十七、FLAN[2021]
论文:
《Finetuned Language Models Are Zero-Shot Learners》。
大型语言模型,例如
GPT-3,已经显示出在few-shot learning方面表现出色。然而,它们在zero-shot learning方面并不成功。例如,GPT-3在阅读理解、问答、和自然语言推理等任务的zero-shot表现要比few-shot表现差得多。其中一个潜在原因是,在没有few-shot示例的情况下,模型很难在与预训练数据格式不相似的prompts上表现良好。在本文中,我们探索了一种简单的方法来提高大型语言模型的
zero-shot性能,从而扩大它们的受众范围。我们利用一种直觉,即自然语言处理任务可以通过自然语言指令来描述,例如, “这部电影评论的情感是积极的还是消极的?”,或者 “将 ‘Hello’ 翻译成文”。我们采用了一个包含137B参数的pretrained语言模型,并进行指令微调instruction tuning:在超过60个NLP数据集的混合样本上对模型进行微调,这些数据集通过自然语言指令来表达。我们将得到的模型称为FLAN,即Finetuned Language Net。为了评估
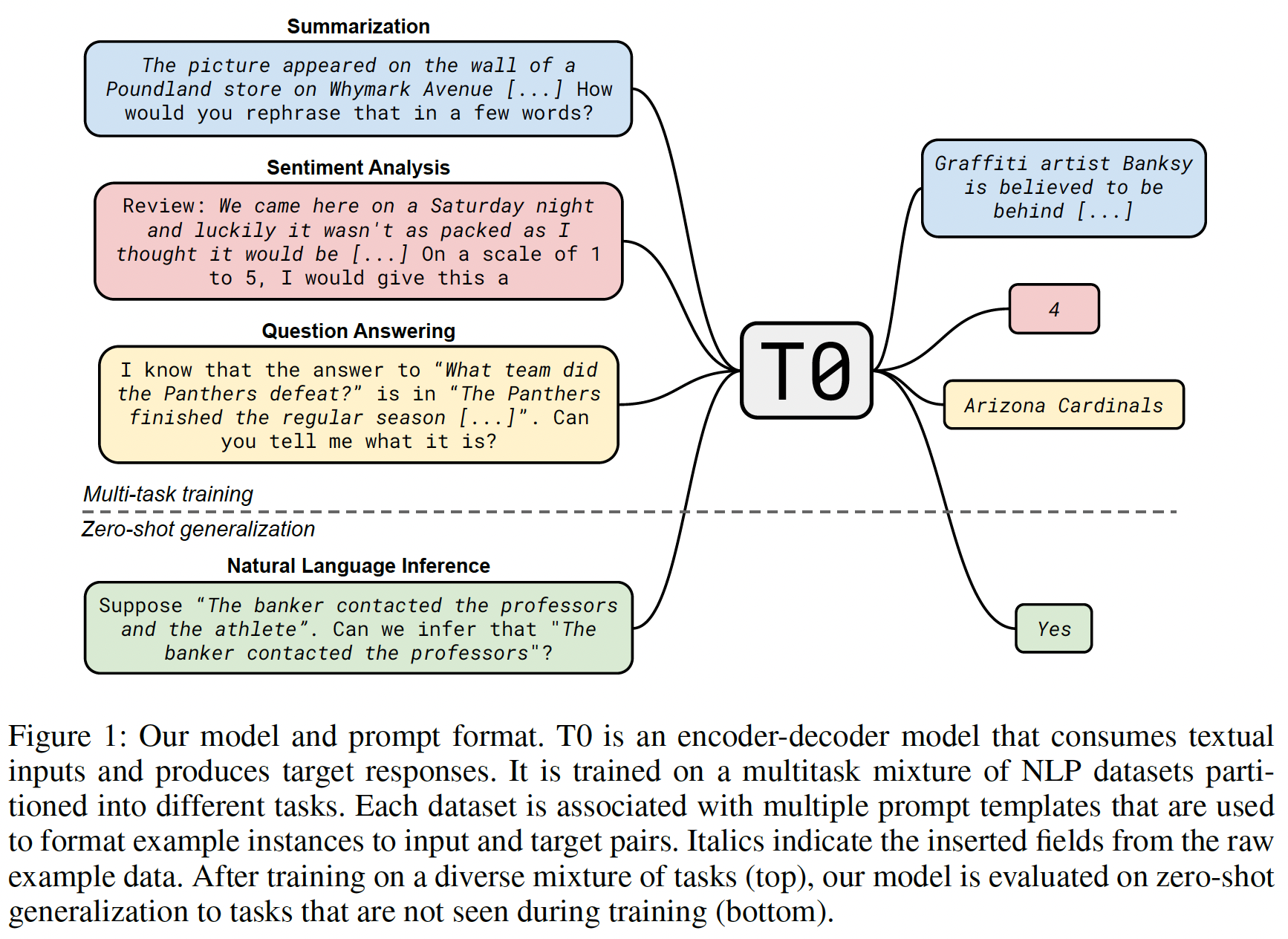
FLAN在未见过的任务上的zero-shot性能,我们根据任务类型将NLP数据集分组成clusters,并保留每个cluster用于评估,同时在其它所有clusters上对FLAN进行指令微调。例如,如Figure 1所示,为了评估FLAN在执行自然语言推理任务的能力,我们在其他一系列NLP任务上(如,常识推理、翻译、情感分析)上对模型进行指令微调。由于这个设置确保FLAN在指令微调中没有见过任何自然语言推理任务,我们随后评估其在zero-shot自然语言推理上的能力。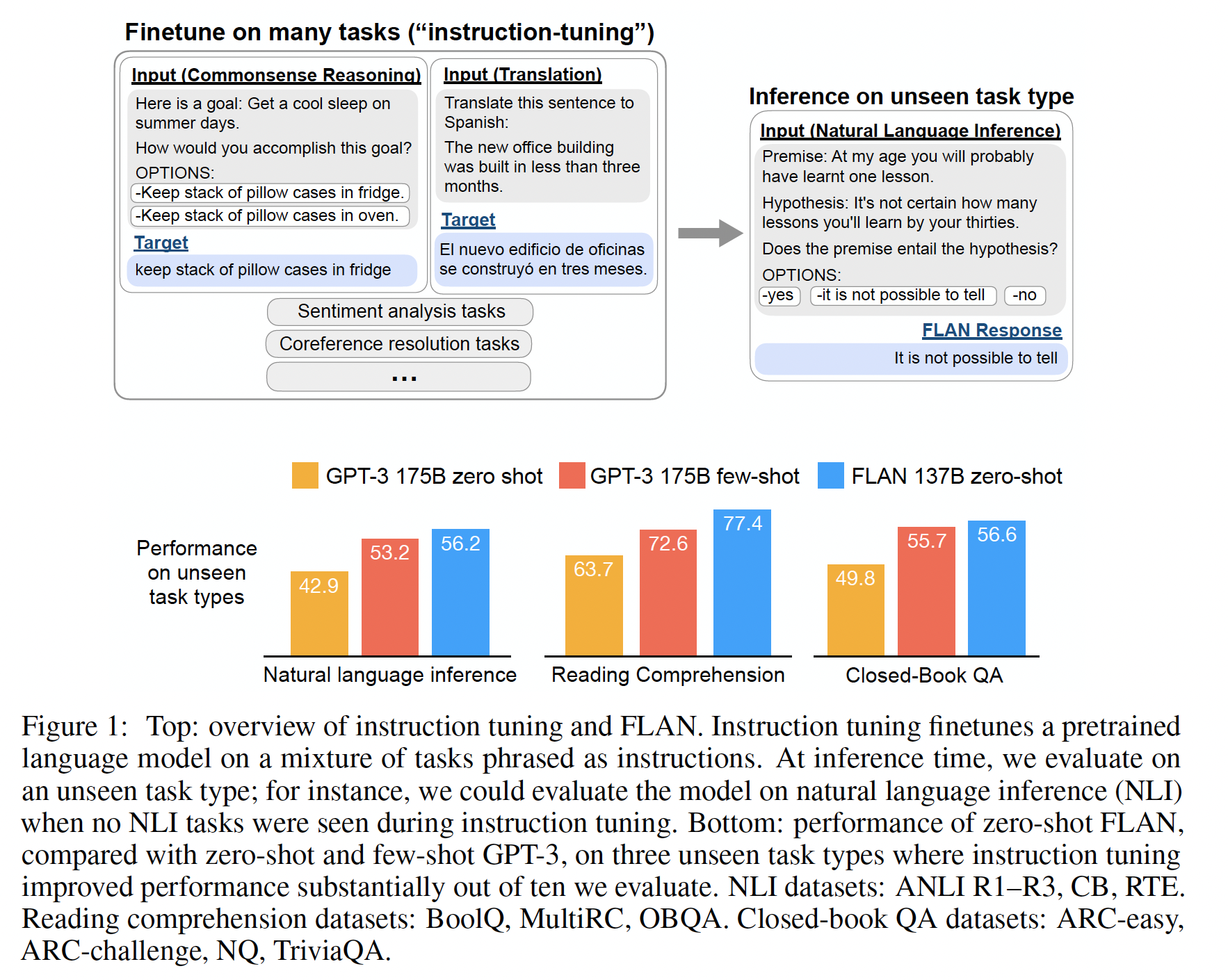
我们的评估结果显示,
FLAN显著提高了base 137B-parameter model的zero-shot性能。FLAN的zero-shot性能在我们评估的25个数据集中有20个优于拥有175B参数的GPT-3的zero-shot性能,甚至在ANLI、RTE、BoolQ、AI2-ARC、OpenbookQA和StoryCloze等任务上远远超过了GPT-3的few-shot表现。在消融研究中,我们发现在指令微调中增加task clusters的数量可以提高对unseen任务的性能,并且指令微调的好处只在足够大的模型规模下显现出来。指令微调的效果并不总是好的,如果下游任务和语言建模预训练目标相同时,指令微调是无效的、甚至是降低性能的。
指令微调是一种简单的方法,如
Figure 2所示,它结合了pretrain–finetune和prompting范式的吸引人的特点,通过使用finetuning的监督来改善语言模型对推理时文本交互的响应。我们的实证结果展示了语言模型通过纯粹的指令来执行任务的有希望的能力。用于加载用于FLAN的指令微调数据集的源代码可在https://github.com/google-research/flan公开获取。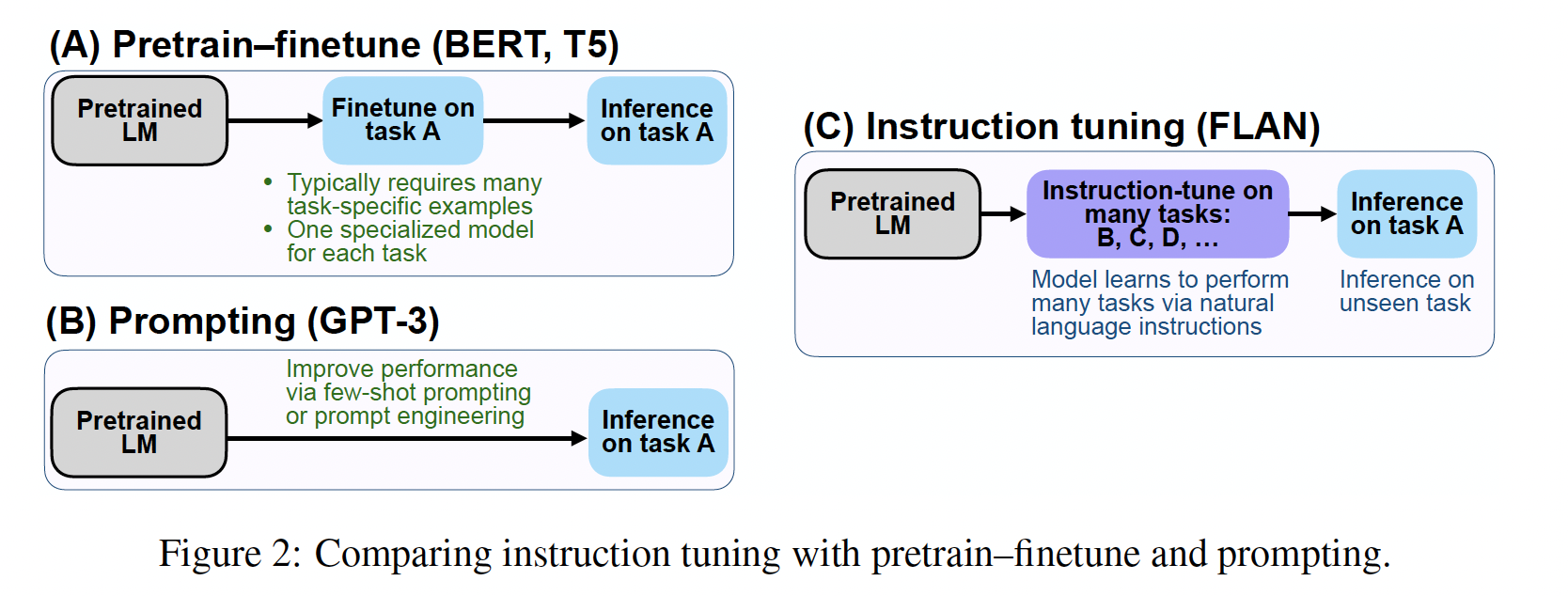
相关工作:我们的工作涉及多个广泛的研究领域,包括
zero-shot learning、prompting、multi-task learning以及用于NLP applications的语言模型。我们在一个扩展的相关工作部分(附录D)中描述了这些广泛领域的先前工作,这里我们描述了两个范围较窄、与我们的工作关系最密切的子领域。我们要求模型对指令作出响应的方式类似于
QA-based task,其目的是通过将NLP任务视为上下文中的问答来统一这些任务。尽管这些方法与我们的方法非常相似,但它们主要关注的是multi-task learning而不是zero-shot learning,并且正如《Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing》所指出的,它们通常不是基于pretrained语言模型中的现有知识的动机。此外,从模型规模和任务范围两方面来看,我们的工作超过了
《Description based text classification with reinforcement learning》和《Meta-tuning language models to answer prompts better》等最近的研究。语言模型的成功导致了对模型遵循指令能力的初步研究。
最近,
《Natural Instructions: Benchmarking generalization to new tasks from natural language instructions》用few-shot示例对具有140M参数的BART进行了指令微调,并在unseen任务上评估其few-shot能力,这与我们的few-shot instruction tuning结果类似。这一有希望的结果(以及《Crossfit: A few-shot learning challenge for cross-task generalization in NLP》的一个结果,虽然没有像我们一样强调指令),表明在一组任务上进行微调可以提高对unseen任务的few-shot性能,即使在较小的模型规模下也是如此。T0以与我们类似的设置对T5进行微调,发现zero-shot learning在具有11B参数的模型中可以得到改善。在与我们模型规模类似的情况下,
OpenAI的InstructGPT模型通过微调和强化学习进行训练,以产生更受人类评分者青睐的输出(《Training language models to follow instructions with human feedback》)。
17.1 模型
指令微调的动机是提高语言模型对
NLP指令的响应能力。其思想是通过使用supervision来教导语言模型执行通过指令来描述的任务,使语言模型学会遵循指令,即使是对于unseen任务也能做到如此。为了评估在unseen任务上的性能,我们将数据集按任务类型分成clusters,并保留每个task cluster进行评估,同时在其余所有clusters上进行指令微调。任务和模板:由于从头创建一个包含多个任务的指令微调数据集需要耗费大量资源,我们将学术界社区中现有的数据集转化为指令格式。我们聚合了
62个公开可用的文本数据集,这些数据集都可以在TensorFlow Datasets上找到,包括语言理解任务和语言生成任务,并将它们合并为一个混合体。Figure 3展示了这些数据集,每个数据集都被归类到12个task clusters中,同一cluster中的数据集属于相同的任务类型。每个数据集的描述、大小和示例可在附录G中找到。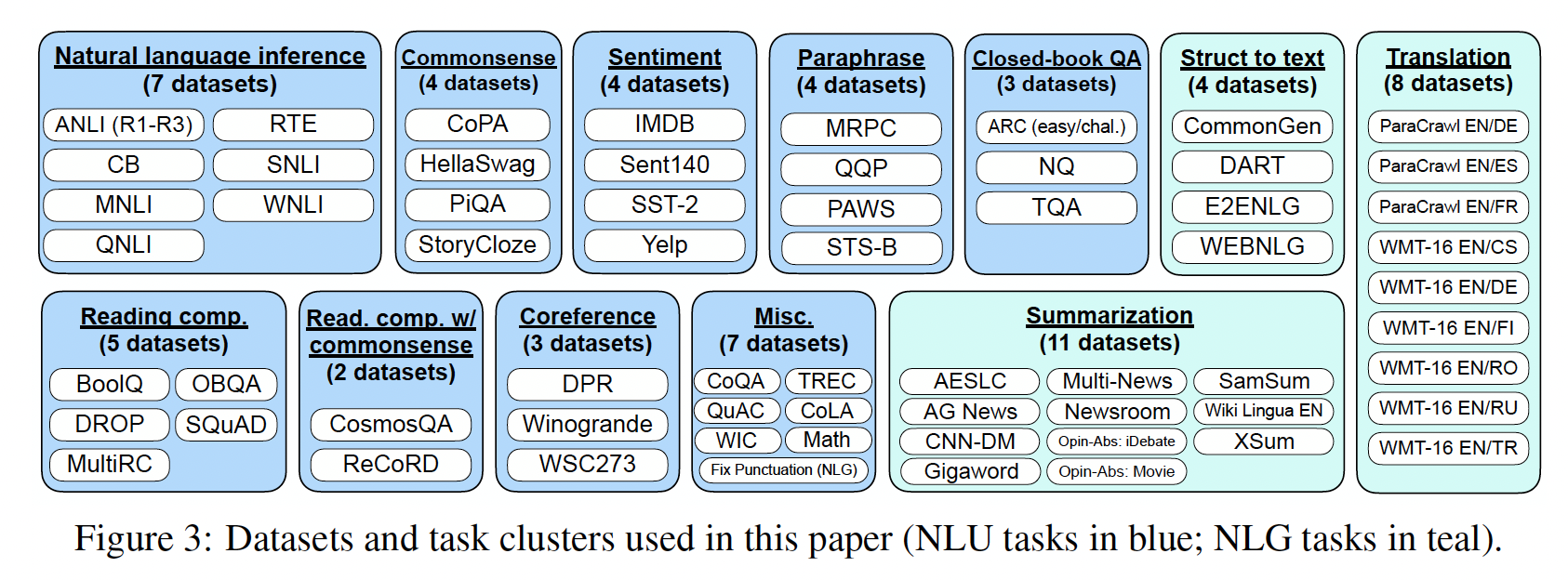
对于每个数据集,我们手动编写了十个
unique的模板,这些模板使用自然语言指令来描述该数据集的任务。尽管十个模板的大部分都描述了原始任务,为了增加多样性,对于每个数据集,我们还包括最多三个"turned the task around"的模板(例如,对于情感分类,我们包括了要求生成电影评论的模板)。然后,我们对pretrained语言模型在所有数据集的混合体上进行指令微调,每个数据集中的样本都按照该数据集的随机选择的指令模板进行格式化。Figure 4展示了一个自然语言推理数据集的多个指令模板。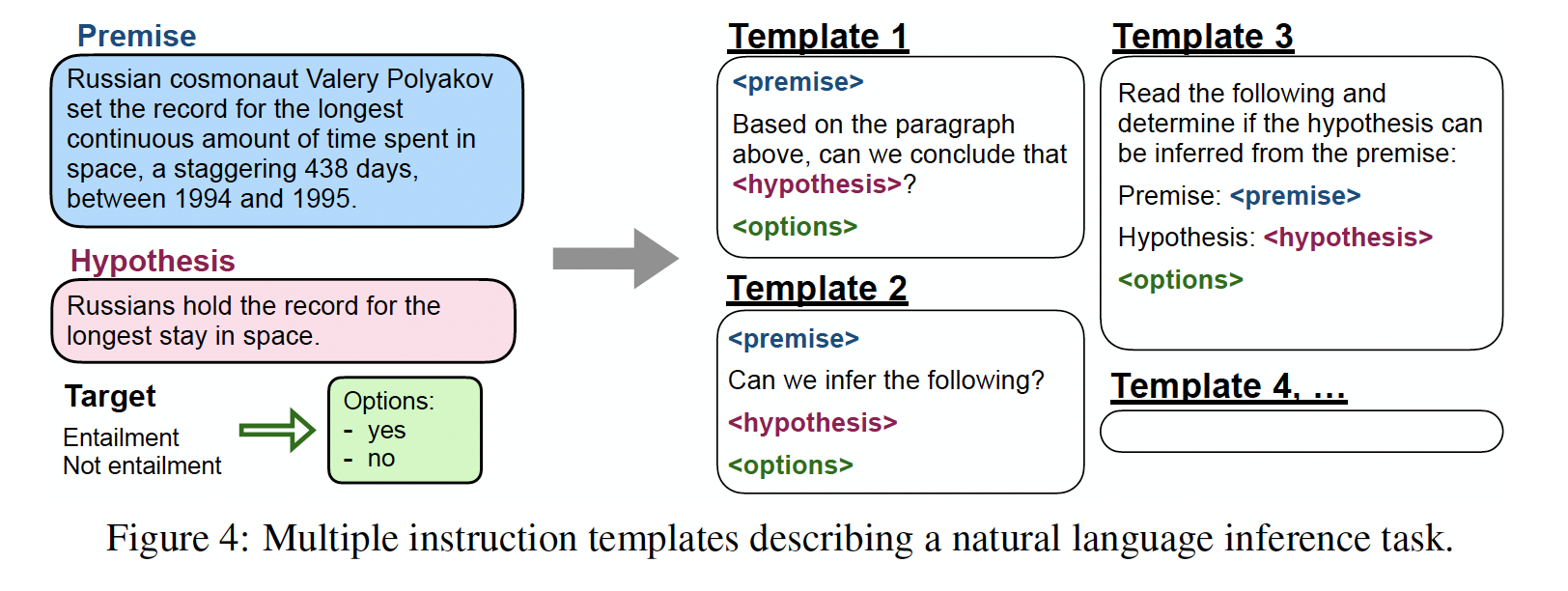
Evaluation Splits:我们对FLAN在指令微调中unseen任务的表现非常感兴趣,因此定义什么算作unseen任务是至关重要的。一些先前的工作通过不允许相同的数据集出现在训练中来定义unseen任务,但我们使用了一个更保守的定义,利用了Figure 3中的task clusters。在这项工作中,只有当在指令微调过程中没有看到task cluster中的数据集时,我们才将数据集unseen任务。例如,如果entailment任务,那么在指令微调中没有出现过任何entailment数据集,而我们对所有其他的task clusters进行了指令微调。因此,要评估task clusters上的zero-shot FLAN,我们进行了task cluster从而用于评估。带
Options的分类任务:给定任务的输出空间可以是几个类别(分类任务)或自由文本(生成式任务)。由于FLAN是一个decoder-only语言模型的指令微调版本,它自然会以自由文本的形式进行响应,因此在生成式任务中不需要进一步的修改。对于分类任务,先前的工作(
GPT-3)使用了一种rank classification方法,例如,只考虑两个输出("yes"和"no"),将概率较高的那个作为模型的预测结果。虽然这个过程在逻辑上是正确的,但它存在不完美之处,因为答案的概率分布可能在表达每个答案的方式上存在不希望的分布(例如,大量的替代方式说"yes"可能会降低分配给"yes"的概率)。因此,我们在分类任务的末尾添加了一个options后缀,其中我们将单词"OPTIONS"添加到分类任务的末尾,并附上该任务的输出类别列表。这样,模型在响应分类任务时就知道哪些选择是期望的。Figure 1中的NLI示例和常识示例显示了options的例子。这不同于将
label映射到target words,这里是将label space主动地添加到了输入中。这相当于让模型做选择题(而不是填空题)。
训练细节:
模型架构和预训练:在我们的实验中,我们使用了
LaMDA-PT,一个包含137B参数的稠密的、从左到右的decoder-only transformer language model。该模型在一系列web文档(包括带有计算机代码的文档)、对话数据、以及维基百科上进行预训练,使用SentencePiece library将文本tokenize为2.49T BPE tokens,词表规模32k。预训练数据中约有10%为非英语数据。请注意,LaMDA-PT只进行了语言模型的预训练(与针对对话来微调的LaMDA相比)。指令微调过程:
FLAN是LaMDA-PT的指令微调版本。我们的指令微调流程将所有数据集混合在一起,并从每个数据集中随机抽样。为了平衡不同数据集的大小,我们将每个数据集的训练样本数限制为30k,并遵从了examples-proportional mixing scheme(T5),最大mixing rate为3k。我们使用具有3e-5学习率的Adafactor优化器对所有模型进行了30k个gradient steps的微调,batch size = 8192 tokens。微调中使用的输入序列长度和目标序列长度分别为1024和256。我们使用packing(T5)将多个训练样本组合成单个序列,使用特殊的EOS token将inputs与targets分开。这个指令微调过程在具有128 cores的TPUv3上大约需要60小时。对于所有的评估,我们报告训练30k steps的final checkpoint的结果。因为是
zero-shot,所以这里没有通过验证集来选择checkpoint。
17.2 实验
17.2.1 主要结果
我们在自然语言推理、阅读理解、闭卷问答、翻译、常识推理、共指消解、以及
struct-to-text等任务上评估了FLAN。如前所述,我们通过将数据集分组为task clusters,并hold out每个cluster以供评估,同时在其他所有task clusters上进行指令微调(即每个evaluation task cluster使用不同的checkpoint)。对于每个数据集,我们评估所有模板的性能均值,这代表了在典型自然语言指令下的期望性能。由于有时可以使用验证集进行manual prompt engineering(GPT-3),对于每个数据集,我们还使用在验证集上性能最佳的模板来获得测试集性能。为了进行比较,我们报告了
LaMDA-PT使用与GPT-3相同的prompts的zero-shot和few-shot结果(因为LaMDA-PT在没有指令微调的情况下不适用于自然指令)。该baseline提供了指令微调对性能提升的直接消融研究。指令微调显著提高了LaMDA-PT在大多数数据集上的性能。我们还展示了
GPT-3 175B和GLaM 64B/64E在的zero性能,这些结果是根据各自的论文报告得出的。根据验证集上的最佳模板,
zero-shot FLAN在25个数据集中有20个超过了zero-shot GPT-3,甚至在10个数据集上超过了GPT-3的few-shot性能。根据验证集上的最佳模板,
zero-shot FLAN在19个可用数据集中有13个超过了zero-shot GLaM,而在19个数据集中的11个超过了one-shot GLaM。
总体而言,我们观察到指令微调对于自然语言指令化的任务(如
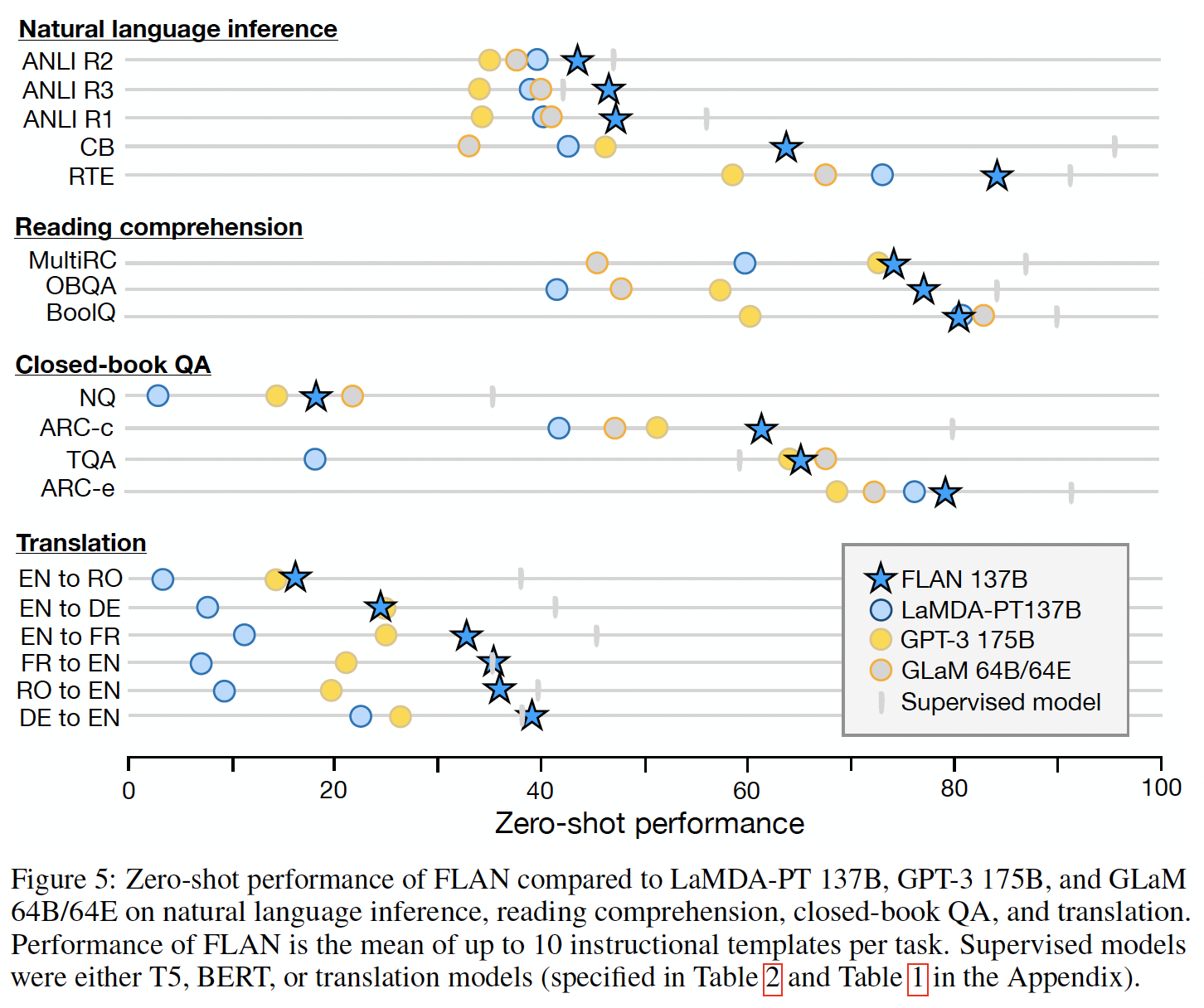
NLI、QA、翻译、struct-to-text等)非常有效,而对于直接以语言建模形式构建的任务,指令微调的效果较小,因为指令在这些任务中会很大程度上重复(例如,常识推理任务和共指消解任务以填写不完整的句子或段落的形式进行)。Figure 5是自然语言推理、阅读理解、闭卷问答、以及翻译任务的结果摘要。自然语言推理(
NLI):在五个NLI数据集上,FLAN的性能远远超过所有基准模型。正如GPT-3原始论文所指出的,GPT-3在NLI上表现不佳的原因之一可能是NLI的样本在无监督训练集中不太可能以自然方式出现,因此以作为句子续写的方式表达起来会很别扭。对于FLAN,我们将NLI表述为更自然的问题形式:"Does <premise> mean that <hypothesis>?"从而获得了更高的性能。阅读理解:在阅读理解任务中,
FLAN在MultiRC和OBQA上优于基准模型。在BoolQ上,FLAN大幅优于GPT-3,而LaMDA-PT在BoolQ上已经取得了很高的性能。闭卷问答:对于闭卷问答任务,
FLAN在所有四个数据集上优于GPT-3。与GLaM相比,FLAN在ARC-e和ARC-c上表现更好,在NQ和TQA上略低一些。翻译:类似于
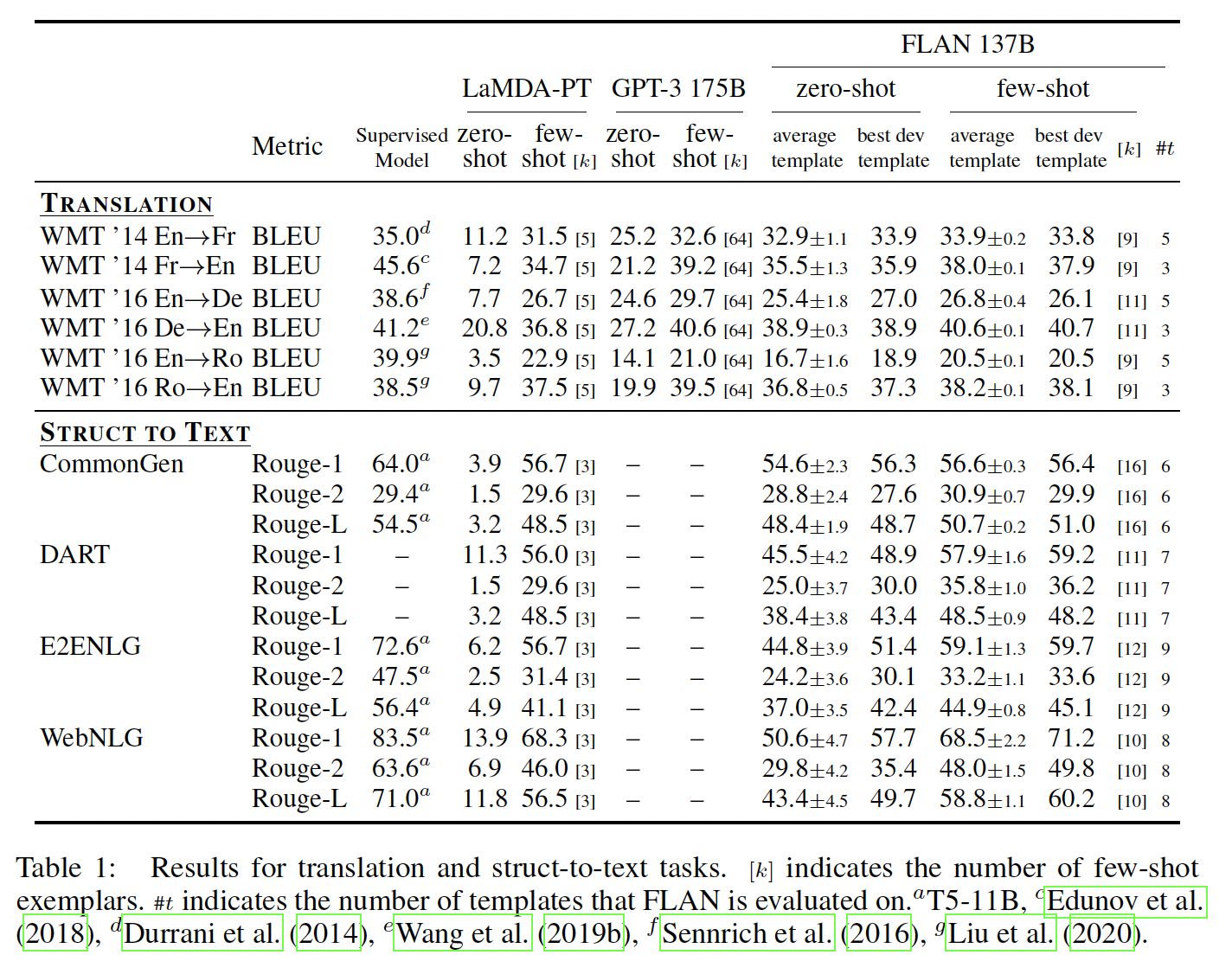
GPT-3,LaMDA-PT的训练数据约有90%是英语,并包含一些其他语言的文本,这些文本并不是专门用来训练机器翻译的。我们还在GPT-3论文中评估的三个数据集上评估FLAN的机器翻译性能:WMT'14的French–English数据集,以及WMT'16的German-English数据集和Romanian–English数据集。与
GPT-3相比,FLAN在所有六个评估上优于zero-shot GPT-3,但在大多数情况下不如few-shot GPT-3。类似于GPT-3,FLAN在翻译成英语方面表现出色,并与监督翻译基准模型相媲美。然而,从英语翻译成其他语言的结果相对较弱,这是可以预料的,因为FLAN使用了English sentencepiece tokenizer,并且大部分预训练数据是英语。其它任务:尽管我们看到了上述任务类别的强大结果,但指令微调的一个局限性是它并未改善许多语言建模任务的性能(例如,以补全句子的形式构建的常识推理任务或共指消解任务)。对于七个常识推理和共指消解任务(详见附录中的
Table 2),FLAN仅在其中三个任务上优于LaMDA-PT。这个负面结果表明,当下游任务与原始的语言建模预训练目标相同时(即在指令很大程度上是冗余的情况下),指令微调是无用的。最后,我们在附录中的
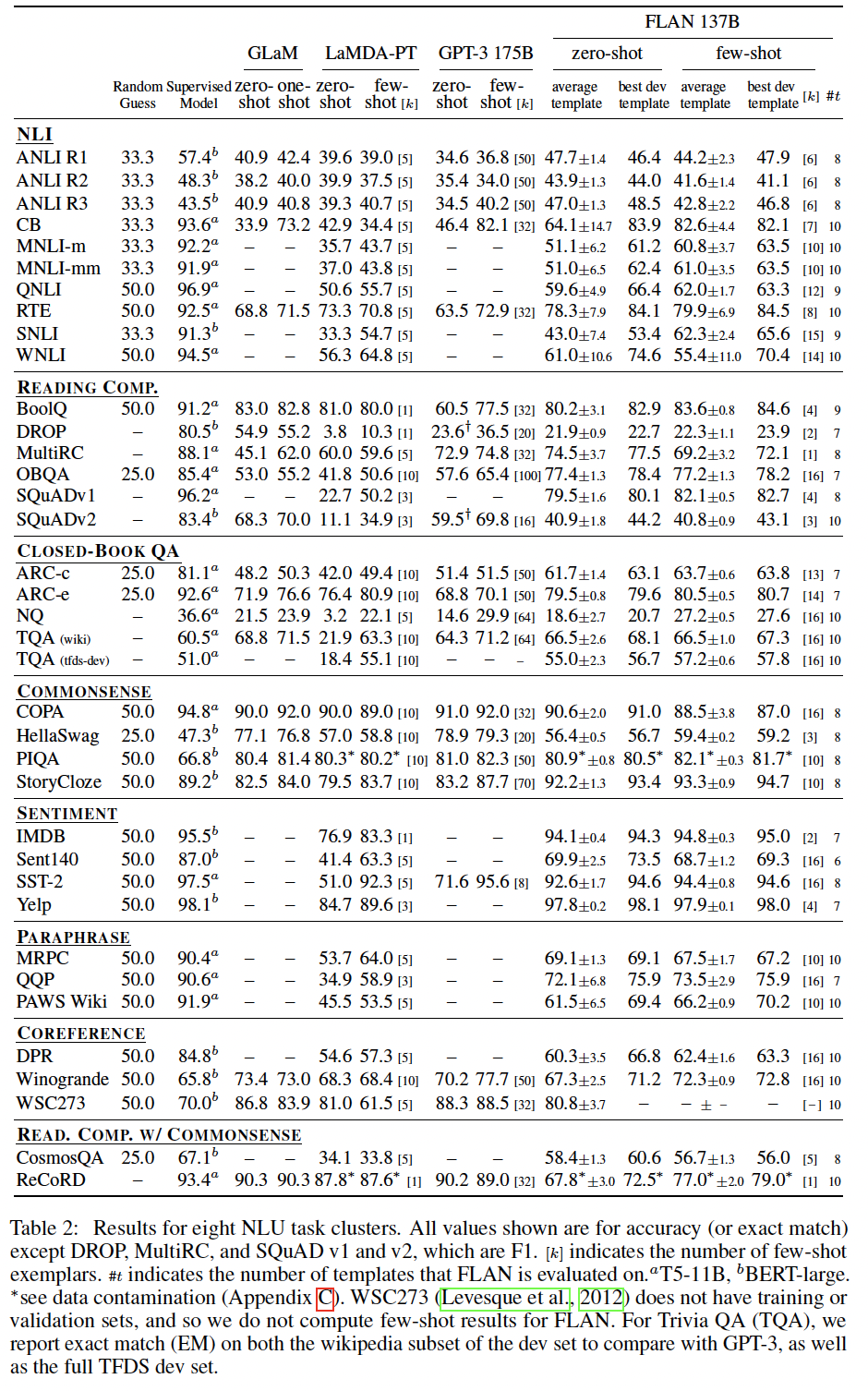
Table 1和Table 2中报告了情感分析、转述检测(paraphrase detection)、以及struct-to-text的结果,以及GPT-3结果不可用的其他数据集。通常情况下,zero-shot FLAN优于zero-shot LaMDA-PT,并且与few-shot LaMDA-PT相当或更好。
17.2.2 消融分析
Instruction tuning clusters数量:在第一个消融实验中,我们研究了指令微调中使用的任务数量和task clusters数量对性能的影响。在这个设置中,我们将NLI、闭卷问答、以及常识推理作为evaluation clusters,并使用剩下的七个task clusters进行指令微调。我们展示了使用一个到七个instruction tuning clusters的结果,其中task clusters按照每个cluster中任务数量递减的顺序添加。Figure 6展示了这些结果。正如预期的那样,当我们添加更多的
task clusters和任务到指令微调中时,三个held-out clusters的平均性能都有所提高(除了情感分析cluster),从而证实了我们提出的指令微调方法在新任务的zero-shot性能上的优势。此外,有趣的是,在我们测试的七个
task clusters中,性能似乎没有达到饱和状态,这意味着通过添加更多task clusters到指令微调中,性能可能会进一步提高。
值得注意的是,这个消融实验不能让我们得出关于哪个
instruction tuning cluster对每个evaluation cluster贡献最大的结论,尽管我们看到sentiment analysis cluster的附加价值很小。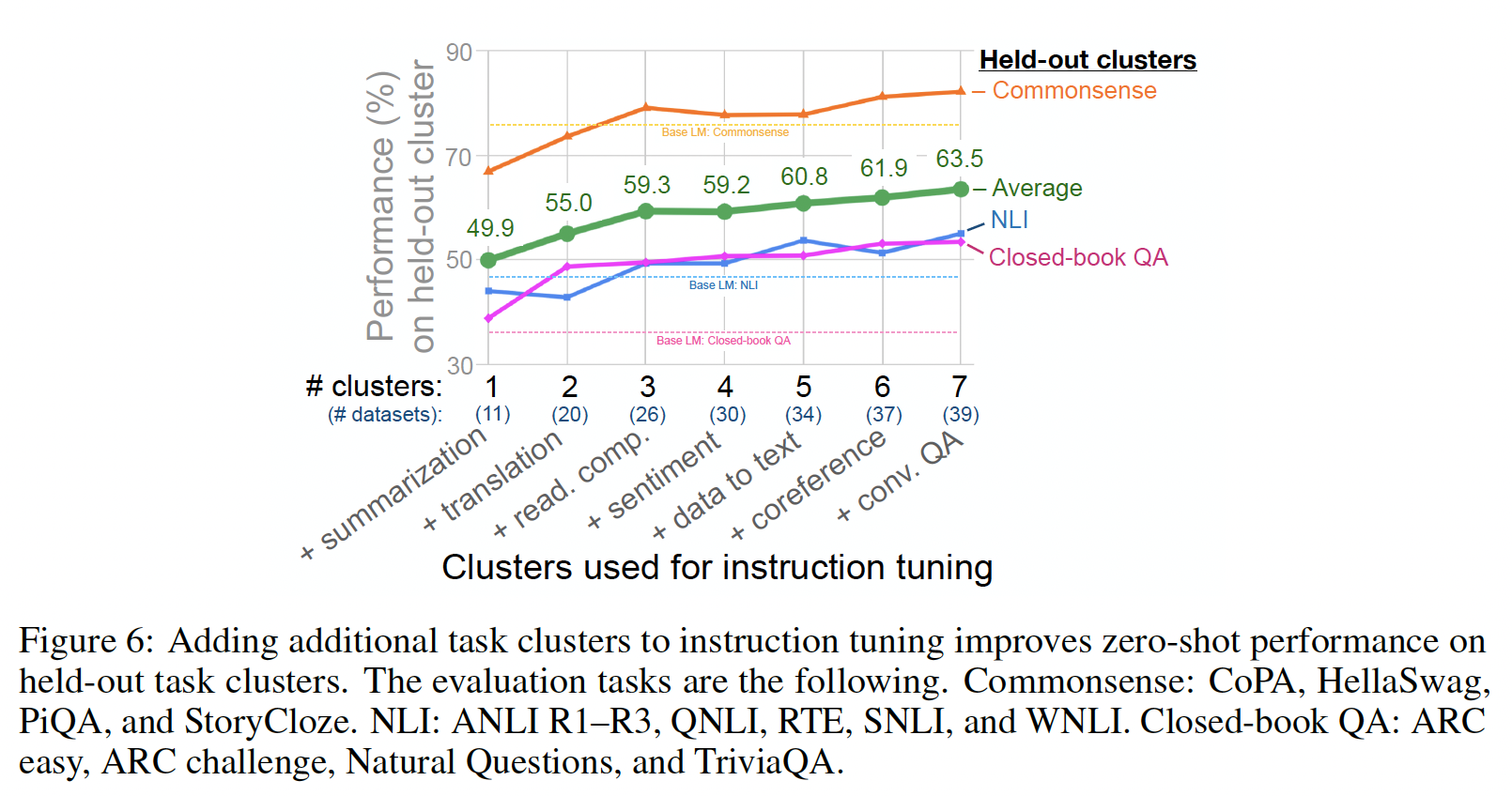
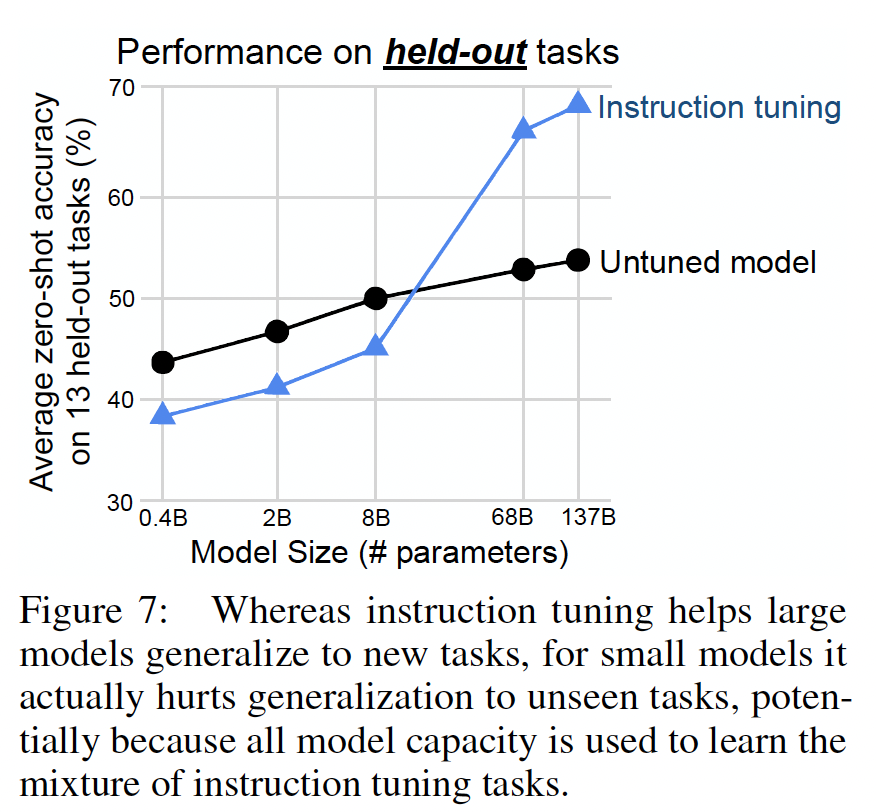
Scaling Laws:正如GPT-3原始论文所展示的,对于更大的模型,语言模型的zero-shot和few-shot能力显著提高,我们接下来探究指令微调的好处如何受到模型规模的影响。使用前面消融实验中的相同cluster split,我们评估了参数为422M, 2B, 8B, 68B, 137B的模型上指导微调的效果。在Figure 7中展示了这些结果。我们可以看到,在约
100B参数的两个模型中,指导微调显著提高了held-out tasks的性能,这与我们论文中的先前结果一致。然而,对于
8B及更小规模的模型,在held-out tasks上的表现却令人深思:指导微调实际上对held-out tasks的性能产生了负面影响。对于这一结果,一个可能的解释是对于小规模模型来说,在指令微调过程中学习的40个任务填满了整个模型容量,导致这些模型在新任务上的表现较差。根据这一潜在解释,对于更大规模的模型,指令微调填满了部分模型容量,同时教会这些模型如何遵循指令,使它们能够利用剩余容量来泛化到新任务上。
指令的作用:在最后的消融研究中,我们探讨了指令在微调过程中的作用,因为一种可能性是性能提升完全来自多任务微调,模型即使没有指令也可以表现得很好。因此,我们考虑了两种没有指令的微调设置。
在
no template设置中,模型只接收输入和输出(例如,对于翻译任务,输入是"The dog runs.",输出是"Le chien court.")。在
dataset name设置中,每个输入都以任务和数据集的名称开头(例如,对于翻译成法语的任务,输入是"[Translation: WMT’14 to French] The dog runs.")。
我们将这两种消融配置与
FLAN的微调过程进行比较,其中FLAN使用了自然语言指令(例如,"Please translate this sentence to French: 'The dog runs.'")。我们针对Figure 5中的四个held-out clusters进行评估。对于
no template设置,我们在zero-shot推理过程中仍使用了FLAN的指令。因为如果我们不使用模板,模型将不知道执行哪个任务。对于仅使用数据集名称进行微调的模型,我们在
zero-shot推理过程中分别报告了使用FLAN指令、以及使用数据集名称的zero-shot性能。
Figure 8显示了结果:这两种消融配置的性能都显著低于FLAN,这表明在处理unseen任务的zero-shot性能中,使用指令是至关重要的。
带
few-shot示例的指令:到目前为止,我们专注于在zero-shot setting中进行指令微调。在这里,我们研究了在推理时有few-shot示例可用时如何使用指令微调。few-shot setting的格式基于zero-shot格式。对于某个输入zero-shot指令。那么,在给定few-shot示例few-shot setting的指令格式为token。在训练和推理时,示例从训练集中随机选择,并且示例的数量限制为16个,并且总序列长度小于960 tokens。我们的实验使用与 ”主要结果“ 章节相同的任务划分和评估过程,因此仅在推理时使用unseen任务的few-shot示例。注意:训练时并没有使用
few-shot,而是zero-shot。如
Figure 9所示,与zero-shot FLAN相比,few-shot示例改善了所有task clusters的性能。示例对于输出空间较大/复杂的任务特别有效,例如struct-to-text、翻译、以及闭卷问答,这可能是因为示例有助于模型更好地理解输出格式。此外,对于所有task clusters,few-shot FLAN的标准差较低,表明对prompt engineering的敏感性降低了。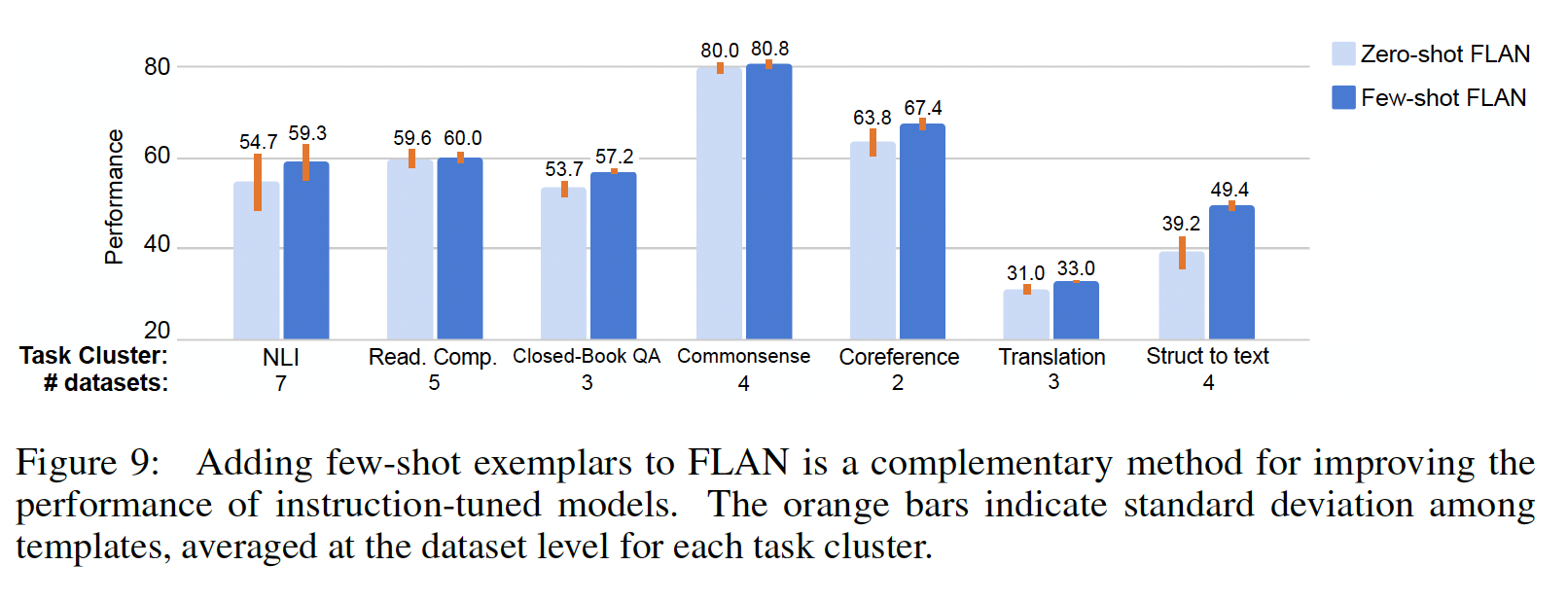
指令微调促进
prompt tuning:根据我们之前观察到的指令微调改善了模型对指令的响应能力的情况,我们可以得出这样的结论:如果FLAN更顺从地执行NLP任务,那么当使用soft prompts(放在输入之前的连续变量,这些变量通过prompt tuning进行优化)进行推理时,它也应该表现出更好的性能。作为进一步的分析,我们根据前面的cluster splits,为每个SuperGLUE任务训练continuous prompts,以便在对任务prompt-tuning时,指令微调过程中没有看到与cluster的任务。我们的prompt setting设置遵循《The power of scale for parameter-efficient prompt tuning》的过程,只是我们使用了长度为10的prompt,权重衰减为1e-4,并且在注意力分数上没有使用dropout;我们在初步实验中发现,这些改变提高了LaMDA-PT的性能。Figure 10显示了这些prompt tuning实验的结果,包括在使用完全监督训练集的情况下、以及在仅有32个训练示例的低资源环境中的情况。我们可以看到:在所有情景下,
FLAN比LaMDA-PT更适合进行prompt tuning。在许多情况下,特别是在低资源设置中,对
FLAN进行prompt tuning可以比对LaMDA-PT进行prompt tuning获得甚至10%以上的改进。
这个结果以另一种方式展示了指令微调如何导致更适合执行
NLP任务的checkpoint。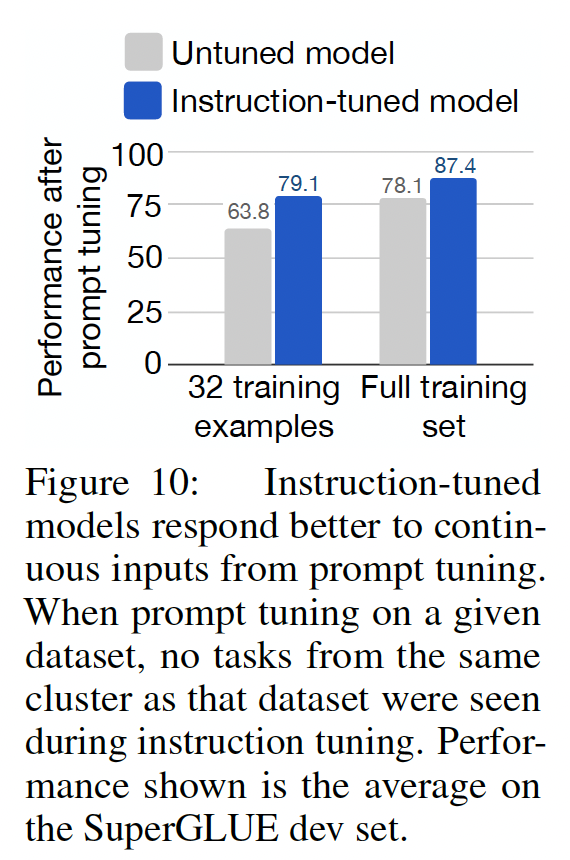
17.3 讨论
大规模语言模型的多样能力引起了对专家模型(每个任务一个模型)和通用模型(一个模型用于多个任务)之间权衡的关注,这对我们的研究具有潜在的影响。尽管人们可能认为
labeled数据在改进专家模型方面具有最自然的作用,但指令微调展示了如何利用labeled数据帮助大型语言模型执行许多unseen任务。换句话说,指令微调对跨任务泛化的积极影响表明,task-specific training是通用语言建模的补充,并激发了对通用模型进一步研究的动机。我们研究的局限性:
任务分配到
clusters中存在一定的主观性(尽管我们尽量使用文献中公认的分类),而且我们只探索了通常只有一句话的相对简短的指令的使用(与给予众包工作者的详细指令相比)。对于我们的评估来说,个别示例可能出现在模型的预训练数据中(预训练数据包括
Web文档),但在事后分析中(附录C),我们并未发现数据重叠显著影响结果的任何证据。最后,
FLAN 137B的规模使其成本较高。
指令微调的未来工作可以包括收集/生成更多的
task clusters进行微调、进行跨语言实验、使用FLAN生成用于训练下游分类器的数据,并使用微调改善模型在bias和公平性方面的行为(《Process for adapting language models to society (palms) with values-targeted datasets》。
十八、T0[2021]
论文
《Multitask Prompted Training Enables Zero-Shot Task Generalization》
最近的工作表明,大型语言模型表现出对新任务进行合理的
zero-shot generalization的能力(GPT-3、《What changes can large scale language models bring? intensive study on hyperclova: Billions-scale korean generative pretrained transformers》)。尽管只是在language modeling objectives上进行了训练,这些模型在它们没有被显式地训练过的新任务上可以表现得相对较好,例如回答一段话的问题或进行摘要。一个有影响力的假设是,大型语言模型对新任务的泛化是多任务学习的隐式过程的结果(
GPT-2)。作为学习预测next word的副产品,语言模型被迫从其预训练语料库中包含的隐式任务的mixture中学习。例如,通过对网络论坛的通用文本进行训练,一个模型可能隐式地学习问答任务的格式和结构。这使得大型语言模型有能力泛化到以自然语言的prompts所呈现的held-out tasks,超越了先前关于泛化到held-out datasets的多任务研究(《Unifiedqa: Crossing format boundaries with a single QA system》、《Crossfit: A few-shot learning challenge for cross-task generalization in nlp》)。然而,这种能力需要一个足够大的模型,并且对其prompts的措辞很敏感(《True few-shot learning with language models》、《Calibrate before use: Improving few-shot performance of language models》、《Prompt programming for large language models: Beyond the few-shot paradigm》)。此外,这种多任务学习到底有多隐式,也是一个悬而未决的问题。考虑到近期语言模型预训练语料库的规模,我们有理由期待一些常见的自然语言处理任务会以显式的形式出现在其预训练语料库中,从而直接在这些任务上训练模型。例如,有许多网站只是包含了一些关于普通问题和答案的列表,这正是闭卷问答任务的监督训练数据(
《How much knowledge can you pack into the parameters of a language model?》)。我们假设,预训练中的这种多任务监督(multitask supervision)在zero-shot generalization中发挥了很大的作用。在本文中,我们专注于以有监督的和大规模多任务的方式显式地训练语言模型。我们的方法是使用由自然语言的
prompts中指定的一组不同任务组成的training mixture。我们的目标是:诱导模型在不需要大规模的情况下更好地泛化到held-out tasks,以及对prompts的措辞选择更加鲁棒。为了将大量的自然语言任务转换成prompted形式,我们为结构化的数据集使用了一种简单的模板语言。我们开发了一个接口从而从公共贡献者那里收集prompt,促进了large multitask mixture with multiple prompts per dataset的收集(《Promptsource: An integrated development environment and repository for natural language prompts》)。然后,我们在任务的一个子集上训练T5 encoder-decoder model的变体(T5、《The power of scale for parameter-efficient prompttuning》),然后在未被模型训练的任务和prompts上评估模型。我们的实验研究了两个问题:
首先,
multitask prompted training是否能提高对held-out tasks的泛化性?第二,在更广泛的
prompts上进行训练是否能提高对prompt措辞的鲁棒性?
对于第一个问题,我们发现多任务训练能够实现
zero-shot task generalization,我们的模型在11个held-out datasets中的9个数据集上与GPT-3的性能相匹配或超过,尽管它比GPT-3小16倍。我们还表明,在BIG-bench基准的14个任务中,该模型在13个任务上比大型baseline语言模型有提高。对于第二个问题,我们发现,在每个数据集上训练更多的
prompts,可以持续地提高中位数,并减少在held-out tasks上的性能方差。对来自更多数据集的prompts进行训练也普遍提高了中位数,但并没有一致地降低方差。T0也是基于指令微调的,这和FLAN非常类似。相关工作:
在这项工作中,我们将语言模型预训练中的隐式多任务学习与显式多任务学习(
《Multitask learning》)区分开来,其中,显式多任务学习是将多个任务混合到一个监督训练过程中的技术。用多任务学习训练的模型早已被证明在NLP中具有更好的性能(《A unified architecture for natural language processing: deepneural networks with multitask learning》)。由于不同的任务有不同的输出,应用多任务学习需要一个共享的格式,各种格式已经被使用(《A joint many-task model: Growing a neural network for multiple NLP tasks》、《The natural language decathlon: Multitask learning as question answering》)。一些多任务的工作还探索了用大型预训练模型对新的数据集进行few-shot generalization和zero-shot generalization(例如,《Exploring and predicting transferability across NLP tasks》、《Crossfit: A few-shot learning challenge for cross-task generalization in nlp》)。自然语言
prompting是将NLP任务以自然语言的格式重新格式化到对应于natural language input的方法。text-to-text pretrained models的发展(如T5)使得prompts成为多任务学习的一个特别有用的方法。例如:《Unifiedqa: Crossing format boundaries with a single QA system》将20个问答数据集改编为question: ... (A)... (B)... (C)... context: ...的单一prompt。而后来的工作,如
《Adapting language models for zero-shot learning by meta-tuning on dataset and prompt collections》和《Entailment as few-shot learner》将一系列数据集分别转换为单个boolean QA prompt、或单个NLI prompt。
虽然有效,但这些
single-prompt方法通常不能泛化到新的prompts或新的任务,其中这些新的prompts或新的任务无法在single-prompt的固定的格式中表达。更加通用的是:
PET以及GPT-3将使用prompts作为所有NLP任务的通用方法加以推广。《Natural instructions: Benchmarking generalization to new tasks from natural language instructions》将这种方法进一步扩展到多任务设置中,对61个狭义定义的任务(如question generation、incorrect answer generation)的prompts进行训练,这些任务改编自9个数据集的众包指令;而我们对62个数据集和NLP文献中传统定义的12个任务进行训练并衡量泛化性。此外,他们的prompts除了指令之外还包括labeled examples,而我们则专注于zero-shot generalization。最后,
FLAN同时进行的工作与我们有类似的研究问题,尽管我们在几个实质性的方面有所不同,例如,prompt多样性、模型规模、held-out-task scheme。我们将详细讨论我们的差异。
最后,在解释
prompts的成功时,主要的假设是:模型学会了将prompts理解为task instructions,这有助于它们泛化到held-out tasks。然而,这种成功在多大程度上取决于held-out tasks的语义意义已经受到挑战(《Do prompt-based models really understand the meaning of their prompts?》、《Cutting down on prompts and parameters: Simple few-shot learning with language models》)。因此,在这项工作中,我们对prompts为什么支持泛化仍然保持未知(agnostic)。我们只宣称,prompts作为多任务训练的自然格式,从经验上支持泛化到held-out tasks。
18.1 衡量泛化到 Held-Out 任务的泛化性
我们首先假设
NLP数据集被划分为任务。我们用 "任务" 一词来指代由一组特定数据集测试的通用NLP能力。为了评估对新任务的zero-shot generalization,我们在任务的一个子集上进行训练,并在一组held-out任务上进行评估。不幸的是,
NLP任务的分类是模糊的,尤其是当人们试图分离出一种独特的skill时。例如,许多数据集评估常识性知识,一些多任务工作(如GPT-3、FLAN)将常识性知识定义为一个独立的任务。然而,常识数据集差别很大,从innate knowledge和小学科学到DIY指令、美国文化规范、以及研究生水平的定理(详细讨论见附录D.1)。注意到按任务分组是一种不完美的启发式方法,我们在组织我们的任务分类学时,偏向于根据任务格式,而不是根据文献中的惯例所要求的技能。我们从这些论文中收集所有的数据集,并排除那些非英语的数据集(这也排除了编程语言、以及结构化的注释,如
parse trees)、或者如果它们需要特殊的领域知识(例如,生物医学)。这就产生了12个任务和62个数据集,这些数据集在我们的training mixture和evaluation mixture中都有publicly contributed prompts(Figure 2),截至目前。所有的实验都使用Hugging Face datasets library中的数据集。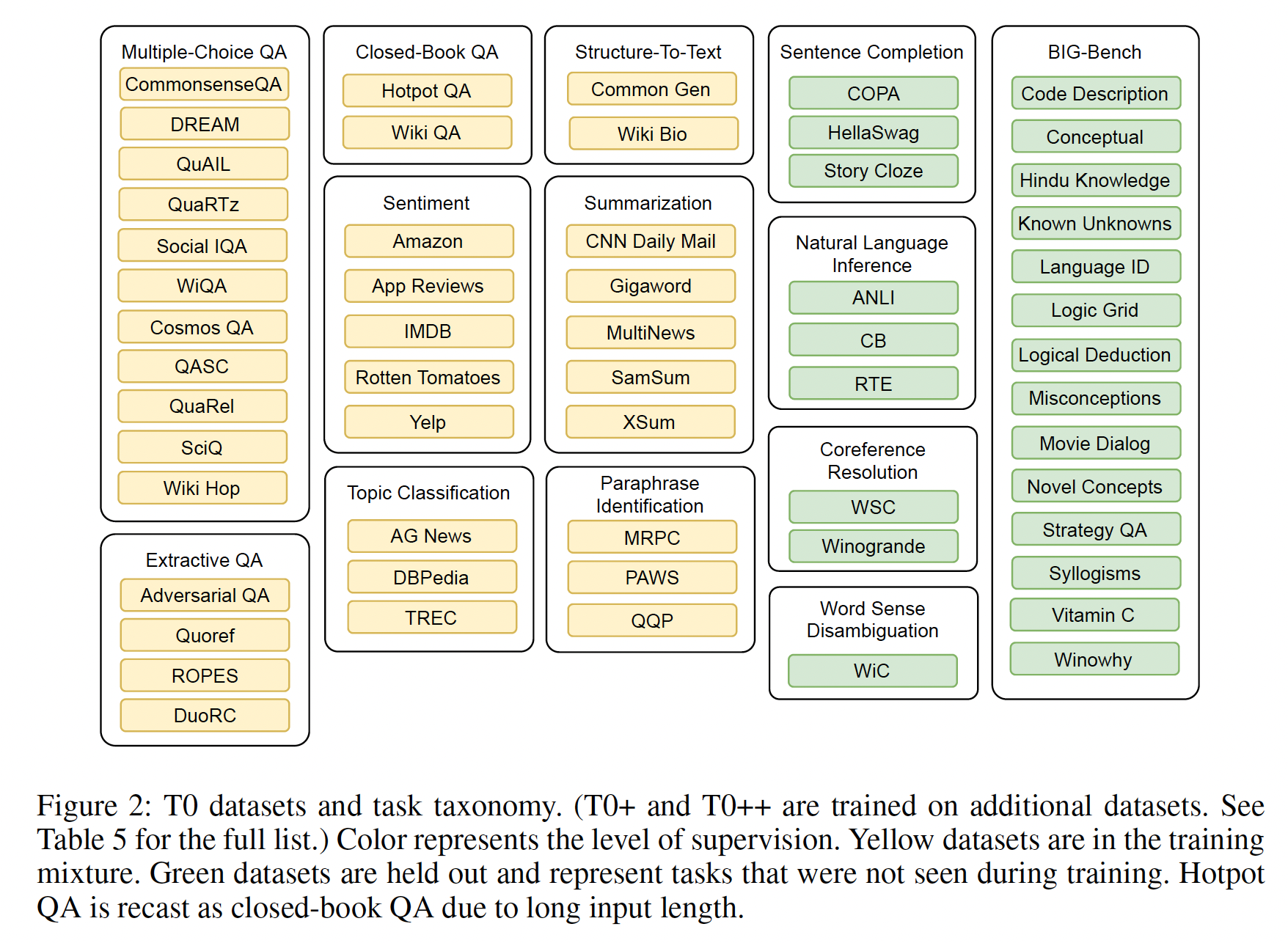
为了测试
zero-shot generalization,我们保留了四个任务的所有组成数据集:自然语言推理(natural language inference: NLI) 、共指解析(coreference resolution)、句子补全(sentence completion)、词义消岐(word sense disambiguation)。我们选择自然语言推理作为
held-out task,因为人类也会将自然语言推理作为held-out task从而进行zero-shot generalize: 大多数人从来没有被明确地训练从而对一个premise sentence是否蕴含或违背一个hypothesis sentence进行分类,但他们发现不经过训练就能直观地执行这项任务(《Anlizing the adversarial natural language inference dataset》)。出于同样的原因,我们也保留共指解析和词义消岐。我们进一步hold out句子补全任务,因为它可能与NLI过于相似(附录D.2详细讨论了这一点)。此外,我们不在
GPT-3用于评估的任何数据集上训练我们的main model,这样我们的主要结果将是一个公平的zero-shot比较。我们还验证了这些任务的数据没有通过预训练语料库而被泄露(附录E)。最后,我们对
BIG-bench的数据集的一个子集进行了进一步的评估。BIG-bench是最近的一个社区驱动的基准,用于创建一个多样化的困难任务集合来测试大型语言模型的能力。BIG-bench的子集包括一个language-oriented的任务的选择,BIGbench的维护者已经为其准备了初步结果,这些任务构成了T5 tokenizer的词汇范围(即只包含英语文本,没有表情符号或其他特殊字符)。所有来自BIG-bench的任务都是新任务,并且在我们的训练中被held out。
18.2 统一的 Prompt 格式
所有的数据集都是以自然语言提示的形式交给我们的模型,以实现
zero-shot experimentation。为了方便编写大量的prompts信息,我们开发了一种templating language和一个应用程序,使其能够轻松地将不同的数据集转换为prompts。我们将一个
prompt定义为由一个input template、一个target template、以及一系列关联的target template组成。模板是一个函数,该函数针对input sequences和target sequences将data example映射为自然语言。实际上,模板允许用户将带任意文本与数据字段、元数据、以及其他用于渲染和格式化原始字段的code相混合。例如,在一个NLI数据集的情况下,example将包括Premise、Hypothesis、Label等字段。一个input template是If {Premise} is true, is it also true that {Hypothesis}?,而一个target template可以定义为label选项{Choices[label]}。这里Choices是prompt-specific metadata,由选项yes, maybe, no组成,对应的标签是entailment (0), neutral (1), contradiction (2)。其他元数据记录了额外的属性,如评价指标。如Figure 3所示,每个data example都被具体化为许多不同的prompt templates。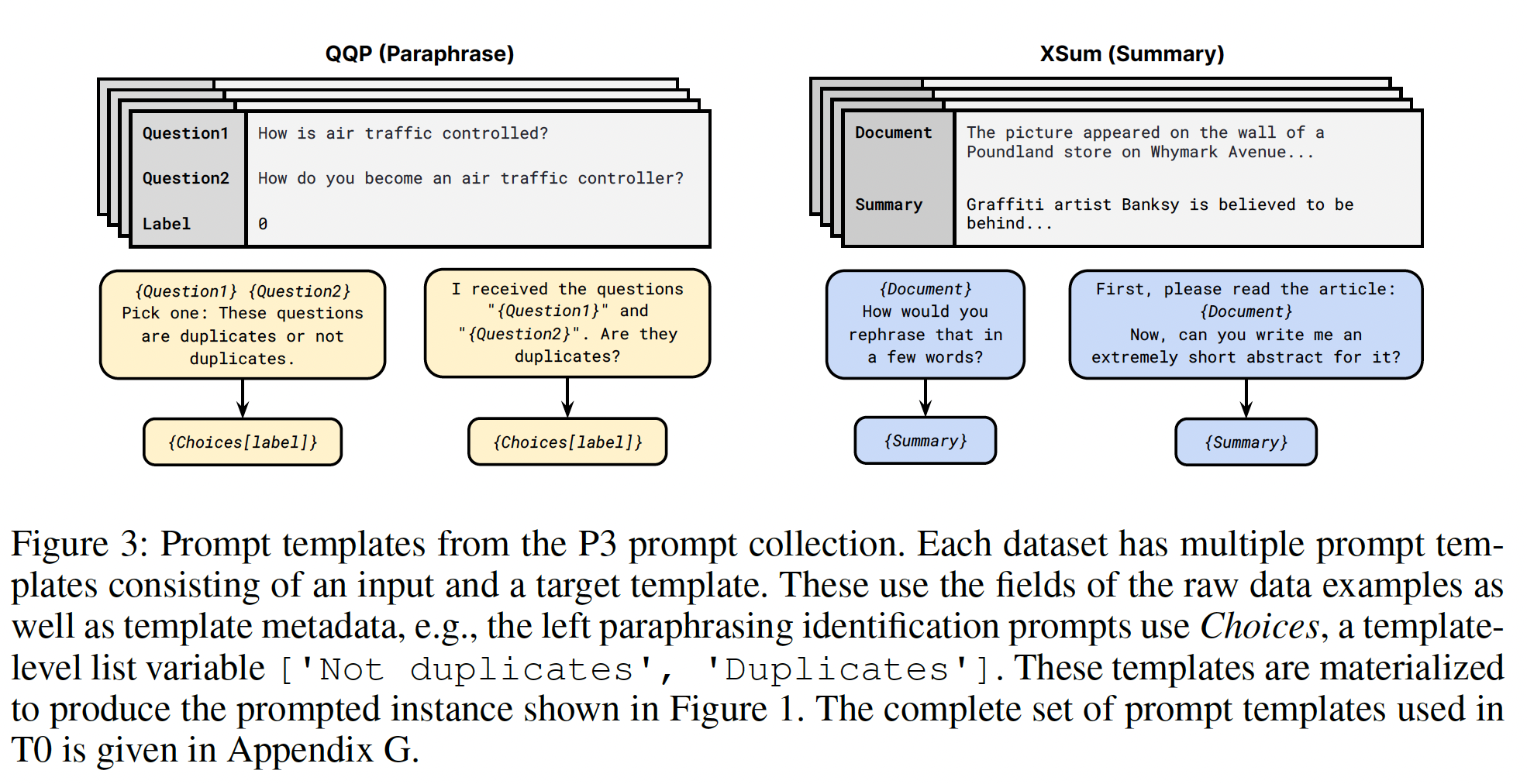
为了开发
prompts,我们建立了一个interface,用于在数据集上交互式地编写prompts。我们在学术界公开呼吁用户贡献prompts。隶属于8个国家24个机构的36位贡献者参与了进来。由于我们的目标是训练一个对prompt format具有鲁棒性的模型,并且,因为什么使得prompt有效的问题仍未悬而未决,我们鼓励贡献者在他们的prompt风格上保持开放,并创造一组多样化的prompts。主要的标注准则是,prompts需要符合语法,并能被一个没有任务经验的流利的英语使用者所理解。此外,需要显式的计数或数字索引的prompts被删除,从而支持自然语言的变体。例如,不是预测从段落中提取答案的span的索引,而是期待模型复制span的文本。有了这些最低限度的限制,我们鼓励prompt作者使用正式的和创造性的prompts以及各种关于数据的排序。大多数
prompts直接对应于原始任务的一个版本,我们也允许这种prompts:改变原始任务的顺序(例如,从摘要中生成一个文档)。这种non-original-task prompts包括在我们的training mixtures中,以提高多样性,但它们没有在评估中报告,因为它们偏离了原始数据集报告的指标和基线。即,根据
output来预测input。prompting language和工具的细节在附录C和《Promptsource: An integrated development environment and repository for natural language prompts》中给出,而prompts本身在附录G中给出。我们收集了英语数据集的prompts,排除了包含潜在有害内容或非自然语言(如编程语言)的数据集。我们把这个集合称为Public Pool of Prompts: P3。截至目前,P3包含177个数据集的2073个prompts(平均每个数据集有11.7 prompts)。实验中使用的prompts都来自P3(除了BIG-bench,它的prompts由其维护者提供)。
18.3 实验
模型:我们在自然语言
prompted数据集的multi-task training mixture上对预训练模型进行了微调。我们的模型使用一个encoder-decoder架构:输入文本被馈入编码器,target text由解码器产生。我们训练的所有模型都是基于
T5。由于T5的预训练目标是生成tokens,而且是只生成那些已从输入文本中删除的tokens,它与prompted datasets的自然文本生成格式不同。因此,我们使用《The power of scale for parameter-efficient prompt tuning》的LM-adapted T5 model(简称T5+LM),该模型是在标准的language modeling objective上对C4的100B额外tokens上进行训练后产生的。训练:我们的主力模型,
T0,是Table 5中详述的multitask mixture上训练的。此外,T0+是相同的模型,具有相同的超参数,只是在加入了GPT-3的评估数据集的mixture上训练。最后,T0++进一步将SuperGLUE加入到training mixture中(除了RTE和CB),这使得NLI和BIG-bench任务成为唯一被held-out的任务。上述的
T0变体都是由11B参数版本的T5+LM初始化的。为了研究scaling的效果,并帮助资源较少的研究人员,我们还训练了T0(3B),它与T0具有相同的training mixture,但是从3B参数版本的T5+LM初始化的(结果报告在附录F)。我们通过选择在训练数据集的
validation splits上产生最高分的checkpoint来进行checkpoint selection。这仍然满足了true zero-shot(《True few-shot learning with language models》)的设置,因为我们不使用任何held-out tasks中的任何样本来选择最佳checkpoint。我们通过合并和混洗所有训练数据集的所有样本来组装我们的
multitask training mixture。这相当于从每个数据集中按照数据集中的样本数量的按比例采样。然而,我们每个训练数据集中的样本数量相差两个数量级。因此,我们遵循T5使用的策略,将任何超过500k个样本的数据集视为有500k/num_templates的样本,从而用于采样,其中num_templates是为该数据集创建的模板数量。考虑到每个数据集被应用到
num_templates个模版上,因此数据集总共生成了我们将
input序列和target序列分别截断为1024 tokens和256 tokens。遵循T5的做法,我们使用packing的方式将多个训练样本合并成一个序列,以达到最大序列长度。我们使用1024个序列的batch size(对应于每个batch包含tokens)和Adafactor优化器。遵循微调T5的标准做法,我们使用1e-3的学习率和0.1的dropout rate。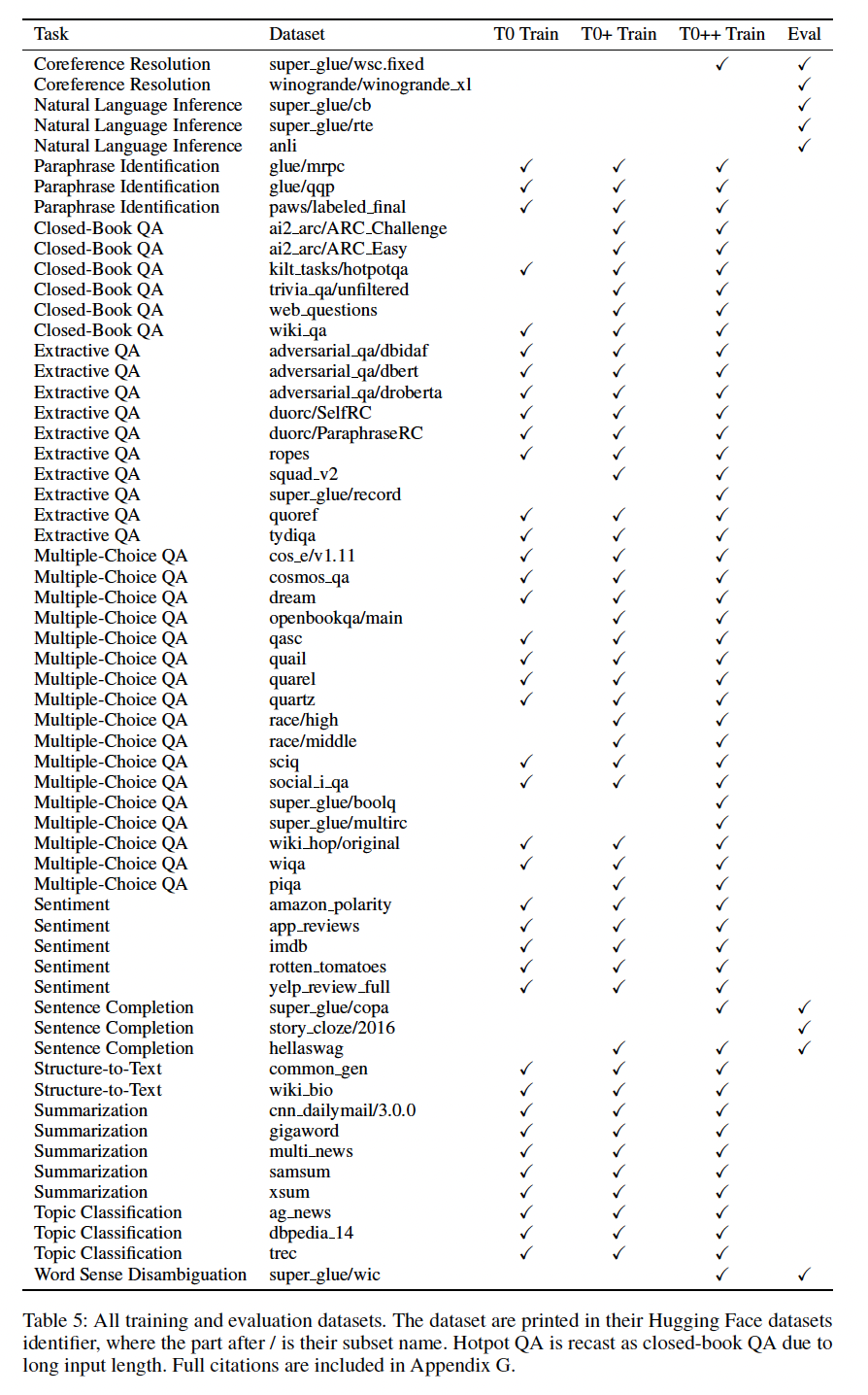
评估:我们在
11个数据集上评估了4个传统NLP任务的zero-shot generalization:自然语言推理、共指解析、词义消岐、句子补全;以及BIG-bench的14个新任务。除非另有说明,否则我们报告的是validation splits的性能。所有报告的数据集都使用准确率作为其衡量指标。对于涉及从几个选项中选择正确完成的任务(如多个选项的问答题),我们遵循
GPT-3的做法,使用rank classification来评估我们的模型:我们计算fine-tuned model下每个目标选项的对数似然,并选择具有最高对数似然的选项作为预测。为了简单起见,我们不对目标选项的对数似然进行长度归一化处理。我们不通过比较不同的
prompts在validation splits上的表现来进行prompt selection;《True few-shot learning with language models》强调了这种策略如何从validation splits中泄露信息,这使得评价不是"true" zero-shot。对于一个给定的数据集,我们报告了该数据集所有prompts的性能中值、以及它们的四分位数范围(Q3 -Q1),从而衡量模型对prompts措辞的鲁棒性。注意,
checkpoint selection是在训练数据集的validation splits上进行的,它不同于这里的validation splits。泛化到
heldout tasks:我们的第一个研究问题是,multitask prompted training是否能提高对heldout tasks的泛化能力。 在Figure 4,我们将T0与我们的T5+LM基线在四个heldout tasks上进行比较。我们的方法在所有的数据集上都比我们的基线有明显的提高,这表明multitask prompted training比只用相同的模型和prompts的语言建模训练有好处。接下来,我们将
T0与截至目前可用的最大的语言模型的zero-shot性能进行比较,即各种GPT-3模型,最高可达175B参数。请注意,GPT-3论文中报告的是单个prompt的性能,而我们报告的是P3中所有prompts的性能的中位数和四分位数范围。我们发现,T0在11个held-out datasets中的9个上与所有GPT-3模型的性能媲美或超过。值得注意的是,T0和GPT-3都没有在NLI任务上训练,但是T0在所有的NLI数据集上的表现都超过了GPT-3,而我们的T5+LM基线没有超越GPT-3。对于其他held-out tasks的大多数数据集来说,情况也是如此。两个例外是Winogrande和HellaSwag数据集,我们在后续讨论。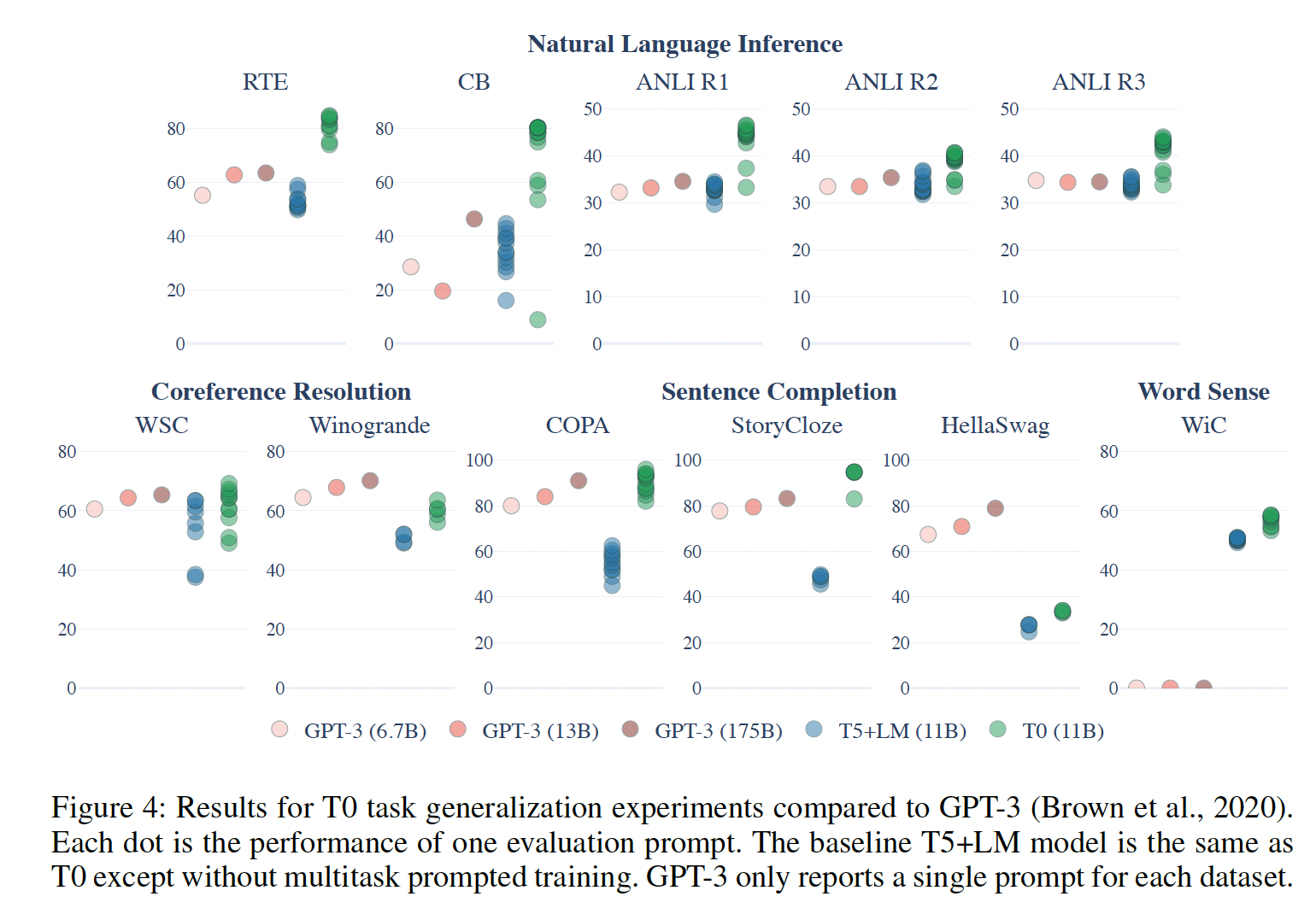
为了在更多的
held-out tasks上评估我们的模型,我们在BIG-bench的一个子集上评估了T0, T0+, T0++的zero-shot。BIG-bench的任务涵盖了我们的训练任务中没有包括的各种新技能,例如推断objects序列的顺序、解决逻辑网格谜题,以及将真实的陈述与常见的错误概念区分开来。BIG-bench的维护者为每个数据集提供了一个prompt,我们用它将我们的模型与一系列由谷歌训练并由BIG-bench维护者评估的初步诊断基线模型进行比较。这些模型是在一个标准的language modeling objective上训练的decoder-only Transformer语言模型,模型大小不一。我们发现,除了StrategyQA之外,至少有一个T0变体在所有任务上的表现超过了所有的基线模型(Figure 5)。在大多数情况下,我们模型的性能随着训练数据集数量的增加而提高(即T0++优于T0+、T0+优于T0)。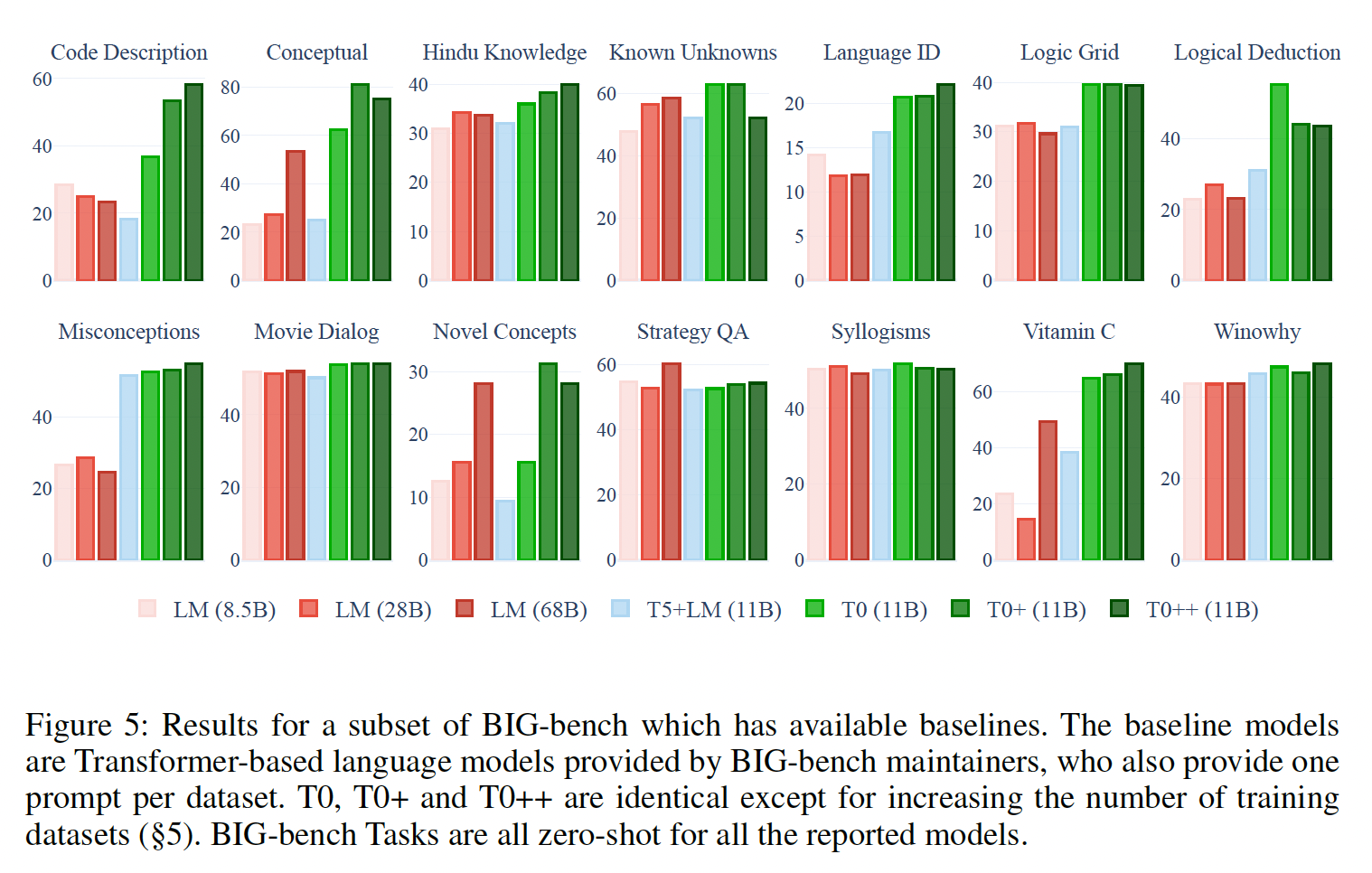
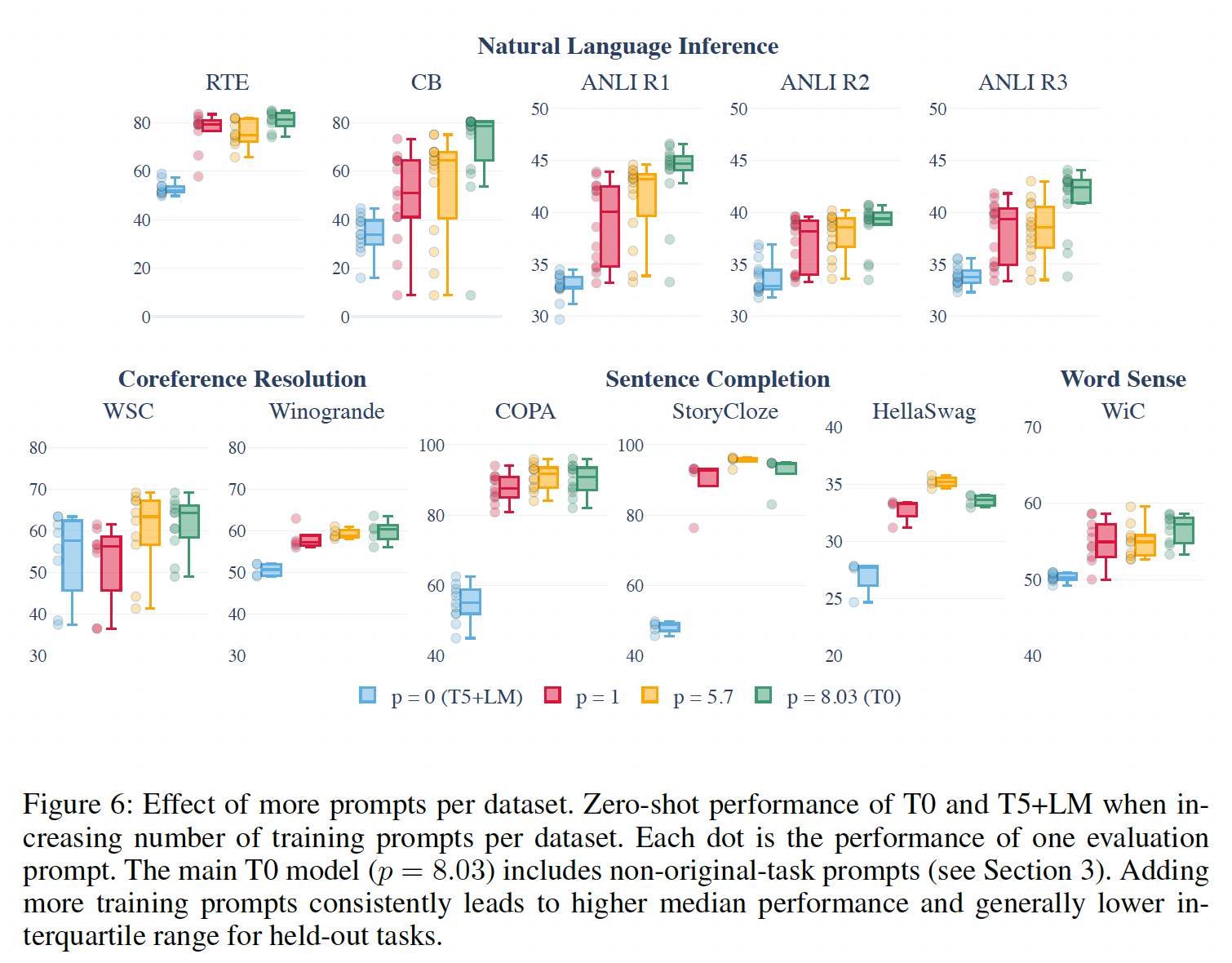
prompt鲁棒性:我们的第二个研究问题是,在更广泛的prompts上进行训练是否能提高对prompts措辞的鲁棒性。我们对每个数据集的平均prompts数量(每个数据集更多
prompts的效果:在这个分析中,我们固定T0与具有不同T0是在一些没有映射到数据集原始任务的prompts上训练的,例如"given an answer, generate a plausible question"。包括这些prompts的结果是8.03(这与我们的主力T0模型相对应)。我们将T0与original-tasks prompts)、original-tasks prompts)和prompted training的T5+LM)的模型进行比较。我们用相同的超参数和相同的步骤数来训练所有模型。Figure 6显示:即使每个数据集只有一个
prompt,held-out tasks性能也能比non-prompted baseline有很大的改善,尽管spread(Q1和Q3之间的四分位数范围)并没有一致地改善。同时,进一步将
1增加到5.7,确实在中位数(8/11个数据集上增加)和spread(7/11个数据集上减少)方面都有额外的改善。这加强了我们的假设,即在每个数据集上训练更多的prompts会导致更好的和更鲁棒的泛化到held-out tasks。最后,我们发现
T0包含了所有的prompts(包括那些不对应于数据集原始任务的prompts),进一步改善了中位数(9/11个数据集上增加)和spread(8/11个数据集上减少),表明对non-original-task prompts的训练也是有益的。
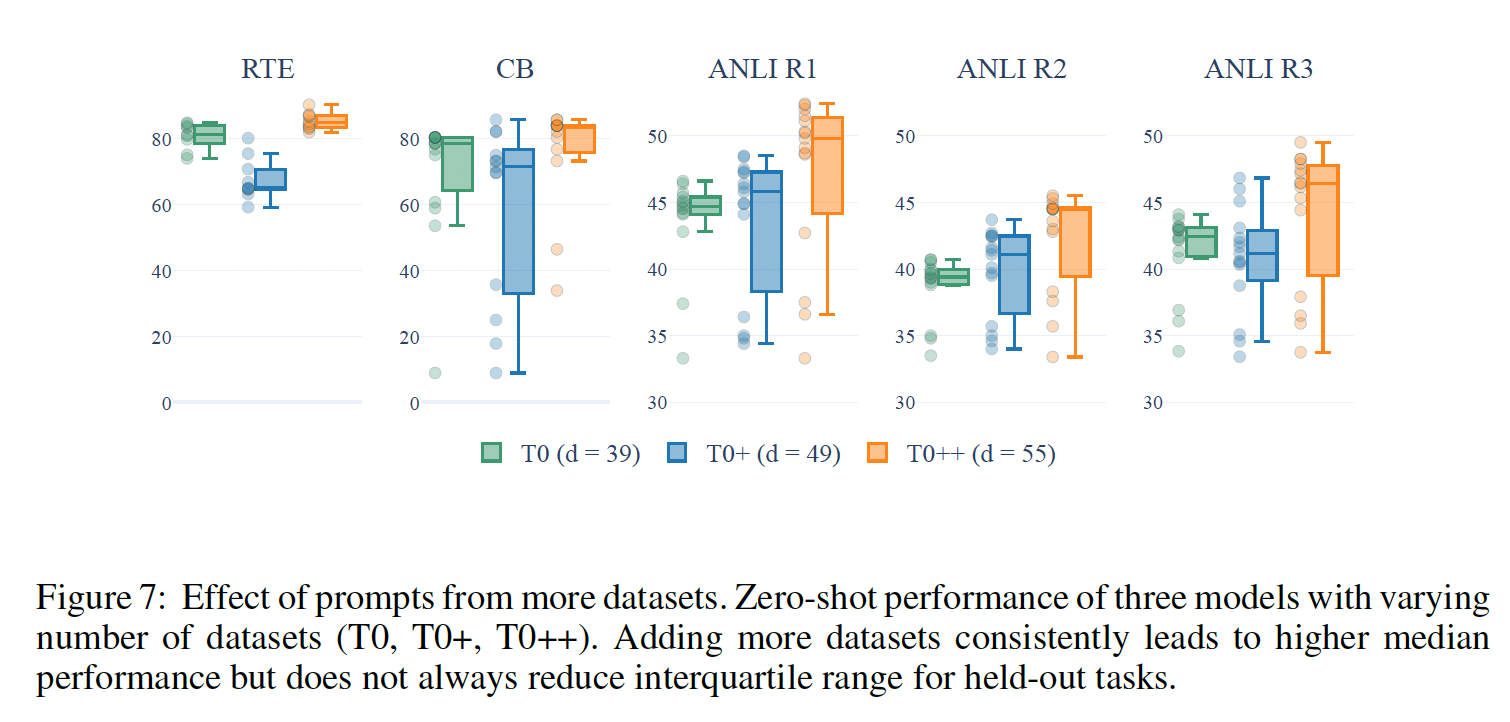
来自更多数据集的
Prompts的效果:这里我们固定prompts,并将39增加到49或55(分别对应T0, T0+, T0++)。Figure 7显示:随着
39增加到49,所有5个被held-out datasets的中位性能都在增加。然而,5个数据集中只有1个数据集的spread有所减少。对于一些数据集(如
ANLI),这是一个伪命题,因为一些prompts总是表现得很差,所以当其他prompts改善时,spread被拉大了。然而,对于其他的数据集(如CB),spread确实随着T0+而减少。当
49增加到55时,所有数据集的中位数性能再次增加,但spread只对5个数据集中的2个减少了。虽然还需要进一步调查,但看来增加prompts的措辞更加鲁棒。
比较
T0和GPT-3的鲁棒性:由于GPT-3只报告了每个数据集的一个prompt,没有标准差,我们通过OpenAI的API在RTE上评估GPT-3,使用我们评估T0的相同的10个prompts,从而估计GPT-3对不同措辞的prompts的鲁棒性。其中一个模板与GPT-3报告的prompts相同,其准确率为58.8%,低于GPT-3报告的63.5%。然而,所有其他9个prompts都产生了大致随机猜测的性能,准确率中值为52.96%,四分位数范围为1.28%。这些结果表明,相比GPT-3,T0可能对prompt formulation更加鲁棒。这是可以理解的,因为
T0被微调从而更适合这些prompts。
18.4 讨论
与我们的工作同时,
《Finetuned language models are zero-shot learners》提出了FLAN,它采用相同的方法:通过multitask prompted training来实现zero-shot generalization。利用与我们类似的混合数据集,他们训练了多个decoder-only的语言模型,每个模型都有一个held-out task(比方说,我们专注于用多个held-out tasks训练一个模型,以评估该模型对不同任务的泛化能力)。与FLAN相比:T0在CB和RTE上的zero-shot性能更好、在Story Cloze和COPA上类似、而在Winogrande和ANLI上更糟。T0++在CB, RTE, COPA上的表现优于FLAN,在Winogrande, ANLI上的表现与FLAN相当。
值得注意的是,尽管
T0和T0++比FLAN小10倍以上(11B vs. 137B的参数),但还是达到了这个性能。T0和FLAN在Winogrande, HellaSwag上的表现都不如GPT-3,对此,FLAN猜想,对于像共指消解这样可以被格式化为补全一个不完整的句子的任务,在prompts中添加任务指令 "基本上是多余的"。根据这个猜想,我们按照FLAN和GPT-3的做法,对这两个数据集进行了不带指令的重新评估,发现它在HellaSwag上的表现从中位数33.65%提高到57.93%,与FLAN的表现相匹配。然而,对于Winogrande,使用FLAN的prompts而不带指令,并没有带来实质性的变化(准确率为62.15%)。令人惊讶的是,
FLAN用一个与T0(11B参数)规模相当的模型(8B参数)进行消融,发现在multitask prompted training后,held-out tasks的性能会下降,而我们发现multitask prompted training至少可以提高小到3B参数的模型的性能(Figure 8)。我们确定了模型之间的两个关键差异,可以解释这种不一致:首先,我们使用了一个
encoder-decoder模型,该模型在被训练成标准语言模型之前,用不同的目标(masked language modeling)进行了预训练,最后在multitask mixture上进行了微调。我们注意到,masked language modeling已多次被证明是一种明显更有效的预训练策略(T5、《Cloze-driven pretraining of self-attention networks》、BERT)。其次,我们的
prompts在长度和创造性方面更有质量上的多样性。例如,考虑我们对Quora Question Pairs: QQP的一个prompt(转述识别):I’m an administrator on the website Quora. There are two posts, one that asks "question1" and another that asks "question2". I can merge questions if they are asking the same thing. Can I merge these two questions?。我们假设,这种多样性可能会产生具体的影响。例如,它可以解释为什么FLAN提出的消融结果中,增加prompts的数量对性能的影响可以忽略不计,而我们在增加更多的prompts时却观察到了改进。我们把对这些差异的影响的全面调查留给未来的工作。
十九、MetaPrompt[2021]
论文:
《Prompt Programming for Large Language Models: Beyond the Few-Shot Paradigm》。
最近大规模自监督语言模型(如
GPT-3)的兴起,以及它们在下游任务上的成功,使我们离task-agnostic的人工智能系统的目标又近了一步。然而,尽管这类模型具有明显的力量,但目前控制它们执行特定任务的方法却极为有限。为了正确评估其能力并从这些模型中提取有用的工作,需要新的方法。在
GPT-3之前,评估和使用这类模型的标准方法涉及对任务数据集的一部分进行微调(《Universal language model fine-tuning for text classification》)。GPT-3在没有微调的情况下在各种任务上取得了SOTA的性能,只使用了few-shot prompts,其中prompts提供了少量的任务示例作为输入的一部分馈入到训练好的模型。然而,虽然few-shot format足以揭示这些任务的惊人表现,但我们认为,在从自监督的语言模型中提取特定的learned behaviors方面,prompting可能比fine-tuning或few-shot format更有效。我们认为,与原始
GPT-3论文的标题(即,Language models are few-shot learners)所暗示的对few-shot format的普遍解释相反,GPT-3在运行期间往往不是真正从few-shot examples中学习任务。与其说是指令(instruction),不如说该方法的主要function是:在模型现有的learned tasks空间中进行任务定位(task location)。这可以从alternative prompts的有效性中得到证明,其中在没有示例或指令的情况下,这些alternative prompts可以激发与few-shot format相当或更好的表现。这促使我们采取新的方法,显式地追求
task location的goal。我们建议探索更通用的prompt programming方法,特别是将任务意图(task intention)和任务结构传达给自监督模型的技术,其中自监督模型的训练模态是自然语言。在很大程度上,自监督语言模型被训练来逼近的
ground truth function就是人类的写作方式。因此,为了与语言模型进行交互和控制,我们应该从人类使用的自然语言的角度来考虑。除了一些注意事项外,我们希望找到一些我们预期人类补全的prompts,通过文本补全的方式来完成目标任务。在本文中,我们研究了
few-shot paradigm,并发现它的性能可以被简单的0-shot prompts相匹配或超过。我们探讨了成功的0-shot prompts的性质,并通过自然语言符号学的视角提出了prompt programming的通用方法。我们展示了一些新颖的prompts,这些prompts迫使语言模型在作出裁决之前将问题分解成若干部分;我们还介绍了metaprompt programming的概念,这种方法将编写task-specific prompt的工作交给语言模型本身。最后,我们讨论了如何将这些想法纳入现有的和未来的benchmarks,使得我们能够更好地探测(probe)大型语言模型的能力。就是类似于
COT的思想来引导模型自动生成few-shot examples。相关工作:最近的文献工作集中在,使用机器学习的传统应用方法来控制自然语言的生成,例如:
调节
output的新架构(《CTRL: A Conditional Transformer Language Model for Controllable Generation》、《GeDi: Generative Discriminator Guided Sequence Generation》)。更先进的采样技术(
《Hierarchical Neural Story Generation》、《The Curious Case of Neural Text Degeneration》)。基于梯度的
prompts优化(《AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts》、《Prefix-Tuning:Optimizing Continuous Prompts for Generation 》)。特定任务的
adapter networks(《Zero-shot Learning by Generating Task-specific Adapters》)。
关于这些最新方法的综述见
《Controllable Neural Text Generation》。过去的工作还探索了通过为每个任务动态地选择最相关的示例来改进few-shot paradigm(《Multi-Step Inference for Reasoning Over Paragraphs》、《Making Pre-trained Language Models Better Few-shot Learners》。相比之下,关于自然语言的
0-shot的prompt programming方法的工作很少被正式化。相反,成功的prompt programming技术主要是在OpenAI's API and AI Dungeon的用户的博客和社交媒体上分享。由于大多数
prompt programming的探索采取了分散的形式,我们在这里汇编所有相关的贡献是不可行的。相反,我们给出了一个简短的、非详尽的探索,这些探索已经超越了few-shot paradigm。《GPT-3 Creative Fiction》对GPT-3的能力做了最全面的综述,他演示了GPT-3写小说、写诗歌、写海豹突击队,以及执行PDF清理等任务。他写了大量关于他使用GPT-3工作的直觉,也写了他的prompt programming方法。《GPT-3: Using Fiction to Demonstrate How Prompts Impact OutputQuality》写过关于prompt提供的上下文对写作质量的影响。《You Can Probably Amplify GPT3 Directly》写过关于通过对话引导GPT-3从而将问题分解成多个步骤来放大GPT-3的数学能力。推特用户
KaryoKleptid也发布了类似的实验(《Seems to work》、《Teaching GPT-3 to do a brute force ’for loop’ checking answers》),使用对话来prompt GPT3(通过AI Dungeon)将问题分解成多个步骤并遵循暴力检查等程序,在数学问题上取得了令人印象深刻的结果。
我们的工作综合并扩展了这些探索所开创的方法,代表了向正式确定有效的自然语言
prompt programming技术迈出了适度一步。
19.1 调研 few-shot prompting
GPT-3在有0-shot prompts、1-shot prompts、n-shot prompts的任务上进行了评估。当提供更多的示例时,GPT-3的表现一直很好,0-shot的表现往往不到n-shot的一半。对这一结果的常见解释是,GPT-3在运行时从示例中学习,这使得它的表现比提供较少或没有示例时更好(《Language models are few-shot learners》)。然而,随着示例数量的增加,性能的提高可以用另一种方式来解释。与其说从示例中学习如何执行任务,不如说这些示例只是用来指导
GPT-3解决什么任务,并鼓励它在回答中遵循prompt的结构。例如,对于某些任务(如翻译任务),少量的样本不足以学习关于该任务的任何实质性内容。相反,
GPT-3必须主要地(如果不是完全地)依靠其trained weights中所包含的源语言和目标语言的词汇知识和语法知识。我们将明确表明,这些prompts主要是引导模型访问现有的知识,而不是将这些任务视为few-shot learning。我们通过研究示例(训练样本)是否有必要,从而来做到这一点。0-shot prompts的成功:由于预算和时间的限制,我们只探讨了一个简单的例子,即一个French-to-English的翻译任务。我们发现,0-shot prompts可以匹配甚至超过标准的few-shot的性能。我们在Table 1中的结果显示,GPT-3论文中所报告的0-shot accuracy甚至可以通过微小的prompt engineering而得到实质性的改善。最重要的是,Figure 1中极其简单的prompt,只包括两种语言的名称和一个冒号,比原始GPT-3论文中的10-shot prompt表现得更好。事实上,我们发现
GPT-3论文中大多数表现最差的0-shot prompts都是如此,特别是问答任务的benchmarks。许多prompts可以很容易地通过简单的格式改变而得到改善,从而使prompt更接近人类写的自然语言。因此,GPT-3的0-shot性能被大大低估了。纠正这种
confusion是很重要的,可以更准确地了解模型能力的性质,以便我们可以更好地学习控制它。事实上,GPT-3有大量functions,这些functions无需在运行期间被学习;这使得0-shot prompting具有很大的灵活性,并鼓励探索更通用的prompt programming方法。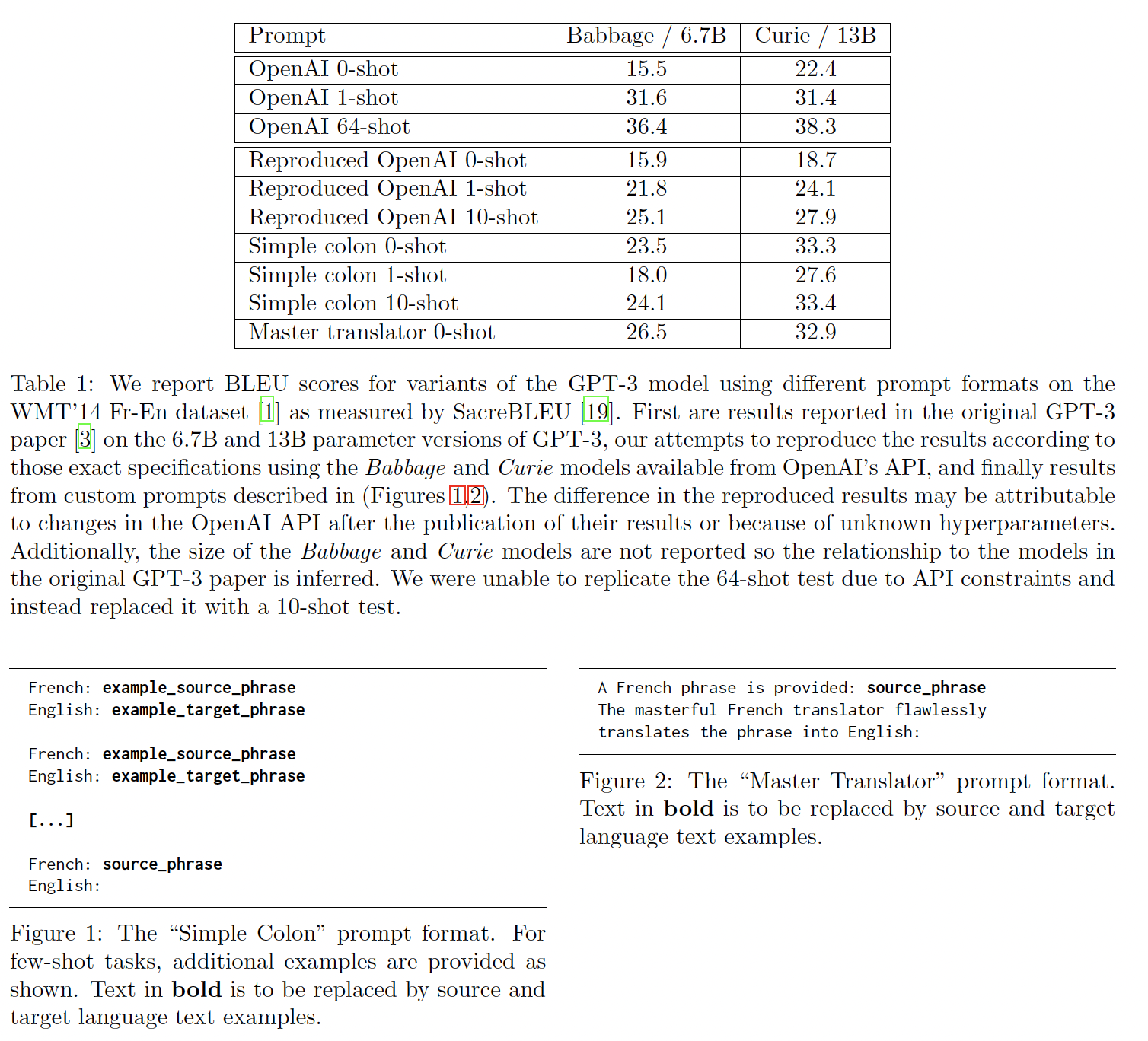
Examples并不总是有用的:在我们的实验中,简单的colon prompt(Figure 1)的1-shot的表现明显比0-shot更差。通过检查GPT-3在这个任务上的输出,我们发现性能下降是由于1-shot示例的语义污染造成的。这是认为示例的语义与任务有关(比如说,示例被解释为连续叙述的一部分),而不是把示例当作categorical guide。事实上,我们发现,在各种任务中,对于普遍的low-shot prompts都存在这个现象。这种来自
few-shot examples的污染效应已经被成功地用于提高GPT-3的性能,通过为每个任务选择in-context examples(《Multi-Step Inference for Reasoning Over Paragraphs》)。
19.2 Prompt Programming
重写
prompt可以使语言模型的表现发生重大变化。这就促使我们提出了一个问题: 是否有一种方法,我们可以遵循该方法来制作更有可能产生预期行为的prompts?对于语言模型(它的输入和输出都是自然语言)的
prompt engineering,可以理解为自然语言的编程。然而,自然语言是不确定的,比传统的编程语言要复杂得多。在本节中,我们将对自然语言编程的理论和方法进行讨论。
19.2.1 语言的 dynamics
为了理解如何
prompt一个自回归语言模型,我们必须首先考虑模型被训练的背景、以及模型所近似的function。GPT-3是在一个自监督的环境下,对数百GB的自然语言进行训练的。自监督是一种无监督学习的形式,其中ground truth labels来自数据本身。在GPT-3的case中,分配给每个样本的ground truth label只是原始数据源中的next token。那么,GPT-3所近似的ground truth function就是决定原始数据中next token的underlying dynamic。这个function,与GPT-3不同,并不是一个黑盒子,但它是巨大的、难以解决地复杂。它是人类语言的function,因为它已经被人类使用并记录在书籍、文章、博客和互联网评论中。一个预测语言
dynamics的系统必然包括人类行为和物理世界的模型(《Building AGI Using Language Models》)。语言的dynamics并没有脱离文化的、心理的和物理的背景;它不仅仅是一种语法的甚至语义的理论。在这个意义上,语言不是一个抽象的概念,而是一个与人类相关的reality的所有方面纠缠在一起的现象。dynamic必须预测语言的实际使用情况,这包括(比如)预测理论物理学家之间的对话。对语言进行建模,和对reality(该reality可能影响语言流动)的每一个方面进行建模一样困难。显然,
GPT-3并没有完美地学习到ground truth function,否则现在的世界看起来会非常不同。然而,它已经在明显的程度上接近了它,这一点从它不仅能够形成语法句子,而且能够连贯地采用文化参考和隐喻,并对复杂的心理的和物理的环境进行建模(《GPT-3 Creative Fiction》)。那么,prompt programming的问题是重要的,因为语言的dynamics是重要的。如果我们要预测一个给定的由人类撰写的文本段落如何继续下去,我们将需要对作者的意图进行建模,并纳入有关该文本段落所指的世界性知识。逆问题(寻找一个
prompt,该prompt能够产生一个或一类continuations)也涉及相同的考虑:就像说服(persuasion)的艺术一样,它需要高层次的心理学概念,如语气、暗示、联想、记忆、风格、可信度、以及模糊性。这就促使我们采用拟人化的方法进行
prompt programming,因为建模GPT-3如何对一个prompt做出反应涉及到对虚拟的human writer(s)的建模。拟人化的方法与模型的拟人化是不同的。GPT-3的dynamics需要对人类进行复杂的预测,但它的行为在几个重要方面与人类不同。在本文中,我们将讨论其中的两个方面:它不像单个的人类作者,而是许多作者的叠加,这促使我们采用减法方法从而用于
prompt programming。在
tokens之间发生大量silent reasoning的情况下,其预测dynamics的能力受到限制,这一限制可由prompting技术部分地克服。
本节的主旨是,为自监督的语言模型制定精确的
prompt programming理论,与写下可观察现实的物理学的Hamiltonian(非常困难)属于同一难度等级。然而,人类还是有优势可以有效地进行prompt programming,因为我们已经进化了,并花了一生的时间学习与手头的dynamics相关的启发式方法。prompt programming是用自然语言编程,它为我们提供了大量我们熟悉但没有名字的functions。我们需要学习一种新的方法论,但方便的是,我们已经学会了最困难的基础。prompt programming的艺术在于:使我们现有的知识适应关于与自回归语言模型互动的特殊性。随后,我们介绍了一些方法和框架,我们发现这些方法和框架有助于制作有效的
prompts。这些方法可以而且应该并行地应用,就像它们在所有形式的人类话语中交织在一起一样。一般来说,强化所需行为的冗余度越多越好,这可以说是由few-shot format的有效性所证明的。由于我们的经验主要来自与
GPT-3的互动,在下面的章节中,我们直接和间接地提到了GPT-3的能力和行为。然而,我们相信这些方法可以推广到prompting任何在大规模人类撰写的语料库上训练的自回归语言模型。
19.2.2 直接的任务规范:构建 signifier
pre-GPT-3模型由于其对世界和人类概念的建模有限,在理解任务的抽象描述方面的能力要小得多。GPT-3在0-shot prompts上的令人印象深刻的表现表明了直接任务规范(task specification)的新的可能性领域。直接任务规范是一个
0-shot prompt,它告诉模型执行一些该模型已经知道如何做的任务。直接任务规范包括为任务构建一个signifier。signifier是一种模式,它决定了预期的行为。直接任务规范可以是任务的名称,如 "翻译";也可以是一个复合描述,如 "重新表述这个二部图,使二年级学生能够理解它,通过强调在现实世界的应用";也可以纯粹是上下文,如Figure 1中简单的冒号prompt。在这些情况下,signifier都没有解释如何完成任务、或提供预期行为的示例;相反,它显式地或隐式地调用它认为语言模型已经学会的functions。直接任务规范可以监督无穷无尽的隐式样本,就像一个无限序列的闭式表达式(
closed-form expression),使得它们非常强大和紧凑。例如,"translate French to English"这句话监督于所有可能的法语短语到英语的映射所构成的集合。一个大型的语言模型,像一个人一样,也学会了一些行为,在这些行为上如何构建一个直接的
signifier是不太明显的。通过示范(demonstration)和代理(proxy)的任务规范可能是激发这些行为的可行的替代策略。
19.2.3 通过示范的任务规范
few-shot examples对于任务规范是有效的,因为具有不同参数的function的连续重复模式是自然语言中常见的。与以前的模型不同,GPT-3鲁棒地学习了语言的这一属性,并且能够在示例从所有上下文中移除的情况下应用它。与直接规范一样,通过示范来规范任务也是GPT-3的一种可能性。有些任务用示例来传达是最有效的,比如当任务需要一个
be-spoke的格式时,描述示例的语言比描述任务本身所需的meta-language更容易理解。需要注意的是,与微调不同的是,
few-shot中的"training examples"是作为一个整体来处理的,不一定会被解释为并行的和独立的。informative context或大量的示例可以帮助缓解Examples don’t always help中提到的few-shot的问题。例如,一个prompt可以将示例嵌入到一个上下文中,使上下文清楚地表明这些示例是一个function的独立实例,而不是一个应该被推断的序列模式。一般来说,无论是从人的角度还是从语言模型的角度,示例在上下文中都是更有效的和更有信息量的。
19.2.4 通过记忆性代理的任务规范
人类交流中使用的另一种方法是代理或类比(
analogy),其中一个记忆性的概念(memetic concept),如一个人物或特性被用作一个意图的代理,后者可能是相当复杂的或细微的。GPT-3显示了对类比的细微理解。通过代理的规范在机制上类似于直接规范,只是signifier从记忆空间/文化意识中提取行为,而不是直接命名行为。例如,你可以问圣雄甘地、安-兰德、埃利泽-尤德考克斯,而不是直接指定回答道德问题的确切标准或使用示例。每个人不仅会有复杂的偏见,而且会对问题的内容做出假设,这可能需要几段文字来证明或描述。
GPT-3对知名人物的模拟能力和抽取文化信息的能力远远超过了大多数人的能力(《GPT-3 Creative Fiction》),所以这种方法对编码复杂的(尤其是开放式的)任务特别有用。由于GPT-3很适合在叙事的上下文中进行嵌入,叙事中的无限自由度也可以用来进一步塑造行为。另一个有效代理的例子是上演老师和学生之间的对话。假设你想和
GPT-3讨论一些事情,你关心的是它应该非常彻底地、简单地解释事情,并在你错误的时候指出来。你可以说"be very thorough, explain things simply, and point out if I’m wrong",但这也可能导致一个幽默的对话,即它总是说你错了,并对你的不理解越来越恼火。更可靠的做法是将讨论呈现为学生和老师之间的讨论,这是一种典型的情况,在这种情况下,所需的属性已经隐含在其中,并且由于记忆的强化,更有可能保持稳定。
19.2.5 作为约束行为的 Prompt Programming
像
GPT-3这样的语言模型的朴素的拟人化的失败方式是这样的:对prompt产生的概率分布不是某个人延续该prompt的方式的分布,而是任何一个人都可以延续该prompt的方式的分布。一个上下文模糊的prompt可能会以相互不连贯的方式继续下去,就像由不同的人在任何合理的上下文中延续prompt一样。像
GPT-3这样的大型生成模型的全能性意味着,如果有各种可能延续prompt的方式(包括所有人类操作者不愿意的方式),它将以多种方式对prompt做出反应。因此,从约束行为的角度来处理prompt programming是很有帮助的:我们希望prompt不仅与所需的延续一致,而且与不需要的延续不一致。考虑一下下面的
prompt:Translate French to English:Mon corps est un transformateur de soi, mais aussi un transformateur pour cette cire de langage.这种
prompt在限制可能的延续到预定任务方面做得很差。最常见的失败模式是,模型的输出不是英语,而是另一个法语句子。在法语句子后面添加一个换行符将增加下一个句子是英语翻译的几率,但是下一个句子仍然有可能是法语,因为prompt中没有任何内容可以排除一个多行短语成为translation subject。将prompt的第一行改为"Translate this French sentence to English"将进一步提高可靠性;在法语句子周围加上引号也是如此,但也可能输出通过引号包围的一段法语(比如,作为法语对话的一部分)。最可靠的是创建一个句法约束,其中任何合理的延续只能是预期的行为,就像Figure 1的简单冒号prompt、以及Figure 2master translator prompt。这个简单的例子是为了
frame一个对prompt programming的动机至关重要的问题:什么样的prompt会导致预期的行为,而且只导致预期的行为?many-shot prompts的成功可以通过这个角度来重塑:如果prompt由一个函数的众多实例组成,那么延续很可能是这个函数的另一个实例;而如果只有一个或几个实例,那么继续符合模式的可能性就较小。
19.2.6 封闭式问题的序列化推理
对于需要推理的任务来说,
prompts以求真模式(truth-seeking patterns)指导语言模型的计算是至关重要的。如果问题迫使裁决由模型的延续的第一个
token来决定,那么计算将受限于单次前向传递。可以合理地预期,某些任务可能在单次传递中难以计算,但如果将其分解为可单独处理的子任务,则可以解决问题。当人类被给予一个封闭式测试时,通常期望在确定答案之前,
subject在working memory或草稿纸上进行计算。看不见的计算可能涉及重新表述问题、概述一个过程、排除答案选项、或将隐式信息转化为显式形式。当我们强迫模型在单次前向传递中产生答案时,我们剥夺了它进行类似的"working memory"或 "草稿空间"(scratch space) 的能力,这些能力可以进行这种操作。与其开放式的延续所暗示的强大理解能力和广博知识相比,
GPT-3在封闭式问题上的表现并不出色。例如,在这个多任务数据集(《Measuring massive multitask language understanding》)上,它在某些部分的得分几乎只是随机猜测的水平。我们怀疑这部分是由于这种格式迫使在延续的第一个token上做出决策。封闭式评估是必要的,因为当前的方法不支持在大型数据集上进行评估,也无法对使用开放式问题的模型进行直接比较。然而,为了更好地了解模型的能力,我们寻求更能反映系统全部能力的评估方法。我们不必改变基准测试,而是可以改变语言模型与其互动的方式。
这个问题在之前的研究中已经被认识到,之前的研究试图通过使用专门的神经网络架构来实现串行推理(
《Low-resource generation of multi-hop reasoning questions》、《Multi-step Reasoning via Recurrent Dual Attention for Visual Dialog》)。我们努力通过仅使用prompt programming来达到同样的效果。对于像
GPT-3这样的Transformer模型,利用 "草稿空间" 的潜在方法包括逐步过程、自我批评(辩论)、以及通过详细阐述问题来激活正确答案的关联性。已经证明,能够让GPT-3将数学问题分解为多步骤的prompts是有效的(《You Can Probably Amplify GPT3 Directly》、《Seems to work》)。这些演示涉及到人类通过交互式引导GPT-3的程序。需要
human-in-the-loop限制了此类基准测试和大规模应用的适用性,但是我们提出,对于许多任务来说,在通过extending reasoning来扩大GPT-3的能力方面,人类互动和task-specific prompts都不是严格必要的,因为GPT-3已经了解许多程序和元程序(meta- procedures)用于演绎地处理问题。在这些情况下,prompt programming的作用再次是signify序列推理任务。例如,"For a problem like this,",这样的种子通常足以指示模型考虑任务的类别并将其分析为各个组成部分。在
extending reasoning时,要避免过早做出决策是至关重要的,否则所有后续计算只会为已经选择的决策进行合理化,而不会提高决策准确性的概率。例如,"Let’s consider each of these answer choices"这样的prompt有助于引导推理的流程朝正确的方向发展。放松对立即决策的限制引入了额外的控制挑战:我们希望延迟决策,但仍然需要以可程序化的形式被检索。动态响应长度使得推理过程何时结束变得不确定;也不能保证决策会以预期的形式或压根就没有决策。每当语言模型对其自身的
prompt做出贡献(连续的自回归步骤而无需干预),就存在偏离预期任务的风险。可以通过停止生成并插入类似于
Thus, the correct answer is的prompt fragment来强制产生一个闭合形式的决策。但是,在插入之前要生成多长时间?在本文的例子中,我们通过使用GPT-3来解决这个问题,在每个generated token之后计算multi-part prompt的next segment的条件概率。在segment是"Thus, the correct answer is"的情况下,其反事实的可能性信号指示了程序是否已经结束。当这个信号达到最大值时,我们插入该segment来强制产生一个决策。一种限制偏离的方法是使用
fill-in-the-blank prompt template,generated sections较短,从而保持模型的正确性,同时保持广泛适用性(Figure 6)。这对于控制双向Transformer模型(如BERT)尤其有前景。
19.2.7 Metaprompt Programming
prompt programming的最大局限性在于:针对特定类型任务来设计prompt的困难性、以及缺乏自动化方法来设计prompt。prompt programming需要人力投入大量时间,因为task-agnostic prompts往往比针对特定任务的prompts效果要差得多。这促使我们创建自动化方法来生成task-specific prompts。先前的研究尝试使用独立的模型生成有效的prompts(《A Call for Clarity in Reporting BLEU Scores》)。相反,我们提出通过
metaprompts来利用语言模型本身。metaprompt是一种概括更一般意图的种子,当与其他信息(如任务的问题)结合时,会展开成具体的prompt。metaprompt可以是一个短语,比如"This problem asks us to",它通过提示问题的意图,为解决问题的步骤提供连续的解释。另外,metaprompt可以采用fill-in-the-blank template的形式,它限制了响应沿着预定的过程,但允许模型填写问题特定的细节。metaprompt示例(Figure 3 ~ 5)是使用GPT-3和OpenAI的API生成的(engine=davinci, temperature=0)。在这些示例中,metaprompt充当特定问题的"wrapper"。任务问题是unformatted的,metaprompts以粗体显示,由GPT-3生成的文本以蓝色显示。这就是
Chain of Thought Prompting: COT的思想。只是COT用于zero-shot,而这里用于生成示例从而进一步用于few-shot。


19.3 未来方向
本文是探索性的,是对未来研究
prompt programming理论和创建自动化prompting方法的呼吁。prompt programming是一个新生的、高度相关的研究领域,需要跨学科的知识和方法。我们正在进入一个新的人机交互模式,任何精通自然语言的人都可以成为一个程序员。我们希望看到prompt programming本身成长为一门学科,并成为理论研究和定量分析的对象。解耦
meta-learning和task location:前面讨论的French-to-English翻译中使用的评分方法(BLEU)仅对大型数据集给出平均分数。我们没有分析得分分布的其他信息。在我们的实验中,我们发现0-shot失败(使用OpenAI的zero-shot prompt)通常是灾难性的。也就是说,翻译任务甚至没有被尝试。例如,我们注意到模型会继续用法语输出另一个句子,或者输出空白或下划线,好像答案应该由学生填写。假设这些示例是在执行
task location,这表明如果将灾难性的失败从分数中去除,0-shot prompts和64-shot prompts的性能将变得更加相似,如果不是相等的。此外,我们怀疑1-shot prompts的性能会明显低于0-shot prompts和64-shot prompts,这是由前面讨论的内容泄漏、以及错误概括等现象引起的。benchmarking的新方法:更通用和强大的语言模型使得更广泛的基准测试方法成为可能和必要。隔离灾难性的失败:我们建议在可能区分任务失败的尝试、以及任务未被尝试的情况下,基准测试报告中同时提供有灾难性失败、以及没有灾难性失败的得分。这提供了关于性能不完美的潜在原因的信息,并有助于识别可能没有可靠传达任务的
prompts。用于评估的
metaprompts:开发有效的meta-prompt templates将允许在封闭式的问题上进行大规模的自动化评估,同时仍然允许一定程度的开放式推理。这对于测试自回归语言模型在超越简单的事实记忆(fact recall)之外的推理能力(例如解决数学问题和物理问题)是至关重要的。由于依赖于多个自回归步骤,
metaprompts固有地伴随着脱轨的风险。一个meta-prompt的可靠性和有效性必须在它可能适用的一系列任务上进行评估,最好是在一系列模型上进行评估。应进一步探索控制脱轨的技术,如fill-in-the-blank templates。用于评估的语言模型:随着语言模型变得越来越强大,使用其他语言模型评估对开放式基准问题的回答质量变得可行。对于许多任务(例如
NP-complete问题),验证解决方案的正确性要比产生正确的解决方案更容易。例如,我们观察到,GPT-3更可靠地注意到一个段落是否奇怪或包含错误,相比较于它能够生成没有错误的非奇怪段落。游戏:由于复杂的语言模型有能力创建虚拟环境的世界模型,我们建议使用基于文本的游戏作为复杂能力的测试。可以使用预先编写的基于文本的游戏来测试世界建模和代理的各个维度,例如
problem solving、信息收集和社交智能(包括欺骗)。虚拟环境可以用于测试语言模型的世界模型的质量和一致性,例如对象持久性、或准确预测玩具环境中事件的物理后果或社交后果的能力。设计可靠地探索预期能力的游戏需要先进的
prompt programming技术。随着人工智能系统在有效代理方面的增加,设计虚拟游戏将对安全评估能力变得越来越关键。
二十、Scratchpad[2021]
论文:
《Show Your Work: Scratchpads for Intermediate Computation with Language Models》。
基于
Transformer的大型语言模型表现出令人惊讶的能力,包括生成代码从而解决简单编程问题的能力(《Evaluating large language models trained on code》、《Program synthesis with large language models》)。然而,这些模型在进行multi-step算法的计算时很吃力,尤其是那些需要精确推理和无限制计算的算法。例如,GPT-3在对超过三位数的数字进行few-shot加法时很吃力(《Language models are few-shot learners》)。同样,大型语言模型也很难预测Python代码的运行结果,即使是模型能够解决的编程任务的Python代码(《Program synthesis with large language models》)。同样,标准的递归神经网络和图神经网络在预测带有循环的简单程序的输出时,也不能系统地进行泛化(《Learning to execute programs with instruction pointer attention graph neural networks》)。因此,语言模型在某种程度上可以编写代码,但似乎不能准确地表达他们所编写的代码的语义,因为他们不能预测代码的执行。这促使人们研究能够进行算法推理(algorithmic reasoning)的网络(《Neural turing machines》、《Learning to execute》、《Learning to execute programs with instruction pointer attention graph neural networks》)。准确表示程序语义的神经网络可以实现各种下游任务,包括程序合成(《Robustfill: Neural program learning under noisy》)、程序分析(《Learning to represent programs with graphs》)和其他算法推理任务(《Neural algorithmic reasoning》)。为什么大型语言模型会在算法推理任务中挣扎?我们认为,这至少部分是由于
Transformer架构应用于这些任务的方式的局限性:模型被要求在一次forward pass中执行这些任务。考虑到固定的层数和固定的计算时间,该模型无法在产生输出之前根据问题的难度调整计算量。之前的工作(《Adaptive computation time for recurrent neural networks》、《Pondernet: Learning to ponder》)已经探索了显式地允许动态选择计算时间从而用于不同子任务的神经架构。在这项工作中,我们提出了一种不同的方法,该方法可以利用现有的Transformer架构和大型的few-shot-capable语言模型:我们修改了task design而不是修改模型或修改训练程序。我们的建议很简单: 允许模型在产生最终答案之前产生一个任意的
intermediate tokens序列,我们称之为scratchpad。例如,在加法问题上,scratchpad包含一个标准的long addition算法的中间结果(见Figure 2)。为了训练模型,我们将算法的中间步骤编码为文本并使用标准的监督训练。本文贡献:
我们为
Transformers引入了"scratchpad"的概念,从而使其在不修改底层架构的情况下更好地进行复杂的离散计算。我们表明,
scratchpad帮助Transformers学会在微调的环境中执行long addition,特别是它们改善了对更大的问题实例的out-of-distribution generalization。我们还发现,
scratchpad帮助Transformers完成了一个更高层次的任务:多项式求值。这一点在few-shot环境下和微调环境下都是如此。最后,我们转到一个更普遍的背景,并表明,训练
Transformers逐行发出带有局部变量标注的full program traces,极大地提高了他们在特定输入上执行给定的计算机程序的结果预测的能力。这一应用在某种意义上取代了其他的应用。
当在微调的场景下应用时,需要人工为每个样本撰写
scratchpad,这个代价有点高。当在few-shot learning场景下应用时,只需要为每一类任务撰写一个prompt,但是效果更差。
相关工作:
本文的任务可以看作是对大型语言模型的一种探索性的批评,即它们在多大程度上只是依赖文本上的表面的统计关联,而没有学习语义知识或世界知识(
《Climbing towards NLU: On meaning, form, and understanding in the age of data》)?对此,《Implicit representations of meaning in neural language models》提供证据表明,pre-trained语言模型确实构建了它们在文本中所描述的情况的语义的近似representations。在程序方面,
《Program synthesis with large language models》通过探索MBPP上的learning to execute task来接近这个问题,我们文章中考虑了这个问题。这个任务背后的想法是探索用于生成代码的神经模型是否也能执行它。虽然这项工作发现现有的模型在执行结果的预测方面表现不佳,但我们表明,增加一个scratchpad可以使这些模型表现得更好。learning to execute方面的工作考虑了:现成的递归神经网络或更专门的架构是否具有inductive bias从而足够适合执行和推理任意代码。neural algorithm induction的相关问题引起了人们的极大兴趣。这项工作提出了新的神经架构,其灵感来自于计算的理论模型,其inductive bias使模型更容易学习algorithm induction任务。有几种algorithm induction的方法专门为序列模型添加了自适应计算时间。具体而言,universal transformer: UT包括自适应计算时间,并在algorithm induction和learning to execute任务上进行评估(《Universal transformers》)。相比之下,scratchpad是一种简单的方式,既可以提供具有自适应计算时间的transformer模型,也可以提供关于如何使用该额外计算的监督,而不需要修改底层架构。algorithm induction也与pre-trained模型有关。《Pretrained transformers as universal computation engines》表明Transformer在某种程度上可以被用作通用计算引擎,通过对自然语言进行预训练,并在非语言任务(包括简单的algorithm induction任务)上微调一小部分权重。最后,语义解析的监督方法可以预测database query的文本,然后执行该query来回答自然语言问题。
20.1 方法
在这项工作中,我们考虑两个相关的问题:
algorithm induction、learning to execute。这两个问题的目标都是让神经网络学会模仿一个函数input-output行为上,它可以由一个简短的程序来表示,比如加法或多项式求值。在
neural algorithm induction中,目标是学习单个算法,每个训练样本给出单个输入和预期的输出,输入和输出以字符串表示。因此,训练数据是对于
learning to execute,我们希望模型能在一些输入上产生程序(以源代码来表示)的结果。如果每个input-output样本是很常见的,但为了简化符号,我们省略这个。这意味着多个算法,每个算法对应一个源代码
本文的主要观点是,为了解决一个给定的算法任务,我们只需将算法的
intermediate steps编码为文本,并训练模型将其发射到一个buffer,我们称之为"scratchpad"。例如,让我们考虑学习long addition的algorithmic induction任务。为了教一个模型学会29 + 57,一个训练样本可能看起来像Figure 2中的文字,其中明确写出了long addition算法的步骤。learning to execute任务也可以用类似的方式进行编码,只是现在我们在input、scratchpad、以及预期输出之前加上了源代码Figure 1显示了一个learning to execute任务的训练样本。在训练时,模型将被提供
input以及target从而用于标准的likelihood-based训练。在测试时间,模型将只被提供input,并被要求预测目标,例如,通过beam search或temperature sampling。原则上,任何序列模型都可用于此。在这项工作中,我们选择使用decoder-only Transformer语言模型,但其他序列模型也可能是有效的,如encoder-decoder模型(T5),或RNN。
添加一个
scratchpad有几个潜在的优势:首先,该模型具有自适应的计算时间,也就是说,它现在可以根据任务在给定输入条件下的复杂性,在必要的时候处理信息。
越复杂的任务,其
intermediate steps越大,那么计算时间越长。第二,模型可以将其计算的中间状态存储在
scratchpad buffer中,并通过关注其上下文来引用它。这消除了在activations中存储所有中间状态的需要。第三,通过迫使模型通过从生成模型中采样来输出具体的中间状态,我们旨在减少
small errors的传播和复合,因为中间状态被量化为token embeddings。最后,检查模型的
scratchpad output可以帮助我们识别常见的错误,并通过修改scratchpad的格式来纠正它们。我们发现这种解释错误的能力在这项工作中很有用。
在所有的实验中,我们使用了
pre-trained dense decoder-only Transformer语言模型,规模从2M到137B参数不等。这些模型在网络文档和对话数据上进行了预训练,并与《Program synthesis with large language models》使用的模型相对应。
20.2 实验
20.2.1 加法
作为第一个任务,我们考虑整数加法。
baseline加法任务将两个数字作为输入,目标是它们的总和。比如说:xxxxxxxxxxInput: 2 9 + 5 7Target: 8 6我们通过在
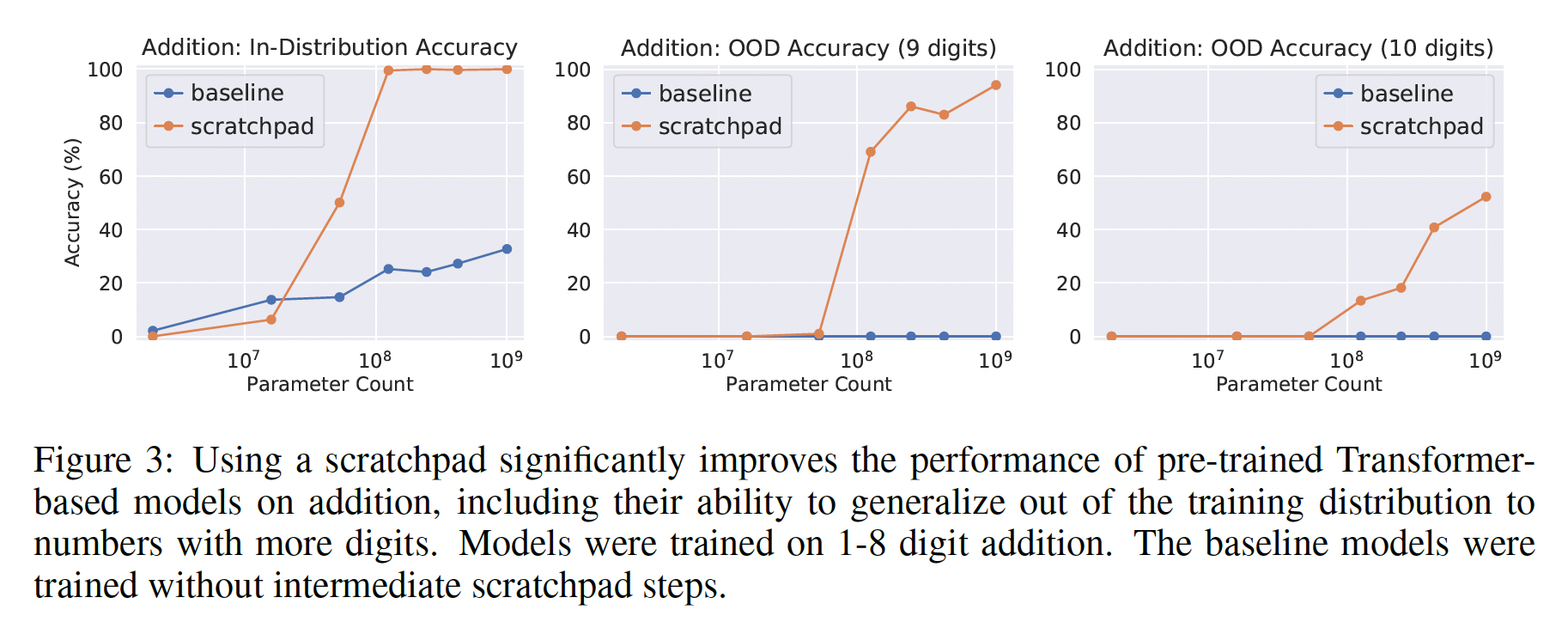
target中包括long addition算法的中间步骤来实现scratchpad,如Figure 2所示。我们在具有1 ~ 8个数字的输入的整数加法问题上训练几个模型。然后我们对in-distribution加法问题(最多8位数的输入)和out-of-distribution加法问题(9位数和10位数的输入)进行性能测试。这些模型在100K个样本上进行了微调了5K步,batch size = 32。in-distribution测试样本有10k个,对于每个out-of-distribution任务都有1K个测试样本。我们研究了性能与模型大小的关系,模型规模从2M到1B参数。我们将模型性能与baseline进行比较,其中baseline不包含scratchpad。结果:
Figure 3比较了scratchpad算法和baseline的性能。我们看到:在超过临界模型规模的情况下,模型能够使用
scratchpad解决加法任务,而没有scratchpad来训练的模型即使在最大的模型规模下也无法做到这一点。在
out-ofdistribution的任务(9位数加法、10位数加法)中,我们发现没有scratchpad来训练的模型完全失败,而用scratchpad来训练的模型随着模型大小的增加而显示出持续的改进。
20.2.2 多项式求值
接下来我们专注于一个稍微
higher-level的任务:多项式求值。受《Analysing mathematical reasoning abilities of neural models》中 "多项式评估" 子问题的启发,我们生成了一个阶次小于或等于3的多项式数据集,其系数为整数,输入被限制在10000个多项式组成的训练数据集、以及一个大小为2000的测试数据集。Figure 4显示了这个任务的一个示例的scratchpad target,多项式的每一项都被独立地求值。和上一节一样,我们将直接执行的结果与使用
scratchpad execution的结果进行比较。在这个实验中,我们使用一个137B参数的pre-trained decoder-only模型在few-shot setting下进行评估,因为以前的工作表明,非常大的模型可能能够以3位或更少的位数的few-shot来执行加法和乘法(GPT-3)。我们在few-shot prompt中使用我们还用一个
8B参数的模型在训练集上微调了2000步来评估fine-tuning setting。这两项评估的结果都显示在Table 1中。我们发现,无论在few-shot还是在微调的setting下,scratchpad execution都明显优于直接执行。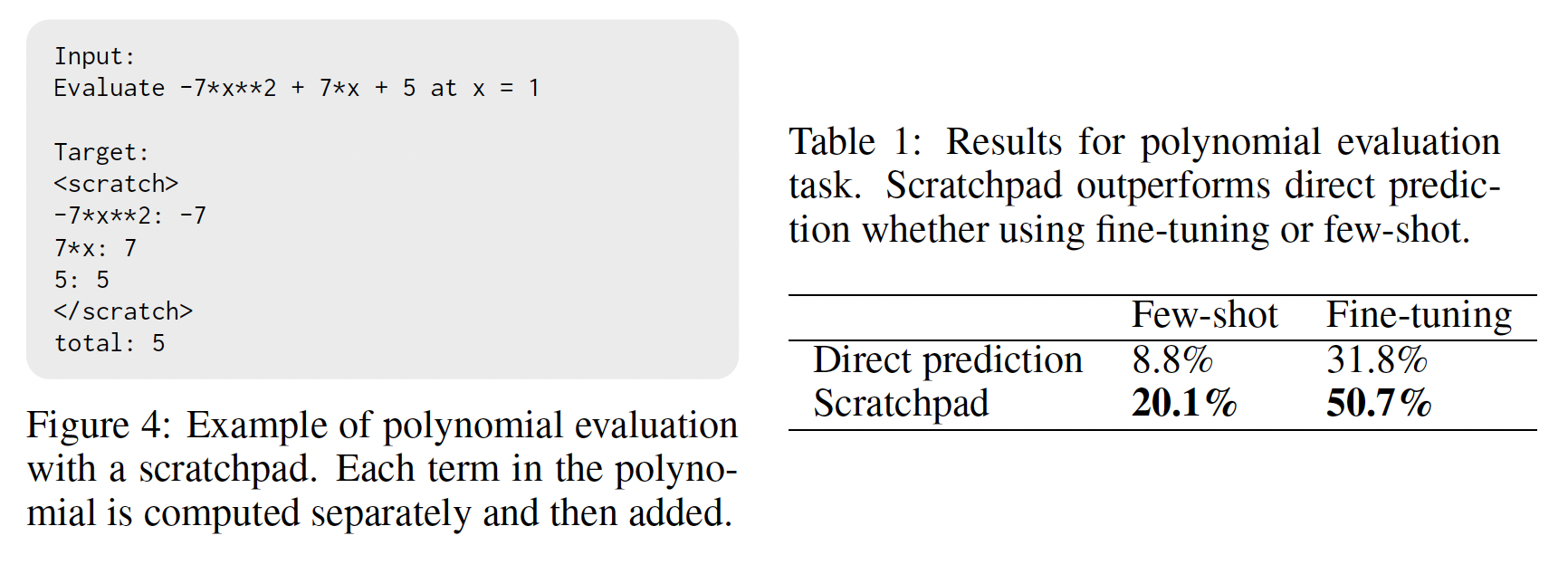
20.2.2 执行 Python 程序
我们已经表明,
scratchpad可以帮助algorithm induction,也就是说,它们可以帮助模型在direct algorithm-specific supervision下学习实现特定的算法。但是,需要为每个新任务手工设计中间状态是次优的。在本节中,我们评估了模型是否可以通过执行任意代码来学习实现一种新的算法。为了测试这种能力,我们沿用了《Program synthesis with large language models》的问题设置,其中要求语言模型预测在给定输入上执行给定Python程序的结果。语言模型在这项任务中表现不佳,即使是在那些模型能够解决的编程任务的程序上(即,语言模型能够补全该程序的代码)也是如此。在这里,我们展示了scratchpad技术可以极大地提高语言模型执行程序的能力。Direct execution prediction:我们的主要baseline是《Program synthesis with large language models》探讨的直接执行预测程序。向模型展示一个函数的源代码,并要求模型预测在特定输入上运行该函数的输出。例如,Figure 1中的函数将一个字符串direct execution prompt和目标显示在Figure 1的"Direct Execution Prediction"框中。如果模型正确地输出了目标字符串,那么这个任务就被认为在这个情况下得到了解决。Execution prediction via scratchpad tracing:如上所述,direct execution prediction要求模型在单个forward pass中正确输出整个函数的执行结果。在《Program synthesis with large language models》的研究中,direct execution prediction在Python程序上表现不佳。因此,我们设计了一个执行任务的scratchpad formulation,其中模型通过首先预测程序执行期间计算的中间状态序列从而来预测程序的输出。形式上,我们训练模型来预测一个交替的序列:被执行的源代码行的顺序、每一行执行后的局部变量的状态。我们称这个对象为
program’s trace,它允许我们跟踪控制流(所执行的操作的序列)、以及每个操作后的状态变化。我们将trace表示为一个字符串,其中复制代码行,并将状态信息表示为一个JSON字典。例如,Figure 1中的"Scratchpad Tracing"框包含了上面讨论的函数的tracing prompt和trace target。具体来说,对于每一个要被
traced的函数,其prompt是由两部分拼接而成:打印
function definition得到的字符串。一行字符串表示在特定的输入上调用该函数:
output = fn_name(input_value),其中fn_name和input_value被替换成相应的函数名和输入值。
在
Figure 1中,注意remove_Occ("PHP", "P")的正确输出是如何显示在trace的最后一行,并分配给变量"output"。如果最后一行中分配给变量output的值与目标输出值(这里是"output": "P")的语义相符,则认为该tracing example具有正确的执行输出。如果所有给定的input-output样本都能正确执行,我们就认为一个任务是正确执行的。我们还可以通过以下方式测试
model prediction和ground truth trace之间是否存在"trace exact match":将trace中的每个状态与ground truth trace中的相应状态进行语义地比较、将预测的源代码行的序列与ground truth sequence进行比较。
实验设置:作为一个概念验证,我们首先表明
scratchpad tracing极大地提高了合成Python数据上的执行性能。然后,我们在《Program synthesis with large language models》的人类编写的Python问题上比较了scratchpad tracing和direct execution。我们发现,一种新的数据增强技术,即使用模型生成的程序作为额外的训练数据,可以显著提高真实数据上的tracing性能,然而这种增强技术会损害direct execution的性能。最后,我们表明,从其他来源纳入tracing data可以进一步提高tracing性能,这表明这里探索的scratchpad tracing技术可以很好地扩展更多数据。在
Python代码的所有实验中,我们使用了一个具有大约137B参数的Transformer模型,上下文窗口大小为1024 tokens、generation限制为512 tokens。除非另有说明,所有的微调运行都使用了batch size = 8182 tokens和3e-5的学习率,模型推理是在解码温度
a. 在合成的 Python 程序上 Scratchpad 击败 Direct Execution
在我们的第一个实验中,我们在简单的合成
Python程序上测试了我们的模型的few-shot和微调的执行能力。这为我们的tracing技术提供了一个概念验证。我们使用了从
《Learning to execute programs with instruction pointer attention graph neural networks》修改的合成Python程序数据集。这些程序包括小整数(0、1、2)、简单的while循环和if语句。我们构建了一个合成程序的语料库,以模仿《Program synthesis with large language models》的MBPP数据集的规模,其中有400个训练程序、100个验证程序和200个测试程序。对于每个程序,从0 ~ 9的范围内采样三个随机整数输入。我们测试了在
few-shot和微调条件下的direct execution和scratchpad tracing。对于few-shot实验,prompts包含三个以前的tracing问题的示例,如附录C所示;对于微调实验,我们对模型进行微调,使其在training split上收敛,这是由验证集的困惑度来判断的。对于
few-shot scratchpad实验,我们注意到模型不会将变量名output分配给trace中的final value,而是继续使用v0(函数final output line的变量名。因此,我们修改了accuracy标准,从检查trace的最后一行的output的值是否正确,改为检查v0的值是否正确。(在朴素的评分标准下,few-shot tracing accuracy大致为零。)这种行为的一个例子见附录D。结果:
Table 2显示了我们在合成Python问题上的结果。不管是在few-shot还是微调的情况下,scratchpad tracing技术都能在200个测试问题上带来更高的overall execution accuracy。微调对scratchpad tracing技术的性能改善也比direct execution的改善要大。
b. 在真实的 Python 程序上 Scratchpad 击败 Direct Execution
在我们的第二组实验中,我们探索了与在真实数据上
direct execution相比,scratchpad execution的表现如何。我们的主要评估数据集是MBPP数据集。MBPP由1000个编程问题组成,每个问题包含一个自然语言规范、一个ground-truth的Python程序和三个input-output测试案例。这些程序涉及使用很多类型的计算,包括整数类型、字符串类型、浮点数类型、字典类型、元组类型等,并包括许多语言特征和控制流结构,如循环、comprehensions、库导入、API调用和递归。MBPP数据集的evaluation split包含500个任务。为了分离出generation window size的影响,我们对这些任务的子集报告了所有的评估指标,对于这些任务来说,ground-truth trace针对所有的这三个input-output examples符合模型的generation window。这就留下了212个测试任务的一个子集。对于基于Transformer的模型来说,增加generation window length和context window length是一个重要的问题,但我们认为它是正交的,并把它留给未来的工作。在极低数据量的情况下性能很差:在我们对
MBPP数据的第一次实验中,我们在374个训练任务(每个任务有3个样本 ,所以总体上有1122个样本)上训练一个scratchpad tracing模型。我们放弃了所有超过context window的训练样本。我们将总体执行结果与在同样的374个训练任务上训练的direct execution模型进行比较。Table 3中标记为"MBPP"的列显示了这个实验的结果。scratchpad execution模型和direct execution模型都没有取得良好的性能(output准确率分别为5%和10%),而direct execution的性能优于scratchpad execution。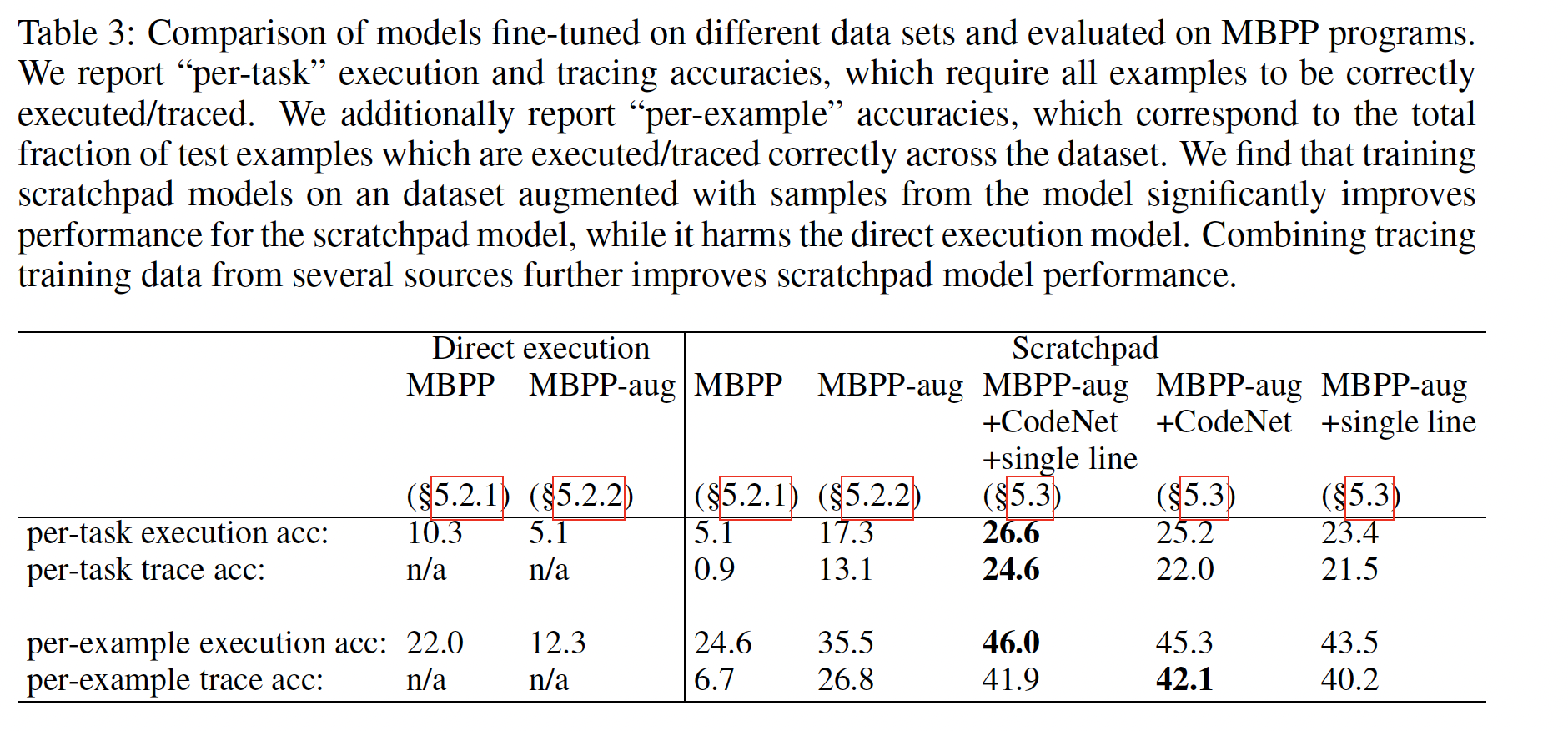
采样的程序是很好的
scratchpad训练数据:接下来,我们采用了一种数据增强技术来增加训练数据集的规模: 如《Program synthesis with large language models》所述,我们首先使用预训练好的137B模型在374个MBPP训练任务上运行few-shot synthesis。对于每个任务,我们在温度80个候选程序execution数据点,其中direct execution数据集既有额外的新程序、又有新的输出。我们可以通过
tracing每个候选程序scratchpad execution模型创建一个类似的tracing数据集。这个过程产生了更大的tracing and execution数据集,有17K个新程序,我们称之为MBPP-aug。从概念上讲,我们利用已有的工具组合来增强数据集,即:神经模型、通过
Python解释器的program execution。我们在这个新的增强数据集MBPP-aug上对direct execution和scratchpad execution进行微调,使用的过程与上述相同。Table 3中的"MBPP-aug"列显示了这个实验的结果。虽然direct execution方法在对这些额外的数据进行训练时,准确率有所下降,但scratchpad execution的性能得到了极大的提高:在增强数据上训练的模型所解决的任务数量,是只在原始MBPP程序上训练的模型的三倍以上。我们还注意到,如果我们衡量整个样本的原始正确性,该模型已经达到了26.8%的exact trace match,这是令人惊讶的高。scratchpad training能很好地利用大型数据集:在这一节中,我们研究从人类编写的程序中收集额外的tracing data是否能进一步提高tracing性能。这将使我们了解,当略微out-of-distribution的tracing data被添加到微调集合时,tracing程序是否有可能很好地扩展。我们使用两个数据集进行实验:Single-line programs:这个数据集包括大约9M个单行Python transformations的样本。Figure 6 (top)显示了这些transformations的例子。每个transformation都包括一组初始变量和相应的值、一行Python代码(这些共同构成了输入)、以及运行这一行后产生的新的变量和值(即,target)。在single-line data上进行训练时,我们不引入中间的scratchpad steps。由于这个数据集没有提供high-level的、多行控制流的样本,但该数据为建模单个代码行的执行提供了良好的监督,而单个代码行的执行是tracing的一个关键组成部分。这些数据是由Fraser Greenlee收集的,可以在https://www.kaggle.com/datasets/frasergreenlee/python-state-changes访问。CodeNet:Project CodeNet数据集由数百万用户提交的大约4000个编程问题组成。这些提交的信息包括对编程问题的正确和不正确的解决方案。然而,从上述MBPP-aug的实验中,我们知道,不正确或broken的程序仍然可以提供有用的训练信号。我们还改进了我们的tracing技术从而允许trace有错误的程序;当达到一个错误时,错误信息会被添加到trace text的末尾,tracing也会停止。我们从CodeNet数据中共提取了670,904 traces。
对于每个数据集,我们首先在这些数据集上微调模型,然后在
MBPP-aug上进行第二次微调直到收敛。结果显示在
Table 3中。如上所述,我们报告了跨任务的execution accuracy。我们还报告了跨任务的trace accuracy,以了解整个trace被准确预测的程度。我们还报告了所有测试样本的原始execution accuracy和trace accuracy,作为比较模型的额外指标。单独对
single-line或CodeNet数据集的训练似乎都比MBPP-aug有所增益(分别提高了23.4%和25.2%的任务执行正确)。然而,结合
CodeNet数据集和single-line数据集似乎能带来最高的性能:对于26.6%的任务,tracing产生了正确的final output;将近四分之一的任务(24.6%)在所有三个例子中都被完美的被traced。
这些结果似乎很有希望:神经网络通常可以准确地
trace程序。具体而言,从最佳模型中贪婪地解码,对几乎42%的traces产生了完全正确的trace。
20.3 局限性和未来工作
Context window size:在这项工作中,我们将实验限制在scratchpad text相符合的model generation window(512 tokens)的问题上。然而,许多问题需要非常长的scratchpad generation。因此,充分实现scratchpad技术的潜力可能需要进一步改进transformer generation window size。这是NLP中一个活跃的研究领域,这方面的改进将有利于scratchpad技术的应用。学习在没有监督的情况下使用
scratchpad:下一步显然是尝试在没有direct supervision的情况下学习使用scratchpad。一个简单的方法是使用强化学习技术:模型正确回答问题将得到奖励,奖励与所使用的scratchpad tokens数量成反比。我们希望学习使用scratchpad是一种可迁移的技能;例如,一个模型有可能使用它所学到的long addition算法,从而成功地迁移到进行多项式计算。
二十一、Can language models learn from explanations in context? [2022]
论文:
《Can language models learn from explanations in context?》
在
NLP中出现了一个新的范式:语言模型的few-shot prompting。大型语言模型似乎表现出一些in-context learning能力,例如它们可以推断出如何执行一项新的语言任务的few-shot(GPT-3):从几个(input, output) pairs的样本(作为模型的上下文窗口)中推断出来,但不需要训练。例如,这些模型可以通过上下文中的几个相关问题和正确答案的样本,更准确地回答简单问题或进行算术任务。虽然并不总是清楚从这些prompts中学习出什么或推断出什么,但prompting是一个不断增长的子领域 (《Pretrain, prompt, and predict: A systematic survey of prompting methods in natural language processing》)。这种从
few-shot prompt中适应新任务的能力与人类适应指令或样本的灵活性有一些相似之处。然而,解释(explanations)在人类学习中也起着核心作用(《Schema acquisition from a single example》):解释突出了任务原则(task principles),使我们能够广泛地进行泛化。例如,解释可以通过将一个简短的答案(如"false")与解决问题所需的更广泛的推理过程联系起来(如"these statements are contradictory; a number cannot be both prime and divisible by 6, which is composite.")。因此,解释可以通过说明将问题与答案联系起来的principles从而澄清预期的任务(intended task)。因此,我们研究了当从
in-context样本中学习时,语言模型是否也能从解释中受益。对答案的解释能否提高few-shot任务表现?请注意,这个问题并不关注可解释性作为帮助用户理解模型的手段;相反,我们关注的是,few-shot explanations是否能够帮助模型本身 "理解" 任务,正如通过性能评估的那样(参考《Symbolic behaviour in artificial intelligence》)。这个问题是有趣的,有多种原因。实际上,它有可能改善
few-shot性能。但更根本的是,这个答案揭示了一个科学问题,即语言模型表现出什么样的in-context learning能力,这是一个正在争论的话题(例如《Rethinking the role of demonstrations: What makes in-context learning work?》、《Do prompt-based models really understand the meaning of their prompts?》)。几个趋同的研究结果表明,解释可能会改善
few-shot表现。首先,具有显式指令或任务描述的prompting是使语言模型适应新任务的一种有效方式《Pretrain, prompt, and predict: A systematic survey of prompting methods in natural language processing》)。此外,为语言模型分解推理过程的步骤,可以提高few-shot表现。对few-shot prompt中的样本的解释同样可以支持推断出正确的任务,从而提高下游的任务表现。语言模型可以从解释中获益,而不一定要以类似人类的方式 "理解" 解释(参见
《Why ai is harder than we think》)。解释在人类话语中很普遍,因此,语言模型在训练中会遇到一些解释,这些解释(由编写解释的人类)旨在澄清understanding和改善future reasoning。例如,网上有许多考试答案,其中包含问题、答案、以及对这些答案的解释,这些解释可以帮助预测该考试中后续问题的答案。这些数据模式可能足以让人学会在看到解释后更好地回答后续问题。我们并不是第一个探索
explanations的人;鉴于人们对prompt tuning越来越感兴趣,还有其他关于in-context中的辅助信息如何影响模型性能的工作,以及大量prompting之外的工作(如training or tuning with explanations)。与之前的工作相比,我们特别关注post-answer explanations的效果,而COT在答案之前提供chains of reasoning。pre-answer explanations和post-answer explanations对模型推理和评价有不同的影响,并提供了不同的科学见解。此外,我们在一个明显具有挑战性和多样性的任务集上进行评估,并包括仔细的对比和分析。我们强调以下的贡献:
我们对
40个不同的、具有挑战性的语言任务进行了注释(对样本进行解释),同时发布了这些annotations。我们在具有或没有
few-shot样本、解释、指令、以及控制条件(control conditions)的prompting之后,评估了几个语言模型。在
few-shot prompt中,对样本的解释可以提高大型模型的性能;即使没有tuning,它们的性能也超过了对应的control conditions。使用小型验证集来调优或选择的解释可以产生更大的效果。
我们用尊重任务、
items和prompt elements之间的依赖性的分层统计模型来分析我们的结果。我们强调了这些方法的更广泛的价值。
COT是把解释放在答案之前,而这篇论文是把解释放在答案之后。这是算法上的唯一区别。放在答案之后的好处是:在推断期间,由于不需要推断出解释而直接推断出答案,因此效率更高。
相关工作:最近的观察表明,语言模型可以通过几个样本来完成任务(
GPT-3,GPT-2),这激发了关于这种学习的基础是什么的讨论:例如,《An explanation of in-context learning as implicit bayesian inference》提出,in-context learning是一种隐式贝叶斯推断的形式。其他研究者质疑所发生的是否真的是 "学习",或者仅仅是恢复以前经历过的任务(MetaPrompt)。例如,《Rethinking the role of demonstrations: What makes in-context learning work?》观察到带有随机标签的prompts对常见的NLP任务(如entailment)的表现只有轻微的影响。在讨论中,我们将描述我们的结果对理解语言模型的in-context learning的贡献。Task instructions:许多先前的工作都将任务指令作为zero-shot prompts(MetaPrompt、《Pretrain, prompt, and predict: A systematic survey of prompting methods in natural language processing》),或作为few-shot prompt的一部分(例如《Cross-task generalization via natural language crowdsourcing instructions》)进行探索。模型对这些prompts中的任务框架很敏感,并且可以从显式地将问题分解为多个步骤中获益(《Reframing instructional prompts to gptk’s language》)。《How many data points is a prompt worth?》估计,至少在训练分类器时,task prompts的价值可以值得很多样本。In-context explanations和reasoning decomposition:《Cross-task generalization via natural language crowdsourcing instructions》探讨了包含任务描述和带有解释的样本的prompts(以及其他特征,如guidelines)。然而,他们并没有估计explanations的独立效果,也没有与control conditions进行比较。《Few-shot self-rationalization with natural language prompts》和《Reframing human-AI collaboration for generating free-text explanations》使用few-shot prompting来鼓励语言模型解释他们的答案,但产生的解释是为了用户解释,而不是为了提高任务表现。《Unsupervise dcommonsense question answering with self-talk》表明,"self-talk"(从模型中采样答案来支持问题,并在上下文中加入这些答案)可以改善问题的回答。
最近的其他工作表明,模型可以从分解推理过程(该推理过程导致答案)的样本中获益(
COT),特别是当它们被增强了external scratchpads以存储中间计算时(《Show your work: Scratchpads for intermediate computation with language models》、《Teaching autoregressive language models complex tasks by demonstration》)。这些分解可以被看作是一种特殊的解释。然而,与COT这样密切相关的工作相比,我们在prompt中的答案之后提供解释,而不是在答案之前提供reasoning chains。然而,我们还是观察到了这些答案后的解释所带来的好处(甚至在一些像算术这样的任务中,计算中间步骤也是有用的)。这是一个关键的区别,与explanations能够为模型提供的独特好处有关。此外,与许多先前的工作相比,我们在更广泛的挑战性任务上进行评估,包括更广泛的matched controls,并提供更深入的统计分析。用指令或解释来训练语言模型:之前的各种工作已经探讨了用任务指令训练或调优语言模型、以及用解释来训练。许多专注于用解释进行调优的工作使用了诸如
span highlighting或word highlighting的方法,而不是自然语言解释,见《Explanation-based human debugging of nlp models: A survey》的评论。虽然这些更广泛的前期工作与 “解释在自然语言处理中可能是有用” 的这一总体想法有关,但它并没有立即影响到in-context explanations如何影响模型(其中,模型没有以任务指令或解释来训练)这一问题。然而,显式地用解释或指令进行训练的模型可能会从in-context explanations中显示出更多的好处(FLAN)。NLP之外的explanations:用解释进行训练也显示出在language之外的领域的好处。例如,解释已经被用于训练或调优计算机视觉的模型、用于通过program induction来解决数学问题、或关系推理和强化学习。缩放和涌现: 虽然语言模型的损失可以随着模型的大小表现出可预测的缩放性(
《Scaling laws for neural language models》),但这些平滑的变化可以导致特定行为的质量差异(《Predictability and surprise in large generative models》):"more is different"(《More is different: broken symmetry and the nature of the hierarchical structure of science》)。举几个例子来说:GPT-3观察到算术任务的表现随着规模的增加而急剧转变。FLAN发现,只有大型语言模型才能从instruction fine-tuning中泛化到执行新任务的zero-shot。
我们发现,解释的好处随着模型规模的扩大而涌现,这与之前的这些发现是一致的。未来更大的(或其他改进的)模型可能会表现出更大的好处。
21.1 方法
数据集:
BIG-bench中选择了40个任务和子任务的子集,这些任务跨越了各种推理类型、技能、领域。例如,metaphor_boolean要求识别一个句子是否正确地转述了另一个句子(如下Figure 1所示)。关于所有使用的任务和选择过程,见附录
A。
语言模型:一组参数从
1B到280B不等的语言模型(《Scaling language models: Methods, analysis & insights from training gopher》)。用解释来标注样本: 如果用更多的样本来调优
prompt,"few-shot"的表现结果会产生误导(《True few-shot learning with language models》)。为了避免类似的问题,我们首先探索untuned explanations的原始效益。为了创建untuned explanations,一个作者在每个数据集中随机选择的15个任务实例(question/answer pairs)上标注了"expert" explanations,这些解释将帮助人类理解问题和答案之间的关系。评估这些untuned explanations将低估optimal explanations的好处,但因此提供了一个有代表性的估计,即在一个新任务上增加解释(而没有调优)的预期好处。随后,我们探讨了在一个小的验证集上为performance而调优的explanations所带来的好处。在
prompt中添加解释会改变其他prompt features,如总长度、内容。为了确定这些lower-level features之一是否驱动了explanations的效果,我们制作了各种control explanations,与语义级别、单词级别、句子级别内容的各个方面相匹配(如下图所示):scrambled explanations:为了确保好处不是由word-level特征引起的,我们与单词被随机混洗过的explanations进行比较。true non-explanations:为了检验重要的是解释的内容,我们与有效的、相关的、但非解释的陈述内容进行比较。other item explanation:最后,我们评估了这些好处是否是由于解释(explanation)和说明(explanandum)之间的直接关系,而不是语言的某些其他特征。为了做到这一点,我们把few-shot prompt的样本拿出来,对解释进行了排列组合,使解释与问题或答案不一致,但prompt中包含的整体句子集合是相同的。

一个独立的、
condition-blind的作者对一个explanations子集的质量进行评分,这些解释明显好于中性或true non-explanations(附录B.3)。我们还为每项任务标注了指令和control non-instructions(见附录B),从而扩大prompts集合(该集合被我们用来评估explanations),从而使我们的结果更有可能推广到新的settings。Prompts and evaluation:我们为每个任务(见Figure 1)构建了几个0-shot prompts和5-shot prompts,这些prompts是任务指令(none、instruction、non-instruction)和样本解释(none、other item explanation、true non-explanation、scrambled explanation)可能组合的一个子集。当然,在0-shot prompts中不可能有explanations,我们省略了control explanations with (non-) instructions的组合,以减少query的数量。我们用一条空行将prompt examples分开。当我们将
explanations应用于一个样本时,我们将它们放在答案之后的一行并以"Explanation:"开始(参考Figure 1);这与之前探索在答案之前解释推理的工作形成对比(例如《Show your work: Scratch pads for intermediate computation with language models》、COT)。在答案之后进行解释的一个好处是,无论是否提供解释,evaluation程序都是相同的,模型将试图在explanation之前产生一个答案。相比之下,答案之前的explanations需要改变evaluation程序,并且需要在评价期间对explanations进行更多的计算。这些方法也提供了不同的科学含义,见讨论部分。我们在每个
prompt下,在所有的task dataset items(除了prompts中包含的items)上对模型性能进行评估。我们仅限于多项选择任务,以prompt和问题为条件来评估模型对每个答案选项的可能性(参考Figure 1)。我们不按答案长度对可能性进行归一化处理,但在一个问题中,答案的长度通常是相似的,而且在一些初步实验中,这种归一化处理并没有提高性能。我们贪婪地从集合中选择可能性最高的答案,并根据任务所定义的答案分数(可能允许多个正确答案或部分评分)对模型的准确率进行评分。Tuning or selecting explanations:未针对模型和任务进行调优的explanations只提供了explanations的潜在好处的弱下限。例如,更好的explanations可能是由对任务或模型更熟悉的专家来做的。为了提供一些关于更优的explanations的潜在好处的见解,我们进行了两个tuning实验。Selecting examples and explanations:我们从为每项任务标注的15个样本中选择了一些样本来建立一个5-shot prompt。我们贪婪地选择了在15 prompt items中预测其余样本的正确答案的最佳表现的样本。也就是说:我们创建了一个在其余
14个问题上表现最好的1-shot prompt。然后通过将其余每个样本附加到这个
1-shot prompt上,创建了14个2-shot prompt,等等。
相对于真正的验证集来说,这种方法稍有
biased,但这种bias只会让我们低估潜在的好处。作为对照,我们比较了在不包括解释的情况下选择样本:即我们在相同的样本集合上进行相同数量的选择,只是省略了explanations,或者选择含有control explanations的样本。这个实验评估了在通过简单地选择样本来tuning prompts时,explanations的好处。Hand-tuned explanations:对于在所有条件下表现都很差的五项任务,我们从表现最好的untuned explanations prompt (without instructions)开始,并编辑explanations的文字,试图提高验证集(其他prompts的10个样本)的表现。这个过程通常涉及相对较小的编辑,例如,更多的"language-like"或教学性的解释(见附录B.6)。手工调优使我们能够得到更优的explanations的更紧的性能下界。
请注意,在上述每种情况下,
tuning是在我们标注过的其他样本的小型验证集上进行的,但tuned prompts随后在其余任务样本的更大集合上进行测试。分析:为了更精确地估计
prompt的不同部分对性能的影响,我们转向hierarchical/ multilevel modeling方法。具体来说,我们拟合hierarchical logistic regressions,该hierarchical logistic regressions考虑到我们结果的多重嵌套的、异质的结构。例如,这些模型考虑了整体任务难度、以及每个问题的特异性的难度所带来的依赖性。这些模型还考虑了不同的
prompt conditions共享内容的事实:例如,一组解释被应用于一组特定的few-shot examples。最后,这些模型还考虑到few-shot examples, explanations, and instructions对不同任务的表现有不同影响的可能性。这些模型通过估计每个hierarchy的特异性效果(idiosyncratic effect)的参数来说明每个因素:例如,一个参数用于每个任务的难度、一个参数用于每个问题(嵌套于每个任务中)的难度、以及一个参数用于每个不同的explanations集合的效果。完整的模型规格见附录D.1.。
21.2 结果
在
Figure 2中,我们展示了在prompt中加入不同类型的内容所产生的性能改善的效果大小的估计。每个point都估计了该prompt component的效果,同时控制和聚合了prompt的其他components的效果。在
prompt中加入few-shot examples,相对于zero-shot prompt,大大改善了成绩。答案的
untuned explanations也能提高成绩,其效果约为few-shot examples的1/3。tuned explanations具有更大的效果。instructions能稍微提高成绩,但比explanations的效果要小。
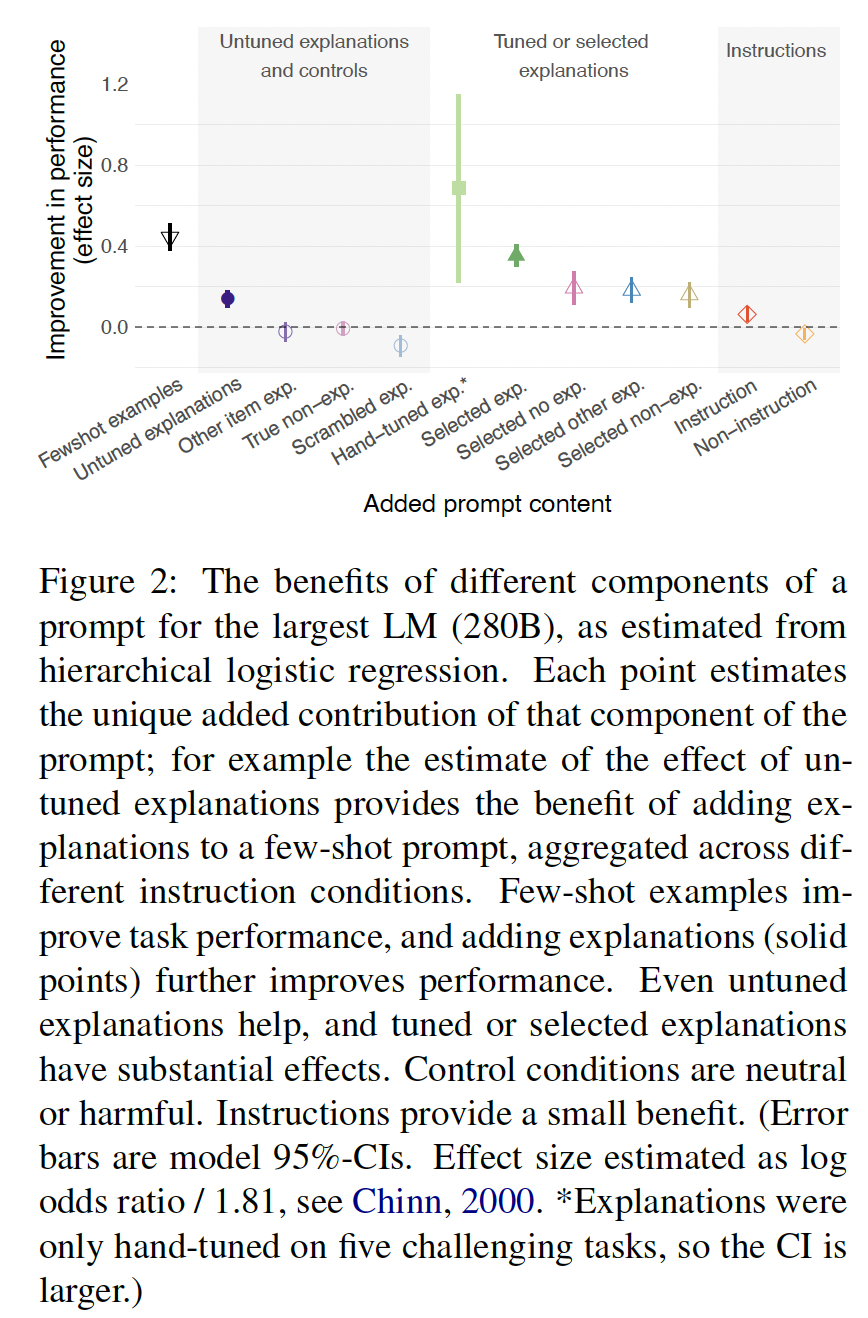
在
Figure 3中,我们展示了不同explanation类型带来的好处的分布情况:相对于matched conditions without explanation,log-score的提高。untuned explanations具有不同的效果,但平均来说是有益的。同时选择样本和解释比单独选择样本带来更一致的改善。
至少在我们评估的五个任务中,
hand-tuning explanations提供了更多的好处。我们还发现,在
prompts with or without task instructions、或者non-instructions中,untuned explanations的效果并没有很大的变化(Figure 5)。
单个任务的结果可以在附录
D.7中找到。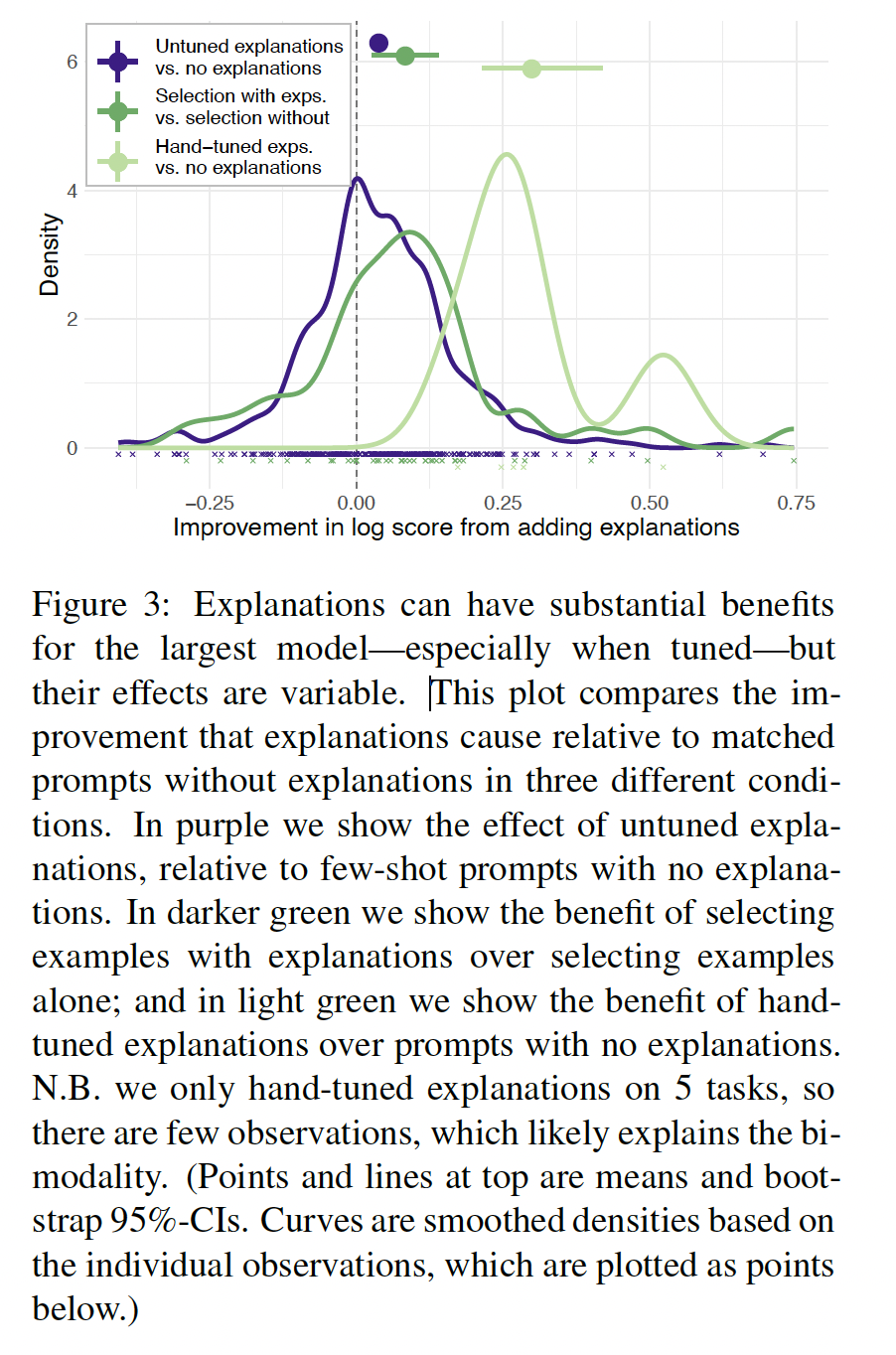
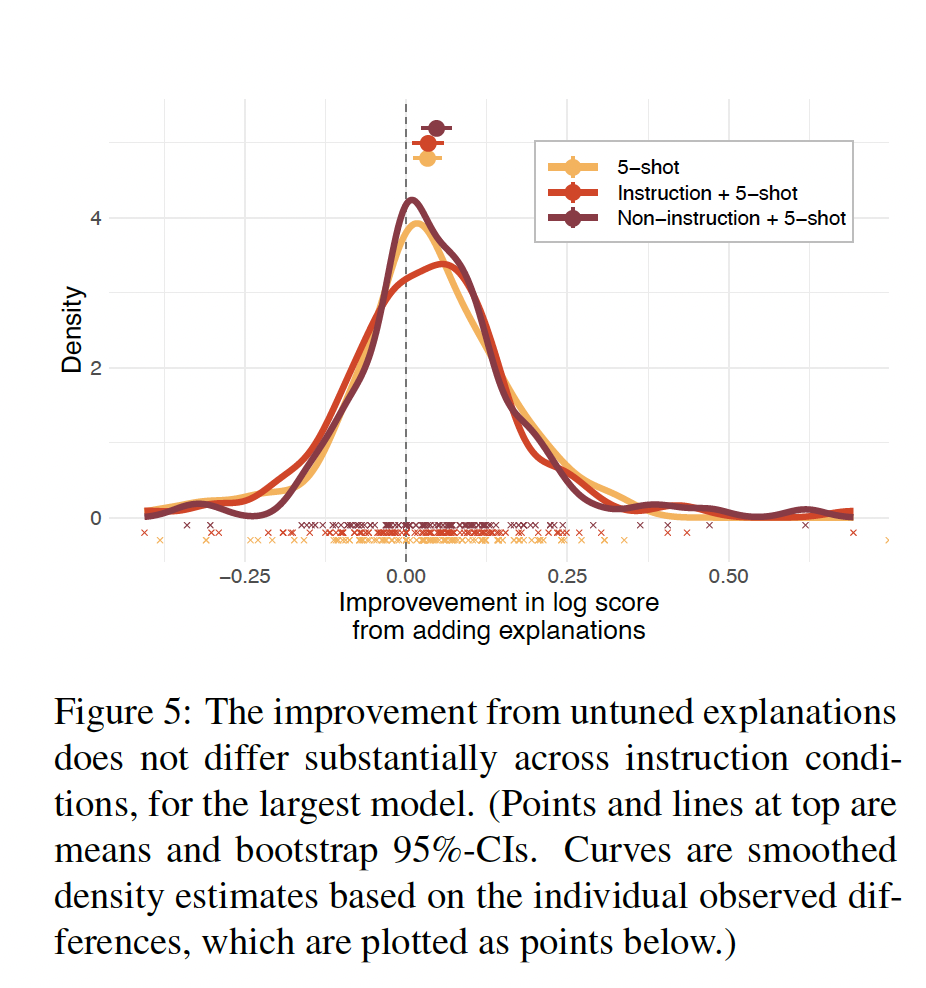
只有大型模型从
untuned explanations中受益:Figure 4显示了不同模型规模的untuned explanations的平均效果的原始总结。untuned explanations对最大的模型的平均性能有一个适度的提高,较小的模型没有受益。hierarchical regression证实了较大的模型从解释中明显受益(附录D.1.2)。
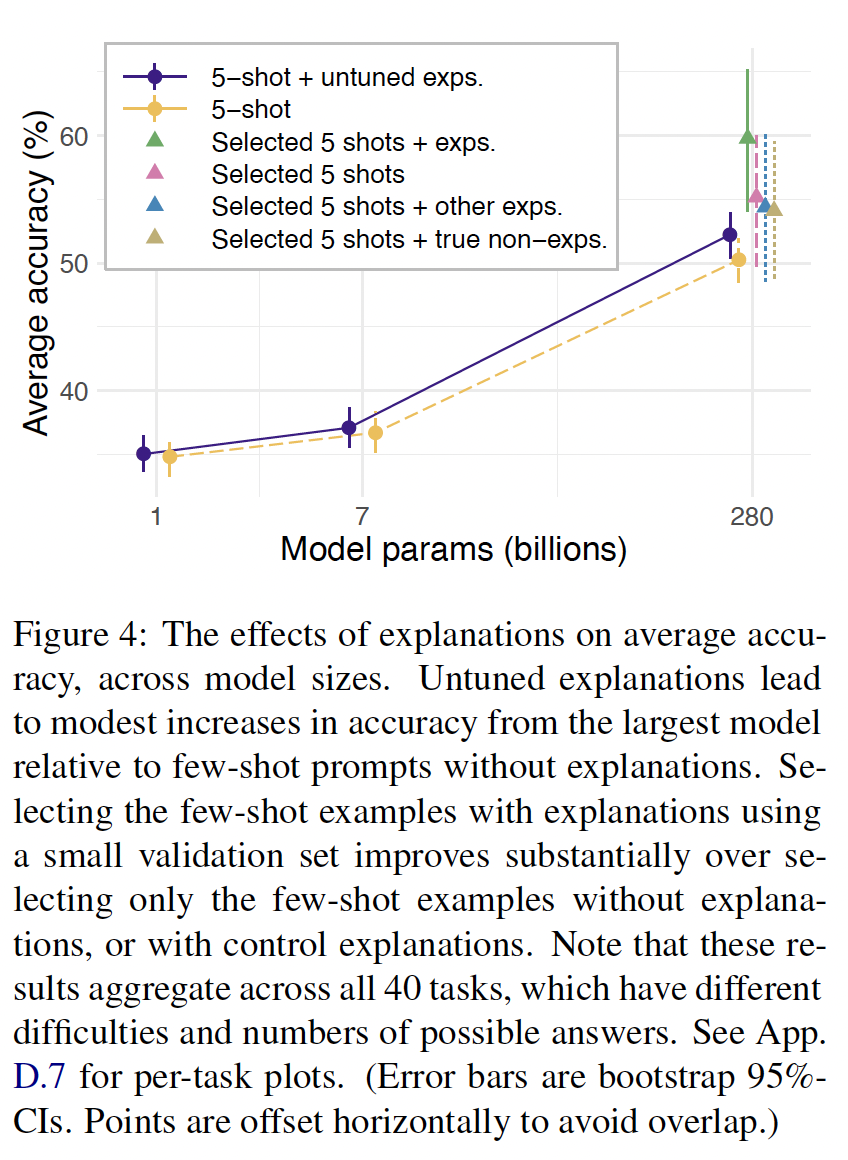
untuned explanations超越了matched control conditions:control explanations和non-instructions对于最大的模型来说是中性的或有害的。也就是说,相对于control conditions,真正的解释,即使是untuned explanations,似乎有独特的好处。我们在
Figure 7中描述了explanations和controls的这种平均效果。真正的explanations甚至超过了带有其它样本的explanations的prompt,这表明好处取决于样本和解释之间的关系,而不是lower-level特征。hierarchical regression证实,对于最大的模型来说,untuned explanations明显优于所有control conditions(附录D.1.3)。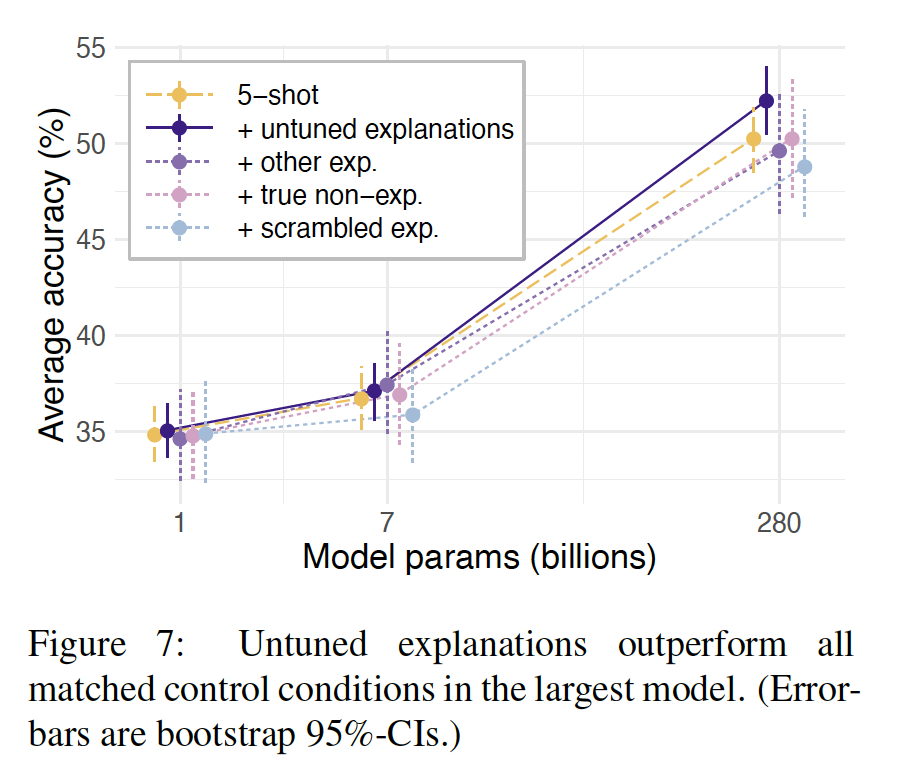
explanations对特定的任务类型有独特的好处吗:如上所述,我们使用的任务是用内容关键词来标注的。我们创建了从常识到数学的8个keyword clusters,并在每个keyword cluster中探讨了explanations的效果(Figure 8)。解释的好处在各cluster中显得相当一致。然而,每个cluster都相对较小,所以对结果的解释不应过于可信。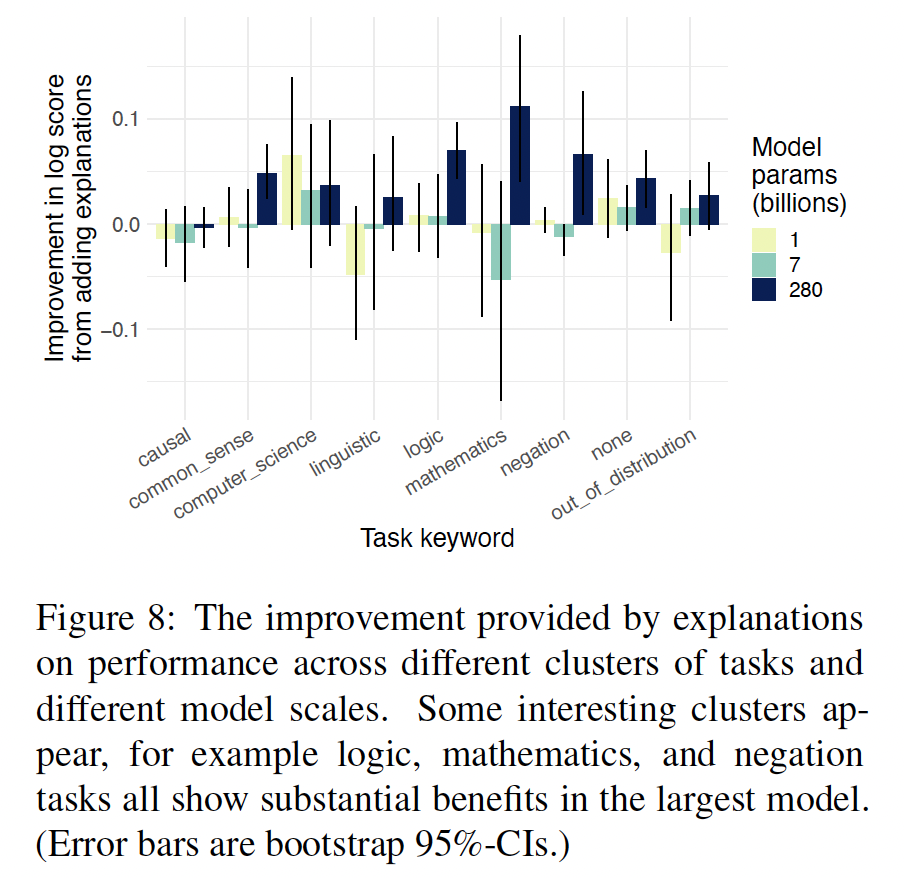
在
Figure 6中,我们显示了在一个prompt中加入explanations所带来的改善,并与该prompt的基线分数作对比。在中等规模的得分的情况下,有一个耐人寻味的凸起,表明有可能出现"zone of proximal development"效应。然而,有几个混杂因素,例如不同任务的答案选项数量不同,影响了可能的分数。尽管如此,这种可能性还是值得在未来的工作中进行调查。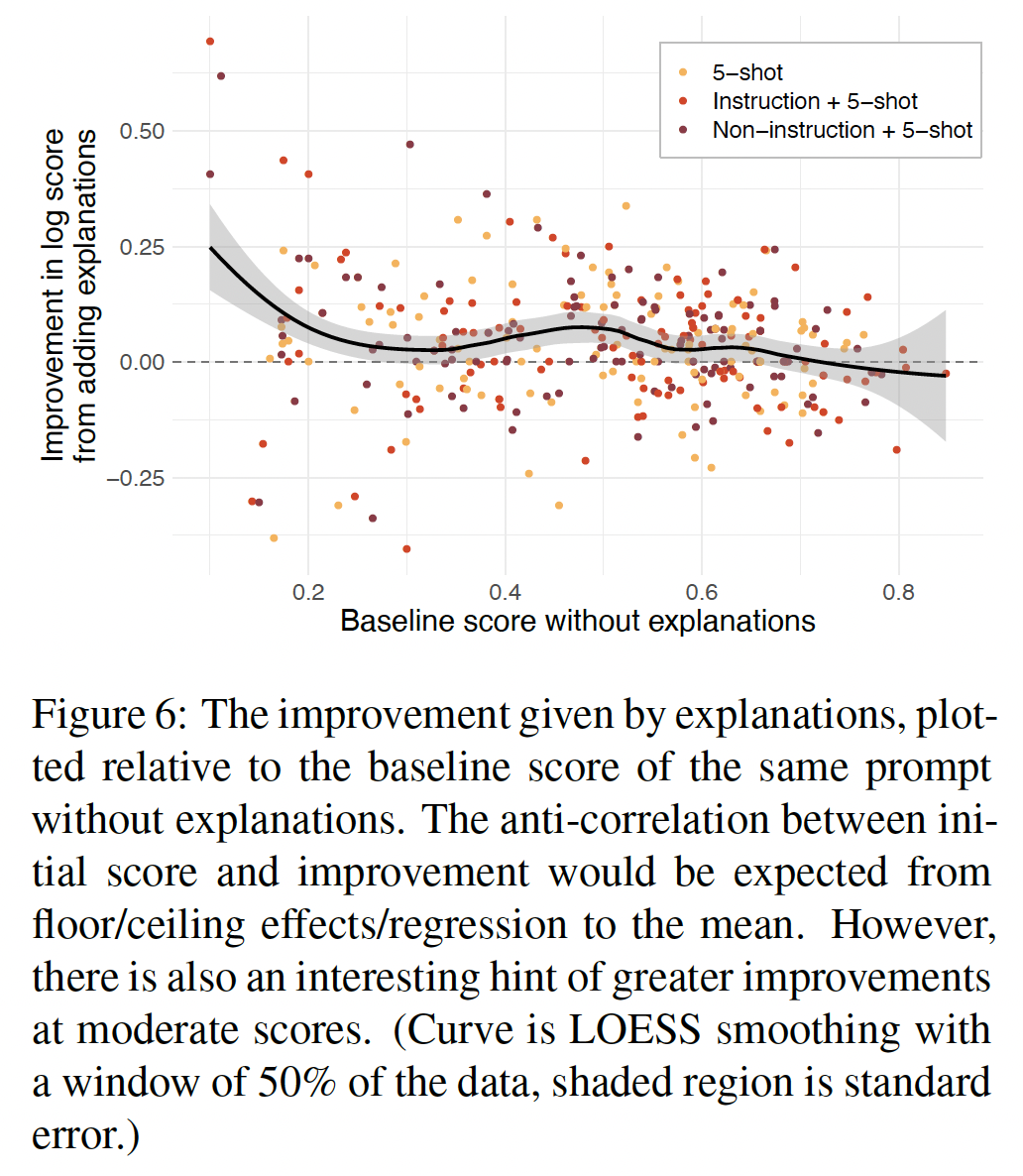
在
Figure 10中,我们显示了在不同的模型规模下,针对zero-shot prompt和few-shot prompts,instructions和non-instructions的平均效果。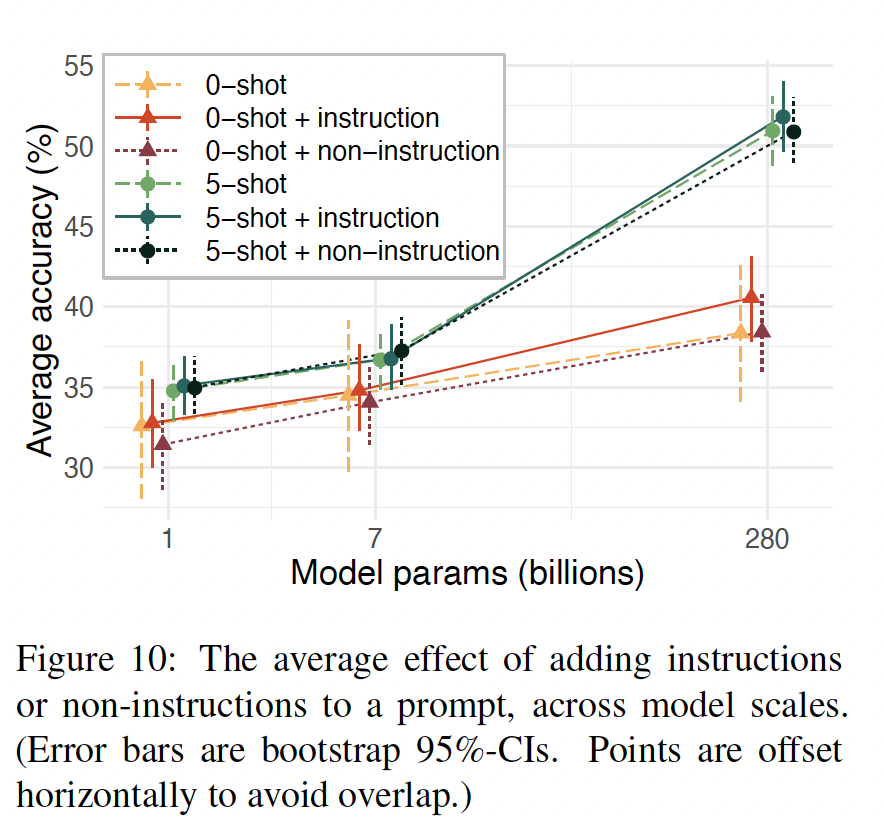
21.3 讨论
explanations能改善few-shot learning吗:是的,但好处取决于模型的规模和explanation的质量。对于一个大型模型来说,即使是untuned explanations也能带来适度但明显的性能改善:这种好处大约是最初添加few-shot examples的三分之一,但却是添加task instructions的两倍。因此,即使不进行tuning,explanations也能提高大型语言模型的few-shot性能。此外,为任务调优
explanations(使用一个小的验证集)可以大大增加其好处:首先,针对
prompt来选择examples with explanations比选择examples alone提供更大的性能改进。其次,在一个固定的样本集合上手工调优
explanations可以提供更大的好处,甚至在具有挑战性的任务上。
虽然性能还远远不够完美,但这些发现表明:
explanations可以改善few-shot prompting。为什么
post-answer explanations是有趣的: 与一些相关的工作(《Show your work: Scratch pads for intermediate computation with language models》、COT)相比,我们专注于在答案之后提供解释,而不是在答案之前提供chains of reasoning。虽然COT没有观察到post-answer explanations的好处,但我们的结果更加positive,可能是由于他们的任务需要more iterative reasoning的事实。除了这种差异,pre-answer和post-answer的解释模式在测试时也有不同的影响,对模型的in-context inference也有不同的科学意义(scientific implications)。在测试期间,
post-answer explanations并不影响evaluation pipeline,因为模型在产生explanation前会产生一个答案。相比之下,pre-answer chains-of-reasoning需要pre-answer chains-of-reasoning从模型输出中解析出答案。为了获得最佳性能,pre-answer reasoning和post-answer explanations可能有互补的、可组合的好处。事实上,《STaR: Bootstrapping reasoning with reasoning》使用了post-answer-hint的 "合理化" 作为他们bootstrapped training procedure的一部分。将问题分解成一系列的步骤往往是有用的,但有些explanations是整体性的,只有在知道答案后才有意义。从科学的角度来看,这两种方法代表了模型可以从
explanations中获益的不同机制:pre-answer chains of reasoning可以让模型在回答前输出一个推理过程并逐步处理问题。相比之下,
post-answer explanations只能通过改变task inference,抽象地塑造推理过程。因为在我们所有的prompt conditions下,模型在问题和答案之间有同等数量的处理步骤,解释的效果归因于关于模型如何处理问题和可能答案的变化。
因此,
explanations的好处来自于in-context learning过程中相当复杂的高阶推理,正如我们接下来讨论的那样。我们的研究结果对语言模型的
in-context learning能力有什么暗示:语言模型适应prompt的过程是有争议的。例如,《Rethinking the role of demonstrations :What makes in-context learning work?》提出了一个有趣的观点,即GPT-3在普通任务(如entailment)上的表现几乎与prompt中的随机答案一样好,因此,他们质疑这些模型是否真的在上下文中 "学习"。在我们的explanations和matched controls之间的比较,使我们能够测试explanations的表面特征(superficial features)是否驱动了它们的好处。具体而言,
other item explanation prompt包含与real explanation prompt相同的句子;explanations只是与不同的样本进行配对。最大的模型显示,即使相对于这个closely-matched control,real explanations也有明显的优势。事实上,对照组似乎并不比no explanations更好。这表明,最大的模型在处理target question的答案时,使用了样本和它们相应的explanations之间的关系,而不是简单地依赖prompt中的单词分布或句子分布。因此,最大的模型似乎确实在上下文中表现出一些相当复杂的高阶推理。虽然这些观察结果并不排除模型只是利用解释来回忆训练中看到的任务的可能性,但我们使用的
BIG-bench collaboration任务是对抗性采样从而是独特的、具有挑战性的,这使得这种可能性有点小。一个可能与过去的发现相调和的情况是,模型是 "懒惰的",在模型可以依赖low-level特征的时候依赖low-level特征,而只在需要high-level特征的挑战性环境中使用high-level特征(参见《When classifying arguments, bert doesn’t care about word order... except when it matters》)。然而,要完全解决这些问题,还需要进一步调查。explanations与instructions的关系如何:虽然之前的工作发现,task instructions比样本更有效(例如Metaprompt),但我们发现,task instructions的效果比few-shot examples or explanations的效果更小。这可能是由于之前的工作在很大程度上执行了tuning instructions,从而使prompts可以说不是"zero-shot"的;也可能与我们评估的任务有关,这些任务是对抗性采样的。具有挑战性的任务可能更难描述,相比较于explaining with examples。无论如何,explanations在不同的instruction conditions下提供类似的好处。因此explanations与instructions可以是互补的。我们的工作与人类语言处理(
human language processing)有什么关系:由于我们受到人类使用explanation的认知工作的启发,并且鉴于积累的证据表明语言模型可以预测大量的human neural language processing(《The neural architecture of language: Integrative modeling converges on predictive processing》、《Shared computational principles for language processing in humans and deep language models》),自然要问我们的工作是否有认知意义(cognitive implications)。然而,语言模型和人类都从explanations中受益的事实并不意味着他们一定是通过相同的机制受益。事实上,我们观察到的explanations的好处比人们对人类的预期好处要小。然而,请注意,我们的许多任务,如评估数学归纳论证(mathematical induction arguments),对许多人类来说是具有挑战性的,即使with instructions, examples, and explanations。human response和model response之间的差异可能部分源于语言模型的贫乏经验,它们没有经历过语言所指的更广泛的背景或情况。相比之下,human explanations从根本上说是实用性和交流性的:解释的目的是在特定的对话和背景下传达一种意义。人类为理解explanations而进行的推理过程大概是由这种互动经验形成的。因此,在更丰富的互动环境中训练的模型可能从explanations中受益更多(《Symbolic behaviour in artificial intelligence》)。相应地,explanations可以为未来调查人类和模型语言处理的相似性和差异性提供一个有趣的环境。我们的研究方法有什么好处:随着研究人员对人工智能表现出的越来越复杂的行为进行研究(
《Symbolic behaviour in artificial intelligence》),我们认为采用行为科学的实验和分析工具将有越来越多的好处。我们特别强调hierarchical regressions的价值,它从统计学上说明了数据的依赖性和不同类型的observed variation。如果不对这些因素进行建模,就会导致诸如"stimulus-as-fixed-effect fallacy"(《The language-as-fixed-effectfallacy: A critique of language statistics in psychological research》)等问题:将刺激或数据集效应误认为是更普遍的原则。因此,适当的hierarchical models对可推广的研究至关重要(《The generalizability crisis》)。我们鼓励其他研究人员采用这些分析工具。局限性:
我们使用的数据集有什么好处和坏处:使用
BIG-bench collaboration的任务,使我们能够在相似的格式中收集一组多样化的、具有挑战性的任务。这些任务涵盖了可能在标准数据集中没有得到很好体现的技能。然而,这些特异的、对抗性采样的任务可能因此不能代表通常应用language model的任务。这种差异可能会放大或压制我们的效果。explanation annotations:本文的一位作者对这个数据集进行了注释,方法是阅读相应的BIG-Bench问题和解决方案,然后尝试写一个解释,帮助人类理解答案。尽管这个过程允许对那些原本可能难以获得注释的任务进行专家注释(例如需要理解数学归纳的任务),但它也有相应的局限性。此外,由于仅有一个作者对解释进行了注释,它们可能是有偏的。模型和训练:用指令来训练或微调的模型(
《Training language models to follow instructions with human feedback》)可能更受益于explanations。事实上,调优一个模型以利用prompt中的explanations可能会改善结果,这将是未来工作的一个令人兴奋的方向。此外,添加
explanations会延长prompt,而目前的语言模型通常有一个固定的上下文长度,这限制了可以解释的样本的数量。因此,explanations在未来的、能处理更长上下文的模型中可能更有用。explanations所提供的改进程度:我们强调,虽然包括answer explanations会在统计学上带来明显的性能改善,但它不会产生完美的性能或完全鲁棒的行为:事实上,如果不进行tuning,好处是不大的。然而,正如大型模型从explanations中获益更多一样,我们希望未来的模型将进一步获益;而且explanations可以与其他技术相结合,产生更大的改进。
二十二、COT[2022]
论文:
《Chain of Thought Prompting Elicits Reasoning in Large Language Models》。
NLP领域最近被语言模型彻底改变。扩大语言模型的规模已被证明可以带来一系列的好处,比如提高性能和样本效率(sample efficiency)。然而,事实证明,仅仅扩大模型规模并不足以在诸如算术、常识推理、以及符号推理等具有挑战性的任务中取得高的效果。我们探讨了如何通过一种简单的方法来解锁大型语言模型的推理能力。我们的方法由两个想法驱动:
首先,用于算术推理的技术可以从自然语言的理由(这些理由导致最终正确答案)中获益。之前的工作通过从头开始训练(
《Program induction by rationale generation: Learning to solve and explain algebraic word problems》)、或微调一个pretrained model(《Training verifiers to solve math word problems》)从而为模型赋予能力来生成自然语言形式的中间步骤;此外还有使用formal language代替自然语言的神经符号方法。其次,大型语言模型提供了令人振奋的前景,即通过
prompting进行in-context few-shot learning。也就是说,与其为每个新的任务微调一个单独的language model checkpoint,不如简单地用一些input-output示例(这些示例用于阐述任务)来"prompt"模型。值得注意的是,这在一系列简单的问答任务中是成功的(GPT-3)。
然而,上述两种想法都有关键的局限性:
对于
rationale-augmented的training和finetuning方法来说,创建关于高质量的rationales的一个大数据集是很昂贵的,这比普通机器学习中使用的简单的input–output pairs要复杂得多。对于
GPT-3使用的传统的few-shot prompting方法,在需要推理能力的任务上效果很差,而且通常不会随着语言模型规模的增加而有实质性的改善(Gohper)。
在本文中,我们结合了这两种思想的优势从而避免各自的局限性。具体而言,在给定一个
prompt的条件下,我们探索了语言模型对推理任务进行few-shot prompting的能力,其中给定的prompt由三要素组成:<input, chain of thought, output>。chain of thought: COT是一系列中间的自然语言推理步骤(这些中间步骤导致了最终输出),我们把这种方法称为chain-of-thought prompting。下图中显示了一个prompt的例子。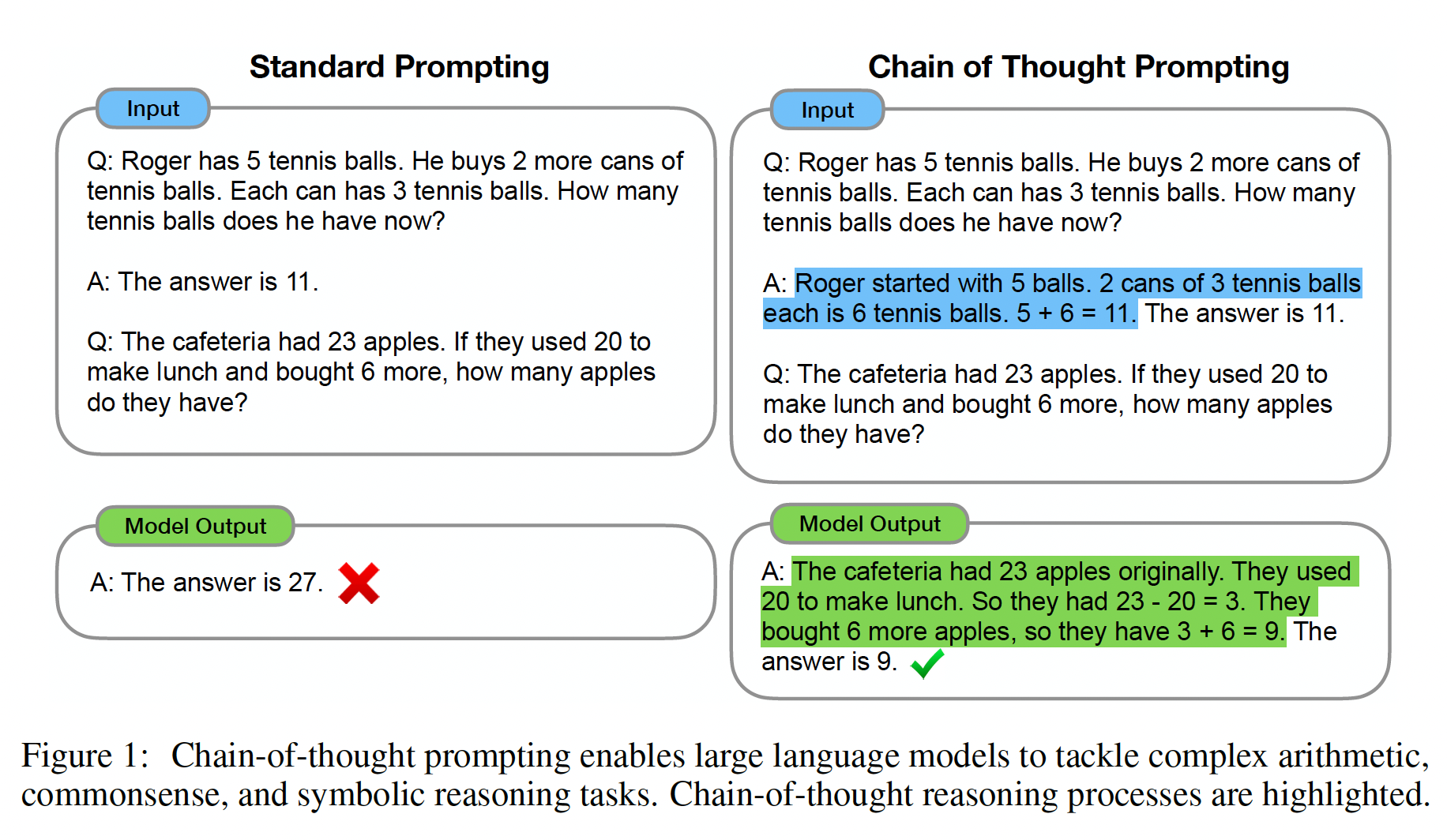
我们对算术推理、常识推理、以及符号推理的
benchmark进行了实证评估,显示chain-of-thought prompting优于标准的prompting,有时达到惊人的程度。下图展示了这样一个结果:在math word问题的GSM8K benchmark上,使用PaLM 540B的chain-of-thought prompting比标准prompting超出很多,并取得了新的SOTA性能。prompting only很重要,因为它不需要大量的训练数据集,而且单个model checkpoint可以执行许多任务而不损失通用性。这项工作强调了大型语言模型如何通过关于任务的几个示例以及自然语言数据来进行学习(比方说,通过大型训练数据集自动学习inputs和outputs的基本模式)。COT只有在使用100B参数的模型时才会产生性能提升,这对于中小模型不利。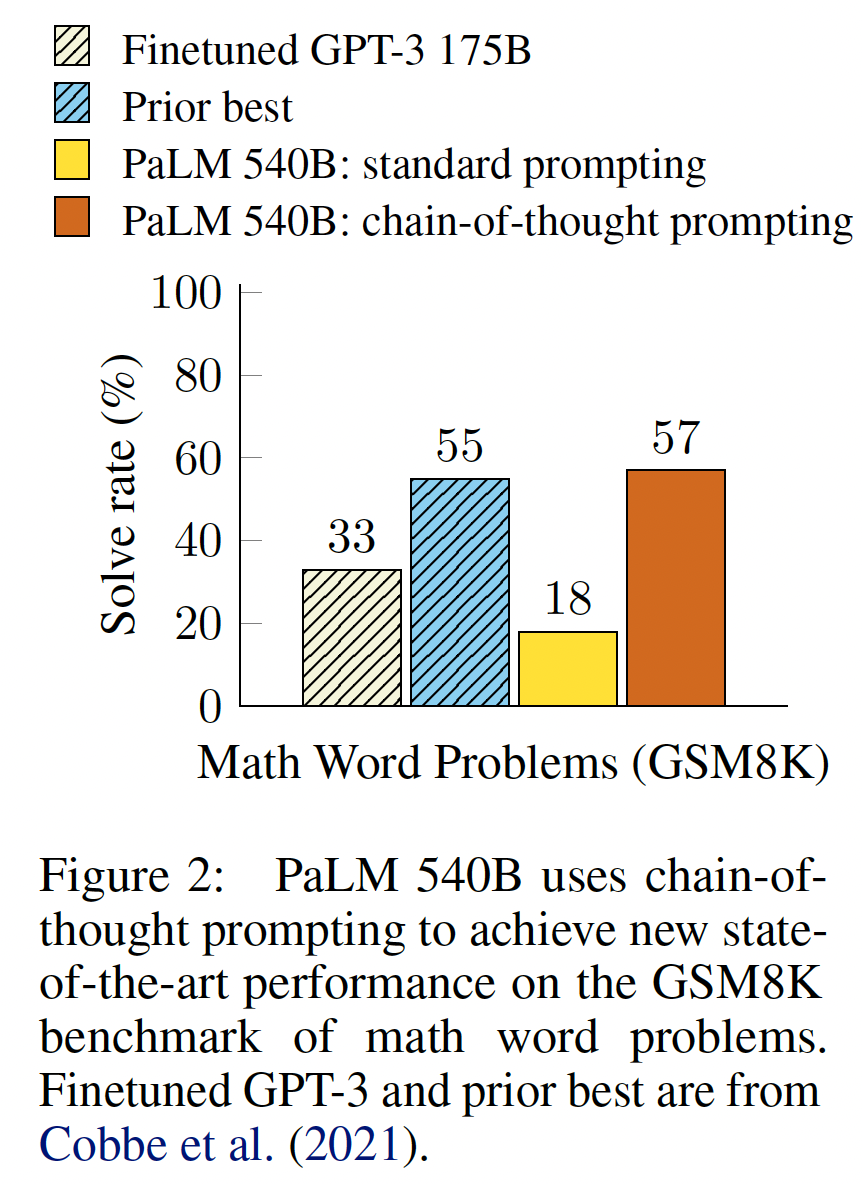
相关工作:这项工作受到了许多研究领域的启发,我们将在论文的附录
C中详细介绍。在这里,我们描述两个方向、以及也许是最相关的一些论文。第一个相关方向是使用中间步骤(
intermediate steps)解决推理问题。《Program induction by rationale generation: Learning to solve and explain algebraic word problems》通过一系列中间步骤,率先提出了使用自然语言推理来解决数学应用题的思想。他们的工作与使用formal language进行推理的文献形成了鲜明对比。《Training verifiers to solve math word problems》扩展了《Program induction by rationale generation: Learning to solve and explain algebraic word problems》的方法,创建了一个更大的数据集,并使用它来微调pretrained language model,而不是从头开始训练模型。在程序合成(
program synthesis)领域,《Show your work: Scratchpads for intermediate computation with language models》利用语言模型,通过首先逐行预测中间计算结果从而来预测Python程序的最终输出,并表明他们的step-by-step预测方法比直接预测最终输出的效果更好。
自然,这篇论文也与最近大量关于
prompting的工作密切相关。自从GPT-3提出的few-shot prompting流行以来,一些通用的方法已经提高了模型的prompting能力,例如自动学习prompts(《The power of scale for parameter-efficient prompt tuning》)、或给模型描述任务的指令(FLAN、T0、《Training language models to follow instructions with human feedback》)。尽管这些方法改进或增加了prompt的输入部分(例如,附加在inputs之前的指令),我们的工作采取了用一个正交的方向来augment带有chain of thought的模型的输出。
22.1 方法
在解决复杂的推理任务(如多步骤的
math word问题)时,考虑一下自己的思维过程。典型的做法是将问题分解成中间步骤,并在给出最终答案之前解决每个中间步骤。例如,After Jane gives 2 flowers to her mom she has 10 ... then after she gives 3 to her dad she will have 7 ... so the answer is 7.。 本文的目标是赋予语言模型以产生类似的chain of thought的能力:一系列连贯的中间推理步骤,从而得出问题的最终答案。我们将证明,对于few-shot prompting,如果在范例中提供chain-of-thought reasoning的阐述,那么足够大的语言模型可以产生chains of thought。下图显示了一个模型产生
chain of thought来解决一个math word问题的例子,如果没有chain of thought则模型就会得到错误的答案。在这种情况下,chain of thought类似于解决方案,但我们仍然选择将其称为chain of thought,以更好地捕获到idea:它模仿了step-by-step thought process从而得出答案。另外,解决方案/解释通常在最终答案之后(而不是在答案之前)。作为一种促进语言模型推理的方法,
chain-of-thought prompting有几个吸引人的特性:首先,
chain of thought原则上允许模型将多步骤问题分解为中间步骤,这意味着更多的计算可以被分配给需要更多推理步骤的问题。第二,
chain of thought为模型的行为提供了一个可解释的窗口,提示它如何得出一个特定的答案,并提供机会来调试推理路径(reasoning path)出错的地方。尽管完全描述support an answer的模型的计算仍然是一个悬而未决的问题。第三,
chain-of-thought reasoning可用于math word问题、常识推理、以及符号操作等任务,并有可能适用于人类通过语言可以解决的任何任务(至少在原则上)。最后,
chain-of-thought reasoning可以很容易地在足够大的现成语言模型中被激发出来,只需将chain of thought sequences的样例纳入exemplars of few-shot prompting中即可。
在实证实验中,我们将观察
chain-of-thought prompting对算术推理(arithmetic reasoning)、常识推理(commonsense reasoning)、以及符号推理(symbolic reasoning)的效果。
22.2 算术推理
我们首先考虑
Figure 1中形式的math word问题,它可以衡量语言模型的算术推理能力。虽然对人类来说很简单,但算术推理是一项语言模型经常陷入困境的任务。令人震惊的是,当与540B参数的语言模型一起使用时,chain-of-thought prompting在几个任务上的表现与特定任务的微调模型相当,甚至在具有挑战性的GSM8K基准上达到了新的SOTA。benchmark:GSM8K、SVAMP、ASDiv、AQuA、MAWPS。这些都是math word问题的数据。一些例子如下表所示。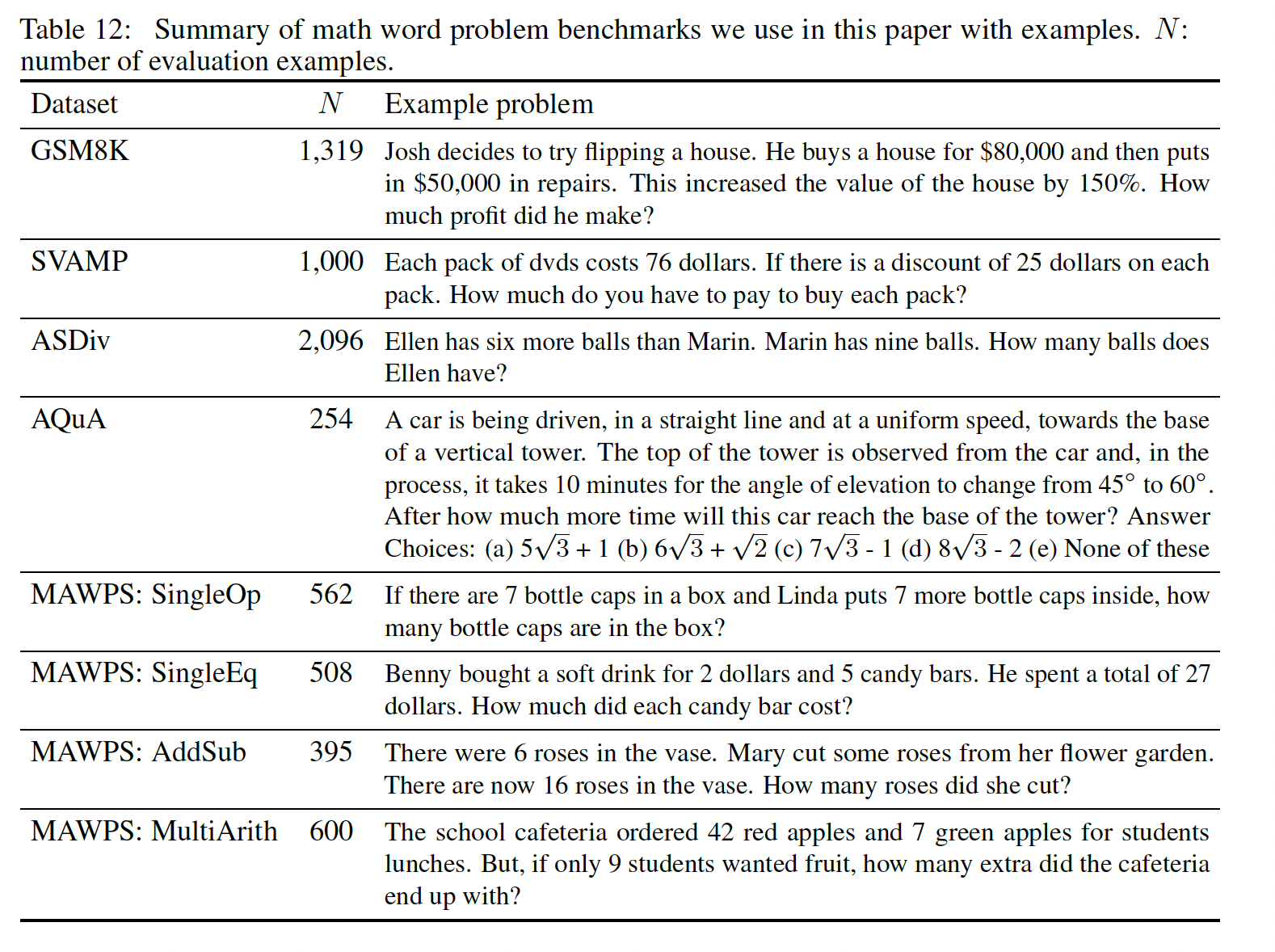
方法:
standard prompting:GPT-3推广的标准的few-shot prompting,其中语言模型在测试期间被馈入in-context exemplars(input-output pair)从而得到输出。如Figure 1的左图所示。chain-of-thought prompting:在few-shot prompting中用一个关于答案的chain of thought来augment每个样例。如Figur3 1的右图所示。
由于大多数数据集只有一个
evaluation split,我们手动组成了八个具有chains of thought的few-shot exemplars从而用于prompting。Figure 1的右图显示了一个chain of thought exemplar,所有八个的案例如Table 20所示。这些特殊的exemplars没有经过prompt engineering。为了研究这种形式的
chain-of-thought prompting是否能在一系列的math word问题上成功地引起推理,我们对所有的基准都使用了这一组八个chain of thought exemplars,除了AQuA,因为AQuA是多选题而不是自由回答。对于AQuA,我们使用了训练集中的四个样例和解答,如Table 21所示。

语言模型:
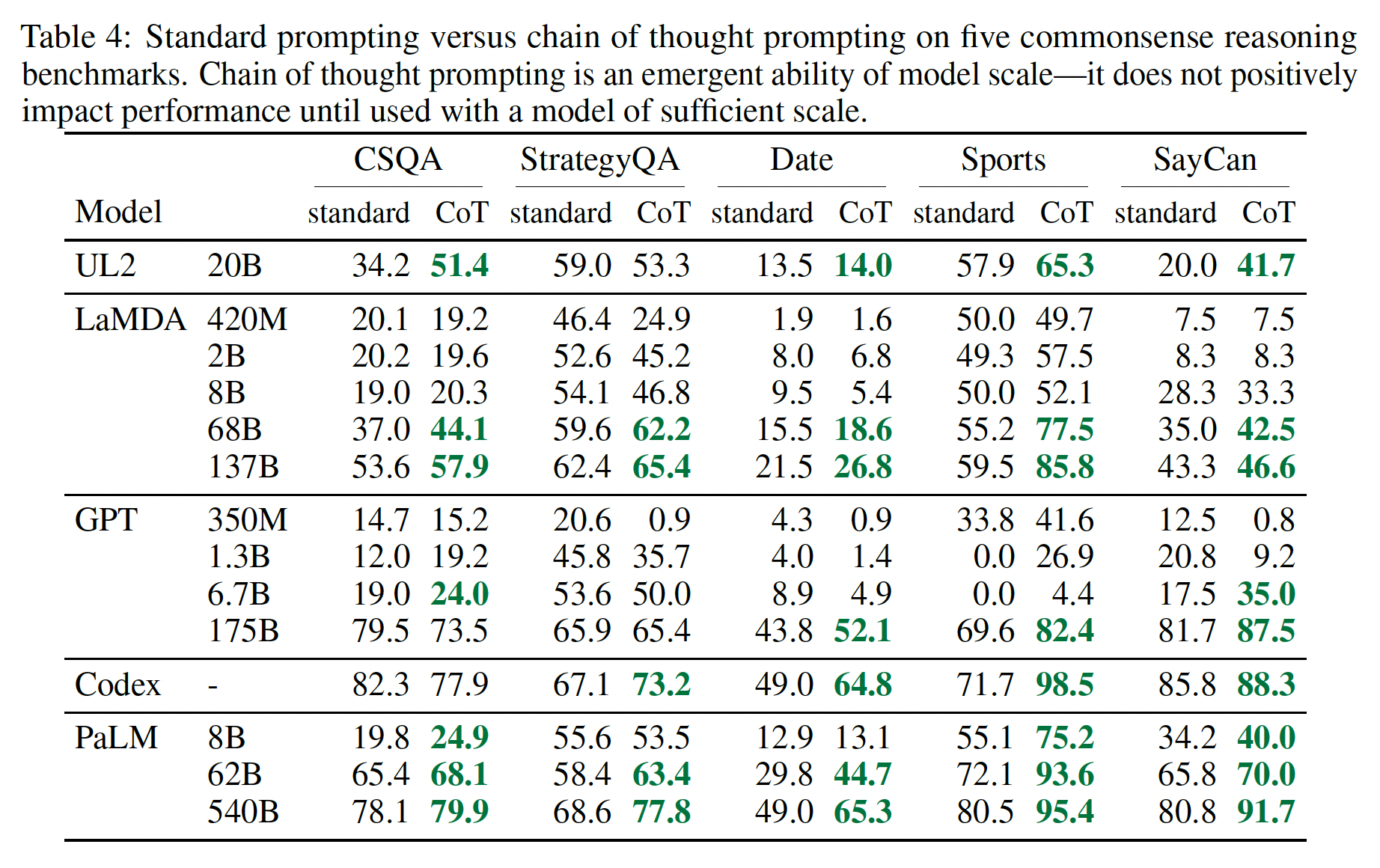
GPT-3:我们使用了text-ada-001、text-babe-001、text-curie-001和text-davinci-002,据推测它们对应于InstructGPT模型的350M、1.3B、6.7B和175B参数。LaMDA:该模型有422M、2B、8B、68B和137B参数。PaLM:该模型有8B、62B和540B参数。UL2 20B。Codex:OpenAI API中为code-davinci-002。
我们通过贪心解码从模型中采样。尽管后续工作表明,
chain-of-thought prompting可以通过在许多sampled generations中采取majority final answer(即,多数投票机制)来改进(《Self-consistency improves chain of thought reasoning in language models》)。对于
LaMDA,我们报告了五个随机种子的平均结果,其中每个种子都有不同的随机混洗的exemplars顺序。由于LaMDA的实验没有显示出不同种子之间的巨大差异,为了节省计算量,我们报告了所有其他模型的single exemplar order(即,采用了固定的顺序)的结果。结果:
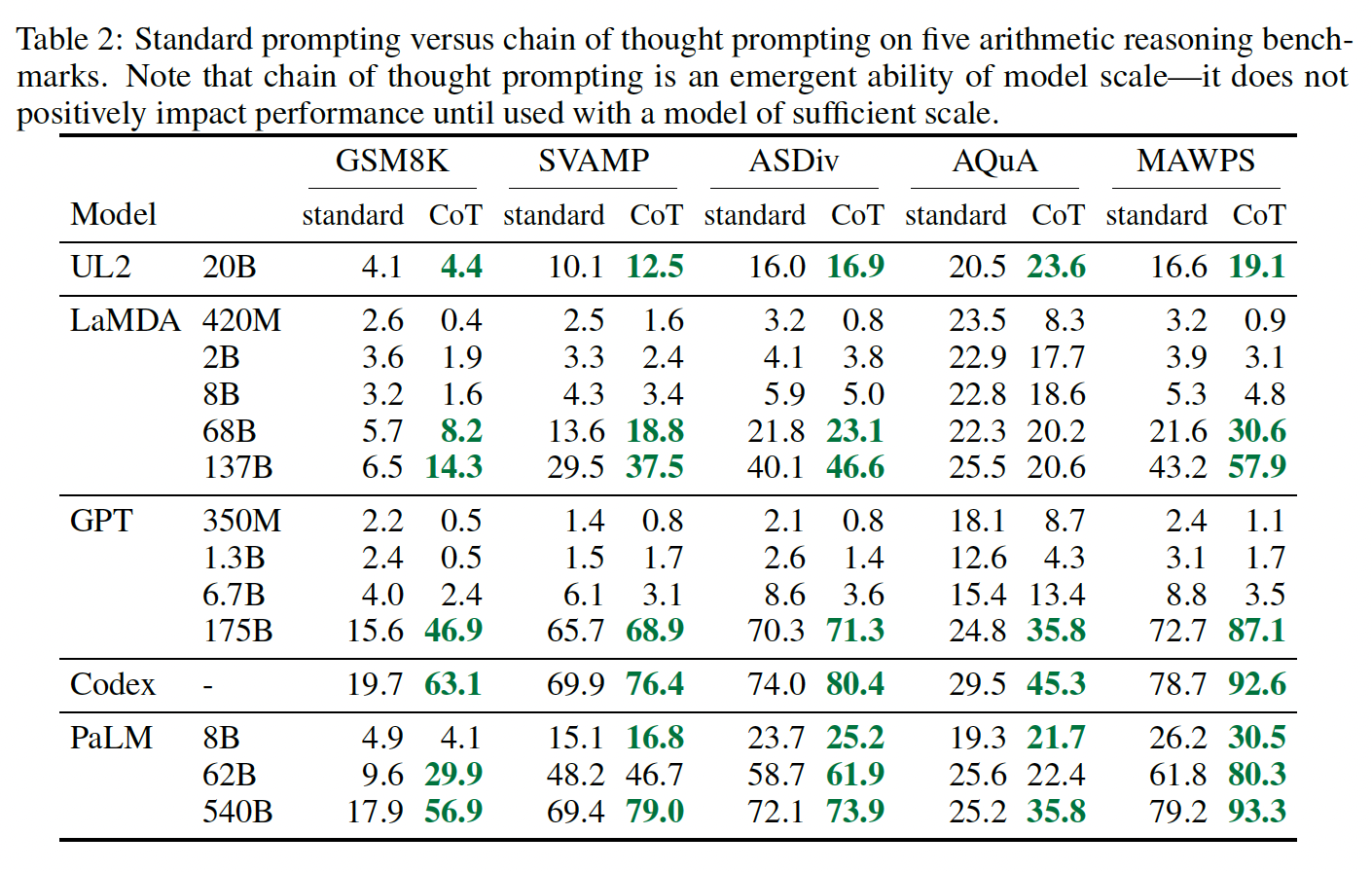
Figure 4总结了chain-of-thought prompting的最强结果,Table 2展示了每个model collection、模型大小、以及benchmark上的所有结果。首先,
Figure 4显示,chain-of-thought prompting是模型规模的一种涌现能力(emergent ability)(《Emergent abilities of large language models》)。也就是说,chain-of-thought prompting对小模型的性能没有积极影响,只有在使用100B参数的模型时才会产生性能提升。我们定性地发现,较小规模的模型产生了流畅的但不合逻辑的chains of thought,导致了比standard prompting更低的性能。其次,
chain-of-thought prompting对于更复杂的问题有更大的性能提升。例如:对于
GSM8K(具有最低的baseline性能的数据集),GPT-3 175B和PaLM 540B模型的性能提高了一倍以上。另一方面,对于
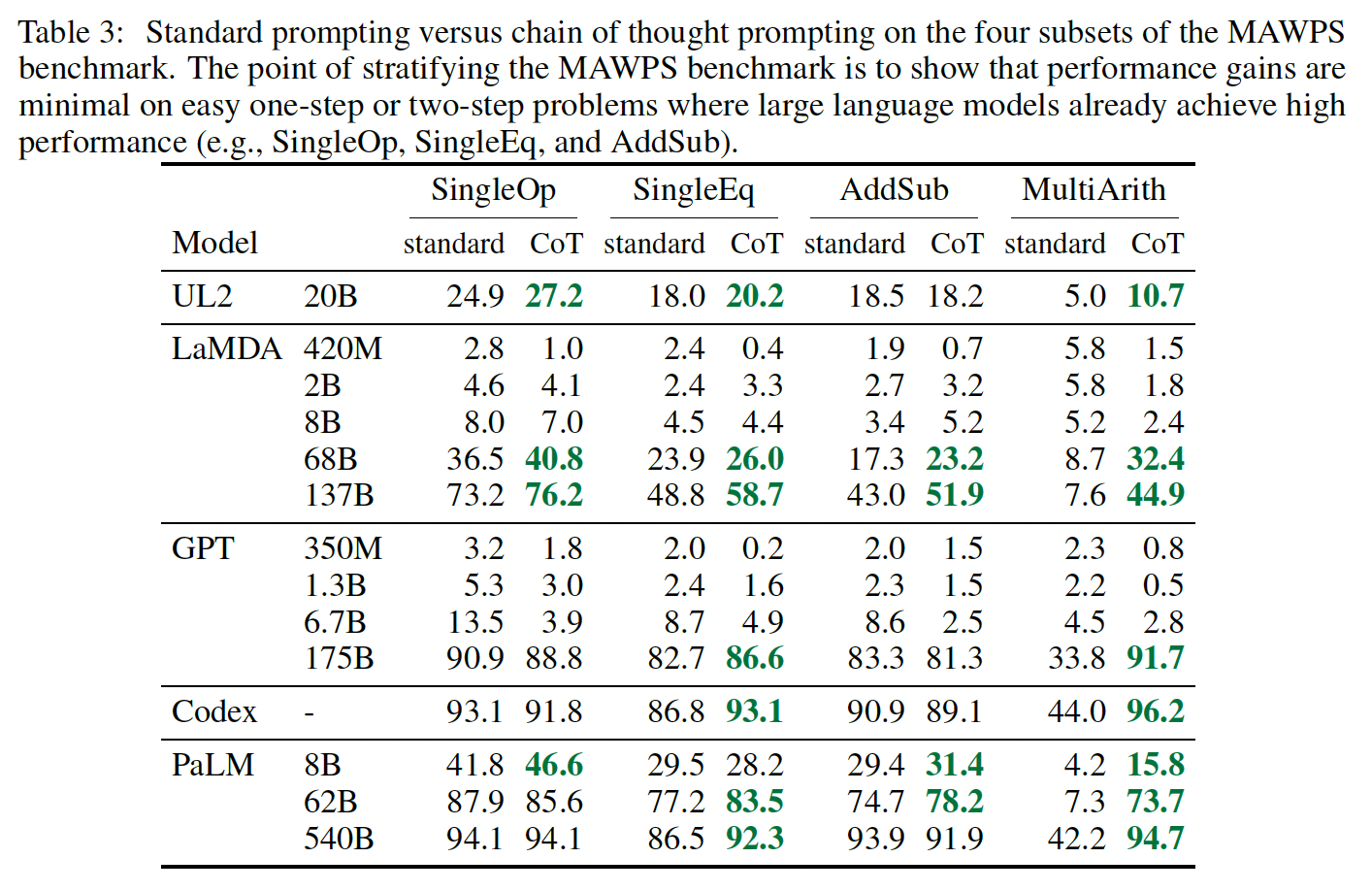
SingleOp(MAWPS中最简单的子集,只需要一个步骤就能解决),性能的提高要么是负数,要么是非常小,如Table 3所示。
第三,通过
GPT-3 175B和PaLM 540B进行的chain-of-thought prompting与之前的SOTA相比更胜一筹,后者通常在labeled training dataset上对特定任务的模型进行微调。Figure 4显示了PaLM 540B是如何使用chain-of-thought prompting在GSM8K、SVAMP和MAWPS上达到新的SOTA的(不过请注意,standard prompting已经超过了SVAMP的现有最佳水平)。在另外两个数据集上,即AQuA和ASDiv,采用chain-of-thought prompting的PaLM 540B达到了SOTA的2%差距以内(参考Table 2)。

为了更好地理解为什么
chain-of-thought prompting有效,我们通过LaMDA 137B对GSM8K手动检查了模型生成的chains of thought。在模型返回正确的最终答案的50个随机例子中,除了两个巧合得出正确答案的例子外,所有生成的chains of thought在逻辑上和数学上也都是正确的(见论文附录D.1,Table 8给出了正确的模型生成的chains of thought的例子)。我们还随机检查了模型给出错误答案的
50个随机例子。这个分析的结论是:46%的chains of thought几乎是正确的,除了一些小错误(calculator error、symbol mapping error、或缺少一个推理步骤)。其他
54%的chains of thought在语义理解或语义连贯性方面有重大错误(见论文附录D.2)。
为了略微了解为什么
scaling能提高chain-of-thought的推理能力,我们对PaLM 62B所犯的错误进行了类似的分析,以及这些错误是否通过scale到PaLM 540B而得到修复。结论是:将PaLM扩展到540B可以修复62B模型中很大一部分的one-step missing error和语义理解错误(见附录A.1,以及图Figure 9所示)。

消融研究:鉴于使用
chain-of-thought prompting所观察到的好处,一个自然的问题是:即是否可以通过其他类型的prompting来实现同样的性能改进。Figure 5显示了一个消融研究,有三种不同的chain of thought变体,如下所述。只有方程(
equation):chain-of-thought prompting可能有帮助的一个原因是它产生了待评估的数学方程,因此我们测试了一个变体,即模型在给出答案前只被提示从而输出一个数学方程。Figure 5显示,equation only prompting对GSM8K的帮助不大,这意味着GSM8K中问题的语义太有挑战性,如果没有chain of thought中的自然语言推理步骤,就不能直接转化为方程。然而,对于只有一步或两步的问题的数据集,我们发现
equation only prompting确实提高了性能,因为方程可以很容易地从问题中得出(如Table 6所示)。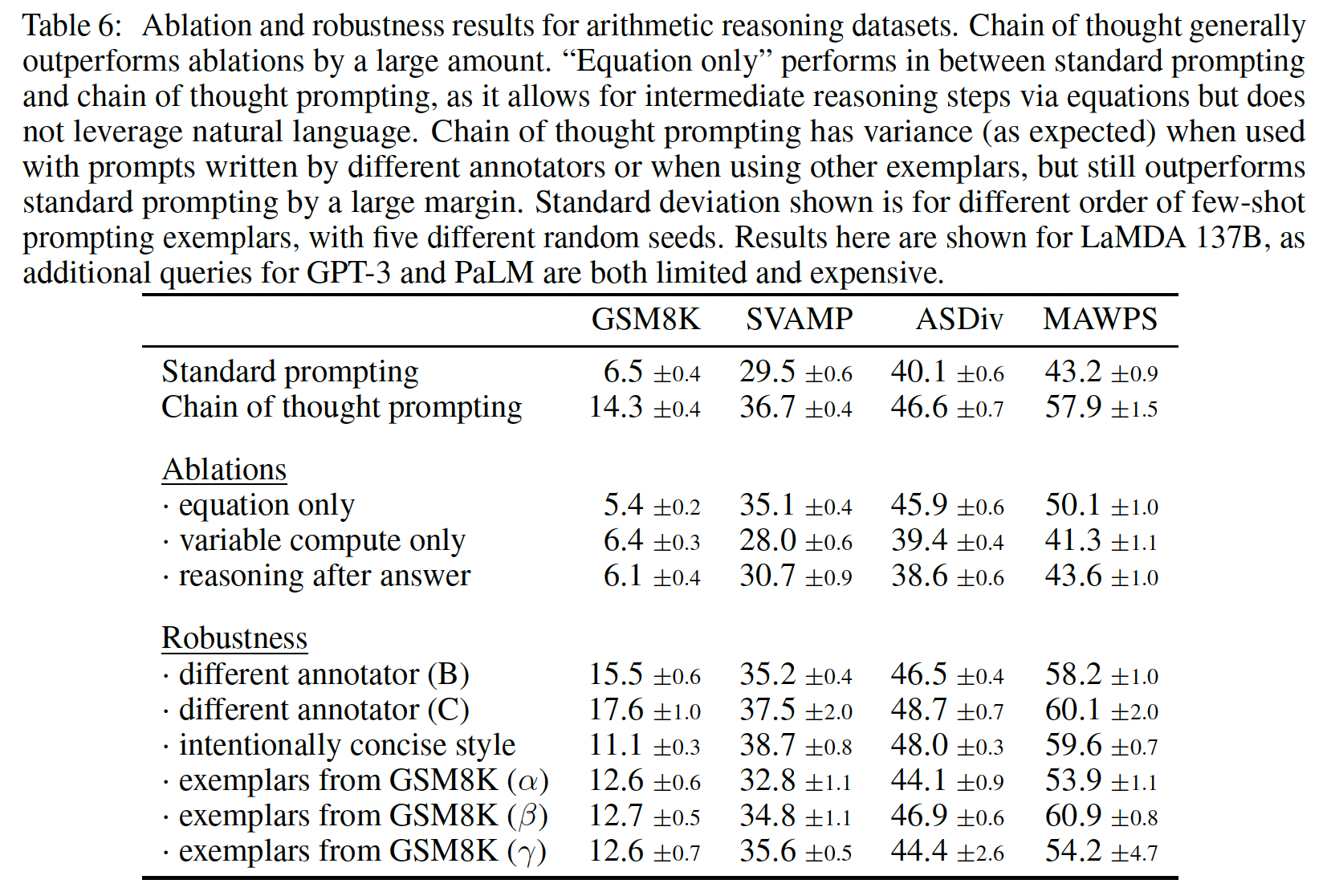
仅仅包含可变的计算:另一个直觉是,
chain of thought允许模型在更难的问题上花费更多的计算(即intermediate tokens)。为了从chain-of-thought reasoning中分离出可变的计算(variable computation)的影响,我们测试了一种配置:在这种配置中,模型被提示输出关于"."的一个序列("..."),其数量等于解决问题所需的方程中的字符数。这个变体的表现与baseline差不多,这表明可变的计算本身并不是chain-of-thought prompting成功的原因,而且通过自然语言来表达intermediate steps似乎也有好处。答案之后的
chain of thought:chain-of-thought prompting的另一个潜在好处可能仅仅是,这种prompts允许模型更好地获取在预训练中获得的相关知识。因此,我们测试了另一种配置,即chain of thought prompt只在答案之后给出,以隔离模型是否真正依赖于所产生的chain of thought来给出最终答案。这个变体的表现与baseline差不多,这表明chain of thought中体现的串行推理(sequential reasoning)除了激活知识外,还有其他的作用。《Can language models learn from explanations in context?》采用了Reasoning after answer的方案,并表明该方案要比标准的prompting更好。与这里的结论矛盾。《Can language models learn from explanations in context?》的解释是:任务的不同。
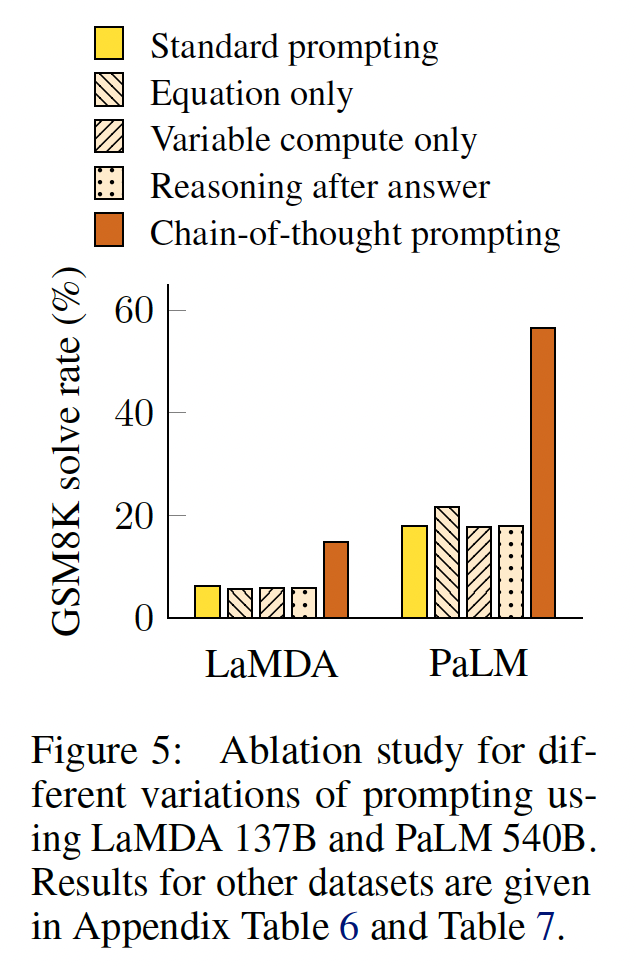
Chain of Thought的鲁棒性:对exemplars的敏感性是prompting方法的一个关键考虑因素。例如,改变few-shot exemplars的排列组合可以使GPT-3在SST-2上的准确率从接近随机(54.3%)到接近SOTA(93.4%)(《Calibrate before use: Improving few-shot performance of language models》)。在这里,我们评估了对不同标注员所写的chains of thought的鲁棒性。除了上述使用Annotator A编写的chains of thought的结果外,本文的另外两位合著者(Annotators B and C)也为相同的few-shot exemplars独立编写了chains of thought(见Table 29, 30)。Annotator A还按照《Training verifiers to solve math word problems》给出的解决方案的风格,写出了另一条比原来的更简洁的chain of thought。

下图显示了
GSM8K和MAWPS上LaMDA 137B的这些结果(其他数据集的消融结果见Table 6, Table 7)。尽管不同的chain of thought annotations之间存在方差,正如在使用exemplar-based prompting时所预期的那样,所有的chain-of-thought prompts都比standard baseline的表现要好很多。这一结果意味着,成功使用chain-of-thought并不取决于特定的语言风格。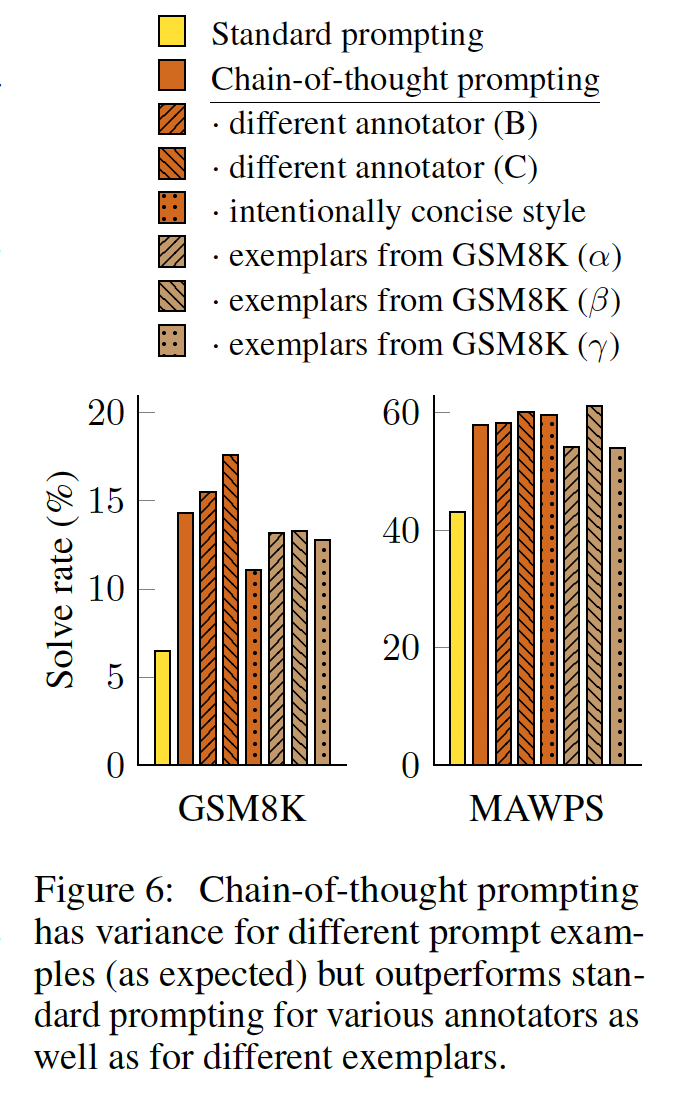
为了证实成功的
chain-of-thought prompting对其他exemplars的作用,我们还用从GSM8K训练集随机抽取的三组eight exemplars进行了实验,这是一个独立的数据源(这个数据集中的样本已经包括了像chain of thought一样的推理步骤)。Figure 6显示,这些prompts的表现与我们手动编写的样例相当,也大大超过了standard prompting的表现。除了对标注员、独立编写的
chains of thought、不同样例、以及各种语言模型的鲁棒性之外,我们还发现,chain-of-thought prompting对算术推理的不同的exemplar orders、以及不同的样例数量(如Table 6所示)都很鲁棒。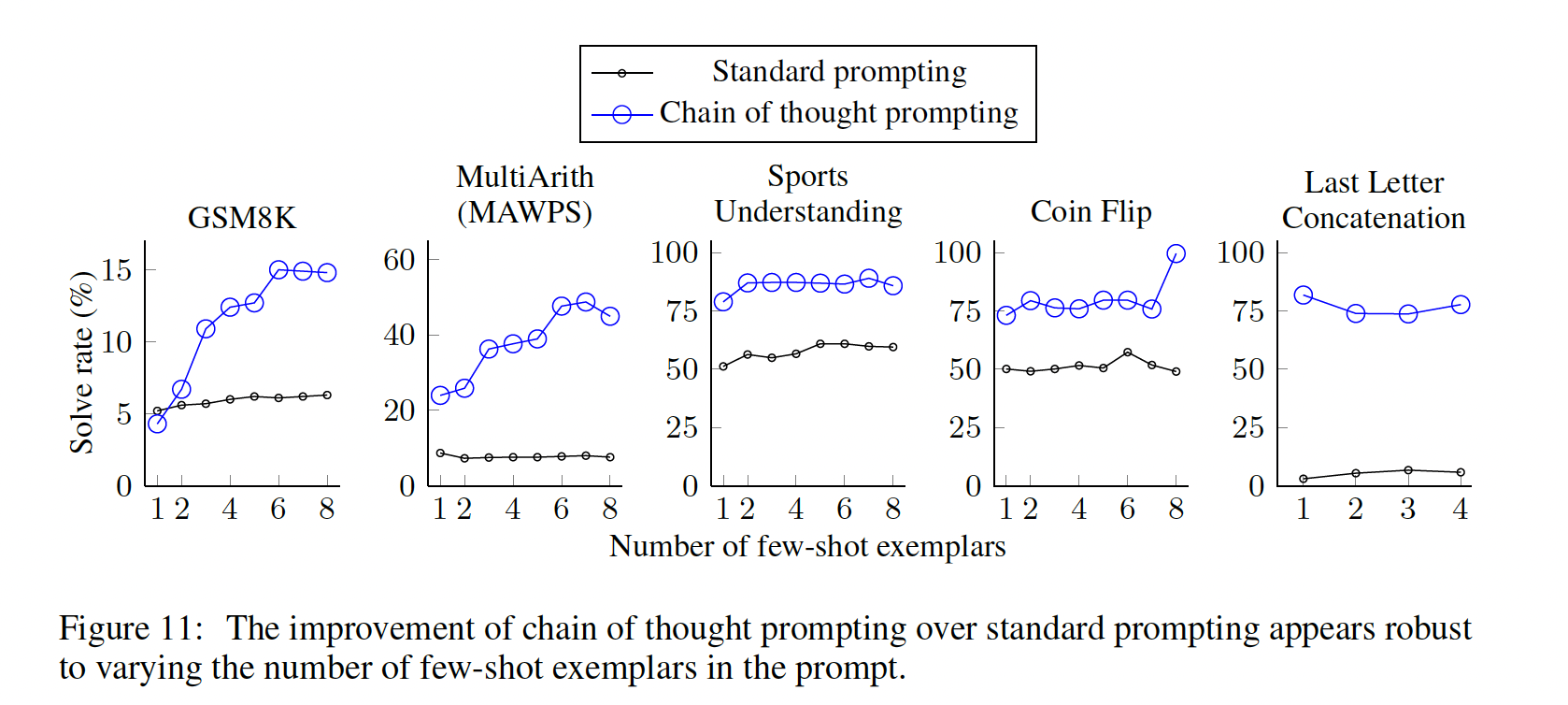
22.3 常识推理
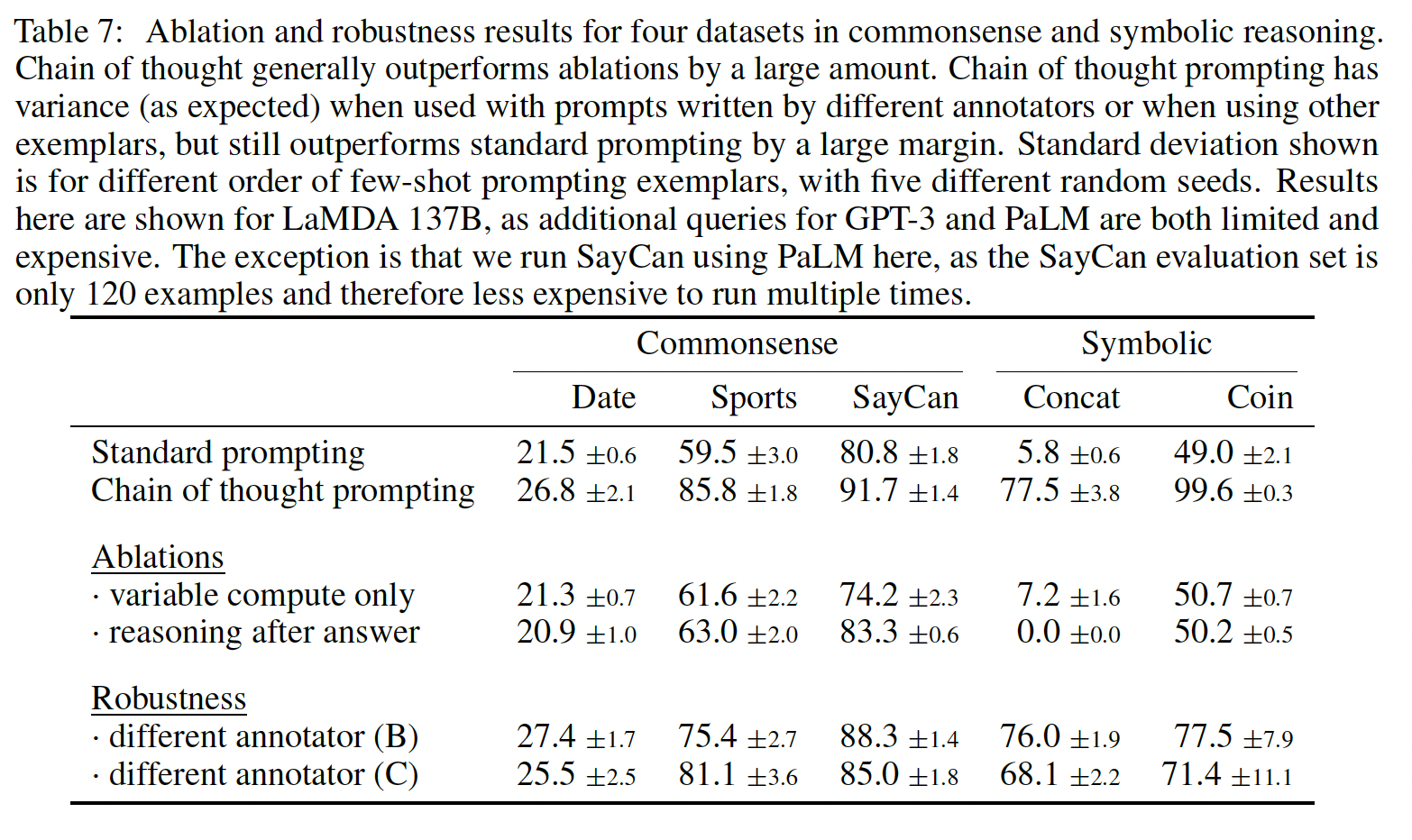
虽然
chain of thought特别适用于math word问题,但chain of thought的基于语言的性质实际上使其适用于一类广泛的常识推理问题,这些问题涉及在通用背景知识的假设下,对物理和人类交互进行推理。常识推理(commonsense reasoning)是与世界交互的关键,但目前的自然语言理解系统仍无法做到。benchmark:五个涵盖不同的常识推理类型的数据集。CSQA:流行的常识推理数据集,它提出了关于世界的常识性问题,涉及复杂的语义,通常需要先验知识。StrategyQA:要求模型推断出一个multi-hop strategy来回答问题。我们从
BIG-bench的工作中选择了两个专门的评价集:Date Understanding:涉及从给定的上下文中推断出一个日期。Sports Understanding:涉及确定一个与体育有关的句子是可信的还是不可信的。
SayCan:涉及将自然语言指令映射到离散集的(discrete set)的机器人动作序列中。
下图显示了所有数据集中带有
chain of thought annotations的例子。
Prompts:我们遵循与上一节相同的实验设置。对于
CSQA和StrategyQA,我们从训练集中随机选择了一些样本,并为它们手动组成了chains of thought,以作为few-shot exemplars。两个
BIG-bench任务没有训练集,所以我们在评估集中选择了开头的十个样本作为few-shot exemplars,并报告了评估集的其余部分的结果。对于
SayCan,我们使用了《Do as I can, not as I say: Grounding language in robotic affordances》使用的训练集中的六个样本,同时也使用了手动组成的chains of thought。
结果:下图展示了
PaLM的这些结果(LaMDA、GPT-3和不同模型比例的完整结果见Table 4)。可以看到:对于所有的任务,扩大模型的规模提高了
standard prompting的性能。chain-of-thought prompting导致了进一步的收益,对PaLM 540B似乎获得了最大的改进。通过chain-of-thought prompting,PaLM 540B取得了相对于baseline的强大性能,在StrategyQA方面超过了之前的SOTA(75.6% vs 69.4%),在sports understanding方面超过了无辅助的体育爱好者(95.4% vs 84%)。
这些结果表明,
chain-of-thought prompting也能提高需要一系列常识性推理能力的任务的表现(尽管注意到在CSQA获得了小的增益)。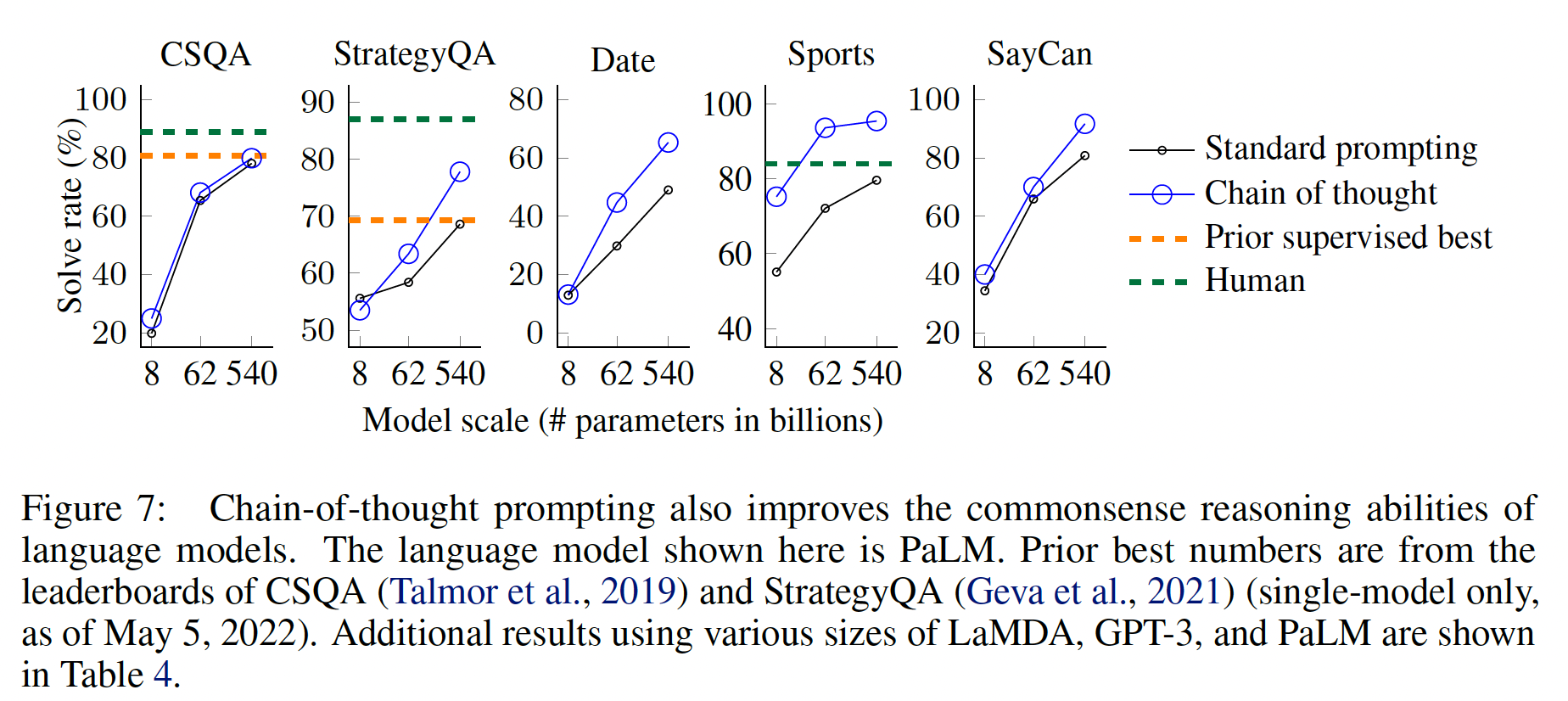
22.4 符号推理
我们最后的实验评估考虑了符号推理(
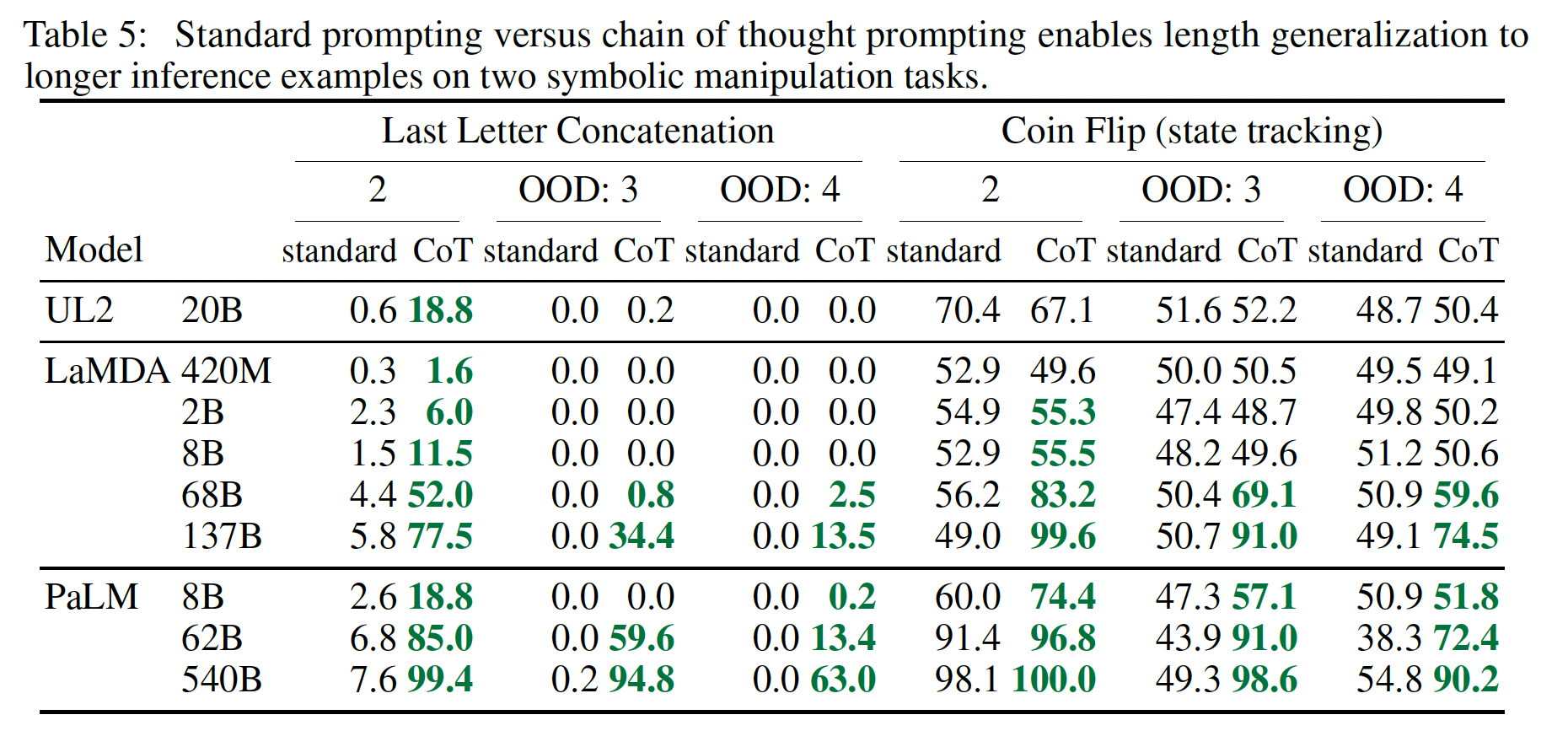
symbolic reasoning),这对人类来说很简单,但对语言模型来说有潜在的挑战性。我们表明,chain-of-thought prompting不仅使语言模型能够完成在standard prompting setting下具有挑战性的符号推理任务,而且还能促进length泛化到比见过的few-shot exemplars更长。任务:两个
toy任务:最后一个字母的拼接:这个任务要求模型将一个姓名中的最后一个字母连接起来(例如,
"Amy Brown" -> "yn")。我们通过随机组合姓名普查数据(https://namecensus.com/)中前一千名的名字和姓氏来产生全名。硬币翻转:这项任务要求模型回答,在人们投掷或不投掷硬币之后,硬币是否仍然是正面朝上(例如,
"A coin is heads up. Phoebe flips the coin. Osvaldo does not flip the coin. Is the coin still heads up?" -> "no")。
由于这些符号推理任务的构造是
well-defined,对于每个任务,我们都考虑了一个in-domain测试集,其中样本的step数与training/few-shot exemplars相同;还有一个out-of-domain: OOD测试集,其中评估的样本比training/few-shot exemplars中的步骤更多。我们的实验设置使用与前两节相同的方法和模型。我们再次为每项任务的
few-shot exemplars手动组成chains of thought,如Figure 3所示。结果:
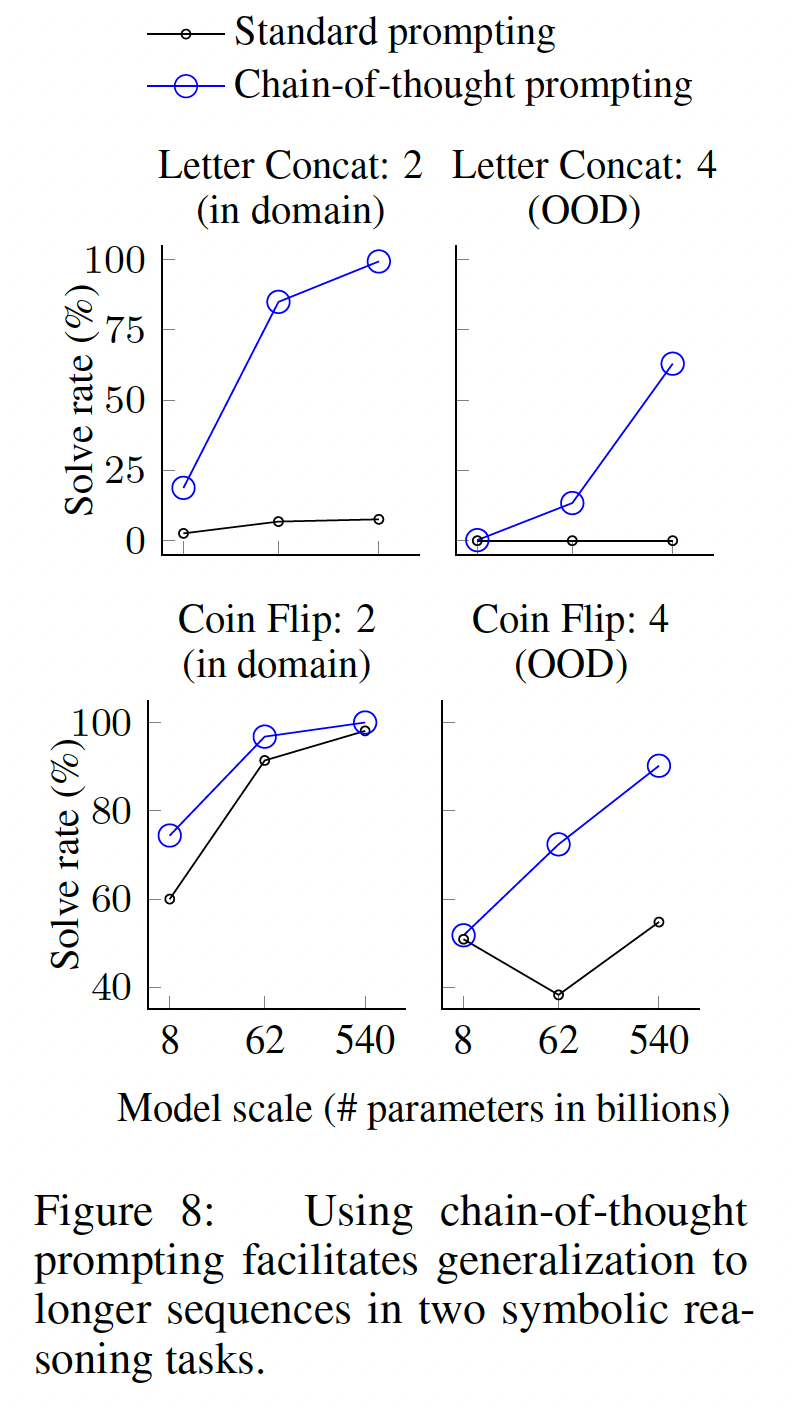
PaLM的这些in-domain和OOD评估结果见下图所示,LaMDA的结果见Table 5。对于
PaLM 540B,chain-of-thought prompting导致了几乎100%的解决率(注意,standard prompting已经解决了PaLM 540的硬币翻转问题,尽管LaMDA 137B没有)。请注意,这些
in-domain评估是 "toy任务",因为完美的解决结构已经由few-shot exemplars中的chains-of-thought提供;模型所要做的就是用测试期间的样本中的新符号重复同样的步骤。然而,小模型还是失败了:只有在
100B的模型参数规模下,才会出现对这三个任务的unseen symbols进行抽象操作的能力。至于
OOD评估,standard prompting对这两项任务都失败了。通过chain-of-thought prompting,语言模型实现了向上的scaling曲线(尽管性能低于in-domain setting)。因此,chain-of-thought prompting促进了长度泛化,对于足够规模的语言模型。
22.5 讨论
我们已经探索了
chain-of-thought prompting作为一种简单的机制来激发大型语言模型中的多步骤的推理行为。我们首先看到,
chain-of-thought prompting在算术推理上有很大程度的改进,产生的改进比消融实验强得多,而且对不同的标注员、范例、以及语言模型都很鲁棒。接下来,关于常识推理的实验强调了
chain-of-thought reasoning的语言性质如何使其普遍适用。最后,我们表明,对于符号推理,
chain-of-thought prompting有助于OOD泛化到更长的序列长度。
在所有的实验中,
chain-of-thought reasoning只是通过提示一个现成的语言模型来引起的。在撰写本文的过程中,没有对语言模型进行微调。作为模型
scale的结果,chain-of-thought reasoning的涌现一直是一个普遍的主题。对于许多推理任务来说,standard prompting有一个平坦的比例曲线,而chain-of-thought prompting会导致scaling曲线急剧增加。chain-of-thought prompting似乎扩大了大型语言模型可以成功执行的任务集合:换句话说,我们的工作强调了standard prompting只为大型语言模型的能力提供了一个下限。这一观察很可能提出了更多的问题,例如,随着模型规模的进一步扩大,我们还能期望推理能力有多大的提高?哪些其他的prompting方法可以扩大语言模型所能解决的任务范围?局限性:
我们首先限定,尽管
chain-of-thought模仿了人类推理者的思维过程,但这并没有回答神经网络是否真的在 "推理",我们将其作为一个开放性问题。第二,尽管在
few-shot setting下,手动地agument具有chains of thought的样例的成本很低;但在微调的场景下,这种标注成本可能是令人望而却步的(尽管这有可能通过synthetic data generation、或者zero-shot generalization来克服)。第三,不能保证推理路径的正确性。改进语言模型的
factual generation是未来工作的一个开放方向。最后,
chain-of-thought reasoning的涌现仅仅发生在大模型中,使得它在现实世界的应用中serve成本很高。进一步的研究可以探索如何在较小的模型中诱发推理。
二十三、Self-Consistency COT[2022]
论文:
《Self-Consistency Improves Chain of Thought Reasoning in Language Models》
尽管语言模型在一系列
NLP任务中表现出了显著的成功,但它们的推理能力往往受到限制,而这个限制不能仅仅通过增加模型规模来克服。为了解决这一不足,《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》提出了chain-of-thought prompting,即提示语言模型生成一系列短句,模仿一个人在解决一个任务时可能采用的推理过程。例如,给定问题: "如果停车场有3辆车,还有2辆车到达,那么停车场有多少辆车?"。语言模型不是直接回答"5",而是被提示用整个chain-of-thought来回答: "停车场里已经有3辆车了。还有2辆到达。现在有3+2=5辆车。答案是5"。据观察,在各种多步骤推理任务中,chain-of-thought prompting能显著提高模型性能。在本文中,我们引入了一种新的解码策略,称为自一致性(
self-consistency),以取代chain-of-thought prompting中使用的贪婪解码策略。self-consistency策略进一步地大幅度提高了语言模型的推理性能。自一致性利用了这样的直觉:复杂的推理任务通常有多条推理路径可以达到正确答案(《Individual differences in reasoning: Implications for the rationality debate?》)。一个问题越是需要深思熟虑和分析(《Intuition and reasoning: A dual-process perspective》),就有越多样化的推理路径来找到答案。下图用一个例子说明了
self-consistency方法。我们首先用chain-of-thought prompting来提示语言模型,然后不是贪婪地解码最佳推理路径,而是提出一个"sample-and-marginalize"的解码程序:我们首先从语言模型的解码器中采样,以产生一组不同的推理路径。
每个推理路径可能导致一个不同的最终答案,因此我们通过边际化(
marginalizing)所采样到的推理路径,从而在final answer set中找到最一致的答案从而作为最佳答案。
这样的方法类似于人类的经验,即如果多种不同的思考方式导致了相同的答案,那么人们对最终答案的正确性就有更大的信心。与其他解码方法相比,
self-consistency避免了困扰贪婪解码的重复性和局部最优性等问题,同时缓解了单个sampled generation的随机性。这种方法要求答案是确定的、唯一的。对于开放式的问题(如,抽取一篇文章的摘要),那么无法应用这个方法。
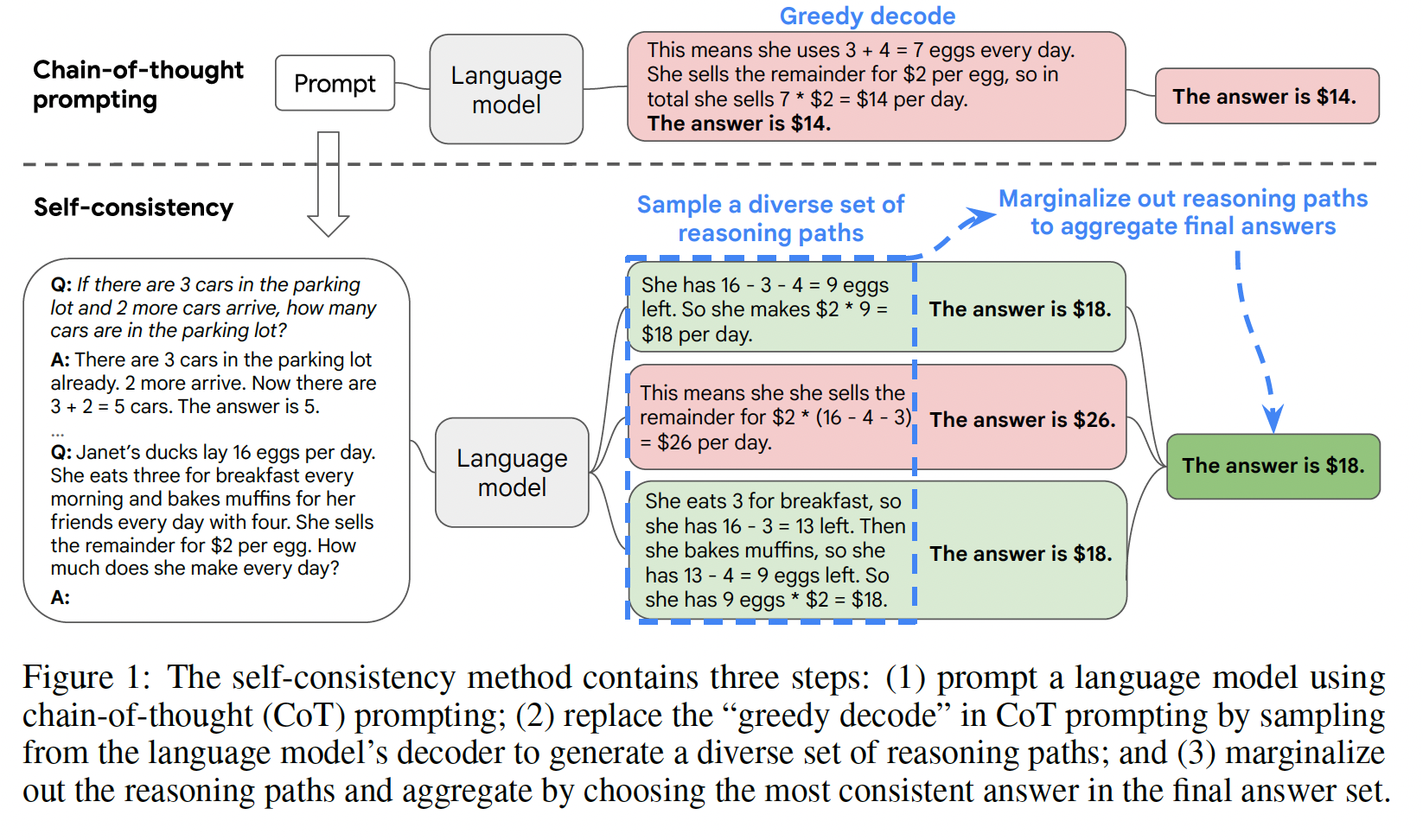
self-consistency比之前的方法简单得多,这些方法要么训练一个额外的verifier(《Training verifiers to solve math word problems》),要么在给定额外的人类标注的情况下训练一个re-ranker以提高generation的质量(《Lamda: Language models for dialog applications》)。相反,self-consistency是完全无监督的,与pre-trained language model一起现成工作,不需要额外的人类标注,并避免任何额外的训练、辅助模型或微调。self-consistency也不同于典型的ensemble方法(在ensemble方法中,多个模型被训练,并且每个模型的输出被汇总起来),它更像一个"self-ensemble",在单个的语言模型之上工作。我们在广泛的算术推理任务和常识推理任务上对四种不同规模的语言模型评估了
self-consistency:公共的UL2-20B、GPT-3-175B、LaMDA-137B、PaLM-540B。在所有四个语言模型上,self-consistency在所有任务中都比chain-of-thought prompting有明显的改善。具体而言,当与PaLM-540B或GPT-3一起使用时,self-consistency在算术推理任务中达到了SOTA,包括GSM8K(+17.9%的绝对准确率提升)、SVAMP(+11.0%的绝对准确率提升)、AQuA(+12.2%的绝对准确率提升),以及诸如StrategyQA(+6.4%的绝对准确率提升)和ARCchallenge(+3.9%的绝对准确率提升)等常识推理任务。在额外的实验中,我们显示self-consistency可以有力地提高NLP任务的性能,在这些任务中,与standard prompting相比,添加chain-of-thought可能会损害性能(《The unreliability of explanations in few-shot prompting for textual reasoning》)。我们还表明,self-consistency明显优于sample-and-rank、beam search、ensemble-based方法,并且对采样策略和imperfect prompts具有鲁棒性。相关工作:
语言模型的
reasoning:众所周知,语言模型在推理任务中很吃力,如算术推理、逻辑推理和常识推理(《Intuition and reasoning: A dual-process perspective》)。之前的工作主要集中在改善推理的专用方法上。与之前的工作相比,self-consistency适用于广泛的推理任务,不需要任何额外的监督或微调,同时还能大幅提高《Chain of thought prompting elicits reasoning in large language models》提出的chain-of-thought prompting方法的性能。语言模型中的
sampling and re-ranking:文献中提出了多种语言模型的解码策略,例如
temperature sampling、top-k sampling、nucleus sampling、minimum Bayes risk decoding以及typical decoding。其他的一些工作试图显式地促进解码过程中的多样性。re-ranking是提高语言模型的generation quality的另一种常见方法。《Lamda: Language models for dialog applications》收集额外的人类标注来训练一个re-ranker用于response filtering。《Training verifiers to solve math word problems》训练一个"verifier"来re-rank所生成的解决方案。与仅仅微调语言模型相比,这大大提高了数学任务的求解率。《Measuring and improving consistency in pretrained language models》通过用额外的consistency loss来扩展预训练,提高了factual knowledge extraction的一致性。
所有这些方法都需要训练一个额外的
re-ranker、或收集额外的人类标注,而self-consistency不需要额外的训练、微调、或额外的数据收集。
抽取
reasoning path:以前的一些工作考虑了特定的方法从而用于识别推理路径(reasoning path),例如:构建
semantic graph(《Exploiting reasoning chains for multi-hop science question answering》)。学习
RNN来检索维基百科图上的推理路径(《Learning to retrieve reasoning paths over wikipedia graph for question answering》)。用人类标注的推理路径对数学问题进行微调(
《Training verifiers to solve math word problems》)。或者用基于启发式的伪推理路径训练一个
extractor(《Multi-hop question answering via reasoning chains》)。
最近,推理过程中多样性的重要性已经被注意到,但只是通过
task-specific training来利用,或者通过在所提取的推理路径上应用额外QA模型(《Multi-hop question answering via reasoning chains》),或者通过在commonsense knowledge graph中引入潜在变量(《Diversifying content generation for commonsense reasoning with mixture of knowledge graph experts》)。与这些方法相比,
self-consistency要简单得多,不需要额外的训练。我们提出的方法只是将推理路径的generation与解码器的采样结合起来,利用聚合来找到最一致的答案,无需额外的模块。语言模型的
consistency:之前的一些工作表明,语言模型在对话(《Towards a human-like open-domain chatbot》)、explanation generation(《Make up your mind! adversarial generation of inconsistent natural language explanations》)和factual knowledge提取(《Measuring and improving consistency in pretrained language models》)中会出现不一致的问题。《Consistency of a recurrent language model with respect to incomplete decoding》用"consistency"来指在recurrent language model中生成一个无限长的序列。《Improving coherence and consistency in neural sequence models with dual-system, neuro-symbolic reasoning》通过增加一个受System-2启发的逻辑推理模块,改善了System 1模型的样本的逻辑一致性。
在本文中,我们关注的是一个稍微不同的
"consistency"概念,即利用不同推理路径之间的答案一致性来提高准确率。
23.1 多样化的推理推荐之间的 Self-Consistency
人类的一个突出方面是,人们的思维方式不同。我们很自然地认为,在需要深思熟虑的任务中,很可能有几种方法来解决这个问题。我们提出,这样的过程可以通过语言模型解码器的
sampling在语言模型中进行模拟。例如,如Figure 1所示,一个模型可以对一个数学问题产生几个貌似合理的回答,而这些回答都能得出相同的正确答案(第一个输出和第三个输出)。由于语言模型不是完美的reasoner,模型也可能产生一个不正确的推理路径、或在其中一个推理步骤中犯错(例如在第二个输出),但这种解决方案不太可能得出相同的答案。也就是说,我们假设正确的推理过程(即使它们是多样化的),往往比不正确的推理过程在最终答案上有更大的一致性。我们通过提出以下
self-consistency方法来利用这一直觉:首先,一个语言模型通过一组人工编写的
chain-of-thought exemplars来被提示。接下来,我们从语言模型的解码器中采样一组候选输出,生成一组多样化的候选推理路径。
self-consistency与大多数现有的采样算法兼容,包括temperature sampling、top-k sampling、以及nucleus sampling。最后,我们通过
marginalizing out被抽样的推理路径,并从generated answers中选择最一致的答案来汇总答案。
更具体而言:假设被生成的答案
prompt和一个问题,self-consistency引入一个额外的潜在变量tokens序列,然后组合得到作为一个例子,考虑
Figure 1中的第三个输出:前几句"She eats 3 for breakfast ... So she has 9 eggs * $2 = $18."构成了"The answer is $18")中的答案18被解析为self-consistency通过对majority vote),即在下表中,我们展示了通过使用不同的答案聚合策略对一组推理任务的
test accuracy。除了多数投票,我们还可以在汇总答案时用(prompt, question)的条件下模型生成GPT-3),即:其中:
token为条件的情况下生成第tokentokens的总数。在下表中,我们显示,采取
"unweighted sum",即直接对"normalized weighted sum"的结果非常相似。我们仔细观察了模型的输出概率,发现这是因为对于每个generations视为"similarly likely"。此外,当汇总答案时,下表中的结果显示,与未归一化的方法相比,"归一化"的加权和产生了更高的准确率。为了完整起见,在下表中我们还报告了采取 "加权平均" 的结果,即每个
下图中没有给出
Unweighted avg,因为Unweighted avg就是等价于Unweighted sum。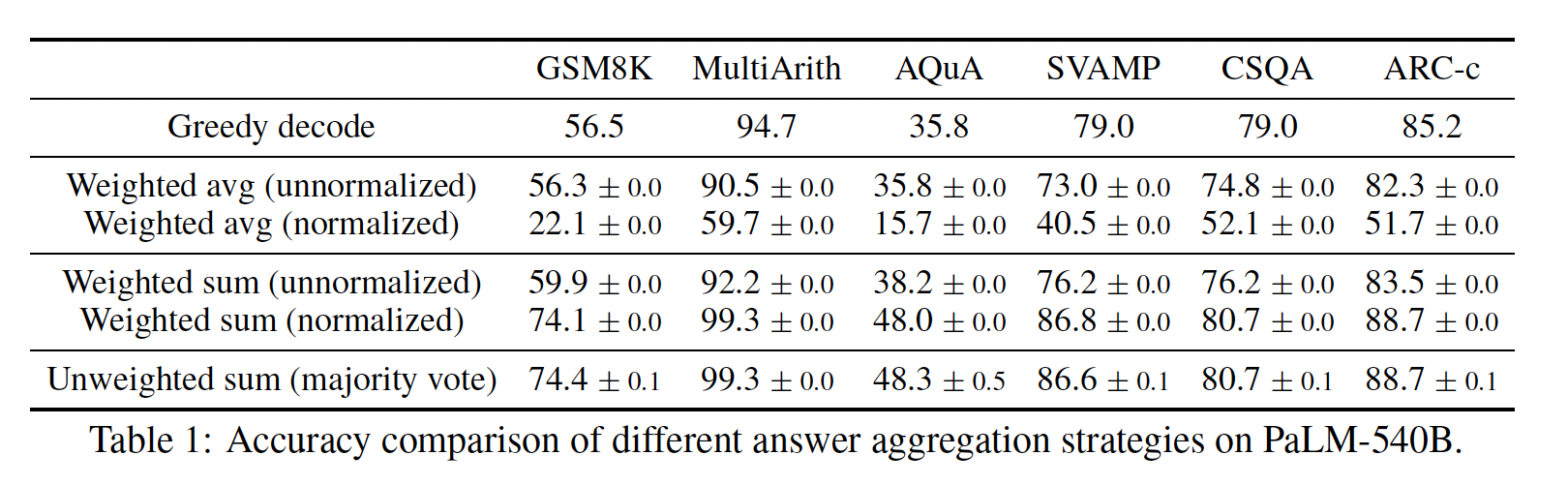
self-consistency在开放式文本生成、以及有固定答案的最佳文本生成之间探索了一个有趣的空间。推理任务通常有固定的答案,这就是为什么研究人员普遍考虑贪婪的解码方法。然而,我们发现,即使预期的答案是固定的,在推理过程中引入多样性也是非常有益的;因此,我们利用采样来实现这一目标。应该注意的是,self-consistency只适用于最终答案来自固定答案集合的问题,但原则上,如果能在多个generations之间定义一个良好的一致性指标(例如,两个答案是否一致或相互矛盾),这种方法可以扩展到开放式文本生成问题。
23.2 实验
任务和数据集:考虑如下的
reasoning benchmark:算术推理:
Math Word Problem Repository(包括AddSub, MultiArith, ASDiv)、AQUA-RAT、GSM8K、SVAMP。常识推理:
CommonsenseQA、StrategyQA、AI2 Reasoning Challenge: ARC。符号推理:
last letter concatenation:,例如,输入是"Elon Musk"、输出应该是"nk"。来自
《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》的Coinflip:一枚硬币是正面朝上的,经过若干次翻转之后,硬币是否还是正面朝上?
语言模型和
prompts:UL2:一个具有20B参数的encoder-decoder模型,在a mixture of denoisers上训练。UL2是完全开源的,在zero-shot SuperGLUE上具有比GPT-3类似的或更好的性能,只有20B参数因此更便于计算。GPT-3:有175B参数。我们使用Codex系列中的两个公共引擎code-davinci-001和code-davinci-002来帮助reproducibility。LaMDA-137B:一个稠密的从左到右的、decoder-only的语言模型,有137B参数,在网络文档、对话数据、以及维基百科的混合体上进行预训练。PaLM-540B:一个稠密的从左到右的decoder-only语言模型,有540B参数,在一个由780B tokens组成的高质量语料库上进行了预训练,其中包括过滤后的网页、书籍、维基百科、新闻文章、源代码、以及社交媒体对话。
我们在
few-shot setting下进行所有的实验,没有训练或微调语言模型。为了进行公平的比较,我们使用了与《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》相同的prompts:对于所有的算术推理任务,我们使用相同的
8个手动编写的exemplars组成的集合。对于每个常识推理任务,我们从训练集中随机选择
4-7个样例,并使用手动编写的chain-of-thought prompts。
所有
prompts的全部细节,如下表所示。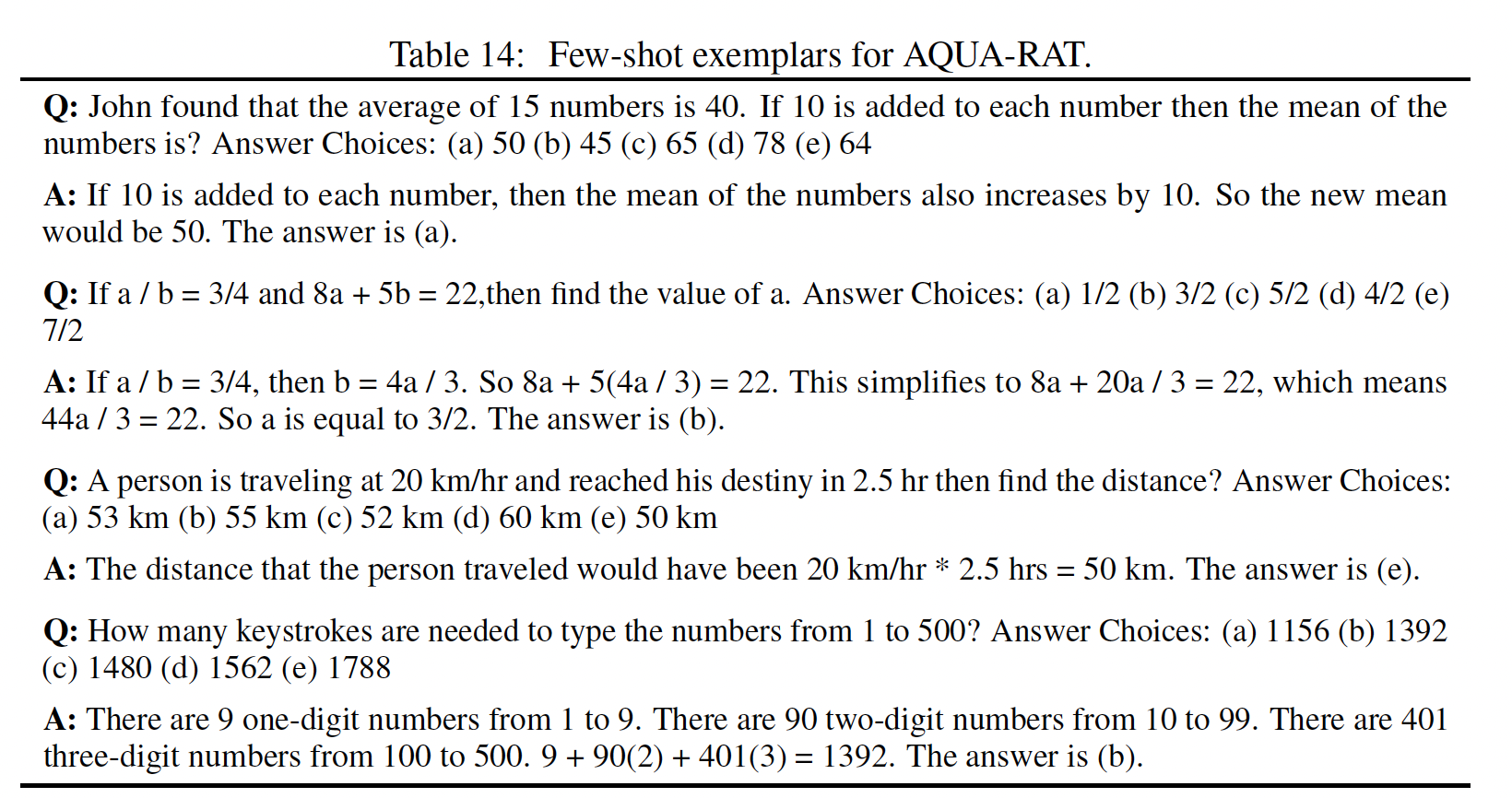





采样方案:为了采样不同的推理路径,我们采用了与
GPT-3、《The curious case of neural text degeneration》建议的类似设置,用于open-text generation。具体而言:对于
UL2-20B和LaMDA-137B,我们应用了T=0.5的temperature sampling,并在概率最高的top-k (k=40) tokens处截断。对于
PaLM-540B,我们应用了T=0.7, k=40。而对于
GPT-3,我们使用T=0.7,没有top-k截断。
我们在后续章节中提供了一个消融研究,以表明
self-consistency对采样策略和超参数通常是鲁棒的。
23.2.1 实验结果
我们报告了
10次运行中的self-consistency的结果,在每次运行中,我们从解码器的中独立采样了40个输出。我们比较的baseline是带有贪婪解码的chain-of-thought prompting,被称为CoT-prompting。算术推理:如下表所示,
self-consistency在所有四个语言模型中的算术推理性能都比chain-of-thought prompting有明显提高。更令人惊讶的是,当语言模型的规模增加时,收益变得更加显著,例如,我们看到UL2-20B的绝对准确率提高了+3% ~ 6%,但LaMDA- 137B和GPT-3则提高了+9% ~ 23%。对于在大多数任务上已经取得高准确率的大型模型(如
GPT-3, PaLM-540B),在AQuA和GSM8K等任务上,self-consistency仍然贡献了显著的额外收益(绝对准确率+12% ~ 18%)。通过self-consistency,我们在几乎所有的任务上都取得了SOTA结果:self-consistency是无监督的、且是任务无关的,这些结果与现有的方法(其中现有的方法需要task-specific training、或者需要用成千上万个样本进行微调)相比更有优势。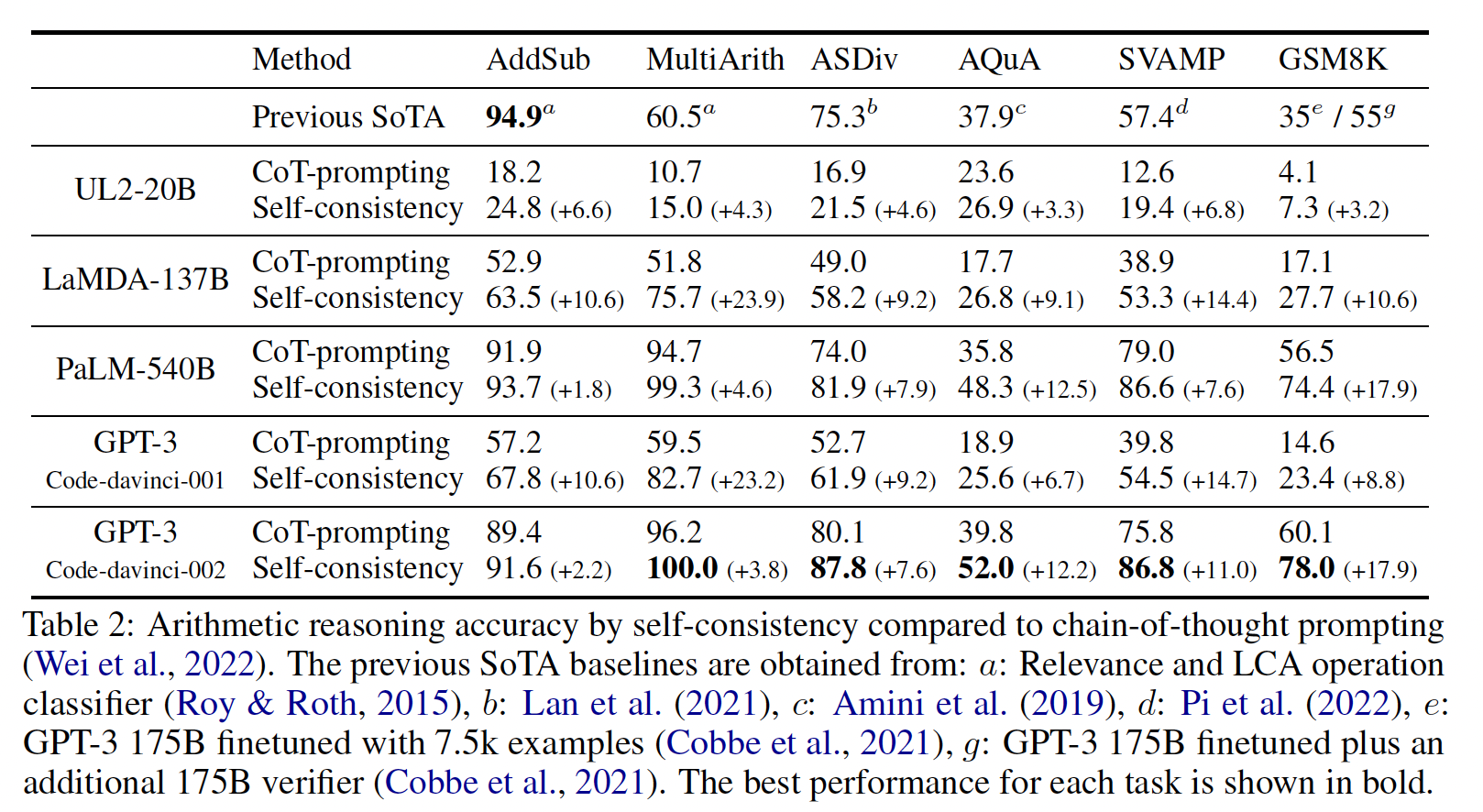
常识推理和符号推理:
Table 3显示了常识推理和符号推理任务的结果。同样,self-consistency在所有四个语言模型中都产生了很大的收益,并在6个任务中的5个任务中获得了SOTA结果。对于符号推理,我们测试了
out-of-distribution:OOD setting,其中input prompt包含2-letters或2-flips的例子,但我们测试了4-letters和4-flips的例子(这种设置更具挑战性,因为PaLM-540B或GPT-3已经可以实现完美的·in-distribution准确率)。在这种具有挑战性的OOD setting中,与具有足够模型规模的CoT-prompting相比,self-consistency的收益仍然相当可观。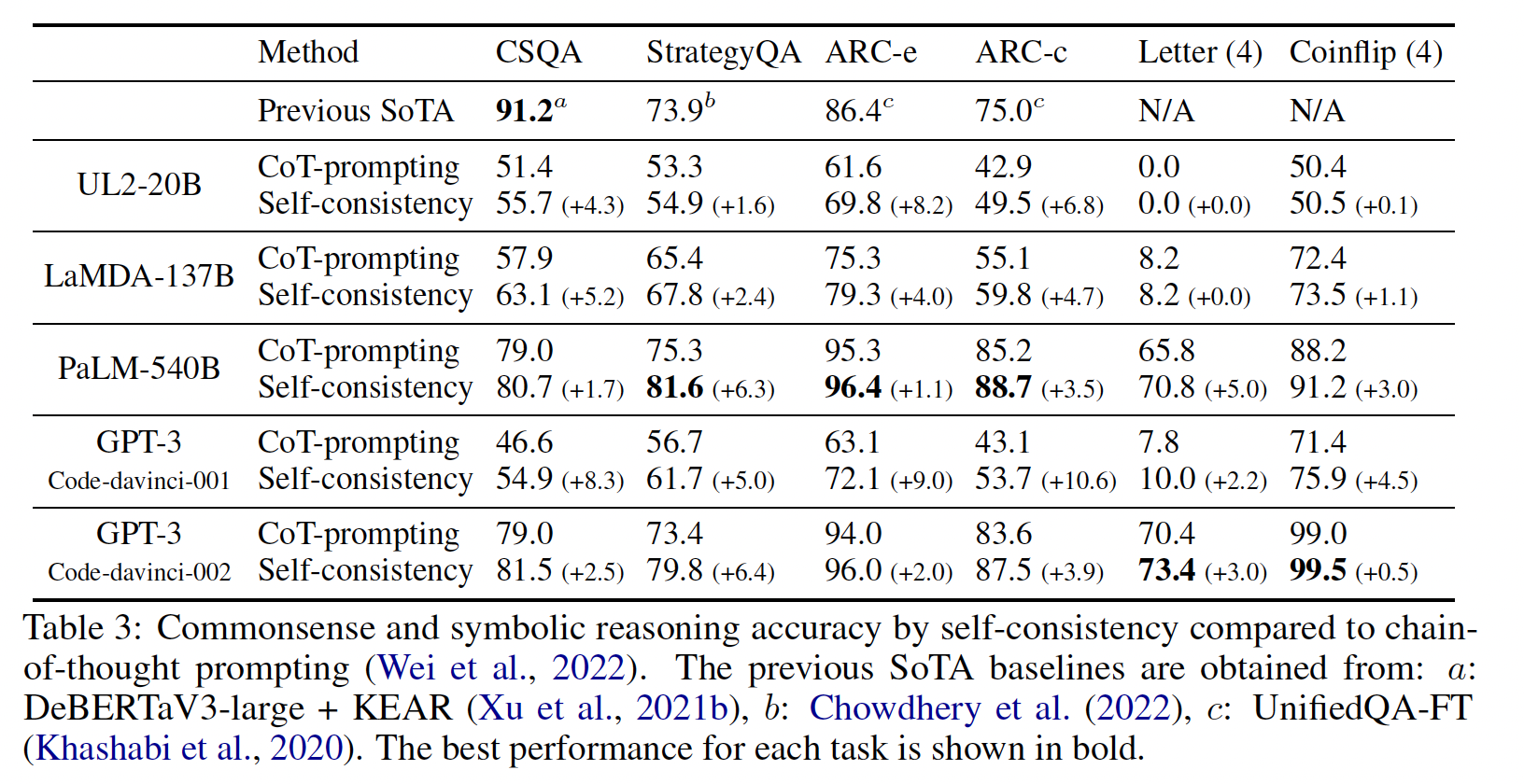
为了显示所采样到的推理路径数量的影响,我们在下图中绘制了关于不同
sampled paths的数量(1, 5, 10, 20, 40)的准确率(10次运行的均值和标准差)。结果显示,采样更多数量的推理路径(如40个)会带来持续更好的性能,进一步强调了在推理路径中引入多样性的重要性。在Table 4中,我们用两个任务中的几个样本表明,与贪婪解码相比,self-consistency产生了一个更丰富的推理路径集合。然而,采样更多的推理路径,需要花费的成本也更高:
40个推理路径带来40倍的推理成本。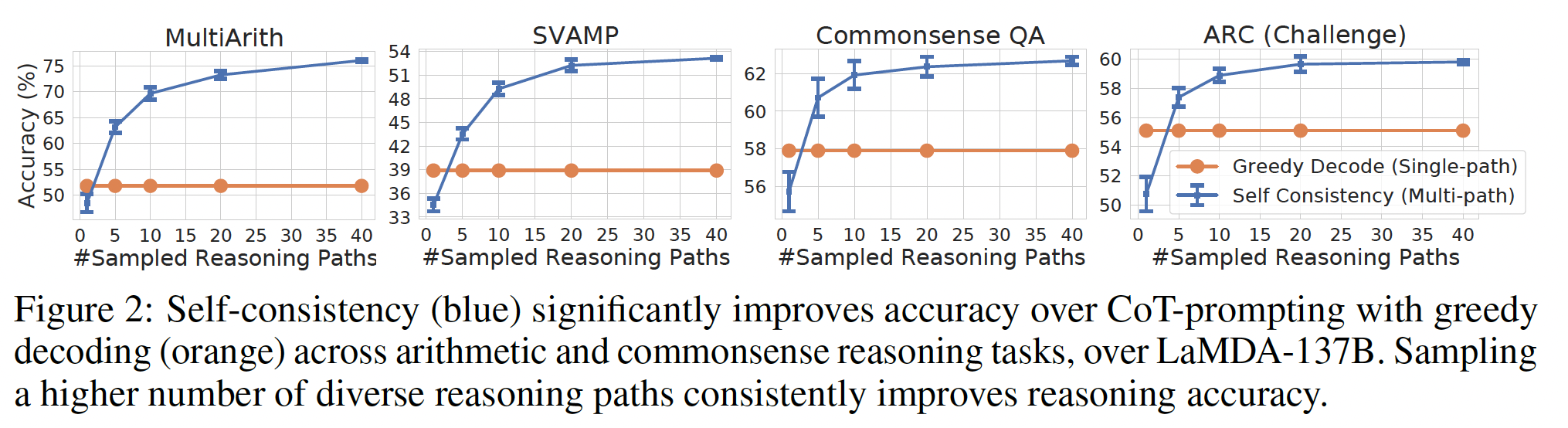

23.2.2 当 Chain-Of-Thought 损害性能时,Self-Consistency 会有帮助
《The unreliability of explanations in few-shot prompting for textual reasoning》表明:在few-shot in-context learning中,与standard prompting相比,有时chain-of-thought prompting可能会损害性能。在这里,我们在一组常见的NLP任务中利用self-consistency进行了一项研究,看看它是否可以帮助弥补这个gap。这些任务包括:闭卷问答任务:
BoolQ、HotpotQA。自然语言推理任务:
e-SNLI、ANLI、RTE。
PaLM-540B上的结果如下表所示。对于一些任务(如ANLI-R1、e-SNLI、RTE),与standard prompting相比,添加chain-of-thought确实会损害性能,但self-consistency能够鲁棒地提升性能并超过standard prompting,使其成为few-shot in-context learning中添加rationales的可靠方法从而用于常见的NLP任务。
23.2.3 和其它现有方法的比较
我们进行了一系列额外的研究,并表明
self-consistency明显优于现有的方法,包括sample-and-rank、beam search和ensemble-based的方法。与
Sample-and-Rank方法的比较:一种常用的提高generation quality的方法是sample-and-rank,即从解码器中采样多个序列,然后根据每个序列的对数概率进行排序(《Towards a human-like open-domain chatbot》)。我们在GPT-3 code-davinci-001上比较了self-consistency与sample-and-rank,方法是从解码器中采样出与self-consistency相同数量的序列,并从排名靠前的序列中获取最终答案。结果如下图所示。虽然sample-and-rank通过额外的sampled sequences和ranking,确实提高了准确率,但与self-consistency相比,其增益要小得多。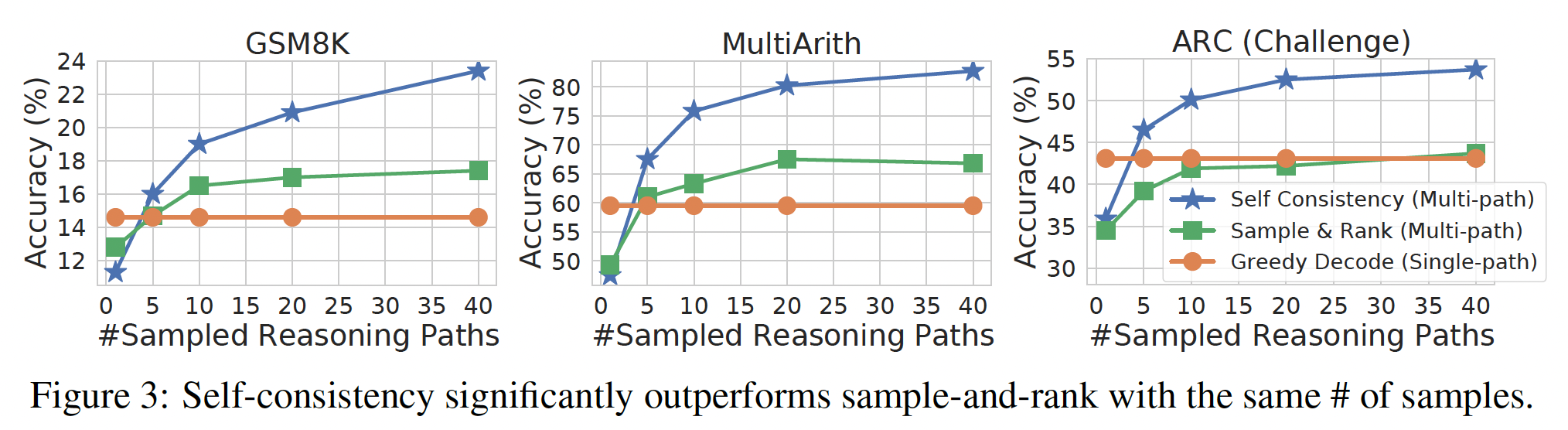
与
Beam Search的比较:在下表中,我们在UL2-20B上将self-consistency与beam search decoding进行了比较。为了进行公平的比较,我们报告了在相同数量的beams和推理路径下的准确率。在这两项任务中,self-consistency都明显优于beam search。注意self-consistency也可以采用beam search来解码每个推理路径(结果显示为"Self-consistency using beam search"),但其性能比self-consistency with sampling要更差。原因是beam search产生的输出的多样性较低(《Mutual information and diverse decoding improve neural machine translation》);而在self-consistency中,推理路径的多样性是取得更好性能的关键。
与
Ensemble-based方法的比较:我们进一步将self-consistency与ensemble-based方法进行比较,从而用于few-shot learning。具体而言,我们考虑通过以下方式进行ensembling:prompt order permutation:我们将prompt中的示例随机排列40次,以缓解模型对prompt order的敏感性。multiple sets of prompts(《Making pre-trained language models better few-shot learners》):我们手动编写3组不同的prompts。
我们在这两种方法中对贪婪解码的答案采取多数投票,作为一个
ensemble。下表显示,与self-consistency相比,现有的ensemble-based方法取得的收益要小得多。此外,请注意,
self-consistency不同于典型的model-ensemble方法:在
model-ensemble方法中,多个模型被训练,它们的输出被汇总。self-consistency的作用更像是在单个语言模型之上的"self-ensemble"。
我们在附录
A.1.3中额外展示了ensembling multiple models的结果,其中model-ensembles的表现比self-consistency差很多。理论上讲,多个
prompts也能提供多样性,同一组prompts的不同排列也能提供多样性。读者猜测:除了多样性之外,还需要强调一致性。Self-Consistency是在同一个模型的同一组prompts的同一个排列上进行的,因此一致性更好。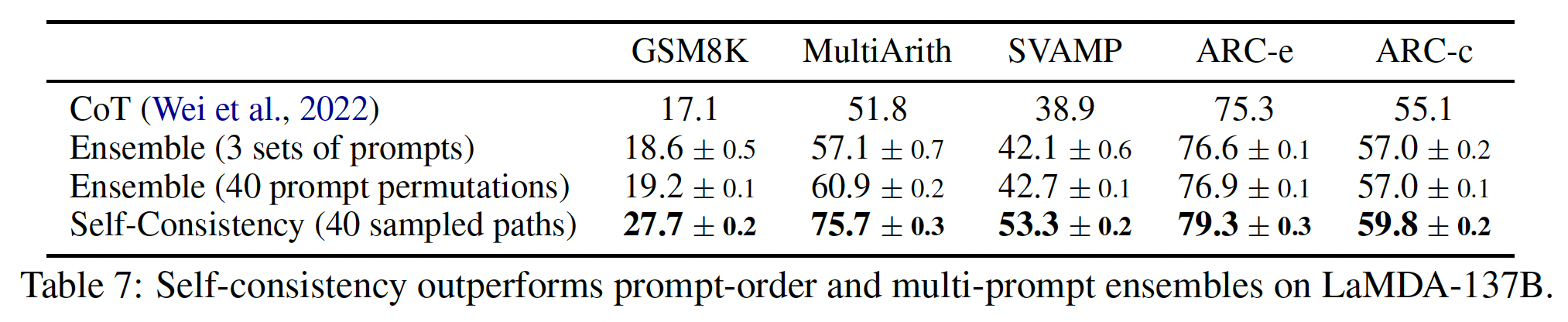
2.2.4 额外的研究
我们进行了一些额外的实验来分析
self-consistency方法的不同方面,包括它对采样策略和超参数的鲁棒性,以及它在imperfect prompts和non-natural-language推理路径下是如何工作的。Self-Consistency对采样策略和scaling的鲁棒性:在PaLM-540B上,我们通过改变temperature sampling中的top-k sampling中的nucleus sampling中的self-consistency对采样策略和超参数是鲁棒的,如左图所示。右图显示,
self-consistency有力地提高了LaMDA-137B模型系列在所有规模上的性能。由于某些能力(如算术)只有在模型达到足够的规模时才会出现,因此较小的模型的增益相对较低。这里面的温度仍然较小,使得输出分布与均匀分布较远。如果温度超参数设置很大,那么输出分布就是均匀分布,最终结果很可能较差。

Self-Consistency改善了Imperfect Prompts的鲁棒性:对于使用人工构建prompts的few-shot learning,人类标注员在创建prompts时有时会犯一些小错误。我们进一步研究了self-consistency是否有助于提高语言模型对imperfect prompts的鲁棒性。我们在下表中显示了结果:虽然imperfect prompts降低了贪婪解码的准确率(17.1 -> 14.9),但self-consistency可以填补gap并有力地改善结果。此外,我们发现
consistency(就与final aggregated answer一致的decodes的百分比而言)与准确率高度相关(如下图所示,在GSM8K上)。这表明,人们可以使用consistency作为一个指标来估计模型的置信度。即,self-consistency赋予了模型 "知道自己不知道" 的某种能力。即,如果多个采样之间的一致性较低,那么可以认为模型结果的置信度较低。
这个可以推广到
generation任务:如果多个generation结果之间的相似度较低,那么置信度较低。相似度可以通过单词重叠的比例来衡量。
Self-Consistency适用于Non-Natural-Language推理路径、以及Zero-shot CoT:我们还测试了self-consistency概念对其他形式的intermediate reasoning的通用性,如方程式:例如,从"There are 3 cars in the parking lot already. 2 more arrive. Now there are 3 + 2 = 5 cars.", 到"3+2=5")。结果显示在
Table 8中("Prompt with equations"):self-consistency仍然通过生成中间方程来提高准确性;然而,与生成自然语言的推理路径相比,收益要小一些,因为方程要短得多,在解码过程中产生多样性的机会也少。此外,我们测试了
self-consistency with zero-shot chain-of-thought(《Large language models are zero-shot reasoners》),并显示self-consistency对zero-shot CoT也有效,并显著提高了结果(+26.2%)。
23.3 讨论
self-consistency的一个局限性是它会产生更多的计算成本。在实践中,人们可以尝试少量的路径(如5个或10个)作为起点,以实现大部分的收益,同时不产生太多的成本,因为在大多数情况下,性能很快就饱和了(Figure 2)。作为未来工作的一部分,人们可以使用
self-consistency来产生更好的监督数据来微调模型,这样在微调之后,模型单次推理运行中就可以给出更准确的预测。此外,我们观察到,语言模型有时会产生不正确或无意义的推理路径(例如,
Table 4中的StrategyQA例子,两个population number并不完全正确),需要进一步的工作来更好地支持模型的rationale generation。
二十四、Zero-Shot CoT[2022]
论文:
《Large Language Models are Zero-Shot Reasoners》
scaling up语言模型的规模是最近自然语言处理的革命的关键因素。大型语言模型的成功往往归功于few-shot learning或zero-shot learning。它可以通过简单地对少数样本(few-shot learning)、或描述任务的指令(zero-shot learning)作为模型的条件输入来解决各种任务。调节语言模型的方法被称为"prompting"(《Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing》)。手动地或自动地设计prompts已成为NLP的一个热门话题。与
LLM在直观的和单步的system-1任务中的出色表现相比,其中具有task-specific few-shot/zero-shot prompting,即使是100B或更多参数规模的语言模型在需要缓慢和多步推理的system-2任务中也曾陷入困境(《Scaling language models: Methods, analysis & insights from training gopher》)。为了解决这一缺陷,COT、Self-Consistency COT提出了chain of thought: COT prompting,其中COT prompting为LLM提供step-by-step reasoning examples,而不是标准的question and answer examples(如下图Figure 1(a)所示)。这样的chain of thought demonstrations有助于模型生成一个推理路径(reasoning path),该推理路径将复杂的推理分解成多个简单的步骤。值得注意的是,有了CoT,reasoning性能就能更好地满足scaling laws,并随着语言模型的大小而跳跃式增长。例如,当与540B参数的PaLM模型相结合时,在几个benchmark reasoning tasks中,chain of thought prompting比标准的few-shot prompting明显提高了性能,例如在GSM8K从17.9% -> 58.1%。CoT prompting的成功,以及其他许多task-specific prompting的工作,经常被归因于LLM的few-shot learning能力。然而我们表明:LLM是优雅的zero-shot reasoner,通过添加一个简单的prompt,"Let's think step by step",从而在回答每个问题之前促进step-by-step thinking(如Figure 1 (d)所示)。尽管简单,我们的Zero-shot-CoT还是成功地以zero-shot的方式生成了一条合理的推理路径,并在标准的zero-shot方法失败的情况下达到了正确答案。重要的是,我们的Zero-shot-CoT是通用的和任务无关的,不像之前的task-specific prompt engineering,后者的形式是few-shot examples或zero-shot templates。我们的Zero-shot-CoT可以促进各种推理任务的step-by-step回答,包括算术推理、符号推理、常识推理、以及其他逻辑推理任务,而无需修改每个任务的prompt。
我们在
Table 2中对Zero-shot-CoT与其他prompting baselines进行了经验评估。虽然我们的Zero-shot-CoT在精心制作的task-specific step-by-step examples中表现不佳,但Zero-shot-CoT与0-shot baseline相比取得了巨大的分数提升,例如:使用InstructGPT 175B模型,在MultiArith上从17.7% -> 78.7%、在GSM8K上从10.4% -> 40.7%。我们还用另一个现成的大型模型PaLM 540B来评估Zero-shot-CoT,在MultiArith和GSM8K上显示出类似的改进幅度。重要的是,在我们single fixed prompt下,zero-shot LLM有一个明显更好的scaling曲线,可与few-shot CoT baseline相媲美。我们还表明,除了Few-shot-CoT需要人为地设计multi-step reasoning prompts之外,如果prompt example question类型和task question类型不匹配,它们的性能就会恶化,这表明对每个任务的prompt设计的高度敏感性。相比之下,这种单个prompt在不同推理任务中的通用性暗示了LLM未被开发和未被研究的zero-shot基础能力,如通用逻辑推理等higher-level的广泛的认知能力。虽然充满活力的LLM领域是从卓越的few-shot learner的前提下开始的(GPT-3),但我们希望我们的工作能鼓励更多的研究来揭示隐藏在这些模型中的high-level、多任务的zero-shot能力。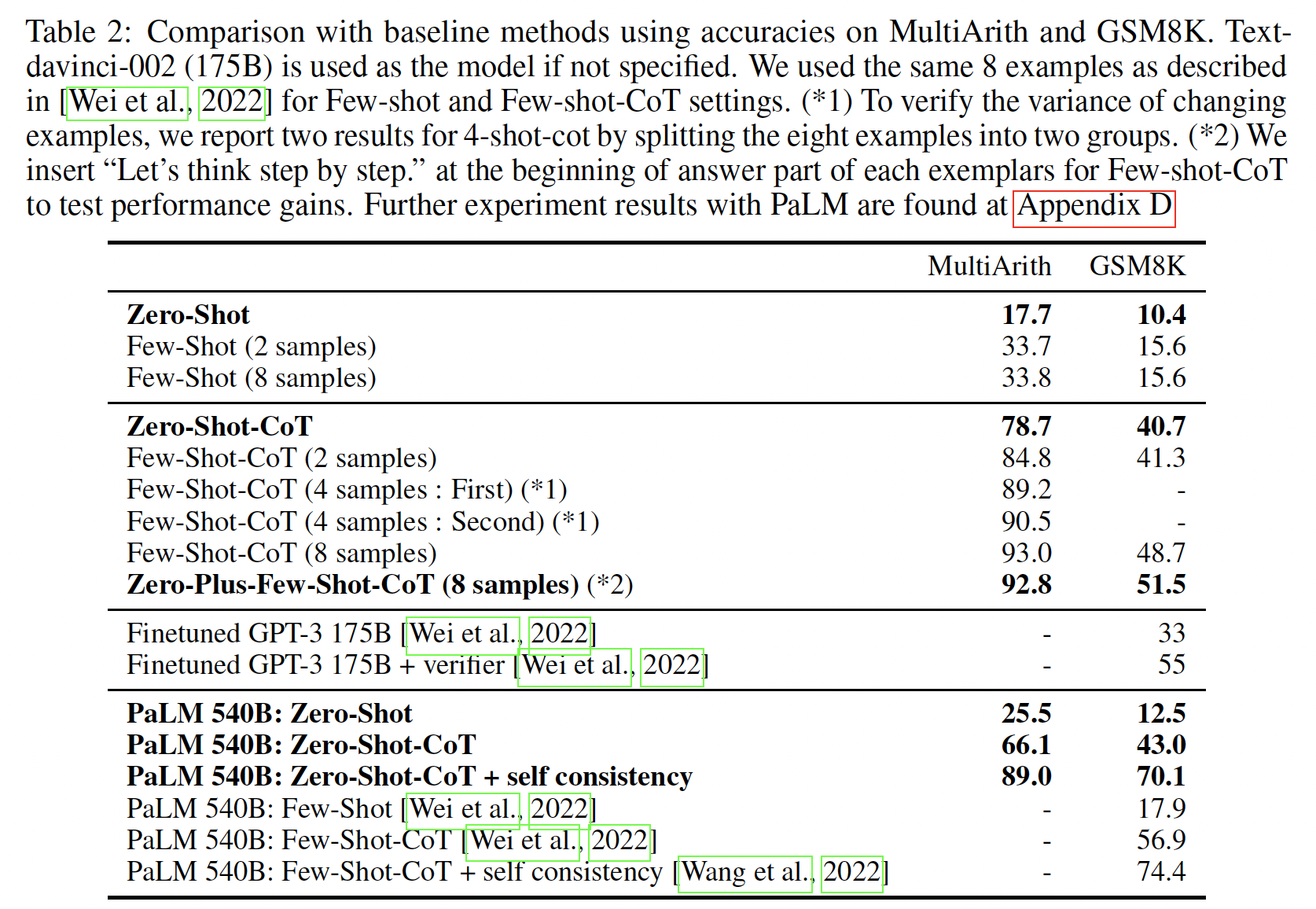
相关工作和讨论:
LLM的推理能力:一些研究表明,pre-trained model通常不擅长推理(reasoning),但通过使其产生step-by-step reasoning,其能力可以大幅提高,要么通过微调、要么通过few-shot prompting(相关工作的总结见Table 6)。与大多数先前的工作不同,我们专注于zero-shot prompting,并表明在各种需要复杂的multi-hop thinking的任务中,一个single fixed trigger prompt大大增加了LLM的zero-shot reasoning(Table 1),特别是当模型被scaled up时(Figure 3)。它还能在不同的任务中产生合理的、可理解的chain of thought,即使最后的预测是错误的,参考原始论文的附录B、附录C(下面的Table 12是一部分表格,全部表格参考论文的附录部分)。
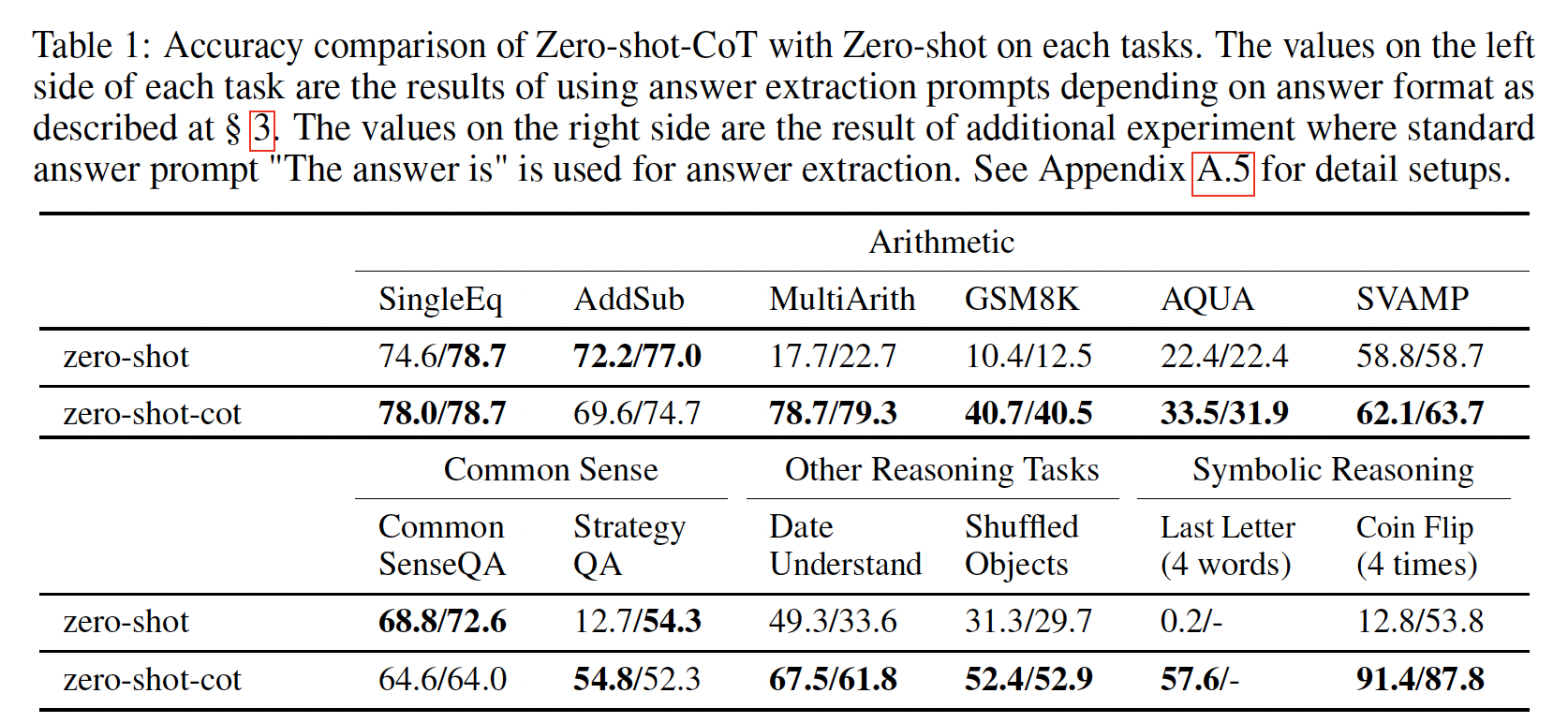
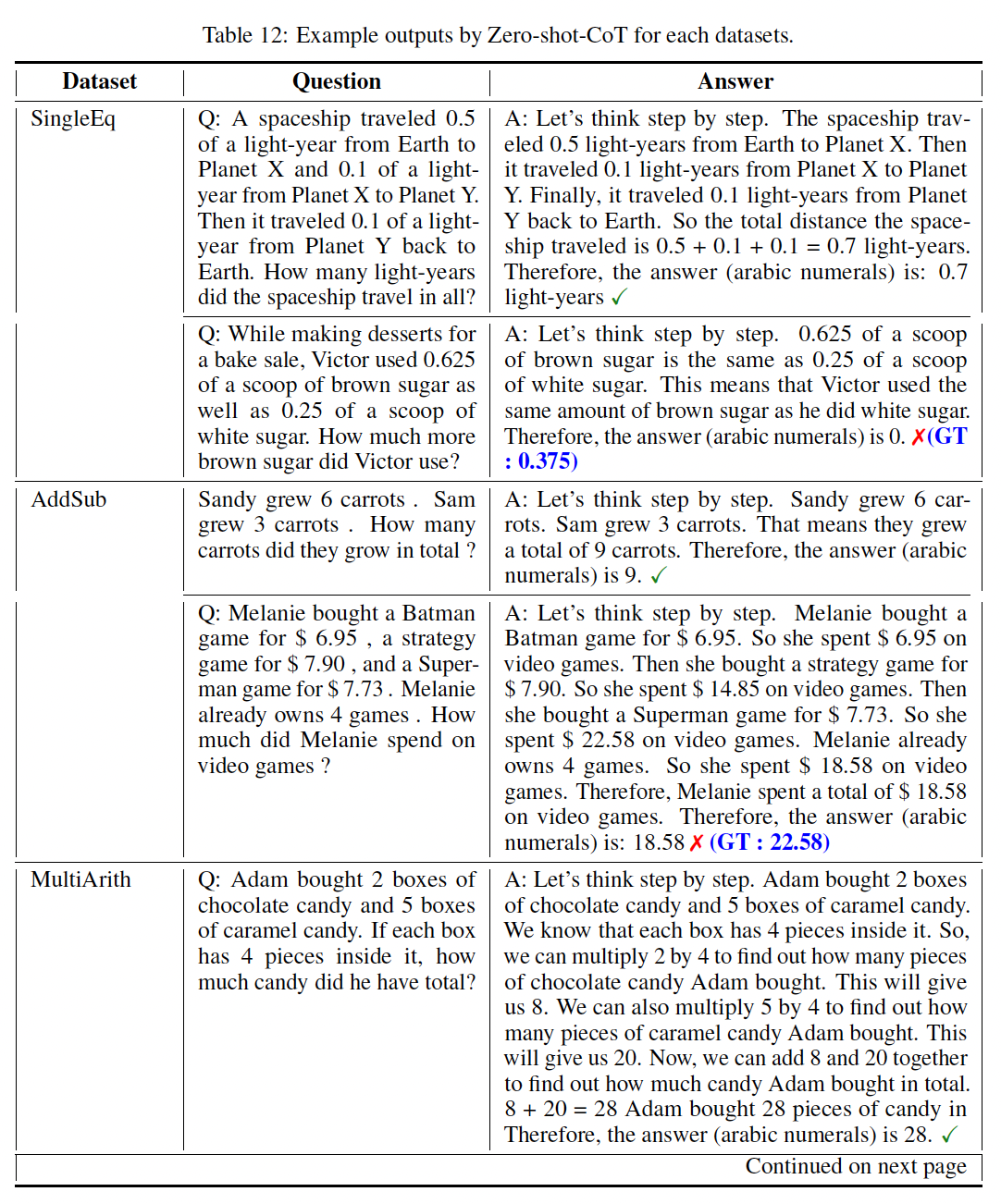
与我们的工作类似,
《Prompt programming for large language models: Beyond the few-shot paradigm》证明了一个prompt,"Let’s solve this problem by splitting it into steps",会促进一个简单算术问题的多步推理。然而,他们将其作为一个task-specific example,并没有对各种各样的推理任务在baseline上进行定量评估。《Unsupervised commonsense question answering with self-talk》提议将常识性问题分解为一系列的information seeking问题,如"what is the definition of [X]"。它不需要demonstrations,但每项推理任务都需要大量的人工的prompt engineering。我们的结果强烈地表明,
LLM是优雅的zero-shot reasoner,而之前的《Chain of thought prompting elicits reasoning in large language models》往往只强调few-shot learning,例如,没有zero-shot baseline的报告。我们的方法不需要耗时的微调或昂贵的sample engineering,并且可以与任何pre-trained LLM相结合,作为所有推理任务的最强的zero-shot baseline。LLM的zero-shot能力:GPT-2表明,LLM在许多system-1任务中具有出色的zero-shot能力,包括阅读理解、翻译和摘要。《Multitask prompted training enables zero-shot task generalization》、《Training language models to follow instructions with human feedback》表明,LLM的这种zero-shot能力可以通过显式地微调模型以遵循指令来提高。虽然这些工作的重点是LLM的zero-shot性能,但我们关注的是system-1任务之外的许多system-2任务,鉴于平坦的scaling曲线,这被认为是对LLM的巨大挑战。此外,Zero-shot-CoT与instruction tuning是正交的;它增加了Instruct GPT3, vanilla GPT3, PaLM的zero-shot(见Figure3)。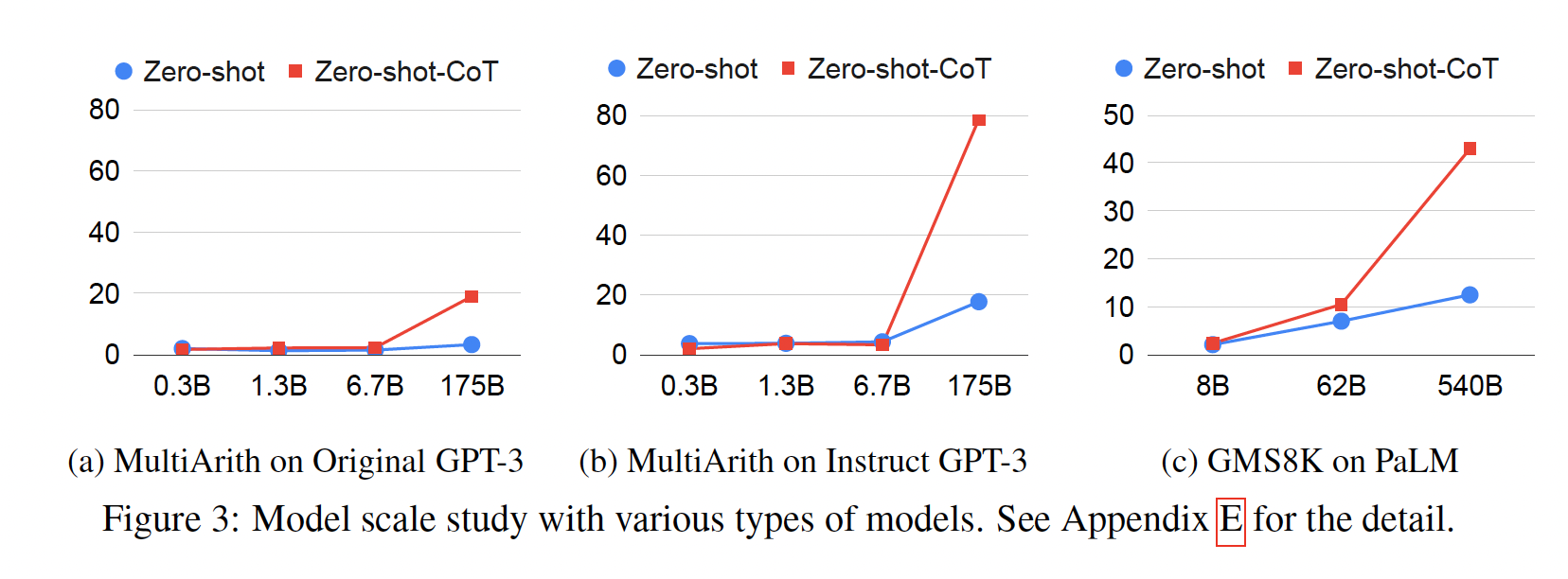
From Narrow (task-specific) to Broad (multi-task) Prompting:大多数prompts都是task-specific的。虽然few-shot prompts是由于task-specific in-context samples,因此,大多数zero-shot prompts也集中在per-task engineering (of templates)。借用《On the measure of intelligence》的术语,这些prompts可以说是在激发LLM的"narrow generalization"或task-specific技能。另一方面,我们的方法是一个multi-task prompt,激发LLM的"broad generalization"或广泛的认知能力,如逻辑推理或system-2本身。我们希望我们的工作可以作为一个参考,不仅可以加速对LLM的逻辑推理的研究,而且可以发现LLM的其他的广泛的认知能力。训练数据集的细节:该工作的一个局限性是缺乏针对
LLM的训练数据集细节的公开信息,例如GPT 001 vs GPT 002、original GPT3 vs Instruct-GPT,以及PaLM模型的数据。然而,所有最近的大型模型(InstructGPT 001 or 002, Original GPT3, PaLM)从Zero-shot到Zero-shot-CoT的性能大增,以及在算术任务和非算术任务中的一致改进,表明这些模型不太可能是简单的记忆,而是捕获了一种任务无关的多步骤推理能力从而用于通用的problem solving。虽然大多数结果是基于InstructGPT的,因为它是性能最好的open-access LLM,但关键结果在PaLM上复现,而且InstructGPT的数据集细节也证实它不是专门为多步骤推理而设计的。局限性和社会影响:我们的工作是基于针对大型语言模型的
prompting方法。LLM已经在来自互联网的各种数据源的大型语料库中进行了训练,并显示出捕捉和放大了训练数据中发现的bias。prompting是一种方法,该方法寻求利用语言模型捕获到的模式,这些模式有利于各种任务,因此prompting也有同样的缺点。也就是说,我们的方法是一种更直接的方式来探究pre-trained LLM内部的complex reasoning,消除了之前的few-shot方法中的in-context learning的混杂因素,并可以导致对LLM中的bias进行更加unbiased的研究。
24.1 背景
我们简要回顾一下构成这项工作的基础的两个核心概念:
large language model and prompting的出现、以及用于多步骤推理的chain of thought: CoT prompting。large language models and prompting:语言模型是一个旨在估计文本上的概率分布的模型。最近,通过更大的模型规模、更大的数据进行scaling improvements,使pre-trained的大型语言模型能够在许多下游的NLP任务中表现出惊人的能力。除了经典的
"pre-train and fine-tune"范式(《Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing》),规模到100B+参数的模型通过in context learning的方式表现出有利于few-shot learning的特性(GPT-3)。其中,在in context learning中,人们可以使用被称为prompt的文本或模板来强烈引导generation来输出目标任务的答案,从而开启一个"pre-train and prompt"的时代(《What makes good in-context examples for gpt-3?》)。在这项工作中,我们把这种具有显式的few task examples的prompts称作few-shot prompts,而把其他仅有模板的prompts称为zero-shot prompts。Chain of thought prompting:多步骤算术推理benchmarks、以及逻辑推理benchmarks特别地挑战了大型语言模型的scaling laws(《Scaling language models: Methods, analysis & insights from training gopher》)。chain of thought: CoT prompting,是few-shot prompting的一个实例,通过将few-shot examples中的答案修改为step-by-step的答案从而提出了一个简单的解决方案,并在这些困难的benchmarks中取得了显著的性能提升,尤其是当与PaLM这样的超大型语言模型结合时。Figure 1的最上面一行显示了标准的few-shot prompting和(few-shot) CoT prompting。值得注意的是,在处理这种困难的任务时,few-shot learning被认为是给定的,在最初的工作中甚至没有报告zero-shot baseline的表现(《Chain of thought prompting elicits reasoning in large language models》)。为了区别于我们的方法,在本工作中,我们将《Chain of thought prompting elicits reasoning in large language models》的方法称为Few-shot-CoT。
24.2 Zero-Shot CoT
我们提出了
Zero-shot CoT,一种用于chain of thought reasoning的zero-shot template-based prompting。它与原始的chain of thought prompting不同,因为它不需要step-by-step few-shot examples,它与之前的大多数template prompting(《Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing》)不同,因为它本身是任务无关的,用单个模板就能激发广泛的任务的multi-hop reasoning。我们方法的核心思想很简单,如Figure 1所述:添加" Let’s think step by step",或添加类似的文本(见Table 4),从而抽取step-by-step reasoning。
两阶段的
prompting:虽然Zero-shot-CoT在概念上很简单,但它使用了两次prompting来提取推理和答案,如Figure 2所解释。相比之下,zero-shot baseline(见Figure 1的左下方)已经使用了"The answer is"的prompting形式,从而以正确的格式提取答案。few-shot prompting,无论是标准的或CoT的,通过显式地设计few-shot example answers以这种格式结束,从而避免了这种answer-extraction prompting的需求(见Figure 1的右上角和左上角)。总之,Few-shot-CoT需要对每个任务的具备特定答案格式的a few prompt examples进行仔细的人力工程,而Zero-shot-CoT需要的工程较少,但需要对LLM提示两次。第一次提示:推理提取(
reasoning extraction)。 在这一步中,我们首先使用一个简单的模板"Q: [X]. A: [T]"将输入的问题prompt[X]是[T]是手工制作的trigger sentencechain of though。例如,如果我们使用"Let’s think step by step"作为trigger sentence,prompt"Q: [X]. A: Let’s think step by step."。更多的trigger examples见Table 4。prompted text第二次提示:答案提取(
answer extraction)。在第二步,我们使用所生成的句子prompted sentence具体来说,我们简单地将三个元素拼接起来,如
"[X'] [Z] [A]",其中[X']表示第一次的prompted text[Z]表示第一步产生的句子[A]表示用于提取答案的trigger sentence。这一步的prompt是self-augmented的,因为该prompt包含由同一语言模型所生成的句子在实验中,我们根据答案格式的不同,使用略有不同的
answer trigger。例如:对于多选题问答,我们使用
"Therefore, among A through E, the answer is"。而对于需要数字答案的数学问题,我们使用
"Therefore, the answer (arabic numerals) is"。
answer trigger句子的清单见Table 9, Table 10(left表示用于answer extraction的默认prompts,right为常规的prompts)。最后,语言模型将prompted text作为输入,生成句子Table 11。
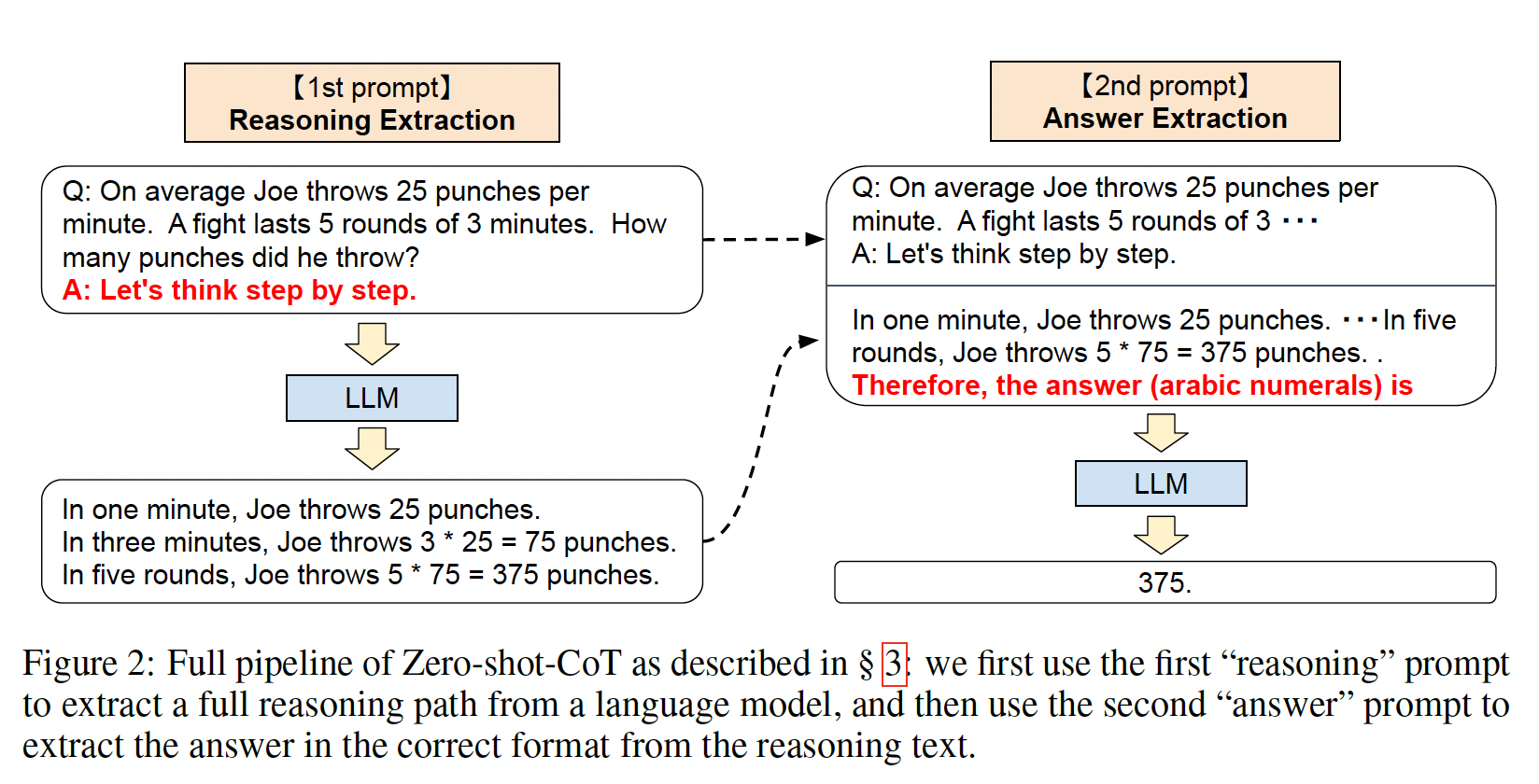
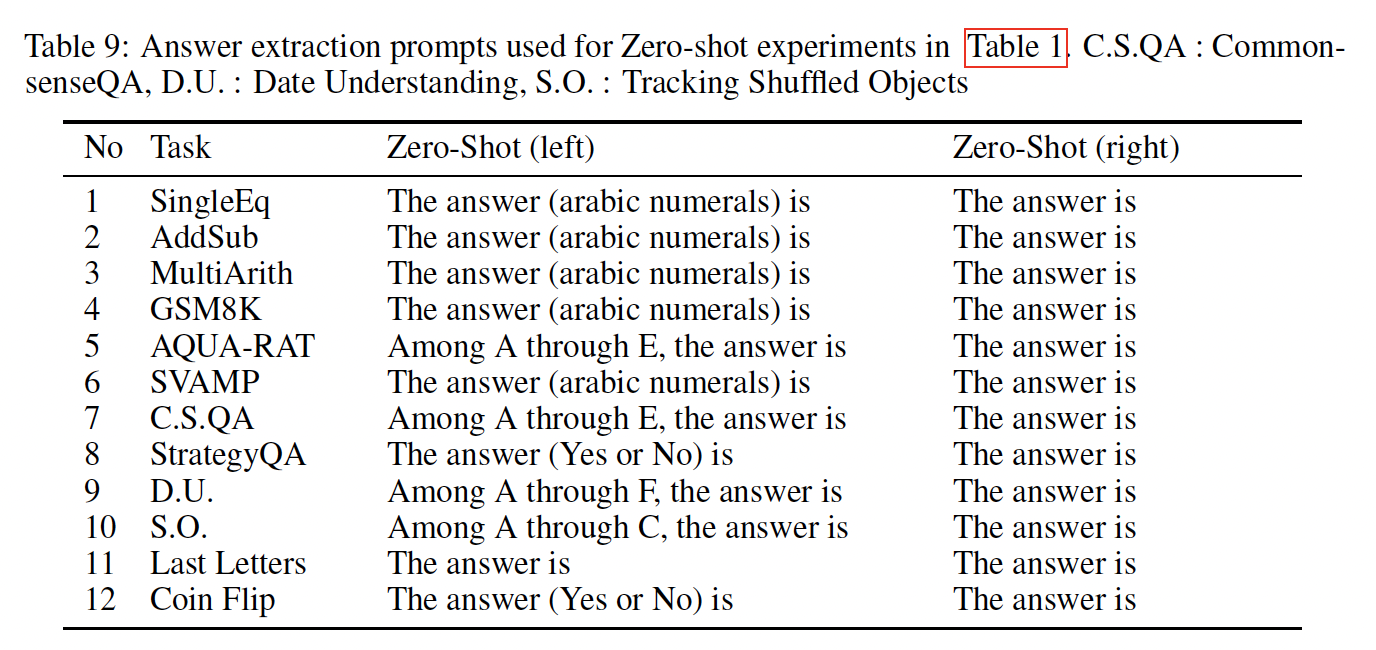

24.3 实验
任务和数据集:我们在来自四类推理任务的
12个数据集上评估了我们的方法,包括算术推理、常识推理、符号推理、以及其他逻辑推理任务。每个数据集的详细描述见附录A.2。算术推理任务:六个数据集,
SingleEq, AddSub, MultiArith, AQUARAT, GSM8K, SVAMP。SingleEq, AddSub包含比较容易的问题,不需要多步计算就能解决任务。MultiArith, AQUA-RAT, GSM8k, SVAMP是更具挑战性的数据集,需要多步推理来解决。
常识推理任务:
CommonsenseQA, StrategyQA。CommonsenseQA提出的问题具有复杂的语义,通常需要基于先验知识进行推理。StrategyQA要求模型推断出一个隐含的multi-hop reasoning来回答问题。
符号推理任务:
Last Letter Concatenation, Coin Flip。Last Letter Concatenation要求模型将每个单词的最后一个字母连接起来。对于每个样本,我们使用随机选择的四个名字。Coin Flip要求模型回答在人们翻转或不翻转硬币后,硬币是否仍然是正面朝上。我们创建了四次翻转或不翻转的样本。
虽然这些任务对人类来说很容易,但语言模型通常表现出平坦的
scaling曲线。其它逻辑推理任务:
BIG-bench中的两个评估集合,Date Understanding和Tracking Shuffled Objects。Date Understanding要求模型从上下文中推断出日期。Tracking Shuffled Objects测试的是模型在给定其初始状态和对象混洗序列的情况下,推断对象最终状态的能力。我们的数据集跟踪了三个shuffled objects。
模型:十七个模型。主要的实验是用
Instruct-GPT3(text-ada/babbage/curie/davinci-001和text-davinci-002)、原始的GPT3(ada, babbage, curie, davinci)和PaLM(8B, 62B, 540B)。此外,我们使用GPT-2、GPT-Neo、GPT-J、T0和OPT进行model scaling的研究。语言模型的大小从0.3B到540B不等。我们既包括标准的模型(如GPT-3和OPT),也包括遵循指令的变体(如Instruct-GPT3和T0)。模型描述细节见附录A.3。除非另有说明,我们在整个实验中都使用text-davinci-002。baseline:我们主要将我们的Zero-shot-CoT与标准的Zero-shot prompting进行比较。对于Zero-shot实验,与Zero-shot-CoT类似的answer prompts被作为默认使用。详见Table 9, Table 10。为了更好地评估
LLM在推理任务上的zero-shot能力,我们还将我们的方法与《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》中的Few-shot和Few-shot-CoT基线进行了比较,使用的是相同的in-context examples。在整个实验中,我们对所有的方法都使用了贪婪解码。对于
zero-shot方法,其结果是确定的。对于few-shot方法,由于in-context examples的顺序可能会影响结果(《Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity》),我们在所有方法和数据集中只用固定的种子运行一次实验,以便与zero-shot方法进行公平的比较。《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》的研究表明,在CoT实验中,样本的顺序并没有造成大的差异。清理答案:在模型通过
answer extraction输出一个文本之后,我们的方法只提取答案文本中首先满足答案格式的部分(参考Figure 2)。例如,如果answer prompting在算术任务中输出 "可能是375和376",我们就提取第一个数字 "375",并将其设置为模型预测值。在多选题的情况下,我们遇到的第一个大字母被设置为预测值。更多细节见Table 11。标准的Zero-shot也遵循同样的思路。对于
Few-shot和Few-shot-CoT方法,我们遵循《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》,首先从模型输出中提取"The answer is "之后的答案文本,并应用相同的answer cleansing来解析答案文本。如果在模型输出中没有找到"The answer is ",我们就从文本的后面进行搜索,并将第一个满足答案格式的文本设置为预测值。Zero-shot-CoT vs. Zero-shot:如下表所示,Zero-shot-CoT在六个算术推理任务中的四个(MultiArith, GSM8K, AQUA, SVAM)、所有符号推理任务、和所有其他逻辑推理任务上大大超越了zero-shot prompting。我们的方法在其余两个算术推理任务(SingleEq和AddSub)中表现平平,这是意料之中的,因为它们不需要多步骤推理。在常识推理任务中,
Zero-shot-CoT并没有提供性能提升。这是意料之中的,因为COT也报告说,即使Few-shot-CoT在Lambda(135B)上也没有提供性能提升,但在与大得多的PaLM(540B)模型结合时,确实改善了StrategyQA,这可能也适用于我们的情况。更重要的是,我们观察到许多生成的chain of thought在逻辑上是正确的,或者只包含人类可以理解的错误(见Table 3),这表明Zero-shot-CoT确实能引起更好的常识推理,即使任务指标没有直接反映它。我们在附录B中提供了由Zero-shot-CoT为每个数据集生成的样本。
与其他
baseline的比较:下表比较了Zero-shot-CoT和基线在两个算术推理基准(MultiArith, GSM8K)上的表现。standard prompting(第一个block)和chain of thought prompting(第2个block)之间的巨大差距表明,这些任务在没有激发多步骤推理的情况下是困难的。Instruct GPT-3 (175B)和PaLM (540B)模型都获得了重大改进。虽然
Zero-shot-CoT的性能自然低于Few-shot-CoT,但它的性能大大超过了标准的、每个任务八个样本的Few-shot prompting。对于
GSM8K,Instruct GPT-3(175B)的Zero-shot-CoT的性能也优于微调的GPT-3、以及大型模型(PaLM, 540B)的standard few-shot prompting。使用PaLM的进一步实验结果见附录D。模型大小对
zero-shot reasoning是否重要:下图比较了MultiArith / GSM8K上各种语言模型的性能。在没有chain of thought reasoning的情况下,随着模型规模的增加,性能不会增加、或者增加缓慢,也就是说,曲线大多是平的。与此相反,对于Original/Instruct GPT-3和PaLM来说,随着模型规模的增大,chain of thought reasoning的性能急剧增加。当模型大小较小时,chain of thought reasoning并不有效。这个结果与《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》中的few-shot实验的结果一致。附录E显示了使用更多种类的语言模型的广泛实验结果,包括GPT-2, GPT-Neo, GPT-J, T0, OPT。我们还手动调查了所生成的chain of thought的质量,大型的模型明显表现出更好的推理能力(每个模型的sampled output见附录B)。Error Analysis:为了更好地理解Zero-shot-CoT的行为,我们手动调查了由具有Zero-shot-CoT prompting的Instruct-GPT3所生成的随机选择的样本。样本见附录C,其中的一些观察结果包括:在常识推理(
CommonsenseQA)中,即使最后的预测不正确,Zero-shot-CoT也经常产生灵活合理的chain of thought。当模型发现难以缩小到一个答案时,Zero-shot-CoT经常输出多个答案选择(参考Table 3)。在算术推理(
MultiArith)中,Zero-shot-CoT和Few-shot-CoT在错误模式方面表现出很大的差异。首先,
Zero-shot-CoT倾向于在得到正确的预测后输出不必要的推理步骤,这导致预测变为不正确的预测。Zero-shot-CoT有时也不开始推理,只是重新表述输入的问题。相比之下,当所生成的
chain of thought包括三元运算时(如(3+2) * 4),Few-shot-CoT往往会失败。
prompt selection如何影响Zero-shot-CoT:我们验证了Zero-shot-CoT对input prompts的稳健性。下表总结了使用16个不同模板(分为三类)的性能。具体来说,遵从
《Do prompt-based models really understand the meaning of their prompts?》,这些类别包括指导性的(鼓励推理)、误导性的(不鼓励推理或鼓励推理但方式错误)、以及不相关的(与推理无关)。结果表明,如果文本是以鼓励chain of thought reasoning的方式写的,即模板属于"instructive"类别,那么性能就会提高。然而,准确率的差异是显著的,这取决于句子。在这个实验中,"Let’s think step by step."取得了最好的结果。有趣的是,我们发现不同的模板鼓励模型以相当不同的方式表达推理(见附录B,每个模板的输出样本)。相反,当我们使用误导性或不相关的模板时,性能并没有提高。如何为Zero-shot-CoT自动创建更好的模板仍然是一个开放的问题。prompt selection如何影响Few-shot-CoT:下表展示了使用来自不同数据集的examples(CommonsenseQA to AQUA-RAT和CommonsenseQA to MultiArith)时Fewshot-CoT的性能。这两种情况下的domain是不同的,但CommonsenseQA and AQUA-RAT的answer format是相同的。令人惊讶的是,来自不同领域(从常识推理到算术推理)但具有相同答案格式(多项选择)的chain of thought examples,在Zero-shot(对于AQUA-RAT)上取得了显著的性能提升,通过相对于Zero-shot-CoT或Few-shot-CoT可能带来的相对改善作为指标。相比之下,当使用不同答案类型的样本时(对
MultiArith而言),性能增益就变得很低了,这证实了之前的工作(《Rethinking the role of demonstrations: What makes in-context learning work?》),即LLM主要利用few-shot examples来推断重复格式,而不是推断任务本身。然而,在这两种情况下,结果都比Zero-shot-CoT差,这肯定了Few-shot-CoT中task-specific sample engineering的重要性。Zero-shot-CoT无需考虑examples的迁移,因为它不需要few-shot examples。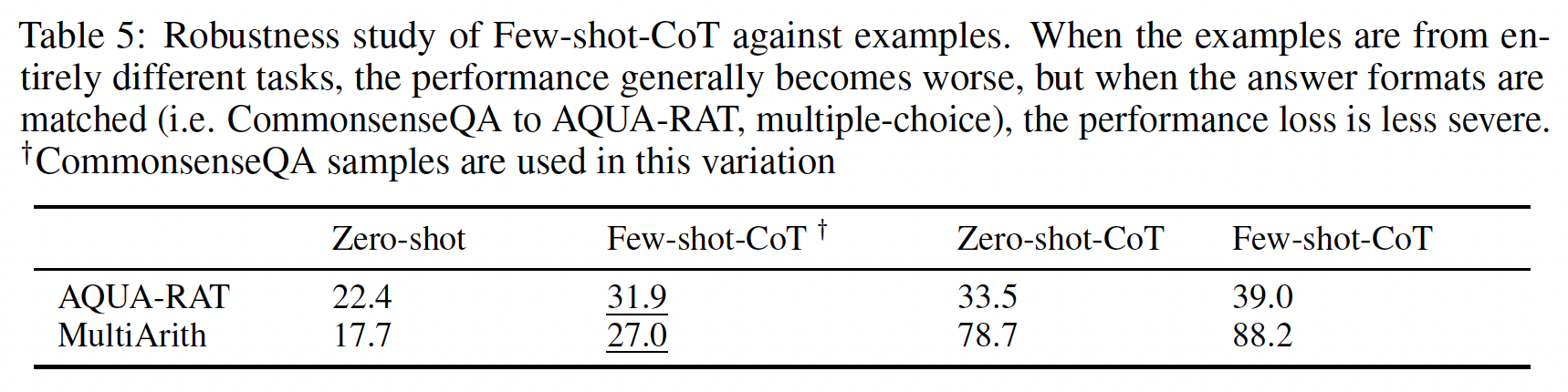
二十五、Auto COT[2022]
论文:
《Automatic Chain of Thought Prompting in Large Language Models》
大型语言模型(
LLM)通过将多步骤问题分解为中间步骤,在复杂的推理任务中表现抢眼。这种推理过程是由最近的一项技术引起的:chain-of-thought: CoT prompting(《Chain of thought prompting elicits reasoning in large language models》)。CoT prompting可以分为两个主要范式:一种范式是:在
test question后添加一个类似于"Let’s think step by step"的单个prompt,以促进LLM中的reasoning chains(《Large language models are zero-shot reasoners》)。由于这种prompting范式与任务无关,不需要input-output demonstrations,,因此被称为Zero-Shot-CoT(下图的左边)。通过Zero-Shot-CoT,LLM被证明是优雅的zero-shot reasoner。Zero-Shot-CoT其实也拼接了reasoning demonstrations,只是它的demonstrations是由模型自动生成的(而不是人工生成的)。另一种范式是具有一个接一个的人工
reasoning demonstrations的few-shot prompting(《Chain of thought prompting elicits reasoning in large language models》) 。每个demonstration都有一个问题和一个reasoning chain。reasoning chain由一个理由(rationale,即一系列中间的推理步骤)和一个预期答案组成。由于所有的demonstrations都是手工设计的,这种范式被称为Manual-CoT(下图的右边)。

在实践中,
Manual-CoT获得了比Zero-Shot-CoT更强的性能。然而,这种优越性能取决于手工设计的有效effective demonstrations。具体来说,对于demonstrations,Manual-CoT涉及到为问题及其reasoning chain的设计所做的不小的努力。此外,人们针对task-specific demonstrations的设计需要做出更多的努力:不同的任务(如算术推理和常识推理任务)需要不同的demonstrations方式。为了消除这种手工设计,我们主张采用另一种
Auto-CoT范式来自动构建带有问题和reasoning chains的demonstrations。具体来说,Auto-CoT利用LLM的"Let’s think step by step" prompt,为demonstrations来one-by-one地生成reasoning chains;也就是说,"let’s think not just step by step, but also one by one"。然而,我们发现,这一挑战不能通过简单的解决方案来有效解决。例如,给定数据集的一个测试问题,检索语义相似的问题并调用Zero-Shot-CoT来生成reasoning chains会失败。尽管LLM是优雅的zero-shot reasoner,但它们并不完美:Zero-Shot-CoT仍然会在reasoning chain中犯错。为了缓解来自
Zero-Shot-CoT的reasoning chain mistakes的影响,我们的分析表明,demonstration questions的多样性是关键所在。基于这一洞察,我们提出了一种自动构建demonstrations的Auto-CoT方法。Auto-CoT包括两个主要步骤:首先,将一个给定的数据集的所有问题划分为几个
clusters。聚类通过一个
pre-trained sentence encoder来进行,如SBERT。其次,从每个
cluster中选择一个有代表性的问题,并使用简单启发式的Zero-Shot-CoT生成它的reasoning chain。
核心思想有两个:
通过
Zero-Shot-CoT来人工构造 ”伪“examples,从而进行Few-Shot-CoT。构造的时候选择多样化的样本,并且过滤掉不满足条件的样本(这个条件是人工定义的规则)。
我们在十个
benchmark reasoning tasks上评估了Auto-CoT,包括:算术推理(MultiArith, GSM8K, AQUA-RAT, SVAMP)、常识推理(CSQA, StrategyQA)、符号推理(Last Letter Concatenation, Coin Flip)。实验结果显示,在GPT-3上,Auto-CoT的性能始终与需要人工设计的Manual-CoT相匹配,甚至超过了后者。这表明,LLM可以通过自动构建demonstrations来进行CoT reasoning。相关工作:这里回顾了构成这项工作的基础的两条研究路线:针对多步骤推理的
chain-of-thought: CoT chain-of-thought、以及用于诱导LLM从demonstrations中学习的in-context learning。Chain-of-thought Prompting:CoT prompting是一种诱导LLM产生中间推理步骤(这些中间推理步骤导致最终答案)的gradient-free技术。《Chain of thought prompting elicits reasoning in large language models》正式研究了语言模型中的CoT prompting的topic。这项技术诱导LLM产生一系列连贯的中间推理步骤,从而导致问题的最终答案。研究表明,LLM可以通过zero-shot prompting: Zero-Shot-CoT(《Large language models are zero-shot reasoners》)、或手动编写的few-shot demonstrations(Manual-CoT)(《Chain of thought prompting elicits reasoning in large language models》)进行CoT reasoning。Zero-Shot-CoT:《Large language models are zero-shot reasoners》表明LLM是一个优雅的zero-shot reasoner,其生成的理由已经反映了CoT reasoning。这一发现激发了我们的工作,即利用self-generated rationales用于demonstrations。在最近的一项工作中(
《Star: Bootstrapping reasoning with reasoning》),通过LLM来生成理由被证明是实用的。在他们的工作中,一个LLM被提示从而生成理由,然后那些导致正确答案的理由被选中。这种选择需要一个带有annotated answers的问题的训练数据集。相比之下,我们的工作考虑了一个更具挑战性的场景,即只给出一组测试问题(没有训练数据集),遵循
《Chain of thought prompting elicits reasoning in large language models》和《Large language models are zero-shot reasoners》的CoT prompting的研究。Manual-CoT:Manual-CoT通过有效的manual demonstrations来激发CoT reasoning能力,从而实现更强的性能。用于reasoning process的demonstrations是人工设计的。然而,人们在设计问题及其reasoning chains方面的努力是不容易的。最近的研究并没有解决这个问题,而是主要集中在手工制作更复杂的demonstrations、或者利用ensemble-like方法。一个趋势是问题分解。在
least-to-most prompting中(《Least-to-most prompting enables complex reasoning in large language models》),复杂的问题被简化为子问题,然后这些子问题被依次解决。另一个趋势是对一个测试问题的多个推理路径进行投票。
《Self-consistency improves chain of thought reasoning in language models》引入了一种self-consistency解码策略,采样LLM的多个输出,然后对最终答案采取多数票。《Rationale-augmented ensembles in language models》和《On the advance of making language models better reasoners》在输入空间中引入随机性,以产生更多不同的输出从而用于投票。他们使用人工设计的demonstrations作为种子集合,并生成额外的理由(rationales):从种子集合中hold out一个问题,并使用剩余的demonstrations来生成LLM对这个问题的理由。
与上述依靠人工设计的
demonstrations的研究路线不同,我们的工作打算消除人工设计并保持具有竞争力的性能。
In-Context Learning:CoT prompting与in-context learning: ICL密切相关。ICL使LLM能够通过馈入一些prompted examples来执行一个目标任务。在没有梯度更新的情况下,ICL允许单个模型普遍地执行各种任务。有各种研究思路来提高ICL的性能:检索与测试实例相关的
demonstrations,其中流行的做法是为给定的test input动态地检索相关的训练样本。用细粒度的信息进行
augmenting,如加入任务指令。操纵
LLM的输出概率,而不是直接计算target labels的可能性。
尽管
ICL很成功,但研究表明,ICL的strength可能会因in-context demonstrations的选择而有很大差异(《Few-shot parameter-efficient fine-tuning is better and cheaper than in-context learning》)。详细来说,prompt的格式,如措辞、或者order of demonstrations,可能会导致性能的波动。最近的一项工作《Rethinking the role of demonstrations: What makes in-context learning work?》甚至质疑ground-truth input-output mapping的必要性:在样本中使用不正确的标签只稍微降低了性能。然而,现有的对
ICL的分析主要是基于标准的分类数据集和多选数据集,这些数据集只有简单的<input -> output> mapping。我们发现,这些发现可能并不适用于具有更复杂的<input -> rationale -> output> mapping的CoT prompting场景。例如,<input -> rationale> mapping或<rationale -> output> mapping中的错误都会导致性能急剧下降 (参考附录A.1)。
25.1 Auto-CoT 的挑战
如前所述,
ICL的性能取决于人工制作的demonstrations。正如在Manual-CoT中所报告的,在一个符号推理任务中,使用不同标注员所写的demonstrations会带来高达28.2%的准确率差异;而在大多数任务中,改变demonstrations的顺序会带来不到2%的变化。这表明,Auto-CoT的关键挑战在于自动构建具有良好的questions and their reasoning chains的demonstrations。回顾一下,
Manual-CoT在demonstrations中手工制作了几个(例如8个)问题。随着similarity-based retrieval方法被广泛用于prompting LLM(《Learning To Retrieve Prompts for In-Context Learning》、《Selective annotation makes language models better few-shot learners 》),一个有希望的候选解决方案是利用similarity-based retrieval来采样demonstration questions。我们遵循CoT研究中更具挑战性的假设,即只给出一组测试问题(没有训练数据集)。遵循《What makes good in-context examples for gpt-3?》,我们使用Sentence-BERT来编码问题。对于测试数据集中的每个问题demonstration questions我们设计了一个
Retrieval-Q-CoT方法,从而检索基于余弦相似度的top-k个相似问题(例如,similarity-based方法进行比较,我们还测试了一种基于更加多样化的方法:Random-Q-CoT,对于每个测试问题,它随机采样Retrieval-Q-CoT和Random-Q-CoT都调用Zero-Shot-CoT来为每个采样到的问题reasoning chainLLM是优雅的zero-shot reasoners。除非另有说明,否则我们使用GPT-3 175B(text-davinci-002)作为LLM。在high level,Retrieval-Q-CoT和Random-Q-CoT都将pair(reasoning chain,其中这个被预测的reasoning chain包含最终答案(像Figure 1的右图)。令我们惊讶的是,
Retrieval-Q-CoT在算术数据集MultiArith上的表现低于Random-Q-CoT(如下表所示)。请注意,这些检索方法最初是在有annotated labels的任务中提出的,然而,调用Zero-Shot-CoT并不能保证reasoning chains的完全正确。因此,我们假设Retrieval-Q-CoT的性能较差是由Zero-Shot-CoT的incorrect reasoning chains造成的。为了测试这个假设,我们在另外两个数据集GSM8K和AQuA上实验Retrieval-QCoT,这两个数据集包含带有annotated reasoning chains的训练集。结果如下表表示。在有annotated reasoning chains的setting下,Retrieval-Q-CoT甚至超过了Manual-CoT。这一结果表明,当有human annotations时,Retrieval-Q-CoT是有效的。虽然
human annotations是有用的,但这种人工努力是不容易的。然而,通过Zero-Shot-CoT自动生成reasoning chains的性能低于Manual-CoT,特别是当question sampling的挑战没有得到解决时。为了设计出更有效的Auto-CoT,我们需要更好地理解其挑战。原始的
Zero-Shot-CoT并没有采用in-context examples,而这里的Random-Q-CoT和Retrieval-Q-CoT借鉴了Zero-Shot-CoT自动生成理由、答案的能力,从而构造一批 ”伪“ 样本用于in-context examples。既然
Zero-Shot-CoT可以这么做,那么所有的Zero-shot方法也可以参考这种方式从而成为Few-shot方法。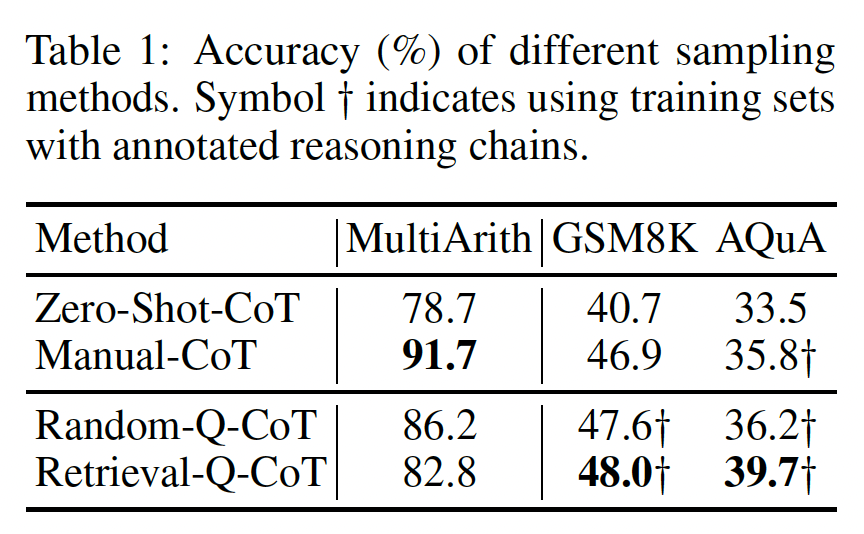
25.1.1 Retrieval-Q-CoT 的失败是由于相似性的误导
由于
Retrieval-Q-CoT像在Manual-CoT中一样使用了一些prompting demonstrations,因此Retrieval-Q-CoT预计也会有竞争性的表现。然而,Retrieval-Q-CoT中的reasoning chains(包括理由和答案)是由Zero-Shot-CoT生成的:它们可能有错误,导致错误的答案。让我们简单地把具有错误答案的demonstrations称为wrong demonstrations。直观地说,在检索到与某个测试问题相似的其它问题后,由Zero-Shot-CoT引导的wrong demonstrations可能会误导同一个LLM对该测试问题进行错误答案的相似推理(即,复制错误)。我们把这种现象称为相似性误导(misleading by similarity)。我们将研究相似性误导是否造成了Retrieval-Q-CoT的低质量的表现。首先,我们在
MultiArith数据集中的所有600个问题上调用了Zero-Shot-CoT。在这些问题中,我们收集了128个问题(记做Zero-Shot-CoT产生了错误的答案(错误率:21.3% = 128/600)。正如我们提到的,通过额外的demonstrations,Retrieval-Q-CoT和Random-Q-CoT有望比Zero-Shot-CoT表现得更有竞争力。在
Zero-Shot-CoT失败的问题中,我们把那些Retrieval-Q-CoT或Random-Q-CoT仍然失败的问题称为它们的unresolved questions。我们用unresolved questions的数量除以128(unresolving rate)。较高的未解决率意味着一种方法更有可能仍然像Zero-Shot-CoT那样犯错。下图显示,Retrieval-Q-CoT的未解决率(46.9%)远远高于Random-Q-CoT(25.8%)。这表明,针对测试问题,在相似的问题被采样的情况下,Retrieval-Q-CoT受到了相似性误导的负面影响。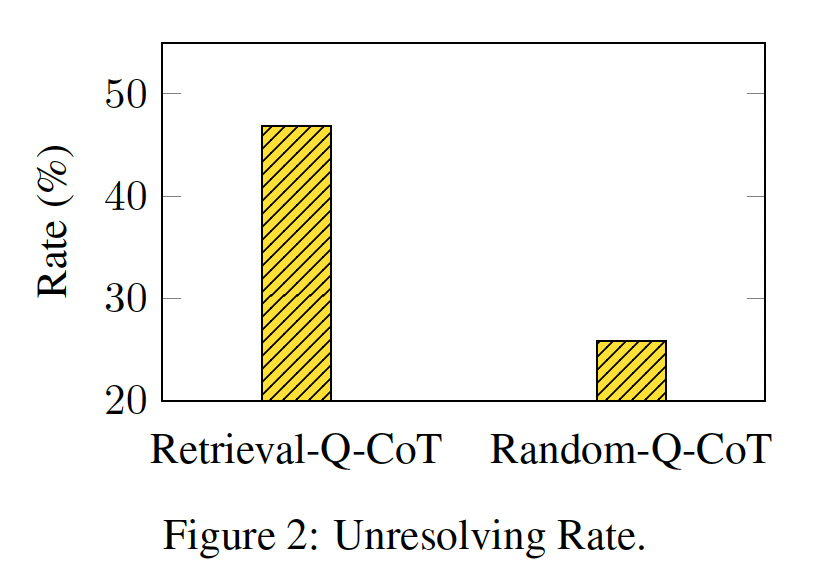
为了说明
Retrieval-Q-CoT的unresolved questions往往是相似的,我们在下表中提出了一个案例。在左边的部分,检索到的demonstration questions与测试问题相似,询问"how long will it take him to cook the rest?"。由Zero-Shot-CoT生成的reasoning chains产生了关于"the total of"而不是"the rest"的答案。遵从
demonstrations,Retrieval-Q-CoT也因为误解了"the rest "的含义而失败。相比之下,Random-Q-CoT更正确地理解了"the rest",而没有犯在demonstrations中的相似错误,这要归功于相对更多样化的(即,随机的)demonstrations。
25.1.2 错误经常落入同一个 Cluster
受
Table 2中观察结果的启发,我们使用k-means将所有600个测试问题划分为cluster,其中每个cluster都包含相似的问题。有了这些cluster和由Zero-Shot-CoT生成的reasoning chains,现在我们很好奇某些cluster是否包含Zero-Shot-CoT经常失败的问题。因此,我们计算每个cluster的错误率(具有有错误的Zero-Shot-CoT答案的问题数量除以问题总数)。如下图所示,有一个
cluster(Cluster 2)存在较高的Zero-Shot-CoT错误率(52.3%)。这种现象可能是广泛的,因为Zero-Shot-CoT可能缺乏一些技能来解决目标任务中的一些常见问题。为了描述的方便,我们把错误率最高的cluster称为frequent-error cluster(例如,下图中的Cluster 2)。因此,以zero-shot方式生成的reasoning chains的不完善所带来的风险是:通过使用similarity-based的方法,在frequent-error cluster内检索出多个相似的问题。对于frequent-error cluster中的测试问题,Retrieval-Q-CoT更容易构建具有多个相似wrong demonstrations。因此,Retrieval-Q-CoT经常犯类似于Zero-Shot-CoT的错误,Figure 2中较高的unresolving rate就重申了这一点。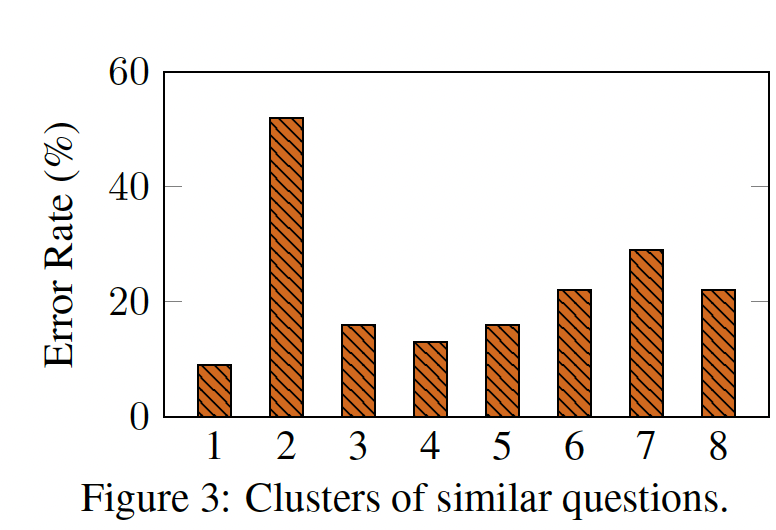
25.1.3 多样性可以缓解相似性误导
到目前为止的分析令人信服地表明,
LLM仍然不是完美的zero-shot reasoner。因此,我们的目标是缓解其Zero-Shot-CoT的错误的影响,特别是在设计Auto-CoT时缓解相似性误导。正如我们将在后面展示的(实验部分),呈现一小部分错误(例如,
8个wrong demonstrations中的1或2个)不会损害测试问题的整体reasoning性能。假设所有wrong demonstrations的问题都属于同一个frequent-error cluster;那么从每个不同的cluster中采样一个问题将导致高于7/8 = 87.5%的机会来构建所有8个correct demonstrations。由于不同的cluster反映了问题的多样化的语义,这种clustering-based sampling方法可以被认为是diversity-based的,这与similarity-based的Retrieval-Q-CoT形成了鲜明对比。一方面,具有多样性的
sampling questions可以缓解相似性误导的影响。另一方面,如果我们把每个
demonstration当作一种技能,多样化的demonstration似乎覆盖了解决目标问题的更多备选技能:即使demonstrations中仍然存在一小部分错误(例如,1/8 = 12.5%),性能也不会受到负面影响(如下图所示)。
尽管如此,
clustering-based sampling方法仍然可能构建出一小部分wrong demonstrations,例如来自frequent-error cluster中的问题。正如我们稍后所显示的,其中一些wrong demonstrations可以用启发式方法消除。例如,wrong demonstrations往往伴随着长的问题和长的理由。使用简单和通用的启发式方法,比如只考虑较短的问题和较短的理由,可以进一步帮助缓解不完善的Zero-Shot-CoT能力的影响。
简单的启发式方法的效果:问题不超过
60 tokens、理由不超过5 reasoning steps。对于算术推理(除了AQuA,因为它是多项选择题),要求答案出现在理由中(从而缓解rationale-answer mismatches)。这种启发式规则强烈依赖于具体的任务,而且依赖于人工的经验。
对于满足上述要求的问题、理由、以及答案,对于第
cluster的候选demonstration我们在使用简单的启发式方法来构建
demonstration之前、以及之后的三次运行来量化其效果。结果如下表所示。可以看到,简单的启发式方法减少了构建demonstrations时错误理由的平均数量。
下图进一步描述了使用和不使用简单的启发式方法时的错误率。错误率的计算方法是错误理由的平均数除以
demonstrations的数量。我们看到,在大多数任务中,我们的方法可以将错误率控制在20%以下(7/10)。
25.2 Auto-CoT
基于前面所述的观察和考虑,我们提出了一种
Auto-CoT方法来自动构建带有questions and reasoning chains的demonstrations。Auto-CoT包括两个主要阶段:问题聚类:将给定数据集的问题划分为几个
clusters。demonstration sampling:从每个cluster中选择一个有代表性的问题,并使用简单启发式的Zero-Shot-CoT生成其reasoning chain。
整个过程如下图所示。
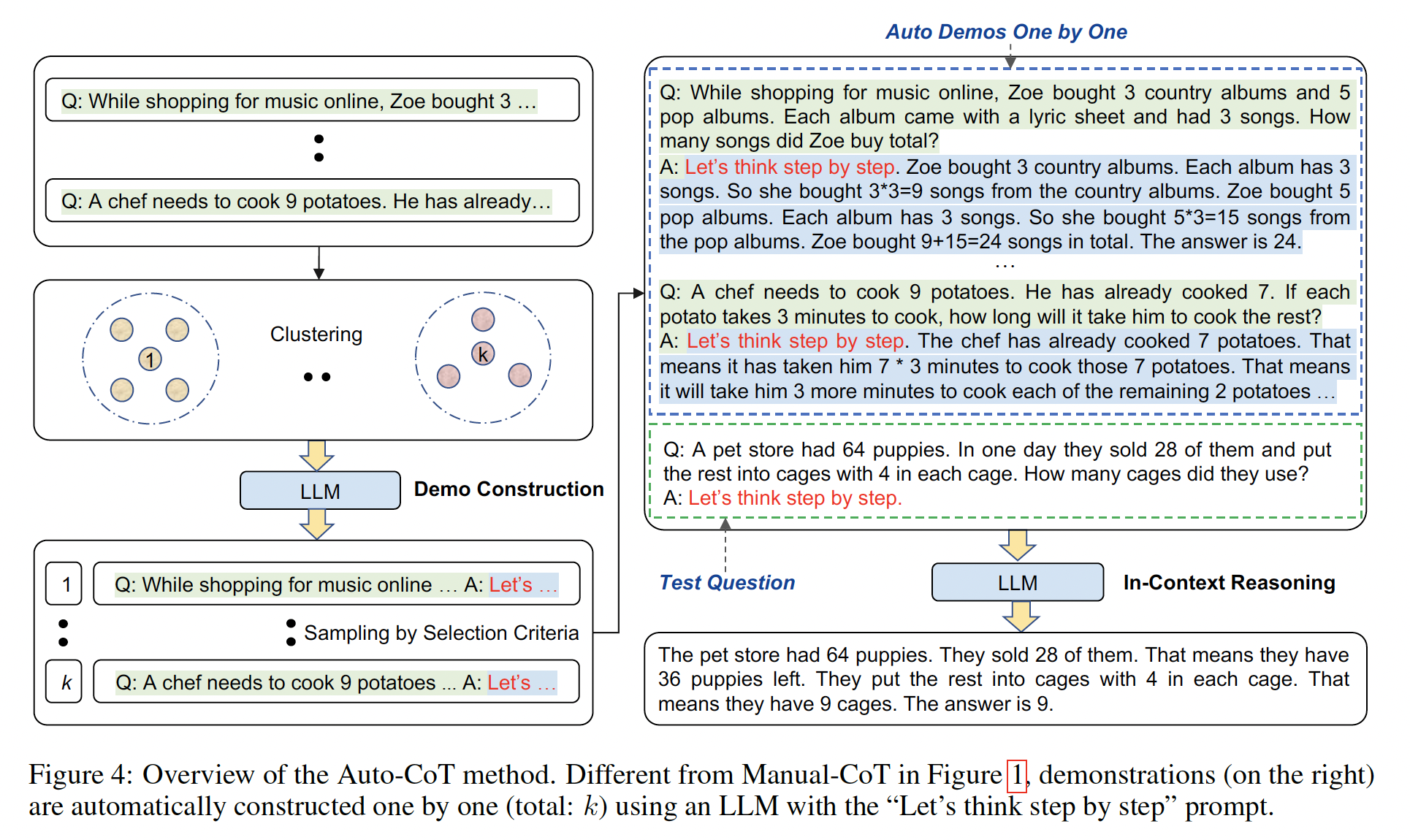
Question Clustering:由于diversity-based clustering可能会缓解相似性误导,我们对一组给定的问题我们首先通过
Sentence-BERT为vector representation。contextualized vectors被平均化,从而形成一个fix-sized的question representation。然后,我们用
k-means聚类算法处理question representations,产生question clusters。对于每个clustercluster
这个
question clustering阶段的算法如下所示。
Demonstration Sampling:在第二阶段,我们需要为这些被采样到的问题生成reasoning chains,然后采样demonstrations(这些demonstrations需要满足我们的selection criteria)。更具体而言,我们为每个
clusterdemonstrationclusterselection criteria。换句话说,更接近clusterclusterprompted input被表述为:[P]是一个单个prompt"Let’s think step to step"。这个构造好的输入被馈入一个使用Zero-Shot-CoT的LLM,从而输出由理由reasoning chain。然后,通过拼接问题、理由、以及答案,构建第cluster的候选demonstration与
《Chain of thought prompting elicits reasoning in large language models》中手工制作demonstrations的criteria类似,我们的selection criteria遵循简单的启发式方法,从而鼓励来采样较简单的问题和理由:对于demonstration60 tokens、理由5 reasoning steps,则选中该demonstration并记做这个人工定义的规则是否通用?读者觉得可能针对不同的任务需要设计不同的规则。
Demonstration Sampling算法如下所示。在对所有clusters进行demonstration sampling后,将有demonstrationsdemonstrations被用来augment一个测试问题in-context learning。具体而言,输入是所有demonstrationsLLM从而获得reasoning chain,最后是答案(Figure 4的右边)。
25.3 实验
这里我们给出主要的实验结果。更多的实验细节和结果可以参考论文的附录部分。
任务和数据集:三类推理任务的十个基准数据集。
算术推理:
MultiArith, GSM8K, AddSub, AQUA-RAT, SingleEq, SVAMP。常识推理:
CSQA, StrategyQA。符号推理:
Last Letter Concatenation, Coin Flip。
实现:除非另有说明,我们使用
text-davinci-002版本的GPT-3 175B。我们选择这个LLM是因为它在public LLM中具有最强的CoT reasoning性能,如《Large language models are zero-shot reasoners》和《Chain of thought prompting elicits reasoning in large language models》的报告。我们还评估了Codex模型(code-davinci-002)作为LLM。遵从《Chain of thought prompting elicits reasoning in large language models》,除了AQuA和Letter(CSQA(StrategyQA(demonstrations数量baseline:Zero-Shot、Zero-Shot-CoT、Few-Shot、Manual-CoT。Zero-Shot-CoT和Manual-CoT如Figure 1所示。Zero-Shot baseline将一个测试问题与prompt "The answer is"拼接起来作为LLM的输入。Few-Shot baseline与Manual-CoT具有相同的LLM输入,只是删除了所有demonstrations的理由。
Auto-CoT在十个数据集上的有竞争力的表现:下表比较了三类推理任务的十个数据集的准确率。Zero-Shot和Zero-Shot-CoT的结果取自《Large language models are zero-shot reasoners》。Few-Shot和Manual-CoT的结果取自《Chain of thought prompting elicits reasoning in large language models》。Auto-CoT的结果是三次随机运行的平均值。
总的来说,
Auto-CoT始终与需要手工设计demonstrations的CoT范式的性能相匹配,甚至超过了后者。由于人工设计的成本,Manual-CoT可能为多个数据集设计相同的demonstrations(例如,算术数据集中的5/6)。相比之下,Auto-CoT更灵活,更加task-adaptive:每个数据集都能得到自己的demonstrations,而且这些demonstrations是自动构建的。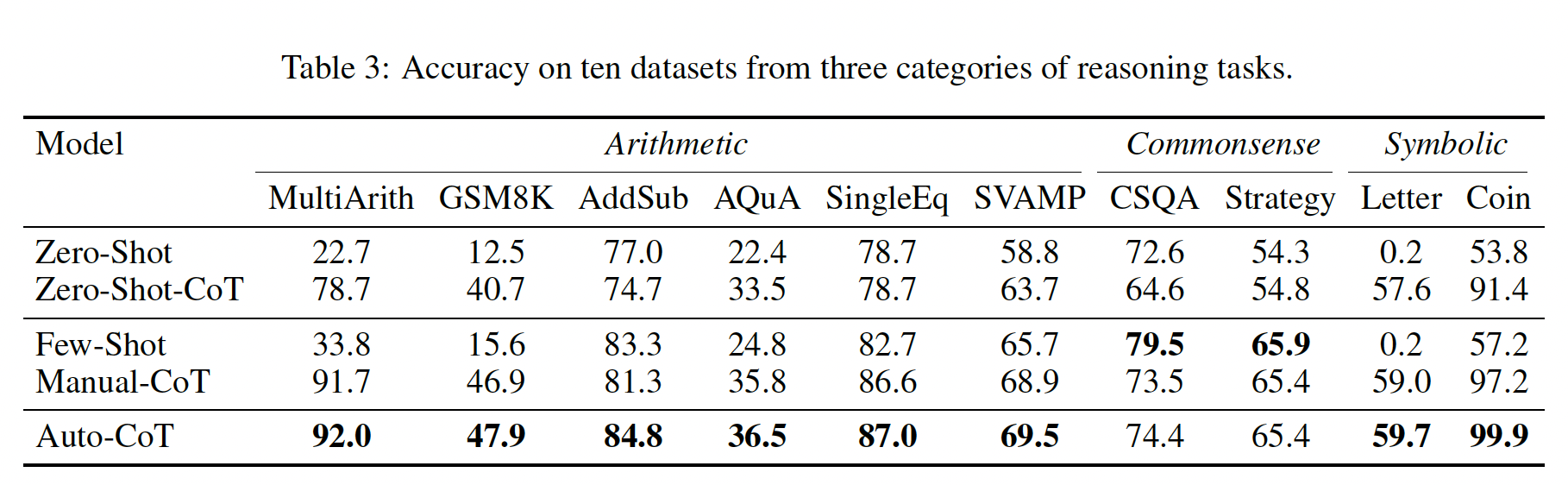
Question Clustering的可视化:下图直观地显示了10个数据集的question clustering(用PCA投影)。该图表明,存在通用的模式,不同的模式可能由来自不同cluster的问题来刻画。这可能是一种例外,因为数据集的作者在创建数据集的时候可能就是分类别来创建的。而真实场景下,数据的聚类分布可能区分度更差。
我们在附录
D中介绍了Auto-CoT的constructed demonstrations。其中MultiArith的demonstrations如下:
使用
Codex LLM的有效性:为了评估使用不同LLM的Auto-CoT的有效性,这里我们将LLM改为Codex模型。如下表所示,与使用GPT-3 (text-davinci-002) LLM的Table 3相比,Codex LLM导致Manual-CoT的性能提高。尽管如此,使用Codex LLM,Auto-CoT的整体性能与Manual-CoT相比仍然具有竞争力,为Auto-CoT的有效性提供了额外的经验证据。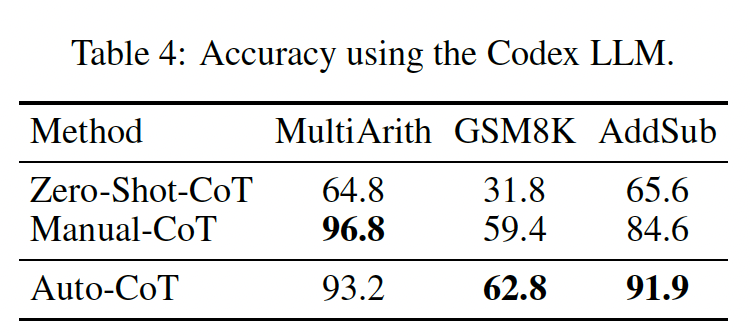
Wrong Demonstrations的效果:回顾我们在前面的讨论,可能存在wrong demonstrations(其答案是错误的)。为了了解多样性是否能减轻这种影响,我们设计了In-Cluster Sampling baseline,通过从与test question的同一cluster中随机采样问题来构建demonstrations。下图比较了在MultiArith上不同数量的wrong demonstrations的准确率。与In-Cluster Sampling相比,Auto-CoT(使用diversity-based clustering)受wrong demonstrations的影响较小:即使遇到50%的wrong demonstrations,其性能也没有明显下降。更具挑战性的
Streaming Setting:CoT研究通常假设一个完整的数据,其中包含所有的测试问题。基于给定的数据集,Auto-CoT采样一些问题从而构建demonstrations。然而,现在我们考虑的是一个更具挑战性的streaming setting,其中每次到达一小批测试问题(例如为了应对这一挑战,我们将
Auto-CoT扩展为一个bootstrapping的版本Auto-CoT*:首先,初始化一个空集合
然后,当第一个
batch的问题Zero-Shot-CoT(由于reasoning chainquestion-chain pairs然后,当
batch b(reasoning chains构建demonstrations(就像Auto-CoT),对每个demonstrations从而进行in-context reasoning。将question-chain pairs从第二个
batch开始,就进行Auto-CoT的算法。
下图比较了在这种
streaming setting下,在MultiArith数据集上,每个batch(对于
batch 1,Auto-CoT*和Zero-Shot-CoT获得相同的准确率。从
batch 2开始,Auto-CoT*的表现与Manual-CoT相当。
这一结果表明,我们的方法在更具挑战性的
streaming setting中仍然有效。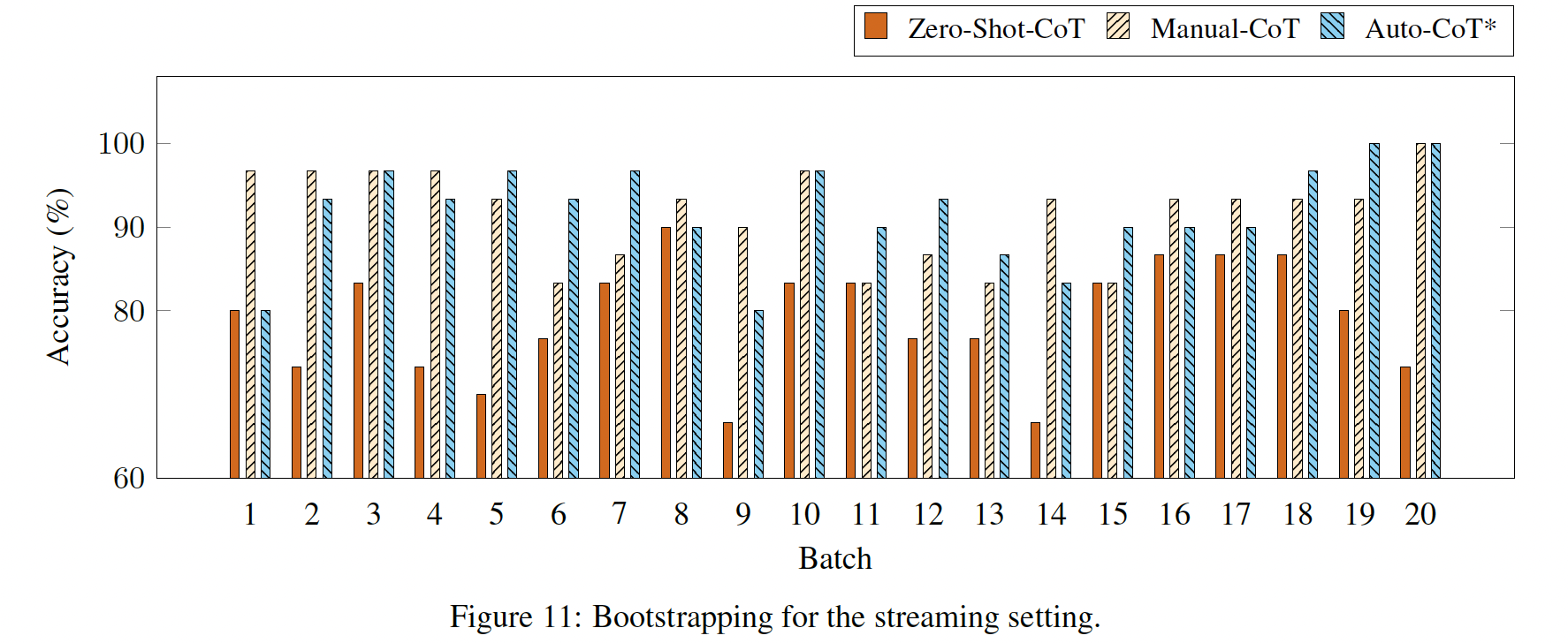
二十六、Least-To-Most Prompting [2022]
论文:
《Least-to-Most Prompting Enables Complex Reasoning in Large Language Models》
尽管深度学习在过去十年中取得了巨大的成功,但人类智能和机器学习之间仍然存在巨大的差异:
(1):给定一个新的任务,人类通常只需要通过一些demonstration examples就可以学会完成,而机器学习则需要大量的标记数据来进行模型训练。(2):人类可以清楚地解释其预测或决策的基本原理,而机器学习基本上是一个黑盒子。(3):人类可以解决比他们以前见过的任何问题更加困难的问题;而对于机器学习,训练样本和测试样本通常处于同一难度水平。
最近提出的
chain-of-thought prompting方法(《Chain of thought prompting elicits reasoning in large language models》)为缩小人类智能和机器智能之间的差距迈出了重要一步。它结合了自然语言理由(natural language rationale)和few-shot prompting(GPT-3)的思想。当与self-consistency解码(《Self-consistency improves chain of thought reasoning in language mod》)进一步整合,而不是使用典型的贪婪解码时,在许多具有挑战性的自然语言处理任务上,few-shot chain-of-thought prompting在很大程度上超过了文献中的SOTA结果,这些SOTA结果是由专门设计的神经模型在数百倍的标注样本的训练下得到的,同时few-shot chain-of-thought prompting也是完全可解释的。然而,
chain-of-thought prompting有一个关键的局限性:它在需要泛化到解决比demonstration examples更难的问题的任务上往往表现不佳,比如组合泛化(compositional generalization)。为了解决这种从易到难的泛化问题,我们提出了least-to-most prompting。它包括两个阶段:首先将一个复杂的问题分解成一系列较容易的子问题。
然后依次解决这些子问题,其中,解决一个给定的子问题是由以前所解决的子问题的答案来推动的。
这两个阶段都是通过
few-shot prompting来实现的,因此在这两个阶段都不存在训练或微调。下图显示了一个least-to-most prompting的使用案例。注意,传递给模型的
prompt包括:说明如何分解复杂问题的examples(图中没有显示),然后是要分解的具体问题(如图所示)。这些子问题类似于
CoT的 ”理由”,然而这里的 “理由” 是模型自动生成的而不是人工撰写的。Auto-CoT也是通过模型自动生成 “理由”, 但是Auto-CoT是通过单步来一次性生成所有 ”理由“;而这里是单步生成一个 ”理由“。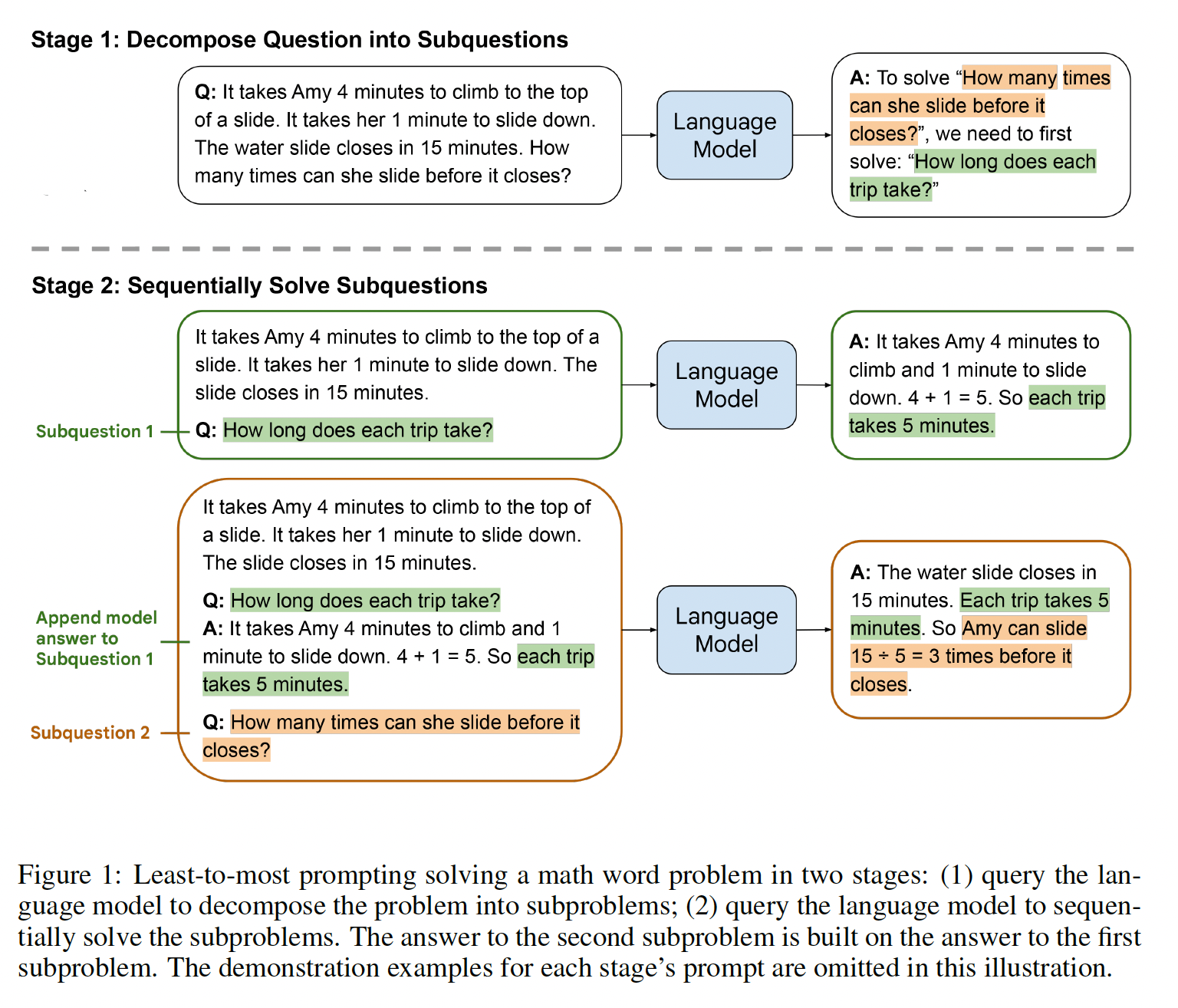
术语
"least-to-most prompting"借用自教育心理学(《A comparison of most-to-least and least-to-most prompting on the acquisition of solitary play skills》),它被用来表示一种技术,该技术使用渐进的prompts序列来帮助学生学习新技能。关于符号操作、组合泛化、以及数学推理的经验结果表明,least-to-most prompting确实可以泛化到比demonstrations的问题更难的问题。相关工作:
compositional generalization:SCAN是一个广泛使用的基准,用于评估组合泛化。在其所有的split中,最具挑战性的是length split,它要求模型泛化到比训练序列更长的测试序列。之前在SCAN上有良好表现的工作大多提出了神经符号(neural-symbolic)架构和语法归纳(grammar induction)技术。与现有的工作不同,我们证明,没有专门设计的模型架构和符号组件来提高compositional generalization能力,least-to-most prompting在任何split(包括length split)上都能达到99.7%的准确率,只需要少量的demonstration examples,而且不需要任何训练或微调。easy-to-hard generalization:除了组合泛化,还有许多其他任务,测试样本比训练样本需要更多的推理步骤来解决,例如,last-letter-concatenation任务。《Neural logicmachines》提出Neural Logic Machin: NLM用于inductive learning和逻辑推理。在小规模任务(如小尺寸块状世界)上训练的NLM可以完美地推广到大规模任务(如大尺寸块状世界)。《Can you learn an algorithm? generalizing from easy to hard problems with recurrent networks》表明,为解决具有少量递归步骤的简单问题(如小尺寸迷宫或国际象棋谜题)而训练的递归网络,可以通过在推理过程中执行额外的递归来解决更复杂的问题(如大尺寸迷宫或国际象棋谜题)。
在我们的方法中,我们通过将一个复杂的问题分解成一系列较容易的问题来实现
easy-to-hard generalization。任务分解:
《Unsupervised question decomposition for question answering》将一个multi-hop问题分解成若干独立的single-hop子问题,这些子问题由一个现成的问答模型来回答。然后,这些答案被汇总从而形成最终的答案。问题分解和答案汇总都是由训练好的模型实现的。《Shepherd pre-trained language models to develop a train of thought: An iterative prompting approach》通过将prompts建模为连续的虚拟tokens,并通过iterative prompting从语言模型中逐步激发相关的知识,来进行multi-hop QA。
与这些方法不同,我们的方法不涉及任何训练或微调。此外,
least-to-most prompting中产生的子问题通常是相互依赖的,必须按照特定的顺序依次解决,这样一些子问题的答案就可以作为解决其他子问题的building block。《Seqzero: Few-shot compositional semantic parsing with sequential prompts and zero-shot models 》通过基于规则的系统将一个问题分解成与SQL query相对应的slot-filling自然语言prompts的序列,将自然语言问题翻译成SQL query。《AI chains: Transparent and controllable human-AI interaction by chaining large language model prompts》提出将大型语言模型的步骤链接起来,使一个步骤的输出成为下一个步骤的输入,并开发了一个交互式系统供用户构建和修改chains。
least-to-most prompting链接了问题分解和子问题解决的过程。
26.1 方法
least-to-most prompting教导语言模型如何通过将一个复杂的问题分解为一系列较简单的子问题来解决。它由两个连续的阶段组成:分解:这一阶段的
prompt包含展示分解的constant examples,然后是待分解的具体问题。子问题的解决。这个阶段的
prompt由三部分组成:演示如何解决子问题的
constant examples。已经回答的子问题以及生成答案所组成的列表(可能是空的)。
接下来要回答的问题。
在
Figure 1所示的例子中,语言模型首先被要求将原始问题分解为子问题。传递给模型的prompt包括:说明如何分解复杂问题的examples(图中没有显示),然后是要分解的具体问题(如图所示)。语言模型发现,原始问题可以通过解决一个中间问题来回答"How long does each trip take?"。在下一个阶段,我们要求语言模型依次解决
problem decomposition阶段所得到的子问题。原始问题被附加为最后的子问题。
求解过程以向语言模型传递一个
prompt而开始,这个prompt包括:说明问题如何解决的例子(图中未显示),然后是第一个子问题"How long does each trip take?"。然后,我们采用语言模型所生成的答案(
"... each trip takes 5 minutes."),并通过将所生成的答案附加到前一个prompt中来构建下一个prompt,然后是下一个子问题(在这个例子中,这恰好是原始问题)。然后,新的
prompt被传回语言模型,由该模型返回最终答案。
least-to-most prompting可以与其他提示技术相结合,如chain-of-thought和self-consistency,但并不是必须得。另外,对于某些任务,least-to-most prompting中的两个阶段可以合并,形成single-pass prompt。
26.2 实验
26.2.1 符号操作
任务:
last-letter-concatenation,其中输入是一个单词列表,输出是列表中每个单词的最后一个字母的拼接。当测试列表与
prompt exemplars中的列表具有相同的长度时,chain-of-thought prompting做得很完美。然而,当测试列表比prompt exemplars中的列表长很多时,它的表现就很差。我们表明,least-to-most prompting克服了这一限制,在长度泛化方面明显优于chain-of-thought prompting。Least-to-most prompting:Table 1展示了任务分解阶段,Table 2展示了子问题的解决阶段。
Chain-of-thought prompting:chain-of-thought prompt如下表所示。它使用的列表与Table 2中的least-to-most prompt相同。唯一区别是:对第二个列表("think, machine, learning")的回答是从头开始建立的,而不是使用第一个列表("think, machine")的输出。
实验结果:我们采用
GPT-3 code-davinci-002。不同prompting方法的结果如下表所示。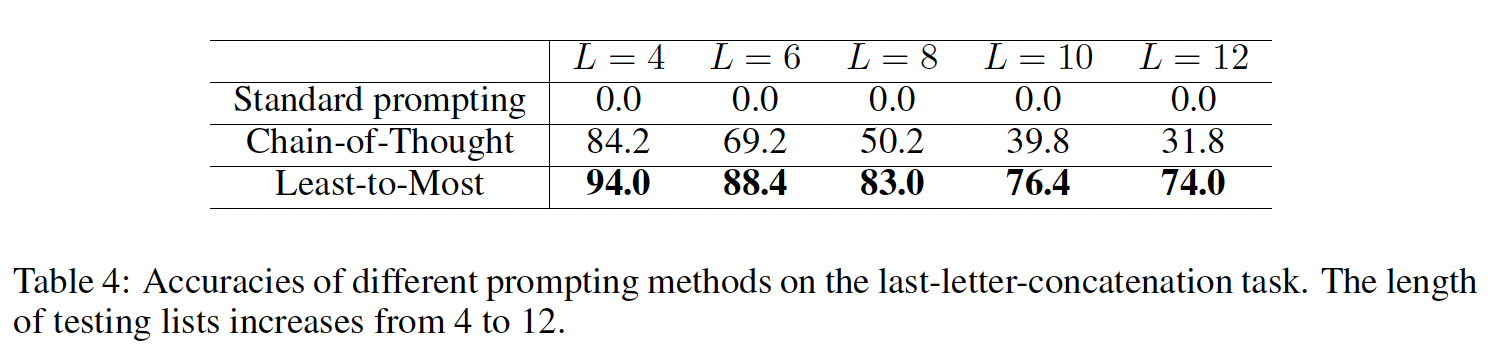
26.2.2 组合泛化
任务:
SCAN,它需要将自然语言命令映射到动作序列,如下表所示。
实验结果如下表所示。

least-to-most prompting:
26.2.3 数学推理
任务:
GSM8K、DROP。我们特别感兴趣的是看大型语言模型结合
least-to-most prompting是否能解决比prompts中看到的更难的问题。在这里,我们只是通过解题步骤的数量来衡量难度。prompt:第一部分:
"“Let’s break down this problem . . .",展示原始问题如何被分解为更简单的子问题;第二部分:展示如何求解子问题。chain-of-thought prompting:移除了least-to-most prompting的第一部分内容。
实验结果:

26.3 局限性
prompts分解通常不能很好地泛化到不同的领域中。因此对于不同的领域,必须设计新的prompt从而进行任务分解,以达到最佳性能。在同一领域内,
decomposition的泛化甚至会有困难。我们观察到,如果为大型语言模型提供那些具有挑战性的问题的正确分解,GSM8K中几乎所有的问题都能被准确地解决。这一发现并不令人惊讶,而且与我们解决数学问题的经验相吻合。每当我们成功地将一个数学问题分解成我们可以解决的更简单的子问题时,我们基本上就解决了原始问题。