一、PNN [2016]
《Product-based Neural Networks for User Response Prediction》
学习和预测用户响应(
response)在信息检索(information retrieval: IR)的许多个性化任务中起到至关重要的作用,例如推荐系统、web搜索、在线广告。用户响应预测的目标是估计用户positive response(如点击、购买等)的概率。这个预测的概率表示用户对特定item(如新闻文章、电商的商品等)的兴趣,并影响后续决策,例如document ranking、广告出价等等。这些
IR任务中的数据集大多数采用multi-field的离散(categorical)形式,例如[Weekday=Tuesday, Gender=Male, City=London]。通常通过one-hot编码将这种形式的特征转换为高维稀疏二元特征。例如包含上述三个field的特征向量被one-hot编码为:许多机器学习模型,包括线性逻辑回归(
logistic regression: LR)、非线性梯度提升决策树(gradient boosting decision tree: GBDT)、分解机(factorization machine: FM)等等,已经被提出来用于处理此类高维稀疏二元特征并产生高质量的用户响应预测。然而,这些模型高度依赖于特征工程来捕获高阶(high-order)潜在模式(latent pattern)。因此面对极端的稀疏性,传统模型可能会受限于从数据中挖掘浅层模式的能力。最近,深度神经网络
DNN在分类和回归任务中表现出强大的能力,包括计算机视觉、语音识别、自然语言处理。在用户响应预测中采用DNN很有前景,因为DNN可以自动学习更具有表达性(expressive)的特征并提供更好的预测性能。但是面对高维输入的场景,DNN模型的参数规模巨大导致难以应用。为了改善
multi-field离散数据交互,《Deep learning over multi-field categorical data: A case study on user response prediction》提出了一种基于FM预训练的embedding方法。该方法基于拼接的embedding向量,并构建了多层感知机MLP来探索特征交互(feature interaction)。然而,
embedding初始化的质量在很大程度上受限于FM。更重要的是,感知机layer的add操作可能无法用于探索multi-field中离散数据的交互。先前的工作表明,可以通过特征向量product操作而不是add操作来有效地探索来自不同field的特征之间的局部依赖关系。为了利用神经网络的学习能力,并以比
MLP更有效的方式挖掘数据的潜在模式,论文《Product-based Neural Networks for User Response Prediction》提出了Product-based Neural Network: PNN,它具有以下特点:使用没有预训练的
embedding层。基于
embedding的特征向量构建一个product layer,从而建模inter-field特征交互。使用全连接的
MLP进一步提取高阶特征模式。
论文出了两种类型的
PNN,分别在product layer执行内积 (inner product)操作(即IPNN)和外积(outer product)操作(即OPNN),从而有效地对交互模式进行建模。论文以在线广告的
CTR预估为例,探讨PNN模型的学习能力。在两个大规模真实世界数据集上的大量实验结果表明:PNN模型在各种指标上始终优于SOTA的用户响应预测模式。相关工作:响应预测(
response prediction)问题通常被表述为基于最大似然或交叉熵的二分类问题。从建模的角度来看,线性逻辑回归(
logistic regression: LR)、非线性梯度提升决策树(gradient boosting decision tree: GBDT)、非线性因子分解机(factorization machine: FM)在工业application中得到广泛应用。然而,这些模型在挖掘高阶潜在模式或学习高质量特征representation方面受到限制。深度学习能够探索高阶潜在模式(
high-order latent pattern)以及泛化的、有表达力的数据representation。DNN的输入通常是稠密实值向量,而multi-field离散(categorical)数据的解决方案尚未得到很好的研究。《Deep learning over multi-field categorical data: A case study on user response prediction》中提出了Factorization-machine supported neural network: FNN,它通过预训练的FM学习离散数据的embedding向量。《A convolutional click prediction model》中提出了Convolutional Click Prediction Model: CCPM来预测广告点击。然而在CCPM中,卷积仅在某种对齐(alignment)的相邻fields上执行,无法对非相邻fields之间的完整交互进行建模。《Sequential click prediction for sponsored search with recurrent neural networks》利用RNN将用户queries建模为一系列用户上下文,从而预测广告点击行为。《Training product unit neural networks》提出了Product unit neural network: PUNN来构建输入的高阶组合。然而,PUNN既不能学习局部依赖(local dependency),也无法产生有界的输出(bounded output)从而适应响应率(response rate)(即点击率)。
在本文中,我们展示了我们的
PNN模型学习局部依赖和高阶特征交互的方式。
1.1 模型
我们以在线广告的
CTR预估为例来描述我们的模型,并探索该模型在各种指标上的表现。CTR预估任务是构建一个预估模型从而估计用户在给定上下文中点击特定广告的概率。每个数据样本由
multi-field的离散数据组成,例如用户信息(性别、城市等)、广告信息(广告ID、广告类目ID)、上下文信息(曝光时刻等)。所有信息都表示为一个multi-field categorical特征向量,其中每个field(例如城市)都是one-hot编码的,如前所述。这种
field-wise的one-hot编码会导致维数灾难和巨大的稀疏性。此外,field之间存在局部依赖性(local dependency)和层级结构 (hierarchical structure)。因此,我们正在寻求一种DNN模型来捕获multi-field离散数据中的高阶潜在模式。我们提出的
product layer的想法来自自动探索特征交互。在FM中,特征交互被定义为两个特征向量的内积。因此,我们提出了Productbased Neural Network: PNN模型。接下来我们详细介绍PNN模型并讨论该模型的两种变体,即Inner Product-based Neural Network: IPNN(采用inner product layer)、Outer Product-based Neural Network : OPNN(采用outer product layer)。PNN模型的架构如下图所示。假设one-hot向量为field,field i在向量中的起始位置为field生成一个embedding向量,即field i生成模型包含以下几层:
第
0层输入层:categorical特征经过one-hot编码之后作为输入。第
1层embedding层:模型从每个field中学得各field的embedding表示。输入位置
第
2层product层:由embedding特征的一阶特征和二阶交互特征拼接而成。其中1和一阶特征进行交互而生成。其中
PNN实现。product层的输出为:其中:
CNN的卷积核,它们在整个输入上进行张量内积。
第
3层到第最后一层:
sigmoid输出层。
模型的损失函数为
logloss: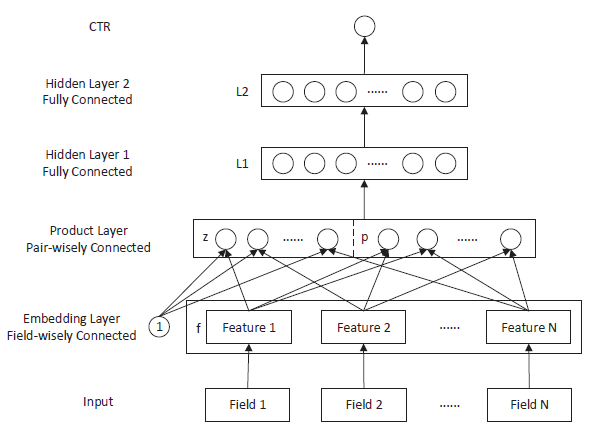
1.1.1 IPNN
Inner Product-based neural network: IPNN:IPNN的特征交互函数为:则有:
则计算
空间复杂度:
时间复杂度:
为降低复杂度,可以将
其中
则有:
则计算
其中
这种分解的代价更高,同时约束更弱。
1.1.2 OPNN
给定两个输入向量,向量内积输出一个标量,而向量外积输出一个矩阵。
Outer Product-based neural network: OPNN利用了向量外积,它和IPNN的唯一区别在于特征交互函数OPNN中,特征交互函数为:与内积产生标量不同,这里的外积产生一个矩阵。则
计算
空间复杂度:
时间复杂度:
为降低复杂度,定义:
此时
则计算
1.1.3 讨论
和
FNN相比,PNN有一个product layer。如果移除product layer中的FNN和PNN完全相同。IPNN和FM模型非常相似。FM模型将抽取的一阶、二阶特征直接送入分类器。IPMM模型将抽取的一阶、二阶特征,首先使用类似CNN的 “核函数” (由DNN。
PNN使用product layer来探索特征交互。向量的product可以视为一系列的 “乘法&加法” 操作,内积和外积只是两种不同的实现。事实上可以定义更通用或者更复杂的
product layer,从而获得PNN更好的探索特征交互的能力。类似于电子电路,乘法相当于
AND、加法相当于OR。product layer似乎学习特征以外的规则。因此我们相信在神经网络中引入product运算将提高网络对multi-field离散数据建模的能力。
1.2 实验
数据集:
Criteo:Criteo 1TB点击日志是著名的广告技术工业benchmark数据集。我们选择连续7天的样本进行训练,第8天的数据进行评估。由于数据规模巨大,因此我们对数据集进行负降采样。我们将降采样比例定为
CTR定义为CTR经过降采样和特征映射之后,我们得到一个数据集,其中包含
7938万个样本,特征维度为164万维。iPinYou:iPinYou数据集是另一个真实世界数据集,记录了超过10天的广告点击日志。经过one-hot编码之后,我们得到一个包含1950万个样本的数据集,特征维度为937.67K。我们保留原始的训练/测试拆分方案:对于每个广告主,最后
3天的数据用作测试集,其余的数据用作训练集。
baseline方法:LR:LR是工业中使用最广泛的线性模型,它易于实现且训练速度快,但是无法捕获非线性信息。FM:FM在推荐系统和用户响应预测任务中有很多成功的应用。FM探索特征交互,这对稀疏数据很有效。FNN:FNN能够捕获multi-field离散数据的高阶潜在模式。CCPM:CCPM是一种用于点击预估的卷积模型。该模型有效地学习local-global特征。然而,CCPM高度依赖特征对齐(feature alignment),并且缺乏解释。IPNN:采用内积的PNN。OPNN:采用外积的PNN。PNN*:该模型的product layer是IPNN product layer和OPNN product layer的拼接。
模型配置:
所有方法都是基于
TensorFlow实现,并采样随机梯度下降SGD来训练。在
FM中,我们采用10维的分解。相应地,我们在网络模型中采用10维的embedding。网络结构:
CCPM有1个embedding层、2个卷积层(具有最大池化)、1个隐层,一共4层。FNN有1个embedding层、3个隐层,一共4层。每种
PNN都有1个embedding层、1个product layer、3个隐层,一共5层。
为了防止过拟合,
LR和FM模型使用L2正则化训练,而FNN, CCPM, PNN使用dropout训练。默认情况下,我们设置
dropout rate = 0.5。下图给出了Criteo数据集上OPNN模型的AUC随着dropout rate变化的曲线。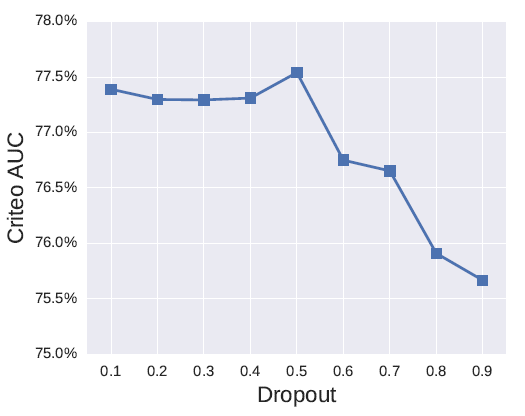
评估指标:我们采用评估指标为
AUC和相对信息增益(Relative Information Gain: RIG)。其中,RIG定义为:NE为归一化的交叉熵。此外,我们还使用
LogLoss和RMSE作为额外的评估指标。
1.2.1 模型对比
不同模型在这两个数据集上的实验结果如下表所示。首先我们关注
AUC性能,表I和表II的结果表明:FM优于LR,证明了特征交互的有效性。神经网络优于
LR和FM,这证明了高阶潜在模式的重要性。PNN在所有数据集上表现最好。另外,结合了
IPNN和OPNN的PNN*没有明显优于IPNN或OPNN。我们认为IPNN和OPNN足以捕获multi-field离散数据中的特征交互。
关于
logloss, RMSE, RIG指标,结论也是类似的。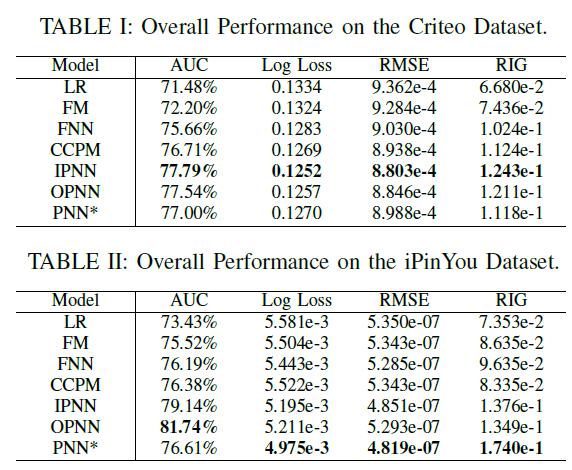
然后我们还在
PNN和baseline模型之间进行t-test。下表给出了两个数据集上logloss损失下计算的p-value。结果验证了我们的模型相对于baseline模型显著提高了用户响应预测性能。
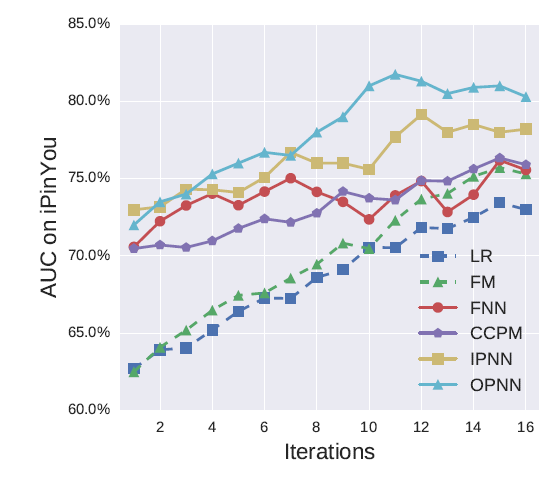
下图显示了在
iPinYou数据集上训练迭代的AUC性能。可以看到:我们发现神经网络模型比
LR和FM收敛得更快。我们还发现,我们提出的两个
PNN比其它网络模型具有更好的收敛性。
1.2.2 消融研究
这里我们讨论神经网络架构的影响。对于
IPNN和OPNN,我们考虑三个超参数:embedding维度、网络深度、激活函数。由于
CCPM和其它神经网络几乎没有相似之处,而PNN*只是IPNN和OPNN的组合,因此我们在这里仅比较FNN、IPNN、OPNN。embedding layer:我们采用了FNN论文中的embedding layer的思想。我们比较了不同的embedding维度,例如[2, 10, 50, 100]。但是当维度增加时,模型训练更加困难,并且模型更容易过拟合。在我们的实验中,我们使用embedding维度等于10。网络深度:我们还通过调整
FNN和PNN中隐层的数量来探索网络深度的影响。我们比较了不同数量的隐层,例如[1,3,5,7]。下图给出了随着网络深度增长的性能。可以看到:一般而言,具有3层隐层的网络在测试集上表现更好的泛化能力。为方便起见,我们将卷积层或者
product layer都称作representation layer。这些层可以用较少的参数捕获复杂的特征模式,因此训练效率高,并且在测试集上可以更好地泛化。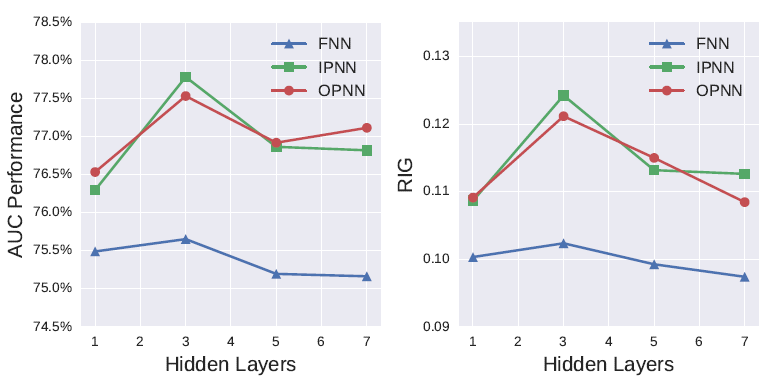
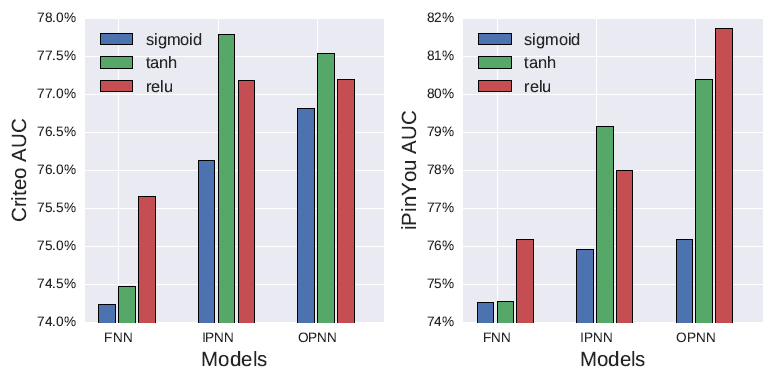
激活函数:我们比较三种主要的激活函数,
sigmoid、tanh、relu。与sigmoid族激活函数相比,relu函数具有稀疏性和梯度计算效率高的优点,有可能在multi-field离散数据上获得更多的好处。下图比较了
FNN、IPNN、OPNN上的这些激活函数。可以看到:tanh激活函数 比sigmoid激活函数具有更好的性能。除了
tanh,我们发现relu函数也有很好的表现。可能的原因包括:稀疏激活,即负输出的节点不会被激活。
高效的梯度传播,没有梯度消失问题或爆炸问题。
计算效率高,只有比较、加法、乘法运算。