聚类
在无监督学习
(unsupervised learning)中,训练样本的标记信息是未知的。无监督学习的目标:通过对无标记训练样本的学习来揭露数据的内在性质以及规律。
一个经典的无监督学习任务:寻找数据的最佳表达
(representation)。常见的有:- 低维表达:试图将数据(位于高维空间)中的信息尽可能压缩在一个较低维空间中。
- 稀疏表达:将数据嵌入到大多数项为零的一个表达中。该策略通常需要进行维度扩张。
- 独立表达:使数据的各个特征相互独立。
无监督学习应用最广的是聚类
(clustering)。- 给定数据集 ,聚类试图将数据集中的样本划分为 个不相交的子集 ,每个子集称为一个簇
cluster。其中: 。 - 通过这样的划分,每个簇可能对应于一个潜在的概念。这些概念对于聚类算法而言,事先可能是未知的。
- 聚类过程仅仅能自动形成簇结构,簇所对应的概念语义需要由使用者来提供。
- 给定数据集 ,聚类试图将数据集中的样本划分为 个不相交的子集 ,每个子集称为一个簇
通常用 表示样本 的簇标记
cluster label,即 。于是数据集 的聚类结果可以用包含 个元素的簇标记向量 来表示。聚类的作用:
- 可以作为一个单独的过程,用于寻找数据内在的分布结构。
- 也可以作为其他学习任务的前驱过程。如对数据先进行聚类,然后对每个簇单独训练模型。
聚类问题本身是病态的。即:没有某个标准来衡量聚类的效果。
可以简单的度量聚类的性质,如每个聚类的元素到该类中心点的平均距离。
但是实际上不知道这个平均距离对应于真实世界的物理意义。
可能很多不同的聚类都很好地对应了现实世界的某些属性,它们都是合理的。
如:在图片识别中包含的图片有:红色卡车、红色汽车、灰色卡车、灰色汽车。可以聚类成:红色一类、灰色一类;也可以聚类成:卡车一类、汽车一类。
解决该问题的一个做法是:利用深度学习来进行分布式表达,可以对每个车辆赋予两个属性:一个表示颜色、一个表示型号。
一、性能度量
聚类的性能度量也称作聚类的有效性指标
validity index。直观上看,希望同一簇的样本尽可能彼此相似,不同簇的样本之间尽可能不同。即:簇内相似度
intra-cluster similarity高,且簇间相似度inter-cluster similarity低。聚类的性能度量分两类:
- 聚类结果与某个参考模型
reference model进行比较,称作外部指标external index。 - 直接考察聚类结果而不利用任何参考模型,称作内部指标
internal index。
- 聚类结果与某个参考模型
1.1 外部指标
对于数据集 ,假定通过聚类给出的簇划分为 。参考模型给出的簇划分为 ,其中 和 不一定相等 。
令 分别表示 的簇标记向量。定义:
其中 表示集合的元素的个数。各集合的意义为:
- :包含了同时隶属于 的样本对。
- :包含了隶属于 ,但是不隶属于 的样本对。
- :包含了不隶属于 , 但是隶属于 的样本对。
- :包含了既不隶属于 , 又不隶属于 的样本对。
由于每个样本对 仅能出现在一个集合中,因此有 。
下述性能度量的结果都在
[0,1]之间。这些值越大,说明聚类的性能越好。
1.1.1 Jaccard系数
Jaccard系数Jaccard Coefficient:JC:它刻画了:所有的同类的样本对(要么在 中属于同类,要么在 中属于同类)中,同时隶属于 的样本对的比例。
1.1.2 FM指数
FM指数Fowlkes and Mallows Index:FMI:它刻画的是:
- 在 中同类的样本对中,同时隶属于 的样本对的比例为 。
- 在 中同类的样本对中,同时隶属于 的样本对的比例为 。
FMI就是 和 的几何平均。
1.1.3 Rand指数
Rand指数Rand Index:RI:它刻画的是:
- 同时隶属于 的同类样本对(这种样本对属于同一个簇的概率最大)与既不隶属于 、 又不隶属于 的非同类样本对(这种样本对不是同一个簇的概率最大)之和,占所有样本对的比例。
- 这个比例其实就是聚类的可靠程度的度量。
1.1.4 ARI指数
使用
RI有个问题:对于随机聚类,RI指数不保证接近0(可能还很大)。ARI指数就通过利用随机聚类来解决这个问题。定义一致性矩阵为:
其中:
- 为属于簇 的样本的数量, 为属于簇 的样本的数量。
- 为同时属于簇 和簇 的样本的数量。
则根据定义有: ,其中 表示组合数。数字
2是因为需要提取两个样本组成样本对。定义
ARI指数Adjusted Rand Index:其中:
:表示同时隶属于 的样本对。
:表示最大的样本对。
即:无论如何聚类,同时隶属于 的样本对不会超过该数值。
:表示在随机划分的情况下,同时隶属于 的样本对的期望。
- 随机挑选一对样本,一共有 种情形。
- 这对样本隶属于 中的同一个簇,一共有 种可能。
- 这对样本隶属于 中的同一个簇,一共有 种可能。
- 这对样本隶属于 中的同一个簇、且属于 中的同一个簇,一共有 种可能。
- 则在随机划分的情况下,同时隶属于 的样本对的期望(平均样本对)为: 。
1.2 内部指标
对于数据集 ,假定通过聚类给出的簇划分为 。
定义:
其中: 表示两点 之间的距离; 表示簇 的中心点, 表示簇 的中心点, 表示簇 的中心点之间的距离。
上述定义的意义为:
- : 簇 中每对样本之间的平均距离。
- :簇 中距离最远的两个点的距离。
- :簇 之间最近的距离。
- :簇 中心点之间的距离。
1.2.1 DB指数
DB指数Davies-Bouldin Index:DBI:其物理意义为:
给定两个簇,每个簇样本距离均值之和比上两个簇的中心点之间的距离作为度量。
该度量越小越好。
给定一个簇 ,遍历其它的簇,寻找该度量的最大值。
对所有的簇,取其最大度量的均值。
显然 越小越好。
- 如果每个簇样本距离均值越小(即簇内样本距离都很近),则 越小。
- 如果簇间中心点的距离越大(即簇间样本距离相互都很远),则 越小。
1.2.2 Dunn指数
Dunn指数Dunn Index:DI:其物理意义为:任意两个簇之间最近的距离的最小值,除以任意一个簇内距离最远的两个点的距离的最大值。
显然 越大越好。
- 如果任意两个簇之间最近的距离的最小值越大(即簇间样本距离相互都很远),则 越大。
- 如果任意一个簇内距离最远的两个点的距离的最大值越小(即簇内样本距离都很近),则 越大。
1.3 距离度量
距离函数 常用的有以下距离:
闵可夫斯基距离
Minkowski distance:给定样本 ,则闵可夫斯基距离定义为:
当 时,闵可夫斯基距离就是欧式距离
Euclidean distance:当 时,闵可夫斯基距离就是曼哈顿距离
Manhattan distance:
VDM距离Value Difference Metric:考虑非数值类属性(如属性取值为:
中国,印度,美国,英国),令 表示 的样本数; 表示 且位于簇 中的样本的数量。则在属性 上的两个取值 之间的VDM距离为:该距离刻画的是:属性取值在各簇上的频率分布之间的差异。
当样本的属性为数值属性与非数值属性混合时,可以将闵可夫斯基距离与
VDM距离混合使用。假设属性 为数值属性, 属性 为非数值属性。则:
当样本空间中不同属性的重要性不同时,可以采用加权距离。
以加权闵可夫斯基距离为例:
这里的距离函数都是事先定义好的。在有些实际任务中,有必要基于数据样本来确定合适的距离函数。这可以通过距离度量学习
distance metric learning来实现。这里的距离度量满足三角不等式: 。
在某些任务中,根据数据的特点可能需要放松这一性质。如:
美人鱼和人距离很近,美人鱼和鱼距离很近,但是人和鱼的距离很远。这样的距离称作非度量距离non-metric distance。
二、原型聚类
原型聚类
prototype-based clustering假设聚类结构能通过一组原型刻画。常用的原型聚类有:
k均值算法k-means。- 学习向量量化算法
Learning Vector Quantization:LVQ。 - 高斯混合聚类
Mixture-of-Gaussian。
2.1 k-means 算法
2.1.1 k-means
给定样本集 , 假设一个划分为 。
定义该划分的平方误差为:
其中 是簇 的均值向量。
- 刻画了簇类样本围绕簇均值向量的紧密程度,其值越小,则簇内样本相似度越高。
k-means算法的优化目标为:最小化 。即: 。
k-means的优化目标需要考察 的所有可能的划分,这是一个NP难的问题。实际上k-means采用贪心策略,通过迭代优化来近似求解。首先假设一组均值向量。
然后根据假设的均值向量给出了 的一个划分。
再根据这个划分来计算真实的均值向量:
- 如果真实的均值向量等于假设的均值向量,则说明假设正确。根据假设均值向量给出的 的一个划分确实是原问题的解。
- 如果真实的均值向量不等于假设的均值向量,则可以将真实的均值向量作为新的假设均值向量,继续迭代求解。
这里的一个关键就是:给定一组假设的均值向量,如何计算出 的一个簇划分?
k均值算法的策略是:样本离哪个簇的均值向量最近,则该样本就划归到那个簇。k-means算法:输入:
- 样本集 。
- 聚类簇数 。
输出:簇划分 。
算法步骤:
从 中随机选择 个样本作为初始均值向量 。
重复迭代直到算法收敛,迭代过程:
初始化阶段:取
划分阶段:令 :
计算 的簇标记: 。
即:将 离哪个簇的均值向量最近,则该样本就标记为那个簇。
然后将样本 划入相应的簇: 。
重计算阶段:计算 : 。
终止条件判断:
- 如果对所有的 ,都有 ,则算法收敛,终止迭代。
- 否则重赋值 。
k-means优点:计算复杂度低,为 ,其中 为迭代次数。
通常 和 要远远小于 ,此时复杂度相当于 。
思想简单,容易实现。
k-means缺点:需要首先确定聚类的数量 。
分类结果严重依赖于分类中心的初始化。
通常进行多次
k-means,然后选择最优的那次作为最终聚类结果。结果不一定是全局最优的,只能保证局部最优。
对噪声敏感。因为簇的中心是取平均,因此聚类簇很远地方的噪音会导致簇的中心点偏移。
无法解决不规则形状的聚类。
无法处理离散特征,如:
国籍、性别等。
k-means性质:k-means实际上假设数据是呈现球形分布,实际任务中很少有这种情况。与之相比,
GMM使用更加一般的数据表示,即高斯分布。k-means假设各个簇的先验概率相同,但是各个簇的数据量可能不均匀。k-means使用欧式距离来衡量样本与各个簇的相似度。这种距离实际上假设数据的各个维度对于相似度的作用是相同的。k-means中,各个样本点只属于与其相似度最高的那个簇,这实际上是硬分簇。k-means算法的迭代过程实际上等价于EM算法。具体参考EM算法章节。
2.1.2 k-means++
k-means++属于k-means的变种,它主要解决k-means严重依赖于分类中心初始化的问题。k-means++选择初始均值向量时,尽量安排这些初始均值向量之间的距离尽可能的远。k-means++算法:输入:
- 样本集 。
- 聚类簇数 。
输出:簇划分 。
算法步骤:
从 中随机选择1个样本作为初始均值向量组 。
迭代,直到初始均值向量组有 个向量。
假设初始均值向量组为 。迭代过程如下:
- 对每个样本 ,分别计算其距 的距离。这些距离的最小值记做 。
- 对样本 ,其设置为初始均值向量的概率正比于 。即:离所有的初始均值向量越远,则越可能被选中为下一个初始均值向量。
- 以概率分布 (未归一化的)随机挑选一个样本作为下一个初始均值向量 。
一旦挑选出初始均值向量组 ,剩下的迭代步骤与
k-means相同。
2.1.3 k-modes
k-modes属于k-means的变种,它主要解决k-means无法处理离散特征的问题。k-modes与k-means有两个不同点(假设所有特征都是离散特征):距离函数不同。在
k-modes算法中,距离函数为:其中 为示性函数。
上式的意义为:样本之间的距离等于它们之间不同属性值的个数。
簇中心的更新规则不同。在
k-modes算法中,簇中心每个属性的取值为:簇内该属性出现频率最大的那个值。其中 的取值空间为所有样本在第 个属性上的取值。
2.1.4 k-medoids
k-medoids属于k-means的变种,它主要解决k-means对噪声敏感的问题。k-medoids算法:输入:
- 样本集 。
- 聚类簇数 。
输出:簇划分 。
算法步骤:
从 中随机选择 个样本作为初始均值向量 。
重复迭代直到算法收敛,迭代过程:
初始化阶段:取 。
遍历每个样本 ,计算它的簇标记: 。即:将 离哪个簇的均值向量最近,则该样本就标记为那个簇。
然后将样本 划入相应的簇: 。
重计算阶段:
遍历每个簇 :
计算簇心 距离簇内其它点的距离 。
计算簇 内每个点 距离簇内其它点的距离 。
如果 ,则重新设置簇中心: 。
终止条件判断:遍历一轮簇 之后,簇心保持不变。
k-medoids算法在计算新的簇心时,不再通过簇内样本的均值来实现,而是挑选簇内距离其它所有点都最近的样本来实现。这就减少了孤立噪声带来的影响。k-medoids算法复杂度较高,为 。其中计算代价最高的是计算每个簇内每对样本之间的距离。通常会在算法开始时计算一次,然后将结果缓存起来,以便后续重复使用。
2.1.5 mini-batch k-means
mini-batch k-means属于k-means的变种,它主要用于减少k-means的计算时间。mini-batch k-means算法每次训练时随机抽取小批量的数据,然后用这个小批量数据训练。这种做法减少了k-means的收敛时间,其效果略差于标准算法。mini-batch k-means算法:输入:
- 样本集 。
- 聚类簇数 。
输出:簇划分 。
算法步骤:
从 中随机选择 个样本作为初始均值向量 。
重复迭代直到算法收敛,迭代过程:
初始化阶段:取
划分阶段:随机挑选一个
Batch的样本集合 ,其中 为批大小。计算 的簇标记: 。
即:将 离哪个簇的均值向量最近,则该样本就标记为那个簇。
然后将样本 划入相应的簇: 。
重计算阶段:计算 : 。
终止条件判断:
- 如果对所有的 ,都有 ,则算法收敛,终止迭代。
- 否则重赋值 。
2.2 学习向量量化
与一般聚类算法不同,学习向量量化
Learning Vector Quantization:LVQ假设数据样本带有类别标记,学习过程需要利用样本的这些监督信息来辅助聚类。给定样本集 ,
LVQ的目标是从特征空间中挑选一组样本作为原型向量 。- 每个原型向量代表一个聚类簇,簇标记 。即:簇标记从类别标记中选取。
- 原型向量从特征空间中取得,它们不一定就是 中的某个样本。
LVQ的想法是:通过从样本中挑选一组样本作为原型向量 ,可以实现对样本空间 的簇划分。对任意样本 ,它被划入与距离最近的原型向量所代表的簇中。
对于每个原型向量 ,它定义了一个与之相关的一个区域 ,该区域中每个样本与 的距离都不大于它与其他原型向量 的距离。
区域 对样本空间 形成了一个簇划分,该划分通常称作
Voronoi剖分。
问题是如何从样本中挑选一组样本作为原型向量?
LVQ的思想是:首先挑选一组样本作为假设的原型向量。
然后对于训练集中的每一个样本 , 找出假设的原型向量中,距离该样本最近的原型向量 :
- 如果 的标记与 的标记相同,则更新 ,将该原型向量更靠近 。
- 如果 的标记与 的标记不相同,则更新 ,将该原型向量更远离 。
不停进行这种更新,直到迭代停止条件(如以到达最大迭代次数,或者原型向量的更新幅度很小)。
LVQ算法:输入:
- 样本集
- 原型向量个数
- 各原型向量预设的类别标记
- 学习率
输出:原型向量
算法步骤:
依次随机从类别 中挑选一个样本,初始化一组原型向量 。
重复迭代,直到算法收敛。迭代过程如下:
- 从样本集 中随机选取样本 ,挑选出距离 最近的原型向量 : 。
- 如果 的类别等于 ,则: 。
- 如果 的类别不等于 ,则: 。
在原型向量的更新过程中:
如果 的类别等于 ,则更新后, 与 距离为:
则更新后的原型向量 距离 更近。
如果 的类别不等于 ,则更新后, 与 距离为:
则更新后的原型向量 距离 更远。
这里有一个隐含假设:即计算得到的样本 (该样本可能不在样本集中) 的标记就是更新之前 的标记。
即:更新操作只改变原型向量的样本值,但是不改变该原型向量的标记。
2.3 高斯混合聚类
高斯混合聚类采用概率模型来表达聚类原型。
对于 维样本空间 中的随机向量 ,若 服从高斯分布,则其概率密度函数为 :
其中 为 维均值向量, 是 的协方差矩阵。 的概率密度函数由参数 决定。
定义高斯混合分布: 。该分布由 个混合成分组成,每个混合成分对应一个高斯分布。其中:
- 是第 个高斯混合成分的参数。
- 是相应的混合系数,满足 。
假设训练集 的生成过程是由高斯混合分布给出。
令随机变量 表示生成样本 的高斯混合成分序号, 的先验概率 。
生成样本的过程分为两步:
- 首先根据概率分布 生成随机变量 。
- 再根据 的结果,比如 , 根据概率 生成样本。
根据贝叶斯定理, 若已知输出为 ,则 的后验分布为:
其物理意义为:所有导致输出为 的情况中, 发生的概率。
当高斯混合分布已知时,高斯混合聚类将样本集 划分成 个簇 。
对于每个样本 ,给出它的簇标记 为:
即:如果 最有可能是 产生的,则将该样本划归到簇 。
这就是通过最大后验概率确定样本所属的聚类。
现在的问题是,如何学习高斯混合分布的参数。由于涉及到隐变量 ,可以采用
EM算法求解。具体求解参考
EM算法的章节部分。
三、密度聚类
- 密度聚类
density-based clustering假设聚类结构能够通过样本分布的紧密程度确定。 - 密度聚类算法从样本的密度的角度来考察样本之间的可连接性,并基于可连接样本的不断扩张聚类簇,从而获得最终的聚类结果。
3.1 DBSCAN 算法
DBSCAN是一种著名的密度聚类算法,它基于一组邻域参数 来刻画样本分布的紧密程度。给定数据集 , 定义:
-邻域: 。
即: 包含了样本集 中与 距离不大于 的所有的样本。
核心对象
core object:若 ,则称 是一个核心对象。即:若 的 -邻域中至少包含 个样本,则 是一个核心对象。
密度直达
directyl density-reachable:若 是一个核心对象,且 , 则称 由 密度直达,记作 。密度可达
density-reachable:对于 和 , 若存在样本序列 , 其中 ,如果 由 密度直达,则称 由 密度可达,记作 。密度相连
density-connected:对于 和 ,若存在 ,使得 与 均由 密度可达,则称 与 密度相连 ,记作 。
DBSCAN算法的簇定义:给定邻域参数 , 一个簇 是满足下列性质的非空样本子集:- 连接性
connectivity: 若 ,则 。 - 最大性
maximality:若 ,且 , 则 。
即一个簇是由密度可达关系导出的最大的密度相连样本集合。
- 连接性
DBSCAN算法的思想:若 为核心对象,则 密度可达的所有样本组成的集合记作 。可以证明 : 就是满足连接性与最大性的簇。于是
DBSCAN算法首先任选数据集中的一个核心对象作为种子seed,再由此出发确定相应的聚类簇。DBSCAN算法:输入:
- 数据集
- 邻域参数
输出: 簇划分
算法步骤:
初始化核心对象集合为空集:
寻找核心对象:
- 遍历所有的样本点 , 计算
- 如果 ,则
迭代:以任一未访问过的核心对象为出发点,找出有其密度可达的样本生成的聚类簇,直到所有核心对象都被访问为止。
注意:
- 若在核心对象 的寻找密度可达的样本的过程中,发现核心对象 是由 密度可达的,且 尚未被访问,则将 加入 所属的簇,并且标记 为已访问。
- 对于 中的样本点,它只可能属于某一个聚类簇。因此在核心对象 的寻找密度可达的样本的过程中,它只能在标记为未访问的样本中寻找 (标记为已访问的样本已经属于某个聚类簇了)。
DBSCAN算法的优点:- 簇的数量由算法自动确定,无需人工指定。
- 基于密度定义,能够对抗噪音。
- 可以处理任意形状和大小的簇。
DBSCAN算法的缺点:- 若样本集的密度不均匀,聚类间距差相差很大时,聚类质量较差。因为此时参数 和 的选择比较困难。
- 无法应用于密度不断变化的数据集中。
3.2 Mean-Shift 算法
Mean-Shift是基于核密度估计的爬山算法,可以用于聚类、图像分割、跟踪等领域。给定 维空间的 个样本组成的数据集 ,给定一个中心为 、半径为 的球形区域 (称作
兴趣域),定义其mean shift向量为: 。Mean-Shift算法的基本思路是:首先任选一个点作为聚类的中心来构造
兴趣域。然后计算当前的
mean shift向量,兴趣域的中心移动为: 。移动过程中,
兴趣域范围内的所有样本都标记为同一个簇。如果
mean shift向量为 0 ,则停止移动,说明兴趣域已到达数据点最密集的区域。
因此
Mean-Shift会向着密度最大的区域移动。下图中:蓝色为当前的
兴趣域,红色为当前的中心点 ;紫色向量为mean shift向量 ,灰色为移动之后的兴趣域。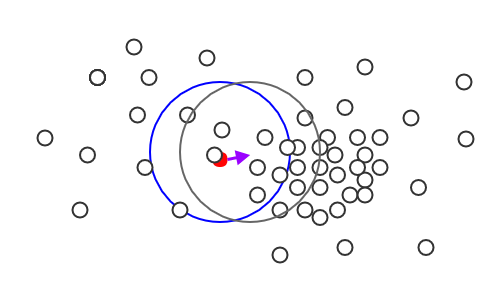
在计算
mean shift向量的过程中假设每个样本的作用都是相等的。实际上随着样本与中心点的距离不同,样本对于mean shift向量的贡献不同。定义高斯核函数为: ,则重新
mean shift向量定义为:其中 称做带宽。 刻画了样本 距离中心点 相对于半径 的相对距离。
Mean_Shift算法:输入:
- 数据集
- 带宽参数
- 迭代阈值 ,簇阈值
输出: 簇划分
算法步骤:
迭代,直到所有的样本都被访问过。迭代过程为(设已有的簇为 ):
在未访问过的样本中随机选择一个点作为中心点 ,找出距它半径为 的
兴趣域,记做 。将 中的样本的簇标记设置为 ( 一个新的簇)。
计算当前的
mean shift向量,兴趣域中心的移动为:在移动过程中,兴趣域内的所有点标记为
访问过,并且将它们的簇标记设置为 。如果 ,则本次结束本次迭代。
设已有簇中,簇 的中心点 与 距离最近,如果 ,则将当前簇和簇 合并。
合并时,当前簇中的样本的簇标记重新修改为 。
当所有的样本都被访问过时,重新分配样本的簇标记(因为可能有的样本被多个簇标记过):若样本被多个簇标记过,则选择最大的那个簇作为该样本的簇标记。即:尽可能保留大的簇。
可以证明:
Mean_Shift算法每次移动都是向着概率密度函数增加的方向移动。在 维欧式空间中,对空间中的点 的概率密度估计为:
其中:
- 表示空间中的核函数, 为带宽矩阵。
- 通常 采用放射状对称核函数 , 为 的轮廓函数, (一个正数)为标准化常数从而保证 的积分为 1 。
- 通常带宽矩阵采用 , 为带宽参数。
因此有: 。则有梯度:
记 的导数为 。取 为新的轮廓函数, (一个正数)为新的标准化常数, 。
则有:
定义 ,则它表示基于核函数 的概率密度估计,始终为非负数。
根据前面定义:,则有: 。
因此 正比于 ,因此
mean shift向量的方向始终指向概率密度增加最大的方向。上式计算 时需要考虑所有的样本,计算复杂度太大。作为一个替代,可以考虑使用 距离 内的样本,即
兴趣域内的样本。即可得到: 。Mean-Shift算法优点:- 簇的数量由算法自动确定,无需人工指定。
- 基于密度定义,能够对抗噪音。
- 可以处理任意形状和大小的簇。
- 没有局部极小值点,因此当给定带宽参数 时,其聚类结果就是唯一的。
Mean_Shift算法缺点:- 无法控制簇的数量。
- 无法区分有意义的簇和无意义的簇。如:在
Mean_Shift算法中,异常点也会形成它们自己的簇。
四、层次聚类
- 层次聚类
hierarchical clustering试图在不同层次上对数据集进行划分,从而形成树形的聚类结构。
4.1 AGNES 算法
AGglomerative NESting:AGNES是一种常用的采用自底向上聚合策略的层次聚类算法。AGNES首先将数据集中的每个样本看作一个初始的聚类簇,然后在算法运行的每一步中,找出距离最近的两个聚类簇进行合并。合并过程不断重复,直到达到预设的聚类簇的个数。
这里的关键在于:如何计算聚类簇之间的距离?
由于每个簇就是一个集合,因此只需要采用关于集合的某个距离即可。给定聚类簇 , 有三种距离:
最小距离 : 。
最小距离由两个簇的最近样本决定。
最大距离 : 。
最大距离由两个簇的最远样本决定。
平均距离: 。
平均距离由两个簇的所有样本决定。
AGNES算法可以采取上述任意一种距离:- 当
AGNES算法的聚类簇距离采用 时,称作单链接single-linkage算法。 - 当
AGNES算法的聚类簇距离采用 时,称作全链接complete-linkage算法。 - 当
AGNES算法的聚类簇距离采用 时,称作均链接average-linkage算法 。
- 当
AGNES算法:输入:
- 数据集
- 聚类簇距离度量函数
- 聚类簇数量
输出:簇划分
算法步骤:
初始化:将每个样本都作为一个簇
迭代,终止条件为聚类簇的数量为 。迭代过程为:
计算聚类簇之间的距离,找出距离最近的两个簇,将这两个簇合并。
每进行一次迭代,聚类簇的数量就减少一些。
AGNES算法的优点:- 距离容易定义,使用限制较少。
- 可以发现聚类的层次关系。
AGNES算法的缺点:- 计算复杂度较高。
- 算法容易聚成链状。
4.2 BIRCH 算法
BIRCH:Balanced Iterative Reducing and Clustering Using Hierarchies算法通过聚类特征树CF Tree:Clustering Feature True来执行层次聚类,适合于样本量较大、聚类类别数较大的场景。
4.2.1 聚类特征
聚类特征
CF:每个CF都是刻画一个簇的特征的三元组: 。其中:- :表示簇内样本数量的数量。
- :表示簇内样本的线性求和: ,其中 为该
CF对应的簇。 - :表示簇内样本的长度的平方和。 ,其中 为该
CF对应的簇。
根据
CF的定义可知:如果CF1和CF2分别表示两个不相交的簇的特征,如果将这两个簇合并成一个大簇,则大簇的特征为: 。即:
CF满足可加性。给定聚类特征
CF,则可以统计出簇的一些统计量:- 簇心: 。
- 簇内数据点到簇心的平均距离(也称作簇的半径): 。
- 簇内两两数据点之间的平均距离(也称作簇的直径): 。
给定两个不相交的簇,其特征分别为 和 。
假设合并之后的簇为 ,其中 , , 。
可以通过下列的距离来度量
CF1和CF2的相异性:簇心欧氏距离
centroid Euclidian distance:,其中 分别为各自的簇心。簇心曼哈顿距离
centroid Manhattan distance: 。簇连通平均距离
average inter-cluster distance:全连通平均距离
average intra-cluster distance:方差恶化距离
variance incress distance: 。
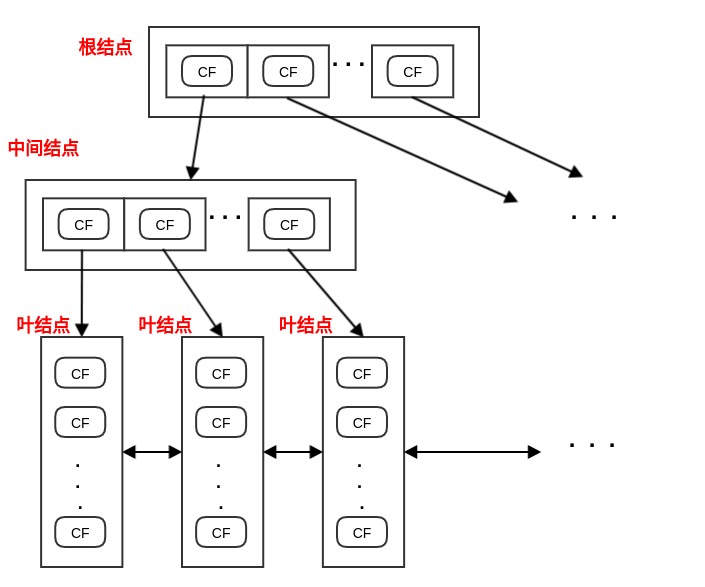
4.2.2 CF 树
CF树的结构类似于平衡B+树 。树由三种结点构成:根结点、中间结点、叶结点。根结点、中间结点:由若干个聚类特征
CF,以及这些CF指向子结点的指针组成。叶结点:由若干个聚类特征
CF组成。- 叶结点没有子结点,因此
CF没有指向子结点的指针。 - 所有的叶结点通过双向链表连接起来。
- 在
BIRCH算法结束时,叶结点的每个CF对应的样本集就对应了一个簇。
- 叶结点没有子结点,因此
CF树有三个关键参数:- 枝平衡因子 :非叶结点中,最多不能包含超过 个
CF。 - 叶平衡因子 :叶结点中,最多不能包含超过 个
CF。 - 空间阈值 :叶结点中,每个
CF对应的子簇的大小(通过簇半径 来描述)不能超过 。
- 枝平衡因子 :非叶结点中,最多不能包含超过 个
由于
CF的可加性,所以CF树中,每个父结点的CF等于它所有子结点的所有CF之和。CF树的生成算法:输入:
- 样本集
- 枝平衡因子
- 叶平衡因子
- 空间阈值
输出:
CF树算法步骤:
初始化:
CF树的根结点为空。随机从样本集 中选出一个样本,放入一个新的
CF中,并将该CF放入到根结点中。遍历 中的样本,并向
CF树中插入。迭代停止条件为:样本集 中所有样本都插入到CF树中。迭代过程如下:
随机从样本集 中选出一个样本 ,从根结点向下寻找与 距离最近的叶结点 ,和 里与 最近的 。
如果 加入到 对应的簇中之后,该簇的簇半径 ,则将 加入到 对应的簇中,并更新路径上的所有
CF。本次插入结束。否则,创建一个新的
CF,将 放入该CF中,并将该CF添加到叶结点 中。如果 的
CF数量小于 ,则更新路径上的所有CF。本次插入结束。否则,将叶结点 分裂为两个新的叶结点 。分裂方式为:
- 选择叶结点 中距离最远的两个
CF,分别作为 中的首个CF。 - 将叶结点 中剩下的
CF按照距离这两个CF的远近,分别放置到 中。
- 选择叶结点 中距离最远的两个
依次向上检查父结点是否也需要分裂。如果需要,则按照和叶子结点分裂方式相同。
4.2.3 BIRCH 算法
BIRCH算法的主要步骤是建立CF树,除此之外还涉及到CF树的瘦身、离群点的处理。BIRCH需要对CF树瘦身,有两个原因:- 将数据点插入到
CF树的过程中,用于存储CF树结点及其相关信息的内存有限,导致部分数据点生长形成的CF树占满了内存。因此需要对CF树瘦身,从而使得剩下的数据点也能插入到CF树中。 CF树生长完毕后,如果叶结点中的CF对应的簇太小,则会影响后续聚类的速度和质量。
- 将数据点插入到
BIRCH瘦身是在将 增加的过程。算法会在内存中同时存放旧树 和新树 ,初始时刻 为空。- 算法同时处理 和 ,将 中的
CF迁移到 中。 - 在完成所有的
CF迁移之后, 为空, 就是瘦身后的CF树。
- 算法同时处理 和 ,将 中的
BIRCH离群点的处理:在对
CF瘦身之后,搜索所有叶结点中的所有子簇,寻找那些稀疏子簇,并将稀疏子簇放入待定区。稀疏子簇:簇内数据点的数量远远少于所有子簇的平均数据点的那些子簇。
将稀疏子簇放入待定区时,需要同步更新
CF树上相关路径及结点。当 中所有数据点都被插入之后,扫描待定区中的所有数据点(这些数据点就是候选的离群点),并尝试将其插入到
CF树中。如果数据点无法插入到
CF树中,则可以确定为真正的离群点。
BIRCH算法:输入:
- 样本集
- 枝平衡因子
- 叶平衡因子
- 空间阈值
输出:
CF树算法步骤:
建立
CF树。(可选)对
CF树瘦身、去除离群点,以及合并距离非常近的CF。(可选)利用其它的一些聚类算法(如:
k-means)对CF树的所有叶结点中的CF进行聚类,得到新的CF树。这是为了消除由于样本读入顺序不同导致产生不合理的树结构。
这一步是对
CF结构进行聚类。由于每个CF对应一组样本,因此对CF聚类就是对 进行聚类。(可选)将上一步得到的、新的
CF树的叶结点中每个簇的中心点作为簇心,对所有样本按照它距这些中心点的距离远近进行聚类。这是对上一步的结果进行精修。
BIRCH算法优点:- 节省内存。所有样本都存放在磁盘上,内存中仅仅存放
CF结构。 - 计算速度快。只需要扫描一遍就可以建立
CF树。 - 可以识别噪声点。
- 节省内存。所有样本都存放在磁盘上,内存中仅仅存放
BIRCH算法缺点:结果依赖于数据点的插入顺序。原本属于同一个簇的两个点可能由于插入顺序相差很远,从而导致分配到不同的簇中。
甚至同一个点在不同时刻插入,也会被分配到不同的簇中。
对非球状的簇聚类效果不好。这是因为簇直径 和簇间距离的计算方法导致。
每个结点只能包含规定数目的子结点,最后聚类的簇可能和真实的簇差距很大。
BIRCH可以不用指定聚类的类别数 。- 如果不指定 ,则最终叶结点中
CF的数量就是 。 - 如果指定 ,则需要将叶结点按照距离远近进行合并,直到叶结点中
CF数量等于 。
- 如果不指定 ,则最终叶结点中
五、谱聚类
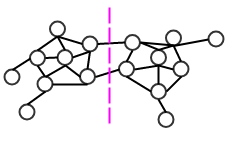
谱聚类
spectral clustering是一种基于图论的聚类方法。谱聚类的主要思想是:基于数据集 来构建图 ,其中:
顶点 :由数据集中的数据点组成: 。
边 :任意一对顶点之间存在边。
距离越近的一对顶点,边的权重越高;距离越远的一对顶点,边的权重越低。
通过对图 进行切割,使得切割之后:不同子图之间的边的权重尽可能的低、各子图内的边的权重尽可能的高。这样就完成了聚类。
5.1 邻接矩阵
在图 中,定义权重 为顶点 和 之间的权重,其中 。
定义 为邻接矩阵:
由于 为无向图,因此 。即: 。
对图中顶点 ,定义它的度 为:所有与顶点 相连的边的权重之和: 。
定义度矩阵 为一个对角矩阵,其中对角线分别为各顶点的度:
对于顶点集合 的一个子集 ,定义 为子集 中点的个数;定义 ,为子集 中所有点的度之和。
事实上在谱聚类中,通常只给定数据集 ,因此需要计算出邻接矩阵 。
基本思想是:距离较近的一对点(即相似都较高),边的权重较高;距离较远的一对点(即相似度较低),边的权重较低。
基本方法是:首先构建相似度矩阵 ,然后使用 -近邻法、 近邻法、或者全连接法。
- 通常相似度采用高斯核: 。此时有 。即: 。
- 也可以选择不同的核函数,如:多项式核函数、高斯核函数、
sigmoid核函数。
-近邻法:设置一个距离阈值 ,定义邻接矩阵 为:
即:一对相似度小于 的点,边的权重为 ;否则边的权重为 0 。
-近邻法得到的权重要么是 0 ,要么是 ,权重度量很不精确,因此实际应用较少。
近邻法:利用
KNN算法选择每个样本最近的 个点作为近邻,其它点与当前点之间的边的权重为 0 。这种做法会导致邻接矩阵 非对称,因为当 是 的 近邻时, 不一定是 的 近邻。
为了解决对称性问题,有两种做法:
只要一个点在另一个点的 近邻中,则认为是近邻。即:取并集。
只有两个点互为对方的 近邻中,则认为是近邻。即:取交集。
全连接法:所有点之间的权重都大于 0 : 。
5.2 拉普拉斯矩阵
定义拉普拉斯矩阵 ,其中 为度矩阵、 为邻接矩阵。
拉普拉斯矩阵 的性质:
是对称矩阵,即 。这是因为 都是对称矩阵。
因为 是实对称矩阵,因此它的特征值都是实数。
对任意向量 ,有: 。
是半正定的,且对应的 个特征值都大于等于0,且最小的特征值为 0。
设其 个实特征值从小到大为 ,即: 。
5.3 谱聚类算法
给定无向图 ,设子图的点的集合 和子图的点的集合 都是 的子集,且 。
定义 和 之间的切图权重为: 。
即:所有连接 和 之间的边的权重。
对于无向图 ,假设将它切分为 个子图:每个子图的点的集合为 ,满足 且 。
定义切图
cut为: ,其中 为 的补集。
5.3.1 最小切图
引入指示向量 ,定义:
则有:
因此 。其中 , 为矩阵的迹。
考虑到顶点 有且仅位于一个子图中,则有约束条件:
最小切图算法: 最小的切分。即求解:
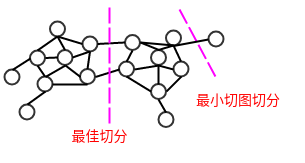
最小切图切分使得不同子图之间的边的权重尽可能的低,但是容易产生分割出只包含几个顶点的较小子图的歪斜分割现象。
5.3.2 RatioCut 算法
RatioCut切图不仅考虑最小化 ,它还考虑最大化每个子图的点的个数。即:- 最小化 :使得不同子图之间的边的权重尽可能的低。
- 最大化每个子图的点的个数:使得各子图尽可能的大。
引入指示向量 ,定义:
则有:
因此 。其中 , 为矩阵的迹。
考虑到顶点 有且仅位于一个子图中,则有约束条件:
RatioCut算法: 最小的切分。即求解:因此只需要求解 最小的 个特征值,求得对应的 个特征向量组成 。
通常在求解得到 之后,还需要对行进行标准化:
事实上这样解得的 不能完全满足指示向量的定义。因此在得到 之后,还需要对每一行进行一次传统的聚类(如:
k-means聚类)。RatioCut算法:输入:
- 数据集
- 降维的维度
- 二次聚类算法
- 二次聚类的维度
输出:聚类簇
算法步骤:
根据 构建相似度矩阵 。
根据相似度矩阵构建邻接矩阵 、度矩阵 ,计算拉普拉斯矩阵 。
计算 最小的 个特征值,以及对应的特征向量 ,构建矩阵 。
对 按照行进行标准化: ,得到 。
将 中每一行作为一个 维的样本,一共 个样本,利用二次聚类算法来聚类,二次聚类的维度为 。
最终得到簇划分 。
5.3.3 Ncut 算法
Ncut切图不仅考虑最小化 ,它还考虑最大化每个子图的边的权重。即:- 最小化 :使得不同子图之间的边的权重尽可能的低。
- 最大化每个子图的边的权重:使得各子图内的边的权重尽可能的高。
引入指示向量 ,定义:
则有:
因此 。其中 , 为矩阵的迹。
考虑到顶点 有且仅位于一个子图中,则有约束条件:
Ncut算法: 最小的切分。即求解令 ,则有:
令 ,则最优化目标变成:
因此只需要求解 最小的 个特征值,求得对应的 个特征向量组成 。然后对行进行标准化: 。
与
RatioCut类似,Ncut也需要对 的每一行进行一次传统的聚类(如:k-means聚类)。事实上 相当于对拉普拉斯矩阵 进行了一次标准化: 。
Ncut算法:输入:
- 数据集
- 降维的维度
- 二次聚类算法
- 二次聚类的维度
输出:聚类簇
算法步骤:
根据 构建相似度矩阵 。
根据相似度矩阵构建邻接矩阵 、度矩阵 ,计算拉普拉斯矩阵 。
构建标准化之后的拉普拉斯矩阵 。
计算 最小的 个特征值,以及对应的特征向量 ,构建矩阵 。
对 按照行进行标准化: ,得到 。
将 中每一行作为一个 维的样本,一共 个样本,利用二次聚类算法来聚类,二次聚类的维度为 。
最终得到簇划分 。
5.4 性质
谱聚类算法优点:
- 只需要数据之间的相似度矩阵,因此处理稀疏数据时很有效。
- 由于使用了降维,因此在处理高维数据聚类时效果较好。
谱聚类算法缺点:
- 如果最终聚类的维度非常高,则由于降维的幅度不够,则谱聚类的运行速度和最后聚类的效果均不好。
- 聚类效果依赖于相似度矩阵,不同相似度矩阵得到的最终聚类效果可能不同。