CNN:图像分类
ImageNet数据集:一个开源的图片数据集,包含超过 1400万张图片和图片对应的标签,包含2万多个类别。自从
2010年以来,ImageNet每年举办一次比赛,即:ImageNet大规模视觉识别挑战赛ILSVRC,比赛使用 1000 个类别图片。2017年7月,
ImageNet宣布ILSVRC于2017年正式结束,因为图像分类、物体检测、物体识别任务中计算机的正确率都远超人类,计算机视觉在感知方面的问题基本得到解决,后续将专注于目前尚未解决的问题。ImageNet中使用两种错误率作为评估指标:top-5错误率:对一个图片,如果正确标记在模型输出的前 5 个最佳预测(即:概率最高的前5个)中,则认为是正确的,否则认为是错误的。最终错误预测的样本数占总样本数的比例就是
top-5错误率。top-1错误率:对一个图片,如果正确标记等于模型输出的最佳预测(即:概率最高的那个),则认为是正确的,否则认为是错误的。最终错误预测的样本数占总样本数的比例就是
top-1错误率。
注:
feature map的描述有两种:channel first,如256x3x3;channel last,如3x3x256。这里如果未说明,则默认采用channel last描述。另外也可以显式指定,如:3x3@256。
一、LeNet
1998年
LeCun推出了LeNet网络,它是第一个广为流传的卷积神经网络。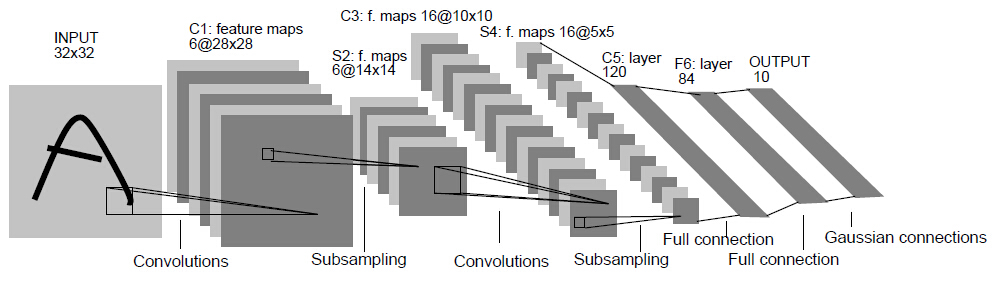
LeNet网络包含了卷积层、池化层、全连接层,这些都是现代CNN网络的基本组件。输入层:二维图像,尺寸为
32x32。C1、C3、C5层:二维卷积层。其中
C5将输入的feature map(尺寸16@5x5)转化为尺寸为120x1x1的feature map,然后转换为长度为120的一维向量。这是一种常见的、将卷积层的输出转换为全连接层的输入的一种方法。
S2、S4层:池化层。使用sigmoid函数作为激活函数。后续的
CNN都使用ReLU作为激活函数。F6层:全连接层。输出层:由欧式径向基函数单元组成。
后续的
CNN使用softmax输出单元。下表中,
@分隔了通道数量和feature map的宽、高。网络层 核/池大小 核数量 步长 输入尺寸 输出尺寸 INPUT - - - - 1@32x32 C1 5x5 6 1 1@32x32 6@28x28 S2 2x2 - 2 6@28x28 6@14x14 C3 5x5 16 1 6@14x14 16@10x10 S4 2x2 - 2 16@10x10 16@5x5 C5 5x5 120 1 16@5x5 120@1x1 F6 - - - 120 84 OUTPUT - - - 84 10
二、AlexNet
- 2012年
Hinton和他的学生推出了AlexNet。在当年的ImageNet图像分类竞赛中,AlexeNet以远超第二名的成绩夺冠,使得深度学习重回历史舞台,具有重大历史意义。
2.1 网络结构
AlexNet有5个广义卷积层和3个广义全连接层。- 广义的卷积层:包含了卷积层、池化层、
ReLU、LRN层等。 - 广义全连接层:包含了全连接层、
ReLU、Dropout层等。
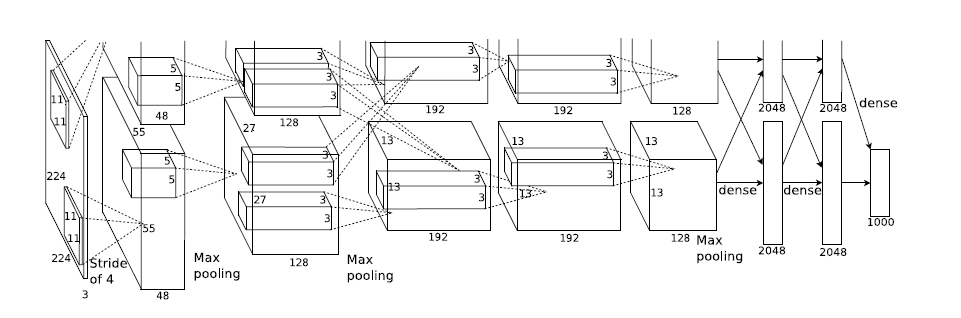
- 广义的卷积层:包含了卷积层、池化层、
网络结构如下表所示:
输入层会将
3@224x224的三维图片预处理变成3@227x227的三维图片。第二层广义卷积层、第四层广义卷积层、第五层广义卷积层都是分组卷积,仅采用本
GPU内的通道数据进行计算。第一层广义卷积层、第三层广义卷积层、第六层连接层、第七层连接层、第八层连接层执行的是全部通道数据的计算。
第二层广义卷积层的卷积、第三层广义卷积层的卷积、第四层广义卷积层的卷积、第五层广义卷积层的卷积均采用
same填充。当卷积的步长为1,核大小为
3x3时,如果不填充0,则feature map的宽/高都会缩减 2 。因此这里填充0,使得输出feature map的宽/高保持不变。其它层的卷积,以及所有的池化都是
valid填充(即:不填充 0 )。第六层广义连接层的卷积之后,会将
feature map展平为长度为 4096 的一维向量。
编号 网络层 子层 核/池大小 核数量 步长 激活函数 输入尺寸 输出尺寸 第0层 输入层 - - - - - - 3@224x224 第1层 广义卷积层 卷积 11x11 96 4 ReLU 3@227x227 96@55x55 第1层 广义卷积层 池化 3x3 - 2 - 96@55x55 96@27x27 第1层 广义卷积层 LRN - - - - 96@27x27 96@27x27 第2层 广义卷积层 卷积 5x5 256 1 ReLU 96@27x27 256@27x27 第2层 广义卷积层 池化 3x3 - 2 - 256@27x27 256@13x13 第2层 广义卷积层 LRN - - - - 256@13x13 256@13x13 第3层 广义卷积层 卷积 3x3 384 1 ReLU 256@13x13 384@13x13 第4层 广义卷积层 卷积 3x3 384 1 ReLU 384@13x13 384@13x13 第5层 广义卷积层 卷积 3x3 256 1 ReLU 384@13x13 256@13x13 第5层 广义卷积层 池化 3x3 - 2 - 256@13x13 256@6x6 第6层 广义连接层 卷积 6x6 4096 1 ReLU 256@6x6 4096@1x1 第6层 广义连接层 dropout - - - - 4096@1x1 4096@1x1 第7层 广义连接层 全连接 - - - ReLU 4096 4096 第7层 广义连接层 dropout - - - - 4096 4096 第8层 广义连接层 全连接 - - - - 4096 1000 网络参数数量:总计约 6237万。
输出
Tensor size采用channel last风格描述。即227x227x3等价于前文的3@227x227。第6层广义连接层的卷积的参数数量最多,约3770万,占整体六千万参数的 60%。
原因是该子层的卷积核较大、输入通道数量较大、输出通道数量太多。该卷积需要的参数数量为: 。
编号 网络层 子层 输出 Tensor size 权重个数 偏置个数 参数数量 第0层 输入层 - 227x227x3 0 0 0 第1层 广义卷积层 卷积 55x55x96 34848 96 34944 第1层 广义卷积层 池化 27x27x96 0 0 0 第1层 广义卷积层 LRN 27x27x96 0 0 0 第2层 广义卷积层 卷积 27x27x256 614400 256 614656 第2层 广义卷积层 池化 13x13x256 0 0 0 第2层 广义卷积层 LRN 13x13x256 0 0 0 第3层 广义卷积层 卷积 13x13x384 884736 384 885120 第4层 广义卷积层 卷积 13x13x384 1327104 384 1327488 第5层 广义卷积层 卷积 13x13x256 884736 256 884992 第5层 广义卷积层 池化 6x6x256 0 0 0 第6层 广义连接层 卷积 4096×1 37748736 4096 37752832 第6层 广义连接层 dropout 4096×1 0 0 0 第7层 广义连接层 全连接 4096×1 16777216 4096 16781312 第7层 广义连接层 dropout 4096×1 0 0 0 第8层 广义连接层 全连接 1000×1 4096000 1000 4097000 总计 - - - - - 62,378,344
2.2 设计技巧
AlexNet成功的主要原因在于:- 使用
ReLU激活函数。 - 使用
dropout、数据集增强 、重叠池化等防止过拟合的方法。 - 使用百万级的大数据集来训练。
- 使用
GPU训练,以及的LRN使用。 - 使用带动量的
mini batch随机梯度下降来训练。
- 使用
2.2.1 数据集增强
AlexNet中使用的数据集增强手段:随机裁剪、随机水平翻转:原始图片的尺寸为
256xx256,裁剪大小为224x224。每一个
epoch中,对同一张图片进行随机性的裁剪,然后随机性的水平翻转。理论上相当于扩充了数据集 倍。在预测阶段不是随机裁剪,而是固定裁剪图片四个角、一个中心位置,再加上水平翻转,一共获得 10 张图片。
用这10张图片的预测结果的均值作为原始图片的预测结果。
PCA降噪:对RGB空间做PCA变换来完成去噪功能。同时在特征值上放大一个随机性的因子倍数(单位1加上一个 的高斯绕动),从而保证图像的多样性。- 每一个
epoch重新生成一个随机因子。 - 该操作使得错误率下降
1%。
- 每一个
AlexNet的预测方法存在两个问题:- 这种
固定裁剪四个角、一个中心的方式,把图片的很多区域都给忽略掉了。很有可能一些重要的信息就被裁剪掉。 - 裁剪窗口重叠,这会引起很多冗余的计算。
改进的思路是:
- 执行所有可能的裁剪方式,对所有裁剪后的图片进行预测。将所有预测结果取平均,即可得到原始测试图片的预测结果。
- 减少裁剪窗口重叠部分的冗余计算。
具体做法为:将全连接层用等效的卷积层替代,然后直接使用原始大小的测试图片进行预测。将输出的各位置处的概率值按每一类取平均(或者取最大),则得到原始测试图像的输出类别概率。
下图中:上半图为
AlexNet的预测方法;下半图为改进的预测方法。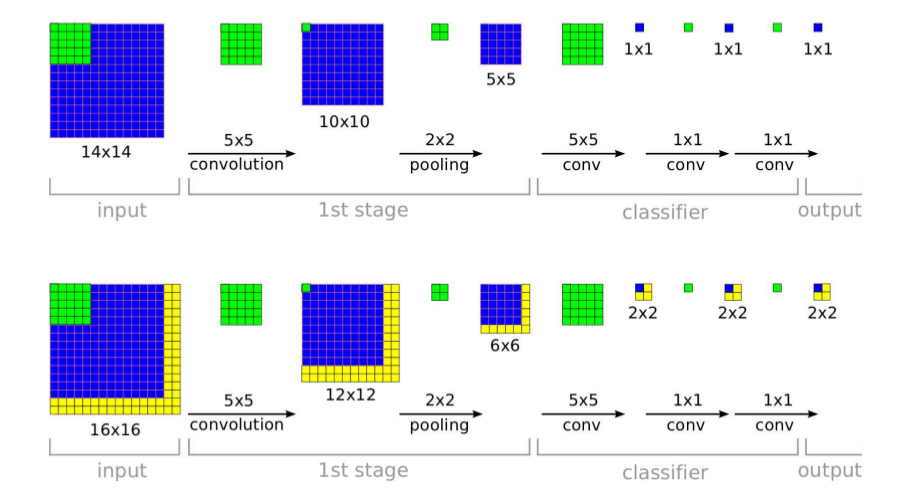
- 这种
2.2.2 局部响应规范化
局部响应规范层
LRN:目地是为了进行一个横向抑制,使得不同的卷积核所获得的响应产生竞争。LRN层现在很少使用,因为效果不是很明显,而且增加了内存消耗和计算时间。- 在
AlexNet中,该策略贡献了1.2%的贡献率。
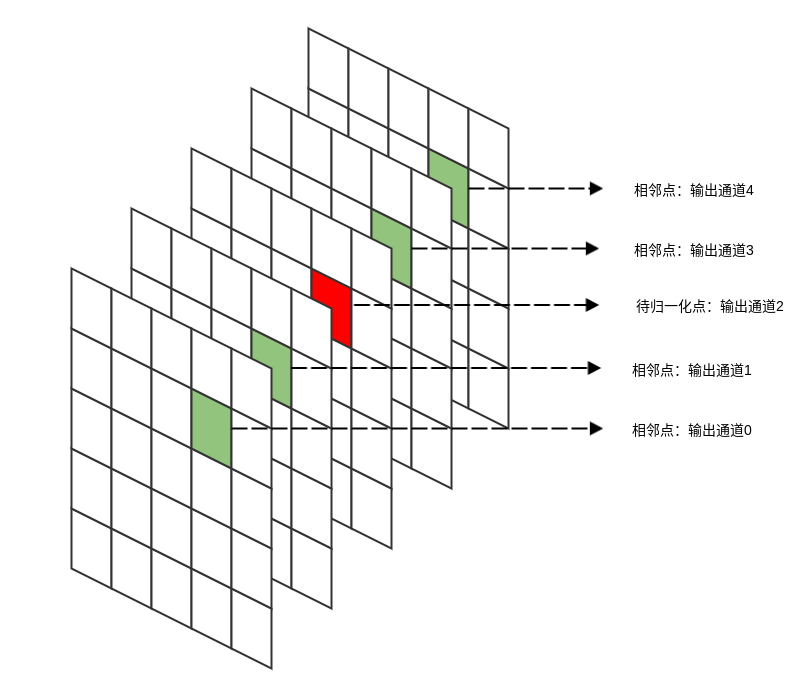
LRN的思想:输出通道 在位置 处的输出会受到相邻通道在相同位置输出的影响。为了刻画这种影响,将输出通道 的原始值除以一个归一化因子。
其中: 为输出通道 在位置 处的原始值, 为归一化之后的值。 为影响第 通道的通道数量(分别从左侧、右侧 个通道考虑)。 为超参数。
一般考虑 。
2.2.3 多GPU 训练
AlexNet使用两个GPU训练。网络结构图由上、下两部分组成:一个GPU运行图上方的通道数据,一个GPU运行图下方的通道数据,两个GPU只在特定的网络层通信。即:执行分组卷积。- 第二、四、五层卷积层的核只和同一个
GPU上的前一层的feature map相连。 - 第三层卷积层的核和前一层所有
GPU的feature map相连。 - 全连接层中的神经元和前一层中的所有神经元相连。
- 第二、四、五层卷积层的核只和同一个
2.2.4 重叠池化
一般的池化是不重叠的,池化区域的大小与步长相同。
Alexnet中,池化是可重叠的,即:步长小于池化区域的大小。重叠池化可以缓解过拟合,该策略贡献了
0.4%的错误率。为什么重叠池化会减少过拟合,很难用数学甚至直观上的观点来解答。一个稍微合理的解释是:重叠池化会带来更多的特征,这些特征很可能会有利于提高模型的泛化能力。
2.2.5 优化算法
AlexNet使用了带动量的mini-batch随机梯度下降法。标准的带动量的
mini-batch随机梯度下降法为:而论文中,作者使用了修正:
- 其中 , , 为学习率。
- 为权重衰减。论文指出:权重衰减对于模型训练非常重要,不仅可以起到正则化效果,还可以减少训练误差。
三、VGG-Net
VGG-Net是牛津大学计算机视觉组和DeepMind公司共同研发一种深度卷积网络,并且在2014年在ILSVRC比赛上获得了分类项目的第二名和定位项目的第一名。VGG-Net的主要贡献是:- 证明了小尺寸卷积核(
3x3)的深层网络要优于大尺寸卷积核的浅层网络。 - 证明了深度对网络的泛化性能的重要性。
- 验证了尺寸抖动
scale jittering这一数据增强技术的有效性。
- 证明了小尺寸卷积核(
VGG-Net最大的问题在于参数数量,VGG-19基本上是参数数量最多的卷积网络架构。
3.1 网络结构
VGG-Net一共有五组结构(分别表示为:A~E), 每组结构都类似,区别在于网络深度上的不同。结构中不同的部分用黑色粗体给出。
卷积层的参数为
convx-y,其中x为卷积核大小,y为卷积核数量。如:
conv3-64表示64个3x3的卷积核。卷积层的通道数刚开始很小(64通道),然后在每个池化层之后的卷积层通道数翻倍,直到512。
每个卷积层之后都跟随一个
ReLU激活函数,表中没有标出。
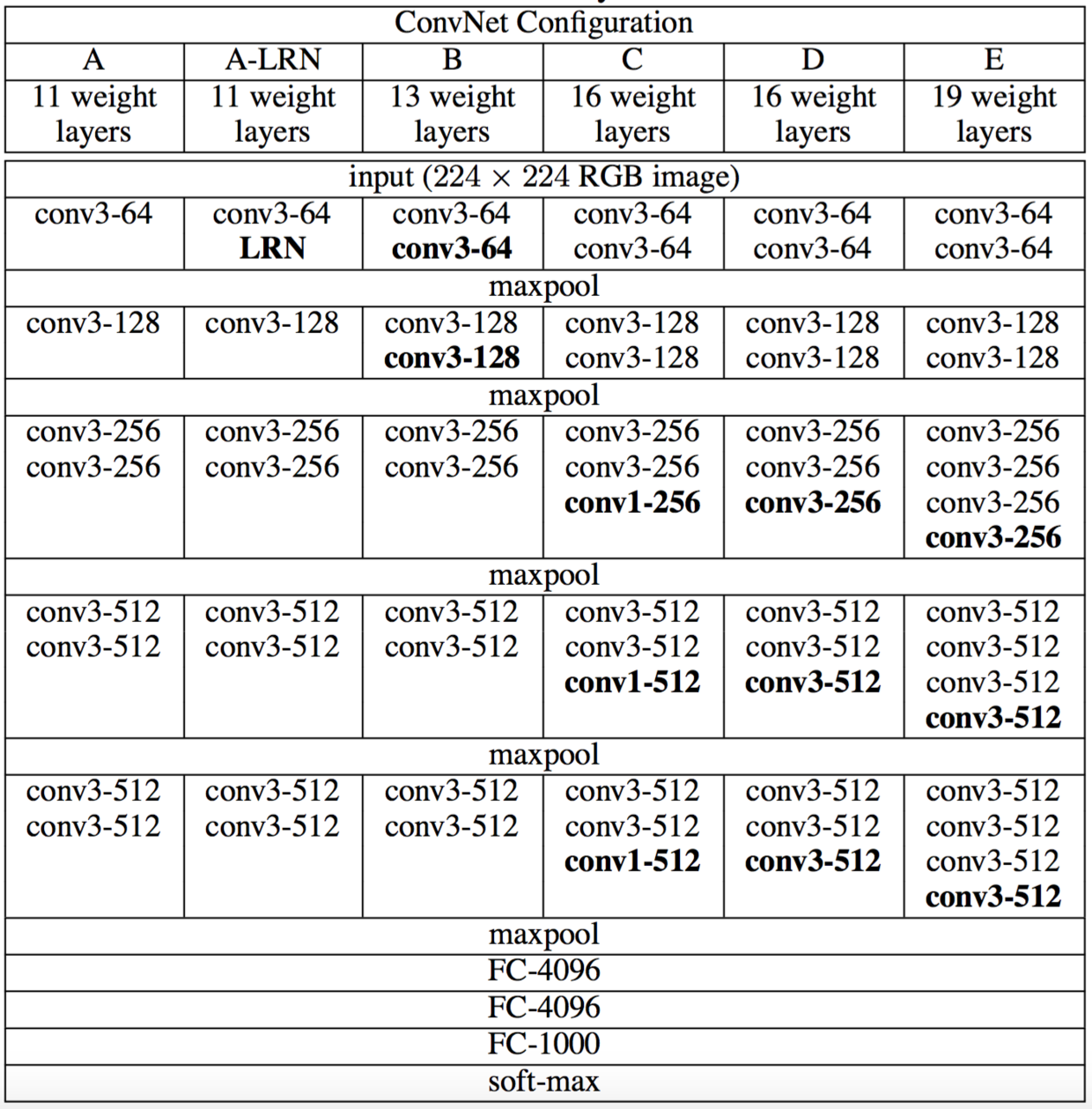
通用结构:
输入层:固定大小的
224x224的RGB图像。卷积层:卷积步长均为1。
填充方式:填充卷积层的输入,使得卷积前后保持同样的空间分辨率。
3x3卷积:same填充,即:输入的上下左右各填充1个像素。1x1卷积:不需要填充。
卷积核尺寸:有
3x3和1x1两种。3x3卷积核:这是捕获左右、上下、中心等概念的最小尺寸。1x1卷积核:用于输入通道的线性变换。在它之后接一个
ReLU激活函数,使得输入通道执行了非线性变换。
池化层:采用最大池化。
- 池化层连接在卷积层之后,但并不是所有的卷积层之后都有池化。
- 池化窗口为
2x2,步长为 2 。
网络最后四层为::三个全连接层 + 一个
softmax层。- 前两个全连接层都是 4096个神经元,第三个全连接层是 1000 个神经元(因为执行的是 1000 类的分类)。
- 最后一层是
softmax层用于输出类别的概率。
所有隐层都使用
ReLU激活函数。
VGG-Net网络参数数量:其中第一个全连接层的参数数量为:
7x7x512x4096=1.02亿,因此网络绝大部分参数来自于该层。与
AlexNet相比,VGG-Net在第一个全连接层的输入feature map较大:7x7 vs 6x6,512 vs 256。网络 A , A-LRN B C D E 参数数量 1.13亿 1.33亿 1.34亿 1.38亿 1.44
3.2 设计技巧
输入预处理:通道像素零均值化。
先统计训练集中全部样本的通道均值:所有红色通道的像素均值 、所有绿色通道的像素均值 、所有蓝色通道的像素均值 。
其中:假设红色通道为通道
0,绿色通道为通道1,蓝色通道为通道2; 遍历所有的训练样本, 遍历图片空间上的所有坐标。对每个样本:红色通道的每个像素值减去 ,绿色通道的每个像素值减去 ,蓝色通道的每个像素值减去 。
多尺度训练:将原始的图像缩放到最小的边 ,然后在整副图像上截取
224x224的区域来训练。有两种方案:
在所有图像上固定 :用 来训练一个模型,用 来训练另一个模型。最后使用两个模型来评估。
对每个图像,在 之间随机选取一个 ,然后进行裁剪来训练一个模型。最后使用单个模型来评估。
- 该方法只需要一个单一的模型。
- 该方法相当于使用了尺寸抖动(
scale jittering) 的数据增强。
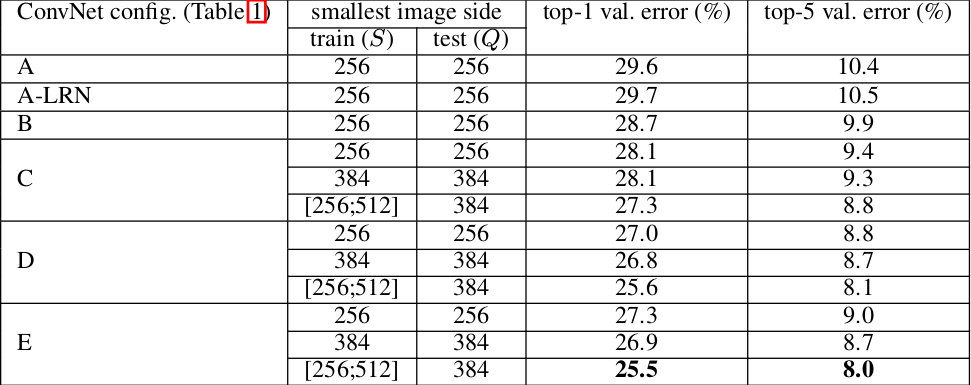
多尺度测试:将测试的原始图像等轴的缩放到预定义的最小图像边,表示为 ( 不一定等于 ),称作测试尺度。
在一张测试图像的几个归一化版本上运行模型,然后对得到的结果进行平均。
- 不同版本对应于不同的 值。
- 所有版本都执行通道像素归一化。注意:采用训练集的统计量。
该方法相当于在测试时使用了尺寸抖动。实验结果表明:测试时的尺寸抖动导致了更好的性能。
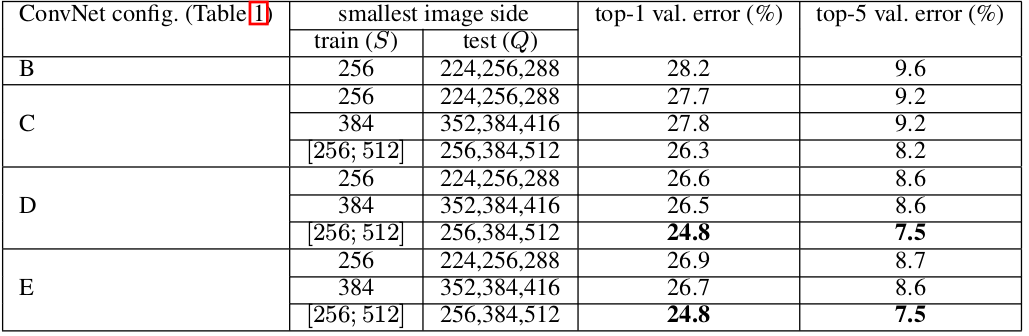
评估有三种方案:
single-crop:对测试图片沿着最短边缩放,然后选择其中的center crop来裁剪图像,选择这个图像的预测结果作为原始图像的预测结果。该方法的缺点是:仅仅保留图片的中央部分可能会丢掉图片类别的关键信息。因此该方法很少在实际任务中使用,通常用于不同模型之间的性能比较。
multi-crop:类似AlexNet的做法,对每个测试图像获取多个裁剪图像,平均每个裁剪图像的预测结果为原始图像的预测结果。该方法的缺点是:需要网络重新计算每个裁剪图像,效率较低。
dense:将最后三个全连接层用等效的卷积层替代,成为一个全卷积网络。其中:第一个全连接层用7x7的卷积层替代,后面两个全连接层用1x1的卷积层替代。该全卷积网络应用到整张图片上(无需裁剪),得到一个多位置的、各类别的概率字典。通过原始图片、水平翻转图片的各类别预测的均值,得到原始图片的各类别概率。
该方法的优点是:不需要裁剪图片,支持多尺度的图片测试,计算效率较高。
实验结果表明:
multi-crop评估方式要比dense评估方式表现更好。另外,二者是互补的,其组合要优于任何单独的一种。下表中,S=[256;512], 。还有一种评估策略:
ensemble error。即:同时训练同一种网络的多个不同的模型,然后用这几个模型的预测结果的平均误差作为最终的ensemble error。有一种术语叫
single-model error。它是训练一个模型,然后采用上述的多种crop/dense评估的组合,这些组合的平均输出作为预测结果。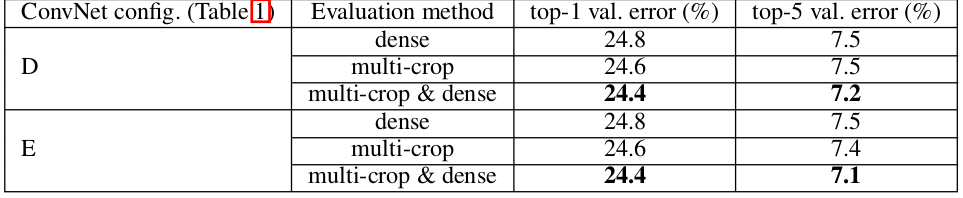
权重初始化:由于网络深度较深,因此网络权重的初始化很重要,设计不好的初始化可能会阻碍学习。
- 论文的权重初始化方案为:先训练结构
A。当训练更深的配置时,使用结构A的前四个卷积层和最后三个全连接层来初始化网络,网络的其它层被随机初始化。 - 作者后来指出:可以通过
Xavier均匀初始化来直接初始化权重而不需要进行预训练。
- 论文的权重初始化方案为:先训练结构
实验结果表明:
- 分类误差随着网络深度的增加而减小。
- 从
A-LRN和A的比较发现:局部响应归一化层LRN对于模型没有任何改善。
四、Inception
Inception网络是卷积神经网络的一个重要里程碑。在Inception之前,大部分流行的卷积神经网络仅仅是把卷积层堆叠得越来越多,使得网络越来越深。这使得网络越来越复杂,参数越来越多,从而导致网络容易出现过拟合,增加计算量。而
Inception网络考虑的是多种卷积核的并行计算,扩展了网络的宽度。Inception Net核心思想是:稀疏连接。因为生物神经连接是稀疏的。Inception网络的最大特点是大量使用了Inception模块。
4.1 Inception v1
4.1.1 网络结构
InceptionNet V1是一个22层的深度网络。 如果考虑池化层,则有29层。如下图中的depth列所示。网络具有三组
Inception模块,分别为:inception(3a)/inception(3b)、inception(4a)/inception(4b)/inception(4c)/inception(4d)/inception(4e)、inception(5a)、inception(5b)。三组Inception模块被池化层分隔。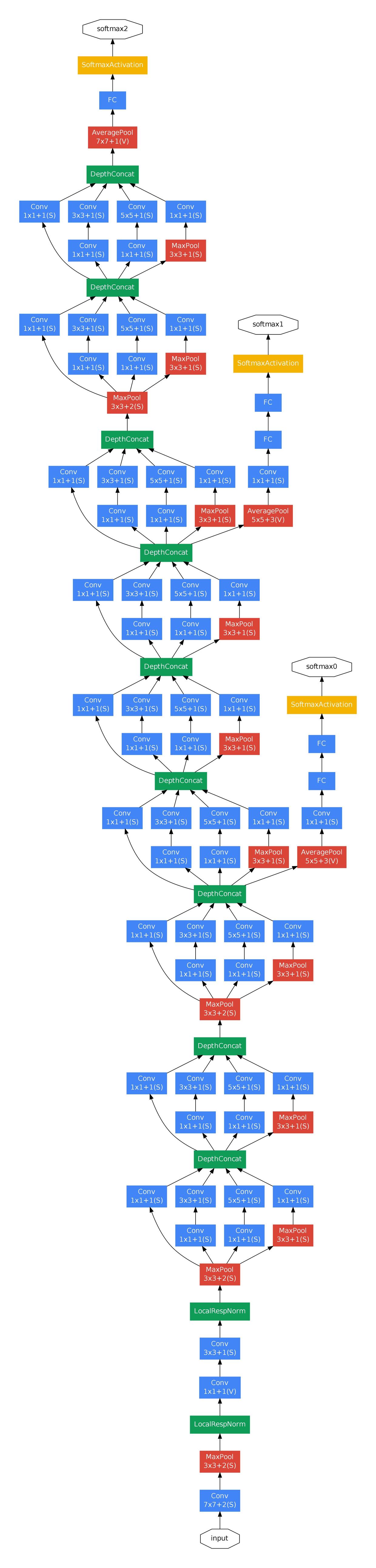
下图给出了网络的层次结构和参数,其中:
type列:给出了每个模块/层的类型。patch size/stride列:给出了卷积层/池化层的尺寸和步长。output size列:给出了每个模块/层的输出尺寸和输出通道数。depth列:给出了每个模块/层包含的、含有训练参数层的数量。#1x1列:给出了每个模块/层包含的1x1卷积核的数量,它就是1x1卷积核的输出通道数。#3x3 reduce列:给出了每个模块/层包含的、放置在3x3卷积层之前的1x1卷积核的数量,它就是1x1卷积核的输出通道数。#3x3列:给出了每个模块/层包含的3x3卷积核的数量,它就是3x3卷积核的输出通道数。#5x5 reduce列:给出了每个模块/层包含的、放置在5x5卷积层之前的1x1卷积核的数量,它就是1x1卷积核的输出通道数。#5x5列:给出了每个模块/层包含的5x5卷积核的数量,它就是5x5卷积核的输出通道数。pool proj列:给出了每个模块/层包含的、放置在池化层之后的1x1卷积核的数量,它就是1x1卷积核的输出通道数。params列:给出了每个模块/层的参数数量。ops列:给出了每个模块/层的计算量。
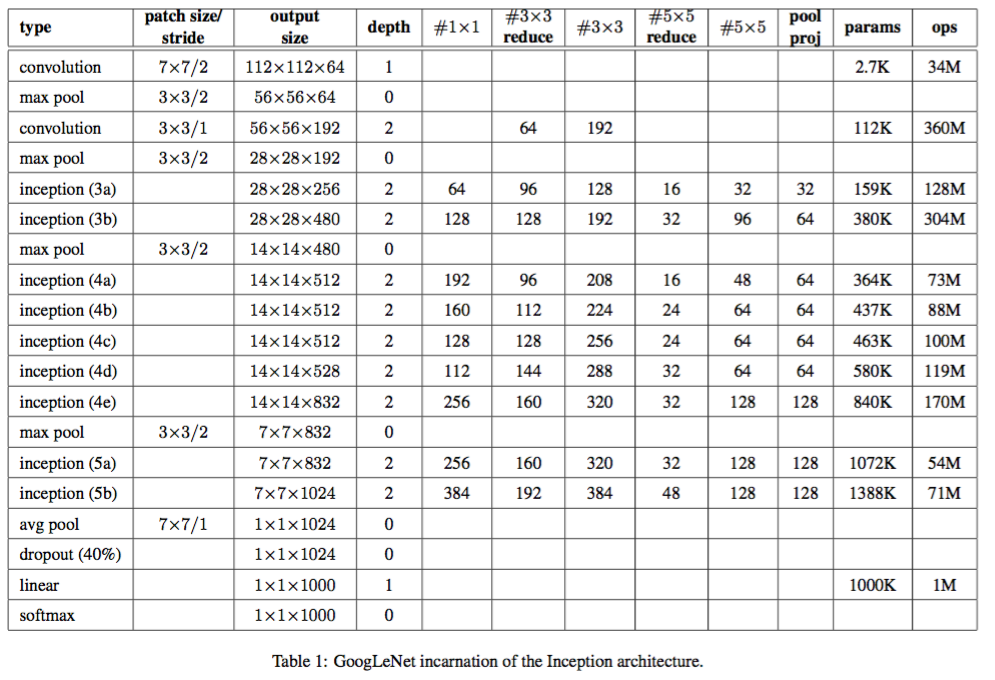
Inception V1的参数数量为 697.7 万,其参数数量远远小于AlexNet(6千万)、VGG-Net(超过1亿)。Inception V1参数数量能缩减的一个主要技巧是:在inception(5b)输出到linear之间插入一个平均池化层avg pool。- 如果没有平均池化层,则
inception(5b)到linear之间的参数数量为:7x7x1024x1024,约为 5 千万。 - 插入了平均池化层之后,
inception(5b)到linear之间的参数数量为:1x1x1024x1024,约为 1百万。
- 如果没有平均池化层,则
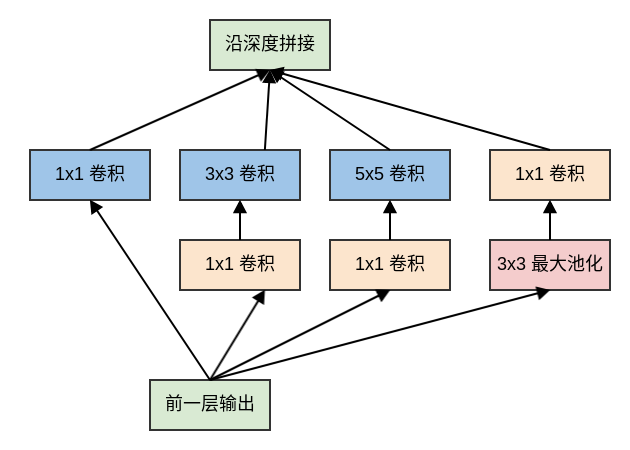
4.1.2 Inception 模块
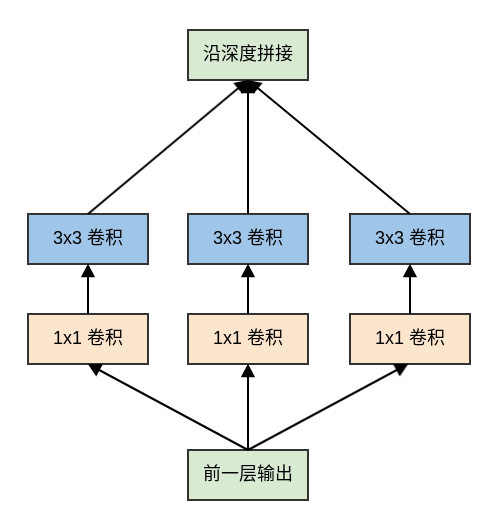
原始的
Inception模块对输入同时执行:3个不同大小的卷积操作(1x1、3x3、5x5)、1个最大池化操作(3x3)。所有操作的输出都在深度方向拼接起来,向后一级传递。三种不同大小卷积:通过不同尺寸的卷积核抓取不同大小的对象的特征。
使用
1x1、3x3、5x5这些具体尺寸仅仅是为了便利性,事实上也可以使用更多的、其它尺寸的滤波器。1个最大池化:提取图像的原始特征(不经过过滤器)。
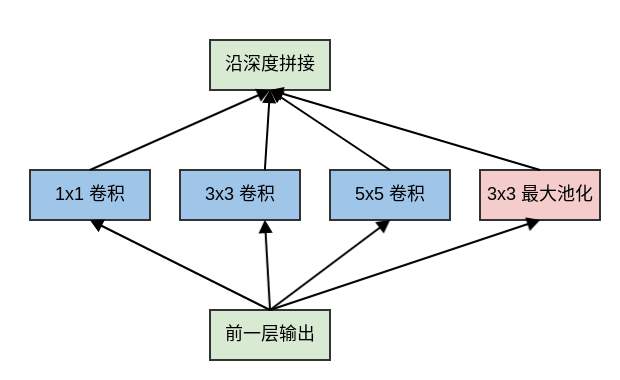
原始
Inception模块中,模块的输出通道数量为四个子层的输出通道数的叠加。这种叠加不可避免的使得Inception模块的输出通道数增加,这就增加了Inception模块中每个卷积的计算量。因此在经过若干个模块之后,计算量会爆炸性增长。解决方案是:在
3x3和5x5卷积层之前额外添加1x1卷积层,来限制输入给卷积层的输入通道的数量。注意:
1x1卷积是在最大池化层之后,而不是之前。这是因为:池化层是为了提取图像的原始特征,一旦它接在1x1卷积之后就失去了最初的本意。1x1卷积在3x3、5x5卷积之前。这是因为:如果1x1卷积在它们之后,则3x3卷积、5x5卷积的输入通道数太大,导致计算量仍然巨大。
4.1.3 辅助分类器
为了缓解梯度消失的问题,
InceptionNet V1给出了两个辅助分类器。这两个辅助分类器被添加到网络的中间层,它们和主分类器共享同一套训练数据及其标记。其中:第一个辅助分类器位于
Inception(4a)之后,Inception(4a)模块的输出作为它的输入。第二个辅助分类器位于
Inception(4d)之后,Inception(4d)模块的输出作为它的输入。两个辅助分类器的结构相同,包括以下组件:
- 一个尺寸为
5x5、步长为3的平均池化层。 - 一个尺寸为
1x1、输出通道数为128的卷积层。 - 一个具有
1024个单元的全连接层。 - 一个
drop rate = 70%的dropout层。 - 一个使用
softmax损失的线性层作为输出层。
- 一个尺寸为
在训练期间,两个辅助分类器的损失函数的权重是0.3,它们的损失被叠加到网络的整体损失上。在推断期间,这两个辅助网络被丢弃。
在
Inception v3的实验中表明:辅助网络的影响相对较小,只需要其中一个就能够取得同样的效果。事实上辅助分类器在训练早期并没有多少贡献。只有在训练接近结束,辅助分支网络开始发挥作用,获得超出无辅助分类器网络的结果。
两个辅助分类器的作用:提供正则化的同时,克服了梯度消失问题。
4.2 Inception v2
Inception v2的主要贡献是提出了Batch Normalization。论文指出,使用了Batch Normalization之后:可以加速网络的学习。
相比
Inception v1,训练速度提升了14倍。因为应用了BN之后,网络可以使用更高的学习率,同时删除了某些层。网络具有更好的泛化能力。
在
ImageNet分类问题的top5上达到4.8%,超过了人类标注top5的准确率。
Inception V2网络训练的技巧有:- 使用更高的学习率。
- 删除
dropout层、LRN层。 - 减小
L2正则化的系数。 - 更快的衰减学习率。学习率以指数形式衰减。
- 更彻底的混洗训练样本,使得一组样本在不同的
epoch中处于不同的mini batch中。 - 减少图片的形变。
Inception v2的网络结构比Inception v1有少量改动:5x5卷积被两个3x3卷积替代。这使得网络的最大深度增加了 9 层,同时网络参数数量增加 25%,计算量增加 30%。
28x28的inception模块从2个增加到3个。在
inception模块中,有的采用最大池化,有的采用平均池化。在
inception模块之间取消了用作连接的池化层。inception(3c),inception(4e)的子层采用步长为 2 的卷积/池化。
Pool+proj列给出了inception中的池化操作。avg+32意义为:平均池化层后接一个尺寸1x1、输出通道32的卷积层。max+pass through意义为:最大池化层后接一个尺寸1x1、输出通道数等于输入通道数的卷积层。
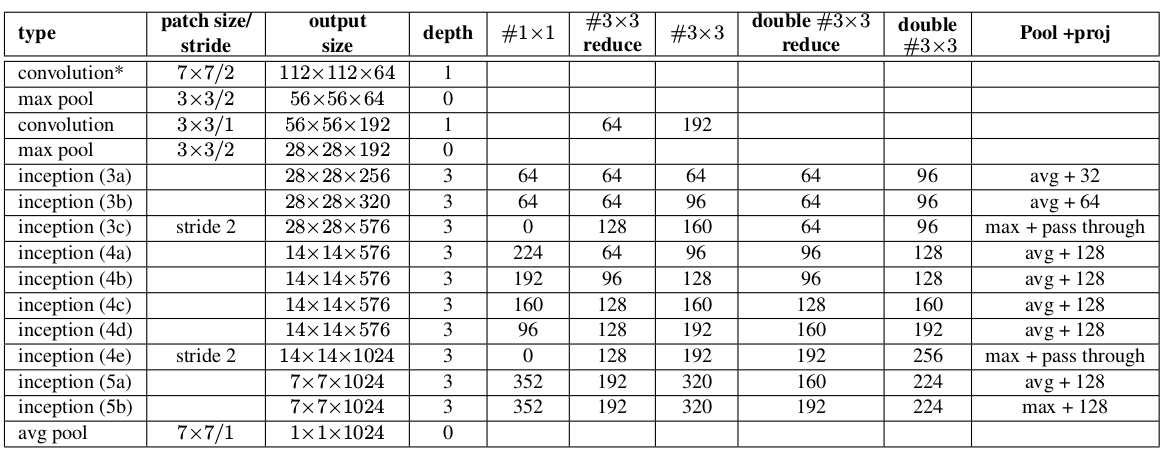
Inception V2的网络参数约为1126万。层 参数数量 conv1 9408 conv2 114688 inception-3a 218094 inception-3b 259072 inception-3c 384000 inception-4a 608193 inception-4b 663552 inception-4c 912384 inception-4d 1140736 inception-4e 1447936 inception-5a 2205696 inception-5b 2276352 fc 1024000 共 11264111 Inception V2在ImageNet测试集上的误差率: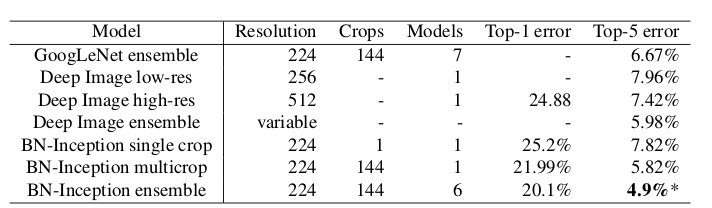
4.3 Inception v3
虽然
Inception v1的参数较少,但是它的结构比较复杂,难以进行修改。原因有以下两点:- 如果单纯的放大网络(如增加
Inception模块的数量、扩展Inception模块的大小),则参数的数量会显著增长,计算代价太大。 Inception v1结构中的各种设计,其对最终结果的贡献尚未明确。
因此
Inception v3的论文重点探讨了网络结构设计的原则。- 如果单纯的放大网络(如增加
4.3.1 网络结构
Inception v3的网络深度为42层,它相对于Inception v1网络主要做了以下改动:7x7卷积替换为3个3x3卷积。3个
Inception模块:模块中的5x5卷积替换为2个3x3卷积,同时使用后面描述的网格尺寸缩减技术。5个
Inception模块:模块中的5x5卷积替换为2个3x3卷积之后,所有的nxn卷积进行非对称分解,同时使用后面描述的网格尺寸缩减技术。2个
Inception模块:结构如下。它也使用了卷积分解技术,以及网格尺寸缩减技术。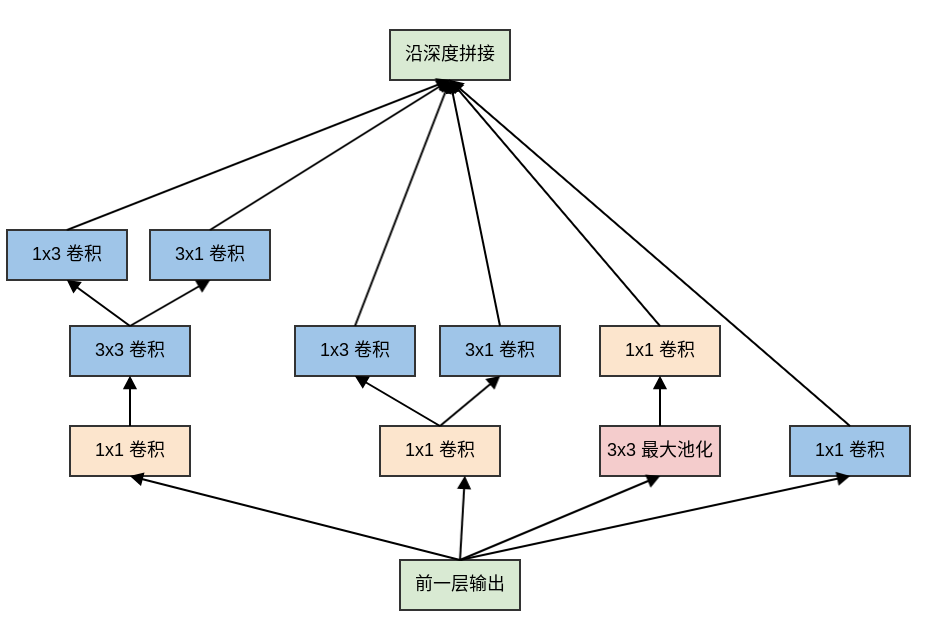
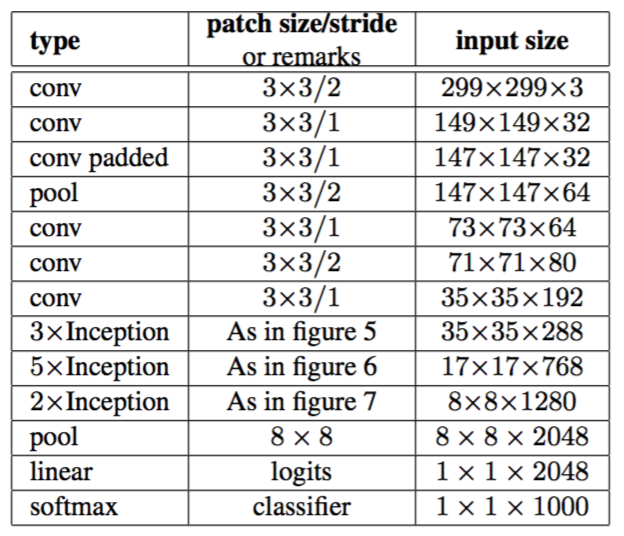
Inception v3的网络结构如下所示:3xInception表示三个Inception模块,4xInception表示四个Inception模块,5xInception表示五个Inception模块。conv padded表示使用0填充的卷积,它可以保持feature map的尺寸。在
Inception模块内的卷积也使用0填充,所有其它的卷积/池化不再使用填充。
在
3xInception模块的输出之后设有一个辅助分类器。其结构如下: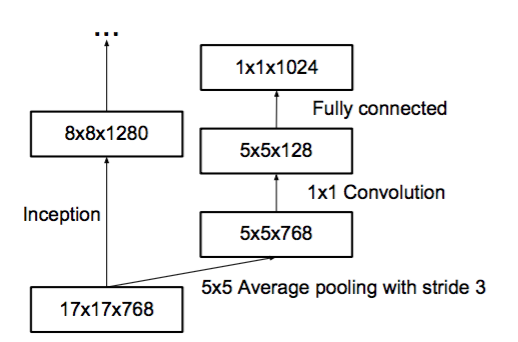
Inception v3整体参数数量约 23,626,728万(论文Xception: Deep Learning with Depthwise Separable Convolutions)。
4.3.2 设计技巧
Inception v3总结出网络设计的一套通用设计原则:避免
representation瓶颈:representation的大小应该从输入到输出缓缓减小,避免极端压缩。在缩小feature map尺寸的同时,应该增加feature map的通道数。representation大小通常指的是feature map的容量,即feature map的width x height x channel。空间聚合:可以通过空间聚合来完成低维嵌入,而不会在表达能力上有较大的损失。因此通常在
nxn卷积之前,先利用1x1卷积来降低输入维度。猜测的原因是:空间维度之间的强相关性导致了空间聚合过程中的信息丢失较少。
平衡网络的宽度和深度:增加网络的宽度或者深度都可以提高网络的泛化能力,因此计算资源需要在网络的深度和宽度之间取得平衡。
4.3.2.1 卷积尺寸分解
大卷积核的分解:将大卷积核分解为多个小的卷积核。
如:使用2个
3x3卷积替换5x5卷积,则其参数数量大约是1个5x5卷积的 72% 。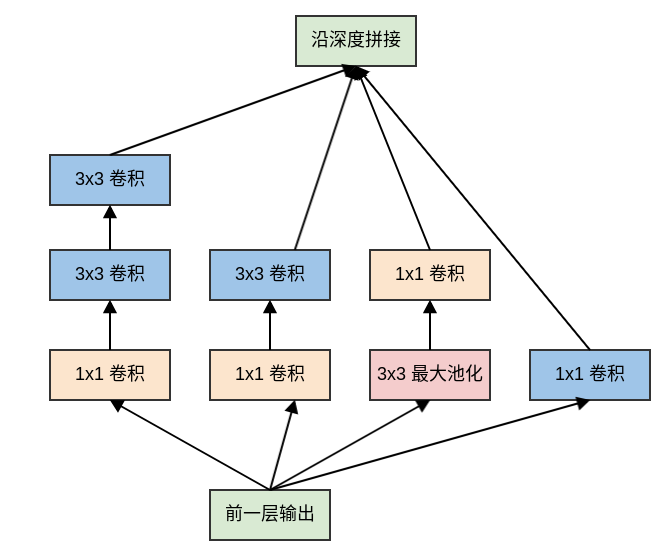
nxn卷积核的非对称分解:将nxn卷积替换为1xn卷积和nx1卷积。- 这种非对称分解的参数数量是原始卷积数量的 。随着
n的增加,计算成本的节省非常显著。 - 论文指出:对于较大的
feature map,这种分解不能很好的工作;但是对于中等大小的feature map(尺寸在12~20之间),这种分解效果非常好。
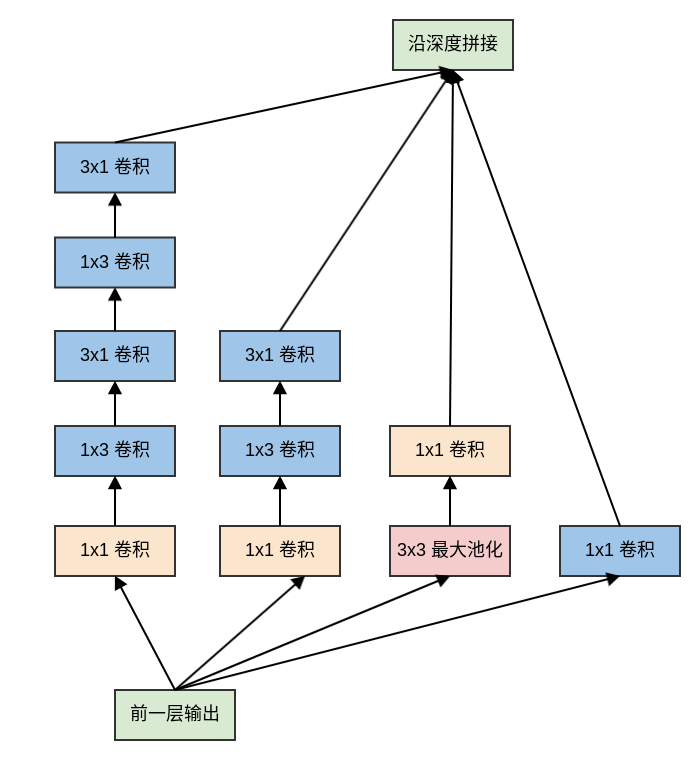
- 这种非对称分解的参数数量是原始卷积数量的 。随着
4.3.2.2 网格尺寸缩减
假设输入的
feature map尺寸为dxd,通道数为k。如果希望输出的feature map尺寸为d/2 x d/2,通道数为2k。则有以下的两种方式:首先使用
2k个1x1的卷积核,执行步长为1的卷积。然后执行一个2x2的、步长为2的池化操作。该方式需要执行 次
乘-加操作,计算代价较大。直接使用
2k个1x1的卷积核,执行步长为2的卷积。该方式需要执行 次
乘-加操作,计算代价相对较小。但是表征能力下降,产生了表征瓶颈。
事实上每个
Inception模块都会使得feature map尺寸缩半、通道翻倍,因此在这个过程中需要仔细设计网络,使得既能够保证网络的表征能力,又不至于计算代价太大。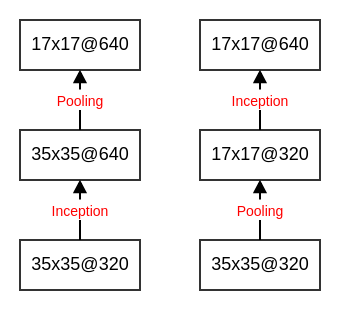
解决方案是:采用两个模块
P和C。- 模块
P:使用k个1x1的卷积核,执行步长为2的卷积。其输出feature map尺寸为d/2 x d/2,通道数为k。 - 模块
C:使用步长为2的池化。其输出feature map尺寸为d/2 x d/2,通道数为k。
将模块
P和模块C的输出按照通道数拼接,产生最终的输出feature map。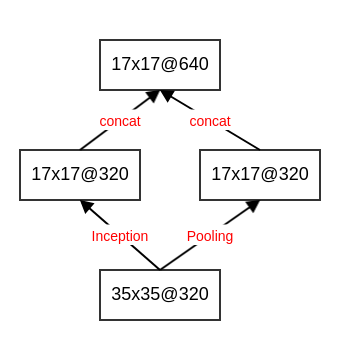
- 模块
4.3.2.3 标签平滑正则化
标签平滑正则化的原理:假设样本的真实标记存在一定程度上的噪声。即:样本的真实标记不一定是可信的。
对给定的样本 ,其真实标记为 。在普通的训练中,该样本的类别分布为一个 函数:。记做 。
采用标签平滑正则化(
LSR:Label Smoothing Regularization)之后,该样本的类别分布为:其中 是一个很小的正数(如 0.1),其物理意义为:样本标签不可信的比例。
该类别分布的物理意义为:
- 样本 的类别为 的概率为 。
- 样本 的类别为 的概率均 。
论文指出:标签平滑正则化对
top-1错误率和top-5错误率提升了大约 0.2% 。
4.4 Inception v4 & Inception - ResNet
Inception v4和Inception-ResNet在同一篇论文中给出。论文通过实验证明了:结合残差连接可以显著加速Inception的训练。性能比较:(综合采用了
144 crops/dense评估的结果,数据集:ILSVRC 2012的验证集 )网络 crops Top-1 Error Top-5 Error ResNet-151 dense 19.4% 4.5% Inception-v3 144 18.9% 4.3% Inception-ResNet-v1 144 18.8% 4.3% Inception-v4 144 17.7% 3.8% Inception-ResNet-v2 144 17.8% 3.7% Inception-ResNet-v2参数数量约为 5500万,Inception-ResNet-v1/Inception-v4的参数数量也在该量级。
4.4.1 Inception v4
在
Inception v4结构的主要改动:修改了
stem部分。引入了
Inception-A、Inception-B、Inception-C三个模块。这些模块看起来和Inception v3变体非常相似。Inception-A/B/C模块中,输入feature map和输出feature map形状相同。而Reduction-A/B模块中,输出feature map的宽/高减半、通道数增加。引入了专用的“缩减块”(
reduction block),它被用于缩减feature map的宽、高。早期的版本并没有明确使用缩减块,但是也实现了其功能。
Inception v4结构如下:(没有标记V的卷积使用same填充;标记V的卷积使用valid填充)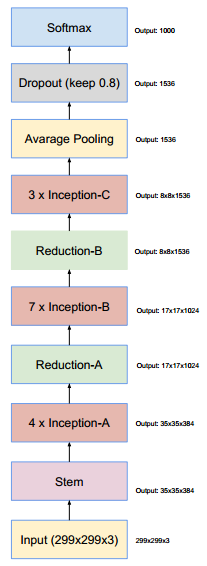
stem部分的结构: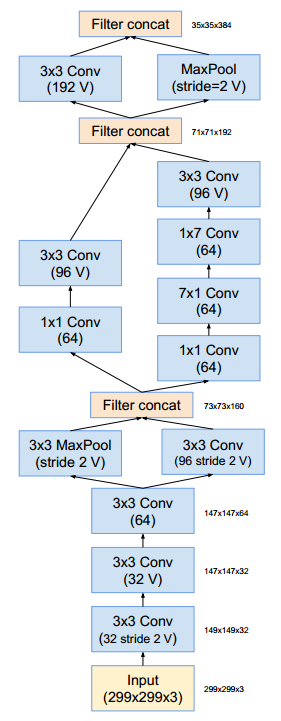
Inception-A模块(这样的模块有4个):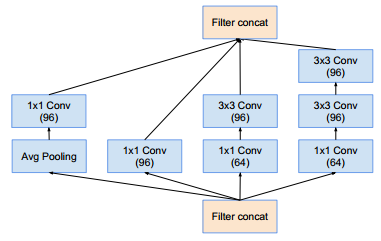
Inception-B模块(这样的模块有7个):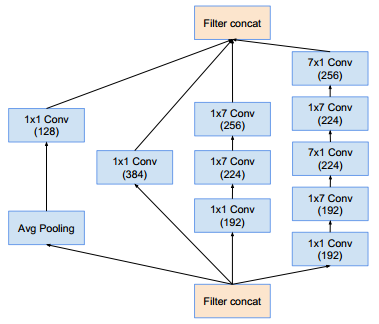
Inception-C模块(这样的模块有3个):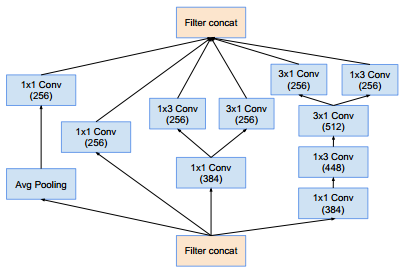
Reduction-A模块:(其中 分别表示滤波器的数量)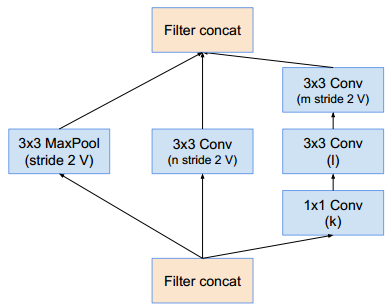
网络 k l m n Inception-v4 192 224 256 384 Inception-ResNet-v1 192 192 256 384 Inception-ResNet-v2 256 256 256 384 Reduction-B模块: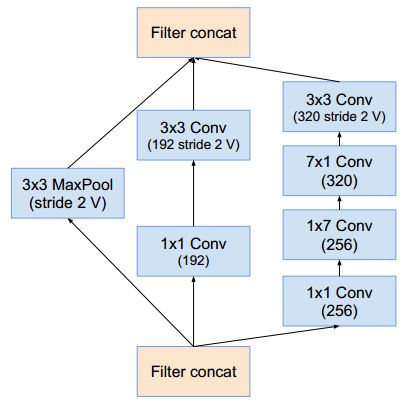
4.4.2 Inception-ResNet
在
Inception-ResNet中,使用了更廉价的Inception块:inception模块的池化运算由残差连接替代。在
Reduction模块中能够找到池化运算。
Inception ResNet有两个版本:v1和v2。v1的计算成本和Inception v3的接近,v2的计算成本和Inception v4的接近。v1和v2具有不同的stem。- 两个版本都有相同的模块
A、B、C和缩减块结构,唯一不同在于超参数设置。
Inception-ResNet-v1结构如下: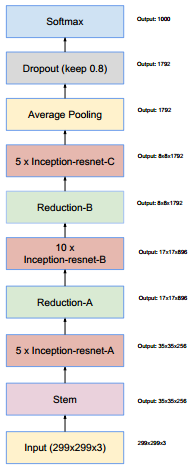
stem部分的结构: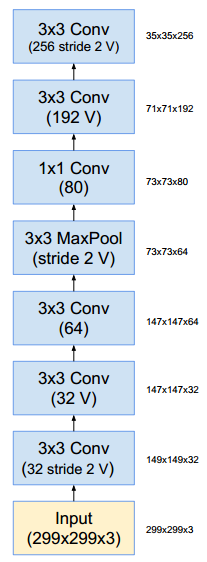
Inception-ResNet-A模块(这样的模块有5个):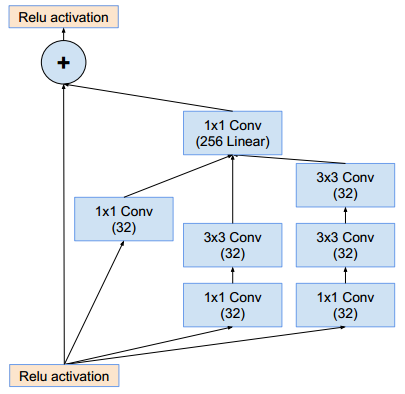
Inception-B模块(这样的模块有10个):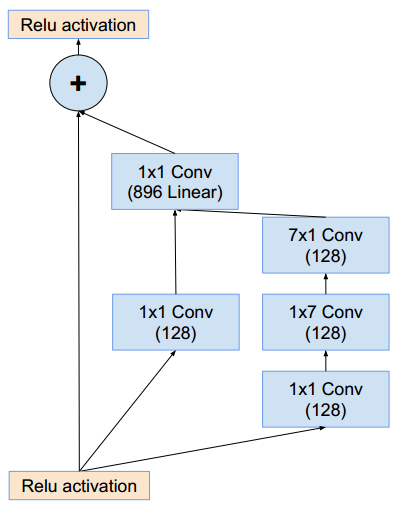
Inception-C模块(这样的模块有5个):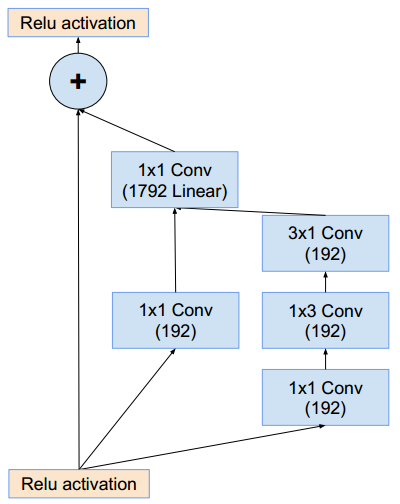
Reduction-A模块:同inception_v4的Reduction-A模块Reduction-B模块: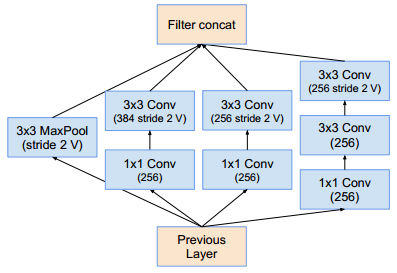
Inception-ResNet-v2结构与Inception-ResNet-v1基本相同 :stem部分的结构:同inception_v4的stem部分。Inception-ResNet-v2使用了inception v4的stem部分,因此后续的通道数量与Inception-ResNet-v1不同。Inception-ResNet-A模块(这样的模块有5个):它的结构与Inception-ResNet-v1的Inception-ResNet-A相同,只是通道数发生了改变。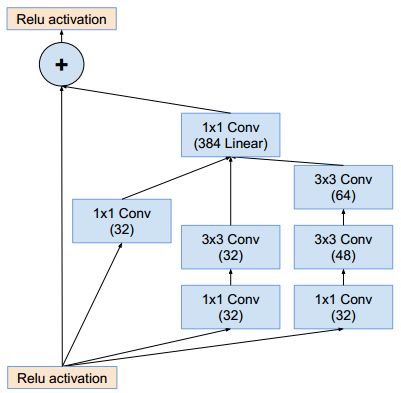
Inception-B模块(这样的模块有10个):它的结构与Inception-ResNet-v1的Inception-ResNet-B相同,只是通道数发生了改变。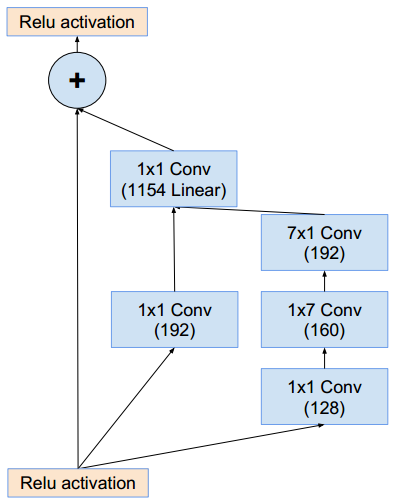
Inception-C模块(这样的模块有5个):它的结构与Inception-ResNet-v1的Inception-ResNet-C相同,只是通道数发生了改变。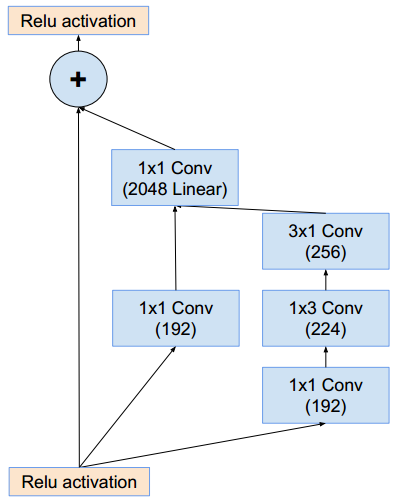
Reduction-A模块:同inception_v4的Reduction-A模块。Reduction-B模块:它的结构与Inception-ResNet-v1的Reduction-B相同,只是通道数发生了改变。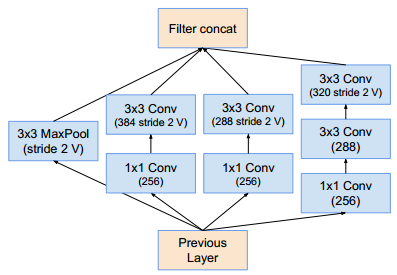
如果滤波器数量超过1000,则残差网络开始出现不稳定,同时网络会在训练过程早期出现“死亡”:经过成千上万次迭代之后,在平均池化之前的层开始只生成 0 。
解决方案:在残差模块添加到
activation激活层之前,对其进行缩放能够稳定训练。降低学习率或者增加额外的BN都无法避免这种状况。这就是
Inception ResNet中的Inception-A,Inception-B,Inception-C为何如此设计的原因。- 将
Inception-A,Inception-B,Inception-C放置在两个Relu activation之间。 - 通过线性的
1x1 Conv(不带激活函数)来执行对残差的线性缩放。
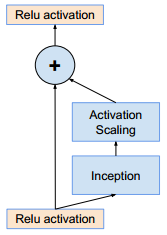
- 将
4.5 Xception
一个常规的卷积核尝试在三维空间中使用滤波器抽取特征,包括:两个空间维度(宽度和高度)、一个通道维度。因此单个卷积核的任务是:同时映射跨通道的相关性和空间相关性。
Inception将这个过程明确的分解为一系列独立的相关性的映射:要么考虑跨通道相关性,要么考虑空间相关性。Inception的做法是:- 首先通过一组
1x1卷积来查看跨通道的相关性,将输入数据映射到比原始输入空间小的三个或者四个独立空间。 - 然后通过常规的
3x3或者5x5卷积,将所有的相关性(包含了跨通道相关性和空间相关性)映射到这些较小的三维空间中。
一个典型的
Inception模块(Inception V3)如下:可以简化为:
- 首先通过一组
Xception将这一思想发挥到极致:首先使用1x1卷积来映射跨通道相关性,然后分别映射每个输出通道的空间相关性,从而将跨通道相关性和空间相关性解耦。因此该网络被称作Xception:Extreme Inception,其中的Inception块被称作Xception块。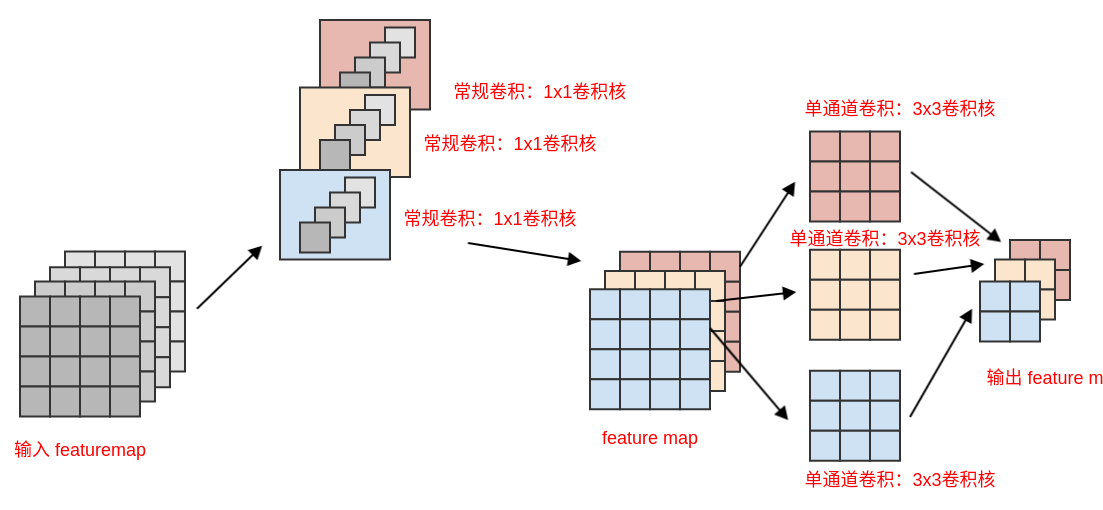
Xception块类似于深度可分离卷积,但是它与深度可分离卷积之间有两个细微的差异:操作顺序不同:
- 深度可分离卷积通常首先执行
channel-wise空间卷积,然后再执行1x1卷积。 Xception块首先执行1x1卷积,然后再进行channel-wise空间卷积。
- 深度可分离卷积通常首先执行
第一次卷积操作之后是否存在非线性:
- 深度可分离卷积只有第二个卷积(
1x1)使用了ReLU非线性激活函数,channel-wise空间卷积不使用非线性激活函数。 Xception块的两个卷积(1x1和3x3)都使用了ReLU非线性激活函数。
- 深度可分离卷积只有第二个卷积(
其中第二个差异更为重要。
对
Xception进行以下的修改,都可以加快网络收敛速度,并获取更高的准确率:- 引入类似
ResNet的残差连接机制。 - 在
1x1卷积和3x3卷积之间不加入任何非线性。
- 引入类似
Xception的参数数量与Inception V3相同,但是性能表现显著优于Inception V3。这表明Xception更加高效的利用了模型参数。根据论文
Xception: Deep Learning with Depthwise Separable Convolutions,Inception V3参数数量为 23626728,Xception参数数量为 22855952 。在
ImageNet上的benchmark为(单个模型,单次crop):模型 top-1 accuracy top-5 accuracy VGG-16 71.5% 90.1% ResNet-152 77.0% 93.3% Inception V3 78.2% 94.1% Xception 79.0% 94.5%
五、ResNet
ResNet提出了一种残差学习框架来解决网络退化问题,从而训练更深的网络。这种框架可以结合已有的各种网络结构,充分发挥二者的优势。ResNet以三种方式挑战了传统的神经网络架构:ResNet通过引入跳跃连接来绕过残差层,这允许数据直接流向任何后续层。这与传统的、顺序的
pipeline形成鲜明对比:传统的架构中,网络依次处理低级feature到高级feature。ResNet的层数非常深,高达1202层。而ALexNet这样的架构,网络层数要小两个量级。通过实验发现,训练好的
ResNet中去掉单个层并不会影响其预测性能。而训练好的AlexNet等网络中,移除层会导致预测性能损失。
在
ImageNet分类数据集中,拥有152层的残差网络,以3.75% top-5的错误率获得了ILSVRC 2015分类比赛的冠军。很多证据表明:残差学习是通用的,不仅可以应用于视觉问题,也可应用于非视觉问题。
5.1 网络退化问题
学习更深的网络的一个障碍是梯度消失/爆炸,该问题可以通过
Batch Normalization在很大程度上解决。ResNet论文作者发现:随着网络的深度的增加,准确率达到饱和之后迅速下降,而这种下降不是由过拟合引起的。这称作网络退化问题。如果更深的网络训练误差更大,则说明是由于优化算法引起的:越深的网络,求解优化问题越难。如下所示:更深的网络导致更高的训练误差和测试误差。
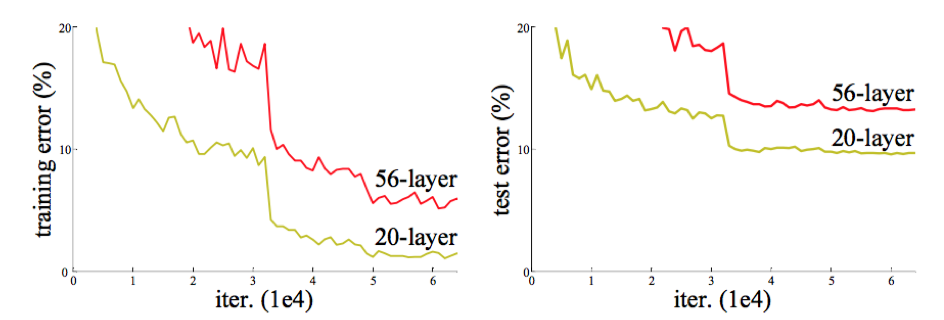
理论上讲,较深的模型不应该比和它对应的、较浅的模型更差。因为较深的模型是较浅的模型的超空间。较深的模型可以这样得到:先构建较浅的模型,然后添加很多恒等映射的网络层。
实际上我们的较深的模型后面添加的不是恒等映射,而是一些非线性层。因此,退化问题表明:通过多个非线性层来近似横等映射可能是困难的。
解决网络退化问题的方案:学习残差。
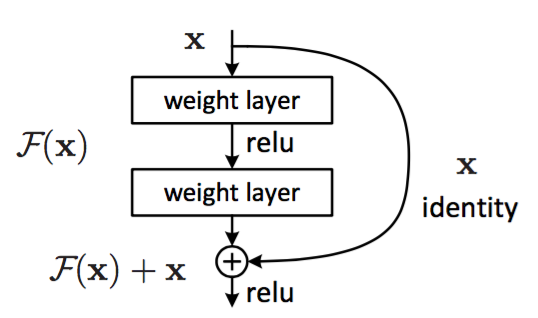
5.2 残差块
假设需要学习的是映射 ,残差块使用堆叠的非线性层拟合残差: 。
其中:
和 是块的输入和输出向量。
是要学习的残差映射。因为 ,因此称 为残差。
+:通过快捷连接逐个元素相加来执行。快捷连接指的是那些跳过一层或者更多层的连接。- 快捷连接简单的执行恒等映射,并将其输出添加到堆叠层的输出。
- 快捷连接既不增加额外的参数,也不增加计算复杂度。
相加之后通过非线性激活函数,这可以视作对整个残差块添加非线性,即 。
前面给出的残差块隐含了一个假设: 和 的维度相等。如果它们的维度不等,则需要在快捷连接中对 执行线性投影来匹配维度: 。
事实上当它们维度相等时,也可以执行线性变换。但是实践表明:使用恒等映射足以解决退化问题,而使用线性投影会增加参数和计算复杂度。因此 仅在匹配维度时使用。
残差函数 的形式是可变的。
层数可变:论文中的实验包含有两层堆叠、三层堆叠,实际任务中也可以包含更多层的堆叠。
如果 只有一层,则残差块退化线性层: 。此时对网络并没有什么提升。
连接形式可变:不仅可用于全连接层,可也用于卷积层。此时 代表多个卷积层的堆叠,而最终的逐元素加法
+在两个feature map上逐通道进行。此时
x也是一个feature map,而不再是一个向量。
残差学习成功的原因:学习残差 比学习原始映射 要更容易。
当原始映射 就是一个恒等映射时, 就是一个零映射。此时求解器只需要简单的将堆叠的非线性连接的权重推向零即可。
实际任务中原始映射 可能不是一个恒等映射:
- 如果 更偏向于恒等映射(而不是更偏向于非恒等映射),则 就是关于恒等映射的抖动,会更容易学习。
- 如果原始映射 更偏向于零映射,那么学习 本身要更容易。但是在实际应用中,零映射非常少见,因为它会导致输出全为0。
如果原始映射 是一个非恒等映射,则可以考虑对残差模块使用缩放因子。如
Inception-Resnet中:在残差模块与快捷连接叠加之前,对残差进行缩放。注意:
ResNet作者在随后的论文中指出:不应该对恒等映射进行缩放。因此Inception-Resnet对残差模块进行缩放。可以通过观察残差 的输出来判断:如果 的输出均为0附近的、较小的数,则说明原始映射 更偏向于恒等映射;否则,说明原始映射 更偏向于非横等映射。
5.3 ResNet 分析
Veit et al.认为ResNet工作较好的原因是:一个ResNet网络可以看做是一组较浅的网络的集成模型。但是
ResNet的作者认为这个解释是不正确的。因为集成模型要求每个子模型是独立训练的,而这组较浅的网络是共同训练的。论文
《Residual Networks Bahave Like Ensemble of Relatively Shallow Networks》对ResNet进行了深入的分析。通过分解视图表明:
ResNet可以被视作许多路径的集合。通过研究
ResNet的梯度流表明:网络训练期间只有短路径才会产生梯度流,深的路径不是必须的。通过破坏性实验,表明:
- 即使这些路径是共同训练的,它们也不是相互依赖的。
- 这些路径的行为类似集成模型,其预测准确率平滑地与有效路径的数量有关。
5.3.1 分解视图
考虑从输出 到 的三个
ResNet块构建的网络。根据:下图中:左图为原始形式,右图为分解视图。分解视图中展示了数据从输入到输出的多条路径。
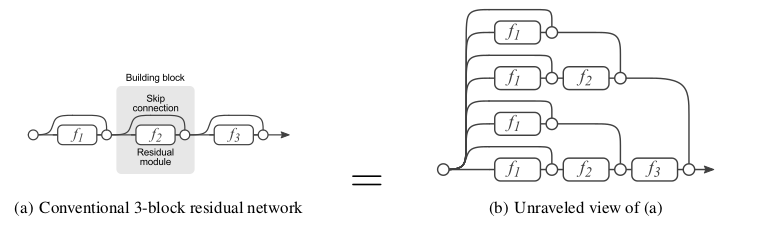
对于严格顺序的网络(如
VGG),这些网络中的输入总是在单个路径中从第一层直接流到最后一层。如下图所示。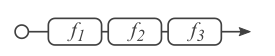
分解视图中, 每条路径可以通过二进制编码向量 来索引:如果流过残差块 ,则 ;如果跳过残差块 ,则 。
因此
ResNet从输入到输出具有 条路径,第 个残差块 的输入汇聚了之前的 个残差块的 条路径。普通的前馈神经网络也可以在单个神经元(而不是网络层)这一粒度上运用分解视图,这也可以将网络分解为不同路径的集合。
它与
ResNet分解的区别是:- 普通前馈神经网络的神经元分解视图中,所有路径都具有相同的长度。
ResNet网络的残差块分解视图中,所有路径具有不同的路径长度。
5.3.2 路径长度分析
ResNet中,从输入到输出存在许多条不同长度的路径。这些路径长度的分布服从二项分布。对于 层深的ResNet,大多数路径的深度为 。下图为一个 54 个块的
ResNet网络的路径长度的分布 ,其中95%的路径只包含 19~35个块。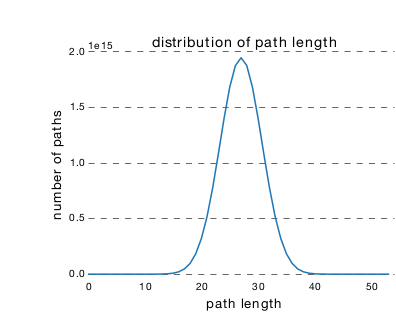
5.3.3 路径梯度分析
ResNet中,路径的梯度幅度随着它在反向传播中经过的残差块的数量呈指数减小。因此,训练期间大多数梯度来源于更短的路径。对于一个包含 54 个残差块的
ResNet网络:下图表示:单条长度为 的路径在反向传播到
input处的梯度的幅度的均值,它刻画了长度为 的单条路径的对于更新的影响。因为长度为 的路径有多条,因此取其平均。
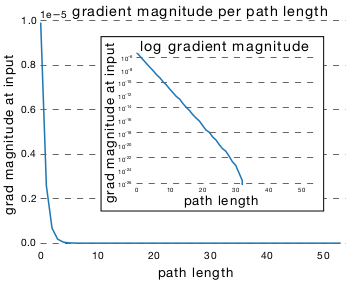
下图表示:长度为 的所有路径在反向传播到
input处的梯度的幅度的和。它刻画了长度为 的所有路径对于更新的影响。它不仅取决于长度为 的单条路径的对于更新的影响,还取决于长度为 的单条路径的数量。
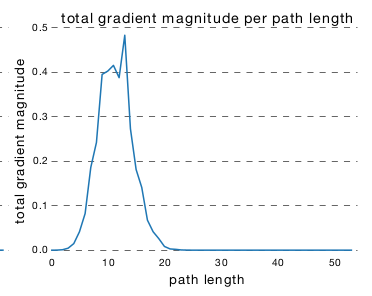
有效路径:反向传播到
input处的梯度幅度相对较大的路径。ResNet中有效路径相对较浅,而且有效路径数量占比较少。在一个54 个块的ResNet网络中:- 几乎所有的梯度更新都来自于长度为 5~17 的路径。
- 长度为 5~17 的路径占网络所有路径的 0.45% 。
论文从头开始重新训练
ResNet,同时在训练期间只保留有效路径,确保不使用长路径。实验结果表明:相比于完整模型的 6.10% 的错误率,这里实现了 5.96% 的错误率。二者没有明显的统计学上的差异,这表明确实只需要有效路径。因此,
ResNet不是让梯度流流通整个网络深度来解决梯度消失问题,而是引入能够在非常深的网络中传输梯度的短路径来避免梯度消失问题。和
ResNet原理类似,随机深度网络起作用有两个原因:- 训练期间,网络看到的路径分布会发生变化,主要是变得更短。
- 训练期间,每个
mini-batch选择不同的短路径的子集,这会鼓励各路径独立地产生良好的结果。
5.3.4 路径破坏性分析
在
ResNet网络训练完成之后,如果随机丢弃单个残差块,则测试误差基本不变。因为移除一个残差块时,ResNet中路径的数量从 减少到 ,留下了一半的路径。在
VGG网络训练完成之后,如果随机丢弃单个块,则测试误差急剧上升,预测结果就跟随机猜测差不多。因为移除一个块时,VGG中唯一可行的路径被破坏。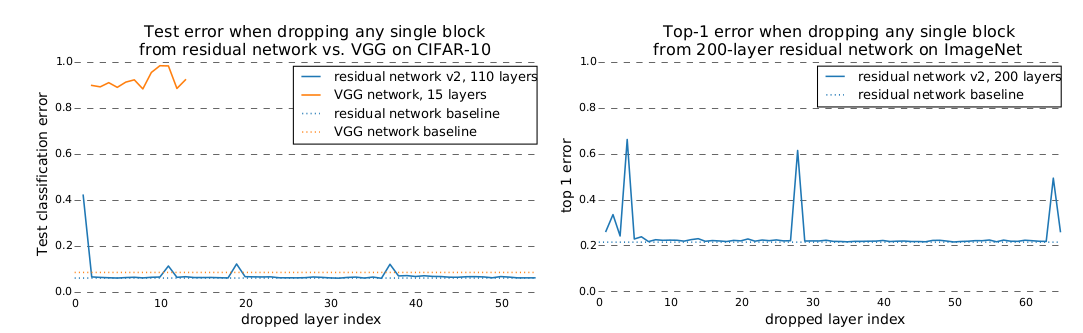
删除
ResNet残差块通常会删除长路径。当删除了 个残差块时,长度为 的路径的剩余比例由下式给定: 。
下图中:
- 删除10个残差模块,一部分有效路径(路径长度为
5~17)仍然被保留,模型测试性能会部分下降。 - 删除20个残差模块,绝大部分有效路径(路径长度为
5~17)被删除,模型测试性能会大幅度下降。

- 删除10个残差模块,一部分有效路径(路径长度为
ResNet网络中,路径的集合表现出一种类似集成模型的效果。一个关键证据是:它们的整体表现平稳地取决于路径的数量。随着网络删除越来越多的残差块,网络路径的数量降低,测试误差平滑地增加(而不是突变)。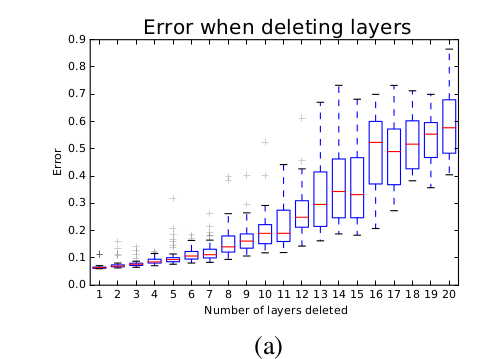
如果在测试时重新排序网络的残差块,这意味着交换了低层映射和高层映射。采用
Kendall Tau rank来衡量网络结构被破坏的程度,结果表明:随着Kendall Tau rank的增加,预测错误率也在增加。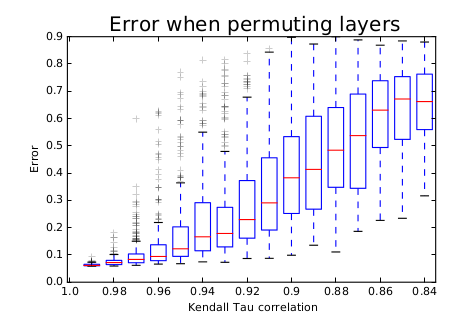
5.4 网络性能
plain网络:一些简单网络结构的叠加,如下图所示。图中给出了四种plain网络,它们的区别主要是网络深度不同。其中,输入图片尺寸 224x224 。ResNet简单的在plain网络上添加快捷连接来实现。FLOPs:floating point operations的缩写,意思是浮点运算量,用于衡量算法/模型的复杂度。FLOPS:floating point per second的缩写,意思是每秒浮点运算次数,用于衡量计算速度。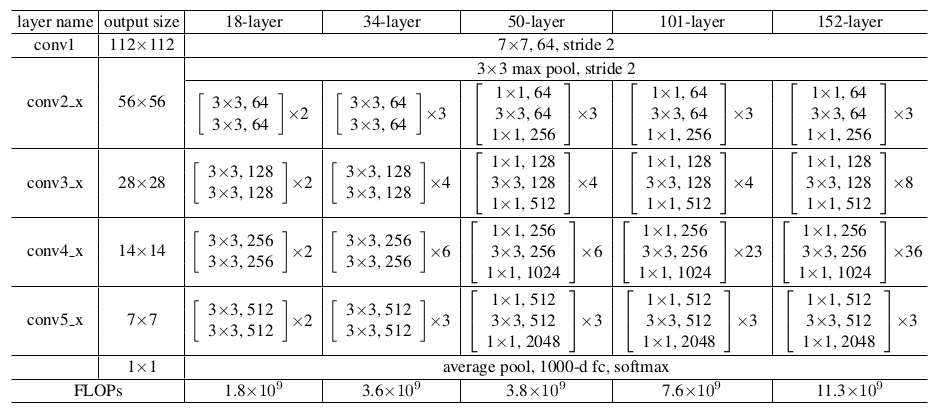
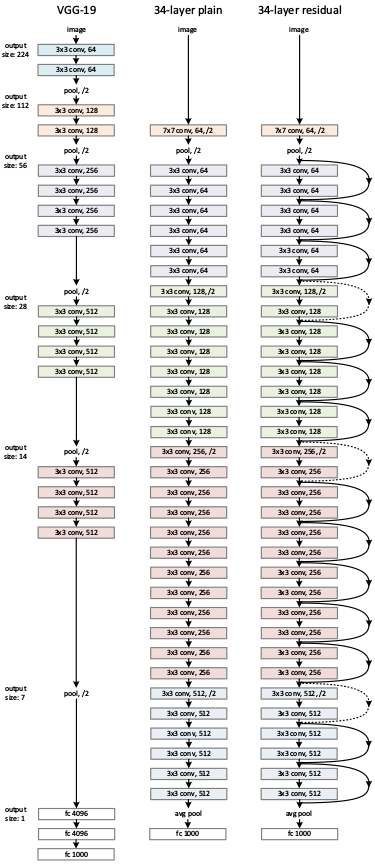
相对于输入的
feature map,残差块的输出feature map尺寸可能会发生变化:输出
feature map的通道数增加,此时需要扩充快捷连接的输出feature map。否则快捷连接的输出feature map无法和残差块的feature map累加。有两种扩充方式:
- 直接通过 0 来填充需要扩充的维度,在图中以实线标识。
- 通过
1x1卷积来扩充维度,在图中以虚线标识。
输出
feature map的尺寸减半。此时需要对快捷连接执行步长为 2 的池化/卷积:如果快捷连接已经采用1x1卷积,则该卷积步长为2 ;否则采用步长为 2 的最大池化 。
计算复杂度:
VGG-19 34层 plain 网络 Resnet-34 计算复杂度(FLOPs) 19.6 billion 3.5 billion 3.6 billion 模型预测能力:在
ImageNet验证集上执行10-crop测试的结果。A类模型:快捷连接中,所有需要扩充的维度的填充 0 。B类模型:快捷连接中,所有需要扩充的维度通过1x1卷积来扩充。C类模型:所有快捷连接都通过1x1卷积来执行线性变换。
可以看到
C优于B,B优于A。但是C引入更多的参数,相对于这种微弱的提升,性价比较低。所以后续的ResNet均采用B类模型。模型 top-1 误差率 top-5 误差率 VGG-16 28.07% 9.33% GoogleNet - 9.15% PReLU-net 24.27% 7.38% plain-34 28.54% 10.02% ResNet-34 A 25.03% 7.76% ResNet-34 B 24.52% 7.46% ResNet-34 C 24.19% 7.40% ResNet-50 22.85% 6.71% ResNet-101 21.75% 6.05% ResNet-152 21.43% 5.71%
六、ResNet 变种
6.1 恒等映射修正
- 在论文
《Identity Mappings in Deep Residual Networks》中,ResNet的作者通过实验证明了恒等映射的重要性,并且提出了一个新的残差单元来简化恒等映射。
6.1.1 新残差块
新的残差单元中,恒等映射添加到
ReLU激活函数之后。它使得训练变得更简单,并且提高了网络的泛化能力。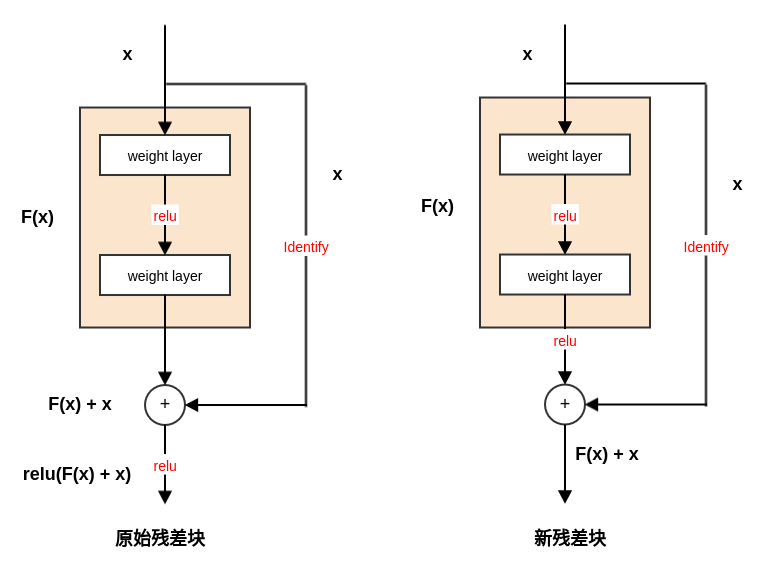
假设 是第 个残差单元的输入特征; 为一组与第 个残差单元相关的权重(包括偏置项), 是残差单元中的层的数量; 代表残差函数。则第 个残差单元的输出为(它也等价于第 个残差单元的输入):
考虑递归,对于任意深的残差单元 ,则有:
因此,对任意深的单元 ,其输入特征 可以表示为浅层单元 的特征 加上一个形如 的残差函数。
这意味着:任意单元 和 之间都具有残差性。
对于任意深的单元 ,其输入特征 可以表示为: 。即:之前所有残差函数输出的总和,再加上 。
与之形成鲜明对比的是常规网络中,输入特征 是一系列矩阵向量的乘积。即为: (忽略了激活函数和
BN)。新的残差单元也更具有良好的反向传播特性。对于损失函数 ,有:
可以看到:
梯度 可以分解为两个部分:
- :直接传递信息而不涉及任何权重。它保证了信息能够直接传回给任意浅层 。
- :通过各权重层来传递。
在一个
mini-batch中,不可能出现梯度消失的情况。可能对于某个样本,存在 的情况,但是不可能出现
mini-batch中所有的样本满足 。这意味着:哪怕权重是任意小的,也不可能出现梯度消失的情况。
对于旧的残差单元,由于恒等映射还需要经过
ReLU激活函数,因此当 时饱和,其梯度为0 。根据
3.和4.的讨论表明:在前向和反向阶段,信号都能够直接传递到任意单元。
6.1.2 快捷连接验证
假设可以对快捷连接执行缩放(如线性的
1x1卷积),第 个残差单元的缩放因子为 ,其中 也是一个可以学习的参数。此时有: ,以及: 。令:,则有:
对于特别深的网络:如果 , 则 发生梯度爆炸;如果 , 则 发生梯度消失。这会丧失快捷连接的好处。
如果对快捷连接执行的不是线性缩放,而是一个复杂的函数 ,则上式括号中第一部分变成: 。其中 为 的导数。
这也会丧失快捷连接的好处,阻碍梯度的传播。
下图所示为对快捷连接进行的各种修改:
为了简化,这里没有画出
BN层。每个权重层的后面实际上都有一个BN层。(a):原始的、旧的残差块。(b):对所有的快捷连接设置缩放。其中缩放因子 。残差有两种配置:缩放(缩放因子 0.5)、不缩放。
(c):对快捷连接执行门控机制。残差由 来缩放,快捷连接由 来缩放。其中 , 。
(d):对快捷连接执行门控机制,但是残差并不进行缩放。(e): 对快捷连接执行1x1卷积。(f):对快捷连接执行dropout,其中遗忘比例为0.5 。在统计学上,它等效于一个缩放比例为0.5的缩放操作。
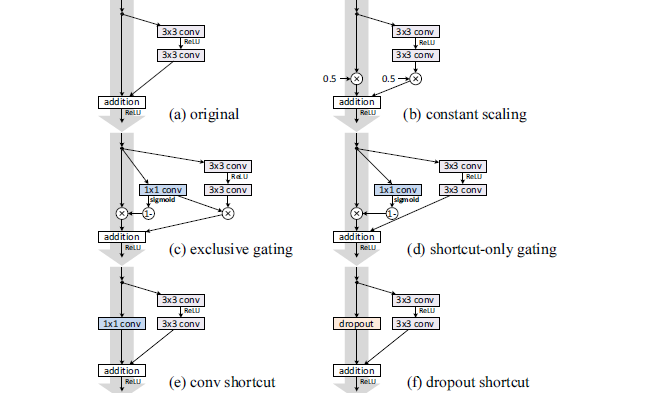
在
CIFAR-10上利用ResNet-110的测试误差如下:(fail表示测试误差超过 20% )on shortcut和on F列分别给出了快捷连接、残差块上的缩放比例。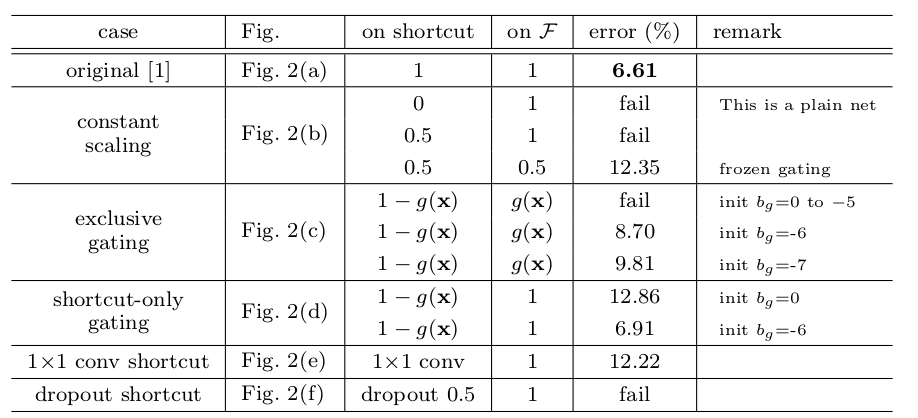
最终结果表明:快捷连接是信息传递最直接的路径,快捷连接中的各种操作都会阻碍信息的传递,以致于对优化造成困难。
理论上,对快捷连接执行
1x1卷积,会引入更多的参数。它应该比恒等连接具备更强大的表达能力。事实上,其训练误差要比恒等连接的训练误差高的多。这意味着模型退化是因为优化问题,而不是网络表达能力的问题。
6.1.3 激活函数验证
设残差块之间的函数为 ,即:
+之后引入 :前面的理论推导均假设 为恒等映射 ,而上面的实验中 。因此接下来考察 的影响。
如下图所示,组件都相同,但是不同的组合导致不同的残差块或 。
(a):原始的、旧的残差块, 。(b):将BN移动到addition之后, 。(c):将ReLU移动到addition之前,。这种结构问题较大,因为理想的残差块的输出范围是 。这里的残差块经过个
ReLU之后的输出为非负,从而使得残差的输出为 ,从而使得前向信号会逐级递增。这会影响网络的表达能力。(d):将ReLU移动到残差块之前,。(e): 将BN和ReLU移动到残差块之前,。
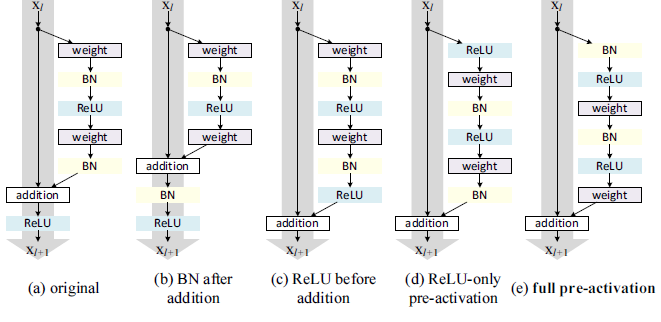
最终结果表明:
full pre-activation效果最好。有两个原因:快捷连接通路是顺畅的,这使得优化更加简单。
对两个权重层的输入都执行了
BN。所有其它四组结构中,只有第二个权重层的输入的到了标准化,第一个权重层的输入并未的到标准化。
6.1.4 网络性能
在
ILSVRC 2012验证集上的评估结果:方法 数据集增强 train crop test crop top-1 误差 top-5 误差 ResNet-152,原始残差块 scale 224x224 224x224 23.0% 6.7% ResNet-152,原始残差块 scale 224x224 320x320 21.3% 5.5% ResNet-152,full pre-activation scale 224x224 320x320 21.1% 5.5% ResNet-200,原始残差块 scale 224x224 320x320 21.8% 6.0% ResNet-200,full pre-activation scale 224x224 320x320 20.7% 5.3% ResNet-200,full pre-activation scale + asp ratio 224x224 320x320 20.1% 4.8% Inception v3 scale + asp ratio 299x299 299x299 21.2% 5.6%
6.2 ResNeXt
通常提高模型准确率的方法是加深网络深度或者加宽网络宽度,但这些方法会增加超参数的数量、参数数量和计算量。
ResNeXt网络可以在不增加网络参数复杂度的前提下提高准确率,同时还减少了超参数的数量。ResNeXt的设计参考了VGG和Inception的设计哲学。VGG:网络通过简单地层叠相同结构的层来实现,因此网络结构简单。其缺点是网络参数太多,计算量太大。Inception:通过执行分裂-变换-合并策略来精心设计拓扑结构,使得网络参数较少,计算复杂度较低。这种分裂-变换-合并行为预期能够达到一个大的dense层的表达能力,但是计算复杂度要低的多。其缺点是:
- 每个“变换”中,滤波器的数量和尺寸等超参数都需要精细的设计。
- 一旦需要训练新的任务(如新任务是一个
NLP任务),可能需要重新设计网络结构。因此可扩展性不高。
ResNeXt结合了二者的优点:- 网络结构也是通过简单地层叠相同结构的层来实现。
- 网络的每一层都执行了
分裂-变换-合并策略。
在相同的参数数量和计算复杂度的情况下,
ResNeXt的预测性能要优于ResNet。- 它在
ILSVRC 2016分类任务中取得了第二名的成绩。 101层的ResNeXt就能够获得超过200层ResNet的准确率,并且计算量只有后者的一半。
- 它在
ResNeXt改进了ResNet网络结构,并提出了一个新的维度,称作“基数”cardinality。基数是网络的深度和网络的宽度之外的另一个重要因素。作者通过实验表明:增加基数比增加网络的深度或者网络的宽度更有效。
6.2.1 分裂-变换-合并
考虑全连接网络中的一个神经元。假设输入为 ,为一个一度的输入向量(长度为 )。假设对应的权重为 。不考虑偏置和激活函数,则神经元的输出为: 。
它可以视作一个最简单的“分裂-变换-合并”:
- 分裂:输入被分割成 个低维(维度为零)嵌入。
- 变换:每个低维嵌入通过对应的权重 执行线性变换。
- 合并:变换之后的结果通过直接相加来合并。
Inception的“分裂-变换-合并”策略:- 分裂:输入通过
1x1卷积被分割成几个低维嵌入。 - 变换:每个低维嵌入分别使用一组专用滤波器(
3x3、5x5等) 执行变换。 - 合并:变换之后的结果进行合并(沿深度方向拼接)。
- 分裂:输入通过
对一个
ResNeXt块,其“分裂-变换-合并”策略用公式表述为:其中:
- 为任意函数,它将 映射为 的一个低维嵌入,并对该低维嵌入执行转换。
- 为转换的数量,也就是基数
cardinality。
在
ResNeXt中,为了设计方便 采取以下设计原则:所有的 具有相同的结构。这是参考了
VGG的层叠相同结构的层的思想。的结构通常是:
- 第一层:执行
1x1的卷积来产生 的一个低维嵌入。 - 第二层 ~ 倒数第二层:执行卷积、池化等等变换。
- 最后一层:执行
1x1的卷积来将结果提升到合适的维度。
- 第一层:执行
6.2.2 ResNeXt 块
一个
ResNeXt模块执行了一组相同的“变换”,每一个“变换”都是输入的一个低维嵌入,变换的数量就是基数C。如下所示:左图为
ResNet块;右图为ResNeXt块。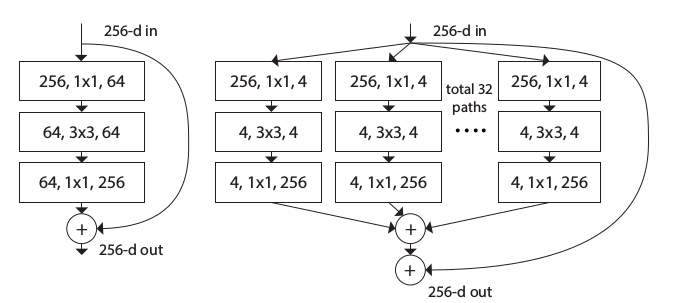
ResNeXt模块有两种等效的形式:图(a)为标准形式,图(b)类似Inception-ResNet模块。其中图(b)的拼接是沿着深度方向拼接。等效的原因是:输入通道数为
128的1x1卷积可以如下拆分:( 设输入张量为 ,输出张量为 ,核张量为 )经过这种拆分,图
(b)就等效于图(a)。其中: 表示输出单元位于 通道, 表示输入单元位于 通道, 表示通道中的坐标。本质原因是
1x1卷积是简单的对通道进行线性相加。它可以拆分为:先将输入通道分组,然后计算各组的子通道的线性和(1x1卷积);然后将所有组的和相加。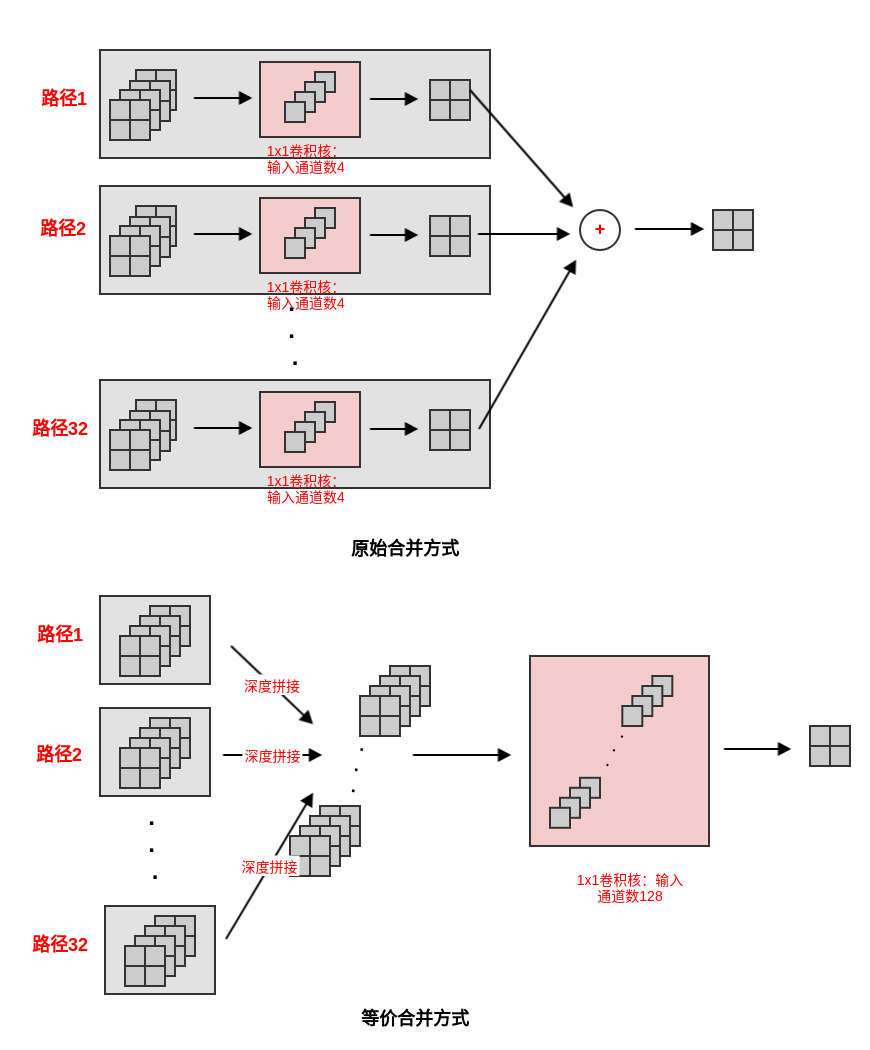
图
(b)与Inception-ResNet模块的区别在于:这里每一条路径都是相同的。图
(c)是一个分组卷积的形式,它就是用分组卷积来实现图(b)。它也是图(b)在代码中的实现方式。
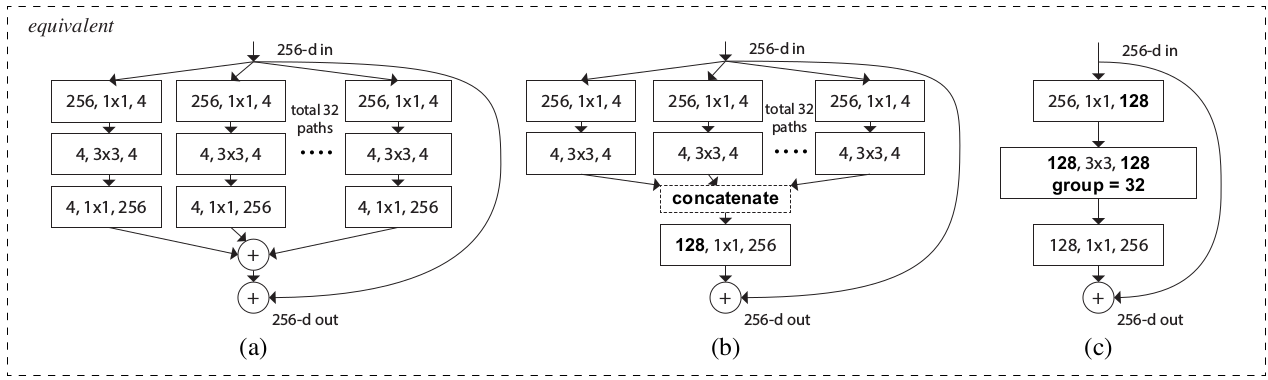
通常
ResNeXt模块至少有三层。事实上它也可以有两层,此时它等效于一个宽的、密集模块。- 此时并没有通过
1x1卷积进行降维与升维,而是在降维的过程中同时进行变换,在升维的过程中也进行变换。 - 如下图所示,它等价于图
(c)中,去掉中间的变换层(128,3x3,128层),同时将第一层、第三层的1x1替换为3x3卷积层。
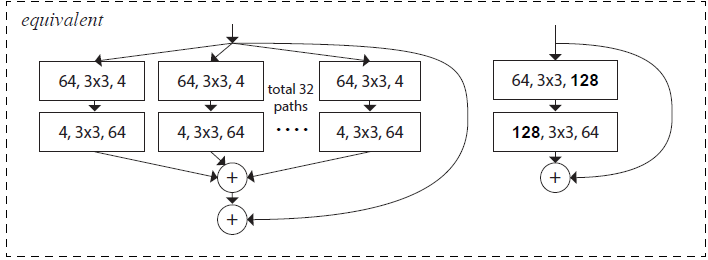
- 此时并没有通过
6.2.3 网络性能
ResNeXt的两种重要超参数是:基数C和颈宽d。- 基数
C:决定了每个ResNeXt模块有多少条路径。 - 颈宽(
bottleneck width)d:决定了ResNeXt模块中第一层1x1卷积降维的维度。
这二者也决定了
ResNeXt模块等价形式中,通道分组卷积的通道数量为Cxd。- 基数
ResNeXt的网络参数和计算量与同等结构的ResNet几乎相同。以ResNet-50为例(输入图片尺寸224x224):ResNeXt-50(32x4d)意思是:基数C=32,颈宽d=4。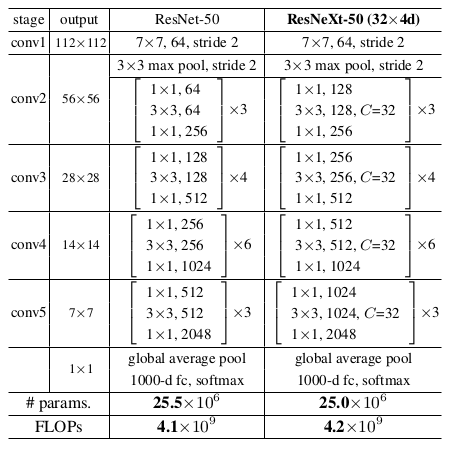
在
ImageNet上进行的对比实验(验证集误差,single crop):基数 vs 颈宽:基数越大越好。
模型 配置 top-1 error(%) ResNet-50 C=1,d=64 23.9 ResNeXt-50 C=2,d=40 23.0 ResNeXt-50 C=4,d=24 22.6 ResNeXt-50 C=8,d=14 22.3 ResNeXt-50 C=32,d=4 22.2 ResNet-101 C=1,d=64 22.0 ResNeXt-101 C=2,d=40 21.7 ResNeXt-101 C=4,d=24 21.4 ResNeXt-101 C=8,d=14 21.3 ResNeXt-101 C=32,d=4 21.2 基数 vs 深度/宽度:基数越大越好。
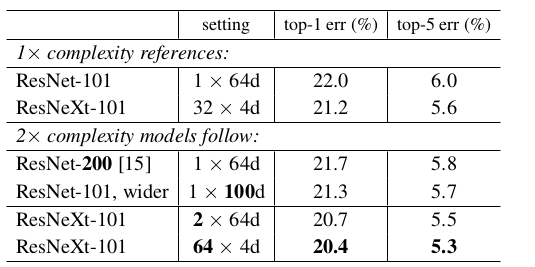
与其它模型的预测能力比较(验证集误差,
single crop):ResNet/ResNeXt的图片尺寸为224x224和320x320;Inception的图片尺寸为299x299。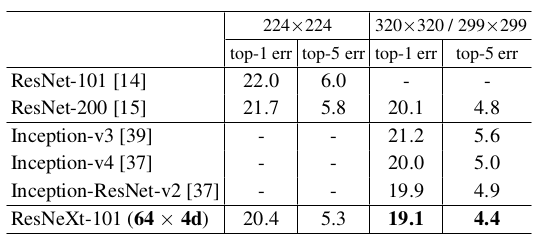
6.3 随机深度网络
随机深度网络提出了训练时随机丢弃网络层的思想,从而能够让网络深度增加到超过1000层,并仍然可以减少测试误差。
如图所示:在
CIFAR-10上,1202层的ResNet测试误差要高于110层的ResNet,表现出明显的过拟合。而1202层的随机深度网络(结合了ResNet)的测试误差要低于110层的ResNet。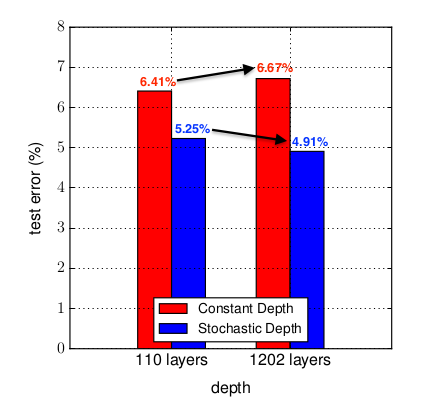
神经网络的表达能力主要由网络深度来决定,但是过深的网络会带来三个问题:反向传播过程中的梯度消失、前向传播过程中的
feature消失、训练时间过长。虽然较浅的网络能够缓解这几个问题,但是较浅的网络表达能力不足,容易陷入欠拟合。
随机深度网络解决这一矛盾的策略是:构建具有足够表达能力的深度神经网络(具有数百层甚至数千层),然后:
在网络训练期间,对每个
mini batch随机地移除部分层来显著的减小网络的深度。移除操作:删除对应的层,并用跳跃连接来代替。
在网络测试期间,使用全部的网络层。
随机深度的思想可以和
ResNet结合。因为ResNet已经包含了跳跃连接,因此可以直接修改。
6.3.1 随机深度
假设
ResNet有 个残差块,则有: 。其中:- 表示第 个残差块的输出, 为第 个残差块的输入(它也是第 个残差块的输出)。
- 为一组与第 个残差单元相关的权重(包括偏置项), 是残差单元中的层的数量。
- 代表残差函数。
假设第 个残差块是否随机丢弃由伯努利随机变量 来指示:当 时,第 个残差块被丢弃;当 时,第 个残差块被保留。
因此有: 。
对随机变量 ,令:
其中 称做保留概率或者存活概率,它是一个非常重要的超参数。
的选择有两个策略:
所有残差块的存活概率都相同: 。
所有残差块的存活概率都不同,且根据残差块的深度进行线性衰减:
其背后的思想是:靠近输入的层提取的是被后续层使用的低级特征,因此更应该被保留下来。
给定第 个残差块的保留概率 ,则网络的深度 的期望为(以残差块数量为单位): 。
对于均匀存活:
对于线性衰减存活:
当 时,无论是均匀存活还是线性衰减存活,都满足 。因此随机深度网络在训练时具有更短的期望深度,从而节省了训练时间。
的选择策略,以及 的大小的选取需要根据实验仔细选择。
- 根据作者的实验结果,作者推荐使用线性衰减存活概率,并选择 。此时有:
- 如果选择更小的 将会带来更大的测试误差,但是会更大的加速训练过程。
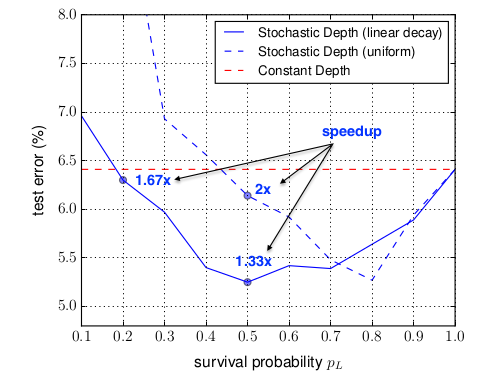
测试时,需要调整残差块的输出: 。
随机深度网络能够大大减少训练时间和测试误差。
训练时间减小是因为:网络训练时,期望深度减小。
测试误差减小是因为:
- 网络训练时期望深度的减少,使得梯度链变短,从而加强了反向传播期间靠近输入层的梯度。
- 随机深度网络可以被理解为一系列不同深度的网络的隐式集成的集成模型。
随机深度网络可以视作 个隐式的神经网络的集成,这些被集成的网络都是权重共享的,类似于
Dropout。- 在训练时,对每个
mini batch,只有其中之一得到了权重更新。 - 在测试时,取所有被集成的网络的平均。
- 在训练时,对每个
随机深度网络和
Dropout都可以被理解为一系列网络的隐式集成。- 随机深度集网络成了一系列具有不同深度的神经网络,而
Dropout集成了一系列具有不同宽度的神经网络。 Dropout与BN配合使用时会失效,而随机深度可以和BN配合使用。
- 随机深度集网络成了一系列具有不同深度的神经网络,而
在随机深度网络中,由于训练时的随机深度,模型的测试误差的抖动相对于
ResNet会偏大。
6.3.2 网络性能
对
ResNet(固定深度和随机深度)在三个数据集上进行比较,测试误差的结果如下:+表示执行了数据集增强。随机深度网络采用 。
CIFAR10/100采用 110 层ResNet,ImageNet采用 152 层ResNet。虽然在
ImageNet上随机深度模型没有提升,但是作者表示这是因为网络本身比较简单(相对ImageNet数据集)。如果使用更深的ResNet,则容易看到随机深度模型的提升。虽然这里模型的测试误差没有提升,但是训练速度大幅提升。
网络 CIFAR10+ CIFAR100+ ImageNet ResNet(固定深度) 6.41 27.76 21.78 ResNet(随机深度) 5.25 24.98 21.98 在
CIFAR-10上,ResNet随机深度网络的深度 、概率 与测试集误差的关系: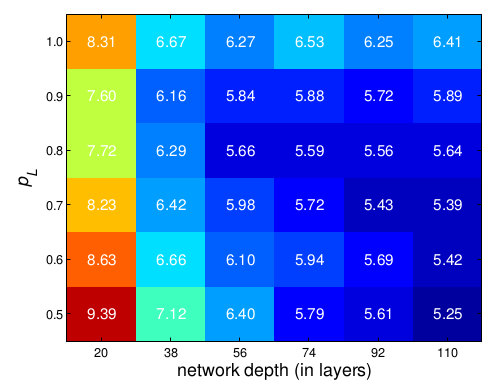
七、SENet
SENet提出了一种新的架构单元来解决通道之间相互依赖的问题。它通过显式地对通道之间的相互依赖关系建模,自适应的重新校准通道维的特征响应,从而提高了网络的表达能力。SENet以2.251% top-5的错误率获得了ILSVRC 2017分类比赛的冠军。SENet是和ResNet一样,都是一种网络框架。它可以直接与其他网络架构一起融合使用,只需要付出微小的计算成本就可以产生显著的性能提升。
7.1 SE 块
SE块(Squeeze-and-Excitation)是SENet中提出的新的架构单元,它主要由squeeze操作和excitation操作组成。对于给定的任何变换 ,其中: 为输入
feature map,其尺寸为,通道数为 ; 为输出feature map,其尺寸为 ,通道数为 。可以构建一个相应的
SE块来对输出feature map执行特征重新校准:- 首先对输出
feature mapsqueeze操作,它对每个通道的全局信息建模,生成一组通道描述符。 - 然后是一个
excitation操作,它对通道之间的依赖关系建模,生成一组权重信息(对应于每个通道的权重)。 - 最后输出
feature map被重新加权以生成SE块的输出。
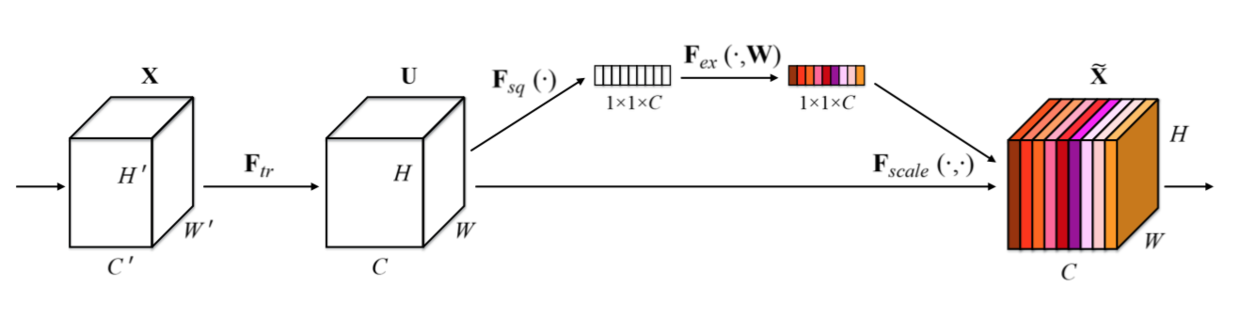
- 首先对输出
SE块可以理解为注意力机制的一个应用。它是一个轻量级的门机制,用于对通道关系进行建模。通过该机制,网络学习全局信息(全通道、全空间)来选择性的强调部分特征,并抑制其它特征。
设 , 为第 个通道,是一个 的矩阵;设 , 为第 个通道,是一个 的矩阵。
需要学习的变换 就是一组卷积核。 为第 个卷积核,记做: , 为第 个卷积核的第 通道,是一个二维矩阵。则:
这里
*表示卷积。同时为了描述简洁,这里忽略了偏置项。输出 考虑了输入 的所有通道,因此通道依赖性被隐式的嵌入到 中。
7.1.1 squeeze 操作
squeeze操作的作用是:跨空间 聚合特征来产生通道描述符。该描述符嵌入了通道维度特征响应的全局分布,包含了全局感受野的信息。
每个学到的滤波器都是对局部感受野进行操作,因此每个输出单元都无法利用局部感受野之外的上下文信息。
在网络的低层,其感受野尺寸很小,这个问题更严重。
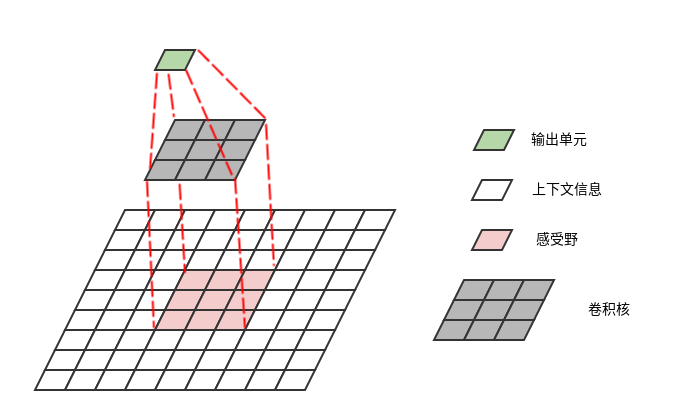
为减轻这个问题,可以将全局空间信息压缩成一组通道描述符,每个通道对应一个通道描述符。然后利用该通道描述符。
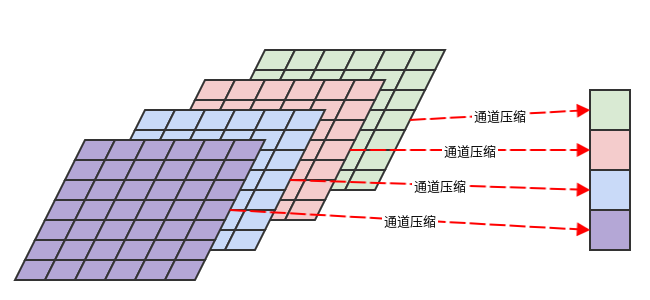
通常基于通道的全局平均池化来生成通道描述符(也可以考虑使用更复杂的聚合策略)。
设所有通道的通道描述符组成一个向量 。则有:
.
7.1.2 excitation 操作
excitation操作的作用是:通过自门机制来学习每个通道的激活值,从而控制每个通道的权重。excitation操作利用了squeeze操作输出的通道描述符 。首先,通道描述符 经过线性降维之后,通过一个
ReLU激活函数。降维通过一个输出单元的数量为 的全连接层来实现,其中 为降维比例。
然后,
ReLU激活函数的输出经过线性升维之后,通过一个sigmoid激活函数。升维通过一个输出单元的数量为 的全连接层来实现。
通过对通道描述符 进行降维,显式的对通道之间的相互依赖关系建模。
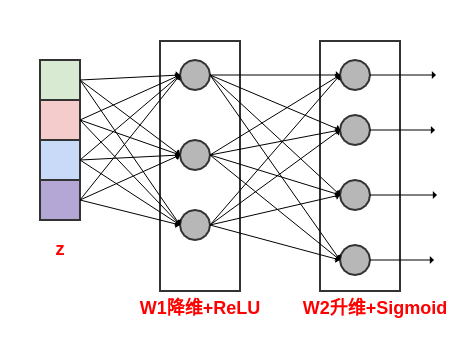
设
excitation操作的输出为向量 ,则有: 。其中: 为
sigmoid激活函数, 为降维层的权重, 为升维层的权重, 为降维比例。在经过
excitation操作之后,通过重新调节 得到SE块的输出。设
SE块的最终输出为 ,则有: 。这里 为excitaion操作的输出结果,它作为通道 的权重。不仅考虑了本通道的全局信息(由 引入),还考虑了其它通道的全局信息(由 引入)。
7.1.3 SE 块使用
有两种使用
SE块来构建SENet的方式:简单的堆叠
SE块来构建一个新的网络。在现有网络架构中,用
SE块来替代原始块。下图中,左侧为原始
Inception模块,右侧为SE-Inception模块。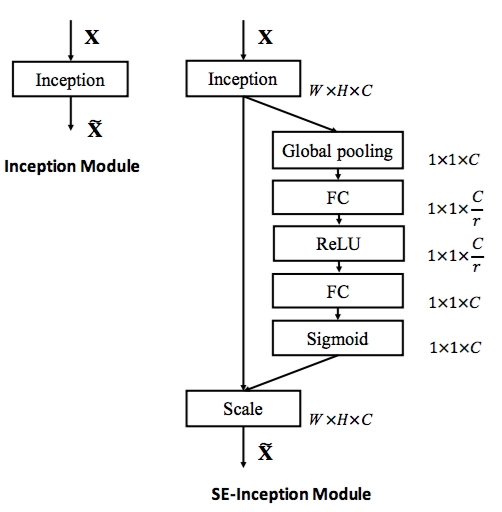
下图中,左侧为原始残差模块,右侧为
SE-ResNet模块。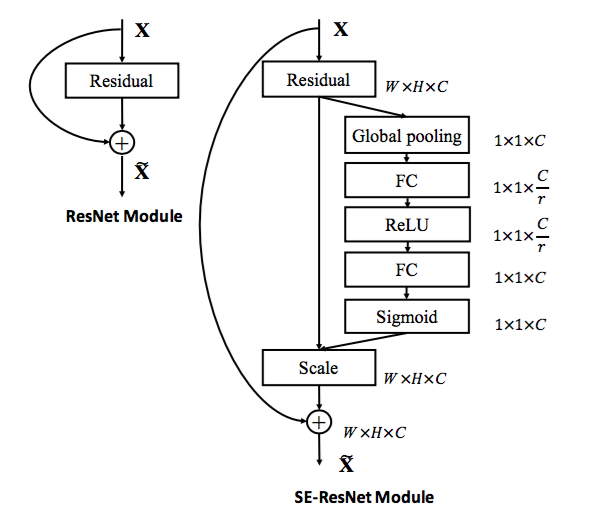
如果使用
SE块来替代现有网络架构中的原始块,则所有额外的参数都包含在门机制的两个全连接层中。引入的额外参数的数量为: 。其中: 表示降维比例(论文中设定为16), 指的是
SE块的数量, 表示第 个SE块的输出通道的维度。如:
SE-ResNet-50在ResNet-50所要求的大约2500万参数之外,额外引入了约250万参数,相对增加了10%。超参数 称作减少比率,它刻画了需要将通道描述符组成的向量压缩的比例。它是一个重要的超参数,需要在精度和复杂度之间平衡。
网络的精度并不会随着 的增加而单调上升,因此需要多次实验并选取其中最好的那个值。
如下所示为
SE-ResNet-50采用不同的 在ImageNet验证集上的预测误差(single-crop)。original表示原始的ResNet-50。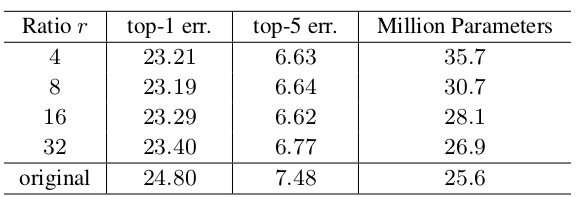
虽然
SE块可以应用在网络的任何地方,但是它在不同深度中承担了不同的作用。在网络较低的层中:对于不同类别的样本,特征通道的权重分布几乎相同。
这说明在网络的最初阶段,特征通道的重要性很可能由不同的类别共享。即:低层特征通常更具有普遍性。
在网络较高的层中:对于不同类别的样本,特征通道的权重分布开始分化。
这说明在网络的高层,每个通道的值变得更具有类别特异性。即:高层特征通常更具有特异性。
在网络的最后阶段的
SE块为网络提供重新校准所起到的作用,相对于网络的前面阶段的SE块来说,更加不重要。这意味着可以删除最后一个阶段的
SE块,从而显著减少总体参数数量,仅仅带来一点点的损失。如:在SE-ResNet-50中,删除最后一个阶段的SE块可以使得参数增加量下降到 4%,而在ImageNet上的top-1错误率的损失小于0.1%。因此:
Se块执行特征通道重新校准的好处可以通过整个网络进行累积。
7.2 网络性能
网络结构:其中
fc,[16,256]表示SE块中的两个全连接层的输出维度。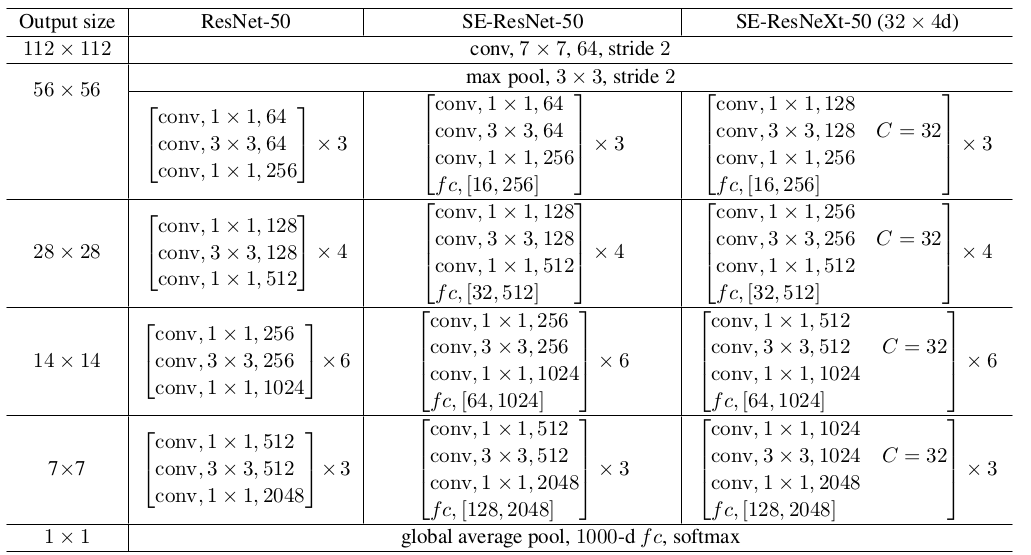
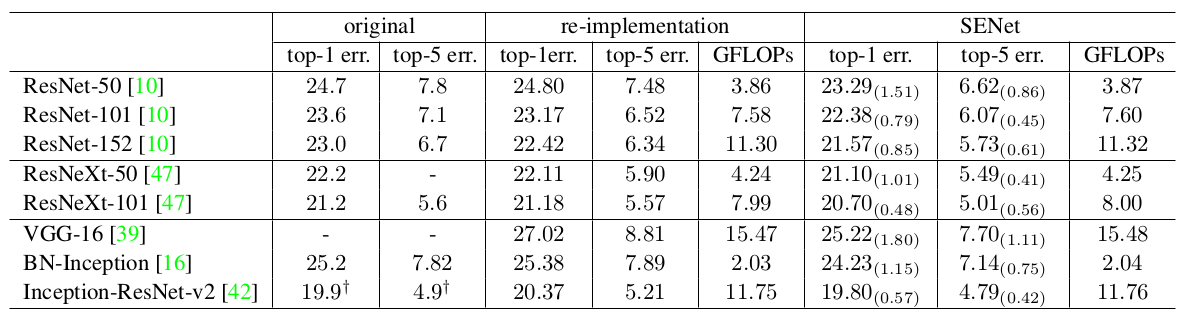
在
ImageNet验证集上的计算复杂度和预测误差比较(single-crop)。original列:从各自原始论文中给出的结果报告。re-implementation列:重新训练得到的结果报告。SENet列:通过引入SE块之后的结果报告。GFLOPs/MFLOPs:计算复杂度,单位为G/M FLOPs。MobileNet采用的是1.0 MobileNet-224,ShuffleNet采用的是1.0 ShuffleNet 1x(g=3)。数据集增强和归一化:
- 随机裁剪成
224x224大小(Inception系列裁剪成299x299)。 - 随机水平翻转。
- 输入图片沿着通道归一化:每个像素减去本通道的像素均值。
- 随机裁剪成

在
ImageNet验证集上的预测误差比较(single-crop):其中
SENet-154(post-challenge)是采用320x320大小的图片来训练的。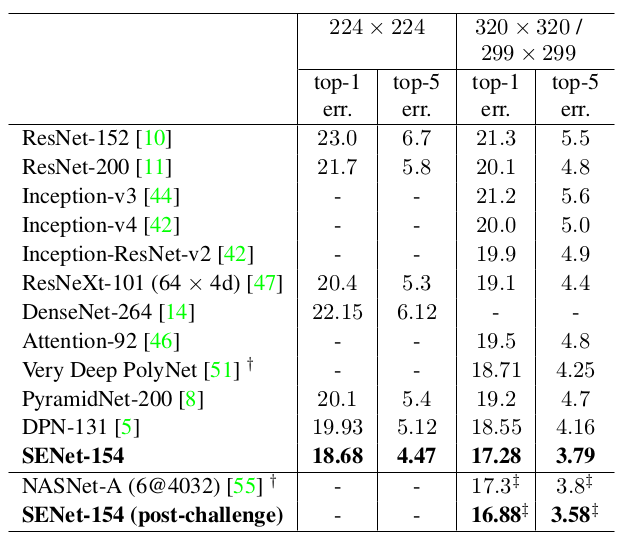
八、 DenseNet
DenseNet不是通过更深或者更宽的结构,而是通过特征重用来提升网络的学习能力。ResNet的思想是:创建从“靠近输入的层” 到 “靠近输出的层” 的直连。而DenseNet做得更为彻底:将所有层以前馈的形式相连,这种网络因此称作DenseNet。DenseNet具有以下的优点:- 缓解梯度消失的问题。因为每层都可以直接从损失函数中获取梯度、从原始输入中获取信息,从而易于训练。
- 密集连接还具有正则化的效应,缓解了小训练集任务的过拟合。
- 鼓励特征重用。网络将不同层学到的
feature map进行组合。 - 大幅度减少参数数量。因为每层的卷积核尺寸都比较小,输出通道数较少 (由增长率 决定)。
DenseNet具有比传统卷积网络更少的参数,因为它不需要重新学习多余的feature map。传统的前馈神经网络可以视作在层与层之间传递
状态的算法,每一层接收前一层的状态,然后将新的状态传递给下一层。这会改变
状态,但是也传递了需要保留的信息。ResNet通过恒等映射来直接传递需要保留的信息,因此层之间只需要传递状态的变化。DenseNet会将所有层的状态全部保存到集体知识中,同时每一层增加很少数量的feture map到网络的集体知识中。
DenseNet的层很窄(即:feature map的通道数很小),如:每一层的输出只有 12 个通道。
8.1 DenseNet 块
具有 层的传统卷积网络有 个连接,每层仅仅与后继层相连。
具有 个残差块的
ResNet在每个残差块增加了跨层连接,第 个残差块的输出为: 。其中 是第 个残差块的输入特征; 为一组与第 个残差块相关的权重(包括偏置项), 是残差块中的层的数量; 代表残差函数。具有 个层块的
DenseNet块有 个连接,每层以前馈的方式将该层与它后面的所有层相连。对于第 层:所有先前层的feature map都作为本层的输入,第 层具有 个输入feature map;本层输出的feature map都将作为后面 层的输入。假设
DenseNet块包含 层,每一层都实现了一个非线性变换 ,其中 表示层的索引。假设
DenseNet块的输入为 ,DenseNet块的第 层的输出为 ,则有:其中 表示 层输出的
feature map沿着通道方向的拼接。ResNet块与它不同。在ResNet中,不同feature map是通过直接相加来作为块的输出。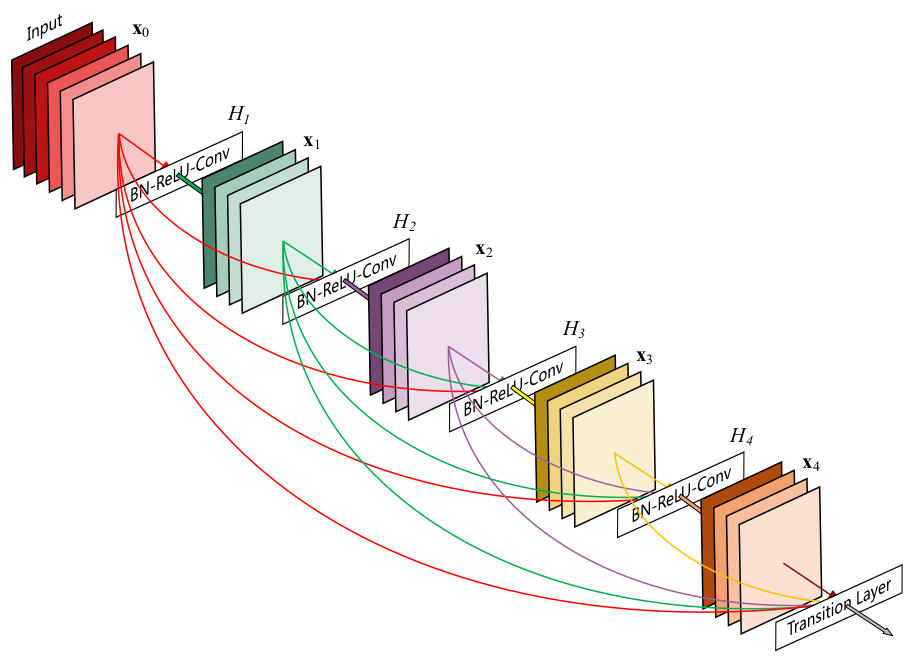
当
feature map的尺寸改变时,无法沿着通道方向进行拼接。此时将网络划分为多个DenseNet块,每块内部的feature map尺寸相同,块之间的feature map尺寸不同。
8.1.1 增长率
DenseNet块中,每层的 输出的feature map通道数都相同,都是 个。 是一个重要的超参数,称作网络的增长率。第 层的输入
feature map的通道数为: 。其中 为输入层的通道数。DenseNet不同于现有网络的一个重要地方是:DenseNet的网络很窄,即输出的feature map通道数较小,如: 。一个很小的增长率就能够获得不错的效果。一种解释是:
DenseNet块的每层都可以访问块内的所有早前层输出的feature map,这些feature map可以视作DenseNet块的全局状态。每层输出的feature map都将被添加到块的这个全局状态中,该全局状态可以理解为网络块的“集体知识”,由块内所有层共享。增长率 决定了新增特征占全局状态的比例。因此
feature map无需逐层复制(因为它是全局共享),这也是DenseNet与传统网络结构不同的地方。这有助于整个网络的特征重用,并产生更紧凑的模型。
8.1.2 非线性变换
- 可以是包含了
Batch Normalization(BN)、ReLU单元、池化或者卷积等操作的复合函数。 - 论文中 的结构为:先执行
BN,再执行ReLU,最后接一个3x3的卷积,即:BN-ReLU-Conv(3x3)。
8.1.3 bottleneck
尽管
DenseNet块中每层只产生 个输出feature map,但是它具有很多输入。当在 之前采用1x1卷积实现降维时,可以减小计算量。的输入是由第 层的输出
feature map组成,其中第0层的输出feature map就是整个DensNet块的输入feature map。
事实上第 层从DensNet 块的输入feature map 中抽取各种特征。即 包含了DensNet 块的输入feature map 的冗余信息,这可以通过 1x1 卷积降维来去掉这种冗余性。
因此这种1x1 卷积降维对于DenseNet 块极其有效。
如果在 中引入
1x1卷积降维,则该版本的DenseNet称作DenseNet-B。其 结构为:先执行BN,再执行ReLU,再接一个1x1的卷积,再执行BN,再执行ReLU,最后接一个3x3的卷积。即:BN-ReLU-Conv(1x1)-BN-ReLU-Conv(3x3)。其中
1x1卷积的输出通道数是个超参数,论文中选取为 。
8.2 过渡层
一个
DenseNet网络具有多个DenseNet块,DenseNet块之间由过渡层连接。DenseNet块之间的层称为过渡层,其主要作用是连接不同的DenseNet块。过渡层可以包含卷积或池化操作,从而改变前一个
DenseNet块的输出feature map的大小(包括尺寸大小、通道数量)。论文中的过渡层由一个
BN层、一个1x1卷积层、一个2x2平均池化层组成。其中1x1卷积层用于减少DenseNet块的输出通道数,提高模型的紧凑性。如果不减少
DenseNet块的输出通道数,则经过了 个DenseNet块之后,网络的feature map的通道数为: ,其中 为输入图片的通道数, 为每个DenseNet块的层数。
如果
Dense块输出feature map的通道数为 ,则可以使得过渡层输出feature map的通道数为 ,其中 为压缩因子。当 时,经过过渡层的
feature map通道数不变。当 时,经过过渡层的
feature map通道数减小。此时的DenseNet称做DenseNet-C。结合了
DenseNet-C和DenseNet-B的改进的网络称作DenseNet-BC。
8.3 网络性能
网络结构:
ImageNet训练的DenseNet网络结构,其中增长率 。- 表中的
conv代表的是BN-ReLU-Conv的组合。如1x1 conv表示:先执行BN,再执行ReLU,最后执行1x1的卷积。 DenseNet-xx表示DenseNet块有xx层。如:DenseNet-169表示DenseNet块有 层 。- 所有的
DenseNet使用的是DenseNet-BC结构,输入图片尺寸为224x224,初始卷积尺寸为7x7、输出通道2k、步长为2,压缩因子 。 - 在所有
DenseNet块的最后接一个全局平均池化层,该池化层的结果作为softmax输出层的输入。
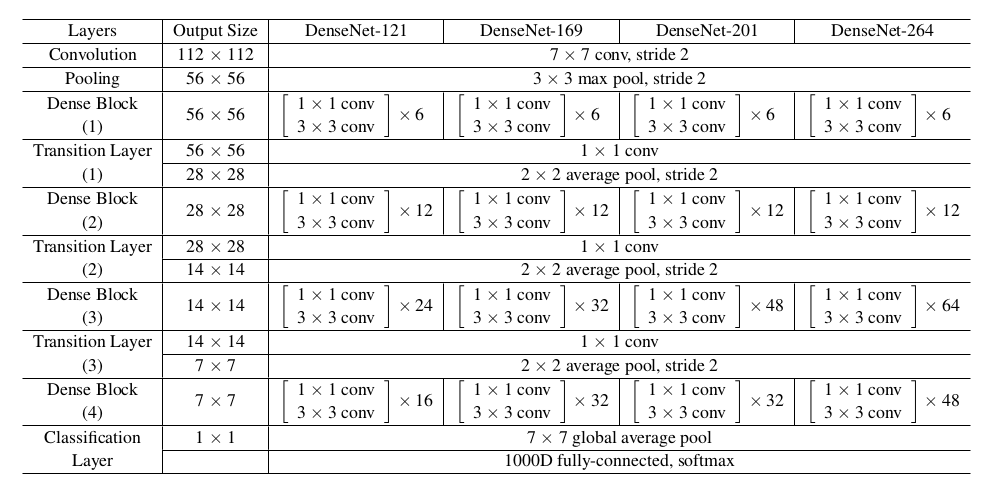
- 表中的
在
ImageNet验证集的错误率(single-crop/10-crop):模型 top-1 error(%) top-5 error(%) DenseNet-121 25.02/23.61 7.71/6.66 DenseNet-169 23.80/22.08 6.85/5.92 DenseNet-201 22.58/21.46 6.34/5.54 DenseNet-264 22.15/20.80 6.12/5.29 下图是
DenseNet和ResNet在ImageNet验证集的错误率的比较(single-crop)。左图为参数数量,右图为计算量。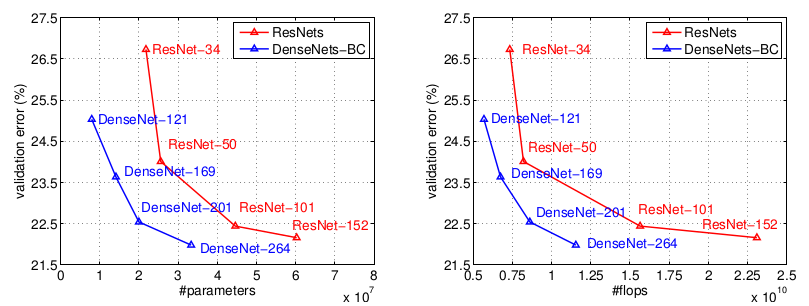
从实验可见:
DenseNet的参数数量和计算量相对ResNet明显减少。- 具有
20M个参数的DenseNet-201与具有40M个参数的ResNet-101验证误差接近。 - 和
ResNet-101验证误差接近的DenseNet-201的计算量接近于ResNet-50,几乎是ResNet-101的一半。
- 具有
DenseNet在CIFAR和SVHN验证集的表现:C10+和C100+:表示对CIFAR10/CIFAR100执行数据集增强,包括平移和翻转。- 在
C10/C100/SVHN三列上的DenseNet采用了Dropout。 DenseNet的Depth列给出的是 参数。
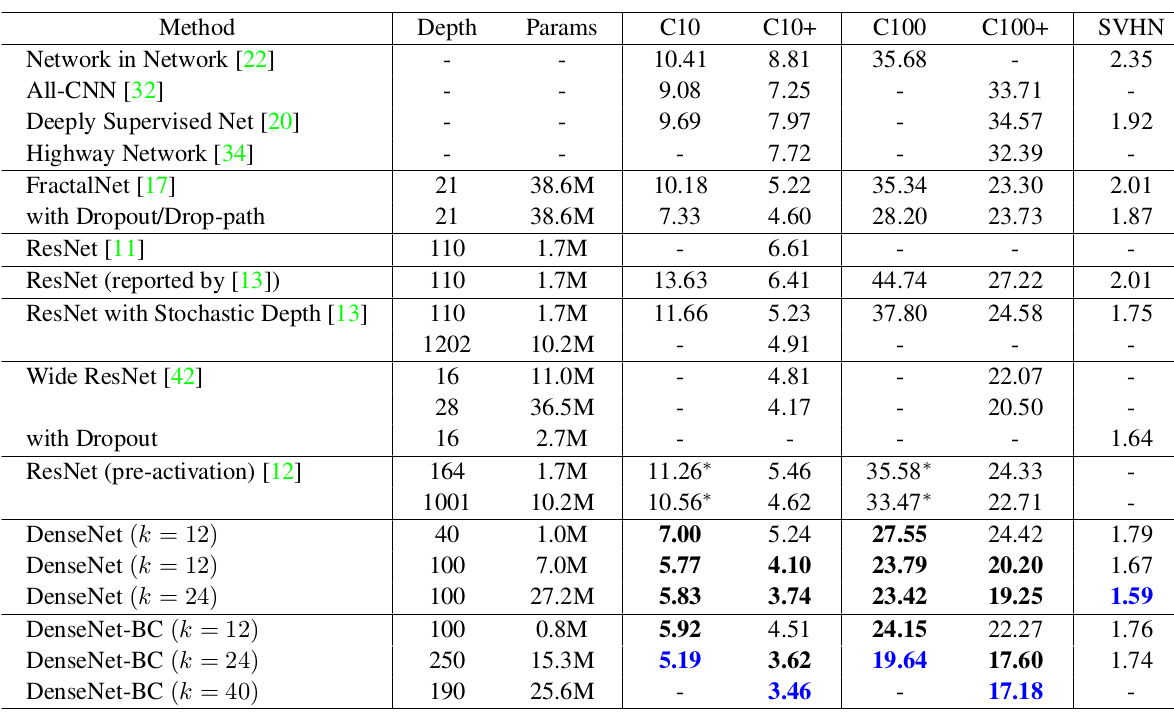
从实验可见:
不考虑压缩因子和
bottleneck, 和 越大DenseNet表现更好。这主要是因为模型容量相应地增长。网络可以利用更大、更深的模型提高其表达学习能力,这也表明了
DenseNet不会受到优化困难的影响。DenseNet的参数效率更高,使用了压缩因子和bottleneck的DenseNet-BC的参数利用率极高。这带来的一个效果是:
DenseNet-BC不容易发生过拟合。事实上在
CIFAR10上,DenseNet从 中,参数数量提升了4倍但是验证误差反而5.77下降到5.83,明显发生了过拟合。而DenseNet-BC未观察到过拟合。
DenseNet提高准确率的一个可能的解释是:各层通过较短的连接(最多需要经过两个或者三个过渡层)直接从损失函数中接收额外的监督信息。
8.4 内存优化
8.4.1 内存消耗
虽然
DenseNet的计算效率较高、参数相对较少,但是DenseNet对内存不友好。考虑到GPU显存大小的限制,因此无法训练较深的DenseNet。假设
DenseNet块包含 层,对于第 层有: 。假设每层的输出
feature map尺寸均为、通道数为 , 由BN-ReLU-Conv(3x3)组成,则:- 拼接
Concat操作 :需要生成临时feature map作为第 层的输入,内存消耗为 。 BN操作:需要生成临时feature map作为ReLU的输入,内存消耗为 。ReLU操作:可以执行原地修改,因此不需要额外的feature map存放ReLU的输出。Conv操作:需要生成输出feature map作为第 层的输出,它是必须的开销。
因此除了第 层的输出
feature map需要内存开销之外,第 层还需要 的内存开销来存放中间生成的临时feature map。整个
DenseNet Block需要 的内存开销来存放中间生成的临时feature map。即DenseNet Block的内存消耗为,是网络深度的平方关系。- 拼接
拼接
Concat操作是必须的,因为当卷积的输入存放在连续的内存区域时,卷积操作的计算效率较高。而DenseNet Block中,第 层的输入feature map由前面各层的输出feature map沿通道方向拼接而成。而这些输出feature map并不在连续的内存区域。另外,拼接
feature map并不是简单的将它们拷贝在一起。由于feature map在Tensorflow/Pytorch等等实现中的表示为 (channel first),或者 (channel last),如果简单的将它们拷贝在一起则是沿着mini batch维度的拼接,而不是沿着通道方向的拼接。DenseNet Block的这种内存消耗并不是DenseNet Block的结构引起的,而是由深度学习库引起的。因为Tensorflow/PyTorch等库在实现神经网络时,会存放中间生成的临时节点(如BN的输出节点),这是为了在反向传播阶段可以直接获取临时节点的值。这是在时间代价和空间代价之间的折中:通过开辟更多的空间来存储临时值,从而在反向传播阶段节省计算。
除了临时
feature map的内存消耗之外,网络的参数也会消耗内存。设 由BN-ReLU-Conv(3x3)组成,则第 层的网络参数数量为: (不考虑BN)。整个
DenseNet Block的参数数量为 ,即 。因此网络参数的数量也是网络深度的平方关系。- 由于
DenseNet参数数量与网络的深度呈平方关系,因此DenseNet网络的参数更多、网络容量更大。这也是DenseNet优于其它网络的一个重要因素。 - 通常情况下都有 ,其中 为网络
feature map的宽、高, 为网络的增长率。所以网络参数消耗的内存要远小于临时feature map消耗的内存。
- 由于
8.4.2 内存优化
论文
《Memory-Efficient Implementation of DenseNets》通过分配共享内存来降低内存需求,从而使得训练更深的DenseNet成为可能。其思想是利用时间代价和空间代价之间的折中,但是侧重于牺牲时间代价来换取空间代价。其背后支撑的因素是:
Concat操作和BN操作的计算代价很低,但是空间代价很高。因此这种做法在DenseNet中非常有效。传统的
DenseNet Block实现与内存优化的DenseNet Block对比如下(第 层,该层的输入feature map来自于同一个块中早前的层的输出):左图为传统的
DenseNet Block的第 层。首先将feature map拷贝到连续的内存块,拷贝时完成拼接的操作。然后依次执行BN、ReLU、Conv操作。该层的临时
feature map需要消耗内存 ,该层的输出feature map需要消耗内存 。- 另外某些实现(如
LuaTorch)还需要为反向传播过程的梯度分配内存,如左图下半部分所示。如:计算BN层输出的梯度时,需要用到第 层输出层的梯度和BN层的输出。存储这些梯度需要额外的 的内存。 - 另外一些实现(如
PyTorch,MxNet)会对梯度使用共享的内存区域来存放这些梯度,因此只需要 的内存。
- 另外某些实现(如
右图为内存优化的
DenseNet Block的第 层。采用两组预分配的共享内存区Shared memory Storage location来存Concate操作和BN操作输出的临时feature map。
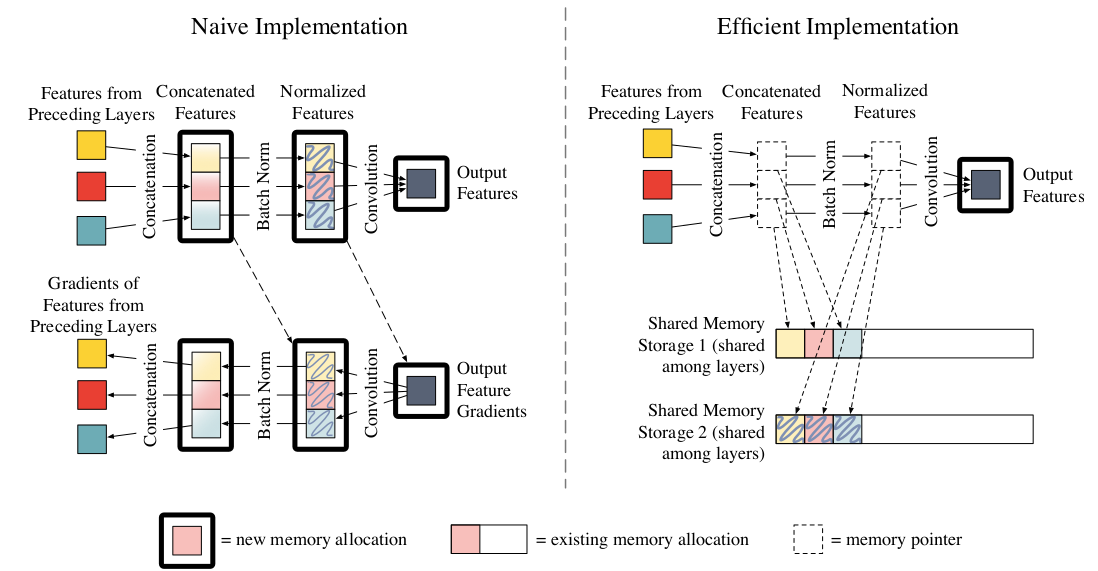
第一组预分配的共享内存区:
Concat操作共享区。第 层的Concat操作的输出都写入到该共享区,第 层的写入会覆盖第 层的结果。对于整个
Dense Block,这个共享区只需要分配 (最大的feature map)的内存,即内存消耗为 (对比传统DenseNet的 )。后续的
BN操作直接从这个共享区读取数据。由于第 层的写入会覆盖第 层的结果,因此这里存放的数据是临时的、易丢失的。因此在反向传播阶段还需要重新计算第 层的
Concat操作的结果。因为
Concat操作的计算效率非常高,因此这种额外的计算代价很低。
第二组预分配的共享内存区:
BN操作共享区。第 层的BN操作的输出都写入到该共享区,第 层的写入会覆盖第 层的结果。对于整个
Dense Block,这个共享区也只需要分配 (最大的feature map)的内存,即内存消耗为 (对比传统DenseNet的 )。后续的卷积操作直接从这个共享区读取数据。
与
Concat操作共享区同样的原因,在反向传播阶段还需要重新计算第 层的BN操作的结果。BN的计算效率也很高,只需要额外付出大约 5% 的计算代价。
由于
BN操作和Concat操作在神经网络中大量使用,因此这种预分配共享内存区的方法可以广泛应用。它们可以在增加少量的计算时间的情况下节省大量的内存消耗。
8.4.3 优化结果
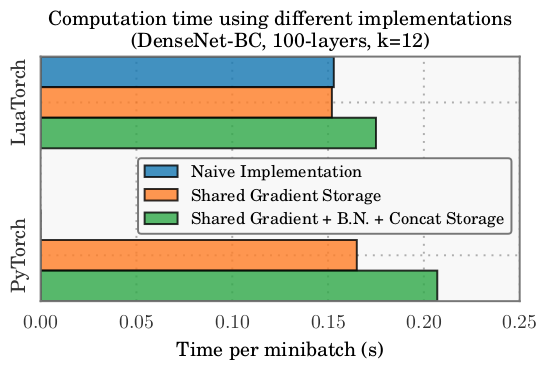
如下图所示,
DenseNet不同实现方式的实验结果:Naive Implementation(LuaTorch):采用LuaTorch实现的,不采用任何的内存共享区。Shared Gradient Strorage(LuaTorch):采用LuaTorch实现的,采用梯度内存共享区。Shared Gradient Storage(PyTorch):采用PyTorch实现的,采用梯度内存共享区。Shared Gradient+BN+Concat Strorate(LuaTorch):采用LuaTorch实现的,采用梯度内存共享区、Concat内存共享区、BN内存共享区。Shared Gradient+BN+Concat Strorate(PyTorch):采用LuaTorch实现的,采用梯度内存共享区、Concat内存共享区、BN内存共享区。
注意:
PyTorch自动实现了梯度的内存共享区。内存消耗是参数数量的线性函数。因为参数数量本质上是网络深度的二次函数,而内存消耗也是网络深度的二次函数。
如前面的推导过程中,
DenseNet Block参数数量 ,内存消耗 。因此 ,即 。
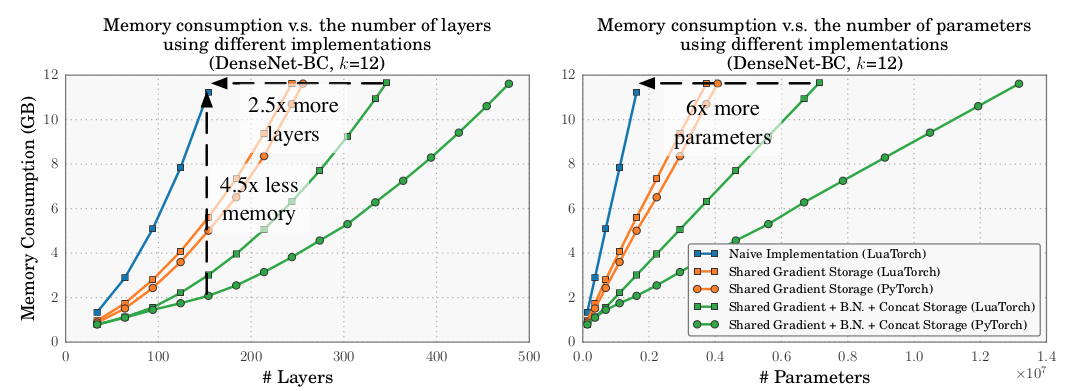
如下图所示,
DenseNet不同实现方式的训练时间差异(NVIDIA Maxwell Titan-X):- 梯度共享存储区不会带来额外时间的开销。
Concat内存共享区、BN内存共享区需要额外消耗 15%(LuaTorch) 或者20% (PyTorch) 的时间。
如下图所示,不同
DenseNet的不同实现方式在ImageNet上的表现(single-crop test):DenseNet cosine使用 学习率。经过内存优化的
DenseNet可以在单个工作站(8 NVIDIA Tesla M40 GPU)上训练 264 层的网络,并取得了top-1 error=20.26%的好成绩。网络参数数量:232 层
DenseNet:k=48,55M参数。 264 层DenseNet:k=32,33M参数;k=48,73M参数。
九、小型网络
目前神经网络领域的研究基本可以概括为两个方向:探索模型更好的预测能力,关注模型在实际应用中的难点。
事实上卷积神经网络在图像识别领域超越了人类的表现,但是这些先进的网络需要较高的计算资源。这些资源需求超出了很多移动设备和嵌入式设备的能力(如:无人驾驶),导致实际应用中难以在这些设备上应用。
小型网络就是为解决这个难点来设计的。
小型网络的设计和优化目标并不是模型的准确率,而是在满足一定准确率的条件下,尽可能的使得模型小,从而降低对计算资源的需求,降低计算延迟。
小型高效的神经网络的构建方法大致可以归为两类:对已经训练好的网络进行压缩,直接训练小网络模型。
模型参数的数量决定了模型的大小,所谓的
小型网络指的是网络的参数数量较少。小型网络具有至少以下三个优势:
较小的模型具有更高效的分布式训练效率。
Worker与PS以及Worker与Worker之间的通信是神经网络分布式训练的重要限制因素。在分布式数据并行训练中,通信开销与模型的参数数量成正比。较小的模型需要更少的通信,从而可以更快的训练。较小的模型在模型导出时开销更低。
当在
tensorflow等框架中训练好模型并准备部署时,需要将模型导出。如:将训练好的模型导出到自动驾驶汽车上。模型越小,则数据导出需要传输的数据量越少,这样可以支持更频繁的模型更新。较小的模型可以在
FPGA和嵌入式硬件上部署。FPGA通常只有小于10MB的片上内存,并且没有外部存储。因此如果希望在FPGA上部署模型,则要求模型足够小从而满足内存限制。
9.1 SqueezeNet 系列
9.1.1 SqueezeNet
squeezenet提出了Fire模块,并通过该模型构成一种小型CNN网络,在满足AlexNet级别准确率的条件下大幅度降低参数数量。CNN结构设计三个主要策略:策略 1:部分的使用
1x1卷积替换3x3卷积。因为1x1卷积的参数数量比3x3卷积的参数数量少了9倍。策略 2:减少
3x3卷积输入通道的数量。这会进一步降低网络的参数数量。策略 3:将网络中下采样的时机推迟到网络的后面。这会使得网络整体具有尺寸较大的
feature map。其直觉是:在其它不变的情况下,尺寸大的
feature map具有更高的分类准确率。
策略
1、2是关于在尽可能保持模型准确率的条件下减少模型的参数数量,策略3是关于在有限的参数数量下最大化准确率。
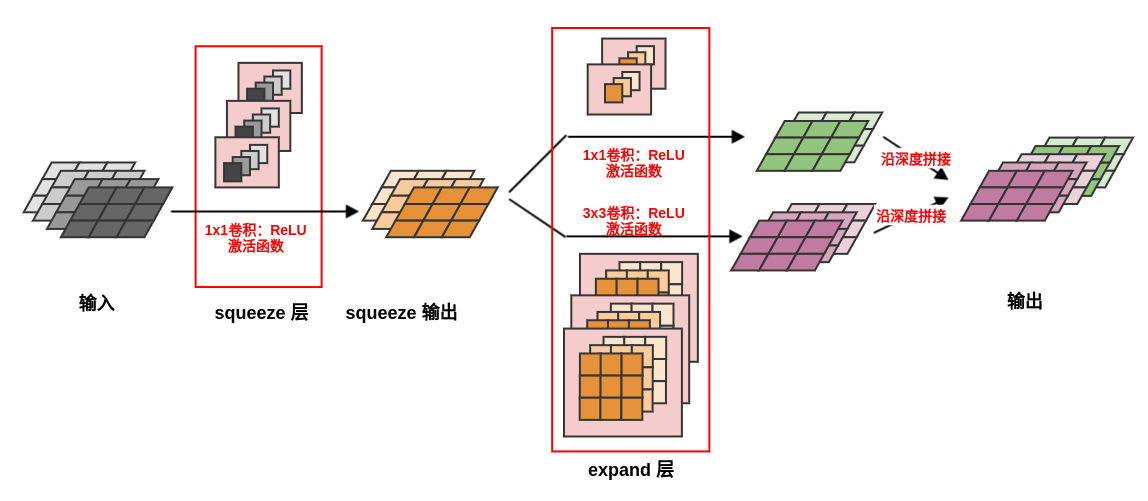
9.1.1.1 Fire 模块
一个
Fire模块由一个squeeze层和一个expand层组成。squeeze层:一个1x1卷积层,输出通道数为超参数 。- 通常选择超参数 满足: 。
- 它用于减少
expand层的输入通道数,即:应用策略2 。
expand层:一个1x1卷积层和一个3x3卷积层,它们卷积的结果沿着深度进行拼接。1x1卷积输出通道数为超参数 ,3x3卷积输出通道数为超参数 。- 选择
1x1卷积是应用了策略1 。
9.1.1.2 网络性能
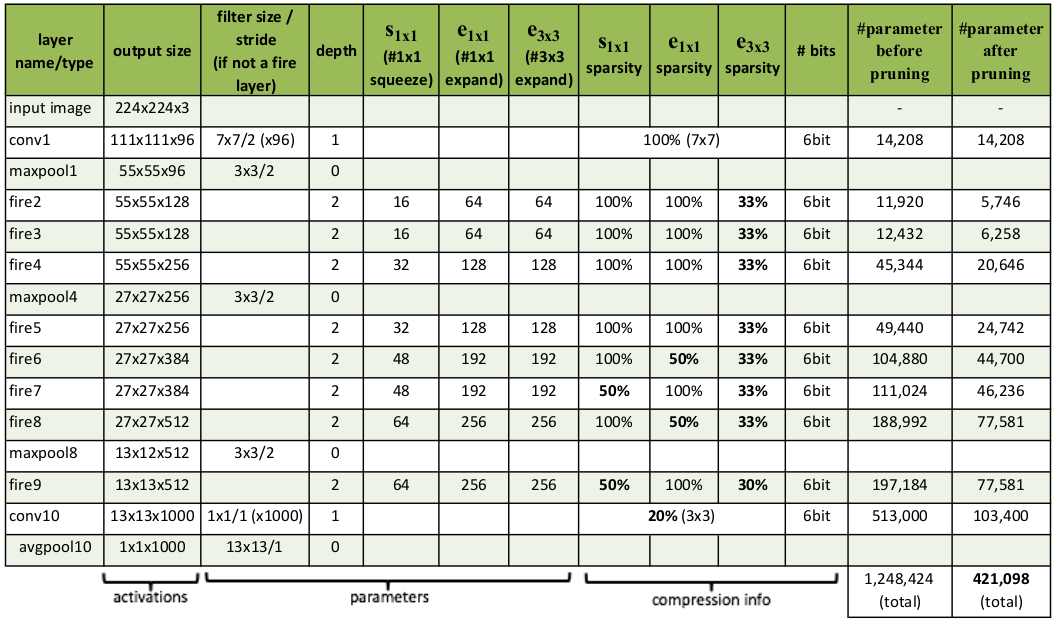
网络设计:
SqueezeNet从一个独立的卷积层(conv1)开始,后跟 8 个Fire模块(fire2~9),最后连接卷积层conv10、全局平均池化层、softmax输出层。- 从网络开始到末尾,每个
Fire模块的输出通道数逐渐增加。 - 在
conv1、fire4、fire8之后执行最大池化,步长为2。这种相对较晚的执行池化操作是采用了策略3。 - 在
expand层中的3x3执行的是same卷积,即:在原始输入上下左右各添加一个像素,使得输出的feature map尺寸不变。 - 在
fire9之后使用Dropout,遗忘比例为 0.5 。

网络参数:
(#1x1 squeeze)列给出了超参数 ,(#1x1 expand)列给出了超参数 ,(#3x3 expand)列给出了超参数 。- ,,, 这四列给出了模型裁剪的参数。
# parameter before pruning列给出了模型裁剪之前的参数数量。# parameter after pruning列给出了模型裁剪之后的参数数量。
模型性能:
- 网络压缩方法列:给出了网络裁剪方法,包括
SVD(Denton et al. 2014)、Network pruning (Han et al. 2015b)、Deep compression (Han et al. 2015a)。 - 数据类型列:给出了计算精度。
- 模型压缩比例列:给出了模型相对于原始
AlexNet的模型大小压缩的比例。 top-1 Accuracy/top-5 Accuracy列:给出了模型在ImageNet测试集上的评估结果。
可以看到,
SqueezeNet在满足同样准确率的情况下,模型大小比AlexNet压缩了 50 倍。如果使用Deep Compression以及6 bit精度的情况下,模型大小比AlexNet压缩了 510 倍。CNN 网络结构 网络压缩方法 数据类型 模型大小 模型压缩比例 top-1 Accuracy top-5 Accuracy AlexNet None 32 bit 240 MB 1x 57.2% 80.3% AlexNet SVD 32 bit 48 MB 5x 56.0% 79.4% AlexNet Network Pruning 32 bit 27 MB 9x 57.2% 80.3% AlexNet Deep Compression 5-8 bit 6.9 MB 35x 57.2% 80.3% SqueezeNet None 32 bit 4.8 MB 50x 57.5% 80.3% SqueezeNet Deep Compression 8 bit 0.66 MB 363x 57.5% 80.3% SqueezeNet Deep Compression 6 bit 0.47 MB 510x 57.5% 80.3% - 网络压缩方法列:给出了网络裁剪方法,包括
a. 超参数设计
定义 为地一个
fire模块的输出通道数,假设每 个fire模块将fire模块的输出通道数增加 。如:,则网络中所有fire模块的输出通道数依次为:因此第 个
fire模块的输出通道数为: 。由于fire模块的输出就是fire模块中expand层的输出,因此 也就是第 个fire模块中expand层的输出通道数。定义 为所有
fire模块的expand层中,3x3卷积数量的比例。这意味着:不同fire模块的expand层中3x3卷积数量的占比都是同一个比例。则有:- 第 个
fire模块的expand层中的1x1卷积数量 。 - 第 个
fire模块的expand层中的3x3卷积数量 。
- 第 个
定义 (
squeeze ratio)为所有fire模块中,squeeze层的输出通道数与expand层的输出通道数的比例,称作压缩比。这意味着:不同fire模块的压缩比都相同。则有:第 个
fire模块的squeeze层的输出通道数为 。
对于前面给到的
SqueezeNet有: 。评估超参数 : , 从
0.15~1.0。在 时,
ImageNet top-5准确率达到峰值86.0%,此时模型大小为19MB。此后进一步增加SR只会增加模型大小而不会提高模型准确率。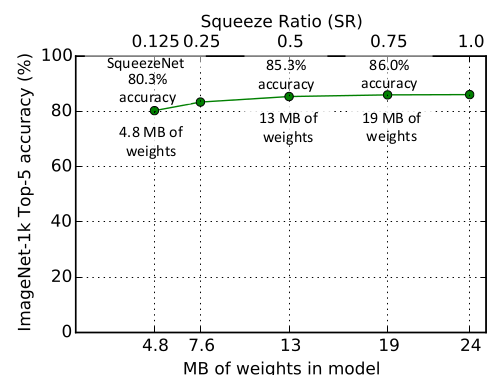
评估超参数 : , 从
1%~99%。在
3x3卷积占比(相对于expand层的卷积数量的占比)为50%时,ImageNet top-5准确率达到85.3%。此后进一步增加3x3卷积的占比只会增加模型大小而几乎不会提高模型准确率。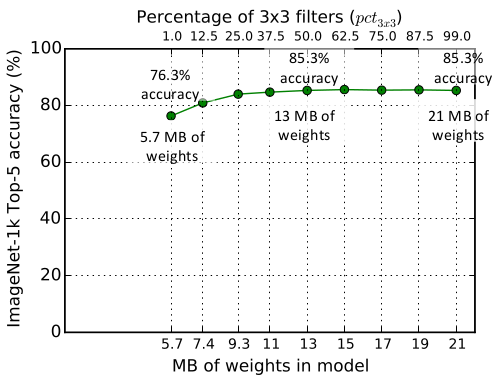
b. 旁路连接
采用
ResNet的思想,可以在SqueezeNet中添加旁路连接。下图中,左图为标准的SqueezeNet,中图为引入简单旁路连接的SqueezeNet,右图为引入复杂旁路连接的SqueezeNet。- 简单旁路连接:就是一个恒等映射。此时要求输入
feature map和残差feature map的通道数相等。 - 复杂旁路连接:针对输入
feature map和残差feature map的通道数不等的情况,旁路采用一个1x1卷积来调整旁路的输出通道数。
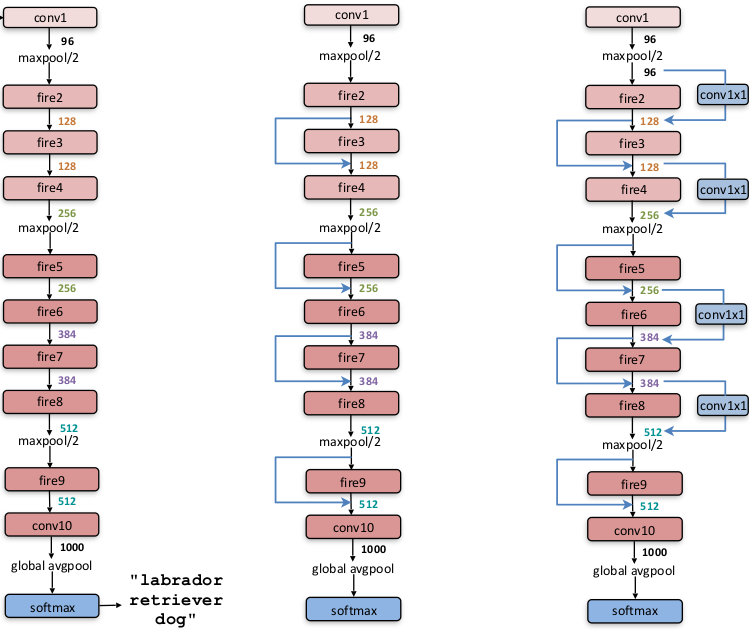
它们在
ImageNet测试集上的表现:模型结构 top-1 准确率 top-5 准确率 model size SqueezeNet 57.5% 80.3% 4.8MB SqueezeNet + 简单旁路连接 60.4% 82.5% 4.8MB SqueezeNet + 复杂旁路连接 58.8% 82.0% 7.7MB 因此添加简单旁路连接能够提升模型的准确率,还能保持模型的大小不变。
- 简单旁路连接:就是一个恒等映射。此时要求输入
9.1.2 SqueezeNext
- 现有的神经网络在嵌入式系统上部署的主要挑战之一是内存和功耗,
SqueezeNext针对内存和功耗进行优化,是为功耗和内存有限的嵌入式设备设计的神经网络。
9.1.2.1 SqueezeNext Block
SqueezeNext块是在Fire块的基础进行修改:- 将
expand层的3x3卷积替换为1x3 + 3x1卷积,同时移除了expand层的拼接1x1卷积、添加了1x1卷积来恢复通道数。 - 通过两阶段的
squeeze得到更激进的通道缩减,每个阶段的squeeze都将通道数减半。
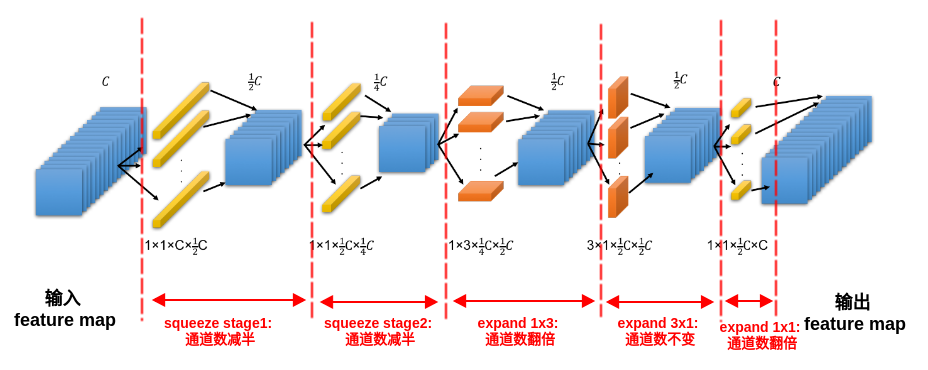
- 将
SqueezeNext块也采用类似ResNet的旁路连接,从而可以训练更深的网络。下图中,左图为
ResNet块,中图为SqueezeNet的Fire块,右图为SqueezeNext块。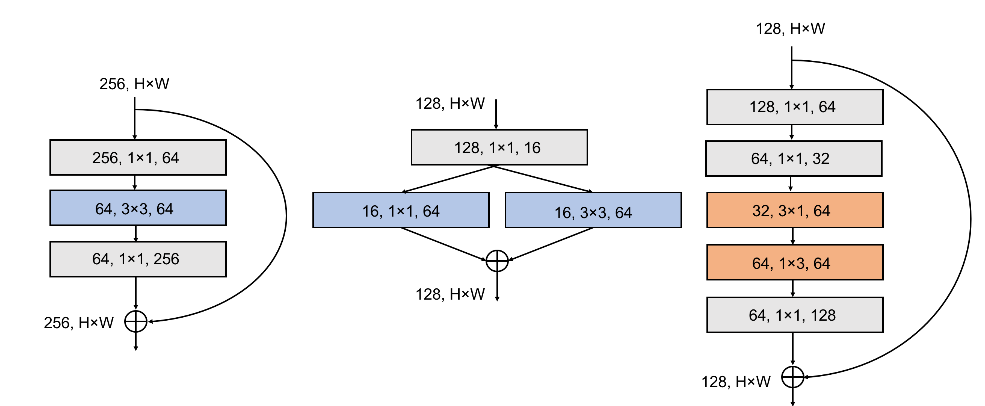
9.1.2.2 网络性能
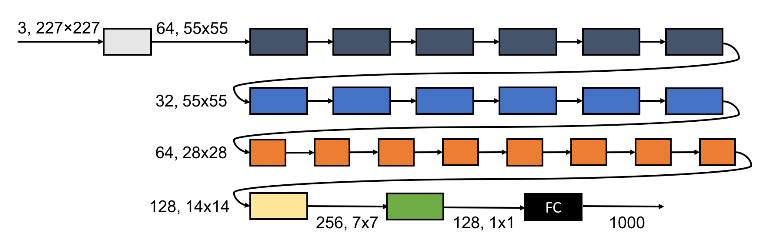
网络结构:如下为一个23层的
SqueezeNext网络(记做SqueezeNext-23)。- 相同颜色的
SqueezeNext块具有相同的输入feature map尺寸和通道数。 - 该网络结构描述为
[6,6,8,1],意思是:在第一个conv/pooling层之后有四组SqueezeNext块,每组SqueezeNext分别有6个、6个、8个、1个SqueezeNext块。 - 在全连接层之前插入一个
1x1卷积层来降低全连接层的输入通道数,从而大幅降低全连接层的参数数量。
23层
SqueezeNext网络的另一种结构(记做SqueezeNext-23v5):结构描述为[2,4,14,1]。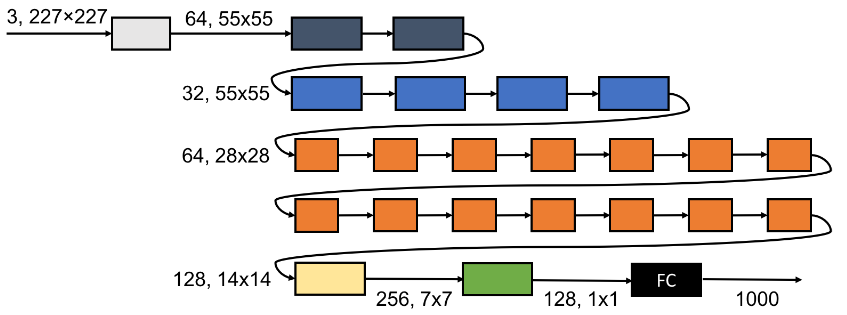
- 相同颜色的
SqueezeNext网络在ImageNet上的预测准确率:- 参数降低倍数是相对于
AlexNet网络的参数而言。 G-SqueezeNext-23是SqueezeNext-23采用分组卷积的版本。
模型 top-1 准确率 top-5 准确率 参数数量(百万) 参数降低倍数 AlexNet 57.10% 80.30% 60.9 1x SqueezeNet 57.50% 80.30% 1.2 51x SqueezeNext-23 59.05% 82.60% 0.72 84x G-SqueezeNext-23 57.16% 80.23% 0.54 112x SqueezeNext-34 61.39% 84.31% 1.0 61x SqueezeNext-44 62.64% 85.15% 1.2 51x - 参数降低倍数是相对于
更宽和更深版本的
SqueezeNext网络在ImageNet上的预测准确率:1.5/2.0分别表示将网络拓宽1.5/2倍。拓宽指的增加网络的feature map的通道数,做法是增加第一个conv的输出通道数。- 括号中的准确率是采用了数据集增强和超参数优化之后的最佳结果。
模型 top-1 准确率 top-5 准确率 参数数量(百万) 1.5-SqueezeNext-23 63.52% 85.66% 1.4 1.5-SqueezeNext-34 66.00% 87.40% 2.1 1.5-SqueezeNext-44 67.28% 88.15% 2.6 VGG-19 68.50% 88.50% 138 2.0-SqueezeNext-23 67.18% 88.17% 2.4 2.0-SqueezeNext-34 68.46% 88.78% 3.8 2.0-SqueezeNext-44 69.59% 89.53% 4.4 MobileNet 67.50%(70.9%) 86.59%(89.9%) 4.2 2.0-SqueezeNext-23v5 67.44%(69.8%) 88.20%(89.5%) 3.2 硬件仿真结果:
括号中的准确率是采用了数据集增强和超参数优化之后的最佳结果。
Time表示模型的推断时间(相对耗时),Energy表示模型的推断功耗。8x8,32KB和16x16,128KB表示仿真硬件的配置:NxN表示硬件具有NxN个PE阵列。processing element:PE是单个计算单元。32KB/128KB表示全局缓存。
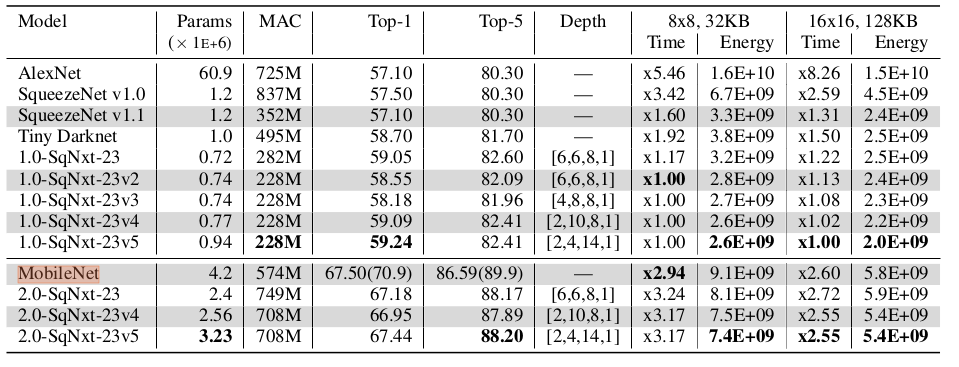
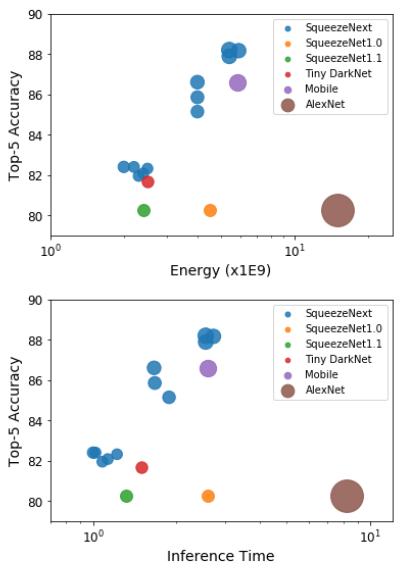
深度可分离卷积的计算密集性较差,因为其
计算/带宽比例较低,所以在某些移动设备上表现较差。一个可分离卷积的计算需要多次
IO和计算才能完成,相比而言普通卷积只需要一次IO和计算。
9.2 MobileNet 系列
9.2.1 MobileNet
MobileNet应用了Depthwise深度可分离卷积来代替常规卷积,从而降低计算量,减少模型参数。MobileNet不仅产生了小型网络,还重点优化了预测延迟。与之相比,有一些小型网络虽然网络参数较少,但是预测延迟较大。
9.2.1.1 深度可分离卷积
对于传统的卷积层,单个输出
feature这样产生:首先由一组滤波器对输入的各通道执行滤波,生成滤波
feature。这一步仅仅考虑空间相关性。然后计算各通道的滤波
feature的加权和,得到单个feature。这里不同位置处的通道加权和的权重不同,这意味着在空间相关性的基础上,叠加了通道相关性。
Depthwise深度可分离卷积打破了空间相关性和通道相关性的混合:首先由一组滤波器对输入的各通道执行滤波,生成滤波
feature。这一步仅仅考虑空间相关性。然后执行
1x1卷积来组合不同滤波feature。这里不同位置处的通道加权和的权重都相同,这意味着这一步仅仅考虑通道相关性。
假设:输入
feature map是一个尺寸为 、输入通道数为 的张量 ,输出feature map是一个尺寸为 、输出通道数为 的张量 。假设核张量为 ,其形状为 。则对于标准卷积过程,有: 。其中: 为输入通道的索引; 为输出通道的索引;为空间索引, 分别为对应空间方向上的遍历变量。
其参数数量为: ;其计算代价为: 。
depthwise深度可分离卷积中,假设核张量为 ,其形状为: 。则对于depthwise深度可分离卷积过程:首先对输入的各通道执行滤波,有: 。输出尺寸为 、输出通道数为 。
其参数数量为:;其计算代价为: 。
然后对每个通道得到的滤波
feature执行1x1卷积,有: 。其中 为1x1卷积的核张量。其参数数量为:;其计算代价为: 。
总的参数数量为:,约为标准卷积的 。
总的计算代价为: ,约为标准卷积的 。
通常卷积核采用
3x3卷积,而 ,因此depthwise卷积的参数数量和计算代价都是常规卷积的 到 。
常规卷积和
Depthwise可分离卷积的结构区别(带BN和ReLU):(左图为常规卷积,右图为Depthwise可分离卷积)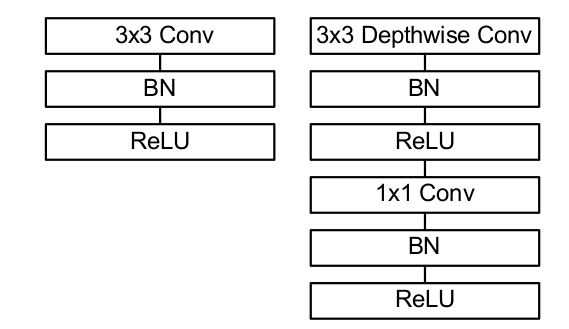
9.2.1.2 网络结构
MobileNeet网络结构如下表所示。其中:Conv表示标准卷积,Conv dw表示深度可分离卷积。- 所有层之后都跟随
BN和ReLU(除了最后的全连接层,该层的输出直接送入到softmax层进行分类)。
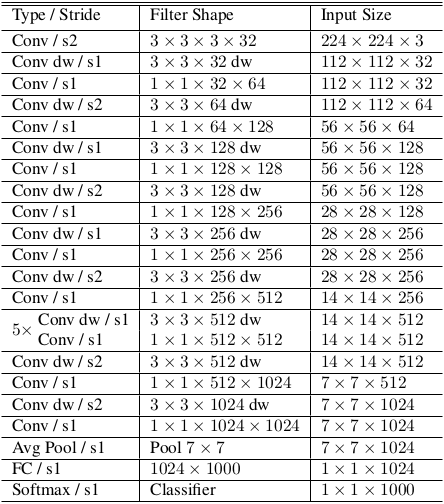
MobileNet大量的参数和计算量都被消耗在1x1卷积上:Conv 1x1包含了所有的1x1卷积层,包括可分离卷积中的1x1卷积。Conv DW 3x3仅包括可分离卷积中的3x3卷积。
层类型 乘-加运算 参数数量 Conv 1x1 94.86% 74.59% Conv DW 3x3 3.06% 1.06% Conv 3x3 1.19% 0.02% 全连接层 0.18% 24.33% 与训练大模型相反,训练
MobileNet时较少的采用正则化和数据集增强技术,因为MobileNet是小模型,而小模型不容易过拟合。论文特别提到:在
depthwise滤波器上使用很少或者不使用L2正则化,因为它们的参数很少。
9.2.1.3 宽度乘子 & 分辨率乘子
尽管基本的
MobileNet架构已经很小,延迟很低,但特定应用需要更快的模型。为此MobileNet引入了两个超参数:宽度乘子、分辨率乘子宽度乘子
width multiplier,记做 。其作用是:在每层均匀的缩减网络(实际上是减小每层网络的输入、输出feature map的通道数量)。宽度乘子应用于第一层(是一个全卷积层)的输出通道数上。这也影响了后续所有
Depthwise可分离卷积层的输入feature map通道数、输出feature map通道数。这可以通过直接调整第一层的输出通道数来实现。
它大概以 的比例减少了参数数量,降低了计算量。
通常将其设置为:0.25、0.5、0.75、1.0 四档。
分辨率乘子
resolution multiplier,记做 。其作用是:降低输出的feature map的尺寸。分辨率乘子应用于输入图片上,改变了输入图片的尺寸。这也影响了后续所有
Depthwise可分离卷积层的输入feature map尺寸、输出feature map尺寸。这可以通过直接调整网络的输入尺寸来实现。
它不会改变模型的参数数量,但是大概以 的比例降低计算量。
如果模型同时实施了宽度乘子和分辨率乘子,则模型大概以 的比例减少了参数数量,大概以 的比例降低了计算量。
假设输入
feature map尺寸为14x14,通道数为512;卷积尺寸为3x3;输出feature map尺寸为14x14,通道数为512。层类型 乘-加操作(百万) 参数数量(百万) 常规卷积 462 2.36 深度可分离卷积 52.3 0.27 的深度可分离卷积 29.6 0.15 的深度可分离卷积 15.1 0.15
9.2.1.4 网络性能
常规卷积和深度可分离卷积的比较:使用深度可分离卷积在
ImageNet上只会降低 1% 的准确率,但是计算量和参数数量大幅度降低。模型 ImageNet Accuracy 乘-加操作(百万) 参数数量(百万) 常规卷积的MobileNet 71.7% 4866 29.3 MobileNet 70.6% 569 4.2 更瘦的模型和更浅的模型的比较:在计算量和参数数量相差无几的情况下,采用更瘦的
MobileNet比采用更浅的MobileNet更好。- 更瘦的模型:采用 宽度乘子(
瘦表示模型的通道数更小)。 - 更浅的模型:删除了
MobileNet中5x Conv dw/s部分(即:5层feature size=14x14@512的深度可分离卷积)。
模型 ImageNet Accuracy 乘-加操作(百万) 参数数量(百万) 更瘦的MobileNet 68.4% 325 2.6 更浅的MobileNet 65.3% 307 2.9 - 更瘦的模型:采用 宽度乘子(
不同宽度乘子的比较:随着 降低,模型的准确率一直下降( 表示基准
MobileNet)。- 输入分辨率:224x224。
with multiplier ImageNet Accuracy 乘-加 操作(百万) 参数数量(百万) 1.0 70.6% 569 4.2 0.75 68.4% 325 2.6 0.5 63.7% 149 1.3 0.25 50.6% 41 0.5 不同分辨率乘子的比较:随着 的降低,模型的准确率一直下降( 表示基准
MobileNet)。- 宽度乘子:1.0 。
- 对应 , 对应 , 对应 , 对应 。
resolution ImageNet Accuracy 乘-加 操作(百万) 参数数量(百万) 224x224 70.6% 569 4.2 192x192 69.1% 418 4.2 160x160 67.2% 290 4.2 128x128 64.4% 186 4.2 根据 和 分辨率为 两两组合得到 16 个模型。
绘制这16个模型的
accuracy和计算量的关系:近似于log关系,但是在 有一个显著降低。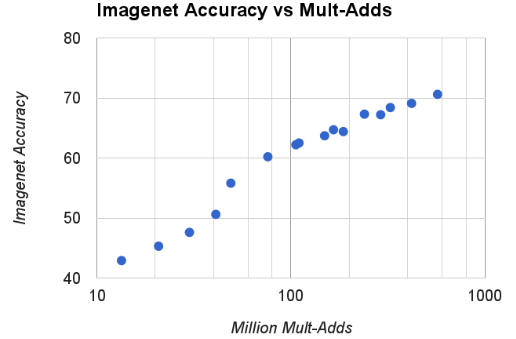
绘制这16个模型的
accuracy和参数数量的关系: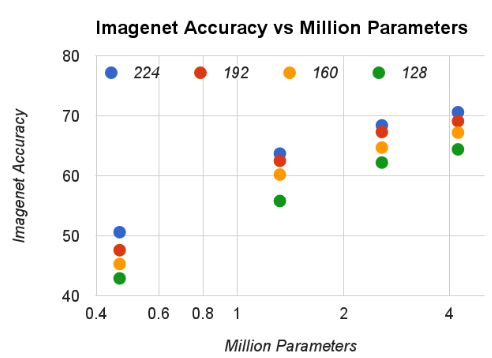
MobileNet和其它模型的比较:MobileNet和VGG 16准确率相近,但是模型大小小了32倍,计算量小了27倍。- 瘦身的
MobileNet(宽度乘子 ,分辨率乘子 )和Squeezenet模型大小差不多,但是准确率更高,计算量小了 22 倍。
模型 ImageNet Accuracy 乘-加 操作(百万) 参数数量(百万) 1.0 MobileNet-224 70.6% 569 4.2 GoogleNet 69.8% 1550 6.8 VGG 16 71.5% 15300 138 0.50 MobileNet-160 60.2% 76 1.32 Squeezenet 57.5% 1700 1.25 AlexNet 57.2% 720 60
9.2.2 MobileNet V2
MobileNet V2创新性的提出了具有线性bottleneck的Inverted残差块。这种块特别适用于移动设备和嵌入式设备,因为它用到的张量都较小,因此减少了推断期间的内存需求。
9.2.2.1 线性bottleneck
一直以来,人们认为与任务相关的信息是嵌入到
feature map中的一个低维子空间。因此feature map事实上有一定的信息冗余。如果缩减feature map的通道数量(相当于降维),则可以降低计算量。MobileNet V1就是采用宽度乘子,从而在计算复杂度和准确率之间平衡。由于
ReLU非线性激活的存在,缩减输入feature map的通道数量可能会产生不良的影响。输入
feature map中每个元素值代表某个特征,将所有图片在该feature map上的取值扩成为矩阵:其中 为样本的数量, 。即:行索引代表样本,列索引代表特征。所有特征由
feature map展平成一维得到。通常 ,则输入矩阵 的秩 。
对于
1x1卷积(不考虑ReLU),则1x1卷积是输入特征的线性组合。输出featuremap以矩阵描述为:其中 , 为输出通道数。
如果考虑
ReLU,则输出featuremap为:对于输出的维度 ,如果 在维度 上的取值均小于 0 ,则由于 的作用, 在维度 上取值均为 0 ,此时可能发生信息不可逆的丢失。
如果
1x1卷积的输出通道数很小(即 较小),使得 ,则 的每个维度都非常重要。一旦经过
ReLU之后 的信息有效维度降低(即 ),则发生信息的丢失。且这种信息丢失是不可逆的。这使得输出
feature map的有效容量降低,从而降低了模型的表征能力。如果
1x1卷积的输出通道数较大(即 较大),使得 ,则 的维度出现冗余。即使 的某个维度被丢失,该维度的信息仍然可以从其它维度得到。
如果
1x1卷积的输出通道数非常小,使得 ,则信息压缩的过程中就发生信息不可逆的丢失。上面的讨论的是
ReLU的非线性导致信息的不可逆丢失。
实验表明:
bootleneck中使用线性是非常重要的。虽然引入非线性会提升模型的表达能力,但是引入非线性会破坏太多信息,会引起准确率的下降。在
Imagenet测试集上的表现如下图: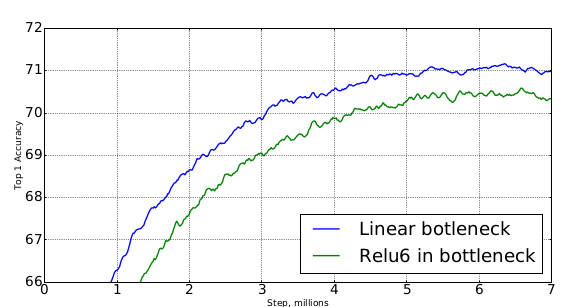
9.2.2.2 bottleneck block
bottleneck block:输入feature map首先经过线性bottleneck来扩张通道数,然后经过深度可分离卷积,最后通过线性bottleneck来缩小通道数。输入
bootleneck输出通道数与输入通道数的比例称作膨胀比。- 通常较小的网络使用略小的膨胀比效果更好,较大的网络使用略大的膨胀比效果更好。
- 如果膨胀比小于 1 ,这就是一个典型的
resnet残差块。
可以在
bottleneck block中引入旁路连接,这种bottleneck block称作Inverted残差块,其结构类似ResNet残差块。在
ResNeXt残差块中,首先对输入feature map执行1x1卷积来压缩通道数,最后通过1x1卷积来恢复通道数。这对应了一个输入
feature map通道数先压缩、后扩张的过程。在
Inverted残差块中,首先对输入feature map执行1x1卷积来扩张通道数,最后通过1x1卷积来恢复通道数。这对应了一个输入
feature map通道数先扩张、后压缩的过程。这也是Inverted残差块取名为Inverted的原因。
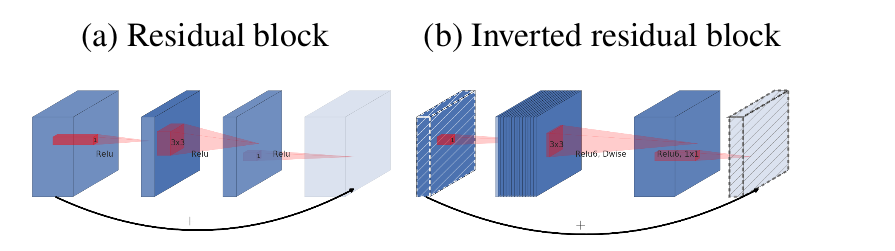
当深度可分离卷积的步长为
1时,bottleneck block包含了旁路连接。当深度可分离卷积的步长不为
1时,bottleneck block不包含旁路连接。这是因为:输入feature map的尺寸与块输出feature map的尺寸不相同,二者无法简单拼接。虽然可以将旁路连接通过一个同样步长的池化层来解决,但是根据
ResNet的研究,破坏旁路连接会引起网络性能的下降。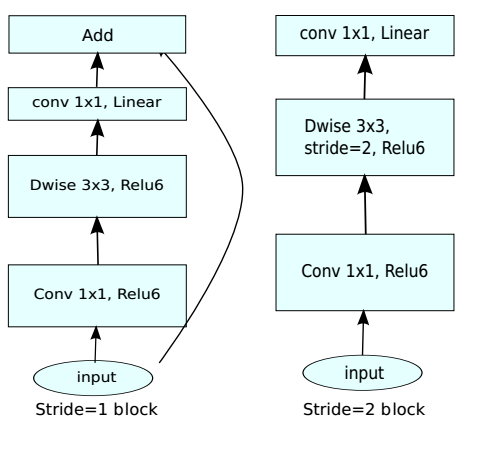
事实上旁路连接有两个插入的位置:在两个
1x1卷积的前后,或者在两个Dwise卷积的前后。通过实验证明:在两个
1x1卷积的前后使用旁路连接的效果最好。在Imagenet测试集上的表现如下图: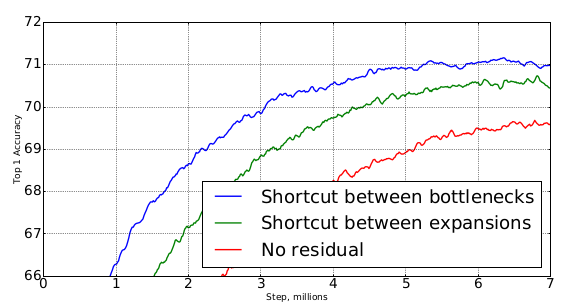
bottleneck block可以看作是对信息的两阶段处理过程:- 阶段一:对输入
feature map进行降维,这一部分代表了信息的容量。 - 阶段二:对信息进行非线性处理,这一部分代表了信息的表达。
在
MobileNet v2中这二者是独立的,而传统网络中这二者是相互纠缠的。- 阶段一:对输入
9.2.2.3 网络性能
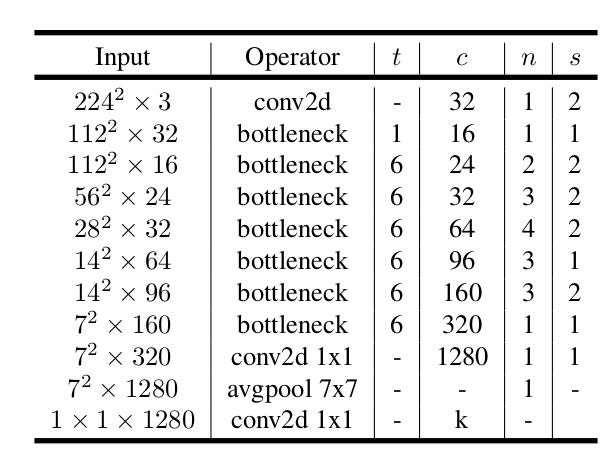
MobileNet V2的设计基于MobileNet v1,其结构如下:每一行代表一个或者一组相同结构的层,层的数量由 给定。
相同结构指的是:
- 同一行内的层的类型相同,由
Operator指定。其中bottleneck指的是bottleneck block。 - 同一行内的层的膨胀比相同,由
t指定。 - 同一行内的层的输出通道数相同,由
c指定。 - 同一行内的层:第一层采用步幅
s,其它层采用步幅1。
- 同一行内的层的类型相同,由
采用
ReLU6激活函数,因为它在低精度浮点运算的环境下表现较好。训练过程中采用
dropout和BN。
与
MobileNet V1类似,MobileNet V2也可以引入宽度乘子、分辨率乘子这两个超参数。网络推断期间最大内存需求(
通道数/内存消耗(Kb)):采用 16 bit 的浮点运算。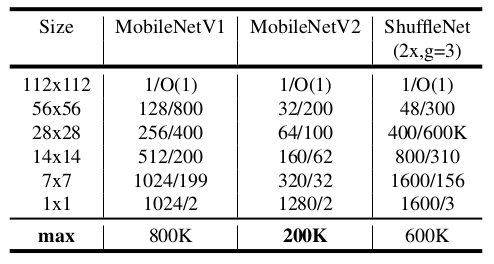
网络在
ImageNet测试集上的表现:- 最后一列给出了预测单张图片的推断时间。
网络 Top 1 Params(百万) 乘-加 数量(百万) CPU MobileNet V1 70.6 4.2 575 113ms ShuffleNet (1.5) 71.5 3.4 292 - ShuffleNet (x2) 73.7 5.4 524 - NasNet-A 74.0 5.3 564 183ms MobileNet V2 72.0 3.4 300 75ms MobileNet V2(1.4) 74.7 6.9 585 143ms
9.3 ShuffleNet 系列
9.3.1 ShuffleNet
ShuffleNet提出了1x1分组卷积+通道混洗的策略,在保证准确率的同时大幅降低计算成本。ShuffleNet专为计算能力有限的设备(如:10~150MFLOPs)设计。在基于ARM的移动设备上,ShuffleNet与AlexNet相比,在保持相当的准确率的同时,大约 13 倍的加速。
9.3.1.1 ShuffleNet block
在
Xception和ResNeXt中,有大量的1x1卷积,所以整体而言1x1卷积的计算开销较大。如ResNeXt的每个残差块中,1x1卷积占据了乘-加运算的 93.4% (基数为32时)。在小型网络中,为了满足计算性能的约束(因为计算资源不够)需要控制计算量。虽然限制通道数量可以降低计算量,但这也可能会严重降低准确率。
解决办法是:对
1x1卷积应用分组卷积,将每个1x1卷积仅仅在相应的通道分组上操作,这样就可以降低每个1x1卷积的计算代价。1x1卷积仅在相应的通道分组上操作会带来一个副作用:每个通道的输出仅仅与该通道所在分组的输入(一般占总输入的比例较小)有关,与其它分组的输入(一般占总输入的比例较大)无关。这会阻止通道之间的信息流动,降低网络的表达能力。解决办法是:采用通道混洗,允许分组卷积从不同分组中获取输入。
- 如下图所示:
(a)表示没有通道混洗的分组卷积;(b)表示进行通道混洗的分组卷积;(c)为(b)的等效表示。 - 由于通道混洗是可微的,因此它可以嵌入到网络中以进行端到端的训练。
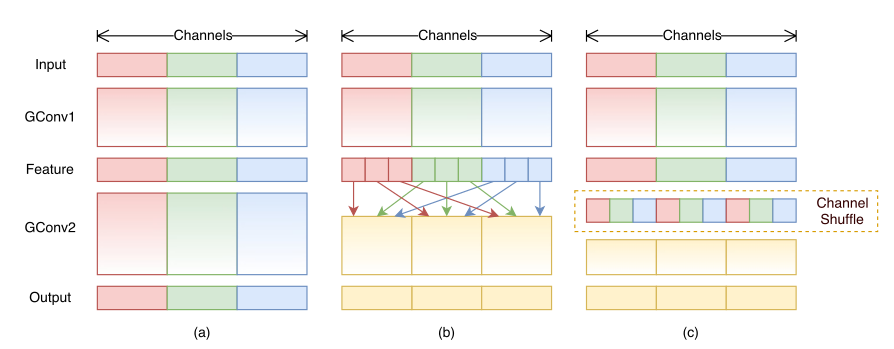
- 如下图所示:
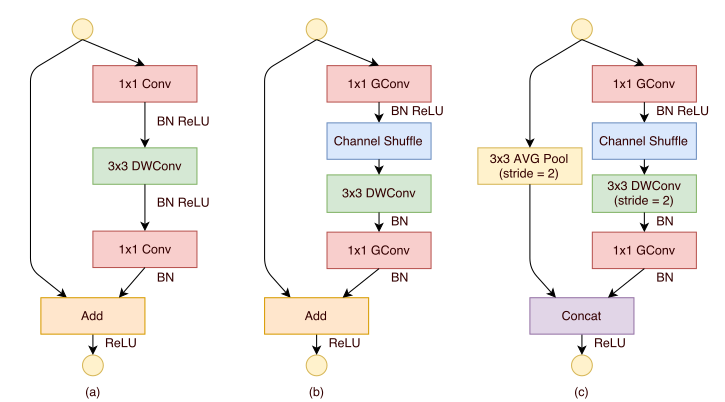
ShuffleNet块的结构从ResNeXt块改进而来:下图中(a)是一个ResNeXt块,(b)是一个ShuffleNet块,(c)是一个步长为2的ShuffleNet块。在
ShuffleNet块中:第一个
1x1卷积替换为1x1分组卷积+通道随机混洗。第二个
1x1卷积替换为1x1分组卷积,但是并没有附加通道随机混洗。这是为了简单起见,因为不附加通道随机混洗已经有了很好的结果。在
3x3 depthwise卷积之后只有BN而没有ReLU。当步长为2时:
恒等映射直连替换为一个尺寸为
3x3、步长为2的平均池化。3x3 depthwise卷积的步长为2。将残差部分与直连部分的
feature map拼接,而不是相加。因为当
feature map减半时,为了缓解信息丢失需要将输出通道数加倍从而保持模型的有效容量。
9.3.1.2 网络性能
在
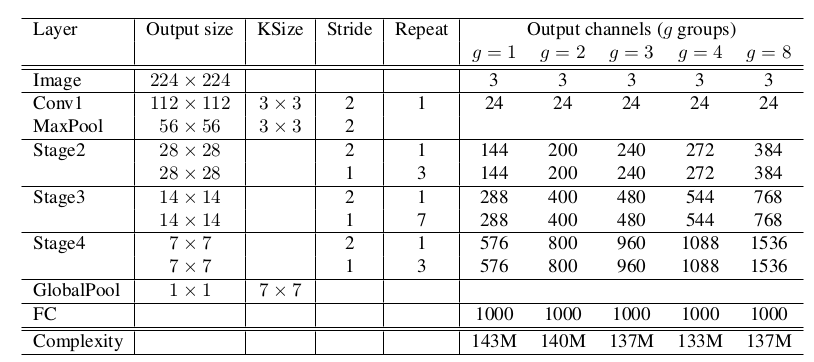
Shufflenet中,depthwise卷积仅仅在1x1卷积的输出feature map上执行。这是因为depthwise很难在移动设备上高效的实现,因为移动设备的计算/内存访问比率较低,所以仅仅在1x1卷积的输出feature map上执行从而降低开销。ShuffleNet网络由ShuffleNet块组成。网络主要由三个
Stage组成。- 每个
Stage的第一个块的步长为 2 ,stage内的块在其它参数上相同。 - 每个
Stage的输出通道数翻倍。
- 每个
在
Stage2的第一个1x1卷积并不执行分组卷积,因此此时的输入通道数相对较小。每个
ShuffleNet块中的第一个1x1分组卷积的输出通道数为:该块的输出通道数的1/4。使用较少的数据集增强,因为这一类小模型更多的是遇到欠拟合而不是过拟合。
复杂度给出了计算量(
乘-加运算),KSize给出了卷积核的尺寸,Stride给出了ShuffleNet block的步长,Repeat给出了ShuffleNet block重复的次数,g控制了ShuffleNet block分组的数量。g=1时,1x1的通道分组卷积退化回原始的1x1卷积。
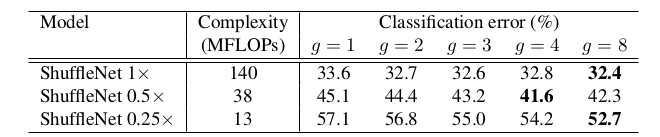
超参数
g会影响模型的准确率和计算量。在ImageNet测试集上的表现如下:ShuffleNet sx表示对ShuffleNet的通道数增加到s倍。这通过控制Conv1卷积的输出通道数来实现。g越大,则计算量越小,模型越准确。其背后的原理是:小模型的表达能力不足,通道数量越大,则小模型的表达能力越强。
g越大,则准确率越高。这是因为对于ShuffleNet,分组越大则生成的feature map通道数量越多,模型表达能力越强。- 网络的通道数越小(如
ShuffleNet 0.25x),则这种增益越大。
随着分组越来越大,准确率饱和甚至下降。
这是因为随着分组数量增大,每个组内的通道数量变少。虽然总体通道数增加,但是每个分组提取有效信息的能力变弱,降低了模型整体的表征能力。
虽然较大
g的ShuffleNet通常具有更好的准确率。但是由于它的实现效率较低,会带来较大的推断时间。
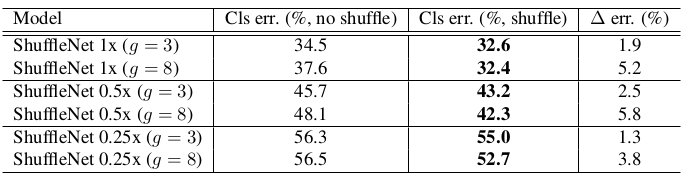
通道随机混洗的效果要比不混洗好。在
ImageNet测试集上的表现如下:- 通道混洗使得分组卷积中,信息能够跨分组流动。
- 分组数
g越大,这种混洗带来的好处越大。
多种模型在
ImageNet测试集上的表现:比较分为三组,每一组都有相差无几的计算量。 给出了在该组中,模型相对于
MobileNet的预测能力的提升。MFLOPs表示乘-加运算量(百万),错误率表示top-1 error。ShuffleNet 0.5x(shallow,g=3)是一个更浅的ShuffleNet。考虑到MobileNet只有 28 层,而ShuffleNet有 50 层,因此去掉了Stage 2-4中一半的块,得到一个教浅的、只有 26 层的ShuffleNet。
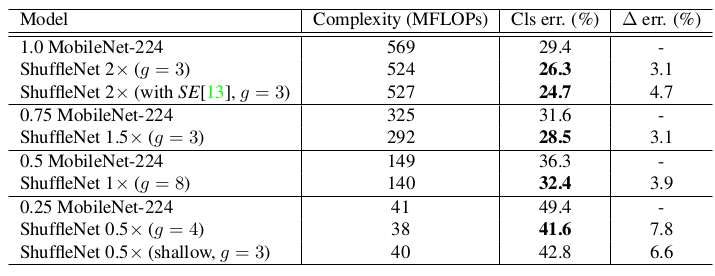
在移动设备上的推断时间(
Qualcomm Snapdragon 820 processor,单线程):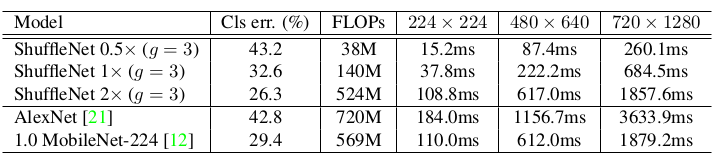
9.3.2 ShuffleNet V2
ShuffleNet V2基于一系列对照实验提出了高效网络设计的几个通用准则,并提出了ShuffleNet V2的网络结构。
9.3.2.1 小型网络通用设计准则
目前衡量模型推断速度的一个通用指标是
FLOPs(即乘-加计算量)。事实上这是一个间接指标,因为它不完全等同于推断速度。如:MobileNet V2和NASNET-A的FLOPs相差无几,但是MobileNet V2的推断速度要快得多。如下所示为几种模型在
GPU和ARM上的准确率(在ImageNet验证集上的测试结果)、模型推断速度(通过Batch/秒来衡量)、计算复杂度(通过FLOPs衡量)的关系。在
ARM平台上batchsize=1, 在GPU平台上batchsize=8。准确率与模型容量成正比,而模型容量与模型计算复杂度成成比、计算复杂度与推断速度成反比。
因此:模型准确率越高,则推断速度越低;模型计算复杂度越高,则推断速度越低。
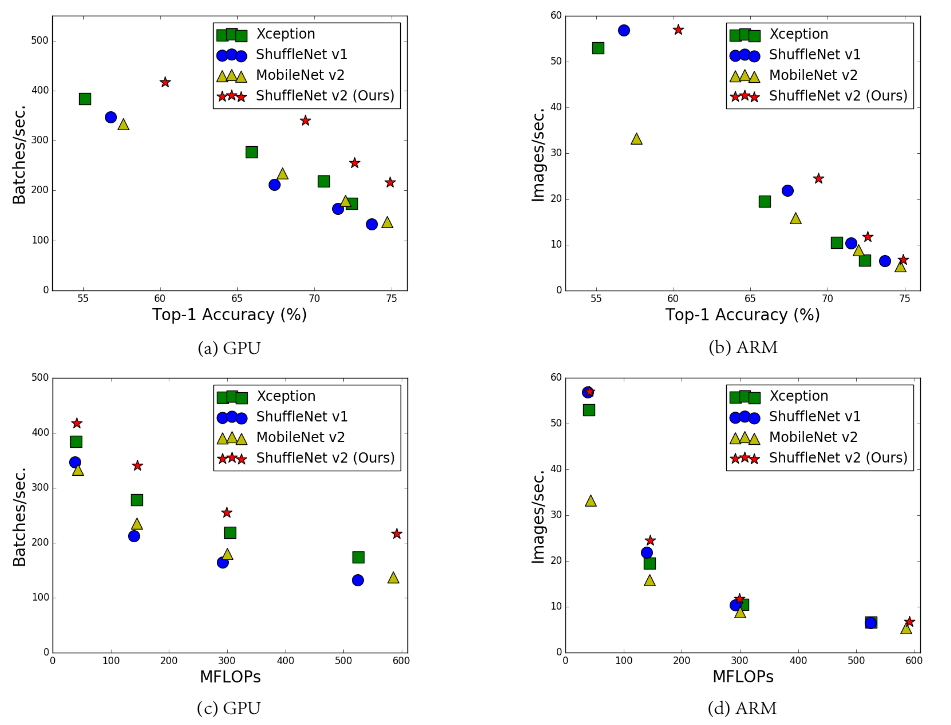
FLOPs和推断速度之间的差异有两个原因:除了
FLOPs之外,还有几个因素对推断速度有重要的影响。- 内存访问量(
memory access cost:MAC):在某些操作(如分组卷积)中,其时间开销占相当大比例。因此它可能是GPU这种具有强大计算能力设备的瓶颈。 - 模型并行度:相同
FLOPs的情况下,高并行度的模型比低并行度的模型快得多。
- 内存访问量(
即使相同的操作、相同的
FLOPs,在不同的硬件设备上、不同的库上,其推断速度也可能不同。
MobileNet V2和ShuffleNet V1这两个网络非常具有代表性,它们分别采用了group卷积和depth-wise卷积。这两个操作广泛应用于其它的先进网络。利用实验分析它们的推断速度(以推断时间开销来衡量)。其中:宽度乘子均为1,
ShuffleNet V1的分组数g=3。从实验结果可知:
FLOPs指标仅仅考虑了卷积部分的计算量。虽然这部分消耗时间最多,但是其它操作包括数据IO、数据混洗、逐元素操作(ReLU、逐元素相加)等等时间开销也较大。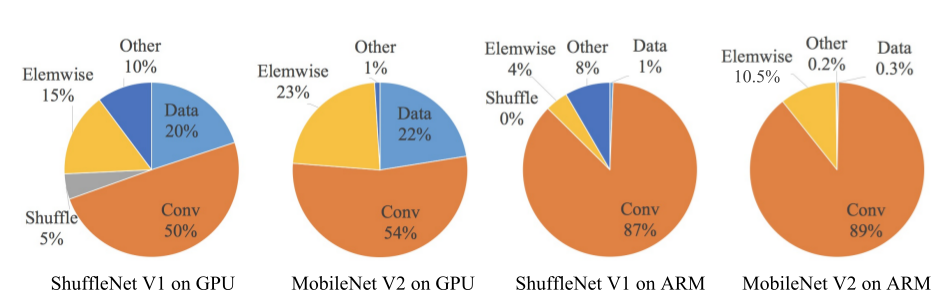
小型网络通用设计准则:
准则一:输入通道数和输出通道数相等时,
MAC指标最小。假设输入
feature map尺寸为 、通道数为 ,输出通道数为 。假设为1x1卷积,则FLOPs为: 。其内存访问量为:输入
featuremap内存访问量+输出featuremap内存访问量+卷积核内存访问量。因此有: 。根据不等式 ,以及 ,则有: 。当 时等式成立。
准则二:大量使用分组卷积会增加
MAC。分组卷积可以降低
FLOPs。换言之,它可以在FLOPs固定的情况下,增大featuremap的通道数从而提高模型的容量。但是采用分组卷积可能增加MAC。对于
1x1卷积,设分组数为g,则FLOPs数为 ,内存访问量为。
当 时, 最小。因此 随着 的增加而增加。
准则三:网络分支会降低并行度。
虽然网络中采用分支(如
Inception系列、ResNet系列)有利于提高模型的准确率,但是它对GPU等具有高并行计算能力的设备不友好,因此会降低计算效率。另外它还带来了卷积核的
lauching以及计算的同步等问题,这也是推断时间的开销。准则四:不能忽视元素级操作的影响。
元素级操作包括
ReLU、AddTensor、AddBias等,它们的FLOPs很小但是MAC很大。在ResNet中,实验发现如果去掉ReLU和旁路连接,则在GPU和ARM上大约有 20% 的推断速度的提升。
9.3.2.2 ShuffleNet V2 block
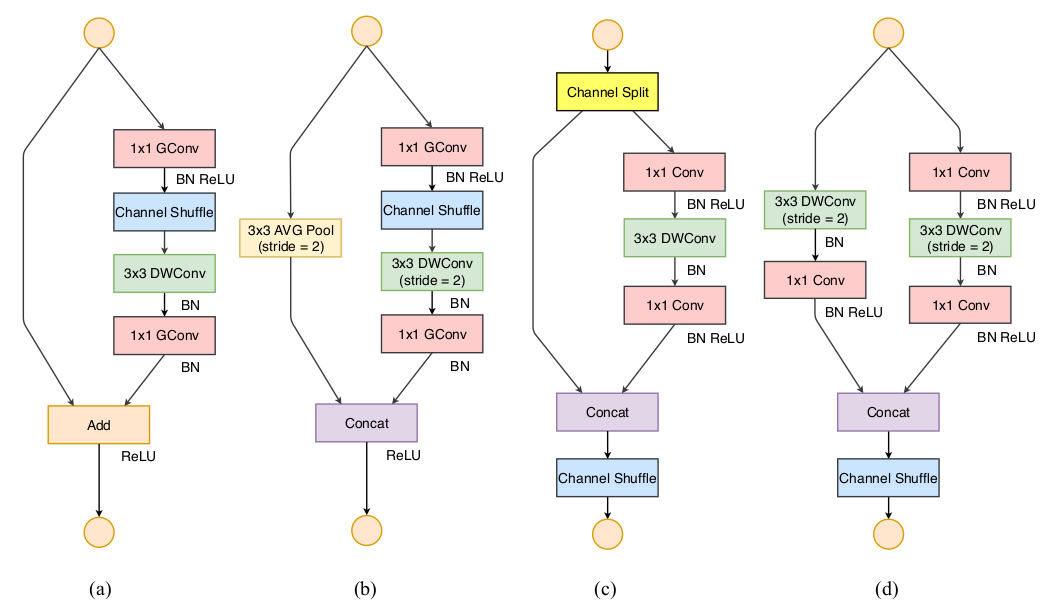
ShuffleNet V1 block的分组卷积违反了准则二,1x1卷积违反了准则一,旁路连接的元素级加法违反了准则四。而ShuffleNet V2 block修正了这些违背的地方。ShuffleNet V2 block在ShuffleNet V1 block的基础上修改。(a),(b)表示ShuffleNet V1 block(步长分别为1、2),(c),(d)表示ShuffleNet V2 block(步长分别为1、2)。其中GConv表示分组卷积,DWConv表示depthwise卷积。当步长为1 时,
ShuffleNet V2 block首先将输入feature map沿着通道进行拆分。设输入通道数为 ,则拆分为 和 。根据准则三,左路分支保持不变,右路分支执行各种卷积操作。
根据准则一,右路的三个卷积操作都保持通道数不变。
根据准则二,右路的两个
1x1卷积不再是分组卷积,而是标准的卷积操作。因为分组已经由通道拆分操作执行了。根据准则四,左右两路的
featuremap不再执行相加,而是执行特征拼接。可以将
Concat、Channel Shuffle、Channel Split融合到一个element-wise操作中,这可以进一步降低element-wise的操作数量。
当步长为2时,
ShuffleNet V2 block不再拆分通道,因为通道数量需要翻倍从而保证模型的有效容量。在执行通道
Concat之后再进行通道混洗,这一点也与ShuffleNet V1 block不同。
9.3.2.3 网络性能
ShuffleNet V2的网络结构类似ShuffleNet V1,主要有两个不同:- 用
ShuffleNet v2 block代替ShuffleNet v1 block。 - 在
Global Pool之前加入一个1x1卷积。
- 用
ShuffleNet V2可以结合SENet的思想,也可以增加层数从而由小网络变身为大网络。下表为几个模型在
ImageNet验证集上的表现(single-crop)。
ShuffleNet V2和其它模型的比较:- 根据计算复杂度分成
40,140,300,500+等四组,单位:MFLOPs。 - 准确率指标为模型在
ImageNet验证集上的表现(single-crop)。 GPU上的batchsize=8,ARM上的batchsize=1。- 默认图片尺寸为
224x224,标记为*的图片尺寸为160x160,标记为**的图片尺寸为192x192。
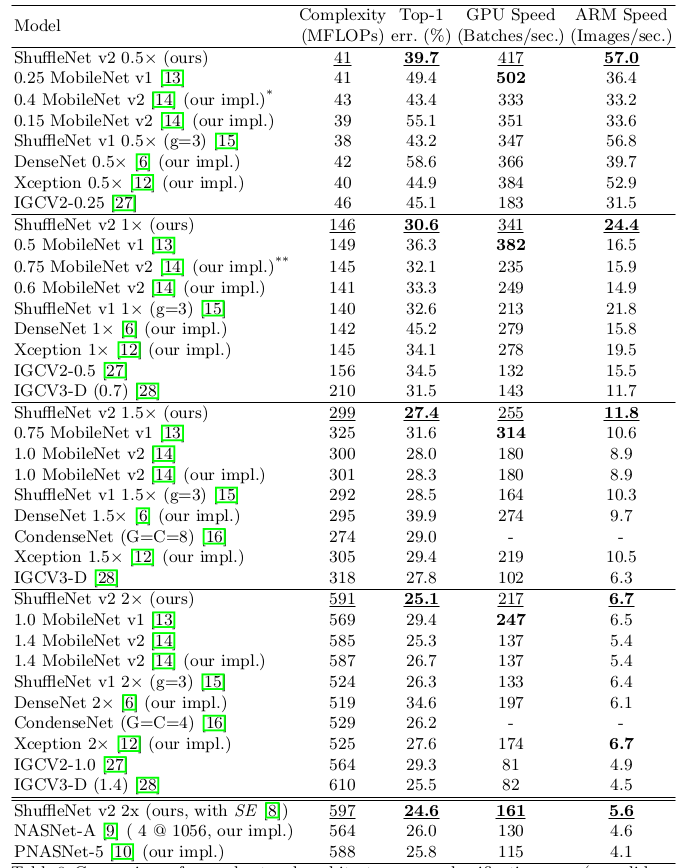
- 根据计算复杂度分成
ShuffleNet V2准确率更高。有两个原因:ShuffleNet V2 block的构建效率更高,因此可以使用更多的通道从而提升模型的容量。在每个
ShuffleNet V2 block,有一半通道的数据()直接进入下一层。这可以视作某种特征重用,类似于DenseNet。但是
ShuffleNet v2 block在特征Concat之后又执行通道混洗,这又不同于DenseNet。
9.4 IGCV 系列
设计小型化网络目前有两个代表性的方向,并且都取得了成功:
- 通过一系列低秩卷积核(其中间输出采用非线性激活函数)去组合成一个线性卷积核或者非线性卷积核。如用
1x3 +3x1卷积去替代3x3卷积 。 - 使用一系列稀疏卷积核去组成一个密集卷积核。如:交错卷积中采用一系列分组卷积去替代一个密集卷积。
- 通过一系列低秩卷积核(其中间输出采用非线性激活函数)去组合成一个线性卷积核或者非线性卷积核。如用
9.4.1 IGCV
简化神经网络结构的一个主要方法是消除结构里的冗余。目前大家都认为现在深度神经网络结构里有很强的冗余性。
冗余可能来自与两个地方:
- 卷积核空间方向的冗余。通过小卷积核替代(如,采用
3x3、1x3、3x1卷积核)可以降低这种冗余。 - 卷积核通道方向的冗余。通过分组卷积、
depth-wise卷积可以降低这种冗余。
IGCV通过研究卷积核通道方向的冗余,从而减少网络的冗余性。- 卷积核空间方向的冗余。通过小卷积核替代(如,采用
事实上解决冗余性的方法有多种:
二元化:将卷积核变成二值的
-1和+1,此时卷积运算的乘加操作变成了加减操作。这样计算量就下降很多,存储需求也降低很多(模型变小)。浮点数转整数:将卷积核的
32位浮点数转换成16位整数。此时存储需求会下降(模型变小)。除了将卷积核进行二元化或者整数化之外,也可以将
feature map进行二元化/整数化。卷积核低秩分解:将大卷积核分解为两个小卷积核 ,如:将
100x100分解为100x10和10x100、将5x5分解为两个3x3。稀疏卷积分解:将一个密集的卷积核分解为多个稀疏卷积核。如分组卷积、
depth-wise卷积。
9.4.1.1 IGCV block
IGCV提出了一种交错卷积模块,每个模块由相连的两层分组卷积组成,分别称作第一层分组卷积primary group conv、第二层分组卷积secondary group conv。第一层分组卷积采用
3x3分组卷积,主要用于处理空间相关性;第二层分组卷积采用1x1分组卷积,主要用于处理通道相关性。每层分组卷积的每个组内执行的都是标准的卷积,而不是
depth-wise卷积。这两层分组卷积的分组是交错进行的。假设第一层分组卷积有
L个分组、每个分组M个通道,则第二层分组卷积有M个分组、每个分组L个通道。第一层分组卷积中,同一个分组的不同通道会进入到第二层分组卷积的不同分组中。
第二层分组卷积中,同一个分组的不同通道来自于第一层分组卷积的不同分组。
这两层分组卷积是互补的、交错的,因此称作交错卷积
Interleaved Group Convolution:IGCV。
这种严格意义上的互补需要对每层分组卷积的输出
feature map根据通道数重新排列Permutation。这不等于混洗,因为混洗不能保证严格意义上的通道互补。
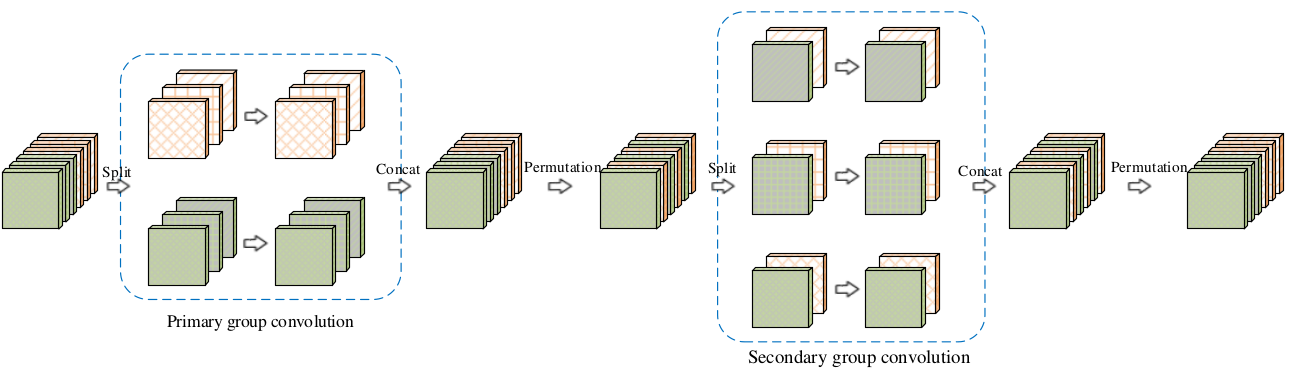
由于分组卷积等价于稀疏卷积核的常规卷积,该稀疏卷积核是
block-diagonal(即:只有对角线的块上有非零,其它位置均为 0 )。因此
IGCV块等价于一个密集卷积,该密集卷积的卷积核由两个稀疏的、互补的卷积核相乘得到。假设第一层分组卷积的卷积核尺寸为 ,则
IGCV块的参数数量为:令 为
IGCV块 的输入feature map通道数量,则 。对于常规卷积,假设卷积核的尺寸为 ,输入输出通道数均为 ,则参数数量为: 。当参数数量相等,即 时,则有: 。
当 时,有 。通常选择 ,考虑到 ,因此该不等式几乎总是成立。于是
IGCV块总是比同样参数数量的常规卷积块更宽(即:通道数更多)。在相同参数数量/计算量的条件下,
IGCV块(除了L=1的极端情况)比常规卷积更宽,因此IGCV块更高效。采用
IGCV块堆叠而成的IGCV网络在同样参数数量/计算量的条件下,预测能力更强。Xception块、带有加法融合的分组卷积块都是IGCV块的特殊情况。当
M=1,L等于IGCV块输入feature map的输入通道数时,IGCV块退化为Xception块。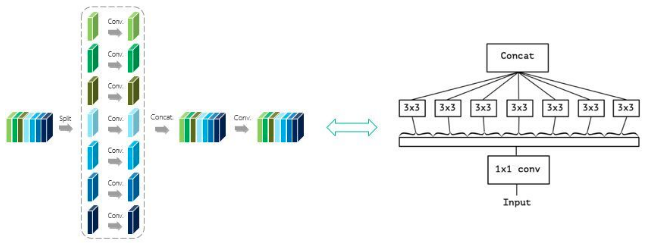
当
L=1,M等于IGCV块输入feature map的输入通道数时,IGCV块退化为采用Summation融合的Deeply-Fused Nets block。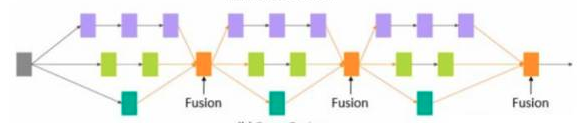
9.4.1.2 网络性能
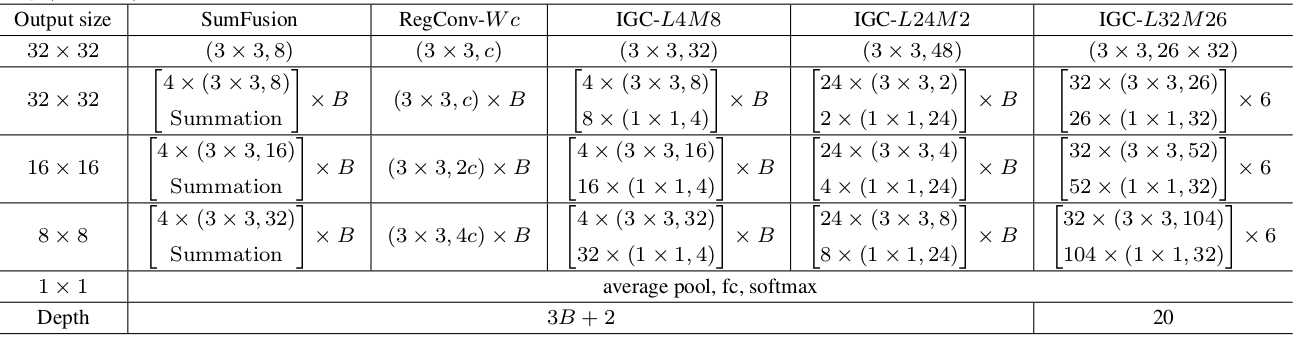
IGCV网络结构如下表所示,其中:RegConv-Wc表示常规卷积,W表示卷积核的尺寸为WxW,c表示通道数量;Summation表示加法融合层(即常规的1x1卷积,而不是1x1分组卷积)。- 在
IGCV块之后紧跟BN和ReLU,即结构为:IGC block+BN+ReLU。 4x(3x3,8)表示分成4组,每组的卷积核尺寸为3x3输出通道数为 8 。- 网络主要包含3个
stage,B表示每个stage的块的数量。 - 某些
stage的输出通道数翻倍(对应于Output size减半),此时该stage的最后一个block的步长为2(即该block中的3x3卷积的步长为2) 。
- 在
IGCV网络的模型复杂度如下所示。SumFusion的参数和计算复杂度类似RegConv-W16,因此没有给出。
IGCV模型在CIFAR-10和CIFAR-100上的表现: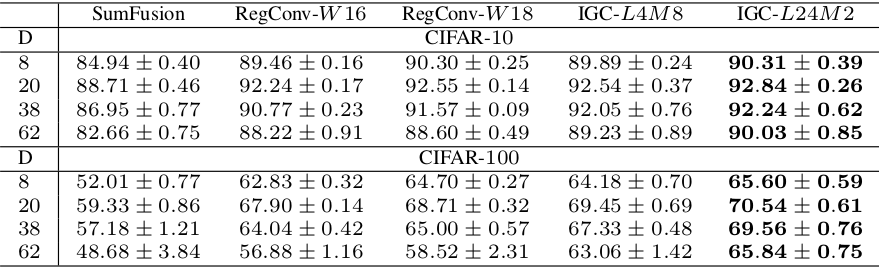
如果增加恒等映射,则结果为:

所有的模型比较:
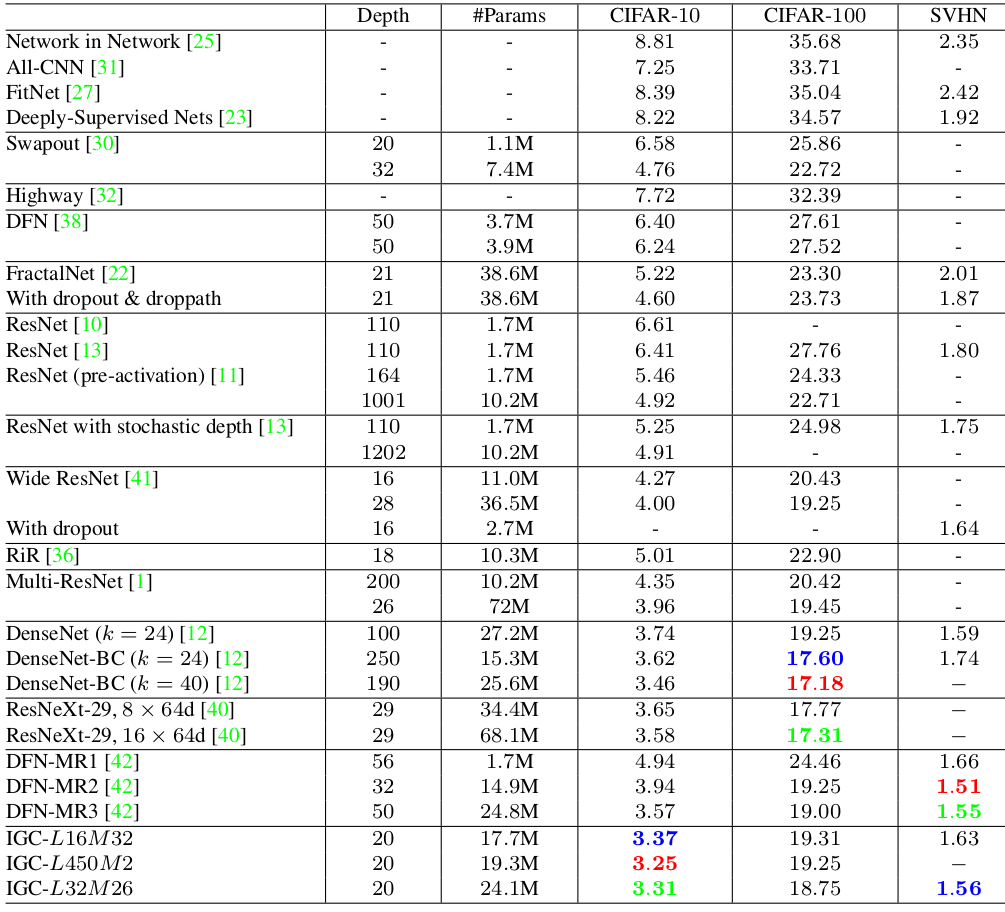
IGCV模型在ImageNet上的表现:(输入224x224,验证集,single-crop)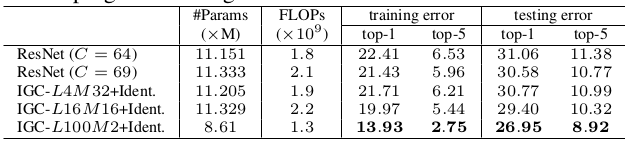
超参数
L和M的选取:通过
IGCV在CIFAR100上的表现可以发现:L占据统治地位,随着 的增加模型准确率先上升到最大值然后缓缓下降。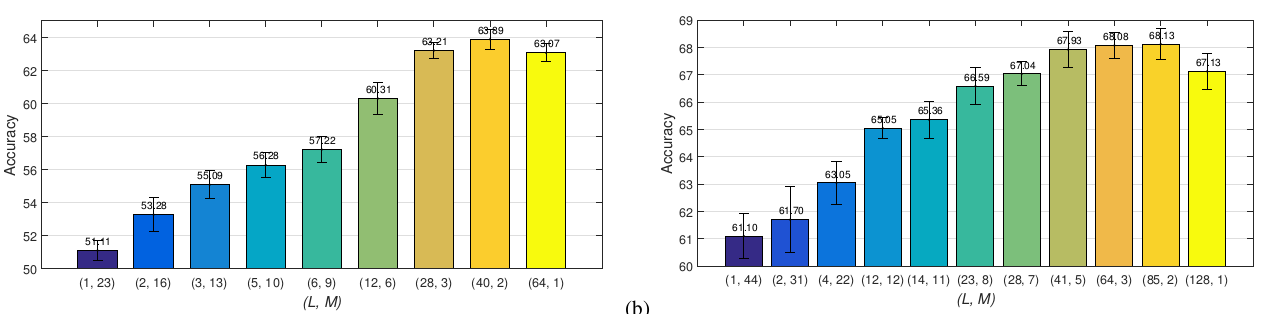
9.4.2 IGCV2
IGCV2 block的主要设计思想是:将IGCV block两个结构化的稀疏卷积核组成的交错卷积推广到更多个结构化的稀疏卷积核组成的交错卷积,从而进一步消除冗余性。
9.4.2.1 IGCV2 block
假设输入
feature map的通道数为 ,卷积核尺寸为 ,输出通道数为 。考虑输入feature map的一个patch(对应卷积核大小),该patch经过卷积之后的结果为: 。其中 是一个长度为 的向量, 是一个长度为 的向量, 是一个 行、 列的矩阵。Xception、deep roots、IGCV1的思想是:将卷积核 分解为多个稀疏卷积的乘积:其中 至少有一个为块稀疏
block-wise sparse矩阵; 为置换矩阵,用于重新调整通道顺序; 为一个密集矩阵。对于
IGCV1, 令 为第 层分组卷积的分组数,则:其中 表示第 层分组卷积的卷积核,它是一个
block-wise sparse的矩阵,其中第 组的卷积核矩阵为 。
IGCV2不是将 分解为 2个block-wise sparse矩阵的乘积(不考虑置换矩阵),而是进一步分解为 个块稀疏矩阵的乘积:其中 为块稀疏矩阵,它对应于第 层分组卷积,即:
IGCV2包含了 层分组卷积; 为置换矩阵。- 为了设计简单,第 层分组卷积中,每个分组的通道数都相等,设为 。
- 如下所示为一个
IGCV2 block。实线表示权重 ,虚线表示置换 ,加粗的线表示产生某个输出通道(灰色的那个通道)的路径。
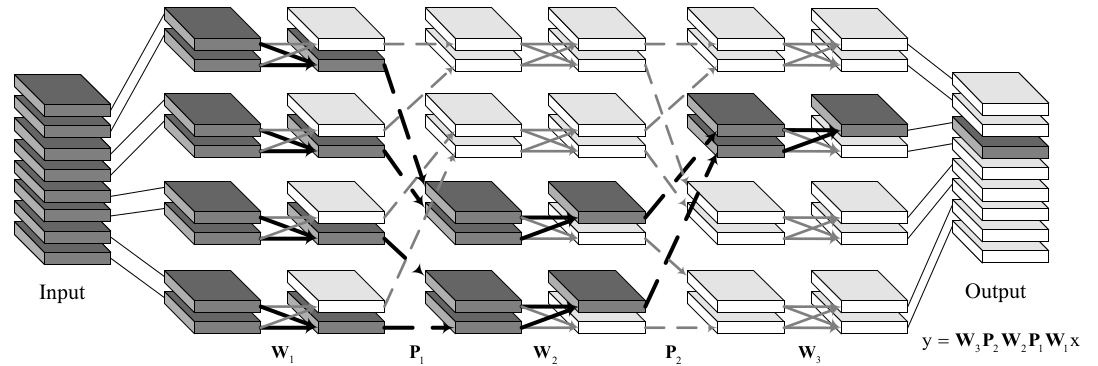
9.4.2.2 互补条件 & 平衡条件
事实上并不是所有的 个块稀疏矩阵的乘积一定就是密集矩阵,这其中要满足一定的条件,即互补条件
complementary condition。互补条件用于保证:每个输出通道,有且仅有一条路径,该路径将所有输入通道与该输出通道相连。要满足互补条件,则有以下准则:
对于任意 , 等价于一层分组卷积,且 也等价于一层分组卷积。且这两层分组卷积是互补的:第一层分组卷积中,同一个分组的不同通道会进入到第二层分组卷积的不同分组中;第二层分组卷积中,同一个分组的不同通道来自于第一层分组卷积的不同分组。
- 其物理意义为:从任意位置 截断,则前面一半等价于一层分组卷积,后面一半也等价于一层分组卷积。
- 可以证明
IGCV2 block满足这种互补条件。
假设
IGCV2 block的输入通道数为 ,输出通道数也为 ,其L层分组卷积中第 层分组卷积每组卷积的输入通道数为 。现在考虑 需要满足的约束条件。对于
IGCV2 block的某个输入通道,考虑它能影响多少个IGCV2 block的输出通道。设该输入通道影响了第 层分组卷积的 个输出通道。因为互补条件的限制,这 个通道在第 层进入不同的分组,因此分别归属于 组。而每个分组影响了 个输出通道,因此有递归公式:
考虑初始条件,在第
1层分组卷积有: 。则最终该输入通道能够影响IGCV2 block的输出通道的数量为: 。由于互补条件的限制:每个输出通道,有且仅有一条路径,该路径将所有输入通道与该输出通道相连。因此每个输入通道必须能够影响所有的输出通道。因此有: 。
考虑仅仅使用尺寸为
1x1和WxH的卷积核。由于1x1卷积核的参数数量更少,因此L层分组卷积中使用1层尺寸为WxH的卷积核、L-1层尺寸为1x1卷积核。假设第1层为
WxH卷积核,后续层都是1x1卷积核,则总的参数数量为: 。- 第一项来自于
1x1分组卷积。对于第 层的分组卷积,输入通道数为 、分组数为 、输出通道数为 。则参数数量为: 。 - 第二项来自于
WxH分组卷积。参数数量为: 。
- 第一项来自于
根据互补条件 ,以及
Jensen不等式有:等式成立时 。这称作平衡条件
balance condition。
考虑选择使得 最小的 。根据
则有: 。
当
Block的输出feature map尺寸相对于输入feature map尺寸减半(同时也意味着通道数翻倍)时,Block的输出通道数不等于输入通道数。设输入通道数为 ,输出通道数为 ,则有:
互补条件: 。
平衡条件:
设
feature map的尺寸缩减发生在3x3卷积,则后续所有的1x1卷积的输入通道数为 、输出通道数也为 。- 对于第 层的分组卷积,参数数量为: 。
- 对于第1层分组卷积,参数数量为: ,其中 为分组数量。
则总的参数数量为: 。等式成立时有:
选择使得 最小的 有: 。
因此对于
feature map尺寸发生缩减的IGCV2 Block,互补条件&平衡条件仍然成立,只需要将 替换为输出通道数 。
9.4.2.3网络性能
IGCV2网络结构如下表所示:其中 为网络第一层的输出通道数量,也就是后面block的输入通道数 。网络主要包含3个
stage,B表示每个stage的块的数量。某些
stage的输出通道数翻倍,此时该stage的最后一个block的步长为2(即该block中的3x3卷积的步长为2) 。每2个
block添加一个旁路连接,类似ResNet。 即在 这种结构添加旁路连接。表示输入通道数为 的
3x3卷积。 表示输出通道数为 的1x1卷积。和 为
IGCV2的超参数。 表示有 层分组卷积,每个组都是 个输入通道的1x1卷积。事实上
IGCV2每个stage都是L层,只是第一层的分组数为 1 。对于
IGCV2(Cx), ;对于IGCV2*(Cx), 。IGCV2*的(3x3,64)应该修改为 。
通过一个简化版的、没有
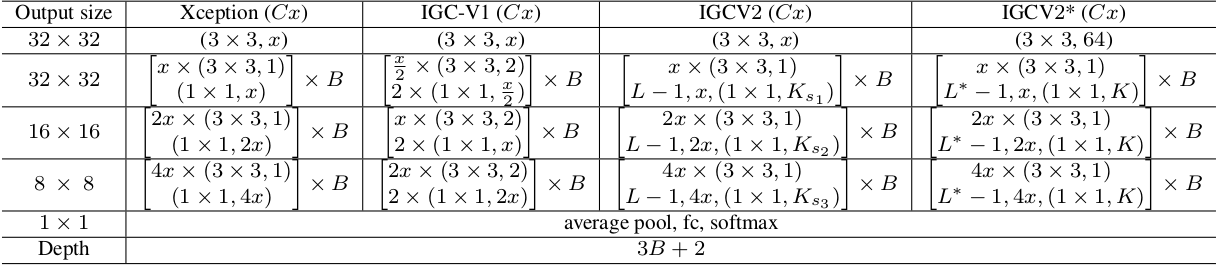
feature map尺寸缩减(这意味着IGCV2 Block的输入、输出通道数保持不变 )的IGCV2网络来研究一些超参数的限制:IGCV2 block最接近互补条件限制条件 时,表现最好。如下所示,红色表示互补条件限制满足条件最好的情况。其中匹配程度通过 来衡量。
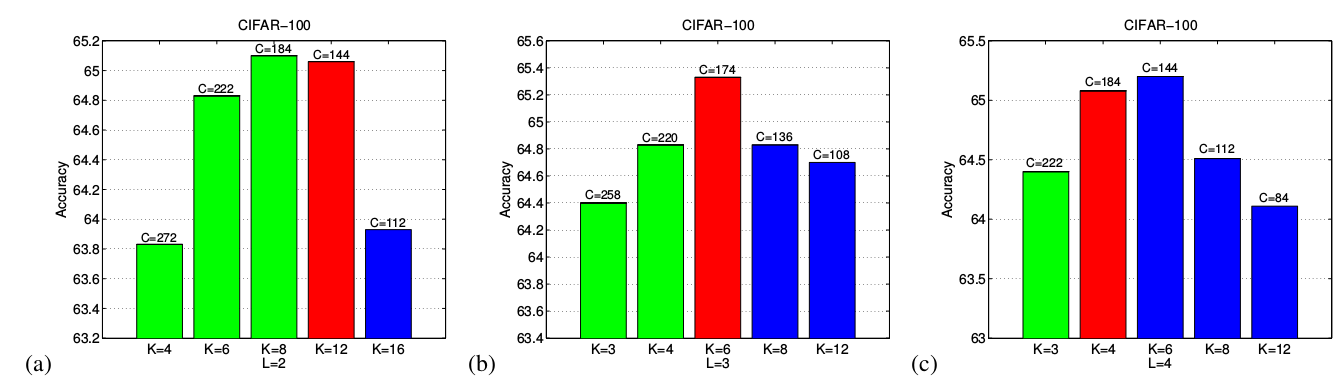
IGCV2 block的 最佳的情况是:网络的宽度(通过 刻画)和稀疏性达到平衡,如下所示。- 下图中,每一种 都选择了对应的
Width(即 )使得其满足互补条件限制,以及平衡条件,从而使得参数保持相同。 Non-sparsity指的是IGCV2 block等效的密集矩阵中非零元素的比例。
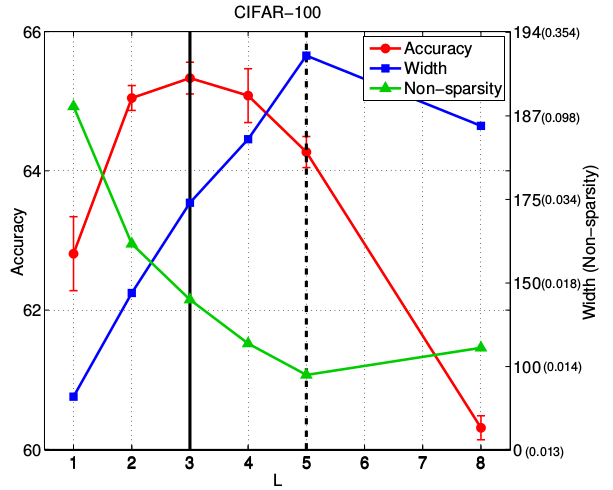
- 下图中,每一种 都选择了对应的
IGCV2网络越深越好、越宽越好,但是加宽网络比加深网络性价比更高。如下图所示:采用IGCV2*,深度用D表示、宽度用C表示。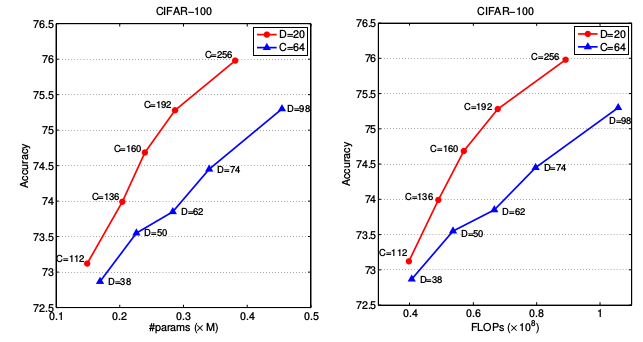
IGCV2网络与不同网络比较: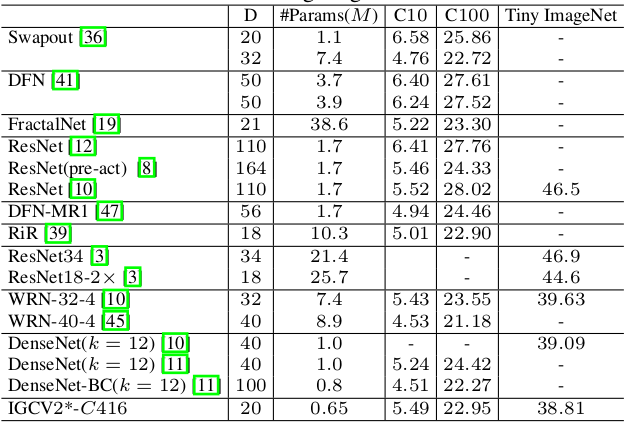
IGCV2网络与MobileNet的比较:(ImageNet)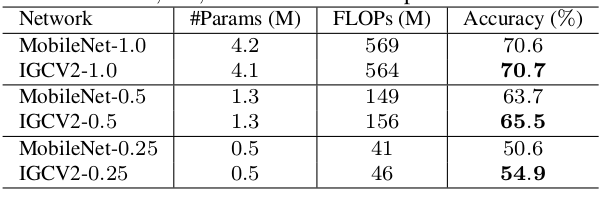
9.4.3 IGCV3
IGCV3结合了块稀疏的卷积核(如:交错卷积) 和低秩的卷积核(如:bottleneck模块),并放松了互补条件。
9.4.3.1 IGCV3 block
IGCV3的block修改自IGCV2 block,它将IGCV2 block的分组卷积替换为低秩的分组卷积。- 首先对输入
feature map进行分组,然后在每个分组中执行1x1卷积来扩张通道数。 - 然后执行常规分组卷积,并对结果进行通道重排列。
- 最后执行分组卷积,在每个分组中执行
1x1卷积来恢复通道数,并对结果进行通道重排。
按照
IGCV2的描述方式,输入feature map的一个patch,经过IGCV3 block之后的结果为:其中 为低秩的块稀疏矩阵; 为置换矩阵,用于重新调整通道顺序 。
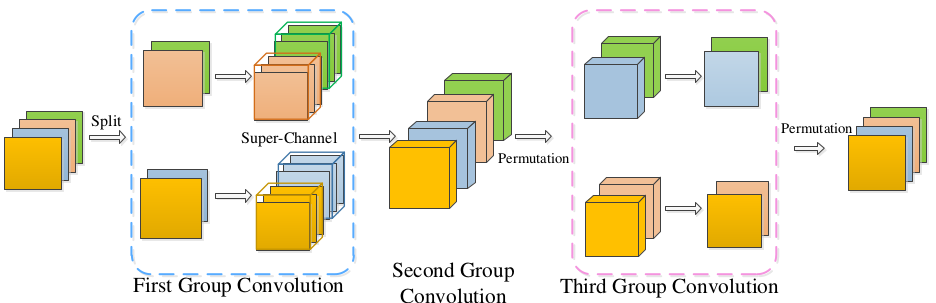
- 首先对输入
下图分别展示了
IGCV1 block、Inverted残差块、IGCV3 block的区别。每个圆圈代表一个通道,箭头代表通道的数据流动。IGCV1块中,两层分组卷积的卷积核都是稀疏的;在Inverted残差块中,两层1x1卷积的卷积核都是低秩的;在IGCV3块中,两层1x1卷积的卷积核是稀疏的,也都是低秩的。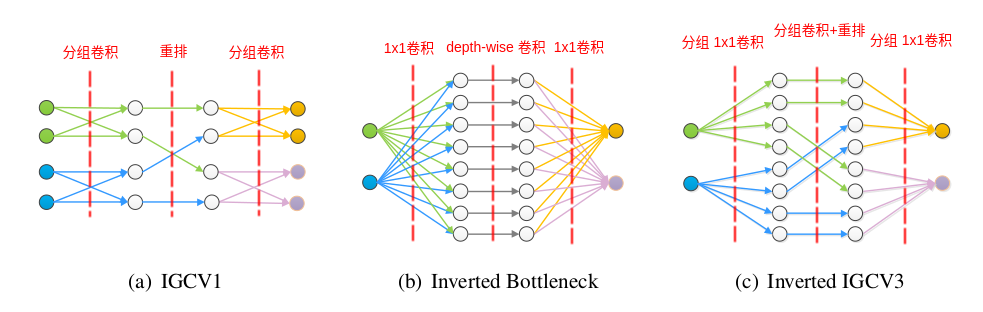
设
IGCV3 block第一层分组卷积(1x1分组扩张卷积) 的分组数量为 ;第二层分组卷积(普通分组卷积)的分组数不变,也是 ;第三层分组卷积(1x1分组压缩卷积)的分组数量为 。则 是非常重要的超参数。
9.4.3.2 loose 互补条件
实验中发现:如果
IGCV3 block如果严格遵守互补条件会导致卷积核过于稀疏,从而导致更大的内存消耗而没有带来准确率的提升。因此
IGCV3 block提出了宽松互补条件loose complementary condition,从而允许输入通道到输出通道存在多条路径。在
IGCV3 block中定义了超级通道Super-Channel,设为 。在一个IGCV3 block中,每个feature map都具有同等数量的Super-Channel。- 输入
feature map的通道数假设为 ,因此每个输入超级通道包含 条普通的输入通道。 - 经过
1x1分组卷积扩张的输出通道数假设为 ,则这里的每个超级通道包含 条普通的通道。 - 经过常规分组卷积的输出通道数也是 ,则这里的每个超级通道也包含 条普通的通道。
- 最后经过
1x1分组卷积压缩的输出通道数也是 ,因此每个输出超级通道包含 条普通的输出通道。
- 输入
loose complementary condition:第一层分组卷积中,同一个分组的不同超级通道会进入到第三层分组卷积的不同分组中;第三层分组卷积中,同一个分组的不同超级通道来自于第一层分组卷积的不同分组。由于超级通道中可能包含多个普通通道,因此输入通道到输出通道存在多条路径。
通常设置 ,即:超级通道数量等于输入通道数量。则每条超级通道包含的普通通道数量依次为:,其中 表示
1x1分组卷积的通道扩张比例。也可以将 设置为一个超参数,其取值越小,则互补条件放松的越厉害(即:输入通道到输出通道存在路径的数量越多)。
9.4.3.3 网络性能
IGCV3网络通过叠加IGCV3 block而成。因为论文中的对照实验是在网络参数数量差不多相同的条件下进行。为了保证IGCV3网络与IGCV1/2,MobileNet,ShuffleNet等网络的参数数量相同,需要加深或者加宽IGCV3网络。论文中作者展示了两个版本:
- 网络更宽的版本,深度与对比的网络相等的同时,加宽网络的宽度,记做
IGCV3-W。参数为: 。 - 网络更深的版本,宽度与对比的网络相等的同时,加深网络的深度,记做
IGCV3-D。参数为: 。
- 网络更宽的版本,深度与对比的网络相等的同时,加宽网络的宽度,记做
IGCV3与IGCV1/2的对比:IGCV3降低了参数冗余度,因此在相同的参数的条件下,其网络可以更深或者更宽,因此拥有比IGCV1/2更好的准确率。
IGCV3和其它网络的在ImageNet上的对比:MAdds用于刻画网络的计算量,单位是百万乘-加运算。- 中的 表示宽度乘子,它大概以 的比例减少了参数数量,降低了计算量。
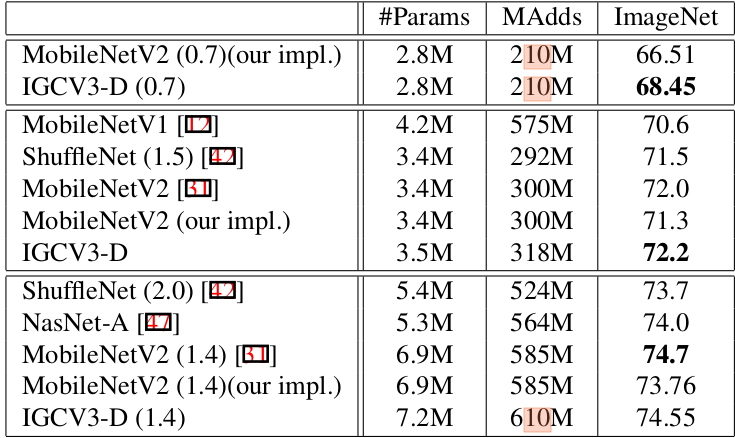
更深的
IGCV网络和更宽的IGCV网络的比较:- 更深的网络带来的效果更好,这与人们一直以来追求网络的
深度的理念相一致。 - 在宽度方向有冗余性,因此进一步增加网络宽度并不会带来额外的收益。

- 更深的网络带来的效果更好,这与人们一直以来追求网络的
ReLU的位置比较:第一个
IGCV3 block的ReLU位置在两个1x1卷积之后;第二个IGCV3 block的ReLU位置在3x3卷积之后;第三个IGCV3 block的ReLU在整个block之后(这等价于一个常规卷积+ReLU)。
超参数 的比较:
只要 都是输入、输出通道数的公约数时,
loose互补条件就能满足,因此存在 的很多选择。实验发现, 比较小、 比较大时网络预测能力较好。但是这里的
IGCV3网络采用的是同样的网络深度、宽度。如果采用同样的网络参数数量,则 可以产生一个更深的、准确率更高的网络。

9.5 CondenseNet
CondenseNet基于DenseNet网络,它在训练的过程中自动学习一个稀疏的网络从而减少了Densenet的冗余性。这种稀疏性类似于分组卷积,但是
CondenseNet从数据中自动学到分组,而不是由人工硬性规定分组。CondenseNet网络在GPU上具有高效的训练速度,在移动设备上具有高效的推断速度。MobileNet、ShuffleNet、NASNet都采用了深度可分离卷积,这种卷积在大多数深度学习库中没有实现。而CondenseNet采用分组卷积,这种卷积被大多数深度学习库很好的支持。准确的说,
CondenseNet在测试阶段采用分组卷积,在训练阶段采用的是常规卷积。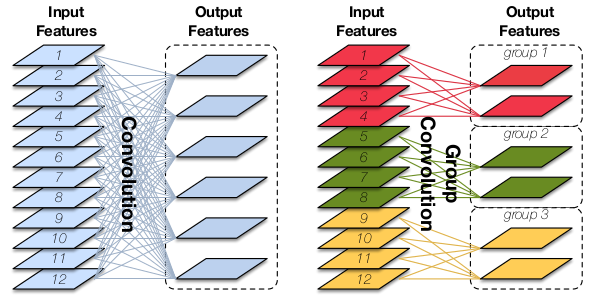
9.5.1 网络剪枝
有一些工作(
Compressing neural networks with the hashing trick、Deep networks with stochastic depth)表明:CNN网络中存在大量的冗余。DenseNet通过直接连接每个层的输出特征与之后的所有层来特征重用。但是如果该层的输出特征是冗余的或者不需要的,则这些连接会带来冗余。CNN网络可以通过权重剪枝从而在不牺牲模型准确率的条件下实现小型化。有不同粒度的剪枝技术:- 独立的权重剪枝:一种细粒度的剪枝,它可以带来高度稀疏的网络。但是它需要存储大量的索引来记录哪些连接被剪掉,并且依赖特定的硬件/软件设施。
filter级别剪枝:一种粗粒度的剪枝,它得到更规则的网络,且易于实现。但是它带来的网络稀疏性较低。
CondenseNet也可以认为是一种网络剪枝技术,它与以上的剪枝方法都不同:CondenseNet的网络剪枝发生、且仅仅发生在训练的早期。这比在网络整个训练过程中都采用L1正则化来获取稀疏权重更高效。CondenseNet的网络剪枝能产生比filter级别剪枝更高的网络稀疏性,而且网络结构也是规则的、易于实现的。
9.5.2 LGC
分组卷积在很多
CNN网络中大量使用。在DenseNet中,可以使用3x3分组卷积来代替常规的3x3卷积从而减小模型大小,同时保持模型的准确率下降不大。但是实验表明:在
DenseNet中,1x1分组卷积代替1x1常规卷积时,会带来模型准确率的剧烈下降。对于一个具有 层的
DenseNet Block,1x1卷积是第 层的第一个操作。该卷积的输入是由当前DenseNet Block内第 层输出feature map组成。因此采用1x1分组卷积带来准确率剧烈下降的原因可能有两个:- 第 层输出
feature具有内在的顺序,难以决策哪些feature应该位于同一组、哪些feature应该位于不同组。 - 这些输出
feature多样性较强,缺少任何一些feature都会减小模型的表达能力。
因此将这些输出
feature强制性的、固定的分配到不相交的分组里会影响特征重用。- 第 层输出
一种解决方案是:在
1x1卷积之前,先对1x1卷积操作的输入特征进行随机排列。这个策略会缓解模型准确率的下降,但是并不推荐。因为可以采用模型更小的
DenseNet网络达到同样的准确率,而且二者计算代价相同。与之相比,特征混洗+1x1分组卷积的方案并没有任何优势。另一种解决方案是:通过训练来自动学习出
feature的分组。考虑到第 层输出
feature中,很难预测哪些feature对于第 层有用,也很难预先对这些feature执行合适的分组。因此通过训练数据来学习这种分组是合理的方案。这就是学习的分组卷积Learned Group Convolution:LGC。在
LGC中:卷积操作被分为多组
filter,每个组都会自主选择最相关的一批feature作为输入。由于这组
filter都采用同样的一批feature作为输入,因此就构成了分组卷积。允许某个
feature被多个分组共享(如下图中的Input Feature 5、12),也允许某个feature被所有的分组忽略(如下图中的Input Feature 2、4)。即使某个
feature被第 层1x1卷积操作的所有分组忽略,它也可能被第 层1x1卷积操作的分组用到。
9.5.3 训练和测试
CondenseNet的训练、测试与常规网络不同。CondenseNet的训练是一个多阶段的过程,分为浓缩阶段和优化阶段。浓缩阶段
condensing stage:训练的前半部分为浓缩阶段,可以有多个condensing stage(如下图所示有2个浓缩阶段)。每个
condensing stage重复训练网络一个固定的iteration,并在训练过程中:引入可以产生稀疏性的正则化、裁剪掉权重幅度较小的filter。优化阶段
optimization stage:训练的后半部分为优化阶段,只有一个optimization stage。在这个阶段,网络的
1x1卷积的分组已经固定,此阶段在给定分组的条件下继续学习1x1分组卷积。
CondenseNet的测试需要重新排列裁剪后的filter,使其重新组织成分组卷积的形式。因为分组卷积可以更高效的实现,并且节省大量计算。通常所有的浓缩阶段和所有的优化阶段采取
1:1的训练epoch分配。假设需要训练 个epoch,有 个浓缩阶段,则:- 所有的浓缩阶段消耗 个
epoch,每个浓缩阶段消耗 个epoch。 - 所有的优化阶段也消耗 个
epoch。
- 所有的浓缩阶段消耗 个
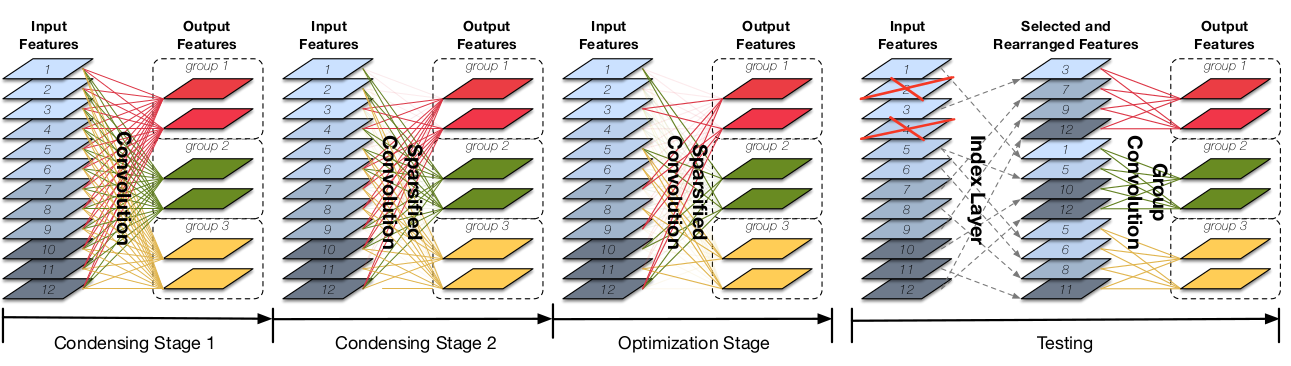
假设卷积核的尺寸为 ,输入通道数为 ,输出通道数为 。当采用
1x1卷积核时4D的核张量退化为一个矩阵,假设该矩阵表示为 。将该矩阵按行(即输出通道数)划分为同样大小的 个组,对应的权重为: 。其中 , 对应第 个分组的第 个输出特征(对应于整体的第 个输出特征)和整体的第 个输入特征的权重。
CondenseNet在训练阶段对每个分组筛选出对其不太重要的特征子集。对于第 个分组,第 个输入特征的重要性由该特征在 分组所有输出上的权重的绝对值均值来刻画: 。如果 相对较小,则删除输入特征 ,这就产生了稀疏性。
为了缓解权重裁剪带来的准确率损失,这里引入
L1正则化。因为L1正则化可以得到更稀疏的解,从而使得删除 相对较小的连接带来的准确率损失较小(因为这些权重大多数为0 或者很小的值)。CondenseNet中引入分组L1正则化group-lasso: 。这倾向于将 的某一列 整体拉向 0 ,使得产生filter级别的稀疏性(而不是权重级别的稀疏性)。
考虑到
LGC中,某个feature可以被多个分组分享,也可以不被任何分组使用,因此一个feature被某个分组选取的概率不再是 。 定义浓缩因子 ,它表示每个分组包含 的输入。如果不经过裁剪,则每个分组包含 个输入;经过裁剪之后,最终保留 比例的输入。
filter裁剪融合于训练过程中。给定浓缩因子 ,则CondenseNet包含 个condensing stage(如上图中, )。在每个
condensing stage结束时,每个分组裁剪掉整体输入 比例的输入。经过 个condensing stage之后,网络的每个分组仅仅保留 的输入。
在每个
condensing stage结束前后,training loss都会突然上升然后下降。这是因为权重裁剪带来的突变。最后一个浓缩阶段突变的最厉害,因为此时每个分组会损失
50%的权重。但是随后的优化阶段会逐渐降低training loss。下图中,学习率采用
cosine学习率。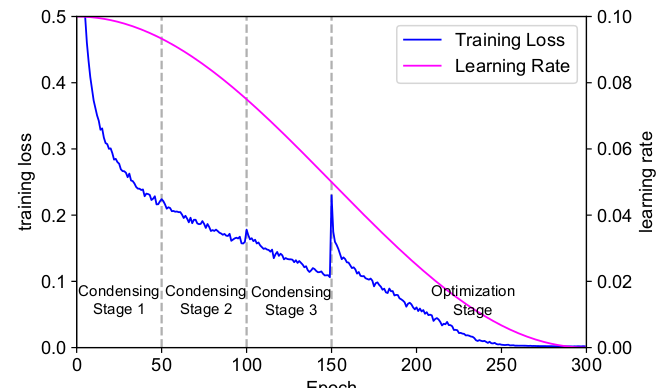
训练完成之后,
CondenseNet引入index layer来重新排列权重裁剪之后剩下的连接,使其成为一个1x1分组卷积。- 训练时,
1x1卷积是一个LGC。 - 测试时,
1x1卷积是一个index layer加一个1x1分组卷积。
下图中:左图为标准的
DenseNet Block,中间为训练期间的CondenseNet Block,右图为测试期间的CondenseNet Block。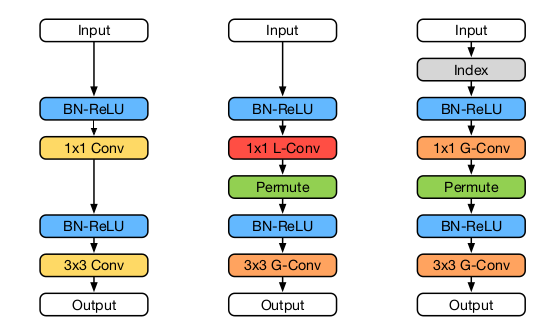
- 训练时,
在训练早期就裁剪了一些权重,而裁剪的原则是根据权重的大小。因此存在一个问题:裁剪的权重是否仅仅因为它们是用较小的值初始化?
论文通过实验证明网络的权重裁剪与权重初始化无关。
9.5.4 IGR 和 FDC
CondenseNet对DenseNet做了两个修改:递增的学习率
increasing growth rate:IGR:原始的
DenseNet对所有的DenseNet Block使用相同的增长率。考虑到DenseNet更深的层更多的依赖high-level特征而不是low-level特征,因此可以考虑使用递增的增长率,如指数增长的增长率: ,其中 为Block编号。该策略会增加模型的参数,降低网络参数的效率,但是会大大提高计算效率。
全面的连接
fully dense connectivity:FDC:原始的
DenseNet中只有DenseNet Block内部的层之间才存在连接。在CondenseNet中,将每层的输出连接到后续所有层的输入,无论是否在同一个CondenseNet Block中。如果有不同的
feature map尺寸,则使用池化操作来降低分辨率。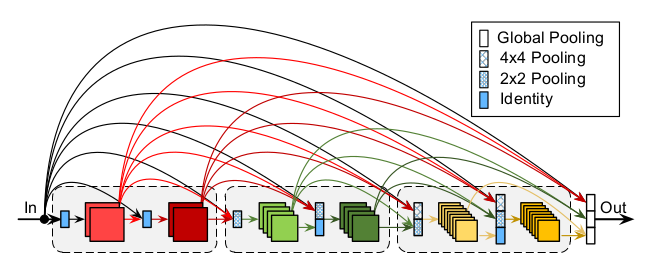
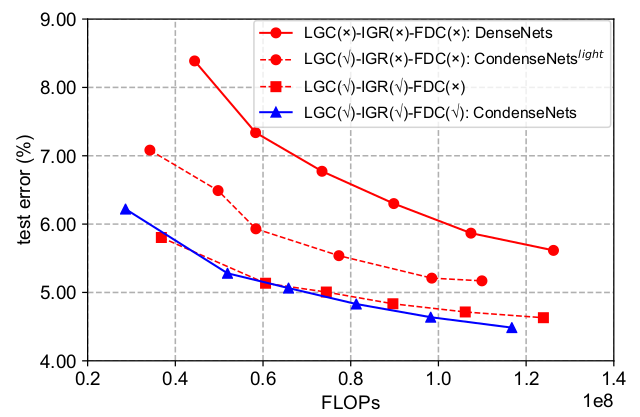
对
LGC、LGR、FDC的实验分析如下:(CIFAR-10数据集)配置:默认 ,
3x3卷积为分组数量为4的分组卷积。LGC:learned group convolution:C=4,1x1卷积为LGC。IGR:exponentially increasing learning rate: 。FDC:fully dense conectivity。
相邻两条线之间的
gap表示对应策略的增益。第二条线和第一条线之间的
gap表示IGC的增益。第三条线和第二条线之间的
gap表示IGR的增益。第四条线和第三条线之间的
gap表示FDC的增益。FDC看起来增益不大,但是如果模型更大,根据现有曲线的趋势FDC会起到效果。
9.5.5 网络性能
CondenseNet与其它网络的比较:(*表示使用cosine学习率训练 600个 epoch)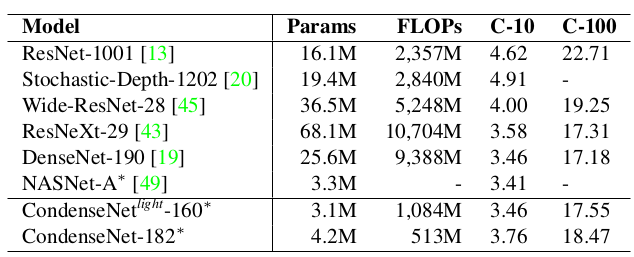
CondenseNet与其它裁剪技术的比较: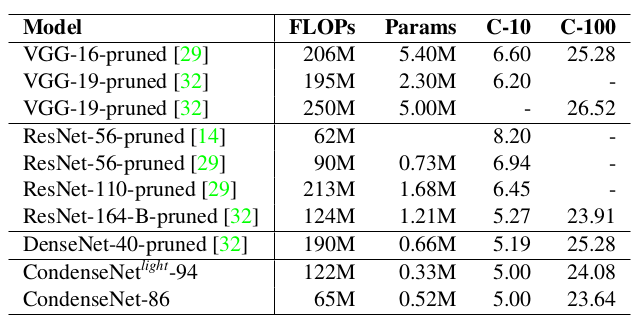
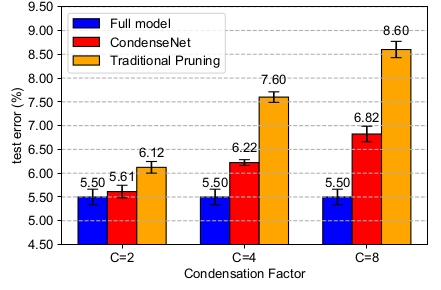
CondenseNet的超参数的实验:(CIFAR-10,DenseNet-50为基准)裁剪策略:(
G=4)Full Model:不进行任何裁剪。Traditional Pruning:在训练阶段(300个epoch)完成时执行裁剪(因此只裁剪一次),裁剪方法与LGC一样。然后使用额外的300个 epoch 进行微调。
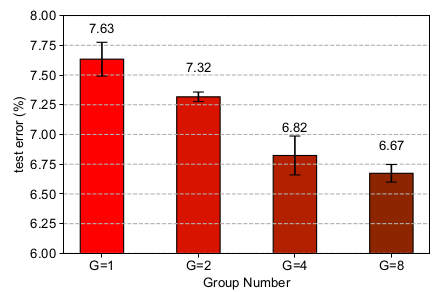
分组数量:(
C=8)- 这里的分组值得是
3x3分组卷积的分组数量。 - 随着分组数量的增加,测试误差逐渐降低。这表明
LGC可以降低网络的冗余性。
- 这里的分组值得是
浓缩因子:(
G=4)可以看到: 可以带来更好的效益;但是 时,网络的准确率和网络的
FLOPs呈现同一个函数关系。这表明裁剪网络权重会带来更小的模型,但是也会导致一定的准确率损失。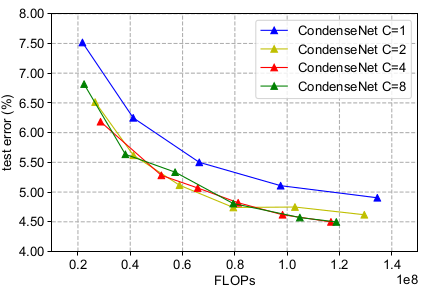
在
ImageNet上的比较:网络结构:
为了降低参数,在
epoch 60时(一共120个epoch)裁剪了全连接层FC layer50% 的权重。思想与1x1卷积的LGC相同,只是 。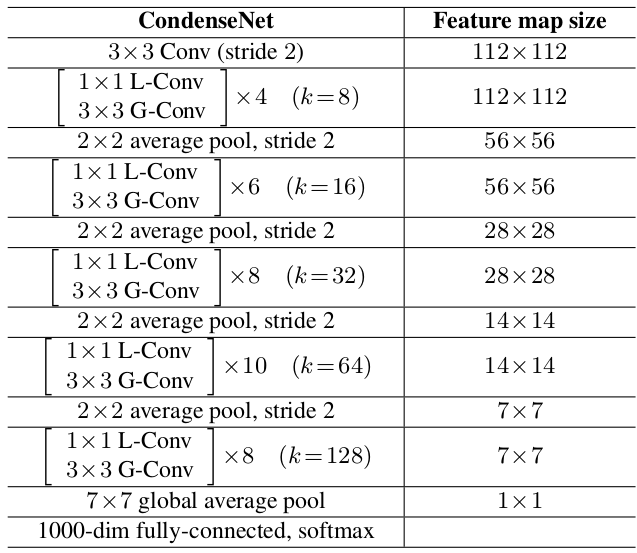
CondenseNet与其它网络的比较: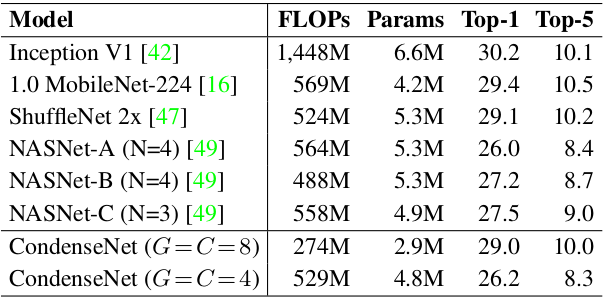
网络在
ARM处理器上的推断时间(输入尺寸为224x224):