一、FM [2011]
《Fast Context-aware Recommendations with Factorization Machines》
推荐系统中的评级预测(
rating prediction)主要依赖于以下信息:who(哪个用户)对what(哪个item,如电影、新闻、商品)如何how评级。有很多方法可以考虑关于who(关于用户的人口统计信息,如年龄、性别、职业)、what(关于item属性的信息,如电影类型、产品描述文本的关键词)的附加数据。除了有关评级事件(
rating event)中涉及的实体的此类数据之外,还可能存在有关评级事件发生当前情况的信息,例如当前位置(location)、时间、周边的人、用户当前心情等等。这些场景信息通常称作上下文 (context)。因为从决策心理学知道一个人的环境和情绪确实会影响他们的行为,所以在推荐系统中利用上下文信息是可取的。上下文感知评级预测(context-aware rating prediction)依赖于谁(who)在何种上下文(context)下如何(how)评价什么(what)的信息。经典的推荐系统方法不考虑上下文信息。一些方法执行数据的预处理(
pre-processing)或后处理(post-processing),使得标准方法具有上下文感知能力。虽然这种临时解决方案可能在实践中起作用,但是它们的缺点是过程中的所有步骤都需要监督和微调。将各种输入数据统一到一个模型中的方法在这方面更为实用,理论上也更为优雅。目前,在预测准确性方面最灵活和最强的方法是
Multiverse Recommendation,它依赖于Tucker分解并允许使用任何离散型上下文(categorical context)。然而,对于现实世界的场景,它的计算复杂度在论文
《Fast Context-aware Recommendations with Factorization Machines》中,作者提出了一种基于分解机 (Factorization Machine: FM)的上下文感知评级预测器。FM包括并可以模拟推荐系统中最成功的方法,包括矩阵分解(matrix factorizion: MF)、SVD++、PITF。作者展示了
FM如何应用于各种上下文字段,包括离散型(categorical)字段、离散集合(set categorical)字段、实值(real-valued)字段。相比之下,Multiverse Recommendation模型只适合于离散型(categorical)上下文变量。除了建模的灵活性之外,
FM的复杂度在Multiverse Recommendation模型的复杂度是为了学习
FM模型的参数,论文提出了一种基于交替最小二乘法(alternating least squares: ALS)的新算法。新算法在给定其它参数的情况下找到一个参数的最优解,并且在几次迭代之后找到所有参数联合最优解。和随机梯度下降(
stochastic gradient descent: SGD)一样,新算法单次迭代的复杂度为和
SGD相比,新算法的主要优点是无需确定学习率。这在实践中非常重要,因为SGD学习的质量在很大程度上取决于良好的学习率,因此必须进行代价昂贵的搜索。这对于ALS来讲不是必需的。最后,论文的实验表明:上下文感知
FM可以捕获上下文信息并提高预测准确性。此外FM在预测质量和运行时间方面都优于SOTA的方法Multiverse Recommendation。
1.1 相关工作
推荐系统的大多数研究都集中在仅分析
user-item交互的上下文无关方法上。在这里,矩阵分解(matrix factorization: MF)方法非常流行,因为它们通常优于传统的knn方法。也有研究将用户属性或
item属性等元数据结合到预测中,从而扩展了矩阵分解模型。然而,如果存在足够的反馈数据,元数据对评分预测的强baseline方法通常只有很少或者没有改善。这种用户属性/item属性和上下文之间的区别在于:属性仅仅被附加到item或者用户(例如,给电影附加一个流派的属性),而上下文被附加到整个评级事件(如,当评级发生时用户当时的心情)。和关于标准推荐系统的大量文献相比,上下文感知推荐系统的研究很少。最基本的方法是上下文预过滤(
pre-filtering)和后过滤 (post-filtering),其中应用标准的上下文无关推荐系统,并在应用推荐器(recommender)之前基于感兴趣的上下文对数据进行预处理、或者对结果进行后处理。更复杂的方法是同时使用所有上下文和user-item信息来进行预测。也有人建议将上下文视为动态的用户特征,即可以动态变化。另外有一些关于
item预测的上下文感知推荐系统的研究,将推荐视为一个排序任务,而本文将推荐视为回归任务。Multiverse Recommendation基于Tucker分解技术来直接分解用户张量、item张量、所有离散上下文变量的张量,从而求解该问题。它将原始的评分矩阵分解为一个小的矩阵其中:
这种方式存在三个问题:
计算复杂度太高:假设每个特征的维度都是
仅能对离散型(
categorical)上下文特征建模:无法处理数值型特征、离散集合型(categorical set)特征。交互特征高度稀疏:这里执行的是
K路特征交互(前面的POLY2模型是两路特征交互),由于真实应用场景中单个特征本身就已经很稀疏,K路特征交互使得数据更加稀疏,难以准确的预估模型参数。
Attribute-aware Recommendation:与通用上下文感知方法的工作对比,对属性感知或专用推荐系统的研究要多得多。有一些工作可以处理用户属性和item属性的矩阵分解模型的扩展,还有一些关于考虑时间效应的工作。然而,所有这些方法都是为特定问题设计的,无法处理我们在本工作中研究的上下文感知推荐的通用设置。当然,对于特定的和重要的问题(如时间感知推荐或属性感知推荐),专用模型的研究是有益的。但是另一方面,研究上下文感知的通用方法也很重要,因为它们提供了最大的灵活性,并且可以作为专用模型的强
baseline。Alternating Least Square Optimization:对于矩阵分解模型,Bell和Koren提出了一种交替优化所有user factor和所有item factor的ALS方法。由于所有user/item的整个factor matrix是联合优化的,因此计算复杂度为ALS的这种复杂度问题是SGD方法在推荐系统文献中比ALS更受欢迎的原因。Pilaszy等人提出一个接一个地优化每个user/item中的factor,这导致ALS算法复杂度为factor的思路与我们将ALS算法应用于FM的思路相同。这两种方法仅适用于矩阵分解,因此无法处理任何上下文,例如我们提出的对所有交互进行建模的
FM中的上下文。此外,我们的ALS算法还学习了全局bias和基本的1-way效应。
1.2 模型
FM模型是一个通用模型,它包含并可以模拟几个最成功的推荐系统,其中包括矩阵分解(matrix factorization: MF)、SVD++、PITF。我们首先简要概述了FM模型,然后详细展示了如何将其应用于上下文感知数据,以及在FM中使用这种上下文感知数据会发生什么。最后我们提出了一种新的快速alternating least square: ALS算法,和SGD算法相比它更容易应用,因为它不需要学习率。
1.2.1 FM 模型
推荐系统面临的问题是评分预测问题。给定用户集合
其中已知部分用户在部分物品上的评分:
其中
通常评分问题是一个回归问题,模型预测结果是评分的大小。此时损失函数采用
MAE/MSE等等。也可以将其作为一个分类问题,模型预测结果是各评级的概率。此时损失函数是交叉熵。
当评分只有
0和1时,这表示用户对商品 “喜欢/不喜欢”,或者 “点击/不点击”。这就是典型的点击率预估问题。
事实上除了已知部分用户在部分物品上的评分之外,通常还能够知道一些有助于影响评分的额外信息。如:用户画像、用户行为序列等等。这些信息称作上下文(
context)。对每一种上下文,我们用变量
上下文的下标从
3开始,因为可以任务用户如下图所示为评分矩阵,其中:
所有离散特征都经过
one-hot特征转换。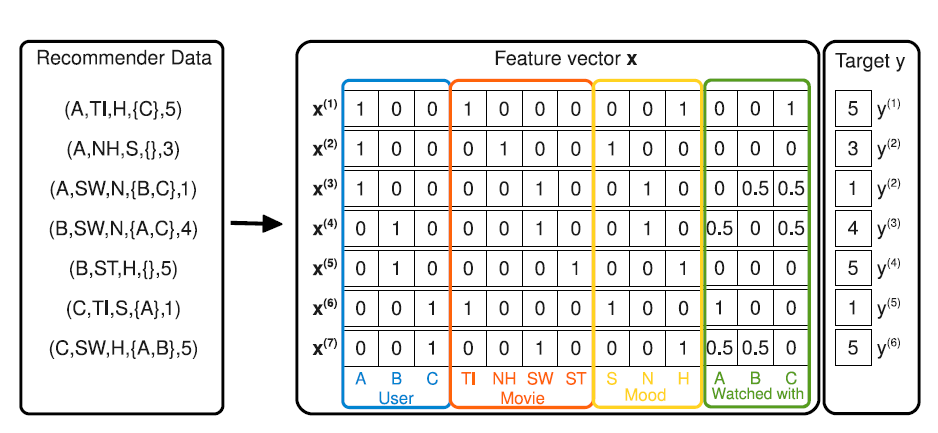
上下文特征(
context)类似属性(property)特征,它和属性特征的区别在于:属性特征是作用到整个用户(用户属性)或者整个物品(物品属性),其粒度是用户级别或者物品级别。
如:无论用户 “张三” 在在评分矩阵中出现多少次,其性别属性不会发生改变。
上下文特征是作用到用户的单个评分事件上,粒度是事件级别,包含的评分信息更充足。
如:用户 ”张三“ 在评价某个电影之前已经看过的电影,该属性会动态改变。
事实上属性特征也称作静态画像,上下文特征也称作动态画像。业界主流的做法是:融合静态画像和动态画像。
另外,业界的经验表明:动态画像对于效果的提升远远超出静态画像。
和
POLY2相同FM也是对二路特征交互进行建模,但是FM的参数要比POLY2少得多。将样本重写为:
则
FM模型为:其中
即:
模型待求解的参数为:
其中:
representation vector,它是
FM模型的计算复杂度为因此有:
其计算复杂度为
将
FM模型和标准的矩阵分解模型进行比较,可以看到:FM也恰好包含这种分解FM模型还包含了所有上下文变量的所有pair对的交互。这表明FM自动包含了矩阵分解模型。FM模型可以用于求解分类问题(预测各评级的概率),也可以用于求解回归问题(预测各评分大小)。对于回归问题,其损失函数为
MSE均方误差:对于二分类问题,其损失函数为交叉熵:
其中:
评级集合为
损失函数最后一项是正则化项,为了防止过拟合,
可以针对每个参数配置一个正则化系数,但是选择合适的值需要进行大量的超参数选择。论文推荐进行统一配置:
对于
对于
对于
FM模型可以处理不同类型的特征:离散型特征 (
categorical):FM对离散型特征执行one-hot编码。如,性别特征:“男” 编码为
(0,1),“女” 编码为(1,0)。离散集合特征(
categorical set):FM对离散集合特征执行类似one-hot的形式,但是执行样本级别的归一化。如,看过的历史电影。假设电影集合为:“速度激情9,战狼,泰囧,流浪地球”。如果一个人看过 “战狼,泰囧,流浪地球”, 则编码为
(0,0.33333,0.33333,0.33333)。数值型特征(
real valued):FM直接使用数值型特征,不做任何编码转换。
FM的优势:给定特征
representation向量的维度时,预测期间计算复杂度是线性的。在交互特征高度稀疏的情况下,参数仍然能够估计。
因为交互特征的参数不仅仅依赖于这个交互特征,还依赖于所有相关的交互特征。这相当于增强了有效的学习数据。
能够泛化到未被观察到的交互特征。
设交互特征 “看过电影
A且 年龄等于20” 从未在训练集中出现,但出现了 “看过电影A” 相关的交互特征、以及 “年龄等于20” 相关的交互特征。于是可以从这些交互特征中分别学习 “看过电影
A” 的representation、 “年龄等于20”的representation,最终泛化到这个未被观察到的交互特征。
1.2.2 ALS 优化算法
a. 最优化解
FM的目标函数最优化可以直接采用随机梯度下降SGD算法求解,但是采用SGD有个严重的问题:需要选择一个合适的学习率。学习率必须足够大,从而使得
SGD能够尽快的收敛。学习率太小则收敛速度太慢。学习率必须足够小,从而使得梯度下降的方向尽可能朝着极小值的方向。
由于
SGD计算的梯度是真实梯度的估计值,引入了噪音。较大的学习率会放大噪音的影响,使得前进的方向不再是极小值的方向。
我们提出了一种新的交替最小二乘(
alternating least square:ALS)算法来求解FM目标函数的最优化问题。与SGD相比ALS优点在于无需设定学习率,因此调参过程更简单。根据定义:
对每个
其中
对于
对于
对于
因此有:
考虑均方误差损失函数:
最小值点的偏导数为
0,有:则有:
ALS通过多轮次、轮流迭代求解在迭代之前初始化参数,其中:
0、方差为每一轮迭代时:
首先求解
然后求解
representation向量的第1维度,然后是第2维,... 最后是第d维。这是为了计算优化的考量。
b. 计算优化
直接求解
ALS的解时复杂度较高:在每个迭代步中计算每个训练样本的对于每个样本,求解
计算
计算
计算
因此求解
有三种策略来降低求解
利用预计算的误差项
利用预计算的
利用数据集
预计算误差项
定义误差项:
考虑到
因此如果计算
首先对每个样本,计算其初始误差:
考虑到
当参数
计算代价由
预计算
如果能够降低计算
重写
定义:
因此如果计算
对每个样本、每个
representation向量维度计算初始计算复杂度为
当参数
计算代价为
一旦得到
计算代价为
数据集
根据:
对于
对于
因此每次更新只需要使用部分样本。总体而言,整体复杂度为
ALS优化算法:输入:
训练样本
输出:模型参数
算法步骤:
参数初始化:
初始化
迭代直至目标函数收敛或者达到指定步数,每一轮迭代过程为:
更新
更新
更新
外层循环为
.
1.3 实验
在本节中,我们根据实验研究了和
SOTA的上下文感知方法Multiverse Recommendation的对比。此外,我们检查了SGD对学习率选择的敏感性,以及我们的ALS优化是否可以在没有学习率这个超参数的情况下成功工作。数据集:
Food数据集:包含212个用户对20个菜单item的6360个评分(从1分到5分),其中包含两个上下文变量:第一个上下文变量捕获用户评分的场景是虚拟的(virtual) 还是真实的 (real)(即用户想象自己饿了、还是用户真的饿了);第二个上下文变量刻画用户的饥饿程度。Adom数据集:包含1524个电影评分(从1分到15分),其中包含五个上下文变量,这些上下文变量关于同伴、工作日、以及其它时间信息。Yahoo! Webscope数据集:包含221367个评分。我们遵循《Multiverse recommendation: n-dimensional tensor factorization for context-aware collaborative filtering》并应用他们的方法来处理数据集。我们生成
baseline方法:我们将context-aware FM和Multiverse Recommendation进行比较。注意:Multiverse Recommendation已经在上述三个数据集上超越了其它上下文感知推荐算法。我们使用
FM no-context作为上下文无感(context-unaware)的baseline,其中仅使用用户变量和item变量生成特征向量,这相当于具有bias项的矩阵分解。这是最强的上下文无关推荐算法之一。FM使用我们提出的ALS算法进行优化,Multiverse Recommendation使用原始论文中提出的SGD算法来学习。评估方式:我们从每个数据集中删除了
5%的样本,用作调优超参数以获得最佳MAE的验证集。在超参数搜索之后,我们对剩下的95%数据集进行5-fold交叉验证,即不再使用验证集。我们报告了5次实验的平均RMSE和MAE。所有方法都是
C++实现的,并在相同的硬件上运行。我们使用ALS优化的FM实现、Multiverse Recommendation实现和数据集生成脚本可以从我们的网站上下载。ALS vs SGD:我们在Webscope数据集上将SGD实现的测试误差和我们的ASL方法进行了比较,实验结果如下图所示。左图绘制了三种学习率选择的测试误差曲线,右侧的两个图分别显示了在10次和100次迭代后不同学习率得到的测试误差曲线(由于ALS没有学习率超参数,因此表现为一条水平直线)。可以看到:SGD的优化效果很大程度上取决于学习率和迭代次数。当精心挑选合适的学习率、足够大的迭代次数(根据验证集执行早停策略从而防止过拟合),SGD可以达到ALS的效果。ALS不需要精心的、耗时的搜索合适的学习率,就可以达到很好的效果。
该实验表明:
SGD需要仔细且耗时地搜索学习率,而ALS不需要这样的搜索因为它没有这个超参数。在预测质量方面SGD的性能与ALS一样好,但是前提是选择了正确的学习率。这使得ALS在应用中明显有利。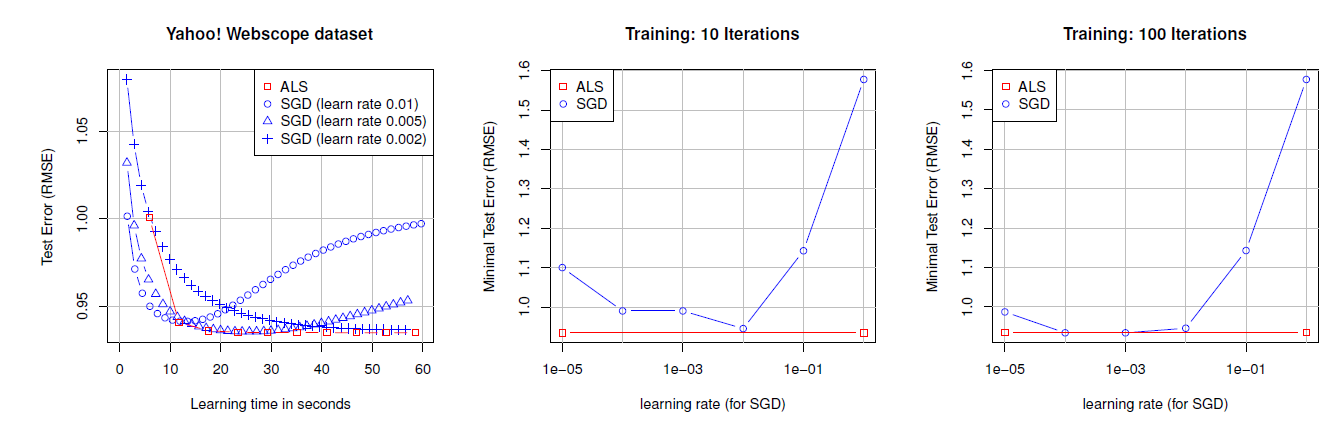
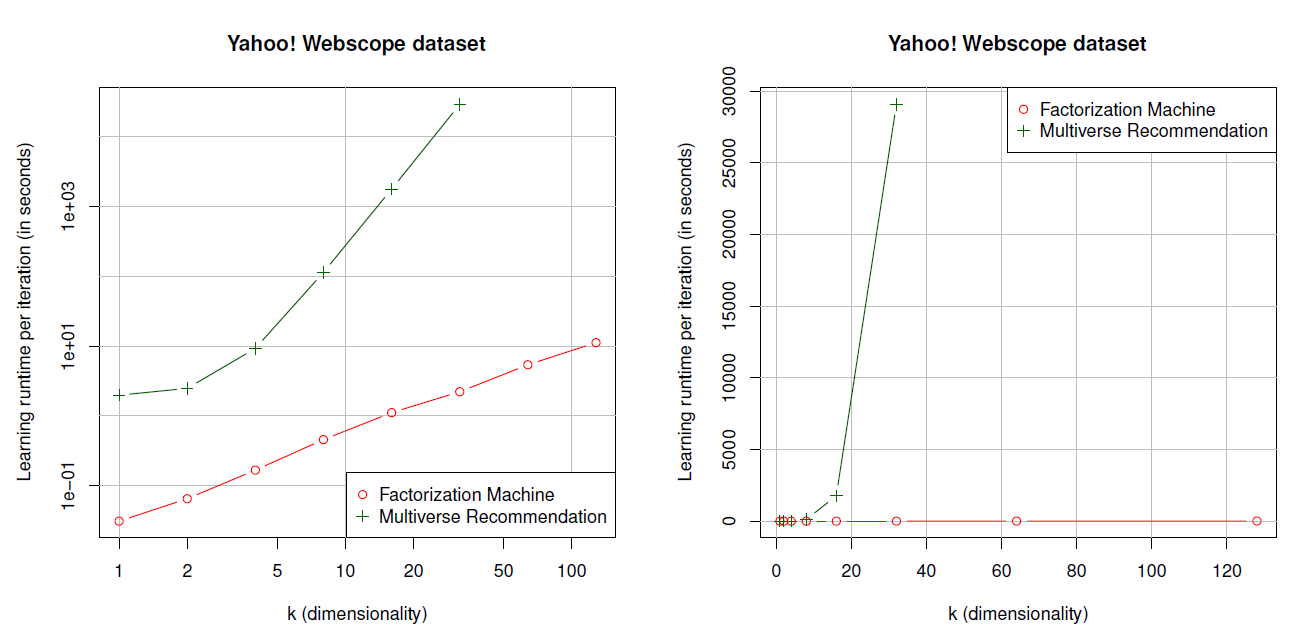
运行时间:
Multiverse Recommendation在实际使用中的主要缺点之一是模型的计算复杂度为FM的计算复杂度对于在本实验中,我们考察所有训练样本的一次完整迭代的运行时间。我们使用
webscope数据集,Multiverse Recommendation,我们选择的最大FM的运行时间是线性的,例如可以在大约11s内完成所有训练样本的完整迭代(对于Multiverse Recommendation的复杂度随着30分钟,而8小时。
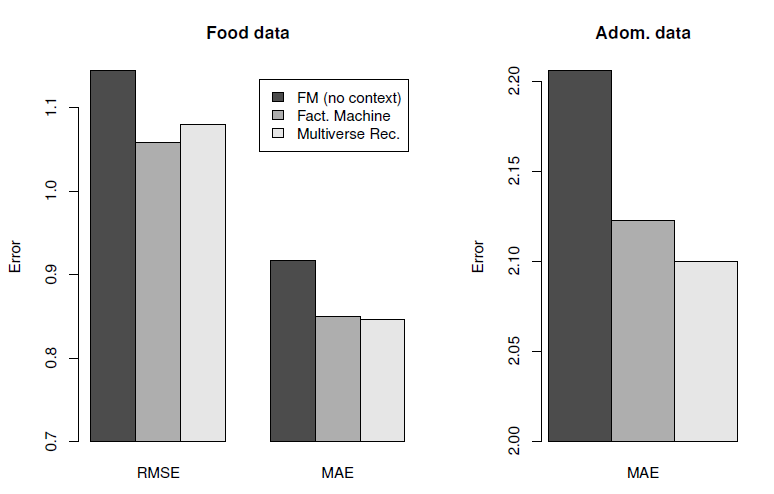
预测质量:最后我们想知道,上下文感知
FM的灵活性和快速运行时间是否会以较差的预测质量为代价。为此我们比较了Food、Adom、Webscope数据集上的预测质量,如下图所示。可以看到:上下文感知
FM和Multiverse Recommendation对Food和Adom数据集的预测质量相当。上下文感知
FM和Multiverse Recommendation都优于上下文无感方法(相当于矩阵分解模型)。
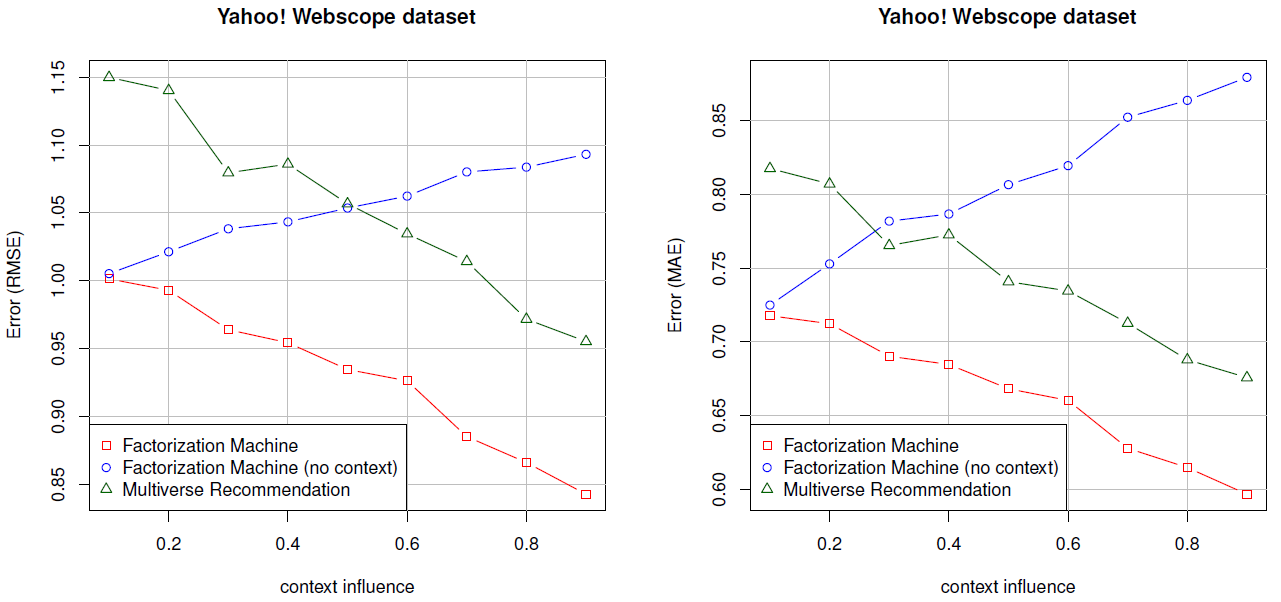
在第三个实验中,我们考察了人工特征丰富的
Webscope数据集,其中上下文变量(由context influence刻画)对于评分的影响越来越大。结果如下图所示,可以看到:上下文感知的
FM和Multiverse Recommendation都受益于对上下文有更强依赖性的评分。当评分更依赖于上下文时,上下文无关
FM的预测质量会变差,因为对于上下文无关FM,上下文是未观测到的,因此它们无法解释这种依赖性。将两种上下文感知方法相互比较,可以看到
FM始终生成比Multiverse Recommendation更好的预测。例如,RMSE下降0.10 ~ 0.15,而MAE下降0.08 ~ 0.10。
结论:实验结果表明:
上下文感知
FM能够考虑上下文信息来增强预测。在运行时间方面
FM是线性的,这使得它们可以应用于大维度的因子、更多上下文变量。相比之下,Multiverse Recommendation无法处理大维度的因子、也无法处理很多上下文变量。FM在运行时间方面的优势并没有以预测质量为代价,相反:在稠密数据集(
Food和Adom)上,上下文感知FM和Multiverse Recommendation的预测质量相当。而在稀疏数据集上,上下文感知
FM的性能优于Multiverse Recommendation。
最后,
ALS优化的FM很容易应用,因为它不像SGD那样对学习率进行昂贵的搜索。