一、ETA [2021]
《End-to-End User Behavior Retrieval in Click-Through Rate Prediction Model》
CTR prediction是推荐系统的核心任务之一。它预测每个user-item pair的个性化的点击概率。最近,研究人员发现,通过考虑用户行为序列,尤其是长期用户行为序列,可以大大提高CTR模型的性能。某电商网站的报告显示,23%的用户在过去5个月内点击次数超过1000次。尽管有大量工作专注于建模用户行为序列,但是由于现实世界系统中严格的inference time的限制,很少有工作能够处理长期用户行为序列。人们提出了两阶段方法来突破极限以获得更好的性能:在第一阶段,设计一个辅助任务来从长期用户行为序列中检索
top-k相似的items。在第二阶段,在
target item和第一阶段选择的k个items之间进行经典的注意力机制。
然而,检索阶段和主体的
CTR任务之间存在information gap。这种目标分歧会大大降低长期用户序列的性能增益。在本文中,受Reformer的启发,我们提出了一种局部敏感哈希(locality-sensitive hashing: LSH)方法,称为End-to-end Target Attention: ETA,它可以大大降低训练和推理成本,并使得采用长期用户行为序列进行端到端的训练成为可能。离线和在线实验都证实了我们模型的有效性。我们将ETA部署到一个大型的真实世界电商系统中,与两阶段的长用户序列的CTR模型相比,商品交易总额(Gross Merchandise Value: GMV)额外提高了3.1%。推荐系统被广泛用于解决信息过载问题。在推荐系统中使用的所有深度学习模型中,
CTR prediction模型是最重要的模型之一。为了提高推荐系统的在线性能,工业界和学术界都非常重视提高CTR模型的AUC。在过去的十年中,CTR模型的性能得到了很大的提高。其中一个显著的里程碑是引入用户行为序列,特别是长期用户行为序列。根据《Lifelong Sequential Modeling with Personalized Memorization for User Response Prediction》的报告,电商网站中23%的用户在过去5个月内点击次数超过1000次。如何有效利用大量的且信息丰富的user behavior变得越来越重要,这也是本文的目标。人们提出了各种方法来建模用户行为序列。
早期的方法,如
sum/mean pooling方法、RNN-based的方法、CNN-based的方法、以及self-attention-based,将不同长度的用户行为序列编码为固定维度的hidden vector。然而,它们在对不同的target items进行打分时无法捕获用户的动态局部兴趣(dynamic local interests)。这些方法还通过编码所有的用户历史行为从而引入了噪音。为了克服全局池化方法的缺点,人们提出
DIN方法。DIN通过target attention机制根据不同的target items生成various user sequence representations,其中target item充当queryitem充当keyvalueDIN使用最近的50个behavior用于target attention,这忽略了长用户行为序列中的丰富信息,显然是次优的。最近,人们提出
SIM和UBR4CTR等SOTA方法。这些方法从较长的用户行为序列中捕获用户的动态兴趣。这些方法分两阶段进行:在第一阶段,设计一个辅助任务从长期用户行为序列中检索
top-k相似的items,以便提前准备好top-k相似的items。在第二阶段,
target item和第一阶段选定的k个items之间进行target attention。
然而,用于检索阶段的信息与
main CTR model不一致或已过时。例如:UBR4CTR和SIM使用category等属性从用户行为序列中选择与target item共享相同属性的items,这与CTR模型的目标不一致。SIM还尝试基于pre-trained embedding来构建离线倒排索引(offline inverted index)。在训练和推理过程中,模型可以搜索top-k“相似” 的items。但大多数CTR模型都采用online learning范式,并且embedding会不断被更新。因此,与在线CTR模型中的embedding相比,离线倒排索引中的pre-trained embedding已经过时。
无论是不一致的目标还是过时的
retrieval vector,都会阻止长期用户行为序列得到充分利用。
在本文中,我们提出了一种称为
ETA的方法,可以实现端到端的长期用户行为的检索,以缓解CTR prediction任务中上述information gap(即不一致的目标和过时的embedding)。我们使用SimHash为用户行为序列中的每个item生成指纹。然后使用汉明距离来帮助选择top-k的item从而用于target attention。我们的方法将retrieval复杂度从CTR模型要评分的target items数量,item embedding的维度。复杂度的降低有助于我们在训练和服务过程中移除离线辅助模型并进行实时检索。与SOTA模型相比,这大大提高了ranking improvements。我们论文的贡献可以概括为三点:我们针对
CTR prediction任务提出了一种端到端的Target Attention方法,称为End-to-end Target Attention: ETA。据我们所知,ETA是第一个以端到端方式使用CTR模型对长期用户行为序列进行建模的工作。离线实验和在线
A/B tests都表明,与SOTA模型相比,ETA实现了显著的性能提升。与两阶段CTR模型相比,将ETA部署到大型现实世界电商平台后,GMV额外提高了3.1%。进行了全面的消融研究,以揭示在
inference time限制的约束下更好地建模用户行为序列的实际经验。我们的方法还可以扩展到其他场景,扩展到需要处理极长序列的其他模型,例如长序列的时间序列预测模型。
其核心思想就是:用近似的
similarity(embedding经过LSH之后的汉明距离)来代替精确的similarity(embedding向量的内积)。
1.1 基础知识
在本节中,我们首先给出
CTR prediction任务的公式。然后我们介绍如何通过SimHash机制生成embedding向量的指纹。
1.1.1 Formulation
CTR prediction任务广泛应用于在线广告、推荐系统和信息检索。它旨在解决以下问题:给定一个impressionitem被展示给一个用户,使用特征向量user click(标记为CTR任务通常被建模为二分类问题。对于每个impressionitem是否被点击从而标记一个二元标签CTR模型以最小化交叉熵损失:其中:
impression的总数;label;
1.1.2 SimHash
SimHash算法最早由《Similarity estimation techniques from rounding algorithms》提出,其中一个著名应用是《Detecting near-duplicates for web crawling》,它通过SimHash based的指纹检测重复的网页。SimHash函数将item的embedding vector作为输入,并生成其二进制指纹。Algorithm 1显示了SimHash的一种可能的实现的伪代码。不用那么啰嗦,可以直接用矩阵乘法来实现:

SimHash满足局部敏感特性(locality-sensitive properties):如果输入向量彼此相似,则SimHash的输出也相似,如Figure 1所示。Figure 1中的每个random rotation都可以看作一个“哈希函数”。旋转是通过将input embedding vector与随机投影列向量Algorithm 1的第2行所示。随机旋转后,球面上的点被投影到signed axes上(Algorithm 1中的第3-7行)。在Figure 1中,我们使用4个哈希函数和两个projection axes,将每个向量映射到一个具有4个元素的signature vector。signature vector中的每个元素要么是1,要么是0。可以进一步使用一个整数对该向量进行解码,以节省存储成本并加快后续的汉明距离计算。例如,
1001可以解码为整数9 = 1*8 + 0*4 + 0*2 + 1。从
Figure 1中我们可以观察到,附近的embedding向量可以以很高的概率获得相同的哈希签名(hashing signature),参见Figure 1下半部与Figure 1上半部的比较。这种观察结果就是所谓的“局部敏感”特性。利用局部敏感特性,embedding向量之间的相似性可以由哈希签名之间的相似性取代。换句话说,两个向量之间的内积可以用汉明距离代替。值得注意的是,
SimHash算法对每个旋转的 “哈希函数” 的选择不敏感。任何固定的random hash vectors就足够了(参见Algorithm 1中的embedding vectors。“
4个哈希函数和两个projection axes”?图中看起来只有一个轴啊,水平轴下方为1、上方为0。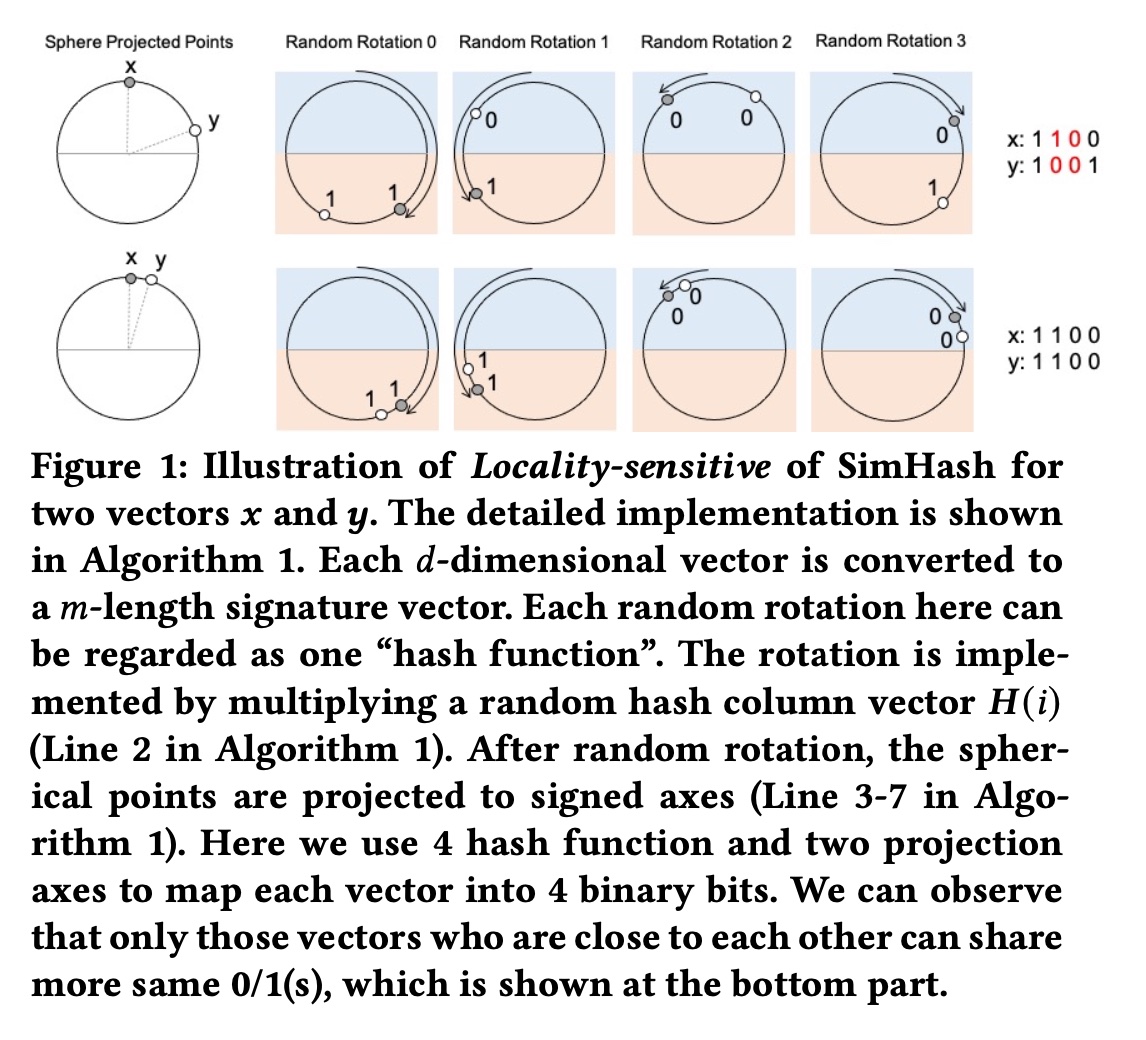
1.2 模型
在本节中,我们首先介绍我们的
End-to-End Target Attention: ETA模型的详细架构。然后介绍ETA模型的不同子模块。最后,我们介绍部署ETA的实际经验。
1.2.1 模型概况
如
Figure 2所示,我们的模型以user/item-side features作为输入,输出某个user-item pair的点击概率。长期用户行为序列
user profiletarget item注意:长期用户行为序列
在
SIM模型中,长期用户行为序列是否包含短期用户行为序列?这个不清楚,SIM的原始论文未说明。在
MIMN和UBR4CTR模型中,只有长期用户行为序列,没有短期用户行为序列。有了这些特征,我们使用长期兴趣提取单元(
Long-term Interest Extraction Unit)、多头目标注意力(Multi-head Target Attention)和Embedding Layer分别将hidden vectors。然后将hidden vectors拼接在一起并馈入到Multi-layer Perception: MLP部分。在
MLP的最后一层,使用sigmoid函数将hiddenvector映射为标量user-item pair的点击概率。此概率可作为下游任务的ranking score。
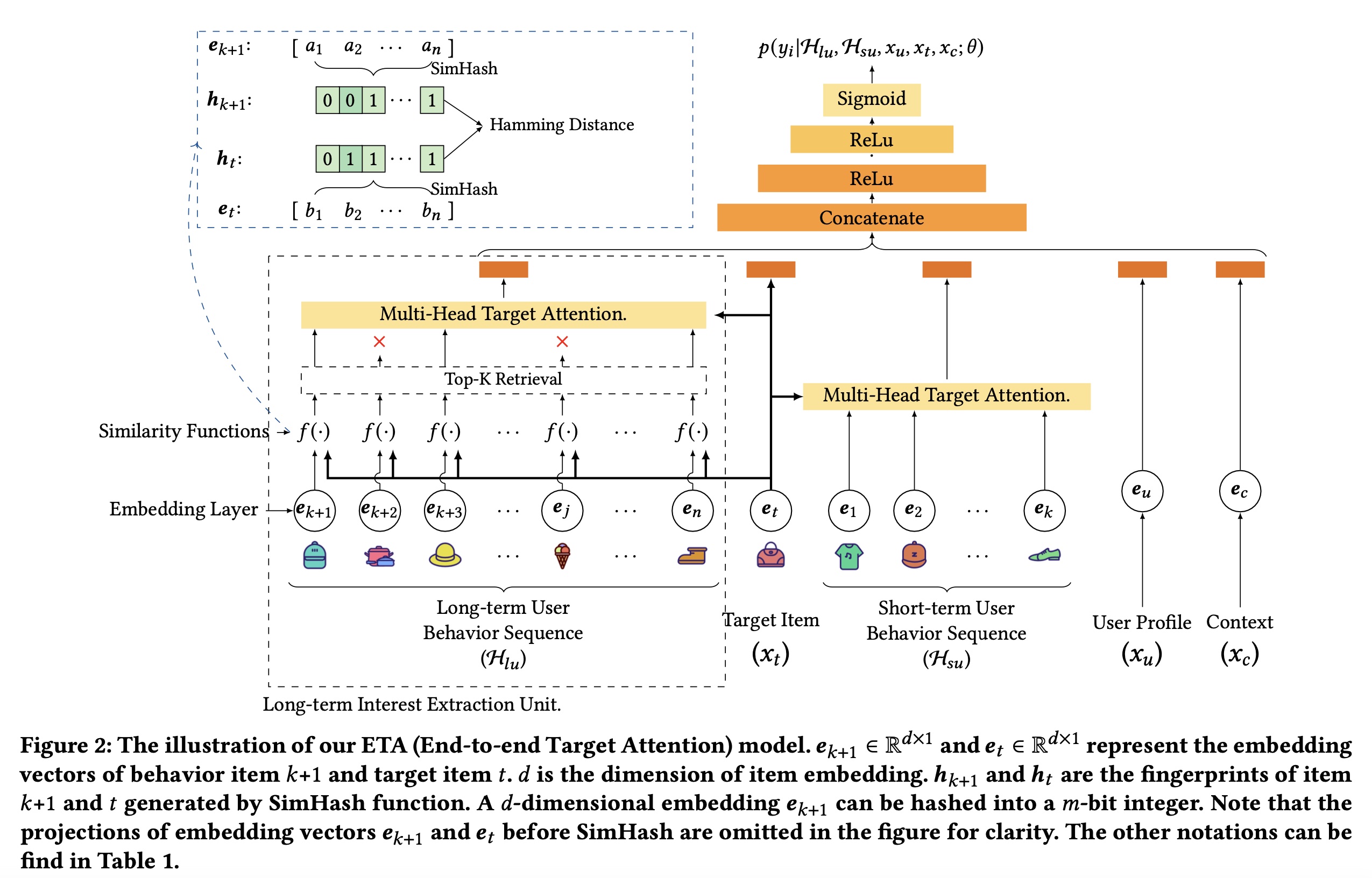
本文中这些符号的含义:

1.2.2 Embedding Layer
对于不同类型的特征,我们采用不同的
embedding技术。原始输入特征主要分为两类:categorical特征和numerical特征。在我们的模型中,我们对
categorical特征使用one-hot encoding。对于
numerical特征,我们首先将特征划分到不同的numerical buckets中。然后我们应用one-hot encoding来识别不同的桶,这与《Interpretable Click-Through Rate Prediction through Hierarchical Attention》的方式类似。
请注意,由于有数十亿个
item ids,one-hot encoding vectors可能非常稀疏。因此,我们将所有one-hot embedding vectors映射到低维hidden vectors以减少参数数量。我们使用itemembedding vector。然后将所有user behavior items的embedding vectors打包成矩阵embedding size:
1.2.3 Multi-head Target Attention
多头注意力机制由
《Attention Is All You Need》首次提出,并广泛应用于CTR prediction任务。在CTR prediction任务中,target item作为queryitem作为keyvaluemulti-head target attention),缩写为TA。multi-head target attention的计算如下:其中:
target item的embedding矩阵;embedding矩阵。item的embedding size。注意,为了清晰起见,我们只选择了一个样本(即,一个target item),而不是一个batch的样本。head数量。矩阵
query、key、value。query, key, value。query中每一行的维度,也是key中每一行的维度;value中每一行的维度。softmax函数用于将内积值转化为
multi-head target attention的主要部分是dot-product attention。dot-product attention由两步组:首先,根据
target item和每个behavior item的相似度。其次,以归一化的相似度作为注意力权重,并计算所有
behavior items的weighted sum embedding。
1.2.4 Long-term Interest Extraction Unit
这部分是我们
ETA模型的主要贡献。它将用户行为序列的长度从数十扩展到数千甚至更长,从而捕获长期用户兴趣。如前所述,multi-head target attention的复杂度为target items的数量(也就是batch size),representation维度。在大型在线系统中,1000,128。因此,直接对数千个长期的user behavior进行multi-head target attention是不可行的。 根据softmax由最大元素主导;因此,对于每个query,我们只需要关注与query最相似的key,这也得到了《Reformer:Theefficient transformer》、《Search-based User Interest Modeling with Lifelong Sequential Behavior Data for Click-Through Rate Prediction》、《User Behavior Retrieval for Click-Through Rate Prediction》的证实。因此我们可以首先从行为序列中检索top-k items,并对这些k个behavior进行multi-head target attention。然而,一个好的检索算法应该满足两个约束:
1):检索部分的目标应该与整个CTR模型保持一致。只有这样,检索到的top-k items才能对CTR模型做出最大贡献。2):检索时间应满足严格的inference time限制,以确保该算法可以应用于实际系统,从而每秒处理数百万个request。
我们在
Table 2中比较了不同的检索算法。SIM和UBR4CTR构建离线倒排索引(offline inverted index),以便在训练和推理期间进行快速搜索。然而,它们用于构建索引的输入是item的属性信息(例如category)或item的pre-trained embedding,这与CTR模型中使用的embedding不同。这种差距违反了上述约束1),并可能导致性能下降。如果直接使用
CTR模型中的embedding并通过内积搜索k-nearest neighbor,则需要2),并且无法在线部署。我们的
ETA使用SimHash将两个向量的内积转换为汉明距离计算,如Figure 2所示。这使得它可以部署在现实世界的推荐系统中。此外,SimHash的局部敏感特性可以确保fingerprint始终可以与CTR模型中的original embedding保持同步。实验章节的评估部分表明这种兼容性可以大大提高性能。如何选择正确的哈希函数、以及检索部分和
ETA其余部分之间的联合学习将在后续章节中说明。

经过
SimHash函数和hamming distance layer后,我们从top-k相似的behavior items,然后执行前面提到的multi-head target attention以生成hidden vector。该向量作为长期用户兴趣的representation,并与其他向量一起输入到MLP layers中。long-term user interest extraction unit的公式如下:其中:
LTI和TA分别是long-term user interest extraction unit和multi-head target attention的缩写。embedding矩阵。target item
相似度函数:如
Figure 2所示,我们使用SimHash函数和汉明距离来计算两个embedding向量的相似度,而不是内积。SimHash函数将上述embedding layer的输出作为输入。对于每个输入的embedding向量,SimHash函数生成其compressed number作为指纹(fingerprint)。SimHash满足局部敏感特性:如果input features彼此相似,则hashing output也相似。因此,embedding向量之间的相似性可以用hashed fingerprints之间的相似性来代替。embedding向量可以编码为m-bit number。然后可以通过汉明距离来测量两个指纹之间的相似性。Top-K Retrieval:与基于内积的模型相比,top-k retrieval layer可以通过汉明距离更有效地找到与target item的top-k相似的user behavior items。两个整数的汉明距离定义为对应bits不同的不同bits positions的数量。为了得到两个
m-bit numbers的汉明距离,我们首先进行XOR运算,然后计算取值为1中的bits数量。如果我们将乘法定义为原子操作,则两个m-digit numbers的汉明距离的复杂度为top-k retrieval的总复杂度为target items的数量。值得注意的是,每次执行
SimHash函数时,hashed fingerprints都可以与模型一起存储在embedding table中。在推理期间,只需要embedding lookup,其复杂性可以忽略不计。
1.3 部署
在本节中,我们展示了如何训练具有检索部分的
ETA。然后我们介绍如何选择SimHash算法中使用的“哈希函数”。然后我们介绍工程优化技巧。Joint learning of retrieval part:在训练阶段,检索部分不需要更新梯度。检索的目标是为接下来的multi-head target attention部分选择query的最近邻的keys。在选择了query的top-k最近邻的keys之后,对这些top-k items的original embedding vectors进行正常的注意力机制和反向传播。检索的唯一事情是在训练开始时初始化一个固定的随机矩阵Algorithm 1)。只要input embedding vectorSimHash的签名就会相应更新。局部敏感特性确保在每次迭代中,使用CTR模型的latest embedding无缝地选择query的top-k nearest keys。因此,检索和CTR模型之间的gap of goal比其他检索方法(例如Table 2中所示的基于离线倒排索引的方法)小得多。从
CTR模型的角度来看,检索部分是透明的,但可以确保模型使用最邻近的items进行multi head attention。实验章节表明,这种无需任何pre-training或offline inverted index building的端到端训练可以大大提高CTR prediction任务的性能。“哈希函数”的选择:
SimHash是一种著名的局部敏感哈希 (locality-sensitive hashing: LSH)算法。SimHash的实现如Algorithm 1所示,其中我们使用固定的random hash vector作为“哈希函数”。任何将字符串映射为随机整数的传统散列函数都可以使用。但是,在我们的算法中,出于对矩阵计算的可扩展性和效率的考虑,我们选择了random hash vector和Algorithm 1的实现,这与Reformer相同。局部敏感哈希是通过随机旋转和投影实现的。随机旋转是指
embedding vector与一个固定的random hashing vectorsinged axes上从而获得binary signature,0附近随机生成。工程优化技巧:当在线部署模型时,
SimHash的计算可以进一步减少一步。针对embedding向量Algorithm 1计算出的长度为signature vectorsignature vector,因为1要么为0。因此,这样可以大大减少内存开销,加快汉明距离的计算速度。两个整数的计算时间可以在
1.4 实验
在本节中,我们进行实验来回答以下研究问题:
RQ1:我们的ETA模型是否优于baseline模型?RQ2:与baseline模型相比,我们的ETA模型的推理时间是多少?推理时间和性能一样重要,因为它决定了模型是否可以在线部署以供服务。RQ3:我们的ETA模型的哪一部分对性能和推理时间贡献最大?
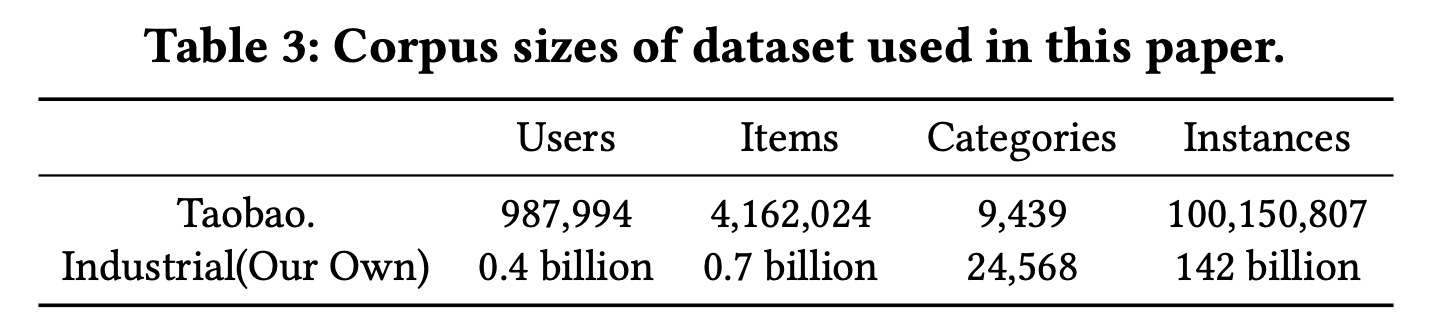
数据集:为了对我们的
ETA模型和baseline模型进行全面比较,我们使用了公共数据集和工业数据集。还进行了在线A/B test。对于公共数据集,我们选择了Taobao数据集,baseline模型SIM和UBR4CTR也采用了该数据集。我们也准备了一个工业数据集作为公共数据集的补充。Table 3简要介绍了数据集。Taobao数据集:该数据集由《Joint optimization of tree-based index and deep model for recommender systems》首次发布,被广泛用作CTR prediction任务和序列推荐任务的公共基准。它由Taobao Mobile App的user behavior日志组成。user behavior包括点击、收藏、添加到购物车、以及购买。该数据集包含100M个实例。平均而言,每个用户大约有101次交互,每个item受到超过24次交互。最近的16个behavior作为短期用户行为序列,最近的256个behavior作为长期用户行为序列。工业数据集:该数据集是从我们自己的在线推荐系统收集的,它是我国顶级的移动
app之一。我们的工业数据集有三个优势:(i):我们的数据集包含impression interaction,这表示item展示给用户但未被用户点击。impression interaction自然是CTR模型的负样本。因此,不需要棘手的负采样。(ii):我们的工业数据集中的用户行为序列更长。有超过142B个实例,平均长度达到938,比公开的Taobao数据集长9倍。(iii):我们的工业数据集具有由多位软件工程师设计的更多特征,更接近现实世界的推荐系统模型。最近的48个behavior作为短期用户行为序列,最近的1024个behavior作为长期用户行为序列。在消融研究中,我们还尝试了长度为{256, 512, 2048}的长期用户行为序列。
baseline:我们将我们的模型与以下主流的CTR prediction baselines。选择每个baseline来回答上述一个或多个相关的研究问题。Avg-Pooling DNN:利用用户行为序列的最简单方法是均值池化,它将不同长度的用户行为序列编码为fixed-size hidden vector。该baseline可以看作是DIN的变体,用均值池化代替target attention,类似于YouTube。与DIN相比,该baseline主要用于显示target attention的必要性。DIN:DIN通过注意力机制来建模具有不同target items的个性化用户兴趣,该注意力机制称为target attention。但是,DIN仅利用短期用户行为序列。DIN (Long Sequence):是配备长期用户行为序列DIN。DIN相比,此baseline用于衡量长期用户行为序列本身的信息增益。SIM(hard):SIM是CTR prediction模型,它提出了一个search unit,以两阶段的方式从长期用户行为序列中提取用户兴趣。SIM(hard)是SIM的一种实现,它在第一阶段按category id搜索top-k behavior items。UBR4CTR:UBR4CTR也是一种两阶段方法,它在CTR prediction任务中利用长期用户行为序列。在UBR4CTR中,通过一个feature selection model准备好query,从而检索最相似的behavior items。它还准备了一个倒排索引以供在线使用。由于UBR4CTR和SIM几乎同时发布,因此它们无法相互比较。在我们的论文中,我们首次比较了UBR4CTR和SIM。SIM(hard)/UBR4CTR + timeinfo:是在对用户行为序列进行编码时带有time embedding的SIM(hard)/UBR4CTR。
在
《Search-based User Interest Modeling with Lifelong Sequential Behavior Data for Click-Through Rate Prediction》中,作者提出SIM(soft)作为基础算法SIM(hard)的变体。他们最终采用SIM(hard)方法作为online serving算法,并在线部署SIM(hard)+timeinfo来服务主要流量。这是因为SIM(hard)不需要pre-training,对系统演进和维护更友好。此外,SIM(hard)+timeinfo可以实现与SIM(soft)相当的性能。因此,我们选择SIM(hard)和SIM(hard)+timeinfo作为我们的强基线。MIMN与DIN是由同一个团队提出的。MIMN提出了一个multi-track offline user interest center来提取长期用户兴趣。在发布时,它通过利用长期用户行为序列实现了SOTA的性能。然而,MIMN被同一支队伍的SIM所击败。由于MIMN对我们的研究问题贡献不大,由于篇幅限制,我们省略了这个基线。评估指标:
离线实验:
AUC作为主要指标,推理时间作为补充指标。推理时间定义为:对某个模型请求的
a batch of items进行评分时的往返时间。我们通过在线部署被测试的模型来服务用户请求从而测量推理时间,这些用户请求是从产品环境中复制而来。为了比较公平性,机器和用户请求数量控制相同。在线
A/B test:CLICK和CTR。CLICK:被点击items的总数。CTR:衡量平台中用户的点击意愿。它的定义为CLICK/PV,其中PV定义为被展示的items的总数。
数据预处理:
Taobao数据集仅包含positive交互,例如评论、点击、收藏、添加到购物车、以及购买。我们使用与MIMN相同的数据预处理方法。首先,对于每个用户,我们选择最后一个
behavior作为正样本。然后,对于该用户,我们随机采样一个与正样本相同
category的新item作为负样本。其余的
behavior items用作特征。
根据正样本的时间戳
80%)、验证集(10%)和测试集(10%)。我们的工业数据集自然有正样本和负样本,因为我们记录了每个用户的所有
impressions。如果用户点击了该item,则impression被标记为正样本;否则,它被标记为负样本。我们使用过去两周的日志作为训练集,
following day的日志作为测试集,这与SIM类似。
实验设置:对于不同数据集上的每个模型,我们使用验证集来调优超参数以获得最佳性能。学习率从
L2正则化项从Adam优化器。Taobao数据集和我们的工业数据集的batch size分别为256、1024。
1.4.1 性能比较
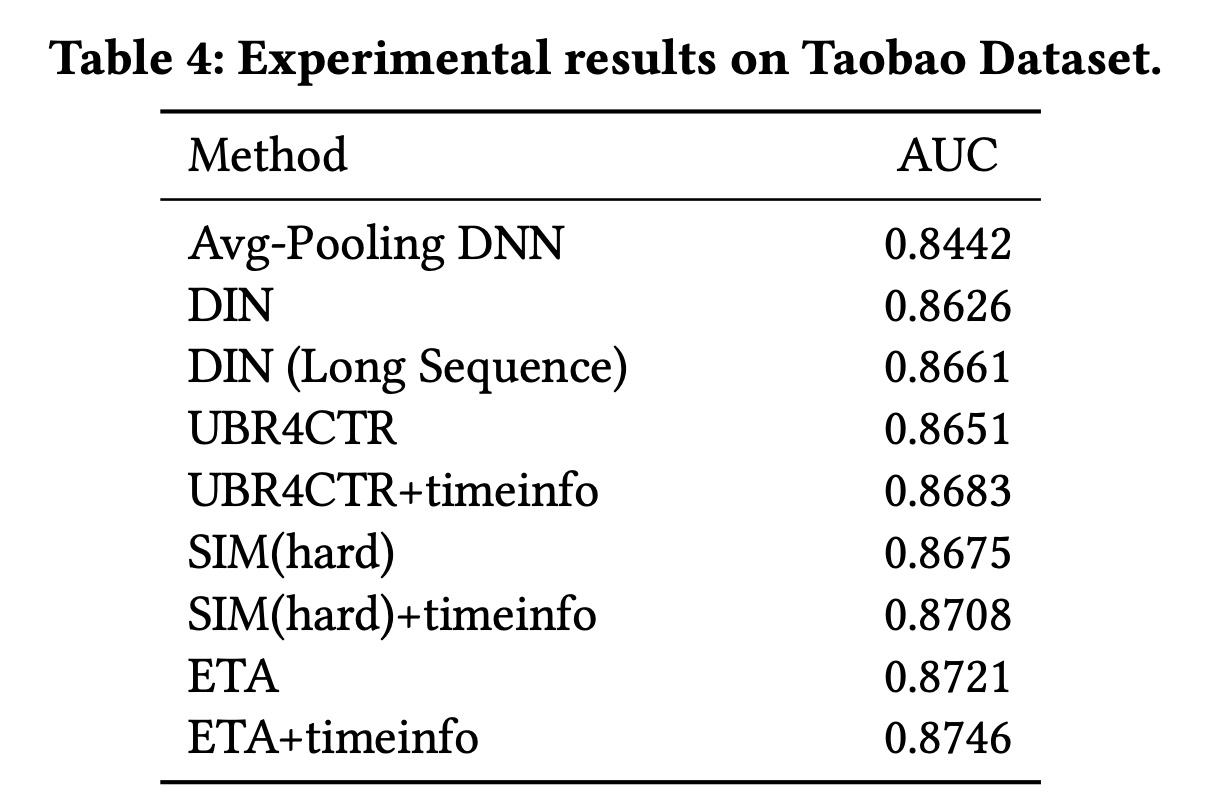
Taobao数据集:Taobao据集上的评估结果如Table 4所示。从表中我们发现:与所有
baselines相比,我们的ETA具有一致的性能改进。ETA比SIM(hard)好0.46%,比DIN(Long Se-sequence)好0.6%。添加
time embedding后,ETA+timeinfo的性能比SIM(hard)+timeinfo高0.38%,比DIN(Long Sequence)高0.85%。在UBR4CTR上也可以观察到类似的结果(即,添加time embedding的效果更好)。
观察到
DIN(Long Sequence)与DIN相比,AUC提高了0.35%,这表明对长期用户行为序列进行建模对于CTR prediction是有效的。我们还发现
UBR4CTR的性能比DIN(Long Sequence)差。这是因为UBR4CTR的feature selection model仅选择特征(例如category、星期几)与target item相同的behavior。UBR4CTR中的这种过滤有助于从序列中去除噪音,但也会导致用户序列变短,当没有足够的items进行top-k retrieval时,这是有害的。我们发现
DIN比Avg-Pooling DNN的性能高出1.84%,这表明使用target attention来编码用户行为序列可以大大提高性能。
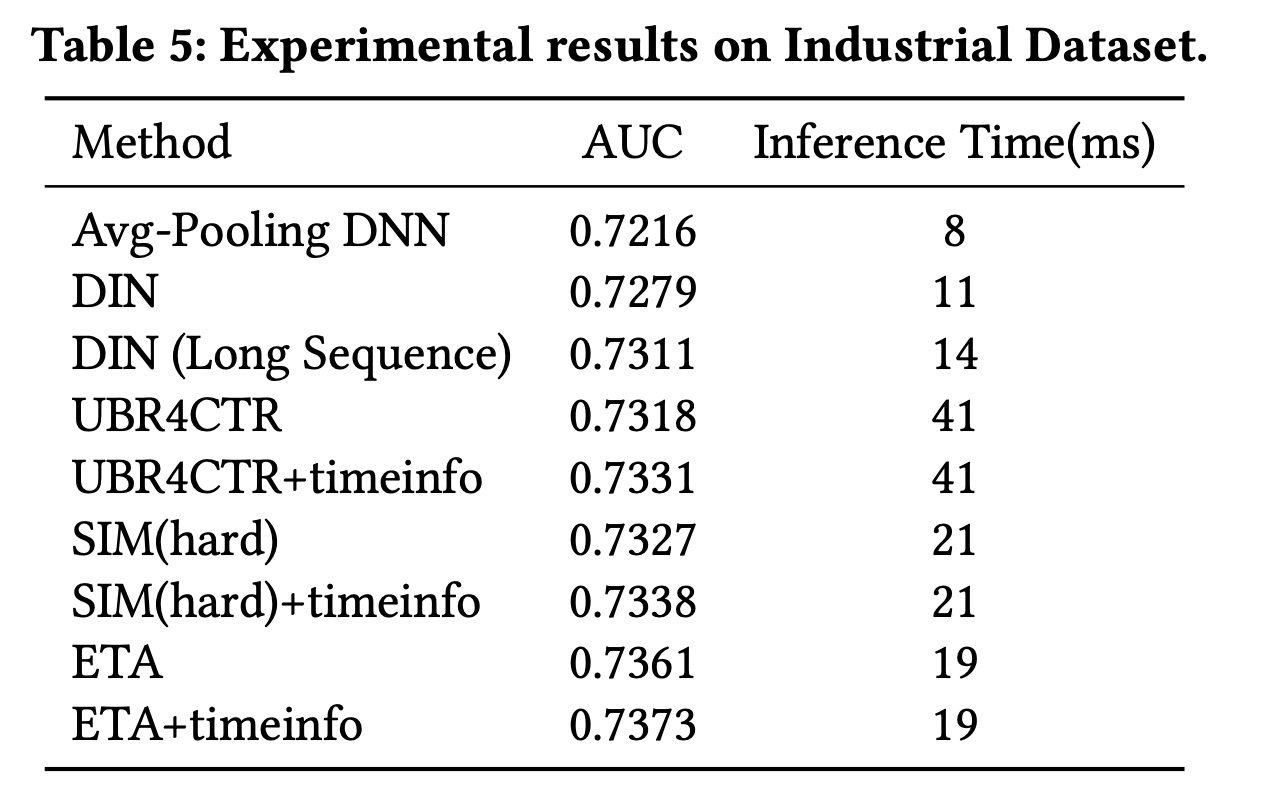
工业数据集:我们自己的工业数据集上的评估结果如
Table 5所示。请注意,CTR模型在AUC上的0.1%改进,可以在我们的在线推荐系统中带来数百万的真实点击和收入。与所有baselines相比,我们的ETA实现了最佳性能。与
SIM(hard)和UBR4CTR相比,我们的base ETA分别实现了0.34%和0.43%的改进。与
SIM(hard)+timeinfo和UBR4CTR+timinfo相比,我们的ETA+timeinfo分别实现了0.35%和0.42%的改进。与
Taobao数据集不同,在工业数据集上SIM(hard)+timeinfo成为最强的baseline,比DIN(Long Sequence)高出0.27%。这有两个原因。一方面,工业数据集中的用户序列长度足够大,对基于长期用户序列的模型友好。工业数据集的平均长度达到了
938,是Taobao数据集的9倍。另一方面,
DNN(Long Sequence)采用均值池化对整个序列进行无选择性地编码,与UBR4CTR、SIM、ETA等基于检索的模型相比,可能会引入噪音。
Taobao数据集上的最强baseline也是SIM(hard)+timeinfo。所以这个结论是错误的,其解释也是不可信的。我们还可以发现
SIM(hard)比UBR4CTR有0.09%的性能提升,这主要是由于对用户行为序列的处理方法不同造成的。在
SIM(hard)中,用户序列被拆分为两个独立的子序列,与Figure 2中的ETA类似:短期用户行为序列k个user behavior组成,从item 1到item k;长期用户行为序列item k+1到item n中选择的其他k个behavior而组成。但是,
UBR4CTR从item 1到item n选择item(Figure 2中的SIM(hard)以100%的概率选中,被UBR4CTR以feature selection model所决定的timeinfo在用户兴趣建模中起着重要作用,因为用户兴趣是动态的并且经常变化。因此SIM(hard)的表现优于UBR4CTR。
在线
A/B Test:在线A/B Test的评估结果如Table 6所示。Table 6显示了与DIN-based的方法相比的性能改进,其中DIN-based的方法没有长期用户行为序列。从Table 6中我们发现:与
DIN-based的方法相比,我们的ETA+timestamp在CTR上实现了6.33%的改进,并带来了9.7%的额外GMV。与最强的基线
SIM(hard)+timeinfo相比,我们的ETA+timeinfo在CTR上额外提高了1.8%,在 GMV 上提高了3.1%。
请注意,
GMV上1%的改进是一个显著的改进,因为这意味着为推荐系统带来了数百万的收入。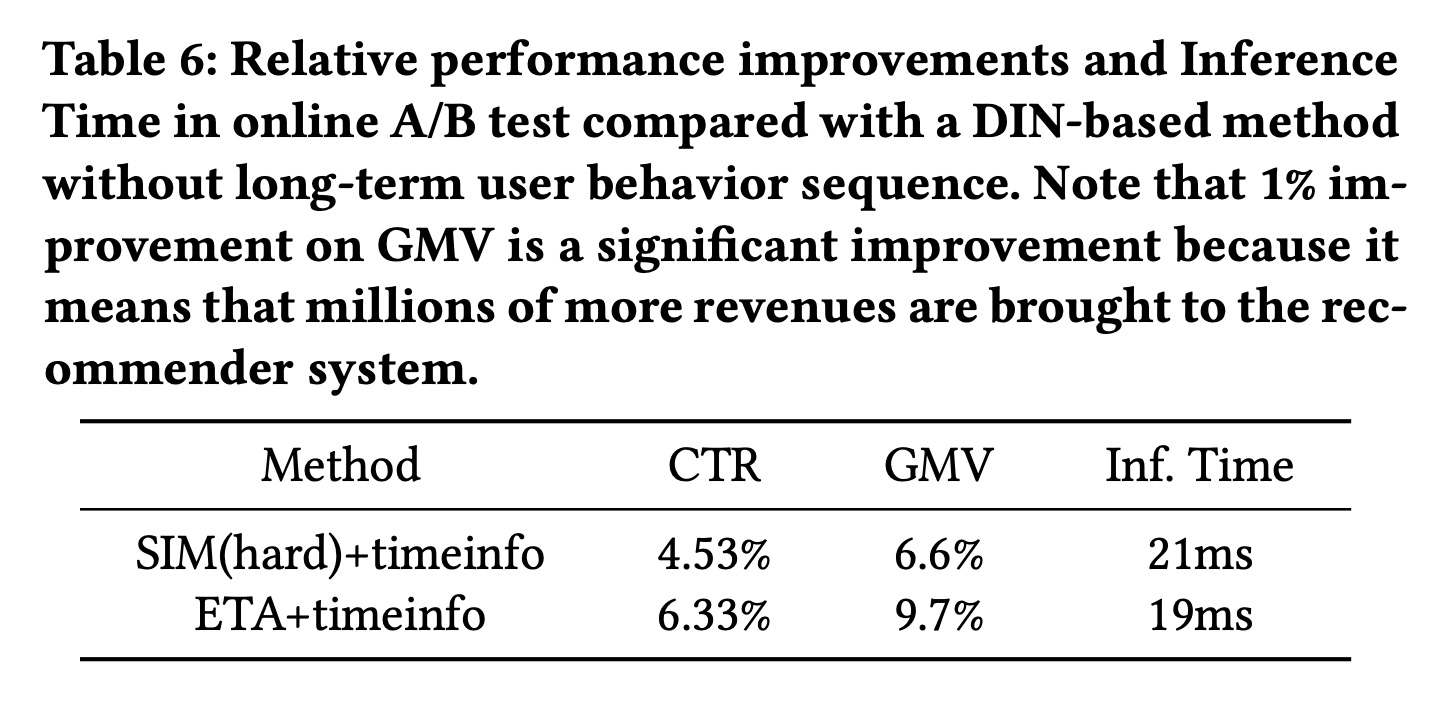
1.4.2 推理时间比较
虽然使用长期用户行为序列可以提高
CTR prediction的性能,但模型复杂度也会相应增加。我们测量了不同模型的推理时间,如Table 5所示。Avg-Pooling DNN的推理时间最短,为8 ms。它仅使用均值池化方法来编码近期的behavior items。将均值池化替换为
target attention后,DIN的推理时间增加了3ms(8ms到11ms)。引入长期用户行为序列后,
DIN (Long Sequence的推理时间又增加了3ms(11ms到14ms)。SIM和我们的ETA的推理时间相当,约为19 ~ 21 ms。UBR4CTR的推理时间最长,因为在检索阶段之前使用了额外的feature selection model,并且在线进行了相对耗时的IDF and BM25 based的程序来获取top-k items。
1.4.3 消融研究
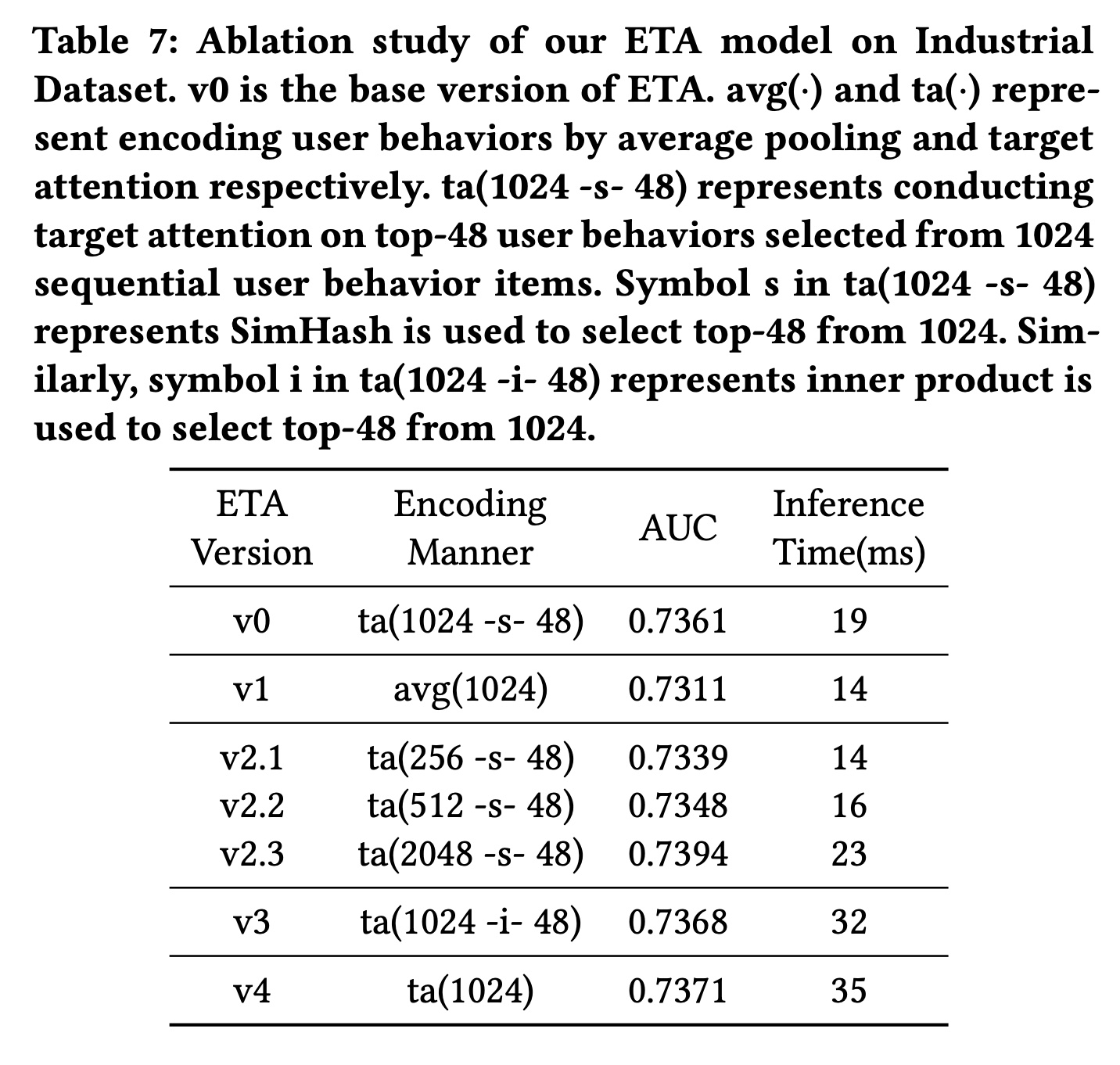
消融研究结果如
Table 7所示,以回答问题RQ3。我们使用编码方式来区分ETA模型的不同版本(v0到v4)。请注意,v0是ETA的基本版本。编码方式列在Table 7的第二列中,其中:avg(·)和ta(·)分别表示通过均值池化和target attention对user behavior进行编码。ta(1024 -s- 48)表示对从1024长度的用户行为序列中选择的top-48 user behaviors进行target attention。ta(1024 -s- 48)中的符号s表示SimHash用于从1024个user behavior中选择top-48;类似地,ta(1024 -i- 48)中的符号i表示内积用于从1024个user behavior中选择top-48。
从
Table 7中,可以得出以下观察结果:(i):直接在原始1024长度的用户行为序列上进行multi-head target attention(v4)可以获得最佳性能,但同时具有最长的推理时间。与
v4相比,我们的base ETA(v0) 选择top-k behaviors进行attention,牺牲了大约0.1%的AUC,并将推理时间减少了46%。(ii):将v3与v0进行比较,在检索阶段用内积替换SimHash可使AUC提高0.07%。然而,推理时间增加了68%,这是我们严格的在线service level agreement: SLA所不可接受的。(iii):当我们改变用户行为序列的长度(v2.x与v0)时,观察到AUC和推理时间之间的权衡。可以根据在线推理时间的要求决定合适的序列长度。
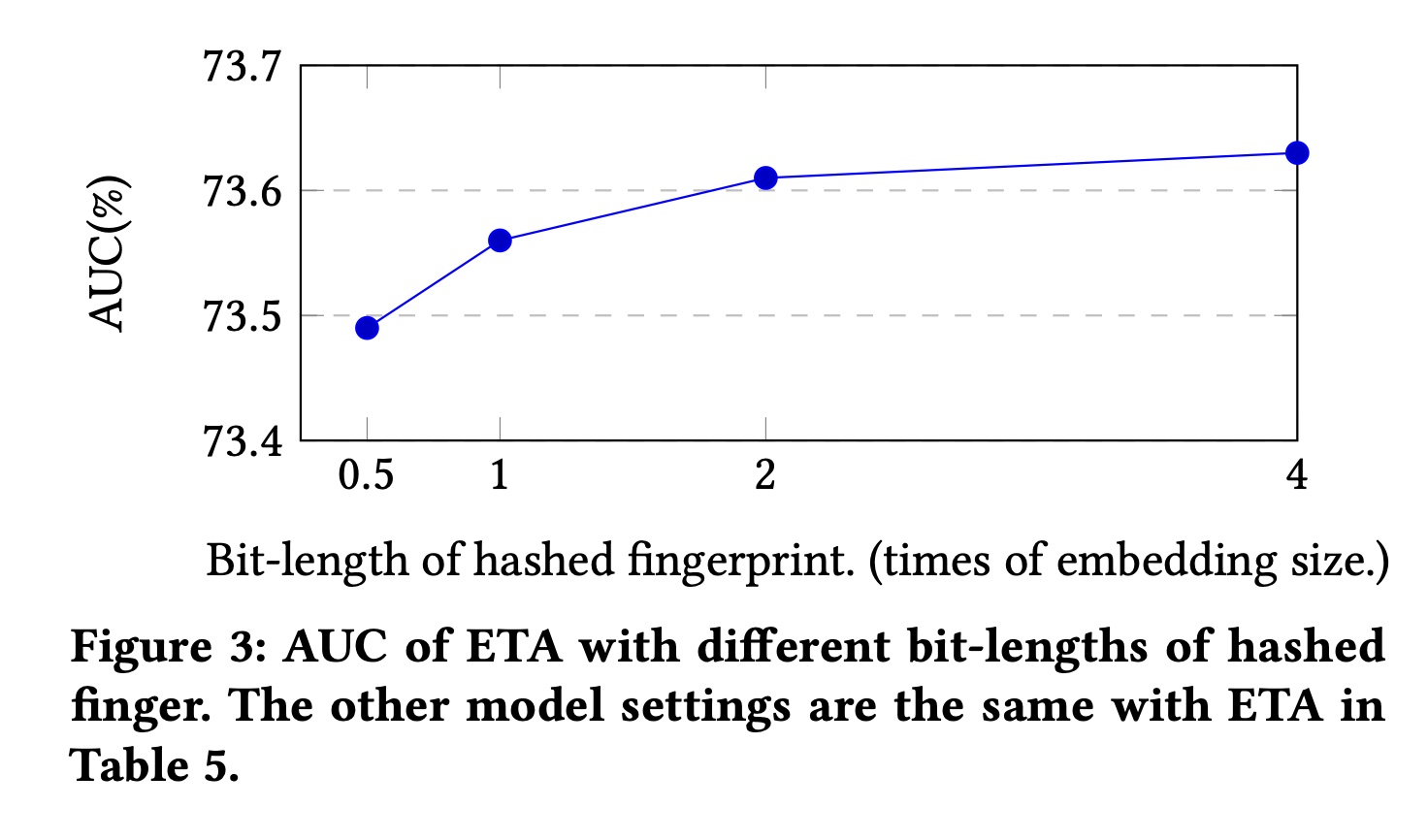
在
Figure 3中,我们还评估了SimHash所生成的哈希指纹bit-length下的性能。如前文所述,指纹的bit-length可以通过SimHash中使用的哈希函数数量来控制。我们可以发现:通过增加
bit-length可以提高AUC。但是,当
bit-length大于2倍embedding size时,AUC的改进变得微不足道。