Prompt Engineering
一、LAMA[2019]
论文:
《Language Models as Knowledge Bases?》
最近,
pretrained的大型语言模型,如ELMo和BERT在NLP中变得越来越重要。这些模型的参数似乎储存了大量的、对下游任务有用的语言知识。这种知识通常可以通过两种方式来访问:在latent context representations上进行conditioning;通过使用原始模型的权重来初始化task-specific model然后再进一步微调。这种类型的知识迁移对于目前在广泛的任务上取得SOTA结果至关重要。相比之下,知识库(
knowledge bases)是通过实现诸如(Dante, born-in, X)这样的query来访问annotated gold-standard relational data的有效解决方案。然而,在实践中,我们经常需要从文本或其他模式中抽取关系数据(relational knowledge)来填充这些知识库。 这需要复杂的NLP pipeline,涉及实体抽取、共指消解、实体链接、关系提取。这些组件通常需要监督数据和固定的schemas。此外,错误很容易在整个pipeline中传播和积累。相反,我们可以尝试
query神经语言模型从而用于关系数据,要求它们在"Dante was born in [Mask]"这样的文本序列中填充masked tokens,如Figure 1所示。在这种情况下,语言模型具有各种有吸引力的特性:它们不需要schema engineering、不需要人类标注、而且它们支持一组开放的query。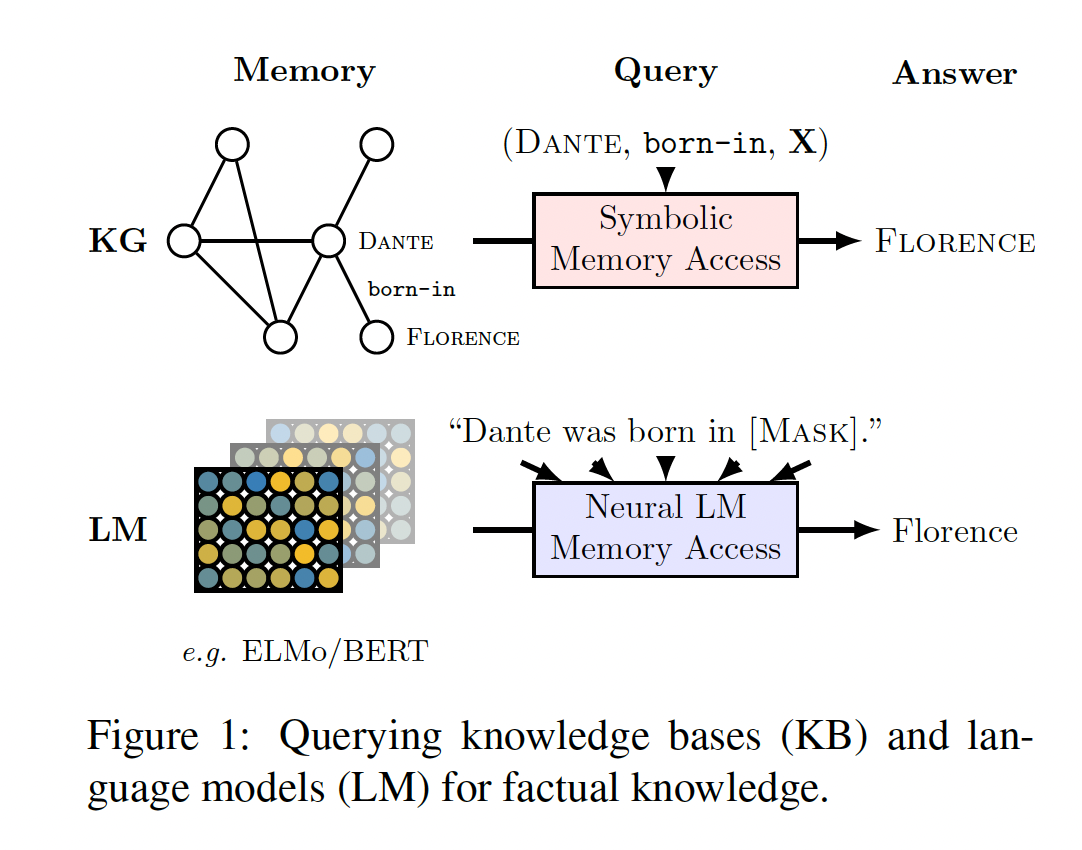
鉴于语言模型作为关系知识(
relational knowledge)的潜在representations的上述特性,我们对ELMo和BERT等现有的pretrained语言模型中已经存在的关系知识感兴趣。它们储存了多少关系知识?对于不同类型的知识(如关于实体的事实、常识、通用问答),这些知识有什么差异?它们在没有微调的情况下的表现与从文本中自动提取的symbolic knowledge base相比如何?除了收集对这些模型更好的一般理解外,我们认为这些问题的答案可以帮助我们设计更好的无监督knowledge representation,可以将事实性知识和常识性知识可靠地迁移到下游任务。为了回答上述问题,我们引入了
LAnguage Model Analysis: LAMA探针(probe),由一组知识源(knowledge sources)组成,每个知识源由一组事实(facts)组成。我们定义,如果一个pretrained语言模型能够成功预测诸如"Dante was born in ___"这样的表达事实的完形填空句子中的masked objects,那么它就知道一个事实(subject, relation, object),如(Dante, born-in, Florence)。我们对各种类型的知识进行测试:存储在Wikidata中的实体之间的关系、来自ConceptNet的概念之间的常识性关系、以及回答SQuAD中自然语言问题所需的知识。在后一种情况下,我们手动将SQuAD问题的一个子集映射到完形填空句子上。我们的调查显示:
最大的
BERT模型(BERT-large)捕获的(准确的)关系知识,与以下二者相当:现成的关系提取器、来自语料库(该语料库是表达相关的知识)的oracle-based entity linker。事实性知识可以从
pretrained语言模型中恢复得很好,然而,对于某些关系(特别是N-to-M关系)来说性能非常差。BERT-large在恢复事实性知识和常识性知识方面一直优于其他语言模型,同时对query的措辞更加鲁棒。BERT-large在open-domain QA方面取得了显著的成果,达到57.1%的precision@10,而使用task-specific supervised relation extraction system构建的知识库则为63.5%。
相关工作:许多研究已经调查了
pretrained的word representations、sentence representations、 以及language models。现有的工作集中在了解word representations的语言属性和语义属性,或者pretrained的sentence representations和语言模型如何将语言知识迁移到下游任务中。相比之下,我们的调查试图回答pretrained的语言模型在多大程度上储存了事实性知识和常识性知识,并将它们与传统relation extraction方法所填充的symbolic knowledge base进行比较。《Don’t count, predict! Asystematic comparison of context-counting vs. context-predicting semantic vectors》对neural word representation方法和更传统的count-based distributional semantic方法在词汇语义任务(如语义相关性和概念分类)上进行了系统的比较分析。他们发现,在大多数所考虑到的任务中,neural word representations的表现优于count-based distributional方法。《Simlex-999: Evaluating semantic models with (genuine) similarity estimation》研究了word representations在多大程度上捕捉了由word pairs之间的相似性所衡量的语义。《Targeted syntactic evaluation of language models》评估了pretrained语言模型的语法性。他们的数据集由一个有语法的句子和一个无语法的句子组成。虽然一个好的语言模型应该给符合语法的句子分配更高的概率,但他们发现LSTM并不能很好地学习语法。另一项工作是研究
pretrained的sentence representations和语言模型将知识迁移到下游自然语言理解任务的能力(《GLUE: A multi-task benchmark and analysis platform for natural language understanding》)。虽然这样的分析揭示了pretrained模型在理解短文方面的迁移学习能力,但它对这些模型是否能与symbolic knowledge base等代表知识的传统方法竞争提供了很少的洞察。最近,
《Right for the wrong reasons: Diagnosing syntactic heuristics in natural language inference》发现:对于自然语言推理,基于BERT的模型学会了严重依赖易犯错的syntactic heuristics,而不是对自然语言输入的更深入理解。《Dissecting contextual word embeddings: Architecture and representation》发现,ELMo中的低层擅长局部的句法关系,而高层可以学习对长距离关系进行建模。同样,
《Assessing bert’s syntactic abilities》发现,BERT对英语句法现象的捕捉非常好。《What do you learn fromcontext? probing for sentence structure in contextualized word representations》调查了语言模型在多大程度上为不同的句法和语义现象编码了句子结构,并发现他们在前者方面表现出色,但对属于后者的任务只提供小的改进。虽然这提供了对语言模型的语言知识的见解,但它并没有提供对其事实知识和常识知识的见解。《Improving language understanding by generative pre-training》介绍了一种基于Transformer的pretrained语言模型,他们称之为生成式预训练(GPT-1)。《Language models are unsupervised multitask learners》(GPT-2) 已经在包含7000本书的图书语料库上进行了训练。与我们的调查最接近的是GPT-2的工作,他们调查了他们的语言模型在一系列下游任务中的zero-shot迁移情况。他们发现,GPT-2在回答CoQA中的问题时达到了55的F1得分,在Natural Questions数据集上达到了4.1%的准确率,在这两种情况下都没有使用标记的question-answer pairs或信息检索步骤。虽然这些结果令人鼓舞,并暗示了非常大的
pretrained语言模型记忆事实知识的能力,但大型GPT-2模型尚未公开,而公开的小版本在Natural Questions上取得的成绩不到1%(比大型模型差5.3倍)。因此,我们决定不将GPT-2纳入我们的研究中。同样,我们也没有将GPT-1纳入本研究,因为它使用了有限的小写字母的词表,使得它与我们评估其他语言模型的方式不兼容。
1.1 方法
1.1.1 背景知识
略。详情参考原始论文。
因为这里都是简单的关于语言模型、
BERT的知识。
1.1.2 The LAMA Probe
我们引入了
LAnguage Model Analysis: LAMA探针来测试语言模型中的事实性知识和常识性知识。它提供了一组由facts的语料库组成的知识源。facts要么是subject-relation-object三元组,要么是question-answer pairs。每个fact都被转换为一个完形填空语句,用于query语言模型的missing token。我们根据每个模型对ground truth token在固定词表中的排名高低来评估该模型。这类似于knowledge base completion文献中的ranking-based指标。我们的假设是,在这些完形填空语句中,ground truth tokens排名高的模型有更多的事实性知识。接下来我们详细讨论每个步骤,并在下面提供关于探针(probe)的考虑。知识源 (
Knowledge Sources):我们涵盖了各种事实性和常识性知识的源。对于每个源,我们描述了事实三元组(或question-answer pairs)的来源,我们如何将它们转化为完形填空模板,以及维基百科中存在多少已知表达特定fact的aligned text。我们在supervised baseline中使用后者的信息,直接从对齐的文本中提取knowledge representations。这些知识源包括:
Google-RE, T-REx, ConceptNet, SQuAD。详细内容参考原始论文。模型:如下
pretrained的、大小写敏感的语言模型(见Table 1):fairseq-fconv (Fs), Transformer-XL large (Txl), ELMo original (Eb), ELMo 5.5B (E5B), BERT-base (Bb), BERT-large (Bl)。为了进行公平的比较,我们让模型在一个统一的词表上生成,这个词表是所有模型的词表的交集(大约
21K个大小写敏感的tokens)。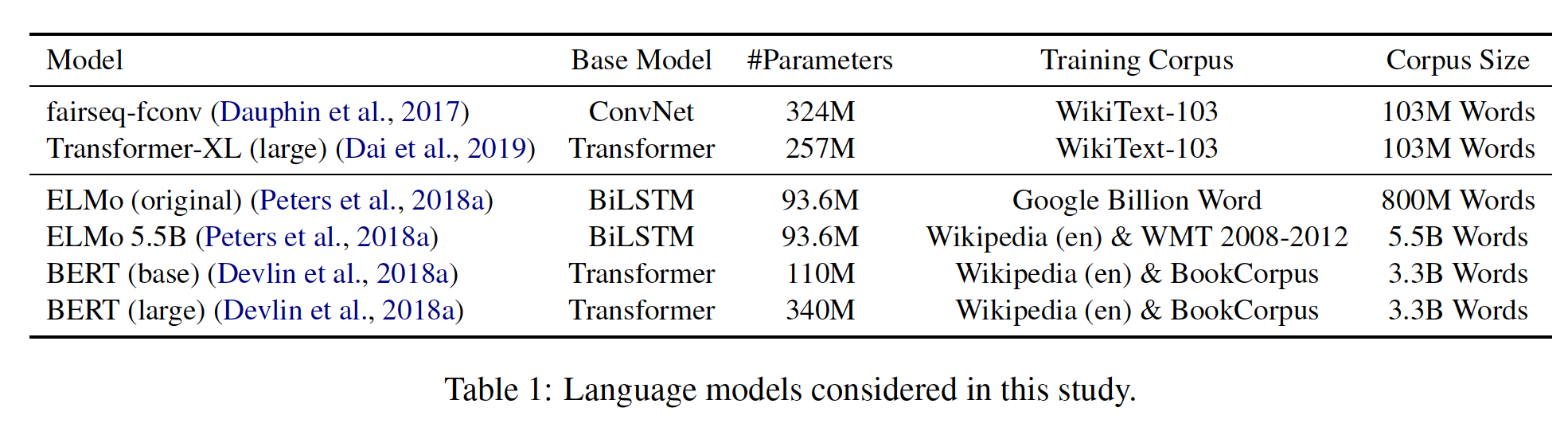
baseline:Freq:对于一个(subject, relation) pair,这个基线根据每个单词在测试数据中作为给定relation的object出现的频率来排序。已知三元组的
(subject, relation),需要补全object。RE:对于relation-based知识源,我们考虑《Context-aware representations for knowledge base relation extraction》的pretrained的Relation Extraction: RE模型。这个模型是在维基百科的一个子语料库上训练的,该子语料库上有Wikidata的关系标注。它使用基于LSTM的编码器和注意力机制从一个给定的句子中提取relation三元组。我们考虑了这个程序的两个版本,它们在实现
entity linking的方式上有所不同:RE_n使用了基于精确字符串匹配的朴素的entity linking解决方案。而
RE_o除了字符串匹配之外,还使用了entity linking的一个oracle。
换句话说,假设我们查询一个句子
test subject-relation factRE从该句子relation实例,不管它的subject或object是否错误,RE都可以返回正确的解DrQA:《Reading wikipedia to answer open-domain questions》介绍了DrQA,一个用于开放领域问答的流行系统。DrQA使用一个两步的pipeline来预测自然语言问题的答案。首先,使用
TF/IDF信息检索步骤,从大量的文档存储(如维基百科)中找到相关文章。然后,在检索到的
top-k篇文章中,一个神经阅读理解模型随后提取答案。
为了避免给语言模型带来竞争优势,我们将
DrQA的预测限制在single-token答案上。
指标:
precision at k (P@k)指标。为了考虑到
subject-relation pair的多个有效对象(即N-M关系),我们遵循《Translating embeddings for modeling multi-relational data》的做法,在测试时将训练数据中除我们测试的object之外的所有其他有效objects从候选中删除。考虑因素:在创建
LAMA探针时,我们做了几个重要的设计决定。下面我们将为这些决定提供更详细的理由。手动定义的模板:对于每种关系,我们手动定义一个模板,用于查询该关系中的
object slot。我们可以预期,模板的选择会对结果产生影响,情况确实如此:对于某些关系,我们发现使用另一个模板查询相同的信息(就一个给定的模型而言),情况有好有坏。我们认为,这意味着我们正在度量语言模型所知道的下限。Single Token:我们只考虑单个token的object作为我们的预测目标。我们包括这一限制的原因是,multi-token decoding增加了许多额外的可调优参数(beam size、候选评分权重、长度归一化、n-gram重复惩罚等),这些超参数掩盖了我们试图测量的知识。此外,well-calibrated的multi-token generation仍然是一个活跃的研究领域,特别是对于双向模型。Object Slots:我们选择只查询三元组中的object slot,而不是subject slot或relation slot。通过包括反向关系(如contains和contained-by),我们也可以查询subject slot。我们不查询
relation slot有两个原因。首先,
relations的表面形式的实现会跨越几个tokens,正如我们上面所讨论的,这构成了一个技术挑战,不在本工作的范围之内。第二,即使我们可以很容易地预测
multi-token短语,关系通常可以用许多不同的措辞来表达,这使得我们不清楚关系的gold standard pattern应该是什么,以及如何在这种情况下衡量准确率。
词表的交集:我们考虑的这些模型是用不同的词表训练的。例如,
ELMo使用一个800K tokens的列表,而BERT只考虑30K tokens。词表的大小可以影响LAMA prob模型的性能。具体来说,词表越大,就越难将gold token排在最前面。出于这个原因,我们考虑了一个由21K个大小写敏感的tokens组成的公共词表,这些tokens是由所有考虑的模型的词表的交集得到的。为了进行公平的比较,我们让每个模型只对这个公共词表中的tokens进行排名。
由于设计上的约束,因此本文的结论是有局限性的:仅限于采用自定义模板的场景、仅限于
single token的object、仅限于object预测、仅限于一个较小词表中的tokens。
1.2 实验结果
我们在
Table 2中总结了主要的结果,它显示了不同模型在所考虑的语料库中的平均精度(P@1)。在本节的其余部分,我们将详细讨论每个语料库的结果。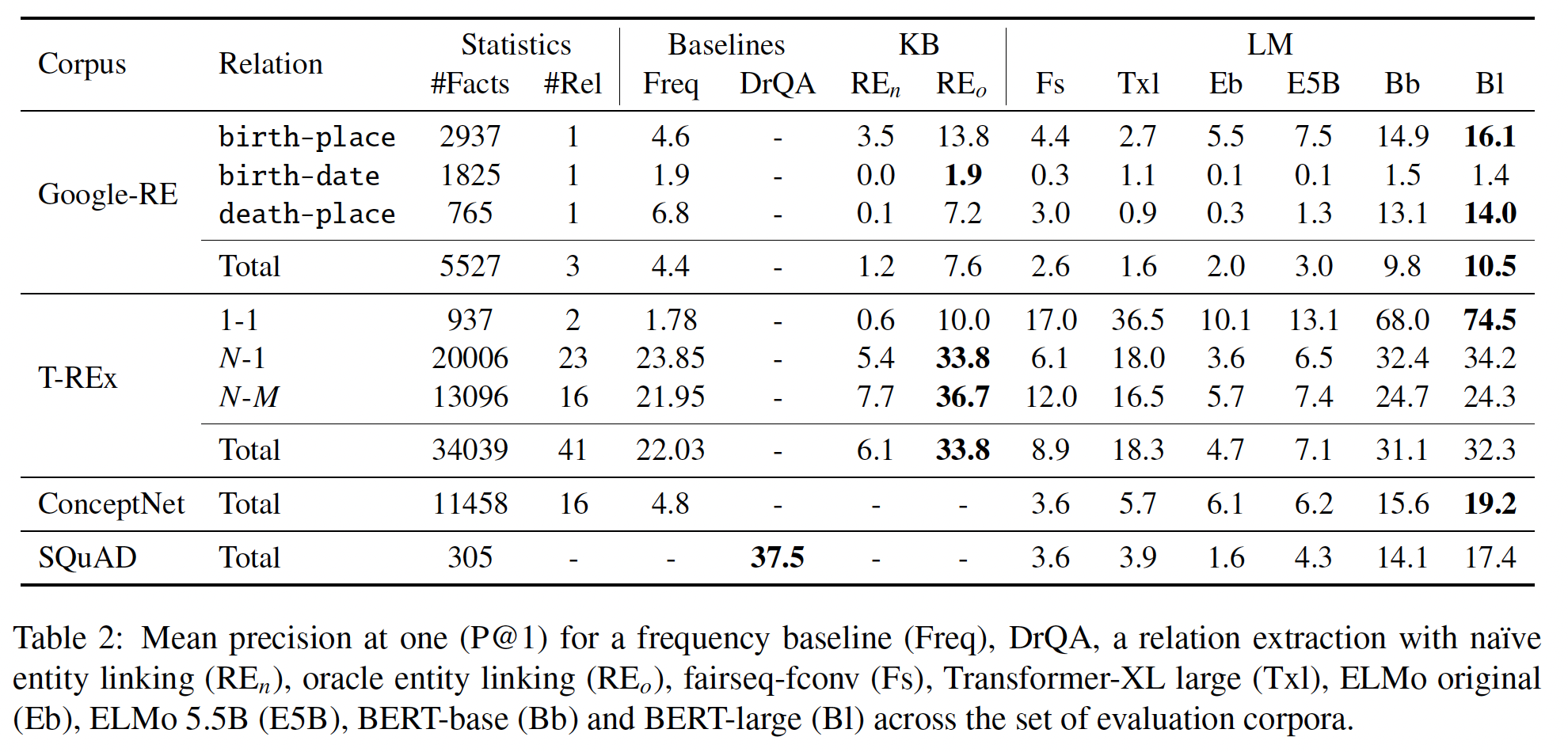
Google-RE:我们使用每种关系的标准完形填空模板来查询语言模型。BERT_base和BERT_large都以很大的幅度超过了所有其他模型。此外,与
oracle-based RE baseline相比,BERT_base和BERT_large分别获得了2.2和2.9的平均准确率改进。此外,
RE基线通过entity linking oracle得到了大量帮助。
值得指出的是,虽然
BERT-large做得更好,但这并不意味着它是出于正确的原因来达到的。模型可能已经从co-occurrence模式中学习了object与subject的关联。T-REx:结果与Google-RE基本一致。按关系类型划分,BERT的性能对于1-to-1 relations(例如,capital of)非常高,对于N-to-M relations则很低。Figure 2显示了所考虑的模型的平均P@k曲线。对于BERT,正确的object在大约60%的情况下被排在top-10、在80%的情况下被排在top-100。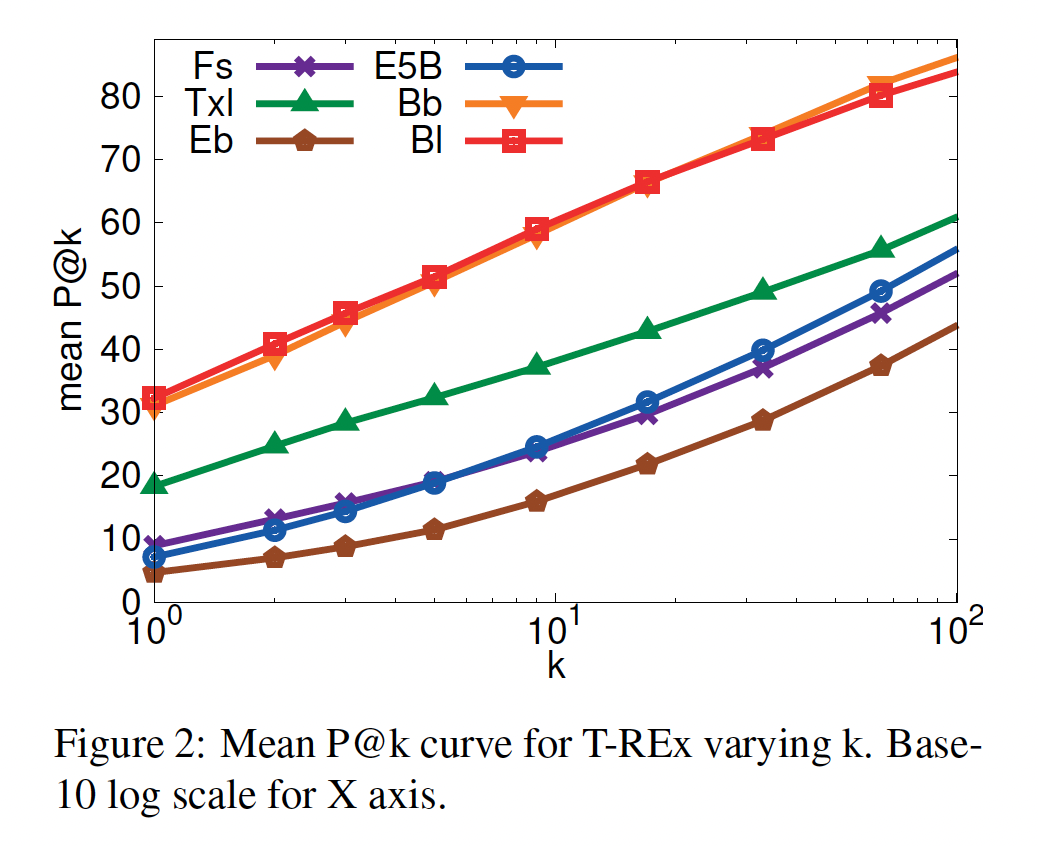
为了进一步研究为什么
BERT取得了如此强大的结果,我们计算了P@1和一组指标之间的皮尔逊相关系数,如Figure 3所示。我们注意到,训练数据中提到一个
object的次数与模型性能呈正相关,而关系的subject次数则不是这样的。此外,预测的对数概率与
P@1强烈正相关。 因此,当BERT对其预测有很高的信心时,它往往是正确的。性能也与
subject向量和object向量之间的余弦相似度呈正相关,并与subject中的tokens数量略有关联。最底部一行给出了
P@1和其它指标之间的相关系数;其它行给出了不同指标之间的相关系数。
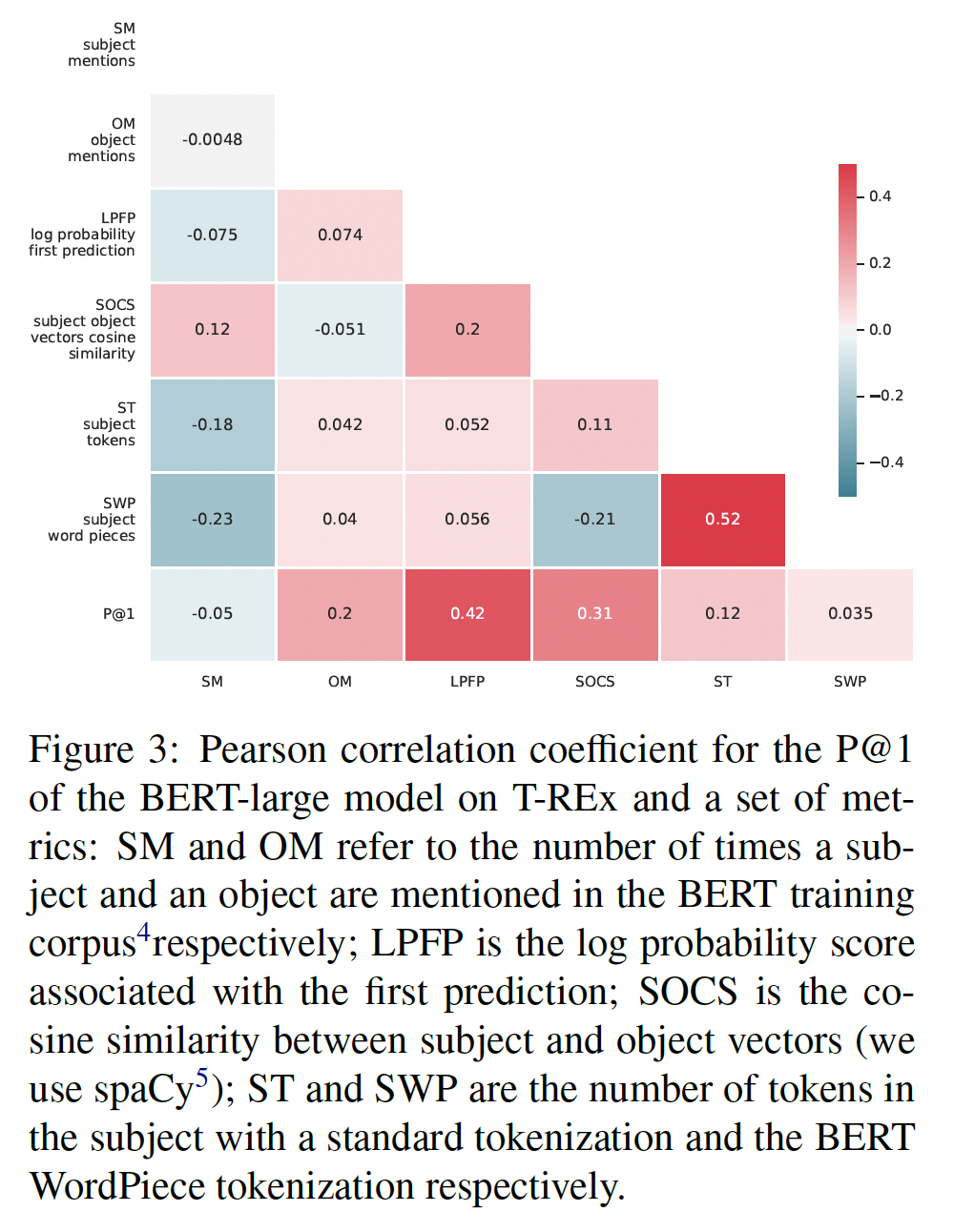
Table 3显示了随机挑选的、BERT-large的完形填空模板query所生成的样本。我们发现,BERT-large通常预测出正确类型的object,即使预测的object本身并不正确。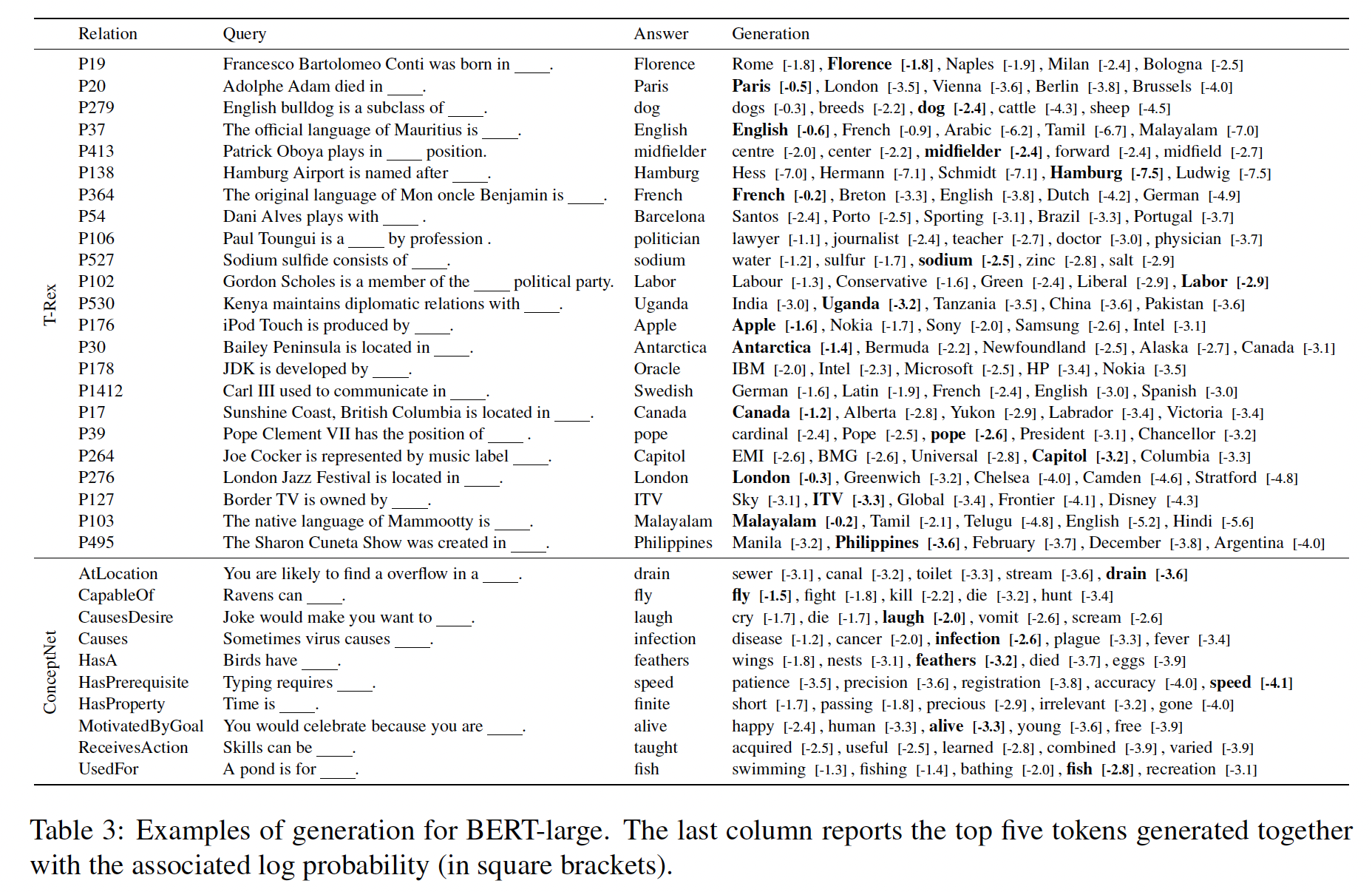
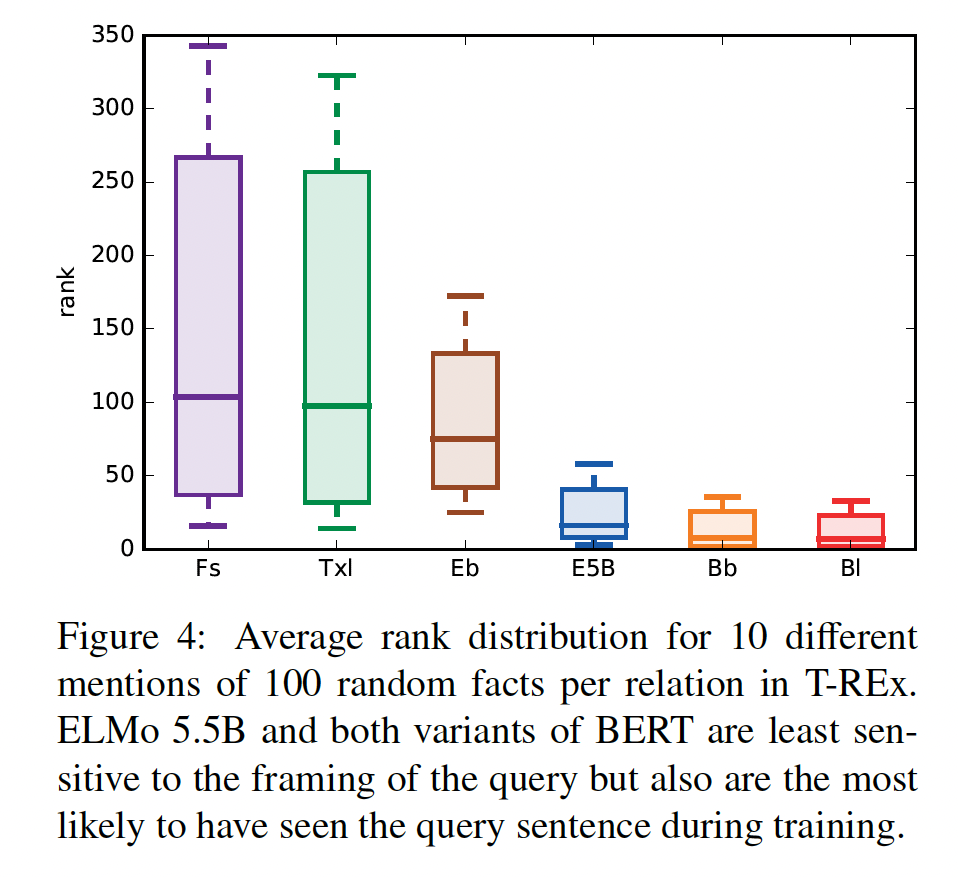
为了了解
pretrained语言模型的性能如何随query特定事实的不同方式而变化,我们分析了每种关系中最多100个随机事实,我们从T-REx中随机选择了维基百科中10个对齐的句子。在每个句子中,我们掩盖fact的object,并要求模型预测它。对于我们的几个语言模型来说,这也测试了它们从训练数据中记忆和回忆句子的能力,因为这些模型已经在维基百科上进行了训练(见Table 1)。Figure 4显示了每个事实的十个query的平均排名的分布。两个
BERT模型和ELMo 5.5B表现出最低的方差,同时将正确的object平均排在靠近顶部的位置。令人惊讶的是,
ELMo original(即,Eb)的性能与BERT相差无几,尽管这个模型在训练期间没有看到维基百科。Eb的性能和BERT还是差距挺大的,作者表述有误?Fairseq-fconv和Transformer-XL在其预测中经历了更高的方差。请注意,BERT和ELMo 5.5B比fairseq-conv和Transformer-XL在维基百科上训练了更多的内容,在训练期间可能看到了更多包含test query的句子。
ConceptNet:结果与Google-RE和T-REx一致。BERT-large模型一直取得了最好的性能。SQuAD:Table 2显示了BERT-large和DrQA在我们的SQuAD任务上的性能差距,其中DrQA的效果要好得多。请再次注意,pretrained语言模型是完全无监督的,它没有经过微调,而且它无法访问专门的信息检索系统。此外,在比较DrQA和BERT-large的P@10时,我们发现差距非常小(BERT-large为57.1、DrQA为63.5)。
二、LPAQA [2019]
论文:
《How Can We Know What Language Models Know?》
近年来,语言模型的主要作用从生成自然文本、或评估自然文本的流畅性,过渡到成为文本理解的有力工具。这种理解主要是通过将语言建模作为用于
feature extractors的预训练任务来实现的,其中,语言建模目标学到的隐向量随后被用于下游语言理解系统。有趣的是,语言模型本身也可以作为文本理解的工具,通过用自然语言制定化
query,直接生成文本答案,或者评估多个选项并挑选最可能的一个。例如,语言模型被用来回答事实性问题、回答常识性查询、或提取关于实体之间关系的事实性知识。无论最终任务是什么,语言模型中包含的知识都是通过提供prompt,让语言模型要么生成prefix的延续(例如,"Barack Obama was born in __"),或者预测完形填空风格的模板中的缺失单词(例如,"Barack Obama is a __ by profession")。然而,虽然这种范式已经被用来实现一些耐人寻味的结果(这些结果关于语言模型所表达的知识),但它们通常依赖于基于实验者的直觉而手工创建的
prompts。这些手动创建的prompts(例如,"Barack Obama was born in ")可能是次优的,因为在训练过程中,语言模型可能已经从完全不同的上下文中学习了目标知识(例如,"The birth place of Barack Obama is Honolulu, Hawaii.")。因此,很有可能由于prompts不是对fact的有效查询,导致语言模型无法检索那些实际上已经知道的事实。因此,现有的结果只是对语言模型所包含的知识程度的一个下限,事实上,语言模型的知识可能比这些初步结果所显示的还要丰富。在本文中,我们提出了一个问题:我们如何才能收紧这个下限,并对SOTA的语言模型所包含的知识有一个更准确的估计?这在科学上和工程上都很有意思,前者是对语言模型所包含的知识的探测(probe),后者则是在使用语言模型作为知识提取系统的一部分时会带来更高的召回率。具体而言,我们专注于
LAMA的设定,他们研究了关于实体之间关系的知识提取。我们提出了两种自动方法来系统地提高prompts的广度和质量,其中这些prompts用于查询relation存在与否。具体来说,如Figure 1所示,这些方法是基于挖掘(mining-based)的方法,其灵感来自于以前的关系提取(relation extraction)方法(《Learning surface text patterns for a question answering system》),以及基于转述(paraphrasing-based)的方法(该方法采用一个seed prompt,无论是手动创建的还是自动挖掘的,并将其转述为其他几个语义相似的表述)。此外,由于不同的prompts在查询不同的(subject, object) pair时可能效果更好,我们还研究了轻量级的ensemble方法,将不同prompts的答案组合在一起。我们在
LAMA基准上进行了实验,这是一个英语基准,旨在测试语言模型检索实体间关系的能力。我们首先证明,改进后的prompts明显提高了这项任务的准确率,通过我们的方法提取的最佳prompt将BERT-base的准确率从31.1%提高到34.1%,BERT-large也获得了类似的收益。我们进一步证明,通过ensembling使用多样化的prompts,进一步提高了准确率,达到39.6%。我们进行了广泛的分析和消融实验,既收集了关于如何最好地查询知识(那些存储在语言模型中的知识)的见解,也收集了关于将知识纳入语言模型本身的潜在方向的见解。最后,我们发布了由此产生的LMPrompt And Query Archive: LPAQA,以促进未来对语言模型中包含的知识进行探测的实验。
相关工作:许多工作都集中在了解
neural NLP models中的内部表征(《Analysis methods in neural language processing: A survey》),或者通过使用外在的probing tasks来研究是否可以从这些representations中预测某些语言属性、或者通过对模型的消融来研究行为如何变化。特别是对于contextualized representations,一套广泛的NLP任务被用来分析句法属性和语义属性,提供证据表明contextualized representations在不同layers上编码语言知识。与
probing the representations本身的分析不同,我们的工作遵循《Language models as knowledge bases?》、《BERT is not a knowledge base (yet): Factual knowledge vs. Name based reasoning in unsupervised QA》对事实性知识的探测。他们使用手动定义的prompts,这可能低估了语言模型的真实性能。在这项工作的同时,《Inducing relational knowledge from BERT》也提出了类似的观点,即使用不同的prompts可以帮助更好地从语言模型中提取relational knowledge,但他们使用的是显式训练的模型从而用于提取关系,而我们的方法是在没有任何额外训练的情况下检查语言模型中包含的知识。此外,以前的一些工作整合了外部知识库,使语言生成过程明确地以符号知识为条件。类似的扩展已经应用于像
BERT这样的pre-trained LM,其中contextualized representations用entity embeddings来增强。相比之下,我们关注的是通过对语言模型的prompts来实现更好的知识检索,而不是修改语言模型。
2.1 从语言模型中检索知识
从语言模型中检索事实性知识,与查询标准的陈述性的知识库(
knowledge base: KB)有很大不同。在标准的知识库中,用户将其信息需求表述为由KB schema和query language所定义的结构化查询。例如,SELECT ?y WHERE {wd:Q76 wdt:P19 ?y}是一个SPARQL query,用于搜索Barack_Obama的出生地。相比之下,语言模型通过自然语言prompts进行查询,例如"BarackObama was born in__",在空白处分配的概率最高的单词将被返回作为答案。与对知识库的确定性查询不同,语言模型不提供正确性或成功的保证。虽然
prompts的想法在从语言模型中提取各种各样知识的方法中很常见,但在本文中,我们特别遵循LAMA的表述,其中事实性知识是三元组subject),object),而prompttokens的一个序列组成,序列中的两个token是subject和object的占位符(例如,"x plays at y position")。通过用subject来替换missing object"LeBron James plays at __ position"):其中:
tokens(如,subject和prompt)给定的条件下来预测空格处的groundtruth因为我们希望我们的
prompts能够最有效地引导语言模型本身所包含的任何知识,所以一个 ”好“ 的prompt应该尽可能多地引导语言模型去预测ground-truth objects。在以前的工作中(
《The natural language decathlon: Multitask learning as question answering》、《Language models are unsupervised multitask learners》、《Language models as knowledge bases?》),prompt。正如导言中所指出的,这种方法不能保证是最优的,因此我们提出了从一小部分训练数据中学习effective prompts的方法,这些数据由每种关系的gold subject-object pairs组成。
2.2 Prompt Generation
首先,我们处理
prompt generation:该任务为每种关系promptsprompts能有效地引导语言模型来预测ground-truth objects。我们采用两种实用的方法:要么从大型语料库中挖掘prompt candidates、要么通过转述来使seed prompt多样化。Prompt Generation的核心是:如何使得prompts多样化、以及如何使用多样化的prompts。这篇论文的
prompts本质上是zero-shot的,那么few-shot是不是会更好?
2.2.1 基于挖掘的 generation
我们的第一个方法受到
template-based relation extraction方法的启发,这些方法是基于这样的观察:在大型语料库中,subjectobjectdistant supervision假设,确定所有的这类WikiPedia句子:该句子同时包含特定关系subject和object;然后提出两种提取prompts的方法:Middle-word Prompts:根据观察,subject和object中间的单词往往是relation的指示,我们直接使用这些单词作为prompts。例如,"Barack Obama was born in Hawaii"通过用占位符替换subject和object被转换成"x was born in y"的prompt。Dependency-based Prompts:《Representing text for joint embedding of text and knowledge bases》指出,在中间不出现单词的模板情况下(例如,"The capital of France is Paris"),基于句法分析的模板可以更有效地进行关系提取。我们遵循这一见解,即用
dependency parser来解析句子,以确定subject和object之间最短的dependency path,然后使用dependency path中从最左边的单词到最右边的单词的phrase spanning作为prompt。例如,上述例子中的dependency path是:其中最左边的单词和最右边的词分别
"capital"和"Paris",给出的prompt是"capital of x is y"。这种方法依赖于外部的
dependency parser,因此不是端到端的方案。
值得注意的是,这些基于挖掘的方法不依赖于任何手动创建的
prompts,因此可以灵活地应用于我们可以获得一组subject-object pairs的任何关系。这将导致多样化的prompts,覆盖了relation在文本中可能表达的各种方式。然而,这也容易产生噪音,因为以这种方式获得的许多prompts可能对该relation的指示性不强(例如,"x, y"),即使它们很频繁出现。基于挖掘的方法依赖于第三方数据源,即维基百科。这在实验部分提到了这一点。因此,如果任务包含的关系不在维基百科中,那么基于挖掘的方法不可用。
2.2.2 基于转述的 generation
我们的第二种生成
prompts的方法更有针对性,它的目的是在相对忠实于原始prompts的情况下提高词汇的多样性。具体而言,我们通过对原始prompts进行转述(paraphrasing),使之成为其他语义相似或相同的表达。例如,如果我们的原始prompts是"x shares a border with y",它可以被转述为"x has a common border with y"、以及"x adjoins y"。这在概念上类似于信息检索中使用的query expansion技术,即重新表述一个给定的query以提高检索性能(《A survey of automatic query expansion in information retrieval》)。虽然许多方法可以用于转述,但我们遵循使用
back-translation的简单方法(《Improving neural machine translation models with monolingual data》、《Paraphrasing revisited with neural machine translation》):这种方法依赖于外部的翻译模型,因此也不是端到端的。
首先将初始
prompt翻译成另一种语言的然后将每个候选翻译成原始语言的
最后,我们根据
round-trip概率进行排名,并保留top T个prompts。其中round-trip概为:其中:
prompt,prompt,final prompt。round-trip概率的物理含义为:给定原始语言输入
2.3 Prompt Selection and Ensembling
这里我们介绍如何使用所生成的
prompts。下面的所有方法都需要一个验证集来筛选以及
ensemble候选的prompts。
2.3.1 Top-1 Prompt Selection
对于每个
prompt,我们可以用以下公式来衡量其预测ground-truth objects的准确率(在训练数据集上):其中:
subject-object pairs的集合。prompt。Kronecker’s delta function,当内部条件为true时返回1,否则返回0。
在用于查询语言模型的最简单的方法中,我们选择准确率最高的
prompt,并只使用这个prompt进行查询。
2.3.2 Rank-based Ensemble
接下来,我们研究了不仅使用
top-1 prompt,而且将多个prompts组合在一起的方法。这样做的好处是,在训练数据中,语言模型可能在不同的上下文中观察到不同的entity pairs,而拥有各种各样的prompts可能会允许引导那些出现在这些不同上下文中的知识。我们的第一种
ensembling方法是一种无参数的方法,对top-ranked prompts的预测进行平均。我们根据训练集上预测objects的准确率对所有的prompts进行排名,并使用top-K prompts的平均对数概率来计算object的概率:其中:
prompt。prompts上,较大的prompts的多样性。
2.3.3 Optimized Ensemble
上述方法对
top K prompts一视同仁,这是次优的,因为到一些prompts比其他prompts更可靠。因此,我们还提出了一种直接优化prompt weights的方法。形式上,我们将其中:
prompts上的一个分布并且被对于每一个
relation,我们要学习对一组不同的candidate prompts进行评分,所以参数的总数是关系数量的gold-standard objects的概率这可以通过固定语言模型,并且学习
2.4 实验
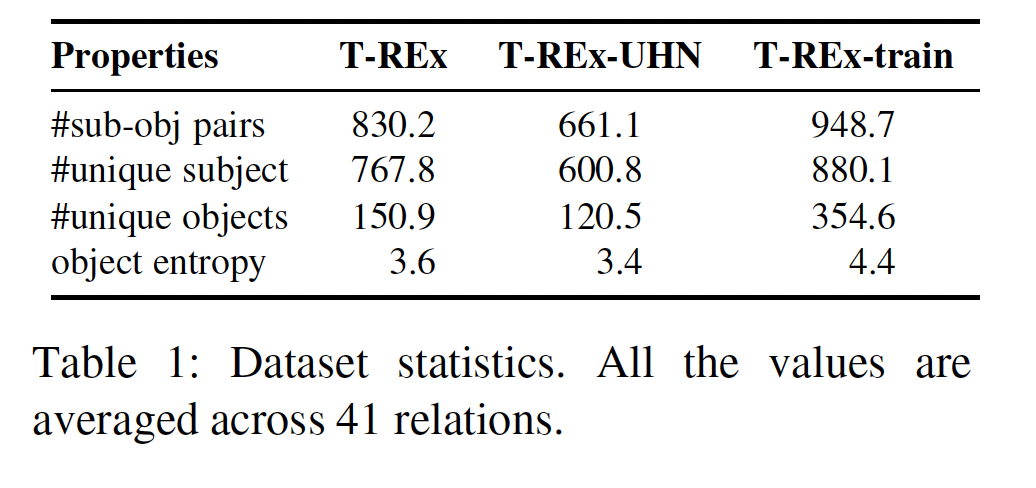
数据集:
LAMA benchmark的T-REx子集。它有一个更广泛的41种关系的集合(相比之下,Google-RE子集只包括3种关系)。每种relation关联来自维基数据的最多1000个subject-object pairs,同时也关联一个手动设计的prompt。为了学习挖掘
prompts、对prompts进行排序、或学习ensemble权重,我们为每个关系创建了一个单独的subject-object pairs训练集,该训练集也来自维基数据,与T-REx数据集没有重叠。我们把这个训练集称为T-REx-train。为了与LAMA中的T-REx数据集保持一致,T-REx-train也被选择为只包含单个token的objects。为了研究我们方法的通用性,我们还报告了我们的方法在
Google-RE子集上的表现,该子集的形式与T-REx类似,但相对较小,只包括三种关系。《BERT is not a knowledge base (yet): Factual knowledge vs. Name based reasoning in unsupervised QA》指出,LAMA中的一些事实可以只根据entities的表面形式来猜测,而不需要记忆事实。他们过滤掉了那些容易猜测的事实,创造了一个更难的基准,表示为LAMA-UHN。我们还对LAMA-UHN的T-REx子集(即T-REx-UHN)进行了实验,以研究我们的方法是否还能在这个更难的基准上获得改进。数据集的统计数据总结在下表中。
模型:
BERT-base, BERT-large。此外,我们实验了一些通过外部
entity representation来增强的pretrained model,如ERNIE(《ERNIE: Enhanced language representation with informative entities》)、KnowBert(《Knowledge enhanced contextual word representations》)。评估指标:
micro-averaged accuracy:首先计算每种关系然而,我们发现一些
relation的objects分布是极其倾斜的(例如native language这个关系,所对应的objects有一半是French),这可能会导致欺骗性的高分。macro-averaged accuracy:首先独立地计算每个unique object的准确率,然后在所有object上取平均。
方法:我们尝试了不同的
prompt generation和selection/ensembling方法,并将其与LAMA中使用的人工设计的prompt进行比较。Majority:为每种relation预测占比多数的object。Man:LAMA中使用的人工设计的prompt。Mine:使用通过中间单词和dependency path从维基百科挖掘的prompt。Mine+Man:将Mine和人工prompt相结合。Mine+Para:为每个relation将排名最高的被挖掘的prompt进行转述。
Man+Para:将人工prompt进行转述。
这些得到的
prompts可以通过TopK或Opti.等方法结合起来。Oracle代表generated prompts的性能上限:如果任何一个prompt使得语言模型成功地预测该object,则该事实被判定为正确。实现细节:
超参数:
我们删除了如下类型的
prompts从而减少噪音:仅仅包含stopwords或标点符号、长度超过10个单词。我们使用在
WMT'19上预训练的round-trip English-German neural machine translation model进行回译,因为English-German是资源最丰富的language pair之一。当优化
ensemble parameter时,我们使用默认参数的Adam,batch size = 32。
2.4.1 评估结果
不同方法的实验结果如
Table 2, Table3所示,分别给出了micro-averaged accuracy、macro-averaged accuracy。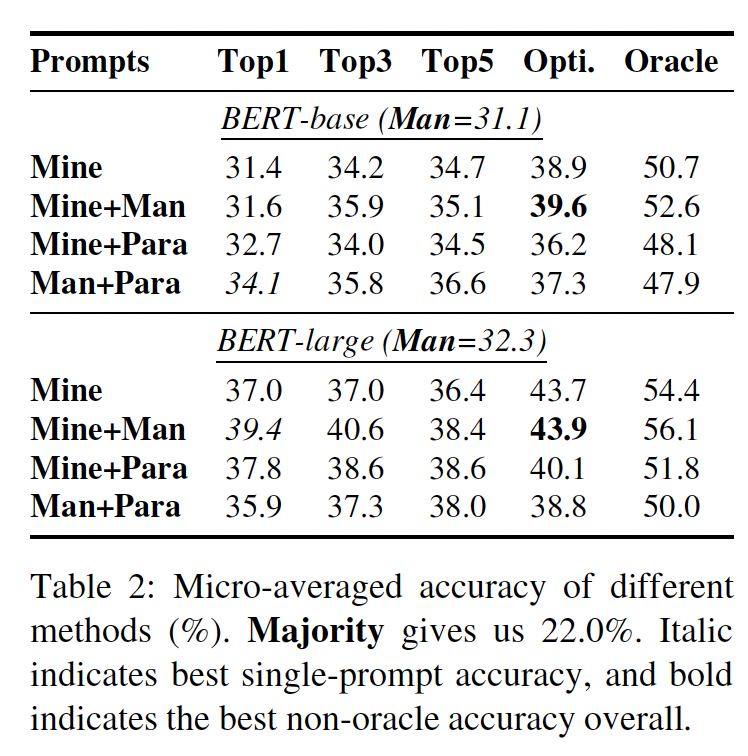
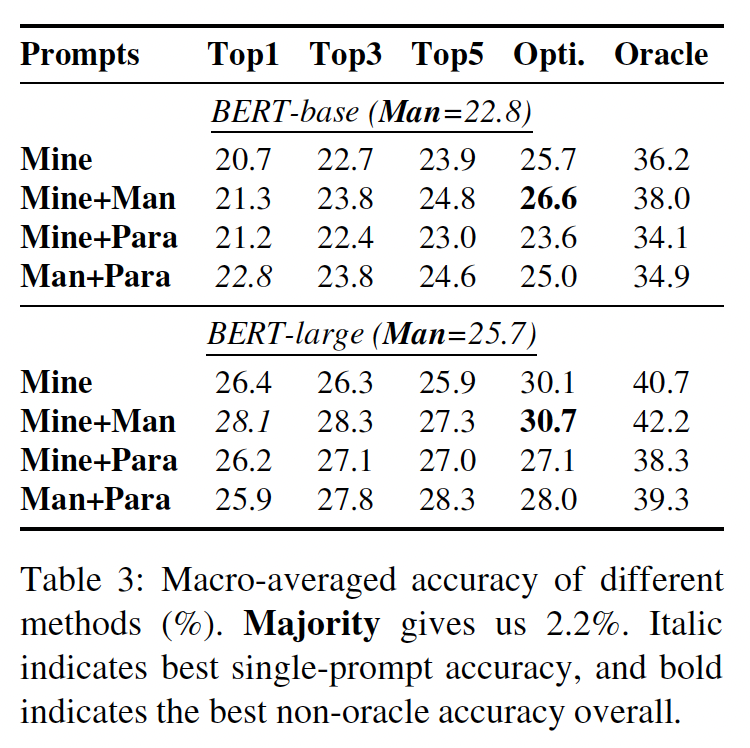
Single Prompt(对应于Table 2, Table3的Top1这一列):所提出的最好的prompt generation方法在BERT-base上将micro-averaged accuracy从31.1%提高到34.1%,而在BERT-large上将micro-averaged accuracy从32.3%提高到39.4%。这表明手动创建的prompt是一个有点弱的下限。Table 4显示了一些mined prompts,与人工promtps相比,这些promtps带来了很大的性能提升。可以看出,使用mined prompts的最大收益似乎发生在人工定义的prompt在语法上更复杂的情况下(例如前面的几个),或者使用比mined prompts更不常见的措辞时(例如后面的几个)。
Prompt Ensembling:Table 2, Table3的Top3, Top5, Opti.这三列给出了ensembling的结果。ensembling多个prompts几乎总是能带来更好的性能。optimized ensemble在BERT-base和BERT-large上进一步将micro-averaged accuracy分别提高到39.6%和43.9%,比rank-based ensemble(即Top3, Top5这两列)要好得多。
这表明,多样化的
prompts确实可以以不同的方式query语言模型,而且optimization-based方法能够找到有效地将不同prompts结合在一起的权重。我们在
Table 5中列出了所学到的top-3 mined prompts的权重,以及与只使用top-1 prompt相比的准确率增益。
我们还在
Figure 2中描述了rank-based ensemble方法的性能与prompts数量的关系。对于
mined prompts,top-2或top-3通常能给我们最好的结果。而对于
mined + paraphrased prompts,top-5是最好的。纳入更多的
prompts并不总能提高准确率,这一发现与optimization-based所学到的权重迅速下降的情况相一致。
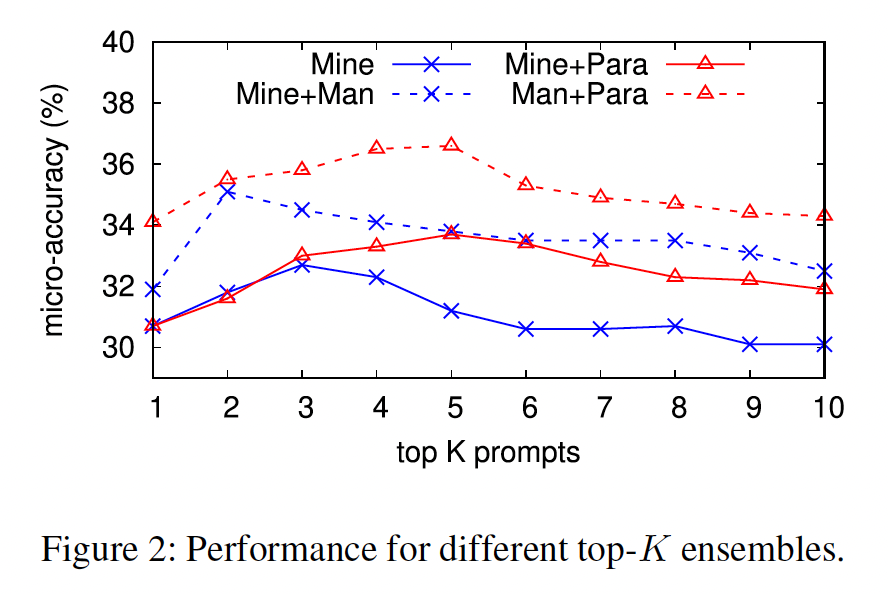
Table 2, Table3的Oracle和Opti.之间的差距表明,使用更好的ensemble方法仍有改进空间。
Mining vs. Paraphrasing:对于
rank-based ensembles(Top1, 3, 5),通过转述产生的prompts通常比mined prompts表现更好。而对于optimization-based ensemble(Opti.),mined prompts表现更好。我们推测,这是因为与转述相比,
mined prompts表现出更多的变化,而适当的加权是最重要的。这种variation的差异可以从每个class的prompts之间的平均编辑距离中观察到,mined prompts和paraphrased promp的编辑距离分别为3.27和2.73。然而,与仅仅使用一个
prompt相比,ensembling paraphrases所带来的改进仍然是显著的(Top1 vs. Opti.)。这表明,即使对prompts进行小的修改,也会导致预测的相对较大的变化。Table 6展示了对一个单词(功能词或内容词)的修改导致显著的准确率提高的案例,表明大型语言模型对查询方式的小变化仍然很脆弱。

Middle-word vs. Dependency-based:我们在Table 7中比较了只使用middle-word prompts、以及将其与dependency-based prompts相拼接的性能。这些改进证实了我们的直觉,即属于dependency path但不在subject and object中间的单词也是relation的指示。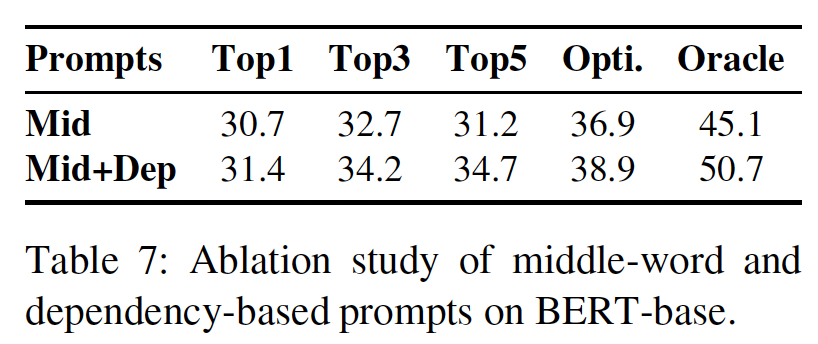
Micro vs. Macro:对比Table 2和Table 3,我们可以看到,macro-averaged accuracy比micro-averaged accuracy低得多,这表明macro-averaged accuracy是一个更具挑战性的指标,它评估了语言模型知道多少unique objects。我们optimization-based方法在BERT-base上将macro-averaged accuracy从22.8%提高到25.7%,在BERT-large上从25.7%提高到30.1%。这再次证实了ensembling多个prompts的有效性,但收益要小一些。值得注意的是,在我们
optimization-based的方法中,ensemble weights是在训练集的每个样本上进行优化的,这更有利于优化micro-averaged accuracy。优化以提高macro-averaged accuracy可能是未来工作的一个有趣的方向,这可能会使prompts更普遍地适用于不同类型的objects。不同语言模型的性能: 在
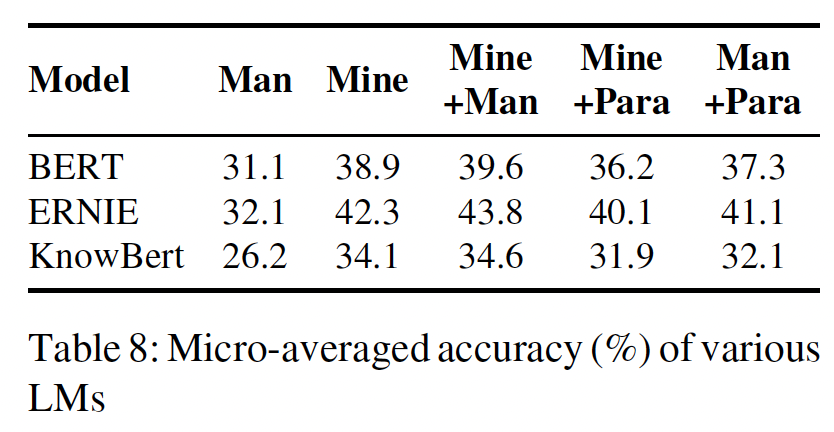
Table 8中,我们将BERT与ERNIE、KnowBert进行了比较,后两种方法通过明确纳入entity embedding来增强外部知识。ERNIE即使在人工prompts的情况下也比BERT好1分,但我们的prompt generation方法进一步强调了两种方法之间的差异。这表明,如果对语言模型进行有效查询,高性能模型之间的差异可能会变得更加明显。KnowBert在LAMA上的表现不如BERT,这与《Knowledge enhanced contextual word representations》的观察相反。这可能是因为在《Knowledge enhanced contextual word representations》中,KnowBert被用来评估multi token subjects/objects,而LAMA只包含single-token objects。
LAMA-UHN Evaluation:Table 9中报告了LAMA-UHN基准的性能。尽管与原始LAMA基准测试的表现相比,整体表现大幅下降(Table 2),但optimized ensembles仍能以较大的优势胜过人工prompts,表明我们的方法在检索无法根据表面形式推断的知识方面是有效的。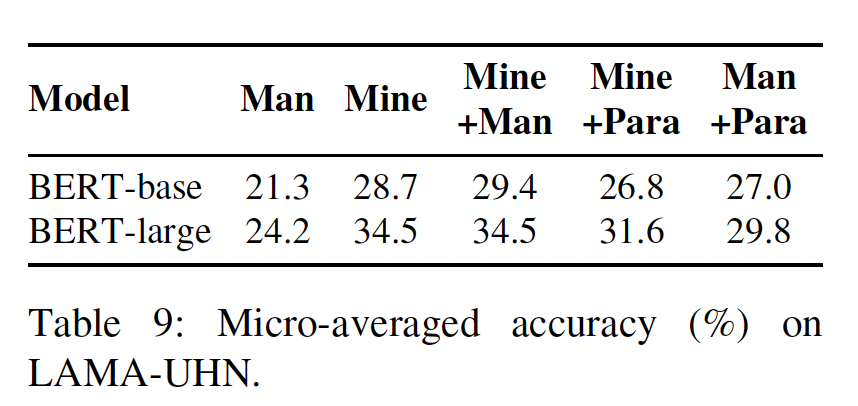
2.4.2 分析
接下来,我们进行进一步分析,以更好地了解哪种类型的
prompts被证明最适合于促进从语言模型中检索知识。Prediction Consistency by Prompt:我们首先分析了在什么条件下prompts会产生不同的预测。我们用下面的公式来定义两个promptsprediction之间的分歧:其中:
如果
promptKronecker’s delta函数,当条件为true时取值为1,否则取值为0。
对于每个关系,我们将两个
prompt的编辑距离(edit distance)归一化为[0, 1],并将normalized distance分成五个区间,区间间隔0.2。我们在下图中为每个bin绘制了一个箱形图从而可视化prediction divergence的分布,bin中的绿色三角形代表平均值,bin中的绿色bar代表中位数。随着编辑距离的变大,
divergence也在增加,这证实了我们的直觉,即非常不同的prompt往往会引起不同的预测结果。Pearson相关系数为0.25,这表明这两个变量之间存在着微弱的相关性。箱线图最下面的
bar代表最小值、最上面的bar代表最大值、箱体的底部代表下四分位数、箱体的顶部代表上四分位数。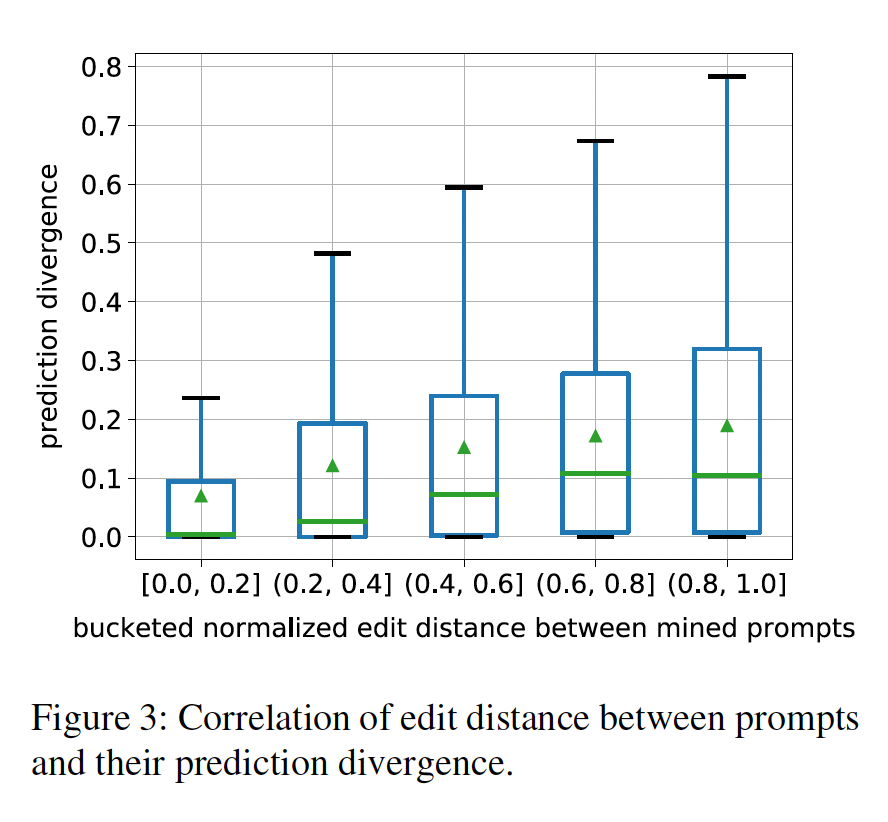
Google-RE上的表现:我们还在下表中报告了optimized ensemble在Google-RE子集中的表现。同样,ensembling diverse prompts可以提高BERT-base和BERT-large模型的准确率。与T-REx子集上的表现相比,收益要小一些,这可能是由于只有三种relation,而其中一种关系(预测一个人的出生日期)特别难,以至于只有一个prompt产生非零准确率。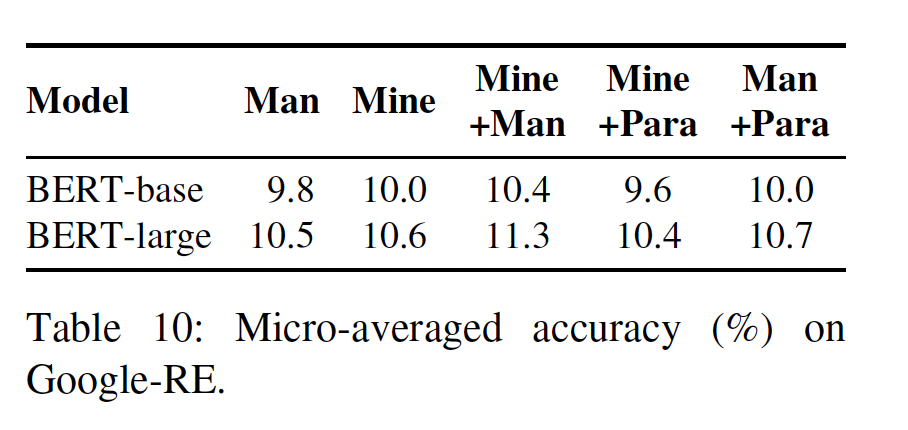
POS-based分析:接下来,我们试图研究哪些类型的prompts往往是有效的,方法是通过检查prompts的词性标注(part-of-speech: POS)模型,其中这些prompts成功地从语言模型中提取知识。在
open information extraction系统中,人工定义的模式经常被用来过滤掉嘈杂的relational phrases。例如,《Identifying relations for open information extraction》结合了下表中列出的三个句法约束,以提高mined relational phrases的一致性和信息量。为了测试这些模式是否也能表明prompts从语言模型中检索知识的能力,我们用这三种模式将我们的方法产生的prompt分为四个cluster,其中"other" cluster包含不符合任何模式的prompts。然后,我们计算每个prompt在所有extracted prompts中的排名,并在下图中用箱线图绘制出排名的分布。
我们可以看到,与这些模式相匹配的
prompts的平均排名要好于"other"组中的prompts,这证实了我们的直觉,即好的prompts应该符合这些模式。一些表现最好的prompts的POS签名是"x VBD VBN IN y"(例如,"x was born in y")、以及"x VBZ DT NN IN y"(例如,"x is the capital of y")。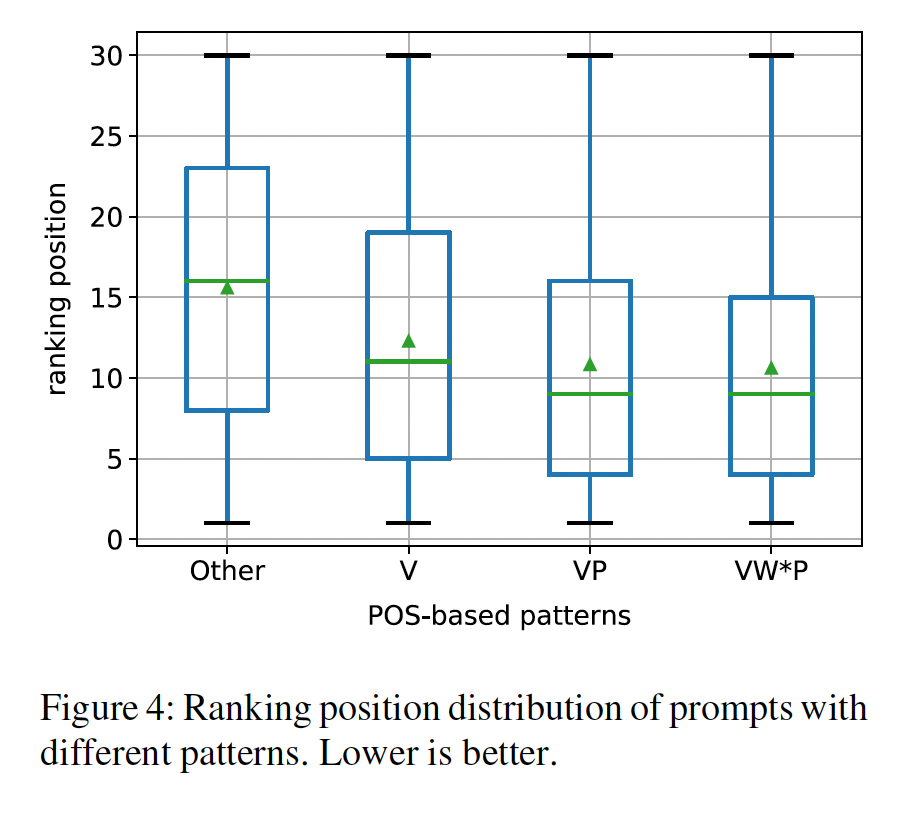
Cross-model Consistency:最后,我们有兴趣知道,我们所提取的prompts是否是针对某一特定模型的,或者它们是否可以跨模型通用。为了做到这一点,我们使用了两种设置:一个是比较
BERT-base和BERT-large,相同的模型架构,但规模不同。另一个是比较
BERT-base和ERNIE,不同的模型架构,但是规模相当。
在每种情况下,我们比较了
optimization-based ensembles在相同的模型上训练时,或在一个模型上训练并在另一个模型上测试时。如Table 12和Table 13所示,我们发现:一般来说,在跨模型的情况下,性能通常会有一些下降(第三列和第五列),但损失往往很小。
query BERT-base时,最高的性能实际上是由在BERT-large上优化的权重实现的。值得注意的是,在另一个模型上优化了权重的最佳准确率为
40.1%和42.2%(Table 12)以及39.5%和40.5%(Table 13),仍然比manual prompts获得的准确率高得多,这表明optimized prompts仍然能在不同的模型上提供大的收益。另一个有趣的观察是,在
ERNIE上的性能下降(Table 13的最后两列)比BERT-large上的性能下降(Table 12的最后两列)更大,表明共享相同架构的模型从相同的prompts中受益更多。
列标题包含两行:第二行表示训练
prompts的模型,第一行表示测试prompts的模型。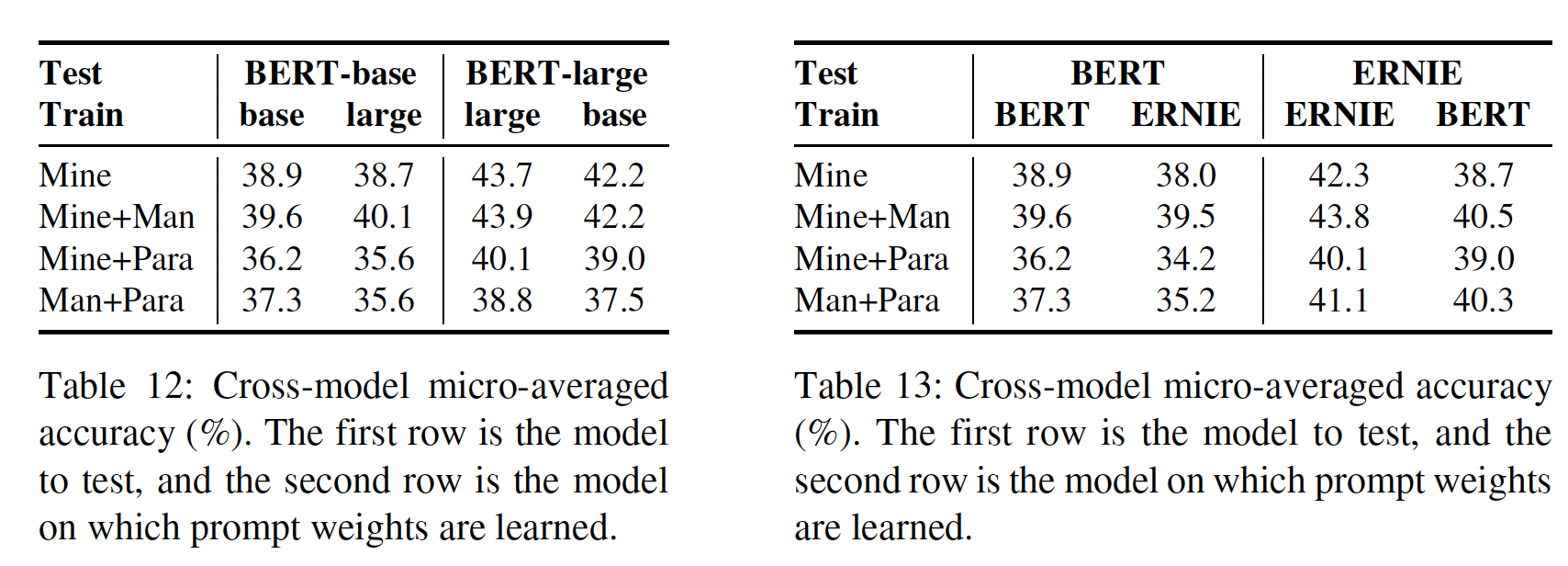
Linear vs. Log-linear Combination:如前所述,我们在主要实验中使用了概率的log-linear组合。然而,也可以通过常规的线性插值来计算概率:我们在下图中比较了这两种结合来自多个
mined prompts的预测的方式。我们假设log-linear combination优于线性组合,因为对数概率使我们有可能惩罚那些在任何certain prompt下非常不可能的objects。因为对数概率可以远小于零,因此,对于在任何
certain prompt下非常不可能的objects,它的softmax中是一个很小的数。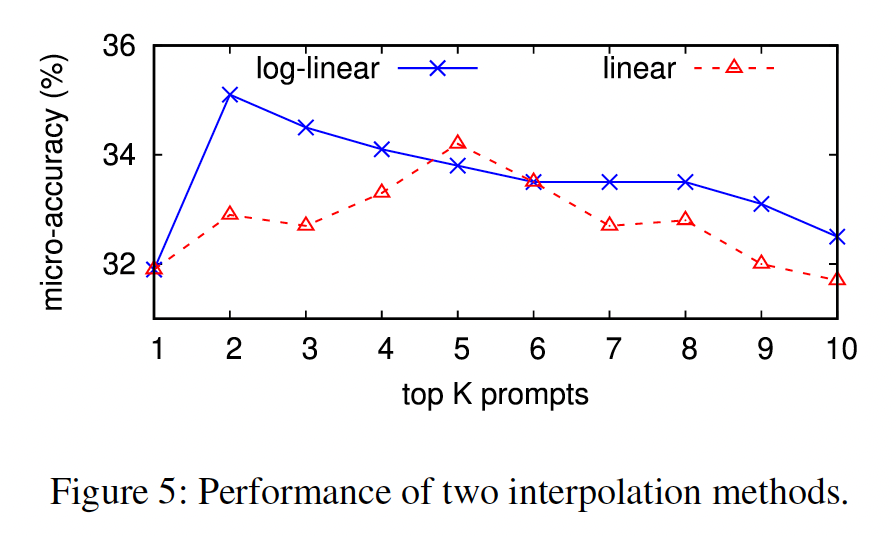
2.5 遗漏的设计元素
最后,除了我们前面提出的主要方法的要素之外,我们还试验了一些额外的方法,这些方法未被证明是非常有效的,因此在我们的最终设计中被省略了。我们在下面简要地描述这些方法,以及粗略的实验结果。
LM-aware Prompt Generation:我们研究了通过解决一个优化问题来生成prompts的方法:其中
pretrained语言模型来参数化。换句话说,这种方法直接寻找
prompt,使得语言模型分配给ground-truth objects的概率最高。然而,我们发现,在我们的初步实验中,由梯度引导的直接优化prompts是不稳定的,并且经常产生不自然的英语prompts。其实这就是
P-Tuning的思想:直接优化prompt embedding而不是prompt本身。因此,我们转而采用了一种更直接的
hill-climbing,从初始prompts开始,然后每次掩码一个token,并以其他tokens为条件用最有可能的token来代替它。这种方法的灵感来自于non-autoregressive machine translation中使用的mask-predict decoding算法(《Mask-predict: Parallel decoding of conditional masked language models》):其中:
prompt中的第token,token的所有其他tokens。我们遵循一个简单的规则,从左到右依次修改
prompt,这样反复进行,直到收敛。我们用这个方法在
T-REx-train数据集上refine了所有的mined prompts和manual prompts,并在下表中显示了它们在T-REx数据集上的表现。经过微调后,oracle性能明显提高;而ensemble性能(包括rank-based和optimization-based)略有下降。这表明,LM-aware fine-tuning有可能发现更好的prompts,但部分的refined prompts可能过拟合于它们被优化的训练集。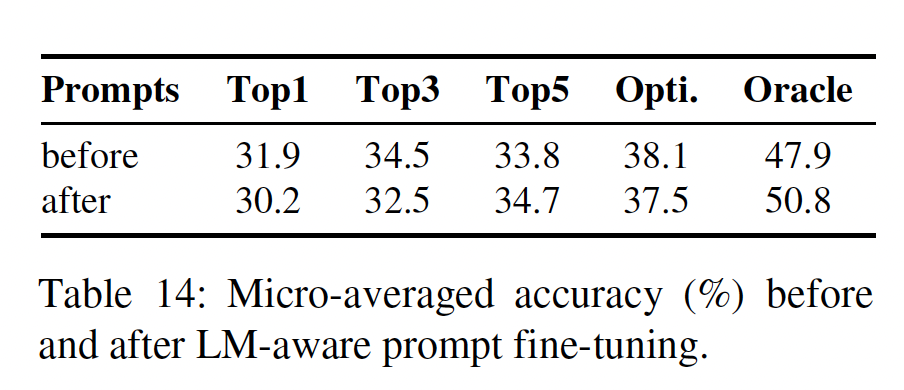
Forward and Backward Probabilities:最后,考虑到类别不平衡、以及模型过度预测majority object的倾向,我们研究了一种方法来鼓励模型预测更强烈一致的subject-object pairs。受
《A diversity promoting objective function for neural conversation models》使用的maximum mutual information objective的启发,我们将每个prompt的backward log probabilityoptimization-based scoring函数objects的搜索空间很大,我们转而采用一种近似的方法,在训练和测试时只计算由forward probability给出的最可能的backward probability。这种方法的思想是:根据
labelprompts来预测《Improving and Simplifying Pattern Exploiting Training》的核心思想。后者成功的原因有两个:后者是few-shots的、后者在forward/backward中调整了prompts的格式。如下表所示,
backward probability带来的改进很小,这表明diversity-promoting scoring函数可能对语言模型的知识检索没有必要。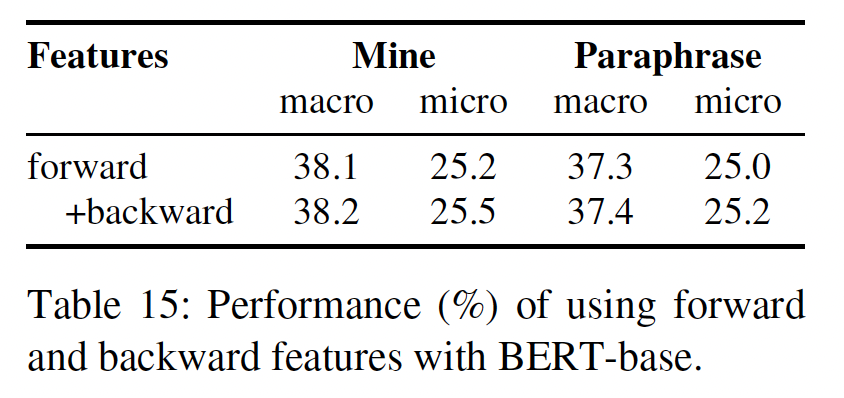
三、AutoPrompt[2020]
论文:
《AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts》
pretrained语言模型(language model: LM)在通过微调来适应下游任务时取得了非凡的成功。尽管很清楚,预训练提高了准确率,但很难确定finetuned LM所包含的知识是在预训练过程中、还是在微调过程中学习的。我们如何才能直接评估finetuned LM中存在的知识,无论是语言的知识、事实的知识、常识的知识,还是特定任务的知识?人们提出了许多技术从而通过分析
pretrained LM的内部表征(internal representation)来获得这种知识。一个常见的策略是使用探测分类器(probing classifier):使用语言模型的representationn作为特征来预测某些属性的浅层分类器(《Whatyou can cram into a single vector: Probing sentence embeddings for linguistic properties》、《Linguistic knowledge and transferability of contextual representations》)。然而,探测分类器需要额外的学习参数,因此容易出现假阳性(false positive);高的探测准确率并不是得出语言模型包含某项知识的充分条件(《Designing and interpreting probes with control tasks》、《Information theoretic probing with minimum description length》)。attention visualization是另一种常见的技术,也有类似的失败模式:注意力得分可能与底层的target knowledge相关,但不是由底层的target knowledge引起的,这导致了对注意力得分作为解释的批评(《Attention is not explanation》、《Attention is not not explanation》)。probing和attention可视化也都难以评估不能被表示为简单的token-level分类任务或sequence-level分类任务的知识。由于这些模型毕竟是语言模型,所以从这些模型中引出知识的一个更直接的方法是
prompting,即把任务转换成语言模型的格式。例如:GPT-2将摘要任务设定为一个语言建模任务,通过在文章末尾附加"TL;DR:"然后从语言模型中生成。同样,
LAMA手动将知识库补全(knowledge base completion)任务重新表述为完形填空测试(即完形填空问题)。
与现有的模型分析方法相比,
prompting是非侵入性的:它不引入大量的额外参数,也不需要直接检查模型的representations。因此,prompting提供了一个关于模型 "知道" 什么的下限,因此是一个更有用的分析工具。然而,不幸的是,prompting需要手动制作上下文从而馈入模型。这不仅耗费时间,而且对于许多任务(例如textual entailment)来说也是不直观的;更重要的是,模型对这种上下文高度敏感:不恰当的上下文会导致人为的低性能(LPAQA)。克服manually specify prompts的需要,将使prompting成为更广泛有用的分析工具。在本文中,我们介绍了
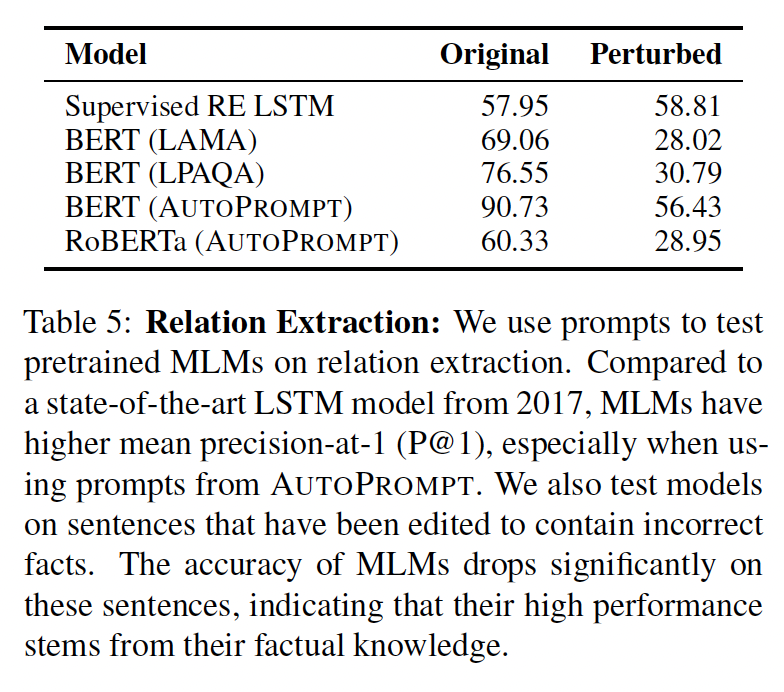
AutoPrompt,一种为任何任务生成prompts的自动方法,如下图所示。给定一个任务,例如情感分析,AutoPrompt通过将原始任务输入(例如评论)与根据模板的trigger tokens集合相结合来创建一个prompt。所有输入都使用相同的trigger tokens集合,并使用《Universal adversarial triggers for attacking and analyzing》提出的gradient-based search策略的变体来学习。对prompt的LM prediction通过对一组相关的label tokens进行 边际化(marginalizing)从而转换为类别概率,其中label tokens集合可以提前学习或人工指定,使得语言模型的评估与其他分类器的评估相同。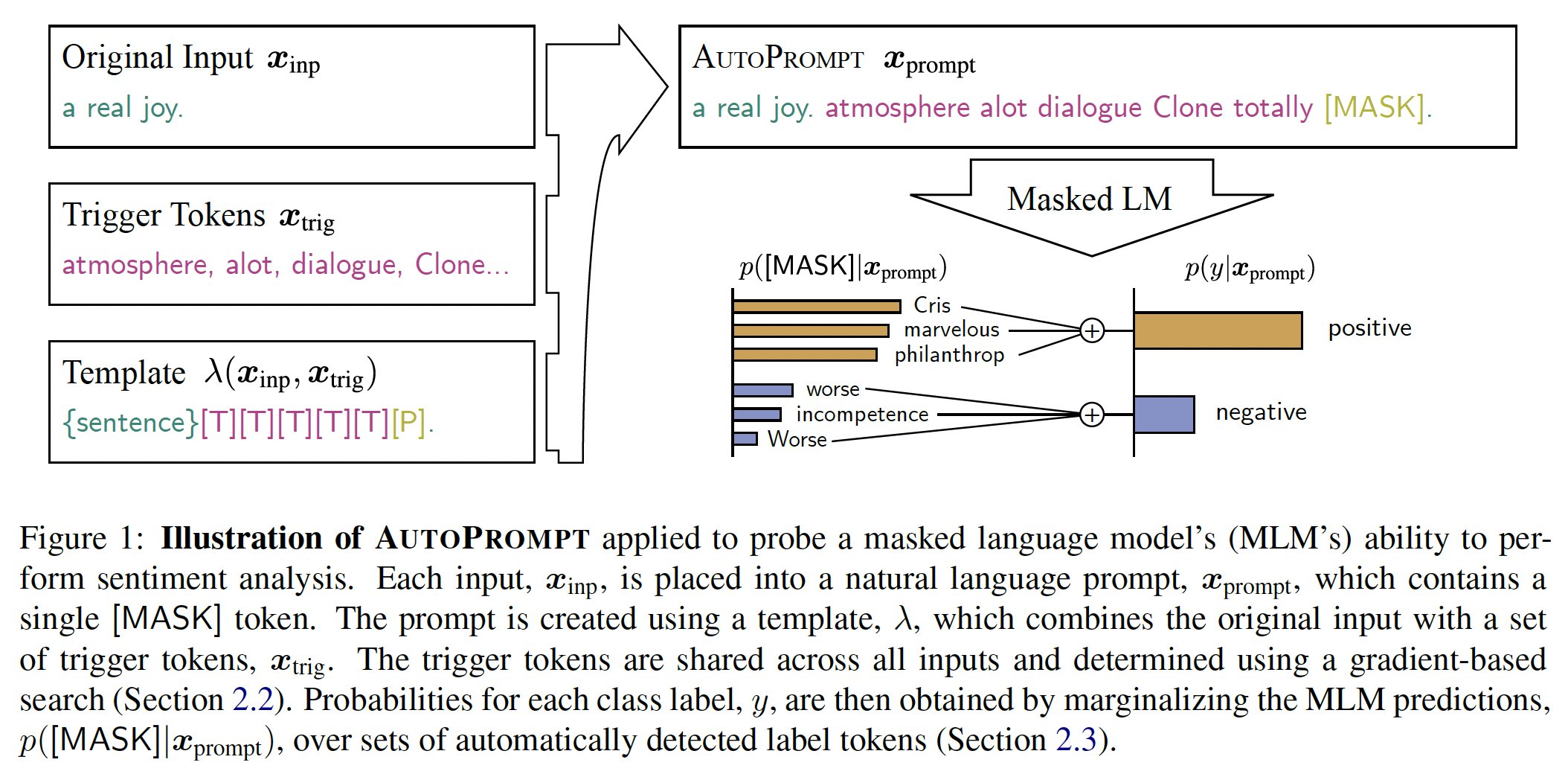
我们在许多实验中验证了
AutoPrompt的有效性。首先,我们使用
AutoPrompt构建prompts,测试pretrained masked language model的情感分析和自然语言推理。我们的测试显示,在没有任何微调的情况下,masked language model: MLM在这两项任务中表现良好:经过适当prompted的RoBERTa在SST-2上实现了91%的准确率,在SICK-E数据集的平衡的变体上的准确率为69%。接下来,我们将
AutoPrompt应用于LAMA的事实检索任务,其中我们构建prompts,比使用人工prompts、以及从语料库挖掘方法生成的prompts更有效地引导MLM的事实知识。具体来说,我们实现了43.3%的precision-at-1,而目前最好的single prompt结果是34.1%。我们还介绍了这项任务的一个变种,类似于关系提取(
relation extraction: RE),测试MLM是否能从给定的文本中提取知识。我们表明,当提供具有真实事实的上下文句子时,MLM实际上可以胜过现有的RE模型,然而,当上下文句子被人为地伪造时,它们就会陷入困境。
最后,尽管
AutoPrompt的目标是分析模型,但我们发现它比微调提供了某些实际优势。首先,
AutoPrompt在低数据的情况下比微调实现了更高的平均准确率、worst-case准确率。此外,与微调不同,
prompting LM不需要大量的磁盘空间来存储模型checkpoints;一旦找到prompt,它就可以用于现成的pretrained LM。这在为多个任务serving模型时是很有利的。
3.1 方法
从
pretrained LM中获取知识的一种自然方式是将任务设定为完形填空问题。然而,编写prompts不仅耗费时间,而且不清楚相同的措辞是否对每个模型都有效,也不清楚什么准则决定了某个特定的措辞是否最能引导出所需的信息。有鉴于此,我们提出了AutoPrompt,一种为特定任务和感兴趣的MLM构建customized prompts的方法从而使MLM产生所需的知识。Figure 1提供了AutoPrompt的说明。该prompt是通过获取原始任务输入(tokens的一个序列或多个序列的集合,例如,Figure 1中的评论),并使用模板将其映射到tokens序列中从而构建。在下面的章节中,我们将描述AutoPrompt如何使用 标记的训练数据来构建prompts,以及如何使用MLM的输出作为任务的prediction。Trigger Tokens集合是基于梯度的搜索算法来自动产生的集合,它的数量token来自于词表注意:这里的
prompts不是位于输入的开头,而是放在输入和输出(即,[MASK] token)之间。出于
prompt construction的目的,我们将原始任务输入Figure 1中的评论,"a real joy.")与馈入MLM的prompt"a real joy. atmosphere alot dialogue Clone totally [MASK].")区分开来。从prompt中的位置,以及任何additional tokens的位置。具体而言,它还必须定义一个特殊的[MASK] token的位置,用于MLM进行完形填空(在模板中用[P]表示,以区别于其他可能出现的[MASK] token)。将prompt信息馈入MLM会产生一个概率分布tokens最有可能填入空白(即,完形填空)。如果
class labels自然对应于词表中的tokens(例如,knowledge base completion任务中的实体名称),这种分布可能很容易被解释为class labels的分布。然而,对于情感分析这样的任务,可能有一组label tokensFigure 1中,"Cris", "marvelous", "philanthrop"都表示positive情感。在这种情况下,类别概率是通过对label tokens的边际化从而得到的:由于只有一个
[MASK] token,因此AutoPrompt仅支持单个token作为label的任务。Gradient-Based Prompt Search:到目前为止,我们已经展示了如何将分类任务重新表述为使用prompt的语言建模任务。在此,我们提出一种基于《Universal adversarial triggers for attacking and analyzing NLP》的automatic prompt construction方法。我们的想法是增加一些"trigger" tokens,这些tokens在所有prompt中都是共享的(在Figure 1的示例模板中用[T]来表示)。这些tokens被初始化为[MASK] tokens,然后迭代式地更新,从而在batch的样本中最大化label likelihood。正式地,在每个
step,我们计算将第trigger tokentokentop-k tokens:其中:
tokeninput embedding。梯度是相对于
input embedding
其实这就是
P-Tuning的思想:直接优化prompt embedding而不是prompt本身。但是,AutoPrompt为了确保更新后的prompt仍然是词表中的一个token,它将寻找了那些与梯度最相似的tokens(通过embedding的内积)。注意:这里没有采用负梯度,因为目标是最大化
注意,计算这个候选集合的成本与模型的一次前向传播和反向传播的成本差不多(点积需要的乘法数量与计算
LM output projection的乘法数量相同)。对于这个集合中的每个候选,我们再对更新后的prompt重新评估方程:并在下一步中保留概率最高的
prompt,这需要模型的label tokens的数量)。Figure 1显示了该方法为情感分析任务产生的一个样例的prompt。Automating Label Token Selection:虽然在某些情况下,label tokens的选择是显而易见的(例如,当class labels直接对应于词表中的单词时),但对于涉及更抽象的class labels的问题(例如,自然语言推断),什么label tokens是合适的就不太清楚了。在本节中,我们开发了一个通用的two-step法来自动选择label tokens集合在第一步中,我们训练一个
logistic分类器,使用[MASK] token的contextualized embedding作为输入来预测class label:我们将分类器的输出写为:
其中:
labelbias。[MASK] token的位置索引。
在第二步中,我们用
MLM的output word embeddinglabel tokens的集合是由得分最高的k个单词来构建:这等价于寻找与
top-k个tokens。假设有
label space的大小为tokens,则一共需要寻找tokens。
与其他
Prompting方法的关系:我们的工作适合于通过prompts来探测语言模型的知识的工作。以前的工作使用人工定义的prompts来研究语言模型的能力。PET方法将手动构建的prompts与半监督学习结合起来用于few-shot learning。我们为任何任务自动创建prompts,这导致了更高的准确率,并打开了新的现象来分析。评估设置:在下面的章节中,我们应用
AutoPrompt来探测BERT_BASE(110M参数)和RoBERTa_LARGE(355M参数)对以下任务的知识:情感分析、自然语言推理(natural language inference: NLI)、事实检索、关系提取。我们使用
PyTorch的实现和transformers Python库提供的pretrained权重。对于情感分析和自然语言推理,我们使用前文描述的基于逻辑回归的启发式方法寻找
label tokens。对于事实检索和关系提取,我们跳过这一步,因为label(实体)直接对应于词表中的tokens。对于所有的任务,我们进行前文所述的
prompt search,进行多次迭代。在每个迭代中,我们使用一个batch的训练数据来确定候选集batch数据上评估updated prompts的label likelihoods,并在下一次迭代搜索中保留最佳trigger token。在每个迭代结束时,我们在
holdout的验证数据集上测量label likelihoods,并将整个搜索过程中发现的最佳prompt作为最终输出。我们使用适当的特定任务的指标对性能进行评估(在一个单独的
holdout测试数据集上):例如,情感分析和自然语言推断采用准确率指标、事实检索采用precision@k指标。
我们的
AutoPrompt实现在http://ucinlp.github.io/autoprompt,并支持在任意数据集上为HuggingFace transformers library中的pretrained模型生成prompt。
3.2 实验
3.2.1 情感分析
数据集:
Stanford Sentiment Treebank: SST-2。设置:
基于
Table 3中的模板的prompt来寻找label tokens。gradient-based prompt search的超参数网格搜索:所有的
prompts都是以用于寻找label set的相同模板来初始化的。手动构建了一个
prompt(在automated prompts生成之前,以避免bias)。我们使用"{sentence} this movie was [P]"作为模板,并分别使用"terrible"和"fantastic"分别作为负面和正面的label tokens。
实验结果如下表所示。我们自动构建的
prompts比人工prompts更有效,而且这些prompts很难用人类的直觉来构建:RoBERTa的最佳模板是"{sentence} atmosphere alot dialogue Clone totally [P]"。上半部分数据为监督学习得到,下半部分为无监督的
prompts得到。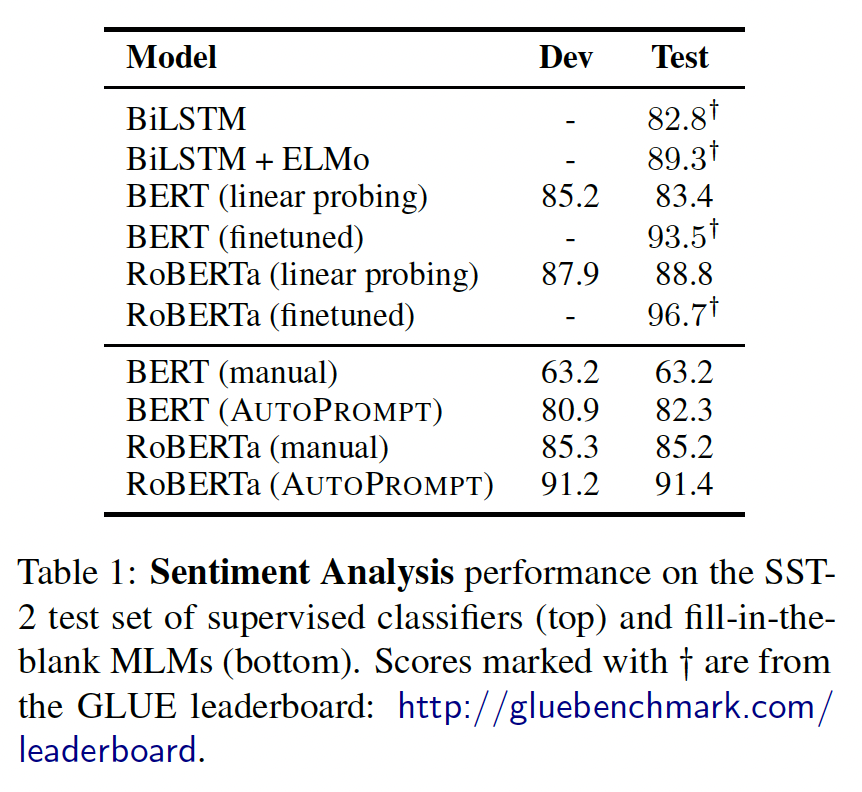
低数据环境下的准确率:虽然
AutoPrompt的目标是探测模型的知识,但我们也发现,它可能是低数据环境下微调的一个可行的替代方案。为了证明这一点,我们在使用训练数据中的{10, 100, 1000}个样本的随机子集时,测量了AutoPrompt的prompts的验证集集准确率。结果如下图所示。我们观察到,虽然微调在情感分析上优于
AutoPrompt,但AutoPrompt在NLI上的表现比微调更好。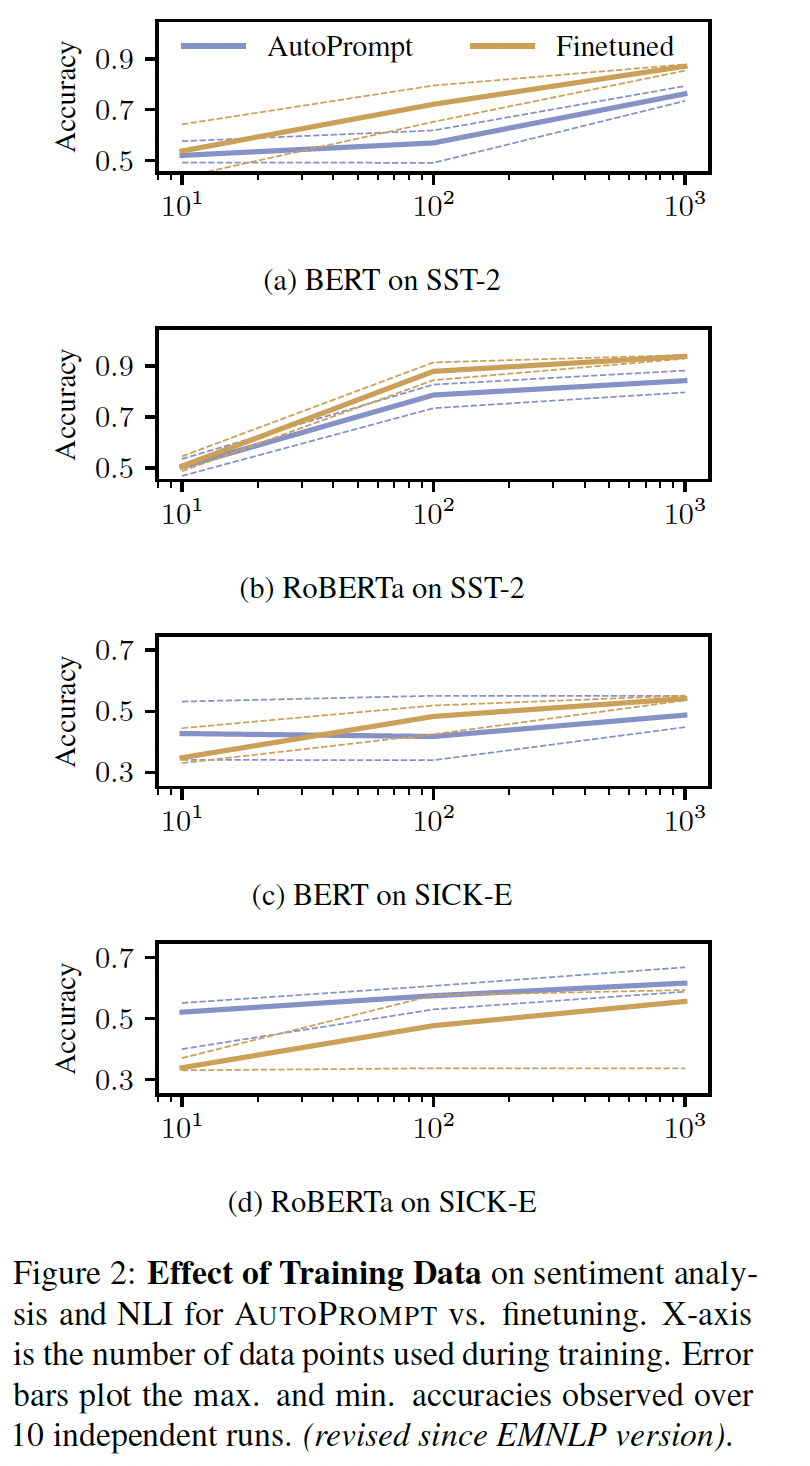
3.2.2 Natural Language Inference: NLI
数据集:
SICK。设置:
基于
Table 3中的模板的prompt来寻找label tokens。gradient-based prompt search的超参数网格搜索:所有的
prompts都是以用于寻找label set的相同模板来初始化的。
结果如下表所示,
AutoPrompt在所有实验中都大大超过了大多数基线。首先,这里没有看到基线;其次,
AutoPrompt也没有超过监督学习的方法。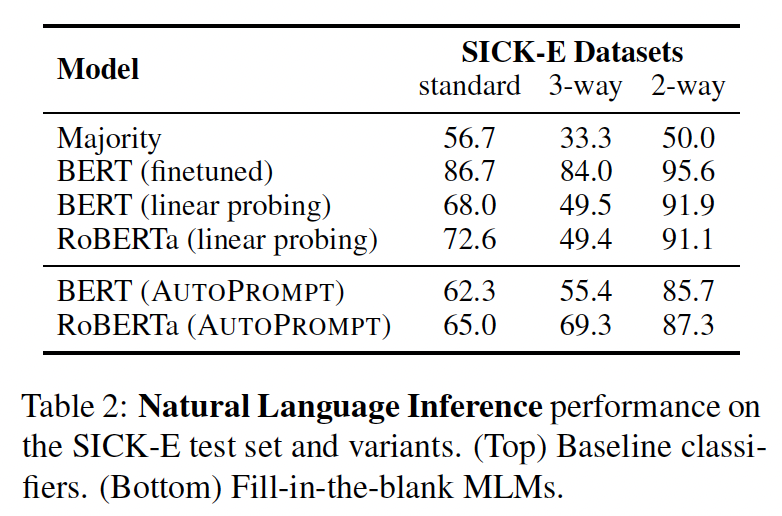
MLM在矛盾上的表现:我们发现,与entailment或neutral相比,contradiction的label tokens更容易解释(Table 3的例子)。我们研究这是否会损害模型在entailment或neutral类别上的表现。我们测量了
3-way balanced SICK-E数据集中每个标签的precision。BERT在contradiction, entailment, neutral情况下分别获得74.9%, 54.4%, 36.8%的precision,而RoBERTa分别获得84.9%, 65.1%, 57.3%。这些结果表明,AutoPrompt对于那些可以用自然的label tokens轻松表达的概念可能更准确。
3.2.3 事实检索
数据集:
LAMA。设置:
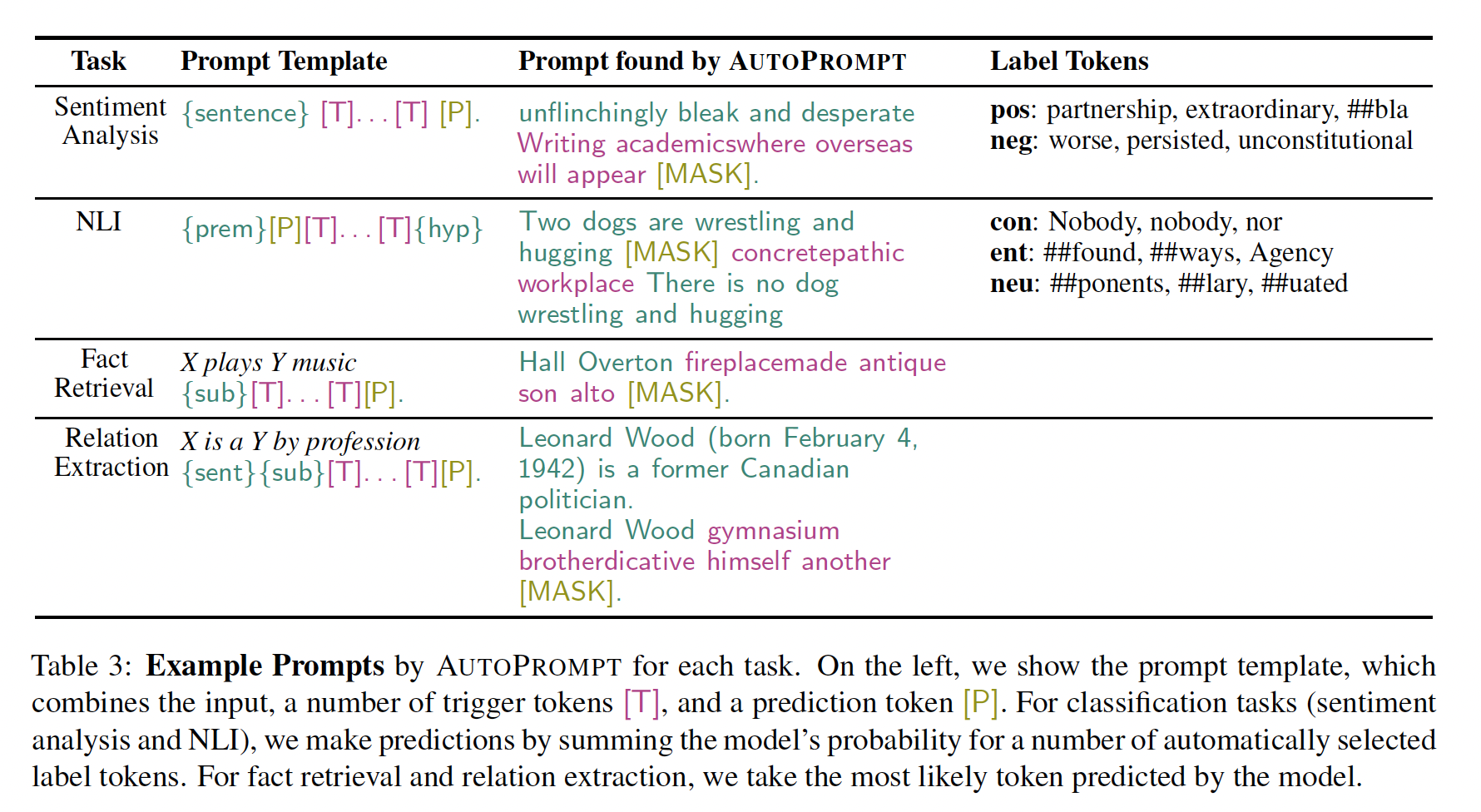
我们将三元组
(sub, rel, obj)映射到模板"{sub}[T]...[T][P]."从而重新表述fact retrieval。其中,trigger tokens是特定于关系rel的,正确的宾语obj是label token。我们使用
LAMA的原始测试集,以下简称Original。我们使用
5或7个tokens的AutoPrompt,并使用T-REx验证集选择搜索参数。我们防止训练数据中作为
gold objects出现的专有名词和专有tokens被选作trigger tokens。这样做是为了防止AutoPrompt通过在prompts中嵌入通用答案来 "作弊"。评估指标:
mean reciprocal rank: MRR、precision-at-1: P@1、precision-at-10: P@10。
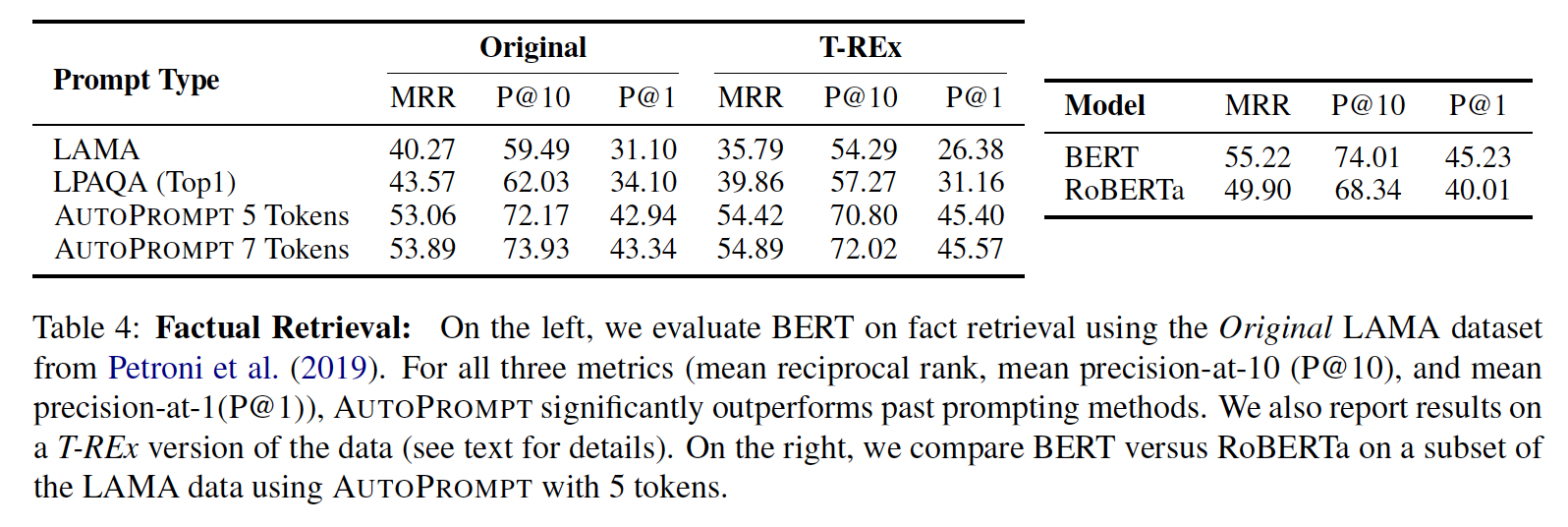
结果如下表所示。
使用
AutoPrompt生成的prompts可以从BERT中更有效地提取事实知识:相对于LAMA,我们在Original上将P@1提高了12个点。尽管
AutoPrompt每个关系只使用一个prompt,但它仍然比LPAQA的ensemble方法(对多达30个prompts的平均预测)高出约9个点。使用
7个trigger tokens取得的分数比5个trigger tokens略高,尽管差异不大。RoBERTa的表现并不比BERT好(右图),这值得在未来的工作中进一步调查。此外,回顾一下,prompts是对模型知识的一个下限:较低的相对性能并不意味着模型实际上知道的更少。
3.2.4 关系提取
数据集:
T-Rex。配置:
我们将三元组
(sub, rel, obj)映射到模板"{sent}{sub}[T]...[T][P]."从而重新表述关系提取 。其中,trigger tokens是特定于关系rel的,正确的宾语obj是label token。为了使监督下的关系提取模型的评价公平,我们修改了标准的评价:对于给定的
relation,只要模型没有预测出主语和宾语的不同relation,我们就给它加分;也就是说,我们忽略了"no relation "的预测、以及所有其他relation。
实验结果如下表所示。
当使用
AutoPrompt时,MLM可以比有监督的关系提取模型更有效地提取关系信息,提供了高达33%的绝对增益。MLM在关系提取环境中的强大结果的一个可能的解释是,他们可能已经知道许多关系。因此,他们可能会直接预测objects,而不是提取它们。为了分离这种影响,我们通过将测试数据中的每个object替换成一个随机的其他object,并对prompt进行同样的改变来人工地扰乱relation extraction数据集。在扰乱的数据上,关系提取模型的准确率没有明显变化。然而
MLM的准确率明显下降。这表明MLM的准确率有很大一部分来自factual knowledge,而不是relation extraction。尽管如此,我们对BERT的prompts还是超过了LAMA和LPAQA对应的prompts,这进一步证明了AutoPrompt能产生更好的prompts。
3.3 讨论
Prompting作为Finetuning的一种替代方法:在解决现实世界的任务时,prompting比finetuning有一些实际的优势:首先,在低数据量的情况下,使用
AutoPrompt生成的prompts可以达到比微调更高的准确率。此外,在试图解决许多不同的任务时,
prompting比finetuning更有优势。具体而言,微调需要为每个单独的任务存储大量的语言模型checkpoints,并大幅增加系统成本和复杂性,因为它需要在同一时间部署许多不同的模型。相反,prompting为所有的任务应用相同的pretrained模型。
Prompting的局限性:有一些现象是很难通过prompts从pretrained语言模型中引导的。在我们对QQP和RTE等数据集的初步评估中,手动生成的prompts、以及用AutoPrompt生成的prompts并没有表现得比随机预测好很多。然而,我们不能从这些结果中得出结论:BERT不知道paraphrasing或entailment的意思。AutoPrompt的局限性:AutoPrompt的一个缺点是,它需要标记的训练数据。尽管其他探测技术(例如线性探测分类器)也需要这样做,但manual prompts依赖于领域/语言的洞察力,而不是labeled data。在
AutoPrompt中,标记的训练数据用于搜索trigger tokens和label tokens。其次,与人类设计的
prompts相比,AutoPrompt生成的prompts缺乏可解释性,这与其他探测技术类似,如线性探测分类器。AutoPrompt的另一个限制是,当训练数据高度不平衡时,它有时会陷入困境。重新平衡训练数据可以帮助缓解这个问题。最后,由于在大的离散的短语空间上的贪婪搜索,
AutoPrompt有时很脆弱;我们把更有效的制作技术留给未来的方向。
还有一个局限性,即:仅支持
single-token作为label的分类任务。
四、PET[2020]
论文:
《Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference》
从样本中学习是许多
NLP任务的主要方法: 一个模型是在一组标记样本上训练出来的,然后从这些样本泛化到unseen的数据。由于语言、领域、以及任务的数量庞大,以及数据标注的成本,在NLP的实际应用中,只有少量的标记样本是很常见的,这使得few-shot learning成为一个非常重要的研究领域。不幸的是,将标准的监督学习应用于小训练集往往表现不佳;许多问题仅仅通过观察几个样本就很难掌握。例如,假设我们得到了以下几段文字:T1: This was the best pizza I’ve ever had.T2: You can get better sushi for half the price.T3: Pizza was average. Not worth the price.此外,设想我们被告知
T1和T2的标签分别是T3的正确标签。仅仅根据这些样本,这是不可能的,因为T3。这说明,如果我们还有任务描述(task description),即帮助我们理解任务内容的文本解释,那么仅凭几个样本来解决一个任务就会变得容易得多。随着
GPT、BERT和RoBERTa等pretrained language model: PLM的兴起,提供任务描述的想法对于神经架构来说已经变得可行: 我们可以简单地将这种自然语言的描述附加到输入中,让PLM预测continuations从而解决任务(GPT-2、《Zero-shot text classification with generative language models》)。到目前为止,这种想法大多是在完全没有训练数据的zero-shot场景中考虑的。在这项工作中,我们表明,在
few-shot setting中,提供任务描述可以成功地与标准的监督学习结合起来。我们引入了Pattern-Exploiting Training: PET,这是一个半监督的训练程序,使用自然语言模式将输入的样本重新表述为cloze-style phrases。如下图所示,PET分三个步骤工作:首先,对于每个模式,在一个小的训练集
PLM进行微调。然后,模型的
ensemble被用来通过soft label来标注一个大的unlabeled dataset最后,在
soft-labeled dataset上训练一个标准的分类器。这里已经得到了
soft label了,为什么还需要继续训练一个标准的分类器?这是因为我们的目标不仅仅是预测未标记数据集unseen的数据。
我们还设计了
iPET,这是PET的一个迭代式的变体:在这个过程中,这个过程反复进行,并且每次迭代时增加了训练集的规模。在多语言的各种任务中,我们表明,只要有少量到中等数量的标记样本,
PET和iPET的表现就大大超过了无监督方法、监督训练和强大的半监督基线。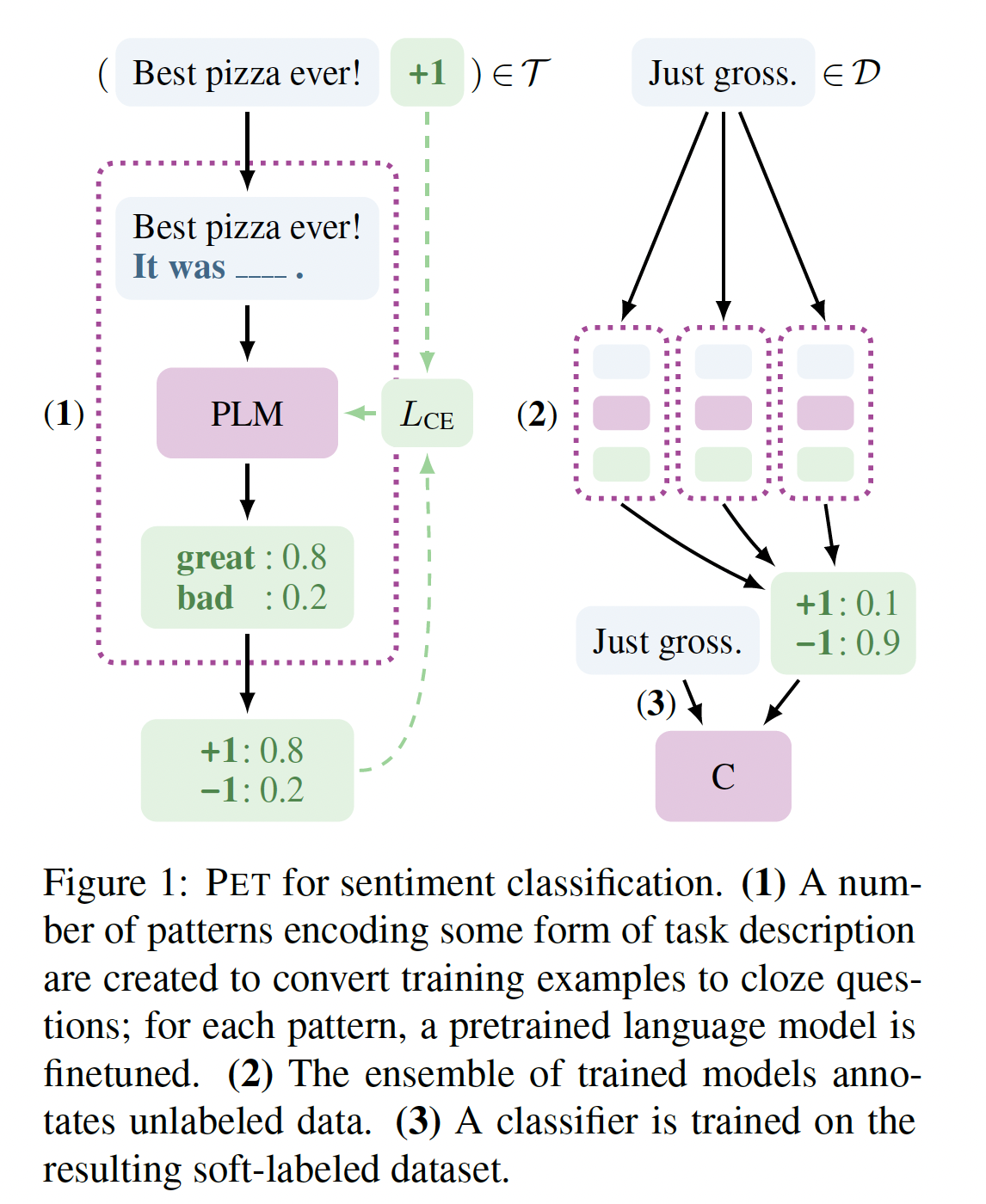
相关工作:
GPT-2以自然语言模式的形式提供提示,从而用于阅读理解和问答等挑战性任务的zero-shot learning。这一想法已被应用于无监督文本分类、常识性知识挖掘、论证关系分类(argumentative relation classification)。《Zero-shot learning of classifiers from natural language quantification》使用任务描述进行zero-shot classification,但需要一个semantic parser。针对关系提取,
《Inducing relational knowledge from BERT》自动识别模式,该模式表达给定的关系。《The natural language decathlon: Multitask learning as question answering》将几个任务重新表述为QA问题。T5将各种问题形式化为语言建模任务,但他们的模式只是松散地类似于自然语言,不适合于few-shot learning。
最近的另一项工作是使用完形填空风格的短语来探测
PLM在预训练期间获得的知识,这包括探测事实的和常识性的知识、语言能力、对稀有词汇的理解、以及进行符号推理的能力。LPAQA考虑的问题是:找到表达给定任务的最佳模式。NLP中的其他few-shot learning方法包括利用相关任务的样本、使用数据增强,其中后者通常依赖于back-translation(《Improving neural machine translation models with monolingual data》)并且需要大量的平行数据(parallel data)。使用
textual class descriptors的方法通常假定每个类别都有丰富的样本可用。相比之下,我们的方法不需要额外的标记数据,并提供一个直观的接口来利用task-specific的人类知识。iPET背后的思想(即,在前几代标注的数据上训练多代模型)与self-training、bootstrapping方法有相似之处,这些方法用于词义消岐、关系提取、parsing、机器翻译、序列序列生成等任务。
4.1 方法
令
masked language model,它的词表为mask tokenlabel集合。我们把任务token序列所构成的短语空间;例如,如果我们将模式(
pattern)定义为一个函数mask token。也就是说,verbalizer为一个injective functionlabel映射到词汇pattern-verbalizer pair: PVP。”模式“ 其实就是模版,它们都是将输入的一个或多个句子转换为一个句子。
使用
PVPinput representationmask token。例如,考虑识别两个句子verbalizer"Yes"、将"No"。给定一个input pair的例子:现在的任务已经从分配一个没有固有意义的标签,变成了回答
masked position最可能的选择是"Yes"还是"No"。核心问题是:
PVP
4.1.1 PET
PVP Training and Inference:令PVP。我们假设可以获得一个小的训练集mask token的序列masked position取值为然后在所有标签上通过
softmax获得概率分布:我们使用
ground-truth分布(一个one-hot)之间的交叉熵来作为损失函数,从而用于微调注意:这里并没有调优
prompts,而是微调模型prompts。注意:这里微调的是模型的
head,模型的head以外的参数保持冻结。prompt engineering的思路是:调优/微调prompts,使得prompts来匹配模型。因此,
PET是微调输出侧(LM head)、prompt engineering是微调输入侧(LM input)。Auxiliary Language Modeling:在我们的应用场景中,只有少量训练样本可用,而且可能发生灾难性遗忘。由于针对某些PVP进行微调的PLM的核心仍然是一个语言模型,我们通过使用语言建模作为辅助任务来解决这个问题。用这个想法最近
《An embarrassingly simple approach for transfer learning from pretrained language models》应用在一个数据丰富的场景中。由于这就是半监督学习的由来:监督信号来自于
这个超参数
为了获得用于语言建模的句子,我们使用未标记的数据集
masked slot进行任何预测。Combining PVPs:我们的方法面临的一个关键挑战是,在没有大型验证集的情况下,很难确定哪些PVP表现良好。为了解决这个问题,我们使用了一种类似于知识蒸馏的策略(《Distilling the knowledge in a neural network》)。首先,我们定义了一组
PVP,这些PVP对给定的任务模板怎么定义?模板的选择至关重要,然而论文没有回答这个问题。
然后我们使用这些
PVP如下:(1):如前所述,我们为每个PVP,这种微调也很便宜。(2):我们使用所有finetuned模型的ensembleclass score合并为:其中:
PVP的权重因子。我们实验了两种权重因子:简单地对所有的
uniform和weighted。LPAQA在zero-shot setting中使用了一个类似的想法。我们使用
softmax将上述分数转化为概率分布《Distilling the knowledge in a neural network》,我们使用soft distribution。所有的pairsoft-labeled训练集为什么用
(3):我们在sequence classification head对PLM
然后,经过微调的模型
Figure 2中描述;一个例子如Figure 1所示。物理含义:
训练期间:基于每个模板来微调,从而为每个模板得到一个
finetuned LM。推断期间:将每个
finetuned LM的预测结果进行投票(平均投票、或者按照预测能力进行投票)。
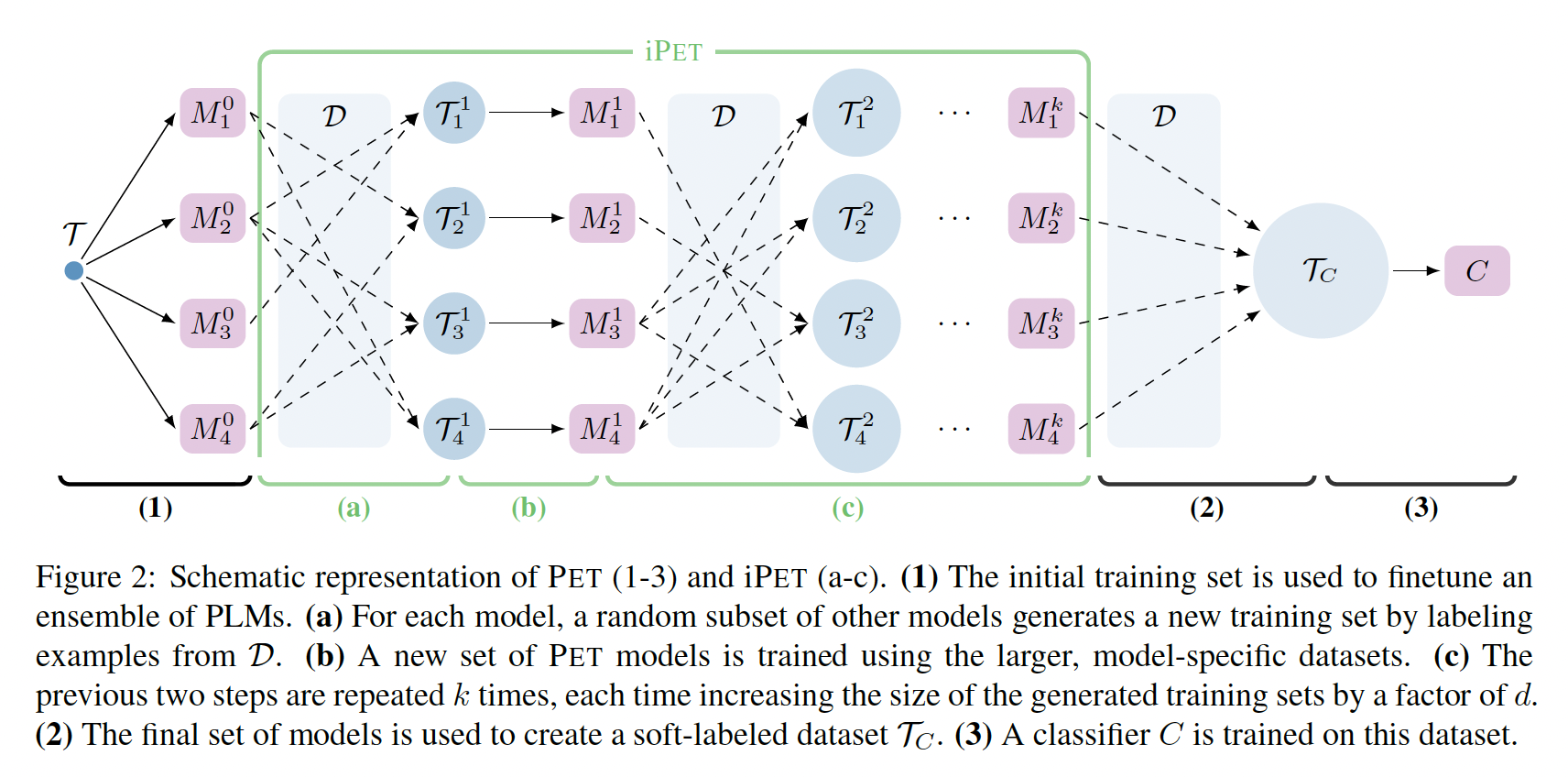
4.1.2 iPET
将所有各个模型的知识蒸馏成单个分类器
为了弥补这一缺陷,我们设计了
iPET,一个关于PET的迭代式变体。iPET的核心思想是:在越来越大的数据集上训练多代模型。为此:首先,我们随机选择一些训练好的
PET模型,然后用这些模型标注来自Figure 2(a)。然后,我们在扩大的数据集上训练新一代的
PET模型,参考Figure 2(b)。这个过程要重复几次,参考
Figure 2(c)。
更正式地,令
PET模型,其中PVPPVP的数量。我们训练即:除了初始的监督信号来自于
soft label。在每轮迭代中,我们将训练集的大小乘以一个固定的常数
每次迭代时,并不是使用所有的未标记数据,而是选择预测效果最好(通过
从前一代中随机选择
注意:这是用其它
finetuned LM来 ”训练“ 当前的第finetuned LM,这和self-training有一定差异。使用这个模型集合,创建标记数据集:
对于每个
因为最终的数据集还包含原始的监督数据集
为了避免在错误标记的数据上训练下一代模型,我们倾向于选择模型的
ensemble对其预测有信心的例子。基本的直觉是,即使没有calibration,标签被预测为高信心的样本通常更有可能被正确分类(《On calibration of modern neural networks》)。因此,当从我们定义
在训练了
PET模型后,我们使用basic PET那样训练经过小幅度调整,
iPET甚至可以在zero-shot setting下使用。为此,我们定义
untrained models集合,10个样本上训练的,这10个样本在所有标签上平均分布 。由于100个样本即,这里并没有标记数据集
对于随后的每一代,我们完全按照
basic iPET进行。
4.1.3 Automatic Verbalizer Search
整体过程又臭又长,都是规则公式,而且没有理论指导和实验说明、效果又不好、找到的
verbalizers的解释性较差,因此不推荐这里的方法(还不如人工设计)。
给定一组模式
token相对应的verbalizationautomatic verbalizer search: AVS,这是在给定训练集verbalizers的程序。这
假设我们已经有一个
PVPtokenverbalization。为此,我们定义其中:
物理含义:类别
这可以让我们很容易地计算出
verbalization,因为:verbalizationsAVS解决这个问题的方法如下: 我们首先给所有的标签分配随机的verbalizations,然后重复地重新计算每个标签的最佳verbalization。由于我们不希望得到的verbalizer强烈地依赖于初始的随机分配,我们只需考虑多个这样的分配。具体来说,我们定义一个初始概率分布
verbalization的概率。对于每个verbalizers物理含义:
verbalizer在所有这些分数使我们能够定义一个概率分布,这个概率分布能更紧密地反映一个单词作为给定标签的
verbalizer的适合程度:其中:
我们重复这个过程,得到概率分布的序列
tokens作为verbalizers。在训练和推理过程中,针对每个标签,我们通过verbalizers上进行平均计算出unnormalized分数我们分析了
AVS在所有任务中的表现,其中tokentokens中,我们只保留10k个tokens。结果显示在
Table 7中。可以看出,精心手工制作的verbalizers比AVS的表现好得多;然而,PET与AVS的表现仍然大大优于常规的监督训练,同时消除了手工寻找合适的verbalizers的挑战。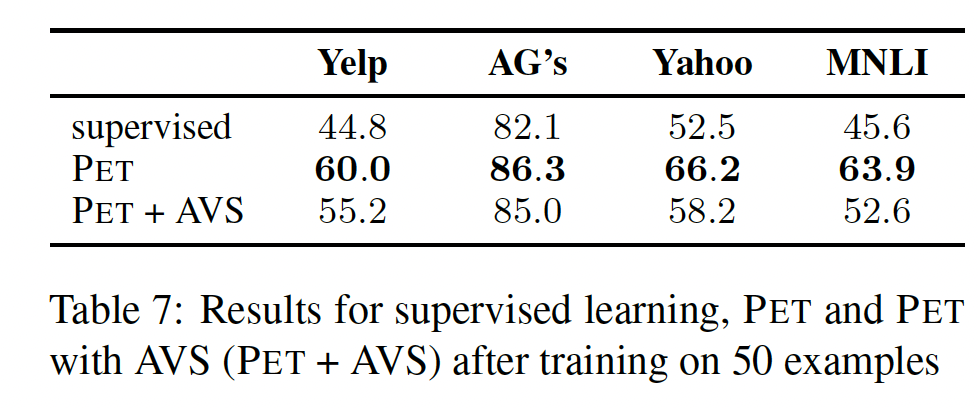
Table 8显示了在Yelp数据集上使用AVS找到的最有可能的verbalizers。虽然这个数据集的大多数verbalizers在直觉上是有意义的,但我们发现AVS在为Yahoo数据集的10个标签中的3个、以及MNLI数据集的所有标签寻找良好的verbalizers时遇到困难。
4.2 实验
数据集:
Yelp Reviews、AG’s News、Yahoo Questions、MNLI。此外,我们使用X-stance来研究PET对其他语言的效果如何。预处理:在一些使用的数据集中,换行是通过字符序列
"\n"来表示的。由于RoBERTa和XLM-R的词表没有换行,我们用一个空格来代替这个"\n"。除了将所有的样本缩短到最大序列长度256个tokens之外,我们不进行任何其他预处理。评估指标:
Yelp, AG's Nes, Yahoo, MNLI采用准确率;x-stance采用macro-average of F1。
配置:
对于所有的英语数据集,我们使用
RoBERTa_large;对于X-stance,我们使用XLM-R。我们调查了
PET和所有baseline在不同训练集大小下的表现;每个模型使用不同的种子训练三次,并报告平均结果。由于我们考虑的是
few-shot setting,我们假设无法获得可以优化超参数的大型验证集。因此,我们对超参数的选择是基于以前工作中的选择和实际考虑:学习率1e-5、batch size = 16、最大的序列长度为256。这种超参数的选择不太科学。
除非另有说明,我们总是使用
PET的weighted变体,并采用辅助语言建模。对于
iPET:我们设定
25%来为下一轮迭代来标注样本,并在每次迭代中将训练样本的数量增加五倍。我们训练多轮迭代 ,直到每个模型至少被训练了
1000个样本,也就是说,我们设置由于我们总是重复训练三次,所以
PVP的ensemble
进一步的超参数和对我们所有选择的详细解释见附录
B。
Patterns:这里我们描述用于所有任务的patterns和verbalizers。我们使用"||"来标识文本segments之间的边界。这里采用的全部都是人工定义的模式。
Yelp:该任务是基于客户的文本评论来估计客户给餐馆的打分,打分从1星到5星。对于给定的输入文本
xxxxxxxxxxP1(a) = It was _. aP2(a) = Just _! || aP3(a) = a. All in all, it was _.P4(a) = a || In summary, the restaurant is _.对于所有的模式,我们定义单个
verbalizerxxxxxxxxxxv(1) = terrible v(2) = bad v(3) = okay v(4) = good v(5) = greatAG’s News:该任务是给定新闻的标题Word(1), Sports(2), Business(3), Science/Tech(4)。对于xxxxxxxxxxP1(x) = _ : a bP2(x) = a ( _ ) bP3(x) = _ - a bP4(x) = a b ( _)P5(x) = _ News: a bP6(x) = [ Category: _ ] a b我们使用一个
verbalizer,它将整数1/2/3/4分别映射到字符串"World"/"Sports"/"Business"/"Tech"。Yahoo:该任务是给定一个问题AG’s News相同的模式,但是将"News"替换为单词"Question"。我们使用一个
verbalizer,它将整数1/2/3/4/5/6/7/8/9/10分别映射到字符串"Society"/"Science"/"Health"/"Education"/"Computer"/"Sports"/"Business"/"Entertainment"/"Relationship"/"Politics"。MNLI:该任务是文本蕴含任务,给定文本pairlabel = 0)、label = 1)、label = 2)。我们定义如下的模式:xxxxxxxxxxP1(x)= "a"? || _, "b"P2(x)= a? || _, b我们考虑如下的两种不同的
verbalizersxxxxxxxxxxv1(0) = Wrong v1(1) = Right v1(2) = Maybev2(0) = No v2(1) = Yes v2(2) = Maybe将这两种模式与两个
verbalizers结合起来,共产生了4个PVP。X-Stance:每个样本label = 0)还是反对(label = 1)。我们使用两个简单的模式:xxxxxxxxxxP1(x) = "a" || _. "b"P2(x) = a || _. b我们定义了一个英语
verbalizer0映射到"Yes"、将1映射到"No";定义了一个French (German) verbalizer"Yes"/"No"替换为"Qui"/"Non"("Ja"/"Nein")。我们没有定义Italian verbalizer,因为X-stance不包含任何意大利语的训练样本。
4.2.1 实验结果
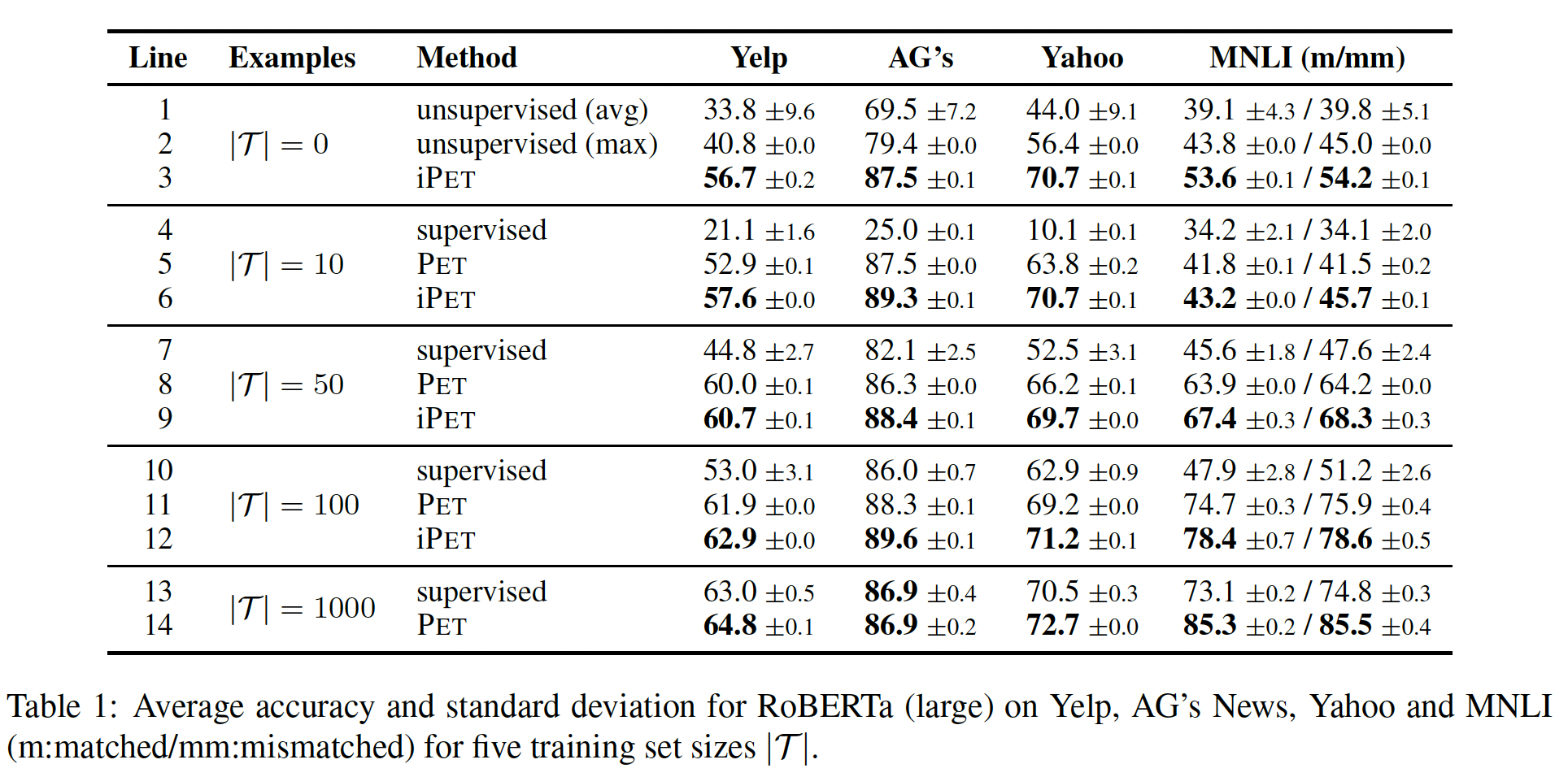
英语数据集:下表显示了英语文本分类和语言理解任务的结果,我们报告了三次
training runs的平均准确率和标准差。第
1-2行(L1-L2)显示了无监督的性能,即没有任何微调的单个PVP(类似于GPT-1)。我们同时给出了所有PVP的平均结果(avg)、以及在测试集上效果最好的PVP的结果(max)。两行之间的巨大差异突出了应对以下事实的重要性:如果不看测试集,我们就没有办法评估哪些PVP表现良好。第三行表明,在所有的数据集上,
Zero-shot iPET明显优于无监督的基线(L3 vs L1)。在AG’s News上,Zero-shot iPET甚至比有1000个样本的标准监督训练表现更好(L3 vs L13)。在只有
10个训练样本的情况下,标准的supervised learning的表现并没有超过随机(L4)。相比之下,PET(L5)的表现比完全无监督的基线(L1-L2)要好得多。使用iPET(L6)迭代多轮,可以得到持续的改进。随着我们增加训练集的大小,
PET和iPET的性能提升变得更小。对于50和100个样本,PET继续大大超过标准的监督训练(L8 vs L7,L11 vs L10);iPET(L9,L12)相比PET仍然给予一致的改善。对于
PET在AG上相对于监督学习没有优势,但仍然提高了所有其他任务的准确率(L14 vs L13)。
与
SOTA的比较:我们将PET与UDA(《Unsupervised data augmentation for consistency training》)和MixText(《Mix-Text: Linguistically-informed interpolation of hidden space for semi-supervised text classification》)进行比较,这两种SOTA的NLP半监督学习方法依赖于数据增强。PET要求任务可以用模式来表达,并且要找到这样的模式;而UDA和MixText都使用back-translation,因此需要成千上万的标记样本来训练机器翻译模型。我们使用
RoBERTa-base进行比较,因为MixText是专门针对12层的Transformer的。UDA和MixText的原始论文都使用大型验证集来优化training steps的数量。相反,我们直接在测试集上尝试这两种方法的几个值,并仅报告获得的最佳结果。尽管如此,Table 2显示,PET和iPET在所有任务中的表现都大大超过了这两种方法,清楚地表明了以PVP的形式纳入人类知识的好处。对于
UDA和MixText,作者这里将测试集作为验证集来使用,这会高估这两个模型的表现。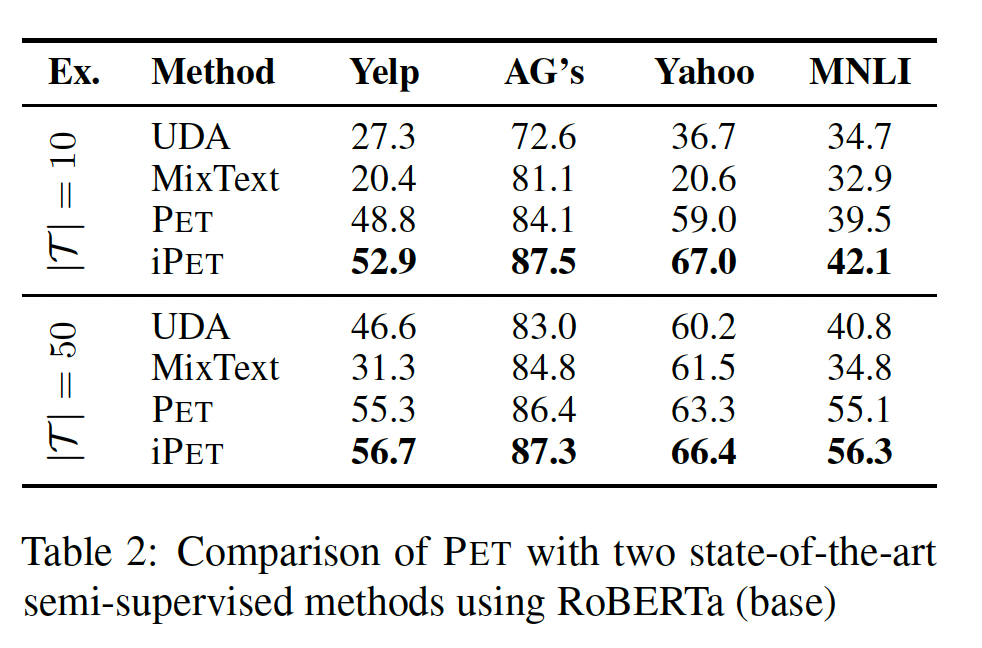
X-Stance:我们在x-stance上评估了PET,以研究PET是否对英语以外的语言有效、以及当训练集具有中等规模时PET是否也会带来改进。与《X-stance: A multilingual multi-target dataset for stance detection》相比,我们没有在验证集上进行任何超参数优化调优,并使用较短的最大序列长度(256 vs 512)来加速训练和评估。为了研究
PET是否在有大量样本时也能带来好处,我们考虑了1000/2000/4000的训练集规模。对于每一种配置,我们分别独立地微调法语模型和德语模型,以便对训练数据进行更直接的下采样。此外,我们在整个法语(
verbalizers,对于德语则使用verbalizers。最后,我们还研究了在法语和德语数据上联合训练的模型的性能(
结果如下表所示。遵从
《X-stance: A multilingual multi-target dataset for stance detection》,我们报告了label 0和label 1的macro-average of the F1,在三次运行上取平均平均值。对于意大利语("It"列),我们报告了德语和法语模型的平均zero-shot跨语言性能,因为没有意大利语训练样本。我们的结果表明,即使在超过1000个样本的训练中,PET在所有语言中都带来了巨大的改进;它还大大地提高了zero-shot跨语言的性能。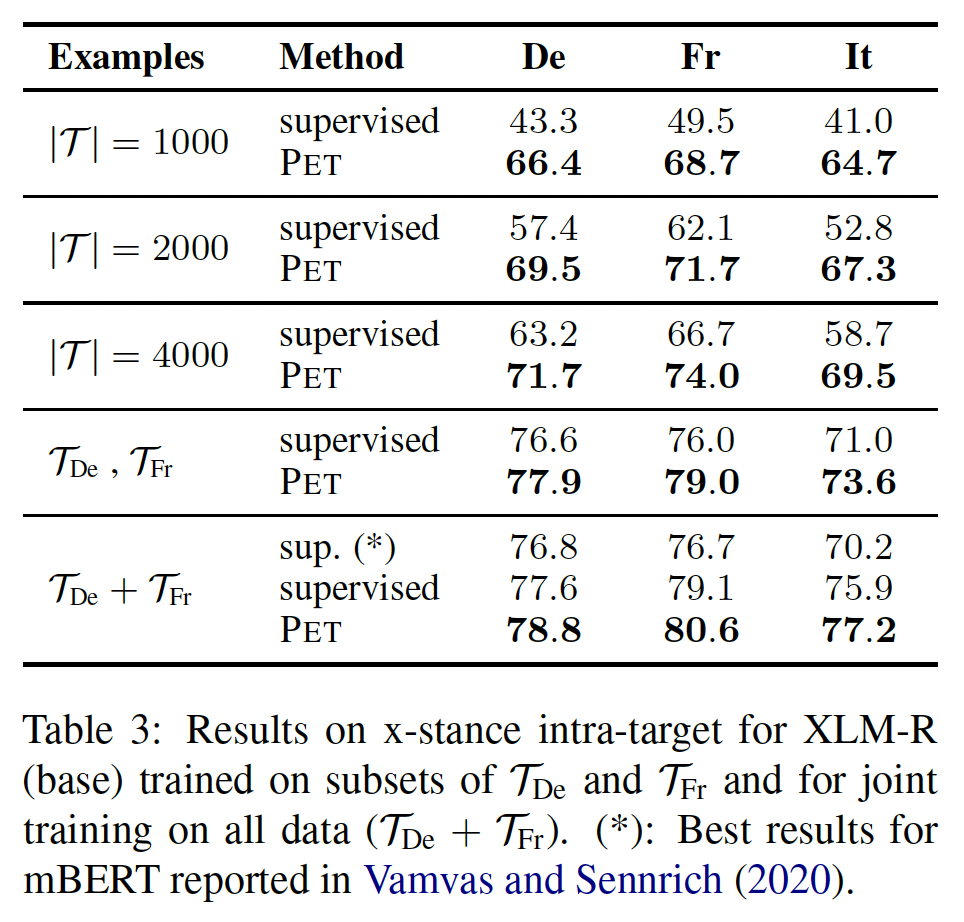
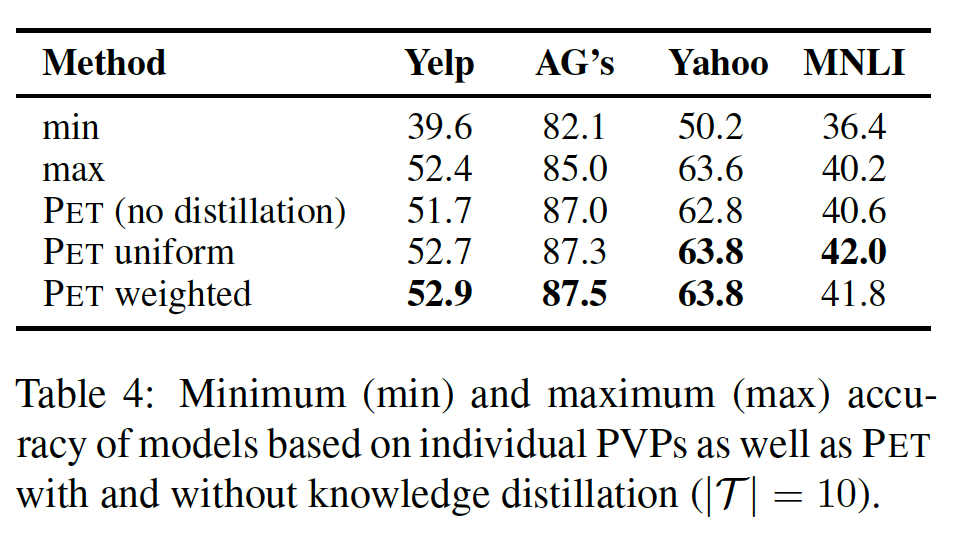
4.2.2 分析
Combining PVPs:我们首先调查PET是否能够应对一些PVP的表现比其他PVP差很多的情况。对于PET与表现最好和最差的模式的性能;我们还包括使用PET模型的ensemble得到的结果,这些模型对应于没有知识蒸馏的单个PVP(即,没有在对于
finetuned模型,最佳模式和最差模式之间的差距也很大,特别是对Yelp而言。然而,
PET不仅能够弥补这一差距,甚至比在所有任务中只使用表现最好的模式更能提高准确率。知识蒸馏比
ensemble带来了一致的改进;此外,它还大大减少了最终分类器的size。我们发现
PET的uniform变体和weighted变体之间没有明显区别。
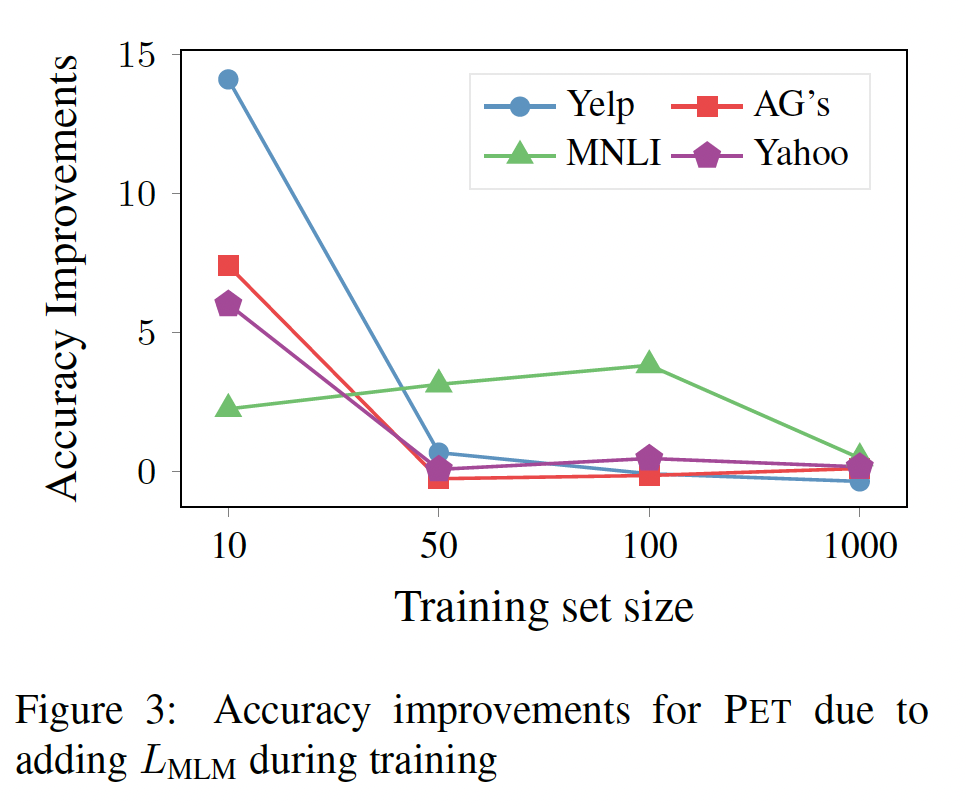
Auxiliary Language Modeling:我们分析了辅助语言建模任务对PET性能的影响。下图显示了添加语言建模任务对四种训练集规模的性能改进。可以看到:在只有
10个样本的训练中,辅助任务是非常有价值的。随着数据的增加,辅助任务变得不那么重要,有时甚至导致更差的性能。
只有在
MNLI中,我们发现辅助语言建模一直都有帮助。
Iterative PET:为了检查iPET是否能够在多轮迭代中改善模型,下图显示了所有轮次的模型在zero-shot setting中的平均性能。每一次额外的迭代确实能进一步提高ensemble的性能。我们没有研究继续这个过程进行更多的迭代是否会有进一步的改善。另一个自然的问题是,通过更积极地增加训练集的大小,是否可以用更少的迭代获得类似的结果。为了回答这个问题,我们跳过
AG's News和Yahoo的第2代和第3代,对于这两项任务,直接让ensembl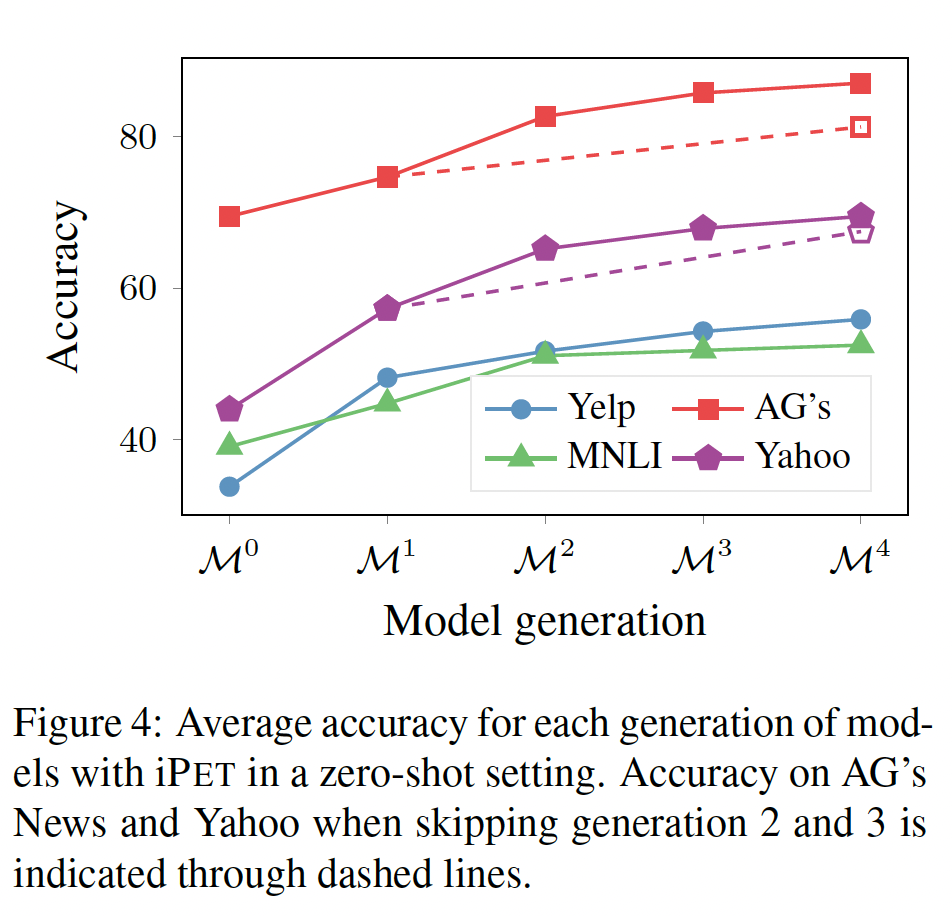
In-Domain Pretraining:与我们的监督基线不同,PET利用了额外的未标记数据集PET相对于监督基线的性能提升至少有一部分可能来自于这个额外的in-domain data。为了测试这一假设,我们只需在
in-domain data上进一步预训练RoBERTa,这是提高文本分类准确性的常见技术。由于语言模型预训练在GPU使用方面很昂贵,我们只对Yelp数据集进行了预训练。下图显示了with/without这种in-domain pretraining的监督学习和PET的结果。虽然预训练确实提高了监督训练的准确率,但监督模型的表现仍然明显比PET差,这表明我们的方法的成功不仅仅是由于使用了额外的未标记数据。有趣的是,
in-domain pretraining对PET也有帮助,表明PET利用未标记数据的方式明显不同于标准的masked language model pretraining。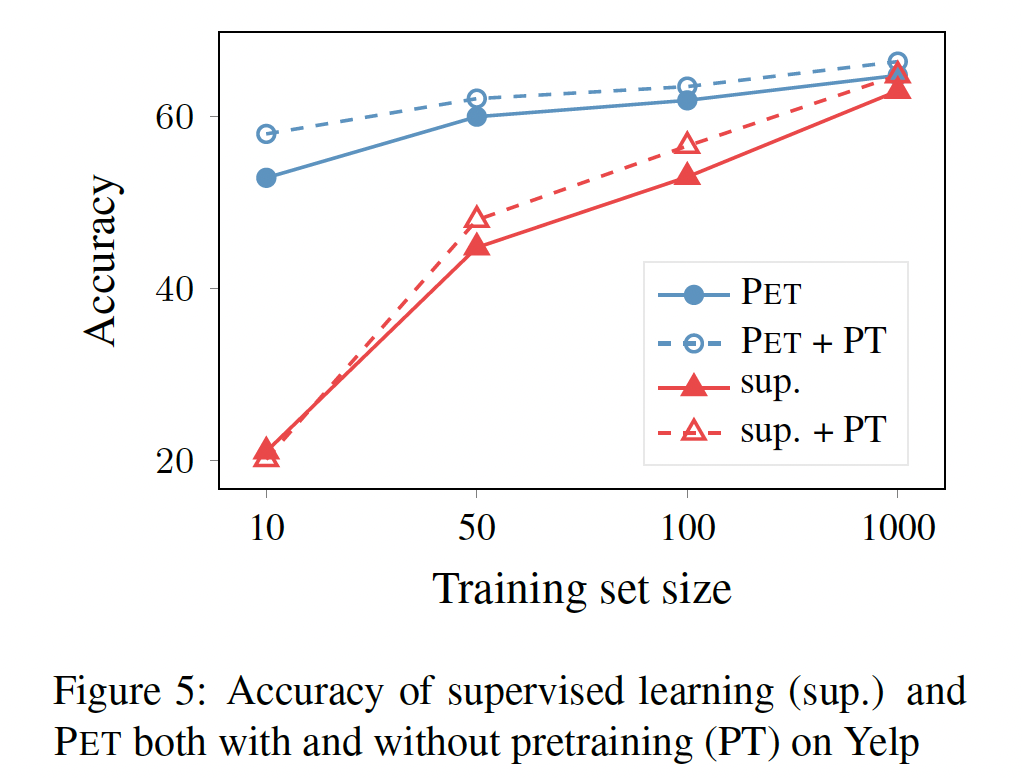
五、PET-2[2021]
论文
《It’s Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners》
在海量语料库上预训练越来越大的语言模型导致了
NLP的巨大改进。一个标准的方法是用一个task-specific head来取代pretrained model的输出层,并在一组labeled training data上微调整个模型。然而,语言建模不仅是一个强大的预训练目标,而且许多任务可以被重新表述为完形填空问题,允许pretrained语言模型在没有任何标记样本、或只有极少数标记样本下解决这些问题(GPT-2、PET)。最近,
《Language models are few-shot learners》介绍了GPT-3,一个拥有175B参数的pretrained语言模型,并表明它具有惊人的few-shot能力: 通过将任务重新表述为语言建模问题,GPT-3在只给定32个标记样本的情况下,对一些SuperGLUE任务取得了接近SOTA的结果。这是通过priming来实现的:GPT-3被馈入了一些demonstrations(由输入和对应的输出组成)从而上下文来用于预测,但没有进行梯度更新。虽然使用起来很简单,但这种方法有两个主要缺点:它需要一个巨大的语言模型才能很好地工作,这使得它在许多现实世界的场景中无法使用,并导致了巨大的碳足迹(
carbon footprint)。它不能扩展到更多的样本,因为大多数语言模型的上下文窗口被限制在几百个
tokens。
priming的另一个替代方案是pattern-exploiting training: PET,它结合了将任务重新表述为完形填空问题、以及常规的gradient-based fine-tuning的思想。虽然PET还需要未标记的数据,但对于许多现实世界的应用,未标记的数据比标记样本更容易获得。最重要的是,PET只在语言模型所预测的答案对应于其词表中的单个token时才起作用;这是一个严重的限制,因为许多任务不容易被这样表述。PET还需要在未标记数据上进行微调(仅微调LM head),其中未标记样本的soft label是通过model ensemble来自动生成的。在这项工作中,我们使
PET适用于需要预测多个tokens的任务。然后我们表明,结合ALBERT,PET及其迭代式变体(iPET)在SuperGLUE上的表现都优于32-shot GPT-3,而只需要GPT-3的0.1%的参数(如下图所示)。此外,用PET训练可以在单个GPU上几个小时完成,而不需要昂贵的超参数调优。最后,我们表明,在缺乏未标记数据的情况下也可以实现类似的性能,并详细分析了促成PET强大性能的因素:它结合多种任务形式的能力、它对难以理解的措辞的弹性、它对标记数据的使用、以及底层语言模型的特性。鉴于PET的 "绿色" 特性,我们认为我们的工作是对环境友好的NLP的一个重要贡献。这篇论文是
PET的扩展,将PET从输出single token的任务扩展到输出multi tokens的任务。主要思想是:muli tokens output概率拆分为多个single tokens output的概率乘积。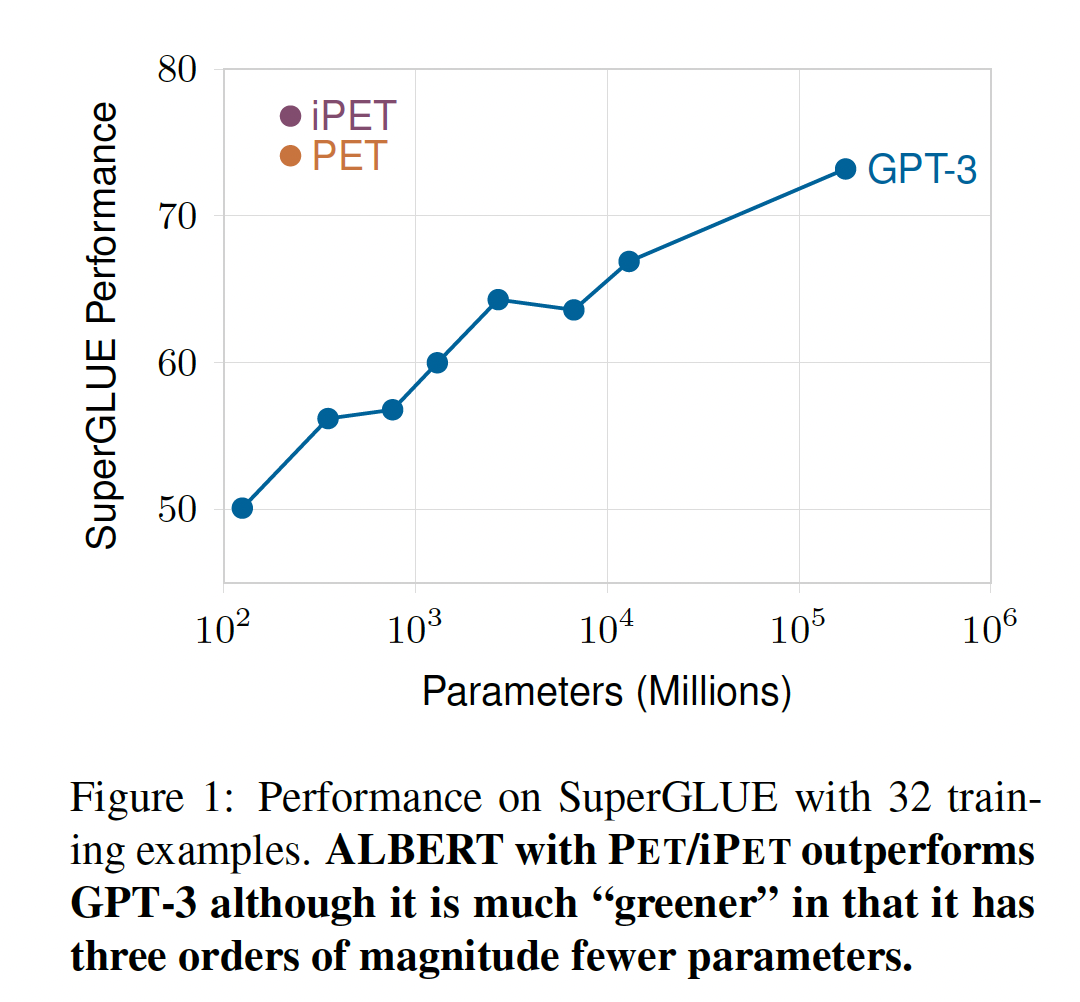
相关工作:通过提供任务描述使语言模型能够进行
zero-shot learning是由GPT-2提出的,并已被应用于文本分类、常识性知识挖掘、论证关系分类(argumentative relation classification)。它也常用于探测语言模型中所包含的知识。由于找到将任务重新表述为被语言模型很好理解的完形填空问题的方法很困难(
LPAQA),《Exploiting cloze questions for few shot text classification and natural language inference》提出了PET,该方法使用知识蒸馏(《Distilling the knowledge in a neural network》)和自训练来轻松结合几个reformulations。我们修改后的
PET版本使用masked language model为文本序列分配概率;这类似于以生成方式使用它们(《BERT has a mouth, and it must speak: BERT as a Markov random field language model》),之前《Masked language model scoring》和《Mask-predict: Parallel decoding of conditional masked language models》已经研究过。与使用基于梯度的优化的
PET相比,GPT-2和GPT-3研究了priming,其中样本作为上下文,但不进行参数更新。最后,我们专注于减少
few-shot learning所需的计算量,这与绿色人工智能中旨在提高模型效率的其他努力密切相关,包括知识蒸馏的技术、剪枝、量化、以及推理期间的early exit策略。
5.1 PET 方法
令
masked language model: MLM,mask token。我们把所有的token序列的集合表示为masks的token序列masked position取值为softmax之前的logits用PET需要一组pattern-verbalizer pairs: PVPs。每个PVP一个模式
mask的完形填空问题。一个
verbalizertoken,这个token代表输出在模式中的task-specific含义。
如下图所示,
PET的核心思想是:从masked position的"correct" token的概率中,推导出其中:
masked position的原始得分,masked position。
对于一个给定的任务,在没有大的验证集的情况下,识别表现良好的
PVP是具有挑战性的。因此,PET使多个PVP的组合(1):对于每个PVPMLM。在实践中,PET为每个模式训练三个MLM,因为性能在不同的runs中会有很大的不同。一共
(2):finetuned MLM的ensemble被用来标注一组未标记的样本:每个未标记的样本soft labels。其中:
(3):所得的soft-labeled dataset通过最小化模型输出和这里仅仅微调
LM head,冻结了语言模型的绝大多数的参数。
由于上述步骤
(2)和(3)与知识蒸馏非常相似(《Distilling the knowledge in a neural network》),我们也将其简单称为蒸馏。重要的是,这个过程不需要在内存中同时保存整个MLM的ensemble,因为每个模型的预测都可以按顺序地计算;因此,它并不比使用单个模型更耗费内存。为了让在不同模式上训练的
MLM有更多机会相互学习,《Exploiting cloze questions for few shot text classification and natural language inference》还提出了iPET,这是PET的一个迭代式的变体,其中若干代模型在由前几代模型所标记的、规模越来越大的数据集上训练。其实现方式如下:首先,像常规
PET一样训练MLM的ensemble。对于每个模型sofe labeled样本上,选定的模型子集对其预测最有信心。然后,每个
这个过程要重复几次,每次都要把
关于进一步的细节,我们参考
PET原始论文。
5.2 多个 Masks 的 PET
PET的一个重要局限性是,verbalizertoken,这对许多任务来说是不可能的。因此,我们将verbalizers泛化为函数inference和training做一些修改。我们进一步推广
PET,因为我们不认为输出空间对每个输入都是相同的:对于每个PVPtoken数量,mask token被替换为masks的作为一个例子,我们考虑对具有标签
P(x) = x. It was _.和一个verbalizerverbalizer将+1映射到单个token "great"、将-1映射到序列"terri" "ble",也就是说,我们假设MLM的tokenizer将单词"terrible"分割成两个token:terri和ble。在这个例子中,对于所有的Figure 3(a)所示。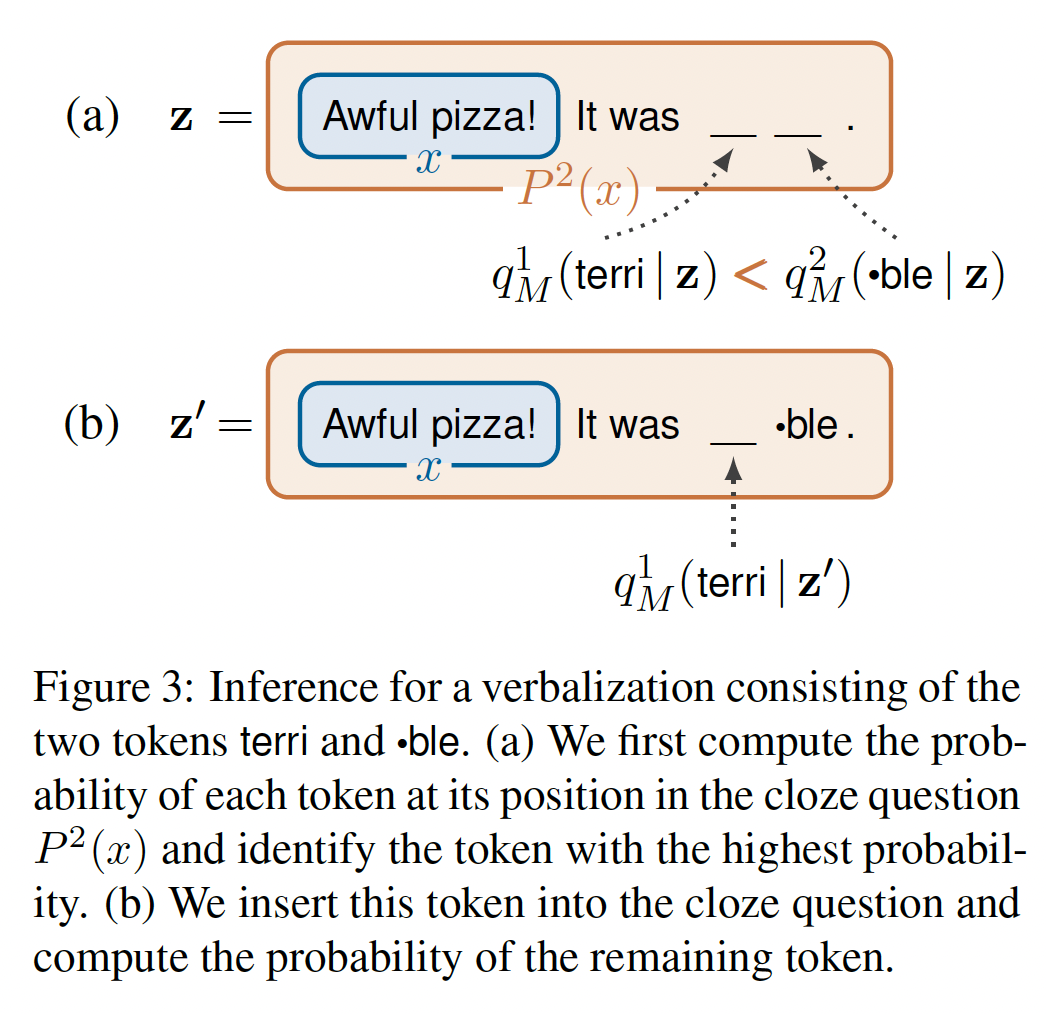
Inference:对于MLM的信心选择next token进行预测。也就是说,我们设置其中:
请注意,与原始
PET不同,sum结果不等于1.0。上式的物理含义为:
首先,在给定
masked position,预测对应的tokens。然后,选择预测概率最大的
masked position(记做token(记做最后,我们计算下面两项的乘积:
给定
masked position对应的token为给定
masked position为masked positions分别为
其中
对于我们的情感分类例子,
Figure 3说明了由于
token的概率(Figure 3(a))。然后,我们选择概率最高的
token,把它放在相应的mask token的位置上,并使用产生的完形填空问题token的概率(Figure 3(b))。最后,对于
Training:对每个训练样本始终插入所要求的最大数量的
mask tokens从而表达任意输出。对于每个
token,其中我们简单地忽略模型对所有mask tokens的预测:
对于我们的例子,这意味着我们通过如下的计算来近似
这可以在一次前向传播中完成,因为它只需要处理一次
Figure 3(a)中的完形填空问题即,训练期间并行解码。注意,测试期间采用了不同的解码方式:每次选择概率最大的
token来解码。由于
multiclass hinge loss并最小化:也就是说,我们要求
1。
5.3 实验
我们在
SuperGLUE上对PET和GPT-3进行了比较。我们无法使用与GPT-3完全相同的训练数据来评估PET,因为对于大多数任务,对于每个测试样本,GPT-3使用不同的训练数据集;而对于其他任务,GPT-3无法提供request所对应的训练数据集。然而,样本的确切选择对GPT-3的性能影响不大。因此,我们通过使用固定的随机种子为每个任务随机选择32个样本来创建新的训练集。我们还为每个任务创建了多达
20k个未标记样本,这是通过从原始训练集中删除所有标签来完成的。我们把产生的训练样本和未标记样本的集合称为FewGLUE。任务:我们描述每个
SuperGLUE任务和我们相应的PVP。我们使用竖线("|")来标识文本片段之间的边界。在考虑的八个任务中,只有COPA, WSC, ReCoRD需要使用具有multi masks的PET。BoolQ:是一个问答任务,每个样本由一段话"yes/no"问题xxxxxxxxxxp. Question: q? Answer: _.p. Based on the previous passage, q? _.Based on the following passage, q? _. p我们定义了两个
verbalizers,分别将包含真实陈述的问题映射为yes/true,将虚假陈述的问题映射为no/false,总共有6个PVP。CB和RTE是像MNLI一样的文本蕴含任务,所以我们使用与PET类似的PVP。对于一个前提xxxxxxxxxxh?| _, p"h"?| _, "p"h?|_. p"h"?|_. "p"我们使用一个
verbalizer,它将蕴含关系映射为yes、矛盾关系映射为no、中性关系映射为maybe。给定一个前提
COPA的任务是在给定两个选项cause)或效果(effect)。为了确定效果,我们使用以下模式:
xxxxxxxxxx"c1" or "c2"? p, so _.c1 or c2? p, so _.对于确定原因,我们使用相同的模式,但用
because代替so。用于
verbalizer是一个恒等映射,即将对于
WiC,给定一个词xxxxxxxxxx"s1" / "s2". Similar sense of "w"? _.s1 s2 Does w have the same meaning in both sentences? _w. Sense (1) (a) "s1" (_) "s2"对于前两种模式,如果
yes作为verbalization,否则采用no。对于第三种模式,我们用b和2作为verbalization。对于
WSC,每个样本由一个带有标识的代词T5, GPT-3,将WSC作为一个生成任务。我们用星号来突出xxxxxxxxxxs The pronoun '*p*' refers to __.s In the previous sentence, the pronoun '*p*' refers to __.s In the passage above, what does the pronoun '*p*' refer to? Answer: __.我们使用恒等映射作为
verbalizer。请注意,WSC与其他任务不同,它需要自由形式的文本补全。这反过来又要求在训练和推理过程中进行一些修改,这些修改将在附录A中讨论。MultiRC:是一个问答任务。给定一个段落BoolQ相同的verbalizer和类似的模式:xxxxxxxxxxp. Question: q? Is it a? _.p. Question: q? Is the correct answer "a"? _.p. Based on the previous passage, q? Is "a" a correct answer? _.对于
ReCoRD,给定一个段落PVP的空间很小,所以我们只使用了一个平凡的PVP:把verbalizer。由于只有一个PVP,就不需要进行知识蒸馏,所以我们直接使用产生的模型作为我们的最终分类器。
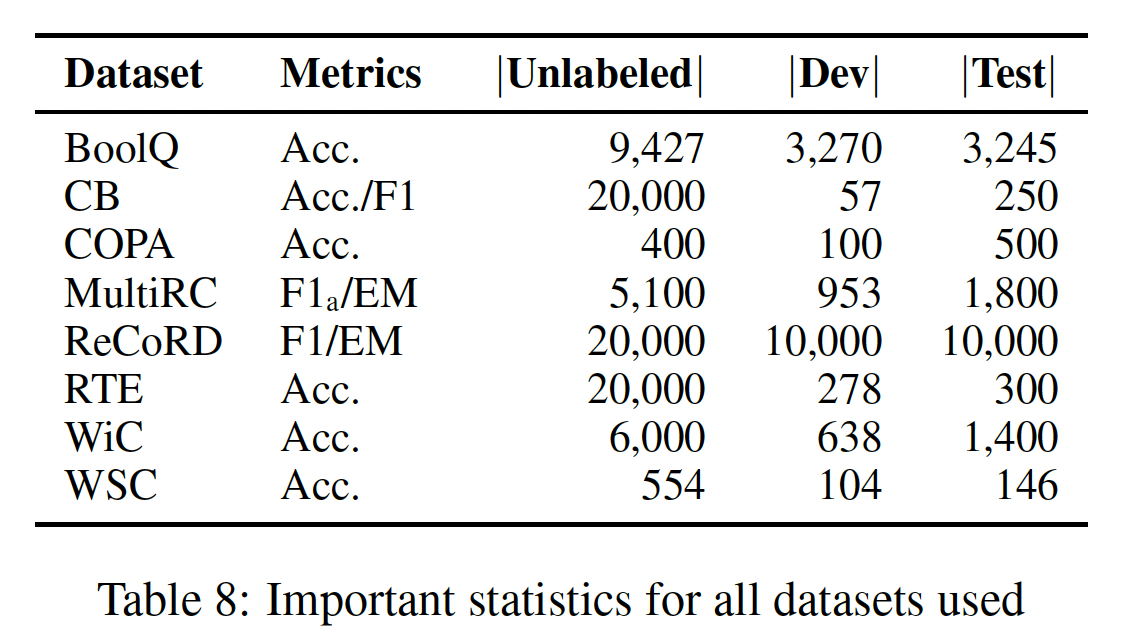
数据集的统计数据如下表所示。
数据预处理:我们不进行任何预处理,只是将所有的样本缩短到最大的序列长度。
配置:作为
PET的底层的语言模型,我们选择ALBERT-xxlarge-v2,这是在常规的完整大小的训练集上进行训练得到的、在SuperGLUE上表现最好的MLM。我们使用同一模型,并辅以sequence classification head,作为我们的最终分类器。我们在
FewGLUE训练集上为所有的SuperGLUE任务运行PET。我们不使用任何验证集来优化超参数;相反,我们使用与《Exploiting cloze questions for few shot text classification and natural language inference》完全相同的设置和超参数,如下表所示。唯一的区别是对于iPET,我们仅训练3代模型以加快训练速度。对于
COPA, WSC, ReCoRD,我们使用我们提出的对PET的修改,从而支持verbalizers将标签映射到多个tokens;对于所有其他任务,我们使用常规PET。我们在所有任务上训练iPET,但COPA, WSC除外,因为它们的未标记数据集包含远低于1,000个样本;ReCoRD也除外,因为我们只使用一个PVP,所以iPET对其没有意义。对于这三项任务,我们只是简单地复用常规PET的结果。COPA:对于COPA,我们在训练期间以50%的概率随机切换两个选项PET模型,我们从每个PVPlogits,即RoBERTa提出的输入格式。WiC:与COPA类似,我们在训练期间随机切换输入句子"|"标识着两个文本段的边界。WSC:与其他SuperGLUE任务不同,T5和GPT-3的WSC formulation要求自由地补全,这意味着对于每个句子然而,在许多情况下,这将使语言模型很容易根据提供的
masks的数量识别出正确的target,因此我们通过随机添加最多三个额外的mask tokens来修改每个target,对于这些mask tokens,我们要求模型预测一个特殊的<pad> token。对于推理,我们总是只随机添加一个mask token,以确保多次评估的结果一致,并按照前文所述进行贪婪解码。然后,我们遵从T5的做法,将语言模型产生的输出映射到标签对于蒸馏,给定一个未标记样本
PET模型提供输入,其中"|"是两个文本片段之间的边界,并在MultiRC:与PET使用的超参数不同,我们在训练和推理过程中对MultiRC使用最大序列长度为512 tokens,因为我们发现许多段落的长度远远超过256 tokens。最终序列分类模型的输入形式为"|"是两个文本片段之间的边界。ReCoRD:对于ReCoRD,我们再次使用最大序列长度为512,因为许多段落需要超过256 tokens。对于一些问题ReCoRD训练集包含大量的答案候选者。为了方便训练,我们把每个样本拆分为多个样本:令9个负样本,为每个10个答案候选。

5.3.1 实验结果
我们的主要结果显示在
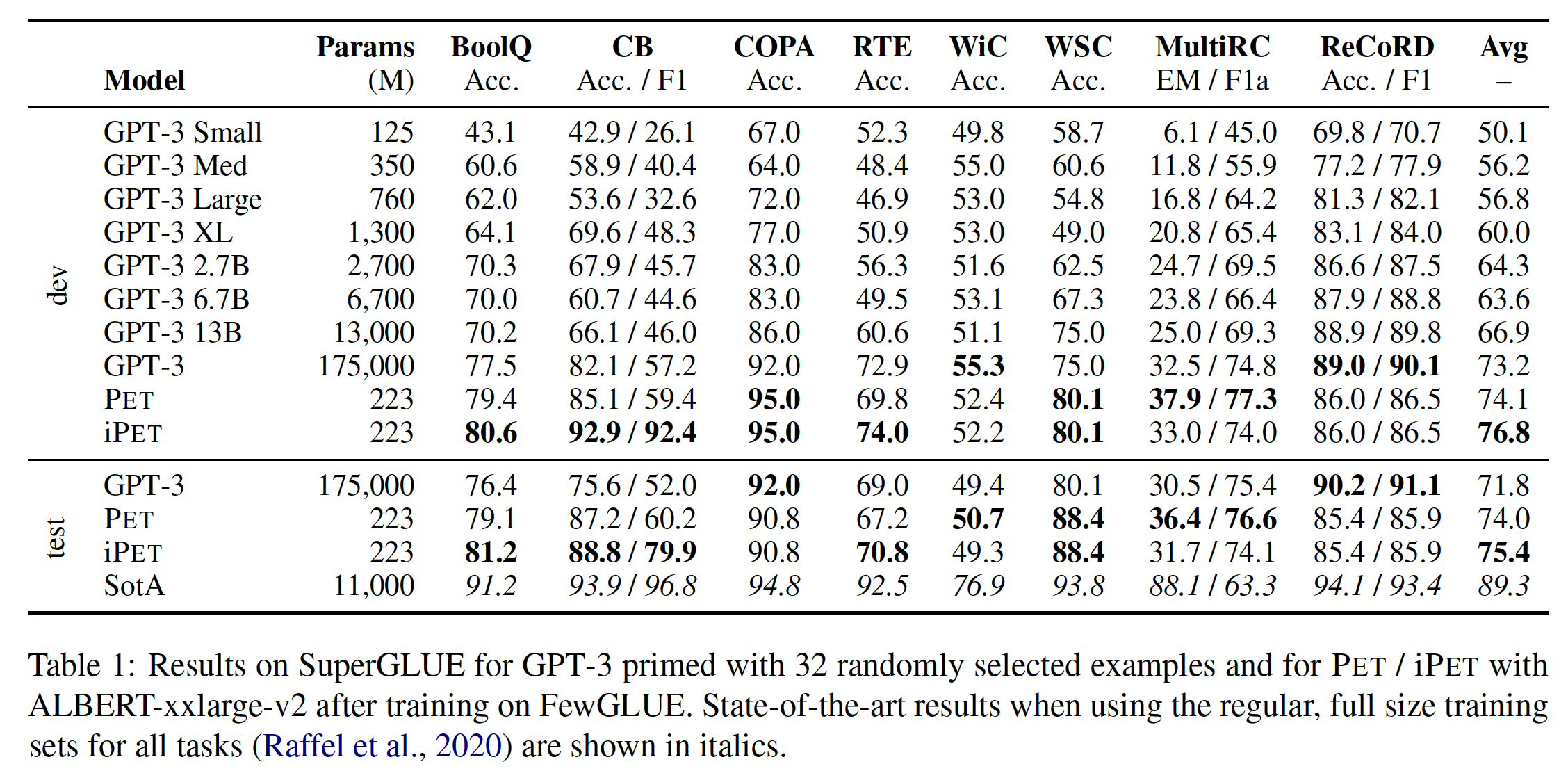
Table 1中。可以看到:带
PET的ALBERT的表现与GPT-3 175B模型相似,后者比前者大785倍。平均而言,
PET的性能比GPT-3 Med这个大小相似的模型要好18个点。在我们使用
iPET的5个任务中,有3个任务的性能得到了进一步的提高,最明显的是CB;但在MultiRC任务上,性能略有下降。尽管
PET的性能很强,但它的性能显然还是比在常规的、full size的SuperGLUE训练集上训练的SOTA模型更差。
5.3.2 分析
我们研究了几个因素对
few-shot性能的重要性:模式和verbalizers的选择、未标记数据和标记数据的使用、以及底层语言模型的属性。我们还研究了我们提出的对PET的修改从而与multiple masks一起工作,并将其与各种baseline进行比较。最后,我们衡量了选择不同的训练样本集合对性能的影响。我们的分析集中在PET上,因为GPT-3并不公开可用。Patterns:将任务重新表述为完形填空问题的方式会对性能产生巨大影响。这些reformulations可以是任意复杂的。例如,GPT-3针对WSC所使用的模式包含一个近30个单词的introductory section。目前还不清楚这种formulation能否、以及如何被优化。为了研究模式和verbalizers的重要性,我们比较了三组PVP:我们在前面内容中定义的初始集合(记做GPT-3使用的单个PVP(记做我们用具有三组模式的
PET来训练ALBERT。所选择的SuperGLUE任务的结果显示在table 2(顶部)。可以看到:GPT-3使用的PVP在RTE上优于我们的PVP,而我们的PVP在MultiRC上表现得更好。这些性能上的巨大差异凸显了找到良好的方法来表述任务为完形填空问题的重要性。由于在没有对大量的样本进行尝试的情况下,很难确定哪些模式表现良好,因此,few-shot方法的一个关键挑战是:如何弥补语言模型不能很好理解的PVP。从用
PET能够做到这一点:结合所有的PVP不仅能够补偿RTE上、以及MultiRC上的较差表现,而且与表现最好的一组模式相比,它甚至进一步提高了三个任务的平均性能。这清楚地表明了精心设计一组合适的模式的潜力,而不是仅仅选择单个formulation而不对其有效性进行评估。
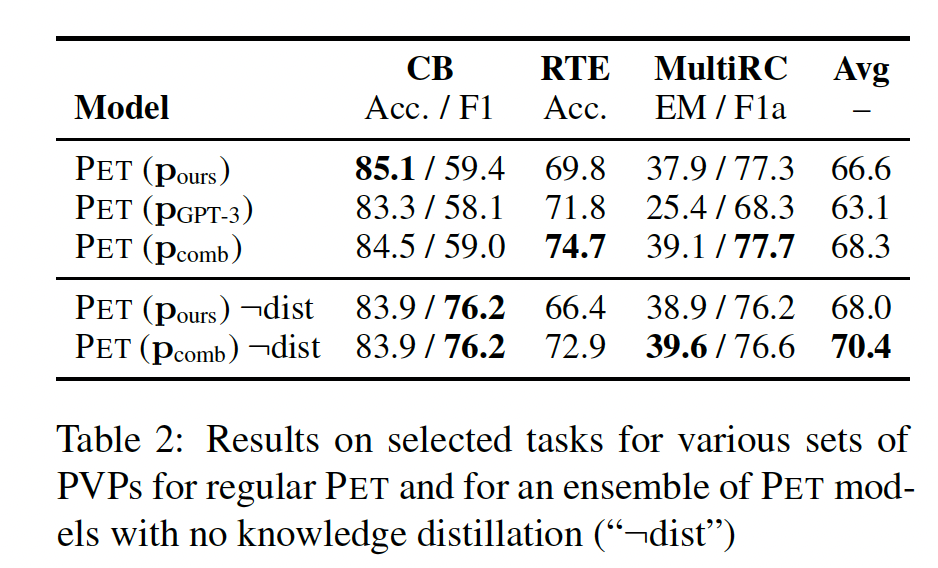
未标记数据的使用:与
GPT-3不同,PET需要未标记数据来将所有基于单个PVP的模型的知识蒸馏成单个分类器。对于iPET,未标记数据还被用来为未来几代模型生成训练集。其基本假设是可以很容易地获得未标记数据,但在现实世界中可能并不总是如此。因此,我们研究了未标记数据对常规PET的重要性。为此,我们比较了PET中最终分类器的性能、以及直接使用对应于每个PVP的模型的ensemble的性能。虽然使用这个ensemble完全消除了对未标记数据的需求,但由于我们遵循PET的默认设置并且每个PVP训练三个模型,PVP的ensemble比distilled model要大PVP,ensemble也比GPT-3小两个数量级。由于微调仅仅作用在
LM head上,因此PVP的ensemble可以共享底层的、被冻结的LM body,所以没有比distilled model大没有蒸馏的结果可以在
Table 2(底部)看到。从三个任务的平均值来看,ensemble的表现甚至比distilled classifier更好。这表明,如果目标只是为了达到良好的性能,那么未标记数据是没有必要的;但是,为了获得单个的、轻量级的模型作为final classifier,则是需要的。这是否说明了:对于
PET,没有必要进行花里胡哨的蒸馏?此外,对于
iPET,蒸馏是否有必要?下图说明了用
iPET训练多代的好处。对于除MultiRC以外的所有任务,从第一代到第二代都有很大的改进,而第三代只实现了轻微的额外改进。平均而言,标准差在后面几代中有所减少,这说明模型之间相互学习,其预测结果趋于一致。最后的蒸馏步骤为除MultiRC之外的所有任务带来了进一步的改进,并将三次training runs的标准差降低到几乎为零,说明PET和iPET是减少微调不稳定性的有效手段。当然,还有进一步的方法来利用未标记数据,如在微调期间保持一个辅助的语言建模目标(
《An embarrassingly simple approach for transfer learning from pretrained language models》)。虽然我们把调研额外使用这类方法的影响留给未来的工作,但我们注意到,它们可以很容易地应用于PET,而没有直接的方法将它们与priming相结合。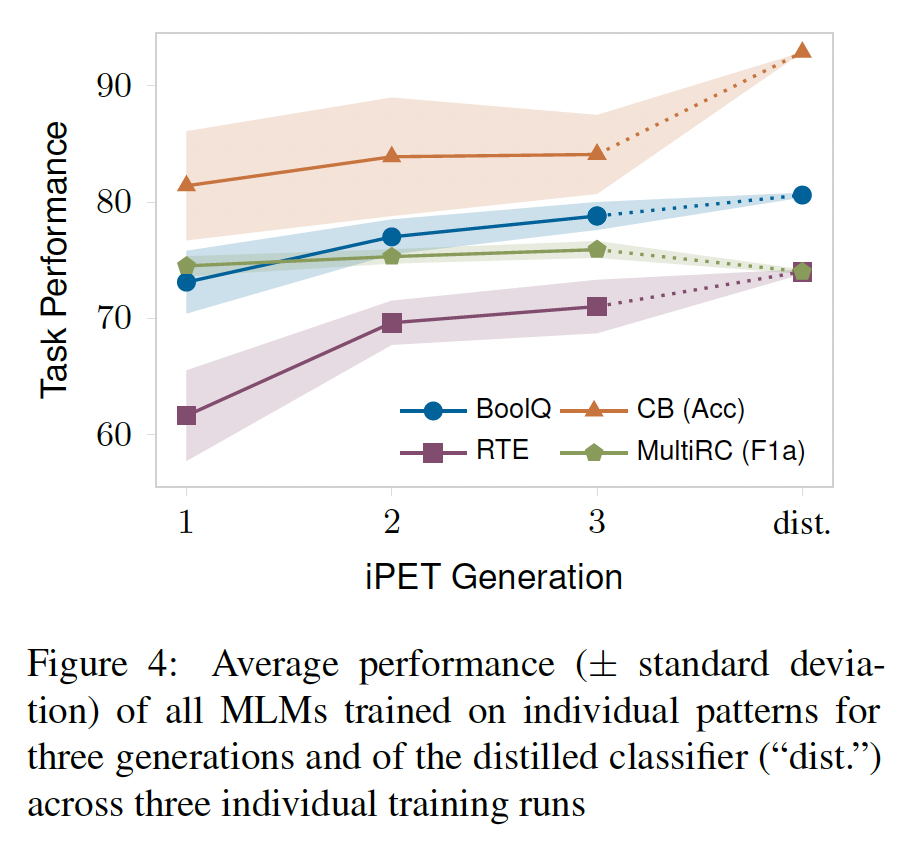
标记数据的使用: 我们接下来研究标记数据使用方式的影响,这是
priming和PET之间的关键区别之一。我们首先将
PET与常规的监督训练(即不使用任何模式)、以及完全无监督的模型(即使用所有PVP但没有labeled训练样本的ensemble)进行比较。给定32个样本,PET明显优于两个baseline(Table 3)。我们接下来将
PET与priming进行直接的比较。然而,我们不能用ALBERT来做,因为它只能处理最多512 tokens的序列,这对一组32个样本来说是不够的。我们改用XLNet来做这个比较。如Table 3所示,XLNet总体上表现比ALBERT差。更重要的是,带有PET的XLNet的表现要比priming好得多。我们无法在
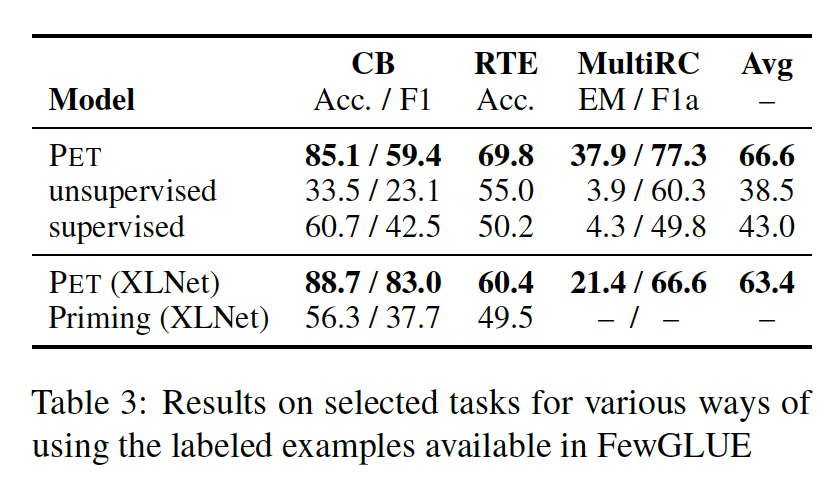
MultiRC上用priming获得结果,因为FewGLUE中的32个样本需要超过10k tokens,所以用标准的Transformer无法处理它们,因为自注意的复杂性是序列长度的平方。这突出了priming的另一个重要问题: 它不能很好地扩展到超过少数几个样本;即使是GPT-3也只能处理多达2048 tokens的序列。虽然有一些Transformer变体可以处理更长的上下文,但这种模型在多大程度上能很好地利用long context spans上的priming examples,还有待研究。priming是无监督的,因此它的效果不如PET,这是可以预期的。我们通过更仔细地观察
GPT-3的结果来进一步研究priming的有效性。为此,Figure 5显示了在每个任务和模型大小的情况下,用32个样本给GPT-3执行priming、以及只用一个样本来priming之间的性能差异。可以看到:对于大多数任务和模型大小来说,用
32个样本的priming只能稍微提高性能。对于某些任务,增加更多的样本甚至会导致更差的性能,特别是对于较小的模型。
对于
ReCoRD,即使是最大的模型,在添加更多的样本时,其性能也略有下降。
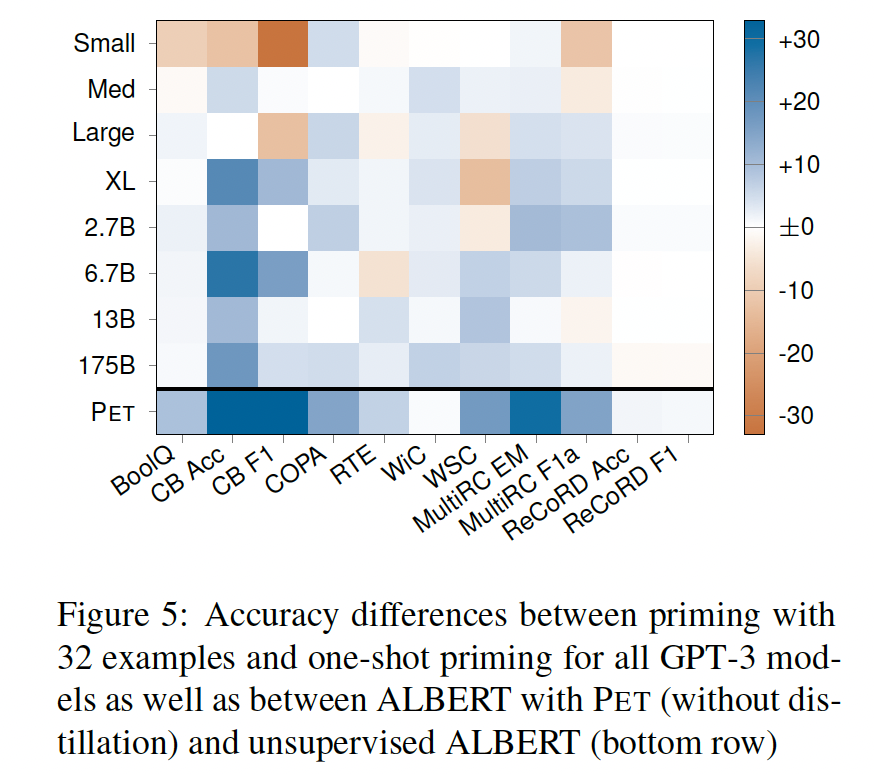
Figure 5的底部一行显示了用PET训练的ALBERT(没有蒸馏)、以及完全无监督的ALBERT模型在所有任务上的性能差异。虽然由于底层模型的不同、以及PVP的不同,结果不能直接比较,但PET的结果与priming相比有更大的性能改进,并且在任何任务中都不会使结果恶化。
模型类型:我们接下来通过比较
ALBERT与RoBERTa_large和GPT-2_medium来研究底层语言模型对PET的影响。由于GPT-2是一个类似于GPT-3的单向模型,它只能处理mask token是最后一个token的模式。因此,我们对CB和RTE使用MultiRC,我们坚持使用我们的原始的模式集合,因为它们已经满足了这个要求。我们也不进行蒸馏,而是报告ensemble的性能,因为没有既定的方法为GPT-2配置一个sequence classification head。Table 4中用PET训练所有三种语言模型的结果表明:使用
ALBERT作为底层语言模型对PET的强大性能至关重要。用
RoBERTa而不是ALBERT会导致平均性能下降8分。然而,RoBERTa仍然明显优于GPT-3 13B,后者比RoBERTa大两个数量级。使用
GPT-2的PET的性能比使用ALBERT和RoBERTa这两个模型的性能差得多。正如GPT-3所预料的那样,性能下降的一个原因可能是,与GPT-3一样,GPT-2是单向的,使需要比较两个序列的任务成为一种挑战。然而,需要注意的是,GPT-2和其他两个模型之间也有其他实质性的差异,最明显的是预训练数据集。不管单向性是否是
GPT-2表现不佳的原因,底层语言模型的双向性对PET很重要,因为它消除了mask token在最末尾的需要,从而使模式的创建更加灵活。单向性不是问题,
GPT-3 175B也是单向的模型,但是在这类任务上可以达到SOTA。
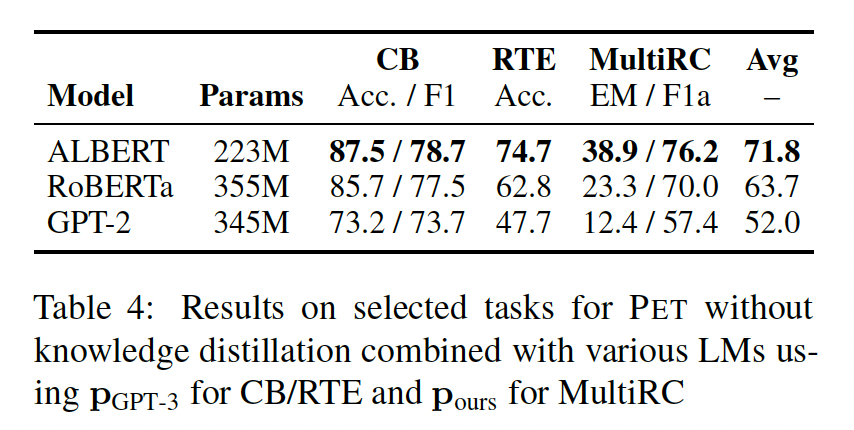
带有多个
masks的PET:我们对PET进行了修改,使其能够适用于需要输出多个tokens。为了研究这一修改的影响,我们研究了需要这样做的三个任务:COPA, WSC, ReCoRD。我们比较了三种策略:我们的解码策略:即按照分配给它们的概率的顺序来预测
tokens,我们称之为max-first。从左到右解码(
ltr):这是许多自回归语言模型的常见做法。并行解码所有
tokens(parallel),这是训练期间所做的。
注意:训练期间是并行解码、但是测试期间是采用了不同的解码策略。
此外,我们将
PET与untrained ALBERT进行比较,以衡量我们提出的训练损失的有效性。结果显示在下表中。可以看到:
在三个任务中,
PET明显优于untrained ALBERT。不进行蒸馏会损害
COPA的性能,但会导致WSC的轻微改善;对于ReCoRD,我们没有进行蒸馏,因为我们只使用一个PVP。除了
WSC之外,我们的解码策略明显优于并行解码,因为WSC的大多数预测只由一个或两个tokens组成;我们的解码策略比从左到右的解码策略表现略好。
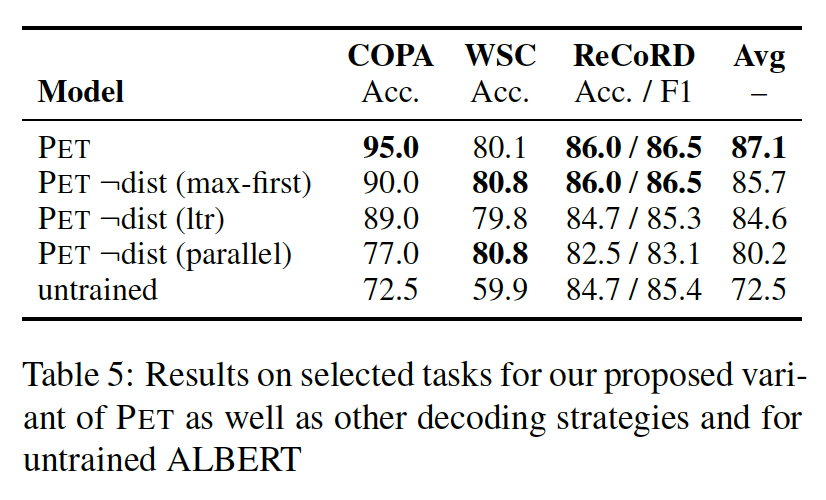
训练样本:回顾一下,我们用
FewGLUE的训练样本进行实验,FewGLUE是原始SuperGLUE训练数据集的一个随机选择的子集。我们使用一个固定的随机种子FewGLUE。令SuperGLUE子集,所以SuperGLUE的另外两个子集,CB, RTE, MultiRC运行PET。为了只测量改变训练集的效果而忽略未标记样本,我们不使用知识蒸馏。下表显示,对于所有的任务,改变训练样本集会导致
PET的性能差异很大。这突出了在比较不同的few-shot方法时,使用相同的样本集的重要性,这就是为什么我们公开了FewGLUE中的特定的样本集。然而,我们注意到,对于所有的随机数种子,PET的平均性能与GPT-3的平均性能相似。虽然我们的结果似乎与
GPT-3的观点相反,即对GPT-3来说,样本的确切选择并不发挥主要作用。但我们怀疑这是由于priming从训练样本中获得的好处比PET少得多(如前所述),因此,训练样本的确切集合对GPT-3模型性能的影响较小。
六、Do Prompt-Based Models Really Understand the Meaning of Their Prompts?[2021]
论文:
《Do Prompt-Based Models Really Understand the Meaning of Their Prompts?》
假设一个人得到两个句子: “在伊拉克还没有发现大规模杀伤性武器”、“在伊拉克发现大规模杀伤性武器”。现在,在没有给出任何其他额外信息的条件下,我们要求这个人回答句子类别是
0还是1。在这种情况下,人们可能需要大量的试错才能清楚如何进行分类(比如,是判断语法是否错误?还是判断是否包含政治言论?)。这种设置类似于近年来在NLP中占主导地位的pretrain-and-finetune设置,在这种设置中,模型被要求将一个sentence representation(例如CLS token)进行分类。相反,假设给一个人如下的
prompt:“假设 '在伊拉克还没有发现大规模杀伤性武器',那么 '在伊拉克发现大规模杀伤性武器' 这句话肯定正确吗?”。那么,这个人能够更准确地执行任务,而且不需要很多样本就能搞清楚任务是什么,这并不奇怪。同样地,用类似的
prompt来重新设置NLP任务,与传统的fine-tuned模型相比,极大地提高了zero-shot和few-shot性能。这样的结果自然会产生这样的假设:每个输入样本中包含的额外prompt text作为语义上有意义的任务指令,帮助模型更快地学习,就像任务指令帮助人类更快地学习一样。这一假设被许多人隐含地假定,并被《Natural instructions: Benchmarking generalization to new tasks from natural language instructions》、PET以及GPT-3明确地论证了。虽然去年出现了论文淘金热,提出了
optimizing prompts的自动化方法,但《Cutting down on prompts and parameters: Simple few-shot learning with language models》比较了这些新提出的方法的representative sample,并报告说PET-2的手动编写的prompts在一系列SuperGLUE任务中的平均表现仍然优于自动搜索的prompts。这样的发现表明,专家起草的prompts是最好的,这加强了上述假设,即模型从有意义的指令中受益。在本文中,在
zero-shot/few-shot setting上,我们通过评估各种语言模型在NLI上的表现来测试这一假设,使用超过30个手动编写的模板、以及13组LM target words,总共超过390个prompts。我们发现:在大多数情况下,当给出不相关或误导性的模板时,模型的学习速度与给出有指导意义的好模板时相同。
此外,从
235M到175B参数的模型都表现出这种行为,instruction-tuned的模型(这些模型是在数百个人工书写的prompts上训练出来的)也是如此。虽然我们证实了
T0的发现,即instruction tuning大大改善了prompts的性能和稳健性,但我们也发现,从某种意义上说,instruction-tuned模型可能过于稳健,与non-instruction-tuned模型相比,对prompts的语义不太敏感。最后,相对于指令模板的含义,模型对
LM target words的选择更为敏感。
总而言之,尽管
prompt-based模型在zero-shot/few-shot learning中得到了极大的改善,但我们发现有限的证据表明:模型的改善来自于模型以类似于人类使用任务指令的方式来理解任务指令。即,并没有很多证据来支持:模型能够理解
prompts这个结论。相关工作:
Prompt-Based Models:在撰写本文时,"prompt tuning"和"prompting"这两个词可以指下面描述的三种方法中的任何一种或组合:Discrete Prompts:用一些模板文本重新格式化每个样本。例如,在一个情感分析任务中,模板可以是{sent} In summary, the restaurant is [prediction],其中predicted mask word可以通过一个预定义的映射(如:{"great" -> positive, "terrible" -> negative})被转换为一个class prediction。prompts可以是手动编写的(PET、《FLEX: Unifying evaluation for few-shot NLP》)或自动生成的(LM-BFF、AutoPrompt)。这种方法通常会调优模型的所有参数,但它的few-shot的性能可以超过非常大的模型(例如GPT-3 175B),尽管使用的是小3个数量级的语言模型(PET-2、ADAPET)。Priming(又称in-context learning):将priming examples放置到evaluation example的前面,其中每个priming example都可以选择包装在一个模板中,如:xxxxxxxxxxQuestion: {sent_1} True or false? {label_1}...Question:{sent_k} True or false? {label_k}Question: {eval_sent} True or false? [prediction].值得注意的是,虽然模型看到了
labeled examples,但模型的参数并没有收到基于这些例子的梯度更新。虽然这种方法很吸引人,但GPT-3报告说,它只在最大的GPT-3模型上表现良好,该模型的API成本很高,难以用于学术研究(详见附录B)。Continuous Prompts:在样本前加上special tokens,这些special tokens可选择用word embeddings进行初始化;但在学习过程中,这些special tokens可以任意更新,这样final embeddings往往不对应于词表中的任何真正的单词(例如,《The power of scale for parameter-efficient prompt tuning》、Prefix-Tning、《Learning how to ask: Querying LMs with mixtures of soft prompts》)。这种方法通常能有效地调优小得多的模型参数集合,但这些方法还没有报告在few-shot settings下取得成功。此外,放弃用自然语言表达的
prompts,使得研究它们的语义变得更加困难,而且不清楚continuous prompts是作为task-specific指令、还是仅仅作为更有效的模型参数(详细分析见《Towards a unified view of parameter-efficient transfer learning》)。
Analyses of Prompts:在本文中,我们专注于离散的prompts,因为我们可以手动编写并控制prompts的措辞和语义。我们通过模型的k-shot性能来衡量prompt语义的影响,其中《How many data points is a prompt worth?》的研究,但他们的研究重点是将整个训练集上的传统微调与PET-2已有的一小组prompts进行比较,而我们的研究重点是在一组更多样化的prompts中的few-shot learning,旨在测试关于prompt语义对few-shot learning速度影响的具体假设。在
high-level上,我们的研究结果与《Natural instructions: Benchmarking generalization to new tasks from natural language instructions》的说法相矛盾,即模型受益于从众包的annotation guides中改编的详细的指令。但要注意的是,他们对 "指令" 的定义更为宽泛,包括priming examples,他们发现 "GPT-3从positive examples中受益最多、从definition中受益较轻、而在negative examples中则恶化"。换句话说,如果我们消融研究priming,把 "指令" 缩小到仅仅是对任务的描述,我们实际上也有同样的发现,即instructions比no instructions只有轻微的好处(参考我们的irrelevant templates)。在类似的情况下,《Can language models learn from explanations in context?》的同期工作发现,prompt的其他组成部分,如对priming examples是有帮助的,但模型对指令是否事实上描述了他们的任务是无动于衷的。最后,越来越多的同期工作也质疑模型需要有意义的指令的程度(
《Prompt waywardness: The curious case of discretized interpretation of continuous prompts》、《Grips: Gradient-free, edit-based instruction search for prompting large language models》)。一个特别值得注意的发现是,《Rethinking the role of demonstrations: What makes in-context learning work?》表明,模型在priming中使用不正确的标签和正确的标签时学习效果一样好,结论是prompts帮助模型学习输入文本的分布和possible labels的空间(而不是任务的特定指令)。
6.1 配置
我们实现了一个人工的
discrete prompt model,其本质上与PET-2的模型相同,只是他们的实现包括一些augmentations,如self-labeling、以及多个prompts的ensembling以获得竞争结果。为了专注于测量ensembling本身的效果,我们的实现不包括这些augmentations功能。遵从T0和FLAN之后,我们通过target words的rank classification来评估。Baseline Model: 在初步实验中,我们对BERT, DistilBERT, RoBERTa, ALBERT, T5进行了微调和prompt-tune。我们发现ALBERT一直产生最好的性能(与PET-2、ADAPET一致),所以我们使用它作为我们的基线模型。Instruction-Tuned Model:我们用两种规模的T0(3B和11B),以及它们的non instruction-tuned版本T5 LM-Adapted(《The power of scale for parameter-efficient prompt tuning》)作为基线进行实验。Very Large Model:我们用最大的GPT-3 (175B)进行实验,通过priming(又称in-context learning))。数据集:我们专注于
NLI,因为所有的T0变体在其训练中都holds out所有的NLI prompts和所有的NLI数据集,这使得它可以与本文中的其他模型进行公平比较。我们使用Recognizing Textual Entailment: RTE数据集,具体而言是RTE的SuperGLUE collection。Random Seeds & Example Sampling:所有实验都是在同一组4个随机种子上运行的。在一个给定的种子中,所有模型看到的都是相同的例子集合。Statistical Tests:我们同时使用ANOVA和它的nonparametric等价物(即,Kruskal-Wallis test)。在发现多个模板之间的显著差异后,我们用独立two-sample t-test and和Wilcoxon rank-sum test来报告pairwise significance。
6.2 模板的效果
我们的研究问题是,模型是否将
prompts理解为类似于人类的有意义的任务指令。为了直观起见,假设一个实验者向人类标注员提供了一个相当容易的任务的informative指令。如果标注员理解该指令,我们希望他们的表现比实验者故意提供误导性指令、实验者进行无关紧要的闲聊、或什么实验者都不说时要好。因此,我们编写了与这些不同情况相对应的各种prompt模板,并评估模型在zero-shot and few-shot setting下使用这些模板的表现。我们写了五类模板(
Table 1所示),每类模板至少有5个(指令性类别的模板则有10个):Instructive:我们将如何向一个从未见过这项任务的人描述NLI任务。Misleading-Moderate:指示模型执行与NLI相关或相近的任务,这样一来,如果模型按照明确的指令执行任务,它在NLI上的表现一般都会很差。Misleading-Extreme:指示模型执行与NLI无关的任务。Irrelevant:将premise、一个与任何NLP任务无关的句子、以及hypothesis拼接起来。Null:将premise、以及hypothesis拼接起来,没有任何额外的文本。
我们用
"prompt"来指一个模板和一个predefined LM target word的unique combination。例如,{"yes" -> entailment, "no" -> non-entailment}是模板{premise} Should we assume that {hypothesis}? [prediction]的默认target words。在这一节中,为了控制target words的影响,我们固定target words为"yes"/"no",这些target words始终表现最好。在下一节中,我们固定了模板,并研究了不同target words的影响。此外,我们进一步控制了标点符号、陈述式与询问式模板、以及拼接的顺序(总是
{premise} some template text {hypothesis}[prediction]).的顺序)。经过初步实验,为避免偷梁换柱,本文所报道的所有
prompts都是在评估前写好的,也就是说,除了一项明确研究标点符号影响的消融研究外,我们不允许追溯性地编辑prompts从而提高性能。
结果:
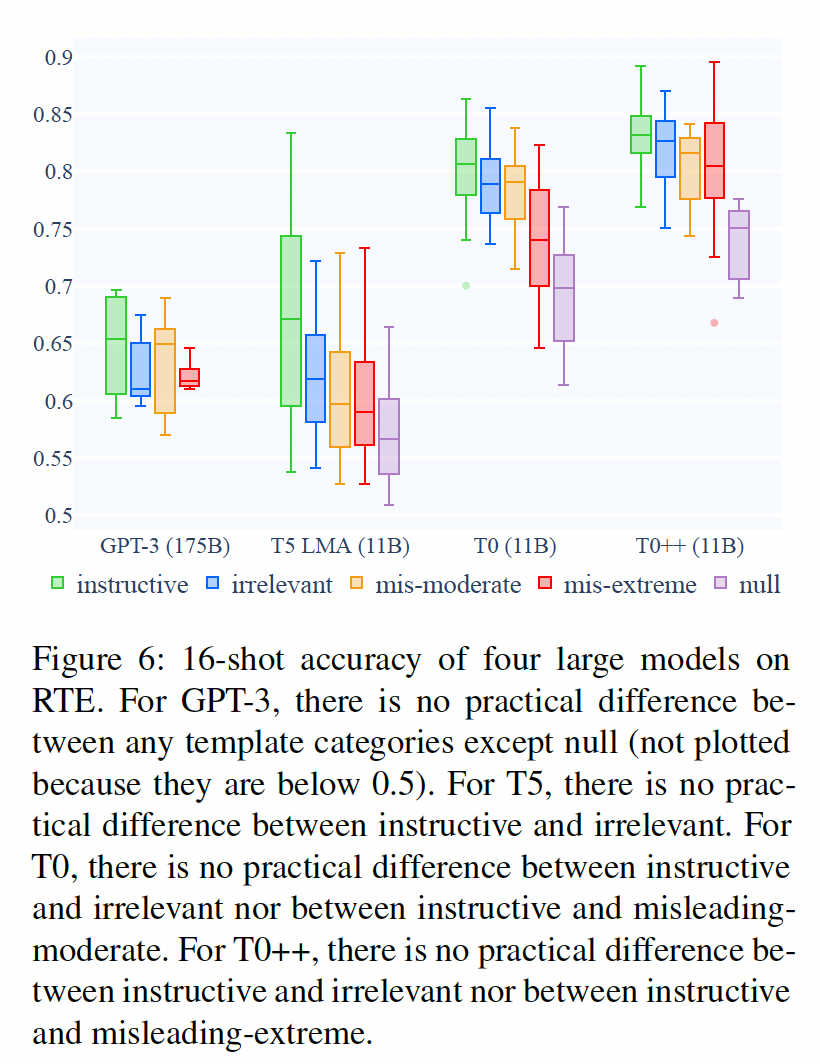
Irrelevant Templates:我们发现,用不相关模板训练的模型与用指令性模板训练的模型,学习速度一样快,在任何次数的shots中都没有实际差别(Figure 2)。这对我们实验的所有模型和所有数据集都是如此,包括最大的GPT-3(Figure 6)。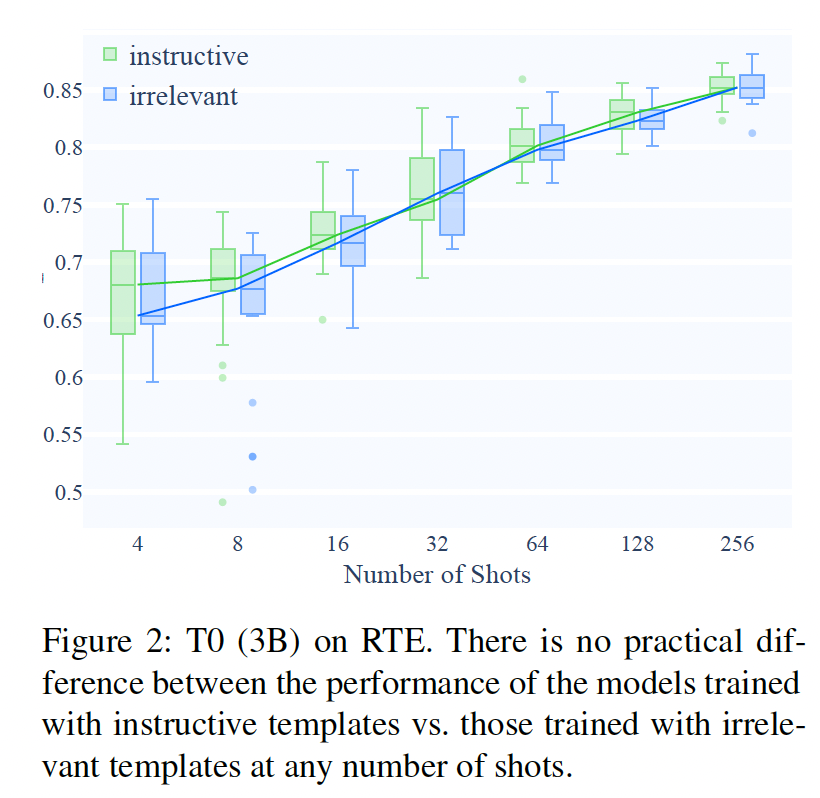
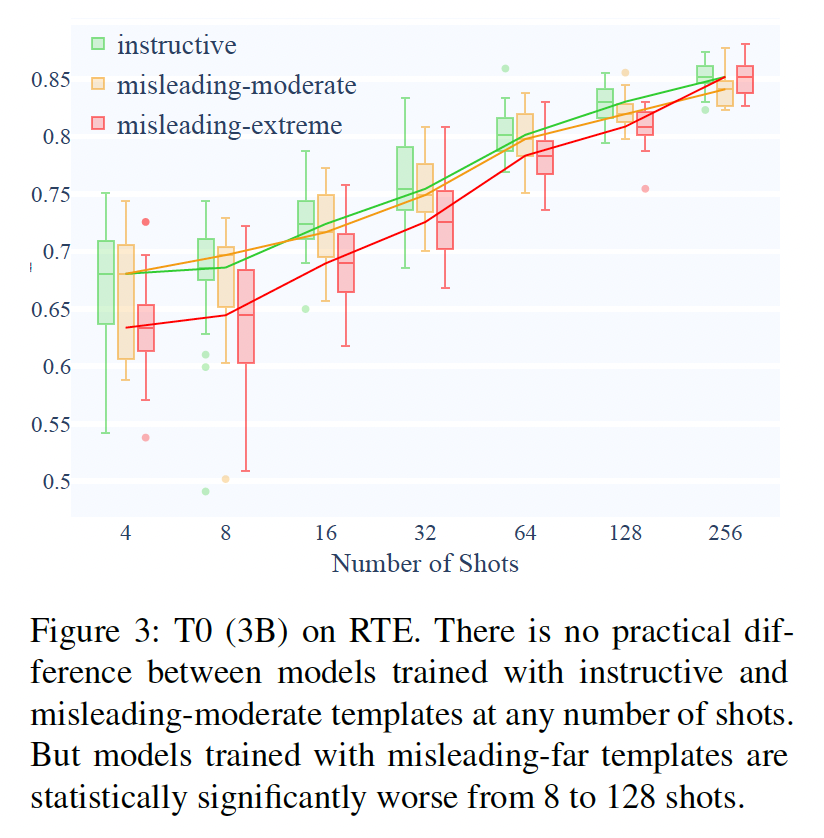
Misleading Templates:用中等误导性的模板(如{premise} Can that be paraphrased as "{hypothesis}"?)与极度误导性的模板(如{premise} Is this a sports news? {hypothesis}).)训练的模型性能之间没有一致的关系:T0(3B和11B)在中等误导性的情况下表现更好(Figure 3)。ALBERT和T5 3B在极端误导性的情况下表现更好(附录E和G.4)。而
T5 11B和GPT-3在这两组上的表现相当(Figure 6;统计意义的总结也见Table 2)。
尽管两个误导性类别之间缺乏模式,然而,一致的是指令性模板上表现出明显更好的性能。
Null Templates:用空模板训练的模型的表现远不如其他类别的模板(所有空模板的结果见附录G)。我们看到,尽管空模板在总体上要差得多,但其中的一些子集(例如,{premise}[mask] {hypothesis})在32-shots上,仍然能够以几乎与平均指令性模板一样的速度学习(Figure 4)。当
shots数量较大时,{premise}[mask] {hypothesis}与指令性模板的效果相差无几。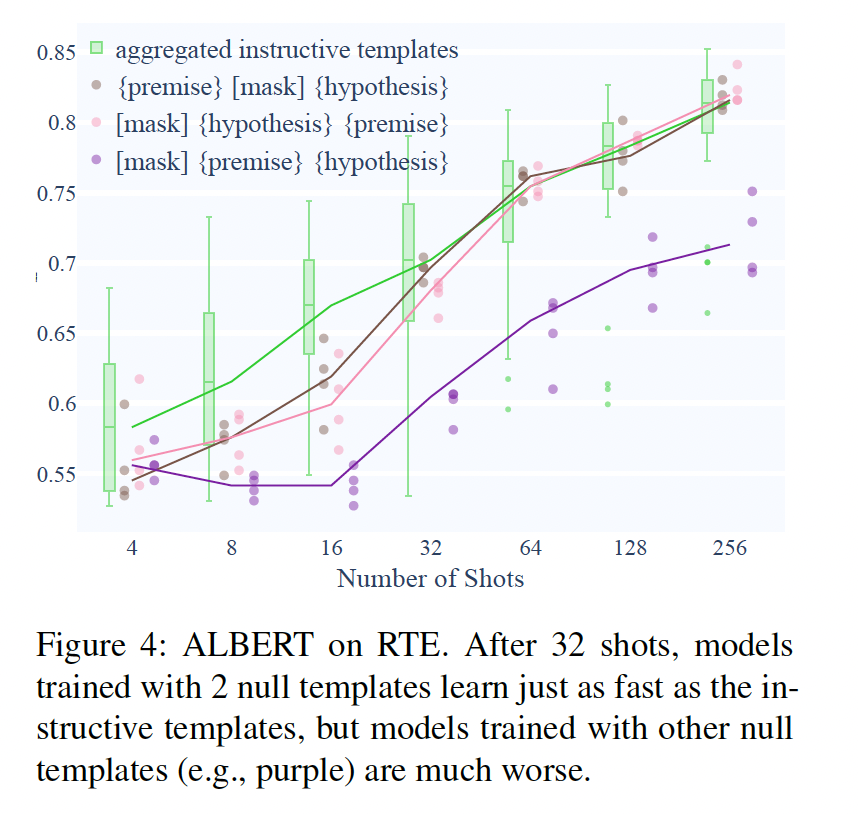
Zero-Shot:到目前为止,我们主要关注的是few-shot的结果。在zero-shot时,所有模型(包括GPT-3 175B)的表现都只略微高于随机猜测,除了指令微调的T0。因此,对于我们的zero-shot性能分析,我们把重点放在T0上。Figure 5显示:在给定指令性模板和任何一类误导性模板的情况下,
T0 3B的性能没有实际差别。T0 11B的表现更好,尽管它也显示出在中度误导性模板和指令性模板之间没有实际差异。最后,
T0++(比其他T0变体在更多的数据集上训练过),是本文中唯一一个在所有类别的prompts中显示出统计学上显著不同性能的模型。然而,仍有一点需要注意的是,它在病态prompts方面的绝对表现可以说是太好,这一点我们将在接下来讨论。
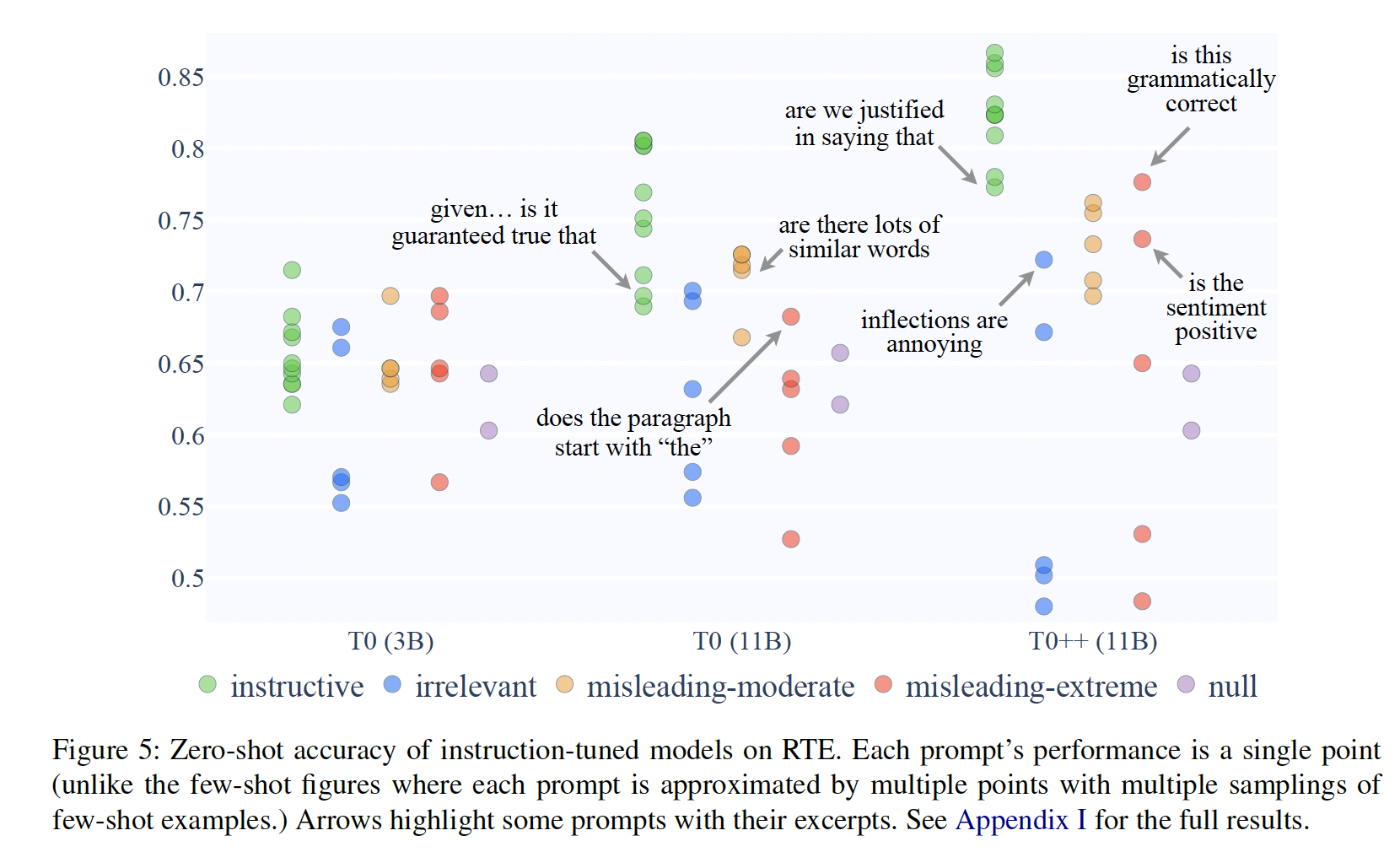
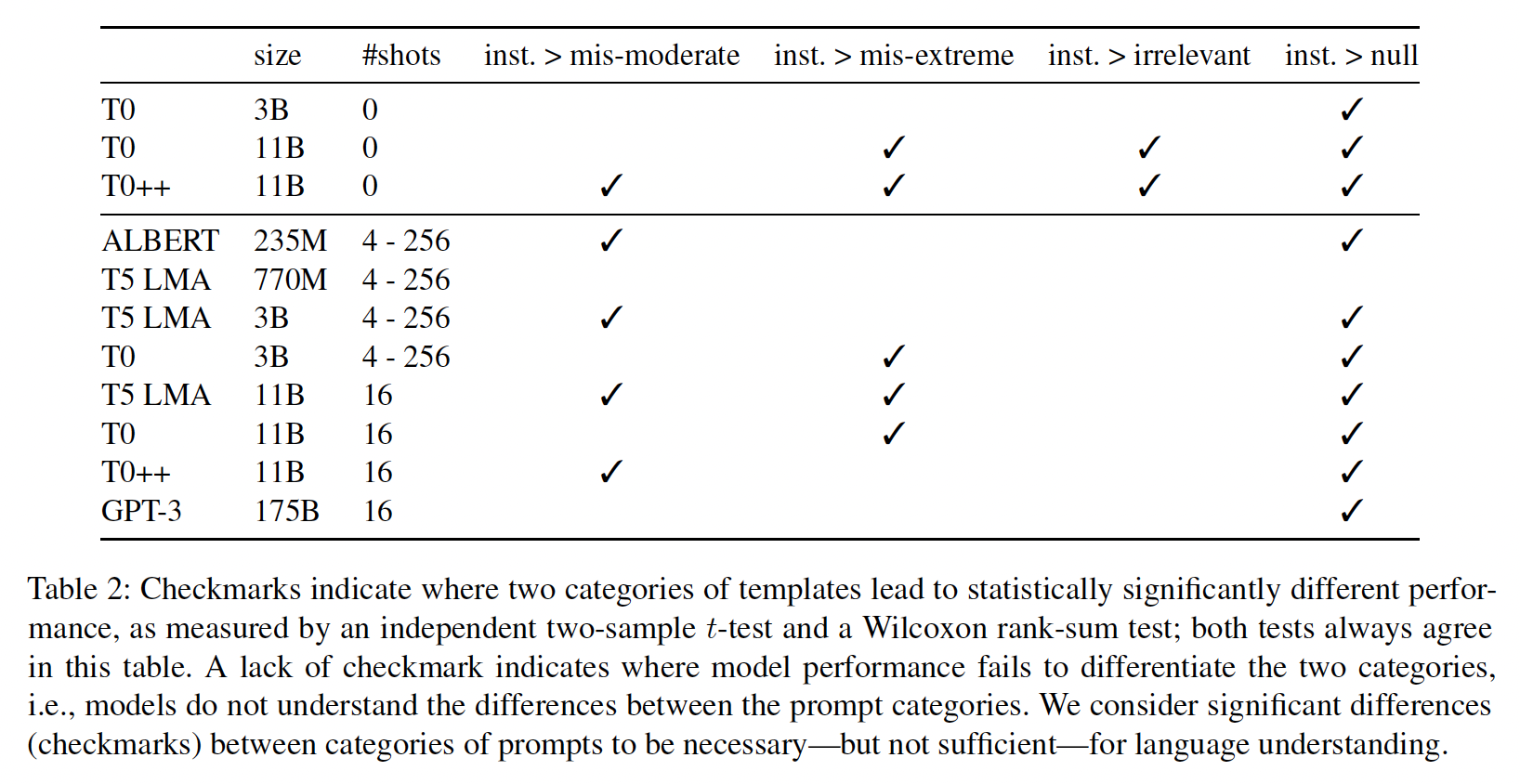
讨论:回顾一下,文献中的一个共同假设是,
prompts需要专家清楚地、正确地描述手头的任务。与此相反,Table 2总结说,除了T0++在zero-shot的情况下,所有模型在一些病态的prompts下的表现基本上与正确的prompts下的表现一样好。值得注意的是,尽管GPT-3比它的竞争对手大得多,但它显示了相同的行为模式,这表明单纯的scaling并不能解决这个问题。同时,来自指令微调的证据是mixed的。尽管《Multitask prompted training enables zero-shot task generalization》正确地认为,指令微调在性能和稳健性方面产生了实质性的改善,但在区分正确指令和病态指令方面,T0有些过于稳健,对prompts的语义不太敏感,相比于few-shot setting下同样大小的T5(Figure 6)。在
zero-shot setting中,我们确实看到,用最多的数据集对最大的模型指令进行微调(T0++),提高了模型对prompts语义的敏感性。这是一个积极的结果,但它伴随着一个警告:仍然存在许多病态prompts的例子,它们的表现与正确的prompts一样好。为了对神经模型中的随机性持宽容态度,我们以更高的标准来要求这项研究,用统计测试来比较类别之间的平均值和中位数。尽管如此,对于我们的研究问题来说,仅仅是存在性证明仍然是令人震惊的。例如,在没有任何梯度更新也没有priming的情况下,令人震惊的是,开箱即用的T0++在极度误导性的{premise} Is that grammatically correct? {hypothesis}下达到了78%的准确率,在中等误导性的指令{premise} Are we justified insaying "{hypothesis}"?下达到了相同的准确率。如果模型真的是在对文本是否符合语法进行分类,它的得分只有52.7%,因为RTE是由专家写的,所有的例子都是符合语法的。即使是表现不佳的模板,指令性模板似乎也是太好。例如,很难想象一个人在像
NLI这样细微的任务中用prompt:{premise} Inflections are annoying and thank god that Middle English got rid of most of them. {hypothesis}在zero-shot setting中得到72%。
6.3 Effect of Target Words
在这个实验中,我们研究了在一个固定的模板下不同的
LM target words的效果。我们写了四类target word,每类至少有3对target words(除了yes-no类):Yes-no:模型将entailment预测为"Yes"、将nonentailment预测为"No"。Yes-no-like:语义上等同于yes-no,但使用表面上不同的词,例如,"true"/"false"、"positive"/"negative"。Arbitrary:语义上与任务没有关系的任意单词,如"cat"代表entailment、"dog"代表non-entailment。Reversed:模型预测出直观上与Yes-no相反的表情,如将nonentailment预测为"Yes"、将entailment预测为"No"。
全部清单见附录
F.3。在Arbitrary类别中,除了《How many data points is a prompt worth?》所使用的常见的英语名字之外,我们还包括语义相似度高的word pairs、相似度低的word pairs、以及在英语中高度频繁出现的word pairs,但我们发现在Arbitrary类别的这些不同子类别中没有一致的差异。结果:对于
ALBERT和T0,我们发现用yes-no targets训练的模型比用yes-no-like targets训练的模型要学习的更快,比用arbitrary targets训练的模型和reversed targets训练的模型要快得多。例如,Figure 7显示了用不同target words训练出来的表现最好的指令性模板。在32 shots,"yes"/"no"与"no"/"yes"的中位准确率之间的差异是22.2%,远远大于不同类别模板的效果差异。对所有模板和targets的组合进行汇总,Figure 8证实了target words的选择比模板的含义重要得多。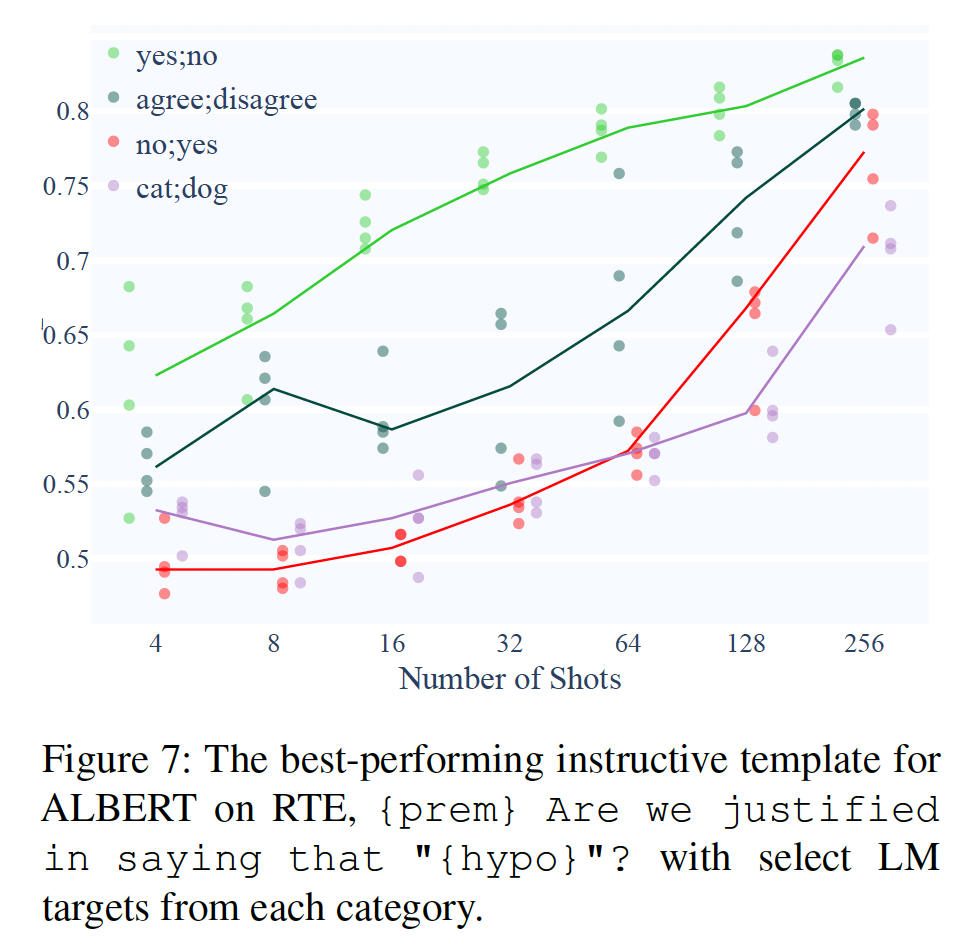
讨论:模型在使用
arbitrary targets和reversed target words时,学习速度始终较慢,这是一个积极的结果:这种类型的性能差异与我们对模型的预期是一致的,因为模型对单词的语义敏感。然而,这些实验中也有几个重要的负面结果。首先,
target words的影响凌驾于整体prompt的语义之上。考虑两种模板与targets的组合:一个不相关的或误导性的模板 +
yes-no targets,例如,{premise} Does the paragraph start with "the"?[yes/no] {hypothesis}。一个有指导意义的模板 +
arbitrary targets,例如:{premise} Based on the previous passage, is it true that "{hypothesis}"? [cat/dog]。
Figure 1显示,像第一种组合往往大大超过了第二种组合的表现。然而,第二种组合只需要弄清一个映射:"Reply 'cat' if entailed and reply 'dog' if not entailed"。对于人类来说,这可以在a few shots中学会,例如,《Universal and uniquely human factors in spontaneous number perception》表明,对于{ more numerous -> star shape, less numerous -> diamond shape}的任意映射,成年人可以在18次试验中达到60%的准确率,而不需要接受任何语言指令。相比之下,许多arbitrary targets下的模型,即使在有指令性模板的64 shots中,也很难达到60%的中位准确率(Figure 10的绿色、Figure 7的红色和紫色)。
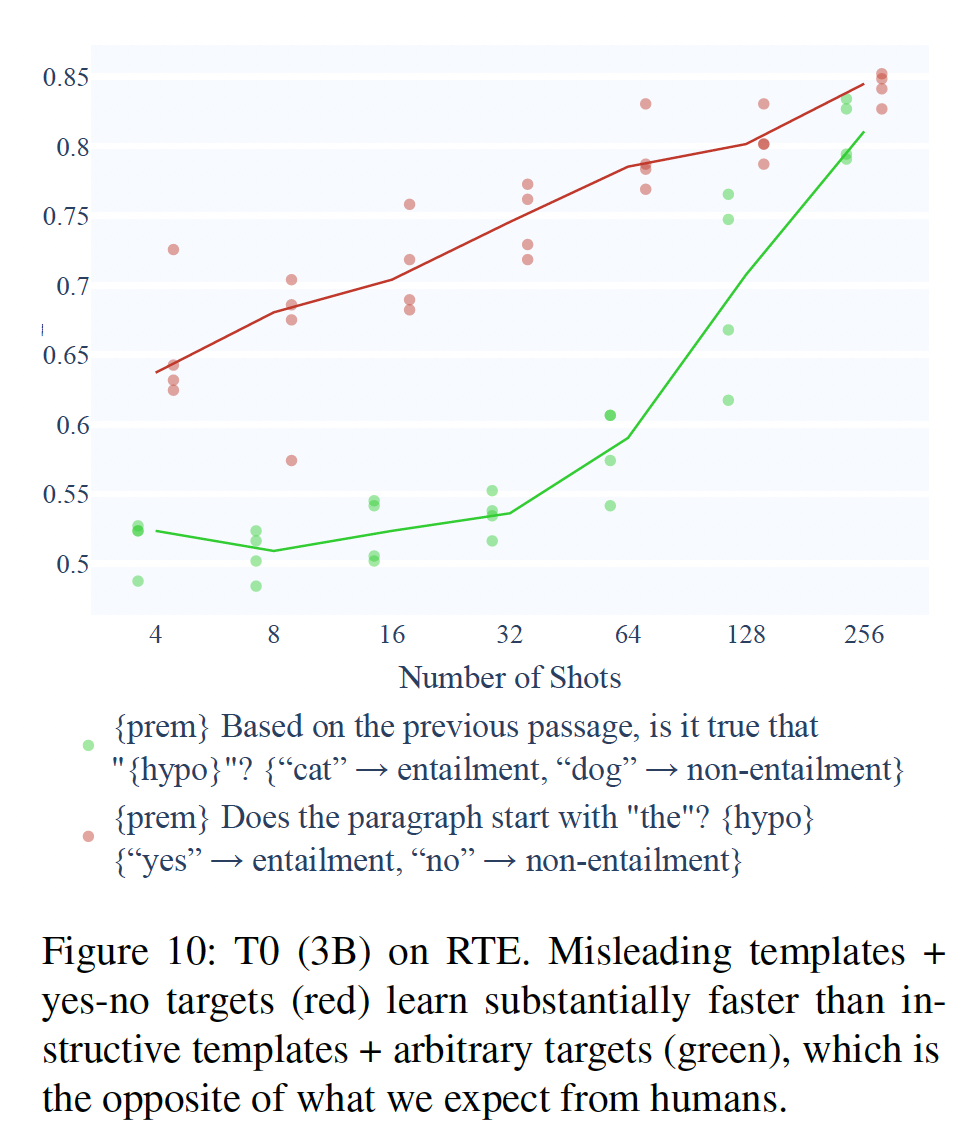
此外,即使给出直观的
yes-no-like targets,如"agree"/"disagree"和"good"/"bad",模型的学习速度也比给出"yes"/"no"时慢很多。如Figure 7(绿色与深绿色)和Figure 8(x轴的第一组与第二组)所示,在yes-no targets和yes-no-like targets targets之间存在着巨大的性能差距,直到256 shots时才缩小。此外,当我们试图通过在模板上附加
"True or false?"等target hints来帮助模型时,性能往往反而下降,这与T0和FLAN的发现相呼应,即在输入序列中包括answer choices使模型在某些任务中表现更差。
6.4 总体讨论
Summary and Interpretation:我们的主要研究问题是,模型是否将prompts理解为类似于人类的有意义的任务指令。同样,假设一个实验者向人类标注员提供了一个相当容易的任务的informative指令。如果标注员理解该指令,我们期望他们的表现比实验者提供误导性的指令、不相关的指令、或根本没有指令时更好。前面的实验显示,大多数模型的性能对指令性模板和不相关模板之间的差异不敏感、对指令性模板和误导性模板之间的差异适度敏感、对指令性模板和空模板之间的差异高度敏感。然而,与模板的影响相比,进一步的实验显示,模型对
target words的语义更加敏感:它们对arbitrary target words或reversed target words的学习速度要慢得多。然而,它们对语义等价的yes-no-like words过于敏感(即"agree"/"disagree"的表现比"yes"/"no"差得多)。而且target words的选择凌驾于模板的语义之上(例如,给定一个具有"yes"/"no" targets的无关模板,比具有arbitrary targets如"cat/dot"的指令性模板的表现好得多)。我们在本文中的主要论点与最近的一系列研究有着相同的逻辑,即语言模型在理想条件下取得良好表现的事实不足以建立语言理解,因为它们在人类灾难性地失败的病态条件(例如,有随机混洗的词序的句子)下也能取得成功。换句话说,模型如此擅长从病态输入中推断出
gold labels的事实,使人们对模型的推断方式是否与人类的推断方式相似产生了重大怀疑。对于我们的结果,模型如此善于从病态指令中学习的事实,同样使人怀疑模型是否以任何类似于人类理解指令的方式将prompts理解为指令。其他解释和未来方向:与任何外在的评价一样,准确率不能直接衡量
understanding。例如,一个人可以完全理解一个指令,但是由于任务本身太难(缺乏能力),或者由于他们出于某种原因忽略了指令(缺乏服从性),他们对指令性模板和不相关的模板的准确率仍然是一样的。我们在下面讨论这两种可能性。缺乏能力:这主要是对
zero shots下的non-instruction-tuned模型的关注,所有模型的表现都只略高于随机猜测,因此,模板类别之间缺乏统计学意义,对于模型是否缺乏对NLI指令的理解、以及模型是否缺乏NLI任务本身的能力是模糊的。这就是为什么我们的研究主要集中在few-shot setting,在这种情况下,缺乏能力就不那么令人担忧了,因为模型确实有能力达到良好的准确率,只是适度低于SOTA的non-few-shot模型。对
NLI指令的理解:知道 “指令” 的含义。NLI任务本身的理解:知道NLI任务是怎么做。另一个反驳是,也许从来没有模型真正推理出一个
premise是否蕴含一个hypothesis。也许它们只是利用了虚假的或启发式的特征,而且,如果它们能够正确地推理出蕴含关系,那么NLI指令的含义就会很重要。这个论点是可能的,不过:首先,它取决于
NLI(或任何其他行为评估)能在多大程度上衡量语言理解,这是一个超出本文范围的复杂争论。其次,在初步实验中(附录
K),我们的模型实际上很好地zero-shot迁移到了HANS,一个旨在诊断模型使用NLI heuristics的数据集,效果相当好。因此,模型不太可能在推理蕴含关系方面完全无能而只依赖启发式方法。
无论如何,进一步区分理解任务指令的能力与理解任务本身的能力是未来工作的一个重要方向。
缺乏服从性:另一种解释是,不相关的
prompts与指令性的prompts表现相同,因为模型只是完全忽略了这些prompts。然而,仅仅是缺乏服从性并不能解释我们的结果。如果模型真的忽略了这些prompts,我们就不应该看到任何类别的prompts之间有任何系统性的差异。相反,我们确实看到了一致的模式,即指令性模版和不相关的模板使模型的学习速度明显快于误导性模板和空模板(Table 2)。一个更细微的反驳是,尽管模型没有完全忽视他们的
prompts,但也许模型"takes less effort"从而使用虚假特征或启发式特征进行预测,而不是正确遵循指令所需的更复杂的句法特征或语义特征(《Predicting inductive biases of pretrained models》、《Learning which features matter: RoBERTa acquires a preference for linguistic generalizations (eventually)》)。然而,仅靠虚假的特征同样不能解释观察到的性能差距。回顾一下,在每个随机种子中,所有的模型都看到完全相同的训练样本(具有相同的虚假特征)。因此,就模型对某些prompts的表现与其他prompts不同而言,这可能是由于prompts中的(虚假的或语义的)特征与数据样本中的虚假的特征之间的一些复杂的交互。这种交互的一个可能的例子是,标点符号对irrelevant模板有很大的影响,但有指令性的模板似乎能够抑制这种影响(附录A)。调查这种交互的性质是未来工作的一个有希望的方向,它提出了一种prompt的语义可能重要的方式,例如,通过影响模型的inductive bias,即使模型不以人类的方式解释或使用指令。
七、How Many Data Points is a Prompt Worth[2021]
论文:
《How Many Data Points is a Prompt Worth?》
pretrained模型用于分类任务的主要方法是通过显式的classifier head进行微调。然而,另一种方法已经出现:通过自回归文本生成、或完形填空任务完成来直接将pretrained语言模型调整为predictor。这种方法在T5微调中被广泛使用,取得了SuperGLUE基准测试的SOTA结果。直接的
language generation进行分类的一个观点是,它允许我们为每个任务选择自定义的prompts。这种方法可以用于zero-shot分类或priming,在低数据情况下,它也可以在微调中提供额外的任务信息给classifier。如果这个观点确实成立,那么自然会问它对模型的样本效率(
sample efficiency)有什么影响,或者更直接地说,一个prompt价值多少个数据点?与许多低数据和pretraining-based的问题一样,这个问题在微调设置、训练过程、以及prompts本身的影响下变得复杂。我们通过使用多样的prompts、多次运行、以及低训练数据微调的最佳实践,从而来分离这些变量。我们引入了一个度量标准,即平均数据优势(average data advantage),来量化prompt在实践中的影响。我们的实验发现,
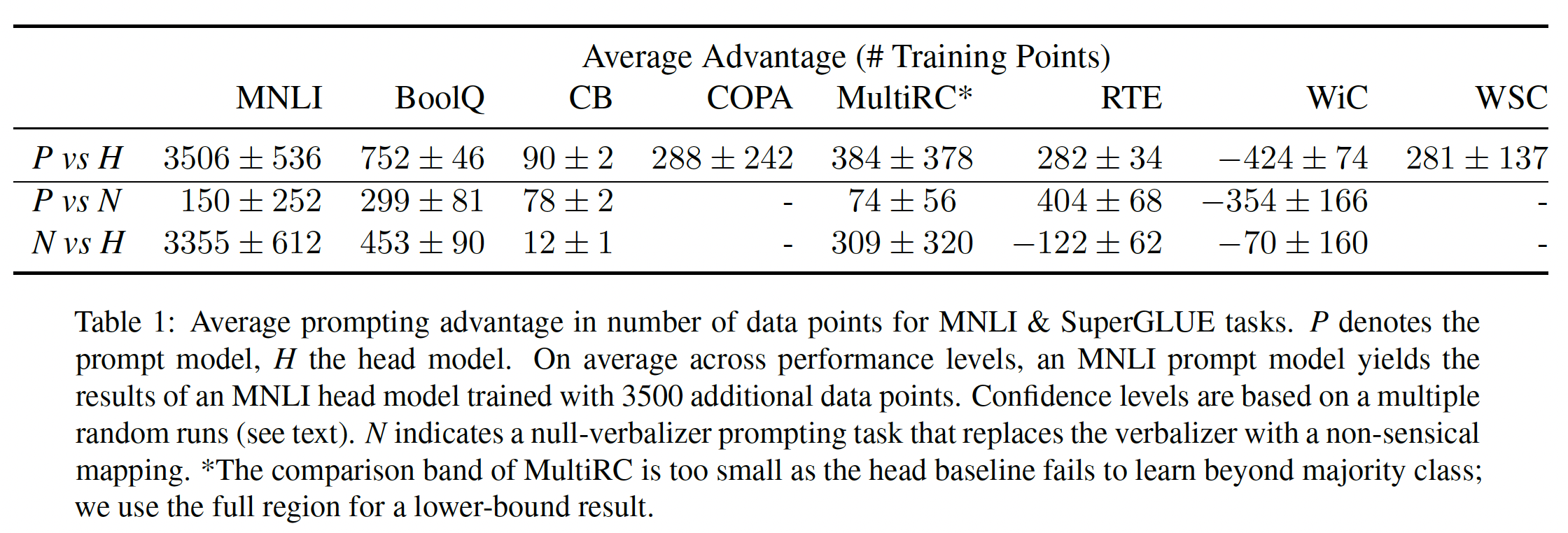
task-targeted prompting的影响可以很好地用直接训练数据来量化,并且在不同任务的性质上存在差异:在
MNLI上,我们发现使用一个prompt大约相当于增加了3500个数据点。在
SuperGLUE上,在RTE上一个prompt大约相当于增加了大约280个数据点、在BoolQ上相当于增加了750个数据点。
在低到中等数据量的情况下,这种优势可以对模型的训练作出实质性的贡献。
相关工作:
prompting已经在基于zero-shot和基于微调方法中被使用过。zero-shot方法试图通过generation利用prompt而无需通过微调来回答一个任务(GPT-2)。GPT-3将这种方法扩展为一种supervised priming方法,通过将训练数据作为priming在推理时使用,以便在回答问题时能够关注它们。T5和其他sequence-to-sequence的pretrained模型使用带有marker prompt的标准的word-based的微调来回答分类任务,并取得了强有力的实验成功。
我们的设置与此不同,我们对使用
task-based prompts and finetuning感兴趣,介于T5和GPT-2之间。我们的设置与
PET最为相似,它声称task-specific prompting有助于迁移学习,特别是在低数据情况下。然而,为了在SuperGLUE上获得最佳结果,PET引入了几个其他扩展:通过额外的pseudo-labeled data进行半监督学习、使用多个不同prompts来训练的模型进行ensembling,并将ensemble蒸馏为线性分类器而不是语言模型。我们的目标是在
supervised fine-tuning中分离出prompting的具体贡献。最后,最近的论文实验了通过针对语言模型进行自动化流程来发现
prompts的方法(LPAQA、《Automatically identifying words that can serve as labels for few-shot text classification》)。我们限制自己使用人工编写的prompts,因为我们想要确定prompting本身是否对supervised task增加了信息。关于automatic prompts是否能够产生相同的影响,这是一个有趣的问题。
7.1 实验设置
考虑文本分类的两种迁移学习设置:
head-based:采用一个通用的head layer接受pretrained representations并预测输出类别。prompt-based:采用一个task-specific pattern字符串,以引导模型生成与给定类别相对应的文本输出。
这两种方法都可以用于使用监督训练数据进行微调,但
prompts进一步允许用户自定义pattern以帮助模型。注意:
prompt-based微调是采用PET的方案,即微调LM head从而适配prompt。而
head-based方案是微调LM head从而适配label(通常是0/1之类的class编号)。对于
prompt model,我们遵循PET中的符号,并将prompt分解为pattern和verbalizer。pattern将输入文本转化为完形填空任务,即一个带有单个或多个masked tokens(这些tokens需要被任务所填充)的序列。masked word prediction被映射到一个verbalizer,它生成一个class(如,"Yes"映射到True、"No"映射到False)。对于同一个任务,可以使用多个pattern-verbalizer pairs: PVPs,它们之间可以在pattern、verbalizer、或者pattern and verbalizer上有所差异。微调是通过训练模型生成正确的
verbalization来完成的。损失函数是正确答案与verbalizer中各tokens的概率分布之间的交叉熵损失。我们复用了PET-2中的pattern choices,示例可在附录A中找到。我们使用相同的
pretrained checkpoint(roberta-large,包含355M参数)来运行所有实验,我们从transformers library中加载它。根据先前的观察,head-based fine-tuning性能存在相当大的变化。我们遵循《On the stability of fine-tuning bert: Misconceptions, explanations, and strong baselines》和《Revisiting few-sample bert fine-tuning》的建议,在低学习率(steps(至少250步,可能超过100 epochs)。我们在
SuperGLUE和MNLI上进行评估。这些数据集包含各种任务,都是英文的,包括entailment任务(MNLI,RTE,CB),多项选择问答任务(BoolQ,MultiRC)、常识推理任务(WSC,COPA,WiC)。我们不将ReCoRD纳入比较范围,因为它已经是一个完形填空任务,没有head-based模型可供比较。数据大小从CB的250个数据点到MNLI的392702个数据点。由于SuperGLUE任务的测试数据不公开,我们保留一部分训练数据(从CB、COPA和MultiRC的50个数据点,到BoolQ的500个数据点)用于dev,并在它们的原始验证集上进行评估。对于MNLI,我们使用可用的对应的验证集和测试集。我们在可用数据的规模上比较模型,从
10个数据点开始指数级增加(因为高数据性能往往饱和)直到完整数据集。例如,对于MultiRC,初始数据点为969个,我们首先保留50个数据点用于dev。这样,我们就有了919个训练数据点,并且我们使用10、15、20、32、50、70、100、150、200、320、500、750、919个训练数据点来训练模型。我们每个实验运行4次以减小方差,总共在所有任务中进行了1892次training runs。在每个点上,我们报告了在该数据量或更低数据量下达到的最佳性能。完整的图表可在附录B中找到。
7.2 实验
Figure 1展示了使用head-based fine-tuning与具有最佳性能pattern的prompt-based fine-tuning之间进行对比的主要结果。除了WiC任务外,prompting在每个任务上都具有显著优势,这与之前的结果(PET-2)报告的结果一致。随着更多的训练数据,两种方法都有所改进,但prompting始终更好,优势的大小各不相同。SuperGLUE中的许多任务具有相对较少的数据点,但在像BoolQ和MNLI这样的大型数据集中我们也看到了优势。为了量化
prompts值得多少数据点,我们首先确定两条曲线在准确率上匹配的最低准确率和最高准确率的y轴的条带。在这些点的水平线表示prompting的优势。然后我们计算该区域的积分,即线性插值曲线之间的面积,除以条带的高度。面积的维度为数据点的数量乘以度量单位,因此除以性能范围就得到了数据点的优势数量。由于low data training对噪声敏感,除了遵循最佳训练实践外,我们对每个bootstrapping来估计这些runs的置信度。具体来说,我们hold out4 head runs和4 prompt runs(共16个组合)中的一个,并计算这些结果的标准差。我们将这些数量报告在
Table 1中作为平均优势。对于几乎所有的任务,我们可以看到prompting在数据效率方面具有显著的优势,平均而言相当于增加了数百个数据点。两条曲线之间的面积,单位是
data point * accuracy。这个面积除以highest acc - lowest acc就得到数据点的数量。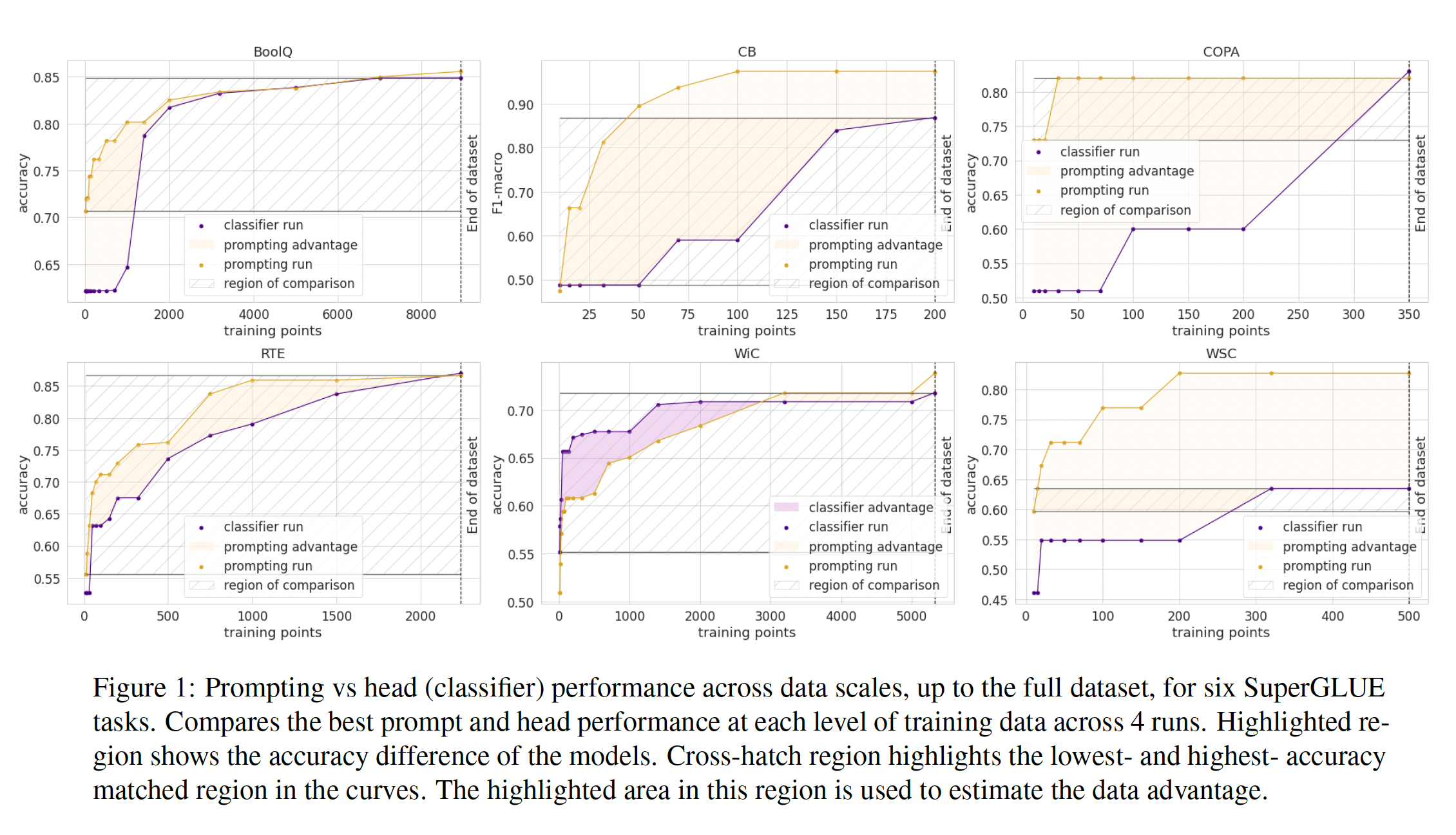
分析:
Impact of Pattern vs Verbalizer:prompts的直觉是,即使只有很少的训练数据,它们也能以自然语言形式引入任务描述。为了更好地理解prompts的zero-shot和自适应特性,我们考虑了一个null verbalizer,这是一个对照组,其中的verbalizer没有经过训练因此无法提供语义信息。对于每个需要填充一个单词的任务(不包括更自由形式的COPA和WSC),我们将verbalizers(例如"yes", "no", "maybe", "right" or "wrong")替换为随机的名字 。这里的
null verbalizer就是《Do Prompt-Based Models Really Understand the Meaning of Their Prompts?》中的arbitrary targets。Table 1显示了标准的prompts相对于null verbalizer的优势。我们发现对于像CB这样的小数据任务,null verbalizer削弱了prompts的许多好处。然而,随着更多的训练数据,模型似乎适应了verbalizer,同时仍然获得了pattern的inductive bias优势。Figure 2展示了在MNLI上的这种dynamic。这个结果进一步表明,即使它与训练的generation过程不是直接类似,prompting仍然能够提供data efficiency。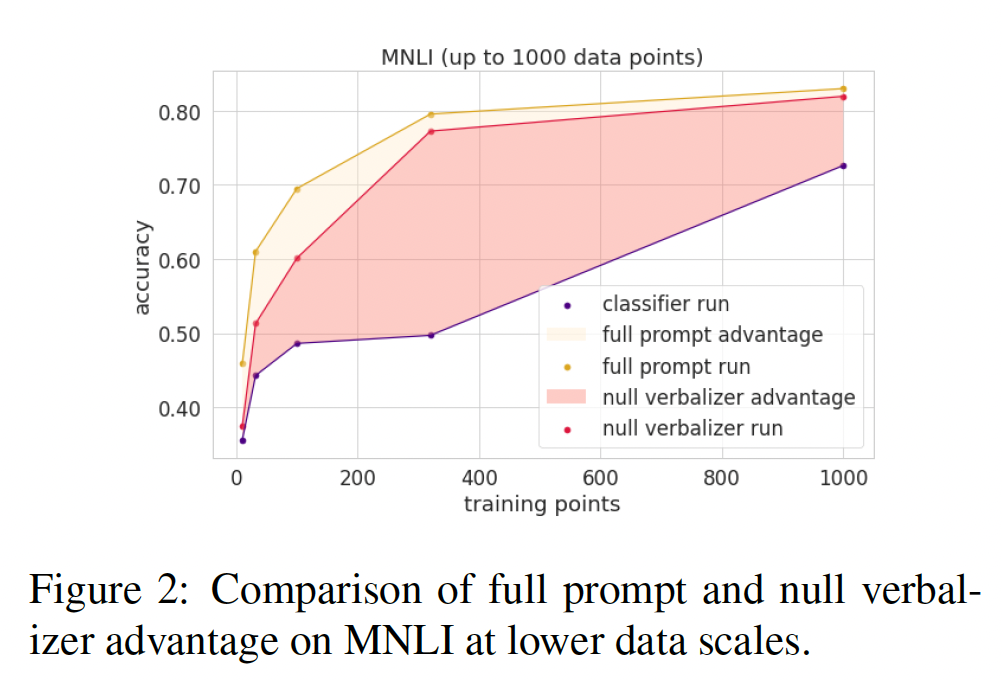
Impact of Different Prompts:如果prompt作为任务的描述,人们会期望不同的有效描述有不同的好处。为了比较我们在每个任务上使用的不同prompts,我们绘制了每个prompt在不同runs中的中位数性能。在几乎每个实验中,我们发现这些曲线的置信区间在很大程度上重叠,这意味着prompt choice不是一个主要的超参数,即随机种子之间的方差通常超过了prompt choice的可能好处。唯一的例外是BoolQ的低数据区域,在这个区域内,其中一个prompt相对于其他prompts具有显著的few-shot优势。我们在Figure 3中绘制了MultiRC的这条曲线,其余曲线见附录C。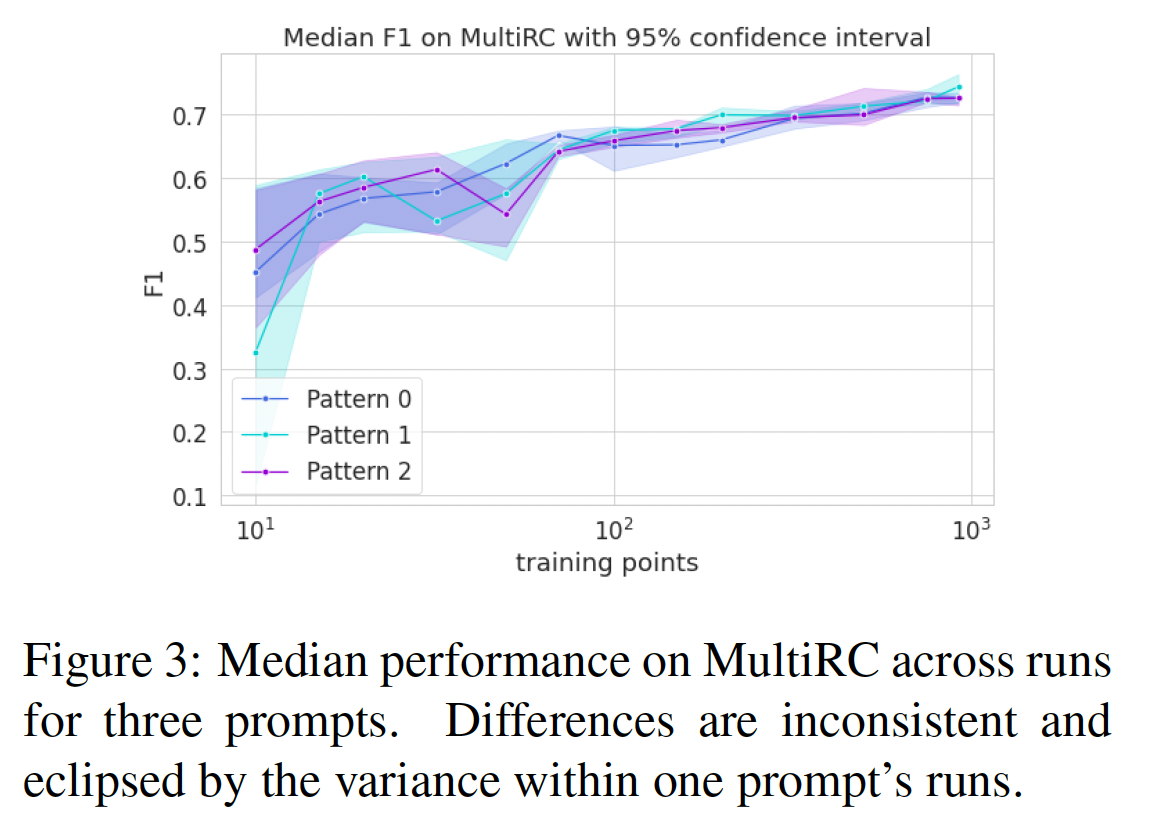
指标敏感性:在计算
advantage时,我们线性地处理每个指标;或者,我们可以为每个任务重新参数化y轴。这个选择对于prompting没有一致的影响。例如,强调接近收敛的gain会增加CB和MNLI上的prompting advantage,但会减少COPA或BoolQ上的prompting advantage。
八、Rethinking the Role of Demonstrations[2022]
论文:
《Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?》
大型语言模型能够执行
in-context learn:通过对少量的(input, label) pair(即,demonstrations)进行调节(conditioning)并对新的输入进行预测,从而仅仅通过inference来执行一项新的任务。然而,人们对模型如何学习、以及demonstrations的哪些方面有助于最终的任务表现了解甚少。在本文中,我们表明,有效的
in-context learning其实并不需要ground truth demonstrations。具体来说,在一系列分类任务和多项选择任务中,用随机标签取代demonstrations中的标签几乎不会损害性能(Figure 1)。这一结果在包括GPT-3系列在内的12种不同的模型中是一致的。这强烈地表明,违背直觉地,该模型并不依赖demonstrations中的input-label mapping来执行任务。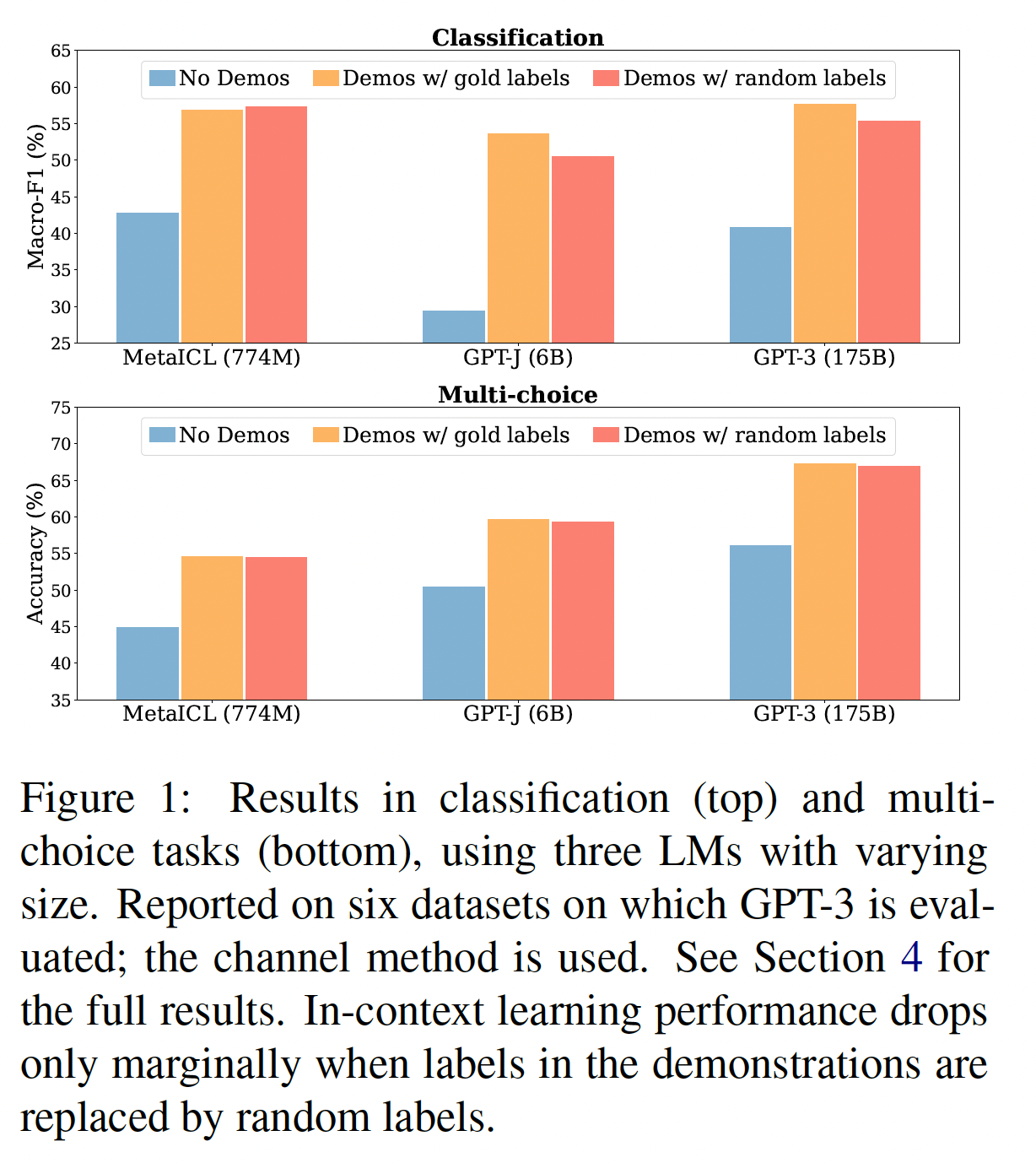
进一步的分析调查了
demonstrations的哪些部分确实对性能有贡献。我们确定了demonstrations的可能方面(例如,label space和输入文本的分布),并评估了一系列demonstrations的变体,以量化每个变体的影响。我们发现:demonstrations所指定的label space、以及输入文本的分布都是in-context learning的关键(不管标签对单个输入是否正确)。指定整体格式也很关键,例如,当
label space未知时,使用随机的英语单词作为标签明显优于不使用标签。带
in-context learning objective的meta-training(MetaICL)放大了这些效果:模型几乎只利用了demonstrations的较简单方面(如格式),而不是input-label mapping。
总之,我们的分析提供了一种理解
demonstrations在in-context learning中的作用的新方法。我们的经验表明:模型反直觉地并不像我们想象的那样依赖于
demonstrations中提供的ground truth input-label mapping。但是模型仍然受益于对
label space、以及输入分布(这二者都由demonstrations指定)的了解。
《Do Prompt-Based Models Really Understand the Meaning of Their Prompts?》的结论,即:模型对target words非常敏感,而模板则不那么重要。在本文中,作者不考虑模板而是直接拼接样本,所以这里的 ”输入分布“ 就是样本的分布;作者固定了
target words,同时考虑在label space内部随机分配标签(而不是在词表空间中随机分配target words)。相关工作:大型语言模型一直是在广泛的下游任务中表现强劲的关键。虽然微调一直是迁移到新任务的流行方法(
BERT),但微调一个非常大的模型(如10B参数)往往是不切实际的。GPT-3提出in-context learning作为学习新任务的另一种方式。如Figure 2所示,语言模型仅通过推理来学习一个新的任务,通过以demonstrations为条件(demonstrations是通过拼接训练样本而来),没有任何梯度更新。in-context learning自推出以来一直是重要的研究焦点。之前的工作提出了更好的问题表述方式、更好的选择标记样本从而用于demonstrations、带有显式的in-context learning objective的meta-training、以及学习follow instructions从而作为in-context learning的变种。同时,一些工作报告了in-context learning的脆弱性和过度敏感性。相对来说,在理解为什么
in-context learning有效方面做的工作较少。《An explanation of in-context learning as implicit bayesian inference》提供了理论分析,认为in-context learning可以被形式化为贝叶斯推断,利用demonstrations来恢复潜在的概念。《Impact of pretraining term frequencies on few-shot reasoning》表明,in-context learning的表现与预训练数据中的term频率高度相关。
据我们所知,本文是第一篇提供实证分析的文章,研究了为什么
in-context learning比zero-shot inference取得了性能提升。我们发现,demonstrations中的ground truth input-label mapping只有很小的影响;我们还衡量了demonstrations中更细粒度的方面的影响。
8.1 实验配置
模型:我们总共实验了
12个模型。我们包括6个语言模型(Table 1所示),它们都是decoder-only、稠密的语言模型。 我们遵从Channel Prompt Tuning的做法,将每个语言模型用两种推理方法,即direct和channel。语言模型的大小从774M到175B不等。我们包括在进行实验时最大的稠密语言模型(GPT-3)和最大的公开发布的稠密语言模型(fairseq 13B)。我们还包括MetaICL,它是从GPT-2 Large初始化的,然后在具有in-context learning objective的监督数据集集合上进行meta-train,并确保我们的评估数据集与meta-training时使用的数据集不重叠。
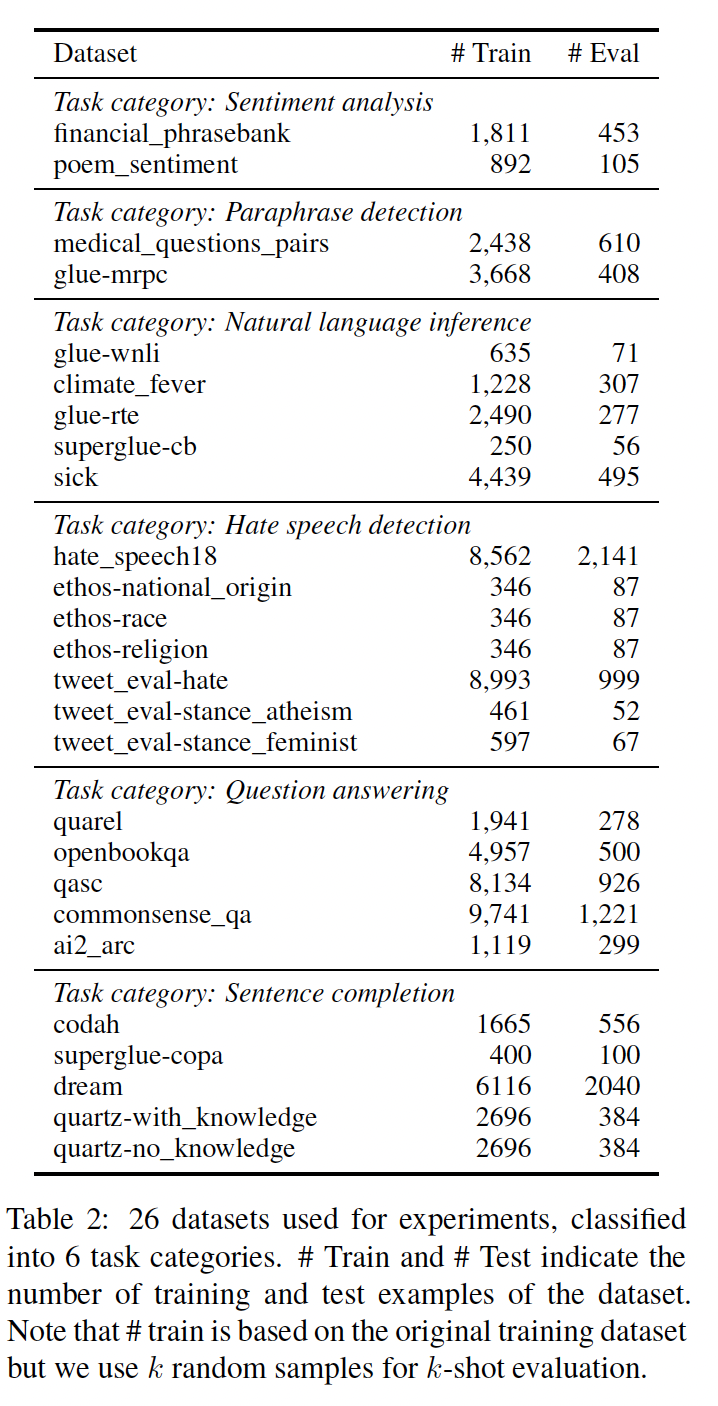
评估数据:我们在
26个数据集上进行评估,包括情感分析、转述检测、自然语言推理、仇恨言论检测、问答和句子补全,如下表所示。我们使用这些数据集是因为它们:是真正的低资源数据集,只有不到
1万个训练样本。包括
GLUE和Super-GLUE中经过充分研究的基准.涵盖了包括科学、社交媒体、金融等不同领域。
其它细节:
除非另有说明,我们在本文的所有实验中默认使用
demonstrations。根据经验,不同的
样本是在训练数据中均匀采样的。
我们使用
5个不同的随机数种子选择一组5次。对于
fairseq 13B和GPT-3,由于资源有限,我们用数据集的一个子集和3个随机种子进行实验。我们报告了分类任务的
Macro-F1和多项选择任务的Accuracy指标。我们计算每个数据集的所有种子上的平均数,然后报告数据集的macro-average。我们使用
minimal templates,从一个样本中形成一个输入序列(即,没有添加除了样本的input text和label之外的任何文本),如Figure 2所示。即,这里没有采用任何
prompt文本。作者对不同的模板也提供了消融分析。
更多细节请参考附录
B。所有的实验都可以从github.com/Alrope123/rethinking-demonstrations中重复进行。
8.2 Ground Truth 不重要
8.2.1 Gold labels vs. random labels
为了了解
demonstrations中正确配对的inputs and labels的影响(我们称之为ground truth input-label mapping),我们比较了以下三种方法:No demonstrations:一种典型的zero-shot方法,不使用任何标记数据。预测是通过test input,Demonstrations w/ gold labels:一种典型的in-context learning方法,使用了input-label pairs拼接起来进行预测。Demonstrations w/ random labels:用随机标签而不是来自gold labels数据的gold labels而形成的。每个注意:这里的随机标签指的是从
label space中随机采样的,而不是任意的、从词表中随机采样的文本。
实验结果如
Figure 3所示。首先,使用
demonstrations with gold labels,比no demonstrations的性能明显提高,这在之前的许多工作中一直被发现。其次,我们发现,用随机标签替换
gold labels只会对性能造成轻微的损害。这一趋势在几乎所有的模型上都是一致的:性能下降的绝对范围是0-5%。在多项选择任务中替换标签的影响(平均1.7%)小于分类任务(绝对2.6%)。这一结果表明,要想获得性能上的提高,并不需要
ground truth input-label pairs。这是反直觉的,因为在典型的监督训练中,正确配对的训练数据是至关重要的:它可以告知模型执行下游任务所需的预期的input-label对应关系。因此,这些模型在下游任务中确实取得了非同寻常的表现。这有力地表明,这些模型能够恢复任务的预期的input-label对应关系。然而,这种input-label对应关系并不是直接从demonstrations中的配对中得到的。同样值得注意的是,
MetaICL的性能下降特别少:绝对值为0.1-0.9%。这表明,带有显式的in-context learning objective的meta-training实际上鼓励模型基本上忽略了input-label mapping,而利用了demonstrations中的其他部分。
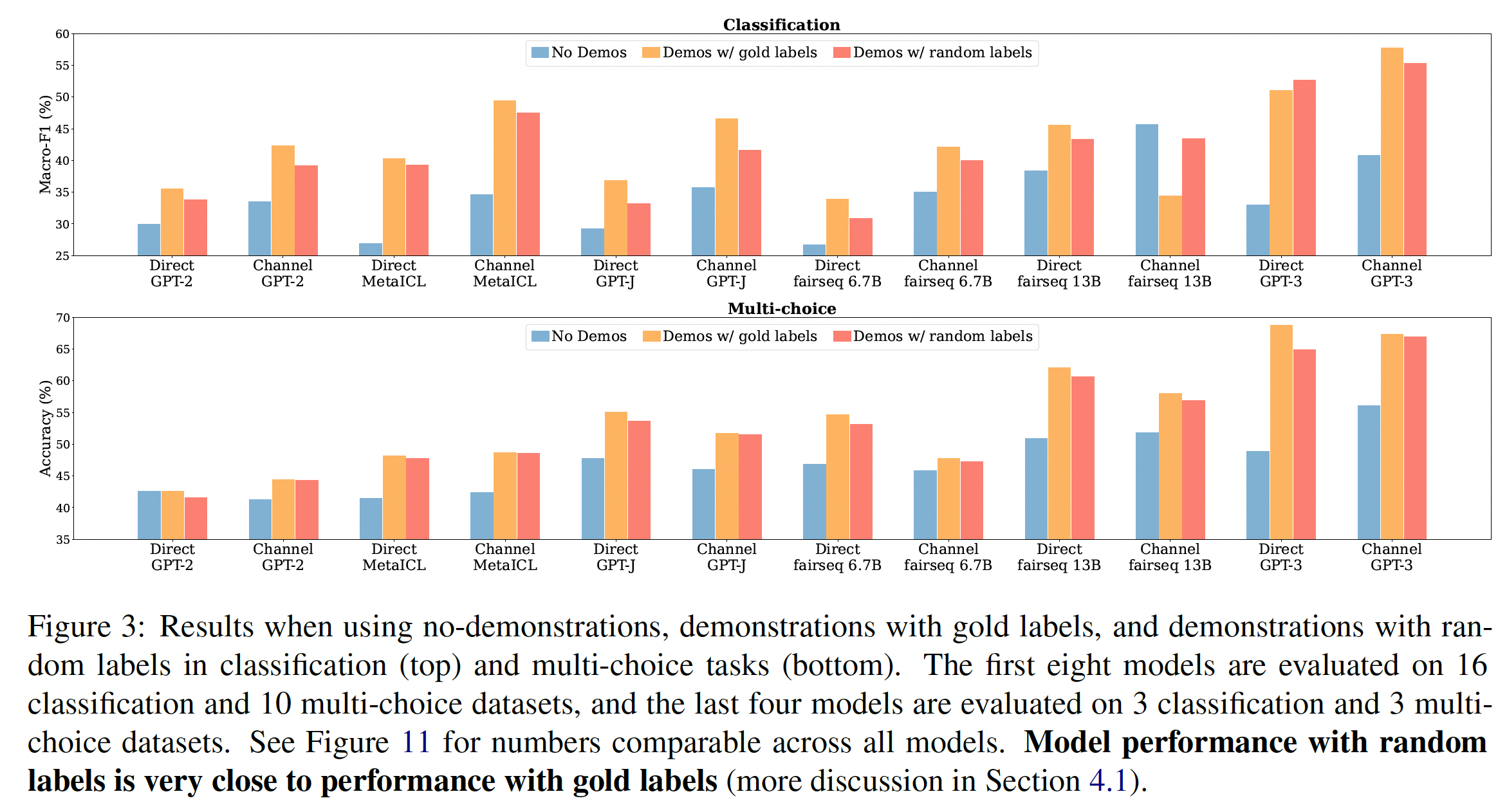
下图是所有模型都是在
3个分类任务和3个多项选择任务上评估的,因此可以相互比较。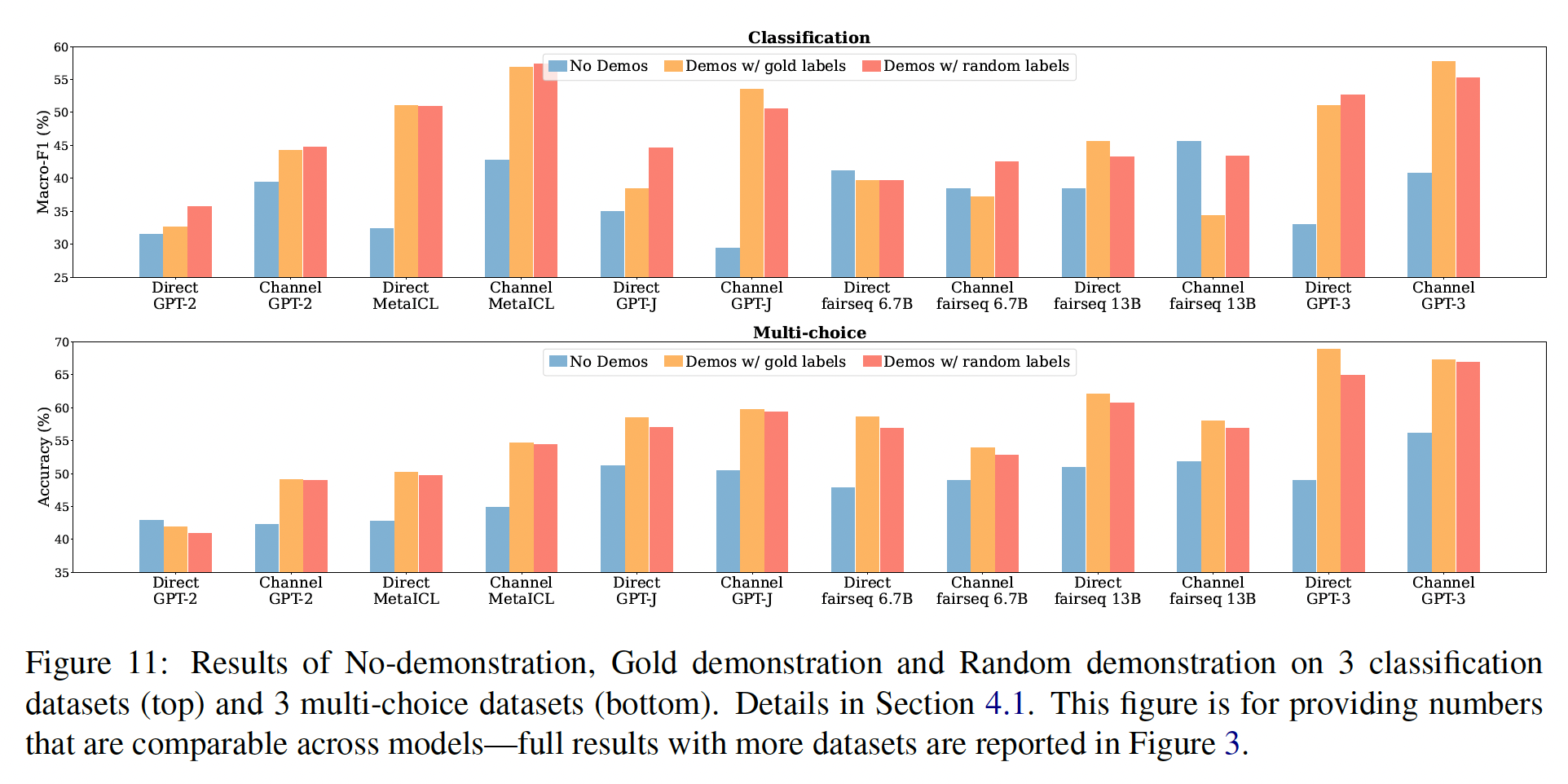
在附录
C.2(如下图所示)中,我们提供了额外的结果,显示:从标签的真实分布(而不是均匀分布)中选择随机标签,可以进一步缩小差距。
下图中,顶部两个子图表示均匀分布中采样、底部两个子图表示从真实分布中采样,纵轴表示与
demonstrations with gold labels的gap。趋势可能取决于数据集,尽管总体趋势在大多数数据集上是一致的。
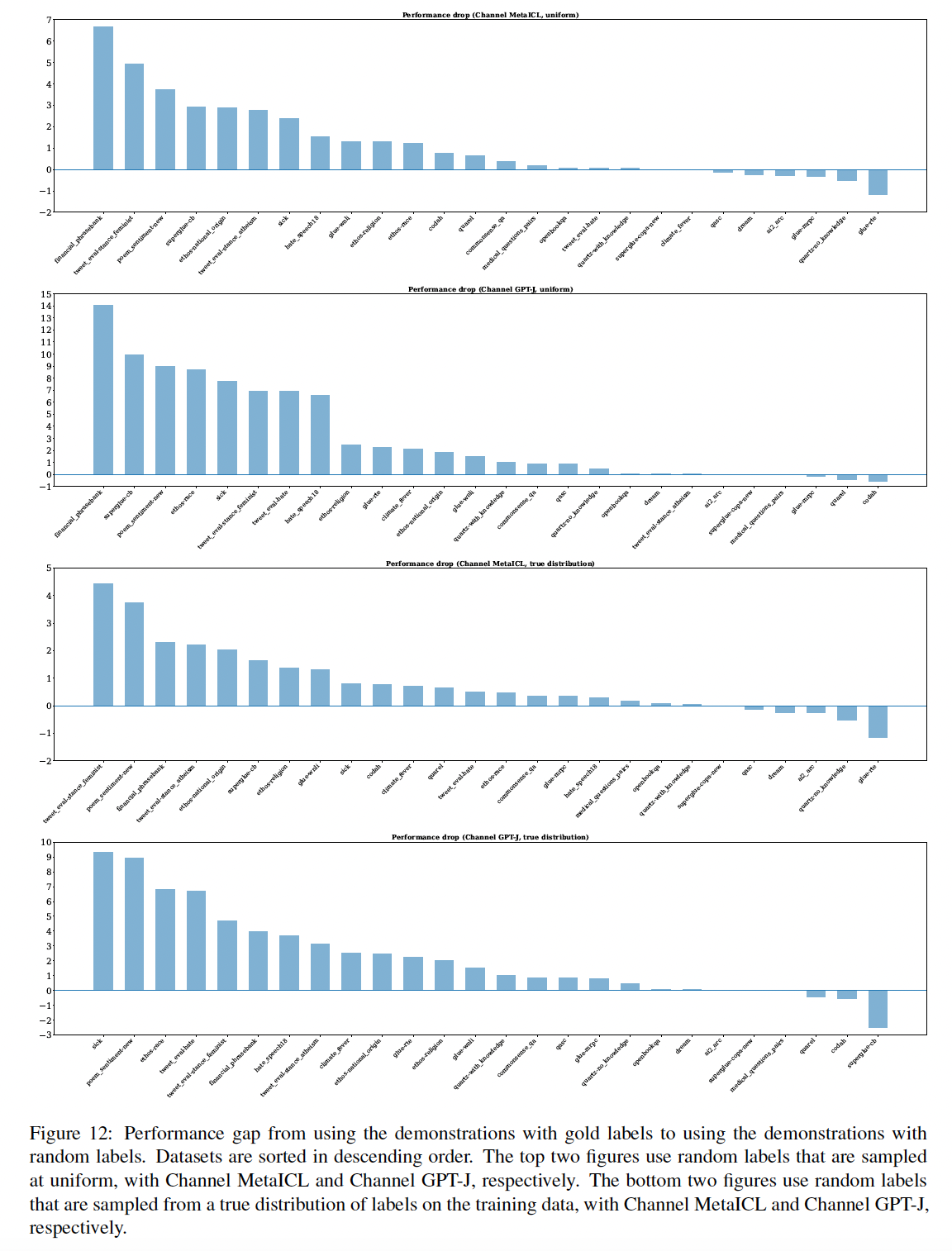
8.2.2 消融分析
对于消融分析,我们在
5个分类数据集、4个多项选择数据集上实验。正确标签的数量是否重要:为了进一步研究
demonstrations中标签的正确率的影响,我们通过改变demonstrations中正确标签的数量来进行消融分析。我们评估了 "有a%正确标签的demonstrations"(pairs、以及pairs(如Algorithm 1所示)。这里,in-context learning,即demonstrations w/ gold labels。即,

结果在
Figure 4中报告。模型性能对demonstrations中正确标签的数量相当不敏感。事实上,总是使用不正确的标签明显优于
no-demonstrations的情况,例如:在分类任务中使用MetaICL、在多项选择任务中使用MetaICL、在多项选择中使用GPT-J,分别得到了92%, 100%, 97%的改进。相比之下,分类任务中的
GPT-J在更多的错误标签下性能下降相对明显,例如,当总是使用错误的标签时,性能下降近10%。不过,总是使用不正确的标签还是明显好于no demonstrations的情况。

这个结果是否在不同的
demonstrations中input-label pairs的数量(Figure 5中报告。首先,即使在小
demonstrations也明显优于no demonstrations的方法,而且在不同gold labels到使用random labels的性能下降始终很小,在0.8 -1.6%之间。demonstrations优于no demonstrations的方法,数据在哪里?作者没有说明。有趣的是,当
gold labels还是使用random labels。这与典型的监督训练相反,在监督训练中,模型性能随着input-label对应关系,而数据的其他组成部分(如,样本输入、样本标签、数据格式)更容易从小数据中恢复,这有可能是较大的虽然
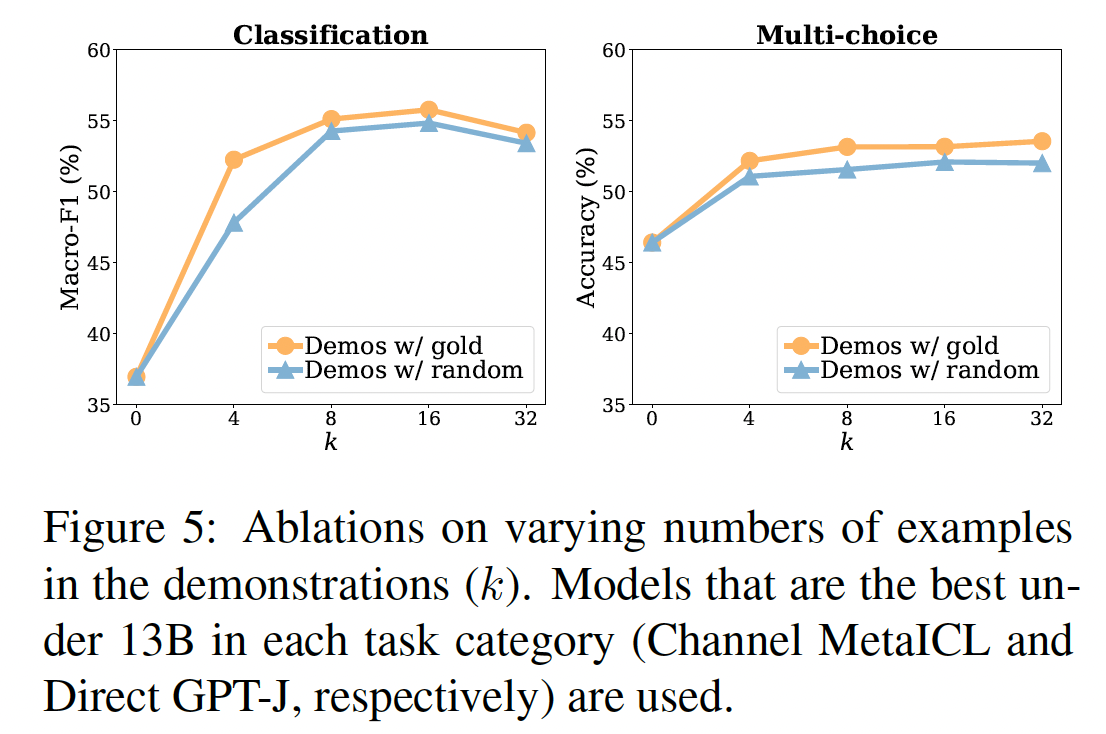
这个结果是否在更好的模版上保持一致:虽然我们默认使用
minimal templates,但我们也探索了手动模板,即以特定数据集的方式手动编写的模板,这些模板取自先前的工作(如Table 3所示)。Figure 6显示,这一趋势(即,用random labels替换random labels几乎没有损害性能)在手动模板上也是如此。值得注意的是,使用手动模板并不总是优于使用minimal templates。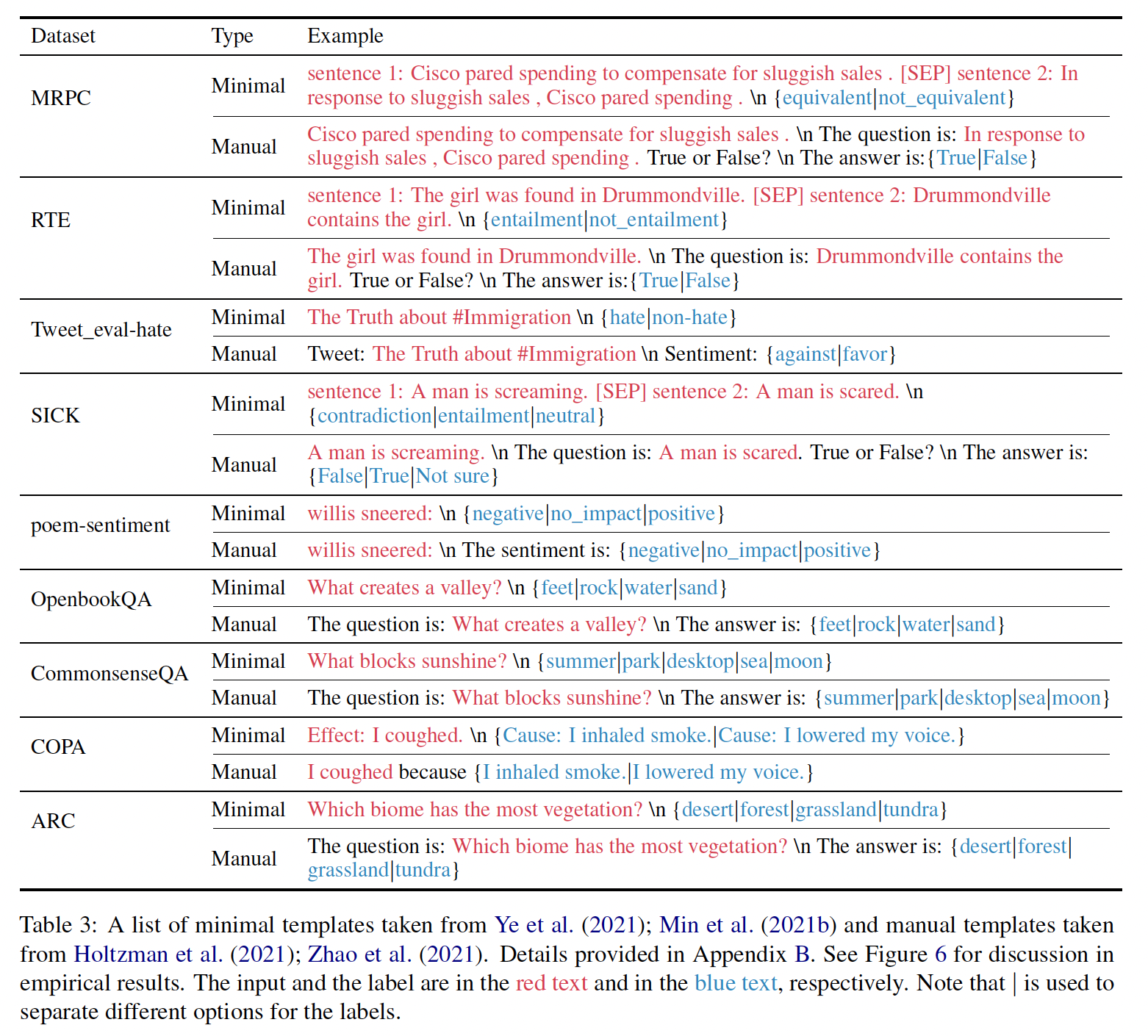
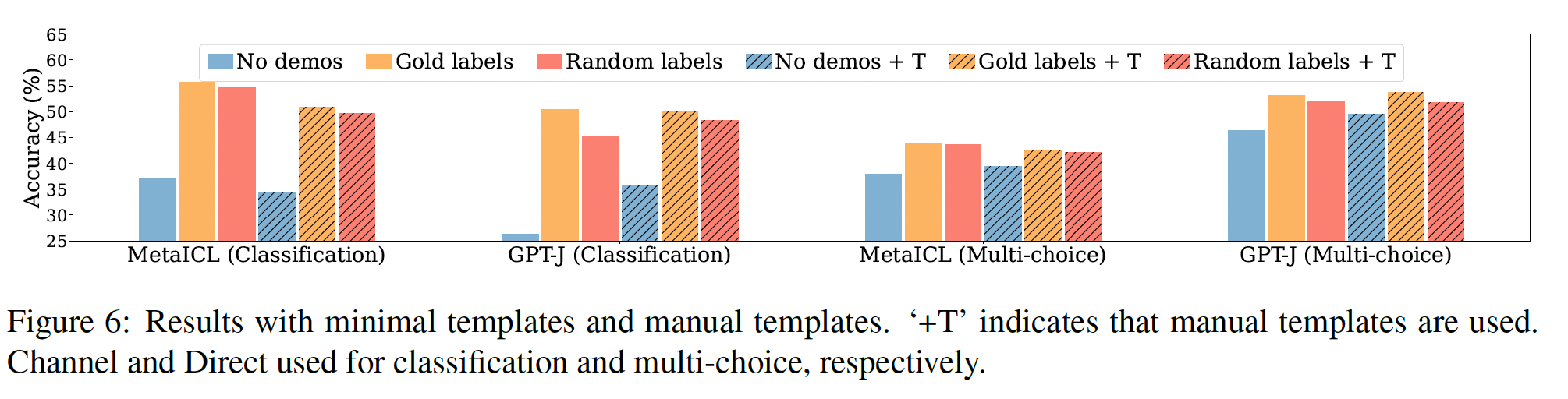
8.3 为什么 In-Context Learning 有效
如前所述,
demonstrations中的ground truth input-label mapping对in-context learning的性能提升影响很小。本节进一步研究了demonstrations中还有哪些方面导致了in-context learning的良好表现。我们确定了demonstrationslearning signal(如Figure 7所示)。input-label mapping:即每个输入输入文本的分布:即
label space:即格式:具体来说,就是使用
input-label pairing作为格式。

我们设计了一系列关于
demonstrations的变体,对每个方面的影响进行了单独量化。 然后,我们还讨论了具有in-context learning objective的meta-training所得到的模型的趋势。在所有的实验中,模型都在5个分类数据集和4个多项选择数据集上进行了评估。实施细节和实例演示分别见附录B和Table 4。
8.3.1 输入文本分布的影响
我们对
OOD demonstrations进行了实验,其中包括out-of-distribution: OOD文本,而不是来自unlabeled训练数据的输入。具体来说,从外部语料库中随机抽出一组demonstrations中取代demonstrations的label space、格式。结果如下图所示。当使用
Channel MetaICL, Direct GPT-J, Channel GPT-J时,无论是在分类任务还是多项选择任务中,使用OOD输入而不是来自训练数据的输入,都会使性能明显下降,绝对值为3-16%。在多项选择任务中使用Direct GPT-J的情况下,甚至明显比no demonstrations要差。Direct MetaICL是一个例外,我们认为这是meta-training的效果。这表明,
demonstrations中的in-distribution inputs极大地促进了性能的提高。这可能是因为以in-distribution text为条件使任务更接近于language modeling,因为在训练期间,语言模型总是以in-distribution text为条件。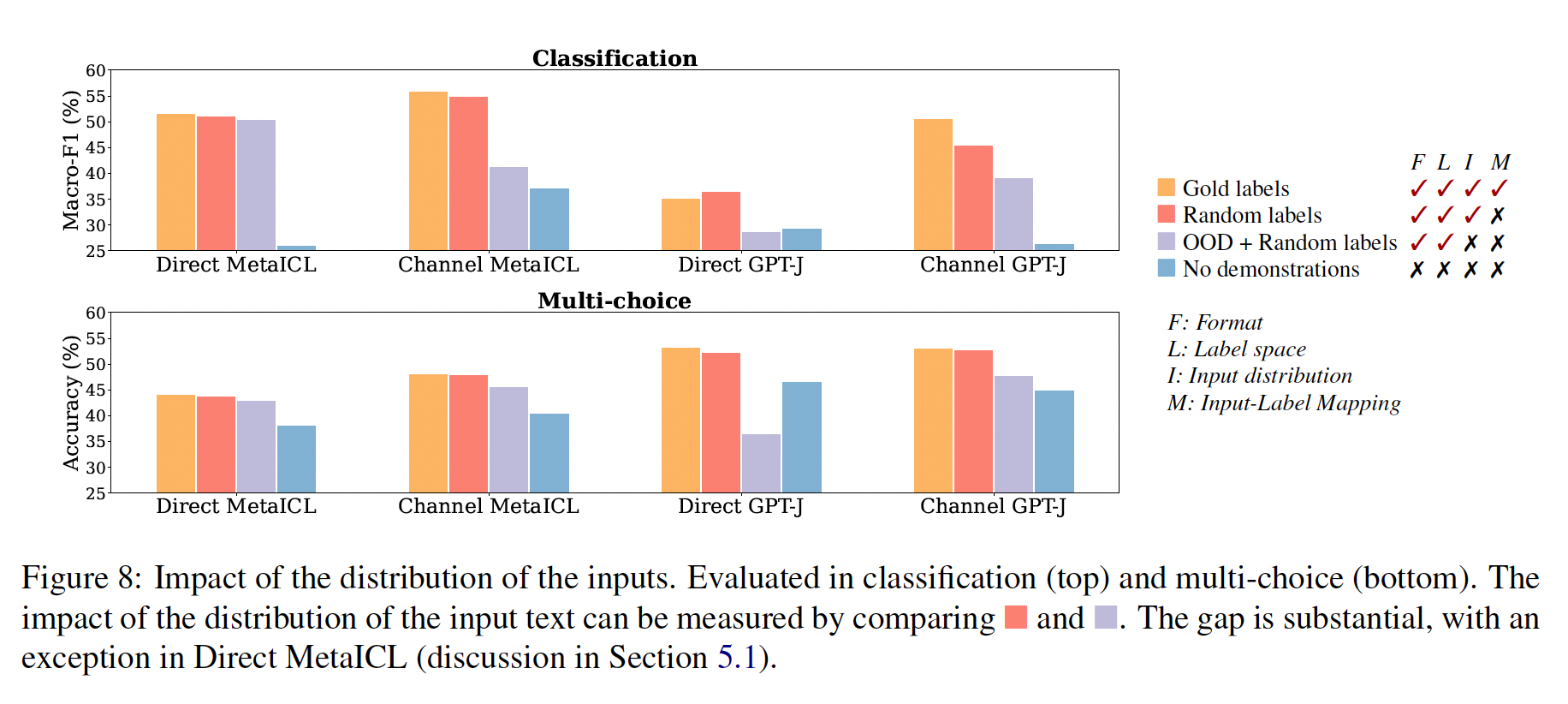
8.3.2 label space 的影响
我们还试验了使用随机英语单词作为所有标签的
demonstrations w/ random English words,用于所有pairs。具体来说,我们随机抽取英语单词的一个子集label space的影响,同时保持了demonstrations的input text分布、格式 。如下图所示,
direct模型和channel模型表现出不同的模式。对于
direct模型,在label space内使用随机标签、以及使用随机英语单词之间的性能差距是很大的,绝对值在5 - 16%之间。这表明,以label space为条件,大大有助于性能的提高。即使对于没有固定标签集合的多项选择任务也是如此。我们假设多项选择任务仍然有一个特定的choice分布(例如OpenBookQA数据集中的"Bolts"或"Screws"等对象)。另一方面,移除输出空间并没有导致
channel模型的显著下降:绝对值有0 - 2%的下降,有时甚至增加。我们假设,这是因为channel模型只以标签为条件,因此没有从了解label space中获益。这与direct模型相反,后者必须产生正确的标签。
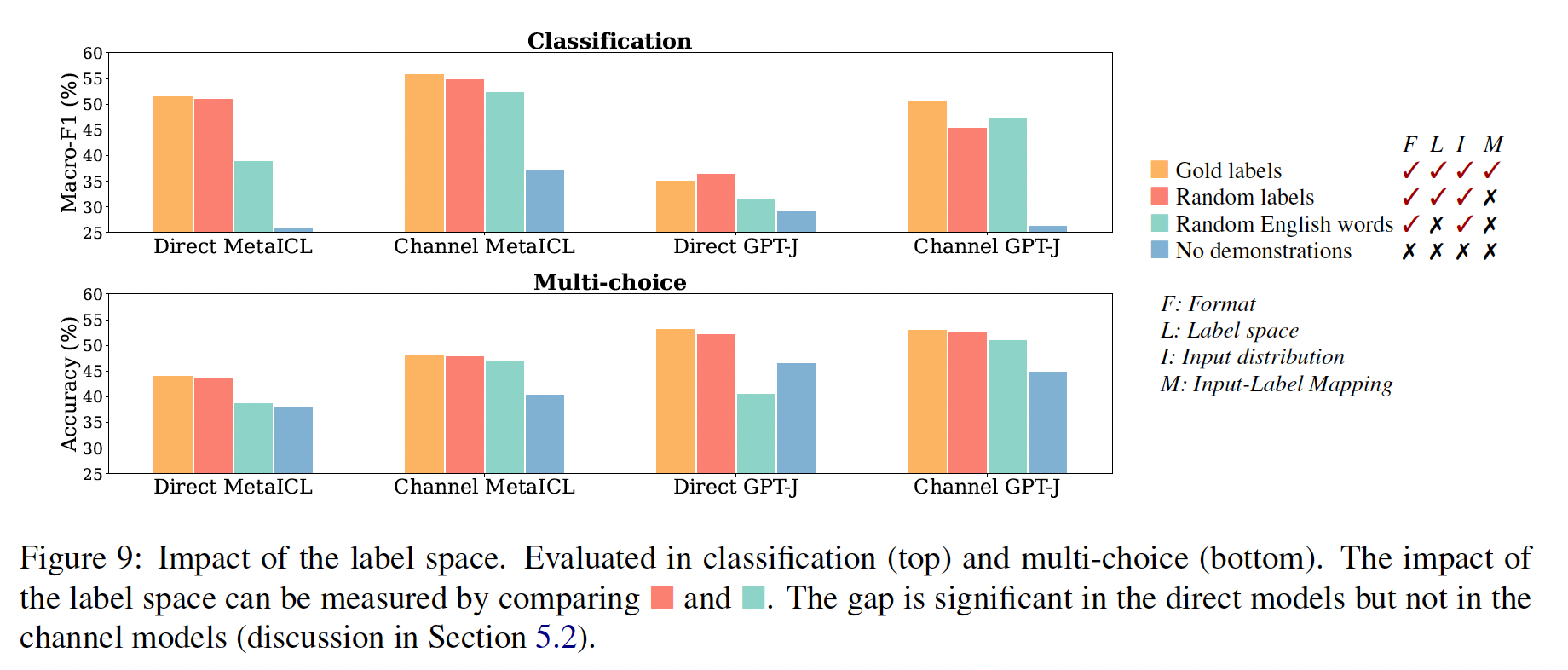
8.3.3 input-label pairing 的影响
前面重点讨论了尽可能保持
demonstrations格式的变体,这里我们讨论改变格式。虽然格式有很多方面,但我们只做了最小的修改,删除了输入到标签的配对。具体而言,我们评估了demonstrations with no labels,其中语言模型以demonstrations with labels only则以"demonstrations with random English words"和"demonstrations with OOD inputs"的no-format对应物。结果如下图所示。
移除格式的结果接近或不如
no demonstrations,表明格式的重要性。这可能是因为以input-label pairs的序列为条件,会触发模型模仿整体格式,并在给定test input时按照预期完成新的样本。更有趣的是,保持格式在保留很大一部分性能提升方面起着重要作用。 例如:
通过
Direct MetaICL, 在分类任务和多项选择任务中,通过简单地从语料库中随机抽取句子并将其与标签集合随机配对(如Figure 10),可以分别保留95%和82%的in-context learning(demonstrations with gold labels)的改进。同样,在
channel模型中,在MetaICL分类任务、GPTJ分类任务、MetaICL多选任务和GPT-J多选任务中,通过简单地将unlabeled训练数据中的每个输入与一个随机的英语单词配对,可以保留in-context learning(demonstrations with gold labels)中82%, 87%, 86%, 75%的改进。
对于所有这些情况,删除输入而不是使用
OOD输入,或者删除标签而不是使用随机英语单词,都会明显变差,说明保持input-label pairs的格式是关键。即使是将
OOD输入和随机标签进行配对,效果也优于No demonstrations。
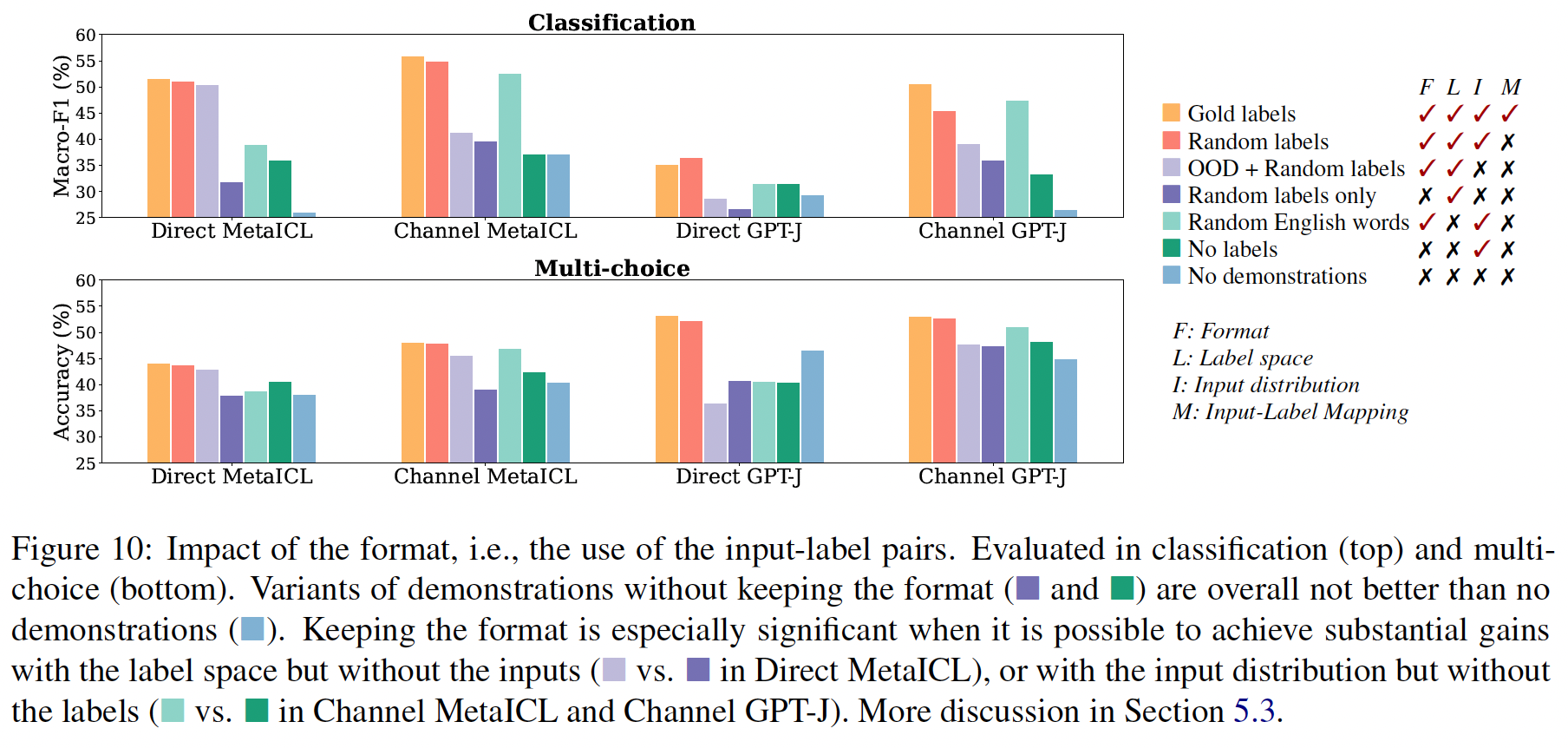
8.3.4 meta-training 的影响
与其他模型不同的是,
MetaICL的训练是以in-context learning objective来训练的,这与最近的工作一致,即在大量有监督的数据集上使用多任务训练(称为meta-training)来泛化到新任务。我们旨在通过仔细检查MetaICL的结果,更好地理解这种meta-training与我们的发现之间的关系。具体而言,我们观察到,到目前为止,我们看到的模式在
MetaICL中比在其他模型中明显更明显。例如,ground truth input-label mapping的影响更小,而保持demonstrations的格式则更重要。在Direct MetaICL中,input-label mapping和输入分布的影响几乎为零,而在Channel MetaICL中,input-label mapping和label space的影响则为零。如
Figure 10所示:在
Direct MetaICL中,(紫色的)OOD + Random labels的效果与Gold labels几乎相同。在
Channel MetaICL中,(浅绿色的)Random labels only的效果与Gold labels几乎相同。
基于这一观察,我们假设
meta-training鼓励模型只利用demonstrations中较简单的方面而忽略其他方面。这是基于我们的直觉:input-label mapping可能更难利用。demonstrations格式可能更容易利用。用于模型训练的
text space可能比用于模型的条件生成的text space更容易利用。
8.4 讨论
在本文中,我们研究了
demonstrations对in-context learning的成功所起的作用。我们发现,demonstrations中的ground truth input-label mapping比人们想象的要不重要得多:在demonstrations中用random labels取代gold labels,只稍微降低了性能。然后,我们确定了demonstrations中的一系列方面,并考察了哪方面对性能提升的实际贡献。结果显示:收益主要来自于
input space和label space的独立规范(independent specification)。如果使用正确的格式,模型仍然可以通过仅保留正确的输入分布、或仅保留正确的标签来保持高达
95%的性能收益。带有
in-context learning objective的meta-training放大了这些趋势。
总之,我们的发现导致了一系列关于
in-context learning的更广泛的指示,以及未来工作的途径。模型是否在测试期间学习:如果我们对学习做一个严格的定义,即,捕获训练数据中给出的
input-label对应关系,那么我们的发现表明,语言模型在测试期间不会学习新的任务。我们的分析表明,模型可能会忽略demonstrations所定义的任务,而是使用来自预训练的先验(prior)。然而,学习一个新的任务可以被更广泛地解释:它可能包括适应
demonstrations所建议的特定的输入、以及标签分布、以及格式,并最终得到更准确的预测。根据这种学习的定义,该模型确实从demonstrations中学习了任务。我们的实验表明,该模型确实利用了demonstrations的各个方面,并实现了性能的提升。语言模型的能力:模型在执行下游任务时,并不依赖
demonstrations中的input-label对应关系。这表明,模型仅从language modeling objective中学到了(隐式的)input-label对应关系,例如,将正面评论与"positive"一词联系起来。这与《Prompt programming for large language models: Beyond the few-shot paradigm》的观点一致,他们声称demonstrations是为了task location,执行任务的固有能力是在预训练时获得的。一方面,这表明
language modeling objective导致了强大的zero-shot能力,即使从朴素的zero-shot准确率上看来这并不总是明显的。另一方面,这表明,在
input-label对应关系尚未被语言模型所捕获到的任务上,in-context learning可能不起作用。这就引出了一个研究问题:如何在in-context learning不能解决的NLP问题上取得进展:我们是否需要一种更好的方法来抽取已经存储在语言模型中的input-label mappings、是否需要一种更好的语言模型objective的变体从而学习更广泛的任务语义、或者是否需要通过对标记数据的微调进行显式的监督。
与
instruction-following模型的联系:之前的工作发现,训练遵循任务的自然语言描述(称为instructions)并在推理时执行新任务的模型是有前景的。我们认为demonstrations和instructions对语言模型的作用基本相同,并假设我们的发现对instruction-following模型是成立的:instructions促使模型恢复它已有的能力,但并没有监督模型学习新的任务语义。T0已经部分地验证了这一点,他们表明模型的性能在不相关的指令、或误导性的指令下不会有太大的下降。我们把对instruction-following模型的更多分析留给未来的工作。大幅提高的
zero-shot性能:我们的一个关键发现是,通过简单地将每个unlabeled input与一个random label配对并将其作为demonstrations,有可能在不使用任何标记数据的情况下实现接近k-shot的性能。这意味着我们的zero-shot baseline level要比以前认为的高得多。未来的工作可以通过放宽获取unlabeled训练数据的假设来进一步提高zero-shot性能。注意:甚至用
OOD输入和随机标签进行配对,也能提升效果。局限性:
任务和数据集类型的影响:本文的重点是已有的
NLP基准中的任务,其中,这些任务有真实的自然语言输入。正如《Extrapolating to unnatural language processing with gpt-3’s in-context learning: The good, the bad, and the mysterious》所观察到的,具有更局限的输入的合成任务实际上可能更多地使用ground truth labels。我们通过研究多个
NLP数据集的平均性能来报告宏观层面的分析,但不同的数据集可能表现不同。附录C.2讨论了这方面的问题,包括发现在一些dataset-model pairs中,使用ground truth labels和使用random labels之间存在较大的差距(例如,在最极端的情况下,在使用GPT-J的financial_ phrasebank数据集上,绝对值接近14%)。自我们论文的第一个版本以来,《Ground-truth labels matter: A deeper look into input-label demonstrations》表明,使用否定的标签(negated labels)大大降低了分类的性能。我们认为,了解模型在多大程度上需要ground truth labels来成功地进行in-context learning是很重要的。扩展到
generation任务:我们的实验仅限于分类任务和多选任务。我们假设,在像generation这样的开放性任务中,ground truth output可能对in-context learning没有必要,但这要留待将来的工作。将我们的实验扩展到这类任务并不简单,因为它需要output的一个变体,该变体具有不正确的input-output对应关系,同时保持正确的output distribution(基于我们在前面的分析,这一点很重要)。
自我们论文的第一个版本以来,
《Text and patterns: For effective chain of thought, it takes two to tango》用chain of thought prompting进行了类似的分析,它产生了一个理由(rationale)来执行复杂任务(如数学问题)。他们表明,虽然在demonstrations中简单地使用一个随机的理由(例如,将不同的样本与同一个理由来配对)会显著降低性能,但其他类型的反事实理由(counterfactual rationales)(例如,错误的方程式)并没有像我们想象的那样降低性能。关于理由的哪些方面重要或不重要的更多讨论,请参考该论文。
九、Overcoming Few-Shot Prompt Order Sensitivity [2021]
论文:
《Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity》
大型预训练语言模型(
pretrained language model: PLM)在以适当的文本上下文为条件时表现出卓越的性能。也许最引人注目的是,当用一个由很少的训练样本组成的上下文来引导时,它们产生的文本分类结果可以与那些fully supervised models相媲美。这种few shot setting,通常被称为"In-context Learning"(GPT-3)。in-context learning的一个核心组成部分是作为上下文的文本prompt。构成一个prompt需要:使用模板进行文本线性化(text linearisation)、以及训练样本拼接(见Table 1的例子)。已经确定的是,模板的结构对性能有很大影响(Autoprompt、LM-BFF、PET2、LPAQA)。然而,据我们所知,没有工作研究过样本排序对In-context Learning成绩的影响。
也许与直觉相反的是,我们发现正确的样本顺序和正确的模板一样,可以产生很大的影响。从
Figure 1中可以看出,对于情感分类任务,一些排列顺序的性能(超过85%的准确率)与监督训练相当,而另一些排列顺序的性能接近于随机(约50%的准确率)。这种顺序敏感性(order sensitivity)在不同的模型中是普遍存在的,尽管增加模型的大小在一定程度上解决了这个问题,但对于一些具有数十亿参数的模型来说,这个问题仍然存在(Figure 1中的Subj任务)。
在我们的分析中,我们发现性能良好的样本顺序之间没有共同点,而且它们在不同的模型规模和任务中不能迁移。在一个
fully-supervised setting中,我们可以依靠一个验证集来选择样本顺序。然而,在验证集的规模非常有限、甚至不可用的few-shot setting中,这是不可取的。相反,我们利用语言模型的生成式特性来构建一个无标签的人工验证集,并将其称为probing set。由于probing set是无标签的,我们使用predicted label分布的统计量,并提出了entropy-based指标来衡量候选prompts的质量。实验结果显示,在所有不同规模(四个数量级)的PLM中,我们可以在11个不同的文本分类任务中实现平均13%的相对改进。总的来说,我们的贡献有以下几点:
我们研究了
In-context Learning的顺序敏感性,我们表明这对于在fews-hot learning下pretrained语言模型的成功至关重要。我们提出了一种简单的、
generation-based的探测方法,以识别性能良好的prompts,而不需要额外的数据。思路:既然没有验证集,那么让语言模型来自动生成一个验证集。
我们的
probing方法对不同规模的pretrained语言模型、以及不同类型的数据集普遍适用且有效,在广泛的任务中平均取得了13%的相对改进。
相关工作:
针对
NLP的Unified Interface Design:以前的工作大多集中在shared-parameters的模型上,对一些任务进行预训练,然后针对不同的任务进行微调,例如ELMo, BERT等。最终,得到多个task-specific的模型。一段时间以来,人们一直试图为
NLP任务设计一个统一的接口(《Ask meanything: Dynamic memory networks for natural language processing》、T5)。与这些工作并行,
GPT-2表明,在语言模型输入的末尾追加trigger tokens(例如"TL;DR")可以使语言模型表现得像摘要模型。语言模型的zero-shot显示了将NLP任务统一到language modelling框架中的潜力,在这个框架中,微调并不是获得良好性能的必要条件。此外,GPT-3表明,任务无关的few-shot性能可以通过扩大语言模型的规模而得到改善。它有时甚至可以与之前SOTA的微调方法竞争。针对
PLM的Prompt Design:prompt design的核心挑战是将训练数据(如果存在的话)转换成文本序列。大多数关于prompt design的工作集中在如何使prompts与语言模型更加兼容。《Language models as knowledge bases?》利用人工努力来设计自然语言句子,然后根据input context进行token prediction。然而,手工制作的模板需要大量的人力,很可能最终会出现次优的性能。最近的工作探索了自动模板构建:
PET2使用完形填空风格的任务来构建模板。LM-BFF使用外部语言模型来生成模板。AutoPrompt使用gradient-guided search来寻找性能最大化的模板。LPAQA使用一种基于挖掘的方法来自动创建多样化的模板。
Prompt Design的顺序敏感性:LM-BFF证明了基于微调的方法不像In-context Learning那样对顺序敏感。KATE利用一个标准规模的训练集,使用最近邻搜索来检索与特定测试样本最相关的训练样本。他们成功地检索到了相关的样本,并得出结论:在检索到这些样本后,它们在prompt中的顺序对性能几乎没有影响。虽然我们的研究与他们的研究有本质的区别,因为我们没有使用标准规模的训练集,但我们确实得出了相反的结论。
以前所有关于
prompt design的工作都集中在prompt的文本质量上,据我们所知,没有一个人详细研究过顺序敏感性。Few-shot Learning:《True few-shot learning with language models》评估了在没有验证集的情况下语言模型的few-shot能力。实验结果表明,以前的工作高估了语言模型在这种(真正的few-shot learning)环境下的few-shot能力。我们的工作则是利用语言模型的生成式特性来构建一个
probing set,而不依赖heldout样本。我们表明,我们的probing方法比依靠验证集要好,因此可以实现真正的few-shot learning。
9.1 方法
9.1.1 Order Sensitivity and Prompt Design
在这里,我们研究了排列顺序的性能与各种因素之间的关系。为了便于观察,我们使用
SST-2数据集中具有平衡标签分布的、由四个样本所组成的固定随机子集(指的是这个随机子集一旦确定下来就固定从而用于下游各种任务),并考虑所有24种可能的样本排列顺序。这一设置如下图中所示。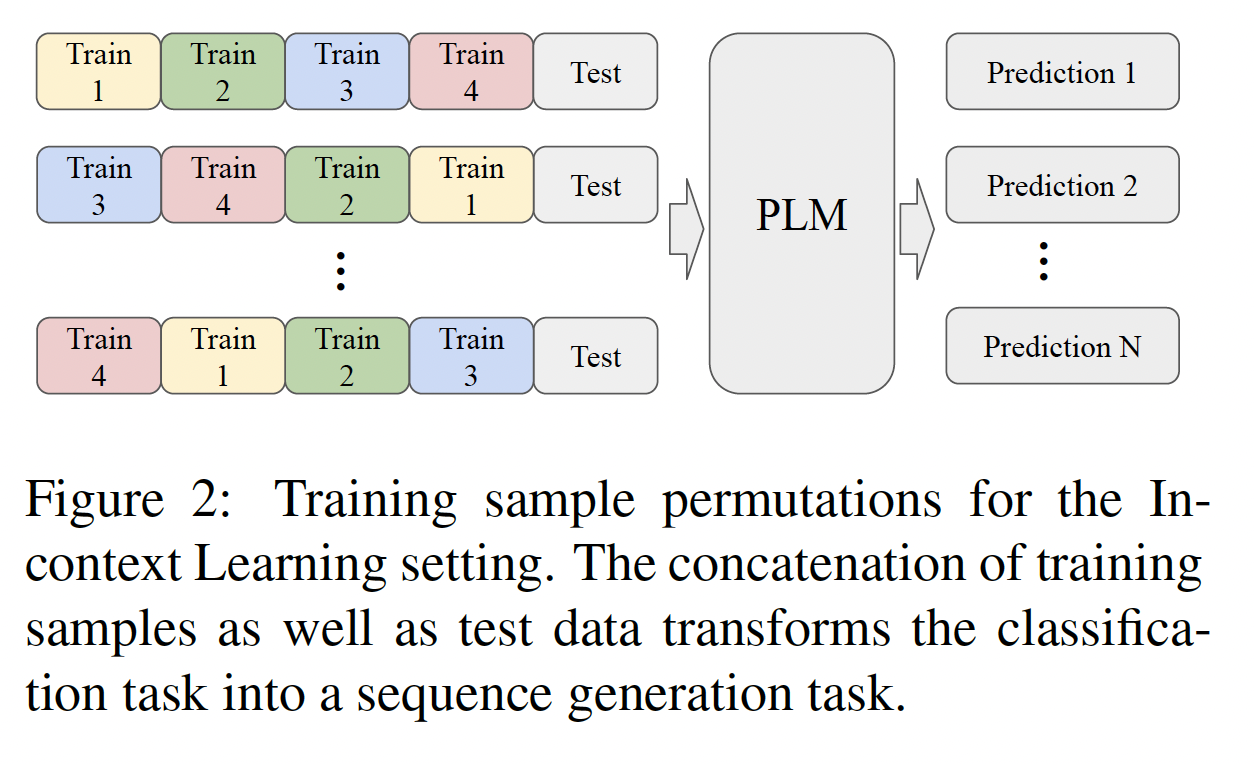
虽然有好处,但增加模型大小并不能保证低方差:我们针对
GPT-2(0.1B-1.5B)和GPT-3(2.7B-175B)的四种不同模型规模,评估了样本顺序。正如我们在Figure 1中观察到的,模型可以获得优异的few-shot性能。我们看到:GPT2-XL(1.5B)模型甚至可以超过90%的准确率,只需给出四个样本。这个结果与那些在6万多个样本上训练的监督模型相当。然而,不同排列的性能变化仍然是一个大问题,特别是对于 "较小" 的模型。同一个模型可以在一种样本顺序下表现出近乎完美的行为,但在另一种样本顺序下又会回落到与随机猜测相当。
虽然增加模型的大小(几个数量级)有时可以缓解这个问题,但它仍然不能完全解决这个问题(特别是如果我们考虑
SST-2以外的任务)。相比之下,supervised fine-tuning方法的不同初始化通常会导致其测试集性能的标准差小于1%(LM-BFF)。
增加训练样本并没有明显地减少方差:为了进一步探索
few-shot prompts的顺序敏感性,我们增加了训练样本的数量,然后采样了一个子集,并且对这个子集测试了最多24种不同顺序。在Figure 3中,我们可以看到,增加训练样本的数量会导致性能的提高。然而,即使有大量的样本,高方差仍然存在,甚至会增加。基于此,我们得出结论:无论训练样本的数量如何,顺序敏感性可能是
In-context Learning的一个基本问题。GPT-2 Small的效果反而下降?
表现好的
prompts不能跨模型迁移: 我们发现,如果将底层模型从GPT2-XL(1.5B)改为GPT2-Large(0.8B),一个特定的排列顺序的性能可能从88.7%下降到51.6%。这表明,一个特定的排列对一个模型效果好,并不意味着它将为另一个模型提供良好的结果。为了验证这一假设,我们使用四个样本的所有可能的顺序排列作为
prompts(一共24个)。然后我们对不同的模型进行以这些prompts为条件的预测,并计算分数之间的pairwise Spearman’s rank correlation coefficient。这些结果显示在Figure 4中。如果有一个共同的表现好的
prompts的模式,那么我们就应该能够观察到不同模型之间的高相关性。然而,即使在同一模型的不同规模中,排列的行为似乎也是随机的。例如,175B和2.7B模型的相关性只有0.05,这意味着2.7B模型的好的排列绝不能保证它对175B模型也能产生好的性能。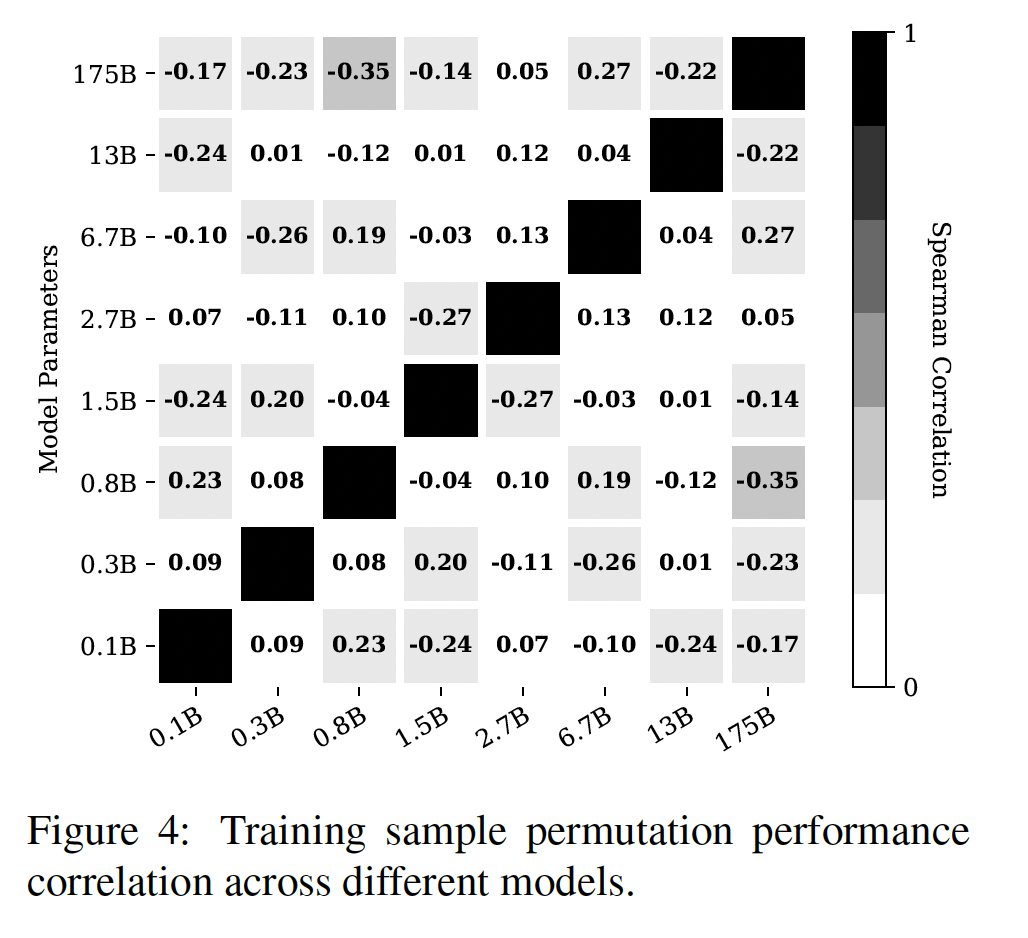
表现好的
label orderings在不同的模型中并不一致:除了训练样本的排序,我们还探索了prompts的label ordering。我们使用上述全部排列的所有模式:六种不同的标签模式。然后我们按照前文的所述,计算不同模型间的pairwise Spearman相关性。如Figure 5所示,label orderings的行为在同一模型的不同规模中再次显得很随机。因此,不可能找出一个在不同模型中表现良好的label ordering。注意:假设
P/N分别代表positive/negative,那么六种标签模式分别为:NNPP, NPNP, NPPN, PNNP, PNPN, PPNN。这里并不是把所有样本的
label独立地放在一起,而是根据label的位置来决定所对应样本的位置。例如,正样本和正样本放在一起、负样本和负样本放在一起。
bad prompts的退化行为:我们对表现好的prompts和不好的prompts进行了错误分析,并观察到大多数失败的prompts都存在高度不平衡的predicted label distributions(Figure 6 (left))。解决这个问题的一个直观方法是按照《Calibrate before use: Improving few-shot performance of language models》的思路,对输出分布进行校准。然而,我们发现,尽管校准导致了更高的性能,但方差仍然很高(Figure 6 (right))。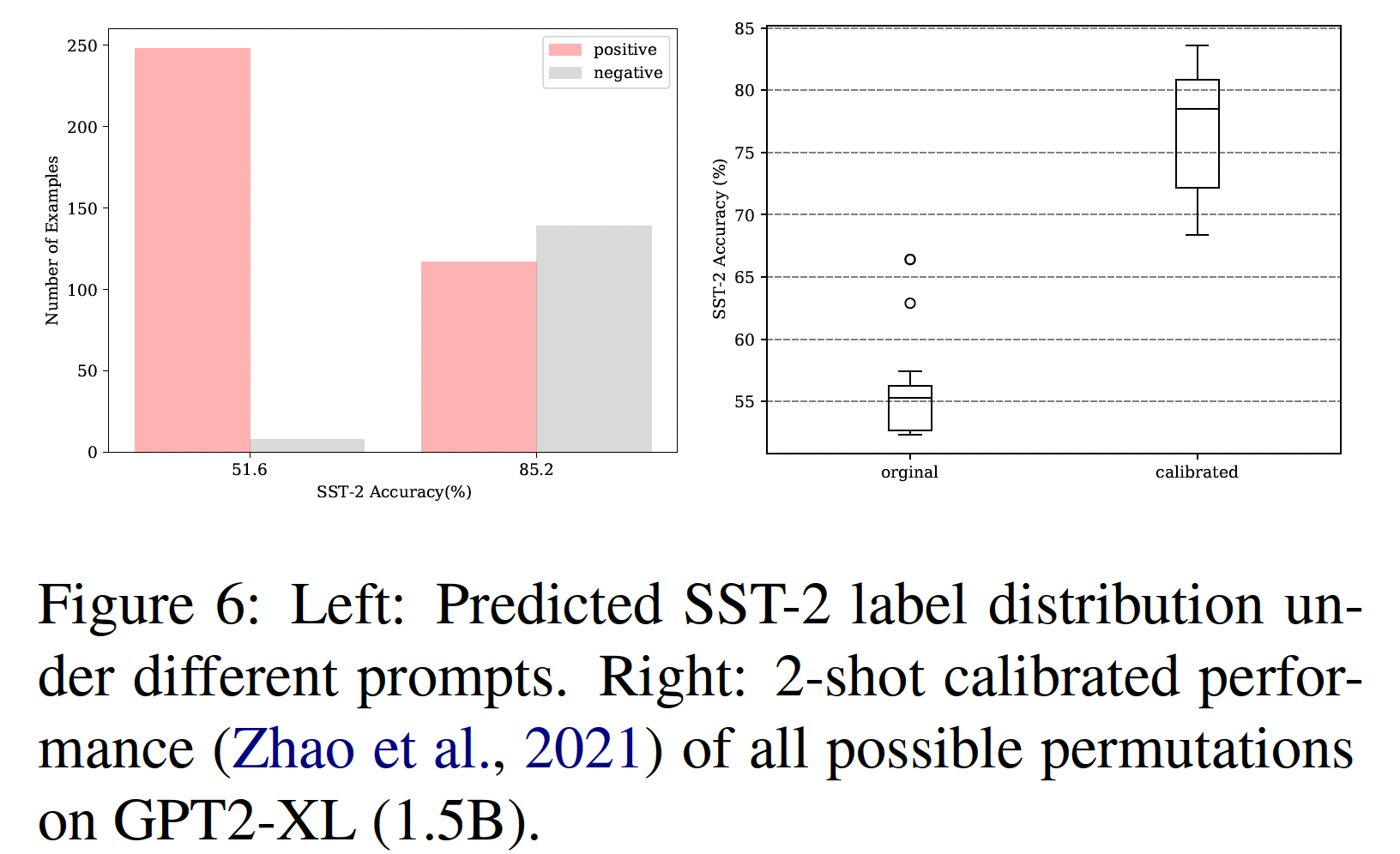
9.1.2 方法
上一节表明,
prompt orderings对性能有很大的影响,同一模型的同一prompt的某些顺序提供了随机猜测的性能,而其他 "更好" 的顺序提供了与监督方法竞争的性能。这表明,可能有各种选择prompt orders的方法来实现更好的性能,但挑战在于如何在不需要额外标签(例如,验证集)的情况下自动地做到这点。因此,在这里我们探讨的问题是:怎样才能自动地生成一个
"probing set",以找到表现好的prompt orderings?我们通过以下方式来解决这个问题:
首先,对于随机选择的训练样本构成的集合,我们使用这个样本集的每一个可能的排序作为候选。
然后,通过使用所有候选
prompts作为上下文来查询语言模型,从而构建一个probing set。最后,使用这个
probing set通过使用probing指标对它们进行排序来确定最佳排序。
假设有
a. 从语言模型中采样以构建 Probing Set
我们提出了一种简单的方法,通过直接从语言模型本身采样,自动构建一个
"probing set"。这种方法使得自动生成probing sets成为可能,而无需获取任何额外的数据。具体来说,给定一组训练样本这将每个样本转化为一个标准格式的句子,将集合中的每个元素线性化为自然语言空间
注意,这里的
lalbel是在训练集上的,而不是验证集/测试集上的。然后,我们定义
function group为:24个可能的排列。对于每个
prompt的候选probing sequence)pretrained语言模型的参数。我们从语言模型中解码时,在特殊的end-of-sentence token(由一个模板来定义)处、或达到generation长度限制时停止解码。我们的probing set构建方法如下图所示,其中,objective是生成一个与训练样本有相似分布的probing set。prompts的prompts:通过prompt,然后用这些新生成的prompt来作为Probing Set。作者没有直接把
probing set,因为probing set是当做验证集来使用的。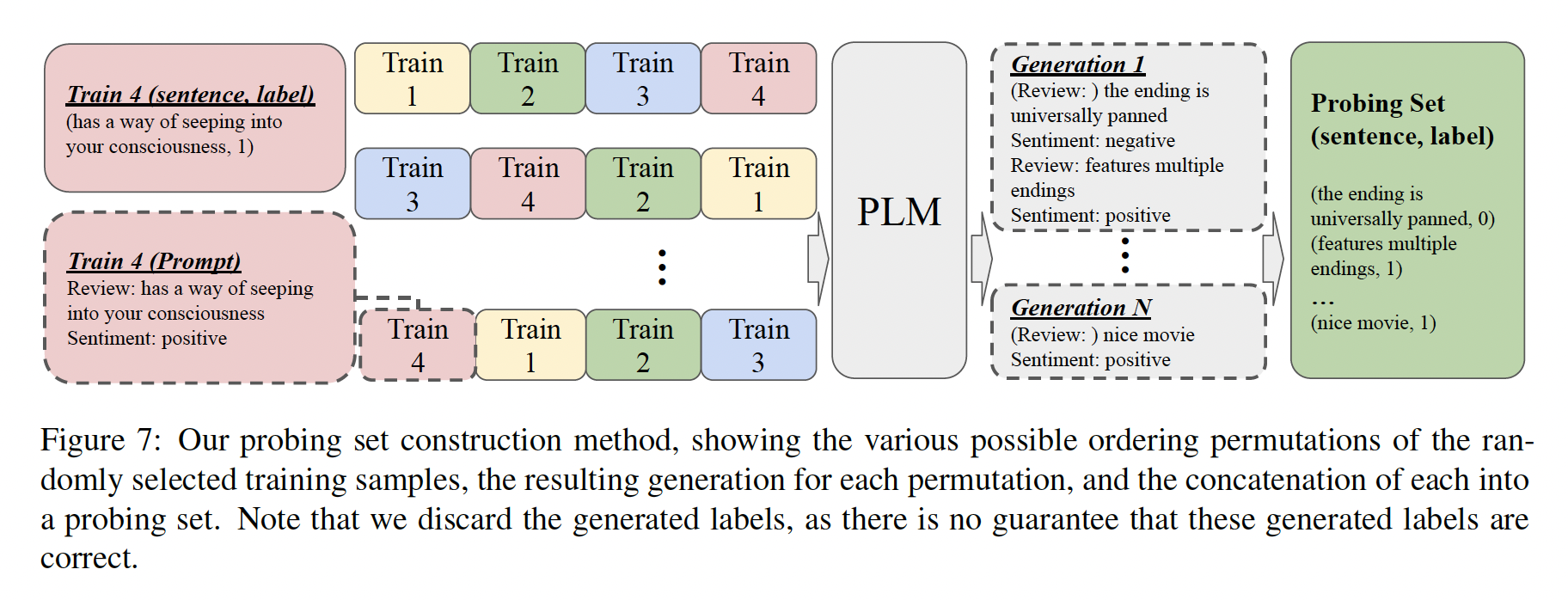
我们对所有可能的
prompt顺序的排列方式运行这个采样过程,并从中提取probing样本probing setprobing set包含了每个句子的predicted label,但并不能保证这些标签的有效性。因此,我们将predicted label从probing set中舍弃,因为我们只对来自于语言模型且对应于输入分布的sampling probes感兴趣。核心思想:既然没有验证集,那么让语言模型自动生成一个验证集出来。当然,这个 “验证集” 的
label是模型预测出来的,因此不保证是有效的。
b. Probing Metrics
一旦我们为给定的样本集构建了一个
probing set,我们现在就可以使用该probing set来确定该特定样本集的最佳prompt ordering。在此,我们探讨两种选择最佳排序的方法: 全局熵(Global Entropy: GlobalE),和局部熵(Local Entropy: LocalE)。全局熵:
GlobalE背后的动机是,确定特定排序的prompts从而避免极不平衡的预测问题(因为我们之前已经确定unbalanced predictions是针对表现不好的prompts的关键性问题)。我们计算数据点
predicted label对于每个标签
target标签集合),我们计算probing set上的标签概率为:然后,我们使用预测的
category label entropy作为GlobalE得分,如下所示:核心思想:类别标签的分布尽可能均匀。
注意:训练集合
probing set、另一次在这里作为上下文局部熵:
LocalE背后的动机是,如果一个模型对所有probing inputs都过于自信,那么该模型的行为很可能不符合预期。至少,它的校准工作做得不好,这也可能是区分不同class的能力差的表现。与
GlobalE的计算类似,我们计算数据点target label然后我们计算每个数据点的平均
prediction entropy作为LocalE得分:LocalE计算的prediction分布的熵,然后对所有数据点取平均。GlobalE计算的是全局上的predicted label分布的熵。由于我们现在有办法对每个
prompt ordering进行打分(根据prompt ordering在probing set上的效果),我们可以根据GlobalE或LocalE分别衡量的性能对每个prompt ordering进行排名。
9.2 实验
我们使用四种不同大小的
GPT-2(有0.1B/0.3B/0.8B/1.5B参数)和两种大小的GPT-3(有2.7B/175B参数)。由于上下文窗口大小有限(GPT-2系列模型最多1024个word-pieces),除了AGNews和DBPedia之外,我们对所有的数据集都采用了4-shot setting。我们的实验是基于
GPT-2模型的open-source checkpoints、以及对OpenAI GPT-3 API的访问。对于probing set的生成,我们将最大generation长度限制为128。我们还使用温度为t=2的采样,我们还利用了block n-gram repetition重复(《A deep reinforced model for abstractive summarization》)来鼓励多样化的generation。我们对每组随机选择的训练样本使用
24种不同的排列,并对每个实验使用5个不同的集合(除了具有175B参数的GPT-3,由于金钱成本高,我们只做两组,每组12种不同的排列),总共有120次run。我们报告了5个不同集合的相应评价指标的平均值和标准差。对于
promot的选择,我们使用LocalE和GlobalE探测指标对自动生成的probing set的candidate prompts进行排名。然后,在现有的24个排列中,我们选择按最高entropy排名的top K样本作为表现好的prompts,在我们的实验中prompts来评估各种数据集的性能,并展示了更好的性能和缩减的方差。即,选择表现最好的
4种排列顺序。我们还提供了一个
majority baseline的结果,它总是预测数据集中的majority label,作为性能的下限。我们还提供了一个oracle从而显示性能的上界,即根据验证集上的prompt性能选择top K性能好的排序。数据集:十一个文本分类数据集,如下表所示。
为了评估,我们对所有数据集的验证集采样了
256个样本,以控制GPT-3的推理成本,因为它需要使用付费的API。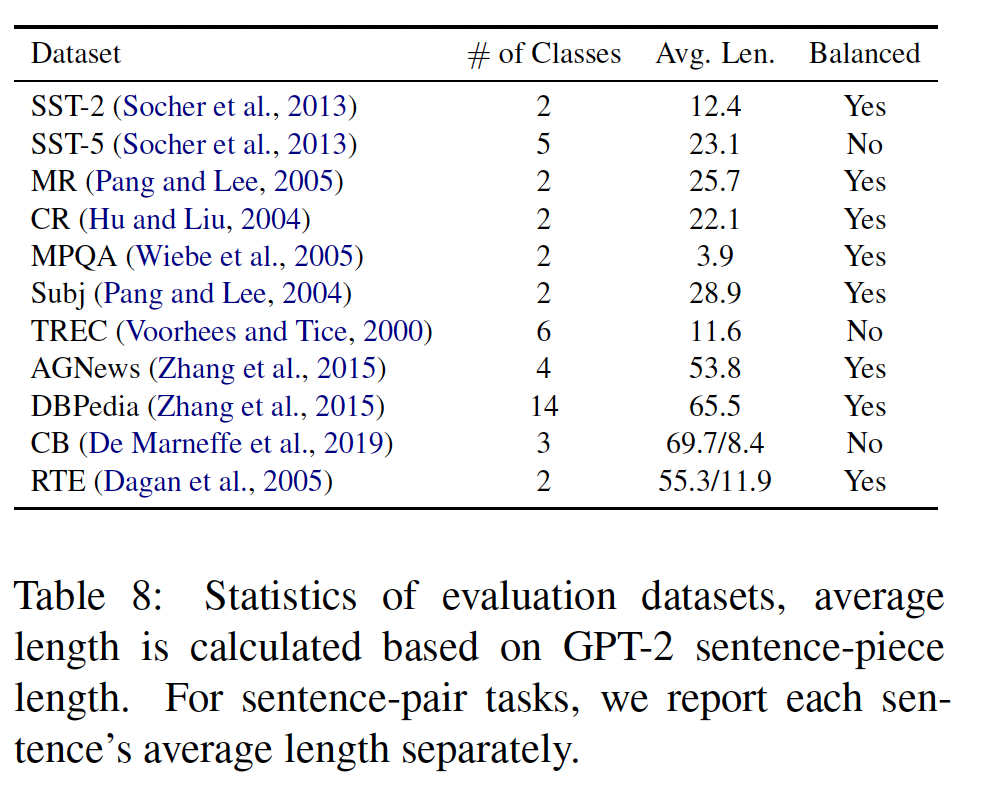
这些任务的
prompts模板如下表所示。
实验结果如
Table 2所示,我们观察到LocalE和GlobalE在所有任务中都有一致的改进。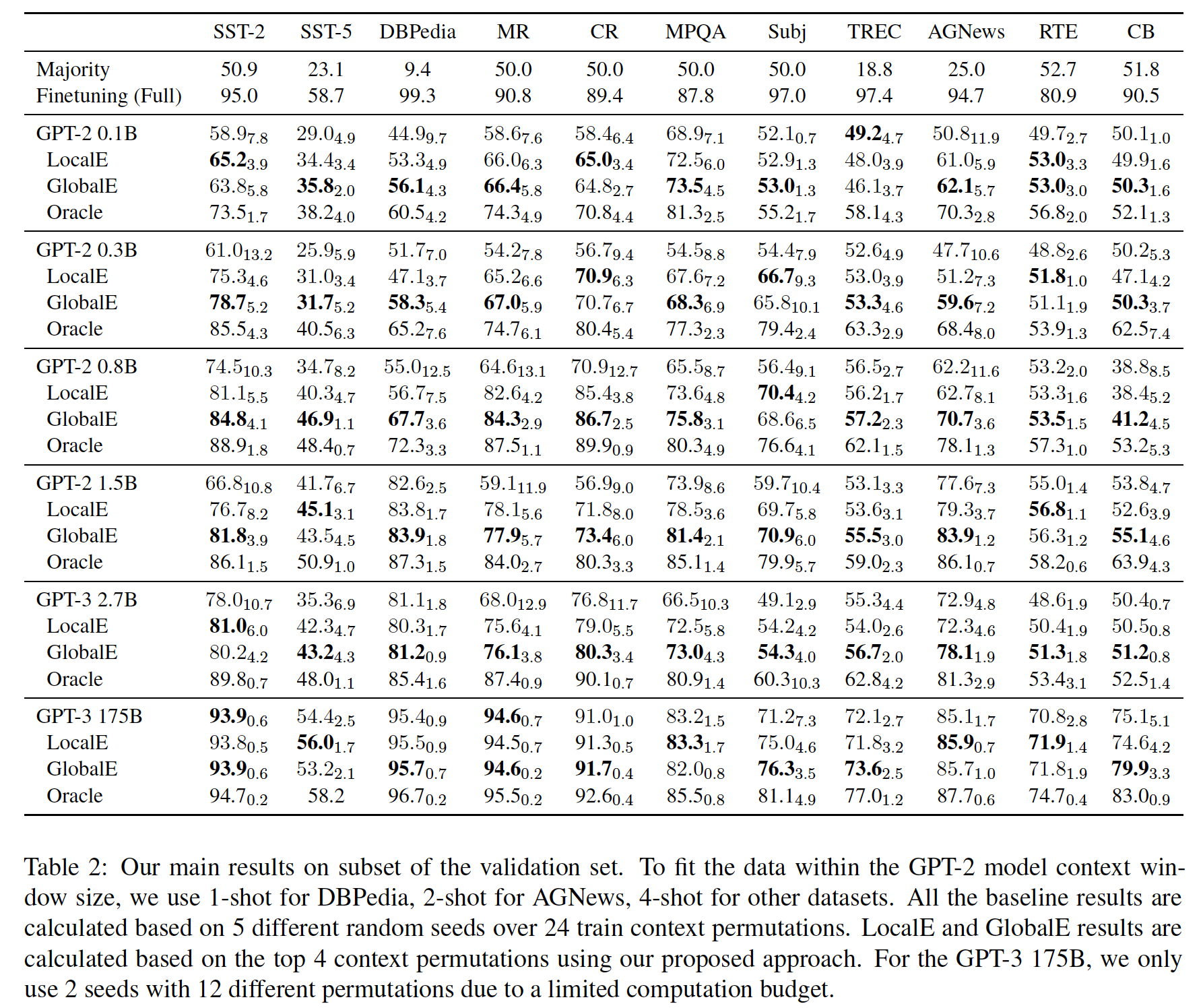
结论:
无论模型大小如何,
entropy-based probing对表现好的prompt的选择是有效的。与不使用probing的prompts相比,GlobalE在11个不同的句子分类任务中平均实现了13%的相对改进;LocalE略逊于GlobalE,与基线模型相比,平均有9.6%的相对改善。使用
Entropy-based probing来排名是鲁棒的:在Figure 8中,我们直观地显示了在改变top K prompt selection的平均性能。sampled prompt orders,这相当于Table 2中的基线模型性能。我们可以观察到,所有数据集的曲线斜率都是负的,这表明我们的方法可以有效地对表现好的
prompts进行排序。虽然
entropy-based probing在不同的模板中都是有效的:我们对类似于LM-BFF和《Calibrate before use: Improving few-shot performance of language models》的四种不同模板(table 4)的Entropy-based probing进行评估,用于SST-2数据集。Table 3的实验结果表明,Entropy-based probing对不同的模板是有效的。这些发现表明,Entropy-based probing特定的模板并不敏感,因为它对所有的情况都能提供改进。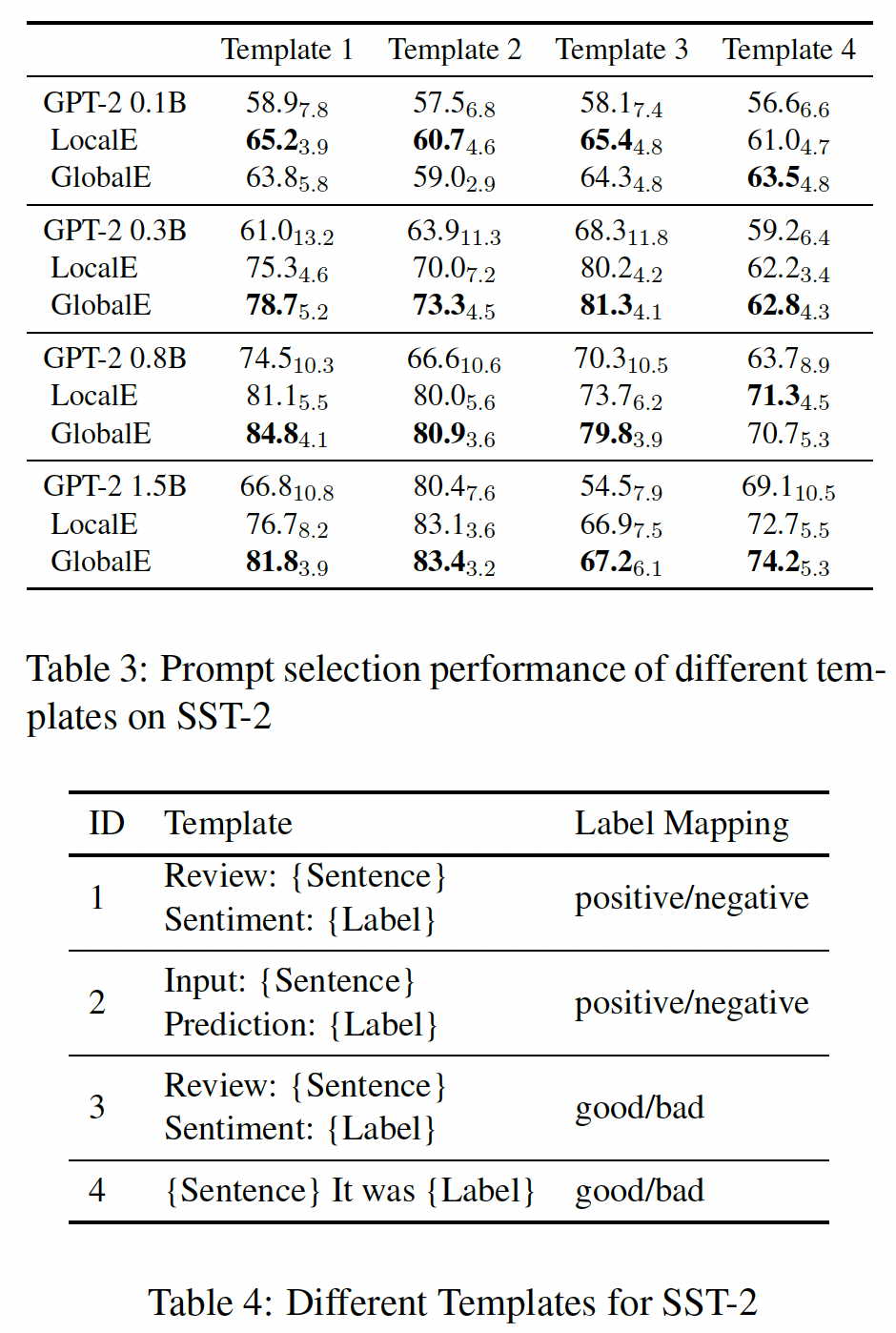
表现好的
permutation selection是In-context Learning的一个安全选择:我们发现,对于受到高prompt variance影响的模型,我们的prompt selection过程可以显示出很大的改进(相对改进达30%)。此外,对于初始prompt性能的方差较低的任务,我们的方法并没有对性能产生负面影响。我们的prompt selection在更糟的情况下提供了边际改善,在大多数情况下平均有13%的相对改善。sentence-pair任务对于较小的模型来说仍然具有挑战性,即使有表现好的permutation selection:对于CB和RTE数据集,GPT-2模型的性能与random baseline的性能没有明显区别。尽管如此,我们发现,我们的方法仍然可以提供小幅的性能提升,尽管这些性能提升仍然在随机猜测或majority vote的水平之内。其中一个原因可能是,对于这些任务上的特定规模的模型,不存在好的prompts。因此,在这种情况下,优化prompts并不是特别有效。在较大的模型规模下,prompt selection可以大大改善CB和RTE的性能(对于GPT-3 175B模型尤其如此),这一观察进一步支持了这一点。Entropy-based probing优于使用训练数据的子集进行调优:如果不依赖generation,prompt selection的另一种方法可以是拆分(有限的)训练数据以形成验证集。为了与这种方法进行比较,我们将4-shot training samples(与Table 2的设置相同)分成两半。然后我们用验证集的表现来选择表现最好的四个prompts。从Table 5中可以看出,这种方法一直优于baseline。然而,两种Entropy-based probing方法在所有的模型大小上都能提供更好的性能。拆分为验证集的方式,相比较于
baseline,也是有所提升的。