二十二、COLD[2020 ] (Pre-Ranking 模型)
近年来,由于互联网服务的快速增长,用户一直在与信息过载作斗争。搜索引擎、推荐系统和在线广告已经成为每天为数十亿用户提供服务的基础信息检索
application。这些系统大多数遵循多阶段级联架构multi-stage cascade architecture,即通过matching、pre-ranking、ranking和reranking等顺序模块sequential modules来提取候选item。下图给出了一个简短的说明。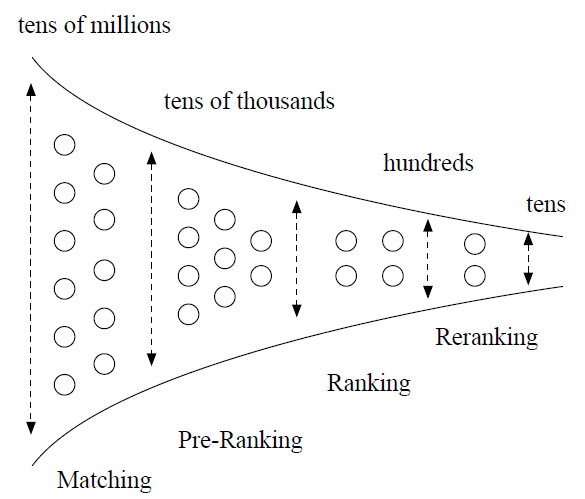
已经有很多论文讨论如何建立一个有效
effective的、高效efficient的ranking系统。然而,很少有工作关注pre-ranking系统。为简单起见,在本文的剩余部分只讨论展示广告系统display advertising system中pre-ranking系统的设计。这里讨论的技术可以很容易应用于推荐系统、搜索引擎等。长期以来,人们认为
pre-ranking只是ranking系统的简化版本。- 一方面,考虑到在线
serving的算力成本computing power cost挑战,需要对更大规模的候选item集合进行排序。以阿里巴巴的展示广告系统为例。传统上,pre-ranking系统要评分的候选集合的规模可以扩展到数万个item,而在后续ranking系统中要评分的候选集合规模则变成数百个item。 - 另一方面,
ranking和pre-ranking系统都有严格的延迟限制,例如10 ~ 20 ms。在这种情况下,pre-ranking系统通常被设计为轻量级排序系统,通过简化ranking模型来处理在线推断的算力爆炸。
- 一方面,考虑到在线
pre-ranking系统的发展历史简介:回顾pre-ranking系统在工业中的发展历史,我们可以简单地从模型的角度将其分为四代,如下图所示。 分别是user、ad、cross的原始特征。 分别是user、ad、cross特征的embedding。第一代是非个性化的
ad-wise统计得分。它通过平均每个广告的最近CTR来计算pre-rank score。score可以高频high frequency更新。缺点:非个性化、无法处理新广告、曝光稀疏广告的
CTR统计不置信。第二代是
Logistic Regression: LR模型。它是浅层机器学习时代大规模ranking模型的轻量级版本,可以以online learning和serving的方式进行部署。缺点:需要大量的手工特征工程、无法捕获特征之间的非线性交互作用。
第三代是基于向量内积的深度学习模型,也是目前
state-of-the-art的pre-ranking模型。在该方法中,user-wise embedding向量和ad-wise embedding向量分别以离线方式预计算,没有user-ad交叉特征,然后在线计算两个向量的内积从而获得pre-rank score。缺点:向量内积的方式过于简单,使得模型效果较差。
尽管和前两代相比,基于向量内积的
DNN显著提升了模型性能,但是它仍然面临量大挑战,还留有进一步改进的空间:- 模型表达能力受限。如
《Learning Tree-based Deep Model for Recommender Systems》所述,模型的表达能力受限于向量内积形式的深度模型。 - 模型更新频率较低。基于向量内积的
DNN的embedding向量需要离线预先计算。这意味着基于向量内积的DNN模型只能以低频方式更新,难以适应最新的数据分布的变化,尤其是在数据发生剧烈变化时(如双十一当天)。
综上所述,上述三代
pre-ranking系统都遵循相同的范式:将算力视为恒定约束,在此基础上开发了与训练系统、serving系统相对应的pre-ranking模型。也就是说,模型的设计和算力的优化是解耦的,这通常会导致模型的简化以适应算力的需求。这会导致次优suboptimal的性能。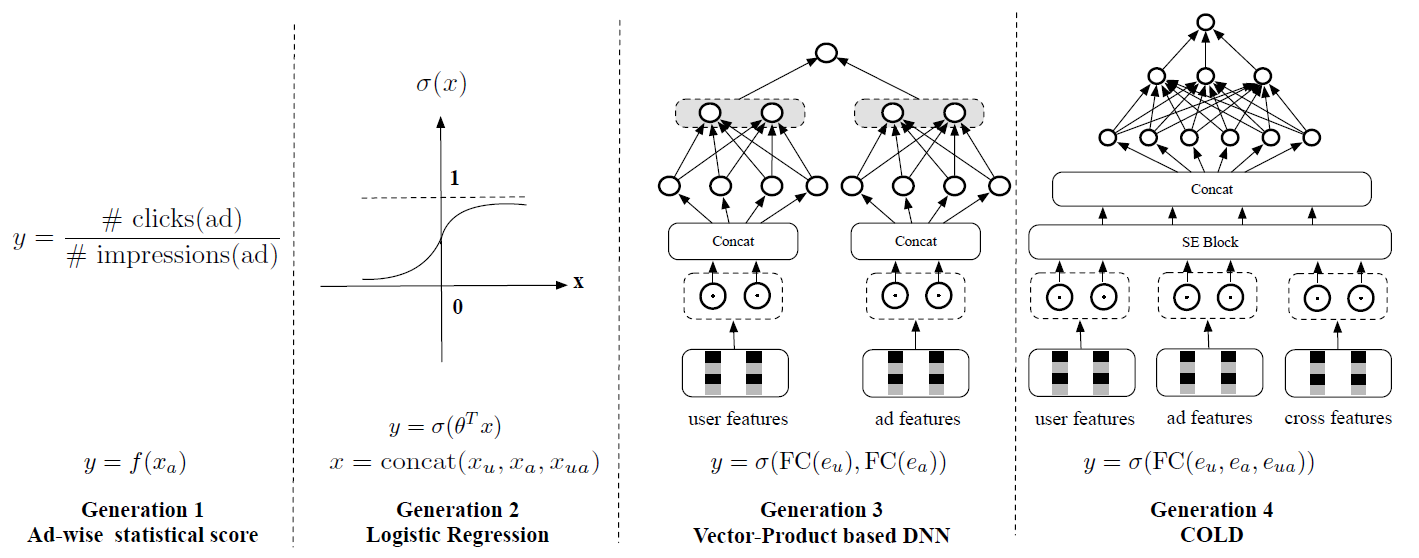
下一代
pre-ranking系统COLD:在论文《COLD: Towards the Next Generation of Pre-Ranking System》中,作者从算法--系统协同设计co-design的角度重新思考了pre-ranking系统的挑战。论文设计了一个新的pre-ranking系统,通过联合优化pre-ranking模型和它所消耗的算力来节省算力,而不是通过限制模型体系结构(这会限制模型性能)。作者将其命名为Computing power cost-aware Online and Lightweight Deep pre-ranking system: COLD,如上图所示。论文将
COLD视为第四代pre-ranking系统。COLD兼顾了模型设计和系统设计。COLD中的算力成本也是一个可以与模型性能联合优化的变量。换句话讲,COLD是一种灵活的pre-ranking系统,模型性能和算力成本之间的trade-off是可控的controllable。COLD的主要特点总结如下:- 具有交叉特征的任意深度模型可以在可控算力成本的约束下应用于
COLD。在论文的真实系统中,COLD模型是一个七层全连接深度神经网络,具有Squeeze-and-Excitation: SEblock。SE block有利于我们进行特征组的选择,以便于从复杂的ranking模型中获得轻量级版本。该选择是通过考虑模型性能和算力成本来执行的。也就是说,COLD模型的算力成本是可控的。 - 通过应用优化技巧(例如,用于加速
inference的并行计算和半精度计算),显著降低了算力成本。这进一步为COLD应用更复杂的深度模型以达到更好性能带来了空间。 COLD模型以online learning和serving的方式工作,为系统带来了出色的能力来应对数据分布变化的挑战。COLD的全在线pre-ranking系统为我们提供了灵活的基础设施,支持新模型开发和快速的在线A/B test,这也是目前ranking系统拥有的最佳系统实践。
下图给出了所有四代
ranking系统在模型表达能力和更新频率方面的比较,其中COLD实现了最佳的trade-off。2019年以来,COLD已经部署在阿里巴巴展示广告系统display advertising system中几乎所有涉及pre-ranking模块的产品中,每天为数亿用户提供高并发请求。和最新的在线的、基于向量内积的DNN版本相比,COLD带来了6%以上的RPM提升,这对于业务而言是一个显著的提升。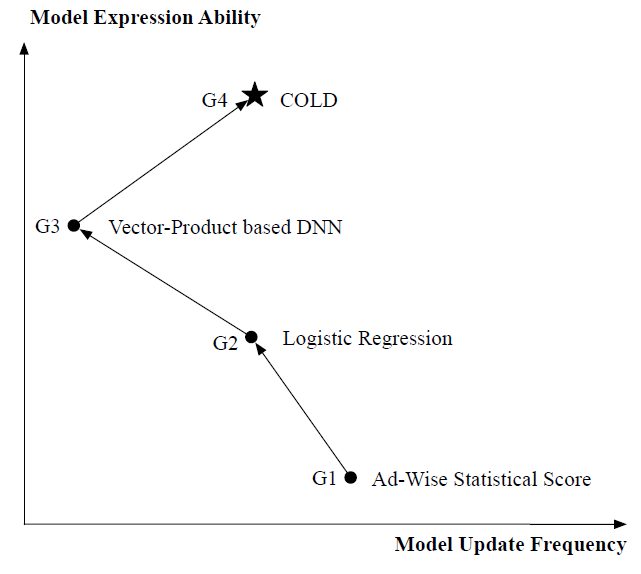
- 具有交叉特征的任意深度模型可以在可控算力成本的约束下应用于
22.1 模型
22.1.1 Pre-Ranking 系统概述
pre-ranking模块可以被视为matching模块和ranking模块之间的连接纽带:它接收matching结果并进行粗选,从而减少用于后续ranking模块的候选集的大小。以阿里巴巴的展示广告系统为例,输入
pre-ranking系统的候选集大小往往达到万级。然后pre-ranking模型通过某些指标(例如eCPM)选择top N候选item。 的量级通常为数百。这些获胜的 个候选item通过复杂的ranking模型进一步排序,从而得到最终结果展示给用户。一般而言,
pre-ranking和ranking具有相似的功能,二者之间最大的区别在于问题的规模。显然,pre-ranking系统要排序的候选集合规模是ranking系统的10倍或者更大。在pre-ranking系统中直接应用ranking模型似乎是不可能的,这将面临算力成本的巨大挑战。如何平衡模型性能和它所消耗的算力是pre-ranking系统的关键考虑因素。基于向量内积的
DNN模型:在深度学习成功的推动下,基于向量内积的DNN模型已经广泛应用于pre-ranking系统并实现了state-of-the-art性能。基于向量内积的
DNN模型的架构由两个并行的子神经网络组成:用户特征被馈入到左侧子网络,广告特征被馈入到右侧子网络。对于每个子网络,特征首先输入embedding层,然后拼接在一起,然后是全连接FC层。这样我们得到两个固定长度的向量 ,它们分别代表用户信息和广告信息。 最后,pre-ranking score计算如下:基于向量内积的
DNN模型的训练遵循与传统ranking模型相同的方式。为了关注pre-ranking模型的关键部分,我们省略了训练的细节。基于向量内积的
DNN模型的pre-ranking系统的缺点:基于向量内积的DNN模型在延迟latency和计算资源方面是高效的。 的向量可以离线预先计算,score可以在线计算。这使得它足以应对算力成本的挑战。下图说明了基础设施的经典实现。和前几代pre-ranking模型相比,基于向量内积的DNN模型取得了显著的性能提升。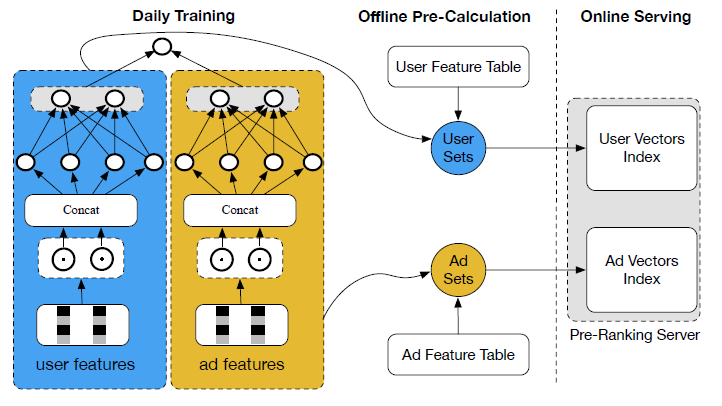
然而,基于向量内积的
DNN模型通过将模型限制为向量内积的形式,过于关注降低算力成本,这导致模型性能欠佳。我们总结了以下缺点:模型表达能力受限于向量内积的形式,无法利用
user-ad交叉特征。《Learning Tree-based Deep Model for Recommender Systems》已经表明:采用复杂的深度模型比向量内积形式网络具有显著的预测效果优势。用户向量 和广告向量 需要枚举所有用户和所有广告进行离线预计算,从而减少计算资源并优化延迟。对于拥有数亿用户和数千万广告的业务,预计算通常需要几个小时,难以适应数据分布的变化。当数据发生剧烈变化时(如双十一当天),这会给模型性能带来很大的伤害。
模型更新频率也受到系统实现的影响。对于基于向量内积的
DNN模型,用户向量索引/广告向量索引版本之间的天级切换需要同时执行,这很难满足两个索引存储在不同在线系统中的情况。根据我们的经验,延迟切换也会损害模型性能。如果用户向量索引切换为新版本,而广告向量索引保留为旧版本,则出现索引不一致,会严重降低在线
serving的效果。因此用户向量索引/广告向量索引需要同时切换。
基于向量内积的
DNN模型的pre-ranking系统的这些缺点源于对算力的过度追求,并且难以完全解决。在接下来的部分中,我们将介绍我们的新的解决方案,它打破了pre-ranking系统的经典设计方法。
22.1.2 COLD
在这一部分,我们将详细介绍我们新设计的
pre-ranking系统COLD。COLD背后的核心思想是:同时考虑模型设计和系统设计。COLD中的算力成本也是一个可以和模型性能联合优化的变量。换句话说,COLD是一个灵活的pre-ranking系统,模型性能和算力成本之间的trade-off是可控的。COLD中的深度pre-ranking模型:基于向量内积的DNN模型通过限制模型架构来降低算力成本,从而导致模型性能损失。与此不同,COLD允许应用深度模型的任意复杂架构来确保最佳模型性能。换句话说,SOTA深度ranking模型可以用于COLD。例如,在我们的真实系统中,我们将
groupwise embedding network: GwEN作为我们的初始模型架构,它是我们ranking系统中在线模型的早期版本。GwEN将feature group-wise embedding的拼接作为输入。注意,交叉特征也包含在GwEN网络的输入中。当然,
pre-ranking直接应用具有复杂架构的深度ranking模型进行在线inference的算力成本是不可接受的,因为要在pre-ranking系统中进行排序的候选集合规模更大。为了应对这一关键挑战,我们采用了两种优化策略:- 一种方法是设计一种灵活的网络架构,可以在模型性能和算力成本之间进行
trade-off。 - 另一种方法是通过应用工程优化技巧进行
inference加速来显著降低算力成本。
- 一种方法是设计一种灵活的网络架构,可以在模型性能和算力成本之间进行
a. 灵活网络架构的设计
一般而言,我们需要引入合适的网络架构设计,从而从初始
GwEN模型的完整版本中得到深度模型的轻量级版本。网络剪枝、特征选择、以及神经架构搜索等技术都可以应用于此。在我们的实践中,我们选择了便于在模型性能和算力成本之间进行可控trade-off的特征选择方法。其它技术也适用,我们留给读者进一步地尝试。具体而言,我们应用
Squeeze-and-Excitation: SEblock进行特征选择。SE block首先在CV中用于显式建模通道之间的内部依赖性。这里,我们使用SE block来获得group-wise特征的重要性权重,并通过度量模型性能和算力成本来选择COLD中最合适的特征。重要性权重计算:令 为第 个
feature group的embedding,总的feature group数量为 。SE block将 压缩为一个标量值 :其中:
- 为一个向量,给出每个
feature group的重要性。 - 为向量拼接。
- 为模型参数。
然后通过
embedding和重要性权重 之间的field-wise相乘从而得到新的加权embedding。SE block相当于让模型自动学习每个feature group embedding的特征重要性。- 为一个向量,给出每个
feature group选择:权重向量 代表每个feature group的重要性。我们使用权重对所有feature group进行排序,并选择top K权重最高的feature group。然后进行离线测试,从而评估选定K个feature group的模型的候选轻量级版本的模型性能和系统性能。评估指标包括GAUC、query per seconds: QPS(衡量模型的吞吐量)、return time: RT(衡量模型的延迟)。通过多次启发式尝试
K次,我们最终选择在给定的系统性能约束下具有最佳GAUC的版本作为我们最终的模型。这样,可以灵活地进行模型性能和算力成本之间的trade-off。
b. 工程优化技巧
除了通过灵活的网络架构设计降低算力成本,我们还从工程角度应用了各种优化技巧,进一步为
COLD应用更复杂的深度模型带来了空间,以达到更好的性能。下面以我们在阿里巴巴的展示广告系统为例,介绍一下实践经验。情况可能因系统而异。读者可以根据实际情况做出选择。在我们的展示广告系统中,
pre-ranking模块的在线inference引擎主要包含两个部分:特征计算和稠密网络计算。- 在特征计算中,引擎从索引系统中提取用户和广告特征,然后计算交叉特征。
- 在稠密网络计算中,引擎首先将特征转换为
emedding向量并将它们拼接起来作为网络的输入。
all level的并行性:为了以低算力成本实现低延迟和高吞吐量的inference,利用并行计算非常重要。因此,我们的系统会尽可能地利用并行性。幸运的是,不同广告的pre-rank分数是相互独立的。这意味着它们可以在一些成本上并行计算,这些成本涉及到一些与用户特征相关的重复计算。在
high level上,一个前端user query将拆分为多个inference query。每个query处理部分广告,并在所有query返回后合并结果。因此,在决定拆分多少个query时需要trade-off。更多的query意味着每个query的广告很少,因此单个query的延迟更低。但是太多的query也会导致巨大的重复计算和系统开销。即划分广告空间,从而在广告空间上并行计算。
此外,由于
query是在我们的系统中使用RPC实现的,更多的query意味着更多的网络流量,并且可能有更高的延迟或失败可能性。在处理每个
query时,多线程处理用于特征计算。同样,每个线程处理部分广告以减少延迟。最后,执行稠密网络
inference时,我们使用GPU来加速计算。
基于列的计算:传统上,特征计算是基于行的方式完成的:广告被一个接一个地处理。然而,这种基于行的方法对
cache不友好。相反,我们使用基于列的方法将一个feature列的计算放在一起。下图说明了两种计算模式。在计算交叉特征的时候(例如红色方块这一列),相同的
user特征会被频繁使用。图(a)为基于行的方式,每次处理交叉特征的时候都需要重新加载user特征;图(b)为基于列的方式,在处理为交叉特征的时候可以重复使用缓存的user特征。通过这种方式,我们可以使用
Single Instruction Multiple Data: SIMD这样的技术来加速特征计算。在计算交叉特征(如
ad_fg & u_fg,右图最右侧一列)时,基于列的计算可以缓存u_fg。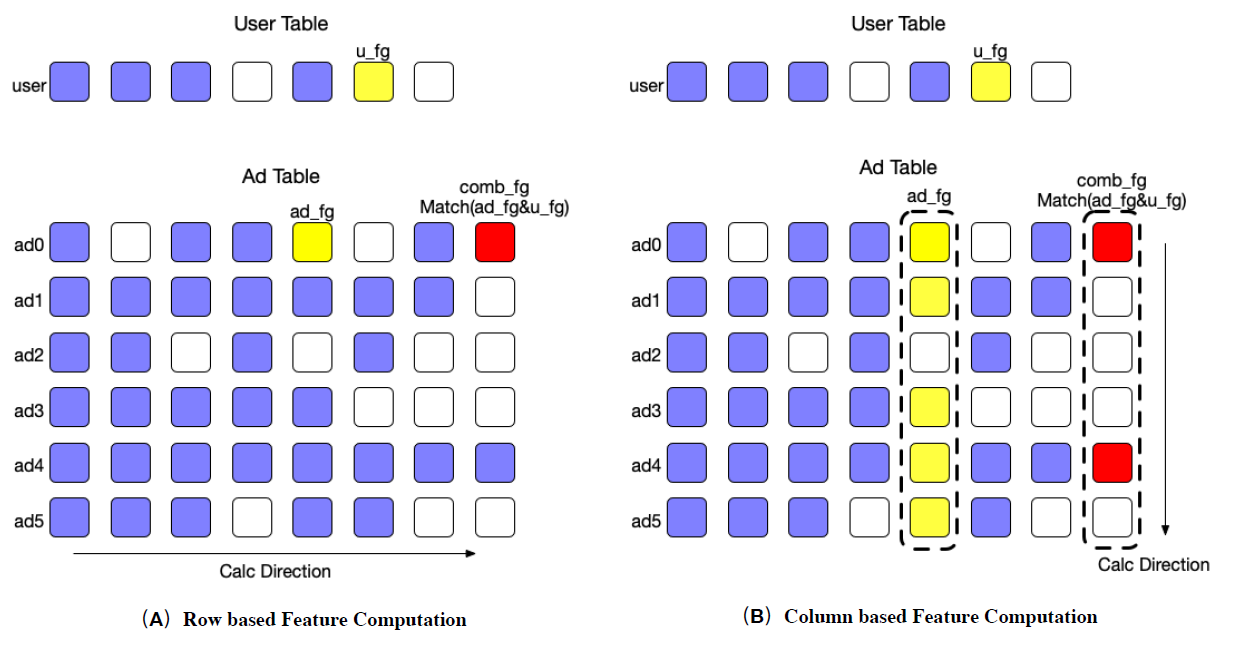
低精度
GPU计算:对于COLD模型,大部分计算是稠密矩阵的乘法,这就留下了优化空间。在英伟达的Turning架构中,T4 GPU为Float16和Int8矩阵乘法提供了极致性能,非常符合我们的case。Float16的理论峰值FLOPS可以比Float32高8倍。然而,
Float16丢失了一些精度。在实践中,我们发现对于某些场景,当我们对某些feature group使用sum-pooling时,稠密网络的输入可能是一个非常大的数字,超过了Float16的表示范围。一种解决方案是使用
normalization layer,如BN层。然而,BN层本身包含的moving-variance参数,其幅度可能甚至更大。这意味着计算图需要混合精度,即全连接层使用Float16、BN层使用Float32。另一种解决方案是使用无参数
parameter-free归一化层。例如,对数函数可以轻松地将大数值转换为合理的范围。但是,log()函数无法处理负值,并且当输入接近零时可能会导致一个巨大的数值。因此,我们设计了一个称为线性对数算子linear-log operator的分段平滑函数来处理这种不必要的行为,即:
linear_log()函数的图形如下图所示。它将Float32数值转换为一个合理的范围。因此如果我们在第一层放置一个linear_log算子,就可以保证网络的输入很小。此外,linear_log()函数是 连续的,因此不会使网络训练更加困难。在实践中,我们发现添加这一层之后,网络仍然可以达到与原始COLD模型相同的精度。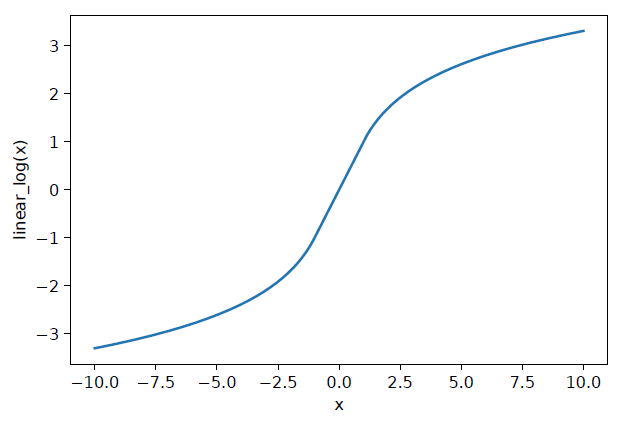
使用
Float16进行inference之后,我们发现CUDA kernel的running time急剧下降,kernel启动时间成为瓶颈。为了提高实际的QPS,我们进一步使用Multi-Process Service: MPS来减少启动kernel的开销。结合Float16和MP,引擎的吞吐量是以前的两倍。
22.1.3 全在线基础设施
受益于不受限制的模型架构,
COLD可以在全在线基础设施fully online infrastructure下实现:训练和serving都以online的方式执行,如下图所示。从行业角度来看,这是目前最好的系统实践。这种基础设施有两个方面的好处:COLD模型的online learning带来了其应对数据分布漂移shift的挑战的出色能力。根据我们的经验,当数据发生剧烈变化时(如双十一当天),
COLD模型相对于基于向量内积的DNN模型的性能提升更为显著,正如我们在实验部分所示。此外,COLD模型的online learning对于新广告更加友好。这是
online learning的优势:能实时学习最新的数据分布。COLD全在线的pre-ranking系统为我们提供了灵活的基础设置,从而支持高效的新模型开发和在线A/B test。注意,对于基于向量内积的
DNN模型,用户侧向量和广告侧向量需要离线预计算并通过索引加载到inference引擎。因此,它涉及多个系统的开发,以进行基于向量内积的DNN模型的两个版本的A/B test。根据我们的经验,获得可靠的A/B test结果的典型时间成本是几天,而COLD则是几个小时。此外,全在线serving也有助于COLD避免基于向量内积的DNN模型所遭受的延迟切换。从下图结构可以看到,
COLD使用了大量的、人工构造的交叉特征cross features。因此COLD中,user信息和ad信息在两个level进行了融合:- 在输入特征
level,COLD显式地、人工地构造了交叉特征,从而融合了user-ad信息。 - 在模型架构
level,COLD通过全连接层,从而融合了user-ad信息。
- 在输入特征
22.2 实验
我们进行仔细的比较,从而评估所提出的
pre-ranking系统COLD的性能。作为一个工业系统,COLD在模型性能和系统性能上都进行了比较。据我们所知,这项任务只有公共数据集或pre-ranking系统(而没有二者的结合)。以下实验在阿里巴巴在线展示广告系统中进行。baseline方法:COLD模型最强的baseline是基于SOTA向量内积的DNN模型,它是我们展示广告系统中在线pre-ranking模型的最新版本。配置:
COLD模型和基于向量内积的DNN模型都使用超过900多亿个样本进行训练,这些样本都是从真实系统的日志中收集的。注意:基于向量内积的DNN模型和COLD模型共享相同的用户特征和广告特征。基于向量内积的DNN模型不能引入任何user-ad交叉特征,而COLD模型使用user-ad交叉特征。为了公平比较,我们还评估了具有不同交叉特征
group的COLD模型的性能。对于
COLD模型,特征embedding向量被拼接在一起,然后被馈送到全连接网络。这个全连接网络的结构是 ,其中 为所有被选中特征的embedding的拼接。对于基于向量内积的模型,全连接层的结构为 。
对于基于向量内积的模型,全连接层表示单侧网络的全连接层。
两种模型的输入特征
embedding维度均设置为16。我们使用
Adam优化器来更新模型参数。
评估指标:
模型性能评估指标:
GAUC作为评估模型离线性能的指标。此外,我们引入了一个新的
top-k召回率指标,从而度量pre-ranking模型和后续ranking模型之间的对齐程度alignment degree。top-k召回率定义为:其中:
top k ad 候选和top m ad 候选是从同一个候选集合(即pre-ranking模块的输入)生成的。top k ad 候选是根据pre-ranking模型排序的,top m ad 候选是根据ranking模型排序的,并且 。- 排序指标为
eCPM = pCTR x 点击出价。
在我们的实验中,
ranking模型使用DIEN,这是在线ranking系统的以前的版本。系统性能评估指标:为了评估系统性能,我们使用的指标包括
Queries Per Seconds: QPS(用于衡量模型的吞吐量)、return time: RT(用于衡量模型的延迟)。这些指标反映了模型在相同大小的pre-ranking候选集合下的算力成本。粗略地说,较低RT下较大的QPS意味着给定模型的算力成本较低。
离线模型效果评估:下表给出了不同模型的离线性能评估结果。可以看到:
COLD保持了与我们之前版本的ranking模型DIEN相当的GAUC,并且与基于向量内积的模型相比,在GAUC和Recall上都取得了显著的提升。
在线
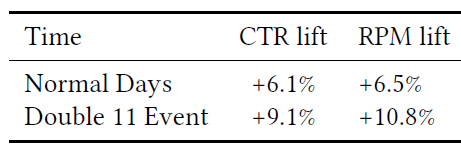
A/B test效果评估:下表显示了COLD模型相对于基于向量内积的DNN模型的在线A/B test提升。 可以看到:- 在正常情况下,
COLD模型实现了6.1%的CTR提升和6.5%的Revenue Per Mille: RPM提升,这对我们的业务意义重大。 - 此外,在双十一活动期间,
COLD模型实现了9.1%的CTR提升和10.8%的RPM提升。这证明了全在线基础设施的价值,在数据急剧变化时,它可以使得模型适应最新的数据分布。
- 在正常情况下,
系统性能的评估:我们评估了使用不同模型的
pre-ranking系统的QPS和RT,如下表所示。基于向量内积的模型在具有2个Intel(R) Xeon(R) Platinum 8163 CPU@2.50GHz (96 cores)和512GB RAM的CPU机器上运行。COLD模型和DIEN在配备NVIDIA T4的一个GPU机器上运行。可以看到:
- 基于向量内积的
DNN模型实现了最佳系统性能,这符合预期。 DIEN算力成本最高,COLD达到算力和效果的平衡。

- 基于向量内积的
消融研究:为了进一步了解
COLD的性能,我们在模型设计视角和工程优化技术视角进行了实验。对于后一种方法,由于很难将所有的优化技术从集成系统中解耦出来并进行比较,因此这里我们仅对GPU低精度计算这个最重要因素进行评估。pre-ranking系统的不同版本COLD模型的trade-off性能:在模型设计阶段,我们使用SE block来获取特征重要性权重,并选择不同的feature group作为模型的候选版本。然后我们进行离线实验以评估模型的QPS,RT,GAUC等性能,如下表所示。*是我们用于产品中的COLD模型的平衡版本,它使用部分交叉特征。可以看到:
COLD模型的算力成本因为特征不同而不同,这符合我们灵活的网络架构设计。- 交叉特征越多的
COLD模型性能越好,这也相应增加了online serving的负担。
通过这种方式,我们可以在模型性能和算力成本之间进行
trade-off。在我们的真实系统中,我们根据经验手动选择平衡的版本。COLD需要大量的、人工构造的交叉特征,这会增加人工特征工程的负担。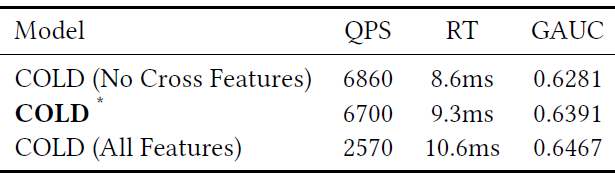
不同
GPU精度的计算比较:实验是在配备NVIDIA T4的GPU机器上运行。在运行实验时,我们从客户端逐渐提高QPS,直到超过1%的服务器响应时间开始超过延迟限制。然后我们将当前QPS记录为可用QPS。实验结果如下表所示。可以看到:Float32版本的可用QPS最低。
单独使用
Float16可以提高大约21%的可用QPS。- 结合
Float16和CUDA MPS,我们可以将可用QPS比Float32提高一倍,并且可以在不超过延迟限制的情况下充分利用GPU。

- 结合
二十三、ComiRec[2020] (matching阶段)
近年来,电商的发展彻底改变了我们的购物方式。推荐系统在电商公司中扮演着重要的角色。传统的推荐方法主要使用协同过滤来预测用户和
item之间的得分。近年来,由于深度学习的快速发展,神经网络在电商推荐系统中得到了广泛的应用。神经推荐系统为用户和item生成representation,并且优于传统的推荐方法。然而,由于电商用户和item的规模较大,很难使用深度模型直接给出每对user-item之间的点击率CTR预估。当前的业界实践是使用fast KNN(如Faiss)来生成候选item,然后使用深度模型结合用户属性和item属性来优化业务指标(如点击率)。最近的一些工作使用
graph embedding方法来获取user representation和item representation,然后用于下游application。例如,PinSage建立在Graph-SAGE基础之上,并将基于图卷积的方法应用于具有数十亿节点和边的生产级数据。GATNE考虑了不同的用户行为类型,并利用异质图embedding方法来学习user representation和item representation。然而,这些方法忽略了用户行为中的序列信息,无法捕获到用户的相邻行为之间的相关性。最近的研究将推荐系统形式化为一个序列推荐
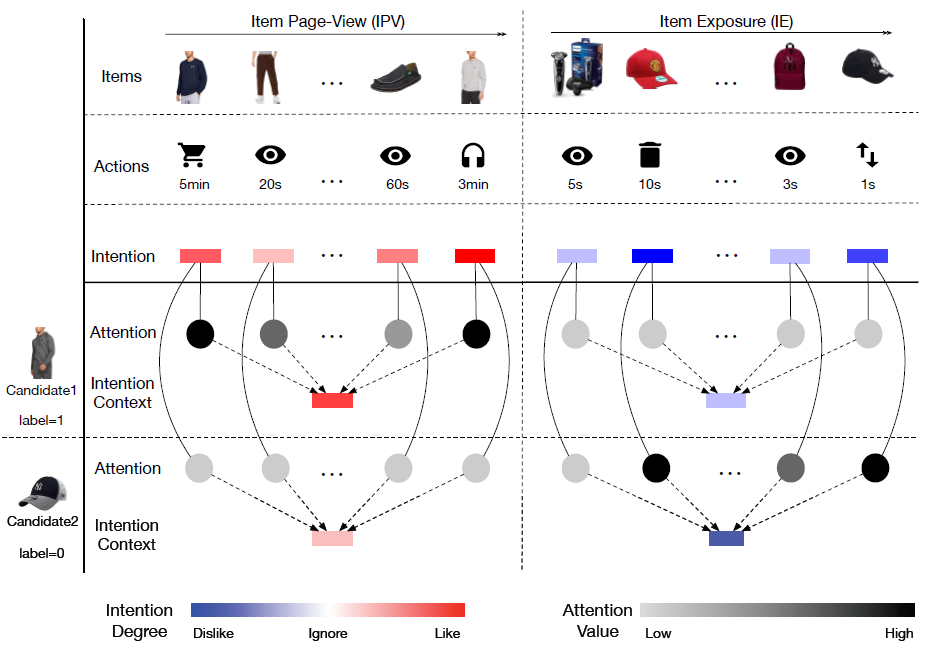
sequential recommendation问题。序列推荐任务是根据用户的行为历史,预测用户可能感兴趣的next item。该任务反映了现实世界的推荐情况。许多近期提出的模型可以从每个用户的行为序列中给出该用户的整体embedding。然而,统一的用户embedding很难代表多种兴趣multiple interests。例如在下图中,点击序列显示了Emma的三种不同兴趣。作为一个现代女性,Emma对珠宝jewelry、手提包handbags、化妆品make-ups很感兴趣。因此,她可能会在这段时间内点击这三个类目的item。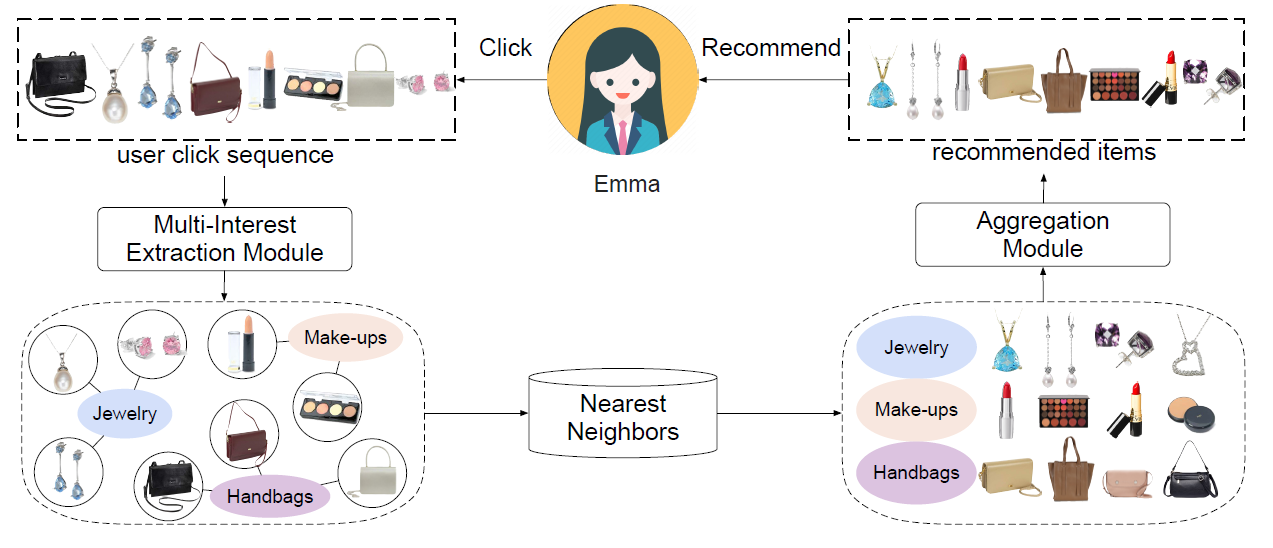
在论文
《Controllable Multi-Interest Framework for Recommendation》中,作者提出了一种新的、可控的多兴趣框架multi-interest framework,称作ComiRec。上图展示了ComiRec多兴趣框架的一个示例。ComiRec的多兴趣模块multi-interest module可以从用户行为序列中捕获用户的多种兴趣,这些兴趣可独立地从大规模item池中检索候选item。ComiRec的聚合模块aggregation module将这些来自不同兴趣的item组合在一起,并输出整体top-N推荐。聚合模块利用可控的因子来平衡推荐的准确性accuracy和多样性diversity
论文对序列推荐进行了实验。另外,
ComiRec框架也成功地部署在阿里巴巴分布式云平台上。十亿级工业数据集的结果进一步证明 了ComiRec在实践中的效果effectiveness和效率efficiency。总而言之,本文的主要贡献是:
- 提出了一个综合的框架
ComiRec,将可控性controllability和多兴趣组件集成在一个统一的推荐系统中。 - 通过在线推荐场景中的
implementing和studying来调研可控性在个性化系统中的作用。 ComiRec框架在两个具有挑战性的真实数据集上为序列推荐实现了state-of-the-art的性能。
相关工作:这里我们将介绍有关推荐系统和推荐多样性的相关文献,以及我们在论文中使用的胶囊网络和注意力机制。
协同过滤方法已经在现实世界的推荐系统中被证明是成功的,它可以找到相似的用户和相似的
item,并在此基础上做出推荐。- 矩阵分解
Matrix Factorizaion: MF是经典推荐研究中最流行的技术,它将用户和item映射到联合潜在因子空间joint latent factor space中,这样user-item交互被建模为该空间中的内积。 - 分解机
Factorization Machine: FM使用分解的参数factorized parameters对变量之间的所有交互进行建模,因此即使在推荐系统等具有巨大稀疏性的问题中也可以估计交互estimate interaction。
- 矩阵分解
神经推荐系统
Neural Recommender System:- 神经协同过滤
Neural Collaborative Filtering: NCF使用神经网络架构对用户和item的潜在特征进行建模。 NFM无缝地结合了FM在建模二阶特征交互时的线性、以及神经网络在建模高阶特征交互时的非线性。DeepFM设计了一个端到端的学习模型,同时强调了低阶特征交互和高阶特征交互以进行CTR预测。xDeepFM扩展了DeepFM,可以显式地学习特定的、阶次有界bounded-degree的特征交互。- 深度矩阵分解
Deep Matrix Factorization: DMF使用深度结构学习的架构deep structure learning architecture,基于显式评分和非偏好non-preference的隐式反馈,学习user representation和item representation的通用低维空间。 DCN保留了深度模型的优点,并引入了一种新颖的交叉网络,该网络在学习特定的、阶次有界的特征交互方面更有效。CMN利用潜在因子模型的全局结构和基于局部邻域的结构的优势,以非线性方式使用深度架构来统一两类CF模型。
- 神经协同过滤
序列推荐
Sequential Recommendation:序列推荐是推荐系统的关键问题。最近很多关于推荐系统的工作都集中在这个问题上。FPMC对于序列basket数据同时包含了一个常见的马尔科夫链和一个普通的矩阵分解模型。HRM扩展了FPMC模型,并采用两层结构来构建最近一次交互的user和item的混合representation。GRU4Rec首次引入了一种RNN-based方法来建模整个session,以获得更准确的推荐。DREAM基于RNN,学习用户的动态representation以揭示用户的动态兴趣。Fossil将similarity-based方法和马尔科夫链平滑地结合在一起,从而对稀疏和长尾数据集进行个性化的序列预测。TransRec将item嵌入到向量空间中,其中用户被建模为在item序列上进行的向量操作vectors operating,从而用于大规模序列的预测。RUM使用了一个memory-augmented神经网络,融合了协同过滤的洞察insights来进行推荐。SASRec使用基于self-attention的序列模型来捕获长周期long-term语义,并使用注意力机制来基于相对较少的动作进行预测。DIN设计了一个局部激活单元local activation unit来自适应地从历史行为中学习关于目标广告的用户兴趣的representation。SDM使用multi-head self-attention模块对行为序列进行编码以捕获多种类型的兴趣,并使用长短期门控融合模块long-short term gated fusion module来融入长期偏好。
推荐多样性
Recommendation Diversity:研究人员已经意识到,只遵循最准确most accurate的推荐可能不会产生最好best的推荐结果,因为最准确的结果往往会向用户推荐相似的item,从而产生无聊的推荐结果。为解决这些问题,推荐item的多样性diversity也起着重要作用。在多样性方面,有聚合多样性
aggregated diversity,指的是向用户推荐长尾item的能力。很多研究聚焦于提高推荐系统的聚合多样性。另外有一些工作聚焦于推荐给单个用户的
item多样性,这指的是推荐给单个用户的item dissimilarity。注意力
Attention:注意力机制的起源可以追溯到几十年前的计算机视觉领域。然而,它在机器学习的各领域中的普及只是近年来才出现的。它最早是由《Neural machine translation by jointly learning to align and translate》引入机器翻译的,后来作为tensor2tensor成为一种突破性的方法。BERT利用tensor2tensor并在NLP方面取得了巨大成功。注意力机制也适用于推荐系统,并在现实世界的推荐任务中相当有用。胶囊网络
Capsule Network: 胶囊的概念最早由《Transforming auto-encoders》提出,并且自从动态路由方法被提出以来就广为人知。MIND将胶囊引入推荐领域,并利用胶囊网络基于动态路由机制来捕获电商用户的多个兴趣,可以用于聚类clustering历史行为并提取多样化的兴趣。CARP首先从用户和item评论文档中抽取观点和aspect,并根据每个逻辑单元的组成观点和aspect推导出每个逻辑单元的representation,从而用于评分预测。
23.1 模型
序列推荐问题:假设有用户集合 、
item集合 。对于每个用户 ,我们有一个用户历史行为序列historical behaviors sequence(根据行为发生时间来排序) ,其中 记录用户 交互的第 个item。给定历史交互数据,序列推荐的问题是预测用户可能交互的下一个item。在实践中,由于对延迟和性能的严格要求,工业推荐系统通常会包含两个阶段,即
matching阶段和ranking阶段。matching阶段对应于检索top-N个候选item,而ranking阶段用于通过更精确的score对候选item进行排序。我们的论文主要聚焦于提高matching阶段的有效性。在本节的剩余部分,我们将介绍我们的可控多兴趣框架ComiRec,并说明ComiRec框架对于序列推荐问题的重要性。由于工业推荐系统的
item池通常由数百万甚至数十亿的item组成,matching阶段在推荐系统中起着至关重要的作用。具体而言,matching模型首先根据用户的历史行为计算user embedding,然后根据user embedding为每个用户检索候选item集合,最后借助于fast KNN算法从大规模item池中选择最近邻的item为每个用户生成候选集合。换句话讲,matching阶段的决定性因素是根据用户历史行为计算的user embedding的质量。现有的
matching模型通常使用RNN来计算用户的embedding,大多数只为每个用户生成一个embedding向量。但是单个embedding缺乏表达能力,因为单个embedding无法代表用户的多种兴趣。为此我们为序列推荐提出了一个多兴趣框架ComiRec,整体如下图所示:模型的输入是一个用户行为序列,其中包含一个
item ID列表,代表用户和item根据发生时间排序的交互。模型的输入都是
item ID,没有任何用户侧辅助信息,也没有任何item侧辅助信息,甚至也没有user ID。item ID被馈入embedding layer并被转换为item embedding。多兴趣抽取模块
multi-interest extraction module接收item embedding并为每个用户生成多个兴趣,然后这些兴趣可用于模型训练和serving。- 对于模型训练,将选择与目标
item embedding最近的兴趣embedding来计算sampled softmax损失。 - 对于模型
serving,每个兴趣embedding将独立检索top-N个最近邻的item,然后将其馈入聚合模块aggregation module。聚合模块通过平衡推荐准确性accuracy和多样性diversity的可控过程来生成整体的top-N个item。
- 对于模型训练,将选择与目标
有多种可选的方法用于构建多兴趣抽取模块,在本文中我们探索了两种方法:动态路由
dynamic routing方法和self-attention方法,对应的框架分别命名为ComiRec-DR和ComiRec-SA。ComiRec是基于interest-level来检索item,trigger为用户的各个兴趣。传统的Item CF是基于interest-level来检索item,trigger为用户的历史互动item。如果获取
interest则有各种不同的方法,因此本论文并没有多少创新点。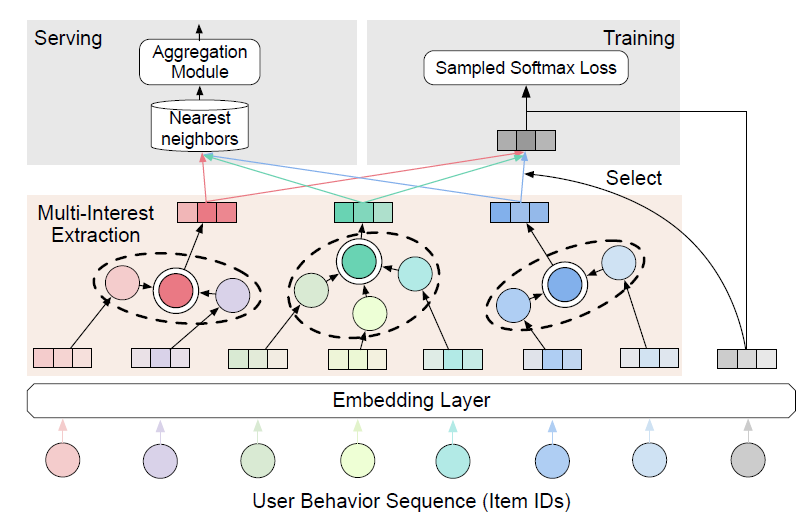
动态路由方法
Dynamic Routing:我们利用动态路由方法作为多兴趣抽取模块。用户序列的item embedding可以视为主胶囊primary capsules,多个用户兴趣可以视为兴趣胶囊interest capsules。我们使用CapsNet中的动态路由方法。这里我们简要介绍计算胶囊向量输入
vector inputs和向量输出vector outputs的动态路由。胶囊是一组神经元,其激活向量activity vectors代表特定类型实体(例如对象或者对象的一部分)的实例化参数instantiation parameters。胶囊向量的长度表示胶囊所代表的实体在当前输入条件下的概率。令 为primary layer中的胶囊 (它就是用户行为序列中第 个item的embedding),然后我们根据primary capsules来计算兴趣胶囊 。我们首先计算预测向量
prediction vector为: ,其中 为转换矩阵。然后兴趣胶囊 的总输入是所有预测向量 的加权和: ,其中 是由迭代式
iterative的动态路由过程所确定的耦合系数coupling coefficients。注意:
primary胶囊 和所有兴趣胶囊之间的耦合系数之和应该为1,即 。我们使用
routing softmax来计算耦合系数,并使用初始logits:其中 表示
primary胶囊 应该耦合到兴趣胶囊 的对数先验概率log prior probability。《Dynamic routing between capsules》提出了一种非线性squashing函数来确保短向量收缩到几乎为零的长度、长向量收缩到略低于1的长度。然后兴趣胶囊 的向量计算为:的计算是自依赖的,因此人们提出动态路由方法来解决这个问题。整个动态路由过程如下述算法所示。然后用户 的输出兴趣胶囊构成矩阵 从而用于下游任务。
动态路由算法:
输入:
primary capsules- 迭代次数
- 兴趣胶囊数量
输出:兴趣胶囊
算法步骤:
对于每个
primary胶囊 和每个兴趣胶囊 ,初始化 。迭代:,执行:
对每个
primary胶囊 ,计算 。对每个兴趣胶囊 ,计算 。
对每个兴趣胶囊 ,计算 。
对每个
primary胶囊 和每个兴趣胶囊 ,更新 :
返回 。
self-attention方法:self-attention方法也可以应用于多兴趣抽取模块。给定用户行为的
embedding,其中 为用户 行为序列的长度,我们使用self-attention机制获得权重向量 ,该权重向量代表用户行为的注意力权重:其中 和 为可训练的参数。
我们根据注意力权重
sum用户行为embedding,从而得到用户的向量representation: 。我们将可训练的
positional embeddings添加到输入embedding中,从而利用用户行为序列的顺序order。positional embedding和item embedding具有相同的维度 ,二者可以直接相加。为了表示用户的整体兴趣,我们需要从用户行为序列中得到聚焦于不同兴趣的多个 。因此,我们需要执行多次
attention。为此我们将 扩展为矩阵 ,因此attention权重向量变成一个attention矩阵 :最终的用户兴趣矩阵 为:
其中 为 的第 列,表示用户的第 个兴趣。
模型训练:在通过多兴趣抽取模块计算用户行为的兴趣
embedding之后,我们使用argmax算子为target item选择相应的用户兴趣embedding向量:其中 表示
target item的embedding。给定一个训练样本 ,我们可以计算用户 和
item交互的可能性为:模型的目标函数是最小化以下负对数似然:
其中 为用户 交互的
item集合。由于计算 的代价昂贵,因此我们使用
sampled softmax technique来训练我们的模型。online serving:对于在线serving,我们使用我们的多兴趣抽取模块来计算每个用户的多个兴趣。用户的每个兴趣向量都可以通过最近邻library(如Faiss)从大规模item池中独立检索top-N个item。由多个兴趣检索的item被馈送到聚合模块中,以确定整体的item候选。最后,在ranking模块中ranking score较高的item被推荐给用户。聚合模块
Aggregation Module:在多兴趣抽取模块之后,我们根据用户的历史行为从而为每个用户获取多个兴趣embedding。每个兴趣embedding可以根据内积邻近性独立检索top-N个item。但是,如何将这些来自不同兴趣的item聚合起来,从而得到整体的top-N个item?一种
basic且直接的方法是根据item和用户兴趣的内积邻近性来合并merge和过滤item,这可以形式化为:其中 为用户 的第 个兴趣
embedding。这是聚合过程最大化推荐准确性
accuracy的有效方法。但是,当前推荐系统不仅仅关注准确性,还关注多样性。这个问题可以形式化为:给定用户 的 个兴趣中检索到的 个item的一个集合 ,目标是找到一个包含 个item的集合 使得预定义的价值函数最大化。我们的框架使用一个可控的过程
controllable procedure来解决这个问题。我们使用以下价值函数 通过可控因子controllable factor来平衡推荐的准确性和多样性:其中 为多样性函数(或者不相似性函数),定义为:
其中
cat(i)为item的类目, 为示性函数。- 如果追求准确性
accuracy,即 ,则我们使用上面简单的方法获取整体的item。 - 如果追求多样性,即 ,则可控模块
controllable module为用户找到最多样化的item。
我们提出了一种贪心推断算法来近似最大化值函数 ,如下述算法所示。
最后,我们在实验中研究了可控因子。
- 如果追求准确性
贪心推断
Greedy Inference算法:输入:
- 候选
item集合 - 输出
item数量
- 候选
输出:
item集合算法步骤:
初始化 。
迭代 ,迭代步骤为:
返回 。
和已有模型的关联:我们将我们的模型和现有模型进行比较。
MIMN:MIMN是ranking阶段的近期代表性工作,它使用memory网络从长的序列行为数据中捕获用户兴趣。MIMN和我们的模型都是针对用户的多种兴趣。对于非常长的序列行为,memory-based架构也可能不足以捕获用户的长期兴趣。和MIMN相比,我们的模型利用多兴趣抽取模块来利用用户的多种兴趣,而不是一个具有memory utilization正则化和memory induction unit的复杂memory网络。MIND:MIND是matching阶段的近期代表性工作,它提出了一种行为到兴趣Behavior-to-Interest: B2I的动态路由,用于自适应地将用户的行为聚合到兴趣representation向量中。和MIND相比,ComiRec-DR沿用了CapsNet使用的原始动态路由方法,可以捕获用户行为的序列信息。我们的框架还探索了一种用于多兴趣抽取的self-attention方法。此外,我们的框架还利用可控聚合模块来平衡基于用户多种兴趣的推荐准确性和多样性。
23.2 实验
这里我们对序列推荐进行实验,以验证我们框架和其它
SOA方法相比的性能。此外,我们还报告了我们框架在十亿级工业数据集上的实验结果。我们在强泛化
strong generalization下评估所有方法的性能。我们将所有用户按照8:1:1的比例分为训练集、验证集、测试集。我们使用训练用户的完整点击序列来训练模型。为了评估,我们从验证用户和测试用户中获取每个用户前80%的行为,以从训练好的模型中推断用户embedding,并通过预测剩余的20%的行为来计算指标。这种设置比弱泛化weak generalization更困难,弱泛化指的是用户行为序列同时用于训练和评估。具体而言,我们采用了训练序列推荐模型的通用设置。设用户 的行为序列为 。每个训练样本使用 的前 个行为来预估第 个行为,其中 。
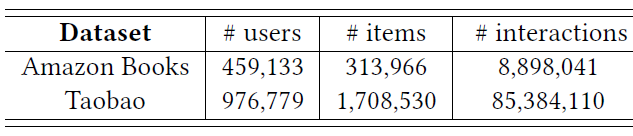
数据集:我们在两个具有挑战性的公共数据集上进行了实验,这些数据集的统计数据如下表所示。
Amazon数据集:包含来自Amazon的商品评论和元数据。在我们的实验中,我们使用Amazon Book子集。每个训练样本的用户行为序列被截断为长度20。Taobao数据集:包含来自淘宝推荐系统中收集的用户行为。在我们的实验中,我们仅使用点击行为并按时间对单个用户的所有行为进行排序。每个训练样本的用户行为序列被截断为长度50。
baseline方法:我们将我们提出的模型ComiRec-SA/ComiRec-DR和SOA的模型进行比较。在我们的实验设置中,模型应该为验证集和测试集中的、训练期间未见过的用户提供预测,因此基于分解的方法不适合这种设置。MostPopular:是一种传统的推荐方法,向用户推荐最后热门的item。YouTube DNN:是工业推荐系统最成功的深度学习模型之一。GRU4Rec:是第一个为推荐引入循环神经网络的工作。MIND:是与我们模型相关的、最新的、SOA的模型。它基于胶囊路由机制设计了一个多兴趣抽取器层multi-interest extractor layer,适用于对历史行为进行聚类clustering并抽取不同的兴趣。
实现:我们的实验是基于
TensorFlow 1.14以及Python 3.6。一些关键的超参数为:embedding维度 ,sampled softmax loss的样本数为10,最大训练迭代次数设置为100万次,多兴趣模块的兴趣embedding数量设置为K = 4。我们使用学习率0.001的Adam优化器进行优化。评估指标:我们使用以下三个常用指标来评估我们提出的模型的性能。
召回率
Recall:为了更好的可解释性,我们使用user粒度的均值而不是全局均值:其中 为用户 的
top-N推荐item集合, 为用户 的测试item集合。命中率
Hit Rate: HR:HR衡量推荐item中包含至少一个用户交互的、正确的item的比例,这在以前的工作中被广泛使用:其中 为示性函数。
Normalized Discounted Cumulative Gain: NDCG:NDCG考虑到了正确推荐item的位置:其中 为用户 推荐列表中的第 个
item。 为归一化常数,表示Ideal Discounted Cumulative Gain: IDCG@N,它是DCG@N的最大可能值。
为了和其它模型进行公平地比较,我们在聚合模块中设置 (从而追求准确性)。所有模型在公共数据集上的序列推荐性能如下表所示,粗体是每列的最佳性能,表中所有数字均为百分比数字(省略了
%)。可以看到:- 我们的模型在所有评估指标上都大大优于所有
SOA的模型。 GRU4Rec的性能优于其它仅为每个用户输出单个embedding的模型。- 和
MIND相比,由于动态路由方式的不同,ComiRec-DR获得了更好的性能。 ComiRec-SA展示了通过self-attention机制捕获用户兴趣的强大能力,并获得了与ComiRec-RD相当的结果。
注意:
MIND检索top-N titem的方式和ComiRec相同。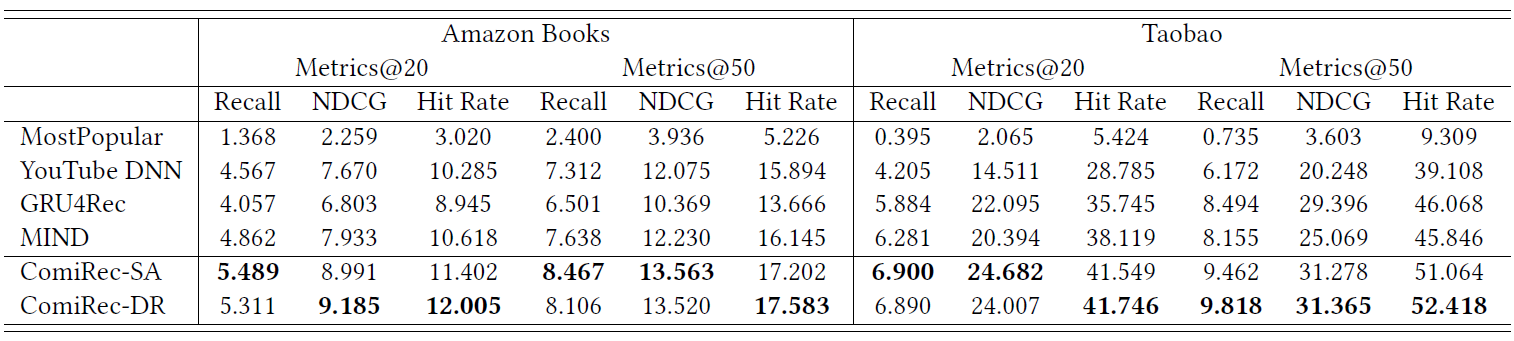
- 我们的模型在所有评估指标上都大大优于所有
参数敏感性:我们研究了兴趣数量 的敏感性。下表说明了当 改变时,我们框架的性能,粗体是每列的最佳性能,表中所有数字均为百分比数字(省略了
%)。可以看到:这两个模型显示出了对超参数 的不同属性。- 对于
Amazon数据集:ComiRec-SA在K=2 or 6时性能最好,而ComiRec-DR在K=4时性能最好。 - 对于
Taobao数据集:当K从2增加到8时ComiRec-DR性能越来越好,但是ComiRec-SA在K=2时性能最好。
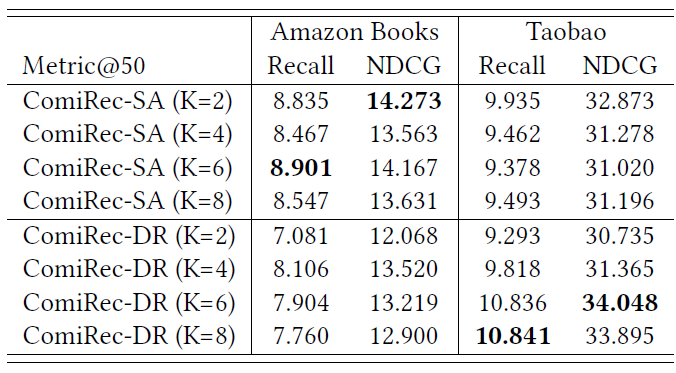
- 对于
可控性研究:推荐多样性在当前的推荐系统中扮演着更重要的角色,许多研究目标是提高推荐多样性
diversity。我们提出的聚合模块可以控制推荐准确性和多样性的平衡。我们使用以下基于
item类目的个体多样性individual diversity定义:其中
cat(i)为item的类目, 为对用户 推荐的第 个item, 为示性函数。下表展示了当我们控制因子 以平衡推荐质量和多样性时,
Amazon数据集的模型性能。粗体是每列的最佳性能,表中所有数字均为百分比数字(省略了%)。可以看到:当可控因子 增加时,推荐多样性显著增加,召回率略有下降。这充分证明了:我们的聚合模块可以通过为超参数 选择合适的值从而实现准确性和多样性之间的最佳trade-off。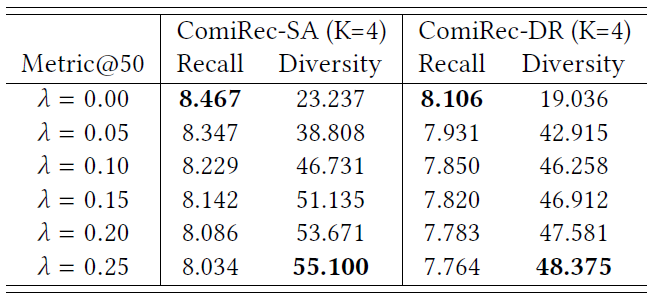
工业数据集:我们在
2020年2月8号手机淘宝App采集的工业数据集上进行了进一步实验,数据集的统计数据如下表所示。工业数据集包含2200万个优质item、1.45亿用户、40亿条user-item交互。
我们的框架已经部署在阿里巴巴分布式云平台上,其中每两个
worker共享一个具有16GB内存的NVIDIA Tesla P100 GPU。我们拆分用户为训练集、验证集、测试集,并使用训练集用户的点击序列来训练我们的模型。为了进行评估,我们使用我们的模型来计算测试集中每个用户的多个兴趣。用户的每个兴趣向量通过fast KNN方法独立地从大规模item池中检索top-N个item。由不同用户兴趣检索的item被馈入到我们的聚合模块。在聚合模块之后, 个item中的top-N个item是最终候选item,用于计算评估指标recall@50。我们在我们的框架和
SOA的序列推荐方法MIND之间进行了离线实验,结果表明我们方法的显著提升:和MIND相比,我们的ComiRec-SA和ComiRec-DR分别将Recall@50提高了1.39%和8.65%。ComiRec并未进行在线A/B test实验。案例研究:下图给出了一个电商用户的案例研究。通过我们的模型,我们从用户的点击序列中生成四个兴趣
embedding,代表四种不同的兴趣。我们发现用户的四个兴趣是关于糖果、礼品盒、手机壳、配件。- 左图展示了用户点击行为序列中,分别与这四个兴趣相对应的点击
item。 - 右图展示了通过兴趣
embedding从工业item池中检索到的item。
值得注意的是,我们的模型仅使用
item ID进行训练,并没有使用人工定义的item类目信息。尽管如此,我们的模型仍然可以从用户行为序列中学习item类目。 我们的模型学习到的每个兴趣大约对应于一个特定类目,并且可以从大规模工业item池中检索同一类目的相似item。
- 左图展示了用户点击行为序列中,分别与这四个兴趣相对应的点击
二十四、EdgeRec[2020]
互联网上可用的信息(如电影、商品、新闻等等)的爆炸性增长和多样性经常让用户不知所措。推荐系统是处理信息过载问题的一种有价值的手段,它从海量候选中选择一个
item列表,以满足用户的多样化需求。在商业推荐系统的大部分场景中,尤其是在手机上,推荐的
item都是以瀑布流的形式waterfall form展示。如下图所示,大部分瀑布流式的推荐系统都是基于cloud-to-edge框架来部署的。当用户在瀑布流式推荐场景中滚动时,移动客户端mobile client首先向云服务器发起分页请求paging request。然后在云服务器上serving的matching模型和ranking模型响应分页请求并生成显示给用户的ranking item列表。在这种情况下,当前的基于cloud-to-edge的瀑布式推荐系统存在以下局限性:系统反馈延迟
Delay for System Feedback:由于cloud-to-edge框架中的分页机制,云端推荐系统无法在相邻的两个分页请求之间及时调整推荐结果,无法进一步满足用户不断变化的需求。以下图为例,用户点击了当前页面第
5个位置的一件衣服,这反映了用户对衣服类目的突然偏好sudden preference。然而,云端推荐系统无法响应,除非用户滚动到下一页,因此无法及时满足用户的需求、降低了用户体验。用户感知延迟
Delay for User Perception:对于服务于云端的推荐模型,由于网络延迟,捕获用户行为存在长达1分钟的延迟,因此它们在响应edge时无法对用户的实时偏好进行建模。以下图为例,用户对页面第
49个位置上item的行为表明该用户目前对收音机的偏好,但是云端的推荐系统无法在下一页推荐类似的收音机,因为云端推荐系统没有及时接收到这些行为。此外,网络带宽进一步限制了当前推荐系统在edge捕获多样的diverse、详细detailed的用户行为。
综上所述,云端推荐系统的局限性在于推荐结果的延迟调整导致无法匹配
edge端用户偏好的实时变化,从而严重损害了商业推荐系统的用户体验。缺陷:实时性不足。除非用户滚动到下一页,否则客户端不会请求新的推荐
list;即使客户端请求新的推荐list,但是云端推荐系统无法及时处理实时用户行为。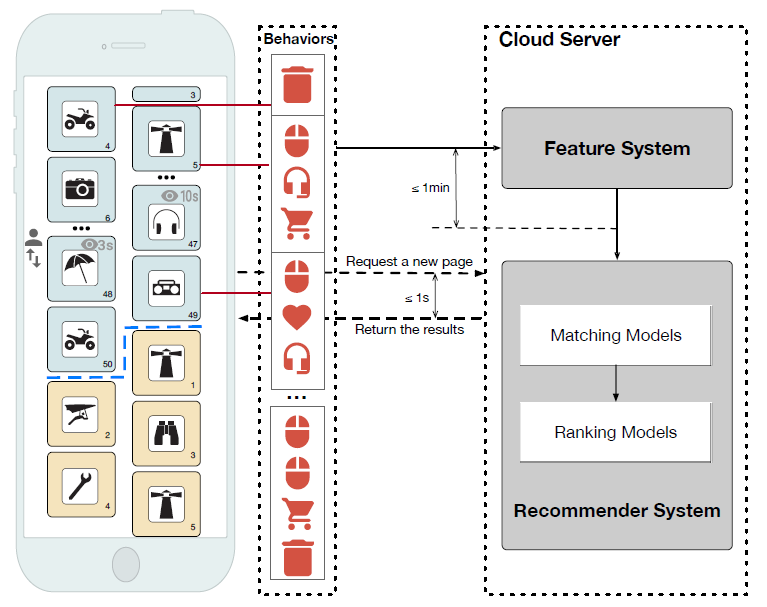
边缘计算
edge computing非常适合需要高实时性能的application,并且有可能解决当前基于cloud-to-edge框架的推荐系统的上述问题。在论文《EdgeRec: Recommender System on Edge in Mobile Taobao》中,论文率先设计并实现了一个新颖的边缘推荐系统recommender system on edge: EdgeRec,该系统实现了实时用户感知Realtime User Perception和实时系统反馈Real-time System Feedback,而无需向云服务器发出额外请求。论文的主要贡献如下:
系统架构
System Architecture:论文设计了EdgeRec架构来在移动设备上进行reranking,与提供候选item的云端推荐系统协作。系统实现
System Implementation:EdgeRec支持大规模神经网络模型,通过跨edge和cloud之间分配模型,考虑了移动设备上的高效计算和存储。用户行为建模
User Behavior Modeling:论文提出异质用户行为序列建模Heterogeneous User Behavior Sequence Modeling来捕获用户不断变化的行为和动作。论文首先设计新颖的特征系统,然后同时考虑交互的
item及其相应的动作,从而同时对user和item之间的正反馈和负反馈进行建模。基于EdgeRec,特征系统中多样化diverse的、详细detailed的用户行为在edge端被收集、存储、和消费,这些行为可以实时馈入模型中。特征体系创新:使用了更多的用户行为特征,不仅仅是点击/转化行为。
1> 行为建模创新:将 `item` 序列和行为序列分别独立建模,从而获取 `item representation` 和行为 `representation` 。理论上讲,分别独立建模降低了模型复杂度。因为将 `item` 序列和行为序列作为 `(item, action)` 一起来建模,相当于引入了交叉特征,而交叉特征会扩大模型容量。
上下文感知重排
Context-aware Reranking:论文提出使用带行为注意力网络的上下文感知重排Context-aware Reranking with Behavior Attention Network,从而在edge端重排reranking。具体而言,论文通过提出的行为注意力机制对候选
item和实时用户行为上下文之间的交互进行建模。依靠基于EdgeRec的edge reranking能力,EdgeRec实现了实时响应以满足用户的需求。
作者对淘宝首页 feeds 的真实流量进行了广泛的离线和在线评估。定量和定性分析都证明了论文提出的 EdgeRec 系统的合理性和有效性。此外,EdgeRec 在在线 A/B test 中贡献了高达 1.57% 的 PV 提升、7.18% 的 CTR 提升、8.87% 的 CLICK提升、10.92% 的 GMV 提升,这对当前的淘宝推荐系统带来了重大改进。现在 EdgeRec 已经上线部署,并服务于主要流量。
24.1 模型
24.1.1 系统
这里我们介绍
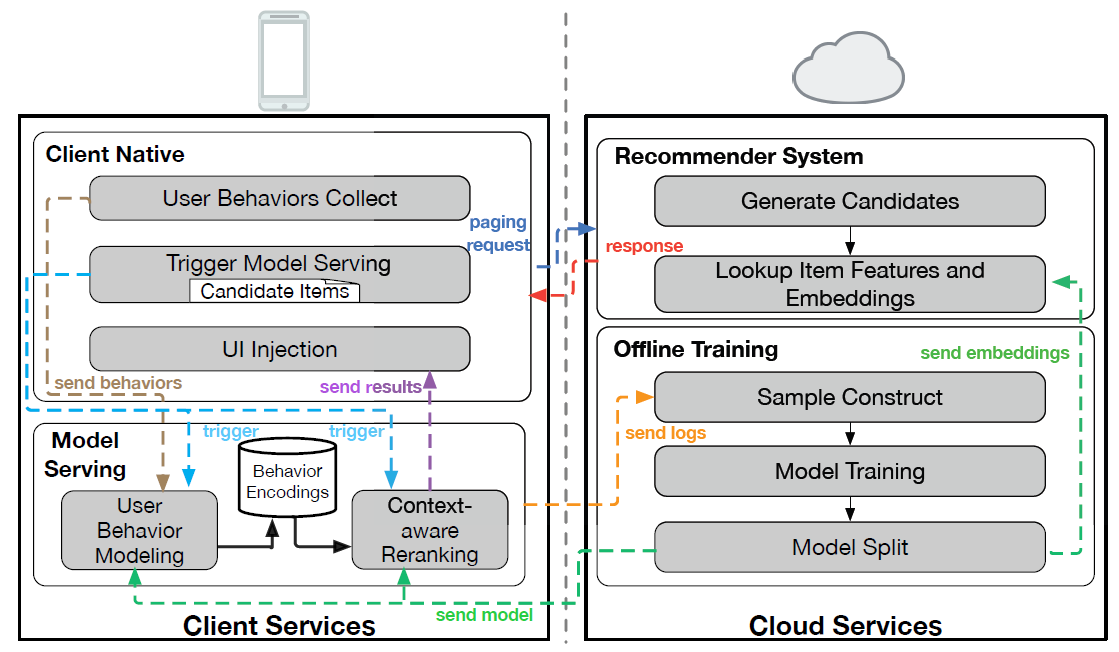
EdgeRec系统,该系统旨在及时捕获丰富的用户行为(即实时感知Real-time Perception)并及时响应用户的需求(即实时反馈Real-time Feedback),而无需向云服务器发出任何额外请求。我们首先概述EdgeRec系统,然后详细说明每个设计良好的模块的实现。系统概述:在下图中我们展示了
EdgeRec系统的概况,其中左侧模块部署在手机淘宝客户端,右侧模块部署在云端。。注意,EdgeRec旨在和云端的推荐系统协作,而不是取代后者。主要的模块和工作流程如下:本地客户端
Client Native: CN:本地客户端首先发起分页请求
paging request,并缓存推荐系统服务器返回的、具有相应特征的候选item。服务器不仅返回推荐的
item list,还返回这些item对应的特征。EdgeRec中分页大小设置为50,为了稳定性,这和淘宝中原始推荐系统的取值一样。同时,从推荐系统服务器返回的item数量设置为100,以便为移动设备上的reranking提供更多空间。然后,本地客户端收集用户对曝光
item的行为并触发model serving模块。从
model serving模块接收到候选item(尚未曝光的)的排名之后,本地客户端调整item的UI显示。
model serving: MS:是EdgeRec系统的核心模块。当model serving被本地客户端触发时:- 首先
model serving对从本地客户端接收到的用户行为和候选item进行特征工程。 - 然后通过基于神经网络的模型,其目的是用户行为建模从而捕获及时的用户行为和上下文感知的
reranking,从而及时响应用户。 - 最后,
model serving将日志发送到云端(为了后续离线模型训练),并将候选item的排名结果返回给本地客户端。
- 首先
Recommender System on server:可以视为EdgeRec中的召回模块,其目的是响应来自本地客户端的分页请求,为候选item提供初始排名。此外,它可以在响应本地客户端之前,从云上的
key-value存储中为候选item查找model serving模块中模型需要的item特征和embedding(例如category embedding)。离线训练
Offline Training: OT模块:- 首先从
model serving收集日志并在模型训练之前构建样本。 - 接下来,训练好的模型被分为三个部分:用户行为建模
User Behavior Modeling的子模型、上下文感知重排Context-aware Reranking的子模型、embedding矩阵(如类目和品牌)。 - 最后,前两个子模型都部署在
model serving模块上,而embedding矩阵作为key-value形式存储在云端。
- 首先从
接下来我们介绍
EdgeRec系统中两个关键模块的实现细节:本地客户端和model serving模块。本地客户端
Client Native: CN:本地客户端一个关键部分是在手机淘宝推荐系统中收集客户端上用户丰富的行为,例如浏览记录、点击记录(更详细的行为在后面会讲到)。这些用户行为随后被存储在设备的数据库中。由于
EdgeRec模型(即Model Serving)的运行是由本地客户端触发的,因此另一个关键的部分是触发model serving的策略。这里我们根据用户的在线实时行为设置了几个触发点trigger points:用户点击了一个item、用户删除了一个item(即长按)、K个item已经曝光但是没有点击。我们认为这三种类型的用户行为揭示了用户在当前推荐系统上的偏好,推荐系统应该及时响应用户(即触发Model Serving)。根据业务规则来设定
trigger。Model Serving:在移动设备上的深度神经网络model serving相比较于传统的云服务面临着许多挑战,例如计算开销和存储开销。EdgeRec模型有两个关键实现,分别针对计算效率和存储效率。其思想是跨edge和cloud来分布模型,这使得EdgeRec支持在移动设备上为推荐系统提供大规模神经网络的serving。计算效率
Computing Efficiency:用户行为建模User Behavior Modeling和上下文感知重排Context-aware Reranking一起训练,但是单独部署并在设备上异步运行。用户行为建模使用
RNN-based序列建模方法,如果它总是从一开始就进行推断(即具有 时间复杂度),那么效率低得多。因此,它通过RNN的循环特性recurrent characteristic(即时间复杂度为 )与用户的online incoming behaviors一起被实时独立推断independently inferred,并产生行为编码behavior encoding。该编码被存储在设备上的数据库中。上下文感知重排将首先从数据库中检索行为编码,然后基于这些行为编码进行模型推断。存储效率
Storage Efficiency:ID类型的特征在推荐模型中很常见而且很重要,我们总是利用embedding技术来转换它们。然而,当在移动设备上serving时,ID embedding面临存储效率的挑战。例如,我们模型中的item品牌是一个ID特征,字典大小大约为150万。当ID通过embedding层转换为维度40的embedding向量时,embedding矩阵的大小为150万 x 40(即大约230MB)。当部署在移动设备上时,具有如此大embedding矩阵的模型将面临存储开销的问题。在
EdgeRec系统中,我们从训练好的模型中提取embedding矩阵以部署在云端的key-value数据库中。当服务器上的推荐系统响应来自本地客户端的分页请求时,这些embedding矩阵将被相应的item检索,并作为item特征发送到客户端。移动设备上的、没有embedding层的剩余模型部分(大约3MB)将把embedding特征作为输入,然后进行模型推断。
此外,我们设计了一个模型版本策略
model version strategy来确保模型更新时的同步,因为在移动设备上成功部署模型可能比在云端部署模型(即embedding矩阵)有更大的延迟,这取决于用户移动设备的当前状态(如,是否连接到wifi、是否连接到3G/4G/5G)。在EdgeRec系统中,我们将为每个训练好的模型生成一个唯一的版本ID。该版本ID与部署在移动设备上的模型、以及存储在云端的embedding矩阵一起保存。本地客户端首先在设备端用模型版本号发起分页请求,然后云端推荐系统获取模型版本号,检索对应版本的embedding矩阵,再响应客户端。版本
ID用于确保模型各组件的一致性。这也意味着需要在云端部署多套embedding(因为可能有的手机客户端未能更新到最新的模型)。
24.1.2 算法
这里我们介绍了用于用户行为建模和上下文感知重排的特征系统和方法。
我们提出的
EdgeRec系统旨在将reranking方法应用于edge targeting waterfall flow推荐场景。给定云端现有推荐系统生成的、缓存在edge端的初始排序item列表 ,对于本地客户端模块触发的model serving模块中的reranking请求 ,我们的目标是找到一个评分函数 ,其中: 为目标item的特征, 为来自初始模型的本地排序上下文local ranking context(从 抽取而来), 为当前推荐环境中的实时用户行为上下文real-time user behavior context(从本地客户端上用户行为序列抽取而来)。这里本地排序上下文指的是推荐系统服务器返回的候选
item列表。考虑本地排序上下文的
reranking模型在以前的工作中已经得到了很好的研究。并且本地排序上下文表示为初始排序候选item之间的list-wise交互,其可以由RNN或者Transformer建模。但是,我们认为实时用户行为上下文对于reranking问题也很重要,尤其是在瀑布推荐场景中,而之前很少有工作考虑过它。接下来我们将介绍如何使用异质用户行为序列建模实时用户行为上下文,以及如何使用行为注意力网络
Behavior Attention Network的上下文感知重排Context-aware Reranking来建模候选item和实时用户行为上下文之间的交互。通过结合边缘计算edge computing系统和上下文感知重排模型,我们可以在推荐系统中实现实时感知Real-time Perception和实时反馈Real-time Feedback,更好地满足用户的在线多样化需求。EdgeRec系统的整体架构如下图所示。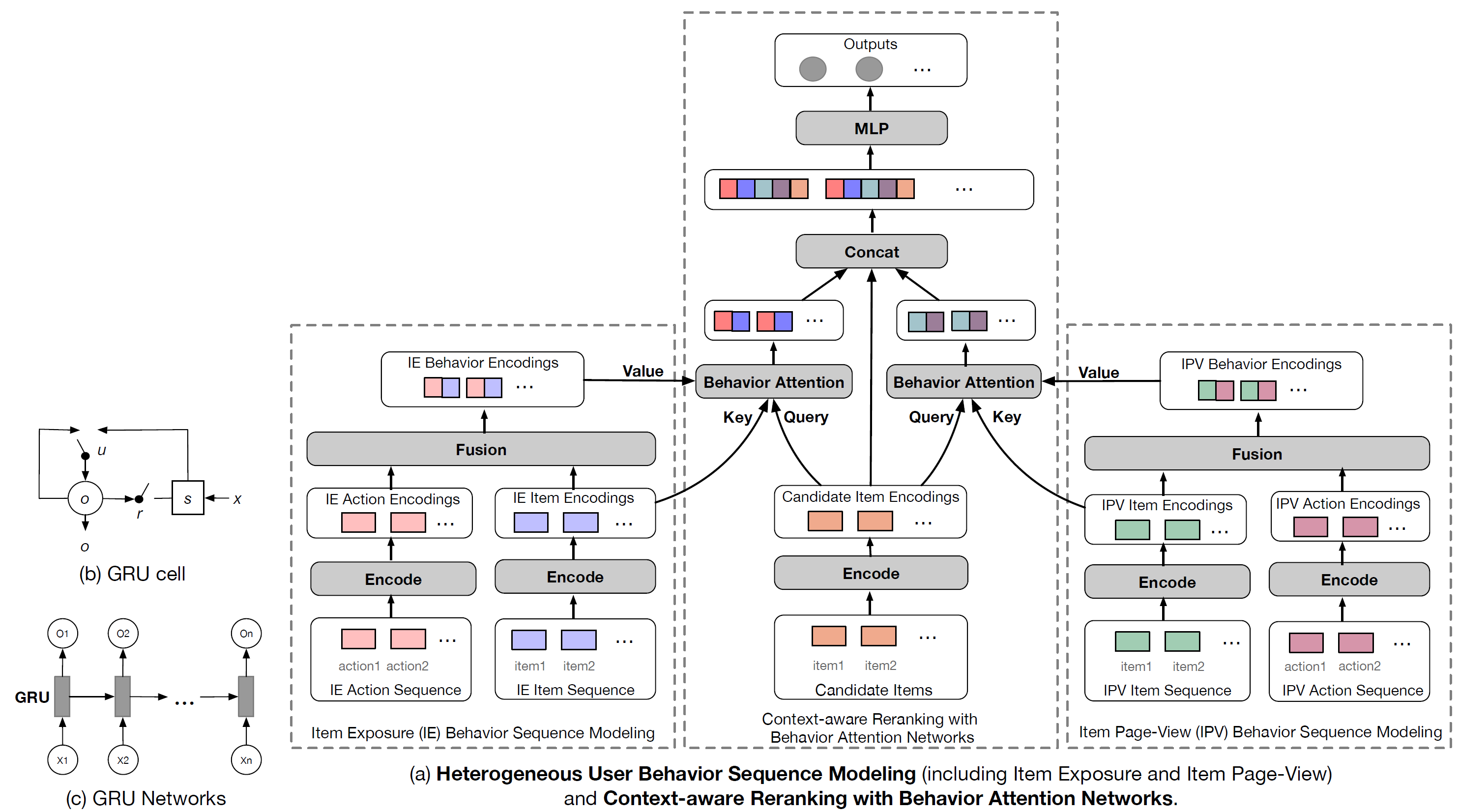
a. 特征系统
这里我们首先讨论我们的特征系统
feature system,然后介绍item曝光上、以及item详情页上的详细用户操作特征以及相应的item特征。洞察
insight: 在个性化搜索和推荐系统的文献中,用户的行为通常被建模从而表征用户的个性化偏好。因此,这些模型仅考虑用户和item之间的直接 “正反馈”positive feedback(例如点击或交易),很少关注间接“负反馈”negative feedback(如跳过或删除)。虽然正反馈相对更清晰、噪音更小,但是实时的负反馈也很重要,尤其是在瀑布流推荐系统中。以在线淘宝推荐系统为例,一个item类目实时多次曝光之后,如果继续曝光该类目的item那么点击率CTR会显著下降。另一方面,以前的工作仅考虑与用户交互的
item的特征(如,类目、品牌)。然而,用户对item的“动作”action也应该受到关注。例如,用户点击一个item之后,其详情页(称作item page-view)中的操作(例如,添加到收藏夹、添加到购物车)反映了用户对该item的真实偏好。此外,尽管用户没有点击某个item,但是对该item曝光的操作(例如滚动速度和曝光)可以代表该item被视为“负反馈” 的程度。有时,如果用户长时间聚焦于某个item曝光而没有点击它,这并不能绝对表明用户不喜欢该item。在目前瀑布流推荐系统中,item展示的信息量越来越大,例如图片更大、关键词更多、甚至自动播放视频,因此点击已经成为一些用户非常“奢侈”的正反馈。最后,基于我们提出的
EdgeRec系统,所有的用户行为特征都在edge(即用户的移动设备)上收集、抽取、和消费。与当前的基于cloud-to-edge的推荐系统相比,这有可能突破网络延迟和带宽的限制。因此,可以结合丰富的、详细的用户行为以更实时的方式推断用户偏好。此外,在用户自己的移动设备上处理和利用用户的原始行为,可以在一定程度上缓解用户数据隐私问题。总而言之,我们工作中的特征系统是新颖的,并且从 “仅依赖正反馈交互” 到 “同时关注正负反馈交互”,从“仅关注交互
item” 到 “同时考虑交互的item及其相应的动作”, 从“准实时方式” 到 “超实时方式”。item曝光用户行为特征Item Exposure User Action Feature:item曝光Item Exposure: IE用户行为揭示了用户在推荐系统当前展示页面中的item曝光上的行为。下图(a)说明了手机淘宝瀑布流推荐系统中的item曝光。
相应用户行为特征可以分类为(下表给出了更详细的细节):
item曝光统计信息(e1~e2)、用户滚动统计信息(e3~e5)、用户删除反馈信息(e6)、时间衰减(e7)。这里我们将item对应的e1 ~ e7拼接起来,作为item的曝光行为特征向量exposure action feature vector。下表中,
e1 ~ e7为item曝光用户行为特征,d1 ~ d12为item详情页用户行为特征,p1~p7为item特征。
item详情页用户行为特征Item Page-View User Action Feature:Item Page-View: IPV用户行为揭示了用户在点击item后在item详情页中的行为。上图(b)说明了手机淘宝中的item详情页,并且相应用户行为特征可以分类为(下表给出了更详细的细节):item详情页统计信息 (d1)、每个区域是否点击(d2 ~ d11)、时间衰减(d12)。这里我们将item对应的d1 ~ d12拼接起来,作为item的详情页行为特征向量page-view action feature vector。item特征Item Feature:除了用户行为特征,我们还需要相应item的特征。item特征可以分类为:离散特征(p1~p6,它们将学习embedding)、从base ranking模型提供的原始特征 (p7)。这里我们将item对应的p1 ~ p7拼接起来,作为item的item feature vector。
b. 异质用户行为序列建模
这里我们将介绍如何对定义为 的实时用户行为上下文
real-time user behavior context进行建模。根据以前的工作,我们也应用序列建模方法。然而,之前的工作仅考虑用户的positive交互item,正如我们前面所讨论的,因此他们不能很好地处理基于我们提出的特征系统的用户行为序列建模。挑战来源于用户行为数据存在两个方面的异质性heterogeneity。因此在我们的工作中,我们提出了异质用户行为序列建模Heterogeneous User Behavior Sequence Modeling: HUBSM,具体而言是针对以下两个异质性:第一个异质性是
item曝光行为和item详情页行为的异质性。由于和item曝光行为相比,item点击行为要稀疏得多(item详情页就是点击之后带来的),如果曝光行为和点击行为以一个序列编码在一起,那么我们相信item曝光行为将占据主导地位。所以我们选择分别对item曝光行为和item详情页行为进行建模,即Item Exposure Behavior Sequence Modeling和Item Page-View Behavior Sequence Modeling。Item曝光行为刻画的是用户的负向意图,而Item详情页行为刻画的是用户的正向意图。所以在构建特征体系的时候,Item曝光用户行为特征描述了哪些行为能够体现用户的 “不喜欢”,Item详情页用户行为特征描述了哪些行为能够体现用户的 “喜欢”。第二个异质性是用
user behavior action和对应的user interacted item的异质性,这代表了两种特征空间。用户行为动作特征揭示了用户在item上行为的分布,而item特征代表了item属性的分布。我们选择首先对用户行为动作和用户交互
item进行独立编码,然后在接下来的上下文感知重排模型中进行关于行为注意力机制Behavior Attention mechanism的融合。
曝光行为和点击行为分开独立建模可以理解,但是将动作序列和
item序列分开独立建模好像讲不通?只有动作、而没有被作用的item无法刻画用户的偏好,只有动作和item结合在一起才能完整地刻画用户偏好。因此第二个异质性是否不成立?item曝光行为序列建模:我们将Item Exposure动作特征向量输入序列定义为 ,对应的item特征向量输入序列为 。其中 为Item Exposure行为序列的预定义最大长度,对于较短的序列我们用零来填充。通过以下方程我们得到了动作编码输出序列 、
item编码输出序列 、融合的行为编码输出序列 :其中 为编码后的动作特征向量、
item特征向量、融合行为向量。item详情页行为序列建模:我们将Item Page-View动作特征向量输入序列定义为 ,对应的item特征向量输入序列为 。其中 为Item Page-View行为序列的预定义最大长度,对于较短的序列我们用零来填充。通过以下方程我们得到了动作编码输出序列 、
item编码输出序列 、融合的行为编码输出序列 :其中 为编码后的动作特征向量、
item特征向量、融合行为向量。如前所述,在
item曝光行为序列建模和item详情页行为序列建模中,对于户行为动作、用户交互item,我们都采用常用的gate recurrent unit: GRU作为我们的编码器函数。我们用多层GRU网络定义序列编码器函数为:其中 为输入序列, 为编码的输出序列, 为
RNN的最终状态。我们采用向量拼接来作为融合函数
fusion function,即:其中 为编码后的动作特征向量, 为编码后的
item特征向量, 为融合后的特征向量。当然,这里可以采用更复杂的编码模型(例如
Transformer),也可以采用更复杂的融合函数(例如DNN)。考虑到移动设备上模型的大小,我们在实现中分别使用了GRU和拼接。最终用户行为上下文 由两个元组构成: 。我们在
EdgeRec的设备上部署HUBSM。基于RNN的循环计算特性,我们对online incoming用户行为进行同步地、实时地建模,如前面内容所述。
c. 上下文感知重排
这里我们研究了我们的
reranking方法的细节,该方法称作行为注意力网络的上下文感知重排Context-aware Reranking with Behavior Attention Networks,以共同捕获local ranking上下文以及候选item,与实时用户行为上下文之间的交互。我们使用
GRU网络对由初始ranking模型排序的候选item序列进行编码,并将最终状态作为local ranking上下文 。借助于注意力技术,我们的reranking模型可以自动搜索与target item排序相关的用户行为上下文部分。以前的
CTR预估模型(如DIN和DUPN)仅学习与target item相关的attend用户历史交互item,因此它们无法基于上述注意力机制对用户行为动作进行建模。作为比较,我们的方法首先从用户行为上下文中attend相关的交互item(也就是找到相似的交互item),然后attentively结合相应的用户行为动作(这些用户行为动作表明用户对这些item的潜在意图),一起作为上下文表示从而指导target item预测。我们在这里称之为Behavior Attention,它特别地同时使用了item曝光行为上下文和item详情页行为上下文。简而言之,首先找到目标
item相似的用户交互item,然后找到对于该item的动作。Candidate Item Sequence Encoder:我们将候选item序列定义为 ,它是由推荐系统服务器中的prior模型生成和排序的。这里的 是候选item序列的预定义最大长度,对于较短的item序列我们使用零来填充。候选
item序列如何生成?猜测可能就是常规的ranking模型得到的。因此EdgeRec需要两套模型:一套是服务器端的常规ranking模型,另一个是EdgeRec模型。我们应用
GRU网络对其进行编码,并将RNN的最终状态表示为local ranking上下文,即:其中: 为候选
item编号后的embedding向量, 为local ranking上下文。因为服务器返回的是有序的
item list,所以这里用GRU网络来捕获序列关系。Behavior Attention:具体到编码为 的target候选item:我们首先分别关注
item曝光行为item编码序列 和item详情页item动作编码序列 。然后我们根据
Bahdanau注意力机制将将注意力分布表示为 以及 。即,计算曝光行为
item/ 详情页行为item和目标item的相似度。最后,我们通过结合注意力分布,以及用户行为序列的融合行为编码
fused behavior encoding和 ,从而生成用户行为上下文 和 。
具体而言,遵循
Transformer中的三元组(Query,Key,Value)的符号,我们在模型中定义 为Query、 为Key、 为Value。我们认为,这里的注意力计算是为了搜索相似或相关的item,因此比较的两个特征空间的representation应该是同质的。这就是为什么我们选择对user behavior actions和相应的user interacted items分别进行编码,并以用户行为item序列作为Key、target item作为Query。比较的两个特征空间也可以是异质的,可以通过一个参数矩阵映射到相同的空间中来。但是论文中的方法是否更好,可以通过实验来比较。
详细信息可以参考以下公式:
其中 为训练的参数。
模型学习:为了建模 ,我们首先简单地将
IPV、IE上的上下文(即 )、target候选的representation(即 )、local ranking上下文(即 )拼接起来,并将它们馈入多层感知机MLP中进行非线性变换,随后使用交叉熵损失进行模型训练。
24.2 实验
- 这里我们通过离线和在线评估,在真实的淘宝推荐系统数据集上验证了我们模型的有效性。
24.2.1 离线评估
数据集:我们从手机淘宝的
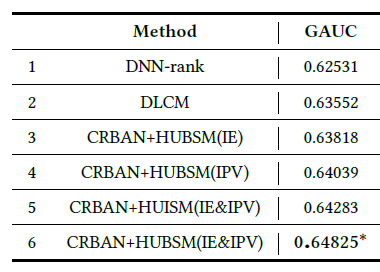
EdgeRec系统收集在线日志以及相应的item特征。具体而言,我们从两个不同日期(2019-11-14和2019-11-15)的日志中随机抽样,并将它们分为训练集(22072671个样本)和测试集(200000个样本)。此外,我们收集的数据集的Item曝光行为序列平均长度为56、Item详情页行为序列的平均长度为26。baseline方法:我们将我们的模型和两种在工业application中广泛应用的代表性方法进行比较,即DNN-rank和DLCM。为了检查我们提出的异质用户行为序列建模
HUBSM和使用行为注意力网络的上下文感知重排CRBAN的有效性,除了我们的完整方法CRBAN+HUBSM(IE&PV)之外,我们还准备了CRBAN的以下变体:CRBAN+HUBSM(IE):仅仅考虑Item曝光行为序列建模IE-BSM。CRBAN+HUBSM(IPV):仅仅考虑Item详情页行为序列建模IPV-BSM。CRBAN+HUISM(IE&IPV):尽管IE曝光行为序列和Item详情页行为序列都被考虑,但是使用DIN而不是HUBSM对用户行为上下文建模。DIN仅考虑历史行为序列和目标item相关性,没有利用到序列的顺序特性。
配置:我们使用
PAI支持的分布式Tensorflow训练模型,训练配置如下:batch size = 512、学习率为0.005、GRU隐单元数量为32、attention隐单元数量为32、MLP隐单元数量为32、优化器为Adam。注意:
DNN-rank和DLCM仅利用云端的特征,因为它们无法捕获edge特征。评估指标:
GAUC是一种广泛使用的推荐指标,通过对用户的AUC取平均。在我们的论文中,我们通过对EdgeRec系统中的本地客户端请求 取平均AUC来扩展GAUC,这可以视为一个reranking session,计算如下:其中: 为请求 的
item曝光量, 为请求 的AUC。不同方法的
GAUC性能如下表所示。这里*表示和baseline(DLCM) 相比,通过t-test在p-value=0.05的统计显著性提升。可以看到:
DLCM优于DNN-rank,这验证了将local ranking context纳入reranking模型的有效性。所有基于
CRBAN的方法都显著优于DLCM。特别地,我们的完整方法CRBAN+HUBSM(IE&IPV)实现了GAUC的2%的显著相对提升。这证明了在reranking模型中考虑实时用户行为上下文的优势。因此,如何对用户行为上下文进行建模是我们将在以下讨论中重点讨论的内容。为了验证我们提出的异质用户行为序列建模方法,我们将
HUBSM(IE&IPV)与HUBSM(IE)、HUBSM(IPV)进行了比较。结果表明:正反馈(即IPV)和负反馈(即IE)的用户行为都有助于对用户行为上下文进行建模。我们还发现
HUBSM(IPV)优于HUBSM(IE),这表明Item详情页用户行为可能比Item曝光用户行为更重要。最后,通过比较
HUBSM(IE&IPV)和HUISM(IE&IPV)的结果表明:通过同时考虑交互item及其相应action的行为注意力机制可以带来效果提升。
24.2.2 在线评估
在线
A/B test:我们在手机淘宝上部署的EdgeRec系统上进行了在线实验(A/B test)。在淘宝瀑布流推荐系统中,在线指标包括PV、CTR、CLICK、GMV,这些指标评估用户在推荐系统中查看(PV)、点击(CTR,CLICK)、购买(GMV)的意愿有多大。EdgeRec已经全面部署在手机淘宝application中,服务于数十亿用户。baseline(即A test)是没有EdgeRec的常规淘宝推荐系统。在这里,数百万不同的随机用户同时分别进行在线A/B test。在2019-10-26到2019-11-08近两周的测试中,拥有完整模型CRBAN+HUBSM(IE&IPV)的EdgeRec平均贡献高达1.57% PV、7.18% CTR、8.87% CLICK、10.92% GMV的提升。这绝对是一项重大的改进,并证明了我们提出的系统的有效性。此外,我们还回顾了淘宝推荐系统中不同展示位置
display position的在线平均item点击率。从下图可以看到:部署EdgeRec后,当前页面末尾的CTR会有很大的提升。这说明在推荐系统中加入实时感知和实时反馈可以大大提高用户的点击意愿,因为推荐系统能够及时满足用户的在线需求。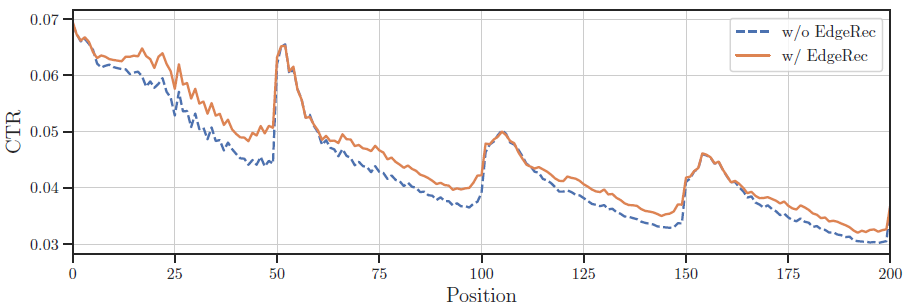
在线系统性能:除了在线
A/B test以展示生产中的业务效果之外,我们还在手机淘宝中进行了EdgeRec的效率测试,从三个关键方面揭示了部署EdgeRec后系统效率的显著提升。用户行为的延迟时间会影响系统捕获用户对
item个性化偏好的及时性,从而影响用户在推荐系统中的体验。由于网络带宽和延迟的限制,仅仅基于
cloud-to-edge框架的推荐系统可能会导致捕获用户行为的延迟时间长达1分钟。然而,部署Edge之后,用户行为可以在设备上被收集和消费,无需任何网络通信开销,这可以使延迟时间在300毫秒以内(例如,从设备上的数据库读取用户行为的时间)。系统的响应时间是影响推荐系统用户体验的另一个因素。当本地客户端随着用户在推荐系统场景中滚动并向系统发送请求时,系统应该及时响应并将已排序的
item提供给用户,否则用户将等待并可能导致用户离开。由于为淘宝上亿用户提供如此复杂的推荐系统模型的计算开销,仅基于云端计算的推荐系统可能会导致包括网络传输在内的
1秒的响应时间。而在EdgeRec中,model serving在每个用户的移动设备上,解决了集中计算开销的问题,使得响应时间在100毫秒以内,无需任何网络通信。系统对用户的平均反馈次数是影响推荐系统用户体验的另一个关键因素。它反映了当用户在推荐系统中浏览时,系统可以调整向用户展示的
item排名的频率。系统调整结果的频率越高,就越能够满足用户在推荐系统中的各种需求。然而,没有
EdgeRec的推荐系统不能使系统反馈的次数变得更大,因为这会加重云端服务器上的计算开销。所以在目前cloud-to-edge的框架下,没有EdgeRec的淘宝推荐系统中用户的平均系统反馈次数为3次,平均分页大小为50(即用户平均发出3次分页请求)。相比之下,EdgeRec中没有显式的分页点,而是根据用户行为由本地客户端来触发。在不增加云端额外计算开销的情况下,EdgeRec中系统反馈的平均次数可以达到15次(即本地客户端平均在一个页面中触发了5次reranking请求,因此总数为15次)。
带
EdgeRec和不带EdgeRec的推荐系统在这三个方面的性能如下表所示。结果数据是在流量高峰时观察到的,并且通过对用户取平均来计算。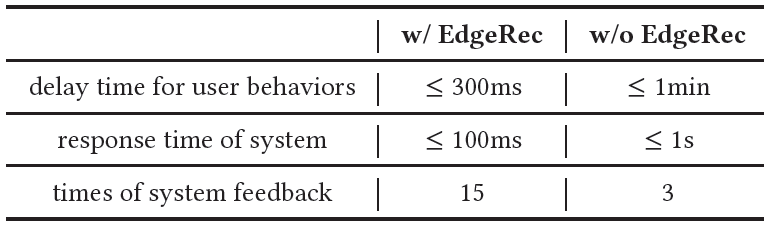
24.2.3 案例研究
我们在下图中对手机淘宝进行了案例研究,以展示异质用户行为序列建模和行为注意力网络的上下文感知重排的有效性。总之,我们有以下观察:
用户在
item详情页中的行为表明用户具有positive intention degree的item偏好,例如添加到购物车或者和客服咨询;而item曝光中的用户行为通常推断出对item的negative intention,如快速划过或删除。这意味着异质用户行为序列建模能够捕获用户对历史交互
item的潜在正向和负向意图。借助于
item详情页中两件相似的衬衫,候选衬衫被预测为postive;借助于item曝光中具有lower negative intention degree的两个相似的交互item,候选帽子被预测为negative。这表明行为注意力网络的上下文感知重排能够利用用户行为上下文对候选
item之间的交互进行建模,从而更好地指导target item的预测。
二十五、DPSR[2020](检索)
近年来,在线购物平台(如
Ebay、沃尔玛、亚马逊、天猫、淘宝、京东)在人们的日常生活中越来越受欢迎。电商搜索帮助用户从数十亿商品中找到用户需要的东西,因此电商搜索是这些平台的重要组成部分,并且在所有渠道中贡献了最大比例的交易。例如,服务于数亿活跃用户的天猫、淘宝、京东等中国顶级电商平台,Gross Merchandise Volume: GMV高达数千亿美元。在论文《Towards Personalized and Semantic Retrieval: An End-to-End Solution for E-commerce Search via Embedding Learning》中,作者将重点关注深度学习最近对电商搜索系统产生的巨大影响。下图给出了京东手机App上搜索的用户界面。
搜索系统的三个组件
Three Components of Search System:下图展示了一个典型的电商搜索系统,它具有三个组件:query处理query processing、候选检索candidate retrieval、排序ranking。query处理将query(例如 “爷爷的手机”)重写为可以由下游组件处理的term-based representation(例如[term 手机] AND [term 爷爷])。这个阶段通常包括词干化tokenization、拼写纠正spelling correction、query扩展query expansion、以及重写rewriting。- 候选检索使用离线构建的倒排索引
inverted indexes,根据term matching高效地检索候选item。这一步将item数量从数十亿减少到数十万,使得fine ranking变得可行。 ranking根据相关性、预估转化率等因子对检索到的候选进行排序。生产系统可能具有级联的ranking steps,其中从上游到下游依次应用从简单到复杂的ranking函数。
在论文中,我们仅关注候选检索阶段,以实现更加个性化
personalized和语义化semantic的搜索结果,因为这个阶段在我们的搜索产品中贡献了最多的bad cases。根据我们的分析,JD.com作为全球最大的电商搜索引擎之一,搜索流量的不满意案例dissatisfaction cases大约20%可以归结于这一阶段的失败。如何在ranking阶段处理这一点不在本文讨论范围内,但是将是我们未来的工作。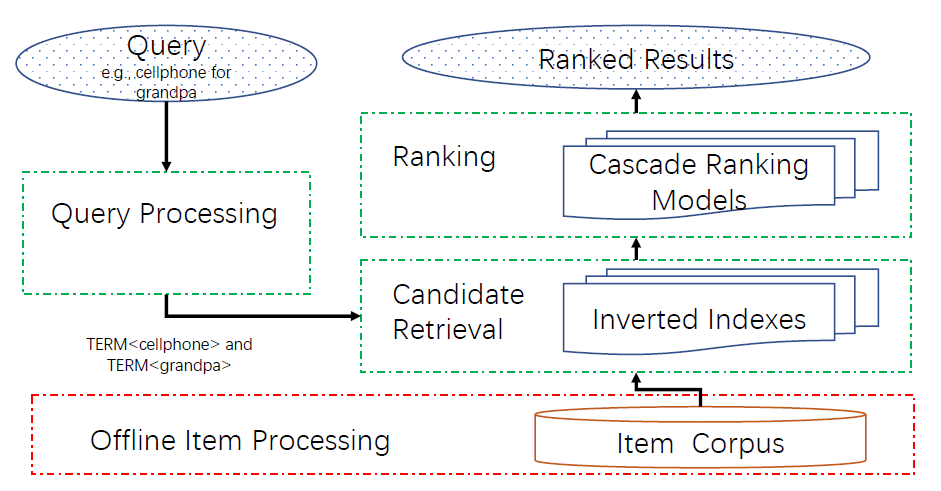
候选检索中的两个挑战
Two Challenges in Candidate Retrieval:如何有效地检索更加个性化和语义相关的item仍然是现代电商搜索引擎面临的主要挑战。语义检索问题
Semantic Retrieval Problem:指的是传统的倒排索引无法检索语义相关、但是不包含query的exact terms的item。正如《Semantic Matching in Search》所述,搜索系统最关键的挑战是query和item之间的term mismatch,尤其是对于电商搜索,item标题通常很短。传统的互联网搜索通常使用
query rewriting来解决这个问题,它将原始query转换为另一个可能更好地代表搜索需求的similar query。但是,很难保证通过middle man“中间人” (即重写的query)来保持相同的搜索意图search intention,并且也不能保证包含不同terms的相关item可以通过有限的rewritten query集合来检索到。个性化检索问题
Personalized Retrieval Problem:指的是传统的倒排索引无法根据当前用户的性别、购买力等特征检索出不同的item。例如,如果用户是女性,那么我们希望检索更多的女性T-shirt,反之亦然。一些基于规则的解决方案已经在我们的系统中使用了很多年,包括:为
item建立tag索引,如购买力、性别等等,就像token进入倒排索引一样;为不同的用户组建立独立的索引。然而,以前的这些方法太过于人工设计hand-crafted,因此很难满足更精巧subtle的个性化需求。
论文的贡献:在论文中,作者提出了深度个性化和语义化的检索
Deep Personalized and Semantic Retrieval: DPSR来解决前述的工业级电商搜索引擎中的两个挑战。论文的贡献可以总结如下:- 论文概述了由离线模型训练、离线索引、在线
serving组成的完整DPSR的embedding检索系统。作者分享了将基于神经网络的候选检索产品化为工业级电商搜索引擎的关键设计决策。 - 论文开发了一种新颖的神经网络模型,该模型具有双塔架构、
query塔为multi-head设计、attention-based损失函数、负采样方法、高效的训练算法和人工监督数据。所有这些对于训练表现最好的模型都是必不可少的。 - 论文展示了作者在构建大规模深度检索训练系统方面所做的努力,其中论文定制化了现有的
TensorFlow API以实现在线/离线一致性、输入数据存储、以及可扩展的分布式训练。论文还展示了作者在构建用于embedding检索的工业级在线serving系统方面所做的努力。 - 论文进行了广泛的
embedding可视化、离线评估、在线A/B test,结果表明论文的检索系统可以帮助找到语义相关的item,并显著改善用户的在线搜索体验,尤其是对于传统搜索系统难以处理的长尾query(转化率提升10%)。
自
2019年以来,论文的DPSR系统已经成功部署在京东的搜索产品中。- 论文概述了由离线模型训练、离线索引、在线
相关工作:
传统的候选检索
Traditional Candidate Retrieval:对于候选检索,大多数研究都集中在学习query rewrites作为一种间接方法来弥合query和doc之间的vocabulary gap。仅有少数的几种新的模型方法,包括矩阵分解的潜在语义索引latent semantic indexing: LSI、概率模型的概率潜在语义索引probabilistic latent semantic indexing: PLSI、自编码模型的语义哈希semantic hashing。所有这些模型都是从doc中的单词共现中无监督学习的,没有任何监督的label。我们的方法和之前的方法不同,因为我们训练了一个监督模型来基于具有相关信号(即
click)的大规模数据集直接优化相关性度量relevance metrics(而不是优化单词共现)。基于深度学习的相关性模型
Deep Learning Based Relevance Model:随着深度学习的成功,大量基于神经网络的模型被提出,以学习query和doc之间语义相关性的方式来改进传统的信息检索information retrieval: IR方法和learning to rank: LTR方法。有关语义匹配和基于深度神经网络的信息检索的全面综述,可以参考
《Semantic Matching in Search》和《An Introduction to Neural Information Retrieval》。特别是DSSM及其后续工作CDSSM开创了使用深度神经网络进行相关性评分的工作。最近,包括DRMM、Duet在内的新模型得到了进一步发展,以将传统的信息检索lexical matching信号(如query term重要性、exact matching)包含在神经网络中。然而,这个方向所提出的大部分工作都集中在ranking阶段,其优化目标和要求与我们在本文工作所关注的候选检索有很大不同。深度神经网络的双塔架构已经在现有的推荐工作中广泛采用,以进一步结合
item特征。这种模型架构在自然语言处理中也被称作双编码器dual encoder。这里我们提出了一个更高级的双塔模型,它由用于query塔的multi-head和基于soft内积(而不是简单内积)的attention损失函数组成。搜索引擎中的
embedding检索Embedding Retrieval in Search Engine:近年来,embedding检索技术已广泛应用于现代推荐系统和广告系统,但是尚未广泛应用于搜索引擎。我们发现了关于在搜索引擎中检索问题的一些工作,但是它们尚未被应用到工业生产系统中。据我们所知,我们是在工业搜索引擎系统中应用embedding检索的首批实践探索之一。
25.1 模型
在我们介绍细节之前,先展示以下我们的
embedding检索系统的全貌。下图说明了我们的生产系统具有以下三个主要模块:离线模型训练
Offline Model Training模块:训练由query embedding模型(即query塔)和item embedding模型(即item塔)组成的双塔模型,分别用于在线serving和离线索引。这种双塔模型架构是一种谨慎且必要的设计,能够实现快速的在线
embedding检索,具体细节在后面讨论。此外,我们在后面还讨论了我们优化离线训练系统的努力。离线索引
Offline Indexing模块:加载item embedding模型(即item塔),从item语料库中计算所有item embedding,然后离线构建embedding索引以支持高效的在线embedding检索。由于不可能在数十亿个
item的item语料库中进行全量搜索,因此我们采用了一种state-of-the-art的算法来来对稠密向量进行有效的最近邻搜索,从而为query embedding找到相似的item embedding。Online Serving模块:加载query embedding模型(即query塔)从而将任何用户输入的query文本转换为query embedding,然后将其馈送到item embedding索引以检索K个相似item。注意,这个在线
serving系统必须以几十毫秒的低延迟来构建。此外,它必须能够scale到每秒数十万次查询query per second: QPS,并且能够灵活地对实验进行敏捷迭代。我们将在后面详细讨论我们为了构建这样一个在线serving系统所作的努力。
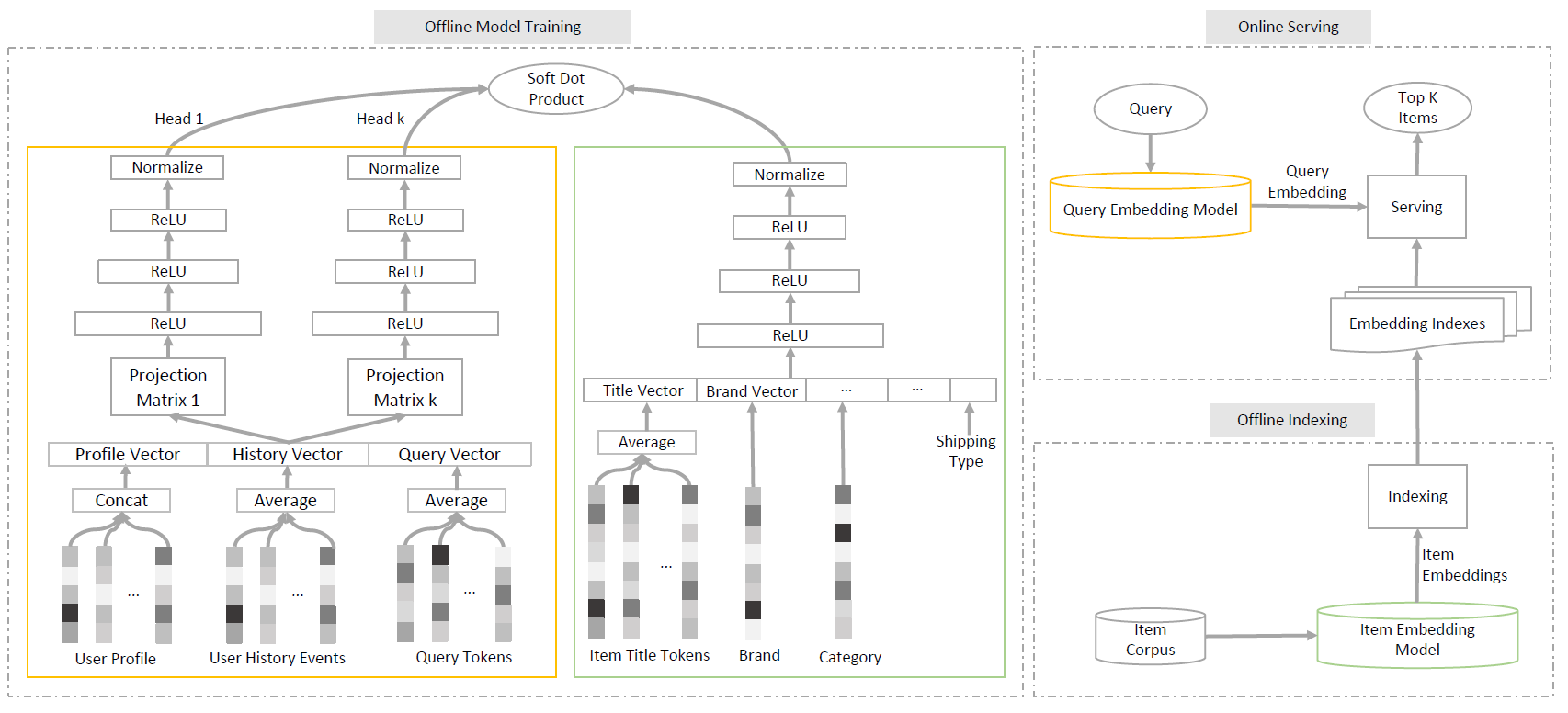
这里将
User Profile的embedding进行Concat,而User History Events, Query Tokens, Item Title Tokens的embedding都是进行Average,有两个原因:- 首先,
User Profile的字段数量是固定的,因此embedding拼接之后的长度是确定的。而User History Events、Query Tokens、Item Title Tokens的embedding数量是可变的,拼接之后的长度是可变的。 - 其次,
User Profile的各字段是异质的,例如 “年龄” 和 “性别” 是不同的,它们的embedding难以直接相加;而User History Event的embedding是同质的,它们可以直接相加。
接下来我们逐步介绍
embedding learning模型,按照双塔架构two tower architecture、query塔的多头设计multi-head design、注意力损失函数attentive loss function、混合负采样hybrid negative sampling、人工监督数据human supervision data的顺序。所有这些对于训练我们的最佳表现的模型都是不可或缺的。
25.1.1 双塔架构
如上图的离线模型训练模块所示,模型由
query塔 和item塔 组成。对于给定的query和item,模型的输出得分为:其中:
- 表示 维空间中
query在query塔的 个输出embedding。 - 表示 维空间中
item在item塔的 个输出embedding。 - 评分函数 计算
query和item之间的最终得分。
研究者和从业人员通常让
query塔 和item塔 都输出一个单一的embedding,即 和 ,并选择内积作为评分函数,即:这种最简单的设置在很多应用中已经被证明是成功的。
- 表示 维空间中
这种双塔架构的关键设计原则是:在模型训练之后,使得
query embedding和item embedding相互独立。所以我们可以分别独立地计算它们。所有的item embedding都可以离线计算,以便为在线快速最近邻搜索构建item embedding index,并且可以在线计算query embedding以处理所有可能的用户query。即使
embedding是独立计算的,由于query塔和item塔之间简单的内积交互,理论上query embedding和item embedding仍然在相同的几何空间中。因此,为给定的query embedding找到K个最近邻的item,等效于最小化给定query的K个query-item pair对的损失。在下面的部分中,我们将介绍一个新颖设计的
query塔 和一个交互函数 ,从而达到出色的、且可解释的检索结果。由于
item representation通常很直接明了,我们仍然简单地保持item塔 不变。item塔 将所有item特征拼接起来作为输入层,然后通过多层感知机MLP(采用ReLU)来输出单个item的embedding,最后归一化为与query embedding相同的长度,如上图离线模型训练模块右侧所示。类似的MLP结构可以在以前的工作中找到。
25.1.2 Multi-head 的 Query 塔
如上图中离线训练模块的左侧所示,
query塔和item塔有两个不同之处:一个投影层
projection layer,将一个输入的稠密representation投影为 个稠密的representation。这里的另一个选择是使用 个独立的embedding集合,但是它需要更大的模型规模。在实践中,我们选择投影层来实现类似的效果,但是模型规模要小得多。个独立的
encoding MLP,每个MLP独立输出一个query embedding,它们可能会捕获query的不同意图。我们将这 个输出embedding称作multi-head representation。这些
multiple query embeddings为query的意图提供了丰富的representation。通常,我们在实践中发现:这可以为多义词query(如apple)捕获不同的语义含义,为商品query(如cellphone)捕获不同的流行品牌,为品牌query(如Samsung)捕获不同的商品。
值得一提的是,
encoding层可以使用任何更强大的神经网络,如RNN和其它state-of-the-art的transformer-based模型。在一项独立的离线研究中,我们使用这些高级模型取得了相似或者稍好一些的结果。但是我们要强调的是,简单的MLP更适合于我们的工业级生产建模系统,因为它对离线训练和在线serving都更加高效,这意味着我们能够向模型训练馈送更多的数据(因为MLP的计算效率高),并部署更少的机器来serving模型。
25.1.3 Attention 损失函数
除了单个
embedding和内积setup之外,这里我们为multiple query embeddings开发了一种更通用的形式。我们将query塔 的 个输出简写为 ,其中 ,item塔 只有一个输出为 。那么query和item之间的soft内积可以定义为:这个评分函数基本上是
query embedding和item embedding之间所有内积的加权和。权重 是从同一组内积的softmax计算而来:其中 为
softmax的温度超参数。注意, 越高,则注意力权重就越均匀。
- 如果 ,那么上述评分函数等价于选择最大的内积,即: 。
- 如果 ,那么上述评分函数等价于
embedding内积的均值。
当 时,上述评分函数退化为传统的
embedding内积形式。
这种
multi-head和multi-head attention有几点不同:- 首先,这里
item只有一个head,而multi-head attention中的item有的 个head。 - 其次,这里内积采用不同
head的加权和来计算,而multi-head attention中的内积就是直接sum而计算。
因此这里
multi-head的物理意义为:计算query的不同意图和item的相似度,然后对于相似度进行加权和。相似度越大的意图,其权重越大。典型的工业点击日志数据集通常只包含
query和item的点击pair对。这些pair对通常都是相关的,因此可以被视为正样本。除此之外,我们还需要通过各种采样技术收集负样本,这将在后面详细讨论。我们将所有训练样本的集合 定义为:其中每个训练样本是一个三元组,由
query、query相关的postive item、以及一个negative item集合 组成。其中 且 中的每个item都和query无关(即 ) ,label信息。然后我们在训练集 上使用带
margin的hinge损失函数:这要求
postive item评分比negative item评分至少高出 。注意,该注意力损失函数仅适用于离线训练。在在线检索期间,每个
query head检索相同数量的item,然后将所有item根据它们与被检索head的内积得分进行排序和截断。
25.1.4 负样本
训练深度模型需要大量的数据。我们探索点击日志,它代表用户的隐式相关反馈
implicit relevance feedback并由query及其点击item组成,从而训练我们的embedding检索模型。直观地,我们可以假设:如果item在给定的query条件下被点击,那么该item和query相关,至少是部分相关。形式地,我们可以将点击日志视为只有正样本的数据集的特例。那么如何有效地收集负样本是这里的一个关键问题。在我们的实践中,我们采用了一种混合方法,该方法混合了两种负样本来源,包括随机负样本和
batch负样本。随机负样本
Random Negatives:随机负样本集合 在所有候选item中均匀采样。形式上,给定所有 个可用
item的集合,我们从均匀分布 中随机抽取一个整数,并将item集合中第 个元素放入到随机负样本集合 中。然而,如果我们直接应用这种均匀采样,则计算成本将非常高,因为每个负样本都必须经过item塔,更不用说对这些负样本进行采样并获取其特征的成本了。为了在保持效果的同时最小化计算成本,我们对一个batch中的所有训练样本使用相同的随机负样本集合。在实践中,我们发现结果与使用纯随机负样本的结果相似,但是前者训练速度要快得多。batch负样本Batch Negatives:将batch中query的正样本视为其它query的负样本,从而得到batch负样本集合 。具体而言,对于一个训练batch:我们可以为第 个样本收集负样本为:
我们可以看到
batch负样本基本上是根据数据集中item频率来采样的。这些随机生成的query-item pair对不太可能偶然相关。具体而言,偶然相关的可能性等于两个随机抽取的点击日志具有彼此相关的item。给定一个包含数亿个点击日志的数据集,这个可能性在训练准确性accuracy方面基本上可以忽略不计。此外,上述
batch负样本的主要优点是item embedding计算的复用。在batch中每个item embedding有一次作为正样本、有 次作为负样本,但是只需要一次特征提取及只需要一次item塔的前向计算。混合比例
Mixing Ratio:最终的完整负样本集合 是上述两个负样本集合的并集:在我们的电商搜索检索实践中,我们发现混合比例参数 对于负样本集合的组成通常很有用。形式上,我们采用 比例的随机负样本、 比例的
batch负样本。我们发现 的值与从模型中检索到的
item的流行度popularity高度相关(参考实验部分),因此对在线指标影响很大。直观地,我们可以看到混合比例 决定了负样本中的item分布,从均匀分布( )到实际item频率的分布( )。通过这种方式,该模型倾向于为较大的 检索到更多流行的item,因为流行的item在随机负样本中出现的频率,相对于在batch负样本中出现的频率更低。如果均匀采样,则所有
item成为负样本的概率都是相同的。如果batch内负采样,则热门item成为负样本的概率更高,这使得模型检索到热门item的概率更低。我们在
DPSR训练算法中总结了带有batch负采样和随机负采样的完整训练算法。每个训练
step的计算复杂度为 ,即batch size的二次方。 因为batch负样本需要在batch中需要为每个query和每个item embedding的pair对之间计算内积。在实践中,由于batch size通常很小(如64或者128),因此二次效应实际上比其它计算成本(如特征提取、梯度计算等)小得多。事实上,由于batch负样本对每个item塔输出的有效利用,总的收敛速度实际上更快。DPSR训练算法:输入:
postive数据集batch size- 最大迭代
step - 混合比例
输出:训练好的
query塔 、item塔算法步骤:
迭代 ,迭代步骤为:
- 采样一个
batch的 个样本 。 - 为这个
batch随机采样一组负样本 。注意, 中的每个正样本都共享这组相同的负样本。 - 从
query塔计算query head embeddings。 - 对
batch以及随机负样本集合 内每个item计算item embeddings。 - 计算损失函数 ,其中包含了
batch负样本集合 。 - 通过反向传播更新
query塔 和item塔 。
返回训练好的
query塔 、item塔 。- 采样一个
25.1.5 人工监督信息
除了使用点击日志数据之外,我们的模型还能够利用额外的人工监督来进一步纠正极端
case,结合先验知识并提高其性能。人工监督来自三个来源:大多数跳过的
item可以从在线日志中自动收集,这些item和相关的query可以用作负样本。即曝光但是未点击的
item可以视为负样本。可以基于领域知识收集人工生成的数据作为人工负样本和人工正样本。例如:
“手机保护套” 被生成为
query“手机”的负样本,因为它们虽然字面上共享相似的产品词”手机“,但是语义上有着显著差异。iPhone 11被生成为query“最新大屏iphone” 的正样本。
基于人工规则来自动生成正样本和负样本。
人工
label和上报的bad case通常用于训练相关性模型。我们将它们作为样本包含在训练数据集中。
这些人工监督数据可以作为正样本和负样本输入到模型中。
这些人工监督数据可以配置更高的样本权重,从而使得模型更关注这些 “特殊” 的样本。
25.2 Embedding 检索系统
我们采用
TensorFlow作为我们训练和在线serving的框架,因为它已经被广泛应用于学术界和工业界。尤其是TensorFlow具有以下优点:训练之前预先建立静态图、训练速度快、训练与在线serving无缝集成。我们基于
TensorFlow的高级API Estimator构建了我们的系统。为了确保最佳性能和系统的一致性,我们还做出了巨大努力来简化现有的Tensorflow package和工业级深度学习系统。
25.2.1 训练系统优化
在线和离线的一致性
Consistency Between Online and Offline:构建机器学习系统的常见挑战之一是保证离线和在线的一致性。典型的不一致通常发生在特征计算阶段,尤其是在离线特征预处理和在线serving系统中使用两个独立的编程脚本时。在我们的系统中,最脆弱的部分是文本
tokenization,它在数据预处理、模型训练、在线serving中进行了三次。意识到这一点,我们用C++实现了一个unique tokenizer,并用一个非常轻量的Python SWIG接口包装它以进行离线数据vocabulary计算,并使用TensorFlow C++自定义运算符进行离线训练和在线serving。因此,可以保证相同的tokenizer代码贯穿原始数据预处理、模型训练、在线预测。压缩的输入数据格式
Compressed Input Data Format:工业搜索和推荐训练系统的典型数据格式通常由三种类型的特征组成:用户特征(例如query、性别、地域)、item特征(例如流行度popularity)、user-item交互特征(例如,item是否被用户看到)。由于训练数据存储所有user-item交互pair对,因此原始输入数据会多次重复用户特征和item特征,这会导致数百TB的磁盘空间占用、更多的数据传输时间、更慢的训练速度。为了解决这个问题,我们自定义了
TensorFlow Dataset来从三个独立的文件中组装训练样本:一个用户特征文件、一个item特征文件、一个包含query, user id , item id的交互文件。用户特征文件、item特征文件首先作为特征lookup字典被加载到内存中,然后交互文件在训练step中迭代,迭代时从内存读取并添加了用户特征和item特征。通过这种优化,我们成功地将训练数据的规模减少为原始大小的10%。在典型的工业级系统中,用户规模在亿级、
item规模在千万级,因此将用户特征文件、item特征文件加载到内存中是个瓶颈。一个解决方案是采用内存数据库,如redis,但是这会增加系统的复杂度(需要维护一套redis集群,以及处理redis请求失败的case)。可扩展的分布式训练
Scalable Distributed Training:在具有参数服务器parameter servers的分布式训练场景中,常见的瓶颈之一是网络带宽。工业界大部分大型机网络带宽是10G bits,对于大型深度学习模型而言远远不够。我们观察到,现有的TensorFlow Estimator实现在处理embedding聚合(例如embedding的sum)时没有得到足够的优化,因此在增加一些worker时网络带宽很快成为瓶颈。为了进一步提高训练速度,我们改进了
TensorFlow官方实现中的embedding聚合操作,将embedding聚合操作移到参数服务器中,而不是在worker中。因此对于每个embedding聚合,在参数服务器和worker之间只需要传输一个embedding,而不是数十个embedding。因此,网络带宽显著降低,分布式训练系统可以扩展到五倍以上的机器。
25.2.2 在线 Serving 系统
DPSR在线serving系统的概述如下图所示。该系统由两个新颖的部分组成:一个是TensorFlow Servable模型、另一个是模型sharding代理。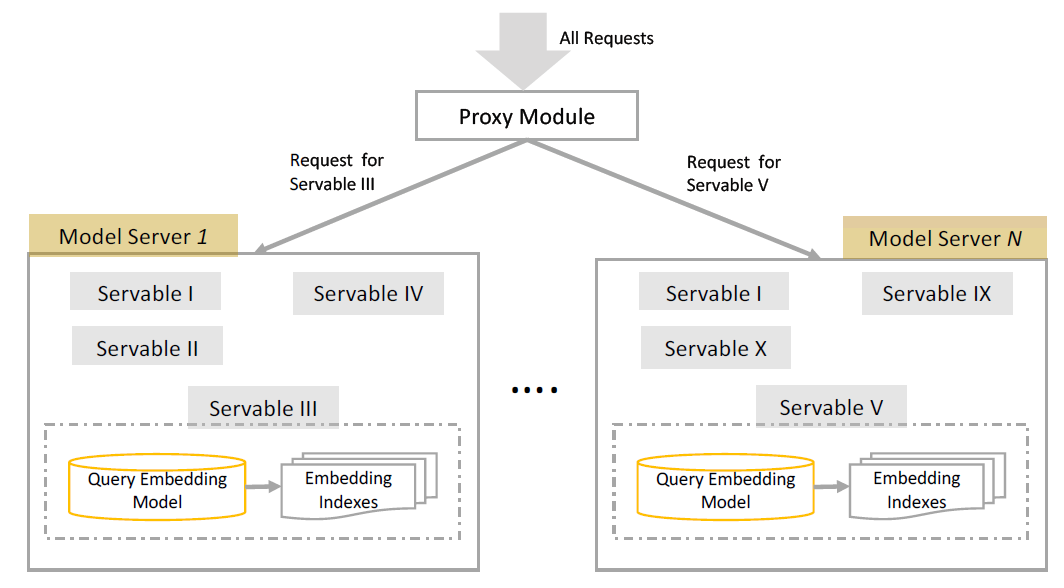
One Servable Model:DPSR的简单实现可以由两个独立的部分组成:query embedding计算和最近邻查找。如果没有精心的设计,可以简单地为它们构建两个独立的在线服务。然而,从以下两个方面来看,这不是最优的系统设计:- 它引入了管理
query embedding模型和item embedding索引之间映射的复杂性,如果发生映射错误,那么将完全导致系统故障。 - 它需要两次网络往返(一次计算
query embedding、一次搜索最近邻)来计算给定query文本的最近邻。
为了克服这些问题,我们通过
TensorFlow Servable框架采取了一种更优化的方法。在该框架中,我们可以将两个部分统一到一个模型中。如上图所示,这两个部分可以封装到一个Servable中。query embedding直接从query embedding model发送到item embedding索引,通过计算机内存而不是计算机网络。这里将
Query Embedding Module和Embedding Indexes部署在一起。对于规模在千万级的item,其Embedding Indexes可能单机内存无法处理。例如,假设embedding size = 128,embedding为双精度浮点,那么1千万item需要消耗9.5 GB内存。- 它引入了管理
模型分片
Model Sharding:系统的进一步扩展需要同时支持数百个DPSR模型在线,用于不同的检索任务、以及各种模型的A/B test。然而,一个由query embedding模型和一个item embedding索引组成的servable模型通常需要数十GB的内存。因此,将所有模型存储在单台机器的内存中变得不可行,我们必须构建一个系统来支持为数百个DPSR模型的serving。我们通过一个代理模块来解决这个问题,这个代理模块的作用是将模型预估请求定向到一个保持相应模型的
model server,如上图所示。这个基础设施不仅是为DPSR设计的,而且是作为一个通用系统来支持我们搜索产品的所有深度学习模型。
25.3 实验
在本节中,我们首先利用
t-SNE可视化embedding结果,以便我们可以直观地了解模型的工作原理。然后我们和不同方法进行比较来评估离线效果。接下来我们报告了我们的搜索产品中的在线A/B test结果。最后我们报告了DPSR系统的离线索引和在线serving耗时,以证明其效率,这在工业环境中至关重要。我们的生产
DPSR模型是在60天用户点击日志的数据集上训练的,其中包含56亿次session。我们在5台48-cores机器的集群中进行分布式训练,共启动了40个worker和5个参数服务器。我们使用了
margin参数 、Adam优化器、学习率0.01、batch size、embedding维度 。训练大约4亿step收敛,耗时约55个小时。
25.3.1 Embedding 可视化
Embedding Topology:为了直观了解我们的embedding检索模型是如何工作的,我们展示了从我们平台中最热门的33个类目中选择的高频item的二维t-SNE坐标。如下图所示,我们可以看到item embedding的结构非常明确和直观。基本上,我们可以看到:
- 与电子产品相关的类目(如手机、笔记本电脑、平板电脑、耳机、显示器)都很好地放置在图的左侧。
- 与家电相关的类目(如冰箱、平板电视、空调、洗衣机)都放置在图的左下方。
- 与食品相关的类目(如零食、速食、饼干、奶粉)都放置在右下方。
- 与清洁和美容相关的类目(如洗面奶、洗发水)都放置在右侧。
- 与衣服相关的类目(如鞋子、跑鞋、毛衣、羽绒服)都放置在右上方。
总体而言,这种合理且直观的
embedding拓扑反映了所提出的模型能够很好地学习item语义,从而使得query embedding能够检索相关item。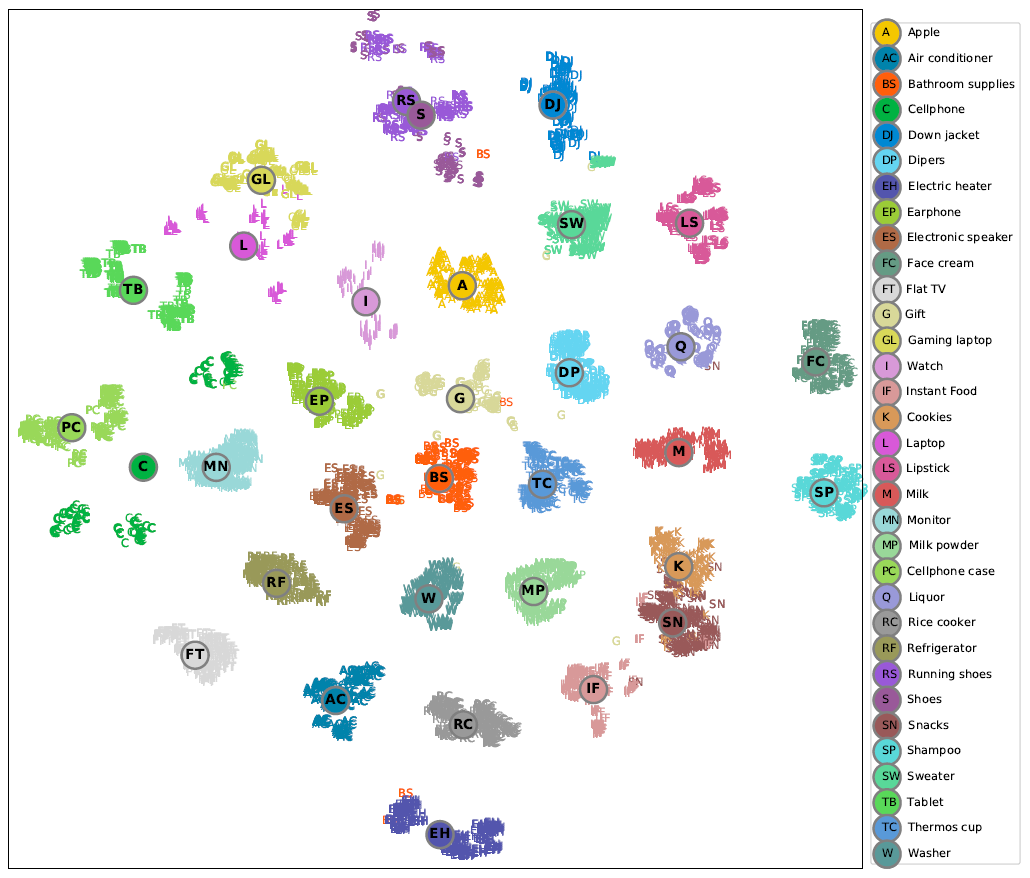
Multi-Head消歧:在下图中,我们还计算了从10个商品类目中选择的高频item的二维t-SNE坐标,以此说明在query塔中使用multi-head的效果。我们在这里使用两个多义词query作为示例,即'apple'和'cellphone',这两个词也在我们平台的top-10 query中。- 在图
(b)中,我们可以看到query 'apple'的两个head分别检索了iPhone/Macbook和apple fruit。 - 在图
c中,我们可以看到query 'cellphone'的两个head分别检索了两个最受欢迎的品牌:华为和小米。
这些都显示了不同的
head能够聚焦于不同的潜在用户意图。相比之下,图(a)中的single-head模型不适用于手机类别,其中iPhone构成了远离其它手机的另一个cluster。这可能是由于最上面的query'apple'的歧义性ambiguity。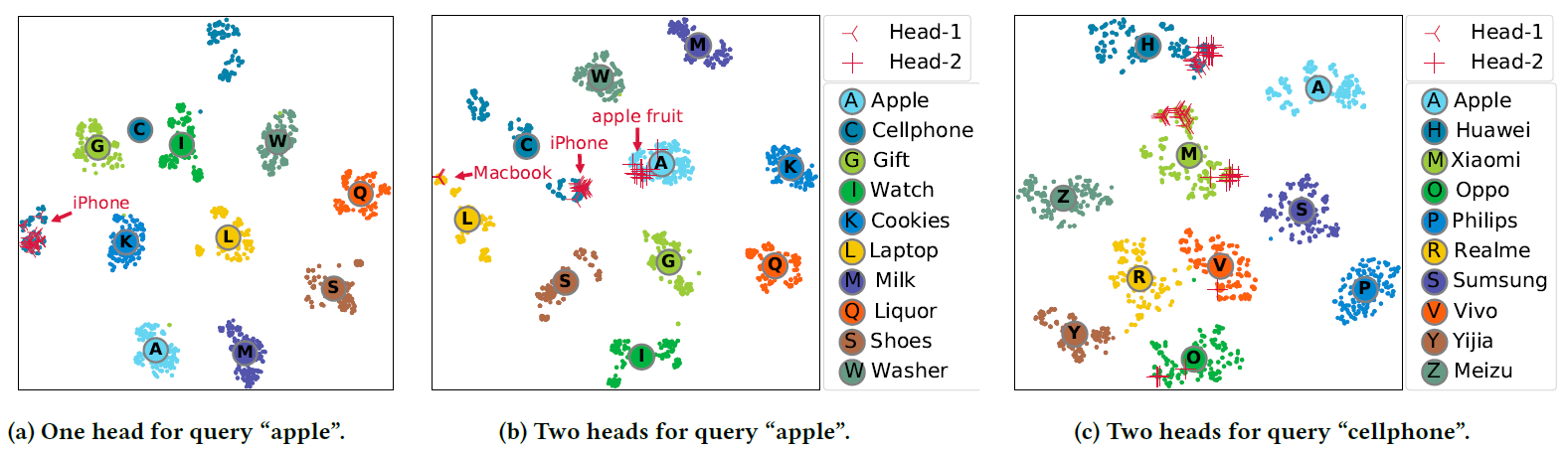
- 在图
语义匹配
Semantic Matching:为了更好地理解我们提出的模型是如何执行的,我们在下表展示了我们的检索产品中的几个good cases。可以看到:通过学习一些单词的语义,DPSR令人惊讶地能够连接bridgingquery和相关的item。例如:大童和3-6岁、自由泳器材和划臂等等。此外,
DPSR能够纠正query中的拼写错误,如v女包 和LV女包、ovivo手机和vivo手机。部分原因是我们利用了token vocabulary的英文字母三元组。我们还观察到类似的汉字错字纠正,主要是从用户点击和n-gram embedding中学到的。
25.3.2 离线评估
评估指标:我们使用以下离线指标来评估检索方法。
Top-k定义为在给定query的N个(我们使用N = 1024)随机item中,相关的item在top-k检索结果中的概率。这个top-k值是通过平均20万个随机query来计算的。更高的top-k表示更好的检索质量,即命中率hit rate。AUC是在一个独立的数据集中计算的,其中人工标记了query-item相关性。label为相关的、不相关的,然后embedding内积或者任何相关性得分(BM2.5)可以被视为预估分。更高的AUC代表更好的检索相关性。time是在48-cores CPU机器上从query文本到1500万个item中最相关的1000个item的总检索时间。该指标决定了一种方法能否应用于工业级检索系统。通常,cutoff时间是50ms,但是最好是20ms。
baseline方法:我们将DPSR和BM2.5、DSSM等baseline进行了比较。BM2.5:是一种基于倒排索引关键词匹配的经典信息检索方法,它使用启发式方法根据term频率和逆文档频率对文档进行评分。我们比较了BM2.5的两个版本:仅unigram、同时包含unigram和bigram(记作BM2.5-u&b)。DSSM:是一个经典的深度学习模型,为ranking而不是检索而设计。我们仍然将它作为baseline进行比较。
另外我们还对比了
DPSR的几个变体:DPSR是指我们模型的普通版本,没有任何用户特征。DPSR-p指的是我们模型的basic个性化的版本,包含额外的用户画像特征,如购买力、性别等。DPSR-h指的是我们模型的完整个性化版本,包含用户画像和用户历史event。
DPSR和上述baseline方法的比较结果如下表所示,可以看到:BM2.5作为一种经典方法表现出了良好的检索质量,但是从1500万个item中检索需要1分多钟,这意味着将其用于在线检索不太现实。- 将曝光未点击
item作为负样本进行采样的DSSM在top-k、MRR、AUC等指标上表现最差。这主要是因为DSSM针对ranking任务进行优化,而ranking任务是与检索任务截然不同的任务。因此,我们可以得出结论:仅使用曝光未点击的item作为负样本并不能训练检索模型。 - 普通版本的
DPSR在baseline方法和其它个性化的DPSR版本中具有最高的AUC得分,这表明纯语义DPSR可以获得最高的检索相关性。 basic个性化版本的DPSR-p方法的结果表明:用户画像特征有助于改善普通版本的检索质量指标(top-k),但是在相关性方面有所折衷。- 完整个性化版本的
DPSR-h在所有模型中具有最佳检索质量指标(top-k),这表明可以从用户历史事件中提取大量信号。
注意:个性化的模型通过权衡相关性指标(
AUC)来提高检索质量指标(top-k),这是合理的。因为检索质量除了相关性之外还包含更多因素,如item流行度、个性化等。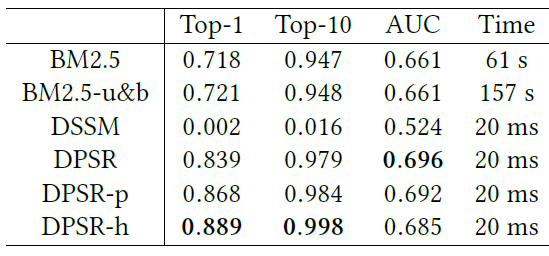
下图说明了随机负样本和
batch负样本的混合比率 影响检索到的item流行度。可以看到:- 负采样中的随机负样本越多,检索到的热门
item就越多(Popularity指标)。 - 但是太多的随机负样本(例如 ) 将损害检索到的
item的相关性(AUC指标)。
因此,我们可以将 参数视为检索流行度
popularity和相关性relevancy之间的tradeoff。在实践中我们发现适当的 或 将有助于显著提升在线指标。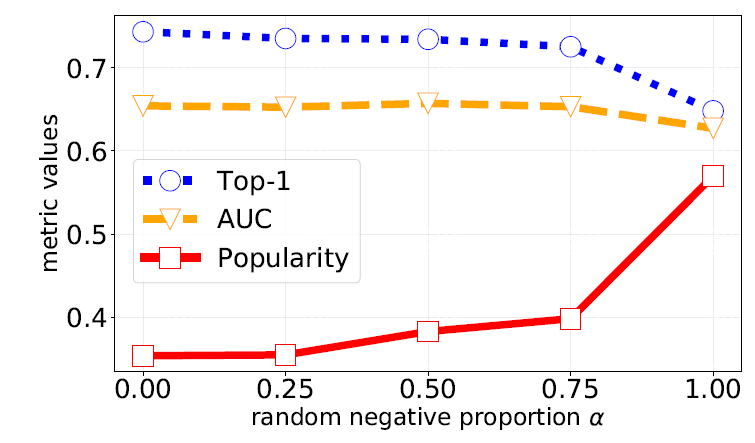
- 负采样中的随机负样本越多,检索到的热门
25.3.3 在线 A/B test
DPSR被设计为我们搜索系统中的一个关键组件,以改善整体用户体验。因此,我们将重点放在DPSR作为附加检索方法,从而对搜索系统的整体改进上。- 在对照组(
baseline)中,包含我们当前生产系统中可用的所有候选item,这些item通过启用了query rewritten的基于倒排索引的方法进行检索。 - 在对实验组(
DPSR)中,除了baseline中的候选item之外,还从我们的DPSR系统中检索了最多1000个候选item。
对照组和实验组都通过相同的
ranking组件和业务逻辑。在这里,我们强调我们的生产系统是一个强大的baseline来进行比较,因为这个系统已经经过数百名工程师和科学家多年的优化,并应用了最先进的query rewriting和文档处理方法来优化候选item的生成。我们首先对检索到的
item的相关性进行了人工评估。具体而言,给定相同的500个长尾query,我们要求人工评估员分别为来自于baseline系统、DPSR系统的结果来标记相关性。标记结果分为三个类别:差bad、一般fair、完美perfect。评估结果如下表所示,可以看到:
DPSR减少了大约6%的bad case从而提高了搜索相关性。这证明了深度检索系统在处理difficult或者unsatisfied的query时特别有效,这些query通常需要语义匹配。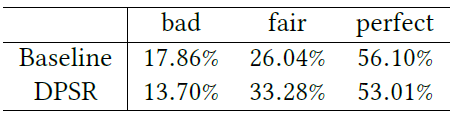
- 在对照组(
然后我们使用标准的
A/B test,在两周内对整个站点流量的10%进行了在线实验。为了保护商业机密,我们只报告了相对的提升,实验结果如下表所示:DPSR检索改进了电商搜索中所有核心业务指标,包括用户转化率user conversation rate: UCVR、gross merchandise value: GMV、query rewrite rate: QRR(query重写率,这被认为是搜索满意度的一个很好的指标)。- 我们还观察到
query塔的2-head版本和个性化版本(记作1-head-p13n)都改进了没有任何用户特征的1-head query塔的普通版本。 - 特别地,我们观察到改进主要来自长尾
query,这对于传统搜索引擎而言通常很难。
25.3.4 效率
我们在下表中展示了我们的离线索引构建和在线最近邻搜索的效率,不包括
query embedding计算。我们报告了使用NVIDIA Tesla P40 GPU和Intel 64-core CPU配置下索引和搜索1500万个item所消耗的时间。结果表明
DPSR可以在CPU上在10ms内检索候选item,并且可以从GPU中受益:索引时间消耗减少85%、搜索延迟减少92%、query per second: QPS吞吐量提高14倍。
我们在下表中报告了使用上述相同
CPU和GPU机器的整体模型serving性能。从query文本到1000个最近邻的总延迟可以在15ms ~ 20ms内完成,这甚至可以与标准倒排索引的检索相媲美。
二十六、PDN[2021](mathcing)
推荐系统在面向用户的电商平台(如淘宝、亚马逊)中很重要,目的是将用户连接到他们喜欢的
item并产生更多利润。由于电商平台中可用的item数量巨大,许多工业系统被设计为具有matching阶段和ranking阶段。具体而言:mathcing阶段期望以低延迟和低计算成本检索一小部分相关的item,而ranking阶段旨在使用更复杂的模型根据用户的兴趣细化这些相关item的排名。在论文《Path-based Deep Network for Candidate Item Matching in Recommenders》中,论文聚焦于matching阶段,因为它是系统的基础部分,也是系统的瓶颈。item-to-item CF(即item-based CF)是一种用于item matching的信息检索解决方案。item-based CF根据两个item的共现co-occurrence来估计item之间的相关性。一些突出的优点使得item-based CF成为业界matching阶段的自然选择:- 由于只使用用户历史交互的
item进行检索,因此item-based CF可以很好地匹配许多在线服务的效率要求。 - 此外,用户的兴趣可能非常多样化。通过考虑每个交互
item,可以最大限度地覆盖用户的兴趣。 - 最后,
item之间的相关性主要是基于海量的用户行为推导出来的。这些信号能够有效识别与交互item相关的item。
但是,这些方法也有一定的局限性:
- 传统的倒排索引难以满足精巧
subtle的个性化需求。通过仅考虑item共现模式,item-based CF无法适应用户的独有特点,如性别、消费能力等。 - 同样,鉴于电商平台中可用的
item数量不断增长,在不考虑辅助信息的情况下,item-based CF可能会受到数据稀疏性问题的影响。
为了克服上述限制,
embedding-based retrieval: EBR,尤其是双塔架构的深度学习网络,最近引起了越来越多的兴趣。简而言之,EBR旨在通过分别嵌入用户画像和item画像来表示每个用户和每个item。从这个意义上来说,matching过程被转移到在embedding空间中执行最近邻nearest neighbor: NN搜索。虽然
representation learning可以在一定程度上缓解数据稀疏性问题,但是这些方法也存在一定的局限性:- 双塔架构不容易显式集成
item之间的共现信息。 - 此外,用户通常表示为单个
embedding向量,这不足以编码用户兴趣的多样性diversity。
即:
item-based CF难以满足个性化personalization,而EBR难以满足多样性diversity。一个普通用户每个月都会与数百个属于不同类目的
item进行交互,这表明用户兴趣的多样性。实际上,在实际的工业系统中,为了同时捕获用户兴趣的多样性diversity并确保个性化personalization,通常有多种策略,例如基于协同过滤模型和不同网络结构的EBR策略的各种倒排索引。这些模型应用于matching任务并且并行部署。注意:候选item通常是使用不同scale的相关性得分生成的。这些得分通常不可比incomparable,因此很难融合起来从而得到更好的结果。作者认为,由于这些策略的高维护成本以及缺乏联合优化,因此这种多策略解决方案可能是次优的。Deep Interest Network: DIN通过target attention引入交互item和target item之间的相似性,以获得更好的推荐。然而,这种注意力机制只是用来融合用户交互序列,而忽略了用户对每个交互item的兴趣。此外,DIN很难应用于matching阶段,因为它需要为每个target item重新计算user representation。受到
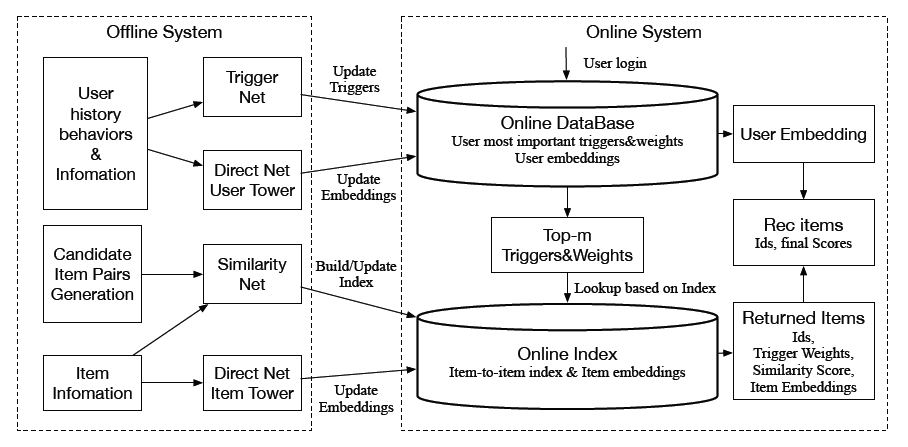
DIN的启发,在论文《Path-based Deep Network for Candidate Item Matching in Recommenders》中,作者提出了一种新的matching架构,叫做Path-based Deep Network: PDN。该架构通过在item-based CF和EBR之间建立联系,将item-based attention和user representation learning分离。在
PDN中,作者使用EBR(即用户画像、交互item序列、item画像)和item-based CF(即item共现)的representation learning思想来适应用户个性化和多样化的兴趣建模,从而获得更好的性能。具体而言,PDN由两个主要的子网组成:Trigger Net: TrigNet、Similarity Net: SimNet。TrigNet通过以下方式被引入:将每个交互item视为一个trigger来编码用户兴趣。也就是说,生成的user representation具有可变维度,使得每个维度都描述了用户对交互item的兴趣。维度 代表用户对交互
item的兴趣强度。类似于
item-based CF,SimNet生成item representation,每个维度描述交互item和target item之间的相似性。维度 代表交互
item和target item的相似性。
注意,由
EBR提取的user representation和item representation的维度是恒定的,而PDN提取的user representation和item representation的维度是可变的,等于用户trigger的数量。如下图所示,通过用户交互item将用户和target item连接起来,我们可以形成一系列2-hop路径。基于这些2-hop路径,PDN通过显式考虑用户的不同兴趣来聚合用户和target item之间的相关性,从而获得更好的性能。具体而言,用户和target item之间的最终相关性是通过显式考虑用户的不同兴趣来计算的,即聚合related two-hop路径的相关性权重relevance weight(路径的one-hop对应于user-item交互,路径的two-hop对应于item-item相关性)。另一个优点是整个模型都是端到端的方式训练的,因此,相关性得分可以以统一的方式相互比较。
值得强调的是,所提出的
PDN具有item-based CF和EBR的优点,可以实现高效的在线处理。- 一方面,通过
feature embedding,我们可以利用TrigNet提取与用户兴趣相关的top m最重要的trigger,以满足实时性要求。 - 另一方面,
SimNet独立于TrigNet工作。我们可以应用并行计算支持离线索引构建,其中使用SimNet计算的item-to-item相关性。
总之,论文的主要贡献:
- 一个新颖的
matching模型。论文通过结合item-based CF和EBR的优势提出了Path-Based Deep Network: PDN。PDN以2-hop路径聚合的形式集成了user attention的所有画像信息、以及target attention的item共现模式。PDN考虑了用户个性化和兴趣多样性,从而实现更好的item matching。 - 高效的在线检索。论文基于
PDN构建了一个工业级的在线matching系统。特别地,论文描述了如何利用PDN以低延迟和低计算成本进行item检索。 - 离线和在线实验。对几个真实世界数据集的大量离线实验表明:
PDN比现有替代方案实现了更好的性能。此外,论文在淘宝推荐系统上对PDN进行了为期两周的A/B test。结果表明:几乎所有指标都获得了很大的性能提升。
目前
PDN系统已经成功部署在手机淘宝App上,处理了主要的在线流量。- 由于只使用用户历史交互的
相关工作:
CF-based方法在构建推荐系统的mathcing阶段相当成功。item-based CF由于其可解释性和高效,已经被广泛应用于工业环境中。其中,item-based CF预先计算item的相似度矩阵,并推荐与用户历史点击item相似的item。早期的工作利用余弦相似度和皮尔逊系数等统计量来估计
item相似性。近年来,有几种方法试图通过优化recommendation-aware目标函数来学习item相似性。SLIM通过最小化原始user-item交互矩阵和重构矩阵之间的损失来学习item相关性。NAIS使用注意力机制来区分用户画像中历史互动item的不同重要性,这和DIN的想法相似。然而由于计算的复杂性,attention-based方法仅适用于ranking阶段。
随着
EBR的成功,基于深度神经网络的双塔架构已经被广泛应用于工业推荐系统,从而通过利用丰富的内容特征来捕获用户的个性化信息。需要注意的是,在matching阶段,要以低延迟和低计算成本处理数十亿甚至数万亿个item,因此两个塔不能相互交互以确保特征提取的并行性。- 基于
DSSM的模型利用用户特征和item特征之间的内积学习相关性。 - 为了提取更具有区分性的用户特征,
Youtube DNN通过平均池化用户行为来扩展用户特征。 - 而
BST利用强大的transformer模型来捕获用户行为序列背后的序列信号。
- 基于
与上述方法不同的是, 我们提出的
PDN结合了item-based CF和EBR-based深度神经网络的优点,构建了user-item子网络以确保类似于EBR的个性化,并构建了item-item子网络类似于item-based CF从而捕获用户的多个兴趣。
26.1 模型
26.1.1 基本概念
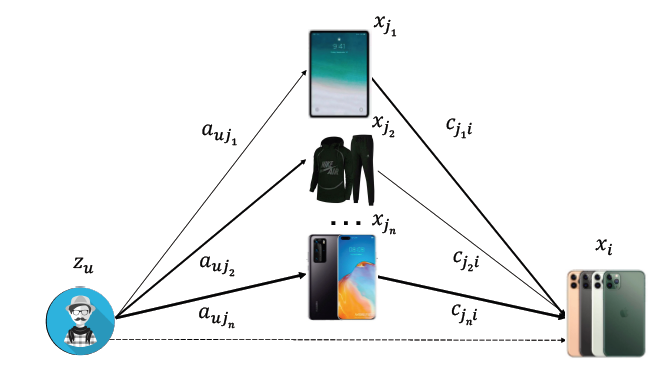
下图以用户和
target item之间的2-hop路径的形式总结了推荐问题。其中 到 代表交互item。边的粗细表示了相关性程度。这里:- 代表用户 的用户信息,例如用户
id、年龄、性别、点击次数、每个类目的购买次数。 - 代表
target item的信息,如item id、品牌id、类目id、月销售额。 - 表示用户 交互的 个
item的信息。 - 表示用户 在这 个
item上的行为信息,如停留市场、购买次数。 - 表示这 个
item和target item的相关性信息,这是从item-based CF算法或者item co-occurrence-based pattern统计而来。
如下图所示,用户和
target item之间存在直接联系(虚线所示),这表明用户对target item的直觉的兴趣intuitive interest。此外,我们可以通过连接交互item来进一步形成 条2-hop路径:第一跳表示用户对交互item的兴趣,第二跳表示交互item对target item之间的相关性。因此,采用上述的可用信息,item matching可以形式化为:其中: 定义为推荐算法, 定义为用户 和
target item之间的相关性得分, 为用户 历史交互的item集合。- 代表用户 的用户信息,例如用户
推荐系统的大部分现有工作,包括
item-based CF和EBR,可以看作是上式的特例。item-based CF的回归形式regression form可以表述为:其中:
- 是一个加权函数,用于捕获用户对每个
trigger的兴趣。 为行为特征向量的维度。 - 表述基于
item co-occurrence信息的、交互item和target item的相关性。
因此,该方法可以视为基于 和 的所有
2-hop路径的权重之和,并且每个路径权重可以计算为 。- 是一个加权函数,用于捕获用户对每个
EBR-based方法中的矩阵分解matrix factorization: MF可以表述:其中:
- 为
target item信息 的embedding向量。 - 为互动
item信息 的embedding向量。 - 为用户信息 的
embedding向量。
MF可以视为 条路径的权重之和。具体而言:一条1-hop路径的权重为 ,n条2-hop路径的权重为 。- 为
YoutubeDNN利用深度神经网络作为矩阵分解的推广,可以表述为:这里
MLP是一个多层感知机,||表示向量拼接。DIN也可以表述为:其中 为逐元素乘法。
注意,根据
target item和每个trigger之间的相关性,DIN可以被视为2-hop路径( )的representation。但是,它需要重新计算每个target item的path representation,使得DIN仅适用于ranking阶段。
为了保证检索效率,
item-based CF构建倒排索引inverted index,而EBR应用KNN搜索进行在线serving。然而,由于两种模型体系结构都受到效率的限制,它们无法利用上图中的所有可用信息,从而导致性能欠佳。例如,item-based CF缺少用户画像和item画像,而EBR缺少item之间的显式共现信息。因此,在本文中我们提出了一种叫做PDN的新型架构,从而支持低延迟的个性化和多样性检索。
26.1.2 PDN
在这一部分,我们介绍了用于推荐系统
matching阶段的Path-based Deep Network: PDN的设计。我们首先介绍PDN的整体架构,然后详细阐述PDN的各个模块,包括Embedding Layer、Trigger Net: TrigNet、Similarity Net: SimNet、Direct Net、Bias Net。根据公式 ,
PDN的基本工作流程可以表述为:其中:
TrigNet、SimNet是前面提到的两个独立的子网络。- 为通过
trigger item的2-hop路径的相关性权重。 Merge(.)是合并每条2-hop路径中相关性权重的函数。- 为获取直接路径
direct path相关性权重relevance weight的函数。 Agg(.)为一个评分函数,用于对 条路径(一条1-hop路径、 条2-hop路径)的相关性权重求和得到用户和target item的最终相关性得分。
为了使
PDN能够执行快速的在线item检索,我们首先将Agg定义为1-hop相关性权重和2-hop相关性权重的summation,然后 也被定义为user representation和target item representation之间的内积。因此,PDN的最终形式为:PDN的整体架构如下图所示(该图最好用彩色观看):Direct Net用于获取1-hop路径的权重从而捕获用户对target item的直观兴趣。TrigNet和SimNet分别获取每条2-hop路径的第一跳权重和第二跳权重,从而捕获细粒度的、针对用户的个性化和多样性的兴趣。Bias Net用于捕获各种类型的选择偏差selection bias从而进一步提供无偏serving。
注意:在每条
2-hop路径中,当TrigNet和SimNet的输出为向量时,它们可以被视为对应边的representation,称之为vector-based PDN。这种setting可能具有更高的模型容量,并且使得在线检索更加复杂。另一方面,当TrigNet和SimNet的输出为标量时,它们可以被视为对应边的权重,称之为scalar-based PDN。和vector-based PDN相比,scalar-based PDN具有较低的自由度,可以减轻基于路径检索的贪心策略在线检索的复杂性。因此,接下来我们介绍了PDN的每个组件,以及scalar-based PDN的设置。整个
PDN模型分为三部分:
Direct Net:直接建模用户和target item之间的相关。这相当于没有用户历史行为、没有上下文的双塔模型。
Bias Net:根据上下文建模不同上下文情况下的bias。它独立建模上下文,而没有联合user representation和item representation。这降低了模型复杂度。
Trigger Net & Similarity Net:直接建模用户历史行为和target item之间的相关性。这里没有用户画像特征、没有上下文特征。
Trigger Net建模trigger重要性,得到user representation为 ,其中 为用户 在trigger(即item)上的重要。该representation大多数情况下都是零,只有在历史行为item上才可能非零。Similarity Net建模item之间相似度,得到target item representation为 ,其中 为item和target item之间的相似度。Merge给出如何融合 和 从而得到用户 和target item之间的相关性。这里存在一个问题:如何迫使模型的子结构预期工作,例如
Direct Net学到user-item直接相关性、Trigger Net学到trigger重要性。这里是否应该增加某些正则化,使得模型朝着预期方向进行优化。
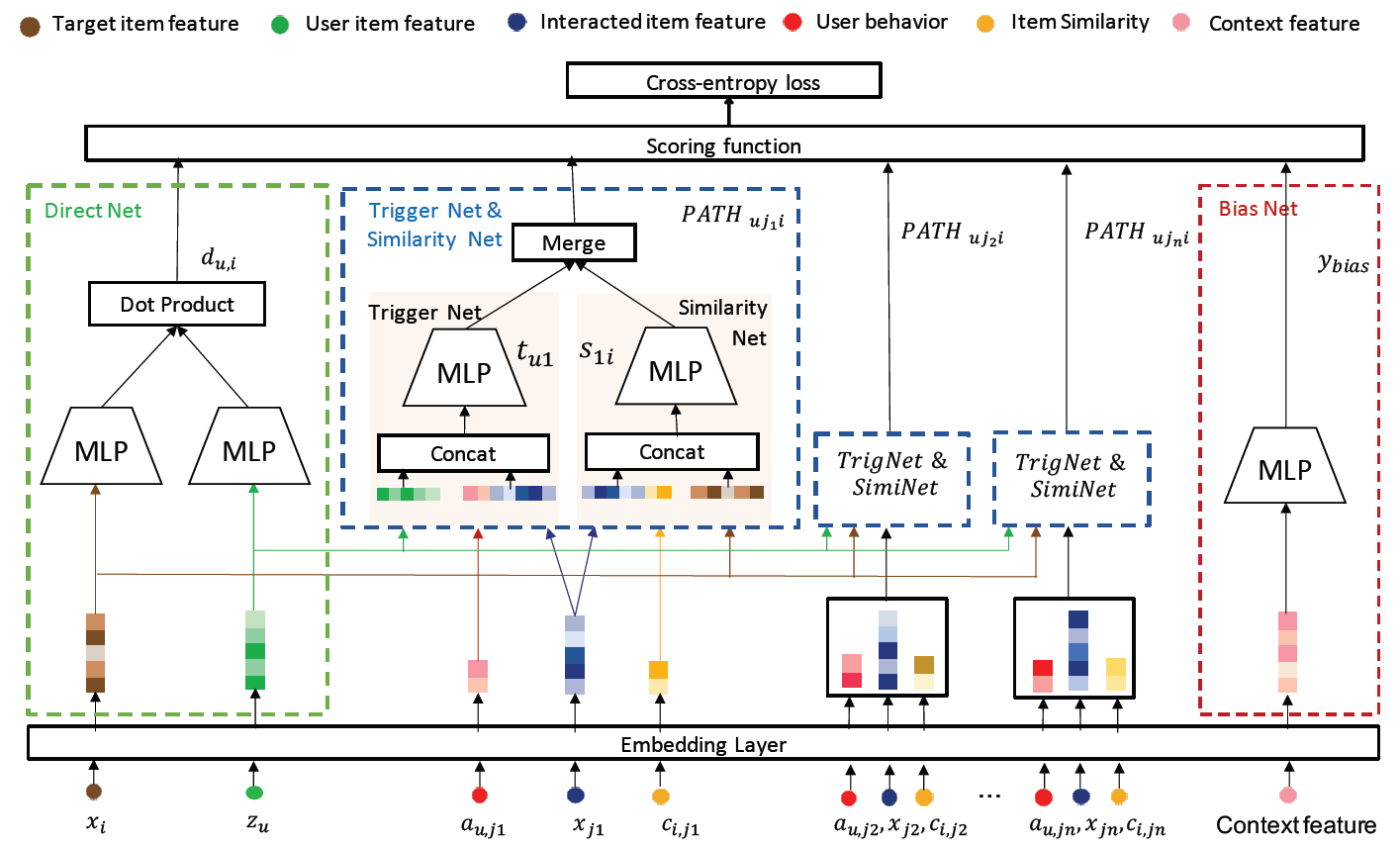
特征组合
Feature Composition和Embedding Layer:如上图所示,我们的推荐系统中有四个特征字段feature field:用户字段 、用户行为字段 、item共现字段 、item字段 (以及交互item集合 也是用的item字段)。 这些字段包括one-hot特征(如用户id、item id、年龄id、品牌id),也包括连续特征(如月销售额、停留时长、item之间的统计相关性)。- 首先,我们通过离散化将连续特征转换为
one-hot特征。 - 然后,我们将每个
one-hot特征投影到固定长度的dense representation中。 - 最后,在
embedding之后,我们拼接属于同一个字段的embedding向量作为该字段的representation。
形式上,用户字段、用户行为字段、
item共现字段、item字段的field representation可以写作: ,其中 为相应字段的embedding维度。- 首先,我们通过离散化将连续特征转换为
Trigger Net和Similarity Net:经过embedding layer之后,我们计算用户和target item之间每条2-hop路径的相关性权重。对于第一跳,我们利用
TrigNet通过计算每个trigger的偏好来捕获用户的多种兴趣。具体而言,给定用户 及其trigger item,偏好得分计算为:其中 为用户
embedding、用户行为embedding、交互item embedding的拼接。 代表用户 对交互item的偏好。当存在 个不同的交互
item时, 可以视为用户 的可变维度的representation。EBR-based方法采用一个固定维度的representation向量来表示用户兴趣,这可能是捕获用户不同兴趣的瓶颈,因为所有关于一个用户不同兴趣的信息混合在一起,导致matching阶段的item检索不准确。与使用固定维度向量对用户representation进行编码的EBR-based方案相比, 显式描述了用户对每个交互item的偏好,可以更好地表达用户的多样化diverse兴趣并且更具有可解释性。值得一提的是,
TrigNet可以使用其它更强大的神经网络,例如Recurrent Neural Network: RNN和transformer-based的模型来建模用户行为。不过我们想强调,一个简单的MLP对我们的工业系统而言更具有性价比cost-effective。一种直觉是:转化
trigger要比点击trigger更重要、转化多次的trigger要比转化一次的trigger更重要、转化长尾trigger要比转化热门trigger更重要。注意,这里的trigger既可以是正向的(点击/购买)、也可以是负向的(不感兴趣/快滑),包含用户所有的历史行为。因此,这里通过
TrigNet自动从用户embedding、用户行为embedding、交互item embedding中抽取trigger重要性。对于第二跳,我们利用
SimNet根据item画像和共现信息来计算每个交互item和target item之间的相关性:其中 为交互
item embedding、共现embedding、target item embedding的拼接。 为item和item之间的相关性。这里的共现很重要:基于什么共现准则?点击共现、还是购买共现、还是不感兴趣共现?个人理解这和任务目标有关。如果任务是点击率预估,那么这里就是点击共现,从而捕获在点击意义下的
item pair相关性。当存在 个不同的交互
item时, 可以视为target item的可变维度的representation。我们强调
SimNet基于item共现信息co-occurrence information和辅助信息side information来显式地学习相关性。从这个意义上讲,它可以独立地部署从而进行item-to-item检索。一种直觉是:共现次数越高的
item pair相似度越高、同类目的item pair相似度更高、同店铺的item pair相似度更高。这相当于将
DIN中的行为embeddingattention聚合拆分为TrigNet + SimNet。
在得到 和 之后,
PDN将它们合并从而得到每个2-hop路径的相关性权重 ,即:这个
Merge函数有两个特点:确保非负;将相关性乘积转换为加法操作,从而方便在线serving。Direct Net:我们进一步使用另一组user embedding和item embedding在更广的范围内建模用户的一般兴趣general interest。例如,女性对连衣裙更感兴趣,而男性对腰带更感兴趣。这可以被认为是将用户直接连接到target item的1-hop路径。因此,我们利用由用户塔和item塔组成的直接网络direct network。具体而言,这两个塔分别通过基于用户字段 和
target item字段 的MLP(采用LeakyReLU激活),从而得到用户representation和item representation。然后direct path的相关性权重可以表述为:其中 为用户 和
target item之间的直接相关性direct relevance。Bias Net:位置偏差position bias和许多其他类型的选择偏差selection bias被广泛研究,并验证为推荐系统中的一个重要因素。例如,用户通常倾向于点击靠近列表顶部显示的item,即使它不是整个语料库中最相关的item。为了在模型训练期间消除选择偏差,我们训练了一个浅层塔,其输入特征有助于
selection bias,例如位置偏差的位置特征position feature、时间偏差temporal bias的小时特征hour feature。得到的偏差logit被添加到主模型的最终logit中,如上图所示。注意,在
serving期间,bias net被移除从而得到无偏的相关性得分。损失函数
Loss Function:用户 是否会点击target item可以视为一个二分类任务。因此,我们将 个路径的相关性权重和bias logit合并,得到 和 之间的最终相关性分数,并将其转换为用户点击概率 :注意,
softplus函数使得相关性分数 的取值范围在 之间,因此我们将其转换为0.0 ~ 1.0之间的概率值。为了训练模型,我们应用交叉熵目标函数:
其中: 是
ground-truth,表示用户 是否点击item。讨论:为了确保
PDN的训练能够收敛到一个更好的最优值,我们仔细设计了每条路径的相关性权重。如前所述,我们利用 而不是其它激活函数来将输出约束为正值(即 和 ),从而实现每条2-hop路径权重的合并。这种将输出限制为正值的处理是直观的,并且符合现实世界的合理性。即: 。
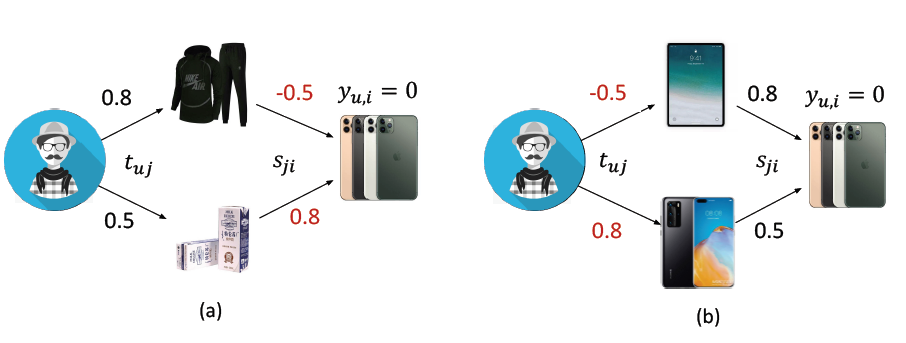
注意,相关性权重本质上可以为负值(即负相关),但是这可能允许
PDN在更广泛的参数空间中搜索局部最优值,这很容易导致过拟合。在下图中,我们通过允许相关性权重为负来说明两个bad cases。在图
(a)中,当一个negative target(label = unclick)被两个完全不相关的trigger连接时,SimNet可能会为一条路径生成一个正的相关性权重,并为另一条路径生成一个负的相关性权重。聚合后,点击概率仍然很低,即与ground-truth完美匹配。因为 。
但是很明显,牛奶不能和手机产生
postive的相关性。这意味着SimNet产生了过拟合。在图
(b)中,TrigNet也可以学习对trigger的negative偏好,从而过拟合数据。
26.1.3 系统
在这一部分,我们详细描述了
PDN在淘宝上进行item推荐的实现和部署。当用户打开手机淘宝App时,推荐系统首先会从包含多达数十亿个item的语料库中为该用户检索数千个相关的item。然后,每个检索到的item都通过ranking模型进行评分,并将根据评分排序的item列表作为推荐给用户展示。在线检索
Onling Retrieval:如前所述,matching阶段需要处理数十亿甚至数万亿个item。为了满足在线实时serving,不可能利用PDN对所有可用item进行评分。基于PDN的架构,很直观的一点是 ,路径相关性权重越大,用户对item感兴趣的可能性就越大。因此,matching问题可以看作是在用户的2-hop邻域中检索具有较大路径权重的item节点。如下图所示,我们通过贪心策略以路径检索的形式实现了在线实时
top-K最近邻检索。具体而言,我们将路径检索分解为两个部分:- 使用
TrigNet的top-m重要的trigger搜索(第一跳)。 - 基于
SimNet生成的索引对每个top-m trigger执行top-k item搜索(第二跳)。
对于
TrigNet,我们将模型部署在实时在线服务中,用于用户trigger的打分。对于SimNet,我们使用该模型以离线方式计算和索引item相关性。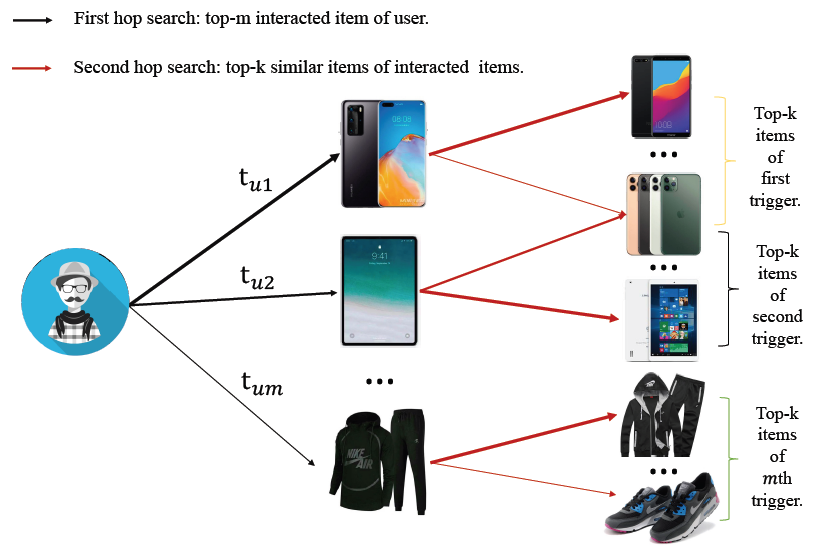
详细而言,
PDN的在线检索可以概括为:索引生成(第一步):基于
SimNet,离线生成语料库中每个item的top-k最相似的item,并与相关性得分 一起存储在数据库中。trigger提取(第二步):当用户打开手机淘宝App时,我们取出用户交互的所有item,并利用TrigNet得到用户所有的trigger的评分 ,并返回top-m trigger。top-k检索(第三步):我们从这些top-m trigger开始查询数据库并获得总共 个候选item。在移除bias feature的情况下,返回top-k item进行推荐:
注意:
- 和 是静态的
representation,这两种representation也可以离线推断并存储在数据库中。在执行在线服务时,可以直接根据user id或者item id来查询它们。 - 推断时评分函数仅使用了
top -m个trigger(训练时使用n个);推断时评分函数使用简化的 、基于加法操作的Merge函数(训练时使用复杂的、基于对数操作的Merge函数)。
- 使用
索引生成
Index Generation:对于具有大型item语料库的工业系统,我们需要压缩item相关性的稠密矩阵,即 ,从而减少索引构建时间成本和存储成本。即使这个过程可以离线完成,计算所有 的item pair对的相关性成本太高,所以我们首先根据候选生成candidate generation将 降低到 ,其中 要比 大一个量级。压缩操作主要包括三个步骤:- 候选
item pair对生成:我们主要从两种策略生成item pair对:一种基于共现信息,例如在同一个session中点击的item;另一种基于item的画像信息,例如同一个品牌。从这个意义上讲,历史没有共现的、但是具有一些相似属性的item pair对也可以被视为候选。 - 候选
item pair对排序:我们使用SimNet提取每个item pair对的相关性得分 。 - 建立索引:对于每个
item,我们获取top-k相似的item组成 的item pair对,同时 也一并存储在数据库中。
值得一提的是,
SimNet可以独立地用于索引,因此也可以用于item-to-item检索。对每个
item基于SimNet生成top k相似的item非常关键。如果对全量item库进行计算,那么每个item需要调用SimNet次,全量计算需要调用SimNet次,即使是离线计算也不现实。为此,需要根据先验知识,挑选出可能相关的item进行打分。- 候选
26.2 实验
- 在这一部分,我们将
PDN和已有的SOA方案进行离线和在线的对比,包括消融研究、模型分析、案例研究。
26.2.1 离线评估
数据集:我们在三个公开的真实数据集上进行实验:
MovieLens、Pinterest、Amazon books。这三个数据集的统计数据如下表所示。按照《Neural collaborative filtering》的设置,我们仅保留至少有20次交互的用户。关于这三个数据集的预处理的更多细节,参考《Neural collaborative filtering》,我们不再赘述。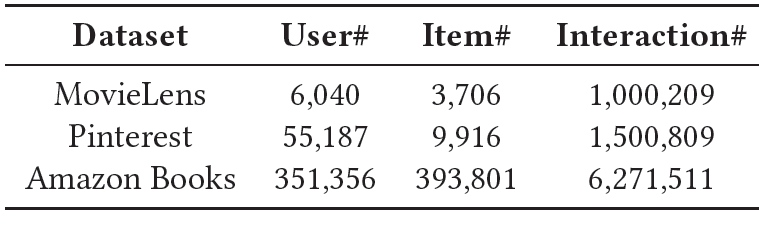
评估方式:为了评估
PDN的性能,我们采用了留一法来评估。对于每个用户,最后一次交互作为target item,而之前的交互item作为用户行为集合。具体而言,我们遵循惯例,在每个test case中使用所有negative items,并在这些negative items中对target item进行排序。我们使用命中率
Hit Ratio: HR和Normalized Discounted Cumulative Gain: NDCG作为性能指标。在这里HR可以解释为基于召回的指标,NDCG可以解释为基于ranking的指标。baseline方法:我们将PDN与以下双塔方法和传统的item-based CF方法进行比较。为了确保公平地比较,超参数调整是通过网格搜索进行的,每种方法都用最佳超参数进行测试。双塔方法如下:
DSSM:DSSM使用embedding来表示用户和item。相关性得分是基于user representation和item representation之间的内积来计算。Youtube DNN:Youtube DNN利用用户的交互序列来得到user representation。它平等地对待用户历史行为中的每个交互item,并采用均值池化来提取用户的兴趣。BST:BST扩展了Youtube DNN,通过利用transformer layer来捕获用户对历史行为序列的短期兴趣。我们使用user representation和item representaiton的内积,而不是MLP。
item-based CF方法如下:Pearson-based CF: PCF:这是标准的item-based CF,它根据皮尔逊系数估计item相关性。SLIM:SLIM通过最小化原始user-item交互矩阵和从item-based CF模型重建的矩阵之间的损失来学习item相关性。
ranking方法如下:DIN:DIN利用target attention来提取用户交互序列和target item之间的关系。
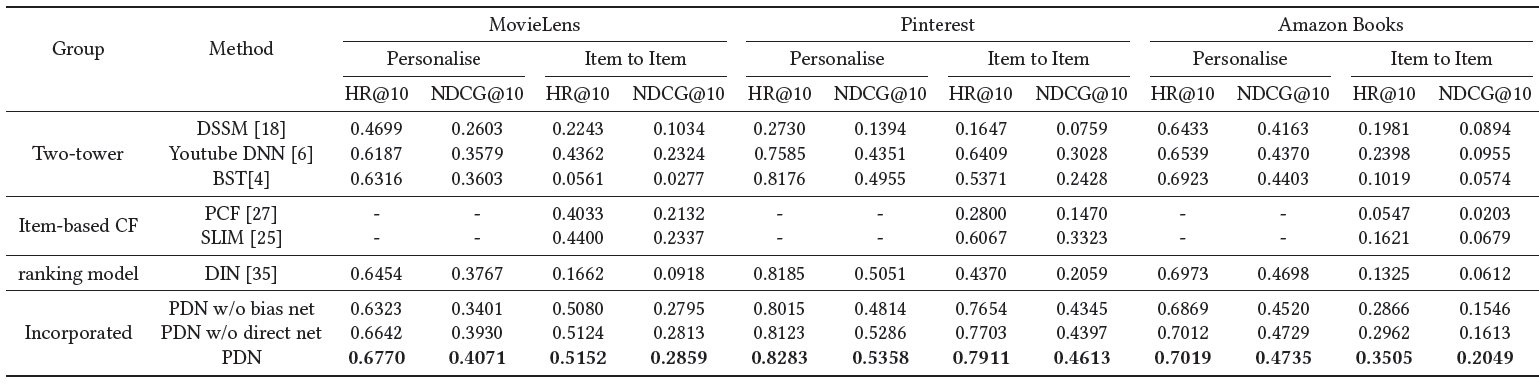
三个公共数据集上
HR@10和NDCG@10的实验结果如下表所示。所有实验重复5次并报告平均结果。最佳结果以粗体突出显示。对baseline方法的提升在0.05水平上具有统计显著性。Personalise是指输出的得分考虑了用户信息,例如PDN和EBR-based方法。值得注意的是,CF无法得到个性化的分数,因此用-表示。Item to Item指的是基于交互item和target item之间的相关性检索。具体而言,item相似度的获取策略是基于item-based CF、SimNet的输出、EBR方法获取的item embedding之间的内积。
显然,在大多数数据集下,
PDN优于所有比较方法。我们观察到:对于个性化检索(
Personalise),DSSM在双塔方法中表现最差,这表明基于用户行为捕获用户兴趣对于推荐系统至关重要。BST的性能优于YouTube DNN,这是因为transformer layer通过考虑用户行为中的序列信息来提取用户的兴趣。PDN实现了最佳性能,主要是因为这些双塔方法用一个固定维度的向量来表示每个用户,这是对不同兴趣进行建模的瓶颈。相比之下,PDN利用TrigNet提取多兴趣的用户representation,每个维度都以细粒度的方式描述了用户对交互item的兴趣。SimNet在得到item和target item之间的相似性方面也很有效。因此,可以通过考虑用户对target item的潜在兴趣来估计更准确的相关性。在线部署时,我们采用
SimNet代替item-based CF来估计item-to-item相似性。因此,我们和item-to-item进行了对比(即下表中带有Item to Item的列)。SimNet在所有Item to Item方法中表现最好。原因是SimNet基于深度神经网络,通过集成双塔方法使用的item画像、以及item-based CF使用的共现信息,显式优化了item之间的相似性。这种方式利用更多的信息来解决CF遇到的稀疏性问题。PDN比DIN表现更好。我们认为DIN忽略了用户对交互item的注意力(而仅考虑target item对交互item的注意力),而PDN同时考虑了user attention和item attention从而获得更好的个性化推荐。基于消融研究,
PDN产生了最佳性能,并且确认每个组件对最终效果都有贡献。
26.2.2 在线实验
A/B test:除了离线研究,我们还通过在淘宝推荐系统中部署我们的方法从而进行为期两周的在线A/B test实验。- 在对照组(即
baseline)中,包含了我们当前生产系统中的所有matching策略。 - 在其中一个实验组,我们应用
SimNet而不是item-based方法来构建倒排索引。
为了公平地比较,在两个
matching阶段之后都采用相同的ranking组件和业务逻辑。注意:在线指标给出的是相对提升,即:下表给出了淘宝上的在线
A/B test实验提升,为期两周: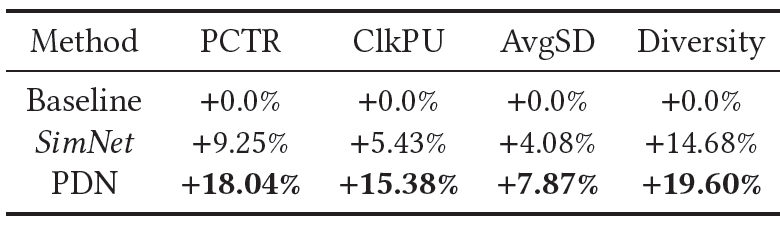
下图给出了
PDN每一天各种指标的在线提升,为期一周: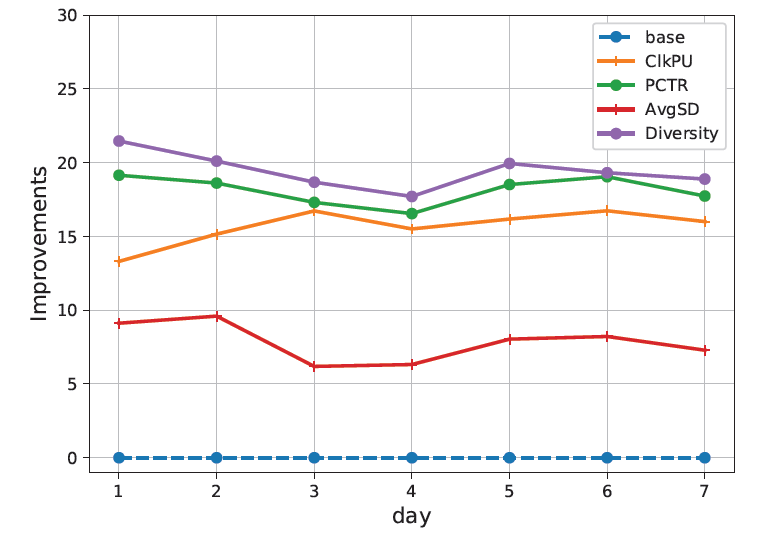
可以看到:
PDN改进了电商推荐系统的所有核心业务指标,包括页面点击率page click-through rate: PCTR、用户点击率user click-through rate: UCTR、每个用户点击量clicks per user: ClkPU、平均session时长average session duration: avgSD,以及多样性diversity。这些都被认为是推荐满意度
recommendation satisfaction的良好指标。其中多样性指标代表了覆盖的类目数量。尤其是个性化的多样性对于现有的生产系统而言通常是比较难的,而PDN大幅度增加了推荐item的多样性,这说明PDN可以通过TrigNet和SimNet来捕获用户的多样化兴趣,提升整体的用户体验。此外,我们还部署了
SimNet来验证它可以独立地用于构建索引,而不是基于item-based CF,从而进行item-to-item检索。这也获得了性能的提升。
- 在对照组(即
在线效率:这里我们报告在线
serving的效率。具体而言,从请求到候选生成candidate generation的整体延迟可以在6.75ms内完成,即queries per second: QPS是在千级别,这与使用标准倒排索引的检索相当。基于巨大的性能提升和低延迟,我们将PDN部署到线上,从而服务于淘宝推荐系统的matching阶段。
26.2.3 案例研究
用户行为序列长度分析:基于淘宝离线日志训练得到的模型,我们研究了用户行为序列长度 对性能的影响。我们根据 对用户进行分组。
如下表所示,我们发现 越小增益越大。评估指标为
HR@300,括号中的百分比表示相对于BST的提升。该结果表明:
PDN对 具有较强的鲁棒性,即使在用户行为序列稀疏的情况下也能获得优异的性能。
如下图所示,我们发现随着 的增加,
PDN生成的候选的多样性逐渐增加,并且显著优于BST。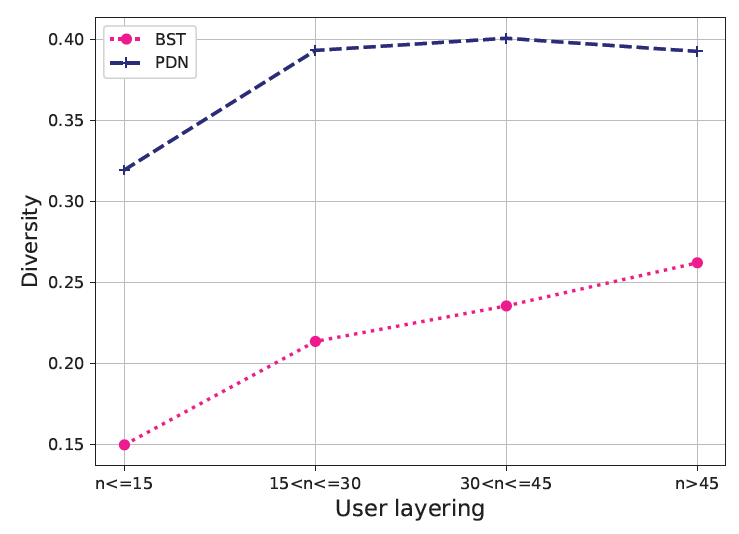
这些结果表明:
PDN能够以细粒度的方式捕获用户的个性化和多样化兴趣,从而改善用户体验。SimNet的多样性diversity和准确性accuracy:为了验证
SimNet的有效性,我们分别利用SimNet和item-based CF提供的相似性,利用相同的trigger item执行item-to-item检索。返回结果的相似性从左到右递减。如下图所示,通过形状像猫的玩偶来检索,
SimNet返回相似的猫形玩偶和印有猫爪图案的杯子,而item-based CF返回月销量高但是和猫无关的玩偶(例如狗形玩偶)。这个结果表明:SimNet可以在不受交互次数(即item销量)干扰的情况下检索更相关和更多样的结果,而item-based CF会遭受 “马太效应”的影响,这引入了对热门item的偏好的bias。换句话说,item-based CF仅基于item co-occurrence信息计算相似性,而我们的方法额外引入了更多信息,如item画像、用户画像、用户行为,从而实现更准确的item相似性估计。
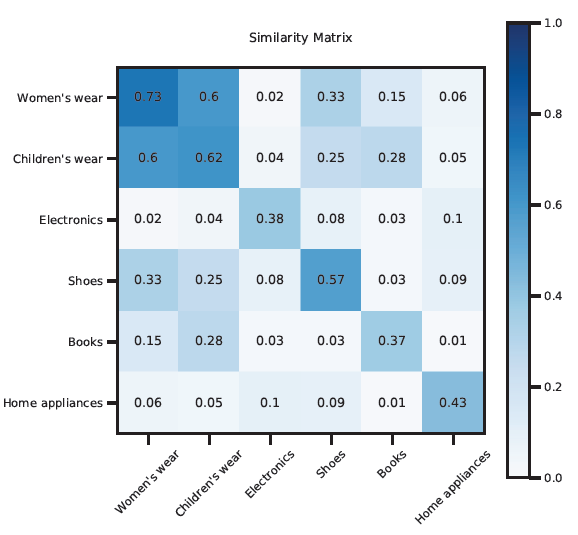
为了进一步验证基于
SimNet的item相似性的可靠性,我们选择一批类目,然后每对类目随机选择1000个item pair对,并基于在线serving的SimNet构建的倒排索引计算它们的平均相似度。如下图所示:- 我们发现属于同一个类目的
item具有更高的相似性。 - 此外,相关类目的相似度高于不相关类目的相似度。例如,无论是 “女装
vs童装” 还是 “电子产品vs家电”,都要比其它类目pair对具有更高的相似度。
- 我们发现属于同一个类目的
TrigNet的个性化和有效性:在公共数据集上,我们基于
TrigNet来探索用户对item的兴趣。如下图所示,user-to-item的trigger权重分别在postive item和negative item上取平均。很明显,postive item的权重高于negative item的权重。这个结果说明了TrigNet的合理性。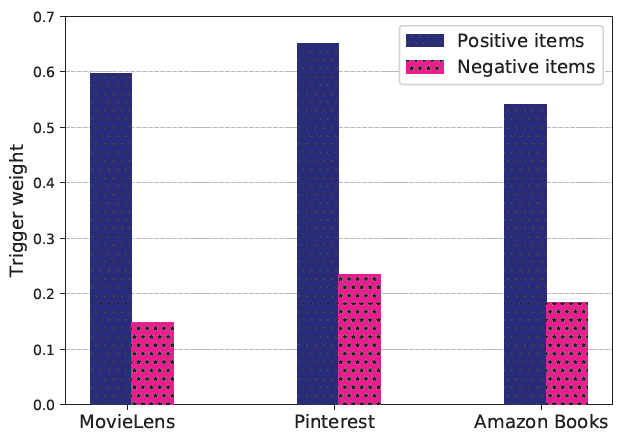
为了验证
TrigNet的个性化能力,我们随机选择了1000名男性和1000名女性,从几个类目中随机选择了500个item,然后基于在线serving的TrigNet对所有user-item pair对进行评分,得到男性和女性之间的平均trigger权重的差异。如下图所示,我们可以发现TrigNet对性别的处理是不同的,从而准确反映用户特点。例如,男性更喜欢电脑、汽车和手表,女性更喜欢花卉、旅游和女鞋。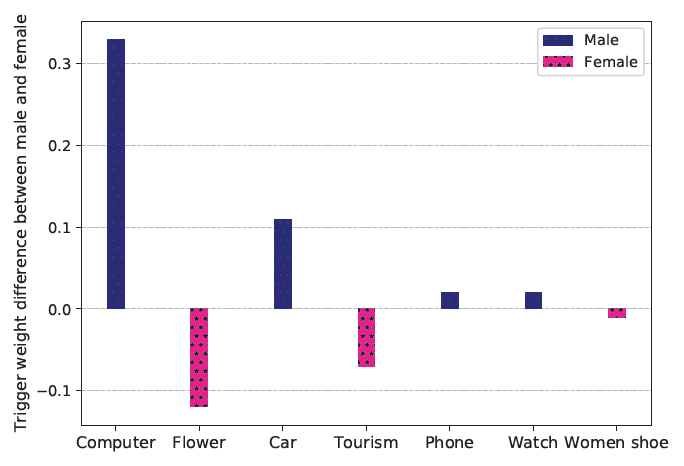
二十七、时空周期兴趣学习网络ST-PIL[2021]
POI推荐是基于位置的社交网络中的一项重要任务,它有助于建模用户和位置之间的关系。最近,学者根据长期兴趣和短期兴趣推荐
POI并取得成功。长期兴趣是通过用户历史到店来获得,短期兴趣是通过最近到店来建模的。这些兴趣通过编码器网络(例如LSTM)来编码。然而,它们未能很好地捕获到周期性的兴趣。人们倾向于在相似的时间或相似的地域访问相似的门店。因此,只有一小部分到店与用户的下一次到访行为高度相关。因此,到店序列作为输入会弱化相关部分的信号。有一些方法试图通过建模周期性来解决这个问题:
DeepMove应用当前的移动状态mobility status来捕获所有到店的周期性。LSTPM使用time slot计算时序相似性temporal similarity从而获得时间加权的轨迹表达time-weighted trajectory representation。
但是,这些方法在学习周期兴趣方面仍然能力有限。
到店上下文,例如空间信息
spatial information、时间信息temporal information,可以用于建模周期兴趣。- 首先,用户活动受时间限制,呈现出天级别模式
daily pattern和小时级别模式hourly pattern。例如,一些用户可能只在周末去度假,另一些用户会在晚上去餐馆。 - 其次,用户在不同地域表现出地域模式
areal pattern。例如,用户在景区参观古迹、在商圈附近购物。 - 第三,用户会在特定时间访问同一个
POI,这就是 小时-区域级别的模式hourly-areal pattern。例如,很多人八点钟去公司上班。
而
DeepMove和LSTPM等之前的方法在学习周期性时并没有充分利用时空信息。受上述分析的启发,论文
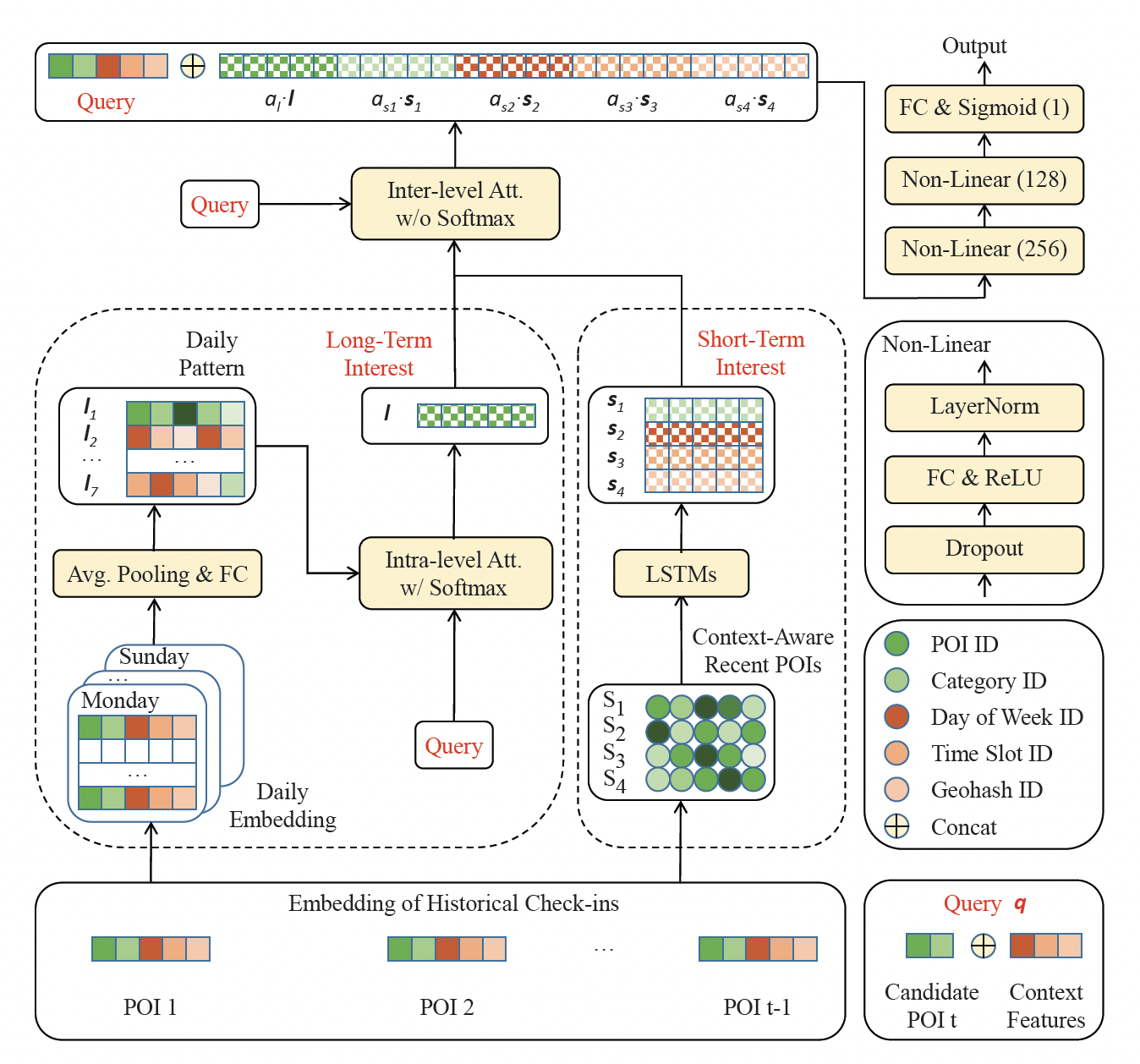
《ST-PIL: Spatial-Temporal Periodic Interest Learning for Next Point-of-Interest Recommendation》提出了一个时空周期兴趣学习网络Spatial-Temporal Periodic Interest Learning network: ST-PIL。具体而言,ST-PIL采用长短期兴趣学习的架构,但是充分利用时空上下文中从历史到店中检索到相关的部分,从而获得周期性兴趣。- 在长期模块中,我们学习天级别的时间周期兴趣,然后利用层内注意力
intra-level attention来得到长期兴趣。 - 在短期模块中,我们构造各种短期兴趣序列,从而分别获取小时粒度、地域粒度、小时 x 地域粒度的时空周期兴趣。
- 最后,我们利用层间注意力
inter-level attention自动融合多个兴趣。
主要贡献:
- 提出了充分考虑时空周期性的思想,具体而言,构建了天级别、小时级别、地域级别、小时-地域级别的周期性。
- 提出了两个层级的注意力:层内注意力从用户的天级模式中学习长期兴趣、层间注意力融合了长期兴趣和短期兴趣。
相关工作:这里简要回顾一下近期关于
POI推荐的一些研究并总结了差异。长期兴趣和短期兴趣的结合最近备受关注,并取得了
state-of-the-art。DRCF通过协同过滤捕获长期兴趣,并通过RNN添加短期兴趣。STGN通过设计时空门spatial-temporal gates来修改LSTM从而提升兴趣。Deep-Move应用RNN-based方法来捕获短期规律,并设计一个历史注意力模块从而利用用户状态的移动周期性mobility periodicity。LSPL和PLSPL使用attention layer来获得长期兴趣,并使用LSTM对近期的连续行为进行建模从而获得短期兴趣。LSTPM使用各种技术得到的所有轨迹来捕获长期兴趣,例如:周期性的时间加权操作、用于捕获短期兴趣的LSTM和geo-dilated LSTM。
之前的这些工作和我们的研究之间的差异是明显的。以前的工作通常从有限的粒度(例如
time slot)中捕获周期性,而我们充分利用时空上下文,并设计有效的注意力操作来自动结合combine。
27.1 模型
已知条件:
- 用户集合 ,
POI集合 ,类目集合 。 - 每个
POI都有一个类目 。 - 空间信息:每个
POI都有一个经纬度,我们使用geohash-5编码,得到geohash编码集合 。每个POI都对应于一个geohash编码。 - 时间信息:我们有一周七天,即 。我们有一天
24小时,即 。 - 用户的第 个到店表示为 。
给定用户的所有历史到店序列 ,以及用户当前的时空信息(即 ),我们预估用户可能到店的
top-k POI。这里要求获取用户的实时地理位置,即用户当前位置和门店
POI匹配。- 用户集合 ,
Long-Term Module:使用周几的时间上下文查找用户的天级别模式daily pattern,并使用注意力机制来建立长期兴趣。天级别模式旨在捕获用户的天级周期性,从周一到周日。
首先,构建七组掩码:第 组掩码表示用户历史到店序列中,每个行为是否是周
k产生的。例如,第一组掩码:
[1,1,0,0,1,0,...0],这表示历史到店序列第一个行为、第二个行为、第五个行为都是周一产生的。接下来,我们用每一组掩码和到店序列进行逐元素相乘(从而得到周
k的行为序列),然后通过均值池化以及一个全连接层(这个全连接层在周一...周日之间共享),从而得到周k的天级别embedding。我们得到七个天级别
embedding,记做 。我们创建一个
query来获取attention,第 个query由候选POI和已知上下文 的拼接组成:其中每个
POI都可以作为候选,但是只有一个是positive的,并且这里的ID都转换为embedding向量。然后我们通过
Bahdanau attention来聚合 :其中 都是
attention的参数。
Short-Term Module:用于捕获基本序列模式和上下文感知(例如hourly周期性 、areal周期性、hourly-areal周期性)。在第 次 到店,假设我们有当前的时间槽
time slot、有area。我们构建四条序列:- 序列 :到访序列中,最近的
5个到访POI。捕获序列模式Sequential Pattern。 - 序列 :到访序列中,最近的、相同
geohash=47的5个到访POI。捕获Areal Pattern。 - 序列 :到访序列中,最近的、相同或者相近小时(
22点、23点、或24点)的5个到访POI。捕获Hourly Pattern。 - 序列 :到访序列中,最近的、相同
geohash=47的、相同或相近小时(22点、23点、或24点)的5个到访POI。捕获Hourly-Areal Pattern。
每个序列都暗含某种行为模式,对于每个序列,我们使用
LSTM来捕获用户对应pattern的兴趣: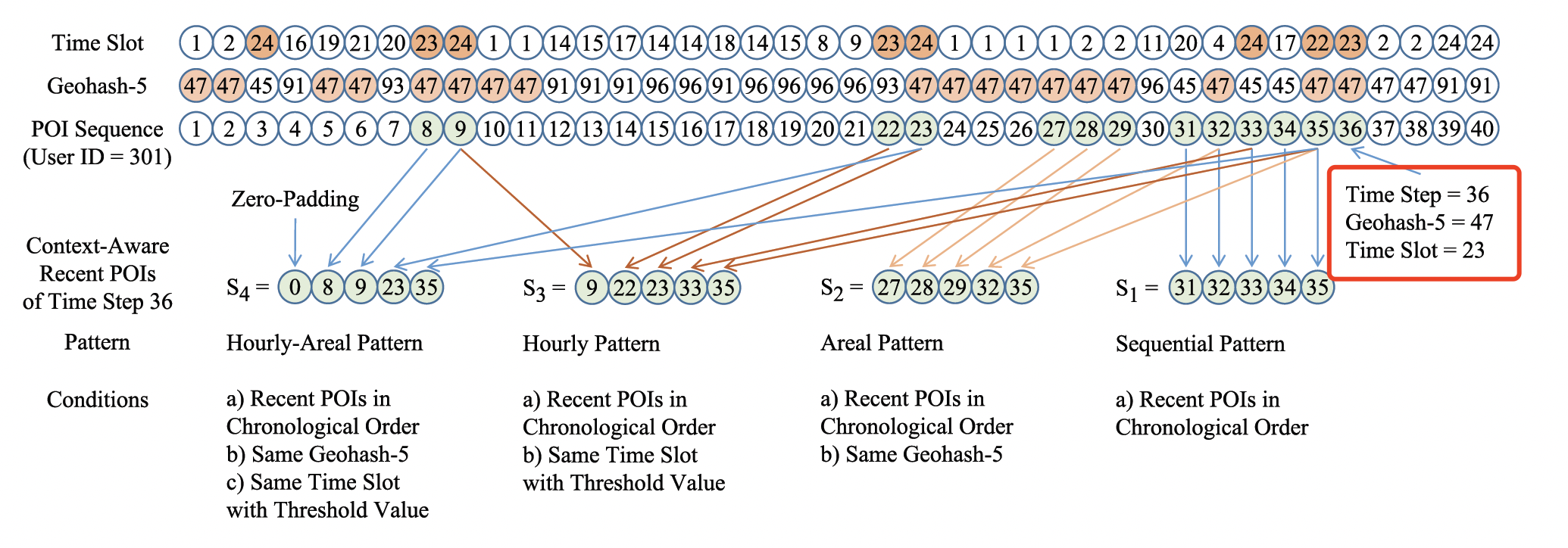
- 序列 :到访序列中,最近的
Inter-level Attention:用于获取用户最终的兴趣。在当前时刻 ,我们有五个兴趣: 。其中, 捕获长期的天级兴趣,其它四个捕获短期的兴趣。我们使用
Bahdanau attention来获取用户最终的兴趣:其中 为
attention权重。然后我们拼接所有的兴趣,得到最终的用户兴趣
representation:这里有几点注意:
- 由于兴趣都来自历史到店,因此我们为
query和各个兴趣添加了一个dropout layer,从而避免在计算注意力权重之前过拟合。 - 其次,当这些兴趣捕获不同的
pattern时,我们通过加权拼接来聚合他们,从而保留独特的模式。 - 此外,我们在注意力权重上放弃了
softmax来改善重要模式的表达能力。
- 由于兴趣都来自历史到店,因此我们为
Prediction Layer:我们将 和 进行拼接,然后馈入MLP。模型的输出为交叉熵:
其中
N为所有候选POI(在所有候选里,只有一个positive)。模型整体架构如下图所示。
27.2 实验
数据集:两个公开的、真实的数据集,来自于
NewYork city: NYC和Tokyo: TKY。 每个到店包含:用户ID、POI ID、类目ID、经度、纬度。数据处理:删除到店人数少于
5的POI,并且对每个用户保留他/她最近的500个到店。评估方式:留一法,每个用户保留最近一次的到店作为测试集,剩余的到店用户训练集和验证集。然后从用户未到店的
POI中挑选20个作为负样本。评估指标为Acc@k、MRR@k。评估结果:
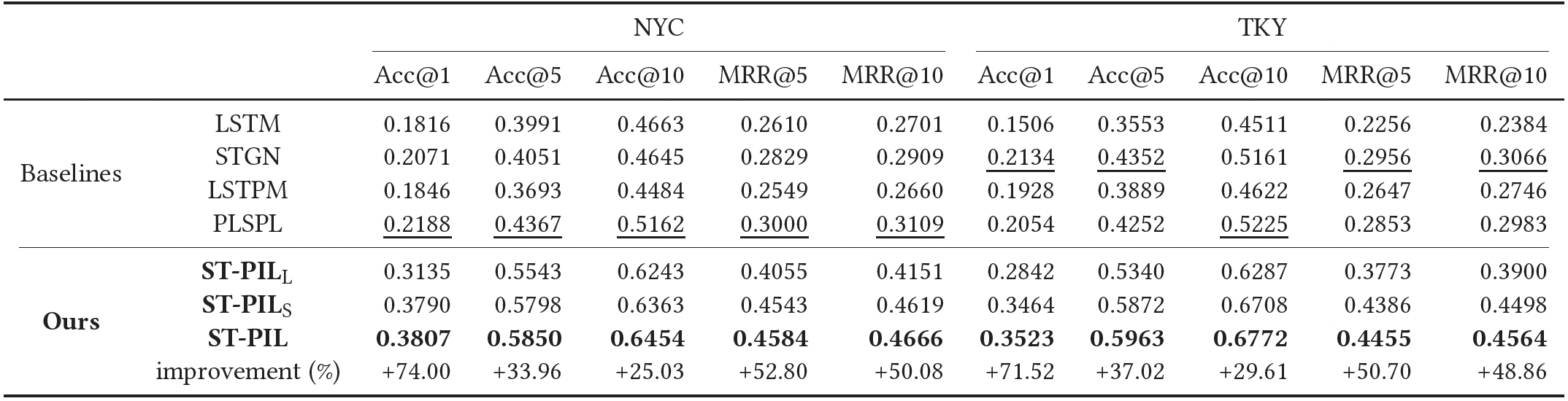
ST-PILL:只有长期兴趣的ST-PIL模型。ST-PILS:只有短期兴趣的ST-PIL模型。ST-PIL明显优于其它方法。ST-PILS优于ST-PILL,而ST-PIL是最好的。这表明同时融合长期兴趣和短期兴趣的价值。
长期模块的
attention研究:att-qk表示长期模块attention且包含query,att-k表示长期模块attention但是不包含query,seq-avg表示长期模块不使用注意力而是取均值。L表示仅使用长期模块而没有短期模块,L+S表示同时使用长期模块和短期模块。结论:带
query的注意力机制效果最佳。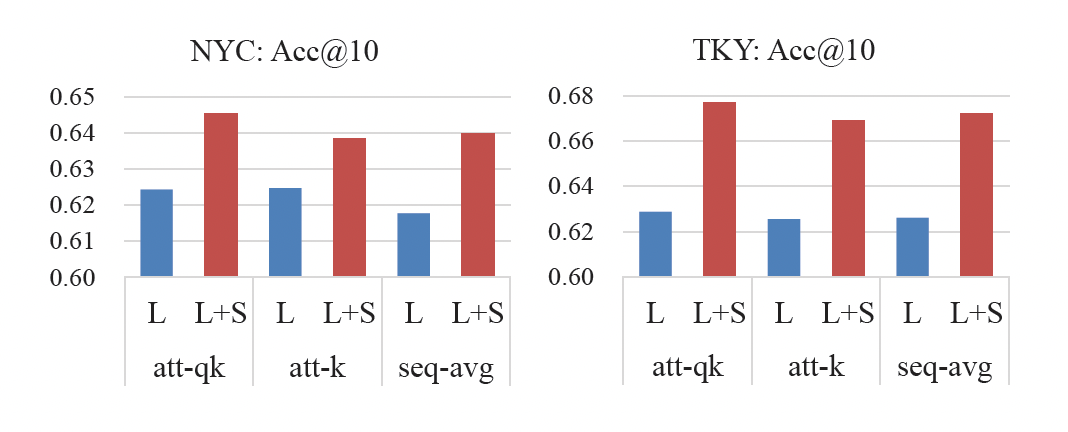
短期模块的四种兴趣研究:依次采用不同的短期兴趣组合,从而评估这些短期兴趣的效用。
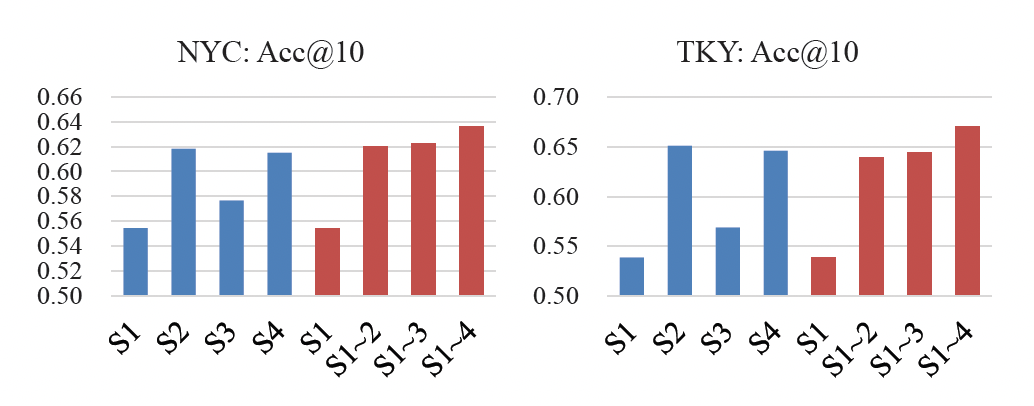
- 就单个兴趣而言,空间周期性(
S2)和时空周期性(S4)优于其它两个,表明它们的影响力强于序列效应和时间周期性。也就是,当用户选择某个区域的POI时,他/她更可能去之前访问过的POI。 - 就组合兴趣而言,
ST-PILS的整体性能优于任何单个短期兴趣。此外,当我们逐渐增加四个短期兴趣时,效果越来越好。这表明这些兴趣是互补的。
- 就单个兴趣而言,空间周期性(
未来工作:设计更加自动化的方法来代替构建不同序列的预操作。