一、DeepCrossing [2016]
《Deep Crossing: Web-Scale Modeling without Manually Crafted Combinatorial Features》
传统的机器学习算法应该充分利用所有输入特征来预测和分类新的样本。然而,简单地使用原始特征很少能够提供最佳结果。因此,无论是工业界还是学术界,都存在大量关于原始特征的特征变换(
feature transformation)的工作。一种主要的特征变换类型是基于多个特征的特征组合(feature combination)函数,并将组合特征(combinatorial features)作为学习器(learner)的输入。这些组合特征有时被称作交叉特征(cross features)或多路特征(multi-way features)。组合特征是强大的工具,尤其是在领域专家(
domain experts)手中。根据我们自己对主力赞助搜索引擎(major sponsored search engine)的体验,组合特征是许多模型中最强大的特征之一。在
Kaggle社区中,顶级数据科学家是制作组合特征的大师,甚至可以交叉(crossing)三到五个维度。 直觉(intuition)以及创造有效的组合特征的能力是他们获胜的重要组成部分。在计算机视觉社区中,类似
SIFT的特征是ImageNet比赛当时SOTA表现背后的关键驱动因素。SIFT特征是在图像块(image patches)上提取的,是特殊形式的组合特征。
组合特征的威力伴随着高昂的成本。在个人开始创建有意义的特征之前,有一个陡峭的学习曲线需要攀登。随着特征数量的增长,管理(
managing)、维护(maintaining)、部署(deploying)组合特征变得具有挑战性。在web-scale的application中,由于特征数量非常庞大,并且在给定数十亿样本的情况下训练和评估周期很长,因此寻找额外的组合特征来改善现有的模型是一项艰巨的任务。深度学习承诺无需人工干预即可从
individual特征中学习。语音、图像领域是最先展示这种潜力的。通过深度卷积神经网络CNN从特定任务中学习的卷积核,已经取代了手工制作的SIFT-like特征,成为图像识别领域的SOTA技术。类似的模型已经应用于NLP application,从零开始构建语言处理模型,而无需进行大量的特征工程(feature engineering)。在论文
《Deep Crossing: Web-Scale Modeling without Manually Crafted Combinatorial Features》中,论文提出Deep Crossing模型,从而将深度学习的成功扩展到了更通用的环境中,其中individual特征具有不同的性质。具体而言,Deep Crossing接受individual的文本(text)特征、离散(categorical)特征、ID特征、数值(numerical)特征,并根据特定任务自动搜索最佳组合。此外,Deep Crossing旨在处理web-scale的application和数据规模。这不仅是因为作者主要对此类application感兴趣,还因为在这种规模下运行的通用模型没有太多选择。值得注意的是,
Deep Crossing在学习过程中确实以某种方式生成了组合特征,尽管Deep Crossing的输出是一个没有这些交叉特征的显式representation的模型。相关工作:无需手工制作特征的深度神经网络的想法并不新鲜。
在
80年代初,Fukushima报道了一个七层的Neocognitron网络,该网络可以从图像的原始像素中识别数字。通过利用部分连接的结构(partially connected structure),Neocognitron实现了平移不变性(shift invariance),这是视觉识别任务中的一个重要特性。CNN是由LeCun等人在90年代后期发明的,具有类似的架构,尤其是部分连接的卷积核。尽管CNN作为recognition engine具有坚实的基础,但是基于SIFT-like特征的分类器主导了图像识别十多年。2012年,Krizhevsky等人提出了AlexNet,它比基于SIFT的baseline的错误率(error rate)降低了接近11个绝对百分点。最近,一个
152层的残差网络在2015年赢得了ImageNet和MS COCO比赛。
深度
CNN的发展鼓舞人心,它表明:即使在十多年来对最佳手动特征进行微调的系统中,深度学习也能够得到改进。换句话说,即使是最有经验的领域专家(domain experts)也可能会错过深度CNN使用特定于任务的filters捕获的特征之间的深度交互(deep interaction)。 意识到这一点对我们在Deep Crossing方面的工作有着深远的影响。深度语义相似性模型
Deep Semantic Similarity Model: DSSM学习一对文本字符串之间的语义相似性,每个字符串都由称作tri-letter gram的稀疏representation所代表。learning算法通过将tri-letter gram嵌入到两个向量(一个query embedding向量、一个document embedding向量)中来优化基于余弦距离的目标函数。学习到的embedding捕获了单词和句子的语义,应用于赞助搜索(sponsored search)、问答、机器翻译,并取得了很好的效果。分解机
Factorization Machine: FM以其通用形式对单个特征之间的d路交互进行建模。在输入非常稀疏的情况下,FM展示出比SVM更好的结果,但是不清楚FM在稠密特征上的表现如何。对于
NLP任务,《Natural language processing (almost) from scratch》构建了一个统一的神经网络架构,避免了特定任务的特征工程。赞助搜索(
Sponsered Search):Deep Crossing是在major sponsored search的背景下讨论的。简而言之,sponsored search负责在自然搜索(organic search)结果旁边展示广告。生态系统中存在三大主体:用户、广告主、搜索平台。平台的目标是向用户展示最符合用户意图(user’s intent)的广告,其中用户意图主要是通过特定的query来表达。以下是接下来讨论的关键概念。query:用户在搜索框中键入的文本字符串。关键词(
keyword):和广告主推广的产品相关的文本字符串,由广告主指定从而匹配用户的query。标题(
title):广告的标题,由广告主指定从而吸引用户的注意力。落地页(
landing page):当用户点击相应广告时,用户到达的广告主的产品网站。match type:为广告主提供的关于keyword和用户query匹配程度的选项,通常是四种类型之一:精确匹配(exact)、短语匹配(phrase)、宽泛匹配(broad)、上下文匹配(contextual)。营销活动(
campaign):一组具有相同设置(例如预算、地域定向)的广告,通常用于将广告主的产品归类。曝光(
impression):向用户展示的广告实例。曝光通常和运行时(run-time)可用的其它信息一起记录。点击(
click):表示用户是否点击了曝光的广告。点击通常和运行时可用的其它信息一起记录。点击率(
click through rate):总点击次数除以总曝光次数。点击预测(
click prediction):搜索平台的点击预估模型,用于预测用户针对给定query点击给定广告的可能性。
sponsored search只是一种web-scale的application。然而,鉴于问题空间的丰富性、各种类型的特征、以及庞大的数据量,我们认为我们的结果可以推广到具有类似规模的其它application。
1.1 Feature Representation
这里使用下表中列出的
individual特征,然后对比这些特征的组合特征。这些individual特征在在线预估阶段可用,也可以用于模型的离线训练。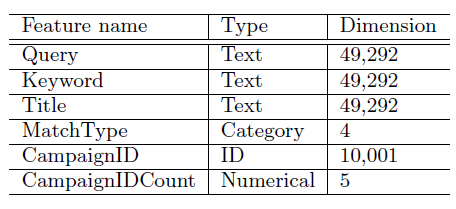
单个特征(
individual features):individual特征表示为一个向量。 对于诸如query之类的文本特征,一个选择是将字符串转换为具有49292维的tri-letter gram。诸如MatchType之类的离散(categorical)特征转换为one-hot向量。sponsored search system中通常有数百万个campaign,简单地将campaign id转换为one-hot向量会显著增加模型的大小。一种解决方案是使用上表中的一对伴随特征(a pair of companion features),其中:CampaignID是one-hot representation,它仅包含点击次数最多的top 10000个campaigns,而剩余所有的campaigns保存在第10000个slot(索引从0开始)。CampaignIDCount覆盖了其它campaigns(也包括top 10000的campaigns)。这是一个数值特征,用于存储每个campaigns的统计信息,如曝光次数、点击率等等。在以下讨论中,这类特征将被称作计数特征(counting feature)。
目前为止,所有的特征都是稀疏特征或计数特征。
组合特征(
combinatorial features):给定单个特征representation和稠密representation。稀疏
representation的一个例子是CampaignId x MatchType组合特征,它的维度是10001 x 4 = 40004维。稠密
representation的一个例子是计算给定CampaignId和MatchType组合下的广告点击次数。
Deep Crossing避免使用组合特征。它适用于稀疏和稠密的individual特征,并支持上述广泛的特征类型。这使得用户可以自由地从他们的特定application中使用他们选择的特征。虽然收集特征并转换为正确的representation仍然需要大量的努力,但是工作仅仅是停留在individual特征的层面,剩余的工作交由模型处理。
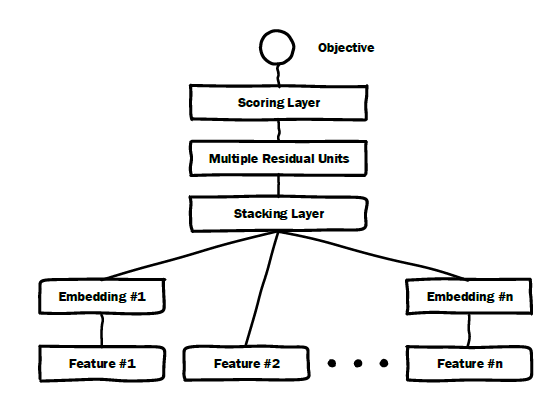
1.2 模型
DeepCrossing模型的输入是原始特征,模型有四种类型的Layer:Embedding Layer:将原始特征映射成embedding向量。假设原始特征
one-hot向量为field i在向量中的起始位置为embedding层的输出为:其中
embedding的维度。通常有embedding之后的维度大大小于原始特征维度。对于某些维度较小的原始特征(如维度小于
256),无需进行embedding层,而是直接输入到Stacking Layer层。如图中的Feature #2。需要指出的是:
embedding layer的维度对于模型的整体大小有着显著的影响。即使对于稀疏特征Deep Crossing使用伴随特征companion features来约束高基数特征(high cardinality)维度的原因(降低Stacking Layer:所有embedding特征和部分原始特征拼接成一个向量:其中:
field的数量,embedding向量。如果是直接输入的原始特征,则one-hot向量。Residual Unit Layer:Deep Crossing使用稍加修改的残差单元(Residual Unit),其中不使用卷积核。据我们所知,这是第一次使用残差单元解决图像识别以外的问题。基于残差单元构建的残差层,其输出为:
其中
relu layer:注意:在一个
DeepCrossing网络中可以有多个残差层。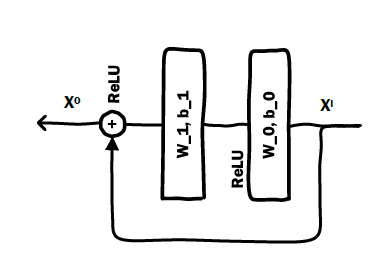
Scoring Layer:sigmoid输出层。其输出为:其中
模型的损失函数为负的
Logloss:其中
ground truth。当然根据具体任务也可以调整为
softmax损失函数或者其他损失函数。Deep Crossing被应用于各种各样的任务。它也适用于样本量差异很大的训练数据。在所有情况下,都是用相同的模型,无需对层、节点、节点类型进行任何调整。我们认为残差单元可能隐含地执行某种正则化从而导致这种稳定性。Early Crossing vs Late Crossing:可以将Deep Crossing和DSSM进行比较。下图是使用logloss作为目标函数的改进型DSSM的架构。修改后的DSSM与点击预测的application更密切相关,它在绿色的虚线左侧保留了DSSM的基础架构,但使用logloss将预测和ground-truth进行比较。DSSM允许两路文本输入,每路文本输入都由文本的tri-letter gram向量来表示。DSSM具有将特征交互延迟到前向传播后期的特点。在到达Cosine Distance节点之前,输入特征通过两条独立路径上的多层变换来完全地嵌入。相比之下,
Deep Crossing最多采用一层single-feature embedding,然后在前向传播的更早阶段开始特征交互。实验中我们发现,
Deep Crossing始终优于DSSM。除了残差单元优越的优化能力之外,在前向传播的早期引入特征交互似乎也起着重要的作用。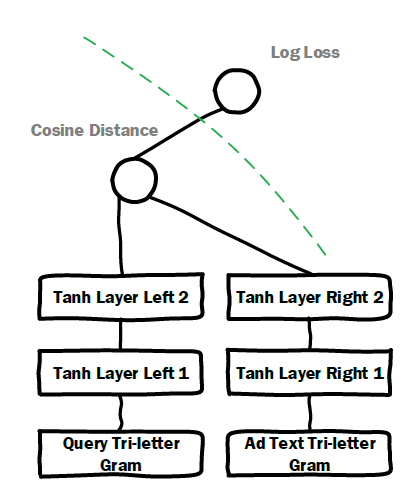
Deep Crossing由CNTK提供支持的multi-GPU平台上实现,具体CNTK实现代码和multi-GPU平台参考原始论文。
1.3 实验
Deep Crossing在主力搜索引擎的曝光和点击日志上训练和评估的。下表给出了实验数据集。每个实验将使用训练集、验证集、测试集的组合,由Data Set列中给出的名字来引用。只有同一个
group中的数据集是兼容的,这意味着不同Type在时间上没有重叠。例如,使用all_cp1_tn_b训练的模型可以使用all_cp1_vd进行验证、使用all_cp1_tt进行测试,因为它们都属于group G_3。数据集的
Task是CP1和CP2。这两个任务分别代表点击预估pipeline中的两个不同模型。在这种情况下,CP1是两者之间更关键的模型,但是这两个模型在系统中是互补的。Rows代表了样本数(单位是百万条),Dims代表了特征维度(单位是千)。
注意,由于测试集中使用的样本量庞大,所有和
baseline相比的实验结果在统计上都是显著的。
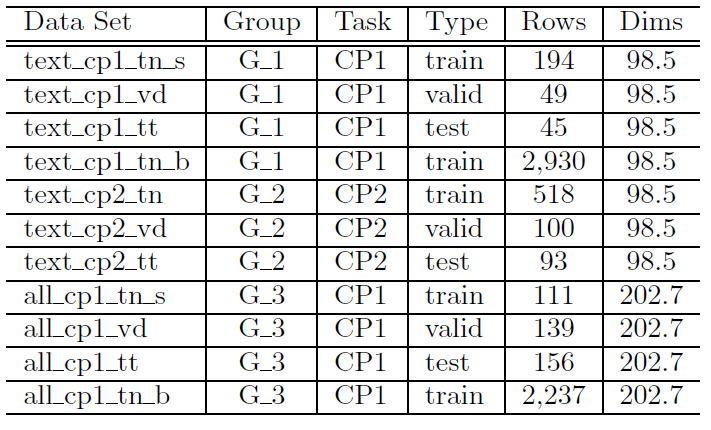
实验中,每个
field embedding维度[512, 512, 256, 128, 64]。
1.3.1 和 DSSM 对比
如前所述,我们有兴趣比较
DSSM和Deep Crossing。为了公平地比较,我们在CP1和CP2的数据上训练了DSSM和Deep Crossing,但是将Deep Crossing模型限制为使用与DSSM相同的数据(即,二者都使用包含一个pair的输入,其中包含query text和keyword or titile text,每个文本都由tri-letter gram向量来表示)。在第一个实验中,点击预估模型在下表中列出的两个数据集上的任务
CP1进行训练。在这两个数据集上,Deep Crossing在相对AUC方面都优于DSSM。注意,这里使用的DSSM是前面描述的logloss版本。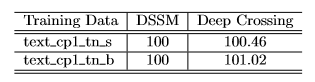
在第二个实验中,两个模型都在
text_cp2_tn数据集上的任务CP2进行了训练,并在text_cp2_tt数据集上进行了测试。下表给出了DSSM、Deep Crossing、以及我们生产系统中运行的模型的性能结果。生产模型在不同的数据集上进行训练,但使用
run-time记录的预测输出在相同的测试集(text_cp2_tt)上进行测试。可以看到:
Deep Crossing的性能比DSSM好,但是比生产模型差。这是意料之中的,因为生产模型使用了更多的特征(包括组合特征)、以及经过多年的改进。尽管如此,通过使用individual query特征和individual标题特征,Deep Crossing距离生产模型仅约1%。
虽然我们已经展示了
Deep Crossing从简单的文本输入pair对中学习的能力,但这并不是它的主要目标。Deep Crossing的真正力量在于处理很多的individual特征,我们将在后续的实验中看到。
1.3.2 文本之外的特征
我们现在考虑
Deep Crossing在任务CP1(训练集all_cp1_tn_s)上的性能,其中包含Feature Representation章节列出的大约20多个特征。本节的实验没有外部baseline,我们只会对比具有不同特征组合的Deep Crossing的性能。这里的目标不是评估相对于其它方法的性能,而是查看
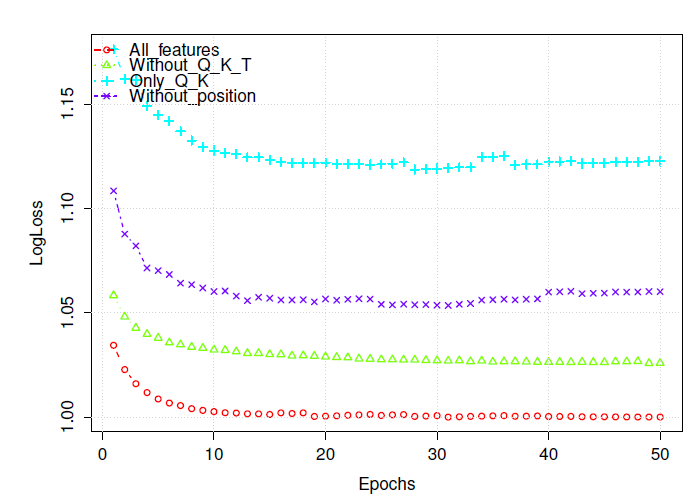
Deep Crossing的实际效果,并证明其性能会随着特征的添加和删除而发生显著变化。我们将在下一小节中在使用相同的丰富的特征集合的情况下,比较Deep Crossing和生产模型的性能。在第一个实验中我们对比不同特征子集的
Deep Crossing的效果,结果下图所示。图中的logloss是不同训练epoch上验证集的相对logloss,定义为实际logloss除以All_features模型在所有epoch的最低logloss。注意,这里计数特征
counting features始终被移除。All_features模型包含除了计数特征以外的所有特征。不出所料,它在本次实验中所有模型中具有最低的logloss。Only_Q_K模型仅使用query text和keyword text,它具有最高的logloss。就相对
logloss而言,Only_Q_K和All_features之间的差距大约是0.12。就AUC而言,这大约是7% ~ 8%的改进。考虑到AUC在0.1% ~ 0.3%的改进通常被认为对于点击模型而言是显著的,所以这里的提升是巨大的。without_Q_K_T是一个去除了query text、keyword text、title text的模型(当然也去除了计数特征)。这意味着去掉大部分文本特征会使相对logloss增加0.025。without_position移除了位置特征(当然也去除了计数特征),相对logloss增加大约0.05。
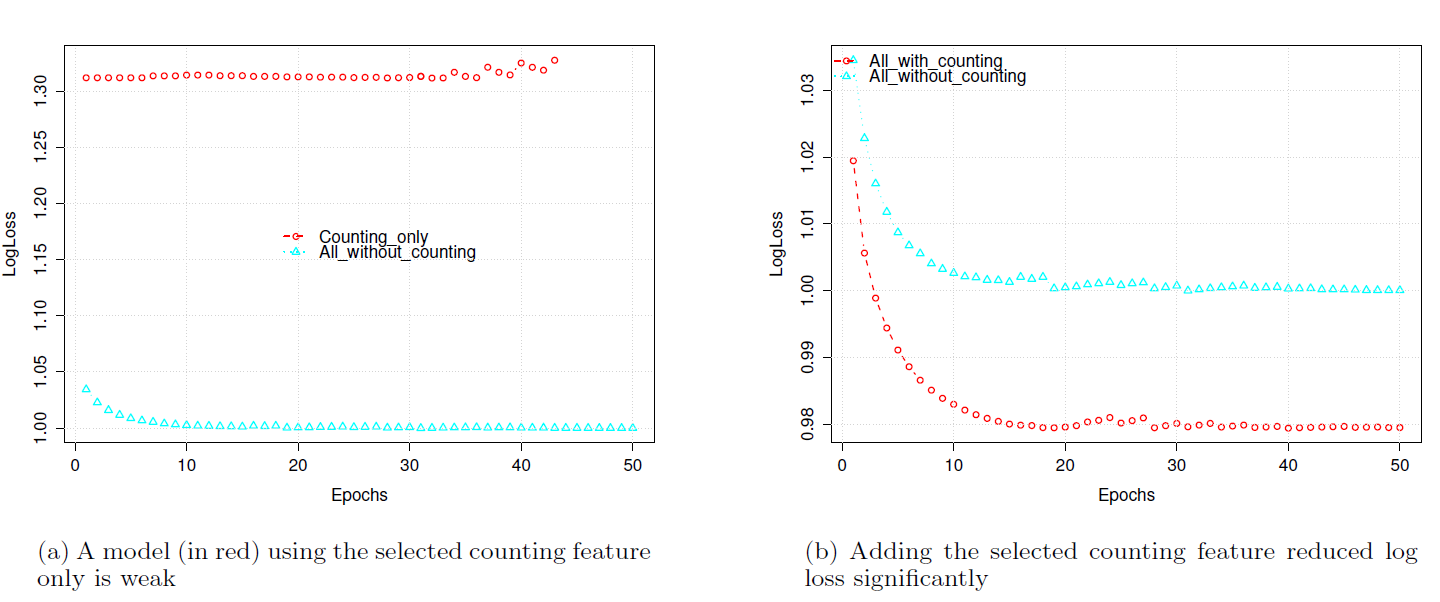
在第二个实验中,我们研究计数特征(
counting features)如何和其余的individual特征交互。如前所述,计数特征在降低高基数(high cardinality)特征的维度方面起着重要作用。我们的完整特征集合有五种类型的计数特征。在本实验中,我们只是使用其中之一来演示效果。图中的相对logloss的基准是All_without_counting模型在所有epoch的最低对数logloss。从图
(a)可以看到,仅Counting_only模型与具有除计数特征之外所有特征的All_without_counting模型相比非常弱。图
(b)显示了添加计数特征后的结果,其中新模型All_with_counting将相对logloss减少了0.02。
1.3.3 和生产模型的比较
到目前为止,问题仍然是
Deep Crossing是否真的可以击败生产模型,这是最终的baseline。为了回答这个问题,我们使用来自生产模型的原始特征的子集训练了一个具有
22亿个样本的Deep Crossing模型。Depp Crossing在任务CP1(all_cp1_tn_b)数据集上进行训练,并在all_cp1_tt上进行测试。生产模型在不同(更大的)的数据及上行进行训练,但使用相同的数据进行测试(基于run-time记录的预测输出)。结果如下表所示(相对
AUC),可以看到:Deep Crossing在任务CP1的离线AUC中的表现轻松超越了生产模型(截至论文发布时,任务CP2的结果尚不可用)。这一结果非常重要,因为
Deep Crossing模型仅使用了一小部分特征,并且模型构建和模型维护的工作量要少得多。