一、DIEN [2019]
《Deep Interest Evolution Network for Click-Through Rate Prediction》
点击付费(
cost per click: CPC)是广告系统中最常见的计费形式之一,广告主需要为广告的每次点击付费。在CPC广告系统中,点击率(click-through rate: CTR)预估的表现不仅会影响到整个平台的最终收入,还会影响到用户体验(user experience)和满意度(satisfaction)。点击率预估建模越来越受到学术界和工业界的关注。在大多数
non-searching的电商场景中,用户不会主动表达当前的意图。设计模型以捕获用户的兴趣及其兴趣的动态(dynamics)提高点击率预估性能的关键。最近,很多CTR模型从传统方法转变到深度CTR模型。大多数深度CTR模型聚焦于捕获来自不同fields的特征之间的交互,而不太关注用户兴趣representation。DIN强调用户兴趣是多样的,并使用attention based的模型来捕获与目标item相关的兴趣,从而获得自适应的兴趣representation。然而,包括DIN在内的大多数兴趣模型都将行为直接视为兴趣,而显式的行为很难充分反映潜在的兴趣。因此这些方法都忽略了挖掘用户行为背后真正的用户兴趣。此外,用户兴趣不断演变(evolve),捕获兴趣的动态对于兴趣representation很重要。基于所有这些观察,论文
《Deep Interest Evolution Network for Click-Through Rate Prediction》提出了深度兴趣演变网络(Deep Interest Evolution Network: DIEN)来提高CTR预估的性能。DIEN中有两个关键模块:一个是从显式的用户行为中提取潜在的时序兴趣(temporal interest),另一个是对兴趣演变过程(interest evolving process)进行建模。恰当的兴趣representation是DIEN模型的基石。在兴趣提取层(
interest extractor layer) ,DIEN选择GRU来建模行为之间的依赖关系。遵循兴趣直接导致连续行为的原则,论文提出了辅助损失,它使用下一个行为(next behavior)来监督当前隐状态(hidden state)的学习。论文将这些具有额外监督信息的隐状态称作兴趣状态(interest state)。这些额外的监督信息有助于为兴趣representation捕获更多的语义信息,并推动GRU的隐状态有效地表达兴趣。更进一步,用户的兴趣是多样化的,这导致了兴趣漂移(
interest drifting)现象:用户在相邻访问中的意图可能非常不同,并且用户的一种行为可能依赖于很久以前的行为。每个兴趣都有自己的演变轨迹(evolution track)。同时,一个用户对不同目标item的点击行为受到不同兴趣部分的影响。在兴趣演变层(
interest evolving layer),论文对于目标item相关的兴趣演变轨迹进行建模。基于从兴趣提取层获得的兴趣序列,论文设计了具有注意力更新门的GRU,即GRU with attentional update gate: AUGRU。AUGRU利用兴趣状态和目标item计算相关性,增强了相关兴趣(relative interests)对于兴趣演变的影响,同时削弱了因为兴趣漂移导致的非相关兴趣的影响。通过在更新门中引入注意力机制,AUGRU可以导致针对不同目标item的、特定的兴趣演变过程。
DIEN的主要贡献如下:论文聚焦电商系统中的兴趣演变现象,并提出了一种新的网络结构来建模兴趣演变过程。建模兴趣演变导致更具表达性的兴趣
representation和更精确的点击率预估。不同于直接将行为作为兴趣,论文专门设计了兴趣提取层。针对
GRU的隐状态较少地针对兴趣representation的问题,论文提出了一种辅助损失。该辅助损失使用连续行为(consecutive behavior)来监督每个step隐状态的学习。这使得隐状态足以代表潜在的兴趣。论文创新地设计了兴趣演变层,其中带有注意力更新门的
GRU加强了目标item相关的兴趣的影响,并克服了兴趣漂移问题。
在公共数据集和工业数据集的实验中,
DIEN显著优于SOTA的解决方案。值得注意的是,DIEN已经部署在淘宝展示广告系统中,并在各种指标下获得了显著的提升(20.7%的点击率提升)。相关工作:凭借深度学习在特征
representation和特征组合方面强大的能力,最近的CTR模型从传统的线性模型或非线性模型转变到深度模型。大多数深度模型遵循Embedding & MLP的结构。基于这种范式,越来越多的模型关注特征之间的交互(interaction):Wide & Deep和DeepFM都结合了低阶特征交互和高阶特征交互来提高表达能力。PNN提出了一个product layer来捕获跨field特征之间的交互模式。
然而,这些方法并不能清晰地反映数据背后的用户兴趣。
DIN引入了注意力机制来激活局部的、与目标item相关的历史行为,并成功地捕获到用户兴趣的多样性特点(diversity characteristic)。然而,DIN在捕获序列行为(sequential behaviors)之间的依赖关系方面很弱。在很多
application领域中,可以随时间记录user-item交互。最近的一些研究表明,这些交互信息可用于构建更丰富的单个用户模型(individual user model)并挖掘额外的行为模式(behavioral pattern)。在推荐系统中:TDSSM联合优化长期用户兴趣和短期用户兴趣,提高推荐质量。DREAM使用RNN结构来研究每个用户的动态representation以及item购买历史的全局序列行为(global sequential behavior)。《Ups and downs: Modeling the visual evolution of fashion trends with one-class collaborative filtering》构建了视觉感知推荐系统,该系统展示了更符合用户和社区(community)不断演变兴趣的产品。《Sequential click prediction for sponsored search with recurrent neural networks》根据用户的兴趣序列衡量用户的相似性,从而提高协同过滤推荐的性能。《Improving native ads ctr prediction by large scale event embedding and recurrent networks》通过使用大规模event embedding和RNN网络的attentional output来改进原始的CTR预估性能。ATRank使用基于注意力的序列框架(attention based sequential framework)来建模异质行为(heterogeneous behavior)。
和序列无关的方法相比,这些方法可以显著提高预测准确性。然而,这些传统的基于
RNN的模型存在一些问题。一方面,它们大多将序列结构的隐状态直接视为潜在兴趣,而这些隐状态缺乏对兴趣
representation的、专门的监督。另一方面,大多数现有的基于
RNN的模型依次地、平等地处理相邻行为之间的所有依赖关系。众所周知,并非所有的用户行为都严格依赖于相邻的行为。每个用户都有多样化的兴趣,每个兴趣都有自己的演变轨迹,因此这些模型可能会受到兴趣漂移的干扰。
为了推动序列结构的隐状态有效地代表潜在兴趣,应该引入对隐状态的额外监督。
DARNN使用click-level的序列预测,它在每次向用户展示每个广告时,对点击动作进行建模。除了点击动作,还可以进一步引入ranking信息。在推荐系统中,ranking loss已经被广泛用于排序任务。与这些ranking loss类似,我们提出了兴趣学习的辅助损失。在每个step,辅助损失使用next clicked item和non-clicked item来监督兴趣representation的学习。为了捕获与目标
item相关的兴趣演变过程,我们需要更灵活的序列学习结构(sequential learning structure)。在问答(question answering: QA)领域,DMN+使用基于注意力的GRU,即attention based GRU: AGRU来推动注意力机制对输入事实(fact)的位置和顺序都保持敏感。在AGRU中,更新门向量被简单地替换为标量的attention score。这种替换忽略了更新门所有维度之间的差异,这种差异包含了从先前序列传输的丰富信息。受到QA中使用的新型序列结构的启发,我们提出了带注意力门的GRU,即GRU with attentional gate: AUGRU,从而在兴趣演变过程中激活相关的兴趣。和AGRU不同,AUGRU中的attention score作用于从更新门计算出的信息。更新门和attention score的结合推动了更专有(specifically)、更敏感(sensitively)的演变过程。
1.1 模型
这里我们详细介绍
DIEN。首先我们简单回顾一下名为BaseModel的、基础的Deep CTR模型。然后我们展示了DIEN的整体结构,并介绍了用于捕获兴趣和建模兴趣演变过程的技术。
1.1.1 BaseModel
Feature Representation:在线展示广告系统中,有四类特征:用户画像特征(
user profile):包括性别、年龄等。用户行为特征(
user behavior):包括用户访问的商品ID列表。广告特征(
AD):广告本身也是商品,因此称作目标商品。它包含商品ID、店铺ID等特征。上下文特征(
Context):包含当前访问时间等特征。
每类特征中每个
field的特征都编码为one-hot向量。例如用户画像中的female特征编码为[0,1]。假设用户画像、用户行为、广告、上下文这四类特征中不同field的one-hot向量拼接之后分别为在序列的
CTR模型中,值得注意的是,用户行为特征包含一个行为列表,每个行为对应一个one-hot向量,可以表示为:其中
one-hot向量。BaseModel的结构:大多数deep CTR模型基于Embedding & MLP结构,因此BaseModel主要由以下部分组成:Embedding部分:embedding是将大规模稀疏特征转换为低维稠密特征的常用操作。在embedding layer,每个特征field对应一个embedding矩阵。例如,visited goods的embedding矩阵可以表示为:其中:
embedding向量,embedding向量维度,对于行为特征的
one-hot向量embedding向量embedding向量列表可以表示为:MLP部分:将来自同一类特征的所有embedding向量馈入一个池化层,得到一个固定长度的向量。然后将来自不同类特征的固定长度向量拼接在一起,馈入MLP网络中得到最终预测结果。
损失函数:深度
CTR模型中广泛使用的损失函数为负的对数似然,它使用目标item的label来监督整体预测结果。即:其中:
item。item的概率。
1.1.2 DIEN
与赞助搜索(
sponsored search)不同,在很多电商平台中,用户并没有清晰地表达他们的意图,因此捕获用户兴趣及其动态(dynamics)对于CTR预估很重要。DIEN致力于捕获用户兴趣并建模兴趣演变过程。如下图所示,
DIEN由几个部分组成。首先,所有离散特征都通过
embedding layer进行转换。接下来,
DIEN采取两个步骤来捕获兴趣演变:兴趣提取层(
interest extractor layer)根据行为序列提取兴趣序列。兴趣演变层(
interest evolving layer)建模与目标item相关的兴趣演变过程。
然后,将最终兴趣的
representation、广告embedding向量、用户画像embedding向量、上下文embedding向量拼接起来。拼接的向量馈入MLP以进行最终的预测。
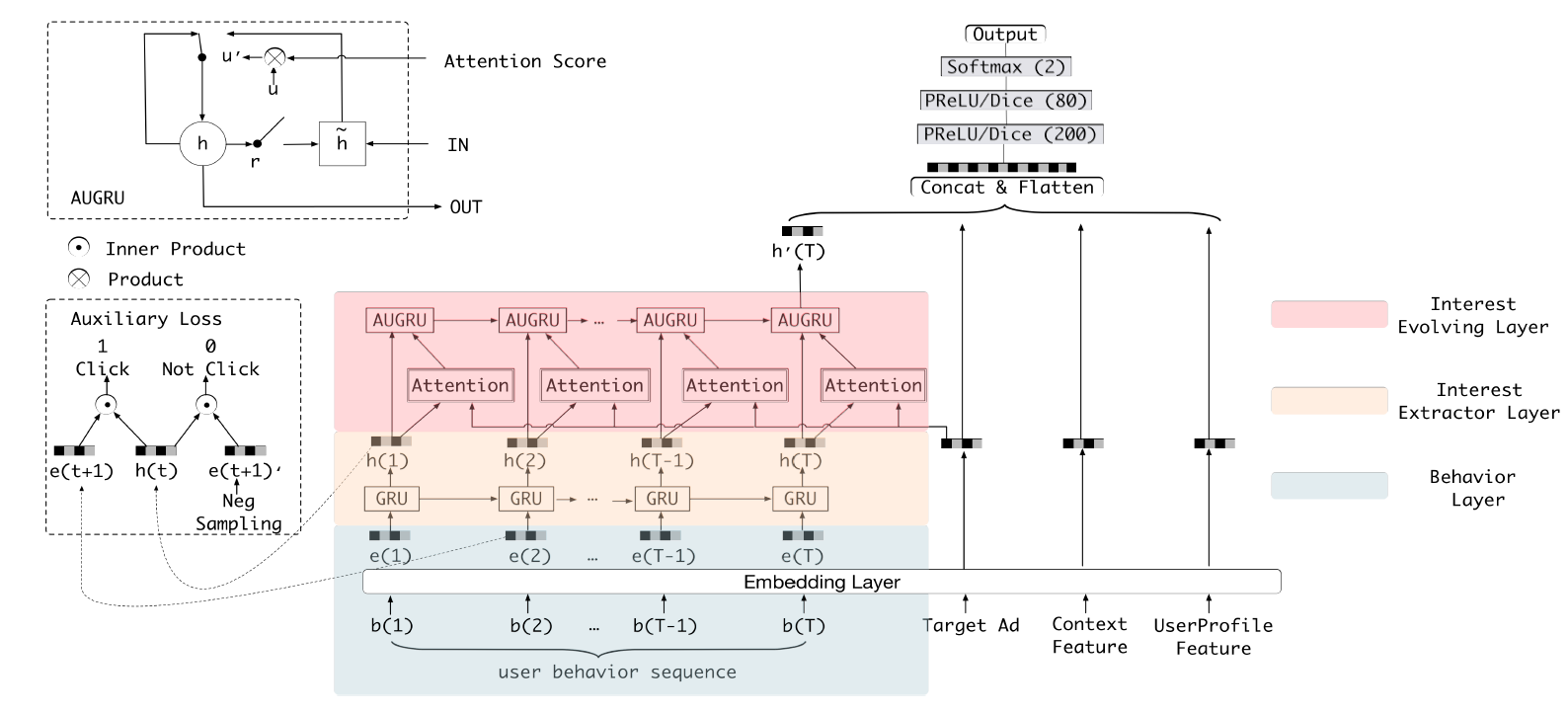
a. Interest Extractor Layer
在电商系统中,用户行为是用户潜在兴趣的载体,用户执行一次行为之后兴趣可能就会发生变化。在兴趣提取器层,我们从连续的用户行为中提取一系列的兴趣状态。
电商系统中用户的点击行为非常丰富,即使在很短时间内(如两周),用户历史行为序列的长度也很长。为了在效率和性能之间平衡,我们采用
GRU建模行为之间的依赖关系,其中GRU的输入是按发生时间排序的行为。GRU克服了RNN的梯度消失问题,比LSTM更快,适用于电商系统。GRU形式化为:其中:
sigmoid激活函数,embedding,它作为GRU的输入。
然而,仅捕获行为之间依赖关系的隐状态
item的点击行为是由最终兴趣触发的,因此损失函数label仅仅监督了最后一个兴趣状态众所周知,用户每一步的兴趣状态都将导致连续的行为,因此我们提出辅助损失,从而利用第
next behavior作为正样本之外,我们还从正样本之外采样了一些item作为负样本。因此得到embedding序列:其中:
embedding,embedding维度。item的embedding向量,item的embedding集合。item以外的所有item中采样得到的item embedding。
辅助损失函数为:
其中:
sigmoid激活函数。item的embedding向量,它作为第postive的监督信息;item的embedding向量,它作为第negative的监督信息。
考虑辅助损失之后,
DIEN模型的整体目标函数为:其中:
CTR预测。通过引入辅助函数,每个隐状态
总体而言,引入辅助函数具有多个优点:
从兴趣学习的角度看,辅助损失函数的引入有助于
GRU的每个隐状态学到正确的兴趣representation。从
GRU优化的角度看,辅助函数的引入有助于缓解GRU的长距离依赖问题,降低反向传播的难度。还有不怎么重要的一点:辅助损失函数为
embedding层的学习提供了更多的语义信息,从而产生更好的embedding矩阵。
b. Interest Evolving Layer
随着外部环境和用户自身认知的共同作用,用户的各种兴趣随着时间的推移也在不断演变。以用户对衣服的兴趣为例,随着人口趋势和用户品味的变化,用户对衣服的偏好也在改变。这种兴趣演变过程直接决定了候选衣服商品的点击率预测。对这种兴趣演变过程进行建模有以下优点:
兴趣演变模块(
interest evolving module)可以提供具有更多相关历史信息的最终兴趣的representation。可以更好地跟随兴趣演变趋势来预测目标
item的点击率。
值得注意的是,在演变过程中兴趣表现出两个特点:
由于兴趣的多样性,兴趣可能会发生漂移(
drift)。兴趣漂移对用户行为产生的影响是:用户可能在某个时间段对各种书籍感兴趣,但是另一个时间段可能对各种衣服感兴趣。尽管兴趣之间会相互影响,但是每种兴趣都有自己的演变过程。如:书籍和衣服的兴趣演变过程几乎是独立的。我们只关注和目标
item相关的兴趣演变过程。
在第一阶段辅助损失的帮助下,我们获得了兴趣序列的
representation。通过分析兴趣演变的特点,我们结合注意力机制的局部激活能力以及GRU的序列学习能力来建模兴趣演变过程。在GRU的每个step,局部激活都可以强化相关兴趣的影响,并减弱无关兴趣(兴趣漂移)的干扰,有助于建模目标item相关的兴趣演变过程。令
我们在兴趣演变模块中使用的
attention score函数定义为:其中:
a各field的embedding向量的拼接向量,
attention score反映了广告a和输入的潜在兴趣接下来,我们将介绍几种结合注意力机制和
GRU对兴趣演变过程进行建模的方法。GRU with attentional input: AIGRU:为了在兴趣演变过程中激活相关的兴趣,我们提出了一种简单的方法,称作带注意力输入的GRU(GRU with attentional input: AIGRU)。AIGRU使用attention score来影响兴趣演变层的输入:其中:
GRU的输入,用于兴趣演变。在
AIGRU中,和目标item相关性较低的兴趣的scale可以通过attention score来减少。理想情况下,和目标item相关性较低的输入可以被降低到零。但是AIGRU效果不是很好,因为即使是零输入也可以改变GRU的隐状态。所以,即使相对于目标item的兴趣较低,也会影响后面兴趣演变过程的学习。Attention based GRU: AGRU:在问答(question answering: QA)领域,DMN+首先提出了基于注意力的GRUattention based GRU: AGRU。通过使用来自注意力机制的embedding信息修改GRU架构之后,AGRU可以有效地提取复杂query中的关键信息。受问答系统的启发之后,我们将
AGRU的使用从提取query中的关键信息,迁移到在兴趣演变过程中捕获相关的兴趣。具体而言,AGRU使用attention score代替GRU的更新门,并直接修改隐状态:其中:
AGRU的隐状态。
在兴趣演变的场景中,AGRU 利用attention score 直接控制隐状态的更新。AGRU 在兴趣演变过程中削弱了目标 item 相关性较低兴趣的影响。将注意力嵌入到 GRU 中提高了注意力机制的影响,帮助 AGRU 克服了 AIGRU 的缺陷。
GRU with attentional update gate: AUGRU:虽然AGRU可以直接使用attention score来控制隐状态的更新,但是它使用了标量(attention scoreGRU(GRU with attentional update gate: AUGRU)来无缝结合注意力机制和GRU:其中:
AUGRU设计的注意力更新门;AUGRU的隐状态。在
AUGRU中,我们保留更新门的原始维度信息,它决定了每个维度的重要性。我们使用attention scoreitem更少相关性的兴趣对隐状态的影响越小。AUGRU更有效地避免了兴趣漂移带来的影响,并推动目标item相关的兴趣平稳演变。
1.2 实验
这里我们在公共数据集、工业数据集上将
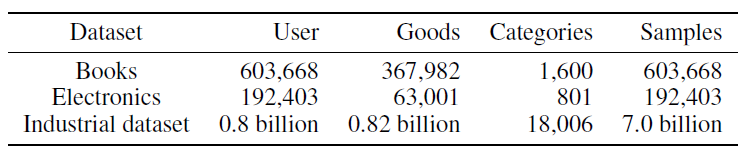
DIEN和SOTA技术进行比较。此外,我们设计了实验来分别验证辅助损失和AUGRU的影响。为了观察兴趣演变的过程,我们展示了兴趣隐状态的可视化结果。最后,我们分享了在线serving的技术和结果。数据集:
公共数据集(
Public Dataset):Amazon数据集。该数据集由商品评论和商品元数据组成。我们使用该数据集的两个子集:Books, Electronics。在这些数据集中我们将评论视为行为,并按照时间对用户的评论排序。假设用户
工业数据集(
Industrial Dataset):由淘宝在线展示广告系统中的曝光日志和点击日志组成。我们将连续
50天点击的广告作为样本,用户点击目标商品之前14天的点击行为作为历史行为序列。其中前49天的样本作为训练集,第50天的样本作为测试集。
这些数据集的统计信息如下表所示。
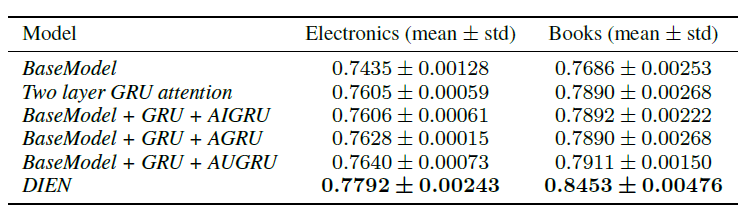
baseline方法:我们将DIEN和一些主流的CTR预估模型进行比较。BaseModel:BaseModel采用与DIEN相同的embedding setting、MLP setting,但是BaseModel使用sum pooling来聚合用户的所有行为embedding。Wide & Deep:Wide & Deep由两部分组成,其deep part和BaseModel相同、wide part为线性模型。PNN:PNN使用product layer来捕获跨field之间的特征交互模式(interactive pattern)。DIN:DIN使用注意力机制来激活目标item相关的用户行为。Two layer GRU Attention:通过双层GRU来建模用户行为序列,并采用注意力机制来关注目标item相关的行为。
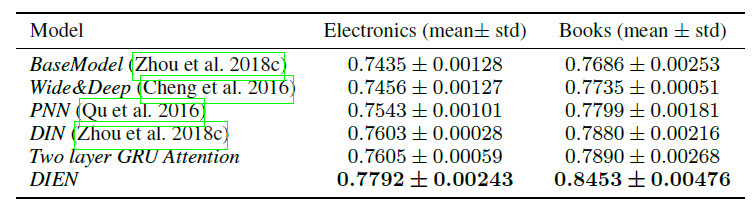
公共数据集的结果:在公共数据集中每个实验重复
5次,取离线AUC的均值和标准差,实验结果如下表所示。可以看到:人工设计特征的
Wide & Deep性能不佳,而自动特征交叉的PNN效果相对较好。旨在捕获兴趣的模型可以明显改善
AUC:DIN激活了相对于目标广告的用户兴趣,Two Layer GRU Attention进一步有效的捕获了兴趣序列中目标广告的相关兴趣。所有这些探索都获得了积极的效果。DIEN不仅可以有效捕获兴趣序列,还可以对与目标item相关的兴趣演变过程建模。兴趣演变模型可以帮助DIEN获取更好的兴趣representation,并准确捕获兴趣动态,从而大幅提升性能。
工业数据集的结果:我们进一步对真实展示广告的数据集进行实验。在工业数据集中,我们在
MLP使用6层FCN layer,维度分别为600, 400, 300, 200, 80, 2,历史行为序列的最大长度为50。实验结果如下表所示。可以看到:Wide & Deep,PNN比BaseModel效果更好。与
Amazon数据集只有一类商品不同,阿里在线广告数据集同时包含多种类型的商品,因此基于注意力的方法(如DIN)可以大幅提升性能。DIEN捕获了目标item相关的兴趣演变过程,并获得最佳效果。
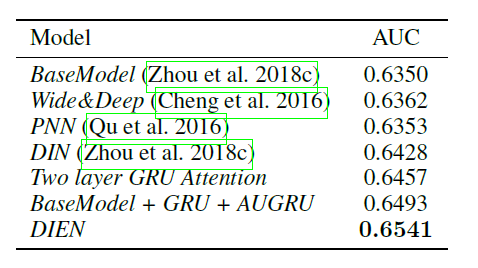
消融研究:这里我们展示
AUGRU和辅助损失的效果。AUGRU的效果:下表给出了不同兴趣演变方法的结果。与
BaseModel相比,Two layer GRU Attention获得了改进,但是它缺乏对兴趣演变进行建模从而限制了能力。AIGRU直接对兴趣演变建模。尽管它效果得到提升,但是在兴趣演变过程中,注意力和演变之间的分裂使得建模过程中丢失了信息。AGRU进一步试图融合注意力和演变过程,但是它没有充分利用更新门针对多个维度更新的优势。AUGRU取得了明显的进步(倒数第二行),它理想地融合了注意力机制和序列学习,有效捕捉了目标item相关兴趣的演变过程。
辅助损失的效果:使用
AUGRU的基础上我们进一步评估辅助损失的效果。公共数据集中,用于辅助损失的负样本都是从当前评论商品之外的item集合中随机抽样的。工业数据集中,用于辅助损失的负样本是所有已曝光但是未点击的广告。如下图所示,整体损失函数
representation生效,其中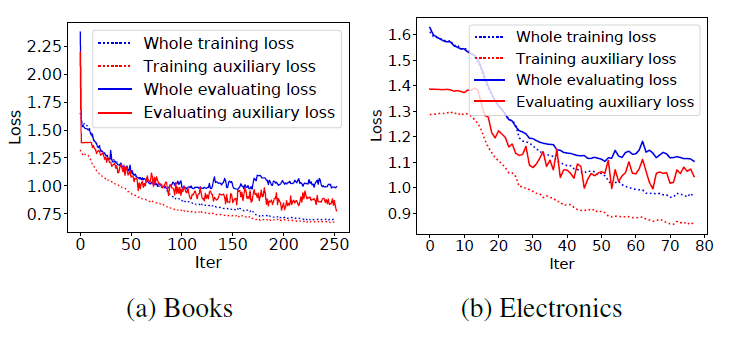
如下表所示,辅助损失为两个公共数据集都带来了很大的改进(最后一行
vs倒数第二行),它反应了监督信息对于学习兴趣序列和embedding表示的重要性。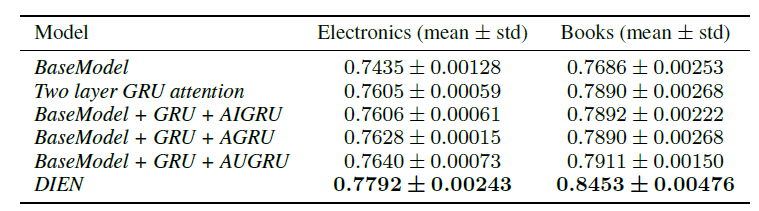
如下表所示,辅助损失为工业数据集也带来了性能提高(最后一行
vs倒数第二行),但是我们可以看到改进并不像公共数据集那样明显。这种差异来源于几个方面:首先,工业数据集具有大量的样本来学习
embedding层,这使得它从辅助损失中获得的收益更少。其次,不同于公共数据集的
item全部属于同一个类目,工业数据集包含阿里所有场景的所有类目item。我们的目标是在一个场景中预测广告的点击率。辅助损失的监督信息可能与目标item是异质的(heterogeneous),所以辅助损失对工业数据集的影响可能相比公共数据集要小,而AUGRU的影响则被放大了。
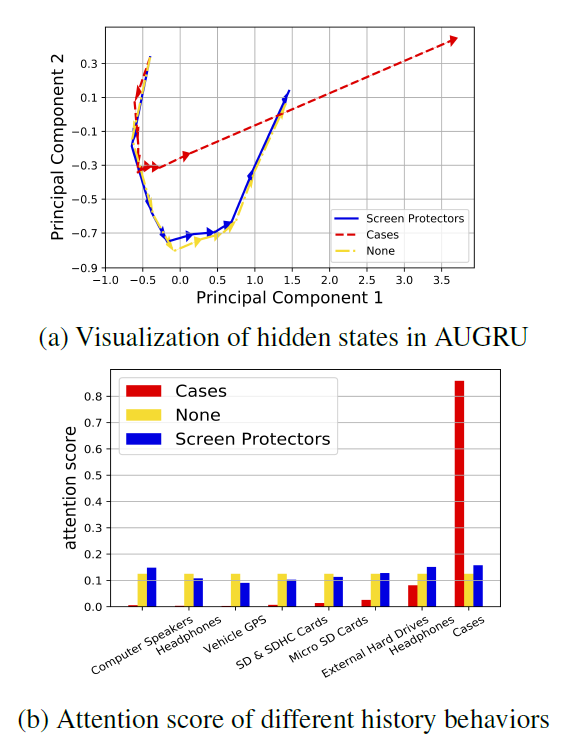
兴趣演变可视化:
AUGRU中隐状态的动态变化可以反映出兴趣演变过程,我们可以将这些隐状态可视化从而探索不同目标item对于兴趣演变的影响。我们通过
PCA将AUGRU的隐状态投影到二维空间中,投影对应的隐状态按照行为发生的顺序连接。其中历史行为来自于以下类目:电脑音箱、耳机、汽车GPS、SD卡、micro SD卡、外置硬盘、手机套。图
a给出了不同目标item的隐状态移动路径。None target的黄色曲线表示原始兴趣序列(所有注意力得分都相等),它表示不受目标item影响的兴趣演变。蓝色曲线表示目标
item为屏幕保护类目的item激活的隐状态,目标item与所有历史行为相关性较小,因此表现出类似黄色曲线的路径。红色曲线表示目标
item为手机套类目的item激活的隐状态,目标item和历史行为密切相关,因此导致较长的路径。
图
b中,和目标item相关的历史行为获得了更大的注意力得分。
在线
A/B test:我们在淘宝的展示广告系统进行在线A/B testing,测试时间从2018-06-07 ~ 2018-07-02,测试结果如下。与BaseModel相比,DIEN的CTR提升20.7%、eCPM提升17.1%、pay per click: PPC降低3%。目前
DIEN已经在线部署并服务于主要流量,业务收入显著增长。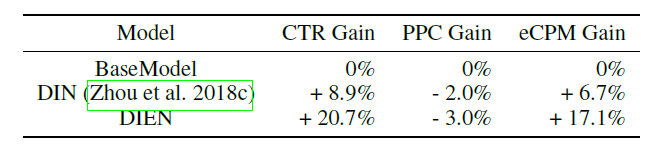
在线
serving:DIEN的在线服务(online serving)是一个巨大挑战。在线系统流量非常高,峰值可超过100万用户/秒。为保证低延迟和高吞吐量,我们采用了几种重要技术来提高serving性能:element parallel GRU以及kernel fusion:融合尽可能多的独立kernel计算,同时GRU隐状态的每个元素并行计算(元素级并行)。Batching:不同用户的相邻请求合并为一个batch,从而充分利用GPU的并行计算能力。模型压缩:通过
Rocket Launching方法来压缩模型从而训练一个更轻量级的网络,该网络尺寸更小但是性能接近原始大模型。例如,在Rocket Launching的帮助下,GRU隐状态的维度可以从108压缩到32。
通过这些技术,
DIEN serving的延迟可以从38.2ms降低到6.6ms,每个worker的query per second: QPS可以达到360。