一、DeepFM [2017]
《DeepFM: A Factorization-Machine based Neural Network for CTR Prediction》
点击率(
CTR)预估在推荐系统中至关重要,即估计用户点击推荐item的概率。在很多推荐系统中,系统的目标是最大化点击次数,因为返回给用户的item可以根据估计的点击率进行排序。而在其它应用场景中,例如在线广告,提高平台的收入也很重要,因此可以将排序策略调整为CTR x bid,其中出价bid是平台在item被用户点击时获取的收益。无论哪种情况,很明显,关键在于正确预估点击率。了解用户点击行为背后隐式的特征交互(
feature interaction)对点击率预估很重要。通过我们在主流app市场的研究,我们发现人们经常在用餐时间下载外卖app,这表明app类别(category)和时间戳之间的交互(二阶交互)可以作为点击率的信号。作为第二个观察,男性青少年喜欢射击游戏和RPG游戏,这意味着app类别、用户性别、年龄的交互(三阶交互)是点击率的另一个信号。一般而言,用户点击行为背后的特征交互可能非常复杂,低阶特征交互和高阶特征交互都应该发挥重要作用。根据谷歌的Wide & Deep模型的见解,同时考虑低阶特征交互和高阶特征交互,比单独考虑任何一种情况都带来了额外的改进。关键的挑战在于有效地建模特征交互。一些特征交互很容易理解,因此可以由专家设计(例如前面的例子)。然而:
大多数其它特征交互都隐藏在数据中,并且难以先验地识别(例如,经典的关联规则 “尿布和啤酒” 是从数据中挖掘出来的,而不是由专家发现的),只能通过机器学习自动捕获。
即使对于易于理解的交互,专家似乎也不太可能对它们进行详尽(
exhaustively)的建模,尤其是当特征数据量很大时。
尽管简单,广义线性模型(例如
FTRL)在实践中表现出不错的表现。然而,线性模型缺乏学习特征交互的能力。一种常见的做法是在线性模型的特征向量中手动包含pairwise的特征交互。但是这种方法很难推广到建模高阶特征交互、或者建模训练数据中从未出现或者很少出现的特征交互。因子分解机(
Factorization Machine: FM)将pairwise特征交互建模为特征之间潜在向量的内积,并显示出非常有希望的结果。虽然理论上FM可以建模高阶特征交互,但是实际上由于复杂性太高,因此通常只考虑二阶特征交互。作为学习特征
representation的强大方法,深度神经网络具有学习复杂特征交互的能力。一些想法将CNN和RNN扩展到CTR预测,但是基于CNN的模型倾向于相邻特征之间的交互,而基于RNN的模型更适合具有顺序依赖性(sequential dependency)的点击数据。FNN模型在应用DNN之前预训练了FM,因此模型受到FM能力的限制。PNN在embedding层和全连接层之间引入了product layer。正如Wide & Deep论文所述,PNN和FNN像其它深度模型一样很少捕获低阶特征交互,而低阶特征交互对于CTR预测也是必不可少的。为了同时建模低阶特征交互和高阶特征交互,Wide & Deep模型结合了线性模型 (wide部分)和深度模型(deep部分)。在Wide & Deep模型中,wide部分和deep部分分别需要两个不同的输入,并且wide部分的输入仍然依赖于专业的特征工程。可以看到,现有模型偏向于低阶特征交互(如
FM模型)、或者偏向于高阶特征交互(如DNN模型)、或者依赖于手动特征工程(如Wide & Deep)。在论文《DeepFM: A Factorization-Machine based Neural Network for CTR Prediction》中,论文证明了有可能导出一个学习模型,该模型能够以端到端的方式同时学习低阶特征交互和高阶特征交互,并且除了原始特征之外无需任何手动特征工程。论文的主要贡献如下:论文提出了一种新的神经网络模型
DeepFM,它集成了FM和DNN架构。DeepFM建模了像FM这类的低阶特征交互,也建模了像DNN这类的高阶特征交互。和Wide & Deep模型不同,DeepFM可以在没有任何特征工程的情况下进行端到端的训练。DeepFM可以有效地训练,因为它的wide部分和deep部分共享相同的输入和embedding向量,这和Wide & Deep不同。在Wide & Deep中,输入向量的维度可能很大,因为在它的wide部分的输入向量包含手动设计的pairwise特征交互,这大大增加了模型的复杂性。论文在
benchmark数据和商业数据上评估了DeepFM,结果显示:和现有的CTR预测模型相比,DeepFM有一致的提升。
相关工作:本文提出了一种新的深度神经网络用于点击率预测。最相关的领域是推荐系统中的点击率预测和深度学习。这里我们讨论这两个领域的相关工作。
点击率预测在推荐系统中起着重要作用。除了广义线性模型和
FM之外,还有一些其它模型用于CTR预测,例如tree-based模型(《Practical lessons from predicting clicks on ads at facebook》)、tensor-based模型(《Pairwise interaction tensor factorization for personalized tag recommendation》)、支持向量机、贝叶斯模型等等。另一个相关的领域是推荐系统中的深度学习。在正文部分我们会提到几种用于
CTR预测的深度学习模型,这里不再赘述。除了
CTR预测之外,推荐任务中还有几种深度学习模型。《Restricted boltzmann machines for collaborative filtering》提出通过深度学习来改进协同过滤。《Improving content-based and hybrid music recommendation using deep learning》通过深度学习提取内容特征来提高音乐推荐的性能。《Deep CTR prediction in display advertising》设计了一个深度学习网络来考虑展示广告的图像特征和基础特征。《Deep neural networks for youtube recommendations》为YouTube视频推荐开发了一个两阶段深度学习框架。
1.1 模型
假设训练集
user和item的、一共field数据。这些field可能是离线的categorical或者连续的。对于离散field,我们进行one-hot编码从而得到one-hot向量。对于连续field,我们直接使用特征本身,或者先离散化(discretization)之后再进行one-hot编码。假设样本
fieldrepresentation为其中
ground truth,表示用户是否点击。
通常
CTR预估任务就是构建模型item的概率。我们的目标是同时学习低阶特征交互和高阶特征交互。为此,我们提出了一个基于
Factorization-Machine: FM的神经网络DeepFM。如下图所示,DeepFM由共享相同输入的两个组件组成:FM组件和deep组件。对于特征
FM组件从而建模二阶特征交互,同时被馈入deep组件从而建模高阶特征交互。所有参数,包括
其中:
CTR;FM组件的输出;deep组件的输出。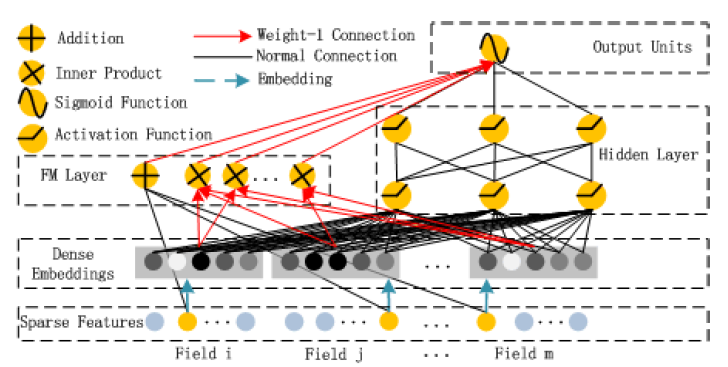
FM组件:如下图所示,该部分是一个FM,用于学习一阶特征和二阶交叉特征。FM组件由两种操作组成:加法(Addition)和内积(Inner Product):其中:
field的embedding维度,第一项
Addition Unit用于对一阶特征重要性建模,第二项Inner Product用于对二阶特征重要性建模。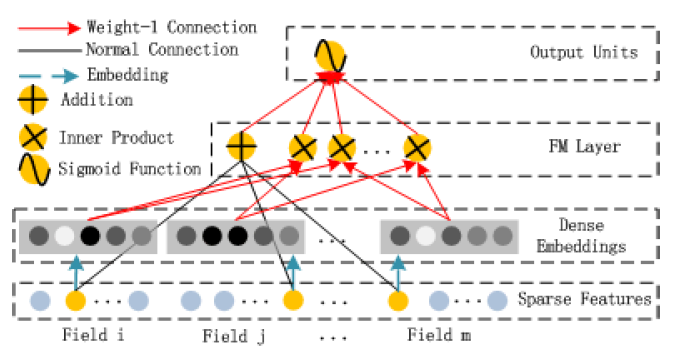
deep组件:如下图所示,该部分是一个全连接的前馈神经网络,用于学习高阶特征交互。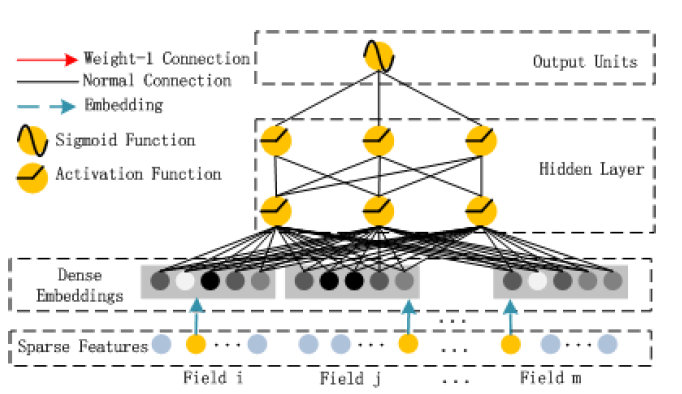
与图像数据、音频数据作为输入(输入纯粹是连续的和稠密的)的神经网络神经网络相比,
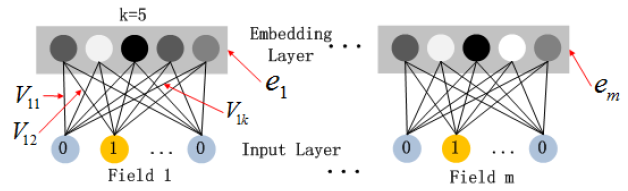
CTR预测的输入有很大的不同,这就需要新的网络架构设计。具体而言,CTR预测的原始特征输入向量通常是高度稀疏的、超高维的、混合了离散和连续的、并按照field分组(如性别、位置、年龄)。这建议在馈入第一个隐层之前,embedding层将输入向量压缩为低维的、稠密的实值向量,否则网络难以训练。下图重点显示了从输入层到
embedding层的子网结构。我们想指出这个子网结构的两个有趣的特性:虽然不同输入
field特征向量的长度可以不同,但是它们的embedding长度FM中的潜在特征向量field特征向量压缩为embedding向量。在
FNN中,FM预训练并用于网络权重的初始化。在这项工作中,我们没有像FNN那样使用FM的潜在特征向量来初始化网络,而是将FM模型作为我们整体学习架构的一部分。因此,我们消除了FM预训练的需要,而是以端到端的方式联合训练整个网络。
假设
embedding层的输出为:field i的embedding向量,其中:
l层,bias向量。最终有:
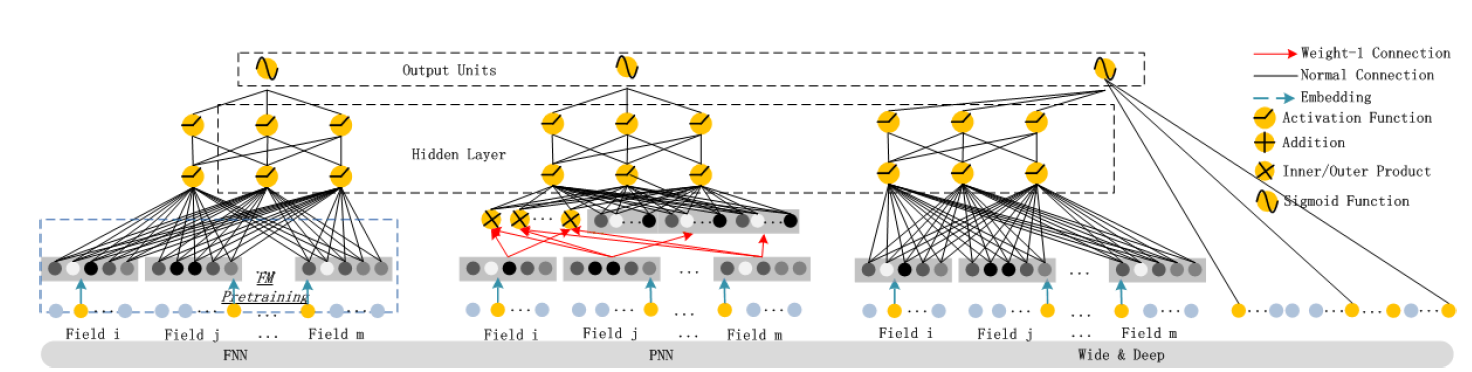
deep部分的网络深度。DeepFM和其它神经网络模型的区别:FNN:FNN是一个FM初始化的前馈神经网络。FM预训练策略有两个限制:embedding参数可能会受到FM的过度影响(over affected);预训练阶段引入的开销降低了模型效率。此外,FNN仅捕获了高阶特征交互。相比之下,
DeepFM不需要预训练,可以同时学习高阶特征交互和低阶特征交互。PNN:为了捕获高阶特征交互,PNN在embedding层和第一个隐层之间强加了一个product layer。根据product运算的不同类型,有IPNN、OPNN、PNN*三种变体,其中IPNN基于向量的内积、OPNN基于向量的外积、PNN*同时采用了IPNN和OPNN结果的拼接。为了使得计算更高效,作者提出了内积和外积的近似计算:通过移除一些神经元来近似计算内积;通过将
然而,我们发现外积结果不如内积结果可靠,因为外积的近似计算丢失了很多信息,使得结果不稳定。内积虽然更可靠,但是仍然存在计算复杂度高的问题,因为
product layer的输出连接到第一个隐层的所有神经元。与
FNN一样,所有PNN都忽略了低阶特交互。与
PNN不同的是,DeepFM中的product layer(即FM的二阶交互)的输出仅连接到最终输出层(一个神经元)。并且DeepFM同时考虑了高阶特征交互和低阶特征交互。Wide & Deep:虽然Wide&Deep也可以对低阶特征和高阶特征同时建模,但是wide部分需要人工特征工程,而这需要业务专家的指导。相比之下,DeepFM直接处理原始特征,不需要任何业务知识。另外,
Wide & Deep的一个直接扩展是:使用FM代替wide部分的LR模型,记作FM & DNN模型,原始的Wide & Deep模型记作LR & DNN模型。FM & DNN模型更类似于DeepFM模型,但是DeepFM在FM和DNN之间共享embedding特征。这种特征embedding的共享策略同时通过低阶特征交互和高阶特征交互来影响特征的representation学习,使得学到的特征representation更加精确。
总而言之,
DeepFM和其它深度模型在四个方面的关系如下表所示。可以看到,DeepFM是唯一不需要预训练和特征工程的模型,同时捕获了低阶特征交互和高阶特征交互。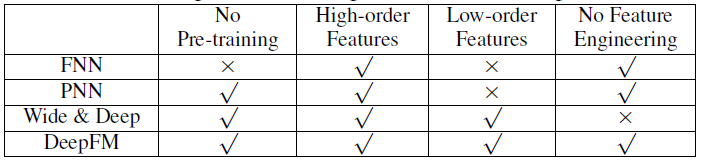
1.2 实验
这里我们根据经验比较
DeepFM和其它SOTA的模型。评估结果表明,我们的DeepFM比任何其它SOTA模型更有效,并且DeepFM的效率可以与其它模型中最好的模型相媲美。数据集:
Criteo Display Ads数据集:用于预测广告点击率的数据集,包含13个连续(continuous)特征,26个离散(categorical)特征。数据包含
7天的11 GB用户日志(约4100万条记录)。我们将数据集拆分为90%训练集和10%测试集。Company*数据集:为了验证DeepFM在实际工业CTR预估中的性能,我们在Company*数据集上进行了实验。我们从华为
App Store的游戏中心收集连续7天的用户点击数据作为训练集,第八天的数据作为测试集,整个训练集+测试集约10亿条记录。在这个数据集中,有app特征(如id、类目category等等)、用户特征(如用户已经下载过的app)、上下文特征(如操作时间)。
评估指标:
AUC和Logloss。baseline方法:我们比较了9种模型,包括:LR, FM, FNN, PNN(3种变体), Wide & Deep, DeepFM。另外,在
Wide & Deep模型中,为了省去手动特征工程的工作量,我们将FM代替了LR作为wide部分。这个变体我们称作FM & DNN,原始的Wide & Deep我们称作LR & DNN。配置:对于
Company*数据集,通过超参数搜索来获取最佳超参数。对于Criteo数据集,超参数为:FNN和PNN:dropout rate = 0.5;采用Adam优化器;三层网络结构,每层的神经元数量分别为400 - 400 - 400;IPNN模型的激活函数为为tanh,其它模型的激活函数为relu。DeepFM:与FNN/PNN相同。LR:使用FTRL优化器。FM:采用Adam优化器;FM的embedding向量维度为10。
1.2.1 性能评估
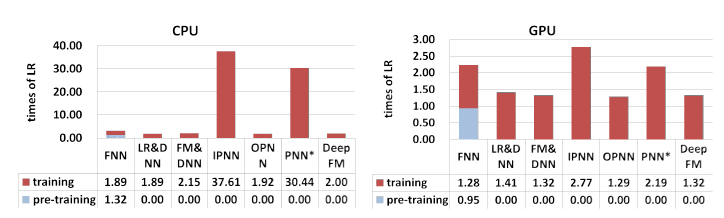
模型效率(
efficiency)对比:深度学习模型的效率对现实世界的application很重要。我们通过以下公式比较不同模型在Ctriteo数据集上的效率:实验结果如下图所示,包括在
CPU(左图)和GPU(右图)上的测试。可以看到:FNN的预训练步骤拉低了它的训练效率。虽然
IPNN和PNN*在GPU上的加速比其它模型更高,但是由于内积的低效运算,IPNN和PNN*的计算成本仍然很高。DeepFM在所有模型中,训练效率几乎是最高的。
效果(
effectiveness)比较:不同模型在这两个数据集上的点击率预测性能如下表所示。可以看到:学习特征交互提高了点击率预测模型的性能。这个观察结果是因为
LR模型(这是唯一不考虑特征交互的模型)比其它模型表现更差。作为最佳模型,
DeepFM在Company*和Criteo数据集上的AUC比LR分别高出0.86%和4.18%(Logloss方面分别为1.15%和5.60%)。同时学习高阶特征交互和低阶特征交互,可以提高
CTR预测模型的性能。DeepFM优于仅学习低阶特征交互的模型(即FM),也优于仅学习高阶特征交互的模型(即FNN、IPNN、OPNN、PNN*)。和第二好的模型相比,
DeepFM在Company*和Criteo数据集上的AUC分别提高了0.37%和0.25%(Logloss方面分别为0.42%和0.29%)。同时学习高阶特征交互和低阶特征交互,并且对高阶特征交互和低阶特征交互共享
feature embedding,可以提高CTR预测模型的性能。DeepFM优于使用单独特征embedding来学习高阶特征交互和低阶特征交互的模型(即LR & DNN和FM & DNN)。和这两个模型相比,DeepFM在Company*和Criteo数据集上的AUC分别提高了0.48%和0.33%(Logloss方面分别为0.61%和0.66%)。
总体而言,我们提出的
DeepFM模型在Company*数据集上的AUC和Logloss分别超过了竞争对手0.37%和0.42%。事实上,离线AUC评估的小幅提升很可能会导致在线CTR的大幅提升。正如Wide & Deep报道的,相比较于LR,Wide & Deep离线AUC提高了0.275%,但是在线CTR提高了3.9%。Company*’s App Store每天的营业额为数百万美元,因此即使点击率提高几个百分点,每年也会带来额外的数百万美元。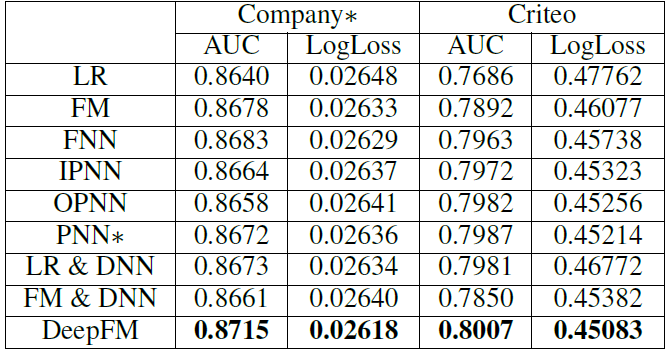
1.2.2 超参数研究
我们在
Company*数据集上研究了不同深度模型的不同超参数的影响,其中包括:激活函数、dropout比率、每层神经元数量、隐层的层数、网络形状。激活函数:根据论文
《 Product based neural networks for user response prediction》,relu和tanh比sigmoid更适合深度模型。这里我们比较了relu和tanh激活函数,结果如下图所示。可以看到:几乎所有的深度学习模型中,
relu比tanh效果更好。但是IPNN是例外,可能原因是relu导致了稀疏性。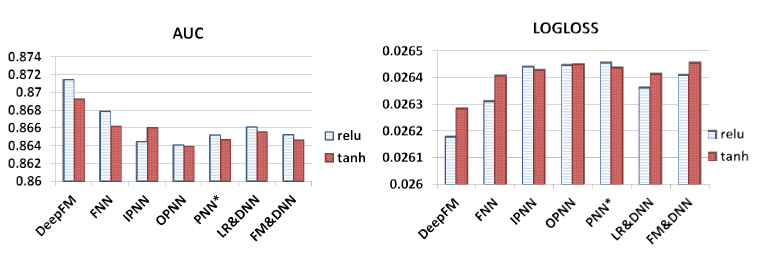
dropout:我们将dropout设置为[1.0, 0.9, 0.8, 0.7, 0.6, 0.5],结果如下图所示。当设置正确的dropout比例(从0.6~0.9)时,模型可以达到最佳性能。这表明向模型添加一定的随机性可以增强模型的鲁棒性。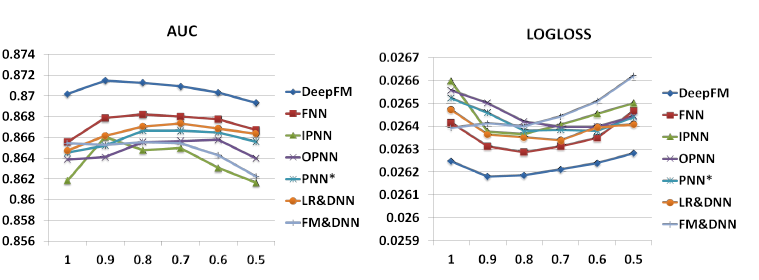
每层的神经元数量:当其它超参数保持不变,增加每层的神经元数量会带来复杂性。
如下图所示,增加神经元数量并不总是带来好处。例如,当每层神经元数量从
400增加到800时,DeepFM性能稳定,而OPNN的表现更差。这是因为过于复杂的模型很容易过拟合。在我们的数据集中,每层200 ~ 400个神经元是个不错的选择。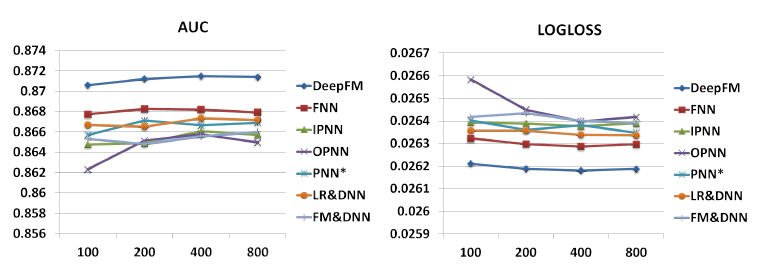
隐层的层数:如下图所示,一开始增加隐层的层数会提高模型性能。但是,如果隐层的层数不断增加,模型的性能就会下降。这种现象也是因为过拟合。
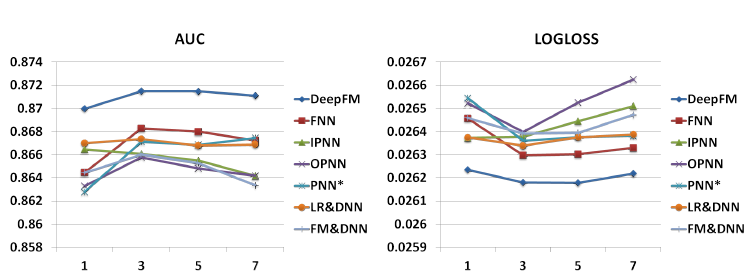
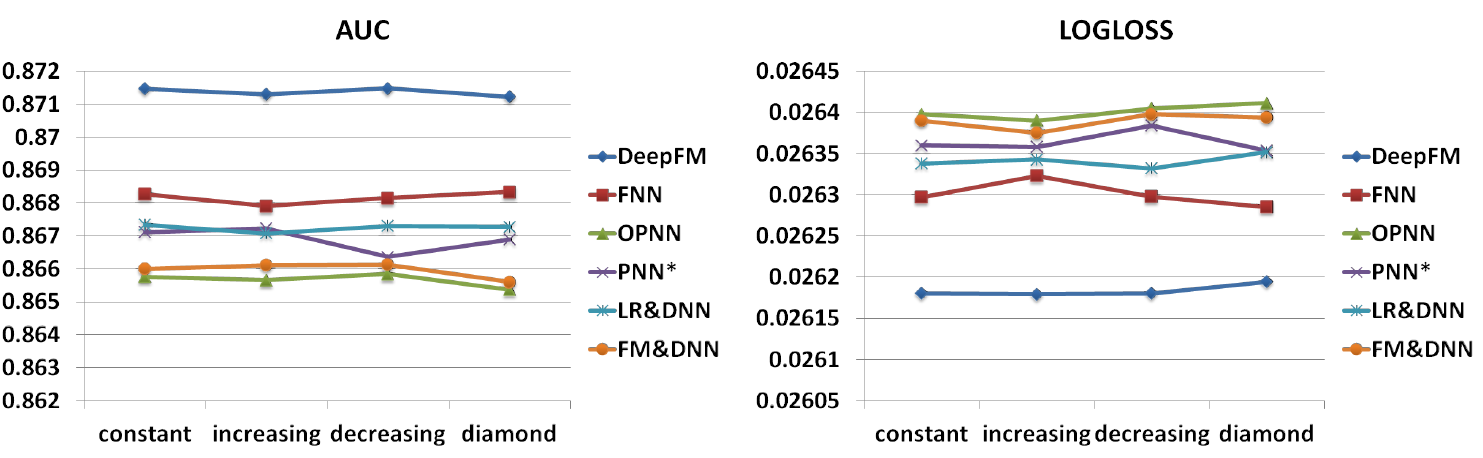
网络形状:我们测试了四种不同的网络形状:恒定形(
constant)、递增形(increasing)、递减形(decreasing)、菱形(diamond)。当我们改变网络形状时,我们固定隐层的数量和神经元总数。例如,当隐层的数量为
3、神经元总数为600时,四种不同形状的每层神经元数量为:恒定性200 - 200 -200、递增形100 - 200 - 300、递减形300 - 200 - 100、菱形150 - 300 - 150。实验结果如下图所示,可以看到:恒定形网络在经验上优于其它三种形状,这与
《Exploring strategies for training deep neural networks》的研究结果一致。