一、PEP [2021]
《Learnable embedding sizes for recommender systems》
基于深度学习的推荐模型利用
embedding技术将这些稀疏的categorical feature映射为实值的稠密向量,以抽取用户偏好和item特性。embedding table可能包含大量的参数,并花费巨大的内存,因为总是有大量的原始特征。因此,embedding table的存储成本最高。一个很好的例子是
YouTube Recommendation Systems。它需要数以千万计的参数用于YouTube video ID的embedding。考虑到当今服务提供商对即时推荐的需求不断增加,embedding table的规模成为深度学习推荐模型的效率瓶颈。另一方面,具有uniform emebdding size的特征可能难以处理不同特征之间的异质性。例如,有些特征比较稀疏,分配太大的embeddding size很可能导致过拟合问题。因此,当所有特征的embedding size是uniform时,推荐模型往往是次优的。现有的关于这个问题的工作可以分为两类:
一些工作(
《Model size reduction using frequency based double hashing for recommender systems》、《Compositional embedding susing complementary partitions for memory-efficient recommendation systems》、《Learning multi-granular quantized embeddings for large-vocab categorical features in recommender systems》)提出,一些密切相关的特征可以共享部分embedding,从而减少整个成本。另一些工作提出依靠人类设计的规则(
《Mixed dimension embeddings with application to memory-efficient recommendation systems》)或神经结构搜索(《Neural input search for large scale recommendation models》、《Automated embedding dimensionality search in streaming recommendations》、《Differentiable neural input search for recommender systems》)为不同特征分配size灵活的embedding。
尽管得到了
embedding size减小的embedding table,但这些方法在推荐性能和计算成本这两个最受关注的方面仍然不能有好的表现。具体来说,这些方法要么获得较差的推荐性能、要么花费大量的时间和精力来获得合适的embedding size。在论文
《Learnable embedding sizes for recommender systems》中,为了解决现有工作的局限性,作者提出了一个简单而有效的pruning-based框架,名为Plug-in Embedding Pruning: PEP,它可以插入各种embedding-based的推荐模型中。论文的方法采用了一种直接的方式:一次性裁剪那些不必要的embedding参数来减少参数数量。具体而言,
PEP引入了可学习的阈值,可以通过梯度下降与emebdding参数共同训练。请注意,阈值被用来自动确定每个参数的重要性。然后,embedding向量中小于阈值的元素将被裁剪掉。然后,整个embedding table被裁剪,从而确保每个特征有一个合适的embedding size。也就是说,embedding size是灵活的。在得到裁剪后的embedding table后,作者在彩票假说(Lottery Ticket Hypothesis: LTH)的启发下重新训练模型。彩票假说表明,与原始网络相比,子网络可以达到更高的准确性。基于灵活的embedding size和LTH,PEP可以降低embedding参数,同时保持甚至提高模型的推荐性能。最后,虽然推荐性能和参数数量之间总是存在
tradeoff,但PEP只需运行一次就可以获得多个裁剪后的embedding table。换句话说,PEP可以一次性生成多个memory-efficient的embedding矩阵,这可以很好地处理现实世界应用中对性能或内存效率的各种需求。PEP至少训练两遍:第一遍用于裁剪、第二遍用于重训练。论文在三个公共基准数据集(
Criteo, Avazu, MovieLens-1M)上进行了广泛的实验。结果表明,与SOTA的baseline相比,PEP不仅可以达到最好的性能,而且可以减少97% ~ 99%的参数。进一步的研究表明,PEP在计算上是相当高效的,只需要一些额外的时间进行embedding size的学习。此外,对所学到embedding的可视化和可解释性分析证实,PEP可以捕获到特征的固有属性,这为未来的研究提供了启示。相关工作:
Embedding参数共享:这些方法的核心思想是使不同的特征通过参数共享来复用embedding。《Learning multi-granular quantized embeddings for large-vocab categorical features in recommender systems》提出了MGQE,从共享的small size的centroid embeddings中检索embedding fragments,然后通过拼接这些fragments生成final embedding。《Model size reduction using frequency based double hashing for recommender systems》使用双哈希技巧(double-hash trick),使低频特征共享一个小的embedding-table,同时减少哈希碰撞的可能性。即,对低频特征的
embedding space分解为两个更小的embedding space从而缓解过拟合、降低模型规模。《Compositional embeddings using complementary partitions for memory-efficient recommendation systems》试图通过组合多个较小的embedding(称为embedding fragments),从一个小的embedding table中为每个feature category产生一个unique embedding vector。这种组合通常是通过embedding fragments之间的拼接、相加、或element-wise相乘来实现的。
然而,这些方法有两个限制:
首先,工程师需要精心设计参数共享比例,以平衡准确性和内存成本。
其次,这些粗略的
embedding共享策略不能找到embedding table中的冗余部分,因此它总是导致推荐性能的下降。
在这项工作中,我们的方法通过从数据中学习,自动选择合适的
emebdding用量。因此,工程师们可以不必为设计共享策略付出巨大努力,并且通过去除冗余参数和缓解过拟合问题来提高模型性能。Embedding Size Selection:最近,一些方法提出了一种新的混合维度的embedding table的范式。具体来说,不同于给所有特征分配统一的embedding size,不同的特征可以有不同的embedding size。MDE(《Mixed dimension embeddings with application to memory-efficient recommendation systems》)提出了一个人为定义的规则,即一个特征的embedding size与它的popularity成正比。然而,这种基于规则的方法过于粗糙,无法处理那些低频但是重要的特征。此外,MDE中存在大量的超参数,需要大量的超参数调优工作。其他一些工作依靠神经架构搜索
Neural Architecture Search: NAS为不同的特征分配了自适应的embedding size。NIS(《Neural input search for large scale recommendation models》) 使用了一种基于强化学习的算法,从人类专家预先定义的候选集中搜索embedding size。NIS采用一个控制器来为不同的embedding size生成概率分布。NIS的控制器被DartsEmb(《Autoemb: Automated embedding dimensionality search in streaming recommendations》)进一步扩展,将强化学习搜索算法替换为可微的搜索。AutoDim(《Memory-efficient embedding for recommendations》)以与DartsEmb相同的方式为不同的feature field分配不同的embedding size,而不是单个特征。DNIS(《Differentiable neural input search for recommender systems》)使候选embedding size是连续的,没有预定义的候选尺寸。
然而,所有这些基于
NAS的方法在搜索过程中需要极高的计算成本。即使是采用微分架构搜索算法的方法,其搜索成本仍然是无法承受的。此外,这些方法还需要在设计适当的搜索空间方面做出巨大努力。与这些工作不同的是,我们的
pruning-based方法可以相当有效地进行训练,并且在确定embedding size的候选集时不需要任何人工努力。
1.1 模型
一般来说,深度学习推荐模型将各种原始特征(包括用户画像和
item属性)作为输入,预测用户喜欢某个item的概率。具体而言,模型将用户画像和item属性的组合(用field的拼接:其中:
feature field数量;feature representation(通常为one-hot向量);;为向量拼接。对于
embedding-based推荐模型为它生成对应的embedding向量:其中:
feature field的embedding矩阵,feature field的unique取值数量,embedding size。模型针对所有
feature field的embedding矩阵为:模型的预测得分为:
其中:
prediction model(如FM),embedding矩阵以外的参数。为了学习模型的参数(包括
embedding矩阵),我们需要优化如下的训练损失:其中:
ground-truth label,通常而言,推荐任务中采用
logloss损失函数:其中:
通过裁剪实现可学习的
embedding size:如前所述,针对memory-efficient embedding learning的可行方案是为不同的特征embeddingembedding sizecolumn-wise sparsity,这等于是缩小了embedding size。如下图所示,
embeddingembedding size。此外,一些不重要的feature embedding,如embedding参数。请注意,稀疏矩阵存储技术可以帮助我们大大节省内存用量。如果某一列被裁剪为零,则意味着该维度不重要;如果某一行被裁剪为零,则意味着该
feature value不重要。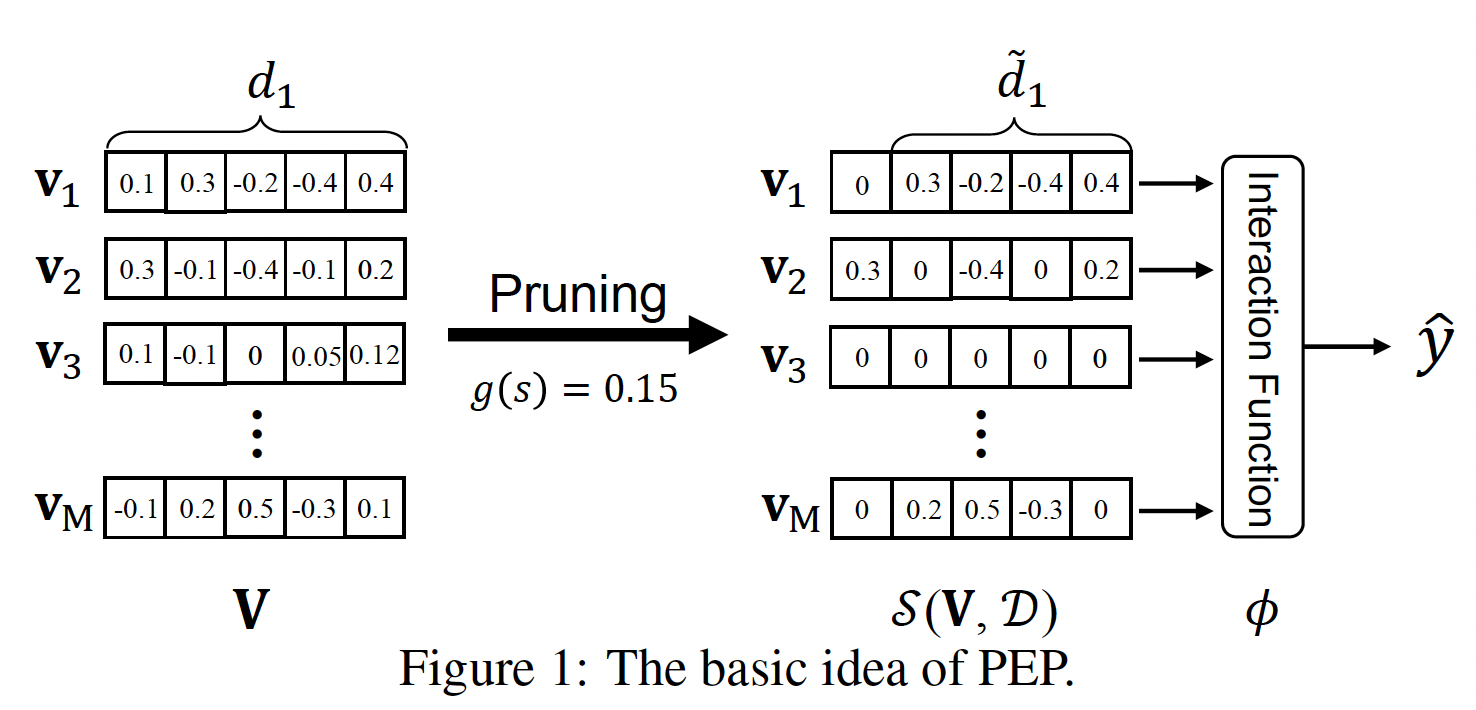
在这种情况下,我们将
embedding size的选择问题转换为学习embedding矩阵column-wise sparsity。为了达到这个目的,我们对其中:
L0范数(即,非零元素的数量);parameter budget,它是对embedding参数总数的约束。这里其实是
global sparsity,而不仅仅是column-wise sparsity。然而,由于
L0范数约束的非凸性,上式的直接优化是NP-hard的。为了解决这个问题,人们研究了L0范数的凸松弛,即L1范数。尽管如此,这类凸松弛方法仍然面临着两个主要问题:首先,计算成本太高,尤其是当推荐模型有数百万个参数时。
其次,参数预算
为了解决这两个问题,受软阈值重参数化的启发(
《Soft threshold weight reparameterization for learnable sparsity》),我们直接优化其中:
embedding矩阵。element-wise的,定义为:裁剪函数的物理意义为:
如果
如果
其中:
pruning parameter。函数
sigmoid函数。根据《Soft threshold weight reparameterization for learnable sparsity》,其中对于
unstructured sparsity,sigmoid函数;对于structured sparsity,1、将负数转换为-1、零保持不变。
采用
然后,可训练的裁剪参数
其中:
Hadamard积。为了解决
sub-gradient来重新表述更新方程如下:其中:
true时返回1、否则返回0。然后,只要我们选择一个连续的函数
sub-gradient也可以用于裁剪阈值
embedding矩阵中的参数用量。然而,为什么我们的PEP可以通过训练数据学习合适的PEP试图在优化过程中更新如下图所示,我们在
MovieLens-1M和Criteo数据集上绘制了with/without PEP的FM的训练曲线,以证实我们的假设。可以看到:我们的PEP可以实现更低的训练损失。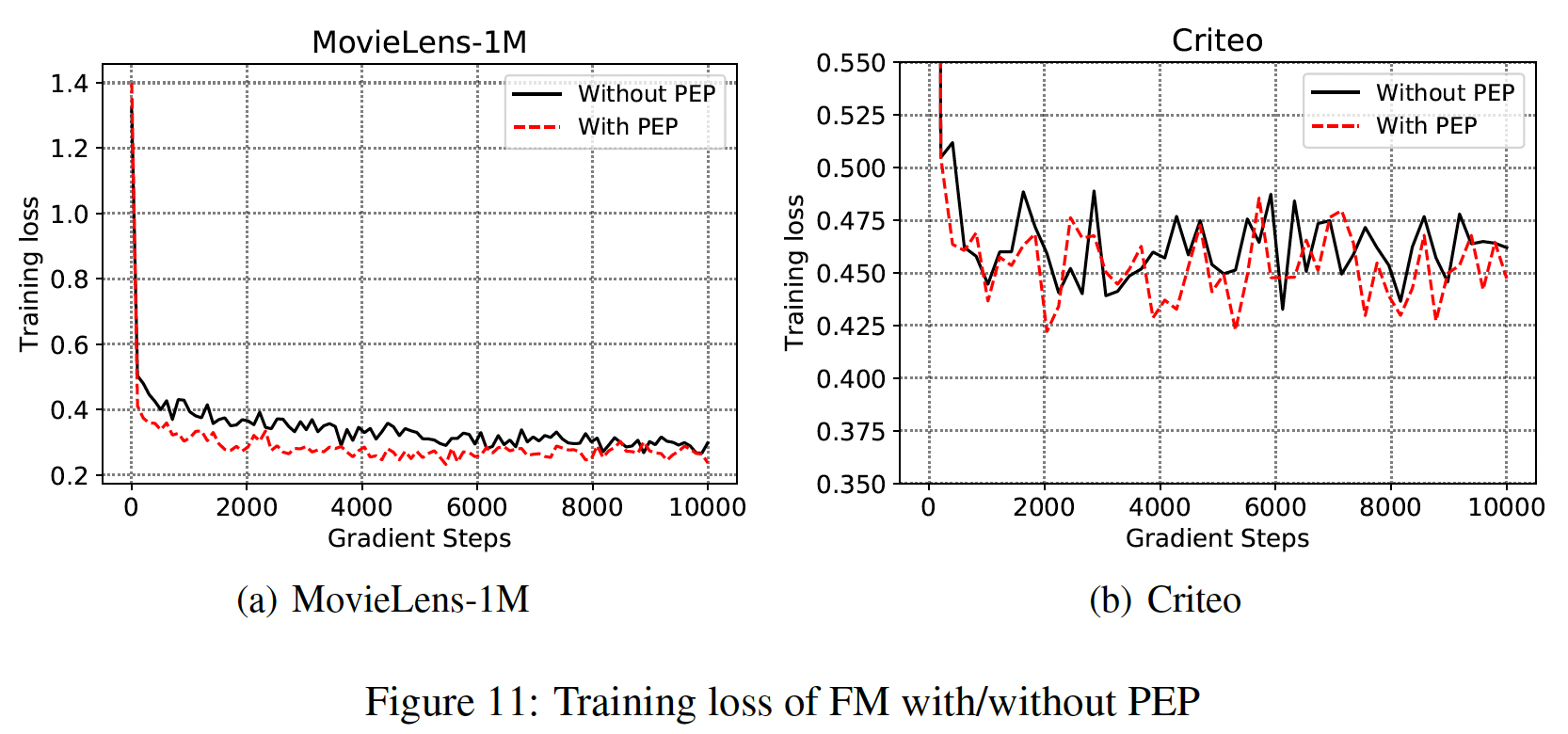
用彩票假说重新训练:在将
embedding矩阵embedding参数应该保留或放弃。然后我们用裁剪后的embedding table重新训练模型。彩票假说(
Lottery Ticket Hypothesis)(《The lottery ticket hypothesis: Finding sparse, trainable neural networks》)说明:随机初始化的稠密网络中的一个子网络可以与原始网络相匹配,当以相同的迭代次数进行隔离训练时。这个子网络被称为中奖票(winning ticket)。因此,我们不是随机地重新初始化权重,而是重新训练基础模型,同时将权重重新初始化为原来(但是被掩码后的)的权重注意,重训练阶段有三种初始化方式:
与第一轮训练独立的随机初始化。
把第一轮训练采用的随机初始化共享到重训练阶段。
把第一轮训练得到的训练好的权重作为重训练阶段的初始化。
LTH和本文采用的是第二种方式。注意,重训练阶段需要把被
masked的embedding element固定为零,且在更新过程中不要更新梯度。为了验证重训练的有效性,我们对比了四种操作:
Without pruning:base model。Without retrain:经过裁剪之后的模型,但是没有重训练。Winning ticket(random reinit):经过裁剪以及重训练之后的模型,但是重训练时采用与第一轮训练所独立的随机初始化。Winning ticket(original init):经过裁剪以及重训练之后的模型,并且共享第一轮训练的初始化权重来随机初始化重训练,即我们的PEP。
可以看到:
在重训练时,与
random reinit相比,original init的winning ticket可以使训练过程更快,并获得更高的推荐准确性。这证明了我们设计的再训练的有效性。random reinit的winning ticket仍然优于未裁剪的模型。通过减少不太重要的特征的embedding参数,模型的性能可以从对那些过度参数化的embedding的降噪中受益。这可以解释为,当embedding size统一时,它很可能会对那些过度参数化的embedding进行过拟合。without retrain的PEP的性能会有一点下降,但它仍然优于原始模型。without retrain和原始模型之间的gap,要比with retrain和without retrain之间的gap更大。这些结果表明,PEP主要受益于合适的embedding size选择。
我们猜测重训练的好处:在搜索阶段,
embedding矩阵中不太重要的元素被逐渐裁剪,直到训练过程达到收敛。然而,在早期的训练阶段,当这些元素没有被裁剪时,它们可能对那些重要元素的梯度更新产生负面影响。这可能使这些重要元素的学习变得次优。因此,重训练步骤可以消除这种影响并提高性能。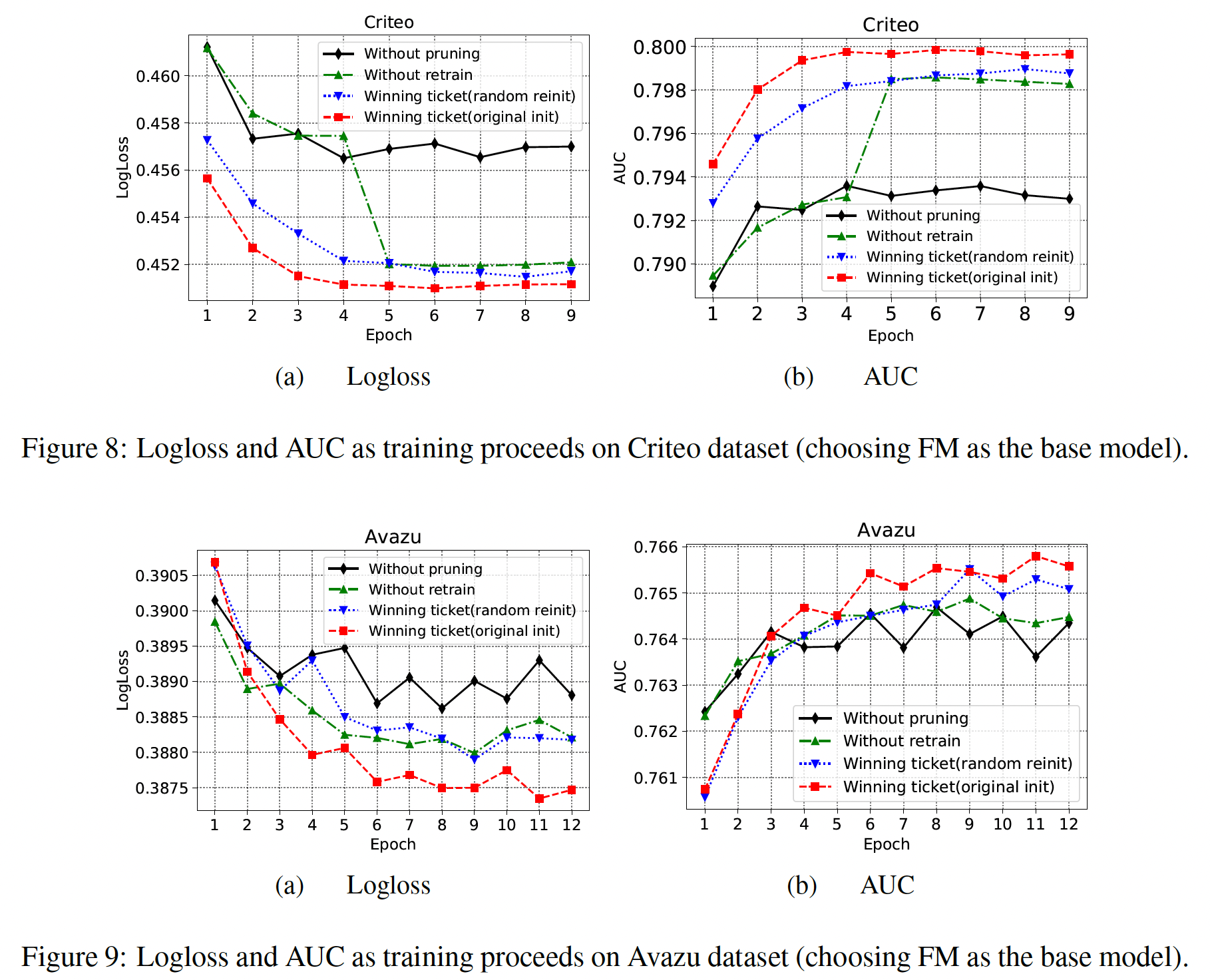
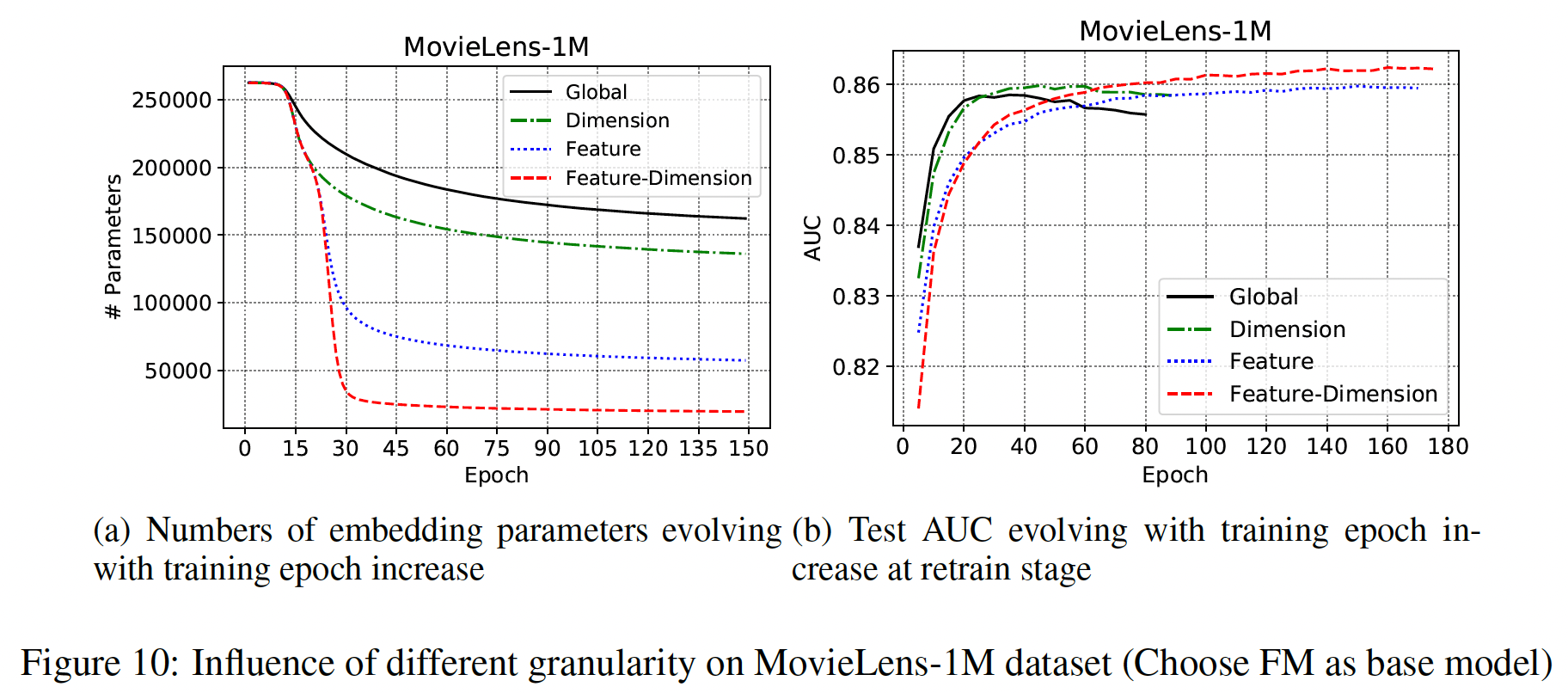
细粒度裁剪:上述方程中的阈值参数
global-wise pruning。然而,embedding向量field的特征也可能有不同的重要性。因此,embedding矩阵中的值需要不同的稀疏性预算,用全局阈值的裁剪可能不是最佳的。为了更好地处理Dimension-Wise:阈值参数embedding中的每个值都将被独立地裁剪,不同field的embedding共享相同的Feature-Wise:阈值参数embedding中的所有值采用相同的标量阈值,不同field的embedding采用不同的标量阈值。Feature-Dimension-Wise:阈值参数
注意,这里的阈值参数并不是人工调优的超参数,而是从数据中学习的可训练参数。
如下图所示:
Feature-Dimension粒度可以比其它粒度的embedding参数减少得更多,并且在retrain阶段获得了最好的性能。Dimension粒度的裁剪可以在较少的训练周期内达到可比的AUC。
PEP算法:输入:初始
embeddingbase modeltarget parameter规模输出:训练好的稀疏
embedding算法步骤:
迭代,直到满足
通过
获取二元
pruning mask将裁剪后的
embedding parameter设置为初始值重训练从而最小化
1.2 实验
数据集:
MovieLens-1M, Criteo, Avazu。MovieLens-1M:遵从AutoInt,我们将评分在1 or 2的样本作为负样本、评分在4 or 5的样本作为正样本。评分为3的样本视为中性样本从而被移除。Criteo:对于数值特征,我们使用log变换从而进行归一化:Creteo/Avazu:频次低于10的特征被认为是'unknown'。所有样本被随机拆分为训练集、验证集、测试集,比例为
80%/10%/10%。
评估指标:
AUC, Logloss。baseline:Uniform Embedding: UE:uniform embedding size。MGQE:从共享的small size的centroid embeddings中检索embedding fragments,然后通过拼接这些fragments生成final embedding。MGQE为不同item学习不同容量的embedding。该方法是embedding-parameter-sharing方法中的最强baseline。Mixed Dimension Embedding: MDE:基于人工定义的规则,即一个特征的embedding size与它的popularity成正比。该方法是SOTA的human-rule-based方法。DartsEmb:SOTA的NAS-based方法,它允许特征自动在一个给定的搜索空间中搜索embedding size。
我们没有比较
NIS,因为它没有开放源代码,并且它的基于深度学习的搜索方法在速度方面太慢。我们将
baseline方法和我们的PEP应用到三种feature-based推荐模型上:FM, DeepFM, AutoInt。实现细节:
在
pruning和re-training阶段,遵从AutoInt和DeepFM,我们采用学习率为0.001的Adam优化器。对于
MovieLens-1M, Criteo, Avazu数据集分别将-15/-150/-150。PEP的粒度设置为:在
Criteo, Avazu数据集上设置为Dimension-wise从而用于PEP-2, PEP-3, PEP-4。PEP-0, PEP-1, PEP-2, PEP-3, PEP-4分别代表不同的稀疏度配置,根据PEP算法中不同的0.05, 0.1, 0.2, 0.3, 0.4这五个稀疏率。其它数据集上设置为
Feature Dimension-wise。
在裁剪之前,所有模型的
base embedding dimension64。在重训练阶段,我们根据训练期间验证集的损失,利用了早停技术。
我们使用
PyTorch来实现我们的方法,并在单块12G内存的TITAN V GPU上以mini-batch size = 1024进行训练。baseline方法的配置:对于
Uniform Embedding,我们的embedding size搜索空间为:MovieLens-1M数据集为[8, 16, 32,64]、Criteo和Avazu数据集为[4, 8, 16],因为当对于其他
baseline,我们首先调优超参数使得模型具有最高的推荐性能、或最高的参数缩减率。然后我们调优这些模型从而达到性能和参数缩减率之间的tradeoff。MDE的搜索空间:维度[4, 8, 16, 32]中搜索,blocks数量[8, 16]中搜索,[0.1, 0.2, 0.3]中搜索。MGQE的搜索空间:维度[8, 16, 32]中搜索,子空间数量[4, 8, 16]中搜索,中心点数量[64, 128, 256, 512]中搜索。DartsEmb搜索空间:三组候选的embedding空间:{1, 2, 8}、{2, 4, 16}、{4, 8, 32}。
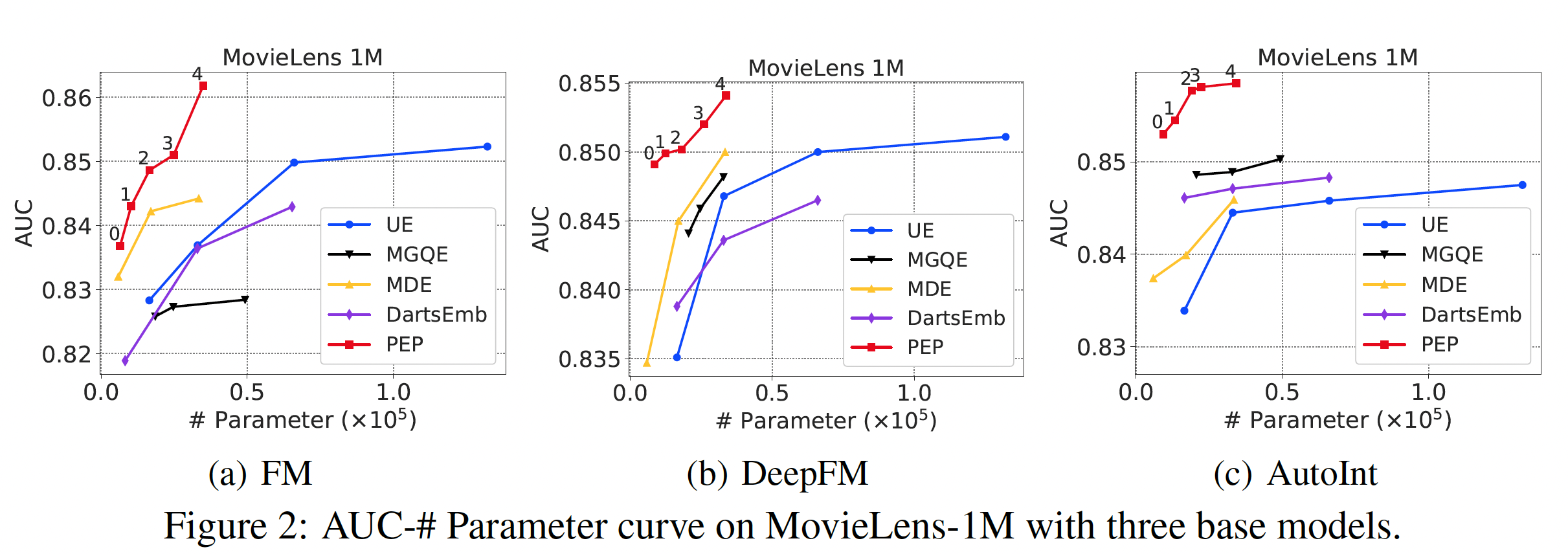
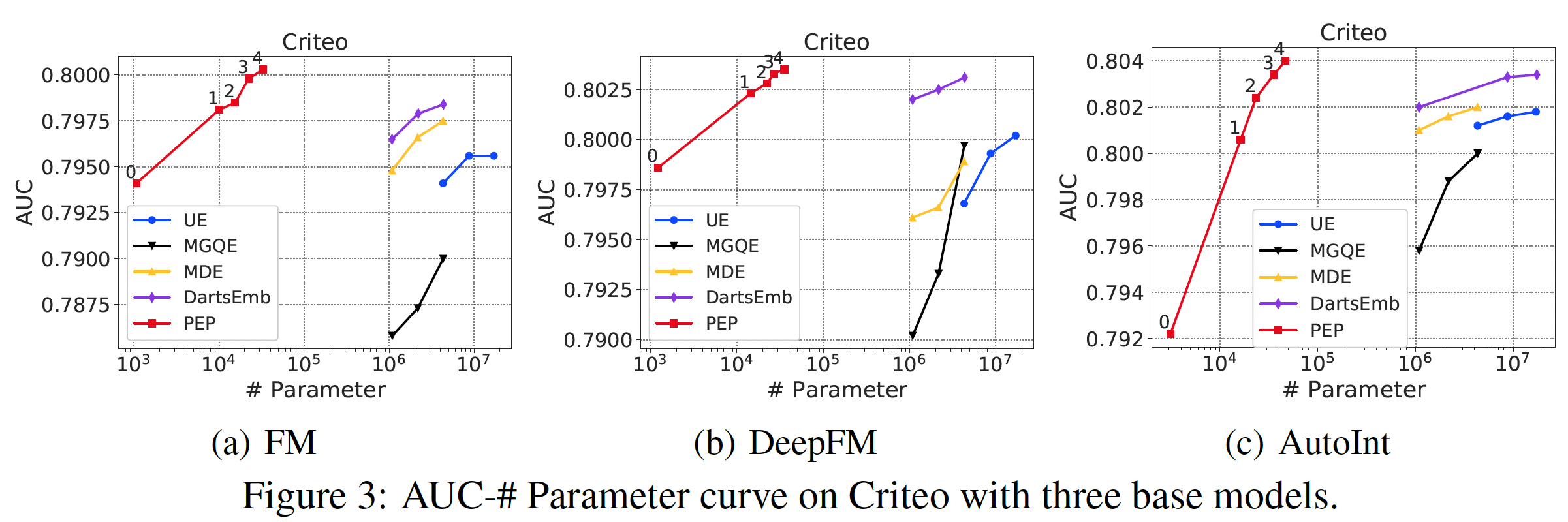
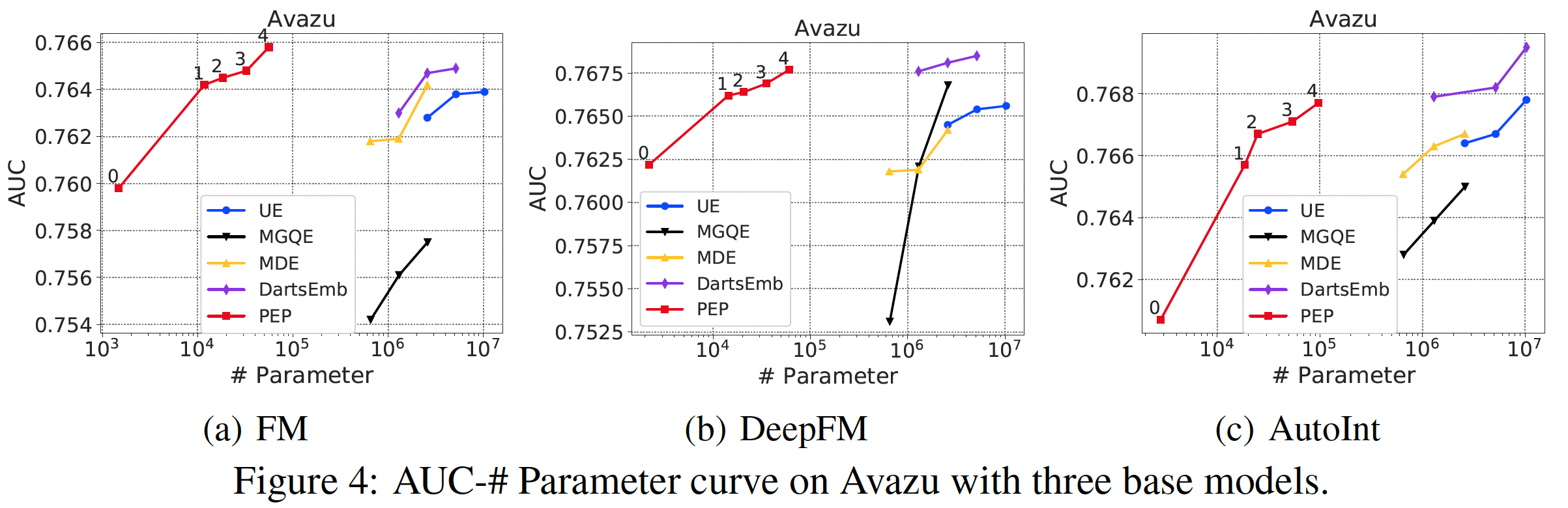
我们在
Figure 2, 3, 4中展示了推荐性能和参数数量的曲线。由于推荐性能和参数数量之间存在tradeoff,曲线是由具有不同稀疏性要求的点组成的。可以看到:我们的方法大大减少了参数的数量。在所有的实验中,我们的
PEP实现了最高的参数缩减率 ,特别是在相对较大的数据集(Criteo和Avazu)中。具体而言,在Criteo和Avazu数据集中,与最佳baseline相比,我们的PEP-0可以减少99.90%的参数用量(量级从embedding矩阵的参数使用率如此之低,意味着只有数百个embedding是非零的。通过将不太重要的特征的embedding设置为零,我们的PEP可以打破现有方法中最小embedding size为1的限制(我们的方法可以实现embedding size = 0)。我们后续对MovieLens数据集进行了更多的分析,以帮助我们理解为什么我们的方法可以实现如此有效的参数缩减。我们的方法实现了强大的推荐性能。我们的方法一直优于基于
uniform embedding的模型,并在大多数情况下取得了比其他方法更好的准确性。具体而言,对于Criteo数据集上的FM模型,在AUC方面,PEP比UE相对提高了0.59%、比DartsEmb相对提高了0.24%。从其他数据集和其他推荐模型的实验中也可以看到类似的改进。值得注意的是,我们的方法可以在极端的稀疏范围内保持强大的
AUC性能。例如,当参数数量只有PEP推荐性能仍然明显优于线性回归模型。
PEP的效率分析:PEP将导致额外的时间成本从而为不同的特征找到合适的size。这里我们研究了计算成本,并比较了PEP和DartsEmb在Criteo数据集上的每个训练epoch的运行时间。我们以相同的batch size实现这两个模型,并在同一平台上测试它们。这里的比较很有误导性。因为
PEP需要重训练,也就是training epoch数量要翻倍。而这里仅仅比较单个epoch的训练时间,这是不公平的比较。下表中给出了三种不同模型的每个
epoch的训练时间。可以看到:我们的
PEP的额外计算成本只有20% ~ 30%,与基础模型相比,这是可以接受的。DartsEmb在其bi-level优化过程中需要将近两倍的计算时间来搜索一个好的embedding size。此外,
DartsEmb需要多次搜索以适应不同的内存预算,因为每次搜索都需要完全重新运行。与DartsEmb不同的是,我们的PEP只需一次运行就可以获得多个embedding方案,这些方案可以应用于不同的应用场景。因此,在现实世界的系统中,我们的PEP在embedding size搜索方面的时间成本可以进一步降低。

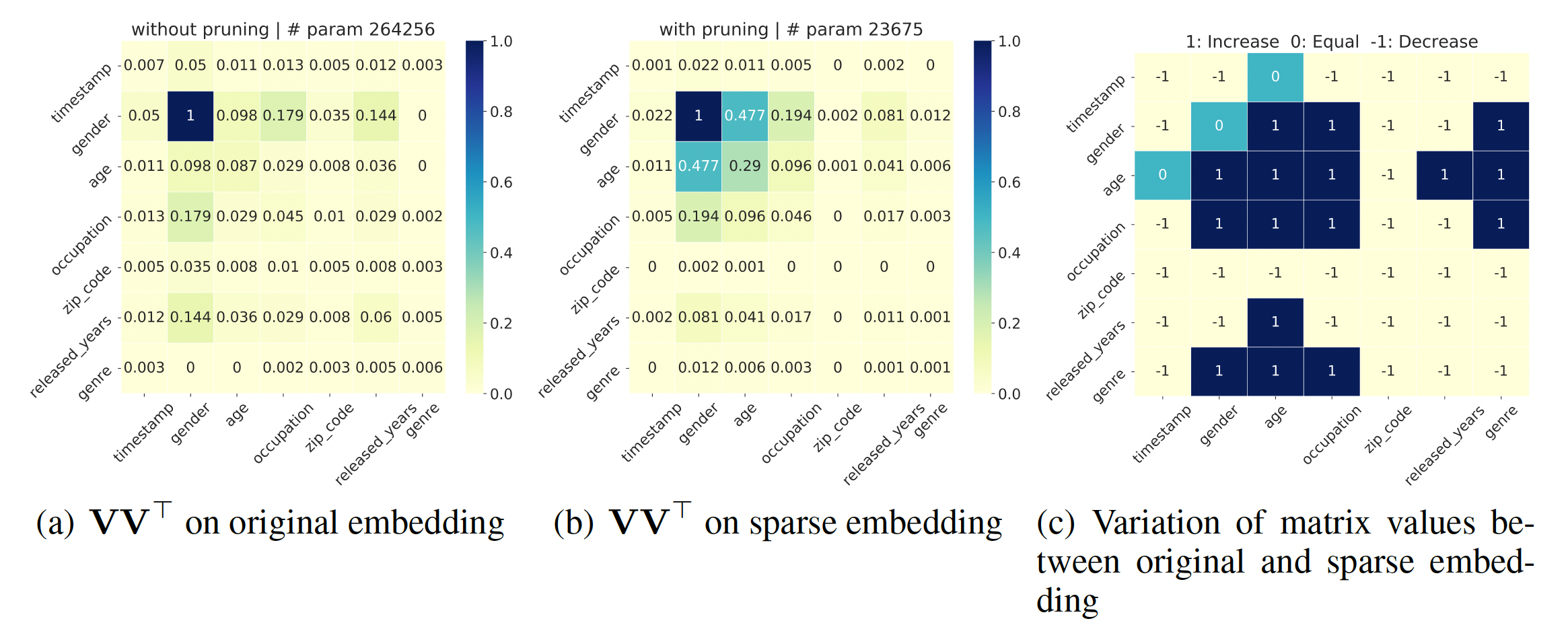
对裁剪后的
embedding进行可解释的分析:在这一节中,我们通过可视化的特征交互矩阵进行可解释的分析,该矩阵由field feature点积结果的绝对值的归一化平均值,其中越高表示这两个field有更强的相关性。可以看到:我们的PEP可以减少不重要的特征交互之间的参数数量,同时保持那些有意义的特征交互的重要性。通过对那些不太重要的特征交互进行降噪,PEP可以减少embedding参数,同时保持或提高准确性。归一化怎么做的?
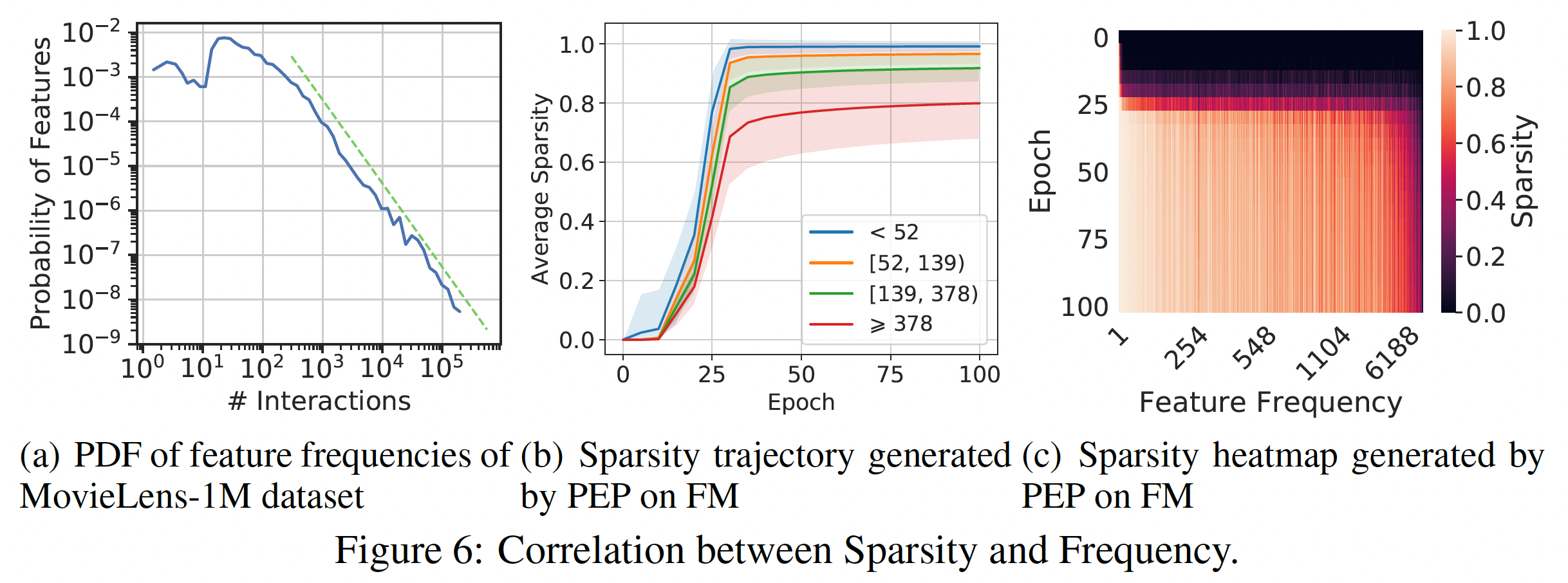
稀疏性和频次之间的相关性:如下图所示,不同特征之间的特征频次是高度多样化的。因此,使用统一的
embedding size可能无法处理它们的异质性,这一特性在embedding size的选择上起着重要作用。因此,最近的一些工作显式利用特征频次。与他们不同的是,我们的PEP以端到端的自动方式缩减参数,从而规避了复杂的人工操作。然而,特征频次是决定一个特征是否重要的因素之一。因此,我们研究我们的方法是否能检测到频次的影响,以及学习到的embedding size是否与频次有关。我们首先分析训练期间的稀疏度轨迹,如下图
(b)所示,不同的颜色表示根据popularity划分的不同的feature group。对于每一组,我们首先计算每个特征的稀疏度,然后计算所有特征上的平均值。图片中的阴影代表一个组内的方差。我们可以看到:PEP倾向于给高频特征分配更大的embedding size,从而确保有足够的表达能力。而对于低频特征,其趋势则相反。这些结果符合这样的假设:高频特征应该有更多的
embedding参数;而对于低频特征的embedding,几个参数就足够了。然后,我们探究了裁剪后的
embedding的稀疏度和每个特征的频次之间的关系,如下图(c)所示。可以看到:大多数
relationship与上述分析一致。一些低频特征被分配了较大的
embedding size,而一些具有较大popularity的特征被分配了较小的embedding size。这说明:像以前的大多数工作那样简单地给高频特征分配更多的参数,并不能处理特征和它们的popularity之间的复杂联系。我们的方法是基于数据进行裁剪,这可以反映出特征的固有属性,从而可以以一种更优雅和有效的方式缩减参数。
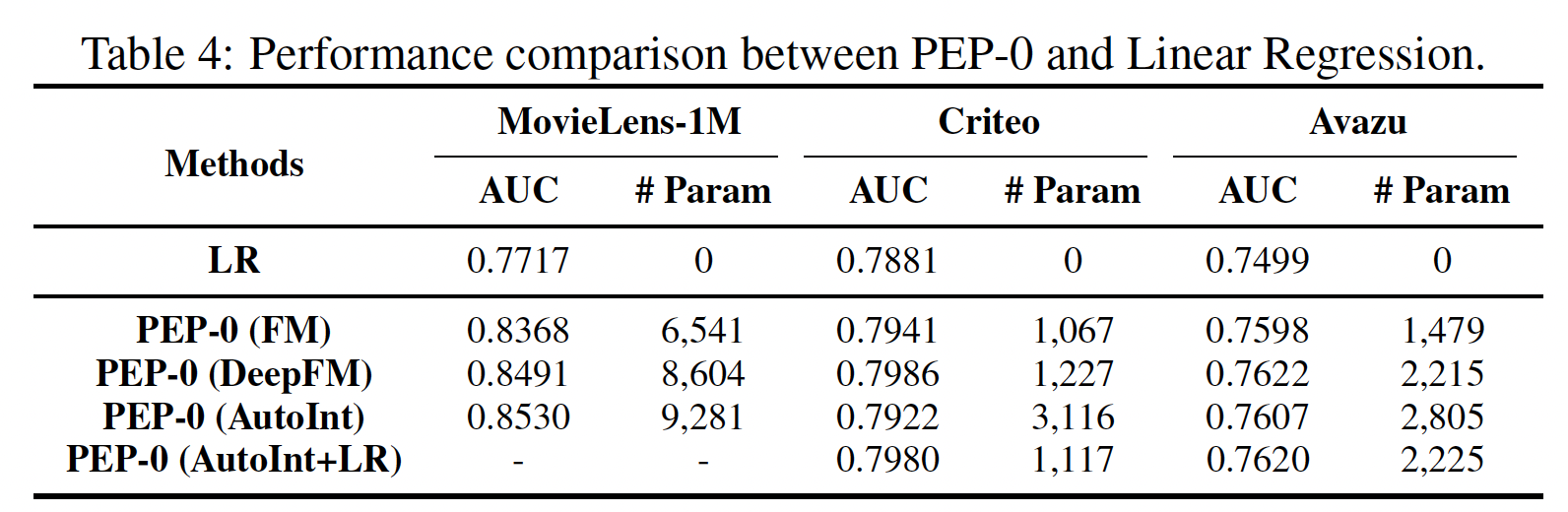
线性回归(
Linear Regression: LR)模型是一个无embedding的模型,只根据原始特征的线性组合进行预测。因此,值得将我们在极稀疏水平上的方法(PEP-0)与LR进行比较,如下表所示。可以看到:我们的
PEP-0在所有情况下都明显优于LR。这一结果证明,我们的PEP-0并不依赖FM和DeepFM中的LR部分来保持强大的推荐性能。因此,即使在极其稀疏的情况下,我们的PEP在现实世界的场景中仍然具有很高的应用价值。值得注意的是,
AutoInt模型不包含LR组件,所以在Criteo和Avazu数据集上AutoInt的PEP-0导致了性能的大幅下降。我们尝试在AutoInt的PEP-0中包含LR,并测试其性能。我们可以看到,在Criteo和Avazu上的准确率超过了没有LR的AutoInt。这可以解释为LR帮助我们的PEP-0获得更稳定的性能。