环境搭建
一、安装 scala
scala的安装与其它编程语言相比有一些特殊:scala并不是安装在系统里,而是安装在你的每一个scala project中。安装步骤:
首先确保安装了
Java 8 JDK:通过命令java -version查看。
有
scala+IntelliJ和scala+sbt两种方式。区别在于:scala+IntelliJ:集成了IntelliJ这个IDE,对新手友好。scala+sbt:在命令行中执行scala,以及使用命令行来利用sbt编译。当前(2019-01-09)最新版本sbt 1.2.8。
scala+sbt安装方式:执行脚本(参考https://www.scala-lang.org/download/)echo "deb https://dl.bintray.com/sbt/debian /" | sudo tee -a \/etc/apt/sources.list.d/sbt.listsudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv \2EE0EA64E40A89B84B2DF73499E82A75642AC823sudo apt-get updatesudo apt-get install sbt然后执行
sbt命令,该命令会同步下载一些jar包。scala+IntelliJ安装方式:下载
IntelliJ Community Edition。安装插件:打开
File->Settings->Plugins,搜索并安装scala(不需要安装其它,如SBT) 。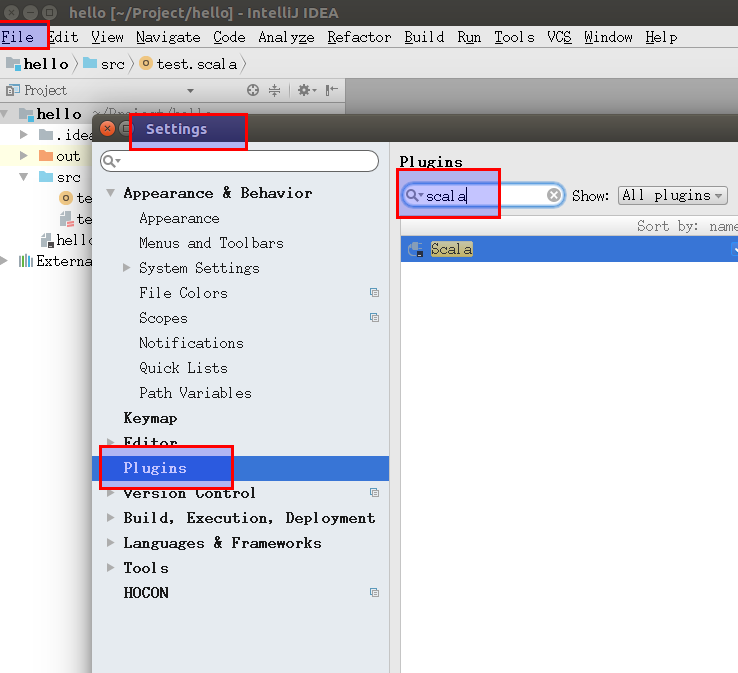
新建
Project,选择Scala,在面板右侧选择IDEA(而不是sbt或者Lightbend Project Starter)。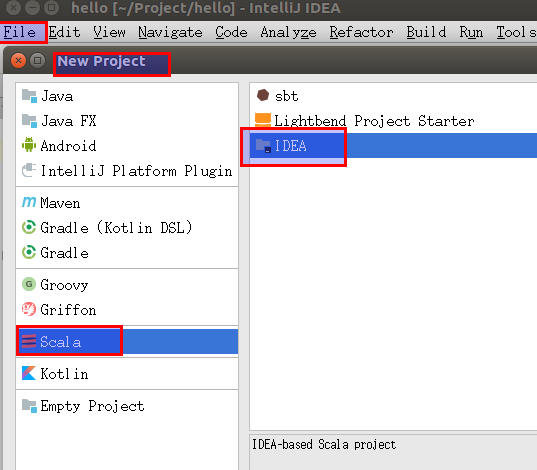
选择
下一步,在填写Project name和JDK/Scala SDK的地方。点击Scala SDK右侧的Create,可以选择下载或者切换到指定版本的Scala SDK。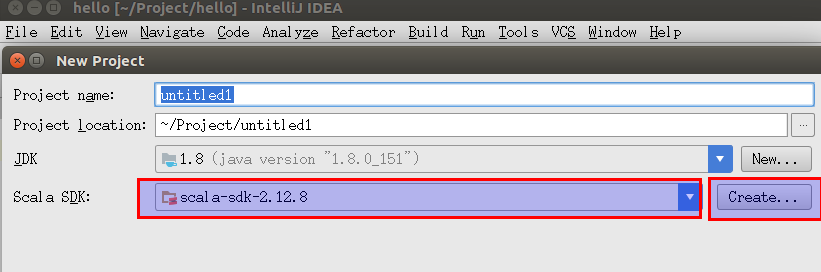
在
src右键单击,选择New->Scala Class。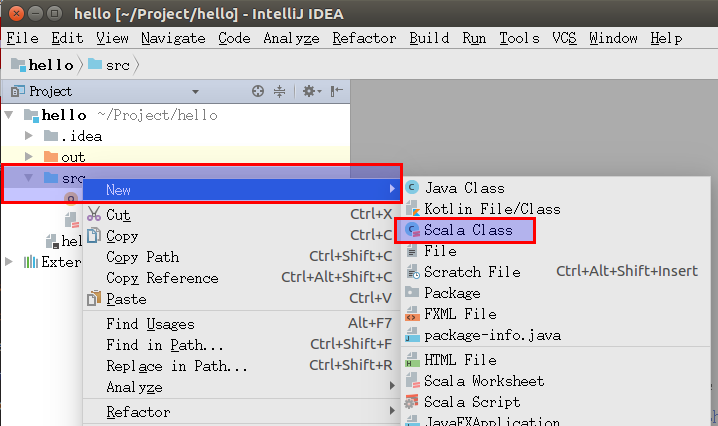
如果需要可执行代码,则
Kind选择Object,并新建一个包含main()方法的object(或者选择extends App) 。在编辑界面右键单击,选择Run,则代码编译并执行。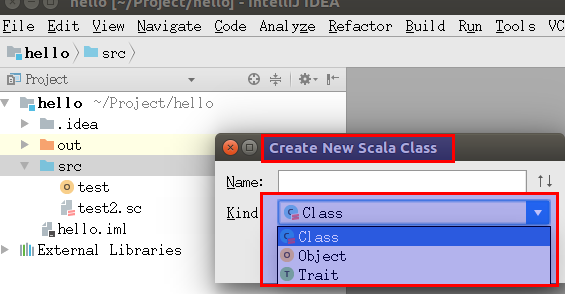
xxxxxxxxxxobject Hello extends App {println("Hello, World!")}如果需要创建
package、Class,则选择常规方式。
如果希望快速验证某些代码片断,则可以创建
Scala Worksheet。方法是:在src右键单击,选择New->Scala Worksheet。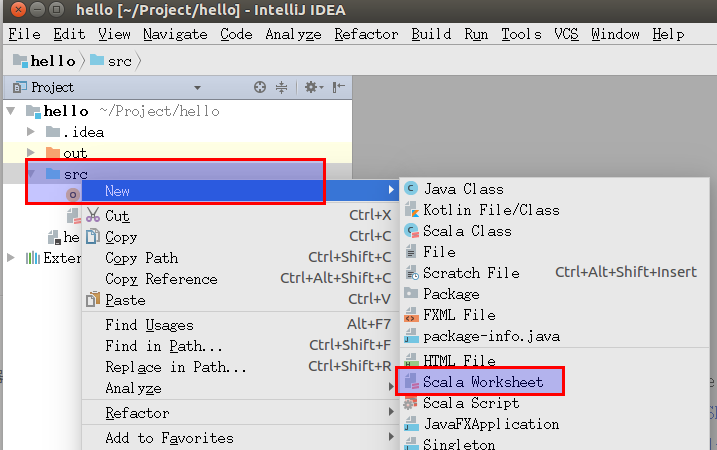
此时当你在编辑器修改了代码之后,代码立即会被求值并展示在编辑器右侧。

二、安装 Jupyter 支持
通过
almond安装scala的jupyter支持:下载
coursier:xxxxxxxxxxcurl -L -o coursier https://git.io/coursier && chmod +x coursier \&& ./coursier --help创建一个
launcher:xxxxxxxxxxSCALA_VERSION=2.12.8 ALMOND_VERSION=0.2.1 #环境变量coursier bootstrap \-r jitpack \-i user -I user:sh.almond:scala-kernel-api_$SCALA_VERSION:$ALMOND_VERSION \sh.almond:scala-kernel_$SCALA_VERSION:$ALMOND_VERSION \--sources --default=true \-o almond安装
kernel:xxxxxxxxxx./almond --install一旦安装完成,则可以安全的删除
lancher。删除方法为:rm -f almond。可以通过命令
jupyter kernelspec list查看支持的kernel:
可以通过
https://github.com/jupyter/jupyter/wiki/Jupyter-kernels查看jupyter官方支持的kernel列表。通过
sparkmagic安装spark的jupyter支持:启用
spark(单机伪分布式):下载
spark:http://spark.apache.org/downloads.html解压缩文件,进入
spark目录下的sbin,执行start-all.sh。如果希望停止,则执行stop-all.sh。默认的
spark ui:http://127.0.0.1:8080/。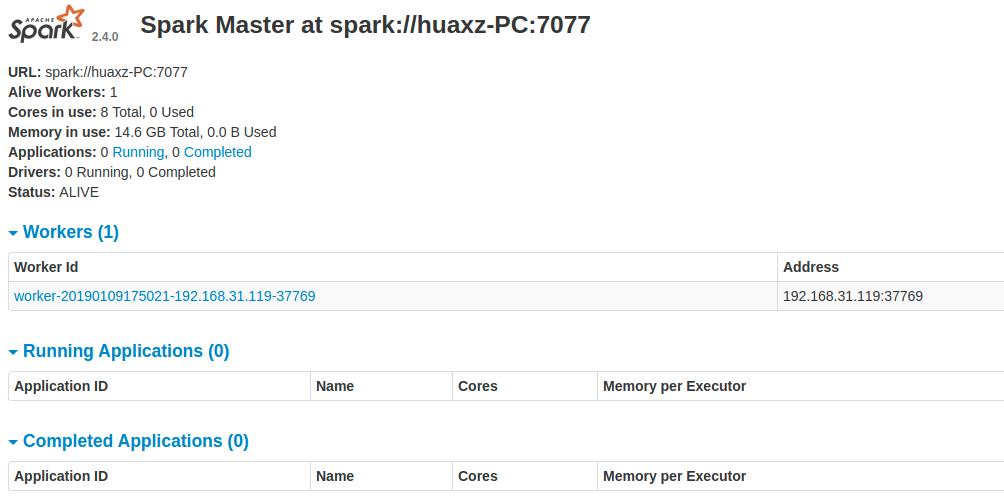
安装
livy依赖:下载
livy:https://livy.incubator.apache.org/download/。解压缩
livy,进入livy文件夹,然后运行bin/livy-server。- 可以在
livy/conf中配置livy-server。 - 需要
export SPARK_HOME变量。 - 默认的
livy ui:http://localhost:8998。
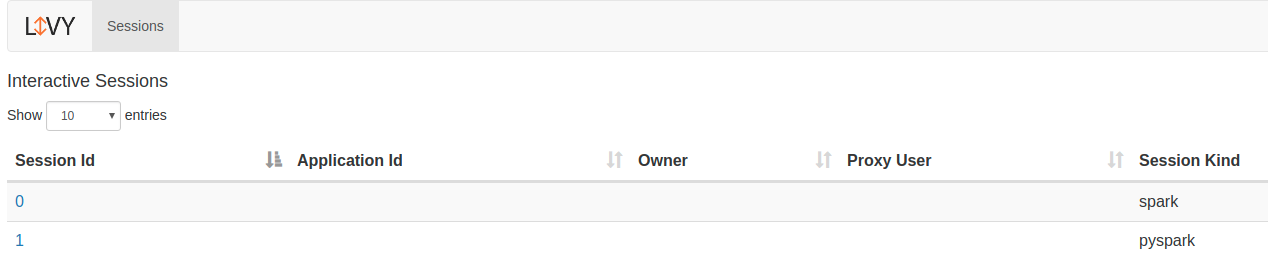
- 可以在
安装必要组件:
xxxxxxxxxxpython3.6 -m pip install sparkmagic # 安装 sparkmagicjupyter nbextension enable --py --sys-prefix widgetsnbextension # 确保 ipywidgets 安装通过
python3.6 -m pip show sparkmagic查看sparkmagic的安装位置,cd到该位置。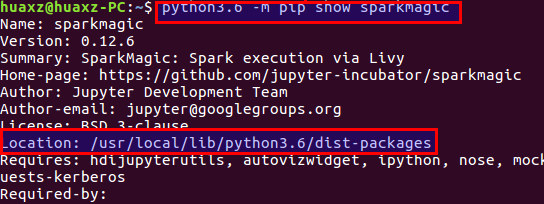
安装一些
kernel(如果某些功能不需要,则不用安装):xxxxxxxxxxjupyter-kernelspec install sparkmagic/kernels/sparkkernel # scala sparkjupyter-kernelspec install sparkmagic/kernels/pysparkkernel # pysparkjupyter-kernelspec install sparkmagic/kernels/pyspark3kernel # pyspark3jupyter-kernelspec install sparkmagic/kernels/sparkrkernel # r spark可选:可以修改
~/.sparkmagic/config.json来修改配置,其内容参考https://github.com/jupyter-incubator/sparkmagic/blob/master/sparkmagic/example_config.json。其中
kernel_xx_credentials中的url给出了livy-server的host:port。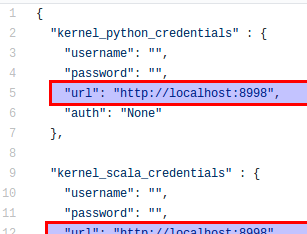
可选:启用
server扩展,从而允许以编程的方式更改集群:xxxxxxxxxxjupyter serverextension enable --py sparkmagic通过
jupyter notebook启动jupyter,新建一个pyspark页面,执行sc或者spark。如果输出正常则安装成功。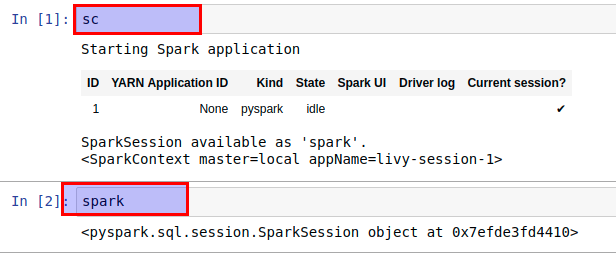
三、Scala 解释器
Scala解释器:一个编写Scala的交互式shell。调用方式为:在命令行中执行命令scala。Scala解释器会对你录入的表达式求值,并输出结果。结果格式为:xxxxxxxxxx变量名 : 结果类型 = 结果值如果表达式中定义了变量,则变量名就是该变量的名字;否则变量名就是
resX,你可以在后续表达式中使用该变量名。- 如果希望在解释器中输入多行代码,只需要按回车。此时解释器会在下一行头部加上竖线
|。如果希望退出该模式,则连续按两次回车即可。 - 退出解释器,则键入
:q或者:quit。 - 如果希望查看对象包含的方法/属性,则可以输入
Obj.然后键入Tab。
- 如果希望在解释器中输入多行代码,只需要按回车。此时解释器会在下一行头部加上竖线
如果希望在解释器中引入第三方包的依赖,则可以使用
sbt来管理。首先创建一个目录,然后在该目录下创建一个名为
build.sbt的文件。然后去
https://search.maven.org中搜索第三方依赖包的坐标。修改该文件,在该文件中,你可以指定
scala版本、依赖包:xxxxxxxxxxname := "Scala Playground"version := "1.0"scalaVersion := "2.10.2" # scala 版本libraryDependencies += "com.twitter" % "algebird-core_2.10" % "0.13.5" # 第三方依赖在该目录下,执行命令
sbt console。
四、IntelliJ 使用
IntelliJ用于查看符号的快捷键:F1:查看该符号的说明文档(如果有的话)。⌥Space:查看该符号的定义代码。⌥⌘F7:查看该符号在哪些地方被用到。⌥⌘B:查看该符号的实现。Ctrl+Shift+P:查看该符号的数据类型。
⌥⌘L:格式化代码。如果项目使用了
Maven,则有可能IntelliJ未能实时跟踪到Maven下载的第三方依赖包,此时IntelliJ的代码提示找不到对应的符号。解决方案:执行
File | Invalidate Caches。如果未能解决,则删除IDEA system directory(Linux下位于~/.<PRODUCT><VERSION>)。
五、Maven 使用