应用
我们将处理以下常见
NLP任务:token classification、掩码语言建模(如BERT)、文本摘要、翻译、因果语言建模(如GPT系列模型 )、问答。
一、Token classification
:
token classification任务可以为文本中的单词或字符分配标签,如:实体命名识别 (
NER):找出句子中的实体(如人物、地点或组织)。词性标注 (
POS):将句子中的每个单词标记为对应的词性(如名词、动词、形容词等)。分块(
chunking):找到属于同一实体的Token(如,找出名词短语、动词短语等)。
1.1 加载数据集
查看数据集:
xxxxxxxxxxfrom datasets import load_datasetraw_datasets = load_dataset("conll2003")print(raw_datasets) # 有三个数据集:train, validation, test# DatasetDict({# train: Dataset({# features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],# num_rows: 14041# })# validation: Dataset({# features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],# num_rows: 3250# })# test: Dataset({# features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],# num_rows: 3453# })# })print(raw_datasets["train"][0]["tokens"]) # 训练集第零个样本的单词序列# ['EU', 'rejects', 'German', 'call', 'to', 'boycott', 'British', 'lamb', '.']print(raw_datasets["train"][0]["ner_tags"]) # 训练集第零个样本的 label 序列# [3, 0, 7, 0, 0, 0, 7, 0, 0]ner_feature = raw_datasets["train"].features["ner_tags"]print(ner_feature) # NER label 的名称# Sequence(feature=ClassLabel(names=['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC'], id=None), length=-1, id=None)print(ner_feature.feature.names) # label 编号从 0 ~ 8 对应的名称# ['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC']# O 表示这个词不对应任何实体。# B-PER/I-PER意味着这个词对应于人名实体的开头/内部。# B-ORG/I-ORG 的意思是这个词对应于组织名称实体的开头/内部。# B-LOC/I-LOC 指的是是这个词对应于地名实体的开头/内部。# B-MISC/I-MISC 表示该词对应于一个杂项实体的开头/内部。
1.2 数据处理
我们的文本需要转换为
Token ID,然后模型才能理解它们。xxxxxxxxxxfrom transformers import AutoTokenizermodel_checkpoint = "bert-base-cased"tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)print(tokenizer.is_fast)# True## 注意,样本,如 raw_datasets["train"][0]["tokens"] 已经是完成了分词,因此这里无需分词步骤 (is_split_into_words 设为 True )inputs = tokenizer(raw_datasets["train"][0]["tokens"], is_split_into_words=True) # 执行 tokenizationprint(inputs)# {# 'input_ids': [101, 7270, 22961, 1528, 1840, 1106, 21423, 1418, 2495, 12913, 119, 102],# 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],# 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]# }print(inputs.tokens())# ['[CLS]', 'EU', 'rejects', 'German', 'call', 'to', 'boycott', 'British', 'la', '##mb', '.', '[SEP]']注意:单词
"lamb"被分为两个子词"la"和"##mb"。这导致了token序列和标签序列之间的不匹配:标签序列只有9个元素,而token序列有12个token。我们需要扩展标签序列以匹配token序列 。这里有两条规则:special token(如,[CLS], [SEP])的标签为-100。这是因为默认情况下-100是一个在我们将使用的损失函数(交叉熵)中被忽略的index。每个
token都会获得与其所在单词相同的标签,因为它们是同一实体的一部分。对于单词内部但不在开头的token,我们将B-替换为I-,因为单词内部的token不是实体的开头。
xxxxxxxxxxdef align_labels_with_tokens(labels, word_ids):# labels : word_id -> label 的映射# word_ids: 每个 token 对应的 word_idnew_labels = []current_word = Nonefor word_id in word_ids:if word_id != current_word: # 遇到一个新的单词current_word = word_idlabel = -100 if word_id is None else labels[word_id]new_labels.append(label)elif word_id is None: # special tokennew_labels.append(-100)else: # 同一个单词内部label = labels[word_id]if label % 2 == 1: # 如果 label 是 B-XXX,那么修改为 I-XXXlabel += 1new_labels.append(label)return new_labels为了预处理整个数据集,我们需要
tokenize所有输入并在所有label上应用align_labels_with_tokens()。为了利用我们的快速分词器的速度优势,最好同时对大量文本进行tokenize,因此我们将编写一个处理样本列表的函数并使用带batched = True的Dataset.map()方法。xxxxxxxxxxdef tokenize_and_align_labels(examples): # examples 是样本的列表tokenized_inputs = tokenizer(examples["tokens"], truncation=True, is_split_into_words=True)all_labels = examples["ner_tags"]new_labels = []for i, labels in enumerate(all_labels):word_ids = tokenized_inputs.word_ids(i) # 获取第 i 个样本的 word_idsnew_labels.append(align_labels_with_tokens(labels, word_ids))tokenized_inputs["labels"] = new_labels # 调整标签return tokenized_inputstokenized_datasets = raw_datasets.map(tokenize_and_align_labels,batched=True, # 一次性处理 batch 的样本remove_columns=raw_datasets["train"].column_names,)print(tokenized_datasets)# DatasetDict({# train: Dataset({# features: ['input_ids', 'token_type_ids', 'attention_mask', 'labels'],# num_rows: 14041# })# validation: Dataset({# features: ['input_ids', 'token_type_ids', 'attention_mask', 'labels'],# num_rows: 3250# })# test: Dataset({# features: ['input_ids', 'token_type_ids', 'attention_mask', 'labels'],# num_rows: 3453# })# })print(tokenized_datasets["train"][0]["input_ids"]) # 训练集第零个样本的 token id 序列# [101, 7270, 22961, 1528, 1840, 1106, 21423, 1418, 2495, 12913, 119, 102]print(tokenized_datasets["train"][0]["labels"]) # 训练集第零个样本的 label id 序列# [-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100]print(tokenized_datasets["train"].features["labels"])# Sequence(feature=Value(dtype='int64', id=None), length=-1, id=None)
1.3 使用 Trainer API 微调模型
a. 构建 mini-batch
前面的数据处理可以批量地将输入文本转换为
input_ids(token id序列),但是我们还需要将样本拼接成mini-batch然而馈入模型。DataCollatorForTokenClassification支持以相同的方式来填充输入文本和label,使得input_ids和labels的长度保持相同。label的padding值为-100,这样在损失计算中就可以忽略相应的预测。注意:
input_ids的padding值为0、labels的padding值为-100。xxxxxxxxxxfrom transformers import DataCollatorForTokenClassificationdata_collator = DataCollatorForTokenClassification(tokenizer=tokenizer)sample_list = [tokenized_datasets["train"][i] for i in range(3)] # 3 个样本,每个样本的序列长度不同print([len(i['labels']) for i in sample_list])# [12, 4, 11]batch = data_collator(sample_list)print(batch)# {'input_ids':# tensor([[ 101, 7270, 22961, 1528, 1840, 1106, 21423, 1418, 2495, 12913,# 119, 102],# [ 101, 1943, 14428, 102, 0, 0, 0, 0, 0, 0,# 0, 0],# [ 101, 26660, 13329, 12649, 15928, 1820, 118, 4775, 118, 1659,# 102, 0]]),# 'token_type_ids':# tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],# [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],# [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]),# 'attention_mask':# tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],# [1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0],# [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0]]),# 'labels':# tensor([[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100],# [-100, 1, 2, -100, -100, -100, -100, -100, -100, -100, -100, -100],# [-100, 5, 6, 6, 6, 0, 0, 0, 0, 0, -100, -100]])}
b. evaluation 指标
用于评估
Token分类效果的传统框架是seqeval。要使用此指标,我们首先需要安装seqeval库:xxxxxxxxxxpip install seqeval然后我们可以通过
load_metric()函数加载它:xxxxxxxxxxfrom datasets import load_metricmetric = load_metric("seqeval")这个评估框架以字符串而不是整数的格式传入
label,因此在将prediction和label传递给它之前需要对prediction/label进行解码。让我们看看它是如何工作的:首先,我们获得第一个训练样本的标签:
xxxxxxxxxxlabels = raw_datasets["train"][0]["ner_tags"]print(labels)# [3, 0, 7, 0, 0, 0, 7, 0, 0]label_names = raw_datasets["train"].features["ner_tags"].feature.nameslabels = [label_names[i] for i in labels]print(labels)# ['B-ORG', 'O', 'B-MISC', 'O', 'O', 'O', 'B-MISC', 'O', 'O']然后我们可以通过更改
labels来创建 ”虚拟” 的prediction:xxxxxxxxxxpredictions = labels.copy() # 注意,需要执行深层拷贝使得 predictions 和 labels 不共享底层数据predictions[2] = "O"metric.compute(predictions=[predictions], references=[labels])metric.compute的输入是一组样本的prediction(不仅仅是单个样本的prediction)、以及一组样本的label。输出为:xxxxxxxxxx{'MISC': {'precision': 1.0, 'recall': 0.5, 'f1': 0.6666666666666666, 'number': 2},'ORG': {'precision': 1.0, 'recall': 1.0, 'f1': 1.0, 'number': 1},'overall_precision': 1.0,'overall_recall': 0.6666666666666666,'overall_f1': 0.8,'overall_accuracy': 0.8888888888888888}可以看到它返回了每个单独实体(如
"MISC"、"ORG")、以及整体的精度、召回率、以及F1分数。对于单独实体还返回出现的次数("number"),对于整体还返回准确率。为了让
Trainer在每个epoch计算一个指标,我们需要定义一个compute_metrics()函数,该函数接受prediction和label,并返回一个包含指标名称和值的字典。这个
compute_metrics()首先对logits执行argmax从而得到prediction(这里无需采用softmax,因为我们只需要找到概率最大的那个token id即可,也就是logit最大的那个token id)。然后我们将prediction和label从整数转换为字符串(注意删除label = -100的label及其对应位置的prediction)。然后我们将prediction字符串和label字符串传递给metric.compute()方法:xxxxxxxxxximport numpy as npdef compute_metrics(eval_preds):logits, labels = eval_predspredictions = np.argmax(logits, axis=-1)# 移除 label = -100 位置的数据 (包括 token 和 label)true_labels = [[label_names[l] for l in label if l != -100] for label in labels]true_predictions = [[label_names[p] for (p, l) in zip(prediction, label) if l != -100]for prediction, label in zip(predictions, labels)]all_metrics = metric.compute(predictions=true_predictions, references=true_labels)return {"precision": all_metrics["overall_precision"],"recall": all_metrics["overall_recall"],"f1": all_metrics["overall_f1"],"accuracy": all_metrics["overall_accuracy"],}
c. 定义模型
由于我们正在研究
Token分类问题,因此我们将使用AutoModelForTokenClassification类。首先我们定义两个字典
id2label和label2id,其中包含从label id到label name的映射:xxxxxxxxxxid2label = {i: label for i, label in enumerate(label_names)}print(id2label)# {0: 'O', 1: 'B-PER', 2: 'I-PER', 3: 'B-ORG', 4: 'I-ORG', 5: 'B-LOC', 6: 'I-LOC', 7: 'B-MISC', 8: 'I-MISC'}label2id = {v: k for k, v in id2label.items()}print(label2id)# {'O': 0, 'B-PER': 1, 'I-PER': 2, 'B-ORG': 3, 'I-ORG': 4, 'B-LOC': 5, 'I-LOC': 6, 'B-MISC': 7, 'I-MISC': 8}然后我们加载预训练好的模型:
xxxxxxxxxxfrom transformers import AutoModelForTokenClassification, TrainingArguments, Trainermodel = AutoModelForTokenClassification.from_pretrained("bert-base-cased", id2label=id2label, label2id=label2id)print(model)# BertForTokenClassification(# (bert): BertModel(# (embeddings): BertEmbeddings(# ...# )# (encoder): BertEncoder(# ...# )# )# (dropout): Dropout(p=0.1, inplace=False)# (classifier): Linear(in_features=768, out_features=9, bias=True)#)注意,预训练好的模型必须和
AutoTokenizer相匹配,这里都是用的"bert-base-cased"。创建模型会发出警告,提示某些权重未被使用(来自
pretrained-head的权重),另外提示某些权重被随机初始化(来新分类头的权重),我们将要训练这个模型因此可以忽略这两种警告。我们可以查看模型配置:
xxxxxxxxxxprint(model.config)# BertConfig {# "_name_or_path": "bert-base-cased",# "architectures": [# "BertForMaskedLM"# ],# "attention_probs_dropout_prob": 0.1,# "classifier_dropout": null,# "gradient_checkpointing": false,# "hidden_act": "gelu",# "hidden_dropout_prob": 0.1,# "hidden_size": 768,# "id2label": {# ...# },# "initializer_range": 0.02,# "intermediate_size": 3072,# "label2id": {# ...# },# "layer_norm_eps": 1e-12,# "max_position_embeddings": 512,# "model_type": "bert",# "num_attention_heads": 12,# "num_hidden_layers": 12,# "pad_token_id": 0,# "position_embedding_type": "absolute",# "transformers_version": "4.25.1",# "type_vocab_size": 2,# "use_cache": true,# "vocab_size": 28996# }然后我们需要定义训练参数,以及登录
Hugging Face(如果不需要把训练结果推送到HuggingFace,则无需登录并且设置push_to_hub=False)。登录:
xxxxxxxxxxhuggingface-cli login定义训练参数:
xxxxxxxxxxfrom transformers import TrainingArgumentsargs = TrainingArguments("bert-finetuned-ner", # 输出模型的名称evaluation_strategy="epoch",save_strategy="epoch",learning_rate=2e-5,num_train_epochs=3,weight_decay=0.01,push_to_hub=True, # 注意,如果你不想 push 到 HuggingFace,设置它为 False)print(args) # 参数含义可以参考前面对应章节的内容# TrainingArguments(# _n_gpu=0, # 如果机器上有 GPU,那么这里表示 GPU 数量# adafactor=False,# adam_beta1=0.9,# adam_beta2=0.999,# adam_epsilon=1e-08,# auto_find_batch_size=False,# bf16=False,# bf16_full_eval=False,# data_seed=None,# dataloader_drop_last=False,# dataloader_num_workers=0,# dataloader_pin_memory=True,# ddp_bucket_cap_mb=None,# ddp_find_unused_parameters=None,# ddp_timeout=1800,# debug=[],# deepspeed=None,# disable_tqdm=False,# do_eval=True,# do_predict=False,# do_train=False,# eval_accumulation_steps=None,# eval_delay=0,# eval_steps=None,# evaluation_strategy=epoch,# fp16=False,# fp16_backend=auto,# fp16_full_eval=False,# fp16_opt_level=O1,# fsdp=[],# fsdp_min_num_params=0,# fsdp_transformer_layer_cls_to_wrap=None,# full_determinism=False,# gradient_accumulation_steps=1,# gradient_checkpointing=False,# greater_is_better=None,# group_by_length=False,# half_precision_backend=auto,# hub_model_id=None,# hub_private_repo=False,# hub_strategy=every_save,# hub_token=<HUB_TOKEN>,# ignore_data_skip=False,# include_inputs_for_metrics=False,# jit_mode_eval=False,# label_names=None,# label_smoothing_factor=0.0,# learning_rate=2e-05,# length_column_name=length,# load_best_model_at_end=False,# local_rank=-1,# log_level=passive,# log_level_replica=passive,# log_on_each_node=True,# logging_dir=bert-finetuned-ner/runs/Apr15_06-45-26_SHAUNHUA-MB0,# logging_first_step=False,# logging_nan_inf_filter=True,# logging_steps=500,# logging_strategy=steps,# lr_scheduler_type=linear,# max_grad_norm=1.0,# max_steps=-1,# metric_for_best_model=None,# mp_parameters=,# no_cuda=False,# num_train_epochs=3,# optim=adamw_hf,# optim_args=None,# output_dir=bert-finetuned-ner,# overwrite_output_dir=False,# past_index=-1,# per_device_eval_batch_size=8,# per_device_train_batch_size=8,# prediction_loss_only=False,# push_to_hub=True,# push_to_hub_model_id=None,# push_to_hub_organization=None,# push_to_hub_token=<PUSH_TO_HUB_TOKEN>,# ray_scope=last,# remove_unused_columns=True,# report_to=['tensorboard'],# resume_from_checkpoint=None,# run_name=bert-finetuned-ner,# save_on_each_node=False,# save_steps=500,# save_strategy=epoch,# save_total_limit=None,# seed=42,# sharded_ddp=[],# skip_memory_metrics=True,# tf32=None,# torchdynamo=None,# tpu_metrics_debug=False,# tpu_num_cores=None,# use_ipex=False,# use_legacy_prediction_loop=False,# use_mps_device=False,# warmup_ratio=0.0,# warmup_steps=0,# weight_decay=0.01,# xpu_backend=None,# )
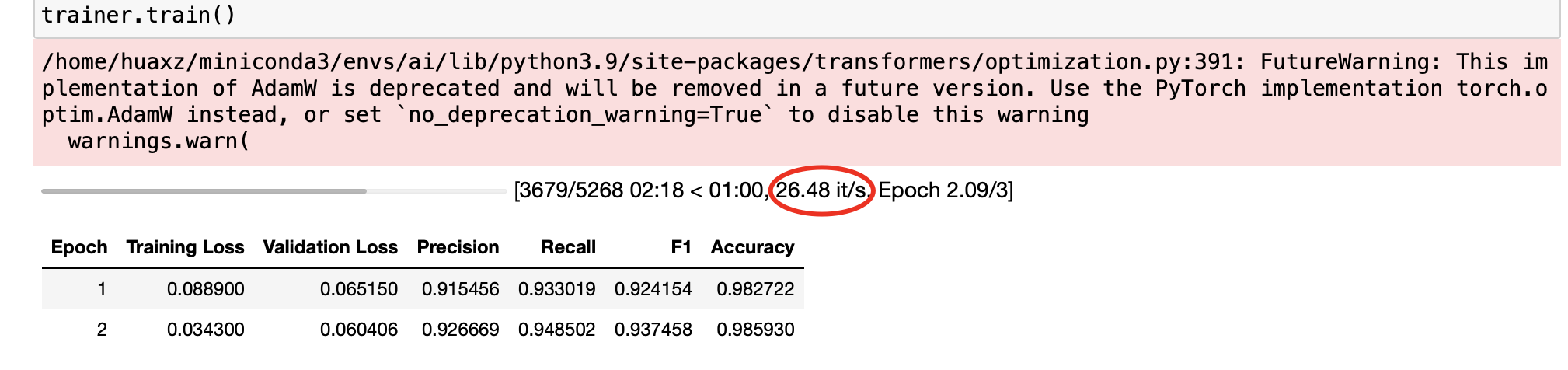
接下来我们构建
Trainer并启动训练:xxxxxxxxxxfrom transformers import Trainertrainer = Trainer(model=model,args=args,train_dataset=tokenized_datasets["train"],eval_dataset=tokenized_datasets["validation"],data_collator=data_collator,compute_metrics=compute_metrics,tokenizer=tokenizer,)trainer.train()# TrainOutput(global_step=5268, training_loss=0.06639557918455896,# metrics={'train_runtime': 198.3512, 'train_samples_per_second': 212.366, 'train_steps_per_second': 26.559, 'total_flos': 923954298531210.0, 'train_loss': 0.06639557918455896, 'epoch': 3.0})建议使用
GPU训练,CPU速度太慢。在MacBook Pro 2018(型号A1990)上训练速度:0.38 iteration/s,在RTX 4090上训练速度26.48 iteration/s。
如果
push_to_hub=True,那么训练期间每次保存模型时(这里是每个epooch保存一次),trainer都会在后台将checkpoint上传到HuggingFace Model Hub。这样,你就能够在另一台机器上继续训练。并且训练完成之后,可以上传模型的最终版本:xxxxxxxxxxtrainer.push_to_hub(commit_message="Training finish!")这
Trainer还创建了一张包含所有评估结果的Model Card并上传。在此阶段,你可以使用Hugging Face Model Hub上的inference widget来测试该模型,并分享给其它人。
1.4 使用微调后的模型
通过指定模型名称来使用微调后的模型:
xxxxxxxxxxfrom transformers import pipelinetoken_classifier = pipeline( # model 参数指定模型名称(对应于 HuggingFace Model Hub、或者模型权重的位置(对应于本地)"token-classification", model="./bert-finetuned-ner/checkpoint-5268"", aggregation_strategy="simple")token_classifier("Wuhan is a beautiful city in China.")# [{'entity_group': 'LOC', 'score': 0.99749047, 'word': 'Wuhan', 'start': 0, 'end': 5},# {'entity_group': 'LOC', 'score': 0.9990609, 'word': 'China', 'start': 29, 'end': 34}]
1.5 自定义训练过程
我们也可以自定义训练过程,从而代替
Trainer API,这样可以对训练过程进行更精细的控制。xxxxxxxxxxfrom torch.utils.data import DataLoaderfrom datasets import load_datasetfrom transformers import AutoTokenizerfrom transformers import DataCollatorForTokenClassificationfrom transformers import AutoModelForTokenClassificationfrom datasets import load_metricfrom tqdm.auto import tqdmimport torch##****************** 创建数据集 **********************model_checkpoint = "bert-base-cased"tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)data_collator = DataCollatorForTokenClassification(tokenizer=tokenizer)def align_labels_with_tokens(labels, word_ids):# labels : word_id -> label 的映射# word_ids: 每个 token 对应的 word_idnew_labels = []current_word = Nonefor word_id in word_ids:if word_id != current_word: # 遇到一个新的单词current_word = word_idlabel = -100 if word_id is None else labels[word_id]new_labels.append(label)elif word_id is None: # special tokennew_labels.append(-100)else: # 同一个单词内部label = labels[word_id]if label % 2 == 1: # 如果 label 是 B-XXX,那么修改为 I-XXXlabel += 1new_labels.append(label)return new_labelsdef tokenize_and_align_labels(examples): # examples 是样本的列表tokenized_inputs = tokenizer(examples["tokens"], truncation=True, is_split_into_words=True)all_labels = examples["ner_tags"]new_labels = []for i, labels in enumerate(all_labels):word_ids = tokenized_inputs.word_ids(i) # 获取第 i 个样本的 word_idsnew_labels.append(align_labels_with_tokens(labels, word_ids))tokenized_inputs["labels"] = new_labels # 调整标签return tokenized_inputsraw_datasets = load_dataset("conll2003")tokenized_datasets = raw_datasets.map(tokenize_and_align_labels,batched=True, # 一次性处理 batch 的样本remove_columns=raw_datasets["train"].column_names,)train_dataloader = DataLoader(tokenized_datasets["train"], shuffle=True, collate_fn=data_collator, batch_size=8,)eval_dataloader = DataLoader(tokenized_datasets["validation"], collate_fn=data_collator, batch_size=8)##****************** 创建模型 **********************label_names = raw_datasets["train"].features["ner_tags"].feature.namesid2label = {i: label for i, label in enumerate(label_names)}label2id = {v: k for k, v in id2label.items()}model = AutoModelForTokenClassification.from_pretrained(model_checkpoint, id2label=id2label, label2id=label2id,)##****************** 创建优化器 **********************from torch.optim import AdamWoptimizer = AdamW(model.parameters(), lr=2e-5)##****************** 调用 accelerator **********************from accelerate import Acceleratoraccelerator = Accelerator()model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(model, optimizer, train_dataloader, eval_dataloader)##****************** 创建调度器 **********************from transformers import get_schedulernum_train_epochs = 3num_update_steps_per_epoch = len(train_dataloader) # 注意,必须在 accelerator.prepare() 之后在调用数据集的 len(...),因为 accelerator.prepare() 可能改变数据集的长度num_training_steps = num_train_epochs * num_update_steps_per_epochlr_scheduler = get_scheduler("linear",optimizer=optimizer,num_warmup_steps=0,num_training_steps=num_training_steps,)##****************** 创建 Repo **********************from huggingface_hub import Repository, get_full_repo_name# model_name = "bert-finetuned-ner-accelerate"# repo_name = get_full_repo_name(model_name)# print(repo_name)output_dir = "bert-finetuned-ner-accelerate"# repo = Repository(output_dir, clone_from=repo_name) # 也可以忽略这一步##****************** 定义 metric 、以及后处理函数 **********************metric = load_metric("seqeval")def postprocess(predictions, labels): # 将模型输出和标签转换为 metric 可接受的格式predictions = predictions.detach().cpu().clone().numpy()labels = labels.detach().cpu().clone().numpy()# 移除 label = -100 位置的数据 (包括 token 和 label)true_labels = [[label_names[l] for l in label if l != -100] for label in labels]true_predictions = [[label_names[p] for (p, l) in zip(prediction, label) if l != -100]for prediction, label in zip(predictions, labels)]return true_labels, true_predictions##****************** 训练流程 **********************progress_bar = tqdm(range(num_training_steps))for epoch in range(num_train_epochs):# Trainingmodel.train()for batch in train_dataloader:outputs = model(**batch)loss = outputs.lossaccelerator.backward(loss)optimizer.step() # 参数更新lr_scheduler.step() # 学习率更新optimizer.zero_grad() # 梯度清零progress_bar.update(1)# Evaluationmodel.eval()for batch in eval_dataloader:with torch.no_grad():outputs = model(**batch)predictions = outputs.logits.argmax(dim=-1)labels = batch["labels"]# 在多进程场景下,可能两个进程将 predictions/labels 在进程内部对齐,但是在进程间不一致,这里需要跨进程对齐predictions = accelerator.pad_across_processes(predictions, dim=1, pad_index=-100)labels = accelerator.pad_across_processes(labels, dim=1, pad_index=-100)predictions_gathered = accelerator.gather(predictions) # 跨进程收集labels_gathered = accelerator.gather(labels)true_predictions, true_labels = postprocess(predictions_gathered, labels_gathered)metric.add_batch(predictions=true_predictions, references=true_labels)results = metric.compute() # 计算验证集的指标print(f"epoch {epoch}:",{ key: results[f"overall_{key}"] for key in ["precision", "recall", "f1", "accuracy"]},)# epoch 0: {'precision': 0.930, 'recall': 0.904, 'f1': 0.917, 'accuracy': 0.982}# epoch 1: {'precision': 0.944, 'recall': 0.912, 'f1': 0.928, 'accuracy': 0.985}# epoch 2: {'precision': 0.948, 'recall': 0.928, 'f1': 0.938, 'accuracy': 0.987}##****************** 保存和上传模型 **********************accelerator.wait_for_everyone() # 所有进程都到达这个阶段然后继续执行,如果任何一个进程未到达,则所有其他进程都要等待unwrapped_model = accelerator.unwrap_model(model) # 获取底层的模型,因为 accelerator 可能在分布式环境中工作unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save) # 用 accelerator.save 来保存if accelerator.is_main_process: # 只有主进程才执行下面的步骤tokenizer.save_pretrained(output_dir) # 保存 tokenizer# repo.push_to_hub(commit_message=f"Training in progress epoch {epoch}", blocking=False) # blocking = False 表示异步推送
二、微调 Masked Language Model
首先为
masked language modeling选择一个合适的预训练模型,如前面用到的"bert-base-cased"。xxxxxxxxxxfrom transformers import AutoModelForMaskedLMmodel_checkpoint = "bert-base-cased"model = AutoModelForMaskedLM.from_pretrained(model_checkpoint)num_parameters = model.num_parameters() / 1_000_000print(f"BERT_Base number of parameters: {round(num_parameters)}M'")# BERT_Base number of parameters: 108M'现在我们来看看
BERT_Base如何补全一个被掩码的单词:xxxxxxxxxxfrom transformers import AutoTokenizerimport torchtokenizer = AutoTokenizer.from_pretrained(model_checkpoint)text = "WuHan City a great [MASK]."inputs = tokenizer(text, return_tensors="pt")print(inputs)# {# 'input_ids': tensor([[ 101, 8769, 3048, 1389, 1392, 170, 1632, 103, 119, 102]]),# 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]),# 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])# }token_logits = model(**inputs).logits # shape: [1, 10, 28996]##************ 找到 [MASK] 的位置并抽取它的 logits ***********mask_token_index = torch.where(inputs["input_ids"] == tokenizer.mask_token_id)[1]print(mask_token_index) # tokenizer.mask_token_id = 103# tensor([7])mask_token_logits = token_logits[0, mask_token_index, :] # shape: [1, 28996]##************ 返回 [MASK] 的 top-k 候选 ***********top_5_tokens = torch.topk(mask_token_logits, 5, dim=1).indices[0].tolist()for token in top_5_tokens:print(f"'>>> {text.replace(tokenizer.mask_token, tokenizer.decode([token]))}'")# '>>> WuHan City a great city.'# '>>> WuHan City a great place.'# '>>> WuHan City a great town.'# '>>> WuHan City a great village.'# '>>> WuHan City a great name.'
2.1 数据集和数据处理
加载数据集:我们在
Large Movie Review Dataset: IMDb上微调BERT_Base。该数据集有训练集、测试集、还有unsupervised等三个split。xxxxxxxxxxfrom datasets import load_datasetimdb_dataset = load_dataset("imdb")print(imdb_dataset)# DatasetDict({# train: Dataset({# features: ['text', 'label'],# num_rows: 25000# })# test: Dataset({# features: ['text', 'label'],# num_rows: 25000# })# unsupervised: Dataset({# features: ['text', 'label'],# num_rows: 50000# })# })数据处理:对于自回归语言建模、以及掩码语言建模,一个常见的预处理步骤是拼接所有样本,然后将整个语料库拆分为相同大小的
block。我们还需要保留word id序列,以便后续用于全词掩码(whole word masking)。xxxxxxxxxxresult = tokenizer("Welcome to WuHan City", is_split_into_words=False) # 执行 tokenizationprint(result)# {# 'input_ids': [101, 12050, 1106, 8769, 3048, 1389, 1392, 102],# 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0],# 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1]# }print(result.word_ids()) # 每个 token 对应的 word id# [None, 0, 1, 2, 2, 2, 3, None]此外,我们删除
text字段和label字段,因为不再需要。我们构建一个函数来执行这些:xxxxxxxxxxdef tokenize_function(examples): # examples 是一个 batch 的样本result = tokenizer(examples["text"]) # result 包含 batch 结果if tokenizer.is_fast: # result.word_ids(i) 返回第 i 个样本的 word id 序列result["word_ids"] = [result.word_ids(i) for i in range(len(result["input_ids"]))]return result# 使用 batched=Truetokenized_datasets = imdb_dataset.map(tokenize_function, batched=True, remove_columns=["text", "label"])print(tokenized_datasets) # word_ids 列是我们人工添加的# DatasetDict({# train: Dataset({# features: ['input_ids', 'token_type_ids', 'attention_mask', 'word_ids'],# num_rows: 25000# })# test: Dataset({# features: ['input_ids', 'token_type_ids', 'attention_mask', 'word_ids'],# num_rows: 25000# })# unsupervised: Dataset({# features: ['input_ids', 'token_type_ids', 'attention_mask', 'word_ids'],# num_rows: 50000# })# })现在我们已经完成了
tokenization。下一步是将它们拼接在一起然后分块。块的大小怎么选择?这取决于GPU的显存大小。此外,还可以参考模型的最大上下文的长度,这可以通过tokenizer.model_max_length属性来判断:xxxxxxxxxxprint(tokenizer.model_max_length)# 512然后我们拼接文本并拆分为大小为
block_size的块。xxxxxxxxxxdef group_texts(examples, chunk_size = 128):# keys() 为 ('input_ids', 'token_type_ids', 'attention_mask', 'word_ids')concatenated_examples = {k: sum(examples[k], []) for k in examples.keys()} # 拼接样本total_length = len(concatenated_examples[list(examples.keys())[0]]) # 计算总的 token 长度total_length = (total_length // chunk_size) * chunk_size # 移除最后一个小于 chunk_size 的块(也可以填充最后一个块到 chunk_size 长度)result = {k: [t[i : i + chunk_size] for i in range(0, total_length, chunk_size)] # 执行分块for k, t in concatenated_examples.items()}result["labels"] = result["input_ids"].copy() # label 就是 input token 序列,因为 MLM 的 label 就是被掩码的 tokenreturn resultlm_datasets = tokenized_datasets.map(group_texts, batched=True)print(lm_datasets)# DatasetDict({# train: Dataset({# features: ['input_ids', 'token_type_ids', 'attention_mask', 'word_ids', 'labels'],# num_rows: 63037# })# test: Dataset({# features: ['input_ids', 'token_type_ids', 'attention_mask', 'word_ids', 'labels'],# num_rows: 61623# })# unsupervised: Dataset({# features: ['input_ids', 'token_type_ids', 'attention_mask', 'word_ids', 'labels'],# num_rows: 126497# })# })以训练集为例,可以看到,样本数量要比原始的
25k个样本要多。因为现在的样本是contiguous token,而不是原始的情感分类样本。现在缺少关键的步骤:在输入的随机位置插入
[MASK] token。这需要在训练过程中动态地插入,而不是静态地提前准备好。
2.2 使用 Trainer API 微调模型
如前所述,我们需要再训练过程中动态地在输入的随机位置插入
[MASK] token。这需要一个特殊的data collator从而可以在训练过程中动态地随机掩码输入文本中的一些token,即DataCollatorForLanguageModeling。我们需要向它传入mlm_probability参数从而指定masked token的占比。我们选择15%,因为这是论文中常用的配置:xxxxxxxxxxfrom transformers import DataCollatorForLanguageModelingdata_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm_probability=0.15)samples = [lm_datasets["train"][i] for i in range(2)]for sample in samples:_ = sample.pop("word_ids") # 移除 word_ids ,否则 data_collator(samples) 抛出异常for chunk in data_collator(samples)["input_ids"]:print(f"\n'>>> {tokenizer.decode(chunk)}'")# >>> [CLS] I rented I AM [MASK] deliberate [MASK]US - YEL [MASK]OW from my video store because of all thedating that surrounded it when it [MASK] first released in 1967. I also heard [MASK] [MASK] first it was seized by U. S. [MASK] if it ever tried to enter this [MASK], [MASK] being a fan of films [MASK] " controversial " I really had to see this for myself. < br / [MASK] < br / > The plot [MASK] centered around a young Swedish drama student named Lena who neighbouring to learn everything she can about [MASK]. In particular [MASK] wants [MASK] focus her attention [MASK] to making some sort of documentary on [MASK] the average Swed# >>> ##e thought about [MASK] political [MASK] such as [MASK] Vietnam War and [MASK] issues in [MASK] [MASK] States. In between asking politicians [MASK] ordinary [MASK] [MASK]mony of Stockholm about their opinions on politics, she [MASK] [MASK] with [MASK] drama [MASK] [MASK] classmates, [MASK] married men. [MASK] br / Quaker < br / > What kills me about I AM CURIOUS - YELLOW is that 40 years ago, this was considered pornographic. Really [MASK] [MASK] sex and nudi [MASK] scenes are few and far between [MASK] even then it's not shot like some cheaply made [MASK]orno [MASK] While my countrymen mind find it shocking, in [MASK]随机掩码的一个副作用是,当使用
Trainer时,我们的评估指标可能是随机的(每一次评估的结果可能各不相同),因为测试集使用的也是相同的DataCollatorForLanguageModeling。然而,我们可以利用Accelerate来自定义训练过程(而不是Trainer封装好的训练过程),从而在训练过程中冻结随机性。全词掩码
whole word masking: WWM:全词掩码是掩码整个单词,而不仅是是掩码单词内的单个token。如果我们想使用全词掩码,我们需要自己构建一个data collator。此时,我们需要用到之前计算的word_ids,它给出了每个token对应的word id。注意,除了与[MASK]对应的label以外,所有的其他label都是-100。xxxxxxxxxximport collectionsimport numpy as npfrom transformers import default_data_collatorwwm_probability = 0.2def whole_word_masking_data_collator(features):for feature in features:word_ids = feature.pop("word_ids")mapping = collections.defaultdict(list) # 存放 word_id 到它包含的 token id list 的映射current_word_index = -1current_word = Nonefor idx, word_id in enumerate(word_ids):if word_id is not None:if word_id != current_word:current_word = word_idcurrent_word_index += 1mapping[current_word_index].append(idx)# 随机掩码 wordmask = np.random.binomial(1, wwm_probability, (len(mapping),)) # 注意,单个元素的元组 (xxx, )input_ids = feature["input_ids"]labels = feature["labels"]new_labels = [-100] * len(labels) # 默认全为 -100for word_id in np.where(mask)[0]: # np.where(mask) 返回一个元组,word_id = word_id.item()for idx in mapping[word_id]: # 被掩码的单词所对应的 token_idnew_labels[idx] = labels[idx]input_ids[idx] = tokenizer.mask_token_idfeature["labels"] = new_labelsreturn default_data_collator(features)samples = [lm_datasets["train"][i] for i in range(2)]batch = whole_word_masking_data_collator(samples)for chunk in batch["input_ids"]:print(f"\n'>>> {tokenizer.decode(chunk)}'")# >>> [CLS] I rented I AM [MASK] [MASK] [MASK] [MASK] - YELLOW from my [MASK] store because of all the controversy that [MASK] it when it was first released [MASK] [MASK]. [MASK] also heard that at first it was [MASK] [MASK] U [MASK] S [MASK] [MASK] if it [MASK] tried to enter this country, therefore [MASK] a fan [MASK] [MASK] [MASK] " [MASK] " I really had [MASK] see this for myself [MASK] [MASK] br / [MASK] < br / > The plot [MASK] [MASK] around a young [MASK] drama student [MASK] Lena who wants to learn everything she [MASK] [MASK] life. In particular she wants to [MASK] her attentions to making some sort of documentary [MASK] what [MASK] average Swed# >>> ##e thought about certain political issues such as the Vietnam War and race issues in [MASK] United States [MASK] In between asking politicians and ordinary denizens of [MASK] about their opinions on politics, [MASK] has [MASK] with [MASK] [MASK] teacher [MASK] [MASK], and married men. [MASK] [MASK] / [MASK] < br [MASK] > What kills me about I [MASK] CURIOUS - [MASK] [MASK] [MASK] [MASK] is that 40 years ago, this was considered pornographic. Really, the sex [MASK] nudity scenes are few and [MASK] [MASK] [MASK] even then it's [MASK] [MASK] like some cheaply made [MASK] [MASK] [MASK]. [MASK] my countrymen mind find [MASK] [MASK], in [MASK]数据集缩小:为了演示的方便,我们将训练集缩小为数千个样本。
xxxxxxxxxxtrain_size = 10_000test_size = int(0.1 * train_size)downsampled_dataset = lm_datasets["train"].train_test_split(train_size=train_size, test_size=test_size, seed=42)print(downsampled_dataset)# DatasetDict({# train: Dataset({# features: ['input_ids', 'token_type_ids', 'attention_mask', 'word_ids', 'labels'],# num_rows: 10000# })# test: Dataset({# features: ['input_ids', 'token_type_ids', 'attention_mask', 'word_ids', 'labels'],# num_rows: 1000# })# })配置
Trainer:接下来我们可以登录Hugging Face Hub(可选的,方式为在命令行中执行命令huggingface-cli login)。xxxxxxxxxxfrom transformers import TrainingArgumentsbatch_size = 64logging_steps = len(downsampled_dataset["train"]) // batch_size # 每个 epoch 打印 training lossmodel_name = model_checkpoint.split("/")[-1]training_args = TrainingArguments(output_dir=f"{model_name}-finetuned-imdb",overwrite_output_dir=True,evaluation_strategy="epoch",save_strategy="epoch",learning_rate=2e-5,weight_decay=0.01,num_train_epochs=3,per_device_train_batch_size=batch_size,per_device_eval_batch_size=batch_size,push_to_hub=False, # 这里暂时先不 push 到 hubfp16=True, # 混合精度训练从而加速训练过程logging_steps=logging_steps, # 设置 logging_stepsremove_unused_columns = False, # 用于 WWM data_collator)from transformers import Trainertrainer = Trainer(model=model,args=training_args,train_dataset=downsampled_dataset["train"],eval_dataset=downsampled_dataset["test"],# data_collator=data_collator,data_collator=whole_word_masking_data_collator # WWM data_collator)默认情况下,
Trainer将删除不属于模型的forward()方法的列。这意味着, 如果你使用WWM data_collator,你还需要设置remove_unused_columns = False,以确保我们不会在训练期间丢失word_ids列。语言模型的困惑度(
perplexity):一个好的语言模型是为语法正确的句子分配高概率,为无意义的句子分配低概率。我们通过困惑度来衡量这种概率。困惑度有多种数学定义,这里我们采用交叉熵损失的指数。因此,我们可以通过Trainer.evaluate()函数计算测试集上的交叉熵损失,然后取结果的指数来计算预训练模型的困惑度:xxxxxxxxxximport matheval_results = trainer.evaluate()print(f">>> Perplexity: {math.exp(eval_results['eval_loss']):.2f}")# >>> Perplexity: 39.75trainer.train()eval_results = trainer.evaluate()print(f">>> Perplexity: {math.exp(eval_results['eval_loss']):.2f}")# >>> Perplexity: 22.11trainer.push_to_hub()tokenizer.save_pretrained(output_dir) # 保存 tokenizer较低的困惑度分数意味着更好的语言模型。可以看到:模型困惑度降低了很多。这表明模型已经了解了一些关于电影评论领域的知识。
使用模型:现在可以通过
Transformers的pipeline来调用微调后的模型:xxxxxxxxxxfrom transformers import pipelinemask_filler = pipeline( # 注意,tokenizer 也需要保存在这个目录下"fill-mask", model="./bert-base-cased-finetuned-imdb/checkpoint-471")preds = mask_filler("WuHan City a great [MASK].")for pred in preds:print(f">>> {pred['sequence']}")# >>> WuHan City a great city.# >>> WuHan City a great place.# >>> WuHan City a great town.# >>> WuHan City a great one.# >>> WuHan City a great name.
2.3 自定义训练过程
DataCollatorForLanguageModeling对每次评估过程采用随机掩码,因此每次训练运行时,我们都会看到困惑度分数的一些波动。消除这种随机性来源的一种方法是在整个测试集上应用一次掩码,然后使用Transformers中的默认data collator。注意,自定义训练过程人工创建了
dataloader,而Trainer API只需要传入dataset而无需创建dataloader。整体代码如下所示:
xxxxxxxxxxfrom transformers import AutoModelForMaskedLMfrom transformers import AutoTokenizerfrom tqdm.auto import tqdmimport torchimport mathfrom datasets import load_datasetfrom transformers import DataCollatorForLanguageModelingimport collectionsimport numpy as npfrom transformers import default_data_collatorfrom torch.utils.data import DataLoaderfrom torch.optim import AdamWfrom accelerate import Acceleratorfrom transformers import get_scheduler##********** 加载 pre-trained model, tokenizer 和数据集 ********model_checkpoint = "bert-base-cased"model = AutoModelForMaskedLM.from_pretrained(model_checkpoint)tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)imdb_dataset = load_dataset("imdb")##********* tokenization ****************def tokenize_function(examples): # examples 是一个 batch 的样本result = tokenizer(examples["text"]) # result 包含 batch 结果if tokenizer.is_fast: # result.word_ids(i) 返回第 i 个样本的 word id 序列result["word_ids"] = [result.word_ids(i) for i in range(len(result["input_ids"]))]return resulttokenized_datasets = imdb_dataset.map(tokenize_function, batched=True, remove_columns=["text", "label"])##********* 分块 ****************def group_texts(examples, chunk_size = 128):# keys() 为 ('input_ids', 'token_type_ids', 'attention_mask', 'word_ids')concatenated_examples = {k: sum(examples[k], []) for k in examples.keys()} # 拼接样本total_length = len(concatenated_examples[list(examples.keys())[0]]) # 计算总的 token 长度total_length = (total_length // chunk_size) * chunk_size # 移除最后一个小于 chunk_size 的块(也可以填充最后一个块到 chunk_size 长度)result = {k: [t[i : i + chunk_size] for i in range(0, total_length, chunk_size)] # 执行分块for k, t in concatenated_examples.items()}result["labels"] = result["input_ids"].copy() # label 就是 input token 序列,因为 MLM 的 label 就是被掩码的 tokenreturn resultlm_datasets = tokenized_datasets.map(group_texts, batched=True)train_size = 10_000test_size = int(0.1 * train_size)downsampled_dataset = lm_datasets["train"].train_test_split( # demo: 减小数据规模train_size=train_size, test_size=test_size, seed=42)##********** 创建 WWM data collator ***********# data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm_probability=0.15)wwm_probability = 0.2def whole_word_masking_data_collator(features):for feature in features:word_ids = feature.pop("word_ids")mapping = collections.defaultdict(list) # 存放 word_id 到它包含的 token id list 的映射current_word_index = -1current_word = Nonefor idx, word_id in enumerate(word_ids):if word_id is not None:if word_id != current_word:current_word = word_idcurrent_word_index += 1mapping[current_word_index].append(idx)# 随机掩码 wordmask = np.random.binomial(1, wwm_probability, (len(mapping),)) # 注意,单个元素的元组 (xxx, )input_ids = feature["input_ids"]labels = feature["labels"]new_labels = [-100] * len(labels) # 默认全为 -100for word_id in np.where(mask)[0]: # np.where(mask) 返回一个元组,word_id = word_id.item()for idx in mapping[word_id]: # 被掩码的单词所对应的 token_idnew_labels[idx] = labels[idx]input_ids[idx] = tokenizer.mask_token_idfeature["labels"] = new_labelsreturn default_data_collator(features)##************ 对测试集进行静态掩码 ***************def insert_random_mask(batch):features = [dict(zip(batch, t)) for t in zip(*batch.values())]masked_inputs = whole_word_masking_data_collator(features)# 对于数据集中的每一列,创建一个对应的 masked 列return {"masked_" + k: v.numpy() for k, v in masked_inputs.items()}# downsampled_dataset = downsampled_dataset.remove_columns(["word_ids"]) # 如果是 whole_word_masking_data_collator 则注释掉这一行eval_dataset = downsampled_dataset["test"].map(insert_random_mask,batched=True,remove_columns=downsampled_dataset["test"].column_names,)eval_dataset = eval_dataset.rename_columns({"masked_input_ids": "input_ids","masked_attention_mask": "attention_mask","masked_labels": "labels",}).remove_columns(["masked_token_type_ids"]) # 移除一些不需要的列##************ 创建 data loader ***************batch_size = 64train_dataloader = DataLoader(downsampled_dataset["train"],shuffle=True,batch_size=batch_size,collate_fn=whole_word_masking_data_collator,)eval_dataloader = DataLoader(eval_dataset, batch_size=batch_size, collate_fn=default_data_collator)##************ 创建训练组件***************optimizer = AdamW(model.parameters(), lr=5e-5)accelerator = Accelerator()model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(model, optimizer, train_dataloader, eval_dataloader)num_train_epochs = 3num_update_steps_per_epoch = len(train_dataloader)num_training_steps = num_train_epochs * num_update_steps_per_epochlr_scheduler = get_scheduler("linear",optimizer=optimizer,num_warmup_steps=0,num_training_steps=num_training_steps,)##********** 在 Hugging Face Hub 上创建一个模型库 (可以忽略) **********# from huggingface_hub import get_full_repo_namemodel_name = "%s-finetuned-imdb-accelerate"%model_checkpoint# repo_name = get_full_repo_name(model_name)# repo_name# rom huggingface_hub import Repositoryoutput_dir = model_name# repo = Repository(output_dir, clone_from=repo_name)##************ 训练和评估 ****************progress_bar = tqdm(range(num_training_steps))for epoch in range(num_train_epochs):# Trainingmodel.train()for batch in train_dataloader:outputs = model(**batch)loss = outputs.lossaccelerator.backward(loss)optimizer.step()lr_scheduler.step()optimizer.zero_grad()progress_bar.update(1)# Evaluationmodel.eval()losses = []for step, batch in enumerate(eval_dataloader):with torch.no_grad():outputs = model(**batch)loss = outputs.losslosses.append(accelerator.gather(loss)) # 跨进程收集每个样本的 losslosses = torch.cat(losses)losses = losses[: len(eval_dataset)] # 获取验证集每个样本的 losstry:perplexity = math.exp(torch.mean(losses))except OverflowError:perplexity = float("inf")print(f">>> Epoch {epoch}: Perplexity: {perplexity}")# >>> Epoch 0: Perplexity: 22.54525292335159# >>> Epoch 1: Perplexity: 21.186613045279536# >>> Epoch 2: Perplexity: 20.757056615284373##*********** 保存、上传微调好的模型 ****************accelerator.wait_for_everyone()unwrapped_model = accelerator.unwrap_model(model)unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save) # 用 accelerator.saveif accelerator.is_main_process:tokenizer.save_pretrained(output_dir)# repo.push_to_hub(# commit_message=f"Training in progress epoch {epoch}", blocking=False# )
三、从头开始训练因果语言模型
这里我们将采用不同的方法并从头开始训练一个全新的因果语言模型。为了减小数据规模从而用于演示,我们将使用
Python代码的子集专注于单行代码的补全(而不是补全完整的函数或类)。
3.1 数据集和数据处理
加载数据集:
CodeParrot数据集来自于Google's BigQuery数据集, 使用了大约180 GB的GitHub dump,包含大约20M个Python文件。创建过程:xxxxxxxxxxSELECTf.repo_name, f.path, c.copies, c.size, c.content, l.licenseFROM`bigquery-public-data.github_repos.files` AS fJOIN`bigquery-public-data.github_repos.contents` AS cONf.id = c.idJOIN`bigquery-public-data.github_repos.licenses` AS lONf.repo_name = l.repo_nameWHERENOT c.binary AND ((f.path LIKE '%.py') AND (c.size BETWEEN 1024 AND 1048575))为了演示的效果,我们进一步仅考虑与
Python数据科学相关的子集。我们使用过滤函数:xxxxxxxxxxfilters = ["pandas", "sklearn", "matplotlib", "seaborn"]def any_keyword_in_string(string, keywords):for keyword in keywords:if keyword in string:return Truereturn False然后我们用这个过滤函数来流式地过滤数据集:
xxxxxxxxxxdef filter_streaming_dataset(dataset, filters):filtered_dict = defaultdict(list)total = 0for sample in tqdm(iter(dataset)):total += 1if any_keyword_in_string(sample["content"], filters):for k, v in sample.items():filtered_dict[k].append(v)print(f"{len(filtered_dict['content'])/total:.2%} of data after filtering.")return Dataset.from_dict(filtered_dict)from datasets import load_datasetsplit = "train" # "valid"data = load_dataset(f"transformersbook/codeparrot-{split}", split=split, streaming=True)filtered_data = filter_streaming_dataset(data, filters)# 3.26% of data after filtering.这个加载数据集并过滤的耗时非常长,可能需要数个小时。过滤之后保留了大约
3%的原始数据,仍然高达6GB,包含大约600k个python文件。HuggingFace提供好了过滤后的数据集:xxxxxxxxxxfrom datasets import load_dataset, DatasetDictds_train = load_dataset("huggingface-course/codeparrot-ds-train", split="train")ds_valid = load_dataset("huggingface-course/codeparrot-ds-valid", split="validation")raw_datasets = DatasetDict( { "train": ds_train, "valid": ds_valid })print(raw_datasets)# DatasetDict({# train: Dataset({# features: ['repo_name', 'path', 'copies', 'size', 'content', 'license'],# num_rows: 606720# })# valid: Dataset({# features: ['repo_name', 'path', 'copies', 'size', 'content', 'license'],# num_rows: 3322# })# })Tokenization:第一步是对数据集进行tokenization。我们的目标单行代码的补全,因此可以选择较短的上下文。这样做的好处是,我们可以更快地训练模型并且需要更少的内存。如果你需要更长的上下文(如,补全函数、类、或自动生成单元测试),那么需要设置较长的上下文。这里我们选择上下文为
128个token(相比之下,GPT2选择了1024个token、GPT3选择了2048个token)。大多数文档包含超过128个token,如果简单地进行数据截断,那么将丢弃大多数的数据。相反,我们使用return_overflowing_tokens来执行tokenizeation从而返回几个块,并且还使用return_length来返回每个块的长度。通常最后一个块会小于上下文大小,我们会去掉这些块从而免于填充,因为这里的数据量已经足够用了。xxxxxxxxxxfrom transformers import AutoTokenizercontext_length = 128tokenizer = AutoTokenizer.from_pretrained("huggingface-course/code-search-net-tokenizer")##********** 如果 return_overflowing_tokens 未设置 **********outputs = tokenizer(raw_datasets["train"][:2]["content"],truncation=True,max_length=context_length,)print(f"Input IDs length: {len(outputs['input_ids'])}")# Input IDs length: 2##********** 如果 return_overflowing_tokens 被设置 **********outputs = tokenizer(raw_datasets["train"][:2]["content"],truncation=True,max_length=context_length,return_overflowing_tokens=True,return_length=True,)print(f"Input IDs length: {len(outputs['input_ids'])}")# Input IDs length: 34print(f"Input chunk lengths: {(outputs['length'])}")# Input chunk lengths: [128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 117,# 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 41]print(f"Chunk mapping: {outputs['overflow_to_sample_mapping']}")# Chunk mapping: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,# 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]可以看到:从两个样本中我们得到了
34个块,其中:outputs['input_ids']存放每个块的数据。outputs['length']存放每个块的长度。可以看到,每个文档的末尾的块,它的长度都小于128(分别为117和41)。由于这种不足128的块的占比很小,因此我们可以将它们丢弃。outputs['overflow_to_sample_mapping']存放每个块属于哪个样本。
然后我们把上述代码封装到一个函数中,并在
Dataset.map()中调用:xxxxxxxxxxdef tokenize(element):outputs = tokenizer(element["content"],truncation=True,max_length=context_length,return_overflowing_tokens=True,return_length=True,)input_batch = []for length, input_ids in zip(outputs["length"], outputs["input_ids"]):if length == context_length: # 过滤掉长度小于 context_length 的块input_batch.append(input_ids)return {"input_ids": input_batch}tokenized_datasets = raw_datasets.map(tokenize, batched=True,remove_columns=raw_datasets["train"].column_names # 我们只需要 input_ids 列,因此移除所有其它的列)print(tokenized_datasets)# DatasetDict({# train: Dataset({# features: ['input_ids'],# num_rows: 16702061# })# valid: Dataset({# features: ['input_ids'],# num_rows: 93164# })# })我们现在有
16.70M样本,每个样本有128个token,总计相当于大约2.1B tokens。作为参考,OpenAI的GPT-3和Codex模型分别在30B和100B个token上训练,其中Codex模型从GPT-3 checkpoint初始化。
3.2 使用 Trainer API 微调模型
我们初始化一个
GPT-2模型。我们采用与GPT-2相同的配置,并确保词表规模与tokenizer规模相匹配,然后设置bos_token_id和eos_token_id。利用该配置,我们加载一个新模型。注意,这是我们首次不使用from_pretrained()函数,因为我们实际上是在自己初始化模型:xxxxxxxxxxfrom transformers import AutoTokenizer, GPT2LMHeadModel, AutoConfigconfig = AutoConfig.from_pretrained("gpt2",vocab_size=len(tokenizer),n_ctx=context_length,bos_token_id=tokenizer.bos_token_id, # 句子开始的 tokeneos_token_id=tokenizer.eos_token_id, # 句子结束的 token)model = GPT2LMHeadModel(config)model_size = sum(t.numel() for t in model.parameters())print(f"GPT-2 size: {model_size/1000**2:.1f}M parameters")# GPT-2 size: 124.2M parameters该模型有
124.2 M参数。在开始训练之前,我们需要设置一个负责创建
batch的data collator。我们可以使用DataCollatorForLanguageModeling,它是专为语言建模而设计。除了batch和padding,它还负责创建语言模型的标签:在因果语言建模中,input也用作label(只是右移一个位置),并且这个data collator在训练期间动态地创建label,所以我们不需要复制input_ids。注意
DataCollatorForLanguageModeling支持掩码语言建模 (Masked Language Model: MLM) 和因果语言建模 (Causal Language Model: CLM)。默认情况下它为MLM准备数据,但我们可以通过设置mlm=False参数切换到CLM:xxxxxxxxxxfrom transformers import DataCollatorForLanguageModelingprint(tokenizer.pad_token, tokenizer.eos_token)# None <|endoftext|>tokenizer.pad_token = tokenizer.eos_token # 利用 eos_token 来填充data_collator = DataCollatorForLanguageModeling(tokenizer, mlm=False)用法示例:
xxxxxxxxxxout = data_collator([tokenized_datasets["train"][i] for i in range(5)])for key in out:print(f"{key} shape: {out[key].shape}")# input_ids shape: torch.Size([5, 128])# attention_mask shape: torch.Size([5, 128])# labels shape: torch.Size([5, 128])接下来就是配置
TrainingArguments并启动Trainer。我们将使用余弦学习率,进行一些warmup,设置有效batch size = 256(per_device_train_batch_size * gradient_accumulation_steps)。gradient_accumulation_steps用于梯度累积,它通过多次前向传播和反向传播但是只有一次梯度更新,从而实现large batch size的效果。当我们使用Accelerate手动创建训练循环时,我们将看到这一点。xxxxxxxxxxfrom transformers import Trainer, TrainingArgumentsargs = TrainingArguments(output_dir="codeparrot-ds",per_device_train_batch_size=32,per_device_eval_batch_size=32,evaluation_strategy="steps", # 每隔若干个 step 执行一次评估save_strategy="epoch", # 每个 epoch 保存一次eval_steps=5_000,logging_steps=5_000,gradient_accumulation_steps=8, # 梯度累积num_train_epochs=1,weight_decay=0.1,warmup_steps=1_000,lr_scheduler_type="cosine",learning_rate=5e-4,save_steps=5_000,fp16=True,push_to_hub=False, # 暂时不推送到 HuggingFace Hub)trainer = Trainer(model=model,tokenizer=tokenizer,args=args,data_collator=data_collator,train_dataset=tokenized_datasets["train"].select(range(100000)), # 为演示目的,仅用 10 万个 batcheval_dataset=tokenized_datasets["valid"].select(range(10000)),)trainer.train()# TrainOutput(# global_step=390,# training_loss=4.230728540665064,# metrics={# 'train_runtime': 235.341,# 'train_samples_per_second': 424.915,# 'train_steps_per_second': 1.657,# 'total_flos': 6521849118720000.0,# 'train_loss': 4.230728540665064,# 'epoch': 1.0}# )tokenizer.save_pretrained("codeparrot-ds") # 保存 tokenizer# trainer.push_to_hub() # 训练完成后,将模型和 tokenizer 推送到 HuggingFace Hub使用模型:现在可以通过
Transformers的pipeline来调用微调后的模型:xxxxxxxxxximport torchfrom transformers import pipelinedevice = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")pipe = pipeline("text-generation", model="./codeparrot-ds/", device=device # 使用 GPU 加速生成过程)txt = """\# create some datax = np.random.randn(100)y = np.random.randn(100)# create scatter plot with x, y"""result = pipe(txt, num_return_sequences=1)print(result)# [{'generated_text': '# create some data\nx = np.random.randn(100)\ny = np.random.randn(100)\n\n# create scatter plot with x, y\ny = rng.randn(n_samples, (1,'}]print([0]["generated_text"]) # 因为训练不充分,这里的结果仅供参考
3.3 自定义训练过程
有时我们想要完全控制训练循环,或者我们想要进行一些特殊的更改,这时我们可以利用
Accelerate来进行自定义的训练过程。众所周知,数学科学的
package中有一些关键字,如plt, pd, sk, fit, predict等等。我们仅关注那些表示为单个token的关键字,并且我们还关注那些带有一个空格作为前缀的关键字版本。xxxxxxxxxxfrom transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained("huggingface-course/code-search-net-tokenizer")keytoken_ids = []for keyword in [ "plt", "pd", "sk", "fit", "predict"," plt", " pd", " sk", " fit", " predict",]:ids = tokenizer([keyword]).input_ids[0]if len(ids) == 1: # 仅考虑单个 token 的关键字keytoken_ids.append(ids[0])else:print(f"Keyword has not single token: {keyword}")print(keytoken_ids)# [8436, 4289, 1201, 2770, 5431, 2564, 2604, 2110, 2872, 4969]我们可以计算每个样本的损失,并计算每个样本中所有关键字的出现次数。然后我们以这个出现次数为权重来对样本的损失函数进行加权,使得模型更加注重那些具有多个关键字的样本。这是一个自定义的损失函数,它将输入序列、
logits、以及我们刚刚选择的关键字token作为输入,然后输出关键字频率加权的损失函数:xxxxxxxxxxfrom torch.nn import CrossEntropyLossimport torchdef keytoken_weighted_loss(inputs, logits, keytoken_ids, alpha=1.0):shift_labels = inputs[..., 1:].contiguous() # input 序列第 i+1 位就是第 i 个标签shift_logits = logits[..., :-1, :].contiguous() # 最后一个位置不需要预测,因为没有 labelloss_fct = CrossEntropyLoss(reduce=False) # 用于计算 per-token 的损失loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))loss_per_sample = loss.view(shift_logits.size(0), shift_logits.size(1)).mean(axis=1) # 该样本的平均损失weights = torch.stack([(inputs == kt).float() for kt in keytoken_ids]).sum( # 每个样本出现的所有关键字的数量axis=[0, 2])weights = alpha * (1.0 + weights)weighted_loss = (loss_per_sample * weights).mean() # 计算 batch 的加权平均损失return weighted_loss加载数据集:
xxxxxxxxxxfrom datasets import load_dataset, DatasetDictcontext_length = 128ds_train = load_dataset("huggingface-course/codeparrot-ds-train", split="train")ds_valid = load_dataset("huggingface-course/codeparrot-ds-valid", split="validation")raw_datasets = DatasetDict( { "train": ds_train, "valid": ds_valid })def tokenize(element):outputs = tokenizer(element["content"],truncation=True,max_length=context_length,return_overflowing_tokens=True,return_length=True,)input_batch = []for length, input_ids in zip(outputs["length"], outputs["input_ids"]):if length == context_length: # 过滤掉长度小于 context_length 的块input_batch.append(input_ids)return {"input_ids": input_batch}tokenized_datasets = raw_datasets.map(tokenize, batched=True,remove_columns=raw_datasets["train"].column_names # 我们只需要 input_ids 列,因此移除所有其它的列)tokenized_dataset.set_format("torch") # 设置为 torch 格式train_dataloader = DataLoader(tokenized_dataset["train"], batch_size=32, shuffle=True)eval_dataloader = DataLoader(tokenized_dataset["valid"], batch_size=32)设置
weight-decay:我们对参数进行分组,以便优化器知道哪些将获得额外的weight-decay。通常,所有的bias项和LayerNorm weight都不需要weight-decay:xxxxxxxxxxweight_decay = 0.1def get_grouped_params(model, no_decay=["bias", "LayerNorm.weight"]):params_with_wd, params_without_wd = [], []for name, param in model.named_parameters():if any(nd in name for nd in no_decay): # 判断 bias 字符串是否出现在 parameter.name 中,因为 parameter.name 可能为 attention1.bias1params_without_wd.append(param)else:params_with_wd.append(param)return [{"params": params_with_wd, "weight_decay": weight_decay},{"params": params_without_wd, "weight_decay": 0.0},]评估函数:由于我们希望在训练期间定期地在验证集上评估模型,因此我们也为此编写一个函数。它只是运行
eval_dataloader并收集跨进程的所有损失函数值:xxxxxxxxxxdef evaluate():model.eval()losses = []for step, batch in enumerate(eval_dataloader):with torch.no_grad():outputs = model(batch["input_ids"], labels=batch["input_ids"])losses.append(accelerator.gather(outputs.loss)) # 跨进程收集每个样本的 lossloss = torch.mean(torch.cat(losses))try:perplexity = torch.exp(loss) # 计算困惑度except OverflowError:perplexity = float("inf")return loss.item(), perplexity.item()这个评估函数用于获取损失函数值、以及困惑度。
完整的训练过程:
xxxxxxxxxxfrom transformers import AutoTokenizerfrom datasets import load_dataset, DatasetDictfrom transformers import AutoTokenizer, GPT2LMHeadModel, AutoConfigfrom torch.optim import AdamWfrom accelerate import Acceleratorfrom transformers import get_schedulerfrom huggingface_hub import Repository, get_full_repo_namefrom tqdm.notebook import tqdmfrom torch.utils.data import DataLoader##************** 加载数据集 ********************tokenizer = AutoTokenizer.from_pretrained("huggingface-course/code-search-net-tokenizer")context_length = 128ds_train = load_dataset("huggingface-course/codeparrot-ds-train", split="train")ds_valid = load_dataset("huggingface-course/codeparrot-ds-valid", split="validation")raw_datasets = DatasetDict( { "train": ds_train, "valid": ds_valid })def tokenize(element):outputs = tokenizer(element["content"],truncation=True,max_length=context_length,return_overflowing_tokens=True,return_length=True,)input_batch = []for length, input_ids in zip(outputs["length"], outputs["input_ids"]):if length == context_length: # 过滤掉长度小于 context_length 的块input_batch.append(input_ids)return {"input_ids": input_batch}tokenized_datasets = raw_datasets.map(tokenize, batched=True,remove_columns=raw_datasets["train"].column_names # 我们只需要 input_ids 列,因此移除所有其它的列)batch_size = 32tokenized_dataset.set_format("torch") # 设置为 torch 格式train_dataloader = DataLoader(tokenized_dataset["train"].select(range(100000),batch_size=batch_size, shuffle=True) # 为演示方便,用了更少的数据eval_dataloader = DataLoader(tokenized_dataset["valid"].select(range(10000),batch_size=batch_size) # 为演示方便,用了更少的数据##************** 定义加权损失函数 ***************keytoken_ids = []for keyword in [ "plt", "pd", "sk", "fit", "predict"," plt", " pd", " sk", " fit", " predict",]:ids = tokenizer([keyword]).input_ids[0]if len(ids) == 1: # 仅考虑单个 token 的关键字keytoken_ids.append(ids[0])else:print(f"Keyword has not single token: {keyword}")def keytoken_weighted_loss(inputs, logits, keytoken_ids, alpha=1.0):shift_labels = inputs[..., 1:].contiguous() # input 序列第 i+1 位就是第 i 个标签shift_logits = logits[..., :-1, :].contiguous() # 最后一个位置不需要预测,因为没有 labelloss_fct = CrossEntropyLoss(reduce=False) # 用于计算 per-token 的损失loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))loss_per_sample = loss.view(shift_logits.size(0), shift_logits.size(1)).mean(axis=1) # 该样本的平均损失weights = torch.stack([(inputs == kt).float() for kt in keytoken_ids]).sum( # 每个样本出现的所有关键字的数量axis=[0, 2])weights = alpha * (1.0 + weights)weighted_loss = (loss_per_sample * weights).mean() # 计算 batch 的加权平均损失return weighted_loss##************** 定义评估函数 ***************def evaluate():model.eval()losses = []for step, batch in enumerate(eval_dataloader):with torch.no_grad():outputs = model(batch["input_ids"], labels=batch["input_ids"])losses.append(accelerator.gather(outputs.loss)) # 跨进程收集每个样本的 lossloss = torch.mean(torch.cat(losses))try:perplexity = torch.exp(loss) # 计算困惑度except OverflowError:perplexity = float("inf")return loss.item(), perplexity.item()##****************** 定义 weight-decay ****************weight_decay = 0.1def get_grouped_params(model, no_decay=["bias", "LayerNorm.weight"]):params_with_wd, params_without_wd = [], []for name, param in model.named_parameters():if any(nd in name for nd in no_decay): # 判断 bias 字符串是否出现在 parameter.name 中,因为 parameter.name 可能为 attention1.bias1params_without_wd.append(param)else:params_with_wd.append(param)return [{"params": params_with_wd, "weight_decay": weight_decay},{"params": params_without_wd, "weight_decay": 0.0},]##***************** 配置模型及其训练组件 *********************config = AutoConfig.from_pretrained("gpt2",vocab_size=len(tokenizer),n_ctx=context_length,bos_token_id=tokenizer.bos_token_id, # 句子开始的 tokeneos_token_id=tokenizer.eos_token_id, # 句子结束的 token)model = GPT2LMHeadModel(config)optimizer = AdamW(get_grouped_params(model), lr=5e-4) # 使用 weight-decayaccelerator = Accelerator(mixed_precision='fp16')model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(model, optimizer, train_dataloader, eval_dataloader)num_train_epochs = 1num_update_steps_per_epoch = len(train_dataloader) # 必须在 accelerator.prepare() 之后执行,因为 accelerator.prepare 可能会改变 dataloadernum_training_steps = num_train_epochs * num_update_steps_per_epochlr_scheduler = get_scheduler(name="linear",optimizer=optimizer,num_warmup_steps=1_000,num_training_steps=num_training_steps,)##***************** 创建 Repository *********************model_name = "codeparrot-ds-accelerate"# repo_name = get_full_repo_name(model_name) #用于推送到 HuggingFace Huboutput_dir = "codeparrot-ds-accelerate"# repo = Repository(output_dir, clone_from=repo_name) #用于推送到 HuggingFace Hub##***************** Training Loop *********************evaluate() # 先评估下结果,看看未训练的模型的效果gradient_accumulation_steps = 8 # 每隔 8 个 step 来累积一次梯度 (可以通过 accumulator 的 gradient_accumulation_steps 选项来优化这里的梯度累积代码)eval_steps = 5_000 # 每隔 eval_steps * gradient_accumulation_steps 步时评估一次model.train()completed_steps = 0 # 存放梯度更新的次数for epoch in range(num_train_epochs):for step, batch in tqdm(enumerate(train_dataloader, start=1), total=len(train_dataloader)):logits = model(batch["input_ids"]).logitsloss = keytoken_weighted_loss(batch["input_ids"], logits, keytoken_ids) # 使用自定义的损失函数if step % 100 == 0:accelerator.print({"lr": lr_scheduler.get_last_lr(),"samples": step * batch_size,"steps": completed_steps, # 梯度更新的次数"loss/train": loss.item(),})loss = loss / gradient_accumulation_steps # 缩放损失从而对梯度取平均accelerator.backward(loss)if step % gradient_accumulation_steps == 0: # 执行梯度更新accelerator.clip_grad_norm_(model.parameters(), 1.0) # 梯度范数裁剪optimizer.step()lr_scheduler.step()optimizer.zero_grad()completed_steps += 1if (step % (eval_steps * gradient_accumulation_steps)) == 0:eval_loss, perplexity = evaluate()accelerator.print({"loss/eval": eval_loss, "perplexity": perplexity})model.train() # 评估完成之后,需要设置为 training 模式accelerator.wait_for_everyone()evaluate() # 再次评估下结果,看看训练好的模型的效果# (4.45915412902832, 86.41439056396484)unwrapped_model = accelerator.unwrap_model(model)unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)if accelerator.is_main_process:tokenizer.save_pretrained(output_dir)# repo.push_to_hub(# commit_message=f"Training in progress step {step}", blocking=False# )
四、文本摘要
文本摘要将长的文章压缩为摘要,这需要理解文章内容并生成捕获了文档主题的连贯的文本。
4.1 数据集和数据处理
加载数据集:我们使用 “多语言亚马逊评论语料库” 来创建一个双语的
summarizer。该语料库由六种语言的亚马逊商品评论组成,通常用于对多语言分类器进行基准测试。然而,由于每条评论都附有一个简短的标题,我们可以使用标题作为我们模型学习的target摘要 。首先下载数据集,这里下载英语和西班牙语的子集:
xxxxxxxxxxfrom datasets import load_datasetspanish_dataset = load_dataset("amazon_reviews_multi", "es")english_dataset = load_dataset("amazon_reviews_multi", "en")print(english_dataset)# DatasetDict({# train: Dataset({# features: ['review_id', 'product_id', 'reviewer_id',# 'stars', 'review_body', 'review_title', 'language', 'product_category'],# num_rows: 200000# })# validation: Dataset({# features: ['review_id', 'product_id', 'reviewer_id',# 'stars', 'review_body', 'review_title', 'language', 'product_category'],# num_rows: 5000# })# test: Dataset({# features: ['review_id', 'product_id', 'reviewer_id',# 'stars', 'review_body', 'review_title', 'language', 'product_category'],# num_rows: 5000# })# })可以看到,对每种语言,
train split有200k条评论、validation split有5k条评论、test split有5k条评论。我们感兴趣的评论信息在review_body和review_title字段。我们可以创建一个简单的函数来查看一些样本:
xxxxxxxxxxdef show_samples(dataset, num_samples=3, seed=42):sample = dataset["train"].shuffle(seed=seed).select(range(num_samples))for example in sample:print(f"\n'>> Title: {example['review_title']}'")print(f"'>> Review: {example['review_body']}'")show_samples(english_dataset)# '>> Title: Worked in front position, not rear'# '>> Review: 3 stars because these are not rear brakes as stated in the item description. At least the mount adapter only worked on the front fork of the bike that I got it for.'# ....然后,我们进行样本过滤。在单个
GPU上训练所有400k条评论(两种语言,每种语言的训练集包含200k条评论)的摘要模型将花费太长时间,这里我们选择书籍(包括电子书)类目的评论。xxxxxxxxxxdef filter_books(example):return (example["product_category"] == "book"or example["product_category"] == "digital_ebook_purchase")spanish_books = spanish_dataset.filter(filter_books)english_books = english_dataset.filter(filter_books)show_samples(english_books)# '>> Title: I'm dissapointed.'# '>> Review: I guess I had higher expectations for this book from the reviews. I really thought I'd at least like it. The plot idea was great. I loved Ash but, it just didnt go anywhere. Most of the book was about their radio show and talking to callers. I wanted the author to dig deeper so we could really get to know the characters. All we know about Grace is that she is attractive looking, Latino and is kind of a brat. I'm dissapointed.'# ....然后,我们需要将英语评论和西班牙语评论合并为一个
DatasetDict对象:xxxxxxxxxxfrom datasets import concatenate_datasets, DatasetDictbooks_dataset = DatasetDict()for split in english_books.keys():books_dataset[split] = concatenate_datasets( [english_books[split], spanish_books[split]])books_dataset[split] = books_dataset[split].shuffle(seed=42)show_samples(books_dataset)# '>> Title: Easy to follow!!!!'# '>> Review: I loved The dash diet weight loss Solution. Never hungry. I would recommend this diet. Also the menus are well rounded. Try it. Has lots of the information need thanks.'# ....现在,
train/validation/test split都是英语和西班牙语的混合评论。现在,我们过滤掉太短的标题。如果
reference摘要(在这里就是标题)太短,则使得模型偏向于仅生成包含一两个单词的摘要。xxxxxxxxxxbooks_dataset = books_dataset.filter(lambda x: len(x["review_title"].split()) > 2)
预处理数据:现在需要对评论极其标题进行
tokenization和编码。首先加载
tokenizer。这里我们使用mt5-base模型。xxxxxxxxxxfrom transformers import AutoTokenizermodel_checkpoint = "/mnt/disk_b/ModelZoo/mt5-base" # 提前下载到本地tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)inputs = tokenizer("I really enjoy reading!")print(inputs)# {'input_ids': [336, 259, 4940, 9070, 11807, 309, 1], 'attention_mask': [1, 1, 1, 1, 1, 1, 1]}print(tokenizer.convert_ids_to_tokens(inputs.input_ids))# ['▁I', '▁', 'really', '▁enjoy', '▁reading', '!', '</s>']特殊的
Unicode字符▁和序列结束符</s>表明我们正在处理SentencePiece tokenizer。SentencePiece tokenizer基于Unigramtokenization算法,该算法对多语言语料库特别有用,因为它允许SentencePiece在不知道重音、标点符号以及没有空格分隔字符(例如中文)的情况下对文本进行tokenization。为了对文本进行
tokenization,我们必须处理与摘要相关的细节:因为label也是文本,它也可能超过模型的最大上下文大小。这意味着我们需要同时对评论和标题进行截断,确保不会将太长的输入传递给模型。Transformers中的tokenizer提供了一个as_target_tokenizer()函数,从而允许你相对于input并行地对label进行tokenize。xxxxxxxxxxmax_input_length = 512 # 评论的长度的上限max_target_length = 30 # 标题的长度的上限def preprocess_function(examples):model_inputs = tokenizer(examples["review_body"], max_length=max_input_length, truncation=True)# Set up the tokenizer for targetswith tokenizer.as_target_tokenizer():labels = tokenizer(examples["review_title"], max_length=max_target_length, truncation=True)model_inputs["labels"] = labels["input_ids"]return model_inputstokenized_datasets = books_dataset.map(preprocess_function, batched=True)
4.2 评估方法
评估指标:衡量文本生成任务(如文本摘要、翻译)的性能并不那么简单。最常用的指标之一是
Recall-Oriented Understudy for Gisting Evaluation: ROUGE得分。该指标背后的基本思想是:将生成的摘要与一组参考摘要(通常由人类创建)进行比较。具体而言,假设我们比较如下的两个摘要:xxxxxxxxxxgenerated_summary = "I absolutely loved reading the Hunger Games"reference_summary = "I loved reading the Hunger Games"比较它们的一种方法是计算重叠单词的数量,在这种情况下为
6。但是,这有点粗糙,因此ROUGE是基于重叠的单词来计算precision和recall。recall:衡量生成的摘要召回了参考摘要(reference summary)中的多少内容。如果只是比较单词,那么recall为:precision:衡量生成的摘要中有多少内容是和参考摘要有关。如果只是比较单词,那么precision为:
在实践中,我们通常计算
precision和recall,然后报告F1-score。我们可以安装rouge_score package,并在datasets中调用该指标。xxxxxxxxxx# pip install rouge_score (首先安装)from datasets import load_metricrouge_score = load_metric("rouge")scores = rouge_score.compute(predictions=[generated_summary], references=[reference_summary])print(scores)# {# 'rouge1': AggregateScore(# low=Score(precision=0.8571428571428571, recall=1.0, fmeasure=0.923076923076923),# mid=Score(precision=0.8571428571428571, recall=1.0, fmeasure=0.923076923076923),# high=Score(precision=0.8571428571428571, recall=1.0, fmeasure=0.923076923076923)),# 'rouge2': AggregateScore(# low=Score(precision=0.6666666666666666, recall=0.8, fmeasure=0.7272727272727272),# mid=Score(precision=0.6666666666666666, recall=0.8, fmeasure=0.7272727272727272),# high=Score(precision=0.6666666666666666, recall=0.8, fmeasure=0.7272727272727272)),# 'rougeL': AggregateScore(# low=Score(precision=0.8571428571428571, recall=1.0, fmeasure=0.923076923076923),# mid=Score(precision=0.8571428571428571, recall=1.0, fmeasure=0.923076923076923),# high=Score(precision=0.8571428571428571, recall=1.0, fmeasure=0.923076923076923)),# 'rougeLsum': AggregateScore(# low=Score(precision=0.8571428571428571, recall=1.0, fmeasure=0.923076923076923),# mid=Score(precision=0.8571428571428571, recall=1.0, fmeasure=0.923076923076923),# high=Score(precision=0.8571428571428571, recall=1.0, fmeasure=0.923076923076923))# }rouge_score.compute()会一次性计算所有指标。输出的含义如下:首先,
rouge_score计算了precision, recall, F1-score的置信区间,即low/mid/high属性。其次,
rouge_score在比较生成的摘要和参考摘要时,会考虑不同的粒度:rouge1是unigram粒度、rouge2是bigram粒度。rougeL和rougeLsum通过在生成的摘要和参考摘要之间查找最长公共子串,从而得到重叠的单词序列。其中,rougeLsum表示指标是在整个摘要上计算的,而rougeL为单个句子的指标的均值。因为上述例子只有一个句子,因此rougeLsum和rougeL的输出结果相同。
强大的
baseline:文本摘要的一个常见baseline是简单地取一篇文章的前三个句子,通常称之为lead-3 baseline。我们可以使用句号(英文使用".")来断句,但这在"U.S."或者"U.N."之类的首字母缩略词上会失败。所以我们将使用nltk库,它包含一个更好的算法来处理这些情况。xxxxxxxxxx# pip install nltk 首先安装 nltkimport nltknltk.download("punkt") # 下载标点符号规则from nltk.tokenize import sent_tokenize # 导入 sentence tokenizerdef three_sentence_summary(text):return "\n".join(sent_tokenize(text)[:3]) # 提取前三个句子print(three_sentence_summary(books_dataset["train"][1]["review_body"]))# I grew up reading Koontz, and years ago, I stopped,convinced i had "outgrown" him.# Still,when a friend was looking for something suspenseful too read, I suggested Koontz.# She found Strangers.由于文本摘要任务的约定是用换行符来分隔每个摘要,因此我们这里用
"\n"来拼接前三个句子。然后我们实现一个函数,该函数从数据集中提取
lead-3摘要并计算baseline的ROUGE得分:xxxxxxxxxxdef evaluate_baseline(dataset, metric):summaries = [three_sentence_summary(text) for text in dataset["review_body"]]return metric.compute(predictions=summaries, references=dataset["review_title"])然后我们可以使用这个函数来计算验证集的
ROUGE分数:xxxxxxxxxxscore = evaluate_baseline(books_dataset["validation"], rouge_score)rouge_names = ["rouge1", "rouge2", "rougeL", "rougeLsum"]rouge_dict = dict((rn, round(score[rn].mid.fmeasure * 100, 2)) for rn in rouge_names)print(rouge_dict)# {'rouge1': 16.77, 'rouge2': 8.87, 'rougeL': 15.55, 'rougeLsum': 15.92}我们可以看到
rouge2分数明显低于其他的rouge分数。 这可能反映了这样一个事实,即评论标题通常很简洁,因此lead-3 baseline过于冗长。
4.3 使用 Trainer API 微调模型
我们首先加载预训练模型。由于文本摘要是一个
seq-to-seq的任务,我们可以使用AutoModelForSeq2SeqLM类加载模型:xxxxxxxxxxfrom transformers import AutoModelForSeq2SeqLMmodel = AutoModelForSeq2SeqLM.from_pretrained(model_checkpoint, device_map='auto') # mt5-base 占用 2.5G 显存对于
seq-to-seq任务,AutoModelForSeq2SeqLM模型保留了所有的网络权重。相反,文本分类任务重,预训练模型的head被随机初始化的网络所替代。然后我们定义超参数和其它参数。我们使用专用的
Seq2SeqTrainingArguments和Seq2SeqTrainer类。xxxxxxxxxxfrom transformers import Seq2SeqTrainingArgumentsbatch_size = 8num_train_epochs = 2 # 为演示方便,暂时仅用 2 个 epochlogging_steps = len(tokenized_datasets["train"]) // batch_size # 每个 epoch 记录一次日志model_name = model_checkpoint.split("/")[-1]args = Seq2SeqTrainingArguments(output_dir=f"{model_name}-finetuned-amazon-en-es",evaluation_strategy="epoch",learning_rate=5.6e-5,per_device_train_batch_size=batch_size,per_device_eval_batch_size=batch_size,weight_decay=0.01,save_total_limit=1, # 最多保存 1 个 checkpoint,因为每个 checkpoint 太大了 (2.5GB)num_train_epochs=num_train_epochs,predict_with_generate=True, # 在评估期间生成摘要从而计算 ROUGE 得分logging_steps=logging_steps,push_to_hub=False, # 是否允许我们将训练好的模型推送到 Hub)predict_with_generate=True会告诉Seq2SeqTrainer在评估时调用模型的generate()方法来生成摘要。然后我们为
Trainer提供一个compute_metrics()函数,以便在训练期间评估模型。这里稍微有点复杂,因为我们需要在计算ROUGE分数之前将output和label解码为文本,从而提供给rouge_score.compute()来使用。此外,还需要利用nltk中的sent_tokenize()函数来用换行符分隔摘要的句子:xxxxxxxxxximport numpy as npdef compute_metrics(eval_pred):predictions, labels = eval_preddecoded_preds = tokenizer.batch_decode(predictions, skip_special_tokens=True) # 对 prediction 解码labels = np.where(labels != -100, labels, tokenizer.pad_token_id) # 用 pad_token_id 替换 label = -100decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True) # 对 label 进行解码decoded_preds = ["\n".join(sent_tokenize(pred.strip())) for pred in decoded_preds] # 对每个样本进行断句decoded_labels = ["\n".join(sent_tokenize(label.strip())) for label in decoded_labels] # 对每个样本进行断句result = rouge_score.compute( # 计算 ROUGE 分predictions=decoded_preds, references=decoded_labels, use_stemmer=True)result = {key: value.mid.fmeasure * 100 for key, value in result.items()} # 仅获取 mid scorereturn {k: round(v, 4) for k, v in result.items()}接下来我们需要为
seq-to-seq任务定义一个data collator。在解码过程中,对于mT5,我们需要将label右移一位从而作为decoder的输入。Transformers提供了一个DataCollatorForSeq2Seq,它为我们动态地填充input和label。要实例化这个collator,我们只需要提供tokenizer和model:xxxxxxxxxxfrom transformers import DataCollatorForSeq2Seqdata_collator = DataCollatorForSeq2Seq(tokenizer, model=model)我们看看这个
collator在输入一个mini batch样本时会产生什么。首先移除所有的类型为字符串的列,因为
collator不知道如何处理这些列:xxxxxxxxxxtokenized_datasets = tokenized_datasets.remove_columns(books_dataset["train"].column_names)# tokenized_datasets 包含的列: review_id, product_id, reviewer_id, stars, review_body, review_title, language, product_category, input_ids, attention_mask, labels# books_dataset["train"] 包含的列: review_id, product_id, reviewer_id, stars, review_body, review_title, language, product_category由于
collator需要一个dict的列表,其中每个dict代表数据集中的一个样本,我们还需要在将数据传递给data collator之前将数据整理成预期的格式:xxxxxxxxxxfeatures = [tokenized_datasets["train"][i] for i in range(2)]print(data_collator(features))# {'input_ids': tensor([[...],# [...]]),# 'attention_mask': tensor([[1...],# [...]]),# 'labels': tensor([[ 298, 259, 5994, 269, 774, 5547, 1],# [ 298, 10380, 304, 13992, 291, 1, -100]]),# 'decoder_input_ids': tensor([[ 0, 298, 259, 5994, 269, 774, 5547],# [ 0, 298, 10380, 304, 13992, 291, 1]])}如果某一个样本比另一个样本要短,那么它的
input_ids/attention_mask右侧将被填充[PAD] token(token ID为0)。 类似地,我们可以看到labels已用-100填充,以确保pad token被损失函数忽略。最后,我们可以看到一个新的decoder_input_ids,它通过在开头插入[PAD] token将标签向右移动来形成。现在开始实例化
Trainer并进行训练了:xxxxxxxxxxfrom transformers import Seq2SeqTrainertrainer = Seq2SeqTrainer(model,args,train_dataset=tokenized_datasets["train"],eval_dataset=tokenized_datasets["validation"],data_collator=data_collator,tokenizer=tokenizer,compute_metrics=compute_metrics,)trainer.train() # 训练trainer.evaluate() # 评估# {'eval_loss': nan,# 'eval_rouge1': 4.0461,# 'eval_rouge2': 0.7318,# 'eval_rougeL': 3.9266,# 'eval_rougeLsum': 3.9468,# 'eval_runtime': 6.6003,# 'eval_samples_per_second': 36.059,# 'eval_steps_per_second': 4.545,# 'epoch': 2.0}# trainer.push_to_hub(commit_message="Training complete", tags="summarization") # 推送到 huggingface使用微调的模型:
xxxxxxxxxxfrom transformers import pipelinesummarizer = pipeline("summarization", model = "./mt5-base-finetuned-amazon-en-es/checkpoint-2000")我们可以将测试集中的一些样本(模型还没有看到)馈入
pipeline,从而了解生成的摘要的质量。我们实现一个简单的函数来一起显示评论、标题、以及生成的摘要:
xxxxxxxxxxdef print_summary(idx):review = books_dataset["test"][idx]["review_body"]title = books_dataset["test"][idx]["review_title"]summary = summarizer(books_dataset["test"][idx]["review_body"])[0]["summary_text"]print(f"'>>> Review: {review}'")print(f"\n'>>> Title: {title}'")print(f"\n'>>> Summary: {summary}'")print_summary(100)
4.4 自定义训练过程
使用
Accelerate来微调mT5的过程,与微调文本分类模型非常相似。区别在于这里需要在训练期间显式生成摘要,并定义如何计算ROUGE分数。创建
dataloader:我们需要做的第一件事是为每个数据集的每个split创建一个DataLoader。 由于PyTorch dataloader需要batch的张量,我们需要在数据集中将格式设置为torch:xxxxxxxxxxfrom datasets import load_datasetfrom datasets import concatenate_datasets, DatasetDictfrom transformers import AutoTokenizerfrom torch.utils.data import DataLoaderfrom transformers import DataCollatorForSeq2Seqfrom transformers import AutoModelForSeq2SeqLM##************* 创建 dataloader *****************##***** 加载数据spanish_dataset = load_dataset("amazon_reviews_multi", "es")english_dataset = load_dataset("amazon_reviews_multi", "en")def filter_books(example):return (example["product_category"] == "book"or example["product_category"] == "digital_ebook_purchase")spanish_books = spanish_dataset.filter(filter_books)english_books = english_dataset.filter(filter_books)##****** 合并这两种语言的数据集books_dataset = DatasetDict()for split in english_books.keys():books_dataset[split] = concatenate_datasets( [english_books[split], spanish_books[split]])books_dataset[split] = books_dataset[split].shuffle(seed=42)##****** 短标题过滤books_dataset = books_dataset.filter(lambda x: len(x["review_title"].split()) > 2)##****** tokenizationmodel_checkpoint = "/mnt/disk_b/ModelZoo/mt5-base" # 提前下载到本地tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)max_input_length = 512 # 评论的长度的上限max_target_length = 30 # 标题的长度的上限def preprocess_function(examples):model_inputs = tokenizer(examples["review_body"], max_length=max_input_length, truncation=True)# Set up the tokenizer for targetswith tokenizer.as_target_tokenizer():labels = tokenizer(examples["review_title"], max_length=max_target_length, truncation=True)model_inputs["labels"] = labels["input_ids"]return model_inputstokenized_datasets = books_dataset.map(preprocess_function, batched=True)tokenized_datasets = tokenized_datasets.remove_columns(books_dataset["train"].column_names)##****** 创建 modelmodel = AutoModelForSeq2SeqLM.from_pretrained(model_checkpoint)##****** data_collatordata_collator = DataCollatorForSeq2Seq(tokenizer, model=model)##********* 创建 dataloadertokenized_datasets.set_format("torch")batch_size = 8train_dataloader = DataLoader(tokenized_datasets["train"],shuffle=True,collate_fn=data_collator,batch_size=batch_size,)eval_dataloader = DataLoader(tokenized_datasets["validation"], collate_fn=data_collator, batch_size=batch_size)创建训练组件:
xxxxxxxxxx##******************** 创建训练组件 *************##****** 优化器from torch.optim import AdamWoptimizer = AdamW(model.parameters(), lr=2e-5)##***** 创建 acceleratorfrom accelerate import Acceleratoraccelerator = Accelerator()model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(model, optimizer, train_dataloader, eval_dataloader)##***** 创建学习率调度器from transformers import get_schedulernum_train_epochs = 10num_update_steps_per_epoch = len(train_dataloader) # 必须在 accelerator.prepare() 之后调用num_training_steps = num_train_epochs * num_update_steps_per_epochlr_scheduler = get_scheduler("linear",optimizer=optimizer,num_warmup_steps=0,num_training_steps=num_training_steps,)##***** 创建 rouge_scorefrom datasets import load_metricrouge_score = load_metric("rouge")后处理:
将生成的摘要进行断句(拆分为
"\n"换行的句子),这是ROUGE需要的格式。xxxxxxxxxximport nltkdef postprocess_text(preds, labels):preds = [pred.strip() for pred in preds]labels = [label.strip() for label in labels]# ROUGE expects a newline after each sentencepreds = ["\n".join(nltk.sent_tokenize(pred)) for pred in preds]labels = ["\n".join(nltk.sent_tokenize(label)) for label in labels]return preds, labels在
Hugging Face Hub创建一个repository来存储模型。如果不需要上传,那么这一步不需要。xxxxxxxxxx# from huggingface_hub import get_full_repo_name# model_name = "test-bert-finetuned-squad-accelerate"# repo_name = get_full_repo_name(model_name)# from huggingface_hub import Repositoryoutput_dir = "results-mt5-finetuned-squad-accelerate"# repo = Repository(output_dir, clone_from=repo_name)
开始训练:(
4090显卡,模型大小2.5G,训练期间占用内存22.7G)xxxxxxxxxxfrom tqdm.auto import tqdmimport torchimport numpy as npprogress_bar = tqdm(range(num_training_steps))for epoch in range(num_train_epochs):## Training 阶段model.train()for step, batch in enumerate(train_dataloader):outputs = model(**batch)loss = outputs.lossaccelerator.backward(loss)optimizer.step()lr_scheduler.step()optimizer.zero_grad()progress_bar.update(1)# Evaluation 阶段model.eval()for step, batch in enumerate(eval_dataloader):with torch.no_grad():generated_tokens = accelerator.unwrap_model(model).generate(batch["input_ids"],attention_mask=batch["attention_mask"],)## 填充所生成的文本## 在多进程场景下,可能两个进程将 predictions/labels 在进程内部对齐,但是在进程间不一致,这里需要跨进程对齐generated_tokens = accelerator.pad_across_processes(generated_tokens, dim=1, pad_index=tokenizer.pad_token_id)labels = batch["labels"]# 如果预处理阶段没有填充那到最大长度,那么这里需要对 label 也进行填充labels = accelerator.pad_across_processes(batch["labels"], dim=1, pad_index=tokenizer.pad_token_id)generated_tokens = accelerator.gather(generated_tokens).cpu().numpy()labels = accelerator.gather(labels).cpu().numpy()# Replace -100 in the labels as we can't decode themlabels = np.where(labels != -100, labels, tokenizer.pad_token_id)if isinstance(generated_tokens, tuple):generated_tokens = generated_tokens[0]decoded_preds = tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)decoded_preds, decoded_labels = postprocess_text(decoded_preds, decoded_labels)rouge_score.add_batch(predictions=decoded_preds, references=decoded_labels)# 计算指标result = rouge_score.compute()# 计算 median ROUGE scoreresult = {key: value.mid.fmeasure * 100 for key, value in result.items()}result = {k: round(v, 4) for k, v in result.items()}print(f"Epoch {epoch}:", result)# 在每个 epoch 结束时保存模型accelerator.wait_for_everyone()unwrapped_model = accelerator.unwrap_model(model)unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)if accelerator.is_main_process:tokenizer.save_pretrained(output_dir)# repo.push_to_hub(# commit_message=f"Training in progress epoch {epoch}", blocking=False# )# Epoch 0: {'rouge1': 5.5492, 'rouge2': 0.6587, 'rougeL': 5.5844, 'rougeLsum': 5.5422}# Epoch 1: {'rouge1': 8.154, 'rouge2': 2.5786, 'rougeL': 8.0205, 'rougeLsum': 7.9891}# Epoch 2: {'rouge1': 13.8772, 'rouge2': 5.9258, 'rougeL': 13.86, 'rougeLsum': 13.858}# Epoch 3: {'rouge1': 14.3815, 'rouge2': 6.0753, 'rougeL': 14.1405, 'rougeLsum': 14.2002}# Epoch 4: {'rouge1': 12.9502, 'rouge2': 5.3787, 'rougeL': 12.8429, 'rougeLsum': 12.8553}# Epoch 5: {'rouge1': 13.613, 'rouge2': 6.2498, 'rougeL': 13.3715, 'rougeLsum': 13.3895}# Epoch 6: {'rouge1': 13.3266, 'rouge2': 6.0245, 'rougeL': 13.0357, 'rougeLsum': 13.0793}# Epoch 7: {'rouge1': 13.8225, 'rouge2': 6.4, 'rougeL': 13.5457, 'rougeLsum': 13.6644}# Epoch 8: {'rouge1': 13.9203, 'rouge2': 6.5123, 'rougeL': 13.6504, 'rougeLsum': 13.6976}# Epoch 9: {'rouge1': 14.374, 'rouge2': 6.9012, 'rougeL': 14.1307, 'rougeLsum': 14.2309}使用:
xxxxxxxxxxfrom transformers import pipelinesummarizer = pipeline("summarization", model = "./mt5-base-finetuned-amazon-en-es/checkpoint-2000")def print_summary(idx):review = books_dataset["test"][idx]["review_body"]title = books_dataset["test"][idx]["review_title"]summary = summarizer(books_dataset["test"][idx]["review_body"])[0]["summary_text"]print(f"'>>> Review: {review}'")print(f"\n'>>> Title: {title}'")print(f"\n'>>> Summary: {summary}'")print_summary(-100)# '>>> Review: The story was all over the place. I felt no connection to Evelyn/Eva/Evie, and the ending was anticlimactic. Thank goodness it was a free book.'# '>>> Title: Neither gripping or emotional.'# '>>> Summary: Good book.'
五、翻译
翻译是另一个
seq-to-seq任务,它非常类似于文本摘要任务。你可以将我们将在此处学习到的一些内容迁移到其他的seq-to-seq问题。
5.1 数据集和数据处理
加载数据集:我们将使用
KDE4数据集,该数据集是KDE应用程序本地化文件的数据集。该数据集有92种语言可用,这里我们选择英语和法语。xxxxxxxxxxfrom datasets import load_dataset, load_metricraw_datasets = load_dataset("kde4", lang1="en", lang2="fr")print(raw_datasets)# DatasetDict({# train: Dataset({# features: ['id', 'translation'],# num_rows: 210173# })# })我们有
210,173对句子,但是我们需要创建自己的验证集:xxxxxxxxxxsplit_datasets = raw_datasets["train"].train_test_split(train_size=0.9, seed=20)split_datasets["validation"] = split_datasets.pop("test") # 将 test 重命名为 validationprint(split_datasets)# DatasetDict({# train: Dataset({# features: ['id', 'translation'],# num_rows: 189155# })# validation: Dataset({# features: ['id', 'translation'],# num_rows: 21018# })# })我们可以查看数据集的一个元素:
xxxxxxxxxxprint(split_datasets["train"][1]["translation"])# {'en': 'Default to expanded threads', 'fr': 'Par défaut, développer les fils de discussion'}我们使用的预训练模型已经在一个更大的法语和英语句子语料库上进行了预训练。我们看看这个预训练模型的效果:
xxxxxxxxxxfrom transformers import pipelinemodel_checkpoint = "Helsinki-NLP/opus-mt-en-fr" # 大约 300MBtranslator = pipeline("translation", model=model_checkpoint)print(translator("Default to expanded threads"))# [{'translation_text': 'Par défaut pour les threads élargis'}]数据预处理:所有文本都需要转换为
token ID。xxxxxxxxxxfrom transformers import AutoTokenizermodel_checkpoint = "Helsinki-NLP/opus-mt-en-fr"tokenizer = AutoTokenizer.from_pretrained(model_checkpoint, return_tensors="tf")但是,对于
target,需要将tokenizer包装在上下文管理器"as_target_tokenizer()"中,因为不同的语言需要不同的tokenization:xxxxxxxxxxmax_input_length = 128max_target_length = 128 # 这里设置了 label 和 input 的最大长度相同(也可以不同)def preprocess_function(examples):inputs = [ex["en"] for ex in examples["translation"]]targets = [ex["fr"] for ex in examples["translation"]]model_inputs = tokenizer(inputs, max_length=max_input_length, truncation=True)with tokenizer.as_target_tokenizer():labels = tokenizer(targets, max_length=max_target_length, truncation=True)model_inputs["labels"] = labels["input_ids"]return model_inputstokenized_datasets = split_datasets.map(preprocess_function,batched=True,remove_columns=split_datasets["train"].column_names,)
5.2 使用 Trainer API 微调模型
这里我们使用
Seq2SeqTrainer,它是Trainer的子类,它可以正确处理这种seq-to-seq的评估,并使用generate()方法来预测输出。首先我们加载一个
AutoModelForSeq2SeqLM模型:xxxxxxxxxxfrom transformers import AutoModelForSeq2SeqLMmodel = AutoModelForSeq2SeqLM.from_pretrained(model_checkpoint)然后我们使用
DataCollatorForSeq2Seq来创建一个data_collator,它不仅预处理输入,也同时预处理label。xxxxxxxxxxfrom transformers import DataCollatorForSeq2Seqdata_collator = DataCollatorForSeq2Seq(tokenizer, model=model)现在我们来测试这个
data_collator:xxxxxxxxxxbatch = data_collator([tokenized_datasets["train"][i] for i in range(1, 3)])print(batch)# {# 'input_ids':# tensor([[47591,12,9842,19634,9, 0,59513,59513,59513,59513,59513, 59513, 59513, 59513, 59513],# [ 1211, 3, 49, 9409, 1211, 3, 29140, 817, 3124, 817, 28149, 139, 33712, 25218, 0]]),# 'attention_mask':# tensor([[1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0],# [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]),# 'labels':# tensor([[577, 5891, 2, 3184, 6,2542, 5,1710, 0, -100, -100, -100, -100, -100, -100, -100],# [1211,3,49,9409,1211, 3, 29140,817, 3124,817, 550,7032,5821,7907, 12649, 0]]),# 'decoder_input_ids':# tensor([[59513,577,5891,2,3184,16,2542,5,1710, 0,59513, 59513, 59513, 59513, 59513, 59513],# [59513,1211,3,49,9409,1211,3,29140,817,3124,817,550,7032,5821,7907,12649]])}可以看到,
label已经用-100填充到batch的最大长度。
评估指标:相比较于父类
Trainer,Seq2SeqTrainer的一个额外功能是,在评估或预测期间调用generate()方法从而进行评估。用于翻译任务的传统指标是
BLUE分数,它评估翻译与label的接近程度。BLUE分数不衡量翻译结果的语法正确性或可读性,而是使用统计规则来确保生成输出中的所有单词也出现在label中。BLUE的一个缺点是,它需要确保文本已被tokenization,这使得比较使用不同tokenizer的模型之间的BLUE分数变得困难。因此,目前用于翻译任务的常用指标是SacreBLUE,它通过标准化tokenization步骤解决这个缺点(以及其他的一些缺点)。xxxxxxxxxx# pip install sacrebleu # 首先安装from datasets import load_metricmetric = load_metric("sacrebleu")该指标接受多个
acceptable labels,因为同一个句子通常有多个可接受的翻译。在我们的这个例子中,每个句子只有一个label。因此,预测结果是关于句子的一个列表,而reference也是关于句子的一个列表。xxxxxxxxxxpredictions = [ "This plugin lets you translate web pages between several languages automatically."]references = [["This plugin allows you to automatically translate web pages between several languages."]]print(metric.compute(predictions=predictions, references=references))# {# 'score': 46.750469682990165,# 'counts': [11, 6, 4, 3],# 'totals': [12, 11, 10, 9],# 'precisions': [91.66666666666667, 54.54545454545455, 40.0, 33.333333333333336],# 'bp': 0.9200444146293233,# 'sys_len': 12,# 'ref_len': 13# }这得到了
46.75的BLUE得分,看起来相当不错。如果我们尝试使用翻译模型中经常出现的两种糟糕的预测类型(大量重复、或者太短),我们将得到相当糟糕的BLEU分数:xxxxxxxxxxpredictions = ["This This This This"] # 大量重复predictions = ["This plugin"] # 翻译太短为了从模型输出转换为文本从而计算
BLUE得分,我们需要使用tokenizer.batch_decode()方法来解码。注意,我们需要清理label中的所有-100。xxxxxxxxxximport numpy as npdef compute_metrics(eval_preds):preds, labels = eval_preds# In case the model returns more than the prediction logitsif isinstance(preds, tuple):preds = preds[0]decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True) # 解码 outputlabels = np.where(labels != -100, labels, tokenizer.pad_token_id) # 替换 -100 为 pad_token_iddecoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True) # 解码 labeldecoded_preds = [pred.strip() for pred in decoded_preds] # 格式清理decoded_labels = [[label.strip()] for label in decoded_labels] # 格式清理result = metric.compute(predictions=decoded_preds, references=decoded_labels)return {"bleu": result["score"]}执行微调:
首先我们创建
Seq2SeqTrainingArguments的实例,其中Seq2SeqTrainingArguments是TrainingArguments的子类。xxxxxxxxxxfrom transformers import Seq2SeqTrainingArgumentsargs = Seq2SeqTrainingArguments(f"marian-finetuned-kde4-en-to-fr",evaluation_strategy="no", # 训练过程中不评估验证集(因为我们会在训练之前和训练结束后分别手动评估验证集)save_strategy="epoch", # 每个 epoch 保存一次learning_rate=2e-5,per_device_train_batch_size=32,per_device_eval_batch_size=64,weight_decay=0.01,save_total_limit=3,num_train_epochs=3,predict_with_generate=True, # 通过 model.generate() 来执行预测fp16=True, # FP16 混合精度训练push_to_hub=False, # 不上传到 HuggingFace Hub)然后我们创建
Seq2SeqTrainer:xxxxxxxxxxfrom transformers import Seq2SeqTrainertrainer = Seq2SeqTrainer(model,args,train_dataset=tokenized_datasets["train"],eval_dataset=tokenized_datasets["validation"],data_collator=data_collator,tokenizer=tokenizer,compute_metrics=compute_metrics,)训练之前,我们首先评估模型在验证集上的
BLUE分数:xxxxxxxxxxprint(trainer.evaluate(max_length=max_target_length)) # 大约10分钟(AMD epyc 7543 CPU, 128G内存, 4090显卡)# {# 'eval_loss': 1.6964517831802368,# 'eval_bleu': 25.572039589826357,# 'eval_runtime': 698.3895,# 'eval_samples_per_second': 30.095,# 'eval_steps_per_second': 0.471# }然后开始训练(模型大小
300M,训练显存消耗15.7G):xxxxxxxxxxtrainer.train() # 每个 epoch 都会保存# trainer.push_to_hub(tags="translation", commit_message="Training complete") # 可选:推送模型到 HuggingFace Hub训练完成之后,我们再次评估模型:
xxxxxxxxxxprint(trainer.evaluate(max_length=max_target_length))# {# 'eval_loss': 0.8559923768043518,# 'eval_bleu': 44.69236449595659,# 'eval_runtime': 669.7527,# 'eval_samples_per_second': 31.382,# 'eval_steps_per_second': 0.491,# 'epoch': 3.0# }可以看到
BLUE分有19.12分的提高。
5.3 自定义训练过程
自定义训练过程如下:
xxxxxxxxxxfrom datasets import load_dataset, load_metricfrom transformers import AutoTokenizerfrom transformers import AutoModelForSeq2SeqLMfrom transformers import DataCollatorForSeq2Seqfrom torch.utils.data import DataLoaderfrom transformers import AdamWfrom accelerate import Acceleratorfrom transformers import get_schedulerimport numpy as npfrom datasets import load_metric##******************** 创建 DataLoader ********************##***** 加载数据集raw_datasets = load_dataset("kde4", lang1="en", lang2="fr")split_datasets = raw_datasets["train"].train_test_split(train_size=0.9, seed=20)split_datasets["validation"] = split_datasets.pop("test") # 将 test 重命名为 validation##***** tokenizationmodel_checkpoint = "Helsinki-NLP/opus-mt-en-fr"tokenizer = AutoTokenizer.from_pretrained(model_checkpoint, return_tensors="tf")max_input_length = 128max_target_length = 128 # 这里设置了 label 和 input 的最大长度相同(也可以不同)def preprocess_function(examples):inputs = [ex["en"] for ex in examples["translation"]]targets = [ex["fr"] for ex in examples["translation"]]model_inputs = tokenizer(inputs, max_length=max_input_length, truncation=True)with tokenizer.as_target_tokenizer():labels = tokenizer(targets, max_length=max_target_length, truncation=True)model_inputs["labels"] = labels["input_ids"]return model_inputstokenized_datasets = split_datasets.map(preprocess_function,batched=True,remove_columns=split_datasets["train"].column_names,)tokenized_datasets.set_format("torch")##******* 创建 data_collatormodel = AutoModelForSeq2SeqLM.from_pretrained(model_checkpoint)data_collator = DataCollatorForSeq2Seq(tokenizer, model=model)##****** 创建 dataloadertrain_dataloader = DataLoader(tokenized_datasets["train"],shuffle=True,collate_fn=data_collator,batch_size=8,)eval_dataloader = DataLoader(tokenized_datasets["validation"], collate_fn=data_collator, batch_size=8)##*************** 创建训练组件 *********************##******* 优化器optimizer = AdamW(model.parameters(), lr=2e-5)##****** acceleratoraccelerator = Accelerator()model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(model, optimizer, train_dataloader, eval_dataloader)##***** 学习率调度器num_train_epochs = 3num_update_steps_per_epoch = len(train_dataloader)num_training_steps = num_train_epochs * num_update_steps_per_epochlr_scheduler = get_scheduler("linear",optimizer=optimizer,num_warmup_steps=0,num_training_steps=num_training_steps,)##***** 创建 Repository (可选)# from huggingface_hub import Repository, get_full_repo_name# model_name = "marian-finetuned-kde4-en-to-fr-accelerate"# repo_name = get_full_repo_name(model_name)output_dir = "marian-finetuned-kde4-en-to-fr-accelerate"# repo = Repository(output_dir, clone_from=repo_name)##******* 评估方法metric = load_metric("sacrebleu")def postprocess(predictions, labels):predictions = predictions.cpu().numpy()labels = labels.cpu().numpy()decoded_preds = tokenizer.batch_decode(predictions, skip_special_tokens=True)labels = np.where(labels != -100, labels, tokenizer.pad_token_id) # 替换 label 中的 -100decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)decoded_preds = [pred.strip() for pred in decoded_preds]decoded_labels = [[label.strip()] for label in decoded_labels]return decoded_preds, decoded_labels##*************** 训练 *********************from tqdm.auto import tqdmimport torchprogress_bar = tqdm(range(num_training_steps))for epoch in range(num_train_epochs):# Trainingmodel.train()for batch in train_dataloader:outputs = model(**batch)loss = outputs.lossaccelerator.backward(loss)optimizer.step()lr_scheduler.step()optimizer.zero_grad()progress_bar.update(1)# Evaluationmodel.eval()for batch in tqdm(eval_dataloader):with torch.no_grad():# 注意:我们需要调用底层模型的 generate() 方法,因此这里需要调用 accelerator.unwrap_model()generated_tokens = accelerator.unwrap_model(model).generate(batch["input_ids"],attention_mask=batch["attention_mask"],max_length=128, # 最大生成序列的长度为 128)labels = batch["labels"]# 需要在 accelerator.gather() 调用之前,首先跨所有进程把 generated_tokens/labels 填充到相同的长度generated_tokens = accelerator.pad_across_processes(generated_tokens, dim=1, pad_index=tokenizer.pad_token_id)labels = accelerator.pad_across_processes(labels, dim=1, pad_index=-100)# 跨进程收集 generated_tokens/labels,收集的结果拼接到 batch 维predictions_gathered = accelerator.gather(generated_tokens)labels_gathered = accelerator.gather(labels)decoded_preds, decoded_labels = postprocess(predictions_gathered, labels_gathered)metric.add_batch(predictions=decoded_preds, references=decoded_labels)results = metric.compute()print(f"epoch {epoch}, BLEU score: {results['score']:.2f}")# 每个 epoch 结束时保存模型accelerator.wait_for_everyone()unwrapped_model = accelerator.unwrap_model(model)unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)if accelerator.is_main_process:tokenizer.save_pretrained(output_dir)# repo.push_to_hub(# commit_message=f"Training in progress epoch {epoch}", blocking=False# )# 训练输出:# epoch 0, BLEU score: 50.54# epoch 1, BLEU score: 53.21# epoch 2, BLEU score: 53.83调用微调好的模型:
xxxxxxxxxxfrom transformers import pipelinetranslator = pipeline("translation", model="./marian-finetuned-kde4-en-to-fr-accelerate")print(translator("Default to expanded threads"))# [{'translation_text': 'Par défaut, développer les fils de discussion'}]
六、问答
这里将使用
SQuAD问答数据集微调一个BERT模型。
6.1 数据集和数据处理
下载数据:
xxxxxxxxxxfrom datasets import load_datasetraw_datasets = load_dataset("squad")print(raw_datasets)# DatasetDict({# train: Dataset({# features: ['id', 'title', 'context', 'question', 'answers'],# num_rows: 87599# })# validation: Dataset({# features: ['id', 'title', 'context', 'question', 'answers'],# num_rows: 10570# })# })print("Context: ", raw_datasets["train"][0]["context"])# Context: Architecturally, ...print("Question: ", raw_datasets["train"][0]["question"])# Question: To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France?print("Answer: ", raw_datasets["train"][0]["answers"])# Answer: {'text': ['Saint Bernadette Soubirous'], 'answer_start': [515]}context和question字段使用起来非常简单。但是answers字段有点棘手,因为它是一个字典并且两个字段都是列表。这是在评估过程中squad metric所期望的格式。answers中的text给出了答案的文本,answer中的answer_start字段给出了答案文本在context中的起始位置。在训练期间,只有一种可能的答案。我们可以使用
Dataset.filter()方法来确认这一点:xxxxxxxxxxprint(raw_datasets["train"].filter(lambda x: len(x["answers"]["text"]) != 1))# Dataset({# features: ['id', 'title', 'context', 'question', 'answers'],# num_rows: 0# })在评估期间,每个问题都有几个可能得答案:
xxxxxxxxxxprint(raw_datasets["validation"][0]["answers"])# {'text': ['Denver Broncos', 'Denver Broncos', 'Denver Broncos'], 'answer_start': [177, 177, 177]}print(raw_datasets["validation"][2]["answers"])# {'text': ['Santa Clara, California', "Levi's Stadium", "Levi's Stadium in the San Francisco Bay Area at Santa Clara, California."], 'answer_start': [403, 355, 355]}数据处理:困难的部分将是为答案生成
label,这将是答案对应于上下文中对应的开始位置和结束位置。首先,我们需要使用
tokenizer将输入中的文本转换为模型可以理解的ID:xxxxxxxxxxfrom transformers import AutoTokenizermodel_checkpoint = "bert-base-cased"tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)print(tokenizer.is_fast)# True你也可以使用其它模型,只要它实现了
fast tokenizer即可。现在我们检查
tokenization:xxxxxxxxxxcontext = raw_datasets["train"][0]["context"]question = raw_datasets["train"][0]["question"]inputs = tokenizer(question, context)print(inputs)# {# 'input_ids': [101, 1706, 2292, ..., 102], # 每个 token 的 token id# 'token_type_ids': [0, 0, 0, ..., 1], # 每个 token 属于 question 还是 context# 'attention_mask': [1, 1, 1, ..., 1] # 每个 token 的 attention mask# }print(tokenizer.decode(inputs["input_ids"]))# [CLS] To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France? [SEP] Architecturally,.... [SEP]这个
tokenizer将会插入special token,从而形成如下格式的句子:xxxxxxxxxx[CLS] question [SEP] context [SEP]然后,上下文可能太长,因此需要截断:
xxxxxxxxxxinputs = tokenizer(question,context,max_length=100, # 最大长度设置为 100truncation="only_second", # 仅截断第二个输入,即上下文stride=60, # 滑动窗口的步长为 60,这使得连续两个截断块之间重叠的 token 数为 40return_overflowing_tokens=True, # 让 tokenizer 知道溢出的 token)for ids in inputs["input_ids"]:print(tokenizer.decode(ids))# [CLS] To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France? [SEP] Architecturally, ...[SEP]# [CLS] To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France? [SEP] statue of the Virgin Mary. ... [SEP]# [CLS] To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France? [SEP] Christ with arms ... [SEP]# [CLS] To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France? [SEP] the Main Building is ... [SEP]# [CLS] To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France? [SEP], a Marian place of ... [SEP]可以看到,我们的样本被分为四个输入,每个输入都包含了整个问题、以及一部分的上下文。
然后我们需要在上下文中找到答案的开始位置和结束位置。我们需要得到字符位置到
token位置之间的映射:xxxxxxxxxxinputs = tokenizer(question,context,max_length=100,truncation="only_second",stride=50,return_overflowing_tokens=True,return_offsets_mapping=True, # 返回字符位置到 token 位置之间的映射)print(inputs.keys())# dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'offset_mapping', 'overflow_to_sample_mapping'])print(inputs["overflow_to_sample_mapping"]) # 每个拆分后的新样本属于拆分前的第几个样本# [0, 0, 0, 0]print(inputs['offset_mapping']) # 每个拆分后的新样本的每个token,在原始样本中的位置,格式为(start_index, end_index)# [# [(0, 0), (0, 2), (3, 7), (8, 11), (12, 15), (16, 22), (23, 27), (28, 37), (38, 44), (45, 47), (48, 52), (53, 55), (56, 59), (59, 63), (64, 70), (70, 71), (0, 0), (0, 13), ..., (0, 0)],# [(0, 0), (0, 2), (3, 7), (8, 11), (12, 15), (16, 22), (23, 27), (28, 37), (38, 44), (45, 47), (48, 52), (53, 55), (56, 59), (59, 63), (64, 70), (70, 71), (0, 0), (152, 155), ..., (0, 0)],# [(0, 0), (0, 2), (3, 7), (8, 11), (12, 15), (16, 22), (23, 27), (28, 37), (38, 44), (45, 47), (48, 52), (53, 55), (56, 59), (59, 63), (64, 70), (70, 71), (0, 0), (271, 275), ..., (0, 0)],# [(0, 0), (0, 2), (3, 7), (8, 11), (12, 15), (16, 22), (23, 27), (28, 37), (38, 44), (45, 47), (48, 52), (53, 55), (56, 59), (59, 63), (64, 70), (70, 71), (0, 0), (420, 421), ..., (0, 0)]# ]print(inputs.sequence_ids(0)) # 第0个新样本的原始样本中每个 token 对应于 question 还是 context# [None, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, None, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, None]print(inputs.token_type_ids) # 新样本中,每个 token 对应于 question 序列还是 context 序列# [# [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],# [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],# [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],# [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]# ]对于多个样本:
xxxxxxxxxxinputs = tokenizer(raw_datasets["train"][2:6]["question"],raw_datasets["train"][2:6]["context"],max_length=100,truncation="only_second",stride=50,return_overflowing_tokens=True,return_offsets_mapping=True,)print(f"The 4 examples create {len(inputs['input_ids'])} new records.")# The 4 examples create 19 new records.print(f"Here is where each comes from: {inputs['overflow_to_sample_mapping']}.")# Here is where each comes from: [0, 0, 0, 0, 1, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3].这些信息将有助于我们将答案映射到对应的
label,其中:如果
label是(0,0),则表明答案不在上下文的相应范围内。否则,如果
label是(start_position, end_position),则表明答案在上下文的相应范围内,其中start_position是答案开始的token index、end_position是答案结束的token index。
xxxxxxxxxxanswers = raw_datasets["train"][2:6]["answers"]start_positions = []end_positions = []for i, offset in enumerate(inputs["offset_mapping"]):sample_idx = inputs["overflow_to_sample_mapping"][i] # 第 i 个新样本对应于原始的第 sample_idx 个样本answer = answers[sample_idx] # 第 sample_idx 个原始样本的答案start_char = answer["answer_start"][0] # 训练样本只有一个答案,获取它的开始end_char = answer["answer_start"][0] + len(answer["text"][0]) # 训练样本只有一个答案,获取它的结束sequence_ids = inputs.sequence_ids(i) # 第i个新样本的原始样本中每个 token 对应于 question 还是 contextidx = 0while sequence_ids[idx] != 1: # 找到 context 的起始为止idx += 1context_start = idxwhile sequence_ids[idx] == 1: # 找到 context 的结束位置idx += 1context_end = idx - 1# 如果答案不在当前新样本中, 则 label 为 (0, 0)# offset 给出当前新样本包含的 token 所对应于原始样本中的位置 (token_start, token_end)if start_char < offset[context_start][0] or end_char > offset[context_end][1]:start_positions.append(0)end_positions.append(0)else: # 答案在当前新样本中idx = context_startwhile idx <= context_end and offset[idx][0] <= start_char: # 答案在新样本中的开始位置idx += 1start_positions.append(idx - 1)idx = context_endwhile idx >= context_start and offset[idx][1] >= end_char: # 答案在新样本中的结束位置idx -= 1end_positions.append(idx + 1)print(start_positions)# [83, 51, 19, 0, 0, 64, 27, 0, 34, 0, 0, 0, 67, 34, 0, 0, 0, 0, 0]print(end_positions)# [85, 53, 21, 0, 0, 70, 33, 0, 40, 0, 0, 0, 68, 35, 0, 0, 0, 0, 0]注意,这要求答案不能太长,使得答案必须位于拆分后的某个新样本的上下文中。
现在我们验证该方法是否正确:
xxxxxxxxxx###************* 答案在新样本的上下文中 ************idx = 0 # 第一个新样本sample_idx = inputs["overflow_to_sample_mapping"][idx]answer = answers[sample_idx]["text"][0] # 直接从 answers 中提取start = start_positions[idx]end = end_positions[idx]labeled_answer = tokenizer.decode(inputs["input_ids"][idx][start : end + 1]) # 从新样本中解码print(f"Theoretical answer: {answer}, labels give: {labeled_answer}")# Theoretical answer: the Main Building, labels give: the Main Building###************* 答案不在新样本的上下文中 ************idx = 4sample_idx = inputs["overflow_to_sample_mapping"][idx]answer = answers[sample_idx]["text"][0]decoded_example = tokenizer.decode(inputs["input_ids"][idx])print(f"Theoretical answer: {answer}, decoded example: {decoded_example}")# Theoretical answer: a Marian place of prayer and reflection, decoded example: [CLS] What is the Grotto at Notre Dame? [SEP] Architecturally, the school has a Catholic character.... [SEP]现在开始准备预处理函数:
xxxxxxxxxxmax_length = 384stride = 128def preprocess_training_examples(examples):questions = [q.strip() for q in examples["question"]] # 清除空格inputs = tokenizer(questions,examples["context"],max_length=max_length,truncation="only_second", # 仅截断 contextstride=stride, # 滑动窗口的步长return_overflowing_tokens=True,return_offsets_mapping=True,padding="max_length", # 填充到全局最大)offset_mapping = inputs.pop("offset_mapping")sample_map = inputs.pop("overflow_to_sample_mapping")answers = examples["answers"]start_positions = []end_positions = []for i, offset in enumerate(offset_mapping):sample_idx = sample_map[i]answer = answers[sample_idx]start_char = answer["answer_start"][0]end_char = answer["answer_start"][0] + len(answer["text"][0])sequence_ids = inputs.sequence_ids(i) # 第i个新样本的原始样本中每个 token 对应于 question 还是 context# Find the start and end of the contextidx = 0while sequence_ids[idx] != 1:idx += 1context_start = idxwhile sequence_ids[idx] == 1:idx += 1context_end = idx - 1# If the answer is not fully inside the context, label is (0, 0)if offset[context_start][0] > start_char or offset[context_end][1] < end_char:start_positions.append(0)end_positions.append(0)else:# Otherwise it's the start and end token positionsidx = context_startwhile idx <= context_end and offset[idx][0] <= start_char:idx += 1start_positions.append(idx - 1)idx = context_endwhile idx >= context_start and offset[idx][1] >= end_char:idx -= 1end_positions.append(idx + 1)inputs["start_positions"] = start_positionsinputs["end_positions"] = end_positionsreturn inputs然后将这个函数应用到
Dataset.map()方法:xxxxxxxxxxtrain_dataset = raw_datasets["train"].map(preprocess_training_examples,batched=True,remove_columns=raw_datasets["train"].column_names,)print(len(raw_datasets["train"]))# 87599print(len(train_dataset))# 88729
处理验证数据集:预处理验证数据会稍微容易一些,因为我们不需要生成
label(除非我们想计算验证集损失,但这个指标并不能真正帮助我们理解模型有多好)。需要注意的是:我们要将模型的预测结果解释为原始上下文的跨度。为此, 我们只需要存储offset_mapping、以及某种方式来将每个创建的新样本与原始样本相匹配。xxxxxxxxxxdef preprocess_validation_examples(examples):questions = [q.strip() for q in examples["question"]]inputs = tokenizer(questions,examples["context"],max_length=max_length,truncation="only_second",stride=stride,return_overflowing_tokens=True,return_offsets_mapping=True,padding="max_length",)sample_map = inputs.pop("overflow_to_sample_mapping")example_ids = [] # 样本ID,由数据集的 id 字段提供,格式为 "56be4db0acb8001400a502ec" 这种for i in range(len(inputs["input_ids"])):sample_idx = sample_map[i] # 第 i 个新样本对应于第 sample_idx 个原始样本example_ids.append(examples["id"][sample_idx]) # 原始样本的样本idsequence_ids = inputs.sequence_ids(i) # 第i个新样本的原始样本中每个 token 对应于 question 还是 contextoffset = inputs["offset_mapping"][i]inputs["offset_mapping"][i] = [o if sequence_ids[k] == 1 else None for k, o in enumerate(offset)]inputs["example_id"] = example_idsreturn inputsvalidation_dataset = raw_datasets["validation"].map(preprocess_validation_examples,batched=True,remove_columns=raw_datasets["validation"].column_names,)print(len(raw_datasets["validation"]))# 10570print(len(validation_dataset))# 10822注意,我们仅保留
context的offset_mapping,而将question的offset_mapping设置为None。这么做是为了后处理步骤做准备。
6.2 使用 Trainer API 微调模型
在这个例子中,
compute_metrics()函数是个难点。由于我们人工降所有样本填充到我们设置的最大长度,因此无需定义data_collator。困难的部分是将模型预测进行后处理,从而得到原始样本中的文本范围。后处理:模型输出的是答案开始位置的
logit、答案结束位置的logit。通常而言,我们需要做如下的处理:首先,屏蔽掉上下文之外的
token所对应的logit,因为答案必须位于上下文中。然后,我们使用
softmax将这些logit转换为概率。然后,我们通过获取对应的两个概率的乘积,从而为每个
(start_token, end_token)组合赋值。最后,我们寻找有效的、答案分数最高的
(start_token, end_token)组合。这里有效指的是,例如,start_token必须位于end_token之前。
在这里我们稍微改变下这个流程,因为我们在
compute_metrics()函数中不需要计算实际得分,因此可以跳过softmax的计算,然后通过start logit和end logit之和来获得(start_token, end_token)组合的得分。这里我们没有用乘积,因为此外,我们也没有对所有可能的
(start_token, end_token)组合进行评分,而是对top n_best的start_token和top n_best的end_token的组合进行评分,其中n_best = 20。为了检验该做法的合理性,我们使用一个预训练好的模型来生成一些
prediction:xxxxxxxxxx##************* 选择预训练好的一个模型来生成 prediction *********small_eval_set = raw_datasets["validation"].select(range(100))trained_checkpoint = "distilbert-base-cased-distilled-squad"tokenizer = AutoTokenizer.from_pretrained(trained_checkpoint)eval_set = small_eval_set.map(preprocess_validation_examples,batched=True,remove_columns=raw_datasets["validation"].column_names,)##************** 切换回 tokenizer,这里用不上,为了后续流程做准备 *****************tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)##************* 执行预测 ********************import torchfrom transformers import AutoModelForQuestionAnsweringeval_set_for_model = eval_set.remove_columns(["example_id", "offset_mapping"]) # 移除不需要的列eval_set_for_model.set_format("torch")device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")batch = {k: eval_set_for_model[k].to(device) for k in eval_set_for_model.column_names} # data 移动到GPUprint(batch)# {'input_ids': tensor(..., device='cuda:0'), 'attention_mask': tensor(..., device='cuda:0')}trained_model = AutoModelForQuestionAnswering.from_pretrained(trained_checkpoint).to(device)with torch.no_grad():outputs = trained_model(**batch)print(outputs)# QuestionAnsweringModelOutput(loss=None,# start_logits=tensor(..., device='cuda:0'),# end_logits=tensor(..., device='cuda:0'), hidden_states=None, attentions=None)由于
Trainer将为我们提供的prediction是NumPy数组格式,我们也进行这种格式转换:xxxxxxxxxxstart_logits = outputs.start_logits.cpu().numpy()end_logits = outputs.end_logits.cpu().numpy()现在,我们需要在原始的
small_eval_set中找到模型对每个样本所预测的答案。一个原始样本可能已经在eval_set中拆分为多个新样本,因此第一步是将small_eval_set中的原始样本映射到eval_set中相应的新样本:xxxxxxxxxximport collectionsexample_to_features = collections.defaultdict(list) # string -> list 的字典for idx, feature in enumerate(eval_set):# feature["example_id"] 存放原始样本的样本编号(一个字符串), idx 为新样本的编号(一个整数)example_to_features[feature["example_id"]].append(idx)现在我们开始执行如前所示的处理流程:
xxxxxxxxxximport numpy as npn_best = 20max_answer_length = 30 # 答案最多 30 个 tokenpredicted_answers = []for example in small_eval_set:example_id = example["id"]context = example["context"]answers = []for feature_index in example_to_features[example_id]:start_logit = start_logits[feature_index] # 第 feature_index 个新样本的 start_logitend_logit = end_logits[feature_index] # 第 feature_index 个新样本的 end_logitoffsets = eval_set["offset_mapping"][feature_index] # 新样本的每个token,在原始样本中的位置,格式为(start_index, end_index)start_indexes = np.argsort(start_logit)[-1 : -n_best - 1 : -1].tolist() # top n 的 start_logitend_indexes = np.argsort(end_logit)[-1 : -n_best - 1 : -1].tolist() # top n 的 end_logitfor start_index in start_indexes:for end_index in end_indexes:# 答案并不是完全位于 context 中,因此不考虑 (这意味着最多只有一个新样本包含完整的答案)if offsets[start_index] is None or offsets[end_index] is None:continue# 如果答案长度为负、或者答案长度超过 max_answer_length,则不考虑if (end_index < start_indexor end_index - start_index + 1 > max_answer_length):continueanswers.append({ # 取 start_token 的开始位置、end_token 的结束位置"text": context[offsets[start_index][0] : offsets[end_index][1]],"logit_score": start_logit[start_index] + end_logit[end_index],})best_answer = max(answers, key=lambda x: x["logit_score"]) # 取 logit_score 的最大值predicted_answers.append({"id": example_id, "prediction_text": best_answer["text"]})print(predicted_answers[:3])# [# {'id': '56be4db0acb8001400a502ec', 'prediction_text': 'Denver Broncos'},# {'id': '56be4db0acb8001400a502ed', 'prediction_text': 'Carolina Panthers'},# {'id': '56be4db0acb8001400a502ee', 'prediction_text': "Levi's Stadium in the San Francisco Bay Area at Santa Clara, California"}# ]评估指标:我们使用
load_metric来加载squad的评估指标:xxxxxxxxxxfrom datasets import load_metricmetric = load_metric("squad")这个指标预期我们提供:
预测答案:一个关于字典的列表,其中字典格式为
{"id": 样本id, "prediction_text": 预测文本}。注意:如果答案太长导致超过
max_answer_length,或者因为原始样本截断导致答案被截断到两个新样本中,那么这个样本就没有预测答案。真实答案:一个关于字典的列表,其中字典格式为
{"id": 样本id, "answers": 一组真实的参考答案}。
现在我们计算预测答案的得分:
xxxxxxxxxxtheoretical_answers = [{"id": ex["id"], "answers": ex["answers"]} for ex in small_eval_set # 从原始样本中]print(predicted_answers[0])# {'id': '56be4db0acb8001400a502ec', 'prediction_text': 'Denver Broncos'}print(theoretical_answers[0])# {'id': '56be4db0acb8001400a502ec', 'answers': {'text': ['Denver Broncos', 'Denver Broncos', 'Denver Broncos'], 'answer_start': [177, 177, 177]}}print(metric.compute(predictions=predicted_answers, references=theoretical_answers))# {'exact_match': 83.0, 'f1': 88.25000000000004}现在把刚才所做的一切放在
compute_metrics()函数中,我们将在Trainer中使用它。通常,compute_metrics()函数只接收一个eval_preds,它包含logits和labels的元组。这里我们需要更多输入,因为我们必须在截断后的新数据集中查找offset。compute_metrics()函数几乎与前面的步骤相同,这里我们只是添加一个小检查,从而防止我们没有提出任何有效的答案(在这种情况下,我们预测一个空字符串)。xxxxxxxxxxfrom tqdm.auto import tqdmdef compute_metrics(start_logits, end_logits, features, examples):##************* 记录每个原始样本被拆分到哪些新样本中 ***********example_to_features = collections.defaultdict(list) # string -> listfor idx, feature in enumerate(features):example_to_features[feature["example_id"]].append(idx)##*************** 获取每个原始样本的预测结果 ***************predicted_answers = []for example in tqdm(examples):example_id = example["id"]context = example["context"]answers = []# 遍历每个原始样本for feature_index in example_to_features[example_id]:start_logit = start_logits[feature_index]end_logit = end_logits[feature_index]offsets = features[feature_index]["offset_mapping"]start_indexes = np.argsort(start_logit)[-1 : -n_best - 1 : -1].tolist() # top-n start_logitend_indexes = np.argsort(end_logit)[-1 : -n_best - 1 : -1].tolist() # top-n end_logitfor start_index in start_indexes:for end_index in end_indexes:# 答案并不是完全位于 context 中,因此不考虑 (这意味着最多只有一个新样本包含完整的答案)if offsets[start_index] is None or offsets[end_index] is None:continue# 如果答案长度为负、或者答案长度超过 max_answer_length,则不考虑if (end_index < start_indexor end_index - start_index + 1 > max_answer_length):continueanswer = {"text": context[offsets[start_index][0] : offsets[end_index][1]],"logit_score": start_logit[start_index] + end_logit[end_index],}answers.append(answer)# 如果找到一组候选答案,则寻找得分最大的那个if len(answers) > 0:best_answer = max(answers, key=lambda x: x["logit_score"])predicted_answers.append({"id": example_id, "prediction_text": best_answer["text"]})else: # 否则没有候选答案,则默认为空字符串predicted_answers.append({"id": example_id, "prediction_text": ""})theoretical_answers = [{"id": ex["id"], "answers": ex["answers"]} for ex in examples]return metric.compute(predictions=predicted_answers, references=theoretical_answers)然后我们检验下该函数:
xxxxxxxxxxprint(compute_metrics(start_logits, end_logits, eval_set, small_eval_set))# {'exact_match': 83.0, 'f1': 88.25000000000004}模型微调:
首先创建模型:
xxxxxxxxxxmodel = AutoModelForQuestionAnswering.from_pretrained(model_checkpoint)我们收到一个警告,有些权重没有使用(来自
pretrained head)、另一些权重是随机初始化的(用于问答任务的)。这仅仅是因为该模型是用于微调。然后,如果我们需要将结果推送到
HuggingFace Hub,则需要登录:xxxxxxxxxx# Jupyter notebook 中from huggingface_hub import notebook_loginnotebook_login()# 或者在 terminal 中执行命令: huggingface-cli login也可以不登录。
之后,我们创建
TrainingArguments:xxxxxxxxxxfrom transformers import TrainingArgumentsargs = TrainingArguments("bert-finetuned-squad",evaluation_strategy="no", # 训练过程中不需要评估save_strategy="epoch", # 每个 epoch 保存一次learning_rate=2e-5,num_train_epochs=3,weight_decay=0.01,fp16=True, # fp16 混合精度训练push_to_hub=False, # 不需要推送到 HuggingFace Hub)注意,由于
compute_metrics()的函数前面,它不支持常规的evaluation loop。一种解决办法是创建Trainer的子类;另一种方法是不在训练过程中评估,而是在训练结束后在自定义loop中进行评估。这里我们选择第二种办法。这就是Trainer API的局限性,也体现了Accelerate库的亮点:完全自定义的training loop。然后我们创建
Trainer:xxxxxxxxxxfrom transformers import Trainertrainer = Trainer(model=model,args=args,train_dataset=train_dataset,eval_dataset=validation_dataset,tokenizer=tokenizer,)trainer.train()# TrainOutput(# global_step=33276,# training_loss=0.8343884834576605,# metrics={'train_runtime': 1781.3809, 'train_samples_per_second': 149.427, 'train_steps_per_second': 18.68, 'total_flos': 5.216534983896422e+16, 'train_loss': 0.8343884834576605, 'epoch': 3.0}# )模型评估:
Trainer的predict()方法将返回一个元组,其中第一个元素将是模型的预测(这里(start_logits, end_logits)组合)。我们将其发送给compute_metrics()函数:xxxxxxxxxxprediction = trainer.predict(validation_dataset).predictionsstart_logits, end_logits = predictionsprint(compute_metrics(start_logits, end_logits, validation_dataset, raw_datasets["validation"]))# {'exact_match': 81.19205298013244, 'f1': 88.62747671089845}很好!作为比较,
BERT文章中报告的该模型的baseline分数是80.8和88.5,所以我们应该是正确的。最后,如果需要的话,我们可以把模型上传到
HuggingFace Hub:xxxxxxxxxxtrainer.push_to_hub(commit_message="Training complete")
使用微调的模型:在
pipeline中使用微调好的模型很简单:xxxxxxxxxxfrom transformers import pipelinemodel_checkpoint = "./bert-finetuned-squad/checkpoint-33276" # 本地路径,或者 huggingface 上的 model idquestion_answerer = pipeline("question-answering", model=model_checkpoint)context = """🤗 Transformers is backed by the three most popular deep learning libraries — Jax, PyTorch and TensorFlow — with a seamless integrationbetween them. It's straightforward to train your models with one before loading them for inference with the other."""question = "Which deep learning libraries back 🤗 Transformers?"print(question_answerer(question=question, context=context))# {'score': 0.9980810880661011,# 'start': 78,# 'end': 105,# 'answer': 'Jax, PyTorch and TensorFlow'}
6.3 自定义训练过程
首先创建
dataloader:xxxxxxxxxxfrom datasets import load_datasetfrom transformers import AutoTokenizerfrom torch.utils.data import DataLoaderfrom transformers import default_data_collatorraw_datasets = load_dataset("squad")model_checkpoint = "bert-base-cased"tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)max_length = 384stride = 128def preprocess_training_examples(examples):questions = [q.strip() for q in examples["question"]] # 清除空格inputs = tokenizer(questions,examples["context"],max_length=max_length,truncation="only_second", # 仅截断 contextstride=stride, # 滑动窗口的步长return_overflowing_tokens=True,return_offsets_mapping=True,padding="max_length", # 填充到全局最大)offset_mapping = inputs.pop("offset_mapping")sample_map = inputs.pop("overflow_to_sample_mapping")answers = examples["answers"]start_positions = []end_positions = []for i, offset in enumerate(offset_mapping):sample_idx = sample_map[i]answer = answers[sample_idx]start_char = answer["answer_start"][0]end_char = answer["answer_start"][0] + len(answer["text"][0])sequence_ids = inputs.sequence_ids(i) # 第i个新样本的原始样本中每个 token 对应于 question 还是 context# Find the start and end of the contextidx = 0while sequence_ids[idx] != 1:idx += 1context_start = idxwhile sequence_ids[idx] == 1:idx += 1context_end = idx - 1# If the answer is not fully inside the context, label is (0, 0)if offset[context_start][0] > start_char or offset[context_end][1] < end_char:start_positions.append(0)end_positions.append(0)else:# Otherwise it's the start and end token positionsidx = context_startwhile idx <= context_end and offset[idx][0] <= start_char:idx += 1start_positions.append(idx - 1)idx = context_endwhile idx >= context_start and offset[idx][1] >= end_char:idx -= 1end_positions.append(idx + 1)inputs["start_positions"] = start_positionsinputs["end_positions"] = end_positionsreturn inputsdef preprocess_validation_examples(examples):questions = [q.strip() for q in examples["question"]]inputs = tokenizer(questions,examples["context"],max_length=max_length,truncation="only_second",stride=stride,return_overflowing_tokens=True,return_offsets_mapping=True,padding="max_length",)sample_map = inputs.pop("overflow_to_sample_mapping")example_ids = [] # 样本ID,由数据集的 id 字段提供,格式为 "56be4db0acb8001400a502ec" 这种for i in range(len(inputs["input_ids"])):sample_idx = sample_map[i] # 第 i 个新样本对应于第 sample_idx 个原始样本example_ids.append(examples["id"][sample_idx]) # 原始样本的样本idsequence_ids = inputs.sequence_ids(i) # 第i个新样本的原始样本中每个 token 对应于 question 还是 contextoffset = inputs["offset_mapping"][i]inputs["offset_mapping"][i] = [o if sequence_ids[k] == 1 else None for k, o in enumerate(offset)]inputs["example_id"] = example_idsreturn inputstrain_dataset = raw_datasets["train"].map(preprocess_training_examples,batched=True,remove_columns=raw_datasets["train"].column_names,)validation_dataset = raw_datasets["validation"].map(preprocess_validation_examples,batched=True,remove_columns=raw_datasets["validation"].column_names,)train_dataset.set_format("torch") # 设置为 torch 格式validation_set = validation_dataset.remove_columns(["example_id", "offset_mapping"]) # 删除模型未使用的列validation_set.set_format("torch")train_dataloader = DataLoader(train_dataset,shuffle=True, # 仅混洗训练集,无需混洗验证集collate_fn=default_data_collator, # 使用默认的 data_collatorbatch_size=8,)eval_dataloader = DataLoader(validation_set, collate_fn=default_data_collator, batch_size=8)然后创建训练组件并进行训练:
xxxxxxxxxxfrom torch.optim import AdamWfrom transformers import AutoModelForQuestionAnsweringfrom accelerate import Acceleratorfrom transformers import get_schedulerimport collectionsimport numpy as npfrom datasets import load_metricmetric = load_metric("squad")def compute_metrics(start_logits, end_logits, features, examples):n_best = 20max_answer_length = 30 # 答案最多 30 个 token##************* 记录每个原始样本被拆分到哪些新样本中 ***********example_to_features = collections.defaultdict(list) # string -> listfor idx, feature in enumerate(features):example_to_features[feature["example_id"]].append(idx)##*************** 获取每个原始样本的预测结果 ***************predicted_answers = []for example in tqdm(examples):example_id = example["id"]context = example["context"]answers = []# 遍历每个原始样本for feature_index in example_to_features[example_id]:start_logit = start_logits[feature_index]end_logit = end_logits[feature_index]offsets = features[feature_index]["offset_mapping"]start_indexes = np.argsort(start_logit)[-1 : -n_best - 1 : -1].tolist() # top-n start_logitend_indexes = np.argsort(end_logit)[-1 : -n_best - 1 : -1].tolist() # top-n end_logitfor start_index in start_indexes:for end_index in end_indexes:# 答案并不是完全位于 context 中,因此不考虑 (这意味着最多只有一个新样本包含完整的答案)if offsets[start_index] is None or offsets[end_index] is None:continue# 如果答案长度为负、或者答案长度超过 max_answer_length,则不考虑if (end_index < start_indexor end_index - start_index + 1 > max_answer_length):continueanswer = {"text": context[offsets[start_index][0] : offsets[end_index][1]],"logit_score": start_logit[start_index] + end_logit[end_index],}answers.append(answer)# 如果找到一组候选答案,则寻找得分最大的那个if len(answers) > 0:best_answer = max(answers, key=lambda x: x["logit_score"])predicted_answers.append({"id": example_id, "prediction_text": best_answer["text"]})else: # 否则没有候选答案,则默认为空字符串predicted_answers.append({"id": example_id, "prediction_text": ""})theoretical_answers = [{"id": ex["id"], "answers": ex["answers"]} for ex in examples]return metric.compute(predictions=predicted_answers, references=theoretical_answers)##************* 创建训练组件 **********************model = AutoModelForQuestionAnswering.from_pretrained(model_checkpoint)optimizer = AdamW(model.parameters(), lr=2e-5)accelerator = Accelerator(mixed_precision='fp16')model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(model, optimizer, train_dataloader, eval_dataloader)num_train_epochs = 3num_update_steps_per_epoch = len(train_dataloader)num_training_steps = num_train_epochs * num_update_steps_per_epochlen_validation = len(validation_dataset)lr_scheduler = get_scheduler("linear",optimizer=optimizer,num_warmup_steps=0,num_training_steps=num_training_steps,)##************** 推送到 HuggingFace Hub (可选)***********# from huggingface_hub import Repository, get_full_repo_name# model_name = "bert-finetuned-squad-accelerate"# repo_name = get_full_repo_name(model_name)output_dir = "bert-finetuned-squad-accelerate"# repo = Repository(output_dir, clone_from=repo_name)##**************** Training Loop *****************from tqdm.auto import tqdmimport torchprogress_bar = tqdm(range(num_training_steps))for epoch in range(num_train_epochs):# Trainingmodel.train()for step, batch in enumerate(train_dataloader):outputs = model(**batch)loss = outputs.lossaccelerator.backward(loss)optimizer.step()lr_scheduler.step()optimizer.zero_grad()progress_bar.update(1)# Evaluationmodel.eval()start_logits = []end_logits = []accelerator.print("Evaluation!")for batch in tqdm(eval_dataloader):with torch.no_grad():outputs = model(**batch)start_logits.append(accelerator.gather(outputs.start_logits).cpu().numpy())end_logits.append(accelerator.gather(outputs.end_logits).cpu().numpy())start_logits = np.concatenate(start_logits) # 拼接所有的 start_logitsend_logits = np.concatenate(end_logits) # 拼接所有的 end_logitsprint("start_logits len: %d; end_logits len:%d; validation_dataset len:%d."%(len(start_logits),len(end_logits), len_validation))# start_logits len: 10822; end_logits len:10822; validation_dataset len:10822start_logits = start_logits[: len_validation] # accelerator 可能在最后添加了一些样本,这里需要截断end_logits = end_logits[: len_validation] # accelerator 可能在最后添加了一些样本,这里需要截断metrics = compute_metrics(start_logits, end_logits, validation_dataset, raw_datasets["validation"])print(f"epoch {epoch}:", metrics)# epoch 0: {'exact_match': 79.09176915799432, 'f1': 86.89534995209642}# epoch 1: {'exact_match': 81.25827814569537, 'f1': 88.58745720707509}# epoch 2: {'exact_match': 81.28666035950805, 'f1': 88.57238479975265}# 在每个 epoch 保存和上传accelerator.wait_for_everyone() # 阻塞每个进程,直到所有进程都到达这里unwrapped_model = accelerator.unwrap_model(model) # 获取底层的模型unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save) # 使用 accelerator.saveif accelerator.is_main_process:tokenizer.save_pretrained(output_dir) # 保存 tokenizer# repo.push_to_hub(# commit_message=f"Training in progress epoch {epoch}", blocking=False# )