一、FINAL [2023]
《FINAL: Factorized Interaction Layer for CTR Prediction》
普通的
multi-layer perceptron: MLP网络在学习multiplicative feature interactions方面效率低下,因此feature interaction learning成为CTR预测的重要主题。现有的feature interaction网络可以有效地补充MLP的学习,但单独使用时,它们的性能往往不如MLP。因此,将它们与MLP网络集成对于提高性能是必要的。这种情况促使我们探索一种更好的MLP backbone替代方案,以取代MLP。 受factorization machines的启发,在本文中,我们提出了FINAL,这是一种factorized interaction layer,它扩展了广泛使用的线性层,并且能够学习二阶feature interactions。与MLP类似,多个FINAL layers可以堆叠成一个FINAL block,从而产生具有指数级增长的feature interactions。我们将feature interactions和MLP统一到单个FINAL block中,并通过经验证明其作为MLP block替代品的有效性。此外,我们探索了两个FINAL blocks的ensemble作为增强型双流CTR模型(enhanced two-stream CTR model),在开放benchmark数据集上创造了新的SOTA。FINAL可以轻松用作building block,并且已在华为的多个应用程序中实现了业务指标增益。我们的源代码将在MindSpore/models和FuxiCTR/model_zoo上提供。CTR预测任务通常被表述为二分类问题,其中包含丰富但异构的特征,例如user profiles, item attributes, and session contexts。因此,feature interaction learning成为CTR预测的重要研究课题。现有方法通常遵循两个方向来建模feature interactions。第一个是使用
multi-layer perceptrons: MLP隐式地学习特征之间的隐藏关系。虽然已经证明MLP理论上可以近似任何有界的连续函数,但在实践中,在给定有限网络大小的情况下,它们在建模combinatorial feature interactions方面很弱 。第二种方法是使用特征之间的
multiplicative operations来显式地建模它们的交互。例如,DCN,FM,xDeepFM,这些方法中的feature combination degree通常与堆叠层数成线性比例,因此需要相当深的架构才能全面覆盖有用的特征组合。然而,由于许多广泛记载的问题,例如gradient explosion/vanishmen(《Which neural net architectures give rise to exploding and vanishing gradients?》)和rank collapse(《Attention is not all you need: Pure attention loses rank doubly exponentially with depth》、《Rank diminishing in deep neural network》),很难优化非常深的模型。
因此,现有方法很难有效地建模高阶
feature interactions。在本文中,我们提出了一个
Factorized Interaction Layer: FINAL来显式地学习multiplicative feature interactions,它可以实现非常高的combination orders而无需繁琐的层堆叠(Figure 1)。受fast exponentiation算法的启发,FINAL采用hierarchical的方式以指数级速度提高feature interaction阶次。在每个hierarchy中,input representations与一系列连续的non-linear layers的representations output相乘,从而逐步增加feature interaction阶次。通过用多个hierarchies处理feature representations,feature interactions的阶次进一步呈指数级增加。基于提出的FINAL模块,我们设计了一个统一的框架,该框架结合了多个FINAL blocks从而在不同视图中学习feature interactions,并且我们通过使用它们的预测作为common teachers来交换它们所编码的互补知识来进行自蒸馏(self-distillation)。我们在四个公共数据集上进行了广泛的实验,结果验证了FINAL的优越性。它还在我们企业举办的多个商业场景的在线实验中取得了显著的成功。FINAL为编写CTR预测模型提供了一种全新而简单的选项,有望为各种推荐场景提供支持。论文创新性一般。
DCN V3也是类似的思路:Exponential Cross Network、以及self-distillation。但是DCN V3采用的是1, 2, 4, 8, 16,...这样的指数,而这里用的1, 3, 9, 27, ...这样的指数。另外,这里的FINAL Block仅仅得到最高指数,而没有使用残差连接,因此往往需要多个不同层的FINAL Block并行拼接。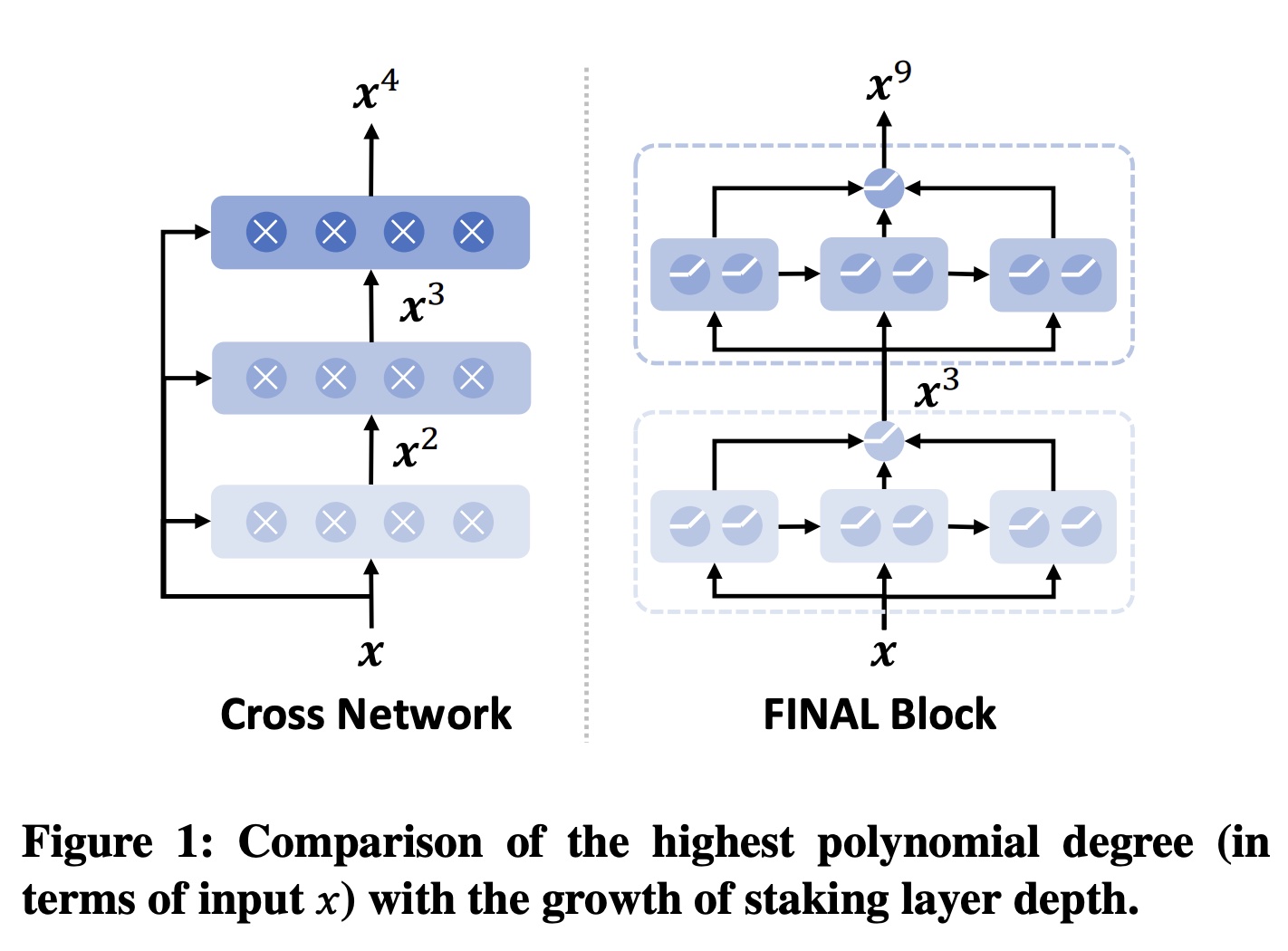
1.1 模型
FINAL总体框架如Figure 2所示。它主要由多个并行的FINAL blocks组成,旨在建模不同的feature interaction模式。每个FINAL block包含几个factorized interaction layers,其中feature interactions的最大阶次随模型深度呈指数级增长。来自不同blocks的预测分数被组合成一个统一的预测分数作为final prediction,它也充当virtual teacher从而self-teach这些blocks以交换和fuse它们的隐藏知识。通过这种方式,可以有效、全面地捕捉复杂的feature interactions。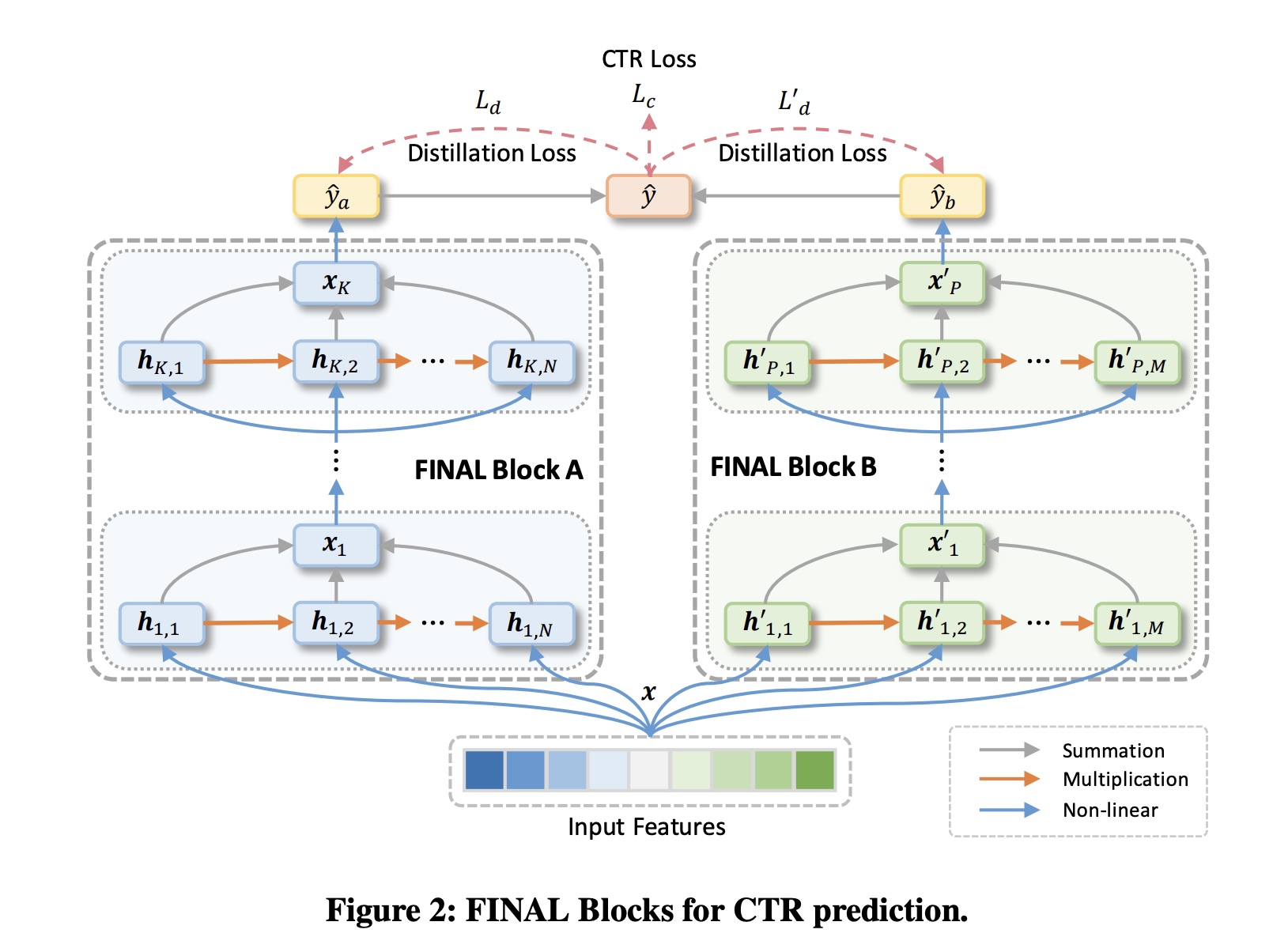
FINAL Block:我们方法的基本单元是FINAL block。它接收一个flattened feature vectorfield,例如one-hot features, embedded categorical features, and numerical features。由于工业场景中精心设计的特征的多样性、复杂性和异质性,特征之间的交互通常可能是很复杂的且隐式的。因此,建模高阶交互对于有效利用特征至关重要。在实践中,如何以最小的model depths实现足够高的交互阶次,对性能和效率都很重要。受
fast exponentiation算法思想的启发,我们设计了一种hierarchical的feature interaction机制来实现指数级的阶次增长。在每个hierarchy中,使用factorized interaction layer通过几个multiplicative operations来提高feature interaction阶次。令factorized interaction layer的输入。它使用以下公式进行转换:其中:
layer output。operation的权重参数和偏置向量,multiplicative interaction的数量。
直观地讲,
feature interaction阶次与multiplicative operations的数量成正比。通过聚合每个step中的中间结果,每个层的输出可以包含multi-granularity的feature interactions。在FINAL block中,我们堆叠多个factorized interaction layers,以便每个层的initial feature interaction degree都成指数级放大。这样,multiplicative operations的FINAL block的最高多项式阶次(就Cross-block Knowledge Transfer:在我们的方法中,我们倾向于使用多个FINAL blocks来从不同视图来学习feature interactions。我们首先使用不同的线性投影层(
linear projection layers)将hidden representations转换为output logits。这些
logits按均值聚合为统一的logit,然后通过sigmoid函数进一步对其进行归一化以进行模型训练(记作
我们使用二元交叉熵损失来计算
CTR prediction loss,如下所示:其中:
label和预测分数,为了促进不同
FINAL block之间的knowledge sharing,我们执行self-knowledge distillation,以赋予它们inter-block knowledge。具体来说,我们使用聚合后的分数block从这个synthesized prediction中学习。以dual-block网络为例(Figure 2),我们用block的normalized prediction scores。它们对应的知识蒸馏损失(knowledge distillation losses)如下:其中:
block-specific predictions。为什么不用
ground-truthteacher?我们使用
task loss和knowledge transfer regularizations来优化模型,模型训练的整体损失函数为:这样,每个
block都知道任务监督信号和cross-block知识,因此可以更好地应对复杂的feature interactions。knowledge transfer regularizations本质上是迫使每个子网的输出都接近模型的整体输出。讨论:最后,我们简要讨论了模型复杂度和兼容性。假设
parallel blocks的数量和隐层维度是常数,那么我们框架的理论复杂度为feature interaction阶次,普通的layer-stacking方法所需的计算复杂度通常为feature interactions时可能具有显著的效率优势。此外,FINAL block是一个即插即用的模块,可以直接插入到现有架构、或替换现有架构的MLP-based的feature interaction模块。因此,FINAL与各种CTR预测方法兼容,并且可以轻松地为它们提供支持。
1.2 实验
数据集:
Criteo, Avazu, MovieLens, and Frappe。为了公平比较,我们重用了
《Adaptive factorization network: Learning adaptive-order feature interactions》发布的预处理数据集,并遵循相同的splitting和预处理程序。评估指标:
AUC。baselines:我们将其与四类现有模型进行比较,按feature interactions阶次分类:一阶(仅使用单个特征):
Logistic Regression: LR。二阶(建模
pair-wise feature interactions):Factorized Machine (FM) and AFM。三阶(建模
triple-wise feature interactions):CrossNet(两层)、CrossNetV2(两层)和CIN(两层)。高阶:
DCN、DCNV2、DeepFM、AutoInt、xDeepFM和SAM。
实现细节:我们基于开源
CTR prediction library,即FuxiCTR, 实现了所有研究的模型。为了进行公平比较,我们遵循《Adaptive factorization network: Learning adaptive-order feature interactions》中的相同实验设置。所有
baseline均使用Adam optimizer进行训练,其中学习率为0.001,batch size为4096,embedding维度为10,MLP隐单元的数量为[400, 400, 400]。我们采用两个
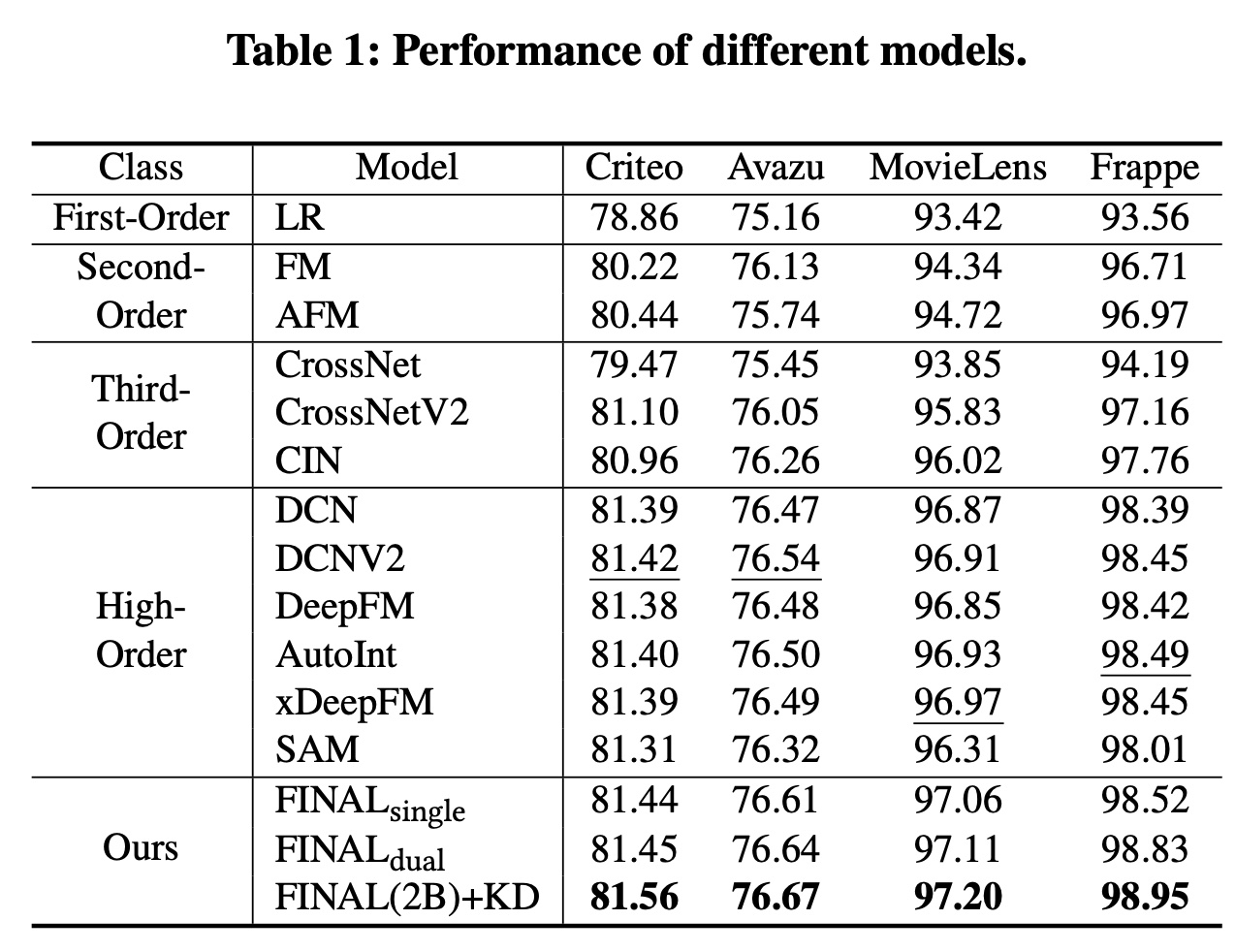
FINAL blocks和两个factorized interaction layers(Table 1展示了在四个数据集上的评估结果,从中我们得到以下发现:首先,
LR在所有数据集上的表现最差,这表明feature interaction modeling在CTR预测中的必要性。其次,能够建模高阶
feature interactions的方法往往会获得更好的性能,这是直观的,因为可以考虑更复杂的feature relatedness。由于FINAL在建模高阶feature interactions方面特别强大,因此它在所有数据集上都获得了最佳性能,并且其优势非常显著(t-test中FINAL在捕获复杂特征关系方面的有效性。第三,
dual-block FINAL model略优于single-block模型。这可能是因为使用多个blocks有助于学习具有不同结构和初始化参数的diverse feature interaction信息。第四,
self-knowledge distillation可以进一步提高multi-block FINAL model的性能。这进一步表明了不同blocks中编码的知识具有互补性,使用知识蒸馏(knowledge distillation)将它们融合可以更好地指导FINAL block learning。
我们的
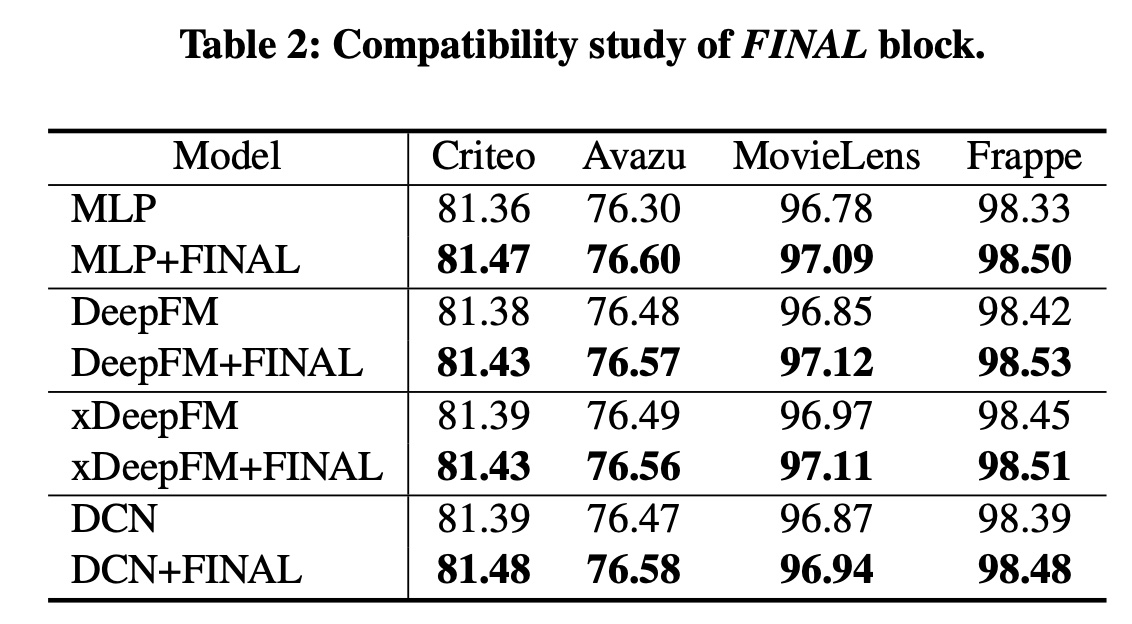
FINAL block是一个即插即用模块,可以提升各种deep CTR模型的性能。为了证明FINAL block的兼容性,我们将其作为MLP block的替代品引入了四种流行的deep CTR模型(即MLP, DeepFM, xDeepFM, and DCN),结果如Table 2所示。我们观察到
FINAL block一致地改进了流行的deep CTR模型。这验证了FINAL确实捕获了这些模型忽略的有用线索。由于FINAL独立于backbone架构,因此它是一个灵活的组件,可用于为实际系统中的各种CTR预测模型提供支持。这本质上是模型的集成,因此效果比原始模型更好是可以预期的。
在线评估:由于其显著的性能提升和低延迟,我们在企业的多个商业场景中部署了
FINAL。在本节中,我们选取两个代表性场景来展示其优越性。News Feed推荐:我们在商业新闻推荐场景中进行在线评估,其中数百万日活用户消费数字新闻文章。在线A/B test持续一个月,从2022年9月25日到10月25日。对于online serving,我们将整个流量的5%作为实验组,其中包括超过300k活跃用户。 我们将我们的方法与精心设计的baseline模型进行了比较。Figure 3总结了连续30天的在线结果。我们的模型在评估期间显示出一致性的在线点击率改进,平均点击率提高了3.17%。additional online inference latency增加了22.22%,这在我们的系统中是可以接受的。实验结果证明了FINAL在feed recommendation中的有效性。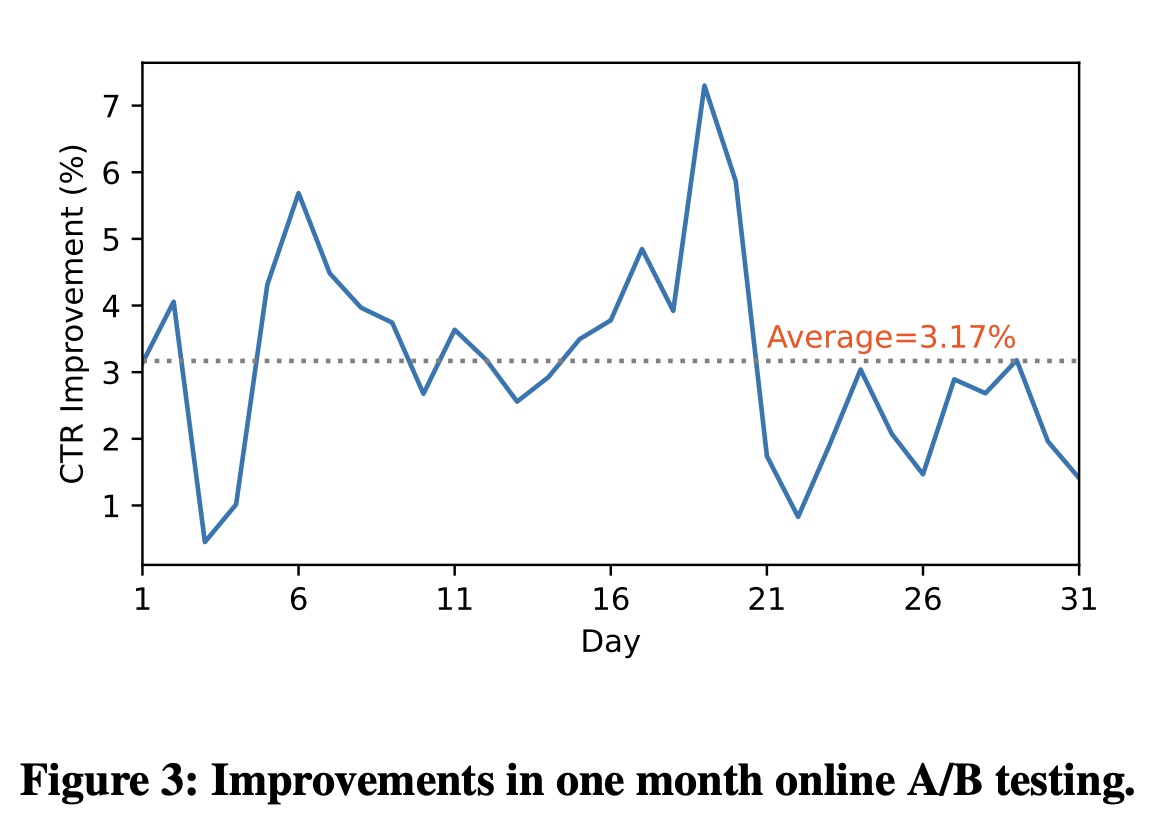
Online advertisement display:在线广告需要同时预测点击率和Post-click conversion rate: CVR。在我们的广告展示场景中,转化对应于安装应用程序、提交注册信息、用户留存(user retention)等事件。多任务学习(
multi-task learning: MTL)是联合CTR and CVR estimation的常用解决方案。一般来说,MTL采用具有shared-bottom结构的模型,其中bottom embedding layers的参数在任务之间共享。然后,应用MLP模块从shared bottom来学习feature interactions并对特定任务进行预测。我们使用FINAL block替此MTL框架中的MLP进行比较。对于online serving,我们随机选择5%的用户作为实验组,通过FINAL-enhanced model提供广告推荐。对照组为另外5%的用户,采用baseline MTL model。连续7天的在线A/B test结果显示,整体CVR增益为5.52%。结果验证了FINAL对于在线广告的有效性。