一、CL4CTR [2022]
《CL4CTR: A Contrastive Learning Framework for CTR Prediction》
许多
CTR prediction工作侧重于设计高级架构来建模复杂的feature interactions,但忽略了feature representation learning的重要性,例如,对每个特征采用一个简单的embedding layer,这会导致次优的feature representations,从而导致CTR prediction的性能较差。例如,低频特征(在许多CTR任务中占大多数特征)在标准的supervised learning settings中较少得到考虑,导致次优的feature representations。在本文中,我们引入自监督学习(self-supervised learning)来直接生成高质量的feature representations,并提出了一个与模型无关的Contrastive Learning for CTR: CL4CTR框架,该框架由三个self-supervised learning signals组成,以规范化feature representation learning:contrastive loss、feature alignment和field uniformity。contrastive module首先通过data augmentation构建positive feature pairs,然后通过contrastive loss最小化每对positive feature pair的representations之间的距离。feature alignment constraint使得来自同一field的特征的representations是接近的。而
field uniformity constraint使得来自不同fields的特征的representations是远离的。
大量实验验证了
CL4CTR在四个数据集上取得了最佳性能,并且具有良好的有效性,以及具有与各种代表性baselines模型的兼容性。CTR prediction旨在预测给定item被点击的概率,已被广泛应用于推荐系统和计算广告等许多应用领域。最近,许多方法通过建模复杂的特征交互(feature interactions: FI) 取得了巨大成功。根据最近的研究,我们将CTR prediction方法分为两类:(1)传统方法,如逻辑回归 (
logistic regression: LR)和基于FM的模型,它们只能建模低阶特征交互。(2)基于深度学习的方法,如
xDeepFM和DCN-V2,可以通过捕获高阶特征交互从而进一步提高CTR prediction的准确性。此外,许多新颖的架构(例如,self-attention、CIN、PIN)已被提出并广泛部署从而捕获复杂的任意阶的特征交互。
尽管在性能上取得了成功,但许多现有的
CTR prediction方法都存在一个固有问题:高频特征比低频特征有更高的机会被训练,导致低频特征的representations不是最优的。在Figure 1中,我们展示了Frappe数据集和ML-tag数据集的特征累积分布(feature cumulative distributions)。我们可以观察到特征频率的明显“长尾”分布,例如,在ML-tag数据集中尾部80%的特征仅出现38次或更少。由于大多数CTR prediction模型通过反向传播来学习feature representations,低频特征由于出现次数较少而无法得到充分训练,导致feature representations不是最优的,从而导致CTR prediction性能也不理想。 先前的一些研究(《A Dual Input-aware Factorization Machine for CTR Prediction》、《An Input-aware Factorization Machine for Sparse Prediction》)也意识到了feature representation learning的重要性,并建议在embedding layer之后部署weight learning模块(即FEN、Dual-FEN),为每个特征分配权重以提升其representations。 然而,额外的weighting模块会增加模型参数和推理时间。 此外,与基于特征交互的方法类似,这些方法仅使用supervised learning signals来优化来自plain embedding layer的feature representations,这不足以产生足够准确的feature representations。 因此,在本文中,我们专注于直接从embedding layer学习准确的feature representations,而不引入额外的加权机制,这是模型无关的并且尚未得到广泛研究。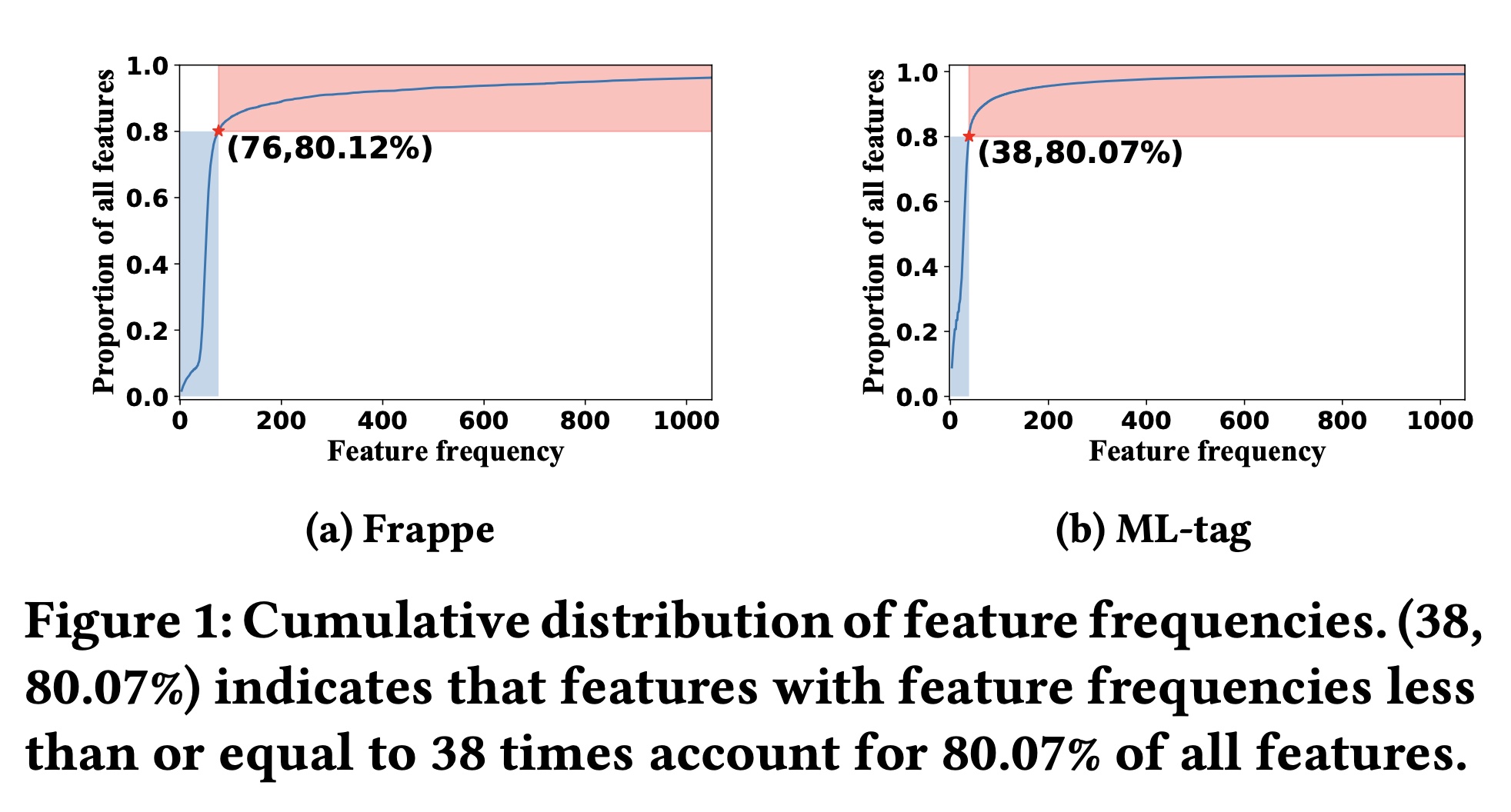
在本文中,我们试图利用自监督学习(
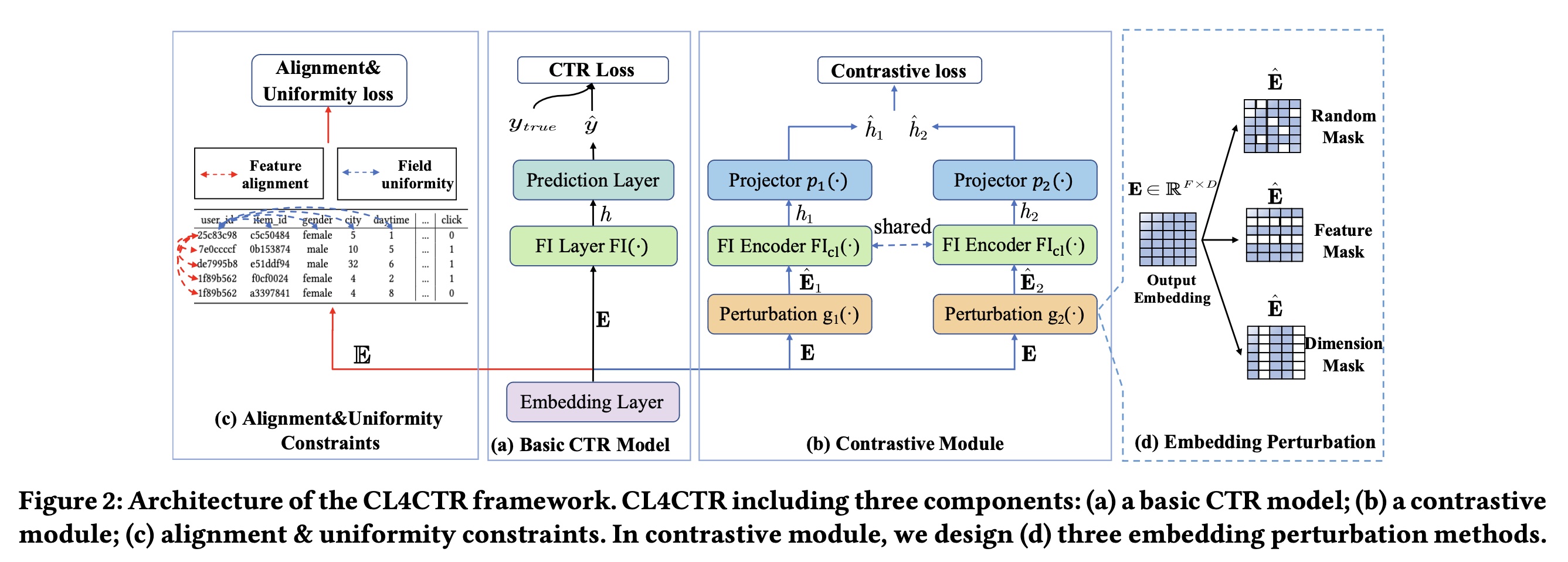
self-supervised learning: SSL)来解决上述问题,其中我们设计self-supervised learning signals作为约束,从而在训练过程中规范化所学到的feature representations。如Figure 2所示,我们提出了一种称为Contrastive Learning for Click Through Rate Prediction: CL4CTR的新框架,该框架由三个关键模块组成:CTR prediction model、contrastive module、以及alignment&uniformity constraints。具体来说:CTR prediction model旨在预测用户点击item的可能性,在CL4CTR框架中可以用大多数现有的CTR模型来代替它。在
contrastive module中,我们设计了三个关键组件:(1)数据增强单元(data augmentation unit),旨在为output embedding生成两个不同的视图作为positive training pairs,其包括三种不同的permutation方法:random mask、feature mask和dimension mask。(2)特征交互编码器(feature interaction encoder),旨在基于来自数据增强单元的perturbed embeddings从而学习紧凑的feature interaction representations。(3)面向任务的对比损失(contrastive loss),旨在最小化positive training pairs之间的距离。
此外,我们引入了两个约束:
feature alignment和field uniformity,以促进contrastive learning。feature alignment迫使来自同一field的特征的representations尽可能接近,而field uniformity迫使来自不同field的特征的representations尽可能远离。
我们的主要贡献总结如下:
我们提出了一个与模型无关的对比学习框架
CL4CTR,它可以以端到端的方式直接提高feature representations的质量。考虑到
CTR prediction任务的独有特点,我们设计了三个自监督学习信号(self-supervised learning signals):contrastive loss、feature alignment constraint以及field uniformity constraint,以提高对比学习的性能。在四个数据集上进行的大量实验表明,只需将
CL4CTR应用于FM即可超越SOTA的方法。更重要的是,CL4CTR与现有方法具有很高的兼容性,即它通常可以提高许多代表性的baselines的性能。
1.1 CL4CTR 框架
1.1.1 CTR Prediction
CTR prediction是一个二分类任务。假设用于训练CTR prediction模型的数据集包含multi-field表格型的数据记录,包含fields和Table 1所示。
最近,如
Figure 2(a)所示,许多CTR prediction模型遵循常见的设计范式:embedding layer、FI layer和prediction layer。Embedding layer:通常,每个输入one-hot vector表示的稀疏高维向量。而embedding layer将稀疏的高维特征向量embedding matrix:其中
embedding size,;表示向量拼接。注意:这里是将
embedding vector,然后拼接成矩阵(而不是一维向量)。另外,我们使用
feature representations,其中field的representation,fieldFeature interaction layer:FI layer通常包含各种类型的交互操作从而捕获任意阶次的特征交互,例如MLP、Cross Network、Cross Network2和transformer layer等。我们将这些结构称为feature interaction encoders,用embedding matrixfeature interaction representationPrediction layer:最后,prediction layer(通常是一个线性回归或MLP模块)根据来自FI layer的紧凑representationssigmoid函数。
最后,利用
predicted labeltrue labelCTR模型常用的损失函数如下:对比学习(
Contrastive learning):如Figure 2所示,除了上述组件之外,我们在embedding layer之上提出了三个contrastive learning signals:contrastive loss、feature alignment constraint和field uniformity constraint,以规范化representation learning。由于这些信号在模型推理过程中不是必需的,我们的方法不会增加推理时间和底层CTR prediction模型的参数。
1.1.2 Contrastive Module
受到自监督学习的成功的启发,我们寻求在
CTR prediction任务中部署contrastive learning,从而生成高质量的feature representations。如Figure 2(b)所示,contrastive module由三个主要组件组成:data augmentation unit、FI encoder和contrastive loss function。在
data augmentation unit中,我们提出了三种不同的面向任务的后验embedding augmentation技术来生成positive training pairs,即每个feature embedding的两个不同视图。然后,我们将两个
perturbed embeddings馈入到同一个FI encoder以生成两个compressed feature representations。最后,应用
contrastive loss来最小化两个compressed feature representations之间的距离。
通过
Output Perturbation实现的Data Augmentation:在自监督学习中,数据增强(Data Augmentation)在提高feature representations的性能方面显示出巨大的潜力。人们提出了不同的、设计良好的augmentation方法,并将它们用于构建同一输入实例的不同视图。例如,在序列推荐(sequential recommendation)场景中,三种广泛使用的augmentation方法是item masking、reordering和cropping(《Self-Supervised Learning for Recommender Systems: A Survey》)。然而,这些方法旨在augment行为序列,并不适合部署在FI-based CTR prediction模型中。因此,我们首先提出了三种面向任务的augmentation方法,旨在为FI-based模型来扰动feature embeddings。如Figure 2(d)所示,我们使用函数data augmentation过程。随机掩码(
Random Mask)。首先,我们介绍random mask方法,它类似于Dropout。该方法以一定的概率embeddingrandom mask生成如下:其中:
1的概率都是特征掩码(
Feature Mask):受先前研究(《Feature generation by convolutional neural network for click-through rate prediction》、《Autoint: Automatic feature interaction learning via self-attentive neural networks》)的启发,我们建议在初始embedding中掩码特征信息,其中feature mask可以按如下方式生成:其中:
如果一个特征被掩码,那么这个特征的
representation将被[mask]替换,它是一个零向量。
维度掩码(
Dimension Mask):feature representations的维度影响deep learning模型的有效性。受FED(《Dimension Relation Modeling for Click-Through Rate Prediction》)的启发,它试图通过捕获维度关系来提高预测性能,我们建议通过替换feature representations中特定比例的维度信息来扰乱初始embedding,这可以描述如下:其中:
1的概率都是
在训练过程中,我们选择上述掩码方法之一来生成两个
perturbed embeddingFigure 2(b)中,采用什么类型的掩码,这是在训练之前就确定好的,而不是在训练过程中动态三选一来选择的。
Feature Interaction Encoder:我们利用一个共享的FI encoder从两个perturbed embeddingfeature interaction信息,如下所示:其中:
FI encoder函数;perturbed embeddings生成的两个compressed representations。值得注意的是,任何
FI encoder都可以部署在我们的CL4CTR中,例如cross-network(《DCN-M: Improved Deep & Cross Network for Feature Cross Learning in Web-scale Learning to Rank Systems》)、self-attention(《Autoint: Automatic feature interaction learning via self-attentive neural networks》)和bi-interaction(《Neural factorization machines for sparse predictive analytics》)。具体来说,我们选择Transformer layer作为我们的主要FI encoder。Transformer layer被广泛用于提取特征之间的vector-level关系。 此外,我们发现一些FI encoders(例如cross network、PIN)生成的compressed representations(fieldFI encoder的representations的维度降低到其中,投影函数
MLP。如果采用了
Transformer Layer,是不是就不需要Projector了?Contrastive Loss Function:最后,应用对比损失函数(contrastive loss function)来最小化上述两个perturbed representations之间的期望距离,如下所示:其中:
batch size,
1.1.3 Feature Alignment and Field Uniformity
为了确保低频特征和高频特征得到同等的训练,一种简单的方法是在训练期间增加低频特征的频率、或降低高频特征的频率。受到其他领域(
CV,NLP)中先前研究(《Understanding the behaviour of contrastive loss》、《Understanding contrastive representation learning through alignment and uniformity on the hypersphere》)的启发,它们可以通过引入两个关键属性(即alignment and uniformity constraints)来实现类似的目标,但它们需要构造positive and negative sample pairs来优化这两个约束。在
CTR prediction任务中,我们发现同一field的特征类似于positive sample pairs,不同field的特征类似于negative sample pairs。因此,我们为CTR prediction中的对比学习提出了两个新属性,即feature alignment和field uniformity,它们可以在训练过程中规范化feature representations。具体而言:feature alignment将来自同一field的特征的representations拉得尽可能接近。相反,
field uniformity将来自不同field的特征的representations推得尽可能远。
Feature Alignment:首先,我们引入feature alignment约束,旨在最小化来自同一field的特征之间的距离。直观地讲,通过添加feature alignment约束,同一field中的特征的representations应该在低维空间中分布得更紧密。正式地,feature alignment的损失函数如下:其中:
feature的embedding,它们来自同一field;fieldembeddings。field Uniformity:现有的CTR prediction方法尚未广泛研究不同field之间的关系。例如,FFM学习每个特征的field-aware representation,而NON提取intra-field信息,但它们的技术不能直接应用于对比学习。不同的是,我们引入field uniformity来直接优化feature representation,从而最小化属于不同fields的特征之间的相似性。field uniformity的损失函数正式定义如下:其中:
《Self-Supervised Learning for Recommender Systems: A Survey》、《SelfCF: A Simple Framework for Self-supervised Collaborative Filtering》)类似,我们使用余弦相似度来正则化negative sample pairs:这里也可以使用其他相似度函数。
field
在
feature alignment约束和field uniformity约束中,我们都发现低频特征和高频特征被考虑的机会是均等的。因此,在训练期间引入这两个约束可以大大缓解低频特征的suboptimal representation问题。对于某些
field,例如item id,它的特征取值范围非常大,那么feature alignment约束和field uniformity约束如何处理?读者猜测是:采样一部分特征而不是使用该field的全部特征。
1.1.4 Multi-task Training
为了将
CL4CTR框架融入CTR prediction场景,我们采用multi-task training策略,以端到端的方式联合优化这三个辅助的自监督学习losses和原始CTR prediction loss。因此,最终的目标函数可以表示如下:其中:
contrastive loss和feature alignment and field uniformity loss。
1.2 实验
数据集:
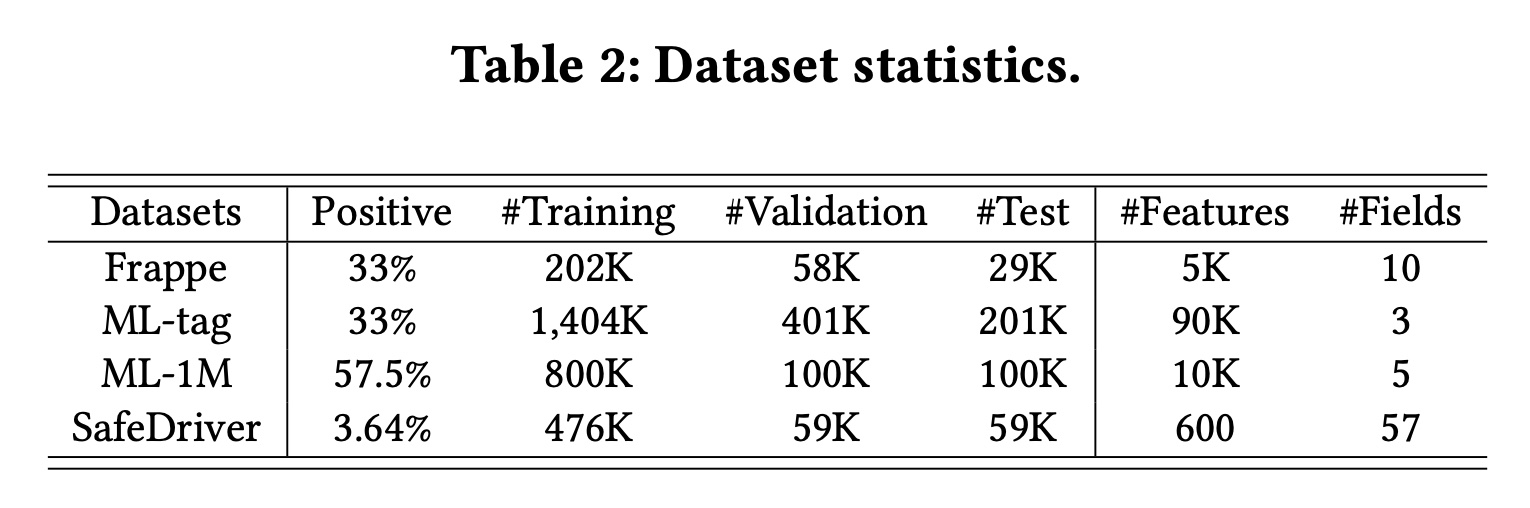
Frappe、ML-tag、SafeDriver和ML-1M。四个数据集的统计数据如Table 2所示。NFM和AFM严格按照7:2:1将Frappe和ML-tag分为训练集、验证集和测试集,我们直接遵循它们的设置。对于
SafeDriver和ML-1M,我们按照《GateNet: Gating-Enhanced Deep Network for Click-Through Rate Prediction》和《DCAP: Deep Cross Attentional Product Network for User Response Prediction》随机将实例分为8:1:1。这些数据集的详细描述可以在链接或参考资料中找到。这些数据集都是
toy数据集,没有工业数据集,因此说服力不是很强。
baselines:为了评估提出的CL4CTR框架,我们将其性能与四类代表性CTR prediction方法行了比较:1)一阶方法,即原始特征的加权和,包括LR。2)基于FM的方法,考虑二阶的特征交互,包括FM、FwFM、IFM和FmFM。3)建模高阶的特征交互的方法,包括CrossNet、IPNN、OPNN、FINT和DCAP。4)ensemble方法或多塔结构,包括WDL、DCN、DeepFM、xDeepFM、FiBi-NET、AutoInt+、AFN+、TFNET、FED和DCN-V2。
所提出的
CL4CTR框架与模型无关。为简单起见,base模型CL4CTR之后记作FM作为base模型来验证CL4CTR的有效性,它仅仅建模二阶的特征交互,除了feature representations之外没有其他参数。因此,feature representations的质量。CL4CTR仅帮助base CTR model的训练,不会向推理过程添加任何操作或参数。有可能在更优秀的
base模型上,CL4CTR的增益会很小甚至消失。因为更优秀的base模型可能学到更好的representation。评估指标:
AUC, Logloss。实现细节:
为了公平比较,我们使用
Pytorch实现所有模型,并使用Adam优化所有模型。Frappe和ML-tag的embedding size设置为64,ML-1M和SafeDriver的embedding size设置为20。同时,batch size固定为1024。SafeDriver的学习率为0.01,其他数据集的学习率为0.001。对于包含
DNN的模型,我们采用相同的结构{400,400,400,1}。所有激活函数均为ReLU,dropout rate为0.5。我们根据验证集上的
AUC执行早停,从而避免过拟合。我们还实现了Reduce-LR-On-Plateau scheduler,当给定指标在四个连续epochs内停止改进时,将学习率降低10倍。每个实验重复
5次,并报告平均结果。在
CL4CTR中,Transformer layers。我们在最终损失函数中使用超参数:
1.2.1 整体比较
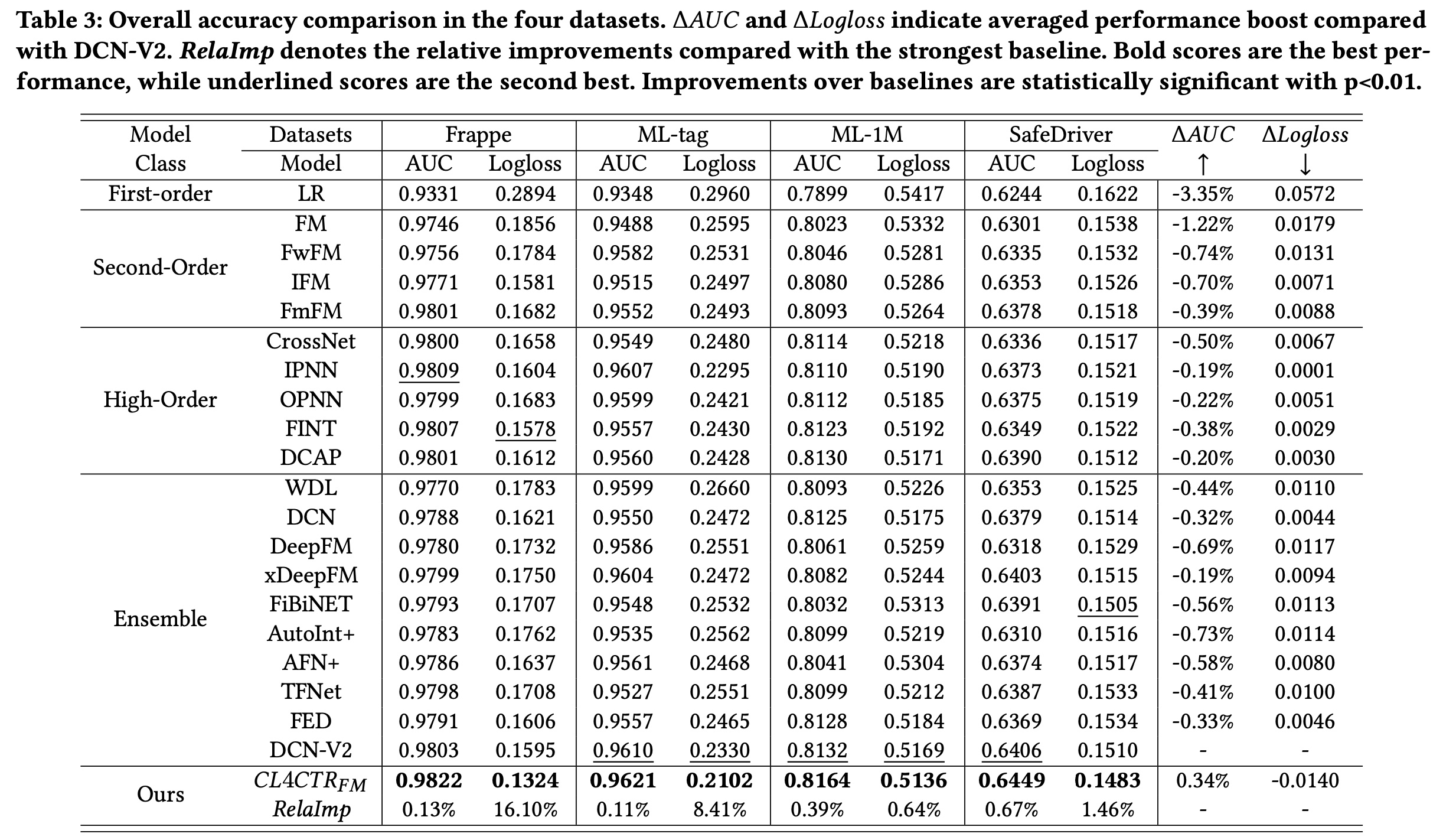
在本节中,我们将
SOTA的CTR prediction模型进行了比较。Table 3显示了所有被比较的模型在四个数据集上的实验结果。 可以观察到:与其他
baselines相比,LR和FM的性能最差,这表明浅层模型不足以进行CTR prediction。其他
FM-based的模型通过引入field importance机制(例如,FwFM和IFM)、或部署新颖的field-pair matrix方法(例如,FmFM)来改进FM。通常,基于
deep-learning的模型(例如,DeepFM、DCN、DCN-V2)将高阶特征交互与精心设计的特征交互结构相结合,比FM具有更好的性能。baselines。在Frappe、ML-tag、ML-1M和SafeDriver上,AUC显著优于最强的基线DCN-V2分别为0.13%、0.11%、0.39%和0.67%(Logloss值分别为16.10%、8.41%、0.64%和1.46%)。此外,我们发现
Logloss的改进比AUC的改进更显著,这表明CL4CTR使我们能够有效地预测真实的点击率。同时,
Table 3显示了平均性能提升(ΔAUC和ΔLogloss)。值得注意的是,大多数SOTA的CTR prediction模型都设计了复杂的网络来产生高级的feature representations和有用的feature interactions来提高性能。然而,我们的CL4CTR仅仅帮助FM通过对比学习从embedding layer学习准确的feature representations,而不是引入额外的模块。我们CL4CTR的改进验证了在CTR prediction任务中学习准确的feature representations的必要性。
1.2.2 Ablation Study
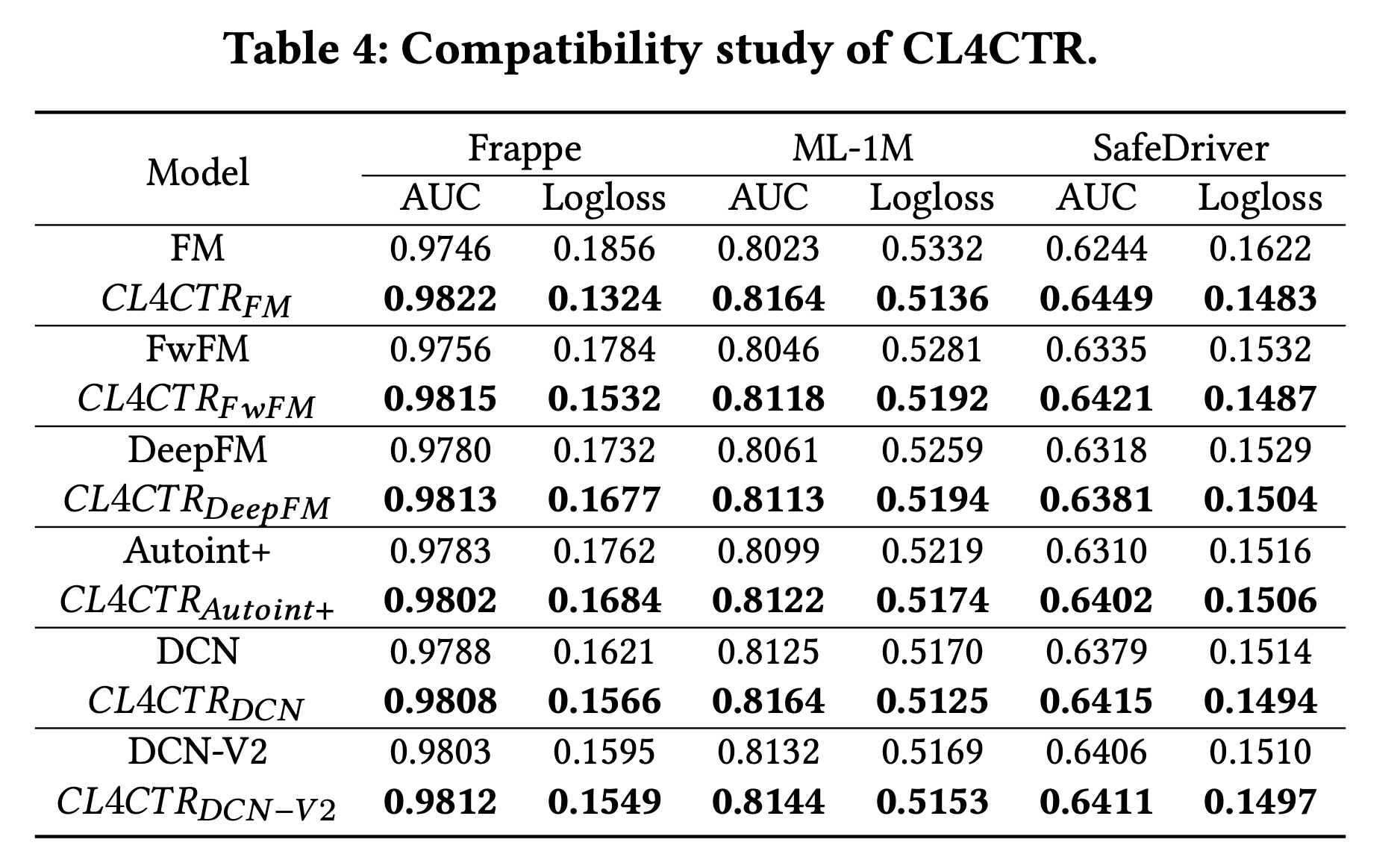
兼容性分析:为了验证
CL4CTR的兼容性,我们将其部署到其他SOTA模型中,例如DeepFM、AutoInt+和DCN-V2。结果如Table 4所示。首先,使用
CL4CTR来learning feature representation可以显著提高CTR prediction的性能。应用CL4CTR后,base模型的性能得到显著提升,这证实了我们通过提高feature representations的质量来提高CTR prediction模型性能的假设,并证明了CL4CTR的有效性。此外,实验结果表明,学习高质量的
feature representations至少与设计高级的特征交互技术一样重要。当这些模型利用监督信号进行训练时,建模复杂的特征交互可以提高CTR模型的性能,这解释了为什么FI-based的模型优于FM。然而,在将自监督信号引入
CTR模型以学习高质量的feature representations后,在配备了CL4CTR的所有模型之间,FM可以取得最佳性能。可能的原因是:在FM中feature representations中的参数,而不会受到其他参数的干扰。因为
FM模型除了embedding layer之外没有其它参数。
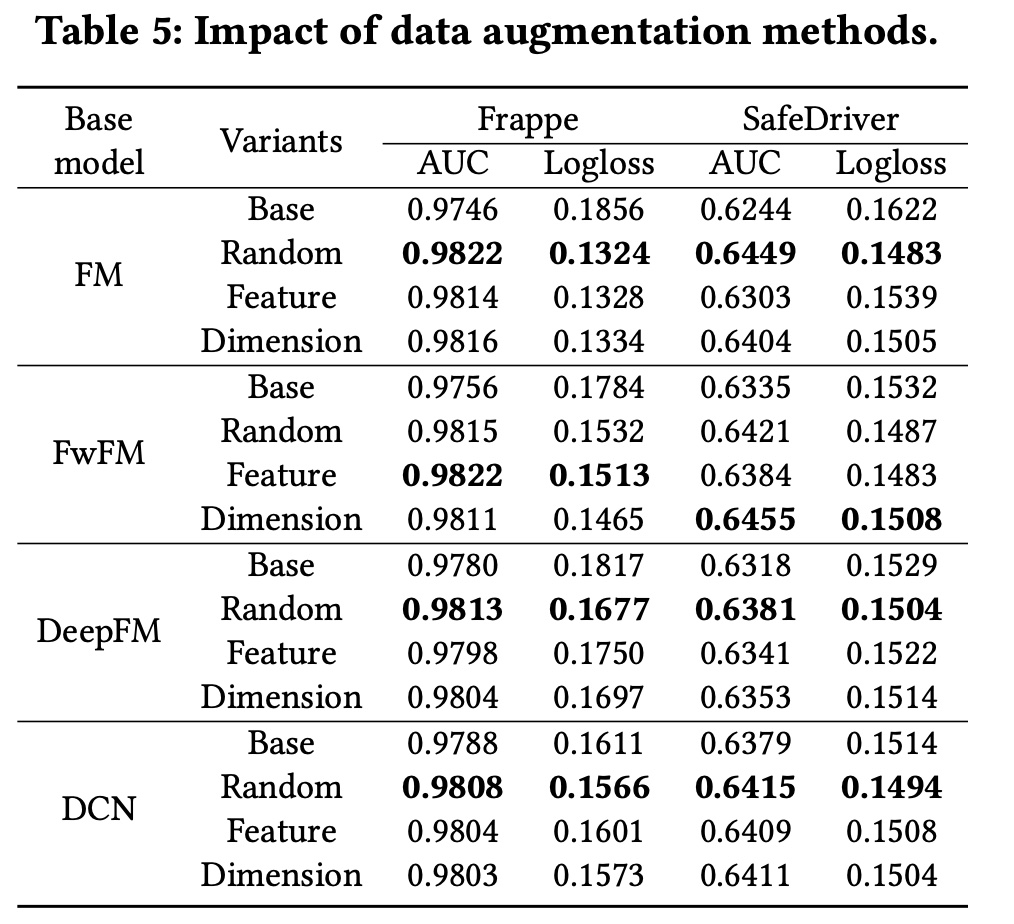
Data Augmentation方法:为了验证我们提出的data augmentation方法的有效性,我们更改了contrastive module中的augmentation方法,并固定了其他settings以进行公平比较。此外,我们选择了不同的baseline模型并将CL4CTR部署到其中,以比较它们在此setting下的性能。Table 5展示了实验结果。在大多数情况下,
random mask方法取得了最佳性能。我们认为random mask比feature mask和dimension mask更具缓和性,因为它省略了element信息。此外,在
Frappe上,FwFM模型使用feature mask方法取得了最佳性能;相反,在SafeDriver上FwFM模型使用dimension mask方法取得了最佳性能,这表明我们提出的augmentation方法是有效的,并且可以用于不同的baseline模型和数据集。
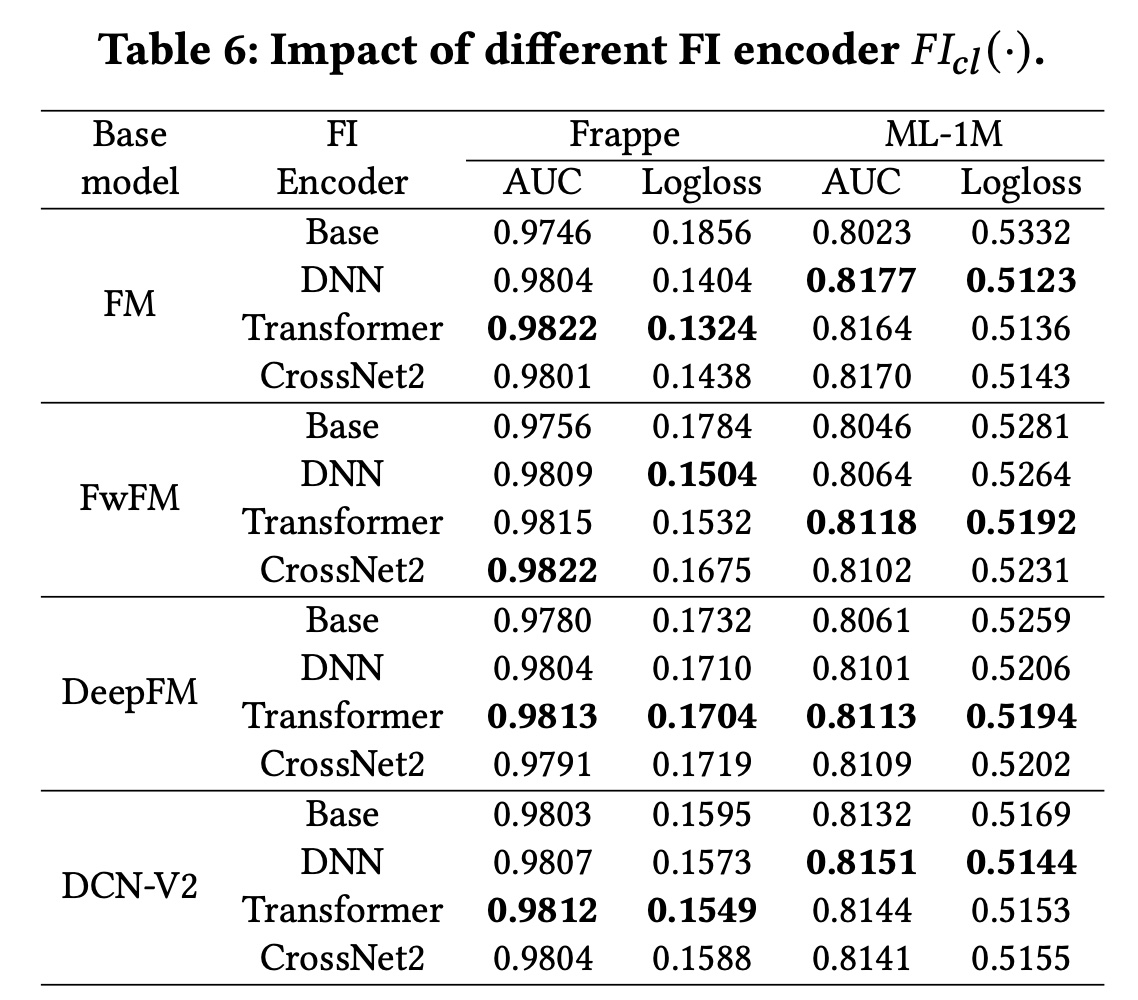
FI Encoder:在contrastive module中,FI encoder也会影响CL4CTR的性能,因为不同结构的FI encoder抽取了不同的信息。例如:Transformer layer可以显式地建模feature-level的高阶特征交互。而
CrossNet2则专注于显式地建模element-level的有界阶次的特征交互。DNN是大多数CTR模型中一种常见且广泛使用的结构,用于隐式地建模bit-level的特征关系。
我们选择上述三种代表性的结构作为
FI encoders并验证其性能。值得注意的是,我们采用了他们论文中报告的三层架构。Table 6展示了实验结果。 可以观察到:使用不同的
FI encoders,CL4CTR可以一致地提高这些baseline模型的性能。此外,由于不同的
FI encoders根据特定的base模型和数据集提取不同的信息,这些模型的性能也不同。然而,带有Transformer layers的CL4CTR在大多数情况下都能达到最佳性能,因为Transformer layer比其他的layers更有效。
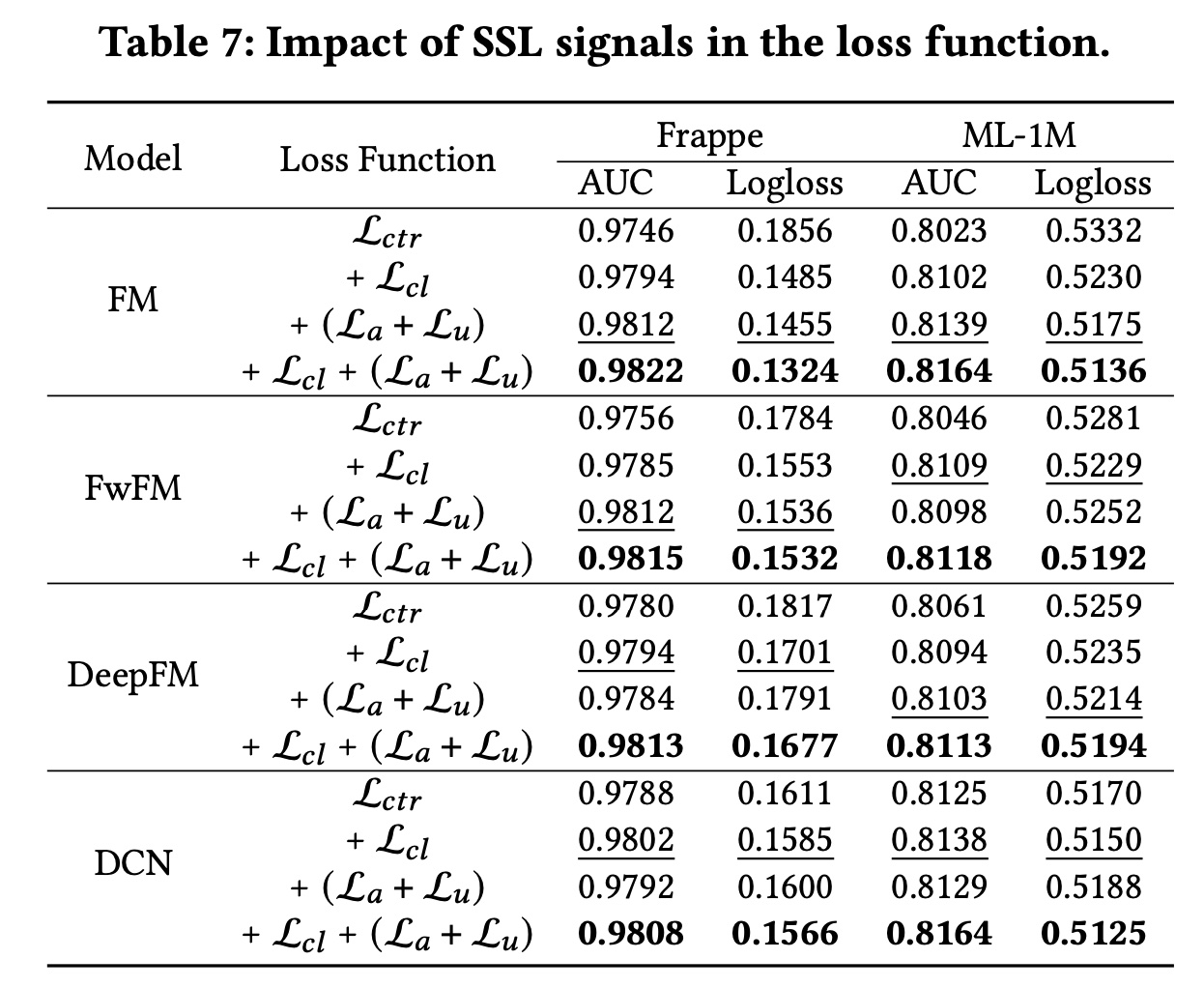
损失函数:在本节中,我们通过分别从
CL4CTR中剔除自监督学习信号(即Table 7所示。首先,我们可以发现,在
baseline模型中部署每一种自监督学习信号都可以提高其性能。此外,通过分别比较
contrastive loss和alignment&uniformity constraints,我们得出结论,它们在不同的数据集和baseline模型中发挥着不同的作用。具体而言:具有
FM的表现优于具有FM。相反,具有
DCN的表现不如具有DCN,这验证了我们的假设。
此外,当
此外,在
Logloss评估的两个数据集上,采用FM的表现始终优于采用FM,这表明将feature alignment and field uniformity引入CTR prediction模型使我们的预测概率更接近true label。
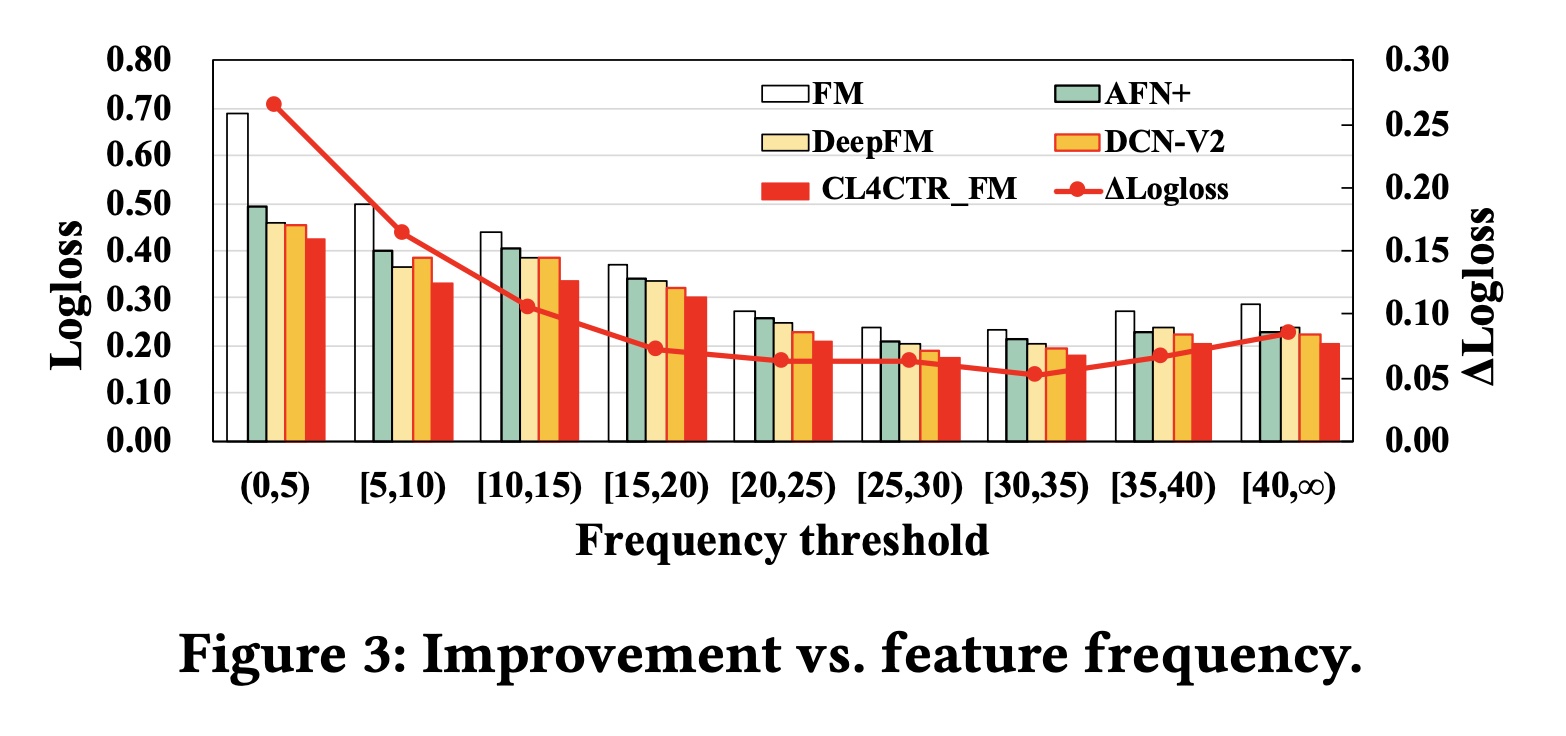
1.2.3 Feature Frequency Analysis
为了验证特征频率对不同模型的影响,我们将
ML-tag测试集按照特征频率进行划分,并计算相应的Logloss,其中ΔLogloss表示应用CL4CTR后相对于base FM模型的提升。Figure 3展示了实验结果。首先,低频特征对
base模型的准确率有负面影响。具体而言,我们展示了FM、三个SOTA模型(AFN+,DeepFM,DCN-V2)、以及当输入子集包含低频特征时,所有模型的表现最差。
随着特征频率的增加,所有模型的性能都在持续提升。
当特征频率超过
20时,所有模型的性能都趋于稳定。
Figure 3证实了我们的假设,即仅使用具有单个监督信号的反向传播来学习低频特征的representations无法实现最佳性能。其次,
CL4CTR可以有效缓解低频特征带来的负面影响,并在不同特征频率范围内保持最佳性能。通过应用alignment&uniformity constraints,我们确保低频特征可以在每个反向传播过程中得到优化,并且与高频特征有同等的机会。此外,contrastive module还可以提高所有特征(包括低频和高频特征)的representations的质量。这里的分组指的是被点击的
label tag的频次。
1.2.4 超参数分析
损失函数中权重的影响:我们进一步研究了不同权重(
{1, 1e-1, 1e-2, 1e-3, 1e-4, 1e-5, 0}中调优settings不变,以便进行公平比较。Figure 4显示了实验结果。此外,在这两个数据集上Logloss的趋势与AUC的趋势一致。 总体而言,对于Frappe和ML-1M数据集,当CL4CTR的性能最佳。具体来说:当
CL4CTR的性能会下降。此外,当
1或1e-1)时,CL4CTR的性能会显著降低。同时,当
CL4CTR的表现更差。

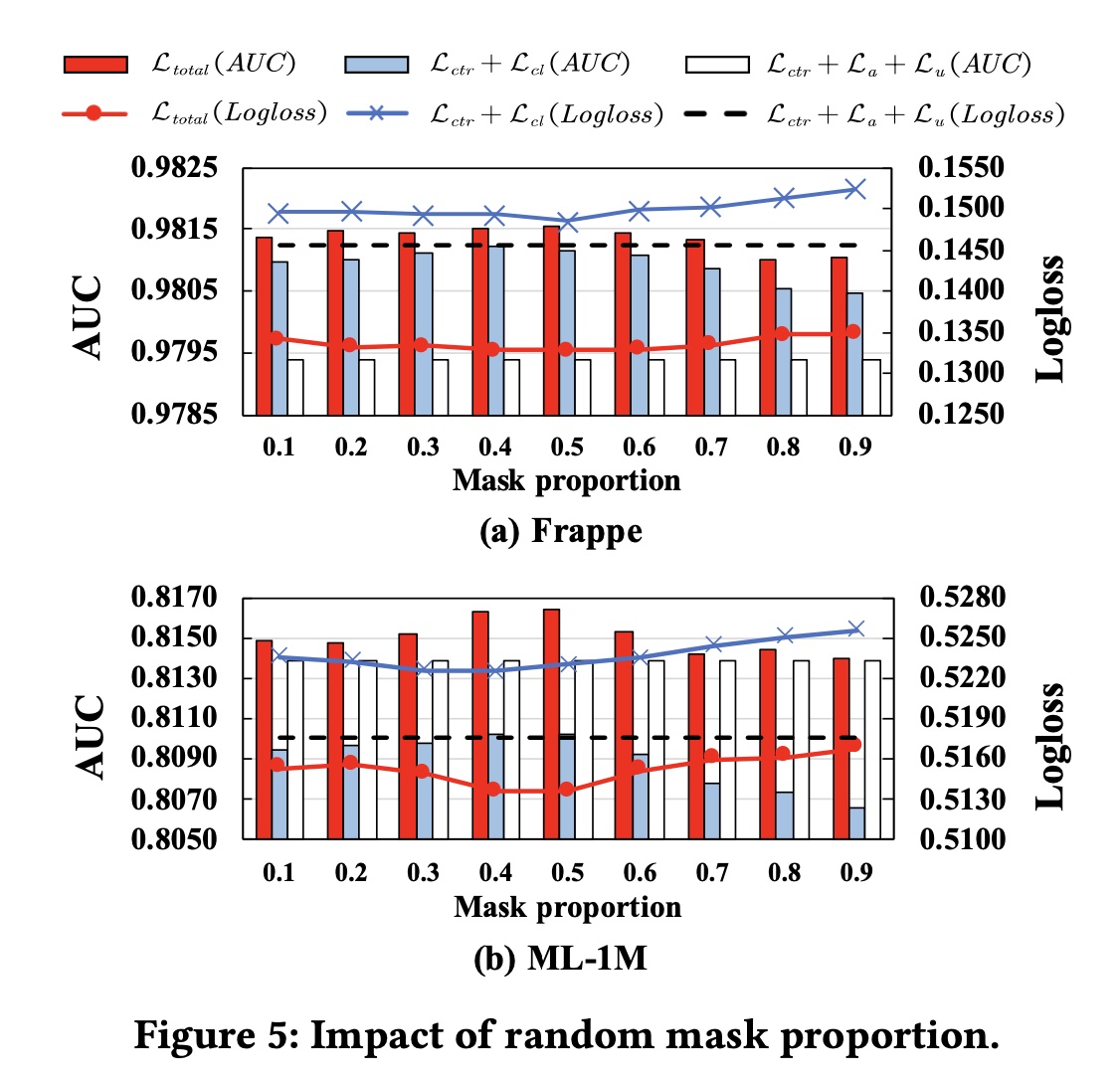
掩码比例:我们在
0.1的步长更改掩码比例Figure 5显示了结果。 对于具有Frappe和ML-1M上的性能显示出相似的趋势。当掩码比例在0.4或0.5左右时,当选择较小的掩码比例(即
0.1到0.3)时,模型性能会略有下降。当掩码比例超过
0.5时,模型性能持续下降,这是因为FI encoders仅使用一小部分信息来生成有效的interaction representations,以计算具有较高掩码比例的contrastive loss。
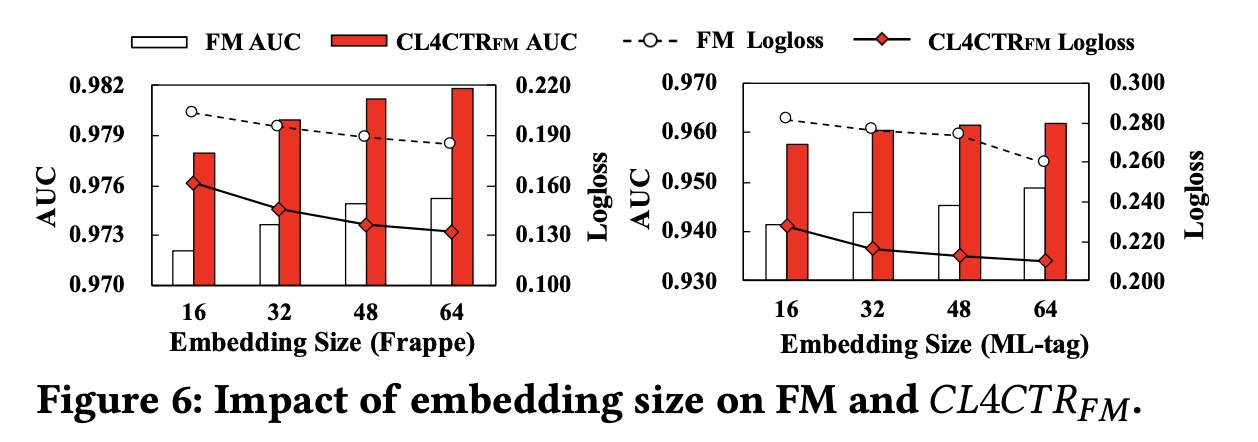
embedding size:我们在embedding layer中将embedding size更改为从16到64,步长为16,并在Figure 6中展示实验结果。可以观察到:
随着
embedding size的增加,同时,
CL4CTR可以提高所有embedding size的FM的性能。此外,与具有
embedding size = 64的FM相比,embedding size = 16的小尺寸下实现了更好的性能。这意味着我们可以通过在FM上应用CL4CTR来减少参数,同时获得更好的结果。