一、FFM [2016]
《Field-aware Factorization Machines for CTR Prediction》
click-through rate: CTR点击率预估在计算广告中起着重要作用。逻辑回归可能是该任务中使用最广泛的模型。给定一个具有label。我们通过求解以下最优化问题从而得到逻辑回归模型:其中:
学习特征交互效应看起来对
CTR预估至关重要。这里我们考虑下表中的人造数据集,以便更好地理解特征交互,其中+表示点击量、-表示不点击量。Gucci的广告在Vogue上的点击率特别高,然而这些信息对于线性模型来说很难学习,因为线性模型分别学习Gucci和Vogue的两个权重。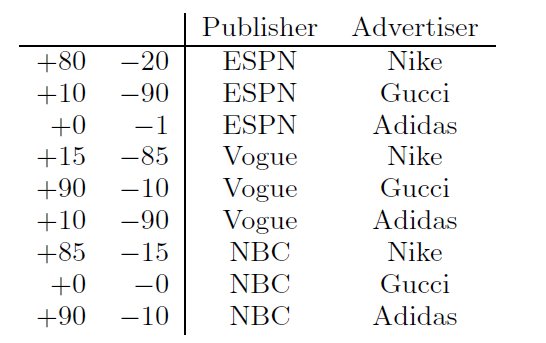
为了解决这个问题,已经有两个模型来学习特征交互效应:
第一个模型是二次多项式映射(
degree-2 polynomial mapping: Poly2),为每个特征交互学习专门的权重。第二个模型是分解机(
factorization machine: FM),通过将特征交互分解为两个潜在向量的乘积来学习特征交互效应。
FM的一种变体,称作成对交互张量分解 (pairwise interaction tensor factorization: PITF),用于个性化的tag推荐。在2012年的KDD Cup中,Team Opera Solutions提出了一种称作因子模型(factor model)作为PITF的泛化,称作field-aware factorization machine: FFM。PITF和FFM的区别在于:PITF考虑了user、item、tag三个特殊的字段(field),而FFM更加通用。由于FFM是针对比赛的整体解决方案,因此对它的讨论是有限的,主要包含以下结论:FFM使用随机梯度SG来解决优化问题。为了避免过拟合,Team Opera Solutions只训练了一个epoch。FFM在Team Opera Solutions尝试的六个模型中表现最好。
在论文
《Field-aware Factorization Machines for CTR Prediction》中,作者旨在具体建立FFM作为CTR预估的有效方法。论文的主要结果如下:尽管
FFM被证明是有效的,但是本文可能是唯一发表的、将FFM应用于CTR预估问题的研究。为了进一步证明FFM在CTR预估方面的有效性,作者使用FFM作为主要模型,从而赢得由Criteo和Avazu主办的两场全球CTR比赛。论文将
FFM和两个相关模型Poly2和FM进行比较。作者首先从概念上讨论为什么FFM可能比它们更好,并通过实验来查看准确性和训练时间方面的差异。论文提出了训练
FFM的技术,包括用于FFM的有效并行优化算法、以及早停以避免过拟合。为了让
FFM可以被大家使用,论文发布了一个开源软件。
1.1 模型
为便于讨论,这里忽略了全局
bias项和一阶项。给定特征向量POLY2模型为:参数个数为
FM模型为:参数个数为
通过重写上式:
计算复杂度降为
Rendle解释了为什么当数据集稀疏时,FM可以比Poly2更好。这里我们用上述人工数据集给出类似的说明。例如,对于
pair (ESPN, Adidas)只有一个负样本:对于
Poly2,可能会为对于
FM,因为(ESPN, Adidas)的预估取决于pair中学习(如(ESPN,Nike), (NBC, Adidas)),所以预测会更准确。
另一个例子是没有针对
(NBC, Gucci)的训练数据:对于
Poly2,对这个pair的预测是无意义的(trivial)。但是对于
FM,因为pair中学习,因此仍然可以做出有意义的预测。
注意,
Poly2的一种朴素实现是将每一对特征视为一个新特征,这使得模型的参数规模为CTR预估任务中的特征数量通常很大,因此Poly2不可行。Vowpal Wabbit: VW这个广泛使用的机器学习package通过哈希来解决这个问题。我们的实现方法也类似,具体而言:其中
FFM的思想来源于个性化tag推荐的PITF。PITF假设有三个可用字段,包括User、Item、Tag,并且在独立的潜在空间中分解(User, Item)、(User, Tag)、(Item, Tag)。FFM将PITF推广到更多字段(如AdID、AdvertiserID、UserID、QueryID),并将其有效地应用于CTR预估。由于
PITF仅针对三个特定字段(User, Item, Tag),而FFM原始论文缺乏对FFM的详细讨论,因此这里我们提供了对CTR预估的FFM的更全面的研究。对于大多数
CTR数据集,特征features可以分组为fields。在我们前面的示例中,ESPN, Vogue, NBC三个特征属于Publisher字段,另外三个特征Nike, Gucci, Adidas属于Advertiser字段。FFM是利用字段信息的FM变体。为了解释
FFM的工作原理,我们考虑以下示例:Publisher (P): ESPN; Advertiser (A): Nike; Gender (G): Male; Clicked: Yes考虑对于
FM,有:在
FM中,每个特征只有一个潜在向量来学习和其它特征的潜在效应(latent effect)。以ESPN为例,Nike的潜在效应(Male的潜在效应 (Nike和Male属于不同的字段,(EPSN, Nike)和(EPSN, Male)的潜在效应可能不一样。在
FFM中,每个特征有若干个潜在向量,这依赖于其它特征的字段数量。例如在这个例子中:其中:
(ESPN, NIKE)的潜在效应由Nike属于Advertiser字段、ESPN属于Publisher字段。(ESPN, Male)的潜在效应由Male属于Gender字段、ESPN属于Publisher字段。(Mike, Male)的潜在效应由Male属于Gender字段、Nike属于Advertiser字段。
FFM模型用数学语言描述为:其中:
field,一共有field(参数数量为
和
FM相比,通常FFM中representation向量的维度要低的多。即:.
1.2 优化算法
FFM模型采用随机梯度下降算法来求解,使用AdaGrad优化算法。在每个迭代步随机采样一个样本
考虑全局
bias以及一阶项,并统一所有的其中:
field f内的所有其它特征;对梯度的每个维度,计算累积平方:
其中
更新参数:
其中
模型参数需要合适的初始化。论文推荐:
1,这是为了防止在迭代开始时
原始论文并没有
论文推荐采用样本级别的归一化,这可以提升模型泛化能力。
注:如果采用
Batch normalization效果可能会更好。论文未采用BN,是因为论文发表时BN技术还没有诞生。FFM的AdaGrad优化算法:输入:
训练集
学习率
最大迭代步
初始化
输出:极值点参数
算法步骤:
初始化参数和
迭代
随机从
计算
计算
遍历所有的项:
计算
遍历所有的项:
计算
遍历所有的维度:
1.3 field 分配
大多数数据集的结构是 :
xxxxxxxxxxlabel feat1:val1 feat2:val2 ...,其中
(feat:value)表示特征索引及其取值。对于FFM,我们扩展上述格式为:xxxxxxxxxxlabel field1:feat1:val1 field2:feat2:val2也就是我们必须为每个特征分配相应的字段。
为某些类型的特征分配字段很容易,但是对于其他一些特征可能比较困难。接下来我们在三种典型类型的特征上讨论这个问题。
离散型特征(
categorical):通常对离散型特征进行one-hot编码,编码后的所有二元特征都属于同一个field。例如,性别字段:G:G-Male:1、G:G-Male:0。数值型特征(
numuerical):数值型特征有两种处理方式:不做任何处理,简单的每个特征分配一个
dummy field。此时FFM退化为Poly2模型。例如论文引用量Cite:Cite:3,其中分配的字段和特征名相同。数值特征离散化之后,按照离散型特征分配
field。例如,论文引用量Cite:3:1,其中3表示特征名(桶的编号)。论文推荐采用这种方式,缺点是:
难以确定合适的离散化方式。如:多少个分桶?桶的边界如何确定?
离散化会丢失一些信息。
离散集合特征(
categorical set)(论文中也称作single-field特征):所有特征都属于同一个field,此时FFM退化为FM模型。如
NLP情感分类任务中,特征就是单词序列。如果对整个
sentence赋一个field,则没有任何意义,因为此时可能的特征范围是天文数字。如果对每个
word赋一个field,则
1.4 实验
这里我们首先提供实验配置的细节,然后我们研究超参数的影响。我们发现,和逻辑回归以及
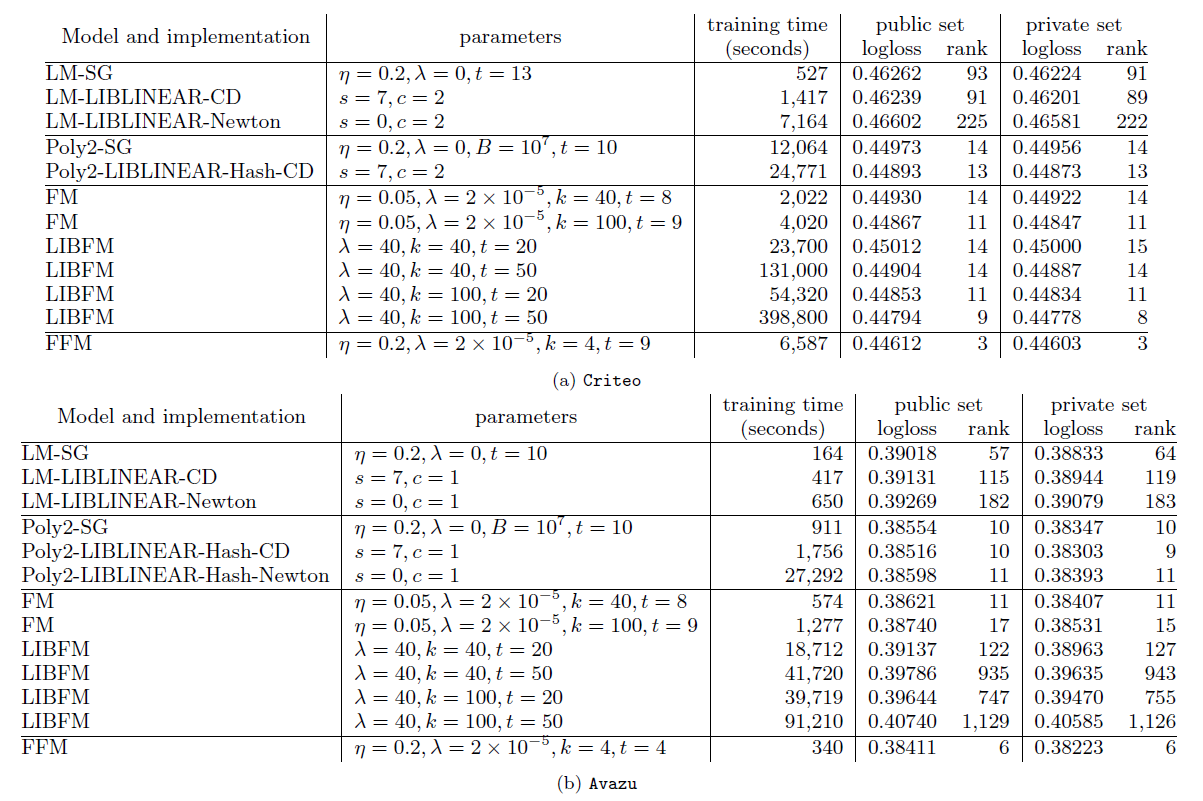
Poly2不同,FFM对epoch数量很敏感,因此我们提出了早停策略。最后我们将FFM和包括Poly2, FM在内的其它baseline进行对比,除了预估准确性之外我们还对比了训练时间。数据集:我们主要考虑来自
Kaggle比赛的两个数据集Criteo和Avazu。对于特征工程,我们主要应用了我们的成功方案,但是移除了复杂的部分。例如,我们在Avazu数据集的成功方案包含了20个模型的ensemble,但是这里我们仅使用最简单的一个。另外,我们使用哈希技巧里生成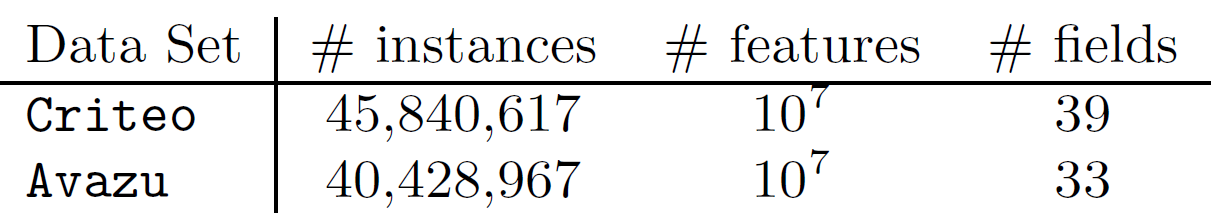
对于这两个数据集,测试集中的标签都是不可用的,所以我们将可用的数据分为训练集和验证集,拆分方式为:对于
Criteo,最后6040618行用于验证集;对于Avazu,最后4218938行用于验证集。我们用以下术语来表示各个不同的数据集:Va:上述拆分的验证集。Tr:从原始训练集中剔除验证集之后,得到的新训练集。TrVa:原始的训练集。Te:原始的测试集,其label未公布,所以我们必须将我们的预测结果提交给评估系统从而获得score分。为了避免测试集过拟合,竞赛组织者将该数据集分为两个子集:public set(竞赛期间score可见)、private set(竞赛期间score不可见且只有竞赛结束后score才公布)。最终排名由private set决定。
配置:所有实验都是在
Linux工作站上运行,该工作站配置为两个Intel Xeo E6-2620 2.0GHz处理器、128GB内存。评估指标:我们考虑
logloss作为评估指标,其中:其中:
label。
超参数影响:我们评估了超参数
representation向量维度)、Criteo新训练集中随机抽取10%样本作为训练集、从Criteo验证集中随机选择10%样本作为测试集。超参数
k这个不同的符号),第二列为平均每个epoch的计算时间,第三列为验证集的logloss。可以看到:不同的
representation向量维度,对模型的预测能力影响不大,但是对计算代价影响较大。所以在FFM中,通常选择一个较小的注意,由于采用了
SSE指令集,所以epoch计算时间几乎相同。
超参数
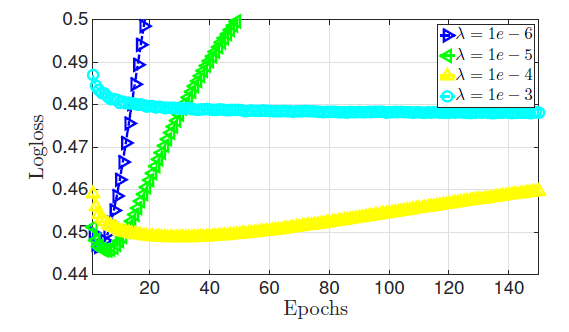
如果正则化系数太小,则模型太复杂,容易陷入过拟合。
如果正则化系数太大,则模型太简单,容易陷入欠拟合。
一个合适的正则化系数不大不小,需要精心挑选。
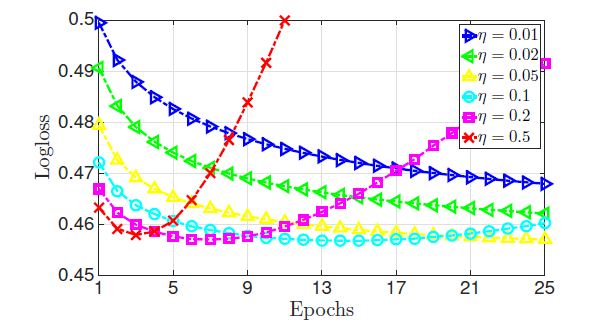
学习率
如果学习率较小,虽然模型可以获得一个较好的性能,但是收敛速度很慢。
如果学习率较大,则目标函数很快下降,但是目标函数不会收敛到一个较低的水平。
早停:
FFM对于训练epoch次数很敏感。为解决该问题,我们对FFM执行早停策略:首先将数据集拆分为训练集、验证集。
在通过训练集训练的每个
epoch结束时,计算验证集的logloss。如果验证集的
logloss上升,则记录当前已训练的epoch次数最后用全量训练数据重新训练模型
epoch。
该方案存在一个潜在的缺点:
logloss对epoch次数高度敏感,以及验证集上的最佳epoch不一定是测试集上的最佳epoch。因此早停得到的模型无法保证在测试集上取得最小的logloss。我们也尝试了其它的避免过拟合的方法,比如
lazy update和ALS-based优化,但是这些方法效果都不如早停策略。我们在
Criteo和Avazu数据集上比较了不同算法、不同优化方式、不同超参数的结果。我们选择了四种算法,包括
LM模型(线性模型)、POLY2模型、FM模型、FFM模型。我们选择了三种优化算法,包括SG(随机梯度下降)、CD(坐标下降)、Newton(牛顿法)、ALS。另外我们还选择了不同超参数。LIBFM支持SG,ALS,MCMC三种优化算法,但是我们发现ALS效果最好。因此这里LIBFM使用ALS优化算法。FM、FFM都是基于SG优化算法来实现的,同时对于SG优化算法采取早停策略。对于非
SG优化算法,停止条件由各算法给出合适的停止条件。
从实验结果可以看到:
FFM模型效果最好,但是其训练时间要比LM和FM更长。LM效果比其它模型都差,但是它的训练要快得多。FM是一种较好的平衡了预测效果和训练速度的模型,这就是效果和速度的平衡。POLY2比所有模型都慢,因为其计算代价太大。从两种
FM的优化方法可见,SG要比ALS优化算法训练得快得多。逻辑回归是凸优化问题,理论上
LM和POLY2的不同优化算法应该收敛到同一个点,但实验表明并非如此。原因是:我们并没有设置合适的停止条件,这使得训练过程并没有到达目标函数极值点就提前终止了。
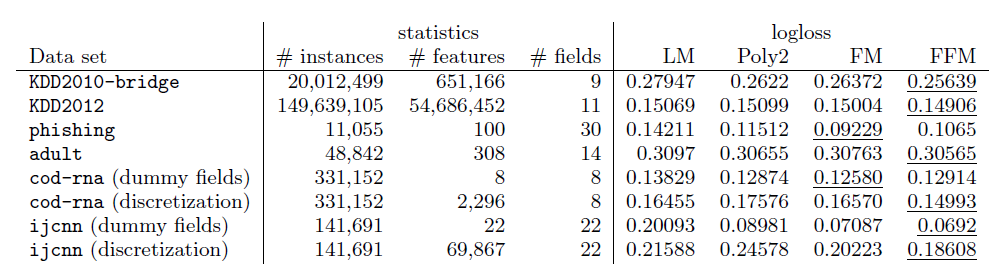
我们比较了其它数据集上不同模型的表现。其中:
KDD2010-bridge,KDD2012,adult数据集包含数值特征和离散特征,我们将数值特征执行了离散化。cod-rna,ijcnn数据集仅仅包含数值特征 ,我们将数值特征进行两种处理从而形成对比:将数值特征离散化、每个数值特征作为一个field(称作dummy fields)。phishing数据集仅仅包含离散特征。
实验结果表明:
FFM模型几乎在所有数据集上都占优。这些数据集的特点是:大多数特征都是离散的。
经过
one-hot编码之后大多数特征都是稀疏的。
在
phishing,adult数据集上FFM几乎没有优势。原因可能是:这两个数据集不是稀疏的,导致FFM,FM,POLY2这几个模型都具有几乎相同的表现。在
adult数据集上LM的表现和FFM,FM,POLY2几乎完全相同,这表明在该数据集上特征交互几乎没有起到什么作用。在
dummy fields的两个数据集上FFM没有优势,说明field不包含任何有用的信息。在数值特征离散化之后,尽管
FFM比FM更有优势,但还是不如使用原始数值特征的FM模型。这说明数值特征的离散化会丢失一些信息。
从实验中总结的
FFM应用场景:数据集包含离散特征,且这些离散特征经过
one-hot编码。经过编码后的数据集应该足够稀疏,否则
FFM无法获取较大收益(相对于FM)。不应该在连续特征的数据集上应用
FFM,此时最好使用FM。