八、RRN[2017]
在推荐系统中,一种常见的方法是研究
Netflix竞赛中介绍的问题形式:给定由用户、电影、时间戳、评分组成的元组所构成的数据集,目标是在给定用户、电影、时间戳的条件下预估评分。然后通过预估评分和实际评分的偏离deviation来衡量预测的效果。这个公式很容易理解,并导致了许多非常成功的方法,如概率矩阵分解
Probabilistic Matrix Factorization: PMF、基于最近邻的方法、聚类。此外,很容易定义适当的性能度量,只需要选择数据集的一个子集进行训练,并用剩余的数据用于测试。但是,当涉及数据中固有的时间方面
temporal aspect和因果方面causal aspect时,这些方法是存在不足。下面的例子更详细地说明了这一点:- 电影观念
Movie Perception的变化:由于社会观念的变化,曾经被认为很糟糕的电影可能现在变得值得观看。为了适当地捕获这一点,电影属性的参数parameter必须随时间变化从而跟踪到这种趋势。 - 季节性变化:虽然没有那么极端,但是人们对于浪漫喜剧、圣诞电影、夏季大片的欣赏相对而言是季节性
seasonal的。而且,用户不太可能在夏天观看关于圣诞老人的电影。 - 用户兴趣:用户的偏好会随着时间而改变。这在在线社区中得到了很好的证实(
《No country for old members: User lifecycle and linguistic change in online communities》),并且可以说也适用于在线消费。由于更成熟或生活方式的改变,用户对特定节目的兴趣可能会变化。任何这方面的变化都会使得现有的用户画像失去意义,但是很难显式地对所有这类变化进行建模。
除了需要建模时间演变
temporal evolution之外,事后评估也违反了因果关系的基本要求。例如,假如知道用户将在未来一个月内对Pedro Almodfiovar产生好感,那么就可以更容易地估计该用户对La Mala Educacifion的看法。换句话讲,当我们使用未来评分来估计当前的review时,我们在统计分析中违反了因果关系。这使得我们在benchmark上报告的准确性无法作为有效评估,从而确定我们的系统能否在实践中运行良好。虽然Netflix prize产生了一系列研究,但是评估不同模型的未来预测future prediction受到训练数据和测试数据的混合分布mixed distribution的阻碍,如下图所示。相反,通过显式建模画像动态profile dynamic,我们可以根据当前趋势来预测未来的行为。下图为
Netflix竞赛中的数据密度。注意,测试数据在近期的评分上的密度要大得多,而训练数据的评分密度要更为均匀。这说明竞赛中提出的问题更多的是利用事后诸葛亮的插值评分interpolating rating(泄露了未来的评分来评估当前评分),而不是预测未来的用户行为。这段话的意思是说:对于真实世界的推荐,测试集不应该是随机选择的,而只能是未来预测
future prediction。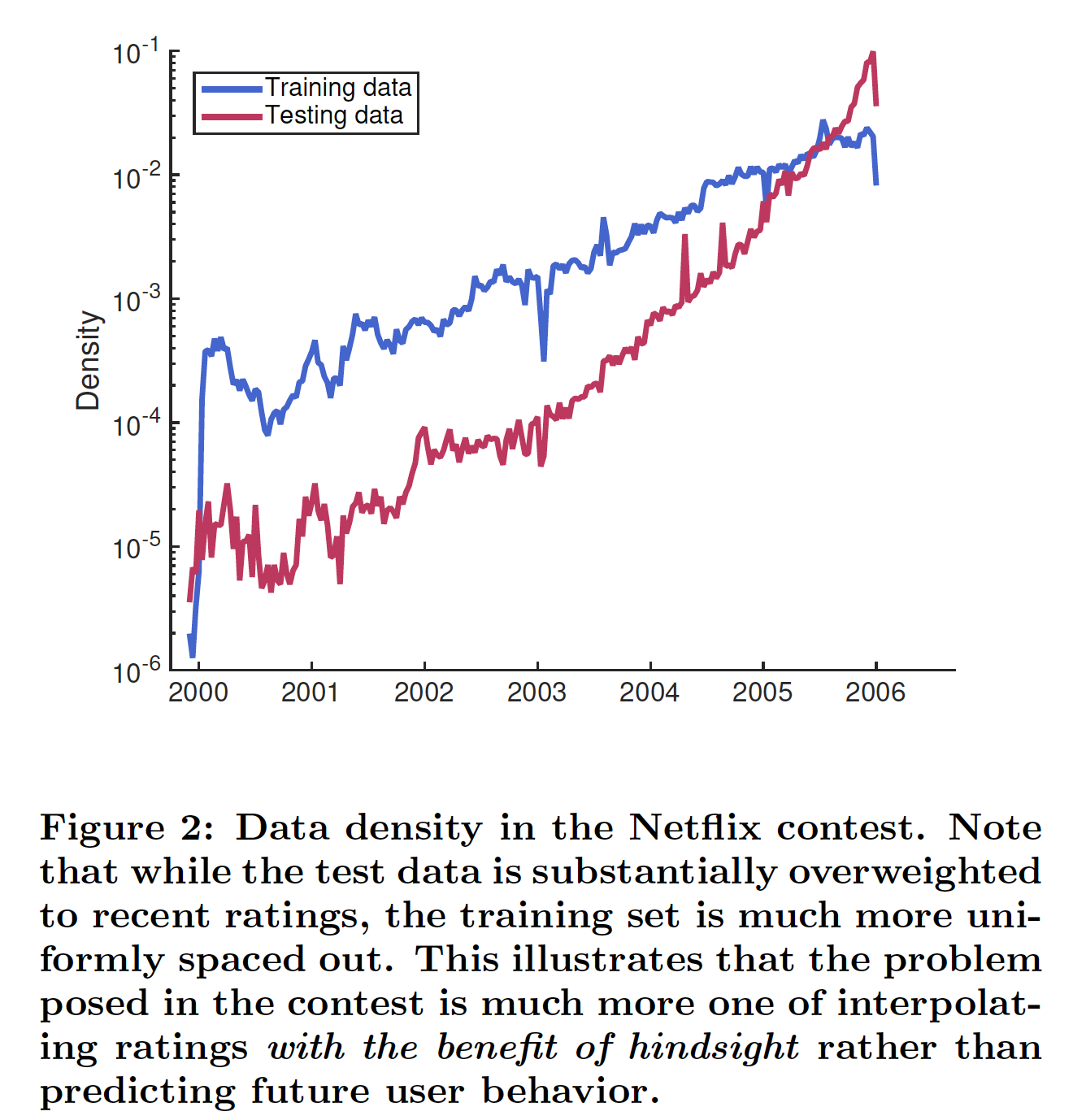
一个能够捕获推荐系统中固有的实际数据分布的模型,除了同时捕获用户集合和电影集合的评分交互之外,还需要能够同时建模每个用户和电影的时间动态
temporal dynamic。这意味着使用潜在变量模型latent variable model来推断控制用户行为和电影行为的、unobserved的状态。下图所示为这类模型的一个例子,该模型与《Collaborative filtering with temporal dynamics》提出的时间模型temporal model之间的区别在于:temporal model使用特定的参数化parametrization来插值时间行为interpolate temporal behavior。相反,前者使用非参数化模型
nonparametric model,该模型能够通过学习固有的用户动态user dynamic和电影动态movie dynamic,从而将行为外推extrapolate到未来。这使得该模型更适合true dynamic,对实验者的统计建模技能要求更低。这段话的意思是:
temporal model显式采用带时间戳的user parameter、带时间戳的movie parameter来建模user representation和movie representation,是transductive learning,它无法应用到未见过的时间戳。- 而前者采用模型(如马尔科夫链模型)来建模
user representation和movie representation,它将时间戳作为模型输入,是inductive learning,能够应用到见过的时间戳。
下图左侧为时间无关
time-independent的推荐,用户parameter和电影parameter都是静态stationary的。右侧为时间相关time-dependent的推荐,用户模型和电影模型都遵循马尔科夫链。
给定模型的整体结构,我们可以自由地为潜在变量
latent variable设定一种特定类型的状态state。流行的选择是假设一个离散的潜在状态(即离散的状态空间)。同样地,我们也可以求助于谱方法spectral method或非参数估计nonparametric estimator,如循环神经网络Recurrent Neural Network: RNN。为了解决梯度消失问题,论文《Recurrent Recommender Networks》使用LSTM。论文
《Recurrent Recommender Networks》的贡献如下:非线性
nonlinear的、非参数化nonparametric的推荐系统已被证明有些难以理解。具体而言,使用非线性函数来代替内积公式在论文的实验中仅显示有限的前景。据作者所知,这是第一篇以完全因果fully causal的、整体integrated的方式解决电影推荐的论文。也就是说,作者相信这是第一个试图捕获用户动态和电影动态的模型。此外,论文的模型是非参数nonparametric的。这使得我们能够建模数据,而不必假设状态空间state space的特定形式。Recurrent Recommender Network: RRN非常简洁,因为模型仅学习动态dynamic而不是状态state。这是与经典的潜在变量模型latent variable model的关键区别之一,其中潜在变量模型花了相当大的精力来用于估计潜在状态latent state。在这个方面上,RRN非常类似于《Autorec: Autoencoders meet collaborative filtering》提出的神经自编码器neural autoencoder。事实上可以将神经自编码器视为RRN模型的一个特例。state:即user representation和movie representation。实验表明,论文的模型优于所有其它模型。例如在现实场景中,作者尝试在给定数据的情况下估计未来的评分。实验表明,论文的模型能够非常准确地捕获外生动态
exogenous dynamic和内生动态endogenous dynamic。此外,论文证明该模型能够准确地预测用户偏好在未来的变化。外生动态:电影收到外界因素(如电影获得大奖)导致电影评分发生变化。内生动态:电影随着上映时间的增加从而导致评分发生变化。
- 电影观念
相关工作:
推荐系统:基础
basic的推荐系统忽略时间信息temporal information。这是一个合理的近似,特别是对于Netflix竞赛,因为在大多数情况下,关于电影的意见opinion和用户的意见不会发生太快、太剧烈的变化。Probabilistic Matrix Factorization: PMF可能最流行的模型之一。PMF尽管简单,但是它在评分预测方面取得了鲁棒的、强大的结果。我们提出的模型采用了与PMF相同的分解来建模稳态效应stationary effect。从这个意义上讲,我们的模型是PMF的一个严格的泛化。TimeSVD++是SVD++矩阵分解算法的时间扩展temporal extension。这里的关键创新是使用一个单独的模型来捕获时间动态,即允许数据中显式的时间偏差temporal bias。这使得TimeSVD++能够以整体的方式integrated fashion来捕获由于评分label的变化以及流行度popularity的变化而导致的时间不均匀性temporal inhomogeneity。注意,
TimeSVD++的特征是手工设计的,依赖于对数据集的深入了解,这使得模型难以移植到新问题,如从电影推荐到音乐推荐或书籍推荐。其次,该模型显式地不估计未来的行为,因为
Netflix比赛不需要估计未来的行为。相反,该模型仅仅在过去的observation之间进行插值。相比之下,我们的模型不依赖于特征工程,并且能够在未看到未来的用户行为的情况下(看到未来的用户行为本来就是不切实际的)预测未来的评分。
可能与我们的方法最密切相关的是
AutoRec,它是少数用于推荐的神经网络模型之一。AutoRec将矩阵分解视为编码问题:找到用户活动user activity的低维representation,以便我们可以从该向量重构所有的用户评分。就评分预测而言,AutoRec是迄今为止最好的神经网络模型之一,并在多个数据集上取得了state-of-the-art的结果。
循环深度网络:下图描述的
graphical model的关键挑战之一是:它要求我们根据observation推断未来的状态,例如通过消息传递message passing或粒子滤波particle filtering(粒子滤波通过非参数化的蒙特卡洛模拟方法来实现递推贝叶斯滤波)。这是昂贵且困难的,因为我们需要将评分的mission model与latent state相匹配。换句话讲,将关于评分的信息feed back到latent state的唯一方法是通过likelihoodSequential Monte Carlo sampling。这种方法需要学习
latent state(作为模型的parameter),这是昂贵且困难的。或者,我们可以简单地学习
mapping作为非参数的状态更新的一部分,即通过Recurrent Neural Network: RNN。关键思想是使用潜在变量自回归模型latent variable autoregressive model,如下所示:其中:
time stepobservation,observationrepresentation,time stepestimate。time steplatent state。
所谓的 ”非参数“ 指的是
latent state不是作为模型的parameter来学习的,而是通过某个函数来生成的。通过函数来生成并更新latent state,然后通过训练数据来学习这个函数,这就是论文的核心思想。上式给出了通用的函数形式,但是还可以引入非线性以及一些解决稳定性和梯度消失的工具。一个流行的选择是
Long Short-Term Memory: LSTM,它捕获时间动态。我们将LSTM作为协同过滤系统的building block。 整体模型如下图所示。状态更新如下:其中:
forget gate,input gate,output gate。sigmoid非线性激活函数。
LSTM中有两种类型的非线性激活函数:- 用于遗忘门、输入门、输出门的
sigmoid非线性激活函数:由于门控单元的性质,门的输出必须是0.0 ~ 1.0之间。因此,如果要替换为新的非线性激活函数,则该激活函数的输出范围也必须满足0.0 ~ 1.0之间。 - 用于
tanh非线性激活函数:用于对输入数据进行非线性变换,因此也可以替换为relu等其它非线性激活函数。但是对于RNN网络需要注意梯度消失和梯度爆炸,这也是为什么通常选择tanh非线性激活函数的原因。但是,也有论文和网上材料指出,通过仔细挑选合适的权重初始化(权重初始化为1附近),那么relu非线性激活函数的模型效果会更好。
为简单起见,在本文中我们使用
LSTM不是唯一的选择,例如也可以选择GRU(GRU的计算成本更低且结果通常相似)。在本文中,我们使用LSTM因为它稍微更通用。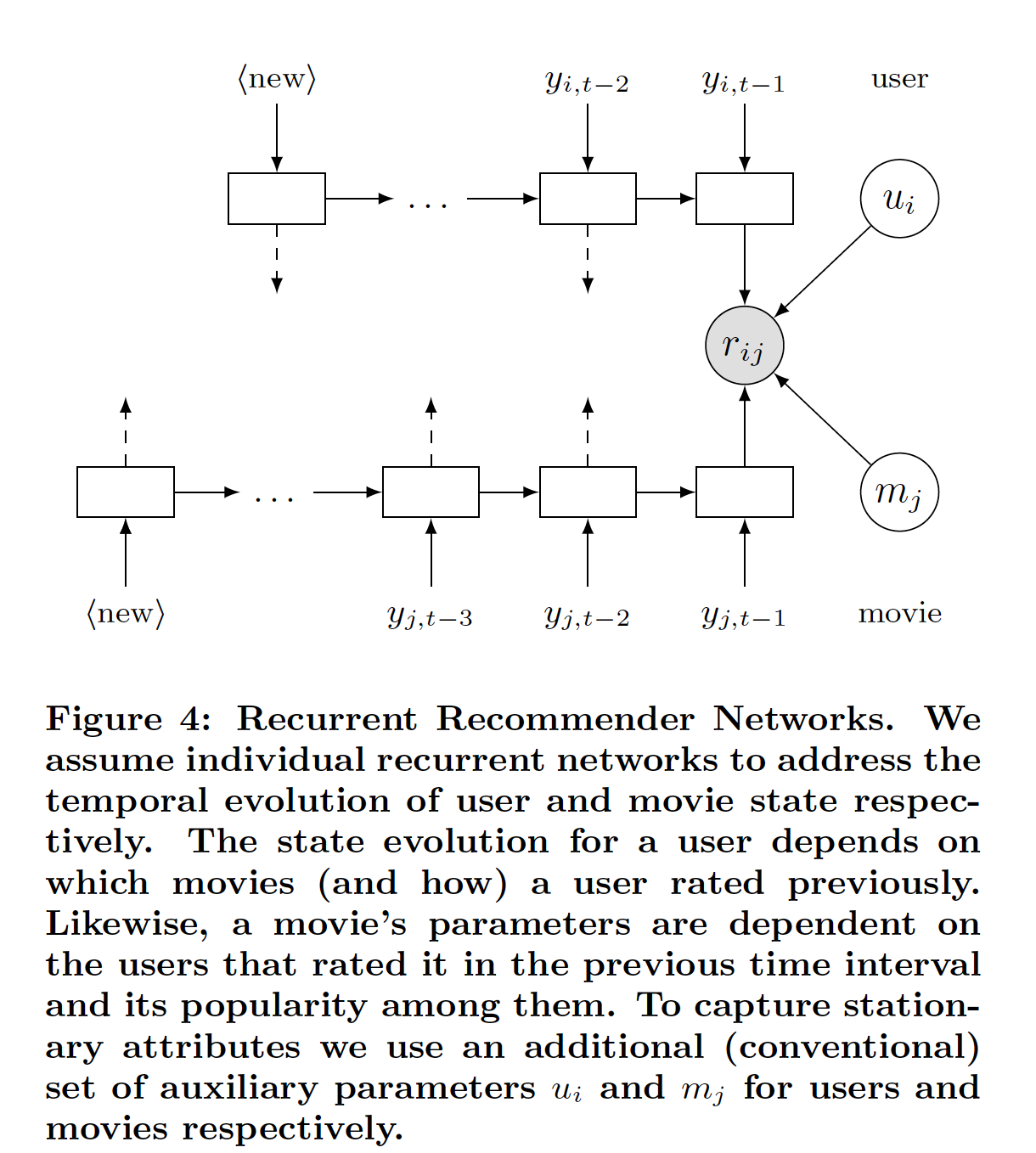
《Session-based recommendations with recurrent neural networks》没有考虑个性化,也没有尝试建模user state transition和item state transition。
8.1 模型
我们使用
LSTM RNN来捕获用户的时间依赖性temporal dependency和电影的时间依赖性。通过这种方式,我们能够融合incorporate过去的observation并以整体的方式预测未来的轨迹。令用户
latent state为latent state为temporal dynamic,我们给两者赋予时间索引,即latent state的更新函数update function。我们将更新函数定义为:其中:
time step- 函数
latent state。
我们不是解决优化问题来找到
user parameter/ movie parameter,而是解决优化问题来找到生成user parameter/movie parameter的函数。这方面类似于深度自编码器,其中深度自编码器学习一个编码器函数来编码过去的评分。然而深度自编码器的目标是最小化重构误差,而这里的问题是最小化预测评分与真实评分之间的误差。
用户状态和电影状态:为简单起见,我们首先描述
user-state RNN,因为movie-state RNN也是以相同的方式来定义的。给定一个包含
time steptime steptime stepwallclock,并且使用其中:
source information投影到embedding空间中的、待学习的变换transformation。注意:
- 由于评分序列的时间跨度很长,因此这里的
time step可以按照天粒度、月粒度、甚至年粒度来进行。此时RNN序列的长度,降低计算复杂度。粒度越长则越反应长期的趋势(短期趋势被抹平)。 - 这种线性投影的方式本质上是:将用户在
time stepembedding进行sum聚合。也可以进行self attention聚合、max pooling聚合等等其它非线性聚合。 embedding的方式添加到field:评分向量field、newbie field、wallclock field。这三个field的投影结果直接拼接在一起。也可以采用更复杂的融合方式(如MLP或者attention)。
LSTM在time step注意,如果在
time steptime step(即no-rating step)不应该包含在RNN中,这可以节省计算。尽管如此,wallclock的引入为模型提供了考虑no-rating step所需的信息,并且额外捕获了诸如rating scale变化、电影年龄之类的效果。rating scale变化指的是,比如某个时刻之前的评分范围是1 ~ 5分,之后的评分范围是1 ~ 10分。为了区分不同的用户,我们添加了用户
- 由于评分序列的时间跨度很长,因此这里的
评分发射
rating emission(即,评分函数):尽管用户状态和电影状态可以随时间变化,但是我们推测仍然存在一些静态分量stationary component来编码固定属性,例如用户画像、用户的长期偏好、电影的题材。为了实现这一点,我们分别用固定的time-varying的dynamic state和stationary state的函数,即:简而言之,标准的分解模型仅考虑了静态效应
stationary effect,而我们使用LSTM从而考虑了更长期的动态更新dynamic update。这使得我们的模型成为矩阵分解matrix factorization模型的严格超集strict superset。这里通过
dynamic user state和dynamic movie state映射到公共的空间。另外,上式等价于经
dynamic state和stationary state拼接之后再内积,即:评分预测
rating prediction:与传统的推荐系统不同,在预测时我们使用外推状态extrapolated state(即通过LSTM生成的state)而不是估计状态estimated state来进行评分预测。也就是说,我们将最新的observation作为输入,更新状态,并根据更新后的状态进行预测。通过这种方式,我们自然会考虑到之前评分带来的因果关系。例如,我们能够解决享乐适应
hedonic adaptation,它指的是在电影推荐的背景下,用户观看了一部令人满意的电影之后,用户对电影的满意度的level会降低。对于令人失望的电影也是类似的。训练:模型的优化目标函数是找到合适的
parameter从而产生最接近实际评分的预测,即:其中:
parameter,(user, movie, timestamp)元组的集合,虽然我们模型中的目标函数和
building block都是相当标准的,但是朴素的反向传播无法轻易地解决这个问题。关键的挑战在于每个单独的评分都同时取决于user-state RNN和movie-state RNN。对于每个单独的评分,通过2个序列的反向传播在计算上是很难进行的。我们可以通过仅考虑user-state RNN的反向传播来稍微缓解这个问题,但是每个评分仍然取决于movie state。反过来,我们也可以仅考虑movie-state RNN,但是每个评分仍然取决于user state。相反,我们提出了一种解决该问题的交替子空间下降策略
alternating subspace descent strategy。也就是说,我们仍然考虑user-state RNN的反向传播,但现在我们假设电影状态是固定的,因此不需要将梯度传播到这些电影序列中。然后我们交替更新用户序列和更新电影序列。这样,我们可以为每个用户(电影)执行一次标准的前向传播和反向传播。这种策略被称作子空间下降subspace descent。
8.2 实验
数据集:
IMDB数据集:包含1998年7月到2013年9月期间收集的140万个评分。Netflix数据集:包含1999年11月到2005年12月期间收集的1亿个评分。
每个数据点是一个
(user id, item id, time stamp, rating)元组,时间戳的粒度为1 day。为了更好地理解我们模型的不同方面,我们在具有不同训练和测试周期的几个不同时间窗口上测试我们的模型。详细的数据统计如下表所示。注意,我们根据时间来拆分数据从而模拟实际情况:我们需要预测未来的评分(而不是对以前的评分插值
interpolate)。测试期间的评分被平均拆分为验证集和测试集。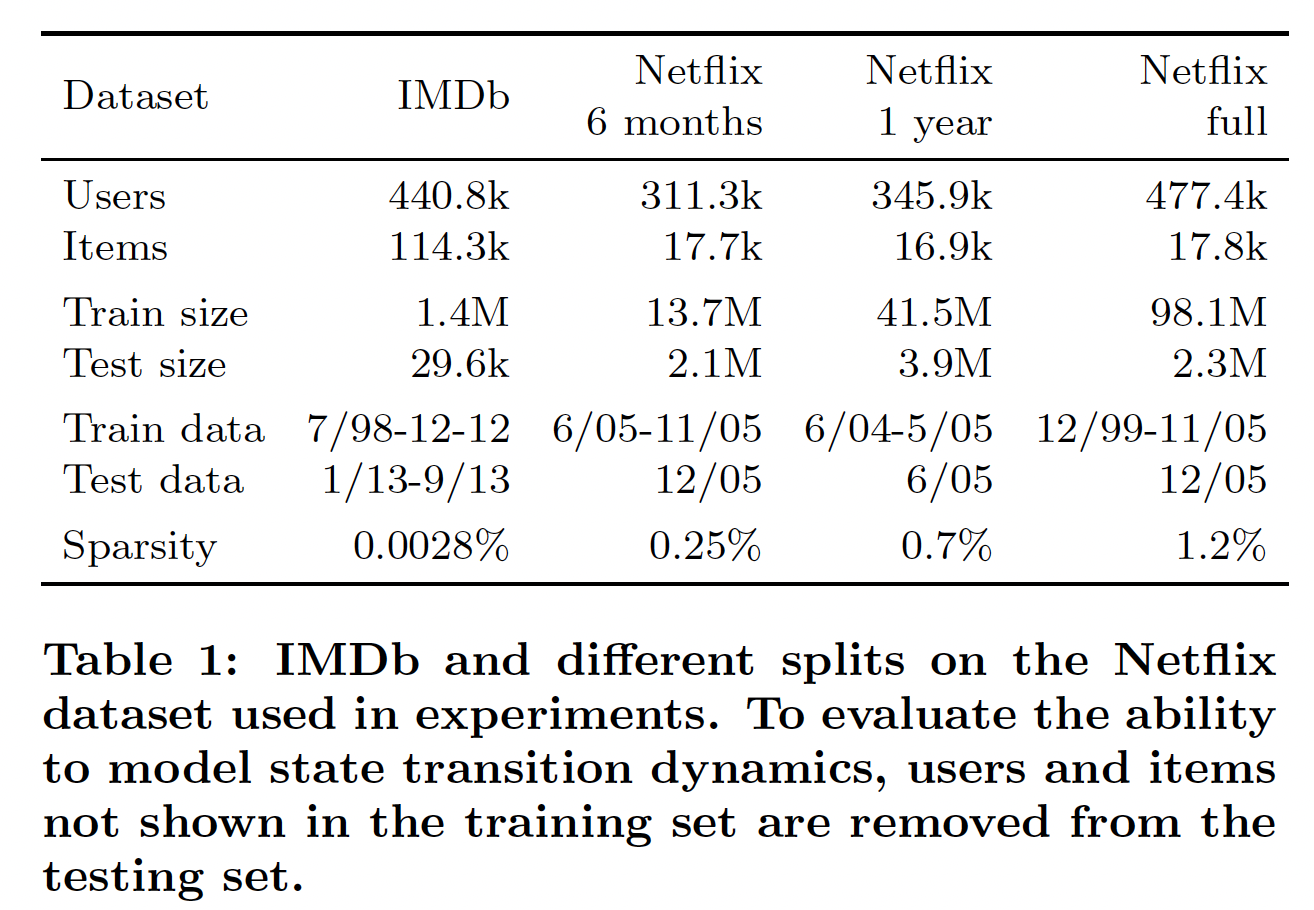
配置:
我们发现即使使用非常少的参数,我们的模型也能够达到良好的准确性。
- 在以下的实验中,我们使用具有
40个隐单元(即input embedding维度40维(即dynamic state维度20维(即LSTM。 - 我们分别对
Netflix和IMDB数据集使用20维和160维的stationary latent factor。
- 在以下的实验中,我们使用具有
我们的模型在
MXNet上实现。我们使用
ADAM来优化神经网络参数、使用SGD来更新stationary latent factor。我们通过交叉验证调优超参数。
我们发现:如果我们首先仅训练
stationary state,然后联合训练完整的模型,则通常可以获得更好的结果。在接下来的实验中,stationary latent state分别由一个小的预训练的PMF初始化(对于Netflix数据集)、以及一个U-AutoRec模型来初始化(对于IMDB数据集)。wallclock
baseline方法:PMF:尽管简单,然而PMF在评分预测方面取得了鲁棒的、强大的结果。由于我们的模型采用与PMF相同的因子分解来建模静态效应,因此和PMF比较的结果直接展示了我们的方法建模temporal dynamic的好处。我们使用LIBPMF,并使用网格搜索grid search来搜索正则化系数factor sizeTimeSVD++:TimeSVD++是捕获temporal dynamic的最成功的模型之一,并在Netflix竞赛中展示了强大的结果。我们使用网格搜索grid search来搜索正则化系数factor sizeAutoRec:AutoRec学习一个自编码器从而将每个电影(或每个用户)编码到低维空间,然后解码从而进行预测。就评分预测而言,它是迄今为止最好的神经网络模型之一,并在多个数据集上取得了state-of-the-art结果。我们使用原始论文中的超参数((latent state维度
我们的评估指标是标准的
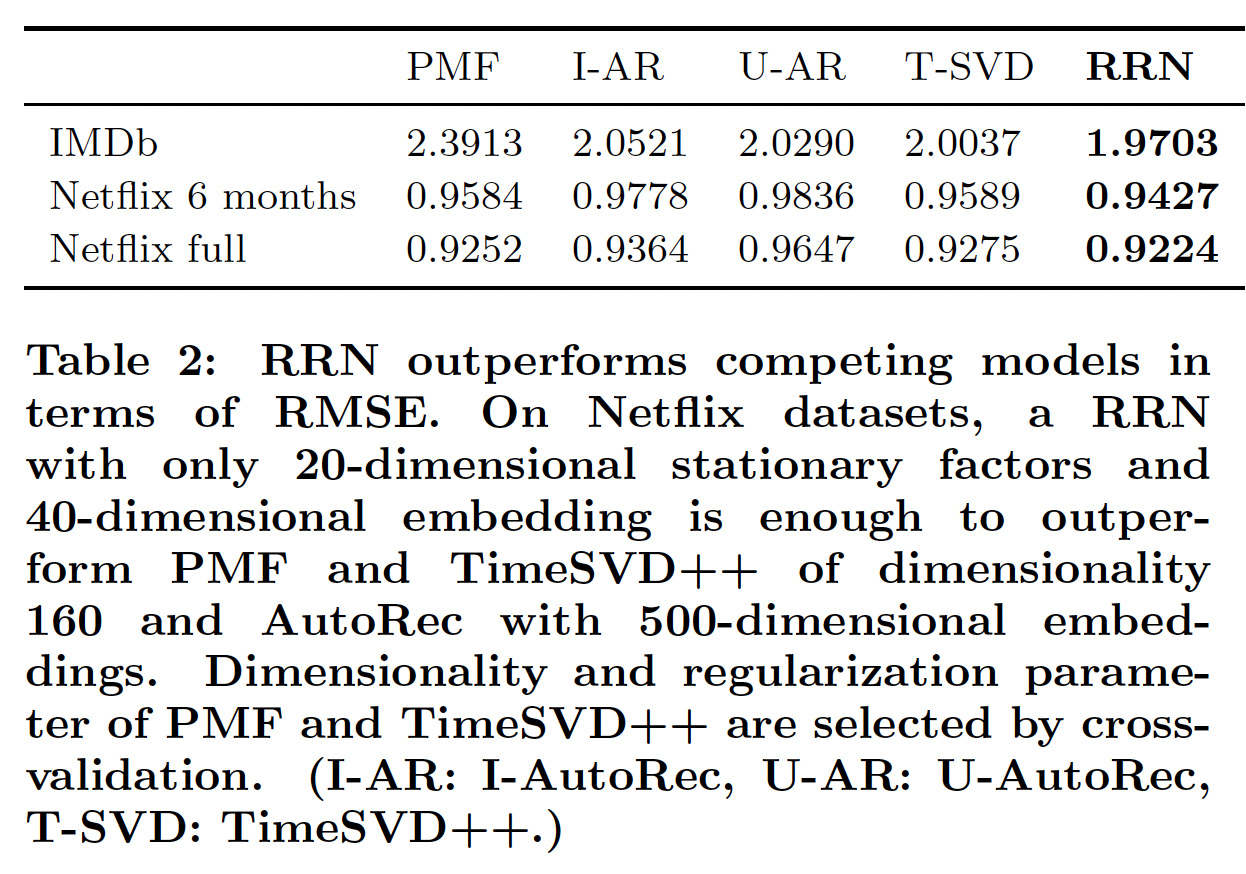
root-mean-square error: RMSE。不同数据集的结果如下表所示。这里,我们对Netflix full和IMDB使用2个月粒度的time step,对6-month Netflix数据集使用1day/7 days(对应于user/movie)粒度的time step。我们将在后续讨论time step粒度的选择。我们将模型运行10个epoch,在每个epoch结束之后计算验证集的RMSE。我们报告在验证集上效果最好的模型在测试集上的测试RMSE。模型准确性
accuracy和大小size:在所有方法中,我们的模型在所有数据集上均达到了最佳的准确性。和
PMF相比,RRN在IMDB上提供了1.7%的改进,在6-month Netflix上提供了1.6%的改进。注意,下表展示的
RMSE高于Netflix竞赛的RMSE,因为我们测试的纯粹是未来的评分。此外,我们的模型非常简洁,因为我们存储转移函数
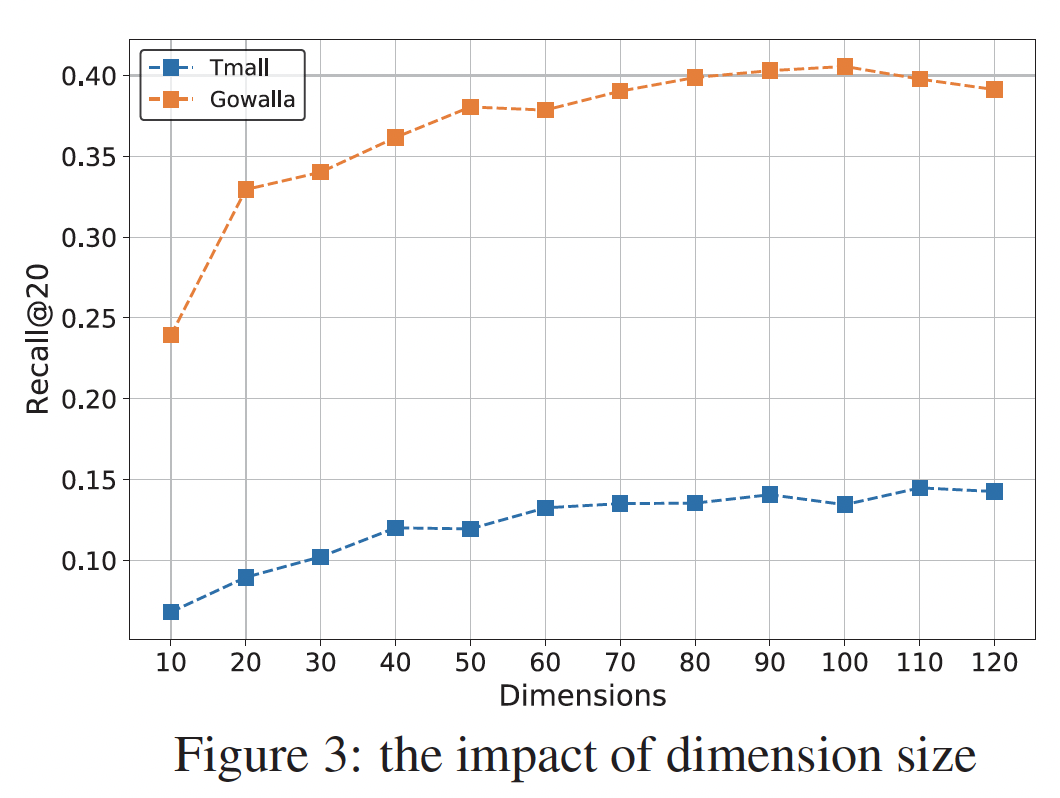
transition function而不是实际状态从而建模temporal dynamic。虽然RRN优于所有baseline,但是RRN比PMF和TimeSVD++小2.7倍、比I-AutoRec小15.8倍。具体而言,具有40维embedding和20维stationary state的RRN足以超越160维的PMF、160维的TimeSVD++、500维的AutoRec。下图展示了
6-month Netflix数据集上的模型大小和RMSE。对于
IMDB,RRN的大小与PMF, TImeSVD++, U-AutoRec相当,但是比I-AutoRec小得多。这是因为RRN使用与分解模型相同维度的stationary state,并且包含一个相对较小的模型来捕获temporal dynamic。我们看到RRN在灵活性和准确性方面的明显优势,而不会牺牲模型大小。
鲁棒性
robustness:RNN在不同数据集上显示出一致的改进,而其它方法在不同数据集上的排名在变化。PMF在IMDB数据集上的表现要比Time-SVD++差得多,这再次强调了对temporal dynamic建模的必要性。但是
PMF在Netflix full和Netflix 6 months上的表现要比Time-SVD++更好,是否说明建模temporal dynamic是无用的?

时间动态:
电影中的外生动态
exogenous dynamic:外生动态指的是电影的评分如何随着外部效应exogenous effect(如电影获奖或得到提名)而变化。我们的目标是了解我们的模型如何对外生动态作出反应。具体而言,我们在
1-year数据集上运行RNN,time step粒度为一个月,并且查看平均预测评分如何沿着时间序列而演变。平均预测评分是根据1000名随机抽样的用户计算而来。这个平均预测评分代表了电影在当时的平均预测评分,并避免了当时谁选择给该电影评分的bias。这里评估的是全体用户中随机选择的,而不是从对某个电影有评分的用户中选择的。后一种方式存在选择偏差
select bias,使得仅评估未来review过该电影的用户。下图展示了获奖电影的平均预测评分。可以看到,当一部电影获奖或得到提名时,预测评分会显著上升,这与数据趋势相符。这证实了我们的预期,即
RNN应该自动适应外生变化exogenous change并调整预测。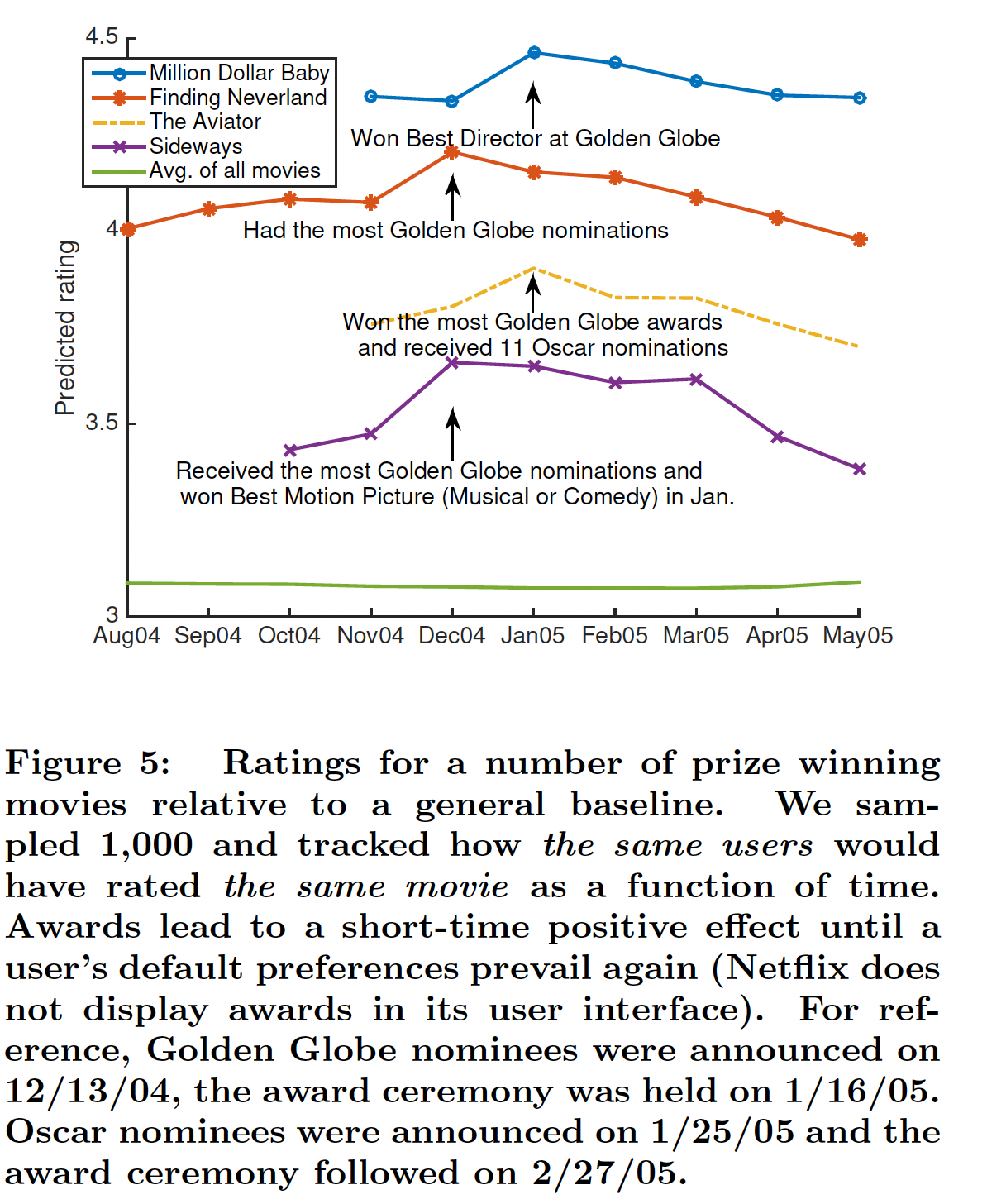
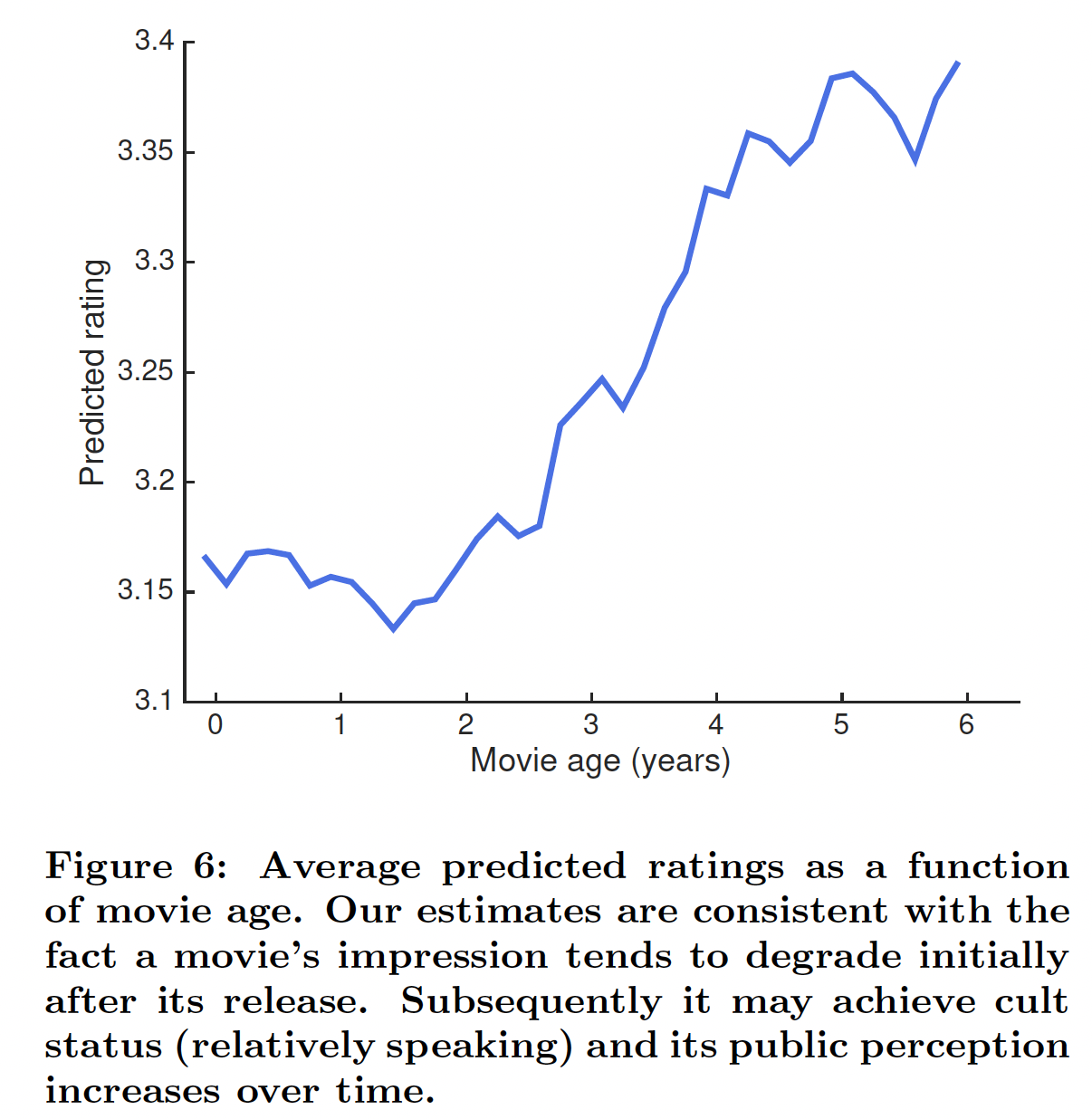
电影中的内生动态
endogenous dynamic:除了外生事件之外,电影还可能由于内生原因而随着时间的推移而发生变化。为了了解RRN如何对内生原因的影响进行建模,我们以2个月粒度的time step对完整的6-year数据集进行了测试。实验与前一个实验相同的方式进行,但是考虑到大多数用户仅在系统上活跃一段时间这个事实,这里对每个time step我们随机采样了5000个当时活跃的用户(因此这里采用的是time step粒度随机选择的用户)。如果用户在time step内对任何电影进行了评分,那么我们认为该用户是活跃的。我们观察评分变化较大的电影,并观察RRN如何建模它的temporal dynamic。首先,我们观察到年龄效应
age effect。也就是说,一部电影的评分往往在上映后的第一年略有下降,然后随着年龄的增长而上升。在下图中,我们看到我们的模型显著地捕获到这种年龄效应并有效地适应。下图为精心挑选的某部电影的平均预测评分。论文并未讲述这种效应产生的原因,只是说明有这种现象。
此外,我们还注意到
RRN如何对具有不同反响的电影进行不同的建模。下图展示了奥斯卡最佳影片提名(蓝色曲线)、以及金酸莓最差影片提名(红色曲线)的预测评分。我们看到每个分组中的电影都显示出符合直觉的一致模式:金酸莓提名电影最初经历了平均评分下降,然后上升;而奥斯卡提名电影在开始时平均评分上升,然后保持相对稳定。注意,这些模式不是简单地通过一个bias项来捕获的shift。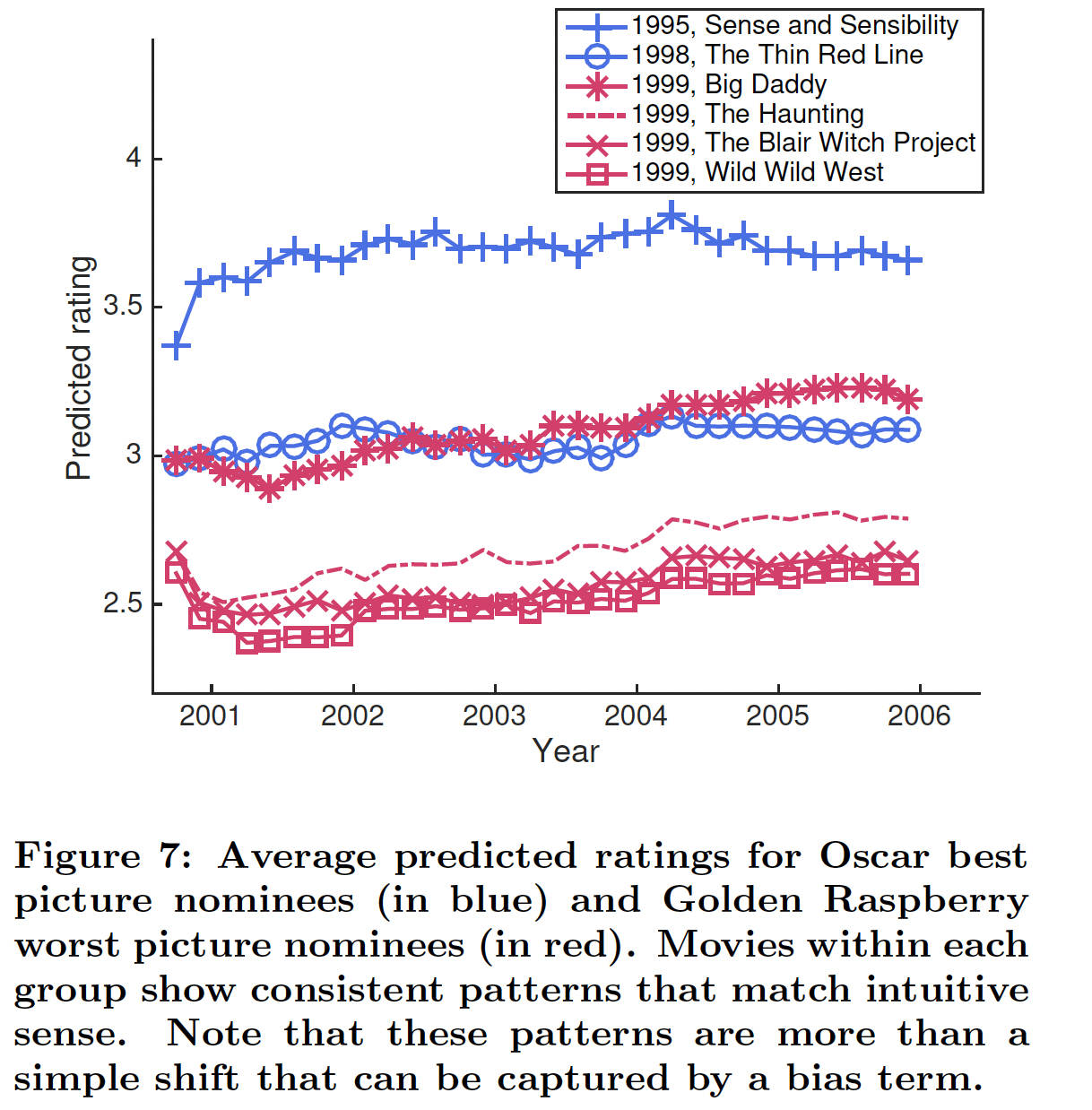
用户偏好
User Interface改变:正如《Collaborative filtering with temporal dynamics》中所指出的,2004年初评分的scale发生了改变。显然,没有考虑到这一点的系统将具有较差的估计准确性。我们在完整的Netflix数据集上测试我们的模型,time step粒度为2个月,并查看每个time step上随机选择的用户所生成的平均评分。注意,由于我们计算随机用户随时间的平均预测,因此我们观察模型的dynamic embedding如何随时间变化。下图显示了按电影发行年份分组的平均预测评分。我们看到所有的曲线在
2004年初都有一个与scale change相匹配的显著上升。这与PMF形成对比,PMF的embedding是静态的,因此随着时间的推移平均预测是恒定的。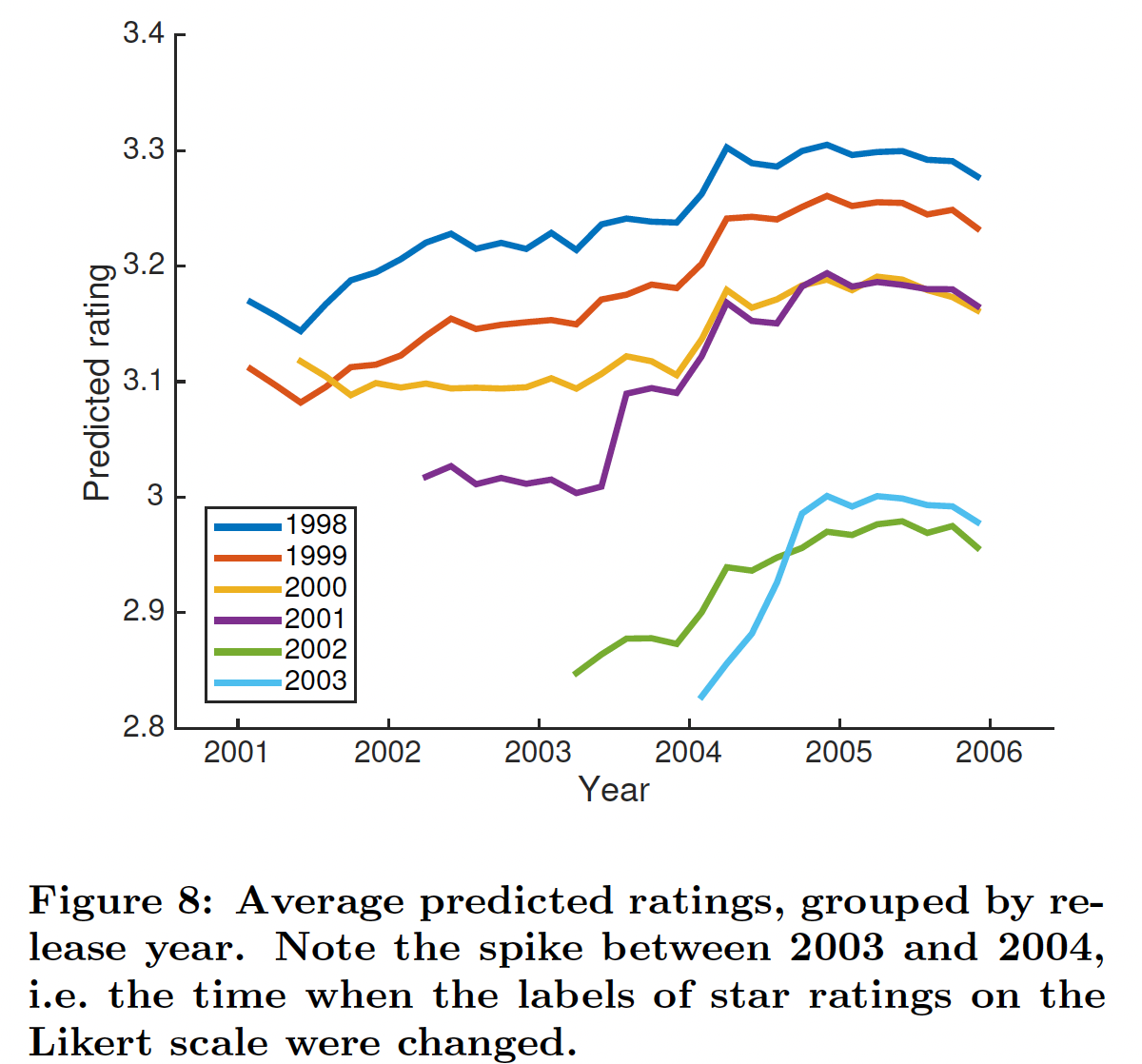
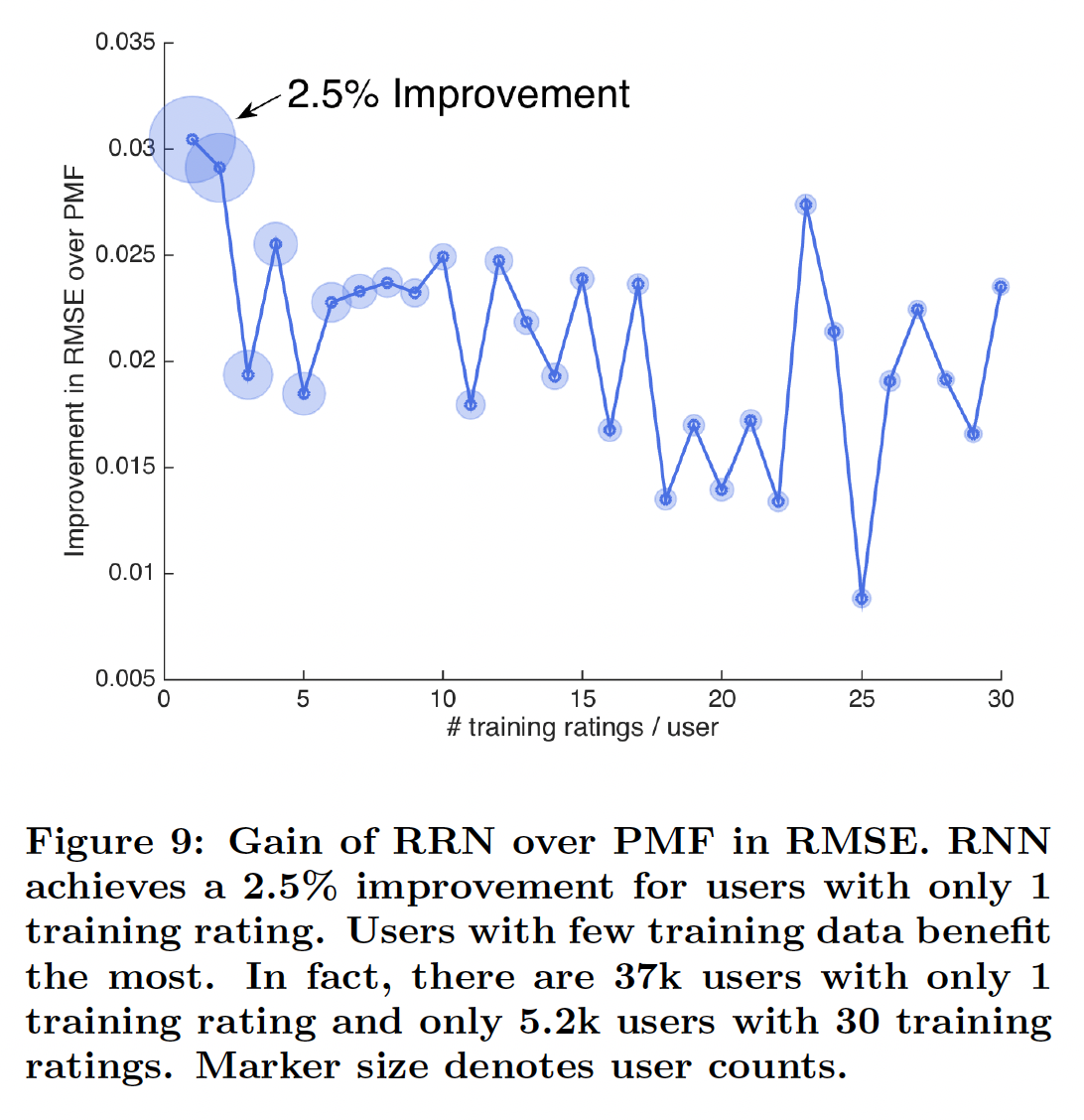
冷启动:为了了解我们模型的优势和劣势,我们在训练集中评分很少的用户和电影上与静态
PMF模型进行了比较。如下图所示,对于训练集中评分很少的用户,
RRN比PMF有所改进。对于训练集中评分非常少的用户,RRN(相比较PMF)的相对改进最大。整体而言,训练集中评分数量越多,则相对改进越小。
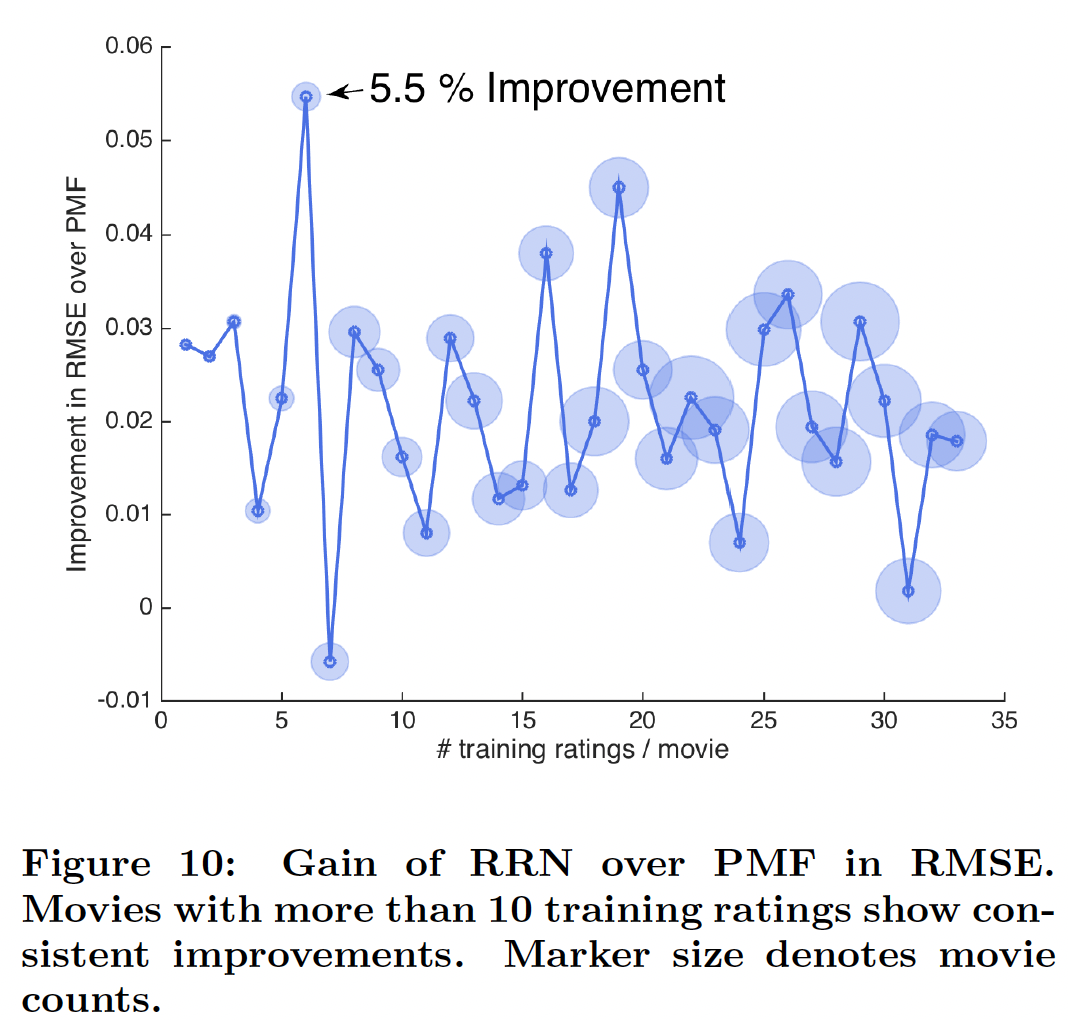
如下图所示,我们发现
RRN仍然一致性地为评分很少的电影提供改进,但是改进幅度与观察次数之间的关系更加noisy。这可能是由于这些电影在测试集中的评分相对较少。这个理由缺乏数据的支撑,因为前面关于评分数量少的用户的结论中,这些用户也可能在测试集中的评分很少。
无需重新训练
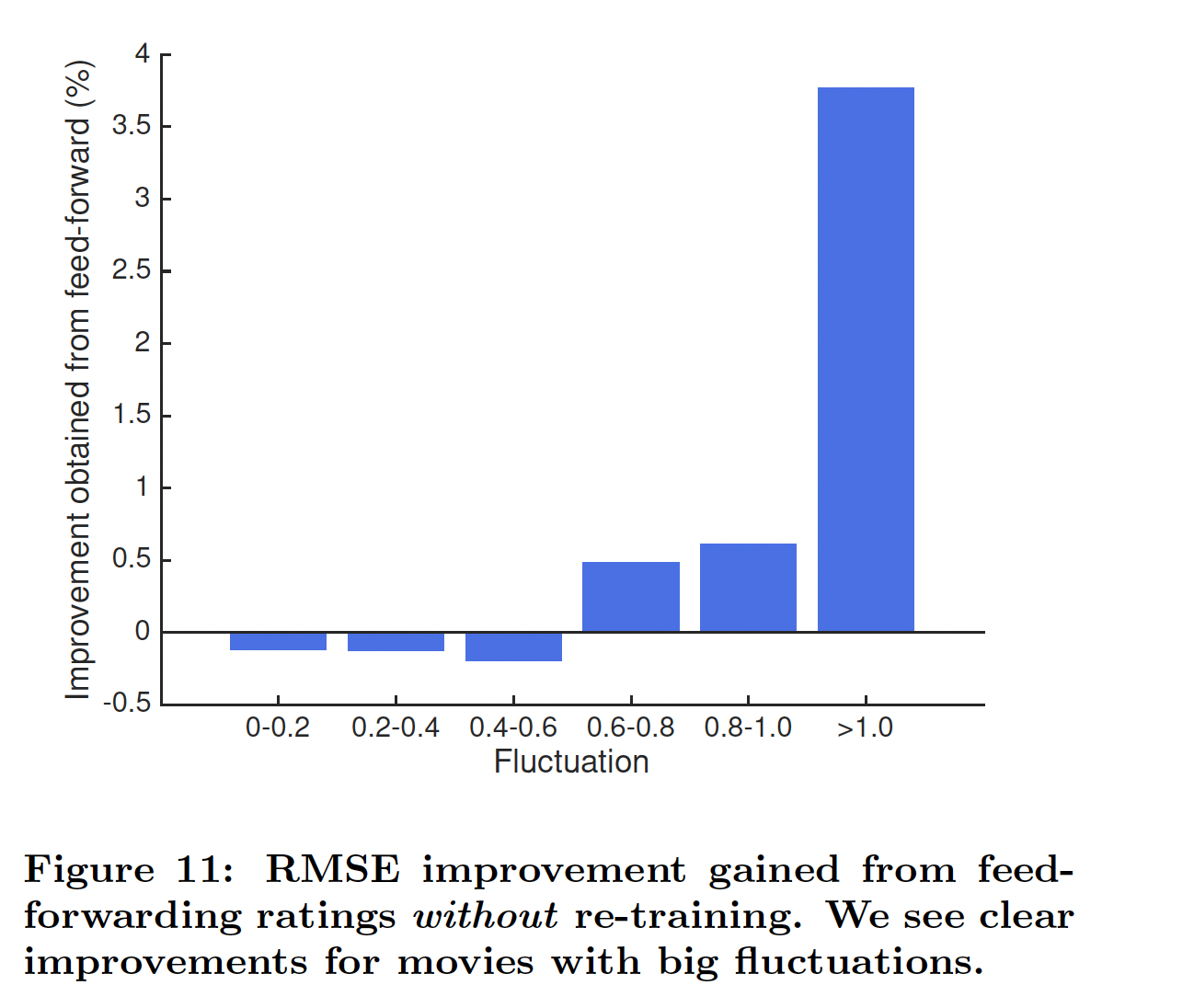
re-training从而融合新数据:估计转移函数transition function而不是估计状态本身的一个优势是:即使没有重新训练re-training,我们也能够融合新观察到的评分信息从而更新状态(只需要将新的评分输入到网络中)。这里,我们在
6-month Netflix数据集上评估该策略。具体而言,我们使用从第一个测试time step观察到的评分来外推状态extrapolate state,并使用外推到的状态来预测第二个time step的评分。我们测试了具有不同的评分波动水平的电影。波动fluctuation被定义为:评分最高的time step的平均评分,与评分最低的time step的平均评分之间的差异。下图总结了该策略的
RMSE改进。我们观察到:虽然我们的预训练模型没有捕获到小的波动,但是它成功地捕获了大的波动,从而显著提高了预测准确性。也就是说,使用RRN不仅缓解了频繁昂贵的重新训练的需要,而且还开辟了提供实时推荐的新途径。通常小的波动不太重要,此时这些电影的评分比较稳定,甚至直接将它们的评分预估为一个恒定值就足够可以。
time step粒度granularity和敏感性sensitivity:较小的time step允许模型频繁地更新并捕获短期影响。然而,这也会导致更长的LSTM序列,从而进一步导致更高的训练成本。下表总结了
6-month数据集上不同粒度(user和movie采用不同的粒度)的训练时间和测试RMSE。这里我们看到了RMSE和训练时间之间的trade-off。可以通过更长的训练时间为代价来获得更好的准确性。注意,性能对粒度不是特别敏感,即使采用最差RMSE的粒度,它也优于所有的baseline模型。这可能是因为RRN是完全通用的,因为它没有假设数据的特定形式或分布。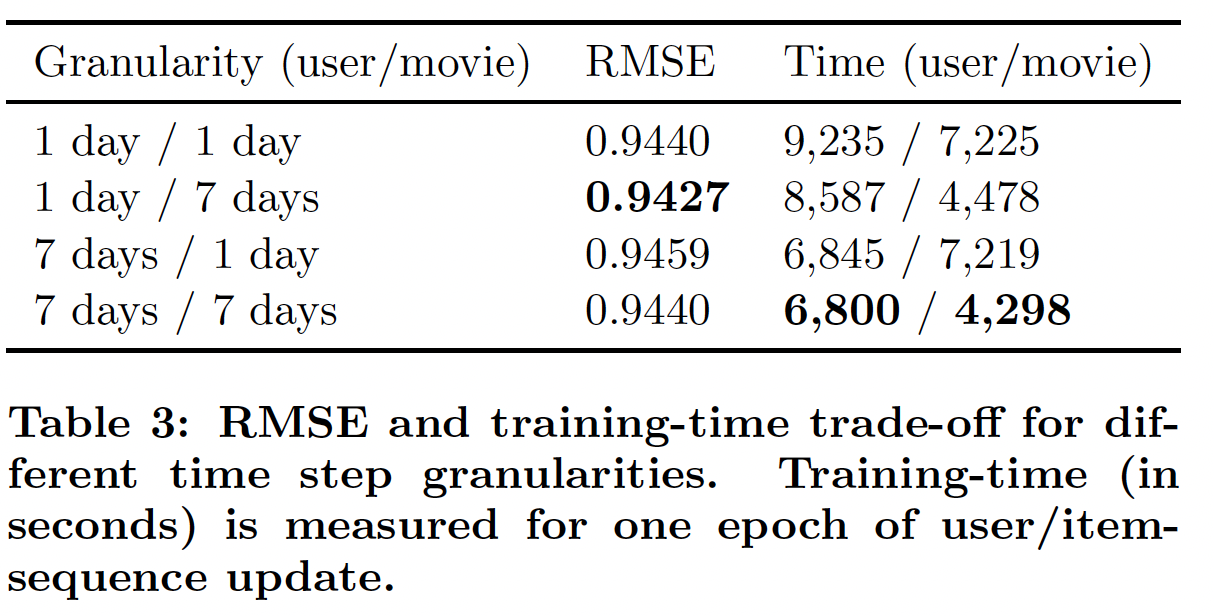
九、Caser[2018]
大多数推荐系统根据用户的一般偏好
general preference来推荐item,但是没有关注用户最近交互的item。例如,一些用户总是更喜欢苹果的产品(而不是三星的产品),这反应了用户的一般偏好。一般偏好代表用户的长期long term的、静态static的行为。另一种类型的用户行为是序列模式
sequential pattern,其中next item或者next action更可能取决于用户最近互动的item或action。序列模式代表了用户的短期short term的、动态dynamic的行为。序列模式源自在相近时间内互动的item之间的某种关系relationship。例如,用户可能会在购买iPhone之后不久购买手机配件,但是通常而言用户是不会突然购买手机配件的(没有人会对手机配件产生长期兴趣)。在这种情况下,仅考虑一般偏好的推荐系统将错过在销售iPhone之后向用户推荐手机配件的机会,因为购买手机配件不是长期的用户行为。top-N序列推荐Sequential Recommendation:令用户集合item集合item序列,记做item在用户行为序列order。注意,absolute timestamp。给定所有用户的行为序列
top-N序列推荐的目标是:通过考虑一般偏好和序列模式,向每个用户推荐一个item list,从而最大化用户的未来需求future need。与传统的
top-N推荐不同,top-N序列推荐将用户行为建模为item的序列sequence,而不是item的集合set(序列是有序的,集合是无序的)。先前工作的局限性:基于马尔科夫链的模型是一种早期的
top-N序列推荐方法,其中action进行推荐。- 一阶马尔科夫链使用最大似然估计
maximum likelihood estimation来学习item-to-item的转移矩阵transition matrix。 Factorized personalized Markov chain: FPMC及其变体通过将转移矩阵分解为两个潜在latent的、低秩low-rank的子矩阵来改进该方法。Factorized Sequential Prediction with Item Similarity Models: Fossil通过对先前的item的latent representation进行加权的sum聚合,从而将该方法推广到高阶马尔科夫链。
但是,现有方法受到两个主要限制:
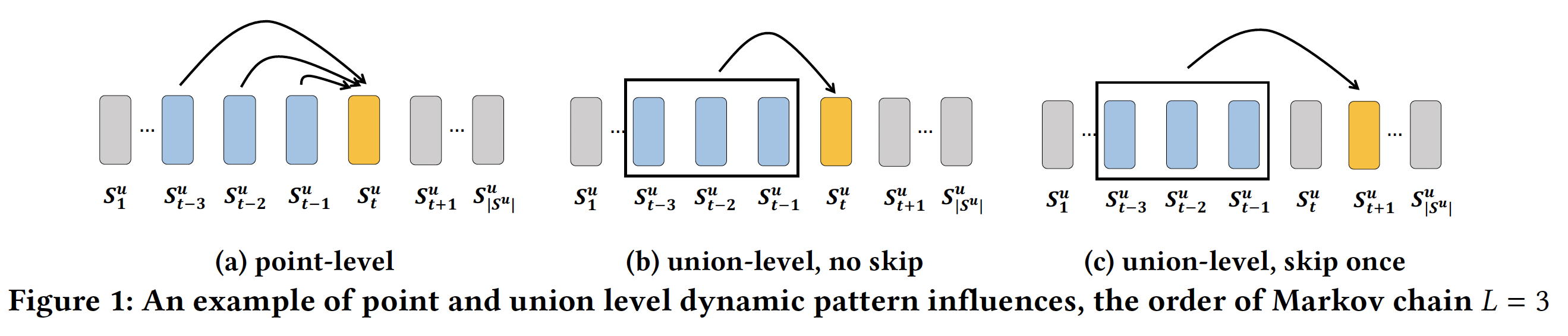
无法建模
union-level的序列模式。如下图(a)所示,马尔科夫链仅建模point-level序列模式,其中每个先前的action(蓝色)独自地individually(而不是协同地collectively)影响target action(黄色)。FPMC和Fossil就属于point-level序列模式。尽管Fossil考虑了一个高阶马尔科夫链,但是它的总体影响overall influence是:从一阶马尔科夫转移矩阵分解的、先前的item latent representation的加权和。这种point-level影响不足以建模下图(b)中的union-level影响,其中若干个先前的action以给定的顺序共同影响target action。例如,同时购买牛奶和黄油之后再购买面粉的概率,要比单独购买牛奶(或者单独购买黄油)之后再购买面粉的概率更高。再例如,同时购买内存和硬盘之后再购买操作系统的概率,要比单独购买其中一个配件之后再购买操作系统的概率更高。假设同时购买牛奶和黄油之后再购买面粉的概率为
point-level的加权和的形式,则有:一种缓解方案是调整加权的权重范围,如选择
不允许
skip行为behavior。现有模型不考虑skip行为的序列模式,如下图(c)所示,其中过去的行为可能会skip几个step之后仍然产生影响。例如,游客在机场、酒店、餐厅、酒吧以及景点依次进行check-ins。虽然机场check-ins和酒店check-ins并不是景点check-ins的直接前驱,但是它们也与景点check-ins密切相关。另一方面,餐厅check-ins和酒吧check-ins对景点check-ins的影响很小(因为到访景点之前不一定需要到访餐厅或到访酒吧,但是几乎一定意味着到访机场和酒店)。skip行为,因为它假设前面的step对紧接的next step有影响。
为了提供关于
union-level影响以及skip行为的证据,论文《Personalized Top-N Sequential Recommendation via Convolutional Sequence Embedding》从两个现实生活数据集MovieLens和Gowalla中挖掘了以下形式的序列关联规则sequential association rule:对于上述形式的规则
support countconfidenceitem对于通过将右侧调整为
skip 1 step或者skip 2 step的影响。下图总结了找到的有效规则数量(过滤掉无效的规则)与马尔科夫阶次
skip步数的关系。过滤条件为:支持度>= 5、置信度>= 50%(作者还尝试了最小置信度为10%, 20%, 30%,但是这些趋势是相似的)。可以看到:大多数规则的阶次为
可以看到
point-level规则,union-level规则。该图还表明,相当多的规则是
skip一步或两步的。
这些发现支持
union-level以及skip行为的影响。注意,这里并不意味着
>= 50%的规则。通常而言,因此下图仅能说明
union-level和skip行为比较重要,但是并不能说明point-level行为不重要,更不能说明union-level和skip行为比point-level行为更重要。事实上,在现实世界的数据集中,point-level行为才是占据统治地位。从论文后面的实验部分(
Caser组件分析)也能验证这一点:point-level行为比union-level行为更重要。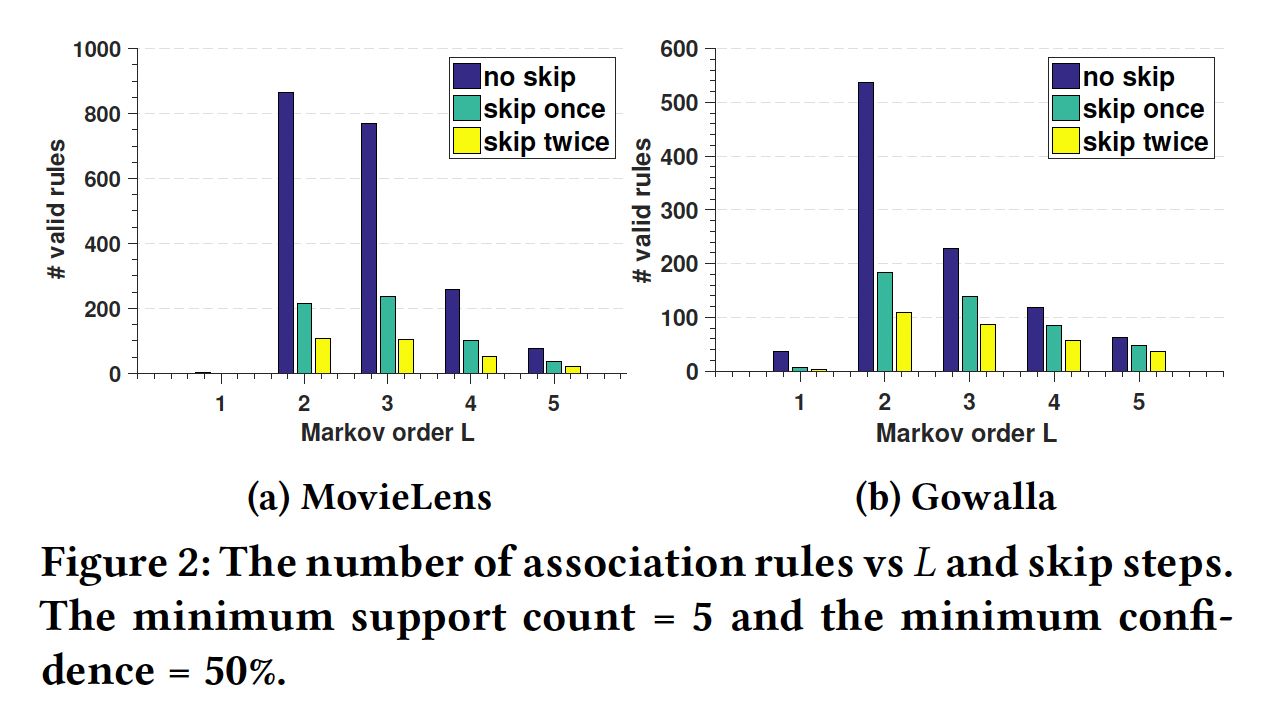
- 一阶马尔科夫链使用最大似然估计
为了解决现有工作的上述限制,论文
《Personalized Top-N Sequential Recommendation via Convolutional Sequence Embedding》提出了一个ConvolutionAl Sequence Embedding Recommendation Model: Caser模型 作为top-N序列推荐的解决方案。Caser利用卷积神经网络,其创新之处在于:将前面item表示为一个embedding矩阵embedding的维度,并且矩阵的行保留了item之间的次序order。论文将这个embedding矩阵视为潜在空间中由item构成的image,并使用各种卷积filter来搜索序列模式从而作为该image的局部特征。然而,与图像识别不同的是,这个image并不是通过input直接给出的,而是必须与所有filter同时学习。论文主要贡献:
Caser使用水平卷积filter和垂直卷积filter来捕获point-level、union-level、以及skip行为的序列模式。Caser同时建模一般偏好以及序列模式,并在单个统一框架中概括了几种现有的state-of-the-art方法。- 在现实生活的数据集上,
Caser优于state-of-the-art的top-N序列推荐方法。
相关工作:
传统的推荐方法,如协同过滤、矩阵分解、以及
top-N推荐,都不适合捕获序列模式,因为它们没有建模action的顺序。序列模式挖掘的早期工作基于统计共现来找到显式的序列关联规则
sequential association rule。这种方法依赖于模式的显式表示explicit representation,因此可能会错过未观察到的状态unobserved state下的模式。此外,这种方法还存在:过大的搜索空间、阈值设置的敏感性(置信度阈值)、大量的规则(大多数规则是冗余的)等等问题。observed state下的模式指的是训练数据中已经观察到的序列模式,unobserved state下的模式指的是所有可能的序列模式。受限玻尔兹曼机
Restricted Bolzmann Machine: RBM是首个成功应用于推荐问题的2层神经网络。自编码器autoencoder框架及其变体降噪自编码器denoising autoencoder也产生了良好的推荐性能。卷积神经网络已用于从用户的评论中提取用户的偏好。这些工作都不是用于序列推荐的。循环神经网络
RNN已被用于session-based推荐。虽然RNN在序列建模方面已展示出卓越的能力,但是其顺序地连接的网络结构在序列推荐setting下可能无法正常工作。因为在序列推荐的问题中,并非所有相邻的action都有依赖关系,例如,用户在购买itemitem1RNN-based方法表现更好。这也意味着,如果数据集中包含的序列模式较少,那么
RNN-based方法的表现会很差。所以应用RNN-based方法之前首先需要评估数据集中序列模式的占比。然而我们提出的方法没有将序列模式建模为邻接
adjacent的action,我们的方法采用了来自CNN的卷积filter,并将序列模式建模为先前item的embedding的局部特征local feature。这种方法在单个统一框架中提供了灵活性,从而同时建模point-level序列模式、union-level建模序列模式、以及skip行为。事实上,我们将展示Caser概括了几种state-of-the-art方法。一个相关的、但是不同的问题是时间推荐
temporal recommendation,例如应该在早晨而不是在晚上推荐咖啡。而我们的top-N序列推荐会在用户购买iPhone后不久推荐手机配件,这与时间无关。显然,这两个问题是不同的,需要不同的解决方案。
9.1 模型
我们提出的
ConvolutionAl Sequence Embedding Recommendation: Caser模型结合了卷积神经网络Convolutional Neural Network: CNN来学习序列特征、以及Latent Factor Model: LFM来学习user specific特征。Caser网络设计的目标是多方面的:同时捕获一般偏好以及序列模式、同时在union-level和point-level进行捕获、捕获skip行为、所有一切都在unobserved space中进行。如下图所示,
Caser由三个组件构成:Embedding Look-up、Convolutional Layers、Fully-connected Layers。为了训练CNN,对于每个用户action序列item作为输入,并将它们的next T items作为target(如下图左侧所示)。这是通过在用户的action序列上滑动一个大小为(u, previous L items, next T items)来表示。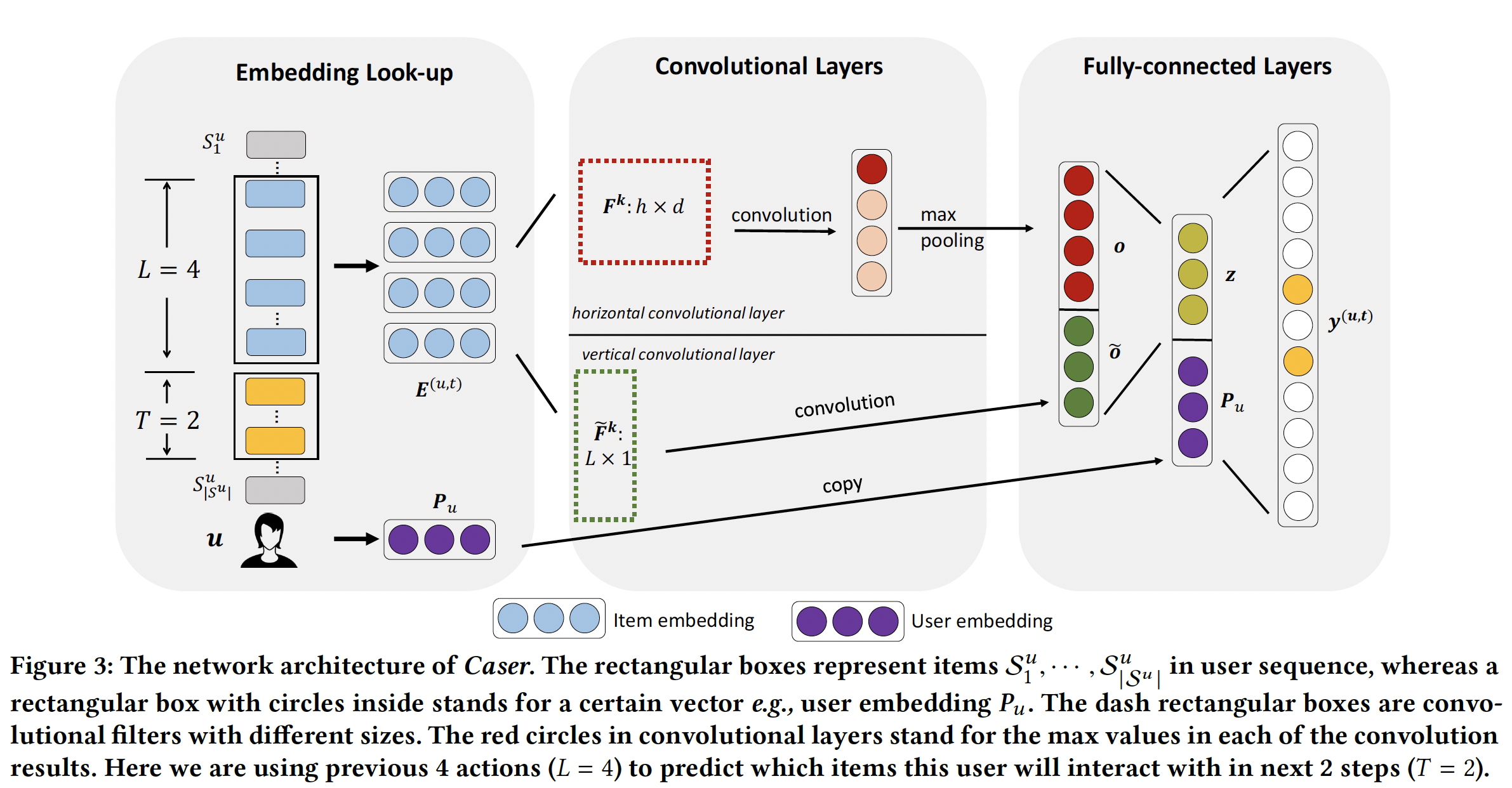
9.1.1 Embedding Look-up
Caser通过将前面item的embedding馈入神经网络中来捕获潜在空间中的序列特征。itemembeddinglatent factor的概念,这里embedding维度。embedding look-up操作检索前面item对应的item embedding,并将它们拼接在一起,从而为用户time stepembedding matrixitem中的第item的embedding。除了
item embedding之外,我们还为用户embedding向量user feature。item embedding和user embedding分别由上图中Embedding Look-up方框中的蓝色圆圈和紫色圆圈来表示。
9.1.2 卷积层
参考在文本分类中使用
CNN的思想,我们的方法将embedding矩阵item组成的image,并将序列模式视为该image的局部特征。这种方法可以使用卷积filter来搜索序列模式。下图展示了两个
horizontal filter(不同颜色的方块代表不同的参数值,颜色越深则数值越大),它们捕获两个union-level的序列模式。这些filter(表示为embedding维度(称作full width)。它们通过在row上滑动从而筛选序列模式的信号。例如,第一个filter通过在潜在维度中具有更大的值(其中酒店和机场具有更大的值)来选择序列模式(Airport, Hotel) -> Great Wall。Latent Space给出的是embedding矩阵,颜色越深则数值越大。Horizontal FIlters给出的是filter矩阵,颜色越深则数值越大。第一个filter主要捕获前面3个维度(filter末尾2个维度的取值几乎为零),而Airport和Hotel的embedding在前面3个维度取值较大、末尾2个维度取值几乎为零。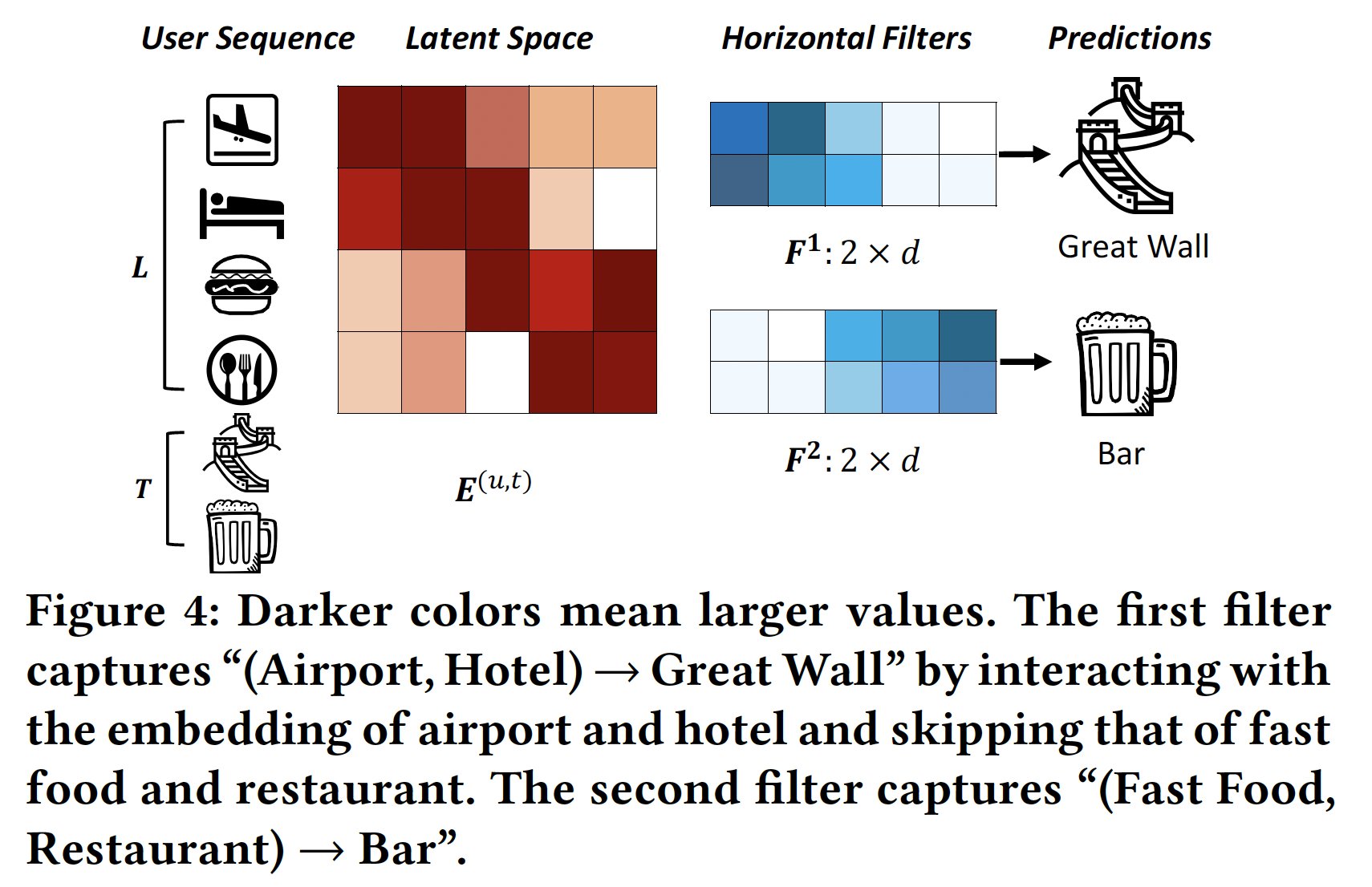
类似地,
vertical filter是一个与图像识别不同,这里的
imageitemembedding向量filter一起同时学习。水平卷积层
Horizontal Convolutional Layer:该层有horizontal filterfilter的高度。例如,如果filter,然后可以选择horizontal dimension(每个水平的行表示一个item的embedding)交互。第其中:
inner product operator,item到第item的embedding。卷积值是
然后我们对
max pooling操作,从而从该特定filter产生的所有卷积值中提取最大值。这个最大值捕获了filter抽取的最重要的特征。因此,对于卷积层的filter,它们最终总的输出为horizontal filter通过embeddingitem交互。模型同时学习embedding和filter从而最小化目标函数,这个目标函数编码了target item的预测误差prediction error。通过滑动不同高度的
filter,模型将会接收到重要的信号,无论这些信号处在什么位置。因此,可以训练horizontal filter从而捕获具有多种union size的union-level序列模式。这
filter可以采用不同的高度,因此这些filter的垂直卷积层
Vertical Convolutional Layer:我们用tilde符号filterfilter其中:
inner product operator,由于内积算子的性质,可以很容易地证明:
其中
item的embedding。因此,通过vertical filter我们可以学习聚合前面item的embedding,类似于Fossil的加权sum来聚合前面item的latent representation。不同之处在于每个filterFossil类似,这些vertical filter通过对前面item的latent representation的加权和来捕获point-level序列模式。然而Fossile对每个用户使用a single weighted sum,我们的方法使用vertical filter为所有用户生成其中
注:
- 原始论文中,垂直卷积层没有使用激活函数,理论上也可以添加激活函数。
- 垂直卷积层并没有使用最大池化,而是直接将不同
filter产生的卷积结果进行拼接。
虽然
vertical filter和horizontal filter的用途都是聚合,但是二者稍有不同:- 每个
vertical filter的尺寸固定为latent的,单次与多个连续的列进行交互是没有意义的。 - 不需要对垂直卷积的结果应用最大池化操作,因为我们希望对每个潜在维度
latent dimension保留聚合结果。
9.1.3 全连接层
我们将两个卷积层的输出拼接起来,并将它们馈入一个全连接层,从而获得更
high-level、更抽象的特征:其中:
bias向量,convolutional sequence embedding,它对前面item的各种序列特征进行编码。为了捕获用户的一般偏好,我们还
look-up了user embeddingoutput layer,即:其中:
bias向量。输出层的值
time stepitemuser embeddinguser embedding- 正如我们将在后文看到的,这使得我们的模型具有概括
generalize其它模型的能力。 - 我们可以用其它被概括模型的参数来预训练
pre-train我们模型的参数。正如《Neural collaborative filtering》所述,这种预训练对模型性能至关重要。
- 正如我们将在后文看到的,这使得我们的模型具有概括
9.1.4 模型训练和推断
为了训练模型,我们将输出层的值
其中:
sigmoid函数。这里本质上是通过负采样技术将
softmax输出转换变sigmoid输出。令
time step的集合。数据集中所有序列的似然likelihood为:其中
为进一步捕获
skip行为,我们通过用next itemnext T target items。采用负的对数似然之后,我们得到目标函数(即二元交叉熵损失):参考已有的工作,对于每个
target item3)。模型参数
grid search调优得到。我们使用Adam优化算法,batch size = 100。为了控制模型复杂度并避免过拟合,我们使用了两种正则化方法:应用于所有参数的
drop ratio = 50%的Dropout技术。我们使用
MatConvNet实现了Caser。整个训练时间与训练样本数量成正比。例如,在4-cores i7 CPU和32 GB RAM的机器上,MovieLens数据大约需要1小时、Gowalla数据需要2小时、Foursquare数据需要2小时、TMall数据需要1小时。这些时间与Fossil的运行时间相当,并且可以通过使用GPU进一步减少。在训练好模型之后,为了在
time steplatent embeddingitem的embedding作为网络的输入。我们向用户item。向所有用户进行推荐的复杂度为注意,
target item数量item数量。读者注:
Caser模型的几个不足的地方:水平卷积虽然 “宣称” 捕获了
union-level序列模式,但是卷积操作本身是non-sequential的。更准确的说法是:水平卷积捕获了union-level的局部模式local mode。如果需要捕获序列模式,那么可以用
RNN代替水平卷积。超参数
filter的大小,它刻画了local mode究竟有多local。目前Caser模型中,fixed。这使得模型不够灵活,因为不同的样本可能需要不同的可以通过
self attention机制自适应地选择相关的item,从而得到自适应的、soft的超参数
local mode影响到未来的第几个target item。目前Caser模型中,fixed。这使得模型不够灵活,因为不同的样本可能需要不同的此外,
Caser模型考虑local mode会影响未来的多个target item。这会引入大量的噪声,因为很可能当前的local mode仅与其中的某个(而不是连续的多个)target item相关。可以通过
target attention机制自适应地选择与target item最相关的item,从而过滤掉无关的item。然后对剩下的item应用CNN或RNN。
9.1.5 和现有模型的联系
Caser vs MF:通过丢弃所有卷积层,我们的模型变成一个普通的LFM,其中user embedding作为user latent factor,它们关联的权重作为item latent factor。MF通常包含bias项,在我们的模型中为MF相同:其中:
Caser vs FPMC:FPMC将分解的一阶马尔科夫链与LFM融合,并通过Bayesian personalized ranking : BPR进行优化。尽管Caser使用了不同的优化准则(即,交叉熵),但是它能够通过将前一个item的embedding复制到hidden layerbias项来概括FPMC:由于
FPMC使用BPR作为准则,因此我们的模型与FPMC并不完全相同。然而,BPR被限制为在每个time step仅有一个target样本和一个negative样本。我们的交叉熵损失没有这些限制。Caser vs Fossil:通过忽略水平卷积层并使用单个vertical filter(即hidden layer正如垂直卷积层中所讨论的那样,这个
vertical filter将前面item的embedding进行加权和,就像在Fossil中一样(然而Fossil使用Similarity Model而不是LFM) ,并将其分解在与马尔科夫模型相同的潜在空间中。另一个区别是
Fossil对每个用户使用一个局部权重,而我们通过vertical filter使用多个全局权重。
9.2 实验
数据集:仅当数据集包含序列模式时,序列推荐才有意义。为了识别这样的数据集,我们对几个公共数据集应用了序列关联规则挖掘
sequential association rule mining,并计算了它们的序列强度sequential intensity: SI:分子是
1到5)找到的,并对支持度(最小支持度为5)和置信度(最低置信度为50%)进行过滤。分母是用户总数。我们使用SI来估计数据集中序列信号sequential signal的强度。下表描述了四个数据集及其
SI。MovieLens是广泛使用的电影评分数据集。Gowalla和Foursquare包含通过user-venue check-ins得到的隐式反馈。Tmall是从IJCAI 2015竞赛中获得的用户购买数据,旨在预测重复的购买者buyer。
根据前人的工作,我们将所有数字评分转换为取值为
1的隐式反馈。我们还删除了冷启动cold-start的用户和item(反馈数量少于item) ,因为处理冷启动推荐通常在文献中被视为一个单独separate的问题。对于MovieLens, Gowalla, Foursquare, Tmall,5, 16, 10, 10。前人的工作所使用的的
Amazon数据集由于其SI太小(Office Products的SI为0.0026,Clothing, Shoes, Jewelry和Video Games的SI为0.0019)而未被使用。换句话讲,该数据集的序列信号远远低于前面的四个数据集。我们将每个用户序列中前
70%的action作为训练集,使用接下来的10%的action作为验证集来调优所有模型的最佳超参数,使用最后的20%的action作为测试集来评估模型性能。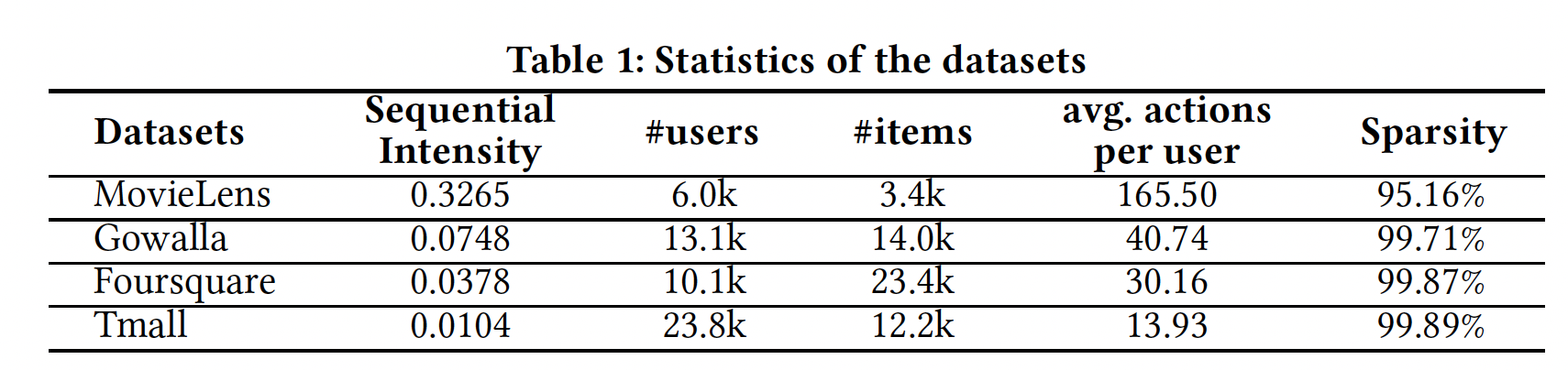
评估指标:
Precision@N和Recall@N:给定一个用户的、长度为action记做action序列中最后20%的action)。则Precision@N、Recall@N定义为:我们报告所有用户的平均
Precision@N和平均Recall@N,并且选择Mean Average Precision: MAP:给定用户的、全量item的推荐列表,记做其中:如果
item位于也有文献移除了
MAP是所有用户的AP均值。
baseline方法:POP:根据item的流行度popularity进行推荐,而流行度取决于item的交互次数。BPR:结合了矩阵分解模型的Bayesian personalized ranking: BPR是对隐式反馈数据进行非序列推荐的state-of-the-art方法。FMC和FPMC:FMC将一阶马尔科夫转移矩阵分解为两个低维子矩阵,而FPMC是FMC和LFM的融合。它们都是state-of-the-art的序列推荐方法。FPMC在每一步都允许推荐一个basket的若干个item。对于我们的序列推荐问题,每个basket都只有一个item。Fossil:Fossil对高阶马尔科夫链进行建模,并使用Similarity Model而不是LFM来建模一般用户偏好。GRU4Rec:GRU4Rec使用RNN来捕获序列依赖性并进行预测。
配置:对每种方法,都在验证集上使用
grid search调优最佳超参数。调优的超参数包括:- 对所有模型(除了
POP):潜在因子维度 - 对
Fossil, Caser, GRU4Rec:马尔科夫链阶次 - 对于
Caser:horizontal filter的高度target数量{identity, sigmoid, tanh, relu}。对于每个高度horizontal filter的数量vertical filter的数量
我们报告每种方法在其最佳超参数
setting下的结果。- 对所有模型(除了
实验结果:下表总结了所有方法的最佳结果。每一行中表现最好的结果以粗体突出显式。最后一列是
Caser相对于最佳baseline的改进,定义为(Caser-baseline)/baseline。结论:- 除了
MovieLens之外,Caser在所有指标上相对于最佳baseline都取得了大幅提升。 - 在
baseline方法中,序列推荐器(如FPMC和Fossil)通常在所有数据集上都优于非序列推荐器(即BPR),这表明考虑序列信息sequential information的重要性。 FPMC和Fossil在所有数据集上的表现都优于FMC,这表明个性化的有效性。- 在
MovieLens上,GRU4Rec的性能接近于Caser,但在其它三个数据集上的性能要差得多。 - 事实上,
MovieLens比其它三个数据集具有更多的序列信号,因此RNN-based的GRU4Rec可以在MovieLens上表现良好,但是在其它三个数据集上效果不佳。此外,GRU4Rec的推荐是session-based的,而不是个性化的,这在一定程度上扩大了泛化误差。

- 除了
接下来我们研究超参数
setting。我们聚焦于MAP超参数,因为它是一个整体的性能指标,并且与其它指标一致。维度
- 在更稠密的
MovieLens数据集上,更大的 - 但是对于其它三个更稀疏的数据集,每个模型都需要更大的
- 对于所有数据集,
Caser通过使用较小的baseline方法。
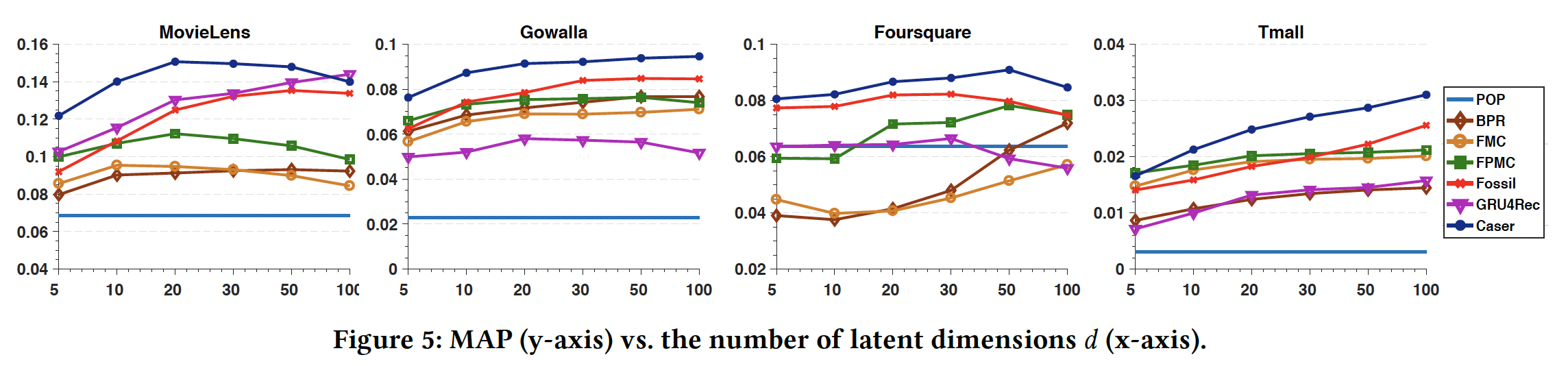
- 在更稠密的
马尔科夫阶次
target数量Caser-1, Caser-2, Caser-3表示target数量Caser,从而研究skip行为的影响。- 在更稠密的
MovieLens数据集上,Caser较好地利用了较大Caser-3表现最好,这表明skip行为的好处。 - 然而,对于稀疏的数据集,并非所有模型都始终受益于较大的
- 在大多数情况下,
Caser-2在这三个稀疏数据集上的表现略优于Caser-1和Caser-3。
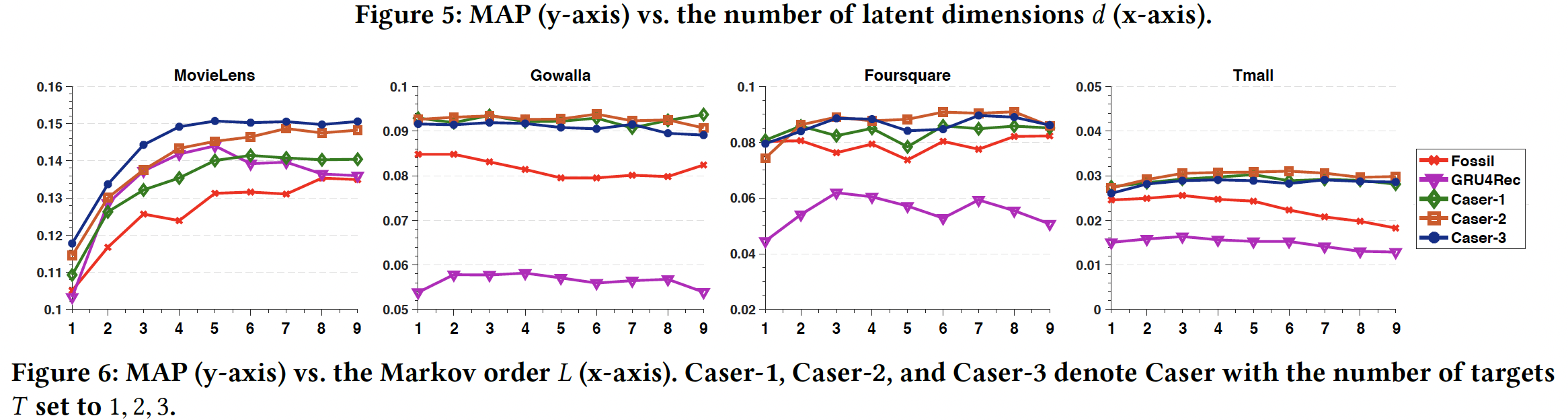
- 在更稠密的
Caser组件分析:现在我们评估Caser每个组件,水平卷积层(即setting。MovieLens和Gowalla的结果如下表所示,其它两个数据集的结果是类似的因此没有列出。对于Caser-x表示启用了组件x的Caser,其中h表示水平卷积层,v表示垂直卷积层,p表示个性化。任何缺失的组件都通过将其对应的位置填充零向量来解决。例如,vh表示采用垂直卷积层和水平卷积层,同时将结论:
Caser-p表现最差,而Caser-h、Caser-v、Caser-vh显著提高了性能,这表明将top-N序列推荐视为传统的top-N推荐将丢失有用的信息(如序列信息),并且同时在union-level和point-level建模序列模式有助于改进预测。- 对于这两个数据集,通过联合使用
Caser的所有组件(即Caser-pvh)可以获得最佳性能。
Caser-pvh与Caser-pv之间的gap刻画了水平卷积层的收益,Caser-pvh与Caser-ph之间的gap刻画了垂直卷积层的收益。可以看到,垂直卷积层要远比水平卷积层更重要,这也间接说明了point-level序列模式要比union-level序列模式更重要。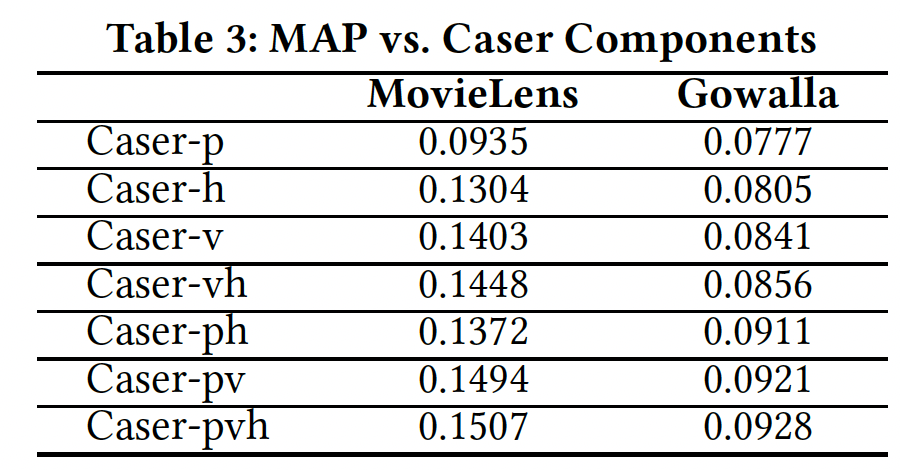
网络可视化:我们仔细研究了一些训练好的网络及其预测。
vertical filter:下图显示了在MovieLens数据集上训练Caser之后,四个vertical filter的值(指的是卷积核的权重)。在微观上四个filter被训练为多元化diverse的,但是在宏观上它们遵循从过去位置past position到最近位置recent position的上升趋势。由于每个vertical filter都是作为对前面action的embedding进行加权的一种方式,这一趋势表明Caser更加重视最近的action,这与传统的top-N推荐有很大不同(传统的top-N推荐认为每个action的重要性是相同的)。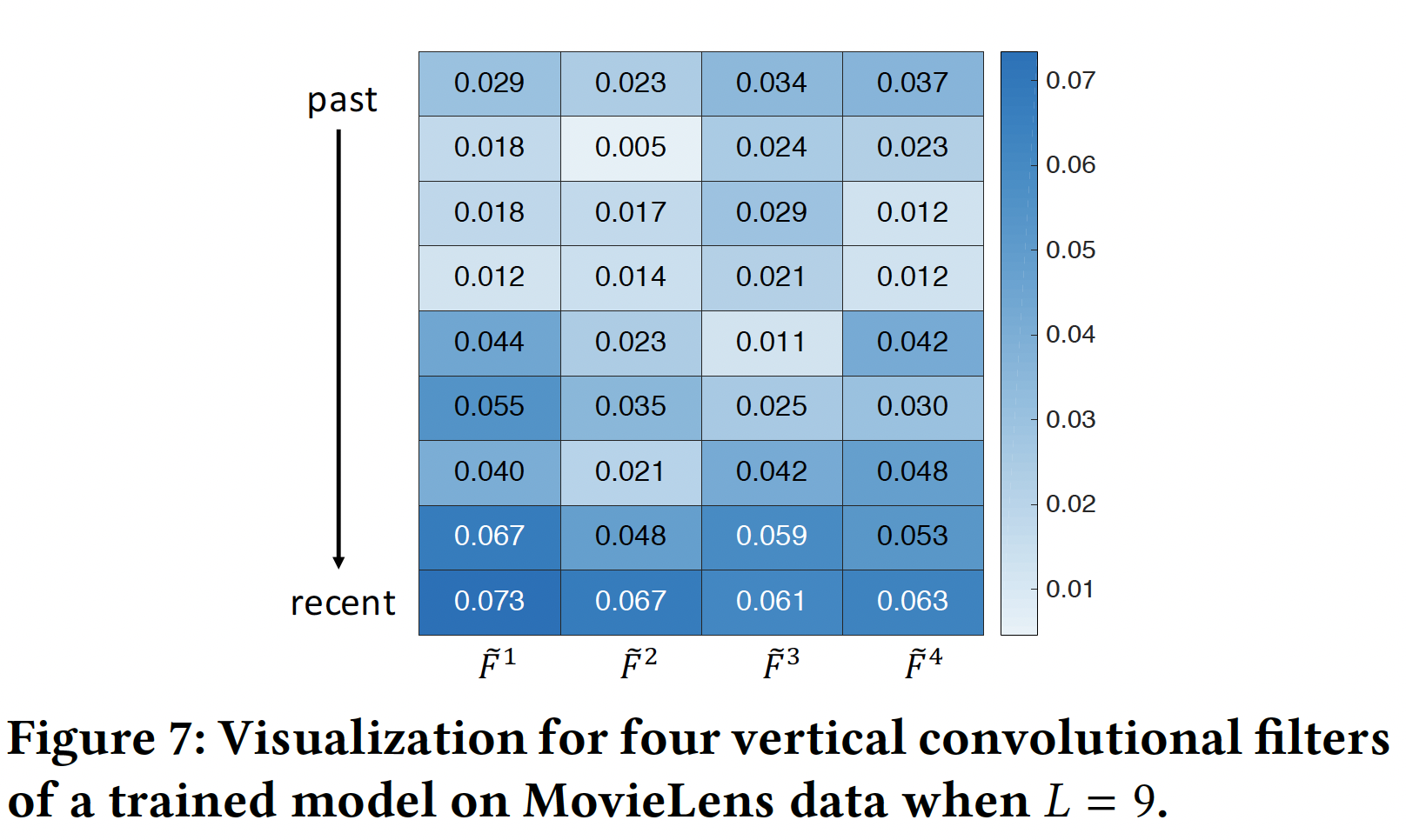
horizontal filter:为了查看horizontal filter的有效性,下图(a)显示了Caser针对一名用户推荐的、排名top N = 3的电影,即:(Mad Max)、Star War)、Star Trek)。该用户的前面13th Warrior)、American Beauty)、Star Trek II)、Star Trek III)、Star Trek IV)。ground truth(即用户序列中的next movie)。注意,下图
(b)显示了将该用户前面embedding屏蔽为全零之后(即item mask),模型预测屏蔽
2(从排名第3)。事实上既然如此,为什么不屏蔽
target attention机制对历史action序列过滤掉与target item无关的action。屏蔽
当同时屏蔽
这项研究清晰地表明:我们的模型正确地捕获到了
union-level序列特征。
十、p-RNN[2016]
传统的推荐系统算法中,通常假设用户历史日志(如点击、购买、或浏览)是可用的。但是这种假设在许多现实世界的推荐场景中并不成立:许多电商网站不需要用户认证也可以下单购买(无法获取历史行为信息),在视频流服务中用户也很少登录,许多网站的回头客占比很少(因此没有历史行为信息)。用户跟踪
user tracking可以部分解决跨session的用户识别问题(例如,通过指纹技术、cookies等等),但是这通常不可靠并且通常会引发隐私问题。因此,在这种情况下,典型的解决方案是采用item-to-item推荐。这里,论文《Parallel Recurrent Neural Network Architectures for Feature-rich Session-based Recommendations》研究如何利用session数据来改进推荐。鉴于没有用户画像(指的是用户历史行为信息),从
session点击中获取尽可能多的信息至关重要。除了session的点击流click-stream数据(被点击的item-ID序列),还可以考虑被点击item的特征。item通常带有丰富的feature representation,如详细的文本描述或图像(比如缩略图)。可以预期,例如,购买特定类型item的用户会点击具有相似文本描述或相似视觉特征的item。图像、文本、甚至更丰富的特征(例如动画gif)是最终被用户所看到的,并且将决定一个item对用户的吸引力。在历史user-specific数据缺失或者不重要的session modeling的setting中,特征变得尤为重要。应该利用这些特征来帮助session modeling过程。item特征也是处理item冷启动问题的一种非常好的方法。这项工作同时利用深度学习技术从视觉信息中抽取高质量特征、以及建模
session(论文还通过bag-of-words从文本中抽取特征)。论文采用parallel RNN: p-RNN架构来联合建模click以及被点击item的特征(文本特征或图像特征)。具体而言,论文并未使用单个RNN(其中所有数据源以拼接的方式作为input使用)来联合建模被点击的item及其特征,而是代替以并行架构parallel architecture,因为数据的性质非常不同:图像特征往往比item-ID的one-hot representation或文本的bag-of-words representation要稠密得多。论文介绍了3种不同的p-RNN架构,它们将click数据与被点击item的特征相结合。不同的架构有不同的共享模型参数,以及不同的隐状态交互。论文还指出,训练
p-RNN并非易事。标准的同时训练standard simultaneous training会浪费网络的容量,因为同一个网络的不同部分可能会从数据中学习相同的关系。因此,论文设计了3种替代的优化程序来训练p-RNN。论文在实验中评估了所提出的p-RNN架构,并与item-kNN进行对比。相关工作:
用于推荐系统的神经模型
neural model:大多数关于深度模型和推荐的工作都集中在经典的协同过滤collaborative filtering: CF上。受限玻尔兹曼机
Restricted Boltzmann Machines: RBMs是最早用于经典CF和推荐系统的神经网络之一。最近,降噪自编码器denoising autoencoder已被用于以类似的方式执行CF。深度学习也被用于跨域推荐,其中使用深度学习技术将item映射到联合潜在空间。Recurrent Neural Models: RNNs:在处理序列数据时,RNN是首选的深度模型。Long Short-Term Memory: LSTM网络是一种已被证明工作得特别好的RNN,它能够解决经常困扰标准RNN模型的梯度消失问题。LSTM的略微简化的版本是我们在这项工作中使用的Gated Recurrent Units: GRUs。session-based推荐:当无法从过去的用户行为构建用户画像时,经典的CF方法(例如矩阵分解)在session-based的setting中失效。这个问题的一个自然解决方案是item-to-item推荐。在这个setting中,从可用的session数据中预先计算出一个item-to-item相似度矩阵,其中在session中经常被一起点击的item被认为是相似的。然后这些相似性被用于推荐。虽然简单,但是这种方法已被证明是有效的并被广泛采用。但是,该方法仅考虑用户的最后一次点击,实际上忽略了之前点击的信息。session中,两个item“共现”的前提是 “兼容”。例如,用户可以在同一个session(比如一个小时内)内点击两篇不同的新闻,但是用户通常难以在同一个session内消费两个不同的马桶(例如该用户最近有装修房子的需求),即使这两个马桶非常相似。马尔科夫决策过程
Markov Decision Processes: MDPs是另一种方法,旨在以session-based方式来提供推荐,同时考虑到最后一次点击之外的信息。最简单的MDP可以归结为一阶马尔科夫链,其中next recommendation可以简单地通过item之间的转移概率transition probability来计算。在session-based推荐中应用马尔科夫链的主要问题是:当试图在所有item上包含所有可能的、潜在的用户行为序列时,状态空间很快变得难以管理。《Session-based Recommendations with Recurrent Neural Networks》是神经模型在session-based推荐中的首次应用,它使用RNN来建模session数据。这项工作仅关注被点击的item ID,而这里我们的目标是建模被点击item的更丰富的representation。feature-rich的推荐:深度模型已被用于从音乐或图像等非结构化内容中抽取特征。在推荐系统中,这些特征通常与更传统的协同过滤模型一起使用。- 深度卷积网络已被用于从音乐中抽取特征,然后将其用于因子模型。
- 最近,
《Collaborative deep learning for recommender systems》引入了一种更通用的方法,其中使用深度网络从item中抽取通用内容特征,然后将这些特征融合到标准CF模型中从而提高性能。这种方法似乎在没有足够user-item交互信息的环境中特别有用。 - 一些工作使用卷积网络抽取图像特征并用于经典的矩阵分解模型从而提高推荐质量。
10.1 模型
作为
baseline,我们采用《Session-based recommendations with recurrent neural networks》中的最佳RNN的setting:单层GRU layer,没有前馈层,采用TOP1 pairwise loss函数,采用session-parallel的mini-batch。网络的输入是被点击的item ID。在训练期间,将预测分数的分布与
session中真实的next event对应的target item id(以one-hot的形式)进行比较,从而计算TOP1损失。为了降低计算成本,在训练期间仅计算target item的分数以及一小部分negative item。于给定的session,我们使用当前mini-batch中其它session中的item作为negative item。target item即真实被点击的那个item,也是我们要预测的ground truth。一个
p-RNN由多个RNN子网组成,每个RNN子网用于item的某个representation/aspect,如一个RNN用于item ID、另一个RNN用于item image、还有一个RNN用于item text。模型有三个输入源:一个
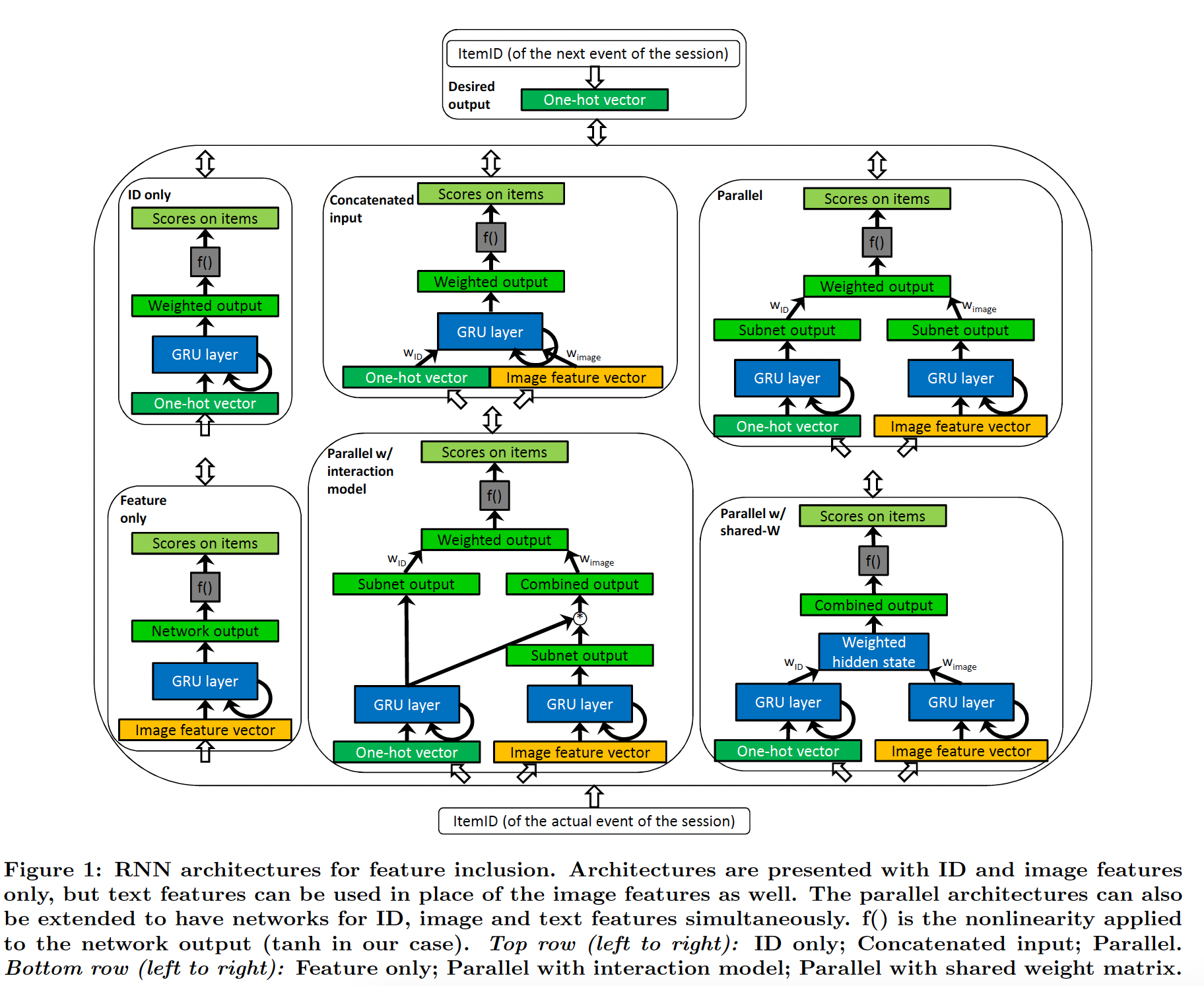
one-hot ID vector代表item ID输入源、一个预先计算的稠密的image feature vector代表item image输入源、一个稀疏的unigram+ bigram text feature vector代表image text输入源。关于特征提取,本文后面将详细介绍。p-RNN架构如下图所示,由于篇幅有限,我们仅展示具有ID和图像特征的架构。对于文本特征,可以与图像特征类似地进行。p-RNN架构还可以同时处理ID、图像特征、文本特征。架构分为两组:
baseline架构:ID only:此架构仅使用one-hot ID vector作为输入,与《Session-based recommendations with recurrent neural networks》中使用的相同。它作为我们实验的baseline。output就是GRU的最后一个hidden state经过一个投影矩阵(即hidden to output权重矩阵)之后的结果。Feature only::此架构的输入是内容特征向量之一(图像或文本)。其它的工作方式与ID only网络类似。Concatenated input:组合不同item representation的最简单方法是将它们拼接起来。该架构的输入是one-hot ID vector和内容特征向量的拼接。input level的融合,不同数据源融合之前,需要分别乘以
p-RNN架构:Parallel:该架构为每个representation训练一个GRU子网,output是从子网hidden layer的拼接中计算出来的(等价于独立计算每个子网的output score并加权output score,然后通过激活函数f())。output level的融合,每个子网的output融合之前,需要分别乘以Parallel shared-W:这种架构与Parallel架构的不同之处在于,每个子网具有共享的hidden to output的权重矩阵 。这种架构中不会为每个子网单独计算output,相反,hidden state的加权和乘以单个权重矩阵来产生output。采用一个共享的权重矩阵大大减少了参数的数量,从而减少了训练时间和过拟合。hidden state level的融合,每个子网的hidden state融合之前,需要分别乘以它的模型容量相比
Parallel更小,并且实验表明其效果相比Parallel更差。Parallel interaction:在该架构中,item feature subnet的隐状态在计算子网的分数之前以逐元素乘积的方式乘以ID subnet的隐状态 。混合session的不同方面来计算item分数,这类似于context-aware偏好建模。类似于
Parallel架构,但是融合发生了两次:一次是output level的融合(和Parallel相同),另一次是对item feature subnet隐状态的加权融合。论文中的图表可能有误(或者论文对该架构的描述有误),这里逐元素乘积的时刻应该是在
subnet output和GRU layer之间,而不应该是subnet output和combined output之间。
读者注:
p-RNN的核心就在于,信息源融合的时机(输入时?hidden state时?输出时?)、融合的方式(拼接?加权和?逐元素乘积?)、融合几次(一次?两次?)。该论文并未评估所有的这些可能性,因此不太完善。并且实验表明仅在输出时进行信息源融合的效果是最佳的(独立处理每一路,并在预测之前融合)。读者注:本文的主要贡献是两点:验证信息源如何融合、以及不同子网的训练方式(交替训练)。最佳的方式是
Parallel架构加Residual或Interleaving训练方式。这种残差式的训练模式,可以作为一种多模型ensemble训练的范式:后续子模型在残差上训练,然后ensemble在一起。
训练
p-RNN:训练p-RNN架构并非易事。由于架构的不同组件从数据中学习相同的关系,整个架构的标准反向传播可能会产生次优结果。这可以通过预训练网络的某些组件并在后续训练剩余组件来避免。这种循环的训练可以进行多次,这得益于交替方法(如ALS) 在矩阵分解中的成功。我们为p-RNN制定了以下训练策略:Simultaneous:每个子网的每个参数都是同时训练的。它作为baseline。Alternating:每个epoch以交替的方式训练子网。如,ID subnet在第一个epoch进行训练,而其它子网是固定的。然后我们在下一个epoch固定ID subnet并训练image subnet,以此类推。当每个子网都被训练一个epoch之后,循环往复。Residual:在先前训练的子网的ensemble的残差上,子网一个接一个地被训练。不会重新循环往复,但是与Alternating方法相比,每个子网的训练时间更长。例如,ID subnet训练10个epoch,然后image subnet在ID subnet的残差上继续训练10个epoch,等等。Interleaving:每个mini-batch交替训练。例如,ID subnet训练一个mini-batch,然后image subnet在ID subnet的残差上继续训练一个mini-batch,以此类推。更频繁的交替允许跨子网进行更平衡的训练,而没有Simultaneous训练的缺点。
读者认为后两种残差式的更新方式是存在一定问题的。
- 如果两个子网之间几乎是独立的(如
Parallel架构),那么一个子网的更新不会影响另一个子网的能力,那么一个子网去学习另一个子网的残差是合理的。这使得两个子网之间能力。 - 如果两个子网之间是耦合的(如
Parallel interaction架构),那么一个子网的更新会影响另一个子网的能力,那么一个子网在学习另一个子网残差的过程中,也会影响这个残差本身。即,子网参数的更新会改变子网学习的目标(即,残差)。这使得模型很难学习(没有固定的目标)。
最终实验部分的效果也验证了这一点:在
Residual和Interleaving学习策略上,Parallel iinteraction架构的效果不如Parallel架构的效果。特征抽取:图像特征
image feature是从视频缩略图thumbnail中抽取的,而文本特征text feature是基于产品描述的。编码图像:我们使用
Caffe深度学习框架实现的GoogleNet从视频缩略图中抽取特征。该网络在ImageNet ILSVRC 2014数据集上被预训练。视频缩略图首先必须按比例缩小和裁剪,以便适应网络的输入。我们从最后一个均值池化层中抽取图像特征。特征向量被归一化为l2范数为1。我们最终得到的image feature representation是一个长度为1024的实值向量。下图通过显示与两个
query image最相似的3个图像来说明图像特征的质量,其中相似度被定义为图像特征向量之间的余弦相似度。鉴于图像特征的质量良好,我们不会将CNN直接插入RNN,因为这会给训练带来不必要的复杂性,而且也不实用。因为:- 这使得网络的收敛速度会慢得多,因为它需要在变化的
item representation上学习模型。 - 网络不适合
item数量较少的数据集,因为1万个item不足以充分利用CNN的潜力。 retraining需要更长的时间(因为模型更复杂、计算复杂度更高)。
另一种可能的选择是在
RNN训练期间微调image feature representation。这对我们的实验没有太大影响,因此我们没有使用微调fine tuning。
- 这使得网络的收敛速度会慢得多,因为它需要在变化的
编码文本:鉴于在线分类广告平台对描述文本长度的严格限制,广告主通常为其
item提供相当简洁的文本。描述文本的主要目的是吸引潜在感兴趣的用户的注意。因此,描述文本通常仅包含item的主要特点,并使用语法错误的句子。此外,用多种语言编写描述文本从而吸引更广泛的受众也很常见。我们的数据集的大部分描述文本使用了3种主要语言,另外也有少数不太常见的语言。鉴于我们数据中非结构化文本和多种语言的固有噪声,我们采用经典的
bag-of-words representation来编码产品描述文本。- 首先,我们将
item的标题和描述文本拼接起来。 - 然后,我们过滤停用词
stopword并从文本中抽取unigram和bigram,并丢弃所有仅出现一次的项。 - 最后,我们使用
TF-IDF对生成的bag-of-words进行加权。
最终的
text feature representation是一个长度为1099425的稀疏向量,平均有5.44个非零元素。我们尝试了其它方法从非结构化文本中抽取特征,例如
distributed bag-of-word、Language Modeling with RNN。然而,我们发现带有TF-IDF的经典bag-of-words最适合我们的数据。我们将此归因于用户生成内容user generated content: UGC的噪音。由于缺乏英文的文本、以及存在多种语言,所以我们无法使用预训练的word representation,如来自word2vec的word embedding。我们尝试在输入特征和网络之间插入
embedding layer,实验结果发现性能更差。因此我们使用经典的bag-of-words/TF-IDF特征作为text feature representation,并直接用于RNN的输入。- 首先,我们将
10.2 实验
数据集:
VIDXL数据集:该数据集是从2个月内从类似YouTube的视频网站收集的,其中包含至少具有预定时长的视频观看事件。在收集期间,item-to-item的推荐展示在精选视频旁边,由一系列不同的算法生成。CLASS数据集:该数据集由在线分类网站的商品查看事件组成。该网站在收集期间也展示了不同算法给出的推荐。
在原始
event-stream的预处理过程中,我们过滤掉了不切实际的长session,因为这些session可能是由于机器人bot流量造成的。我们删除了单个事件的session,因为它们对session-based推荐没有用。我们还删除了频次低于五次的item,因此低频的item不适合建模。每个数据集最后一天的
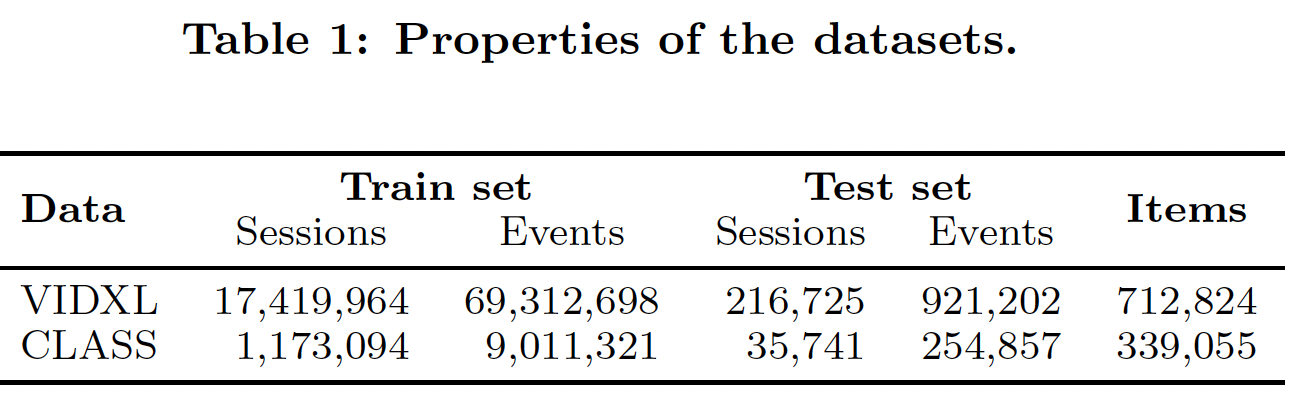
session作为 测试集,其它session作为训练集。每个session要么分配给训练集、要么分配给测试集,我们不在session中间拆分数据。对于测试集session中的item,如果它们不在训练集中那么我们也会将它们过滤掉。数据集的统计信息如下表所示。
评估方式:我们评估
next-event prediction task,即,给定session事件,算法预测session的next event。我们将测试集session中的事件一个接一个地馈入训练好的模型,然后检查next event的item的排名。当session结束后,网络的隐状态重置为零。由于推荐系统一次只能推荐几个
item,用户选择的实际item(即next item,也称作target item)应该包含在推荐列表的前面几个item中。因此,我们的主要评估指标是recall@20,即:在所有test case的推荐列表的top-20中,具有target item的case的比例。召回不考虑target item的实际排名,只需要它位于推荐列表的top-N。这很好地建模了某些实际场景,在这些场景中推荐位置和顺序无关紧要。召回率通常也与重要的在线KPI密切相关,如点击率CTR。实验中使用的第二个指标是
Mean Reciprocal Rank: MRR@20,它是target item的排名倒数reciprocal rank的均值。如果target item的rank > 20,那么排名倒数设为零。MRR考虑target item的排名,这适用于推荐顺序很重要的场景,例如尾部排名的item仅在屏幕滚动之后才可见。
10.2.1 基于缩略图的视频推荐
我们从视频的缩略图中抽取图像特征。我们对不同架构和训练策略进行了实验,从而了解图像数据如何有助于提高推荐准确性。
和
《Session-based Recommendations with Recurrent Neural Networks》类似,所有网络使用adagrad来优化TOP1损失。ID only网络和feature only网络的参数(如dropout、学习率、动量、batch size等等)在留出hold out的验证集上进行了优化。然后在完整的训练集(包括验证集)上重新训练网络,并在测试集上测量最终结果。由于
VIDXL数据集太大,更复杂网络的子网使用对应的ID only网络或feature only网络的最佳超参数。子网的权重被设置为相等,因为我们没有得到显著不同的结果(除非任何一个子网的权重设为零,此时才会有显著不同的结果)。为了加快评估速度,我们计算了
target item与50000个最热门item的排名。评估列表的长度会影响评估指标,列表越长则
recall指标越高、precision指标越低。但是对于相同的评估列表,不同算法之间的比较仍然是公平的。下表总结了不同架构和训练策略的效果。在本实验中,对于
baseline架构,隐单元数量设为100。对于p-RNN,每个子网的隐单元设为100。网络训练了10个epoch,因为之后的损失没有显著变化。我们将这些网络与item-kNN算法进行了比较。由于额外的信息源和网络整体容量的增加,具有
100 + 100个隐单元的p-RNN可以轻松超越具有100个单元 的ID only网络。因此,我们还评估了200个隐单元的ID only网络的准确性从而作为一个强大的baseline。结论:
baseline方法之间:与
《Session-based Recommendations with Recurrent Neural Networks》类似,RNN(即,ID only网络)的性能大大优于item-kNN baseline。RNN在这项任务上的召回率非常高,因此更先进的架构很难显著改善这一结果。仅在图像特征上训练的网络(即,
Feature only网络)明显比ID only网络更差,甚至比item-kNN更差,这表明item特征序列本身并不足以很好地建模session。将
ID和图像特征拼接起来作为网络的输入,因为在训练期间更强的输入占主导地位,因此该网络(即Concatenated网络)的性能与ID only网络的性能相差无几。单个
GRU layer很难同时处理两种类型的输入,导致性能与ID only网络的性能非常相似。使用朴素的方法添加item特征没有明显的好处,因此我们建议改用p-RNN架构。
p-RNN架构之间:若干个
p-RNN架构的性能显著优于ID only网络这个强大的baseline。由于baseline的高召回率,这些新颖的架构主要提升了MRR,即:它们没有找到更多的target item,但是它们对target item进行了更合适的排名。性能最好的架构是经典的
Parallel架构。通过简单的Simultaneous训练,它在MRR指标上显著优于ID only网络,但是在recall指标上稍差。通过
Simultaneous训练,p-RNN的不同组件从数据中学习相同的关系,因此没有利用网络的全部容量。因此,我们建议使用其它训练策略。
训练策略之间(对于
Parallel架构):- 最好的训练策略是
Residual训练,紧随其后的是Interleaving训练,但Alternating训练也紧随其后。 - 使用
Risidual训练的Parallel架构在MRR指标上比ID only网络显著提升,同时实现了类似的召回率。和item-kNN相比,Risidual训练的Parallel架构的改进更大,召回率提升12.21%、MRR提升18.72%。
- 最好的训练策略是
可以看到
Shared-W的效果不如Parallel的效果,这是可以预期的,因为Shared-W的模型容量更低。在
Residual和Interleaving学习策略上,Parallel interaction架构的效果不如Parallel架构的效果,原因如前所述。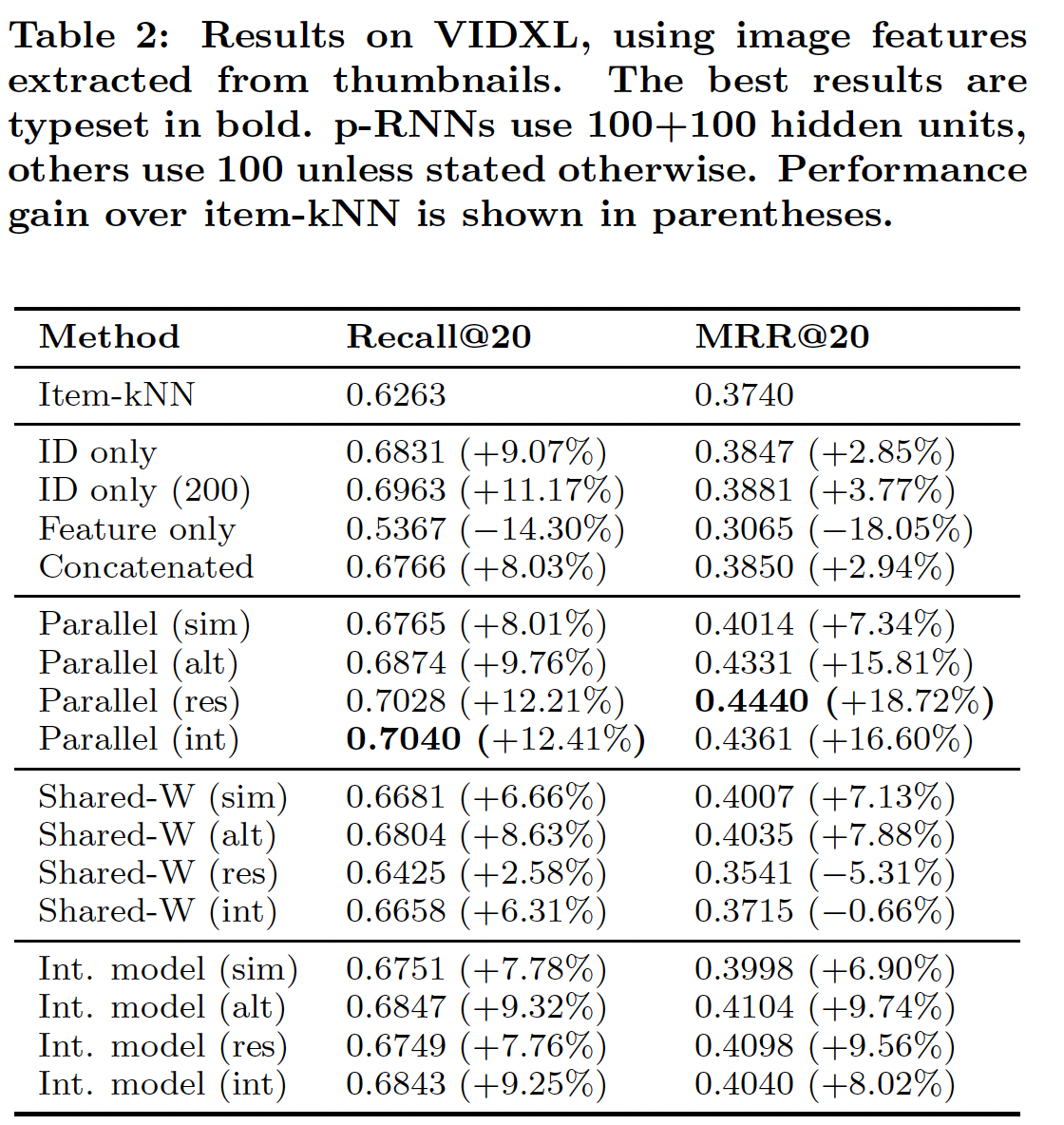
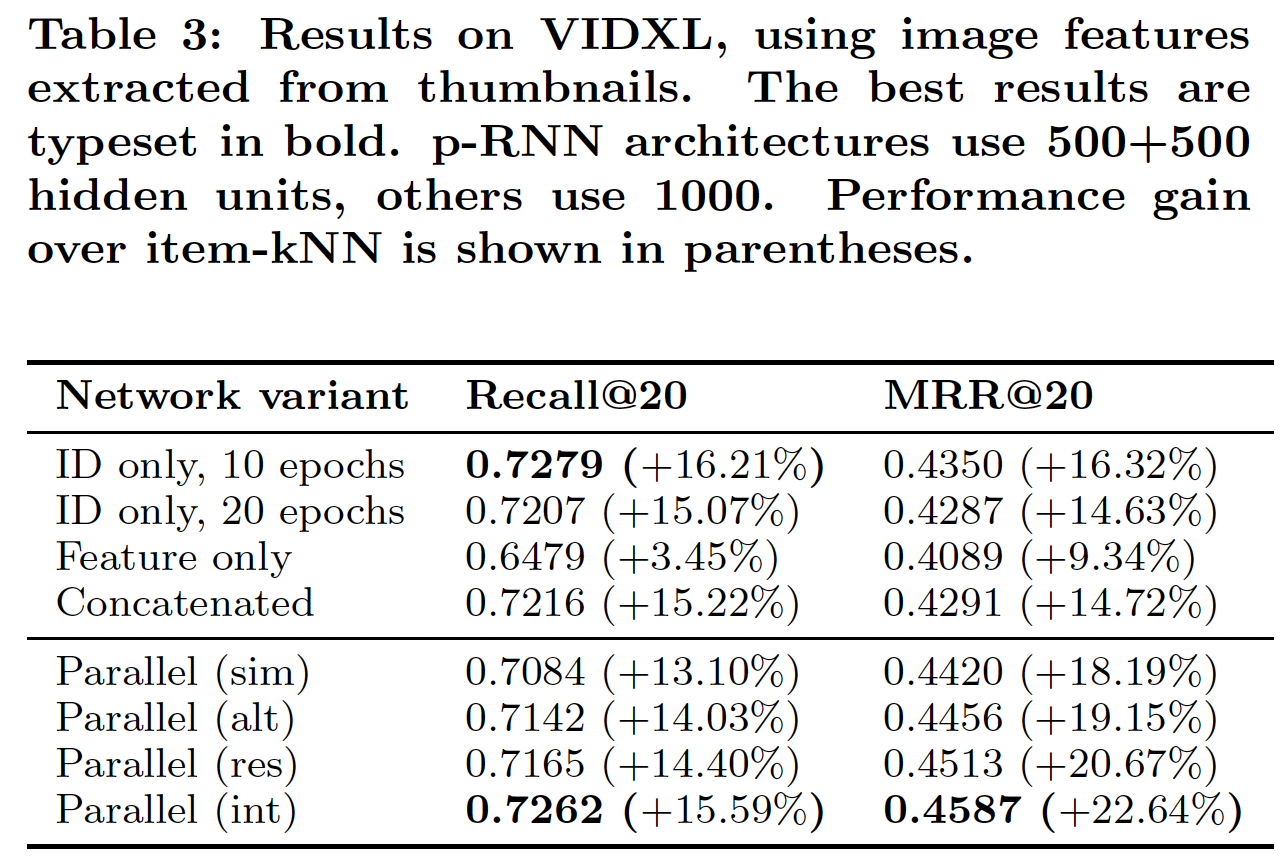
通过增加隐单元数量,
RNN的模型容量增加,因此这个参数对模型性能有很大的影响。然而,这个参数也遵循收益递减规模 。我们发现超过1000个隐单元的结果并没有显著改善,因此我们实验了具有1000个隐单元的non-parallel架构,以及具有500 + 500个隐单元的性能最好的Parallel架构,从而确认在增加网络容量和/或epoch数量的收益递减时,添加item特征也可以使得session modeling受益。下表给出了实验结果。随着隐单元的增加,网络性能会提高,甚至
Feature only网络的性能也优于item-kNN baseline,因为网络的容量足以利用图像特征中的信息。但是除此之外,结果之间的关系与前面的实验结果相似。进一步增加隐单元的数量和/或
epoch的数量并没有显著提高任何网络的性能,但是Parallel架构在MRR方面显著优于更大模型容量的ID only网络,并且具有相似的召回率。这意味着我们的架构以及我们的训练策略可以显著提高网络性能,即使随着网络容量的增加而收益递减。换句话讲,添加额外的数据源(
item特征)可以提高推荐的准确性。然而,处理多个数据源需要特殊的架构(Parallel架构)和训练策略(Residual或Interleaving)。
10.2.2 使用产品描述
我们在
CLASS数据集上重复了上一个实验,即baseline RNN有1000个隐单元、Parallel架构每个子网有500个隐单元,其中特征是从产品描述文本而不是图像中抽取的。实验设置与前面相同,只是我们选择在评估期间对所有item排名,因为该数据集的item set规模明显更小(相比VIDXL数据集),因此可以在合理的时间内进行全面的评估。结果如下表所示,可以看到结果与前面图像特征实验的结果一致。
- 在
MRR指标上,Feature only网络明显优于item-kNN baseline。这证实了可以有效地利用文本特征来产生更好的排名。 - 但是,与
ID only的网络相比,Feature only网络的效果较差。这表明单独的文本特征是不够的。 - 在文本特征和
ID拼接作为输入的情况下,Concatenated网络的性能类似于ID only网络,类似于前面的实验 。 - 我们提出的
non Simultaneous训练策略在训练Parallel架构时至关重要,Simultaneous训练策略在推荐准确性方面显然不是最佳的。Residual训练策略被证明是该实验中的最佳训练策略,相比ID only网络,其召回率提高了6%、MRR提高 了6.5%。 - 注意,进一步增加
baseline RNN的隐单元数量或epoch数量并没有进一步改善结果。
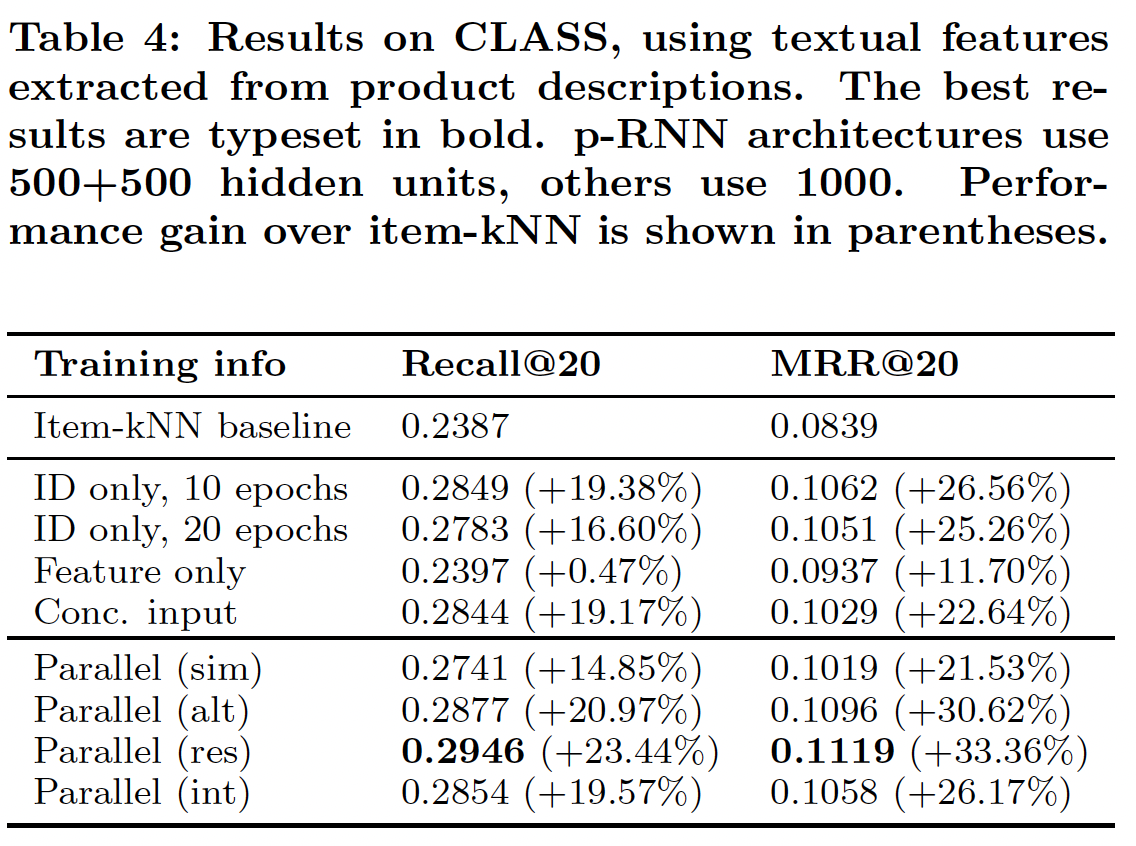
- 在
在下图中,通过我们的方法与
item-kNN和具有1000个隐单元的ID only网络进行比较,从而说明了我们的解决方案(每个子网500个隐单元)的能力。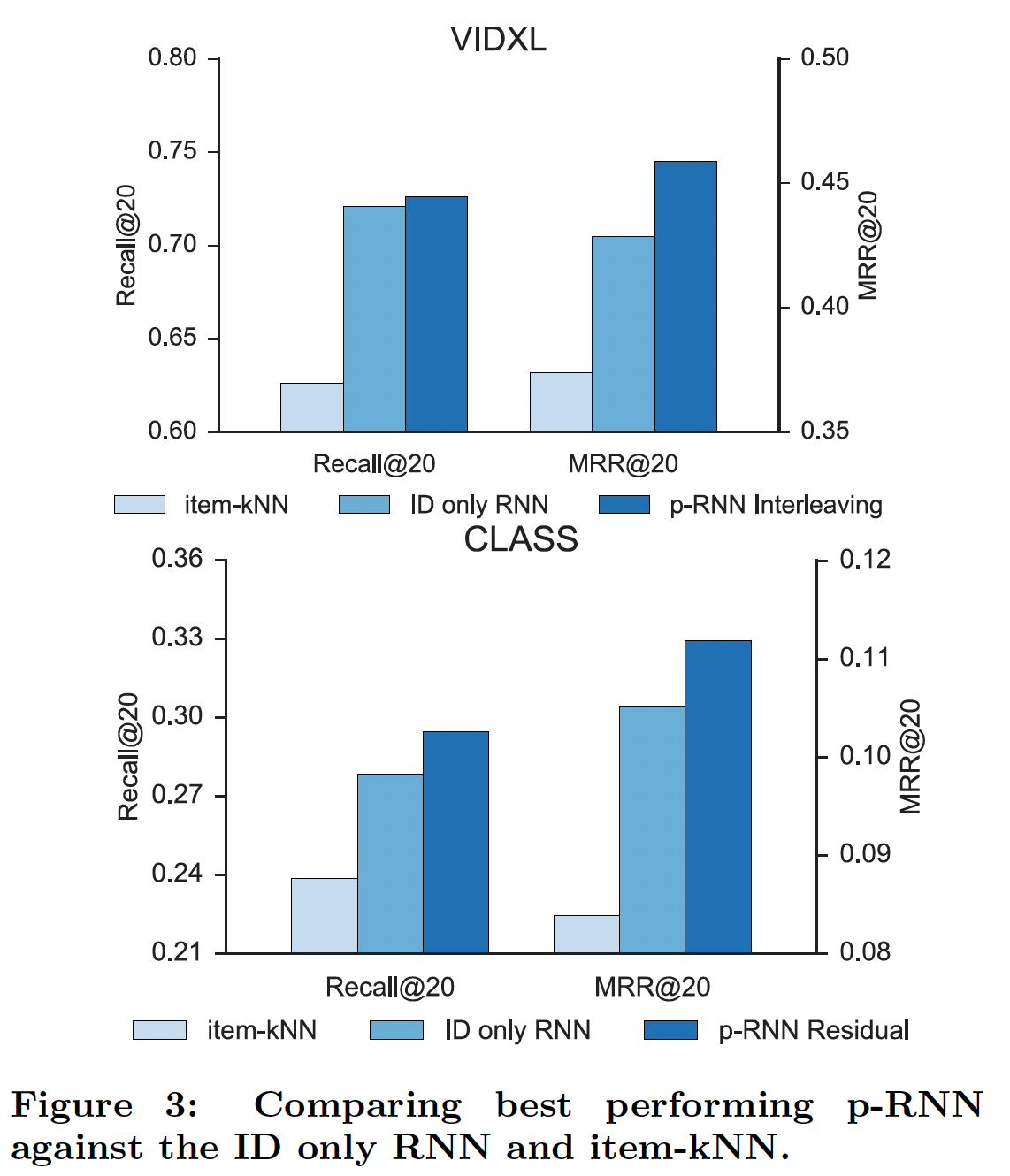
十一、GRU4Rec Top-k Gains [2018]
在推荐系统中,
RNN已被应用于session-based推荐,并取得了令人印象深刻的结果。与传统的similarity-based方法相比,RNN的优势在于它们可以有效地建模整个session的用户交互(如点击、查看等等)。通过建模整个session,RNN实际上可以学到session的“主题theme”,从而提供比传统方法更准确的推荐(效果提升在20% ~ 30%之间)。推荐的主要目标之一是根据用户偏好对
item进行排名。即,item list尾部的item(用户不喜欢的item)的确切排名或评分并不那么重要,但是将用户喜欢的item正确地排名在item list头部(如top 5/10/20的位置)非常重要。为了通过机器学习实现这一点,通常必须利用learning to rank技术,具体而言是ranking目标和ranking loss函数。当前的session-based RNN方法使用ranking loss函数,具体而言是pairwise ranking loss函数。与大多数深度学习方法一样,选择良好的
ranking loss会对模型性能产生非常重要的影响。- 由于深度学习方法需要在多个
layer上传播梯度,损失函数的梯度会反向传播,因此损失函数的质量会影响优化的质量和模型的参数。 - 此外,由于推荐任务的特性,通常需要大输出空间
large output space(因为系统的item set较大)。这为ranking loss的设计带来了独特的挑战。我们将看到,解决这个大输出空间问题的方式对于模型性能非常关键。
在论文
《Recurrent Neural Networks with Top-k Gains for Session-based Recommendations》中,作者分析用于session-based推荐的RNN中使用的ranking loss函数。这种分析导致了一组新的ranking loss函数,与之前的常用损失函数相比,RNN的性能提高了35%而没有显著的计算开销。论文本质上设计了一组新的损失函数,它结合了深度学习的learning、以及learning to rank的文献。来自工业界的若干个数据集的实验结果表明:论文方法的推荐准确性得到显著提升。结合这些改进,RNN与传统memory-based协同过滤方法的差异提高到53%(以MRR和Recall@20指标衡量),这表明深度学习方法为推荐系统领域带来了潜力。- 由于深度学习方法需要在多个
相关工作:
session-based推荐中采用的主要方法之一是item-to-item推荐方法,该方法主要用于缺失用户画像(指的是用户历史行为信息)时的session-based推荐。在该setting中,item-to-item相似度矩阵是从可用的session数据中预先计算的,并且在session中经常被一起点击的item被认为是相似的。然后在session期间使用这个相似度矩阵向用户推荐当前点击item最相似的item。Long Short-Term Memory: LSTM网络是一种RNN,已被证明可以解决困扰普通类型RNN的优化问题。LSTM的一个稍微简化的版本是我们在这项工作中使用的Gated Recurrent Unit: GRU。RNN已被成功应用于session-based推荐领域。《Session-based Recommendations with Recurrent Neural Networks》为session-based推荐任务提出了一个具有pairwise ranking loss的RNN。《Improved Recurrent Neural Networks for Session-based Recommendations》提出了数据增强技术来提高用于session-based推荐的RNN的性能,但是这些技术具有增加训练时间的副作用,因为单个session被拆分为若干个sub-session进行训练。《Parallel Recurrent Neural Network Architectures for Feature-rich Session-based Recommendations》提出了通过特征信息(如来自被点击item的文本和图像)增强的RNN用于session-based推荐,并显示出比普通RNN模型更好的性能。
RNN也被用于更标准的user-item协同过滤setting,其目的是建模user factor和item factor的演变,结果不那么引人注目,所提出的方法几乎没有优于标准的矩阵分解方法。这是意料之中的,因为在数据集的时间范围内,没有强有力的证据表明用户口味的演变,并且对不在相同session中消费的item进行序列建模(指的是协同过滤中未考虑session信息),可能不会带来很大收益。这项工作涉及的另一个领域是针对推荐系统量身定制的损失函数。在这个领域,特别是在矩阵分解技术的背景下,已有一些工作。协同过滤中最早的
learning to rank技术之一是由《COFIRANK Maximum Margin Matrix Factorization for Collaborative Ranking》引入的。本质上,该论文引入了一个listwise loss函数以及用于优化因子的alternating bundle方法。后续一些工作为协同过滤引入了更多的ranking loss函数。注意,这些损失函数虽然在矩阵分解中运行良好,但是并不能以任何方式保证它们是RNN的最佳选择,因为在RNN中进行反向传播要比在矩阵分解中更加困难。事实上,我们将看到BPR(一种流行的损失函数)需要进行重大修改,从提高session-based推荐中的RNN的效果。与在深度网络中对大输出空间进行采样从而对语言模型进行有效损失计算相关的另一项工作是
blackout方法(《Blackout: Speeding up recurrent neural network language models with very large vocabularies》),该方法本质上应用了类似于《Session-based Recommendations with Recurrent Neural Networks》中使用的采样过程,以便有效地计算categorical cross-entropy loss。
11.1 输出采样
我们将
《Session-based Recommendations with Recurrent Neural Networks》中实现的RNN算法称作GRU4Rec。在本节中,我们将重新审视GRU4Rec如何对输出进行负采样并讨论其重要性。我们扩展了负采样技术,增加了additional sample,并认为这对于提高推荐准确性至关重要。注意,“样本” 有两种含义:一种含义是用于训练的实例,也称作
example;另一种含义是采样程序所采样到的实例。在这一章节,我们避免使用 “样本”,而代替以example(用于模型训练)、sample(用于采样程序)。在每个训练
step中,GRU4Rec将session中当前事件event的item(以one-hot向量表示)作为输入。网络的输出对应于item set中每个item的分数score,代表每个item成为session中的next item的可能性。训练过程会遍历
session中的所有事件。基于backpropagation through time: BPTT训练的复杂度为training event的数量,item set规模)。计算所有item的分数是非常不切实际的,因为这使得模型unscalable。因此,GRU4Rec使用采样机制并在训练期间仅计算item set的某个子集的分数。神经网络通常并不是每次训练一个实例
example,而是每次训练一批example,这种做法被称作mini-batch training。mini-batch training有若干好处:- 更好地利用当前硬件的并行化能力,从而训练更快
training faster。 - 产生比随机梯度训练更稳定的梯度,从而收敛更快
converging faster。
GRU4Rec引入了基于mini-batch sampling。对于mini-batch中的每个example,相同mini-batch的其它example作为negative sample,如下图所示。从算法实现的角度来看,这种方法是实用的,并且对于GPU也可以有效地实现。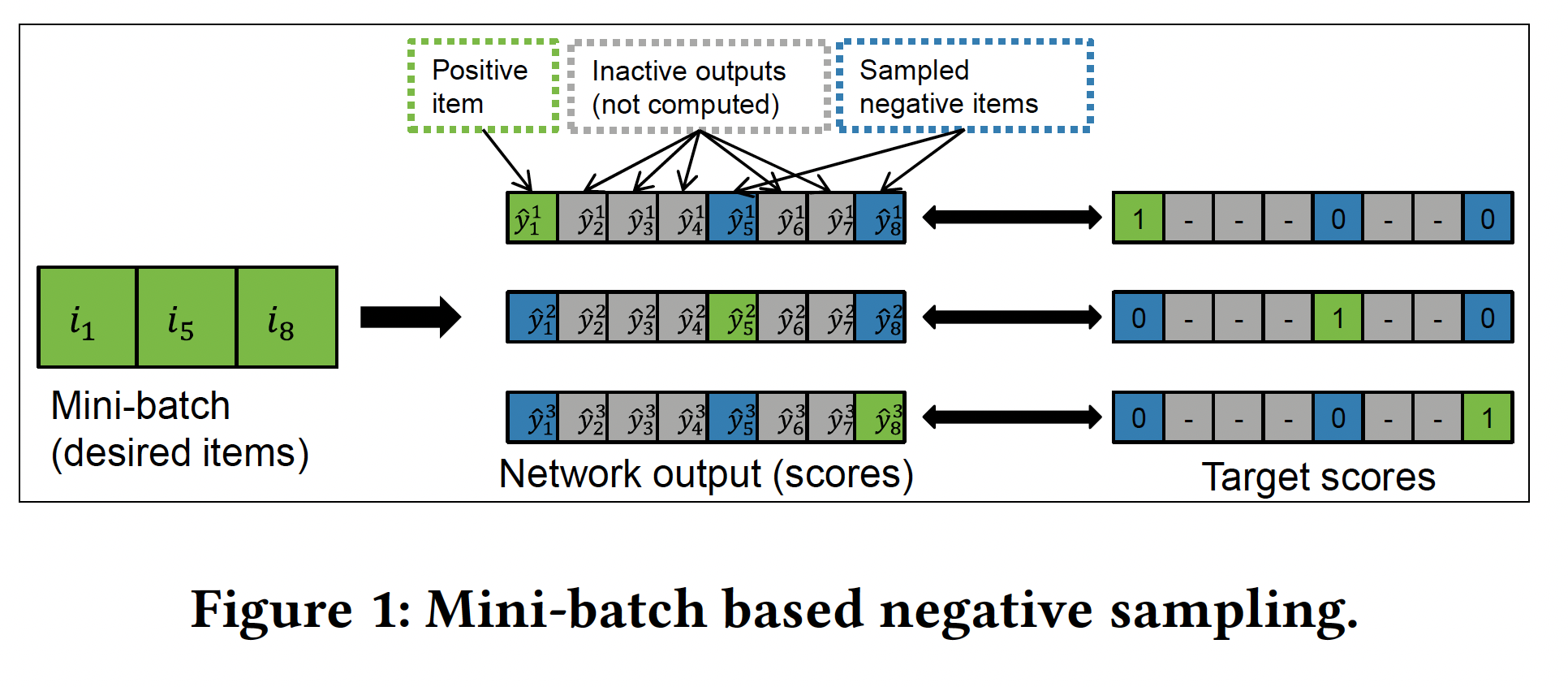
- 更好地利用当前硬件的并行化能力,从而训练更快
可以使用三种不同的
listwise ranking loss函数之一来训练网络(参考后面的小节)。所有损失函数都需要target item(即next item的ground truth)的分数、以及至少一个negative item(即target item以外的item)的分数。ranking loss的一个特性是:模型只有当target item的分数没有大幅超越negative item的分数时才会进行学习,否则item已经按正确的顺序排列因此模型没有什么可学的(此时梯度接近于零,模型参数几乎不更新)。因此,在进行负采样时,采样到高分item作为negative item中至关重要。一个
item是否高分取决于实际计算分数的context(即item序列)。热门item在许多情况下通常分数都很高,因此基于热度的采样popularity-based sampling是一种很好的采样策略。mini-batch sampling基本上是一种popularity-based sampling的形式,因为一个item作为negative item的概率与它在数据集中出现的频次(即,热门程度)成正比。一个
item在数据集中出现次数越多,则它成为target item的机会越多,那么它的平均预估分也就越高。popularity-based sampling的问题在于:当算法学到将target item排在热门item之上,模型几乎停止学习(因为target item已经排序正确,模型接下来没什么可学的),但是模型对于长尾高分item(这部分item不是热门的因此未被负采样,但是预估分数仍然很高) 的排序仍然可能不准确。即,模型对热门
item学习较好,对中长尾item的学习较差。另一方面,如果使用均匀负采样,那么由于大量低分
negative item的存在,均匀负采样会减慢学习速度(对于大部分negative item,target item已经排序正确因此模型没什么可学)。但是,如果无限期训练,可能会产生整体上更准确的模型(相比popularity-based sampling)。根据我们的经验,
popularity-based sampling通常会产生更好的结果(因为均匀负采样需要“无限期”训练才能得到更好的结果)。将负采样与
mini-batch联系起来有若干实际好处,但由于以下三个原因导致过于严格:mini-batch size一般较小,从几十到几百不等。如果item set的规模很大,那么较小的采样规模使得无法包含所有高分的negative item。mini-batch size对训练有直接影响。例如,我们发现使用更小的mini-batch size(30 ~ 100)进行训练会产生更准确的模型。但是由于并行化,在GPU上使用更大的mini-batch size训练会更快。mini-batch sampling方法本质上是popularity-based的,这通常是一个很好的策略,但可能不是对所有数据集都是最优的。第三条理由有点无赖,作者并未给出一些例子来说明。
因此,我们使用
additional sample来扩展GRU4Rec。我们采样了item用作mini-batch内所有example所共享的negative item。 这些additional sample与来自mini-batch sampling的sample一起使用,其中mini-batch size。additional sample可以通过任何策略采样得到。我们以itemsupport(即数据集中出现的次数)。popularity-based sampling。
添加更多
sample自然会增加复杂度,因为输出单元的数量从popularity-based sampling)增加到additional sample)。然而,计算很容易并行化,因此当sample规模达到一定规模之前,增加更多sample对于现代GPU上的训练时间并没有实际增加。既然
additional sample的核心是增加高分negative item,那么我们可以根据先验知识,为每个target item构建一批高分的negative item。例如 :当前用户历史点击的item、当前用户相似的用户历史点击的item(基于user-to-user规则)、已有高分negative item相似的item(基于item-to-item规则),等等。这些就是hard负样本。注意:
- 训练期间不仅要有
hard负样本,还要有easy负样本(即低分negative item)。至于采样到的negative item的分数分布是否和item set保持一致,可以探讨。 - 验证、测试、上线推断期间,必须使得采样到的
negative item的分数分布和item set保持一致,否则评估结果可能没有说服力。
然而,
additional sample的有效实现并非易事。根据GPU上的分布进行采样目前还没有得到很好的支持,因此采样速度很慢,因此它应该由CPU处理或者需要某种形式的解决方法。- 如果由
CPU处理,则被采样的item ID应该与mini-batch的item ID一起提供给GPU。然而,每次生成一个新的mini-batch时对分布进行采样需要一些时间,因此GPU的执行经常被中断,导致GPU利用率低,从而训练缓慢。 - 如果利用
GPU上某种形式的解决方法,则基于分布的采样被转换为包含多个GPU操作的一个序列,与我们使用的深度学习框架的内置采样方法相比,整体执行速度更快。
在这两种情况下,单次采样几个
item的效率都低于单次采样大量item的效率。因此,我们还实现了一个缓存cache用于预采样pre-sample以及存储大量negative sample。当训练用完这些sample并且一旦缓存变空(每用一个sample就会清空对应的缓存),就会重新计算缓存。我们发现,与完全不使用缓存的方案相比,预采样1千万到1亿个item ID显著提高了训练速度。- 如果由
11.2 损失函数设计
本小节中,我们检查
GRU4Rec中实现的损失函数并确定它们的弱点。我们提出了两种方法来解决交叉熵损失函数的数值不稳定性numerical instability。我们展示了当我们向输出中添加更多sample时,使用TOP1 pairwise loss和BPR pairwise loss的learning如何降级degrade,并提出一组基于pairwise losse的损失函数来缓解这个问题。我们注意到,虽然我们的目标是改善
GRU4Rec,但是本小节中提出的损失函数也可以与其它模型一起使用,例如矩阵分解模型。
11.2.1 categorical cross-entropy
categorical cross-entropy衡量了预测的概率分布该损失函数常用于机器学习和深度学习,特别是多类分类问题。
next item推荐任务可以解释为分类任务,其中class label是系统中的item id,每个item序列所分配的label是该序列的next item。 在single-label场景下(如next item推荐),真实分布是next item的one-hot向量,其中target item对应的元素为1而其它所有位置全零。预测的概率分布由分配给每个item的预测分数组成。注意,output score需要执行转换从而形成分布的形式,常见的转换是使用softmax。交叉熵本身是一个
pointwise loss,因为它是在单个coordinate上(即分布上的每个点)定义的独立损失的总和。将交叉熵与softmax相结合会在损失函数中引入listwise属性,因为coordinate现在不再是独立的了。结合交叉熵与softmax,我们得到如下的、定义在score上的损失函数(假设target item的索引为其中:
itemitem set大小。修复不稳定性
instability:GRU4Rec中可用的损失函数之一是带softmax的交叉熵。《Session-based Recommendations with Recurrent Neural Networks》在实验部分报告了交叉熵比其它损失函数略好的结果,但是论文认为交叉熵损失对于大部分超参数空间而言是不稳定的,因此建议不要使用它。这种不稳定性来自于有限的数值精度
limited numerical precision。假设存在item- 计算
- 通过
前者引入了一些噪声,而后者不允许
transformation和loss分开使用(即,transformation和loss融合在一起,无法分离使用)。这两种方法都可以稳定stabilize损失函数,我们没有观察到这两种变体的结果存在任何差异。- 计算
11.2.2 TOP1&BPR
GRU4Rec提供了两个基于pairwise loss的损失函数。pairwise loss将target item分数与一个negative item进行比较。如果target item分数低于negative item分数,那么损失较大。GRU4Rec对每个target item计算多个negative item的损失,因此损失函数由这些pairwise loss的均值组成。这导致了一个listwise loss函数,它由多个pairwise loss组成。其中一个损失函数是
TOP1,其定义为:其中:
negative item数量,negative item上迭代,target item。这是一个由两部分组成的、启发式的组合损失:
- 第一部分旨在将
target item分数推高到negative item分数之上。 - 第二部分旨在将
negative item分数降低到零。这一部分充当正则化器regularizer,但它并不是直接约束模型权重,而是惩罚negative item的高分。由于每个item在某个训练example中都充当negative item,因此通常会降低整体的分数。
- 第一部分旨在将
另一个损失函数是基于流行的
Bayesian Personalized Ranking: BPR损失,其定义为:该损失函数最大化
target item分数超过negative item分数的概率。由于概率
梯度消失
vanishing gradient:取每个pairwise loss的均值会产生不想要的副作用。我们分析TOP1损失和BPR损失相对于target item分数TOP1损失和BPR损失相对于target item分数对于
pairwise loss,人们通常希望得到高分的negative item,因为这些sample会产生大的梯度。或者直观而言,如果negative item的分数已经远低于target item的分数,那么就不再可以从该negative item中学到任何东西了。我们将
negative item记做negative irrelevant item,negative item记做negative relevant item。对于一个negative irrelevant itemnegative irrelevant item基本上不会对总梯度增加任何东西。同时,平均梯度总是被negative item的数量所打折(即,除以sample数量negative irrelevant item数量的增加速度比negative relevant item数量的增加速度更快,因为大多数item作为negative item是不相关irrelevant的。对于non popularity-based sampling以及大的sample数量,情况尤其如此。因此,随着sample数量本质上是由于
negative relevent item的稀疏性导致。- 如果
negative relevent item和negative irrelevent item的数量是1:1的关系,那么negative relevent item也同比例的增加。 - 如果
negative relevent item和negative irrelevent item的数量是1:100000的关系,那么negative relevent item数量几乎不变(negative relevent item),因此使得损失函数的梯度下降很多。
注意,
TOP1损失对于negative relevant item也有些敏感,这是损失函数设计中的疏忽。虽然这种情况不太可能发生,但是也不能排除。例如,在将一个冷门的target item与非常热门的sample进行比较时,尤其在学习的早期阶段,target item分数可能远低于这个热门sample的分数。我们专注于损失函数对于
target item分数negative item分数这意味着即使某些
negative itemrelevant的,损失函数的梯度也会随着negative item数量- 如果
11.2.3 ranking-max 损失
为了克服随着
sample数量pairwise loss的、新的listwise loss系列。基本思想是:将target item分数与最相关的negative item分数进行比较。令最相关的negative item(即分数最大的negative item)为max函数是不可微的,因此无法应用于梯度下降。因此,我们使用softmax函数代替max从而保持损失函数的可微性。注意,这里的softmax变换仅用于negative item(即排除negative item中寻找最大的分数。这使得在negative item都需要考虑它获得最大分数的可能性。基于这个总体思路,我们现在推导出TOP1-max损失函数和BPR-max损失函数。softmax在交叉熵损失、ranking-max损失中有所区别:- 在交叉熵损失中需要考虑
target item和negative item,即target item的集合大小 - 在
ranking-max损失中仅考虑negative item,即target item的集合大小。
另外这里的
softmax还可以引入温度超参数- 在交叉熵损失中需要考虑
TOP1-max损失函数:TOP1-max损失相当简单,它被定义为:其中:
softmax值。可以对所有
negative item应用正则化(即,negative item应用正则化。但是我们发现对最大分数的negative item应用正则化的实验效果更好,因此我们保持这种方式。TOP1-max损失的梯度是对单个pairwise梯度的加权平均(注意,negative item分数的softmax值- 如果
example将有更大的权重。这解决了更多sample导致梯度的问题,因为negative irrelevant item将被忽略,最终梯度将指向negative relevant item的梯度。 - 如果所有的
sample都是irrelevant的,那么每个pairwise梯度将接近于零。这不是什么问题,因为如果target item分数大于所有negative item分数,则没有什么可以学习的。
不幸的是,
TOP1-max损失对于分数很大的negative item是敏感的,如TOP1 pairwise loss本身所引起的,与我们的聚合方式无关。- 如果
BPR-max:BPR的概率性解释为,最大化target item分数其中:
negative itemtarget item分数高于最大分数的negative item
我们想要最小化负的对数似然,则得到损失函数:
这个损失函数对于
target itemBPR-max的梯度是单个BPR梯度的加权平均,权重为negative item如果
softmax。否则这个相对权重就是一个平滑的softmax。这意味着当
negative item之间的权重分布会更均匀,但是较高分数的negative item将得到更多关注。随着negative item上。这是一种理想的行为。
读者注:
BPR-max并不是简单地对BPR的softmax加权,而是移动了log的位置:Top1-max损失函数仅仅是将Top1损失的均匀权重softmax权重BPR-max损失函数将BPR的均匀权重log函数变为作用于另一个版本的
BPR-max是:这个损失函数似乎比论文中的
negative item是敏感的(如损失函数(
TOP1-max和BPR-max损失)对于negative itemsoftmax scoretarget itemnegative item才会被更新。这是有益的,因为如果negative item的分数很低,则不需要进行参数更新 。- 如果一个
negative item的分数远高于其它negative item,那么它的参数将是唯一被更新的,并且梯度将与target item分数和negative item分数之间pairwise loss的梯度一致。 - 如果如果
negative item的分数比较平衡,那么梯度介于上述梯度和零之间。
- 如果一个
下图描述了在不同
target item排名的条件下,BPR损失的梯度和BPR-max损失的梯度(针对target item分数target item排名指的是超过target item分数的negative item数量,例如rank 0表示target item分数高于所有negative item。较小的rank值意味着negative relevant item较少。该图描述了两种损失相对于
epoch(训练开始)、第十个epoch(训练结束)对整个数据集进行评估:- 左图没有使用
additional sample,仅使用来自mini-batch size = 32的batch内其它example。 - 中图和右图添加了
2048个additional negative item,其中右图聚焦于前200的排名。
可以看到:
当有更多
negative relevant item(即rank值更大)时,BPR的梯度略高。这是很自然的,因为BPR-max关注的是最接近sample,而忽略了其它negative relevant item。当target item排名在list末尾时,这减慢了BPR-max的学习,但是差异并不显著。另一方面,随着
negative relevant item数量的减少(即rank值更小),BPR的梯度迅速消失。梯度消失的点与sample总量有关。- 在
sample总量较小的情况下(左图),BPR的梯度在rank = 5附近开始消失。相比之下,BPR-max直到rank 0才开始消失。 - 同时,随着
sample的增多(中图),BPR梯度非常低(例如在右图看到rank = 5时BPR的梯度相比左图要小得多),即使对于rank 100 - 500也是如此。相比之下,BPR-max的梯度仍然是在rank较小的点才开始显著下降。
这意味着,比如说,我们可以优化算法将
target item的排名从500优化到50,但是很难继续推进到排名为5(因为这时发生了梯度消失,模型无法继续学习)。并且发生梯度消失的点随着sample量的增加而提前。另一方面,BPR-max表现良好,并且能够一路提高target item分数。- 在
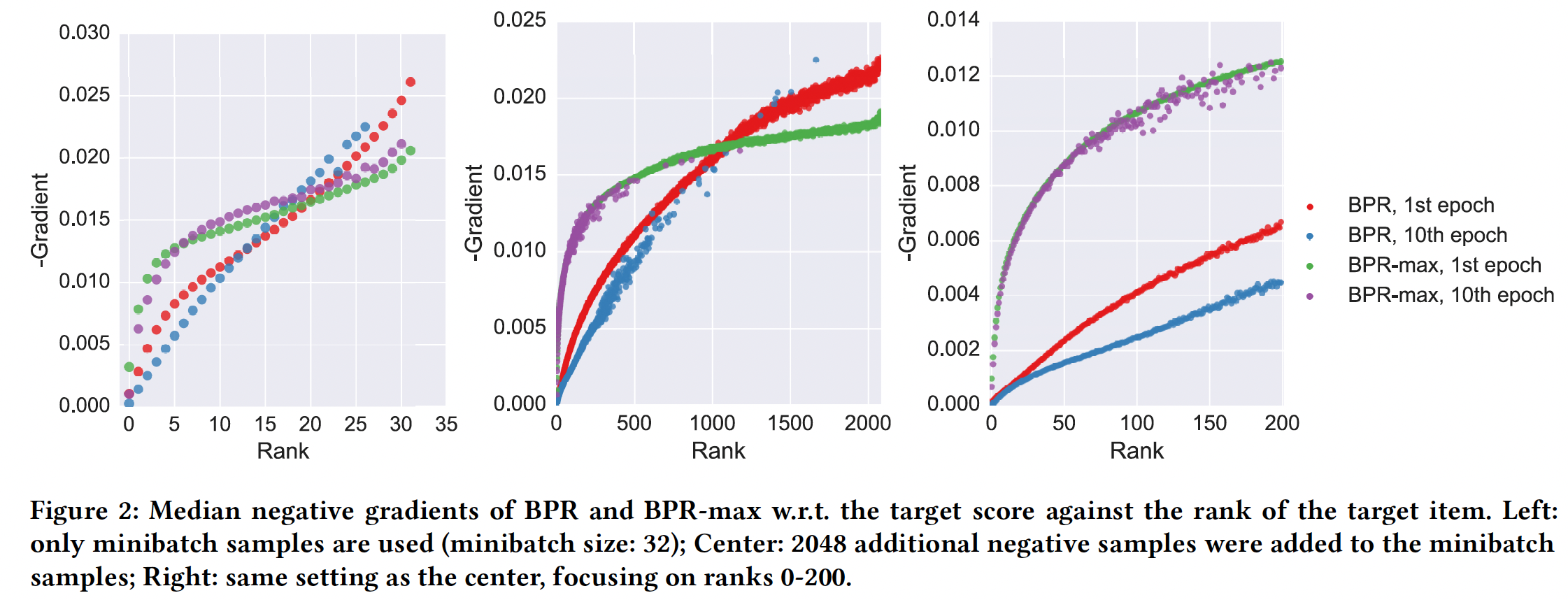
- 左图没有使用
分数正则化
score regularization的BPR-max:尽管我们表明启发式的TOP1损失对于分数非常高的negative relevant item很敏感,但是在《Session-based Recommendations with Recurrent Neural Networks》中发现它的性能优于BPR。据我们的观察,TOP1-max也是优于BPR-max。部分原因在于很少同时出现TOP1的正则化部分保证TOP1中的分数正则化对整个学习过程非常有益,因此即使损失函数可能不是理论上的最优,它也可以取得很好的效果。GRU4Rec支持两种形式的正则化:模型参数的dropout和L2正则化。TOP1的正则化与这些正则化是不同的。根据我们的经验,模型参数的L2正则化会降低模型性能。我们的假设是:某些模型权重不应该被正则化,如用于计算更新门update gate和复位门reset gate的权重矩阵。对negative item高分进行惩罚可以约束模型,但是没有显式地正则化权重。因此,我们也在
BPR-max损失函数中添加了分数正则化。我们尝试了几种分数正则化的方法。性能最好的一种方法是:我们将negative item分数设置在独立的零均值高斯分布上,高斯分布的方差与softmax分数成反比。这需要对接近negative item分数进行更强的正则化,这在我们的case中是理想的。我们最小化负的对数似然并像以前一样进行函数近似,从而得到最终形式的
BPR-max损失函数:其中:正则化项是
negative item分数进行加权L2正则化,权重为softmax分数这里的正则化与
TOP1正则化有三个区别:- 这里使用平方正则化,而
TOP1使用 - 这里使用了正则化系数
TOP1没有使用系数。猜测的原因是:在TOP1中损失部分和正则化部分处于同一个量级(0.0 ~ 1.0之间),而这里的损失部分和正则化部分处于不同量级。 - 这里更关注
negative item的高分,使得尽可能将negative item高分打压下来。而TOP1是一视同仁,认为negative item高分的下降,与negative item低分的下降,效用是相同的。
这意味着我们也可以改造
TOP1损失,利用平方正则化、正则化系数、以及权重- 这里使用平方正则化,而
11.3 实验
数据集:
RSC15数据集:基于RecSys Challange 2015的数据集,其中包含来自在线电商的点击事件和购买事件。这里我们仅保留点击事件。VIDEO数据集和VIDXL数据集:是专属数据集proprietary dataset,其中包含来自在线视频服务的观看事件。CLASS数据集:也是一个专属数据集,包含来自在线分类站点的网页浏览事件。
数据集经过轻微的预处理,然后划分为训练集和测试集。单个
session要么属于训练集、要么属于测试集。我们基于session首个事件的时间来拆分数据集。RSC15数据集以及拆分与《Session-based Recommendations with Recurrent Neural Networks》中的完全相同。VIDXL数据集和CLASS数据集以及拆分与《Parallel Recurrent Neural Network Architectures for Feature-rich Session-based Recommendations》中的完全相同。VIDEO数据集与《Session-based Recommendations with Recurrent Neural Networks》中的来源相同,但是子集略有不同。
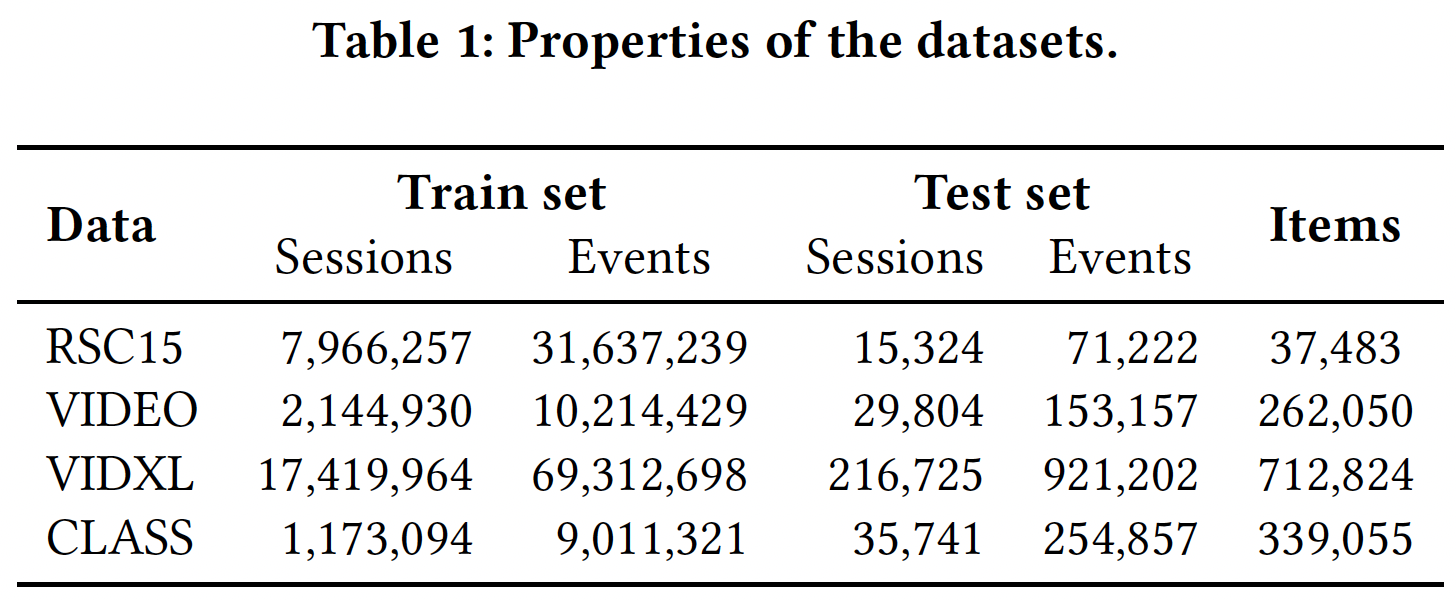
下表给出了数据集的主要特性。
评估方式:我们评估
next item prediction,即我们迭代测试集session以及它们包含的事件。对于每个事件,算法都预测该session的next event对应的item。由于VIDXL测试集很大,我们将target item分数与测试期间最热门的50000个item的分数进行比较。由于推荐系统一次只能推荐几个
item,用户选择的实际item应该包含在推荐列表的前面几个item中。因此,我们的主要评估指标是recall@20,即:在所有test case的推荐列表的top-20中,具有target item的case的比例。召回不考虑target item的实际排名,只需要它位于推荐列表的top-N。这很好地建模了某些实际场景,在这些场景中推荐位置和顺序无关紧要。召回率通常也与重要的在线KPI密切相关,如点击率CTR。实验中使用的第二个指标是
Mean Reciprocal Rank: MRR@20,它是target item的排名倒数reciprocal rank的均值。如果target item的rank > 20,那么排名倒数设为零。MRR考虑target item的排名,这适用于推荐顺序很重要的场景,例如更尾部排名的item仅在屏幕滚动之后才可见。baseline方法和配置:我们的baseline是原始的GRU4Rec算法,我们的目标是对其进行改进。我们将原始论文提出的TOP1损失视为baseline。隐层有100个单元。- 我们还对比了
item-kNN的性能,这是next item prediction的一个natural baseline。 RSC15、VIDXL、CLASS的结果直接取自相应的论文(《Session-based Recommendations with Recurrent Neural Networks》、《Parallel Recurrent Neural Network Architectures for Feature-rich Session-based Recommendations》)。VIDEO数据集以《Session-based Recommendations with Recurrent Neural Networks》中给出的最佳超参数进行评估。- 我们针对所提出的改进在单独的验证集上进行单独的超参数调优。
这些方法在
Python中的Theano框架下实现。- 我们还对比了
11.3.1 additional sample
第一组实验检查了
additional negative item对于推荐准确性的影响。我们在CLASS数据集和VIDEO数据集上进行了实验。由于结果非常相似,因此我们剔除了VIDEO数据集的结果从而节省一些空间。下图描述了不同损失函数(TOP1、交叉熵、TOP1-max、BPR-max)的网络的性能。我们度量了不同数量的additional sample下的推荐准确性,也度量了没有任何采样并计算所有得分时的推荐准确性(即x轴为ALL的点)。正如我们之前所讨论的,后一种情况更具理论性,因为它是不可scalable的。正如理论所暗示的,
TOP1损失不能很好地处理大量的sample。当增加少量的additional sample时,模型性能略有提高,因为包含negative relevant item的机会在增加。但是随着sample的继续增加,模型性能迅速下降,因为会包含大量negative irrelevant item。另一方面,所有其它三个损失函数都对添加更多
sample反应良好。对于交叉熵损失,收益递减的点发生在大约几千个
additional sample。而
TOP1-max在那个点之后开始略微降低准确性。BPR-max随着更多的sample而性能一直提升,但是在使用到所有item时会略微降低准确性。BPR-max使用所有item时,会失去随机性。众所周知,一定程度上的随机性有利于学到更好的模型。
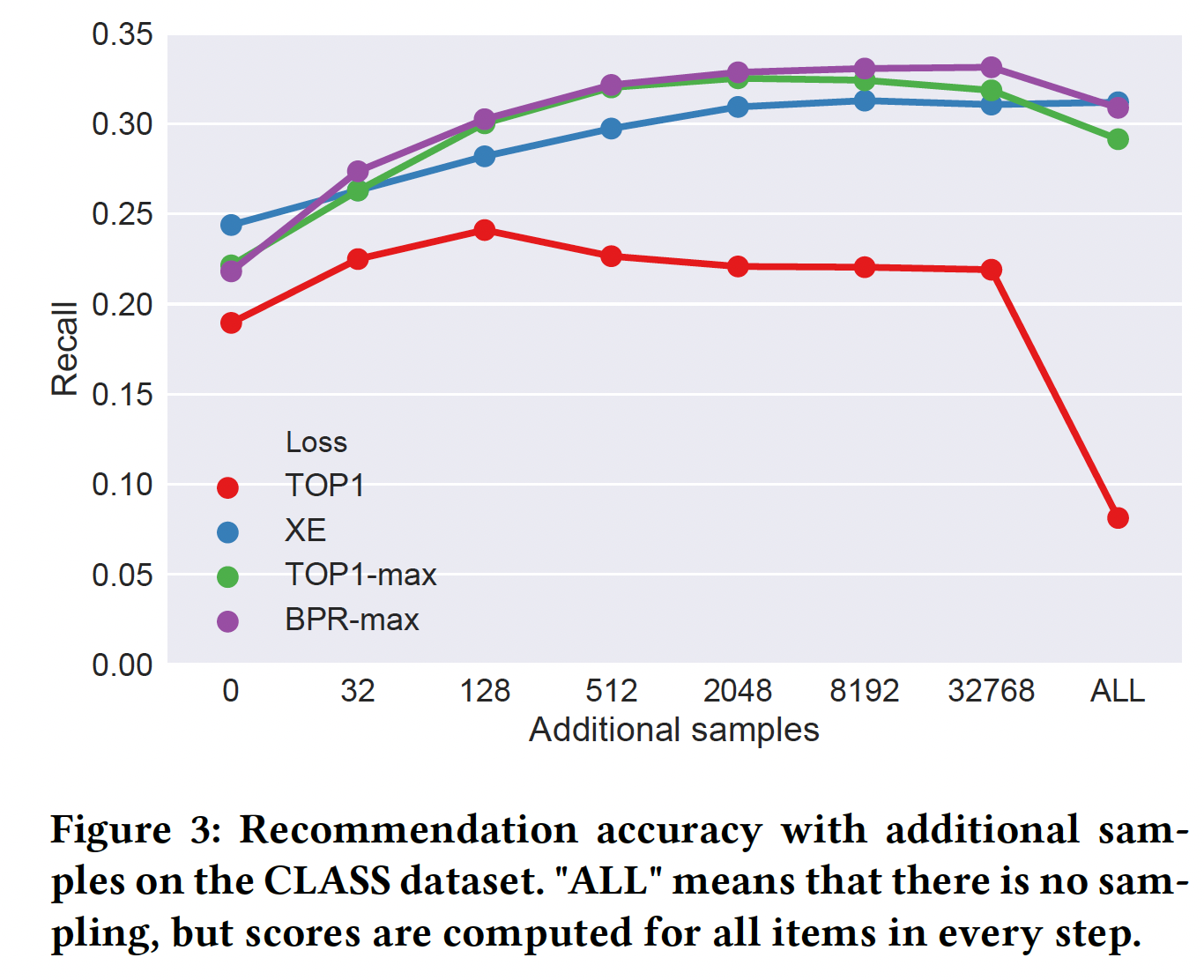
添加
additional sample会增加计算成本,但由于现代GPU上易于并行化,大部分成本都得到了缓解。下图显示了不同sample size的训练时间。注意,y轴的时间为对数坐标。实际的训练时间不仅取决于数据集,还取决于模型超参数(尤其是
mini-batch size)以及框架如何支持某些用于计算损失函数的算子。然而,所有损失的趋势都是相似的。- 例如,网络的完整训练大约需要
6 ~7分钟,即使增加到512个additional sample也不会增加训练时间。 - 在收益递减的点,即在
2048个additional sample时,训练时间仍然在7 ~ 8分钟左右,只是略有增加。 - 在那之后,由于超出了我们使用的
GPU的并行化能力,训练时间迅速增加。
VIDEO数据集上的趋势也是相似的,训练时间从20分钟左右开始,在2048个additional sample时开始增加(到24分钟),此后迅速增加。这意味着与数据增强方法不同,我们提所提出的方法在实践中使用时可以是零成本或很少的额外成本的。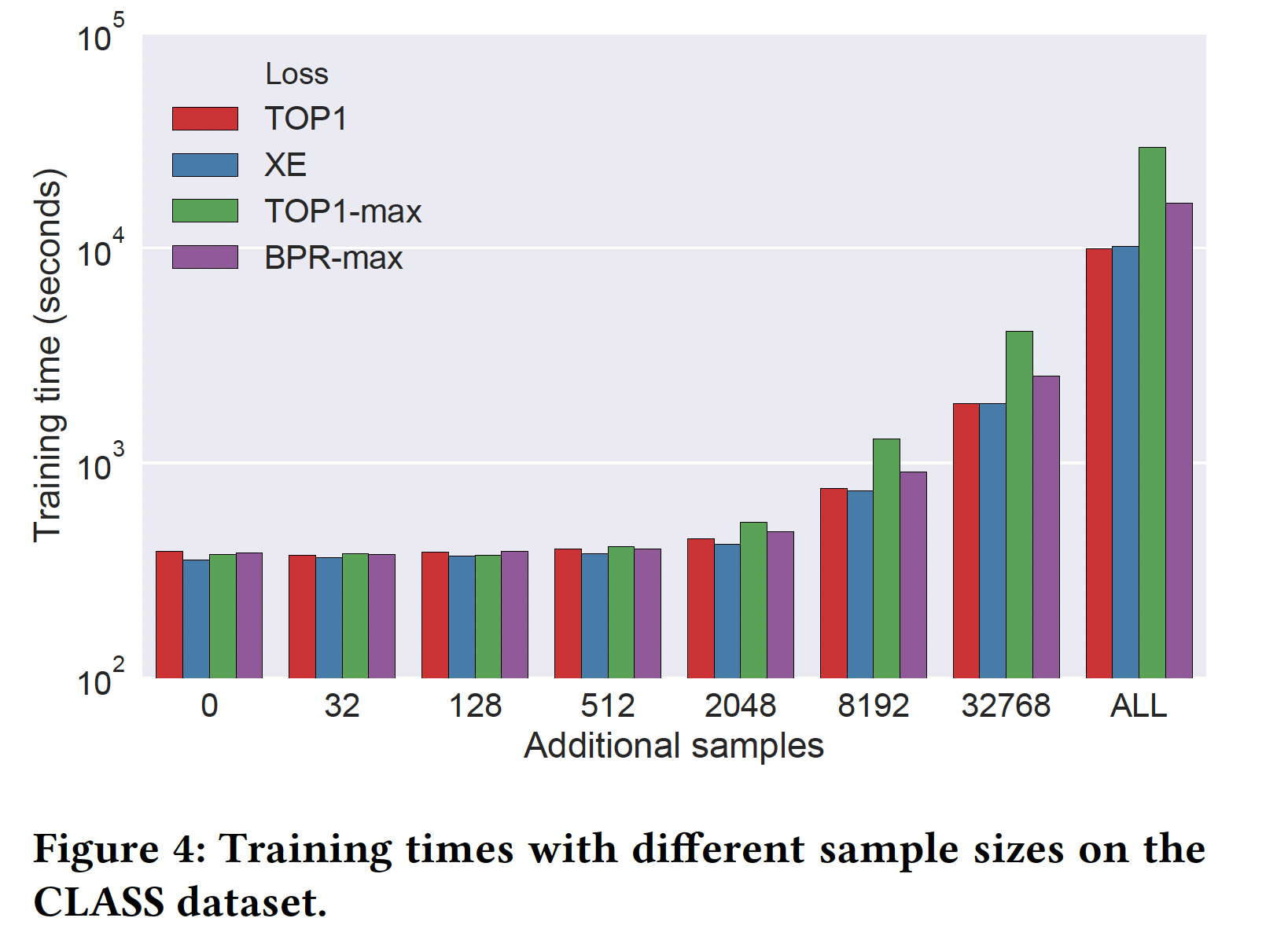
- 例如,网络的完整训练大约需要
在接下来的实验中,我们对控制采样的
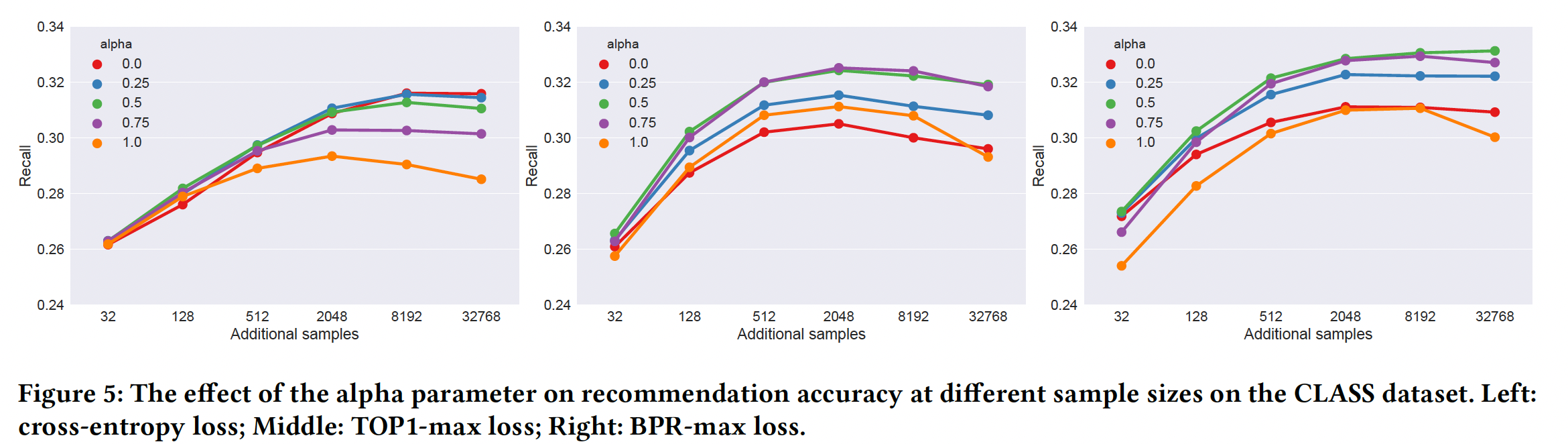
TOP1-max、BPR-max在不同对于交叉熵,当
sample size较小时它倾向于较高的sample size较大时它倾向于较低的sample在sample size非常有限并且训练开始阶段非常有用,但是可能很快就会耗尽。 因此,如果我们有办法(例如足够大的sample size)切换到更平衡的采样,那么可能是有益的。此外,在这种情况下,均匀采样可以被少量的、从minibatch采样得到的popularity based sample所补充。另一方面,
ranking-max loss似乎更喜欢中间略偏高一点的值,而在极端情况下的表现最差。我们假设这主要是由于:- 它们是基于
pairwise losse,而这通常需要popular sample。 - 它们采用了
score regularization:通过popularity based sampling,最热门item的分数将降低到超出预期的水平,因此效果较差。
- 它们是基于
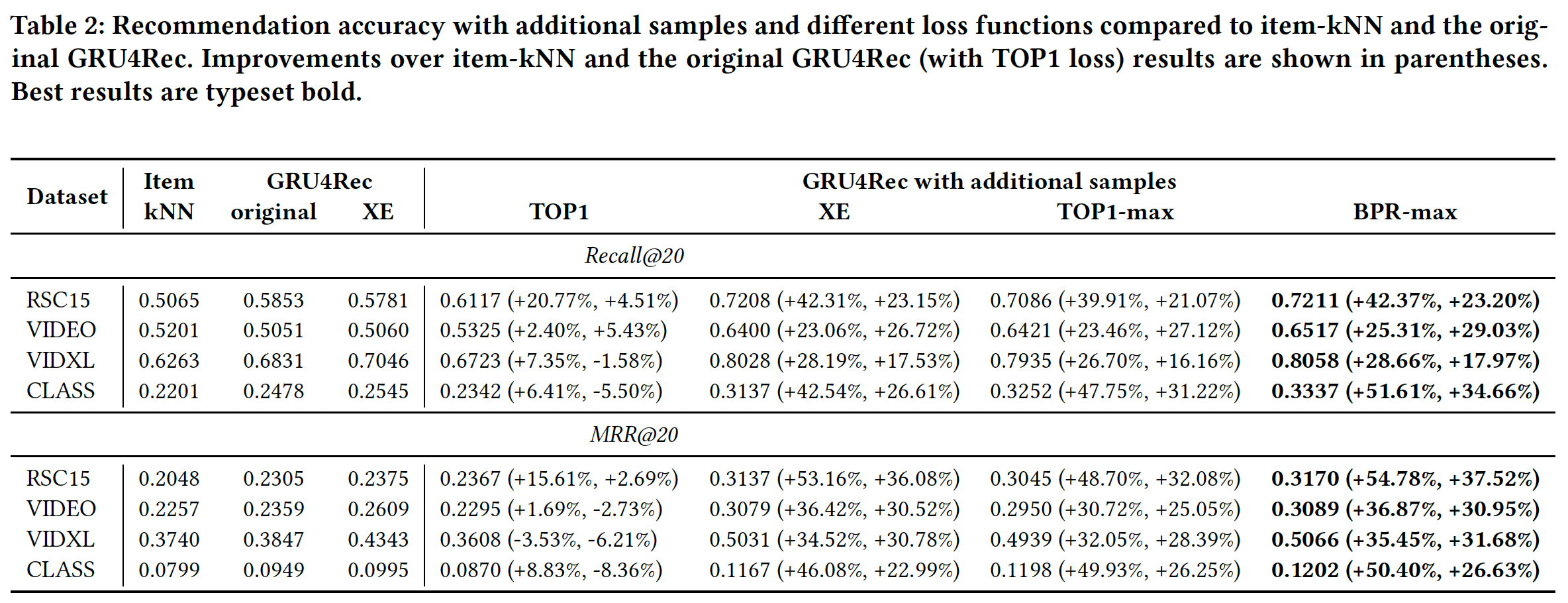
11.3.2 损失函数
我们度量了所提出的改进在
baseline上的性能增益。准确性的大幅提升来自于additional sample和损失函数的组合。下图展示了我们最重要的结果。除了原始版本的GRU4Rec和item-kNN之外,我们还包括了没有additional sampling的交叉熵cross-entropy: XE损失的结果,从而确认固定交叉熵损失的性能仍然略好于TOP1。additional sample和适当的损失函数的组合,其效果是惊人的,其最好的结果比原始GRU4Rec的准确性高出18% ~ 37.5%、比item-kNN的准确性高出55%。当都采用additional sample时,BPR-max的性能与交叉熵相似或更好。实际上发现带
additional sample的交叉熵损失函数已经效果很好了,将交叉熵损失替换为ranking-max损失的收益不大。在
RSC15上,《Improved Recurrent Neural Networks for Session-based Recommendations》使用数据增强报告了recall@20大约在0.685、MRR@20大约在0.29。与我们的解决方案不同,数据增强大大增加了训练时间。数据增强和我们的改进并不互斥,因此通过结合这两种方法,可以获得更好的结果。
11.3.3 统一的 item representation
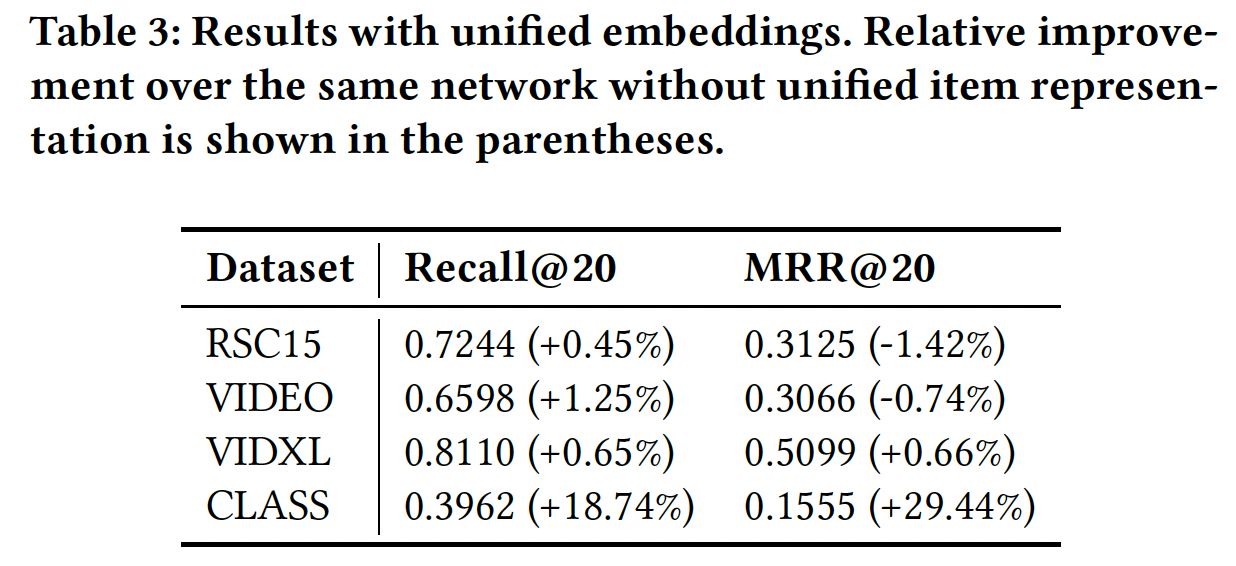
以前的实验没有发现在
GRU layer之前使用embedding layer的任何好处。embeddinhg layer的作用是将item ID转换为潜在representation空间。在推荐系统的术语中,item embedding对应于item feature vector。现有的GRU网络已有另外一个item feature matrix,它是output weight matrix的形式。通过统一representation,即在embedding layer和output layer之间共享权重矩阵,我们可以更快地学习更好的item representation。初步实验(如下表)显式,对于大多数数据集,
recall@20有额外的轻微改进,而MRR@20则略有下降。然而,对于CLASS数据集,当使用统一embedding时,召回率和MRR都显著增加。此外,统一embedding还具有将整体内存占用和模型大小减少约4倍的额外好处。作者并没有探索这里的原因,遗憾。
11.3.4 在线测试
基于本文提出的改进,在
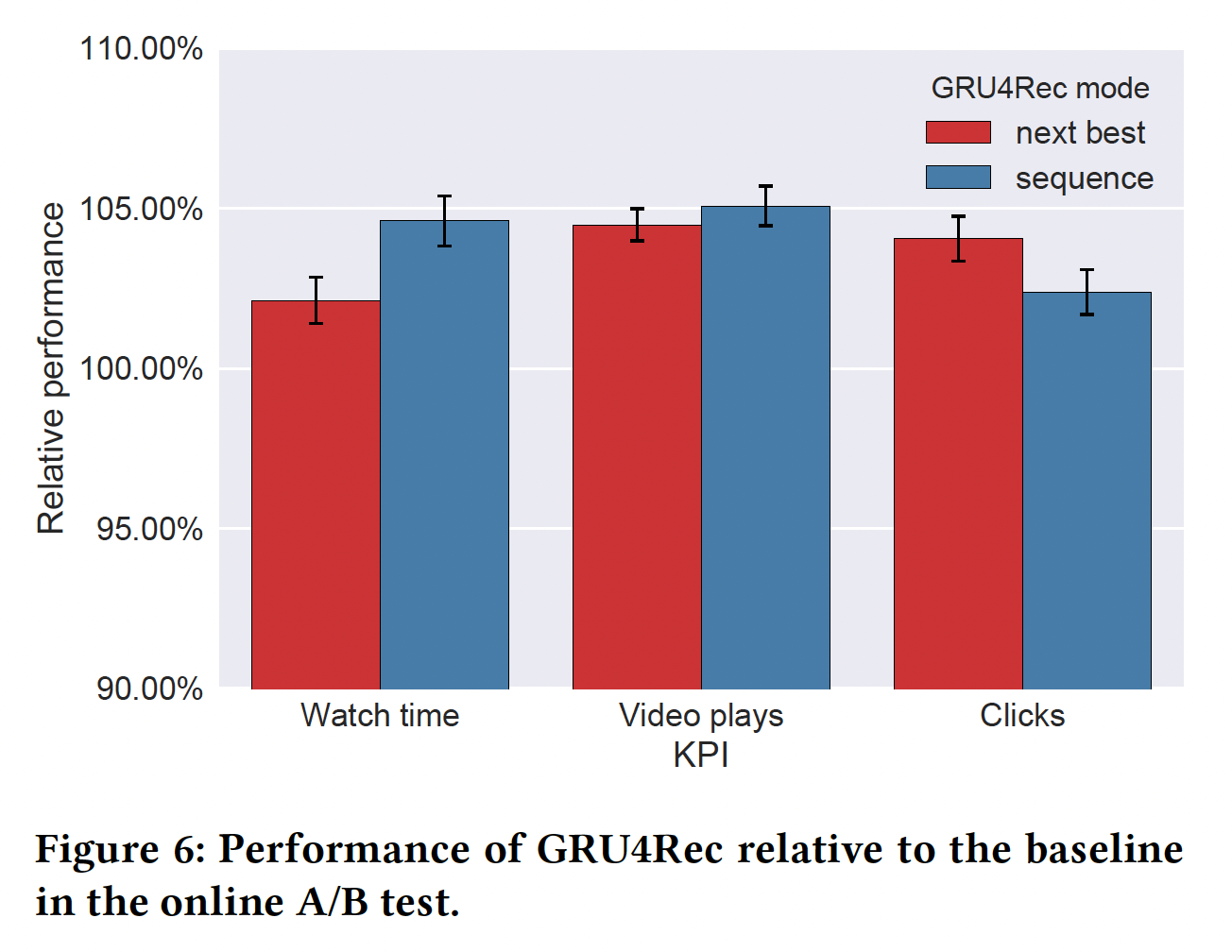
online video portal上的大规模在线A/B test中评估GRU4Rec在技术上也变得可行。推荐展示在每个视频页面上,并且在页面加载后立即可用。该网站具有自动播放功能,类似于Youtube上的。如果用户点击推荐的某个item、或者通过自动播放来访问推荐的某个item(这意味着用户开始访问推荐队列),那么系统不会计算新的推荐列表,因此用户可以与一组推荐的item进行多次交互。用户也可以直接访问视频(而不是通过推荐列表的方式,比如直接访问视频的url地址),那么系统为该用户生成一组新的视频推荐。实验配置:将
GRU4Rec与经过微调的复杂推荐逻辑进行比较,持续时间为2.5个月。用户分为三组:第一组由
baseline逻辑提供推荐服务。第二组由
GRU4Rec以next best来提供推荐服务,这意味着算法推荐的item很可能是用户session中的next item。第三组由
GRU4Rec以sequence mode来提供推荐服务,其中GRU4Rec根据迄今为止的session来生成一个item序列。序列是贪婪地生成的,即算法假设它的next guess到目前为止是正确的。sequence mode会生成next item、next next item... 等等的序列,而不是next item。
机器人
bot和power用户(例如,长时间播放视频的用户)会从评估结果中过滤掉,因为它们可能会扭曲结果。机器人是根据user agent过滤的。每天过滤掉身份不明的机器人和power用户以及具有不切实际行为模式的用户。受过滤影响的non-bot用户比例非常低(占比大约0.1%)。评估指标:我们使用不同的
KPI来评估效果,每个KPI都与推荐请求的数量相关:观看时长是该组观看视频的总秒数,视频播放量是改组至少观看了一定时长的视频数量,点击量是改组点击推荐的次数。当实验组和对照组的请求数量几乎相等时,总量的比较结果与均值的比较结果几乎相同。
下图展示了
GRU4Rec相对于复杂逻辑的相对性能增益。error bar代表p=0.05的置信区间。GRU4Rec在两种预测模式下都优于baseline。观看时长提高了5%、视频播放量提高 了5%、点击量提高了4%。- 在观看时长和视频播放量方面,
sequence mode比next best的表现更好,但是在点击量方面则不然。这是因为sequence mode更适合自动播放功能,从而导致用户的点击量减少。另一方面,虽然基于next best guess的预测是相关的,但是它们是更加多样化的,并且用户更有可能跳过推荐列表中的视频。sequence mode更适合视频系列video series和其它紧密结合的视频。 - 我们还注意到,随着两种预测模式同时运行,并通过反馈环
feedback loop从彼此的推荐中学习,它们之间观看时长和视频播放量的差异开始慢慢消失。
十二、SASRec[2018]
序列推荐系统的目标是将用户行为的个性化模型
personalized model(基于历史活动)与基于用户最近行为的context概念相结合。从序列动态sequential dynamic中捕获有用的模式pattern具有挑战性,主要是因为输入空间的维度随着作为context的历史行为的数量呈指数增长。因此,序列推荐的研究主要关注如何简洁地捕获这些高阶动态high-order dynamic。马尔科夫链
Markov Chains: MC是一个典型的例子,它假设next action仅依赖于前一个(或者前几个)行为,并已成功用于刻画短程short-range的item转移transition从而用于推荐。另一项工作使用循环神经网络RNN通过隐状态summarize所有先前的行为,从而用于预测next action。这两种方法虽然在特定情况下很强大,但是在某种程度上仅限于某些类型的数据。MC-based方法通过作出强有力的简化假设,在高度稀疏的setting中表现良好,但可能无法捕获更复杂场景的复杂动态intricate dynamic。- 相反,
RNN虽然具有表达能力,但是需要大量数据(特别是稠密数据)才能超越更简单的baseline。
最近,一种新的序列模型
Transfomer在机器翻译任务中实现了state-of-the-art的性能和效率。与现有的使用卷积模块或循环模块的序列模型不同,Transformer完全基于一种叫做self-attention的注意力机制,该机制非常高效并且能够揭示句子中单词之间的句法模式syntactic pattern和语义模式semantic pattern。受到这种方法的启发,论文
《Self-Attentive Sequential Recommendation》寻求将自self-attention机制应用于序列推荐问题。论文希望这个想法可以解决上述两个问题:一方面能够从过去的所有行为中提取上下文(类似于RNN),但另一方面能够仅根据少量行为来构建预测(类似于MC)。具体而言,论文构建了一个Self-Attention based Sequential Recommendation: SASRec模型, 该模型在每个time step自适应地为先前的item分配权重(如下图所示)。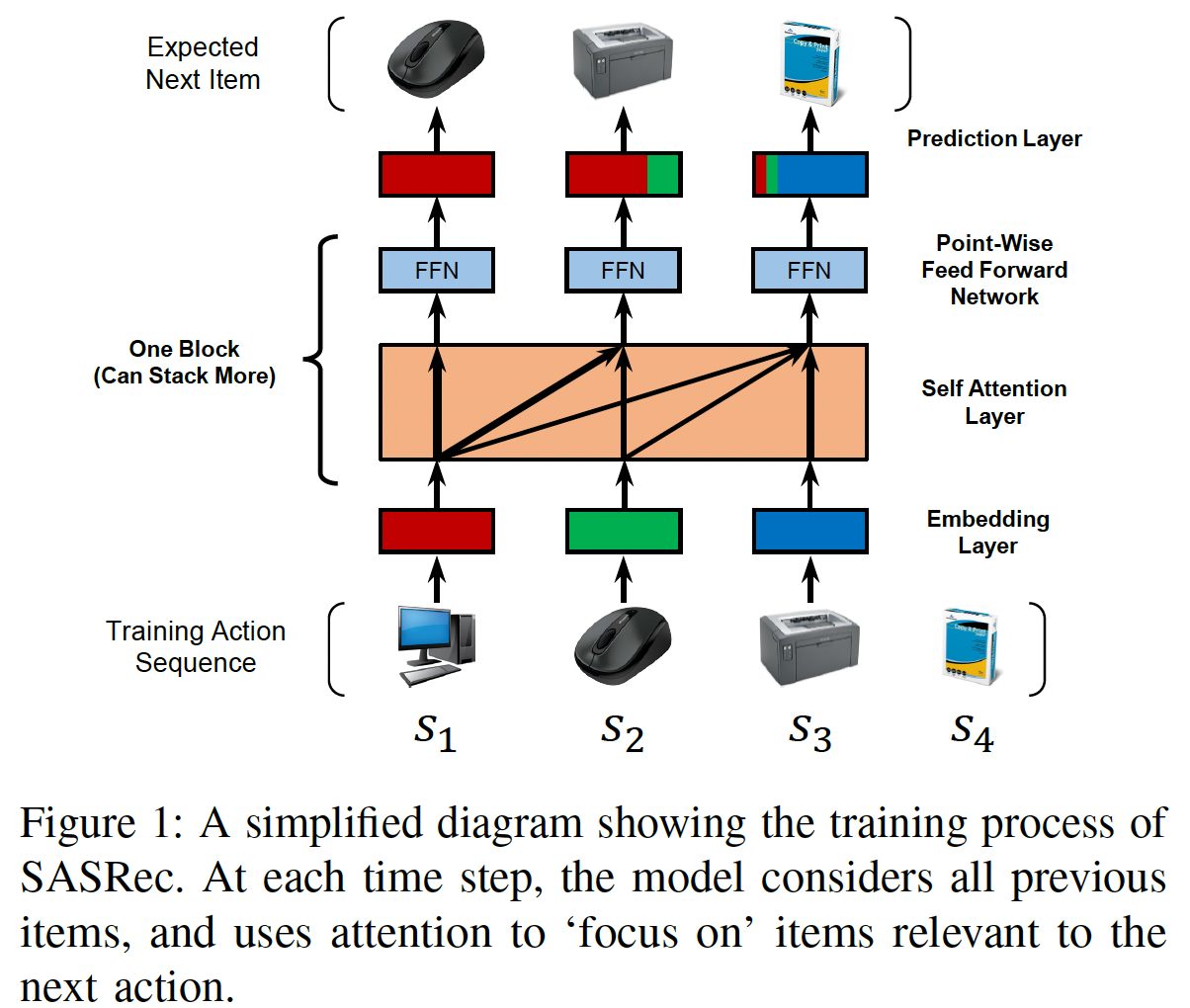
所提出的模型在几个
benchmark数据集上显著优于state-of-the-art的、MC/CNN/RNN-based的序列推荐方法。具体而言,论文将模型性能作为数据集稀疏性的函数来进行检查,其中模型性能与前面描述的pattern密切相关。由于self-attention机制,SASRec倾向于在稠密数据集上考虑长期依赖,而在稀疏数据集上关注最近的行为。而这被证明对于自适应地处理不同密度density的数据集至关重要。此外,
SASRec的核心组件(即self-attention block)适用于并行加速,从而使得模型比CNN/RNN-based的替代方案快一个数量级。此外,论文分析了SASRec的复杂性和可扩展性,进行了全面的消融研究以展示关键组件的效果,并将注意力权重可视化从而定性地揭示模型的行为。相关工作:有一些工作与我们密切相关。在讨论序列推荐之前,我们首先讨论通用推荐
general recommendation,然后是时间推荐temporal recommendation。最后我们介绍了注意力机制,尤其是我们模型核心的self-attention模块。通用推荐
General Recommendation:推荐系统专注于根据历史反馈(如点击、购买、喜欢)来建模用户对
item的偏好。用户反馈可以是显式的(如评分)或隐式的(如点击、购买、评论)。由于解释non-observed数据的模糊性ambiguity,建模隐式反馈可能具有挑战。为了解决这个问题,
《Collaborative filtering for implicit feedback datasets》提出了point-wise方法、《BPR: bayesian personalized ranking from implicit feedback》提出了pairwise方法来解决这些挑战。Matrix Factorization: MF方法试图发现潜在维度来表示用户的偏好和item的属性,并通过user embedding和item embedding之间的内积来估计交互。此外,另一个方向的工作基于
Item Similarity Models: ISM,并没有显式地使用潜在因子建模每个用户(如FISM)。他们学习一个item-to-item的相似度矩阵,然后用户对item的偏好是通过该item与该用户历史交互item之间的相似性来衡量。最近,由于深度学习在相关问题上的成功,深度学习技术已被引入推荐领域。一个方向的工作旨在使用神经网络来抽取
item特征(如图像特征、文本特征等等)从而进行content-aware推荐。另一个方向的工作旨在取代传统的
MF。例如NeuMF通过多层感知机来估计用户偏好,而AutoRec使用自编码器来预测评分。
时间推荐
Temporal Recommendation:追溯到Netflix Prize时代,时间推荐通过显式建模用户活动的时间戳,从而在各种任务上显示出强大的性能。TimeSVD++通过将时间分成若干区间segment,并在每个区间中分别对用户和item进行建模,从而取得了很好的效果。 此类模型对于理解那些表现出显著时间漂移temporal drift的数据集(例如,过去10年电影偏好如何变化、用户在下午4点访问什么样的企业)至关重要。序列推荐(或
next-item推荐)与此不同,因为序列推荐仅考虑操作的顺序,并且建模与时间无关的顺序模式sequential pattern。本质上,序列模型试图根据用户最近的活动建模用户行为的context,而不是考虑temporal pattern本身。序列推荐
Sequential Recommendation:许多序列推荐系统试图建模item-item转移矩阵,并将其作为捕获连续item之间的序列模式的一种手段。例如,FPMC融合了一个MF项、以及一个item-item项从而分别捕获长期偏好和短期转移。本质上,被捕获的短期转移是一阶马尔科夫链Markov Chain: MC,而高阶马尔科夫链假设next action与之前的几个行为有关。由于最近一个访问的item通常是影响用户next action的最关键因素(本质上是提供context),因此基于一阶马尔科夫链的方法表现出强大的性能,尤其是在稀疏数据集上。还有一些方法采用考虑更多先前
item的高阶马尔科夫链。具体而言,Convolutional Sequence Embedding: Caser是一种CNN-based方法,将item的embedding矩阵视为image,并运用卷积运算来抽取转移transition。除了基于马尔科夫链的方法之外,另一个方向的工作采用
RNN来建模用户序列。利用GRU4Rec使用GRU建模点击序列从而用于session-based推荐,而《Recurrent neural networks with top-k gains for session-based recommendation》改进了GRU4Rec并进一步提高了Top-N推荐的性能。在每个time step,RNN将last step的状态和当前行为作为输入。尽管人们已经提出了诸如session parallelism之类的技术来提高效率,但是step之间的依赖关系使得RNN的效率更低。注意力机制:注意力机制已被证明在各种任务中是有效的。本质上,这种机制背后的思想是:序列输出
sequential output中的每个输出都依赖于某些输入的relevant部分,而这些输入部分是模型应该持续关注的。 基于注意力的方法的额外好处是,方法更容易解释。最近,注意力机制已被引入推荐系统,例如Attentional Factorization Machine: AFM学习每个特征交互对于content-aware推荐的重要性。然而,上面使用的注意力技术本质上是原始模型的附加组件
additional component,如attention+RNN、attention+FM等等。最近,一种纯粹基于注意力的sequence-to-sequence,叫做Transfomer,在之前RNN/CNN-based方法主导的机器翻译任务上实现了state-of-the-art的性能和效率。Transformer模型在很大程度上依赖于所提出的self-attention模块来捕获句子中的复杂结构,并检索relevant word(在source language)从而生成next word(在target language)。受
Transformer的启发,我们试图建议一个基于self-attention方法的、新的序列推荐模型,然而序列推荐问题与机器翻译问题有很大不同因此需要专门设计的模型。
12.1 模型
令用户集合为
item集合为setting下,给定用户next item。在训练过程中,在time stepitem来预测next item(即,第item)。如下图所示,可以方便地将模型的输入视为
shifted版本:embedding layer、若干个self-attention block、以及一个prediction layer来构建序列推荐模型。我们还分析了它的复杂性,并进一步讨论了SASRec与相关模型的不同之处。
12.1.1 Embedding Layer
我们将训练序列
如果训练序列长度超过
如果训练序列长度小于
padding item直到序列长度为注意,训练序列按照发生时间从远到近的顺序排列,因此
padding item填充在左侧(代表最远时刻)。
对于每个
itemembedding向量embedding维度。所有item的embedding向量构成了embedding矩阵itemembedding向量。对于序列
itemembedding向量postion的item的embedding。序列input embedding matrix记做positionitem的embedding,并且对于padding item采用常数Positional Embedding:我们将在后面章节看到,由于self-attention模型不包含任何循环模块或卷积模块,因此它对于先前item的position是无感知的。因此,我们将一个可学习的position embedding矩阵input embedding中:其中:
position的position embedding,它是我们还尝试了
《Attention is all you need》中使用的固定的position embedding,单发现这在我们的case中导致性能更差。我们在实验中定量和定性地分析了position embedding的影响。
12.1.2 Self-Attention Block
《Attention is all you need》中定义的scaled dot-product attention为:其中:
query矩阵,key矩阵,value矩阵。item数量(每一行代表一个item),query/key embedding的维度,value embedding的维度,并且直观而言,
attention layer计算所有value的加权和,其中queryvaluequerykeyinteraction有关。比例因子softmax的计算出现数值不稳定从而影响效果。也可以用超参数
Self-Attention layer:在机器翻译等NLP任务中,注意力机制通常采用《Attention is all you need》提出了一个self-attention方法,它使用相同的对象作为query、key、以及value。在我们的case中,self-attention操作将embeddingattention layer:其中:
self-attention的representation,第representation(对应于time step
引入投影可以使得模型更加灵活。例如,模型可以学习非对称交互
asymmetric interaction,即<query i, key j>和<query j, key i>可以有不同的交互。因果关系
Causality:由于序列的性质,模型在预测第item时,只能考虑开始的前item。然而,self-attention layer的第item的embedding的输入信息,这不符合真实的情况。因此,我们通过禁止attention。即:
key的时刻不能超过query的时刻。Point-Wise Feed-Forward Network:尽管self-attention能够使用自适应权重聚合所有先前item的embedding,但是它仍然是一个线性模型。为了赋予模型非线性并考虑不同潜在维度之间的交互,我们应用一个point-wise的、双层的feed-forward network: FFN到所有的FFN是跨time step共享权重的:其中:
注意,
注意,这里只有一个
ReLU,为什么?个人猜测是为了方便后面直接接入output layer。
12.1.3 Stacking Self-Attention Blocks
在第一层
self-attention block之后,item的embedding,即self-attention block来学习更复杂的item transition可能是有益的。具体而言,我们堆叠self-attention block(即,一个self-attention layer和一个FFN),并且第block(然而,当网络更深时,有几个问题变得更加严重:
- 增加的模型容量导致模型过拟合。
- 训练过程变得不稳定(由于梯度消失等)。
- 具有更多参数的模型通常需要更多的训练时间。
受到
《Attention is all you need》的启发,我们执行以下操作来缓解这些问题:其中:
self attention layer或FFN。也就是说,对于
block中的每个layer- 我们在输入到
layer normalization。 - 我们对
dropout。 - 此外,我们将输入
我们接下来依次介绍这些操作。
残差连接
Residual Connections:在某些情况下,多层神经网络已经证明了分层hierarchically地学习有意义特征的能力。然而,在提出残差网络之前,简单地添加更多层并不容易得到更好的性能。残差网络背后的核心思想是:通过残差连接将low-layer特征传播到更高的层。因此,如果low-layer特征有用,模型可以轻松地将它们传播到最后一层。同样地,我们假设残差连接在我们的
case中也很有用。例如,现有的序列推荐方法表明,最近一个访问的item对预测next item起着关键作用。然而,经过几个self-attention block之后,最近一个访问的item的embedding与之前的所有item纠缠在一起。添加残差连接从而将最近一个访问的item的embedding传播到最后一层将使模型更容易利用low-level信息。假设在
time stepnext item,那么self attention layer的残差连接为:这里有一个细节:是采用
position embedding)、还是采用position embedding)?论文并未提及。这可以通过实验来验证。Layer Normalization:layer normalization用于跨特征对输入进行归一化(即,零均值和单位方差),这有利于稳定和加速神经网络的训练。和batch normalization不同,layer normalization中使用的统计数据独立于同一个batch中的其它样本。具体而言,假设输入是包含了一个样本中所有特征的向量
layer normalization定义为:其中:
Hadamard积)。
Dropout:为了缓解深度神经网络中的过拟合问题,Dropout正则化技术已被证明在各种神经网络架构中是有效的。Dropout的思想很简单:在训练期间以概率turn off神经元,并在测试期间使用所有神经元。除了在
self attention layer或FFN上应用dropout之外,我们还在embeddingdropout layer。
12.1.4 Prediction Layer
在
self-attention block之后,给定开始的item我们基于next item。具体而言,我们采用一个MF layer来预测与itemrelevance:其中:
item的条件下,itemnext item的relevance,也称作交互分interaction score。item embedding矩阵。
因此,一个更高的
itemnext item。我们根据Shared Item Embedding:为了降低模型大小并缓解过拟合,我们考虑在MF layer中使用item embedding注意:
使用同一套
item embedding的一个潜在问题是:它们的内积不能表示非对称的item转移,例如itemitemFPMC这样的方法倾向于使用异质heterogeneous的item embedding(即,然而,我们的模型没有这个问题,因为它学习了非线性变换。例如,
FFN可以通过同一套item embedding轻松实现不对称:embedding显著提高了我们模型的性能。Explicit User Modeling:为了提供个性化推荐,现有方法通常采用以下两种方法之一:- 学习一个显式的
user embedding从而表达用户的偏好(如MF、FPMC、Caser)。 - 考虑用户之前的行为,并从之前访问的
item的embedding中导出一个隐式的user embedding(如FSIM、Fossil、GRU4Rec)。
我们的方法属于后者,因为我们通过考虑用户的所有行为来生成
embeddinguser embedding,例如:其中
user embedding矩阵。然而,我们根据经验发现添加显式的
user embedding并不能提高性能(可能是因为模型已经考虑了所有用户的行为)。- 学习一个显式的
12.1.5 Network Training
回忆一下我们通过截断或填充从而将每个用户行为序列(排除最后一个行为)
output:其中
<pad>表示padding item。我们的模型以序列
next item)。我们采用二元交叉熵损失作为目标函数:其中:
session所组成的集合。注意,我们忽略当
上式本质是
softmax交叉熵损失的负采样版本,它是pointwise loss。我们也可以考虑pairwise loss。网络通过
Adam优化器进行优化。在每个epoch中,我们为每个序列中的每个time step随机生成一个negative item
12.1.6 复杂度分析
空间复杂度:我们模型中待学习的参数来自
embedding,以及self-attention layer、FFN、layer normalization中的参数,参数的总数为FPMC的时间复杂度:我们模型的计算复杂度主要来自于
self-attention layer和FFN,即self-attention layer的self-attention layer中的计算是完全可并行的,这适合GPU加速。相反,RNN-based方法(如GRU4Rec)依赖于time step(即,time steptime step我们经验性地发现我们的方法比采用
GPU的RNN/CNN-based方法快十倍以上(结果类似于《Attention is all you need》中机器翻译任务的结果),并且最大长度benchmark数据集,在测试阶段,对于每个用户,在计算
embeddingMF方法相同。评估每个item的计算复杂度为处理长的序列:尽管我们的实验从经验上验证了我们方法的效率,但最终它无法扩展到非常长的序列。我们有望在未来调查一些方向:
- 使用
restricted self-attention(《A time-restricted self-attention layer for asr》),它仅关注最近的行为而不是所有行为,并且可以在更高的layer考虑远距离行为distant action。 - 如
《Personalized top-n sequential recommendation via convolutional sequence embedding》中那样将长序列分段 。
- 使用
未来工作:
结合丰富的上下文信息(如停留时长、行为类型
action type、location、设备等等)来扩展模型。通过这些上下文信息,我们不仅知道行为序列中每个行为作用的
item,还知道发生该行为的上下文。研究处理非常长的序列。
12.1.7 讨论
我们发现
SASRec可以视为某些经典协同过滤模型的推广generalization。我们还在概念上讨论了我们的方法和现有方法如何处理序列建模。SASRec可以简化为一些现有模型:Factorized Markov Chains: FMC:FMC分解一阶的item转移矩阵,并且依赖于最近的一个itemnext item如果我们将
self-attention block设为零、使用非共享的item embedding、并且移除position embedding,SASRec将简化为FMC。此外,
SASRec还与Factorized Personalized Markov Chains: FPMC密切相关,后者融合MF和FMC从而分别捕获用户偏好和短期动态:其中:
遵从上面类似于
FMC的简化操作,并添加显式的user embedding(通过向量拼接),SASRec等效于FPMC。Factorized Item Similarity Models: FISM:FISM通过考虑itemitem之间的相似性来估计对item如果我们使用一个
self-attention layer(不包含FFN)、在item上设置均匀的注意力权重(即item embedding、并移除position embeddnig,则SASRec将简化为FISM。因此,我们的模型可以被视为用于next item推荐的自适应的、分层的、序列的item similarity model。
MC-based推荐:马尔科夫链Markov Chains: MC可以有效地捕获局部序列模式local sequential pattern,它假设next item仅依赖于前面的item。现有的MC-based的序列推荐方法要么依赖于一阶马尔科夫链(如FPMC, HRM, TransRec)、要么依赖于高阶马尔科夫链(如Fossil, Vista, Caser)。基于一阶马尔科夫链方法往往在稀疏数据集上表现最好。相比之下,基于高阶马尔科夫链的方法有两个限制:- 需要在训练之前指定马尔科夫链的阶次
- 效率和效果无法很好地随阶次
scale,因此
我们的方法解决了第一个问题,因为
SASRec可以自适应地关注相关的前面的item(如,在稀疏数据集上仅关注最近一个item,以及在稠密数据集上关注更多的item)。此外,对于第二个问题,我们的模型建模了前面
item,并且- 需要在训练之前指定马尔科夫链的阶次
RNN-based推荐:另一个方向的工作使用RNN来建模用户行为序列。RNN通常用于建模序列,但是最近的研究表明:CNN和self-attention在某些序列的setting中表现得比RNN更强。我们的
self-attention based模型可以从item similarity model中推导出来,这是用于推荐的序列建模的合理替代方案。对于RNN,除了并行计算效率低下外,它们的最大路径长度(从输入节点到相关的输出节点)为long-range dependency。
12.2 实验
我们进行实验并回答以下几个问题:
RQ1:SASRec是否超越了state-of-the-art方法(包括CNN/RNN-based方法)?RQ2:SASRec架构中各种组件的影响是什么?RQ3:SASRec的训练效率和可扩展性(关于n的)如何?RQ4:注意力权重是否能够学到与position相关的、或者与item属性相关的有意义的pattern?
数据集:我们在来自现实世界应用程序的四个数据集上评估我们的方法。数据集在领域
domain、平台platform、稀疏性sparsity方面差异很大:Amazon:来自于Amazon.com的数据集,其中Amazon上的top-level产品类别被视为单独的数据集。我们考虑两个类别,美妆Beauty、游戏Games。该数据集以高度的稀疏性和可变性variability而著称。Steam:来自于一个大型在线视频游戏分发平台Steam。数据集包含2567538名用户、15474款游戏、7793069条英文评论,时间跨度从2010年10月到2018年1月。该数据集还包含可能对未来工作有用的丰富信息,如用户游戏时长(小时)、游戏定价信息、媒体评分(对游戏的评分)、游戏类别category、游戏开发者developer等等。MovieLens:用于评估协同过滤算法的、广泛使用的benchmark数据集。我们使用包含100万用户评分的版本MovieLens-1M。
我们遵循与
《Factorizing personalized markov chains for next-basket recommendation 》、《Translation-based recommendation》、《Fusing similarity models with markov chains for sparse sequential recommendation》相同的预处理程序:对于所有数据集,我们将评论或评分的存在视为隐式反馈(即,用户和
item的交互),并使用时间戳来确定行为的顺序。对于评分,如果太低是不是要移除?否则高分和低分没有差异。
我们丢弃频次低于
5的用户、以及频次低于5的item。我们将每个用户
这个和
GRU4Rec的不同。在GRU4Rec中,仅在用户之间完整的session划分数据集(即,user-level),而不对session内部进行拆分(即,session-level)。区别在于:user-level的划分:测试用户是全新的,相当于冷启动cold-start。session-level的划分:测试用户不是全新的,已经在训练期间见过用户前面的
数据集的统计特性参考下表。我们看到:两个
Amazon数据集的actions per user和actions per item更少,Steam的actions per item更高,而MovieLens-1m是最稠密的数据集。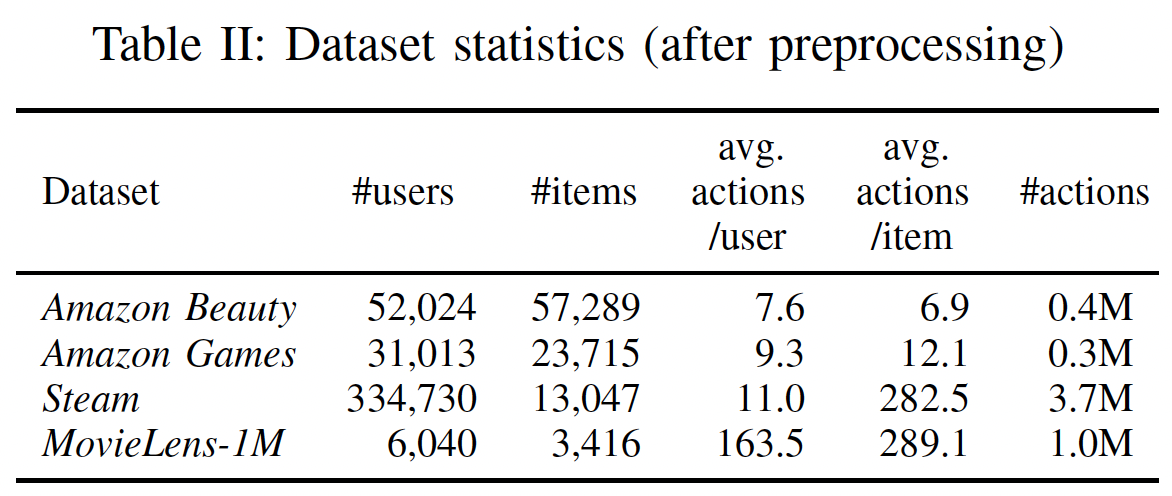
baseline方法:我们考虑三组baseline。第一组
baseline仅考虑用户反馈而不考虑行为顺序的通用推荐方法general recommendation method:PopRec:这是一个简单的baseline,根据item的热门程度(即数据集中的频次)对item进行排名。Bayesian Personalized Ranking: BPR:是一种从隐式反馈中学习个性化排名的经典方法。biased的矩阵分解模型作为底层的推荐器recommender。
第二组
baseline包含基于一阶马尔科夫链的序列推荐方法,它考虑最近一个访问的item:Factorized Markov Chains: FMC:一阶马尔科夫链方法。FMC使用两个item embedding来分解item转移矩阵,并根据最近一个访问的item生成推荐。Factorized Personalized Markov Chains: FPMC:FPMC组合了矩阵分解和分解的一阶马尔科夫链,从而捕获了用户的长期偏好以及item-to-item的转移。Translation-based Recommendation: TransRec:一种state-of-the-art的一阶序列推荐方法,它将每个用户建模为一个翻译向量translation vector从而捕获从current item到next item的转移。
最后一组
baseline包含基于深度学习的序列推荐方法,这些方法考虑了最近访问的一些item或者所有访问的item:GRU4Rec:一种开创性的、使用RNN来建模用户行为序列的session-based推荐方法。我们将每个用户的反馈序列视为一个session。一个用户只有一个
session。理论上最好进行时间间隔的拆分,将用户行为序列基于时间间隔拆分为多个session,使得每个session集中体现用户的某个意图。GRU4Rec+:GRU4Rec的改进版本(《Recurrent neural networks with top-k gains for session-based recommendations》),它采用不同的损失函数和采样策略,并在Top-N推荐上显示出显著的性能提升。Convolutional Sequence Embeddings: Caser:最近提出的一种CNN-based方法,它通过对item的embedding矩阵应用卷积运算来捕获高阶马尔科夫链,并实现了state-of-the-art的序列推荐性能。
由于其它序列推荐方法(如
PRME, HRM, Fossil)在类似数据集上的性能逊色于上述baseline,因此我们不考虑与它们进行比较。我们也不包含TimeSVD++, RRN等时间推荐方法temporal recommendation method,因为它们的setting与我们这里考虑的不同。配置:
- 为了公平地比较,我们使用带
Adam优化器的TemsorFlow来实现BPR, FMC, TransRec。对于GRU4Rec, GRU4Rec++, Caser,我们使用相应作者提供的代码。 - 对于除了
PopRec之外所有方法,我们从{10, 20, 30, 40, 50}中考虑潜在维度 - 对于
BPR, FMC, FPMC, TransRec,我们考虑L2正则化并且正则化系数从{0.0001, 0.001, 0.01, 0.1, 1}之间选择。 - 所有其它超参数和初始化策略都是对应方法的作者所建议的。我们使用验证集调优超参数,如果验证集性能在
20个epoch内没有提高,那么终止训练。
- 为了公平地比较,我们使用带
SASRec实现细节:对于默认版本的
SASRec中的架构,我们使用两个self-attention block(positional embedding。embedding layer和prediction layer中的item embedding是共享的。我们使用
TensorFlow实现了SASRec。优化器是Adam,学习率为0.001,batch size = 128。MovieLens-1m的dropout rate = 0.2,而其它三个数据集由于稀疏性因此dropout rate = 0.5。数据集越稀疏所以
dropout rate越大?可能需要进行超参数调优来观察实验效果。MovieLens-1m的最大序列长度
我们在后面检查
SASRec的不同变体以及不同超参数的性能。SASRec的代码公布在https://github.com/kang205/SASRec。评估指标:我们使用两个常见的
Top-N指标Hit Rate@10, NDCG@10来评估推荐性能。Hit@10计算了ground-truth的next item出现在推荐列表的top 10个item比例(分母为推荐列表的个数,即推荐结果中有多少是命中的)。注意,由于我们对每个用户仅有一个
test item,因此Hit@10相当于Recall@10,并且与Precision@10成正比(Precision@10还要除以推荐列表长度,这里是10)。而
NDCG@10是一个position-aware的指标,它在排名靠前的位置分配更大的权重。
为了避免对所有
user-item pair进行大量的计算,我们对每个用户随机采样100个negative item,并将这些negative item与ground-truth item进行排名。我们根据这101个item的排名来评估Hit@10和NDCG@10指标。
12.2.1 不同方法结果比较
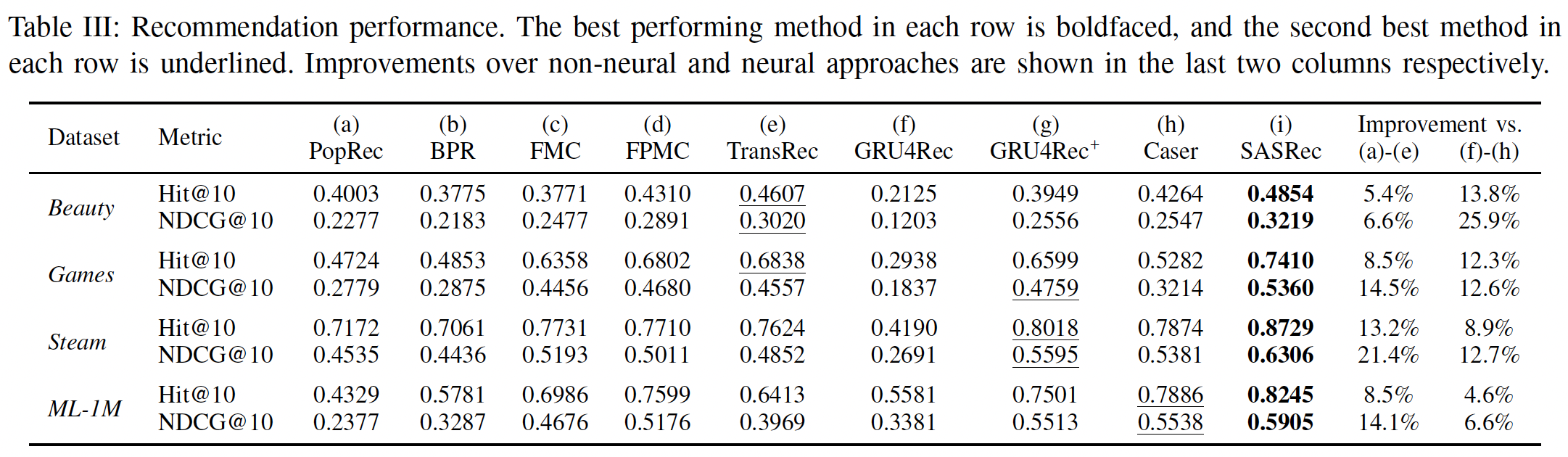
下表展示了所有方法在四个数据集上的推荐性能(用于回答问题
RQ1)。考虑排除
SASRec以外的其它方法在所有数据集上的表现,我们发现一种通用模式,即:non-neural方法((a) ~ (e))在稀疏数据集上表现更好,而神经网络方法((f) ~ (h))在稠密数据集上表现更好。这可能是由于神经网络方法具有更多参数来捕获高阶转移
high order transition(即,它们具有表达能力但是容易过拟合),而精心设计但更简单的模型在高度稀疏的setting中更有效。我们的方法
SASRec在稀疏数据集和稠密数据集上都优于所有baseline,并且相对于最强的baseline在Hit Rate上平均提升6.9%、在NDCG上平均提升9.6%。一个可能的原因是我们的模型可以自适应地关注不同数据集上不同范围内的
item(例如,在稀疏数据集上仅关注前一个item,在稠密数据集上关注更多的item)。我们在后面内容进一步分析了这种行为。
在下图中,我们还通过展示
10到50的变化时所有方法的NDCG@10指标,从而分析关键超参数SASRec在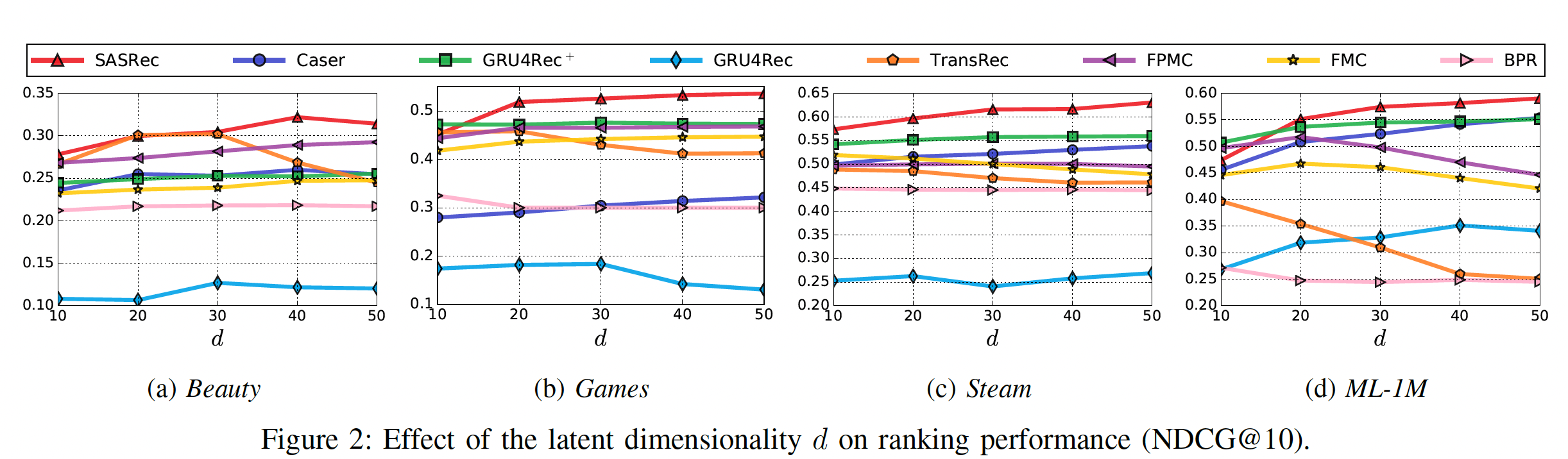
12.2.2 消融研究
由于我们的架构中有许多组件,我们通过消融研究来分析它们的影响(用于回答问题
RQ2)。下表显示了我们的默认方法及其8个变体在所有四个数据集上的性能(Remove PE(Positional Embedding):没有positional embeddingitem的注意力权重仅取决于item embedding。也就是说,该模型根据用户过去的行为进行推荐,但是行为的顺序并不重要。该变体可能适用于用户行为序列通常较短的稀疏数据集。该变体在最稀疏的数据集
Beauty上的表现优于默认的模型,但是在其它更稠密的数据集上的表现更差。移除
positional embedding不一定效果下降,主要还是要看数据集的性质。Unshared IE(Item Embedding):我们发现,使用两种item embedding(非共享的item embedding)会一致性地损害性能,可能是由于过拟合。Remove RC(Residual Connections):我们发现,移除残差连接之后模型性能显著更差。这大概是因为lower layer中的信息(如,最近一个item的embedding,第一个block的output)无法轻易地传播到最后一层,而这些lower layer中的信息对于推荐非常有用,尤其是在稀疏数据集上。Remove Dropout:我们的结果表明,dropout可以有效地正则化模型从而实现更好的性能,尤其是在稀疏数据集上。结果还暗示了:过拟合在稠密数据集上不严重。过拟合在稠密数据集上也比较严重,只是相对稀疏数据集而言不太严重。
因为稀疏数据集更容易陷入过拟合,因此更需要正则化。
Number of blocks:- 毫不奇怪, 零个
block的结果较差,因为模型效果仅取决于最近一个item。 - 带有一个
block的变体的表现相当不错。 - 带有两个
block的变体(即default模型)的表现仍然进一步提升,尤其是在稠密数据集上,这意味着hierarchical self-attention structure有助于学习更复杂的item转移。 - 带有三个
block的变体可以获得与default模型(即两个block)相似的性能。
- 毫不奇怪, 零个
Multi-head:Transformer的作者发现使用multi-head的注意力很有用,它将注意力应用于case中,two head attention的性能始终比single-head attention稍差。这可能是由于我们的问题中的Transformer中,
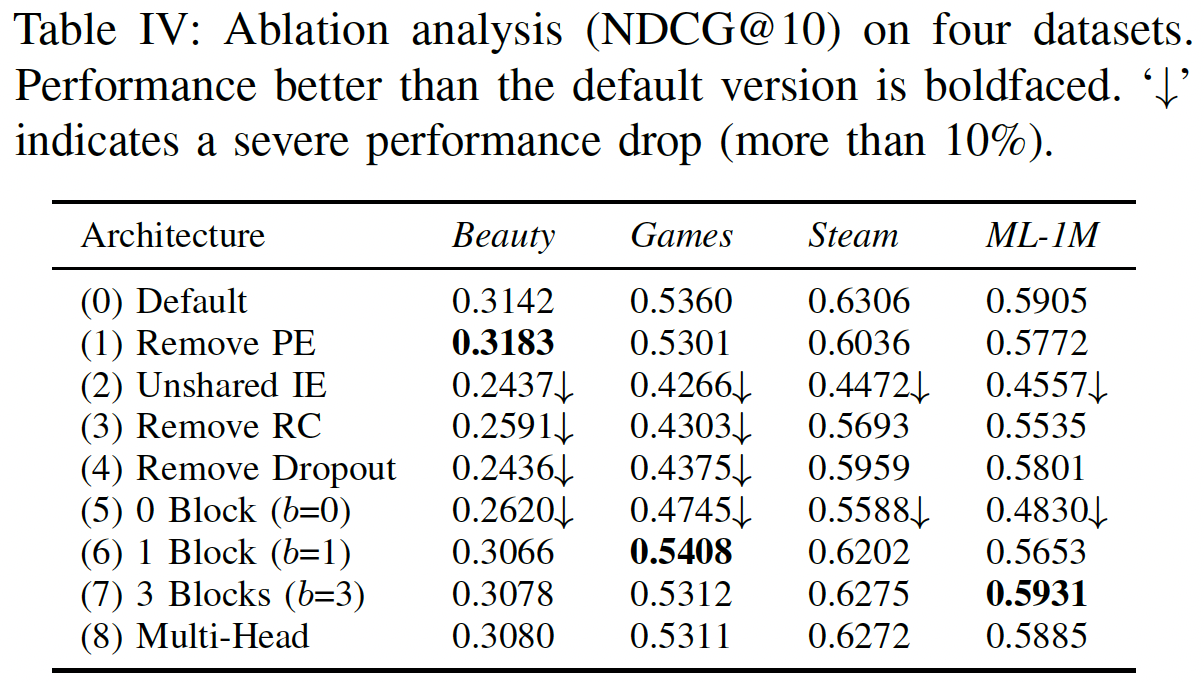
12.2.3 训练效率和可扩展性
我们评估了我们模型的训练效率的两个方面(用于回答问题
RQ3):训练速度(一个训练epoch所花费的时间)、收敛时间(达到令人满意的性能所花费的时间)。我们还根据最大长度GTX-1080 Ti GPU进行。训练效率:下图展示了使用
GPU加速的、基于深度学习的方法的效率。GRU4Rec由于性能较差而被省略。为公平比较,Caser和GRU4Rec+有两种训练选项:使用完整的训练数据、或仅使用最近的200个行为(SASRec中就是使用最近的200个行为)。- 在计算速度上,
SASRec一个epoch的模型更新时间仅为1.7秒,比Caser快11倍(19.1 s/epoch))、比GRU4Rec+快18倍(30.7s/epoch)。 - 在收敛速度上,
SASRec在ML-1M数据集上大约在350秒内收敛到最佳性能,而其它模型需要更长的时间。 - 我们还发现,使用完整数据可以提高
Caser和GRU4Rec+的性能。
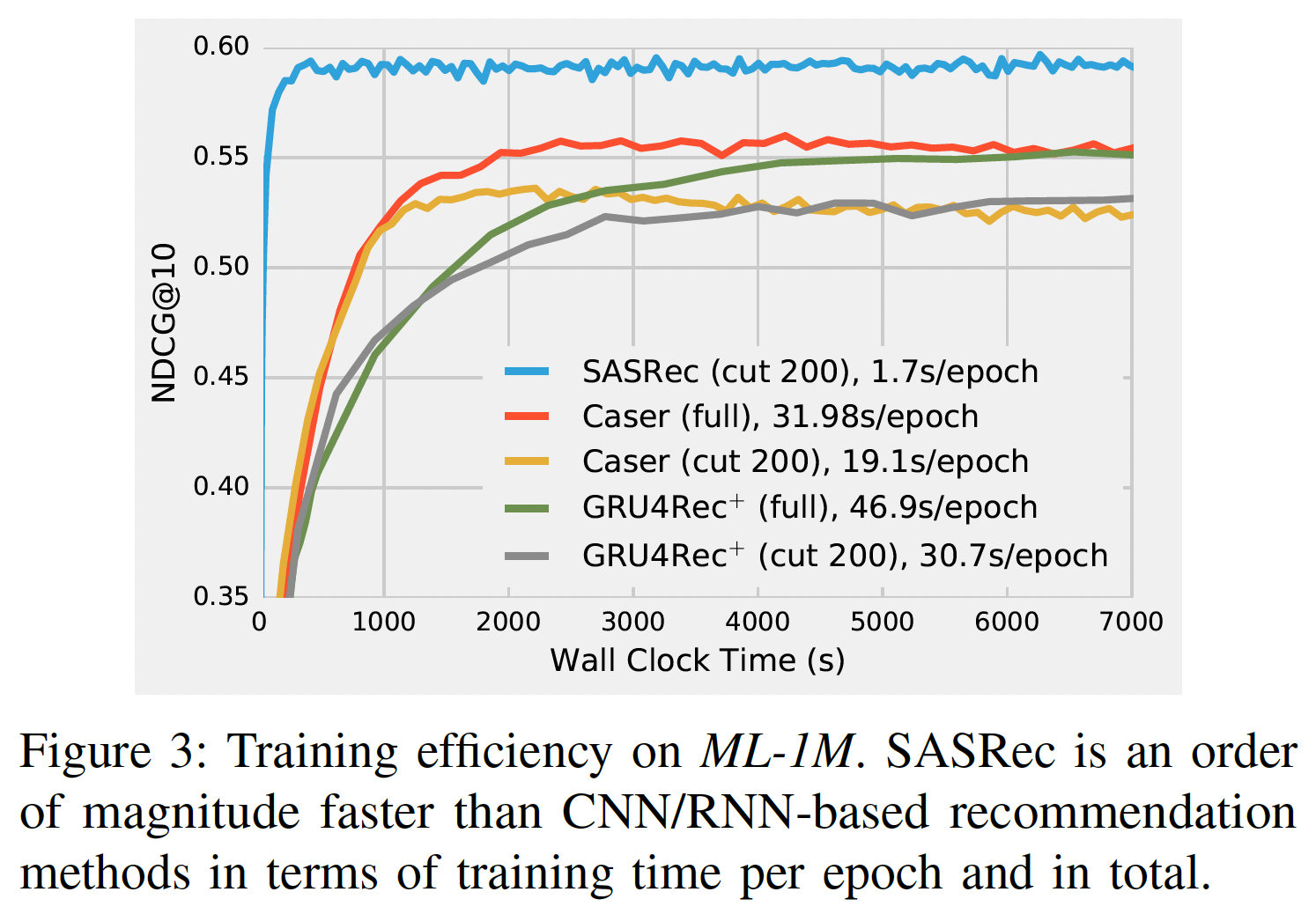
- 在计算速度上,
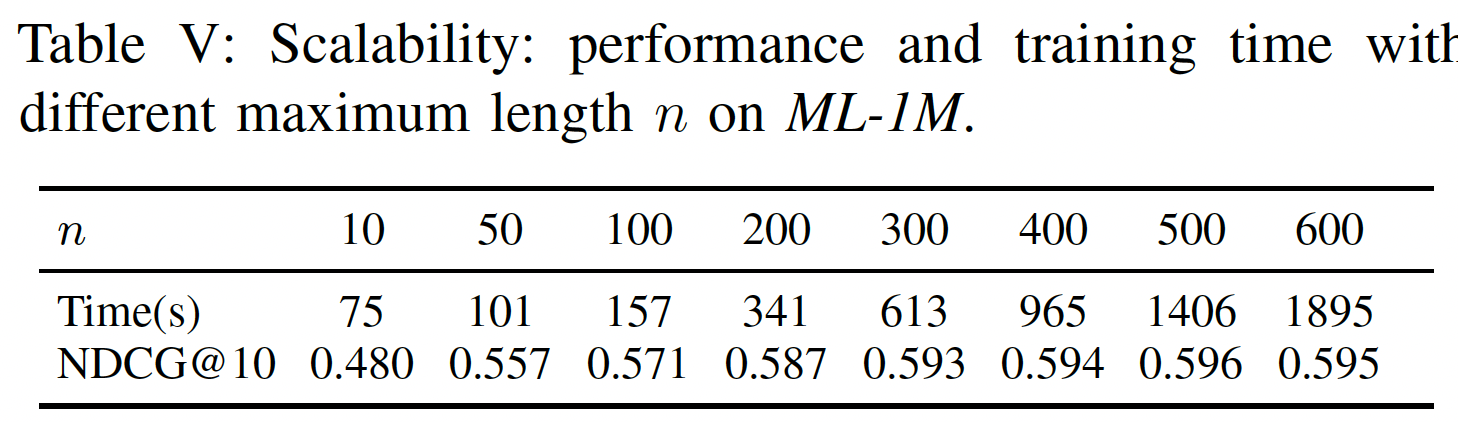
可扩展性:与标准
MF方法一样,SASRec与用户总数、item总数、action总数呈线性关系。一个潜在的可扩展性问题是最大长度GPU并行化。这里我们测量SASRec在不同SASRec的可扩展性,并分析它是否可以在大多数情况下处理序列推荐。下表显示了具有不同序列长度的
SASRec的性能和效率。- 较大的
99.8%的行为序列)。 - 然而,即使
2000秒内完成训练,这仍然比Caser和GRU4Rec+更快。
因此,我们的模型可以轻松地扩展到多达数百个行为的用户行为序列,这适用于典型的评论数据集和购买数据集。我们计划在未来研究处理非常长的序列的方法。
- 较大的
12.2.4 可视化
回想一下,在
time stepself-attention机制根据前面item的position embedding和item embedding自适应地为它们分配权重。为了回答RQ4,我们检查所有训练序列,并通过展示position上的平均注意力权重、以及item之间的平均注意力权重来揭示有意义的pattern。position上的注意力:下图展示了最近15个time step在最近15个position上的平均注意力权重的四种热力图。注意,我们在计算平均权重时,分母是有效权重的个数,从而避免短序列中padding item的影响。我们考虑了不同热力图之间的一些比较:
(a) vs (c):这种比较表明:- 对于稀疏数据集
Beauty,SASRec倾向于关注更近more recent的item。 - 对于稠密数据集
ML-1M,SASRec倾向于关注不那么近less recent的item。
这是使我们的模型能够自适应地处理稀疏数据集和稠密数据集的关键因素,而现有方法往往仅侧重于某一头。
即,表明我们的
self-attention机制的行为是自适应的。- 对于稀疏数据集
(b) vs (c):这种比较展示了使用positional embedding: PE的效果。- 没有
positional embedding(即,(b),注意力权重基本上均匀分布在先前的item上。 - 有
positional embedding(即,(c),也是默认的模型),模型对position更敏感,因为模型倾向于关注最近的item。
即,表明我们的
self-attention机制的行为是position-aware的。- 没有
(c) vs (d):由于我们的模型是分层hierarchical的,这里展示了不同block之间的注意力是如何变化的。显然,high layer的注意力往往集中在更近more recent的position上。这大概是因为第一个self-attention block已经考虑了所有之前的item,而第二个block不需要考虑很远的position。即,表明我们的
self-attention机制的行为是hierarchical的。此外,既然第二个
block不需要考虑很远的position,那么是否使用简单的last representation就可以?毕竟self-attention block的计算复杂度比直接引入last representation更高。
总而言之,可视化表明我们的
self-attention机制的行为是自适应的、position-aware的、以及hierarchical的。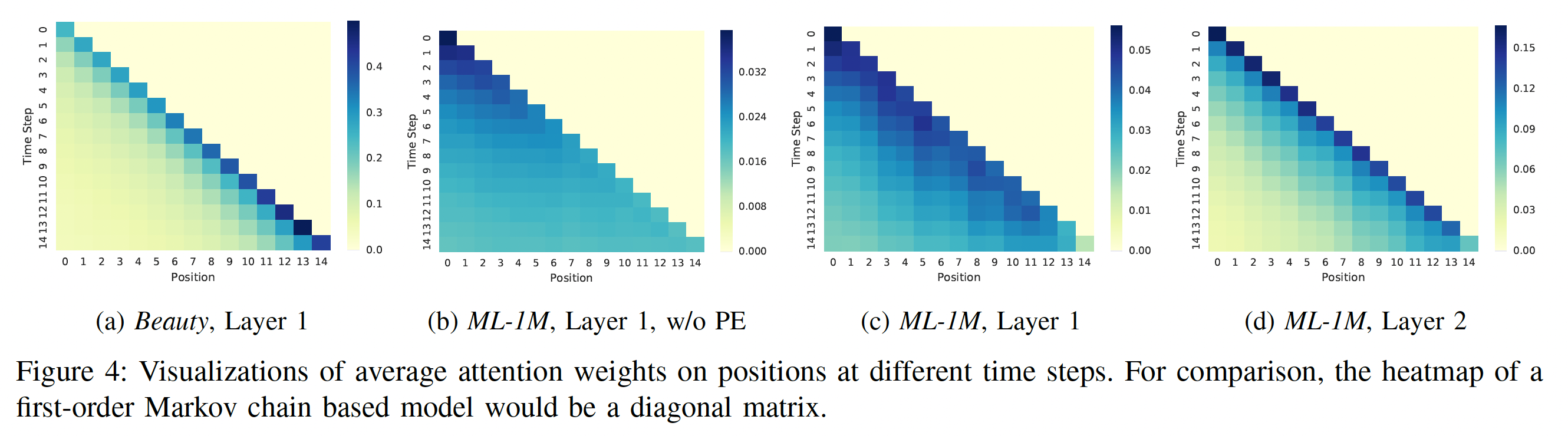
item之间的注意力:展示几个精心挑选的item之间的注意力权重可能没有统计学意义。在MovieLens-1M上,每部电影都有多个类别。为了进行更广泛的比较,我们随机选择两个不相交的集合,每个集合包含来自4个类别的200部电影:科幻Sci-Fi、浪漫Romance、动画Animation、恐怖Horror(注,这两个集合共享相同的四个类别)。第一个集合用于query,第二个集合用于key。下图展示了两个集合内不同
item之间的平均注意力权重的热力图(item粒度的,而不是类别粒度的),每个集合内的item根据类别进行分组。我们可以看到:热力图大概是一个块对角矩阵block diagonal matrix,这意味着注意力机制可以识别相似的item(如,同一个类别的item),并倾向于在相似item之间分配更大的权重(SASRec事先不知道类别,我们也没有将item类别作为特征馈入模型)。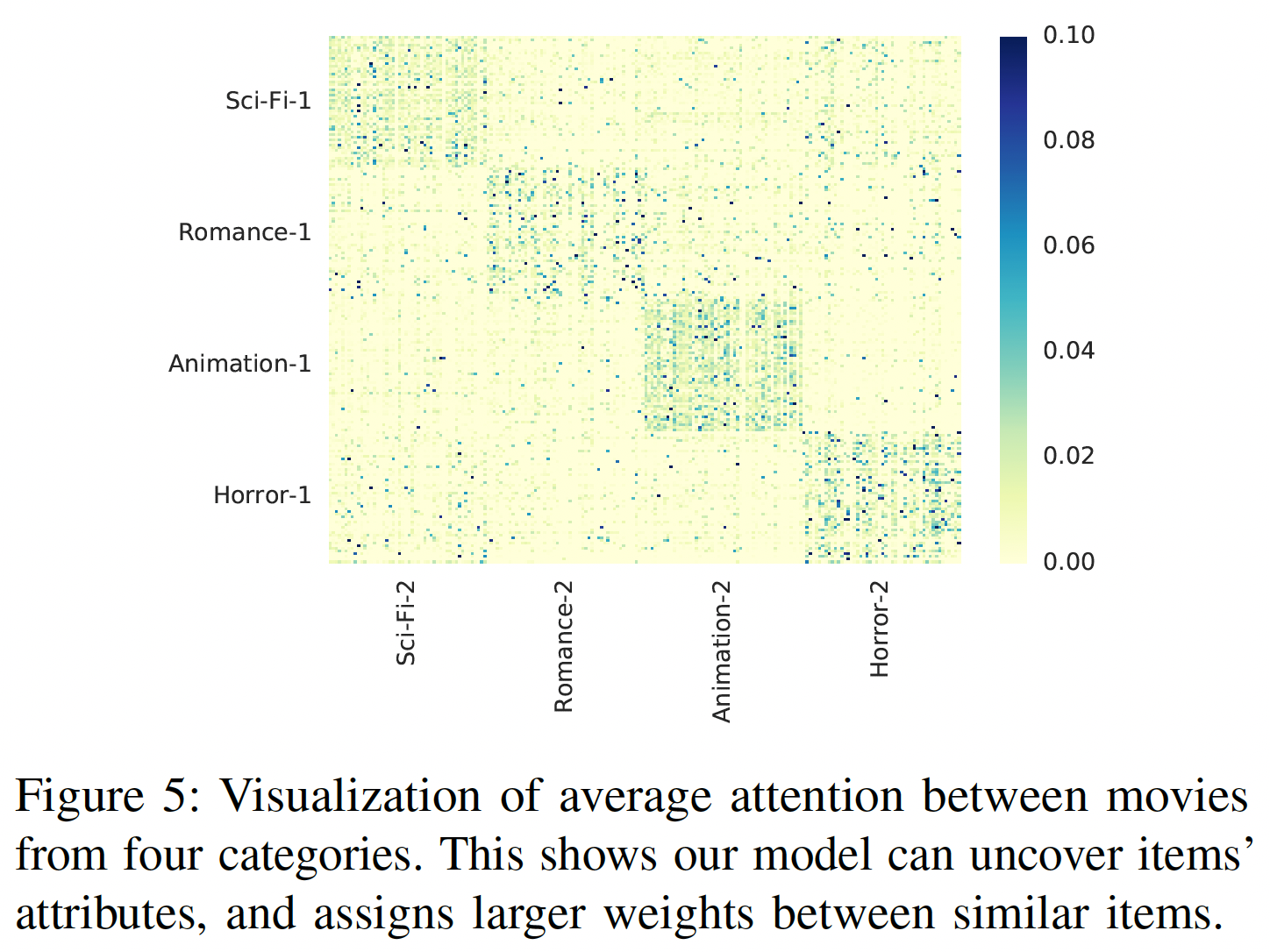
十三、RUM[2018]
在许多现实世界的
application中,用户当前的兴趣受到他们历史行为的影响。例如,人们在购买智能手机之后可能会购买手机壳或耳机等配件,人们可能会继续购买他们以前有过良好体验的同一品牌的衣服。为了建模这种现象,人们已经提出了一些方法来使用用户历史记录
user historical record进行序列推荐。例如,《Factorizing personalized markov chains for next-basket recommendation》采用马尔科夫链对用户行为序列进行建模,《Context-aware sequential recommendation》和《dynamic recurrent model for next basket recommendation》利用RNN来嵌入先前购买的商品从而进行当前兴趣预测current interest prediction。现有方法取得了令人振奋的结果,但是它们倾向于将用户以前的所有记录
record压缩为一个固定的hidden representation。如下图所示,用户购买手机壳(item E)的关键原因可能是他之前购买了一部手机(item B),而之前其它购买的商品不一定与这个new purchase(即,手机壳)有关。然而,RNN(和其它的latent representation方法)会强制将所有先前的item(即item A到item D)summarize到一个向量(即,next interest。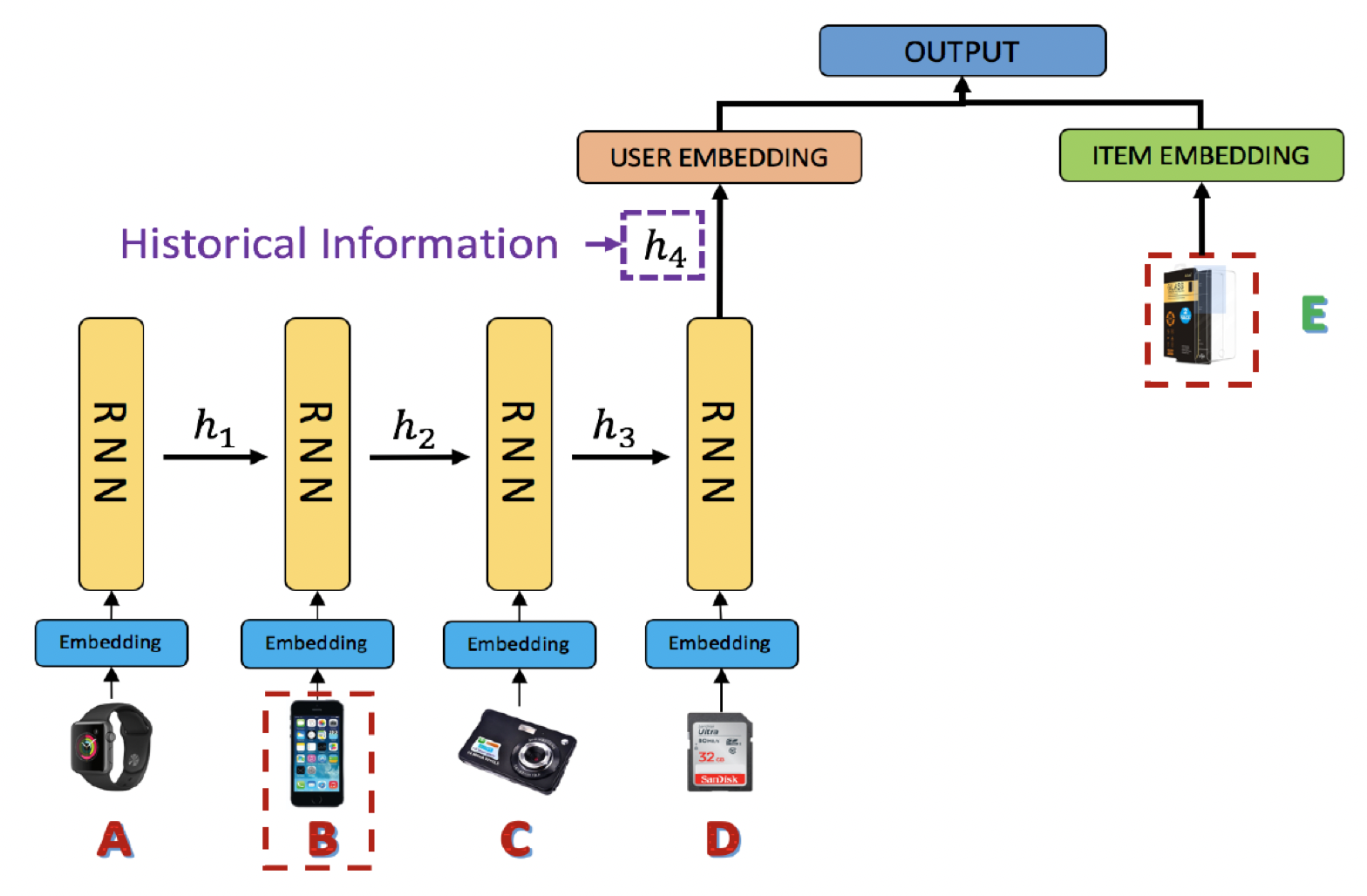
不同历史记录(它们用于
next interest prediction)的这种区分性的缺乏导致了两个不利的后果:- 在序列推荐中弱化了高相关
item的信号。 - 忽略这样的高相关性信号使我们难以理解和解释序列推荐。
为了缓解这些问题,论文
《Sequential Recommendation with User Memory Networks》将用户行为视为描述神经图灵机neural turing machine: NTM的决策程序,并提出使用external memory来建模用户历史记录。凭借显式地、动态地、和有效地表达、存储和操作记录的能力,external memory network: EMN已经在许多序列预测任务中展示出良好的性能,例如知识问答question answering: QA、natural language transduction: NLT、knowledge tracking: KT。EMN架构不是合并先前的状态state来进行预测,而是引入了一个memory matrix来将状态分别存储在memory slot中。然后通过在这个矩阵上设计适当的操作,EMN与传统的RNN/LSTM模型相比在许多任务中实现了显著的提升。受到
EMN的启发,论文《Sequential Recommendation with User Memory Networks》提出了一种将Recommender system和external User Memory network相结合的新颖框架,简称RUM。然后论文进一步研究RUM在top-N推荐任务上的直觉和性能。下图(b)和(c)说明了论文提出的框架的基本思想:- 对于每个用户,引入一个
external user memory matrix来维护该用户的历史信息。与传统的RNN hidden vector相比,这丰富了representation capacity。 - 在进行预测时,
memory matrix被注意力地attentively读出read out从而生成一个embedding来作为user representation,其中注意力机制学习先前记录对于当前推荐的不同重要性。 - 在处理完序列中的每个
item后,将重写memory从而更新用户历史user history。
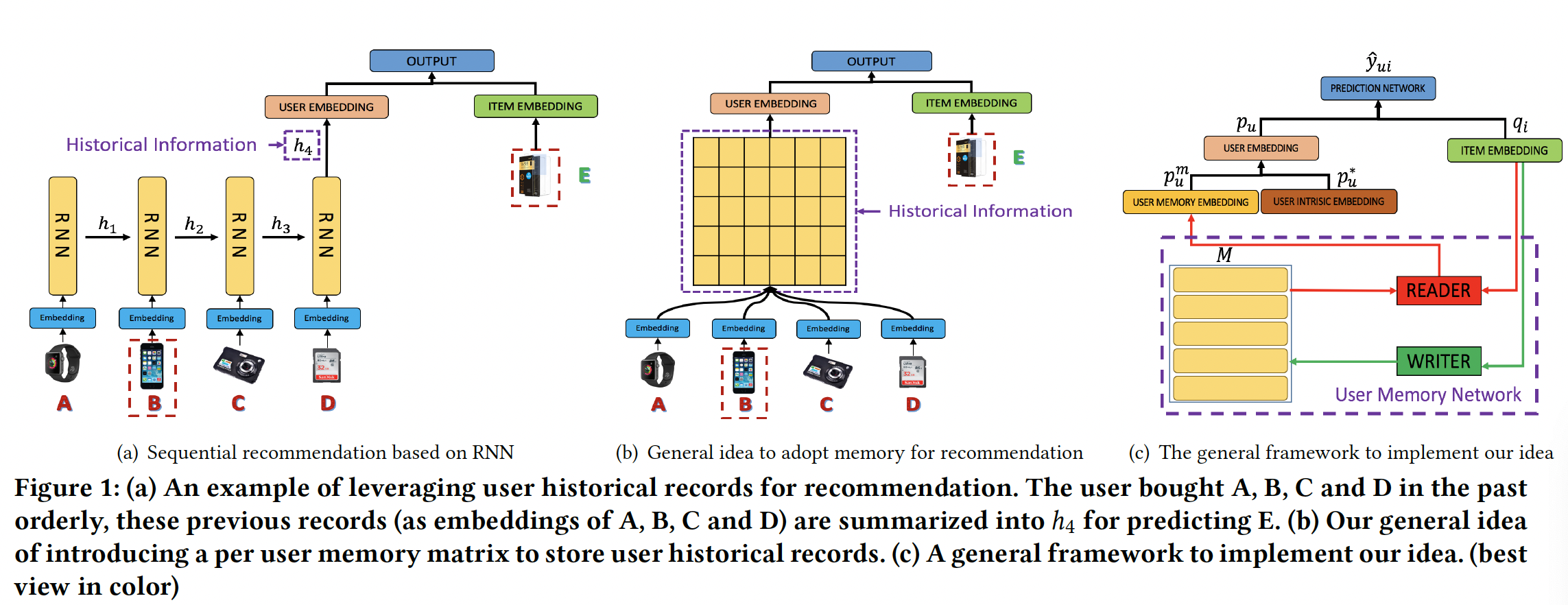
为了更好地探索论文的想法,作者提供了框架的两个规范
specification,即item-level RUM和feature-level RUM,它们分别建模item-level的用户记录和feature-level的用户记录。与现有方法相比,论文的方法基于memory network对用户历史记录进行了更细粒度的使用,提高了推荐性能,同时基于注意力分析抽取了消费者行为的直观的因果关系intuitive causality。总之,这项工作的主要贡献包括:
- 论文提出将协同过滤的洞察
insight与memory-augmented neural network: MANN相结合从而进行推荐。这种结合以更有效的方式利用了用户历史记录。据作者所知,这是将MANN引入推荐系统领域的首次尝试。 - 论文研究了两个具有不同
representation和operation设计的潜在memory network(item-level和feature-level)。论文进一步研究并比较了它们在序列推荐和top-N推荐任务中的表现。 - 论文还将所提出的模型与
state-of-the-art的方法进行了比较,并通过对现实世界数据集的定量分析来验证所提出模型的优越性。分析结果表明论文的方法能够更有效地利用用户历史记录。 - 论文进一步提供实证分析
empirical analyse来解释所提出的模型如何、以及为什么推荐一个item。分析结果表明通过memory network中的注意力机制,所提出的模型能够直观地解释用户历史记录如何影响该用户当前的和未来的决策。
- 在序列推荐中弱化了高相关
相关工作:我们的工作本质上是序列推荐和
memory-augmented neural network的集成。接下来我们回顾一下这两个研究方向的相关工作。序列推荐:在文献中,人们已经提出了许多模型以序列方式利用用户历史记录来进行
future behavior的预测和推荐。通过集成矩阵分解和马尔科夫链,
factorized personalized Markov chain: FPMC将相邻行为之间的转移信息transition information嵌入到item latent factor从而进行推荐。而
hierarchical representation model: HRM通过利用representation learning作为latent factor从而进一步扩展了这个想法。这些方法主要对每两个相邻记录之间的局部序列模式
local sequential pattern进行建模。为了建模
multiple-step序列行为,《Fusing Similarity Models with Markov Chains for Sparse Sequential Recommendation》采用马尔科夫链来提供稀疏序列的推荐。《A dynamic recurrent model for next basket recommendation》提出了dynamic recurrent basket model: DREAM来捕获全局序列模式global sequential pattern并学习基于recurrent neural network: RNN的dynamic user interest representation。在DREAM中,用户的所有历史记录都被嵌入到RNN的final hidden state中,从而代表该用户的当前偏好。DREAM这种方法取得了相对于HRM和FPMC的显著改进。类似地,
《Session-based recommendations with recurrent neural networks》、《Improved recurrent neural networks for session-based recommendations》利用用户之前的点击和购买行为,使用RNN对短期偏好进行建模,从而用于session-based推荐。《Translation-based recommendation》采用度量空间学习metric space learning方法来学习用于序列推荐的、加性additive的user-item关系。除了电商之外,序列推荐也被应用于
POI推荐、音乐推荐、浏览browsing推荐等各种application场景。
现有模型通常将用户先前的记录隐式编码为一个
latent factor或hidden state,而不区分每条记录在预测当前兴趣时可能扮演的不同角色。然而,在这项工作中,我们利用user memory network来存储和操作每个用户先前的记录,这有助于增强用户历史的表达能力。Memory-Augmented Neural Network:近年来出现了能够有效处理序列数据的external memory network: EMN。简而言之,EMN利用一个memory matrix来存储历史的hidden state。通过正确读取和更新这个memory matrix,EMN可以在许多面向序列的任务上获得更好的性能。遵循这个思想,《End-to-end memory networks》设计了一个端到端的memory-augmented model,它在训练期间需要的监督信息显著减少从而使其更好地适用于real-world setting。最近,研究人员已经成功地将EMN的概念应用于多个领域,如question answering: QA、natural language transduction: NLT、knowledge tracking: KT。通常,
EMN由两个主要组件构成:一个memory matrix用于维护state、一个controller用于操作(包括读取和写入)。更具体而言:对于读取过程,大多数方法采用注意力机制来读取
memory matrix。即,对于输入memory matrix中每个memory slotsimilarityslot的注意力权重为:其中
memory被注意力attentively地读出read out。对于写入过程,
《Neural turing machines》通过考虑内容和slot location来更新user memory,从而促进facilitatememory的所有location。然而,
《Meta-learning with memory-augmented neural networks》提出了一种单纯地content-based的写入策略,称之为least recently used access: LRUA,从而将memory写入到最少使用的memory location、或者最近使用的memory location。
在本文中,我们旨在将
EMN的思想应用于推荐系统,从而更有效地利用用户历史行为。这种应用方式还有待学术界探索。
13.1 模型
- 在本节中,我们首先介绍我们的通用框架,详细说明如何将
user memory network与协同过滤相结合。然后,我们通过描述通用框架的两个具体实现(即,item-level user memory network和feature-level user memory network)来聚焦于设计memory component,从而从不同的角度审视我们的框架。
13.1.1 通用框架
为了更好地理解,我们首先将广泛使用的矩阵分解
matrix factorization: MF模型重新描述为神经网络。假设有item(item集合为one-hot格式的user ID/ item ID可以作为输入并馈送到架构中,然后look-up layer将这些sparse representation投影到稠密向量中(即user embedding/ item embedding)。假设用户
user embedding为itemembedding为MF模型中likeness scorememory enhanced user embedding:为了在我们的框架中利用用户历史记录,我们从两部分生成一个用户的embedding:- 一个部分与用户的
memory component有关,该组件对用户以前的记录进行编码(称作memory embedding,记做 - 另一个部分是一个
free vector,用于编码不受用户先前行为影响的内在偏好intrinsic preference(称作intrinsic embedding,记做
memory embedding类似于传统的RNN-based方法中的hidden vector。然而,hidden vector盲目地将用户的所有历史记录压缩成一个固定的向量,而在我们的框架中,用户记录通过更具表达能力的结构(个性化的memory matrix这种方式内存消耗大(每个用户分配一个
memory matrix,内存需求为memory slot个数,memory embedding维度)。此外,模型的mini-batch训练也是一个难点。具体而言:
对于用户
memory embeddingitem embedding其中
然后,通过将
memory embeddingintrinsic embeddingfinal user embedding为:其中
其中
我们还测试了逐元素乘法合并、以及向量拼接合并,但是它们的效果都不如加权加法合并。加权加法合并的另一个优点是:我们可以调整权重超参数
memory机制进行推荐的效果,这将在实验部分展示。
- 一个部分与用户的
预测函数:在进行预测时,我们将
final user embeddingitem embedding其中
《Neural collaborative filtering》中的prediction neural network。在这里,我们选择sigmoid内积训练:我们采用二元交叉熵作为模型优化的损失函数,要最大化的目标函数为:
其中:
ground truth,如果用户item1,否则取值为0。item的集合,item的集合。我们从unobserved的item集合negative item。应该注意的是,非均匀采样策略可能会进一步提高性能,我们将非均匀采样策略留待未来的工作。
在这个等式中,我们通过前两项来最大化我们预测结果的可能性,最后一项对所有模型参数正则化从而避免过拟合。在训练阶段,我们通过随机梯度下降
stochastic gradient descent: SGD来学习模型参数。memory updating:在每次购买行为之后,我们通过以下方式更新user memory matrixdynamic nature:在接下来的内容中,我们将描述个性化的
memory matrixitem-level和feature-level设计
13.1.2 Item-level RUM
在本节中,我们首先通过简单的方式扩展以前的方法来实现我们的思想(如下图
(a))。与现有模型类似,我们将每个item视为一个单元unit,并建模先前购买的item对下一个item的影响。许多工作表明(《Factorizing personalized markov chains for next-basket recommendation》、《Learning hierarchical representation model for nextbasket recommendation》),用户最近的行为可能对当前决策更重要。因此,对于每个用户memory matrixitem的embedding,如下图(a)中的紫色虚线框所示。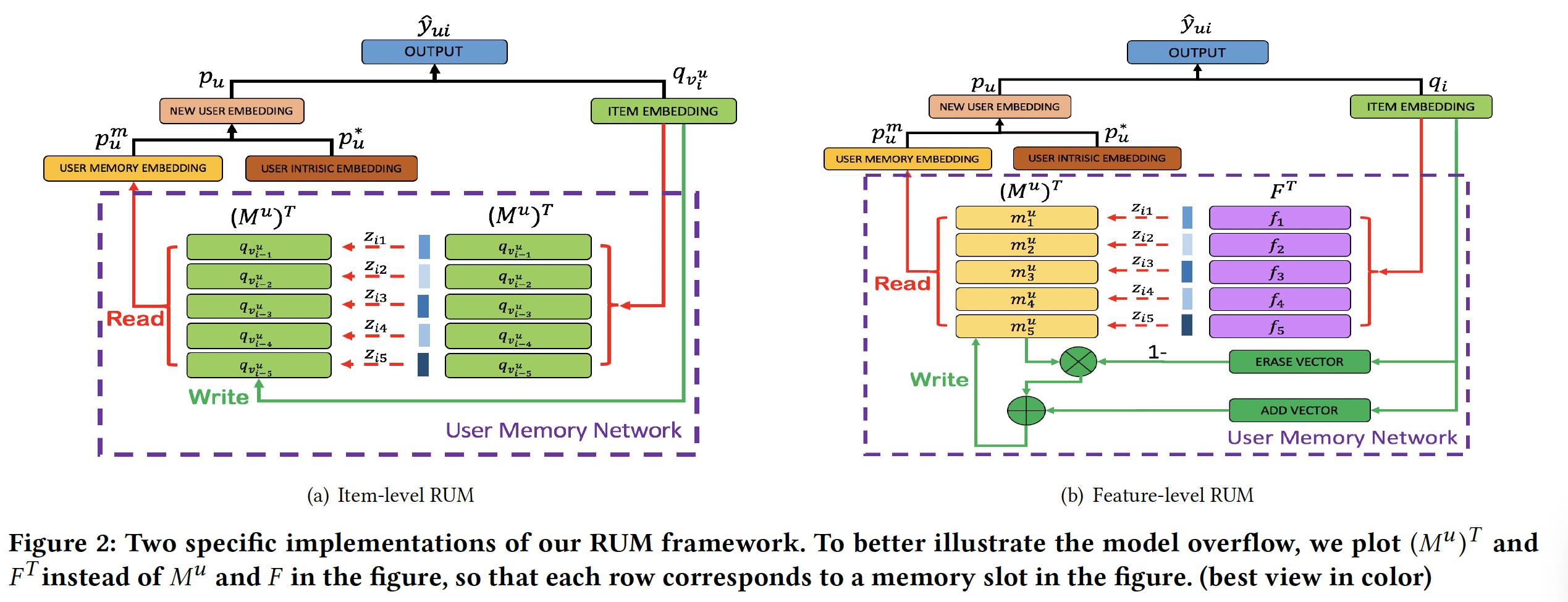
假设用户
item集合定义为:item。令
itemembedding。假设memory matrix有memory slot),即column vector。我们设计reading操作和writing操作如下:reading操作:直观上看,之前的item可能对当前的item有不同的影响,影响越大的item在final memory embedding中应该越重视。形式上,在我们的模型中,当对user-item pairFPMC类似的方式来计算user memoryitem与当前item其中
strength超参数。然后我们使用
memory embedding,这为我们提供了一个能力:根据用户历史行为对当前item的影响来访问用户历史行为。即:与之前的模型不同,我们不会在
reading过程中强行合并所有item embedding。相反,我们现将这些item embedding单独存储在item给予更多的关注。这为我们提供了一种更细粒度的方法来利用用户历史记录。writing操作:如前所述,用户最近的行为通常对当前的预测起着更重要的作用。因此,我们采用简单的first-in-first-out: FIFO机制来维护user memory matrixitem。具体而言,用户
memory matrixitem。假设当前item是memory matrix为:memory时,最早的item将被替换,memory未满时,直接添加item而不必替换memory内的任何其它item。
这种做法的思想类似于
DIN。由于DIN。但是,与
DIN相比,这里的size的,因此需要进行序列padding或截断,因此会一定程度上损害性能。
13.1.3 Feature-level RUM
受到经典潜在因子模型
latent factor model: LFM推荐的启发,我们进一步探索在feature-level上实现RUM框架。在LFM中,我们假设用户在作出购买决策时可能会考虑一组产品特征product feature,并且LFM中的每个embedding维度代表了产品域product domain中的一个潜在特征,其中所有的潜在特征张成了一个latent representation space。然后,LFM将用户对这些特征的偏好估计为该空间中的向量。在这项工作中,我们使用
memory network的能力来显式地建模这些潜在特征。直观而言,用户对这些特征的偏好应该动态地反映在该用户的购买行为中。例如,如果用户在新购买的iPhone上体验非常好,那么该用户未来可能会继续在品牌brand特征上选择苹果的产品。受这些直觉的启发,我们维持用户对
memory matrix中不同特征的偏好。这些特征将被读取从而生成user memory embedding, 并由该用户购买的每个item来写入。更具体而言,我们将我们的方法形式化为一个key-value memory neural network,如下图(b)所示。我们首先设计了一个
global latent feature table: GLFT来存储每个feature的embedding,并且在进行预测时,item将与这个table交互从而识别其相关的特征。对于每个用户,我们利用
user memory matrixGLFT上特征的偏好。基于上述识别的特征,该用户会注意力attentively地合并memory embedding。与
LFM中的全局特征空间一样,这里的global latent feature table在所有用户之间共享,而memory matrix以个性化的方式进行per-user level的维护。最后,我们使用
item embedding更新user memory matrix
形式上,令用户
embedding为itemembedding为global latent feature table为embedding。对于用户memory matrix定义为embedding。reading操作:为了使得读取过程可微,我们采用soft-attention机制来读取user memory matrix。具体而言,在对user-item pairitemglobal latent feature table中每个特征的相关性:其中
strength超参数。我们也使用
memory matrix中的slot,从而计算该用户的memory embedding:这里的
reading操作和Item-level RUM的reading操作的区别在于注意力权重的生成:Item-level RUM中,Feature-level RUM中,Feature-level RUM的参数更多、模型容量更高。writing操作:受神经图灵机neural turing machine: NTM的启发,在写入user memory matrix擦除:我们首先从
erase vectorsigmoid函数,erase parameter。给定注意力权重和擦除向量,feature preference memory更新为:其中:
因此:仅当该
location的注意力权重和erase element均为1时,这个memory location才会被重置为零;当该location的注意力权重为零或者erase element为零,那么memory vector保持不变。添加:当擦除操作之后,我们使用一个
add vectorfeature preference memory:其中:
add parameter。
这种
erase-add更新策略允许在学习过程中遗忘和加强user feature preference embedding,并且模型可以通过学习erase parameter和add parameter来自动地决定哪些信号需要减弱、哪些信号需要加强。这种更新方式类似于
RNN,按顺序地馈入RNN之后一个状态而feature-level RUM有feature-level RUM每次更新的是不同的slot,那么一定程度上丢失序列信息。甚至feature-level RUM不知道哪个item是最近购买的,而根据现有的研究表明,最近购买的item是相当重要的。
13.1.4 讨论和分析
为了提供对我们的方法的更多洞察,我们分析了
item-level RUM和feature-level RUM之间的关系。然后通过将其与matrix factorization: MF和factorized personalized Markov chain: FPMC进行比较,我们进一步将我们的方法与以前的方法联系起来。Item-level RUM和Feature-level RUM:一般而言,item-level RUM和feature-level RUM都是下图(c)所示同一框架的特定实现。但是,它们从不同的角度管理用户历史信息。item-level RUM将每个item视为一个单元unit,并将item embedding直接存储在memory matrix中,其中memory matrix旨在捕获item-to-item的转移模式transition pattern。- 然而在
feature-level RUM中,历史信息以feature-centered的方式被利用。memory matrix用于存储用户偏好在不同潜在维度上的embedding,并且每个item都被间接用于改变这些embedding。
在实际应用中使用这些模型时,实际上存在
explanation-effectiveness的trade-off:item-level RUM可以明确地告诉我们过去哪些item对于当前决策更重要,这为系统提供了一定的可解释能力。- 然而,
feature-level RUM在black box中通过更细粒度的建模可以获得更好的性能。
我们将在后的内容讨论更多细节和实验结果。
RUM和MF的关系:当user memory network设置为不可用时(即,user memory embedding设置为全零的向量),RUM将简化为传统的MF。然而,通过启用user memory network,RUM可以从历史行为中收集有价值的信息,这可以提高Top-N推荐任务的性能,如后面的实验所示。RUM和FPMC的关系:RUM和FPMC都利用用户的历史行为来预测当前行为。为了对每个用户建模item-to-item转移模式,FPMC构建张量分解模型,并在Bayesian personalized ranking: BPR准则下进行优化。目标函数如下:其中:
basket,basket中购买item
当应用于序列推荐时,
FPMC中的每个basket仅包含一个item,因此有:其中:
item(即时刻item) 的embedding。为展示我们模型与
FPMC的区别,我们考虑item-level RUM并且仅使用一个memory slot(即,通过将
RUM的user intrinsic embeddingFPMC中的user embeddingRUM的损失函数可以重写为:对比
FPMC与一阶的item-level RUM共享相同的预测函数(即,observed的交互、unobserved的交互:FPMC通过最大化margin来学习模型。RUM分别尝试最大化
实际上,我们也可以使用
Bayesian personalized ranking: BPR来优化RUM,此时,FPMC相当于一个一阶的item-level RUM从而用于序列推荐。基于以上分析,我们可以看出
RUM是一个非常通用的推荐框架。一方面,RUM是许多现有推荐模型的推广。另一方面,RUM可以通过将merge函数、predict函数、以及reading/writing策略修改为其它的形式,从而为我们提供机会来探索其它有前景的模型。未来工作:
- 通过引入用户评论、产品图像等辅助信息,我们可以将
feature-level RUM中的memory unit与不同的语义对齐,因此我们可以构建一个更可解释的推荐系统。 - 此外,我们的
RUM模型是一个具有灵活泛化能力的框架,因此我们可以研究其它类型的memory network设计(而不仅限于这里的item-level RUM和feature-level RUM),从而使得我们的框架适应不同的应用场景。
- 通过引入用户评论、产品图像等辅助信息,我们可以将
13.2 实验
数据集:我们在
Amazon数据集上进行了实验。该数据集包含1996年5月至2014年7月亚马逊的user-product购买行为。我们在四个产品类别上评估我们的模型,包括即时视频Instant Video、乐器Musical Instrument、汽车Automotive、婴儿护理Baby Care。为了提供序列推荐,我们选择至少有
10条购买记录的用户进行实验,最终数据集的统计数据如下表所示: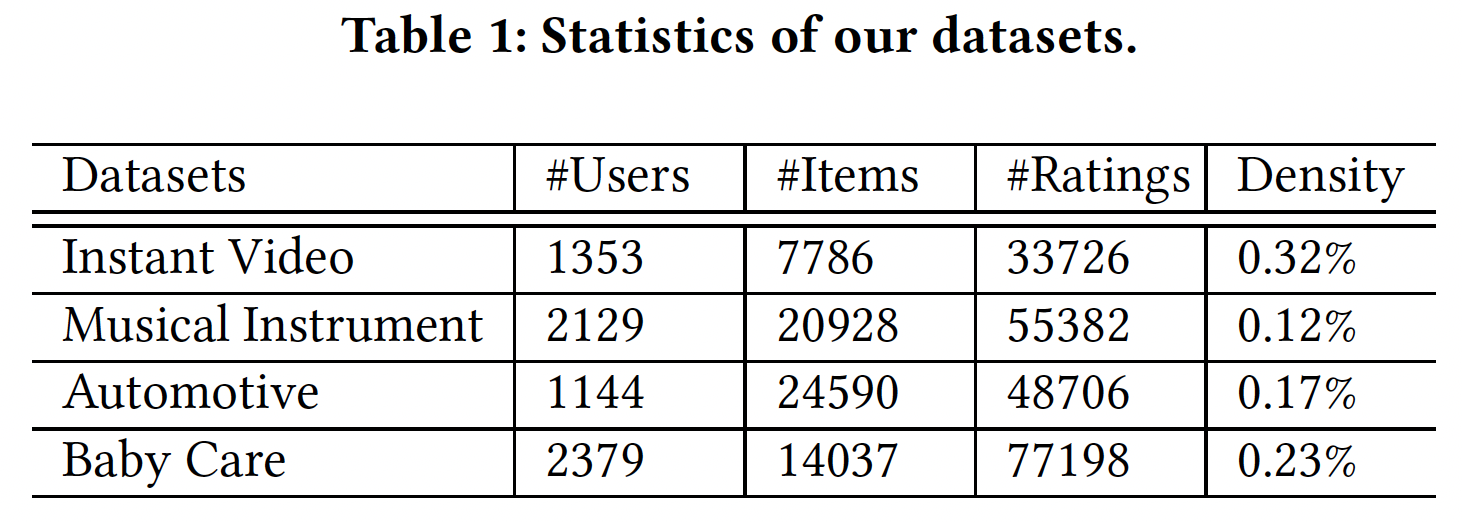
评估指标:对于每个模型,我们定义为用户
item的预测分数(根据预测分数进行降序排列,分数越高排则名越靠前)。假设测试集中用户
item集合为Precision (P), Recall (R), F1-score:我们采用per-user的均值而不是全局均值从而为了更好的可解释性:Hit-ratio(HR):命中率HR给出了可以收到至少一个正确推荐的用户占比:其中:
normalized discounted cumulative gain(NDCG):NDCG通过考虑ground truth item的排名来评估性能:其中:
DCG@N所有可能取值的最大值,此时每个grount-truth都排在非ground-truth之前)。DCG@N是位于推荐列表中的ground-truth收益的加权和,其中收益固定为1,权重为ground-truth的排名。最大的DCG@N需要推荐列表满足两个条件:- 所有
ground-truth都位于DCG@N中,即累加的项足够多。 - 所有
ground-truth的排名都最低,即
- 所有
Baseline方法:MostPopular: MP:非个性化的、基于热门item的推荐。其中item的热门程度根据它在数据集中出现的频次来得到。BPR:bayesian personalized ranking,一种流行的top-N推荐方法。我们采用矩阵分解作为BPR的prediction component。FPMC:factorized personalized Markov chains,它是基于马尔科夫链的、state-of-the-art的序列推荐模型之一。在我们的数据集中,每个item都被视为一个basket。DREAM:dynamic recurrent basket model,它是RNN-based的、state-of-the-art的序列推荐方法。
配置:
- 在实现我们的方法时,模型参数首先根据均匀分布随机初始化,然后通过随机梯度下降
SGD进行更新。SGD的学习率是在{1, 0.1, 0.01, 0.001, 0.0001}的范围内通过网格搜索来确定的。 memory slot数量20。merge函数中设置权重超参数- 对于每个购买的
item(即,positive instance),我们从用户未交互的item中均匀采样一个negative instance。 embedding维度{10, 20, 30, 40, 50}范围内网格搜索来确定。- 正则化系数
{0.1, 0.01, 0.001, 0.0001}范围内网格搜索来确定。 - 在我们的实验中,每个用户的购买记录按照购买时间排序,每个用户的前
70%的item用于训练、剩余的item用于测试。 - 我们为每个用户推荐
5个item,即推荐列表长度
- 在实现我们的方法时,模型参数首先根据均匀分布随机初始化,然后通过随机梯度下降
模型整体性能:我们首先研究默认设置(
item-level RUM和feature-level RUM的性能,如下表所示。可以看到:非个性化的
Most Popular方法几乎在所有情况下都给出了最差的性能。由于它没有考虑用户的个性化信息,因此这一观察突出了个性化在推荐任务中的重要性。正如预期的那样,通过单独分析用户并直接优化
ranking-based目标函数,在大多数情况下BPR的性能优于Most Popular。FPMC和DREAM在大多数指标上都可以达到比BPR更好的性能,而这两种方法之间的差异不是很明显。考虑到BPR和FPMC之间的主要区别在于后者以序列方式对用户历史记录进行建模,这一观察结果验证了序列推荐有助于提高推荐性能。有趣的是,
DREAM在instant video上获得了比FPMC更好的性能。DREAM建模用户的multi-step behavior而不是pair-wise behavior,能够更好地捕获用户对视频偏好的长期兴趣。然而,在其它数据集上,
pair-wise的短期影响可能更有助于预测next behavior,但是DREAM通过RNN将之前的所有item均等equally地合并为单个hidden vector,这可能会削弱序列推荐的pair-wise信号。这突出了我们动机的重要性,即需要一个精心设计的机制来自动地确定哪些先前的
item对当前兴趣预测很重要。在稠密数据集上,
multi-step behavior可能更重要;在稀疏数据集上,pair-wise behavior可能更重要。而instant video数据集是这四个数据集中最稠密的。令人振奋的是,我们发现在大多数情况下,
item-level RUM或feature-level RUM的性能都优于最佳baseline。这些结果表明了我们提出的序列推荐方法的有效性。这实际上并不惊讶,因为我们模型中的
memory机制和reading/writing设计为建模用户历史记录提供了更好的表达能力。通过在更细粒度的
level上建模item关系,feature-level RUM在大多数指标上都优于item-level RUM。这很直观,因为两个item的功能可能不直接相关,但是它们可能具有一些共同的特征,这些特征可能会影响用户的决策,例如它们都属于同一个品牌。
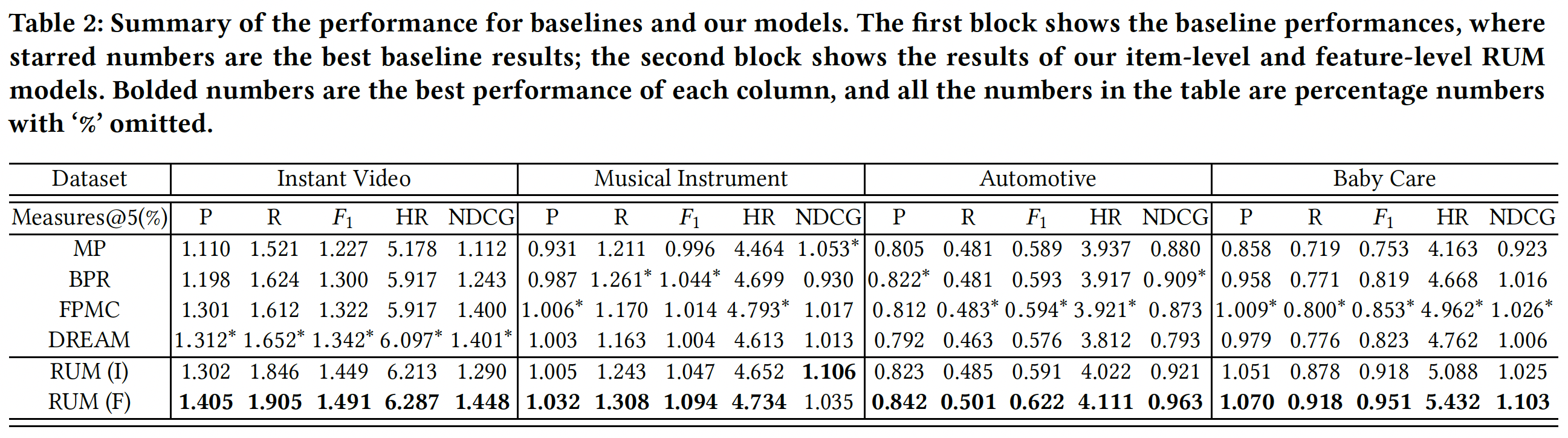
权重超参数
memory是否有助于、以及如何帮助序列推荐。为此,我们分析权重超参数merge函数中memory embedding相对于intrinsic embedding的重要性。具体而言,我们通过在
0 ~ 1的范围内以0.1的步长调整F1@5上的性能。结果如下图所示。可以看到:- 当
memory component不可用(即feature-level RUM和item-level RUM都简化到相同的模型并共享相同的性能。在这种情况下,它们都在所有数据集中给出了不利的结果(但不一定是最差的)。 - 加入了
memory network之后,模型性能大幅提升,并且在 - 然而,当
memory embedding的权重继续上升时,模型性能下降。这一观察在四个数据集上是一致的。
这些结果表明:考虑用户历史行为记录的序列影响
sequential influence确实有助于提供更好的推荐,但是过分关注这个最近购买信号recent purchase signal可能会削弱用户的内在偏好intrinsic preference。这些结果进一步验证了学术界经常观察到的现象:短期用户偏好和长期用户偏好对于个性化推荐都很重要。
- 当
Item-level RUM中的AttentionWeights的直觉:为了说明item-to-item转移的直觉intuition,我们在下图展示了一些示例用户(每个用户一个子图),这些用户是从Baby Care数据集上带5个memory slot的item-level RUM(即,这里只有
6个case,所以一些结论不具备说服力?最好给出一批case的统计结果。当用户购买第
item时(对应于x轴,用蓝色小网格表示),我们在该用户的子图中绘制一个长度为5的列向量(如上面中间子图中,(15,14)对应处的、高度为5的细长条)。这个列向量对应于y轴的位置item上的注意力权重item的注意力越高。当用户继续购买item时,最近购买的5个item被保留在memory中,因此列向量填充的位置从左下角到右上角。基于这幅图,我们得到以下有趣的观察:通常,靠近对角线的网格的颜色较深。这意味着历史最有影响力的
item通常是距离当前行为附近的item。这进一步证实了item-level RUM背后的假设,即:最近的行为对当前的决策更为重要。然而,最有影响力的
item的具体位置并不总是最近的,这可以解释为什么FPMC仅通过建模pair-wise相邻行为并未取得良好的性能。此外,我们发现了两种有趣的用户行为模式:
某些行为序列是由最近行为连续触发的(用绿色实线框来表示),这符合
FPMC的假设。我们称之为one-to-one的行为模式。一个真实的例子是用户购买了一些婴儿配方奶粉,然后购买了奶瓶,这导致该用户接下来购买了奶嘴,而这些奶嘴导致该用户进一步购买了奶嘴清洁器。
某些行为序列中,多个行为主要受到相同的历史行为的影响(用棕色虚线框来表示),而这多个行为之间的关系并不那么重要。我们称之为
one-to-multiple的行为模式。一个真实的例子是用户购买了婴儿床,然后该用户为婴儿床购买了防水床垫保护套、蚊帐,然后又购买了床铃来装饰婴儿床。在这种情况下,我们的带注意力机制的
RUM模型可以根据大规模的用户购买记录自动学习先前item的重要性。这优于假设相邻影响adjacent influence的FPMC,也优于合并所有先前行为的RNN。
基于这些发现的模式,
item-level RUM可以从序列行为的角度解释推荐系统,这与以前通常利用辅助信息(如用户文本评论)进行解释的方法不同。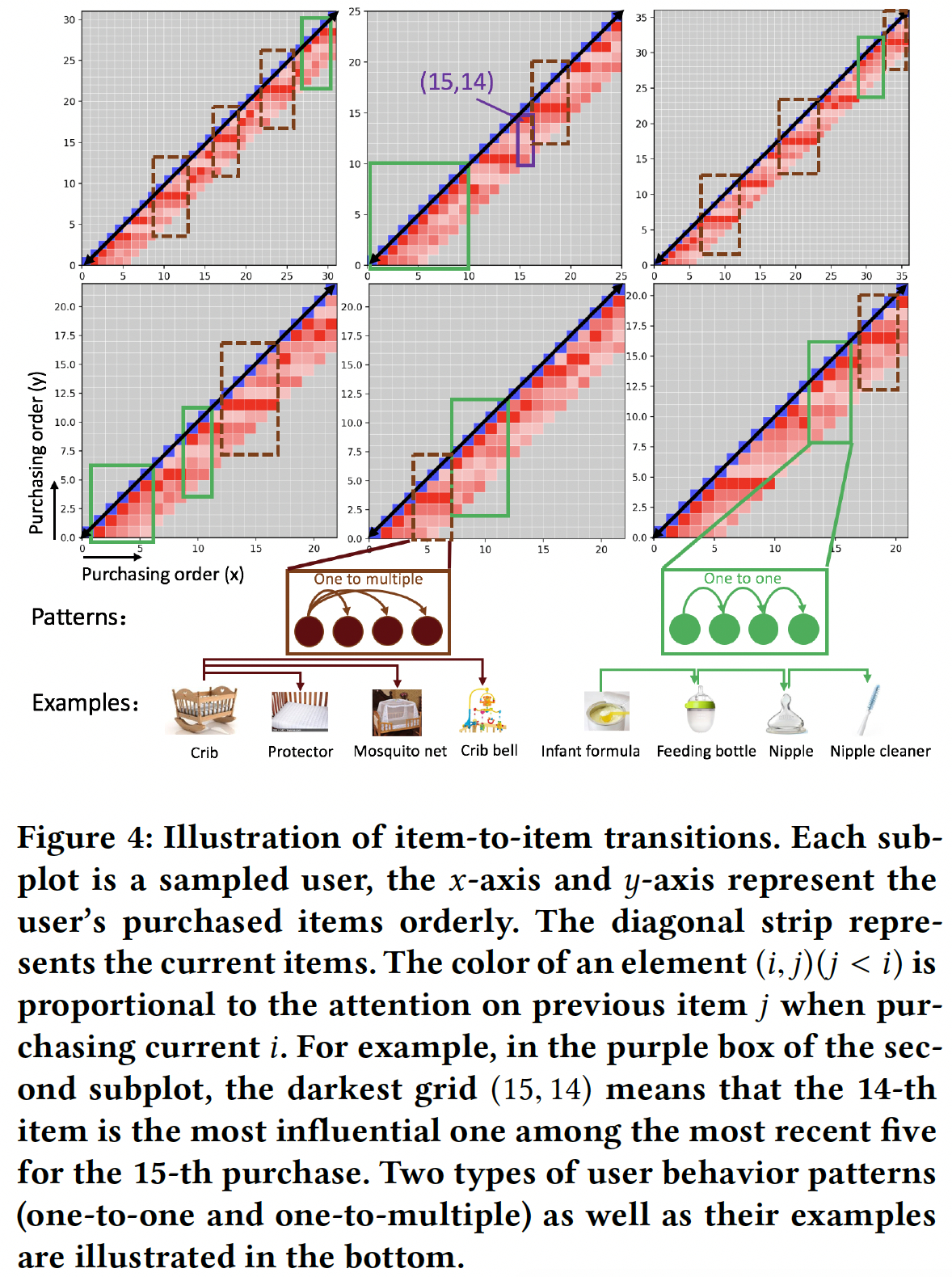
十四、SHAN[2018]
不同于传统的推荐系统,在序列推荐场景存在新的挑战:
- 首先,用户行为仅反映了他们的隐式反馈(如,是否购买),而不是显式反馈(如,评分)。这种类型的数据会带来更多的噪音,因为我们无法区分用户是不喜欢
unobserved item、还是仅仅因为没有意识到它们。因此,通过传统的潜在因子模型latent factor model直接优化这样的one-class分数(如1或0)是不合适的。 - 其次,越来越多的数据来源于
session或交易transaction,形成了用户的序列模式sequential pattern和短期偏好。例如,用户离开机场后更喜欢在酒店休息而不是运动,用户在购买相机后更可能购买相机相关的配件而不是衣服。然而,以前的方法主要关注用户的通用品味general taste,而很少考虑序列信息,这导致重复的推荐repeated recommendation。
在文献中,研究人员通常分别使用独立的模型来分别刻画用户的长期偏好(即,通用品味)和短期偏好(即序列模式),然后将它们集成在一起。例如,
FPMC分解观察到的user-item矩阵从而学习用户的长期偏好,并利用item-item转移信息来建模序列信息sequential information,然后将二者线性相加从而获得最终分数。然而,这些模型忽略了用户通用品味的动态变化,即,用户的长期偏好会随着时间的推移而不断演变。为每个用户学习一个静态的、低维的向量来建模该用户的通用品味是不够的。此外,这些模型主要通过线性模型来为
user-item交互、item-item交互分配固定权重,这限制了模型的表达能力。已有研究表明,非线性模型可以更好地建模用户活动中的user-item交互。为此,论文
《Sequential Recommender System based on Hierarchical Attention Network》提出了一种新颖的方法,即Sequential Hierarchical Attention Network: SHAN,从而解决next item推荐问题。注意力机制可以自动为用户分配item的不同影响(即,权重)从而捕获动态特性dynamic property,而层次结构hierarchical structure结合了用户的长期偏好和短期偏好。具体而言:- 首先将用户和
item嵌入到低维稠密空间中。 - 然后使用
attention layer计算用户长期行为中每个item的权重,并使用这个权重对长期行为中的item vector进行加权和从而生成用户的long-term representation。 - 之后,使用另一个
attention layer将近期的用户序列行为与long-term representation相结合。
同一个
user embedding向量在两个attention network中作为context信息,从而计算不同用户的不同权重。为了学习模型参数,论文采用Bayesian personalized ranking: BPR优化准则来生成一个pair-wise损失函数。从实验中,可以观察到论文所提出的模型在两个数据集上优于state-of-the-art的算法。最后,论文的贡献如下:
- 论文引入注意力机制来建模用户动态
user dynamic、个人偏好从而进行序列推荐。 - 通过层级结构,论文结合用户的长期偏好和短期偏好来生成用户的
high-level hybrid representation。 - 论文对两个数据集进行了实验,结果表明所提出的模型在召回率和
AUC指标上始终优于state-of-the-art方法。
- 首先,用户行为仅反映了他们的隐式反馈(如,是否购买),而不是显式反馈(如,评分)。这种类型的数据会带来更多的噪音,因为我们无法区分用户是不喜欢
相关工作:
为了联合建模用户的个性信息
individual information和序列信息,人们引入了马尔科夫链来用于传统的推荐。《Factorizing personalized markov chains for next-basket recommendation》结合了分解方法(用于建模用户的通用品味)、以及马尔科夫链(用于挖掘用户序列模式)。遵从这个思想,研究人员利用不同的方法来抽取这两种不同的用户偏好。《Playlist prediction via metric embedding》和《Personalized ranking metric embedding for next new poi recommendation》使用metric embedding从而将item投影到低维欧氏空间中的点point,从而用于play list预测、以及successive location预测。《Factorization meets the item embedding: Regularizing matrix factorization with item co-occurrence》利用word embedding从item-item共现中抽取信息,从而提高矩阵分解性能。
然而,这些方法在捕获
high-level的user-item交互方面的能力有限,因为不同组件component的权重是固定的。最近,研究人员转向推荐系统中的图模型和神经网络。
《Unified point-of-interest recommendation with temporal interval assessment》提出了一种双加权bi-weighted的低秩low-rank的图构建模型graph construction model,该模型将用户的兴趣和序列偏好,与时间间隔评估temporal interval assessment相结合。《Wide & deep learning for recommender systems》将wide linear model与cross-product feature transformation相结合,并采用深度神经网络来学习feature embedding之间的高度非线性交互。然而,该模型需要特征工程来设计交叉特征,而交叉特征在高度稀疏的真实数据中很少观察到。为解决这个问题,
《Neural factorization machines for sparse predictive analytics》和《Attentional factorization machines: Learning the weight of feature interactions via attention networks》分别设计了B-Interaction layer和attentional pooling layer,从而基于传统的分解机factorization machine: FM技术自动学习二阶特征交互。《Sessionbased recommendations with recurrent neural networks》和《Recurrent recommender networks》采用循环神经网络RNN来挖掘轨迹数据trajectory data中的用户动态user dynamic和item偏好。然而,在许多实际场景中,session中的item可能不会遵守严格的顺序(例如,在线购物中的交易),此时RNN不太适用。除此之外,
《Learning hierarchical representation model for nextbasket recommendation》和《Diversifying personalized recommendation with user-session context》学习了user hierarchical representation,从而结合用户的长期偏好和短期偏好。我们遵循这个
pipeline,但是有以下贡献:我们的模型建立在
hierarchical attention network之上,可以捕获动态的长期偏好和短期偏好。一些
RNN-based推荐方法也是捕获动态的长期偏好,而MF-based推荐方法才是捕获静态的长期偏好。我们的模型利用
user-item交互的非线性建模。它能够学习不同用户对相同item的不同的item influence(即,权重)。
14.1 模型
令
item集合,user-item反馈数据(如,用户的连续check-in记录、连续的购买交易记录)中抽取信息。对于每个用户
time step的总数,time stepitem集合。- 对于给定的
time stepitem集合next item的重要因素。 - 另一方面,在
time stepitem集合,记做
在后面的内容中,我们将
time stepitem set,将time stepitem set。形式上,给定用户
next item。- 对于给定的
我们根据用户偏好的以下特点,提出了一种基于
hierarchical attention network的新方法,如下图所示。这些特点为:用户偏好在不同的
time step是动态dynamic的。不同的
item对将要被购买的next item有不同的影响。对于不同的用户,相同的
item可能对next item prediction产生不同的影响。例如,用户
A/B的行为序列都是A和B之间存在差异(例如年龄、性别、收入水平等等),导致相同的行为序列得到不同的注意力权重。
我们方法的基本思想是:通过联合学习长期偏好和短期偏好从而为每个用户生成一个
hybrid representation。更具体而言,我们首先将稀疏的user input和item input(即,one-hot representation)嵌入到低维稠密向量中。之后,我们通过结合长期偏好和短期偏好的双层结构来学习每个用户的hybrid representation。- 为了捕获
time steplong-term user representation,它是长期的item setitem embedding的加权和,权重由user embedding导出的、attention-based pooling layer来生成。 - 为了进一步结合短期偏好,
final hybrid user representation将long-term user representation和短期item set中的item embedding相结合,其中权重根据另一个attention-based pooling layer学习而来。
如上所述,我们的模型同时考虑了动态的长期用户偏好和动态的短期用户偏好。此外,通过使用不同的、学到的权重,长期用户偏好和短期用户偏好对将要购买的
next item具有不同的影响。最后,值得指出的是,相同
item在不同用户上的影响也是不同的,因为attention layer中权重的学习过程是由user embedding指导的,而user embedding是个性化的。接下来我们详细介绍我们模型的各个部分。
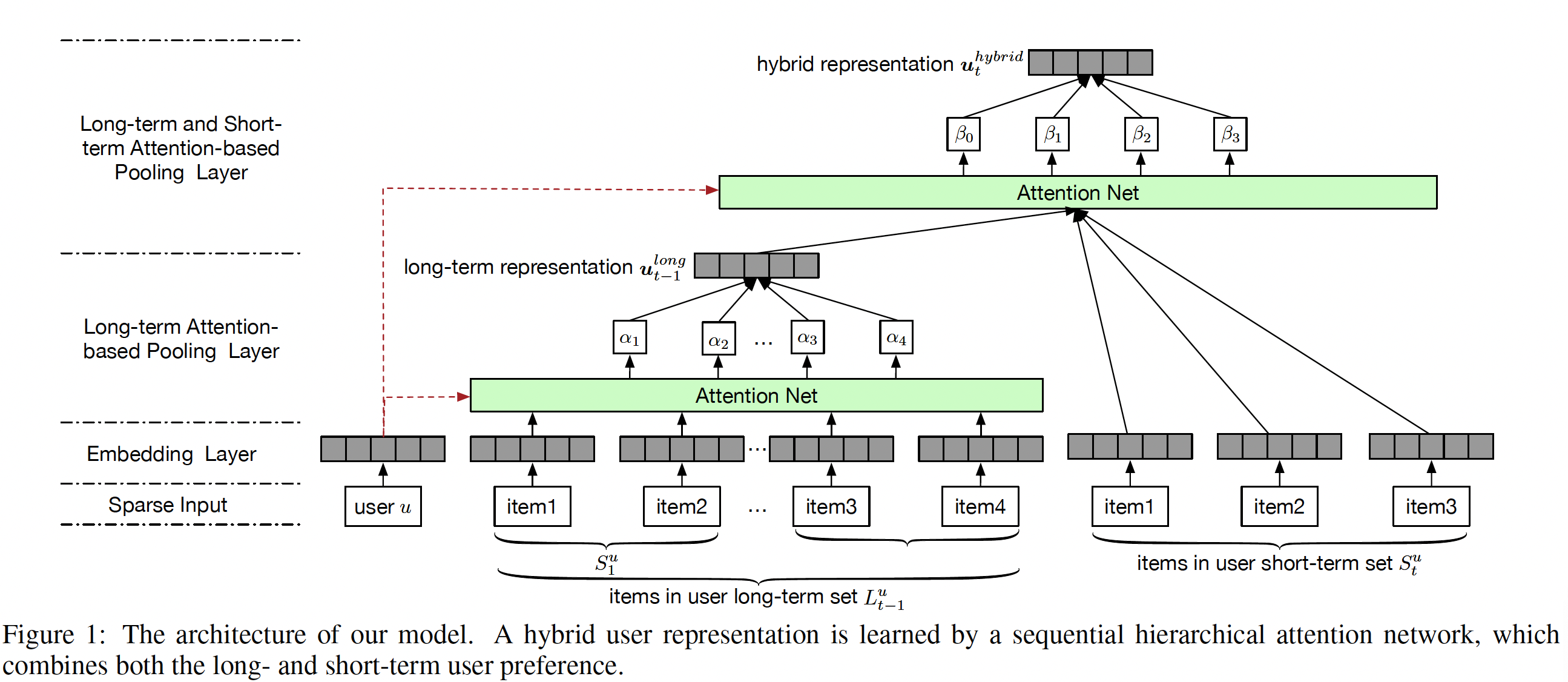
Embedding Layer:与自然语言处理中的、离散的word symbol类似,原始的user ID和item ID的表达能力非常有限。因此,我们的模型首先采用embedding layer将user ID和item ID(即,one-hot representation)嵌入到两个连续的低维空间中。形式上,令
user embedding矩阵,令item embedding矩阵,其中embedding空间的维数。user embedding向量。itemitem embedding向量。从理论上讲,传统的矩阵分解相当于一个双层神经网络:第一层为
user和item构建低维的embedding,第二层执行内积运算。然而,通过矩阵分解的embedding只能捕获low-level、bi-linear、以及静态的representation,这限制了模型的表达能力。不同的是,我们的模型基于这些basic embedding来学习high-level、非线性的、动态的user representation,这些将在后面解释。Long-term Attention-based Pooling Layer:在序列推荐系统中,长期偏好和短期偏好分别对应于用户的通用品味和序列行为。- 由于用户的长期
item set通常会随着时间而变化,因此为每个用户学习静态的长期偏好rerepsentation并不能完全表达长期偏好的dynamic。 - 另一方面,从最新的长期
item set中重构long-term user representation更为合理。 - 此外,我们认为相同的
item可能在不同用户上产生不同的影响。例如,假设用户itemitemnext item时,item
为了满足上述要求,我们提出使用已经成功应用于许多任务的注意力机制。注意力机制首先计算给定用户的长期
item set中每个item的重要性,然后聚合这些item的embedding从而形成long-term user preference representation。形式上,注意力网络定义为:其中:
user embedding向量,item set中itemitem embedding。ReLU非线性激活函数。
与传统的注意力模型对每个用户的每个
input使用相同的context向量不同(即,global的),我们将用户embeddingcontext向量(因此不同用户的context向量不同,即personalized的)。注意,和
DIN/RUM不同,这里的attention并不是将target item与历史item进行注意力计算,而是将用户静态偏好(以item进行注意力计算。对于
DIN/RUM,相同用户的、不同的target item会得到不同的注意力权重,因此在推断期间对于每个候选item都需要重新计算。此外,不同用户的、相同的
target item会得到相同的注意力权重,因此它是non-personalized的。对于
SHAN,相同用户的、不同的target item会得到相同的注意力权重,因此在推断期间对于每个候选item无需重新计算。此外,不同用户的、相同的
target item会得到不同的注意力权重,因此它是personalized的。
本质上,
SHAN的注意力机制是类似于self-attention,它仅用到了target user侧的信息,而并没有使用target item侧的信息。由于没有进行user-item的信息交互,因此有利于模型的在线推断(类似于双塔模型的架构比较容易在线部署,例如将target user侧的emebdding离线计算好并推送到线上,target item侧的embedding实时计算并基于embedding向量的相似度来做召回)。最后,我们计算
long-term user representationitem embedding的加权和,即:- 由于用户的长期
Long- and Short-term Attention-based Pooling Layer:除了用户的通用品味之外,还需要考虑用户的序列行为(即,短期偏好)。短期偏好对于预测next item很重要,并且已有研究将长期偏好和短期偏好相结合从而进行序列推荐。然而,在这些早期工作中,短期偏好和长期偏好的交互仍然是线性的。并且,item被分配以相同的权重,这无法反映item对next item prediction的影响,因此限制了模型的性能。与建模用户长期偏好类似,我们也采用注意力网络,从而为
long-term representation和短期item set中的item的embedding分配权重,进而捕获用户high-level representation。正式地,其中:
user embedding向量,item set中itemitem embedding。注意,当long-term user representation。
类似地,
user embedding被作为context vector从而实现个性化的注意力(即,相同item在不同用户上分配不同的权重)。在获得归一化的注意力分数之后,hybrid user representation计算为:其中
总而言之,
item对预测next item的贡献。此外,两个层级的注意力网络可以捕获user和item之间的非线性交互。这里的注意力机制并不是基于向量内积的,而是基于
MLP的,因此引入了非线性交互。注意,
《Learning hierarchical representation model for nextbasket recommendation》还可以通过使用最大池化聚合final representation来实现非线性的目的。但是,它同时丢失了很多信息。我们将通过实验证明我们的模型可以实现比它更好的性能。注意力加权和聚合的方式是介于
sum池化和max池化之间的版本:- 当注意力均匀分布时,注意力加权和聚合退化为
sum池化。 - 当注意力极度不均时,注意力加权和聚合退化为
max池化。
此外,还可以通过
CNN/RNN来进行聚合,它们是与sum池化、max池化完全不同的聚合方式。模型推断
Model Inference:当计算出hybrid user representationitem但是,用户交易记录是一种隐式数据。由于数据稀疏性问题和
unobserved data的模糊性ambiguity,我们很难直接优化偏好分我们模型的目标是在给定用户在时刻
item set和短期item set的情况下,提供一个ranked list。因此,我们更感兴趣的是item的排名而不是真实的偏好分。遵循BPR优化准则,我们为我们的模型提出一个pair-wise ranking目标函数。我们假设用户更喜欢next purchased item而不是unobserved item,并在itemitemranking order其中
time stepnext item,bootstrap sampling生成的unobserved item。对于每个
observationpairwise preference order的一个集合maximizing a posterior: MAP来训练我们的模型:其中:
user embedding和item embedding待学习参数集合,logistic function,为什么使用不同的正则化系数?用一个正则化系数不行吗?猜测的原因是不同的参数的取值不同,这可以通过后面的消融实验来验证。如果使用同一个正则化系数,那么该系数的选择被取值较大的参数所主导(可以通过统计参数范数的均值来观察)。进一步地,是否需要针对每个参数设置一个正则化系数?
SHAN算法:输入:
- 长期
item setitem set - 学习率
- 长期
输出:模型参数集合
算法步骤:
从正态分布
从均匀分布
为什么采用不同的权重初始化策略?论文并未解释。
重复以下过程直到算法收敛:
混洗
observation集合observation- 随机从
unobserved item - 计算
- 计算
- 使用梯度下降来更新参数集合
- 随机从
返回参数集合
14.2 实验
我们进行实验回答以下几个问题:
- 与其它
state-of-the-art方法相比,我们的模型的性能如何? - 在我们模型中,长期偏好和短期偏好的影响是什么?
- 超参数(如正则化参数、
embedding维度)如何影响模型性能?
- 与其它
数据集:
Tmall数据集:包含中国最大的在线购物网站(即,Tmall.com)上的用户行为日志。Gowalla数据集:记录了用户在location-based社交网站Gowalla中check-in的时间的point-of-interest: POI信息。
我们专注于这两个数据集上过去七个月生成的数据。在此期间,少于
20个交互的item被剔除。此后,将一天内的用户记录视为一个session(即,交易transaction)来表示短期偏好,并删除所有的singleton session(即,session中仅有一个item)。类似于
《Diversifying personalized recommendation with user-session context》,我们随机选择最近一个月20%的session进行测试,其余的用于训练。我们还在每个session中随机保留一个item作为待预测的next item。预处理之后,这两个数据集的基本统计信息如下表所示:

评估指标:我们采用两个广泛使用的指标
Recall@N和AUC。Recall@N指标评估在所有测试session中,ground truth item排在top-N的case占所有ground truth item的比例。AUC指标评估ground truth item在所有item中的排名有多高。这里将
ranking list中非ground truth的其它item视为负样本,将ground truth item视为正样本,因此AUC指标严重依赖于负样本的采样方式。事实上,
Recall@N指标也会依赖于负样本的采样方式。
baseline方法:TOP:基于流行度的推荐,其中流行度通过训练集中item的出现频次来统计。BPR:BPR是一种用于隐式用户反馈数据的、state-of-the-art的pairwise learning to rank框架。我们选择矩阵分解作为internal predictor。FPMC:该方法通过矩阵分解建模用户偏好、通过一阶马尔科夫链建模序列信息,然后通过线性方式将它们组合起来进行next basket recommendation。FOSSIL:该方法将factored item similarity和马尔科夫链相结合,从而建模用户的长期偏好和短期偏好。注意,我们将session的长度是可变的。HRM:该方法生成user hierarchical representation来捕获序列信息和通用品味。我们使用max pooling作为聚合操作,因为这样可以达到最佳效果。SHAN:这是我们提出的模型,它使用两个注意力网络来挖掘长期偏好和短期偏好。我们还展示了简化版本的性能(叫做
SAN),它忽略了层次结构,并通过单个注意力网络从长期item set和短期item set中计算item的权重。
为了公平地比较,所有
model-based方法都基于BPR优化准则来优化一个pair-wise ranking目标函数。对比结果:下图展示了所有方法在
Tmall和Gowalla数据集上的Top-5 to Top-100的召回率和AUC指标。从结果可以看到:SHAN在Tmall数据集的所有指标下始终以较大的优势优于所有其它方法。- 具体而言,与第二好的方法(即
HRM)相比,SHAN在Tmall数据集上和Gowalla数据集上的召回率指标分别提高了33.6%和9.8%。这表明:我们的模型通过注意力网络为long-term representation和short-term representation捕获了更high-level的、更复杂的、非线性的信息,而HRM可能会通过hierarchical max pooling操作丢失很多信息。 - 此外,
SHAN的性能优于SAN,可能是因为长期item set的item数量远远多于短期item set。因此,单个注意力网络很难为属于短期item set的较少、但是更重要的item分配适当的权重。
- 具体而言,与第二好的方法(即
HRM在大多数情况在这两项指标下的表现普遍优于FPMC。具体而言,
HRM在Tmall和Gowalla数据集上的Recall@50的相对性能(相对于FPMC方法)提升分别为6.7%和4.5%。这证明了多个因子factor之间的交互可以通过最大池化操作来学习。此外,尽管是简单的最大池化,该操作引入的非线性交互将提高模型性能。另外,
SHAN实现了比HRM更好的性能,这表明注意力网络在建模复杂交互方面比最大池化更强大。在大多数情况下,所有混合模型(即,
FPMC, FOSSIL, HRM, SHAN)在两个数据集的不同指标下均优于BPR。以AUC为例,混合模型相对于BPR的性能提升持续保持在非常高的水平。这表明序列信息对于我们的任务非常重要,而BPR忽略了它。另外,SHAN在这些混合模型中获得了最佳性能。令人惊讶的是,在
Tmall数据集上,当50继续增加时,TOP方法在召回率方面超越了BPR,甚至在AUC指标上超越了FPMC。这种现象可以解释为:
- 用户在网上购物时可能倾向于购买热门
item。因此,当TOP方法可以达到更好的性能。 - 相反,由于
Gowalla数据集中的用户check-in数据更加个性化,因此TOP方法的性能要比其它方法差很多。
最后,我们的模型可以在不同的
baseline。- 用户在网上购物时可能倾向于购买热门
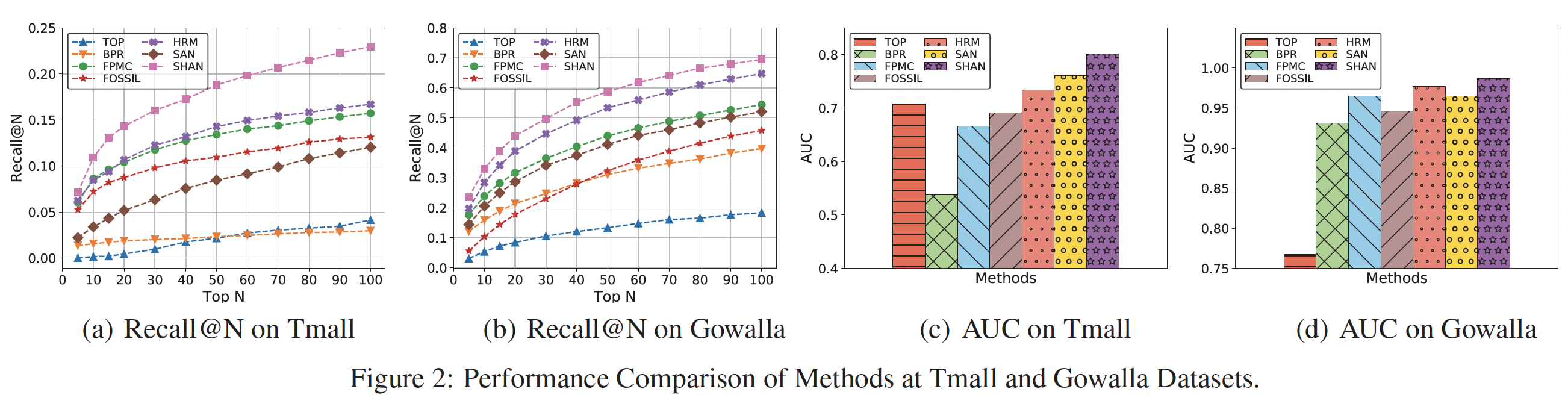
不同组件的影响:为了评估每个组件对
final user hybrid representation的贡献,我们进行实验来分析下表中每个组件。SHAN-L表示仅建模用户的通用品味,SHAN-S表示仅建模用户的短期偏好。与同样仅建模长期偏好的
BPR相比,SHAN-L实现了更好的性能。例如,BPR在Tmall数据集和Gowalla数据集上的Recall@20指标分别为0.019和0.204。这表明通过动态方式dynamic way来建模通用品味,要比通过固定的embedding向量更好。SHAN-S在很大程度上优于SHAN-L,这表明短期序列信息在predicting next item task上更为重要。令人惊讶的是,
SHAN-S在两个数据集上都优于HRM。例如,HRM在Tmall数据集和Gowalla数据集上的AUC指标分别为0.734和0.966。原因可能是SHAN-S中的basic user embedding vector(它融合了user basic preference)是通过短期item set中每个item的权重从而计算得到的。因此,SHAN-S还考虑了用户的静态通用品味、以及序列信息从而生成hybrid representation。结果还表明:一层的注意力网络优于两层的最大池化操作。
SHAN-S在Tmall数据集上的Recall@20指标要好于SHAN。这表明在该数据集上,用户在上一个session中的点击行为对当前session中的next clicked item没有太大影响。最后,在大多数情况下,
SHAN的性能优于两个单组件的模型。这表明:将动态的用户通用品味添加到SHAN-S有助于预测next item。因为SHAN-S仅仅是结合了用户的basic的、fixed的偏好以及序列行为。
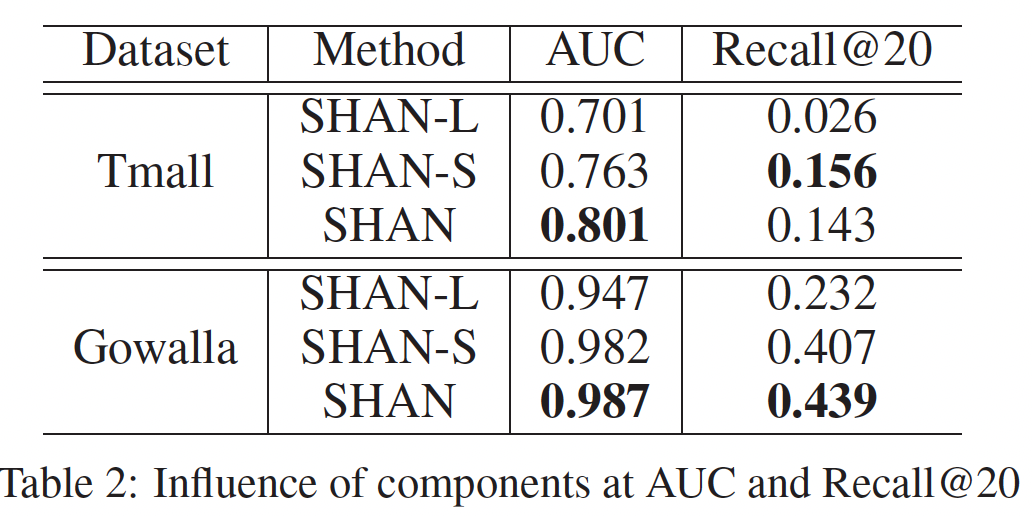
超参数的影响:这里我们研究正则化系数和
embedding size对模型的影响。由于篇幅所限,我们仅展示Recall@20指标下的结果。在我们的模型中,我们利用
user embedding和item embedding正则化系数Recall@20指标的影响。可以看到:当
可以看到,
我们进一步研究了维度大小
user embedding和item embedding的size有关,还与注意力网络中的MLP参数有关。为简单起见,user embedding和item embedding的size是相同的。可以看到:大的
item,并且将更有利于通过注意力网络构建high-level的因子交互factor interaction。这种现象类似于传统的潜在因子模型。在实验中,我们将100,从而平衡两个数据集的计算成本和推荐质量。