Scipy
Scipy的核心计算部分是一些Fortran数值计算库:- 线性代数使用
LAPACK库 - 快速傅立叶变换使用
FFTPACK库 - 常微分方程求解使用
ODEPACK库 - 非线性方程组求解以及最小值求解使用
MINPACK库
- 线性代数使用
一、 常数和特殊函数
1. constants 模块
scipy的constants模块包含了众多的物理常数:constants.c:真空中的光速constants.h:普朗克常数constants.g:重力加速度constants.m_e:电子质量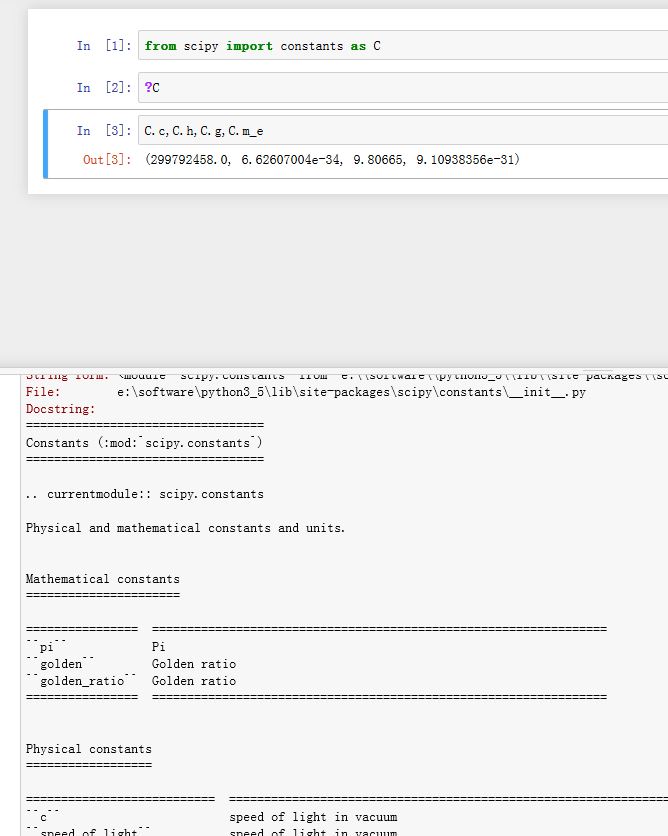
在字典
constants.physical_constants中,以物理常量名为键,对应的值是一个含有三元素的元组,分别为:常量值、单位、误差。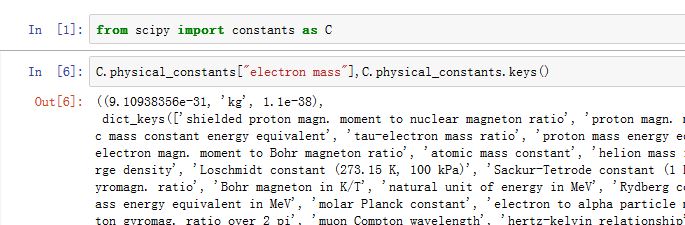
constants模块还包含了许多单位信息,它们是 1 单位的量转换成标准单位时的数值:C.mile:一英里对应的米C.inch:一英寸对应的米C.gram:一克等于多少千克C.pound:一磅对应多少千克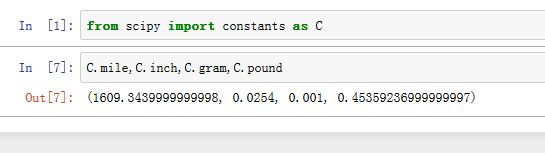
2. special 模块
scipy的special模块是个非常完整的函数库,其中包含了基本数学函数、特殊数学函数以及numpy中出现的所有函数。这些特殊函数都是ufunc函数,支持数组的广播运算。gamma函数:special.gamma(x)。其数学表达式为: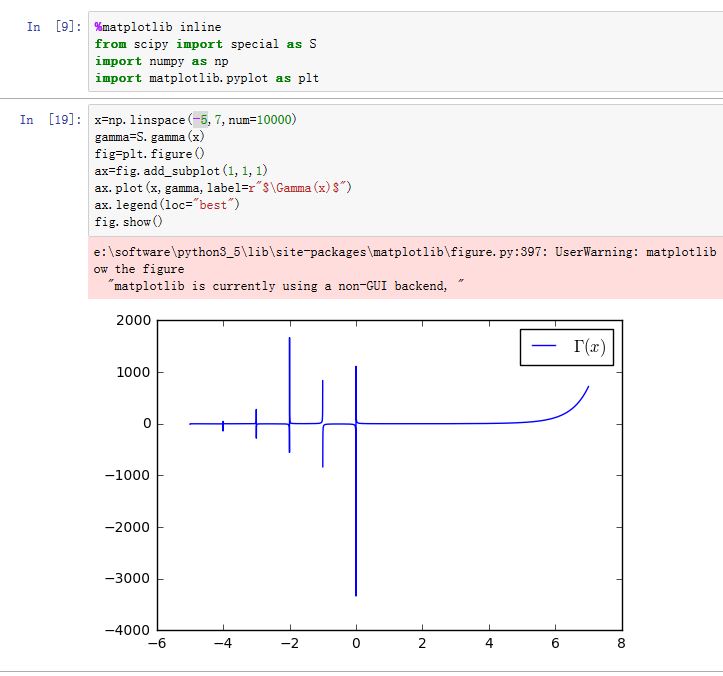
gamma函数是阶乘函数在实数和复数系上的扩展,增长的非常迅速。1000的阶乘已经超过了双精度浮点数的表示范围。为了计算更大范围,可以使用gammaln函数来计算 的值:special.gammaln(x)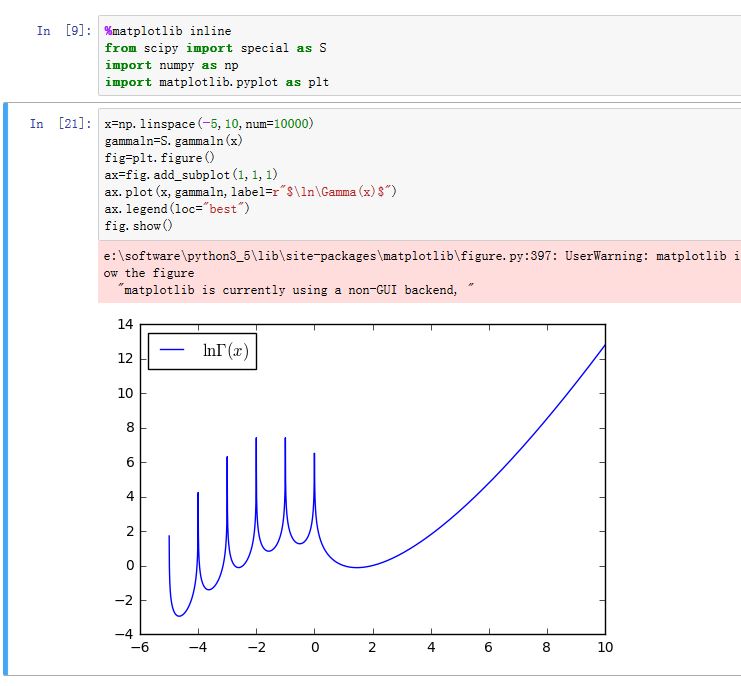
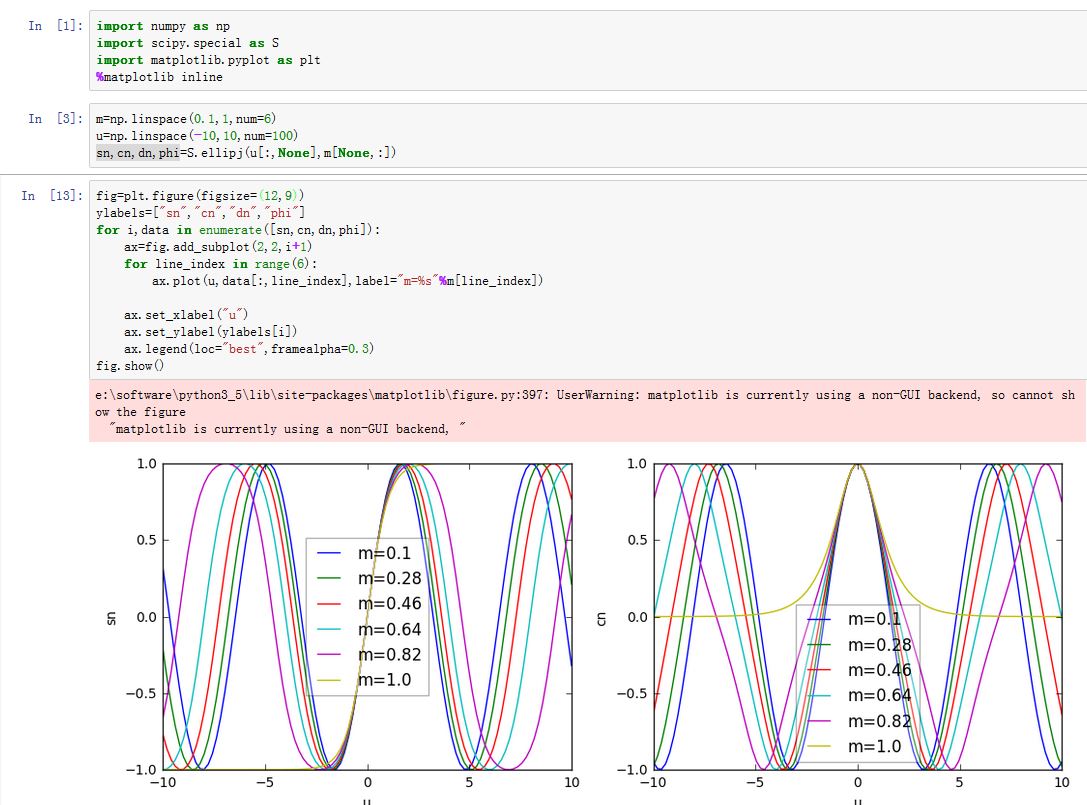
计算雅可比椭圆函数:
sn,cn,dn,phi=special.ellipj(u,m),其中:sn=cn=dn=phi=u=
special模块的某些函数并不是数学意义上的特殊函数。如log1p(x)计算的是 。这是因为浮点数精度限制,无法精确地表示非常接近 1的实数。因此 的值为 0 。但是 的值可以计算。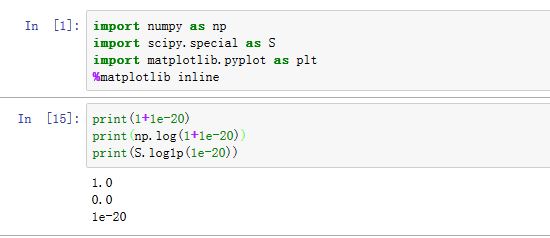
二、 拟合与优化
scipy的optimize模块提供了许多数值优化算法。求解非线性方程组:
scipy.optimize.fsolve(func, x0, args=(), fprime=None, full_output=0, col_deriv=0,xtol=1.49012e-08, maxfev=0, band=None, epsfcn=None, factor=100, diag=None)func:是个可调用对象,它代表了非线性方程组。给他传入方程组的各个参数,它返回各个方程残差(残差为零则表示找到了根)x0:预设的方程的根的初始值args:一个元组,用于给func提供额外的参数。fprime:用于计算func的雅可比矩阵(按行排列)。默认情况下,算法自动推算full_output:如果为True,则给出更详细的输出col_deriv:如果为True,则计算雅可比矩阵更快(按列求导)xtol:指定算法收敛的阈值。当误差小于该阈值时,算法停止迭代maxfev:设定算法迭代的最大次数。如果为零,则为100*(N+1),N为x0的长度band:If set to a two-sequence containing the number of sub- and super-diagonals within the band of the Jacobi matrix, the Jacobi matrix is considered banded (only for fprime=None)epsfcn:采用前向差分算法求解雅可比矩阵时的步长。factor:它决定了初始的步长diag:它给出了每个变量的缩放因子
返回值:
x:方程组的根组成的数组infodict:给出了可选的输出。它是个字典,其中的键有:nfev:func调用次数njev:雅可比函数调用的次数fvec:最终的func输出fjac:the orthogonal matrix, q, produced by the QR factorization of the final approximate Jacobian matrix, stored column wiser:upper triangular matrix produced by QR factorization of the same matrix
ier:一个整数标记。如果为 1,则表示根求解成功mesg:一个字符串。如果根未找到,则它给出详细信息
假设待求解的方程组为:
那么我们的
func函数为:xxxxxxxxxxdef func(x):x1,x2,x3=x.tolist() # x 为向量,形状为 (3,)return np.array([f1(x1,x2,x3),f2(x1,x2,x3),f3(x1,x2,x3)])数组的
.tolist()方法能获得标准的python列表而雅可比矩阵为:
xxxxxxxxxxdef fprime(x):x1,x2,x3=x.tolist() # x 为向量,形状为 (3,)return np.array([[df1/dx1,df1/dx2,df1/df3],[df2/dx1,df2/dx2,df2/df3],[df3/dx1,df3/dx2,df3/df3]])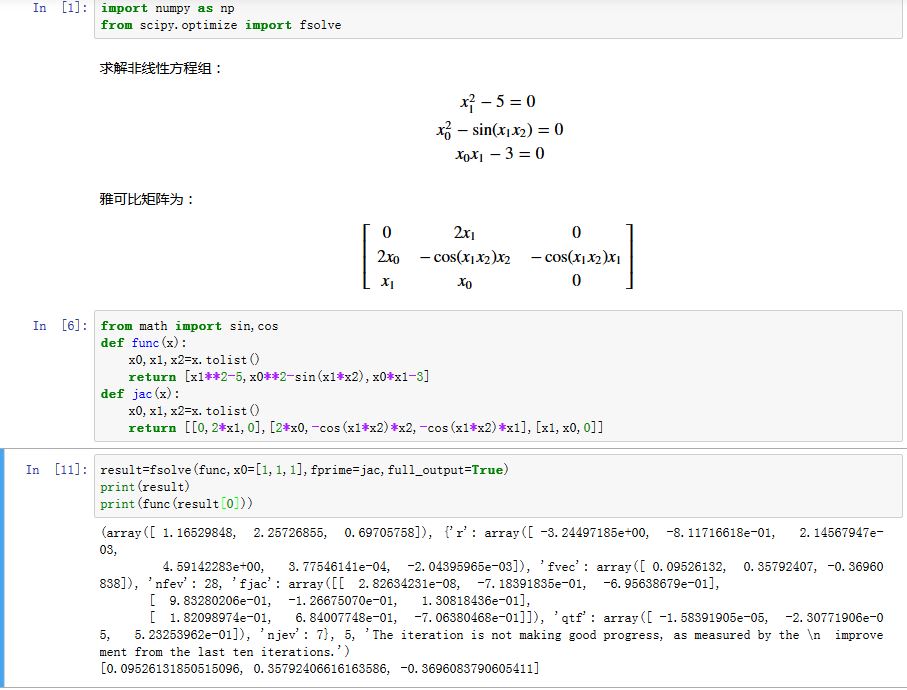
最小二乘法拟合数据:
xxxxxxxxxxscipy.optimize.leastsq(func, x0, args=(), Dfun=None, full_output=0, col_deriv=0,ftol=1.49012e-08, xtol=1.49012e-08, gtol=0.0, maxfev=0, epsfcn=None,factor=100, diag=None)func:是个可调用对象,给出每次拟合的残差。最开始的参数是待优化参数;后面的参数由args给出x0:初始迭代值args:一个元组,用于给func提供额外的参数。Dfun:用于计算func的雅可比矩阵(按行排列)。默认情况下,算法自动推算。它给出残差的梯度。最开始的参数是待优化参数;后面的参数由args给出full_output:如果非零,则给出更详细的输出col_deriv:如果非零,则计算雅可比矩阵更快(按列求导)ftol:指定相对的均方误差的阈值xtol:指定参数解收敛的阈值gtol:Orthogonality desired between the function vector and the columns of the Jacobianmaxfev:设定算法迭代的最大次数。如果为零:如果为提供了Dfun,则为100*(N+1),N为x0的长度;如果未提供Dfun,则为200*(N+1)epsfcn:采用前向差分算法求解雅可比矩阵时的步长。factor:它决定了初始的步长diag:它给出了每个变量的缩放因子
返回值:
x:拟合解组成的数组cov_x:Uses the fjac and ipvt optional outputs to construct an estimate of the jacobian around the solutioninfodict:给出了可选的输出。它是个字典,其中的键有:nfev:func调用次数fvec:最终的func输出fjac:A permutation of the R matrix of a QR factorization of the final approximate Jacobian matrix, stored column wise.ipvt:An integer array of length N which defines a permutation matrix, p, such that fjacp = qr, where r is upper triangular with diagonal elements of nonincreasing magnitude
ier:一个整数标记。如果为 1/2/3/4,则表示拟合成功mesg:一个字符串。如果解未找到,则它给出详细信息
假设我们拟合的函数是 ,其中 为参数。假设数据点的横坐标为 ,纵坐标为 ,那么我们可以给出
func为:xxxxxxxxxxdef func(p,x,y):a,b,c=p.tolist() # 这里p 为数组,形状为 (3,); x,y 也是数组,形状都是 (N,)return f(x,y;a,b,c))其中
args=(X,Y)而雅可比矩阵为 ,给出
Dfun为:xxxxxxxxxxdef func(p,x,y):a,b,c=p.tolist()return np.c_[df/da,df/db,df/dc]# 这里p为数组,形状为 (3,);x,y 也是数组,形状都是 (N,)其中
args=(X,Y)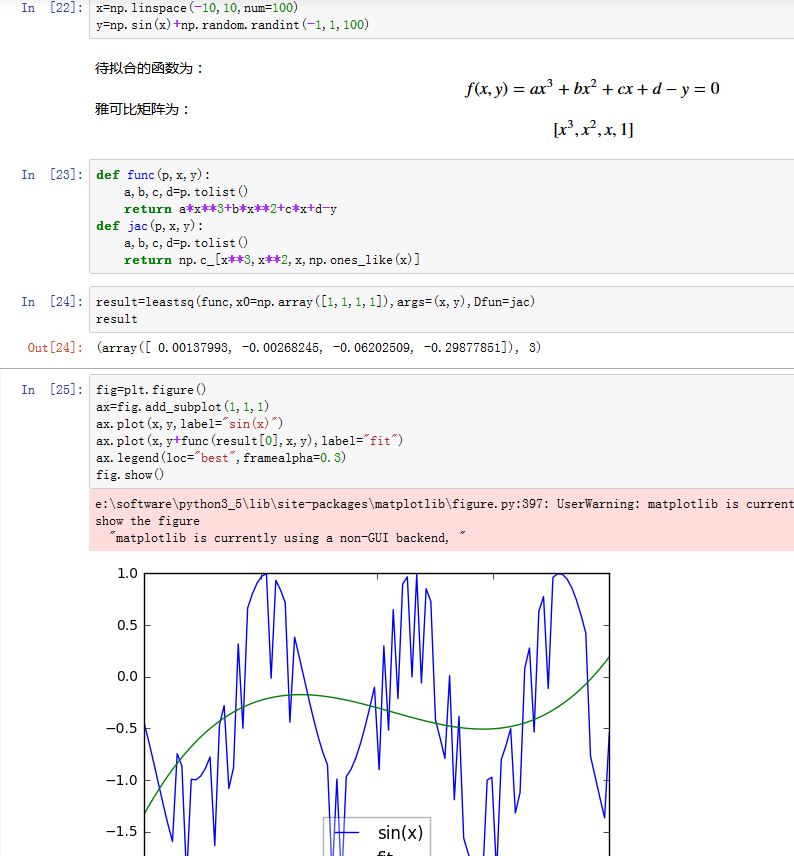
scipy提供了另一个函数来执行最小二乘法的曲线拟合:xxxxxxxxxxscipy.optimize.curve_fit(f, xdata, ydata, p0=None, sigma=None, absolute_sigma=False,check_finite=True, bounds=(-inf, inf), method=None, **kwargs)f:可调用函数,它的优化参数被直接传入。其第一个参数一定是xdata,后面的参数是待优化参数xdata:x坐标ydata:y坐标p0:初始迭代值sigma:y值的不确定性的度量absolute_sigma: If False, sigma denotes relative weights of the data points. The returned covariance matrix pcov is based on estimated errors in the data, and is not affected by the overall magnitude of the values in sigma. Only the relative magnitudes of the sigma values matter.If True, sigma describes one standard deviation errors of the input data points. The estimated covariance in pcov is based on these values.check_finite:如果为True,则检测输入中是否有nan或者infbounds:指定变量的取值范围method:指定求解算法。可以为'lm'/'trf'/'dogbox'kwargs:传递给leastsq/least_squares的关键字参数。
返回值:
popt:最优化参数pcov:The estimated covariance of popt.
假设我们拟合的函数是 ,其中 为参数。假设数据点的横坐标为 ,纵坐标为 ,那么我们可以给出
func为:xxxxxxxxxxdef func(x,a,b,c):return f(x;a,b,c)#x 为数组,形状为 (N,)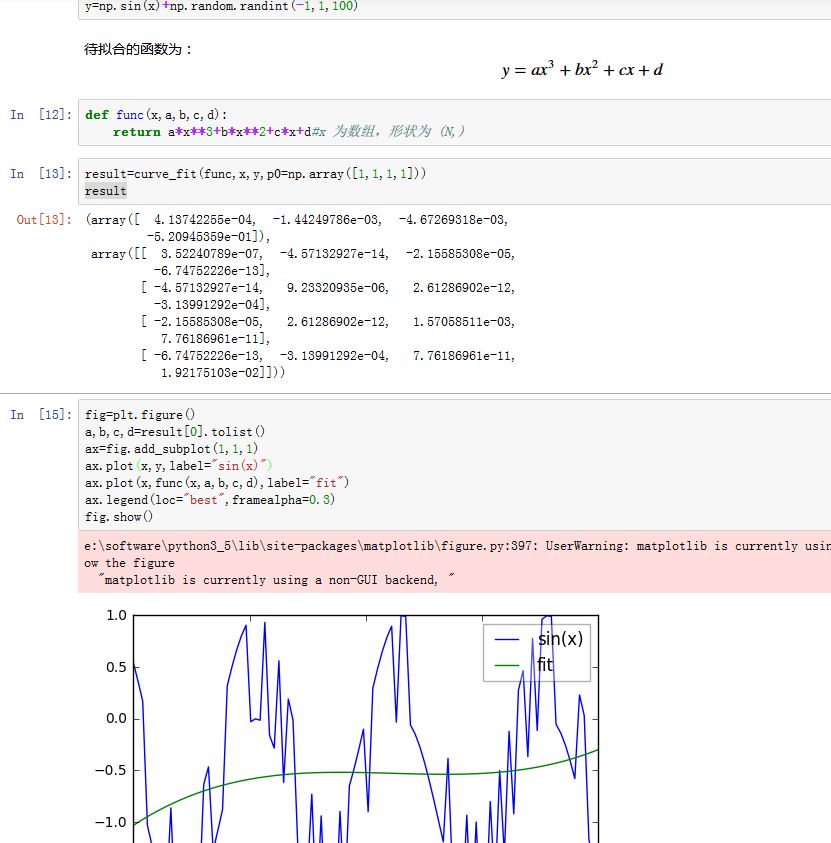
求函数最小值:
xxxxxxxxxxscipy.optimize.minimize(fun, x0, args=(), method=None, jac=None, hess=None,hessp=None, bounds=None, constraints=(), tol=None, callback=None, options=None)fun:可调用对象,待优化的函数。最开始的参数是待优化的自变量;后面的参数由args给出x0:自变量的初始迭代值args:一个元组,提供给fun的额外的参数method:一个字符串,指定了最优化算法。可以为:'Nelder-Mead'、'Powell'、'CG'、'BFGS'、'Newton-CG'、'L-BFGS-B'、'TNC'、'COBYLA'、'SLSQP'、'dogleg'、'trust-ncg'jac:一个可调用对象(最开始的参数是待优化的自变量;后面的参数由args给出),雅可比矩阵。只在CG/BFGS/Newton-CG/L-BFGS-B/TNC/SLSQP/dogleg/trust-ncg算法中需要。如果jac是个布尔值且为True,则会假设fun会返回梯度;如果是个布尔值且为False,则雅可比矩阵会被自动推断(根据数值插值)。hess/hessp:可调用对象(最开始的参数是待优化的自变量;后面的参数由args给出),海森矩阵。只有Newton-CG/dogleg/trust-ncg算法中需要。二者只需要给出一个就可以,如果给出了hess,则忽略hessp。如果二者都未提供,则海森矩阵自动推断bounds:一个元组的序列,给定了每个自变量的取值范围。如果某个方向不限,则指定为None。每个范围都是一个(min,max)元组。constrants:一个字典或者字典的序列,给出了约束条件。只在COBYLA/SLSQP中使用。字典的键为:type:给出了约束类型。如'eq'代表相等;'ineq'代表不等fun:给出了约束函数jac:给出了约束函数的雅可比矩阵(只用于SLSQP)args:一个序列,给出了传递给fun和jac的额外的参数
tol:指定收敛阈值options:一个字典,指定额外的条件。键为:maxiter:一个整数,指定最大迭代次数disp:一个布尔值。如果为True,则打印收敛信息
callback:一个可调用对象,用于在每次迭代之后调用。调用参数为x_k,其中x_k为当前的参数向量
返回值:返回一个
OptimizeResult对象。其重要属性为:x:最优解向量success:一个布尔值,表示是否优化成功message:描述了迭代终止的原因
假设我们要求解最小值的函数为: ,则雅可比矩阵为:
则海森矩阵为:
于是有:
xxxxxxxxxxdef fun(p):x,y=p.tolist()#p 为数组,形状为 (2,)return f(x,y)def jac(p):x,y=p.tolist()#p 为数组,形状为 (2,)return np.array([df/dx,df/dy])def hess(p):x,y=p.tolist()#p 为数组,形状为 (2,)return np.array([[ddf/dxx,ddf/dxdy],[ddf/dydx,ddf/dyy]])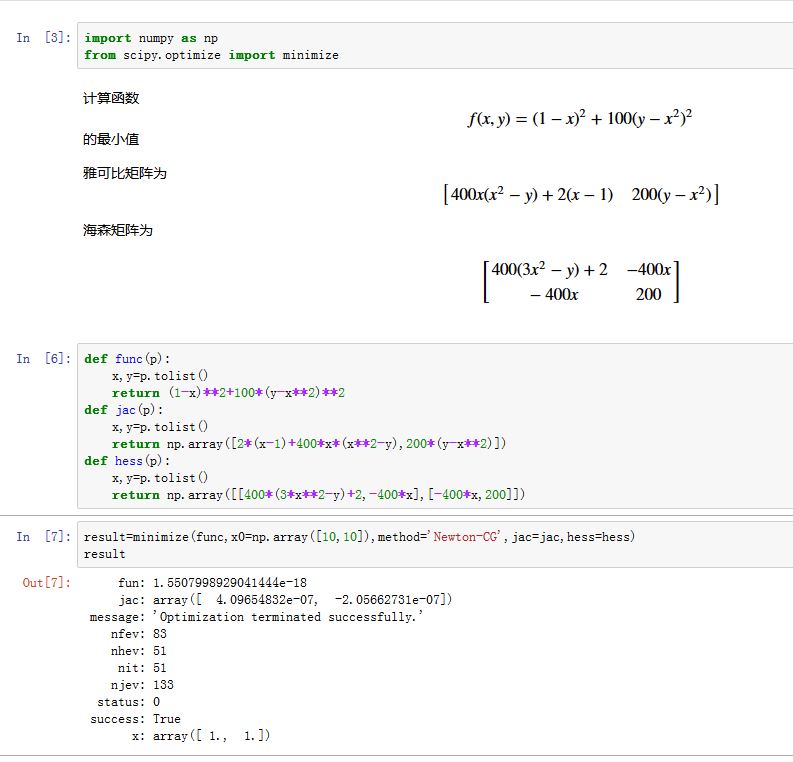
常规的最优化算法很容易陷入局部极值点。
basinhopping算法是一个寻找全局最优点的算法。xxxxxxxxxxscipy.optimize.basinhopping(func, x0, niter=100, T=1.0, stepsize=0.5,minimizer_kwargs=None,take_step=None, accept_test=None, callback=None,interval=50, disp=False, niter_success=None)func:可调用函数。为待优化的目标函数。最开始的参数是待优化的自变量;后面的参数由minimizer_kwargs字典给出x0:一个向量,设定迭代的初始值niter:一个整数,指定迭代次数T:一个浮点数,设定了“温度”参数。stepsize:一个浮点数,指定了步长minimizer_kwargs:一个字典,给出了传递给scipy.optimize.minimize的额外的关键字参数。take_step:一个可调用对象,给出了游走策略accept_step:一个可调用对象,用于判断是否接受这一步callback:一个可调用对象,每当有一个极值点找到时,被调用interval:一个整数,指定stepsize被更新的频率disp:一个布尔值,如果为True,则打印状态信息niter_success:一个整数。Stop the run if the global minimum candidate remains the same for this number of iterations.
返回值:一个
OptimizeResult对象。其重要属性为:x:最优解向量success:一个布尔值,表示是否优化成功message:描述了迭代终止的原因
假设我们要求解最小值的函数为: ,于是有:
xxxxxxxxxxdef fun(p):x,y=p.tolist()#p 为数组,形状为 (2,)return f(x,y)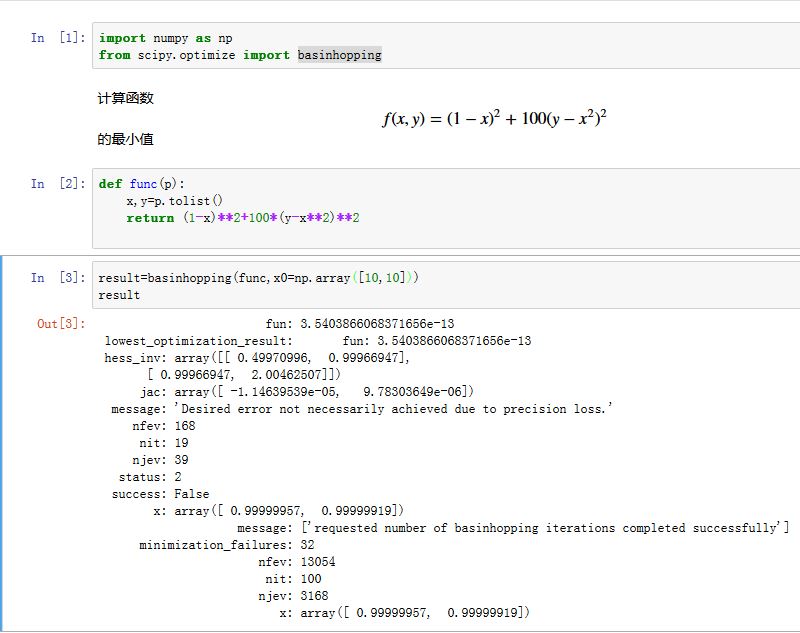
三、线性代数
numpy和scipy都提供了线性代数函数库linalg。但是scipy的线性代数库比numpy更加全面。numpy中的求解线性方程组:numpy.linalg.solve(a, b)。而scipy中的求解线性方程组:xxxxxxxxxxscipy.linalg.solve(a, b, sym_pos=False, lower=False, overwrite_a=False,overwrite_b=False, debug=False, check_finite=True)a:方阵,形状为(M,M)b:一维向量,形状为(M,)。它求解的是线性方程组 。如果有 个线性方程组要求解,且a,相同,则b的形状为(M,k)sym_pos:一个布尔值,指定a是否正定的对称矩阵lower:一个布尔值。如果sym_pos=True时:如果为lower=True,则使用a的下三角矩阵。默认使用a的上三角矩阵。overwrite_a:一个布尔值,指定是否将结果写到a的存储区。overwrite_b:一个布尔值,指定是否将结果写到b的存储区。check_finite:如果为True,则检测输入中是否有nan或者inf
返回线性方程组的解。
通常求解矩阵 ,如果使用
solve(A,B),要比先求逆矩阵、再矩阵相乘来的快。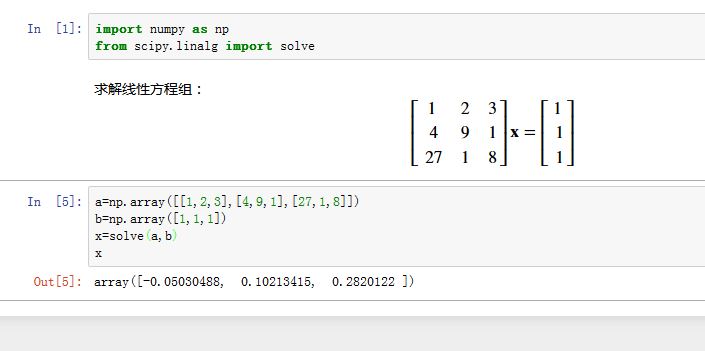
矩阵的
LU分解:xxxxxxxxxxscipy.linalg.lu_factor(a, overwrite_a=False, check_finite=True)a:方阵,形状为(M,M),要求非奇异矩阵overwrite_a:一个布尔值,指定是否将结果写到a的存储区。check_finite:如果为True,则检测输入中是否有nan或者inf
返回:
lu:一个数组,形状为(N,N),该矩阵的上三角矩阵就是U,下三角矩阵就是L(L矩阵的对角线元素并未存储,因为它们全部是1)piv:一个数组,形状为(N,)。它给出了P矩阵:矩阵a的第i行被交换到了第piv[i]行
矩阵
LU分解:其中: 为转置矩阵,该矩阵任意一行只有一个1,其他全零;任意一列只有一个1,其他全零。 为单位下三角矩阵(对角线元素为1), 为上三角矩阵(对角线元素为0)
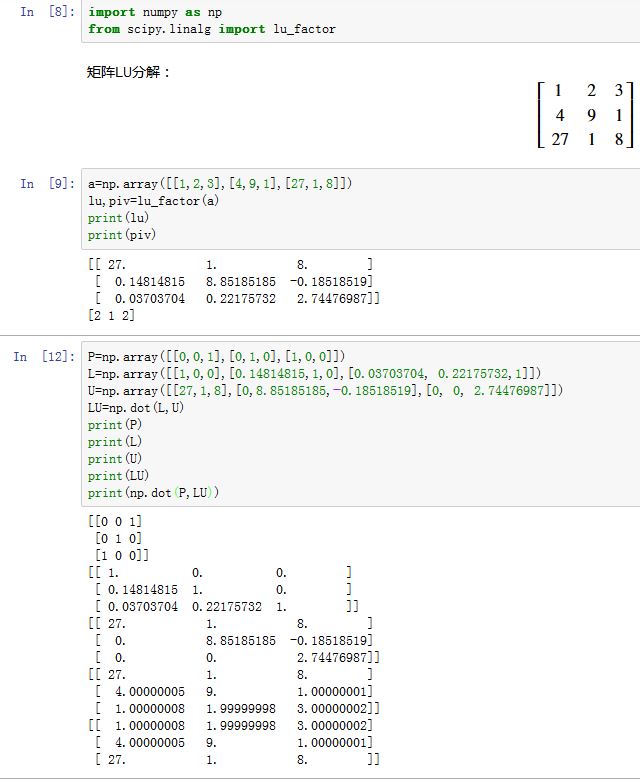
当对矩阵进行了
LU分解之后,可以方便的求解线性方程组。xxxxxxxxxxscipy.linalg.lu_solve(lu_and_piv, b, trans=0, overwrite_b=False, check_finite=True)lu_and_piv:一个元组,由lu_factor返回b:一维向量,形状为(M,)。它求解的是线性方程组 。如果有 个线性方程组要求解,且a,相同,则b的形状为(M,k)overwrite_b:一个布尔值,指定是否将结果写到b的存储区。check_finite:如果为True,则检测输入中是否有nan或者inftrans:指定求解类型.- 如果为 0 ,则求解:
- 如果为 1 ,则求解:
- 如果为 2 ,则求解:
lstsq比solve更一般化,它不要求矩阵 是方阵。 它找到一组解 ,使得 最小,我们称得到的结果为最小二乘解。xxxxxxxxxxscipy.linalg.lstsq(a, b, cond=None, overwrite_a=False, overwrite_b=False,check_finite=True, lapack_driver=None)a:为矩阵,形状为(M,N)b:一维向量,形状为(M,)。它求解的是线性方程组 。如果有 个线性方程组要求解,且a,相同,则b的形状为(M,k)cond:一个浮点数,去掉最小的一些特征值。当特征值小于cond * largest_singular_value时,该特征值认为是零overwrite_a:一个布尔值,指定是否将结果写到a的存储区。overwrite_b:一个布尔值,指定是否将结果写到b的存储区。check_finite:如果为True,则检测输入中是否有nan或者inflapack_driver:一个字符串,指定求解算法。可以为:'gelsd'/'gelsy'/'gelss'。默认的'gelsd'效果就很好,但是在许多问题上'gelsy'效果更好。
返回值:
x:最小二乘解,形状和b相同residures:残差。如果 大于N或者小于M,或者使用了gelsy,则是个空数组;如果b是一维的,则它的形状是(1,);如果b是二维的,则形状为(K,)rank:返回矩阵a的秩s:a的奇异值。如果使用gelsy,则返回None
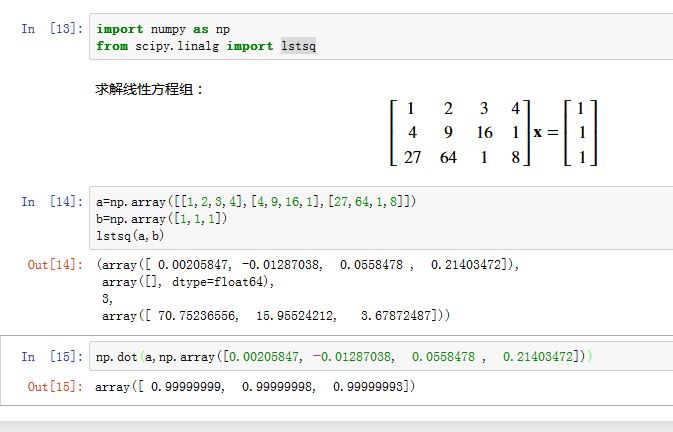
求解特征值和特征向量:
xxxxxxxxxxscipy.linalg.eig(a, b=None, left=False, right=True, overwrite_a=False,overwrite_b=False, check_finite=True)a:一个方阵,形状为(M,M)。待求解特征值和特征向量的矩阵。b:默认为None,表示求解标准的特征值问题: 。 也可以是一个形状与a相同的方阵,此时表示广义特征值问题:left:一个布尔值。如果为True,则计算左特征向量right:一个布尔值。如果为True,则计算右特征向量overwrite_a:一个布尔值,指定是否将结果写到a的存储区。overwrite_b:一个布尔值,指定是否将结果写到b的存储区。check_finite:如果为True,则检测输入中是否有nan或者inf
返回值:
w:一个一维数组,代表了M特特征值。vl:一个数组,形状为(M,M),表示正则化的左特征向量(每个特征向量占据一列,而不是一行)。仅当left=True时返回vr:一个数组,形状为(M,M),表示正则化的右特征向量(每个特征向量占据一列,而不是一行)。仅当right=True时返回
numpy提供了numpy.linalg.eig(a)来计算特征值和特征向量右特征值: ;左特征值: ,其中 为特征值的共轭。
令 ,令
则有:
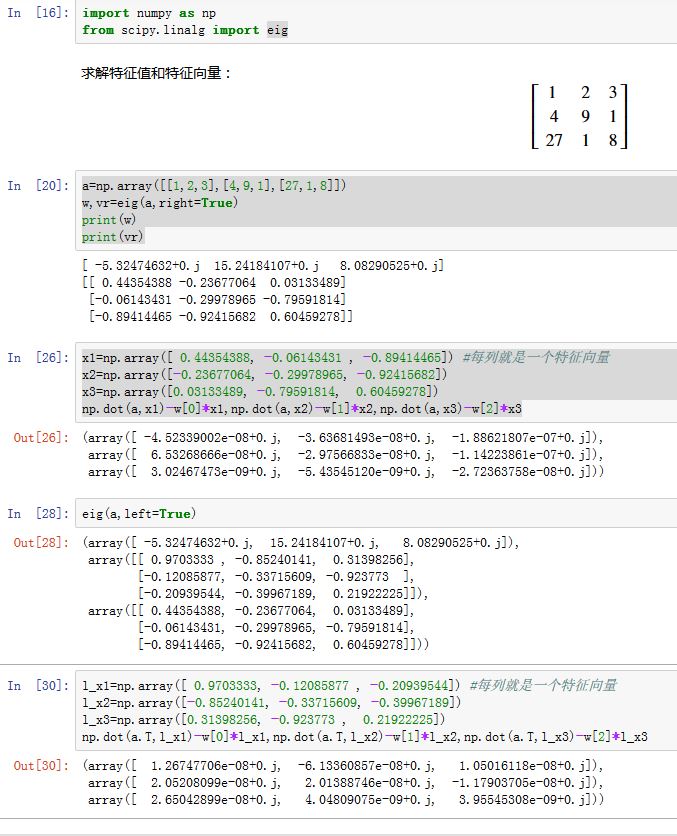
矩阵的奇异值分解: 设矩阵 为 阶的矩阵,则存在一个分解,使得: ,其中 为 阶酉矩阵; 为半正定的 阶的对焦矩阵; 而 为 阶酉矩阵。
对角线上的元素为 的奇异值,通常按照从大到小排列。
xxxxxxxxxxscipy.linalg.svd(a, full_matrices=True, compute_uv=True, overwrite_a=False,check_finite=True, lapack_driver='gesdd')a:一个矩阵,形状为(M,N),待分解的矩阵。full_matrices:如果为True,则 的形状为(M,M)、 的形状为(N,N);否则 的形状为(M,K)、 的形状为(K,N),其中K=min(M,N)compute_uv:如果True,则结果中额外返回U以及Vh;否则只返回奇异值overwrite_a:一个布尔值,指定是否将结果写到a的存储区。overwrite_b:一个布尔值,指定是否将结果写到b的存储区。check_finite:如果为True,则检测输入中是否有nan或者inflapack_driver:一个字符串,指定求解算法。可以为:'gesdd'/'gesvd'。默认的'gesdd'。
返回值:
U: 矩阵s:奇异值,它是一个一维数组,按照降序排列。长度为K=min(M,N)Vh:就是 矩阵
判断两个数组是否近似相等
np.allclose(a1,a2)(主要是浮点数的精度问题)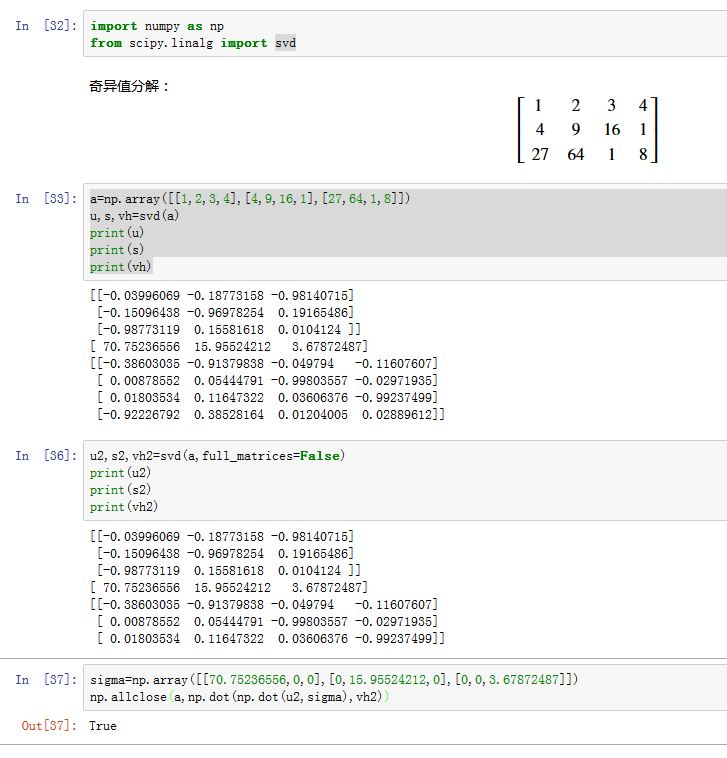
四、 统计
scipy中的stats模块中包含了很多概率分布的随机变量- 所有的连续随机变量都是
rv_continuous的派生类的对象 - 所有的离散随机变量都是
rv_discrete的派生类的对象
- 所有的连续随机变量都是
1. 连续随机变量
查看所有的连续随机变量:
xxxxxxxxxx[k for k,v in stats.__dict__.items() if isinstance(v,stats.rv_continuous)]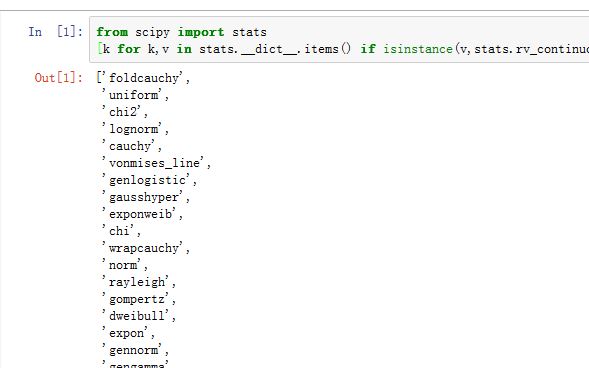
连续随机变量对象都有如下方法:
rvs(*args, **kwds):获取该分布的一个或者一组随机值pdf(x, *args, **kwds):概率密度函数在x处的取值logpdf(x, *args, **kwds):概率密度函数在x处的对数值cdf(x, *args, **kwds):累积分布函数在x处的取值logcdf(x, *args, **kwds):累积分布函数在x处的对数值sf(x, *args, **kwds):生存函数在x处的取值,它等于1-cdf(x)logsf(x, *args, **kwds):生存函数在x处的对数值ppf(q, *args, **kwds):累积分布函数的反函数isf(q, *args, **kwds) :生存函数的反函数moment(n, *args, **kwds)n-th order non-central moment of distribution.stats(*args, **kwds):计算随机变量的期望值和方差值等统计量entropy(*args, **kwds):随机变量的微分熵expect([func, args, loc, scale, lb, ub, ...]):计算 的期望值median(*args, **kwds):计算该分布的中值mean(*args, **kwds):计算该分布的均值std(*args, **kwds):计算该分布的标准差var(*args, **kwds):计算该分布的方差interval(alpha, *args, **kwds):Confidence interval with equal areas around the median.__call__(*args, **kwds):产生一个参数冻结的随机变量fit(data, *args, **kwds):对一组随机取样进行拟合,找出最适合取样数据的概率密度函数的系数fit_loc_scale(data, *args):Estimate loc and scale parameters from data using 1st and 2nd moments.nnlf(theta, x):返回负的似然函数
其中的
args/kwds参数可能为(具体函数具体分析):arg1, arg2, arg3,...: array_like.The shape parameter(s) for the distributionloc: array_like.location parameter (default=0)scale: array_like.scale parameter (default=1)size: int or tuple of ints.Defining number of random variates (default is 1).random_state: None or int or np.random.RandomState instance。If int or RandomState, use it for drawing the random variates. If None, rely on self.random_state. Default is None.
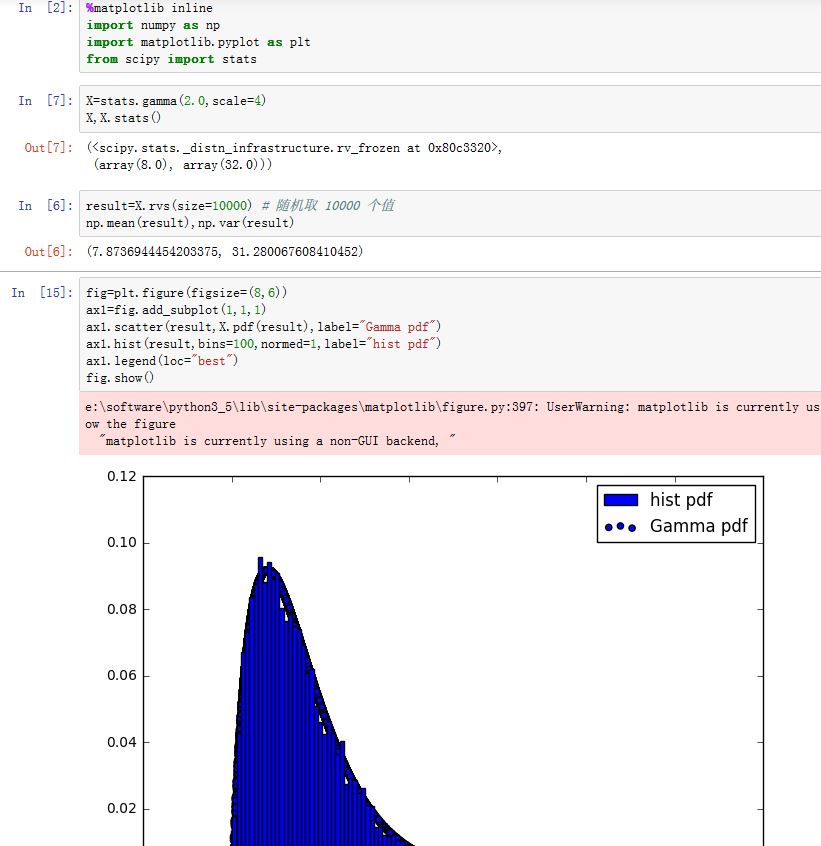
这些连续随机变量可以像函数一样调用,通过
loc和scale参数可以指定随机变量的偏移和缩放系数。- 对于正态分布的随机变量而言,这就是期望值和标准差
2. 离散随机变量
查看所有的连续随机变量:
xxxxxxxxxx[k for k,v in stats.__dict__.items() if isinstance(v,stats.rv_discrete)]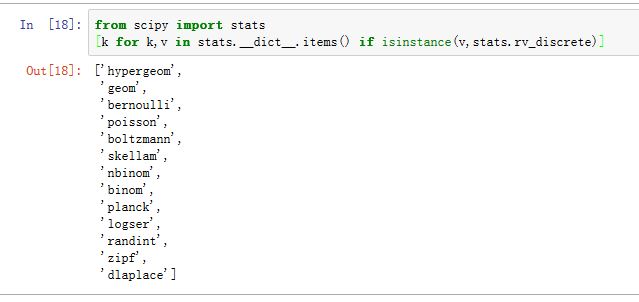
离散随机变量对象都有如下方法:
rvs(<shape(s)>, loc=0, size=1):生成随机值pmf(x, <shape(s)>, loc=0):概率密度函数在x处的值logpmf(x, <shape(s)>, loc=0):概率密度函数在x处的对数值cdf(x, <shape(s)>, loc=0):累积分布函数在x处的取值logcdf(x, <shape(s)>, loc=0):累积分布函数在x处的对数值sf(x, <shape(s)>, loc=0):生存函数在x处的值logsf(x, <shape(s)>, loc=0, scale=1):生存函数在x处的对数值ppf(q, <shape(s)>, loc=0):累积分布函数的反函数isf(q, <shape(s)>, loc=0):生存函数的反函数moment(n, <shape(s)>, loc=0):non-central n-th moment of the distribution. May not work for array arguments.stats(<shape(s)>, loc=0, moments='mv'):计算期望方差等统计量entropy(<shape(s)>, loc=0):计算熵expect(func=None, args=(), loc=0, lb=None, ub=None, conditional=False):Expected value of a function with respect to the distribution. Additional kwd arguments passed to integrate.quadmedian(<shape(s)>, loc=0):计算该分布的中值mean(<shape(s)>, loc=0):计算该分布的均值std(<shape(s)>, loc=0):计算该分布的标准差var(<shape(s)>, loc=0):计算该分布的方差interval(alpha, <shape(s)>, loc=0)Interval that with alpha percent probability contains a random realization of this distribution.__call__(<shape(s)>, loc=0):产生一个参数冻结的随机变量
我们也可以通过
rv_discrete类自定义离散概率分布:xxxxxxxxxxx=range(1,7)p=(0.1,0.3,0.1,0.3,0.1,0.1)stats.rv_discrete(values=(x,p))只需要传入一个
values关键字参数,它是一个元组。元组的第一个成员给出了随机变量的取值集合,第二个成员给出了随机变量每一个取值的概率
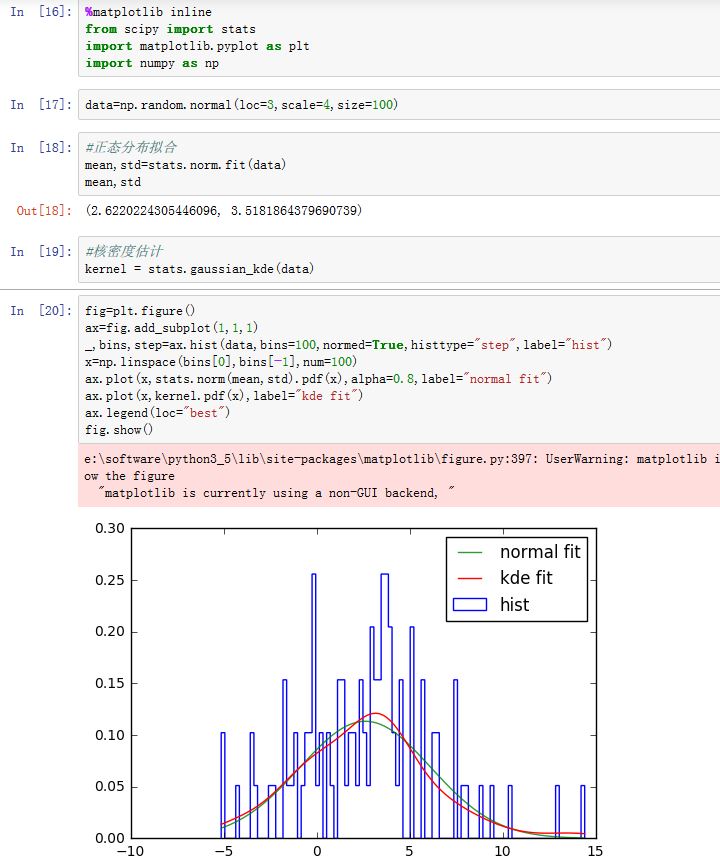
3. 核密度估计
通常我们可以用直方图来观察随机变量的概率密度。但是直方图有个缺点:你选取的直方图区间宽度不同,直方图的形状也发生变化。核密度估计就能很好地解决这一问题。
核密度估计的思想是:对于随机变量的每一个采样点 ,我们认为它代表一个以该点为均值、 为方差的一个正态分布的密度函数 。将所有这些采样点代表的密度函数叠加并归一化,则得到了核密度估计的一个概率密度函数:
其中:
- 归一化操作就是 ,因为每个点代表的密度函数的积分都是 1
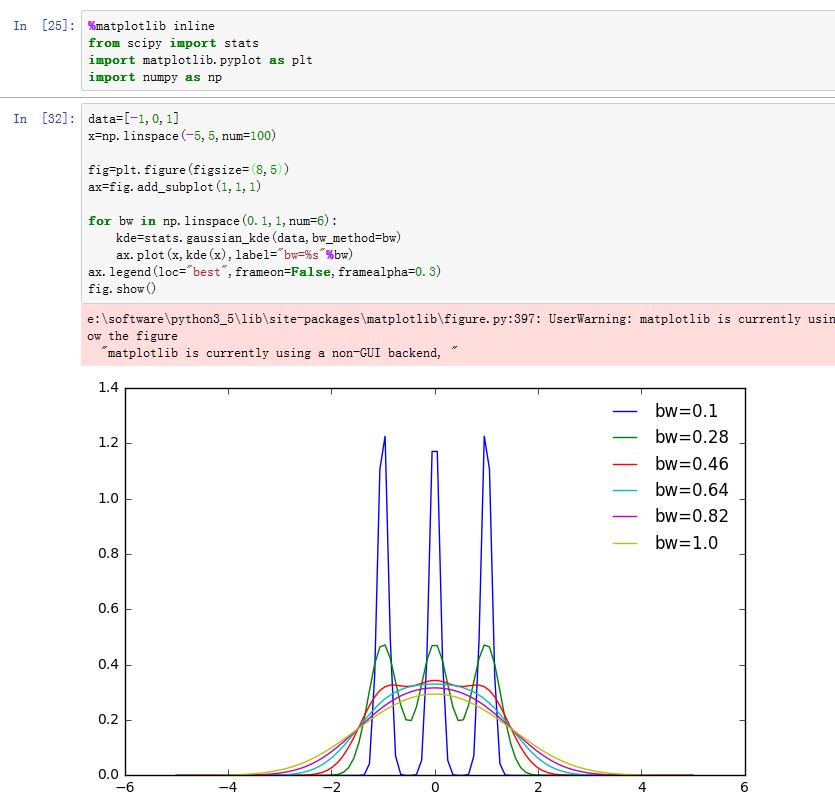
- 就是带宽参数,它代表了每个正态分布的形状
如果采用其他的分布而不是正态分布,则得到了其他分布的核密度估计。
核密度估计的原理是:如果某个样本点出现了,则它发生的概率就很高,同时跟他接近的样本点发生的概率也比较高。
正态核密度估计:
xxxxxxxxxxclass scipy.stats.gaussian_kde(dataset, bw_method=None)参数:
dataset:被估计的数据集。bw_method:用于设定带宽 。可以为:- 字符串:如
'scott'/'silverman'。默认为'scott' - 一个标量值。此时带宽是个常数
- 一个可调用对象。该可调用对象的参数是
gaussian_kde,返回一个标量值
- 字符串:如
属性:
dataset:被估计的数据集d:数据集的维度n:数据点的个数factor:带宽covariance:数据集的相关矩阵
方法:
evaluate(points):估计样本点的概率密度__call__(points):估计样本点的概率密度pdf(x):估计样本的概率密度
带宽系数对核密度估计的影响:当带宽系数越大,核密度估计曲线越平滑。
4. 常见分布
二项分布:假设试验只有两种结果:成功的概率为 ,失败的概率为 。 则二项分布描述了独立重复地进行 次试验中,成功 次的概率。
概率质量函数:
期望:
方差:
scipy.stats.binom使用n参数指定 ;p参数指定 ;loc参数指定平移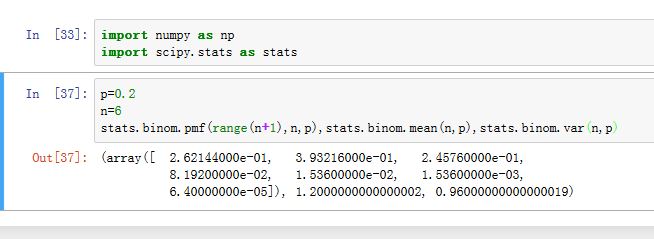
泊松分布:泊松分布使用 描述单位时间(或者单位面积)中随机事件发生的平均次数(只知道平均次数,具体次数是个随机变量)。
概率质量函数:
其物理意义是:单位时间内事件发生 次的概率
期望:
方差:
在二项分布中,如果 很大,而 很小。乘积 可以视作 ,此时二项分布近似于泊松分布。
泊松分布用于描述单位时间内随机事件发生的次数的分布的情况。
scipy.stats.poisson使用mu参数来给定 ,使用loc参数来平移。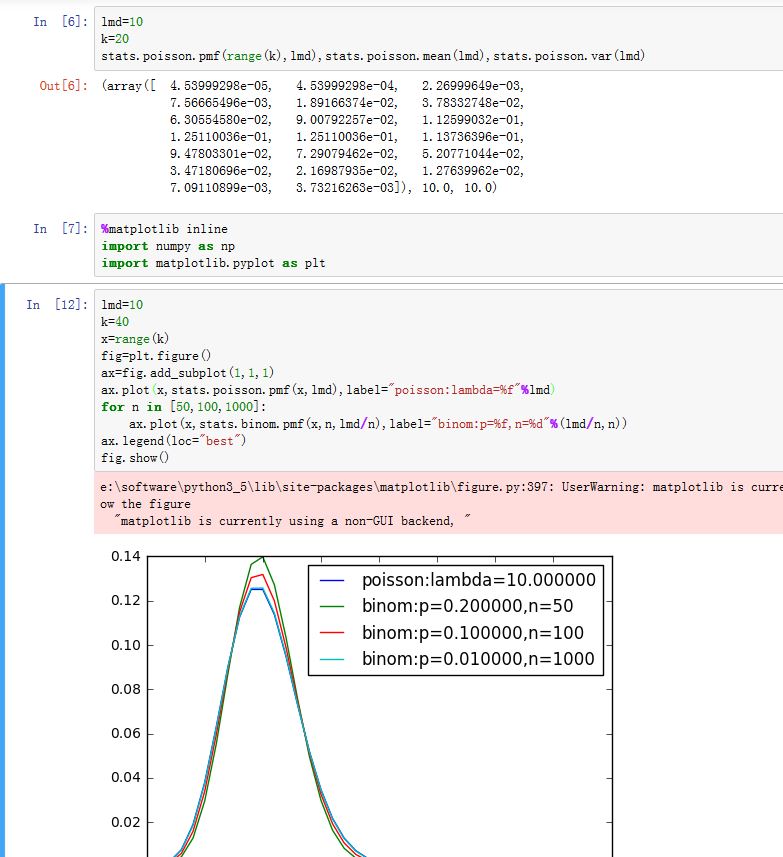
用均匀分布模拟泊松分布:
xxxxxxxxxxdef make_poisson(lmd,tm):'''用均匀分布模拟泊松分布。 lmd为 lambda 参数; tm 为时间'''t=np.random.uniform(0,tm,size=lmd*tm) # 获取 lmd*tm 个事件发生的时刻count,tm_edges=np.histogram(t,bins=tm,range=(0,tm))#获取每个单位时间内,事件发生的次数max_k= lmd *2 # 要统计的最大次数dist,count_edges=np.histogram(count,bins=max_k,range=(0,max_k),density=True)x=count_edges[:-1]return x,dist,stats.poisson.pmf(x,lmd)该函数首先随机性给出了
lmd*tm个事件发生的时间(时间位于区间[0,tm])内。然后统计每个单位时间区间内,事件发生的次数。然后统计这些次数出现的频率。最后将这个频率与理论上的泊松分布的概率质量函数比较。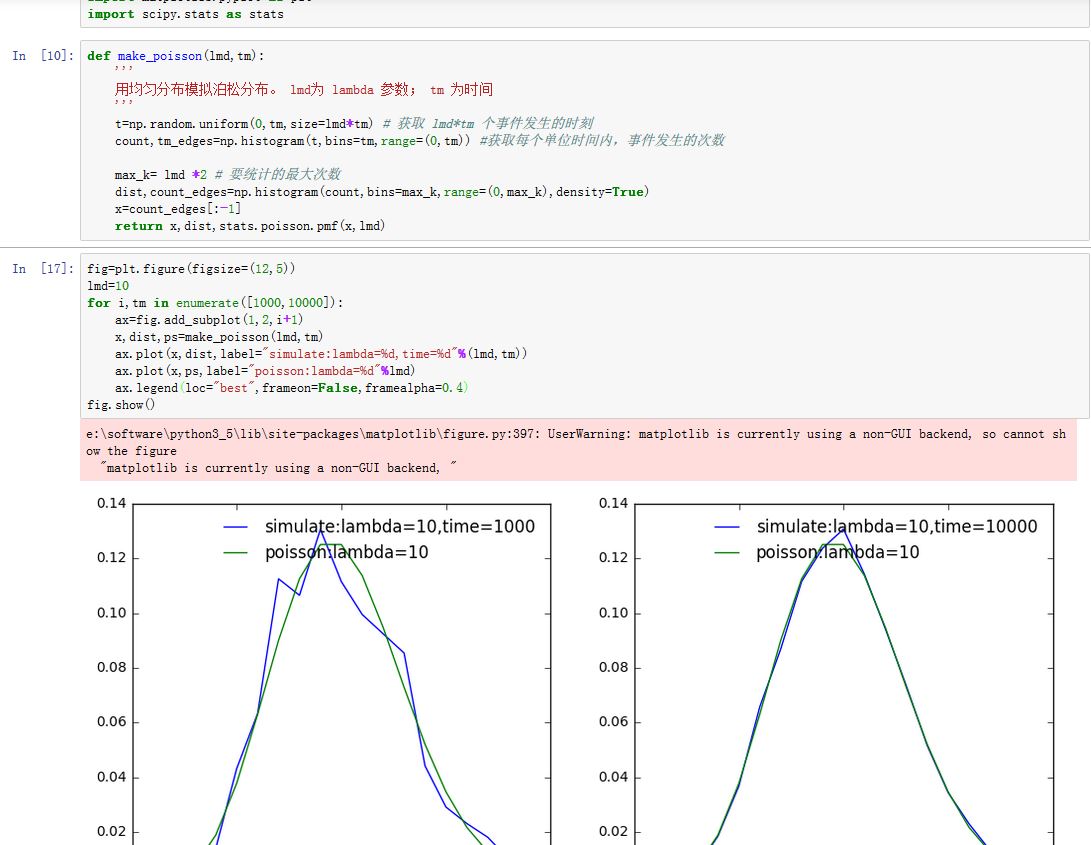
指数分布:若事件服从泊松分布,则该事件前后两次发生的时间间隔服从指数分布。由于时间间隔是个浮点数,因此指数分布是连续分布。
- 概率密度函数:, 为时间间隔
- 期望:
- 方差:
在
scipy.stats.expon中,scale参数为 ;而loc用于对函数平移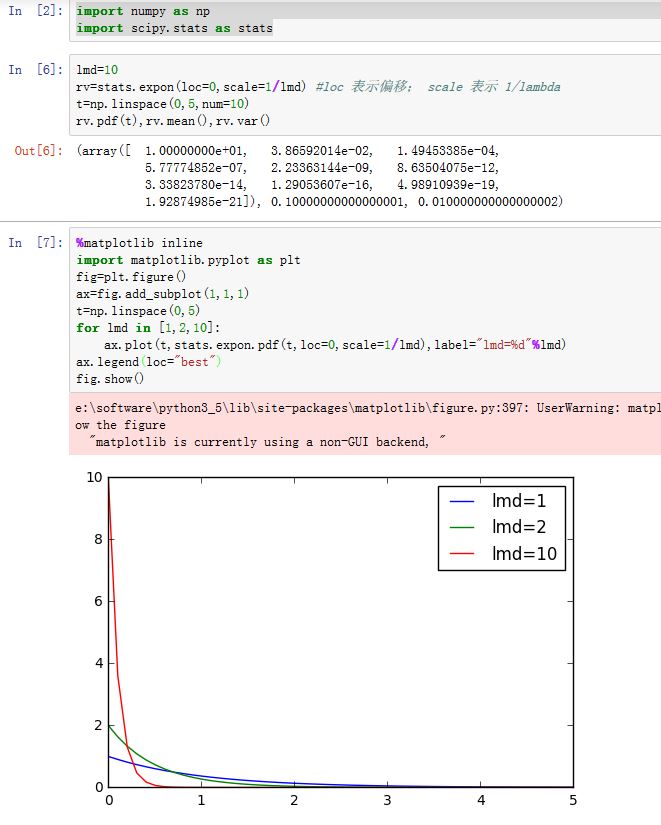
用均匀分布模拟指数分布:
xxxxxxxxxxdef make_expon(lmd,tm):'''用均匀分布模拟指数分布。 lmd为 lambda 参数; tm 为时间'''t=np.random.uniform(0,tm,size=lmd*tm) # 获取 lmd*tm 个事件发生的时刻sorted_t=np.sort(t) #时刻升序排列delt_t=sorted_t[1:]-sorted_t[:-1] #间隔序列dist,edges=np.histogram(delt_t,bins="auto",density=True)x=edges[:-1]return x,dist,stats.expon.pdf(x,loc=0,scale=1/lmd) #scale 为 1/lambda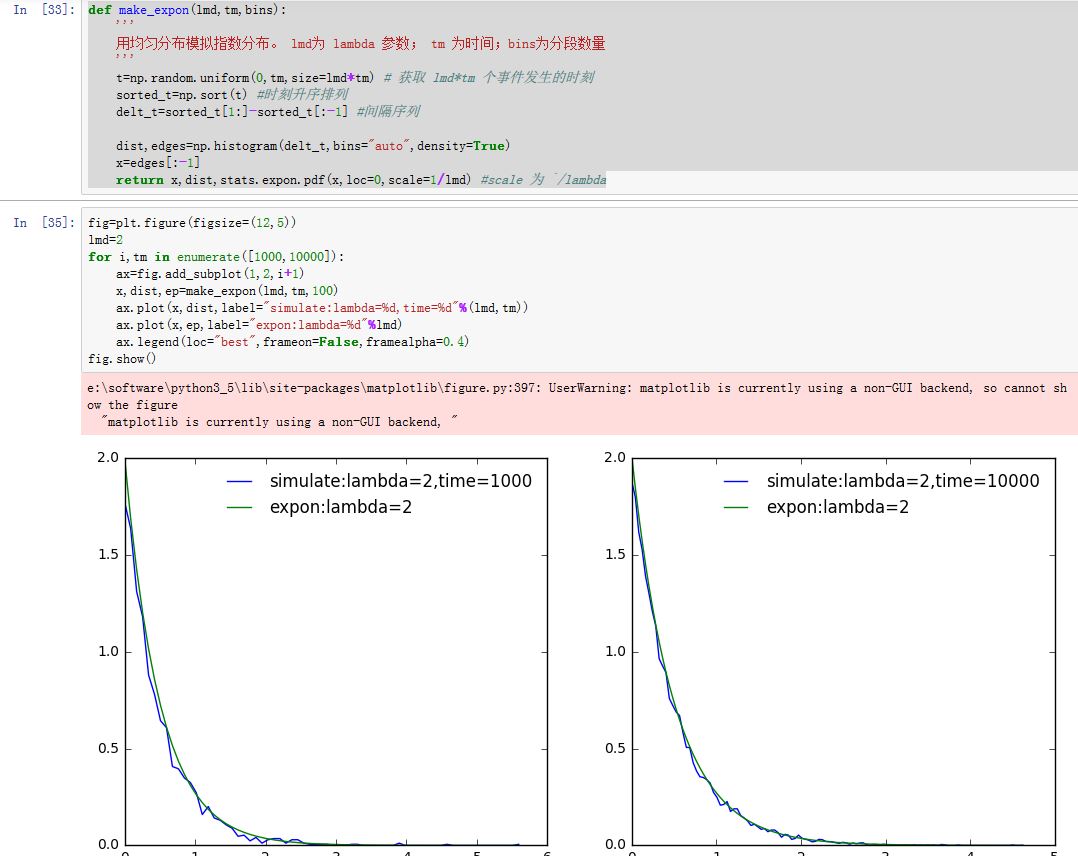
伽玛分布:若事件服从泊松分布,则事件第 次发生和第 次发生的时间间隔为伽玛分布。由于时间间隔是个浮点数,因此指数分布是连续分布。
- 概率密度函数:, 为时间间隔
- 期望:
- 方差:
在
scipy.stats.gamma中,scale参数为 ;而loc用于对函数平移,参数a指定了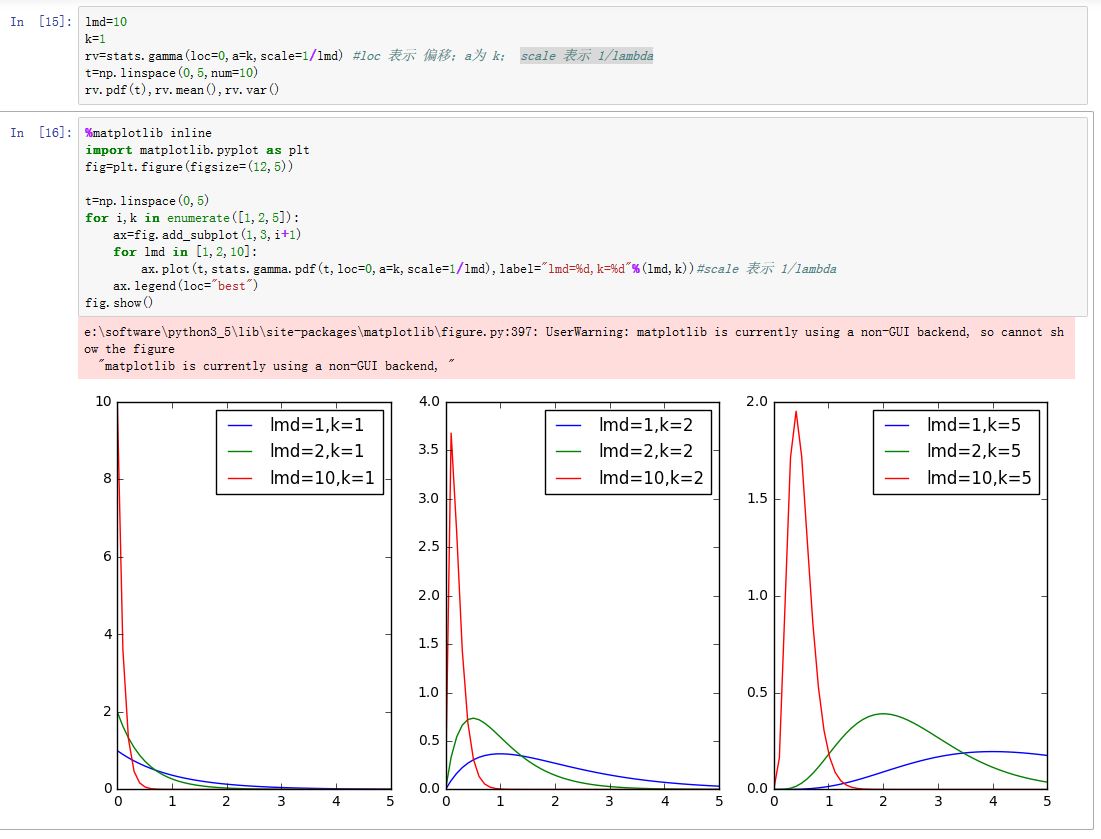
用均匀分布模拟伽玛分布:
xxxxxxxxxxdef make_gamma(lmd,tm,k):'''用均匀分布模拟伽玛分布。 lmd为 lambda 参数; tm 为时间;k 为 k 参数'''t=np.random.uniform(0,tm,size=lmd*tm) # 获取 lmd*tm 个事件发生的时刻sorted_t=np.sort(t) #时刻升序排列delt_t=sorted_t[k:]-sorted_t[:-k] #间隔序列dist,edges=np.histogram(delt_t,bins="auto",density=True)x=edges[:-1]return x,dist,stats.gamma.pdf(x,loc=0,scale=1/lmd,a=k) #scale 为 1/lambda,a 为 k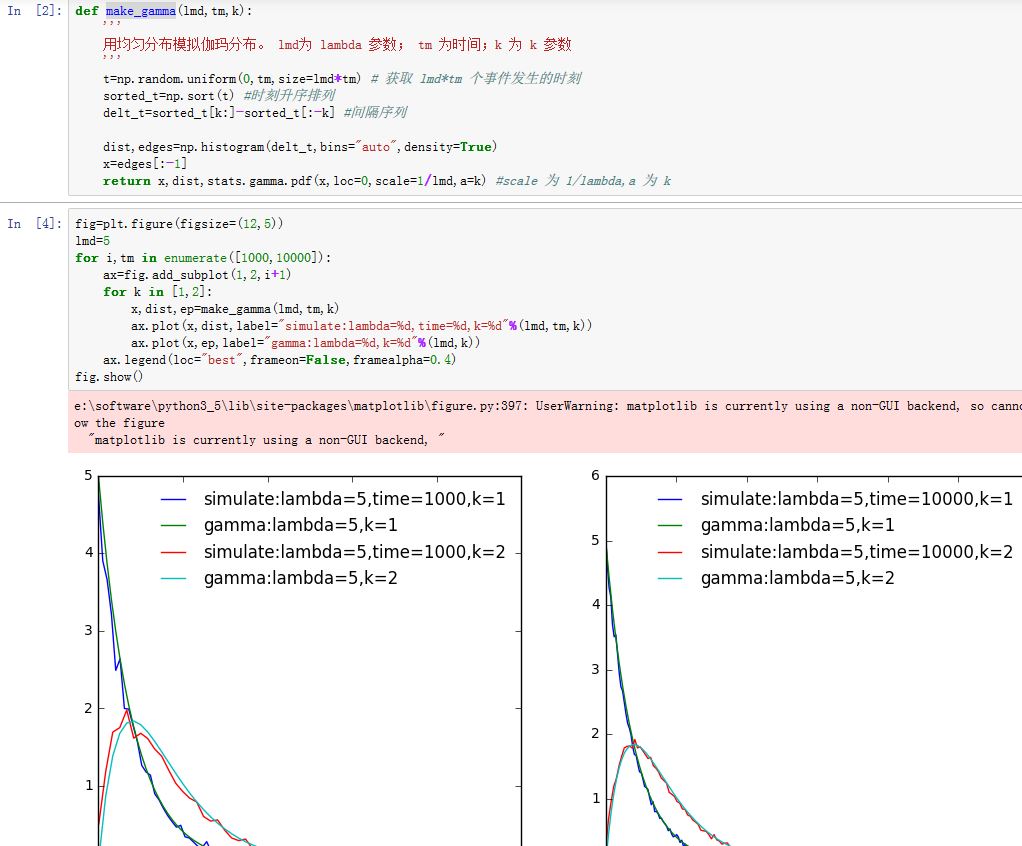
五、数值积分
scipy的integrate模块提供了集中数值积分算法,其中包括对常微分方程组ODE的数值积分。
1. 积分
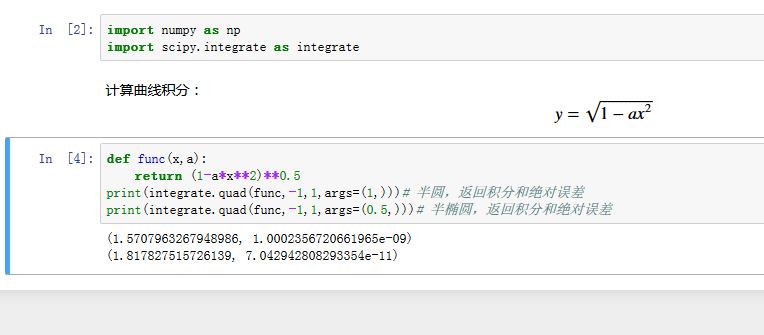
数值积分函数:
xxxxxxxxxxscipy.integrate.quad(func, a, b, args=(), full_output=0, epsabs=1.49e-08,epsrel=1.49e-08, limit=50, points=None, weight=None, wvar=None,wopts=None, maxp1=50, limlst=50)func:一个Python函数对象,代表被积分的函数。如果它带有多个参数,则积分只在第一个参数上进行。其他参数,则由args提供a:积分下限。用-numpy.inf代表负无穷b:积分上限。用numpy.inf代表正无穷args:额外传递的参数给funcfull_output:如果非零,则通过字典返回更多的信息- 其他参数控制了积分的细节。参考官方手册
返回值:
y:一个浮点标量值,表示积分结果abserr:一个浮点数,表示绝对误差的估计值infodict:一个字典,包含额外的信息
多重定积分可以通过多次调用
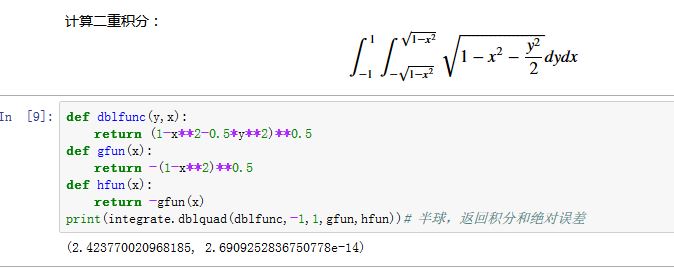
quad()实现。为了调用方便,integrate模块提供了dblquad()计算二重定积分,提供了tplquad()计算三重定积分。二重定积分:
xxxxxxxxxxscipy.integrate.dblquad(func, a, b, gfun, hfun, args=(),epsabs=1.49e-08, epsrel=1.49e-08)func:一个Python函数对象,代表被积分的函数。它至少有两个参数:y和x。其中y为第一个参数,x为第二个参数。这两个参数为积分参数。如果有其他参数,则由args提供a:x的积分下限。用-numpy.inf代表负无穷b:x的积分上限。用numpy.inf代表正无穷gfun:y的下边界曲线。它是一个函数或者lambda表达式,参数为x,返回一个浮点数。hfun:y的上界曲线。它是一个函数或者lambda表达式,参数为x,返回一个浮点数。args:额外传递的参数给funcepsabs:传递给quadepsrel:传递给quad
返回值:
y:一个浮点标量值,表示积分结果abserr:一个浮点数,表示绝对误差的估计值
三重定积分:
xxxxxxxxxxscipy.integrate.tplquad(func, a, b, gfun, hfun, qfun, rfun, args=(),epsabs=1.49e-08, epsrel=1.49e-08)func:一个Python函数对象,代表被积分的函数。它至少有三个参数:z、y和x。其中z为第一个参数,y为第二个参数,x为第三个参数。这三个参数为积分参数。如果有其他参数,则由args提供a:x的积分下限。用-numpy.inf代表负无穷b:x的积分上限。用numpy.inf代表正无穷gfun:y的下边界曲线。它是一个函数或者lambda表达式,参数为x,返回一个浮点数。hfun:y的上界曲线。它是一个函数或者lambda表达式,参数为x,返回一个浮点数。qfun:z的下边界曲面。它是一个函数或者lambda表达式,第一个参数为x,第二个参数为y,返回一个浮点数。rfun:z的上边界曲面。它是一个函数或者lambda表达式,第一个参数为x,第二个参数为y,返回一个浮点数。args:额外传递的参数给funcepsabs:传递给quadepsrel:传递给quad
返回值:
y:一个浮点标量值,表示积分结果abserr:一个浮点数,表示绝对误差的估计值
2. 求解常微分方程组
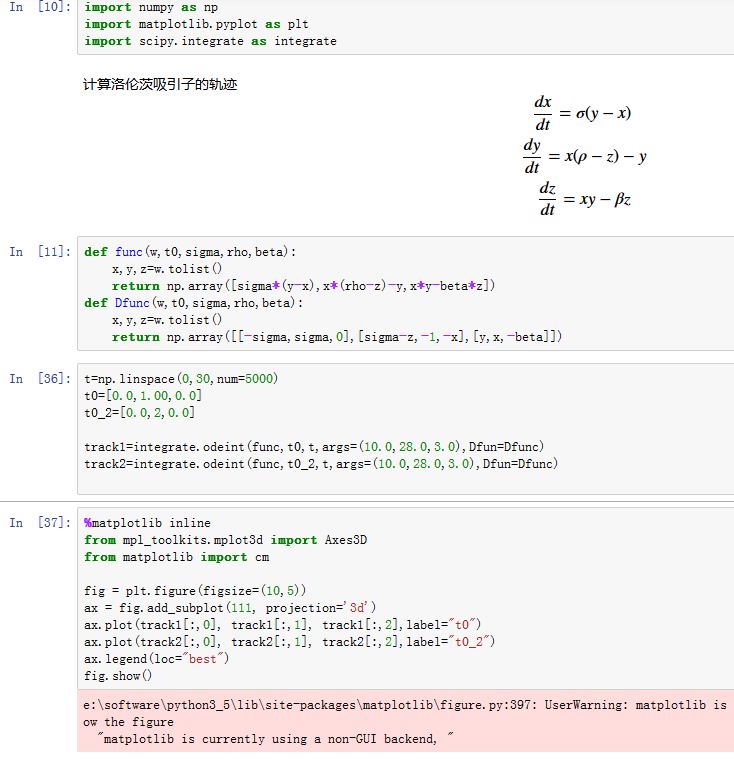
求解常微分方程组用:
xxxxxxxxxxscipy.integrate.odeint(func, y0, t, args=(), Dfun=None, col_deriv=0, full_output=0,ml=None, mu=None, rtol=None, atol=None, tcrit=None, h0=0.0, hmax=0.0,hmin=0.0, ixpr=0, mxstep=0, mxhnil=0, mxordn=12, mxords=5, printmessg=0)func:梯度函数。第一个参数为y,第二个参数为t0,即计算t0时刻的梯度。其他的参数由args提供y0:初始的yt:一个时间点序列。args:额外提供给func的参数。Dfun:func的雅可比矩阵,行优先col_deriv:一个布尔值。如果Dfun未给出,则算法自动推导。该参数决定了自动推导的方式full_output:如果True,则通过字典返回更多的信息printmessg:布尔值。如果为True,则打印收敛信息- 其他参数用于控制求解的细节
返回值:
y:一个数组,形状为(len(t),len(y0)。它给出了每个时刻的y值infodict:一个字典,包含额外的信息
六、 稀疏矩阵
稀疏矩阵是那些矩阵中大部分为零的矩阵。这种矩阵只用保存非零元素的相关信息,从而节约了内存的使用。
scipy.sparse提供了多种表示稀疏矩阵的格式。scipy.sparse.lialg提供了对稀疏矩阵进行线性代数运算的函数。scipy.sparse.csgraph提供了对稀疏矩阵表示的图进行搜索的函数。scipy.sparse中有多种表示稀疏矩阵的格式:dok_matrix:采用字典保存矩阵中的非零元素:字典的键是一个保存元素(行,列)信息的元组,对应的值为矩阵中位于(行,列)中的元素值。这种格式很适合单个元素的添加、删除、存取操作。通常先逐个添加非零元素,然后转换成其他支持高效运算的格式lil_matrix:采用两个列表保存非零元素。data保存每行中的非零元素,row保存非零元素所在的列。coo_matrix:采用三个数组row/col/data保存非零元素。这三个数组的长度相同,分别保存元素的行、列和元素值。coo_matrix不支持元素的存取和增删,一旦创建之后,除了将之转换成其他格式的矩阵,几乎无法对其进行任何操作和矩阵运算。