一、FmFM [2021]
《FM2: Field-matrixed Factorization Machines for Recommender Systems》
CTR预估所涉及的数据通常是multi-field categorical data,这类数据具有以下特性:首先,所有的特征都是
categorical的,并且是非常稀疏的,因为其中许多是id。因此,特征的总数很容易达到数百万或数千万。其次,每个特征都唯一地属于一个
field,而且可能有几十到几百个field。
针对
ctr预测问题的一个卓越模型是具有交叉特征的逻辑回归。当考虑到所有的交叉特征时,产生的模型等同于二阶的多项式核。然而,要考虑所有可能的交叉特征需要太多的参数。为解决这个问题,人们提出了matrix factorization: MF和factorization machine: FM,这些方法通过两个feature embedding向量的点乘来学习交叉特征的影响。在FM的基础上,人们提出了Field-aware Factorization Machine: FFM,从而考虑field信息来建模来自不同field pair的不同的特征交互。最近,人们又提出了Field-weighted Factorization Machine: FwFM模型,以一种更加parameter-efficient的方式来考虑field信息。现有的考虑
field信息的模型要么有太多的参数(如FFM),要么不是很有效(如FwFM)。论文《FM2: Field-matrixed Factorization Machines for Recommender Systems》建议使用两个特征向量之间的field matrix来建模这两个特征向量之间的交互,其中矩阵是为每个field-pair单独学习的。论文表明,field-pair matrix方法在保持计算空间和时间效率的同时,实现了良好的准确性。
1.1 模型
假设有
unique特征fieldsfield,记做给定数据集
label表示是否点击;active的。LR模型为:其中:
然而,线性模型缺乏表示特征交互的能力。由于交叉特征可能比那些单一特征更重要,在过去的几十年里,人们提出了许多改进。
Poly2:然而,线性模型对于诸如CTR预估这样的任务来说是不够的,在这些任务中,特征交互是至关重要的。解决这个问题的一般方法是增加feature conjunction。已有研究表明,Degree-2 Polynomial: Poly2模型可以有效地捕获特征交互。Poly2模型考虑将其中:
FM:Factorization Machine:FM为每个特征学习一个embedding向量FM将两个特征embedding向量其中:
在涉及稀疏数据的应用中(如
CTR预估),FM的表现通常优于Poly2模型。原因是,只要特征本身在数据中出现的次数足够多,FM总能为每个特征学习到一些有意义的embedding向量,这使得内积能很好地估计两个特征的交互效应(interaction effect),即使两个特征在数据中从未或很少一起出现。FFM:然而,FM忽略了这样一个事实:当一个特征与其他不同field的特征交互时,其行为可能是不同的。Field-aware Factorization Machines: FFM通过为每个特征(如embedding向量来显式地建模这种差异,并且只使用相应的embedding向量field虽然
FFM比FM有明显的性能改进,但其参数数量是FFM的巨大参数数量是不可取的。因此,设计具有竞争力的和更高内存效率的替代方法是非常有吸引力的。FwFM:在FwFM中,feature pair其中:
field pairFwFM的公式为:FwFM是FM的扩展,即它使用额外的权重feature pair的不同交互强度。FFM可以隐式地建模不同feature pair的不同交互强度,因为FFM为每个特征embedding向量,每个向量fieldfield特征的不同交互。
最近,也有很多关于基于深度学习的
CTR预测模型的工作。这些模型同时捕获了低阶交互和高阶交互,并取得了明显的性能改进。然而,这些模型的在线推理复杂性比浅层模型要高得多。通常需要使用模型压缩技术,如剪枝、蒸馏或量化来加速这些模型的在线推理。在本文中,我们专注于改进低阶交互,所提出的模型可以很容易地作为这些深度学习模型中的浅层组件。我们提出了一个新的模型,将
field pair的交互表达为一个矩阵。与FM和FwFM类似,我们为每个特征学习一个embedding向量。 我们定义一个矩阵fieldfield其中:
featureembedding向量。featurefield。fieldfield注意:
embedding向量不同。此外,考虑到 “fieldfieldfieldfield
我们称这个模型为
Field-matrixed Factorization Machine: FmFM(也叫做FM2):FmFM是FwFM的扩展,它使用一个二维矩阵FwFM中的标量field pair的交互。通过这些矩阵,每个特征的embedding空间可以被转换到另外的embedding空间。我们将这些矩阵命名为Field-Matrix。核心思想:将
FwFM中的标量下图展示了
feature pairfield。计算可以分解为三步:Embedding Lookup:从embedding table中查找feature embedding向量转换:将
fieldfield点乘:最终的交互项将是
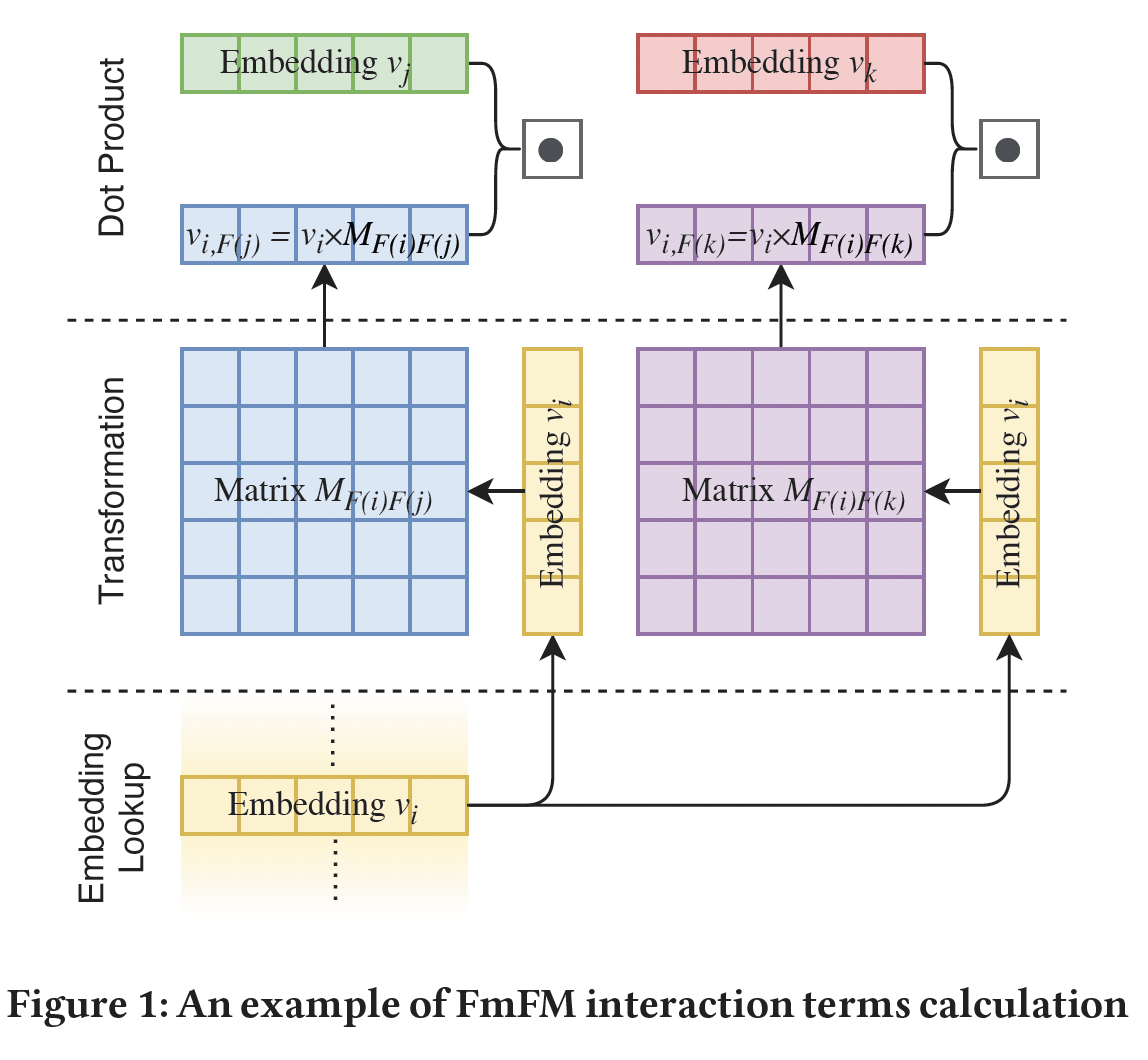
1.2 FM2 作为统一框架
FM家族的统一框架:FM:下图展示了FM中特征交互的计算。如果将FmFM中所有的field matrix都固定为单位矩阵,那么FmFM将退化为FM。由于单位矩阵是固定的、不可训练的,因此我们定义其自由度为0。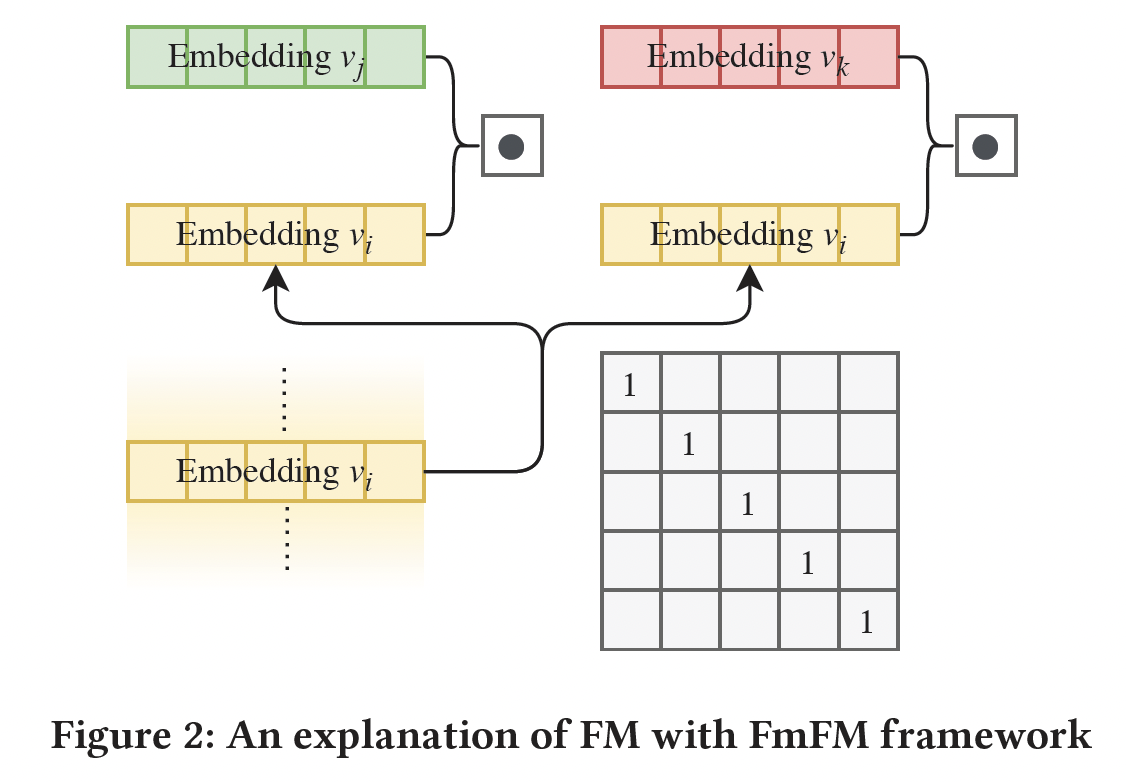
FwFM:下图展示了FwFM中特征交互的计算。如果将FmFM中的field pair取不同的值,那么FmFM将退化为FwFM。我们定义FwFM的自由度为1。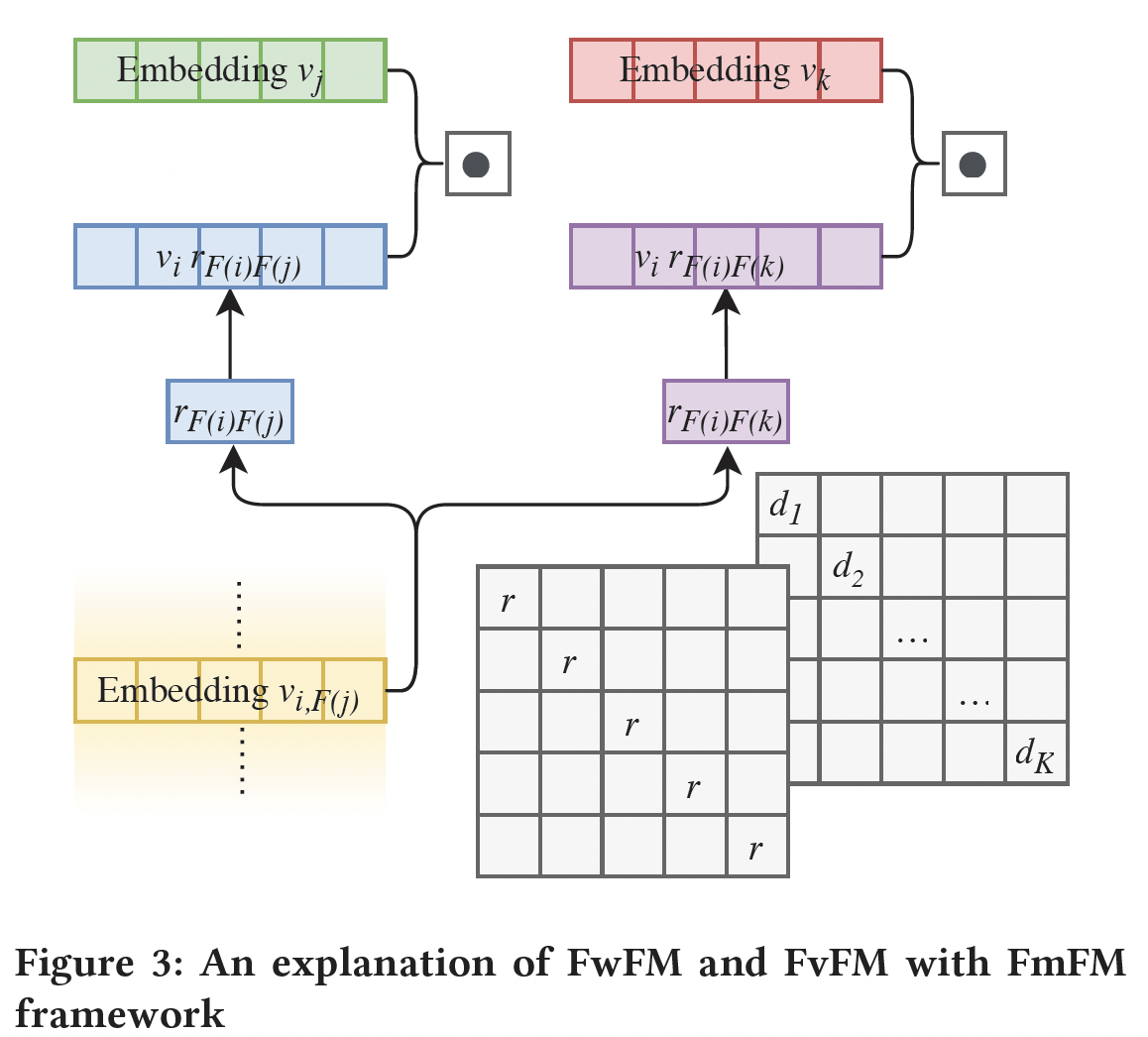
FvFM:根据Figure 3的线索,我们将FmFM中的field pair选择不同的对角矩阵,如Figure3的右边的矩阵所示,那么:其中:
我们将这种方法命名为
Field-vectorized Factorization Machine: FvFM,它的自由度为2。FmFM:它具有一个矩阵的所有自由度,即自由度为3。我们预期FmFM比其他FM模型有更强大的预测能力。
总之,我们发现
FM、FwFM、FvFM都是FmFM的特例,唯一的区别是它们的field matrix的限制。根据它们的灵活性,我们把它们总结在下表中。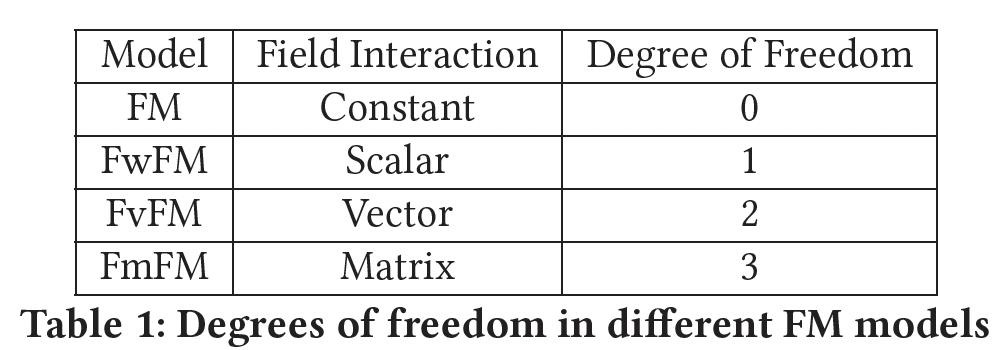
FmFM与OPNN的关系:FmFM也可以看做是通过加权外积来建模两个feature embedding vector的交互:OPNN也提出通过外积来建模特征交互。然而,FmFM在以下两个方面与OPNN不同:首先,
FmFM是一个简单的浅层模型,没有像OPNN中那样的全连接层。我们可以将FmFM作为任何深度CTR模型的一个浅层组件或构建块。其次,
FmFM支持针对不同feature field的可变embedding size。
FFM vs FmFM,即Memorization vs Inference:与上述其他FM不同,FFM不能被改造成FmFM框架。下图展示了FFM中特征交互的计算。FFM不共享feature embedding,因此对于每个特征都有embedding从而分别与其它field进行交叉。在训练过程中,这些field-specific embedding将被独立学习,而且这些embedding之间没有任何限制,即使它们属于同一特征。这种
FFM机制给了模型最大的灵活性来拟合数据,而且大量的embedding参数也具有惊人的记忆能力。同时,即使有数十亿的样本需要训练,也总是存在着过拟合的风险。特征分布的属性是一个长尾分布,而不是均匀分布,这使得feature pair的分布更加不平衡。以下图为例。假设
feature pairembedding,因此embeddingfeature pair可能占据了训练数据的绝大部分,而低频的feature pair(占据了feature pair中的绝大多数)则不能被很好地训练。FmFM使用共享embedding向量,因为每个特征只有一个embedding向量。它利用一个变换过程,将这一个embedding向量投影到其他field。这基本上是一个推理过程,那些embedding向量embedding向量field matrix,向量是可以前向变换和反向变换。这就是FFM和FmFM的根本区别:在同一特征中那些可变换的中间向量(即,feature pair。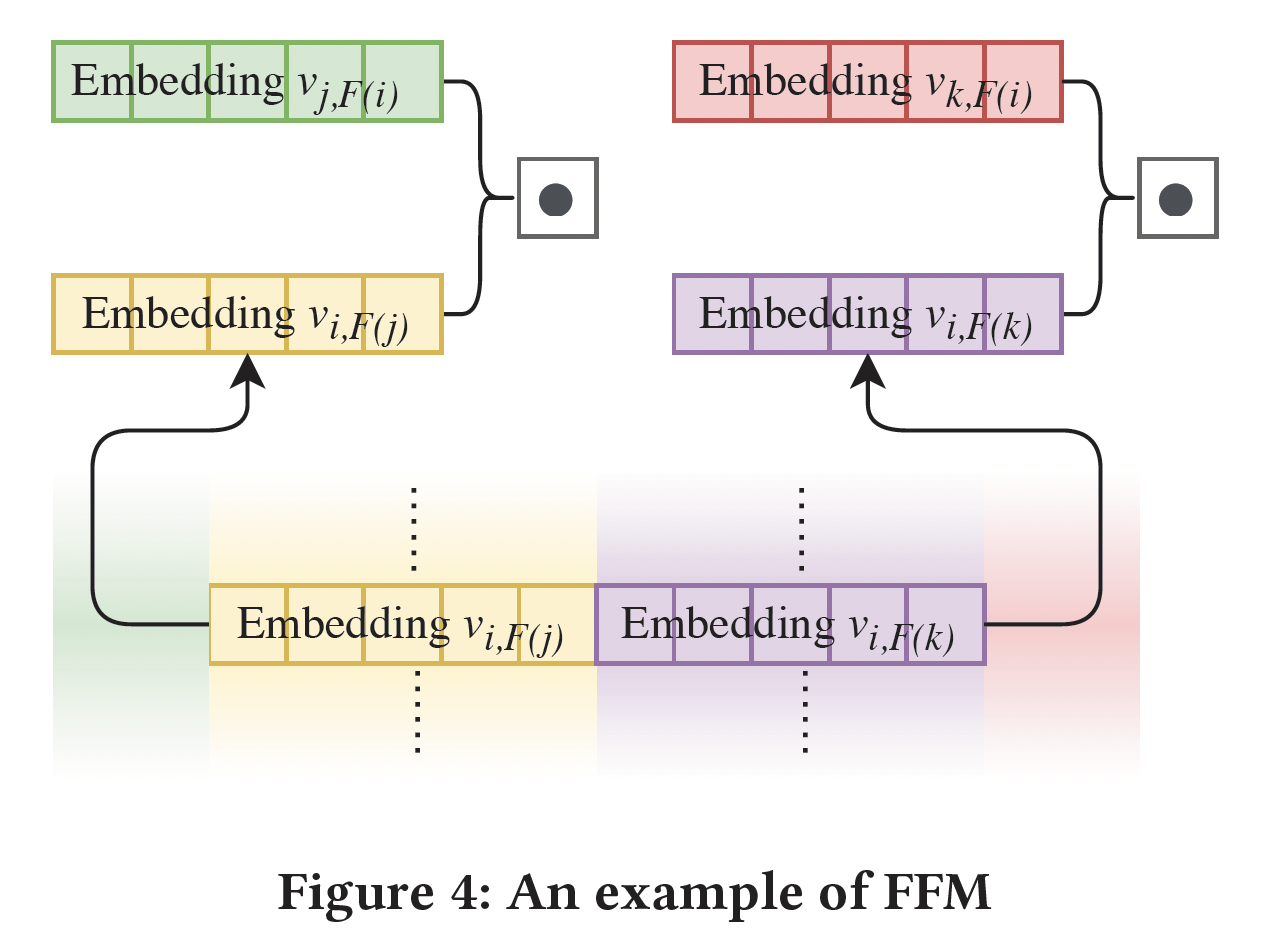
回到
Figure 1的例子。即使feature pairfeature embeddingfeature pair(如field matrixfieldfieldfeature pair尽管
FFM和FmFM之间有这种差异,但它们有更多的共同点。Figure 4和Figure 1之间一个有趣的观察是:当所有变换完成后,FmFM模型变成了FFM模型。我们可以缓存那些中间向量,避免在运行时进行矩阵操作。细节将在下一节讨论。相反,
FFM模型无法被改造成FmFM模型。那些field feature embedding table是独立的,因此很难将它们压缩成单个feature embedding table,并在需要时恢复它们。模型复杂度:
FM的参数数量为embedding向量。FwFM对每个field对使用FwFM的参数总数为FmFM对每个field对使用FwFM的参数总数为FFM的参数数量为embedding向量。
在下表中,我们比较了到目前为止提到的所有模型的复杂度。我们还列出了每个模型的估计参数规模(模型配置,如
embedding size,参考实验部分),这些模型使用了公共数据集Criteo。这些数字可以让我们对每个模型的规模有一个直观的印象。FM、FwFM和FmFM的规模相近,而FFM的规模比其他模型大十几倍。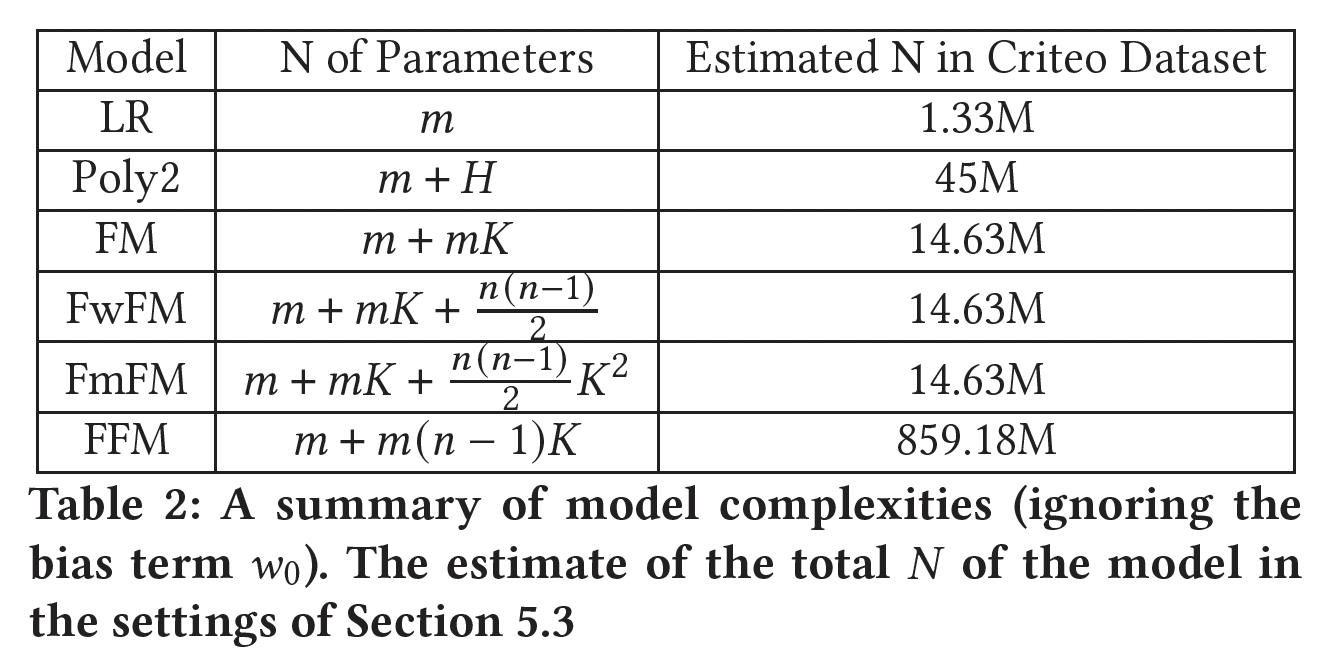
1.3 模型优化
这里我们可以设计出
3种策略来进一步降低FmFM的复杂度:field-specific embedding dimension:它是FmFM的一个独特属性,允许我们在embedding table中使用field-specific的维度,而不是全局的固定长度这里
field-specific的维度是通过对训练好的embedding table进行降维来实现的。因此需要训练两遍。缓存中间向量:避免矩阵运算从而在运行时减少
FmFM的计算复杂度(仅用于推断期间)。减少线性项:用
field-specific权重来代替。
这里面提到的优化方法大多数都不实用,无法优化训练速度,而仅聚焦于优化推断速度。实际上,如果想优化推断速度,那么可以用模型剪枝、模型量化、模型蒸馏技术。
Field-specific Embedding Dimension:为了进行点积,FM要求所有feature embedding的向量维度field。改进后的模型如FwFM、FvFM也采用了这个特性。然而,向量维度当我们利用
FmFM中的矩阵乘法时,它实际上并不要求field matrix是方阵:我们可以通过改变field matrix的shape来调整输出向量的维度。这一特性给了我们另一种灵活性,可以在embedding table中按需设置field-specific维度,如下图所示。embedding向量的维度决定了它所能携带的信息量。例如,field user_gender可能只包含3个值(male, female, other),field top_level_domain可能包含超过1M个特征。因此,user_gender的embedding table可能只需要5维,而field top_level_domain的embedding table可能需要7维,因此它们之间的field matrix的shape为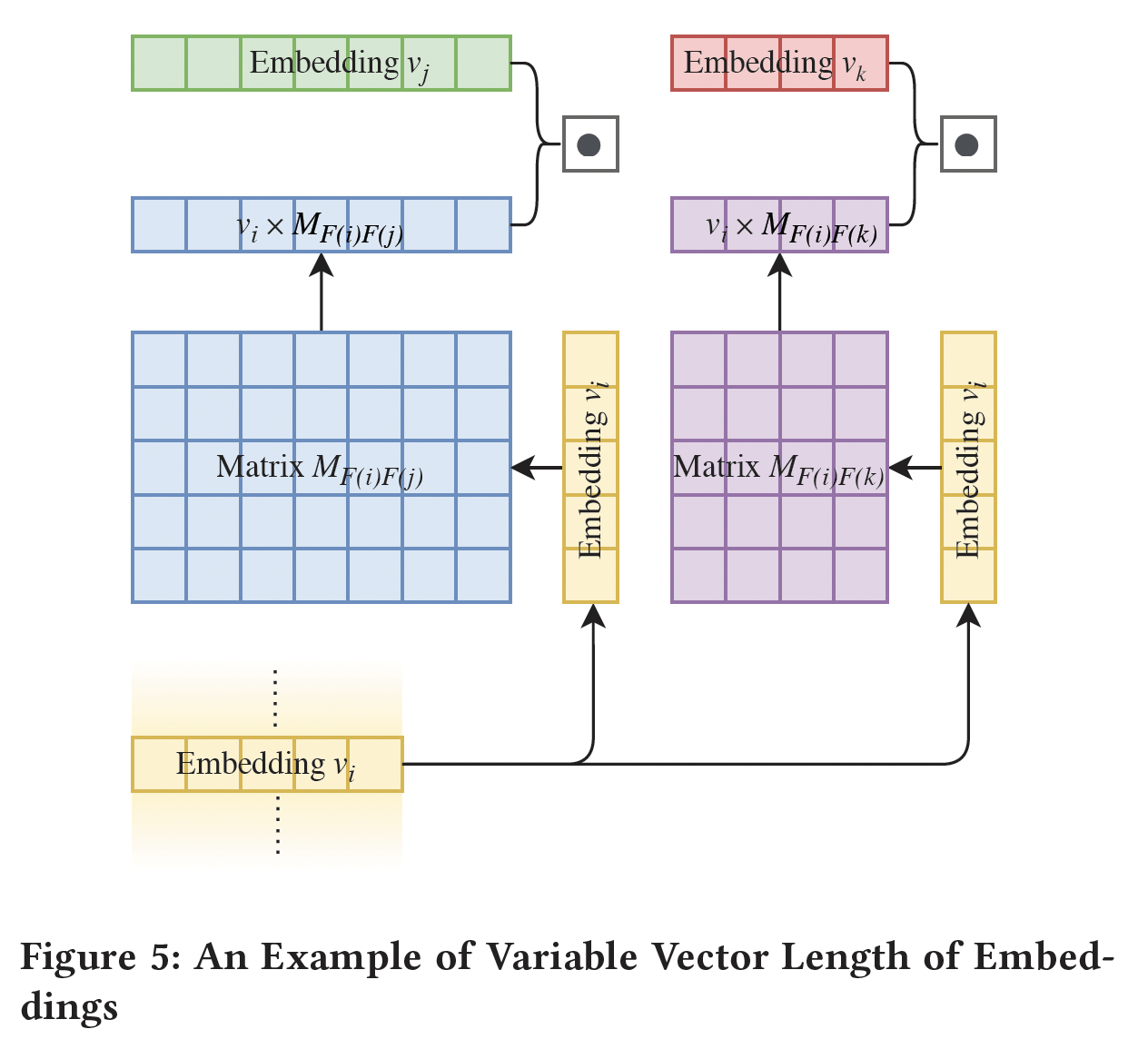
为了在不损失模型性能的前提下设计
field-specific embedding vector dimension,我们提出了一种2-pass方法:在第一个
pass,我们对所有field使用较大的固定的embedding向量维度,如FmFM训练为完整模型。从完整的模型中,我们了解到每个field有多少信息(方差),然后我们在每个field的embedding table上应用标准的PCA降维方法。从实验部分中我们发现,包含95%原始方差的新维度是一个很好的tradeoff。有了这个新的
field-specific的维度设置,我们在第二个pass中从头开始训练模型。与第一个完整的模型相比,所得到的第二个模型没有任何明显的性能损失。
这种方法训练时间翻倍。一般而言,
CTR预测任务的数据集很大、模型也比较复杂,因此整体训练时间会很长。翻倍的训练时间不太有利。并且,这种方法还需要仔细设计
field matrix的shape,增加了开发成本。下表显示了
Criteo数据集中每个field通过PCA进行优化后的维度。可以看到,这些维度的范围很大,从2到14,而且大部分维度都小于10。平均7.72,低于FwFM的最佳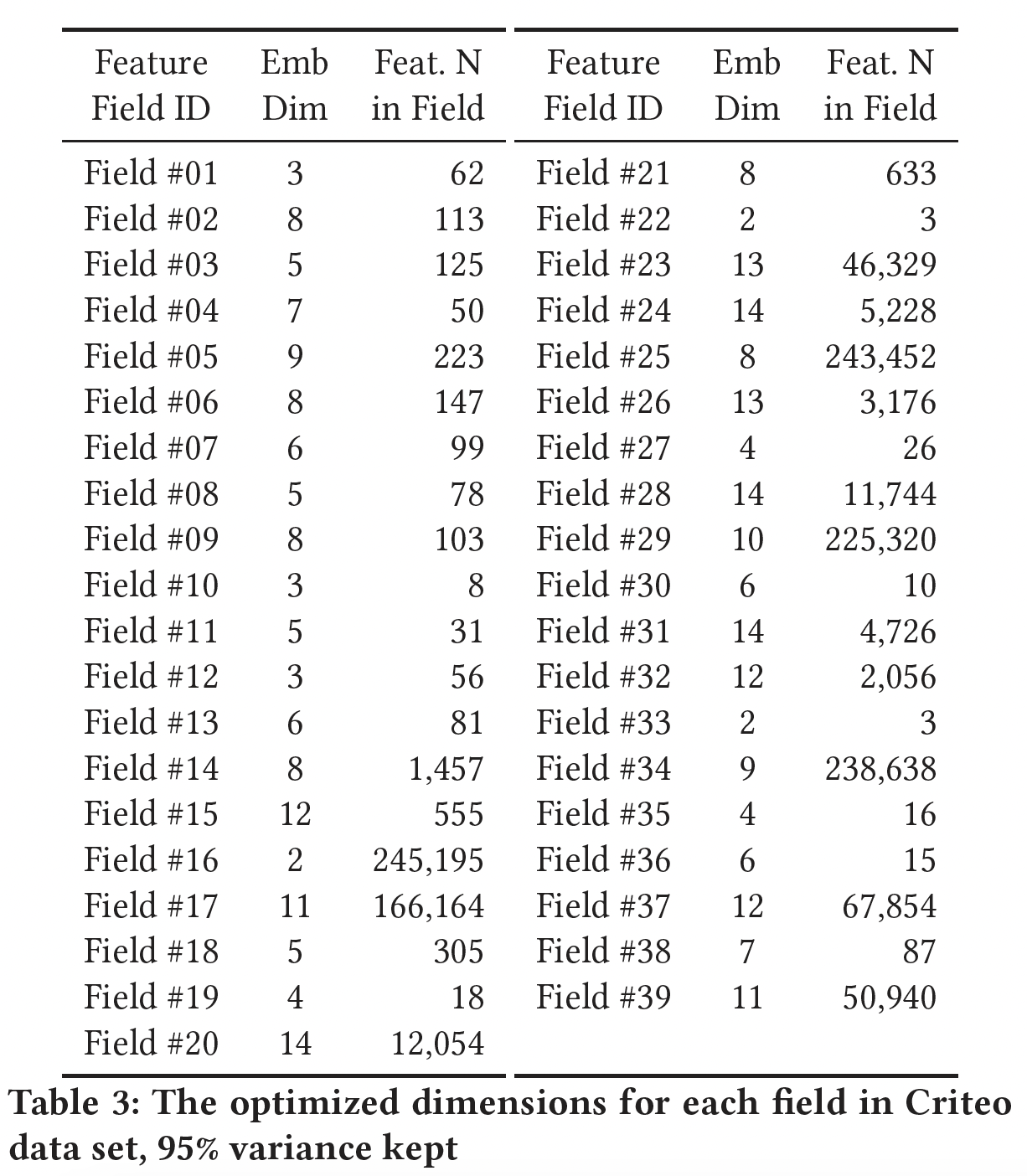
Intermediate Vectors Cache:在参数数量上,FmFM是一个比FFM更低复杂度的模型。但是FmFM在变换步骤中需要昂贵的矩阵运算。在下表中,我们列出了每个模型的浮点运算(Floating Point Operations: FLOPs)的数量,并以典型的设置对其进行估计。注:典型设置为:
DNN隐层的单元数,DNN的隐层数量,AutoInt中新空间的维度,DeepLight中FwFM和DNN组件的稀疏率。在这些
FM模型中,FmFM需要最多的操作来完成其计算,大约是FwFM和FFM的DNN模型快。如前所述,我们已经表明,通过缓存所有的中间向量,可以将FmFM模型转化为FFM模型。在这个意义上,我们可以把它的操作数量减少到与FM和FFM相同的量级,这几乎是20倍的速度。首先,如何缓存?论文并未提到细节。
其次,缓存中间向量仅在推理期间有效,因为此时所有参数都已经学好并固定不动。然而在训练期间,每经过一个
training iteration参数都发生更新,因此缓存的中间向量到下一个iteration就没有意义。因此,读者估计,FmFM的训练时间会非常的长。最后,这里给的计算复杂度及其估计值是针对推理期间的,而不是训练期间的。而
95% variance是在训练完成之后进行的,在训练期间不可用。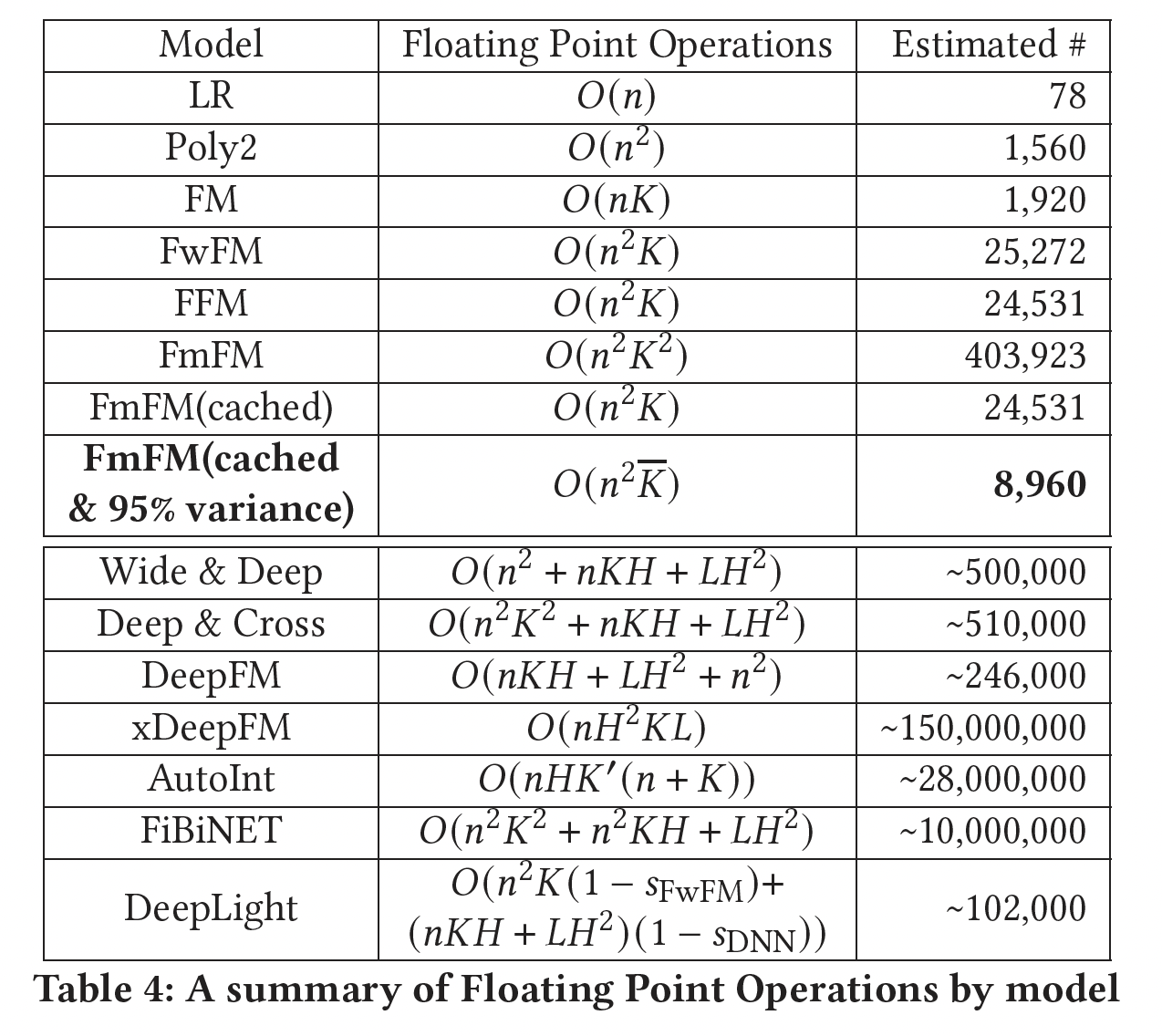
Embedding Dimension and Cache Optimization Combined:当我们把field-specific embedding dimensional optimization和缓存优化结合起来时,推理速度可以快得多,而且所需的内存也可以大大减少。这得益于FmFM的另一个特性:交互矩阵是对称的。这意味着:证明见原始论文。
因此,我们可以选择缓存那些
field embedding维度较低的中间向量,并在推理过程中与其他特征向量进行点乘。例如,在Table 3中,两个特征field #16和field #28。有了这个对称性,当我们计算由于
field matrix2(field #16)增加到14(中间向量),然后与维度也为14的14个单位的内存用于中间向量的缓存,在推理过程中需要2*14个FLOPs。相比之下,后者
14(field #28)缩减到2(中间向量),然后与维度也是2的2个单位的内存,并在推理中花费2*2 FLOPs。因此缓存维度为2的中间向量,可以节省7倍的内存和时间,而没有任何精度损失。
通过这两种优化技术的结合,
FmFM模型的时间复杂度大大降低。在Table 4中,我们估计优化后的模型只需要8,960个FLOPs,这只是FFM的1/3左右。在实验部分中,我们将说明这个优化的模型可以达到与完整模型相同的性能。Soft Pruning:field-specific embedding dimension实际上也起到了类似于剪枝的作用。传统的剪枝,如DeepLight,给出了保留或放弃一个field或一个field pair的二元决定。而field-specific embedding dimension给了我们一个新的方法:按需确定每个field和field pair的重要性,并给每个field分配一个系数(即,emebdding维度)来代表其重要性。例如,在Table 3的FmFM模型中,cross field#17和#20是一个高强度的field pair,它在推理过程中需要11个单位的缓存和2*11个FLOPs;相反,一个低强度的field pair,即cross field#18和#22,只需要2个单位的缓存和2*2个FLOPs。缓存空间大小就是
field pair中最短的那个emebdding维度。在传统的剪枝方法中,当我们放弃一个
field pair时,它的信号就完全消失了。而在我们的方法中,一个field pair仍然以最小的代价保留主要信息(即,很小的embedding维度)。这是一个soft pruning的版本,类似于Softmax。它的效率更高,在soft pruning过程中性能下降更少。然后这种剪枝方法依赖于
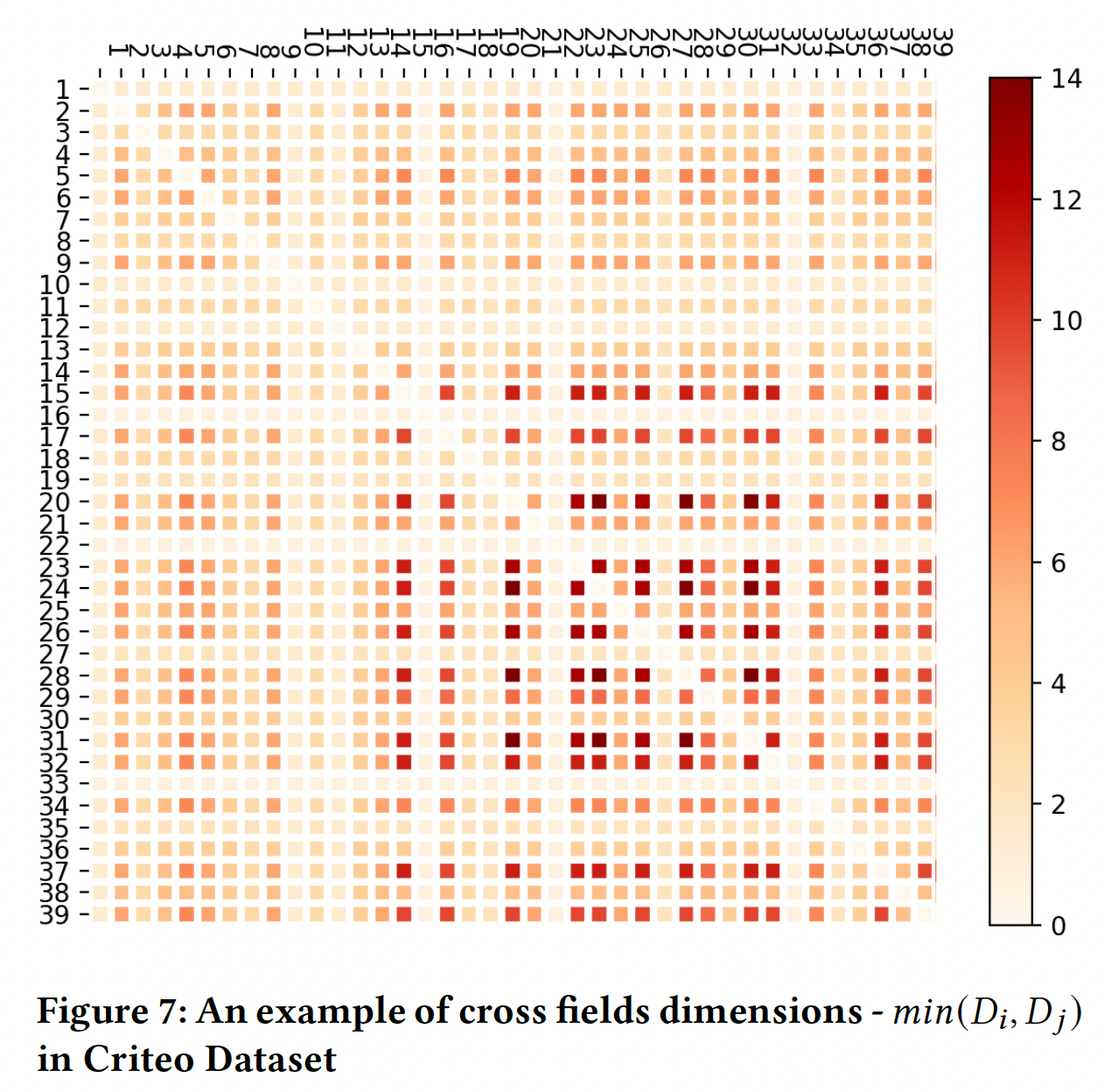
emebdding维度,而embedding维度是针对embedding table进行降维而得到的。这意味着在正式训练之前,先要完成一个训练从而得到embedding table。此外,PCA降维方法无法应用到大规模embedding table。Figure 6显示了Criteo数据集中field pair和label之间的互信息分数的热力图,它代表了field pair在预测中的强度。Figure 7显示了cross field dimension,这是两个field之间的较低维度,它表示每个field pair的参数和计算成本。显然,这两个热力图是高度相关的,这意味着优化后的FmFM模型在那些强度较高的field pair上分配了更多的参数和更多的计算,而在强度较低的field pair上分配了较少的参数和较少的计算。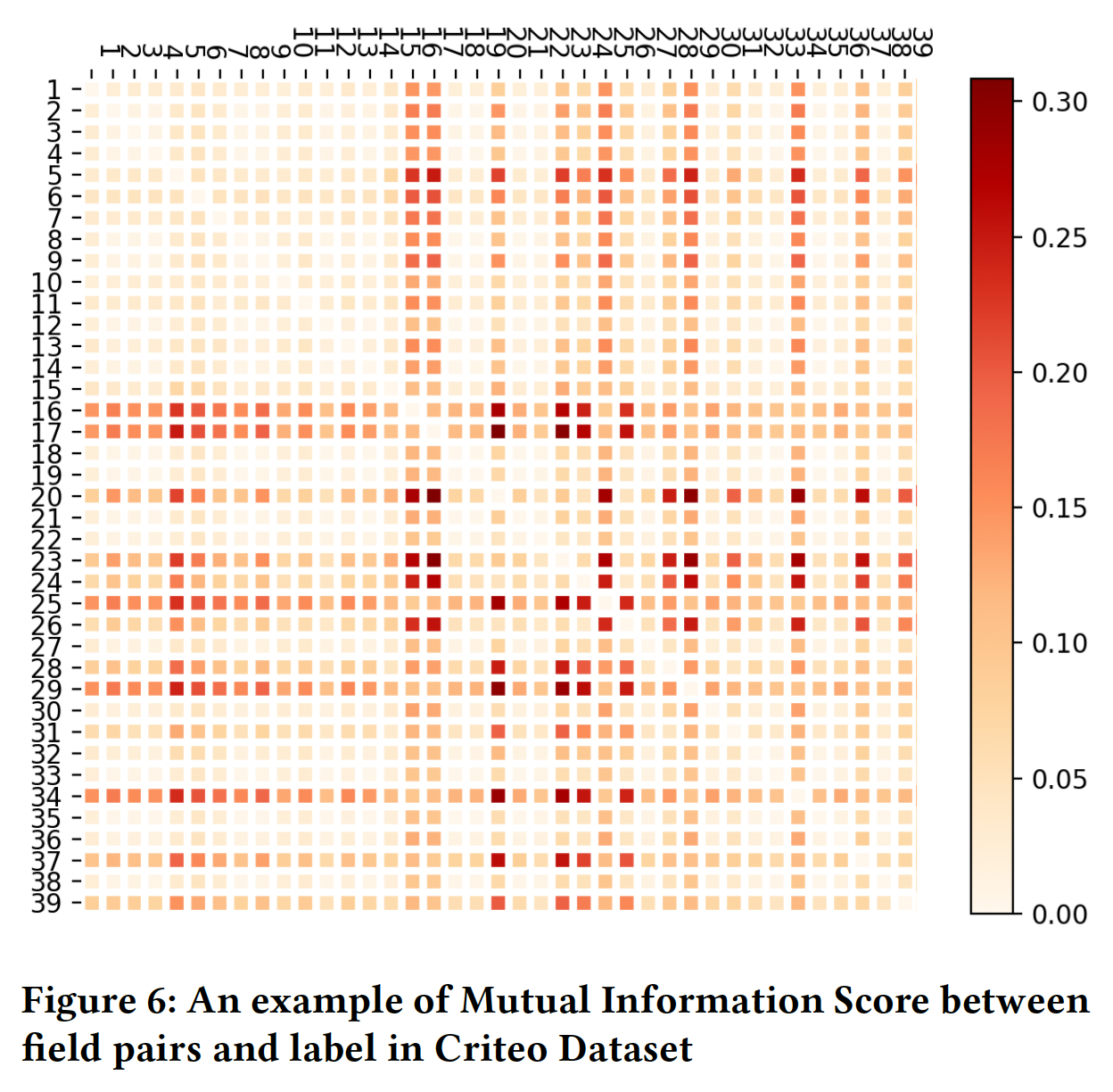
线性项:线性部分为:
这需要为每个特征
embedding向量embedding向量。我们遵从
FwFM的方法,通过学习一个field-specific向量field在本文的其余部分,我们默认对
FwFM、FvFM和FmFM应用这种线性项优化。
1.4 实验
数据集:
Criteo、Avazu。我们遵循那些已有的工作,将每个数据集随机分成三部分,
80%用于训练、10%用于验证、10%用于测试。对于
Criteo数据集中的数值特征,我们采用Criteo竞赛冠军提出的对数变换来归一化数值特征:对于
Avazu数据集中的date/hour特征,我们将其转换为两个特征:day_of_week(0-6)、hours(0-23)。我们还删除了两组数据中那些低于阈值的低频特征,并用该
field的默认"unknown"特征来替换。Criteo数据集的阈值为8,Avazu数据集的阈值为5。
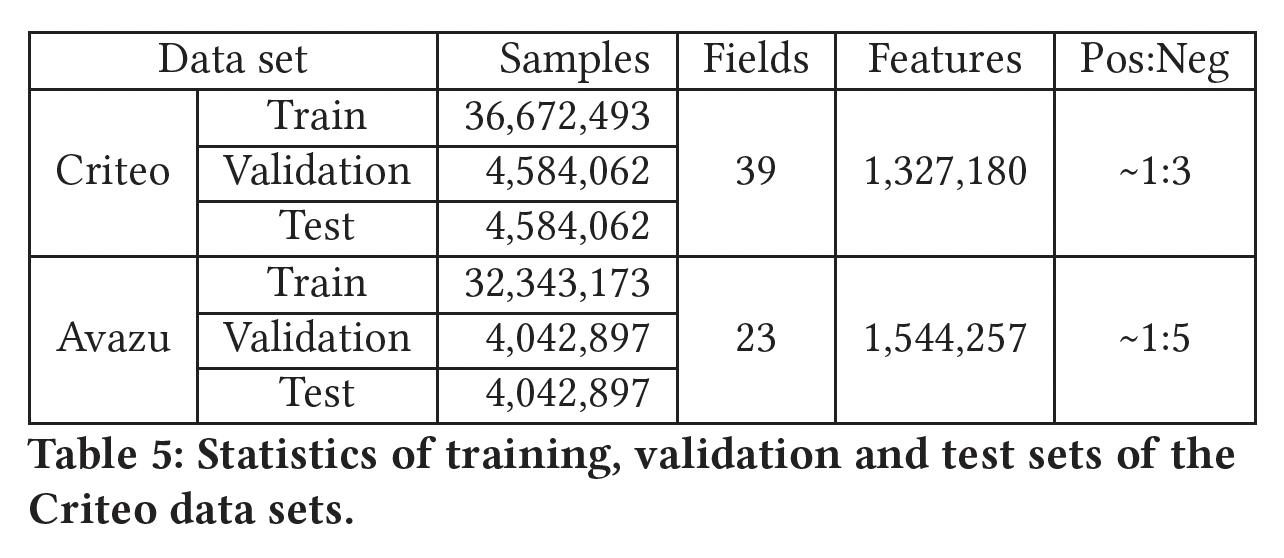
归一化后的数据集的统计数字如下表所示:
baseline方法:LR、FM、FwFM、FFM、FvFM、FmFM。我们遵循
PNN原始论文中LR和FM的实现,并遵循FwFM原始论文中FFM和FwFM的实现。评估指标:验证集的
AUC, logloss。模型配置:对于那些
SOTA模型,它们都是DNN模型,可能需要更多的超参数调优,我们从它们的原始论文中提取它们的性能(AUC和Log Loss),以保持它们的结果最佳。我们列出他们的结果只是为了参考。Deep & Cross网络是一个例外,因为他们的论文只列出了logloss而没有列出AUC。因此,我们实现了他们的模型,得到了类似的性能。对于所有模型中的正则化系数
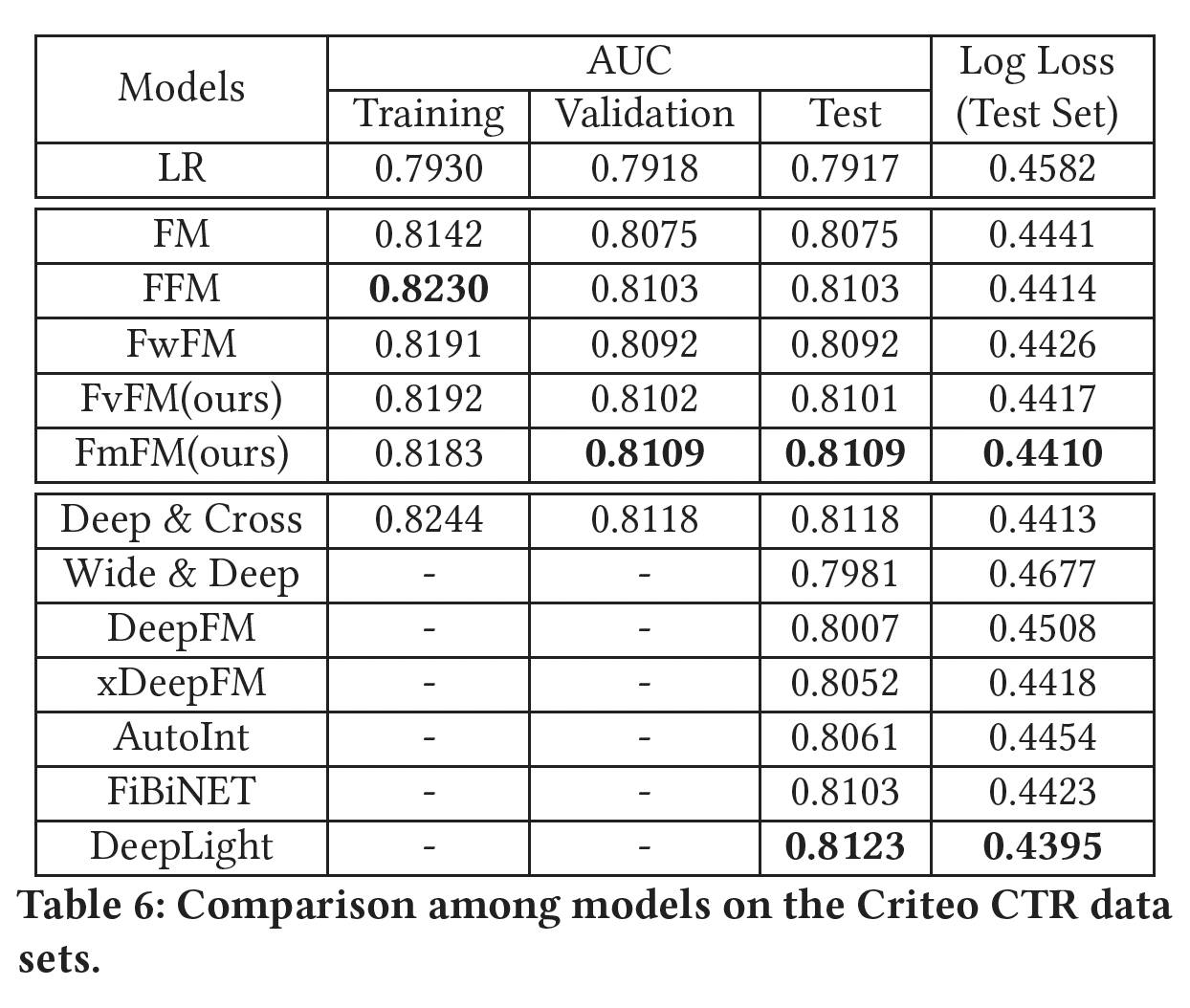
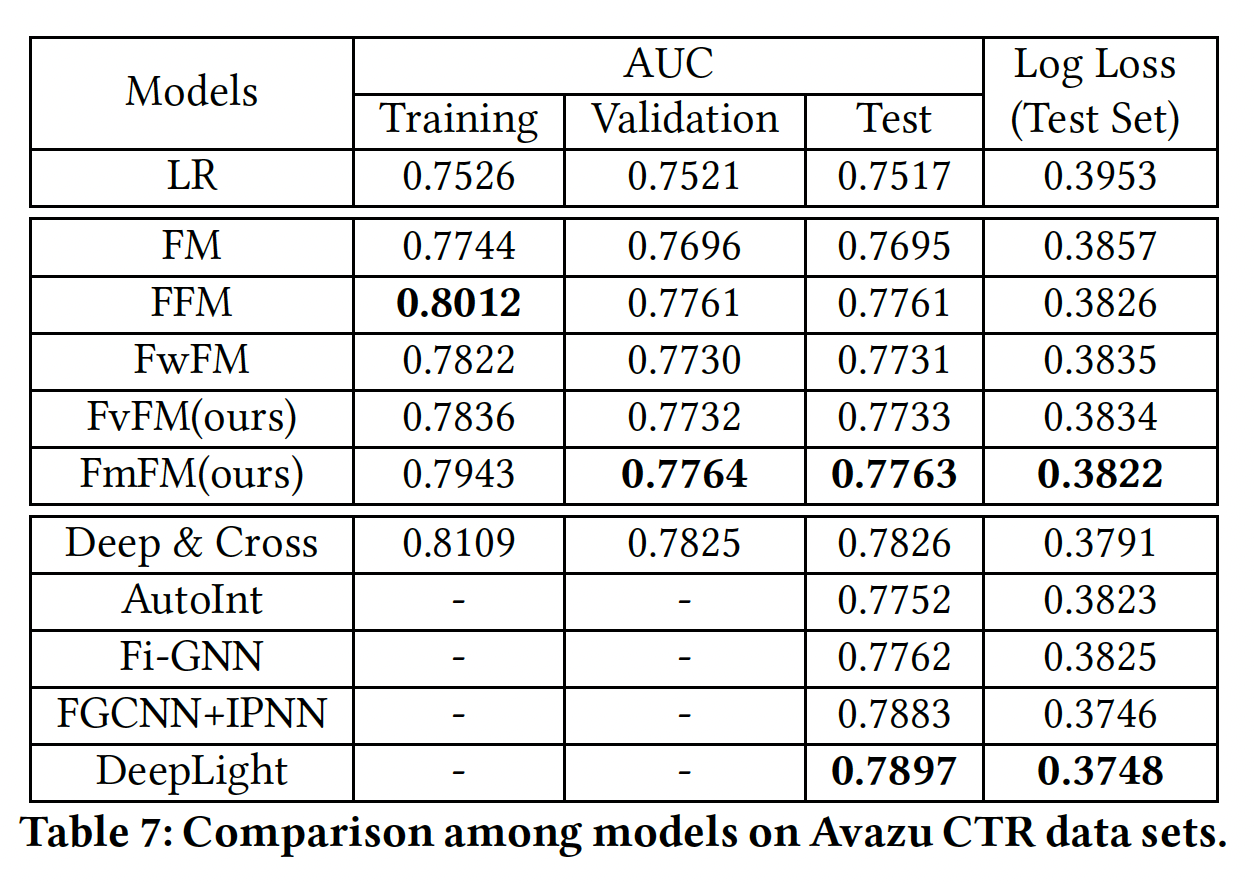
模型评估结果如下所示,其中对于
FmFM我们不采用任何优化手段。可以看到:在这两个数据集上,
FvFM和FmFM都能取得比LR、FM和FwFM更好的性能,这也是我们所预期的。令人惊讶的是,
FmFM在两个测试集上都能取得比FFM更好的性能。正如我们之前提到的,即使FFM是一个比FmFM大几十倍的模型,我们的FmFM模型仍然在所有浅层模型中得到最好的AUC。FmFM和FFM的性能相差无几,非常接近。此外,如果我们比较训练集和测试集之间的
AUC差异,我们发现factorization machine模型中最低的一个,这肯定了我们前面的假设:那些低频特征在交互矩阵的帮助下也被训练得不错,这种机制帮助FmFM避免过拟合。这里的数据和结论都不正确,
0.0074,最低的是LR模型。
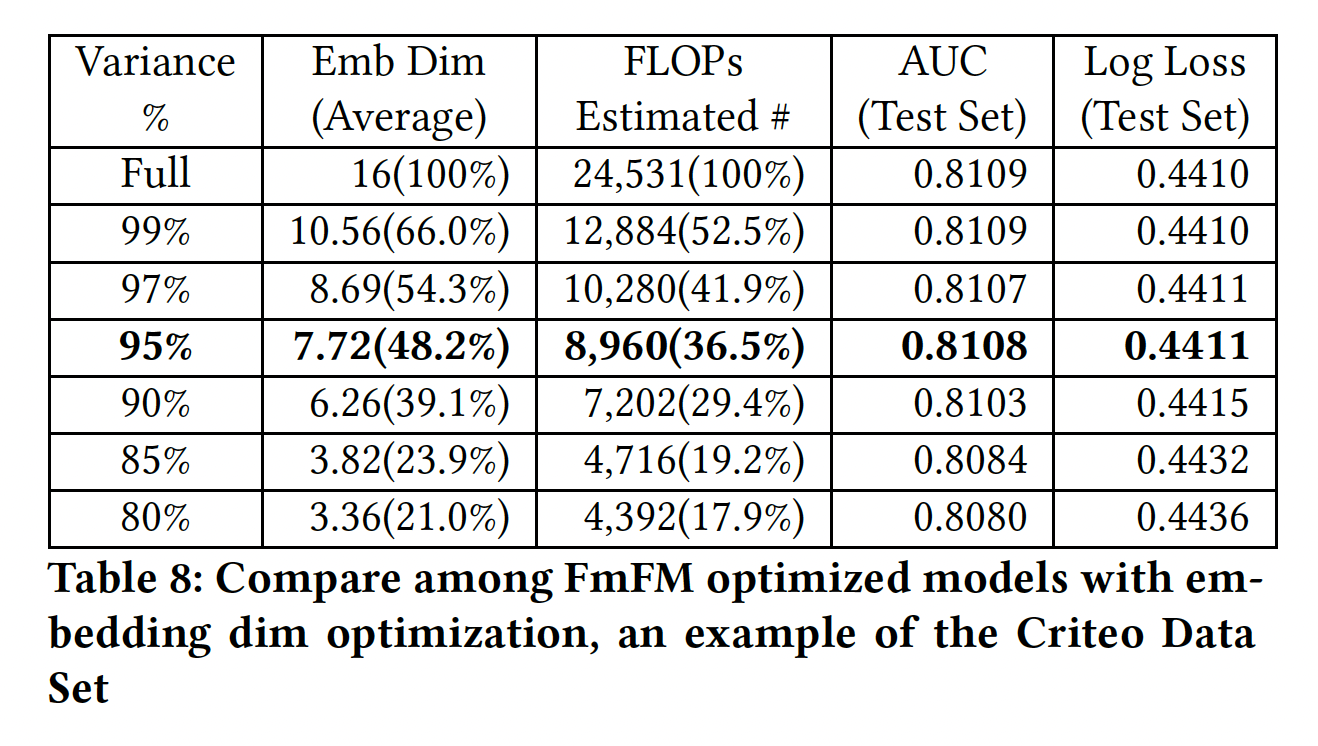
Embedding Dimension Optimization:在这一部分,我们前面描述的方法,即我们有一个full size的模型,我们可以为每个field提取其embedding table,然后我们利用标准的PCA降维。在这里,我们做了几个实验,比较降维对模型性能的影响,并试图在模型大小、速度和性能之间找到一个平衡点。我们使用
Criteo数据集,PCA降维中分别保持99%, 97%, 95%, 90%, 85%, 80%的方差,并估计平均embedding维度和FLOPS(具有缓存的中间向量)。在新的维度设置下,我们分别训练这些FmFM模型的第二遍,并观察测试集的AUC和Log Loss变化。结果如下表所示。可以看到:当我们保持较少的
PCA方差时,平均embedding维度明显减少。当我们保持
95%的方差时,与full size模型相比,只有不到1/2的emebdding维度和1/3的计算成本,而模型的性能没有明显变化。因此,当我们优化FmFM的embedding维度时,95%的方差是一个很好的tradeoff。
下图 显示了这些模型的性能(
AUC)和它们的计算复杂性(FLOPs)。与所有的baseline模型相比,作为一个浅层模型,优化后的FmFM模型得到了更高的AUC以及更低的FLOPs,除了Deep&Cross和DeepLight。然而FmFM的计算成本比这两个ensemble了DNN模块和浅层模块的复杂模型(即,Deep&Cross和DeepLight)要低得多,其FLOPs分别只有它们的1.76%和8.78%。较低的FLOPs使得FmFM在计算延迟受到严格限制时更受欢迎,这也是实时在线广告CTR预测和推荐系统中的常见情况。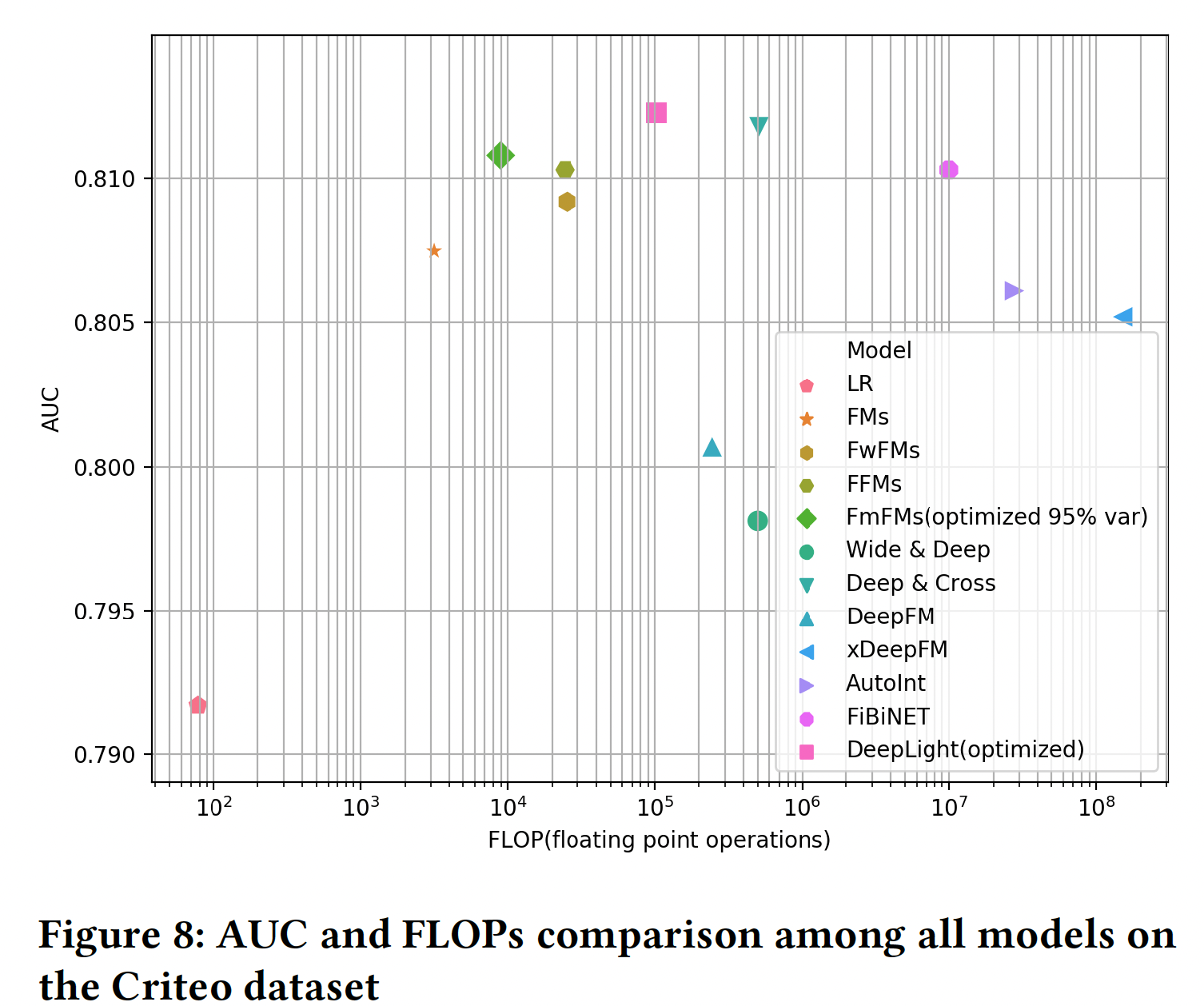
1.5 讨论
未来方向:
FmFM仍然是一个线性模型,我们可以将非线性层引入到field交互中,让模型成为非线性模型,这样就更加灵活。所有的
FM模型实际上都是二阶模型,它最多允许2个field交互。这种限制主要是因为点积的原因。在未来,我们可以引入三维张量,允许3个field的交互,或者甚至更高阶次。这项工作可能需要更多的模型优化,因为有太多的三阶交互。我们可以结合
DNN模型,如Wide & Deep、DeepFM、DeepLight,并尝试将FmFM作为DNN模型的一个构建模块,以进一步提高其性能。