一、ESM2 [2019]
《Entire Space Multi-Task Modeling via Post-Click Behavior Decomposition for Conversion Rate Prediction》
从互联网上大量可用的
options中为用户发现有价值的产品或服务已经成为现代在线application(如电商、社交网络、广告等等)的基本功能(fundamental functionality)。推荐系统(Recommender System)可以起到这个作用,为用户提供准确(accurate) 、及时(timely) 和个性化(personalized)的服务。下图显示了电商平台中在线推荐的架构。它包含两个基础部分(fundamental component),即系统推荐(system recommendation)和用户反馈(user feedback)。在分析了用户的长期行为(
long-term behavior)和短期行为(short-term behavior)之后,推荐系统首先召回了大量相关(related)的item。然后,根据几种排序指标(ranking metrics)(例如点击率Click-Through Rate: CTR、转化率Conversion Rate: CVR等等)对召回的item进行排序并向用户展示。接下来,当浏览推荐的
item时,用户可能会点击并最终购买感兴趣的item。这就是电商交易中的典型的用户行为序列路径(user sequential behavior path)“曝光(impression)--> 点击(click) --> 购买(purchase)”。
推荐系统收集了用户的这些反馈,并将其用于估计更准确的排序指标,这对于下一轮生成高质量的推荐确实非常关键。这里,本文重点关注后点击(
post-click)的CVR估计(estimation)任务。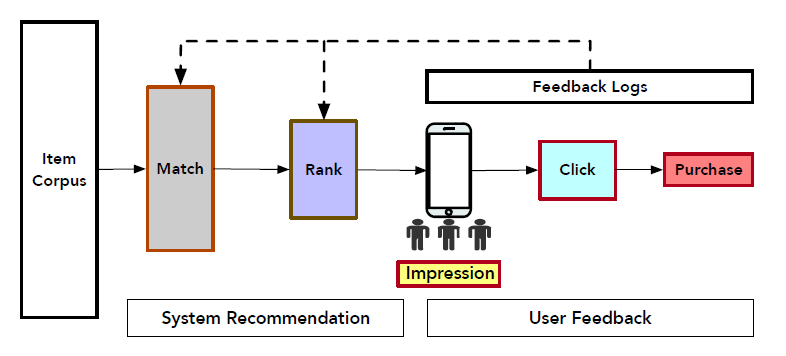
但是,
CVR估计中的两个关键问题使得该任务相当具有挑战性,即样本选择偏差(sample Selection Bias: SSB)和数据稀疏性(Data Sparsity: DS)。SSB指的是训练空间和推断空间之间数据分布的系统性差异(systematic difference)。即:常规的CVR模型仅在点击的样本上进行训练,但是在所有曝光样本上进行推断(inference)。直觉地,点击样本仅仅是曝光样本的一小部分,并且受到用户
self-selection(如用户点击)的偏见(biased)。因此,当CVR模型在线serving时,SSB问题将降低其性能。此外,由于和曝光样本相比,点击样本相对更少。因此来自行为序列路径 “点击 --> 购买” 的训练样本数量不足以拟合
CVR任务的大的参数空间,从而导致DS问题。
如下图所示说明了传统
CVR预估中样本选择偏差问题,其中训练空间仅由点击样本组成,而推断空间是所有曝光样本的整个空间。另外,从曝光到购买,数据量是逐渐减少。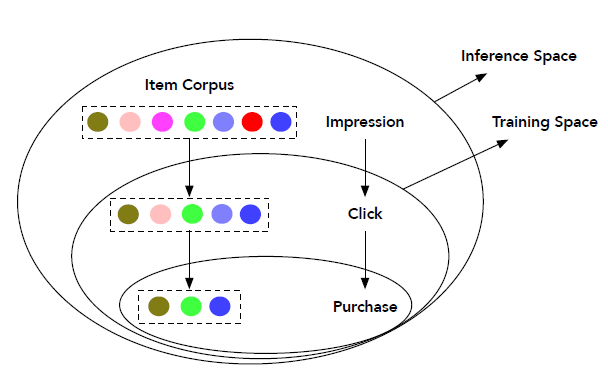
如何处理
SSB和DS问题对于开发高效的工业级推荐系统至关重要。已经有一些研究来应对这些挑战。例如,Entire Space Multi-Task Model: ESMM模型通过多任务学习框架在用户行为序列路径 “曝光--> 点击 --> 购买” 上定义了CVR任务。它使用整个空间上的所有曝光样本进行训练,以完成两个辅助任务(
auxiliary task)(即post-view CTR和post-view CTCVR)。因此,当在线推断时,从CTR和CTCVR导出的CVR也适用于相同的整个空间,从而有效地解决了SSB问题。此外,
CVR网络和具有丰富标记样本的辅助CTR网络共享相同的特征representation,这有助于缓解DS问题。
尽管
ESSM通过同时处理SSB和DS问题从而获得了比传统方法更好的性能,但是由于购买行为的训练样本很少(根据来自淘宝电商平台的大规模真实交易日志,不到0.1%的曝光行为转化为购买),它仍然难以缓解DS问题。在对日志进行详细分析之后,论文
《Entire Space Multi-Task Modeling via Post-Click Behavior Decomposition for Conversion Rate Prediction》发现用户总是在点击之后采取了一些和购买相关的动作(purchase-related action)。例如,由于某些原因(如等待折扣),用户可以将青睐的item添加到购物车(或者wish list)中,而不是立即购买。此外,这些行为确实比购物行为更加丰富。有鉴于此,该论文提出了后点击行为分解(post-click behavior decomposition)的新思想。具体而言,在点击和购买之间并行(
parallel)地插入不相交的购买相关(purchase-related)的决定性动作(Deterministic Action: DAction)、以及购买无关的其它动作(Other Action: OAction),形成一个新颖的 “曝光 --> 点击 -->D(O)Action--> 购买” 的用户行为序列图(user sequential behavior graph)。其中任务关系由条件概率明确地定义。此外,在这个图上定义模型能够利用整个空间上的所有曝光样本以及来自后点击行为(post-click behavior)的额外的丰富的监督信号,这将有效地共同解决SSB和DS问题。在论文
《Entire Space Multi-Task Modeling via Post-Click Behavior Decomposition for Conversion Rate Prediction》中,作者借助深度神经网络来体现上述思想。具体而言,论文提出了一种新颖的深度神经网络推荐模型,称作Elaborated Entire Space Supervised Multi-task Model: ESM2。ESM2包含三个模块:共享embedding模块(shared embedding module: SEM)、分解预估模块(decomposed prediction module: DPM)、序列合成模块(sequential composition module: SCM)。首先,
SEM通过线性的全连接层将ID类型的one-hot特征向量嵌入到dense representation中。然后,这些
embedding被馈入到后续的DPM中。在该DPM中,各个预测子网通过在整个空间上对所有曝光样本进行多任务学习来并行(parallel)预估分解的子目标(decomposed sub-target)的概率。最后,
SCM根据图上定义的条件概率规则(conditional probability rule),依次合成最终的CVR和一些辅助概率。在图的某些子路径(sub-path)上定义的multiple losses用于监督ESM2的训练。
本文的主要贡献:
据我们所知,我们是第一个引入后点击行为分解(
post-click behavior decomposition)的思想来在整个空间内对CVR建模的。显式分解(explicit decomposition)产生了一个新的用户行为序列图 “曝光 --> 点击 -->D(O)Action--> 购买 ”。我们提出了一种名为
ESM2的新颖的神经推荐方法,该方法根据用户行为图(user behavior graph)上定义的条件概率规则,在多任务学习框架中同时对CVR预估任务和辅助任务进行建模。通过收集大量带标签的的后点击行为数据(
post-click action data),ESM2可以有效解决SSB和DS问题。我们的模型在现实世界的离线数据集上比典型的
SOTA方法获得了更好的性能。我们还将其部署在我们的在线推荐系统中,并取得了显著的提升,证明了其在工业应用中的价值。
相关工作:我们提出的方法通过在整个空间上采用多任务学习框架来专门解决
CVR预估问题。因此,我们从以下两个方面简要回顾了最相关的工作:CVR预估、多任务学习。CVR预估:CVR预估是许多在线应用的关键组成部分,例如搜索引擎(search engines)、推荐系统(recommender systems)、在线广告(online advertising)。然而,尽管最近CTR方法得到了蓬勃发展,很少提出针对CVR任务的文献。事实上,CVR建模是非常具有挑战性的,因为转化行为是极为罕见的事件,只有极少量的曝光item最终被点击和购买。近年来,由于深度神经网络在特征
representation和端到端建模(end-to-end modeling)方面的卓越能力,因此在包括推荐系统在内的许多领域都取得了重大进展。在本文中,我们也采用了深度神经网络对CVR预估任务进行了建模。与上述方法相比,我们基于一种新颖的后点击行为分解(post-click behavior decomposition)思想,提出了一个新颖的用户行为序列图 “曝光 --> 点击 -->D(O)Action--> 购买 ” 。根据图中定义的条件概率规则,我们的网络结构经过专门设计,可以并行预测几个分解的子目标(decomposed sub-target),并依次合成从而形成最终的CVR。多任务学习:由于用户的购买行为在时间上具有多阶段性(
multi-stage nature),如曝光、点击、购买,先前的工作试图通过多任务框架来形式化CVR预估任务。例如:《multi-task learning for recommender systems》通过同时对ranking任务和rating prediction任务建模,提出了一个基于多任务学习的推荐系统。《Modeling task relationships in multi-task learning with multi-gate mixture-of-experts》提出了一种多任务学习方法,称作multi-gate mixture-of-experts: MMOE, 以从数据中明确学习任务关系。《Neural Multi-Task Recommendation from Multi-Behavior Data》提出一种神经多任务推荐模型(neural multi-task recommendation model)来学习不同类型行为之间的级联关系(cascading relationship)。相反,我们通过关联(
associating)用户的序列行为图来同时建模CTR和CVR任务,其中任务关系由条件概率明确定义。《Perceive your users in depth: Learning universal user representations from multiple e-commerce tasks》提出学习跨多个任务的通用用户representation,以实现更有效的个性化。我们也通过跨不同任务共享
embedded特征来探索这种思想。最近,
《Entire space multi-task model: An effective approach for estimating post-click conversion rate》提出了用于CVR预估的entire space multi-task model: ESMM模型。它将CTR任务和CTCVR任务作为辅助任务添加到主CVR任务中。我们的方法受到
ESMM的启发,但有以下显著的不同:我们提出了一个新颖的后点击行为分解(post-click behavior decomposition)的思想来重构一个新的用户行为序列图 “曝光 --> 点击 -->D(O)Action--> 购买”。通过在这个图上定义模型,可以同时形式化最终的CVR任务以及辅助任务。我们的方法可以利用整个空间的所有曝光样本以及来自用户后点击行为(
post-click behaviors)的丰富的监督信号,这些监督信号和购买行为高度相关,因此可以同时解决SSB和DS问题。
1.1 模型
在实践中,一个
item从曝光到购买,这之间可能存在多种类型的序列动作(sequential action)。例如,在点击一个感兴趣的item之后,用户可以毫不犹豫的直接购买它,或者将其添加到购物车中然后最终进行购买。这些行为路径如下图(a)所示。图(a)为区分从曝光到购买的、包含后点击行为的多条路径(multiple path),例如 “曝光 --> 点击 --> 添加到购物车 --> 购买” 。我们可以根据几个预定义的、特定的和购买相关(
purchase-related)的后点击动作(post-click action)来简化和分组这些路径,即添加到购物车(Shopping Cart: SCart)、添加到愿望清单(Wish list: Wish),如下图(b)所示。图(b)为描述简化的购买过程的有向图,其中边上的数字表示不同路径的稀疏性。根据我们对真实世界在线日志的数据分析,我们发现只有
1%的点击行为最终会转化为购买行为,这表明购买训练样本很少。然而,SCart和Wish这样的一些后点击动作的数据量远大于购买量。如,10%的点击会转化为加购物车。此外,这些后点击动作与最终购买行为高度相关。例如,12%的加购物车行为会转化为购买行为、31%的加愿望清单行为会转化为购买行为。考虑到后点击行为(
post-click behaviors)和购买行为高度相关,我们如何以某种方式利用大量的后点击行为从而使得CVR预估收益?直观地讲,一种解决方案是将购买相关的后点击动作与购买行为一起建模到多任务预测框架(multi-task prediction framework)中。关键是如何恰当地形式化它们,因为它们具有明确的序列相关性(sequential correlation)。例如,购买行为可能是以SCart或Wish行为为条件的。为此,我们定义了一个名为Deterministic Action: DAction的单个节点node来合并这些预定义的、特定的与购买相关的后点击动作,例如SCart和Wish,如下图(c)所示。DAction有两个性质:与购买行为高度相关、具有来自用户反馈的丰富的确定性(deterministic)的监督信号。例如,1表示执行某些特定操作(即在点击之后添加到购物车中、或者点击之后添加到愿望清单中),0表示未执行这些操作。我们还在点击和购买之间添加了一个名为
Other Action: OAction的节点,以处理DAction以外的其它后点击行为。借此方式,传统的行为路径 “曝光 --> 点击 --> 购买” 就变为新颖(novel)的、精巧(elaborated)的用户行为序列图 “曝光 --> 点击 -->D(O)Action--> 购买”,如下图(c)所示。通过在该图上定义模型,可以利用整个空间上的所有曝光样本以及来自
D(O)Action的额外的丰富的监督信号,这可以有效地避免SSB和DS问题。我们称这种新颖的想法为后点击行为分解(post-click behavior decomposition)。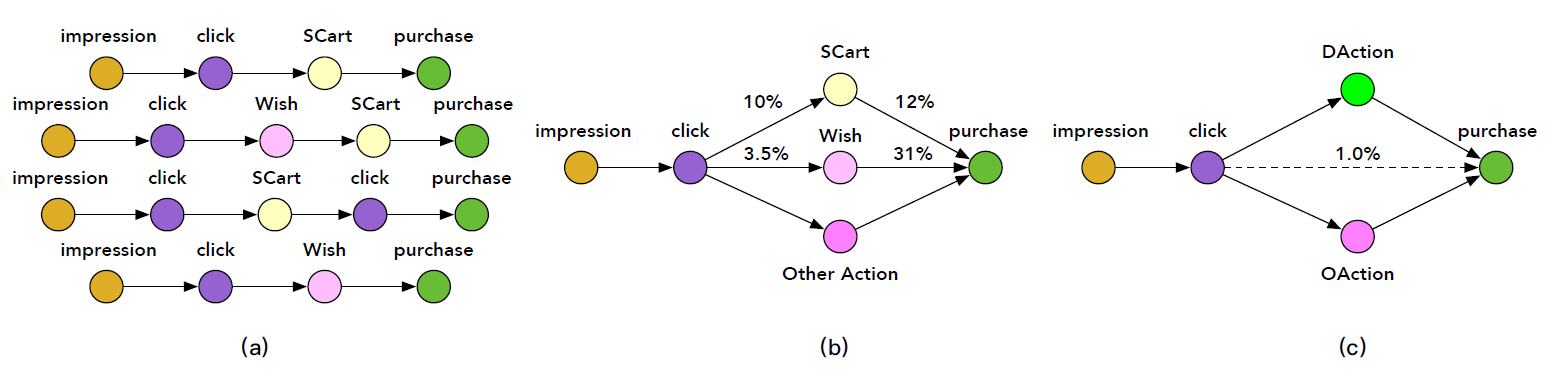
1.1.1 条件概率分解
这里我们根据上图
(c)中定义的有向图来介绍CVR的条件概率分解(conditional probability decomposition),以及相关的辅助任务。定义
itempost view ctritem其中:
itemitem
定义
itemclick-through DAction CVRitemDAction动作的条件概率。这由有向图中的路径 “曝光 --> 点击 -->DAction” 来描述。从数学上讲,这可以写成:其中:
itemDAction动作。这里假设:如果用户未点击
itemDAction动作。即:DAction” 。考虑到点击(
定义
itemCVRitemitemD(O)Action--> 购买” 来描述。从数学上讲,这可以写成:其中:
itemDAction-> 购买” 。这里我们假设DAction(OAction-> 购买” 。这里我们假设OAction(
定义
itemclick-through CVR为itemD(O)Action--> 购买” 来描述。从数学上讲,这可以写成:考虑到如果没有点击就没有任何购买,即:
则上式简化为:
因此,上式可以通过将有向图 “曝光 --> 点击 -->
D(O)Action--> 购买” 分解为 “曝光 --> 点击”、以及 “点击 -->D(O)Action--> 购买”,并根据链式法则chain rule整合之前所有的公式(即
1.1.2 ESM2 模型
从前面推导可以看到:
hidden probability variable)DAction“ 的条件概率。DAction-> 购买” 的条件概率。OAction-> 购买” 的条件概率。
此外,这四个子目标(
sub-target)在整个空间中定义,并且可以使用所有曝光样本进行预测。以SSB问题。 实际上根据前面的推导,intermediate variable)。由于SSB。另一方面, 给定用户的日志,
ground truth label是可用的,这些label可用于监督这些子目标。因此,一种直观的方法是通过多任务学习框架同时对它们进行建模。为此,我们提出了一种新颖的深度神经推荐模型(
neural recommendation model),称作Elaborated Entire Space Supervised Multi-task Mode: ESM2,用于CVR预估。ESM2之所以取这个名字是因为:首先,
其次,派生的
ESM2由三个关键模块组成:一个共享的
embedding模块(Shared Embedding Module: SEM)。SEM将稀疏特征嵌入到稠密的representation中。一个分解(
decomposed)的预估模块(Decomposed Prediction Module: DPM)。DPM可以预估分解目标的概率。一个顺序(
sequential)的合成(composition)模块(Sequential Composition Module: SCM)。SCM将预估分解目标的概率按顺序合成在一起,以计算最终的CVR以及其它相关的辅助任务(即CTR、CTAVR、CTCVR)。
整体模型如下图所示。
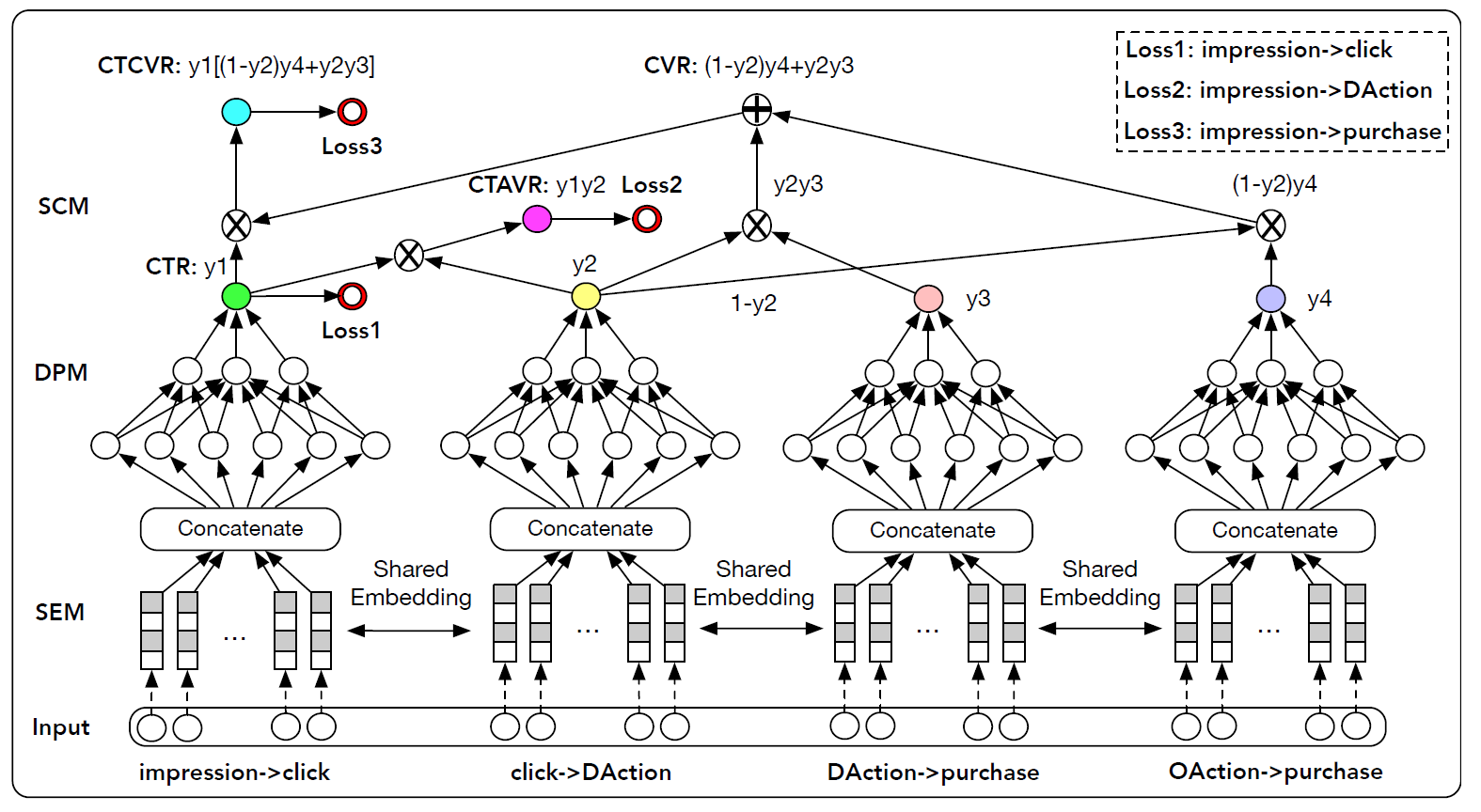
共享的
embedding模块:首先我们设计一个共享的embedding模块,从而嵌入来自user field、item field、user-item cross field的所有稀疏ID特征和稠密数值特征。用户特征包括
user ID、年龄、性别、购买力等等。item特征包括item ID、价格、历史日志统计的历史累计CTR和历史累计CVR等等。user-item特征包括用户对item的历史偏好分(historical preference score)等等。稠密特征首先基于它们的边界
boundary来离散化,然后将其表示为one-hot向量。
令第
one-hot之后为one-hot特征为:其中
由于
one-hot编码的稀疏性,我们使用线性的全连接层将它们嵌入到dense representation中。令第embedding矩阵为embedding为:第
embedding特征为:分解预估模块 :然后一旦获得了所有的特征
embedding,就将这些embedding拼接到一起,馈入几个分解的预估模块,并由每个模型共享。DPM中的每个预估网络分别在 “曝光 --> 点击”、“点击 -->DAction”、“DAction--> 购买”、“OAction--> 购买” 等路径上预估分解的target的概率。在本文中,我们采用多层感知机(
Multi-Layer Perception: MLP)作为预估网络。除了输出层之外,所有非线性激活函数均为ReLU。对于输出层,我们使用Sigmoid函数将输出映射为0.0 ~ 1.0之间的概率值。从数学上讲,这可以写成:其中:
sigmoid函数。MLP学到的映射函数,
例如,上图中的第一个
MLP输出了估计的概率(estimated probability)post-view CTR。顺序合成模块:最后我们设计了一个顺序合成模块,根据前面描述的公式合成上述预估概率,从而计算转化率
auxiliary target)(包括post-view CTRclick-through DAction CVRclick-through CVR如上图的顶部所示,顺序合成模块是一个无参的前馈神经网络,它表示购买决策有向图(
purchasing decision digraph)所定义的条件概率。注意:
所有任务共享相同的
embedding,使这些任务使用所有曝光样本进行训练。即在整个空间上对这些任务进行建模,从而在推断阶段不会出现SSB问题。轻量级的分解预估模块由共享的
embedding模块严格正则化,其中共享的embedding模块包含了大部分的训练参数。我们的模型提出了一种高效的网络设计,其中共享的
embedding模块可以并行运行,因此在在线部署时可以有较低的latency。
训练目标:令
ground truth label(是否点击、是否发生deterministic action、是否发生购买行为)。然后我们定义所有训练样本的联合post-view pCTR为:其中
label空间使用负的对数函数进行变换之后,我们得到
logloss:类似地,我们得到
其中:
DAction label空间label空间最终的训练目标函数为:
其中:
ESM2模型中的所有参数。1.0。
需要强调的是:
添加中间损失(
intermediate loss)来监督分解后的子任务,可以有效地利用后点击行为中丰富的标记数据,从而缓解模型受到DS的影响。所有损失都是从整个空间建模的角度来计算的,这有效解决了
SSB的问题。
1.2 实验
为了评估
ESM2模型的有效性,我们针对从现实世界电商场景中收集的离线数据集和在线部署进行了广泛的实验。我们将ESM2和一些代表性的SOTA方法进行比较,包括GBDT、DNN、使用过采样over-sampling思想的DNN、ESMM等。首先我们介绍评估设置(
setting),包括数据集准备、评估指标、对比的SOTA方法的简要说明、以及模型实现细节。然后我们给出比较结果并进行分析。接着我们介绍消融研究。最后我们对不同的后点击行为进行效果分析。数据集:我们通过从我们的在线电商平台(世界上最大的第三方零售平台之一)收集用户的行为序列和反馈日志来制作离线数据集。
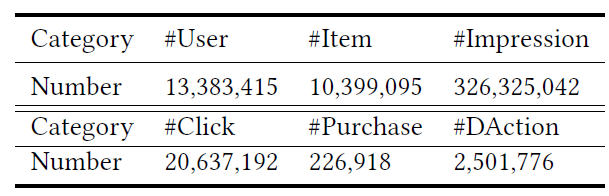
我们得到超过
3亿个样本,其中包含用户特征、item特征、user-item交叉特征以及序列的反馈标签(sequential feedback label)(如,是否点击、是否DAction、是否购买)。下表给出了离线数据集的统计信息。我们将离线数据集进一步划分为不相交的训练集、验证集、测试集。
评估指标:为了全面评估
ESM2模型的有效性,并将其和SOTA方法进行比较,我们使用三种广泛采纳的指标:AUC、GAUC、F1 score。AUC刻画了模型的排序能力(ranking ability):其中:
GAUC首先根据每个用户ID从而将数据划分为不同的组,然后在每个组中计算AUC,最后对每个组的AUC加权平均。即:其中:
1。AUC。
F1 score定义为:其中
precision、recall。
baseline方法:GBDT:梯度提升决策树(gradient boosting decision tree: GBDT)。它遵循gradient boosting machine: GBM的思想,能够为回归任务和分类任务提供有竞争力的、高度健壮robust的、可解释性的方法。本文中,我们将其作为non-deep learning-based方法的典型代表。DNN:我们还实现了一个深度神经网络baseline模型,该模型具有和ESM2中单个分支相同的结构和超参数。和ESM2不同,它是用 “点击 --> 购买” 或者 “曝光 --> 点击” 路径上的样本进行训练,从而分别预估转化率DNN-OS:由于 “曝光 --> 购买” 和 “点击 --> 购买” 路径上的数据稀疏性,很难训练具有良好泛化能力的深度神经网络。为了解决该问题,我们训练一个叫做DNN-OS的深度模型,它在训练期间利用了过采样(over-sampling)策略来增加正样本。它具有与上述DNN模型相同的结构和超参数。ESMM:为了公平地进行比较,我们为ESMM使用与上述深度模型相同的主干结构(backbone structure)。ESMM直接在用户序列路径 “曝光 --> 点击 --> 购买” 上对转化率进行建模,而没有考虑和购买相关的后点击行为(post-click behavior)。
简而言之:
前三种方法分别从 “曝光 --> 点击”、“点击 --> 购买” 路径上的样本来学习预估
而对于
ESMM和我们的ESM2,则是通过在整个空间上直接建模预估
实验配置:
对于
GBDT模型,以下超参数是根据验证集AUC来选择的:树的数量为
150。树的深度为
8。拆分一个顶点的最小样本量为
20。每次迭代的样本采样率
0.6。每次迭代的特征采样率为
0.6。损失函数为
logistic loss。
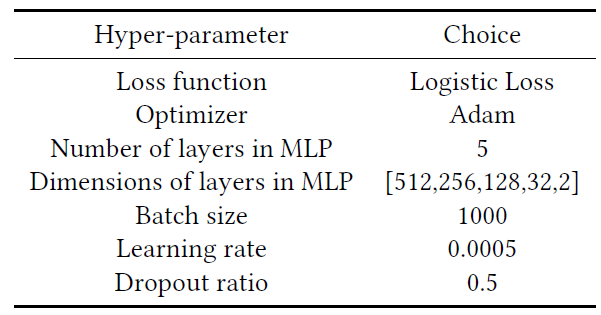
对基于深度神经网络的模型,它们基于
TensorFlow实现,并使用Adam优化器。学习率为
0.0005,mini-batch size = 1000。在所有模型中,使用
logistic loss。MLP有5层,每层的尺寸分别为512, 256, 128, 32, 2。dropout设置为dropout ratio = 0.5。
这些配置(基于深度神经网络的模型)如下表所示。
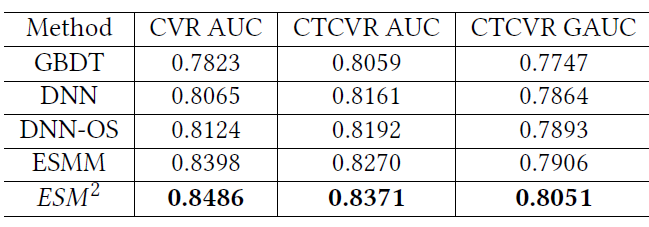
离线数据集的评估结果如下表所示。可以看到:
DNN方法相比较GBDT模型在CVR AUC、CTCVR AUC、CTCVR GAUC上分别获得了0.0242、0.0102、0.0117的增益。这证明了深度神经网络的强大representation能力。和普通的
DNN不同,DNN-OS使用过采样策略来解决DS问题,从而获得比DNN更好的性能。对于
ESMM,它针对 “曝光 --> 点击 --> 购买” 路径来建模,从而试图同时解决SSB和DS问题。得益于对整个空间的建模以及丰富的训练样本,它的性能优于DNN-OS。尽管如此,
ESMM忽略了后点击行为的影响,仍然受到购买训练样本稀疏的困扰,因此仍然难以解决DS问题。我们提出的
ESM2进一步利用了这些后点击行为。在多任务学习框架下并行预测一些分解的子目标之后,ESM2依次合成这些预测从而形成最终的CVR。可以看到,我们的
ESM2超越了所有的其它方法。例如,ESM2相较于ESMM模型在CVR AUC、CTCVR AUC、CTCVR GAUC上分别获得了0.0088、0.0101、0.0145的增益。值得一提的是,离线AUC增加0.01总是意味着在线推荐系统收入的显著增加。
对于
F1 score,我们分别通过为CVR和CTCVR设置不同的阈值来报告几个结果。首先,我们根据预估的
CVR或CTCVR分数对所有样本进行降序排序。然后,由于
CVR任务的稀疏性(大约1%的预估样本为正样本),我们选择三个阈值:top @ 0.1%、top @ 0.6%、top @ 1%,从而将样本划分为positive group和negative group。最后,我们计算在这些不同阈值下,预估结果的
precision, recall, F1 score。
评估结果在下表中给出。可以观察到和
AUC/GAUC类似的趋势。同样地,我们的ESM2方法在不同的配置下也达到了最佳性能。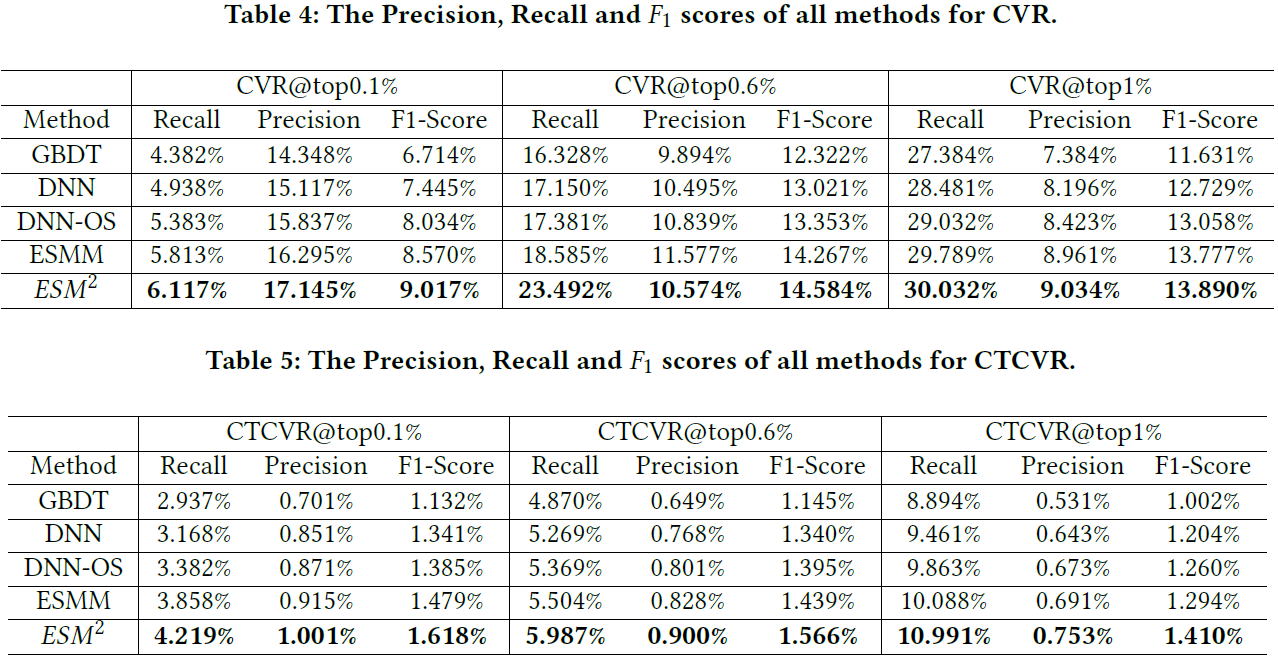
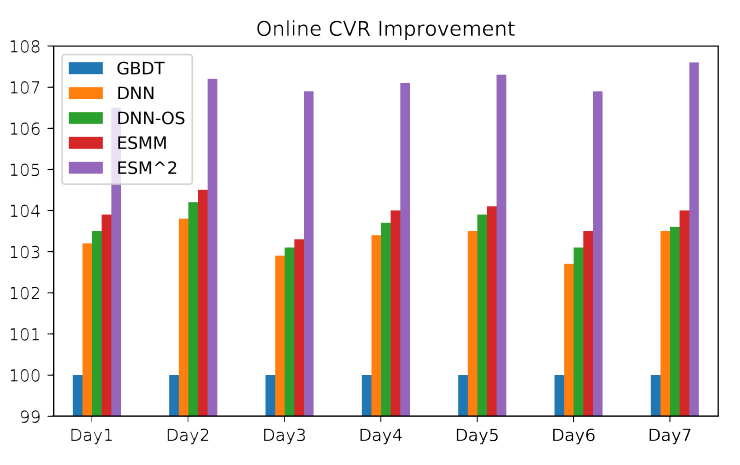
在线性能:在我们的推荐系统中部署深度网络模型并不是一件容易的事情,因为推荐系统每天服务于数亿用户。例如,在流量高峰时每秒超过
1亿用户。因此,需要一个实用的模型来进行高吞吐量、低延迟的实时CVR预估。例如,在我们的系统中,应该在不到100毫秒的时间内为每个访客预测数百个推荐的item。得益于并行的网络结构,我们的模型计算效率高,可以在20毫秒内响应每个在线请求。为了使在线评估公平(
fair)、置信(confident)、可比较(comparable),A/B test的每种部署的方法都包含相同数量的用户(例如数百万用户)。在线评估结果如下图所示,其中我们使用GBDT模型作为baseline。可以看到:DNN, DNN-OS, ESMM的性能相当,明显优于baseline模型,并且ESMM的性能稍好。我们提出的
ESM2显著优于所有的其它方法,这证明了它的优越性。此外,
ESM2相比ESMM在CVR上提升了3%,这对于电商平台具有显著的商业价值。
以上结果说明了:
深度神经网络比
tree-based的GBDT具有更强的representation能力。在整个样本空间中的多任务学习框架可以作为解决
SSB和DS问题的有效工具。基于后点击行为分解(
post-click behaviors decomposition)的思想,ESM2通过在整个空间上对CVR建模并利用deterministic行为中大量的监督信号来有效解决SSB和DS问题,并获得最佳性能。
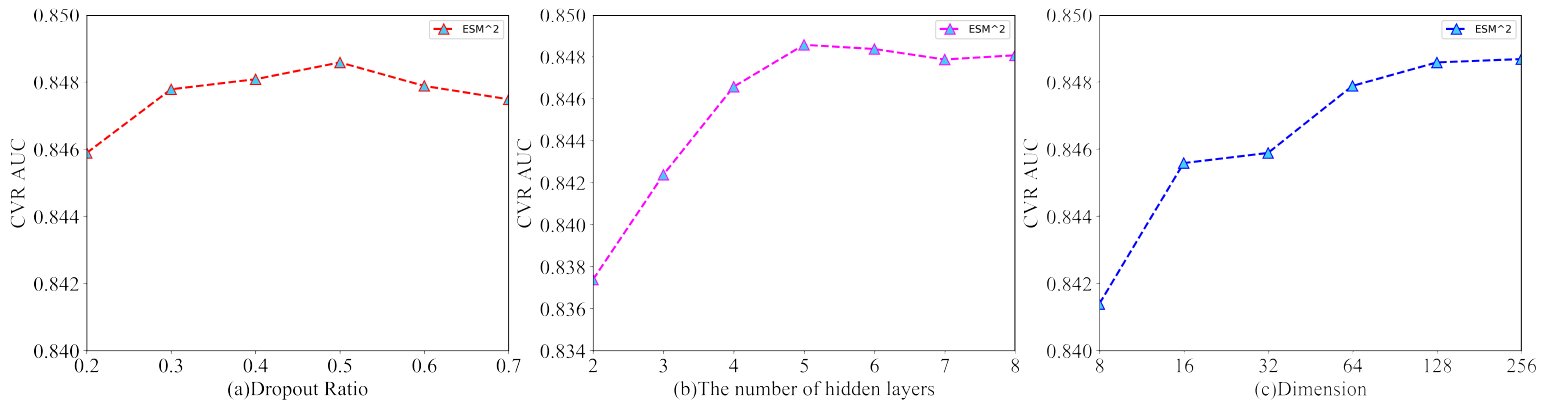
消融研究:这里我们介绍详细的消融研究,包括深度神经网络的超参数设置、嵌入稠密数值特征(
embedding dense numerical features)的有效性、以及分解的后点击行为的选择。深度神经网络的超参数:这里我们以三个关键的超参数(
dropout rate、隐层的层数、item特征的embedding维度)为例,从而说明了我们的ESM2模型中的超参数选择过程。dropout rate指的是通过在训练过程中随机停止(deactivating) 一些神经单元的正则化技术。通过引入随机性,可以增强神经网络的泛化能力。我们在模型中尝试了不同的
dropout rate,从0.2到0.7。如图(a)所示,dropout rate = 0.5时性能最佳。因此,如果没有特别指出,那么实验中我们默认将dropout rate设为0.5。增加网络的深度可以提高模型容量,但是也可能导致过拟合。因此,我们根据验证集的
AUC仔细设置了这个超参数。从图
(b)可以看到:在开始阶段(即从两层增加到五层),增加隐层的数量会不断提高模型的性能。但是,模型在五层达到饱和,后续增加更多的层甚至会略微降低验证AUC,这表明模型可能对训练集过拟合。因此,如果没有特别指出,那么实验中我们默认使用五层的隐层。item特征embedding的维度是一个关键的超参数。高维特征可以保留更多信息,但是也可能包含噪声并导致模型复杂度更高。我们尝试了不同的超参数设置,并在图
(c)中给出结果。可以看到:增加维度通常会提高性能,但是在维度为128时性能达到饱和。而继续增加维度没有更多收益。因此,为了在模型容量和模型复杂度之间的trade-off,如果没有特别指出,那么实验中我们默认将item特征embedding的维度设为128。
嵌入稠密数值特征的有效性:在我们的任务中有几个数值特征。
一种常见的做法是首先将它们离散为
one-hot向量,然后将它们与ID特征拼接在一起,然后再通过线性投影层将它们嵌入到稠密特征。但是,我们认为对数值特征的离散化one-hot向量表示可能会损失一定的信息。另一种方案将数值特征归一化,然后使用
tanh激活函数来嵌入它们,即:其中:
(-1,+1)之间。然后我们将归一化的数值特征和嵌入的
ID特征拼接在一起,作为ESM2模型的输入。和基于离散化的方案相比,归一化的方案获得了
0.004的AUC增益。因此,如果没有特别指出,那么实验中我们默认对稠密的数值特征使用基于归一化的方案。
分解的后点击行为的有效性:当分解后点击行为时,我们可以将不同的行为聚合到
DAction节点中。例如only SCart、only Wish、SCart and Wish。这里我们评估不同选择的有效性,结果如下表所示。可以看到:
SCart and Wish的组合达到了最佳的AUC。这是合理的,因为和其它两种情况相比,SCart and Wish有更多的购买相关的标记数据来解决DS问题。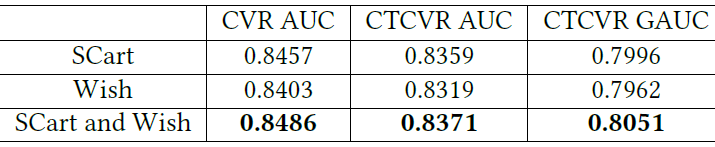
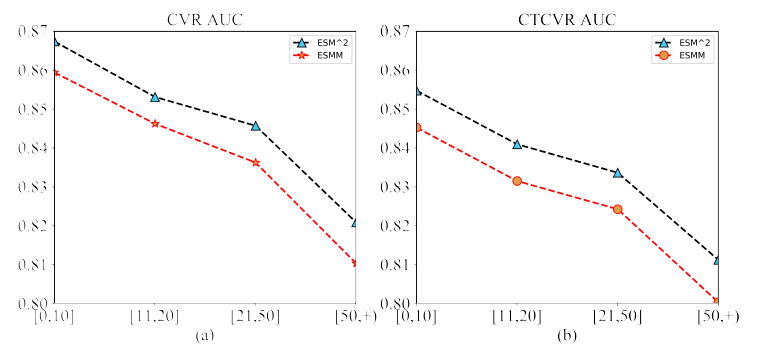
用户行为的性能分析:为了了解
ESM2的性能以及和ESMM的区别,我们根据用户购买行为的次数将测试集分为四组:[0,10]、[11,20]、[21,50]、[51, +)。我们报告了每组中两种方法的CVR AUC和CTCVR AUC,结果如下图所示。可以看到:两种方法的
CVR AUC(CTCVR AUC) 都随着购买行为次数的增加而降低。但是我们观察到,每组中
ESM2相对于ESMM的相对增益在增加,即0.72%、0.81%、1.13%、1.30%。
通常,具有更多购买行为的用户总是具有更活跃的后点击行为,例如
SCart和Wish。我们的ESM2模型通过添加DAction节点来处理此类后点击行为,该节点由来自用户反馈的deterministic信号来监督学习。因此,它在这些样本上比ESMM具有更好的表示能力,并在具有高频购买行为的用户上获得了更好的性能。论文没有分析为什么模型在更多购买行为的用户的
AUC上下降。这表明模型在这些高购买行为的用户上学习不充分,是否可以将他们作为hard样本?或者把购买次数作为特征从而让模型知道这个信息?