二十六、T5 [2020]
训练一个机器学习模型来执行自然语言处理任务,往往需要该模型能够以适合
downstream learning的方式来处理文本。这可以被粗略地看作是开发通用的知识,使模型能够 "理解" 文本。这种知识的范围可以是low-level的(如单词的拼写或含义),也可以是high-level的(如 “小提琴太大从而无法装入大多数背包”)。在现代机器学习实践中,提供这种知识很少是显式的;相反,提供这种知识往往是作为辅助任务的一部分来学习。例如,历史上常见的方法是使用word vector,将单词映射到一个continuous representation中,理想情况下,相似的单词映射到相似的向量。这些向量通常是通过一个objective来学习的,例如,鼓励co-occurring的单词在continuous space中相互靠近。最近,在一个数据丰富的任务上对整个模型进行预训练变得越来越常见。理想情况下,这种预训练使模型发展出通用的能力和知识,然后可以迁移到下游任务中。在计算机视觉的迁移学习应用中,预训练通常是通过在
ImageNet这样的大型标记数据集上的监督学习来完成的。相比之下,NLP中的现代迁移学习技术通常在未标记数据上使用无监督学习进行预训练。这种方法最近被用来在许多最常见的NLP benchmark中获得SOTA的结果。除了经验上的优势,NLP的无监督预训练特别有吸引力,因为由于互联网的存在,未标记的文本数据大量存在。例如,Common Crawl项目每月产生约20TB文本数据(从网页中提取的文本)。这对神经网络来说是一种自然的契合:神经网络已经被证明具有卓越的可扩展性scalability,也就是说,仅仅通过在更大的数据集上训练更大的模型,往往可以获得更好的性能。这种综合作用导致了最近的大量工作用于为
NLP开发迁移学习方法,产生了广泛的预训练objective、未标记数据集、benchmarks、微调方法等等。这个新兴领域的快速进展和技术的多样性会使我们很难比较不同的算法、区分新贡献的效果、以及了解现有的迁移学习方法的空间。出于对更严格理解的需要,论文《Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer》利用一个统一的迁移学习方法,使我们能够系统地研究不同的方法,并推动该领域的现有局限性。作者将他们的模型和框架称为Text-to-Text Transfer Transformer: T5。论文的基本思路是:将每一个文本处理问题作为一个
"text-to-text"的问题,即以文本为输入、产生新的文本作为输出。这种方法受到以前NLP任务的统一框架的启发,包括将所有文本问题作为问答任务(《The natural language decathlon: Multitask learning as question answering》)、语言建模任务(《Language models are unsupervised multitask learners》)、以及span extraction任务(《Unifying question answering text classification via span extraction》)。最重要的是,text-to-text框架允许我们直接将相同的模型、objective、训练程序、以及解码过程应用于我们考虑的每一项任务。论文利用这种灵活性,对各种基于英语的NLP问题进行性能评估,包括问答、文档摘要、以及情感分类等等。通过这种统一的方法,我们可以比较不同的迁移学习objective、未标记的数据集、以及其他因素的有效性,同时通过扩大模型和数据集的规模从而探索迁移学习在NLP中的局限性。作者强调:论文的目标不是要提出新的方法,而是要对该领域的现状提供一个全面的视角。因此,论文的工作主要包括对现有技术的综述、探索、以及经验比较。作者还通过
scale up来自他们的系统性研究的insights(训练模型达到110亿个参数)来探索当前方法的局限性,在论文考虑的许多任务中获得SOTA的结果。为了进行这种规模的实验,作者引入了"Colossal Clean Crawled Corpus: C4",这是一个由数百GB的、从网上抓取的干净英语文本组成的数据集。认识到迁移学习的主要作用是可以在数据稀缺的环境中利用预训练的模型,作者发布了他们的代码、数据集、以及预训练好的模型。
26.1 配置
26.1.1 模型
由于
Transformer越来越流行,我们研究的所有模型都是基于Transformer架构的。我们没有提供这个模型的全面定义,而是让感兴趣的读者参考原始论文(《Attention is all you need》)。总的而言,我们的
encoder-decoder Transformer的实现密切遵循《Attention is all you need》中的原始形式:首先,一个关于
token的输入序列被映射成一个embedding sequence,然后被馈入到编码器。编码器由一堆
"blocks"组成,每个block包括两个子组件:一个self-attention layer,以及后面跟一个小的feed-forward network。layer normalization被应用于每个子组件的输入。我们使用简化版的layer normalization,其中activations仅仅被rescale而没有additive bias。在
layer normalization之后,一个residual skip connection将每个子组件的input添加到其output。dropout被用于feed-forward network内部、skip connection、attention weights、以及整个stack的input和output。
解码器的结构与编码器相似,只是它在每个
self-attention layer之后包括一个标准的注意力机制,这个注意力机制关注编码器的输出。解码器中的自注意力机制使用一种自回归或因果的
self-attention,它只允许模型关注past outputs。final decoder block的输出被馈入一个具有softmax output的dense layer,其权重与input embedding matrix共享。Transformer中的所有注意力机制都被拆分成独立的"heads",这些heads的output在被进一步处理之前被拼接起来。
由于
self-attention是order-independent的(即,它是对集合的操作),所以向Transformer提供一个显式的position signal是很常见的。虽然最初的
Transformer使用正弦的position signal、或learned position embeddings,但最近使用relative position embeddings变得更加普遍。relative position embeddings不是为每个位置使用一个fixed embedding,而是根据自注意力机制中正在比较的"key"和"query"之间的offset产生不同的learned embedding。我们使用
relative position embeddings的简化形式,其中每个"embedding"只是一个标量,被添加到用于计算注意力权重的相应logit中。为了提高效率,我们还在模型的所有层中共享position embedding parameters,尽管在同一个给定的层中每个attention head使用不同的learned position embedding。positional embedding向量的维度为1维,因此用法是:其中:
relative position embedding组成的矩阵,通常情况下,要学习固定数量的
relative position embeddings,每个embedding对应于可能的key-query offsets取值。在这项工作中,我们对所有的模型使用32个relative position embeddings,它对应的offsets范围是0到128(根据对数来增加),超过128的offsets将分配一个相同的relative position embedding(即,oov)。请注意,一个给定的层对超过128个token的relative position不敏感,但后续的层可以通过结合前几层的局部信息建立对更大offsets的敏感性。综上所述,我们的模型与
《Attention is all you need》提出的原始Transformer大致相当,只是去掉了Layer Norm bias、将layer normalization置于residual path之前、并使用不同的position embedding方案。由于这些架构变化与我们在迁移学习的实证调查中考虑的实验因素是正交的,我们将其影响的消融留给未来的工作。作为我们研究的一部分,我们对这些模型的可扩展性进行了实验,即:当具有更多的参数或更多的层时,模型的性能会发生怎样的变化。
训练大型模型可能是不容易的,因为它们可能无法适应在单台机器上,而且需要大量的计算。因此,我们使用模型并行和数据并行的组合,在
Cloud TPU Pods的"slices"上训练模型。TPU pods是multi-rack机器学习超级计算机,包含1024个TPU v3芯片,通过高速2D mesh互连且支持CPU主机。我们利用Mesh TensorFlow library从而方便实现模型并行和数据并行。
26.1.2 Colossal Clean Crawled Corpus
以前关于自然语言处理的迁移学习的大部分工作都是利用大型未标记数据集进行无监督学习。在本文中,我们对评估这种未标记数据的质量、特性、以及规模的影响感兴趣。为了生成满足我们需要的数据集,我们利用
Common Crawl作为从网络上爬取的文本来源。Common Crawl以前曾被用作自然语言处理的文本数据源,例如,训练N-gram语言模型、作为常识推理的训练数据、为机器翻译挖掘parallel texts、作为预训练数据集、甚至只是作为测试optimizers的巨型文本语料库。Common Crawl是一个公开的web archive,它通过从爬取的HTML文档中删除markup和其他non-text内容来提供"web extracted text"。这个过程每月产生约20TB的爬取的文本数据。不幸的是,大部分产生的文本不是自然语言。相反,它主要包括胡言乱语或模板文本,如menu、错误信息、或重复的文本。此外,大量的爬取文本包含的内容不太可能对我们考虑的任何任务有帮助(攻击性语言、占位符文本、源代码等)。为了解决这些问题,我们使用了以下启发式方法来清理Common Crawl的web extracted text:我们只保留以终结标点符(即句号、感叹号、问号或尾部引号)结束的行。
我们丢弃了任何少于
5个句子的网页,只保留了包含至少3个单词的行。我们删除了任何含有 "肮脏、顽皮、淫秽或其他不良单词的清单" 中任何单词的网页。
许多被爬取的页面包含
warning,该warning说应该启用Javascript,因此我们删除了任何带有Javascript的行。一些页面有占位符
"lorem ipsum"文本,我们删除了任何出现"lorem ipsum"短语的页面。一些页面无意中包含代码。由于大括号
"{"出现在许多编程语言中(如在网络上广泛使用的Javascript),而不是在自然文本中,我们删除了任何含有大括号的网页。为了对数据集去重,对于数据集中任何
three-sentence span的多次出现,我们仅保留其中的一次出现而丢弃其它地方的出现。
此外,由于我们的大多数下游任务都集中在英语文本上,我们使用
langdetect来过滤掉任何未被分类为英语(分类概率至少为0.99)的网页。我们的启发式方法受到过去使用Common Crawl作为自然语言处理的数据来源的启发,例如:《Learning word vectors for 157 languages》也使用自动化的语言检测器过滤文本并丢弃短行。《Dirt cheap web-scale parallel text from the common crawl》和《Learning word vectors for 157 languages》都进行line-level去重。
然而,我们选择创建一个新的数据集,因为之前的数据集使用了更有限的启发式过滤方法、没有公开提供、和/或范围不同(例如,仅限于新闻数据,只包括
Creative Commons内容,或专注于机器翻译的平行训练数据)。为了组装我们的
base dataset,我们下载了2019年4月的web extracted text,并应用了上述的过滤。这产生了一个文本集合,它不仅比用于预训练的大多数数据集大了几个数量级(约750GB),而且还包括相当干净和自然的英语文本。我们把这个数据集称为Colossal Clean Crawled Corpus: C4,并将其作为TensorFlow Datasets的一部分发布。我们在实验部分考虑了使用该数据集的各种替代版本的影响。
26.1.3 下游任务
我们在本文中的目标是:度量通用语言学习
general language learning的能力。因此,我们在一组不同的benchmark上研究下游任务的性能,包括机器翻译、问答、抽象摘要、以及文本分类。具体来说,我们度量了如下任务的性能:GLUE和SuperGLUE文本分类meta-benchmarks、CNN/Daily Mail抽象摘要、SQuAD问答、以及WMT English to German, French, Romanian的翻译。所有的数据都来自于TensorFlow Datasets。GLUE和SuperGLUE各自包括一组文本分类任务,旨在测试通用语言理解能力:CoLA:句子可接受性acceptability判断。SST-2:情感分析。MRPC, STS-B, QQP:转述/句子相似性。MNLI, QNLI, RTE, CB:自然语言推理。WNLI, WSC:共指消解coreference resolution。COPA:句子补全。WIC:词义消歧word sense disambiguation。MultiRC, ReCoRD, BoolQ:问答。
我们使用
GLUE和SuperGLUE基准所分发的数据集。为了简单起见,在微调时,我们通过将GLUE的所有组成的数据集拼接起来,从而将GLUE benchmark中的所有任务(以及类似的SuperGLUE)作为单个任务。正如《A surprisingly robust trick for Winograd schema challenge》所建议的,我们还将Definite Pronoun Resolution : DPR数据集纳入SuperGLUE任务。CNN/Daily Mail数据集是作为一个问答任务引入的,但被《Abstractive text summarization using sequence-to-sequence RNNs beyond》改造为文本摘要;我们使用《Get to the point: Summarization with pointer-generator networks》的非匿名版本作为抽象摘要abstractive summarization任务。SQuAD:是一个常见的问答benchmark。在我们的实验中,我们将question和context馈入模型,并要求模型逐个token地生成答案。对于
WMT English to German翻译,我们使用与《Attention is all you need》相同的训练数据(即News Commentary v13, Common Crawl, Europarl v7),以及相同的newstest2013作为验证集。对于
English to French翻译,我们使用WMT 2015年的标准训练数据、以及newstest2014作为验证集。对于
English to Romanian,这是一个标准的lower-resource机器翻译benchmark,我们使用WMT2016的训练集和验证集。请注意,我们只对英语数据进行预训练,所以为了学习翻译,给定的模型将需要学习用一种新语言来生成文本。
26.1.4 Input 和 Output 格式
为了在上述不同的任务上训练一个单一的模型,我们把所有我们考虑的任务都变成了
"text-to-text"的形式,即:一些文本馈入模型作为上下文或条件,然后要求模型产生一些输出文本。这个框架同时为预训练和微调提供了一个一致的training objective。具体而言,不管是什么任务,模型都是用最大似然objective来训练的。为了为模型指定需要执行的任务,我们在把原始输入序列馈入模型之前,给input添加一个task-specific的前缀。例如,如果要求模型将句子
"That is good."从英语翻译成德语,模型将被馈入序列"translate English to German: That is good.",并被训练从而输出"Das ist gut."。对于文本分类任务,模型只是预测与
target label相对应的单个单词。例如,在MNLI benchmark上,目标是预测一个前提premise是否蕴含("entailment")、矛盾("contradiction")、或者中性("neutral")一个假设hypothesis。经过我们的预处理,输入序列变成"mnli premise: I hate pigeons. hypothesis: My feelings towards pigeons are filled with animosity.",相应的target单词是"entailment"。请注意,如果我们的模型在文本分类任务中输出的文本与任何可能的标签文本都不对应,就会出现问题。例如,如果模型输出的是
"hamburger",而该分类任务唯一可能的标签是"entailment"、"neutral"、或"contradiction"。在这种情况下,我们总是把模型的输出算作是错误的,尽管我们从未在任何一个我们的trained models中观察到这种行为。请注意,用于给定任务的文本前缀的选择本质上是一个超参数。我们发现改变前缀的
exact wording的影响有限,因此没有对不同的prefix choice进行广泛的实验。下图是我们的text-to-text框架,其中有一些input/output的例子。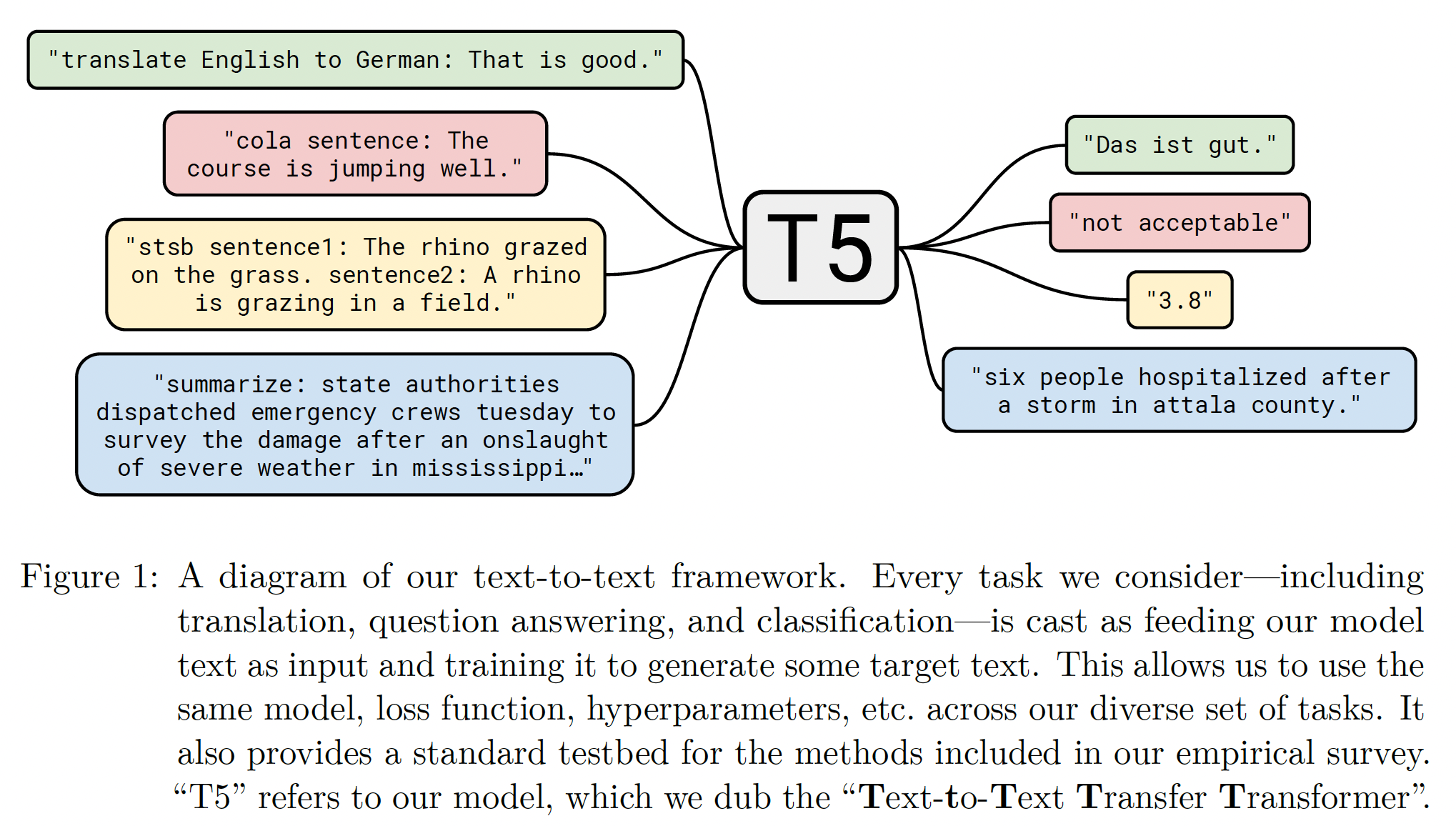
每个任务的
preprocessed inputs的完整例子(来自论文附录D):其中
{XXX}、{YYY}等表示占位符(代表一段文本),Processed input:的冒号后面的内容才是馈入到模型中的字符串。注意:
Original input表示原始的输入,Original target表示原始的label(都是整数或浮点数),Processed input表示处理后的输入,Processed target表示处理后的label(都是字符串)。CoLA:Original input:Sentence: "{XXX}."Processed input: "cola sentence: {XXX}."Original target: 1Processed target: "acceptable"RTE:xxxxxxxxxxOriginal input:Sentence 1: "{XXX}."Sentence 2: "{YYY}."Processed input: "rte sentence1: {XXX}. sentence2: {YYY}."Original target: 1Processed target: "not_entailment"MNLI:xxxxxxxxxxOriginal input:Hypothesis: "{XXX}."Premise: "{YYY}."Processed input: "mnli hypothesis: {XXX}. premise: {YYY}."Original target: 2Processed target: "contradiction"MRPC:xxxxxxxxxxOriginal input:Sentence 1: "{XXX}."Sentence 2: "{YYY}."Processed input: "mrpc sentence1: {XXX}. sentence2: {YYY}."Original target: 1Processed target: "equivalent"QNLI:xxxxxxxxxxOriginal input:Question: "{XXX}?"Sentence: "{YYY}."Processed input: "qnli question: {XXX}? sentence: {YYY}."Original target: 0Processed target: "entailment"QQP:xxxxxxxxxxOriginal input:Question 1: "{XXX}?"Question 2: "{YYY}?"Processed input: "qqp question1: {XXX}? question2: {YYY}?"Original target: 0Processed target: "not_duplicate"SST2:xxxxxxxxxxOriginal input:Sentence: "{XXX}."Processed input: "sst2 sentence: {XXX}."Original target: 1Processed target: "positive"STSB:xxxxxxxxxxOriginal input:Sentence 1: "{XXX}."Sentence 2: "{YYY}."Processed input: "stsb sentence1: {XXX}. sentence2: {YYY}."Original target: 3.25Processed target: "3.2"CB:xxxxxxxxxxOriginal input:Hypothesis: "{XXX}."Premise: "{YYY}?"Processed input: "cb hypothesis: {XXX}. premise: {YYY}?"Original target: 1Processed target: "contradiction"COPA:xxxxxxxxxxOriginal input:Question: "{XXX}"Premise: "{YYY}."Choice 1: "{ZZZ1}."Choice 2: "{ZZZ2}."Processed input: "copa choice1: {ZZZ1}. choice2: {ZZZ2}. premise: {YYY}. question: {XXX}"Original target: 1Processed target: "True"MultiRC:xxxxxxxxxxOriginal input:Answer: "{XXX}."Paragraph: "{YYY}."Question: "{ZZZ}?"Processed input: "multirc question: {ZZZ}? answer: {YYY}. paragraph: {XXX}."Original target: 1Processed target: "True"WiC:[]表示占位符。xxxxxxxxxxOriginal input:POS: "[Y/N]"Sentence 1: "{XXX}."Sentence 2: "{YYY}."Word: "[word]"Processed input: "wic pos: [Y/N] sentence1: {XXX}. sentence2: {YYY}. word: [word]"Original target: 0Processed target: "False"WSC DPR:xxxxxxxxxxOriginal input:Span 2 text: "it"Span 1 text: "stable"Span 2 index: 20Span 1 index: 1Text: "The stable was very roomy, with four good stalls; a large swinging window opened into the yard , which made it pleasant airy."Processed input: "wsc: The stable was very roomy, with four good stalls; a large swinging window opened into the yard , which made *it* pleasant airy."Original target: 1Processed target: "stable"CNN/Daily Mail:xxxxxxxxxxOriginal input: "{XXX}."Processed input: "summarize: {XXX}."Original target: "{YYY}."Processed target: "{YYY}."SQuAD:xxxxxxxxxxOriginal input:Question: "{XXX}?"Context: "{YYY}."Processed input: "question: {XXX}? context: {YYY}."Original target: "{ZZZ}"Processed target: "{ZZZ}"WMT English to German:xxxxxxxxxxOriginal input: "{XXX}."Processed input: "translate English to German: {XXX}."Original target: "{YYY}."Processed target: "{YYY}."WMT English to French:xxxxxxxxxxOriginal input: "{XXX}."Processed input: "translate English to French: {XXX}."Original target: "{YYY}."Processed target: "{YYY}."WMT English to Romanian:xxxxxxxxxxOriginal input: "{XXX}."Processed input: "translate English to Romanian: {XXX}."Original target: "{YYY}."Processed target: "{YYY}."
我们的
text-to-text框架遵循以前的工作,将多个NLP任务转换一个共同的格式:《The natural language decathlon: Multitask learning as question answering》提出了"Natural Language Decathlon",这是一个benchmark,对一组10个NLP任务使用一致的question-answer格式。Natural Language Decathlon还规定:所有模型必须是多任务的,即能够同时处理所有的任务。相反,我们允许在每个单独的任务上分别对模型进行微调,并使用简短的
task prefix,而不是显式的question-answer格式。《Language models are unsupervised multitask learners》通过将一些输入作为前缀馈入模型,然后对输出进行自回归采样,来评估语言模型的zero-shot learning的能力。例如,自动化摘要是通过馈入一个文档,后面跟着"TL;DR:"("too long, didn’t read"的缩写)的文字,然后通过自回归地解码来预测摘要。我们主要考虑这样的模型:在用单独的解码器生成输出之前,用编码器显式处理
input。并且我们关注迁移学习而不是zero-shot learning。最后,
《Unifying question answering text classification via span extraction》将许多NLP任务统一为"span extraction",其中对应于possible output choices的文本被附加到input,模型被训练为:抽取对应于正确choice的input span。相比之下,我们的框架也允许生成式任务,如机器翻译和抽象摘要,在这些任务中不可能列举所有
possible output choices。
我们能够直接将我们所考虑的所有任务转换成
text-to-text的格式,但STS-B除外,它是一个回归任务,目标是预测1到5分之间的相似度分数。我们发现这些分数大多以0.2为增量,所以我们简单地将任何分数四舍五入到最接近的0.2增量,并将结果转换为数字的字符串表示(例如,浮点数2.57将被映射为字符串"2.6")。在测试时,如果模型输出的字符串对应于
1到5之间的数字,我们就将其转换为浮点值。否则,我们就将模型的预测视为不正确。这就有效地将STS-B回归问题改成了21-class分类问题。另外,我们还将
Winograd任务(GLUE中的WNLI,Super-GLUE中的WSC,以及我们添加到SuperGLUE中的DPR数据集)转换成更简单的格式,更适合于text-to-text框架。Winograd任务中的样本包括一个包含歧义代词ambiguous pronoun的文本段落,该代词可能指代段落中的多个名词短语。例如,文本段落"The city councilmen refused the demonstrators a permit because they feared violence.",其中包含一个歧义代词"they",可以指代"city councilmen"或"demonstrators"。我们将WNLI、WSC、以及DPR任务转换为text-to-text问题,通过突出文本段落中的ambiguous pronoun并要求模型预测其所指的名词。上面提到的例子将被转化为:输入"The city councilmen refused the demonstrators a permit because *they* feared violence.",模型将被训练来预测target文本"The city councilmen"。对于
WSC来说,样本包含段落、歧义代词、候选名词、以及反映候选代词是否匹配的True/False标签(忽略任何文章)。我们只对有True标签的样本进行训练,因为我们不知道具有"False"标签的样本的正确名词目标。在评估时,如果模型输出中的单词是候选名词短语中的一个子集(或者反之),我们就给它一个"True"标签,否则就给它一个"False"标签。这就删除了大约一半的WSC训练集,但是DPR数据集增加了大约1000个代词解析样本。DPR的样本都有正确的指代名词标注,因此很容易以上述格式使用这个数据集。WNLI的训练集和验证集与WSC的训练集有很大的重叠。为了避免验证样本泄露到我们的训练数据中(这是实验部分的多任务实验中的一个特殊问题),我们从来不在WNLI上训练,也不报告WNLI验证集的结果。忽略WNLI验证集上的结果是标准做法,因为它对训练集来说是 "对抗性的",即验证样本都是具有相反标签的训练样本的轻微扰动版本。因此,每当我们报告验证集时(除了特殊说明之外),我们在GLUE的平均分数中不包括WNLI。将WNLI的样本转换为上述的"referent noun prediction"的变体是比较麻烦的;我们在论文附录B中描述了这个过程。
26.2 实验
我们对新的预训练
objective、模型架构、未标记数据集等技术进行了经验性的调查,希望能够区分出它们的贡献和意义。我们通过采取合理的
baseline并一次改变setup的一个方面来系统地研究这些贡献。这种"coordinate ascent"的方法可能会错过二阶效应(例如,一些特定的无监督objective可能在比我们的baseline setting更大的模型上效果最好),但对我们研究中的所有因素进行组合探索将是非常昂贵的。我们的目标是在一组不同的任务上比较各种不同的方法,同时保持尽可能多的因素固定。为了满足这一目标,在某些情况下,我们并不完全复制现有的方法。
例如,像
BERT这样的encoder-only模型被设计为对每个input token产生一个预测,或对整个输入序列产生一个预测。这使得它们适用于分类任务或span prediction任务,但不适用于翻译任务或抽象式生成等生成式任务。因此,我们考虑的模型架构没有一个是与BERT相同的,也没有一个是由encoder-only组成的架构。相反,我们测试了精神上相似的方法。例如,我们考虑了与
BERT的"masked language modeling" objective类似的objective,我们也考虑了在文本分类任务上与BERT行为类似的模型架构。
26.2.1 Baseline
我们对
baseline的目标是:要反映典型的现代实践。我们使用一个简单的denoising objective来预训练一个标准的Transformer,然后在我们的每个下游任务中分别进行微调。模型:我们使用了
《Attention is all you need》提出的标准的encoder-decoder Transformer。虽然许多用于自然语言处理的迁移学习的现代方法使用encoder-only或decoder-only,但我们发现:使用标准的encoder-decoder架构在生成任务和分类任务上都取得了良好的效果。我们在后续实验部分探讨了不同模型架构的性能。我们的
baseline模型被设计成:encoder和decoder各自的大小和配置与BERT_BASE相似。具体而言:encoder和decoder都由12个block组成,每个block包括self-attention、可选的encoder-decoder attention(这个只有decoder有)、以及一个前馈神经网络。每个
block中的前馈神经网络包括一个输出维度为ReLU非线性层和另一个稠密层。另一个稠密层的维度,论文并未直接说明,猜测也是
所有注意力机制的
"key"和"value"矩阵的内部维度为12个头。所有其他子层和
embedding的维度为
总的来说,这导致了一个具有大约
220M个参数的模型。这大约是BERT_BASE的参数数量的两倍,因为我们的baseline模型包含两个stack而不是一个。对于正则化,我们在模型中任何地方都使用了dropout rate = 0.1。训练:所有的任务都被表述为
text-to-text的任务。这使我们能够始终使用标准的最大似然进行训练。对于优化,我们使用AdaFactor。在测试时我们使用贪婪解码,即在每个timestep选择概率最高的logit。预训练:在微调之前,我们在
C4上对每个模型进行512,batch size = 128。只要有可能,我们将多个序列 "打包" 到批次的每个条目entry中,因此我们的batch大约包含token。总的来说,这个batch size和training step的数量相当于对token进行预训练。这比BERT和RoBERTa要少得多,后者使用了大约2.2T的token。只使用token的结果是合理的计算预算,同时仍然提供了足够的预训练量从而获得可接受的性能。我们在后续实验部分考虑了预训练关于更多training step的影响。请注意,token只涵盖了整个C4数据集的一部分,所以我们在预训练期间从不重复任何数据。在预训练期间,我们使用一个 "逆平方根" 的学习率调度:
training iteration,warm-up steps(在我们的所有实验中设置为0.01,然后学习率呈指数衰减直到预训练结束。我们还试验了使用三角学习率,这产生了稍好的结果,但需要提前知道总的training steps。由于我们将在一些实验中改变training steps的数量,我们选择了更通用的逆平方根调度。微调:我们的模型在所有的任务中都被微调为
high-resource任务(即有大数据集的任务)和low-resource任务(小数据集)之间的权衡,前者从额外的微调中获益、后者则迅速过拟合。在微调期间,我们继续使用bath size = 128,序列长度为512(即每个batchtoken)。在微调时,我们使用0.001的恒定学习率。我们每5000步保存一个checkpoint,并报告与最佳验证性能相对应的model checkpoint的结果。对于在多个任务上微调的模型,我们为每个任务独立选择best checkpoint。对于所有的实验,除非特别说明,我们报告验证集结果从而避免模型选择以及报告测试集结果。
预训练的
training step数量是微调期间的两倍。此外,预训练的学习率从1.0指数下降到0.001381,然而微调的学习率固定为一个很低的值0.001。Vocabulary:我们使用SentencePiece将文本编码为WordPiece tokens。在所有的实验中,我们使用了32,000个wordpieces的词表。由于我们最终在English to German, French, Romanian的翻译上对我们的模型进行了微调,所以我们还要求我们的词表涵盖这些非英语语言。为了解决这个问题,我们将C4中使用的Common Crawl中的页面分类为德语、法语、以及罗马尼亚语。然后,我们在英语、德语、法语、罗马尼亚语的比例为10:1:1:1的数据混合体上训练我们的SentencePiece模型。这个词表在我们模型的输入和输出中都是共享的。请注意,我们的词表使得我们的模型只能处理预先确定的、固定的语言集合。无监督
objective:受BERT的"masked language modeling" objective和"word dropout"正则化技术的启发,我们设计了一个objective,随机采样然后丢弃输入序列中15%的token。所有dropped-out tokens的consecutive spans都被单个哨兵token所取代。每个哨兵token都被分配一个token ID,该ID对序列来说是唯一的。哨兵token ID是被添加到我们的词表中的special token,不对应于任何wordpiece。target序列的组成方式如下:所有的dropped-out spans、间隔以对应的哨兵token、最后加上一个哨兵token来标记target序列结束。我们选择掩码
consecutive spans of tokens,并且仅预测dropped-out tokens,是为了减少预训练的计算成本。我们在实验部分对预训练objective进行了深入研究。下图给出了一个例子:原始的文本为
"Thank you for inviting me to your party last week."。处理之后,输入为
"Thank you <X> me to your party <Y> week.",target为"<X> for inviting <Y> last <Z>"。
注意:这里每一个哨兵
token都是序列中唯一的(不必要求全局唯一),它们起到 “锚” 的作用,使得能够根据targets和inputs来恢复原始输入。假设哨兵token都是[MASK](即,BERT的做法),那么模型无法知晓"last"是对应第一个drop位置、还是第二个drop位置。是否要求每个序列中,哨兵
token出现的次序相同?比如,序列S1中哨兵token出现的次序为<X><Y><Z>,那么序列S2中哨兵token出现的次序是否可以为<Z><X><Y>?
Baseline性能:我们介绍了使用上述baseline实验程序的结果,以了解在我们这组下游任务中可以期待什么样的性能。理想情况下,我们会在研究中多次重复每个实验,以获得我们结果的置信区间。不幸的是,由于我们运行了大量的实验,这将是非常昂贵的。作为一个更便宜的选择,我们从头开始训练我们的baseline模型10次(即用不同的随机初始化和数据集混洗),并假设这些runs of base model的方差也适用于每个实验变体。另外,我们还度量了在没有预训练的情况下,在所有下游任务中训练我们的模型baseline setting下,预训练对我们的模型有多大的好处。在正文中报告结果时,我们只报告了所有
benckmark scores的一个子集,从而节省空间和方便解释:对于
GLUE和SuperGLUE,我们仅报告了所有子任务的平均得分(如官方所规定的)。对于所有的翻译任务,我们报告由
SacreBLEU v1.3.0提供的BLEU分数,其中包括"exp"平滑和"intl"tokenization。我们将WMT English to German, English to French, English to Romanian的分数分别称为EnDe, EnFr, EnRo。对于
CNN/Daily Mail,我们发现模型在ROUGE-1-F, ROUGE-2-F, ROUGE-L-F指标上的表现高度相关,因此我们单独报告ROUGE-2-F得分。同样,对于
SQuAD,我们发现"exact match"(简称EM)和"F1"得分的表现高度相关,因此我们只报告"exact match"得分。我们在论文附录E的Table 16中提供了所有实验在每个任务上取得的每一个分数。
我们的结果表的格式是,每一行对应于一个特定的实验配置,每一列给出每个
benchmark的分数。我们将在大多数表格中包括baseline配置的平均性能。凡是baseline配置出现的地方,我们都会用 "★" 来标记(如Table 1的第一行)。我们还将用黑体标出特定实验中在任何最大(最好)分数的两个标准差之内的分数(包括最大分数自身)。baseline结果如下表所示:总的来说,我们的结果与现有的类似规模的模型相媲美。例如,
BERT_BASE在SQuAD上取得了80.8的exact match分数,在MNLI-matched上取得了84.4的准确率,而我们分别取得了80.88和84.24(见Table 16)。请注意,我们不能直接将我们的
baseline与BERT_BASE进行比较,因为我们的是一个encoder-decoder模型,而且预训练的步数大约是BERT_BASE的1/4。不出所料,我们发现预训练在几乎所有的
benchmark中都提供了显著的增益。唯一的例外是WMT English to French翻译,它是一个足够大的数据集,预训练的增益是很微小的。我们在实验中加入了这项任务,从而测试迁移学习在high-resource条件下的行为。由于我们执行
early stopping并选择best-performing checkpoint,我们的baseline和"no pre-training"之间的巨大差异强调了预训练在数据有限的任务上有多大的改善。虽然我们在本文中没有显式地衡量数据效率的提高,但我们强调这是迁移学习范式的主要好处之一。
至于
inter-run方差,我们发现对于大多数任务来说,标准差小于任务baseline得分的1%。这一规则的例外情况包括CoLA, CB, COPA,它们都是GLUE和SuperGLUE基准的low-resource任务。例如,在CB上,我们的baseline model的平均F1得分是91.22、标准差是3.237(见Table 16),这可能部分是由于CB的验证集只包含56个样本。请注意,GLUE和SuperGLUE的分数是组成每个benchmark的所有任务的平均分数来计算的。因此,我们警告说,单独使用GLUE和SuperGLUE分数时,CoLA, CB, COPA的高inter-run方差会使模型难以比较。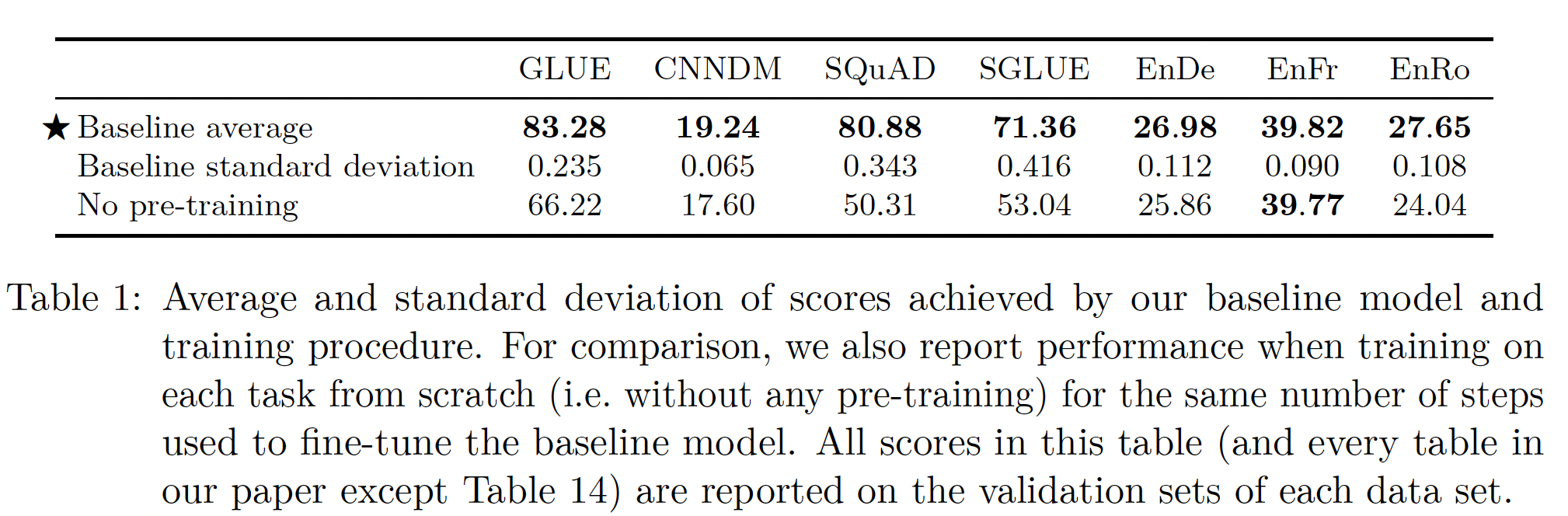
论文附录
E的Table 16:
26.2.2 架构
这里我们回顾并比较针对
encoder-decoder架构的不同变体。模型架构:不同架构的一个主要区别因素是,模型中不同注意力机制所使用的
"mask"。回顾一下,Transformer中的自注意力操作将一个序列作为输入,并输出一个相同长度的新序列。输出序列的每个条目是通过计算输入序列的条目的加权平均而产生的。具体而言,令然后,
attention mask被用来将某些权重归零,从而限制在给定的output timestep中可以关注哪些输入条目。我们将考虑的mask的图示如下图所示。例如,causal mask(Figure 3,中间)当满足
我们考虑的第一个模型结构是一个
encoder-decoder Transformer,它由two layer stacks组成:编码器,它被馈入一个输入序列。
编码器使用一个
"fully-visible"的attention mask,这允许自注意力机制在产生每个输出条目时注意任何输入条目。解码器,它生成一个新的输出序列。
解码器使用
"causal"的attention mask,这阻止了模型在生成第"see into the future"。
Figure 4的左侧显示了这种结构变体的示意图。标准的
encoder-decoder的decoder的输入有两个:来自于encoder、来自于target序列。而这里的decoder的输入其实也有两个,只是因为绘图的关系,这里并没有绘制出来而已。此外,这里只是把
decoder画在encoder上方而已,也可以把decoder画在encoder的右侧。Transformer decoder可以作为一个语言模型language model: LM,这构成了我们考虑的第二个模型结构,如下图中间部分所示。语言模型通常被用于压缩或序列生成。然而,它们也可以在
text-to-text框架中使用,只需将inputs序列和targets序列拼接起来即可。例如,考虑English to German翻译。如果我们有一个input句子"That is good."和target句子"Das ist gut.",那么拼接后的输入序列为"translate English to German: That is good. target: Das ist gut."。 我们将简单地训练模型从而对拼接后的输入序列进行next-step prediction。loss函数是仅考虑target部分还是考虑input + target整体?理论上讲,我们需要计算的是target部分。但是看这里的描述,感觉是input和target。可以通过实验来评估这里。此外,如果建模了
input文本进行无监督的 ”预训练“。此外,实验部分表面,
decoder-only的表现要比Enc-Dec更差,有可能是因为这里loss函数考虑了如果我们想获得模型对这个例子的预测,那么我们将序列
"translate English to German: That is good. target:"馈入模型,然后要求模型自回归地生成剩余部分。通过这种方式,该模型可以预测一个给定输入序列的输出序列。在
text-to-text setting中使用语言模型的一个基础的和经常被引用的缺点是:causal masking迫使模型在生成第representation时关注考虑前面的
English to German翻译的例子。我们需要提供一个prefix(也叫做context)序列、以及一个target序列。在causal masking的情况下,prefix中第representation只能取决于prefix中前面的条目。而这是不必要的限制。在
Transformer-based的语言模型中,只需改变masking pattern就可以避免这个问题。在prefix序列部分,我们不使用causal mask而是使用fully-visible mask,如下图右侧所示。我们称这种模式为prefix LM。在上面提到的
English to German翻译的例子中,fully-visible mask将被应用于前缀"translate English to German: That is good. target:",causal mask将用于预测目标"Das ist gut."。在
text-to-text框架中使用prefix LM最初是由《Generating Wikipedia by summarizing long sequences》所提出。最近,《Unified language model pre-training for natural language understanding generation》表明:这种架构在各种text-to-text任务上是有效的。这个架构类似于一个encoder-decoder模型,其参数在编码器和解码器之间共享,并且encoder-decoder的注意力被整个input序列和target序列的full attention所取代。
如果
Encoder和Decoder的宽度相同,那么T5(下图中的左侧)长得很像一个Encoder,只是它前50%的层是全连接的、后50%的层不包含 “未来的连接”。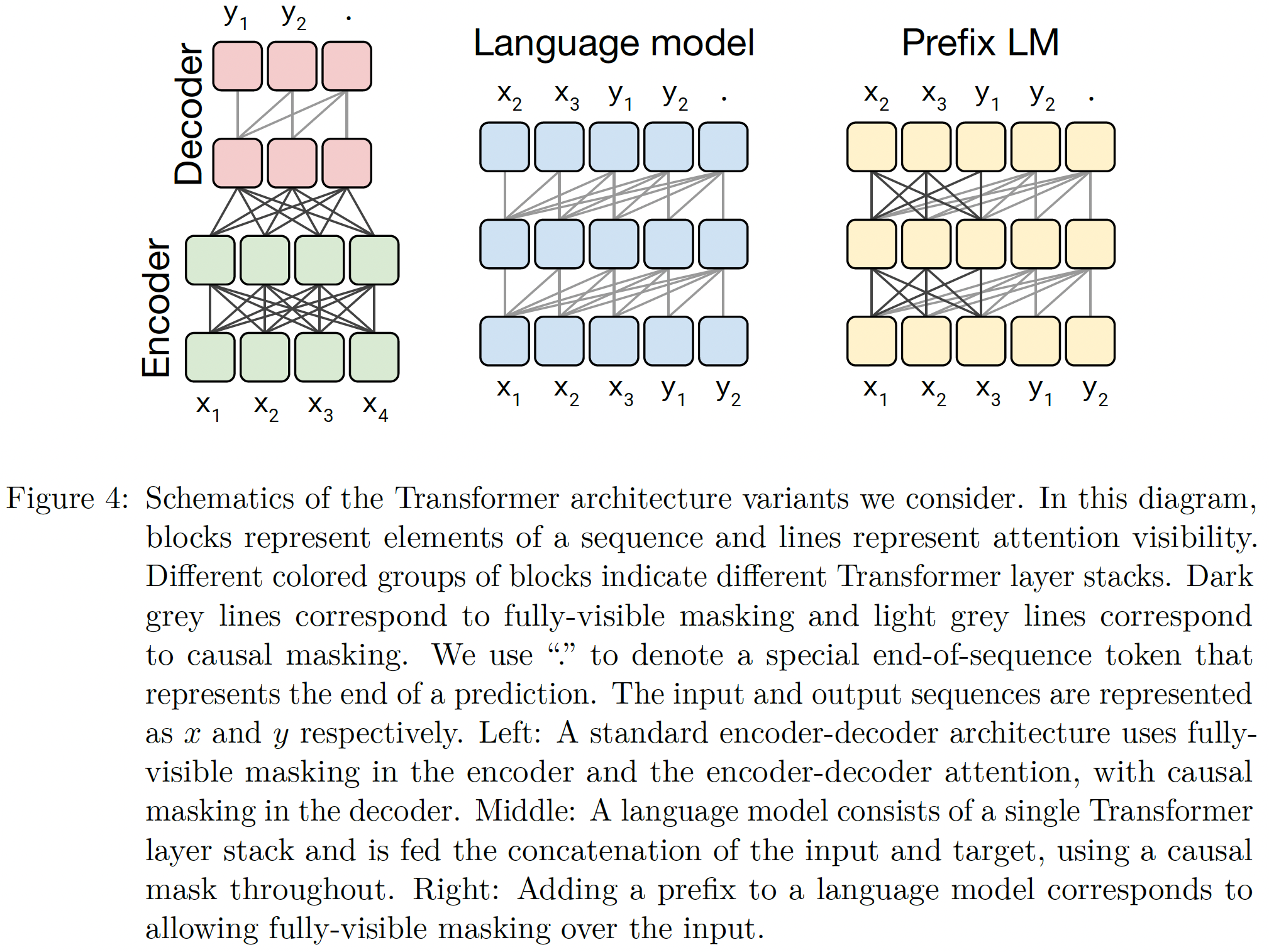
我们注意到,对于分类任务,当遵循我们的
text-to-text框架时,prefix LM架构与BERT非常相似。对于分类任务,
prefix LM架构的label只有一个单词代表类别,如Figure 4右图所示,此时退化为:输入为x1, x2, x3, y1、输出为x2, x3, y1, '.',而且decoder之间是全连接的。这和
BERT非常类似,但是二者之间存在:BERT的objective是恢复被masked的单词。因此输入为x1, x2, x3, [mask], ".",然后仅考虑[mask]上的输出并进行预测。而
prefix LM是自回归模型,需要预测每个位置的next token。
为了了解原因,考虑
MNLI benchmark中的一个例子,前提premise是"I hate pigeons.",假设hypothesis是"My feelings towards pigeons are filled with animosity.",而正确的标签是"entailment"。要把这个例子馈入语言模型,我们要把它转化为"mnli premise: I hate pigeons. hypothesis: My feelings towards pigeons are filled with animosity. target: entailment"。其中,fully-visible prefix对应于"mnli premise: I hate pigeons. hypothesis: My feelings towards pigeons are filled with animosity. target:",这可以被视为是类似于BERT中使用的"classification" token。因此,我们的模型将对整个input有full visibility,然后通过输出"entailment"这个单词来完成分类任务。给定task prefix的条件下,该模型很容易学会输出有效的class label。因此,
prefix LM和BERT架构之间的主要区别是:在prefix LM中,classifier被简单地集成到Transformer decoder的输出层。不同模型架构的比较:为了比较这些架构变体,我们希望每个模型都能以某种有意义的方式是相等
equivalent的,例如,两个模型具有相同数量的参数、或者对于给定的(input-seq, target-seq) pair时两个模型具有相同的计算量。不幸的是,不可能同时根据这两个标准来比较一个encoder-decoder模型和一个language model架构。要知道为什么,首先要注意:一个具有
L + L层的encoder-decoder模型(指的是编码器L层且解码器L层)与一个具有2L层的语言模型的参数数量大致相同。然而,具有L + L层的encoder-decoder模型的计算成本将与只有L层的语言模型大致相同。 这是因为:语言模型中的L层必须同时应用于输入序列和输出序列;而encoder-decoder模型中,编码器只应用于输入序列、解码器只应用于输出序列。注意,这里的参数数量相等、计算量相等仅仅是近似的:由于
encoder-decoder attention的存在,decoder中还存在一些额外的参数;attention layer中也存在一些计算成本,这些成本与序列长度呈二次方的关系。然而在实践中,我们观察到L层语言模型与L + L层的encoder-decoder模型的step times几乎相同,这表明二者计算成本大致相当。此外,对于我们考虑的模型规模,encoder-decoder attention层的参数数量约为总参数数的10%,因此我们做了一个简化的假设,即L + L层的encoder-decoder模型的参数数量与2L层语言模型相同。为了提供一个合理的比较手段,我们考虑了
encoder-decoder模型的多种配置。我们将把BERT_BASE的层数和参数数量分别称为L和P。我们将用M来指代L + L层的encoder-decoder模型(或只用L层decoder-only模型,即语言模型)处理一个给定的input-target pair所需的FLOPs数量。总的来说,我们将比较:一个
L + L层的encoder-decoder模型,模型有2P个参数,计算成本为M FLOPs。一个
L + L层的encoder-decoder模型,但是参数在编码器和解码器之间共享,导致P个参数和M FLOPs计算成本。一个
L/2 + L/2层的encoder-decoder模型,模型有P个参数,计算成本为M/2 FLOPs。一个
L层的decoder-only prefix LM模型,模型有P个参数,计算成本为M FLOPs。一个
L层的LM模型,模型有P个参数,计算成本为M FLOPs。
注:这里没有考虑
encoder-only模型,因为它无法执行文本生成任务。objective函数:我们对比了basic language modeling objective、our baseline denoising objective。我们包括language modeling objective,因为它历来被用作预训练objective,并且它自然适合我们考虑的语言模型架构。对于
encoder-decoder model和prefix LM,我们从未标记的数据集中抽取一个span的文本,并选择一个随机点,将其分成prefix部分和target部分。对于标准语言模型,我们训练该模型来预测从头到尾的整个
span。
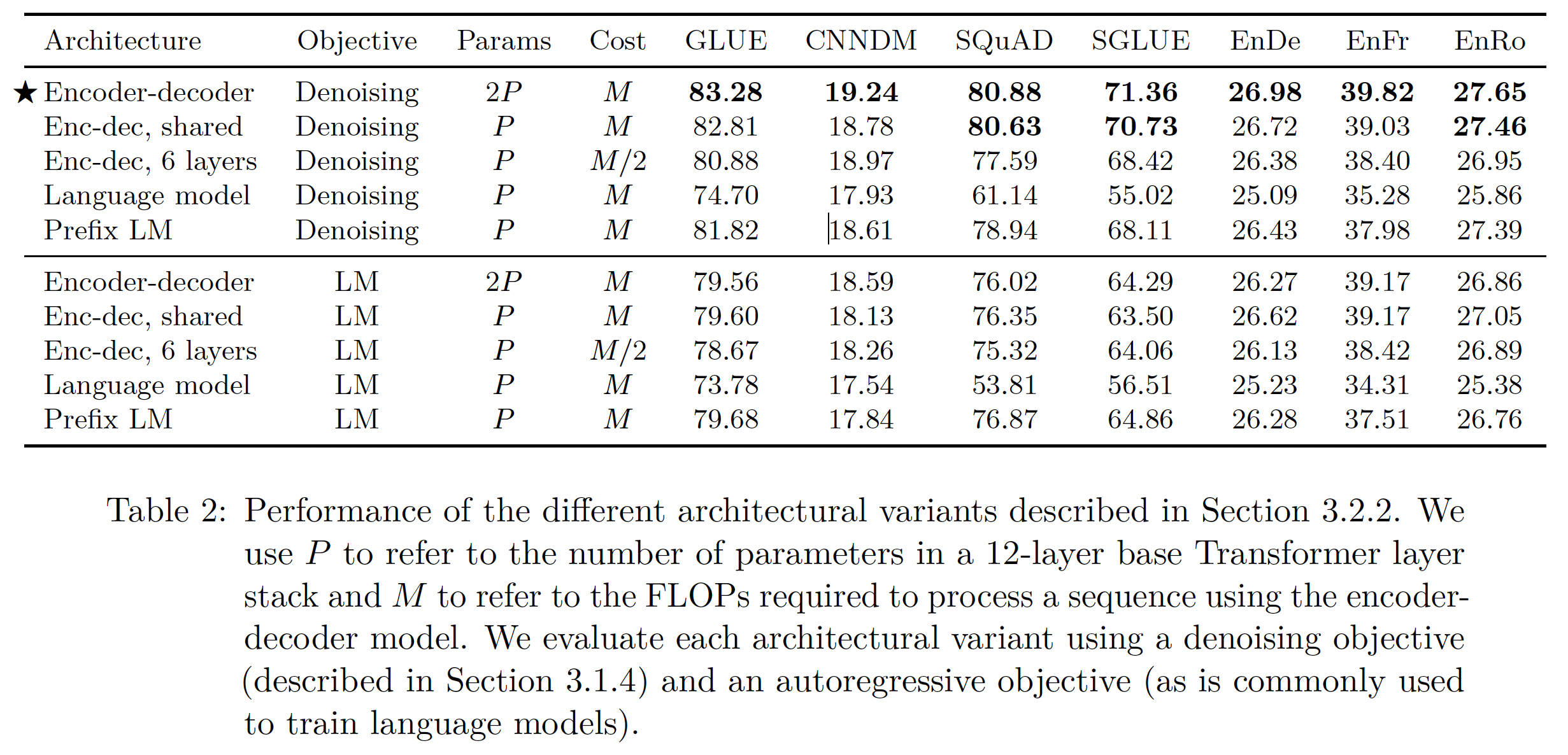
denoising objective就是MLM的objective,language modeling objective就是LM的objective。结果:每个架构所取得的分数都如下表所示,可以看到:
对于所有的任务,具有
denoising objective的encoder-decoder架构表现最好。这个变体具有最高的参数数量(2P),但计算成本与仅有P个参数的decoder-only模型相同。令人惊讶的是,在编码器和解码器之间共享参数的表现几乎一样好。
同时进行的工作
ALBERT也发现:在Transformer block之间共享参数可以是降低总参数数的有效手段,而不会牺牲很多性能。将编码器和解码器的层数减半,明显地损害了性能。
共享参数的
encoder-decoder的性能优于decoder-only prefix LM,这表明增加一个显式的encoder-decoder attention是有益的。最后,我们证实了一个广泛存在的概念:即与
language modeling objective相比,使用denoising objective总能带来更好的下游任务表现。
26.2.3 无监督 Objective
总体而言,我们所有的
objective都会接受一个关于token ID的序列,这个序列对应于来自未标记文本数据集中的一个tokenized的span of text。token序列被处理从而产生一个(被破坏的)input序列和一个相应的target序列。然后,像往常一样用maximum likelihood训练模型以预测target序列。这些
objective的例子如下表所示。例如:原始的文本是
"Thank you for inviting me to your party last week."Prefix LM:编码器的输入为"Thank you for inviting",解码器的输出为"me to your party last week."。BERT-style:编码器的输入为"Thank you for <M> <M> to your party apple week.",解码器的输出为"Thank you for inviting me to your party last week."。注意,这里除了
<M>替换之外,还替换了"last"为随机的token(这里为"apple")。这里和
BERT不同。BERT是encoder-only模型,仅预测被掩码的token。并且BERT中不同token之间是独立地被掩码。而这里考虑预测整个原始序列,而且每次掩码整个span。Deshuffling:编码器的输入为"party me for you to . last you inviting week Thank",解码器的输出为"Thank you for inviting me to your party last week."。MASS-style:编码器的输入为"Than you <M> <M> me to your party <M> week.",解码器的输出为"Thank you for inviting me to your party last week."。它和
BERT-style很像,然而BERT-style中会执行token的随机替代,而这里没有。iid.noise, replace spans:编码器的输入为"Thank you <X> me to your party <Y> week.",解码器的输出为"<X> for inviting <Y> last <Z>"。iid.noise指的是每个token的掩码事件是相互独立的。此外,对于连续的masked token被合并成masked span。它就是论文baseline用到的objective。iid.noise, drop tokens:编码器的输入为"Thank you me to your party week.",解码器的输出为"for inviting last"。random spans:编码器的输入为"Thank you <X> to <Y> week.",解码器的输出为"<X> for inviting me <Y> your party last <Z>"。它和
iid.noise, replace spans的区别在于:这里直接针对span进行掩码(而不是针对token),其中掩码的位置、span长度都是随机的。

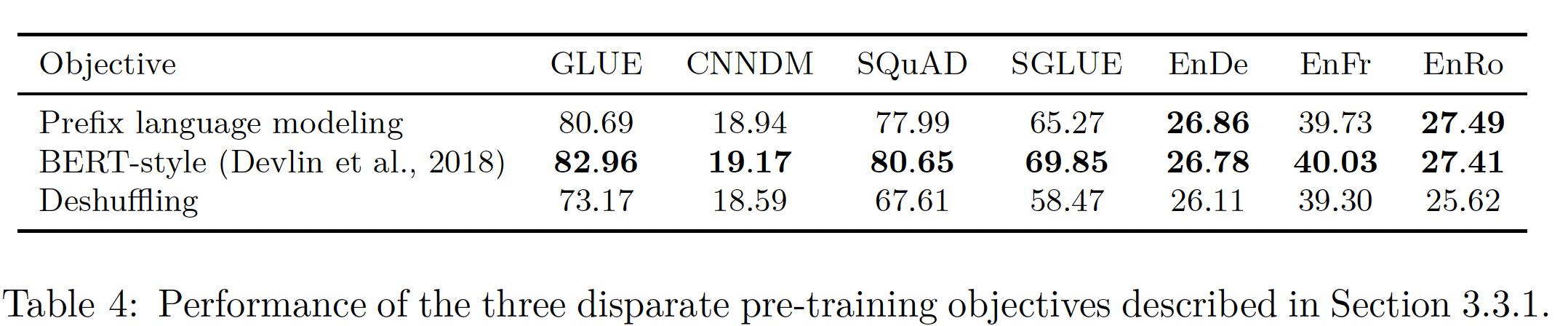
不同的
High-Level方法:首先,我们比较了三种技术,它们受到常用objective的启发,但在方法上有很大不同:"prefix language modeling" objective:这种技术将a span of text分成两部分,一部分作为编码器的输入序列,另一部分作为由解码器预测的target序列。"masked language modeling" objective启发的objective:"masked language modeling"需要a span of text,并破坏了15%的token。在所有corrupted tokens中,90%被替换成一个特殊的mask token、10%被替换成一个随机token。由于
BERT是一个encoder-only模型,它在预训练期间的目标是在编码器的输出端重建masked tokens。在encoder-decoder的情况下,我们只是将完整的原始序列作为target。请注意,这与我们的baseline objective不同,在baseline objective中只使用corrupted tokens作为target;我们在实验中比较了这两种方法。deshuffling objective:这种方法需要一个token序列,对其进行混洗,然后使用完整的原始序列作为target。
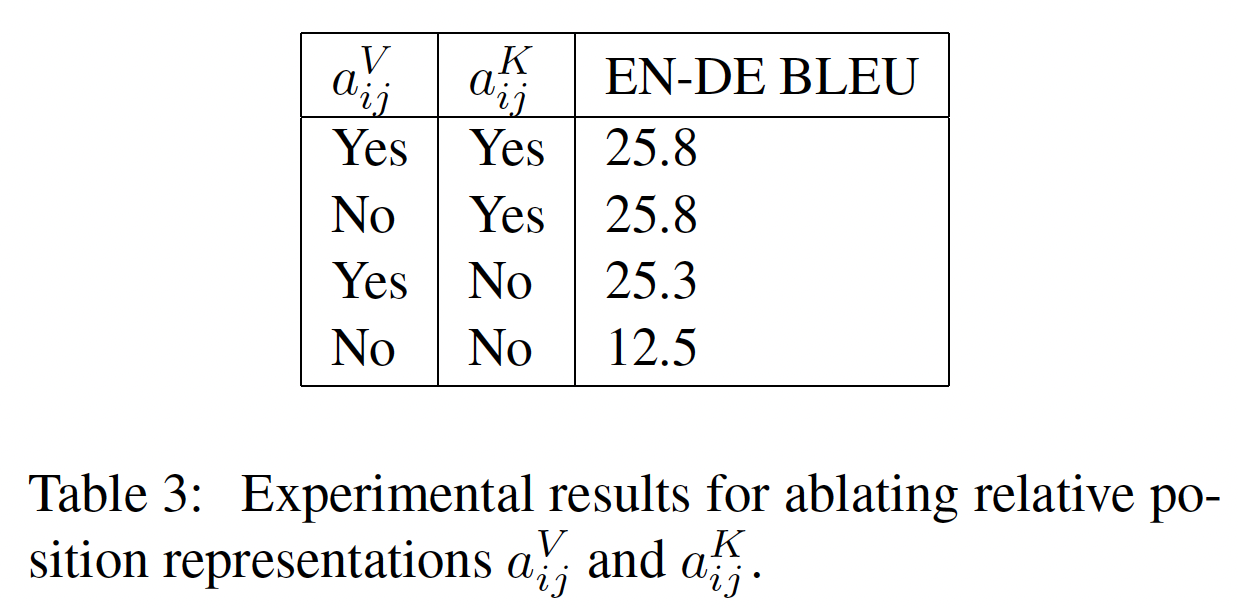
Table 3的前三行提供了这三种方法的inputs和targets的例子。这三个objectives的性能如下表所示。可以发现:总的来说,
BERT-style objective表现最好,尽管prefix language modeling objective在翻译任务上达到了类似的性能。事实上,BERT objective的动机是为了超越基于语言模型的预训练。deshuffling objective的表现比prefix language modeling objective和BERT-style objective都要差很多。
简化
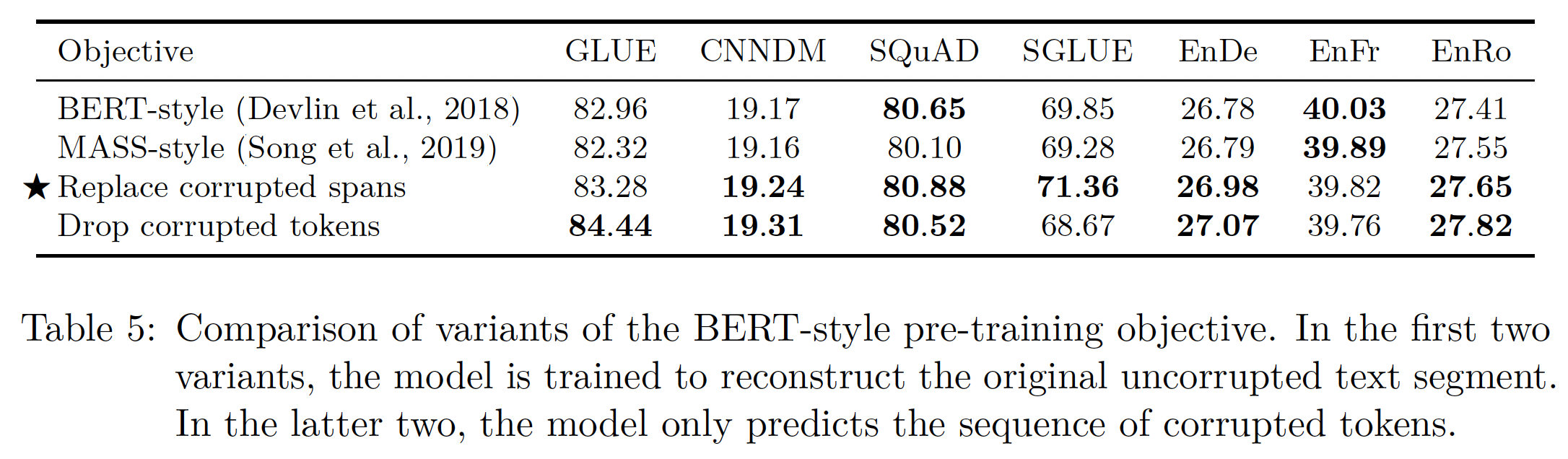
BERT Objective:基于上一节的结果,我们现在将重点探索对BERT-style denoising objective的修改。这个objective最初是作为一个预训练技术而提出的,用于为分类和span prediction而训练的encoder-only模型。因此,有可能对其进行修改,使其在我们的encoder-decoder text-to-text setup中表现得更好或更有效。首先,我们考虑
BERT-style objective的一个简单变体:不包括random token而仅有mask token(占所有token中的比例为15%)。MASS使用了一个类似的masking objective,所以我们把这个变体称为"MASS-style" objective。其次,我们有兴趣看看是否有可能避免预测完整的原始序列,因为这需要解码器在长序列上的
self-attention。我们考虑了两种策略:首先,我们不是用一组
mask token来一一对应地替换每个corrupted token,而是用单个unique mask token来替换整个区间的corrupted tokens。然后,我们将所有的corrupted span、以及所有的unique mask token的拼接作为target序列。这就是我们在
baseline中使用的pre-training objective,如Table 3中的第五行所示(即iid.noise, replace spans)。其次,我们还考虑了一个变体:仅仅从输入序列中完全删除
corrupted tokens,而让模型按顺序重建dropped tokens。其中,我们将dropped tokens的拼接作为target序列,如Table 3中的第六行所示(即iid.noise, drop tokens)。
下表展示了原始的
BERT-style objective和这三种objective的比较结果。可以看到:在我们的
setting中,所有这些变体的表现都很相似。唯一的例外是,由于
dropping corrupted tokens在CoLA上的得分明显较高(60.04,而我们的baseline average为53.84,见Table 16),所以dropping corrupted tokens在GLUE得分上产生了小的改善。这可能是由于CoLA涉及到对一个给定的句子在语法和句法上是否可以接受进行分类,而能够确定什么时候缺少tokens与detecting acceptability密切相关。然而,在
SuperGLUE上,dropping tokens的表现比replacing tokens的表现要更差。replace corrupted spans和drop corrupted spans都有潜在的吸引力,因为它们使target序列更短,从而使训练更快。
变化的
Corruption Rate:到目前为止,我们一直在破坏15%的token,这是BERT中使用的值。同样,由于我们的text-to-text框架与BERT的不同,我们有兴趣看看不同的破坏率corruption rate是否对我们更有效。我们在下表中比较了10%, 15%, 25%, 50%的破坏率。可以看到:总体而言,我们发现破坏率对模型的性能影响有限。唯一的例外是,我们考虑的最大破坏率(
50%)导致GLUE和SQuAD的性能明显下降。使用更大的破坏率也会导致更长的
targets序列,这有可能会减慢训练速度。在
encoer-decoder架构中,更小的破坏率导致更长的encoder-input和更短的decoder-input;更大的破坏率导致更短的encoder-input和更长的decoder-input。在序列生成任务中,生成一个token的计算成本较高(在decoder侧),而编码一个token的计算成本较低(在encoder侧)。
基于这些结果和
BERT的历史先例,我们将在未来使用15%的破坏率。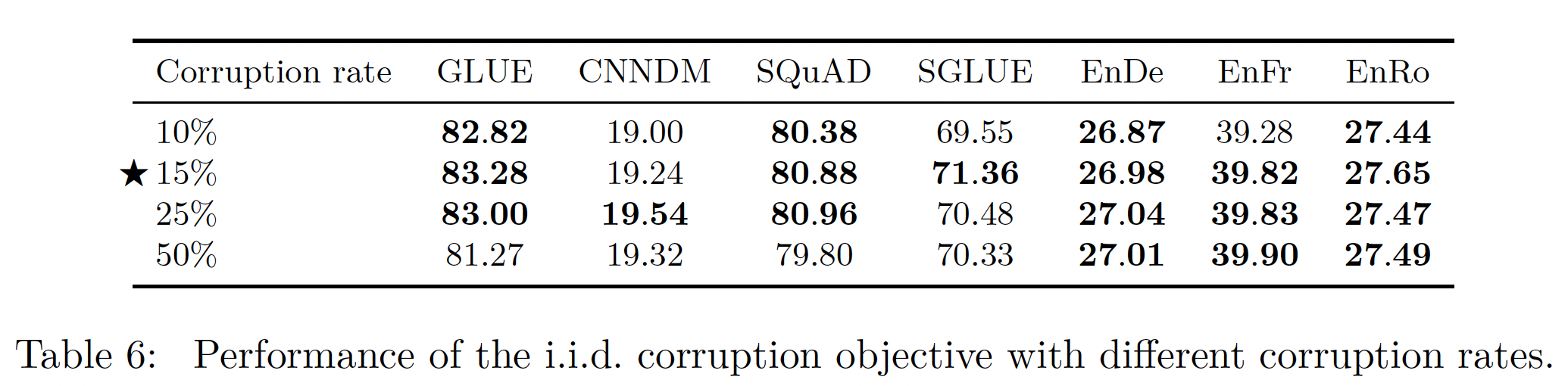
Corrupting Spans:我们现在转向通过预测更短的targets序列来加速训练。到目前为止,我们所使用的方法是对每个input token进行独立同分布地判断,以决定是否对其进行破坏。当多个consecutive tokens被破坏时,它们被视为一个"span",并使用单个unique mask token来替换整个span。用单个token替换整个span的结果是:未标记的文本数据被处理成较短的序列。由于我们使用的是一个
i.i.d. corruption strategy,所以并不总是有大量的corrupted tokens连续出现。因此,我们可以通过专门破坏spans of tokens,而不是以i.i.d.的方式破坏单个tokens来获得额外的加速。corrupting spans以前也被认为是BERT的pre-training objective,SpanBERT发现它可以提高性能。为了测试这个想法,我们考虑一个
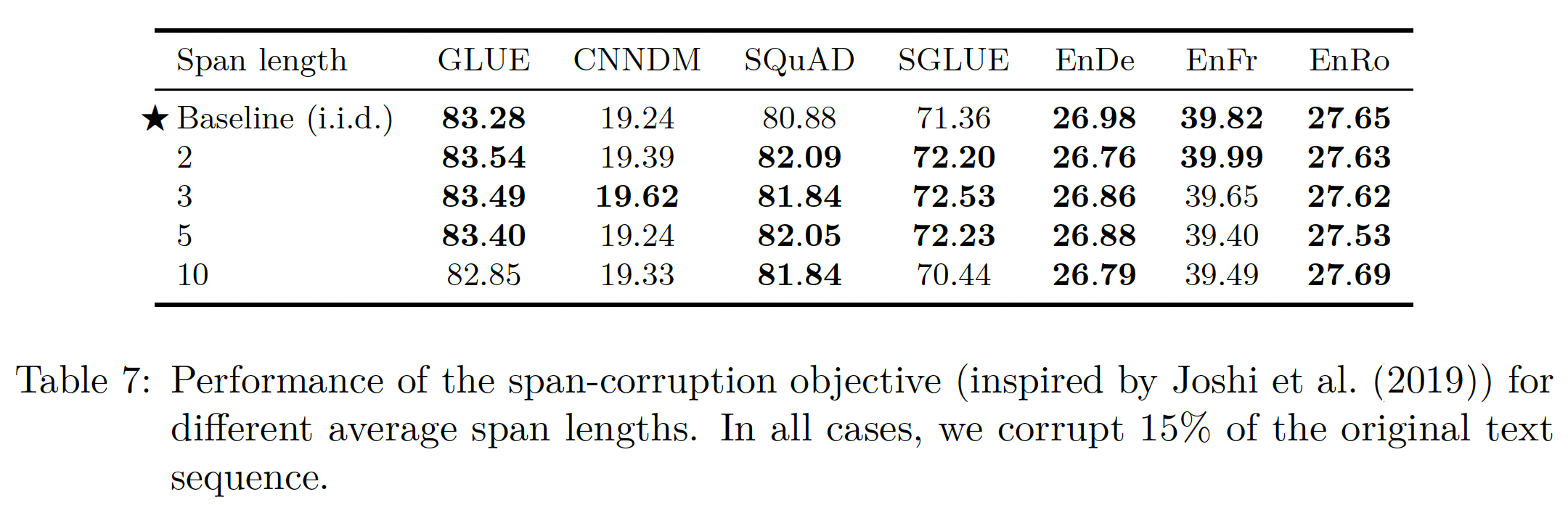
objective,它专门破坏连续的、随机间隔的spans of tokens,即Table3中的random spans objective。这个objective可以通过corrupted tokens的比例、以及corrupted spans的总数进行参数化。然后随机选择span length从而满足这些指定的参数。例如,如果我们正在处理一个有500个token的序列,并且我们指定15%的tokens应该被破坏,并且总共应该有25个span,那么corrupted tokens总数将是500*0.15=75,平均span length将是75/25=3。我们在下表中比较了
span-corruption objective和i.i.d-corruption objective。我们在所有情况下使用15%的破坏率,并使用2, 3, 5, 10的平均span length进行比较。可以看到:这些
objective之间的差异有限,尽管在某些情况下,平均span length为10的版本略微低于其他值。在大多数
non-translation benchmarks上,使用3的平均span length略微(但明显)优于i.i.d. objective。
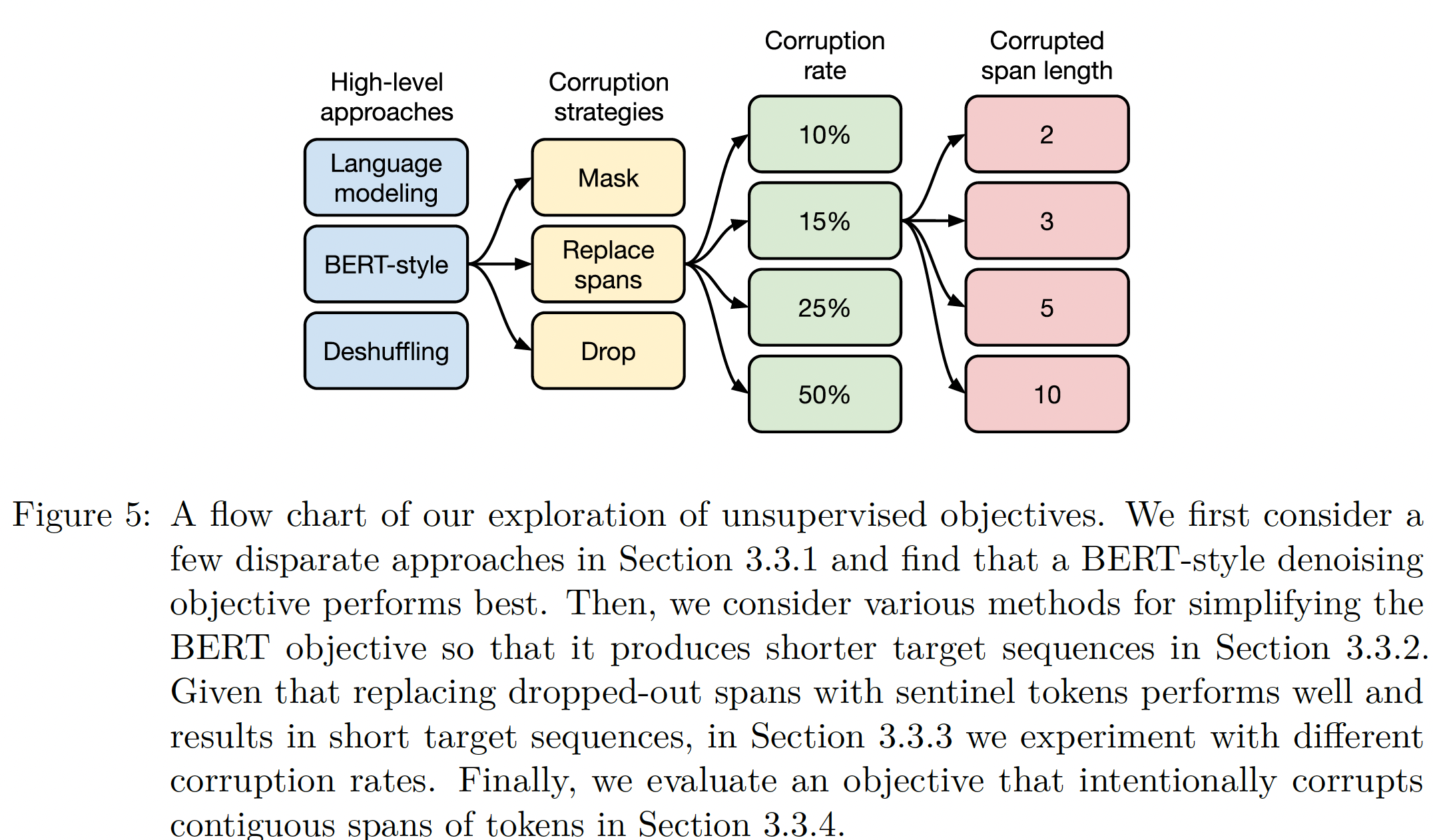
讨论:下图显示了我们在探索无监督
objective期间所做选择的流程图。总体而言,对于预训练而言,我们观察到的最显著的性能差异是
denoising objective优于language modeling和deshuffling。在我们探索的
denoising objective的众多变体中,我们没有观察到明显的差异。然而,不同的
objective会导致不同的序列长度,从而导致不同的训练速度。这意味着,在我们这里考虑的denoising objective中的选择,主要应根据其计算成本来进行(即,尽量选择target序列较短的objective)。我们的结果还表明,对于我们所考虑的任务和模型来说,对类似于我们这里所考虑的
objective的额外探索可能不会导致显著的收益。
26.2.4 预训练数据集
和
unsupervised objective一样,预训练数据集本身也是迁移学习pipeline的一个重要组成部分。然而,与objective和benchmars不同的是,新的预训练数据集通常不被视为重大贡献,而且通常不会与预训练模型和代码一起发布。相反,它们通常是在介绍新方法、或新模型的过程中被引入。因此,不同的预训练数据集的比较相对较少,也缺乏用于预训练的 "标准" 数据集。为了更深入地探究预训练数据集对性能的影响,在本节中我们比较了我们的C4数据集的变体、以及其他潜在的预训练数据源。我们将所有的C4数据集的变体作为TensorFlow Datasets的一部分发布。未标记数据集:在创建
C4数据集时,我们开发了各种启发式方法来过滤来自Common Crawl的web-extracted文本。我们感兴趣的是:这种过滤是否提升了下游任务的性能。此外,我们也比较了其它过滤方法、以及其他常见的预训练数据集。为此,我们比较了我们的baseline模型在以下数据集上预训练后的表现:C4:它作为baseline,制作方法如前文所述。Unfiltered C4:未被过滤的C4的替代版本。请注意,我们仍然使用langdetect来抽取英文文本。因此,我们的"unfiltered"变体仍然包含一些过滤。RealNews-like:我们通过额外过滤C4来生成另一个未标记的数据集,只包括来自"RealNews"数据集(《Defending against neural fake news》)中使用的一个domain的内容。WebText-like:WebText数据集只使用了提交给Reddit并获得至少3分的网页内容。提交给Reddit的网页的分数是根据赞同(upvote)或反对(downvote)该网页的用户比例计算的。使用Reddit分数作为质量信号背后的想法是:该网站的用户只会对高质量的文本内容进行投票。为了生成一个可比较的数据集,我们首先尝试从
C4中删除所有不是来自OpenWebText工作所编制的列表中的URL的内容。然而,这导致了相对较少的内容(只有大约2GB),因为大多数网页从未出现在Reddit上。回顾一下,C4是基于一个月的Common Crawl数据而创建的。为了避免使用一个过小的数据集,我们因此从Common Crawl下载了2018年8月至2019年7月的12个月的数据,然后应用针对C4的启发式过滤,然后应用Reddit过滤器。这产生了一个17GB的WebText-like数据集,其大小与原始的40GB WebText数据集是可比的。Wikipedia:我们使用来自TensorFlow Datasets的English Wikipedia文本数据,其中省略了文章中的任何markup或reference章节段落。Wikipedia + Toronto Books Corpus:使用Wikipedia的预训练数据的一个缺点是,它只代表自然文本的一个可能的领域(百科全书文章)。为了缓解这一问题,BERT将来自Wikipedia的数据与Toronto Books Corpus : TBC相结合。TBC包含从电子书中抽取的文本,这代表了不同领域的自然语言。BERT的普及使得Wikipedia + TBC的组合被用于许多后续的工作中。
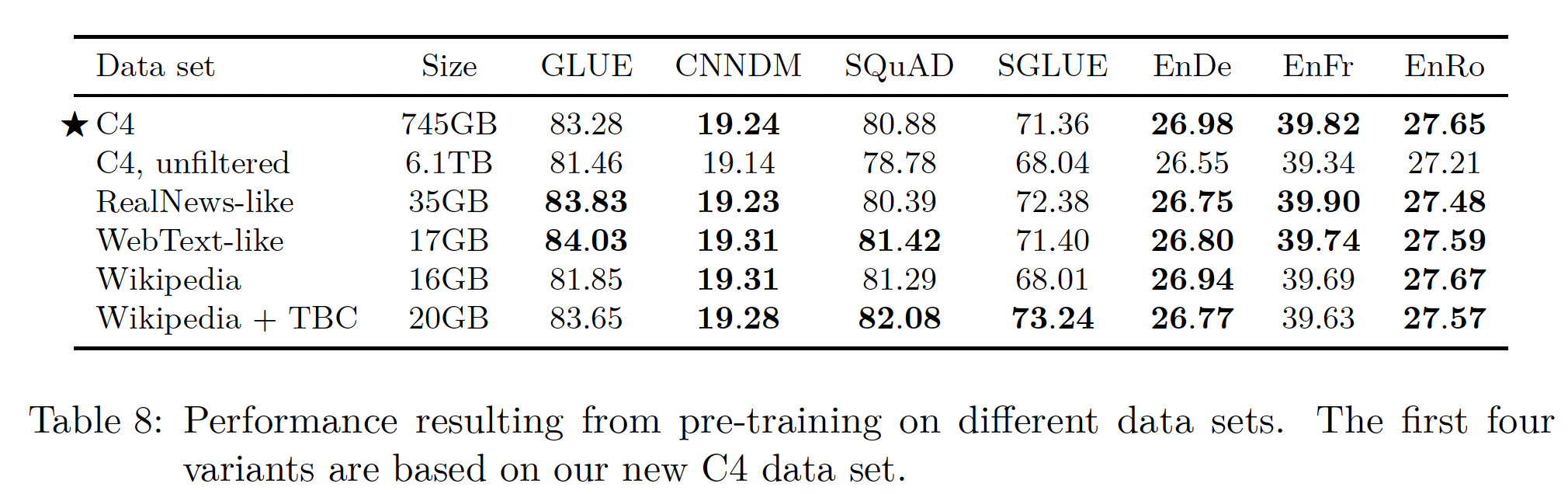
在这些数据集上进行预训练后取得的结果如下表所示。
第一个明显的收获是,从
C4中移除启发式过滤会统一降低性能,并使未过滤的变体在每个任务中表现最差。除此之外,我们发现在某些情况下,具有更受限领域的预训练数据集的表现优于多样化的
C4数据集。例如:使用
Wikipedia + TBC语料库产生了73.24分的SuperGLUE分数,超过了我们的C4数据集的71.36。这几乎完全归功于MultiRC的Exact Match得分从25.78(C4 baseline)提升到50.93(Wikipedia + TBC,见Table 16所示)。MultiRC是一个阅读理解数据集,其最大的数据来源来自于小说书籍,这正是TBC所涵盖的领域。同样,使用
RealNews-like的数据集进行预训练,使ReCoRD的Exact Match得分从68.16提高到73.72。ReCoRD是一个在新闻文章上衡量阅读理解的数据集。作为最后一个例子,使用
Wikipedia的数据在SQuAD上产生了明显的(但不那么引人注目)的收益。SQuAD是一个问答数据集,其段落来源自Wikipedia。是否有数据泄露问题?
SQuAD和Wikipedia数据集都来自同一个地方。但是作者并未说明。
在之前的工作中也有类似的观察,例如
《SciBERT: A pretrained language model for scientific text》发现,在research papers的文本上对BERT进行预训练,提高了其在科学任务上的表现。这些发现背后的主要教训是:对
in-domain未标记数据的预训练可以提高下游任务的性能。RoBERTa还观察到:在一个更多样化的数据集上进行预训练,在下游任务上产生了改进。这一观察也激励了自然语言处理在domain adaptation的平行研究方向。“更多样化的数据集“ 意味着
out-domain,而本文的结论是in-domain。既然二者都能提高下游任务的性能,是否意味着只要增加数据规模即可,而无需关心是in-domain还是out-domain?当然,噪音数据除外,增加更多的噪音还会损害任务的性能。只在单一领域进行预训练的一个缺点是,所得到的数据集往往小得多。例如,
WebText-like变体表现与C4数据集一样好甚至更好,但Reddit-based filtering产生的数据集比C4小约40倍,尽管它基于Common Crawl的12倍的数据。数据集小很多并不一定意味着是缺点。如果数据集更小,但是效果相当,那么这意味着节省了预训练的时间成本和硬件成本。
请注意,在我们的
baseline setting中,我们只对token进行预训练,这只比我们考虑的最小的预训练数据集大8倍左右。我们将在下一节研究在什么时候使用一个更小的预训练数据集会带来问题。假设平均每个
token为四个字符占据四个字节,那么34B大约136GB,是16GB的8.5倍。由于C4数据集是745GB,这表明C4的预训练甚至不足一个epoch。
预训练数据集的规模:我们用来创建
C4的pipeline被设计为能够创建非常大的预训练数据集。有了这么多的数据,我们就可以在不重复样本的情况下对模型进行预训练。目前还不清楚在预训练期间重复样本对下游性能是有帮助还是有害,因为我们的pre-training objective本身就是随机的,可以帮助防止模型多次看到完全相同的数据。为了测试未标记数据集规模的影响,我们在人为截断的
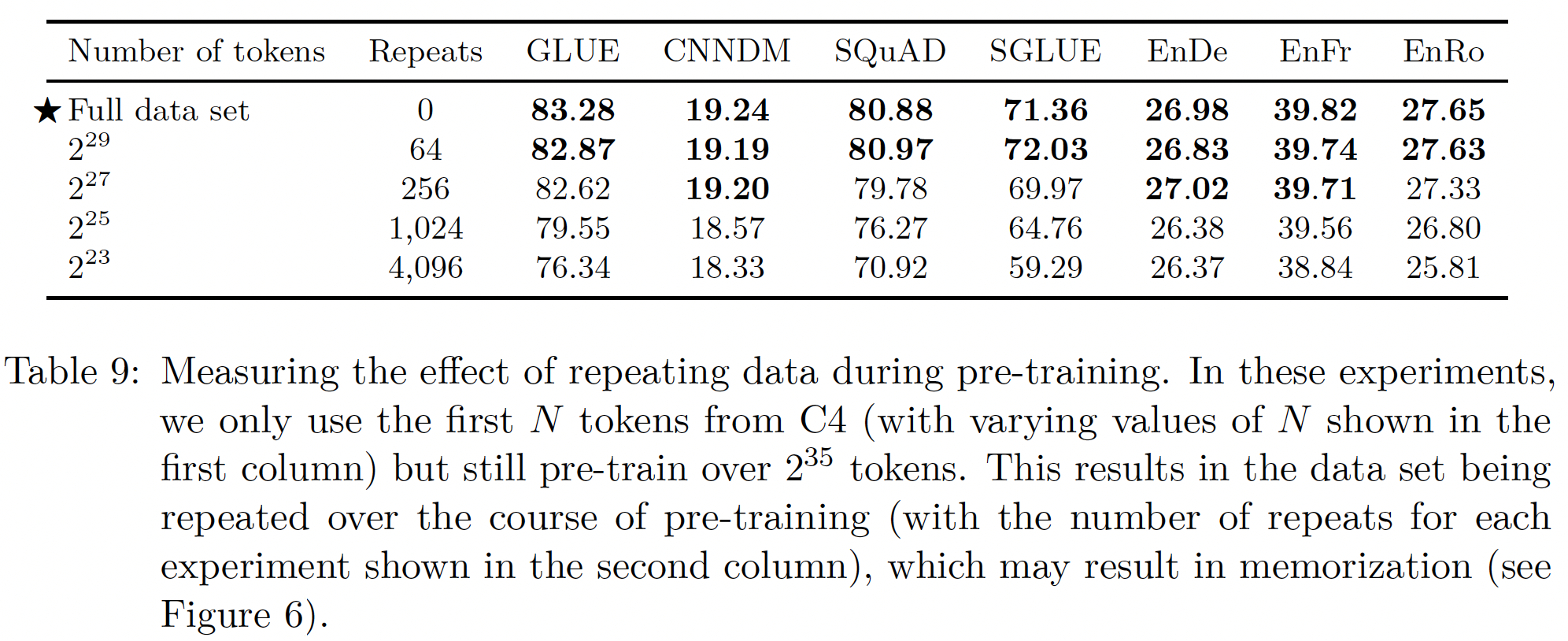
C4版本上预训练了我们的baseline模型。回顾一下,我们在token(C4总规模的一小部分)上预训练我们的baseline模型。我们考虑在由token组成的C4的截断变体上进行训练。这些规模对应于在预训练过程中分别重复数据集64, 256, 1024, 4096次(从而确保每个预训练的总token预算是固定的)。由此产生的下游性能如下表所示(注意,这里
Full dataset指的并不是完成的C4数据集,而是34B个token的截断的C4数据集):正如预期的那样,性能随着数据集的缩小而下降。我们怀疑这可能是由于这个事实:模型开始记忆预训练数据集。
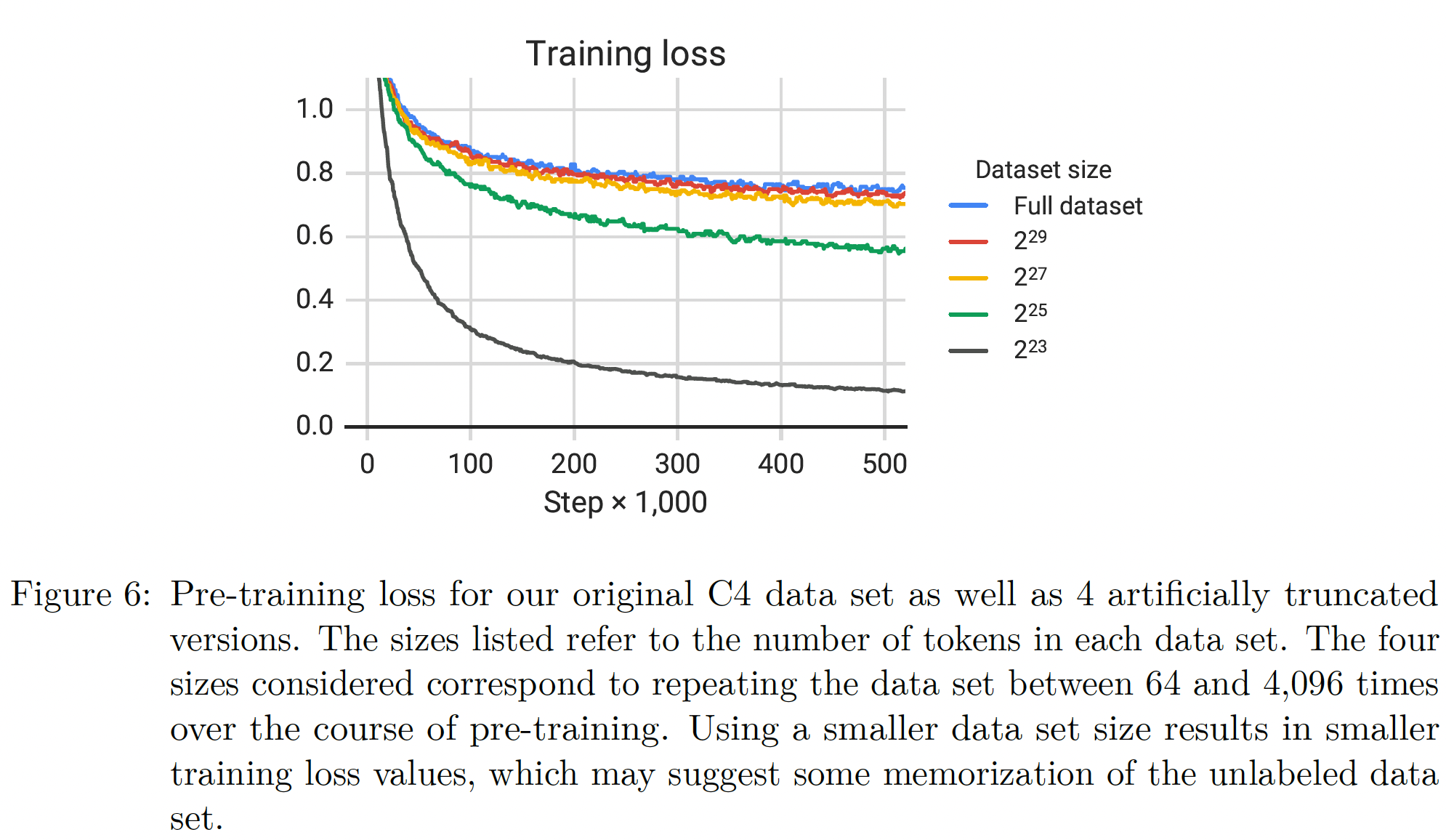
为了衡量这是否属实,我们在
Figure 6中绘制了每个数据集规模的训练损失。事实上,随着预训练数据集规模的缩小,模型的训练损失明显变小,这表明可能存在记忆现象。《Cloze-driven pretraining of self-attention networks》同样观察到:截断预训练数据集的规模会降低下游的任务表现。当预训练数据集只重复
64次时,这些影响是有限的。这表明,一定数量的重复预训练数据可能不会造成伤害。然而,考虑到额外的预训练数据可能是有益的(在后面的实验将展示这一点),而且获得额外的未标记数据是廉价和容易的,我们建议尽可能地使用大的预训练数据集。这种影响对于较大的模型规模来说可能更加明显,也就是说,较大的模型可能更容易对较小的预训练数据集过拟合。
26.2.5 训练策略
到目前为止,我们已经考虑了这样的
setting:模型的所有参数都在无监督任务上进行预训练,然后再在各个监督任务上进行微调。在本节中,我们将比较不同的微调方案、以及在多个任务上同时训练模型的方法。微调方法:有人认为,对模型的所有参数进行微调会导致不理想的结果,特别是在
low-resource任务上(《To tune or not to tune? adapting pretrained representations to diverse tasks》)。早期关于文本分类任务的迁移学习的结果主张只微调一个小分类器的参数,该分类器被馈入由fixed pre-trained model所产生的sentence embedding。这种方法不太适用于我们的encoder-decoder模型,因为整个解码器必须被训练成针对给定的任务输出target sequences。相反,我们专注于两种替代的微调方法,这些方法只更新我们的encoder-decoder模型的参数子集。第一种微调方法是
"adapter layers"(《Parameter-efficient transfer learning for NLP》、《Simple, scalable adaptation for neural machine translation》),其动机是为了在微调时保持大部分原始模型是固定的。adapter layers是额外的dense-ReLU-dense blocks(即,new feed-forward network) ,在Transformer的每个block中的每个已有的feed-forward networks之后添加。这些新的new feed-forward networks被设计成使其输出维度与输入相匹配。这使得它们可以被插入到网络中,而无需对结构或参数进行额外的改变。假设
Transformer中FFN的输出为1024维,那么可以添加一个new FFN,其输入维度为1024维、中间隐层维度为1024维。它的原理是:
pretrained model已经学到了良好的representation,而微调期间adapter layer负责将新的数据投影到这个representation space,而不是让pretrained model去学习新的representation space。即:数据适配模型,而不是模型适配数据。在进行微调时,只有
adapter layer和layer normalization参数被更新。这种方法的主要超参数是new feed-forward network的内部维度第二种微调方法是
"gradual unfreezing"(《Universal language model fine-tuning for text classification》)。在gradual unfreezing中,随着时间的推移,越来越多的模型参数被微调。gradual unfreezing最初被应用于由单个stack组成的语言模型架构。在这种情况下,在微调开始时,只有最后一层的参数被更新;然后在训练了一定数量的updates后,倒数第二层的参数也被包括在内。以此类推,直到整个网络的参数被微调。为了使这种方法适用于我们的encoder-decoder模型,我们在编码器和解码器中平行地逐渐解冻各层,在对编码器和解码器都从顶部开始解冻。由于我们的
input embedding matrix和output classification matrix的参数是共享的,我们在整个微调过程中更新它们。回顾一下,我们的
baseline模型中编码器和解码器各由12层组成,微调了12组,每组n组中微调从第12-n层到12层。我们注意到,
《Universal language model fine-tuning for text classification》建议在每个epoch之后再微调一个额外的层。然而,由于我们的监督数据集的大小变化很大,而且我们的一些下游任务实际上是许多任务的混合物(GLUE和SuperGLUE),我们反而采用了更简单的策略,即每
这些微调方法的性能比较见下表所示。对于
adapter layers,我们使用d=32/ 128/ 512/ 2048。可以看到:类似过去的结果(
《Parameter-efficient transfer learning for NLP》、《Simple, scalable adaptation for neural machine translation》),像SQuAD这样的lower-resource任务在小的higher resource任务需要大的维度来实现合理的性能。这表明,只要维度与任务规模相适应,
adapter layers可能是一种有前途的技术从而在较少参数上进行微调。注意,在我们的
case中,我们将GLUE和SuperGLUE各自作为一个单一的 "任务",将它们的子数据集拼接起来,所以尽管它们包括一些low-resource数据集,但合并后的数据集足够大,以至于需要一个大的gradual unfreezing在所有的任务中都造成了轻微的性能下降,尽管它在微调期间确实提供了一些加速。通过更仔细地调优unfreezing schedule,可能会得到更好的结果。
第一行
All parameters指的是微调所有的模型参数。整体而言,
"gradual unfreezing"的效果要好得多。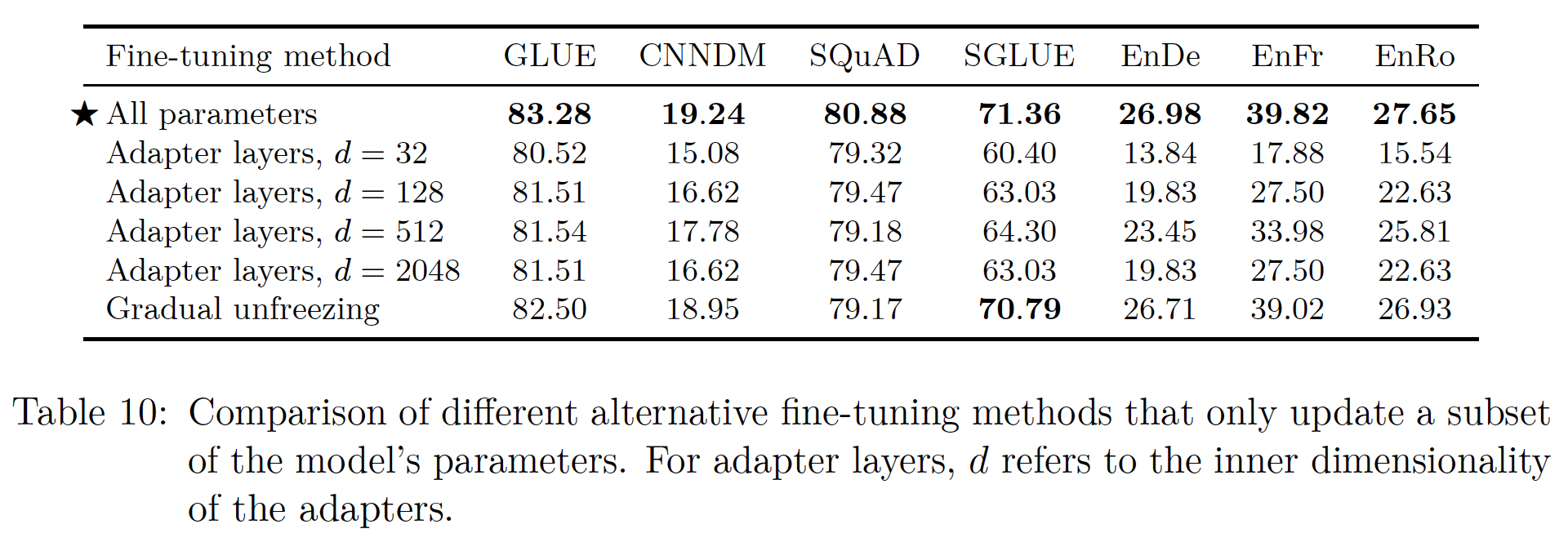
多任务学习:到目前为止,我们一直在单个无监督学习任务上预训练我们的模型,然后在每个下游任务上单独进行微调。另一种被称为 "多任务学习" 的方法,是一次在多个任务上训练模型。这种方法的目标通常是训练一个可以同时执行许多任务的单一模型,也就是说,该模型和它的大部分参数在所有任务中都是共享的。
我们在一定程度上放松了这一目标,而是研究一次对多个任务进行训练的方法,以便最终产生在每个单独任务上表现良好的单独的
parameter settings。例如,我们可能在许多任务上训练一个单一的模型,但在报告性能时,我们可以为每个任务选择一个不同的checkpoint。这就放松了多任务学习的框架,与我们迄今为止所考虑的pre-train-then-fine-tune的方法相比,使其处于更平等的地位。我们还注意到,在我们统一的
text-to-text框架中,"多任务学习" 仅仅对应于将数据集混合在一起。 由此可见,通过将预训练的无监督任务视为被混合在一起的任务之一(其它的任务还包括下游的监督学习任务),我们仍然使用多任务学习来在未标记数据上训练。相比之下,多任务学习在NLP中的大多数应用都增加了task-specific的分类网络,或者为每个任务使用不同的损失函数。正如
《Massively multilingual neural machine translation in the wild: Findings and challenges》所指出的,多任务学习中一个极其重要的因素是,模型应该在每个任务中训练多少数据。我们的目标是不对模型进行under-train或over-train:即,我们希望模型能够看到足够多的来自给定任务的数据使模型能够很好地执行任务,但又不希望看到太多的数据以至于模型记住了训练集。如何准确地设置来自每个任务的数据比例取决于各种因素,包括数据集的大小、学习任务的 "难度"(即模型在能够有效执行任务之前必须看到多少数据)、正则化等等。另一个问题是 "任务干扰" 或 "负转移
negative transfer"的可能性,即在一项任务上取得良好的表现会阻碍另一项任务的表现。考虑到这些问题,我们首先探索了各种策略从而用于设置来自每个任务的数据比例。《Can you tell me how to get past Sesame Street? Sentence-level pretraining beyond language modeling》也进行了类似的探索。examples-proportional mixing:模型对一个给定任务的过拟合速度的一个主要因素是任务的数据集规模。因此,设置混合比例mixing proportion的一个自然方法是按照每个任务的数据集的大小来采样。这相当于将所有任务的数据集串联起来,并从合并后的数据集中随机采样。然而,请注意,我们包括我们的
unsupervised denoising task,它使用的数据集比其他任务的数据集大几个数量级。因此,如果我们简单地按照每个数据集的大小采样,模型看到的绝大多数数据将是未标记的,它将对所有的监督任务under-train。即使没有无监督任务,一些任务(如WMT English to French)也非常大,同样会占据大部分的batch。为了解决这个问题,我们在计算比例之前对数据集的大小设置了一个人为的
"limit"。具体而言,如果即,将数据集大小设置一个阈值
temperature-scaled mixing:缓解数据集规模之间巨大差异的另一种方法是调整混合率的 "温度"。这种方法被multilingual BERT使用,以确保模型在low-resource语言上得到充分的训练。为了实现与温度1.0。当examples-proportional mixing;随着equal mixing。我们保留了数据集规模的限制
equal mixing:在这种情况下,我们以相等的概率从每个任务中抽取样本。具体而言,每个batch中的每个样本都是从均匀随机采样的训练集中而来(注,均匀指的是数据集本身)。这很可能是一个次优策略,因为模型在low-resource任务上会迅速过拟合,而在high-resource任务上则欠拟合。我们主要把它作为一个参考点reference point,说明当比例设置得不理想时,可能会出现什么问题。
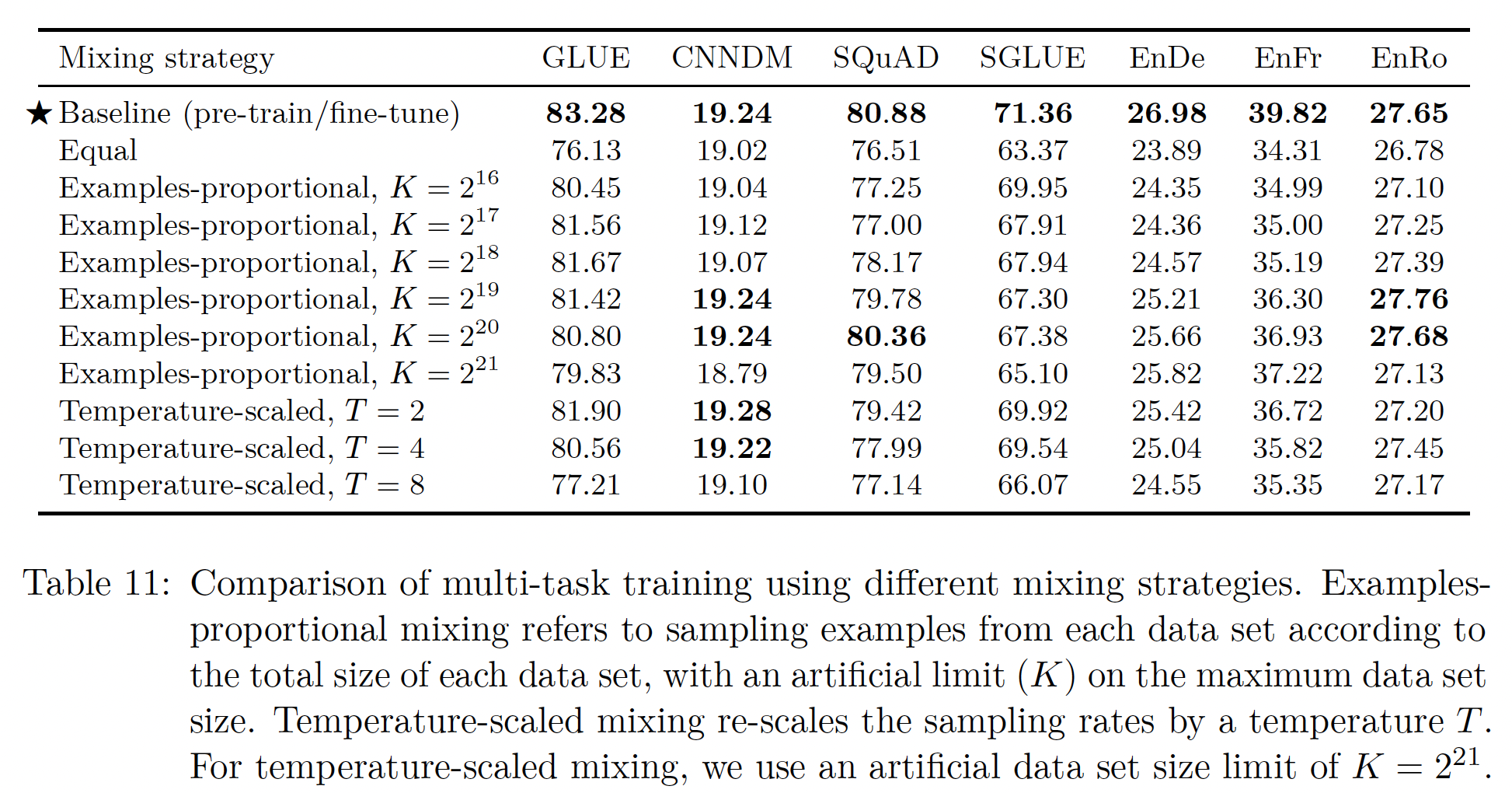
为了将这些混合策略与我们的
baseline pre-train-then-fine-tune进行平等的比较,我们对多任务模型进行相同的总步数训练:pre-train-then-fine-tune效果要差。注意,
T5的多任务训练其实就是把多个任务的数据集混合在一起,实验比较了不同的混合比例。这里没有微调阶段。equal mixing策略尤其导致性能急剧下降,这可能是因为low-resource任务已经过拟合、high-resource任务没有看到足够的数据、或者模型没有看到足够多的未标记的数据来学习通用语言能力。对于
examples-proportional mixing策略,我们发现对于大多数任务来说,存在sweet spot",在那个WMT English to French翻译,这是一个high-resource任务,它总是受益于较高的最后,我们注意到,
temperature-scaled mixing也提供了一种从大多数任务中获得合理性能的方法,其中
《Massively multi-lingual neural machine translation in the wild: Findings and challenges》和《The natural language decathlon: Multitask learning as question answering》之前已经观察到多任务模型的表现优于在每个单独任务上训练的单独模型,而且《Multi-task deep neural networks for natural language understanding》和《Snorkel MeTaL: Weak supervision for multi-task learning》已经表明多任务setup可以在非常相似的任务中带来好处。接下来,我们将探讨如何缩小多任务训练与
pre-train-then-fine-tune方法之间的差距。相比微调,多任务方法有几个优势:
多任务模型只需要维护一个模型就可以处理多个任务。而微调方法需要针对每个任务微调一个模型,最终得到多个模型,这不利于模型的部署和管理。
多任务模型可以跨任务泛化,有助于已有任务和新任务的预测性能。
将多任务学习与微调相结合:回顾一下,我们正在研究一个宽松的多任务学习版本,在这个版本中,我们在一个混合任务上训练一个单一的模型,但允许我们使用模型的不同
checkpoints来评估性能。我们可以通过考虑以下情况来扩展这种方法:模型一次性在所有任务上进行预训练,然后在单个监督任务上进行微调。这是MT-DNN使用的方法,该方法在推出时在GLUE和其他benchmark上取得了SOTA的性能。我们考虑这种方法的三种变体:在第一种情况下,我们采用
examples-proportional mixture对模型进行预训练,其中我们还希望,在预训练模型适应单个任务之前,混合许多监督源可以帮助它获得一组更普遍的 "技能"。为了直接衡量这一点,我们考虑了第二个变体,即我们在相同的
examples-proportional mixture(pre-training mixture中省略了一个下游任务。然后,我们在预训练时遗漏的任务上对模型进行微调。我们对每一个下游任务重复这一过程。我们称这种方法为
"leave-one-out"多任务训练。这模拟了现实世界的情况,即预训练好的模型在预训练期间没有看到的任务上被微调。注意,多任务预训练提供了监督任务的一个
diverse mixture。由于其他领域(如计算机视觉)使用监督数据集进行预训练,我们有兴趣看看从multi-task pre-training mixture中省略无监督任务是否仍然产生良好的结果。因此,在我们的第三个变体中,我们用examples-proportional mixture进行预训练。
在所有这些变体中,我们都遵循我们的标准程序,先进行
这些方法的比较结果如下表所示。为了比较,我们还包括了我们的
baseline(pre-train-then-fine-tune)和标准的多任务学习(没有微调)在examples-proportional mixture上的结果。可以看到:在多任务预训练之后进行微调,其结果与我们的
baseline相当。这表明,在多任务学习之后使用微调可以帮助缓解前文中描述的不同混合率之间的一些trade-off问题。有趣的是,
leave-one-out训练的性能只是稍微差一点,这表明一个在各种任务上训练过的模型仍然可以适应新的任务(即多任务预训练可能不会导致夸张的任务干扰)。最后,除了翻译任务外,
supervised multi-task pre-training在每种情况下都表现得很差。这可能表明,翻译任务从预训练中获益较少,而无监督的预训练在其他任务中是一个重要因素。
既然多任务(包括无监督预训练任务)加微调的效果,并没有显著超越无监督预训练加微调,那么为什么要用多任务?不仅费时费力,还需要收集更多的监督数据。因此,无监督预训练 + 微调即可,最重要的就是搜集大型高质量的预训练数据集。
根据
MT-DNN的结论,多任务加微调是可以提升效果的。在MT-DNN中,不同的任务共享backbone,但是每个任务具有task-specific输出。而在T5中,所有任务共享同一个模型(不仅共享backbone,也共享输出层),因此可能影响多任务的利用。为此,后续的ExT5聚焦于改善多任务的利用。
26.2.6 Scaling
机器学习研究的 "惨痛教训" 认为,能够利用额外计算的通用方法最终会战胜依赖人类专业知识的方法。最近的结果表明,对于自然语言处理中的迁移学习,这可能成立,即:已经多次证明,与更精心设计的方法相比,
scaling up可以提高性能。然而,有多种可能的scale方式,包括使用更大的模型、对模型进行更多step的训练、以及ensembling。在本节中,我们通过在如下的前提下来比较这些不同的方法:"你刚刚得到了4倍的计算量,你应该如何使用它?"我们从我们的
baseline模型开始,它有220M的参数,分别预训练BERT_BASE类似。在增加模型规模的实验中,我们遵循
BERT_LARGE的指导方针,使用head = 16的注意力机制。然后,我们产生了两个变体,分别对应于16层和32层(注,编码器解码器都为16层、以及编码器和解码器都为32层),产生的模型的参数是我们原始模型的2倍和4倍。这两个变体也有大约2倍和4倍的计算成本。利用我们的
baseline和这两个更大的模型,我们考虑了三种使用4倍计算量的方法:用相同的模型训练4倍的step、用2倍大的模型训练2倍的step、用4倍大的模型训练相同的step。当我们增加训练
step时,为了简单起见,我们同时扩大预训练step和微调step。请注意,当增加预训练step时,我们实际上包括了更多的预训练数据,因为C4是如此之大以至于我们在训练让模型看到
4倍的数据的另一种方法是将batch size增加4倍。由于更有效的并行化,这有可能导致更快的训练。然而,用4倍大的batch size进行训练可能会产生与4倍多的training step不同的结果(《Measuring the effects of data parallelism on neural network training》)。我们包括一个额外的实验,用4倍大的batch size训练我们的baseline模型,从而比较这两种情况。在我们考虑的许多
benchmark上,通过使用model ensemble进行训练和评估来获得额外的性能是常见的做法。这提供了一种使用额外计算的正交方式。为了比较其他的scaling方法和ensembling,我们还测量了ensemble的性能,其中这个ensemble由4个单独预训练和微调的模型组成。在将logits馈入output softmax之前,我们对整个ensemble的logits进行平均,以获得aggregate prediction。与其预训练4个单独的模型,一个更便宜的选择是采用一个预训练的模型,并产生4个单独的微调版本。虽然这没有使用我们整个4倍的计算预算,但我们也包括了这种方法,看看它是否能产生与其他scaling方法相竞争的性能。下游任务的同一个监督数据集上,如何产生四个微调版本?论文并未说明。一个简单的方案是:对监督数据集执行四次不同的
train/validate/test数据集拆分,每种拆分训练一个微调版本。下表显示了应用这些不同的
scaling方法后取得的性能。不足为奇的是,增加训练时间和/或模型规模一直在改善
baseline。训练
4倍的step或使用4倍大的batch size之间没有明显的赢家,尽管两者都有好处。一般来说,与单纯增加训练时间或
batch size相比,增加模型规模会导致性能的额外提升。从
baseline到1xsize, 4 x training steps和1x size, 4 x batch size是增加训练时间或batch size。而从baseline到4 x size, 1 x training steps是增加模型规模。后者的提升幅度更大。在我们研究的任何任务中,我们没有观察到训练一个
2倍大的模型(但是增加2倍训练时间)和训练一个4倍大的模型之间有很大的区别。这表明,增加训练时间和增加模型规模可以作为提高性能的补充手段。我们的结果还表明,
ensembling提供了一种正交的、有效的手段,通过scale来提高性能。在一些任务中(
CNN/DM、WMT English to German、WMT English to Romanian),将4个完全独立训练的模型ensembling起来的结果明显优于其他所有的scaling方法。将预训练好的模型分别进行微调从而实现
ensembling,也比baseline有了很大的性能提高,这表明该方法是更便宜的提高性能的手段。唯一的例外是
SuperGLUE,它的ensembling方法都没有比baseline有明显的提高。我们注意到,不同的
scaling方法有不同的trade-off,这些trade-off与它们的性能是分开的。例如,相对于小模型,使用更大的模型会使下游的微调和推理更加昂贵。
另外,我们注意到,
ensembling
因此,在选择
scaling方法时,对模型的最终使用的考虑是很重要的。
26.2.7 所有东西放在一起
我们现在利用我们的系统性研究的见解来确定我们可以在流行的
NLP benchmark上将性能推到什么程度。我们从我们的baseline training方法开始,并做了以下改变:Objective:我们将baseline中的i.i.d. denoising objective换成了span-corruption objective,这是受SpanBERT的启发。具体来说,我们使用平均span length为3,并破坏原始序列的15%。我们发现,这个objective产生了略微更好的性能,同时由于target序列长度较短,计算效率略高。更长时间的训练:我们的
baseline模型使用了相对较少的预训练(是BERT的1/4、是XLNet的1/16、是RoBERTa的1/64)。幸运的是,C4足够大,我们可以在不重复数据的情况下训练更长的时间。我们发现,额外的预训练确实是有帮助的,增加
batch size或者增加training step数量都可以带来这种好处。因此我们选择序列长度512、batch size为1M steps,对应于总共约1T个预训练token(约为我们baseline的32倍)。我们表明在
RealNews-like, WebText-like, Wikipedia + TBC等等数据集上进行预训练,在很多下游任务上的表现会优于在C4上的预训练。然而,这些数据集的变体非常小,在对1T个token进行预训练的过程中,它们会被重复数百次。由于我们表明,这种重复可能是有害的,所以我们选择继续使用C4数据集。模型规模:我们还展示了如何扩大
baseline模型的规模来提高性能。然而,在计算资源有限的情况下,使用较小的模型对于微调或推理是有帮助的。基于这些因素,我们用一组model size来训练模型:Base:这是我们的baseline模型,它有大约220M个参数。Small:我们考虑一个较小的模型,它通过使用head = 8的注意力、以及在编码器和解码器中各只有6层来缩小baseline模型的规模。这个变体有大约60M个参数。Large:由于我们的baseline使用BERT_BASE规模的编码器和解码器,我们还考虑了一个变体,其中编码器和解码器的规模和结构都与BERT_LARGE相似。具体来说,这个变体使用head = 16的注意力、以及编码器和解码器各24层,导致大约770M个参数。3B and 11B:为了进一步探索使用更大的模型时可能出现的性能,我们考虑了另外两个变体。在这两种情况下,我们都使用24层的编码器和解码器、以及对于
3B变体,我们使用head = 32的注意力,这导致了大约2.8 B个参数。对于
11B变体,我们使用head = 128的注意力,这导致了大约11 B个参数。
我们选择扩大
TPU)对于像Transformer的前馈网络中的大型稠密矩阵乘法是最有效的。注:在
mT5论文中,作者提到:对T5的改进版本选择扩大
多任务预训练:我们表明在微调前对无监督和有监督任务的
multi-task mixture进行预训练,效果与单独对无监督任务进行预训练一样好。这是MT-DNN所倡导的方法。它还有一个实际的好处,就是能够在整个预训练期间监测 "下游" 任务的表现,而不是仅仅在微调期间监测。因此,我们在最后一组实验中使用了多任务预训练。我们假设,训练时间较长的大型模型可能会受益于较大比例的未标记数据,因为它们更有可能对较小的训练数据集过拟合。然而,我们也注意到,在多任务预训练之后进行微调,可以缓解因选择次优比例的未标记数据而可能出现的一些问题。 基于这些想法,我们在使用标准的
example-proportional mixing之前,为我们的未标记数据使用以下数据集规模阈值(即,Small为710,000、Base为2,620,000、Large为8,660,000、3B为33,500,000、11B为133,000,000。对于所有的模型变体,在预训练期间,我们还将WMT English to French和WMT English to German数据集的有效数据集规模限制在1M个样本。对单个
GLUE和SuperGLUE任务进行微调:到目前为止,在对GLUE和SuperGLUE进行微调时,我们将每个benchmark中的所有数据集拼接起来,这样我们只对GLUE和SuperGLUE的模型进行一次微调。这种方法使我们的研究在逻辑上更简单,但我们发现,与单独对每个任务进行微调相比,这在某些任务上牺牲了少量的性能。在单个任务上进行微调的一个潜在问题是,我们可能会对
low-resource的任务迅速过拟合,然而可以通过对所有任务进行训练从而得到缓解。例如,对于许多low-resource的GLUE任务和SuperGLUE任务来说,我们batch size为512的序列会导致整个数据集在每个batch中出现多次。。因此,在对每个GLUE和SuperGLUE任务进行微调时,我们使用较小的batch size,batch size = 8的长度为512的序列。我们还每
1000步而不是每5000步保存checkpoints,从而确保我们在模型过拟合之前能够获得模型的参数。beam search:我们之前所有的结果都是使用贪婪解码greedy decoding的报告。对于具有长输出序列的任务,我们发现使用beam search可以提高性能。具体而言,我们在WMT翻译、以及CNN/DM摘要任务中使用beam width = 4和测试集:由于这是我们的最后一组实验,我们报告的是测试集而不是验证集的结果。
对于
CNN/Daily Mail,我们使用随着数据集分发的标准测试集。对于
WMT任务,这相当于使用newstest2014进行English-German测试、newstest2015进行English-French测试、newstest2016进行English-Romanian测试。对于
GLUE和SuperGLUE,我们使用benchmark evaluation servers来计算官方测试集的分数。对于
SQuAD,在测试集上进行评估需要在一个benchmark server上运行推理。不幸的是,该服务器上的计算资源不足以从我们最大的模型中获得预测结果。因此,我们继续报告SQuAD验证集的性能。幸运的是,在SQuAD测试集上表现最好的模型也在验证集上报告了结果,所以我们仍然可以与表面上SOTA的模型进行比较。
除了上面提到的那些变化,我们使用与我们的
baseline相同的训练程序和超参数(AdaFactor优化器、用于预训练的逆平方根学习率调度、用于微调的恒定学习率、dropout正则化、词表大小等)。概括起来就是几点:预训练数据集要大、模型规模要大、目标函数要合适。至于多任务预训练,对最终效果影响不大。下游任务微调和
beam search,这是通用做法并且,通常不难实现。这组最后的实验结果如下表所示。
总的来说,在我们考虑的
24个任务中,我们在18个任务上取得了SOTA的性能。正如预期的那样,我们最大的(11B参数)模型在所有任务中的模型大小变体中表现最好。我们的
T5-3B模型变体确实在一些任务中击败了以前的SOTA,但将模型规模扩展到11B个参数是实现我们最佳性能的最重要因素。
具体而言:
我们取得了
SOTA的GLUE平均得分90.3分。值得注意的是,在自然语言推理任务MNLI、RTE和WNLI中,我们的表现大大优于之前的SOTA。就参数数量而言,我们的
11B模型变体是已经提交给GLUE benchmark的最大模型。然而,大多数提交的最佳成绩都使用了大量的ensembling和计算来产生预测结果。对于
SQuAD,我们在Exact Match得分上超过了之前的SOTA,超过了1分。对于
SuperGLUE,我们在SOTA的基础上做了很大的改进(从平均得分84.6到88.9)。我们在任何一项
WMT翻译任务上都没有达到SOTA的性能。这可能部分是由于我们使用了一个纯英语的未标记数据集。我们还注意到,这些任务中的大多数最佳结果都使用了回译back-translation,这是一种复杂的数据增强方案。在低资源的English to Romanian benchmark上的SOTA也使用了额外的跨语言无监督训练形式(《Cross-lingual language model pretraining》)。最后,在
CNN/Daily Mail上,我们达到了SOTA性能,尽管只是在ROUGE-2-F得分上取得了显著的成绩。
为了实现其强大的结果,
T5将我们的实验研究的洞察与前所未有的规模相结合。请注意,我们发现扩大预训练数量(总的预训练token数量)、或扩大baseline模型的规模会产生巨大的收益。鉴于此,我们有兴趣衡量我们引入T5的"non-scaling"变化对其强大性能的贡献有多大。因此,我们进行了一个最后的实验,比较了以下三种配置:标准的
baseline模型在token上进行预训练。标准的
baseline模型在1T的token上进行预训练(即与T5使用的预训练量相同),我们称之为"baseline-1T"。T5-Base。
请注意,
baseline-1T和T5-Base之间的差异包括我们在设计T5时所作的"non-scaling"变化。因此,比较这两个模型的性能给我们提供了一个具体的衡量标准,即我们的系统性研究中的洞察的影响。实验结果如下表所示。可以看到:
baseline-1T在所有任务上都超越了baseline,这表明额外的预训练提高了baseline模型的性能。T5-Base在所有的下游任务上都大大超过了baseline-1T。这表明,规模并不是促成T5成功的唯一因素。我们假设,较大的模型不仅受益于其规模的增加,而且也受益于这些non-scaling因素(如,多任务预训练、针对每个子任务进行微调、beam search等等)。
26.3 反思
在完成了我们的系统性研究后,我们首先总结了一些最重要的发现。我们的研究结果为哪些研究途径可能更有希望、或更没有希望提供了一些高层次的视角。最后,我们概述了一些主题,我们认为这些主题可以为该领域的进一步发展提供有效方法。
经验之谈:
text-to-text:我们的text-to-text框架提供了一种简单的方法,使用相同的损失函数和解码程序对各种文本任务进行单个的模型训练。我们展示了这种方法如何成功地应用于生成任务,如抽象摘要、分类任务(如自然语言推理)、甚至回归任务(如STS-B)。尽管它很简单,但我们发现text-to-text框架获得了与task-specific架构相当的性能,并在与scale相结合时最终产生了SOTA的结果。架构:虽然一些关于
NLP的迁移学习的工作已经考虑了Transformer的架构变体,但我们发现原始的encoder-decoder形式在我们的text-to-text框架中效果最好。尽管encoder-decoder模型使用的参数是"encoder-only"( 如BERT)或"decoder-only"(语言模型)架构的两倍,但encoder-decoder模型的计算成本相似。我们还表明,共享编码器和解码器中的参数并没有导致性能的大幅下降,同时将总参数规模减半。unsupervised objective:总的来说,我们发现大多数denoising objective,即训练模型以重建随机破坏的文本,在text-to-text setup中表现相似。因此,我们建议使用产生短的target序列的objective,以便无监督的预训练在计算上更有效率。数据集:我们引入了
Colossal Clean Crawled Corpus: C4,它包括从Common Crawl web dump中启发式地清理过的文本。在将C4与使用额外过滤的数据集进行比较时,我们发现在in-domain unlabeled data上进行训练可以提高一些下游任务的性能。然而,对single domain的约束通常会导致更小的数据集。我们另外表明,当未标记的数据集小到在预训练过程中重复多次时,性能会下降。这就促使我们在通用语言理解任务中使用像
C4这样的大型的、多样化的数据集。训练策略:我们发现,在微调过程中更新预训练模型的所有参数的方法,优于那些旨在更新较少参数的方法,尽管更新所有参数是最昂贵的。
我们还试验了各种方法从而单次训练模型从而用于多个任务,在我们的
text-to-text setting中,这只是相当于在构建batch时将不同数据集的样本混合起来。多任务学习的首要问题是设定每个任务的混合比例。我们最终没有找到一种设置混合比例的策略,使得与pre-train-then-fine-tune的基本方法的性能相匹配。然而,我们发现,在混合任务上进行预训练后再进行微调,可以产生与无监督预训练相当的性能。Scaling:我们比较了各种利用额外计算的策略,包括在更多的数据上训练模型、训练一个更大的模型、以及使用模型的一个ensemble。我们发现每一种方法都能显著提高性能,尽管在更多的数据上训练一个较小的模型,往往比在更少的step中训练一个较大的模型要好得多。我们还表明,模型
ensemble可以提供比单个模型更好的结果,这提供了一种利用额外计算的正交手段。此外,有两种ensemble策略:每个子模型都是完全单独地pre-training and fine-tuning、预训练得到一个base预训练模型然后微调得到多个子模型。我们发现后者要比前者的效果更差,虽然后者的效果仍然大大优于没有ensemble的baseline模型。突破极限:我们结合上述洞察,训练了更大的模型(多达
11B个参数),从而在我们考虑的许多benchmark中获得SOTA的结果。对于无监督训练,我们从C4数据集中抽取文本,并应用denoising objective从而破坏连续的spans of tokens。在对单个任务进行微调之前,我们对multi-task mixture进行了预训练。此外,我们的模型是在超过1T个token上训练的。为了便于复制、扩充、以及应用我们的成果,我们公布了我们的代码、
C4数据集、以及每个T5变体的预训练模型权重。
展望:
大型模型的不便之处:我们研究的一个不令人惊讶但重要的结果是,大型模型往往表现更好。用于运行这些模型的硬件不断变得更便宜、更强大,这一事实表明,扩大规模可能仍然是实现更好性能的一种有希望的方式。然而,在一些应用和场景中,使用较小或较便宜的模型总是有帮助的。
例如,大模型部署的难度较大,很多真实场景都有硬件限制或
latency的限制。与此相关的是,迁移学习的一个有益用途是可以在
low-resource任务上获得良好的性能。low-resource任务经常发生在缺乏资金来标记更多数据的环境中。因此,low-resource的应用往往也只能获得有限的计算资源,这就会产生额外的成本。因此,我们主张研究能用更便宜的模型实现更强性能的方法,以便将迁移学习应用到它能产生最大影响的地方。目前沿着这些方向的一些工作包括知识蒸馏、参数共享、以及条件计算。更有效的知识抽取:回顾一下,预训练的目标之一是为模型提供通用的 "知识",以提高其在下游任务中的表现。我们在这项工作中使用的方法,也是目前常见的做法,是训练模型对
corrupted spans of text进行降噪。我们怀疑这种简单的技术可能不是教给模型通用知识的一个非常有效的方法。更具体地说,如果能够达到良好的微调性能,而不需要首先在
1T个文本token上训练我们的模型,将是非常有用的。沿着这些思路,一些同时进行的工作通过预训练一个模型来区分真实文本和机器生成的文本来提高效率(《Electra: Pre-training text encoders as discriminators rather than generators》)。任务之间相似性的公式化:我们观察到,对未标记的
in-domain data进行预训练可以提高下游任务的性能。这一发现主要依赖于基本的观察,比如SQuAD是使用Wikipedia的数据创建的。制定一个关于预训练和下游任务之间的 "相似性" 的更严格的概念将是有用的,这样我们就可以对使用什么来源的未标记数据做出更有原则的选择。在计算机视觉领域有一些早期的经验性工作。一个更好的任务关联性relatedness概念也可以帮助选择有监督的预训练任务,这已经被证明对GLUE benchmark有帮助(《Sentence encoders on STILTs: Supplementary training on intermediate labeled-data tasks》)。语言无关模型:我们失望地发现,在我们研究的翻译任务中,
English-only pre-training没有达到SOTA的结果。我们也有兴趣避免需要提前指定一个可以编码哪些语言的词表的困难。为了解决这些问题,我们有兴趣进一步研究语言无关language-agnostic的模型,即无论文本的语言如何,都能以良好的性能执行特定的NLP任务的模型。
二十七、mT5[2020]
目前的自然语言处理
pipeline经常使用迁移学习,即在一个数据丰富的任务上对模型进行预训练,然后再对下游感兴趣的任务进行微调。这种模式的成功部分归功于预训练模型的parameter checkpoints的发布。这些checkpoints使NLP社区的成员能够在许多任务上迅速获得强大的性能,而不需要自己进行昂贵的预训练。作为一个例子,《Exploring the limits of transfer learning with a unified text-to-text transformer》发布的Text-to-Text Transfer Transformer: T5模型的pre-trained checkpoints已经被用来在许多benchmarks上取得SOTA的结果。不幸的是,这些语言模型中的许多都是只对英语文本进行预训练的。鉴于世界上大约80%的人口不讲英语,这极大地限制了它们的使用。社区解决这种English-centricity问题的方式之一是发布了数十种模型,每一种模型是在单一的non-English语言上进行预训练的。一个更普遍的解决方案是制作多语言模型multi-lingual models,这些模型在多种语言的混合体上进行预训练。这类流行的模型有mBERT、mBART、XLM-R,它们分别是BERT、BART和RoBERTa的多语言变体。在论文
《mT5: A massively multilingual pre-trained text-to-text transformer》中,作者继续这一传统,发布了T5的多语言变体mT5。论文对mT5的目标是产生一个大规模的多语言模型,并尽可能少地偏离用于创建T5的配方。因此,mT5继承了T5的所有基因,如:通用的text-to-text格式、基于大规模经验研究的设计、以及规模。为了训练mT5,论文引入了C4数据集的一个多语言变体,称为mC4。为了验证
mT5的性能,论文包含了在几个benchmark数据集上的结果,在许多情况下显示出SOTA的性能。论文发布了预训练模型和代码,以便社区可以利用他们的工作。
27.1 T5 和 C4 的背景
T5是一个预训练的语言模型,其主要区别在于它对所有text-based的NLP问题使用了统一的"text-to-text"格式。这种方法对于生成式任务(如机器翻译或抽象摘要)来说是很自然的,因为任务格式要求模型以某些输入为条件来生成文本。对于分类任务来说,这种方法比较特殊:在分类任务中,
T5被训练来输出标签的文本(例如情感分类中的"positive"或"negative"),而不是一个类别ID。这种方法的主要优点是:它允许对每个任务使用完全相同的训练目标(最大似然),这实际上意味着一组超参数可以用于任何下游任务的有效微调。
《Unifying question answering and text classification via span extraction》和《The natural language decathlon: Multitask learning as question answering》提出了类似的统一框架。给定这种任务格式的
sequence-to-sequence的结构,T5使用《Attention is all you need》最初提出的basic的encoder-decoder Transformer架构。T5在masked language modeling的"span-corruption" objective上进行预训练,其中input tokens的consecutive spans被替换为a mask token,模型被训练为重建masked-out tokens(而不是完整的原始序列)。T5的另一个区别因素是它的规模,预训练的模型规模从60M到11B个参数。这些模型是在大约1T个token的数据上预训练的。未标记数据来自于C4数据集,该数据集收集了约750GB的英文文本,来源是公共的Common Crawl网络爬虫。C4包括启发式方法,只抽取自然语言(移除了模板和其他乱七八糟的东西),此外还有数据去重、以及语言过滤(仅保留英文文本,当然由于语言检测不是100%准确所以可能还有极其少量的非英文文本)。T5的预训练objective、模型架构、scaling strategy、以及许多其他设计选择都是根据《Exploring the limits of transfer learning with a unified text-to-text transformer》详细描述的大规模实验研究来选择的。
27.2 mC4 和 mT5
我们在本文中的目标是:创建一个大规模的多语言模型,尽可能地遵循
T5的配方。为此,我们开发了一个涵盖101种语言的C4数据集的扩展版本,并对T5进行了调整从而更好地适应这种多语言特性。
27.2.1 mC4
C4数据集被明确地设计为只有英语:任何没有被langdetect赋予至少99%的英语概率的网页都被丢弃了。相比之下,对于mC4,我们使用cld3来识别超过100种语言。由于其中一些语言在互联网上相对稀少,因此我们利用了Common Crawl迄今为止发布的所有71个月的网络爬虫数据。这比用于C4的源数据要多得多,因为仅2019年4月的网络爬虫就足以提供大量的英语数据。C4中一个重要的启发式过滤步骤是:删除那些没有以英语结束标点符号所结束的行。由于这对许多语言来说是不合适的,因此我们采用了一个"line length filter",要求网页至少包含三行共计200个或更多的字符的文本。此外,我们将遵循C4的过滤方法,在不同的文档中对行文本去重,并过滤含有bad words的页面。最后,我们使用cld3检测每个页面的主要语言,并移除置信度低于70%的页面。在应用这些过滤之后,我们将剩余的网页按语言分组,并将所有拥有
10k个或更多网页的语言纳入语料库。这产生了107种由cld3定义的"languages"的文本。然而,我们注意到,其中六种语言只是同一口语的文字变体(例如,ru是西里尔文字的俄语、ru-Latn是拉丁文字的俄语)。每种语言的网页计数的柱状图如下图所示。
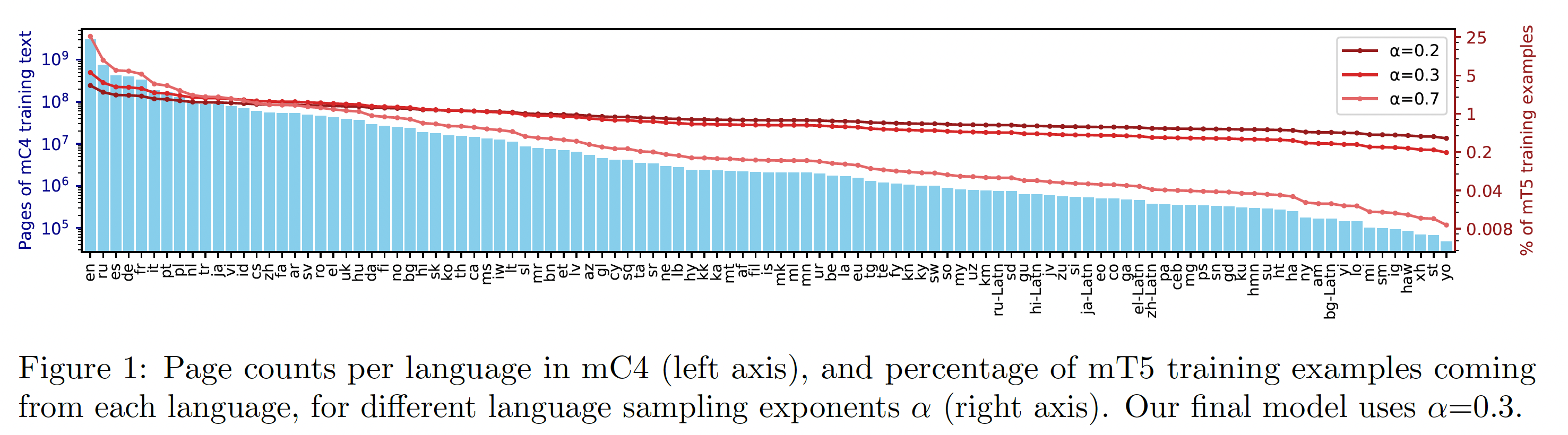
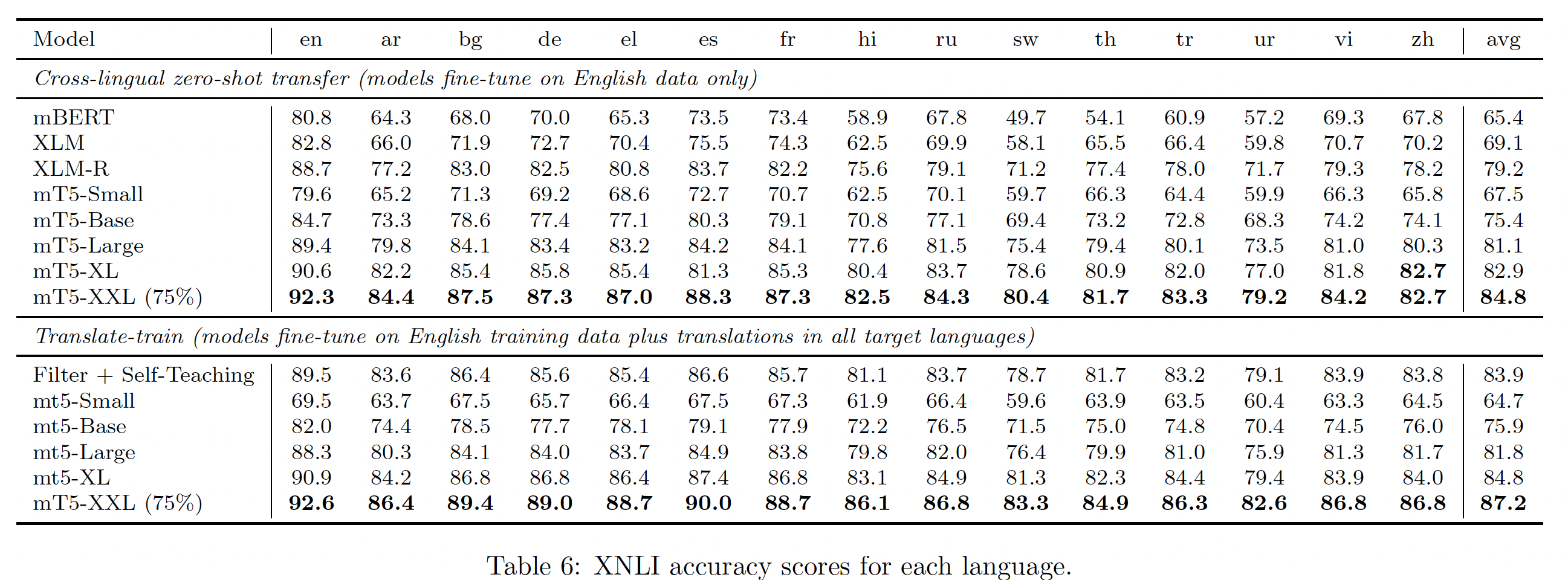
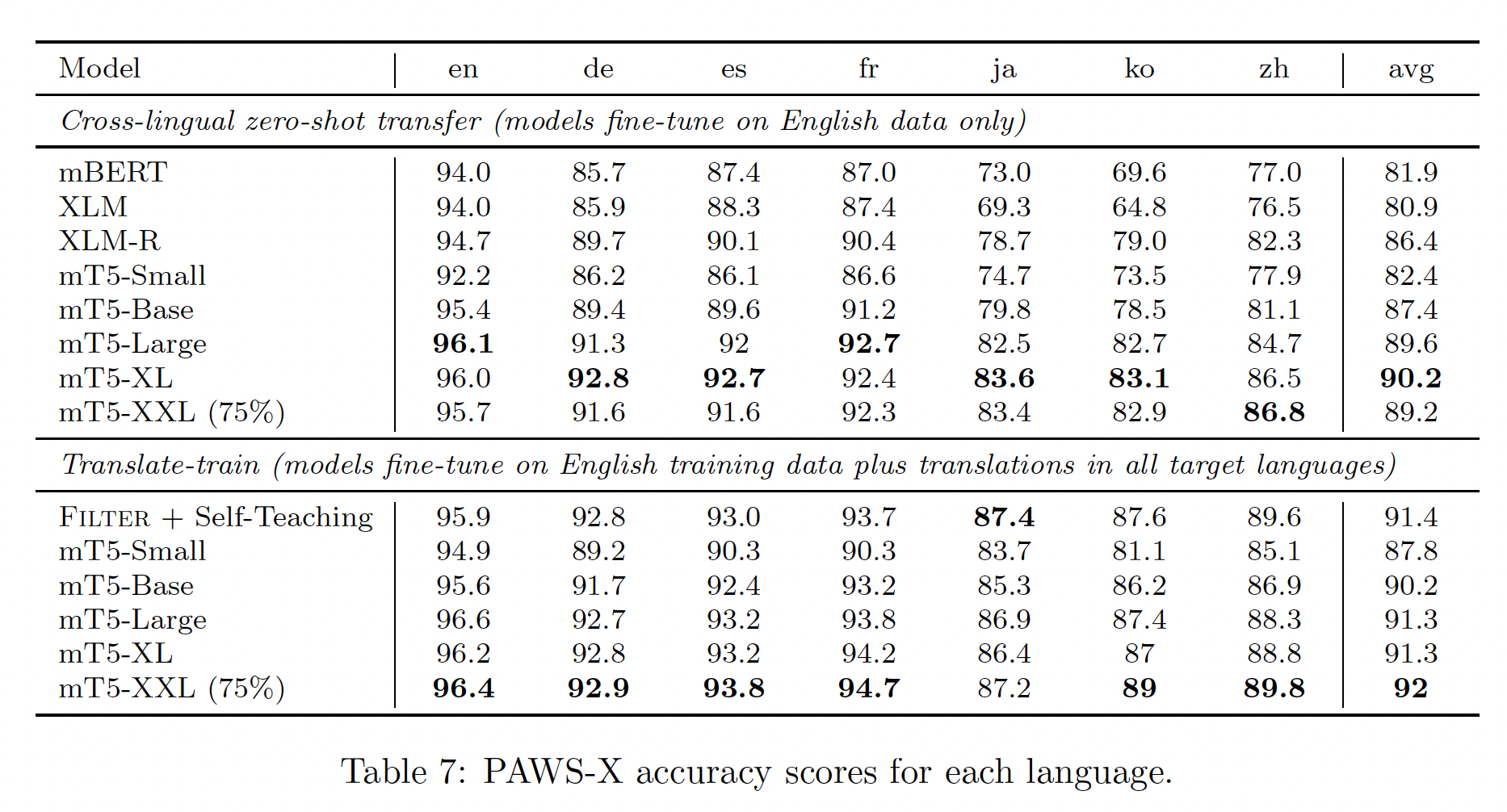
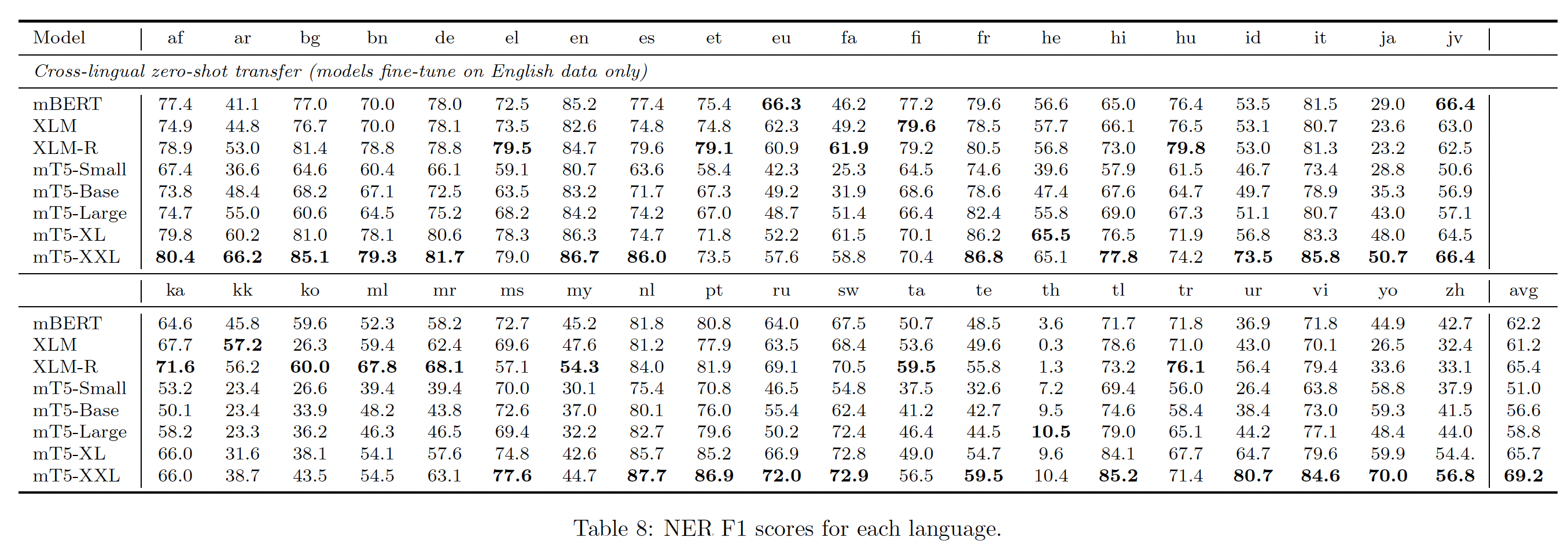
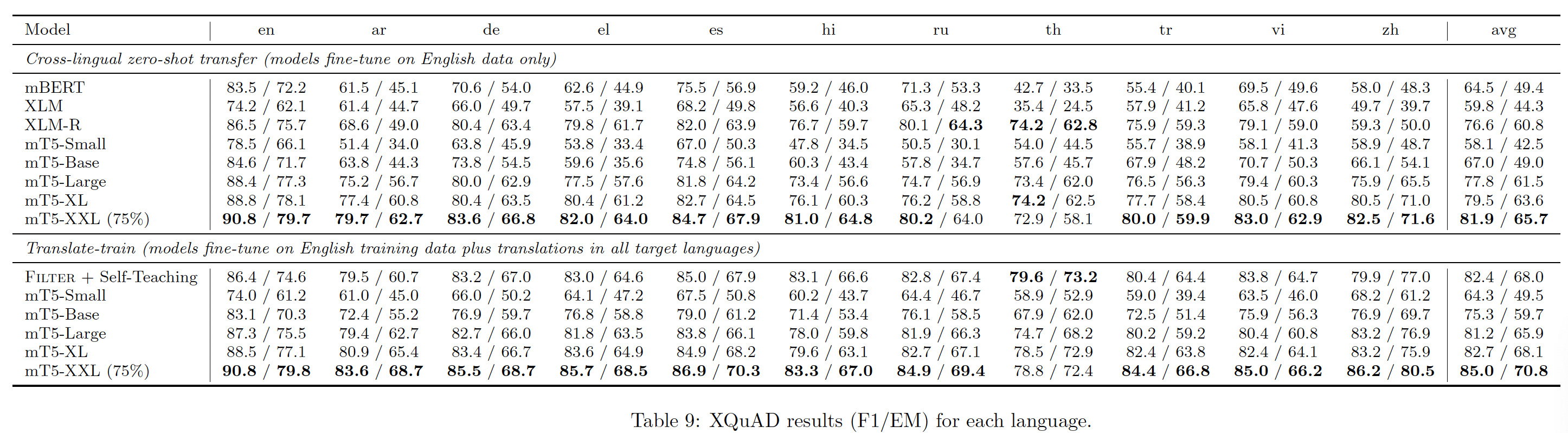
详细的数据集统计,包括每种语言的
token数量,如下表所示。其中,mT5这一列表示mT5训练数据中,来自给定语言的数据的占比。这个占比是经过Tokens/Pages比例差异较大。中文语料的规模是英文语料的
1.5%左右,非常非常少。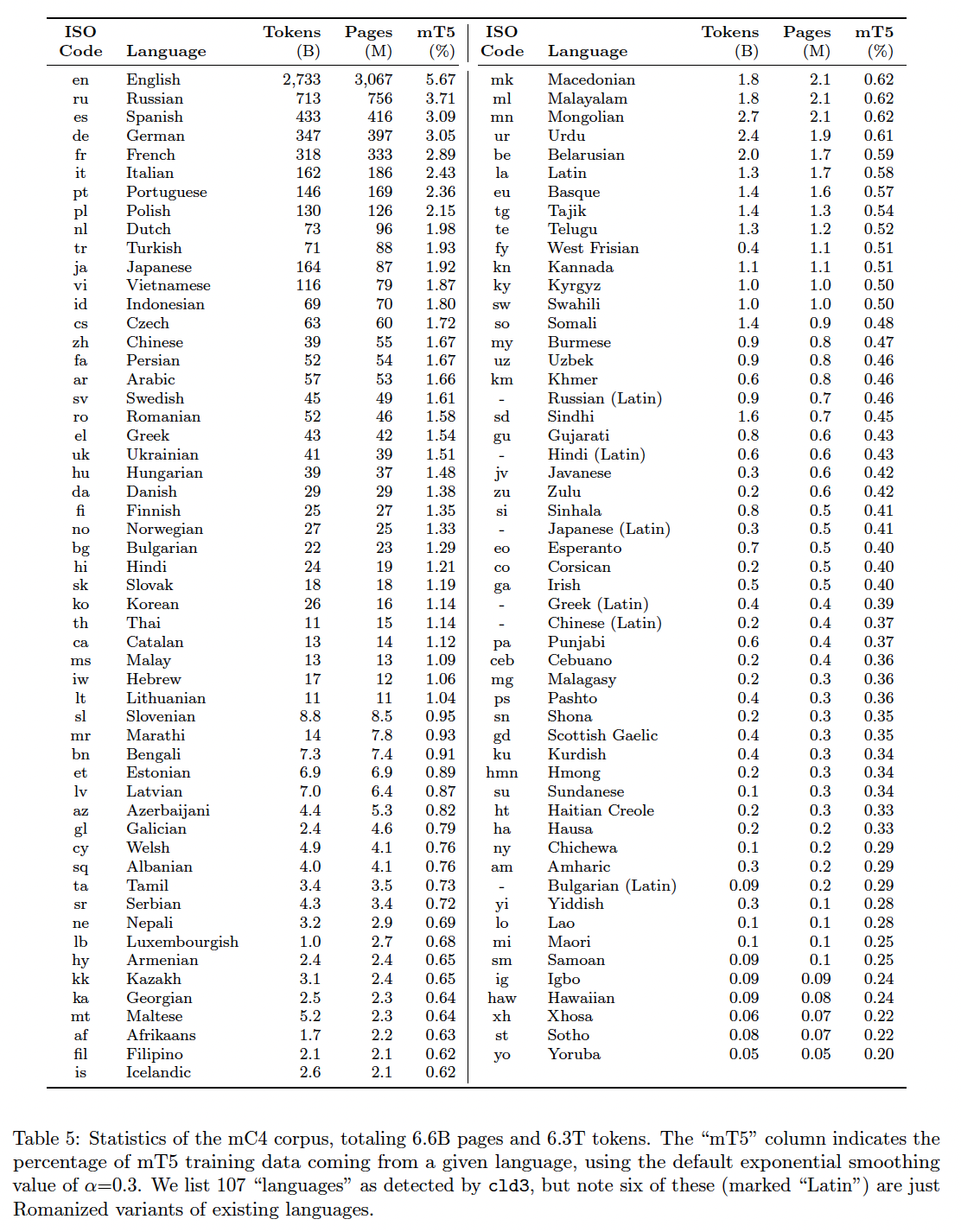
27.2.2 mT5
我们用于
mT5的模型结构和训练程序与T5非常相似。具体而言,我们以T5.1.1(https://github.com/google-research/text-to-text-transfer-transformer/blob/master/released_checkpoints.md#t511) 为基础,该配方通过使用GeGLU非线性函数、 在较大的模型中缩放dropout来预训练,从而改善T5。注意,原始的
T5论文中,在较大的模型中缩放TPU)对于像Transformer的前馈网络中的大型稠密矩阵乘法是最有效的。”预训练多语言模型的一个主要因素是如何对每种语言的数据进行采样。归根结底,这种选择是一种零和游戏:
如果对
low-resource语言的采样过于频繁,模型可能会过拟合。如果
high-resource语言采样不足,模型就会欠拟合。
因此,我们采取了(
《Unsupervised cross-lingual representation learning at scale》、《Massively multilingual neural machine translation in the wild: Findings and challenges》)中使用的方法,通过按照概率low-resource语言,其中:超参数
low-resource语言上训练的概率的提升程度。之前的工作所使用的值包括:用于mBERT的XLM-R的MMNMT的high-resource语言和low-resource语言的性能之间给出了一个合理的折中。我们的模型涵盖了超过
100种语言,这就需要一个更大的词表。遵从XLM-R,我们将词表规模增加到250K个wordpieces。与T5一样,我们使用SentencePiece的wordpiece模型,该wordpiece模型在训练期间使用相同的语言采样率进行训练。为了适应像中文这样的大字符集的语言,我们使用了
0.99999的字符覆盖率character coverage,但也启用了SentencePiece的"byte-fallback"功能从而确保任何字符串都可以被唯一编码。byte-fallback:将UNK token回退到UTF-8字节序列。
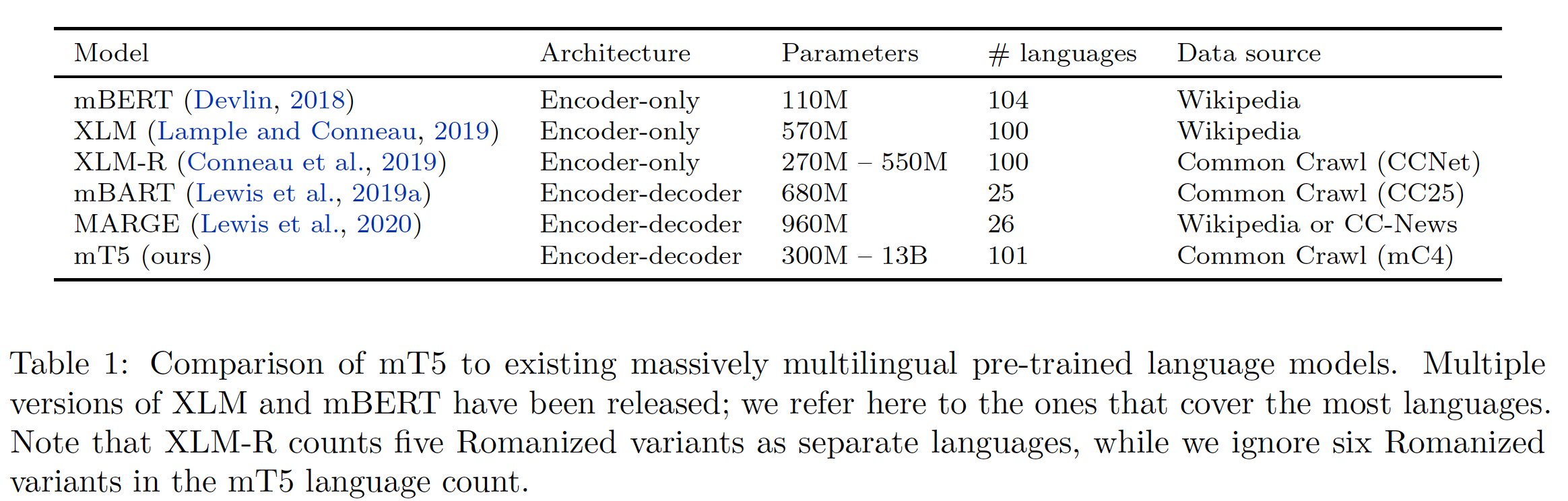
27.2.3 和相关模型的比较
为了说明我们的新模型的背景,我们提供了一个与现有的大规模多语言预训练语言模型的简要比较。为了简洁起见,我们把重点放在支持几十种以上语言的模型上。下表给出了
mT5与最相似模型的high-level比较。mBERT是BERT的多语言版本。与我们使用mT5的方法类似,mBERT尽可能地遵循BERT的配方(相同的架构、objective等)。主要的区别是训练集(指的是和BERT的区别,而不是和mT5的区别)。mBERT不是在English Wikipedia和Toronto Books Corpus上进行训练(这是BERT的训练集),而是在Wikipedia上训练多达104种语言。因为
Toronto Books Corpus是英文的,而不是多语言的。XLM也是基于BERT,但包括改进的方法来预训练多语种语言模型。许多预训练的XLM版本已经发布;最大规模的多语言变体是在Wikipedia的100种语言上训练的。XLM-R是XLM的改进版本,它基于RoBERTa模型。XLM-R是在Common Crawl的100种语言的数据上用跨语言的masked language modeling objective进行训练。为了提高预训练数据的质量,首先在
Wikipedia上训练一个n-gram语言模型,只有在n-gram模型赋予它高的可能性时,才会保留Common Crawl中的一个页面(《Ccnet: Extracting high quality monolingual datasets from web crawl data》)。mBART是一个基于BART的多语言encoder-decoder模型。mBART是在与XLM-R相同的数据中的25种语言子集上,结合span masking和sentence shuffling的objective进行训练。MARGE是一个多语言encoder-decoder模型,它被训练为通过检索其他语言的文档来重建一种语言的文档。它使用来自Wikipedia和CC-News的26种语言的数据。
27.3 实验
数据集:为了验证
mT5的性能,我们在XTREME多语言benchmark的6个任务上评估了我们的模型:XNLI entailment task覆盖14种语言。XQuAD/MLQA/TyDi QA阅读理解benchmark分别覆盖10/7/11种语言。来自
XTREME的WikiAnn的Named Entity Recognition: NER数据集覆盖40种语言。PAWS-X paraphrase identification dataset覆盖7种语言。
我们将所有的任务转化为
text-to-text的格式,即生成label text(XNLI和PAWS-X)、entity tags and labels(WikiAnn NER)、或者直接生成答案(XQuAD、MLQA和TyDi QA)。对于NER,如果有多个实体,那么它们将按照出现的顺序拼接起来;如果没有实体,那么target文本就是"None"。我们考虑这些任务的变体,即模型只在英语数据上进行微调(
"zero-shot")、或在每个目标语言的数据(这些数据来自于从英语利用机器翻译而来)上进行微调("translate-train")。由于仅在英语数据上微调,因此模型没有见过除了英语以外的其他语言的数据,因此称为
"zero-shot"。为简洁起见,关于这些
benchmark的进一步细节请参考《Xtreme: A massively multilingual multi-task benchmark for evaluating cross-lingual generalization》。配置:
对于预训练:
按照最初的
T5配方,我们考虑五种模型尺寸:Small(300M参数)、Base(600M参数)、Large(1B参数)、XL(4B参数)、XXL(13B参数)。与相应的T5模型变体相比,参数数量的增加来自于mT5中使用的较大的词表。batch size = 1024,输入序列长度为1024个token,预训练步数为1M(对应于总计大约1T个input token)。这与T5的预训练量相同,约为XLM-R的1/6。由于时间限制,我们只报告了mt5-XXL训练750K步的结果。最终结果和进一步的实验将在我们的公共代码库中更新。我们使用
T5在预训练时使用的反平方根学习率调度,学习率设置为warm-up步的数量。按照
T5.1.1的配方,我们在预训练期间不应用dropout。我们使用与
T5相同的self-supervised objective,15%的token被掩码、平均noise span length为3。
对于微调:
我们对所有任务使用
0.001的恒定学习率和0.1的dropout。在
zero-shot setting中,我们对XNLI使用batch size为PAWS-X/NER/XQuAD/MLQA/TyDi QA使用batch size为对于
early stopping,我们每200步保存一个checkpoint,并选择在验证集上具有最高性能的checkpoint。
Table 2列出了我们的主要结果,Table 6 ~ 11列出了每项任务每种语言的结果。我们最大的模型mT5-XXL在我们考虑的所有任务中都达到了SOTA。请注意,与我们的模型不同,
InfoXLM得益于平行训练数据parallel training data,而X-STILT则利用了与目标任务相似的任务的labeled data。总的来说,我们的结果强调了模型容量在跨语言representation learning中的重要性,并表明scaling up一个简单的预训练配方可以成为更复杂技术的一种可行的替代,其中这些更复杂的技术依赖于语言模型过滤、平行数据、或中间任务。在
"translate-train" setting中, 我们还在所有XTREME分类任务和问答任务上匹配或超过SOTA的技术。对于这些任务,我们对labeled English data和机器翻译的组合进行了微调。这允许与Filter以及XLM-R基线进行直接比较。然而,请注意,这个设置不同于XTREME "translate-train"(《Xtreme: A massively multilingual multi-task benchmark for evaluating cross-lingual generalization》),它不包括英语数据。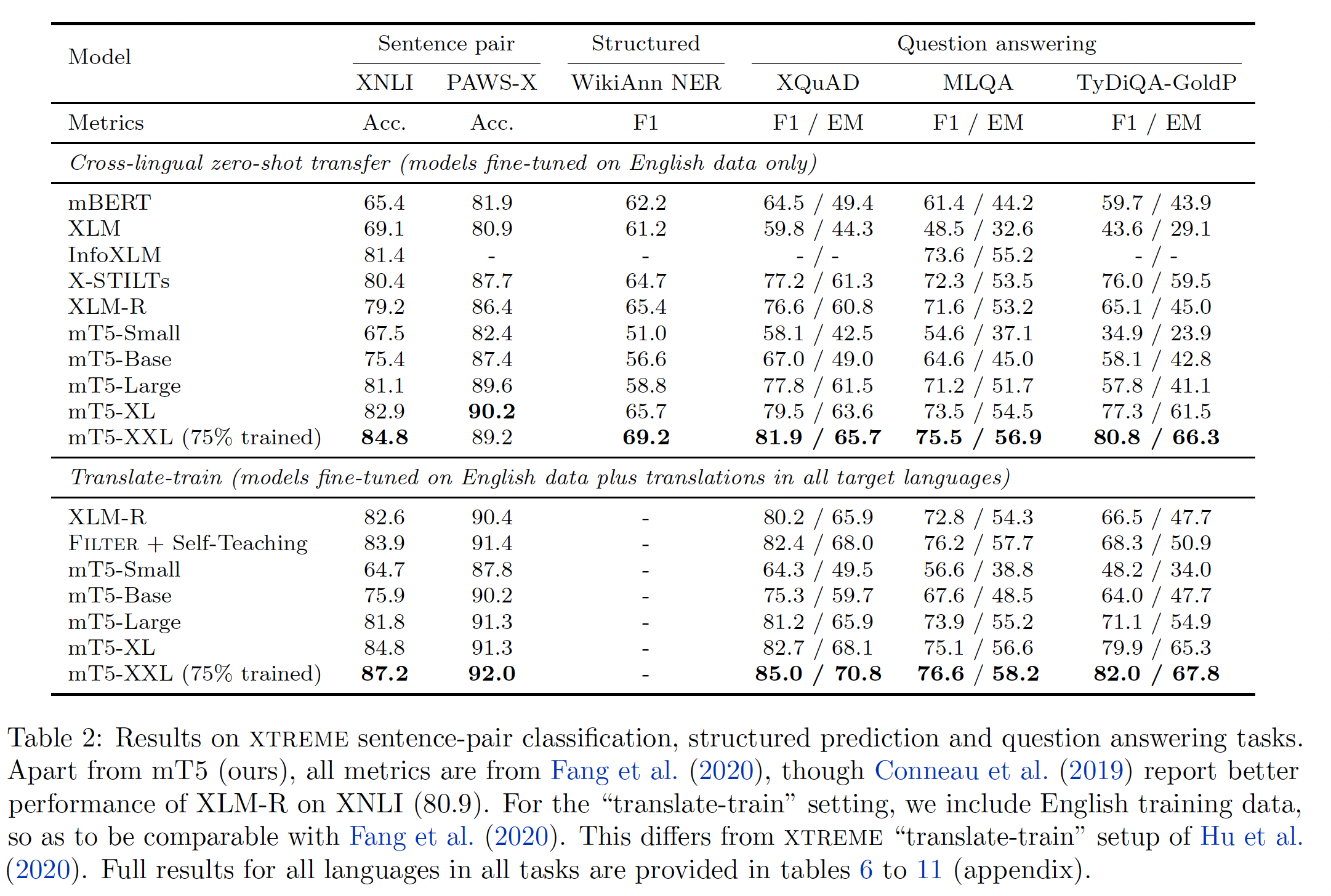
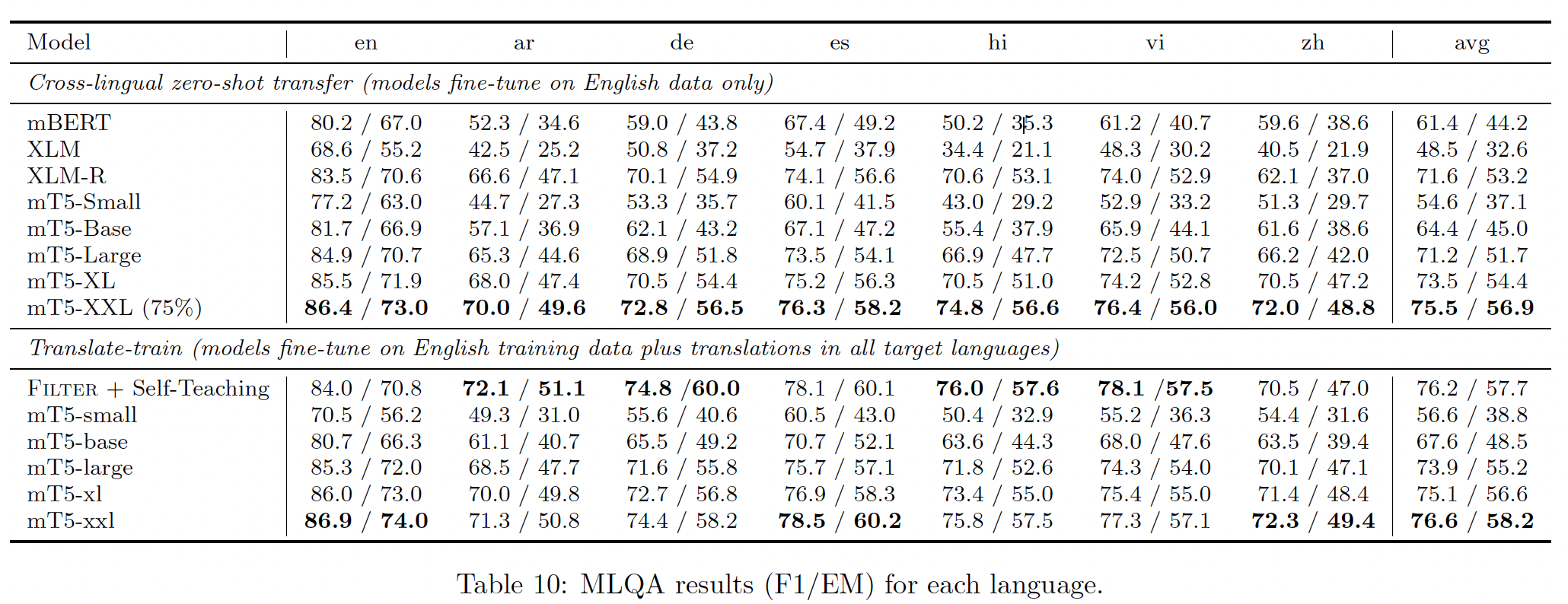
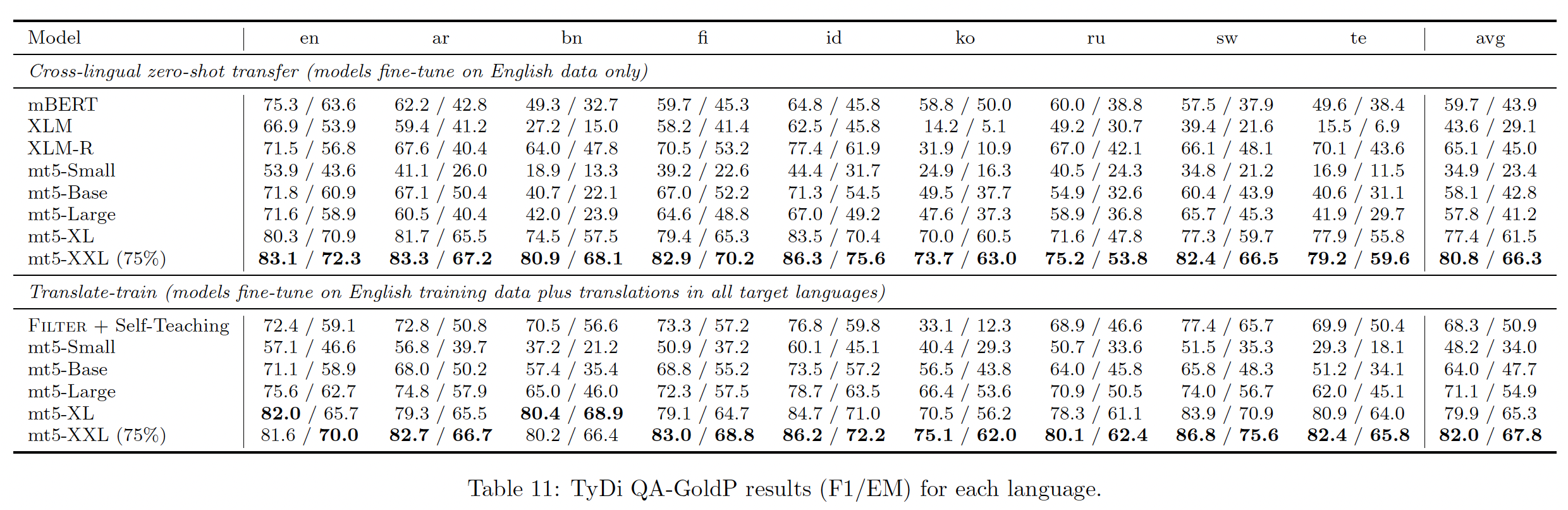
据观察,与专门为某一语言训练的类似规模的 "专用" 模型相比,大规模多语言模型在该语言上的表现不佳。为了量化这种情况,我们比较了
mT5和T5在SQuAD阅读理解benchmark上微调后的表现。结果如下表所示,其中T5的结果来自原始论文。虽然
Small和Base的mT5模型落后于它们对应的英语T5模型,但我们发现大型模型缩小了差距。这表明可能存在一个转折点,过了这个转折点,模型就有足够的能力有效地学习101种语言。T5仅在英文语料上训练。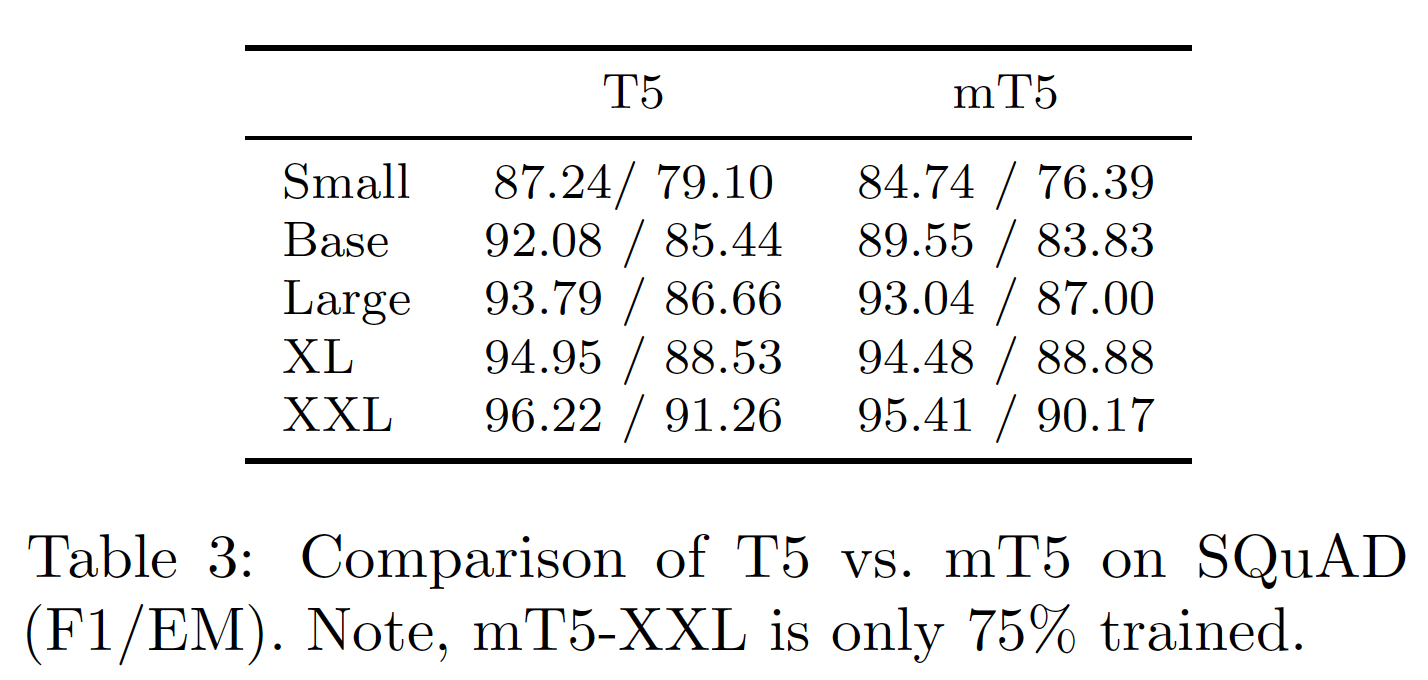
消融研究:我们执行了六种消融研究,以
Large模型作为baseline:将
dropout增加到0.1,希望能减轻对low-resource语言的过拟合。将序列长度减少到
512,就像在T5中使用的那样。将预训练
objective中的平均noise span length增加到10,因为我们观察到的每个token的字符比T5更少。调整语言采样指数
{0.2, 0.7},分别被MMNM和mBERT所使用。在
mC4 data pipeline中关闭"line length filter"。用
103种语言的维基百科数据来补充mC4。为什么用更多数据反而效果下降?论文没有解释其中的原因。个人猜测是引入更多数据,但是没有相应地调整语言采样指数
Table 4显示了这些消融对XNLI zero-shot准确性的影响。在每种情况下,XNLI的平均得分都低于mT5-Large基线,证明了我们选择的设置是合理的。line length filter提供了+2点的提升,证明了从Common Crawl中过滤低质量的页面是有价值的。将语言采样指数
0.7,预期会提高high-resource语言的性能(如俄语81.5 -> 82.8),同时损害low-resource语言的性能(如Swahili75.4 -> 70.6),平均效果为负。相反,将语言采样指数
0.2,会使一种长尾语言略微提高(Urdu73.5 -> 73.9),但在其他地方则有害。
Table 12和Table 13分别提供了XNLI上每一种语言的详细指标,以及我们在zero-shot XQuAD上的消融性能,显示了大致相同的趋势。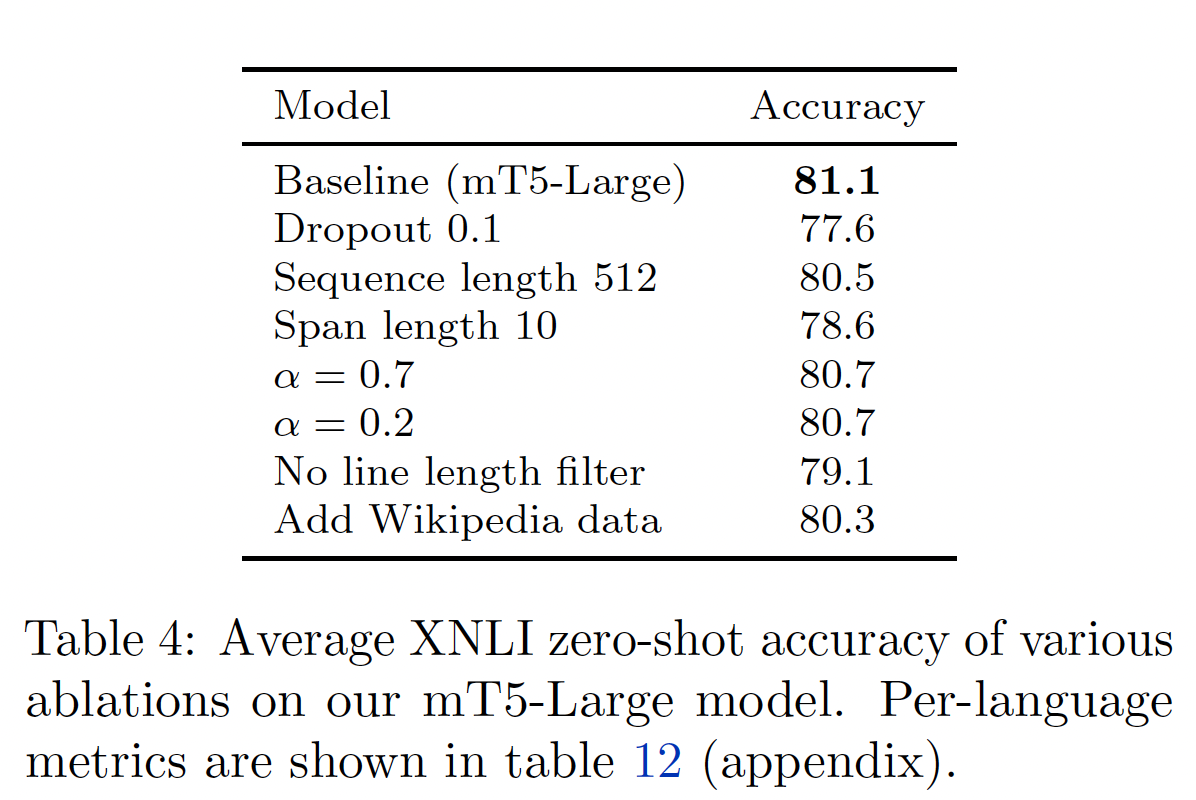
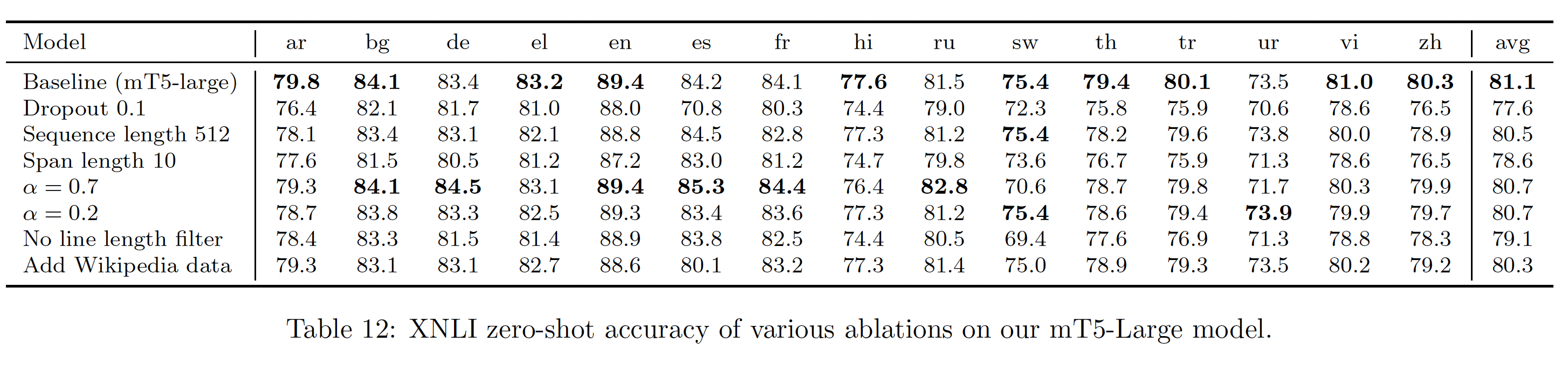

二十八、ExT5[2021]
迁移学习是最近的
NLP进展的基石。虽然自监督的预训练已被证明在利用大量未标记数据方面非常有效,但关于多任务co-training的setup中的迁移学习,仍有许多需要探索。之前的开创性工作,如T5和MT-DNN已经在多任务co-training的范式中展示了一定程度的前景,然而存在灾难性遗忘catastrophic forgetting的挑战。为了证明与transfer有关的positive affinity,任务往往必须被精心挑选。在许多情况下,也可能获得负向迁移negative transfer。这使得很难根据经验策划一组任务从而用于迁移学习。虽然标准的预训练通常采用自监督的
language modeling objective的变体,某些类型的技能(如常识性知识),即使使用大量未标记的数据也只能以缓慢的速度获得。随着越来越大的模型被训练出来,开发更加sample-efficient的pre-training setting变得更重要,并且可以通过多任务学习multi-task learning来解决。论文
《ExT5: Towards extreme multi-task scaling for transfer learning》首次探索并提出了Extreme Multi-task Scaling,针对多任务预训练的一种新范式。与之前最大的工作《Muppet: Massive multi-task representations with pre-finetuning》相比,ExT5将任务数量增加了一倍,并聚焦于多任务预训练而不是微调,这使得ExT5能够与标准预训练进行直接比较。论文的proposal是基于这样的洞察:尽管在微调过程中,负向迁移是常见的,但一般来说,大量的、多样化的预训练任务集合,要比针对预训练任务的最佳组合的expensive search更好。为此,论文引入了
ExMix:一个由107个有监督的NLP任务组成的庞大集合,将被纳入多任务预训练setup。作者以encoder-decoder友好的格式处理所有的任务,以方便支持在所有任务中共享所有的参数。作者推测,在尽可能多的任务、分布、以及领域中的ensembling effect会产生一个一致的net-positive outcome。这与早期的多任务学习结果相呼应(《Multitask learning》、《A model of inductive bias learning》),表明在足够多的任务中学习到的bias很可能会被泛化到从同一环境中抽取的unseen任务中。此外,论文的实验证明,所提出的ExMix mixture优于人工筛选的任务的最佳mixture。核心要点:
自监督任务和
107个有监督任务,用相同的格式进行统一的训练。没必要针对具体的任务挑选最佳的监督任务组合,直接大量的监督任务组合即可。
最后,作者提出了
ExT5模型,它是一个T5模型,在supervised ExMix的mixture、以及self-supervised C4 span denoising上进行预训练。ExT5在公认的benchmark上,如SuperGLUE、GEM、Rainbow、以及Closed-Book QA任务上,优于SOTA的T5模型。
综上所述,本文的贡献如下:
提出了
ExMix:一个由107个有监督的NLP任务组成的集合从而用于Extreme Multi-task Scaling,每个任务被格式化从而用于encoder-decoder训练。ExMix的任务数量大约是迄今为止最大的研究(《Muppet: Massive multi-task representations with pre-finetuning》)的两倍,在不同的任务系列中总共有18M个标记样本。给定大量任务的集合,论文进行了严格的实验研究,评估常见任务系列之间的迁移。实验结果表明:在
fine-tuning transfer的基础上筛选一个pre-training mixture并不简单。因此,搜索针对多任务预训练的最佳任务子集,这是具有挑战性且难以实现的。使用
ExMix,论文在C4数据集的span-denoising objective的基础上预训练一个模型,产生了一个新的预训练模型ExT5。ExT5在SuperGLUE、GEM、Rainbow、Closed Book Question Answering、以及ExMix之外的其他几个任务上的表现优于SOTA的T5,同时也更加sample-efficient。
相关工作:
通过多任务来改善
NLP模型:《A unified architecture for natural language processing: Deep neural networks with multitask learning》利用多任务学习来完成相对简单的任务,如词性标注Part-of-Speech tagging。《Sentence encoders on stilts: Supplementary training on intermediate labeled-data tasks》使用四个任务(具有大型数据集)intermediate的微调阶段进行自然语言理解。类似地,
《Multi-task deep neural networks for natural language understanding》提出了MT-DNN,它使用的setup规模为30个左右的任务、以及高达440M的参数。最近,
《Muppet: Massive multi-task representations with pre-finetuning》使用了大约50个任务和规模达440M参数的模型。《Don’t stop pretraining: Adapt language models to domains and tasks》采取了另一种方法,即继续预训练一个模型,但使用domain-specific的数据作为intermediate step。《The natural language decathlon: Multitask learning as question answering》提出了一个类似于T5的统一框架。最近,
《Finetuned language models are zero-shot learners》也说明了多任务学习阶段如何在~137B参数的规模上大大改善大型语言模型的zero-shot prompting性能。人们还努力为特定的任务定制
pre-training objective,例如,问答question answering任务、对话任务、和span selection任务。
不同任务之间的关系:
《Identifying beneficial task relations for multi-task learning in deep neural networks》进行了一项与我们相似的研究,但针对更传统的NLP任务,如chunking、CCG tagging、POS tagging等。最近,
《Exploring and predicting transferability across NLP tasks》对各种分类/回归、问答、以及序列标注任务之间的关系进行了深入研究,并提出了一个task-embedding framework来预测这种关系。《UNIFIEDQA: Crossing format boundaries with a single QA system》也进行了类似的实验,但具体到问答数据集/格式,形成了一个强大的QA模型,称为UnifiedQA。UnifiedQA也是基于T5框架的。最近,
《What’s in your head? emergent behaviourin multi-task transformer models》阐述并分析了在相关的co-training任务(如QA和摘要)之间,encoder-only Transformer的behavior transfer。在
NLP之外,《A convex formulation for learning task relationships in multi-tasklearning》引入了一个学习task relationship的凸优化的objective,《On better exploring and exploiting task relationships in multitask learning: Joint model and feature learning》在各种不同的数据集上探索和利用task relationship。
选择要迁移的任务:
我们的实验试图从经验上选择一组任务来迁移。沿着这些思路,
《Learning to select data for transfer learning with Bayesian optimization》使用具有相似性措施的贝叶斯优化方法来自动选择来自不同domainn的相关数据。类似地,
《AutoSeM: Automatic task selection and mixingin multi-task learning》使用multi-armed bandits来选择任务,并使用高斯过程Gaussian Process来控制所选任务的混合率。最近的另一波工作是根据人工定义的特征来选择合适的迁移语言(
《Choosing Transfer Languages for Cross-Lingual Learning》、《Ranking Transfer Languages with Pragmatically-Motivated Features for Multilingual Sentiment Analysis》)。除了
NLP领域,《Efficiently identifying task groupings for multi-task learning》提出了一种方法,根据任务梯度来选择迁移的任务。
上述所有的工作都是选择为感兴趣的下游任务定制的数据。如果试图以类似的方式训练一个通用的预训练模型,就会出现类似于我们正文部分所提到的计算瓶颈。
预训练的
Transformer:Transformer模型,如T5, BERT, GPT-3依靠大型无标签语料库进行自监督学习。鉴于pre-train-finetune范式的广泛成功,寻找合适的预训练任务也成为一个活跃的研究领域。虽然已经有证据表明,supplementary pre-training task有助于提高性能,但这项工作是第一个大规模的多任务预训练模型。Scaling Laws:Transformer的scaling laws最近引起了很多关注,特别是与模型大小有关的。在
《Scaling laws for neural language models》中,作者进一步研究了与数据集大小有关的scaling(在同一预训练语料库上)。为此,这项工作可以被解释为在可用于预训练的高质量的、多样化的标记任务的数量方面进行scaling up的尝试。
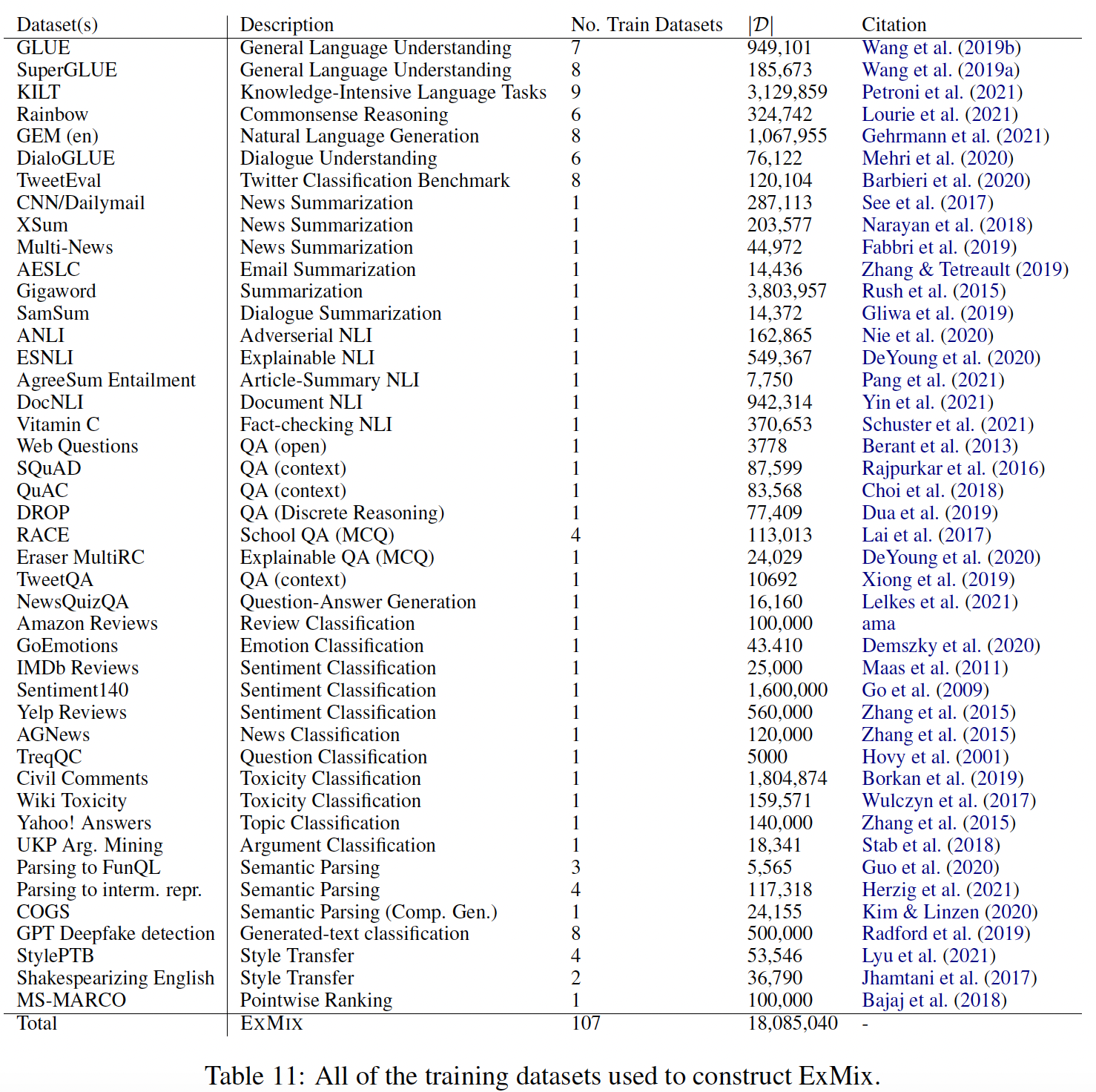
28.1 ExMix 任务集合
为了探索
Extreme Task Scaling范式,我们引入了ExMix(Extreme Mixture),这是一个由107个不同的英语NLP任务组成的集合,共有18M个样本。遵从T5,我们将所有的任务格式化为text-to-text的样本,以便进行多任务训练。这种统一的格式也使简单的implementation成为可能,而不需要像以前的工作那样来提供task-specific的head/loss、loss scaling或显式的梯度积累。在从
ExMix中选择样本时,每个数据集的样本都是按单个数据集的大小成比例来采样的,每个数据集的取样率上限为这个采样率上限是如何设定的?论文并未说明。
尽管
ExMix中的任务来自不同的数据集,而且都有自己的细微差别,但ExMix任务大致代表了以下任务族task family:分类
classification(single segment)。自然语言推理
natural language inference(two segments)。阅读理解
reading comprehension。闭卷问答
closed-book question answering: CBQA。常识推理
commonsense reasoning。语义解析
semantic parsing。对话
dialogue。摘要
summarization。
虽然也存在其他
task group,但上述的任务族涵盖了ExMix的大部分。这个任务集合还可以实现多任务学习,其规模是以前工作(《Muppet: Massive multi-task representations with pre-finetuning》)的两倍。下表总结了
ExMix中包括的107个数据集。表中的一些行代表了现有的benchmark(它们将几个任务组合在一起)。在每个集合中,我们使用包含英语训练数据的数据集:GLUE benchmark:CoLA, SST-2, MRPC, QQP, STS-B, MNLI, QNLI, RTE, WNLI等任务。SuperGLUE benchmark:BoolQ, CB, COPA, MultiRC, ReCoRD, RTE, WiC, WSC等任务。KILT benchmark:FEVER, AIDA, WNED, T-REx , NQ, HoPo, TQA, ELI5, WoW等任务。Rainbow benchmark:NLI, CosmosQA, HellaSWAG, PIQA, SocialIQA, WinoGrande等任务。GEM (en):Wiki-Lingua, WenNLG , CommonGEN, E2E, DART, ToTTo, Wiki-Auto, TurkCorpus等任务。DialoGLUE:Banking77, HWU64, CLINC150, SGD, TOP等任务。TweetEval:Emotion Recognition, Emoji Prediction, Irony Detection, Hate Speech Detection, Offensive Language Identification, Sentiment Analysis, Stance Detection等任务。
28.1.1 ExMix 任务之间的迁移关系
我们的目标是在
ExMix上预训练一个模型,以提高下游的性能。要问的一个自然问题是,哪些任务对下游性能有负向影响?具体来说,在用于多任务预训练时,是否存在ExMix的一个子集能导致更好的representation?显然,测试所有可能的ExMix中包含的任务数量),因为预训练过程的成本很高。相反,我们使用类似任务的代表性子集,并执行实验成本较低的co-training程序(即,multi-task fine-tuning)。稍后,我们将探讨这些结果是否可以为任务选择提供信息,从而用于多任务预训练。为了研究
ExMix中任务族之间的迁移,我们构建了每3个任务构成的子集(如下表所示),每个子集按照其任务族进行划分。利用这些子集,我们评估了多任务学习(co-training)setup中任务族之间的迁移。虽然其他类型的任务在ExMix中可用,但我们没有包括它们,因为它们不足以代表一个任务族,而且会以二次方的速度scale up需要训练的模型数量。这里考虑的不是任务之间的迁移,而是任务族之间的迁移。
实验设置:我们在每一对任务族上微调一个模型(即一次
6个数据集)。为了确保任务之间的平衡,我们在任务族内按比例采样,但在任务族之间均匀采样。例如,在评估classification任务和NLI任务之间如何相互迁移时,NLI样本和classification样本的总体比例是1:1,然而NLI内部的MNLI:ANLI的采样比例是按比例的(大约是2.4:1)。作为reference(即,baseline),我们还在每个任务族上训练一个模型,每个任务族的内部是按比例采样。baseline是没有族间迁移学习的模型;实验组是有族间迁移学习的模型。注意,这里族间采样是1 : 1的。总的来说,这导致训练了
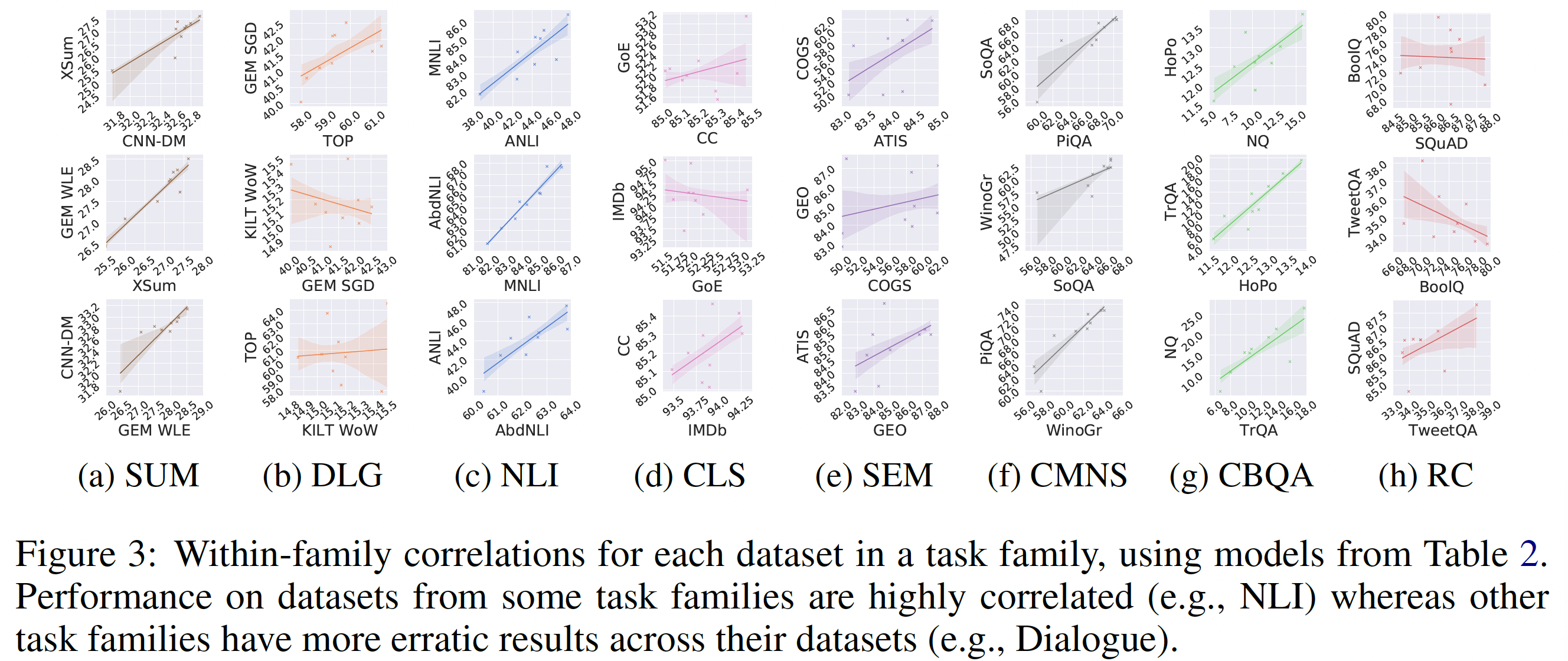
baseline),Table 1所示,我们的实验使用34个模型。每个模型在已发布的T5.1.1_BASE checkpoint的基础上进行微调,使用batch size = 128和200k steps。我们在下表中总结了我们的结果。第
co-trained的模型在100k步(相同数据预算)和200k步(相同计算预算)的结果。最后一行中,平均数的计算不包括家族内模型(即对角线元素)。最后一列表示一个source family为其他任务族提供的平均增益。我们观察到:
尽管存在一些特定的
task-family pair显示出正向迁移(如,与NLI共同训练有助于大多数其他任务),但与族内训练相比,在跨任务族训练时,负向迁移更为常见。在相同的数据预算下,
56个族间的关系中,有21个比族内的模型表现更差;在相同的计算预算下,表现更差的数据增加到38。虽然不同任务族之间大量的负向迁移是一个预期的结果,但有趣的趋势体现在个别关系中。例如,摘要任务通常似乎会损害大多数其他任务族的性能,而
CBQA任务对多任务的微调高度敏感。
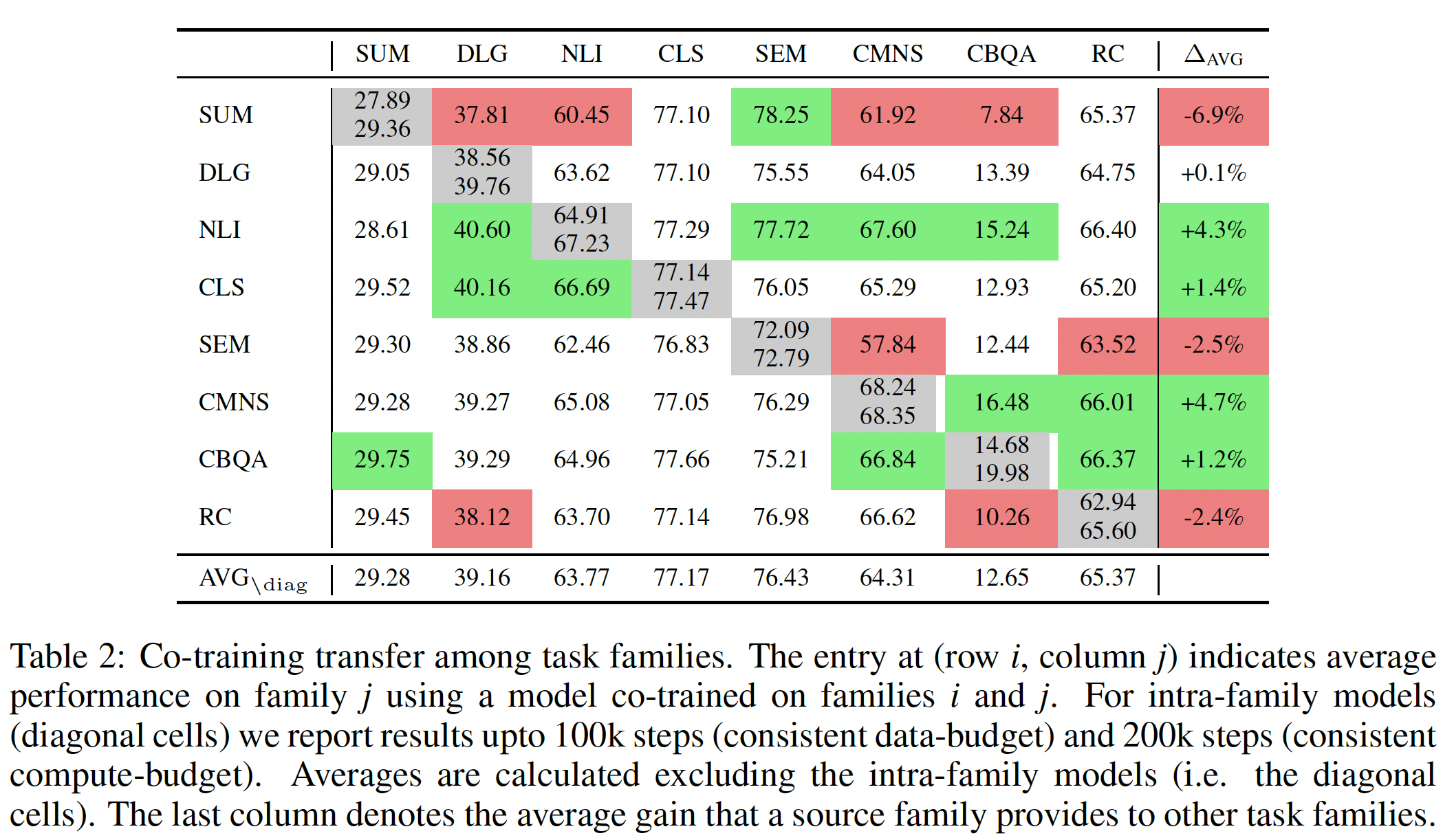
我们还使用与
Table 2相同的模型在下图中报告了族内数据集的相关性。在大多数情况下,我们看到同一族的数据集之间存在正相关关系。然而,在少数情况下,我们观察到一个相反的趋势。例如,在GEM schema-guided的对话数据集上表现较好的微调模型在KILT Wizard-of-Wikipedia上取得的分数较低。这里是用
baseline模型来评估族内的两个数据集。这一初步的探索性分析强调了
ExMix作为系统地研究task relationship的工具的潜力,以及在预训练的representation之上朴素地利用多任务学习的潜在挑战。族内迁移学习效果较好,族间迁移学习效果不好。
28.1.2 微调 task relationship 是否有助于定制一个 pretraining mixture?
前面的观察表明:在现有的
pre-trained checkpoint之上进行多任务co-training并不简单,而且常常导致负向迁移。然而,背后的task relationship可能有助于有效地搜索ExMix的理想子集进行多任务预训练。为此,我们选择了一组最有前景的任务族,将其纳入多任务预训练的
setup中,按照它们对其他目标任务族提供的平均相对改善的程度对任务族进行排序(Table 2的最后一列)。具体而言,我们将ExMix中的NLI、commonsense、classification和closed-book QA任务纳入多任务预训练设置中,形成了48个任务的mixture(下表中Best-effort这一行)。然后,我们在SuperGLUE上对得到的模型进行微调,在下表中与T5.1.1和ExT5(包含所有ExMix任务)进行比较。虽然这个模型的表现略微优于
T5.1.1,但它并没有产生比ExT5更好的结果。此外,正如我们在任务扩展实验(接下来的内容)中所报告的那样,它并没有优于随机选择的55个任务的平均表现。我们的结论是,多任务微调期间的负向迁移不一定会抑制预训练。虽然我们不能直接得出结论,即
ExMix的理想子集不存在,但我们的实验表明,随机包括更多不同的预训练任务一般会提高下游任务的性能。还必须指出的是,我们的最终目标是找到一种mixture从而导致一个可用于大量下游任务的通用预训练模型,而不仅仅是针对SuperGLUE定制化的mixture。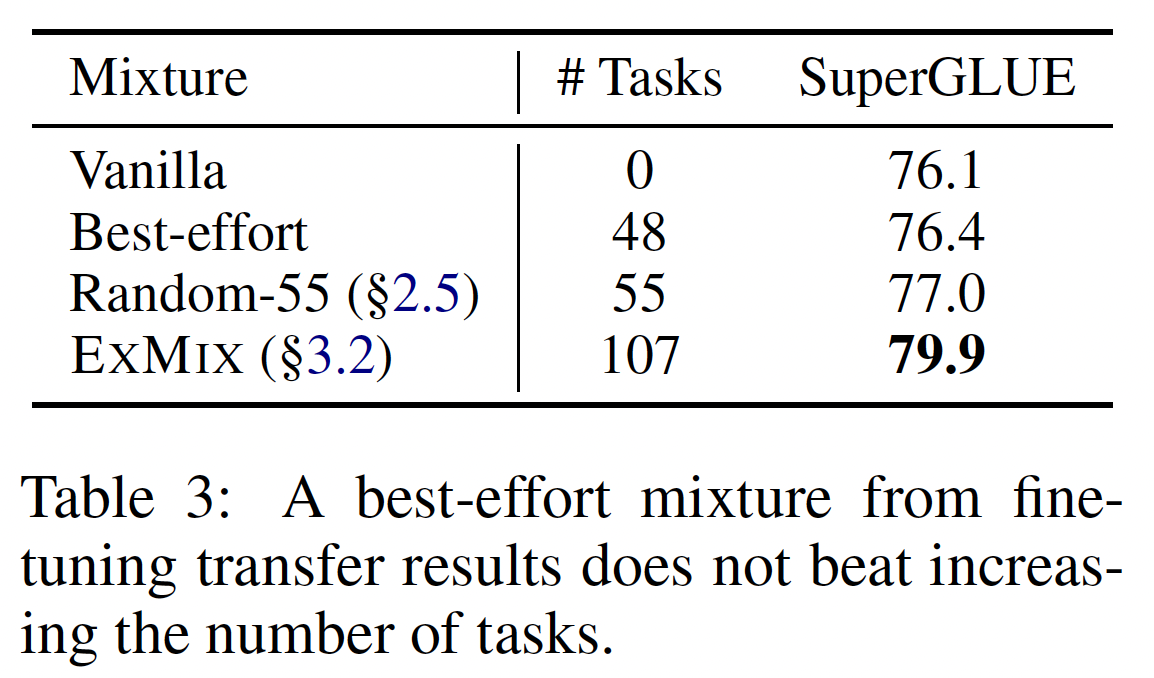
28.1.3 多任务预训练 VS Pre-Finetuning
另一种利用多任务学习的方法不是在
ExMix上进行预训练,而是作为预训练和微调的中间步骤,这被《Muppet: Massive multi-task representations with pre-finetuning》称为预微调pre-finetuning。我们进行实验来比较预训练和预微调。我们从一个标准的T5 base checkpoint开始,用ExMix进行预微调。在这个阶段之后,我们在SuperGLUE上进行微调。下表比较了预微调和我们提出的多任务预训练。我们还报告了两种方案中模型的总计算量(以处理的
token总数来衡量)。结果表明:多任务预训练明显优于预微调。一个潜在的假设是:多任务预训练缩小了预训练数据分布和微调数据分布之间的差距,因为预训练阶段更接近于微调。相反,将预训练和预微调分离成两个不同的阶段可能会诱发对预训练任务的灾难性遗忘。因此,在
ExT5中,我们选择了多任务预训练而不是预微调。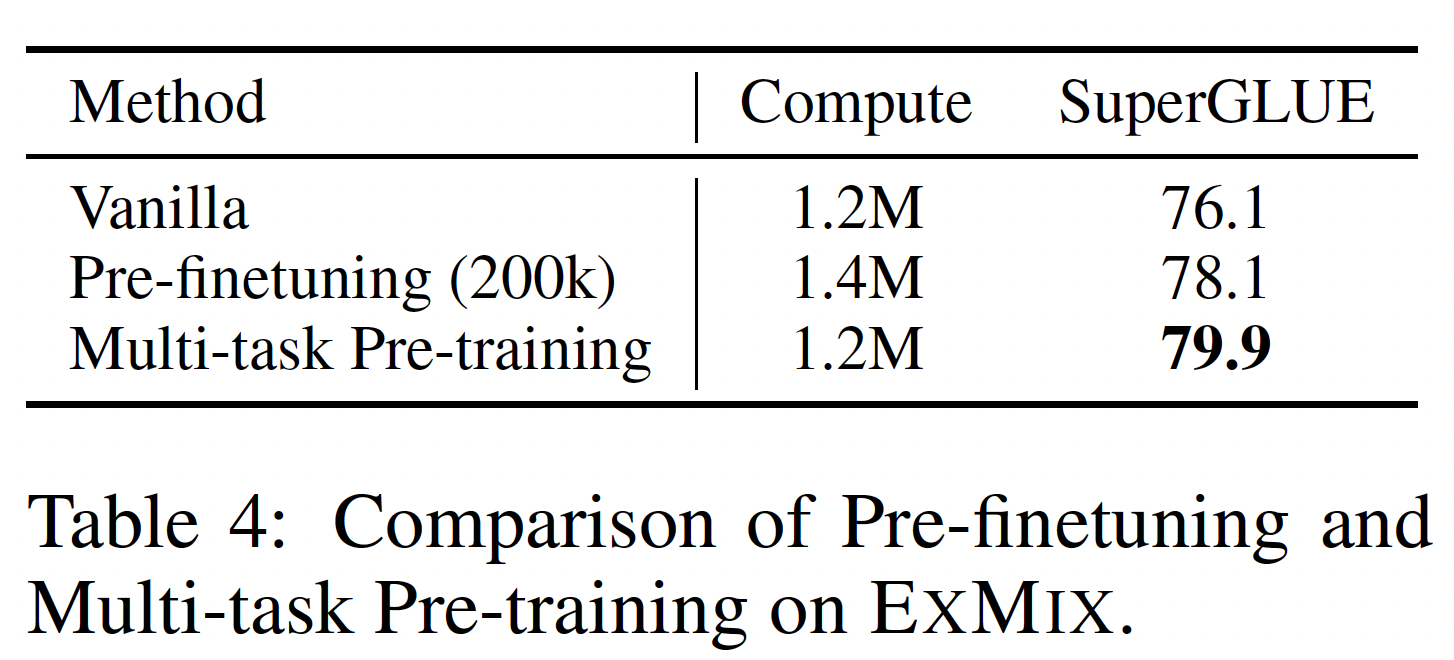
28.1.4 应该混合多少标记数据
这里我们将探讨在大规模多任务预训练中,
C4与ExMix样本的比例如何影响性能。正如后面的内容所提到的,这是由一个超参数pre-training batch中,C4样本的数量大约是ExMix样本数量的C4是自监督预训练数据,ExMix是多任务监督数据。从下图的结果中,我们发现:
在多种
ExMix在与自监督C4预训练混合时提高了下游性能。用
C4预训练)训练的模型的效果最差。
这个结果很重要,因为它表明,虽然
ExMix改善了预训练过程,但在大型非结构化语料库上的自监督训练仍然是至关重要的。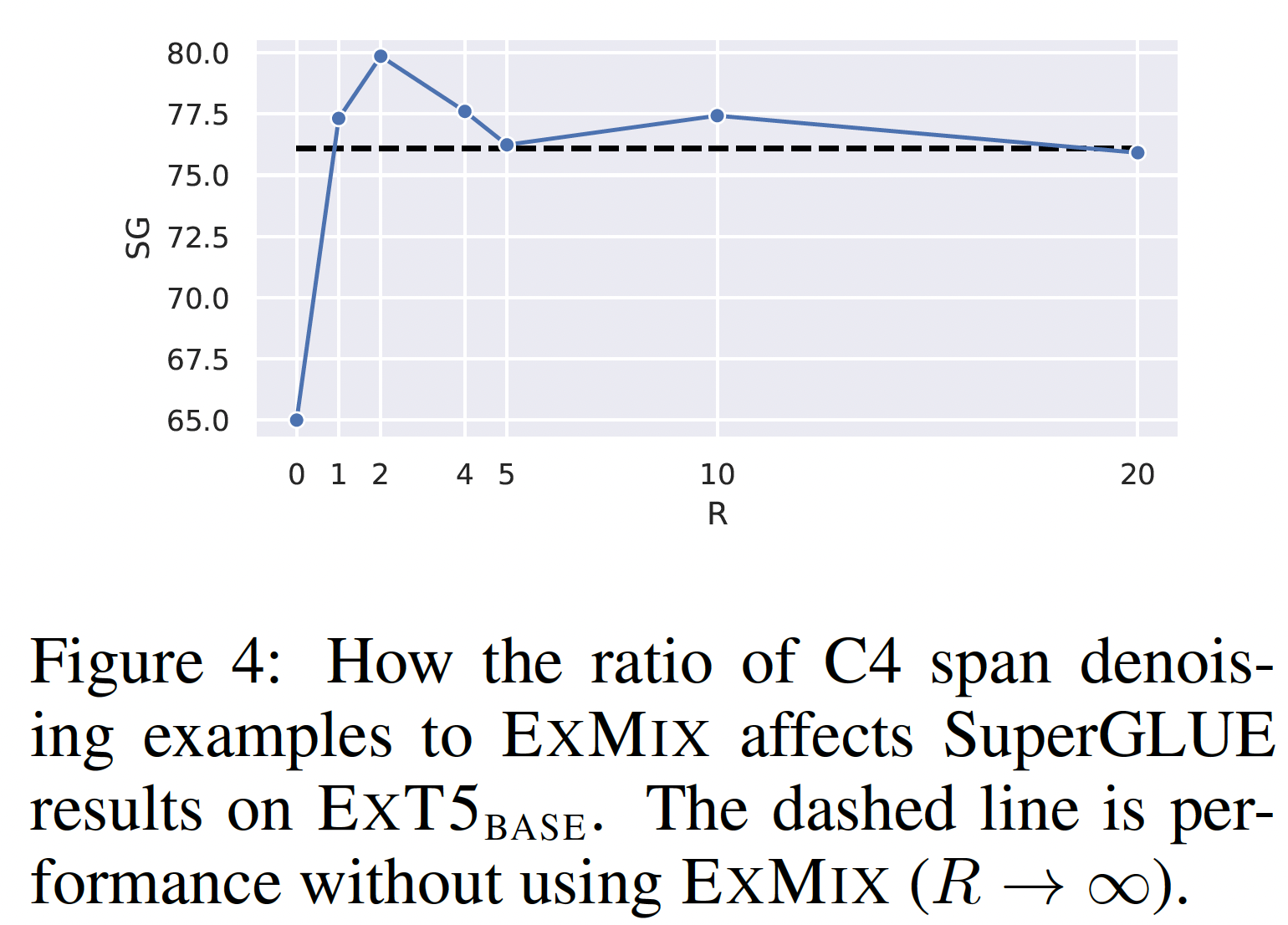
28.1.5 Task Scaling
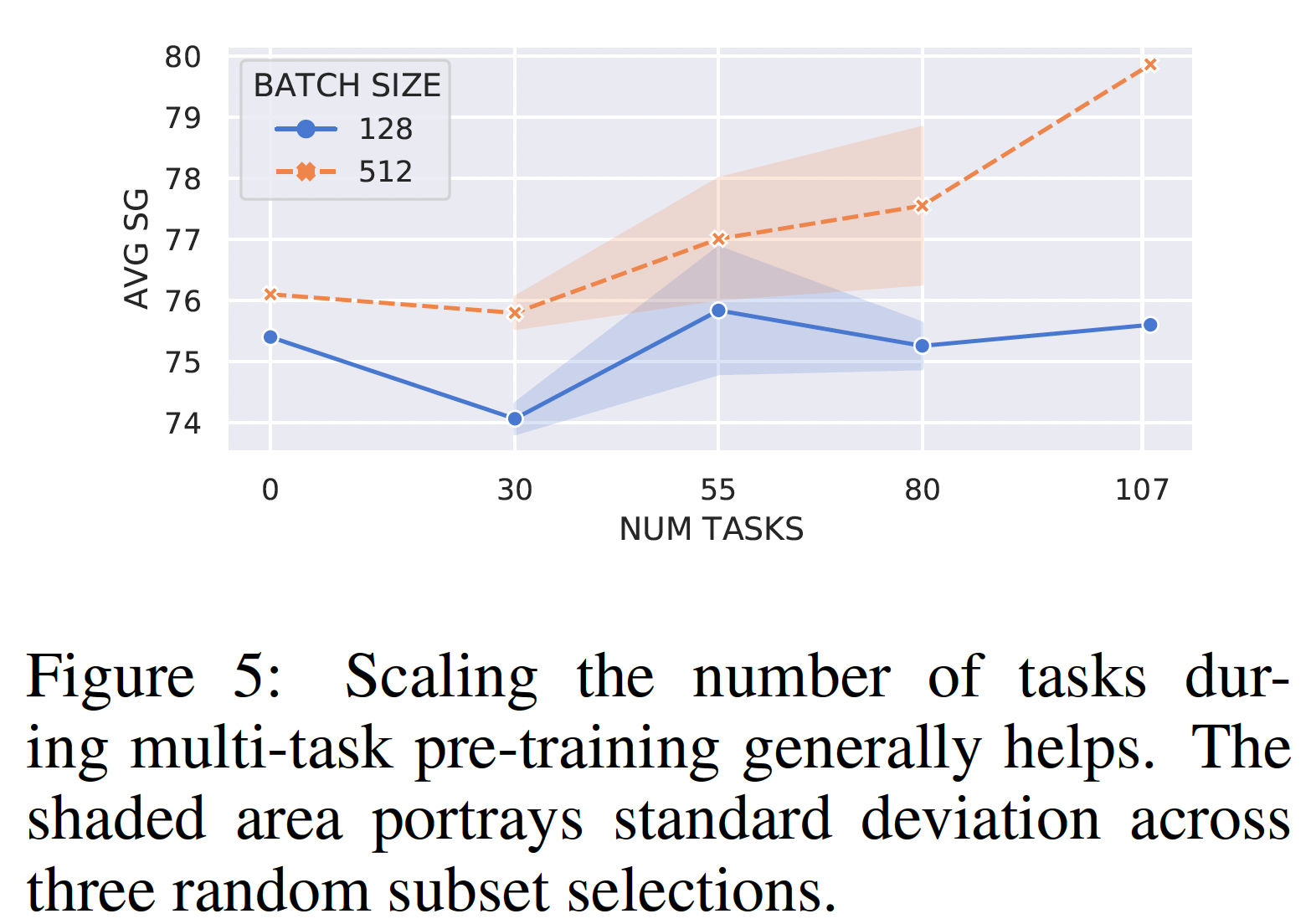
这里我们探讨了模型的性能如何随着大规模多任务预训练设置中的任务数量的增加而变化。我们随机选择
30、55和80个任务(每个任务都是最后一个任务的超集),对一个BASE大小的模型进行524k步的预训练,并在SuperGLUE上对其进行微调。我们用batch size=128/256(两种实验配置) 、以及C4样本和ExMix样本的比例)来训练我们的模型,因为这种配置对我们的BASE大小的模型效果最好。我们在三个随机种子(用于任务子集选择)上重复这个过程,并在下图中报告平均分数。总的来说,我们可以看到:
在大
batch size的情况下,增加任务数量通常有助于下游的性能。这加强了我们的直觉,即scale up任务有助于模型效果。在小
batch size的情况下,上升趋势较小,表明大的batch size对大量的任务是必不可少的。这是直观的,因为多任务学习导致梯度是有噪声的(《Gradient surgery for multi-task learning》)。关于为什么会出现这种情况的另一个解释是:大
batch训练甚至可以为单任务模型提供好处(《Don’t decay the learning rate,increase the batch size》),《An empirical model of large-batch training》正式确定了这种趋势。
28.1.6 利用 ExMix 改善 Sample Efficiency
我们假设,
extreme multi-task scaling也能提高预训练的样本效率。为了测试这一点,我们从ExMix中排除了SuperGLUE,对一个large model进行了200k步的预训练,并在预训练的早期阶段在SuperGLUE上对其进行了几次微调。即,最多进行了
200k步的预训练,然后把其中的第20k, 50k, 100k, 200k预训练的checkpoint用于下游微调。结果如下图所示。我们发现:
ExMix的预训练明显比普通的自监督预训练更节省样本。注意,仅在20k的预训练step上,我们的ExT5模型已经达到了75.8的SuperGLUE score,比完全预训练的BERT large model高出约+4%(注,BERT large model的数据并没有在下图中展示)。注意,这里的预训练指的是利用
pre-trained model初始化的预训练,并没有从头开始。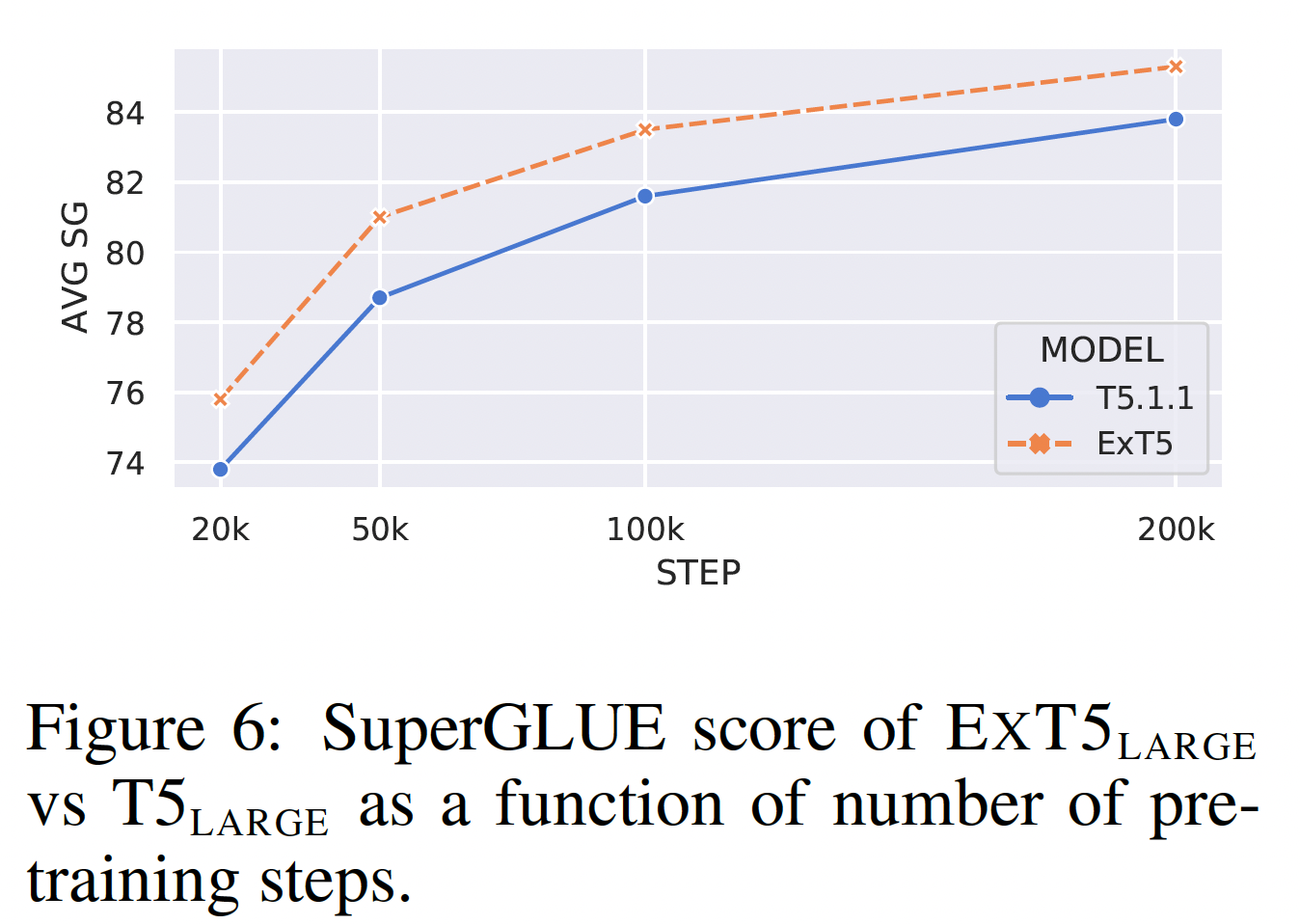
28.2 ExT5 模型
为了克服多任务
co-training的挑战,即前面讨论的负向迁移和灾难性遗忘,本文的剩余部分通过extreme multi-task scaling重新审视T5引入的多任务预训练范式。这里引入ExT5,一个预训练的sequence-to-sequence Transformer encoder-decoder模型,它基于流行的T5框架。
28.2.1 训练 T5
预训练:我们在混合了
C4和ExMix的mixture上进行预训练,以C4样本相对于ExMix样本的采样比例。我们使用的C4 objective与T5使用的objective相同,每个任务都优化了标准的sequence-to-sequence cross-entropy loss。ExT5的训练step数量与T5模型相同,并且ExT5看到的token总数也与T5模型相同。具体而言,我们对我们的模型进行预训练,总step数量为1M,batch size = 2048,序列长度为512。结果在预训练期间,模型总共看到了大约1T的token(包括无监督数据集和有监督数据集)。我们在所有的实验中使用
T5.1.1架构,它使用GEGLU激活函数而不是经典Transformer模型中的ReLU。对于优化,我们使用Adafactor。学习率的schedule为:在开始的10k个step使用0.01的常数学习率,然后使用平方根倒数的学习率。ExT5也使用与T5相同的tokenizer。虽然我们发现
BASE大小的模型很有效,但我们使用ExT5模型。这是因为我们推测,更大容量的模型会更容易过拟合监督数据集,而且也更不容易受到灾难性遗忘的影响。模型越大,则自监督数据集占比越大,因为监督数据集太小从而容易陷入过拟合,以及更不容易受到灾难性遗忘的影响。
微调:为了公平比较,我们对
T5和ExT5采用了相同的微调程序,尽管我们发现ExT5在微调时通常受益于较小的学习率(ExT5采用T5变体采用这里是下游任务,而不是前面提到的 “多任务” (用于预训练)。
具体到每个任务:
SuperGLUE:我们以类似于T5的方式,将整个SuperGLUE作为一个mixture进行微调。我们总共微调了200k步,batch size = 128。在SuperGLUE上选择checkpoint时,我们遵循T5的惯例,为每个任务选择最佳checkpoint,以便与在单个任务上进行微调的模型进行公平比较。一次预训练得到多个
checkpoint,每个任务一个checkpoint。GEM:我们报告了所有数据集的测试集结果,除了CommonGen和ToTTo,我们在这两个数据集上报告了验证集结果。我们扫描了不同的学习率GEM-metrics计算的。对于每个数据集,我们使用验证集上的BLEU、ROUGE-1、ROUGE-2和ROUGE-L分数的平均值来选择最佳model checkpoint。我们使用贪婪解码策略,以与最初的GEM论文保持一致。CBQA:我们报告验证集的结果,并扫描了不同的学习率Rainbow:我们在所有数据集上进行多任务co-train,并扫描了不同的学习率WMTMachine Translation:我们在三个WMT集合上微调我们的模型,即EnDe、EnFr和EnRo。我们使用一个恒定的学习率dropout rate = 0.1。我们用batch size = 4096,最多400k步,并报告峰值的验证集BLEU score。 我们使用beam size = 4,以及ARC:我们报告了Challenge set的分数,batch size = 32,并扫描了不同的学习率CoNLL-03 NER:我们将NER转换为seq2seq,将target写成tags和entities的有序序列(例如"When Alice visited New York" -> "[PER] Alice [LOC] New York")。准确率是在sentence level上衡量的,只有当prediction与reference sequence完全匹配时,才认为它是正确的。
28.2.2 实验
实验配置:我们的实验同时考虑了
within-mixture task和out-of-mixture task(即一个任务是否包括在ExMix中)。within-mixture task衡量任务从多任务预训练和extreme task scaling中受益的程度。与T5的co-trained model类似,我们继续从预训练的ExT5 checkpoint对目标任务进行微调。对于
out-of-mixture task,我们考虑可能是新的未见过的任务、未包括在ExMix mixture中的任务,以测试对unseen task的泛化效果。
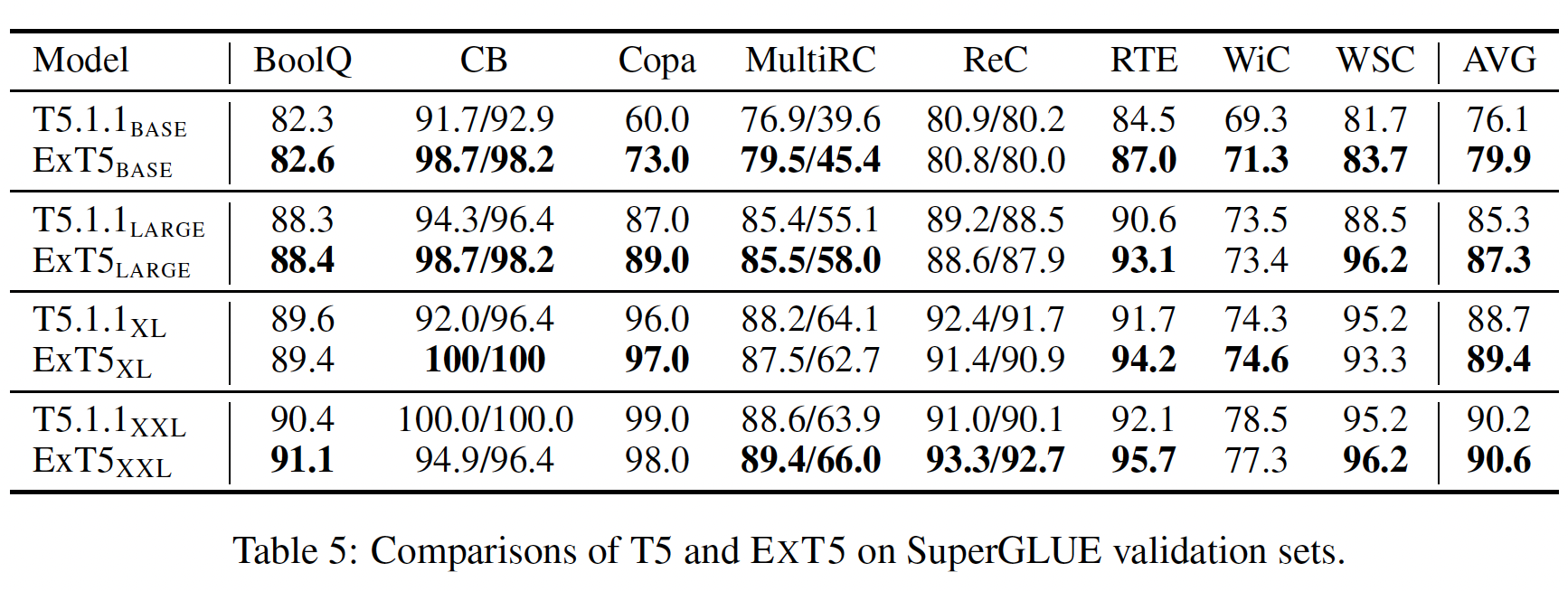
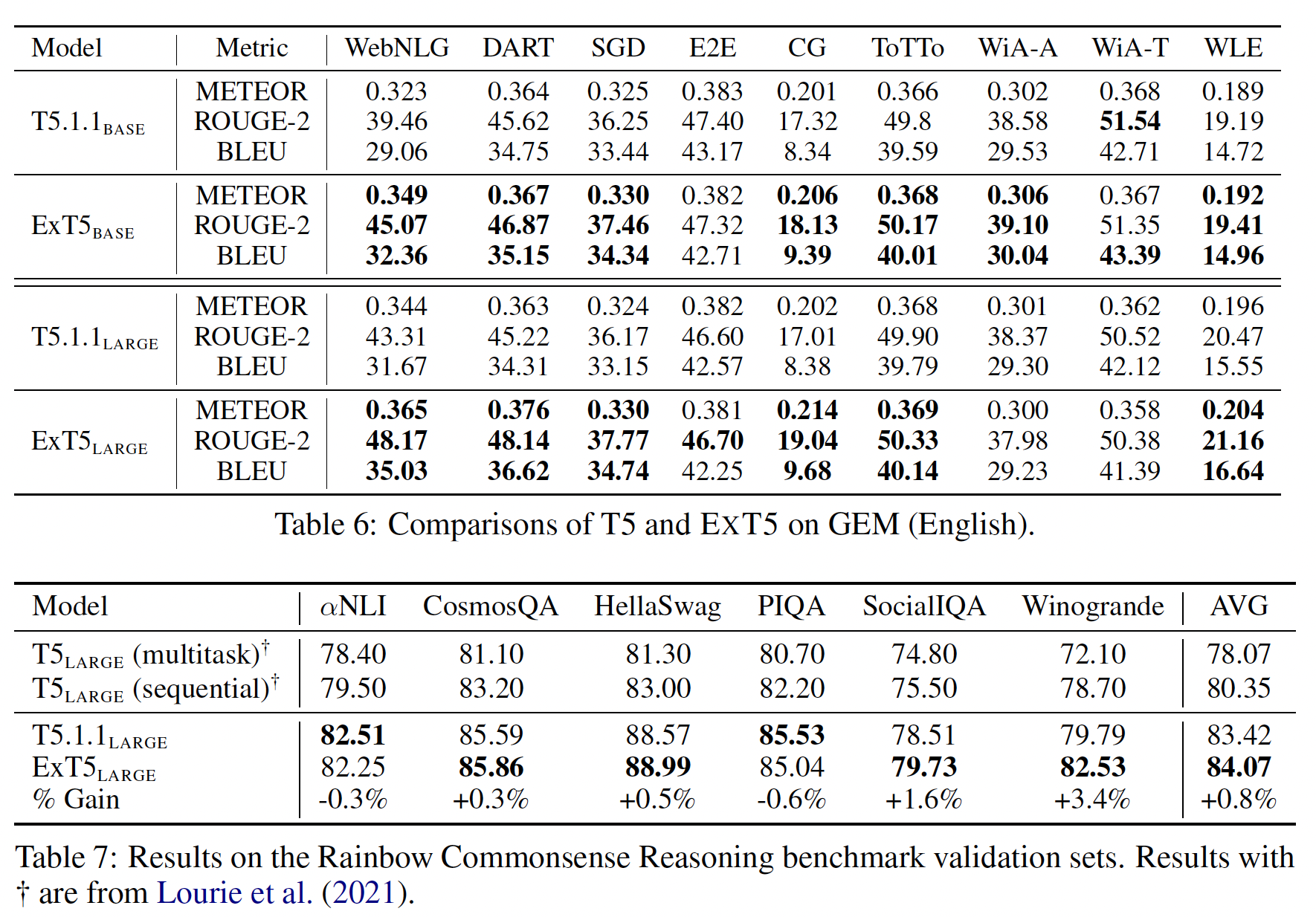
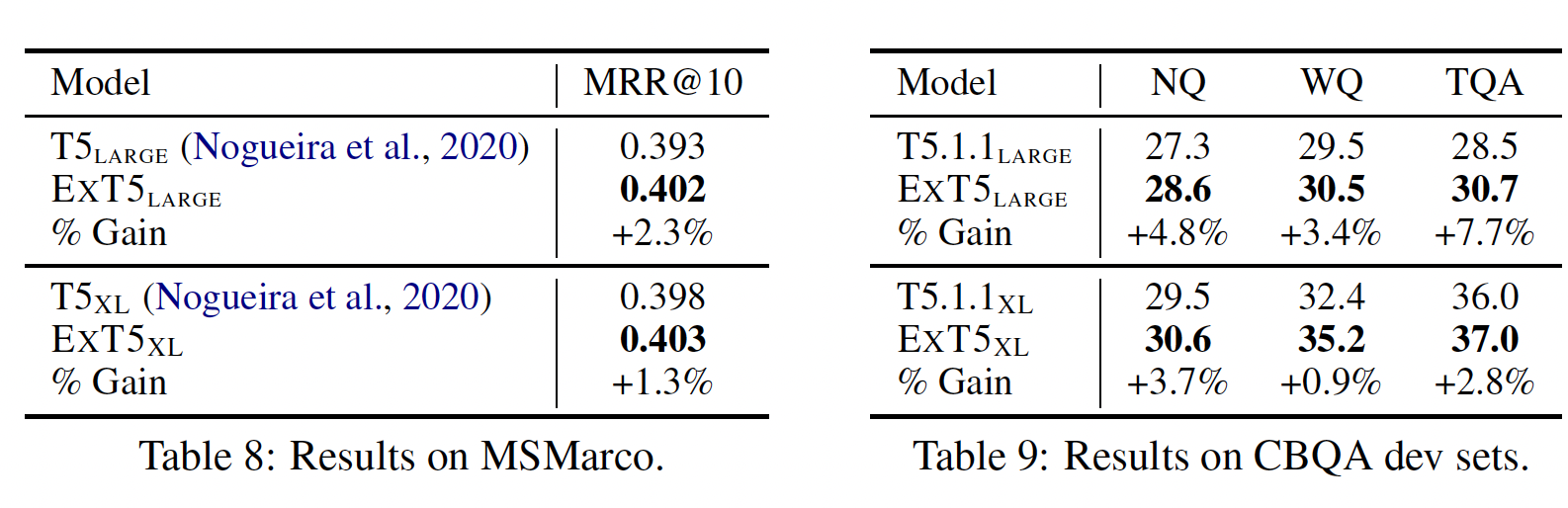
within-mixture task实验结果:我们报告了SuperGLUE (Table 5)、GEM (Table 6)、Rainbow (Table 7)、MsMarco (Table 8)、以及CBQA datasets (Table 9)的结果。总的来说,我们观察到ExT5在一系列的模型大小上都持续地超过了强大的T5 baseline。在
SuperGLUE上,我们的BASE/LARGE/XL模型分别取得了相对+5%/+2.3%/+0.7%的收益。在
GEM上,ExT5在9个任务中的6个超越了T5,而在其他3个任务中保持了相同的水平。值得注意的是,在WebNLG这样的数据集上,large model的收益大约是+11% ROUGE。在
Rainbow上,ExT5比T5平均高出+0.7%。最后,在
question answering和ranking方面,ExT5在两种不同的规模下都大大超过了T5。
out-of-mixture task实验结果:我们也有兴趣在ExMix之外的任务上评估ExT5,并假设ExT5的extreme multi-task pre-training将导致在新的未见过的环境中获得更好的性能。具体来说,我们在以下任务中微调和评估:Machine Translation:将句子从英语翻译成其他语言。推理
Reasoning:回答ARC上的科学问题。命名实体识别
Named Entity Recognition:从CoNLL-2003 NER数据集的句子中提取所有实体。
实验结果如下表所示。可以看到:
ExT5超越了T5 baseline。最大的改进是在ARC科学推理任务上,也许是由于ExMix中大量的QA任务。然而,NER和MT任务并在ExMix中并没有类似的数据集,但是性能也得到了改善。这表明ExT5所学到的representation更具有通用性,可以适应新的objective,即使输出是一种新的语言。从实用的角度来看,
ExT5的这种改进的通用性是非常令人鼓舞的,因为对于任何新的目标任务ExT5的extreme multi-task pre-training已经提供了改进的结果。因此,只有当训练数据集的数量大幅增加时,才值得重复预训练ExT5。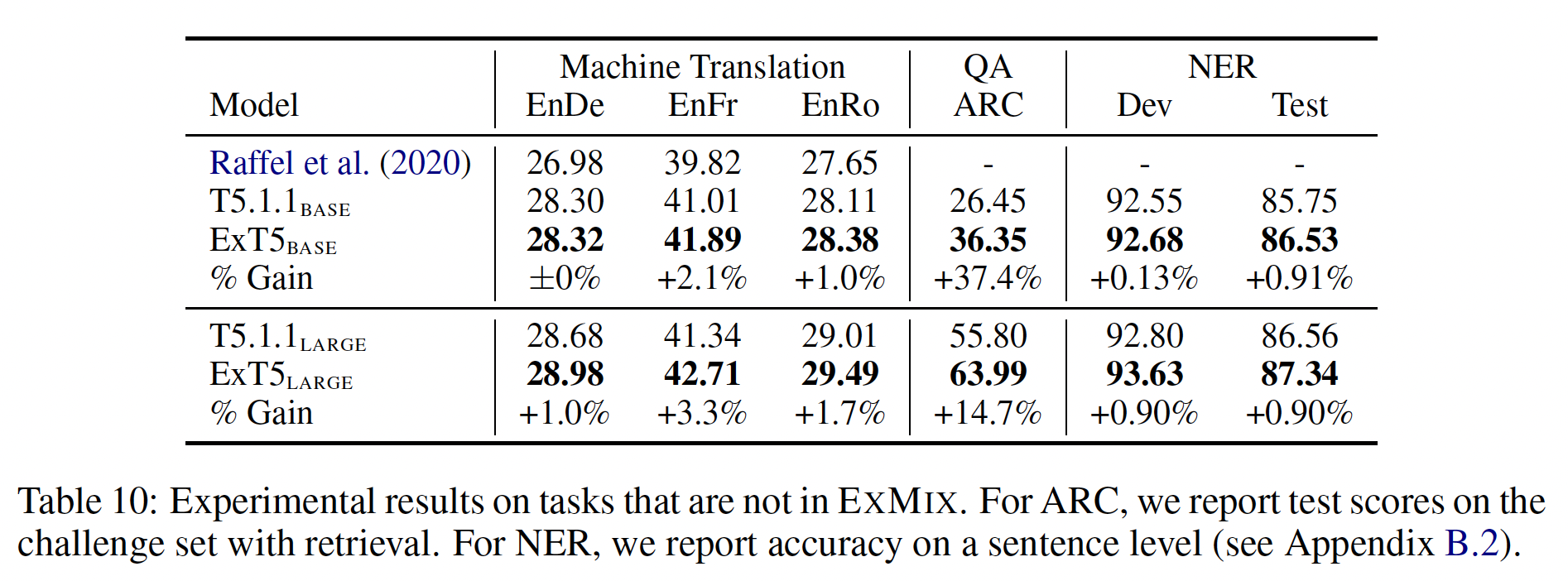
28.3 结语
局限性:尽管我们尽最大努力在尽可能多的代表性任务上进行评估,同时为一组给定的迁移学习实验保持
task partition之间的平衡,但任何显式地将数据集抽象为 "任务族" 的研究都高度依赖于与任务族的representative dataset的性质、domain和表达能力有关的细微差别。在本文中,我们构建了子集从而包含多样化的数据集,我们试图将任务族划分为尽可能的相互排斥。然而,必须承认,没有一个数据集是完全孤立的,任何一组数据集都只是一个更大的 "任务族" 的代表。另外,像
BLEU/ROUGE这样的lexical metric是有用的,但并不能全面反映一个模型在文本生成任务上的真正表现。未来工作:
我们相信,
ExT5的多语言版本将是这项工作的自然延伸。这样一个模型将需要特别注意,不仅要平衡任务族,而且要平衡任务语言。ExMix的多语言版本可以为分析多语言NLP模型如何在不同语言间迁移提供一个更强大的基础。我们还假设,引入旨在利用多任务学习
setup的inductive bias的建模创新可以推动ExT5所显示的强大性能的边界。其他解决方案,如梯度操作,也可能进一步改善
extreme multi-task scaling,尽管代价是更复杂的实现。
二十九、Muppet[2021]
最近语言模型预训练的成功是引人注目的,至少部分是由于使用自我监督而没有任何人工标记的数据。然而,对于许多任务,我们已经有了相关问题的训练样本,我们应该能够利用这些样本。最近的工作表明,多任务
multi-task和多阶段multi-stage的微调方案有收益,但很难知道哪些中间任务会有最好的迁移。在论文《Muppet: Massive Multi-task Representations with Pre-Finetuning》中,作者展示了多任务监督调优multi-task supervised tuning,如果在足够大的规模下用许多不同的任务进行调优,可以成为任务无感知task-agnostic的预训练的有效第二阶段,消除了预先选择最佳中间任务的需要。更具体而言,除了学习语言任务的标准
pre-training/fine-tuning方法外,作者引入了一个新的中间阶段,即预微调pre-finetuning。预微调涉及一个大规模的多任务学习步骤(4.8M个总的训练样本),在大约50个分类、摘要、问答、以及常识推理等任务上进行。作者相信,在任务数量和任务类型方面,他们是第一个研究这种规模的多任务学习。作者特别表明,标准的多任务方案可能是不稳定的,而且往往不能学习高质量的representation。然而,作者引入了一种新的训练方案,该方案使用loss scaling和task-heterogeneous batch,从而使gradient steps在多个不同的竞争任务中得到更加均匀地平衡,大大改善了训练的稳定性和整体性能。作者把他们的预微调模型称为Massive Multi-task RePresentation with PrE-fineTuning: MUPPET。广泛的实验表明:将预微调纳入
RoBERTa模型和BART模型会产生一致的改进,而无需指定具体的intermediate transfer task。这些增益在低资源任务下尤其强大,因为在低资源任务下,用于微调的标记数据相对较少。论文还研究了为什么预微调比以前的多任务方案更出色。作者首先比较了不同的优化技术来稳定训练,发现使用task-heterogeneous batch和task-rebalancing loss scaling很重要。论文还表明,规模是有效的多任务学习的关键。作者从经验上看到了任务数量的临界点(通常超过15个):较少的任务会使representation退化,而在论文能够扩展的范围内,拥有更多任务似乎可以线性地提高性能。论文的贡献包括:
论文表明:可以通过一个额外的阶段进一步改善预训练的
representation,作者称之为预微调pre-finetuning,它利用了大规模的多任务学习。作者展示了标准的pre-trained representation,当通过预微调进一步refine后,可以持续改善下游任务的性能。论文引入了一种新的多任务训练方案,以实现有效的大规模的
learning,该方案使用了loss scaling和task-heterogeneous batch。论文探讨了规模对多任务学习的影响,并展示了多任务训练中存在的临界点,超过这个临界点,增加任务的数量就会改善
generalizable representation。论文围绕
standard pre-trained representation的数据效率、以及它们各自的预微调的representation进行了研究。论文表明,pre-finetuned model在微调时需要的数据更少。
相关工作:在最近的文献中,多任务学习
multi-task learning是一个越来越活跃的话题。最近的进展(如MT-DNN)显示:通过利用多任务学习,我们可以在传统预训练的基础上进一步提高几个language benchmark的性能。然而,T5显示:在更大的模型之上加入多任务学习,并没有改善标准的pre-training/finetuning。因此,人们还没有完全了解多任务学习在不同的预训练方法中的效果。最近
《Unifiedqa: Crossing format boundaries with a single qa system》利用跨数据集的迁移学习,从而展示了在一系列QA任务上做多任务学习的训练可以提高T5的性能。与我们的方法不同,他们将所有的数据转换为seq2seq格式、较小的Multi Task Learning: MTL规模、有不同的batching strategy、并且只聚焦于改善QA任务。我们的工作表明:即使是看起来非常不同的数据集,例如,摘要和extractive QA,也可以通过改善模型的representation来相互帮助。我们的工作旨在探索更大规模的多任务学习。通过纳入更多的任务,我们表明我们可以持续地改善几个领域的
language benchmark。与T5相反的是,我们表明纳入多任务学习确实能带来更好的representation。
29.1 模型
在多任务学习中,平衡来自不同任务的
loss可能是一个挑战:upsampling可能导致低资源任务low resource task的过拟合,downsampling可能导致特定任务的不当学习improper learning。当任务规模更大时,这种困难尤其明显。这里介绍了我们的预微调方法,通过引入新的优化、loss scaling和任务采样方案从而更好地平衡每个mini-batch的更新,导致更稳定和更准确的多任务训练。多样化的任务:为了学习通用的
language representation,我们包括许多领域的各种任务。我们选择了四个不同领域的语言任务:分类classification、 常识推理commonsense reasoning、 机器阅读理解machine reading comprehension、摘要summarization。在下表中,我们显示了每个任务类型的细分,以及在预微调期间每个任务的样本数量。总的来说,我们的多任务setup在4个系列任务中学习了超过4.8M个监督样本。所有任务如下:
xxxxxxxxxxCoLA , SST-2 , MRPC , QQP , MNLI , QNLI , RTE , WNLI , SuperGLUE , Bool Q , MultiRC , WIC , WSC , CB , COPA , AG News , IMDB , MultiNLI , SNLI , HANS , Rotten Tomatoes , Yelp Polarity , Eraser Multi RC , Wiki QA , Trec , SciTail , CNN Daily Mail , Billsum , XSUM , Aeslc , Multinews , Math QA , Openbook QA , SWAG , HellaSWAG , RACE , CommonSense QA , Cosmos QA , AI2 ARC - Easy , AI2 ARC - Challenge , SCIQ , SQUAD , NQ , DROP , RECORD , Hotpot , TriviaQA
标准的损失函数:为了在多个数据集上进行训练,我们的模型包含
task-specific head,每个head都优化task-specific loss。下表总结了损失函数。每个loss都用接下来要描述的loss scaling进行缩放。在loss scaling之后,每个任务的梯度在进行模型更新步骤之前被平均。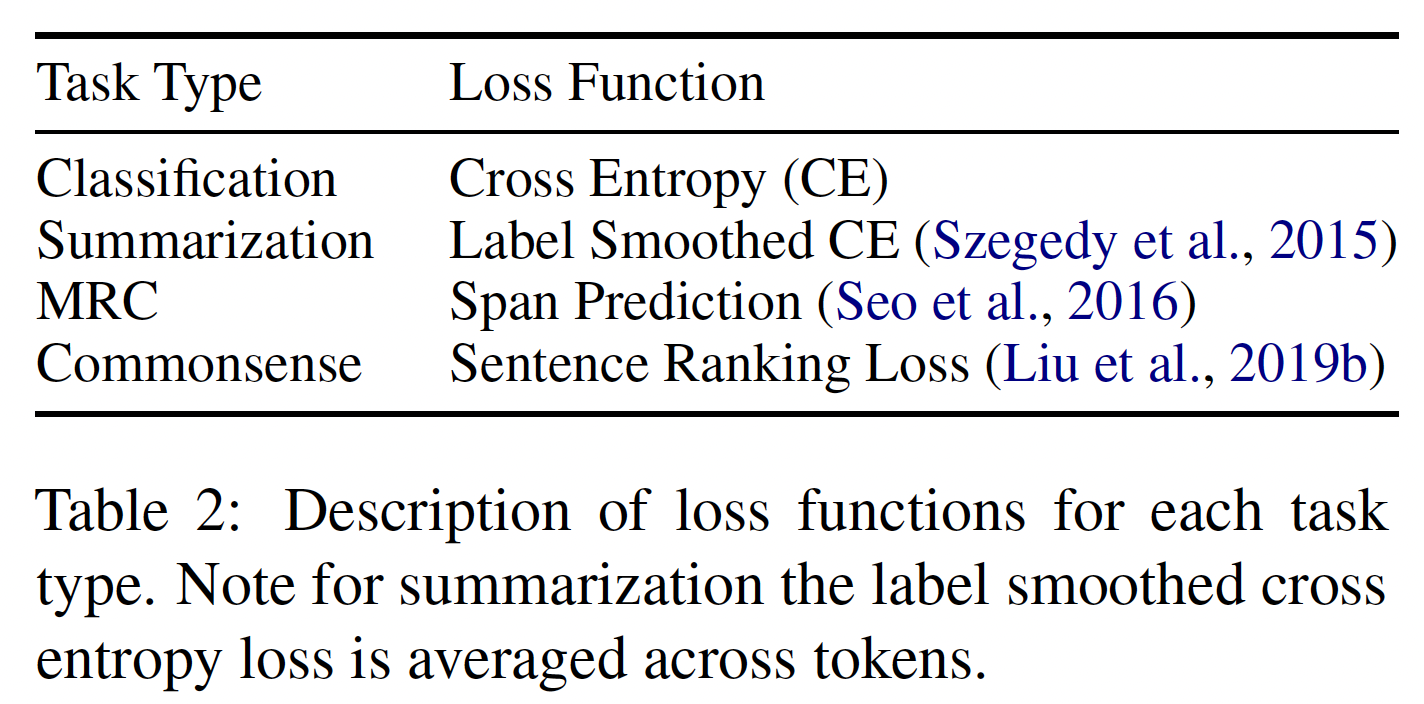
优化:我们展示了两种针对大规模学习
multi-task representation的优化策略:跨任务累积梯度(Heterogeneous Batch)、以及利用Better Finetuning。跨任务累积梯度:我们的模型试图优化的不是一个单一的目标,而是几个可能相互竞争的目标,以便在模型训练期间为几个任务创建一个
unified representation。在梯度下降过程中,沿着单个任务的梯度移动可能不是模型学习跨任务的单个unified representation的最佳方向。为了克服这个问题,我们确保我们的模型优化的每个batch都由几个任务组成。每个worker从我们的任务集合中随机采样一个batch,然后计算梯度,并累积到final update。ExT5对所有任务使用T5的objective,因此可以避免相互竞争的优化目标。根据经验,我们使用
64个GPU进行预微调,导致每个batch由64个sampled task的梯度组成。在实验部分中,我们展示了这样的策略是如何让我们的模型对下游任务的微调有一个更好的representation的。即,每个
GPU对应一个任务,然后所有任务的梯度累加起来。Better Finetuning:在预微调中,我们不是从头开始训练,而是用从自监督的预训练中学到的representation来初始化我们的模型。这可以继承pre-trained representation中的知识,加快训练速度。《On the stability of fine-tuning bert: Misconceptions, explanations, and strong baselines》表明:pre-trained model的标准微调可能是不稳定的,这在我们的案例中可能会加剧,因为我们同时在一组不同的任务上进行训练。因此,我们采用了R3F/R4F方法(《Better fine-tuning by reducing representational collapse》)来解决这个问题。具体而言,
R3F/R4F包括一个额外的损失项,确保输入空间的小扰动导致similar representation,这可以用来在预微调期间学习更鲁棒的representation。R3F添加了一个正则化项:其中:
head对应的输出分布;KL散度。这可以理解为一种数据增强方法。
在早期的实验中,我们发现
R3F是让MUPPET对BART起作用的关键。所有其他的微调和预微调都是用标准的SGD完成的。
Loss Scaling:loss scaling方法引入了对每个样本的损失的乘法加权。已经提出了各种loss scaling技术,从inverse training loss的动态缩放、到各自数据集中样本数量的简单缩放。由于预微调优化了几种不同类型的任务和数据集,每种任务和数据集都有自己的输出空间,因此
loss scaling成为确保稳定训练的关键。在最初的实验中,我们尝试了各种形式的loss scaling,但最有效的是我们下面描述的新方法。令
data-pointprediction的数量。例如,对于二分类任务,2;而对于生成任务,vocabulary size(因为我们对生成的每个token的损失进行平均)。 我们对数据点损失进行缩放:我们发现,这种静态缩放的效果非常好,在早期实验中超过了其他
loss scaling方法。对于生成任务在每个位置的输出是
softmax得到的一个分布。采样:在多任务
setup中平衡各种任务的另一种方法是对较小的数据集进行up-sample,对较大的数据集进行down-sample,从而实现数据集大小之间的uniformity。现有的多任务学习中的数据集采样方法的结果是矛盾的,但最近的工作表明,它对
pre-trained representation的多任务学习效果不好。例如,T5表明,所有各种形式的采样都没有改善overusing数据集的natural size。我们还发现,在最初的实验中,对数据集进行采样始终不利于在
pre-trained representation上的多任务学习。具体而言,我们看到了难以处理的过拟合问题和稳定性问题。因此,我们选择在所有的实验中保持数据集的自然分布(即,没有采样)。实验配置:我们选择了
RoBERTa和BART作为我们最初的预训练模型来进一步预微调。对于每个任务类型,我们使用不同的预测方案:每个
Sentence Prediction数据集都得到一个独立的classification head。对于
Commonsense和MRC,我们为每个任务利用一个单独的unified head。因为实验中我们发现:为每个独立的Commonsense和MRC数据集使用不同的head会导致严重的过拟合。对于
Summarization,我们没有添加任何参数,而是按原样使用BART decoder和output layer。
对于这两个模型,我们对
Base model和Large model都进行了预微调程序。每个模型都用64个GPU进行训练。训练到收敛的时间从1天到4天不等,取决于配置。超参数如下:

29.2 实验
29.2.1 预微调的实验结果
我们首先表明:预微调改善了预训练模型的
representation。为此,我们在一组任务上对我们的pre-finetuned model进行了微调。对于每个单独的下游任务,我们使用固定的超参数搜索来优化简单的超参数,如学习率、
Adam、和dropout。我们在两个Table中展示了我们的结果:Table 3显示了我们在GLUE benchmark以及两个MRC任务(SQuAD、ReCoRD)上的结果。Table 4报告了其他的Sentence Prediction任务以及Commonsense任务的结果。
我们还包括
MT-DNN、ELECTRA和RoBERTa模型的结果。对于Summarization任务,我们表明:我们预微调的BART模型优于所有其他摘要任务的baseline。这两个table都报告了pre-finetuning阶段的可用数据集。鉴于我们的
pre-finetuned model现在通过使用classification head对预微调任务有了了解,我们在微调期间可以选择是否使用这些head。一般而言,我们发现重用classification head对小数据集的MRC、Commonsense、以及Sentence Prediction任务是有益的。总的来说,通过预微调进一步
refine的pre-trained representation优于标准的pre-trained representation。我们在较大的数据集上看到了更小的增益,很可能是因为如果微调的数据集很大,我们就不需要事先
refine representation。在较小的数据集上,我们看到了巨大的收益。例如:
在
RTE上预微调的RoBERTa-BASE模型提高了接近9分,与RoBERTa-Large的准确性相媲美。而预微调的
RoBERTa-Large模型在RTE上获得了新的SOTA,与比它大一个数量级的模型相匹敌。
我们不只是在
sentence prediction任务上有所提高,而是在我们测量的每一组任务上都有所提高。例如,我们在HellaSwag数据集上达到了新的SOTA,以前的SOTA是通过利用一个新的微调方法实现的。我们的方法没有增加参数数量或任何复杂度,但在为下游任务来refine feature方面相当成功。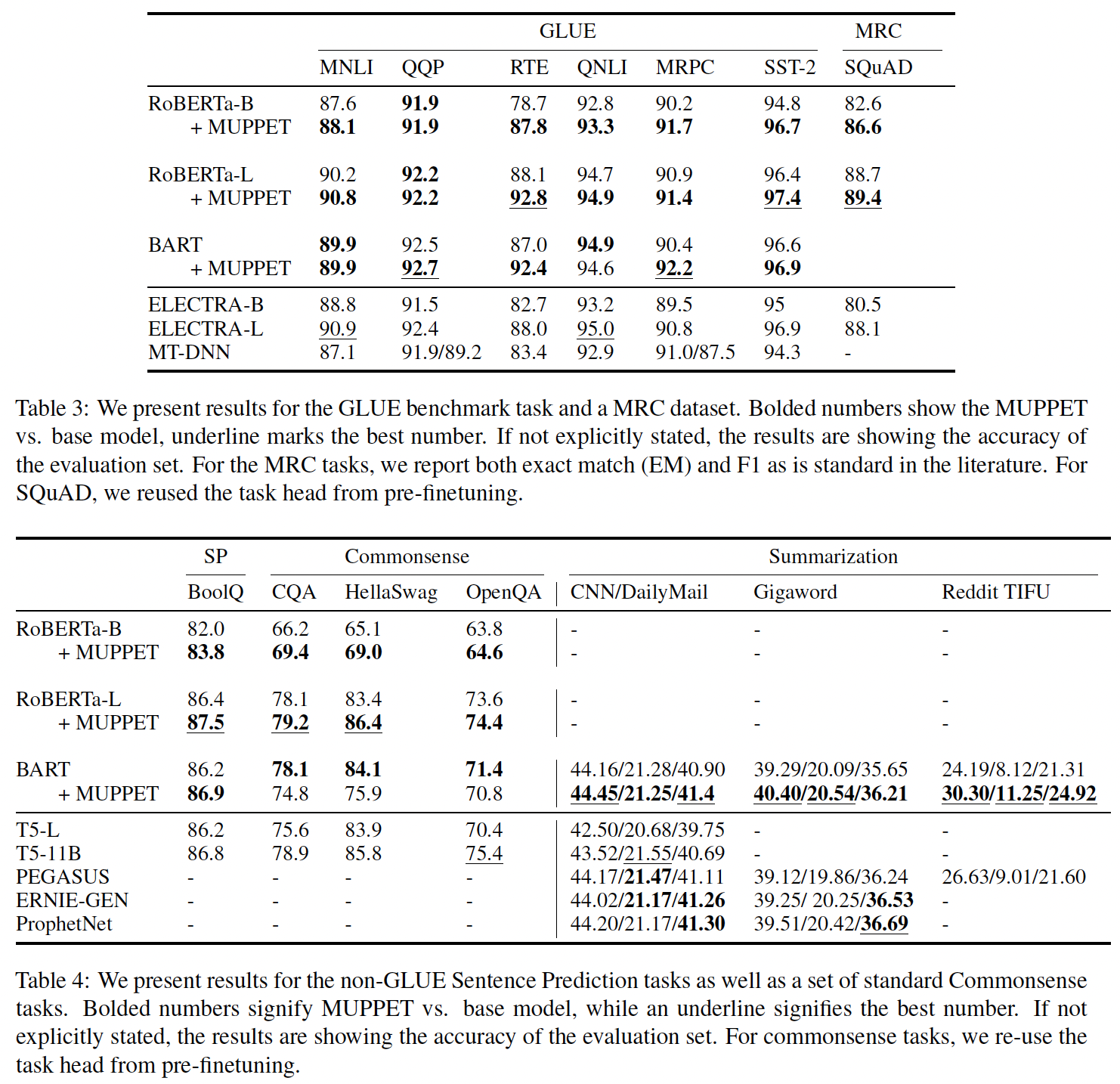
微调不在
Pre-Finetuning Domain的任务:我们还报告了未包含在pre-finetuning data中的任务的性能。为此,我们在一组任务上对我们的模型进行了微调,这些任务包括:用于分类任务的
ANLI和Hyperpartisan。用于摘要任务的
Arxiv和PubMed。用于
structured prediction任务的、来自Penn Treebank数据集的Chunking、Constituency Parsing、以及Part-Of-Speech tagging。
结果如
Table 5和Table 6所示。可以看到:在不同的任务类型和数据集上,我们的模型的
MUPPET变体的表现一直优于baseline。注意,这里的
MUPPET变体指的是base模型(如RoBERTa)的MUPPET变体。作为一个特例,我们对
RoBERTa的MUPPET变体在臭名昭著的ANLI数据集上进行了深入分析,并看到了同样的pattern。pre-finetuned model的表现一直优于它们的base模型。RoBERTa-B + MUPPET要比base模型更差。
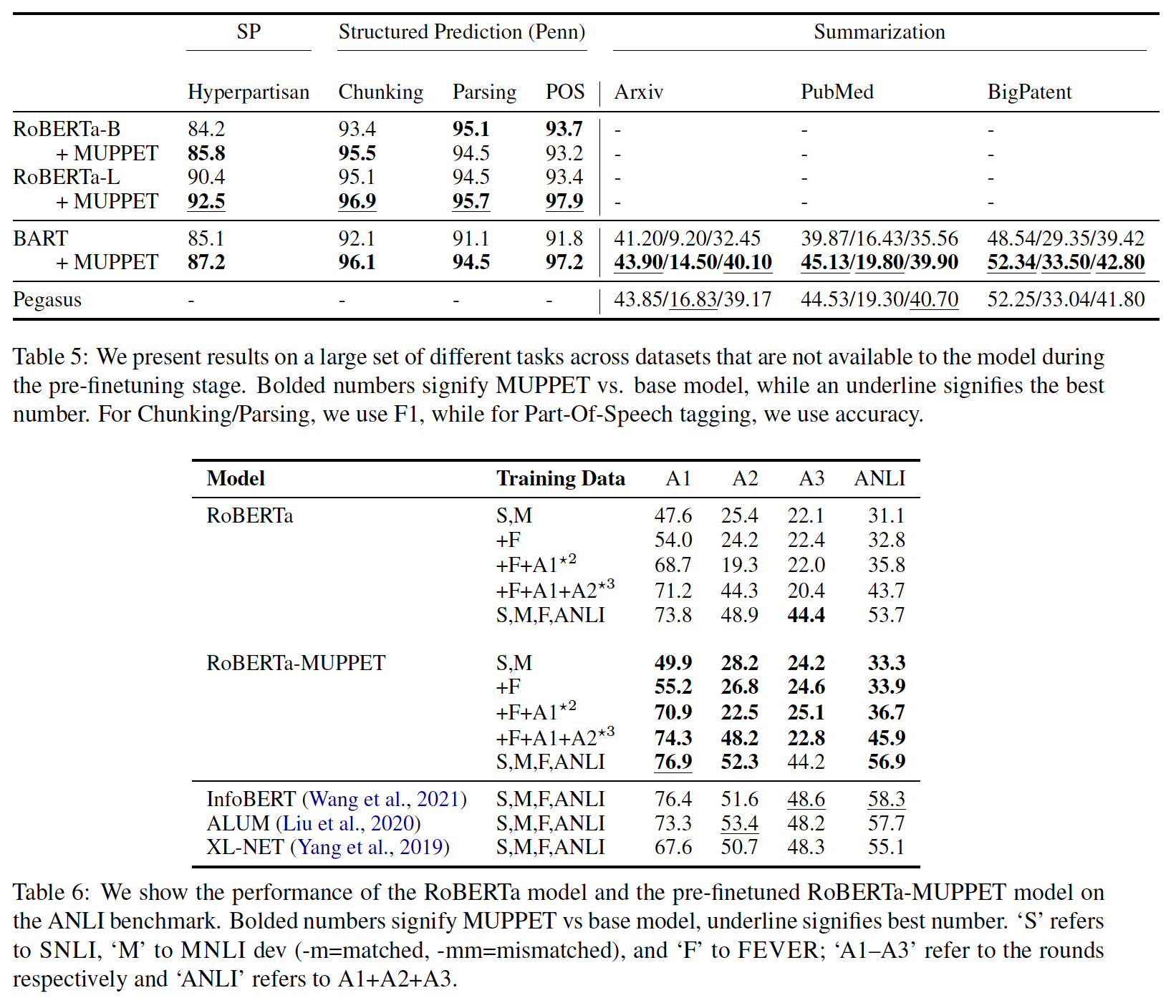
29.2.2 理解大规模的多任务
scale的重要性:我们想探讨的第一个方向是多任务学习的规模。以前的工作(如T5和MT-DNN)聚焦在大约十几个数据集的多任务学习的规模上。就我们所知,我们的论文拥有迄今为止最大的多任务学习的setup。因此,我们有兴趣从经验上探索扩大数据集的数量对多任务学习期间学到的representation的影响。我们用不同数量的数据集来预微调了一组
RoBERTa-Base模型。我们训练七个模型,其中前六个包含10 ~ 40个数据集,而且第A将包含用于预微调模型B的所有数据集。对于每个
pre-finetuned model,我们对五个数据集(STS-B, BoolQ, RACE, SQuAD, MNLI)进行微调,并将结果绘制在下图中。我们在第一次预微调中包括这五个数据集(即,10个数据集的版本),以消除在后期添加它们所产生的bias。我们看到几个有趣的模式:首先,对于个别任务(如
RTE),增加预微调规模单调地提高了性能。这与其他论文的观点一致,即首先在MNLI上进行训练,然后在RTE上进行微调。其次,对于其他数据集,我们看到在小于
15个数据集的情况下进行多任务学习,不利于下游任务的微调。这也与其他的实验观察一致,即T5报告说:多任务学习加微调,并没有改善仅仅微调的效果。然而,当我们增加任务的数量超过某个临界点时,我们
pre-trained representation似乎变得更加通用。此外,尽管取决于数据集,这个临界点大致在10 ~ 25个任务之间。这表明:以前观察到的多任务学习的局限性并不是根本性的,而是可以归因于缺乏足够的规模。
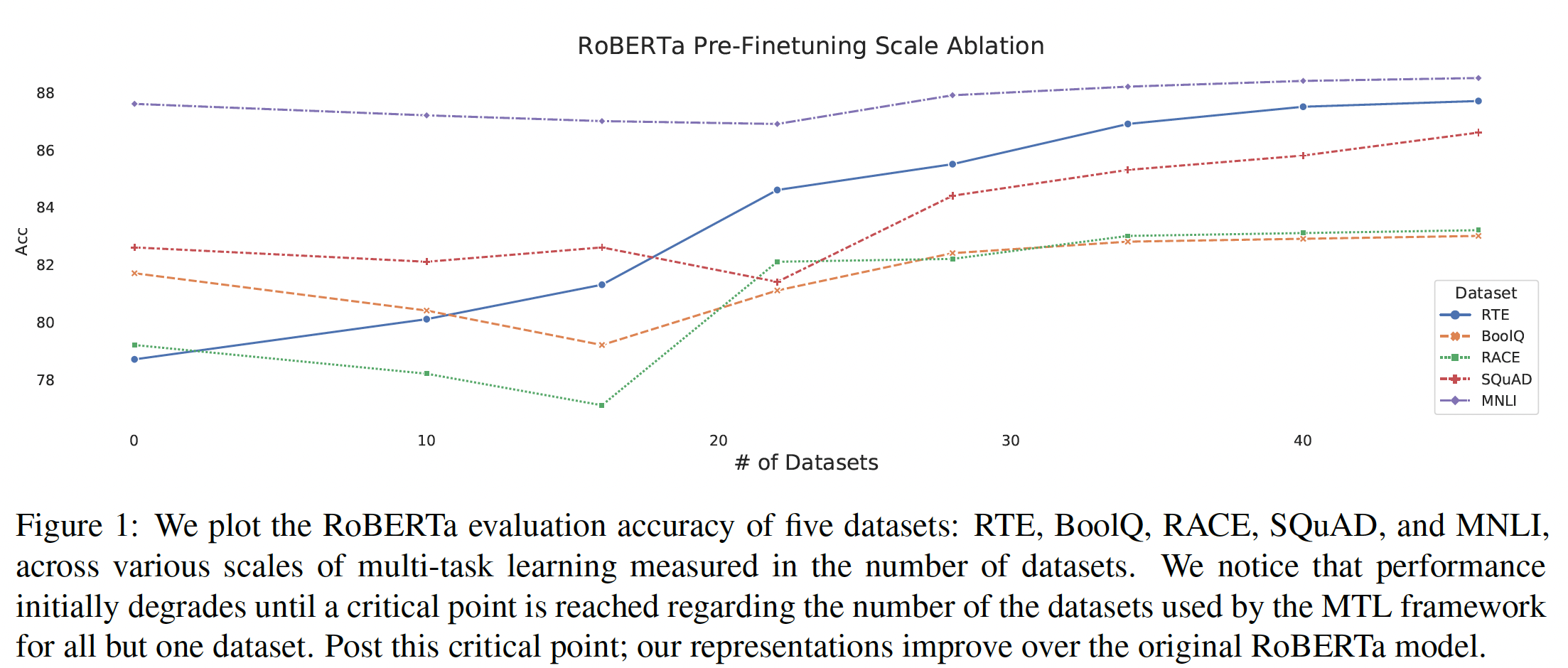
Heterogenous Batch的重要性:学习可泛化的representation的另一个关键因素是如何实现多任务学习,特别是对batch的选择。为了更好地量化这一趋势,我们试验了三种平衡方案:dataset homogenous, batch homogenous, batch heterogenous。dataset homogenous:从数据集中依次选择batch。所以我们首先在数据集A上训练,然后在数据集B上训练,等等。batch homogenous:选择只包含来自同一任务的数据的batch。因此,所有梯度都来自同一个数据集。因此在训练期间,首先在全部数据集中随机选择一个数据集,然后再随机选择该数据集的一个batch。batch heterogeneous:单个update包含来自多个不同数据集的batch,跨不同的任务。我们首先创建homogenous sub-batch,计算每个GPU每个sub-batch的损失,然后在GPU之间进行聚合。因此,单次的梯度更新包含各种数据集和各种任务。
为了分析
heterogeneous batch的重要性,我们使用上述三种数据选择方法在35个随机选择的任务上训练一个RoBERTa-Base模型。然后我们在上一节提到的同样的五个数据集(STS-B, BoolQ, RACE, SQuAD, MNLI)上对这三个模型进行微调。实验结果如下图所示。可以看到:
batching strategy对于有效的多任务学习很重要。我们的发现也与(《Better fine-tuning by reducing representational collapse》)一致,后者认为数据集的sequential training会恶化generalizable representation。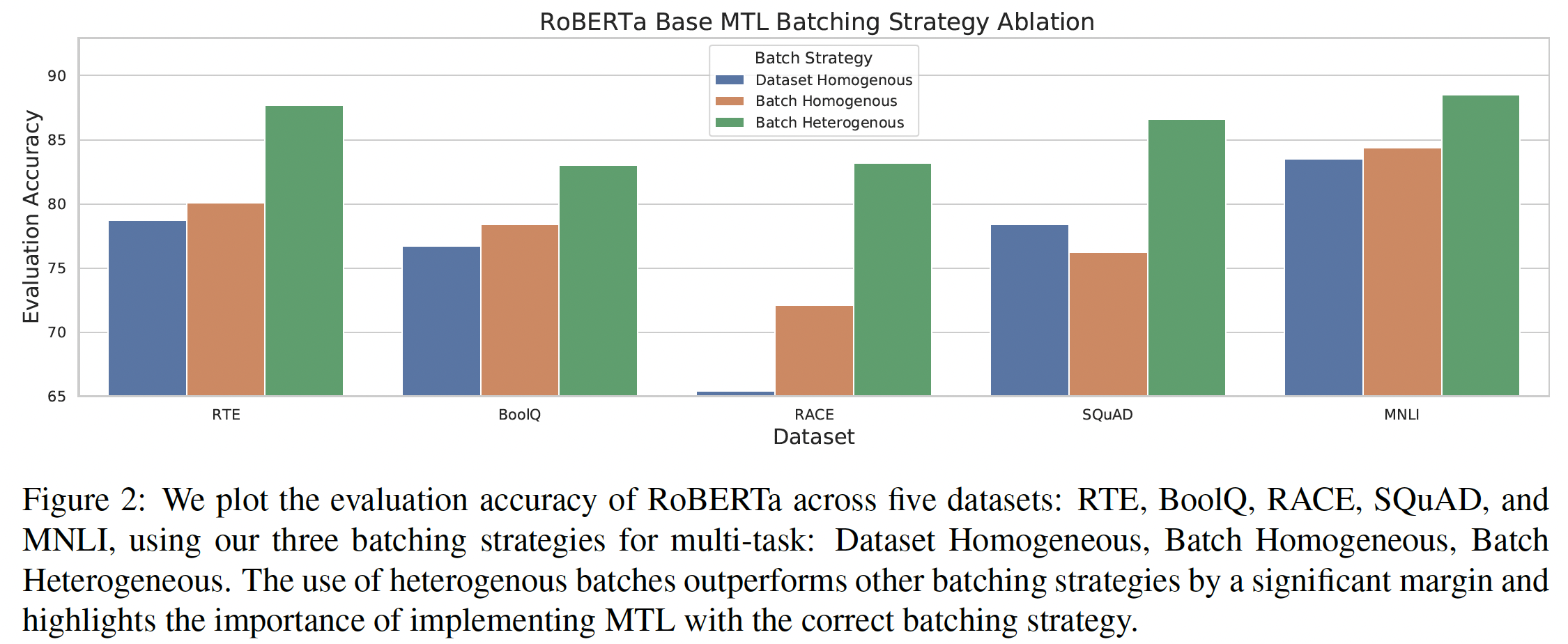
低资源实验:前文提到,数据集规模较小的数据集往往能从多任务学习中得到更多的改善。为了验证这一假设,我们研究了两个因素:预微调的规模、以及微调的规模(微调数据集的大小)。
我们选择三个没有在预微调中使用的数据集,从而作为微调数据集。我们还为每个微调数据集选择九个
partition,每个partition是该数据集的10% ~ 100%之间均匀随机采样得到的。然后,我们用前面实验中已经得到的每个
pre-finetuning checkpoint来微调每个low-resource split。我们绘制微调结果的热力图,如下所示。可以看到:出现了多种模式。首先,随着我们增加多任务学习的规模(纵轴),可以得到更好的
representation从而用于下游任务的微调。此外,在更大的规模上,
pre-finetuned model比标准的pre-trained model的数据效率高得多。具体到下图中的
34/40的预微调规模,我们看到我们比基本的RoBERTa模型(第0行)以更少的资源达到了更高的验证集准确率。
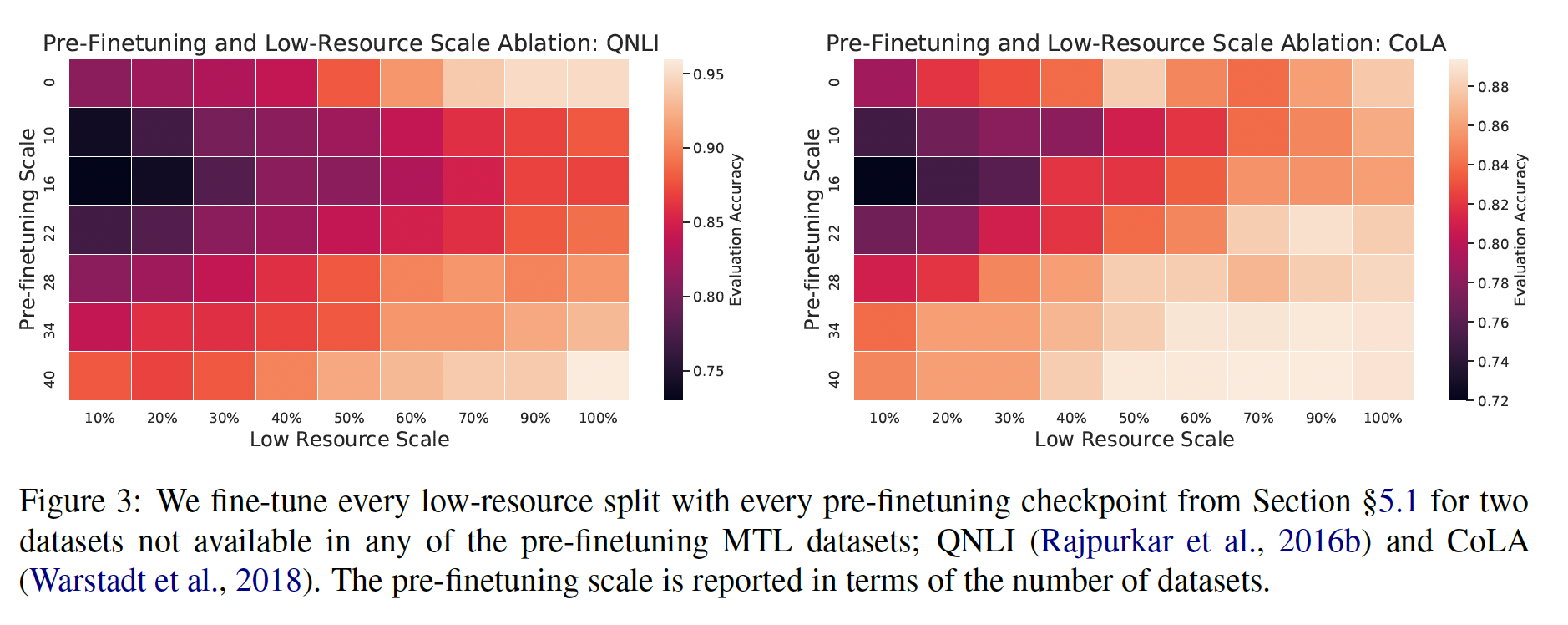
三十、Self-Attention with Relative Position Representations[2018]
递归、卷积、注意力机制以不同的方式纳入关于位置的信息。
RNN通过hidden stateinput elements,因此可能需要显式地编码位置信息,从而能够使用sequence order。一种常见的方法是使用
position encoding,它与输入元素相结合,从而将位置信息暴露给模型。这些position encoding可以是位置的确定性函数、或者learned representation。CNN在每个卷积的kernel size范围内固有地捕获相对位置,然而它们已经被证明仍然受益于position encoding。对于既不采用卷积、也不采用递归的
Transformer来说,纳入位置信息的explicit representation是一个特别重要的考虑,因为该模型完全不受sequence ordering的影响。因此,atention-based model已经使用了position encoding、或基于距离的biased attention weight。在论文
《Self-Attention with Relative Position Representations》中,作者提出了一种有效的方法,将relative position representation纳入Transformer的自注意力机制中。论文的方法可以被看作是Transformer的自注意力机制的扩展,其中考虑来自相同输入的任何两个元素之间的任意关系。相关工作:
Self-Attention:给定输入序列self-attention layer包含attention head,每个head将输入序列head得到的第其中:
30.1 模型
我们提出对自注意力的扩展,从而考虑输入元素之间的
pairwise relationship。在这个意义上,我们将input建模为一个labeled, directed, fully-connected graph。输入元素edge representation的动机是,其中:我们分别修改了
edge representation可以在不同的attention head之间共享。这个扩展对于一些任务来说可能是很重要的,在这些任务中,一个给定的
attention head所选择的edget type的信息对于下游的encoder layer或decoder layer是有用的。然而,正如实验部分所探讨的,这对于机器翻译任务来说可能是不必要的。我们通过简单加法纳入
edge representation的主要动机是为了高效的实现。相对位置信息与两个元素相关,因此相对位置信息在计算
attention期间加入。而绝对位置信息仅与元素本身有关,因此绝对位置信息在input期间加入。Relative Position Representation:由于序列是线性结构,因此edge可以捕获输入元素之间的relative position difference的信息。我们所考虑的最大相对位置的绝对值被截断为unique edge label:然后我们学习
relative position representation:高效的实现:
由于需要考虑任意两个元素之间的相对位置信息,因此对于长度为
head之间共享relative position representation,将其空间复杂性降低到relative position representation。假设batch size为batch的自注意力的空间复杂度从考虑到最大相对位置的绝对值被截断为
对于一个
batch中的所有序列、head、position,Transformer使用并行的矩阵乘法从而高效地计算self-attention。在没有relative position representation的情况下,每个head和序列,每个矩阵乘法计算所有位置的representation。即:
然而在我们的
relative position representation中,不同position pair的representation是不同的。这使得我们无法在一次矩阵乘法中计算所有position pair的所有第一项与传统的
Transformer相同,第二项包含relative position representation。对于第二项,我们可以通过
tensor reshape从而计算head和batch对相同的方法可以用于计算
steps/second降低了7%左右。如果不这么做,可能会降低更多。然而论文没有给出对比数据。
30.2 实验
数据集:
WMT 2014机器翻译任务。WMT 2014 English-German数据集,包括大约4.5M个sentence pair。2014 WMT English-French数据集,包括大约36M个sentence pair。
配置:
我们使用
32768大小的word-piece vocabulary。我们按相近长度对
sentence pair进行batch,并将每个batch的input tokens和output tokens限制在4096/GPU。 每个training batch包含大约25,000个source tokens和25,000个target tokens。我们使用
Adam优化器,Transformer相同的warmup策略(4k个step的预热)和decay策略。在训练过程中,我们采用了
0.1的label smoothing。评估时,我们使用
beam size = 4的beam search,惩罚系数为对于
base模型:我们使用了
6个encoder layer和6个decoder layer,attention head数量为8,feed forward inner-layer维度为dropout rate = 0.1。当使用
relative position encoding时,我们截断距离为layer和head使用unique edge representation。我们在
8个K40 GPU上训练了100k步,并且没有使用checkpoint averaging。
于
big模型:我们使用了
6个encoder layer和6个decoder layer,attention head为16,feed forward inner-layer维度为EN-DE数据集使用dropout rate = 0.3,对于EN-FR数据集使用dropout rate = 0.1。当使用
relative position encoding时,我们截断距离为layer使用unique edge representation。我们在
8个p100 GPU上训练了300k步,并对最后20个checkpoint进行了平均,每隔10分钟保存一次checkpoint。
baseline:使用正弦position encoding的Transformer。实验结果如下表所示,可以看到:
对于
English-to-German,我们的方法比baseline分别提高了0.3 BLEU和1.3 BLEU。对于
English-to-French,我们的方法比baseline分别提高了0.5 BLEU和0.3 BLEU。
在我们的实验中,我们没有观察到同时包含
sinusoidal position encoding和relative position representation的任何好处(相对于仅包含relative position representation)。relative position representation的效果提升不多,并且更难并行化,因此性价比不高?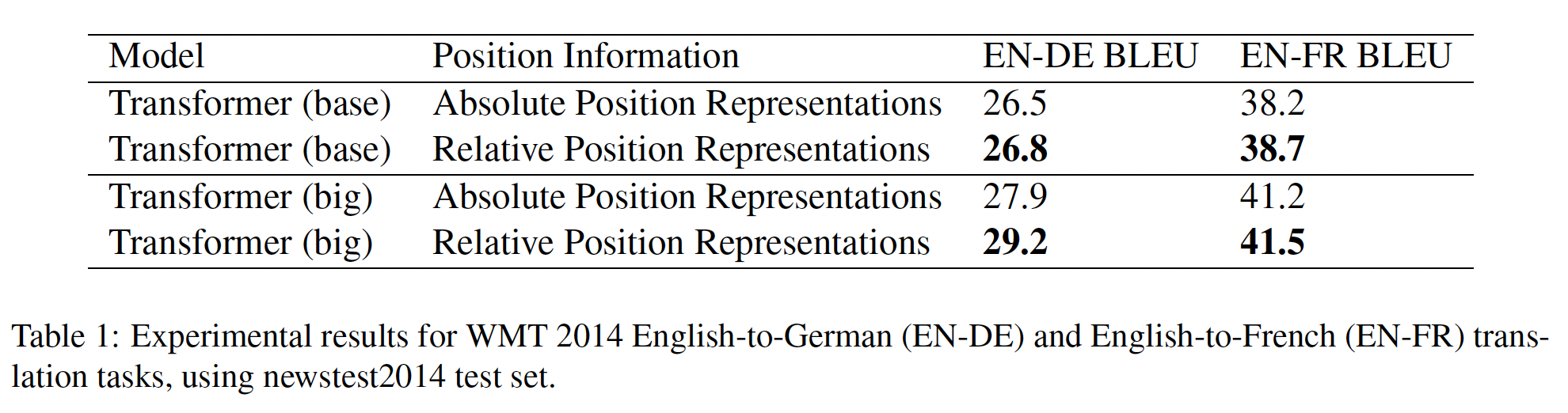
消融实验:这里的所有实验都使用了没有任何
absolute position representation的base模型配置。BLEU score是在newstest2013 WMT English-to-German任务中使用验证集计算的。我们评估了不同的
BLEU score似乎没有什么变化。由于我们使用多个encoder layer,精确的relative position信息可能会传播到距离
我们还评估了是否包含