一、AFN [2020]
《Adaptive Factorization Network: Learning Adaptive-Order Feature Interactions》
手工制作有用的交叉特征是昂贵的、耗时的,而且结果可能无法泛化到未见过的特征交互。为了解决这个问题,人们提出了
Factorization Machine: FM,通过将交叉特征的权重参数化为原始特征的embedding向量的内积从而显式地建模二阶交叉特征。为了更加通用,在最初的工作中还引入了涉及高阶特征组合的高阶FM(HOFM)。尽管有卓越的预测能力,但在
FM/HOFM中仍有两个关键问题需要回答:首先,我们应该考虑交叉特征的最大阶次是什么?虽然较大的阶次可以建模更复杂的特征交互,并且似乎是有益的,但交叉特征的数量会随着最高阶次的增加而呈指数级增长,从而导致高的计算复杂度。这限制了高阶交叉特征的实际使用。
其次,在最高阶数下有用的交叉特征集合是什么?必须认识到,并非所有的特征都包含针对估计目标的有用信号,不同的交叉特征通常具有不同的预测能力。不相关的特征之间的交互可以被认为是噪音,对预测没有贡献,甚至会降低模型的性能。
AFM通过用注意力分数来reweighing每个交叉特征来区分特征交互的重要性。然而,在复杂的特征组合上应用注意力机制会大大增加计算成本。因此,AFM旨在仅仅建模二阶的特征交互。
在论文
《Adaptive Factorization Network: Learning Adaptive-Order Feature Interactions》中,作者认为现有的因子分解方法未能适当地回答上述两个问题。通常而言,现有的因子分解方法是按照列举、以及过滤的方式来建模特征交互:首先定义最大阶次,然后枚举最大阶次以内的所有交叉特征,最后通过训练来过滤不相关的交叉特征。这个过程包括两个主要的缺点:首先,预设最大阶数(通常较小)限制了模型在寻找有
discriminative的交叉特征方面的潜力,因为要在表达能力和计算复杂性之间进行trade-off。其次,考虑所有的交叉特征可能会引入噪音并降低预测性能,因为并非所有无用的交叉特征都能被成功过滤掉。
因此,论文
《Adaptive Factorization Network: Learning Adaptive-Order Feature Interactions》提出了Adaptive Factorization Network: AFN,从数据中自适应地学习任意阶次的交叉特征及其权重。其关键思想是:将feature embedding编码到一个对数空间中,并将特征的幂次转换为乘法。AFN的核心是一个对数神经转换层(logarithmic neural transformation layer),由多个vector-wise对数神经元组成。每个对数神经元的目的是:在可能有用的特征组合中,自动学习特征的幂次(即,阶次)。在对数神经转换层上,AFN应用前馈神经网络来建模element-wise的特征交互。与FM/HOFM不同的是,AFN能够自适应地从数据中学习有用的交叉特征,而且最大阶次可以通过数据自动学到。论文主要贡献:
据作者所知,他们是第一个将对数转换结构与神经网络结合起来,从而建模任意阶次的特征交互。
基于所提出的对数转换层,作者提出了
AFN从而从数据中自适应地学习任意阶次的交叉特征及其权重。作者表明:
FM/HOFM可以被解释为AFN的两种特例,并且AFN中学到的阶次允许在不同的交叉特征中rescaling feature embedding。论文在四个公共数据集上进行了广泛的实验。结果表明:所学的交叉特征的阶次跨度很大;与
SOTA方法相比,AFN取得了卓越的预测性能。
1.1 背景
Feature Embedding:遵从传统,我们将每个输入样本表示为一个稀疏的向量:其中:
feature field的数量,feature field的representation,由于大多数
categorical features是稀疏的、高维的,一个常见的做法是将它们映射到低维潜空间中的稠密向量(即,embedding)。具体而言,一个categorical featureone-hot encoded vector,然后计算embedding向量其中
feature fieldembedding matrix。对于数值特征
representation是一个标量categorical feature之间的交互,其中:
fieldembedding vector(由该field内的所有特征取值所共享)。
最终我们得到
feature embedding集合FM或其他模型。FM:FM显式建模高维数据的二阶特征交互。从公式上看,FM的预测为:其中
直观地,第一项
feature embedding的pair-wise内积之和。此外,
Higher-Order Factorization Machine: HOFM用于捕获高阶的特征交互:其中:
feature embedding的element-wise的乘积之和。HOFM的时间复杂度为feature embedding的维度。由于计算复杂度高,HOFM很少被应用于真正的工业系统。FM和HOFM的一个共同局限性是:它们以相同的权重来建模所有的特征交互。由于并非所有的交叉特征都是有用的,纳入所有的交叉特征进行预测可能会引入噪音并降低模型性能。如前所述,一些方法致力于缓解这一问题:
AFM利用注意力机制为不同的交叉特征分配非均匀的权重,xDeepFM只为保留的交叉特征学习权重。然而,这些方法引入了额外的成本,并且在模型训练前仍被限制在一个预设的最大特征交互阶次discriminative的高阶交叉特征的机会。在本文中,我们建议从数据中自适应地学习任意阶交叉特征。最大阶次和交叉特征集合都将通过模型训练自适应地确定,从而在不牺牲预测能力的前提下实现高计算效率。
Logarithmic Neural Network: LNN:对数神经网络(Logarithmic Neural Network)最初是为了近似unbounded的非线性函数而提出的。LNN由多个对数神经元组成,其结构如下图所示。从形式上看,一个对数神经元可以表述为:LNN的理念是将输入转换到对数空间,将乘法转化为加法,除法转化为减法,幂次转化为乘法。尽管多层感知机(multi-layer perceptron: MLP)是众所周知的通用函数逼近器,但当输入无界时,它们在逼近某些函数如乘法、除法和幂次方面的能力有限。相反,LNN能够在整个输入范围内很好地逼近这些函数。在本文中,我们利用对数神经元来自适应地学习数据中交叉特征的每个
feature field的幂次。我们强调LNN和我们提出的AFN之间的三个关键区别:AFN学到的幂次被应用到vector-wise level,并且在相同field的所有feature embedding之间共享。我们模型的输入是待学习的
feature embedding。因此,我们需要使用一些技术来保持梯度稳定,并学习适当的feature embedding和combination。在
AFN中,我们在学到的交叉特征上进一步应用前馈隐层,以增强我们模型的表达能力。AFN有几个显著的缺点:要求
embedding为正数,这对模型施加了很强的约束。由于大多数
embedding在零值附近,一个很微小的扰动(如计算精度导致的计算误差)就可能对模型产生影响,因此读者猜测模型难以训练。
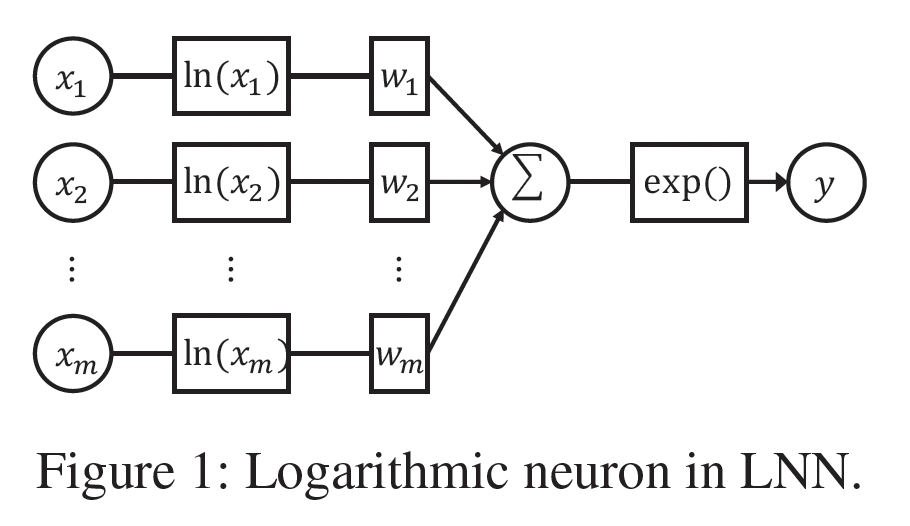
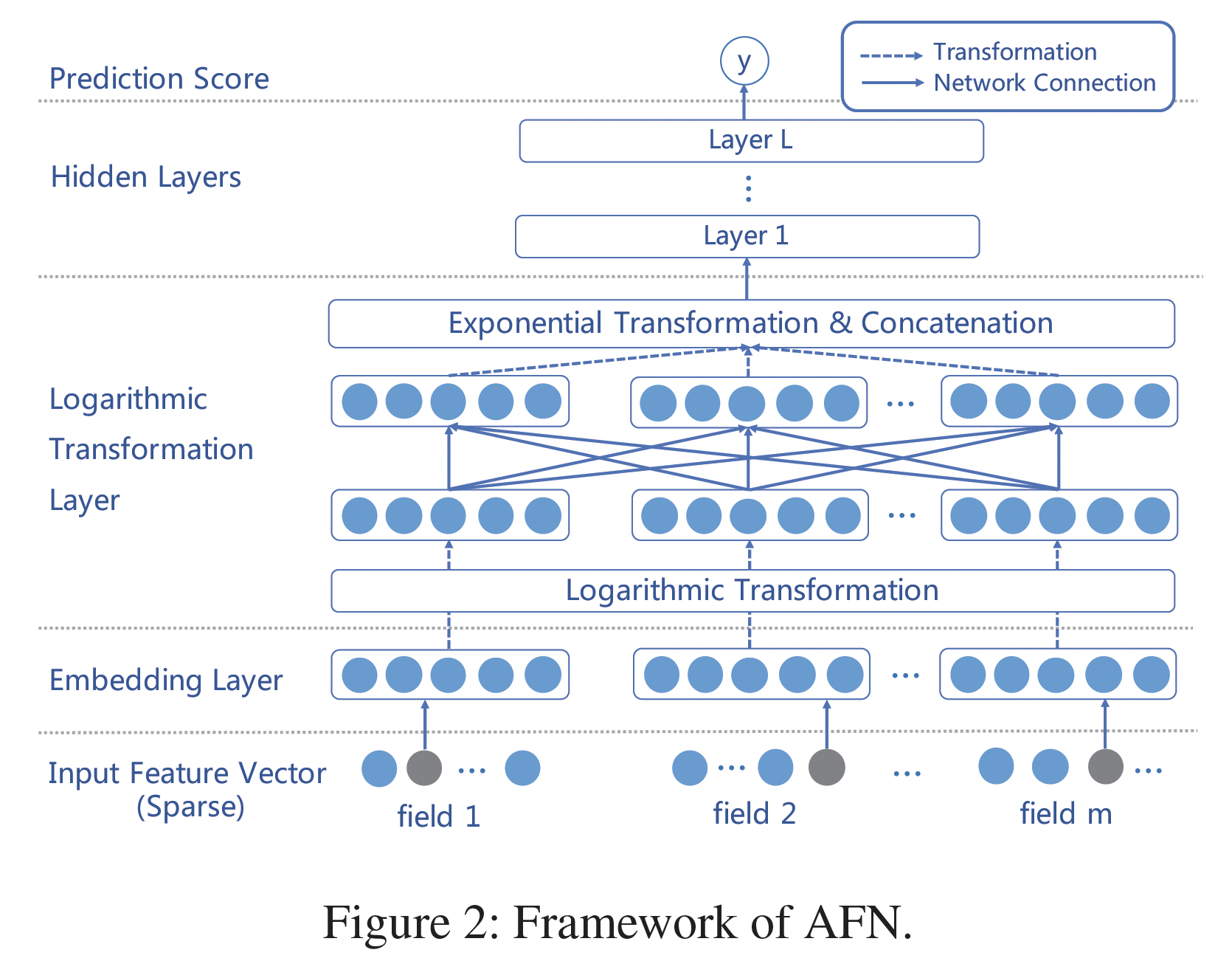
1.2 模型
AFN的整体结构如下图所示。Input Layer and Embedding Layer:AFN的inpyt layer同时采用sparse categorical feature和numerical feature。如前所述,所有的原始输入特征首先被转换为共享潜在空间的embedding。这里我们介绍两个实现
embedding layer的关键技术:首先,由于我们将对后续的层中的
feature embedding进行对数转换,我们需要保持embedding中的所有数值为正数。如何确保
embedding中的所有数值都是正的?论文没有说明。此外,embedding非负,这对模型施加了一个很强的约束。然后,即使采用了非负的embedding,然后对于接近零的embedding,它的 “对数--指数” 变换非常敏感,一个很微小的扰动(如计算精度导致的计算误差)就可能对模型产生影响,因此读者猜测模型较难训练。其次,建议在
zero embedding中加入一个小的正值(如
最后,
embedding layer的输出是positive feature embedding的一个集合:Logarithmic Transformation Layer:AFN的核心是对数转换层(logarithmic transformation layer),它学习交叉特征中每个feature field的幂(即阶次)。该层由多个vector-wise的对数神经元组成,第vector-wise对数神经元的输出为:其中:
feature field上的系数;element-wise的;对上式的主要观察是:每个对数神经元
feature field的二阶交叉特征。因此,我们可以使用多个对数神经元来获得任意阶次的不同feature combination作为该层的输出。注意,系数矩阵
0或1,其中Feed-forward Hidden Layers and Prediction:在对数转换层上,我们堆叠了几个全连接层从而组合所得到的交叉特征。我们首先将所有的交叉特征拼接起来作为前馈神经网络的输入:
其中:
然后我们将
其中:
最后,隐层的输出
其中:
prediction layer的权重向量和偏置。
Optimization:目标函数针对不同的任务(分类、回归、ranking)而做出相应的选择。常见的目标函数是对数损失:其中:
sigmoid函数。我们采用
Adam优化器进行随机梯度下降。此外,我们对logarithmic transformation、exponential transformation和所有隐层的输出进行batch normalization: BN。有两个原因:首先,
feature embeddingembedding往往涉及大的负值,并有显著的方差,这对后续几层的参数优化是有害的。由于BN可以缩放并shift输出为归一化的数值,因此它对AFN的训练过程至关重要。其次,我们在对数转换层之后采用多层神经网络。对隐层的输出进行
BN有助于缓解协方差漂移问题,从而导致更快的收敛和更好的模型性能。
Ensemble AFN with DNN:之前的工作(Wide&Deep、DeepFM、xDeepFM)提出将基于交叉特征的模型(如FM)的预测结果与基于原始特征的神经方法的预测结果进行ensemble,以提高性能。类似地,我们也可以将AFN与深度神经网络进行结合。为了执行AFN和神经网络之间的ensemble,我们首先分别训练这两个模型。之后,我们建立一个ensemble模型来结合两个训练好的模型的预测结果:其中:
AFN和DNN的预测结果,ensemble model可以通过logloss损失来进行训练。我们把这个ensemble模型称为"AFN+"。我们的
ensemble方法与DeepFM使用的方法有些不同:DeepFM的feature embedding在FM和DNN之间共享,而我们将AFN和DNN的embedding layer分开从而避免干扰。主要的原因是:与DeepFM不同,AFN中的embedding value的分布应该始终保持positive,这和DNN中embedding value的分布相差甚远。众所周知,在
CTR预测任务中,DNN模型的参数主要集中在embedding table。这里用到了两套embedding table,模型参数翻倍。根据我们的实验,这种分离方法略微增加了模型的复杂性,但会带来更好的性能。
讨论:
理解
AFN中的阶次:AFN通过对数转换层学习交叉特征中每个特征的阶次。由于对数转换层的权重矩阵AFN学到的特征阶次,我们借鉴了field-aware factorization machine: FFM的一些思想。在
FFM中,每个特征都关联feature embedding,其中feature field的数量。FFM与FM的区别在于,每个特征在与不同field的其它特征进行交互时采用不同的embedding。FFM的启示是:要避免不同field的特征空间之间的干扰。 在AFN中,每个特征的阶次可以被看作是相应feature embedding的一个比例因子。例如,考虑一个取值从0到1之间的embedding,大于1的阶次会缩小embedding值,而小于1的阶次则扩大embedding值。通过与FFM的类比,当与不同field的其它特征进行交互时,可以利用AFN学到的阶次来rescale feature embedding。与
FM和HOFM的关系:我们首先表明,FM可以被看作是AFN的一个特例。根据公式feature embedding的幂次element-level上近似于一个简单的sum函数,那么AFN可以准确地恢复FM。类似地,当我们有足够多的对数神经元来提供最大阶次内的所有交叉特征,并允许隐层近似
sum函数时,AFN能够恢复HOFM。时间复杂度:令
feature embedding维度和feature field数量。在AFN中,对数神经元可以在AFN的总时间复杂度是至于
HOFM,假设HOFM的时间复杂度与交叉特征的最大阶次AFN中,由于其自适应的交叉特征生成方式,AFN的时间成本与CIN接近。
1.3 实验
数据集:
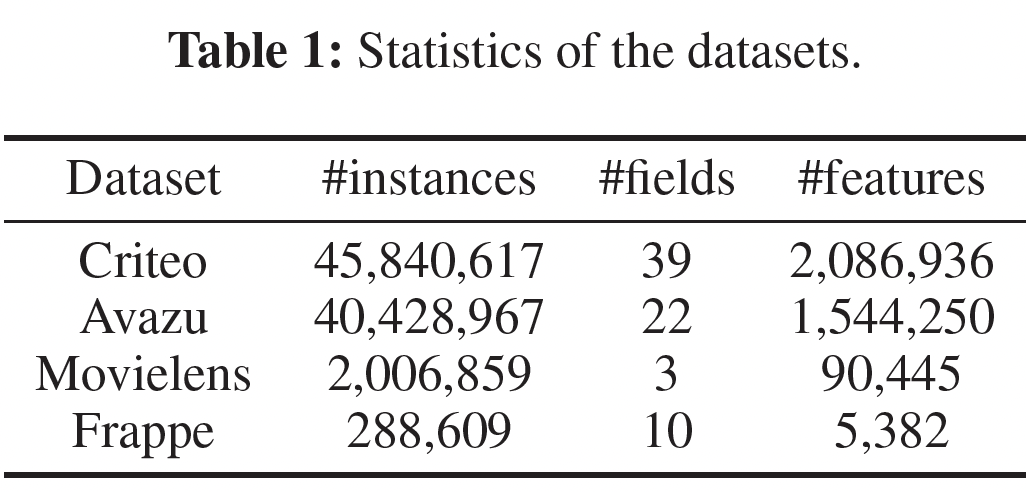
Criteo:包含13个数值特征和26个categorical feature。Avazu:包含22个feature field,包括用户特征和广告属性。Movielens:我们将每个tagging record((user ID, movie ID, tag)三元组)转换为一个特征向量来作为输入。target为:用户是否为电影分配了一个特定的tag。Frappe:我们将每条日志(user ID, app ID, context features)转换为一个特征向量来作为输入。target为:用户是否在上下文中使用过该app。
所有数据集的统计信息如下表所示。
评估指标:
AUC, Logloss。baseline方法:一阶方法(对原始特征进行线性相加):
Linear Regression: LR。考虑二阶交叉特征的
FM-based方法:FM、AFM。建模高阶特征交互的高级方法:
HOFM、NFM、PNN、CrossNet、CIN。涉及
DNN作为组件的ensemble方法:Wide&Deep(为公平比较,我们省略了手工制作的交叉特征),DeepFM、Deep&Cross、xDeepFM。
实现细节:
使用
Tensorflow实现、采用Adam优化器、学习率0.001、mini-batch size = 4096。对于
Criteo/Avazu/Movielens/Frappe数据集,默认的对数神经元数量1500/1200/800/600。AFN中默认使用3个隐层、每层400个神经元。为了避免过拟合,根据验证集的
AUC进行early-stopping。在所有的模型中,我们将
feature embedding的维度设置为10。我们对所有涉及
DNN的方法使用相同的神经网络结构(即3层:400-400-400)以进行公平的比较。HOFM的最高阶次设为3。所有其他的超参数都是在验证集上调优的。
对于每个经验结果,我们运行实验
3次并报告平均值。
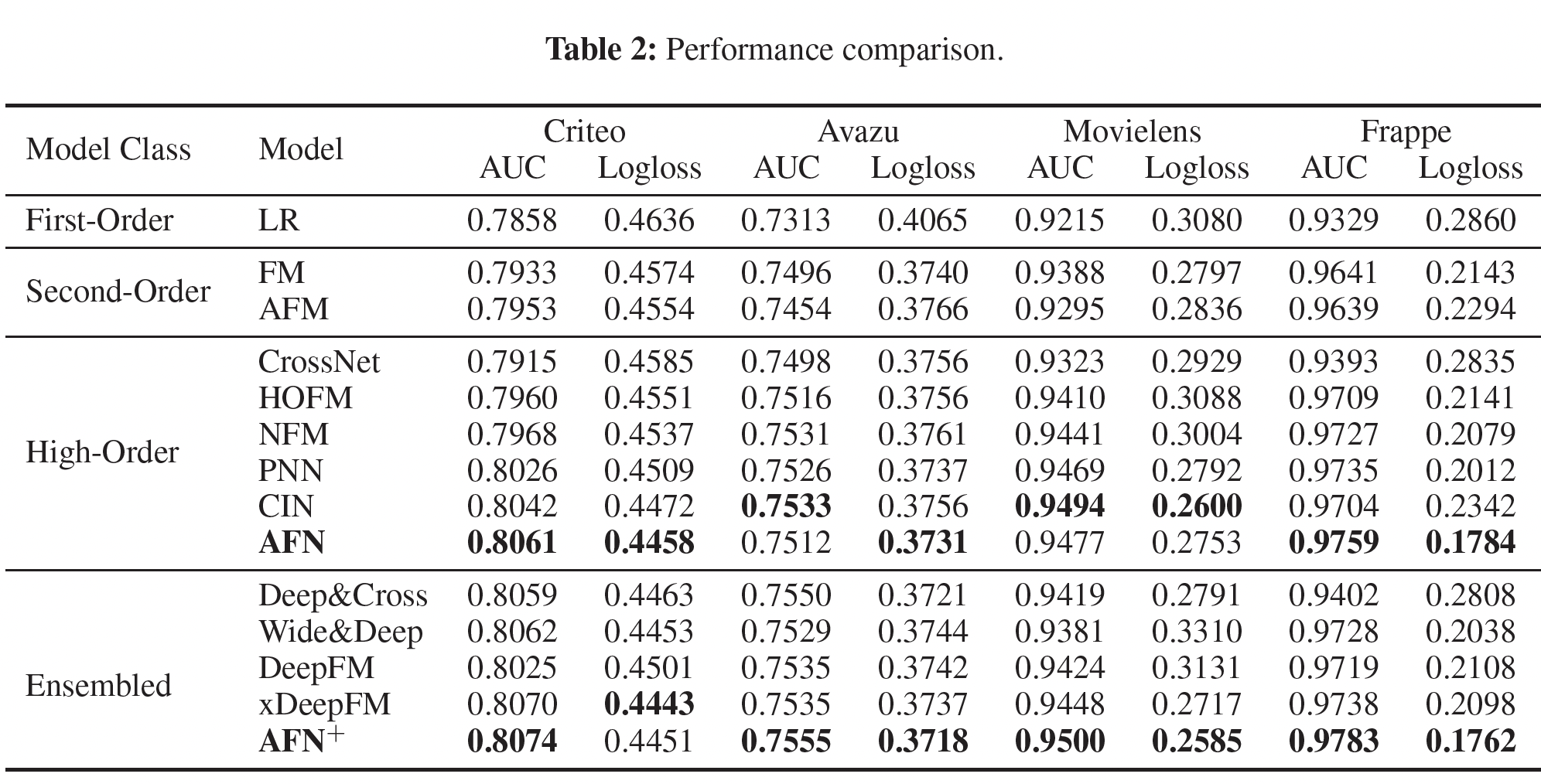
单模型的比较:单模型的比较如下表所示。可以看到:
AFN在所有的数据集上产生了最好的或有竞争力的性能。对于
Criteo和Frappe,AFN比第二好的模型CIN要好得多。对于
Movielens,AFN取得了第二好的性能。对于
Avazu,AFN取得了最好的logloss,而AUC适中。
关于较简单的模型在
Movielens和Avazu上的良好表现,我们猜测这两个数据集的预测更多依赖于低阶交叉特征,AFN的优势因此受到限制。请注意,Movielens只包含三个feature field,找到有用的高阶交叉特征的好处可能是微不足道的。AFN在所有数据集上的表现一直优于FM和HOFM,这验证了学习自适应阶次的交叉特征比建模固定阶次的交叉特征可以带来更好的预测性能。利用高阶交叉特征的模型通常优于基于低阶交叉特征的模型,特别是当
feature field的数量很大时。这与高阶特征交互具有更强的预测能力的直觉是一致的。
AFN并没有在所有数据集上展示出显著的提升。ensemble模型的比较:ensemble模型的比较如下表所示。可以看到:AFN+在四个数据集上取得了最佳性能。平均而言,AFN相比xDeepFM,在AUC和logloss上分别取得了0.003和0.012的改善。这表明,
AFN学到的自适应阶次的交叉特征与DNN建模的隐式特征交互有很大不同,因此在结合两种不同类型的特征交互进行预测时,性能增益显著提高。
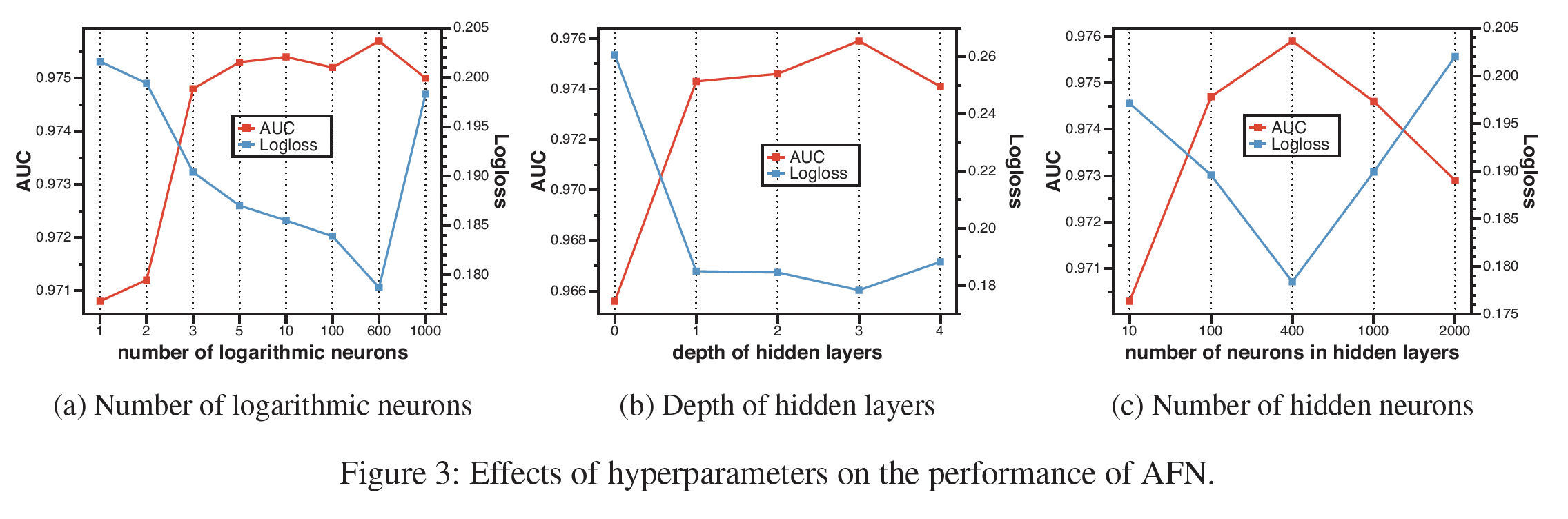
超参数研究:我们只提供
Frappe的结果,因为其他三个数据集的结果是相似的。对数神经元的数量:如下图
(a)所示:当神经元的数量变大时,
AFN的性能呈现上升趋势,随后是下降趋势。这表明应该采用适当数量的对数神经元,在表达能力和泛化之间做出权衡,以达到最佳性能。令人惊讶的是,即使对数神经元的数量少于
5个,AFN的优势也很稳定。这一结果表明,找到少量的discriminative交叉特征对预测的准确性至关重要,而AFN对于找到这些关键的交叉特征是有效的。
隐层深度:如下图
(b)所示:在学到的自适应阶次的交叉特征上堆叠隐层有利于提高模型性能。
值得注意的是,
AFN的性能并不高度依赖于隐层的数量。当深度被设置为0时,AFN仍然可以取得相当好的结果。这证明了对数转换层在学习discriminative交叉特征方面的有效性。
隐层神经元数量:如下图
(c)所示:AFN的性能首先随着神经元数量的增加而增长。这是因为更多的参数给模型带来了更好的表达能力。当隐层的神经元数量超过
600时,性能开始下降,这是由于过拟合导致的。
学到的阶次:下图显示了在
Criteo数据集上整个训练过程中特征阶次的变化。从下图
(a)可以看到:各个feature field的阶次通常以0为中心,在[-1,1]的范围内。这与典型的factorization-based的方法截然不同,在这种方法中,每个特征的阶次要么为0、要么为1。学到的特征阶次的relaxation允许原始feature embedding在组成不同的交叉特征时被rescale。下图
(b)给出了交叉特征的阶次的分布,其中交叉特征的阶次是组成它的各个特征的阶次的绝对值之和来计算的。可以看到:在训练过程中,学到的交叉特征的阶次被逐渐优化。最终的交叉特征阶次分布在一个很宽的范围内(从
4到10),而不是像许多factorization-based方法那样被固定在一个预定义的值上(例如2)。
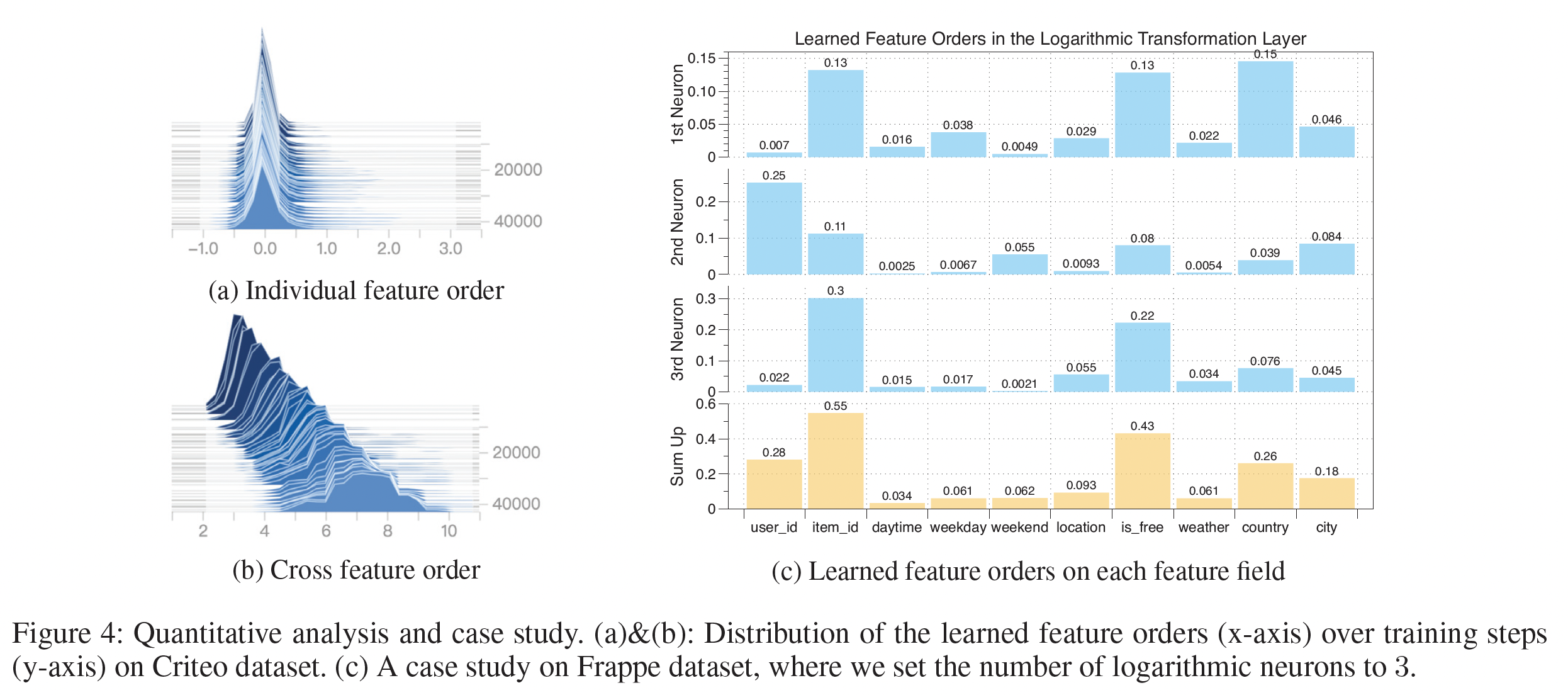
案例研究:我们对
Frappe数据集进行了案例研究。为了说明问题,我们将对数神经元的数量限制为3个。Figure 4(c)提供了每个神经元上单个特征阶次的绝对值和总和。从图中,我们可以大致推断出,三个交叉特征
(item id, is free, country), (user id, item id), (item id, is free)在各自的对数神经元中被学习。此外,通过
sum三个神经元的特征阶次,发现最discriminative的feature field是item id, is free, user id。这是合理的,因为user id和item id是协同过滤中最常用的特征;而is free表示用户是否为mobile app付费,是用户对app偏好的一个有力指标。