一、MDE [2020]
《Mixed Dimension Embeddings with Application to Memory-Efficient Recommendation Systems》
标准的
embedding做法是:将objects以固定的统一纬度(uniform dimension: UD)当
embedding维度当
embedding维度objects数量很大时,内存消耗就成为一个问题。例如,在推荐模型中,embedding layer可以占到存储模型所需内存的99.9%以上,而在large-scale setting中,它可能会消耗数百GB甚至数百TB。不仅内存消耗是一个瓶颈,模型太大也容易过拟合。
因此,寻找新颖
embedding representation是一个重要的挑战,其中该embedding representation使用更少的参数,同时保留下游模型的预测性能。在现实世界的
applications中,object的频率往往是严重倾斜的。例如:对于
full MovieLens数据集,top 10%的用户收到的query数量和剩余90%的用户一样多、top 1%的item收到的query数量和剩余99%的item一样多。此外,在
Criteo Kaggle数据集上,top 0:0003%的indices收到的query数量与剩余3200万个indices一样多。
为了在推荐中利用
heterogeneous object popularity,论文《Mixed Dimension Embeddings with Application to Memory-Efficient Recommendation Systems》提出了mixed dimension(MD) embedding layer,其中一个specific-object的embedding维度随着该object的popularity而变化,而不是保持全局统一。论文的案例研究和理论分析表明:MD embedding的效果很好,因为它们不会在rare embedding上浪费参数,同时也不会欠拟合popular embedding。此外,在测试期间,MD embedding通过有效地分配参数从而最小化popularity-weighted loss。论文贡献:
论文提出了一种用于推荐系统的
mixed dimension embedding layer,并提供了一种新颖的数学方法来确定具有可变popularity的特征的尺寸。这种方法训练速度快、易于调优、并且在实验中表现良好。通过矩阵补全(
matrix completion)和factorization model,论文证明了在有足够的popularity倾斜的情况下,mixed dimension embedding在内存有限的情况下会产生较低的失真,在数据有限的情况下会有更好的泛化效果。对于内存有限的领域,论文推导出最佳特征维度。这个维度只取决于特征的
popularity、参数预算、以及pairwise交互的奇异值谱。
1.1 背景
与典型的协同过滤(
collaborative filtering: CF)相比,CTR预测任务包括额外的上下文。这些上下文特征通过索引集合(categorical)和浮点数(continuous)来表达。这些特征可以代表关于点击事件或个性化事件的上下文的任意细节。第categorical特征可以用一个索引categorical特征,我们还有one-hot向量。我们使用
SOTA的deep learning recommendation model: DLRM作为一个现成的深度模型。各种深度CTR预测模型都是由内存密集型的embedding layer驱动的。embedding layer的大小和预测性能之间的权衡似乎是一个不可避免的权衡。对于一个给定的模型embedding layercategorical特征。通常,每个categorical特征都有自己的独立的embedding matrix:embedding layer,categorical的embedding matrix。相关工作:最近的工作提出了类似、但实质上不同的
non-uniform embedding架构的技术,尤其是针对自然语言处理领域(《Groupreduce: Block-wise low-rank approximation for neural language model shrinking》、《Adaptive input representations for neural language modeling》)。这些方法都不适合用于CTR预测,因为它们忽略了CTR中固有的feature-level结构。还有一些方法是为
RecSys embedding layer提出神经架构搜索(neural architecture search : NAS)(《Neural input search for large scale recommendation models》),其中使用强化学习算法来构建embedding layer。与计算昂贵的NAS相比,我们表明non-uniform embedding layer的架构搜索可以简化为调优一个超参数,而不需要NAS。由于我们的理论框架,模型搜索的这种简化是可能的。此外,与以前所有的non-uniform embedding的工作相比,我们从理论上分析了我们的方法。此外,过去的工作并没有从经验上验证他们的方法所推测的工作机制。从
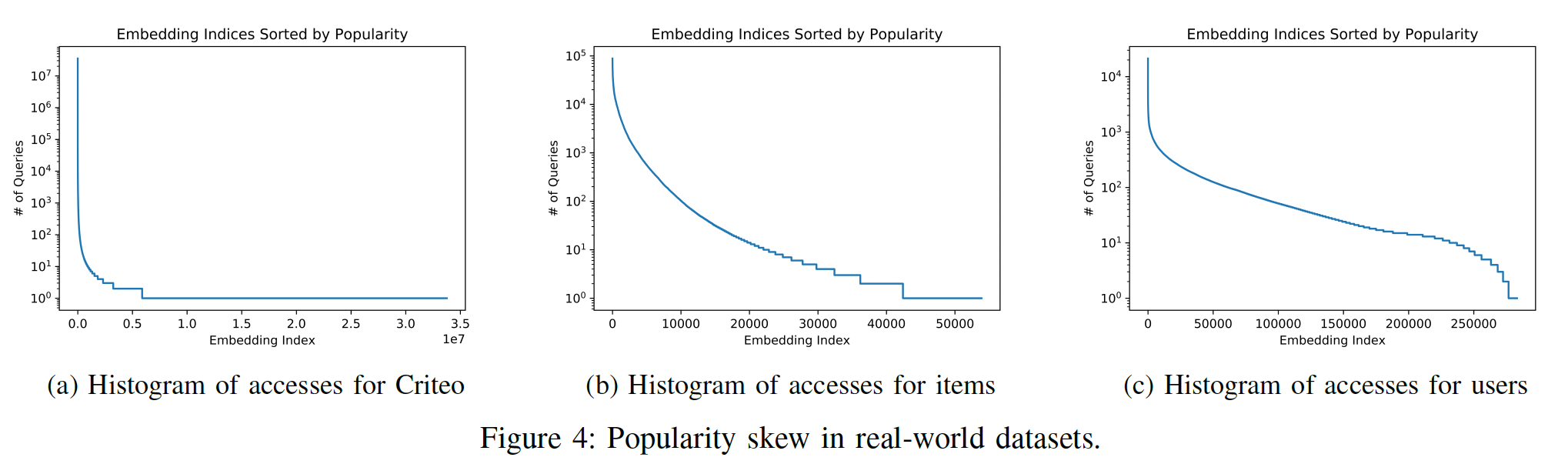
popularity倾斜的角度来看,embedding normalization实际上隐含了对rare embeddings的惩罚,而不是对popular embeddings的惩罚。这是因为更大一部分的training updates仅包含rare embeddings的norm penalty signal(而很少包含rare出现的事件)。如下图所示,图
(a)表示Criteo Kaggle数据集中所有特征的access的直方图;图(b), (c)分别为MovieLens数据集的user feature, item feature的access的直方图。这些图都是典型的长尾分布。
1.2 模型
MD embedding layer架构block组成,每个block对应一个categorical field。这些block定义为block的矩阵;categorical特征的embeding size;categorical特征的词表大小;categorical特征共享的base dimension,且满足MD embedding,然后
一个关键问题是如何确定
embedding sizePower-law Sizing Scheme:我们定义block-level概率block中的embedding的平均查询概率。当block与特征一一对应(我们这里的情况),那么假设
categorical feature都是单值(而不是多值的),那么对于词表大小为categorical feature,每个取值出现的平均概率为更一般的情况下,
block-wise伯努利采样矩阵。那么Popularity-Based Dimension Sizing为:其中:无穷范数是元素绝对值中的最大值;
embedding size都等于embedding size与它们的popularity成正比。理论分析见原始论文。
注意:这里仅考虑
field-level的popularity,而没有考虑value-level的popularity。例如,“学历” 这个field中,低学历的value占比更大,需要更高的维度。论文中的这种维度分配方式,使得词表越大的
field,其维度越小;词表越小的field,其维度越大。例如,“性别” 只有两个取值,该field被分配的embedding维度最大。论文中的这种维度分配是启发式的规则,并不是从数据中学到的。
1.3 实验
baseline方法:统一的DLRM。实验结果:
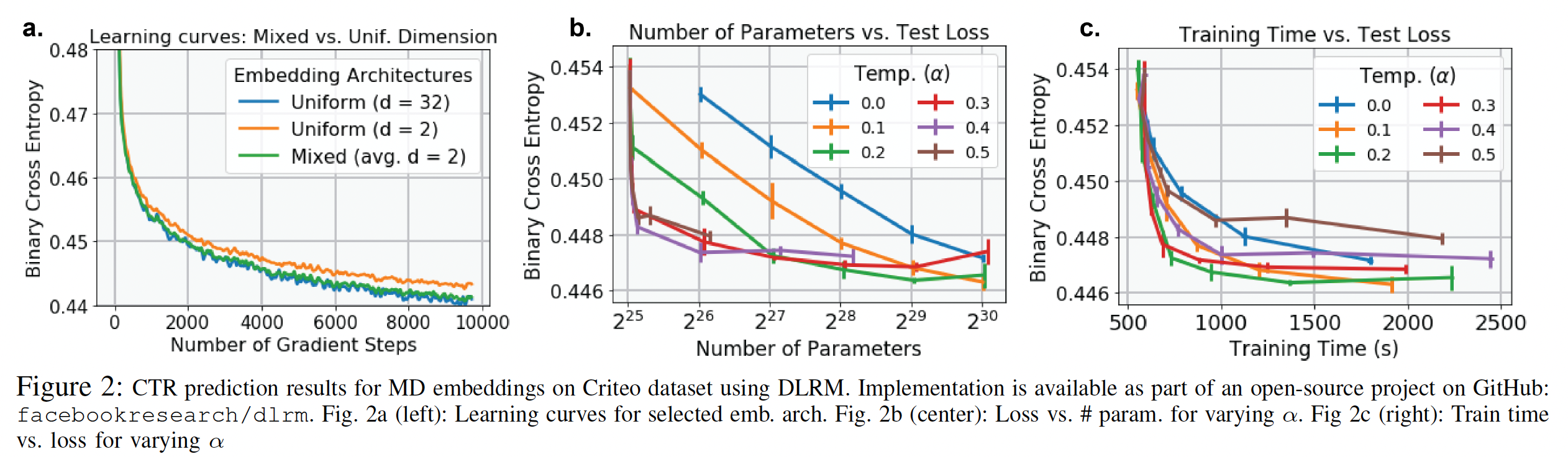
MD embedding产生的learning curve与UD embedding相当(下图(a)),但是参数规模减少了16倍。MD embedding layer改善了每种parameter budget下的memory-performance(下图(b))。最佳温度
parameter budget,对于较小的预算,较高的温度会导致更低的loss。embedding获得的性能以0.1%的准确性优势略微优于UD embedding,但是参数规模约为UD embedding的一半。MD embedding的训练速度比UD embedding快两倍(下图(c))。