一、SIM [2020]
《Search-based User Interest Modeling with Lifelong Sequential Behavior Data for Click-Through Rate Prediction》
点击率(
Click-Through Rate: CTR)预估建模在推荐系统(recommender system)和在线广告(online advertising)等工业应用中起着至关重要的作用。由于用户历史行为数据(user historical behavior data)的快速增长,以学习用户兴趣的意图representation为重点的用户兴趣建模(user interest modeling)被广泛引入CTR预估模型。然而,由于真实在线系统中计算负担和存储负担的限制,大多数提出的方法只能对长度最多数百的用户行为序列数据进行建模。事实证明,丰富的用户行为数据具有巨大的价值。例如,在全球领先的电商网站之一的淘宝网中,有
23%的用户在过去五个月内点击了1000多种商品。如何设计一种可行的解决方案来对长的用户行为序列数据(long sequential user behavior data)进行建模,这一直是一个开放而热门的话题,吸引了来自工业界和学术界的研究人员。研究的一个分支借鉴了
NLP领域的思想,提出使用memory network对长的用户行为序列数据进行建模,并取得了一些突破。阿里巴巴提出的MIMN是一项典型的工作,它是通过共同设计(co-design)学习算法和serving system来达到SOTA的。MIMN是第一个可以对长度可达1000的用户行为序列进行建模的工业级解决方案。具体而言,
MIMN将一个用户多样化(diverse)的兴趣增量地(incrementally)嵌入到固定大小的memory matrix中。该矩阵将通过每个新的行为进行更新,这样用户建模的计算就和CTR预估解耦。因此,对于在线serving而言,latency将不再是问题。而存储代价依赖于memory matrix的大小,该大小远远小于原始的用户行为序列。在长期兴趣建模(
long-term interest modeling)中可以找到类似的思想。然而,对于memory network-based方法来建模任意长的序列数据仍然是具有挑战性的。实际上我们发现:当用户行为序列的长度进一步增加,比如增加到10000甚至更多时,对给定一个特定的候选item的情况下,MIMN无法精确地捕获用户的兴趣。这是因为将用户所有的历史行为编码到固定大小的memory matrix会导致大量的噪声被包含在memory unit中。另一方面,正如
DIN在以前的工作中指出的,一个用户的兴趣是多样化(diverse)的,并且在面对不同候选item时会有所不同。DIN的关键思想是:在面对不同的候选item时,从用户行为序列中搜索有效信息,从而建模用户的特定兴趣(special interest)。通过这种方式,我们可以解决将用户所有兴趣编码为固定大小的参数(parameter)的挑战。DIN确实为使用用户行为序列数据的CTR建模带来了很大的提升。但是,如前所述,面对长的用户行为序列数据,DIN的搜索公式的计算成本和存储成本是不可行的。因此,我们能否应用类似的搜索技巧,并设计一种更有效的方法来从长的用户行为序列数据中提取知识?
在论文
《Search-based User Interest Modeling with Lifelong Sequential Behavior Data for Click-Through Rate Prediction》中,作者通过设计一个新的建模范式来解决这一挑战,并将其命名为基于搜索的兴趣模型(Search-based Interest Model: SIM)。SIM采用了DIN的思想,并且仅捕获与特定候选item相关的用户兴趣。在
SIM中,用户兴趣是通过两个级联(cascaded)的搜索单元(search unit)来提取的:通用搜索单元(
General Search Unit: GSU):充当原始的、任意长的行为序列数据的通用搜索,并具有来自候选item的query信息,最终得到和候选item相关的用户行为序列子集(Sub user Behavior Sequence: SBS)。为了满足
latency和计算资源的严格限制,在GSU中使用了通用、但是有效的方法。根据我们的经验,可以将SBS的长度缩短为数百个,并且可以过滤原始的、长的用户行为序列数据中的大部分噪声信息。精准搜索单元(
Exact Search Unit: ESU):对候选item和SBS之间的精确关系进行建模。在这里,我们可以轻松应用DIN或DIEN提出的类似方法。
论文主要贡献:
提出了一种新的范式
SIM,用于长的用户行为序列数据进行建模。级联的两阶段搜索机制的设计使得SIM具有更好的能力,可以在可扩展性(scalability)和准确性(accuracy)方面为长期(life-long)的用户行为序列数据建模。介绍了在大规模工业系统中实现
SIM的实践经验。自2019年以来,SIM已经部署在阿里巴巴展示广告系统(display advertising system)中,带来了7.1%的CTR提升和4.4%的RPM提升。现在SIM正在服务于主要流量。将长的用户行为序列数据建模的最大长度提高到
54000,比已发布的SOTA行业解决方案MIMN大54倍。
相关工作:
用户兴趣模型(
User Interest Model):基于深度学习的方法在CTR预估任务中取得了巨大的成功。在早期,大多数前期作品使用深度神经网络来捕获来自不同
field的特征之间的交互,以便工程师可以摆脱枯燥的特征工程的工作。最近,我们称之为用户兴趣模型(User Interest Model)的一系列工作聚焦于从用户历史行为中学习潜在用户兴趣的representation,这些工作使用不同的神经网络架构(如CNN, RNN, Transformer, Capsule等等)。DIN强调用户的兴趣是多样化的,并引入了一种attention机制来捕获用户对不同target item的diverse兴趣。DIEN指出,用户历史行为之间的时间关系对于建模用户漂移(drifting)的兴趣非常重要。在DIEN中设计了一个基于GRU的、带辅助损失的兴趣抽取层(interest extraction layer)。MIND认为,使用单个向量来表示一个用户不足以捕获用户兴趣的变化的特性(varying nature)。在MIND中引入了胶囊网络(Capsule network)和动态路由方法(dynamic routing method),从而学习用户兴趣的、以多个向量表示的representation。受到
self-attention架构在seq-to-seq learning任务重成功的启发,DSIN引入了Transformer来对用户的cross-session和in-session中的兴趣进行建模。
长期用户兴趣(
Long-term User Interest):MIMN的论文中显示了在用户兴趣模型中考虑长期历史行为序列可以显著提高CTR模型的性能。尽管更长的用户行为序列为用户兴趣建模带来了更多有用的信息,但是它极大地增加了在线serving sysem的延迟和存储负担,同时也为point-wise的CTR预估带来了大量的噪声。一系列工作聚焦于解决长期用户兴趣建模中的挑战。长期用户兴趣建模通常基于非常长的、甚至是
life-long的历史行为序列来学习用户兴趣representation。《Lifelong Sequential Modeling with Personalized Memorization for User Response Prediction》提出了一种Hierarchical Periodic Memory Network,用于对每个用户进行life-long序列建模,其中对序列模式进行个性化memorization。《Adaptive user modeling with long and short-term preferences for personalized recommendation》选择一个attention-based框架来结合用户的长期偏好和短期偏好。他们采用了attentive Asymmetric-SVD范式来对长期兴趣建模。《Practice on Long Sequential User Behavior Modeling for Click-through Rate Prediction》提出了一种memory-based的架构,称作MIMN。该架构将用户的长期兴趣嵌入到固定大小的memory network中,从而解决用户兴趣数据的大容量存储问题。并且他们设计了一个UIC模块来增量记录新的用户行为,从而解决latency的限制。但是,
MIMN在memory network中放弃了target item的信息,而target item已经被证明对于用户兴趣建模很重要。
1.1 模型
通过建模用户行为数据来预估
CTR,这已经被证明是有效的。典型地,attention-based CTR模型(如DIN, DIEN)设计复杂的模型结构,并且包含attention机制,以通过从用户行为序列中搜索有效知识来捕获用户的多样化兴趣。其中搜索的input来自于不同的候选item。但是在现实世界的系统中,这些模型只能处理长度小于
150的短期(short-term)行为序列数据。另一方面,长期(long-term)用户行为数据很有价值,并且对长期兴趣进行建模可以为用户带来更多样化的推荐结果。我们似乎陷入了一个两难的境地:在现实世界的系统中,我们无法通过有效而复杂的方法来处理有价值(
valuable)的life-long用户行为数据。为应对这一挑战,我们提出了一种新的建模范式,称之为基于搜索的兴趣模型Search-based Interest Model: SIM。SIM遵循两阶段搜索策略,可以有效地处理长的用户行为序列。我们首先介绍
SIM的总体工作流程,然后详细介绍我们提出的两种搜索单元(search unit)。SIM遵循一个级联的two-stage search策略,其中包含两个单元:通用搜索单元(General Search Unit: GSU)、精确搜索单元(Exact Search Unit: ESU)。SIM的整体工作流如下图所示。第一阶段:我们利用
GSU从原始的长期行为序列中寻找top-K相关(relevant)的子行为序列,其复杂度为线性时间复杂度。这里K通常要比原始序列的长度要短得多。如果有时间和计算资源的限制,则可以执行一种有效的搜索方法来搜索相关(
relevant)的子行为序列。在后续内容中,我们提供了GSU的两种简单实现:软搜索(soft-search)和硬搜索(hard-search)。GSU采取一种通用(general)但有效(effective)的策略来减少原始的行为序列的长度,从而满足对时间和计算资源的严格限制。同时,长期用户行为序列中可能会破坏用户兴趣建模的大量噪声可以在第一阶段通过搜索策略进行过滤。第二阶段:
ESU将经过过滤的用户行为子序列作为输入,并进一步捕获精确的用户兴趣。由于长期用户行为序列的长度已经减少到数百,因此可以应用复杂体系结构的精巧(
sophisticated) 的模型,如DIN, DIEN等等。
然后遵循传统的
Embedding&MLP范式,将精确的长期用户兴趣的输出、以及Other Feature作为输入。注意:尽管我们分别介绍了这两个阶段,但是实际上它们是一起训练的。
长期用户行为序列是否包含短期用户行为序列?论文未说明这一点。看结构图的描述,似乎不包含。
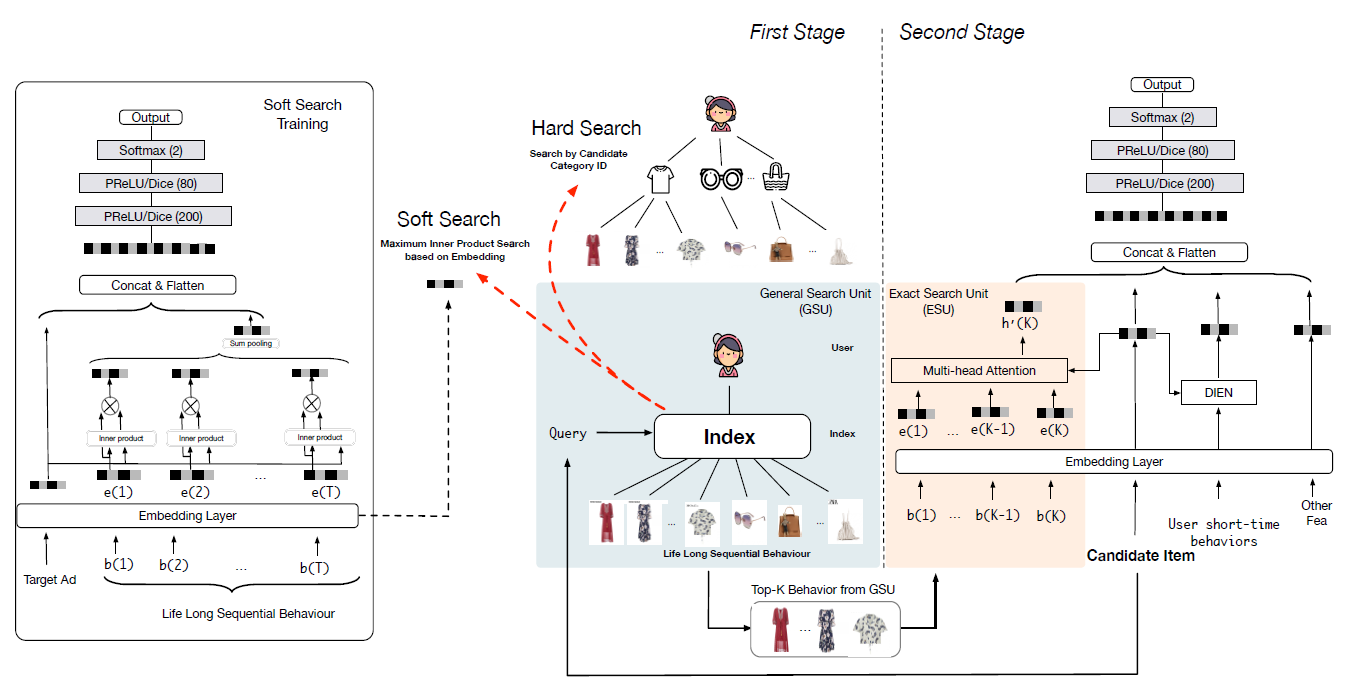
1.1.1 General Search Unit
给定一个候选
item(即将被CTR模型打分的target item),只有一部分用户行为有价值。这部分用户行为与最终用户决策密切相关。挑选出这些相关(relevant)的用户行为有助于用户兴趣建模。然而,使用整个用户行为序列直接对用户兴趣进行建模将带来巨大的资源占用和响应延迟(
latency),这在实际应用中通常是无法接受的。为此,我们提出了一个通用搜索单元(general search unit: GSU),从而减少用户兴趣建模中用户行为的输入数量。这里,我们介绍两种通用的搜索单元:硬搜索(hard-search)和软搜索(soft-search)。给定用户行为的列表
item),item的相关性得分(relevant score)top-K的相关(relevant)行为作为行为子序列(sub behaviour sequence)。K的大小对模型性能的影响如何?论文并未进行消融实验。硬搜索和软搜索的区别在于相关的分
其中:
target item的类目。embedding向量,target item的embedding向量。item embedding的维度,对于软搜索,
GSU和ESU共享相同的embedding参数。
硬搜索(
hard-search):硬搜索模型是非参数(non-parametric) 的。只有和候选item相同类目(category)的行为被挑选出来,然后得到一个子行为序列并发送给ESU。硬搜索非常简单,稍后在实验中我们证明它非常适合在线
serving。对于
hard-search,如何选择top-k?因为它的score要么为0、要么为1。这使得相同category的行为,其score全部为1。软搜索(
soft-search):在软搜索模型中,首先将one-hot向量,然后嵌入到低维向量为了进一步加速成千上万个用户行为的
top-K搜索,基于embedding矩阵sublinear time)的最大内积搜索(Maximum Inner Product Search: MIPS)方法ALSH用于搜索和target item最相关的top-K行为。其中distinct行为的embedding向量组成。借助训练好的
embedding和最大内积搜索方法,成千上万个用户行为可以减少到数百个。需要注意的是:长期(
long-term)数据和短期(short-term)数据的分布是不同的。因此,在软搜索模型中直接使用从短期用户兴趣建模中学到的参数可能会误导长期用户兴趣建模。所以在本文中,软搜索模型的参数是在基于长期行为数据的辅助CTR预估任务下训练的,如上图左侧的软搜索训练(soft search training)所示。用户整体行为序列的
representation行为
representationtarget Ad向量Multi-Layer Perception: MLP)的输入,从而建模辅助任务。注意,如果用户行为序列增长到一定程度,则不可能将整个用户行为序列馈入辅助任务的模型。这种情况下,可以从长的用户行为序列中随机采样子序列,子序列仍然遵循原始行为序列相同的分布。
作者提到 “对于软搜索,
GSU和ESU共享相同的embedding参数“,这意味着embedding layer的训练不仅依赖于main task,还依赖于这里的辅助任务。
1.1.2 Exact Search Unit
在第一个搜索阶段,我们从长期用户行为中选择和
target item最相关的top-K子用户行为序列Exact Search Unit: ESU)。ESU是一个以attention-based的模型。考虑到这些选出来的用户行为横跨了很长时间,因此每个用户行为的贡献是不同的,所以涉及到每个行为的时间属性(
temporal property)。具体而言,target item和选出来的K个用户行为的时间间隔temporal distance)信息。embedding矩阵embedding矩阵representation,记作time info用向量拼接还是直接逐元素相加?可以做个消融实验分析。我们利用
multi-head attention来捕获用户的多样化兴趣:其中:
attention score,head的attention。head的权重矩阵。
最终的用户长期
diverse兴趣表示为:head数量。然后MLP中用于点击率预估。最终模型同时使用了长期用户行为和短期用户行为,其中:
长期用户行为使用
ESU来抽取长期用户兴趣representation短期用户行为使用
DIEN来抽取短期用户兴趣representation
长期用户兴趣
representationrepresentationOther feature representation一起拼接作为后续MLP的输入。长期用户兴趣由长期用户行为来捕获,这里使用
GSU + ESU的原因是序列太长,DIEN无法处理。短期用户兴趣由短期用户行为来捕获,这里使用
DIEN是因为序列较短因此可以更精细地建模。对于较短的序列,没必要使用GSU来硬过滤。最后,我们在交叉熵损失函数下同时训练
GSU和ESU:其中:
如果
GSU为软搜索模型,则如果
GSU使用硬搜索模型,那么
ESU单元的损失,这也是SIM模型主任务的目标损失。GSU单元的损失。如果
GSU为硬搜索,则由于硬搜索没有参数,因此不考虑其损失。如果
GSU为软搜索,则它是SIM模型辅助任务的目标损失。辅助任务也是一个CTR预估任务,只是它采用了更简单的架构(没有multi-head、没有DIEN)、更少的特征(没有短期用户行为、没有Other feature)。
这个辅助损失函数本质上是强制
GSU部分学到的embedding是任务相关的。SIM、DeepMCP、DMR等模型都是类似的思想,要求模型的子结构也能够捕获到CTR相关的信息,从而使得约束了模型的解空间。
1.1.3 在线实现
这里我们介绍在阿里巴巴的展示广告系统(
display advertising system)中实现SIM的实际经验。life-long用户行为数据在线serving的挑战:工业级的推荐系统或广告系统需要在一秒钟内处理的大量的流量请求,这需要CTR模型实时响应。通常,serving latency应该小于30毫秒。下图简要说明了我们在线展示广告系统中用于CTR任务的实时预测Real Time Prediction: RTP系统。该系统由两个关键组件组成:计算节点(Computation Node)、预估server。考虑到
lifelong的用户行为,在实时工业系统中建立长期的用户兴趣model serving就变得更加困难。存储和延迟的限制可能是长期用户兴趣模型的瓶颈。实时请求的数据量(数据量 = 请求条数 x 单条请求的数据量)会随着用户行为序列长度的增加而线性增加。此外,我们的系统在流量高峰时每秒可为超过100万用户提供服务。因此,将长期模型部署到在线系统是一个巨大的挑战。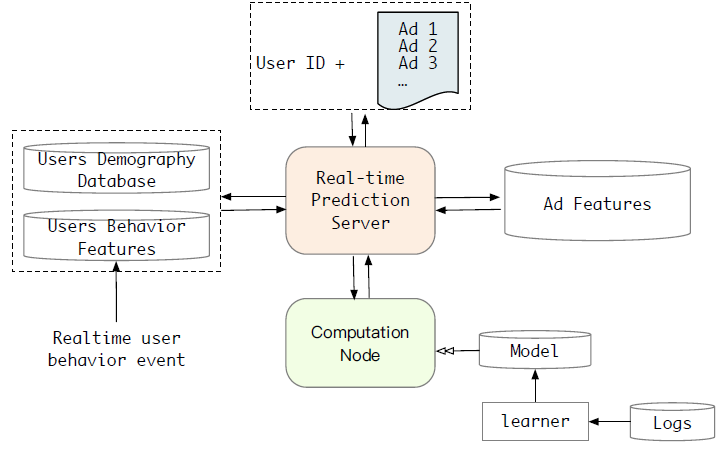
在线
serving系统:前面我们提出了两种类型的GSU:软搜索模型和硬搜索模型。对于软搜索模型和硬搜索模型,我们对从阿里巴巴在线展示广告系统收集的工业数据进行了广泛的离线实验。我们观察到软搜索模型生成的
top-K行为数据与硬搜索模型的结果极为相似。换句话讲,软搜索的大部分top-K行为通常属于target item相同类目(category)的。这是我们场景中数据的一个特色。在电商网站中,属于同一类目的item在大多数情况下是相似的。考虑到这一点,尽管在离线实验中软搜索模型的性能要比硬搜索模型稍好,但是在平衡性能提升和资源消耗之后,我们选择硬搜索模型将SIM部署到我们的广告系统中。对于硬搜索模型,包含所有长的用户行为序列数据的索引是关键组件。我们观察到,行为可以通过其所属类目自然访问到。为此,我们为每个用户建立一个两级的结构化索引
two-level structured index,并将其命名为用户行为树(user behavior tree: UBT),如下图所示。简而言之,
UBT遵循Key-Key-Value数据集结构:第一个key是user-id,第二个key是category id,最后一个value是属于每个类目的特定的行为item。UBT被实现为分布式系统,最大容量可达22TB,并且足够灵活以提供高吞吐量的query。然后,我们将
target item的category作为我们的硬搜索query。在
GSU之后,用户行为的长度可以从一万多个减少到数百个。因此,可以缓解在线系统中lifelong行为的存储压力。下图显示了
SIM的新CTR预估系统。新系统加入了一个硬搜索模块,以从长的用户行为序列数据中寻找target item相关的有效行为(effective behaviors)。注意:
GSU的UBT的索引可以离线构建。这样,在线系统中的GSU的响应时间可以非常短,与GSU的索引构建相比可以忽略。此外,其它用户特征可以并行计算。如何解决
category不平衡问题?例如,某些类目的商品特别多,另一些类目的商品很少。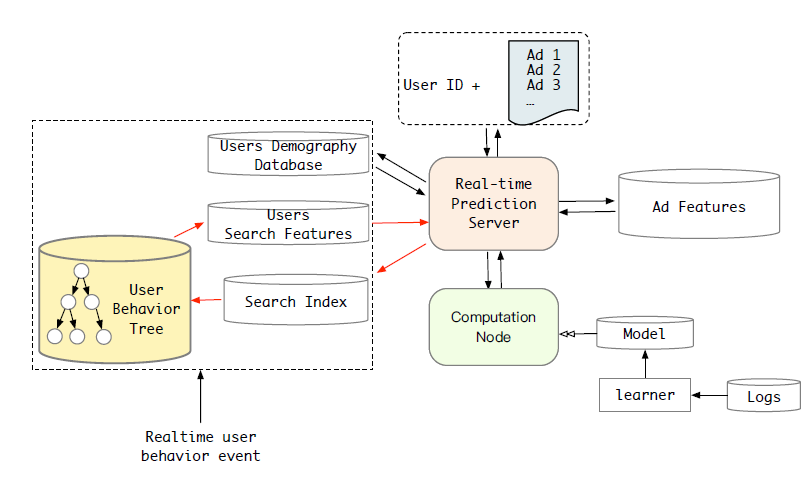
1.2 实验
这里我们详细介绍了我们的实验,包括数据集、实验配置、模型比较、以及一些相应的分析。由于
SIM已经部署在我们的在线广告系统中,因此我们还会进行仔细的在线A/B test,并比较几个著名的工业级的模型。数据集:我们在两个公共数据集、以及阿里巴巴在线展示广告系统收集的工业数据集进行了模型比较。
Amazon Dataset:由Amazon的商品评论和元数据(meta-data)组成。我们使用Amazon数据集的Books子集,该子集包含75053个用户、358367个item、1583个类目(category)。对于该数据集,我们将评论视为一种交互行为,并按时间对一个用户的评论进行排序。
Amazon Books数据集的最大行为序列长度为100。我们将最近的10个用户行为划分为短期(short-term)用户序列特征,将最近的90个用户行为划分为长期(long-term)用户序列特征。这些预处理方法已经在相关作品中广泛使用。Taobao Dataset:是来自淘宝推荐系统的用户行为集合。数据集包含几种类型的用户行为,包括点击、购买等。它包含大约800万用户的用户行为序列。我们采用每个用户的点击行为,并根据时间对其进行排序从而构建用户行为序列。
Taobao Dataset的最大行为序列长度为500。我们将最近的100个用户行为划分为短期用户序列特征,将最近的400个用户行为划分为长期用户序列特征。数据集将很快公开。Industrial Dataset:是从阿里巴巴在线展示广告系统收集的。样本是由曝光日志构建的,标签为是否点击。训练集是由过去49天的样本组成,测试集是第50天的样本组成,这是工业建模的经典设置。在这个数据集中,每个样本的用户行为特征包含最近
180天的历史行为序列作为长期行为特征,以及最近14天的历史行为序列作为短期行为特征。超过30%的样本包含长度超过1万的行为序列数据。此外,行为序列的最大长度达到54000,这比MIMN中的行为序列长54倍。
这些数据集的统计信息如下表所示。注意,对于
Industrial Dataset,item为广告。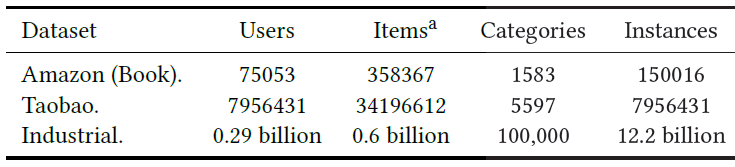
baseline方法:我们将SIM和以下主流的CTR预估模型进行比较。DIN:是用户行为建模的早期工作,旨在针对候选item进行用户行为的软搜索。和其它长期用户兴趣模型相比,DIN仅将短期用户行为作为输入。Avg-Pooling Long DIN:为了比较长期用户兴趣下的模型性能,我们对长期行为应用了均值池化操作(没有使用任何attention操作),并将long-term embedding、以及其它特征embedding拼接起来。MIMN:它巧妙地设计了模型体系结构从而捕获长期的用户兴趣,实现了SOTA性能。SIM(hard):我们提出的SIM模型,其中第一阶段使用硬搜索,并且在ESU中没有time embedding。SIM(soft):我们提出的SIM模型,其中第一阶段使用软搜索,并且在ESU中没有time embedding。SIM(hard/soft) with Timeinfo:我们提出的SIM模型,其中第一阶段使用硬搜索/软搜索,并且在ESU使用time embedding。
实验配置:我们采用与相关工作(即
MIMN)相同的实验配置,以便可以公平地比较实验结果。对所有模型,我们使用
Adam优化器。我们使用指数衰减,学习率从
0.001开始。全连接网络
FCN的layer设置为200 x 80 x 2。embedding维数设置为4。我们使用
AUC作为模型性能的评估指标。
下表显式了所有模型在公共数据集上的比较结果。
a表示SIM采用软搜索且没有时间间隔的embedding。b没有在Amazon Dataset上实验,因为该数据集没有时间戳数据。和
DIN相比,具有长期用户行为特征的其它模型的性能要好得多。这表明长期用户行为对CTR预估任务很有帮助。和
MIMN相比,SIM取得了显著提升,因为MIMN将所有未过滤的用户历史行为编码到固定长度的memory中,这使得难以捕获多样化的长期用户兴趣。SIM使用两阶段搜索策略从庞大的历史行为序列中搜索相关的行为,并针对不同target item来建模多样化的长期用户兴趣。实验结果表明:
SIM优于所有其它长期兴趣模型。这充分证明了我们提出的两阶段搜索策略对于长期用户兴趣建模很有用。而且,包含time embeding可以实现进一步的提升。
在这个
Taobao数据集中,MIMN的指标与原始MIMN中的指标对不上,可能的原因是:这里的Taobao数据集与之前的Taobao数据集不同。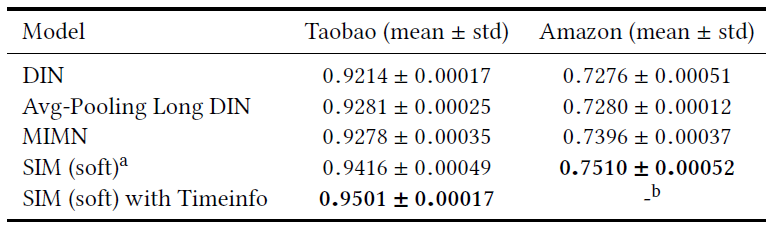
消融研究--两阶段搜索的有效性:如前所述,我们的
SIM模型使用两阶段搜索策略。第一阶段遵循通用搜索策略,从而过滤得到与
target item相关的历史行为。第二阶段对第一阶段的行为进行
attention-based的精确(exact)搜索,从而准确地(accurately)捕获用户对于target item的多样化的长期兴趣。
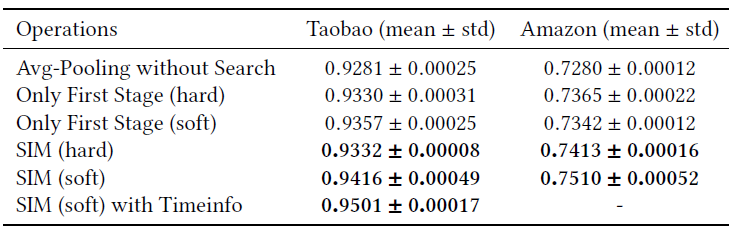
这里我们通过对长期历史行为应用不同操作的实验来评估所提出的两阶段搜索架构的有效性。这些不同的操作如下:
Avg-Pooling without Search:仅仅简单地应用均值池化来聚合长期行为embedding,没有使用任何过滤。它和Avg-Pooling Long DIN相同。Only First Stage(hard):在第一阶段对长期历史行为应用硬搜索,并通过对过滤后的结果应用均值池化从而得到固定大小的、聚合的embedding,从而作为MLP的输入。即没有第二阶段搜索策略。Only First Stage (soft)几乎和Only First Stage(hard),但是前者采用软搜索而不是硬搜索。我们根据预训练(
pre-trained)的embedding向量,离线计算target item和长期用户行为之间的内积相似度得分。然后根据相似度得分选择top 50个相关行为来进行软搜索。最后三个实验是我们提出的两阶段搜索架构的搜索模型。
实验结果如下表所示,可以看到:
与简单的均值池化
embedding相比,所有具有过滤策略的方法都极大地提高了模型性能。这表明在原始的长期行为序列中确实存在大量的噪声,而这些噪声可能会破坏长期用户兴趣的学习。和仅进行一阶段搜索的模型相比,我们提出的具有两阶段搜索策略的搜索模型通过在第二阶段引入
attention-based的搜索而取得了进一步的提升。这表明:精确地建模用户对target item的多样化的长期兴趣,有助于CTR预估任务。并且在第一阶段搜索之后,过滤后的行为序列通常比原始序列短得多,attention操作不会给在线RTP系统带来太多负担。包含
time embedding的模型得到了进一步的提升,这表明不同时期peroid的用户行为的贡献是不同的。
我们进一步对阿里巴巴在线展示广告系统收集的工业数据集进行实验,下表给出了实验结果。
a表示该模型目前已经部署在我们的在线serving系统,并且服务于主要的流量。SIM相比MIMN在AUC上提升了0.008,这对于我们的业务而言意义重大。和第一阶段使用硬搜索相比,第一阶段使用软搜索的性能更好。
在第一阶段,硬搜索和软搜索这两种搜索策略之间只有微小的差距。
在第一阶段应用软搜索会花费更多的计算资源和存储资源。因为软搜索需要在
online serving中使用最近邻搜索,而硬搜索只需要从离线构建的两级索引表中检索。因此,硬搜索更加有效且系统友好。对两种不同的搜索策略,我们对来自工业数据集的超过
100万个样本和10万个具有长期历史行为的用户进行了统计。结果表明:硬搜索策略保留的用户行为可以覆盖软搜索策略的75%。
最后,我们在第一阶段选择更简单的硬搜索策略,这是在效率(
efficiency)和性能 (performance)之间的trade-off。

在线
A/B test:自2019年以来,我们已经在阿里巴巴的展示广告系统中部署了SIM。从2020-01-07 ~ 2020-02-07,我们进行了严格的在线A/B test实验,从而验证SIM模型。和MIMN(我们的最新模型)相比,SIM在阿里巴巴的展示广告场景中获得了巨大收益,如下表所示。现在,SIM已经在线部署并每天为主要场景流量提供服务,这为业务收入的显著增长做出了贡献。下表为
2020-01-07 ~ 2020-02-07期间,SIM相对于MIMN的在线效果提升,其中模型应用于淘宝App首页的“猜你喜欢” 栏目。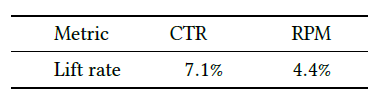
Rethinking Search Model:我们在用户长期兴趣建模方面做出了巨大努力,所提出的SIM在离线和在线评估方面都取得了良好的性能。但是 ,由于进行了精确的长期兴趣建模,SIM的性能会更好吗?SIM是否会倾向于推荐和人们长期兴趣相关的item?为回答这两个问题,我们制定了另一个指标,即点击样本的
Days till Last Same Category Behaviorcateogry)的item上的最近行为距离当前点击事件的时间间隔。例如,用户
itemitemitem)。如果将点击事件记作Days till Last Same Category Behavior为5,即对于给定的模型,可以使用
long-term interest)或短期兴趣(short-term interest)上的选择偏好(selection preference) 。经过在线
A/B test之后,我们根据提出的SIM和DIEN(这是短期的CTR预估模型的最新版本)的点击样本。点击样本越多则说明模型效果越好(模型找的越准)。根据
>14天)、短期的(<14天)。方框显示了不同SIM模型点击样本的提升比例(相对于DIEN模型)。曲线表示不同可以看到:在短期部分(
SIM和DIEN在过去14天中都具有短期的用户行为特征。在长期部分,SIM提升比例更大。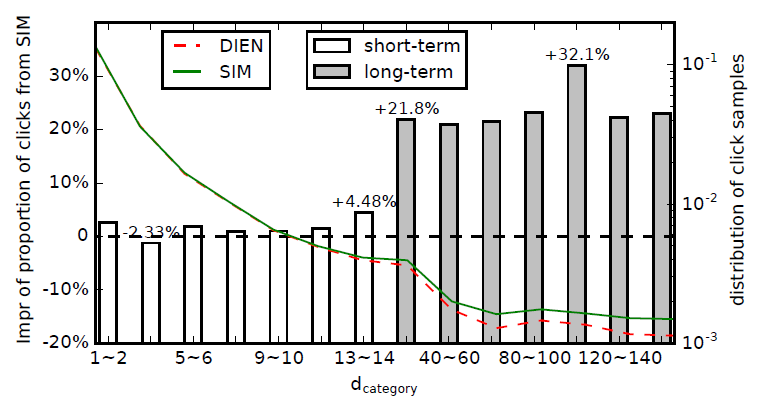
此外在工业数据集上,我们统计了
target item相同类目的历史行为的概率。结果如下表所示(在线a/b test对应的点击样本,在离线上统计到的)。结果表明:
SIM的提升确实是更好的长期兴趣建模的结果。并且和DIEN相比,SIM倾向于推荐与人们长期行为有关的item。
读者注:这里假设
A/B test时流量相等,因此点击量的差异等价于CTR的差异。部署的实践经验:这里我们介绍了在线
serving系统中实现SIM的实践经验。阿里巴巴的高流量是众所周知的,它在流量高峰时每秒为超过
100万用户提供服务。此外,对于每个用户,RTP系统需要计算数百个候选item的预估CTR。我们对整个离线用户行为数据建立一个两阶段索引,该索引每天都会更新:第一阶段是user id;在第二阶段,一个用户的life-long行为数据由该用户所交互的类目来索引。虽然候选
item的数量为数百,但是这些item的类目数量通常少于20。同时,来自GSU的每个类目的子行为序列的长度被截断为不超过200(原始的行为序列长度通常小于150)。这样,来自用户的每个请求的流量是有限的并且可以接受的。此外,我们通过
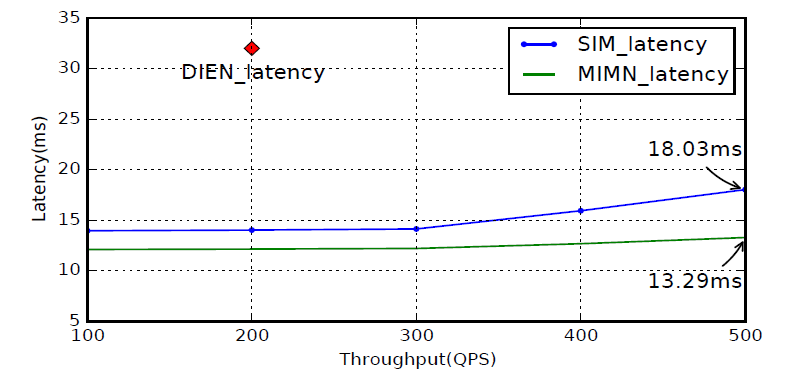
deep kernel fusion优化了ESU中multi-head attention的计算。下图显示了我们的实时
CTR预估系统相对于DIEN,MIMN,SIM流量的效率。值得注意的是:MIMN可以处理的最大用户行为长度是1000,而这里显示的性能是基于截断的行为数据(MIMN和DIEN中,用户行为的长度被截断为1000)。而
SIM中的用户行为的长度不会被截断,并且可以扩展到54000,使得最大长度可以扩展到54倍。针对一万个行为的SIM serving,相比于截断用户行为的MIMN serving,latency仅增加了5ms。DIEN的最大流量为200,因此图中只有一个点。