一、FwFM [2018]
《Field-weighted Factorization Machines for Click-Through Rate Prediction in Display Advertising》
CTR预估所涉及的数据通常是multi-field categorical data,这类数据具有以下特性:首先,所有的特征都是
categorical的,并且是非常稀疏的,因为其中许多是id。因此,特征的总数很容易达到数百万或数千万。其次,每个特征都唯一地属于一个
field,而且可能有几十到几百个field。
下表是一个用于
CTR预估的现实世界multi-field categorical data set的例子。
multi-field categorical data的特性对建立有效的机器学习模型进行CTR预测提出了几个独特的挑战:特征交互(
feature interaction)是普遍存在的,需要专门建模。在和标签关联方面,特征拼接(feature conjunction)与单个特征不同。例如,nba.com上展示的耐克广告的点击率,通常比所有网站上耐克广告的平均点击率、或nba.com上展示的所有广告的平均点击率高很多。这种现象在文献中通常被称为特征交互。来自一个
field的特征往往与来自其他不同field的特征有不同的交互。例如,我们观察到,来自field GENDER的特征通常与field ADVERTISER的特征有很强的交互,而它们与field DEVICE_TYPE的特征交互却相对较弱。这可能是由于具有特定性别的用户更偏向于他们正在观看的广告,而不是他们正在使用的设备类型。需要注意潜在的高模型复杂性。由于实践中通常有数以百万计的特征,模型的复杂性需要精心设计和调整,以适应模型到内存中。
为了解决这些挑战的一部分,研究人员已经建立了几个解决方案,
Factorization Machine: FM和Field-aware Factorization Machine: FFM是其中最成功的:FM通过将pairwise特征交互的影响建模为两个embedding向量的内积来解决第一个挑战。然而,field信息在FM中根本没有被利用。最近,
FFM已经成为CTR预估中表现最好的模型之一。FFM为每个特征学习不同的embedding向量,从而用于当特征与其他不同field的特征进行交互。通过这种方式,第二个挑战被显式地解决了。然而,FFM的参数数量是特征数量乘以field数量的数量级,很容易达到数千万甚至更多。这在现实世界的生产系统中是不可接受的。
在论文
《Field-weighted Factorization Machines for Click-Through Rate Prediction in Display Advertising》中,作者引入了Field-weighted Factorization Machines: FwFM来同时解决所有这些挑战。论文贡献:经验表明,不同的
field pairs与label的关联程度明显不同。按照同样的惯例,论文称它为field pair interaction。基于上述观察,论文提出了
Field-weighted Factorization Machine: FwFM。通过引入和学习field pair weight matrix,FwFM可以有效地捕获field pair interaction的异质性。此外,FwFM中的参数比FFM中的参数少几个数量级,这使得FwFM成为现实世界生产系统中的首选。FwFM通过用embedding vector representation取代线性项的binary representation而得到进一步的增强。这种新的处理方法可以有效地帮助避免过拟合,提高预测性能。论文在两个真实世界的
CTR预估数据集上进行了综合实验,以评估FwFM与现有模型的性能。实验结果表明:FwFM仅用FFM的4%的参数就能达到有竞争力的预测性能。当使用相同数量的参数时,FwFM比FFM的AUC提升了0.9%。
1.1 模型
假设有
unique特征fieldsfield,记做给定数据集
label表示是否点击;active的。例如,假设有两个
field:性别、学历,那么field,field,它们的取值都是0或1。LR模型为:其中:
注意,因为这里将
label取值空间设为{1, -1}而不是{1, 0},因此这个损失函数与交叉熵不同,而是指数损失函数。Poly2:然而,线性模型对于诸如CTR预估这样的任务来说是不够的,在这些任务中,特征交互是至关重要的。解决这个问题的一般方法是增加feature conjunction。已有研究表明,Degree-2 Polynomial: Poly2模型可以有效地捕获特征交互。Poly2模型考虑将其中:
FM:Factorization Machine: FM为每个特征学习一个embedding向量FM将两个特征embedding向量其中:
在涉及稀疏数据的应用中(如
CTR预估),FM的表现通常优于Poly2模型。原因是,只要特征本身在数据中出现的次数足够多,FM总能为每个特征学习到一些有意义的embedding向量,这使得内积能很好地估计两个特征的交互效应(interaction effect),即使两个特征在数据中从未或很少一起出现。FFM:然而,FM忽略了这样一个事实:当一个特征与其他不同field的特征交互时,其行为可能是不同的。Field-aware Factorization Machines: FFM通过为每个特征(如embedding向量来显式地建模这种差异,并且只使用相应的embedding向量field虽然
FFM比FM有明显的性能改进,但其参数数量是FFM的巨大参数数量是不可取的。因此,设计具有竞争力的和更高内存效率的替代方法是非常有吸引力的。
field pair的交互强度:我们特别感兴趣的是,在field level,交互强度是否不同。即,不同feature pair的平均交互强度是否不同。这里的平均交互强度指的是:给定一个field pair,它包含的所有feature pair的平均交互强度。例如,在
CTR预估数据中,来自field ADVERTISER的特征通常与来自field PUBLISHER的特征有很强的交互,因为advertiser通常针对一群有特定兴趣的人,而PUBLISHER的受众自然也是按兴趣分组的。另一方面,field HOUR_OF_DAY的特征往往与field DAY_OF_WEEK的特征没有什么交互,这不难理解,因为凭直觉,它们的交互对点击量没有什么贡献。为了验证
field pair interaction的异质性,我们使用field pairfield pair的交互强度:其中:
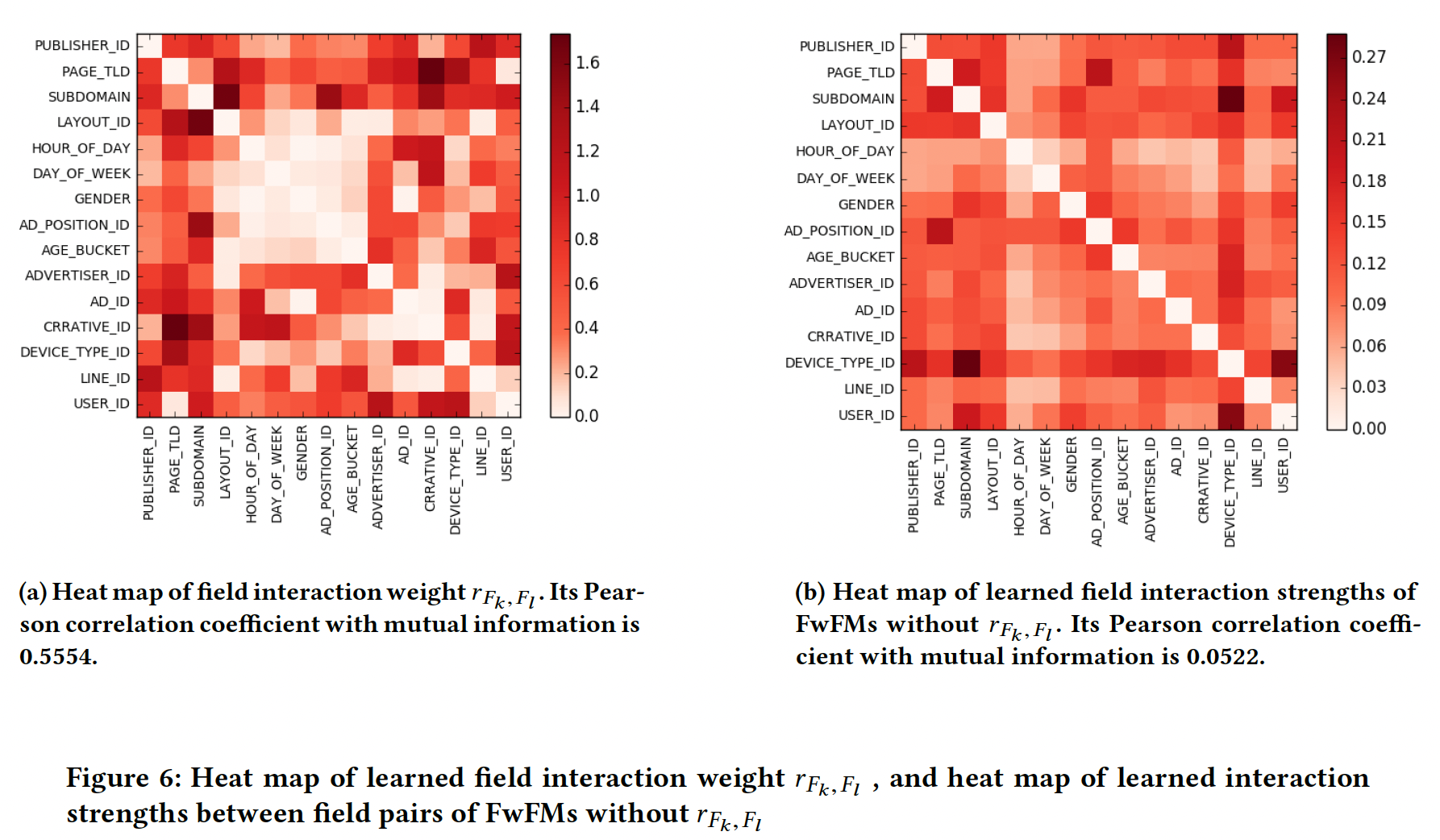
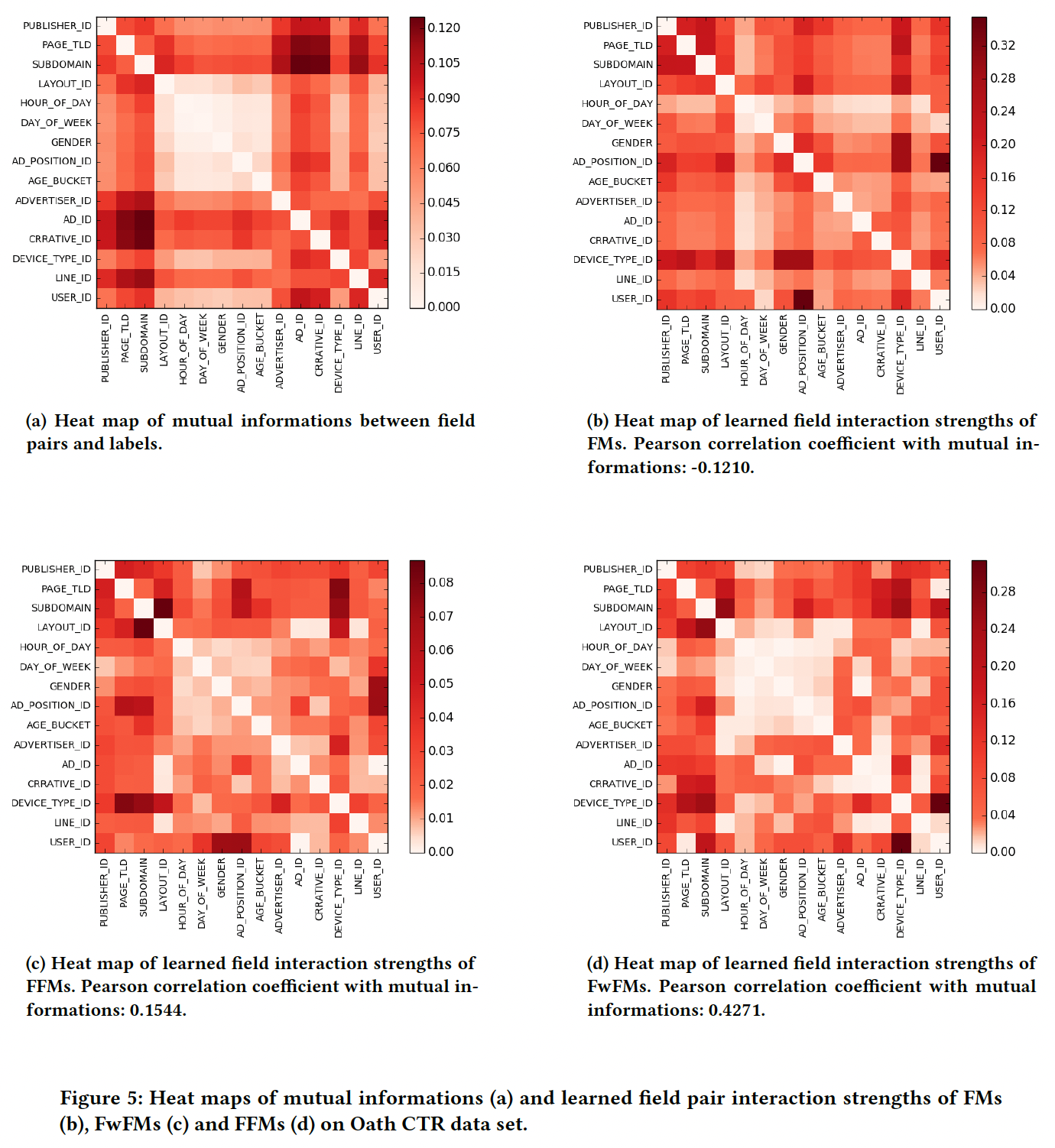
下图是每个
field pair和标签之间的互信息的可视化,由Oath CTR数据计算得出。不出所料,不同field pair的交互强度是相当不同的。一些field pair有非常强的交互,如(AD_ID,SUBDOMAIN)、(CREATIVE_ID,PAGE_TLD),而其他一些field pair有非常弱的交互,如(LAYOUT_ID,GENDER)、(Day_OF_WEEK,AD_POSITION_ID)。虽然分析结果并不令人惊讶,但我们注意到,现有的模型都没有考虑到这种
field level interaction的异质性 。这促使我们建立一个有效的机器学习模型来捕获不同field pair的不同交互强度。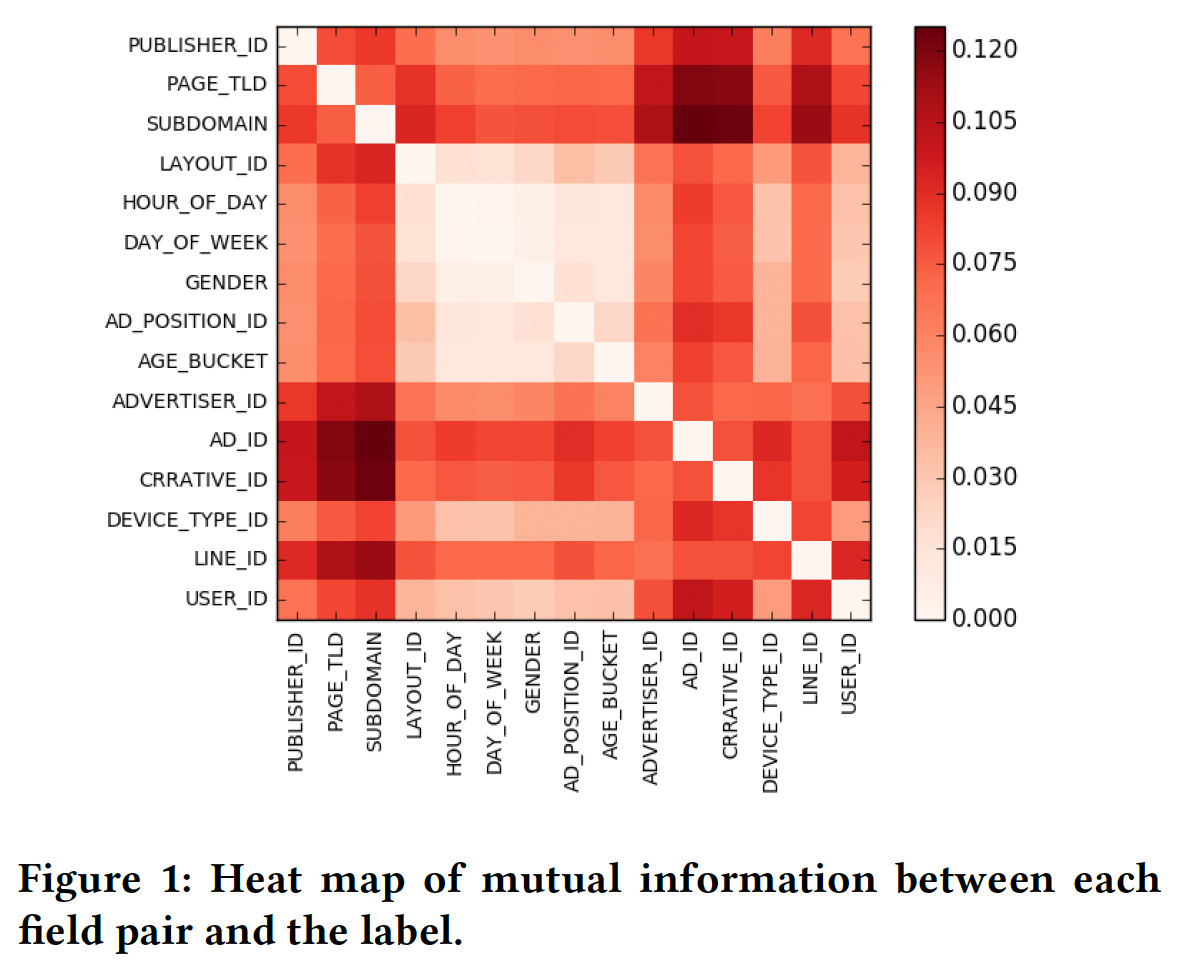
FwFM:我们提出对不同field pair的不同交互强度进行显式的建模,其中feature pair其中:
field pair核心要点:在
FM基础上乘以进一步地,我们是否可以在
field的概念之上继续遵循这种做法。比如,可以把field进行分组:用户年龄、性别等等field是一组,item类别、品牌等等是另一组、用户历史行为序列是其它一组,然后设定field group的权重:其中
field group之间的权重。我们将得到的模型称为
Field-weighted Factorization Machine: FwFM。模型复杂度:
FM的参数数量为embedding向量的参数数量。FwFM使用了额外的field pair,因此总的参数数量为FFM的参数数量为embedding向量。考虑到通常
FwFM的参数与FM相当,显著少于FFM。
线性项:我们认为,
embedding向量我们为每个特征学习一个线性权重
FwFM的线性项变为:这需要
FwFM的总参数数量为FwFM_FeLV。这相当于为每个特征学习两个
embedding:embeddingembedding首先,这种方法的表达能力更强。
其次,实现起来更简单。原始的线性项需要把特征表示成
sparse形式从而节省内存和计算量(大量的零存在),在实现的时候需要特殊的逻辑(稀疏张量的转换和计算)。而这里直接用embedding lookup,与现有的逻辑保持一致。
或者,我们为每个
field学习一个线性权重此时总的参数数量为
FwFM_FiLV。这相当于为每个
field学习一个embedding。原始线性权重的
FwFM记做FwFM_LW。或者我们是否可以用
1的向量,一定程度上降低了参数规模同时缓解过拟合。原因如下:考虑在后面的实验部分,确实发现参数更少的
FwFM_FiLV的测试AUC更高。那么是否1的向量时效果还要好?
1.2 实验
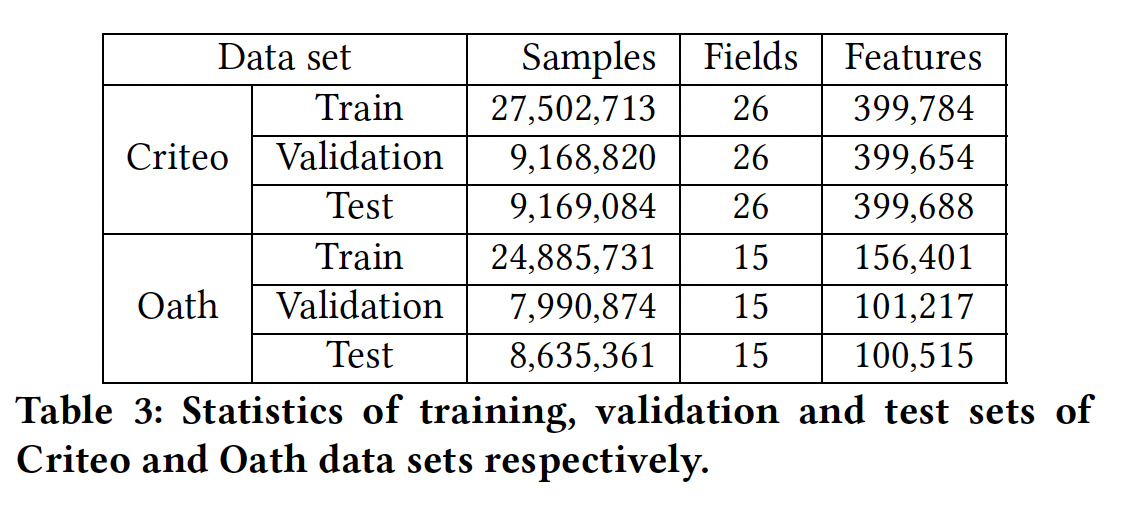
数据集:
Criteo CTR数据集:我们将数据按60%: 20%: 20%随机分成训练集、验证集和测试集。Oath CTR数据集:我们使用两周的点击日志作为训练集,下一天的数据作为验证集、下下一天的数据作为测试集。对于
Oath CTR数据集,正样本的比例通常小于1%。我们对负样本进行降采样,使正负样本更加平衡。对验证集和测试集不做降采样,因为评估应该在反映实际流量分布的数据集上进行。
对于这两个数据集,我们过滤掉所有在训练集中出现少于
NULL特征代替,其中Criteo数据集中被设置为20,在Oath数据集中为10。这两个数据集的统计数字如下表所示:
实现:我们使用
LibLinear来训练Poly2,并使用哈希技巧将feature conjunctions哈希到Tensorflow中实现。Tensorflow中FwFM的结构如下图所示。输入是一个稀疏的二元向量
field。对每个样本而言每个field都有一个且只有一个活跃的特征。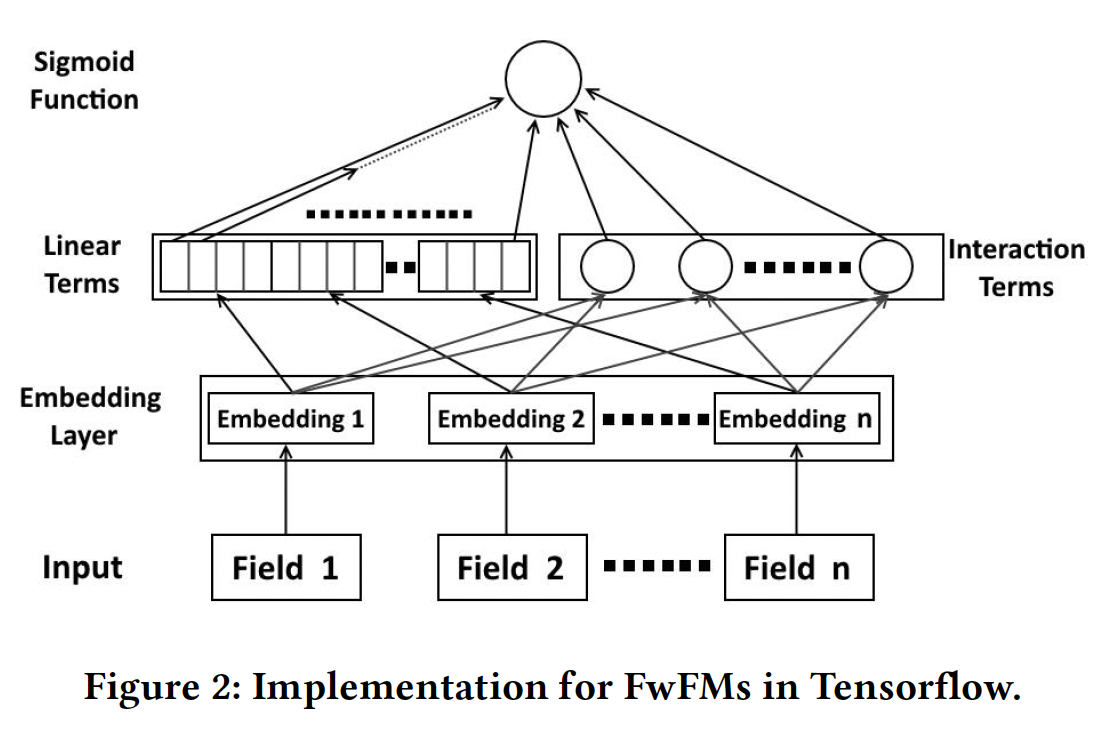
FwFM和已有模型的比较:我们评估了带原始线性项的FwFM,即FwFM_LW。对于所有的超参数,我们在验证集上进行调优,然后在测试集上进行评估。可以看到:在两个数据集上,
FwFM都能取得比LR、Poly2和FM更好的性能。这种改进来自于FwFM显式地建模了field pair的不同交互强度。FFM总是在验证集和测试集上获得最佳性能。然而,FwFM的性能相比FFM具有相当的竞争力。
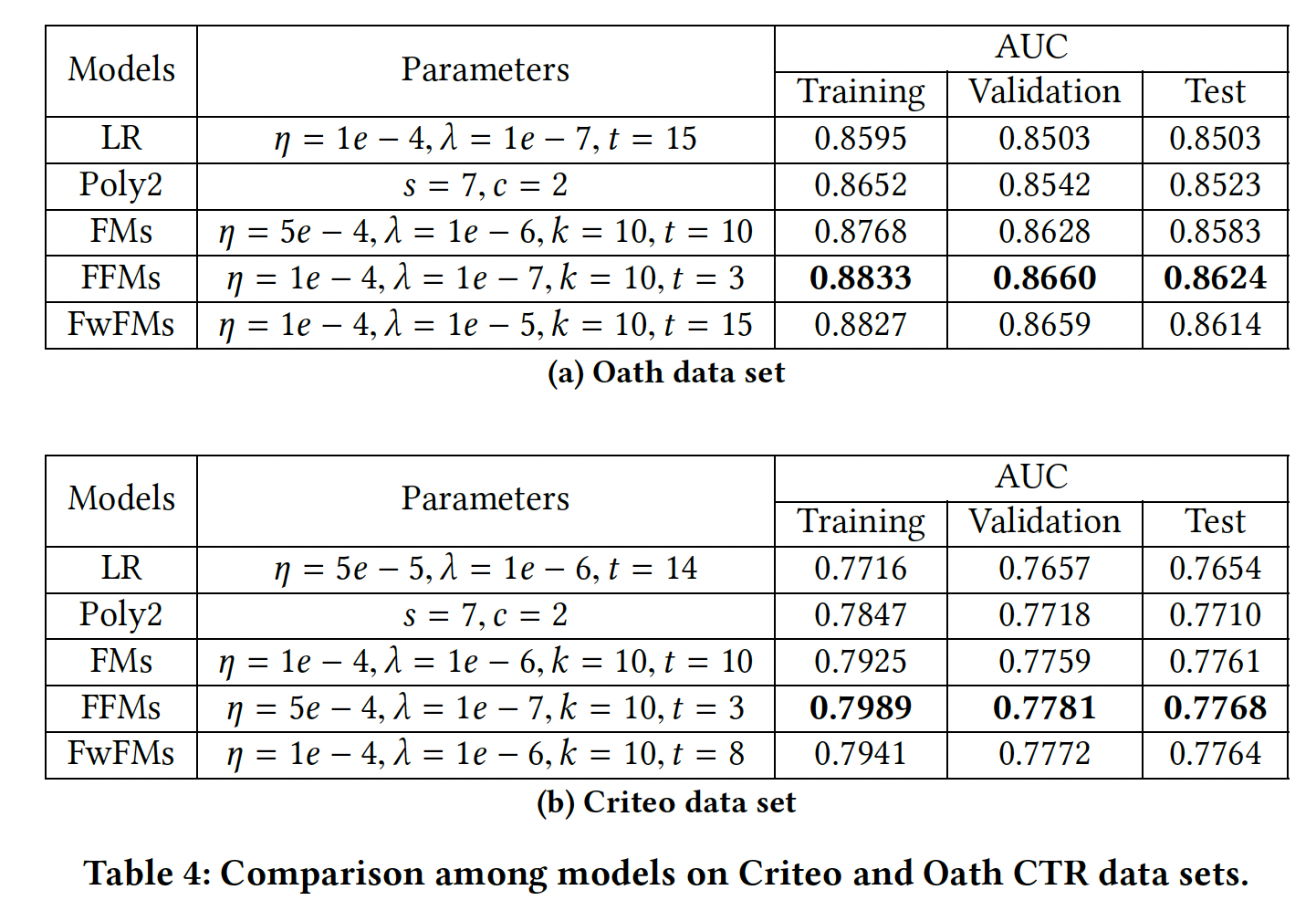
FwFM与FFM在具有相同参数规模的情况下的比较:FFM的一个关键缺点是其参数数量在FFM的参数数量:使用较小的《Field-aware factorization machines in a real-world online advertising system》提出对FFM使用较小的这里我们通过选择合适的
FFM和FwFM的参数数量相同。我们不计算线性项的参数,因为它们与交互项的数量相比可以忽略。我们选择FwFM在Criteo和Oath数据集的测试集上得到更好的表现,提升幅度分别为0.70%和0.45%。
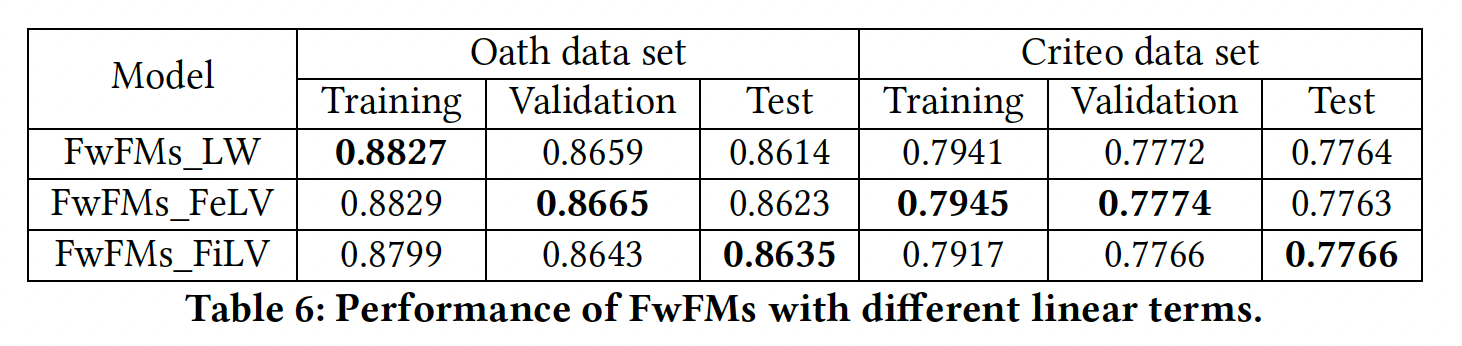
具有不同线性项的
FwFM:下表给出了不同线性项的FwFM的性能。可以看到:FwFM_LW和FwFM_FeLV在训练和验证集上比FwFM_FiLV能取得更好的性能。原因是这两个模型的线性项(FwFM_FiLV(FwFM_FiLV更好地拟合训练集和验证集。然而,
FwFM_FiLV在测试集上得到了最好的结果,这表明它有更好的泛化性能。此外,当我们使用相同数量的参数将
FwFM_FiLV与FFM进行比较时,在Oath数据集和Criteo数据集上的AUC提升分别为0.92%和0.47%。
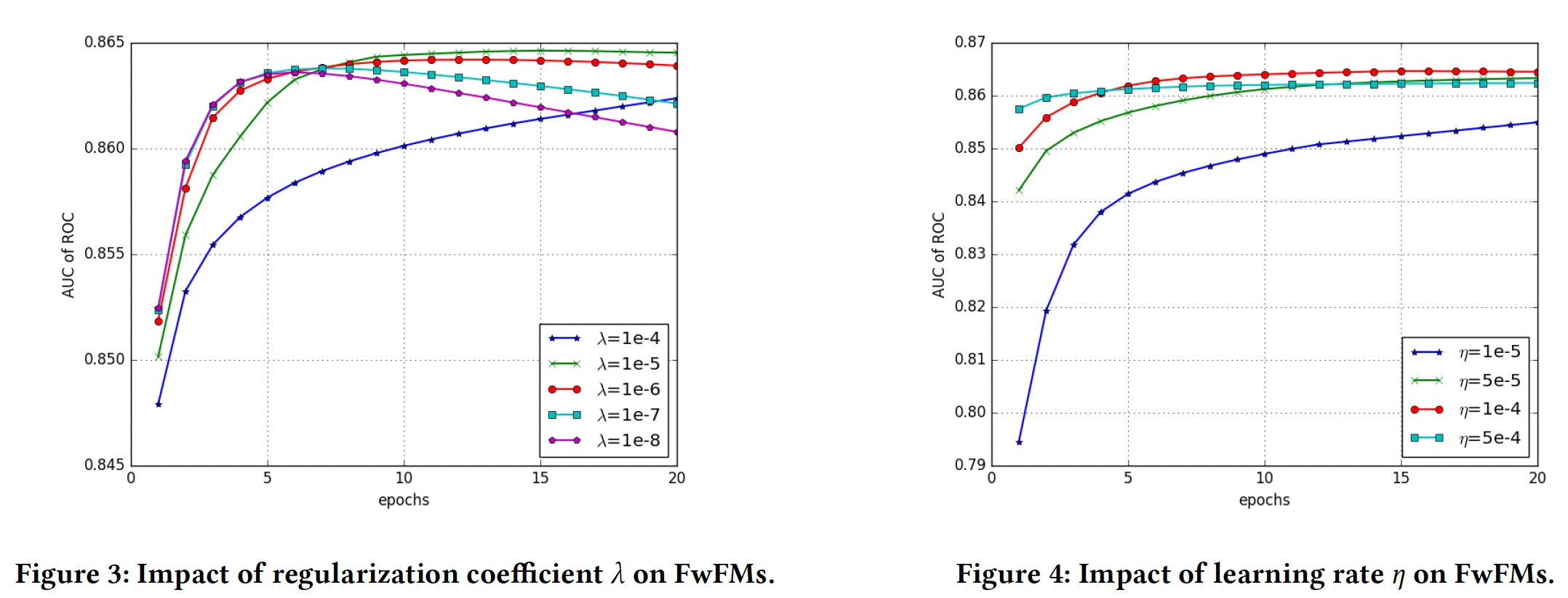
超参数调优:以下所有的评估都是
FwFM_FiLV模型在Oath验证集上进行的。L2正则化系数Figure3所示,正则化系数作用于所有的
parameters。学习率
Figure4所示,我们选择embedding维度
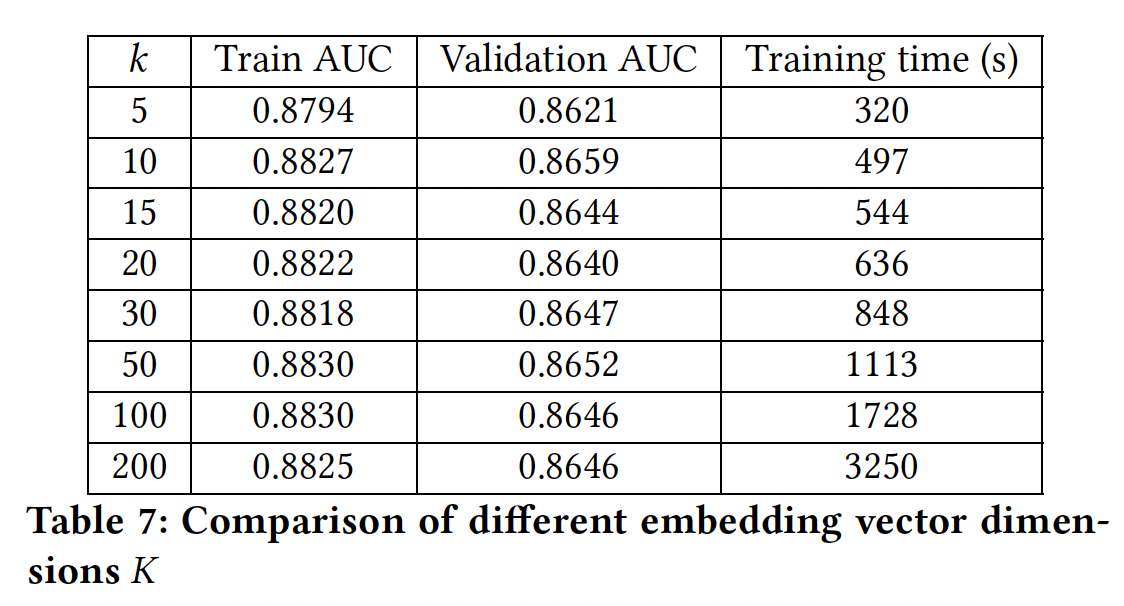
学到的
field交互强度:这里我们比较了FM、FFM和FwFM在捕获不同field pair的交互强度方面的能力。我们的结果表明,由于field pair交互权重FwFM可以比FM和FFM更好地建模交互强度。field pair的交互强度通过互信息(field pair和标签之间的互信息Figure 5(a)中通过热力图进行了可视化。为了衡量学到的
field交互强度,我们定义了以下指标:其中:
feature pairfeature pair对于
FM,对于
FFM,对于
FwFM,
注意,我们将内积项的绝对值相加,否则正值和负值会相互抵消。
如果一个模型能够很好地捕捉到不同
field pair的交互强度,我们期望其学习到的field交互强度接近于互信息Figure 5中以热力图的形式绘制了由FM, FFM, FwFM学到的field交互强度,以及field pair和标签之间的互信息field交互强度与互信息的匹配程度。从
Figure 5(b)中我们观察到:FM学到的交互强度与互信息完全不同。这并不奇怪,因为FM在建模特征交互强度时没有考虑field信息。从
Figure 5(c)中我们观察到:FFM能够学习与互信息更相似的交互强度。从
Figure 5(d)中我们观察到:FwFM学到的交互强度的热力图与互信息的热力图非常相似。
为了了解权重
field pair的交互强度方面的重要性,我们在Figure 6中绘制了FwFM(退化回FM)的学到的field交互强度。可以看到:Figure 5(a)的互信息热力图、Figure 5(d)的FwFM学到的field交互强度都非常相似。这意味着field pair的不同交互强度。