽然将MF和MLP相结合的NeuMF的思想部分受到NTN的启发,但是在允许MF和MLP学习不同的embedding集合方面,我们的NeuMF比NTN更灵活、更通用。最近,谷歌公布了他们用于
App推荐的Wide & Deep方法。Deep组件同样在特征embedding之上使用MLP,据报道它具有很强的泛化能力。虽然他们的工作重点是结合用户和item的各种特征,但是我们的目标是探索纯协同过滤系统的DNN。我们表明,DNN是对user-item交互建模的一个很有前景的选择。据我们所知,以前从未有工作对此进行研究过。
16.1 模型
16.1.1 基本概念
我们首先将问题形式化并讨论现有的带隐式反馈的协同过滤解决方案。然后我们简短地概括了广泛使用的
MF模型,并强调其内积造成的局限性。从隐式数据中学习
Learning from Implicit Data:令 表示用户数量、 表示item数量。定义从用户隐式反馈implicit feedback得到的user-item交互矩阵 为:注意:
- 表示用户 和
item之间存在交互,然而这并不意味着用户 真的喜欢item。 - 表示用户 和
item之间不存在交互,这也并不意味着用户 真的不喜欢item,可能是因为用户 没注意到item。
这给从隐式数据中学习带来了挑战,因为隐式数据仅提供了关于用户偏好
users' preference的带噪音的信号noisy signals。虽然观察到的item至少反映了用户对item的兴趣,但是未观察到的item可能只是缺失的数据missing data,并且天然natural缺乏负反馈negative feedback。带隐式反馈的推荐问题被表述为估计 中未观察到的
item的得分score的问题,其中这些score用于对item进行排序。model-based方法假设数据可以由底层模型生成(或描述)。形式上, 模型可以抽象为学习:其中:
- 表示对交互 的预估分
predicted score。 - 表示模型参数; 表示将模型参数映射到预估分的函数,我们称之为交互函数
interaction function。
为了估计参数 ,现有方法通常遵循优化目标函数的机器学习范式。文献中最常用的目标函数有两种:
point-wise loss和pair-wise loss。- 作为显式反馈
explicit feedback大量工作的自然延伸,point-wise loss通常定义为最小化 和目标值 之间的平方损失。为了处理negative data的缺失,他们要么将所有未观察到的item视为负样本、要么从未观察到的item中采样负样本。 pair-wise loss的思想是:观察到的item应该比未观察到的item的排名更高。因此,它不是最小化 和目标值 之间的损失,而是pair-wise learning最大化观察到的item和未观察到的item之间的边距margin。
更进一步地,我们的
NCF框架使用神经网络参数化交互函数 从而估计 。因此,NCF自然支持point-wise learning和pair-wise learning。- 表示用户 和
矩阵分解
Matrix Factorization: MF:MF将每个用户、每个item都和潜在特征向量latent feature vector相关联。令 表示用户 的潜在特征向量, 表示用户 的潜在特征向量。MF估计estimate交互 为 和 的内积:其中 为潜在空间
latent space的维度。正如我们所看到的,
MF对用户潜在因子latent factor和item潜在因子的双向交互two-way interaction进行建模,假设潜在空间的每个维度彼此独立,并以相同的权重线性组合它们。因此,MF可以视为潜在因子的线性模型。下图说明了内积函数如何限制
MF的表达能力。为了更好地理解示例,有两个设置settings需要事先说明。- 首先,因为
MF将用户和item都映射到相同的潜在空间,所以两个用户之间的相似性也可以用内积来衡量(或者它们潜在向量之间的余弦相似度来衡量)。 - 其次,不失一般性,我们使用
Jaccard系数(用户A观察到的item集合与用户B观察到的item集合之间的Jaccard系数)作为MF需要恢复的、两个用户之间的真实相似度ground-truth similarity。
我们首先关注图
(a)中的前三行(用户)。很容易有 。因此, 在潜在空间中的几何关系可以如图(b)所示绘制。现在,让我们考虑一个新的用户 ,其输入如图
(a)中的虚线所示。所以我们有 ,这意味着 最类似于 、其次是 、最后是 。但是,如果MF模型将 放置在最接近 的位置(图(b)中用虚线显示的两个选择),则会导致 更靠近 而不是更靠近 ,而这会导致更大的排序损失ranking loss。这个例子显示了
MF使用简单的、且固定的内积来估计低维潜在空间中复杂的user-item交互的限制。在这个例子中,我们注意到解决该问题的一种方法是使用更大的潜在因子数量 (即更高维的潜在空间)。 然而,这种方法可能会对模型的泛化能力产生不利影响(如,过拟合),尤其是在数据稀疏的环境中。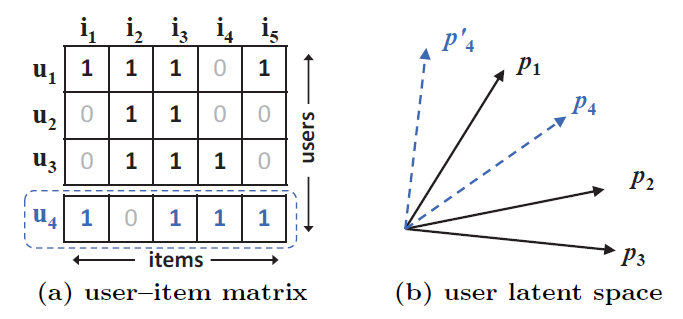
- 首先,因为
在本文中,我们通过从数据中使用
DNN学习交互函数来解决MF的这个限制。- 我们首先介绍了通用的
NCF框架,详细说明了如何学习NCF的概率模型,该模型强调了隐式数据的二元属性binary property。 - 然后我们证明了
MF可以在NCF下表达和推广。 - 为了探索用于协同过滤的
DNN,我们接着提出NCF的实例化,使用多层感知机multi-layer perceptron: MLP来学习user-item交互函数。 - 最后,我们提出了一个新的神经矩阵分解模型,它在
NCF框架下集成了MF和MLP,从而统一了MF的线性和MLP的优势来建模user-item潜在结构latent structures。
- 我们首先介绍了通用的
16.1.2 NCF 通用框架
为了允许全
full神经网络来处理协同过滤, 我们采用multi-layer representation来建模user-item交互 ,如下图所示。其中前一层的输出作为后一层的输入。底部输入层由两个特征向量 和 组成,分别表示用户 输入特征和
item输入特征。输入特征向量可以自定义
customized从而支持广泛的用户建模和item建模,例如上下文感知context-aware建模、content-based建模、neighbor-based建模。由于这项工作聚焦于纯粹pure的协同过滤设置setting,我们仅采用user id和item id作为输入特征,并将其转换为稀疏的one-hot向量。基于输入的这种通用特征表示
generic feature representation,我们的方法可以通过使用内容特征来表示用户和item,从而轻松地解决冷启动问题cold-start problem。输入层之上是
embedding层,它是一个全连接层,将稀疏表示sparse representation投影到稠密向量dense vector。得到的user embedding(item embedding)可以视为潜在因子模型背景下的用户潜在向量(item潜在向量)。然后,用户
embedding和item embedding被馈入多层神经架构,我们称之为神经协同过滤层neural collaborative filtering layers,从而将潜在向量映射为预估分。神经
CF层的每一层都可以自定义,从而发现user-item交互的某些潜在结构。最后一个隐层X的维度决定了模型的能力。最终的输出层是预估分 ,并通过最小化 和目标值 之间的
point-wise loss来进行训练。我们注意到训练模型的另一种方法是执行
pair-wise learning,例如使用Bayesian Personalized Ranking和margin-based loss。由于本文的重点是神经网络建模部分,我们将扩展NCF的pair-wise learning作为未来的工作。

我们形式化
NCF预测模型为:其中:
- 分别表示用户和
item的潜在因子矩阵latent factor matrix。 - 表示交互函数 的模型参数。
由于交互函数 定义为一个多层神经网络,因此它可以被形式化为:
其中 为输出层的映射函数, 为第 层神经协同过滤层的映射函数,并且一共有 层神经协同过滤层。
- 分别表示用户和
为了学习模型参数,现有的
point-wise方法主要使用平方损失进行回归:其中:
表示 中观测交互的集合。
表示负样本的集合,它们是所有未观测交互,或者从未观测交互中采样而来。
表示训练样本 的权重超参数。通常选择 ,即观察到交互的
user-item权重高于未观察到交互的user-item。这里 表示未观察到交互的样本。
虽然平方损失可以通过假设观测值
observations由高斯分布产生来解释,但是我们指出这可能与隐式数据不符。这是因为对于隐式数据,目标值 是二元的1或者0,表示用户 是否和item进行了交互。这里我们提出了一种用于学习point-wise NCF的概率方法,该方法特别关注隐式数据的二元属性binary property。考虑到隐式反馈的
one-class特性,我们可以将 的值视为一个label:1表示item和用户 相关,0表示item和用户 不相关。预估分 表示item和用户 的相关程度。为了赋予NCF这样的概率解释,我们需要将输出 限制在[0.0, 1.0]之间。这可以通过使用概率函数(例如Logistic或Probit函数)作为输出层 的激活函数轻松实现。通过这种setting,我们将似然函数定义为:使用负的对数似然,我们得到:
这是
NCF方法需要最小化的目标函数,其优化可以通过执行随机梯度下降stochastic gradient descent: SGD来完成。细心的读者可能已经意识到它与二元交叉熵损失binary cross-entropy loss(也称作对数损失log loss)相同。通过对
NCF进行概率处理,我们将带有隐式反馈的推荐作为二元分类问题来解决。由于分类感知classification-aware的log loss在推荐文献中很少被研究,我们在这项工作中对其进行了探索,并在实验中证明了其有效性。对于负样本集合 ,我们在每次迭代中从未观察的交互中均匀随机采样,并控制采样比例
sampling ratio(这个比例是相对于观察到的交互数量)。虽然非均匀采样策略(例如,item popularity-biased)可能会进一步提高性能,但是我们将这个探索留作未来的工作。
16.1.3 广义矩阵分解 GMF
我们现在展示如何把
MF解释为我们NCF框架的一个特例。由于MF是最流行的推荐模型,并在文献中进行了广泛的研究,因此能够复原MF使得NCF可以模拟一大族因子分解模型。由于
NCF输入层的user ID(或者item ID)是one-hot编码,因此得到的embedding向量可以视为user(或者item)的隐向量。令用户 的潜在向量 为 ,item的潜在向量 为 。我们将第一层神经协同过滤层的映射函数定义为:其中 为向量之间的逐元素乘积。
然后我们将结果向量投影到输出层:
其中 为激活函数, 为输出层的权重向量。
直观地讲,如果我们选择 为恒等映射、并且令 为全
1的向量,那么我们就可以准确地复原MF模型。在
NCF框架下,MF可以很容易地推广和扩展。例如:如果我们允许 可以从数据中学习(而不是固定的常量),那么它将导致
MF的一个变体,这个变体允许MF模型学习各潜在维度的不同重要性。如果我们对 使用非线性函数,那么它将导致
MF的一个变体,这个变体是一个非线性模型,并且可能比线性MF模型更具有表达能力。在这项工作中,我们在
NCF框架下实现了一个广义版本的MF,它使用sigmoid函数作为 ,并且以对数损失为目标从数据中学习 。其中:我们称这个模型为广义矩阵分解
Generalized Matrix Factorization: GMF。
16.1.4 多层感知机
由于
NCF使用两路分别对用户和item进行建模,因此通过将这两路特征拼接起来从而组合它们的特征是很直观的。这种设计已经在多模态multimodal深度学习工作中广泛采用。 然而,简单的向量拼接并没有考虑用户潜在特征和item潜在特征之间的任何交互,这不足以建模协同过滤效果。为了解决这个问题,我们提出在拼接向量上添加隐层,使用标准MLP来学习用户潜在特征和item潜在特征之间的交互。从这个意义上讲,我们可以赋予模型很大程度的灵活性和非线性从而学习 和 之间的交互,而不是像GMF那样只使用一个固定的逐元素乘积。具体而言,我们的
NCF框架下的MLP模型定义为:其中 分别为第 层感知机的权重矩阵、偏置向量、激活函数。
对于
MLP层的激活函数,可以自由选择sigmoid、tanh、ReLU等。sigmoid函数将每个神经元限制在(0.0,1.0)之间,这可能会限制模型的性能。众所周知,sigmoid受到饱和saturation的影响:当神经元的输出接近0或1时,神经元就会停止学习。尽管
tanh是更好的选择并且已经被广泛采用,但是它只能一定程度上缓解sigmoid的问题。因为tanh可以视作sigmoid的rescale版本:最终我们选择
ReLU,它在生物学上更合理,并且被证明是非饱和non-saturated的。此外,它鼓励稀疏激活sparse activations(即大多数神经元是非激活的) ,非常适合稀疏数据并使得模型不太可能过拟合。我们的实验结果表明:ReLU的性能略优于tanh,而tanh又明显优于sigmoid。
对于网络结构的设计,最常见的解决方案是采用塔式模式
tower pattern,其中底层最宽、接下来每一层的神经元数量依次减少。基本假设是:对更高层使用更少的隐单元,使得更高层能够学习数据的更抽象的特征。我们根据经验实现了塔式结果,将每个连续层的神经元数量减半。
16.1.5 融合 GMF 和 MLP
到目前为止,我们已经开发了
NCF的两个实例:GMF应用一个linear kernel来建模潜在特征交互。MLP使用一个non-linear kernel来从数据中学习非线性交互。
那么接下来的问题是:我们如何在
NCF框架下融合GMF和MLP,以便它们可以相互加强从而更好地建模复杂的user-item交互?一个简单的解决方案是:让
GMF和MLP共享相同的embedding层,然后组合combine它们交互函数的输出。这种方式与著名的神经张量网络Neural Tensor Network: NTN有着相似的精神。具体而言,将
GMF和one-layer MLP相结合的模型可以表述为:然而,共享
GMF和MLP的embedding可能会限制模型的性能。这意味着GMF和MLP使用相同大小的embedding。对于两个子模型最佳embedding大小差异很大的数据集,该解决方案可能无法获得最佳的集成ensemble。为了给融合模型
fused model提供更大的灵活性,我们允许GMF和MLP学习单独的embedding,并通过拼接它们最后一个隐层来组合这两个模型。下图给出了我们的方案,其公式如下:其中:
- 和 分别表示
GMF和MLP部分的user embedding。 - 和 分别表示
GMF和MLP部分的item embedding。 - 如前所述,我们使用
ReLU作为MLP layer的激活函数。
该模型结合了
MF的线性和DNN的非线性,从而对user-item潜在结构进行建模。我们将该模型称作神经矩阵分解Neural Matrix Factorization: NeuMF。模型相对于每个参数的导数可以用标准的反向传播来计算,由于空间限制这里省略了标准反向传播的描述。
NeuMF类似于DeepFM,它们相同点在于:都使用线性部分来直接捕获特征交互;都使用非线性DNN来捕获非线性交互;都通过拼接两部分来同时捕获线性和非线性交互。区别在于:
NeuMF的线性部分仅捕获user和item之间的二阶交互,而DeepFM捕获所有特征之间的二阶交互。但是这里NeuMF只有user id和item id特征,因此它们之间的二阶交互也意味着所有特征的二阶交互。NeuMF的两个组件独立使用embedding,而DeepFM使用共享的embedding。

预训练:由于
NeuMF目标函数的非凸性non-convexity,基于梯度的优化方法只能找到局部最优解。据报道,初始化对深度学习模型的收敛和性能起着重要作用。由于NeuMF是GMF和MLP的集成ensemble,我们提出使用GMF和MLP的预训练模型初始化NeuMF。我们首先使用随机初始化来训练
GMF和MLP,直到收敛。然后我们使用
GMF和MLP模型的参数作为NeuMF相应参数部分的初始化。唯一的调整是在输出层,我们将两个模型的权重拼接起来作为初始化:其中:
- 和 分别表示预训练的
GMF模型和MLP模型的 向量。 - 是决定两个预训练模型之间
tradeoff的超参数。
- 和 分别表示预训练的
为了从头开始训练
GMF和MLP,我们采用Adaptive Moment Estimation: Adam优化器,它通过对频繁参数frequent parameters执行较小的更新、对不频繁参数infrequent parameters执行较大的更新,从而调整每个参数的学习率。和普通SGD相比,Adam方法为两种模型都产生了更快的收敛速度,并缓解了调整学习率的痛苦。在将预训练参数输入
NeuMF之后,我们使用普通SGD而不是Adam进行优化。这是因为Adam需要保存动量信息momentum information以正确更新参数。由于我们仅使用预训练模型的参数来初始化NeuMF并放弃保存动量信息,因此不适合使用基于动量的方法进一步优化NeuMF。
16.2 实验
我们进行实验以回答以下三个问题:
RQ1:我们提出的NCF方法是否优于state-of-the-art的隐式协同过滤方法?RQ2:我们提出的优化框架(带负采样的log loss)如何用于推荐任务?RQ3:更深层的网络是否有助于从user-item交互数据中学习?
接下来,我们首先介绍实验配置,然后回答上述三个问题。
数据集:我们在两个公共数据集上进行实验。
MovieLens:一个电影评分数据集,该数据集已经被广泛用于评估协同过滤算法。我们使用包含100万个评分的版本,其中每个用户至少有20个评分。虽然它是一个显式反馈数据集,但是我们有意选择它来研究从显式反馈的隐式信号中学习的性能。为此,我们将其转换为隐式数据,其中每一项被标记为
0或1,表明用户是否对该item进行了评分。Pinterest:一个基于内容的图像推荐数据集。原始数据非常大,但是非常稀疏。例如超过20%的用户只有一个pin,这使得评估协同过滤算法变得困难。因此,我们以与MovieLens数据相同的方式过滤数据集,仅保留至少有20次交互的用户。结果我们得到一个包含55,187个用户、1,500,809个互动的子集。每个互动都表示用户是否将图片钉到用户的board上。
这些数据集的统计信息如下表所示。
Sparsity表示未观测到互动的user-item pair占比。
评估方式:为了评估
item推荐的性能,我们采用了广泛使用的leave-one-out评估。对于每个用户,我们将hold-out其最近的交互作为测试集,并使用剩余的数据进行训练。由于在评估过程中,每个用户对所有的
item进行排序太耗时,因此我们遵循了常见的策略:随机抽取100个用户未交互的item,然后在100个item中对测试item进行排序。ranked list的性能由Hit Ratio: HR和Normalized Discounted Cumulative Gain: NDCG来判断。在没有特别说明的情况下,我们将这两个指标的ranked list长度截断为10。因此:HR直观地衡量测试item是否出现在列表的top-10中。NDCG通过为排名靠前的hit分配更高的分数来说明hit的position。
我们为每个测试用户计算这两个指标并报告了平均得分。
baseline方法:我们将NCF方法(GMF/MLP/NeuMF)和以下方法进行比较:ItemPop:根据互动数量来判断item的流行度popularity从而对item进行排序。这是一种对推荐性能进行基准测试benchmark的非个性化方法。ItemKNN:这是标准的基于item的协同过滤方法。我们遵循《Collaborative fi ltering for implicit feedback datasets》的设置从而使其适应隐式数据。BRP:该方法使用pairwise ranking loss来优化MF模型,使得模型适合从隐式反馈中学习。这是一个极具竞争力的item推荐baseline。我们使用固定的学习率并报告最佳性能。eALS:这是item推荐的state-of-the-art MF方法。它优化了平方损失,将所有未观察到的交互视为负样本,并通过item流行度对它们进行非均匀加权。由于eALS显示出优于均匀加权方法WMF的性能,因此我们不会进一步报告WMF的性能。
由于我们提出的方法旨在对用户和
item之间的关系进行建模,因此我们主要与user-item模型进行比较。我们省略了与item-item模型的比较,如SLIM, CDAE,因为性能差异可能是由于使用个性化的用户模型引起的(因为SLIM, CDAE这些模型是item-item模型)。实验配置:
我们基于
Keras实现了我们的方法。为了确定
NCF方法的超参数,我们为每个用户随机抽取了一个交互作为验证集,并在其上调优了超参数。我们测试了
batch size为[128, 256, 512, 1024]、learning rate为[0.0001, 0.0005, 0.001, 0.005]。所有
NCF模型都是通过优化log loss来学习的,其中我们为每个正样本采样了四个负样本。对于从头开始训练的
NCF模型,我们使用高斯分布(均值为0、标准差为0.01)来随机初始化模型参数,并使用mini-batch的Adam优化器来优化模型。由于
NCF的最后一个隐层决定了模型的能力(因为NCF的隐层维度采用逐层减半的策略),我们将其称为预测因子predictive factors,并评估了维度为[8, 16, 32, 64]。值得注意的是,维度较高的预测因子可能会导致过拟合并降低性能。
如果没有特别说明,那么我们为
MLP使用三层的隐层。例如,如果预测因子维度为8,那么神经CF层的架构为32 -> 16 -> 8,embedding size为16。对于预训练的
NeuMF, ,从而允许预训练的GMF和MLP对NeuMF的初始化做出同等的贡献。
16.2.1 RQ1 性能比较
下图显示了
HR@10和NDCG@10在不同预测因子维度方面的性能。对于
MF方法BPR和eALS,预测因子的维度等于潜在因子的维度。对于ItemKNN,我们测试了不同邻域大小并报告了最佳性能。由于ItemPop性能较弱,因此下图中省略了ItemPop从而更好地突出个性化方法的性能差异。首先,我们可以看到
NeuMF在两个数据集上都实现了最佳性能,明显优于state-of-the-art的eALS和BPR(平均而言,相对于eALS和BPR的提升为4.5%和4.9%)。对于
Pinterest数据集,NeuMF使用8维预测因子也大大超越了64维预测因子的eALS和BPR。这表明NeuMF通过融合线性MF和非线性MLP模型从而具有高的表达能力。其次,另外两种
NCF方法(GMF和MLP)也表现出相当强劲的性能。在它们之间,MLP的表现略差于GMF。注意,可以通过添加更多隐层来进一步提升MLP的性能(参考下面的实验),这里我们仅展示三层隐层的MLP性能。对于小的预测因子维度,
GMF在两个数据集上均优于eALS。尽管GMF在大的预测因子为维度上过拟合,但是它的最佳性能优于eALS或者与eALS相当。GMF使用自动学习的加权权重,而eALS根据item流行度来加权。最后,
GMF显示出对BPR的持续改进,表明分类感知classification-aware的log loss对推荐任务的有效性。因为GMF和BPR是学习相同的MF模型、但是具有不同的目标函数。
下图显示了
Top-K推荐列表的性能,其中排序位置K的范围从1 ~ 10。为了使图更加清晰,我们展示了NeuMF的性能,而不是所有三种NCF方法。可以看到:- 和其它方法相比,
NeuMF在不同位置上表现出一致的提升。我们进一步进行了one-sample paired的t检验,验证所有提升对于 具有统计显著性。 - 在所有的
baseline方法中,eALS在MovieLens上的性能优于BPR(相对提升约5.1%),而在Pinterest方面的性能低于BPR。这与《Fast matrix factorization for online recommendation with implicit feedback》的发现一致,即BPR由于其pairwise ranking-aware learner而可以成为强大的排序器。 - 基于邻域的
ItemKNN表现不如基于模型的方法。 Item Pop表现最差,说明有必要对用户的个性化偏好进行建模,而不是仅仅向用户推荐热门item。
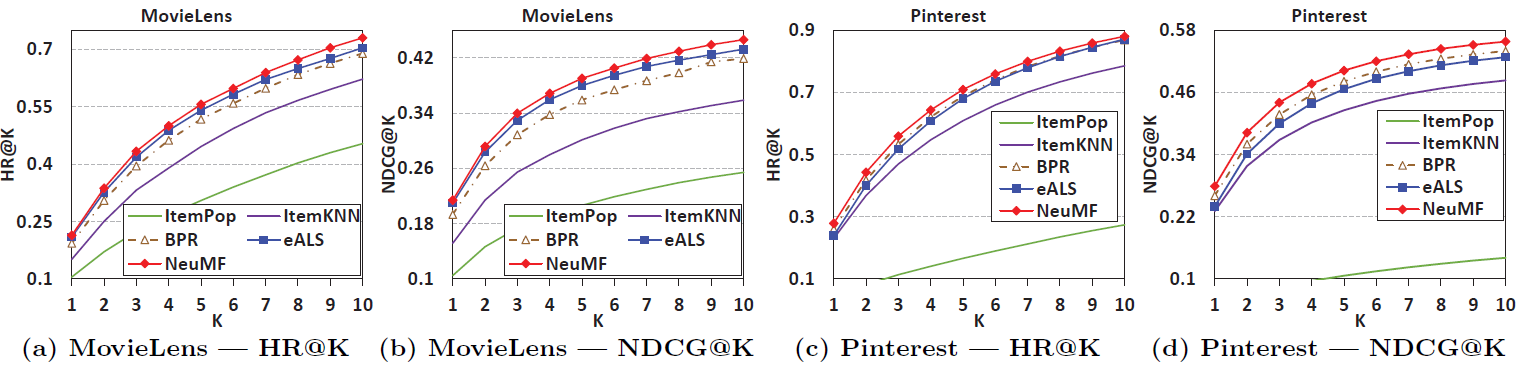
- 和其它方法相比,
预训练的效用
utility:为了证明预训练对NeuMF的效用,我们比较了两个版本的NeuMF的性能--有预训练、没有预训练。对于没有预训练的NeuMF,我们使用Adam通过随机初始化来学习。结果如下表所示。可以看到:
- 经过预训练的
NeuMF在大多数情况下取得了更好的性能,仅在预测因子维度为8的MovieLens时预训练方法的性能稍差。 - 在
MovieLens和Pinterest数据集上,使用预训练的NeuMF的相对提升分别为2.2%和1.1%。这一结果证明了我们预训练方法对初始化NeuMF的有效性。
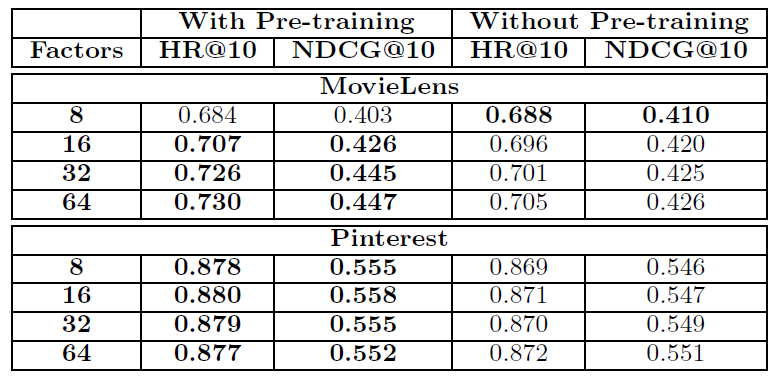
- 经过预训练的
16.2.2 RQ2 负采样的 Log Loss
为了处理隐式反馈的
one-class性质,我们将推荐转换为二元分类任务。通过将NCF视为概率模型,我们使用log loss对其进行了优化。下图显示了在
MovieLens上NCF方法每次迭代的训练损失(所有训练样本的均值)和推荐性能,其中预测因子维度为8。Pinterest上的结果也显示了相同的趋势,由于篇幅所限,这里没有给出Pinterest上的结果。首先,可以看到随着迭代次数的增加,
NCF模型的训练损失逐渐减少,推荐性能得到提升。最有效的更新发生在前
10次迭代中,更多的迭代可能会使模型发生过拟合(例如,尽管NeuMF的训练损失在10次迭代之后不断减少,但是推荐性能实际上会下降)。其次,在三种
NCF方法中,NeuMF的训练损失最低、其次是MLP、最次是GMF。推荐性能也呈现同样的趋势,即NeuMF > MLP > GMF。
上述发现为优化
log loss以从隐式数据中学习的合理性rationality和有效性effectiveness提供了经验证据。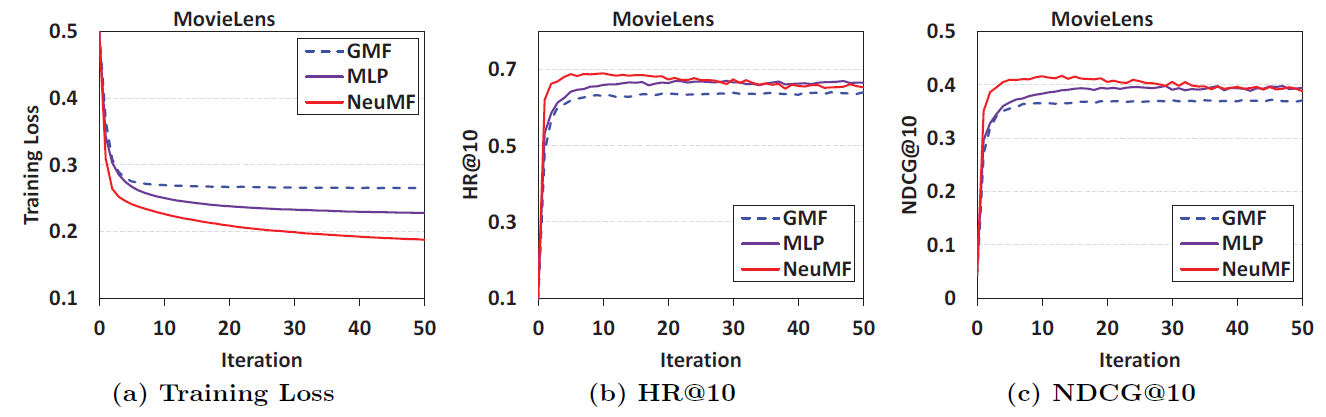
pointwise log loss相对于pairwise目标函数的一个优势是负样本的灵活采样比例。虽然pairwise目标函数只能将一个采样的负样本和一个正样本配对,但是在pointwise log loss中我们可以灵活控制采样比例。为了说明负采样比例对
NCF方法的影响,我们在下图中展示了NCF方法在不同负采样比例下的性能。其中预测因子维度为16。注意:BPR对于每个正样本采样一个负样本从而构成pair对,因此它的表现是一条直线。可以看到:
- 在
NCF中,每个正样本仅一个负样本不足以实现最佳性能,采样更多的负样本是有利的。 - 将
GMF和BPR进行比较,我们可以看到:采样比例为1的GMF的性能与BPR相当,而较大采样比例的GMF的性能明显优于BPR。这显示了pointwise log loss相对于pairwise BPR loss的优势。 - 在这两个数据集上,最佳采样比例约为
3 ~ 6。在Pinterest数据集上,我们发现采样比例大于7时,NCF方法的性能开始下降。这表明:过于激进地设置采样比例可能会对性能产生不利影响。
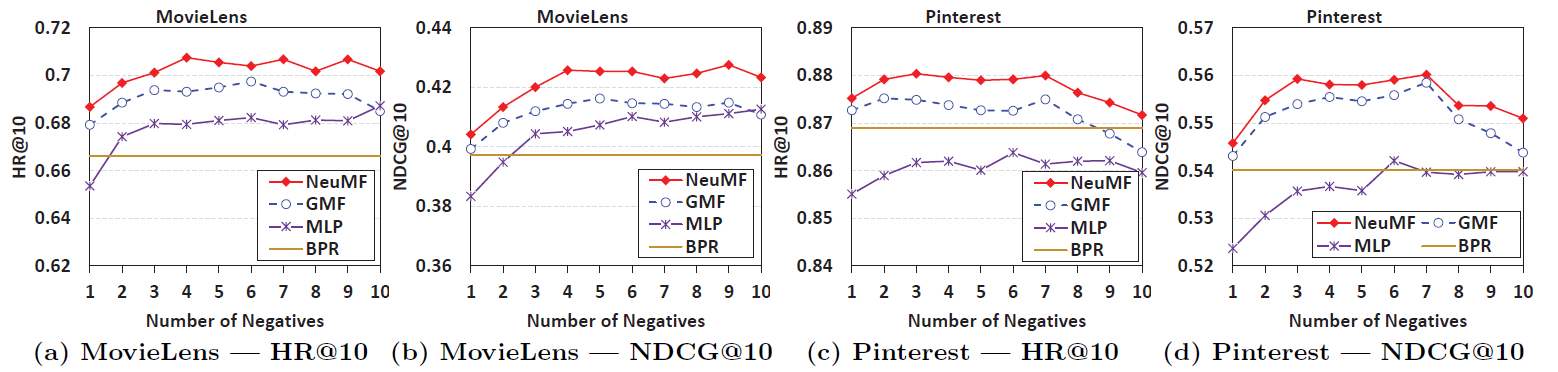
- 在
16.2.3 RQ3 网络深度
由于用神经网络学习
user-item交互函数的工作很少,所以很好奇使用深层的网络结构是否有利于推荐任务。为此,我们进一步研究了具有不同隐层数量的MLP,结果总结在下表中。MLP-3表示具有三层隐层(除了embedding层和输出层)的MLP方法,其它符号类似。可以看到:即使对于具有相同能力的模型,堆叠更多的层也有利于性能。这一结果非常令人振奋,表明使用深层模型进行协同推荐的有效性。
我们将性能提升归因于堆叠更多非线性层带来的高度非线性。为了验证这一点,我们进一步尝试堆叠线性层,使用恒等映射作为激活函数,结果其性能比使用
ReLU非线性激活函数差得多。对于没有隐层的
MLP-0(即embedding层直接投影到预测),性能非常弱,并不比非个性化的Item-Pop好。这验证了我们前面的论点:即简单地拼接用户潜在向量和item潜在向量,不足以对特征交互进行建模,因此需要用隐层来进行转换。
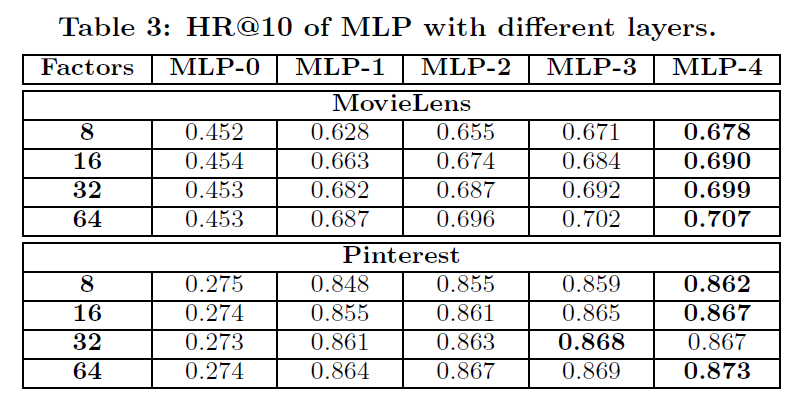
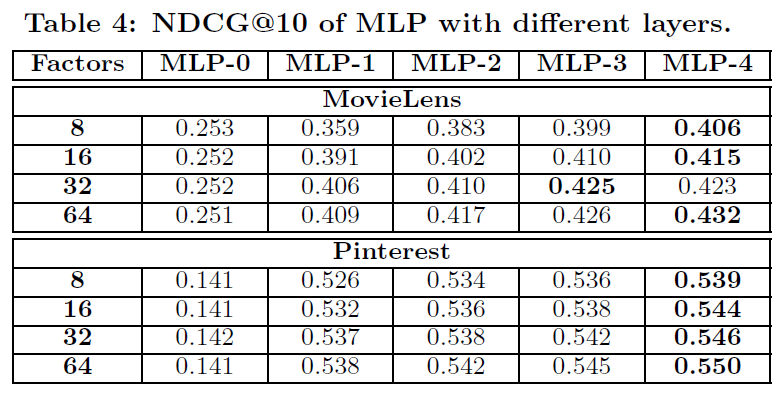
十七、NGCF[2019]
个性化推荐无处不在,已广泛应用于电商、广告、社交媒体等众多在线服务。个性化推荐的核心是根据购买和点击等历史交互
historical interaction来估计用户接受某个item的可能性。协同过滤
collaborative filtering: CF通过假设行为相似的用户对item表现出相似的偏好来解决这个问题。为了实现这个假设,一个常见的范式paradigm是参数化parameterize用户和item以重建历史交互,并根据参数parameter来预估用户偏好。一般而言,可学习的
CF模型有两个关键组件key component:embedding:将用户和item转换为向量化的representation。- 交互建模:基于
embedding重建历史交互。
例如:
- 矩阵分解
matrix factorization: MF直接将user id / item id映射到embedding向量,并使用内积对user-item交互进行建模。 - 协同深度学习
collaborative deep learning通过整合从item的丰富的辅助信息side information中学到的deep representation来扩展MF embedding function。 - 神经协同过滤模型
neural collaborative filtering model用非线性神经网络代替MF的内积交互函数。 translation-based CF model使用欧氏距离作为交互函数。
尽管这些方法很有效,但是我们认为它们不足以为
CF产生令人满意的embedding。关键原因是embedding函数缺乏关键协同信号collaborative signal的显式编码,这种编码隐藏在user-item交互中从而揭示用户(或item)之间的行为相似性。更具体而言,大多数现有方法仅使用描述性特征(例如ID和属性)来构建embedding函数,而没有考虑user-item交互。因此,由此产生的embedding可能不足以捕获协同过滤效果effect。user-item交互仅用于定义模型训练的目标函数。因此,当embedding不足以捕获CF时,这些方法必须依靠交互函数来弥补次优suboptimal的embedding的不足。虽然将
user-item交互集成到embedding函数中在直观上很有用,但是要做好并非易事。特别是在实际应用中,user-item交互的规模很容易达到数百万甚至更大,这使得提取所需要的的协同信号变得困难。在论文《Neural Graph Collaborative Filtering》中,作者通过利用来自user-item交互的高阶连通性high-order connectivity来应对这一挑战,这是一种在交互图结构interaction graph structure中编码协同信号的自然方式。下图说明了高阶连通性的概念。待推荐的用户是 ,在
user-item交互图的左子图中用双圆圈来标记。右子图显示了从 扩展的树结构。高阶连通性表示从任何节点到达 的、路径长度 的路径。这种高阶连通性通常包含丰富的语义,而这些语义携带了协同信号。例如:- 路径 表示 和 之间的行为相似度,因为这两个用户都和
item进行了交互。 - 更长的路径 表明 很可能接受 ,因为 相似的用户 之前已经消费过
item。 - 此外,从 的整体视角来看,
item比item更可能引起 的兴趣,因为有两条路径连接 ,而只有一条路径连接 。
论文提出对
embedding函数中的高阶连通性信息进行建模。论文没有将交互图扩展为实现起来很复杂的树,而是设计了一种神经网络方法在图上递归地传播embedding。这是受到图神经网络最近发展的启发,可以将其视为在embedding空间中构建信息流information flow。具体而言,作者设计了一个embedding propagation layer,它通过聚合交互的item(或者user)的embedding来改进refine用户(或者item)的embedding。通过堆叠多个embedding propagation layer,模型可以显式强制embedding来捕获高阶连通性中的协同信号。以上图为例,堆叠两层可以捕获 的行为相似性,堆叠三层可以捕获 的潜在推荐。信息流的强度(层之间的可训练权重来估计的)决定了 和 的推荐优先级。论文在三个公共
benchmark上进行了广泛的实验,验证了神经图协同过滤Neural Graph Collaborative Filtering: NGCF方法的合理性和有效性。最后值得一提的是,尽管在最近的一种名叫
HOP-Rec的方法中已经考虑了高阶连通性信息,但是它仅用于丰富训练数据。具体而言,HOPRec的预测模型仍然是MF,而且它是通过优化用高阶连通性增强的损失函数来训练的。和HOP-Rec不同,NGCF贡献了一种新技术将高阶连通性集成到预测模型中,从经验上讲,它比HOP-Rec更好地嵌入CF。总而言之,论文的主要贡献:
- 论文强调在基于模型的
CF方法的embedding函数中利用协同信号的重要性。 - 论文提出了
NGCF,这是一种基于图神经网络的新推荐框架,它通过执行embedding传播,以高阶连通性的形式对协同信号进行显式编码。 - 论文对三个百万规模的数据集进行实证研究。大量结果证明了
NGCF的state-of-the-art性能,以及通过神经embedding传播来提高embedding质量方面的有效性。
论文回顾了现有的
model-based CF、graph-based CF、基于图神经网络的方法的现有工作,这些方法和本文的工作最为相关。这里,论文强调这些方法和NGCF的不同之处。Model-Based CF方法:现代推荐系统通过向量化表示vectorized representation来参数化parameterize用户和item,并基于模型参数重建user-item交互数据。例如,MF将每个user ID和item ID投影为embedding向量,并在它们之间进行内积以预测交互。为了增强embedding函数,已经付出了很多努力来融合诸如item content、社交关系、item关系、用户评论、外部知识图谱等辅助信息side information。虽然内积可以迫使观察到的、交互的
user embedding和item embedding彼此接近,但是其线性不足以揭示用户和item之间复杂的非线性关系。为此,最近的努力侧重于利用深度学习技术来增强交互函数,从而捕获用户和item之间的非线性特征交互。例如,神经协同模型(如NeuMF)采用非线性神经网络作为交互函数。同时,基于翻译的CF模型,例如LRML用欧氏距离来建模交互强度interaction strength。尽管取得了巨大的成功,但我们认为
embedding函数的设计不足以为协同过滤产生最佳的embedding,因为协同过滤信号只能被隐式implicitly地捕获。总结这些方法,embedding函数将描述性特征descriptive feature(如ID特征和属性特征)转换为向量,而交互函数作为向量上的相似性度量。理想情况下,当user-item交互被完美重建时,行为相似性的传递特性transitivity property可以被捕获。然而,前面示例(高阶连通性概念的示例)中显示的这种传递效应transitivity effect并没有被显式地编码,因此无法保证间接连接的用户和item在embedding空间中也是接近的。如果没有对协同信号进行显式编码,就很难获得满足所有特性的embedding。即,传统的方法仅优化了
user-item的一阶邻近性,并没有优化高阶邻近性。另外这种邻近性并不是在模型结构中显式编码的,而是通过目标函数来优化的。Graph-Based CF方法:另一个研究方向利用user-item interaction graph来推断用户偏好。早期的努力,如
ItemRank和BiRank采用标签传播的思想来捕获协同效应CF effect。为了给一个用户在所有item上打分,这些方法将用户历史交互的item打上label,然后在图上传播标签。由于推荐分是基于历史互动item和目标item之间的结构可达性structural reachness(可以视为一种相似性)而获得的,因此这些方法本质上属于基于邻域neighbor-based的方法。然而,这些方法在概念上不如基于模型的协同过滤方法,因为它们缺乏模型参数来优化推荐目标函数(既没有模型参数、又没有目标函数、更没有优化过程)。最近提出的
HOP-Rec方法通过将基于图的方法和基于embedding的方法相结合来缓解这个问题(缺乏模型参数来优化推荐目标函数的问题)。该方法首先执行随机游走以丰富用户和multi-hop连接的item之间的交互。然后它基于丰富的user-item交互数据(通过高阶连通性增强的正样本)训练具有BPR目标函数的MF从而构建推荐模型。HOP-Rec优于MF的性能证明,结合连通性信息有利于在捕获CF效应时获得更好的embedding。然而,我们认为HOP-Rec没有充分探索高阶连通性,它仅仅用于丰富训练数据,而不是直接有助于模型的embedding函数(因为推断时不会用到正样本增强技术,而是用到embedding函数)。此外,HOP-Rec的性能在很大程度上取决于随机游走,这需要仔细地调优,例如设置合适的衰减因子。图卷积网络
Graph Convolutional Network:通过在user-item交互图上设计专门的图卷积运算,我们使NGCF有效地利用高阶连通性中的CF信号。这里我们讨论现有的、也采用图卷积运算的方法。GC-MC在user-item交互图上应用了图卷积网络graph convolution network: GCN,但是它仅使用一个卷积层来利用user-item之间的直接连接。因此,它无法揭示高阶连通性中的协同信号。PinSage是一个工业解决方案,它在item-item图中采用了多个图卷积层从而进行Pinterest图像推荐。因此,CF效应是在item关系的层面上捕获的,而不是在集体collective的用户行为的层面上。Spectral CF提出了一种谱卷积操作来发现谱域中用户和item之间的所有可能的连接。通过图邻接矩阵的特征分解,可以发现user-item pair对之间的连接。然而,特征分解导致了很高的计算复杂度,非常耗时并且难以支持大规模的推荐场景。
17.1 模型
NGCF模型的架构如下图所示(给出了用户 和item之间的affinity score),其中包含三个组件components:- 一个
embedding层:提供user embedding和item embedding。 - 多个
embedding传播层:通过注入高阶连通性关系来refine embedding。 - 一个
prediction层: 聚合来自不同传播层的refined embedding并输出user-item的相似性得分affinity score。
- 一个
17.1.1 Embedding Layer
遵循主流推荐模型,我们用
embedding向量 来描述用户 ,用embedding向量 来描述item,其中 为embedding维度。这可以看做是将参数矩阵parameter matrix构建为embedding look-up table:其中 为用户数量, 为
item数量。值得注意的是,这个
embedding table作为user embedding和item embedding的初始状态(refine之前的状态),并以端到端的方式进行优化。在传统的推荐模型如
MF和神经协同过滤中,这些ID embedding直接输入一个交互层interaction layer来实现分数预估。相比之下,在我们的
NGCF框架中,我们通过在user-item交互图上传播embedding来refine embedding。这导致了对推荐更有效的embedding,因为embedding的refinement步骤显式地将协同信号注入到embedding中。
17.1.2 Embedding Propagation
接下来我们基于
GNN的消息传递框架,沿着图结构捕获协同信号并优化user embedding和item embedding。我们首先说明单层embedding传播层Embedding Propagation Layer的设计,然后将其推广到多个连续传播层。一阶传播
First-order Propagation:直观地,交互的item提供了关于用户偏好的直接证据。类似地,消耗一个item的用户可以被视为item的特征,并用于度量两个item的协同相似性collaborative similarity。我们在此基础上在连接connected的用户和item之间执行embedding传播,用两个主要操作来形式化formulating流程:消息构建message construction和消息聚合message aggregation。消息构建:对一个连接的
user-item pair对 ,我们定义从 到 的消息为:其中:
- 为
message embedding。 - 为
message encoding函数,函数的输入为item embedding、user embedding、系数 。 - 系数 控制了
edge上传播的衰减系数decay factor。
在本文中,我们定义 为:
其中:
- 为可训练的权重参数从而为传播提取有用的信息, 为变换后的维度。
- 为逐元素乘积。
- 为
为用户 的邻域大小(即直接连接的
item数量), 为item的邻域大小(即直接连接的用户数量)。
与仅考虑 贡献的传统图卷积网络
graph convolution network不同,这里我们额外将 和 之间的交互通过 编码到被传递的消息中。这使得消息依赖于 和 之间的相似度affinity,例如从相似的item传递更多消息。这不仅提高了模型的表示能力representation ability,还提高了推荐性能。遵循图卷积网络,我们将 设置为图拉普拉斯范数
graph Laplacian norm,其中 为用户 的一阶邻居集合、 为item的一阶邻居集合。从
representation learning的角度来看, 反映了历史互动item对用户偏好的贡献程度。从消息传递的角度来看,考虑到被传播的消息应该随着路径长度
path length衰减, 可以解释为折扣系数discount factor。消息聚合:在这一阶段,我们聚合从用户 的邻居传播的消息来
refine用户 的representation。具体而言,我们定义聚合函数为:其中:
表示在第一个
embedding传播层之后获得的用户 的representation。LeakyReLU激活函数允许消息对正positive信号和小负negative信号进行编码。除了从邻域 传播的消息之外,我们还考虑了 的自连接
self-connection:这个自连接保留了 的原始特征信息。
注意:这里的 和 定义中的共享。即对于 和 我们都用 来映射、对于交叉特征 我们用 来映射。也可以使用独立的映射矩阵来分别映射 和 。
类似地,我们可以通过与
item连接的用户传播的消息来获得item的representation。总而言之,
embedding传播层的优势在于显式利用一阶连通性信息来关联user representation和item representation。在广告和推荐场景中,
item的直接邻域(和item有互动的用户集合)可能高达百万甚至千万级别,而用户 的直接邻域(用户 互动的历史item集合)通常都比较小。如何处理这种非对称的、庞大的邻域是一个难点。高阶传播
High-order Propagation:基于一阶连通性first-order connectivity建模来增强representation,我们可以堆叠更多embedding传播层来探索高阶连通性high-order connectivity信息。这种高阶连通性对于编码协同信号以估计用户和item之间的相关性分数relevance score至关重要。通过堆叠 个embedding传播层,用户(或者item)能够接收来自L-hop邻居传播的消息。在第 步中(),用户 的
representation被递归地表示为:其中被传播的消息定义为:
其中:
为可训练的参数矩阵, 为变换后的维度。
注意:这里对于 和 我们都用 来映射、对于交叉特征 我们用 来映射。也可以使用独立的映射矩阵来分别映射 和 。
为前一层的
item representation,它记住了(l-1) - hop邻域的消息。为前一层的
user representation,它也也记住了(l-1) - hop邻域的消息。
类似地,我们也可以得到
item在第 层的representation。如下图所示为针对用户 的三阶
embedding传播,像 这样的协同信号可以在embedding传播过程中捕获。即,来自 的消息被显式编码在 中(由红线标识)。因此,堆叠多个embedding传播层无缝地将协同信号注入到representation learning过程。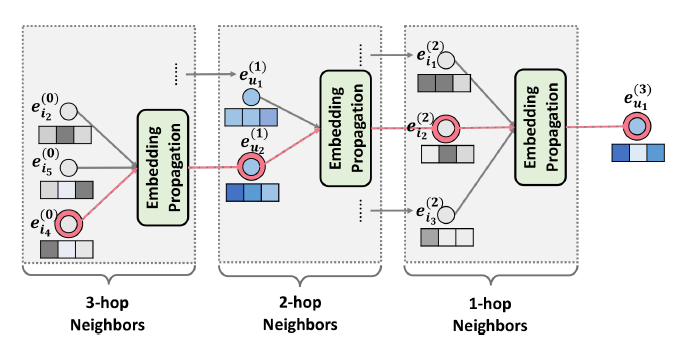
矩阵形式的传播规则
Propagation Rule in Matrix Form:为了提供embedding传播的整体视图holistic view,并便于batch实现,我们提供了layer-wise传播规则的矩阵形式:其中:
为第 层
embedding传播层得到的用户representation和item representation。 为初始的representation,即 。为单位矩阵, 为
user-item graph的拉普拉斯矩阵:其中 为
user-item交互矩阵, 为全零矩阵; 为邻接矩阵, 为对角的degree matrix( )。因此 的非对角线元素为:
它就是 。
通过实现矩阵形式的传播规则,我们可以用一种相当有效的方式同时更新所有用户和所有
item的representation。这种方式允许我们抛弃节点采样过程(这个节点采样过程通常用于图卷积网络,使得图卷积网络可以应用于大规模的graph)。对于工业场景海量用户(如十亿级)和海量
item(如亿级),那么矩阵形式是不可行的,因为现有的计算资源无法处理如此规模的矩阵。
17.1.3 Model Prediction
经过 层传播,我们得到了用户 的多个
representation,即 。由于在不同层中获得的representation强调通过不同连通性传递的消息,因此它们在反映用户偏好方面有不同的贡献。因此,我们将这些representation拼接起来,构成用户 的最终representation。对于
item,我们也进行同样的操作,即将不同层学到的item representaiton拼接起来得到item的最终representation。最终我们得到user representation和item representation为:其中
||表示向量拼接。通过这种方式,我们不仅用
embedding传播层丰富了initial embeddings(即embedding层得到的初始embedding),还允许通过调整 来控制传播范围。注意,除了拼接之外,还可以应用其它聚合方式,如加权平均、最大池化、
LSTM等,这意味着在组合不同阶次的连通性时有不同的假设。使用拼接聚合的优势在于它的简单性,因为它不需要学习额外的参数,并且它已经在最近的图神经网络中证明非常有效。最后,我们使用内积来估计用户 对目标
item的偏好:在这项工作中,我们强调
embedding函数的学习,因此仅使用内积这种简单的交互函数。其它更复杂的选择,如基于神经网络的交互函数,留待未来的研究工作。
17.1.4 Optimization
为了学习模型参数,我们优化了在推荐系统中广泛应用的
pairwise BPR loss。该损失函数考虑了观察到的和未观察到的user-item交互之间的相对顺序。具体而言,
BPR假设观察到的user-item交互更能够反映用户的偏好,因此应该比未观察到的交互分配更高的预测值。因此目标函数为:其中:
- 表示
pairwise训练数据。 为观察到的交互的集合, 为未观察到的交互的集合。 - 为
sigmoid函数。 - 为所有的训练参数集合, 为
L2正则化系数。
我们使用
mini-batch的Adam优化算法来优化预估模型。具体而言,对于一个batch的随机采样的三元组 ,我们在L步传播之后建立它们的representation,然后利用损失函数的梯度来更新模型参数。- 表示
模型大小
Model Size:值得指出的是,尽管NGCF在每个传播层 获得了一个embedding矩阵 ,但是它只引入了很少的参数:两个规模为 的权重矩阵。具体而言,这些embedding矩阵来自于embedding look-up table,并基于user-item图结构和权重矩阵转换而来。因此,和最简单的、基于
embedding的推荐模型MF相比,我们的NGCF只是多了 个参数。考虑到 通常是小于5的数,并且 通常设置为embedding size(远小于用户数量和item数量),因此这个额外的参数规模几乎可以忽略不计。例如,在我们实验的
Gowalla数据集(20k用户和40k item)上,当embedding size = 64并且我们使用3个尺寸为64 x 64的传播层时,MF有450万参数,而我们的NGCF仅使用了2.4万额外的参数。总之,
NGCF使用很少的额外参数来实现高阶连通性建模。Message and Node Dropout:虽然深度学习模型具有很强的表示能力,但通常会出现过拟合现象。Dropout是防止神经网络过拟合的有效解决方案。遵从图卷积网络的前期工作,我们提出在NGCF中采用两种dropout技术:message dropout和node dropout。message dropout:随机丢弃传出的消息outgoing message。具体而言,我们以概率 丢弃 。因此在第 个传播层中,只有部分消息可用于refine representation。node dropout:随机阻塞一个节点并丢弃该节点传出的所有消息。对于第 个传播层,我们随机丢弃 个节点,其中 为dropout ratio。
注意,
dropout仅用于训练并且必须在测试期间禁用。message dropout使得representaion对于user-item之间单个连接具有更强的鲁棒性,而node dropout则侧重于减少特定用户或特定item的影响。我们在实验中研究message dropout和node dropout对于NGCF的影响。
17.1.5 讨论
这里我们首先展示
NGCF如何推广SVD++,然后我们分析NGCF的时间复杂度。NGCF和SVD++:SVD++可以看做是没有高阶传播层的NGCF的特例。具体而言,我们将 设置为
1。在传播层中,我们禁用了转换矩阵和非线性激活函数。然后, 和 分别被视为用户 和item的最终representation。我们把这个简化模型称作NGCF-SVD,它可以表述为:显然,通过分别设置 以及 ,我们可以准确地恢复
SVD++模型。此外,另一个广泛使用的
item-based CF模型FISM也可以被视为NGCF的特例,其中上式中 。时间复杂度:我们可以看到,逐层
layer-wise传播规则是主要的操作。- 对于第 个传播层,矩阵乘法的计算复杂度为 ,其中 为拉普拉斯矩阵中的非零项数量, 为当前层的维度, 为前一层的维度。
- 对于预测层只涉及内积,它的时间复杂度为 。
因此,
NGCF的整体复杂度为 。根据经验,在相同的实验设置下,MF和NGCF在Gowalla数据集上的训练成本分别为20秒左右和80秒左右,在推断期间MF和NGCF的时间成本分别为80秒和260秒。
17.2 实验
我们在真实世界的三个数据集上进行实验,从而评估我们提出的方法,尤其是
embedding传播层。我们旨在回答以下研究问题:RQ1:和state-of-the-art的CF方法相比,NGCF的表现如何?RQ2:不同的超参数setting(如,层的深度、embedding传播层、layer-aggregation机制、message dropout、node dropout)如何影响NGCF?RQ3:如何从高阶连通性中受益?
数据集:我们选择三个
benchmark数据集Gowalla、Yelp2018、Amazon-book。这些数据集可公开访问,并且在领域、规模、稀疏性等方面各不相同。Gowalla数据集:这是从Gowalla获得的check-in数据集,用户通过checking-in来共享他们的位置location。为了确保数据集的质量,我们使用10-core setting,即保留至少有十次交互的用户和item。Yelp2018:来自2018年的Yelp挑战赛的数据集,其中餐馆、酒吧等当地企业被视为item。为了确保数据质量,我们也使用10-core setting。Amazon-book:Amazon-review是一个广泛使用的产品推荐数据集,这里我们从中选择了Amazon-book。同样地,我们使用10-core setting来确保每个用户和每个item至少有十次交互。
对于每个数据集,我们随机选择每个用户
80%的历史交互构成训练集,其余的20%历史交互作为测试集。在训练集中,我们随机选择10%的交互作为验证集来调整超参数。对于每个观察到的
user-item交互,我们将其视为一个正样本,然后进行负采样策略:将用户和历史没有互动的负item构建pair对。这些数据集的统计信息如下表所示。
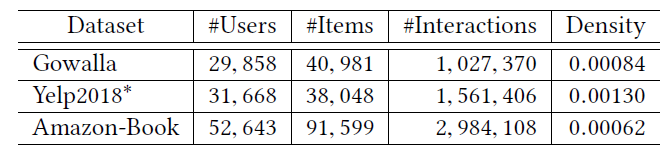
评估指标:对于测试集中的每个用户,我们将用户未交互的所有
item视为负item。然后每个方法输出用户对所有item(除了训练集中的正item)的偏好分。为了评估top-K推荐和偏好排序preference ranking,我们采用了两种广泛使用的评估指标:recall@K和ndcg@K,默认情况下K=20。我们报告测试集中所有用户的平均指标。baseline方法:为了证明有效性,我们将NGCF方法和以下方法进行比较:MF:这是通过贝叶斯个性化排名Bayesian personalized ranking: BPR损失函数优化的矩阵分解方法,它仅利用user-item直接交互作为交互函数的目标值target value。NeuMF:这是state-of-the-art的神经网络协同过滤模型。该方法拼接user embedding和item embedding,然后使用多个隐层从而捕获用户和item的非线性特征交互。具体而言,我们采用两层的普通架构,其中每个隐层的维度保持不变。CMN:这是state-of-the-art的memory-based模型,其中user representation通过memory layer有意地组合相邻用户的memory slot。注意,一阶连接用于查找和相同item交互的相似用户。HOP-Rec:这是一个state-of-the-art的graph-based模型。该方法利用从随机游走得到的高阶邻居来丰富user-item交互数据。PinSage:该方法在item-item graph上应用GraphSAGE。在这里,我们将该方法应用于user-item交互图。具体而言,我们采用了两层图卷积层,并且隐层维度设为embedding size。GC-MC:该模型采用GCN encoder来生成user representations和item representation,其中仅考虑一阶邻居。具体而言,我们使用一层图卷积层,并且隐层维度设为embedding size。
我们也尝试了
Spectral CF,但是发现特征分解导致很高的时间成本和资源成本,尤其是当用户数量和item数量很大时。因此,尽管该方法在小数据集上取得了不错的性能,但是我们没有选择和它进行比较。为了公平地比较,所有方法都优化了
BPR loss。参数配置:我们在
Tensorflow中实现了我们的NGCF模型。所有模型的
embedding size固定为64。对于
HOP-Rec,我们选择随机游走step的调优集合为{1,2,3},学习率的调优集合为{0.025, 0.020, 0.015, 0.010}。我们使用
Adam优化器优化除了HOP-Rec之外的所有模型,其中batch size固定为1024。在超参数方面,我们对超参数应用网格搜索:学习率搜索范围
{0.0001, 0.0005, 0.001, 0.005}、L2正则化系数搜索范围 、dropout ratio搜索范围{0.0, 0.1, ... , 0.8}。此外,我们对
GC-MC和NGCF应用node dropout技术,其中dropout ratio搜索范围为{0.0, 0.1, ... , 0.8}。我们使用
Xavier初始化器来初始化模型参数。我们执行早停策略:如果在连续
50个epoch中,验证集的recall@20指标没有提升,则提前停止训练。为了建模三阶连通性,我们将
NGCF L的深度设置为3。在没有特殊说明的情况下,我们给出了三层embedding传播层的结果,node dropout ratio = 0.0、message dropout ratio = 0.1。
17.2.1 RQ1 性能比较
我们从比较所有方法的性能开始,然后探索高阶连通性建模如何提升稀疏环境下的性能。
下表报告了所有方法性能比较的结果。可以看到:
MF在三个数据集上的表现不佳。这表明内积不足以捕获用户和item之间的复杂关系,从而限制了模型性能。NeuMF在所有情况下始终优于MF,证明了user embedding和item embedding之间非线性特征交互的重要性。然而,
MF和NeuMF都没有显式地对embedding学习过程中的连通性进行建模,这很容易导致次优suboptimal的representation。与
MF和NeuMF相比,GC-MC的性能验证了融合一阶邻居可以改善representation learning。然而,在
Gowalla中,GC-MC在ndcg@20指标行不如NeuMF。原因可能是GC-MC未能充分探索用户和item之间的非线性特征交互。大多数情况下,
CMN通常比GC-MC得到更好的性能。这种改进可能归因于神经注意力机制neural attention mechanism,它可以指定每个相邻用户的注意力权重,而不是GC-MC中使用的相同权重、或者启发式权重。PinSage在Gowalla和Amazon-Book中的表现略逊于CMN,但是在Yelp2018中的表现要好得多。同时HOP-Rec在大多数情况下总体上取得了显著的提升。这是讲得通的,因为
PinSage在embedding函数中引入了高阶连通性,HOP-Rec利用高阶邻居来丰富训练数据,而CMN只考虑相似的用户。因此,这表明了对高阶连通性或高阶邻居建模的积极影响。NGCF始终在所有数据集上产生最佳性能。具体而言,NGCF在Gowalla、Yelp2018、Amazon-Book数据集中在recall@20方面比最强baseline分别提高了11.68%、11.97%、9.61%。通过堆叠多个
embedding传播层,NGCF能够显式探索高阶连通性,而CMN和GC-MC仅利用一阶邻居来指导representation learning。这验证了在embedding函数中捕获协同信号的重要性。此外,和
PinSage相比,NGCF考虑多粒度表示multi-grained representation来推断用户偏好,而PinSage仅使用最后一层的输出。这表明不同的传播层在representation中编码不同的信息。并且,对
HOP-Rec的改进表明embedding函数中的显式编码CF可以获得更好的representation。HOP-Rec效果也不错,而且计算复杂度不高、简单易于实现。
我们进行
one-sample的t-test,p-value < 0.05表明NGCF对最强baseline(下划线标明)的改进在统计上是显著的。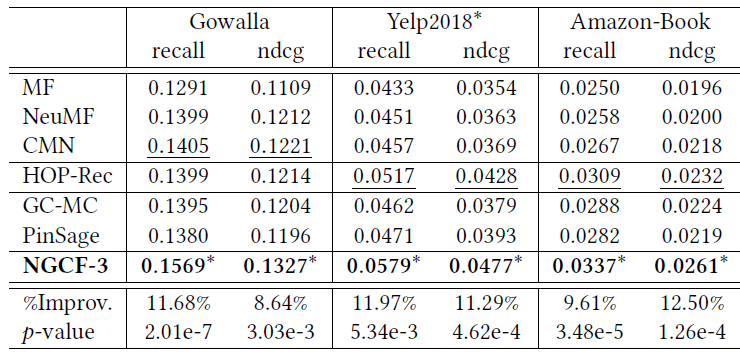
稀疏性问题通常限制了推荐系统的表达能力,因为不活跃用户的少量交互不足以生成高质量的
representation。我们考察利用连通性信息connectivity information是否有助于缓解稀疏性问题。为此,我们对不同稀疏性水平的用户组user group进行了实验。具体而言,基于每个用户的交互次数,我们将测试集分为四组,每组的用户具有相同的交互次数。以
Gowalla数据集为例,每个用户的交互次数分别小于24、50、117、1014。下图展示了
Gowalla、Yelp 2018、Amazon-Book数据集的不同用户组中关于ndcg@20的结果。背景的直方图表示每个分组中的用户量,曲线表示ndcg@20指标。我们在recall@20方面看到了类似的性能趋势,但是由于空间限制而省略了该部分。可以看到:
NGCF和HOP-Rec始终优于所有用户组的所有其它baseline。这表明利用高阶连通性可以极大地促进非活跃用户的representation learning,因为可以有效地捕获协同信号。因此,解决推荐系统中的稀疏性问题可能是有希望的,我们将其留待未来的工作中。- 联合分析图
(a),(b),(c),我们观察到前两组取得的提升(例如,在Gowalla数据集中NGCF对于< 24和< 50的最佳baseline上分别提高了8.49%和7.79%)比其它组更为显著(例如,在Gowalla数据集中NGCF对于< 1014的最佳baseline提高了1.29%)。这验证了embedding传播有利于相对不活跃的用户。
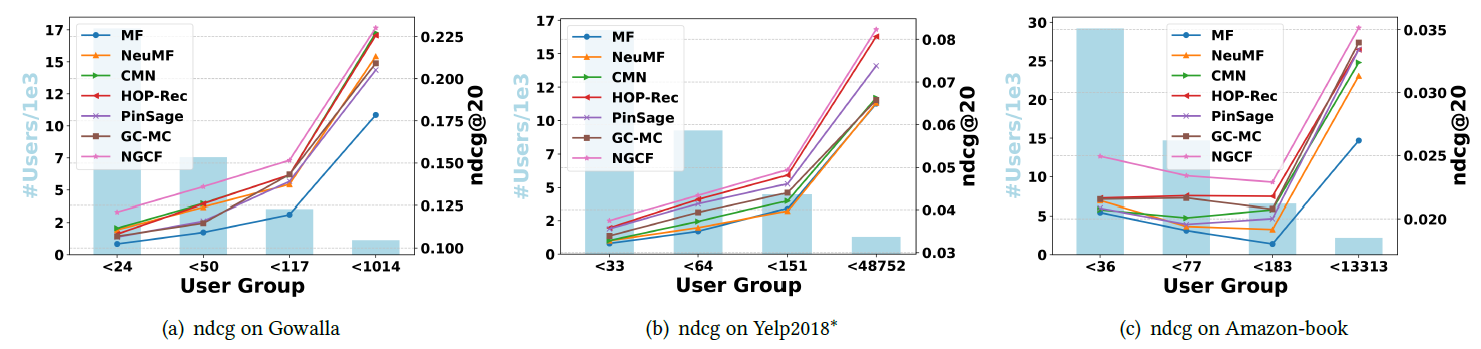
17.2.2 RQ2 NGCF 研究
由于
embedding传播层在NGCF中起着举足轻重的作用,因此我们研究了它对于性能的影响。- 我们首先探索层数的影响,然后我们研究拉普拉斯矩阵(即用户 和
item之间的折扣因子 ) 如何影响性能。 - 此外,我们分析了关键因素的影响,例如
node dropout和message dropout。 - 最后,我们还研究了
NGCF的训练过程。
- 我们首先探索层数的影响,然后我们研究拉普拉斯矩阵(即用户 和
层数的影响:为了研究
NGCF是否可以从多个embedding传播层中受益,我们改变了模型深度。具体而言,我们探索了层数为{1,2,3,4}。下表给出了实验结果,其中NGCF-3表示具有三层embedding传播层的模型,其它符号类似。联合下表和上表(所有方法性能比较结果表)可以看到:增加
NGCF的深度可以大大提升推荐效果。显然,NGCF-2和NGCF-3在所有方面都比NGCF-1实现了一致的提升,因为NGCF-1仅考虑了一阶邻居。我们将所有提升归因于
CF效应的有效建模:协同用户相似性collaborative user similarity和协同信号collaborative signal分别由二阶连通性和三阶连通性承载carried。当在
NGCF-3之后进一步堆叠传播层时,我们发现NGCF-4在Yelp 2018数据集上过拟合。这可能是因为太深的架构会给representation learning带来噪音。而其它两个数据集上的边际提升证明了三层传播层足以捕获
CF信号。当传播层数变化时,
NGCF在三个数据集上始终优于其它方法。这再次验证了NGCF的有效性,从而表明显式建模高阶连通性可以极大地促进推荐任务。
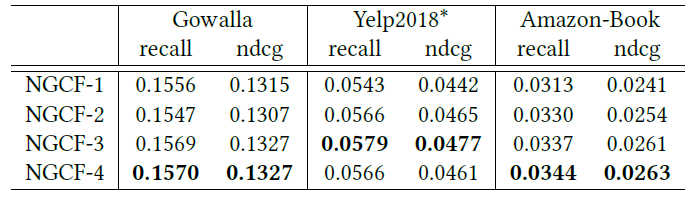
embedding传播层的效果和Layer-Aggregation机制:为了研究embedding传播层(即图卷积层)如何影响性能,我们考虑了使用使用不同layer的NGCF-1变体。具体而言,我们从消息传递函数中删除了节点及其邻居之间的
representation交互,并将其设置为PinSage和GC-MC的representation交互,分别称为 和 。对于 :
其中 为非线性激活函数。
缺少 和 的交互,也缺少图拉普拉斯范数。
对于 :
其中: 为节点 的第 阶邻域(每个节点和 的路径距离为 ); 为非线性激活函数。
此外,基于
NGCF-SVD,我们得到NGCF的关于SVD++的变体,称作 。我们在下表中显示了实验结果,并且可以发现:
NGCF-1始终优于所有变体。我们将改进归因于representation交互(即 ),这使得消息的传播依赖于 和 之间的affinity以及注意力机制等等函数。同时,所有变体仅考虑线性变换。因此,这验证了我们
embedding传播函数的合理性和有效性。在大多数情况下, 的性能不如 和 。这表明节点本身传递的消息( 没有
item到用户的消息传递、只有用户到item的消息传递)和非线性变换的重要性。联合下表和上表(所有方法性能比较结果表)可以看到:当将所有层的输出拼接在一起时, 和 分别比
PinSage和GC-MC获得更好的性能。这表明layer-aggregation机制的重要性。
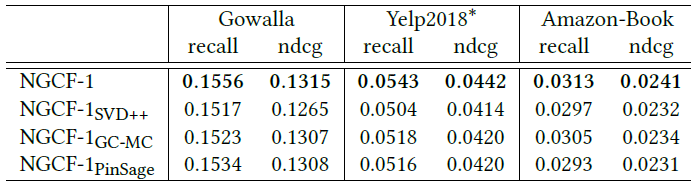
dropout效果:遵从GC-MC的工作,我们采用了node dropout和message dropout技术来防止NGCF过拟合。下图给出了message dropout rate和node dropout rate在不同数据集上对评估指标的影响。在两种
dropout策略之间,node dropout提供了更好的性能。以Gowalla为例,设置 将导致最好的recall@20(0.1514),这优于message dropout得到最好的recall@20(0.1506) 。一个可能的原因是:丢弃来自特定用户和特定
item的所有outgoing message使得representation不仅可以抵抗特定边的影响,还可以抵抗节点的影响。因此,node dropout比message dropout更有效,这和GC-MC工作的发现相一致。我们认为这是一个有趣的发现,这意味着
node dropout可以成为解决图神经网络过拟合的有效策略。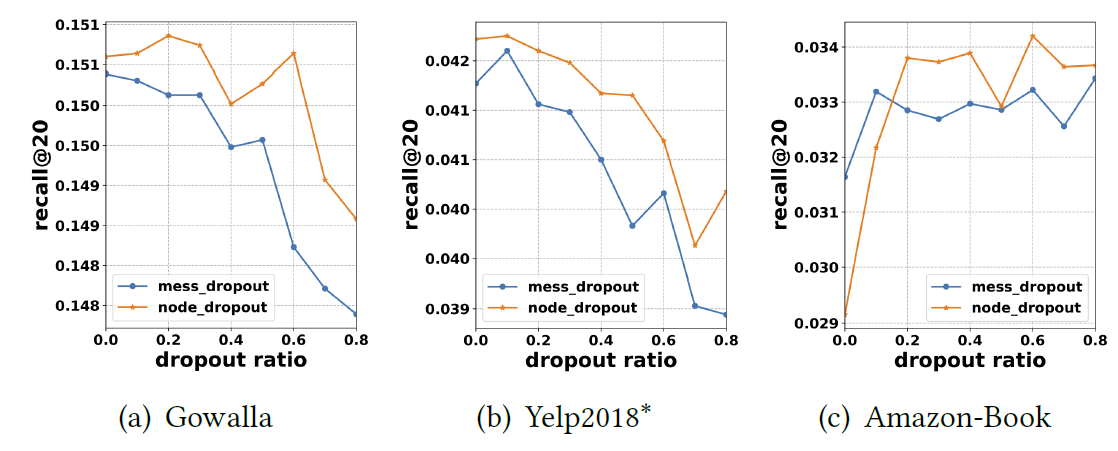
Epoch对测试性能影响:下图给出了MF和NGCF在每个epoch的测试性能(recall@20)。由于空间限制,我们省略了ndcg@20指标,因为该指标的性能趋势和recall@20是类似的。可以看到:
NGCF在三个数据集上表现出比MF更快的收敛速度。这是合理的,因为在
mini-batch中优化交互pair对时,涉及间接相连的用户和item。这样的观察证明了NGCF具有更好的模型容量,以及在embedding空间中执行embedding传播的有效性。
17.2.3 RQ3 高阶连通性的效果
这里我们试图了解
embedding传播层如何促进embedding空间中的representation learning。为此,我们从Gowalla数据集中随机选择了6个用户及其相关的item。我们观察他们的representation如何受到NGCF深度的影响。下图
(a)和(b)分别显示了来自MF(即NGCF-0)和NGCF-3的representation的可视化(通过t-SNE)。每个星星代表Gowalla数据集中的一个用户,和星星相同颜色的点代表相关的item。注意,这些
item来自测试集,并且这些item和用户构成的pair对不会出现在训练过程中。可以看到:
用户和
item的连通性很好地反映在embedding空间中,即它们嵌入到空间中相近的位置。具体而言,
NGCF-3的representation表现出可识别的聚类,这意味着具有相同颜色的点(即相同用户消费的item)倾向于形成聚类。联合分析图
(a)和图(b)中的相同用户(例如12201黄色星星和6880蓝色星星),我们发现:当堆叠三层embedding传播层时,他们历史item的embedding往往更加靠近。这定性地验证了所提出的embedding传播层能够将显式的协同信号(通过NGCF-3)注入到representation中。
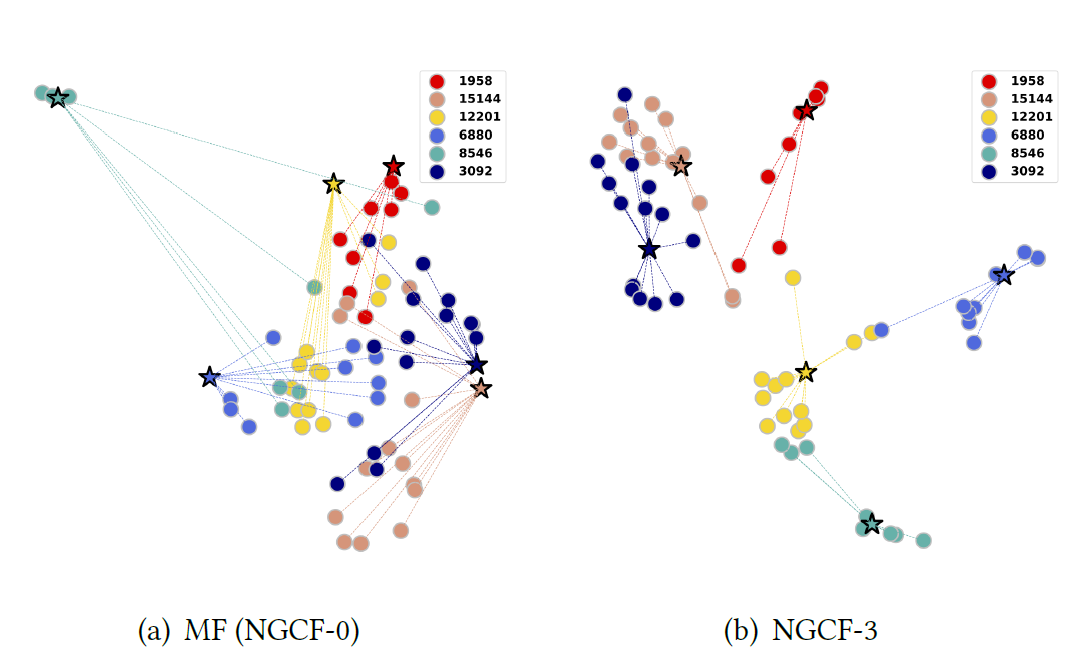
将来的工作:
- 结合注意力机制进一步改进
NGCF,从而在embedding传播过程中学习邻居的可变权重,以及不同阶连接性的可变权重。这将有利于模型的泛化和可解释性。 - 探索关于
user/item embedding和图结构的对抗学习,从而增强NGCF的鲁棒性。这项工作代表了在基于模型的CF中利用消息传递机制开发结构知识的初步尝试,并开辟了新的研究可能性。
- 结合注意力机制进一步改进
十八、LightGCN[2020]
为减轻网上的信息过载,推荐系统已被广泛部署以执行个性化的信息过滤。推荐系统的核心是预测用户是否会和
item进行交互,例如点击、评论、购买、以及其它形式的交互。因此,协同过滤collaborative filtering: CF仍然是用于个性化推荐的基础fundamental任务。其中,CF专注于利用历史user-item交互来实现预测。CF最常见的范式是学习潜在特征(也称为embedding)来表示用户和item,并基于embedding向量进行预测。矩阵分解是一种早期的此类模型,它直接将
user ID直接映射到user embedding。后来一些研究发现,利用用户的历史交互作为输入来增强
augmentinguser ID可以提高embedding的质量。例如:SVD++展示了用户历史交互在预测用户评分方面的好处。Neural Attentive Item Similarity: NAIS区分了历史交互中item的重要性,并显示了在预测item ranking方面的改进。
从
user-item交互图interaction graph来看,这些改进可以视为来自于用户子图结构user subgraph structure(更具体而言,这子图结构就是用户的直接邻居)来改进embedding learning。为了深化高阶邻居子图结构的使用,人们提出了
NGCF从而为CF实现了state-of-the-art的性能。NGCF从图卷积网络Graph Convolution Network: GCN中汲取灵感,遵循相同的传播propagation规则来refine embedding:特征变换feature transformation、邻域聚合neighborhood aggregation、非线性激活nonlinear activation。
尽管
NGCF已经显示出有希望的结果,但是LightGCN的作者认为NGCF的设计相当沉重heavy和冗余burdensome:很多操作毫无理由地直接从GCN继承下来(而并没有对GCN进行彻底的理论研究和消融分析)。因此,这些操作不一定对CF任务有用。具体而言,GCN最初是针对属性图attributed graph上的节点分类node classification任务提出的,其中每个节点都有丰富的属性作为输入特征。而在CF的user-item交互图中,每个节点(user或者item)仅由一个one-hot ID来描述,除了作为标识符之外没有任何具体的语义。在这种情况下,给定ID embedding作为输入,执行多层非线性特征变换(这是现代神经网络成功的关键)不会带来任何好处,反而会增加模型训练的难度。为了验证这一想法(即
NGCF中的这些操作不一定对CF任务有用),在论文《LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation》中,作者对NGCF进行了广泛的消融研究。通过严格的控制实验(在相同的数据集拆分和评估协议上),作者得出结论:从GCN继承的两个操作,特征转换和非线性激活,对NGCF的有效性effectiveness没有贡献。更令人惊讶的是,删除这两个操作会显著提高准确性accuracy。这反映了在图神经网络中添加对目标任务无用useless操作的问题:不仅没有带来任何好处,反而降低了模型的有效性。受到这些经验发现的启发,作者提出了一个名为
LightGCN的新模型,其中仅包括GCN最重要的组件component用于协同过滤 ,即:邻域聚合。具体而言:- 在将每个用户(
item)和ID embedding关联之后,模型在user-item交互图上传播embedding来refine这些embedding。 - 然后,模型将不同传播层
propagation layer学习的embedding以加权和的方式聚合,从而获得用于预测的最终embedding。
整个模型简单而优雅,不仅更容易训练,而且比
NGCF和其它state-of-the-art方法(如Mult-VAE)获得了更好的实验性能。总而言之,论文的主要贡献如下:
经验表明:
GCN两种常见设计,特征变换和非线性激活,对协同过滤的有效性没有正面影响。论文提出了
LightGCN,它通过仅包含GCN中最重要的组件进行推荐,从而在很大程度上简化了模型设计。论文通过遵循相同的实验
setting,在实验中对比了LightGCN和NGCF,并展示了实质性的提升。论文还从技术和经验两个角度对
LightGCN的合理性进行了深入分析。
相关工作:
协同过滤:协同过滤
Collaborative Filtering: CF是现代推荐系统中的一种流行技术。CF模型的一种常见范式是将用户和item参数化为embedding,并通过重建历史user-item交互来学习embedding参数。早期的CF模型,如矩阵分解matrix factorization: MF将用户(或item)的ID映射到embedding向量中。最近的神经推荐模型如NCF和LRML使用相同的embedding组件,但是同时增强了基于神经网络的交互建模interaction modeling。除了仅使用
ID信息之外,另一种类型的CF方法将历史item视为用户已经存在pre-existing的特征,从而实现更好的user representation。例如,FISM和SVD++使用历史item的ID embedding的加权均值作为目标用户的embedding。最近,研究人员意识到历史item对塑造个人兴趣有不同的贡献。为此,人们引入了注意力机制来捕获不同的贡献,如ACF和NAIS,从而自动学习每个历史item的重要性。当以user-item二部图的形式重新审视历史交互时,性能的提高可以归因于局部邻域(一阶邻域)的编码,这可以改进embedding learning。即,将历史
item视为用户行为特征,这是一种二部图上的局部邻域编码技术。用于推荐的图方法:另一个相关的研究方向是利用
user-item图结构进行推荐。之前的工作,如
ItemRank,使用标签传播机制label propagation mechanism在图上直接传播用户偏好分user preference score,即鼓励相连的节点具有相似的label。最近出现的图神经网络graph neural network: GNN揭示了图结构建模,尤其是高阶邻居,从而指导embedding learning。- 早期的研究定义了谱域
spectral domain上的图卷积,例如拉普拉斯特征分解Laplacian eigen-decomposition(《Spectral Networks and Locally Connected Networks on Graphs 》)和切比雪夫多项式Chebyshev polynomial(《Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering》),但是它们的计算成本很高。 - 后来,
GraphSage和GCN重新定义了空域spatial domain中的图卷积,即聚合邻域的embedding从而refine目标节点的embedding。由于其可解释性interpretability和效率efficiency,它们很快成为GNN的流行公式并被广泛使用。 - 受图卷积力量的推动,
NGCF、GC-MC、PinSage等最近的努力使得GCN适应于user-item交互图,并捕获高阶邻域中的CF信号从而进行推荐。
值得一提的是,最近的一些努力提供了对
GNN的深入洞察insight,这激发了我们开发LightGCN。具体而言,《Simplifying Graph Convolutional Networks》认为GCN不必要的复杂性,通过移除非线性、并将多个权重矩阵融合为一个从而开发简化的GCN(simplified GCN: SGCN)模型。LightGCN和SGCN的一个主要区别是:它们是针对不同的任务开发的,因此模型简化的合理性是不同的。具体而言:SGCN用于节点分类,对模型的可解释性和效率进行了简化。- 相比之下,
LightGCN用于协同过滤,其中每个节点只有一个ID特征。因此,我们执行简化的理由更充分:非线性和权重矩阵对于CF毫无用处,甚至会损害模型训练。
对于节点分类准确性,
SGCN与GCN相当(有时弱于)。对于CF准确性,LightGCN的性能大大优于GCN(比NGCF提高了15%以上)。最后,同时进行的另一项工作
《Revisiting Graph based Collaborative Filtering: A Linear Residual Graph Convolutional Network Approach》也发现非线性在NGCF中是不必要的,并为CF开发了线性GCN模型。相比之下,我们的LightGCN更进了一步:我们删除了所有冗余参数,仅保留了ID embedding,使模型像MF一样简单。- 早期的研究定义了谱域
18.1 模型
18.1.1 NGCF
- 我们首先介绍
NGCF,这是一个具有代表性的、state-of-the-art的GCN推荐模型。然后我们对NGCF进行消融研究,以判断NGCF中每个操作的有效性。本节的贡献是表明GCN中的两种常见操作,特征转换和非线性激活,对协同过滤没有正面影响。
a. NGCF 介绍
首先每个用户和每个
item都关联一个ID embedding。令 表示用户 的ID embedding、 表示item的ID embedding。NGCF利用user-item交互图来传播embedding,即:其中:
- 分别为用户 和
item在第 层的refined embedding。 - 为非线性激活函数。
- 为用户 直接交互的
item集合, 为与item直接交互的user集合。 - 为第 层可训练的权重矩阵,用于执行特征变换。
通过传播 层,
NGCF得到了 个embedding来描述一个用户、得到了 个embedding来描述一个item。然后
NGCF拼接这 个embedding从而获得最终的user embedding和item embedding,并使用内积来生成预估分。- 分别为用户 和
NGCF很大程度上遵循了标准的GCN,包括使用非线性激活函数 和特征变换矩阵 。然而,我们认为这两种操作对于协同过滤不是太有用。在半监督节点分类任务中,每个节点都有丰富的语义特征作为输入,例如一篇文章的标题和关键词。因此,执行多层非线性变换有利于特征学习。
然而在协同过滤中,
user-item交互图的每个节点只有一个id作为输入,没有具体的语义。在这种情况下,执行多层非线性变换无助于学习更好的特征。更糟糕的是,执行多层非线性可能会增加训练的难度。接下来我们将提供实验的证据。
b. NGCF 实验探索
我们对
NGCF进行消融研究,从而探索非线性激活和特征变换的影响。我们使用NGCF作者发布的代码,在相同的数据集拆分和评估协议上运行实验,以保持尽可能公平地比较。由于
GCN的核心是通过传播来refine embedding,因此我们对相同embedding size下的embedding质量更感兴趣。因此,我们将获得最终embedding的方式从拼接(即 )改为求和(即 )。注意,这种变更对于NGCF的性能影响不大,但是使得以下消融研究更能够表明GCN的refined embedding质量。我们实现了
NGCF的三个简化的变体:NGCF-f:删除特征变换矩阵 。NGCF-n:删除非线性激活函数 。NGCF-fn:同时删除特征变换矩阵和非线性激活函数。
对于这三个变体,我们保持所有超参数(例如学习率、正则化系数、
dropout rate等等)和NGCF的最佳配置相同。我们在下表中报告了
Gowalla和Amazon-Book数据集上2-layer setting的结果。可以看到:- 删除特征变换(即
NGCF-f)导致在所有三个数据集上对NGCF的持续提升。 - 相比之下,删除非线性激活函数(即
NGCF-n)不会对准确性accuracy产生太大影响。 - 如果我们同时删除特征变换矩阵和非线性激活函数(即
NGCF-fn),那么性能会得到显著提高。
根据这些观察,我们得出以下结论:
- 添加特征变换对
NGCF产生负面影响,因为在NGCF和NGCF-n这两个模型中删除特征变换(即NGCF-f和NGCF-fn)显著提高了性能。 - 添加非线性激活函数在包含特征变换时影响很小(
NGCF vs NGCF-n),但是在禁用特征变换时会产生负面影响(NGCF-f vs NGCF-fn)。 - 总体而言,特征变换和非线性激活函数对
NGCF产生了相当负面的影响。因为通过同时移除它们,NGCF-fn表现出比NGCF的巨大提升(召回率相对提高9.57%)。
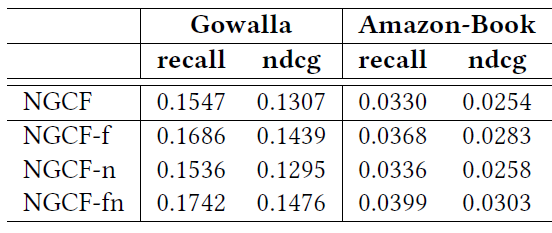
为了更深入地了解表中获得的分数,以及理解为什么
NGCF在这两种操作下(特征变换和非线性激活)恶化,我们在下图中绘制了训练损失和测试recall。可以看到:
在整个训练过程中,
NGCF-fn的训练损失要比NGCF, NGCF-f, NGCF-n低得多。NGCF-fn的训练损失和测试的recall曲线保持一致,并且这种较低的训练损失成功地转化为更好的推荐准确性。NGCF和NGCF-f之间的比较显式了类似的趋势,只是提升幅度较小。
从上述证据中我们可以得出结论:
NGCF的性能恶化源于训练难度,而不是过拟合。从理论上讲,
NGCF比NGCF-f具有更强的表示能力,因为将权重矩阵 设置为单位矩阵 可以完全恢复NGCF-f模型。然而在实践中,NGCF表现出比NGCF-f更高的训练损失和更差的泛化性能。非线性激活的加入进一步加剧了表示能力和泛化性能之间的差异。NGCF相比NGCF-f更高的训练损失,这就是训练难度的表现。理论上NGCF的模型容量更大,那么训练损失应该更低。假如NGCF模型的训练损失更低、但是测试auc反而更差,那么就是过拟合的表现。为了完善这一部分内容,我们主张在设计推荐模型时,进行严格的消融研究以明确每个操作的影响是非常重要的。否则,包含不太有用的操作会使得模型不必要地复杂化、增加模型训练难度、甚至降低模型的有效性。
18.1.2 LightGCN
前述分析表明:
NGCF是一种用于协同过滤的沉重的、冗余的GCN模型。在这些发现的推动下,我们设定了一个目标,即通过包含GCN最基本的组件进行推荐从而开发一个轻量light而有效effective的模型。简单的模型具有以下优势:更容易解释、更容易训练和维护、技术上更容易分析模型行为并将其修改为更有效的方向,等等。在这一部分,我们首先展示我们设计的
Light Graph Convolution Network: LightGCN模型,如下图所示。在LightGCN中,仅对前一层邻居的embedding执行归一化求和normalized sum。所有其它操作,如自连接self-connection、特征转换、非线性激活等等,都被删除。这在很大程度上简化了GCN。在Layer Combination中,我们对每一层的embedding求和以获得最终representation。然后我们对
LightGCN进行深入分析,以展示其简单设计背后的合理性。最后我们描述了如何针对推荐来进行模型训练。
a. LightGCN
GCN的基本思想是通过在图上平滑特征来学习节点的representation。为了实现这一点,它迭代式地执行图卷积graph convolution,即将邻居的特征聚合为目标节点的新representation。这种邻域聚合可以抽象为:其中 为一个聚合函数(图卷积的核心),它考虑了目标节点及其邻居节点在第 层的
representation。很多工作都提出了 ,如:
GIN中的weighted sum聚合器、GraphSAGE中的LSTM聚合器、BGNN中的bilinear interaction聚合器等等。然而,大多数工作都将特征转换或非线性激活与 函数联系起来。尽管这些聚合器在具有语义输入特征的节点分类任务或图分类graph classification任务上表现良好,但是它们可能对协同过滤造成负担(参考前面的初步分析结果)。Light Graph Convolution: LGC:在LightGCN中,我们采用简单的加权和聚合器,删除了特征变换和非线性激活。LightGCN中的图卷积操作定义为:对称的归一化项 遵从标准的
GCN的设计,这样可以避免embedding的幅度(即向量的幅长)随着图卷积运算而增加。这里也可以应用其它选择,如 范数。但是根据经验,我们发现这种对称归一化具有良好的性能(参考后面实验的结果)。值得注意的是:在
LGC中,我们只聚合相连的邻居,没有聚合目标节点本身(即自连接)。这和大多数现有的图卷积操作不同,现有的图卷积通常聚合扩展的邻域(包含节点自身)并需要专门处理自连接。这是因为:层组合操作layer combination operation本质上捕获了和自连接相同的效果,因此在LGC中没有必要包含自连接。关于层组合操作的内容接下来介绍,并且我们还将证明层组合操作和自连接本质上是相同的效果。
层组合和模型预测
Layer Combination and Model Prediction:在LightGCN中,唯一可训练的模型参数是第0层的embedding,即所有用户的 和所有item的 。当给定这些embedding时,可以通过LGC计算更高层的embedding。在 层
LGC之后,我们进一步结合在每一层获得的embedding,从而得到最终的user representation和最终的item representation:其中 表示第 层
embedding在构成final embedding中的重要性。它可以被视为要手动调优的超参数,也可以被视为要自动优化的模型参数。在我们的实验中,我们发现将 统一设为 通常会带来良好的性能。因此,我们没有设计特殊的组件来优化 ,从而避免不必要地复杂化LightGCN并保持其简单性。和
NGCF采用多层embedding的拼接聚合不同,LightGCN采用多层embedding的加权和聚合。我们执行层组合
layer combination从而获得final representation的原因有三个:- 随着层数的增加,
embedding会过度平滑over-smooth。因此,简单地使用最后一层是有问题的。 - 不同层的
embedding捕获不同的语义。例如,第一层对有交互的用户和item强制执行平滑,第二层平滑与交互item(用户)重叠的用户(item),更高层捕获更高阶的邻近性proximity。因此,将它们组合起来将使得representation更加全面。 - 将不同层的
embedding以加权和的方式组合,可以捕捉到带自连接的图卷积的效果,这是GCN中的一个重要技巧。
模型预测被定义
user final representation和item final representation的内积:- 随着层数的增加,
矩阵形式:我们提供了
LightGCN的矩阵形式,以便于实现以及和现有模型的讨论。假设
user-item交互矩阵为 ,其中 为用户数量、 为item数量。如果用户 和item有交互则 ,否则 。然后我们得到user-item交互图的邻接矩阵为:令第
0层的embedding矩阵为 ,其中 为embedding size。则我们可以得到LGC的矩阵等价形式为:其中 是一个对角矩阵(也称度矩阵), 表示 中第 行非零元素的个数, 为对称归一化的矩阵。
最后,我们得到用于模型预测的
final embedding矩阵为:.
b. 模型分析
我们进行模型分析以证明
LightGCN简单设计背后的合理性。首先我们讨论了与
Simplified GCN的联系,这是最近的一个线性GCN模型,它将自连接集成到图卷积中。这个分析表明通过层组合,LightGCN包含了自连接的效果。因此,LightGCN不需要在邻接矩阵中加入自连接。然后我们讨论和
Approximate Personalized Propagation of Neural Predictions: APPNP的联系,这是最近的一个GCN变体,它通过从Personalized PageRank的启发来解决过度平滑问题。这个分析表明了LightGCN和APPNP之间的潜在等效性。因此,我们的LightGCN在具有可控过度平滑controllable oversmoothing的长距离传播方面享受同样的好处。最后,我们分析了第二层
LGC,以展示它如何平滑用户及其二阶邻居。这为LightGCN的工作机制提供更多的洞察insights。与
SGCN的关联:在论文《Simplifying Graph Convolutional Networks》中,作者论证了GCN对节点分类的不必要的复杂性,并提出了SGCN。SGCN通过删除非线性并将权重矩阵压缩为一个权重矩阵来简化GCN。SGCN中的图卷积定义为:其中 为单位矩阵,它添加到 上从而构成自连接。
在下面的分析中,为简单起见,我们省略了 项,因为该项仅仅对
embedding执行缩放re-scale。在
SGCN中,最后一层得到的embedding用于下游预测任务,可以表示为:其中 表示组合数。
上述推导表明:将自连接插入到 并在其上传播
embedding,本质上等效于在每个LGC层传播的embedding的加权和。添加自连接相当于将每一层的
embedding向更高层传播,此时最后一层embedding隐含了各层的embedding信息。这相当于不带自连接的、LGC的各层embedding的直接聚合。和
APPNP的关联:在最近的一项工作《Predict then propagate: Graph neural networks meet personalized pagerank》中,作者将GCN和Personalized PageRank联系起来,从中得到启发,并提出一个叫做APPNP的GCN变体。该变体可以在没有过度平滑oversmoothing风险的情况下进行长距离传播。受到
Personalized PageRank中的传送设计teleport design的启发,APPNP用起始特征starting feature(即第0层embedding)补充每个传播层,这可以平衡balance保留局部性locality(即靠近根节点以减轻过度平滑)和利用大的邻域的信息的需要。APPNP中的传播层定义为:其中 为传播中控制起始特征保留的
teleport probability, 为归一化的邻接矩阵。在
APPNP中,最后一层用于最终预测,即:我们可以看到:通过相应的设置 ,
LightGCN可以完全恢复APPNP使用的预测embedding。因此,LightGCN在对抗过度平滑方面具有APPNP的优势:通过适当地设置 ,我们允许使用大的 进行具有可控过度平滑controllable oversmoothing的长程long-range建模。另一个细微的区别是:
APPNP在邻接矩阵中添加了自连接。然而,正如我们之前所展示的,由于LightGCN采用了不同层embedding的加权和,因此自连接是冗余的。二阶
embedding的平滑性:由于LightGCN的线性和简单性,我们可以深入了解它如何平滑embedding。这里我们分析一个两层LightGCN来证明其合理性。以用户侧为例,直观地,第二层平滑了在交互
item上有重叠overlap的所有用户。具体而言,我们有:可以看到,如果另一个用户 和目标用户 有共同的交互
item,那么 对 的平滑强度smoothness strength由以下系数来衡量:如果 和 没有共同的交互
item,那么该系数为零。这个系数相当容易解释:二阶邻居 对 的影响由以下因素决定:
- 共同交互
item的数量(即: ),数量越多则影响越大。 - 共同交互
item的流行度popularity(即: ),流行度越低(即越能够代表用户的个性化偏好)则影响越大。 - 用户 的活跃度(即:),越不活跃则影响越大。
这种可解释性很好地满足了
CF在度量用户相似性时的假设,并证明了LightGCN的合理性。由于
LightGCN公式的对称性,我们可以在item方面得到类似的分析。- 共同交互
LightGCN和SGCN的一个主要区别在于:LightGCN和SGCN是针对不同的任务开发的,因此模型简化的合理性是不同的。具体而言:SGCN用于节点分类,对模型的可解释性和效率进行简化。相比之下,LightGCN用于协同过滤CF,其中每个节点只有一个ID特征。因此我们做简化的理由更充分:非线性和权重矩阵对于协同过滤毫无用处,甚至会损害模型训练。
c. 模型训练
LightGCN的可训练参数只是第0层的embedding,即 。换句话讲,模型复杂度和标准的矩阵分解matrix factorization: MF相同。我们采用贝叶斯个性化排序
Bayesian Personalized Ranking损失函数。BPR loss是一种pairwise loss,它 鼓励观察到的item的预测高于未观察到的对应item:其中 控制了 正则化强度。
- 我们采用
Adam优化器,并以mini-batch的方式优化。 - 我们知道其它可能会改进
LightGCN训练的高级负采样策略,如hard负采样和对抗采样adversarial sampling。我们把这个扩展放在未来,因为它不是这项工作的重点。
- 我们采用
注意,我们没有引入
GCN和NGCF中常用的dropout机制。原因是我们在LightGCN中没有特征变换权重矩阵,因此在embedding层上执行 正则化足以防止过拟合。这展示了LightGCN简单性的优点:比NGCF更容易训练和调优。NGCF需要额外地调优两个dropout rate(node dropout和message dropout),并将每层的embedding归一化为单位长度。还可以学习层的组合系数 ,或者使用注意力网络对组合系数进行参数化,这在技术上是可行的。即:个性化层的组合系数 ,以便为不同的用户启用自适应阶次的平滑。例如,稀疏用户可能需要来自高阶邻居的更多信号,而活跃用户则只需要来自低阶邻居的更少信号。
活跃用户具有大量的一阶
item邻居,因此使用低阶邻居就可以得到良好的用户representation;稀疏用户具有很少的一阶item邻居,因此需要高阶邻居来补充从而得到更好的用户representation。然而,我们发现在训练数据上学习 并没有带来改进。这可能是因为训练数据不包含足够的信号来学习可泛化到未知数据的好的 。我们还尝试从验证数据中学习 ,这是受到
《λOpt: Learn to Regularize Recommender Models in Finer Levels》的启发,它在验证数据上学习超参数。我们发现性能性能略有提升(小于1%)。我们将探索 的最佳设置(如针对不同的用户和
item来进行个性化)作为未来的工作。
18.2 实验
我们首先描述实验设置,然后和
NGCF进行详细比较。NGCF是和LightGCN最相关、但是更复杂的方法。接下来我们将LightGCN和其它state-of-the-art方法进行比较。为了证明LightGCN中的设计合理性并揭示其有效的原因,我们进行了消融研究和embedding分析。最后我们研究了超参数。数据集:为了减少实验工作量并保持公平的比较,我们密切遵循
NGCF工作的配置。我们从NGCF作者那里获取了实验数据集(包括训练集、测试集的拆分),其统计数据如下表所示。Gowalla和Amazon-Book和NGCF论文中使用的完全一致,因此我们直接使用NGCF论文中的结果。- 唯一的例外是
Yelp 2018数据集,这是一个修订版本。根据NGCF作者的说法,之前的版本没有过滤掉测试集中的冷启动item,他们只向我们分享了修订版本。因此,我们在Yelp 2018数据集上重新运行了NGCF。 - 评估指标是由
all-ranking协议(用户的所有未交互的item都是候选item)计算的recall@20和ndcg@20。
对比方法:主要的对比方法是
NGCF,其表现优于多种方法,包括基于GCN的模型GC-MC, PinSage、基于神经网络的模型NeuMF, CMN、以及基于分解的模型MF, Hop-Rec。由于比较是在相同评估协议下的相同数据集上进行的,因此我们没有进一步和这些方法进行比较(仅仅比较了NGCF)。我们还进一步比较了两种相关的、且具有竞争力的
CF方法:Mult-VAE:这是一种基于变分自编码器variational autoencoder: VAE的、基于item的CF方法。它假设数据是从多项式分布中生成的,并使用变分推断variational inference进行参数估计。我们运行作者发布的代码,并在
[0, 0.2, 0.5]中调优dropout rate、在[0.2, 0.4, 0.6, 0.8]中调优 。模型架构是原始论文中建议的架构:600 -> 200 -> 600。GRMF:该方法通过添加图拉普拉斯正则化器graph Laplacian regularizer来平滑矩阵分解。为了公平地比较item推荐,我们将评分预测损失调整为BPR loss。GRMF的目标函数为:其中 在 之间调优,其它的超参数设置和
LightGCN相同。此外,我们还比较了一个给拉普拉斯图增加归一化的变体:
这被称作
GRMF-norm。这两种GRMF方法通过拉普拉斯正则化器在训练中引入embedding平滑(测试时还是原始的embedding而没有平滑),而我们的LightGCN在预测模型中实现了embedding平滑。
超参数配置:
- 与
NGCF相同,所有模型的embedding大小固定为64,embedding参数使用Xavier方法初始化。 - 我们使用
Adam优化器优化LightGCN,并使用默认的学习率0.001和默认的batch size = 1024(在Amazon-Book上,我们将batch size增加到2048以提高训练速度)。 - 正则化系数 在 范围内搜索,大多数情况下最优值为 。
- 层组合系数 统一设置为 ,其中 为层数。
- 我们在
1 ~ 4的范围内测试 ,当 时可以获得令人满意的性能。 - 早停和验证策略与
NGCF相同。通常,1000个epoch足以让LightGCN收敛。
我们的实现在
TensorFlow和PyTorch中都可用。- 与
18.2.1 模型比较
与
NGCF比较:我们与NGCF进行了详细的比较,下表中记录了不同层(1层到4层)的性能,还显示了每个指标的相对提升比例。其中NGCF在Gowalla和Amazon-Book上的结果来自于NGCF原始论文。我们在下图中进一步绘制了
training loss和testing recall的训练曲线training curves,从而揭示LightGCN的优势,并明确训练过程。训练曲线是每隔20个epoch收集一次训练损失和测试召回率。Yelp2018结果的趋势和Gowalla/Amazon-Book相同,因为篇幅有限这里忽略Yelp2018的结果曲线。可以看到:
在所有情况下,
LightGCN的表现都远远超过NGCF。例如在
Gowalla数据集上,NGCF论文中报告的最高召回率为0.1570,而我们的LightGCN在4层设置下可以达到0.1830%,高出16.56%。平均而言,三个数据集的召回率提高了
16.52%、ndcg提高了16.87%,这是相当显著的提升。可以看到
LightGCN的性能优于NGCF-fn。NGCF-fn是删除特征变换和非线性激活的NGCF变体。由于NGCF-fn仍然包含比LightGCN更多的操作(如,自连接、图卷积中user embedding和item embedding之间的交互、dropout),这表明这些操作对于NGCF-fn也可能是无用的。增加层数可以提高性能,但是增益会逐渐减少。一般的观察是:将层数从
0(即矩阵分解模型)增加到1会导致最大的性能增益,并且在大多数情况下使用3层会导致令人满意的性能。这一观察结果和NGCF的发现一致。在训练过程中,
LightGCN始终获得较低的训练损失,这表明LightGCN比NGCF更容易拟合训练数据。此外,较低的训练损失成功地转化为更好的测试准确性accuracy,这表明了LightGCN强大的泛化能力。相比之下,
NGCF较高的训练损失和较低的测试准确性反映了训练好如此重型heavy的模型的实际难度。
注意,在图中我们显示了两种方法在最佳超参数设置下的训练过程。虽然提高
NGCF的学习率可以降低其训练损失(甚至低于LightGCN),但是无法提高测试召回率,因为以这种方式降低训练损失只能为NGCF找到无效解trivial solution。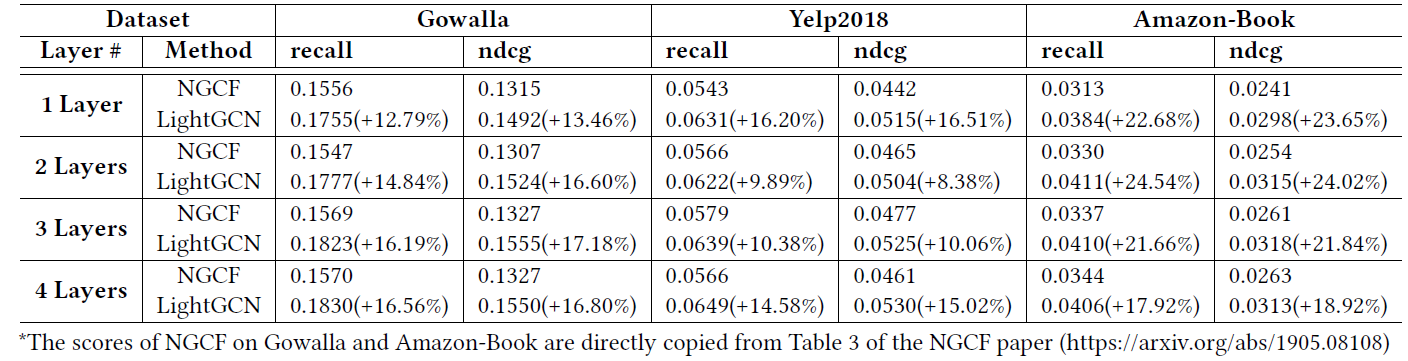
和
SOA模型的比较:下表给出了LightGCN和其它baseline方法的性能比较。我们展示了我们可以为每种方法获得的最佳得分。可以看到:
LightGCN在所有三个数据集上始终优于其它方法,证明了其简单而合理的设计的有效性。注意:
LightGCN可以通过调整 进一步提升效果(参加后面的消融研究),而这里我们仅使用统一的 设置以免过度调优over-tuning。在所有
baseline中:Mult-VAE表现出最强的性能,优于GRMF和NGCF。GRMF的性能与NGCF相当,优于MF,这表明使用拉普拉斯正则化器强制embedding平滑的效果。- 通过在拉普拉斯正则化器中加入归一化,
GRMF-norm在Gowalla上优于GRMF、在Yelp2018和Amazon-Book上没有任何收益。
18.2.2 消融研究
我们通过展示层组合
layer combination和对称的sqrt归一化如何影响LightGCN的性能来进行消融研究。为了证明前面分析的
LightGCN的合理性,我们进一步研究了embedding smoothness(这是LightGCN有效的关键原因)的影响。层组合的影响:下图显示了
LightGCN及其变体LightGCN-single的结果。其中LightGCN-single不使用层组合,即仅仅将 用于 层LightGCN的最终预测。由于篇幅有限,我们省略了
Yelp2018上的结果,这与Amazon-Book显示出类似的趋势。可以看到:聚焦
LightGCN-single,我们发现:当层数从1增加到4时,它的性能先提升然后下降;在大多数情况下,峰值点在2层,然后迅速下降到4层这个最差点。这一结果表明:使用一阶和二阶邻居来平滑节点的
embedding对于CF非常有用,而在使用高阶邻居时会遇到过度平滑的问题。聚焦
LightGCN,我们发现:它的性能随着层数的增加而逐渐提高。即使使用4层,LightGCN的性能也不会下降。这证明了
layer combination解决过度平滑的有效性,正如我们前面技术分析中(和APPNP的关联)所表述的那样。比较这两种方法,我们发现:
LightGCN在Gowalla上的表现始终优于LightGCN-single,但是在Amazon-Book和Yelp2018上则不然(其中2层LightGCN-single表现最好)。对于这种现象,在得出结论之前需要注意两点:
LightGCN-single是LightGCN的特例。如果将 ,其它 ,则LightGCN降级为LightGCN-single。- 在
LightGCN中,我们没有调优 而是简单地将其设为 。因此我们可以看到通过调优 进一步提高LightGCN性能的潜力。
对称
sqrt归一化:在LightGCN中,我们在执行邻域聚合时对每个邻域embedding采用对称sqrt归一化 。为了研究其合理性,我们在这里探索了三种不同的选择:- 仅使用左侧目标节点的系数,即左侧归一化,用
-L来表示。 - 仅使用右侧邻居节点的系数,即右侧归一化,用
-R来表示。 - 使用
L1归一化,即移除平方根,用-L1来表示。
注意,如果移除整个归一化本身,那么训练会变得数值不稳定,并且会受到
not-a-value:NAN问题的影响,因此这里我们不会比较这个配置。下表给出了
3层LightGCN的结果, 可以看到:- 一般而言,最佳设置是使用对称
sqrt归一化(即LightGCN的当前设计)。移除任何一侧都会大大降低性能。 - 次优设置是仅在左侧使用
L1归一化,即LightGCN-L1-L,这相当于通过in degree将邻接矩阵归一化为随机矩阵stochastic matrix。 - 两侧对称归一化有助于
sqrt归一化(即LightGCN vs LightGCN-L/LightGCN-R),但是会降低L1归一化的性能(即LightGCN-L1 vs LightGCN-L1-L/LightGCN-L1-R)。
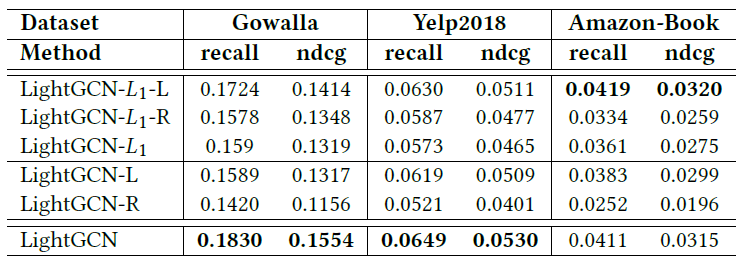
- 仅使用左侧目标节点的系数,即左侧归一化,用
Embedding Smoothness分析:正如我们在前面分析的那样,一个2层LightGCN根据用户交互item上重叠overlap的用户来平滑用户的embedding,两个用户之间的平滑强度smoothing strength根据以下公式来衡量:我们推测这种
embedding平滑是LightGCN有效性的关键原因。为了验证这一点,我们首先将用户embedding的平滑性定义为:其中
embedding的L2范数用于消除embedding幅度scale的影响。类似地,我们可以获得
item embedding的平滑性定义。理论上如果两个用户平滑强度 较大,则他们之间应该越相似,即 很小。因此 可以视为一种平滑性损失
smoothness loss,该值越小那么embedding越平滑。下表显式了矩阵分解(即使用 进行模型预测)、
2层的LightGCN-single(即使用 进行模型预测)这两个模型的平滑性。注意:2层LightGCN-single在推荐准确性方面远远超过MF。可以看到:
LightGCN-single的平滑性损失远远低于MF。这表明,通过进行light graph convolution,embedding变得更平滑、更适合用于推荐。
18.2.3 超参数研究
当
LightGCN应用于新数据集时,除了标准的超参数学习率之外,最重要的超参数是L2正则化系数 。这里我们研究了一个2层的LightGCN的性能针对超参数 变化的曲线,如下图所示。可以看到:LightGCN对 相对不敏感。即使当 时,LightGCN也比NGCF要好。而NGCF额外使用dropout来防止过拟合。这表明
LightGCN不太容易过拟合,因为LightGCN中唯一可训练的参数是第0层的ID embedding,所以模型很容易训练和正则化。Yelp 2018、Amazon-Book、Gowalla数据集上, 的最佳取值分别为 。当 时,模型性能下降得很快,这表明太强的正则化将对模型正常训练产生负面影响,因此不鼓励这样做。
我们相信
LightGCN的洞察对推荐模型的未来发展具有启发意义。随着链接图数据linked graph data在实际应用中的流行,基于图的模型在推荐中变得越来越重要。通过显式地利用预测模型中实体之间的关系,基于图的模型优于传统的监督学习方案(如隐式利用实体之间关系的分解机FM)。例如,最近的一个趋势是利用辅助信息,如
item知识图、社交网络、多媒体内容,从而进行推荐。在这个过程中,GCN已经建立了state-of-the-art技术。然而,这些模型也可能会遇到NGCF的类似问题,因为user-item交互图也由相同的、可能不必要的神经操作建模。我们未来计划在这些模型中探索LightGCN的思想。另一个未来的方向是个性化层组合权重 ,以便为不同的用户启用自适应阶次的平滑。例如,稀疏用户可能需要来自高阶邻居的更多信号,而活跃用户可能只需要低阶邻居的信号。
最后,我们将进一步探索
LightGCN简单性的优势,研究非采样回归损失non-sampling regression loss是否存在快速解决方案,并将其流式传输streaming到在线工业场景。
十九、Sampling-Bias-Corrected Neural Modeling[2019](检索)
推荐系统帮助用户在很多互联网服务中发现感兴趣的内容,包括视频推荐、
app推荐、以及在线广告targeting。在很多情况下,这些系统在严格延迟latency的要求下,将数十亿用户连接到来自数百万甚至数十亿规模的内容语料库中的item。一种常见的做法是将推荐视为检索和排序问题
retrieval-and-ranking problem,并设计一个两阶段系统。也就是说,一个scalable检索模型首先从大型语料库中检索一小部分相关的item,然后一个排序模型基于一个或多个目标(例如点击或用户评分)对检索到的item进行重排re-rank。这里我们聚焦于为个性化推荐构建一个真实世界的、可扩展scalable的检索系统。给定
{user, context, item}三元组,构建可扩展检索模型的常见解决方案是:- 分别学习
{user, context}的query representation和{item}的item representation。 - 在
query representation和item representation之间使用简单的评分函数(如内积)来获得为query量身定制的推荐。
其中,
context通常表示具有动态性质的变量,如一天中的时间、用户正在使用的设备。面对众所周知的冷启动问题
cold-start problem,现实世界的系统需要适应数据分布data distribution的变化,以便更好地呈现新鲜的内容fresh content。近年来,由于深度学习在计算机视觉和
NLP方面的成功,有大量工作将深度神经网络DNN应用于推荐。deep representation非常适合在低维embedding空间中编码复杂的用户状态和item内容特征。这里以双塔DNN模型为例,如下图所示,其中左塔编码了{user, context}、右塔编码了{item}。
DNN模型计算softmax时通常不会考虑所有可能的item,而是使用来自固定词表fixed vocabulary的负样本来优化训练。但是在流式streaming在线训练online learning场景下,词表不再固定(因为新item的不断涌入),因此另一种优化方式是考虑batch softmax优化,其中item概率是在一个随机batch中的所有item上计算的,从而作为训练双塔DNN的通用方法。然而正如实验所示,
batch softmax受采样偏差sampling bias的影响,可能会严重限制模型性能,特别是在item分布高度倾斜的情况下。MLP模型研究了重要性采样importance sampling以及相应的偏差缩减bias reduction技术。受到这些工作的启发,论文《Sampling-Bias-Corrected Neural Modeling for Large Corpus Item Recommendations》提出使用估计的item频率来纠正batch softmax的采样偏差sampling bias。与固定词表相比,论文提出的方法可以处理流式数据streaming data,其中词表和item分布随着时间发生变化。此外,论文还提出了一种通过梯度下降来估计item频率的新算法。另外,论文应用偏差校正建模bias-corrected modeling,并扩展scale它来构建个性化的YouTube推荐检索系统。最后,论文还介绍了一种序贯sequential训练策略,旨在结合流式数据以及系统的indexing组件、serving组件。论文主要贡献:
- 流式频率估计
Streaming Frequency Estimation:论文提出了一种新的算法,从而在词表和item分布动态变化的情况下估计流式数据中的item频率。论文的分析结果给出了估计的方差和偏差。论文还提供了仿真来证明该方法在捕获数据动态方面的有效性。 - 建模框架
Modeling Framework:论文为构建大规模检索系统提供了一个通用的建模框架。具体而言,论文将估计的item频率融合到batch softmax的交叉熵损失中,以减少in-batch item的采样偏差。 YouTube推荐:论文描述了如何应用建模框架为YouTube推荐构建大规模检索系统。论文介绍了端到端系统,包括训练组件、索引组件、服务组件。- 离线和在线实验:论文对两个真实世界的数据集进行了离线实验,并证明了采样偏差校正的有效性。论文还表明,为
YouTube构建的检索系统可以提高在线实验中的互动engagement指标。
- 分别学习
相关工作:这里我们概述了相关工作,并强调了这些工作与我们贡献的联系。
内容感知和神经推荐器
Neural Recommender:利用用户和item的内容特征对于提高泛化能力和缓解冷启动问题至关重要。有一系列研究侧重于将内容特征纳入经典的矩阵分解
matrix factorization: MF框架。例如,广义矩阵分解模型(如SVDFeature和Factorization Machine: FM)可用于融合item内容特征。这些模型能够捕获双线性bi-linear,即特征之间的二阶交互。近年来,深度神经网络
DNN已被证明可以有效提高推荐准确性。由于高度的非线性,DNN相比于传统的分解方法,可以提供更强大的捕获复杂特征交互的能力。《Neural Collaborative Filtering》直接应用了协同过滤的直觉,并提供了一种neural CF: NCF的架构来对user-item交互进行建模。在NCF框架中,user embedding和item embedding被拼接起来并通过多层神经网络传递从而获得最终预测。我们的工作在两个方面与NCF不同:- 我们利用双塔神经网络对
user-item交互进行建模,以便可以在亚线性时间内对大量item语料库进行推断。 NCF的学习依赖于point-wise损失(例如平方损失或者对数损失),而我们引入了多类softmax损失并显式建模了item频率。
在另一项工作中,深度循环模型(如
LSTM)将时间信息和历史事件融合到推荐中。除了学习独立的user representation和item representation之外,还有另一些工作专注于设计神经网络,特别 是learned to rank系统。值得一提的是,多任务学习multi-task learning一直是优化复杂推荐系统多个目标的核心技术。《Wide Deep Learning for Recommender Systems》引入了一个Wide & Deep框架,该框架具有联合训练的wide线性模型和deep神经网络模型。- 我们利用双塔神经网络对
极端分类
Extreme Classifcation:softmax是模型中最常用的函数之一,可用于预测高达数百万个label的大型输出空间。许多研究一直专注于为大类别
large number of classes训练softmax分类模型。当类别数量非常大时,一种广泛使用的加速训练技术是对类别子集进行采样。《Adaptive Importance Sampling to Accelerate Training of a Neural Probabilistic Language Model》表明,良好的采样分布应该能够适应模型的输出分布。为了避免计算采样分布的复杂性,很多现实世界的模型采用简单的分布,例如均匀分布。最近《Adaptive Sampled Softmax with Kernel Based Sampling》设计了一种高效且自适应的kernel based采样方法。尽管sampled softmax在各个领域取得了成功,但是不适用于label具有内容特征的情况。在这种情况下,自适应采样仍然是一个悬而未决的问题。各种工作表明,
tree-based的标签结构,例如hierarchical softmax,可用于构建大规模分类模型,同时显著减少推断时间。这些方法通常需要基于某些离散属性categorical attributes的预定义树结构。因此,它们不适用于融合多种类型的输入特征。双塔模型:构建具有双塔的神经网络最近已经成为几种
NLP任务的流行方法,包括建模sentence相似性、response建议、基于文本的信息检索。我们的工作对这方面的研究做出了贡献,具体而言是证明了双塔模型在构建大规模推荐系统方面的有效性。值得注意的是,与上述文献中的很多语言任务相比,我们关注的是语料库规模更大的问题,这在我们的目标
application(如YouTube)中很常见。通过在线实验,我们发现显式建模item频率对提高该setting中的检索准确性至关重要。然而,这个问题在现有的工作中并未得到很好的解决。
19.1 模型
19.1.1 模型框架
我们考虑推荐问题的常见
setting,其中我们有一个query集合,以及一个item集合 。其中 为query数量、 为item数量。令
query集合由特征向量集合 来表示,item集合由特征向量集合 来表示。这里 都是各种特征(例如稀疏的ID特征和稠密的数值特征)的混合,并且可能维度非常高。其中 为query特征空间、 为item特征空间。在个性化场景中,我们假设 完全捕获了用户信息和上下文信息。推荐任务的目标是检索给定
query的item子集。注意,我们从有限数量的
query和item开始解释,但是我们的建模框架并没有这样的假设。即
query集合以及item集合可能都不是固定的,而是动态增加的。我们旨在建立一个具有两个
parameterized embedding函数的模型,这两个函数为:这两个函数将模型参数 和
query/item特征映射到一个 维embedding空间。我们聚焦于 是由两个深度神经网络表示的情况。模型的输出是两个
embedding的内积,即:任务目标是是从由 个样本组成的训练集 中学习模型参数 ,其中 :
- 表示
query和item的pair对。 - 为每个
pair对的奖励reward。通常我们将互动engagement的视频视为正的label,但是我们构建了一个奖励 来反映用户对视频互动的程度。例如, 表示观看时间很短的点击行为, 表示整个视频都看完了的点击行为。
- 表示
直观地看,检索问题可以被视为一个多分类问题。给定一个
query,从 个item中挑选候选item的概率的常见选择是基于softmax函数,即:进一步地,我们考虑以下加权对数似然函数作为损失函数,权重为
reward:当 非常大时,在计算 中的分母时包含所有候选
item是不可行的。一个常见的想法是使用item的子集。我们聚焦于处理流式数据streaming data。因此,与从固定语料库中抽取负样本来训练MLP模型不同,我们考虑仅使用in-batch的item来作为同一个batch内所有其它query的负样本。准确地说,给定mini-batch中的 个pair对 ,batch softmax为:在我们的目标
application中,in-batch的item通常从幂律分布中采样而来。结果, 引入了对full softmax的很大的bias:热门的item由于被包含在一个batch中的可能性很高,从而被过度惩罚为负样本。受到sampled softmax模型中使用的logQ校正的启发,我们通过以下等式校正:这里 表示在一个随机
batch中item的采样概率。我们把 的估计estimation推迟到下一节详述。的物理意义:在所有正样本中,样本
item出现的概率。因为训练batch都是正样本的pair。通过校正,我们有(注意,对于
positive样本我们仍然使用 函数):然后我们得到
batch损失函数为:我们以学习率 来在
SGD中更新模型参数,即:注意, 不需要一组固定的
query或候选item。因此,上述更新方程可用于分布随时间变化的流式训练数据streaming training data。采样方差校正的训练算法:
输入:
embedding函数 。- 学习率 。
输出:训练好的模型参数 。
算法步骤:
反复迭代直到模型收敛,迭代步骤为:
- 从
stream中接收或者随机采样一个batch的训练样本 。 - 根据频率估计
frequency estimation算法来预估每个 的采样概率 。 - 计算损失函数 。
- 更新模型参数 。
- 从
返回训练好的模型参数 。
最近邻搜索
Nearest Neighbor Search:一旦学习了embedding函数 , 那么inference包含两个步骤:- 计算
query embedding。 - 对从
embedding函数 预先计算的一组item embedding执行最近邻搜索。
对于近似的最大内积搜索
maximum inner product search: MIPS问题,低延迟检索通常采用基于哈希技术的高效相似性搜索系统,而不是计算所有item的内积来得到top item。因为这不是我们关注的重点,因此不再详述。- 计算
归一化和温度
Normalization and Temperature:经验上,我们发现增加embedding归一化可以提高模型的可训练性trainability,从而导致更好的检索质量。即:此外,我们添加温度 到每个
logit从而锐化sharpen预测结果,即:在实践中, 是一个超参数,并根据最大化检索指标(如
recall或precision)来调优。
19.1.2 频率估计
在本节中,我们详细说明流的频率估计
streaming frequency estimation。考虑随机
batch的一个stream,其中每个batch包含一组item。问题是估计每个batch中,命中hitting每个item的概率(即包含每个item的概率)。一个关键的设计准则是:当有多个训练
jobs(即workers)时,可以用一个完全分布式的估计distributed estimation来支持分布式训练。在单机训练或分布式训练中,一个
unique global step代表trainer消耗的data batch编号,并且和每个采样的batch关联。在分布式setting下,global step通常通过参数服务器parameter servers在多个workers之间同步。因此,我们可以利用global step,将一个item的频率 的估计转换为 的估计,其中 表示item的两次连续hit之间的平均step。例如,如果每隔50 step采样到一个item,那么我们有 。使用
global step为我们提供了两个好处:- 通过读取和修改
global step,多个worker隐式地同步了频率估计。 - 的估计可以通过简单的移动平均更新
moving average update来实现。这种方式可以适应分布的变化distribution change。
- 通过读取和修改
为了记录不同
item的平均hit间隔,使用固定的item词表通常不现实(因为不断有新的item出现),这里我们应用哈希数组来记录。注意,引入哈希可能会导致潜在的哈希冲突,我们在后文中重新讨论这个问题并提出改进算法。我们分配两个长度为 的数组 和 。假设 是一个将任何
item映射到 中的整数的哈希函数,其中哈希映射可以基于ID或者其他任何item特征。那么对于给定的item, 记录当 被hit时的latest step, 记录 的 估计。我们使用数组 来帮助更新数组 。 一旦
item在global step t中出现(即hit),我们依次更新数组 和数组 为:其中:
- 为
item最近一次出现的间隔。 - 基于加权平均来更新
item的出现间隔,其中:最近的出现间隔权重为 ,历史平均出现间隔的权重为 。 - 更新为 ,即
item的最新的出现gloal step。
为了得到
item的采样概率估计 ,我们可以简单地认为 。物理意义:
item出现频率 = 1 /item出现的平均周期。这里B记录每个item出现的平均周期(以移动均值来更新)。- 为
流式频率估计算法
Streaming Frequency Estimation:输入:
- 学习率 。
- 长度为 的数组 和 。
- 哈希函数 ,其输出空间为 。
输出:每个
item的采样概率 。算法步骤:
训练期间:
迭代,直到停止条件。迭代步骤为:
采样一个
batch的item。对于每个item,执行:
推断期间:
对于任意
item,采样概率为 。
对于给定的
item,假设两次连续hit之间的step遵循随机变量 表示的分布,其中随机变量的均值为 。这里我们的目标是从样本流stream中估计 。随机变量 表示
item出现的周期。每当这个
item在global step t的batch中出现时, 是 的一个新样本。因此,上述更新可以理解为以固定学习率 运行SGD来学习这个随机变量的均值。理论上,如果没有哈希碰撞的情况下,接下来的命题
Proposition显示了这个在线估计的偏差bias和方差variance。命题:假设 为随机变量 独立同步分布采样得到的采样序列。令 。考虑一个在线估计
online estimation,其中 :则:
- 估计的偏差为: 。
- 估计的方差为: 。
其中 为 的初始估计。
证明见原始论文。
上式表明:
当 时,估计的偏差 。
理想的初始化 将导致每一个
step的无偏估计。估计的方差的上界由 给出。可以看到学习率 在两个方面影响方差:
- 较大的学习率导致依赖于初始误差 的第一项更快下降。
- 较大的学习率增加了取决于 方差的第二项,并且这一项不会随着时间而减少。
分布式更新:我们考虑分布式训练框架,其中模型的
parameter分布在一组称作参数服务器parameter server的服务器上,多个worker独立地处理训练数据,并与参数服务器通信以获取和更新模型parameter。Streaming Frequency Estimation算法可以扩展到这个setting。- 数组
A、B、global step这些参数分布在参数服务器上。 - 每个
worker采样一个mini-batch的item,并从参数服务器获取 。 - 然后每个
worker更新 并发送回参数服务器。
因此,
Streaming Frequency Estimation算法可以和神经网络的异步随机梯度下降训练一起执行。- 数组
多重哈希
Multiple Hashing:受到count-min sketch中类似思想的启发,我们扩展了Streaming Frequency Estimation算法以利用多个哈希函数来缓解由于哈希碰撞而导致的item频率高估。我们给出 个数组 和 个数组 。每个数组 的更新遵循Streaming Frequency Estimation算法相同的步骤。考虑到哈希碰撞, 可能是对
item的hit间隔的低估,因为可能另一个不同的item也被存储到该分桶。因此在推断时,我们使用 个估计值的最大值来表示hit间隔。多重哈希
Streaming Frequency Estimation:输入:
- 学习率 。
- 长度为 的 个数组 和 个数组 。
- 输出空间为 的 个哈希函数 。
输出:每个
item的采样概率 。算法步骤:
训练期间:
迭代,直到停止条件。迭代步骤为:
采样一个
batch的item。对于每个item,执行:
推断期间:
对于任意
item,采样概率为 。
19.1.3 Youtube 的神经检索系统
我们应用所提出的建模框架并对其进行扩展
scale,以针对YouTube中的一个特定产品构建大规模神经检索系统neural retrieval system。该产品根据用户正在观看的视频(称为种子视频)生成视频推荐。推荐系统由两阶段组成:检索
retrieval、排序ranking。在检索阶段我们有多个检索器,每个检索器在给定用户和种子视频的条件下生成数百个候选推荐视频。这些候选视频随后由排序模型进行打分和重排。在本节中,我们聚焦于在检索阶段构建一个新的、额外的检索器。
这里的检索模型对每个种子视频输出数百个候选推荐,因此每个种子视频就是一个
trigger。假如用户有很多种子视频,那么就将这些trigger召回的结果进行合并。因此可以看到:模型每次仅处理一个种子视频,而不是将所有种子视频馈入到模型中。至于是处理单个种子视频、还是处理历史种子视频序列,哪个效果更好,可能需要通过实验来分析。
模型概览:我们构建的
YouTube神经检索模型由query网络和候选candidate网络组成,如下图所示。在任何时间点,用户正在观看的视频(即种子视频),提供了关于用户当前兴趣的强烈信号。 因此,我们利用了用户观看历史中的大量种子视频的特征。构建候选tower是为了从候选视频特征中学习。训练
label:视频点击被视为正的label。此外,对于每次点击我们构建了一个奖励 来反映用户对视频的不同程度的互动engagement。例如, 表示观看时间很短的点击视频, 表示整个视频都看完了。奖励用于损失函数的样本加权。视频特征:我们使用的视频特征包括离散特征和连续特征。
离散特征包括视频
ID、频道ID。对于这些实体entity中的每一个,我们都创建embedding层从而将每个离散特征映射到稠密向量。通常我们处理两种类型的离散特征:
- 某些特征是离散的单个值,如视频
ID对于每个视频仅有一个取值。因此我们有一个embedding向量来表示它。 - 某些特征是离散的多个值,如视频的主题可能包含多个取值。因此我们有多个
embedding向量,并取它们的加权作为该特征的embedding。
为了处理
out-of-vocabulary的实体,我们将这些oov实体随机分配到一组固定的哈希桶中,并学习每个哈希桶的embedding。哈希桶对于模型捕获YouTube中可用的新实体很重要。对哈希之后的
ID进行embedding,这解决了需要人工为实体分配ID的映射工作。- 某些特征是离散的单个值,如视频
用户特征:除了种子视频之外,我们还使用了用户的观看历史来捕获用户的兴趣。其中一个用户特征的例子是:用户最近观看的 个视频
id的序列。我们将观看历史视为bag of words: BOW,并通过视频id的embedding的均值来表示它。在
query塔中,用户特征和种子视频特征在input layer融合,然后通过前馈神经网络传递。对于相同类型的
id,embedding是在相关特征之间共享的。例如,同一组视频id embedding用于种子视频、候选视频、用户历史观看视频。我们实验了非共享
embedding,但是没有观察到显著的模型质量提升。
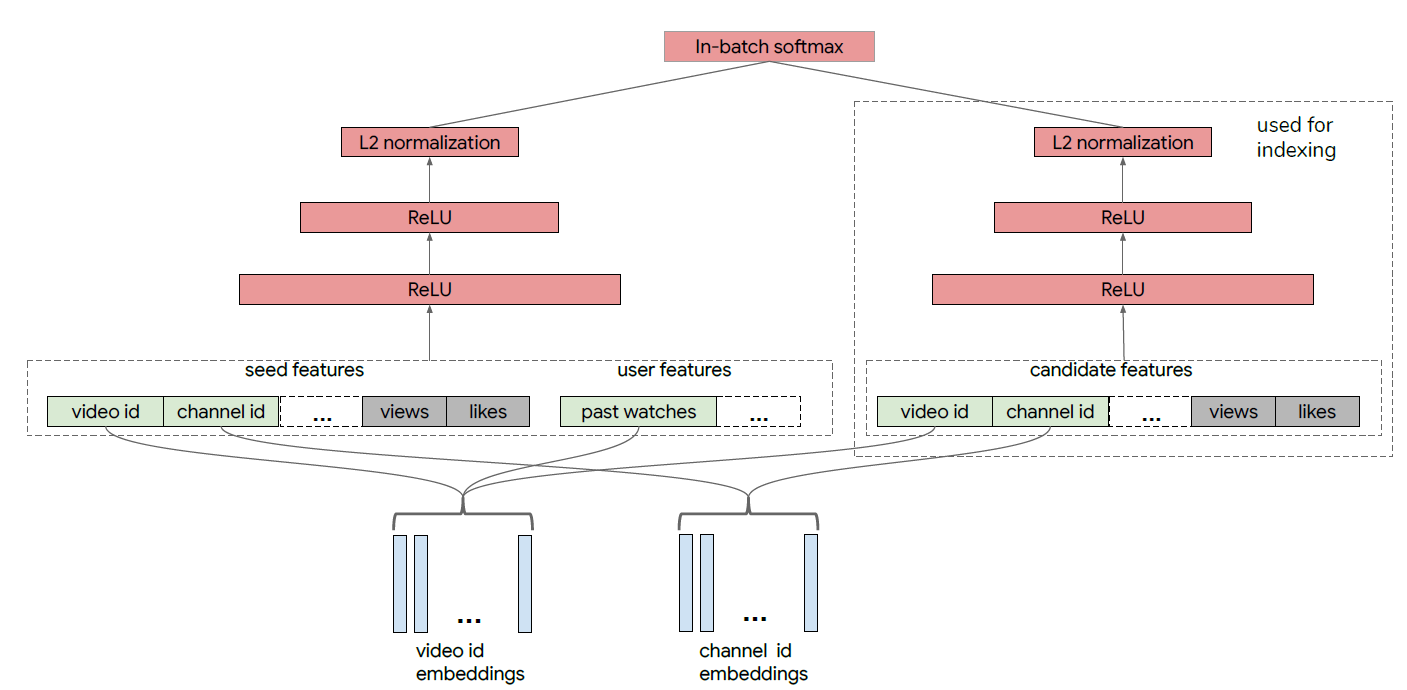
序贯训练
sequential training:我们的模型在Tensorflow中实现,并在分布式系统(包含多个worker和parameter server)上使用分布式梯度下降进行训练。在YouTube中,每天都会生成新的训练数据,训练集也相应地按天进行组织。模型训练以下列方式利用这种序贯结构
sequential structure:trainer按照从最老的训练样本到最近的训练样本按顺序使用数据。一旦trainer赶上最新一天的训练数据,它就会等待第二天的训练数据到达。通过这种方式,模型能够跟上最新的数据分布的变化。训练数据本质上是由
trainer以流式streaming的方式消费的,我们应用Streaming Frequency Estimation算法 (如果使用多个哈希,则使用多重哈希Streaming Frequency Estimation算法 )来估计item频率。Indexing和Model Serving:检索系统中的index pipeline会定期创建一个Tensorfow SavedModel用于在线serving。index pipeline分为三个阶段:候选样本生成candidate example generation、embedding inference、embedding indexing,如下图所示。- 在候选样本生成阶段,基于一定的标准从
YouTube语料库中挑选一组视频。这些视频的特征被提取并添加到候选样本中。 - 在
embedding inference阶段,Neural Retrieval Model的右塔(候选item塔)用于计算候选样本的embedding。 - 在
embedding indexing阶段,我们训练一个基于树和量化哈希技术的、Tensorfow-based的embedding index model。我们掩盖了细节,因为这不是本文的重点。 - 最后,
serving中使用的SavedModel是通过Neural Retrieval Model的query塔和indexing model拼接在一起而创建的。
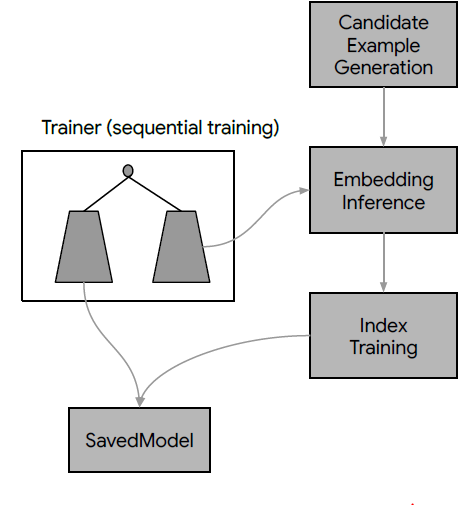
- 在候选样本生成阶段,基于一定的标准从
19.2 实验
- 这里我们展示了实验结果,以证明所提出的
item频率估计和建模框架的有效性。
19.2.1 频率估计仿真
为了评估
Streaming Frequency Estimation算法和多重哈希Streaming Frequency Estimation算法的有效性,我们从仿真研究开始,首先将应用每个算法来拟合固定的item分布,然后在某个step后改变item分布。具体而言,在我们的
setting中,我们使用一组固定的 个item,并且每个item都根据概率 独立采样,其中 。我们在一个输入流
input stream上进行仿真,其中每个step都采样一个batch的item。这里 中的每个item都是以概率 进行有放回的采样。因此我们要拟合的item的hit概率为 。我们在前 个
step保持固定的采样分布,然后在剩下的step中切换为另一个采样分布 。为了评估
esitmation的准确性accuracy,我们计算esitmation的概率集合 和实际的概率集合 之间的 距离,然后进行归一化从而作为估计误差estimation error。即:具体而言,我们报告了学习率 的影响,以及多重哈希的影响。
学习率 的影响:我们设置 、、数组 和 的长度均为 。此外,我们使用全零来初始化数组 、用值
100来初始化数组 。分布切换发生在step的地方。我们使用一个哈希函数并运行Streaming Frequency Estimation算法。下图给出了不同的学习率 在一组
global step上的估计误差。可以看到:- 三条曲线都收敛到某个误差水平
error level,该误差水平来自于哈希冲突和估计方差estimation variance。 - 学习率越高,算法对分布变化的适应能力越强,但是最终方差更高,如前述的命题所示。
可以在学习初期以高的学习率快速收敛,然后用低的学习率降到更低的方差,这样可以结合两方面的优势。
- 三条曲线都收敛到某个误差水平
多重哈希的影响:在第二个仿真中我们运行多重哈希
Streaming Frequency Estimation算法,并使用不同数量(以参数 表示)的哈希函数进行实验。对于不同的 ,我们选择不同的数组大小 ,从而使得哈希桶的总数保持不变。下图显示了 的估计误差曲线。可以看到:多个哈希函数可以减少估计估计误差,即使是在参数数量相同的情况下。
19.2.2 Wikipedia Page 检索
在本节中,我们在维基百科数据集上进行页面
page检索实验,以展示采用偏差校正sampling-bias-corrected的batch loss的效果。数据集:我们考虑预测维基百科页面之间的站内链接
intra-site link的任务。- 对于给定的一对源页面和目标页面 ,如果存在从 到 的链接,则
label = 1,否则label = 0。 - 每个页面都由一组内容特征表示,包括页面
URL、页面标题中n-grams单词组成的bag-of-word: BOW的representation、页面类目的bag-of-word: BOW的representation。
我们对英文的
graph进行了实验,它包含530万个页面、43亿条链接、51万个标题n-grams、40.34万个unique类目。- 对于给定的一对源页面和目标页面 ,如果存在从 到 的链接,则
模型:我们将链接预测视为检索问题,其中给定一个源页面,任务是从页面语料库中检索目标页面。因此,我们训练了一个双塔神经网络,其中左塔映射源页面特征、右塔映射目标页面特征。
input feature embedding在两个塔之间共享。- 每个塔都有两个全连接的
ReLU层,维度为[512,128]。
baseline:我们将所提出的、采用偏差校正的
batch softmax(即 ,记作correct-sfx) 和没有任何校正的batch softmax(即 ,记作plain-sfx)进行比较,从而证明偏差校正的效果。此外,我们还考虑了推荐任务的隐式反馈建模中广泛采用的均方损失。损失是在观察到的
pair对上的MSE和正则化项的组合。这个正则化项迫使所有未观察到的pair对的距离尽可能到一个常数的先验prior(通常为0.0,表示不存在链接)。具体而言,这个损失函数为:
其中:
- 为所有观察到的
pair对; 为 的补集,表示未观察到的pair对。 - 为一个正的超参数,表示正则化系数。
在矩阵分解中,这种损失通常使用交替最小二乘法
alternating least square: ALS或者坐标下降法coordinate descent: CD来训练。最近,Krichene等人通过随机梯度下降SGD扩展了Gramian计算方法到非线性的场景。我们称之为mse-gramian。- 为所有观察到的
配置:
对于所有方法,我们使用
batch size = 1024、Adagrad优化器、学习率0.01、训练step数1000万。对于频率估计,我们使用 、 千万、 。
我们保留
10%的链接用于评估,其中评估指标为Recall@K。该指标本质上是针对页面语料库在top k个候选中包含真实label的平均概率。mse-gramian中的超参数 通过线性搜索进行调优,并报告最佳结果。归一化和温度
Normalization and Temperature:- 我们发现归一化输出层总是可以提高模型性能和训练稳定性,因此我们只显示出归一化的结果。
- 我们对
plain-sfx和correct-sfx实验了多个温度值 。
实验结果如下表所示。可以看到:
- 对于每个温度值,
correct-sfx大大优于相应的plain-sfx。 - 温度对于性能的影响很有趣,这表明在应用归一化输出层时必须仔细调优温度超参数。
- 基于
batch softmax的方法比mse-gramian具有更好的性能。
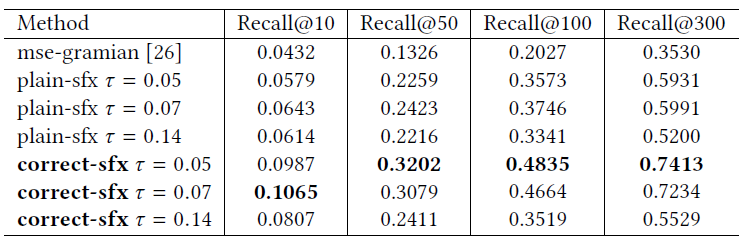
- 对于每个温度值,
19.2.3 YouTube 实验
我们基于前面所述的神经检索系统在
YouTube上进行了离线和在线实验。我们使用的YouTube训练数据包含每天数十亿次点击的视频,并且数据集包含多天。配置:
- 如前所述,
input feature embedding在query塔和候选塔之间共享。我们对两个塔都使用三层DNN,隐层维度为[1024, 512, 128]。 - 对于模型训练,我们使用
Adam优化器、学习率0.2、batch size = 8192。 - 对于频率估计,我们使用 千万、 、 。
- 我们应用序贯训练。对于本节中的实验,每隔几个小时周期性地构建从
YouTube语料库中选择的、大约1000万个视频的索引。索引的语料库可能会随着时间的推移而发生变化,例如有新上传的视频。
- 如前所述,
离线实验:我们为所有点击的视频分配 ,并通过点击视频的召回率来评估模型性能。我们简化了离线实验的奖励函数。
为了结合序贯训练,我们在 天(设置为
15天)之后评估模型性能,此时trainer完成追赶catch-up阶段并开始等待新的数据。对于 之后的每一天,我们保留10%的数据进行评估。为了说明每周的模式pattern,我们报告了连续7天的平均离线结果,即 到 。结果如下表所示。再次可以看到:
- 和
mse-gramian相比,使用batch softmax有着显著提升。 - 在具有不同温度 的设置中,
correct-sfx的表现优于plain-sfx。
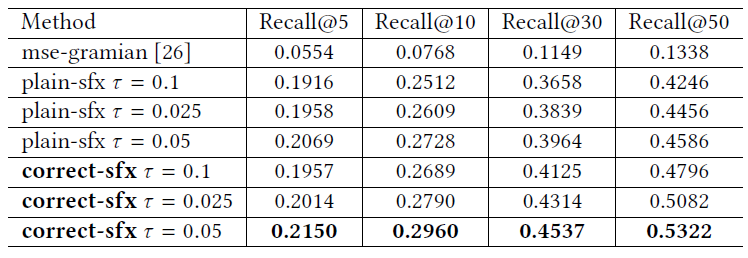
- 和
在线实验:我们还在
YouTube上的A/B test测试框架中进行在线实验。对于控制组的用户,视频是从生产系统中推荐的。对于实验组,将神经检索系统中的候选item添加到检索阶段之后(从而一起进入排序阶段)。由于仅仅向用户推荐他/她可能点击的视频还不够(还需要考虑观看完播率 ),因此在线实验中,我们用奖励训练模型,从而反映用户对点击视频的真实互动
engagement。因此我们报告了点击一致的互动指标(即在点击基础之上再考虑互动),结果如下表所示。可以看到:
- 增加神经检索系统大大改善了以前的生产系统。
- 使用
correct-sfx的模型比使用plain-sfx的baseline表现好得多,这证明了采样偏差校正的有效性。

二十、EGES[2018](Matching 阶段)
互联网技术不断重塑商业格局,如今电商无处不在。阿里巴巴是中国最大的电商平台,它使得全世界各地的个人或公司都可以在线开展业务。阿里巴巴拥有
10亿用户,2017年的商品交易总额Gross Merchandise Volume: GMV为37670亿元,2017年的收入为1580亿元。在著名的 “双十一” 这个中国最大的网络购物节,2017年的GMV约为1680亿元。在阿里巴巴的各类在线平台中,最大的在线consumer-to-consumer: C2C平台淘宝贡献了阿里巴巴电商总流量的75%。淘宝拥有
10亿用户和20亿item(即商品),最关键的问题是如何帮助用户快速找到需要的、感兴趣的item。为了实现这一目标,基于用户偏好preference从而为用户提供感兴趣的item的推荐技术成为淘宝的关键技术。例如,手机淘宝首页(如下图所示)是根据用户历史行为而通过推荐技术生成的,贡献了总推荐流量的40%。此外,推荐贡献了淘宝的大部分收入和流量。总之,推荐已经成为淘宝和阿里巴巴的GMV和收入的重要引擎。下图中,用虚线矩形框突出显示的区域是针对淘宝上十亿用户的个性化。为了更好的用户体验user experience,我们还生成了吸引人的图像和文本描述。
尽管学术界和工业界的各种推荐方法取得了成功,例如协同过滤
collaborative filtering: CF、基于内容的方法、基于深度学习的方法,但是由于用户和item的十亿级的规模,这些方法在淘宝上面临的问题变得更加严重。推荐系统在淘宝面临三大技术挑战:可扩展性
scalability:尽管很多现有的推荐方法在较小规模的数据集(即数百万用户和item)上运行良好,但是在淘宝的、大得多的数据集(即10亿用户和20亿item)上无法运行。稀疏性
sparsity:由于用户往往只与少量item进行交互,因此很难训练出准确的推荐模型,尤其是对于交互次数很少的用户或item。这通常被称作稀疏性问题。冷启动
cold start:在淘宝,每小时都有数百万新的item不断上传。这些item没有用户行为。处理这些item或预测用户对这些item的偏好具有挑战性,这就是所谓的冷启动问题。稀疏性和冷启动都是因为数据太少导致的,冷启动是完全没有历史交互,而稀疏性是只有很少的历史交互。
为了解决淘宝的这些挑战,我们在淘宝的技术平台中设计了一个两阶段的推荐框架。第一阶段是
matching,第二阶段是ranking。- 在
matching阶段,我们为每个用户,根据该用户的历史交互的每个item生成相似item的候选集合candidate set。 - 在
ranking阶段,我们训练一个深度神经网络模型,该模型根据每个用户的偏好对候选item进行排序。
由于上述挑战,在这两个阶段我们都必须面对不同的独特问题
different unique problems。此外,每个阶段的目标不同,导致技术解决方案也不同。在论文《Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba》中,我们专注于如何解决matching阶段的挑战,其中核心任务是根据用户的行为计算所有item之间的pairwise相似性similarity。在获得item的pairwise相似性之后,我们可以生成候选item的集合,以便在ranking阶段进一步个性化。为了实现这一点,我们提出从用户的行为历史构建一个
item graph,然后应用state-of-art的graph embedding方法来学习每个item的embedding,我们称之为Base Graph Embedding: BGE。通过这种方式,我们可以根据从item embedding向量的内积计算出的相似性来生成候选item集合。注意,以前的工作使用CF-based方法来计算item之间的相似性,而CF-based方法仅考虑用户行为历史中item的共现co-occurrence。但是在我们的工作中,通过在item graph中使用随机游走,我们可以捕获item之间的高阶相似性。因此,我们的方法优于CF-based方法。然而,在很少交互、甚至没有交互的情况下学习
item的精确embedding仍然是一个挑战。为了缓解这个问题,我们提出使用辅助信息side information来提升enhanceembedding过程,我们称之为Graph Embedding with Side information: GES。例如,属于同一类目category或同一品牌brand的item在embedding空间中应该更接近。通过这种方式,我们可以在很少交互甚至没有交互的情况下获得item的精确embedding。然而,在淘宝中有数百种类型的辅助信息,如类目、品牌、价格等等。直观而言,不同的辅助信息对学习
item的embedding应该有不同的贡献。因此,我们进一步提出了一种在学习带辅助信息的embedding时的加权机制,称作Enhanced Graph Embedding with Side information: EGES。本文主要贡献:
- 基于淘宝多年的实践经验,我们设计了一种有效的启发式
heuristic方法,从淘宝上十亿用户的行为历史构建item graph。 - 我们提出了三种
embedding方法(BGE、GES、EGES)来学习淘宝中20亿item的embedding。我们进行离线实验以证明BGE、GES、EGES和其它embedding方法相比的有效性。 - 为了在淘宝中为十亿级用户和
item部署所提出的方法,我们在我们团队搭建的XTensorflow: XTF平台上构建了graph embedding system。我们表明,所提出的框架显著提高了手机淘宝App的推荐性能,同时满足了双十一当天训练效率和serving的即时响应instant response的需求。
相关工作:这里我们简要回顾
graph embedding、带辅助信息的graph embedding、以及用于推荐的graph embedding的相关工作。Graph Embedding:graph embedding算法已经作为一种通用的网络表示方法,它们已被用于很多实际application。在过去的几年里,该领域有很多研究专注于设计新的embedding方法。这些方法可以分为三类:LINE等分解方法尝试近似分解邻接矩阵并保留一阶和二阶邻近性。- 深度学习方法增强
enhance了模型捕获图中非线性的能力。 - 基于随机游走的技术在图上使用随机游走来获得非常有效的
node representation,因此可用于超大规模网络。
在本文中,我们的
embedding框架基于随机游走。带辅助信息的
Graph Embedding:上述graph embedding方法仅使用网络的拓扑结构,存在稀疏性和冷启动的问题。近年来,很多工作试图结合辅助信息来增强graph embedding方法。大多数工作基于具有相似辅助信息的节点在embedding空间中应该更接近的假设来构建他们的任务。为了实现这一点,《Discriminative deep random walk for network classification》和《Max-margin deepwalk: Discriminative learning of network representation》提出了一个联合框架来优化带分类器函数的embedding目标函数。论文《Representation learning of knowledge graphs with hierarchical types 》进一步将复杂的知识图谱嵌入到具有层级结构hierarchical structure(如子类目)的节点中。此外,也有一部分工作将节点相关的文本信息融合到
graph embedding中。另外,《Heterogeneous network embedding via deep architectures》提出了一个深度学习框架来为异质graph embedding同时处理文本和图像特征。在本文中,我们主要处理淘宝中
item相关的离散辅助信息,例如类目category、品牌brand、价格等,并在embedding框架中设计了一个hidden layer来聚合不同类型的辅助信息。用于推荐的
Graph Embedding:推荐一直是graph embedding最流行的下游任务之一。有了node representation,就可以使用各种预测模型进行推荐。在
《Personalized entity recommendation: A heterogeneous information network approach》和《Meta-graph based recommendation fusion over heterogeneous information networks》中,user embedding和item embedding分别在meta-path和meta-graph的监督下在异质信息网络heterogeneous information network中学习。-
《Personalized entity recommendation: A heterogeneous information network approach》为推荐任务提出了一个线性模型来聚合embedding。 《Meta-graph based recommendation fusion over heterogeneous information networks》提出将分解机factorization machine: FM应用于embedding以进行推荐。
《Collaborative knowledge base embedding for recommender systems》提出了一个联合embedding框架,从而为推荐任务学习graph, text, image的embedding。《Scalable graph embedding for asymmetric proximity》提出了graph embedding来捕获节点推荐node recommendation的非对称相似性asymmetric similarity。在本文中,我们的
graph embedding方法被集成到一个两阶段推荐平台中。因此,embedding的性能将直接影响最终的推荐结果。-
20.1 模型
我们首先介绍
graph embedding的基础知识,然后详细说明我们如何根据用户的行为历史来构建item graph,最后我们研究了在淘宝中学习item embedding的方法。Graph Embedding:这里我们概述了graph embedding,以及最流行的一种graph embedding方法 :DeepWalk。我们是在DeepWalk的基础上提出了matching阶段的graph embedding方法。给定一个图 ,其中 代表节点集合、 代表边集合。
graph embedding是为每个节点 在低维空间 中学习一个低维representation,其中 。换句话讲,我们的目标是学习一个映射函数 ,即把 中的每个节点表示为一个 维的向量。受到
word2vec的启发,Perozzi等人提出了DeepWalk来学习图中每个节点的embedding。他们首先通过在图中运行随机游走来生成节点序列,然后应用Skip-Gram算法来学习图中每个节点的representation。为了保持图的拓扑结构,他们需要解决以下最优化问题:其中:
- 为节点 的邻居节点集合,它可以定义为节点 的
1-hop或者2-hop节点集合。 - 定义了在给定节点 的情况下,拥有上下文节点 的条件概率。
接下来,我们首先介绍如何根据用户的历史行为构建
item graph,然后提出基于DeepWalk的graph embedding方法,从而为淘宝中的20亿item生成低维representation。- 为节点 的邻居节点集合,它可以定义为节点 的
构建
Item Graph:这里,我们将详细说明从用户历史行为构建item graph。实际上,用户在淘宝上的行为往往是连续的,如图
(a)所示。以往的CF-based方法仅考虑item的共现co-occurrence,而忽略了可以更准确地反映用户偏好的序列信息sequential information。 然而,不可能使用用户的全部历史记录(来作为一个序列),有两个原因:- 条目
entry太多,导致计算成本和空间成本太高。 - 用户的兴趣会随着时间而漂移
drift。
因此在实践中,我们设置了一个时间窗口,仅选择用户在窗口内的行为。这称为
session-based用户行为。根据经验,时间窗口的大小为一个小时。例如图(a)中,包含用户 的一个session、用户 的两个session、用户 的两个session。在我们获得
session-based用户行为之后,如果两个item相连地consecutively出现,则它们通过有向边连接。如下图(b)所示:item D和item A相连,因为用户 先后陆续访问了item D和item A。这种图构建方式捕获了序列关系。如果是连接
session内的任意两个item,则捕获了共现关系。利用淘宝上所有用户的协同行为
collaborative behaviors,我们根据所有用户行为中两个相连item的出现总数为每条边 分配一个权重。具体而言,边 的权重等于所有用户行为历史中item转移到item的频次。通过这种方式,构建的item graph可以基于淘宝中所有用户的行为来表示不同item之间的相似性。图(b)为根据图 得到的加权有向图 。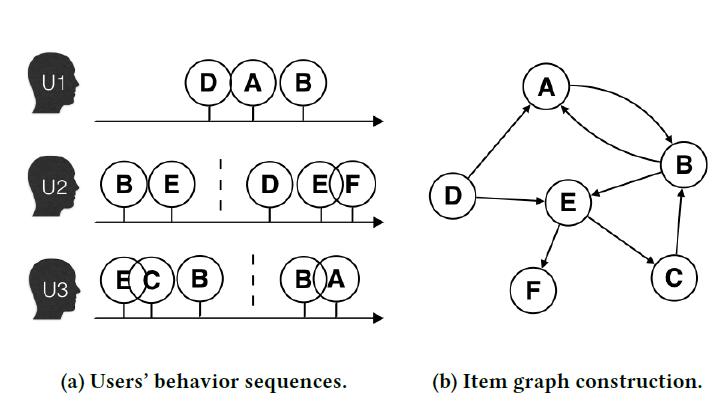
在实践中,我们在抽取用户行为序列之前需要过滤掉无效数据
invalid data和异常行为abnormal behaviors,从而消除噪声。目前,以下行为在我们的系统中被视为噪声:- 如果点击之后停留的时间少于一秒钟,那么点击可能是无意的,则需要移除。
- 淘宝上有一些 “过度活跃” 的用户,他们实际上是作弊用户
spam users。根据我们在淘宝上的长期观察,如果单个用户在不到三个月内,总购买数量大于1000或者总点击数量大于3500,则该用户很可能是作弊用户。我们需要过滤掉这些用户的行为。 - 淘宝的零售商不断地更新商品的详细信息。在极端情况下,一个商品在经过长时间的更新之后,在淘宝上可能变成完全不同的商品,即使它们具有相同的商品
id。因此,我们删除了这些id相关的item(即更新前后,该id代表了完全不同的商品)。
- 条目
Base Graph Embedding: BGE:在得到有向加权图(记作 )之后,我们采用DeepWalk来学习每个节点在 中的embedding。令 表示 的邻接矩阵, 表示从节点 指向节点 的边的权重。我们首先基于随机游走生成节点序列,然后对节点序列运行
Skip-Gram算法。随机游走的转移概率定义为:其中 为
outlink邻居的集合,即 的出边outedge指向的节点集合。通过运行随机游走,我们可以生成许多序列,如下图
(c)所示。然后我们应用Skip-Gram算法(如图(d)所示)来学习节点embedding,从而最大化随机游走序列中两个节点的共现概率occurrence probability。这导致了以下的最优化问题:其中 是随机游走序列中上下文节点的窗口大小。
使用独立性假设,我们有:
其中:
应用负采样技术,则最优化问题可以转化为:
其中: 表示节点 的负样本集合, 为
sigmoid函数。根据经验,负样本规模越大则最终结果越好。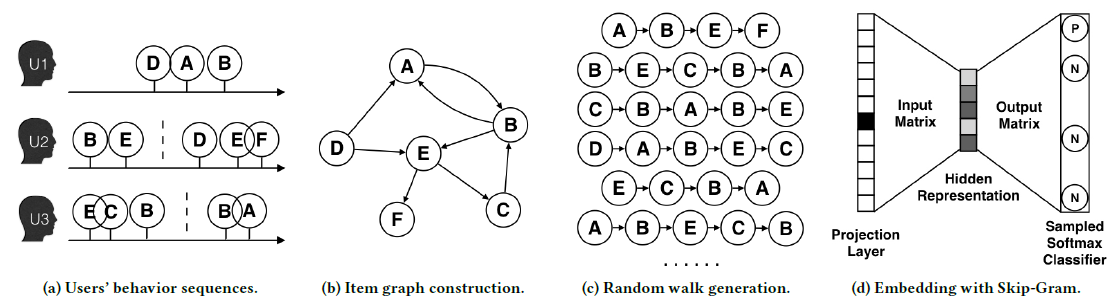
Graph Embedding with Side information: GES:通过应用上述embedding方法,我们可以学习淘宝中所有item的embedding,从而捕获用户行为序列中的高阶相似性。而这种高阶相似性在以前的CF-based方法中被忽略。然而,学习 “冷启动”item(即那些没有用户交互的item)的accurate embedding仍然具有挑战性。为了解决冷启动问题,我们提出使用附加到冷启动
item的辅助信息side information来增强enhanceBGE。在电商推荐系统的上下文中,辅助信息指的是item的类目category、门店shop、价格price等信息,这些信息在ranking阶段被广泛用作关键特征,但是在matching阶段很少使用。我们可以通过在graph embedding中融合辅助信息来缓解冷启动问题。例如,优衣库(相同门店)的两件帽衫(相同类目)可能看起来很像;喜欢尼康镜头的用户也可能对佳能相机(相似类目、相似品牌)感兴趣。这意味着具有相似辅助信息的item应该在embedding空间中更接近。基于这个假设,我们提出了如下图所示的GES方法。我们使用 来表示
item或辅助信息的embedding矩阵,具体而言:- 表示
item embedding矩阵。 - 表示第 种类型辅助信息的
embedding矩阵,一共有 种类型的辅助信息。
其中 为
embedding维度。注意,item embedding维度和辅助信息embedding维度都设为相同的值。为了融合辅助信息,我们将
item的 个embedding向量拼接起来,并用均值池化来来聚合item相关的所有embedding,即:其中: 为
item聚合后的embedding; 为 的第 行,表示item的item embedding向量或者第 类辅助信息的embedding向量。所有节点聚合后的embedding构成了embedding矩阵 。是
graph embedding矩阵,它是通过DeepWalk算法得到。但是这里辅助信息embedding矩阵 如何得到?论文并未给出明确的回答。通过这种方式,我们融合了辅助信息,使得具有相似辅助信息的
item在embedding空间中更为接近。这使得冷启动item的embedding更为准确accurate,并提高了离线和在线性能。下图为
GES和EGES的总体架构。SI表示辅助信息side information,SI 0表示item本身。Sparse Features往往是item ID以及不同SI的one-hot向量。Dense Embeddings是item和相应SI的representation。Hidden Representation是一个item及其相应SI的embedding聚合结果。
- 表示
Enhanced Graph Embedding with Side information: EGES:尽管GES的性能有所提升,但是在embedding过程中融合不同类型的辅助信息时仍然存在问题。在GES中,我们假设不同类型的辅助信息对于最终embedding的贡献相等,这不符合现实。例如:购买了iPhone的用户会因为Apple这个品牌而倾向于查看Macbook或iPad;用户可能在同一家门店购买不同品牌的衣服,因为比较方便convenience而且价格更低(因为可能存在折扣)。因此,不同类型的辅助信息对用户行为中item共现co-occurrence的贡献不同。为了解决这个问题,我们提出了
EGES方法来聚合不同类型的辅助信息。EGES框架和GES相同,它的基本思想是:不同类型的辅助信息在它们的embedding被聚合时有不同的贡献。因此,我们提出一个加权均值池化层来聚合辅助信息的embedding。定义一个加权的权重矩阵 ,其中 表示在第 个
item中,第 种类型辅助信息的加权系数。- (即 的第一列)表示
item embedding自己的权重。 表示item的item embedding权重。 - (即 的第 列)表示第 种辅助信息的权重。 表示
item的第 种辅助信息的权重。
注意:这里对不同的节点设置个性化的权重分布,而不是采用统一的权重分布。考虑到
embedding参数数量为 ,因此权重矩阵的参数规模是embedding参数的 。那么加权均值聚合的结果为:
这里我们使用 函数的原因是为了确保辅助信息的权重大于零。
给定节点 以及上下文节点 ,令 为上下文节点 的
embedding。令 为label(如是否点击),则EGES的目标函数为:我们基于梯度下降法来求解最优化问题,其梯度为:
对于冷启动
item,虽然item embedding未知,但是辅助信息embedding可以获取。- (即 的第一列)表示
EGES框架算法:输入:
- 图
- 辅助信息
- 每个节点作为起始点的随机游走数量
- 随机游走序列长度
Skip-Gram窗口大小- 负样本数量
embedding维度
输出:
item embedding矩阵和辅助信息embedding矩阵 。- 权重矩阵 。
算法步骤:
初始化 。
迭代 ,迭代步骤为:
迭代 ,迭代步骤为:
- 通过随机游走得到序列: 。随机游走概率由 决定。
- 执行加权
SkipGram算法: 。
返回 。
加权
Skip-Gram算法:输入:
- 。
Skip-Gram窗口大小- 负样本数量
- 随机游走序列长度
- 随机游走序列
SEQ
输出:更新后的 。
算法步骤:
迭代, ,迭代步骤为:
为当前节点。遍历窗口,,迭代步骤为:
正样本梯度更新(
label = 1):更新 : 。
迭代,,更新:
负样本梯度更新(
label = 0), ,迭代过程为:从 中负采样出顶点 。
更新 : 。
迭代,,更新:
未来方向:
- 首先是在
graph embedding方法中利用attention机制,这可以提供更大的灵活性来学习不同类型辅助信息的权重。 - 其次是将文本信息纳入到我们的方法中,从而利用淘宝
item中大量的评论信息。
- 首先是在
20.2 系统部署
这里我们介绍我们的
graph embedding方法在淘宝中的实现和部署。我们首先对支撑淘宝的整个推荐平台进行high-level的介绍,然后详细说明与我们embedding方法相关的模块。下图给出了淘宝推荐平台的架构。该平台由两个子系统组成:
online和offline。在线子系统主要组件
component是淘宝个性化平台Taobao Personality Platform: TPP和排序服务平台Ranking Service Platform: RSP。典型的工作流程如下图所示:- 当用户打开手机淘宝
App时,TPP抽取用户的最新信息并从离线子系统中检索一组候选item,然后将候选item馈送到RSP。 RSP使用微调的DNN模型对候选item集合进行排序,并将排序结果返回给TPP。- 用户在淘宝的访问行为被收集并保存为离线子系统的日志数据。
- 当用户打开手机淘宝
实现和部署
graph embedding方法的离线子系统的工作流如下所示:包含用户行为的日志被检索。
item graph是基于用户的行为构建的。在实践中,我们选择最近三个月的日志。在生成
session-based用户行为序列之前,我们会对数据执行反作弊处理anti-spam processing。 剩余的日志包含大约6000亿条,然后根据前面所述方法构建item graph。为了运行我们的
graph embedding方法,我们采用了以下的解决方案:- 将整个
graph拆分为多个子图,这些子图可以在淘宝的Open Data Processing Service: ODPS分布式平台中并行处理。每个子图中大约有5000万个节点。 - 为了在图中生成随机游走序列,我们在
ODPS中使用我们基于迭代iteration-based的分布式graph framework。随机游走生成的序列总量为1500亿左右。
- 将整个
为了实现所提出的
embedding算法,我们的XTF平台使用了100个GPU。在部署的平台上,离线子系统中的所有模块(包括日志检索、反作弊处理、item graph构建、随机游走序列生成、embedding、item-to-item相似度计算)都可以在不到六个小时内处理完毕。因此,我们的推荐服务可以在很短的时间内响应用户的最新行为。
20.3 实验
这里我们进行了大量的实验来证明我们提出的方法的有效性。
首先,我们通过链接预测任务对这些方法进行离线评估。然后,我们在手机淘宝
App上报告在线实验结果。最后,我们展示了一些真实案例,从而在淘宝上深入洞察我们提出的方法。
20.3.1 离线评估
链接预测
Link Prediction:链接预测任务用于离线实验,因为它是graph中的一个基础问题fundamental problem。给定一个去掉了某些边的
graph,链接预测任务是预测链接的出现。我们随机选择1/3的边作为测试集中的ground truth并从graph中移除,剩余的graph作为训练集。我们随机选择未链接的节点pair对作为负样本并加入到测试集,负样本数量和ground truth数量相等。为了评估链接预测的性能,我们选择AUC作为评估指标。数据集:我们选择使用两个数据集进行链接预测任务,它们包含不同类型的辅助信息。
Amazon数据集:来自Amazon Electronics的数据集。item graph通过 “共同购买co-purchasing“ 关系(在提供的数据中表示为also_bought)来构建,并使用了三种类型的辅助信息:类目、子类目、品牌。Taobao数据集:来自手机淘宝App的数据集。item graph根据前述方法来构建。需要注意的是,为了效率和效果,Taobao数据集使用了十二种类型的辅助信息,包括:商家retailer、品牌、购买力水平purchase level、年龄、性别、款式style等等。根据多年在淘宝的实践经验,这些类型的辅助信息已经被证明是有用的。
这两个数据集的统计信息如下表所示(
#SI表示辅助信息数量)。我们可以看到这两个数据集的稀疏性都大于99%。
baseline方法:我们对比了四种方法:BGE、LINE、GES、EGES。LINE捕获了graph embedding中的一阶邻近性和二阶邻近性。我们使用作者提供的实现,并使用一阶邻近性和二阶邻近性运行它,结果分别表示为LINE(1st)和LINE(2nd)。- 我们实现了所提出的
BGE、GES、EGES等三种方法。
配置:
- 所有方法的
embedding维度均设为160。 - 对于我们的
BGE/GES/EGES,随机游走的长度为10,每个节点开始的游走次数为20,上下文窗口大小为5。
- 所有方法的
实验结果如下表所示,括号中的百分数是相对于
BGE的提升比例。可以看到:GES和EGES在两个数据集上的AUC都优于BGE、LINE(1st)、LINE(2st)。这证明了所提出方法的有效性。换句话讲,稀疏性问题通过结合辅助信息得到了缓解。比较两个数据集上的提升,我们可以看到
Taobao数据集上的提升更为显著。我们将此归因于Taobao数据集上使用的大量有效且信息丰富的辅助信息。当在
GES和EGES之间比较,我们可以看到Amazon数据集上的性能提升比Taobao数据集更大。可能是因为Taobao上GES的表现已经很不错了,即0.97。因此EGES的改善并不突出。而在Amazon数据集上,EGES显著优于GES。
基于这些结果,我们可以观察到融合辅助信息对于
graph embedding非常有用,并且可以通过对各种辅助信息的embedding进行加权聚合来进一步提高准确性accuracy。
20.3.2 在线评估
我们在
A/B test框架中进行在线实验,实验目标是手机淘宝App首页的点击率Click-Through-Rate: CTR。我们实现了上面的
graph embedding方法,然后为每个item生成一些相似的item作为候选推荐。淘宝首页的最终推荐结果由基于dnn模型的ranking引擎生成。在实验中,我们在ranking阶段使用相同的方法对候选item进行排序。如前所述,相似item的质量直接影响了推荐结果。因此,推荐性能(即CTR)可以代表不同方法在matching阶段的有效性。我们将这四种方法部署在一个
A/B test框架中,2017年11月连续7天的实验结果如下图所示。其中,Base代表一种item-based CF方法,在部署graph embedding方法之前已经在淘宝内部广泛使用。Base方法根据item共现co-occurrence和用户投票权重计算两个item之间的相似度,并且相似度函数经过精心调优从而适合淘宝的业务。可以看到:
EGES和GES在CTR方面始终优于BGE和Base,这证明了在graph embedding中融合辅助信息的有效性。- 此外,
Base的CTR优于BGE。这意味着经过精心调优的CF-based方法可以击败简单的embedding方法,因为在Base方法中已经利用了大量人工设计的启发式策略。 EGES始终优于GES,这和离线实验结果相一致。这进一步证明了辅助信息的加权聚合优于平均聚合。
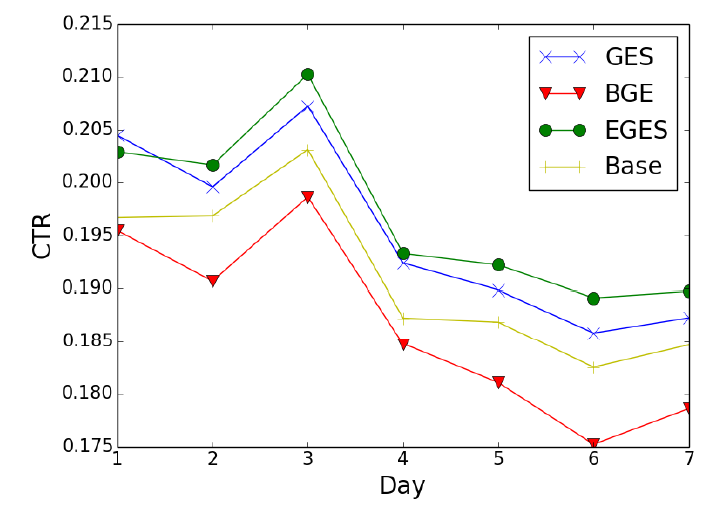
20.3.3 案例研究
这里我们展示了淘宝中的一些真实案例来说明我们方法的有效性。这些案例从三个方面来研究:
EGES embedding的可视化、冷启动item、EGES中的加权权重。embedding可视化:我们通过tensorflow提供的可视化工具,将EGES学到的item embedding可视化,结果如下图所示。下图为一组随机选择的运动鞋的embedding的可视化,item embedding通过PCA投影到二维平面中,其中不同颜色代表不同的类目。从图
(a)中,我们可以看到不同类目的鞋子在不同的cluster中。这里一种颜色代表一类鞋子,例如羽毛球鞋、乒乓球鞋、足球鞋。这证明了融合辅助信息来学习
emebdding的有效性,即具有相似辅助信息的item应该在embedding空间中更接近。从图
(b)中,我们进一步分析了羽毛球鞋、乒乓球鞋、足球鞋三种鞋子的embedding。我们观察到一个有趣的现象:羽毛球鞋和乒乓球鞋的embedding距离更接近、和足球鞋的embedding距离更远。这一现象可以解释为:在中国,喜欢乒乓球的人和喜欢羽毛球的人有很多重叠。然而喜欢足球的人和喜欢室内运动(如乒乓球、羽毛球)的人,有很大的不同。从这个意义上讲,向看过乒乓球鞋的人推荐羽毛球鞋,要比推荐足球鞋要好得多。
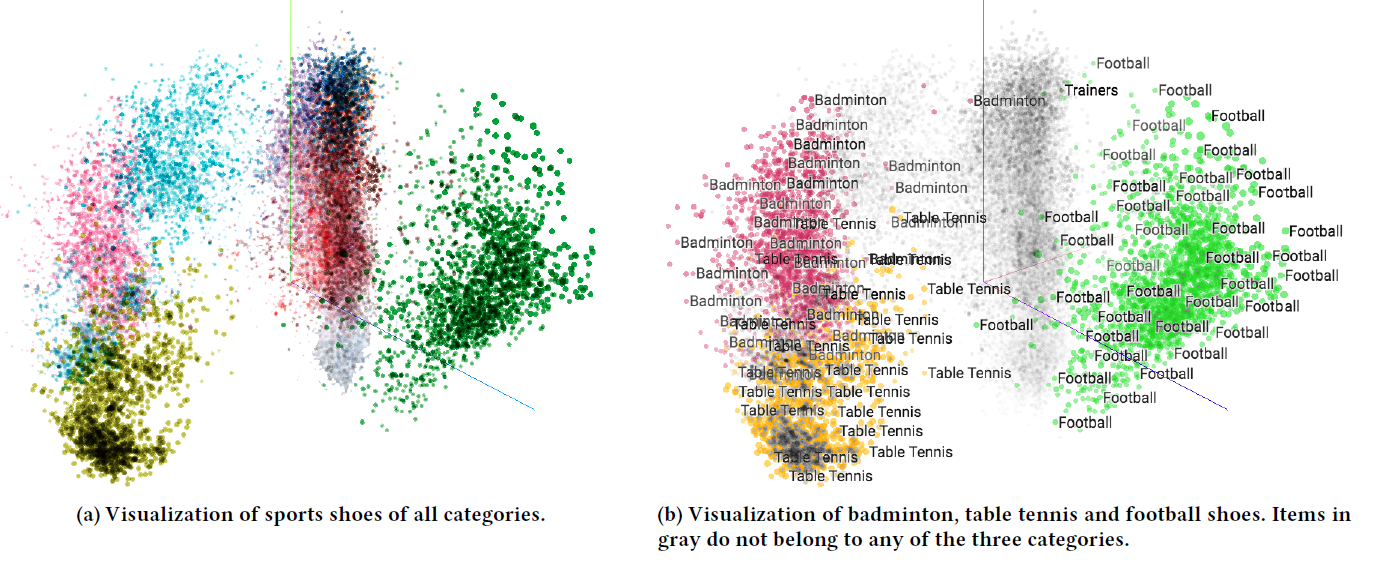
冷启动
item:对于淘宝中的新item,无法从item graph中学习到embedding,并且之前CF-based的方法也无法处理冷启动item。因此,我们利用新item的辅助信息的平均embedding来表示一个冷启动item。然后我们根据item embedding的内积从所有item中检索和冷启动item最相似的item。结果如下图所示,我们给出了冷启动
item的top 4相似item。在图中,我们为每个相似item标注了与冷启动item相关的辅助信息的类型,其中cat意思是category可以看到:
- 尽管缺少用户对冷启动
item的行为,但是可以利用不同的辅助信息来有效地学习它们embedding(就top相似item的质量而言)。 item的门店shop对于衡量两个item的相似性非常有用,这也和下面介绍的辅助信息的权重保持一致。

- 尽管缺少用户对冷启动
辅助信息权重:我们将
item的不同类型辅助信息的权重可视化。我们选择了不同类目的8个item,并从学到的权重矩阵 中提取与这些item相关的所有辅助信息的权重。结果如下图所示,其中每一行记录一个item的权重结果。有几点值得注意:
- 不同
item的权重分布不同,这和我们的假设相一致,即不同的辅助信息对最终representation的贡献不同。 - 在所有
item中,代表item本身embedding的"Item"权重始终大于所有其它辅助信息的权重。这证实了一种直觉,即item embedding本身仍然是用户行为的主要来源,而辅助信息为推断用户行为提供了额外的提示。 - 除了
"Item"之外,"Shop"的权重始终大于其它辅助信息的权重。这和淘宝中的用户行为一致,即用户倾向于在同一家店铺购买item,这是为了便利性convenience和更低的价格(即店铺的折扣)。
- 不同
二十一、SDM[2019](Matching 阶段)
工业级大规模推荐系统需要能够准确预测用户的偏好,并快速响应用户当前的需求。淘宝是中国最大的电商网站,支持数十亿的
item和用户。系统首先为用户检索一组候选item,然后应用ranking模块生成最终推荐。在这个过程中,matching模块检索到的候选item的质量在整个系统中起着关键作用。目前,淘宝上部署的
matching模型主要基于item-based CF方法。然而,这些方法对静态的user-item交互进行建模,并且无法很好地捕获用户整个行为序列中的动态变换dynamic transformation。因此,这类方法通常会导致同质推荐homogeneous recommendation。为了准确了解用户的兴趣interest和偏好preference,应该将序列的顺序信息sequential order information融入matching模块。在论文
《SDM: Sequential Deep Matching Model for Online Large-scale Recommender System》中,我们通过在matching阶段引入深度序列推荐模型deep sequential recommendation model(而不是item-based CF模型)来考虑用户兴趣的动态演变dynamic evolution。当人们开始在淘宝上使用网上购物服务时,他们的行为会累积成相对较长的行为序列。行为序列由
session组成,而session是在给定时间范围内发生的用户行为列表。用户通常在一个session中具有明确的独特unique购物需求。而当用户开始新session时,用户的兴趣可能会发生急剧变化。直接对序列建模而忽略这种内在的session结构会损害性能。因此,我们将用户最近的交互session称为短期行为short-term behaviors,将历史的其它session称为长期行为long-term behaviors。我们对这两部分分别建模,从而编码短期行为和长期行为的固有信息inherent information,这些信息可用于表示用户的不同兴趣level。我们的目标是在用户行为序列之后召回top N的item作为matching候选。在短期
session建模方面,基于循环神经网络RNN的方法在session-based推荐中表现出有效的性能。此外,人们进一步提出了注意力模型attention model,强调了短期session中最近一次点击的主要目的和效果,从而避免了由于用户的随机行为引起的兴趣转移interest shift。然而,他们忽略了用户在一个
session中有多个兴趣点。我们观察到用户关心item的多个方面,如类目category、品牌brand、颜色、款式style和店铺声誉reputation等等。在对最喜欢的item做出最终决定之前,用户会反复比较很多item。因此,使用单个dot-product注意力representation无法反映在不同购买时间发生的多样的diverse兴趣。相反,首先为机器翻译任务提出的multi-head attention允许模型共同关注不同位置的多重的不同信息。多头结构multi-head structure通过代表不同视角views的偏好来自然地解决多重兴趣multiple interests的问题。因此,我们提出了我们的多兴趣模块multi-interest module,从而使用multi-head attention来增强RNN-based的序列推荐器sequential recommender。同时,有了这种self-attention,我们的模块可以通过过滤掉偶然发生的点击来表达准确的用户偏好。用户的长期偏好总是会影响当前的决策。直观地,如果用户是
NBA篮球迷,那么用户可能会查看/点击和NBA球星相关的大量的item。当用户现在选择买鞋时,NBA明星的球鞋会比普通球鞋更吸引用户。因此,同时考虑长期偏好long-term preferences和短期行为short-term behaviors至关重要。已有文献将当前短期
session和长期偏好简单地组合。然而,在现实世界的应用中,用户的购物需求是多种多样且丰富的,他们的长期行为也是复杂和多样的。和NBA球星相关的东西仅占长期行为的很少一部分。与当前短期session相关的长期用户偏好无法在整体长期行为representation中突出显示,应该保留长期行为representation中与短期session相关的信息。
在我们的
matching模型中,我们设计了一个门控融合模块gated fusion module来合并全局(长期)和局部(短期)偏好特征。门控融合模块的输入是用户画像embedding、长期representation向量、短期representation向量。然后学习门控向量gate vector来控制LSTM中不同gate的融合行为fusion behaviors,以便模型可以精确地捕获兴趣相关性以及用户对长期兴趣/短期兴趣的attention。- 一方面,长期
representation向量中和短期session最相关的信息和短期representation向量融合。 - 另一方面,用户可以更准确地关注长期兴趣/短期兴趣。
和标量权重的
attention-like模型不同,门控向量在我们的超复杂神经网络中具有更强大的决策表示能力。本文主要贡献:
我们通过考察短期
short-term行为和长期long-term行为,为现实世界应用中的大规模推荐系统开发了一种新颖的序列深度匹配sequential deep matching: SDM模型。我们对短期行为和长期行为分别建模,代表不同level的用户兴趣。我们提出通过
multi-head self-attention模块对短期session行为进行建模,从而编码和捕获多种兴趣倾向interest tendencies。门控融合模块用于有效结合长期偏好和当前购物需求,从而结合它们的相关信息而不是简单的组合。
我们的
SDM模型在现实世界中的两个离线数据集上进行了评估,表明优于其它state-of-the-art方法。为了证明SDM在工业应用中的可扩展性,我们成功地将它部署在淘宝推荐系统的生产环境中。自2018年12月份以来,SDM模型一直在线有效运行。和以前的在线系统相比,SDM取得了显著的提升。
SDM主要解决了现实世界应用中的以下两个固有问题:- 在一个
session中可能存在多个兴趣倾向interest tendencies。 - 长期偏好可能无法和当前
session兴趣有效融合。
- 在一个
相关工作:
工业中的
Deep Matching:为了在工业推荐系统中开发更有效的matching模型,许多研究人员采用具有强大表达能力的深度神经网络。基于矩阵分解
Matrix Factorization: MF的模型尝试将pairwise的user-item隐式反馈分解为user vector和item vector。YouTubeDNN使用深度神经网络来学习user embedding和item embedding。这两种embedding分别从它们对应的特征来生成。预测相当于在所有item中搜索user vector的最近邻。此外,
《Learning Tree-based Deep Model for Recommender Systems》提出了一种新颖的tree-based的大规模推荐系统,它可以提供新颖的item并克服向量搜索的计算障碍。最近,基于
graph embedding的方法被应用于许多工业应用中,从而补充或替代传统的方法。《Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba》提出从用户的历史行为构建一个item graph,然后应用state-of-the-art的graph embedding方法来学习每个item的embedding。为了解决冷启动和数据稀疏问题,他们结合了item的辅助信息来增强embedding过程。《Graph Convolutional Neural Networks for Web-Scale Recommender Systems》在Pinterest上开发并部署了一个有效effective且高效efficient的图卷积网络,从而生成包含图结构和节点特征信息的node embedding。
但是这些模型无法很好地考虑用户偏好的动态和演变。在这项工作中,我们通过引入序列推荐
sequential recommendation从而在matching阶段考虑这一点。序列感知推荐:序列推荐旨在对用户的偏好进行建模,并以序列方式从观察到的动作中预测用户的未来动作,例如
next click或者next purchase。早先,
FPMC和HRM通过联合矩阵分解和马尔科夫链对序列中相邻item之间的局部序列行为进行建模。最近,深度神经网络为推荐系统带来了强大的表达和泛化能力。《Session-based recommendations with recurrent neural networks》首先应用GRU根据用户当前的短期会话进行推荐。- 之后,
《Neural attentive session-based recommendation》利用注意力机制提取用户的主要意图,特别是对于较长的会话,并取得了更好的结果。 《STAMP: short-term attention/memory priority model for session-based recommendation》随后创建了一个新的短期注意力优先attention priority模型而不是RNN,然后指出会话中最近一次点击的重要性。- 除了
RNN之外,《Personalized top-n sequential recommendation via convolutional sequence embedding》和《A Simple Convolutional Generative Network for Next Item Recommendation》提出了卷积序列embedding推荐模型作为解决方案。 《Self-attentive sequential recommendation》和《Next item recommendation with self-attention》使用self-attention架构来编码用户的动作历史。《Towards Neural Mixture Recommender for Long Range Dependent User Sequences》构建了一个M3模型,该模型可以通过门控机制组合上述不同方法。
但是这些方法忽略了单次会话中的多样的兴趣。
《Sequential recommendation with user memory networks》将memory机制引入序列推荐模型,该系统设计了一个用户记忆增强神经网络memory-augmented neural network: MANN来表达feature-level兴趣。- 对于更细粒度的用户偏好,
《Taxonomy-aware multi-hop reasoning networks for sequential recommendation》和《Improving sequential recommendation with knowledge-enhanced memory networks》使用知识库信息来增强key-value记忆网络的语义表示semantic representation,称作知识增强序列推荐器knowledge enhanced sequential recommender。
然而,这些方法的的额外存储、手动特征设计、
memory network的计算量,由于用户和item的规模巨大,因此在工业界是不被接受的。考虑用户长期稳定的偏好也很重要。
《Learning from history and present: next-item recommendation via discriminatively exploiting user behaviors》通过拼接用户的会话行为representation以及历史购买行为的稳定偏好,从而提出了BINN模型。《Sequential Recommender System based on Hierarchical Attention Networks》提出了一种新颖的两层分层注意力网络来推荐用户可能感兴趣的next item。《A Long-Short Demands-Aware Model for Next-Item Recommendation》使用多时间尺度来表达长短期需求,并将它们融合到一个层级结构中。
另一个统一通用兴趣和序列兴趣的例子是
Recurrent Collaborative Filtering(《Recurrent Collaborative Filtering for Unifying General and Sequential Recommender》),它在多任务学习框架中结合了RNN序列模型和矩阵分解方法。《PLASTIC: Prioritize Long and Short-term Information in Top-n Recommendation using Adversarial Training》通过对抗训练做了同样的组合。简单的组合不足以融合长短期偏好,而多任务和对抗性方法不适用于工业应用。在本文中,我们提出了多头自注意力
multi-head self-attention来捕获短期会话行为中的多个用户兴趣,并使用门控机制在现实世界的application中有效且高效地结合长期偏好。
21.1 模型
令 为用户集合, 为
item集合。我们的模型考虑用户 是否会在时刻 和item交互。对于用户 ,我们可以通过行为发生时间的升序排序来获取用户的
latest session。受到
session-based推荐的启发,我们重新制定了session的生成规则:- 后端系统记录的、具有相同
session ID的交互属于同一个session。 - 时间间隔小于
10分钟(或者更长,这取决于具体场景)的相邻交互也合并为一个session。 session的最大长度设置为50,即session长度超过50时将开始新的session。
用户 的
latest session为最近的那个session,被视为短期行为,即: ,其中 为序列长度。用户 的长期行为long-term behaviors是过去7天的、发生在 之前的行为,记作 。我们的推荐任务是:给定用户 的短期行为 和长期行为 ,我们需要为用户推荐
item。- 后端系统记录的、具有相同
21.1.1 总体架构
SDM的通用网络结构如下图所示。主要由三部分组成:用户预测网络user prediction network、训练training、在线服务online serving。
用户预测网络
user prediction network:- 网络以短期行为 和长期行为 作为输入。
- 被编码为时刻 的短期行为
representation, 被编码为长期的行为representation。 - 这两种
representation通过门控神经网络gated neural network组合,从而得到用户行为向量user behavior vector。 其中 为embedding size。 - 网络的目标是预测下一个交互
item。
令 为所有
item embedding组成的item embedding矩阵,第 行 为item的embedding向量。我们通过内积来计算用户 在时刻 和item交互的可能性(非归一化的):然后我们通过
softmax进行归一化:训练
training:在训练过程中,时刻 的positive label是下一个交互item。考虑到实际应用中的大量item,我们采用对数均匀采样器log-uniform sampler从 中采样negative labels(不包括 )。然后由softmax layer生成预测类别概率。这称作sampled-softmax。我们应用交叉熵损失函数:
其中:
- 为 的采样子集,包括
positive label和negative labels。 - 分别代表 与每个 的内积。
- 是每个采样
item的预估概率分布。 - 是
item的真实概率分布。当item为postive label时 ,当item为negative label时 。
- 为 的采样子集,包括
在线服务
online serving:我们将模型部署在我们的在线推荐系统上。item embedding矩阵 被导入到一个高效的K-Nearest-Neighborhood: KNN相似性similarity搜索系统。同时,用户预测网络部署在机器学习的高性能实时推断inference系统上。这种架构遵循YouTube的视频推荐。当用户使用我们的在线服务时,用户会和很多
item进行交互,用户对item的反馈将被后端系统记录下来。这些反馈信息将被处理,然后作为用户的行为日志存储在数据库中。从海量日志中抽取的有用信息将被构造为我们模型所需的结构化数据。在时刻 ,用户的历史行为(短期行为 和长期行为 )被输入到推断系统中,然后生成用户行为向量 。
KNN搜索系统根据内积检索最相似的item,然后推荐top-N个item。
21.1.2 用户预测网络
这里我们详细说明如何在用户预测网络中编码 和 ,以及如何融合这两种
representation,如下图所示。每个 被嵌入到一个向量 中,然后通过
LSTM、multi-head self-attention、以及attention网络得到短期行为representation。长期行为基于各种辅助信息(包括
item id)来描述,即item ID()、一级类目 ()、叶子类目()、品牌()、店铺()。然后通过attention网络和稠密的全连接网络进行编码,从而得到长期行为representation。长期行为
attention网络分别针对各个辅助信息进行,而不是针对item进行。这可以分别捕获用户对不同辅助信息的偏好,而不是捕获用户对一组辅助信息的偏好。前者的模型容量更小、后者的模型容量更大。和 通过门向量 来融合到
fused into用户行为向量 。是用户画像
embedding,它参与了短期行为中的attention网络、以及长期行为中的attention网络。
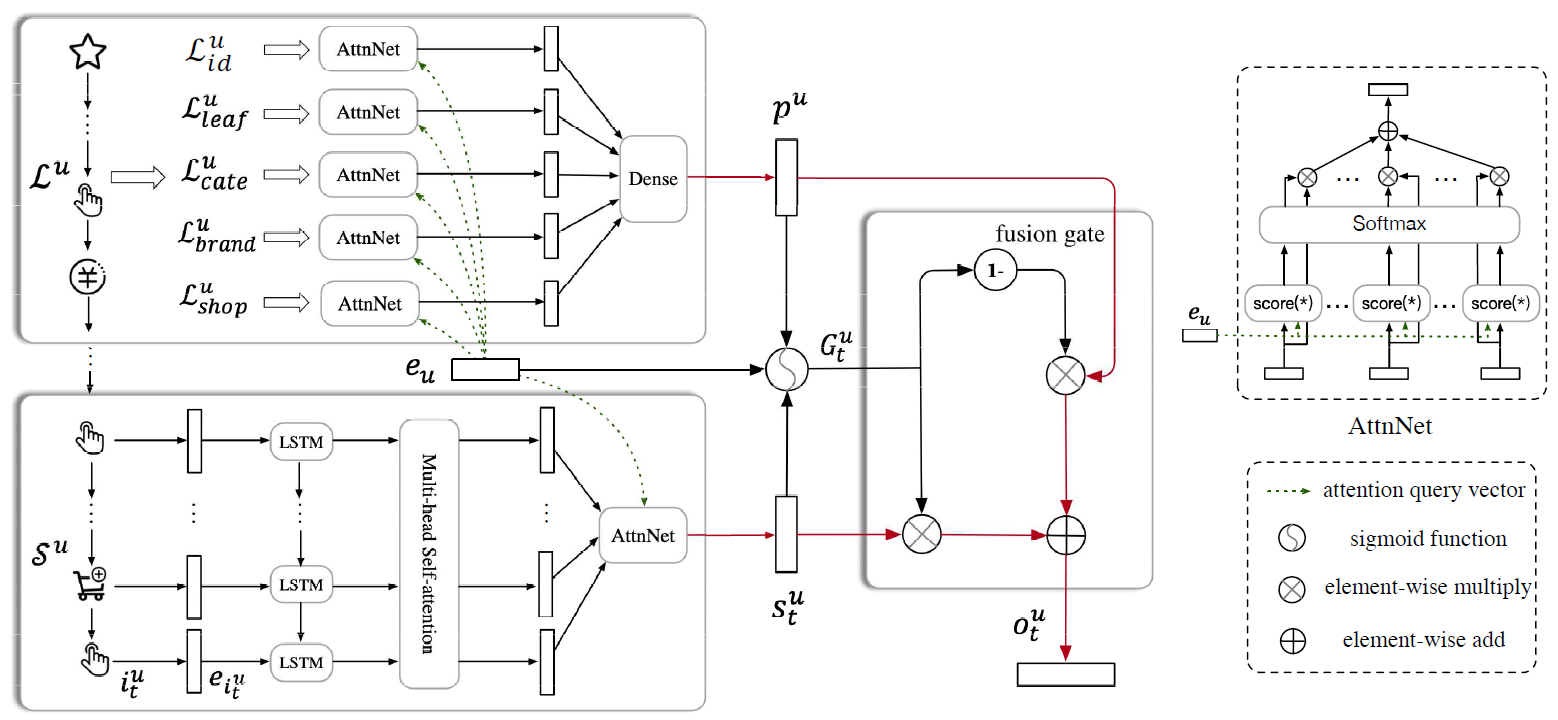
LSTM之后再接入AttnNet,此时的输出已经没有序列信息了(加权聚合)。因此,是否移除LSTM的效果会更好?这个可以通过实验来解决。这里用户
representation作为AttnNet的query,并且没有拼接到最终的representation。这个框架以item为中心来设计。长期行为
attention网络采用“先对辅助信息序列计算AttnNet、再对结果进行Dense” 的方式,也可以 “先对辅助信息进行Dense、再对结果计算AttnNet”的方式。具体哪个更好?可以通过实验来解决。实验部分提到:可以用
next N item作为N个正样本。这种方式可以增加正样本数量从而提高模型效果。fusion gate采用向量化的输出,得到element-wise的加权权重。这比标量的权重粒度更细,效果更好。带辅助信息的
Input Embedding:在淘宝的推荐场景中,用户不仅关注特定item本身,还关注品牌、店铺、价格等。比如,有些人倾向于购买特定品牌的item,另一些人倾向于购买来自他们信任店铺的item。此外,由于大规模item造成的稀疏性,仅通过item ID的特征级别feature level对item进行编码远远不能令人满意。因此,我们从不同的特征尺度feature scales描述一个item,即item ID、叶子类目、一级类目、品牌、店铺,这些称作辅助信息side information集合 。每个输入
item表示为一个由embedding layer转换的稠密向量 ,以便它们可以直接馈入深度神经网络:其中: 为
item的特征 的embedding,embedding size为 ; 为特征 的变换矩阵; 为one-hot向量。类似地,用户画像可以从不同的特征尺寸
feature scales来描述用户 ,如年龄、性别、life stage。用户 的用户画像输入表示为一个稠密向量 :其中: 为用户画像特征集合, 为特征 的
embedding向量。Recurrent Layer:给定用户 的embedding短期行为序列 ,为了捕获和表征短期序列数据中的全局时间依赖性,遵从session-based推荐,我们应用LSTM网络作为循环单元recurrent cell。在时刻 ,LSTM将 的短期行为序列编码为一个hidden output vector,我们称之为序列偏好representation。我们将 传递给注意力网络以获得更高阶的表示。注意力机制:在网购的场景下,用户通常会交替浏览一些不相关的
item,这种情况称作偶然点击causal clicks。不相关的动作会以某种方式影响序列中 的representation。我们使用self-attention网络来减少那些无关动作的影响。此外,
attention网络可以通过为每个部分分配不同的权重得分,从而将各种向量聚合为一个整体的表示presentation。multi-head self-attention:用户可能有多个兴趣点。例如,当你在浏览一条裙子时,颜色和新颖的款式都是做决定的关键因素。单个注意力网络自然不足以捕获多个方面的representation。multi-head attention允许模型共同关注jointly attend来自不同位置的不同representation子空间的信息,并且可以从兴趣的多个视图multiple views建模用户偏好 。令
LSTM hidden output为 ,multi-head self-attention的输出记作 ,则有:其中:
表示输出层线性变换的权重矩阵, 表示
head数量,每个head的维度为 。每个 表示单个潜在兴趣:
其中 分别表示第 个
head的query,key,value的映射矩阵。
user attention:对于不同的用户,他们通常甚至对相同的item集合表现出不同的偏好。因此,在self-attention网络之后,我们添加了一个用户注意力模块user attention module来挖掘更细粒度的个性化信息,其中 作为query向量。因此,时刻 的短期行为
representation计算为:
长期行为融合:从长期视角来看,用户一般会在各个维度上积累了不同层次
level的兴趣。用户可能经常访问一组相似的店铺并重复购买属于同一个类目的item。因此,我们还从不同的特征尺度feature scales对长期行为 进行编码。由多个子集组成:(
item ID)、(一级类目)、(叶子类目)、(品牌)、(店铺) 。例如, 包含用户 过去一周内互动过的店铺。考虑到在线环境下的快速响应,每个子集中的条目entry通过attention-based池化嵌入并聚合到一个整体向量overall vector中。每个 被 转换成稠密向量 (它和 共享相同的特征变换矩阵)。然后我们使用用户画像
embedding作为query向量来计算attention score,并且获得 的representation为:然后我们拼接 、馈入到全连接神经网络,从而得到用户的长期行为
representation:注意:短期行为使用序列建模,长期行为使用
attention建模。二者使用相同的特征转换矩阵,但是短期行为建模使用不同特征尺度embedding的拼接作为item的representation,而长期行为建模直接对每个特征尺度的embedding来进行。为了结合长期行为和短期行为,我们精心设计了一个以 作为输入的门控神经网络
gated neural network。门向量gate vector用于决定在时刻 ,短期行为和长期行为的贡献比例:最终的用户行为向量 为:
其中 为逐元素乘积。
21.2 实验
数据集:我们构建了一个
offline-online的train/validation/test框架来开发我们的模型。我们的代码和离线数据集可以从https://github.com/alicogintel/SDM获取。离线数据集:模型在两个离线的现实世界电商数据集上进行评估:一个是手机淘宝
App在线系统的日常日志中采样的大型数据集,另一个来自JD。Taobao离线数据集:我们随机选择在2018年12月连续8天内交互超过40个item的活跃用户。此外,我们过滤交互超过1000个item的用户。我们认为这些用户是作弊用户spam user。然后我们收集这些过滤后的活跃用户的历史交互数据,其中前7天用于训练,第8天用于测试。我们过滤掉数据集中出现次数少于
5次的item。session分割遵循前述的规则,并且每个 的最大长度限制为20。在训练阶段,我们移除长度小于
2的session。在测试阶段,我们在第
8天选择了大约1万个活跃用户以便快速评估。这些用户在第8天的top 25%短期session会被输入模型,剩余的交互是ground truth。此外,用户可能会在一天内多次浏览某些
item,我们不鼓励重复推荐,因此我们在用户的测试数据中仅保留这些item一次。JD离线数据集:由于这个数据集比较稀疏和较小,我们选择了三周的user-item交互日志进行训练,第四周的交互日志进行测试。数据构建和清洗过程和Taobao相同。
在线数据集:我们选择效果最好的离线模型部署在淘宝的生产环境上。训练数据来自手机淘宝
App最近7天的、没有采样的user-item交互日志。数据清洗过程和离线训练数据集相同。在线的用户和
item规模扩大到亿级,可以覆盖淘宝最活跃的item,并且使用更多的长期行为。在线模型以及相应的item特征和用户特征天级更新。
这些数据集的统计特征如下表所示。

评估指标:
离线评估指标:为了评估不同方法的离线有效性,我们使用了
HitRate@K、Precision@K、Recall@K、F1@K等指标。HitRate@K表示测试集ground truth在top K推荐列表中的命中率,定义为:在我们的实验中,我们使用 和 。
令用户 召回的候选
item集合为 (其中 ) ,而用户 的ground truth集合为 。Precision@K反映了候选item中有多少是用户真正感兴趣的,计算公式为:Recall@K反映了用户真实感兴趣的item有多少被候选召回,计算公式为:为了结合
precision和recall,我们定义F1@K为:我们最终计算测试集中所有用户的
Precision@K、Recall@K、F1@K的均值作为最终结果。
在线评估指标:我们考虑最重要的在线指标:
pCTR、pGMV、和discovery。pCTR定义为每个pv的点击率,其中每个pv可以为用户推荐20个item。pGMV定义为每1000次pv的商品交易总额Gross Merchandise Volume: GMV。除了在线流量和收入,我们还考虑了用户的购物体验。我们定义
discovery指标来衡量推荐系统可以为用户提供多少新颖的item。其中分母为过去
15天,用户 点击的所有类目的数量,分子是用户 点击的新类目的数量。 我们对测试集中所有用户取平均。
baseline方法:我们使用以下方法在两个离线数据集上和我们的模型进行比较。我们还包含了用于消融研究的、SDM的五个变体。Item-based CF:它是行业中主要的候选item生成方法之一,利用协同过滤方法生成用于推荐的item-item相似度矩阵。DNN:YouTube提出的一种基于深度神经网络的推荐方法。item向量和user向量被拼接并馈入到多层前馈神经网络中。GRU4REC:它是首次应用循环神经网络解决session-based推荐,明显优于传统方法。NARM:它是GRU4REC的改进版本,具有全局的和局部的attention-based结构。它探索了一种具有注意力机制的混合编码器hybrid encoder来建模用户的行为序列。SHAN:它将用户的历史稳定偏好和近期的购物需求,与层次注意力网络hierarchical attention network结合起来。BINN:它应用RNN-based方法来编码当前的消费动机和历史购买行为。它通过拼接操作来生成统一的representation。SDMMA:仅有multi-head self-attention的SDM模型。PSDMMA:在SDMMA之上,添加了用户attention模块从而挖掘细粒度个性化信息的SDM模型。PSDMMAL:在PSDMMA之上,它结合了短期行为representation和长期行为representation的SDM模型。PSDMMAL-N:在PSDMMAL之上,它在训练期间,在当前时刻使用接下来的N个item作为target classes,在本实验中 。PSDMMAL-NoS:在PSDMMAL之上,不包含短期行为中的辅助信息和长期行为中的辅助信息,即仅有item id,而没有类目、子类目、品牌、店铺等辅助信息。
配置:
我们通过分布式
Tensorflow实现这些深度学习模型。为了公平比较,所有这些模型共享相同的训练集和测试集,也共享相同的item特征、user特征、以及其它的训练超参数。离线实验的训练中,我们使用
5个参数服务器parameter severs: PSs以及6个GPU(Tesla P100-PCIE-16GB)的worker, 平均训练速度30 global steps/秒;在线实验训练中,我们使用
20个参数服务器以及100 GPU worker,平均训练速度450 global steps/秒。我们使用学习率为
0.001的Adam优化器,当梯度范数超过阈值5时通过梯度缩放来裁剪梯度。我们使用
batch size = 256的mini-batch,并将长度相似的序列组织成一个batch。任何
embedding和模型参数都是从头开始学习的,没有预训练。embedding和模型的参数通过orthogonal initializer来初始化。对于循环神经网络,我们使用带
dropout(dropout rate = 0.2)的多层LSTM以及残差网络,其中dropout和残差网络应用在上下两层LSTM之间。LSTM的hidden size在离线和在线实验中分别设置为64和128。我们设置了不同的setting,因为我们需要在离线实验中高效率地评估模型性能(因此离线的hidden size更小)。对于
multi-head attention结构,我们在离线和在线实验中分别将head数量设置为4和8。我们使用
layer normalization和residual adding操作。item embedding向量维度、短期行为向量维度、长期行为向量维度、用户行为向量维度和LSTM保持一致。在在线
serving期间,我们的模型对检索top 300 item的matching过程耗时大约15ms。
不同模型的离线数据集结果如下表所示。我们从这些模型的所有训练
epoch中选择最佳结果。总体而言,除了
YouTube-DNN之外,基于深度学习的方法显著优于传统的item-based CF方法。- 在
YouTube-DNN中,item序列上的均值池化忽略了item之间内在的相关性,严重影响了推荐质量(Recall, Precision)。 GRU4REC和NARM考虑了短期行为的演变。它们的性能优于原始DNN模型。SHAN和BINN在几乎所有指标上都能击败GRU4REC,原因是它们包含了更多个性化信息,包括长期行为和用户画像representation。
- 在
我们提出的
SDMMA使用了multi-head attention结构,并且比NARM具有压倒性优势。我们在下面内容进行了详细的案例研究,从而进一步解释multi-head attention如何很好地捕获多种兴趣。通过引入用户画像
representation,PSDMMA提升了模型,因为不同类型的用户关注item的不同方面。短期representation越准确,用户就越能够在候选列表中找到他们感兴趣的item,这是有道理的。但是很难为用户推荐潜在的、新颖的item。应该通过考虑长期行为来推断更精确的偏好。通过考虑长期偏好,
PSDMMAL可以显著击败上述所有模型。与
SHAN和BINN不同,PSDMMAL应用fusion gate来结合短期行为representation和长期行为representation。和层次注意力hierarchical attention结构相比,gate具有更强大的决策representation能力。SHAN简单地将用户画像representation作为query向量来决定长期偏好representation和短期偏好representation的注意力权重。我们提出的PSDMMAL对用户画像representation、短期偏好representation、长期偏好representation之间的特定相关性specific correlation建模。我们在下面内容给出了一个有趣的案例,可以正确解释fusion gate的设计。PSDMMAL-N是我们最好的变体,它在训练过程中将接下来的5个item作为target classes。它可以召回更多样化的item、满足更广泛的用户需求、更适合推荐系统的matching任务。PSDMMAL-NoS的结果表明:如果没有辅助信息,我们的模型性能将急剧下降。
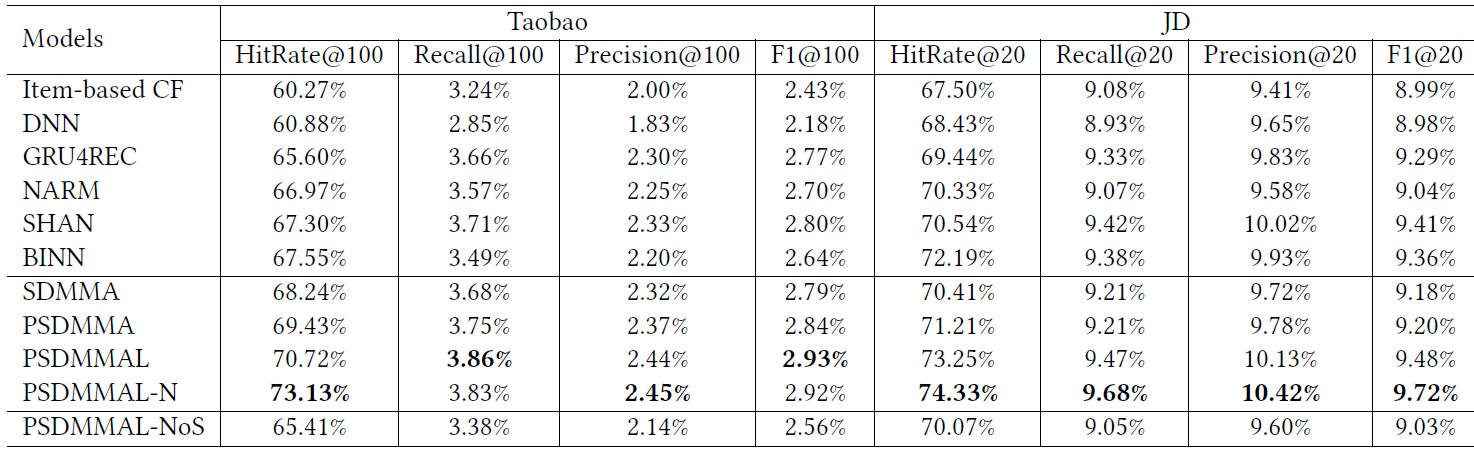
在线
A/B test结果:目前淘宝上的matching算法是一个两阶段的方法:- 我们定义
trigger item为用户最近交互的item。item-based CF首先生成item-item相似度矩阵,然后tirgger item通过相似度矩阵召回相似item。 - 接着根据用户的点击和购买日志,通过
gradient boosting tree将这些召回的item重排为matching候选集。
这种方法是我们的在线
baseline,我们仅将其替换为我们的模型作为标准的A/B test。我们在手机淘宝
App的生产环境上部署了PSDMMAL-N(这是我们最好的SDM版本,记作short and long-term),以及没有长期行为的PSDMMA版本(记作short-term)。下图显示了2018年12月期间连续7天的在线结果。可以看到:- 我们的模型以较大的优势优于
baseline,其中PSDMMAL-N在pCTR/pGMV/discovery上的总体平均提升为7.04%/4.50%/24.37%。 - 融入长期行为会带来更多的改善。长期行为总是表明个人偏好,可以影响用户当前的购物决策。
注意,自
2018年12月以来,我们的SDM模型一直在线运行良好。
- 我们定义
multi-head attention的影响:我们探索了SDM模型中不同head数量的影响。直观地讲,随着head数量的增加,短期session的representation将变得更加准确。下表报告了离线
Taobao数据集的结果,其中 。在本实验中,PSDMMAL中只有head数量的不同,模型隐单元维度 。可以看到:
head数量引起的变化在四个指标上保持一致。- 当
head数量小于4时,模型效果和head数量呈正相关。 - 当
head数量大于4时,模型效果会急剧恶化。
我们可以得出结论:更多的
head数量不一定是正向的,因为 变小导致更差的、每个head的representation。在我们的setting中,head数量为4可以得到最好的结果。
- 当
multi-head attention可视化:我们从离线Taobao测试数据集中采样一个短期session,然后可视化了该短期session中不同head的注意力权重,如下图所示。我们选择
LSTM的最后一个hidden output作为multi-head attention中的query向量,从而得到附加到 上的注意力权重。可以看到:
head1和head2主要集中在session的前面几个item,即白色羽绒服。head3捕获了人们对大衣的兴趣,而head4更关注牛仔裤。
Fusion Gate:将短期偏好representation和长期偏好representation直接逐元素乘法、拼接、加法,这些简单的组合方法忽略了长期偏好中一小部分和当前短期偏好有很强的相关性。我们在Taobao离线数据集上验证了不同组合方法的性能,如下表所示,其中 。可以看到:我们提出的门控融合网络
gated fusion network准确地捕获了multi-level用户偏好并取得了最佳结果。长期偏好中与当前短期偏好高度相关的信息可以与当前短期偏好向量融合。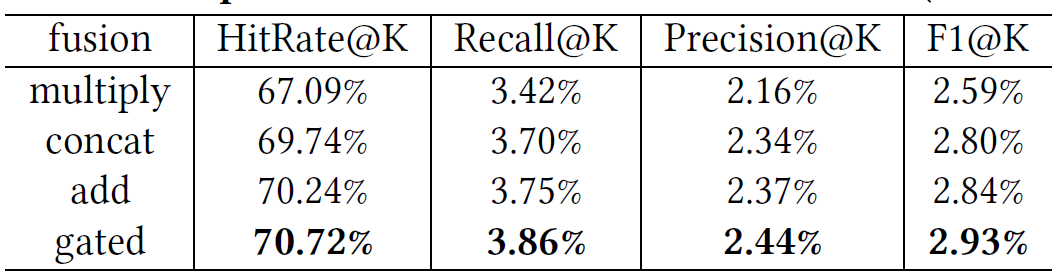
Fusion Gate可视化:为了更好地解释fusion gate,我们使用淘宝上的一个采样用户的真实案例来解释门控的功能。如下图所示, 包含我们模型推荐的、同时后来也被用户所点击的
item集合。从短期行为 可以看到:用户正在浏览各种杯子,包括红酒杯、冠军杯。
我们的模型能够直接推荐冠军杯,因为冠军杯与用户短期行为的最后一次点击有关。这意味着用户当前更可能对冠军杯感兴趣,并且
gate允许保留这些信息。从长期行为 可以看到:用户曾经点击过与短期行为相关的红酒
red wine,但是也发生过很多与短期行为无关的点击,如啤酒、削皮刀、小盘子。我们的门控融合能够捕获到长期行为中最相关的红酒
item,并结合短期行为中的红酒杯item,从而生成推荐的红酒醒酒器item。
这个
case表明我们的gate模块具有有效、准确的融合能力fusion ability。