一、TWIN V2 [2024]
《TWIN V2: Scaling Ultra-Long User Behavior Sequence Modeling for Enhanced CTR Prediction at Kuaishou》
在大型推荐系统中,建模长期用户兴趣对于
CTR prediction任务的重要性正逐渐引起研究人员和从业者的关注。现有的研究工作,如SIM和TWIN,出于效率考虑,通常采用两阶段方法来建模长期用户行为序列:第一阶段使用
search-based的机制,即General Search Unit: GSU,从长序列中快速检索与target item相关的a subset of sequences。而第二阶段使用
Exact Search Unit: ESU对检索到的结果计算interest scores。
鉴于用户行为序列跨越整个生命周期,可能达到
TWIN-V2,这是TWIN的增强版,其中采用分而治之的方法来压缩life-cycle behaviors并发现更准确更多样化的用户兴趣。具体来说,离线阶段,我们通过
hierarchical clustering方法将life-cycle behaviors中具有相似特性的items归为一个cluster。通过clusters的规模,我们可以将远远超过GSU retrieval的online inference。Cluster-aware target attention可以提取用户的全面的、多方面的长期兴趣,从而使最终的推荐结果更加精准和多样化。在数十亿规模的工业级数据集上的大量离线实验、以及线上
A/B test,证明了TWIN-V2的有效性。在高效的部署框架下,TWIN-V2已成功部署到快手主流量中,从而服务于数亿日活用户。CTR prediction对于互联网应用至关重要。例如,快手(中国最大的短视频分享平台之一)已将CTR prediction作为其ranking system的核心组件。最近,人们投入了大量精力来对CTR prediction中的用户长期历史行为进行建模。由于生命周期中的behaviors的长度很长,modeling life-cycle user behaviors是一项具有挑战性的任务。尽管现有研究不断努力延长historical behavior modeling的长度,但尚未开发出可以对用户整个生命周期进行建模的方法,从而覆盖application中高达1 million behaviors。 现代工业系统采用了两阶段方法,以便在可控的推理时间内尽可能多地利用用户历史记录。具体来说:在第一阶段,通用搜索单元 (
General Search Unit: GSU) 模块用于过滤长期历史行为,选择与target item相关的items。在第二阶段,精确搜索单元 (
Exact Search Unit: ESU) 模块对filtered items进行进一步处理,通过target attention提取用户的长期兴趣。
GSU的粗粒度的pre-filtering使系统能够在online inference过程中以更快的速度建模更长的历史行为。许多方法尝试了不同的GSU结构来提高pre-filtering的准确率,例如ETA、SDIM和TWIN。 尽管现有的第一阶段的GSU很有效,但它们通常存在长度限制,无法对整个生命周期的user behaviors进行建模。例如:SIM、ETA和SDIM可以过滤最大长度为TWIN将最大长度扩展到
在部署过程中,
TWIN使用最近的10,000 behaviors作为GSU的输入。不幸的是,这10,000 behaviors仅涵盖了用户在快手App中最近三到四个月的历史记录,无法涵盖user behavior的整个生命周期。如Figure 1所示,我们分析了快手App中过去三年的user behavior。medium and high user groups在三年内可以观看App使用时长的大部分(60% + 35% = 95%)。因此,modeling the full life-cycle behaviors可能会增强用户体验并提高平台的商业收益。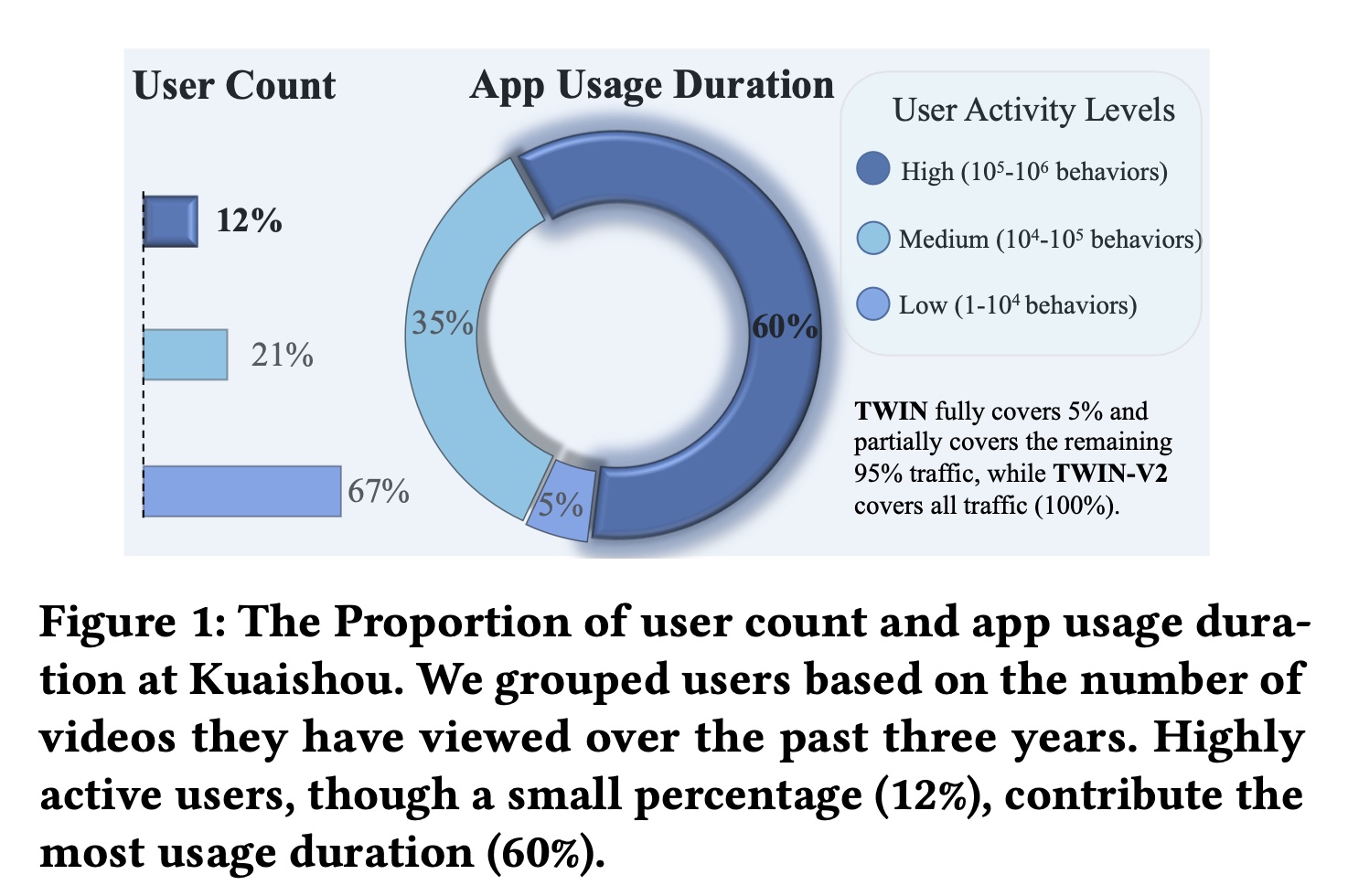
为了解决这个问题,我们提出了
TWIN-V2,这是TWIN的增强版,使其能够对user behavior的全生命周期进行建模。TWIN-V2采用分而治之的方法,将完整的生命周期历史(full life-cycle history)分解为不同的clusters,并使用这些clusters来建模用户的长期兴趣。具体来说,我们将模型分为两个部分:离线和在线。在离线部分,我们使用层次聚类(
hierarchical clustering)将life-cycle behaviors中的相似items聚合到clusters中,并从每个cluster中提取特征以形成一个虚拟的item。在在线部分,我们利用
cluster-aware target attention从而基于clustered behaviors来提取长期兴趣。在这里,attention scores根据相应的cluster size被重新加权。
大量实验表明,
TWIN-V2在各种类型用户上提升了性能,从而带来更准确和多样化的推荐结果。 本文主要贡献总结如下:我们提出
TWIN-V2从极长的user behavior中捕获用户兴趣,成功地延长了user modeling across the life cycle的最大长度。hierarchical clustering和cluster-aware target attention提升了long sequence modeling的效率,建模了更准确、更多样化的用户兴趣。大量离线实验和在线实验验证了
TWIN-V2在超长用户行为序列的扩展方面的有效性。我们分享了
TWIN-V2的部署实践,包括离线处理和在线服务。TWIN-V2已经服务于快手每日约4亿活跃用户的主要流量。
TWIN V2 vs TWIN V1的在线指标提升,要比TWIN V1 vs SIM低得多。这意味着TWIN V2上线之后,系统的商业增益没有那么大。本文旨在将
long-term history modeling扩展到生命周期级别,同时保持效率。Table 1总结了TWIN-V2与之前工作的比较。TWIN V2比TWIN多了一步:先对用户行为序列进行聚类,并对每个cluster构造一个virtual item来代表这个cluster。然后将这些virtual items馈入TWIN中。但是,
TWIN V2的效果依赖于一个训练好的recommendation model。我们需要从这个recommendation model中获取item embedding从而进行聚类、以及virtual item的构造。然而,论文没有提到这个recommendation model是如何创建和训练的,在实验部分也没有说这个recommendation model的性能对于TWIN V2效果的影响。从 “TWIN-V2 的部署” 这一章节来看,我们只需要提供一个初始的
recommendation model,然后在训练过程中可以用上一轮的TWIN-V2模型作为这个recommendation model从而优化下一轮的TWIN-V2。从这个角度来看,recommendation model似乎不是特别重要?此外,读者猜测初始的
recommendation model来自于训练好的TWIN-V1模型。
1.1 方法
本节详细阐述了所提出的模型,详细介绍了从整体工作流到
deployment framework的整个过程。符号总结如下。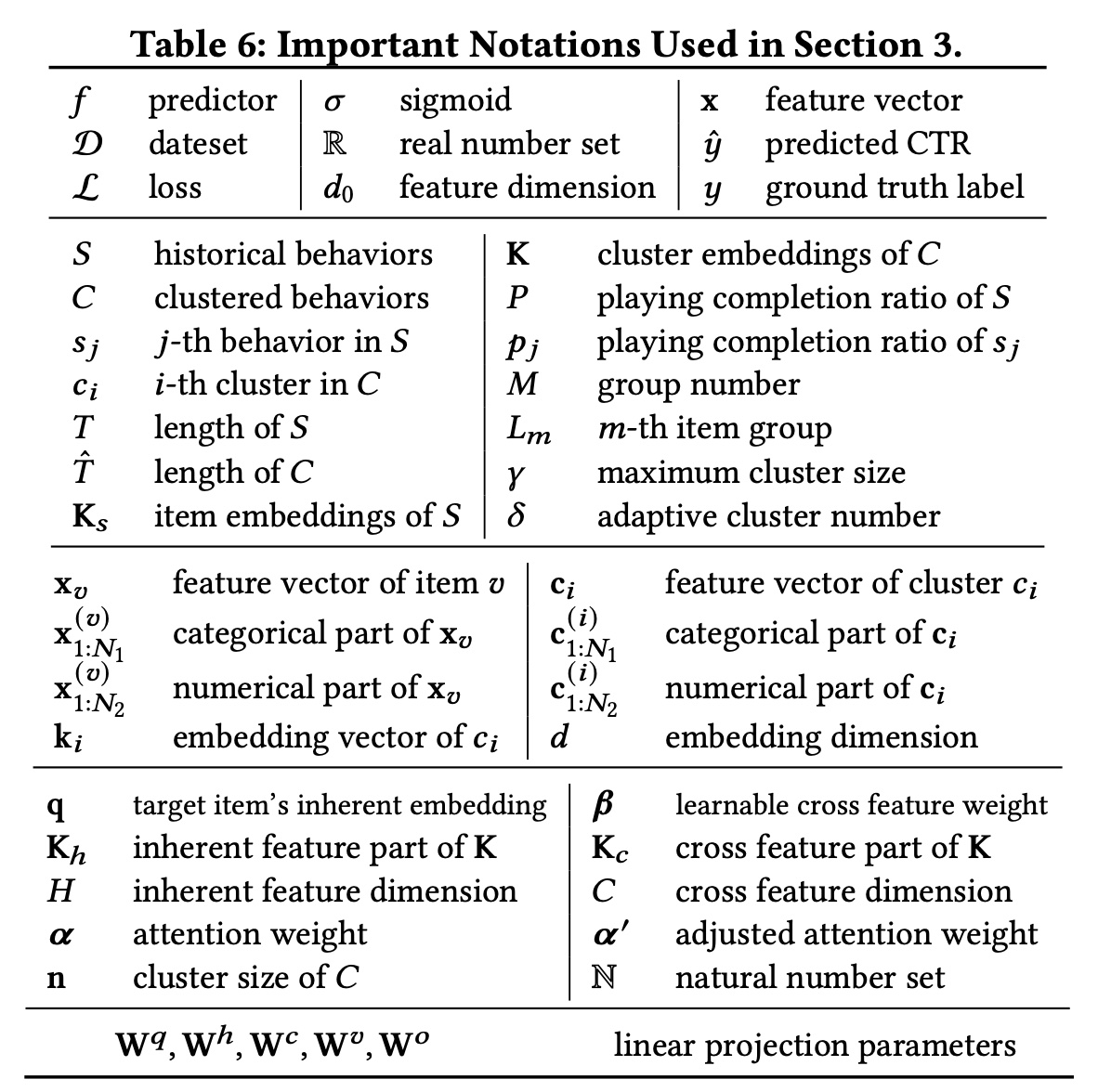
1.1.1 基础知识
CTR prediction的核心任务是预测用户点击某一个item的概率。令feature representation,令label。CTR prediction的过程可以写成:其中:
sigmoid函数。CTR模型predicted probability。
模型
其中:
1.1.2 整体工作流
Figure 2展示了TWIN-V2的整体框架,包括离线和在线部分。本文重点介绍life-cycle behavior modeling。因此我们强调这一部分并省略其他部分。 由于整个生命周期的behavior对于online inferring来说太长,我们首先在离线阶段对behaviors进行压缩。User behavior通常包括许多相似的视频,因为用户经常浏览他们喜欢的主题。因此,我们使用hierarchical clustering将用户历史中具有相似兴趣的items聚合到clusters中。Online inferring使用这些clusters及其representation vectors来捕获用户的长期兴趣。 在online inferring过程中,我们采用两阶段方法进行life-cycle modeling:首先,我们使用
GSU从clustered behaviors中检索与target item相关的top 100 clusters。然后,我们使用
ESU从这些clusters中提取长期兴趣。
在
GSU和ESU中,我们实现了cluster-aware target attention,并调整不同clusters的权重。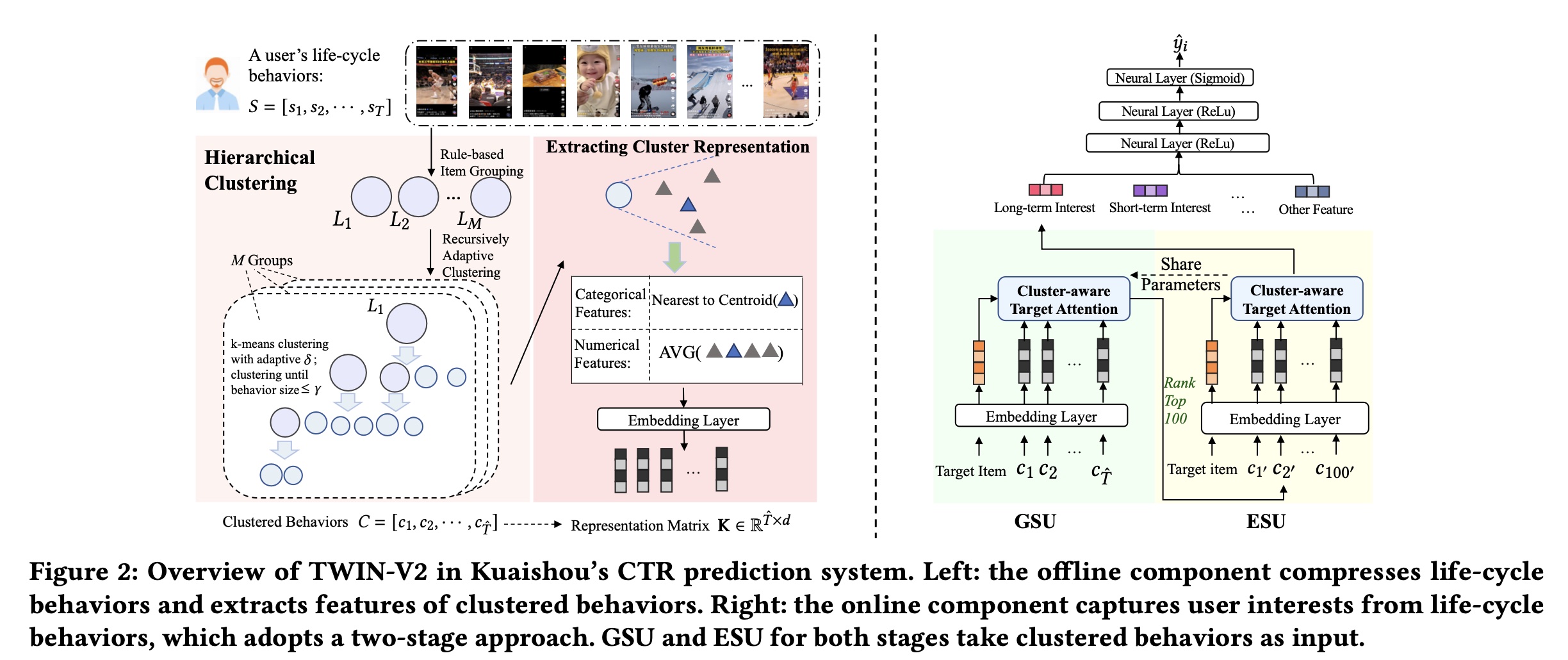
1.1.3 Life-Cycle User Modeling
考虑到用户在生命周期中的历史行为具有超长序列,我们首先采用分而治之的方法压缩这些
behaviors,然后从compressed behaviors中提取用户的长期兴趣。
a. Hierarchical Clustering Over Life Cycle
对于用户
items的一个序列life-cycle behaviors的数量,item。用户可能在similar items。例如,一个喜欢NBA比赛的用户在其历史中可能拥有数百个与篮球相关的视频。因此,一个自然的想法是将similar items聚合成clusters,用一个cluster来表示许多similar items,从而减小正式地,我们旨在使用压缩函数
behavior sequence其中:
clustered behaviorsclustered items的第具体而言,我们采用分层聚类(
hierarchical clustering)方法来实现Algorithm 1所示。在第一步中,我们简单地将
historical behaviors分成几组。我们首先根据用户playing time ratio将historical items分为historical item,这个playing time ratio记作在第二步中,我们递归地对每组的
life-cycle historical behaviors进行聚类,直到每个cluster中的items数量不超过k-means方法对behaviorsembeddingsrecommendation model中获得。maximum cluster size的超参数。这意味着我们需要一个
pre-trained模型从而获得pre-trained模型的质量会影响TWIN-V2的效果。

接下来,我们将详细说明
Algorithm 1背后的原理:Item Grouping:在短视频场景中,视频的完播率(playing completion ratio)可以看作是用户对视频感兴趣程度的指标。我们首先按完播率对behaviors进行分组,以确保final clustering results具有相对一致的playing time ratio。如果不这样做,将导致每个cluster内的分布不平衡,因为k-means仅考虑item embeddings。函数playing time ratio的范围分成五个相等的部分。5。在电商场景下,我们可以按照
action type对behaviors进行分组,如click, add_cart, purchase。Recursively Adaptive Clustering:我们选择hierarchical clustering而不是single-step clustering,因为用户历史是个性化的,因此设置通用的clustering iterations数量是不切实际的。我们还动态设置
number of clusters(items数量的0.3次方),允许clustering适应不同规模的behaviors。当
item size低于clustering过程停止,其中20。
单次迭代逻辑:
首先从
groupItem Grouping所初始化,刚开始包含group。如果
groupitem数量低于groupcluster。当前迭代结束,进入下一轮迭代。如果
groupitem数量大于等于groupKmeans聚类,cluster数量为groupitem数量的0.3次方。聚类后的每个cluster都追加到
这种做法使得每个
cluster的item size都小于在我们的实践中,平均
cluster size约为cluster的数量),大大缩短了life-cycle behaviors的长度。用于聚类的item embeddingsrecommendation model中获得的,这意味着clustering是由协同过滤信号所指导的。因此,我们通过将
similar items聚合到clusters中,将原本很长的用户行为序列
b. Extracting Cluster Representation
获得
clustersitems of each cluster中抽取特征。为了最大限度地减少计算和存储开销,我们使用一个virtual item来表示features of each cluster。 我们将item features分为两类(numerical and categorical),并使用不同的方法抽取它们。Numerical features通常使用标量来表示,例如视频时长和用户播放视频的时间。Categorical features通常使用one-hot (or multi-hot)向量来表示,例如video ID和author ID。
正式地,给定一个任意
item为简单起见,我们使用
categorical features,numerical features。对于cluster我们计算其包含的所有
items的所有numerical features的平均值作为numerical feature representation:对于
categorical features,由于它们的平均值没有意义,我们采用距离clusteritem来表示cluster其中:
itemembeddings。这些embeddings可以从注意:这是将距离质心最近的
item的categorical feature作为这个cluster的categorical feature。
因此,整个
clusteraggregated, virtual item featureembedding layers之后,每个cluster的特征都被嵌入到一个向量中,例如,对于embedding向量为GSU和ESU模块根据这些embedded vectors估计每个cluster与target item之间的相关性。item(即,virtual item),作为这个cluster的代表。
c. Cluster-aware Target Attention
遵从
TWIN,我们同时在ESU和GSU中采用了相同的有效的注意力机制,将clustersrepresentations作为输入。给定
clustered behaviorsembedding layer得到由representation vectors组成的矩阵cluster的特征embedding向量。对于
numerical featurebucktize,然后再做embedding。然后我们使用
target attention机制来衡量target item与historical behaviors的相关性。我们首先应用TWIN中的“Behavior Feature Splits and Linear Projection”技术来提升target attention的效率,详细信息见论文附录A.2。该方法将item embeddings拆分为固有的部分和交叉的部分。target item的固有特征的向量。clustered behaviors的固有embedding和交叉embedding,其中target item与clustered behaviors之间的relevance scores其中:
由于
clusters中的item counts千差万别,clusters与target item之间的关系。假设两个clusters具有相同的相关性(与target item的相关性),则具有更多items的cluster应该更重要,因为items越多意味着用户偏好越强。因此,我们根据cluster size调整relevance scores:其中:
clusters的大小,每个元素clustercluster size。在
GSU阶段,我们使用clustered behaviors(总长度为relevance scores最高的top 100 clusters。然后,将这100 clusters被输入到ESU,在那里根据relevance scores对它们进行聚合,从而得到用户长期兴趣的representation:其中
为了简单起见,这个等式中的符号被稍微滥用:在
ESU阶段设置其中每个
cluster的relevance scorecluster size我们使用具有
4个头的多头注意力来获得最终的长期兴趣:其中
备注:利用从
GSU中的hierarchical clustering中得出的behaviors,使模型能够容纳更长的历史行为,从而在我们的系统中实现life-cycle level modeling。与TWIN相比,GSU的life-cycle behaviors的input涵盖了更广泛的历史兴趣,从而提供了更全面、更准确的用户兴趣建模。此外,虽然现有的方法使用
top 100 retrieved behaviors作为ESU的输入,但TWIN-V2使用100 clusters。这些clusters涵盖了超过100 behaviors,使ESU能够对更广泛的behaviors进行建模。所有这些优势带来了更加准确和多样化的推荐结果,这在实验章节中得到了验证。
1.1.4 TWIN-V2 的部署
我们将部署
TWIN-V2的实践分为两个部分:在线和离线,如Figure 3所示。在
Figure 3中,我们以单个用户为例进行说明。当系统收到用户的request时:它首先从离线处理好的
user life-cycle behaviors中提取behavioral features。然后,使用
GSU和ESU,将behavioral features建模长期兴趣的input从而用于CTR模型以进行预测。
我们使用一个
nearline trainer来进行real-time model training,该trainer使用实时用户交互数据(数据在8分钟的时间窗口内)增量地更新模型参数。对于
life-cycle behaviors,我们应用hierarchical clustering和feature extraction来处理它们。这是通过周期性的offline processing和updates进行的。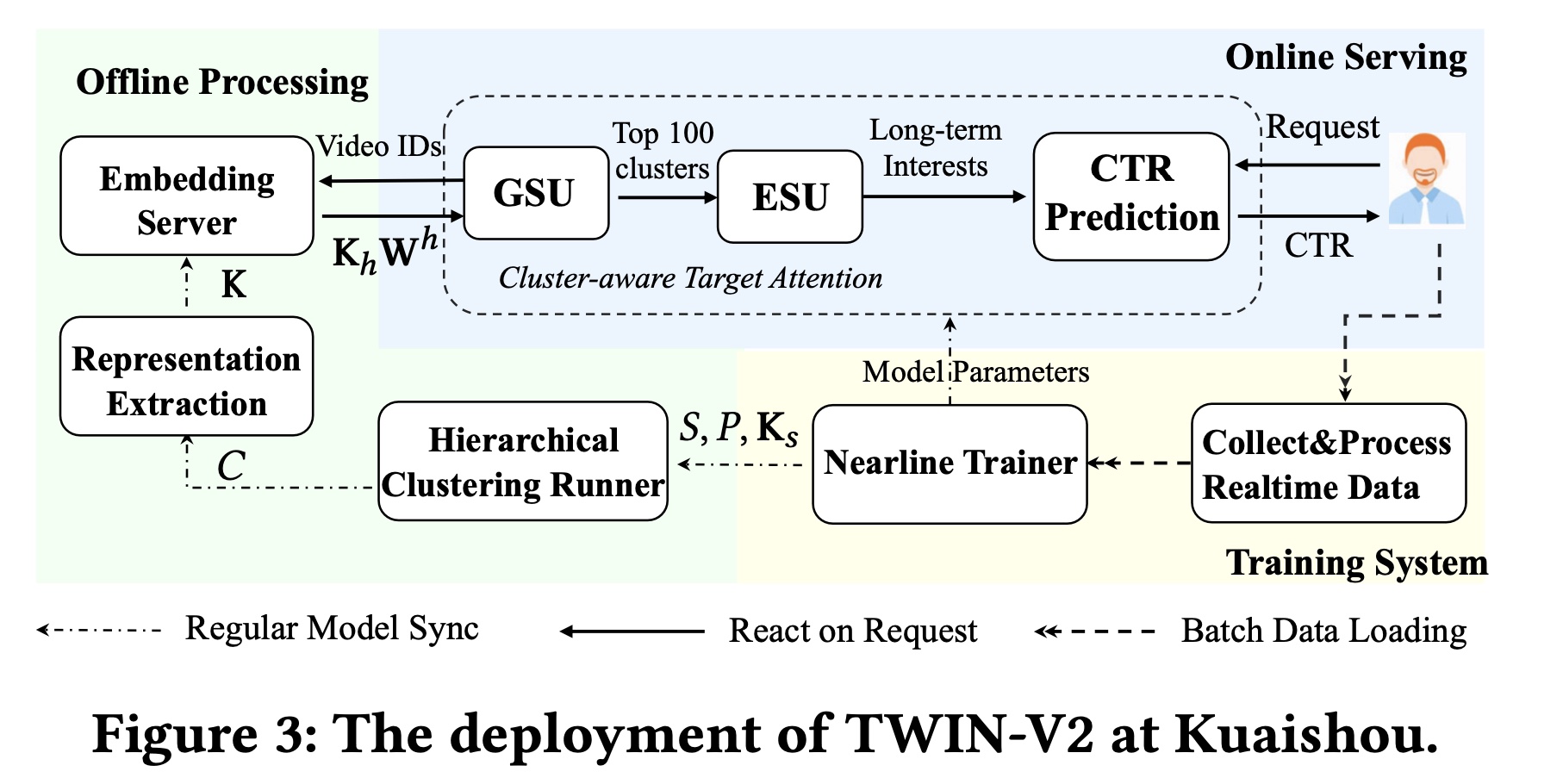
Offline Processing:离线处理旨在压缩用户的整个life-cycle behaviors。考虑到快手的用户数量是十亿级的,我们会定期压缩他们的life-cycle behaviors。hierarchical clustering runner每2周执行一次全面更新。我们将
hierarchical clustering中的maximum cluster size20,导致平均cluster size约为10。通过cluster representation extraction,每个cluster被聚合为一个虚拟item。在我们的实践中,historical behavior被压缩为原始长度的10%,从而将存储成本降低了90%。我们为
embedding server采用了TWIN中提出的inherent feature projector,每15分钟从最新的CTR模型刷新一次projector的参数。Online Serving:用户向系统发送request后,离线系统将数据特征发送到GSU,GSU计算behavior-target relevance scoresESU选择并聚合top 100 clustered behaviors作为长期兴趣从而用于CTR模型的预测。为了确保online inference的效率,我们保留了TWIN的precomputing and caching策略(即,预计算并缓存TWIN-V2是TWIN的增量部署:TWIN对最近几个月的behaviors进行建模,而TWIN-V2对整个生命周期的behaviors进行建模,使得它们相互补充。
1.2 实验
在本节中,我们通过进行大量的离线实验和在线实验来验证
TWIN-V2的有效性。数据集:由于
TWIN-V2是为极长的user behaviors而设计的,因此需要使用具有丰富用户历史的数据集。据我们所知,目前还没有平均历史长度超过App中提取了连续五天的用户交互数据作为训练集和测试集。样本由点击日志构成,并以click为标签。为了捕获用户的life-cycle历史,我们进一步追溯了每个用户的过去所有行为,每个用户的最大历史长度为100,000。Table 2展示了该工业数据集的基本统计数据。每天的前23个小时用作训练集,而最后一个小时用作测试集。这种测试集会不会有偏?因为最后一个小时的交互数据的分布可能与前
23个小时不同。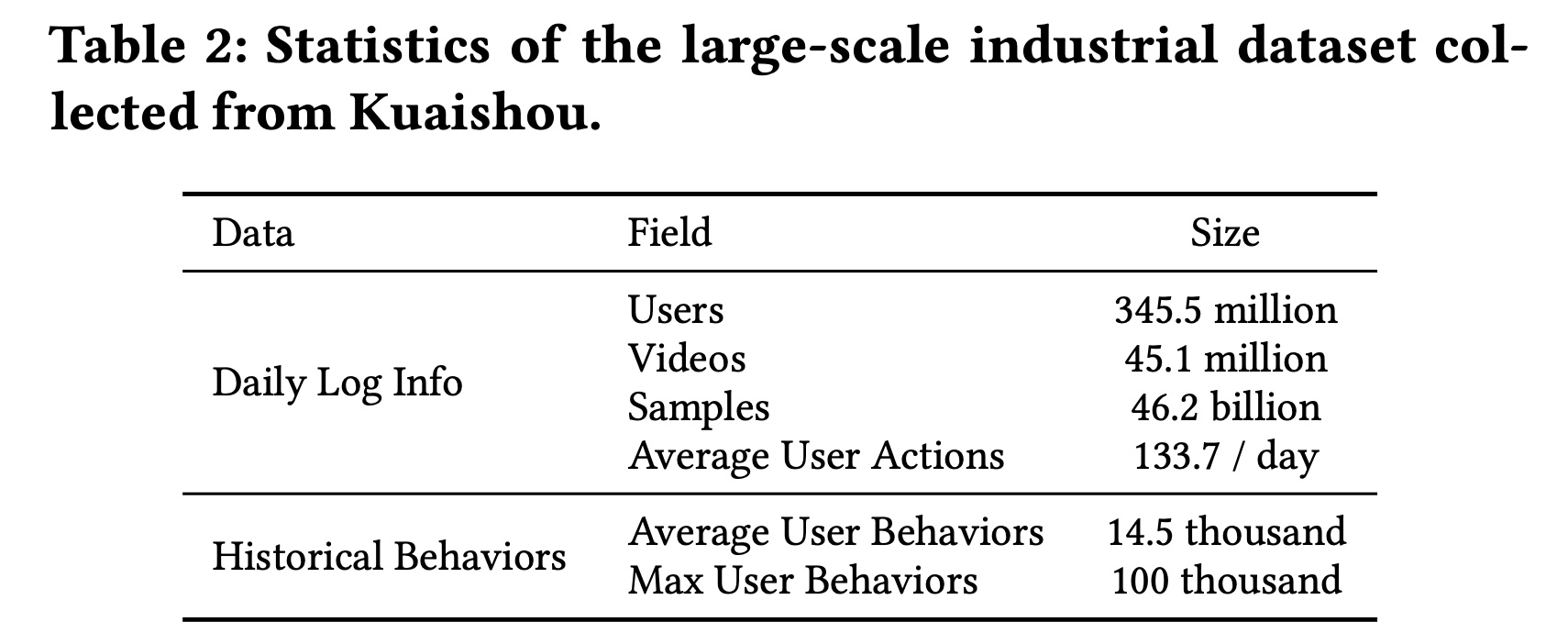
baseline:遵循常见做法(《Sampling Is All You Need on Modeling Long-Term User Behaviors for CTR Prediction》、《TWIN: TWo-Stage Interest Network for Lifelong User Behavior Modeling in CTR Prediction at Kuaishou》),鉴于我们的重点是建模极长的用户历史记录,我们将TWIN-V2与以下SOTA baselines进行比较:(1) Avg-Pooling:一种利用均值池化的简单方法。(2) DIN:它为推荐算法引入了target attention。(3) SIM Hard:Hard-search是指GSU根据category过滤长期历史。(4) SIM Soft:Soft search涉及通过计算target item和历史记录中的items之间的向量点积来选择top-k items。(5) ETA:它采用局部敏感哈希(Locality Sensitive Hashing: LSH)来促进端到端的训练。(6) SDIM:GSU通过收集与target item共享相同哈希签名(hashing signature)的behaviors来聚合长期历史。(7) SIM Cluster:由于SIM Hard依赖于annotated categories,我们通过video embeddings的聚类对其进行了改进。GSU检索与target item位于相同cluster中的历史行为。在这里,我们将所有items聚类为1,000 groups。(8) SIM Cluster+:这是SIM Cluster的高级变体,其cluster数量增加到10,000个。(9) TWIN:它为GSU和ESU阶段提出了一种有效的target attention。
为了确保公平比较,除了
long-term interest modeling外,我们在模型的所有方面都保持一致。评估指标和评估设置:
我们使用一天中连续
23个小时的样本作为训练数据,并使用接下来一个小时的样本进行测试。我们连续5天评估所有算法并报告5天的平均性能。相当于将算法重复
5次并报告平均性能。至于评估指标,我们采用了广泛使用的
AUC和Group AUC: GAUC。我们计算了连续5天这两个指标的均值和标准差。GAUC对所有用户的AUC进行加权平均,权重设置为该用户的样本数。GAUC消除了用户之间的bias,以更精细和公平的粒度评估模型性能。
实现细节:
对于所有模型,我们都使用
industrial context中相同的item and user features,包括video ID, author ID and user ID等大量属性。TWIN-V2将单个用户历史长度限制为最多100,000 items,从而对life-cycle user behavior进行聚类。如前文所述,TWIN-V2经验性地将历史行为压缩为原始大小的约10%,从而导致GSU中的maximum input length约为10,000。对于其他两阶段模型,输入
GSU的历史行为最大长度限制为10,000 behaviors。对于
DIN和Avg-Pooling,recent history的最大长度为100,因为它们不是为long-term behaviors而设计的。Avg-Pooling事实上可以支持任意长度的用户行为序列。为什么这里截断为100?所有两阶段模型都利用
GSU来检索top 100 historical items并将它们输入ESU从而用于interest modeling。batch size设置为8192。Adam的学习率为5e-6。
1.2.1 整体性能
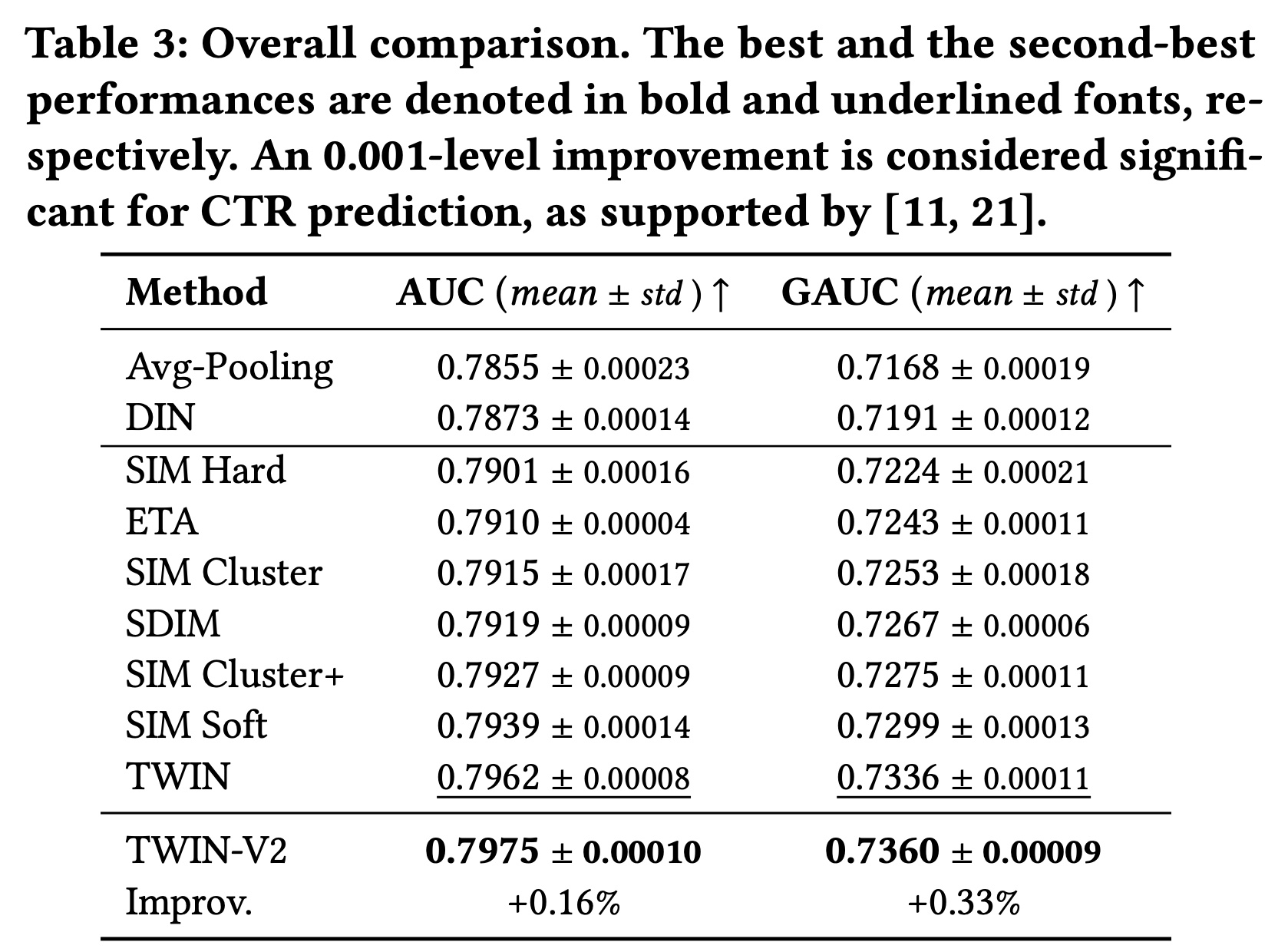
从
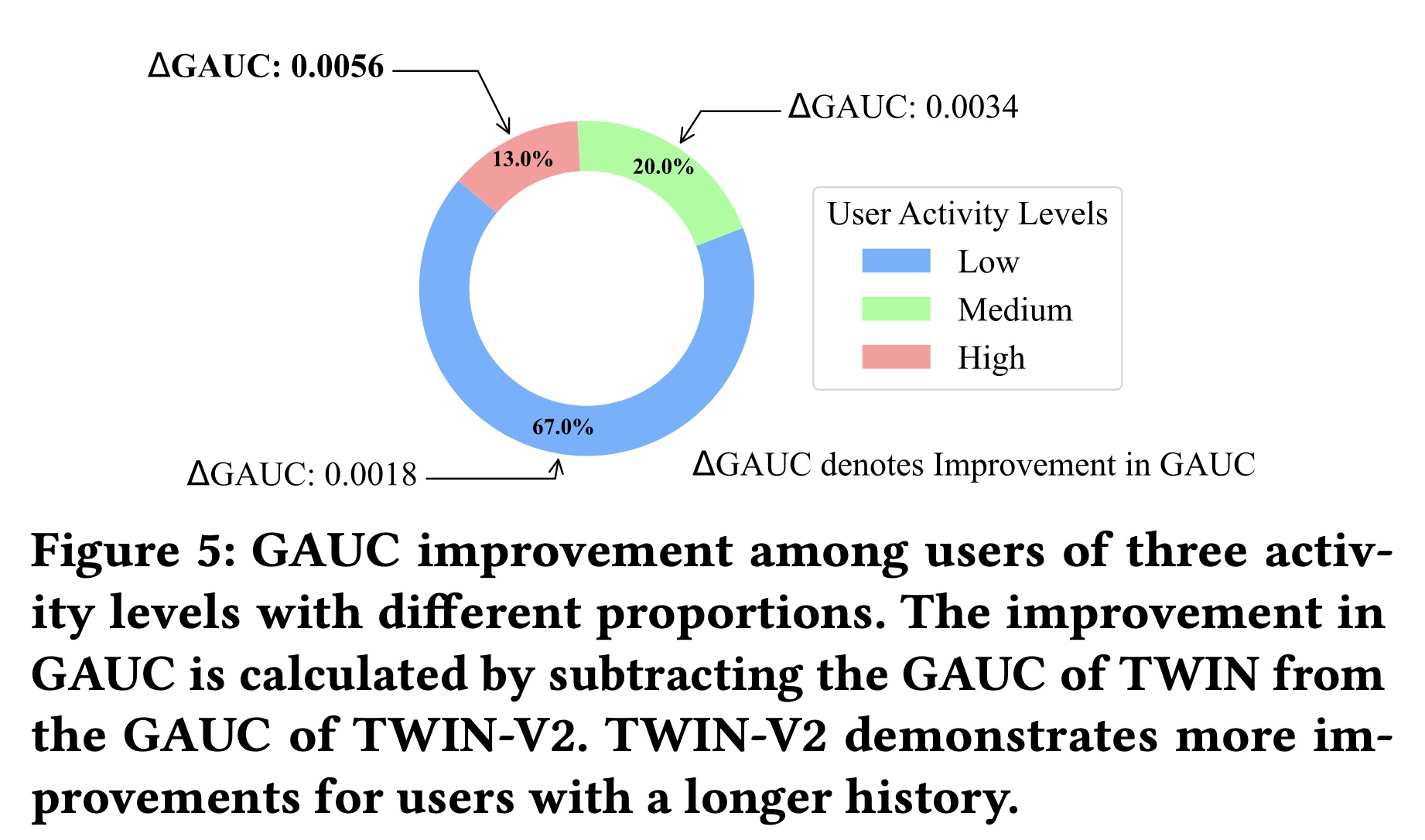
Table 3的结果中,我们得出以下观察结果:TWIN-V2的表现远超其他基线。现有文献(《Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate》、《DCN V2: Improved Deep & Cross Network and Practical Lessons for Web-Scale Learning to Rank Systems》)表明,AUC提高0.001对CTR prediction具有重要意义,足以产生online benefits。TWIN-V2比表现第二好的TWIN模型有所改进,AUC提高了0.0013,GAUC提高了0.0024。这些改进验证了TWIN-V2的有效性。TWIN-V2在GAUC上的相对改进高于AUC上的相对改进。GAUC提供了更细粒度的模型指标。GAUC的较大改进表明TWIN-V2在各种类型的用户中都实现了提升,而不仅仅是在整体样本上表现更好,而且它在特定子集上也表现出色。由于TWIN-V2包含更长的行为序列,我们相信它在高度活跃的用户群体中取得了更大的进步,这一假设在附录A.3中得到了验证(如Figure 5所示)。
1.2.2 消融研究
我们进行了一项消融研究,以调查核心模块在
TWIN-V2中的作用以及我们设计背后的原理。不同
Hierarchical Clustering方法的比较:我们的hierarchical clustering方法有两个主要特点:1):它利用动态clustering numbersizes of behaviors。2):k-means clustering是非均匀的,最终导致不同大小的clusters。
我们首先验证自适应的
cluster number“Binary”。此外,为了测试均匀cluster sizes的效果,我们创建了一个在balanced k-means clustering结果的变体,记作“Balanced&Binary”。在这个变体中,每次k-means iteration之后,对于larger cluster中的一部分item,如果它们比另一部分item更靠近另一个cluster的质心,则这些items会被移动到另一个cluster中,以确保最终两个cluster的大小相等。Table 4报告了对TWIN-V2和这两个变体的统计分析。在这三种方法中,我们的方法实现了最高的
cluster accuracy。这表明我们的方法创建的clusters中,items具有更紧密匹配的representation vectors,从而导致每个cluster内的items具有更高的相似度。cluster accuracy:每个item和它所属的cluster的质心进行cos相似度计算,然后取平均。我们的方法还实现了最短的运行时间,证实了自适应
此外,我们还报告了这些方法在测试集上的性能,如
Figure 4 (left)。
这些结果验证了自适应方法(
adaptive method)可以在每个cluster内分配更相似的items,并与其他方法相比加快了hierarchical clustering的过程。
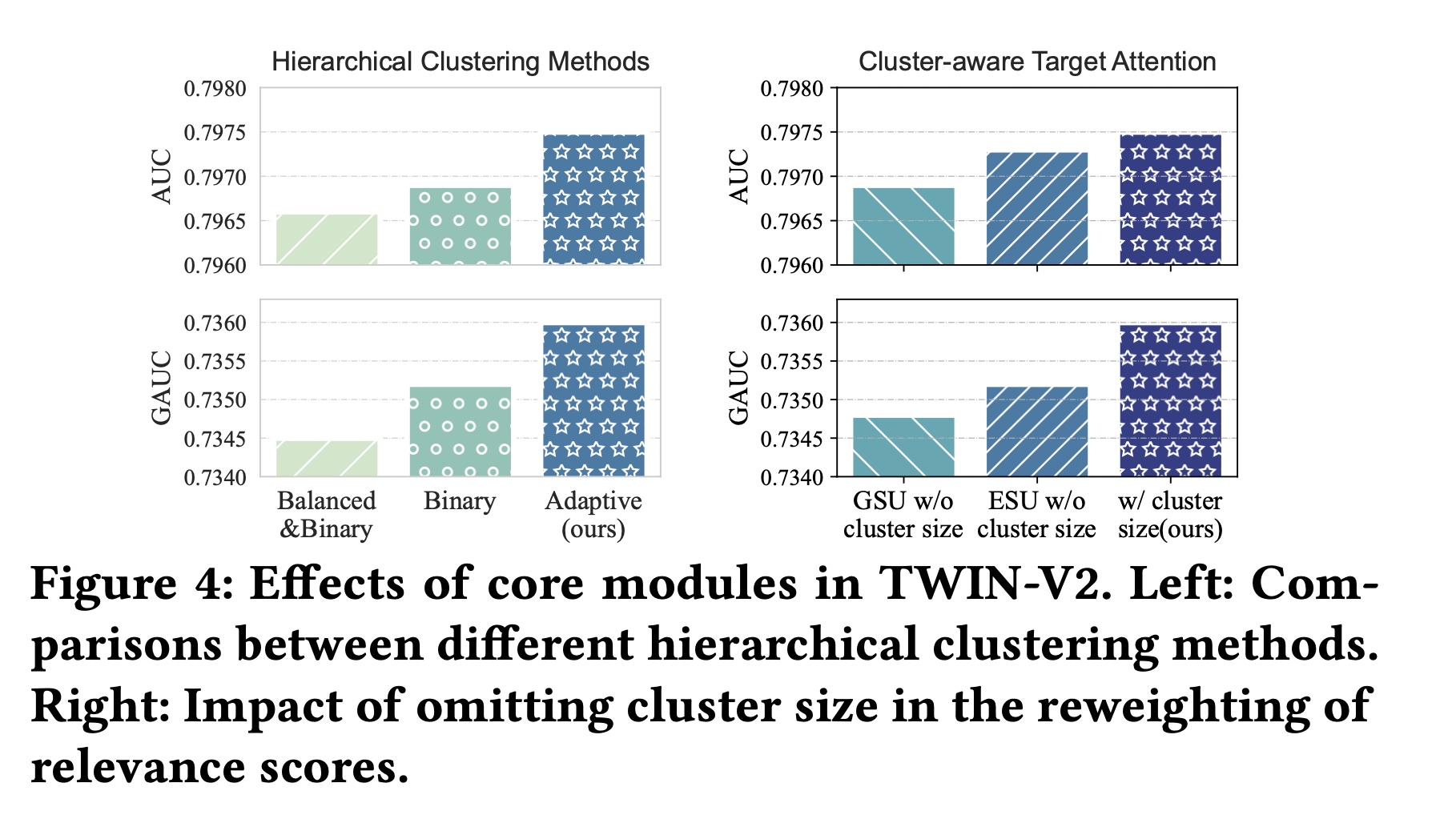
Cluster-aware Target Attention的有效性:在提出的cluster-aware target attention中,与TWIN相比,主要区别在于使用clustered behavior作为输入,并根据cluster size重新加权attention scores。我们分别从GSU和ESU中删除了cluster size reweighting部分,以评估其对性能的影响。具体来说,我们分别将GSU和ESU的Figure 4 (right)显示了实验结果。省略reweighting会导致性能下降,这验证了通过cluster size来调整attention scores的有效性。
1.2.3 在线实验
我们进行了在线
A/B test,以验证TWIN-V2在我们工业级系统中的性能。Table 5显示了TWIN-V2在快手三个代表性场景(Featured-Video Tab, Discovery Tab, and Slide Tab)中在观看时长(Watch Time)和推荐结果多样性方面的相对改进。观看时长衡量用户花费的总时间。
多样性是指模型推荐结果的多样性,比如视频类型的丰富性。
多样性指标公式s是什么?这里没给出来。
从结果来看,
TWIN-V2可以更好地建模用户兴趣,从而提升观看时长。此外,通过建模更长的历史行为,TWIN-V2可以发现更多样化的用户兴趣,从而带来更加多样化的推荐结果。