一、FNN [2016]
《Deep Learning over Multi-field Categorical Data – A Case Study on User Response Prediction》
用户响应(
user response)(如点击click-through或转化conversion)预测在很多web applications中起着至关重要的作用,包括web搜索、推荐系统、sponsored搜索广告、展示广告(display advertising)。例如,和传统线下广告相比,在线广告精准定向(targeting)到单个用户的能力是核心优势。所有这些targeting技术本质上都依赖于系统预测特定用户是否会认为潜在广告是 “相关” 的,即用户在特定上下文中点击给定广告的概率。sponsored搜索广告、上下文广告、以及最近出现的实时竞价(realtime bidding: RTB)展示广告在很大程度上依赖于模型预测广告点击率CTR的能力。当今应用的
CTR预估模型大多数是线性的,从逻辑回归、朴素贝叶斯到FTRL逻辑回归、贝叶斯概率回归,所有这些都是基于大量的、基于one-hot编码的稀疏特征。线性模型具有易于实现、学习效率高的优点,但性能相对较低,因为无法它无法学习非平凡的(nontrivial)模式来捕获原始特征之间的交互(interaction)。另一方面,非线性模型能够利用不同的特征组合,因此有可能提高预估性能。例如:分解机(
factorization machine: FM)将用户和item的二元特征映射到低维连续空间中,并通过向量内积自动探索特征交互;梯度提升树(gradient boosting tree: GBT)在生成每棵决策树/回归树的同时自动学习特征组合。然而,这些模型不能利用不同特征的所有可能组合,并且在大特征空间中计算量很大。此外,很多模型需要特征工程来手动设计输入特征。
主流的广告点击率预估模型的另一个问题是:大多数预测模型结构浅、表达能力有限,无法从复杂和海量数据中建模潜在模式。因此,它们的数据建模和泛化能力仍然受限。
近五年来,深度学习在计算机视觉、语音识别、自然语言处理等领域取得了成功。由于视觉信号、听觉信号、文本信号已知在空间/时间上相关,因此新引入的、在深层结构上的无监督训练能够探索这种局部依赖性(
local dependency)并建立特征空间的稠密representation,使神经网络模型能够有效地直接从原始特征输入中学习高阶特征。凭借这样的学习能力,深度学习将是估计在线用户响应(如广告点击率)的理想选择。然而,
CTR预估中的大多数输入特征都是multi-field的,而且是不连续的(discrete) 、离散的(categorical),例如用户所在城市(London, Paris)、设备类型(PC, Mobile)、广告类目(Sports, Electronics)。另外,输入特征之间的局部依赖性是未知的。因此,了解深度学习如何通过在此类大型multi-field离散特征上学习特征representation来改进CTR预估是非常有意义的。距FNN论文作者所知,到目前为止还没有使用深度学习方法估计广告点击率的文献。 此外,在大型输入特征空间上训练深度神经网络DNN需要训练大量参数,这在计算上是昂贵的。例如,不同于图像和音频领域,在CTR预估任务中,假设在第一层大约有100万个二元输入特征和100个隐单元,那么构建第一层神经网络就需要1亿个权重参数。在论文
《Deep Learning over Multi-field Categorical Data – A Case Study on User Response Prediction》中,作者以广告点击率预估作为示例,通过使用有监督和无监督方式的embedding方法在大型multi-field离散特征空间上研究深度学习。论文介绍了两种类型的深度学习模型,称为因子分解机支持的神经网络(Factorization Machine supported Neural Network: FNN)、基于采样的神经网络(Sampling-based Neural Network: SNN)。具体而言:FNN使用分解机来初始化监督学习的embedding layer,从而将高维稀疏特征有效地降维到低维稠密连续特征。SNN是一个深度神经网络,由基于采样的受限玻尔兹曼机(sampling-based restricted Boltzmann machine: SNN-RBM)或者基于采样的降噪自编码器(sampling-based denoising auto-encoder: SNN-DAE)提供支持,并且使用了一种负采样方法。
基于
embedding layer,论文构建了具有全连接的多层神经网络,从而探索非平凡(non-trivial)的数据模式。论文对多个真实世界广告主的广告点击数据进行的实验表明:所提出的模型对CTR预估的一致性(consistent)的改进优于SOTA的模型。相关工作:点击率在在线广告中至关重要。为了最大化收入和用户满意度(
satisfaction),在线广告平台必须预测每个展示广告的预期用户行为,并最大化用户点击的期望。当前的大多数模型使用基于一组稀疏二元特征的逻辑回归,这些特征是通过
one-hot编码从原始离散特征(categorical feature)转换而来的。在这个过程中需要大量的特征工程。将维度很高的特征向量嵌入到低维
embedding空间,这对于预测任务很有用,因为它降低了数据和模型的复杂性,并提高了训练和预测的效果(effectiveness)和效率(efficiency)。人们已经提出了各种embedding方法。例如因子分解机(Factorization machine: FM)最初是为协同过滤推荐而提出的,被认为是最成功的embedding模型之一。FM天然地可以通过将任意两个特征映射到低维潜在空间中的向量,从而估计它们之间的交互。深度学习是人工智能研究的一个分支,它试图开发新技术使得计算机能够处理复杂的任务(诸如识别
recognition和预测prediction)。深度神经网络DNN能够从训练数据中提取不同抽象级别的隐藏结构(hidden structures)和内在模式(intrinsic patterns),目前已经成功应用于计算机视觉、语音识别、自然语言处理。此外,在无监督预训练的帮助下,我们可以获得良好的特征representation,引导学习朝着更好泛化的极小值区域发展。通常,这些深度模型有两个学习阶段:第一阶段通过无监督学习(即受限玻尔兹曼机
RBM或堆叠降噪自编码器SDAE)执行模型初始化,使模型捕获输入数据的分布。第二阶段涉及通过反向传播的监督学习对初始化模型进行微调。我们的深度学习模型的新颖之处在于第一层初始化,其中输入的原始特征是从原始离散特征转换而来的高维稀疏二元特征。这种高维稀疏二元特征使得大规模训练传统
DNN变得困难。与NLP中使用的word embedding技术相比,我们的模型处理更通用的multi-field离散特征,而没有任何假设的数据结构,如word alignment以及letter-n-gram等。
1.1 模型
里我们将详细讨论两种
DNN架构,即因子分解机支持的神经网络(Factorization-machine supported Neural Networks: FNN)、基于采样的神经网络(Sampling-based Neural Networks: SNN)。这输入的离散特征是
field-wise one-hot的。对于每个field(例如city),有多个unit,每个unit代表该field的一个特定值(例如city=London),并且只有一个postive unit(取值为1)、其它所有unit都是negative(取值为0)。编码后的特征记作CTR预估模型以及我们DNN模型的输入。
1.1.1 FNN
我们的第一个模型
FNN基于因子分解机FM,网络结构如下图所示。网络分为以下几层:第
0层输入层:离散特征经过one-hot编码之后作为输入,该层也被称作sparse binary feature层。第
1层embedding层:输入层经过局部连接生成embedding向量,该层也被称作dense real layer层。第
2层到第hidden layer。最后一层:
sigmoid输出层。
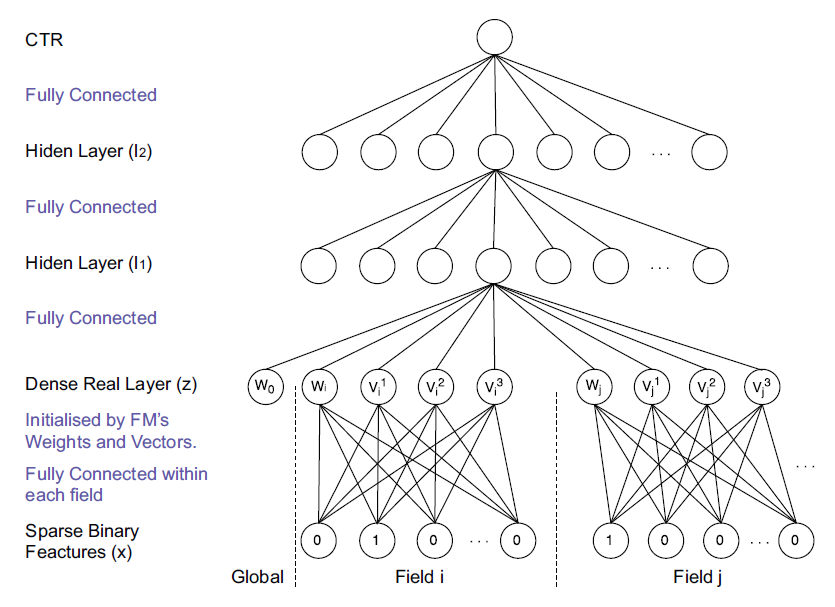
FNN的核心在于embedding向量的生成。假设one-hot向量为field,field i在向量中的起始位置为每个
field生成一个embedding向量,即field i生成bias。因此embedding层的输出为:输入位置
FM模型初始化,即:其中
在
FM模型中,bias参数,embedding向量。field模型采用逐层预训练,一旦初始化后就冻结
一旦求解出
其中
网络每层通过
layer-wise RBM逐层预训练来初始化。通过这种方式,上述神经网络可以更有效地从分解机
representation中学习,从而很自然地绕过了高维二元输入的计算复杂性问题。不同隐层可以看作是不同的内部函数,捕获了数据样本的不同representation形式。因此,该模型具有更强的捕获内在数据模式的能力。在底层使用
FM的想法是由卷积神经网络CNN启发的,CNN通过在相邻层的神经元之间强制执行局部连接模式来利用空间局部相关性。同样地,第一层隐层的输入连接到特定field的输入单元。此外,底层不是全连接的,因为FM对one-hot稀疏编码输入执行field-wise训练,从而允许局部稀疏(local sparsity),如上图中的虚线所示。FM在潜在空间中学习良好的结构数据representation,有助于构建任何更好的模型。但是,FM的乘积规则和DNN的求和规则之间出现了细微的差异。然而,如果观察到的判别性的信息(discriminatory information)是高度模糊的(在我们的广告点击场景下是这样的),后验权重(来自DNN)不会显著偏离先验权重(来自FM)。此外,隐层(
FM层除外)中的权重通过使用对比散度contrastive divergence的layer-wise RBM预训练进行初始化,这有效地保留了输入数据集中的信息。FM的初始权重通过随机梯度下降SGD进行训练。注意,我们只需要更新连接到positive input单元的权重,这在很大程度上降低了计算复杂度。在对
FM和上层进行预训练后,我们应用监督微调(反向传播)以最小化交叉熵的损失函数:其中
ground-truth label。通过反向传播的链式法则,可以有效地更新包括
FM权重在内的FNN权重。当
0,因此只需要更新
1.1.2 SNN
SNN的模型如下图(a)所示。SNN和FNN的区别在于第一层的结构和训练方法。SNN的第一层是全连接的:其中
为了初始化第一层的权重,我们在预训练阶段尝试了受限玻尔兹曼机(
restricted Boltz- mann machine: RBM)和降噪自编码器(denoising auto-encoder: DAE)。为了处理训练大型稀疏
one-hot编码数据的计算问题,我们提出了一种基于采样的RBM(如下图(b),记作SNN-RBM),以及基于采样的DAE(如下图(c),记作SNN-DAE),从而有效地计算第一层的初始权重。我们不是为每个训练样本集合建模整个
feature set。对于每个特征field,每个训练样本只有一个positive value feature,例如city= London,并且我们随机采样negative units(取值为零)。图(b)和(c)中的黑色单元是未采样到的,因此在预训练数据样本时被忽略。使用采样的单元,我们可以通过对比散度(contrastive divergence)训练RBM,并通过SGD使用无监督方法训练DAE,从而大大降低数据维度,并具有高的recovery性能。此外,实值稠密向量用作
SNN中其它层的输入。通过这种方式,我们可以显著降低计算复杂度,进而可以快速计算初始权重,然后执行反向传播来微调
SNN模型。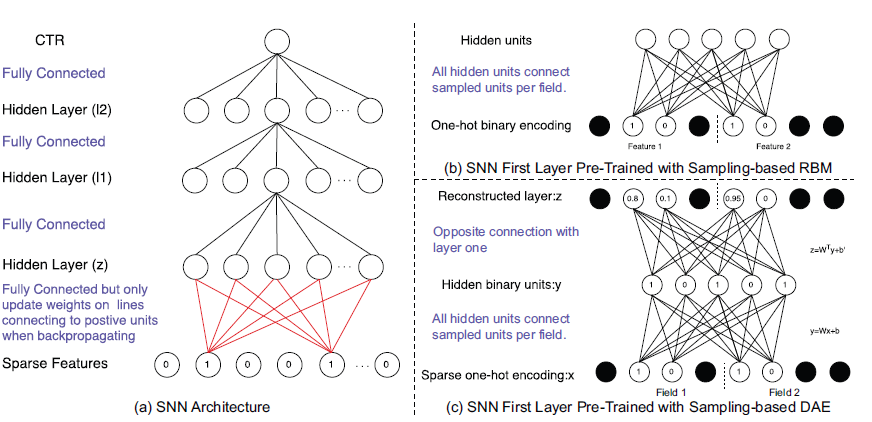
1.1.3 正则化
为了防止过拟合,我们在损失函数中加入了广泛使用的
L2正则化,例如FNN中的正则化项为:另一方面,我们还实现了
dropout,并在实验中对这两种正则化方式进行了比较。
1.2 实验
数据集:我们基于
iPinYou数据集评估我们的模型,这是一个公开的真实世界展示广告(display ad)数据集,包含每个广告曝光信息和相应的用户点击反馈。数据日志由不同的广告主以每条记录的格式进行组织。数据集包含
1950万个数据样本,共有14790个positive label(正样本)。所有的特征都是离散的,特征包括user agent、partially masked IP、地区、城市、广告交易平台、域名(domain)、URL、广告位ID等等。经过one-hot编码后,整个数据集中的二元特征数量为937.67K。在我们的实验中,我们分别使用来自广告主
1458、2259、2261、2997、3386以及整个数据集的训练数据。baseline方法:LR:逻辑回归是一种实现简单、训练速度快的线性模型,广泛用于在线广告点击率预估。FM:因子分解机是一种非线性模型,即使在具有巨大稀疏性的问题中也能估计特征交互。FNN:我们提出的分解机支持的神经网络,如前所述。SNN:我们提出的基于采样的神经网络,其中基于采样的RBM表示为SNN-RBM、基于采样的DAE表示为SNN-DAE。
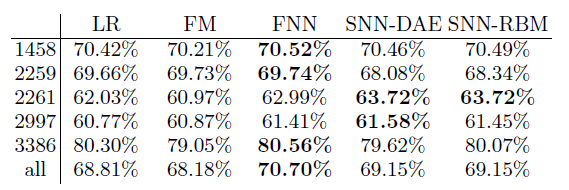
为了衡量每个模型的
CTR预估性能,我们使用AUC指标。下表给出了
5个不同广告主和整个数据集上不同模型的比较结果。可以看到:FM并没有显著优于LR,这意味着二阶组合特征不足以捕获底层数据模式。在所有测试集上,
FNN和SNN的性能超越了LR和FM。基于
FM学习的潜在结构,FNN进一步学习这些潜在特征之间的有效模式,并提供对FM的一致提升。SNN-DAE和SNN-RBM的性能大体上是一致的,即SNN的结果几乎相同。
超参数调优:深度神经网络需要调优相当多的超参数,这里展示我们如何实现我们的模型以及调优超参数。
我们使用随机梯度下降来训练模型,训练
epoch的数量由早停策略来自动决定。我们尝试了不同的学习率(
[1, 0.1, 0.01, 0.001, 0.0001]),并选择在验证集上最佳性能的学习率。对于
SNN-RBM和SNN-DAE的负采样unit,我们尝试每个field的negative units数对于隐层的激活函数,我们尝试了线性函数、
sigmoid函数、tanh函数,最终发现tanh函数的结果最优。
架构选择:在我们的模型中,我们通过固定所有层的尺寸来研究具有
[3, 4, 5]层隐层的架构,并发现具有三层隐层(即,包括输入层、输出层一共有五层)的架构在AUC性能方面最佳。但是如何选择层的尺寸是一个困难。假设具有
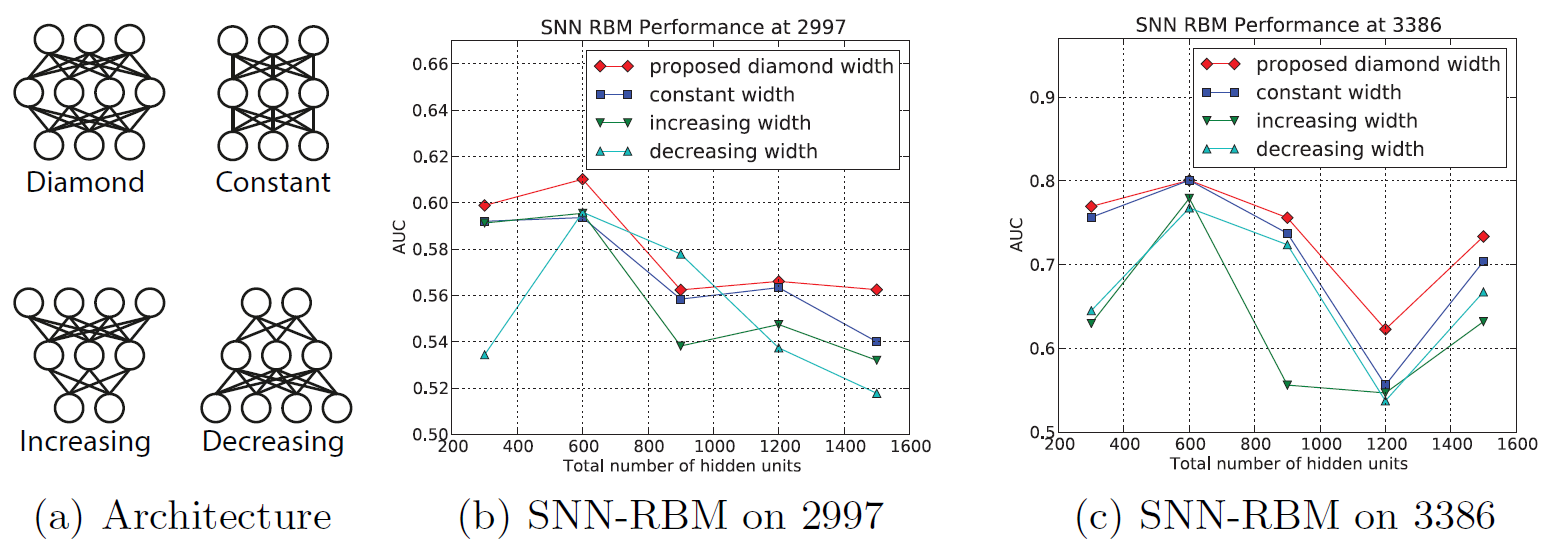
[100, 200, 300, 400, 500],那么一共有事实上除了尺寸增加、尺寸不变、尺寸减小之外,还有一种更有效的结果,即菱形结构,如下图
(a)所示。我们将这几种网络结构在不同数据集上进行比较。可以看到:菱形架构在几乎所有层尺寸设置中都优于其它架构。这种菱形之所以有效,可能是因为这种特殊形状的神经网络对模型容量有一定的约束,这在测试集上提供了更好的泛化能力。
另一方面,菱形架构的最佳隐单元总数为
600,即(200,300,100)的组合。这取决于训练样本的数量。针对小规模数据集,如果有太多隐单元可能会导致过拟合。
正则化:我们比较了
L2正则化和dropout。下图显示了SNN-RBM模型采用不同正则化的性能比较。可以看到:在所有情况下dropout都优于L2。dropout更有效的原因是:在馈入每个训练样本时,每个隐单元都以dropout rate的概率从网络随机排除,即每个训练样本都可以视为一个新的模型,并将这些模型平均为bagging的特殊case,这有效地提高了DNN模型的泛化能力。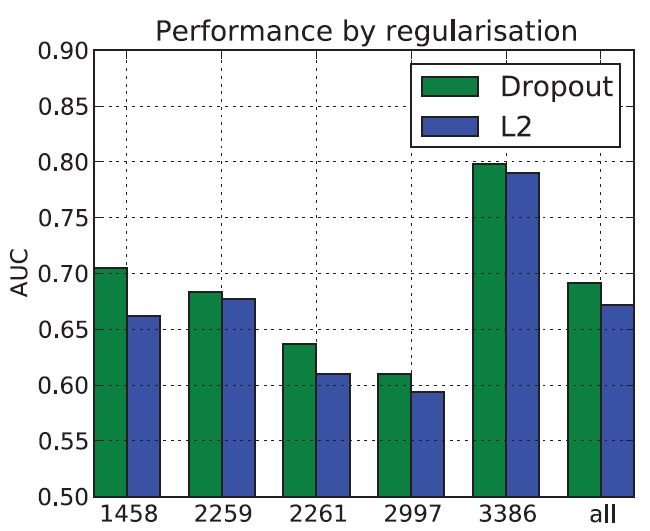
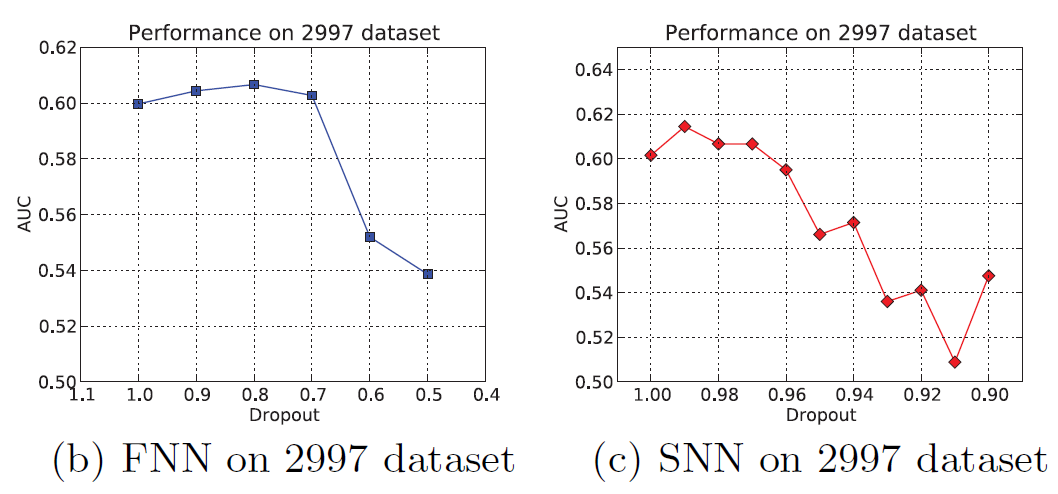
dropout rate:下图显示了FNN和SNN中,AUC性能如何随着的dropout rate的增加而变化。这里的dropout rate指的是每个神经单元处于激活状态的概率(而不是丢弃的概率)。可以看到:两个模型的性能在开始时都有上升的趋势,然后随着
dropout rate的不断降低而急剧下降。这两种模型的区别在于对
dropout的敏感性不同。模型
SNN对dropout rate很敏感,这可能是由于SNN第一层的全连接而引起的。模型
FNN对dropout rate相对不敏感,这是因为FNN第一层部分连接而引起的。当一些隐单元被丢弃时,FNN更鲁棒。
因此,
FNN和SNN最佳性能时的dropout rate有很大不同。对于FNN,最佳dropout rate大约为0.8,对于SNN大约为0.99。