一、AutoEmb [2020]
《AutoEmb: Automated Embedding Dimensionality Search in Streaming Recommendations》
deep learning based recommender systems: DLRSs的架构通常主要由三个关键部分组成:embedding layer:将高维空间中的原始的user/item特征映射到低维embedding空间中的稠密向量。hidden layer:进行非线性变换以转换输入特征。output layer:根据hidden layer的representation对特定的推荐任务进行预测。
大多数现有的研究都聚焦在为
hidden layer和output layer设计复杂的神经网络架构,而embedding layer并没有获得太多的关注。然而,在拥有海量user和item的大规模真实世界推荐系统中,embedding layer在准确推荐中发挥着巨大的关键作用。embedding最典型的用途是将一个ID(即user ID或item ID)转换成一个实值向量。每个embedding都可以被认为是一个latent representation。与手工制作的特征相比,经过良好学习的embedding已经被证明可以显著提高推荐性能。这是因为embedding可以降低categorical变量的维度(如one-hot id),并有意义地在潜空间中代表user/item。大多数现有的
DLRSs在其embedding layer中往往采用统一的固定维度。换句话说,所有的user(或item)共享相同的、固定的embedding size。这自然引起了一个问题:我们是否需要为不同的user/item采用不同的embedding size?为了研究这个问题,论文
《AutoEmb: Automated Embedding Dimensionality Search in Streaming Recommendations》对movielens-20m数据集进行了初步研究。对于每个用户,作者首先选择该用户的固定比例的评分作为测试集,然后选择embedding维度为2/16/128的DLRS的推荐性能在mean-squared-error: MSE和准确率方面的变化。更低的MSE(或更高的准确率)意味着更好的性能。注意,作者在这项工作中把user/item的交互次数称为popularity。从图中可以看到:随着popularity不同
embedding size的模型的性能增加,但较大的embedding size获益更多。较小的
embedding size首先工作得更好,然后被较大的embedding size所超越。
这些观察结果是非常符合预期,因为
embedding size通常决定了待学习的模型参数的数量、以及由embedding所编码信息的容量。一方面,较小的
embedding size往往意味着较少的模型参数和较低的容量。因此,当popularity小的时候,它们可以很好地工作。然而,当随着popularity的增加,embedding需要编码更多的信息,较低的容量会而限制其性能。另一方面,更大的
embedding size通常表示更多的模型参数和更高的容量。它们通常需要足够的数据从而被良好地训练。因此,当popularity小的时候,它们不能很好地工作;但随着popularity的增加,它们有可能捕获更多的信息。
鉴于
user/item在推荐系统中具有非常不同的popularity,DLRSs应该允许不同的embedding size。这一特性在实践中是非常需要的,因为现实世界的推荐系统是popularity高度动态的streaming。例如,新的交互会迅速发生,新的用user/item会不断增加。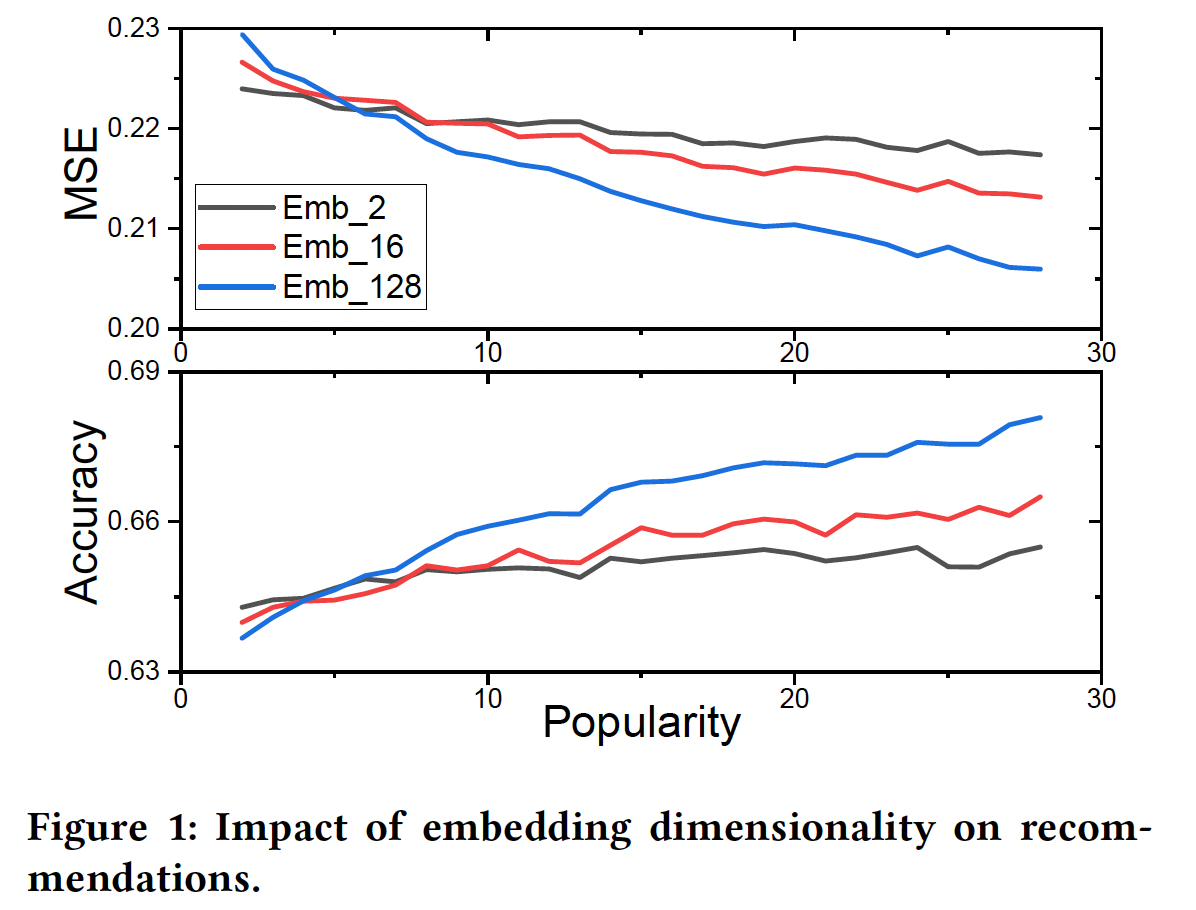
在论文
《AutoEmb: Automated Embedding Dimensionality Search in Streaming Recommendations》中,作者的目标是在streaming setting下,在embedding layer为不同的user/item实现不同的embedding size。这里面临着巨大的挑战:首先,现实世界的推荐系统中的
user/item的数量非常大,而且popularity是高度动态的,很难为不同的user/item手动选择不同的embedding size。其次,在现有的
DLRSs中,first hidden layer的输入维度通常是统一的和固定的,它们很难接受来自embedding layer的不同维度。
作者试图解决这些挑战,从而建立了一个基于端到端的可微的
AutoML框架(即,AutoEmb),它可以通过自动的、动态的方式利用各种embedding size。论文通过现实世界的电商数据中的实验来证明了所提出的框架的有效性。相关工作:
deep learning based recommender system:近年来,一系列基于深度学习技术的神经推荐模型被提出,性能提升明显(如,NCF, DeepFM, DSPR, MV-DNN, AutoRec, GRU4Rec)。然而,这些工作大多集中在设计复杂的神经网络架构上,而对embedding layer没有给予过多关注。AutoML for Neural Architecture Search:《Neural input search for large scale recommendation models》首次将NAS用于大规模的推荐模型,并提出了一种新型的embedding方式,即Multi-size Embedding: ME。然而,它不能应用于streaming recommendation setting,其中popularity不是预先知道的而是高度动态的。
1.1 模型
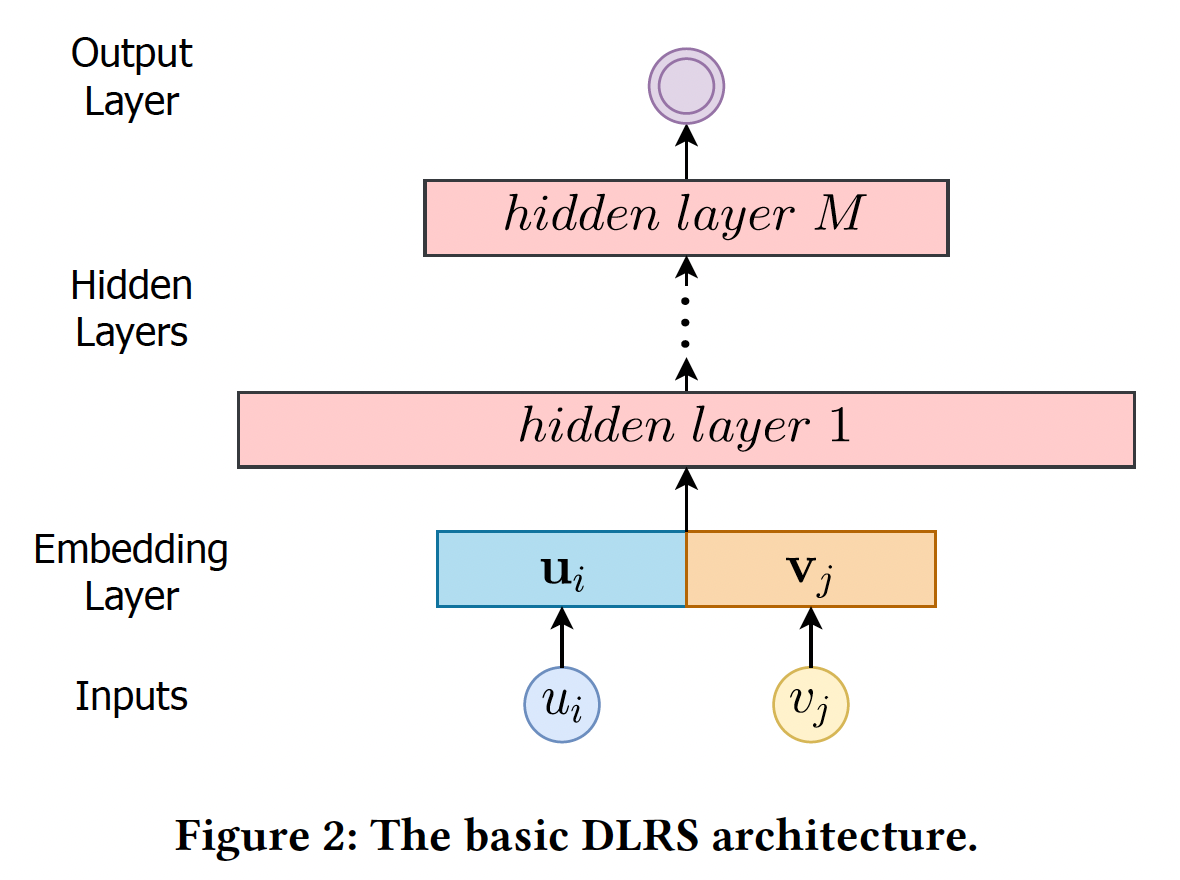
Basic DLRS架构:我们在下图中阐述了一个basic的DLRS架构,它包含三个部分:embedding layer:将user ID/item IDembedding向量hidden layer:是全连接层,将embedding向量hierarchical feature representation。output layer:生成prediction从而用于推荐。
给定一个
user-item的交互,DLRS首先根据user ID和item ID进行embedding-lookup过程,并将两个embedding拼接起来;然后DLRS将拼接后的embedding馈入hidden layer并进行预测。 然而,它有固定的神经网络架构,不能处理不同的embedding size。接下来,我们将加强这个basic的DLRS架构,以实现各种embedding size。AutoEmb仅聚焦于user id和item id的embedding size优化,而没有考虑其他的categorical feature。并且论文描述的算法仅应用streaming recommendation setting。论文的思想比较简单:为每个
id分配embedding size,然后用强化学习进行择优。难以落地,因为最终得到的模型,参数规模几乎增长到换一个思路:给定一个
baseline model,我们可以将baseline model的embedding size划分为NIS),然后由控制器来选择需要横跨几个子维度。这种方法和NIS的区别在于:NIS的控制器是独立的自由变量,每个变量代表对应的概率。虽然控制器没有包含item的popularity信息,可以自由变量的update次数就代表了item出现的频次,因此隐式地包含了popularity信息。而这个思路里,控制器的输入包含了
item的popularity信息,可以给予控制器一定的指导。
Enhanced DLRS架构:正如前面所讨论的,当popularity较低时,具有较少模型参数的shorter embedding可以产生更好的推荐;而随着popularity的增加,具有更多模型参数和更高容量的longer embedding可以获得更好的推荐性能。在这个观察的激励下,为具有不同popularity的user/item分配不同的embedding size是非常理想的。然而,basic DLRS架构由于其固定的神经网络架构而无法处理各种embedding size。解决这一挑战的基本思路是将各种
embedding size转换为同一维度,这样DLRS就可以根据当前user/item的popularity选择其中一个transformed embedding。下图说明了embedding的转换和选择过程。假设我们有embedding空间embedding维度(即,embedding size)分别为embedding空间的embedding集合为embedding向量其中:
bias向量。经过线性变换,我们将原始
embedding向量embeddingmagnitude)变化很大,这使得它们变得magnitude-incomparable。为了解决这一难题,我们对转换后的embeddingBatch- Norm与Tanh激活:其中:
mini-batch的均值,mini-batch的方差,Tanh激活函数将embedding归一化到0~1之间。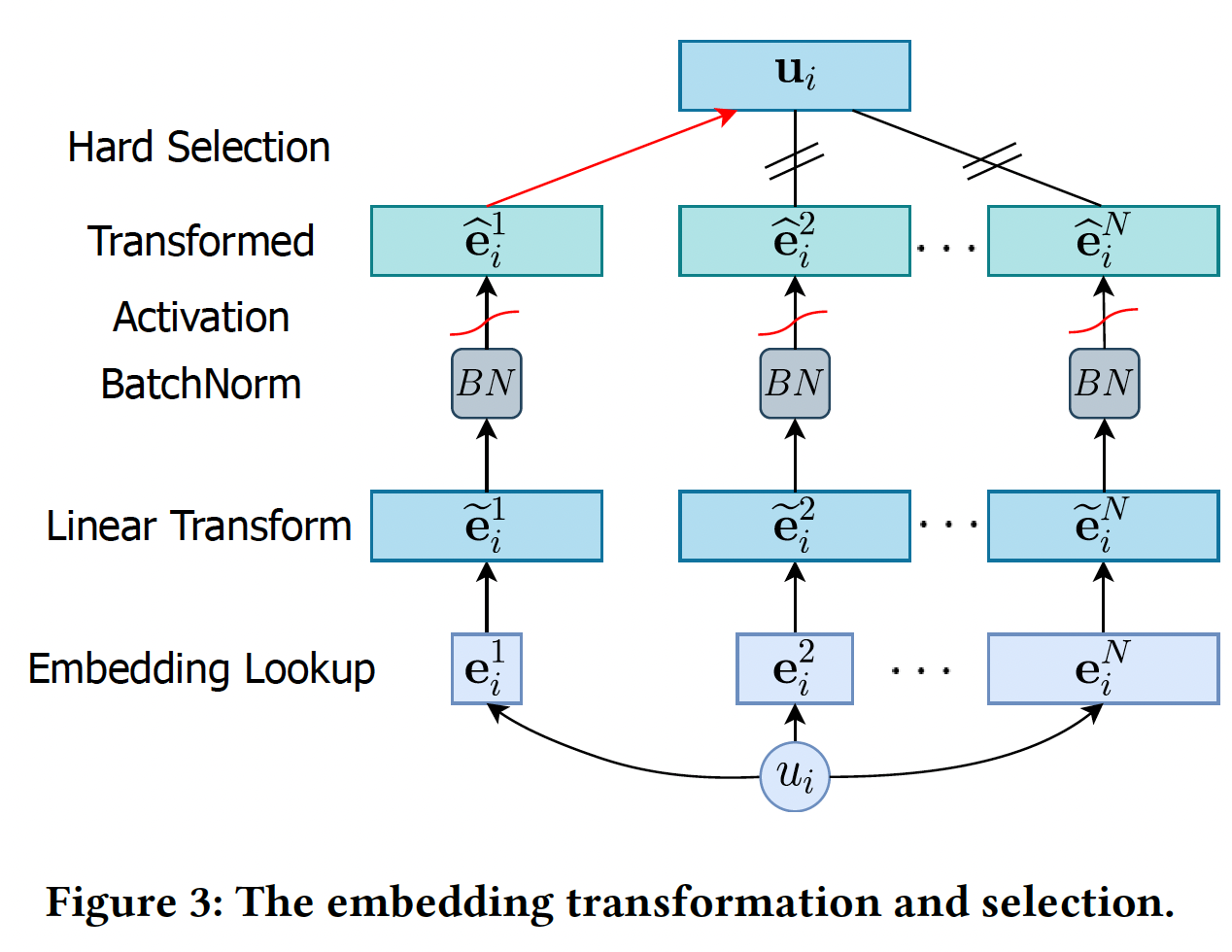
给定一个
itemembedding集合magnitude-comparable的转换后的embedding根据
popularity,DLRS将选择一对转换后的embeddinguseritemrepresentation:embedding size是由一个控制器controller选择的,将在后面详细介绍。然后,我们将user representation和item representation拼接起来,即output layer从而生成useritem为了获得理想的效果,
embedding table占据了模型的绝大部分参数,因此embedding table使得模型的规模几乎翻了Controller:我们提出了一种基于AutoML的方法来自动确定embedding size。具体而言,我们设计了两个控制器网络,分别决定user embedding size和item embedding size,如下图所示。对于一个特定的
user/item,控制器的输入由两部分组成:user/item的当前popularity、上下文信息(如previous超参数和loss)。上下文信息可以被看作是衡量previously分配给user/item的超参数是否运作良好的信号。换句话说,如果previous超参数工作得很好,那么这次生成的新的超参数应该有些类似。controller的输入特征具体都是什么?论文并未说明。也不必深究,因为论文的应用价值不高。该控制器接收上述输入,通过几层全连接网络进行转换,然后生成
hierarchical feature representation。output layer是具有Softmax layer。在这项工作中,我们用user controller的item controller的embedding空间的概率。controller自动选择最大概率的空间作为final embedding空间,即:有了控制器,
embedding size搜索的任务就简化为优化控制器的参数,从而根据user/item的popularity自动生成合适的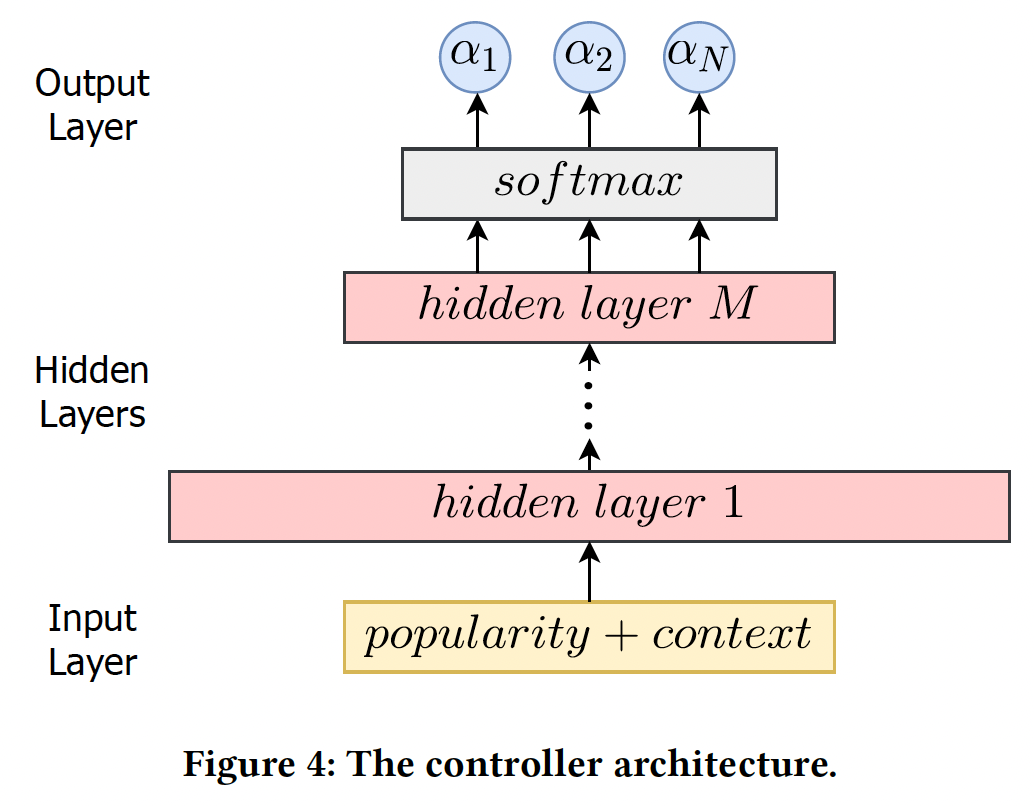
Soft Selection:上面的控制器对embedding空间进行了hard selection,即:每次我们只从控制器中选择一个具有最大概率的embedding空间。这种hard selection使得整个框架不是端到端的可微的。为此,我们选择了一种soft selection:有了
soft selection,enhanced DLRS是端到端的可微的。新的结构如下图所示,我们增加了transformed embedding layer,它对embedding空间进行soft selection,选择过程由两个控制器(分别用于user和item)来决定。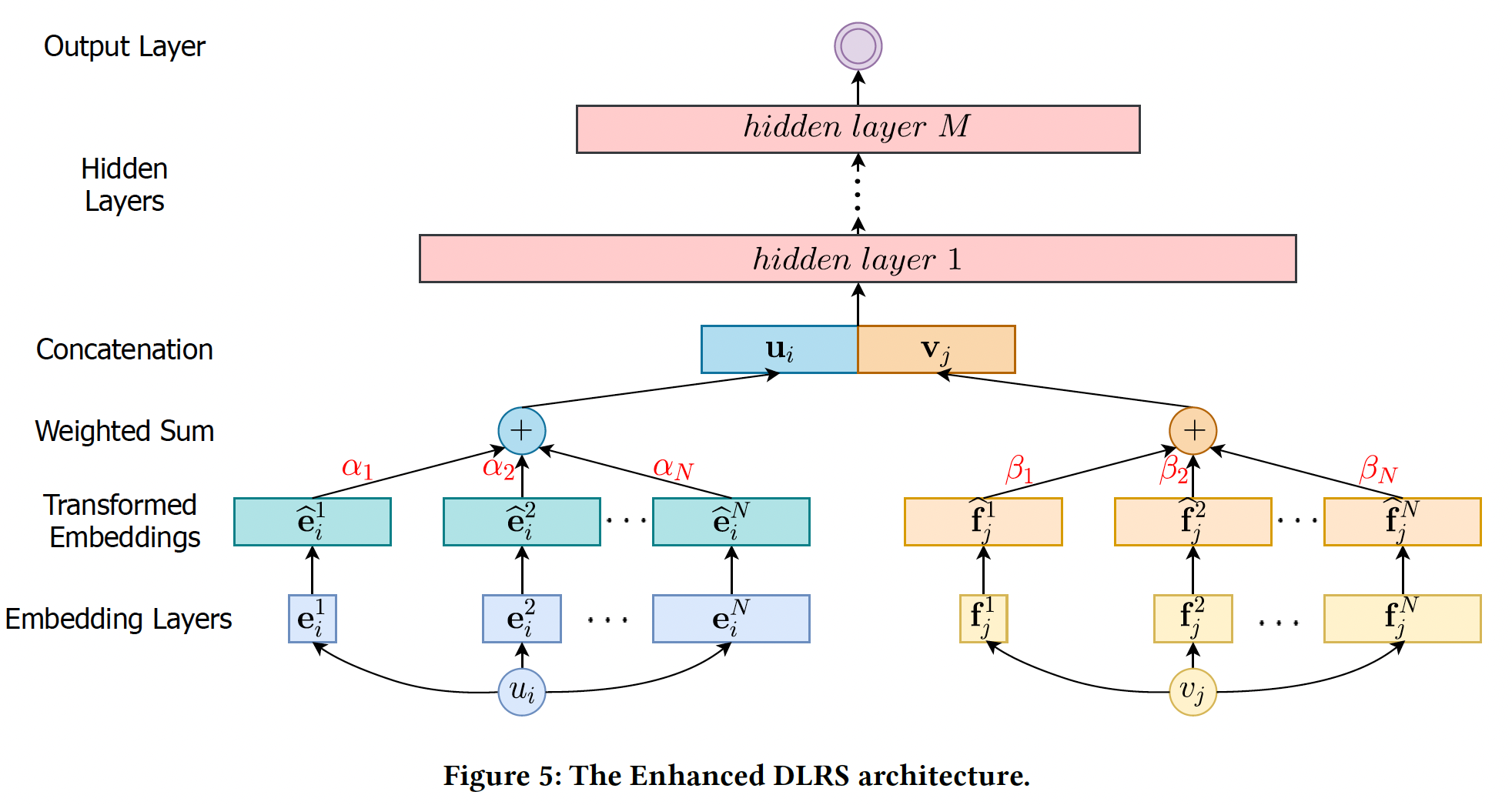
优化方法:优化任务是联合优化
DLRS的参数(如differentiable architecture search: DARTS)技术概念的启发,我们为AutoEmb框架采用了基于DARTS的优化,通过梯度下降分别优化训练损失DLRS的参数embedding dimensionality search的目标是找到使验证损失DLRS的参数bilevel优化问题,其中因为优化内层的
DARTS的近似方案:其中
training step来估计值得注意的是,与计算机视觉任务上的
DARTS不同,我们没有推导离散架构的阶段(即,DARTS根据softmax概率选择最可能的操作来生成离散的神经网络架构)。这是因为随着新的user-item交互的发生,user/item的popularity是高度动态的,这使我们无法为user/item选择一个特定的embedding size。DARTS based Optimization for AutoEmb算法:输入:
user-item交互、以及ground-truth标签输出:训练好的
DLRS参数算法步骤:
迭代直到收敛,迭代步骤:
从
previous的user-item交互中随机采样一个mini-batch的验证数据。基于梯度下降来更新
其中
first-order approximation。收集一个
mini-batch的训练数据。基于当前参数
基于当前参数
DLRS的prediction。评估
prediction的效果并记录下来。通过梯度下降来更新
值得注意的是,在
batch-based streaming recommendation setting中,优化过程遵循"evaluate, train, evaluate, train..."的方式。 换句话说,我们总是不断地收集新的user-item交互数据。当我们有一个完整的mini-batch的样本时,我们首先根据我们的AutoEmb框架的当前参数进行预测,评估预测的性能并记录下来;然后我们通过最小化prediction和ground truth label之间的损失来更新AutoEmb的参数。接下来我们收集另一个mini-batch的user-item交互,执行同样的过程。因此,不存在预先拆分的验证集和测试集。换句话讲:为了计算
previous的user-item交互中采样一个mini-batch,作为验证集。没有独立的测试阶段,即没有预先拆分的测试集。
遵循
《Streaming recommender systems》中的streaming recommendation setting,我们也有离线参数估计阶段和在线推理阶段:在离线参数估计阶段,我们使用历史上的
user-item交互来预先训练AutoEmb的参数。然后我们在线启动
AutoEmb,在在线推理阶段持续更新AutoEmb参数。
1.2 实验
数据集:
Movielens-20m, Movielens-latest, Netflix Prize data。统计数据如下表所示。对于每个数据集,我们使用
70%的user-item交互进行离线参数估计,其他30%用于在线学习。为了证明我们的框架在embedding selection任务中的有效性,我们消除了其他的上下文特征(如,用户的年龄、item的category)从而排除其他特征的影响。但为了更好地推荐,将这些上下文特征纳入框架是很简单的。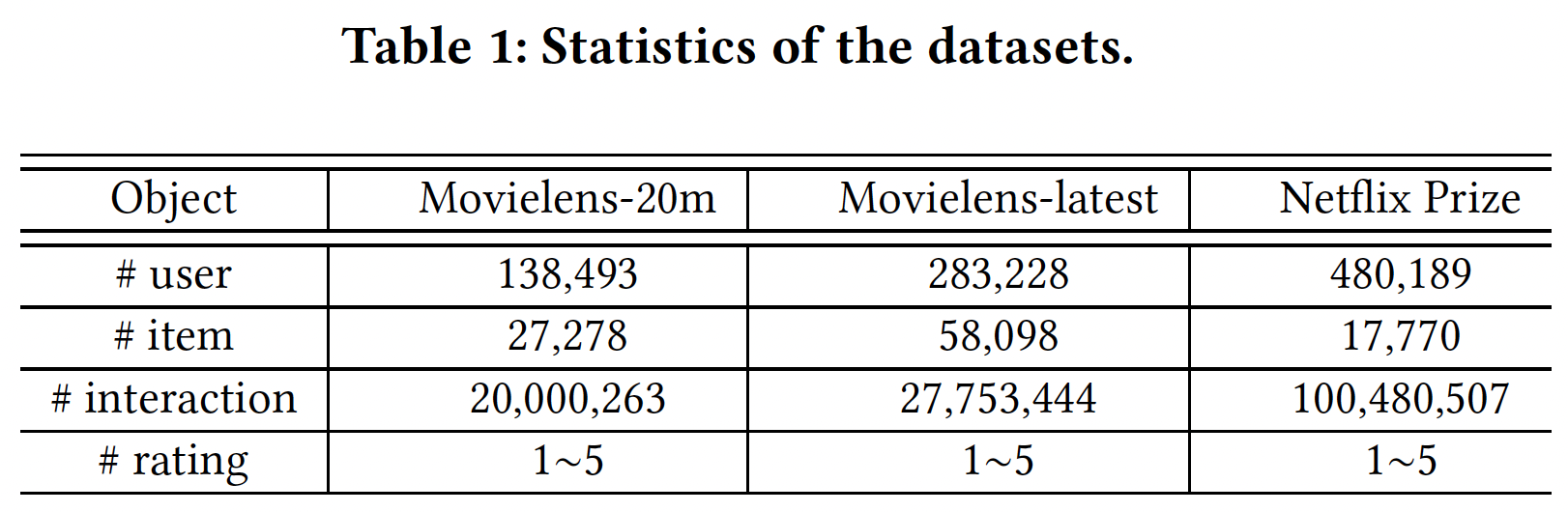
实现细节:
对于
DLRS:embedding layer:选择embedding sizeembedding维度为128。我们将每个user/item的三个embedding拼接起来,这大大改善了embedding的lookup速度。hidden layer:我们有两个隐层,大小为256*512和512*512。output layer:我们做两类任务:对于
rating regression任务,输出层为512*1。对于
rating classification任务,输出层为512*5,采用Softmax激活,因为有5类评级。
对于控制器:
input layer:输入特征维度为38。hidden layer:我们有两个隐层,大小为38*512和512*512。output layer:形状为512*3,采用Softmax激活函数,并输出
batch-size = 500,DLRS和控制器的学习率分别为0.01和0.001。AutoEmb框架的所有超参数都通过交叉验证来调优。相应地,我们也对baseline进行了超参数调优,以进行公平的比较。
评估指标:
对于回归任务,我们首先将评分二元化为
{0, 1},然后通过最小化mean-squared-error: MSE损失来训练框架。性能可以通过MSE损失和准确率来评估(我们使用0.5作为阈值来分配标签)。如何二元化,作者并未说明。读者猜测是用当前评分除以最大评分(如,
5分)从而得到0 ~ 1之间的浮点数。对于分类任务,评分
1~5被视为5个类,框架通过最小化交叉熵损失(CE loss)进行训练。性能由交叉熵和准确率来衡量。
baseline方法:Fixed-size Embedding:为所有的user/item分配了一个固定的embedding size。为了公平比较,我们将embedding size设定为146 = 2 + 16 + 128。换句话说,它占用的内存与AutoEmb相同。Supervised Attention Model: SAM:它具有与AutoEmb完全相同的架构,同时我们通过端到端的监督学习的方式,在同一个batch的训练数据上同时更新DLRS的参数和控制器的参数。Differentiable architecture search: DARTS:它是标准的DARTS方法,为三种类型的embedding维度训练
值得注意的是,
Neural Input Search model和Mixed Dimension Embedding model不能应用于streaming recommendation setting,因为它们假设user/item的popularity是预先知道的和固定的,然后用大的embedding size来分配高popularity的user/item。然而,在现实世界的streaming recommender system中,popularity不是预先知道的,而是高度动态的。在线阶段的比较结果如下表所示。可以看到:
SAM的表现比FSE好,因为SAM根据popularity在不同维度的embedding上分配注意力权重,而FSE对所有user/item都有一个固定的embedding维度。这些结果表明,推荐质量确实与user/item的popularity有关,而引入不同的embedding维度并根据popularity调整embedding上的权重可以提高推荐性能。DARTS优于SAM,因为像DARTS这样的AutoML模型在验证集上更新控制器的参数,可以提高泛化能力,而像SAM这样的端到端模型在同一个batch训练数据上同时更新DLRS和控制器的参数,可能导致过拟合。这些结果验证了AutoML技术比传统的监督学习在推荐中的有效性。我们提出的模型
AutoEmb比标准DARTS模型有更好的性能。DARTS在三种embedding维度上为每个user/item分别训练了user/item的这些权重可能不会被很好地训练,因为这个user/item的交互有限。AutoEmb的控制器可以纳入大量的user/item交互,并从中捕获到重要的特征。另外,控制器有一个显式的
popularity输入,这可能有助于控制器学习popularity和embedding维度之间的依赖关系,而DARTS则不能。这些结果证明了开发一个控制器而不仅仅是实值权重的必要性。在离线参数估计阶段之后,在线阶段的大多数
user/item已经变得非常popular。换句话说,AutoEmb对热门user/item有稳定的改进。
综上所述,所提出的框架在不同的数据集和不同的指标上都优于
baseline。这些结果证明了AutoEmb框架的有效性。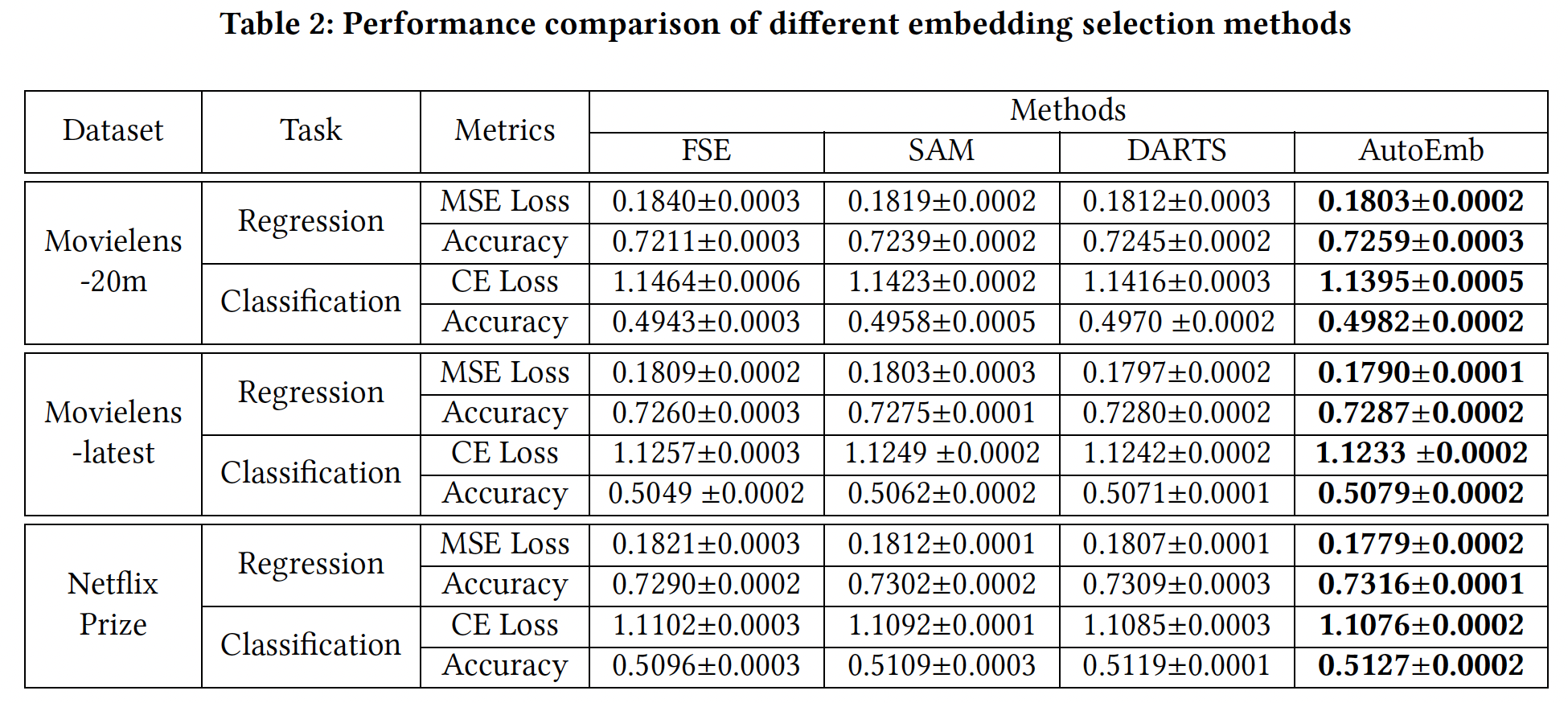
我们将调查所提出的控制器是否能根据各种
popularity产生适当的权重。因此,我们比较了没有控制器的FSE、有监督注意力控制器的SAM、以及有基于AutoML的控制器的AutoEmb。Figure 6显示了Movielens-20m数据集的结果,其中x轴是popularity,y轴对应的是性能。由于篇幅有限,我们省略了其他数据集的类似结果。可以看到:当
popularity较小时,FSE的表现比SAM和AutoEmb差。这是因为较大维度的embedding需要足够的数据才能很好地学习。参数较少的小型embedding可以快速捕捉一些high-level的特性,这可以帮助冷启动预测。随着
popularity的提高,FSE的表现超过了SAM。这个结果很有趣,但也很有启发性,原因可能是,SAM的控制器过拟合少量的训练样本,这导致了次优的性能。相反,
AutoEmb的控制器是在验证集上训练的,这提高了它的泛化能力。这个原因也将在下面的小节中得到验证。AutoEmb总是优于FSE和SAM,这意味着所提出的框架能够根据popularity自动地、动态地调整不同维度的embedding的权重。为了进一步探究
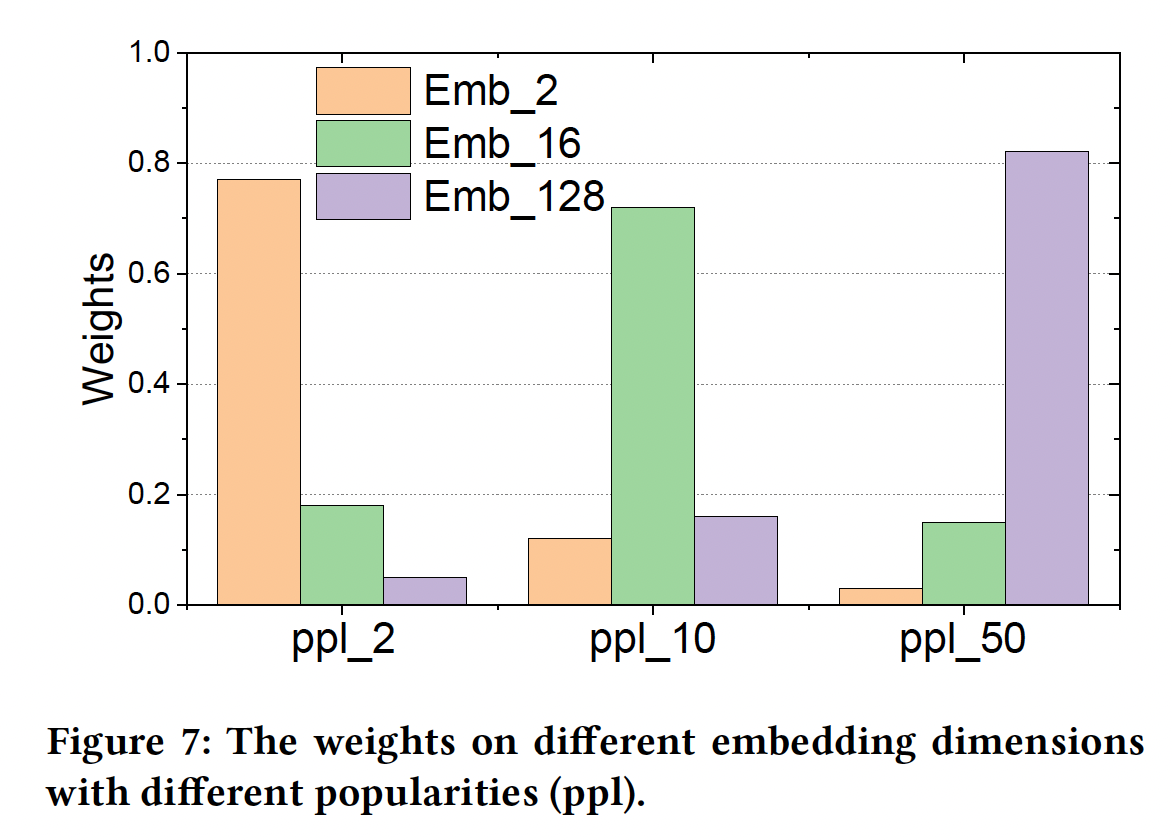
AutoEmb的控制器根据popularity产生的权重,我们在Figure 7中画出了不同popularity的权重分布。我们可以观察到:在小的popularity下,分布倾向于小维度的embedding;而随着popularity的增加,分布倾向于大维度的embedding。这一观察验证了我们的上述分析。
综上所述,
AutoEmb的控制器可以通过自动的、动态的方式为不同的popularity产生合理的权重。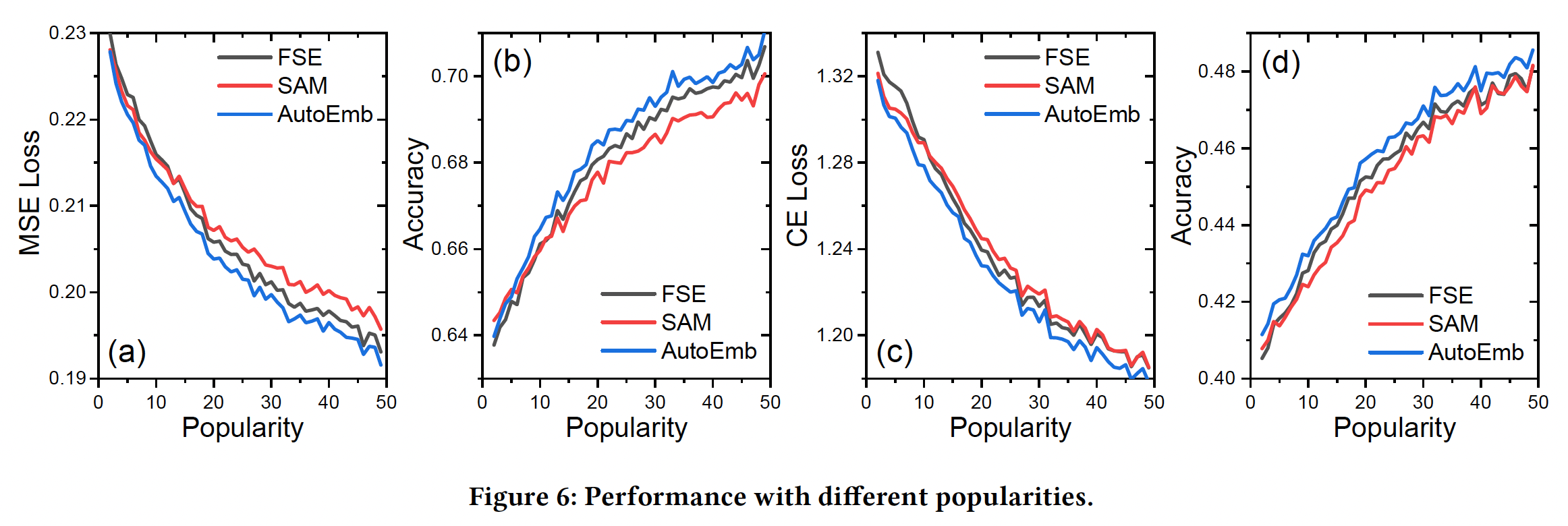
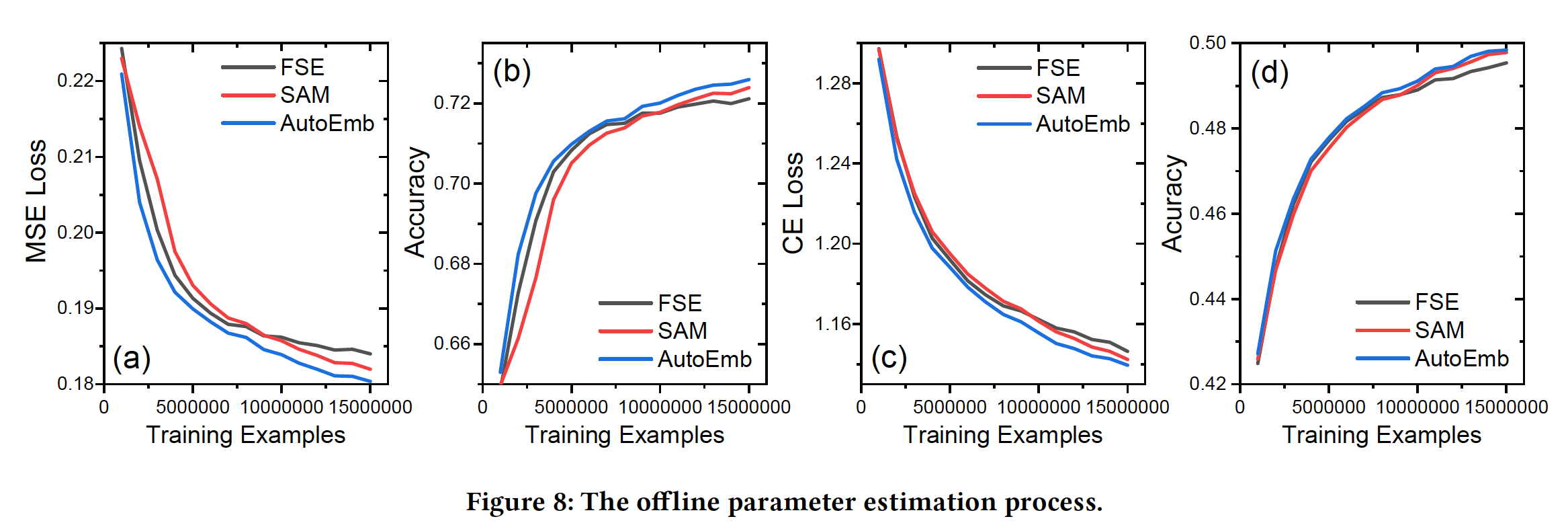
不同数据规模下的性能:训练基于深度学习的推荐系统通常需要大量的
user-item交互数据。我们提出的AutoEmb框架在DLRS中引入了一个额外的控制器网络、以及一些额外的参数,这可能使它难以被很好地训练。我们在下图中展示了优化过程,其中x轴是训练样本的数量,y轴对应的是性能。可以看到:在早期训练阶段,
SAM的表现最差,因为它的控制器对少量的训练样本过拟合。随着数据的增加,
SAM的过拟合问题逐渐得到缓解,SAM的表现优于FSE,这验证了在不同embedding维度上加权的必要性。AutoML在整个训练过程中优于SAM和FSE。尤其是在训练样本不足的早期训练阶段,它能明显提高训练效果。