一、Wide&Deep [2016]
《Wide & Deep Learning for Recommender Systems》
推荐系统可以被视为搜索排序系统(
search ranking system),其中输入query是用户和上下文信息的集合,输出是item的ranked list。给定一个query,推荐任务是在数据库中找到相关(relevant)的item,然后根据某些指标(如点击或购买)对item进行排序。类似于通用的搜索排序问题,推荐系统中的一个挑战是实现记忆(
memorization)和泛化(generalization)。memorization可以大概定义为学习item之间或特征之间频繁的共现(co-occurrence),并利用历史数据中可用的相关性(correlation)。而generalization基于相关性的传递性(transitivity of correlation),并探索历史从未发生或很少发生的新的特征组合(new feature combination)。基于
memorization的推荐通常更具有话题性(topical),并且和用户历史互动过的item直接相关。和memorization相比,generalization倾向于提高推荐item的多样性(diversity)。在论文《Wide & Deep Learning for Recommender Systems》中,作者聚焦于Google Play商店的app推荐问题,但是这种方法应该适用于通用推荐系统。对于工业环境中的大规模在线推荐和排序系统,逻辑回归等广义线性模型(
generalized linear model)被广泛采用,因为它们简单(simple)、可扩展(scalable)、可解释(interpretable)。这些模型通常使用
one-hot编码,并且对编码后的二元稀疏特征进行训练。例如,如果用户安装了Netflix app,那么二元特征user_installed_app=netflix的取值为1。可以使用对稀疏特征的叉积(
cross-product)变换从而有效地实现memorization,例如交叉特征AND(user_installed_app=netflix, impression_app=pandora),如果用户安装了Netflix app并且被曝光过Pandora app,该交叉特征的取值为1。这解释了feature pair的共现(co-occurrence)如何与target label相关。可以通过使用更粗粒度的交叉特征来添加generalization,例如AND(user_installed_category=video, impression_category=music),但通常需要手动进行特征工程。叉积变换(
cross-product transformation)的一个限制是它们不能泛化到没有出现在训练数据中的query-item feature pair。embedding-based模型,例如分解机(factorization machine: FM)或深度神经网络DNN,可以通过为每个query特征或item特征学习一个低维稠密embedding向量来泛化到历史未见过(unseen)的query-item feature pair,并且特征工程的负担更小。然而,当底层的
query-item矩阵稀疏时,例如具有特定偏好的用户或者特定领域的小众item,那么很难为query和item学习有效的低维representation。在这种情况下,大多数query-item pair对之间没有交互,但是稠密embedding将导致所有query-item pair对之间的非零预测,因此可能会过度泛化(over-generalize)并做出不太相关的推荐。另一方面,具有叉积特征变换的线性模型可以用更少的参数记住这些特定偏好或者小众产品的 “异常规则(
exception rules)”。
在论文
《Wide & Deep Learning for Recommender Systems》中,作者通过联合训练线性模型组件和神经网络组件,提出了Wide & Deep学习框架,从而在一个模型中同时实现了memorization和generalization。论文的主要贡献包括:联合训练具有
embedding的神经网络模型、以及具有特征变换的线性模型的Wide & Deep学习框架,从而用于具有稀疏输入的通用推荐系统。在拥有超过
10亿活跃用户、100万app的mobile app store Goole Play上实现和评估Wide & Deep。开源了模型的实现以及
TensorFlow中的高级API。虽然想法很简单,但是作者表明Wide & Deep框架显著提高了mobile app store的app下载率(acquisition rate),同时满足了训练和serving速度的要求。
相关工作:
embedding:将带叉积变换的wide线性模型与带稠密embedding的deep神经网络模型相结合的想法受到先前工作的启发,例如分解机(factorization machine: FM)。FM通过将两个变量之间的交互(interaction)分解为两个低维embedding向量之间的内积,从而为线性模型增加泛化能力。在本文中,我们通过神经网络(而不是内积)来学习
embedding之间的高度非线性交互,从而扩展模型容量。联合训练 & 快捷连接:在语言模型中,已经提出了
RNN和具有n-gram特征的最大熵模型的联合训练,以通过学习输入和输出之间的直接权重来显著降低RNN的复杂性(如隐层大小)。在计算机视觉中,深度残差学习(deep residual learning)已被用于降低训练更深模型的难度,并通过跳过一层或多层的快捷连接(shortcut connection)来提高准确性。神经网络和图模型(graph model)的联合训练也应用于从图像中估计人体姿态。在这项工作中,我们探索了前馈神经网络和线性模型的联合训练,其中线性模型是将稀疏特征和输出单元直接相连,从而用于稀疏输入数据的通用推荐和排序问题。
推荐系统:在推荐系统文献中,协同深度学习(
collaborative deep learning)将内容信息的深度学习和评分矩阵的协同过滤(collaborative filtering: CF)相结合。之前也有关于mobile app推荐系统的工作,如AppJoy,它在用户的app使用记录上应用CF。和之前工作中基于
CF或基于内容的方法不同,我们联合训练Wide & Deep模型。
memorization和generalization对于推荐系统都很重要。wide线性模型可以使用叉积特征变换有效地记住稀疏特征交互,而deep神经网络可以通过低维embedding泛化到以前未见过的特征交互。我们提出了Wide & Deep学习框架来结合这两种模型的优势。即:广义线性模型表达能力不强,容易欠拟合;深度神经网络模型表达能力太强,容易过拟合。二者结合就能取得平衡。
1.1 模型
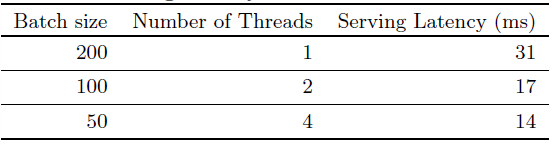
app推荐系统的整体架构如下图所示。推荐的流程如下:当用户访问
app store时产生一个query,它包含用户特征(如用户画像)和上下文特征(如当前时刻LBS信息、设备信息)。推荐系统返回一个
app list(也称作曝光impression),用户可以在这些app list上执行某些操作,如点击或购买。这些用户操作,连同query和曝光,作为learner的训练数据记录在日志中。
由于数据库中有超过一百万个
app,因此很难在服务延迟要求(通常在query对每个app进行详尽(exhaustively)地评分。因此,推荐系统收到query的第一步是检索(retrieval)。检索系统使用各种信号返回与query最匹配的item的short list,这些信号通常是机器学习模型和人类定义规则的组合。减少候选池之后,
ranking系统根据分数score对所有item进行排序。这个分数通常是action label)app age、app历史统计数据)。在本文中,我们聚焦于使用
Wide & Deep学习框架的ranking模型。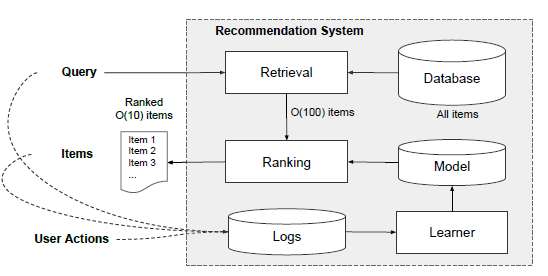
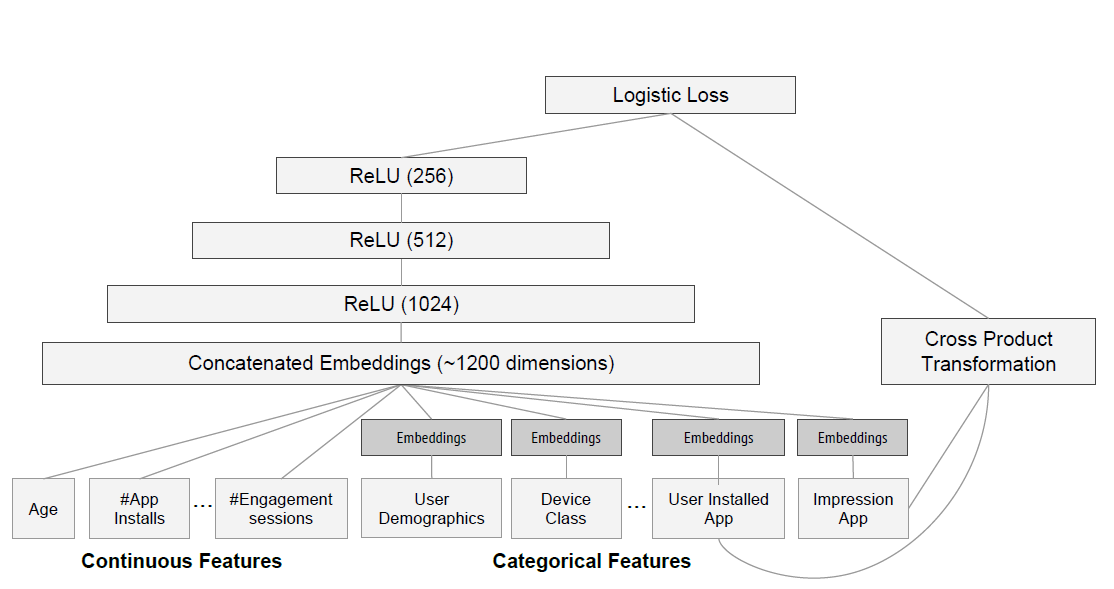
Wide & Deep模型包含一个wide组件和一个deep组件,模型架构如下图所示。wide组件:wide组件是一个广义线性模型:其中
这里的输入特征包括原始输入特征、以及特征变换之后的特征。最重要的特征变换之一是叉积变换(
cross-product transformation),定义为:其中
对于二元特征,叉积变换(例如
AND(gender=female, language=en))当且仅当构成特征(如gender=femal以及language=en)全部为1时才取值为1,否则取值为0。这捕获了二元特征之间的交互(interaction),并给广义线性模型增加了非线性。deep组件:deep组件是一个前馈神经网络。对于离散(categorical)特征,原始输入是特征字符串(如language="en")。这些稀疏的高维离散特征都首先被转换为低维稠密的实值向量,通常被称作embedding向量。embedding向量的维度通常在embedding向量随机初始化,然后训练来最小化模型的目标损失函数。这些低维稠密embedding向量然后在前向传播中被馈入到神经网络的隐层。具体而言,每个隐层执行以下计算:其中:
bias向量。
联合训练(
Joint Training):wide组件和deep组件使用它们输出加权和的对数几率(log odds)作为预测,从而组合这两个组件。注意,联合训练和集成训练存在区别:
组合方式的差异:
在集成训练中,各个模型在彼此不了解的情况下独立训练,并且它们的预测仅在推断时(而不是在训练时)进行组合。
相比之下,联合训练通过在训练时考虑
wide组件和deep组件以及它们的加权和来同时优化所有参数。
模型大小的差异:
对于集成训练而言,由于训练是独立的,每个独立的模型的大小通常需要更大(例如,具有更多特征和变换),从而达到合理准确性的
ensemble。相比之下,对于联合训练,
wide部分只需要通过少量的叉积特征变换来补充deep部分的弱点,而不是full-size的wide模型。
Wide & Deep模型的联合训练是通过使用mini-batch随机优化,将输出梯度同时反向传播到模型的wide部分和deep部分来完成的。在实现中,我们使用带L1正则化的Follow-the-regularized-leader: FTRL算法作为wide部分的优化器,使用AdaGrad算法作为deep部分的优化器。对于逻辑回归问题,模型的预测是:
其中:
class label,sigmoid函数。||表示向量拼接。deep部分最后一个隐层的输出隐向量,deep部分的隐层数量。wide部分的加权系数,deep部分的加权系数,bias。
1.2 实现
Wide&Deep模型的实现如下图所示。模型的Pipeline分为三个部分:数据生成(data generation)、模型训练(model training)、模型服务(model serving)。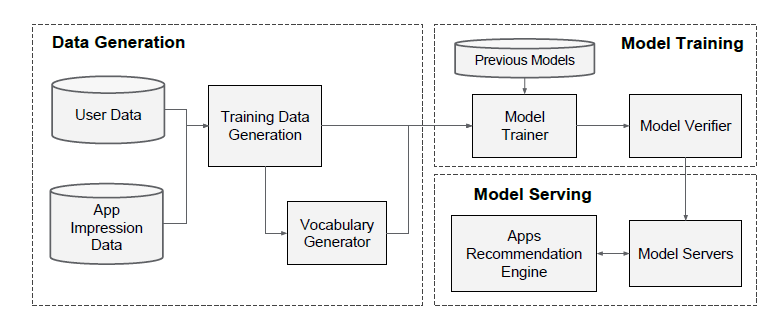
数据生成(
data generation):此阶段把一段时间内的用户曝光数据生成训练样本,每个样本对应一次曝光,标签为用户是否产生行为(如:下载app)。在这个阶段执行两个特征工程:
离散的字符串特征(如
app name)映射成为整数ID,同时生成映射字典(vocabulary)。注意:对于出现次数低于指定阈值(如
10次)的字符串直接丢弃,这能够丢弃一些长尾的、罕见的字符串,降低字典规模。连续特征归一化为
[0,1]之间的值:将特征取值
模型训练(
model training):我们在实验中使用的模型结构如下图所示。在训练过程中,我们的输入层接收训练数据和词表(vocabularies),并生成稀疏特征、稠密特征以及label。wide组件包括用户已经安装app、用户曝光app的叉积变换。对于
deep组件,每个离散特征学习一个32维的embedding向量。我们将所有embedding特征和稠密特征拼接在一起,产生大约1200维的稠密向量,然后馈入3个ReLU层,最后馈入logistic输出单元。Wide & Deep模型在超过5000亿个样本上进行了训练。每次有新的训练数据集到达时,模型都需要重新训练。然而,每次从头开始重新训练在计算上代价昂贵,并且会延迟从数据arrival到serving一个updated模型之间的时间。为了应对这一挑战,我们实现了一个热启动(
warm-starting)系统,该系统使用先前模型的embedding和线性模型权重(即wide部分)来初始化新模型。在将模型加载到
model servers之前,先对模型进行一次试运行,从而确保它不会在serving实时流量时造成问题。作为一种健全性检查(sanity check),我们根据经验对照前面的模型来验证模型质量。
模型服务(
model serving):模型经过训练和验证后,我们将其加载到model servers中。对于每个请求,
server从app检索系统接收一组app候选,以及接收用户特征,从而对每个app进行打分。然后,app根据最高分到最低分进行排序,我们按照这个顺序向用户展示app。分数是通过在Wide & Deep模型上运行前向推断来计算的。为了以
10ms的速度处理每个请求,我们通过并行运行较小的batch来执行多线程并行(multithreading parallelism)从而优化性能,而不是在单个batch推断步骤中对所有候选app进行打分。
1.3 实验
为了在真实世界的推荐系统中评估
Wide & Deep learning的有效性,我们进行了在线实验,并从几个方面评估了系统:app下载(acquisition)、serving性能。app下载:我们在A/B test框架中进行了为期3周的实时在线实验。对照组:我们随机选择
1%的用户并展示由先前版本的排序模型生成的推荐,这是一个高度优化的wide-only逻辑回归模型,具有丰富的叉积特征变换。实验组:我们随机选择
1%的用户提供由Wide & Deep模型生成的推荐,并使用相同的特征集合来训练。对照组
2:我们随机抽取1%的用户提供具有deep部分deep-only神经网络模型生成的推荐,并使用相同的特征集合来训练。
实验结果如下表所示,可以看到:
Wide & Deep模型相对于对照组将app acquisition rate提升了+3.9%(统计显著)。Wide & Deep模型相对于deep-only模型有+1%的提升(统计显著)。
除了在线实验之外,我们还展示了离线
holdout数据集上的AUC性能。可以看到:虽然Wide & Deep的离线AUC略高,但是对在线流量的影响更为显著。一个可能的原因是离线数据集中曝光和label是固定的,而在线系统可以通过将generalization和memorization相结合来生成新的探索性推荐,并从新的用户响应(user response)中学习。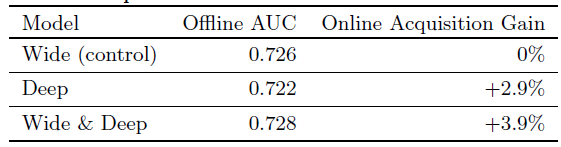
serving性能:由于我们的商业mobile app store面临很高的流量,因此提供高吞吐量和低延迟的服务具有挑战性。在流量峰值,我们的推荐server每秒可以处理超过1000万个app。使用单线程,对单个batch中的所有候选app进行打分需要31ms。我们实现了多线程并行,并将每个
batch拆分为更小的尺寸,这将客户端延迟显著降低到14ms(包括serving开销),如下表所示。