一、SDIM [2022]
《Sampling Is All You Need on Modeling Long-Term User Behaviors for CTR Prediction》
丰富的
user behavior数据已被证明对CTR prediction应用程序具有重要价值,尤其是在工业推荐、搜索或广告系统中。然而,由于对online serving time的严格要求,真实世界的系统要充分利用长期用户行为并不容易。大多数先前的工作采用retrieval-based的策略,即首先检索少量用户行为以供后续使用。然而,retrieval-based的方法是次优的,会造成信息丢失,并且很难平衡检索算法的效果和效率(effectiveness and efficiency)。在本文中,我们提出了
Sampling-based Deep Interest Modeling: SDIM,一种简单而有效的sampling-based的端到端方法,用于建模长期用户行为。我们从多个哈希函数中采样以生成target item的hash signatures、以及用户行为序列中每个behavior item的hash signatures,并通过直接收集behavior items来获取用户兴趣,这些behavior items与target item具有相同的hash signatures。behavior item就是用户的历史行为序列中的feature item。我们从理论上和实验上表明,所提出的方法在建模长期用户行为方面与标准的
attention-based的模型性能相当,同时速度快得多。我们还介绍了SDIM在我们系统中的部署。具体来说,我们通过设计一个名为Behavior Sequence Encoding: BSE的独立模块,将最耗时的部分behavior(即,behavior sequence hashing)从CTR模型中分离出来。BSE对于CTR server来说是无延迟的,使我们能够建模极长的用户行为序列。离线和在线实验证明了SDIM的有效性。SDIM现在已经在线部署在美团APP的搜索系统中。CTR prediction是工业应用系统中的一项基本任务。用户兴趣建模(user interest modeling)旨在从历史行为数据中学习用户的隐含兴趣,已被广泛引入现实世界系统,并有助于显著改善ctr prediction。人们提出了各种模型来建模用户兴趣。其中,
DIN通过考虑给定的target item与历史行为的相关性来自适应地计算用户兴趣。DIN引入了一种新的注意力模块,称为target attention,其中target item充当queryuser behavior充当keyvalueDIN-based的方法近年来已成为建模用户兴趣的主流解决方案。然而,online serving time的严格要求限制了可以使用的用户行为序列的长度。因此,大多数工业系统截断了用户行为序列,只提供最近的50个行为用于用户兴趣建模,这导致了信息损失。随着互联网的快速发展,用户在电商平台上积累了越来越多的
behavior数据。以淘宝为例,他们报告23%的用户半年内在淘宝APP中的行为超过1000次。在美团APP中,有超过60%的用户一年内至少有1000次行为,有超过10%的用户一年内至少有5000次行为。对于工业系统来说,如何有效地利用更多的user behavior来更准确地估计用户兴趣变得越来越重要。最近,有人提出了一些方法来从长行为序列中建模用户的长期兴趣:
MIMN通过设计一个独立的User Interest Center: UIC模块,将user interest modeling从整个模型中分离出来。虽然UIC可以节省大量的online serving time,但它使得CTR模型无法从target item中挖掘信息,而这已被证明是用户兴趣建模的关键。因此,MIMN只能建模shallow user interests。SIM和UBR4CTR采用两阶段框架来处理长期用户行为。他们从序列中检索top-k相似的items,然后将这些items馈入后续的注意力模块。如《 End-to-End User Behavior Retrieval in Click-Through RatePrediction Model》所指出的,这些方法的retrieve objectives与CTR模型的目标不一致,并且离线倒排索引(offline inverted index)中的pre-trained embedding不适合online learning systems。为了提高检索算法的质量,
ETA(《 End-to-End User Behavior Retrieval in Click-Through RatePrediction Model》)提出了一种LSH-based的方法,以端到端的方式从user behavior中检索top-k相似的items。它们使用locality-sensitive hash: LSH将items转换成hash signatures(hash signatures),然后根据它们到target item的汉明距离检索top-k相似的items。LSH的使用大大降低了计算items之间相似度的代价,ETA取得了比SIM和UBR4CTR更好的结果。
SIM、UBR4CTR和ETA都是retrieval-based的方法。retrieval-based的方法具有以下缺点:从整个序列中检索
top-k相似的items是次优的,并且会产生对用户长期兴趣的有偏的估计。在用户具有丰富behavior的情况下,检索到的top-k items可能都与target item相似,并且estimated user interest representation将是不准确的。其核心在与:对于行为丰富的用户,应该取较大的
k从而捕获所有的informative行为;对于行为很少的用户,应该采用较小的k从而过滤掉噪音。但是实际应用中,k是全局统一的。此外,很难平衡检索算法的有效性和效率。以
SIM (hard)为例,他们使用简单的检索算法,因此其性能比其他方法差。相比之下,UBR4CTR在复杂的检索模块的帮助下实现了显著的改进,但其推理速度变得慢了4倍,这使得UBR4CTR无法在线部署,尤其是对于long-term user behaviors modeling。
在本文中,我们提出了一个简单的
hash sampling-based的方法来建模长期用户行为。首先,我们从多个哈希函数中采样,生成
target item的hash signatures、以及用户行为序列中每个item的hash signatures。然后,我们没有使用某种
metric来检索top-k相似的items,而是直接从整个序列中收集与target item共享相同hash signatures的behavior items来形成用户兴趣。
我们方法的内在思想是:用
LSH碰撞概率来近似用户兴趣的softmax distribution。我们从理论上表明,这种简单的sampling-based的方法产生了与softmax-based target attention非常相似的注意力模式,并实现了一致的模型性能,同时时间效率更高。因此,我们的方法类似于直接在原始的长序列上计算注意力,而没有信息损失。我们将提出的方法命名为Sampling-based Deep Interest Modeling: SDIM。传统的
softmax-based target attention:首先计算attention score,然后将历史行为序列根据attention score聚合起来。聚合的权重就是attention score distribution。这里的方法是:首先用
LSH去碰撞,然后将历史行为序列根据是否碰撞从而聚合起来。,权重是0/1,表示是否与target item的哈希值相同,即是否碰撞。因此这里的方法会考虑到与target item相似的所有item,并且不需要target attention计算。我们还介绍了在线部署
SDIM的实践。具体来说,我们将我们的框架分解成两个部分:Behavior Sequence Hashing(BSE) server、CTR server,其中这两个部分是分开部署的。行为序列哈希(behavior sequence hashing)是整个算法中最耗时的部分,该部分的解耦大大减少了serving time。更多细节将在后续章节介绍。我们在公共数据集和工业数据集上进行实验。实验结果表明:
SDIM获得了与标准的attention-based的方法一致的结果,并且在建模长期用户行为方面优于所有竞争baselines,并且具有相当大的加速。SDIM已经在中国最大的生活服务电商平台美团的搜索系统中部署,并带来了2.98%的CTR提升和2.69%的VBR提升,这对我们的业务非常重要。综上所述,本文的主要贡献总结如下:
我们提出了
SDIM,这是一个hash sampling-based的框架,用于为CTR prediction建模长期用户行为。我们证明了这种简单的sampling-based的策略产生了与target attention非常相似的注意力模式。我们详细介绍了我们在线部署
SDIM的实践。我们相信这项工作将有助于推进community,特别是在建模长期用户行为方面。在公共数据集和行业数据集上进行了大量实验,结果证明了
SDIM在效率和效果方面的优越性。SDIM已经部署在美团的搜索系统中,为业务做出了重大贡献。
本质上是通过
LSH实现了target attention。
1.1 基础知识
1.1.1 Task Formulation
CTR prediction是工业界的推荐、搜索和广告系统中的核心任务。CTR任务的目标是估计用户点击item的概率,定义如下:其中:
CTR模型中的可训练参数;label。给定输入特征
CTR模型:
1.1.2 Target Attention
target attention的概念最早由DIN提出,并广泛应用于CTR任务中的用户兴趣建模。target attention将target item作为query,将用户行为序列中的每个item作为key和value,并使用attention算子从用户行为序列中soft-search相关的部分。然后通过对用户行为序列进行加权和来获得用户兴趣。具体而言,将
target item指定为representations指定为request,CTR模型要评分的target items数量。hidden size。
令
target item的representation。target attention计算item的点积相似度,然后以归一化相似度作为权重,得到用户兴趣的representation:矩阵形式可以写成:
其中:
计算
target attention是不可行的。
1.1.3 Locality-Sensitive Hash (LSH) and SimHash
局部敏感哈希(
Locality-sensitive hash: LSH)是一种在高维空间中高效查找最近邻居的算法技术。LSH满足局部保持性(locality-preserving property):邻近的向量很可能获得相同的哈希值,而远处的向量则不会。得益于此特性,LSH-based的signature已广泛应用于互联网搜索系统等许多应用中。随机投影方案 (SimHash)是LSH的一种有效实现。SimHash的基本思想是:采样一个随机投影(由单位法向量+1或-1)。具体而言,给定一个输入其中:
hashed output位于哪一侧。对于两个向量
hash code的取值时,我们才说它们发生冲突:虽然单个哈希值可以用于估计相似度,但是我们可以使用多个哈希值,从而降低估计误差。在实践中,通常采用
SimHash(即,多轮哈希)算法,其中在第一步中,
SimHash随机采样其中:
这些哈希码被分为
为了降低不相似的
items具有相同哈希码的概率,该算法将每组hash signatures。有关更多详细信息,请参阅《Mining of Massive Datasets》。对于第
hash signatures相同时,其中:
“AND”运算符,最后,每个
hash signature对应的分组可以被看作是一次LSH,从而用于期望的计算,从而降低estimation的方差。注意:读者对这一段文字进行了重新润色。原始论文讲的不太清楚。
Figure 1底部显示了(4, 2)参数化的SimHash算法的示例,其中我们使用4个哈希函数并将每2个哈希码聚合为hash signatures(黄色和绿色)。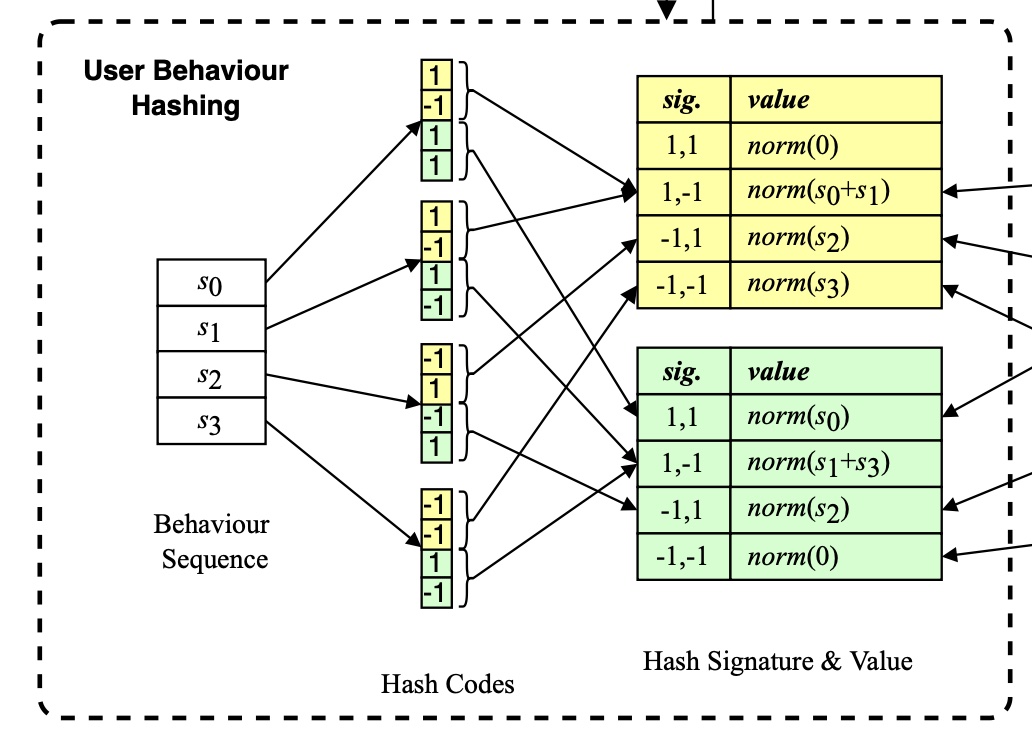
1.2 方法
在本节中,我们介绍了我们的框架从而在系统中实现
SDIM。Figure 1中可以看到high-level的概述。该框架由两个独立的servers组成:Behavior Sequence Encoding (BSE) server和CTR server,稍后将详细介绍。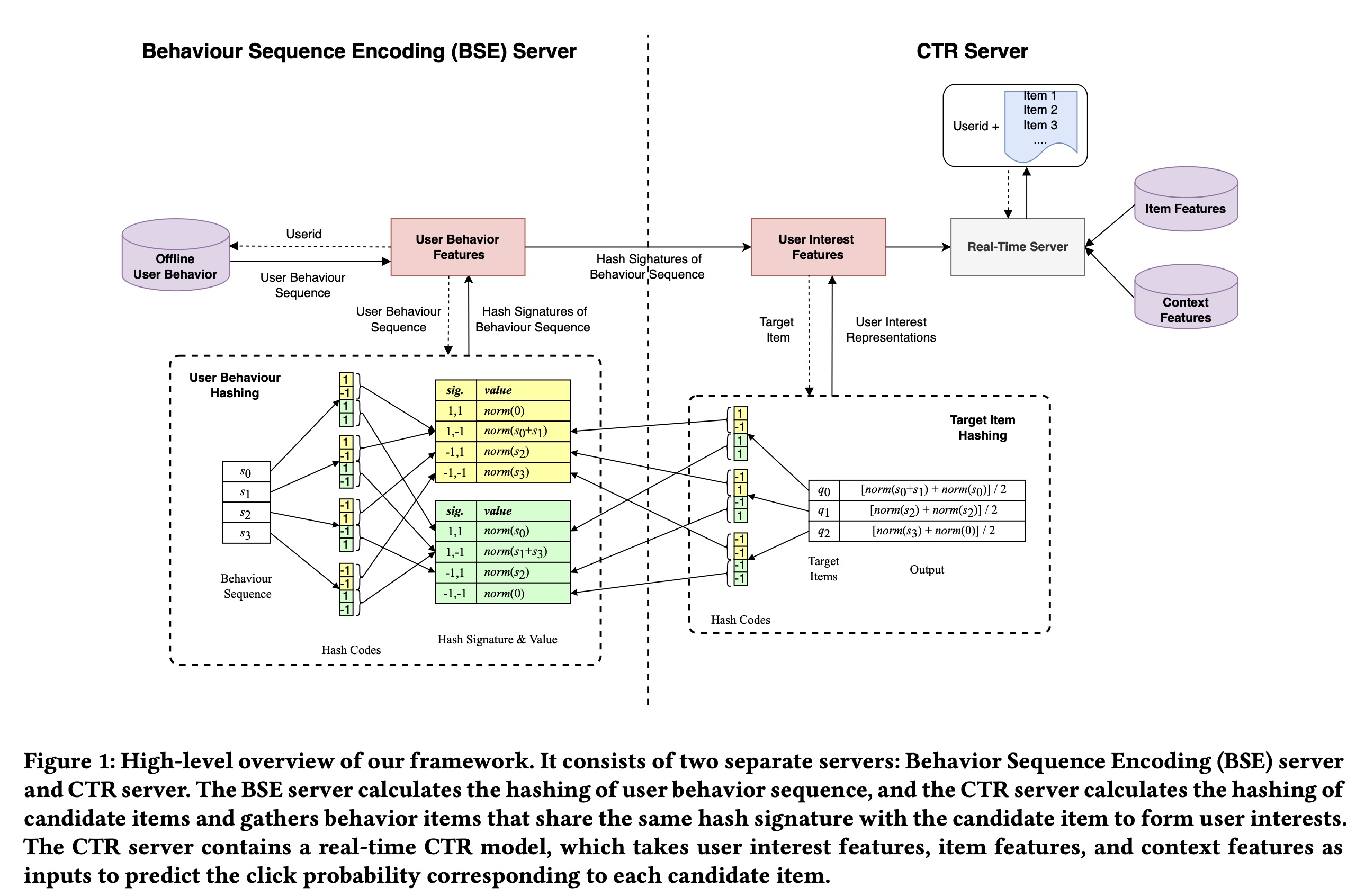
1.2.1 User Behavior Modeling via Hash-Based Sampling
Hash Sampling-Based Attention:第一步,我们采样多个哈希函数并生成user behavior items和target items的哈希码。与ETA类似,我们使用从正态分布中采样的固定的random hash vectors作为“哈希函数”。经过哈希处理后,ETA计算items之间的汉明距离(Hamming distance)作为用户兴趣分布(user interest distribution)的近似值,从而用于选择top-k相似的items。这里我们提出了一种更高效、更有效的方法来近似用户兴趣。 由于具有局部保留的属性(locality-preserving property),相似的向量落入同一个哈希桶的概率很高,因此user behavior items和target item之间的相似性可以通过它们具有相同哈希码(signature)的频率或碰撞概率来近似。这导致我们假设哈希碰撞的概率可以成为用户兴趣的有效估计器。 基于这一观察,我们提出了一种使用LSH来获取用户兴趣的新方法。经过哈希处理后,我们通过将具有相同的behavior itemsbehavior items都关联了同一个target item其中:
item。target itemhash signatures,则target iteml2正则化,用于对兴趣分布进行正则化。我们还尝试使用
l2正则化模型的性能相当。但是,l2正则化的实现效率更高,因此我们使用l2正则化。
Multi-Round Hashing:总是有一个小概率使得不相似的behavior items与target item共享相同哈希码,从而给模型带来噪音。为了降低这种可能性,我们使用前面描述的多轮哈希算法。 具体来说,我们使用SimHash算法。我们并行采样并执行hash signatures。只有当hash signature时,我们才认为它们发生碰撞:其中:
hash signatures的输出被平均,从而作为对用户兴趣的低方差的估计。它可以表示为:
1.2.2 Analysis of Attention Patterns
Hash Sampling-Based Attention的期望:在我们的方法中,随着《Similarity estimation techniques from rounding algorithms》):注意:在计算用户兴趣之前,我们对
因此,
SDIM产生的user interest representation的期望为:注意:原始论文的公式有问题,漏掉了
sum归一化而不是l2正则化。随着分组数量
estimation error会非常小。在实践中,我们对在线模型使用Figure2中绘制了SDIM产生的注意力权重target attention产生的注意力权重Figure2中我们可以看出,SDIM的注意力权重与target attention中的softmax函数很好地吻合,因此,从理论上讲,我们的方法可以获得非常接近target attention的输出。我们将提出的方法命名为SDIM,即Sampling-based Deep Interest Modeling。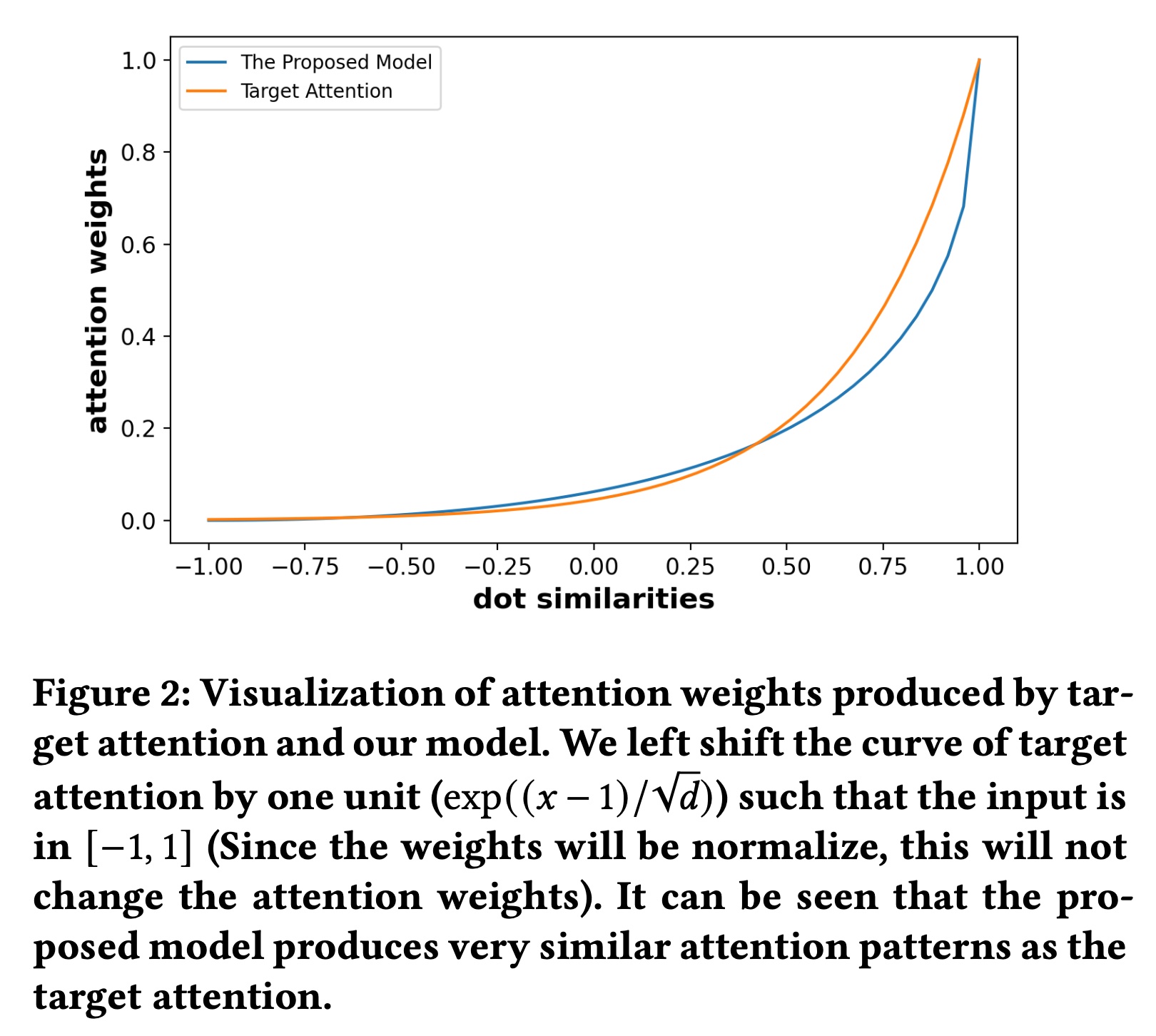
SDIM中的宽度参数items提供更多注意力方面所起的作用。 记target itemitem随着
items。 让我们考虑两种极端情况:当
target item完全相同的items。如果我们使用category属性进行哈希处理,则算法的behavior类似于SIM(hard)。因此,我们的算法可以看作是SIM(hard)的扩展,它也会考虑category ID不同但非常相似的behavior items。当
target item和用user behavior items将始终具有相同的hash signatures。
因此,
SDIM非常灵活,可以通过分配不同的
1.2.3 Implementation and Complexity Analysis
在本小节中,我们将详细说明
SDIM比标准的attention-based的方法快很多倍。让我们回顾一下
target attention中计算用户兴趣的公式,即,target vector与行为序列相乘来获得注意力权重,然后使用注意力权重对行为序列进行加权和。因此,在target attention中获取用户兴趣的representation需要两次矩阵乘法,该算法的时间复杂度为SDIM将用户兴趣的计算分解为两部分:behavior sequence hashing、target vector hashing。注意,用户行为序列是用户的固有特征,与target item无关,这意味着无论target item是什么,用户的behavior sequence hashing的结果都是固定的。因此,对于每个用户,我们只需要在每个request中计算一次用户行为序列的hash transform。因此,SDIM将时间复杂度从1,比标准的target attention快了相当多倍。经过哈希之后,与
target item共享相同hash signature的sequence items被选中,并被相加从而形成用户兴趣。在Tensorflow中,此步骤可以通过tf.batch_gather算子实现,该算子是Tensorflow的原子算子(atomic operator),时间成本可以忽略不计。SDIM最耗时的部分是行为序列的多轮哈希(multi-round hashing),即将Approximating Random Projection)算法降低到SDIM比标准的attention-based方法快得多。在我们的场景中,SDIM在训练user behavior modeling部分时实现了10到20倍的速度提升。
1.2.4 Deployment of the Whole System
本节将介绍如何成功在线部署
SDIM。如前所述,整个算法分为两部分:behavior sequence hashing、target vector hashing。behavior sequence hashing与target item无关,这促使我们构建一个专门的server来维护user-wise behavioral sequence hashes。我们将系统分为两部分:
Behavior Sequence Encoding (BSE) server和CTR Server,如Figure 1所示。BSE Server负责维护user-wise behavior sequence hashes。当收到user behavior的list时,BSE server从多个哈希函数中采样,并为行为序列中的每个item生成hash signatures。然后根据item signatures将它们分配到不同的buckets中,每个buckets对应一个hash signature,如Figure 1所示。hash buckets被传递给CTR Server,从而建模target item-aware的用户兴趣。CTR Server负责预测target items的点击率。当收到target items(batch size = B)时,CTR Server会将每个target item进行哈希得到signatures,并从相应的buckets中收集item representations。用户兴趣特征与其他特征拼接起来,然后被馈入到复杂的CTR模型中,以获得每个target item的预测概率。我们的CTR模型的整体结构如Figure 3所示。该模型以target item特征、上下文特征、短期用户兴趣特征、以及长期用户兴趣特征作为输入,并使用multilayer perceptron来预测target items的点概率。根据论文实验章节的描述,长期用户行为序列包含了短期用户行为序列,二者不是正交的。
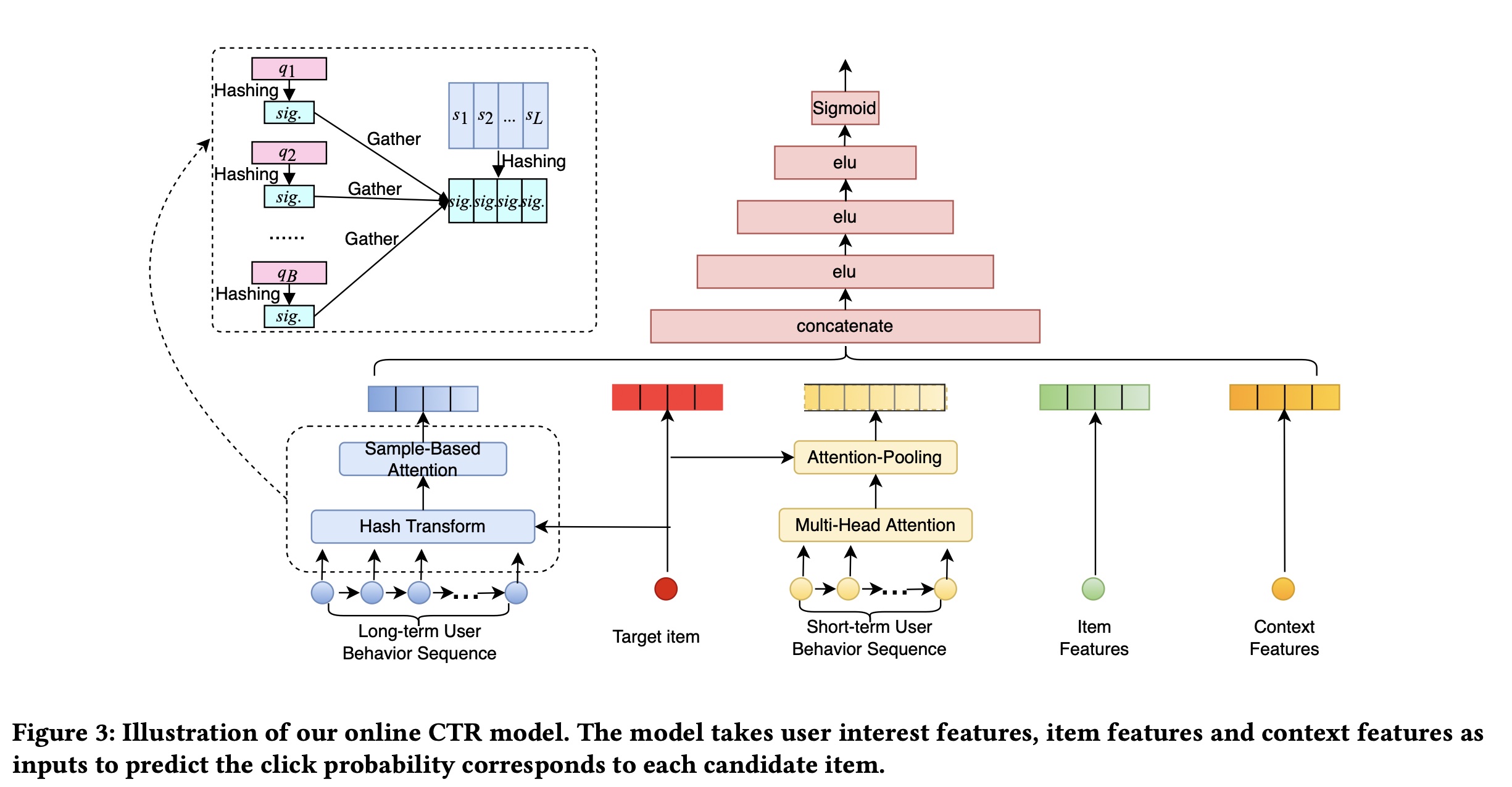
请注意,
SDIM不需要改变CTR模型的结构,它可以自然地插入现有的主流CTR架构中。所提出的框架在训练阶段是端到端的:user interest modeling与CTR模型的其余部分联合训练,我们只在online serving阶段单独部署它们。 将BSE Server和CTR Server解耦后,BSE的计算对于CTR Server来说是无延迟的。在实际应用中,我们将BSE Server放在CTR Server之前,并与retrieval模块并行计算。分开部署后,计算用户长期兴趣的时间成本只在于
target items的哈希,其时间复杂度为behavior的用户兴趣建模。从CTR Server的角度来看,这个时间复杂度就像增加了一个common feature一样。在Table 1中,我们比较了不同方法的时间复杂度。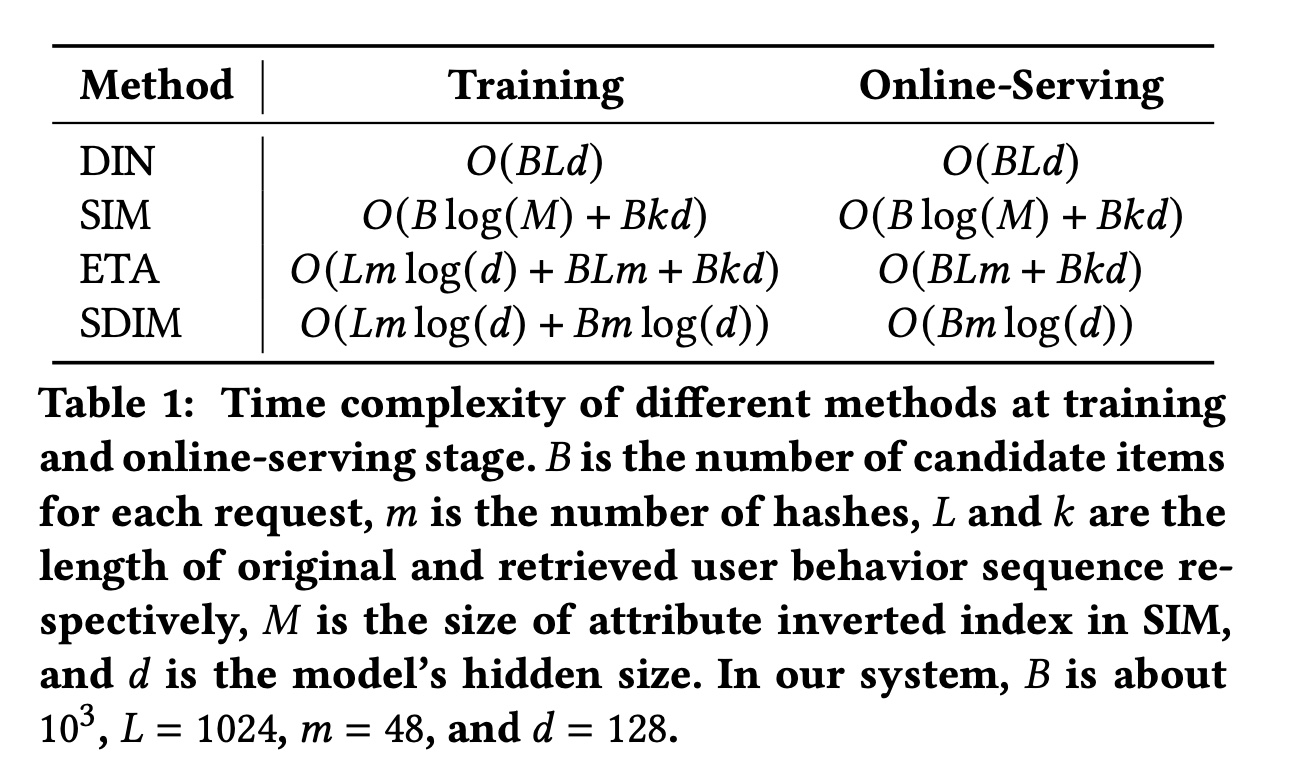
我们的
serving系统与MIMN有些相似。最大的区别在于我们的系统可以建模用户的deep interests,而MIMN只能建模shallow interests。关于
Servers传输成本的注释:对于每个request,我们都需要将bucket representations从BSE Server传输到CTR Server。请注意,我们使用固定数量的哈希函数,因此无论用户的behavior有多长,我们只需要将bucket representations的固定长度的向量传输到CTR Server。在我们的在线系统中,此向量的大小为8KB,传输成本约为1ms。
1.3 实验
为了验证
SDIM的有效性,我们在公共数据集和真实工业数据集上进行了实验。对于公共数据集,我们遵循以前的工作选择Taobao数据集。对于工业数据集,我们使用从美团搜索系统收集的真实数据进行实验。Taobao数据集:淘宝数据集由《Learning Tree-based Deep Model for Recommender Systems》发布,在先前的工作(《Search-based User Interest Modeling with Lifelong Sequential Behavior Data for Click-Through Rate Prediction》、《User Behavior Retrieval for Click-Through Rate Prediction》)中被广泛用于离线实验。此数据集中的每个实例由五个field的特征组成:user ID, item ID, category ID, behavior type, and timestamp。遵循《User Behavior Retrieval for Click-Through Rate Prediction》,我们根据时间戳额外引入了“is_weekend”特征以丰富上下文特征。我们以与
MIMN和ETA相同的方式对数据进行预处理。具体来说,我们使用首次的behavior作为输入来预测第behavior。我们根据timestep将样本分为训练集(80%)、验证集(10%)和测试集(10%)。选择最近的16个behavior作为短期序列,选择最近的256个behavior作为长期序列。工业数据集:该数据集来自中国最大的生活服务电商平台美团
APP的平台搜索系统。我们选取连续14天的样本进行训练,选取接下来两天的样本进行评估和测试,训练样本数量约为10 Billion。选取最近的50个behavior作为短期序列,选取最近的1024个behavior作为长期序列。如果user behavior数量未达到此长度,则使用默认值将序列填充到最大长度。除了user behavior特征外,我们还引入了约20个重要的id特征来丰富输入。
评估指标:对于离线实验,我们遵循以前的工作,采用广泛使用的
AUC进行评估。我们还使用训练和推理速度 (Training & Inference Speed: T&I Speed) 作为补充指标来显示每个模型的效率。对于在线实验,我们使用点击率(Click-Through Rate: CTR) 和访问购买率(Visited-Buy Rate: VBR)作为在线指标。baseline方法:我们将SDIM与以下建模长期用户行为的主流工业模型进行比较:DIN:DIN是工业系统中建模用户兴趣的最流行模型之一。然而,由于DIN的时间复杂度高,它不适合用于建模长期用户行为。在这个baseline中,我们只使用短期用户行为特征,而不使用长期用户行为特征。DIN (Long Seq.):对于离线实验,为了测量长期用户行为序列的信息增益,我们为DIN配备了长行为序列。我们为Taobao数据集设置DIN (Avg-Pooling Long Seq.):该baseline由《End-to-End User Behavior Retrieval in Click-Through Rate Prediction Model》和《Search-based User Interest Modeling with Lifelong Sequential Behavior Data for Click-Through Rate Prediction》引入,其中DIN用于建模短期用户兴趣,而长期用户兴趣则通过对长期behavior进行均值池化操作获得。我们将此baseline表示为DIN(Avg-Pooling)。SIM(《Search-based User Interest Modeling with Lifelong Sequential Behavior Data for Click-Through Rate Prediction》):SIM首先通过category ID从整个序列中检索top-k相似的items,然后将target attention应用于top-k items从而获取用户兴趣。我们遵从以前的工作来比较SIM(hard),因为性能几乎与他们在线部署SIM(hard)相同。UBR4CTR(《User Behavior Retrieval for Click-Through Rate Prediction》):UBR4CTR是一种两阶段方法。在第一阶段,他们设计了一个
feature selection模块来选择特征来形成query,并以倒排索引的方式存储user behavior。在第二阶段,将检索到的
behavior馈入到target attention-based的模块以获取用户兴趣。
ETA(《End-to-End User Behavior Retrieval in Click-Through Rate Prediction Model》):ETA应用LSH将target item和用户行为序列编码为binary codes,然后计算item-wise hamming distance以选择top-k个相似的items用于后续的target attention。MIMN(《Practice on Long Sequential User Behavior Modeling for Click-Through Rate Prediction》) :与SIM是由同一个团队提出的。由于作者声称SIM击败了MIMN并且他们在线部署了SIM,因此我们仅与SIM进行比较,并省略了MIMN的baseline。
对于所有
baseline和SDIM,我们使用相同的特征(包括timeinfo特征)作为输入,并采用相同的模型结构,long-term user behavior modeling除外。所有模型都使用相同长度的长期用户行为:Taobao的
1.3.1 Taobao 数据集的结果
Table 2显示了不同模型在Taobao数据集上的总体结果。我们可以得出以下结论:(1):SDIM在建模长期用户行为方面的表现与DIN(Long Seq.)相当,但速度却是DIN(Long Seq.)的5倍。如上所述,SDIM可以模拟与target attention非常相似的注意力模式,因此SDIM可以匹敌甚至超越DIN(Long Seq.)的性能。(2):SDIM的表现优于所有用于建模长期用户行为的baseline模型。具体而言,SDIM比SIM高1.62%、比UBR4CTR高1.02%、比ETA高1.01%。我们还注意到,与
DIN相比,DIN(Long Seq.)的AUC提高了2.21%,这表明建模长期用户行为对于CTR prediction的重要性。SIM、UBR4CTR和ETA的性能不如DIN(Long Seq.),这是由于retrieval of user behaviors造成的信息丢失。这些retrieval操作可能有助于从序列中去除噪音,但当top-k retrieval没有足够的informative behavior时则是有害的。(3):SDIM比DIN(Long Seq.)、SIM和UBR4CTR的效率高得多。效率的提高可以归因于将算法的时间复杂度降低到SDIM也比ETA效率高得多。ETA也使用LSH对target item和行为序列进行哈希,哈希操作的时间复杂度与SDIM相同。哈希之后,ETA计算汉明距离并选择top-k items从而用于target attention,时间复杂度为SDIM仅引入了一个gather算子,然后是ETA效率高得多。
对于
T&I Speed指标,对比的基线为DIN(Long Seq.),它的速度为1.0。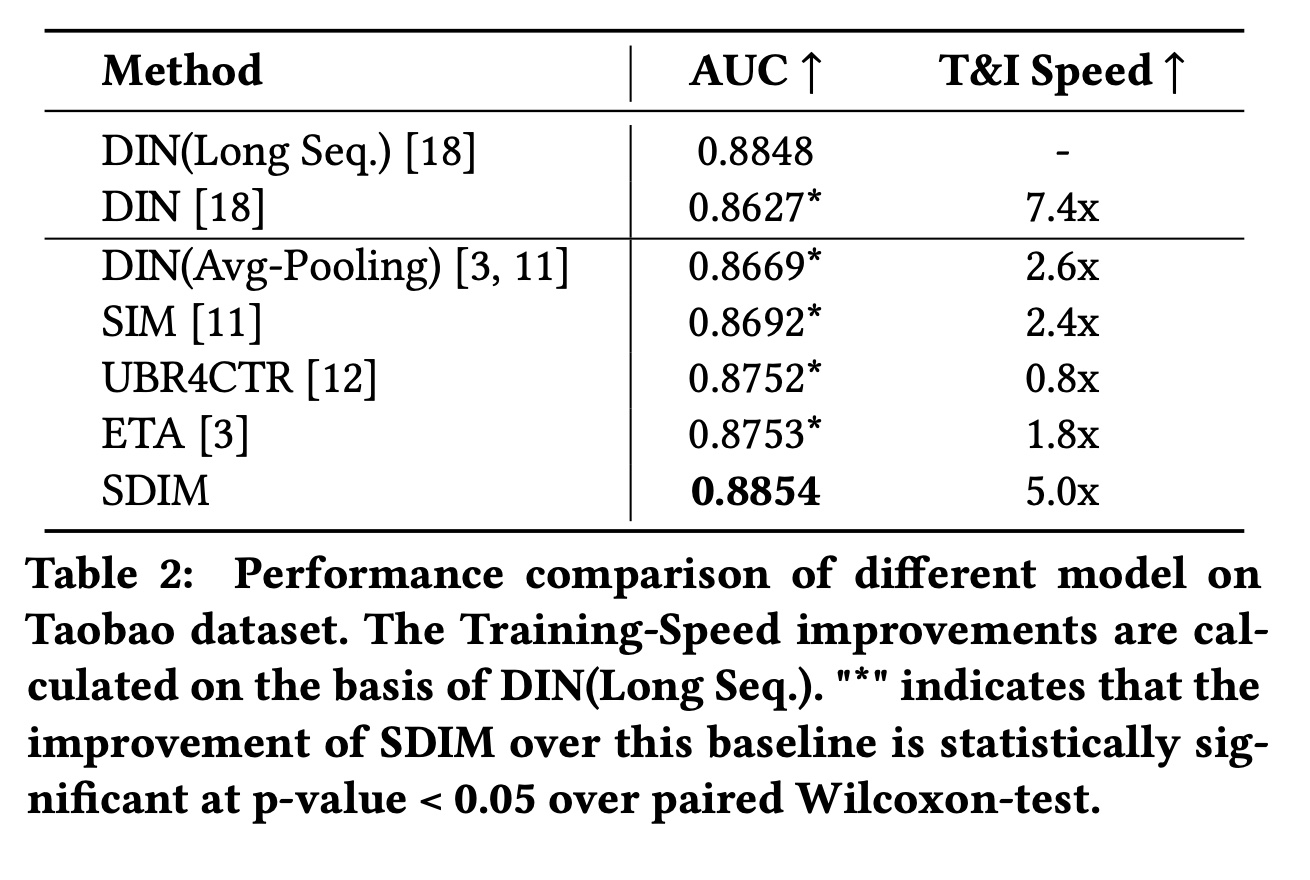
1.3.2 工业数据集的结果
Table 3显示了不同模型在工业数据集上的总体结果。与
Taobao数据集的结果类似,在工业数据集上,SDIM优于所有竞争基线,并且与DIN(Long Seq.)表现相当。我们的SDIM与SIM、UBR4CTR和ETA相比,分别实现了1.92%、2.08%、1.38%的改进,同时比这些方法快得多。由于工业数据集中的用户序列长度足够大,这对
retrieve-based的方法很友好,因此它们似乎应该与DIN(Long Seq.)表现相当。然而,Table 3中的结果表明它们的性能与DIN(Long Seq.)存在一些差距。我们认为这是因为用户的兴趣通常是多样化的,人们经常想购买新categories的item,尤其是在我们的food search案例中。当面对新category中的target item时,这些检索算法很难从用户的历史行为中准确地挑选出最有价值的item。与
Taobao数据集相比,工业数据集每次request包含的target items更多,因此SDIM在该数据集上可以获得更大的加速比。工业数据集的用户行为序列也更长(retrieve-based的方法也可以获得更大的加速比。
实验结果证明了
SDIM的优越性。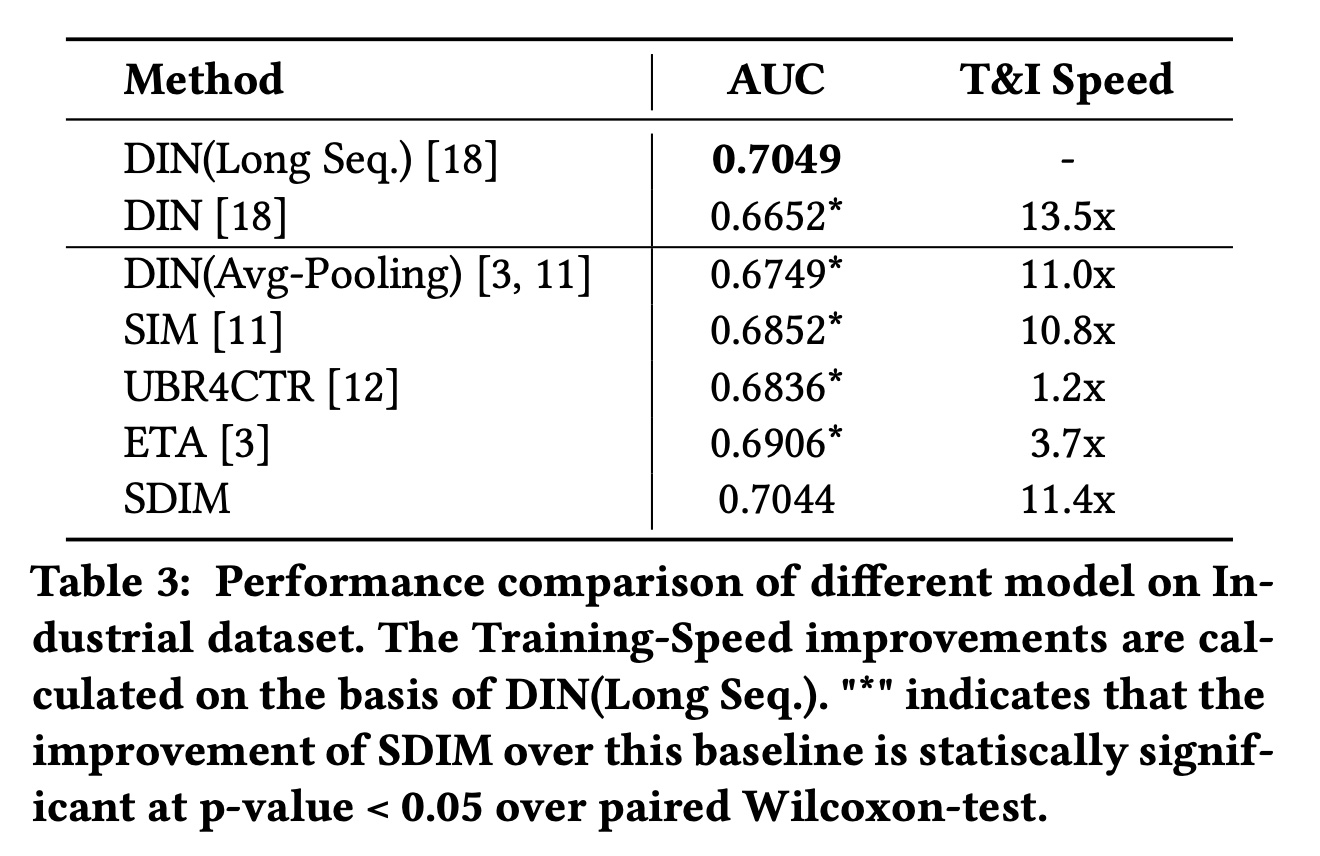
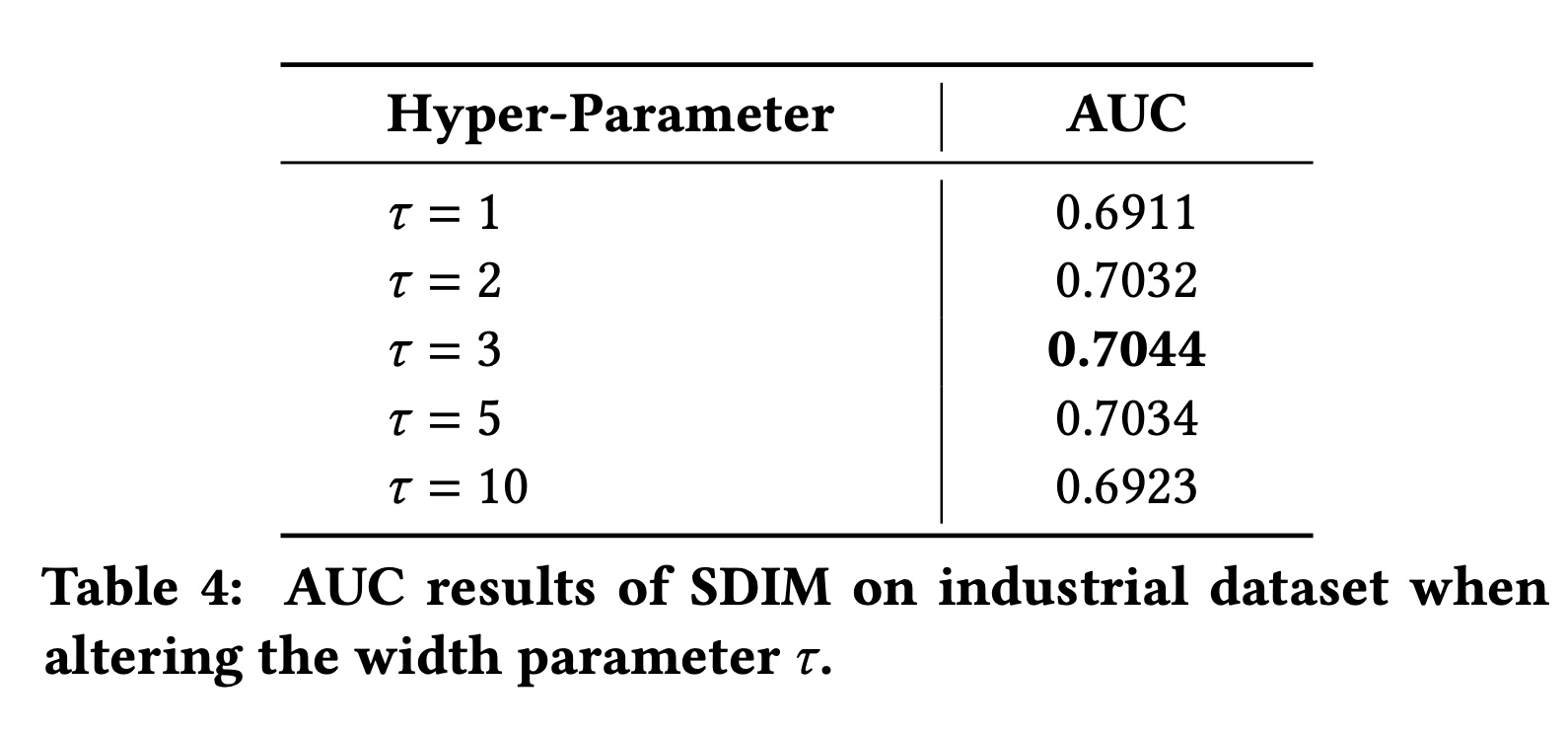
1.3.3 超参数分析
SDIM中有两个重要的超参数:哈希函数的数量hash signatures的宽度对
hashing-based attention的估计误差。随着sampled hash function数量的增加,estimated user interest将更接近公式为了评估
estimation error,我们评估SDIM的性能。我们还实现了SDIM的变体,它直接使用公式中的期望碰撞概率hash signatures数量趋于无限时SDIM的behavior。结果如Figure 4所示。可以看出,当
inference速度。但是这里没有不同trade-off。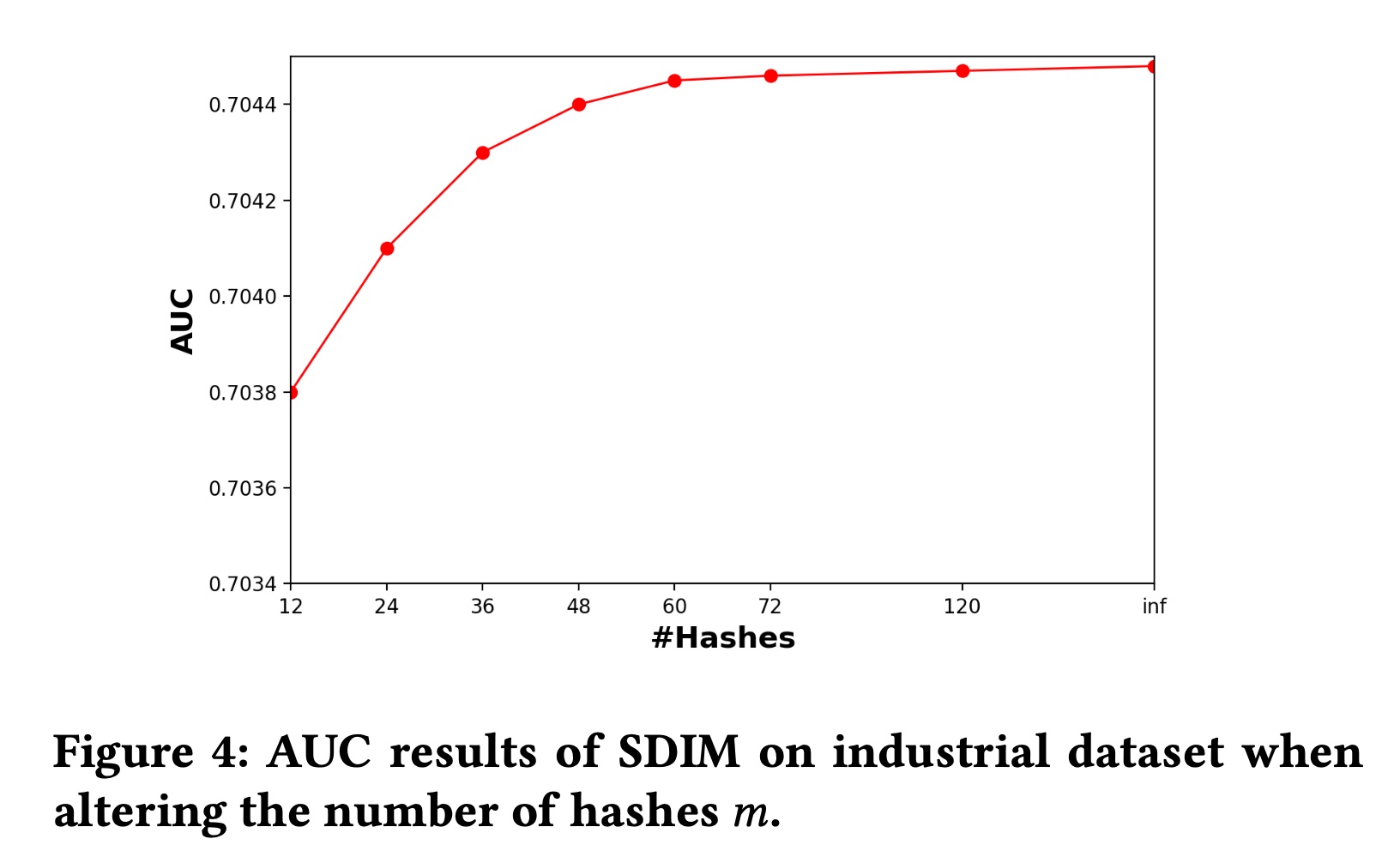
对
items更加关注。我们通过改变SDIM的不同注意力模式。结果如Table 4所示。从
Table 4中我们可以看出:当
SDIM表现良好。为了平衡有效性和效率,我们在在线模型中使用Table 1的算法复杂度分析结果)。当
behavior。相反,当
items才有机会用于用户兴趣,这对行为较少的用户不友好。
1.3.4 短期用户兴趣建模
我们还进行了额外的实验来测试
SDIM在建模短期user behavior方面的表现。但请注意,SDIM主要是为了解决工业推荐系统的长期用户兴趣建模的问题而提出的,人们可以直接插入full target attention或更复杂的模块来建模短序列。我们进行这个实验只是为了展示模型在特殊情况下的表现。我们在
Taobao数据集上进行了这个实验,结果如Table 5所示。结果表明,SDIM在建模短序列方面仍然可以达到与标准的target attention模型相当的结果,同时效率更高。是否可以把所有的
target attention(长期的、短期的)都换成SDIM?进一步地,是否可以把用户行为序列分成不同的区间,在每个区间都应用SDIM?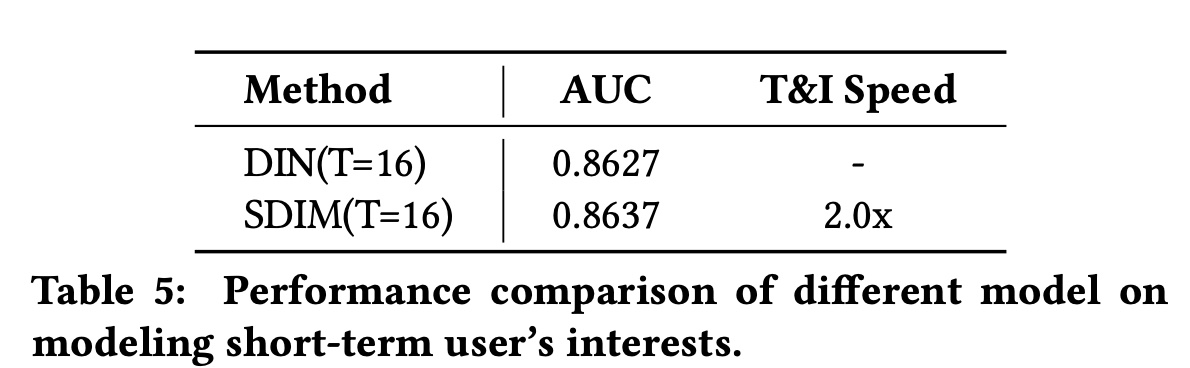
1.3.5 Online A/B Test
为验证
SDIM的有效性,我们还进行了严格的online A/B testing。对于online A/B testing,baseline模型是美团搜索系统中之前的在线CTR模型,该模型仅使用短期用户行为序列。测试模型采用与base模型相同的结构和特征,但在此基础上加入了long-term user interests modeling模块,该模块包含用户最近1024或2000次behavior。我们使用所提出的SDIM来建模长期用户兴趣,并将该测试模型表示为SDIM (T = 1024)和SDIM (T = 2000)。测试持续14天,每个模型分别分配10%的美团搜索流量。A/B testing结果如Table 6所示。SDIM (T=2000)与base模型相比,CTR提升2.98%(p-value < 0.001),VBR提升2.69%(p-value < 0.005),考虑到美团APP的流量巨大,这可以大大提高线上利润。SDIM (T=2000)的推理时间与Base(w/o long seq.)相比增加了1ms。推理时间的增加主要是由于BSE Server和CTR Server之间的传输时间。
我们还尝试部署模型,该模型直接使用
target attention来建模T = 1024的长期用户行为序列。然而,它的推理时间大大增加了约50%(25ms-30ms),这对于我们的系统来说是不可接受的。因此我们不能让这个模型在线上进行14天的A/B testing。SDIM的性能与这个模型相当,但节省了95%的在线推理时间。SDIM目前已在线部署并服务于美团首页搜索系统的主要流量。