一、DCN [2017]
《Deep & Cross Network for Ad Click Predictions》
点击率(
CTR)预估是一个大规模问题,对价值数十亿美金的在线广告行业至关重要。在广告行业中,广告主向媒体平台付费从而在媒体的网站上展示他们的广告。一种流行的付费方式是按点击付费(cost-per-click: CPC),其中仅发生点击的时候平台才向广告主收费。因此,平台的收入很大程度上依赖于准确预估点击率的能力。特征工程一直是许多预测模型成功的关键。识别常见的、预测性(
predictive)的特征,并同时探索未见的(unseen)或罕见的交叉特征(cross feature)是做出良好预测的关键。然而,这个过程并不简单,而且通常需要手动特征工程或详尽的搜索(exhaustive searching)。web-scale推荐系统的数据大多数是不连续(discrete)的、离散(categorical)的,导致特征空间庞大而稀疏,这对特征探索带来了挑战。因此大多数大型系统限制为线性模型,如逻辑回归(logistic regression)。线性模型简单(
simple)、可解释(interpretable)、且易于扩展(scale),然而它们的表达能力有限。另一方面,交叉特征(cross features)已被证明在提高模型的表达能力方面具有重要意义。不幸的是,交叉特征通常需要手动特征工程或详尽的搜索(exhaustive search)来识别 。此外,泛化到未见过的特征交互(unseen feature interactions) 是困难的。DNN模型能够自动学习特征交互(feature interactions),然而它们隐式地生成所有交互,并且在学习某些类型的交叉特征(cross features)时不一定有效。在论文
《Deep & Cross Network for Ad Click Predictions》中,通过引入一种新颖的神经网络结构,交叉网络(cross network),以自动方式显式应用特征交叉(feature crossing),从而避免特定于任务的特征工程。交叉网络由多个交叉层组成,其中交互的最高阶(highest-degree)由层的深度决定。每一层在现有阶次交互的基础上产生更高阶的交互,并保留来自前一层的交互。交叉网络和深度神经网络
DNN联合训练。DNN虽然可以捕获跨特征(across features)的非常复杂的交互,但是和交叉网络相比,DNN需要几乎高一个数量级的参数、无法显式地形成交叉特征(cross features)、并且可能无法有效地学习某些类型的特征交互。通过联合训练交叉网络和DNN网络,模型可以有效地捕获预测性的特征交互,并且在Criteo CTR数据集上提供了SOTA的性能。相关工作:由于数据集的大小和维度的急剧增加,已经提出了许多方法来避免大量的任务特定(
task-specific)的特征工程,这些方法大多数基于embedding技术和神经网络。因子分解机(
Factorization machine: FM)将稀疏特征投影到低维稠密向量上,并从向量内积中学习特征交互。field感知因子分解机(field-aware factorization machine: FFM)进一步允许每个特征学习多个向量,其中每个向量与一个field相关联。遗憾的是,
FM和FFM的浅层结构限制了它们的表达能力(representative power)。已经有工作将FM扩展到更高阶,但是一个缺点在于它们的大量参数会产生高昂的计算成本。由于
embedding向量和非线性激活函数,深度神经网络DNN能够学习重要的高阶(high-degree)特征交互。残差网络最近的成功使得训练非常深的网络成为可能。
Deep Crossing扩展了残差网络,并通过stacking所有类型的输入来实现自动特征学习feature learning。
深度学习的显著成功引发了对其表达能力的理论分析。有研究表明,在给定足够多的隐单元或隐层的情况下,
DNN能够在某些平滑性假设(smoothness assumption)下以任意准确性逼近任意函数。此外在实践中,已经发现DNN在参数数量适中的情况下运行良好。一个关键的原因是:大多数具有实际兴趣(practical interest)的特征都不是任意的。然而,剩下的一个问题是:在代表这种实际兴趣的特征方面,
DNN是否确实是最有效的。在Kaggle竞赛中,很多获胜解决方案中的手工制作特征都是低阶(low-degree)的,以显式的格式(explicit format)并且有效。另一方面,DNN学习的特征是隐式的,且高度非线性。这为设计一个能够比通用DNN更有效、更显式地学习有界阶次特征交互的模型提供了启发。Wide & Deep模型就是这种精神的典范,它将交叉特征(cross features)作为线性模型的输入,并与DNN模型联合训练线性模型。然而,Wide & Deep的成功取决于交叉特征的正确选择,这是一个指数问题,目前还没有明确有效的方法。论文
《Deep & Cross Network for Ad Click Predictions》提出了深度交叉网络(Deep & Cross Network: DCN)模型,该模型支持具有稀疏和稠密输入的web-scale自动特征学习。DCN有效地捕获有界阶次的特征交互,学习高度非线性交互,不需要手动特征工程或详尽的搜索,并且计算成本低。论文的主要贡献包括:
提出了一种新颖的交叉网络,它在每一层显式地应用特征交叉,有效地学习有界阶次的、预测性的交叉特征,并且无需手动特征工程或详尽的搜索。
交叉网络简单而有效。根据设计,多项式最高阶次在每一层都增加,并且由层的深度来决定。网络由最低阶到最高阶的所有阶次的、系数不同的交叉项(
cross terms)来组成。交叉网络内存高效,易于实现。
实验结果表明,采用交叉网络的
DCN的logloss比DNN更低,而且DCN的参数数量相比DNN要少了接近一个量级。
1.1 模型
我们将描述
DCN模型的架构,如下图所示。DCN模型从embedding and stacking层开始,然后是并行的交叉网络和深度网络,然后是一个组合层(combination layer)从而拼接了来自两个网络的输出。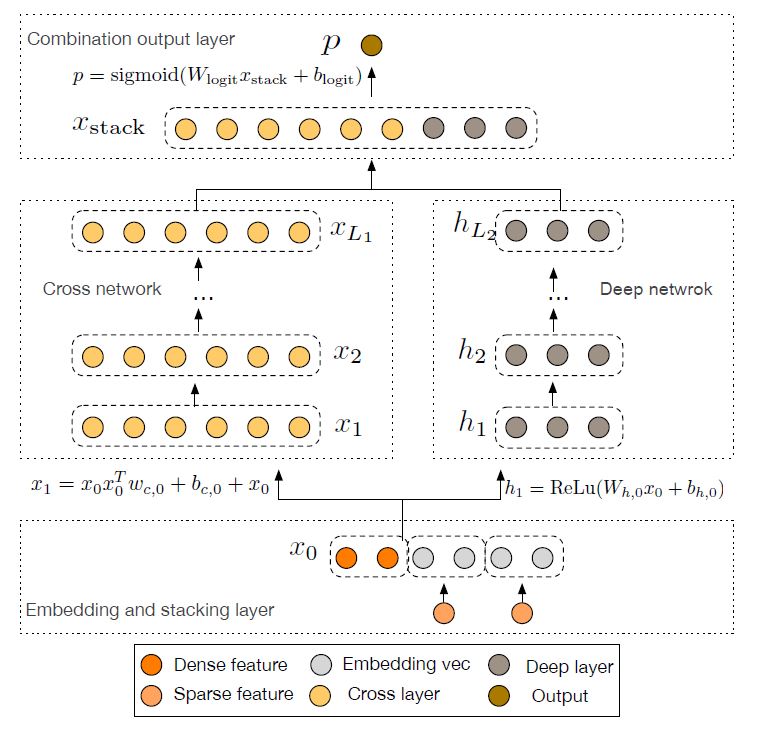
Embedding and Stacking Layer:我们考虑具有稀疏和稠密特征的输入数据。在CTR预估等web-scale推荐系统中,输入主要是离散特征,如country=usa。这些特征通常被编码为one-hot向量,如[0, 1, 0]。然而,这通常会导致大型词表vocabulary的高维特征空间。为了降低维度,我们采用
embedding技术将这些二元特征转换为实值的稠密向量(通常称作embedding向量):其中:
field的one-hot向量。field的embedding向量。embedding矩阵,embedding size,field的词表大小。
最后我们将
embedding向量以及归一化的稠密特征stack(即拼接)到单个向量中:其中:
field的数量,Cross Network:我们新颖的交叉网络的核心思想是:以有效的方式应用显式的特征交叉。交叉网络由交叉层(
cross layers)来组成,每层可以公式化为:其中:
注意:这里没有非线性激活函数,因此每一层的输出都是
每个交叉层在特征交叉函数
单个交叉层的可视化如下图所示。
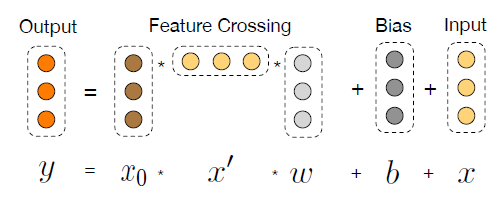
高阶特征交互:交叉网络的特殊结构导致交叉特征的阶次随着层的深度而增加。
事实上,交叉网络包含输入
cross term)复杂度分析:假设交叉层的数量为
交叉网络的时间和空间复杂度在输入维度
deep组件(DCN的deep部分)相比,交叉网络引入的复杂度可以忽略不计,使得DCN的整体复杂度保持在和传统DNN相同的水平。这种效率得益于矩阵rank-one属性(即这个矩阵的秩为1),这使得我们能够生成所有交叉项,而无需计算或存储整个矩阵。
交叉网络的参数太少从而限制了模型的容量。为了捕获高度非线性交互,我们引入了一个并行的深度网络(
Deep Network)。Deep Network:深度网络是一个全连接的前馈神经网络,每一个deep layer可以公式化为:其中:
复杂度分析:假设所有隐层的维度都是
deep network的参数数量为:其中:
输入为
后续的
Combination Layer:组合层将来自两个网络的输出拼接起来,并将拼接后的向量馈入标准的logits层。对于二类分类问题,这可以公式化为:
其中:
||表示向量拼接。logits层的权重向量,logits层的bias,sigmoid(.)为sigmoid激活函数。
模型的损失函数为带正则化的对数似然函数:
其中:
label,L2正则化系数。我们联合训练交叉网络和深度网络,因为这允许每个
individual网络在训练期间了解其它网络。
1.2 理论分析
这里我们从理论上分析
DCN的交叉网络,从而了解它的有效性。交叉网络 可以理解为:多项式逼近(polynomial approximation)、FM泛化(generalization to FM)、或者有效投影(efficient projection)。在这里为了讨论方便,我们假设所有的
bias项都是零。记degree),并且如果多项式中有多个交叉项,则多项式的
degree(也称作阶次)为所有交叉项中degree的最大值。多项式逼近(
polynomial approximation):根据Weierstrass逼近定理,任何在一定平滑性假设(smoothness assumption)下的函数都可以通过多项式以任意准确性逼近。因此我们从多项式逼近的角度来分析交叉网络。特别是,交叉网络以一种有效的、表达能力强的、以及更好地泛化到真实世界数据集的方式来逼近相同阶次的多项式。定义多项式:
该多项式的项一共有
我们表明,在只有
定理:考虑一个
reproduces)了以下的多项式:其中:
证明见原始论文。
FM泛化(generalization to FM):交叉网络和FM模型一样具有参数共享(parameter sharing)的精神,并进一步将其扩展到更深的结构。相同点:在
FM模型中,特征DCN中,特征参数共享不仅使模型更加高效,而且使模型能够泛化到未见(
unseen)的特征交互,并对噪声具有更强的鲁棒性。例如,以具有稀疏特征的数据集为例。如果两个二元特征不同点:
FM是一种浅层结构,仅限于表达二阶交叉项。相反,DCN能够表达FM不同,交叉网络中的参数数量仅随输入维度
有效投影
efficient projection:交叉网络的每一层都是在pariwise interaction),然后投影到其中:
行向量包含了
pariwise interaction投影矩阵是一个分块对角矩阵,由
1.3 实验
这里我们在一些热门的分类数据集上评估
DCN的性能。数据集为
Criteo Display Ads数据集,用于预测广告点击率。数据集包含13个整数特征和26个离散特征(categorical features),这些离散特征的基数(cardinality)都很高。数据集包含
7天的11GB用户日志,大约4100万条记录。我们使用前6天的数据进行训练,第7天的数据随机分成大小相等的验证集和测试集。对于该数据集,
logloss的0.001的改进都被认为具有实际意义。当考虑到庞大的用户规模,预测准确性的小幅提升可能会导致公司收入的大幅增加。实现:
DCN是用TensorFlow实现的,我们简要讨论使用DCN进行训练的一些实现细节。数据处理和
embedding:通过应用对数变换(
log transform)来对实值特征进行归一化。对于离散特征,我们将特征嵌入到维度为
embedding向量。然后拼接所有embedding从而得到一个维度为1026的向量。
优化(
optimization):我们使用Adam优化器应用了mini-batch随机优化,batch size设置为512。我们在深度网络部分采用了batch normalization,并将梯度裁剪设为100。正则化(
regularization):我们使用了早停策略(early stopping),因为我们发现L2正则化或dropout没有效果。超参数:我们根据隐层数量、隐层维度、初始学习率、交叉层的数量执行
grid search,然后在实验中报告最佳超参数的结果。对于所有模型(包括
baseline),隐层数量从2 ~ 5、隐层维度从32 ~ 1024,初始学习率从1e-4 ~ 1e-3,增量为1e-4。对于
DCN模型,交叉层数量从1 ~ 6。
所有实验都在训练
step = 150000处早停,超过该时刻开始发生过拟合。
baseline方法:我们将DCN和五种模型进行比较:没有交叉网络的DCN模型(DNN)、逻辑回归 (LR)、因子分解机(FM)、Wide & Deep(W&D)、Deep Crossing(DC)。DNN:embedding层、输出层、超参数调优过程和DCN完全相同,它和DCN模型的唯一区别在于DNN没有交叉层。LR:我们使用了Sibyl,一种用于分布式逻辑回归的大规模机器学习系统。整数特征在对数尺度下离散化。交叉特征是由复杂的特征选择工具来选择的。所有的single特征都被使用。FM:我们使用一个带有专属细节(proprietary details)的FM-based模型。W&D:和DCN不同的是,W&D的wide组件将原始稀疏特征作为输入,并依赖于详尽的搜索(exhaustive searching)和领域知识(domain knowledge)来选择预测性的交叉特征。我们跳过了和
W&D的比较,因为没有什么好的方法来选择交叉特征。DC:和DCN相比,DC没有形成显式的交叉特征。DC主要依靠stacking(即embedding向量拼接) 和残差单元来构建隐式交叉特征。我们应用了和
DCN相同的embedding层(即stacking),然后是另一个ReLU层作为一系列残差单元的输入。残差单元的层数从1 ~ 5来调优,隐层维度从100到1026来调优。
1.3.1 性能比较
这里我们首先比较不同模型的
logloss性能,然后我们详细比较了DCN和DNN,即进一步研究了交叉网络带来的影响。不同模型的最佳测试
logloss参考下表。最佳超参数为:DCN模型:使用2层deep layer,每层维度1024;使用6层cross layer。cross layer的维度不需要调优,因为该层的维度就等于DNN模型:使用5层deep layer,每层维度1024。DC模型:使用5层残差单元,残差单元的输入维度为424、残差单元隐层维度为537。LR模型:使用42个交叉特征。
可以看到:
最佳的性能是在最深的交叉架构中发现的,这表明交叉网络的高阶特征交互是有价值的。
DCN大大优于所有其他模型。特别是,它优于SOTA的DNN模型,但是仅使用了DNN中消耗的40%的内存。

对于每个模型的最佳超参数设置,我们还报告了
10次独立运行的测试集logloss的均值和标准差::DCNDNNDCDCN始终大幅优于其它模型。考虑到交叉网络仅引入了
DCN与其deep network,一个传统的DNN,进行比较,并在改变内存预算和loss阈值的同时展示了实验结果。给定一定数量参数,
loss被报告为在所有学习率和模型结构中最好的验证损失。我们的计算中省略了embedding层中的参数数量,因为它在两个模型中都相同。下表报告了实现目标
logloss阈值所需的最少参数数量(比如7.9万个参数)。可以看到,DCN的内存效率比single DNN高出近一个量级。这要归功于更有效地学习有界阶次特征交互的交叉网络。
下表比较了受固定内存预算影响的神经网络模型的性能,指标为验证集
logloss。可以看到,DCN始终优于DNN。在小型参数(
small-parameter)的情况下,cross network中的参数数量和deep network中的参数数量相当,显著的改进表明cross network在学习有效特征交互方面更有效。在大型参数(
large-parameter)的情况下,DNN弥补了一些差距,但是DCN仍然在很大程度上优于DNN。这表明DCN可以有效地学习某些类型的有意义的特征交互,这些特征交互即使是巨大的DNN模型也无法学习。

我们通过展示将交叉网络引入给定
DNN模型的效果来更详细地分析DCN。我们给出在相同的层数和层维度的情况下比较DNN和DCN的最佳性能,然后对于每个设置,我们展示了验证集logloss如何随着添加更多cross layer而变化。下表给出了
DCN和DNN模型在logloss上的绝对差异(需要乘以DCN超越了DNN。Nodes表示deep network隐层维度,layers表示cross network深度。DNN模型相当于将DCN模型的cross layer层数设为0。可以看到:在相同的实验设置下,来自
DCN模型的最佳logloss始终优于来自相同结构的single DNN模型。所有超参数的改进都是一致的,这缓解了初始化和随机优化带来的随机性的影响。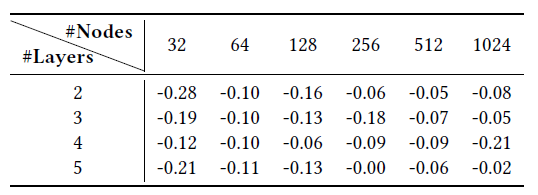
下图显示了我们在随机选择的设置上增加
cross layer层数对验证logloss的改进。cross layer层数为0表示single DNN模型。layers表示deep layer层数,nodes为deep layer隐层维度。不同的符号表示deep network不同的超参数。可以看到:
当向
DNN模型中添加1个cross layer时,会有明显的改进。随着更多
cross layer的引入,对于某些设置的logloss继续下降,表明引入的交叉项在预测中是有效的;对于其他设置的logloss开始波动,甚至略有增加,这表明引入的更高阶次的特征交互没有帮助。
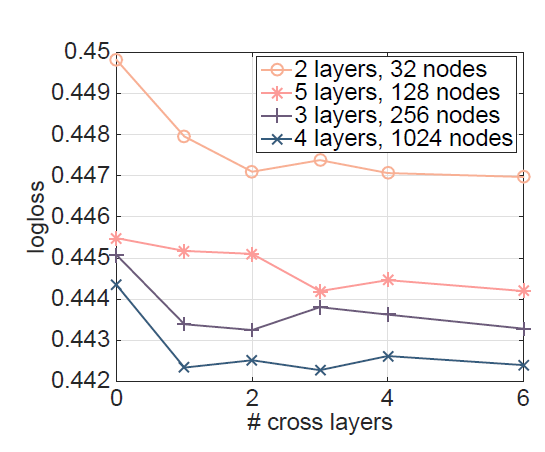
1.3.2 Non-CTR 数据集
我们表明
DCN在Non-CTR预测问题上表现良好。我们使用了来自UCI repository的forest covertype数据集(包含581012个样本和54个特征)、以及Higgs数据集(包含1100万个样本和28个特征) 。数据集被随机拆分为训练集(90%)、测试集(10%)。我们对超参数进行
grid search,其中:deep layer层数从1 ~ 10、层的维度从500 ~ 300。cross layer的层数从4 ~ 10。对于DCN,输入向量直接馈送到cross network因此不需要探索cross layer的维度。残差单元的层数从
1~5,其中隐层维度从50 ~ 300。
对于
forest covertype数据集,DCN以最少的内存消耗实现了 最佳的准确率0.9740。DNN和DC均达到0.9737。此时最佳超参数设置为:DCN:8层维度为54的cross layer,6层维度为292的deep layer。DNN:7层维度为292的deep layer。DC:4层残差单元,残差单元的输入维度为271、残差单元隐层维度为287。
对于
Higgs数据集,DCN达到了最好的测试logloss 0.4494,而DNN达到了0.4506。DCN在使用DNN一半的内存并且超越了DNN。此时最佳超参数设置为:DCN:4层维度为28的cross layer、4层维度为209的deep layer。DNN:10层维度为196的deep layer。