Datasets
一、基本概念
Datasets是一个用于轻松地访问和共享数据集的库,这些数据集是关于音频、计算机视觉、以及自然语言处理等领域。Datasets可以通过一行来加载一个数据集,并且可以使用Hugging Face强大的数据处理方法来快速准备好你的数据集。在Apache Arrow格式的支持下,通过zero-copy read来处理大型数据集,而没有任何内存限制,从而实现最佳速度和效率。Arrow是一种特定的数据格式,以列式的memory layout存储数据。这提供了几个显著的优势:Arrow的标准格式允许zero-copy read,这实际上是消除了所有的序列化开销。Arrow是语言无关的,它支持不同的编程语言。Arrow是面向列的,因此在查询和处理数据切片或列时,它的速度更快。Arrow允许copy-free地移交给标准的机器学习工具,如Numpy, Pandas, PyTorch, TensorFlow。Arrow支持多种列类型(可能是嵌套类型)。
Datasets使用Arrow作为它的局部缓存系统,这允许datasets由on-disk cache来支持,这是用于fast lookup的内存映射。这种架构允许在设备内存相对较小的机器上使用大型数据集。import osimport psutilimport timeitfrom datasets import load_dataset# Process.memory_info 为字节,因此需要转换为 MBmem_before = psutil.Process(os.getpid()).memory_info().rss / (1024 * 1024)wiki = load_dataset("wikipedia", "20220301.en", split="train")mem_after = psutil.Process(os.getpid()).memory_info().rss / (1024 * 1024)print(f"RAM memory used: {(mem_after - mem_before)} MB")# RAM memory used: 50 MBArrow数据实际上是从磁盘进行内存映射的,而不是加载到内存中。内存映射允许访问磁盘上的数据,并利用虚拟内存功能进行fast lookup。xxxxxxxxxxs = """batch_size = 1000for i in range(0, len(wiki), batch_size):batch = wiki[i:i + batch_size]"""time = timeit.timeit(stmt=s, number=1, globals=globals())print(f"Time to iterate over the {wiki.dataset_size >> 30} GB dataset: {time:.1f} sec, ie. {float(wiki.dataset_size >> 27)/time:.1f} Gb/s")# Time to iterate over the 18 GB dataset: 70.5 sec, ie. 2.1 Gb/s在使用
Arrow的内存映射数据集上进行迭代,速度很快。安装:
xxxxxxxxxxpip install datasetsconda install -c huggingface -c conda-forge datasets如果希望安装
Audio特性,执行命令:xxxxxxxxxxpip install datasets[audio]sudo apt-get install libsndfile1 # 手动安装 libsndfilepip install 'torchaudio<0.12.0' # 对 MP3 的支持sudo apt-get install sox # 对 MP3 的支持如果希望安装
Image特性,执行命令:xxxxxxxxxxpip install datasets[vision]音频数据集就像文本数据集一样被加载。然而,音频数据集的预处理略有不同。你需要一个
feature extractor,而不是一个tokenizer。音频输入也可能需要重新采样其采样率,从而匹配你正在使用的预训练模型的采样率。例如:
xxxxxxxxxxfrom datasets import load_dataset, Audiofrom transformers import AutoFeatureExtractor#### feature extractorfeature_extractor = AutoFeatureExtractor.from_pretrained("facebook/wav2vec2-base")def preprocess_function(examples):audio_arrays = [x["array"] for x in examples["audio"]]inputs = feature_extractor(audio_arrays,sampling_rate=16000,padding=True,max_length=100000,truncation=True,)return inputsdataset = load_dataset("PolyAI/minds14", "en-US", split="train")dataset = dataset.cast_column("audio", Audio(sampling_rate=16000)) # 重新采样dataset = dataset.map(preprocess_function, batched=True) # 逐样本地抽取特征dataset = dataset.rename_column("intent_class", "labels")#### Pytorchfrom torch.utils.data import DataLoaderdataset.set_format(type="torch", columns=["input_values", "labels"])dataloader = DataLoader(dataset, batch_size=4)#### TensorFlowimport tensorflow as tftf_dataset = dataset.to_tf_dataset(columns=["input_values"],label_cols=["labels"],batch_size=4,shuffle=True)同样地,图像数据集就像文本数据集一样被加载。图像数据集也需要一个
feature extractor,而不是一个tokenizer。对图像进行数据增强在计算机视觉中很常见,你可以随意使用任何数据增强的库。例如:
xxxxxxxxxxfrom datasets import load_dataset, Imagefrom torchvision.transforms import Compose, ColorJitter, ToTensor#### 数据增强jitter = Compose([ColorJitter(brightness=0.5, hue=0.5), ToTensor()])def transforms(examples):examples["pixel_values"] = [jitter(image.convert("RGB"))for image in examples["image"]]return examplesdataset = load_dataset("beans", split="train")dataset = dataset.with_transform(transforms)#### Pytorchfrom torch.utils.data import DataLoaderdef collate_fn(examples):images = []labels = []for example in examples:images.append((example["pixel_values"]))labels.append(example["labels"])pixel_values = torch.stack(images)labels = torch.tensor(labels)return {"pixel_values": pixel_values, "labels": labels}dataloader = DataLoader(dataset, collate_fn=collate_fn, batch_size=4)文本数据集需要一个
tokenizer。例如:
xxxxxxxxxxfrom datasets import load_datasetfrom transformers import AutoTokenizerdataset = load_dataset("glue", "mrpc", split="train")tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")#### 编码def encode(examples):return tokenizer(examples["sentence1"], examples["sentence2"],truncation=True, padding="max_length")dataset = dataset.map(encode, batched=True)dataset = dataset.map(lambda examples: {"labels": examples["label"]}, batched=True)#### Pytorchimport torchdataset.set_format(type="torch",columns=["input_ids", "token_type_ids", "attention_mask", "labels"])dataloader = torch.utils.data.DataLoader(dataset, batch_size=32)#### TensorFlowimport tensorflow as tffrom transformers import DataCollatorWithPaddingdata_collator = DataCollatorWithPadding(tokenizer=tokenizer, return_tensors="tf")tf_dataset = dataset.to_tf_dataset(columns=["input_ids", "token_type_ids", "attention_mask"],label_cols=["labels"],batch_size=2,collate_fn=data_collator,shuffle=True)Hugging Face Hub包含了很多数据集,我们可以从Hub上下载和上传数据集。下载数据集:
xxxxxxxxxxfrom datasets import load_datasetdataset = load_dataset("glue", "mrpc")上传数据集:
首先安装必要的库:
xxxxxxxxxxpip install huggingface_hub然后再命令行中登录
Hugging Face账户:xxxxxxxxxxhuggingface-cli login最后在代码中上传数据集:
xxxxxxxxxxdataset.push_to_hub("huaxz/dataset_demo")
Datasets会存储以前下载和处理的数据集,因此当你需要再次使用它们时,可以直接从cache中重新加载它们。这避免了重新下载数据集或重新应用处理函数。Datasets为cache文件分配一个指纹fingerprint。指纹跟踪数据集的当前状态。初始指纹是使用来自Arrow table的哈希、或Arrow files的哈希 (如果数据集在磁盘上)来计算的。通过组合前一状态的指纹、以及哈希最近应用的变换,从而计算随后的指纹。xxxxxxxxxxfrom datasets import Datasetsdataset1 = Datasets.from_dict({"a": [0, 1, 2]})dataset2 = dataset1.map(lambda x: {"a": x["a"] + 1})print(dataset1._fingerprint)# 85ad8fa07d5f63f5print(dataset2._fingerprint)# 3761ff563081e590注意,需要确保所有的
transform是可以pickle序列化或dill序列化的,否则Datasets使用一个随机的指纹并且抛出一个警告(此时transformer是不可哈希的)。当禁用缓存时,
Datasets会重新计算所有的内容。此时,每次都会生成缓存文件并将它们写入临时目录。Python session结束时,临时目录中的缓存文件将被删除。Features定义为数据集的内部结构,它用于指定底层的序列化格式。Features包含了从列名和类型到ClassLabel的所有高级信息,因此可以视为是数据集的backbone。Features的格式很简单:dict[column_name, column_type]。它是列名和列类型的字典。xxxxxxxxxxfrom datasets import load_datasetdataset = load_dataset('glue', 'mrpc', split='train')print(dataset.features)# {'sentence1': Value(dtype='string', id=None),# 'sentence2': Value(dtype='string', id=None),# 'label': ClassLabel(names=['not_equivalent', 'equivalent'], id=None),# 'idx': Value(dtype='int32', id=None)}其中:
Value特征表明idx数据类型为int32、sentence1/sentence2数据类型为string。label特征表明label包含两个类别:'not_equivalent', 'equivalent'。我们可以通过ClassLabel.int2str()以及ClassLabel.str2int()对label执行整数和字符串之间的转换。xxxxxxxxxxprint(dataset.features['label'].int2str(0))# 'not_equivalent'print(dataset.features['label'].str2int('equivalent'))# 1
另外还有一些有用的特征类型:
Sequence:包含多个特征。xxxxxxxxxxfrom datasets import load_datasetdataset = load_dataset('squad', split='train')print(dataset.features['answers'])# Sequence(feature={'text': Value(dtype='string', id=None), 'answer_start': Value(dtype='int32', id=None)}, length=-1, id=None)Array2D/Array3D/...:包含可变长度的数据。xxxxxxxxxxfrom datasets import Features, Array2Dfeatures = Features({'a': Array2D(shape=(None, None), dtype='int32')})print(features)# {'a': Array2D(shape=(None, None), dtype='int32', id=None)}Audio:包含音频类型的数据,该特征具有三个重要的字段:array:存放解码的音频数据,以一维的array来表示。path:所下载的音频文件的路径。sampling_rate:音频文件的采样率。
xxxxxxxxxxfrom datasets import load_dataset, Audiodataset = load_dataset("PolyAI/minds14", "en-US", split="train")print(dataset[0]["audio"])# {'array': array([ 0., 0.00024414, -0.00024414, ..., -0.00024414, 0., 0.], dtype=float32),# 'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~JOINT_ACCOUNT/602ba55abb1e6d0fbce92065.wav',# 'sampling_rate': 8000}
Batch mapping:以batch mode来执行Dataset.map()是非常强大的,可以加速数据预处理过程,并自由地控制生成的数据集的规模。但是,注意
batch中每一列的行数应该相同:xxxxxxxxxxfrom datasets import Datasetdataset = Dataset.from_dict({"a": [0, 1, 2]})# batch 中, 新的列 b 有 6 行,而旧的列 a 有 3 行, 抛出异常dataset.map(lambda batch: {"b": batch["a"] * 2}, batched=True)# ArrowInvalid: Column 1 named b expected length 3 but got length 6'dataset_with_duplicates = dataset.map(lambda batch: {"b": batch["a"] * 2},remove_columns=["a"], batched=True)
二、load_dataset() 原理
一个
dataset是包含如下内容的目录:- 一些通用格式的数据文件,如
JSON, CSV, Parquet, text等等格式。 - 一个可选的
dataset script,如果它需要一些代码来读取数据文件。这用于加载所有格式和结构的文件。
load_dataset()函数从本地或Hugging Face Hub获取dataset。Hub是一个central repository,它存储了Hugging Face的数据集和模型。如果数据集仅包含数据文件,那么
load_dataset()会根据数据文件的扩展名(如json, csv, parquet,text等等)来自动推断如何加载数据文件。如果数据集有一个
dataset script,那么load_dataset()从Hugging Face Hub下载并导入dataset script。dataset script中的代码定义数据集信息(描述、Features、原始文件的URL等等),并讲述Datasets如何从dataset script生成和展示样本。dataset script从原始文件的URL下载数据集文件,生成数据集并将其缓存在磁盘上的Arrow table中。 如果你以前下载过该数据集,那么Datasets将从缓存中重新加载它,从而避免重复下载。
- 一些通用格式的数据文件,如
构建一个数据集:首次加载数据集时,
Datasets获取原始数据文件,并将其构建为一个table,这个table由行组成并且包含带类型的列。有两个主要的类负责构建数据集:BuilderConfig和DatasetsBuilder。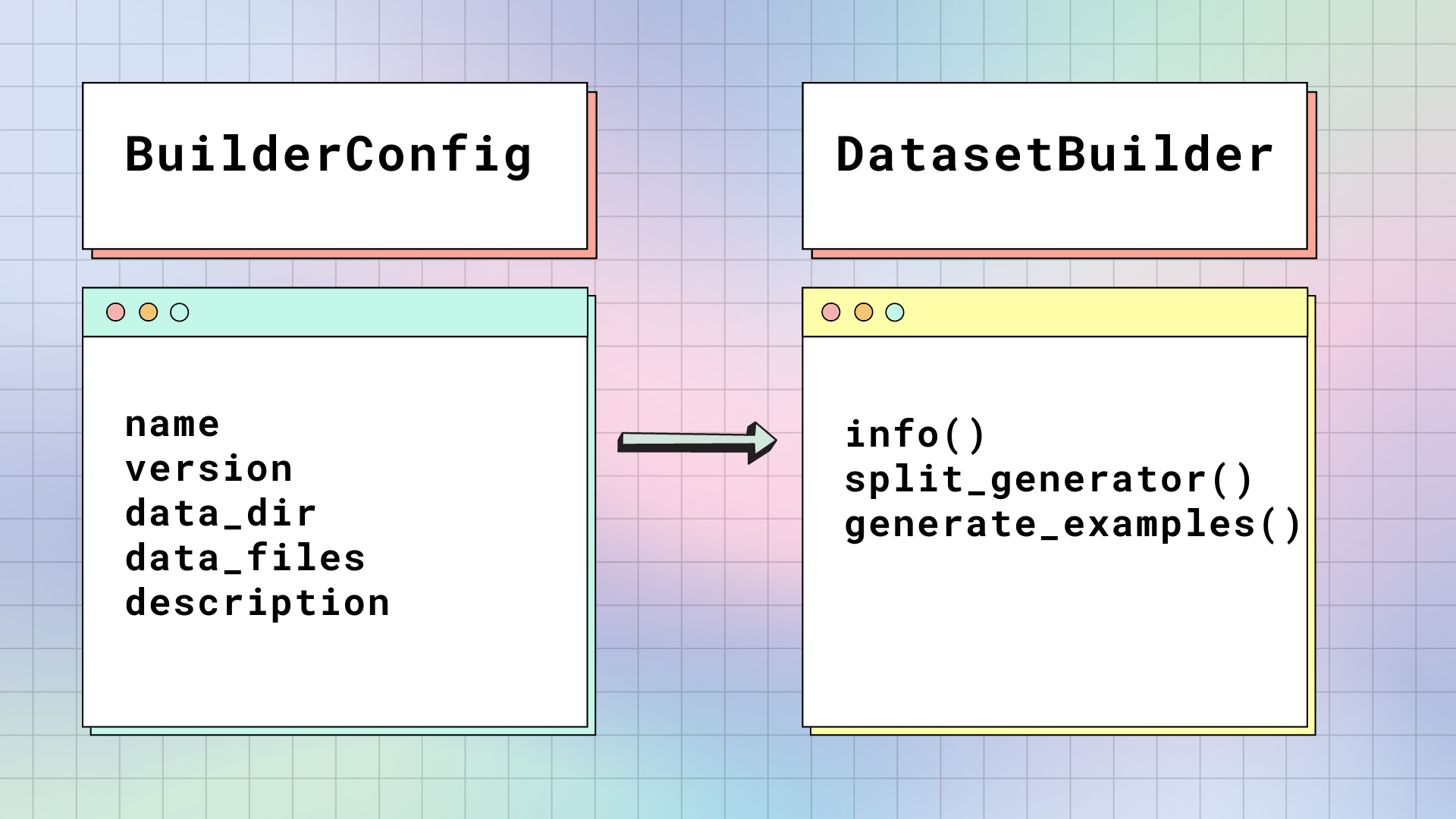
BuilderConfig:BuilderConfig是DatasetsBuilder的配置类,包含以下基本属性:name:数据集的简称。version:数据集的版本id。data_dir:包含数据文件的本地目录的路径。data_files:本地数据文件的文件名。description:数据集的描述。
如果你想向你的数据集添加额外的属性,如
class label,你可以创建base BuilderConfig class的子类。有两种方法可以填充BuilderConfig类及其子类的属性:- 在数据集的
DatasetsBuilder.BUILDER_CONFIGS()属性中,提供一组预定义的BuilderConfig类(或子类)的实例。 - 当你调用
load_dataset()时,任何不是特定于该方法的关键字参数都将用于设置BuilderConfig类的关联属性(如果属性已经设置过,那么这里将覆盖它)。
你还可以设置
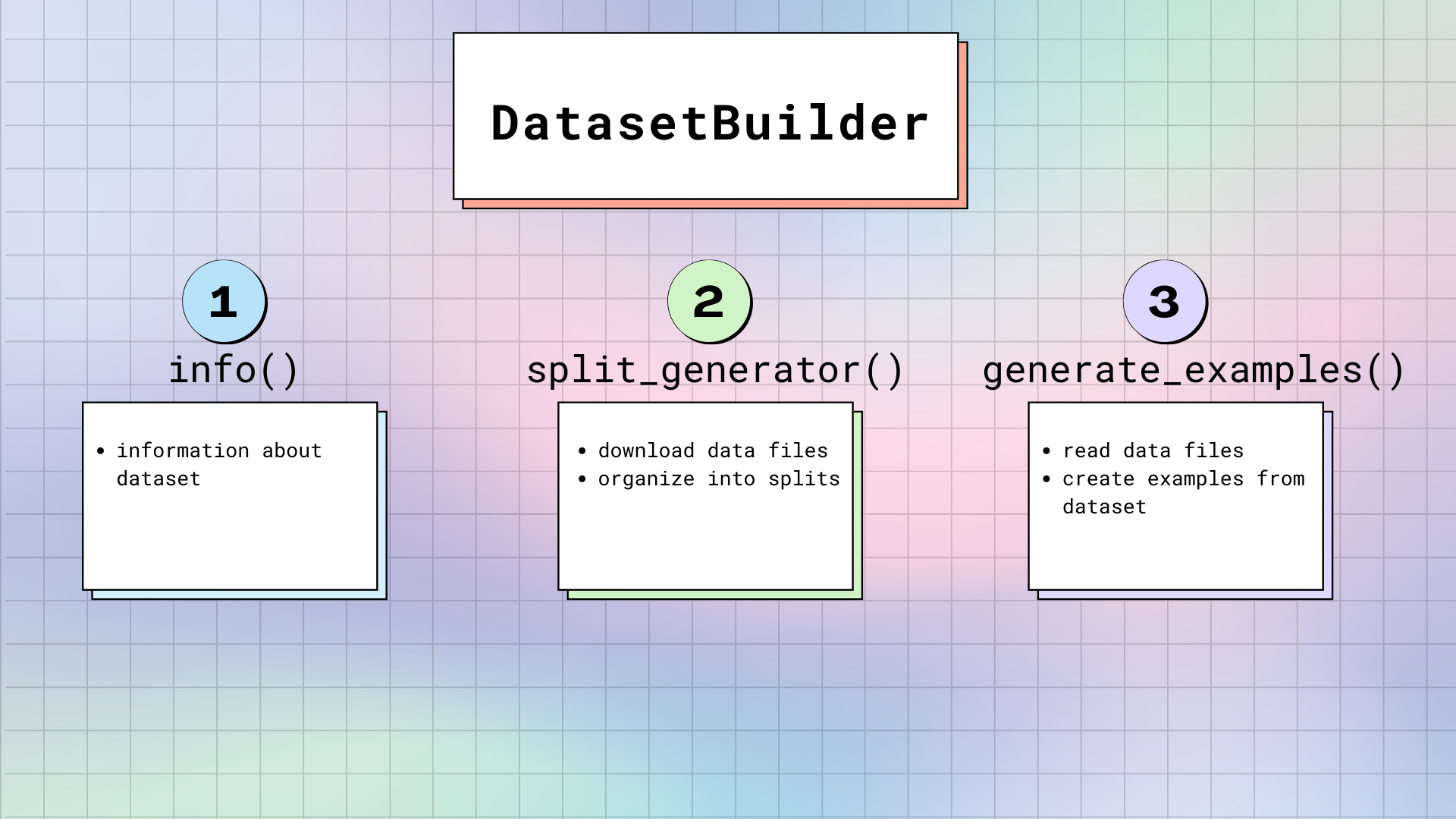
DatasetBuilder.BUILDER_CONFIG_CLASS到BuilderConfig的任意自定义子类。DatasetsBuilder:DatasetBuilder访问BuilderConfig中的所有属性来构建实际的数据集。DatasetBuilder有三个主要的方法:DatasetBuilder._info():负责定义数据集属性。当你调用dataset.info时,Datasets返回存储在这里的信息。同样地,这里也指定了Features(Features提供了每一列的名称和类型)。DatasetBuilder._split_generator():下载或检索数据文件,将它们组织为splits(即,训练集、验证集、测试集的拆分)。该方法有一个
DownloadManager,可以从本地文件系统下载或获取文件。在DownloadManager中,有一个DownloadManager.download_and_extract()方法,它接受URL到原始数据文件的字典,并下载所请求的文件。可接受的输入包括:单个URL或路径、URL或路径的列表/字典。任何压缩文件类型(如TAR, GZIP, ZIP)都将被自动解压。文件下载完成之后,
SplitGenerator会将它们组织成splits。SplitGenerator包含split的名称,以及任何关键字参数(这些关键字参数用于提供给DatasetBuilder._generate_examples()方法)。这些关键字参数可以特定于每个split,并且通常至少包括每个split的数据文件的本地路径。DatasetBuilder._generate_examples():为一个split读取并解析数据文件。然而,它根据来自DatasetBuilder._info()的features指定的格式来生成样本。DatasetBuilder._generate_examples()的输入实际上是DatasetBuilder._split_generator()的关键字参数中所提供的路径。数据集是使用
Python generator生成的,该生成器不会将所有数据加载到内存中。因此,生成器可以处理大型数据集。但是,在将生成的样本刷新到磁盘上的数据集文件之前,它们存储在一个ArrowWriter buffer中。这意味着被生成的样本是以batch的方式写入的。如果数据集样本消耗大量的内存(如图像、视频),请确保在DatasetBuilder中为DEFAULT_WRITER_BATCH_SIZE属性指定一个较低的值。我们建议不要超过200 MB的大小。
没有
loading script:有时候我们希望能够快速使用一个数据集。实现一个dataset loading script有时会碍事。Datasets消除了这个障碍,它使从Hug加载任何数据集成为可能,而无需dataset loading script。用户只需要将数据文件上传到Hug上的dataset repository中。loading script-free方法使用huggingface_hub library来列出dataset repository中的文件。你也可以提供本地目录的路径,而不是repository name。根据可用的数据文件格式,Datasets自动选择一个data file builder来为你创建数据集。维持完整性:为了确保数据集是完整的,
load_dataset()将对下载的文件执行一系列的测试,确保所有内容都在那里。以下数据将被验证:下载文件的列表、下载文件的字节数量、下载文件的SHA256 checksum、生成的DatasetDict的split数量、生成的DatasetDict的每个split中的样本数。如果数据集没有通过验证,很可能数据集的原始
host在数据文件中做了一些更改。在这种情况下,会引发一个错误,警告数据集已更改。要忽略错误,需要在load_dataset()中指定ignore_verifications=True。每当看到验证错误时,请随时在相应的数据集"Community"选项卡中发起一个discussion或pull request,以便更新该数据集的完整性检查。Datasets将每个数据集看作一个内存映射文件,这个内存映射文件提供了RAM和文件系统存储之间的映射,从而允许Datasets访问和操作数据集的元素而无需将数据集完全加载到内存中。内存映射文件也在多个进程之间共享,这使得像Dataset.map()之类的方法可以并行化,而无需移动或者拷贝数据集。在底层,些功能都是由apache Arrow内存格式和pyarrow库提供的支持,使得数据加载和处理速度非常快速。Datasets通常能以GB/s级别的速度迭代数据集。通过上述的方法就已经能够解决大多数大数据集加载的限制,但是有时候我们不得不使用一个很大的数据集, 该数据集甚至无法存储在笔记本电脑的硬盘上。例如,如果我们尝试下载整个
Pile数据集,我们需要825GB的可用磁盘空间。为了处理这种情况,Datasets提供了一个流式功能,这个功能允许我们动态下载和访问数据集元素而不需要下载整个数据集。
三、API
3.1 DatasetInfo
DatasetInfo:包含数据集的信息。xxxxxxxxxxclass datasets.DatasetInfo( description: str = <factory>, citation: str = <factory>, homepage: str = <factory>, license: str = <factory>, features: typing.Optional[datasets.features.features.Features] = None, post_processed: typing.Optional[datasets.info.PostProcessedInfo] = None, supervised_keys: typing.Optional[datasets.info.SupervisedKeysData] = None, task_templates: typing.Optional[typing.List[datasets.tasks.base.TaskTemplate]] = None, builder_name: typing.Optional[str] = None, config_name: typing.Optional[str] = None, version: typing.Union[str, datasets.utils.version.Version, NoneType] = None, splits: typing.Optional[dict] = None, download_checksums: typing.Optional[dict] = None, download_size: typing.Optional[int] = None, post_processing_size: typing.Optional[int] = None, dataset_size: typing.Optional[int] = None, size_in_bytes: typing.Optional[int] = None )参数:
description:一个字符串,指定数据集的描述。citation:一个字符串,指定数据集的BibTeX citation。homepage:一个字符串,指定数据集的官方URL。license:一个字符串,指定数据集的licence。features:一个Features对象,指定数据集的特征。post_processed:一个PostProcessedInfo对象,指定数据集的后处理信息。supervised_keys:一个SupervisedKeysData对象,指定用于监督学习的input feature和label(如果该数据集有的话)。builder_name:一个字符串,指定创建数据集的GeneratorBasedBuilder子类的名称。通常与相应的script name相匹配。它也是dataset builder class name的snake_case版本。config_name:一个字符串,指定从BuilderConfig派生的配置的名称。version:一个字符串,指定数据集的版本。splits:一个字典,指定split name和metadata之间的映射。download_checksums:一个字典,指定URL到被下载的数据集checksum和对应metadata之间的映射。download_size:一个整数,指定为生成数据集而下载的文件的大小(单位字节)。post_processing_size:一个整数,指定后处理之后数据集的大小(单位字节)。dataset_size:一个整数,指定所有split的Arrow table的组合后的大小(单位字节)。size_in_bytes:一个整数,指定数据集关联的所有文件的总大小(包括下载的文件和Arrow文件,单位字节)。task_templates:TaskTemplate的一个列表,指定训练和评估期间预处理数据集的task template。每个模板都将数据集的Features转换为标准化的列名和类型。config_kwargs:额外的关键字参数,传递给BuilderConfig并在DatasetBuilder中使用。
注意:这些属性在
DatasetInfo创建时被赋值,并可能在随后被更新。方法:
from_directory(dataset_info_dir: str, fs = None):从dataset_info_dir中的JSON文件中创建DatasetInfo。它将重写所有的DatasetInfo的metadata。参数:
dataset_info_dir:一个字符串,指定存放metadata file的目录。fs:一个fsspec.spec.AbstractFileSystem,指定从哪里下载文件。
write_to_directory(dataset_info_dir, pretty_print = False, fs = None):将DatasetInfo和license写入dataset_info_dir中的JSON文件。参数:
pretty_print:一个布尔值,指定JSON是否是pretty-printed的。- 其它参数参考
from_directory()。
3.2 Dataset
Dataset:数据集的基类,基于Apache Arrow table来实现。xxxxxxxxxxclass datasets.Dataset(arrow_table: Table,info: Optional[DatasetInfo] = None,split: Optional[NamedSplit] = None,indices_table: Optional[Table] = None,fingerprint: Optional[str] = None,)参数:文档未指定,源码也没有。
属性:
info:返回一个DatasetInfo对象,包含数据集中的所有metadata。split:返回一个NamedSplit对象,对应于named dataset split。builder_name/citation/config_name/dataset_size/description/download_checksums/download_size/features/homepage/license/size_in_bytes/supervised_keys/version:参考DatasetInfo的属性。format:返回一个字典,表示数据集的格式。shape:返回一个Tuple[int, int],表示数据集的形状(列数,行`数)。column_names:返回一个字符串列表,表示数据集的列名。num_rows:返回一个整数,表示数据集的行数。num_columns:返回一个整数,表示数据集的列数。cache_files:返回一个字典的列表,表示数据集背后的、包含Apache Arrow table的缓存文件。data:返回一个Tabe对象,表示数据集背后的Apache Arrow table。
方法:
add_column(name: str, column: Union[list, np.array], new_fingerprint: str) -> Dataset:向数据集中添加列。参数:
name:一个字符串,指定列名。column:一个列表或np.array,指定列数据。new_fingerprint:一个字符串,指定新的指纹。
返回一个
Dataset。add_item(item: dict, new_fingerprint: str) -> Dataset:向数据集中添加一行。参数:
item:一个字典,指定行数据。字典的key就是列名,需要提供全部列名。- 其它参数参考
add_column。
返回一个
Dataset。from_file():从Arrow table的文件中初始化一个数据集。xxxxxxxxxxfrom_file(filename: str,info: Optional[DatasetInfo] = None,split: Optional[NamedSplit] = None,indices_filename: Optional[str] = None,in_memory: bool = False,) -> Dataset参数:
filename:一个字符串,指定数据集的文件名。info:一个DatasetInfo对象,指定数据集的信息。split:一个NamedSplit对象,指定数据集的split。indices_filename:一个字符串,指定索引的文件名。in_memory:一个布尔值,指定是否将数据拷贝到内存。
返回一个
Dataset。from_buffer():从Arrow buffer中初始化一个数据集。xxxxxxxxxxfrom_buffer(buffer: pa.Buffer,info: Optional[DatasetInfo] = None,split: Optional[NamedSplit] = None,indices_buffer: Optional[pa.Buffer] = None,) -> Dataset参数:
buffer:一个pyarrow.Buffer,指定Arrow buffer。indices_buffer:一个pyarrow.Buffer,指定索引的Arrow buffer。- 其它参数参考
from_file()。
返回一个
Dataset。from_pandas():从pandas.DataFrame转换为一个pyarrow.Table进而创建一个数据集。Arrow Table中的列类型是从DataFrame中的pandas.Series中推断而来。在non-object Series的情况下,Numpy dtype被直接转换为对应的Arrow类型。在object Series的情况下,我们需要查看Series中的Python object来猜测数据类型。注意:
object Series可能没有包含足够的信息来推断Arrow类型,例如DataFrame的长度为零、或者Series仅包含None/nan对象,此时Arrow type被设为null。可以通过构造显式的features来避免。xxxxxxxxxxfrom_pandas(df: pd.DataFrame,features: Optional[Features] = None,info: Optional[DatasetInfo] = None,split: Optional[NamedSplit] = None,preserve_index: Optional[bool] = None,) -> Dataset参数:
df:一个pandas.DataFrame对象,指定数据集的数据内容。features:一个Features对象,指定数据集的特征。preserve_index:一个布尔值,指定是否将pandas索引存储为数据集中的额外的列。默认值为
None,表示将索引存储为额外的列(RangeIndex除外,它仅被存储为metadata)。使用True,则强制将索引存储为列(包括RangeIndex)。其它参数参考
from_file()。
返回一个
Dataset。from_dict():从字典转换为一个pyarrow.Table进而创建一个数据集。xxxxxxxxxxfrom_dict(mapping: dict,features: Optional[Features] = None,info: Optional[DatasetInfo] = None,split: Optional[NamedSplit] = None,) -> Dataset参数:
mapping:一个字典对象,指定数据集的数据内容,它将字符串映射到Array或Python列表。- 其它参数参考
from_pandas()。
返回一个
Dataset。from_list():从字典的列表转换为一个pyarrow.Table进而创建一个数据集。xxxxxxxxxxfrom_list(mapping: List[dict],features: Optional[Features] = None,info: Optional[DatasetInfo] = None,split: Optional[NamedSplit] = None,) -> Dataset参数:
mapping:一个字典的列表,其中每个字典代表一行数据,字典的key就是列名,需要提供全部列名。- 其它参数参考
from_dict()。
返回一个
Dataset。from_csv():从CSV文件中创建数据集。xxxxxxxxxxfrom_csv(path_or_paths: Union[PathLike, List[PathLike]],split: Optional[NamedSplit] = None,features: Optional[Features] = None,cache_dir: str = None,keep_in_memory: bool = False,**kwargs,) -> Dataset参数:
path_or_paths:一个path-like对象或者path-like对象的列表,指定CSV文件的路径。split:一个NamedSplit对象,指定被赋予到数据集上的split name。features:一个Features对象,指定数据集特征。cache_dir:一个字符串,指定缓存数据的目录。默认为"~/.cache/huggingface/datasets"。keep_in_memory:一个布尔值,指定是否拷贝数据到内存。**kwargs:关键字参数,传递给padans.read_csv()。
返回一个
Dataset。from_generator():从迭代器中创建一个数据集。xxxxxxxxxxfrom_generator(generator: Callable,features: Optional[Features] = None,cache_dir: str = None,keep_in_memory: bool = False,gen_kwargs: Optional[dict] = None,**kwargs,) -> Dataset参数:
generator:一个可调用对象,表示一个generator function,它可以yield样本。gen_kwargs:一个字典,它作为关键字参数被传递给generator。你可以定义一个分片的数据集,其中在gen_kwargs中传递分片列表。kwargs:额外的关键字参数,用于传递给GeneratorConfig。- 其它参数参考
from_csv()。
返回一个
Dataset。示例(分片数据集):
xxxxxxxxxxdef gen(shards):for shard in shards:with open(shard) as f:for line in f:yield {"line": line}shards = [f"data{i}.txt" for i in range(32)]ds = Dataset.from_generator(gen, gen_kwargs={"shards": shards})from_json():从JSON文件中创建数据集。xxxxxxxxxxfrom_json(path_or_paths: Union[PathLike, List[PathLike]],split: Optional[NamedSplit] = None,features: Optional[Features] = None,cache_dir: str = None,keep_in_memory: bool = False,field: Optional[str] = None,**kwargs,) -> Dataset参数:
field:一个字符串,指定数据集被包含在JSON文件的哪个字段,所对应的field name。kwargs:关键字参数,传递给JsonConfig。- 其它参数参考
from_csv()。
返回一个
Dataset。from_parquet():从Parquet文件中创建数据集。xxxxxxxxxxfrom_parquet(path_or_paths: Union[PathLike, List[PathLike]],split: Optional[NamedSplit] = None,features: Optional[Features] = None,cache_dir: str = None,keep_in_memory: bool = False,columns: Optional[List[str]] = None,**kwargs,) -> Dataset参数:
columns:一个字符串的列表,如果不是None,那么仅从文件中读取这些列。可以进行嵌套,如a.b, a.d.e。kwargs:关键字参数,传递给ParquetConfig。- 其它参数参考
from_csv()。
返回一个
Dataset。from_text():从文本文件中创建数据集。xxxxxxxxxxfrom_text(path_or_paths: Union[PathLike, List[PathLike]],split: Optional[NamedSplit] = None,features: Optional[Features] = None,cache_dir: str = None,keep_in_memory: bool = False,**kwargs,) -> Dataset返回一个新的
Dataset。参数:
kwargs:关键字参数,传递给TextConfig。- 其它参数参考
from_csv()。
返回一个
Dataset。from_sql():从SQL query或database table中创建数据集。xxxxxxxxxxfrom_sql(sql: Union[str, "sqlalchemy.sql.Selectable"],con: Union[str, "sqlalchemy.engine.Connection", "sqlalchemy.engine.Engine", "sqlite3.Connection"],features: Optional[Features] = None,cache_dir: str = None,keep_in_memory: bool = False,**kwargs,) -> Dataset参数:
sql:一个字符串或者sqlalchemy.sql.Selectable对象,指定一个table name或者待执行的sql query。con:一个字符串或者sqlalchemy.engine.Connection或者sqlalchemy.engine.Engine或者sqlite3.Connection,用于初始化一个database connection。**kwargs:关键字参数,用于SqlConfig。- 其它参数参考
from_csv()。
返回一个
Dataset。unique( column: str ) -> list:返回指定列的unique element的列表。参数:
column:一个字符串,指定列名。返回值:该列
unique元素组成的列表。flatten(new_fingerprint: Optional[str] = None, max_depth=16) -> Dataset:对数据集的所有列进行展平,返回当前数据集的、列被展平了的copy。每个struct type列被展平为:每个struct filed一个列。非struct type列被保留。参数:
new_fingerprint:一个字符串,指定数据集经过变换之后的新的指纹。如果为None,那么这个新的指纹是基于一个哈希来计算得到,这个哈希考虑了前一个指纹、以及transform argument。max_depth:一个整数,指定最多展平多少层。
返回一个
Dataset(拷贝后的新数据集)。cast():对数据集的列进行类型强制转换,返回当前数据集的被类型转换的copy。xxxxxxxxxxcast(features: Features,batch_size: Optional[int] = 1000,keep_in_memory: bool = False,load_from_cache_file: bool = True,cache_file_name: Optional[str] = None,writer_batch_size: Optional[int] = 1000,num_proc: Optional[int] = None,) -> Dataset参数:
features:一个Features对象,指定数据集要强制转换的新的features。features的字段名必须匹配当前的列名。并且底层的数据能够支持转换到目标类型。对于困难的转换,如string <-> ClassLabel,你必须使用map来进行转换。batch_size:一个整数,指定强制类型转换的每个batch的样本数。如果batch_size <= 0或者batch_size == None,那么将整个数据集作为单个batch来强制类型转换。keep_in_memory:一个布尔值,是否拷贝数据到内存中。load_from_cache_file:一个布尔值,如果一个缓存文件已经存储了当前的计算,那么使用这个缓存文件而不是重新计算。cache_file_name:一个字符串,指定缓存文件的路径名。如果未指定,则自动生成缓存文件名。writer_batch_size:一个整数,指定cache file writer每次写操作时写入多少行。该值是内存占用和处理速度之间的trade-off:取值越大则处理速度更快(因为查找次数更少),取值越小则内存占用更少。num_proc:一个整数,指定多进程处理时的进程数。默认不使用多进程。
返回一个
Dataset(拷贝后的新数据集)。cast_column(column: str, feature: FeatureType, new_fingerprint: Optional[str] = None) -> Dataset:强制类型转换指定的列。参数:
column:一个字符串,指定列名。feature:一个FeatureType对象,表示目标的类型。new_fingerprint:参考cast()。
返回一个
Dataset。remove_columns(column_names: Union[str, List[str]], new_fingerprint: Optional[str] = None) -> Dataset:返回数据集的一个copy版本,该版本移除数据集中的某些列及其关联的内容。参数:
column_names:一个字符串或者字符串列表,指定要被移除的列。new_fingerprint:参考cast()。
返回一个
Dataset(拷贝后的新数据集)。你也可以通过带
remove_columns的Dataset.map()方法来移除列,但是map()方法是原地修改(而不会拷贝一个新的数据集),因此速度更快。rename_column( original_column_name: str, new_column_name: str, new_fingerprint: Optional[str] = None) -> Dataset:返回数据集的一个copy版本,该版本重命名了数据集的指定列。参数:
original_column_name:一个字符串,指定旧的列名。new_column_name:一个字符串,指定新的列名。new_fingerprint:参考cast()。
返回一个
Dataset(拷贝后的新数据集)。rename_columns(column_mapping: Dict[str, str], new_fingerprint: Optional[str] = None) -> Dataset:返回数据集的一个copy版本,该版本重命名了数据集的一些列。参数:
column_mapping:一个字典,键为旧的列名、值为新的列名。new_fingerprint:参考cast()。
返回一个
Dataset(拷贝后的新数据集)。class_encode_column(column: str, include_nulls: bool = False) -> Dataset:将指定的列强制类型转换为datasets.features.ClassLabel,并更新数据集。参数:
column:一个字符串,指定被强制类型转换的列名。include_nulls:一个布尔值,指定class label中是否包含null value。如果为True,则null value被编码为None。
返回一个
Dataset。__len__() -> int:返回数据集的行数。__iter__():迭代从而每次迭代产生样本。如果已经通过Dataset.set_format()来设置了格式,那么迭代返回的row将具有指定的格式。formatted_as():用于在with表达式中使用,它设置了__getitem__所返回的格式。xxxxxxxxxxformatted_as(type: Optional[str] = None,columns: Optional[List] = None,output_all_columns: bool = False,**format_kwargs,)参数:
type:一个字符串,指定输出类型,可以为None, 'numpy', 'torch', 'tensorflow', 'pandas', 'arrow'。None意味着__getitem__返回Python对象。columns:一个字符串列表,指定输出中哪些列需要被格式化。None意味着__getitem__返回所有的列。output_all_columns:一个布尔值,指定是否在输出中保留un-formatted列(作为python对象)。**format_kwargs:关键字参数,被传递给一些转换函数,如np.array, torch.tensor, tensorflow.ragged.constant。
可以通过
Dataset.format来查看数据集的格式。set_format():设置getitem所返回的格式。数据格式化是on-the-fly应用的。xxxxxxxxxxset_format(type: Optional[str] = None,columns: Optional[List] = None,output_all_columns: bool = False,**format_kwargs,)参数:参考
formatted_as()。也可以通过
Dataset.set_transform()来使用自定义的变换从而用于格式化。如果你在调用
Dataset.set_format()之后再调用Dataset.map()从而创建一个新的列,那么这个新的列也会被格式化。set_transform():利用transform来转换getitem所返回的内容。transform是on-the-fly应用到batch上的。xxxxxxxxxxset_transform(transform: Optional[Callable],columns: Optional[List] = None,output_all_columns: bool = False,)参数:
transform:一个可调用对象,给出了用户自定义的转换。它的输入是一个batch(以字典的形式,键位列名、值为该列在batch内的值)作为输入并返回一个batch作为输出。这个可调用对象再getitem返回之前的时刻被调用。columns:一个字符串列表,如果指定,则表示转换仅发生在这些列上,此时transform的输入仅包含这些列作为key的字典。output_all_columns:一个布尔值,指定是否输出所有的列。如果为True,则未包含在transform中的列也被输出。
reset_format():恢复getitem的格式为,对所有的列返回python对象。with_format():设置getitem所返回的格式。几乎类似于set_format()。xxxxxxxxxxwith_format(type: Optional[str] = None,columns: Optional[List] = None,output_all_columns: bool = False,**format_kwargs,)参数:参考
set_format()。Dataset.set_format()是原地修改操作,而Dataset.with_format()返回一个新的Dataset。with_transform():利用transform来转换getitem所返回的内容。几乎类似于set_transform()。xxxxxxxxxxwith_transform(transform: Optional[Callable],columns: Optional[List] = None,output_all_columns: bool = False,)参数:参考
set_transform()。Dataset.set_transform()是原地修改操作,而Dataset.with_transform()返回一个新的Dataset。__getitem__(key):用于对列索引(key为列名字符串)或行索引(key为整数索引、或者索引集合、或布尔值集合)。返回指定索引的值。cleanup_cache_files() -> int:清理数据集缓存目录中的所有缓存文件,当前使用的缓存文件(如果有的话)除外。返回被清除的文件的数量。
运行此命令时要小心,确保当前没有其他进程正在使用其他缓存文件。
map():对数据集中每个样本执行一个函数(以单个样本的形式或batch的形式),并更新数据集。如果函数返回的列在数据集中已存在,则覆盖该列。xxxxxxxxxxmap(function: Optional[Callable] = None,with_indices: bool = False,with_rank: bool = False,input_columns: Optional[Union[str, List[str]]] = None,batched: bool = False,batch_size: Optional[int] = 1000,drop_last_batch: bool = False,remove_columns: Optional[Union[str, List[str]]] = None,keep_in_memory: bool = False,load_from_cache_file: bool = None,cache_file_name: Optional[str] = None,writer_batch_size: Optional[int] = 1000,features: Optional[Features] = None,disable_nullable: bool = False,fn_kwargs: Optional[dict] = None,num_proc: Optional[int] = None,suffix_template: str = "_{rank:05d}_of_{num_proc:05d}",new_fingerprint: Optional[str] = None,desc: Optional[str] = None,) -> Dataset参数:
function:一个可调用对象,它被应用到样本上。它的签名为:如果
batched=False且with_indices=False且with_rank=False,那么函数签名为function(example: Dict[str, Any]) -> Dict[str, Any]。如果
batched=False且with_indices=True且/或with_rank=True,那么函数签名为function(example: Dict[str, Any], extra_args) -> Dict[str, Any]。其中
extra_args包含一个或两个参数,对应于with_indices=True且/或with_rank=True。如果
batched=True且with_indices=False且with_rank=False,那么函数签名为function(batch: Dict[str, List]) -> Dict[str, List]。如果
batched=True且with_indices=True且/或with_rank=True,那么函数签名为function(batch: Dict[str, List], extra_args) -> Dict[str, List]。
对于更高级的用法,
function也可以返回一个pyarrow.Table。此外,如果function返回None,那么map将执行该function并保留数据集不变。如果没有提供function,则默认为恒等映射:lambda x : x。with_indices:一个布尔值,指定是否提供样本索引作为function的输入。此时,function的签名应该是function(example, idx[, rank])。with_rank:一个布尔值,指定是否将rank作为function的输入。此时,function的签名应该是function(example[, idx], rank)。rank是用于分布式环境。input_columns:一个字符串或字符串列表,指定哪些列传递给function(作为关键字参数)。如果为None,则一个映射到所有格式化列的字典将被作为一个参数传递给function。batched:一个布尔值,指定是否batch执行。如果为True,那么传递给function的是一个batch的样本;否则传递给function的是单个样本。batch_size:一个整数,指定batch size。当batched = True时才生效。如果batched = True且batch size <= 0或batch size = None,则整个数据集作为一个batch。drop_last_batch:一个布尔值,当最后一个batch的大小小于batch_size时,是否丢弃掉这个小的batch。当batched = True时才生效。remove_columns:一个字符串或字符串列表,指定哪些列要被移除。这些列将在function执行之后、数据集样本更新之前被移除。例如,假设数据集的列为['a','b','c'],function根据'c'创建了一个新的列'new_c',如果要移除列['b', 'c'],那么最终的数据集包含两列['a', 'new_c'](而不是仅有一列['a'])。keep_in_memory:一个布尔值,指定是否保存数据集到内存中(而不是写入一个缓存文件)。`load_from_cache_file:一个布尔值,当为True时,如果已经有一个缓存文件存储了function的计算,那么使用这个缓存文件而不是重新计算。当为False时,始终重新计算。cache_file_name:一个字符串,指定缓存文件的路径名。用于load_from_cache_file。writer_batch_size:一个整数,指定cache file writer每次写操作时写入多少行。features:一个Features对象,指定一个特定的Features来存储缓存文件,而不是自动生成一个Features。disable_nullable:一个布尔值,指定是否在数据集中不允许null值。fn_kwargs:一个字典,用于为function提供关键字参数。num_proc:一个整数,指定用于生成缓存的最大进程数量。suffix_template:一个字符串,如果指定了cache_file_name,那么suffix_template用于指定cache_file_name的后缀。默认的模板为"_{rank:05d}_of_{num_proc:05d}"。例如,假设
cache_file_name为ABC.arrow,而rank=1, num_proc=4,那么最终的缓存文件名为ABC_000001_of_000004.arrow。new_fingerprint:一个字符串,指定新的指纹。如果为None,则新的指纹根据一个哈希值来计算,这个哈希值来自于前一个指纹、以及transform参数。desc:一个字符串,表示有意义的描述,用于进度条的展示。
返回一个
Dataset。filter():应用一个filter function到数据集中所有的样本(以单个样本的形式或batch的形式),并更新数据集,使得数据集仅包含filter function返回为True的样本。xxxxxxxxxxfilter( function: Optional[Callable] = None,with_indices=False,input_columns: Optional[Union[str, List[str]]] = None,batched: bool = False,batch_size: Optional[int] = 1000,keep_in_memory: bool = False,load_from_cache_file: bool = True,cache_file_name: Optional[str] = None,writer_batch_size: Optional[int] = 1000,fn_kwargs: Optional[dict] = None,num_proc: Optional[int] = None,suffix_template: str = "_{rank:05d}_of_{num_proc:05d}",new_fingerprint: Optional[str] = None,desc: Optional[str] = None,) -> Dataset参数:
function:一个可调用对象,它的签名类似于map()中的function,但是这里的function必须返回一个布尔值(表示是否保留该样本)。- 其它参数参考
map()。
返回一个
Dataset。select():创建一个新的数据集,这个新的数据集的row是根据索引(以列表或array来提供)从原始数据集检索得到。xxxxxxxxxxselect( indices: Iterable,keep_in_memory: bool = False,indices_cache_file_name: Optional[str] = None,writer_batch_size: Optional[int] = 1000,new_fingerprint: Optional[str] = None,) -> Dataset参数:
indices:一个可迭代对象,表示一组索引。- 如果
indices对应于一个连续的区间,那么Arrow table仅仅是简单的切片。 - 如果
indices对应于多个连续的区间,那么会创建索引映射indices mapping。 - 否则,会创建一个新的
Arrow table。
- 如果
其它参数参考
map()。
返回一个新的
Dataset(样本粒度的拷贝)。sort():创建一个新的数据集,该数据集根据指定的列来排序。目前使用
pandas排序算法,因此该列必须是pandas兼容的类型(尤其不是嵌套类型)。这也意味着用于排序的列能够完全加载到内存中。xxxxxxxxxxsort( column: str,reverse: bool = False,kind: str = None,null_placement: str = "last",keep_in_memory: bool = False,load_from_cache_file: bool = True,indices_cache_file_name: Optional[str] = None,writer_batch_size: Optional[int] = 1000,new_fingerprint: Optional[str] = None,) -> Dataset参数:
column:一个字符串,指定根据哪一列来排序。reverse:一个布尔值,指定是否降序排列。如果为True则降序排列,否则升序排列。kind:一个字符串,指定pandas排序算法,可以为{'quicksort', 'mergesort', 'heapsort', 'stable'},默认为'quicksort'。注意,'stable'、'mergesort'都在幕后使用timsort,一般而言,实际的实现会因为数据类型而异。null_placement:一个字符串,指定None值应该排在头部 ('first')还是尾部 ('last')。indices_cache_file_name:一个字符串,指定用于排序的索引的缓存文件名(而不是自动生成)。- 其它参数参考
map()。
返回一个新的
Dataset(拷贝后的新数据集)。shuffle():创建一个新的数据集,该数据集随机混洗了row。目前混洗使用
numpy随机数生成器。xxxxxxxxxxshuffle( seed: Optional[int] = None,generator: Optional[np.random.Generator] = None,keep_in_memory: bool = False,load_from_cache_file: bool = True,indices_cache_file_name: Optional[str] = None,writer_batch_size: Optional[int] = 1000,new_fingerprint: Optional[str] = None,) -> Dataset参数:
seed:一个整数,当generator = None时指定随机数种子来初始化默认的BitGenerator。如果为None,那么从操作系统中抽取新的、不可预测的entropy。generator:一个numpy.random.Generator,指定随机数生成器。如果为None,则默认为BitGenerator(PCG64)。- 其它参数参考
sort()。
返回一个新的
Dataset(拷贝后的新数据集)。train_test_split():返回一个datasets.DatasetDict,它具有两个随机拆分的子集(train和test的Dataset splits)。该方法类似于
scikit-learn的train_test_split()。xxxxxxxxxxtrain_test_split(test_size: Union[float, int, None] = None,train_size: Union[float, int, None] = None,shuffle: bool = True,stratify_by_column: Optional[str] = None,seed: Optional[int] = None,generator: Optional[np.random.Generator] = None,keep_in_memory: bool = False,load_from_cache_file: bool = True,train_indices_cache_file_name: Optional[str] = None,test_indices_cache_file_name: Optional[str] = None,writer_batch_size: Optional[int] = 1000,train_new_fingerprint: Optional[str] = None,test_new_fingerprint: Optional[str] = None,) -> DatasetDict参数:
test_size:一个整数或浮点数,表示测试集大小。如果是整数,则表示测试集的绝对大小;如果是浮点数,则必须是0.0到1.0之间,表示测试集相对于整个数据集的比例。如果为
None,则测试集就自动设为训练集的补集;如果test_size = None, train_size = None,那么默认为test_size = 0.25, train_size = 0.75。train_size:一个整数或浮点数,表示训练集大小。参考test_size。shuffle:一个布尔值,指定是否在拆分之前首先混洗数据集。stratify_by_column:一个字符串,指定label列的列名,用于执行分层拆分(使得拆分之后,训练集/验证集中的label分布和整体数据集保持一致)。其它参数参考
shuffle()。
返回一个
datasets.DatasetDict。shard():执行数据集分片,并返回第index个分片。确保在使用任何随机操作(如
shuffle())之前执行分片。最好在dataset pipeline的早期使用分片操作。xxxxxxxxxxshard( num_shards: int,index: int,contiguous: bool = False,keep_in_memory: bool = False,indices_cache_file_name: Optional[str] = None,writer_batch_size: Optional[int] = 1000,) -> Dataset参数:
num_shards:一个整数,指定将数据集拆分为多少个分片。index:一个整数,指定选择和返回第几个分片。contiguous:一个布尔值,指定是否为分片选择连续的索引block。- 其它参数参考
shuffle()。
返回一个
Dataset。分片算法是确定性的:
- 如果
contiguous=False,那么dataset.shard(n, i)将包含满足这种条件的样本:样本索引除以n的余数为i。 - 如果
contiguous=True,那么dataset.shard(n, i)将连续地分片,并且满足:datasets.concatenate([dataset.shard(n, i, contiguous=True) for i in range(n)])仍然等于dataset的样本及其原始顺序。
to_tf_dataset():根据底层的Dataset创建一个tf.data.Dataset。这个tf.data.Dataset将从数据集中加载和collatebatch数据,并适用于传递给model.fit()或model.predict()等方法。如果数据集同时包含
inputs和labels,那么这个数据集的yield将产生一个字典,该字典包含inputs和labels的键;如果没有labels,那么yield仅包含一个原始的tf.Tensor。xxxxxxxxxxto_tf_dataset( batch_size: int,columns: Optional[Union[str, List[str]]] = None,shuffle: bool = False,collate_fn: Optional[Callable] = None,drop_remainder: bool = False,collate_fn_args: Optional[Dict[str, Any]] = None,label_cols: Optional[Union[str, List[str]]] = None,prefetch: bool = True,)参数:
batch_size:一个整数,指定batch size。columns:一个字符串或字符串列表,指定tf.data.Dataset中包含当前数据集的哪些列。可以使用collate_fn创建的、但是不在dataset原始列中的列名。shuffle:一个布尔值,指定是否在加载时混洗数据集。推荐在训练期间设置为True,在验证和评估期间设置为False。drop_remainder:一个布尔值,指定是否在加载时丢弃最后一个incomplete batch。collate_fn:一个可调用对象,用于将list of samples转换为一个batch。collate_fn_args:一个字典,作为关键字参数传递给collate_fn。label_cols:一个字符串或字符串列表,指定哪一列是label列。因为有些模型在内部计算损失函数(而不是让Keras来计算),因此需要指定label列。prefetch:一个布尔值,指定是否在独立的线程中运行dataloader,并维持一个小buffer的batch数据用于训练,即batch预取。这可以提高性能。
返回一个
tf.data.Dataset。push_to_hub():将数据集作为一个Parquet dataset推送到hub上。推送是通过HTTP请求进行的,无需git或git-lfs。结果的
Parquet文件是自包含的。如果你的数据集包含Image数据或Audio数据,那么Parquet文件将存储图片文件或音频文件的bytes。你可以通过设置embed_external_files为False来禁止这个行为。xxxxxxxxxxpush_to_hub( repo_id: str,split: Optional[str] = None,private: Optional[bool] = False,token: Optional[str] = None,branch: Optional[str] = None,max_shard_size: Optional[Union[int, str]] = None,shard_size: Optional[int] = "deprecated",embed_external_files: bool = True,)参数:
repo_id:一个字符串,指定repository ID(推动的目的地),例如"<organization>/<dataset_id>"。split:一个字符串,指定提供给数据集的split name,默认为self.split。private:一个布尔值,指定是否设置dataset repository为私有的。token:一个字符串,指定用于Hugging Face Hub的authentication token。如果未指定,则使用huggingface-cli登录时在本地保存的token。如果未指定且用户也没有登录,则抛出异常。branch:一个字符串,指定数据集要推送到哪个分支。默认为你的repository的默认分支(通常为"main"分支)。max_shard_size:一个整数或字符串,指定上传到hub的数据集分片的最大大小。如果为字符串,则需要提供单位,如"5MB"。shard_size:一个整数,被废弃,推荐使用max_shard_size。embed_external_files:一个布尔值,指定是否在分片中嵌入file bytes。具体而言,这将在推送之前为以下类型的字段执行如下操作:Audio/Image:移除本地路径信息,然后再Parquet文件中嵌入文件内容。
save_to_disk(dataset_path: str, fs=None):保存数据集到目录或S3FileSystem。参数:
dataset_path:一个字符串,指定本地路径或者一个remote URI从而指定数据集存放的位置。fs:一个S3FileSystem,指定数据集存放的位置。和dataset_path二选一。
注意,对于本地的图片数据和音频数据,
arrow file存储的是这些数据的文件路径。如果你希望存储这些数据的内容,那么你需要首先读取它们,然后在arrow file中包含它们的内容。load_from_disk(dataset_path: str, fs=None, keep_in_memory: Optional[bool] = None) -> Dataset:从save_to_disk()存储的目录中加载数据集。参数:
keep_in_memory:一个布尔值,指定是否加载数据集到内存。如果为None,那么数据集根据datasets.config.IN_MEMORY_MAX_SIZE非零时才拷贝到内存。- 其它参数参考
save_to_disk()。
返回一个
Dataset。flatten_indices():通过展平indices mapping来创建并缓存一个新的Datasetxxxxxxxxxxflatten_indices(keep_in_memory: bool = False,cache_file_name: Optional[str] = None,writer_batch_size: Optional[int] = 1000,features: Optional[Features] = None,disable_nullable: bool = False,new_fingerprint: Optional[str] = None,) -> Dataset参数:参考
map()。返回值:一个新的
Dataset。to_csv():数据集导出为csv文件。xxxxxxxxxxto_csv(path_or_buf: Union[PathLike, BinaryIO],batch_size: Optional[int] = None,num_proc: Optional[int] = None,**to_csv_kwargs,) -> int参数:
path_or_buf:一个文件路径,或者一个BinaryIO,指定目标csv文件。batch_size:一个整数,指定单次写入的样本数量。默认由datasets.config.DEFAULT_MAX_BATCH_SIZE决定。num_proc:一个整数,指定多进程的进程数量。默认不使用多进程。to_csv_kwargs:关键字参数,用于传递给pandas.DataFrame.to_csv()。
返回一个整数,表示已经写了多少个字符或字节。
to_pandas( batch_size: Optional[int] = None, batched: bool = False) -> Union[pd.DataFrame, Iterator[pd.DataFrame]]:将数据集转换为pandas.DataFrame。对于较大的数据集,也可以返回一个generator。参数:
batched:一个布尔值,如果为True则返回一个generator(它yield批量的样本)。如果为False则返回整个数据集。batch_size:参考to_csv()。
返回一个
pandas.DataFrame或者一个generator。to_dict(batch_size: Optional[int] = None, batched: bool = False) -> Union[dict, Iterator[dict]]:将数据集转换为Python字典。对于较大的数据集,也可以返回一个generator。参数:参考
to_pandas。返回值一个字典或者一个
generator。to_json():将数据集导出为JSON文件。xxxxxxxxxxto_json(path_or_buf: Union[PathLike, BinaryIO],batch_size: Optional[int] = None,num_proc: Optional[int] = None,lines: Optional[bool] = True,**to_json_kwargs,) -> int参数:
lines:一个布尔值,指定是否输出JSON lines格式。to_json_kwargs:关键字参数,传递给pandas.DataFrame.to_json()。- 其它参数参考
to_csv()。
返回一个整数,表示已经写了多少个字符或字节。
to_parquet():将数据集导出为parquet文件。xxxxxxxxxxto_parquet(path_or_buf: Union[PathLike, BinaryIO],batch_size: Optional[int] = None,num_proc: Optional[int] = None,**parquet_writer_kwargs,) -> int参数:
parquet_writer_kwargs:关键字参数,传递给pyarrow.parquet.ParquetWriter。- 其它参数参考
to_csv()。
返回一个整数,表示已经写了多少个字符或字节。
to_sql():导出数据集到SQL数据库。xxxxxxxxxxto_sql(name: str,con: Union[str, "sqlalchemy.engine.Connection", "sqlalchemy.engine.Engine", "sqlite3.Connection"],batch_size: Optional[int] = None,**sql_writer_kwargs,) -> int参数:
name/con:参考from_sql。batch_size:参考to_csv()。sql_writer_kwargs:关键字参数,传递给Dataframe.to_sql()。
返回一个整数,表示已经写入了多少行记录。
add_faiss_index():添加一个dense index(使用Faiss)来用于快速检索。默认情况下,索引是在指定的列上的向量上完成的。如果要在GPU上运行,也可以指定设备。xxxxxxxxxxadd_faiss_index( column: str,index_name: Optional[str] = None,device: Optional[int] = None,string_factory: Optional[str] = None,metric_type: Optional[int] = None,custom_index: Optional["faiss.Index"] = None, # noqa: F821batch_size: int = 1000,train_size: Optional[int] = None,faiss_verbose: bool = False,dtype=np.float32,)参数:
column:一个字符串,指定在哪一列的向量上添加这个dense index。index_name:一个字符串,指定新加的dense index的名字。这个名词常被用于get_nearest_examples()或search()。device:一个整数或者整数列表。如果是正整数,则指定GPU的编号;如果是负整数,则表示所有的GPU。如果是正整数列表,则表示在指定的一组GPU上运行。默认使用CPU。string_factory:一个字符串,它被传递给Faiss的index factory来创建dense index。metric_type:一个整数,指定指标的类型。例如,faiss.METRIC_INNER_PRODUCT或faiss.METRIC_L2。custom_index:一个faiss.Index,指定自定义的Faiss index。batch_size:一个整数,指定单词添加多少个vector到FaissIndex。train_size:一个整数,如果index需要训练,那么指定多少个vector来训练。faiss_verbose:一个布尔值,开启faiss的日志输出。dtype:一个数据类型,指定dense index的numpy array类型。默认为np.float32。
示例(
FAISS语义检索):xxxxxxxxxxfrom transformers import AutoTokenizer, AutoModelimport torch######### 加载预训练模型 #########model_ckpt = "sentence-transformers/multi-qa-mpnet-base-dot-v1"tokenizer = AutoTokenizer.from_pretrained(model_ckpt)model = AutoModel.from_pretrained(model_ckpt)device = torch.device("cuda")model.to(device) # 移动到 GPU########## 函数: 获取 batch 样本的 cls emebdding ######def get_embeddings(text_list):encoded_input = tokenizer(text_list, padding=True, truncation=True, return_tensors="pt")encoded_input = {k: v.to(device) for k, v in encoded_input.items()}model_output = model(**encoded_input)return model_output.last_hidden_state[:, 0]embedding = get_embeddings(comments_dataset["text"][0])print(embedding.shape)########### 对数据集增加 cls emebdding 列 #######embeddings_dataset = comments_dataset.map(lambda x: {"embeddings": get_embeddings(x["text"]).detach().cpu().numpy()[0]})########## 对数据集增加 faiss index #########embeddings_dataset.add_faiss_index(column="embeddings")######### 获取 query emebdding #######question = "What is your name?"question_embedding = get_embeddings([question]).cpu().detach().numpy()print(question_embedding.shape)########## 检索 query 最相似的 top-k 样本 ######scores, samples = embeddings_dataset.get_nearest_examples("embeddings", question_embedding, k=5)add_faiss_index_from_external_arrays():添加一个dense index(使用Faiss)来用于快速检索。索引是在external_arrays的向量上创建的。如果要在GPU上运行,也可以指定设备。xxxxxxxxxxadd_faiss_index_from_external_arrays(external_arrays: np.array,index_name: str,device: Optional[int] = None,string_factory: Optional[str] = None,metric_type: Optional[int] = None,custom_index: Optional["faiss.Index"] = None, # noqa: F821batch_size: int = 1000,train_size: Optional[int] = None,faiss_verbose: bool = False,dtype=np.float32,)参数:
external_arrays:一个np.array对象,指定在哪一列(外部的列)的向量上添加这个dense index。- 其它参数参考
add_faiss_index()。
save_faiss_index(index_name: str, file: typing.Union[str, pathlib.PurePath]):保存FaissIndex到磁盘。参数:
index_name:一个字符串,指定faiss index的列名。file:一个字符串,指定序列化之后的faiss index所保存的文件的文件名。
load_faiss_index():从硬盘加载FaissIndex。xxxxxxxxxxload_faiss_index(index_name: str,file: typing.Union[str, pathlib.PurePath],device: typing.Union[int, typing.List[int], NoneType] = None )参数:
device:add_faiss_index()。- 其它参数参考
save_faiss_index()。
add_elasticsearch_index():添加一个text index(使用ElasticSearch)来用于快速检索。这是原地操作。xxxxxxxxxxadd_elasticsearch_index(column: str,index_name: Optional[str] = None,host: Optional[str] = None,port: Optional[int] = None,es_client: Optional["elasticsearch.Elasticsearch"] = None, # noqa: F821es_index_name: Optional[str] = None,es_index_config: Optional[dict] = None,)参数:
column/index_name:参考add_faiss_index()。host:一个字符串,指定ElasticSearch运行的主机,默认为'localhost'。port:一个字符串,指定ElasticSearch运行的端口号,默认为'9200'。es_client:一个Elasticsearch对象,如果host和port都是None,那么使用这个elasticsearch client来创建text index。es_index_name:一个字符串,指定被用于创建text index的elasticsearch index name。es_index_config:一个字典,指定elasticsearch index的配置。默认的配置为:xxxxxxxxxx{"settings": {"number_of_shards": 1,"analysis": {"analyzer": {"stop_standard": {"type": "standard", " stopwords": "_english_"}}},},"mappings": {"properties": {"text": {"type": "text","analyzer": "standard","similarity": "BM25"},}},}
load_elasticsearch_index():加载已有的text index(使用ElasticSearch)用于快速检索。xxxxxxxxxxload_elasticsearch_index(index_name: str,es_index_name: str,host: typing.Optional[str] = None,port: typing.Optional[int] = None,es_client: typing.Optional[ForwardRef('Elasticsearch')] = None,es_index_config: typing.Optional[dict] = None )参数:参考
add_elasticsearch_index()。list_indexes():列出所有attached indexes的列名。get_index(index_name: str ) -> BaseIndex:返回指定列上attached indexes的列名。参数:
index_name:一个字符串,指定列名。drop_index(index_name: str):移除指定列上的index。参数:参考
get_index()。search():在数据集中寻找与给定query最近邻的样本,返回临近度得分。xxxxxxxxxxsearch(index_name: str,query: typing.Union[str, <built-in function array>],k: int = 10 ) -> scores (List[List[float])参数:
index_name:一个字符串,指定索引的名字。query:一个字符串或一个np.ndarray,指定query。如果index_name对应于text index,那么query是一个字符串;如果index_name是一个vector index,那么query是一个np.ndarray。k:一个整数,指定寻找最近邻的多少个。
返回一组最近邻的样本的近邻分。
search_batch():在数据集中寻找与给定的一组query最近邻的样本,返回针对每个query的临近度得分。xxxxxxxxxxsearch_batch(index_name: str,queries: typing.Union[typing.List[str], <built-in function array>],k: int = 10 ) -> total_scores (List[List[float])参数:参考
search()。返回多组最邻近的样本的近邻分,每一组对应一个
query。get_nearest_examples(index_name: str, query: Union[str, np.array], k: int = 10) -> scores (List[float]):类似于 search()。参数:参考
search()。返回一组最近邻的样本的近邻分。
get_nearest_examples_batch(index_name: str, queries: typing.Union[typing.List[str], <built-in function array>], k: int = 10) -> total_scores (List[List[float]):参考search_batch()。参数:参考
search_batch()。返回多组最邻近的样本的近邻分,每一组对应一个
query。prepare_for_task(task: Union[str, TaskTemplate], id: int = 0) -> Dataset:通过将数据集的Features强制类型转换为标准化的列名和列类型(由dataset.tasks中描述),从而为给定的task来准备数据集。仅供一次性使用,因此在强制类型转换之后,所有的
task template都将从datasets.DatasetInfo.task_templates中移除。参数:
task:一个字符串或者TaskTemplate,指定为哪个任务准备数据集。如果是字符串,那么必须为:
"text-classification"或"question-answering"。如果是
TaskTemplate,那么必须是dataset.tasks中定义的task templates之一。目前支持(位于
dataset.tasks内):xxxxxxxxxxAudioClassification, AutomaticSpeechRecognition, ImageClassification, LanguageModeling, QuestionAnsweringExtractive, Summarization, TextClassification
id:一个整数,当支持多个相同类型的task template时,显式标识task template所需的id。
返回一个
Dataset。align_labels_with_mapping(label2id: Dict, label_column: str) -> Dataset:根据输入的label2id来对齐数据集的label ID和label name。注意,对齐的过程中,对label name使用小写。参数:
label2id:一个字典,指定label name到label ID的映射。label_column:一个字符串,指定数据集的哪一列为label列。
返回值一个
Dataset。
datasets的函数:datasets.concatenate_datasets():拼接多个Dataset到单个Dataset。xxxxxxxxxxconcatenate_datasets(dsets: List[Dataset],info: Optional[DatasetInfo] = None,split: Optional[NamedSplit] = None,axis: int = 0,) -> Dataset参数:
dsets:一个Dataset的列表,指定多个数据集。info:一个DatasetInfo,指定新的Dataset的信息,如描述信息等等。axis:一个整数,可以为0或1,表示沿着行拼接(0,从上到下拼接)或者列拼接(1,从左到右拼接)。
datasets.interleave_datasets():将几个数据集交错而成一个新的数据集。新的数据集是通过在source dataset之间进行交错迭代从而获得样本。xxxxxxxxxxinterleave_datasets(datasets: List[DatasetType],probabilities: Optional[List[float]] = None,seed: Optional[int] = None,info: Optional[DatasetInfo] = None,split: Optional[NamedSplit] = None,stopping_strategy: Optional[str] = "first_exhausted",) -> DatasetType参数:
datases:一个Dataset或IterableDataset的列表,指定对哪些数据集进行交错。probabilities:一个浮点数列表。- 如果为
None,则表示在每个源数据集之间轮流迭代(即第一个样本来自于第一个源数据集,第二个样本来自于第二个源数据集,...)。 - 如果不是
None,则每次根据给定的概率随机选择一个源数据集来进行迭代。
- 如果为
seed:一个整数,指定随机数种子,用于配合probabilities来随机选择一个源数据集。info:一个DatasetInfo对象,指定新数据集的信息。split:一个NamedSplit对象,指定dataset split的名字。stopping_strategy:一个字符串,目前支持两种策略:"first_exhausted ":一旦某个数据集耗尽样本,则停止构建数据集。"all_exhausted":每个数据集至少被完全迭代过一次,当且仅当所有数据集都被迭代过一次,则停止构建数据集。注意,此时新数据集的规模可能非常大。如果probabilities = None,那么新数据集的规模为max_length_datasets*num_dataset;如果probabilities != None,并且如果某个数据集的访问概率非常低,那么新数据集可能包含非常非常多的样本。
返回一个
Dataset(当datases是Dataset列表时)或IterableDataset(当datases是IterableDataset列表时)。datasets.enable_caching():启用缓存。当对数据集应用
transform时,数据被存储在缓存文件中。缓存机制允许重新加载已经计算过的、现有的缓存文件。重新加载数据集是可能的,因为缓存文件是使用数据集指纹dataset fingerprint命名的,指纹在每次transform后都会更新。如果禁用缓存,那么当对数据集应用
transform时,Datasets library将不再重新加载缓存的数据文件。具体而言,如果禁用缓存:- 缓存文件总是被重新创建。
- 缓存文件被写入临时目录,当会话关闭时,该目录将被删除。
- 使用随机哈希而不是数据集指纹来命名缓存文件。
- 使用
datasets.Dataset.save_to_disk()来保存一个transformerd dataset或者在会话关闭时删除transformerd dataset。 - 缓存不会影响
datasets.load_dataset()。如果要从头重新生成数据集,应该使用datasets.load_dataset()中的download_mode参数。
datasets.disable_caching():禁用缓存。datasets.is_caching_enabled() -> bool: 返回缓存是否被启用。
class DatasetDict:继承自Python dict,包含Dataset的字典,其中键为split name(如'train', 'test'等等)。它也包含一些dataset transform方法,如map/filter,作用到每个split上。属性:
data -> Dict[str, Table]:一个字典,返回每个split的Apache Arrow table。cache_files -> Dict[str, Dict]:一个字典,返回每个split的缓存文件。num_columns -> Dict[str, int]:一个字典,返回每个split的列数。num_rows -> Dict[str, int]:一个字典,返回每个split的行数。column_names -> Dict[str, List[str]]:一个字典,返回每个split的列名。shape -> Dict[str, Tuple[int]]:一个字典,返回每个split的形状(列数,行数)。
方法:参考
Dataset的对应方法,其中DatasetDict的方法会应用到字典中的每个Dataset上,并且返回DatasetDict而不是Dataset。xxxxxxxxxxunique(column: str) -> Dict[str, List]cleanup_cache_files() -> Dict[str, int]map( function: Optional[Callable] = None,with_indices: bool = False,with_rank: bool = False,input_columns: Optional[Union[str, List[str]]] = None,batched: bool = False,batch_size: Optional[int] = 1000,drop_last_batch: bool = False,remove_columns: Optional[Union[str, List[str]]] = None,keep_in_memory: bool = False,load_from_cache_file: bool = True,cache_file_names: Optional[Dict[str, Optional[str]]] = None,writer_batch_size: Optional[int] = 1000,features: Optional[Features] = None,disable_nullable: bool = False,fn_kwargs: Optional[dict] = None,num_proc: Optional[int] = None,desc: Optional[str] = None,) -> DatasetDictfilter( function,with_indices=False,input_columns: Optional[Union[str, List[str]]] = None,batched: bool = False,batch_size: Optional[int] = 1000,keep_in_memory: bool = False,load_from_cache_file: bool = True,cache_file_names: Optional[Dict[str, Optional[str]]] = None,writer_batch_size: Optional[int] = 1000,fn_kwargs: Optional[dict] = None,num_proc: Optional[int] = None,desc: Optional[str] = None,) -> DatasetDictsort( column: str,reverse: bool = False,kind: str = None,null_placement: str = "last",keep_in_memory: bool = False,load_from_cache_file: bool = True,indices_cache_file_names: Optional[Dict[str, Optional[str]]] = None,writer_batch_size: Optional[int] = 1000,) -> DatasetDictshuffle( seeds: Optional[Union[int, Dict[str, Optional[int]]]] = None,seed: Optional[int] = None,generators: Optional[Dict[str, np.random.Generator]] = None,keep_in_memory: bool = False,load_from_cache_file: bool = True,indices_cache_file_names: Optional[Dict[str, Optional[str]]] = None,writer_batch_size: Optional[int] = 1000,) -> DatasetDictset_format(type: Optional[str] = None,columns: Optional[List] = None,output_all_columns: bool = False,**format_kwargs,)reset_format()formatted_as( type: Optional[str] = None,columns: Optional[List] = None,output_all_columns: bool = False,**format_kwargs,)with_format( type: Optional[str] = None,columns: Optional[List] = None,output_all_columns: bool = False,**format_kwargs,) -> DatasetDictwith_transform(transform: Optional[Callable],columns: Optional[List] = None,output_all_columns: bool = False,) -> DatasetDictflatten(max_depth=16) -> DatasetDictcast(features: Features) -> DatasetDictcast_column(column: str, feature) -> DatasetDictremove_columns(column_names: Union[str, List[str]]) -> DatasetDictrename_column(original_column_name: str, new_column_name: str) -> DatasetDictrename_columns(column_mapping: Dict[str, str]) -> DatasetDictclass_encode_column(column: str, include_nulls: bool = False) -> DatasetDictpush_to_hub( repo_id,private: Optional[bool] = False,token: Optional[str] = None,branch: Optional[None] = None,max_shard_size: Optional[Union[int, str]] = None,shard_size: Optional[int] = "deprecated",embed_external_files: bool = True,)save_to_disk(dataset_dict_path: str, fs=None)load_from_disk(dataset_dict_path: str, fs=None,keep_in_memory: Optional[bool] = None) -> DatasetDictfrom_csv(path_or_paths: Dict[str, PathLike],features: Optional[Features] = None,cache_dir: str = None,keep_in_memory: bool = False,**kwargs,) -> DatasetDictfrom_json( path_or_paths: Dict[str, PathLike],features: Optional[Features] = None,cache_dir: str = None,keep_in_memory: bool = False,**kwargs,) -> DatasetDictfrom_parquet(path_or_paths: Dict[str, PathLike],features: Optional[Features] = None,cache_dir: str = None,keep_in_memory: bool = False,columns: Optional[List[str]] = None,**kwargs,) -> DatasetDictfrom_text( path_or_paths: Dict[str, PathLike],features: Optional[Features] = None,cache_dir: str = None,keep_in_memory: bool = False,**kwargs,) -> DatasetDictprepare_for_task(task: Union[str, TaskTemplate], id: int = 0) -> DatasetDictclass datasets.IterableDataset:基于python generator实现的迭代式数据集。xxxxxxxxxxclass IterableDataset(ex_iterable: _BaseExamplesIterable,info: Optional[DatasetInfo] = None,split: Optional[NamedSplit] = None,format_type: Optional[str] = None,shuffling: Optional[ShufflingConfig] = None,token_per_repo_id: Optional[Dict[str, Union[str, bool, None]]] = None,)参数:文档未给出,同时源码也未给出。
属性:参考
Dataset。xxxxxxxxxxinfo, split, builder_name, citation, config_name, dataset_size, description, download_checksums, download_size, features, homepage, license, size_in_bytes, supervised_keys, version方法:
skip(n) -> IterableDataset:创建一个新的IterableDataset,它跳过了旧IterableDataset的前n的元素。参数:
n:一个整数,指定跳过多少个元素。返回一个新的
IterableDataset。take(n) -> IterableDataset:创建一个新的IterableDataset,它仅包含旧IterableDataset的前n的元素。参数:
n:一个整数,指定包含多少个元素。返回一个新的
IterableDataset。下列方法参考
Dataset,其中IterableDataset的方法返回IterableDataset而不是Dataset。xxxxxxxxxxfrom_generator(generator: Callable,features: Optional[Features] = None,gen_kwargs: Optional[dict] = None,) -> IterableDatasetremove_columns(column_names: Union[str, List[str]]) -> IterableDatasetcast_column(column: str, feature: FeatureType) -> IterableDatasetcast(features: Features) -> IterableDataset__iter__()map( function: Optional[Callable] = None,with_indices: bool = False,input_columns: Optional[Union[str, List[str]]] = None,batched: bool = False,batch_size: int = 1000,drop_last_batch: bool = False,remove_columns: Optional[Union[str, List[str]]] = None,fn_kwargs: Optional[dict] = None,) -> IterableDatasetrename_column(original_column_name: str, new_column_name: str) -> IterableDatasetfilter(function: Optional[Callable] = None,with_indices=False,input_columns: Optional[Union[str, List[str]]] = None,batched: bool = False,batch_size: Optional[int] = 1000,) -> IterableDatasetshuffle(seed=None, generator: Optional[np.random.Generator] = None,buffer_size: int = 1000) -> IterableDataset
class datasets.IterableDatasetDict:继承自Python dict,包含IterableDataset的字典,其中键为split name(如'train', 'test'等等)。它也包含一些dataset transform方法,如map/filter,作用到每个split上。方法:参考
DatasetDict的对应方法,其中IterableDatasetDict的方法返回IterableDatasetDict而不是DatasetDict。xxxxxxxxxxmap( function: Optional[Callable] = None,with_indices: bool = False,with_rank: bool = False,input_columns: Optional[Union[str, List[str]]] = None,batched: bool = False,batch_size: Optional[int] = 1000,drop_last_batch: bool = False,remove_columns: Optional[Union[str, List[str]]] = None,keep_in_memory: bool = False,load_from_cache_file: bool = True,cache_file_names: Optional[Dict[str, Optional[str]]] = None,writer_batch_size: Optional[int] = 1000,features: Optional[Features] = None,disable_nullable: bool = False,fn_kwargs: Optional[dict] = None,num_proc: Optional[int] = None,desc: Optional[str] = None,) -> IterableDatasetDictfilter( function,with_indices=False,input_columns: Optional[Union[str, List[str]]] = None,batched: bool = False,batch_size: Optional[int] = 1000,keep_in_memory: bool = False,load_from_cache_file: bool = True,cache_file_names: Optional[Dict[str, Optional[str]]] = None,writer_batch_size: Optional[int] = 1000,fn_kwargs: Optional[dict] = None,num_proc: Optional[int] = None,desc: Optional[str] = None,) -> IterableDatasetDictshuffle( seeds: Optional[Union[int, Dict[str, Optional[int]]]] = None,seed: Optional[int] = None,generators: Optional[Dict[str, np.random.Generator]] = None,keep_in_memory: bool = False,load_from_cache_file: bool = True,indices_cache_file_names: Optional[Dict[str, Optional[str]]] = None,writer_batch_size: Optional[int] = 1000,) -> IterableDatasetDictwith_format( type: Optional[str] = None,columns: Optional[List] = None,output_all_columns: bool = False,**format_kwargs,) -> IterableDatasetDictcast(features: Features) -> IterableDatasetDictcast_column(column: str, feature) -> IterableDatasetDictremove_columns(column_names: Union[str, List[str]]) -> IterableDatasetDictrename_column(original_column_name: str, new_column_name: str) -> IterableDatasetDictrename_columns(column_mapping: Dict[str, str]) -> IterableDatasetDict
3.3 Features
class datasets.Features(*args, **kwargs):一个特殊的字典,定义了数据集的内部结构。Features通过dict[str, FieldType]类型的字典来实例化,其中键是列名、值为该列的类型。FieldType可以为:datasets.Value:该特征指定了single typed value,如int64或string。datasets.ClassLabel:该特征指定了一个字段,该字段包含一组预定义的类别,这些类别关联了一些整数标签(数据集中以整数标签来存储)。- 一个
python字典:该特征指定了一个嵌套的字段,其中将sub-field名称映射到sub-field类型。 - 一个
python列表或datasets.Sequence:该特征指定了一个字段,该字段包含对象的一个列表。python列表或datasets.Sequence的每个元素都是single sub-feature。 - 一个
Array2D/Array3D/Array4D/Array5D:该特征是多维数组。 - 一个
Audio:该特征存储音频文件的绝对路径,或者存储音频文件的相对路径("path"键)映射到音频内容("bytes"键)的字典。 - 一个
Image:该特征存储图片文件的绝对路径、或者np.ndarray对象、或者PIL.Image.Image对象,或者存储图片文件的相对路径("path"键)映射到图片内容("bytes"键)的字典。 Translation/TranslationVariableLanguages:仅用于机器翻译。
方法:
copy() -> Features:创建当前Features的deep copy。decode_batch(batch: dict[str, list[Any]]) -> dict[str, list[Any]]:对一个batch的数据根据当前的特征格式来解码。参数:
batch:一个字典,表示一个batch的数据。返回解码后的数据。
decode_column(column: list[Any], column_name: str) -> list[Any]:对一列数据根据当前的特征格式来解码。参数:
column:一个列表,包含一列数据。column_name:一个字符串,表示列名。
返回解码后的数据。
decode_example(example: dict[str, Any], token_per_repo_id: Optional[Dict[str, Union[str, bool, None]]] = None) -> dict[str, Any]:根据当前的特征格式来解码一个样本。参数:
example:一个字典,表示数据集的一行(代表一个样本)。token_per_repo_id:一个字典,为了从Hub上的私有repository中访问和解码音频文件、图像文件,可以传递一个字典repo_id (str) -> token (bool or str)。
返回解码后的样本。
encode_batch(batch: dict[str, list[Any]]) -> dict[str, list[Any]]:编码batch样本到Arrow的格式。参数:
batch:一个batch的样本。返回编码后的
batch的样本。encode_example(example: dict[str, Any]) -> dict[str, Any]:编码单个样本到Arrow的格式。参数:
example:单个样本。返回编码后的样本。
flatten(max_depth=16) -> Features:特征展平,返回展平后的特征。每个
dictionary column被移除,并代之以它包含的所有subfields。新的字段名字由原始的里恶名和subfield name拼接而成,如<original>.<subfield>。如果有多层嵌套,那么为<original>.<subfield>.<subsubfield>。参数:
max_depth:一个整数,指定最多展平多少层。from_arrow_schema( pa_schema: pyarrow.Schema) -> Features:从Arrow Schema构建Features。from_dict(dic: dict[str, Any]) -> Features:从字典中构建Features。我们使用"_type"键来推断feature FieldType的dataclass name。reorder_fields_as(other: Features) -> Features:重新排列当前Features的字段,从而匹配other Features的字段顺序。字段的顺序很重要,因为它关系到底层的
arrow data。
示例:
xxxxxxxxxxfrom datasets import Features, Sequence, Valuef1 = Features({"root": Sequence({"a": Value("string"), "b": Value("string")})})f2 = Features({"root": {"b": Sequence(Value("string")), "a": Sequence(Value("string"))}})assert f1.type != f2.type # 字段的顺序很重要f1.reorder_fields_as(f2)assert f1.reorder_fields_as(f2).type == f2.typeclass datasets.Sequence( feature: typing.Any, length: int = -1, id: typing.Optional[str] = None):根据单个类型、或者类型的字典来构建feature的一个列表。参数:
feature:单个类型、或者类型的字典的一个列表。length:一个整数,指定sequence的长度。
示例:
xxxxxxxxxxfrom datasets import Features, Sequence, Value, ClassLabeleatures = Features({'post': Sequence(feature={'text': Value(dtype='string'),'upvotes': Value(dtype='int32'),'label': ClassLabel(num_classes=2, names=['hot', 'cold'])})})class datasets.ClassLabel:用于整数类别标签的feature type。xxxxxxxxxxclass datasets.ClassLabel(num_classes: dataclasses.InitVar[typing.Optional[int]] = None,names: typing.List[str] = None,names_file: dataclasses.InitVar[typing.Optional[str]] = None,id: typing.Optional[str] = None)参数:
num_classes:一个整数,指定类别的数量。所有的标签取值必须小于num_classes。names:一个字符串列表,指定整数类别的类别名字,这些字符串的顺序很重要,对应于对应的整数标签。names_file:一个字符串,存储类别名字,每行一个。
底层的
label存储为整数。你可以使用负的整数代表unknown/missing的label。方法:
cast_storage( storage: typing.Union[pyarrow.lib.StringArray, pyarrow.lib.IntegerArray]) -> pa.Int64Array:将一个Arrow array强制类型转换为ClassLabel arrow storage类型。只有pa.string()和pa.int()这两种类型能够执行这种强制类型转换。参数:
storage:一个pa.StringArray或pa.IntegerArray类型,表示要被强制类型转换的PyArrow array。
返回值一个
pa.Int64Array。int2str( values: typing.Union[int, collections.abc.Iterable] ):将整数转换为class name字符串。如果有负的整数,则抛出异常。参数:
values:一个整数或整数的可迭代对象,表示待转换的整数。返回值一个字符串或字符串的可迭代对象,表示
class name。str2int(values: typing.Union[str, collections.abc.Iterable]):将class name字符串转换为整数。参数:
values:一个字符串或字符串的可迭代对象,表示待转化的class name。返回一个整数或整数的可迭代对象,表示
class label。
示例:
xxxxxxxxxxfrom datasets import Featureseatures = Features({'label': ClassLabel(num_classes=3, names=['bad', 'ok', 'good'])})class dataset.Value(dtype: str, id: typing.Optional[str] = None ):值类型。可以为如下类型:xxxxxxxxxxnull bool int8 int16 int32 int64 uint8 uint16 uint32 uint64 float16 float32 (alias float) float64 (alias double) time32[(s|ms)] time64[(us|ns)] timestamp[(s|ms|us|ns)] timestamp[(s|ms|us|ns), tz=(tzstring)] date32 date64 duration[(s|ms|us|ns)] decimal128(precision, scale) decimal256(precision, scale) binary large_binary string large_string参数:
dtype:一个字符串,表示具体的类型。如Value(dtype='int32')。示例:
xxxxxxxxxxfrom datasets import Featuresfeatures = Features({'stars': Value(dtype='int32')})class datasets.Translation(languages: typing.List[str], id: typing.Optional[str] = None ):用于翻译的FeatureConnector,其中翻译的每个样本包含固定的语言实例。参数:
languages:一个字符串列表,表示样本包含的语言。方法:
flatten():将Translation feature展平到一个字典中。
Translation特征的输入输出:- 输入:每个样本对应一个字典,该字典将
language code字符串映射到translation字符串。 - 输出:一个字典,该字典将
language code字符串映射到以Text特征的translation。
示例:
xxxxxxxxxxdatasets.features.Translation(languages=['en', 'fr', 'de'])# 样本生成期间:yield {'en': 'the cat','fr': 'le chat','de': 'die katze'}class datasets.TranslationVariableLanguages:用于翻译的FeatureConnector,其中翻译的每个样本包含可变的语言实例。xxxxxxxxxxclass datasets.TranslationVariableLanguages(languages: typing.Optional[typing.List] = None,num_languages: typing.Optional[int] = None,id: typing.Optional[str] = None)参数:
languages:一个字符串列表,表示样本包含的语言。num_languages:一个整数,表示最大的实例数量。
方法:
flatten():将TranslationVariableLanguages feature展平到一个字典中。
TranslationVariableLanguages特征的输入输出:- 输入:每个样本对应一个字典,该字典将
language code字符串映射到一个或多个translation字符串。 - 输出:一个字典,
"language"键对应了一个可变长度的一维张量(升序排列),代表language code;"translation"键对应了一个可变长度的一维张量(与language张量对齐且升序排列),代表翻译文本。
示例:
xxxxxxxxxxdatasets.features.TranslationVariableLanguages(languages=['en', 'fr', 'de'])# 样本生成期间:yield {'en': 'the cat','fr': ['le chat', 'la chatte,']'de': 'die katze'}# 返回{'language': ['en', 'de', 'fr', 'fr'],'translation': ['the cat', 'die katze', 'la chatte', 'le chat'],}class datasets.Array2D/Array3D/Array4D/Array5D:代表2D/3D/4D/5D的数组。xxxxxxxxxxclass datasets.Array2D(shape: tuple, dtype: str, id: typing.Optional[str] = None)class datasets.Array3D(shape: tuple, dtype: str, id: typing.Optional[str] = None)class datasets.Array4D(shape: tuple, dtype: str, id: typing.Optional[str] = None)class datasets.Array5D(shape: tuple, dtype: str, id: typing.Optional[str] = None)参数:
shape:一个元组,代表数组每个维度的大小。dtype:一个字符串,代表数组元素的类型。
示例:
xxxxxxxxxxfrom datasets import Featuresfeatures = Features({'x': Array2D(shape=(1, 3), dtype='int32')})features = Features({'x': Array3D(shape=(1, 2, 3), dtype='int32')})features = Features({'x': Array4D(shape=(1, 2, 2, 3), dtype='int32')})features = Features({'x': Array5D(shape=(1, 2, 2, 3, 3), dtype='int32')})class datasets.Audio:音频特征,用于从音频文件中抽取音频数据。xxxxxxxxxxclass datasets.Audio(sampling_rate: typing.Optional[int] = None, mono: bool = True, decode: bool = True, id: typing.Optional[str] = None )参数:
sampling_rate:一个整数,指定采样率。如果为None,则使用负的采样率。mono:一个布尔值,指定是否通过跨通道的平均采样从而将音频信号转换为单声道。decode:一个布尔值,指定是否解码音频数据。如果为False,则以格式{"path": audio_path, "bytes": audio_bytes}的格式返回底层的字典。
方法:
cast_storage(storage: typing.Union[pyarrow.lib.StringArray, pyarrow.lib.StructArray] ) -> pa.StructArray:将一个Arrow array强制类型转换为Audio arrow storage类型。可以强制类型转换的Arrow array类型包括:pa.string()(它必须包含"path"数据)、pa.struct({"bytes": pa.binary()})、pa.struct({"path": pa.string()})、pa.struct({"bytes": pa.binary(), "path": pa.string()})(顺序不重要)。decode_example( value: dict, token_per_repo_id: typing.Union[typing.Dict[str, typing.Union[str, bool, NoneType]], NoneType] = None):解码音频文件到音频数据。参数:
value:一个字典,包含两个key:"path",指定音频文件的相对路径;"bytes":音频文件的字节。token_per_repo_id:个字典,为了从Hub上的私有repository中访问和解码音频文件、图像文件,可以传递一个字典repo_id (str) -> token (bool or str)。
encode_example( value: typing.Union[str, dict] ) -> dict: 编码样本到一个字典,用于Arrow格式。参数:
value:一个字符串或字典,作为Audio特征的input。
embed_storage(storage: StructArray, drop_paths: bool = True ) -> pa.StructArray:将音频文件嵌入到Arrow array。参数:
storage:一个pa.StructArray,指定被嵌入的PyArrow。drop_paths:一个布尔值,指定是否将path设为None。
返回一个
Audio arrow storage类型的Array,格式为pa.struct({"bytes" : pa.binary(), "path" : pa.string()})。flatten():展平当前特征到一个字典。
Audio特征的输入和输出:输入:可以为:
- 一个字符串:表示音频文件的绝对路径。
- 一个字典,包含:
"path"键,给出音频文件相对于archive文件的相对路径;"bytes"键,给出音频文件的字节内容。 - 一个字典,包含:
"path"键,给出音频文件相对于archive文件的相对路径;"array"键,给出包含音频样本的数组;"sampling_rate"键,给出一个整数,对应于音频样本的采样率。
示例:
xxxxxxxxxxfrom datasets import load_dataset, Audiods = load_dataset("PolyAI/minds14", name="en-US", split="train")ds[0]["audio"]class datasets.Image(decode: bool = True, id: typing.Optional[str] = None ):图片特征。参数:
decode:一个布尔值,指定是否解码图片数据。如果为False,则以格式{"path": image_path, "bytes": image_bytes}的格式返回底层的字典。
方法:
cast_storage( storage: typing.Union[pyarrow.lib.StringArray, pyarrow.lib.StructArray, pyarrow.lib.ListArray]) -> pa.StructArray:将一个Arrow array强制类型转换到Image arrow storage类型。可以强制类型转换的Arrow array类型包括:pa.string()(它必须包含"path"数据)、pa.struct({"bytes": pa.binary()})、pa.struct({"path": pa.string()})、pa.struct({"bytes": pa.binary(), "path": pa.string()})(顺序不重要)、pa.list(*)(必须包含image array data)。参数:参考
datasets.Audio.cast_storage()。decode_example(value: dict, token_per_repo_id = None ):参考datasets.Audio.decode_example()。embed_storage(storage: StructArray, drop_paths: bool = True) -> pa.StructArray:参考datasets.Audio.embed_storage()。encode_example( value: typing.Union[str, dict, numpy.ndarray, ForwardRef('PIL.Image.Image')]):参考datasets.Audio.encode_example()。flattern():参考datasets.Audio.flattern()。
Image特征的输入和输出:输入:可以为:
- 一个字符串:表示图片文件的绝对路径。
- 一个字典,包含:
"path"键,给出图片文件相对于archive文件的相对路径;"bytes"键,给出图片文件的字节内容。 - 一个
np.ndarray:代表一张图片的numpy array。 - 一个
PIL.Image:一个PIL image对象。
示例:
xxxxxxxxxxfrom datasets import load_dataset, Imageds = load_dataset("beans", split="train")ds.features["image"]
3.4 DatasetBuilder
class datasets.DatasetBuilder:所有数据集的抽象基类。xxxxxxxxxxclass datasets.DatasetBuilder(cache_dir: typing.Optional[str] = None,config_name: typing.Optional[str] = None,hash: typing.Optional[str] = None,base_path: typing.Optional[str] = None,info: typing.Optional[datasets.info.DatasetInfo] = None,features: typing.Optional[datasets.features.features.Features] = None,use_auth_token: typing.Union[str, bool, NoneType] = None,repo_id: typing.Optional[str] = None,data_files: typing.Union[str, list, dict, datasets.data_files.DataFilesDict, NoneType] = None,data_dir: typing.Optional[str] = None,name = 'deprecated',**config_kwargs)参数:
cache_dir:一个字符串,指定缓存数据的位置,默认为"~/.cache/huggingface/datasets"。config_name:一个字符串,指定数据集配置的名字。不同的配置拥有不同的子目录和版本。如果未提供,则使用默认的配置(如果有的话)。hash:一个字符串,指定数据集代码的哈希,用于更新缓存目录。base_path:一个字符串,指定一个那个目录作为下载文件的base目录。features:一个Features对象,制定数据集的Features。use_auth_token:一个字符串或者布尔值,用于访问Datasets Hub。如果为True,则从~/.huggingface"获取token;如果为字符串,则直接指定token。repo_id:一个字符串,指定dataset repository的ID。data_files:一个字符串或者序列或者映射,指定源数据文件的路径。data_dir:一个字符串,指定包含源数据文件的目录的路径。如果data_files未提供,那么使用os.path.join(data_dir, '**')。name:一个字符串,指定数据集的配置名(被废弃,推荐用config_name)。config_kwargs:关键字参数,传递给对应的builder配置类。
DatasetBuilder有三个主要的方法:info():对数据集进行说明,包括特征名字、特征类型、数据形状、版本、split等等。download_and_prepare():下载源数据并写入磁盘。xxxxxxxxxxdownload_and_prepare(output_dir: typing.Optional[str] = None,download_config: typing.Optional[datasets.download.download_config.DownloadConfig] = None,download_mode: typing.Optional[datasets.download.download_manager.DownloadMode] = None,ignore_verifications: bool = False,try_from_hf_gcs: bool = True,dl_manager: typing.Optional[datasets.download.download_manager.DownloadManager] = None,base_path: typing.Optional[str] = None,use_auth_token: typing.Union[str, bool, NoneType] = None,file_format: str = 'arrow',max_shard_size: typing.Union[int, str, NoneType] = None,num_proc: typing.Optional[int] = None,storage_options: typing.Optional[dict] = None,**download_and_prepare_kwargs)参数:
output_dir:一个字符串,指定数据集的输出目录。默认为"~/.cache/huggingface/datasets"。download_config:一个DownloadConfig对象,指定下载配置。download_mode:一个DownloadMode对象,指定下载/生成的模式。默认为REUSE_DATASET_IF_EXISTS。ignore_verifications:一个布尔值,指定是否忽略对下载的数据进行校验。try_from_hf_gcs:一个布尔值,指定是否从Hf google cloud storage下载prepared dataset。dl_manager:一个DownloadManager对象,指定使用哪个下载管理器。base_path:一个字符串,指定用哪个目录作为下载文件的base目录。use_auth_token:一个字符串,参考DatasetBuilder构造方法。file_format:一个字符串,指定数据文件的格式。支持"arrow"和"parquet"。如果是"parquet",那么图片数据和音频数据将被嵌入到Parquet文件中,而不是指向本地文件的路径。max_shard_size:一个字符串或整数,指定每个分片所写入的最大字节数。仅支持对"parquet"格式使用默认的"500MB"的大小。这个size是基于未压缩的数据大小,因此对于Parquet compression,分片文件可能要小于max_shard_size。num_proc:一个整数,指定用于下载和生成本地数据集的进程数。默认不使用多进程。storage_options:一个字典,key-value pair,被传入缓存文件系统。download_and_prepare_kwargs:额外的关键字参数。
as_dataset(split: typing.Optional[datasets.splits.Split] = None, run_post_process = True, ignore_verifications = False, in_memory = False ):生成一个数据集。参数:
split:一个Split,指定返回数据的哪个子集。run_post_process:一个布尔值,指定是否对数据集运行后处理。ignore_verifications:一个布尔值,指定是否忽略对下载后/处理后的数据集的信息进行校验。in_memory:一个布尔值,指定是否将数据拷贝到内存中。
class datasets.BuilderConfig:Builder配置的基类。xxxxxxxxxxclass datasets.BuilderConfig(name: str = 'default',version: typing.Union[str, datasets.utils.version.Version, NoneType] = 0.0.0,data_dir: typing.Optional[str] = None,data_files: typing.Optional[datasets.data_files.DataFilesDict] = None,description: typing.Optional[str] = None)class datasets.DownloadManager:下载管理器。xxxxxxxxxxclass class datasets.DownloadManager(dataset_name: typing.Optional[str] = None,data_dir: typing.Optional[str] = None,download_config: typing.Optional[datasets.download.download_config.DownloadConfig] = None,base_path: typing.Optional[str] = None,record_checksums = True)class datasets.StreamingDownloadManager:流式下载管理器。xxxxxxxxxxclass datasets.StreamingDownloadManager(dataset_name: typing.Optional[str] = None,data_dir: typing.Optional[str] = None,download_config: typing.Optional[datasets.download.download_config.DownloadConfig] = None,base_path: typing.Optional[str] = None)class datasets.DownloadConfig:下载配置xxxxxxxxxxclass datasets.DownloadConfig(cache_dir: typing.Union[str, pathlib.Path, NoneType] = None,force_download: bool = False,resume_download: bool = False,local_files_only: bool = False,proxies: typing.Optional[typing.Dict] = None,user_agent: typing.Optional[str] = None,extract_compressed_file: bool = False,force_extract: bool = False,delete_extracted: bool = False,use_etag: bool = True,num_proc: typing.Optional[int] = None,max_retries: int = 1,use_auth_token: typing.Union[bool, str, NoneType] = None,ignore_url_params: bool = False,download_desc: typing.Optional[str] = None)class class datasets.DownloadMode:下载模式的枚举类。包括:xxxxxxxxxxREUSE_DATASET_IF_EXISTS # 默认行为,重用下载的数据,重用数据集REUSE_CACHE_IF_EXISTS # 重用下载的数据,不重用数据集FORCE_REDOWNLOAD # 既不重用下载的数据,也不重用数据集class datasets.Split:数据集拆分的枚举类。包括:xxxxxxxxxxTRAIN # 训练集VALIDATION # 验证集TEST # 测试集ALL # 整个数据集
3.5 加载数据集
数据集加载:
datasets.list_datasets(with_community_datasets = True, with_details = False ):列出Hugging Face Hub上所有的可用数据集。参数:
with_community_datasets:一个布尔值,指定是否包含社区提供的数据集。with_details:一个布尔值,指定是否返回完整的细节而不是简称。
datasets.load_dataset():从Hugging Face Hub或本地加载数据集。注意,也可能下载的是
dataset script,然后该脚本从任意其他地方下载数据集。xxxxxxxxxxload_dataset(path: str,name: Optional[str] = None,data_dir: Optional[str] = None,data_files: Optional[Union[str, Sequence[str], Mapping[str, Union[str, Sequence[str]]]]] = None,split: Optional[Union[str, Split]] = None,cache_dir: Optional[str] = None,features: Optional[Features] = None,download_config: Optional[DownloadConfig] = None,download_mode: Optional[DownloadMode] = None,ignore_verifications: bool = False,keep_in_memory: Optional[bool] = None,save_infos: bool = False,revision: Optional[Union[str, Version]] = None,use_auth_token: Optional[Union[bool, str]] = None,task: Optional[Union[str, TaskTemplate]] = None,streaming: bool = False,num_proc: int = None,**config_kwargs,) -> Union[DatasetDict, Dataset, IterableDatasetDict, IterableDataset]参数:
path:一个字符串,指定数据集的路径或名字。对于本地数据集:
- 如果
path是一个本地目录(仅包含数据文件),那么Datasets基于目录的内容加载一个通用的dataset builder(如,csv, json, text)。 - 如果
path是一个本地的dataset script或包含一个本地的dataset script,那么从这个dataset script加载dataset builder。
对于
Hugging Face Hub数据集:- 如果
path是一个dataset repository(仅包含数据文件),那么Datasets基于repository的内容加载一个通用的dataset builder(如,csv, json, text)。 - 如果
path是一个带有dataset script的dataset repository,那么从这个dataset script加载dataset builder。
- 如果
name:一个字符串,指定数据集配置的名字。data_dir:一个字符串,指定数据集配置的data_dir。data_files:一个字符串或字符串序列或字符串映射,指定源数据文件的路径。split:一个字符串或Split,指定加载数据集的哪个部分。如果为None,则返回一个字典,该字典包含所有的split。cache_dir:一个字符串,指定读写数据的缓存位置,默认为"~/.cache/huggingface/datasets"。features:一个Features,指定数据集的特征类型。download_config:一个DownloadConfig,指定下载配置。download_mode:一个DownloadMode,指定下载模式。ignore_verifications:一个布尔值,指定是否验证下载/处理的数据集。keep_in_memory:一个布尔值,指定是否拷贝数据集到内存中。save_infos:一个布尔值,指定是否保存数据集信息(如checksums/size/splits/...)。revision:一个字符串或Version,指定加载dataser script的哪个版本。默认为"main"分支。use_auth_token:一个字符串或布尔值,参考DatasetBuilder构造方法。task:一个字符串,指定该数据集需要为哪个任务进行prepare从而训练和评估。将会对数据集的Features强制类型转换,从而匹配该任务的标准列名和列类型。streaming:一个布尔值。如果为True,则不会下载数据文件,而是流式地迭代该数据集。仅txt, csv, jsonl文件支持流式下载,而Json文件需要完整地下载。num_proc:一个整数,指定下载和生成数据集的进程数。默认不使用多进程。config_kwargs:关键字参数,被传递给BuilderConfig和DatasetBuilder。
如果
streaming = False,返回一个Dataset或DatasetDict。- 如果
split不是None,则返回Dataset。 - 如果
split = None,则返回DatasetDict,它包含每个split。
或者,如果
streaming = True,则返回一个IterableDataset或IterableDatasetDict。datasets.load_from_disk(dataset_path: str, fs=None, keep_in_memory: Optional[bool] = None) -> Union[Dataset, DatasetDict]:从磁盘上加载数据集,该数据集之前通过Dataset.save_to_disk()写入到磁盘的。参数:
dataset_path:一个字符串,指定数据集的本地路径或远程URI。fs:一个S3FileSystem或fsspec.spec.AbstractFileSystem,指定远程文件系统用于下载文件。keep_in_memory:一个布尔值,指定是否拷贝数据集到内存。
返回一个
Dataset或DatasetDict,这取决于dataset_path是否包含单个split还是多个split。datasets.load_dataset_builder():从Hugging Face Hub或本地数据集中加载一个dataset builder。一个
dataset builder可以用于探查数据集的通用信息而无需下载该数据集。xxxxxxxxxxload_dataset_builder(path: str,name: Optional[str] = None,data_dir: Optional[str] = None,data_files: Optional[Union[str, Sequence[str], Mapping[str, Union[str, Sequence[str]]]]] = None,cache_dir: Optional[str] = None,features: Optional[Features] = None,download_config: Optional[DownloadConfig] = None,download_mode: Optional[DownloadMode] = None,revision: Optional[Union[str, Version]] = None,use_auth_token: Optional[Union[bool, str]] = None,**config_kwargs,) -> DatasetBuilder参数:参考
load_dataset()。返回一个
DatasetBuilder。datasets.get_dataset_config_names():对于给定的数据集,返回可用的配置名字的列表。xxxxxxxxxxget_dataset_config_names(path: str,revision: Optional[Union[str, Version]] = None,download_config: Optional[DownloadConfig] = None,download_mode: Optional[DownloadMode] = None,dynamic_modules_path: Optional[str] = None,data_files: Optional[Union[Dict, List, str]] = None,**download_kwargs,)参数:参考
load_dataset()。datasets.get_dataset_infos():获取数据集的源信息,返回一个字典,键位配置名字、值为DatasetInfoDict。xxxxxxxxxxget_dataset_infos(path: str,data_files: Optional[Union[Dict, List, str]] = None,download_config: Optional[DownloadConfig] = None,download_mode: Optional[DownloadMode] = None,revision: Optional[Union[str, Version]] = None,use_auth_token: Optional[Union[bool, str]] = None,**config_kwargs,)参数:参考
load_dataset()。datasets.get_dataset_split_names():对于给定的数据和配置,返回可用split的列表。xxxxxxxxxxget_dataset_split_names(path: str,config_name: Optional[str] = None,data_files: Optional[Union[str, Sequence[str], Mapping[str, Union[str, Sequence[str]]]]] = None,download_config: Optional[DownloadConfig] = None,download_mode: Optional[DownloadMode] = None,revision: Optional[Union[str, Version]] = None,use_auth_token: Optional[Union[bool, str]] = None,**config_kwargs,)参数:
config_name:一个字符串,指定数据集配置的名字。- 其它参数参考
load_dataset()。
datasets.inspect_dataset():将dataset script拷贝到本地磁盘从而允许探查和修改它。xxxxxxxxxxinspect_dataset(path: str, local_path: str, download_config: Optional[DownloadConfig] = None, **download_kwargs)参数:
local_path:一个字符串,指定dataset script要拷贝到哪里。- 其它参数参考
load_dataset()。
你可以传入一些参数到
load_dataset从而配置数据加载。例如,对于csv文件的加载,你可以指定sep参数:xxxxxxxxxxload_dataset("csv", data_dir="path/to/data/dir", sep="\t")针对不同文件格式的配置类,可以在
load_dataset中指定相应的参数:class datasets.packaged_modules.text.TextConfig:针对文本文件的BuilderConfig。xxxxxxxxxxclass datasets.packaged_modules.text.TextConfig(name: str = 'default',version: typing.Union[str, datasets.utils.version.Version, NoneType] = 0.0.0,data_dir: typing.Optional[str] = None,data_files: typing.Optional[datasets.data_files.DataFilesDict] = None,description: typing.Optional[str] = None,features: typing.Optional[datasets.features.features.Features] = None,encoding: str = 'utf-8',errors: typing.Optional[str] = None,chunksize: int = 10485760,keep_linebreaks: bool = False,sample_by: str = 'line' )class datasets.packaged_modules.csv.CsvConfig:针对csv文件的BuilderConfig。xxxxxxxxxxclass datasets.packaged_modules.csv.CsvConfig(name: str = 'default',version: typing.Union[str, datasets.utils.version.Version, NoneType] = 0.0.0,data_dir: typing.Optional[str] = None,data_files: typing.Optional[datasets.data_files.DataFilesDict] = None,description: typing.Optional[str] = None,sep: str = ',',delimiter: typing.Optional[str] = None,header: typing.Union[int, typing.List[int], str, NoneType] = 'infer',names: typing.Optional[typing.List[str]] = None,column_names: typing.Optional[typing.List[str]] = None,index_col: typing.Union[int, str, typing.List[int], typing.List[str], NoneType] = None,usecols: typing.Union[typing.List[int], typing.List[str], NoneType] = None,prefix: typing.Optional[str] = None,mangle_dupe_cols: bool = True,engine: typing.Optional[str] = None,converters: typing.Dict[typing.Union[int, str], typing.Callable[[typing.Any], typing.Any]] = None,true_values: typing.Optional[list] = None,false_values: typing.Optional[list] = None,skipinitialspace: bool = False,skiprows: typing.Union[int, typing.List[int], NoneType] = None,nrows: typing.Optional[int] = None,na_values: typing.Union[str, typing.List[str], NoneType] = None,keep_default_na: bool = True,na_filter: bool = True,verbose: bool = False,mskip_blank_lines: bool = True,thousands: typing.Optional[str] = None,decimal: str = '.',lineterminator: typing.Optional[str] = None,quotechar: str = '"',quoting: int = 0,escapechar: typing.Optional[str] = None,comment: typing.Optional[str] = None,encoding: typing.Optional[str] = None,dialect: typing.Optional[str] = None,error_bad_lines: bool = True,warn_bad_lines: bool = True,skipfooter: int = 0,doublequote: bool = True,memory_map: bool = False,float_precision: typing.Optional[str] = None,chunksize: int = 10000,features: typing.Optional[datasets.features.features.Features] = None,encoding_errors: typing.Optional[str] = 'strict',on_bad_lines: typing.Literal['error', 'warn', 'skip'] = 'error')class datasets.packaged_modules.json.JsonConfig:针对json文件的BuilderConfig。xxxxxxxxxxclass datasets.packaged_modules.json.JsonConfig(name: str = 'default',version: typing.Union[str, datasets.utils.version.Version, NoneType] = 0.0.0,data_dir: typing.Optional[str] = None,data_files: typing.Optional[datasets.data_files.DataFilesDict] = None,description: typing.Optional[str] = None,features: typing.Optional[datasets.features.features.Features] = None,field: typing.Optional[str] = None,use_threads: bool = True,block_size: typing.Optional[int] = None,chunksize: int = 10485760,newlines_in_values: typing.Optional[bool] = None)class datasets.packaged_modules.parquet.ParquetConfig:针对parquet文件的BuilderConfig。xxxxxxxxxxclass datasets.packaged_modules.parquet.ParquetConfig(name: str = 'default',version: typing.Union[str, datasets.utils.version.Version, NoneType] = 0.0.0,data_dir: typing.Optional[str] = None,data_files: typing.Optional[datasets.data_files.DataFilesDict] = None,description: typing.Optional[str] = None,batch_size: int = 10000,columns: typing.Optional[typing.List[str]] = None,features: typing.Optional[datasets.features.features.Features] = None)class datasets.packaged_modules.sql.SqlConfig:针对sql的BuilderConfig。xxxxxxxxxxclass datasets.packaged_modules.sql.SqlConfig(name: str = 'default',version: typing.Union[str, datasets.utils.version.Version, NoneType] = 0.0.0,data_dir: typing.Optional[str] = None,data_files: typing.Optional[datasets.data_files.DataFilesDict] = None,description: typing.Optional[str] = None,sql: typing.Union[str, ForwardRef('sqlalchemy.sql.Selectable')] = None,con: typing.Union[str, ForwardRef('sqlalchemy.engine.Connection'),ForwardRef('sqlalchemy.engine.Engine'), ForwardRef('sqlite3.Connection')] = None,index_col: typing.Union[str, typing.List[str], NoneType] = None,coerce_float: bool = True,params: typing.Union[typing.List, typing.Tuple, typing.Dict, NoneType] = None,parse_dates: typing.Union[typing.List, typing.Dict, NoneType] = None,columns: typing.Optional[typing.List[str]] = None,chunksize: typing.Optional[int] = 10000,features: typing.Optional[datasets.features.features.Features] = None)class datasets.packaged_modules.imagefolder.ImageFolderConfig:针对ImageFolder的BuilderConfig。xxxxxxxxxxclass datasets.packaged_modules.imagefolder.ImageFolderConfig(name: str = 'default',version: typing.Union[str, datasets.utils.version.Version, NoneType] = 0.0.0,data_dir: typing.Optional[str] = None,data_files: typing.Optional[datasets.data_files.DataFilesDict] = None,description: typing.Optional[str] = None,features: typing.Optional[datasets.features.features.Features] = None,drop_labels: bool = None,drop_metadata: bool = None)class datasets.packaged_modules.audiofolder.AudioFolderConfig:针对AudioFolder的BuilderConfig。xxxxxxxxxxclass datasets.packaged_modules.audiofolder.AudioFolderConfig(name: str = 'default',version: typing.Union[str, datasets.utils.version.Version, NoneType] = 0.0.0,data_dir: typing.Optional[str] = None,data_files: typing.Optional[datasets.data_files.DataFilesDict] = None,description: typing.Optional[str] = None,features: typing.Optional[datasets.features.features.Features] = None,drop_labels: bool = None,drop_metadata: bool = None)
修改
Datasets的日志等级:xxxxxxxxxximport datasetsdatasets.logging.set_verbosity_info()# 或者 datasets.utils.logging.set_verbosity# 可用等级:# datasets.logging.CRITICAL, datasets.logging.FATAL# datasets.logging.ERROR# datasets.logging.WARNING, datasets.logging.WARN# datasets.logging.INFO# datasets.logging.DEBUGclass datasets.table.Table(table: Table):对pyarrow Table的一个封装,是InMemoryTable, MemoryMappedTable, ConcatenationTable的基类。Table类实现了pyarrow Table的所有基础属性和方法,除了如下的Table transform:xxxxxxxxxxslice, filter, flatten, combine_chunks, cast, add_column, append_column, remove_column, set_column, rename_columns, dropdatasets.table.list_table_cache_files( table: Table) -> List[str]:返回指定的table所加载的缓存文件的路径。参数:
table:一个Table对象,表示指定的Table。