一、DeepLight [2021]
《DeepLight: Deep Lightweight Feature Interactions for Accelerating CTR Predictions in Ad Serving》
在
CTR预测任务上,广义线性模型和factorization machine : FM取得了巨大的成功。然而,由于缺乏学习更深层次特征交互的机制,它们的预测能力有限。为了解决这个问题,基于embedding的神经网络提出同时包含浅层组件(来学习低阶特征交互)、DNN组件(来学习高阶特征交互),如Wide&Deep, DeepFM, NFM, DCN, xDeepFM, AutoInt, AutoFIS。尽管这些新颖的模型有所改进,但与诸如LR或FM的简单模型相比,预测速度慢了数百倍。随之而来的一个问题是:我们是否能够为高质量的深度模型提供令人满意的模型延迟和资源消耗,从而用于广告服务中的实时响应?为实现这一目标,实际解决方案需要应对以下挑战:
(C1)高质量:用于服务的“瘦身”模型预期与原始的“臃肿”模型一样准确。(c2)低延迟:服务延迟应该非常低,以保持高Query per second: QPS、以及很少的超时。(C3)低消耗:在在线广告服务中,pull模型的checkpoint并将其存储在内存中的内存成本应该很低。
然而,所有现有的基于
embedding的神经网络,如DeepFM, NFM, xDeepFM, AutoInt,仍然专注于增加模型复杂度以实现(C1),同时牺牲(C2)和(C3)。虽然人们提出了一些方法,如AutoCross来提高模型效率,但它们没有采用DNN框架,未能达到SOTA。为了共同解决这些挑战,论文《DeepLight: Deep Lightweight Feature Interactions for Accelerating CTR Predictions in Ad Serving》提出了一种有效的模型,即所谓的field-weighted embedding-based neural network: DeepFwFM,通过field pair importance matrix来改进FM模块。DeepFwFM在经验上与xDeepFM一样强大,但效率更高。如下图所示,DeepFwFM的每个组件都有一个approximately sparse structure,这意味着结构剪枝的优势并可能导致更紧凑的结构。通过裁剪DeepFwFM的DNN组件并进一步压缩浅层组件,得到的深度轻量化结构(即,DeepLight)大大减少了推理时间,仍然保持了模型性能。
据作者所知,这是第一篇研究裁剪
embedding based的DNN模型以加速广告服务中的CTR预测的论文。总之,所提出的DeepFwFM在快速的、准确的推断方面具有巨大潜力。与现有的基于embedding的神经网络相比,该模型具有以下优点:为了解决
(C1)高质量的挑战,DeepFwFM利用FwFM中的field pair importance的思想,以提高对低阶特征交互的理解,而不是探索高阶特征交互。值得注意的是,与SOTA的xDepFM模型相比,这种改进以非常低的复杂性达到了SOTA,并且在深度模型加速方面仍然显示出巨大的潜力。(C1)高质量的挑战并不是由DeepLight解决的,而是由基础模型FwFM解决的。为了解决
(C2)低延迟的挑战,可以对模型进行裁剪以进一步加速:裁剪深度组件中的冗余参数以获得最大的加速。
移除
FwFM中的week field pair以获得额外的显著加速。
由此产生的轻量化结构最终几乎达到一百倍的加速。
为了解决
(C3)低消耗的挑战,可以促进embedding向量的稀疏性,并保留最多的discriminant signal,这会产生巨大的参数压缩。
通过克服这些挑战(
C1-C3),由此产生的稀疏DeepFwFM(即所谓的DeepLight),最终不仅在预测方面,而且在深度模型加速方面取得了显著的性能。它在Criteo数据集上实现了46倍的速度提升,在Avazu数据集上达到了27倍的速度,而不损失AUC。源代码参考https://github.com/WayneDW/sDeepFwFM。
1.1 模型
注:这篇论文的核心是如何对
DeepFwFM进行压缩,而不是提出DeepFwFM。事实上,DeepFwFM就是DNN作为deep组件、FwFM作为wide组件的神经网络,毫无新意 。此外,
DeepLight的剪枝方法也是工程上的应用(把训练好的模型中的接近于零的权重裁剪掉),而没有多少创新点。实验部分提示了基于剪枝的模型设计方案:首先设计较大容量的模型从而提升模型的表达能力,然后执行剪枝从而降低
latency、减少过拟合。这种方案的一个潜在缺点是:训练资源消耗更大。
1.1.1 DeepFwFM
给定数据集
label,二阶多项式模型
其中:
FM模型其中:
embedding向量的集合;embedding向量;embedding向量的维度。可以看到,
FM模型将参数规模从Deep & Cross通过一系列的cross操作来建模高阶交互:其中:
通过进一步组合
DNN组件,我们可以获得xDeepFM,这是CTR预测中的SOTA模型。尽管xDeepFM在建模特征交互方面具有强大的性能,但众所周知,它比DeepFM的成本要高得多,并增加了速度较慢。因此我们考虑FwFM模型,并提出了Deep Field-weighted Factorization Machine: DeepFwFM:其中:
FwFM模型,用于建模二阶特征交互。DNN的参数(包括权重矩阵和bias向量)。field的embedding向量,fieldembedding向量。这就是
FwFM原始论文中 的FwFM_FiLV,用embedding向量,field pair重要性矩阵,它建模field pair的交互强度。field。
DeepFwFM有两个创新:DeepFwFM比xDeepFM快得多,因为我们不试图通过浅层组件来建模高阶(三阶甚至或更高)的特征交互。尽管xDeepFM包含强大的compressed interaction network: CIN来逼近任意固定阶次的多项式,但主要缺点是CIN的时间复杂度甚至高于xDeepFM中的DNN组件,导致了昂贵的计算。DeepFwFM比DeepFM更准确,因为它克服了矩阵分解中的稳定性问题,并通过考虑field pair importance导致更准确的预测。
如下图所示,
DeepFM通过FM组件中每个hidden node与输出节点之间的weight-1 connection(即,feature embedding之间内积的权重为1)来建模低阶特征交互,然而,这无法适应局部几何结构,并牺牲了鲁棒性。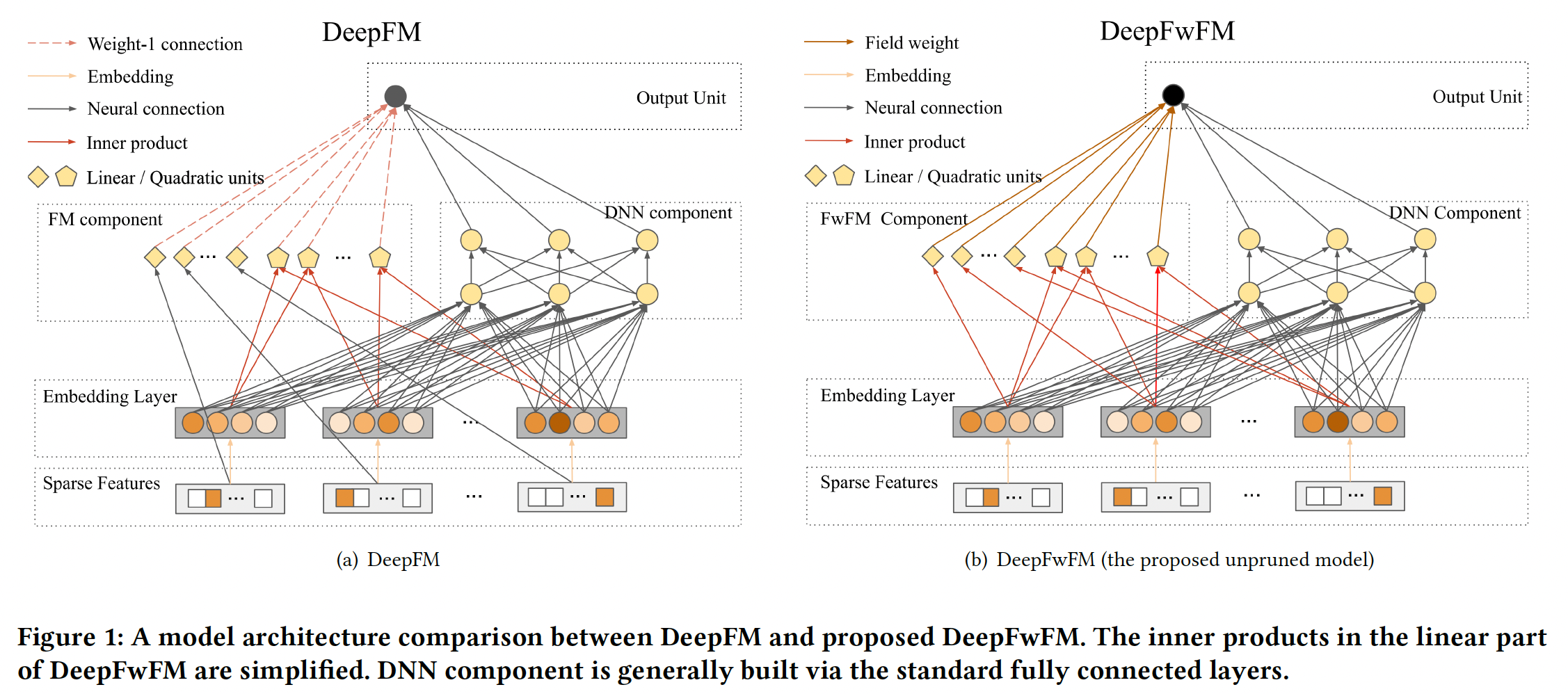
为了证明我们模型的优势,我们对
DeepFwFM的计算复杂性进行了定量分析。给定embedding sizeembedding layer只有lookup(即field数量 为DNN组件的floating point operations: FLOPs为FwFM组件的FLOPs为类似地,我们可以得到
DeepFM和xDeepFM的计算复杂度,如下表所示。可以看到:xDeepFM的CIN层需要DNN组件的操作数量。FM组件和FwFM组件比DNN组件快得多。
尽管
DeepFwFM的计算复杂度较好,但是它仍然未能将延迟降低到一个良好的水平。事实上,由于包含DNN组件,DeepFwFM可能会慢数百倍,这会显著降低在线CTR预测的速度。
1.1.2 DeepLight
DNN组件无疑是导致高延迟问题并且无法满足在线要求的主要原因。因此,需要一种适当的加速方法来加速预测。为什么采用结构剪枝:深度模型加速三种主要方法组成:结构剪枝(
structural pruning)、知识蒸馏(knowledge distillation)、量化(quantization),其中结构剪枝方法因其显著的性能而受到广泛关注。此外,DeepFwFM的每个组件,如DNN组件、field pair interaction matrixembedding向量,都具有高度稀疏的结构,如Figure 2所示。这促使我们考虑结构剪枝以加速浅层组件和DNN组件。对于其他选择:
量化在推断期间采用了定点精度。然而,它没有充分利用
DeepFwFM每个组件的稀疏结构,甚至对模型性能有损。知识蒸馏技术通过训练小网络(即
student model)以模仿大网络(即teacher model),但它存在以下问题:学生模型从教师模型学习的能力有限。
如果性能恶化,很难清楚这是由于教师模型导致、还是由于教学过程导致。
这就是我们在这项工作中采用结构剪枝的原因。
如何进行结构剪枝:
设计:我们建议裁剪以下三个组件(在
DeepFwFM模型的背景下),而不是简单地以统一的稀疏率应用剪枝技术。这三个组件专门设计用于广告预测任务:剪枝
DNN组件的权重(不包括bias)从而移除神经元连接。剪枝
field pair interaction matrixfield interaction。注意:移除冗余的
field interaction,意味着建模时无需考虑对应field之间的内积计算。剪枝
embedding向量中的元素,从而导致稀疏的embedding向量。
结合以上努力,我们获得了所需的
DeepLight模型,如下图所示。DeepLight是一种稀疏的DeepFwFM,它提供了一种整体方法,通过在推理期间修改训练好的架构来加速推理。注意,
DeepLight是用于训练好的模型,是一种剪枝算法,而不是一种训练算法。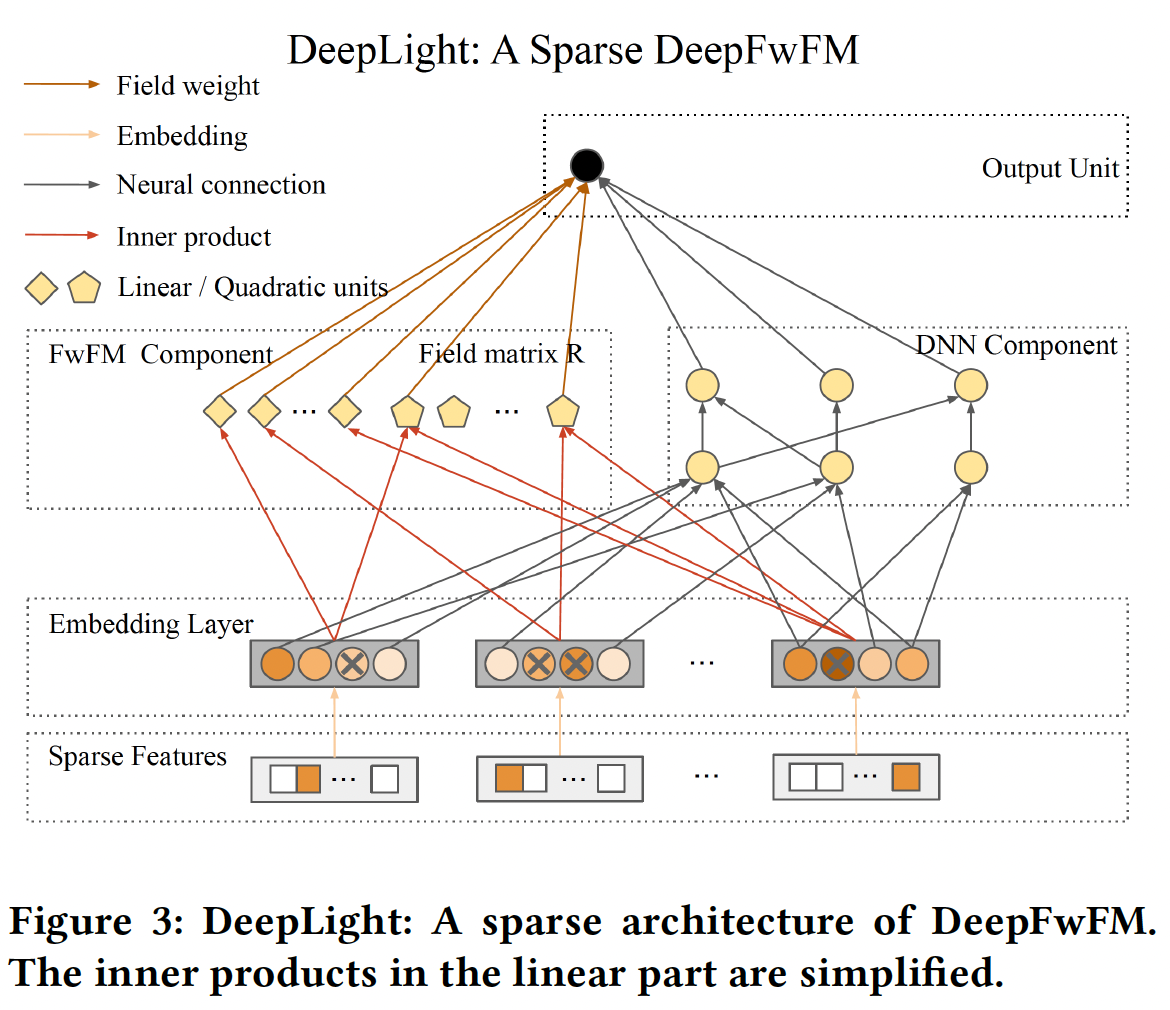
优点:通过实验表明:
与原始
DNN组件相比,稀疏的DNN组件的计算复杂度要低得多。它导致最大的计算加速。sparse field pair interaction matrixFwFM组件的显著加速。此外,裁剪field pair selection。一旦裁剪了field pairfeature pair都将被丢弃。AutoFIS也实现了类似类型的field pair selection。sparse embedding大大减少了内存使用,因为feature embedding主导了CTR预测深度学习模型中的参数数量。
实现:从过度参数化的模型中选择一个良好的稀疏网络是
NP难的,并且无法保证最优算法能够解决它。在结构剪枝领域有大量的经验研究,包括权重剪枝、神经元剪枝、以及其他单元剪枝。考虑到我们的模型只包含一个标准的FwFM组件和一个普通的DNN组件,我们进行了权重剪枝,并寻求在不调用专用库的情况下实现高稀疏性和加速。定义稀疏率
99%的权重都被裁剪。结构剪枝算法:
输入:
训练好的
target model目标稀疏率
阻尼因子
输出:剪枝后的模型
算法步骤:
剪枝:对于
训练网络一个
iteration。这是为了在每次裁剪之后,重新训练模型从而进行微调,以便错误修剪的权重有可能再次变得活跃。
对模型的每个组件
更新组件当前轮次的裁剪比例
这是设置自适应的裁剪比例,使得在早期剪枝的很快(裁剪比例较大)、在后期剪枝很慢(裁剪比例较小)。
注意:这种裁剪方式无法确保最终模型能够得到
根据权重的
magnitude,裁剪最小的
降低计算复杂度:
DNN组件是导致高推断时间的瓶颈。在DNN组件的剪枝之后,FwFM组件成为限制,这需要对field matrixembedding层的剪枝对计算没有显著的加速。在对
DNN组件的权重设置一个中等大小的bias)的情况下,相应的加速可以接近理想的95%时,我们可能无法达到理想的加速比,因为bias的计算和稀疏结构(如compressed row storage: CRS)的开销。关于field matrixDNN组件中的目标稀疏率降低空间复杂度:在
embedding layer中进行剪枝也显著减少了DeepFwFM中的参数数量,因此节省了大量内存。在embedding layer中,至于
DNN组件,权重参数的数量(不包括bias)可以从field matrix由于
DeepFwFM中的总参数由embedding向量参数所主导 ,embedding向量上的
1.2 实验
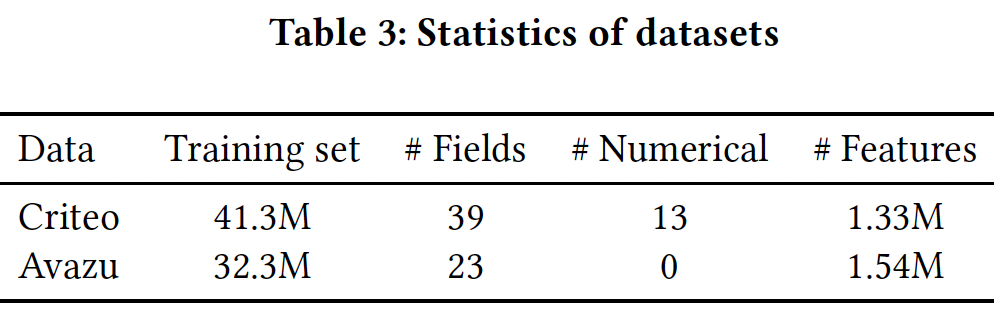
数据集:
Criteo, Avazu。对于
Criteo数据集,我们采用由Criteo竞赛获胜者提出的对数转换来归一化数值特征:此外,我们还将所有频次低于
8的特征视为"unknown"。我们将数据集随机分成两部分:90%用于训练、剩下的10%用于测试。对于
Avazu数据集,我们使用10天的点击记录,并随机拆分80%的样本用于训练、剩下的20%用于测试。我们还将所有频次低于5的特征视为"unknown"。
数据集的统计信息如下表所示。
评估指标:
LogLoss, AUC。baseline方法:在emebdding-based神经网络模型中,我们选择DeepFM, NFM, xDeepFM作为baseline,因为它们具有与DeepFwFM相似的架构,也是CTR预测的SOTA模型。最终,六个baseline模型为:LR, FM, FwFM, DeepFM, NFM, xDeepFM。实现细节:我们使用
PyTorch训练模型。Criteo数据集:为了对
Criteo数据集进行公平比较,我们遵循DeepFM和xDeepFM原始论文中的参数设置,并将学习率设置为0.001。embedding size设为10。DeepFM, NFM, xDeepFM的DNN组件默认设置为:网络架构为
400 x 400 x 400。drooout rate为0.5。
此外,我们也将裁剪后的
DeepFwFM与更小尺寸的DeepFwFM进行比较。对于这些更小尺寸的DeepFwFM,它们的DNN组件分别为:25 x 25 x 25(记做N-25)、15 x 15 x 15(记做N-25)。原始尺寸的未裁剪DeepFwFM记做N-400。对于
xDeepFM,CIN的架构为100 x 100 x 50。我们微调了
L2惩罚,并将其设置为3e-7。我们在所有实验中使用
Adam优化器,batch size = 2048。
Avazu数据集:保持了与Criteo数据集相同的设置,除了embedding size设为20、L2惩罚为6e-7、DNN网络结构为300 x 300 x 300。
关于实践中的训练时间(而不是推理时间),所有模型之间没有太大的差异。
FwFM和DeepFwFM的速度略快于DeepFM和xDeepFM,这是由于FwFM与DeepFwFM在线性项上的创新(用内积代替线性项)。DeepFwFM和其它稠密模型的比较:对没有剪枝的密集模型的评估显示了过度参数化模型所表现出的最大潜力,如下表所示。可以看到:LR在所有数据集上的表现都比其他模型都要差,这表明特征交互对于提高CTR预测至关重要。大多数
embedding-based神经网络的表现优于低阶方法(如LR和FM),这意味着建模高阶特征互动的重要性。低阶的
FwFM仍然胜过NFM和DeepFM,显示了field matrixNFM利用黑盒DNN隐式地学习低阶特征交互和高阶特征交互,由于缺乏显式识别低阶特征交互的机制,可能会过拟合数据集。在所有
embedding-based神经网络方法中,xDeepFM和DeepFwFM在所有数据集上效果最好。然而,xDeepFM的推理时间远远超过DeepFwFM。
稀疏化模型
DeepLight:我们选择阻尼因子2个epoch,然后训练8个epoch用于剪枝。我们每隔10个iteration剪枝一次从而降低计算代价。即:前
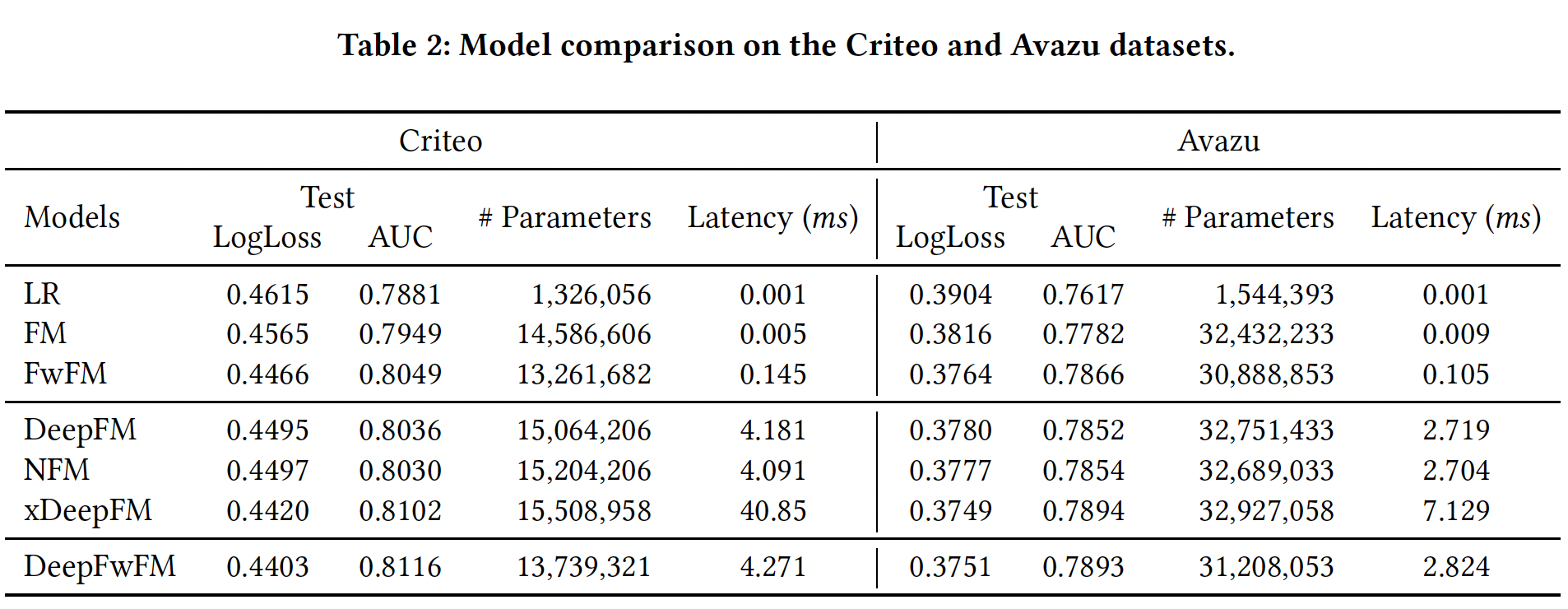
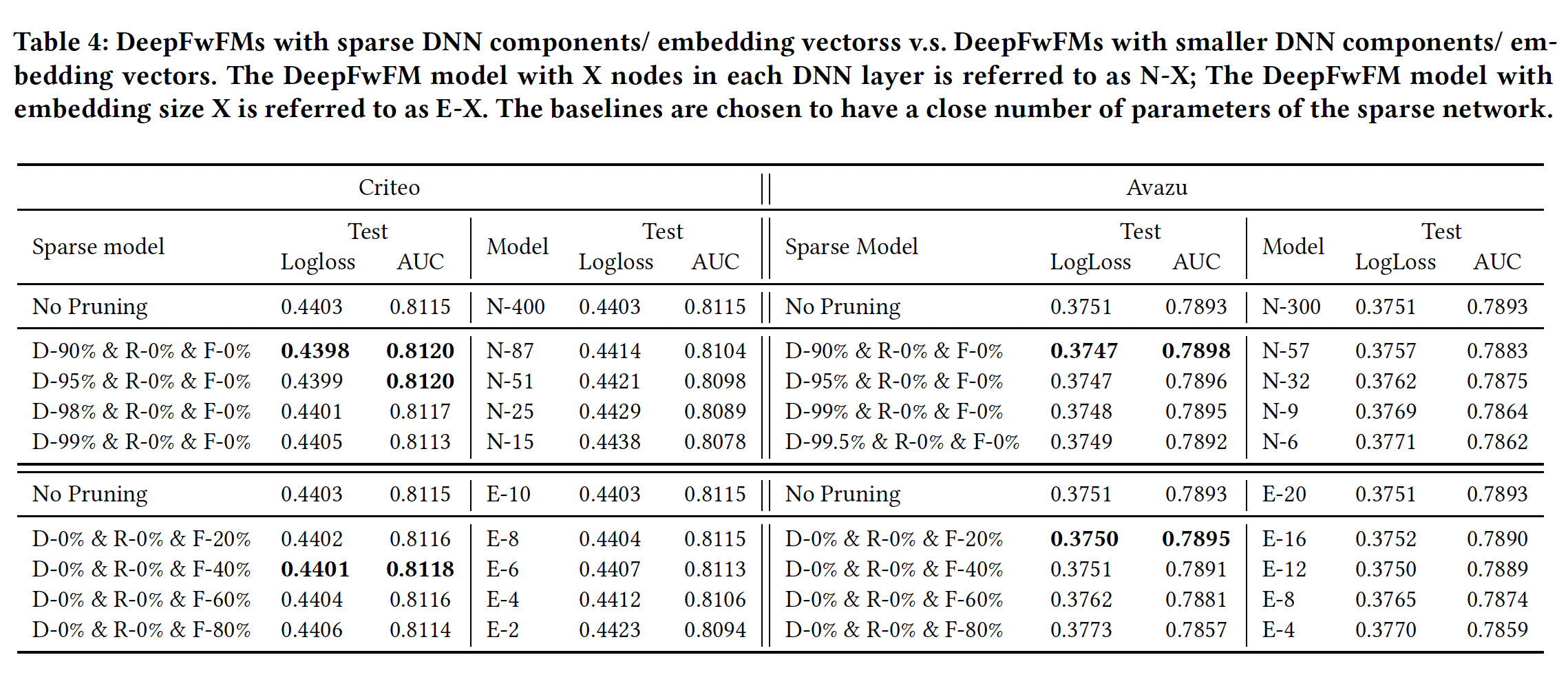
2个epoch训练好模型;后面的8个epoch执行剪枝。DNN剪枝加速:仅裁剪DNN组件的权重,DNN的bias、field matrixembedding layer的参数照常处理。我们尝试不同的剪枝率,并将不同稀疏率的网络与较小结构的网络进行比较。结果如Table 4所示。可以看到:具有稀疏
DNN组件的DeepFwFM优于稠密DeepFwFM,即使在Criteo数据集上稀疏率高达95%。在我们将Criteo数据集上的稀疏率提高到99%之前,这一现象保持不变。相比之下,具有类似参数规模的相应小型网络,如
N-25和N-15,获得的结果比原始的N-400要差得多,显示了裁剪过度参数化的网络相比从较小的网络训练更强大。
在
Avazu数据集上,我们得到同样的结论。稀疏模型在90%的稀疏率下获得了最好的预测性能,只有当稀疏率大于99.5%时才会变差。关于模型加速,从下图中可以看到:较大的稀疏率总是带来较低的延迟。因此在这两个数据集上,稀疏模型在性能超越原始稠密模型的基础上,都实现了高达
16倍的推理速度提升。这里获得的好处主要是更低的延迟。虽然模型性能略有提升,但是低于
0.1%,因此效果不显著。但是,和
N-25, N-15这两个更小的网络相比,DeepLight的性能提升比较显著。然而DeepLight的训练时间也更长。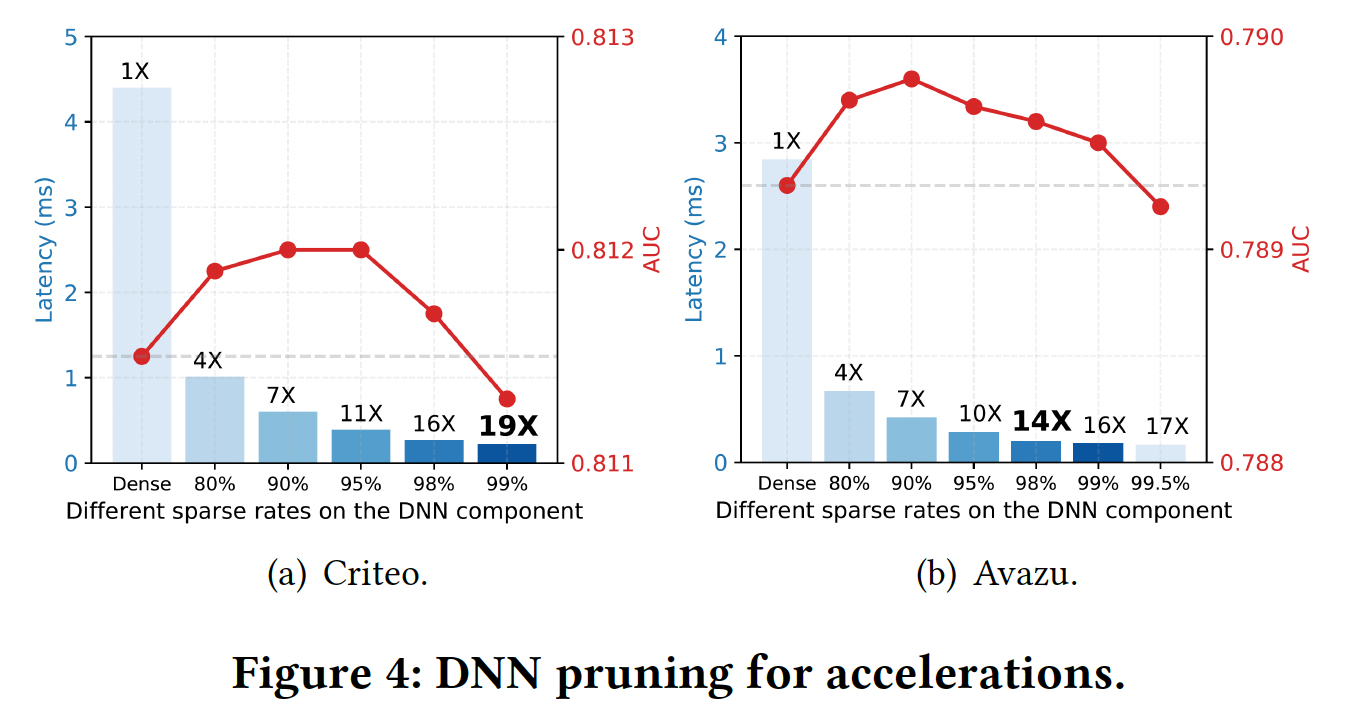
Field MatrixDNN组件进行高稀疏度化之后,我们已经获得了显著的加速,接近20倍。为了进一步提高速度,增加DNN组件的稀疏率可能会有降低性能的风险,并且由于矩阵计算的开销,不会产生明显的加速。从Figure 2可以看出,field matrixfield matrix我们根据
field matrixDNN组件已经被剪枝的基础上),如下图所示。可以看到:我们可以在不牺牲性能的情况下对field matrix95%的稀疏率,此外推断速度可以进一步加快2到3倍。因此,我们最终可以在不牺牲性能的情况下获得46倍和27倍的速度提升。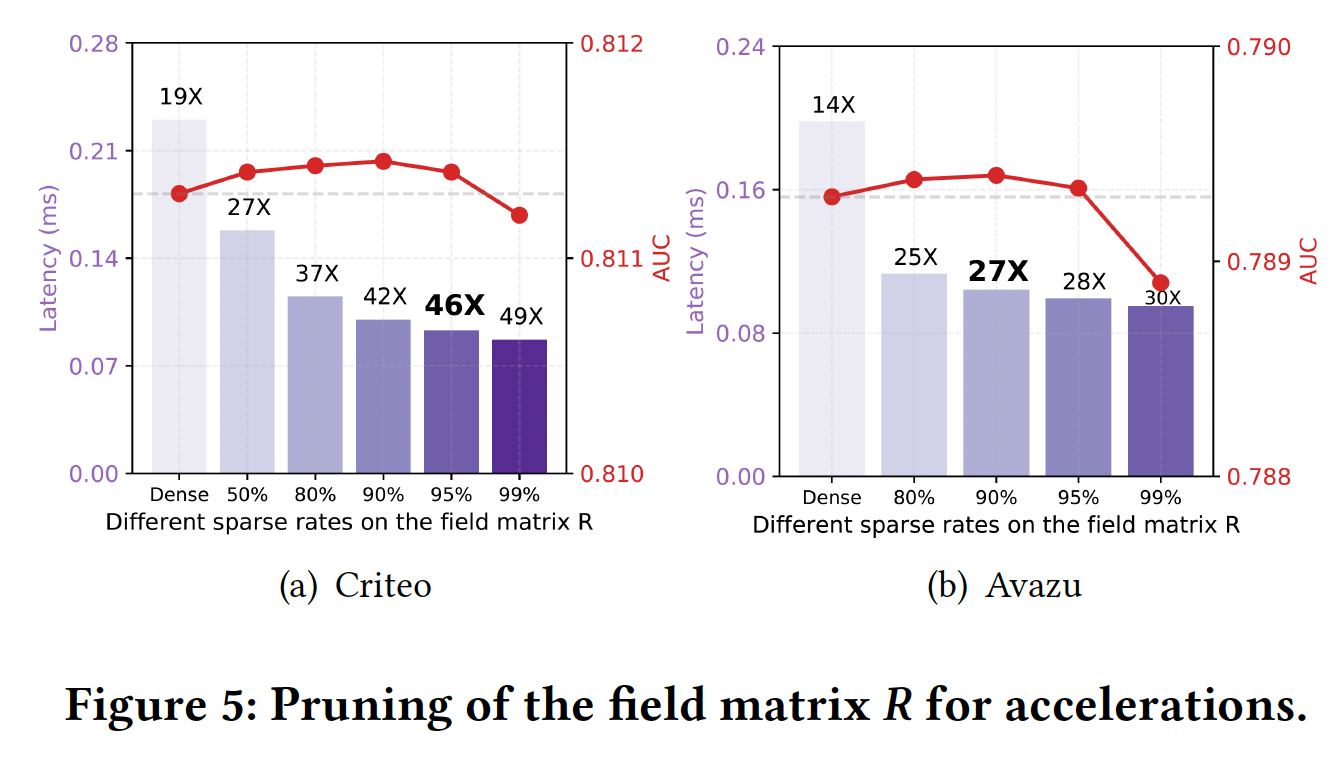
Embedding Vector剪枝用于节省内存:关于embedding的剪枝,我们发现为所有field的embedding设置一个全局阈值,比为每个field的embedding向量设置单独的阈值获得略好的性能。因此,我们在全局阈值的基础上进行了实验。如下图所示:
Criteo数据集上可以采用较高的稀疏率,如80%,并保持几乎相同的性能。相比之下,在
Avazu数据集上比较敏感,当采用60%的稀疏率时,性能开始低于稠密模型。
从下表可以看到,大多数模型优于较小的
embedding size的baseline模型(称为E-X),这说明了使用大的embedding size,然后在过度参数化的网络上应用剪枝技术以避免过拟合。剪枝
embedding似乎并没有带来多少AUC提升(0.03%左右,非常微小)。
DeepFwFM的结构剪枝:从上述实验中,我们看到DNN组件和field matrix对于性能驱动的任务:
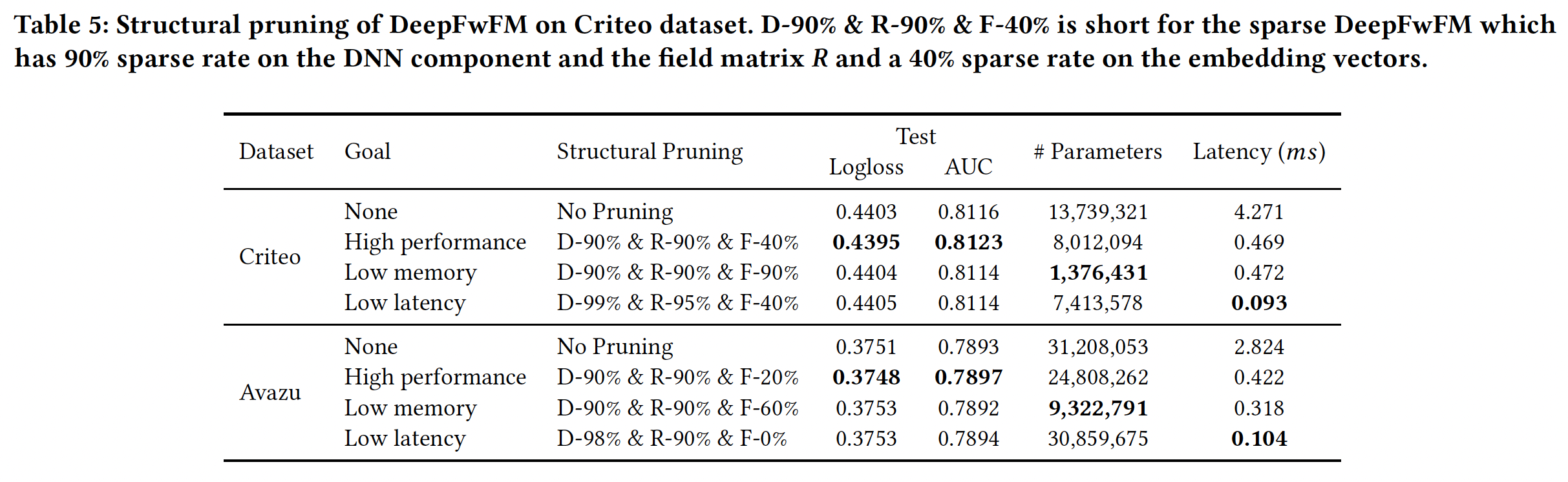
在
Criteo数据集上,我们可以通过sparse DeepFwFM将SOTA AUC从0.8116提高到0.8223,其中DNN组件和field matrix90%、embedding向量中的剪枝率为40%。该模型被称为D-90% & R-90% & F-40%。在
Avazu数据集上,我们可以通过sparse DeepFwFM将SOTA AUC从0.7893提高到0.7897,其中DNN组件和field matrix90%、embedding向量中的剪枝率为20%。该模型被称为D-90% & R-90% & F-20%。
这里的剪枝对于性能提升非常微小,几乎可以忽略。因为太小的提升可能由于超参数配置、随机因素等等的影响,而观察不到。
对于内存驱动的任务:在
Criteo数据集和Avazu数据集上的内存节省分别高达10倍和2.5倍。对于延迟驱动的任务:我们使用结构为
D-99% & R-95% & F-40%的DeepLight在Criteo数据集上实现了46倍的速度提升,使用结构为D-98% & R-90% & F-0%的DeepLight在Avazu数据集上实现了27倍的速度提升,而且没有损失准确性。
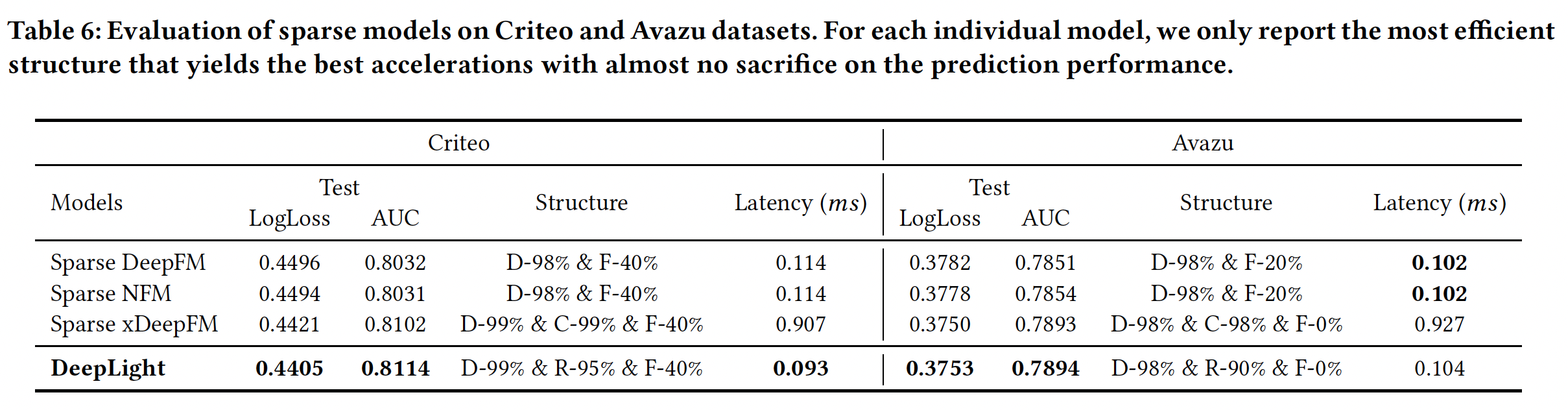
DeepLight和其它稀疏模型的比较:对于其他模型,我们也尝试了在不牺牲性能的情况下加速预测的最佳结构。关于xDeepFM中的CIN组件,我们用C-99%表示CIN组件的99%的稀疏率。结果如下表所示。可以看到:所有
embedding-based的神经网络都采用高稀疏率来保持性能。此外,
DeepLight在预测时间上与sparse DeepFM和sparse NFM相当,但在Criteo数据集上的AUC至少提高了0.8%,在Avazu数据集上提高了0.4%。DeepLight获得了与xDeepFM相似的预测性能,但其速度几乎是10倍。