传统CTR 预估模型
CTR预估模型主要用于搜索、推荐、计算广告等领域的CTR预估,其发展经历了传统CTR预估模型、神经网络CTR预估模型。传统
CTR预估模型包括:逻辑回归LR模型、因子分解机FM模型、梯度提升树GBDT模型等。其优点是:可解释性强、训练和部署方便、便于在线学习。本章主要介绍传统
CTR预估模型。
一、LR 模型[2007]
在
cost-per-click:CPC广告中广告主按点击付费。为了最大化平台收入和用户体验,广告平台必须预测广告的CTR,称作predict CTR: pCTR。对每个用户的每次搜索query,有多个满足条件的广告同时参与竞争。只有pCTR x bid price最大的广告才能竞争获胜,从而最大化eCPM:基于最大似然准则可以通过广告的历史表现得统计来计算
pCTR。假设广告曝光了100次,其中发生点击5次,则pCTR = 5%。其背后的假设是:忽略表现出周期性行为或者不一致行为的广告,随着广告的不断曝光每个广告都会收敛到一个潜在的真实点击率 。这种计算
pCTR的方式对于新广告或者刚刚投放的广告问题较大:新广告没有历史投放信息,其曝光和点击的次数均为
0。刚刚投放的广告,曝光次数和点击次数都很低,因此这种方式计算的
pCTR波动非常大。如:一个真实
CTR为5%的广告必须曝光1000次才有85%的信心认为pCTR与真实CTR的绝对误差在1%以内。真实点击率越低,则要求的曝光次数越多。
为解决这个问题,论文
《Predicting Clicks: Estimating the Click-Through Rate for New Ads》提出利用LR模型来预测新广告的CTR。从经验上来看:广告在页面上的位置越靠后,用户浏览它的概率越低。因此广告被点击的概率取决于两个因素:广告被浏览的概率、广告浏览后被点击的概率。
因此有:
假设:
在广告被浏览(即:曝光)到的情况下,广告被点击的概率与其位置无关,仅与广告内容有关。
广告被浏览的概率与广告内容无关,仅与广告位置有关。
广告可能被拉取(推送到用户的页面),但是可能未被曝光(未被用户浏览到)。
则有:
第一项 就是我们关注和预测的
CTR。第二项与广告无关,是广告位置(即:广告位)的固有属性。
可以通过经验来估计这一项:统计该广告位的总拉取次数 ,以及总曝光次数 ,则:
这也称作广告位的曝光拉取比。
1.1 数据集构造
通常广告主会为一个订单
order给出多个竞价词term,如:xxxxxxxxxx41Title: Buy shoes now,2Text: Shop at our discount shoe warehouse!3Url: shoes.com4Terms: {buy shoes, shoes, cheap shoes}.此时广告系统会为每个竞价词生成一个广告,每个广告对应相同的
Title/Text/Url、但是不同的竞价词。数据集包含
1万个广告主,超过1百万个广告、超过50万竞价词(去重之后超过10万个竞价词)。注意,不同的竞价词可能会展示相同的广告。样本的特征从广告基本属性中抽取(抽取方式参考后续小节)。广告的基本属性包括:
landing page落地页:点击广告之后将要跳转的页面的url。bid term:广告的竞价词。title:广告标题。body:广告的内容正文。display url:位于广告底部的、给用户展示的url。clicks:广告历史被点击的次数。views:广告历史被浏览的次数。
将每个广告的真实点击率
CTR来作为label。考虑到真实点击率
CTR无法计算,因此根据每个广告的累计曝光次数、累计点击次数从而得到其经验点击率 来作为CTR。
为了防止信息泄露,训练集、验证集、测试集按照广告主维度来拆分。最终训练集包含
70%广告主、验证集包含10%广告主、测试集包含20%广告主。每个广告主随机选择它的1000个广告,从而确保足够的多样性。因为同一个广告主的广告之间的内容、素材、风格相似度比较高,点击率也比较接近。
对于有专业投放管理的那些优质广告主,在数据集中剔除它们。因为:
优质广告主的广告通常表现出不同于普通广告主的行为:
- 两种广告主的广告具有不同的平均点击率
- 优质广告主的广告的点击率方差较低(表现比较稳定)、普通广告主的广告的点击率方差较高(表现波动大)
广告平台更关注于普通广告主,因为这些普通广告主的数量远远超过优质广告主的数量,而且这些普通广告主更需要平台的帮助。
对于曝光量少于
100的广告,在数据集中剔除它们。因为我们使用经验点击率 来近似真实CTR来作为label,对于曝光次数较少的广告二者可能相差很远,这将导致整个训练和测试过程中产生大量噪音。曝光阈值的选取不能太大,也不能太小:
- 阈值太小,则导致
label中的噪音太多。 - 阈值太大,则离线训练样本(大曝光的广告)和在线应用环境(大量新广告和小曝光广告)存在
gap,导致在线预测效果较差。
- 阈值太小,则导致
1.2 LR模型
论文将
CTR预估问题视作一个回归问题,采用逻辑回归LR模型来建模,因为LR模型的输出是在0到1之间。其中 表示从广告中抽取的第 个特征(如广告标题的单词数量), 为该特征对应的权重。采用负号的原因是使得权重、特征和
pCTR正相关:权重越大则pCTR越大。模型通过
limited-memory Broyden-Fletcher-Goldfarb-Shanno:L-BFGS算法来训练。模型的损失函数为交叉熵:
权重通过均值为零、方差为 的高斯分布来随机初始化。其中 为超参数,其取值集合为
[0.01,0.03,0.1,0.3,1,3,10,30,100],并通过验证集来选取最佳的值。
通过实验发现, 的效果最好。
论文采取了一些通用的特征预处理方法:
模型添加了一个
bias feature,该特征的取值恒定为1。即:将偏置项 视为 。对于每个特征 ,人工构造额外的两个非线性特征::, 。加
1是防止 取值为0。对所有特征执行标准化,标准化为均值为
0、方差为1。注意:对于验证集、测试集的标准化过程中,每个特征的均值、方差使用训练集上的结果。
对所有特征执行异常值截断:对于每个特征,任何超过均值
5个标准差的量都被截断为5个标准差。如:特征 的均值为
20,方差为2。则该特征上任何大于30的值被截断为30、任何小于10的值被截断为10。注意:对于验证集、测试集的异常值截断过程中,每个特征的均值、方差使用训练集上的结果。
评价标准:
baseline:采用训练集所有广告的平均CTR作为测试集所有广告的pCTR。即:测试集里无论哪个广告,都预测其
CTR为一个固定值,该值就是训练集所有广告的平均CTR。评估指标:测试集上每个广告的
pCTR和真实点击率的平均KL散度。KL散度衡量了 和真实点击率之间的偏离程度。一个理想的模型,其KL散度为0,表示预估点击率和真实点击率完全匹配。为了更好的进行指标比较,论文实验中也给出了测试集的
MSE(均方误差)指标。
模型不仅可以用于预测新广告的
pCTR,还可以为客户提供优化广告的建议。可以根据模型特征及其重要性来给广告主提供创建广告的建议,如:广告标题太短建议增加长度。
1.3 特征工程
1.3.1 Term CTR Feature Set
不同竞价词的平均点击率存在明显的差异,因此在预测某个广告的点击率时,相同竞价词的其它类似广告可能有所帮助。
因此论文对此提出两个特征,称作相同竞价词特征集
Term CTR Feature Set。对于广告
ad的竞价词term(记作 )针对该
term竞价的其它广告主所有广告的数量:由于同一个广告主的不同广告之间相关性比较强,因此这里用其它广告主的广告作为特征来源。否则容易出现信息泄露。
针对该
term竞价的其它广告主的广告点击率(经过归一化):其中:
是训练集上所有广告的平均点击率
是针对该
term竞价的其它广告主所有广告的数量是针对该
term竞价的其它广告主所有广告的平均点击率是平滑系数,为了防止某些新的
term出现导致 。如果不采取平滑,则有 。代表了
term竞价的广告数量的先验强度,默认取值为1。实验发现,结果对 的取值不敏感。
模型新增这两个特征的实验结果如下图所示,可见
term ctr feature set使得评估指标 “平均KL散度” 提升了13.28%。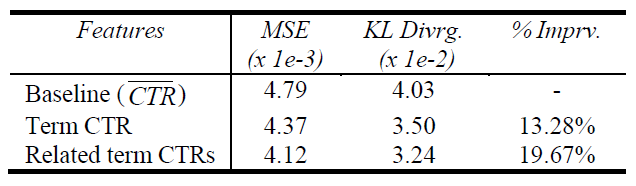
1.3.2 Related Term CTR Feature Set
预测某个广告的点击率时,相关竞价词的其它类似广告可能也有所帮助。
如:广告
a的竞价词是 “电脑”,广告b的竞价词是 “买电脑”,则广告b的点击率对于预测广告a的点击率是有帮助的。考虑竞价词的子集/超集。
给定一个竞价词
t,定义其相关广告集合为 (一个竞价词term可能包含多个单词word,这里不考虑word之间的词序):如:
t是red shoes- 如果广告的竞价词是
buy red shoes,则该广告属于t的 - 如果广告的竞价词是
shoes,则该广告属于t的 - 如果广告的竞价词是
red shoes,则该广告属于t的 - 如果广告的竞价词是
blue shoes,则该广告属于t的
- 如果广告的竞价词是
由 的定义可知:
- 广告集合 代表广告的竞价
term和t完全匹配。 - 广告集合 代表广告的竞价
term比t少了 个单词之外其它单词完全相同(不考虑词序)。 - 广告集合 代表广告的竞价
term比t多了 个单词之外其它单词完全相同(不考虑词序)。
假设
*为任意数值,则定义:- 表示
t的任何超集(不考虑词序)作为竞价term的广告的集合。 - 表示
t的任何子集(不考虑词序)作为竞价term的广告的集合。
- 广告集合 代表广告的竞价
定义相关竞价词的一组特征,它们称为相关竞价词特征集
Related Term CTR Feature Set:在
term相关的竞价词上竞价的其它广告主所有广告的数量:在
term相关的竞价词上竞价的其它广告主所有广告的平均点击率:其中 表示广告
x的真实点击率。和
Term CTR Feature Set一样,这里也采用平滑:其中 表示平滑系数。
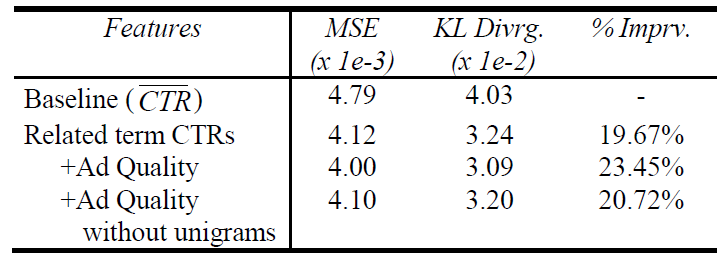
论文中采取了 一共
5x5=25种组合,得到25 x 2 =50个related term ctr特征。测试集的 “平均KL散度” 表明:采用这一组特征之后,取得了接近20%的提升。
1.3.3 Ad Quality Feature Set
即使是同一个竞价
term,不同广告的点击率也存在显著差异。从经验来看,至少有五种粗略的要素影响用户是否点击:外观
Appearance:外观是否美观。吸引力
Attention Capture:广告是否吸引眼球。声誉
Reputation:广告主是否知名品牌。落地页质量
Landing page quality:点击广告之后的落地页是否高质量。虽然用户只有点击之后才能看到落地页,但是我们假设这些落地页是用户熟悉的广告主(如
ebay, amazon),因此用户在点击之前就已经熟知落地页的信息。相关性
Relevance:广告与用户query词是否相关。
针对每个要素,论文给出一些特征:
外观
Appearance:- 广告标题包含多少个单词。
- 广告标题是在广告体内还是在广告体外。
- 标题是否正确的大小写首字母。
- 广告标题是否包含了太多的感叹号、美元符号或其它标点符号。
- 广告标题用的是短词还是长词。
吸引力
Attention Capture:- 标题是否包含暗示着转化的单词,如
购买 buy、加入join、订阅subscribe等等。 - 这些转化词是否出现在广告体内还是广告体外 。
- 标题是否包含数字(如折扣率,价格等)。
- 标题是否包含暗示着转化的单词,如
声誉
Reputation:底部展示的
URL是否以.com/.net/.org/.edu结尾。底部展示的的
url多长。底部展示的
url分为几个部分。如
books.com只有两部分,它比books.something.com更好。底部展示的
url是否包含破折号或者数字。
因为好的、短的
.com域名比较贵,因此url体现了广告主的实力。落地页质量
Landing page quality:- 落地页是否包含
flash。 - 落地页页面哪部分采用大图。
- 落地页是否符合
W3C。 - 落地页是否使用样式表。
- 落地页是否弹出广告。
- 落地页是否包含
相关性
Relevance:- 竞价词是否出现在标题。
- 竞价词的一部分是否出现在标题。
- 竞价词或者竞价词的一部分是否出现在广告体内。
- 如果出现,则竞价词或者竞价词的一部分占据广告体的几分之一。
最终在这
5个要素种抽取了81个特征。某些特征可以出现在多个要素里,如:广告内容中美元符号数量。该特征可能会增加吸引力,但是会降低外观。
除了以上
5个内容要素,还有一个重要的内容要素:广告文本的单词。我们统计广告标题和正文中出现的
top 10000个单词,将这1万个单词出现与否作为unigram特征。因为某些单词更容易吸引用户点击,因此unigram特征能够弥补注意力要素遗漏的特征。注意:构造特征时,标题和正文的
unigram分别进行构造。即:单词是否出现在标题中、单词是否出现在正文中。如下所示:单词
shipping更倾向于在高CTR广告中出现,这意味着shipping更容易吸引用户点击。图中的三条曲线从上到下依次代表:- 每个单词在高
CTR广告中出现的平均频次。 - 每个单词在所有广告中出现的平均频次。
- 每个单词在低
CTR广告中出现的平均频次。
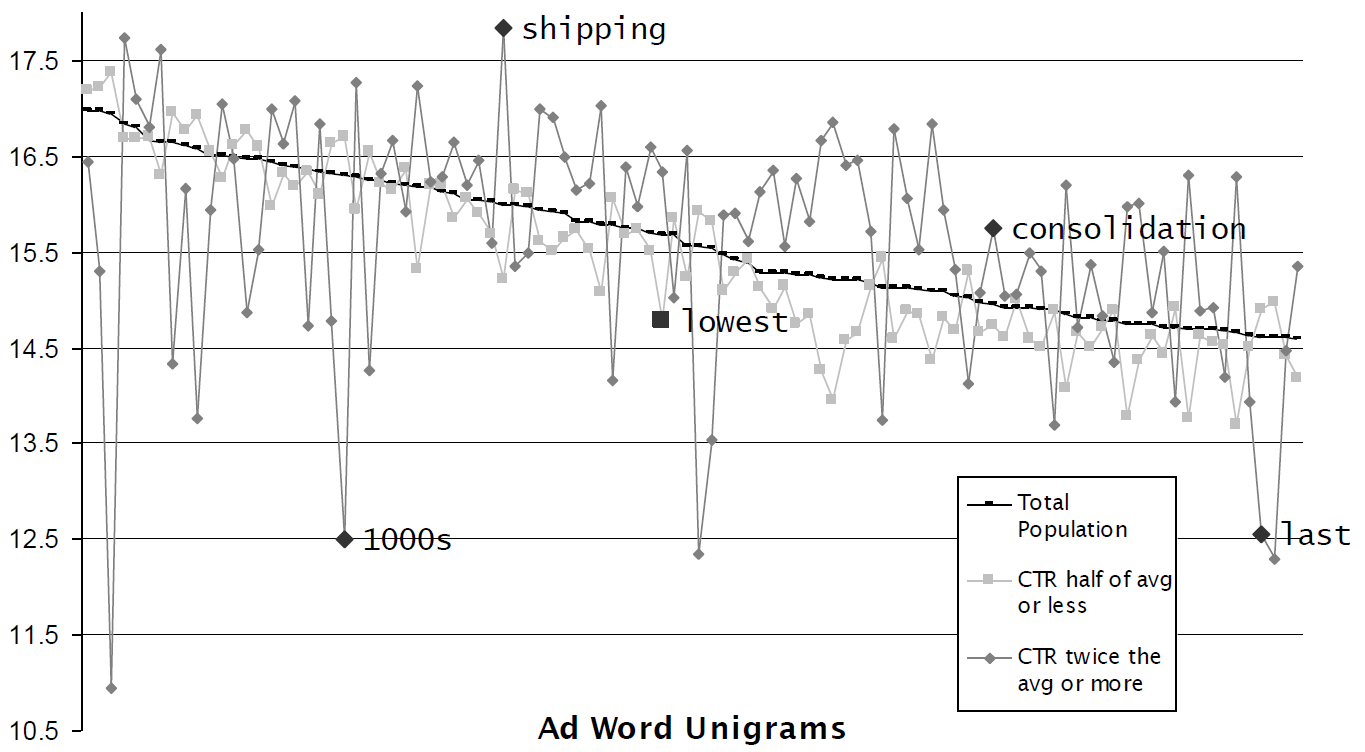
- 每个单词在高
以上5个内容要素,以及
unigram特征一起构成了广告质量特征集Ad Quality Feature Set。结果表明:该组特征能够显著提升性能,将测试集的 “平均
KL散度” 提升约3.8 %。考虑去掉
unigram特征,结果表明:- 仅仅
5个因素的81个特征能够提升约1.1 %。 unigram特征能够提升约2.7 %。
- 仅仅
1.3.4 Order Specificity Feature Set
有的订单定向比较窄。如:
xxxxxxxxxx41Title: Buy shoes now,2Text: Shop at our discount shoe warehouse!3Url: shoes.com4Terms: {buy shoes, shoes, cheap shoes}.该订单的竞价词都和
shoes相关,定向比较狭窄。而有的订单定向比较宽,如:
xxxxxxxxxx41Title: Buy [term] now,2Text: Shop at our discount warehouse!3Url: store.com4Terms: {shoes, TVs, grass, paint}该订单的竞价词不仅包含
shoes,还包括TV、grass等等。我们预期:定向越宽的订单,其平均
CTR越低;定向越窄的订单,其平均CTR越高。为了考虑捕捉同一个订单内不同广告的联系,论文提出了订单维度特征集
Order Specificity Feature Set。同一个订单中,去重之后不同竞价词
term的数量:同一个订单中,竞价词
term的类别分布。分布越集中,定向越窄;分布越分散,定向越宽。- 利用搜索引擎搜索每个竞价词
term,并通过文本分类算法对搜索结果进行分类,将每个竞价词term划分到74个类别中。 - 计算每个订单的竞价词
term的类别熵,并将类别熵作为特征。
- 利用搜索引擎搜索每个竞价词
采用该特征集之后,测试集的 “平均
KL散度” 提升约5.5 %。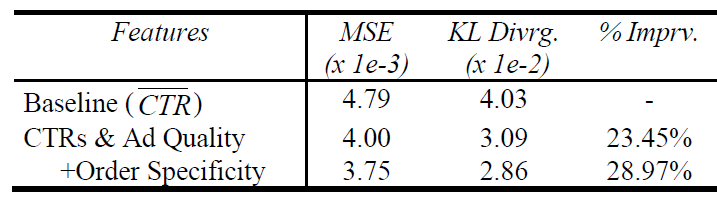
1.3.5 Search Data Feature Set
事实上可以通过使用外部数据来构造特征。
如:给定一个竞价词
term,可以通维基百科来判断它是否是一个众所周知的词,也可以通过同义词词库来查找其同义词等等。因此构建外部搜索数据特征集
Search Data Feature Set,其中包括:每个竞价词
term,网络上该term出现的频率。这可以利用搜索引擎的搜索结果中包含该
term的网页数量来初略估计。每个竞价词
term,搜索引擎的query中出现该term的频率。这可以用近三个月搜索引擎的搜索日志中,
query里出现该term的数量来粗略估计。
这两个特征离散化为
20个桶,仔细划分桶边界使得每个桶具有相同数量的广告。单独采用该特征集之后,测试集的 “平均
KL散度” 提升约3.1 %。但是融合了前面提到的特征之后没有任何改进,这意味着该特征集相比前面的几个特征集是冗余的。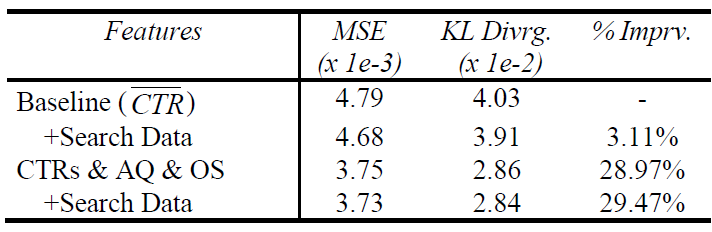
1.3.6 更多特征
当独立的考虑每个
feature set时,测试集的 “平均KL散度” 提升效果如下:related term ctr feature set:19.67%。ad quality feature set:12.0%。unigram features along:10.2%。order specificity feature set:8.9%。search data feature set:3.1%。
有几个特征探索方向:
可以将广告的竞价词
term进行聚类,从而提供广告之间的关系。这是从语义上分析竞价词term的相似性。这组特征称作Related Term Feature Set。可以基于用户的
query来构造特征。在完全匹配条件下竞价词和用户搜索词完全相同,但是在更宽松的匹配下竞价词和搜索词可能存在某种更广义的关联。此时了解搜索词的内容有助于预测广告的点击率。
因此可以基于用户的搜索词
query term来构建特征,如:query term和bid term相似度、query term的单词数、query term出现在广告标题/广告正文/落地页的频次。可以将落地页的静态排名和动态排名信息加入特征。如:用户访问落地页或者域名的频率、用户在落地页停留的时间、用户在落地页是否点击回退等等。
一个推荐的做法是:在模型中包含尽可能多的特征。这带来两个好处:
更多的特征带来更多的信息,从而帮助模型对于广告点击率预测的更准。
更多的特征带来一定的冗余度,可以防止对抗攻击。
广告主有动力来攻击特征来欺骗模型,从而提升广告的
pCTR,使得他的广告每次排名都靠前。假设模型只有一个特征,该特征是 ”竞价词是否出现在标题“ 。广告主可以刻意将竞价词放置到广告标题,从而骗取较高的
pCTR。一旦模型有多个特征,那么广告主必须同时攻击这些特征才能够欺骗模型。这种难度要大得多。
1.4 特征重要性
由于模型采用逻辑回归,因此可以直观的通过模型权重看到哪些特征具有最高权重、哪些特征具有最低权重。
模型的
top 10和bottom 10权重对应的特征如下: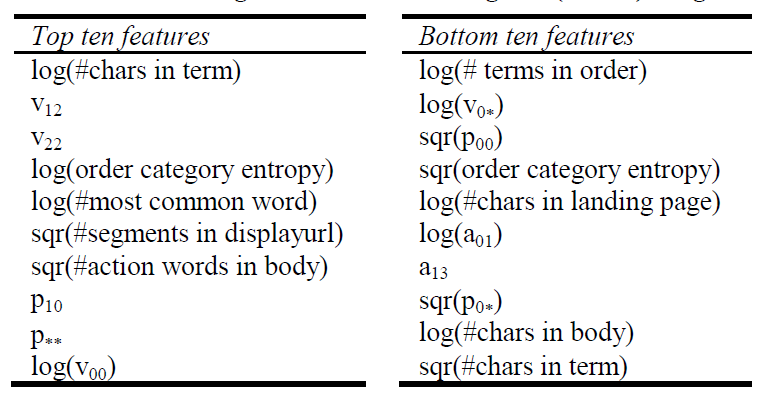
特征的权重不一定直接表示其重要性,因为特征之间不是独立的。
假设有一个重要的特征是文本中每个单词的平均长度(即:平均多少个字符) ,但我们并没有直接给出这个特征,而是给出相关的两个特征:文本总字符数 、文本总单词数 。那么我们会发现:特征 具有一个较大的正权重、特征 有一个较大的负权重。
因为 ,所以特征 和特征 正相关,而特征 和特征 负相关。
在
unigram features中,top 10和bottom 10权重对应的特征如下。可以看到:
- 排在前面的是更为成熟
established的实体词,如official,direct,latest,version。 - 排在后面的是更为吸引眼球的实体词,如
quotes, trial, deals, gift, compare。
从经验上看:用户似乎更愿意点击声誉更好的、更成熟的广告,而不愿意点击免费试用、优惠类的广告。

- 排在前面的是更为成熟
1.5 曝光量
假设模型能准确预估广告的点击率,一个问题是:广告经过多少次曝光之后,观察到的点击率和预估的点击率接近。
定义观察到的点击率为:
定义预测的点击率为:
其中:
是广告的曝光次数, 为广告的点击次数, 为先验
CTR, 是先验曝光次数。是模型预估得到的
pCTR,而 是一个超参数。是结合了模型预估的
pCTR和广告已经产生的曝光、点击之后,预测的点击率。模型预测的
pCTR没有考虑广告当前的曝光、点击,因此需要修正。
定义期望绝对损失
expected absolute error:EAE:其中: 表示给定曝光的条件下,点击
click次的概率。它通过统计其它广告得到。EAE刻画了在不同曝光量的条件下,模型给出的 和CTR的绝对误差。这和模型优化目标平均KL散度不同。baseline和LR模型的EAE结果如下所示。可以看到:- 在广告的曝光量超过
100时,baseline和LR模型的EAE几乎相同。 - 在广告的曝光量小于
50时,LR模型的EAE更低。
因此模型对于曝光量
100以内的广告具有明显优势。这也是前面预处理将100次曝光作为阈值截断的原因。对于百万级别广告的广告系统,如果在广告曝光的前
100次期间对广告的CTR预估不准,则导致这些广告以错误的顺序展示,从而导致收入减少和用户体验下降。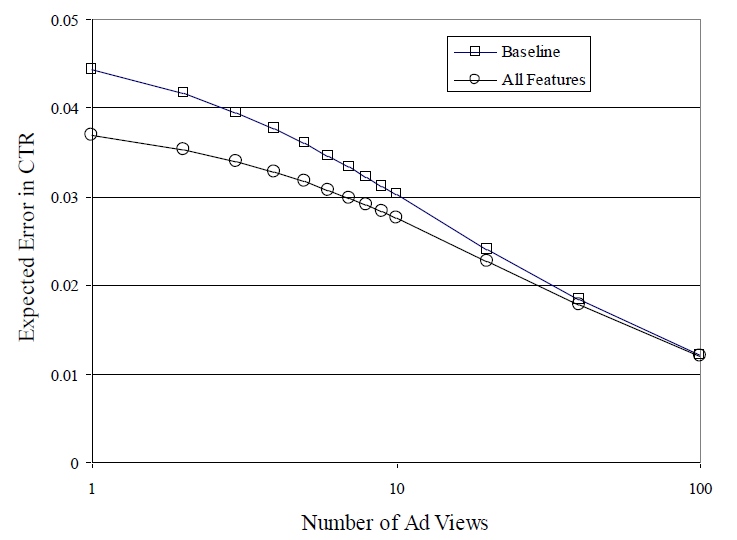
- 在广告的曝光量超过
预处理选择
100次曝光作为截断阈值,是希望样本的观察CTR具有合理的置信水平。事实上有一些广告系统更关注于曝光量更大的广告,希望对这些广告能够预测更准确。更大曝光量意味着
label中更少的噪音,模型会学习得效果更好。但是这也意味着广告样本不包含那些被系统判定为低价值的广告,因为系统没有给这些低价值广告足够多的曝光机会。
当曝光阈值提升到
1000次时,模型效果如下。可以看到:曝光量超过1000的广告比曝光量100的广告,模型预测效果(以测试集的平均KL散度为指标)提升了40%左右((41.88-29.47)/29.47)。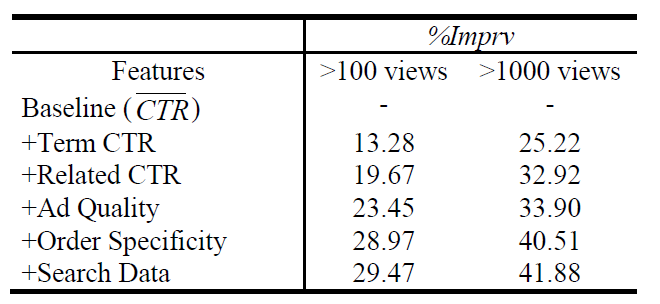
二、POLY2 模型[2010]
LR模型只考虑特征之间的线性关系,而POLY2模型考虑了特征之间的非线性关系。捕获非线性特征的一个常用方法是采用核技巧,如高斯核
RBF,将原始特征映射到一个更高维空间。在这个高维空间模型是线性可分的,即:只需要考虑新特征之间的线性关系。但是核技巧存在计算量大、内存需求大的问题。
论文
《Training and Testing Low-degree Polynomial Data Mappings via Linear SVM》提出多项式映射polynomially mapping数据的方式来提供非线性特征,在达到接近核技巧效果的情况下大幅度降低内存和计算量。
设低维样本空间为 维度,低维样本 。
多项式核定义为: 。其中 为超参数, 为多项式的度
degree。根据定义,多项式核等于样本在高维空间向量的内积:
其中 是映射函数。
当 时,有:
使用 是为了 的表达更简洁。
如果不用核技巧,仅仅考虑使用一个多项式进行特征映射,则我们得到:
结合
LR模型,则得到POLY2模型:新增的组合特征一共有 个。
POLY2模型的优缺点:优点:除了线性特征之外,还能够通过特征组合自动捕获二阶特征交叉产生的非线性特征。
缺点:
参数太多导致计算量和内存需求发生爆炸性增长。
如计算广告场景中,原始样本特征可能达到上万甚至百万级别,则特征的交叉组合达到上亿甚至上万亿。
数据稀疏导致二次项参数训练困难,非常容易过拟合。
参数 的训练需要大量的 都非零的样本。而大多数应用场景下,原始特征本来就稀疏(非零的样本数很少),特征交叉之后更为稀疏(非零的样本数更少)。这使得训练 的样本明显不足,很容易发生过拟合。
三、FM模型[2011]
推荐系统中的评级预测
rating prediction主要依赖于以下信息:谁who(哪个用户)对什么what(哪个item,如电影、新闻、商品)如何how评级。有很多方法可以考虑关于who(关于用户的人口统计信息,如年龄、性别、职业)、what(关于item属性的信息,如电影类型、产品描述文本的关键词)的附加数据。除了有关评级事件
rating event中涉及的实体的此类数据之外,还可能存在有关评级事件发生当前情况的信息,例如当前位置location、时间、周边的人、用户当前心情等等。这些场景信息通常称作上下文context。因为从决策心理学知道一个人的环境和情绪确实会影响他们的行为,所以在推荐系统中利用上下文信息是可取的。上下文感知评级预测context-aware rating prediction依赖于谁who在何种上下文context下如何how评价什么what的信息。经典的推荐系统方法不考虑上下文信息。一些方法执行数据的预处理
pre-processing或后处理post-processing,使得标准方法具有上下文感知能力。虽然这种临时解决方案可能在实践中起作用,但是它们的缺点是过程中的所有步骤都需要监督和微调。将各种输入数据统一到一个模型中的方法在这方面更为实用,理论上也更为优雅。目前,在预测准确性方面最灵活和最强的方法是
Multiverse Recommendation,它依赖于Tucker分解并允许使用任何离散型上下文categorical context。然而,对于现实世界的场景,它的计算复杂度 太高了,其中 是因子分解的维度, 是所涉及变量的数量。在论文
《Fast Context-aware Recommendations with Factorization Machines》中,作者提出了一种基于分解机Factorization Machine: FM的上下文感知评级预测器。FM包括并可以模拟推荐系统中最成功的方法,包括句子分解matrix factorizion: MF、SVD++、PITF。作者展示了
FM如何应用于各种上下文字段,包括离散型categorical字段、离散集合set categorical字段、实值real-valued字段。相比之下,Multiverse Recommendation模型只适合于离散型categorical上下文变量。除了建模的灵活性之外,
FM的复杂度在 和 上都是线性的(即 ),这允许使用上下文感知数据进行快速预测和学习。相比之下,Multiverse Recommendation模型的复杂度是 ,在 上是多项式的。为了学习
FM模型的参数,论文提出了一种基于交替最小二乘法alternating least squares: ALS的新算法。新算法在给定其它参数的情况下找到一个参数的最优解,并且在几次迭代之后找到所有参数联合最优解。和随机梯度下降
stochastic gradient descent: SGD一样,新算法单次迭代的复杂度为 ,其中 为训练样本的数量。和
SGD相比,新算法的主要优点是无需确定学习率。这在实践中非常重要,因为SGD学习的质量在很大程度上取决于良好的学习率,因此必须进行代价昂贵的搜索。这对于ALS来讲不是必需的。最后,论文的实验表明:上下文感知
FM可以捕获上下文信息并提高预测准确性。此外FM在预测质量和运行时间方面都优于state-of-the-art的方法Multiverse Recommendation。
3.1 相关工作
推荐系统的大多数研究都集中在仅分析
user-item交互的上下文无关方法上。在这里,矩阵分解matrix factorization: MF方法非常流行,因为它们通常优于传统的knn方法。也有研究将用户属性或
item属性等元数据结合到预测中,从而扩展了矩阵分解模型。然而,如果存在足够的反馈数据,元数据对评分预测的强baseline方法通常只有很少或者没有改善。这种用户属性/item属性和上下文之间的区别在于:属性仅仅被附加到item或者用户(例如,给电影附加一个流派的属性),而上下文被附加到整个评级事件(如,当评级发生时用户当时的心情)。和关于标准推荐系统的大量文献相比,上下文感知推荐系统的研究很少。最基本的方法是上下文预过滤
pre-filtering和后过滤post-filtering,其中应用标准的上下文无关推荐系统,并在应用推荐器recommender之前基于感兴趣的上下文对数据进行预处理、或者对结果进行后处理。更复杂的方法是同时使用所有上下文和user-item信息来进行预测。也有人建议将上下文视为动态的用户特征,即可以动态变化。另外有一些关于
item预测的上下文感知推荐系统的研究,将推荐视为一个排序任务,而本文将推荐视为回归任务。Multiverse Recommendation基于Tucker分解技术来直接分解用户张量、item张量、所有离散上下文变量的张量,从而求解该问题。它将原始的评分矩阵分解为一个小的矩阵 和 个因子矩阵 :其中:
这种方式存在三个问题:
- 计算复杂度太高:假设每个特征的维度都是 ,则计算复杂度为 。一旦上下文特征数量 增加,则计算复杂度指数型增长。
- 仅能对离散型
categorical上下文特征建模:无法处理数值型特征、离散集合型categorical set特征。 - 交叉特征高度稀疏:这里执行的是
K路特征交叉(前面的POLY2模型是两路特征交叉),由于真实应用场景中单个特征本身就已经很稀疏,K路特征交叉使得数据更加稀疏,难以准确的预估模型参数。
Attribute-aware Recommendation:与通用上下文感知方法的工作对比,对属性感知或专用推荐系统的研究要多得多。有一些工作可以处理用户属性和item属性的矩阵分解模型的扩展,还有一些关于考虑时间效应的工作。然而,所有这些方法都是为特定问题设计的,无法处理我们在本工作中研究的上下文感知推荐的通用设置。当然,对于特定的和重要的问题(如时间感知推荐或属性感知推荐),专用模型的研究是有益的。但是另一方面,研究上下文感知的通用方法也很重要,因为它们提供了最大的灵活性,并且可以作为专用模型的强
baseline。Alternating Least Square Optimization:对于矩阵分解模型,Bell和Koren提出了一种交替优化所有user factor和所有item factor的ALS方法。由于所有user/item的整个factor matrix是联合优化的,因此计算复杂度为 。标准ALS的这种复杂度问题是SGD方法在推荐系统文献中比ALS更受欢迎的原因。Pilaszy等人提出一个接一个地优化每个user/item中的factor,这导致ALS算法复杂度为 ,因为避免了矩阵求逆。一次优化一个factor的思路与我们将ALS算法应用于FM的思路相同。这两种方法仅适用于矩阵分解,因此无法处理任何上下文,例如我们提出的对所有交互进行建模的
FM中的上下文。此外,我们的ALS算法还学习了全局bias和基本的1-way效应。
3.2 模型
FM模型是一个通用模型,它包含并可以模拟几个最成功的推荐系统,其中包括矩阵分解matrix factorization: MF、SVD++、PITF。我们首先简要概述了FM模型,然后详细展示了如何将其应用于上下文感知数据,以及在FM中使用这种上下文感知数据会发生什么。最后我们提出了一种新的快速alternating least square: ALS算法,和SGD算法相比它更容易应用,因为它不需要学习率。
3.2.1 FM 模型
推荐系统面临的问题是评分预测问题。给定用户集合 、物品集合 ,模型是一个评分函数:
表示用户 对物品 的评分。
其中已知部分用户在部分物品上的评分: 。目标是求解剩余用户在剩余物品上的评分:
其中 为 的补集。
通常评分问题是一个回归问题,模型预测结果是评分的大小。此时损失函数采用
MAE/MSE等等。也可以将其作为一个分类问题,模型预测结果是各评级的概率。此时损失函数是交叉熵。
当评分只有
0和1时,这表示用户对商品 “喜欢/不喜欢”,或者 “点击/不点击”。这就是典型的点击率预估问题。
事实上除了已知部分用户在部分物品上的评分之外,通常还能够知道一些有助于影响评分的额外信息。如:用户画像、用户行为序列等等。这些信息称作上下文
context。对每一种上下文,我们用变量 来表示, 为该上下文的取值集合。假设所有的上下文为 ,则模型为:
上下文的下标从
3开始,因为可以任务用户 和商品 也是上下文的一种。如下图所示为评分矩阵,其中:
所有离散特征都经过
one-hot特征转换。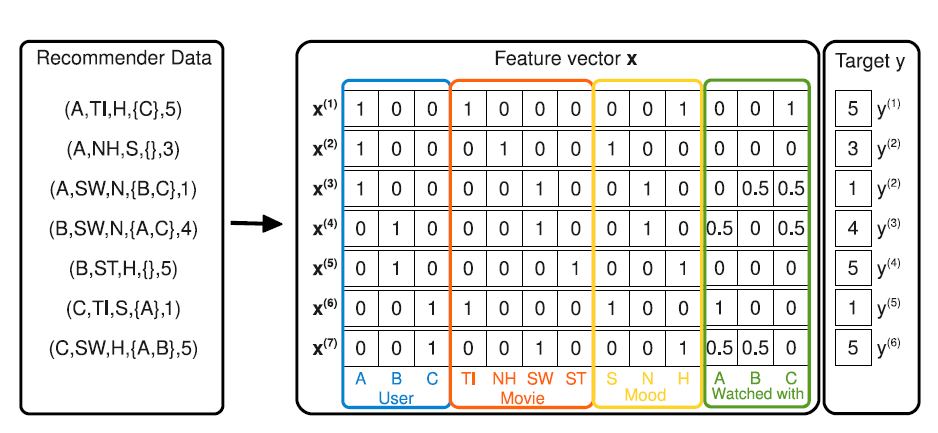
上下文特征
context类似属性property特征,它和属性特征的区别在于:属性特征是作用到整个用户(用户属性)或者整个物品(物品属性),其粒度是用户级别或者物品级别。
如:无论用户 “张三” 在在评分矩阵中出现多少次,其性别属性不会发生改变。
上下文特征是作用到用户的单个评分事件上,粒度是事件级别,包含的评分信息更充足。
如:用户 ”张三“ 在评价某个电影之前已经看过的电影,该属性会动态改变。
事实上属性特征也称作静态画像,上下文特征也称作动态画像。业界主流的做法是:融合静态画像和动态画像。
另外,业界的经验表明:动态画像对于效果的提升远远超出静态画像。
和
POLY2相同FM也是对二路特征交叉进行建模,但是FM的参数要比POLY2少得多。将样本重写为:
则
FM模型为:其中 是交叉特征的参数,它由一组参数定义:
即:
模型待求解的参数为:
其中:
- 表示全局偏差。
- 用于捕捉第 个特征和目标之间的关系。
- 用于捕捉 二路交叉特征和目标之间的关系。
- 代表特征 的
representation vector,它是 的第 列。
FM模型的计算复杂度为 ,但是经过数学转换之后其计算复杂度可以降低到 :因此有:
其计算复杂度为 。
将
FM模型和标准的矩阵分解模型进行比较,可以看到:FM也恰好包含这种分解 。此外,FM模型还包含了所有上下文变量的所有pair对的交互。这表明FM自动包含了矩阵分解模型。FM模型可以用于求解分类问题(预测各评级的概率),也可以用于求解回归问题(预测各评分大小)。对于回归问题,其损失函数为
MSE均方误差:对于二分类问题,其损失函数为交叉熵:
其中:
- 评级集合为 一共两个等级。
- 为样本 预测为评级 的概率,满足:
损失函数最后一项是正则化项,为了防止过拟合, 。其中 为参数 的正则化系数,它是模型的超参数。
可以针对每个参数配置一个正则化系数,但是选择合适的值需要进行大量的超参数选择。论文推荐进行统一配置:
- 对于 ,正则化系数为 ,这表示不需要对全局偏差进行正则化。
- 对于 ,统一配置正则化系数为 。
- 对于 ,统一配置正则化系数为 。
FM模型可以处理不同类型的特征:离散型特征
categorical:FM对离散型特征执行one-hot编码。如,性别特征:“男” 编码为
(0,1),“女” 编码为(1,0)。离散集合特征
categorical set:FM对离散集合特征执行类似one-hot的形式,但是执行样本级别的归一化。如,看过的历史电影。假设电影集合为:“速度激情9,战狼,泰囧,流浪地球”。如果一个人看过 “战狼,泰囧,流浪地球”, 则编码为
(0,0.33333,0.33333,0.33333)。数值型特征
real valued:FM直接使用数值型特征,不做任何编码转换。
FM的优势:给定特征
representation向量的维度时,预测期间计算复杂度是线性的。在交叉特征高度稀疏的情况下,参数仍然能够估计。
因为交叉特征的参数不仅仅依赖于这个交叉特征,还依赖于所有相关的交叉特征。这相当于增强了有效的学习数据。
能够泛化到未被观察到的交叉特征。
设交叉特征 “看过电影
A且 年龄等于20” 从未在训练集中出现,但出现了 “看过电影A” 相关的交叉特征、以及 “年龄等于20” 相关的交叉特征。于是可以从这些交叉特征中分别学习 “看过电影
A” 的representation、 “年龄等于20”的representation,最终泛化到这个未被观察到的交叉特征。
3.2.2 ALS 优化算法
a. 最优化解
FM的目标函数最优化可以直接采用随机梯度下降SGD算法求解,但是采用SGD有个严重的问题:需要选择一个合适的学习率。学习率必须足够大,从而使得
SGD能够尽快的收敛。学习率太小则收敛速度太慢。学习率必须足够小,从而使得梯度下降的方向尽可能朝着极小值的方向。
由于
SGD计算的梯度是真实梯度的估计值,引入了噪音。较大的学习率会放大噪音的影响,使得前进的方向不再是极小值的方向。
我们提出了一种新的交替最小二乘
alternating least square:ALS算法来求解FM目标函数的最优化问题。与SGD相比ALS优点在于无需设定学习率,因此调参过程更简单。根据定义:
对每个 ,可以将 分解为 的线性部分和偏置部分:
其中 与 无关。如:
对于 有:
对于 有:
对于 有:
因此有:
考虑均方误差损失函数:
最小值点的偏导数为
0,有:则有:
ALS通过多轮次、轮流迭代求解 即可得到模型的最优解。在迭代之前初始化参数,其中: 通过零初始化, 的每个元素通过均值为
0、方差为 的正太分布随机初始化。每一轮迭代时:
首先求解 ,因为相对于二阶交叉的高阶特征,低阶特征有更多的数据来估计其参数,因此参数估计更可靠。
然后求解 。这里按照维度优先的准确来估计:先估计所有
representation向量的第1维度,然后是第2维,... 最后是第d维。这是为了计算优化的考量。
b. 计算优化
直接求解
ALS的解时复杂度较高:在每个迭代步中计算每个训练样本的 和 。对于每个样本,求解 和 的计算复杂度为:
- 计算 的复杂度为 ,计算 的复杂度为 。
- 计算 的复杂度为 ,计算 的复杂度为 。
- 计算 的复杂度为 ,计算 的复杂度为 。
因此求解 的计算复杂度为 。
有三种策略来降低求解 的计算复杂度,从 降低到 ,其中 表示平均非零特征的数量:
- 利用预计算的误差项 降低 的计算代价 。
- 利用预计算的 项降低交叉特征的 的计算代价。
- 利用数据集 的稀疏性降低整体计算代价。
预计算误差项 :
定义误差项:
考虑到 ,则有:
因此如果计算 的计算代价较低,则计算 的计算复杂度也会降低。
首先对每个样本,计算其初始误差:
考虑到 的计算复杂度为 ,因此 的计算复杂度为 。
当参数 更新到 时,重新计算误差:
计算代价由 决定 (根据下面的讨论,其计算复杂度为 )。
预计算 值:
如果能够降低计算 的代价,则整体计算复杂度可以进一步降低。由于 的复杂度为 ,因此重点考虑 的计算复杂度。
重写 ,有:
定义:
因此如果计算 的计算代价较低,则 的计算复杂度也会降低。
对每个样本、每个
representation向量维度计算初始 值:计算复杂度为 。
当参数 更新到 时,重新 值:
计算代价为 。
一旦得到 ,则有:
计算代价为 。
数据集 的稀疏性:
根据:
对于 ,其计算复杂度为
对于 , 我们只需要迭代 中 的样本,即 的样本。
因此每次更新只需要使用部分样本。总体而言,整体复杂度为 ,其中 表示平均非零特征的数量。
ALS优化算法:输入:
- 训练样本
- 随机初始化的方差
输出:模型参数
算法步骤:
参数初始化:
初始化 :
迭代直至目标函数收敛或者达到指定步数,每一轮迭代过程为:
更新 :
更新 :
更新 :
外层循环为 ,内层循环为 。这是为了充分利用 。
.
3.3 实验
在本节中,我们根据实验研究了和
state-of-the-art的上下文感知方法Multiverse Recommendation的对比。此外,我们检查了SGD对学习率选择的敏感性,以及我们的ALS优化是否可以在没有学习率这个超参数的情况下成功工作。数据集:
Food数据集:包含212个用户对20个菜单item的6360个评分(从1分到5分),其中包含两个上下文变量:第一个上下文变量捕获用户评分的场景是虚拟的virtual还是真实的real(即用户想象自己饿了、还是用户真的饿了);第二个上下文变量刻画用户的饥饿程度。Adom数据集:包含1524个电影评分(从1分到15分),其中包含五个上下文变量,这些上下文变量关于同伴、工作日、以及其它时间信息。Yahoo! Webscope数据集:包含221367个评分。我们遵循《Multiverse recommendation: n-dimensional tensor factorization for context-aware collaborative filtering》并应用他们的方法来处理数据集。我们生成 一共九个数据集。
baseline方法:我们将context-aware FM和Multiverse Recommendation进行比较。注意:Multiverse Recommendation已经在上述三个数据集上超越了其它上下文感知推荐算法。我们使用
FM no-context作为上下文无感context-unaware的baseline,其中仅使用用户变量和item变量生成特征向量,这相当于具有bias项的矩阵分解。这是最强的上下文无关推荐算法之一。FM使用我们提出的ALS算法进行优化,Multiverse Recommendation使用原始论文中提出的SGD算法来学习。评估方式:我们从每个数据集中删除了
5%的样本,用作调优超参数以获得最佳MAE的验证集。在超参数搜索之后,我们对剩下的95%数据集进行5-fold交叉验证,即不再使用验证集。我们报告了5次实验的平均RMSE和MAE。所有方法都是
C++实现的,并在相同的硬件上运行。我们使用ALS优化的FM实现、Multiverse Recommendation实现和数据集生成脚本可以从我们的网站上下载。ALS vs SGD:我们在Webscope数据集上将SGD实现的测试误差和我们的ASL方法进行了比较,实验结果如下图所示。左图绘制了三种学习率选择的测试误差曲线,右侧的两个图分别显示了在10次和100次迭代后不同学习率得到的测试误差曲线(由于ALS没有学习率超参数,因此表现为一条水平直线)。可以看到:SGD的优化效果很大程度上取决于学习率和迭代次数。当精心挑选合适的学习率、足够大的迭代次数(根据验证集执行早停策略从而防止过拟合),SGD可以达到ALS的效果。ALS不需要精心的、耗时的搜索合适的学习率,就可以达到很好的效果。
该实验表明:
SGD需要仔细且耗时地搜索学习率,而ALS不需要这样的搜索因为它没有这个超参数。在预测质量方面SGD的性能与ALS一样好,但是前提是选择了正确的学习率。这使得ALS在应用中明显有利。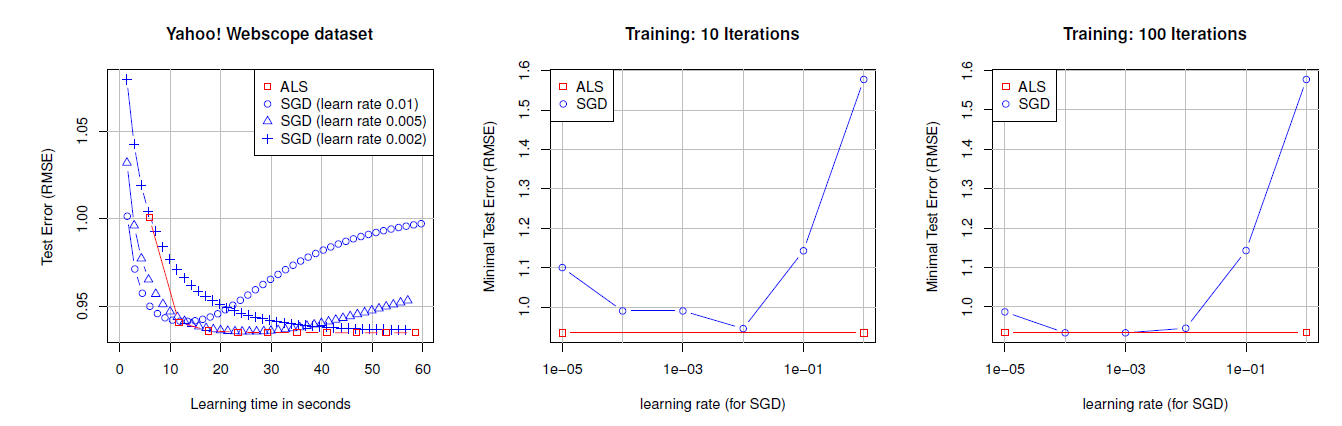
运行时间:
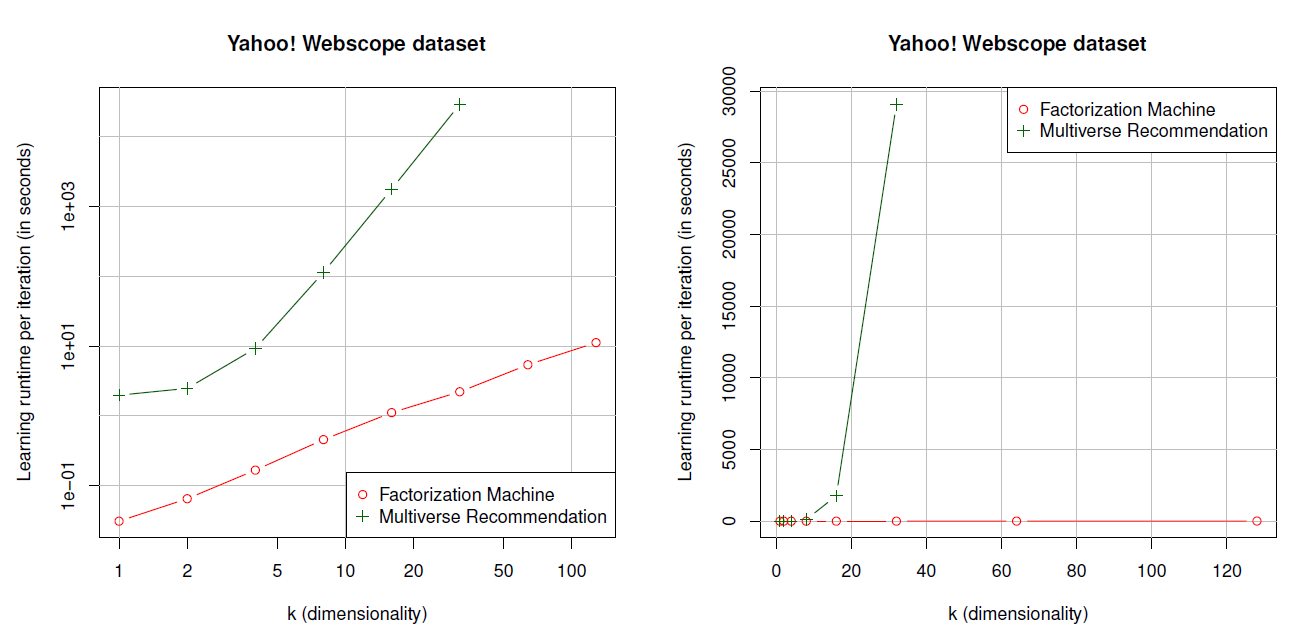
Multiverse Recommendation在实际使用中的主要缺点之一是模型的计算复杂度为 ,这对于学习和预测都是一个问题。这意味着即使对于标准的非上下文感知推荐系统,运行时间对于分解维度 上也是二次的,对于上下文感知问题至少是三次的。这使得很难应用于较大的因子维度 和较多的变量数量 。相反,FM的计算复杂度对于 和 都是线性的,即 。在本实验中,我们考察所有训练样本的一次完整迭代的运行时间。我们使用
webscope数据集, , 。对于Multiverse Recommendation,我们选择的最大 。实验结果如下图所示(单位为妙),其中左图为对数尺度。可以看到,实验结果和理论复杂度分析相匹配:FM的运行时间是线性的,例如可以在大约11s内完成所有训练样本的完整迭代(对于 )。Multiverse Recommendation的复杂度随着 的增加而增加,使得 的运行时间已经是30分钟,而 的运行时间大约是8小时。
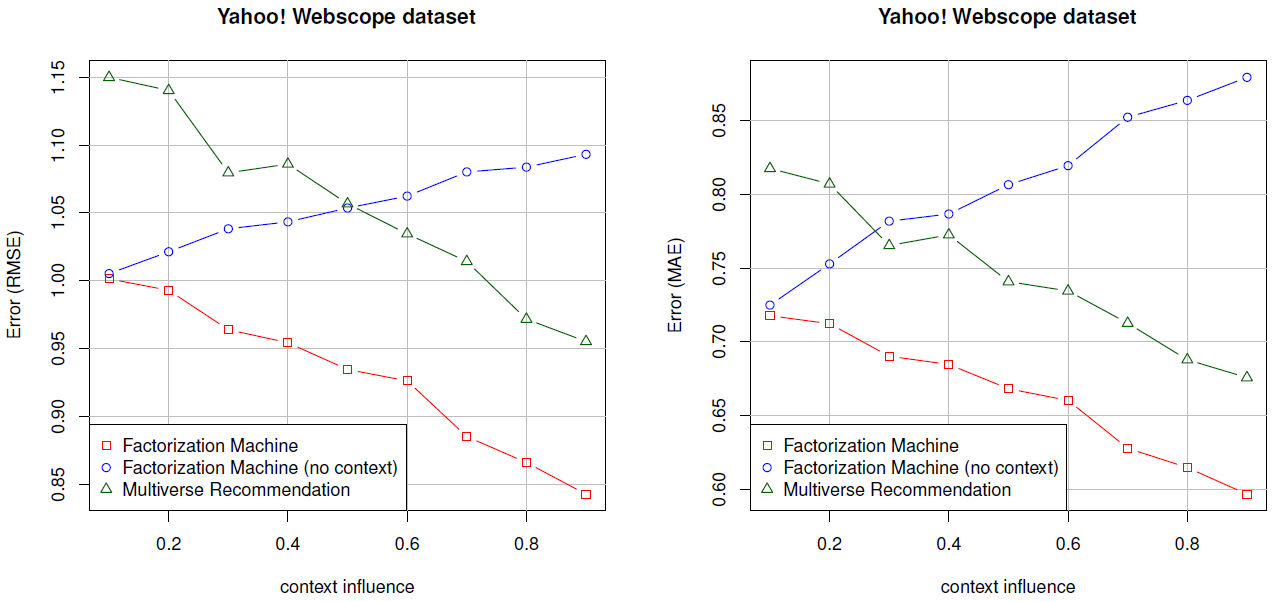
预测质量:最后我们想知道,上下文感知
FM的灵活性和快速运行时间是否会以较差的预测质量为代价。为此我们比较了Food、Adom、Webscope数据集上的预测质量,如下图所示。可以看到:- 上下文感知
FM和Multiverse Recommendation对Food和Adom数据集的预测质量相当。 - 上下文感知
FM和Multiverse Recommendation都优于上下文无感方法(相当于矩阵分解模型)。
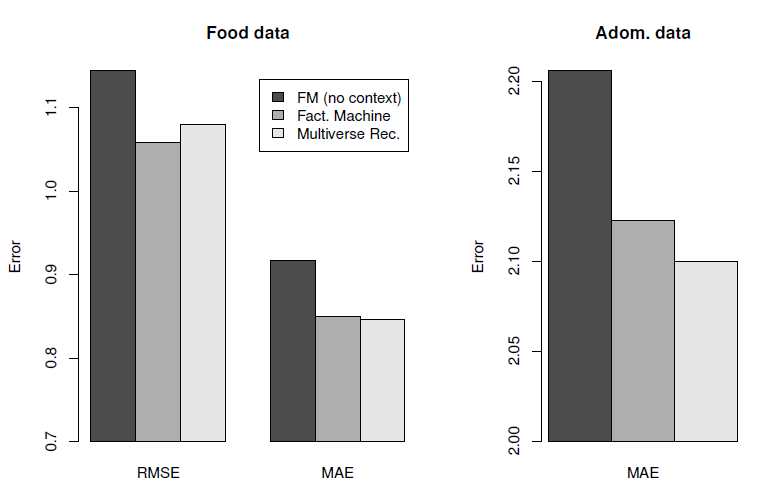
在第三个实验中,我们考察了人工特征丰富的
Webscope数据集,其中上下文变量(由context influence刻画)对于评分的影响越来越大。结果如下图所示,可以看到:- 上下文感知的
FM和Multiverse Recommendation都受益于对上下文有更强依赖性的评分。 - 当评分更依赖于上下文时,上下文无关
FM的预测质量会变差,因为对于上下文无关FM,上下文是未观测到的,因此它们无法解释这种依赖性。 - 将两种上下文感知方法相互比较,可以看到
FM始终生成比Multiverse Recommendation更好的预测。例如,RMSE下降0.10 ~ 0.15,而MAE下降0.08 ~ 0.10。
- 上下文感知
结论:实验结果表明:
上下文感知
FM能够考虑上下文信息来增强预测。在运行时间方面
FM是线性的,这使得它们可以应用于大维度的因子、更多上下文变量。相比之下,Multiverse Recommendation无法处理大维度的因子、也无法处理很多上下文变量。FM在运行时间方面的优势并没有以预测质量为代价,相反:- 在稠密数据集(
Food和Adom)上,上下文感知FM和Multiverse Recommendation的预测质量相当。 - 而在稀疏数据集上,上下文感知
FM的性能优于Multiverse Recommendation。
- 在稠密数据集(
最后,
ALS优化的FM很容易应用,因为它不像SGD那样对学习率进行昂贵的搜索。
四、FFM模型[2016]
click-through rate: CTR点击率预估在计算广告中起着重要作用。逻辑回归可能是该任务中使用最广泛的模型。给定一个具有 个样本的数据集 ,其中 为输入的 维特征向量, 为label。我们通过求解以下最优化问题从而得到逻辑回归模型:其中: 为正则化参数, 。
学习特征交叉效应看起来对
CTR预估至关重要。这里我们考虑下表中的人造数据集,以便更好地理解特征交叉,其中+表示点击量、-表示不点击量。Gucci的广告在Vogue上的点击率特别高,然而这些信息对于线性模型来说很难学习,因为线性模型分别学习Gucci和Vogue的两个权重。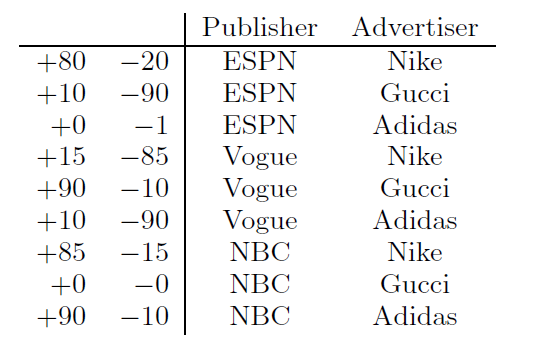
为了解决这个问题,已经有两个模型来学习特征交叉效应:
- 第一个模型是二次多项式映射
degree-2 polynomial mapping: Poly2,为每个特征交叉学习专门的权重。 - 第二个模型是分解机
factorization machine: FM,通过将特征交叉分解为两个潜在向量的乘积来学习特征交叉效应。
FM的一种变体,称作成对交互张量分解pairwise interaction tensor factorization: PITF,用于个性化的tag推荐。在2012年的KDD Cup中,Team Opera Solutions提出了一种称作因子模型factor model作为PITF的泛化,称作field-aware factorization machine: FFM。PITF和FFM的区别在于:PITF考虑了user、item、tag三个特殊的字段field,而FFM更加通用。由于FFM是针对比赛的整体解决方案,因此对它的讨论是有限的,主要包含以下结论:FFM使用随机梯度SG来解决优化问题。为了避免过拟合,Team Opera Solutions只训练了一个epoch。FFM在Team Opera Solutions尝试的六个模型中表现最好。
在论文
《Field-aware Factorization Machines for CTR Prediction》中,作者旨在具体建立FFM作为CTR预估的有效方法。论文的主要结果如下:- 尽管
FFM被证明是有效的,但是本文可能是唯一发表的、将FFM应用于CTR预估问题的研究。为了进一步证明FFM在CTR预估方面的有效性,作者使用FFM作为主要模型,从而赢得由Criteo和Avazu主办的两场全球CTR比赛。 - 论文将
FFM和两个相关模型Poly2和FM进行比较。作者首先从概念上讨论为什么FFM可能比它们更好,并通过实验来查看准确性和训练时间方面的差异。 - 论文提出了训练
FFM的技术,包括用于FFM的有效并行优化算法、以及早停以避免过拟合。 - 为了让
FFM可以被大家使用,论文发布了一个开源软件。
- 第一个模型是二次多项式映射
4.1 模型
为便于讨论,这里忽略了全局
bias项和一阶项。给定特征向量 ,POLY2模型为:参数个数为 ,计算复杂度为 。
实际上计算复杂度为 ,其中 为平均非零特征数量。
FM模型为:参数个数为 ,计算复杂度为 。
通过重写上式:
计算复杂度降为 。
实际上计算复杂度为 ,其中 为平均非零特征数量。
Rendle解释了为什么当数据集稀疏时,FM可以比Poly2更好。这里我们用上述人工数据集给出类似的说明。例如,对于
pair (ESPN, Adidas)只有一个负样本:- 对于
Poly2,可能会为 学习一个非常负的权重。 - 对于
FM,因为(ESPN, Adidas)的预估取决于 ,并且 和 也可以从其它pair中学习(如(ESPN,Nike), (NBC, Adidas)),所以预测会更准确。
另一个例子是没有针对
(NBC, Gucci)的训练数据:- 对于
Poly2,对这个pair的预测是无意义的trivial。 - 但是对于
FM,因为 和 仍然可以从其它pair中学习,因此仍然可以做出有意义的预测。
- 对于
注意,
Poly2的一种朴素实现是将每一对特征视为一个新特征,这使得模型的参数规模为 。由于CTR预估任务中的特征数量通常很大,因此Poly2不可行。Vowpal Wabbit: VW这个广泛使用的机器学习package通过哈希来解决这个问题。我们的实现方法也类似,具体而言:其中 是一个用户指定的超参数。
FFM的思想来源于个性化tag推荐的PITF。PITF假设有三个可用字段field,包括User、Item、Tag,并且在独立的潜在空间中分解(User, Item)、(User, Tag)、(Item, Tag)。FFM将PITF推广到更多字段(如AdID、AdvertiserID、UserID、QueryID),并将其有效地应用于CTR预估。由于
PITF仅针对三个特定字段(User, Item, Tag),而FFM原始论文缺乏对FFM的详细讨论,因此这里我们提供了对CTR预估的FFM的更全面的研究。对于大多数
CTR数据集,特征features可以分组为字段fields。在我们前面的示例中,ESPN, Vogue, NBC三个特征属于Publisher字段,另外三个特征Nike, Gucci, Adidas属于Advertiser字段。FFM是利用字段信息的FM变体。为了解释
FFM的工作原理,我们考虑以下示例:xxxxxxxxxx11Publisher (P): ESPN; Advertiser (A): Nike; Gender (G): Male; Clicked: Yes考虑对于
FM,有:在
FM中,每个特征只有一个潜在向量来学习和其它特征的潜在效应latent effect。以ESPN为例, 用于学习和Nike的潜在效应()、和Male的潜在效应 () 。然而,因为Nike和Male属于不同的字段,(EPSN, Nike)和(EPSN, Male)的潜在效应可能不一样。在
FFM中,每个特征有若干个潜在向量,这依赖于其它特征的字段数量。例如在这个例子中:其中:
(ESPN, NIKE)的潜在效应由 和 学习,因为Nike属于Advertiser字段、ESPN属于Publisher字段。(ESPN, Male)的潜在效应由 和 学习,因为Male属于Gender字段、ESPN属于Publisher字段。(Mike, Male)的潜在效应由 和 学习,因为Male属于Gender字段、Nike属于Advertiser字段。
FFM模型用数学语言描述为:其中: 表示第 个特征所属的
field,一共有 个field( )。参数数量为 ,计算复杂度为 ,其中 是样本中平均非零特征数。
和
FM相比,通常FFM中representation向量的维度要低的多。即:.
4.2 优化算法
FFM模型采用随机梯度下降算法来求解,使用AdaGrad优化算法。在每个迭代步随机采样一个样本 来更新参数,则 退化为:
考虑全局
bias以及一阶项,并统一所有的 ,则有:其中: 表示
field f内的所有其它特征; 表示:对梯度的每个维度,计算累积平方:
其中 是 的第 个分量, ; 是 的第 个分量, 。
更新参数:
其中 是用户指定的学习率, 。
模型参数需要合适的初始化。论文推荐:
- 从均匀分布 中随机初始化。
- 初始值为
1,这是为了防止在迭代开始时 太大,从而导致前进方向较大的偏离损失函数降低的方向。
原始论文并没有 的项,因此个人推荐采用 零均值、方差为 的正态分布来初始化它们。
论文推荐采用样本级别的归一化,这可以提升模型泛化能力。
注:如果采用
Batch normalization效果可能会更好。论文未采用BN,是因为论文发表时BN技术还没有诞生。FFM的AdaGrad优化算法:输入:
- 训练集
- 学习率
- 最大迭代步
- 初始化 的参数
输出:极值点参数
算法步骤:
初始化参数和 :
迭代 步,每一步的过程为:
随机从 中采样一个样本
计算 :
计算 ,更新
遍历所有的项::
计算 ,更新
遍历所有的项:
- 计算
- 遍历所有的维度::计算 ,并更新
4.3 field 分配
大多数数据集的结构是 :
xxxxxxxxxx11label feat1:val1 feat2:val2 ...,其中
(feat:value)表示特征索引及其取值。对于FFM,我们扩展上述格式为:xxxxxxxxxx11label field1:feat1:val1 field2:feat2:val2也就是我们必须为每个特征分配相应的字段。
为某些类型的特征分配字段很容易,但是对于其他一些特征可能比较困难。接下来我们在三种典型类型的特征上讨论这个问题。
离散型特征
categorical:通常对离散型特征进行one-hot编码,编码后的所有二元特征都属于同一个field。例如,性别字段:G:G-Male:1、G:G-Male:0。数值型特征
numuerical:数值型特征有两种处理方式:不做任何处理,简单的每个特征分配一个
dummy field。此时 ,FFM退化为Poly2模型。例如论文引用量Cite:Cite:3,其中分配的字段和特征名相同。数值特征离散化之后,按照离散型特征分配
field。例如,论文引用量Cite:3:1,其中3表示特征名(桶的编号)。论文推荐采用这种方式,缺点是:
- 难以确定合适的离散化方式。如:多少个分桶?桶的边界如何确定?
- 离散化会丢失一些信息。
离散集合特征
categorical set(论文中也称作single-field特征):所有特征都属于同一个field,此时 ,FFM退化为FM模型。如
NLP情感分类任务中,特征就是单词序列。- 如果对整个
sentence赋一个field,则没有任何意义,因为此时可能的特征范围是天文数字。 - 如果对每个
word赋一个field,则 等于词典大小,计算复杂度 无法接受。
- 如果对整个
4.4 实验
这里我们首先提供实验配置的细节,然后我们研究超参数的影响。我们发现,和逻辑回归以及
Poly2不同,FFM对epoch数量很敏感,因此我们提出了早停策略。最后我们将FFM和包括Poly2, FM在内的其它baseline进行对比,除了预估准确性之外我们还对比了训练时间。数据集:我们主要考虑来自
Kaggle比赛的两个数据集Criteo和Avazu。对于特征工程,我们主要应用了我们的成功方案,但是移除了复杂的部分。例如,我们在Avazu数据集的成功方案包含了20个模型的ensemble,但是这里我们仅使用最简单的一个。另外,我们使用哈希技巧里生成 个特征。这两个数据集的统计信息如下: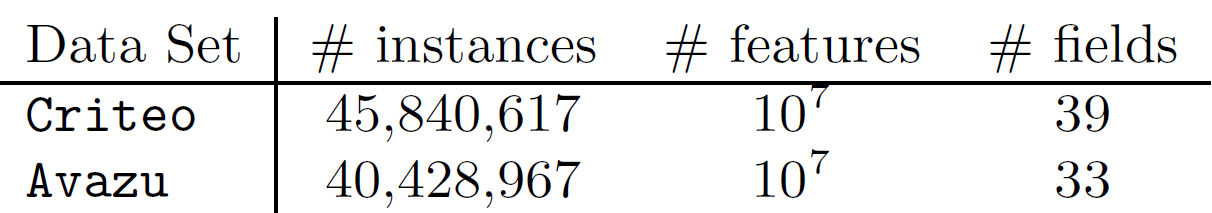
对于这两个数据集,测试集中的标签都是不可用的,所以我们将可用的数据分为训练集和验证集,拆分方式为:对于
Criteo,最后6040618行用于验证集;对于Avazu,最后4218938行用于验证集。我们用以下术语来表示各个不同的数据集:Va:上述拆分的验证集。Tr:从原始训练集中剔除验证集之后,得到的新训练集。TrVa:原始的训练集。Te:原始的测试集,其label未公布,所以我们必须将我们的预测结果提交给评估系统从而获得score分。为了避免测试集过拟合,竞赛组织者将该数据集分为两个子集:public set(竞赛期间score可见)、private set(竞赛期间score不可见且只有竞赛结束后score才公布)。最终排名由private set决定。
配置:所有实验都是在
Linux工作站上运行,该工作站配置为两个Intel Xeo E6-2620 2.0GHz处理器、128GB内存。评估指标:我们考虑
logloss作为评估指标,其中:其中:
- 为测试样本数量, 为测试样本
label。 - 为模型参数, 根据不同的模型可以为 。
- 为测试样本数量, 为测试样本
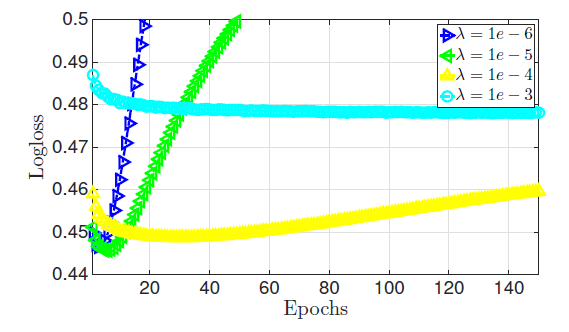
超参数影响:我们评估了超参数 (
representation向量维度)、 (正则化项系数)、 (学习率)的影响。所有结果都是在验证集上得到。为了加快实验,我们从Criteo新训练集中随机抽取10%样本作为训练集、从Criteo验证集中随机选择10%样本作为测试集。超参数 的实验效果如下图所示。第一列为不同 的取值(论文中用
k这个不同的符号),第二列为平均每个epoch的计算时间,第三列为验证集的logloss。可以看到:不同的
representation向量维度,对模型的预测能力影响不大,但是对计算代价影响较大。所以在FFM中,通常选择一个较小的 值。注意,由于采用了
SSE指令集,所以 时每个epoch计算时间几乎相同。
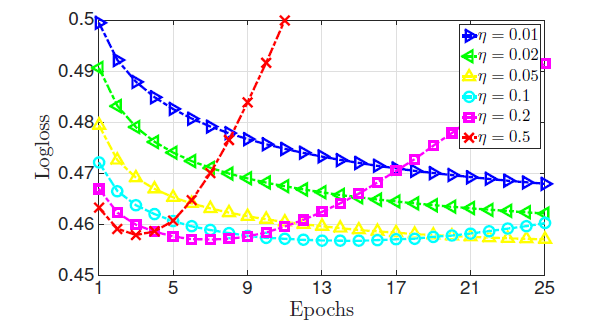
超参数 的实验效果如下图所示。可以看到:
- 如果正则化系数太小,则模型太复杂,容易陷入过拟合。
- 如果正则化系数太大,则模型太简单,容易陷入欠拟合。
一个合适的正则化系数不大不小,需要精心挑选。
学习率 的实验效果如下图所示:可以看到:
- 如果学习率较小,虽然模型可以获得一个较好的性能,但是收敛速度很慢。
- 如果学习率较大,则目标函数很快下降,但是目标函数不会收敛到一个较低的水平。
早停:
FFM对于训练epoch次数很敏感。为解决该问题,我们对FFM执行早停策略:- 首先将数据集拆分为训练集、验证集。
- 在通过训练集训练的每个
epoch结束时,计算验证集的logloss。 - 如果验证集的
logloss上升,则记录当前已训练的epoch次数 ,并停止当前训练。 - 最后用全量训练数据重新训练模型 个
epoch。
该方案存在一个潜在的缺点:
logloss对epoch次数高度敏感,以及验证集上的最佳epoch不一定是测试集上的最佳epoch。因此早停得到的模型无法保证在测试集上取得最小的logloss。我们也尝试了其它的避免过拟合的方法,比如
lazy update和ALS-based优化,但是这些方法效果都不如早停策略。我们在
Criteo和Avazu数据集上比较了不同算法、不同优化方式、不同超参数的结果。我们选择了四种算法,包括
LM模型(线性模型)、POLY2模型、FM模型、FFM模型。我们选择了三种优化算法,包括SG(随机梯度下降)、CD(坐标下降)、Newton(牛顿法)、ALS。另外我们还选择了不同超参数。LIBFM支持SG,ALS,MCMC三种优化算法,但是我们发现ALS效果最好。因此这里LIBFM使用ALS优化算法。FM、FFM都是基于SG优化算法来实现的,同时对于SG优化算法采取早停策略。- 对于非
SG优化算法,停止条件由各算法给出合适的停止条件。
从实验结果可以看到:
FFM模型效果最好,但是其训练时间要比LM和FM更长。LM效果比其它模型都差,但是它的训练要快得多。FM是一种较好的平衡了预测效果和训练速度的模型,这就是效果和速度的平衡。POLY2比所有模型都慢,因为其计算代价太大。- 从两种
FM的优化方法可见,SG要比ALS优化算法训练得快得多。 - 逻辑回归是凸优化问题,理论上
LM和POLY2的不同优化算法应该收敛到同一个点,但实验表明并非如此。原因是:我们并没有设置合适的停止条件,这使得训练过程并没有到达目标函数极值点就提前终止了。
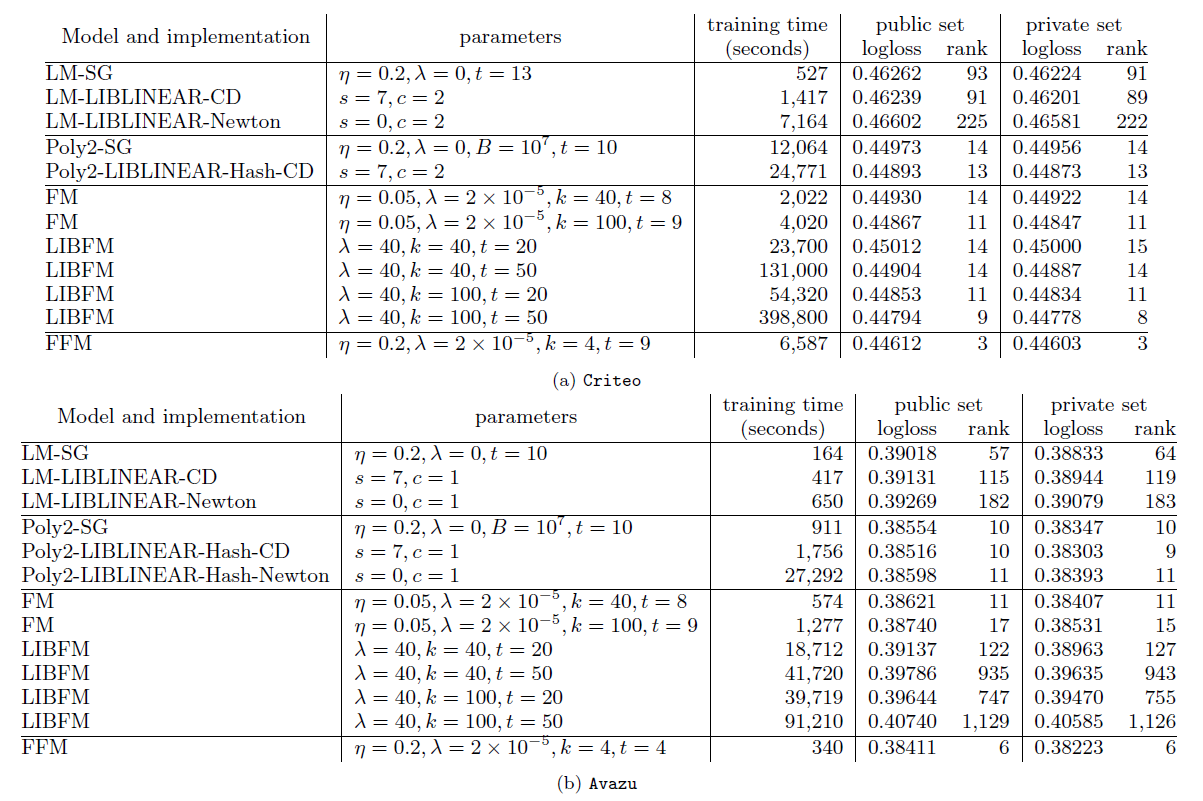
我们比较了其它数据集上不同模型的表现。其中:
KDD2010-bridge,KDD2012,adult数据集包含数值特征和离散特征,我们将数值特征执行了离散化。cod-rna,ijcnn数据集仅仅包含数值特征 ,我们将数值特征进行两种处理从而形成对比:将数值特征离散化、每个数值特征作为一个field(称作dummy fields)。phishing数据集仅仅包含离散特征。
实验结果表明:
FFM模型几乎在所有数据集上都占优。这些数据集的特点是:- 大多数特征都是离散的。
- 经过
one-hot编码之后大多数特征都是稀疏的。
在
phishing,adult数据集上FFM几乎没有优势。原因可能是:这两个数据集不是稀疏的,导致FFM,FM,POLY2这几个模型都具有几乎相同的表现。在
adult数据集上LM的表现和FFM,FM,POLY2几乎完全相同,这表明在该数据集上特征交叉几乎没有起到什么作用。在
dummy fields的两个数据集上FFM没有优势,说明field不包含任何有用的信息。在数值特征离散化之后,尽管
FFM比FM更有优势,但还是不如使用原始数值特征的FM模型。这说明数值特征的离散化会丢失一些信息。
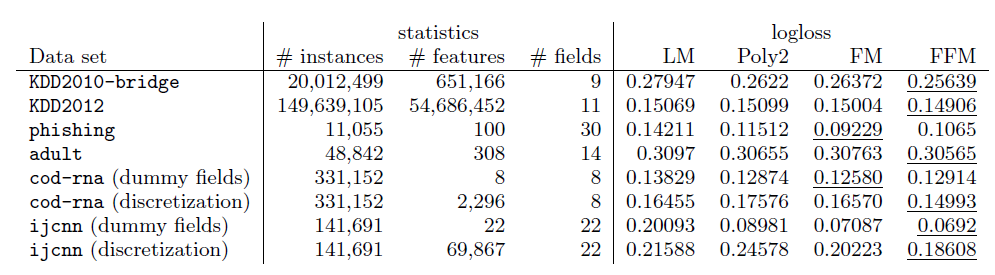
从实验中总结的
FFM应用场景:- 数据集包含离散特征,且这些离散特征经过
one-hot编码。 - 经过编码后的数据集应该足够稀疏,否则
FFM无法获取较大收益(相对于FM)。 - 不应该在连续特征的数据集上应用
FFM,此时最好使用FM。
- 数据集包含离散特征,且这些离散特征经过
五、GBDT-LR 模型[2014]
数字广告
didital advertising是一个价值数十亿美元的产业,并且每年都在急剧增长。在大多数在线广告平台中,广告的投放是动态的,根据用户的兴趣来个性化投放。机器学习在计算候选广告对用户的预期效用expected utility方面发挥着核心作用,并以这种方式提高了市场效率。Varian(论文《Position auctions》)和Edelman等人(论文《 Internet advertising and the generalized second price auction: Selling billions of dollars worth of keywords》)在2007年发表的开创性论文描述了由Google和Yahoo!开创的点击出价bid per click、点击扣费pay per click。同年,微软也在建立一个基于相同拍卖模型(论文《Predicting clicks: Estimating the click-through rate for new ads》)的sponsored search市场。广告拍卖auction的效率取决于点击率预估的准确性accuracy和校准calibration。点击率预估系统需要健壮性robust和适应性adaptive,并且能够从大量数据中学习。点击率预估系统是大多数在线广告系统的核心。Facebook拥有超过7.5亿的日活用户、超过100万的活跃广告主,因此预估广告的点击率是一项具有挑战性的机器学习任务。论文《Practical Lessons from Predicting Clicks on Ads at Facebook》分享了满足这些要求的、从真实世界数据执行的实验中得出的洞察insight。在
sponsored search广告中,user query用于检索和query显式或者隐式匹配的候选广告。在Facebook中,广告不是与query相关,而是指定人口统计特性和兴趣的定向targeting。因此,当用户访问Facebook时,合格eligible的广告数量可能超过sponsored search搜索量。为了处理每个请求的大量候选广告(每当用户访问Facebook时都会触发广告请求),Facebook将首先构建一系列计算代价递增的、级联cascade的classifiers(即matching、ranking等一系列模型)。在本文中,论文关注级联分类器最后阶段的点击率预估模型,即为最终候选广告集合生成预测的模型。论文发现:将决策树与逻辑回归相结合的混合模型比这两种方法中的任何一个都高出
3%以上。这种提升对于整体系统性能有重大影响。许多基础的超参数会影响系统的最终预测性能。毫不意外,最重要的是拥有正确的特征:比其它特征,那些捕获有关用户历史信息和广告历史信息的特征占统治地位。一旦有了正确的特征和正确的模型(决策树加逻辑回归),其它因素就发挥了很小的作用(即使是很小的改进,在如此规模的任务中也很重要)。针对数据新鲜度freshness、学习率模式schema、数据采样而选择最佳处理方式会稍微改善模型,尽管改善的幅度远不如添加高价值特征、或者选择正确的模型。论文从实验设置概述开始,然后评估不同的概率线性分类器
probabilistic linear classifiers以及不同的在线学习算法。在线性分类的背景下,论文继续评估特征变换和数据新鲜度的影响。受到实际经验教训的启发,尤其是在数据新鲜度和在线学习方面,论文提出了一个模型架构,该架构包含一个在线学习层
online learning layer,同时生成相当紧凑的模型。接下来描述了在线学习层所需的一个关键组件,即online joiner,它是一种实验性的基础设施,可以生成实时训练数据real-time training data的实时流live stream。最后,论文提出了用内存、计算时间、处理大量数据和准确性进行
tradeoff的方法。包括为大规模application优化内存和延迟的使用方法,以及训练数据规模和准确性之间权衡的研究。
5.1 实验配置
为了实现严格可控的实验,我们选取了
2013年第四季度的任意一周,从而作为离线训练数据。我们将离线数据划分为训练集和测试集,并使用它们来模拟流式数据streaming data,从而进行在线训练和预估。论文中的所有实验都使用相同的训练集/测试集。评估指标:由于我们最关心的是各个因素
factors对于机器学习模型的影响,因此我们使用预估的准确性来评估,而不是与利润和收入直接相关的指标。在这里我们使用归一化熵Normalized Entropy: NE和校正calibration作为我们的主要评估指标。归一化熵(更准确地讲,归一化交叉熵
Normalized Cross- Entropy)等于每次曝光的平均对数损失除以背景熵background entropy。假设样本集合有 个样本,样本集合的经验
CTR为 (它等于所有正类样本数量除以总样本数量)。假设第 个样本预测为正类的概率为 ,其真实标签为 。定义背景点击率
background CTR为样本集合经验CTR,它的熵定义为背景熵:背景熵衡量了样本集合的类别不平衡程度,也间接的衡量了样本集合的预测难度。
类别越不均衡预测难度越简单,因为只需要将所有样本预测为最大的类别即可取得非常高的准确率。
定义模型在样本集合熵的损失函数为:
每个样本的损失为交叉熵。
定义归一化熵
NE为:模型在所有样本的平均损失函数除以背景熵。需要除以 是为了剔除样本集合大小的影响。
NE相对损失函数的优势在于:NE考虑了样本集预测的难易程度。在平均损失相同的情况下,样本集越不均衡则越容易预测,此时NE越低。归一化熵可以用于计算相对信息增益
Relative Information Gain: RIG,其中RIG = 1 - NE。校正
Calibration是平均预估点击率和经验点击率的比值。换句话讲,它是期望点击次数和实际观察到点击次数的比值。calibration是一个非常重要的指标,因为准确且校准良好的CTR预估对于在线竞价和拍卖的成功至关重要。calibration和1.0的差异越小,模型越好。
注意,
AUC也是评估模型能力的一个很好的指标,但是AUC反应的模型对样本的排序能力:auc=0.8表示80%的情况下,模型将正样本预测为正类的概率大于模型将负样本预测为正类的概率。在现实环境中,我们期待预测是准确的,而不仅仅是获得最佳的排序,从而避免潜在的投放不足
under-delivery、以及投放过度over-delivery。NE衡量的预估好坏并不隐式地反映calibration。例如,如果模型高估了2倍,然后我们使用一个全局的因子0.5来固定地校准:- 因为校准不改变模型的排序能力,所以
AUC保持不变。 - 因为校准后的
pCTR分布与样本的标签分布距离更近,所以NE会得到改善。
有关这些指标的深入研究,可以参考
《Predictive model performance: Offline and online evaluations》。- 因为校准不改变模型的排序能力,所以
5.2 预估模型结构
这里我们展示了一个混合模型结构:
boosted decision trees: BDT和概率稀疏线性分类器probabilistic sparse linear classifier的拼接,如下图所示。其中输入特征通过BDT进行变换,每棵子树的输出都被视为稀疏线性分类器的离散输入特征。BDT已经被证明是非常强大的特征变换。- 我们首先展示了决策树是非常强大的输入特征变换,可以显著提高概率线性分类器。
- 然后我们展示了更新鲜
fresher的训练数据如何导致更准确的预估,这激发了使用在线学习方法来训练线性分类器的思想。 - 最后我们比较了两个概率线性分类器家族的许多在线学习变体。
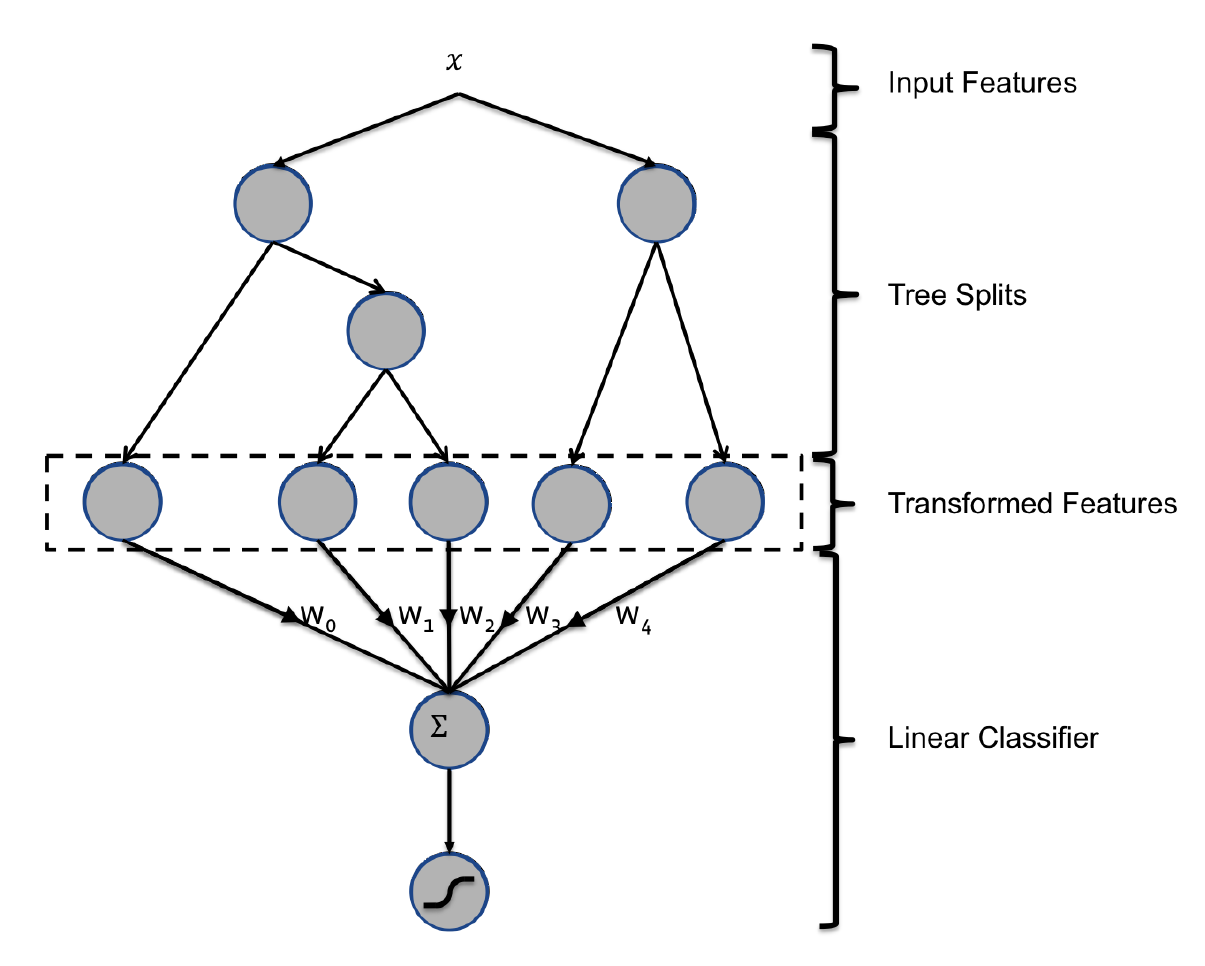
5.2.1 决策树特征变换
有两种最简单的特征转换方式:
连续特征离散化:将连续特征的取值映射到一个个分散的分桶里,从而离散化。这里桶的数量和边界难以确定,通常有两种方法:
- 通过人工根据经验来设定分桶规则。
利用后续的分类器来显式的学习这个非线性映射,从而学习出有意义的分桶数量和边界。
离散特征交叉:类似
FM模型采用二路特征交叉(或者更高阶)来学习高阶非线性特征。对于连续特征可以先离散化之后再执行特征交叉,如
kd树就是典型的代表。
Boosted decisition tree:BDT就是结合了上述两种方式的一个强大的特征提取器。对于BDT,我们将每棵子树视为一个离散特征,其叶结点的编号为特征的取值并执行one-hot编码。假设
BDT有两棵子树,第一棵有3个叶结点,第二棵有2个叶结点。则样本提取后有两个特征:第一个特征取值为{1,2,3},第二个特征取值为{1,2}。假设某个样本被划分到第一棵子树的叶结点2,被划分到第二棵子树的叶结点1,则它被转换后的特征为:[0,1,0,1,0]。其中:前三项对应于第一个离散特征的one-hot,后两项对应于第二个离散特征的one-hot。我们使用的
BDT为梯度提升树Gradient Boosting Machine:GBM,其中使用了经典的L2-TreeBoost算法。在每次学习迭代中,都会创建一棵子树对残差进行建模。我们可以将基于BDT的变换理解为一种监督特征编码:- 它将一组实值向量
real-valued vector转换为一组二元向量binary-valued vector。 - 每棵子树从根节点到叶节点的遍历表示某些特征转换规则。
- 在转换后的二元向量上拟合线性分类器本质上是学习每个规则的权重。
- 它将一组实值向量
我们进行了实验以显示将树特征作为线性模型输入的效果。我们对比了两种逻辑回归模型:一种具有树特征变换,另一种具有普通特征(未变换的)。我们还对比了一个
BDT模型。对比结果如下表所示,可以看到:- 树特征变换有助于将归一化熵降低
3.4%以上。这是一个非常显著的提升。 - 有意思的是,单独使用
LR和单独使用Tree模型具有相差无几的预测准确性(实际上LR稍微好一点),但是它们的组合使得准确性大幅上升。
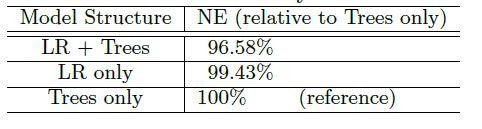
- 树特征变换有助于将归一化熵降低
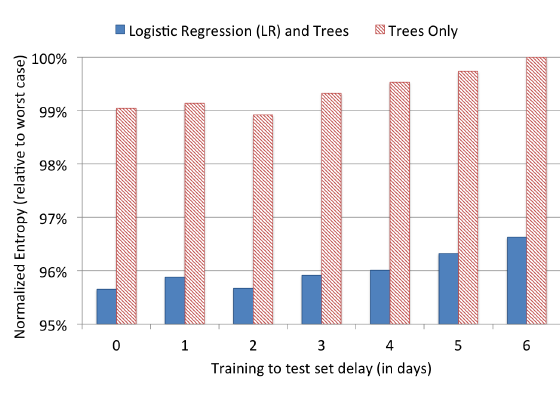
5.2.2 数据新鲜度
点击率预估系统通常部署在数据分布随时间变化的动态环境中。我们研究了训练数据新鲜度
freshness对于预测性能的影响。为此,我们在某一天训练一个模型并在连续几天内对其进行测试。我们为BDT模型、带tree-transformed的逻辑回归模型进行实验。实验中,我们训练一天的数据,并评估连续六天中每一天的归一化熵。结果如下图所示,指标是相对于最差的
NE的比例(最差的NE发生在Trees only模型延迟6天时)。可以看到:- 随着训练集和测试集之间延迟的增加,两种模型的预估准确性显著下降。
- 通过将每周训练改为每天训练,
NE可以减少大约1%。
这些发现表明:每天进行重新训练是值得的。
考虑数据新鲜度,我们需要用最新的样本更新模型。有两种更新策略:
- 每天用最新的数据重新训练模型。重新训练模型所需的时间各不相同,取决于训练样本的数量、子树的数量、每棵子树的叶节点数量、
cpu、内存等因素。通常在大规模集群中可以在几个小时内完成训练。 - 每天或者每隔几天来训练特征提取器
BDT,但是用最新的数据在线近乎实时地训练LR线性分类器。
- 每天用最新的数据重新训练模型。重新训练模型所需的时间各不相同,取决于训练样本的数量、子树的数量、每棵子树的叶节点数量、
5.2.3 学习率
为了最大限度地提高数据新鲜度,一种选择是在线训练线性分类器,即在带
label的曝光信息到达时直接训练。这里我们评估了几种为基于SGD的逻辑在线学习设置学习率的方法。per-coordinate基于特征的学习率:在第 次迭代特征 的学习率为:其中: 为模型的超参数; 为第 次迭代的梯度在特征 的分量。
- 特征 的梯度越大,说明该特征方向波动较大,则学习率越小,学习速度放慢。
- 特征 的梯度越小,说明该特征方向波动较小,则学习率越大,学习速度加快。
per-weight维度加权学习率:在第 次迭代特征 的学习率为:其中: 为模型的超参数, 为截至到第 次迭代特征 上有取值的所有样本数量。
在广告场景中,这些特征在大多数情况下都没有取值,因此对应的权重很难有更新机会。
- 特征 上有取值的样本越多,则可供学习的样本也多,则学习率越小,学习速度放慢。
- 特征 上有取值的样本越少,则可用学习的样本也少,则学习率越大,学习速度加快。
per-weight square root基于权重开方的学习率:在第 次迭代特征 的学习率为:global全局学习率:在第 次迭代所有特征的学习率都为:constant常量学习率:在第 次迭代所有特征的学习率都为:
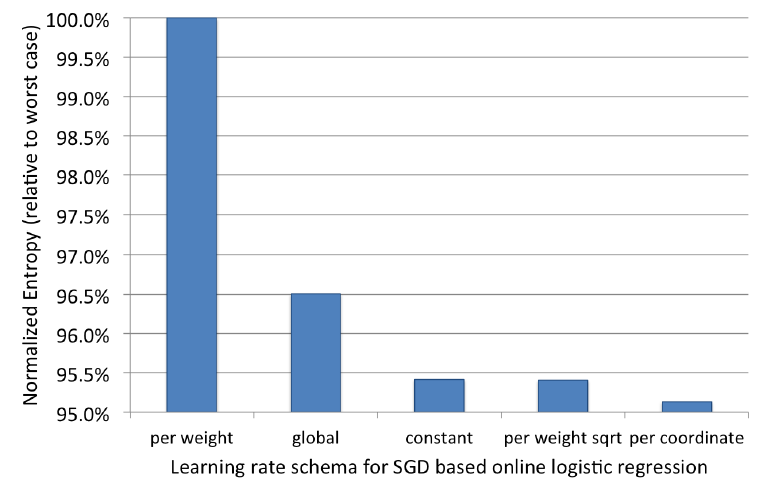
前三种方式针对每个特征都有不同的学习率,最后两种方式对所有特征采用相同的学习率。所有超参数都通过网格搜索来调优,最优值如下表所示。

我们将学习率下限设定为
0.00001从而用于在线的continuous learning。我们使用上述学习率方案在相同数据集上训练和测试LR模型,实验结果如下图所示。可以看到:per-coordinate方法获得最好的表现,而per-weight效果最差。per-weight square root和constant方案具有相似、但是稍差的效果。全局学习率表现不佳,其主要原因是:每个特征上训练样本数量不平衡。
一些高频特征上(如:“是否男性” 特征)的样本数量较多,而另一些低频特征(如:“是否明星” )上的样本数量较少。在全局学习率策略下,低频特征学习率太快降低到很小的值,使得最优化难以收敛到最优点。
虽然
per-weight策略解决了该问题,但是它仍然表现不佳。主要原因是:虽然它对低频特征的学习率控制较好,但是它对高频特征的学习率控制较差。它对所有特征的学习率都下降得太快,在算法收敛到最优点之前训练就过早终止了。这解释了为什么该方案是所有学习率方案中最差的。
5.3 ONLINE DATA JOINER
如前所述,更新鲜的训练数据会提高预估准确性。这里我们介绍一个实验系统,该系统生成用于在线学习训练线性分类器的实时训练数据。我们将这个系统称作
online joiner,因为它的关键操作是以在线方式将label(是否点击)和训练数据(广告曝光)进行关联。在线训练框架最重要的是为模型提供在线学习的标注样本。点击行为比较好标记,但是“不点击”行为难以标记。因为广告并没有一个“不点击”按钮来获取不点击的信息。因此,如果一个曝光在一个时间窗内未发生点击行为,则我们标记该次曝光是未点击的。
之所以要设定一个时间窗,是因为广告曝光和用户点击之间存在时间差。这里有两个原因:
给用户曝光一个广告后,用户不会立即点击。如:用户会简单浏览广告的内容再决定是否点击。对于视频类广告,用户甚至会观看完整视频之后再决定是否点击。
因此曝光事件和点击事件这两个事件存在时间差。
广告系统的曝光日志和点击日志通常都是分开的、独立的实时数据流。这两个数据流回传到在线训练系统可能并不是同步的,存在数据回传时间差。
这个等待时间窗口需要仔细调优:
- 如果窗口太长,那么会延迟实时训练数据,数据
freshness较差。同时为了存储更长时间的曝光数据内存代价也较高。 - 如果窗口太短,那么会导致部分点击丢失,因为相应的曝光可能已经被标记为
no click并移出内存。这会对点击覆盖率click coverage产生不利影响。其中点击覆盖率指的是成功关联曝光的点击占所有点击的比例。
因此,
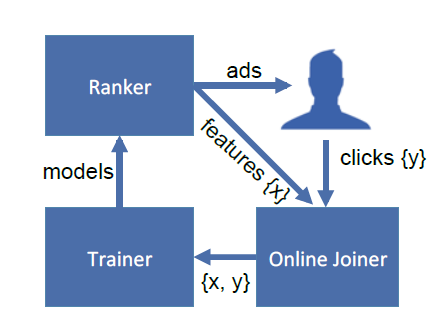
online joiner必须在新近程度recency和点击覆盖率之间取得平衡。点击覆盖率低意味着实时训练集会有bias:经验CTR略低于ground truth。这是因为如果等待时间足够长,那么标记为no click的部分曝光会被标记为click。通过挑选合适的时长,可以降低经验的CTR偏差到百分之一以下,同时内存代价也可以接受。Facebook在线训练框架如下图所示:- 用户浏览
Facebook时向Ranker模块发送一个广告请求,请求中包含request ID。 Ranker模块根据在线模型的预测结果,向用户返回一个广告,同时在曝光实时数据流中增加一条曝光日志。- 如果用户点击广告,则前端打点系统上报点击事件,在后台点击实时数据流中增加一条点击日志。
- 通过
Oneline Joiner模块实时获取最近一个时间窗的曝光、点击日志,并拼接样本特征来构造训练集。 Trainer模块根据构造的训练集执行在线训练,训练好的模型部署到线上供Ranker模块使用。
这会形成一个数据闭环,使得模型能够捕捉到最新的数据分布。
- 用户浏览
在线训练需要增加对实时训练数据的异常保护。假设实时训练数据出现问题(如:前端打点上报出现异常、
Online Joiner工作异常等),导致大量的点击数据丢失。那么这批实时训练样本存在缺陷,它们的经验CTR非常低甚至为0。如果模型去学习这样一批样本,则模型会被带偏:对任何测试样本,模型都会预测出非常低、甚至为零的点击率。根据广告点击价值
eCPM = BID x pCTR,一旦预估点击率pCTR为零则广告的eCPM为零。那么这些广告几乎没有竞争力,竞争失败也就得不到曝光机会。因此需要增加实时训练数据的异常检测机制。如:一旦检测到实时训练数据的分布突然改变,则自动断开online trainer和online joiner的连接。
5.4 优化技巧
子树的数量:在
GBDT-LR模型中子树的数量越大模型表现越好,但是计算代价、内存代价越高。随着子树的增多,每增加一棵子树获得的效益是递减的。这就存在平衡:新增子树的代价和效益的平衡。我们将子树的数量从
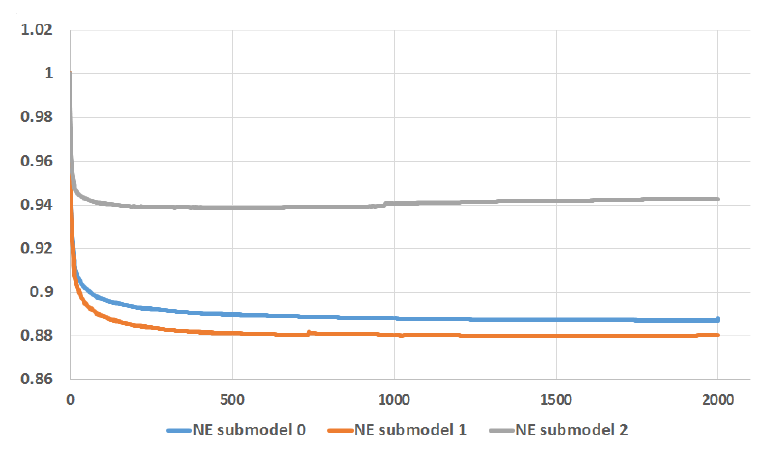
1增加到2000,并使用一整天的数据训练模型、第二天的数据测试模型性能。我们限制每棵子树的叶子不超过12个。和之前的实验类似,我们使用归一化熵NE作为评估指标。实验如下图所示,其中
NE submodel0, NE submodel1使用全量训练数据、不同的超参数来训练,而NE submodel2使用1/4的训练数据。可以看到:NE随着子树数量的增加而下降,但是最后增加的1000棵子树获得的效益很低。几乎所有的NE改善都来自于前500棵子树,最后1000棵子树得到的NE下降不足0.1%。NE submodel2由于训练数据更少,使得模型在1000棵子树之后出现过拟合(NE增加)。
特征的数量:特征数量是另一个模型属性,可以影响到估计准确性和计算性能之间的
tradeoff。特征越多模型表现越好,但是计算代价、内存代价越高。但是随着特征的增多,尤其是无效特征的增多,每增加一个特征获得的效益是递减的。这就存在平衡:新增特征的代价和效益的平衡。为了更好地理解特征数量的影响,我们首先评估特征重要性。我们使用统计的
Boosting Feature Importance,有三种统计方法(如XGBoolst/LightGBM):weight:特征在所有子树中作为分裂点的总次数。gain:特征在所有子树中作为分裂点带来的损失函数降低总数。cover:特征在所有子树中作为分裂点包含的总样本数。
通常情况下,少数特征贡献了大部分解释,而剩余特征仅具有微小的贡献。如下图所示,
top 10特征贡献了大于一半的重要性,最后300个特征贡献了不到1%的重要性。下图中,左轴给出了对数尺度的特征重要性,右轴给出了累计特征重要性。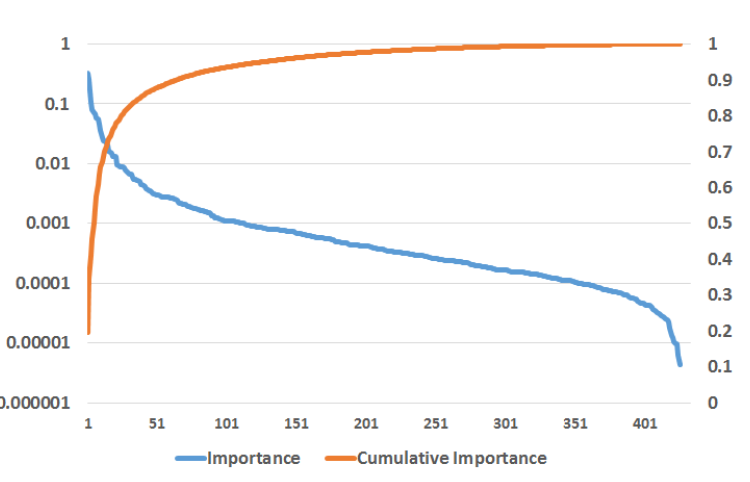
基于这一发现,我们进一步试验仅保留
top10,top20,top50,top100,top200重要性的特征,并评估模型性能的影响。实验结果如下,可以看到:归一化熵随着我们包含更多特征而具有类似的收益递减特性。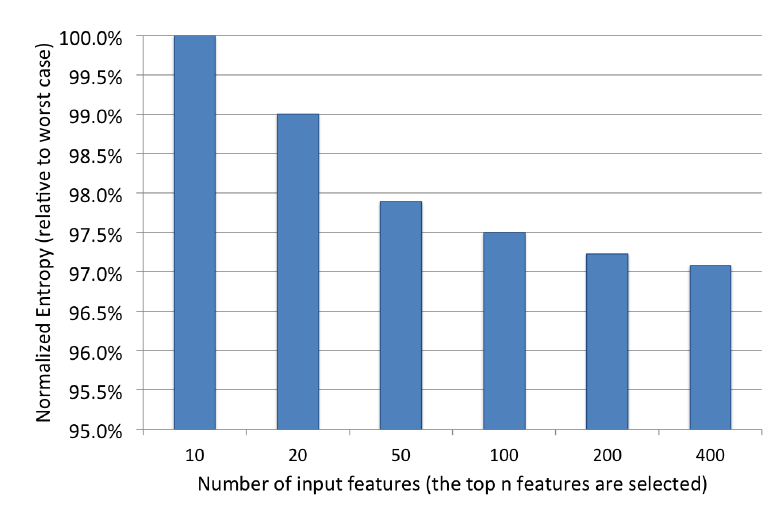
接下来我们将对历史特征
historica features和上下文特征contextual features进行研究。出于数据敏感性和公司政策,我们无法透露我们使用的实际特征的详细信息。上下文特征可以是本地时间、星期几等,历史特征可以是广告累计的点击量等。历史特征和上下文特征:
BDT模型中用到的特征分类两类:上下文特征和历史统计特征。- 上下文特征:曝光广告的当前上下文信息。如:用户设备、用户所在页面的信息等等。
- 历史统计特征:广告的历史统计行为,或者用户的历史统计行为。如:广告的上周平均点击率,用户的历史平均点击率。
这里我们研究这两种类型的特征如何影响系统性能。
首先我们检查这两类特征的相对重要性。我们通过按重要性对所有特征进行排序,然后计算
top k个重要特征中历史特征的百分比。结果如下所示,其中Y轴表示在top k特征中历史特征的占比。可以看到:历史特征比上下文特征提供了更多的解释。按照重要性排序的
top 10特征都是历史特征。在所有top 20特征中,只有2个上下文特征,而历史特征占据了75%。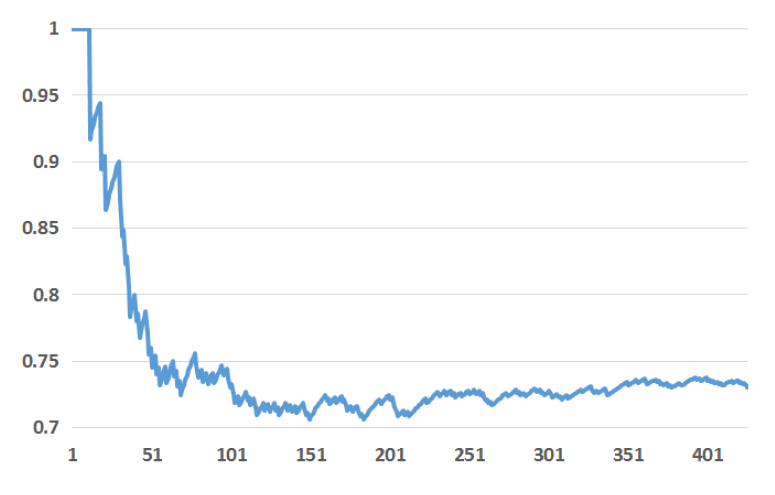
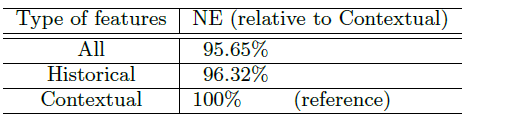
为了更好地比较这两类特征,我们训练了两个仅包含上下文特征和历史特征的
BDT模型,然后将这两个模型与所有特征的完整模型进行比较,结果如下表所示。我们再次验证,总体而言,历史特征比上下文特征发挥更大的作用。在仅有上下文特征的情况下,我们的NE损失了4.5%。相反,在仅有历史特征的情况下,我们的NE损失小于1%。应该注意的是:上下文特征对于处理冷启动问题非常重要。对于新用户和新广告,上下文特征对于合理的点击率预估是必不可少的。
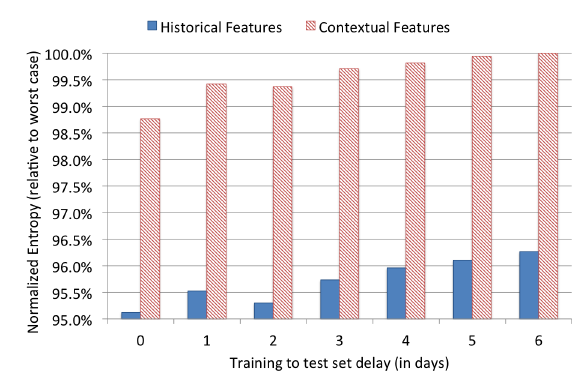
最后,我们在连续几周内评估仅有历史特征或仅有上下文特征的训练模型,以测试这两种类型特征对数据新鲜度的依赖性。实验结果如下图所示。可以看到:具有上下文特征的模型比具有历史特征的模型更依赖于数据新鲜度。这符合我们的直觉,因为历史特征描述了长期累计的用户行为,这比上下文特征要稳定得多。
5.5 训练大量数据
Facebook每天的广告曝光量非常大。即使是每个小时,数据样本也可能上亿。用于控制训练成本的常用技术是减少训练数据量。本节中,我们评估两种降采样技术,均匀降采样和负降采样。在每种情况下,我们训练一组包含600棵树的boosted tree model,并是使用calibration和 归一化熵来评估这些模型。均匀降采样:所有样本都以同一个概率 来随机采样。该方法容易实现,且采样后的样本分布和采样前保持不变。这样使得训练数据集的分布基本和线上保持一致。
我们评估了
0.001,0.01,0.1,0.5,1这几种采样率。结果表明:更多的数据带来更好的模型。但是采用10%的训练样本相对于全量样本仅仅损失了1%的预测能力,而训练代价降低一个量级。在该采样率下的calibration甚至没有性能下降。注意:calibration越接近1.0越好。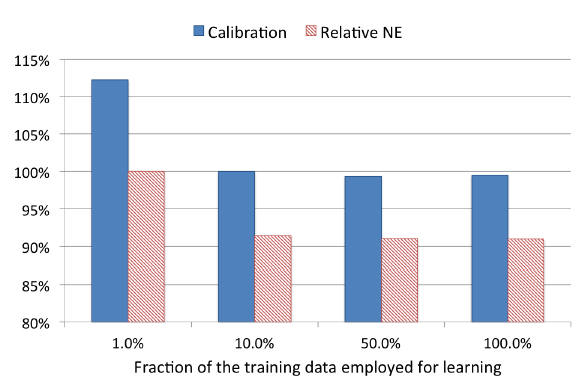
负降采样:保留所有的正样本,仅负样本以概率 来随机采样。该方法可以缓解类别不平衡问题。但是,采样后的样本分布和采样前不再相同,导致训练集的分布和线上不再保持一致。因此需要对模型进行校准。
我们评估了
0.0001, 0.001, 0.01, 0.1这几种采样率。可以看到:负采样率对训练模型的性能有显著影响。将负采样率设置为0.025可以实现最佳性能。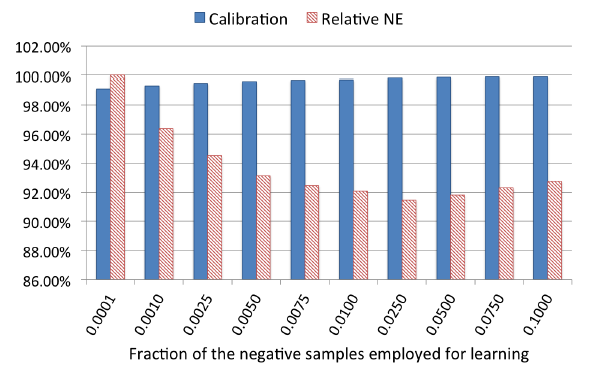
Re-Calibration:负降采样可以加快训练速度,改善模型能力。但是负采样中的训练数据分布和线上数据分布不一致,因此必须对模型进行校准。假设采样之前样本集的平均
CTR为0.1%。当执行采样率为0.01的负降采样之后,由于正样本数量不变、负样本数量降低到之前的0.01,因此采样后的样本集的平均CTR为10%。此时需要校准模型,使得模型的预估平均CTR尽可能与线上的平均CTR一致。假设模型预估的结果为 ,则校准后的预估结果为:其中 为负采样比例。
5.6 总结
我们从
Facebook广告数据的实验中提出了一些实践经验教训,这激发了用于点击率预估的有前途的混合模型架构。- 数据新鲜度很重要,至少每天都值得重新训练。在本文中,我们进一步讨论了各种在线学习方案。我们还展示了允许生成实时训练数据的基础设施。
- 使用
BDT转换实值输入特征显著提高概率线性分类器的预测准确性。这激发了一种混合模型架构,该架构将BDT和稀疏线性分类器拼接起来。 - 具有
per-coordinate学习率的LR模型比其它正在研究的LR SGD学习率方案表现更好。
同时我们还描述了在大规模机器学习中优化内存和延迟的技巧:
- 我们提出了
BDT的子树数量和准确性之间的trade-off。保持较少的子树数量从而减少内存和计算量是有利的。 BDT提供了一种通过特征重要性进行特征选择的便捷方法。可以激进地减少使用特征的数量,同时预测准确性只会略微下降。- 我们分析了上下文特征和历史特征的效果。对于有历史特征的广告和用户,这些特征提供了比上下文特征更出色的预测性能。
- 最后,我们讨论了对训练数据进行降采样的方法,如均匀采样和负采样。
六、FTRL工程应用[2013]
在线广告是一个价值数十亿美金的行业,它是机器学习巨大成功的案例之一。赞助搜索广告
sponsored search advertising、上下文广告contextual advertising、展示广告display advertising、实时竞价拍卖real-time bidding auction都在很大程度上依赖于模型准确、快速、可靠地预估广告点击率的能力。这种问题设置problem setting也推动该领域解决大规模问题,即使在十年前,这也是几乎不可想象的。典型的工业模型可以使用相应的大规模特征空间,每天提供数十亿次事件的预测,然后从产生的大量数据中学习。论文
《Ad Click Prediction: a View from the Trenches》介绍了一系列案例研究,这些案例研究来自于最近在谷歌用于赞助搜索广告的CTR部署系统的实验setting。这些改进包括基于FTRL-Proximal在线学习算法(具有极好的稀疏性sparsity和收敛性convergence)的传统监督学习环境下的改进,以及per-coordinate学习率的使用。因为
CTR预估问题已经得到了很好的研究,所以作者选择关注一系列不太受关注、但是在工作系统中同样重要的主题。作者探索内存节省memory savings、性能分析performance analysis、 预测置信度confidence in predictions、calibration、特征管理feature management等问题,其严谨性和传统上用于设计有效学习算法的问题相同。最后,作者还详细介绍了几个没有收益的方向,尽管这些方向在其他文献中取得了理想的效果。因此,论文的目的是让读者了解理论进步和实际工程之间的密切关系,并展示在复杂动态系统中应用传统机器学习方法时出现的深层挑战。同时,论文也分享可能适用于其它大规模问题领域的技巧和洞察。
6.1 系统概览
当用户进行搜索
query时,基于广告主选择的竞价词,系统将候选广告集合与query进行匹配。然后,拍卖机制决定是否向用户展示这些广告、广告展示的顺序、以及广告主在用户点击广告时支付的价格。除了广告主出价之外,拍卖的一个重要输入是:对于每个广告 ,估计用户点击广告的概率 。我们系统中使用的特征来自于各种来源,包括
query、广告创意文本、各种与广告相关的元数据。数据往往非常稀疏,每个样本通常只有一小部分非零特征。诸如正则化的逻辑回归之类的方法非常适合这类问题。每天需要进行数十亿次预测,并在观察到新的样本时快速更新模型。当然,这个数据生产速度意味着训练数据集是巨大的。数据是由一个基于Photon system的流式服务streaming service提供的。由于近年来大规模学习
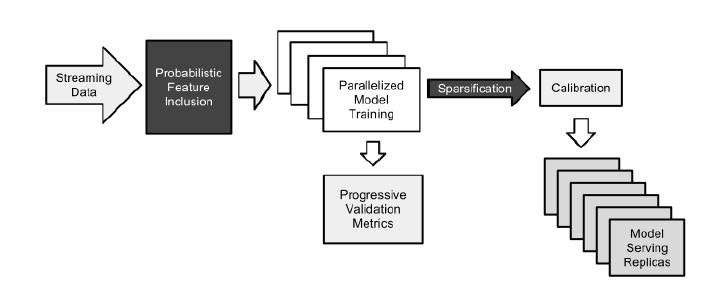
large-scale learning得到了很好的研究,我们没有在本文中投入大量篇幅详述我们的系统架构。然而我们注意到,我们的训练方法和Google Brain团队描述的Downpour SGD方法相似,不同之处在于我们训练的是单层模型而不是多层神经网络。这使得我们能够处理更大的数据集和更大的模型(模型具有数十亿个参数)。因为训练好的模型被复制到很多数据中心进行serving,因此我们更关心serving时的稀疏化,而不是训练期间的稀疏化。我们系统的整体框架如图所示:
Probalistic Feature Inclusion:概率性特征纳入模块,主要用于降低特征数量来优化内存。Parallelized Model Training:多模型并行训练模块,主要用于超参数选择中,提高多模型并行训练的效率。Calibration:模型校准模块,主要用于校准模型的系统性预测bias。Progressive Validation Metrics:模型性能分析模块,主要用于分析模型在验证集上的性能。Model Serving Replicas:模型部署模块,主要用于部署模型到线上。
6.2 在线学习和稀疏性
6.2.1 FTRL-Proximal
对于大规模学习,广义线性模型(例如逻辑回归)的在线算法具有许多优势。尽管特征向量 可能有数十亿维,但是通常每个样本只有数百个非零值。这可以通过从磁盘或网络的流式样本
streaming examples来对大型数据集进行有效的训练,因为每个训练样本只需要考虑一次。如果我们采用逻辑回归来建模,那么我们可以使用以下在线框架。
在时刻 ,假设样本特征为 ,给定模型参数 ,那么预估的点击率为 ,其中 为
sigmoid函数。假设我们观察到了label,那么logloss为:显然有:
在线梯度下降
online gradient descent: OGD已经被证明对此类问题非常有效,能够以最少的计算资源产生出色的预测准确性。然而,在实践中另一个关键考虑因素是最终模型的大小。由于模型可以稀疏存储,因此 中非零权重的数量是内存占用的决定因素。不幸的是,
OGD在生成稀疏模型方面并不是特别有效。事实上,简单地将L1正则化添加到损失函数中,基本上永远不会产生完全为零的权重。更复杂的方法,如FOBOS和梯度截断,确实成功地引入了稀疏性。和FOBOS相比,Regularized Dual Averaging: RDA算法产生了更好的准确性accuracy和稀疏性sparsity的tradeoff。然而,我们已经观察到梯度下降风格的方法可以在我们的数据集上产生比
RDA更好的准确性。那么,我们能否同时获得RDA提供的稀疏性和OGD提供的准确性?答案是肯定的,使用Follow The (Proximally) Regularized Leader: FTRL-Proximal算法。在没有正则化的情况下,FTRL-Proximal与标准的OGD相同,但因为它使用模型权重 的alternative lazy representation,L1正则化可以更有效地实现。FTRL-Proximal算法在另一篇论文中(《Follow-the-regularized-leader and mirror descent: Equivalence theorems and L1 regularization》)以便于理论分析的方式构建。这里我们专注于描述一个实际的实现。给定梯度序列 ,
OGD的更新为:其中: 为
non-increasing的学习率调度learning rate schedule,例如 。定义 ,那么
FTRL-Proximal算法使用以下更新:其中: 为学习率的函数,例如 。
从表面上来看,
FTRL-Proximal和OGD的更新方程非常不同。但是当我们取 时,二者会产生相同的权重向量序列。 然而,当 的FTRL-Proximal更新在产生稀疏性方面做得更好(参考下面实验的结果)。乍一看,人们可能会认为
FTRL-Proximal更新比梯度下降更难实现,或者需要存储所有历史的权重。然而,实际上只需要存储单个向量(每个 对应一个值),因为我们可以将argmin重写为:因此,如果我们存储 ,则有:
则 的解可以
per-coordinate来计算到:其中 。
因此,
FTRL-Proximal在内存中存储 ,而OGD在内存中存储 。下面描述的算法采用这种方法(还添加了per-coordinate学习率调度,我们接下来要讨论的),并支持强度为 的L2正则化。或者我们可以直接存储 而不是 ,然后当 时,我们刚好存储的就是标准的梯度下降之后的权重 。
注意当 为常数、 时,很容易看出
FTRL-Proximal等于OGD,因为我们有:这正是梯度下降所起到的作用。
Per-Coordinate FTRL-Proximal的逻辑回归算法(带L1正则化和L2正则化):输入:
- 超参数
- 数据集
输出:训练好的模型权重
算法步骤:
初始化: 。其中 存储累计梯度向量。
迭代 ,迭代步骤为:
读取特征向量 ,令 为当前样本的非稀疏特征集合。
更新非稀疏特征对应的权重:对 有
其中 。注意: 是和时刻 相关的。
计算预估点击率 。
读取
labey。更新非稀疏特征对应的梯度相关的信息:对 有
FTRL-Proximal优化算法的实验结果如下表所示。评估指标为AucLoss = 1- AUC。考虑到损失一般是越小越好,而AUC是越大越好,因此我们采用1 - AUC。OGD-Count会维护它看到某个特征的次数。在计数超过阈值 之前,权重固定为零;在计数超过 之后,在线梯度下降照常进行。我们调整 值使得它与FTRL-Proximal相同的准确性。使用较大的 会导致更差的AucLoss。可以看到:在模型大小和准确性
tradeoff方面,带L1正则化的FTRL-Proximal显著优于RDA和FOBOS。总体而言,这些结果表明
FTRL-Proximal显著改善了稀疏性,同时具有相同或更好的预测准确性。
6.2.2 per-coordinate 学习率
OGD的标准理论建议使用全局学习率调度 ,该学习率对于所有coordinates都是相同的。我们在FTRL-Proximal中采用per-coordinate学习率:该学习率在某种意义上几乎是最优的
near-optimal。我们通过验证集仔细选择 和 从而得到良好的性能。根据经验:
- 的最佳值根据特征和数据集的不同而有很大差异。
- 通常就足够了,这只是确保早期的学习率不会太高。
我们还尝试对于 使用
0.5以外的幂次。
如前所述,
Per-Coordinate FTRL-Proximal算法要求我们跟踪每个特征的累计梯度、以及累计平方梯度。后面会介绍另一种节省内存的公式,其中累计平方梯度在多个模型上均摊。我们通过测试两个相同的模型来评估
per-coordinate学习率的影响:一个使用单个全局学习率,另一个使用per-coordinate学习率。超参数 为每个模型单独调优。我们在一个有代表性的数据集上运行,并使用
AucLoss作为我们的评估指标。结果表明:与全局学习率baseline相比,使用per-coordinate学习率将AucLoss降低了11.2%。在我们的设置中,AucLoss降低1%就被认为是很大的。
6.3 内存优化
如前所述,我们使用
L1正则化从而节省预测期间的内存。在这里,我们将描述在训练期间节省内存的其它技巧。特征优化:在很多具有高维数据的领域中,绝大多数特征都是极为稀疏的。事实上在我们的一些模型中,一半的
unique特征在数十亿个样本的整个数据集中仅出现一次。跟踪这些稀疏特征的统计数据是昂贵的,这些特征永远不会有任何实际用途。不幸的是,我们事先不知道哪些特征将是稀疏的。预处理数据从而去除稀疏特征在
online setting中是有问题的:- 额外读取然后写入数据的代价非常昂贵。
- 并且如果删除某些特征(例如,如果特征出现的次数少于 次),则不再尝试使用这些特征建模,从而难以评估预处理在准确性方面的代价。
一类方法通过
L1正则化来实现训练中的稀疏性,不需要跟踪特征的任何统计。随着训练的进行,这允许删除信息较少的特征。然而我们发现,与在训练中跟踪更多特征、并仅为serving进行稀疏化的方法(如FTRL-Proximal)相比,这种稀疏化方式导致了不可接受的准确性损失。我们探索的另一类方法是概率性的特征纳入
probabilistic feature inclusion,其中新特征在首次出现时以概率方式纳入模型中。这实现了预处理数据的效果,但是可以在online setting中执行。我们为该方法测试了两种实现方式:Poisson Inclusion:当我们遇到模型中不存在的特征时,我们仅以概率 将其添加到模型中。一旦添加了一个特征,在随后的观察中,我们会像往常一样更新权重和相关统计数据。在将特征添加到模型之前,需要查看特征的次数遵循期望值为 的几何分布。Bloom Filter Inclusion:我们使用一组滚动的counting Bloom filters,从而检测训练中遇到了 次的特征。一旦某个特征出现超过 次(根据过滤器),我们将其添加到模型中,并将其用于后续观察中的训练。注意,该方法也是概率性的,因为
counting Bloom filters可能会出现false positives(但是不会出现false negatives)。也就是说,我们有时会纳入一个实际发生的次数少于 次的特征。
这些方法的实验效果如下表所示。可以看到:这两种方法都运行良好,但是布隆过滤器方法为
RAM节省和预测质量损失提供了更好的tradeoff。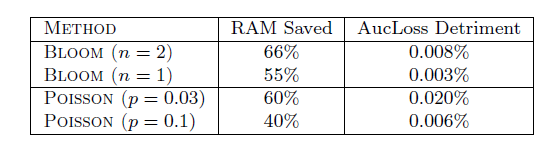
固定精度浮点数:通常我们用
32位或者64位浮点数来存储模型参数。实际中发现:几乎所有的参数取值都在[-2, +2]之间。同时,分析表明:对模型参数取如此高的精度完全没有必要。这促使我们探索使用16位固定精度的q.23编码,而不是浮点编码。在q2.13编码中:1个bit表示正负、2个bit表示整数部分、13个bit表示小数部分。采用
16位浮点数带来的精度下降会导致OGD过程中产生累积舍入误差。事实上在使用32位浮点数(而不是64位浮点数)时,我们也能够观察到舍入误差。一个简单的随机舍入策略可以缓解该问题:其中:
- 为原始的参数。
- 为引入随机舍入策略调整后的参数,它以
q2.13格式存储。 - 为一个随机数,它从
0~1均匀分布随机采样。
最终在没有损失模型预测能力的情况下,相比于
64位双精度浮点数,采用q2.13精度之后模型大小降低了75%。多模型并行训练:有时候我们需要训练多个模型,这些模型采用相同的算法但是不同的超参数来训练,这些模型称作变种模型。最后选择最佳的超参数及对应的模型。
一种简单的方式是:先用给定的算法训练好一个模型,然后用该模型作为变种模型的初始化点来训练变种模型。这种方式比较简单,容易实现。但是缺点是:无法处理特征裁剪、或者学习率调整等场景。
实际上有一些数据可以在多个模型之间共享,如:训练样本。另一些数据无法在多个模型之间共享,如:每个模型的参数值。我们可以在同一张哈希表中存储每个模型的参数值,从而分摊存储
key(一个字符串或者哈希后的数值)的成本。任何不具有指定特征的变体都会将该特征的权重存储为零,从而浪费少量空间。此外,我们将这些特征的学习率设为零。这使得我们可以同时并行训练多个模型,所有
per-coordinate元数据的平摊成本被降低。通过这种方式不仅节省了内存,还节省了网络带宽(因为每个样本只需要读取一次)、节省CPU(只需要查找一个哈希表,并且从训练数据中只需要生成一次特征而不是每个模型一次)、以及节省磁盘。单值结构
Single Value Structure:有时我们希望一起评估非常多的模型变体的集合,这些变体仅通过添加或删除一小部分特征而不同。在这里,我们可以使用一种更为压缩的数据结构,这种结构既有损lossy又特别,但实际上却给出了非常有用的结果。这个
Single Value Structure仅为per-coordinate存储一个权重值,该值由包含该特征的所有模型变体共享,而不是为每个模型变体存储单独的权重值。一个bit-field用于跟踪哪些模型变体包含给定的特征。注意,这在本质上《Fast prediction of new feature utility》的方法相似,但是也允许评估特征删除和特征添加。和多模型并行训练相比,增加模型变体的RAM成本增长要慢得多。假设使用
OGD优化,则整个学习过程如下(设维度 由所有变种模型共享):计算所有变种模型在该维度的参数更新值:
其中: 为模型数量, 为所有模型在特征 上共享的参数, 表示模型 的具体参数。
计算最新的共享参数值:
我们对比了使用
Single Value Structure训练的大量模型变体和使用多模型并行训练的相同变体。结果显示:不同变体的相对性能几乎相同,但是Single Value Structure在RAM占用方面中节省了一个数量级。学习率计算:如前所述,我们需要存储每个特征的累计梯度、以及累计平方梯度。虽然可以通过精确地计算梯度来得到学习率的准确值,但是可以对学习率计算进行粗略的近似。
假设特征 (比如说 “最近一年是否购买过广告主的产品”)出现时,点击事件和不点击事件是相互独立的(虽然实际上很难成立,但是不影响下面的推导过程)。设特征 出现时,有 次点击、 次未点击。则点击概率为: 。设我们采用逻辑回归模型,则有梯度:
假设逻辑回归采用
one-hot特征,当特征 出现时 ,因此:点击时(此时 )梯度 ,未点击时(此时 )梯度 。则coordinate的累计平方梯度为:这里我们假设每次点击的概率 是固定的。
则
coordinate的学习率为:因此可以基于每个特征上发生的点击/不点击计数来近似累计平方梯度,从而调整学习率。允许这样做的原因:学习率是模型的超参数,其取值不必非常精确。实验表明:这种方式得到的学习率,与采用累计平方梯度得到的学习率,二者表现相当。
在多模型并行训练中,由于所有变种模型都具有相同的特征点击/不点击计数,因此存储 的成本被摊销,总的存储成本较低。
另外,计数可以使用可变长度
bit编码,并且绝大多数特征不需要很多bit。这可以进一步降低存储成本。训练数据降采样:在典型的推荐、搜索等场景中,点击率
CTR通常远低于50%。这意味着正样本非常少,正样本在CTR预估任务的学习中更具有价值。因此我们可以通过负降采样来显著减少训练集大小,同时保证对模型预测能力的影响降到最低。负降采样方式为:所有正样本被保留、负样本保留 比例,其中 。负降采样会导致模型产生预测偏差,这种偏差可以通过为每个样本赋予一个系数来解决:正样本系数为
1、负样本系数为 。这种系数放大了每个样本的损失,因此也同步地缩放了梯度。数学上,令 为样本 被降采样的概率(要么为1要么为 ),而每个样本系数为 (要么为1要么为 ) ,那么:这意味着:降采样训练数据上的期望加权损失函数等于原始数据集上的损失函数。
实验表明:即使是非常大比例的负降采样( 值非常小),对最终模型准确性的影响也是微乎其微的,而且和具体的 值无关。
6.4 模型评估
虽然可以直接利用实时流量来评估模型效果,但是这种评估的代价太大:在实时流量中上新模型可能会降低这些流量的收入,因为新模型的效果在评估之前是未知的,可能更好、但是大多数情况下是更坏。
可以通过历史日志来评估模型效果。由于不同的评估指标衡量了模型在不同方面的能力,因此我们评估了一组指标:
aucloss(即:1-auc)、logloss、平方误差。为了保持一致性,这些指标都是越小越好。
6.4.1 渐进式验证
我们通常使用渐进式验证
progressive validation(有时称作在线损失),而不是交叉验证、也不是在hold out数据集上评估。因为学习过程中计算梯度无论如何都需要计算一个prediction,所以我们可以低成本地将这些prediction以每小时汇总的方式输出,用于后续分析。我们还根据各种数据sub-slices计算这些指标,例如按照国家、query主题、layout等进行细分。假设当前待学习的样本为 , 为了学习该样本:
oneline learning模型会首先预测该样本,得到预测值 ;然后基于预测值计算损失 和参数梯度 ;最后根据参数梯度来更新参数。在这个过程中,我们可以很容易的将样本的预测值 记录下来供后续的模型评估。我们每个小时汇总一次,得到该小时内每个样本的真实值、预测值。基于这些数据得到小时级别的模型评估指标。因此可以得到随时间推进的模型能力变化趋势。
这种方式中,每个样本都被用来训练,同时每个样本也被用来预测:训练完 来预测 、训练完 来预测 、... 。这使得我们可以将
100%的数据用于训练和验证。相比较于传统的交叉验证只有部分数据用于验证,这里的验证集更大,得到的验证结果也更具有统计意义。这很重要,因为某些性能的改进可能需要在大规模的验证集上评估才有意义(如:改进可能很小,比如千分之五),置信度才比较高。
用绝对值来评估模型能力可能会产生误导。假如某个场景点击率是
50%,另一个场景点击率是2%。事实上前者的logloss的绝对值可能会超过后者,因为logloss及其它指标可能会根据问题的难度(即贝叶斯风险)而变化。这个问题非常重要。因为
CTR会根据不同国家/地区、以及query而不同。query在一天中的不同时段的分布不同,因此评估指标的均值会在一天之内发生变化。因此我们更关注相对变化:模型的评估指标相对于
baseline的变化。根据我们的经验,随着时间的推进,相对变化会更加稳定。需要注意的是:我们必须在同一批数据上产生的同一个指标才有比较意义。如:
A模型在某个时间段上得到的模型指标,和B模型在另一个时间段上得到的模型指标之间不可比较。因为A模型和B模型的评估数据都不同。
6.4.2 通过可视化加深理解
大规模机器学习的一个隐藏陷阱是:统计指标可能受到数据中某些属性分布的影响。如:给定一个验证集,模型
A的准确率比模型B更高。很有可能该验证集中 “女性” 用户非常多,而模型A对于 “女性” 用户的预测比模型B更准。因此我们不仅要给出模型在整体验证集上的评估指标,还要在验证集数据的每个切片
slice上给出评估指标。如:模型在每个国家上的评估指标、模型在每个性别上的评估指标、模型在每个主题上的评估指标 .... 。因为有数百种方法可以对数据进行有意义的切片,所以我们必须能够有效地检查数据的可视化
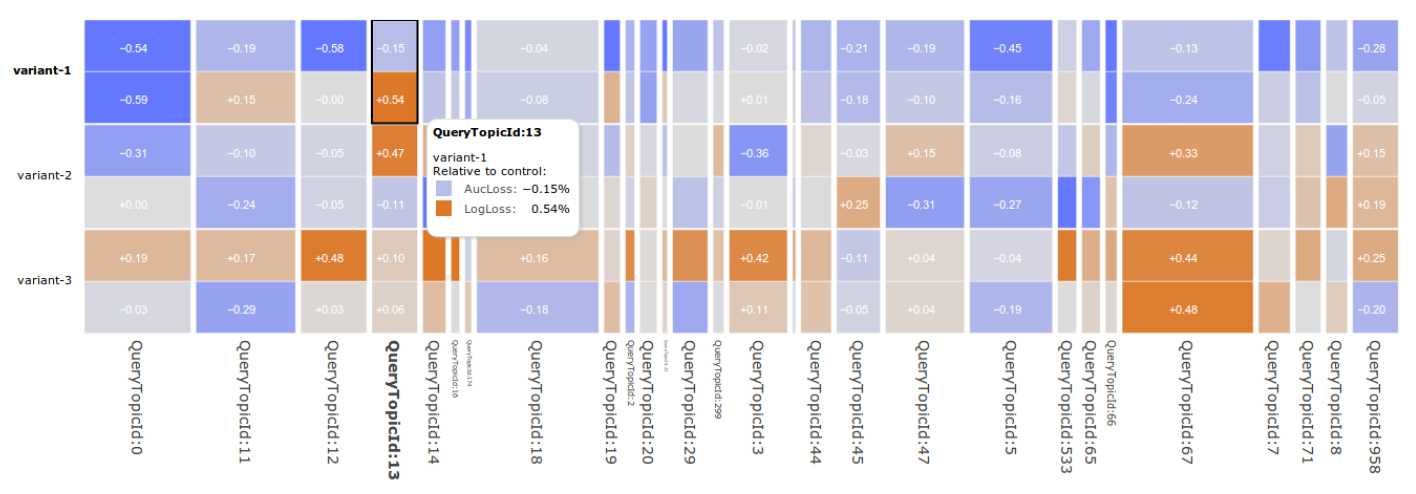
summary。为此,我们开发了一种称为GridViz的高维交互式可视化,可以全面了解模型性能。来自GridViz的一个视图的截图如下图所示,该图展示了baseline模型相比,三个模型(不包括baseline模型)的一组根据query主题的切片。其中AucLoss和LogLoss的结果基于一系列query主题来计算。指标值由彩色单元格表示,行与模型名称相对应,列与数据的每个
unique切片相对应。列的宽度表示切片的重要性,并且可以设置为反映诸如曝光次数、或点击次数之类的统计量。下图中,列宽反映了曝光次数。
单元格的颜色反映了与
baseline相比的指标值,这有助于快速扫描异常值和感兴趣的区域,从而直观地了解整体性能。- 当列足够宽时将显示所选指标的数值,否则所选指标数值不展示。
- 可以选择多个指标,这些指标将一起显示。
当用户将鼠标悬停在单元格上之时,会弹出给定单元格的详细报告。
由于存在数百种可能的切片,我们设计了一个交互式界面,允许用户通过下拉菜单或切片名称正则化表达式选择不同的切片。
可以对列进行排序并修改色标的动态范围从而适配手头的数据。
总体而言,该工具使得我们能够显著提高我们对各种数据集的模型性能的理解深度,并确定需要改进的高影响区域。
6.5 置信度
对很多
application,重要的是不仅要预估广告的点击率,还要量化预估的置信度。置信度可以用于衡量和控制explore-exploit tradeoffs。通常采用置信区间confidence intervals来评估不确定性,但是在这里不适用:标准的方法用于评估完全收敛的
batch学习模型,且没有正则化。而
FTRL模型是在线学习,不再满足独立同分布IID的样本假设,因此甚至无法定义收敛性。并且模型是经过正则化的。标准的方法需要求解一个
n x n矩阵的逆,这里n的规模达到数十亿甚至百亿,因此无法计算。此外,至关重要的是,任何置信度估计都需要在预测时以极低的成本进行计算。也就是说,置信度估计的耗时和预估本身的耗时差不多。
为此,我们提出了一种称之为不确定性得分
uncertainty score的启发式方法,它在计算上易于处理,并且在衡量预估准确性的质量方面做得很好。uncertainty score的核心思想是:学习算法本身在用于控制学习率的per-coordinate计数器 中保存了不确定性的概念,其中 。 较大的特征获得了较小的学习率,正是因为我们相信当前的权重更有可能是准确的。假设我们对样本进行归一化,使得样本每个特征的取值都归一化到
1以内,即: 。对于逻辑回归模型,损失函数的梯度为: 。 考虑到 因此有: 。为简单起见我们令 ,因此
FTRL-Proximal等价于OGD。给定样本 ,其预估的不确定性为:因此对于样本 ,定义模型预测的不确定性得分为: 。这种方式定义的置信度指标计算非常方便。
其物理意义是:由于学习的不充分导致预测结果的不确定性。因为一旦学习充分,则模型参数 非常稳定,在前后两次迭代之间的变化几乎为零。
为验证这种置信度指标的有效性,我们执行以下实验:
首先在真实数据集 上训练模型
A,但是使用稍微不同的特征。然后丢弃真实数据的标记 ,用模型
A的预测结果 来代替 ,从而产生了替代数据集 。在数据集 上用
FTRL算法训练模型B。对于样本 ,假设模型
A的预测结果为p,模型B的预测结果为 。则得分误差为:其中 是 的反函数,它根据预测概率计算得分 。
的物理意义为:由于标记噪声的引入,导致模型预测的波动范围。
最后计算 ,观察该指标是否和得分误差 相符。
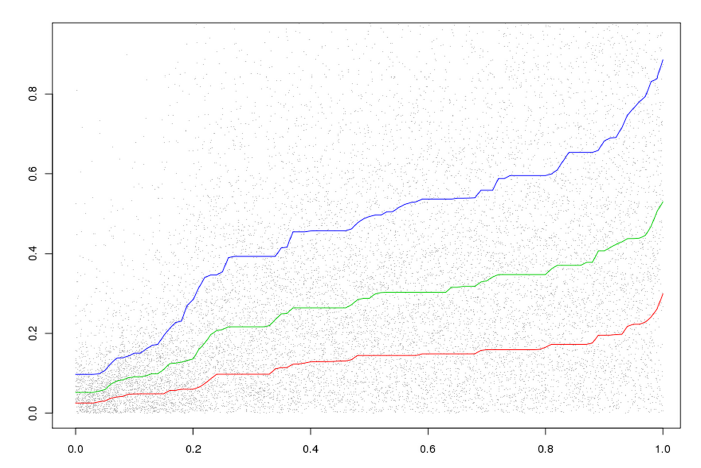
实验结果如下图所示。横坐标表示每一个样本的得分误差 ,纵坐标表示每个样本的不确定性分 ,
x/y轴归一化成0~1之间。曲线分别代表:相同得分误差的所有样本中,25%, 50%, 75%百分位的不确定分连接而成的曲线。可以看到,得分误差 和不确定性得分 成正向关系:得分误差越大,不确定性得分越大。实验结果表明: 和得分误差 比较匹配,而且置信度指标计算量非常小。
6.6 模型校正
准确的、且经过良好校正
calibration的CTR预估不仅对于竞价至关重要,还允许将竞价中的优化问题(如拍卖机制优化、出价优化)和机器学习问题解耦。很多因素可能会导致模型产生系统性偏差,如:模型的前提假设不成立、优化算法本身的缺陷、训练或预测期间无法获取某些重要特征。为解决该问题,我们提出
calibration layer来校正预测的CTR,使得预测CTR和经验CTR适配。假设模型在数据集 上的平均预测
CTR为 ,数据集 的经验CTR为 ,其中 。预测偏差bias为 。模型校正是提供一个校正函数 ,使得校正后的平均预测
CTR尽可能接近 。一个简单方法是基于泊松回归来校正。定义: ,其中 都是待学习的参数,通过泊松回归在数据集 上学习。
一个通用的方法是利用分段线性函数来拟合
bias曲线,其中必须满足 是单调递增函数。如:采用isotonic回归。这种方式的优点是通用性更强,无论平均预测CTR较高还是较低,它都能很好的校正。值得注意的是,如果没有很强的、额外的假设,系统中固有的反馈回路使得我们无法为校正的影响
impact提供理论上的保证。对于数据集,我们通常需要对不同数据区间对应的子集进行校正。因为很有可能模型对 “女性” 用户预测的平均
CTR偏高,对“男性”用户预测的平均CTR偏低,但是整体预测的平均CTR较好。这时我们需要分别针对 “女性” 用户、“男性” 用户分别进行模型校正。
6.7 自动特征管理
可扩展
scalable的机器学习的一个重要方面是管理installation的规模,包括构成机器学习系统的所有配置、开发人员、代码、计算资源。一个有趣的案例是机器学习特征空间的管理。我们可以将特征空间刻画为上下文和语义的一组信号,其中每个信号(例如“广告中的单词”、“原产国”等等)都可以转换为一组实值特征以供学习。在大多数系统中,许多开发人员可能会异步地进行信号开发。一个信号可能有许多版本,比如特征升级。工程团队可能会消费那些并不是他们直接开发的信号。信号可以在多个不同的学习平台上使用,并应用于不同的学习问题。
为了处理
use cases的组合增长,我们部署了元数据索引,用于管理数百个活跃模型对数千个输入信号的消费。- 索引会针对各种问题被手动或自动地注释,比如废弃、特定于某些平台、特定于某些领域。
- 新模型和活跃模型消费的信号由自动告警系统审核。
- 不同学习平台共享一个通用的接口,用于向中央索引报告信号消费。
- 当一个信号被废弃时(例如,当有新版本可用时),我们可以快速识别信号的所有消费者并跟踪替换操作。当信号的改进版本可用时,可以提醒消费者尝试新版本。
- 新信号可以通过自动测试进入审核,并列入白名单以供纳入。白名单既可用于确保生产系统的正确性,也可以用于使用自动特征选择的学习系统。
- 没有任何消费者的信号自动标记,从而自动进行代码清理和相关数据的删除。
有效的自动化信号消费管理可以确保在第一时间内正确地完成更多的学习。这减少了浪费和重复的工程工作,节省了很多工程时间。在运行学习算法之前验证配置的正确性,可以消除很多模型不可用的情况,从而节省大量潜在的资源浪费。
6.8 无效的探索
这里我们简要报告几个(可能令人惊讶)没有产生显著收益的方向。
积极的特征哈希
Aggressive Feature Hashing:近年来,出现了一系列工作围绕使用特征哈希来降低大规模机器学习的内存成本。我们测试了这种方法,但是发现:这种方式会带来模型预测能力的明显下降,因此无法应用。dropout:基于dropout的正则化并不会带来任何好处,甚至会降低模型预测能力。其根本原因是:在CTR预估任务中数据特征非常稀疏,经过dropout之后更为稀疏。在计算机视觉任务中,输入特征是非常密集的,且标签是比较干净的。此时
dropout将高度相关的特征分离开,从而产生更健壮的分类器。而在
CTR预估任务中,输入特征是非常稀疏的,且标签是带噪音的。此时dropout会显著降低学习的数据量,降低学习效果。Feature Bagging:通过在特征空间上 个重叠子集来获取 个训练样本子集,然后基于这些样本子集训练 个模型。对于未知样本,最终这 个模型的预测均值为该样本的预测结果。这是一种管理bias-variance tradeoff的潜在有效方法。该方法略微降低模型预测能力,大约损失AucLoss的0.1%到0.6%。特征向量归一化
Feature Vector Normalization:由于每个样本的非稀疏特征不同,导致样本特征向量的长度不同。我们尝试将样本归一化 ,最终效果不理想。我们猜测原因是:per-coordinate的学习率和样本归一化相互作用,导致效果下降。
七、LS-PLM 模型[2017]
点击率
click-through rate: CTR预估是价值数十亿美金的在线广告行业的核心问题。为了提高CTR预估的准确性,越来越多的数据被牵涉进来,使得CTR预估成为一个大规模的机器学习问题,具有海量样本和高维特征。传统的解决方案是应用以并行方式训练的线性逻辑回归
logistic regression: LR模型。具有 正则化的LR模型可以生成稀疏解,使得在线预估更快。不幸的是,
CTR预估问题是一个高度非线性的问题。特别是,用户点击的生成涉及很多复杂的因素,例如广告质量、上下文信息、用户兴趣以及这些因素的复杂交互。为了帮助LR模型捕获非线性,人们探索了特征工程技术feature engineering technique,这既费时又费力。另一个方向是通过精心设计的模型捕获非线性。
Facebook使用混合模型,将决策树和逻辑回归相结合。决策树起到了非线性特征变换的作用,其输出被馈入LR模型。然而,基于树的方法不适合非常稀疏和非常高维的数据。Rendle S. 2010引入了因子分解机Factorization Machine: FM,它涉及使用二阶函数(或使用其它阶数的函数)的特征之间的交互。但是,FM无法拟合数据中的所有通用非线性模式(比如比二阶更高的高阶模式)。
在论文
《Learning Piece-wise Linear Models from Large Scale Data for Ad Click Prediction》中,作者提出了一个分段线性模型以及针对大规模数据的训练算法,并将其命名为大规模分段线性模型Large Scale Piecewise Linear Model: LS-PLM。LS-PLM遵循分而治之的策略,即先将特征空间划分为若干个局部区域,然后在每个区域拟合一个线性模型,最后得到加权线性预测组合的输出。注意:这两步是以监督方式同时学习的,旨在最小化预测损失。LS-PLM在三个方面优于web-scale的数据挖掘:- 非线性
nonlinearity:有了足够多的划分区域,LS-PLM可以拟合任何复杂的非线性函数。 - 可扩展性
scalability:和LR模型类似,LS-PLM可以扩展到海量样本和高维特征。论文设计了一个分布式系统,可以在数百台机器上并行训练模型。在阿里巴巴在线生产系统中,每天都会训练和部署数十个具有数千万参数的LS-PLM模型。 - 稀疏性
sparsity:模型稀疏性是工业场景中online serving面临的实际问题。论文展示了具有 和 正则化的LS-PLM可以实现良好的稀疏性。
带有稀疏正则化的
LS-PLM的学习可以转化为一个非凸、非可微的优化问题,这个问题很难解决。论文针对此类问题提出了一种基于方向导数directional derivatives和拟牛顿法的有效优化方法。由于能够捕获非线性模式、以及对海量数据的可扩展性,
LS-PLM已经成为阿里巴巴在线展示广告系统display advertising system中的主力CTR预估模型,并从2012年初以来为数亿用户提供服务。它还应用于推荐系统、搜索引擎、以及其它产品系统。
7.1 模型
给定数据集 ,其中:
LS-PLM算法基于分而治之的策略,将整个特征空间划分为一些局部区域,对每个区域采用广义线性分类模型:其中:
将样本划分到 个区域, 对每个空间进行预测, 用于对结果进行归一化。
为模型参数。其中:
一种简单的情形是:
此时有:
这可以被认为是一种混合模型:
其中:
表示样本划分到区域 的概率。它满足:
表示在区域 中,样本 属于正类的概率。
我们主要研究这种简单的模型。
读者注:该模型的参数空间放大了 倍。考虑到
CTR预估场景中,逻辑回归模型的参数规模可以高达十亿级,因此 不能太大。但是太小的 无法捕获足够多的非线性,因此该模型比较鸡肋。下图说明了在一个
demo数据集中,该LS-PLM和LR模型的差异。图A)是demo数据集,这是一个二分类问题,红点属于正类、蓝点属于负类。图B)显示了使用LR模型的分类结果,图C)显示了使用LS-PLM模型的分类结果。可以清晰地看到LS-PLM能够捕获到数据中的非线性模式。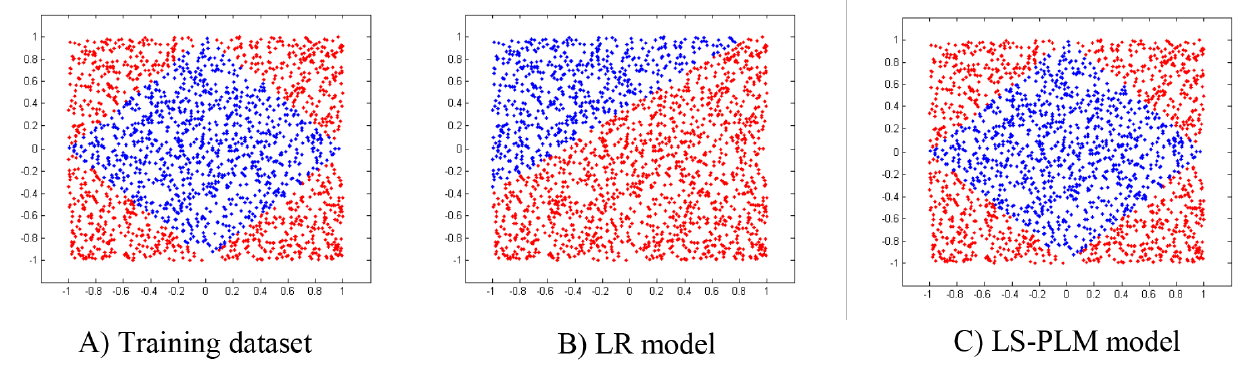
LS-PLM模型的目标函数为:其中:
loss是负的对数似然损失函数:和 是 和 正则化项:
这些正则化先计算每个维度在各区域的正则化,然后将所有维度的正则化直接累加。
- 正则化主要用于特征选择。在我们的模型中,特征的每个维度都和 个参数相关联。 正则化预期将单个特征的所有 个参数推到零,即抑制那些不太重要的特征。
- 主要用于模型稀疏性,但是它也有助于特征选择。它可以强制特征的参数尽可能为零,这有助于提高模型的解释能力和泛化性能。
但是, 范数和 范数都是非平滑函数。这导致目标函数是非凸的和非光滑的,使得很难应用那些传统的梯度下降优化方法或
EM方法。
7.2 优化算法
定义方向导数为:
当 时, 就是使得函数值 下降的方向。其中
对应于参数 的方向。
定义符号函数 为:
定义投影函数 为:
它表示将 投影到 定义的象限
orthant。
如前所述,我们针对大规模
CTR预估问题的目标函数既不是凸函数、也不是平滑函数。在这里,我们提出了一种通用且有效的优化方法来解决此类非凸问题。由于我们目标函数的负梯度并不是对所有的 都存在,因此我们采用方向 来替代,其中该方向是最小化方向导数 。方向导数 对任何 和方向 都存在,这就是下面的引理。
引理:当目标函数 由一个损失函数、一个 正则化项、一个 正则化项组成时(比如前述的目标函数),那么方向导数 对任何 和方向 都存在。
证明过程:
第一项:因为 是光滑的、可微的,所以有:
这里的向量点积是将两个张量展平为两个一维向量,再进行点积。
第二项:
根据:
其中: 为 的第 列组成的向量; 是 的第 列组成的向量。
则有:
第三项:
考虑到:
因此有:
最终得到方向导数。
注意:这里的方向导数中假设 ,即右方向导数。
由于方向导数 对任何 和方向 都存在,因此当 的负梯度不存在时,我们选择最小化方向导数 的方向作为下降方向。
由于代价函数降低的幅度与方向 的长度有关,因此我们约束方向 的长度 ,其中 是一个常数。因此我们得到一个带约束的最优化问题:
命题:给定一个光滑的损失函数 、以及一个目标函数 ,则有界的、且最小化方向导数 的方向 如下:
其中:
证明见原始论文。
受
OWLQN方法的启发,我们还限制模型参数在每次迭代中不改变符号sign。在第 次迭代,给定最小化方向导数的方向 和旧的模型参数 ,则下一轮参数的象限约束为:即:
- 当 时,新的 在不改变符号。
- 当 时,我们为新的 选择由 决定的象限。
得到最小化方向导数的方向 之后,我们并不是沿着 的方向更新参数,而是沿着由
LBFGS计算的下降方向来更新模型参数(从而加快收敛速度,因为二阶优化算法收敛速度更快)。此时需要计算在给定象限上目标函数的逆海森矩阵,其中用到辅助向量 的序列。最后得到参数更新的方向 。 这里我们采用两个技巧:首先,我们约束参数更新的方向位于针对于 的象限。
其次,由于我们的目标函数是非凸的,我们无法保证 为正定的。我们使用 作为条件来确保 是正定矩阵:当 时,采用 来更新;新当 时,采用 来更新。
其中 为参数更新的方向。
给定参数更新方向,我们使用回溯线性搜索
backtracking line search来找到合适的步长 。和QWLQN一样,我们将新的 投影到 给定的象限:因此要想参数 符号发生改变,唯一的机会是当 时基于 的符号来改变。
LS-PLM模型优化算法:输入:训练集
输出:模型参数
步骤:
随机初始化参数 。
迭代: ,其中 为最大迭代步数。迭代步骤为:
计算 、 、 。
判断停止条件:如果 满足停止条件(如 ,或者 ),则停止迭代并返回 。否则继续迭代,并更新 :
上述伪代码相比标准
LBFGS算法仅有几处不同:- 使用最小化非凸目标函数的方向导数的方向 代替负梯度。
- 更新方向被约束到由所选方向 定义的给定象限。当 是非正定矩阵时,切换到 。
- 在线性搜索期间,每个搜索点都投影到前一个点的象限。
7.3 模型实现
这里我们首先提供针对大规模数据的
LS-PLM模型的并行实现,然后介绍一个有助于大大加快训练过程的重要技巧。为了在大规模
setting中应用LS-PLM模型优化算法,我们使用分布式学习框架实现它,如下图所示。这是parameter server的变体。在我们的实现中,每个计算节点同时运行一个server节点和一个worker节点,目的是:- 最大限度地利用
CPU的计算能力。在传统的parameter server setting中,server节点作为分布式KV存储来使用,具有push/pull操作的接口,计算成本低。将server节点与worker节点一起运行可以充分利用算力。 - 最大限度地利用内存。今天的机器通常有大内存,例如
128 GB。通过运行在同一个计算节点上,server节点和worker节点可以更好地共享和利用大内存。
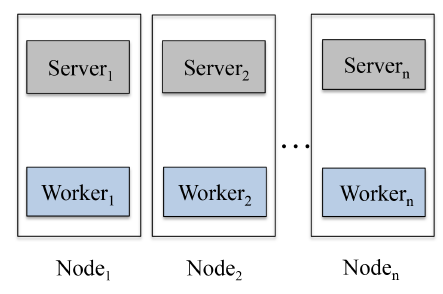
简而言之,框架中有两个角色:
- 第一个角色是
worker节点。每个worker结点存储部分训练样本,以及一个局部模型。该局部模型仅仅保存用于训练本地样本的模型参数。 - 第二个角色是
server节点。每个server结点分别独立的存储全局模型中的一部分。
在每次迭代过程中:
- 每个
worker首先用本地数据和局部模型计算损失和下降方向(数据并行)。 - 然后
server将损失loss、方向 、以及其它需要用于计算 的项汇总,从而计算 (模型并行)。 - 最终
worker同步最新的 。
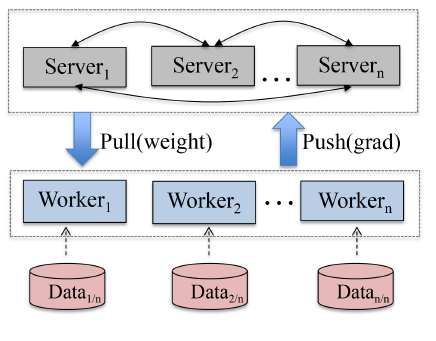
- 最大限度地利用
除了通用并行实现之外,我们还优化了在线广告环境中的实现。
CTR预估任务中的训练样本通常具有非常相似的共同特征common feature模式。如下图所示:用户U1在一个session中看到三条广告,因此产生三个样本。事实上,这三个样本共享U1的画像特征(如:年龄、性别、城市、兴趣爱好等)。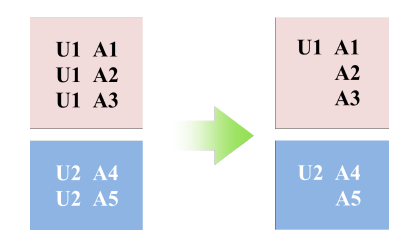
由于大量的计算集中在 和 , 因此可以将计算拆解成样本共享特征和样本非共享特征:
其中: 表示样本的共享特征, 为样本的非共享特征。
对于共享特征,每个用户只需要计算一次并保存起来,后续该用户的所有样本都可以直接复用该计算结果。
具体而言,我们在以下三个方面优化了具有共同特征的并行实现技巧::
- 将训练样本根据共享特征分组(如:“年龄、城市、性别” ),共享特征相同的样本划分到同一个
worker中。 - 每组共享特征仅需要存放一次,从而节省内存。如:“年龄 = 20, 城市 = 北京,性别 = 女” 这组特征只需要存放一次,该组的所有样本不需要重复存储该组特征。
- 在更新损失函数和梯度时,每组共享特征只需要计算一次,从而提高计算速度。
由于阿里巴巴的生产数据具有共享特征的模式,因此该技巧可以大幅度提高训练速度。在
100个worker、每个worker12个CPU core、11GB内存的条件下,实验结果表明:内存显著降低到1/3,计算速度加快12倍左右。
- 将训练样本根据共享特征分组(如:“年龄、城市、性别” ),共享特征相同的样本划分到同一个
7.4 实验
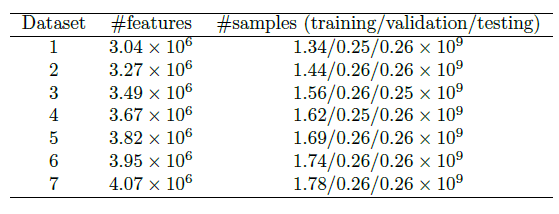
数据集:我们的数据集来自于阿里巴巴的移动展示广告产品系统。我们在连续的一段时间收集了七个数据集,旨在评估所提出模型的一致性
consist性能。在每个数据集中,训练集/验证集/测试集是从不同的日期不相交地收集的,比例约为7:1:1。我们的评估指标为AUC。数据集的详细数据如下表所示。
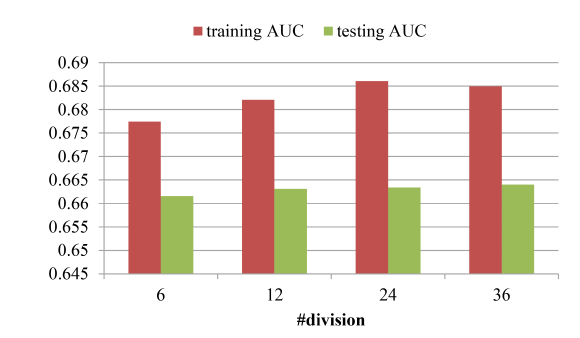
区域数量 的效果:参数 的物理意义是区域数量,它控制了模型的容量。
越大则模型容量越大,拟合能力越强,但是模型训练代价也越大。因此实际应用中必须在模型的拟合能力和训练成本之间平衡。
模型在数据集
1上的结果如下图所示。我们测试了M = 6,12,24,36。可以看到:- 当 时,模型测试
AUC明显强于 。 - 当 时,模型测试
AUC相对于 虽然有所提升,但是提升幅度很小。因此后续实验采用 。
- 当 时,模型测试
正则化的效果:为了使得模型更简单、泛化能力更强,我们使用了了 和 正则化来约束模型使得模型更稀疏。这里我们评估这两个正则化的效果,结果如下表所示。可以看到:
- 不出所料, 和 正则化都可以使得我们的模型更稀疏。
- 仅采用 正则化,最终保留了
9.4%的非零权重,从而保留了18.7%的特征。 - 仅采用 正则化,最终保留了
1.9%的非零权重,从而保留了12.7%的特征。 - 联合采用 正则化和 正则化,最终得到更稀疏的模型,以及泛化能力更强的模型。
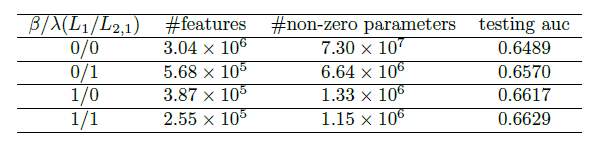
在这个实验中:; 和 在范围
{0.01, 0.1, 1, 10}内执行网格搜索,最后 表现最佳。和
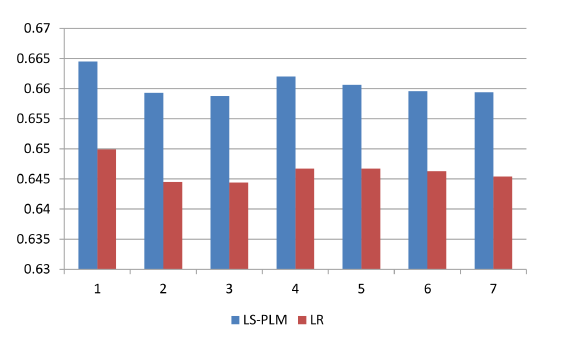
LR的对比:LS-PLM和LR模型在7个数据集上的对比如下图所示(评估指标为测试auc)。所有超参数通过
grid search搜索。其中:LS-PLM的超参数 , 最佳超参数为 。LR采用 正则化,超参数 ,最佳超参数为 。
可以看到:
LS-PLM显著超越了LR,平均AUC提升为1.4%,这对于在线广告系统的整体性能有显著影响。- 此外这个提升是稳定的,这确保了
LS-PLM可以安全地部署到在线生产系统中。