一、DCN V3 [2024]
《DCNv3: Towards Next Generation Deep Cross Network for Click-Through Rate Prediction》
Deep & Cross Network及其衍生模型面临四个主要限制:现有的显式
feature interaction方法的性能通常弱于隐式的deep neural network: DNN,从而削弱了它们的必要性。许多模型在增加
feature interactions的阶数时无法自适应地过滤噪声。大多数模型的
fusion方法无法为其不同子网络提供合适的监督信号。虽然大多数模型声称可以捕获高阶
feature interactions,但它们通常通过DNN以隐式的和不可解释的方式进行,这限制了模型预测的可信度。
为了解决已发现的局限性,本文提出了下一代深度交叉网络:
Deep Cross Network v3: DCNv3,以及它的两个子网络:Linear Cross Network: LCN和Exponential Cross Network: ECN用于CTR预测。DCNv3在feature interaction modeling中可解释性的同时,线性地和指数地增加feature interaction的阶数,实现真正的Deep Crossing,而不仅仅是Deep & Cross。此外,我们采用Self-Mask操作来过滤噪声,并将Cross Network中的参数数量减少一半。在fusion layer,我们使用一种简单但有效的multi-loss trade-off and calculation方法Tri-BCE,来提供适当的监督信号。在六个数据集上的全面实验证明了DCNv3的有效性、效率和可解释性。大多数
interaction-based的CTR预测模型都遵循DCN提出的范式,该范式旨在构建显式的和隐式的feature interactions,并融合不同interaction information的predictions以增强可解释性和准确性。尽管当前的CTR范式非常有效,但仍存在一些需要克服的局限性:explicit interactions的必要性有限:如Figure 1所示,大多数仅使用显式feature interactions的模型(例如CIN)的AUC性能低于81.3,而deep neural network: DNN的AUC性能更好,为81.4。这表明大多数explicit modeling方法的性能弱于implicit DNN,这无疑削弱了集成显式feature interactions的必要性。然而,一些工作也强调了DNN在捕获multiplicative feature interactions方面的局限性。因此,有必要探索一种更有效的方法用于显式feature interactions。噪声过滤能力低下:许多研究指出
CTR模型包含大量冗余feature interactions和噪声,尤其是在高阶feature interactions中。因此,大多数CTR模型仅使用两到三个网络层来构建,放弃了对有效高阶feature interaction信息的explicit capture。同时,为模型过滤噪声通常会产生额外的计算成本,从而导致更长的训练时间和推理时间,可能会抵消提高模型准确率所带来的好处。监督信号不足且没有区分性:大多数同时使用显式和隐式
feature interaction方法的模型都需要一个fusion layer来获得最终预测。然而,它们只使用final prediction来计算损失,而不是为不同方法本身提供适当的监督信号。这削弱了监督信号的有效性。此外,一些研究,例如Figure 1中的CL4CTR,试图引入辅助损失来提供额外的监督信号。然而,这通常会引入额外的计算成本和loss trade-off超参数,增加了超参数调优的难度。因此,一种简单、高效、有效的计算监督信号的方法至关重要。缺乏可解释性:如
Figure 1所示,大多数模型集成DNN来建模隐式高阶feature interactions,并实现81.3到81.5之间的AUC性能。这证明了隐式feature interactions的有效性。然而,隐式feature interactions缺乏可解释性,这降低了CTR模型预测的可信度。
为了解决这些局限性,本文提出了下一代
deep cross network:Deep Cross Network v3: DCNv3,以及它的两个子网络:Linear Cross Network: LCN和Exponential Cross Network: ECN。DCNv3集成了低阶的和高阶的feature interactions,同时通过避免使用DNN进行隐式高阶feature interaction modeling来确保模型的可解释性。具体而言,我们引入了一种新的指数增长的Deep Crossing方法来显式地建模高阶feature interactions,并将以前的交叉方法归类为Shallow Crossing。同时,我们设计了一个Self-Mask操作来过滤噪声并将Cross Network中的参数数量减少一半。在fusion layer,我们提出了一种简单而有效的multi-loss计算方法,称为Tri-BCE,为不同的子网络提供合适的监督信号。本文贡献:
据我们所知,这是第一篇仅使用显式
feature interaction modeling而不集成DNN就实现令人惊讶的性能的作品,这可能与过去CTR prediction文献中的流行范式形成鲜明对比。因此,这项工作可能会激发对feature interaction modeling的进一步回顾和创新。我们引入了一种新颖的
feature interaction modeling方法,称为Deep Crossing,它随着层数的增加而呈指数增长,从而实现真正的deep cross network。该方法显式地捕获feature interaction信息,同时使用Self-Mask操作将参数数量减少一半并过滤噪声。我们提出了一种新颖的
CTR模型,称为DCNv3,它通过两个子网络LCN和ECN显式地捕获低阶和高阶feature interactions。此外,我们引入了一种简单而有效的multi-loss trade-off and calculation方法,称为Tri-BCE,以确保不同的子网络接收适当的监督信号。在六个数据集上进行的全面实验证明了
DCNv3的有效性、效率和可解释性。根据我们的实验结果,我们的模型在多个CTR预测benchmarks上取得了第一名的排名。
论文核心思想还可以,就是效果可能没有达到预期,导致作者搞了一些
tricky的操作(比如所谓的self-mask)来提升性能,导致实验的对比结果不太可信。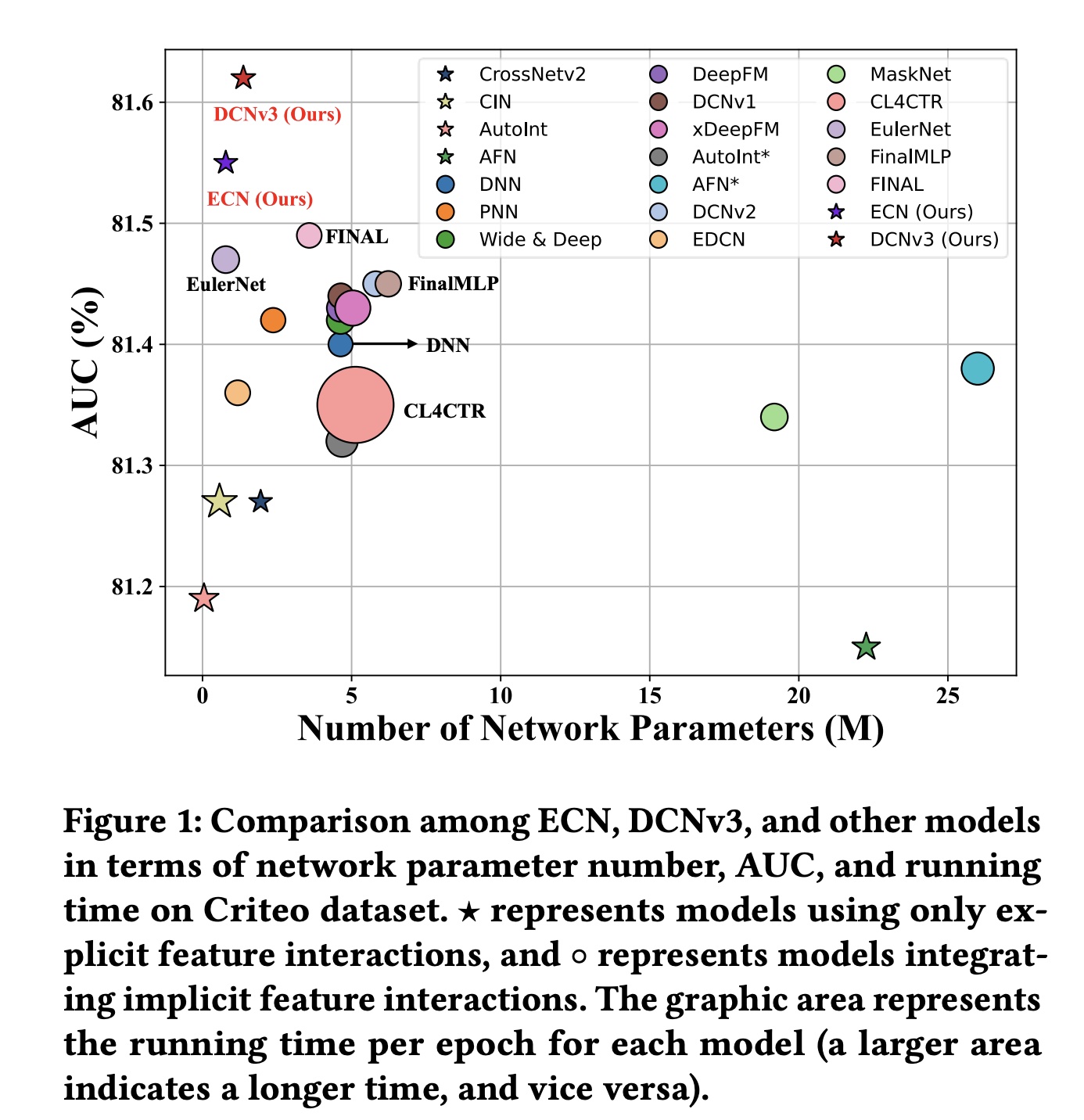
Feature Interaction:隐式
feature interaction旨在使用DNN自动学习复杂的non-manually defined的数据模式和高阶feature interactions。它效率高,表现良好,但缺乏可解释性。显式
feature interaction旨在通过预定义的函数直接建模输入特征之间的组合和关系,从而提高模型的可解释性。
线性增加显式
feature interaction的一种流行方法是Hadamard Product将特征feature interaction的方法是所谓 “更有效地生成高阶特征” 指的是用更少的层数获得更高阶的特征。
1.1 模型
模型架构如下图所示。
ECN和LCN的主要区别在与左侧的输入。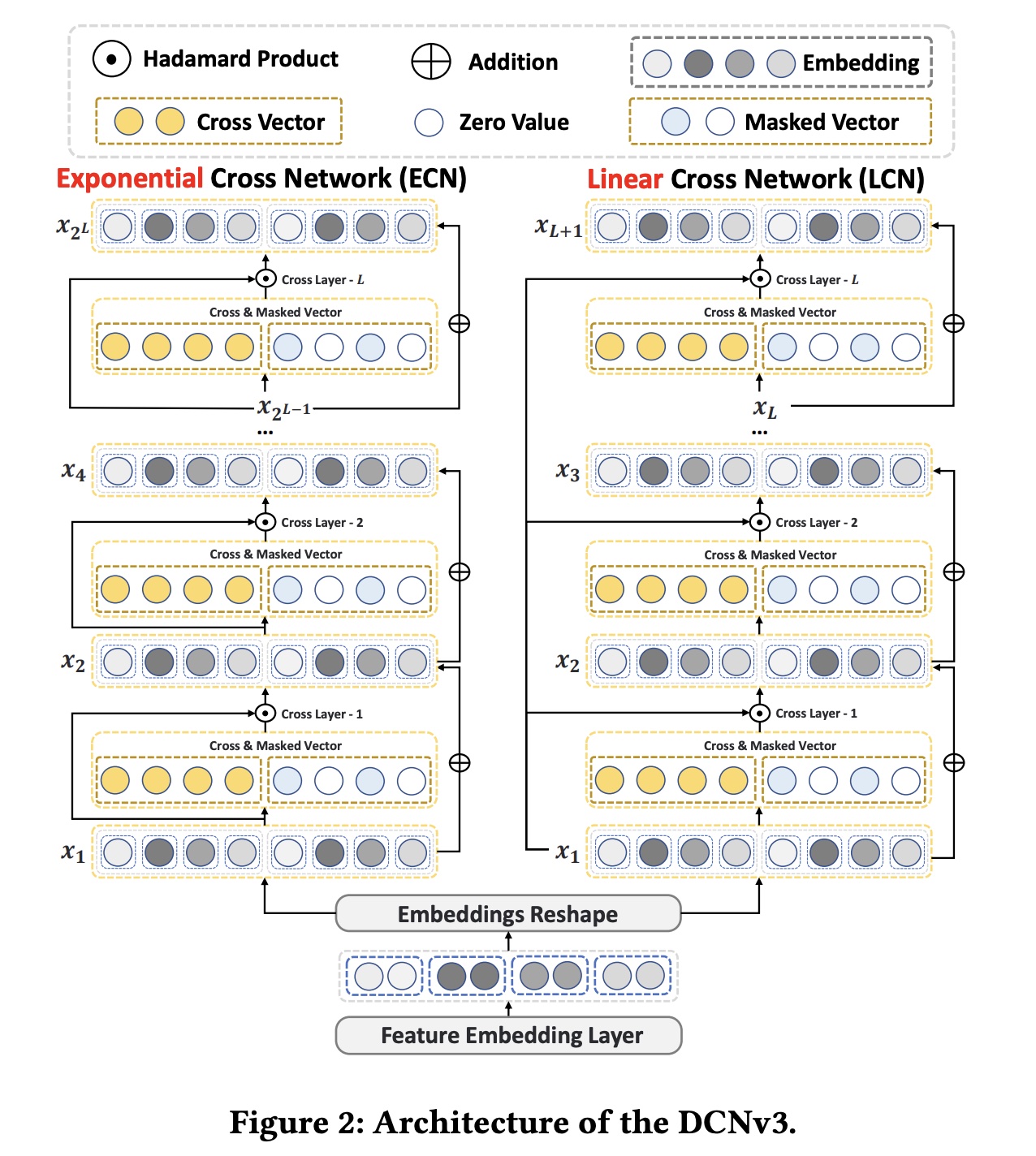
1.1.1 Embedding & Reshape Layer
CTR prediction任务的输入multi-field categorical data,使用one-hot encoding来表示。大多数CTR预测模型利用embedding layer将它们转换为低维稠密向量:
其中:embedding matrix ,embeddin 维度,field 的vocabulary size 。
在我们的模型中,为了使网络能够从
multi-views中获得更丰富的信息,我们使用分块操作来reshape the embeddings,将它们分成两个不同的视图:其中:
original view,another view。进一步,我们可以得到
reshaping后的resulting embedding:其中:
fields数量,embedding维度,LCN和ECN的输入。chunk()函数是什么?作者讲的不明不白。读者猜测是:将每个field的embedding向量一分为二;左半边拼接起来,构成original view;右半边拼接起来,构成anoher view。这么做的目的是为了下游的
Self-Mask操作而准备的。但是,为什么不用FFM来做投影呢?
1.1.2 Deep Cross Network v3
LCN:用于具有线性增长的低阶(浅)的explicit feature interaction。其递归公式如下:其中:
original view)的Cross Vector。feature interaction。Mask表示Self-Mask(在another view),稍后将详细介绍。为什么将
Mask拼接上来而不是与
由于线性增长的
feature interaction方法难以在有限的层数内捕获高阶交互,因此我们引入ECN来实现真正的、高效的deep cross network。ECN:作为DCNv3的核心结构,用于指数级增长的高阶(深度)explicit feature interaction。其递归公式为:其中:
feature interaction。从
Figure 3可以看出,原始的Cross Network v2本质上是一种shallow crossing方法,通过层的堆叠实现feature interactions阶次的线性增长。实验表明,DCNv2中交叉层的最佳数量为2或3,其大部分性能来自负责隐式交互的DNN。相比之下,ECN将feature interactions阶次的指数级增长,从而在有限的层数内实现特征的Deep Crossing,显式地捕获高阶feature interactions。
Self-Mask:Figure 3可视化了不同crossing方法的计算过程。Cross Vectorbit-level建模特征之间的交互,而权重矩阵feature fields的固有重要性。然而,正如一些论文指出的那样,并非所有feature interactions都对CTR任务中的最终预测有益。因此,我们在another view中引入了Self-Mask操作来过滤掉feature interactions中的噪声信息(对应于original view的交互信息的完整性(对应于Self-Mask操作如下:其中
LN表示LayerNorm:增益向量
这里也可以使用其他
mask机制,例如基于伯努利分布的random Mask、基于Top-K选择的learnable Mask等。为了确保我们提出的模型简单而有效,我们使用LayerNorm对50%的零值,以滤掉噪声并提高计算效率。Fusion:大多数先前的CTR模型试图建模显式和隐式feature interactions,这本质上意味着同时捕获低阶和高阶feature interactions。我们的DCNv3通过整合LCN和ECN来实现这一点,避免使用可解释性较差的DNN:其中:
Mean表示均值运算,last number。ECN、LCN和DCNv3的预测结果。
1.1.3 Tri-BCE Los
Tri-BCE loss calculation and trade-off方法如Figure 4所示。我们使用广泛采用的二元交叉熵损失(即Logloss)作为DCNv3的primary and auxiliary loss:其中:
ground-truth,batch size。primary loss,ECN和LCN预测结果的auxiliary losses。
为了给每个子网络提供合适的监督信号,我们为它们分配了自适应权重:
并联合训练它们以实现
Tri-BCE loss:注意,
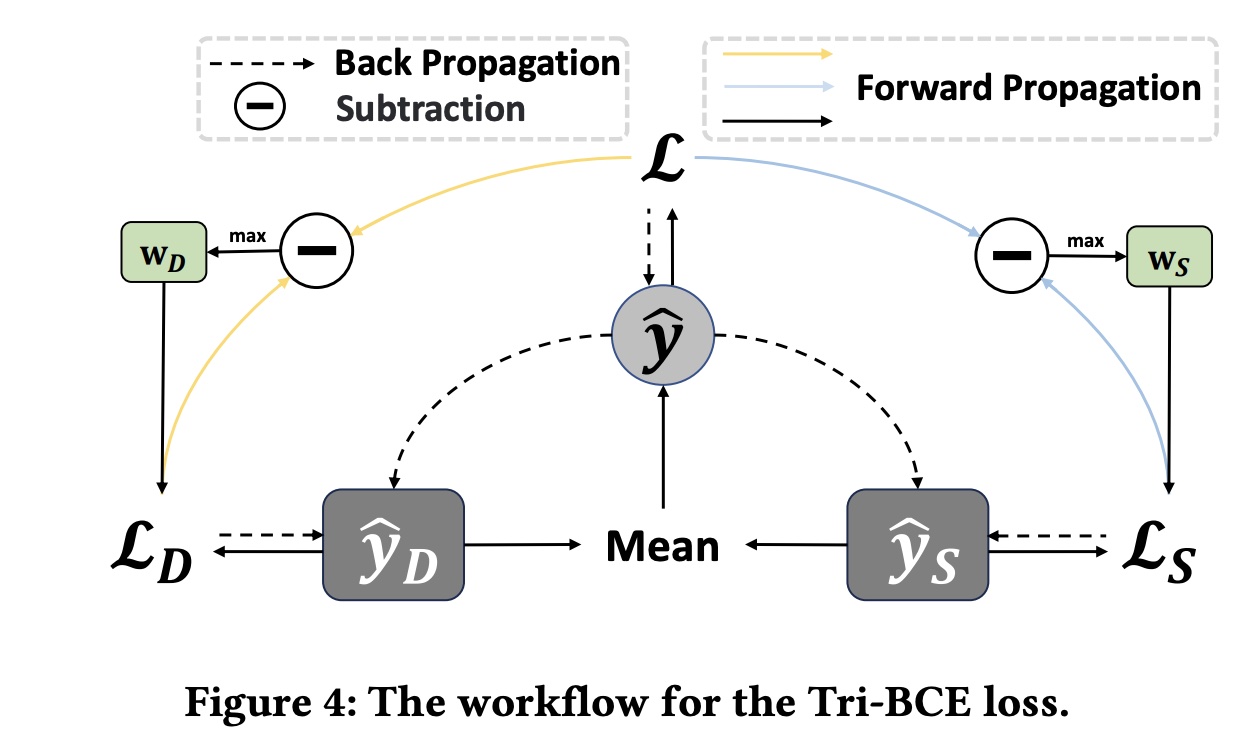
如
《TF4CTR:Twin Focus Framework for CTR Prediction via Adaptive Sample Differentiation》所示,向子网络提供单一监督信号通常不是最优的。我们提出的Tri-BCE loss通过提供自适应权重(该权重在整个学习过程中变化)来帮助子网络学习更好的参数。理论上,我们可以推导出由其中:
类似地,
可以观察到,对于
Tri-BCE loss还提供了基于ground-truth labelprimary and auxiliary loss之间的差异自适应地调整其权重。因此,Tri-BCE loss为子网络提供了更合适的监督信号。
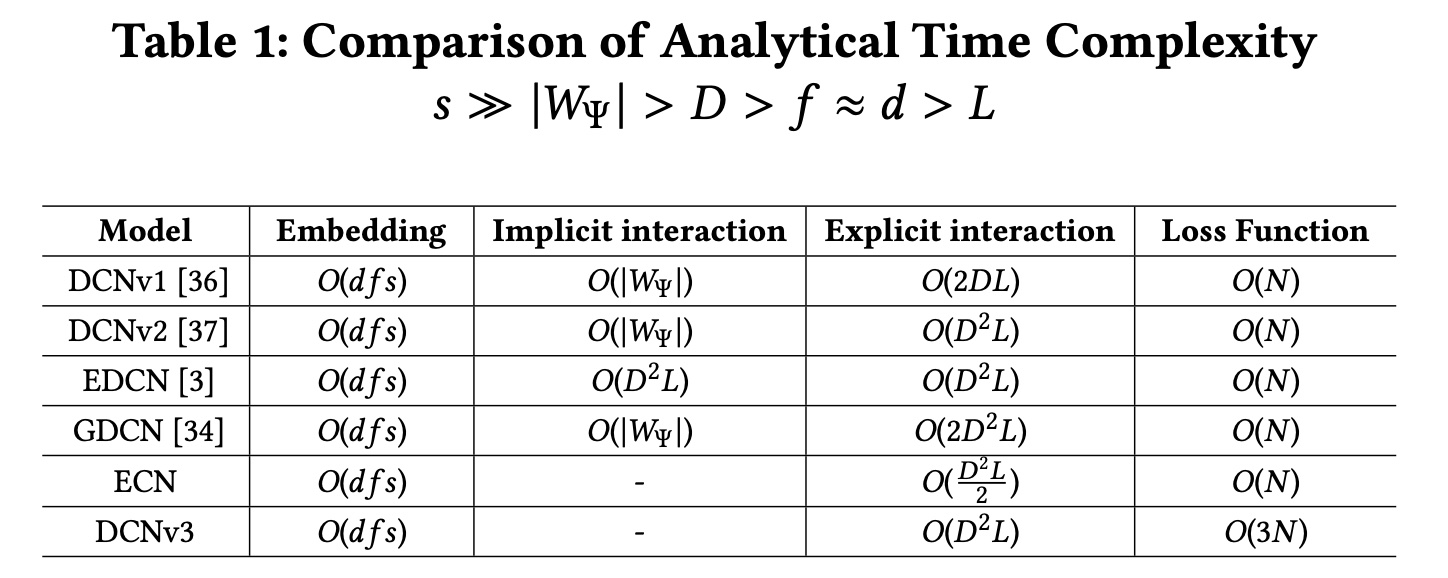
1.1.4 复杂度分析
为了进一步比较
DCN系列模型的效率,我们讨论并分析了不同模型的时间复杂度。令DNN中预定义的参数数量。其他变量的定义可以在前面的部分中找到。为了清楚起见,我们在Table 1中进一步提供了不同变量大小的比较。我们可以得出:所有模型对于
embedding的时间复杂度相同。因此,我们仅在实验部分可视化non-embedding参数。除了我们提出的
ECN和DCNv3之外,所有其他模型都包含隐式交互以增强预测性能,这会产生额外的计算成本。在显式交互方面,
ECN仅具有比DCNv1更高的时间复杂度,而GDCN的时间复杂度是ECN的四倍。由于我们的
DCNv3使用Tri-BCE loss,因此DCNv3的loss计算时间复杂度是其他模型的三倍。但这并不影响模型的推理速度。
时间复杂度只看
1.2 实验
四个研究问题(
research question: RQ):RQ1:DCNv3在性能方面是否优于其他CTR模型?它们在大规模的和高度稀疏的数据集上表现良好吗?RQ2:DCNv3与其他CTR模型相比是否更有效率?RQ3:DCNv3是否具有可解释性和过滤噪音的能力?RQ4:不同的配置如何影响模型?
数据集:
Avazu, Criteo, ML-1M, KDD12, iPinYou, and KKBox。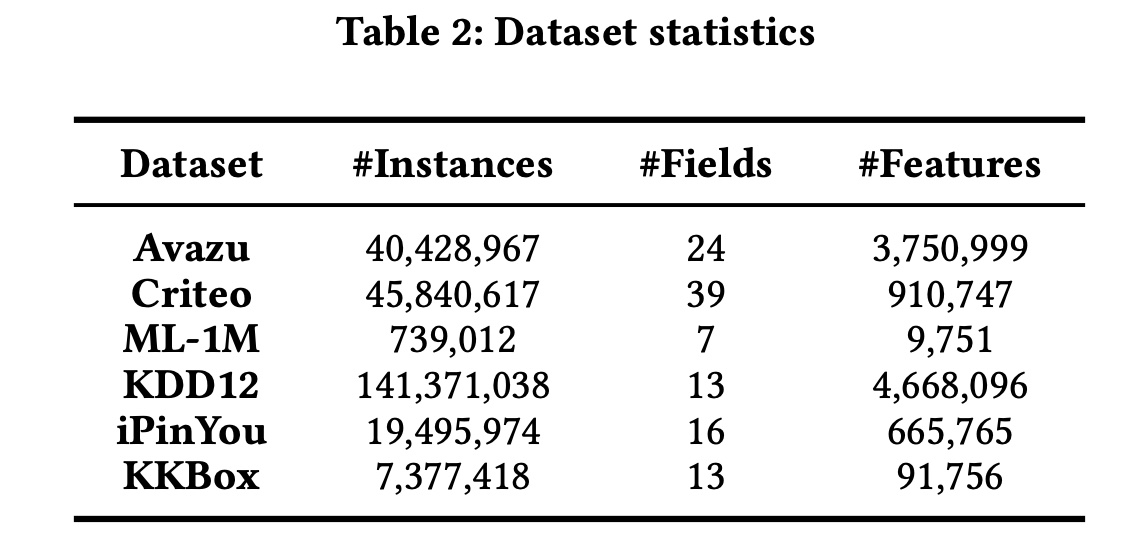
数据集预处理:我们遵循
《Open benchmarking for click-through rate prediction》中概述的方法。对于
Avazu数据集,我们将其包含的时间戳字段转换为三个新的feature fields:hour, weekday, and weekend。对于
Criteo和KDD12数据集,我们通过将每个numeric valuenumerical feature fields离散化:我们设置了一个阈值,用默认的
"OOV" token替换低频的categorical features。我们将Criteo、KKBox和KDD12的阈值设置为10,将Avazu和iPinYou的阈值设置为2,将小数据集ML-1M的阈值设置为1。
更具体的数据处理过程和结果可以在我们的开源运行日志和配置文件中找到,我们在此不再详述。
评估指标:
Logloss, AUC。这里
Logloss是baseline方法:我们将DCNv3与一些SOTA模型进行了比较 (*表示将原始模型与DNN网络集成):(1):由于ECN是一个执行显式feature interactions的独立网络,在两个大规模数据集上,我们将其与几个也执行显式feature interactions的模型进行了比较。例如:LR实现了一阶feature interactions。FM及其衍生模型FM、FwFM、AFM、FmFM实现了二阶特征交互。CrossNetv1、CrossNetv2、CIN、AutoInt、AFN、FiGNN实现了高阶feature interactions。
(2):为了验证DCNv3相对于包含隐式feature interactions的模型的优越性,我们进一步选择了几个高性能的代表性的baseline,例如PNN和Wide & Deep;DeepFM和DCNv1;xDeepFM;AutoInt*;AFN*;DCNv2和EDCN、MaskNet;CL4CTR、EulerNet、FinalMLP和FINAL。
实现细节:我们使用
PyTorch实现所有模型,并参考现有作品 。我们使用Adam optimizer优化所有模型,默认学习率设置为0.001。为了公平比较,我们将KKBox的embedding维度设置为128,将其他数据集的embedding维度设置为16。Criteo、ML-1M和iPinYou数据集的batch size设置为4,096,其他数据集的batch size设置为10,000。为了防止过拟合,我们采用patience = 2的早停。baseline模型的超参数是根据 (《An open-source CTR prediction library》、《Open benchmarking for click-through-rate prediction》)及其原始论文中提供的最佳值进行配置和微调的。 有关模型超参数和数据集配置的更多详细信息,请参阅我们简单易懂的运行日志,此处不再赘述。
1.2.1 RQ1 整体性能
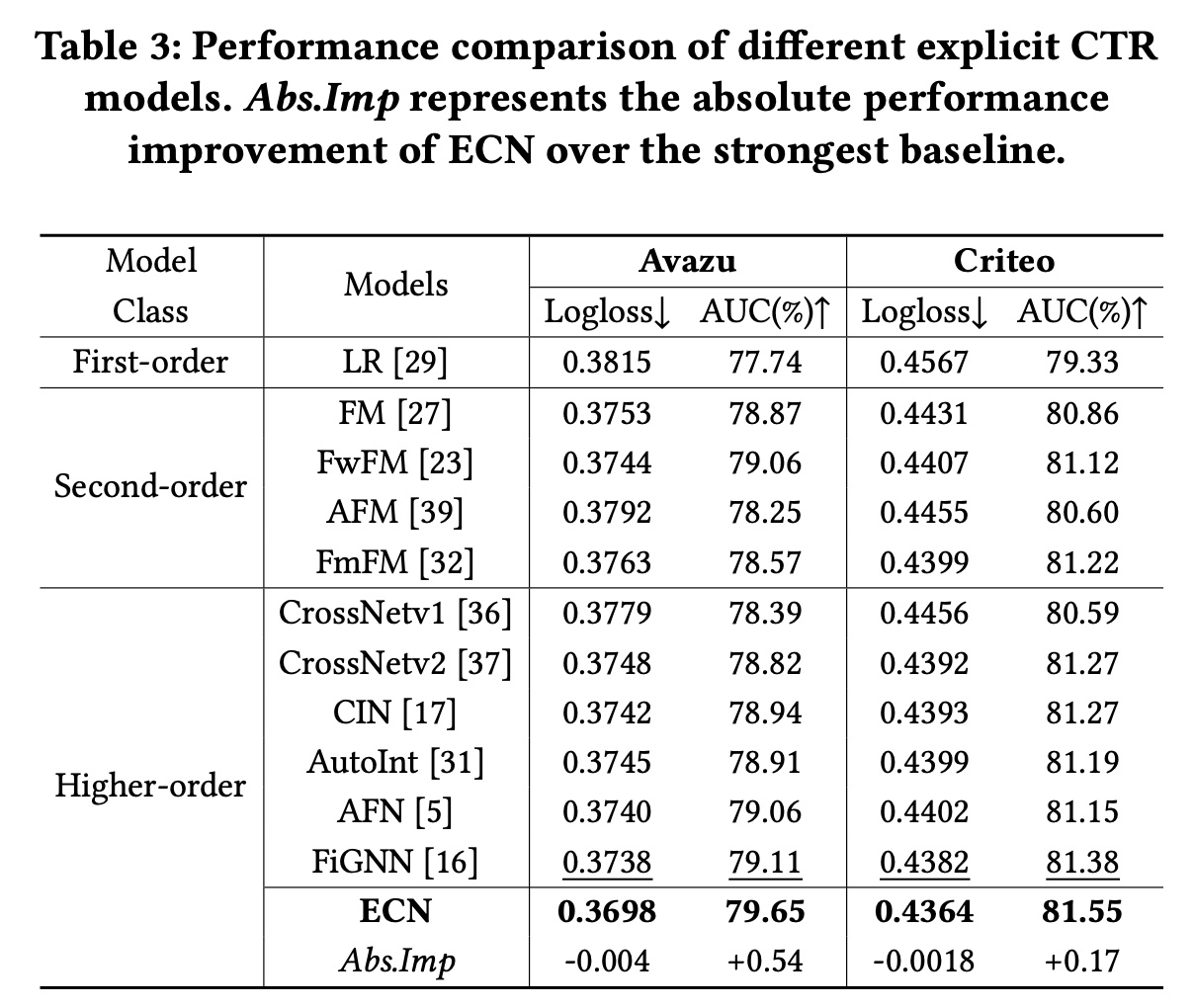
与仅使用显式
feature interactions的模型进行比较:由于ECN模型显式地以feature interactions为特征,我们选择了11个代表性的模型进行比较,分为一阶、二阶和高阶等等。我们用粗体表示性能最好的,用下划线表示得分次好的。实验结果如Table 3所示,我们可以得出以下结论:通过比较
Table 3和Table 4,我们发现大多数仅仅使用显式feature interactions的模型通常比集成隐式feature interactions的模型表现更差,甚至比简单的DNN更差。这无疑削弱了显式feature interactions的必要性。总体而言,捕获高阶
feature interactions通常可以提高模型性能。例如:FM在两个大规模数据集Avazu和Criteo上的表现优于LR。而
CrossNetv2在Avazu上的表现优于除FwFM之外的所有一阶和二阶feature interaction模型。
这证明了高阶
feature interactions的有效性。更复杂的模型结构不一定会带来性能提升。与
FM相比,AFM引入了更复杂的注意力机制,但并没有取得更好的性能,这一点在《Open benchmarking for click-through rate prediction》中也有所报道。但是,与CrossNetv1相比,CrossNetv2扩展了权重矩阵的规模,从而带来了一定程度的性能提升。因此,我们应该仔细设计模型架构。FiGNN在显式feature interaction模型中取得了最佳的baseline性能。然而,与FiGNN相比,我们的ECN在Avazu数据集上仍然实现了Logloss下降0.4%、AUC增加0.54%,在Criteo数据集上实现了Logloss下降0.18%、AUC增加0.17%,均在统计显著水平上超过0.001。这证明了ECN的优越性。
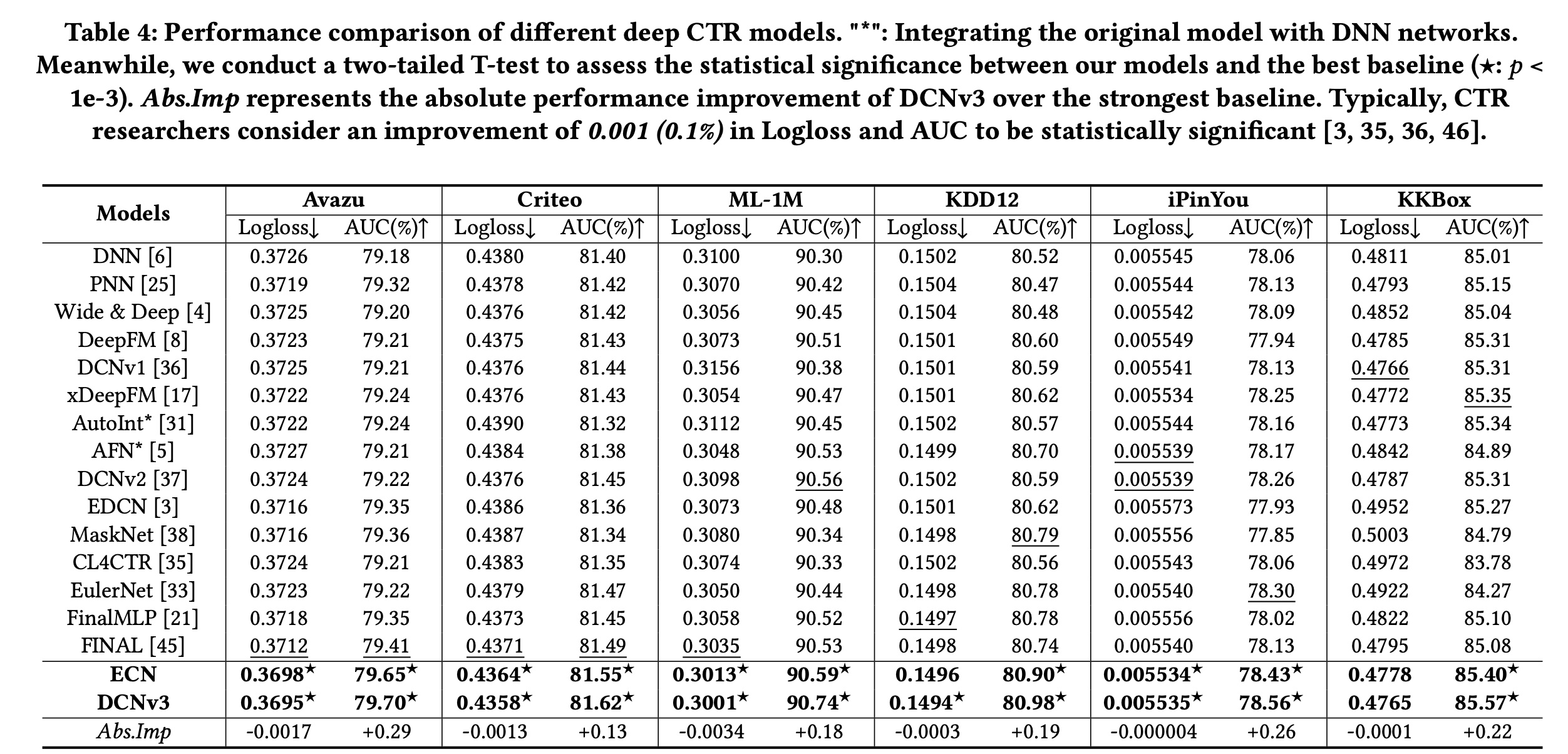
与集成隐式
feature interactions的模型的比较:为了进一步全面研究DCNv3在各种CTR数据集(例如,大规模稀疏数据集)上的性能优势和泛化能力,我们选择了15个有代表性的baseline模型和6个基准数据集。我们用粗体突出显示ECN和DCNv3的性能,并用下划线突出最佳baseline性能。Table 4展示了实验结果,从中我们可以得出以下观察结果:总体而言,
DCNv3在所有六个数据集上都取得了最佳性能,与最强的baseline模型相比,平均AUC提高了0.21%,平均Logloss降低了0.11%,均超过了0.1%的统计显著阈值。这证明了DCNv3的有效性。FinalMLP模型在Avazu和Criteo数据集上取得了良好的性能,超越了大多数结合显式和隐式feature interactions的CTR模型。这证明了隐式feature interactions的有效性。因此,大多数CTR模型试图将DNN集成到显式feature interaction模型中以提高性能。然而,DCNv3仅使用显式feature interactions就实现了SOTA性能,表明仅使用显式feature interaction进行建模的有效性和潜力。DCNv3在所有六个数据集上都实现了优于ECN的性能,证明了LCN在捕获低阶feature interactions和Tri-BCE loss方面的有效性。值得注意的是,在iPinYou数据集上,我们观察到所有模型的Logloss值都在0.0055水平左右。这是由于数据集中正样本和负样本之间的不平衡,其他工作也报告了类似的结果。ECN在AUC方面优于所有baseline模型,唯一的例外是KKBox数据集上的Logloss optimization,ECN比DCNv1弱。这进一步证明了ECN的有效性,因为它通过指数级增长的feature interactions和噪声过滤机制捕获高质量的feature interaction信息。
1.2.2 深入研究 DCNv3
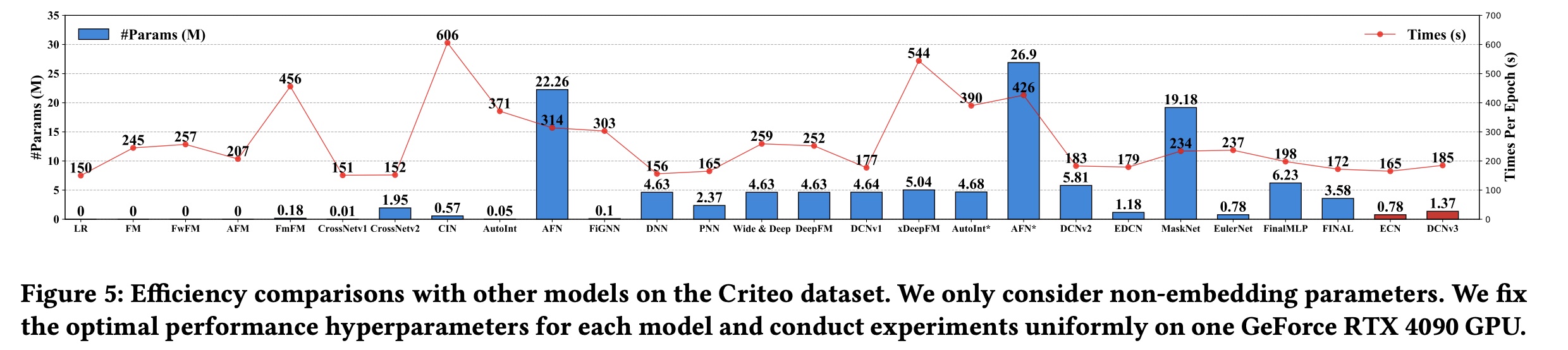
效率比较(
RQ2):为了验证DCNv3的效率,我们为25个baseline模型固定了最优超参数,并比较了它们的参数数量(四舍五入到小数点后两位)和运行时间(五次运行的平均值)。实验结果如Figure 5所示。我们可以得出:显式
CTR模型通常使用较少的参数。例如,LR, FM, FwFM, and AFM的non-embedding参数几乎为零,而FmFM, CrossNet, CIN, and AutoInt都需要少于1M的参数。值得注意的是,参数数量并不总是与时间复杂度相关。虽然CIN仅使用0.57M个参数,但其每个epoch的训练时间最多达到606秒,因此不适合实际生产环境。FiGNN和AutoInt面临同样的问题。在所有模型中,
LR模型的运行时间最短,为150秒。CrossNetv1和CrossNetv2紧随其后,在提升性能的同时,时间几乎不增加。这证明了CrossNet及其系列模型的效率。作为deep CTR模型的基本组成部分,DNN仅需156秒。由于CTR并行结构的parallel-friendly特性,一些精心设计的deep CTR模型(如DCNv2、FinalMLP和FINAL)在运行时间没有大幅增加的情况下显著提高了预测准确率。我们提出的
ECN和DCNv3是DCN系列中参数效率最高的模型,分别仅需0.78M和1.37M个参数即可实现SOTA性能。同时,在运行时间方面,DCNv3始终优于FinalMLP, FINAL, DCNv2, and DCNv1等强大的baseline模型。这证明了DCNv3的时间效率。尽管由于使用了Tri-BCE loss,DCNv3比ECN多需要20秒,但它仍然与DCNv2相当。值得注意的是,loss的额外计算成本仅在训练期间产生,不会影响实际应用中的推理速度。这进一步证明了ECN和DCNv3的效率。
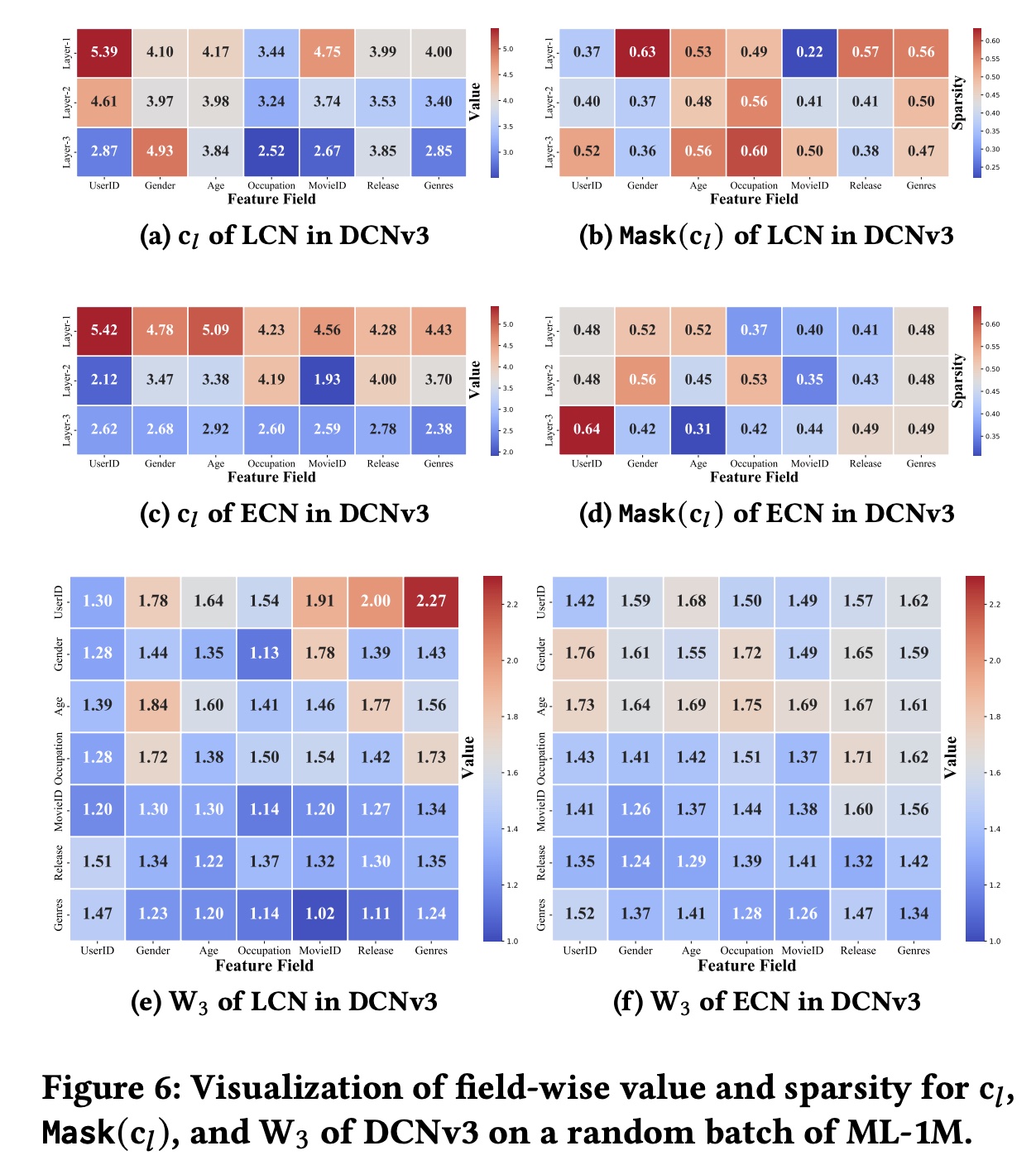
DCNv3的可解释性和噪声过滤能力(RQ3):可解释性在CTR预测任务中至关重要,因为它可以帮助研究人员理解预测并增加对结果的信心。在本节中,我们研究动态的Cross & Masked Vector和静态的Figure 6所示(Value表示每个feature field的Frobenius范数),我们可以得出以下观察结果:从
Figure 6 (a∼d)中,我们观察到UserID在LCN和ECN的第一层都具有很高的重要性,但随着层数的增加而降低。同时,
UserID的
feature field变得重要时,其在UserID, Occupation, Age fields)。这证明了我们引入的Self-Mask操作的有效性,该操作通过更积极地为某些feature fields分配零值来进一步过滤掉噪音。从
Figure 6 (e, f)中,我们观察到LCN和ECN在同一层捕获不同的feature interaction信息。在
LCN中,3阶特征的重要性从而生成4阶feature interactions。相反,在
ECN中,feature interactions。
因此,对于
UserID × Genres,与LCN相比,ECN展示了更低的重要性。这进一步证明了DCNv3的有效性。总体而言,我们观察到高阶
feature interactions的重要性低于低阶feature interactions,这在一些工作中也有类似的报道。例如,在Figure 6中,(f)与(e)相比,鲜红色块较少;并且(a)中的蓝色块随着层数的增加逐渐变暗,(b)中的情况类似。
消融研究(
RQ4):为了研究DCNv3各组件对其性能的影响,我们对DCNv3的几种变体进行了实验:w/o TB:使用BCE代替Tri-BCE的DCNv3。w/o LN:没有LayerNorm的Self-Mask。
消融实验结果如
Table 5所示。可以看到:ECN和LCN与DCNv3相比都表现出一定的性能损失,这表明有必要同时捕获高阶和低阶feature interactions。与
ECN相比,LCN的表现始终不佳,证明了指数级feature interaction方法的优越性。同时,
w/o TB的变体也导致一定程度的性能下降,在KKBox上尤为明显。LayerNorm的目的是保证Self-Mask保持0.5左右的masking rate,因此删除它会导致masking rate不稳定,从而导致一些性能损失。
这些证明了
DCNv3中每个组件的必要性和有效性。为什么没有移除
Self-Mask的对比实验?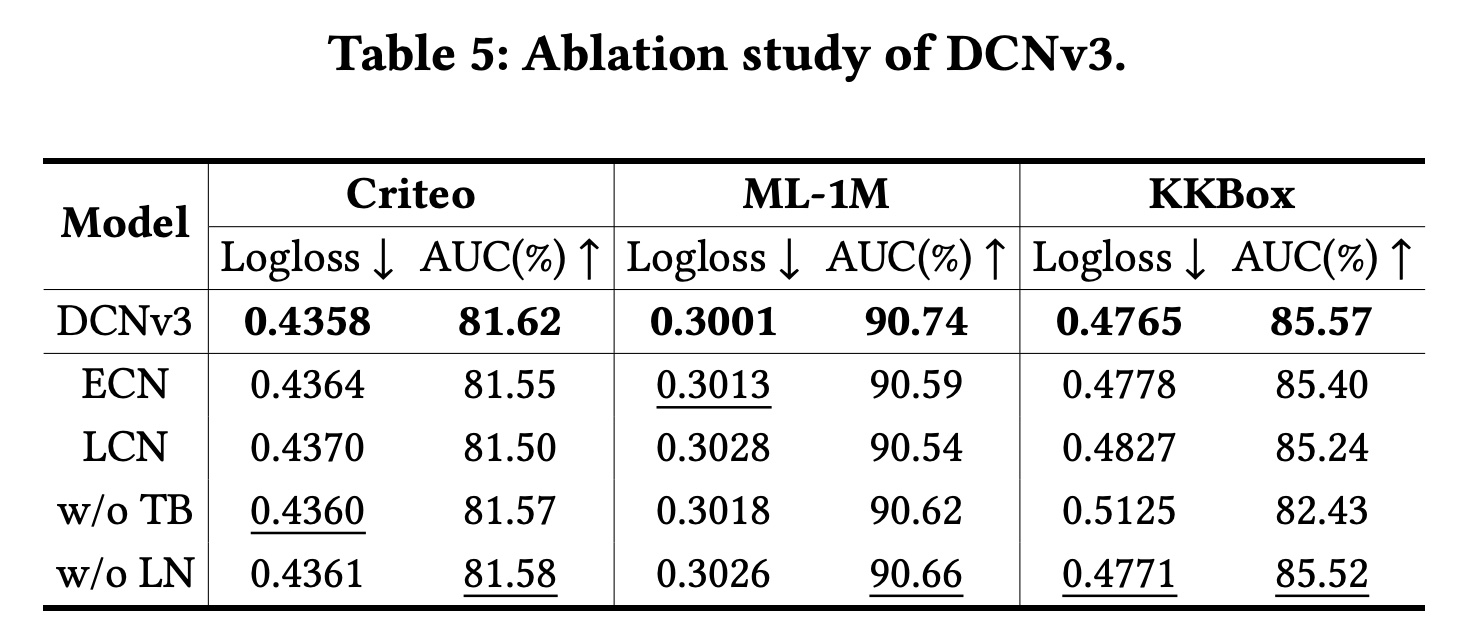
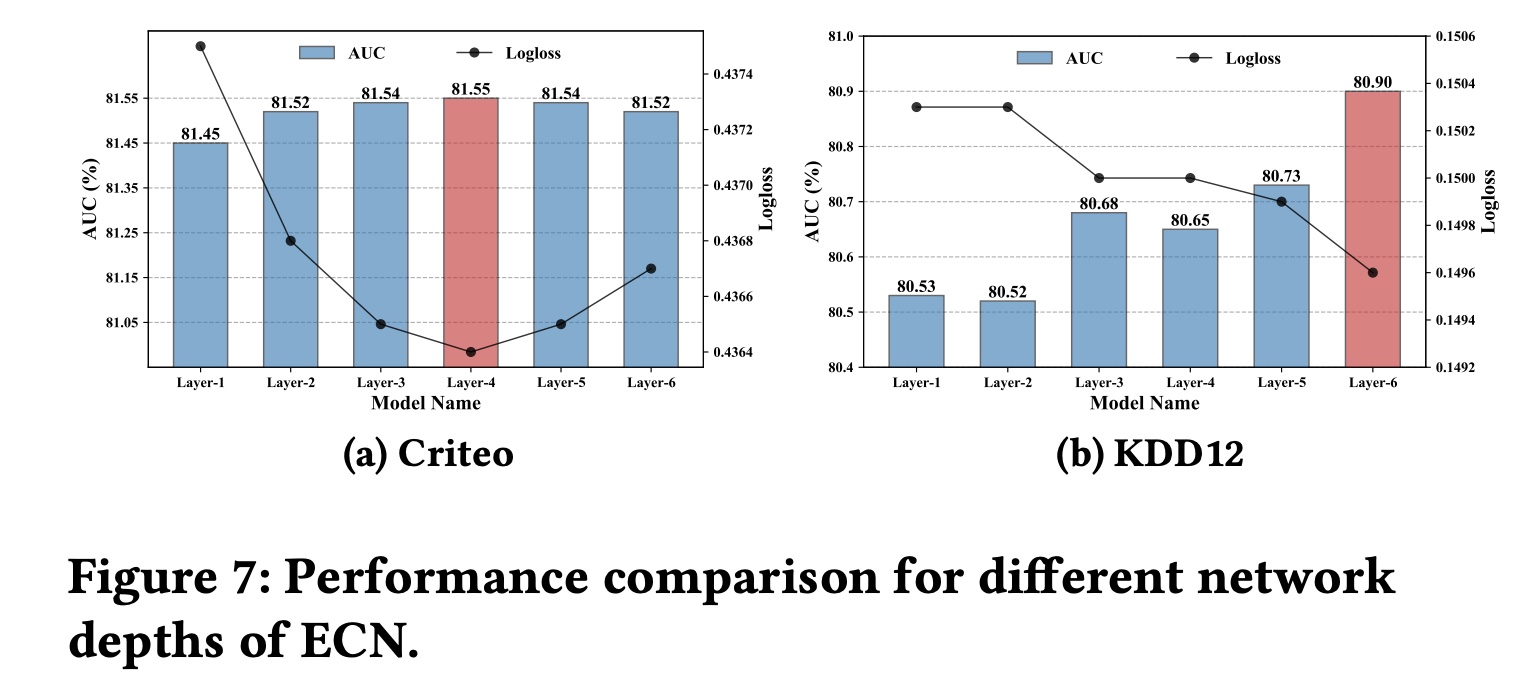
网络深度的影响(
RQ4):为了进一步研究不同神经网络深度对ECN性能的影响,我们在两个大规模CTR数据集Criteo和KDD12上进行了实验。Figure 7显示了ECN在测试集上的AUC和Logloss性能。从
Figure 7中我们观察到:在
Criteo数据集上,该模型在4层的深度下实现了最佳性能,这表明ECN最多可以捕获feature interactions。在
KDD12数据集上,ECN在6层的深度下实现了最佳性能,这意味着它捕获了feature interactions。
相比之下,在线性增长的
CrossNetv2中实现相同阶次的feature interactions分别需要ECN凭借其指数级增长的feature interaction机制轻松实现了这一点。这进一步证明了ECN的有效性。