四十七、GLM-130B[2022]
大型语言模型(
large language model: LLM),尤其是那些参数超过100B的语言模型,已经呈现出有吸引力的scaling laws,并突然涌现(emergent)出zero-shot能力和few-shot能力。其中,具有175B参数的GPT-3在各种benchmark上用32个标记样本产生了比完全监督的BERT-Large模型更好的性能,从而开创了100B-scale LLM的研究。然而,GPT-3(以及其他100B-scale的模型)的模型本身、以及如何训练该模型,迄今为止都没有向公众开放。训练如此规模的高质量LLM,并与大家分享模型和训练过程,是非常有价值的。因此,论文
《GLM-130B: An Open Bilingual Pre-trained Model》的目标是在考虑到伦理问题的前提下,预训练一个开放的、高度准确的100B-scale的模型 。在作者的尝试过程中,作者认识到,与训练10B-scale的模型相比,在预训练的效率、稳定性和收敛性方面,预训练如此规模的dense LLM会带来许多意想不到的技术挑战和工程挑战。在训练OPT-175B和BLOOM-176B时也同时观察到类似的困难,进一步证明了GPT-3作为先驱研究的意义。在该论文中,作者介绍了
100B-scale模型(即,GLM-130B)的预训练,包括工程工作、模型设计选择、针对效率和稳定性的训练策略,以及针对可负担推理(affordable inference)的量化。由于人们普遍认识到,从计算上来说,枚举所有可能的设计来训练100B-scale LLM是不经济的,因此作者不仅介绍了训练GLM-130B的成功部分,也介绍了许多失败的方案和经验教训。特别是,训练的稳定性是训练如此规模的模型的成功的决定性因素。与OPT-175B中手动调整学习率和BLOOM-176B中牺牲性能使用embedding norm等做法不同,作者尝试了各种方案,发现embedding gradient shrink的策略可以显著稳定GLM-130B的训练。具体而言,
GLM-130B是一个具有130B个参数的双语(英文和中文)的双向的dense model,在2022年5月6日至7月3日期间,在96个NVIDIA DGX-A100(40G * 8)GPU节点的集群上预训练了超过400B个token。作者没有使用GPT-style的架构,而是采用了通用语言模型(General Language Model: GLM)算法(《Glm: General language model pretraining with autoregressive blank infilling》),以利用其双向注意力的优势、以及自回归的blank infilling objective。下表总结了GLM-130B、GPT-3和另两个开源工作(OPT-175B和BLOOM-176B)、以及PaLM 540B(一个更大的模型)作为参考。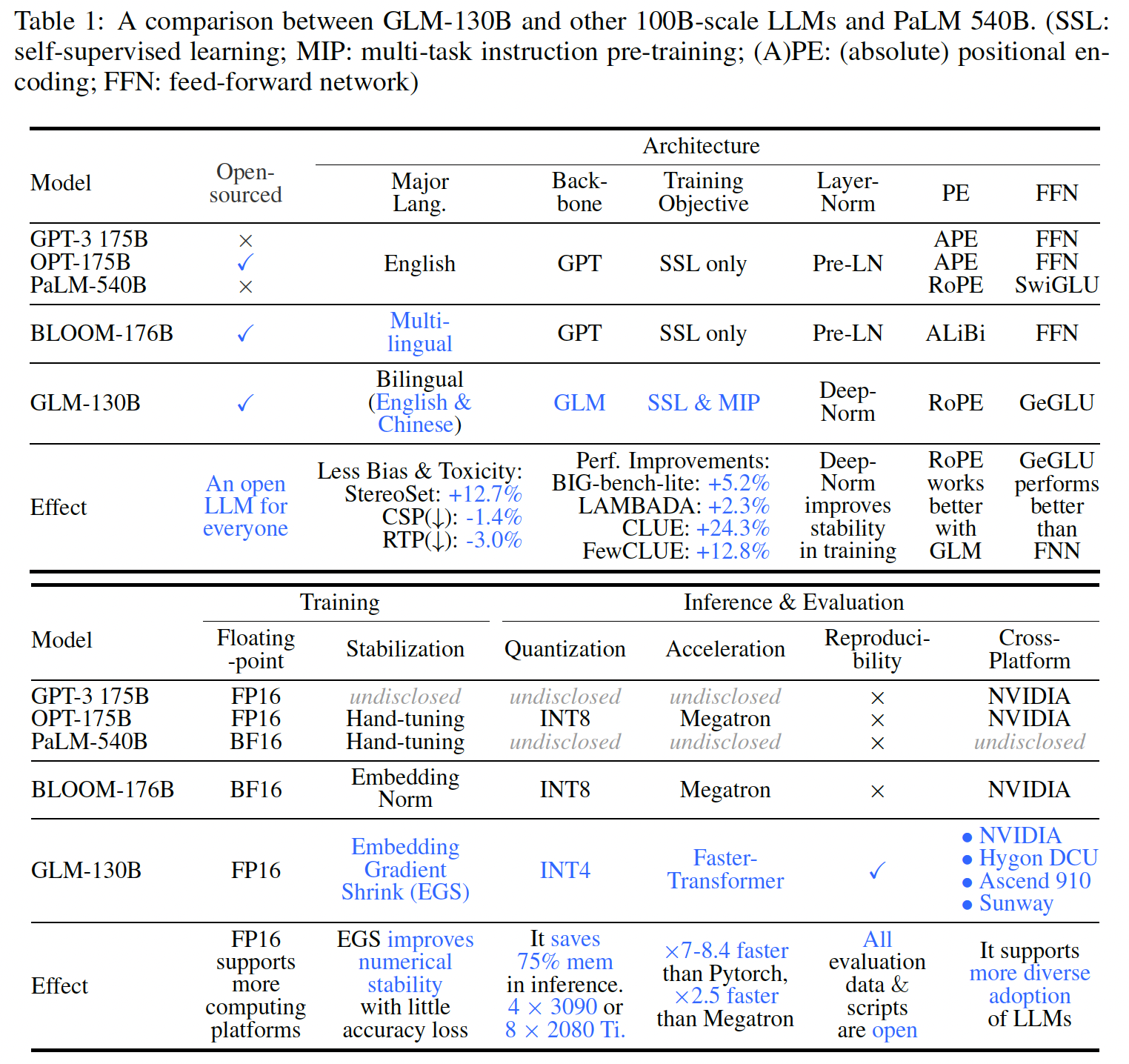
总之,概念上的独特性、以及工程上的努力使
GLM-130B在广泛的benchmark(总共112个任务)上表现出超过GPT-3的性能,在许多情况下也超过了PaLM 540B。此外,OPT-175B和BLOOM-176B中没有观察到超过GPT-3的性能(参考图Figure 1(a))。对于
zero-shot性能,GLM-130B在LAMBADA上优于GPT-3 175B(+5.0%)、OPT-175B(+6.5%)、以及BLOOM-176B(+13.0%),并在Big-bench-lite上取得比GPT-3更好的性能。对于
5-shot的MMLU任务,GLM-130B比GPT-3 175B(+0.9%)和BLOOM-176B(+12.7%)更好。作为一个中文的双语
LLM,它的结果明显优于ERNIE TITAN 3.0 260B(最大的中文LLM),在7 zero-shot的CLUE数据集上(+24.26%)和5 zero-shot的FewCLUE数据集上(+12.75%)。
重要的是,正如图
Figure 1(b)所总结的那样,GLM-130B作为一个开放的模型,其bias和generation toxicity明显低于100B-scale的同类模型。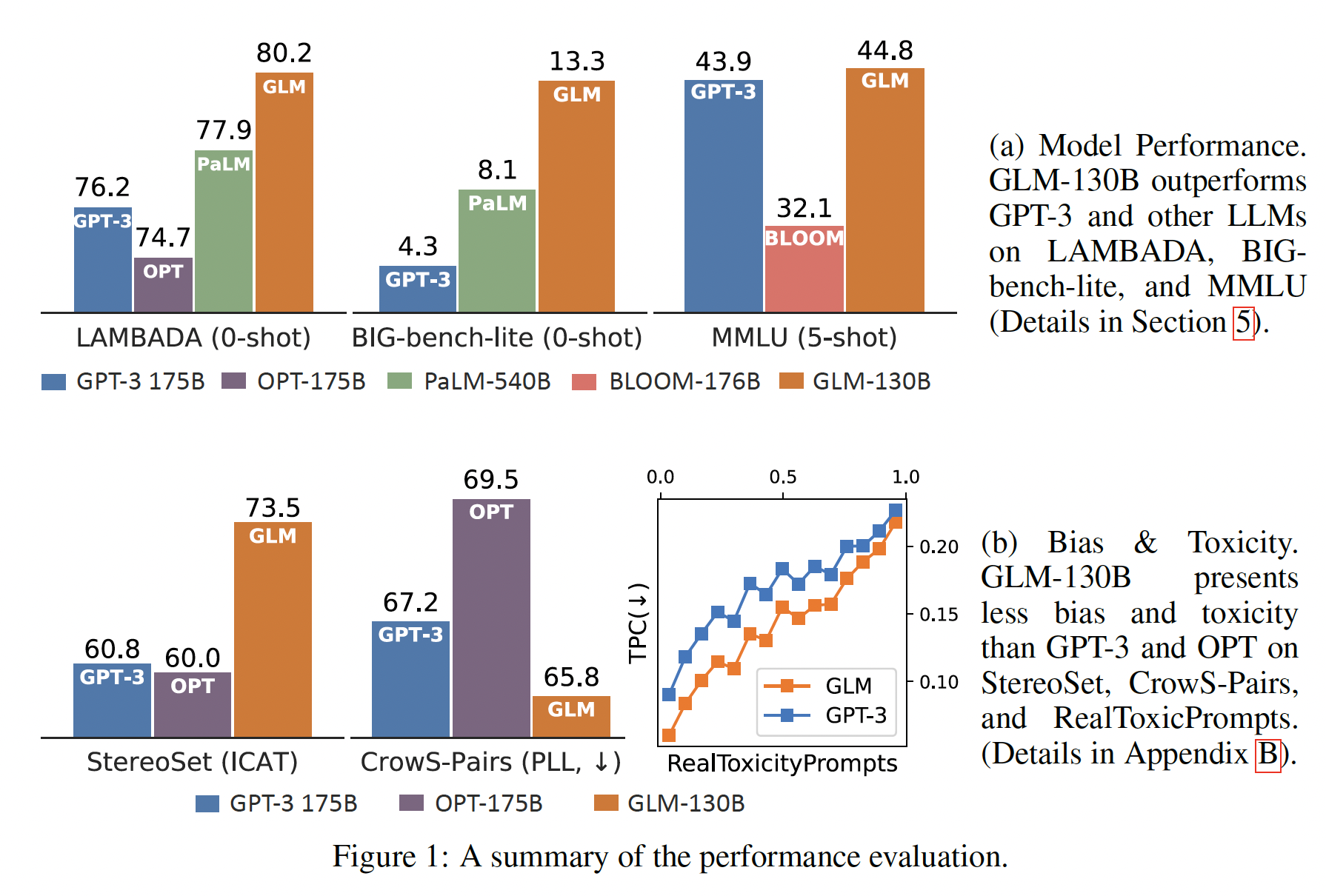
最后,作者设计
GLM-130B是为了让尽可能多的人能够进行100B-scale LLM的研究:首先,没有像
OPT和BLOOM那样使用175B以上的参数,而是决定采用130B的规模,因为这样的规模支持在单台A100服务器(8个40G A100 GPU)上进行推理。其次,为了进一步降低对
GPU的要求,作者将GLM-130B量化为INT4精度,而OPT和BLOOM只能达到INT8。由于GLM架构的独特属性,GLM-130B的INT4量化带来的性能下降可以忽略不计,例如,在
LAMBADA上为-0.74%,在MMLU上甚至为+0.05%,使其仍然优于未压缩的GPT-3。这使得GLM-130B在4个RTX 3090(24G)或8个RTX 2080 Ti(11G)的服务器上实现了快速推理,这是迄今为止使用100B-scale LLM所需的最实惠的GPU。
作者开源了
model checkpoint、代码、训练日志、相关工具包和经验教训。相关工作:这里我们将回顾
GLM-130B的相关工作,包括预训练、迁移、和推理,这些工作利用web-scale语料库的自监督学习,近年来深深影响了学术界和社会。Pre-Training:平凡的语言模型指的是decoder-only的自回归模型(如GPT),但它也承认(recognize)任何形式的文本上的自监督目标。最近,基于transformer的语言模型呈现出迷人的scaling law:随着模型规模的扩大,新的能力涌现了,从1.5B规模的语言模型、10B规模的语言模型,到100B规模的GPT-3。后来,尽管出现了许多
100B-scale LLM的英文版本和中文版本,但它们没有向公众提供,或者只能通过有限的API访问。LLM的封闭性严重阻碍了其发展。GLM-130B的努力,以及最近的ElutherAI、OPT-175B和BLOOM-176B,旨在为我们的社区提供高质量的开源LLM。另外,使GLM-130B与其他项目不同的是,GLM-130B注重LLM对所有研究人员和开发者的包容性(inclusivity)。从我们对模型规模的决定,对模型架构的选择,以及允许模型在主流的GPU上进行快速推理,GLM-130B相信,对所有人的包容性才是实现LLM对人们承诺的福利的关键。Transferring:尽管微调一直是迁移学习的事实方式,但由于LLM的规模巨大,其转移学习一直集中在prompting和in-context learning上。继类似的LLM之后,在这项工作中,我们的评估也是在这种环境下进行的。然而,最近的一些尝试是关于语言模型的parameter-efficient learning(《Parameter-efficient transfer learning for nlp》)和prompt tuning(即P-tuning)。在这项工作中,我们不关注它们,并将它们在GLM-130B上的测试留在未来的研究中。Inference:现在大多数可公开访问的LLM都是通过有限的API提供服务的。在这项工作中,我们努力的一个重要部分是对LLM的高效和快速的推断。相关工作可能包括蒸馏、量化、以及剪枝。最近的工作(《Llm. int8 (): 8-bit matrixmultiplication for transformers at scale》)表明,由于outlier dimension的特殊分布,OPT-175B和BLOOM-176B等LLM可以被量化为8 bit。然而,在这项工作中,我们根据我们对
LLM架构选择的新见解,证明GLM对INT4权重量化的scaling law。这种量化,加上我们在使GLM-130B适应FasterTransformer方面的工程努力,使得GLM-130B可以在少至4个RTX 3090 (24G) GPU或8个GTX 1080 Ti (11G) GPU上有效推断。它实现了LLM对公众的经济可用性,并分阶段实现了我们对LLM的包容性的承诺。
47.1 GLM-130B 的设计选择
一个机器学习模型的架构定义了它的归纳偏置(
inductive bias)。然而,人们已经意识到,探索LLM的各种架构设计在计算上是负担不起的。我们介绍并解释GLM-130B的独特的设计选择。
47.1.1 架构
GLM作为Backbone:最近大多数100B-scale LLM(如GPT-3、PaLM、OPT和BLOOM),都遵循传统的GPT风格的decoder-only autoregressive language modeling架构。在GLM-130B中,我们反而尝试探索双向的General Language Mode: GLM作为其backbone的潜力。GLM是一个基于transformer的语言模型,利用autoregressive blank infilling作为其training objective。简而言之,对于一个文本序列text spantoken:mask token,从而获得被破坏的文本序列corrupted spans之间的交互,它们之间的可见性是由对它们的顺序进行随机抽样的permutation来决定的。pre-training objective被定义为:其中:
permutation的集合,span数量。text span。text span中,所有位于token。
GLM对unmasked contexts的双向注意力使GLM-130B区别于使用单向注意力的GPT-style LLMs。为了同时支持understanding和generation,它混合了两种corruption objective,每种objective由一个special mask token来标识:[MASK]:句中的short blank,它们的长度加起来等于输入句子长度的某个比例(这个比例是一个超参数)。[gMASK]:随机长度的long blank,它们出现在句子末尾并且具有所提供的prefix context。
从概念上讲,具有双向注意力的
blank infilling objective能够比GPT-style model更有效地理解上下文:当使用
[MASK]时,GLM-130B的表现与BERT和T5相似。当使用
[gMASK]时,GLM-130B的表现与PrefixLM(如,UniLM)相似。
在下图中,根据经验,
GLM-130B超越了GPT-3和PaLM 540B,在zero-shot LAMBADA上提供了80.2%的创纪录的高准确率。通过设置注意力掩码,GLM-130B的单向变体(unidirectional variant)与GPT-3和OPT-175B相当。我们的观察结果与现有的研究结果一致。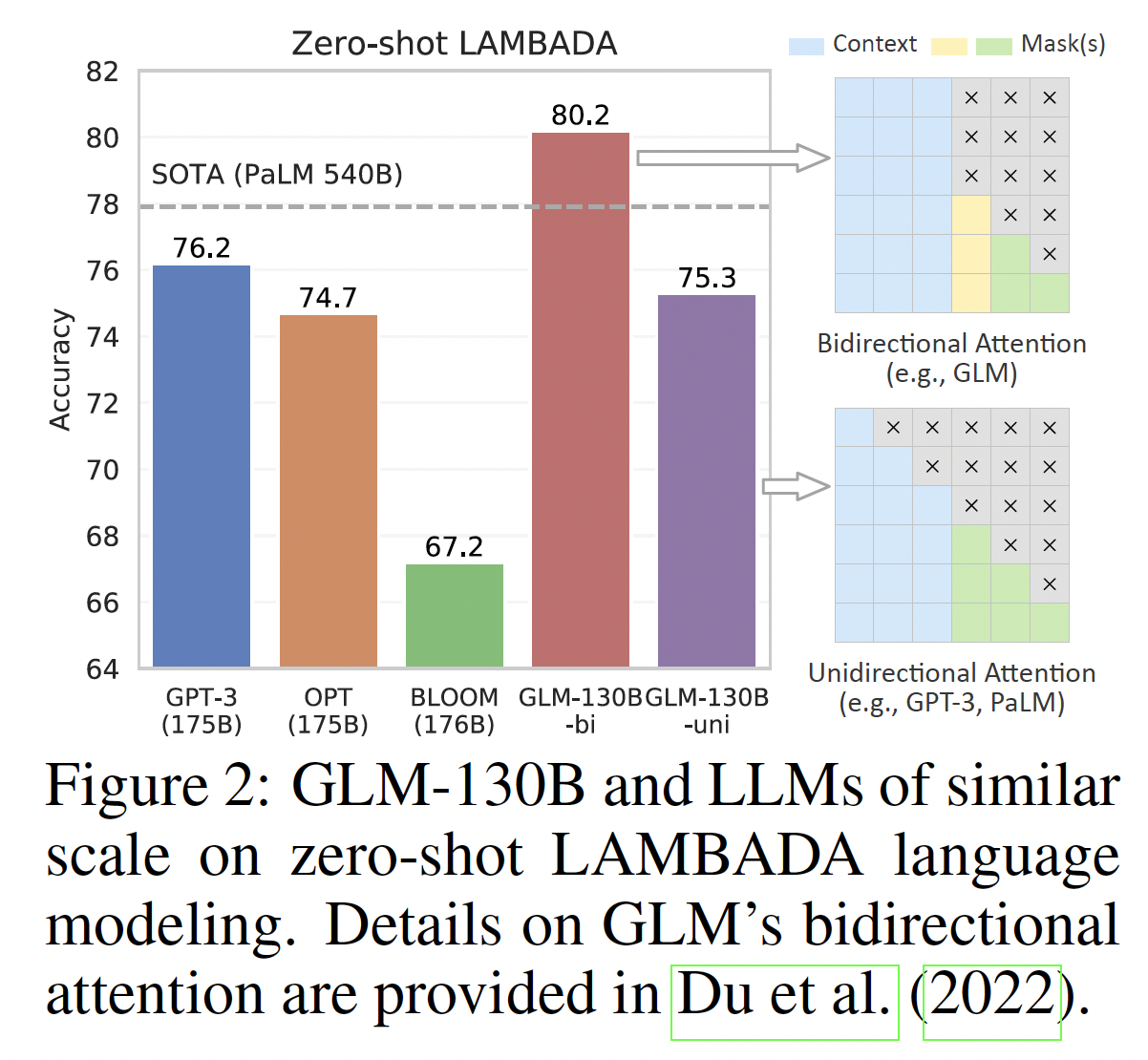
Layer Normalization: LN:训练不稳定是训练LLM的一个主要挑战(如Figure 11所示,训练一些100B-scale model时的崩溃情况)。适当选择LN可以帮助稳定LLM的训练。我们尝试了现有的做法,例如Pre-LN、Post-LN、Sandwich-LN,遗憾的是这些做法无法稳定我们的GLM-130B test run(详见图Figure 3(a)和附录技术细节中Layer Normalization的内容)。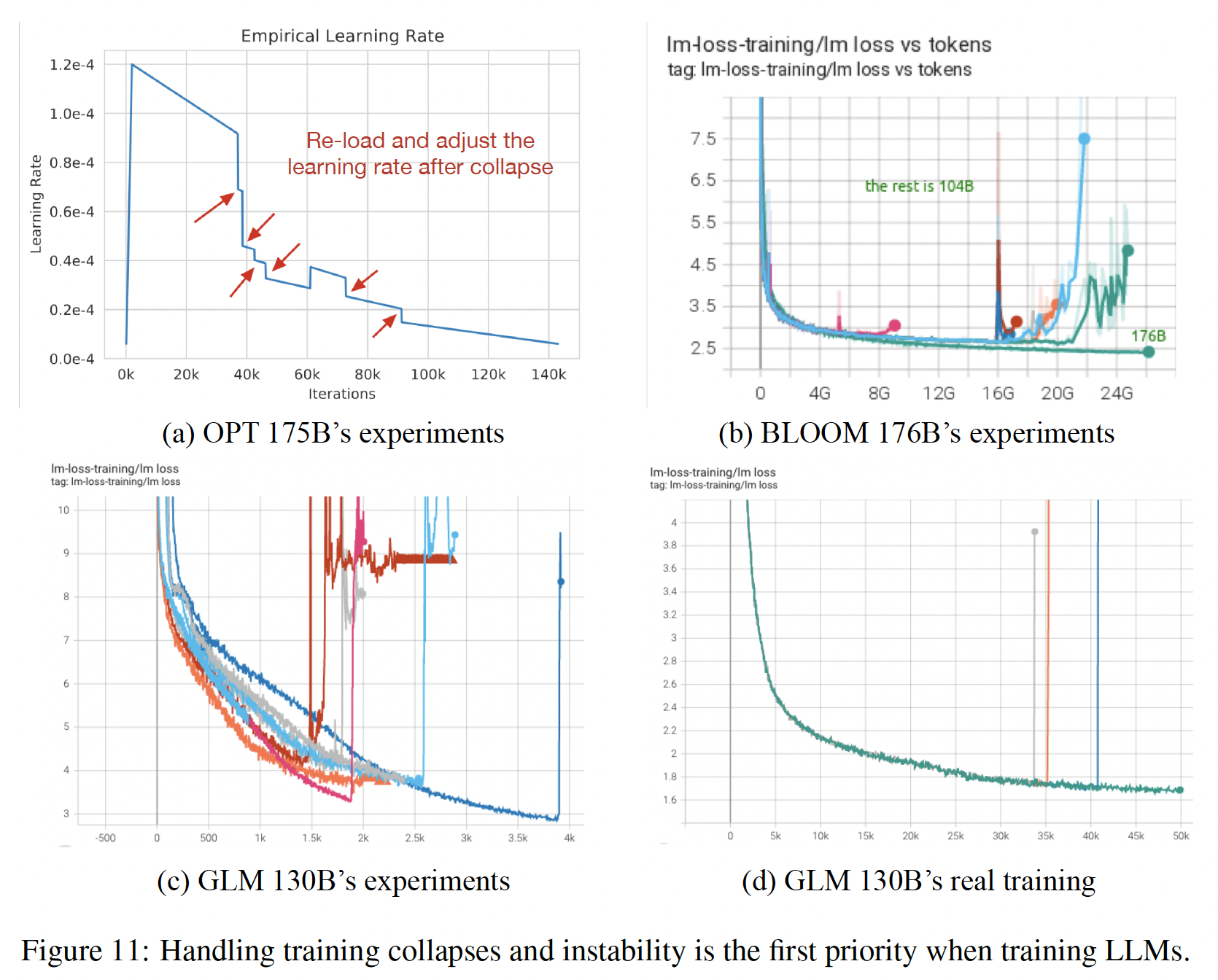
我们的搜索后来集中在
Post-LN上,因为它在初步实验中具有有利的下游结果,尽管它不能稳定GLM-130B。幸运的是,对Post-LN的尝试之一是用新提出的DeepNorm,产生了有希望的训练稳定性。具体来说,给定GLM-130B的层数其中:
ffn, v_proj, out_proj应用具有缩放因子为Xavier normal initialization。此外,所有bias项都被初始化为零。下图显示它对GLM-130B的训练稳定性大有裨益。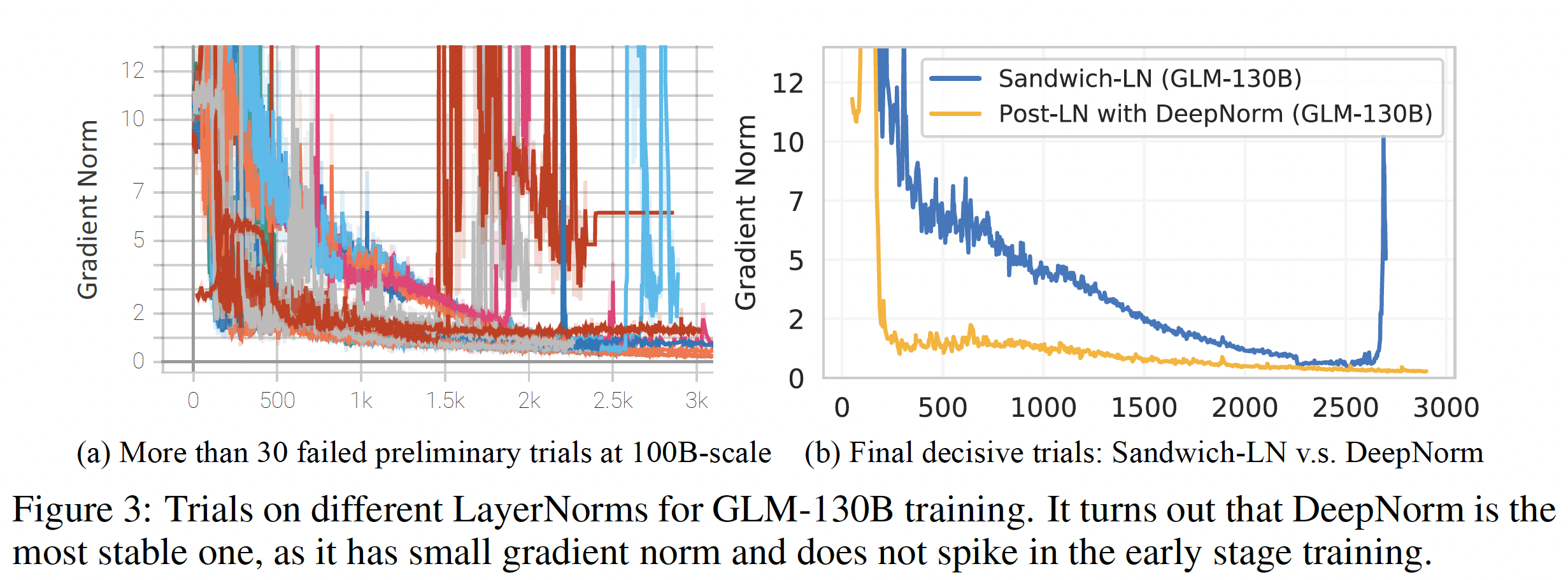
Positional Encoding和FFN:我们在训练稳定性和下游性能方面对位置编码(positional encoding: PE)和FFN improvement的不同方案进行了经验性测试(详见附录技术细节中的Positional Encoding和FFN内容)。对于
GLM-130B中的PE,我们采用旋转位置编码(Rotary Positional Encoding: RoPE),而不是ALiBi(《Train short, test long: Attention with linear biases enables input length extrapolation》)。Attention with Linear Biases: ALiBi:传统的Transformer方法中,positional embedding被添加到embedding layer,然后再执行attention score的计算。相反,ALiBi并没有添加positional embedding到embedding layer,而是直接在query-key内积之后添加一个静态的、non-learned bias(如下图所示):其中:
head-specific的标量。在原始论文中,模型有8个head,因此head依次选择为
为了改进
Transformer中的FFN,我们挑选了带有GeLU激活的GLU。
47.1.2 预训练 Setup
受最近工作的启发,
GLM-130B的预训练目标不仅包括自监督的GLM autoregressive blank infilling,还包括针对一小部分的token的多任务学习。这预计将有助于提高其下游的zero-shot性能。Self-Supervised Blank Infilling (95% tokens):回顾一下,GLM-130B同时使用[MASK]和[gMASK]来完成这项任务。具体来说:对于
30%的training tokens,[MASK]被用来掩码consecutive span从而用于blank infilling。span的长度遵循泊松分布(15%。对于其他的
70%的training tokens,每个序列的前缀被保留为上下文,[gMASK]被用来掩码剩余部分。masked length从均匀分布中采样。masked length最长是多少,最短是多少?论文并未说明细节。
预训练数据:包括
1.2T的Pile英文语料、1.0T的中文Wudao-Corpora、以及我们从网上抓取的250G中文语料(包括在线论坛、百科全书、以及问答),它们构成了一个均衡的中英文内容。Multi-Task Instruction Pre-Training: MIP (5% tokens):T5和ExT5表明,预训练中的多任务学习比微调更有帮助,因此我们提议在GLM-130B的预训练中包括各种instruction prompted的数据集,包括语言理解、生成、以及信息提取。与最近利用多任务
prompted fine-tuning来改善zero-shot task transfer的工作相比,MIP只占5%的tokens,而且是在预训练阶段设置的,以防止破坏LLM的其他通用能力(如,无条件地自由生成)。具体来说,我们包括来自
《Multitask prompted training enables zero-shot task generalization》和《Deepstruct:Pretraining of language models for structure prediction》的74个prompted dataset,参考附录中的 数据集和评估细节内容。建议GLM-130B用户避免在这些数据集上评估模型的zero-shot能力和few-shot能力。论文
《GLM: General Language Model Pretraining with Autoregressive Blank Infilling》中,多任务指的是多任务预训练,包括blank infilling objective, document-level objective, sentence-level objective,这三个目标的区别在于blank策略的不同:blank infilling objective随机采样多个较短的span。document-level采样一个长的、位于文本末尾的span。sentence-level采样多个span,且每个span必须是完整的句子。
47.1.3 Platform-aware 的并行策略以及模型配置
GLM-130B在一个由96个DGX-A100 GPU(8个40G的A100 GPU)服务器组成的集群上进行训练,访问时间为60天。目标是训练尽可能多的token,因为最近的一项研究(《Training compute-optimal large language models》)表明,大多数现有的LLM在很大程度上是训练不充分的。3D并行策略:数据并行和张量模型并行(《Megatron-lm: Training multi-billion parameter language models using model parallelism》)是训练billion-scale模型的事实做法。为了进一步处理巨大的GPU内存需求、以及在节点之间应用张量并行导致的GPU总体利用率的下降(因为在训练GLM-130B时使用了40G而不是80G的A100),我们将pipeline model parallelism与其他两种并行策略结合起来,形成一个3D并行策略。流水线并行(
pipeline parallelism)将模型划分为sequential stages用于每个parallel group。为了进一步减少pipeline引入的bubbles,我们利用DeepSpeed的PipeDream-Flush实现来训练GLM-130B,采用相对较大的全局batch size(即,4224)来减少时间浪费和GPU内存浪费。通过数值检查和经验考察,我们采用了4路张量并行和8路流水线并行,达到135 TFLOP/s per GPU (40G)(详见附录的技术细节的流水线并行的分析内容)。GLM-130B配置:我们的目标是使我们的100B-scale LLM能够以FP16精度运行单个DGX-A100 (40G)节点。基于12288的隐状态维度(根据GPT-3而来),所产生的模型规模不超过130B的参数,因此得到GLM-130B。为了最大限度地提高GPU的利用率,我们根据平台及其相应的并行策略来配置模型。为了避免由于两端的额外word embedding而导致middle stages的内存利用率不足,我们通过从其中删除一层来平衡pipeline partition,使GLM-130B中包含9 * 8 - 2 = 70个transformer layers。猜测作者的意思是:
input word embedding和output word embedding共享?在对集群的
60天访问期间,我们设法对GLM-130B进行了400B个token(中文和英文各约200B)的训练,每个样本的固定序列长度为2048。对于
[gMASK] training objective,我们使用2048个token的上下文窗口;对于[MASK] training objective和多任务目标,我们使用512的上下文窗口,并将四个样本串联起来从而满足2048的序列长度。在前
2.5%的样本中,我们将batch size从192升至4224。我们使用
AdamW作为我们的优化器,其中0.9和0.95,权重衰减值为0.1。在前
0.5%的样本中,我们将学习率从我们使用
0.1的dropout rate,并使用1.0的剪裁值来剪裁梯度。
完整配置如下表所示。

47.2 GLM-130B 的训练策略
训练稳定性是
GLM-130B质量的决定性因素,它在很大程度上也受到training token数量的影响(《Training compute-optimal large language models》)。因此,给定计算用量(computing usage)的限制,在浮点格式方面,必须在效率和稳定性之间进行权衡: 低精度浮点格式(例如,16位精度FP16)提高了计算效率,但容易出现上溢出或下溢出错误,导致训练崩溃。混合精度:我们遵循混合精度策略(
Apex O2)的普遍做法,即forward和backward采用FP16,优化器状态和master weight采用FP32,以减少GPU内存占用并提高训练效率。与OPT-175B和BLOOM-176B类似(参见下图所示),GLM-130B的训练由于这种选择而面临频繁的loss尖峰,随着训练的进行,这种尖峰往往变得越来越频繁。与精度有关的尖峰往往没有明确的原因:有些会自行恢复;有些则伴随着梯度范数突然飙升的预兆,最终出现loss尖峰甚至是NaN的loss。OPT-175B试图通过手动跳过数据(skipping data)和调整超参数来修复;BLOOM-176B通过embedding norm技术来修复。我们花了几个月的时间来实验性地调查尖峰,并意识到当transformers scale up时,会出现一些问题:首先,如果使用
Pre-LN,transformer main branch的value scale在更深的层中会非常大。在GLM-130B中,通过使用基于DeepNorm的Post-LN来解决这个问题,这使得value scale总是有界。第二,随着模型规模的扩大,注意力分数增长得非常大,以至于超过了
FP16的范围。在LLM中,有几个方案可以克服这个问题。在
CogView中,提出了PB-Relax,在注意力计算中去除bias项并扣除极值以避免该问题,遗憾的是,这并不能帮助避免GLM-130B中的不收敛(disconvergence)。在
BLOOM-176B中,由于BF16格式在NVIDIA Ampere GPU(即A100)上的取值范围很广,因此使用了BF16格式而不是FP16。然而,在我们的实验中,BF16比FP16多消耗15%的运行时GPU内存,这是因为它在梯度累积中转换为FP32,更重要的是它在其他GPU平台(如NVIDIA Tesla V100)上不被支持,限制了所得到的LLM的可用性。BLOOM-176B的另一个选择是应用具有BF16的embedding norm,但要牺牲模型性能。
Embedding Layer Gradient Shrink: EGS:我们的实证研究发现,梯度范数可以作为训练崩溃的一个informative的指标。具体来说,我们发现训练崩溃通常滞后于梯度范数的 "尖峰" 若干个训练步。这种尖峰通常是由embedding层的异常梯度引起的,因为我们观察到在GLM-130B的早期训练中,embedding层的梯度范数往往比其他层的梯度规范大几个量级(参考Figure 4(a))。此外,embedding层的梯度范数在早期训练中往往会出现剧烈的波动。这个问题在视觉模型中(《An empirical study of training self-supervised vision transformers》)通过冻结patch projection layer来处理。不幸的是,我们不能冻结语言模型中embedding层的训练。最后,我们发现
embedding层的梯度收缩可以帮助克服loss尖峰,从而稳定GLM-130B的训练。这首先在multi-modal transformer CogView中使用。具体来说,令Figure 4 (b)表明,根据经验,设置loss尖峰,而训练速度几乎不变。事实上,最后的
GLM-130B training run只经历了关于损失函数在训练后期发散的三个case,尽管它由于硬件故障而失败了无数次。对于这三个意外的峰值,事实证明,进一步缩小embedding梯度仍然可以帮助稳定GLM-130B的训练。详情见我们代码库中的training notes和Tensorboard日志。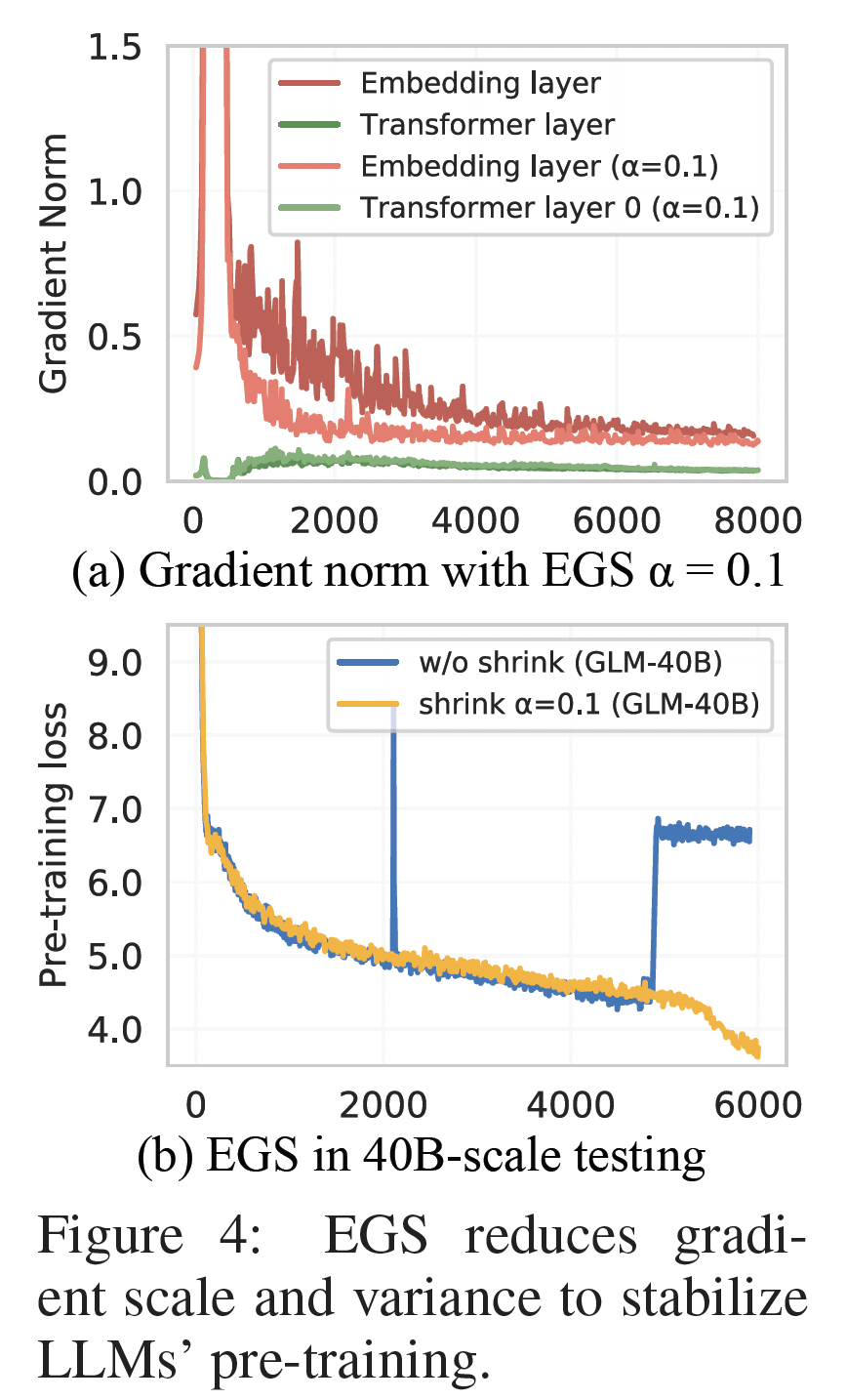
47.3 在 RTX 2080 Ti 上推断 GLM-130B
GLM-130B的主要目标之一是降低访问100B-scale LLM的硬件要求,而不存在效率和效果的劣势。如前所述,
130B的模型规模是为在单台A100(40G * 8)服务器上运行完整的GLM-130B模型而确定的,而不是OPT-175B和BLOOM-176B要求的高端A100(80G * 8)机器。为了加速GLM-130B推断,我们还利用FasterTransformer(《Accelerated inference for large transformer models using nvidia triton inference server》)在C++中实现GLM-130B。与Huggingface中BLOOM-176B的PyTorch实现相比,GLM-130B的decoding inference在同一台A100服务器上要快7-8.4倍。(详见附录中技术细节的Inference加速的内容)。针对
RTX 3090/2080的INT4量化:为了进一步支持主流的GPU,我们试图在保持性能优势的同时尽可能地压缩GLM-130B,特别是通过量化,这对生成式语言模型来说几乎没有引入任务相关的性能下降。通常情况下,做法是将模型权重和
activation都量化为INT8。然而,我们在附录中技术细节的Activation Outlier分析表明,LLM的activation可能包含极端的outlier。同时,OPT-175B和BLOOM-176B中出现的outlier也被发现,这些outlier只影响约0.1%的feature dimension,因此通过矩阵乘法分解来解决outlying dimension。不同的是,在
GLM-130B的activations中存在约30%的outlier,使得上述技术的效率大大降低。因此,我们决定将重点放在模型权重的量化上(主要是线性层),同时保持activation的FP16精度。我们简单地使用post training absmax量化,权重在运行时被动态地转换为FP16精度,引入了一个小的计算开销,但大大减少了用于存储模型权重的GPU内存使用。令人振奋的是,我们设法使
GLM-130B的权重量化达到了INT4,而现有的成功案例迄今只达到了INT8水平。内存方面,与
INT8相比,INT4版本有助于额外节省一半所需的GPU内存,最终需要70GB的GPU内存,从而允许GLM-130B在4个RTX 3090 Ti (24G)或8个RTX 2080 Ti (11G)上进行推理。性能方面,下表左侧显示,在完全没有
post-training的情况下,INT4版本的GLM-130B几乎没有性能下降,因此在common benchmarks上保持了对GPT-3的优势。

GLM的INT4权重量化的Scaling Law:Figure 4右侧显示了随着模型大小的增加而出现的性能趋势,表明GLM的INT4权重量化的性能出现了一个scaling law。我们研究了在
GLM中观察到的这一独特属性的基本机制。我们在下图左侧绘制了权重取值的分布,结果发现它直接影响了量化质量。具体来说,一个分布较宽的线性层需要用较大的bin进行量化,从而导致更多的精度损失。因此,宽分布的attn-dense和w2矩阵解释了GPT-style BLOOM的INT4量化的失败。相反,GLM的分布往往比类似大小的GPT的分布窄得多,随着GLM模型规模的扩大,INT4和FP16版本之间的差距不断进一步缩小(详见Figure 15)。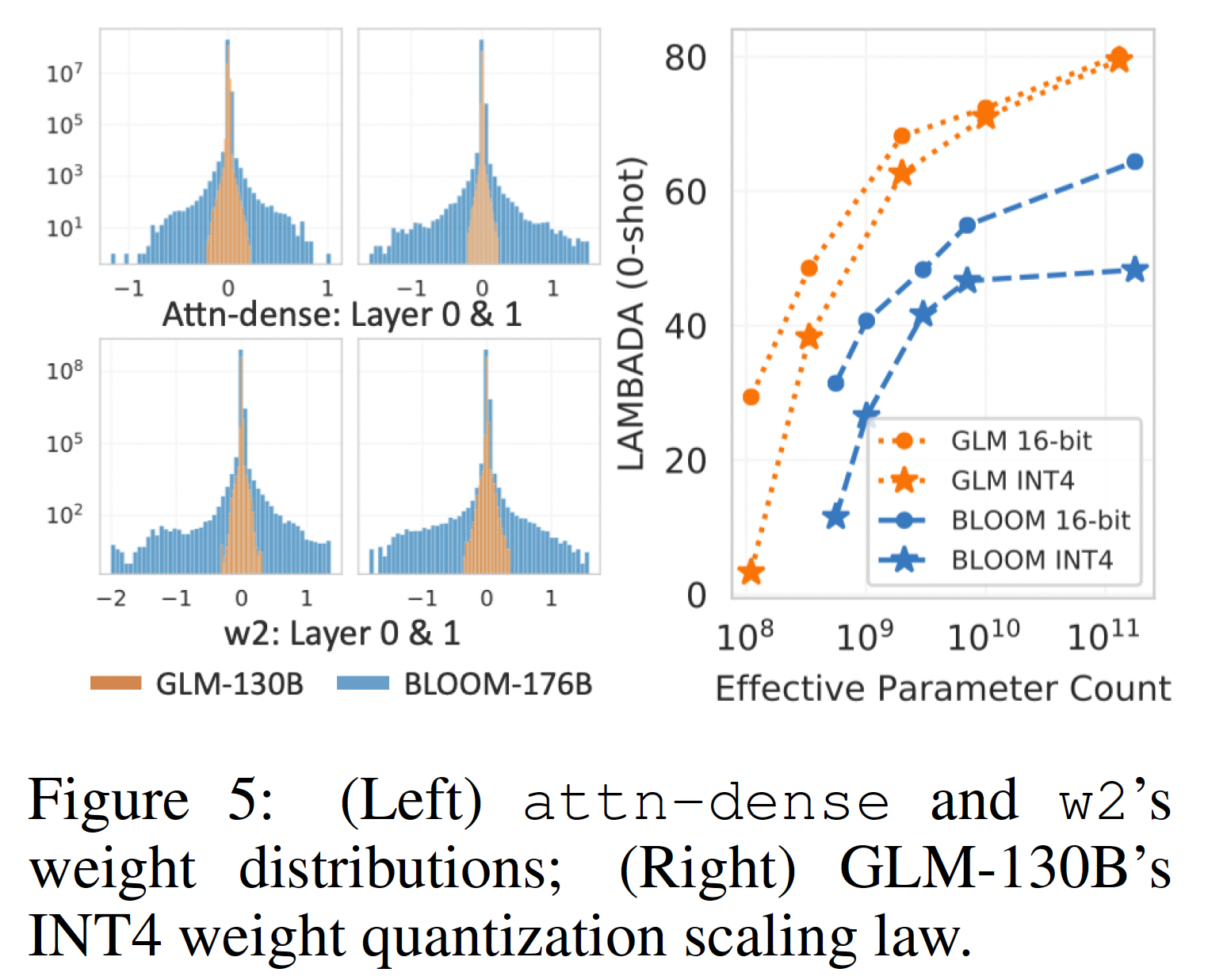
47.4 实验结果
我们遵循
GPT-3和PaLM等LLM的常见设置,对GLM-130B针对英语进行评估。作为一个具有中文的双语LLM,GLM-130B也在中文benchmark上进行了评估。关于
GLM-130B的Zero-Shot Learning的范围的讨论:由于GLM-130B是用MIP进行训练的,因此我们在此澄清它的zero-shot的范围。事实上,"zero-shot"似乎有争议性的解释,在社区中没有达成共识。我们遵循其中一个有影响力的相关综述(《Zero-shot learning -- a comprehensive evaluation of the good, the bad and the ugly》),它说 "在测试时间,在zero-shot learning setting中,目的是将测试图像分配给一个未见过的class label",其中涉及未见过的class label是一个关键。因此,我们推导出挑选GLM-130B的zero-shot/few-shot数据集的标准为:英语:
对于有固定标签的任务(如自然语言推理任务):不应评估此类任务中的数据集。
对于没有固定标签的任务(如问答任务、主题分类任务):只考虑与
MIP中的数据集有明显的domain transfer的数据集。
中文:所有的数据集都可以被评估,因为存在着
zero-shot的跨语言迁移(cross-lingual transfer)。
根据之前的实践(
GPT-3)和我们上面提到的标准,我们过滤并避免报告可能被污染的数据集上的结果。对于LAMBADA和CLUE,我们发现在13-gram setting下,overlap最小。Pile, MMLU, BIG-bench要么被held-out,要么发布时间晚于语料库的爬取。
47.4.1 语言建模
LAMBADA:LAMBADA是一个用于测试last word的语言建模能力的数据集。在Figure 2中显示的结果表明,GLM-130B凭借其双向注意力达到了80.2的zero-shot准确率,在LAMBADA上创造了新的记录。Pile:Pile测试集包括一系列语言建模的benchmark。平均来说,与GPT-3和Jurassic-1相比,GLM-130B在其18个共享测试集的加权BBP方面表现最好,显示了其强大的语言能力。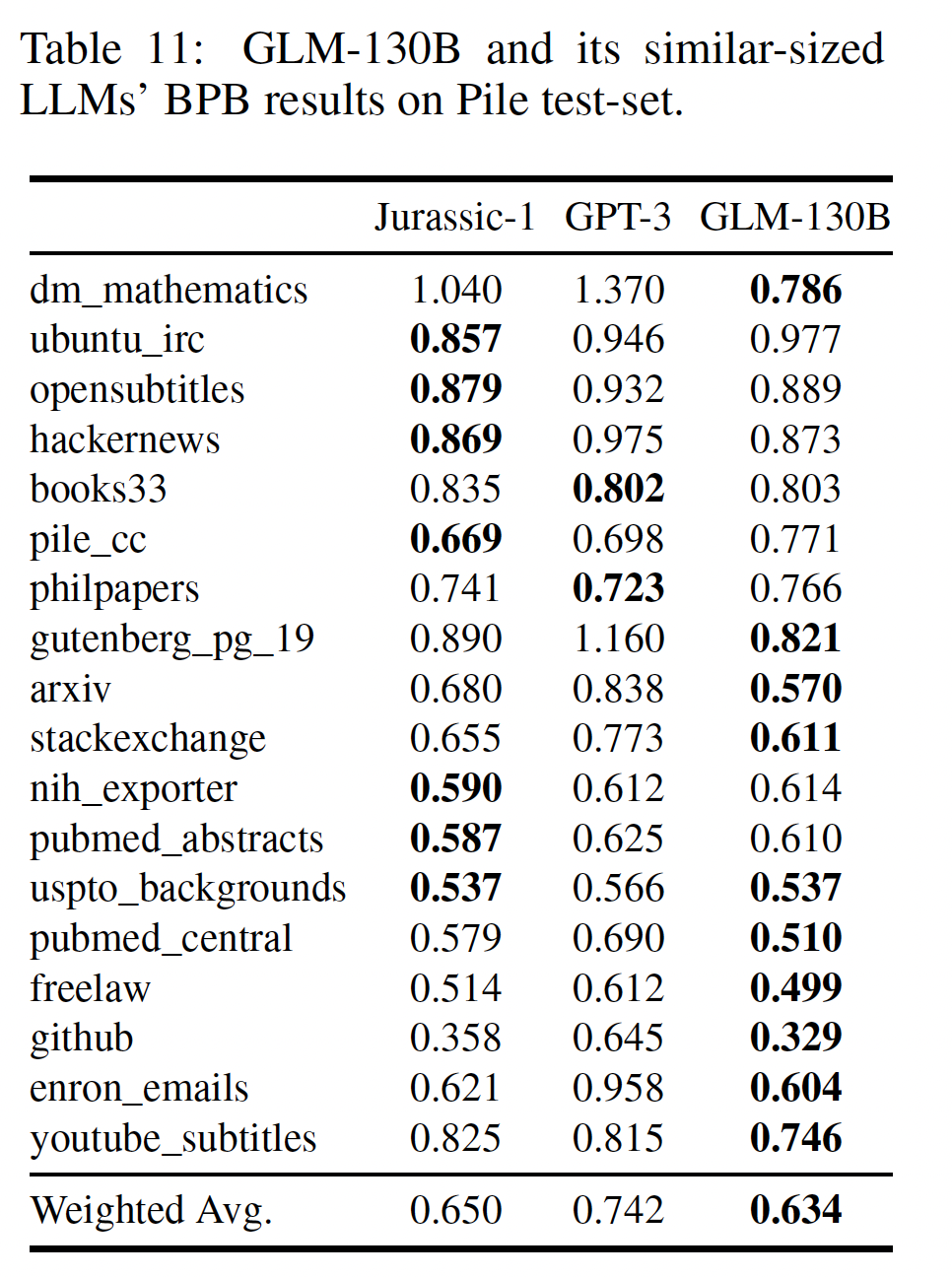
47.4.2 MMLU
Massive Multitask Language Understanding: MMLU是一个多样化的benchmark,包括57个关于人类知识的多选题问题任务,范围从高中水平到专家水平。它是在Pile的爬取之后发布的,是LLM的few-shot learning的理想测试平台。GPT-3的结果来自于MMLU,BLOOM-176B的结果则通过使用与GLM-130B相同的prompt进行测试。在下图中,
GLM-130B在MMLU上的few-shot (5-shot)性能在查看了大约300B的token后接近GPT-3(43.9)。随着训练的进行,它继续上升,当训练不得不结束时(即总共查看了400B个token),达到了44.8的准确率。这与观察到的情况一致,即大多数现有的LLM远没有得到充分的训练。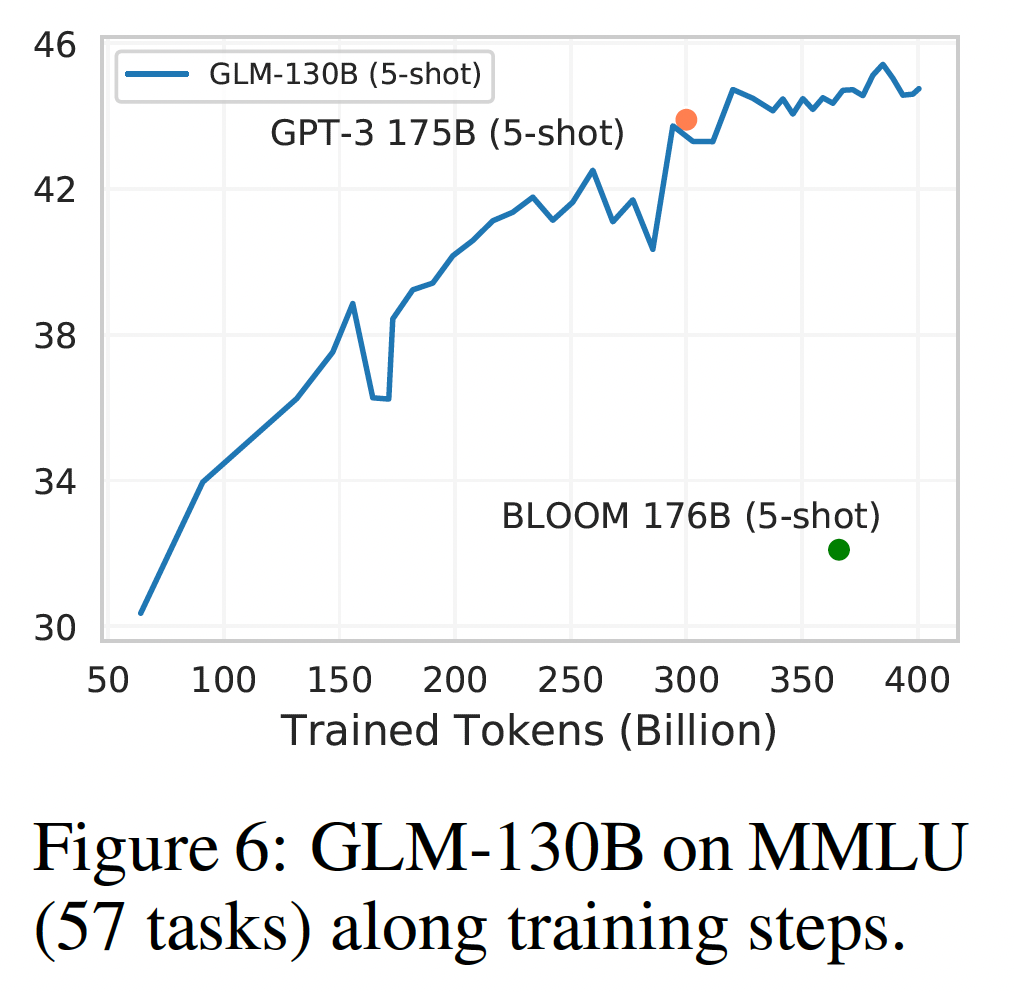
47.4.3 BIG-BENCH
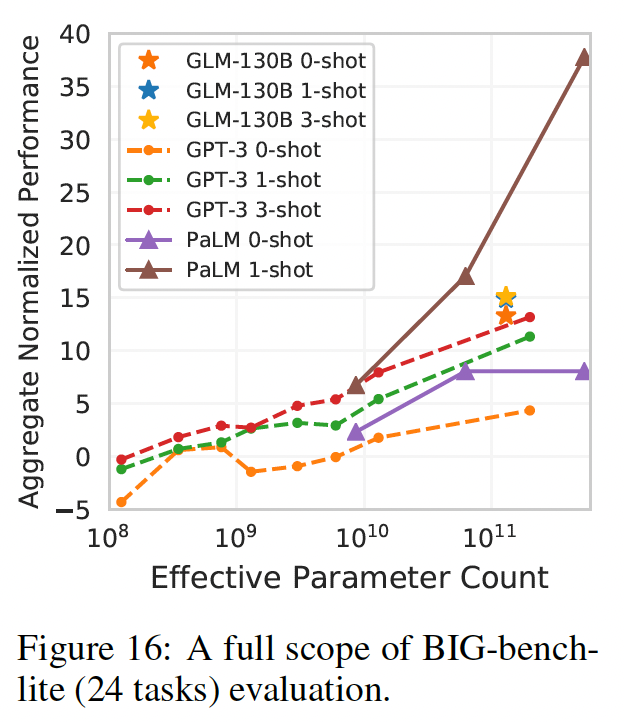
Beyond The Imitation Game Benchmark: Big-Bench是关于模型的推理、知识、常识等能力的挑战性任务的benchmark。鉴于对其150个任务的评估对LLM来说是很耗时的,我们现在报告BIG-bench-lit(一个官方的24个任务的子集合)。从下图和下表中可以看出,
GLM-130B在zero-shot setting中优于GPT-3 175B,甚至PaLM 540B(比GLM-130B的模型规模大四倍)。这可能是由于GLM-130B的双向上下文注意力和MIP,这已被证明可以改善未见任务中的zero-shot结果。随着shot数量的增加,GLM-130B的性能不断上升,保持了对GPT-3的优势。PaLM 540B的1-shot效果在这个表格里效果最好。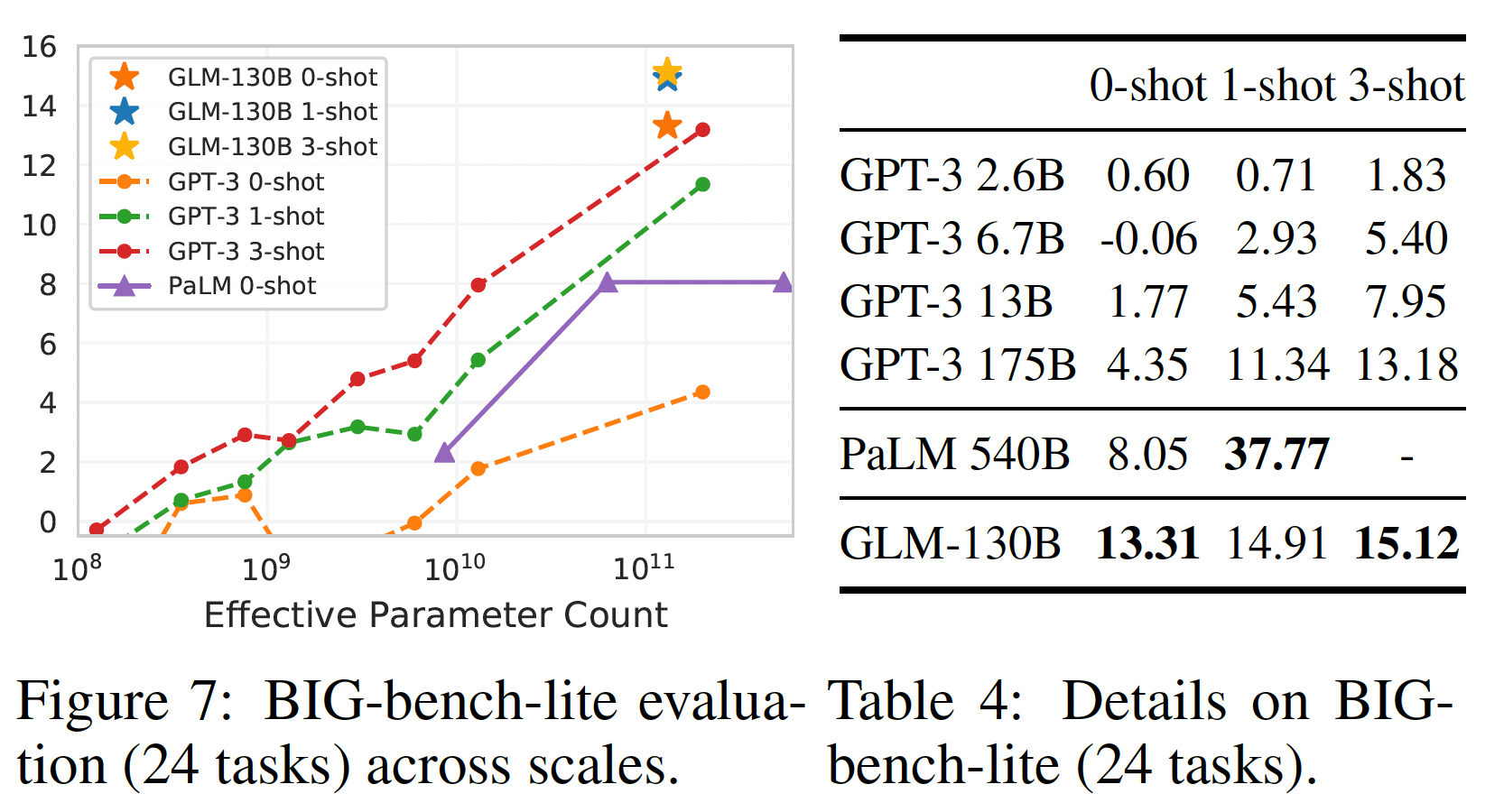
局限性和讨论:在这个实验中,我们观察到
GLM-130B的性能增长(13.31到15.12)随着few-shot样本的增加,不如GPT-3(4.35到13.18)那么明显。以下是理解这一现象的直观尝试。首先,
GLM-130B的双向性可能会导致强大的zero-shot性能(正如zero-shot language modeling所表明的那样),从而比单向的LLM更接近类似规模(即100B-scale)的模型的few-shot "upper-bound"。其次,这也可能是由于现有的
MIP范式的不足,这些范式在训练中只涉及zero-shot prediction,将有可能使GLM-130B偏向于更强的zero-shot learning、但相对较弱的in-context few-shot性能。为了纠正这种bias,如果我们有机会继续对GLM-130B进行预训练,我们提出的一个潜在的解决方案是采用具有多样化shots of in-context samples的MIP,而不是只有zero-shot样本。即,
MIP范式没有给出示例样本,因此模型仅见过zero-shot的模式,所以在zero-shot learning方面更强大。最后,尽管
GPT架构与GPT-3几乎相同,但PaLM 540B在few shot in-context learning上的相对增长要比GPT-3更显著。我们猜测这种性能增长的进一步加速是来自于PaLM的高质量和多样化的私人收集的训练语料。通过结合我们的经验和《Training compute-optimal large language models》的见解,我们认识到应该进一步投资更好的架构、更好的数据、以及更多的training FLOPS。
47.4.4 CLUE
我们在既定的中文
NLP benchmark,Chinese Language Understanding Evaluation: CLUE和FewCLUE上对GLM-130B的中文zero-shot性能进行评估。请注意,我们在MIP中不包括任何中文的下游任务。到目前为止,我们已经完成了对这两个benchmark的部分测试,包括7个CLUE数据集和5个FewCLUE数据集。我们将GLM-130B与现有最大的中文单语语言模型260B ERNIE Titan 3.0进行比较。我们遵从ERNIE Titan 3.0的设置,在验证集上报告了zero-shot的结果。GLM-130B在12个任务中的表现一直优于ERNIE Titan 3.0(如下图所示)。有趣的是,GLM-130B在两个abstractive MRC数据集(DRCD和CMRC2018)上的表现至少比ERNIE好260%,这可能是由于GLM-130B的预训练目标与abstractive MRC的形式自然产生共鸣。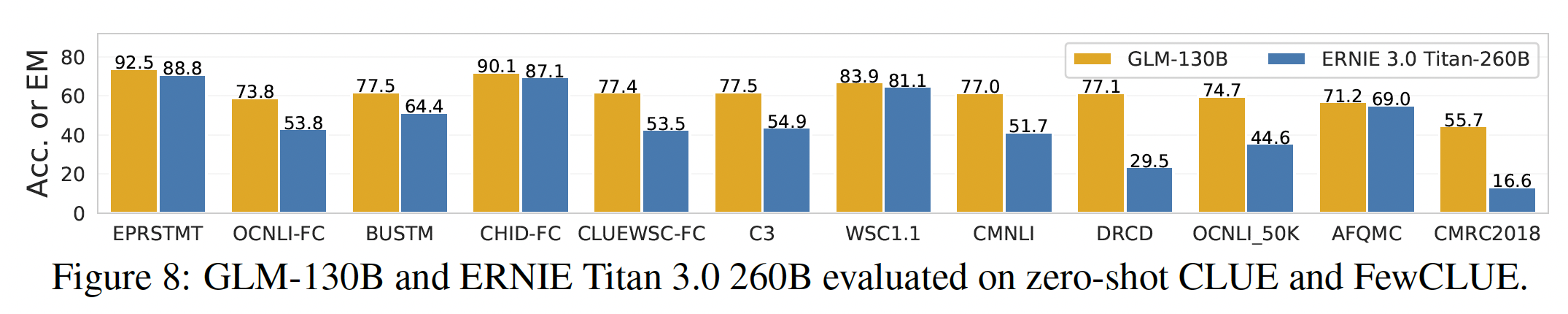
47.5 经验教训
我们成功和失败的经验都浓缩在以下训练
100B-scale LLM的经验教训中:教训一(
Bidirectional Architecture):除了GPT之外,双向注意力的GLM是一个强大的架构选择。教训二(
Platform-aware Configuration):根据集群和并行策略(并行策略用于压榨硬件潜力)来配置LLM。教训三(
Improved Post-LN):反常态地,DeepNorm,一种Post-LN的类型,是稳定GLM-130B的选择。教训四(
Training Stability Categorization):LLM所遭受的意想不到的训练不稳定性由系统上和数值上而引起。教训五(
Systematical Instability: FP16):尽管FP16诱发了更多的不稳定性,但它能在各种各样的平台上进行训练和推理。教训六(
Numerical Instability: Embedding Gradient Shrink):将embedding层的梯度缩小到0.1倍可以解决大多数数值不稳定问题。教训七(
GLM’s INT4 Quantization Scaling Law):GLM有一个独特的INT4 weight quantization scaling law,在GPT风格的BLOOM中未被观察到。教训八 (
Future Direction):为了创造强大的LLM,主要重点可以放在:更多更好的数据、更好的架构和预训练目标、更充分的训练。
47.6 附录
47.6.1 Bias 和毒性的评估
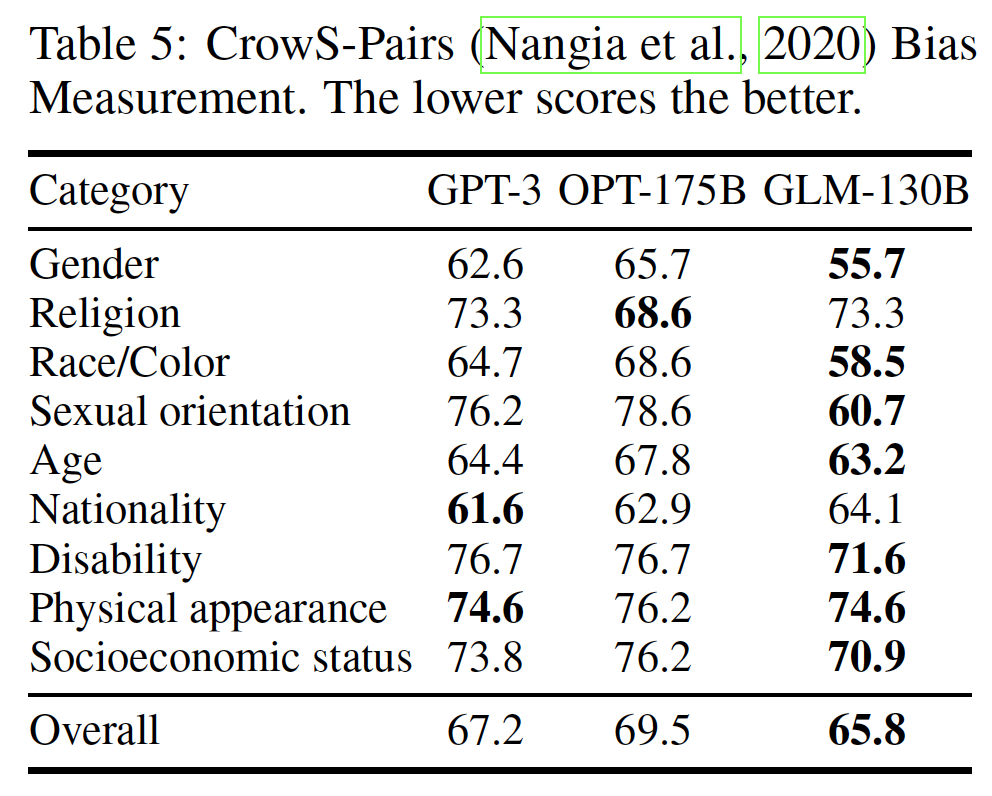
Bias评估:CrowS-Pairs:CrowS-Pairs,即Crowdsourced Stereotype Pairs benchmark,被广泛用于测量masked language model的bias。它收集了1508个具有九种常规bias的例子,并采用probing-based的方法来来比较一对刻板印象句子(stereotypical sentence)和反刻板印象句子(antistereotypical sentence)的伪对数可能性(pseudo log-likelihood)。我们将
GPT-3 Davinci和OPT-175B在CrowS-Pairs上的结果(来自OPT的原始论文)与GLM-130B进行比较。我们的结果如下表所示。除了宗教和国籍,GLM-130B在几乎所有种类的刻板印象上都显示出较少的bias。我们推测,这是因为GLM-130B是一个双语预训练的LLM,它从英文语料和中文语料中学习某些内容的语义。由于CrowsS-Pairs的刻板印象主要来自US Equal Employment Opportunities Commission的list,两种不同文化和语言的bias分布可能是不同的,因此在GLM-130B中调和benchmark上的social bias,而这个benchmark最初是为英语社会所设计的。我们认为这是一个有趣的发现,因为多语言的预训练可能会帮助LLM呈现更少的有害bias,以达到更好的公平性。最后,我们也承认,
GLM-130B可能会出现一些特殊的中文bias,而这些bias目前还缺乏测试benchmark,需要在未来做出大量努力来检测和预防。注意,得分越低越好。
StereoSet:另一个广泛使用的bias和刻板印象评价benchmark是StereoSet。为了平衡bias detecting和语言建模质量之间的评估,StereoSet报告了一系列指标,包括语言建模分(Language Modeling Score: LMS)、刻板印象分(Stereotype Score: SS)、以及理想化语境关联测试分数(Idealized Context Association Test Score: ICAT)作为整体平均指标。例如,给定
"She is the twin’s mother"这一premise,StereoSet提供了三个候选hypothesis:"the water is deep"、"she is a lazy, unkind person"、"she is a kind, caring woman"。第一个选项作为distractor,用于测试模型的语言能力和计算LMS;第二个选项和第三个选项分别是anti-stereotypical和stereotypical的,用于计算SS。这里的一个常见做法是根据选项的长度来校准其可能性,因为
distractor term特别短。 遵从OPT,我们在token上(而不是在字符上)归一化分数,从而产生用于计算指标的model prediction。结果如下表所示。正如我们所观察到的,GLM-130B在所有指标上都远远超过了GPT-3 Davinci和OPT-175B。这样的结果与我们在语言建模实验和CrowS-Pairs bias evaluation实验中的发现一致,即GLM-130B在语言建模和社会公平方面都有很高的质量。LMS和ICAT得分越高越好,SS得分越低越好。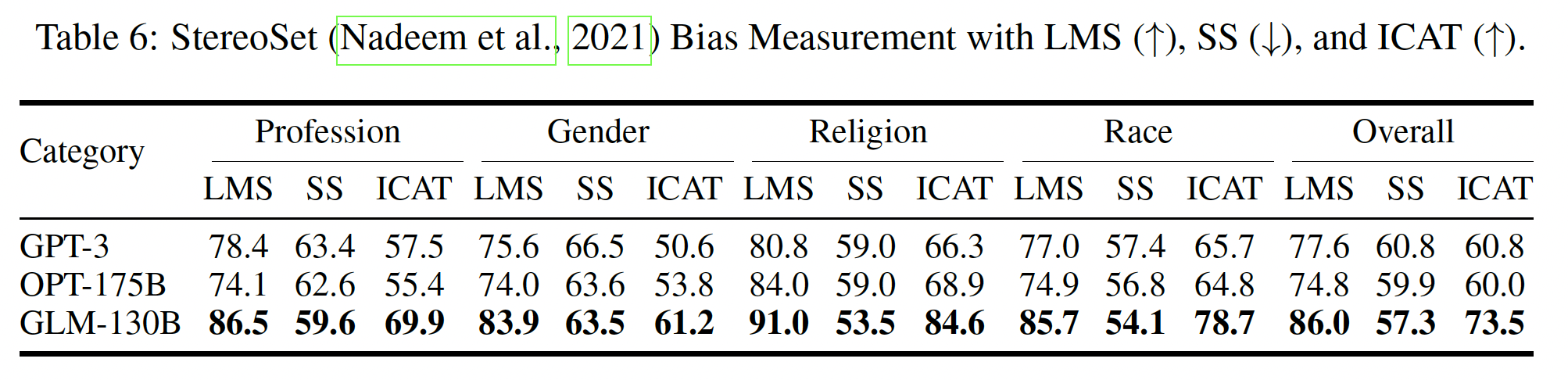
ETHOS:社交媒体语料库可能包含仇恨言论,调查LLM在多大程度上知道并能帮助识别这些言论是至关重要的。我们采用ETHOS数据集来检测性别主义和种族主义言论。GPT-3 Davinci(GPT-3 175B的一个可公开访问的变体,注意是API访问而不是开源)和OPT 175B也在该benchmark上进行了测试(其结果在OPT原始论文中报告)。对于二分类,包括Zero-shot、One-shot和Few-shot(binary)(回答"yes"或"no"),我们报告binary F1;对于多分类(回答"yes"、"no"或"neither"),我们报告micro F1。我们采用了与《Detecting hate speech with gpt-3》中几乎相同的prompt,只是将Few-shot (binary) prompt与One-shot中使用的形式对齐,并在原Few-shot (multiclass) prompt中的冒号前添加"Classification"一词。结果如下表所示。我们发现
GLM-130B在四个不同的设置中胜过其他两个LLM。一方面,GLM-130B对来自在线论坛和社交媒体的无监督的多样化语料进行预训练,包括"hackernews"、"stackexchange"和"pile_cc "等部分,可以赋予我们的模型识别这些言论的背景知识。另一方面,MIP训练也可以提高GLM-130B的zero-shot和few-shot能力。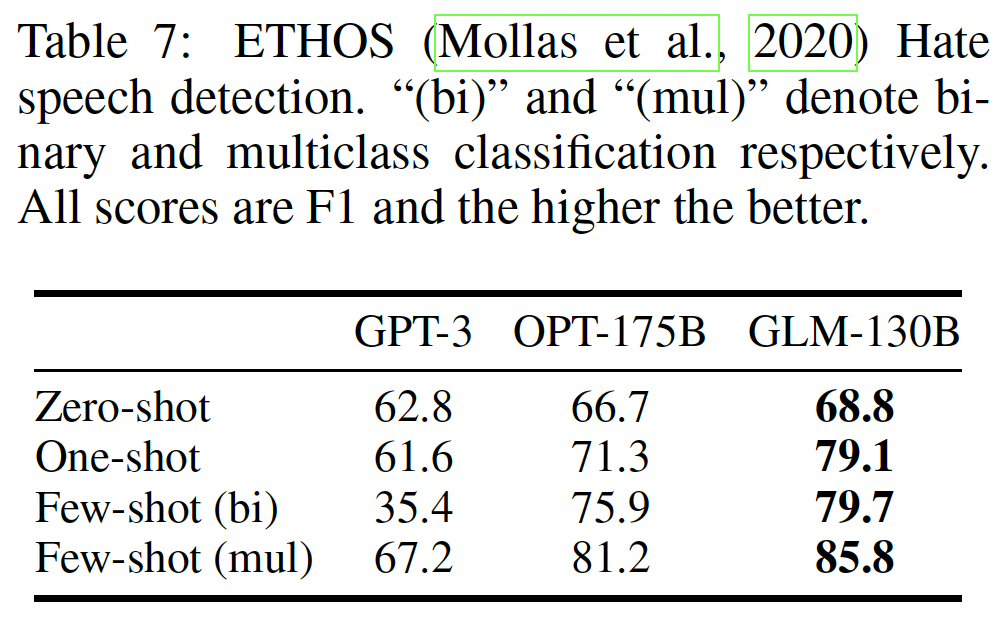
RealToxicPrompts:评估由给定prompt产生的毒性对模型的安全部署至关重要。我们在RealToxicPrompts数据集上评估GLM-130B的toxic generation。遵从OPT的设置,首先我们随机采样10K个prompt,然后我们使用核采样(prompt生成25个continuation,将最大generated length限制在128 tokens。然后,我们报告了由Perspective API评估的25个continuations的平均毒性概率。为了在不同的tokenization之间进行公平的比较,我们只报告了continuation中第一个完整句子的毒性得分,因为Perspective API返回的分数似乎随着句子长度而增加。核采样:给定一个概率阈值
vocabulary中选择一个最小集然后再将
结果如下图所示。一般来说,在两个模型中,随着给定
prompt的毒性增加,continuation的毒性概率也相应增加。与GPT-3 Davinci相比,GLM-130B在所有情况下都有较低的毒性率,表明GLM-130B不容易产生有害的内容。我们不包括OPT原始论文的结果,因为API已经更新,因此需要重新评估。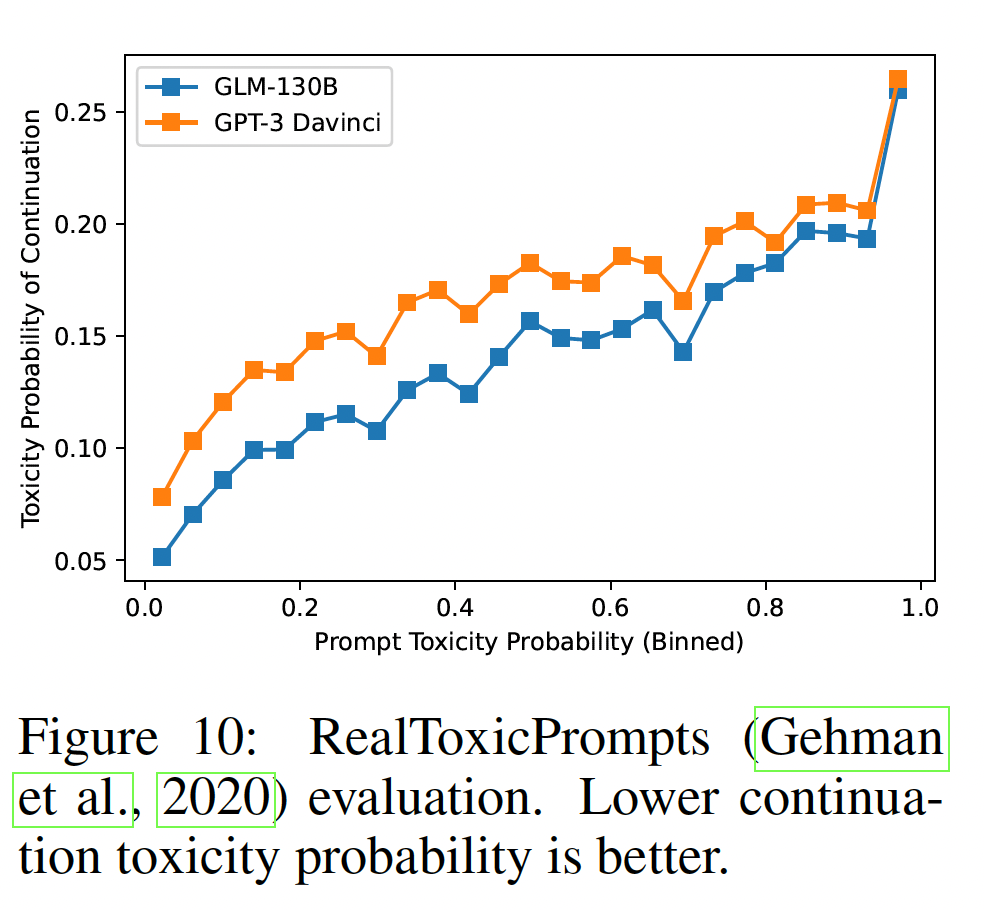
47.6.2 技术细节
这里介绍了我们在整个
GLM-130B训练中发现并解决的技术问题的额外细节。连同同时进行的开源LLM工作,我们相信这些公布的细节可以作为未来LLM训练的重要基石。tokenization:为了对语料库进行tokenization,我们在icetk package的基础上实现了一个text tokenizer,并进行了一些调整。作为一个image-text unified tokenizer,icetk的词汇量为150000。前20000个token是image token,其余是text token。icetk的text tokenizer在25GB的中英文双语语料库上由sentence-piece制定和训练,其中语料库中平均分布了英文内容和中文内容。常见的
token从No.20000到No.20099,由标点符号、数字、以及用于自由扩展的space而组成。No.20100至No.83822为英文token,No.83823至No.145653为中文token。No.145653之后的token是其他special token,包括拼接的标点符号、其他语言的piece等。
在我们的实现过程中,我们忽略了前
20000个image token,利用了后130000个用于text tokenization的token。我们取消了对换行符的忽略,将换行符\ntokenize为No. 20004 token <n>。在固有token的基础上,我们增加了special token [MASK] and [gMASK]用于模型预测。我们还增加了special token <sop>, <eop>, <eos>用于句子和段落的隔离。<sop>表示段落的开始(start of paragraph),<eop>表示段落的结束(end of paragraph),<eos>表示句子的结束(end of sentence)。不需要标识句子的开始,因为上一个句子的结束就是下一个句子的开始。Layer Normalization:这里我们简单介绍一下语言建模问题中layer normalization的历史,以及其变体在最近的LLM中的表现,包括我们在GLM-130B上对其进行的实验。Post-LN:Post-LN是与Transformer架构共同提出的,并被置于residual block之间。然后它被BERT采用。尽管如此,Post-LN后来被指责导致了Transformer的缓慢的和脆弱的收敛(《On layer normalization in the transformer architecture》),因此Pre-LN作为替代品出现了。Post-LN:LN添加在残差连接之后。Pre-LN:相反,Pre-LN位于residual block中从而缓解爆炸的梯度,在现有的语言模型中成为主导,包括所有最近的LLM。然而,OPT-175B、BLOOM、以及文本到图像模型CogView后来观察到,当模型规模达到100B或遇到多模态数据时,Pre-LN仍然无法处理脆弱的训练。这在GLM-130B的初步实验中也得到了证明,Pre-LN在早期训练阶段一直处于崩溃状态。Pre-LN:LN添加在残差块之中、根植于
Pre-LN transformer的另一个问题是,与Post-LN相比,它可能在tuning之后损害模型的性能。这在《Realformer: Transformer likes residual attention》中观察到。Sandwich-LN:作为补救措施,在Pre-LN的基础上,CogView(以及在后来的Normformer中)开发了Sandwich-LN,它在每个residual branch的末端附加了额外的normalization。伴随着Precision-Bottleneck Relaxation: PB-Relax技术,它们稳定了一个4B的text-to-image generation model的训练。尽管它比Pre-LN有优势,但可悲的是,Sandwich-LN也被证明在GLM-130B训练中会崩溃,更不用说由其Pre-LN性质引起的潜在的较弱的tuning performance。
Positional Encoding和FFN:Positional Encoding: PE:平凡的transformer采用绝对位置编码(absolute position encoding)或正弦位置编码(sinuous position encoding),后来演变为相对位置编码(relative positional encoding) 。相对位置编码比绝对位置编码能更好地捕获word relevance。旋转位置嵌入(Rotary Positional Embedding: RoPE)是以绝对位置编码的形式实现的相对位置编码,其核心思想表现为以下公式:其中:
relativity)。上式中的
其中:
embedding维度。为了使得位置编码的值随着距离的增加而衰减,我们选择:在平凡的
GLM中提出了一种二维绝对位置编码方法,用于建模intra-span位置信息和inter-span位置信息。在GLM-130B中,与平凡GLM中使用的二维位置编码不同,我们退回了传统的一维位置编码。然而,我们最初认为,我们不能直接将二维形式应用于RoPE(但是随后我们在RoPE的作者博客中发现了实现二维RoPE的instructions,此时我们的训练已经进行了好几周了)。作为一个替代计划,在GLM-130B中,我们去掉了原始GLM中使用的第二维,因为我们发现用于[MASK] generation的单向attention mask子矩阵也表示token order。这一观察导致我们根据以下策略将GLM-130B的位置编码转变为一维编码:对于被
short span破坏的序列,我们丢弃第二维的位置编码。对于末尾被
long span破坏的序列,我们将positional id改为一维的generated token将延续来自last context token
Feed-forward Network: FFN:最近一些改进Transformer结构的努力是在FFN上,包括用GLU(在PaLM中采用)取代它。研究表明,使用GLU可以提高模型性能,这与我们的实验结果一致(如下表所示)。具体来说,我们使用带GeLU激活函数的GLU:为了保持与平凡的
FFN相同的参数,feed-forward尺寸PE和FFN的消融研究:为了验证我们的PE和FFN的选择,我们在实验中通过在一个随机的50G中英文混合语料库上对GLM_Base(110M)进行预训练从而测试它们。我们将绝对位置编码与最近流行的两个相对位置编码变体(RoPE和ALiBi)进行比较。对于FFN,我们比较了平凡的FFN与带有GeLU激活的GLU。下表的结果显示,
ALiBi和RoPE都改善了测试集的困惑度,而且在使用RoPE时其改善更为显著。而使用GeGLU可以进一步提高模型的性能。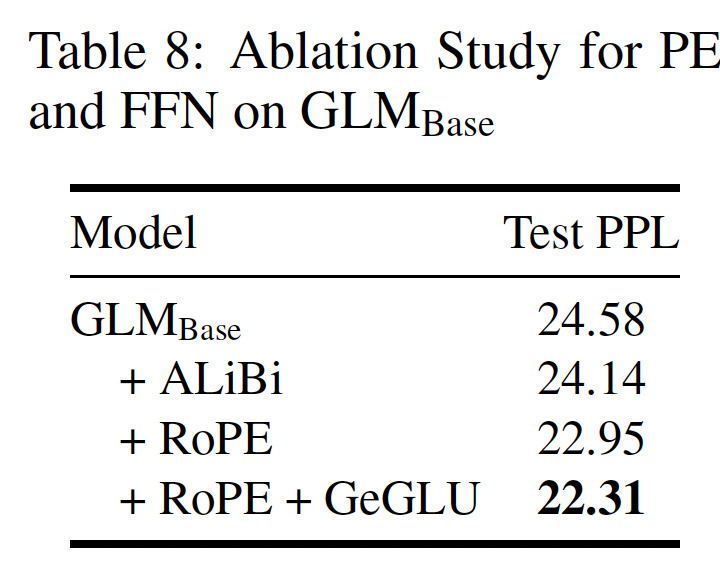
流水线并行的分析:在流水线并行中,每个
stage由三个操作组成(如下图(a)所示):forward(记做F)、backward(记做B)、以及optimizer step(记做U)。然而,朴素的sequential pipeline implementation会导致难以忍受的大量气泡。改进的Gpipe(《Gpipe: Efficient training of giant neural networks using pipeline parallelism》)(如下图(b)所示)策略通过将数据分割成micro-batch,大大减少了气泡:micro-batch越多,一次iteration中可以同时计算的stage就越多。最近的PipeDream-Flush(《Memory-efficient pipeline-parallel dnn training》)(如下图(c))通过不同stage的forward和backward交织,减少forward activation的内存占用,进一步优化了GPU内存的使用。我们分析
GLM-130B预训练中的气泡占比。假设pipeline segment的数量为micro-batch的数量为micro-batch的forward时间和backward时间分别为forward和backward耗时对于较大数量的
micro-batchGPipe的实验表明,当forward recomputation技术允许computational communication有一定的重叠,流水线气泡时间的总百分比降低到可以忽略的水平,从而表明由流水线并行引入的气泡并没有严重消耗训练效率。一般来说,为了充分利用硬件,通常会将模型放入由多个节点组成的
model parallel groups,并尽量使用每个节点的全部内存。在这种情况下,我们可以自由调整流水线模型并行和张量模型并行的比例。由于数据并行几乎不影响计算时间,我们假设数据并行的规模为从上式中可以看出,增加张量并行的规模将进一步降低气泡比例。然而,张量并行规模不能无限制地增加,这将降低计算粒度,并大大增加通信成本。因此,我们可以得出结论:张量模型并行的规模应该随着模型规模的增加而缓慢增加,但不能超过单台机器的显卡数量。在
GLM-130B的训练中,实验表明,在DGX-A100系统中,最佳的张量并行规模是3.8%,足以证明流水线模型并行的效率。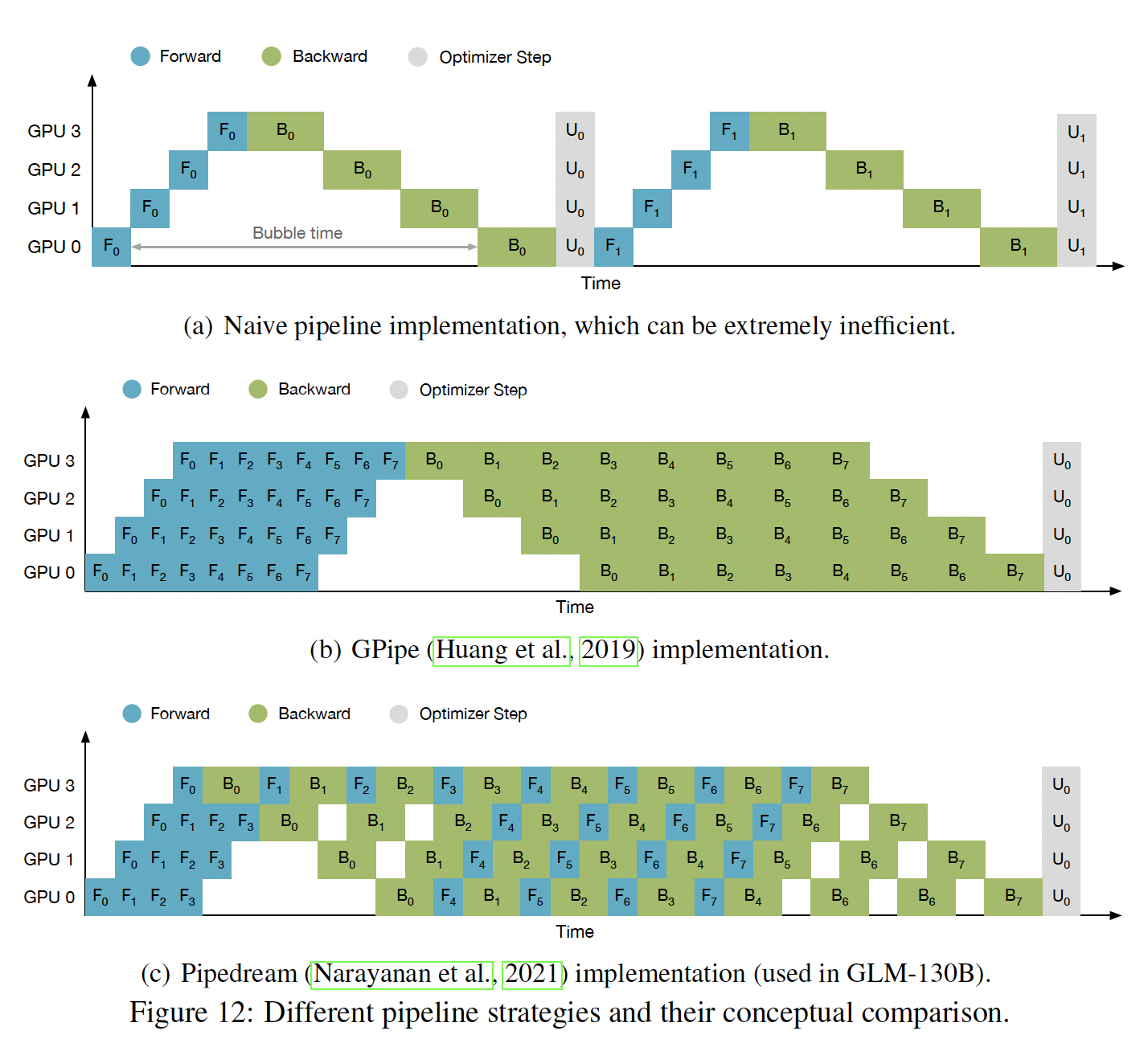
Inference加速:一个模型的普通PyTorch实现很容易阅读和运行,但对于LLM来说,它的速度会慢得令人难以忍受。基于NVIDIA的FasterTransformer(https://github.com/NVIDIA/FasterTransformer),我们花了两个月的时间将GLM-130B实现为C++语言,以加快推断速度,其中包括以下主要优化:优化耗时的操作,如
GeGLU、Layer Normalization和SoftMax。减少
GPU内核调用,例如,将MultiheadAttention融合到一个computation kernel中。在调用
cuBLAS时指定最佳性能的算法。通过提前转置(
transposing)模型参数来提高计算效率。在
FP16计算中使用half2,使half的访问带宽和计算吞吐量加倍。
目前我们将
GLM-130B的完整FasterTransformer实现打包成一个即插即用的docker image,以方便用户使用,我们还在努力将其适配到我们的Pytorch实现,只需改变一行代码。下表显示了我们加速的
GLM-130B实现、以及迄今为止在Hugging-face Transformers中默认可用的BLOOM-176B实现之间的比较。我们对GLM-130B的实现可以比BLOOM-176B的Pytorch实现快7.0 ~ 8.4倍。加速LLM从而获得可容忍的响应速度,这可能是LLM普及的关键。
Activation Outlier分析:如前所述,GLM-130B的权重可以被量化为INT4,以大幅度减少inference中的参数冗余。然而,我们也发现GLM-130B的activation(即层与层之间的隐状态)不能被适当量化,因为它们包含value outlier,这在同时进行的文献中也有建议(《Llm. int8 (): 8-bit matrix multiplication for transformers at scale》)。GLM-130B的独特之处在于,其30%的维度可能出现value outlier(如下图所示),而其他基于GPT的LLM(例如OPT-175B和BLOOM 176B)只有很少的outlying dimension。因此,《Llm. int8 (): 8-bit matrix multiplication for transformers at scale》提出的分解矩阵乘法从而进行更高精度的计算,这一解决方案不适用于GLM-130B。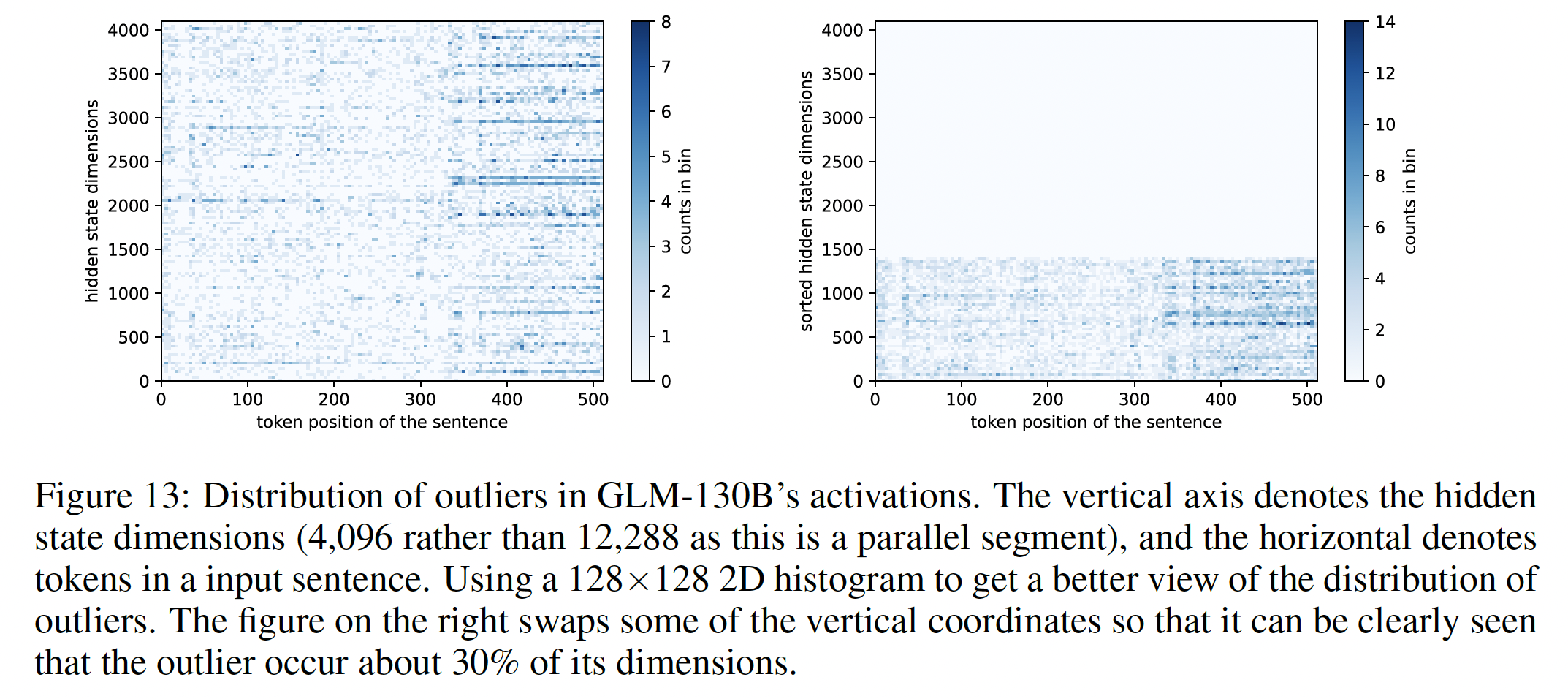
我们研究这些
outlier是否可以在LLM量化中被忽略,答案是"No"。这些值可能比典型的activation值大几个数量级(如下图所示)。虽然大多数值(占隐状态中99.98%的维度)保持在6以下,但那两个outlying dimension可以达到50甚至超过100。据推测,它们是GLM-130B(以及潜在的其他LLM)记忆一些固定的世界知识或语言知识的重要线索。因此,在量化过程中删除或忽略它们会导致显著的性能下降。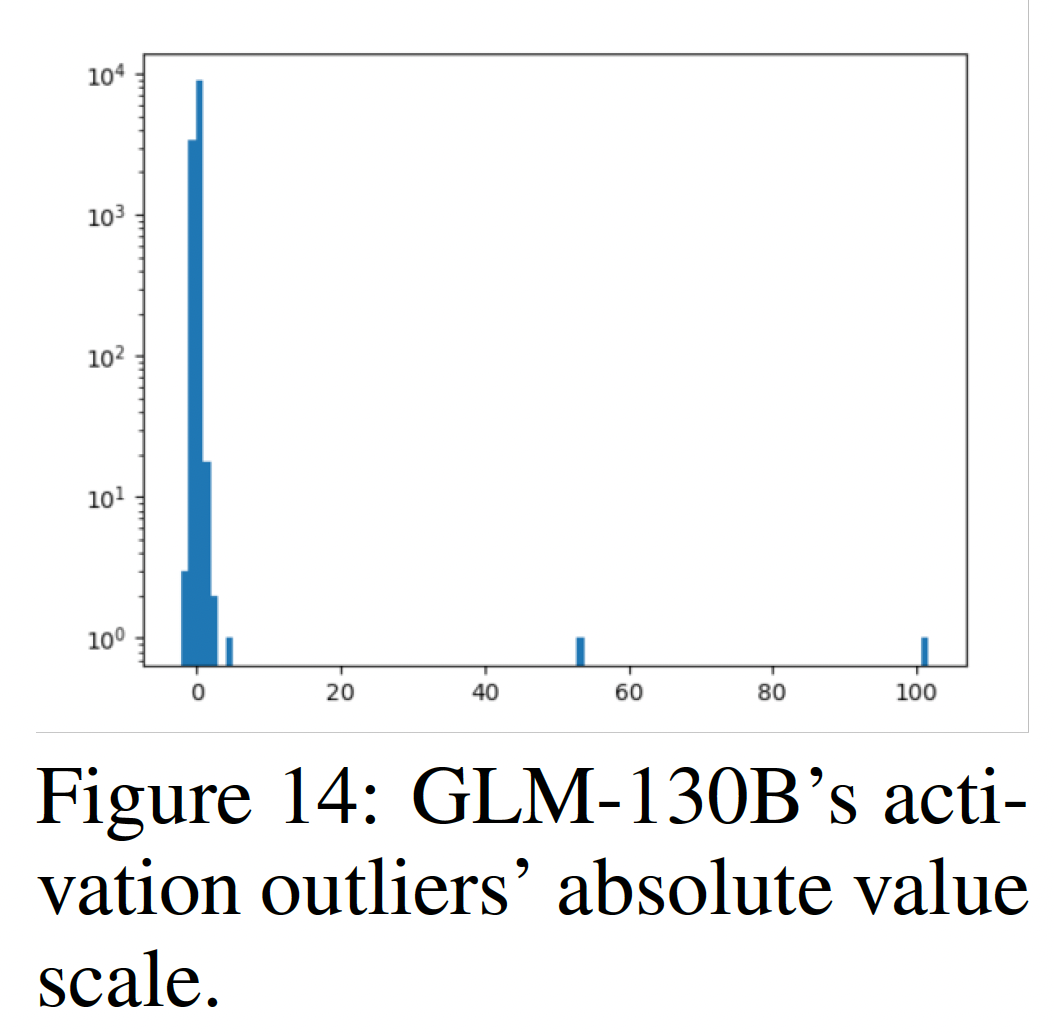
权重量化:
Absmax量化:是一种对称量化,即对于张量其中:
bit width)。Zeropoint量化:是一种非对称量化,即对于张量其中:
Col/Row-wise量化:对权重矩阵使用单个缩放因子往往会导致更多的量化错误,因为一个单个outlier会降低所有其他元素的量化精度。一个常见的解决方法是按行或列对权重矩阵进行分组,每组单独进行量化,并有独立的缩放因子。
量化的设置:我们的目标是在不损害模型性能的情况下尽可能地节省
GPU内存。在实践中,我们只对线性层进行量化(线性层占据了大部分的transformer参数),而对input/output embedding、layer normalization和bias项不做任何改变。在INT4的量化精度下,两个INT4权重被压缩成一个INT8权重以节省GPU的内存使用。我们采用Absmax量化,因为我们发现它足以保持模型的性能,而且它比zeropoint量化更加计算高效。在推断过程中,只有quantized weight被存储在GPU内存中;线性层的FP16权重在运行时被逆量化(dequantized)。不同规模的模型的量化效果:
110M到10B规模的GLM模型来自GLM的原始论文。虽然较小规模的GLM的结构与GLM-130B不一样,但我们认为training objective是量化的关键因素。下表显示了不同规模的GLM系列模型、以及BLOOM系列模型采用不同量化方法时在LAMBADA数据集上的性能。几乎所有的模型都在INT8精度下保持性能。在INT4精度下,GLM的性能比BLOOM的性能要好,当它规模扩大时。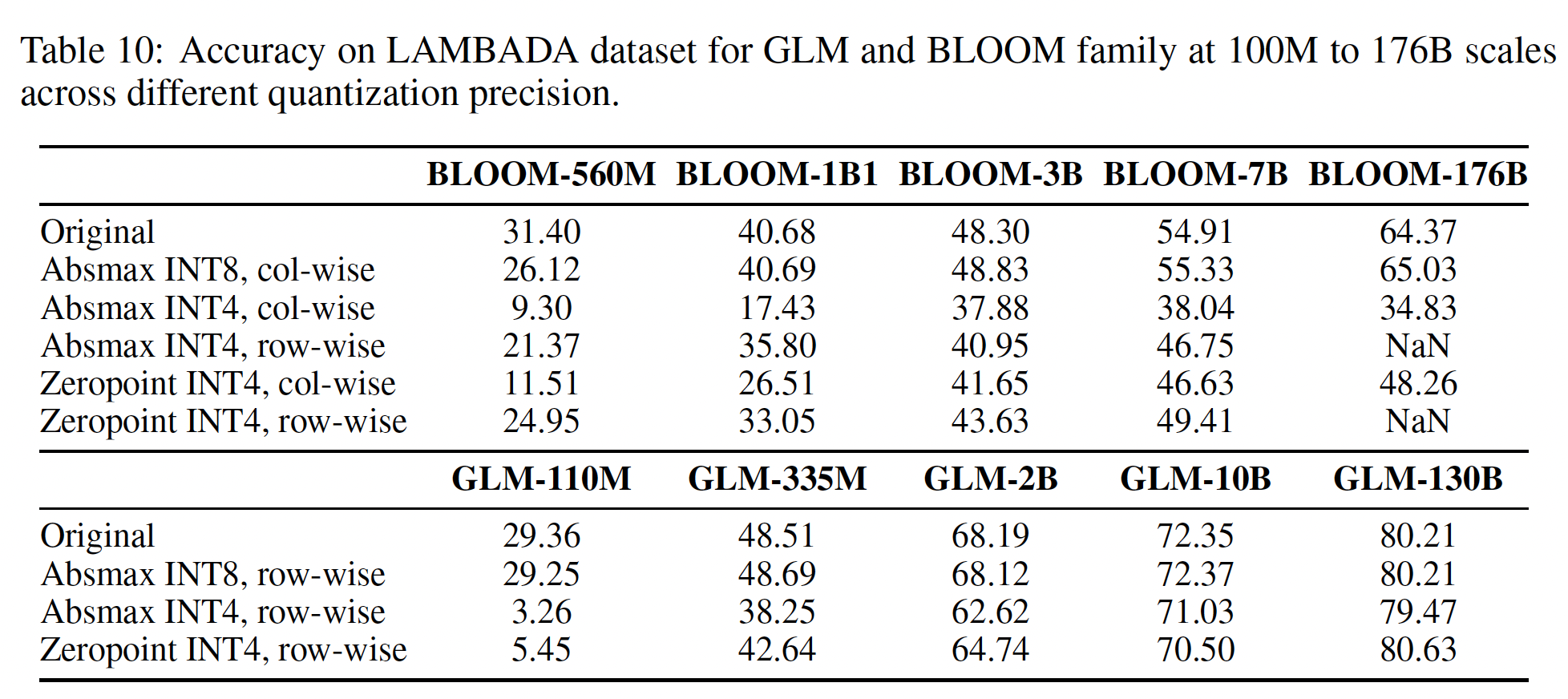
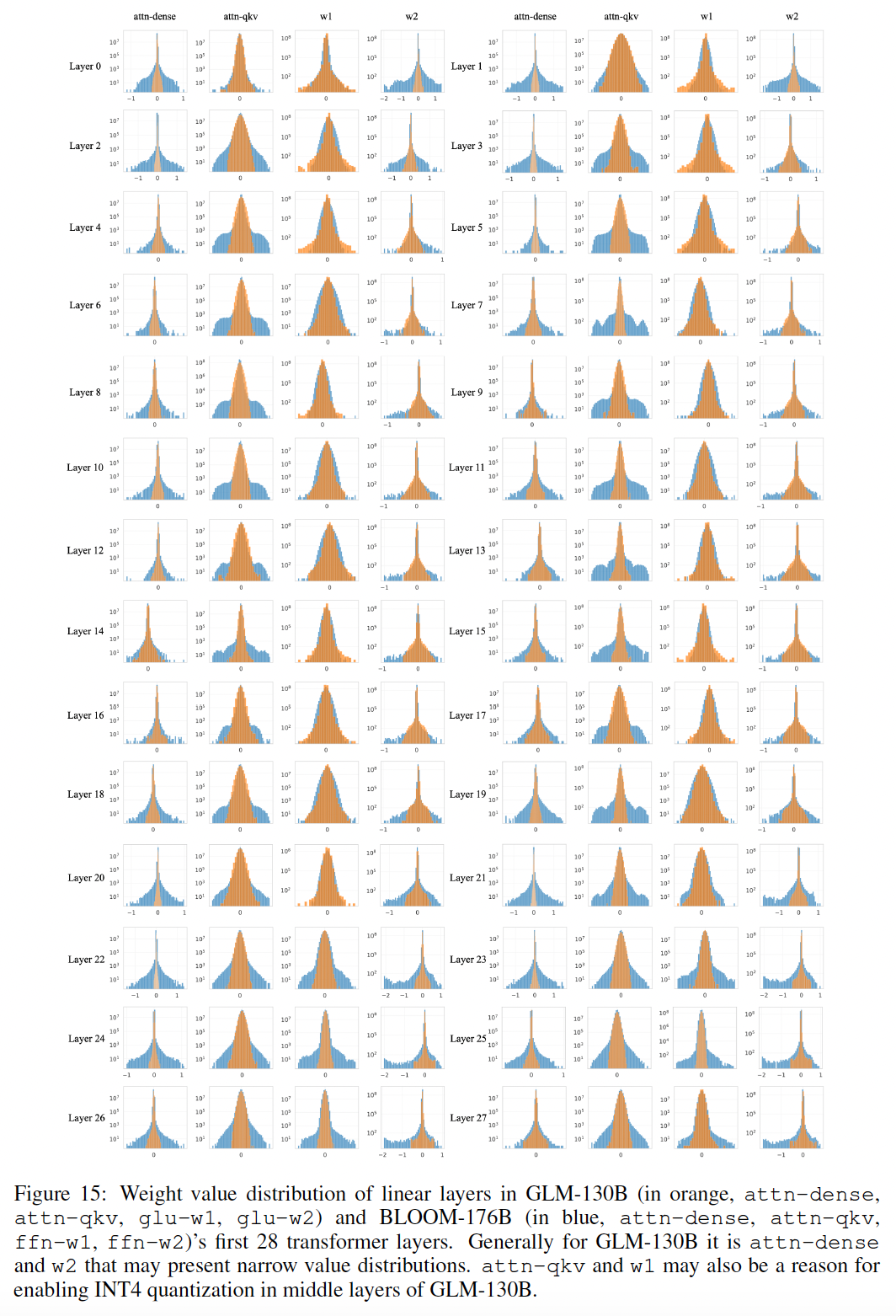
权重分布的分析:为了实现
INT4权重量化,我们用直方图分析了GLM-130B和对应的BLOOM-176B中主要线性层的权重取值分布(如下图所示)。横轴表示权重取值,纵轴表示该值的数量(在对数尺度下)。我们可以看到,主要是BLOOM-176B中的w2线性层呈现偏斜的分布,这将阻碍对称量化的进行。相反,GLM-130B的w2形状良好,没有许多outlier和偏斜的分布,因此为其INT4量化铺平了道路,性能损失不大。
47.6.3 数据集和评估细节
多任务指令预训练
Multi-task Instruction Pre-training: MIP:遵从T5、FLAN、T0、Ext5的做法,我们在GLM-130B的MIP训练中包括许多prompted instruction数据集,这占了训练token的5%。T0数据集的所有prompt来自PromptSource;DeepStruct数据集的prompt是新创建的。它们的构成如下表所示,由T0和PromptSource的自然语言理解和自然语言生成数据集、以及DeepStruct的information extraction数据集组成。在GLM-130B的训练中,我们计算出每个数据集中大约有36%的样本被看过。T0最初拆分数据集从而用于两个部分:multi-task prompted training、zero-shot task transfer。我们最初计划只包括T0的multi-task prompted training部分、以及DeepStruct的训练集,但由于错误,我们在MIP中同时包括了multi-task prompted training部分和zero-shot task transfer部分,而排除了DeepStruct数据集。我们在23k步左右修复了这个错误,然后我们的模型继续在正确的数据集版本上训练。Natural Language Understanding and Generation:我们采用了来自PromptSource的数据集和相应的prompt。对于每个数据集中的所有prompted sample,我们设置了每个数据集最大100k个样本的截断,并将其合并为MIP数据集。prompted sample和数据集的细节在PromptSource的GitHub repo中提供。Information Extraction:基于DeepStruct的数据集、以及一个用于信息提取任务的多任务语言模型预训练方法,我们为其部分数据集创建instructions和prompts(如下表所示)。我们将信息提取任务重新表述为instruction tuning格式,以允许zero-shot generalization到新的抽取模式。对于每个数据集的所有prompted sample,我们设置了每个数据集最大200k个样本的截断,因为信息提取数据集的比语言理解数据集和语言生成数据集少(指的是集合数量更少,而不是数据集内的样本数更少)。对于KELM和PropBank数据集,由于它们的原始规模巨大,我们从它们的prompted example中各取500k个样本。
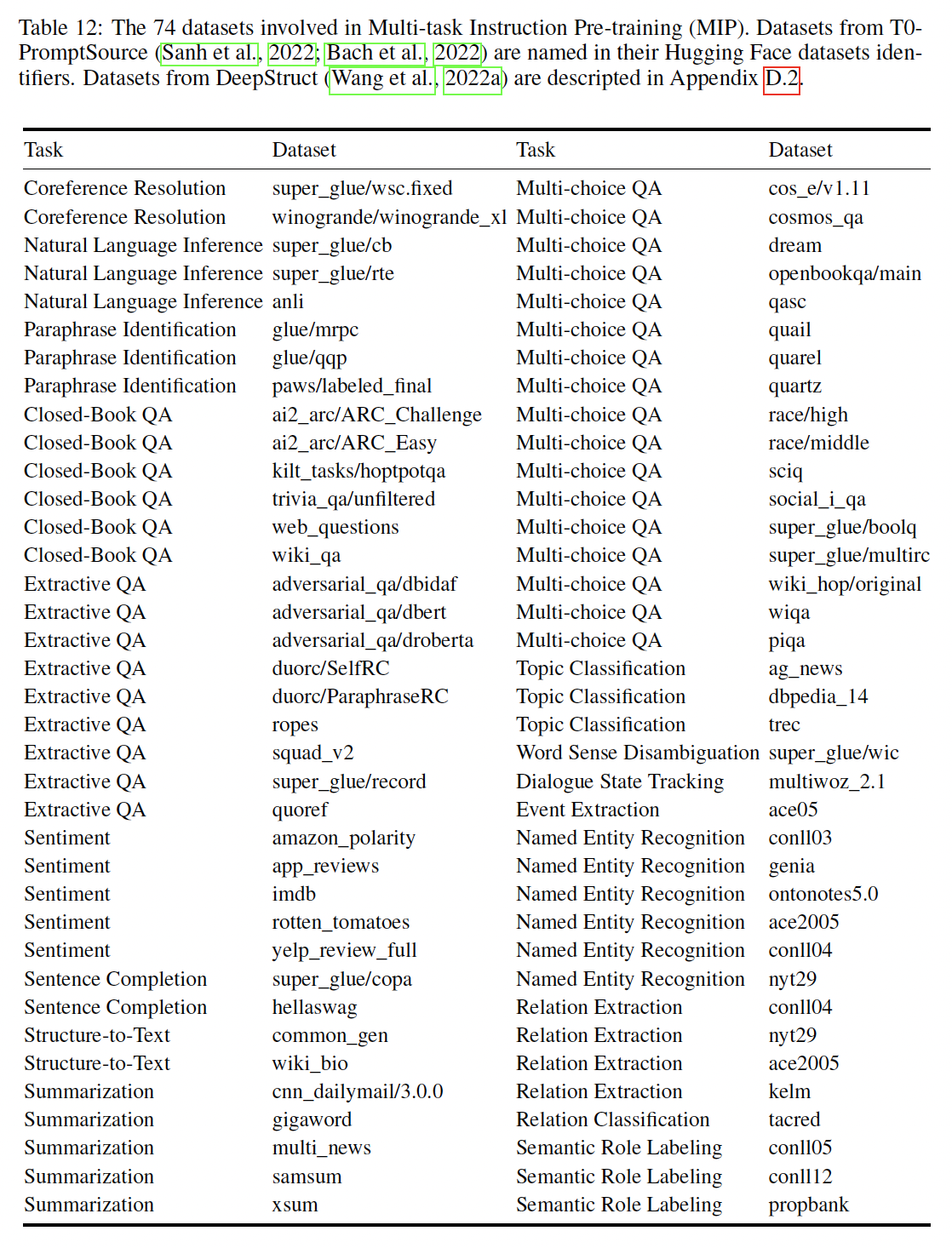
在
MIP中针对DeepStruct的数据和prompts:DeepStruct中所有数据集的prompts和instructions是由作者手动创建的。每个数据集的介绍、任务描述和完整的prompts都附在下面的内容中。为了允许template infilling,我们将所有prompts写进Jinja模板。当一个数据集样本以我们的格式被提供时,Jinja引擎将把它渲染成带有instructions的prompted sample。对
GLM-130B的信息提取能力进行更系统的评估是留给未来工作的,因为这项工作集中在LLM的训练和设计细节上。对话状态跟踪(
Dialogue State Tracking):我们采用Multiwoz 2.1对话状态追踪数据集。该数据集被重新表述为两个任务,每个任务有一个相应的prompt:对话状态跟踪:给定关于一组特定的
slots,要求模型从对话中提取信息,例如,"taxi_arrival_time"、"destination"。槽位填充(
slot filling):模型应填充一个给定的槽,并识别没有答案的情况。
事件抽取(
Event Extraction):我们采用ACE05事件提取数据集,遵循《Entity, relation, and event extraction with contextualized span representations》中的设置。该数据集被重新表述为有三个prompts的两个任务,具体如下:事件论据提取:给定文本中的
trigger和其论据角色列表,要求模型从提供的文本中提取论据。论据识别:给定一个
trigger和某个论据角色(argument role),如果该论据存在于所提供的文本中,则要求该模型提取该论据;否则,该模型应不产生任何结果。
联合实体和关系抽取(
Joint Entity and Relation Extraction):联合实体和关系抽取旨在识别一段文本中的命名实体并判断它们之间的关系。它与知识获取(knowledge acquisition)密切相关,其最终目标是将非结构化的网络内容结构化为知识三元组(例如,"(London, capital_of, Britain)")。该任务可以被格式化为一个pipeline framework(命名实体识别和关系提取的组合)或端到端的训练。在这项工作中,我们采用了三个经典的联合实体和关系提取数据集:
CoNLL04、NYT、以及ACE2005。在GLM-130B中,我们遵循《Deepstruct: Pretraining of language models for structure prediction》将这种挑战格式化为sequence-to-sequence generation,其中我们的输入是原始文本,输出是三元组。我们在这里只对这些数据集进行relation-related的任务,而将entity-related的任务留在命名实体识别部分。关系抽取(
Relation Extraction):给定一个关系候选列表,在这里我们提取由 "头实体"、"关系 "、"尾实体" 组成的知识三元组。例如,给定输入"In Kunming the 800-some faculty and student established the National Southwestern Associated University",模型输出可能是(National Southwestern Associated University, location of formation, Kunming)。条件关系抽取(
Conditional Relation Extraction):给定单个关系候选(relation candidate),模型判断输入文本是否包含该关系。如果是,则提取所有相关的三元组;如果不是,则不生成。知识槽填充(
Knowledge Slot Filling):从文本中指定一个特定的实体,并要求模型提取所有以该实体为头的三元组。关系分类(
Relation Classification):给定文本中的两个实体,要求模型根据候选关系列表来判断它们之间的关系。
然而,现有的联合实体和关系提取数据集具有最小的关系模式。例如,
CoNLL04只包含五个不同的关系;最多样化的NYT数据集包含24个Freebase predicates。为了让模型能够捕捉到多样化的潜在verbalized predicates,我们用来自KELM的自动生成的knowledge-text aligned data来扩展任务。我们不包括其他distantly supervised的数据集(例如,T-Rex),由于这些数据可能是极其噪音的。对于
KELM数据,由于它是基于完整的Wikidata模式(其中包含太多的关系,无法枚举),我们为关系提取和知识槽填充的任务创建了两个KELM-specific prompts。命名实体识别(
Named Entity Recognition:NER):命名实体识别是一项任务,旨在从原始文本语料库中识别命名实体,并为其分配适当的实体类型。例如,在In 1916 GM was reincorporated in Detroit as "General Motors Corporation".这句话中,"通用汽车公司"("General Motors Corporation")可能属于organization这种实体。我们根据命名实体识别数据集
CoNLL03、OntoNotes 5.0、GENIA设计了两种不同类型的任务。我们还包括来自联合实体和关系数据集的命名实体识别子任务。命名实体识别:给定可能的实体类型列表(例如,地点、人、组织),从提供的文本内容中提取所有相关的实体。
实体定型(
Entity Typing):实体定型是命名实体识别的重要衍生任务之一。它的目的是对entity mention的正确类型进行分类 ,并经常作为后处理附加在entity mention extraction上。
关系分类(
Relation Classification):关系分类是信息提取的一项基本任务,它从两个给定实体之间的候选列表中确定关系。这个问题是一个长期存在的问题,因为它受制于数据标注的巨大成本,因为知识密集型(knowledge-intensive)任务的人工标注需要受过教育的标注员,而标注员的费用很高。关系提取中事实上的数据创建方法依赖于
distant supervision,它自动将knowledge base中现有的知识三元组与文本内容相匹配。它假定这种alignment在某些条件下是正确的。这里我们只包括TacRED数据集,并基于它创建几个不同的任务。关系分类:最传统的任务表述。给出文本中的两个实体,从一个候选列表中对它们的关系进行分类。该形式可以直接回答关系,也可以以三元组的形式回答(类似于关系提取)。
知识槽填充(
Knowledge Slot Filling):将任务改为,给定头部实体和关系从而确定尾部实体在输入文本中是否存在。如果没有,则不生成任何东西。Yes or No问题:把问题变成一个类似于自然语言推理的任务。例如,给定句子"The series focuses on the life of Carnie Wilson, daughter of Brian Wilson, founder of the Beach Boys.",模型将被要求通过回答 "是" 或 "否" 来判断(Carnie Wilson, father, Brian Wilson )这样的三元组是否正确。
语义角色标注(
Semantic Role Labeling):语义角色标注是一项由来已久的任务,它希望识别与句子中给定谓语(predicate)相关的语义论据。例如,在"Grant was employed at IBM for 21 years where she held several executive positions."这个句子和其中的谓语"employed",语义角色标注将Grant作为主语,将IBM作为第二宾语。我们根据语义角色标注数据集
CoNLL05、CoNLL12和PropBank创建两个不同的任务。语义角色标注:传统的任务形式,即在文本中注释一个动词(即谓语),要求模型生成相关的语义角色。
语义角色填充:给定一个动词和一个潜在的语义角色,要求模型判断该角色在句子中是否存在并生成它。
谓语识别:给定一个句子的片段及其相应的语义角色,识别它与哪个动词有关。
Big-Bench-Lite评估:最近的工作显示,LLM有能力进行超越传统语言任务的reasoning。作为回应,BIG-bench最近通过从全球研究人员那里众包新型的任务来测试LLM的新能力。出于经济上的考虑,我们在原150个任务的BIG-bench的一个官方子集上评估GLM-130B,即有24个任务的BIG-bench-lite。这些任务可以分为两类:一类是基于带有答案选项的多选题问答任务,另一类是不带答案选项的答案直接生成任务。对于第一类,我们评估每个选项的完整内容的概率,并挑选概率最大的选项作为答案;对于第二类,我们使用贪婪解码来生成答案。在BIG-bench中进行的所有评估都是基于[MASK],因为这里的答案通常是短文。在24个BIG-bench-lite数据集上的三个LLM的所有结果都显示在下表和下图。我们采用了BIG-bench的原始prompt,并使用官方的实现来生成启动样本(priming example)用于few-shot评估和计算最终得分。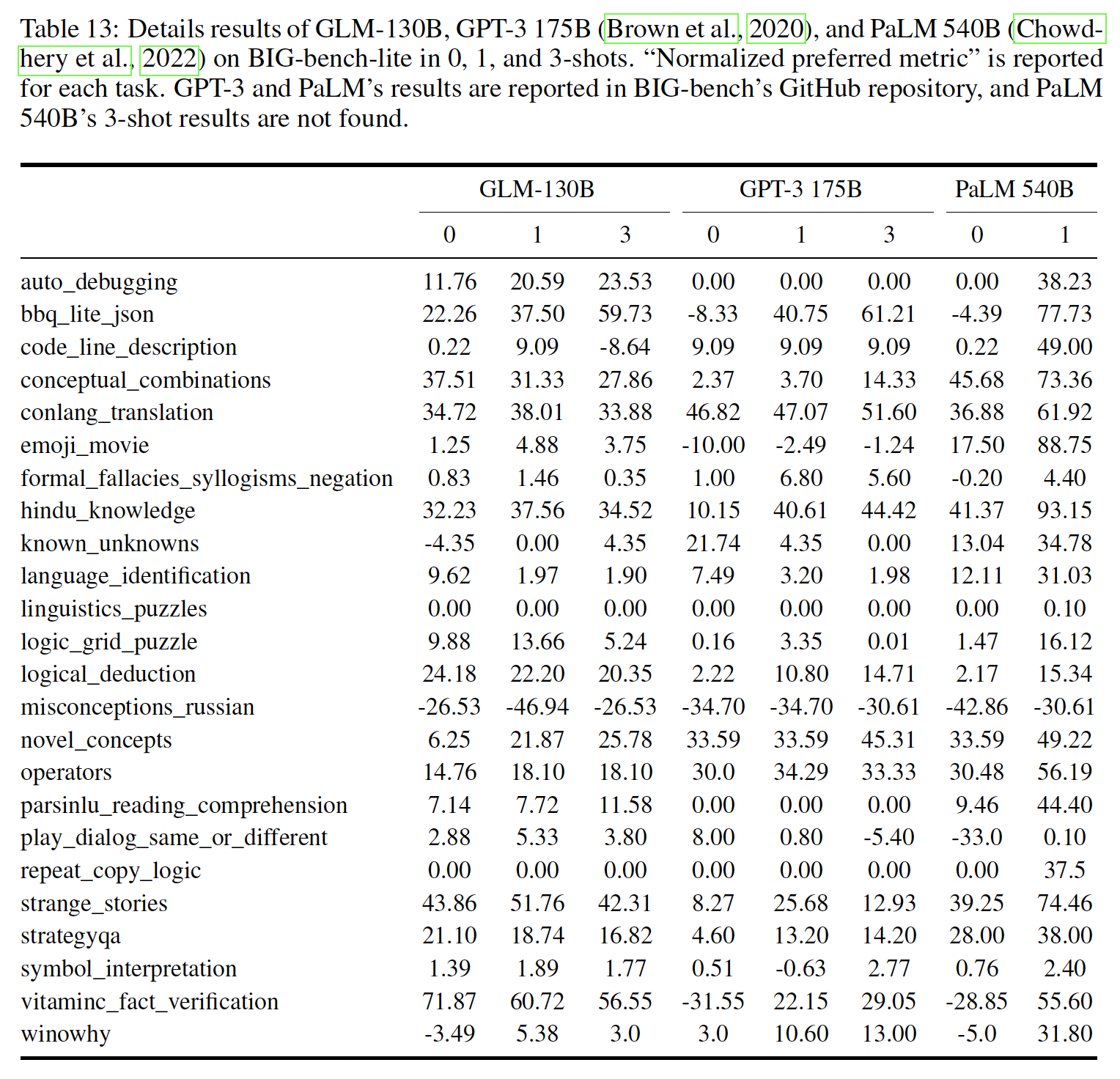
MMLU评估:下表中显示了GLM-130B和BLOOM 176B的57个MMLU数据集的所有结果。在前面内容中,我们报告了GLM-130B、GPT-3 175B和BLOOM 176B的加权平均准确率(即每个样本的准确率平均值),遵循原始的benchmark setting。 下面是一个具有1-shot priming的prompted example。我们预测next token为['A', 'B', 'C', 'D']的概率,并将概率最大的token作为答案。xThe following are multiple choice questions about philosophy.According to d'Holbach, people always act according to _____.(A) free choices (B) dictates of the soul (C) necessary natural laws (D) undetermined willAnswer: (C) necessary natural lawsEpicurus holds that philosophy is:(A) not suitable for the young. (B) not suitable for the old. (C) important, but unpleasant. (D) none of the above.Answer: (
Language Modeling评估:LAMBADA:我们遵循GPT-2中的评估设置,利用stop-word filter从而选择出得分最大的valid final word prediction作为我们的答案。我们使用beam size = 16的beam search解码策略,最大generation长度限制为5。遵从《The lambada dataset:Word prediction requiring a broad discourse context》的要求,我们预测的final word是一个自然的英语单词(即可能由多个token组成),而不是单个GLM-130B token。最后,我们用字符串匹配来判断正确性。Pile:Pile是一个全面的语言建模benchmark,最初包括来自不同领域的22个不同文本数据集。我们在18个数据集的一部分上报告了我们的结果,《Jurassic-1: Technical details and evaluation》报告了baseline的结果。与传统的语言建模基准不同,Pile评估报告了bits-per-byte: BPB的困惑度,以避免不同词表的模型之间的不匹配比较。因为一般而言,如果不加以限制,具有较大词表的语言模型在困惑度比较中会受到青睐。在评估中,我们严格遵循《The pile: An 800gb dataset of diverse text for language modeling》中的setting,利用[gMASK]和具有双向注意力的1024长的上下文,剩余的1024个token以自回归方式计算BBP。加权平均BBP是根据每个共享数据集在Pile训练集中的比例计算的。下表中报告了
Pile测试集的详细指标。我们观察到,与GPT-3相比,GLM-130B在phil_papers和pile_cc上的表现明显较弱,这可能是由于GLM-130B的双语特性、以及缺乏更多样化和高质量的私有语料库。
中文理解评估:在此,我们阐述了我们用于
CLUE和FewCLUE评估的prompts。在中文数据集中,提示遇到了一些挑战,因为中文文本是由单个字符而不是单词组织的,在许多情况下导致verbalizers的长度不等。尽管针对数据集的校准可以帮助缓解这一问题,但过于具体的技术在实施中会很复杂。我们在本文中的评估采用了一种更容易解决的方法,利用GLM-130B的独特功能。由于GLM-130B是一个带有英文MIP的双语LLM,我们采用了《Promptsource: An integrated development environment and repository for natural language prompts》的类似任务中的英文的prompts和verbalizers来进行中文数据集的评估,并发现这些策略相当有效。在评估指标方面,除了DRCD和CMRC2018这两个问答数据集报告了EM,其他数据集报告了准确率。
47.6.4 更广泛的影响
本文介绍了一个具有
130B参数的开放式双语预训练语言模型。目前,大多数拥有超过100B参数的预训练语言模型被政府和大公司所私有。其中少数的政府或大公司提供了有限的付费的inference API。相比之下,GLM-130B的权重和代码向任何对LLM感兴趣的人开放。此外,我们通过speed-up implementation和INT4量化,大大降低了推理的硬件要求。这篇论文可以对研究界、个人开发者、小公司和社会产生更广泛的影响。对人工智能研究的影响:大多数研究机构无法承担预训练大型语言模型的巨大成本。因此,除了政府和大公司的雇员之外,大多数研究人员只能通过付费来使用有限的
inference API。通过inference API,研究人员只能把模型的输出作为黑盒子来分析,这限制了潜在工作的范围。通过GLM-130B,研究人员可以分析与特定输入相对应的模型参数和内部状态,从而对LLM的理论、能力和缺陷进行深入研究。研究人员还可以修改模型结构和权重,以验证所提出的算法,从而改进LLM。通过
INT4量化,GLM-130B可以在流行的GPU上进行推理,如4个RTX 3090或8个RTX 2080 Ti,这可以很容易地从云服务中获得。因此,买不起DGX-A100等强大的data-center GPU server的研究人员也可以利用GLM-130B。对个人开发者和小公司的影响:想要将
LLM整合到其业务中的个人开发者和小公司只能选择付费inference API。增加的成本会阻碍他们的尝试。相反,GLM-130B可以部署在他们拥有的流行的硬件上,或者可以通过云服务访问,以降低成本。此外,他们可以利用蒸馏技术来获得较小的模型,在他们的特定任务上保持可比的性能。虽然一些开发者可能缺乏自行完成部署和蒸馏的能力,但我们相信随着GLM-130B和未来更多开放的LLM,相应的工具包和服务提供商,将变得更加可用。我们还注意到,目前大多数
LLM应用都是基于prompt engineering,部分原因是inference API的限制。在下游场景中,如在线客服,公司积累了大量的人类产生的数据,其中包含领域知识。通过开源的权重和代码,开发者可以在他们的数据上对GLM-130B进行微调,以减轻domain knowledge的差距。
环境影响:对大型语言模型的主要关注之一是其巨大的能源使用和相关的碳排放。据估计,
GPT-3使用了500吨的碳排放足迹(CO2eq)。在60天的训练过程中,我们总共消耗了442.4MWh的电力。考虑到当地电网的0.5810公斤/千瓦时的碳效率,预训练释放了257.01吨的二氧化碳。这大约是GPT-3的碳足迹的一半,可能是由于高效的并行策略和NVIDIA的硬件改进。这个碳排放量大约相当于18个普通美国人一年的排放量。然而,我们相信随着GLM-130B的发布,可以为复制100B-scale LLM节省更多的碳排放。
四十八、GPT-NeoX-20B[2022]
在过去的几年里,围绕自然语言处理的大型语言模型(
large language model: LLM)的研究出现了爆炸性增长,主要是由基于Transformer的语言模型的令人印象深刻的性能所推动,如BERT、GPT-2、GPT-3和T5。这些研究的最有影响的成果之一是:发现大型语言模型的性能和参数数量呈现可预测的幂律(power law)关系,其中诸如宽深比(width/depth ratio)等结构细节在很大范围内对性能的影响很小(《Scaling laws for neural language models》)。其结果是大量的研究集中在将Transformer模型扩展到更大的规模上,从而产生了超过500B参数的稠密模型,这是在几年前几乎无法想象的里程碑。稠密模型指的是类似于
GPT-3这种,没有采用mixture-of-experts的模型。今天,有几十个公开宣布的大型语言模型,最大的
LLM的参数比GPT-2多两个数量级,即使在这个规模,也有近十种不同的模型。然而,这些模型几乎都是受保护的大型组织的知识产权,并且被限制在商业API,只能根据request来提供使用,或者根本不能供外部人员使用。据我们所知,唯一免费公开的比GPT-2更大的稠密的自回归语言模型是GPT-Neo(2.7B参数)、GPT-J-6B、Megatron-11B、Pangu-a-13B以及最近发布的FairSeq模型(2.7B、6.7B、13B参数)。在论文
《GPT-NeoX-20B: An Open-Source Autoregressive Language Model》中,作者介绍了GPT-NeoX-20B,一个20B参数的开源的自回归语言模型。作者通过permissive license向公众免费开放模型权重,其动机是相信开放LLM对于推动广泛领域的研究至关重要,特别是在人工智能安全、机制上的可解释性、以及研究LLM能力如何扩展等方面。LLM的许多最有趣的能力只有在超过一定数量的参数时才会涌现,而且它们有许多属性根本无法在较小的模型中研究。虽然安全问题经常被作为保持模型权重私有化的理由,但作者认为这不足以防止滥用,而且对于能够获得SOTA语言模型的少数组织之外的研究人员来说,这在很大程度上限制了探究和研究LLM的能力。此外,作者在整个训练过程中以均匀的1000步的间隔提供partially trained checkpoint。作者希望通过免费提供在整个训练过程中的广泛的checkpoint,从而促进对LLM的training dynamics的研究,以及上述的人工智能安全性和可解释性等领域的研究。在研究
GPT-NeoX-20B的过程中,作者发现了几个值得注意的现象,与已有的文献不一致:作者在一个包含重复数据的数据集上进行训练,训练超过一个
epoch,但没有看到性能损失的证据。虽然
《 Measuring massive multitask language understanding》声称,few-shot prompting并不能提高他们任务的性能,但作者发现,这实际上是GPT-3特有的现象,并不适用于GPT-NeoX-20B或FairSeq模型。最后,作者发现
GPT-NeoX-20B是一个强大的few-shot learner,与规模相当的GPT-3模型和FairSeq模型相比,从few-shot examples中获得的性能提升要大得多。作者看到GPT-J-6B也是如此,作者假设这可能是由于GPT-J-6B选择了相同的训练数据。
最后,训练和评估代码在
https://github.com/EleutherAI/gpt-neox上公开,也可以在那里找到下载整个训练过程中模型权重的链接。
48.1 模型设计和实现
GPT-NeoX-20B是一个autoregressive transformer decoder model,其结构基本遵循GPT-3的结构,但有一些明显的改变,如下所述。我们的模型有20B参数,其中19.9B参数是"non-embedding"参数,《Scaling laws for neural language models》认为这是用于scaling laws analysis的适当数量。我们的模型有44层,隐层维度大小为6144,有64个head。
48.1.1 模型架构
虽然我们的架构与
GPT-3基本相似,但也有一些明显的区别。在本节中,我们对这些不同之处进行了high-level的概述,但请读者参考GPT-3的原始论文以了解模型架构的全部细节。我们的模型架构几乎与GPT-J相同,但我们选择使用GPT-3作为参考,因为没有关于GPT-J设计的典型出版物作为参考。Rotary Positional Embeddings:我们使用rotary embedding(《RoFormer: Enhanced transformer with rotary position embedding》),而不是GPT模型中使用的learned positional embedding,这是基于我们之前在训练LLM中使用rotary embedding的积极的经验。rotary embedding是static relative positional embedding的一种形式。简而言之,它们扭曲了emebdding空间,使位置token对位置token的注意力线性地依赖于更正式地说,标准的多头注意力方程为:
其中:
token embedding。注意:通常而言,通过在
token embedding上添加positional embedding从而得到query投影矩阵和key投影矩阵。
而
rotary embedding将这个方程修改为:其中:
block diagonal matrix),其中第block是一个2D rotation,旋转角度为其中,
虽然
《RoFormer: Enhanced transformer with rotary position embedding》将rotary embedding应用于整个embedding向量,但我们遵从《GPT-J-6B: A6 billion parameter autoregressive language model》,而是只将rotary embedding应用于embedding向量维度的前25%。我们的初步实验表明,这在性能和计算效率上取得了最佳平衡。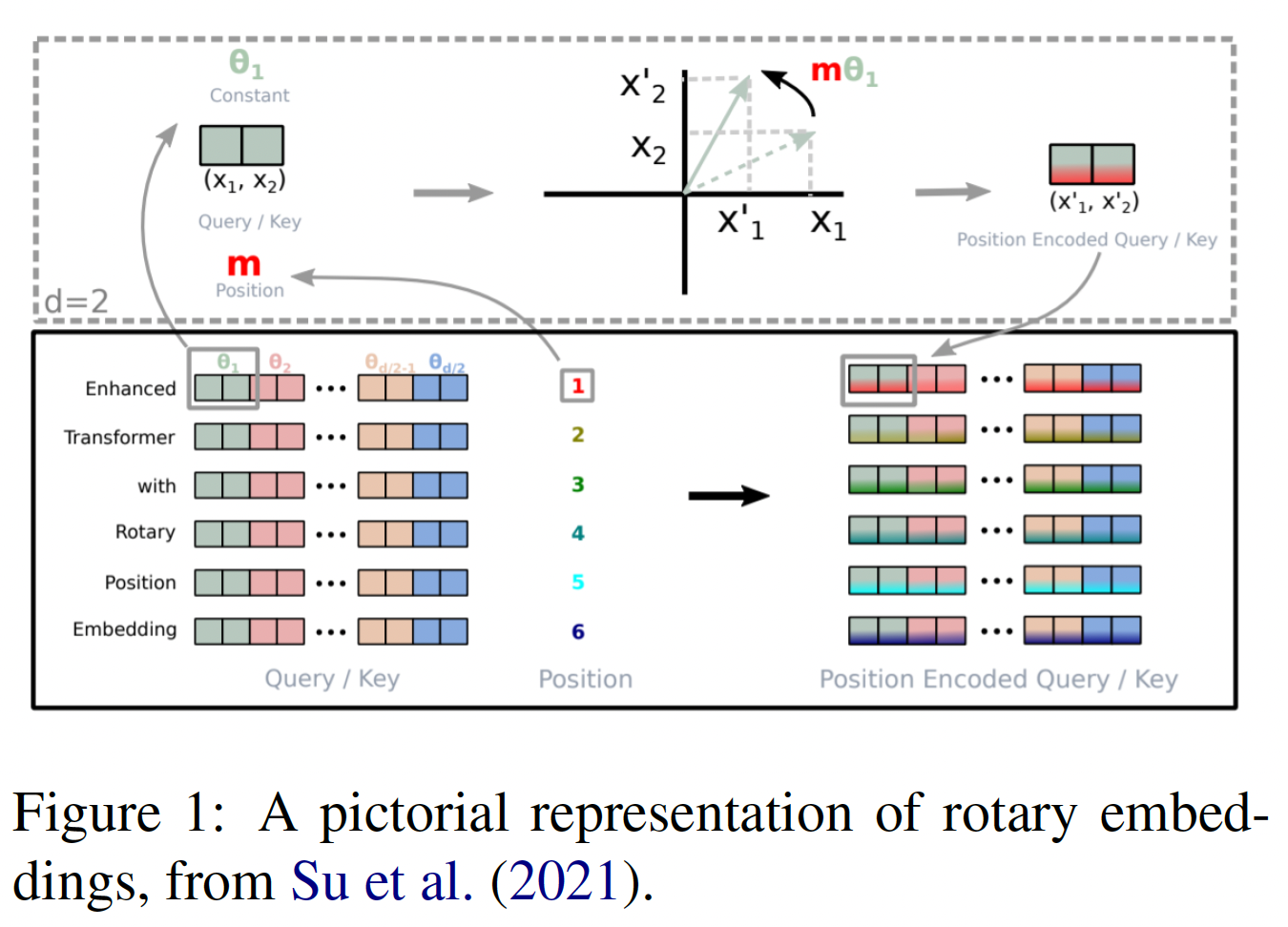
并行计算
Attention Layer + FF Layer:我们并行地计算注意力层和前馈层(Feed-Forward: FF),并将结果相加,而不是串行地运行。这主要是为了提高效率,因为在op-sharding的情况下,每个残差加法(residual addition)都需要在前向传递和后向传递中进行一次all-reduce(《Megatron-LM: Training multi-billion parameter language models using model parallelism》)。通过并行计算Attention和FF,可以在执行单个all-reduce之前对结果进行局部规约(reduce)。在Mesh Transformer JAX中,这导致了15%的吞吐量增加,同时在训练的早期,与串行地运行它们的损失曲线相当。由于我们代码中的一个疏忽,我们无意中应用了两个独立的
Layer Norm,而不是像GPT-J-6B那样使用一个tied layer norm。tied layer norm的方式为:相反,我们的代码实现为:
不幸的是,这只是在我们训练到很远的时候才注意到,无法重新开始。随后的小规模实验表明,
untied layer norm对性能没有影响,但为了透明性起见,我们还是希望强调这一点。初始化:对于残差前的
Feed-Forward output layers,我们使用了《Mesh-Transformer-JAX: Model parallel implementation of transformer languagemodel with JAX》中介绍的初始化方案,activation随着深度和宽度的增加而增长,分子为2可以补偿注意力层和前馈层被组织为并行的事实。对于所有其他层,我们使用
《Transformers without tears: Improving the normalization of self-attention》的small init方案所有的
Dense层:虽然GPT-3使用《Generating long sequences with sparse transformers》介绍的技术交替使用dense层和sparse层,但我们却选择完全使用dense层来降低实现的复杂性。
48.1.2 其它
软件库:我们的模型是使用建立在
Megatron和Deep-Speed基础上的代码库进行训练的,以促进高效和直接地训练具有数百亿个参数的大型语言模型。我们使用官方的PyTorch v1.10.0发布的二进制包,用CUDA 11.1编译。该软件包与NCCL 2.10.3捆绑在一起,从而用于分布式通信。硬件:我们在
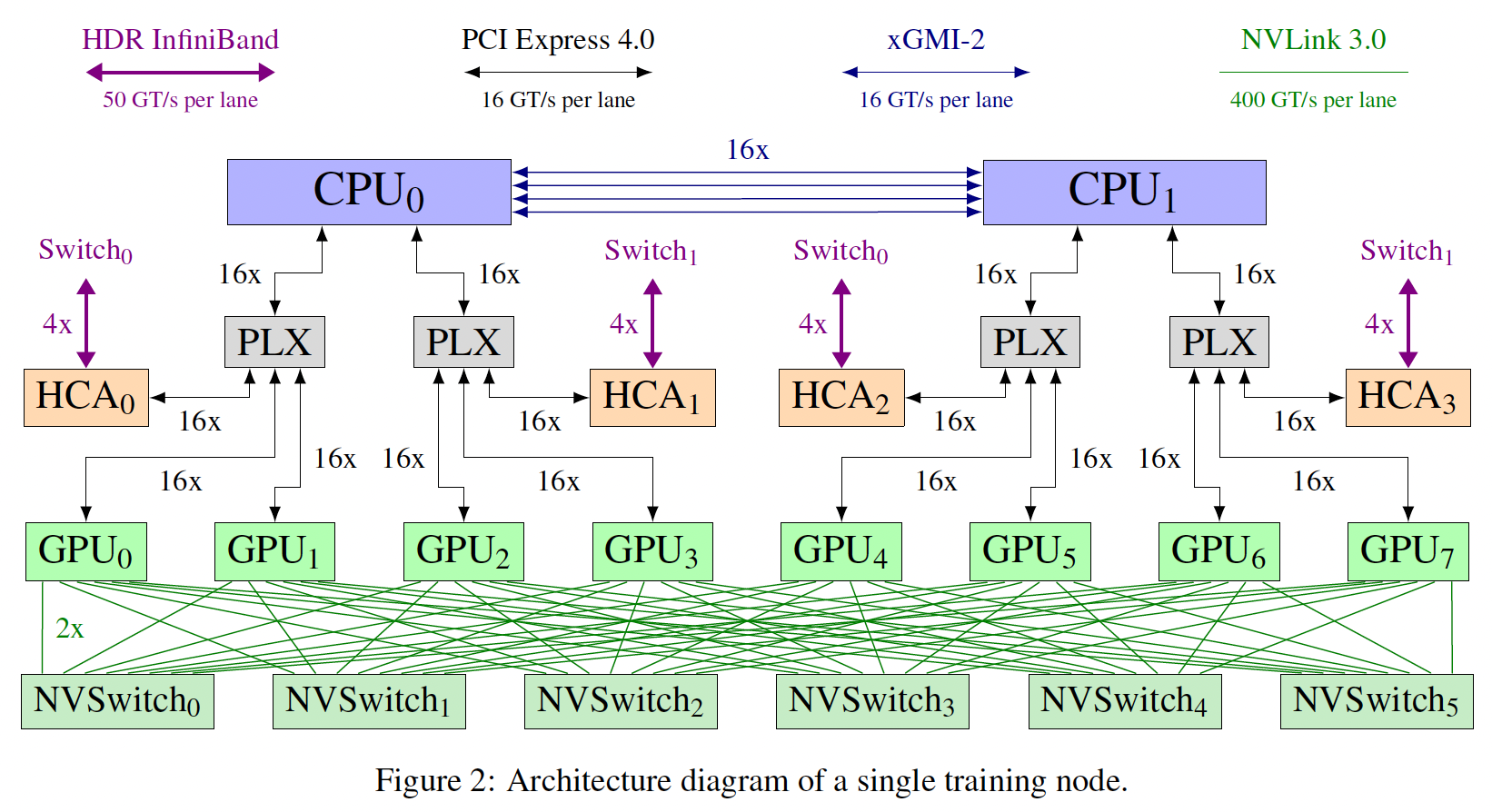
12台Supermicro AS-4124GO-NART服务器上训练GPT-NeoX-20B,每台服务器有8个NVIDIA A100-SXM4-40GB GPU,并配置了两个AMD EPYC 7532 CPU。所有的GPU都可以通过四个ConnectX-6 HCA中的一个直接访问InfiniBand switched fabric,从而用于GPU Direct RDMA。两个NVIDIA MQM8700-HS2R交换机通过16条链路连接,构成了这个InfiniBand网络的主干,每个节点的CPU socket有一条链路连接到每个交换机。下图显示了一个节点的简化概览,该节点为训练而配置。
48.2 训练
由于对
20B参数的模型进行超参数调优的难度很大,我们选择使用GPT-3的超参数值来指导我们对超参数的选择。由于
GPT-3没有以我们的20B规模训练一个模型,我们在他们的13B模型和175B模型的学习率之间进行插值,得出的学习率为0.97e-5。基于较小的模型上的实验结果,我们选择
0.01的weight decay。为了达到更高的训练吞吐量,我们选择使用与
GPT-3的175B模型相同的batch size:大约3.15M token,或者1538个上下文其中每个上下文2048 token(即,batch size = 1538,序列长度2048),总共训练150k步,采用余弦学习率调度从而在训练结束时衰减到原始学习率的10%。我们使用
AdamW优化器,其中ZeRO optimizer来扩展AdamW,通过将optimizer states切分到各台worker机器上从而来减少内存消耗。由于这种规模的模型权重和优化器状态不适合在单个
GPU上使用,我们使用Megatron-LM介绍的张量并行方案、与PipeDream介绍的流水线并行方案相结合,从而在一组GPU上分配模型。为了训练
GPT-NeoX-20B,我们发现,考虑到我们的硬件设置,分配模型的最有效方式是将张量并行大小设置为2、将流水线并行大小设置为4。 这允许最密集的通信过程,张量并行、流水线并行发生在一个节点内,而数据并行通信发生在节点边界上。通过这种方式,我们能够实现并保持每个GPU的117 TFLOPS的效率。

训练数据:
GPT-NeoX-20B是在Pile上训练的,这是一个专门为训练大型语言模型而设计的大规模的数据集。它由22个数据源的数据组成,粗略地分为5个类别:学术写作:
Pubmed Abstracts and PubMed Central、arXiv、FreeLaw、USPTO Backgrounds、PhilPapers、NIH Exporter。网络爬取和互联网资源:
CommonCrawl、OpenWebText、StackExchange、Wikipedia (English)。散文:
BookCorpus、Bibliotik、Project Gutenberg。对话:
Youtube subtitles、Ubuntu IRC、OpenSubtitles、Hacker News、EuroParl。其它杂项:
GitHub、DeepMind Mathematics dataset、Enron Emails。
总的来说,
Pile数据由超过825GB的原始文本数据组成。数据来源的多样性反映了我们对通用语言模型的渴望。某些数据子集被升采样以获得更平衡的数据分布。相比之下,GPT-3的训练数据包括网络爬取(web-scrape)数据、books数据集、Wikipedia。当把这项工作中的结果与GPT-3进行比较时,训练数据几乎肯定是最大的、已知的unknown factor。关于Pile的全部细节可以在技术报告《The Pile: An 800GB dataset of diverse text for language modeling》和相关数据表《Datasheet for the Pile》中找到。特别值得注意的是,
Pile包含了StackExchange的爬取,并被预处理成Q/A形式。关于微调数据的句法结构对下游性能的影响,有大量的、不断增长的工作。虽然到目前为止还没有专注于prompted pretraining的系统工作,但最近的工作《Neural language models are effective plagiarists》观察到,Pile的StackExchange子集的格式化(formulation)似乎严重影响了code generation。Tokenization:对于GPT-NeoX-20B,我们使用了与GPT-2类似的BPE-based tokenizer,总的词表规模同样为50257。tokenizer有三个主要变化:首先,我们在
Pile的基础上训练一个新的BPE tokenizer,利用其不同的文本来源来构建一个更通用的tokenizer。第二,
GPT-2 tokenizer将字符串开始处的tokenization视为non-space-delimited token。与GPT-2 tokenizer相比,GPTNeoX-20B tokenizer无论如何都要应用一致的space delimitation。这解决了关于tokenization input的前缀空格符存在与否的不一致问题。 下图中可以看到一个例子。第三,我们的
tokenizer包含用于重复空格符的token,其中重复空格符的数量从1个空格到24个空格。这使得GPT-NeoX-20B tokenizer能够使用较少的token对具有大量空格的文本进行tokenize,例如,程序源代码、或arXiv LATEX源代码文件。例如,
NeoX-20B可以将连续的4个空格视为一个token,这在python代码中经常见到。相比之下,GPT-3将4个空格视为四个token,每个空格一个token。

GPT-NeoX-20B tokenizer和GPT-2 tokenizer在50257个token中共享36938个,重叠度为73.5%。总体而言,GPT-NeoX-20B tokenizer使用更少的token数量来tokenizePile验证集,但是使用了更多的token来tokennizeC4数据集。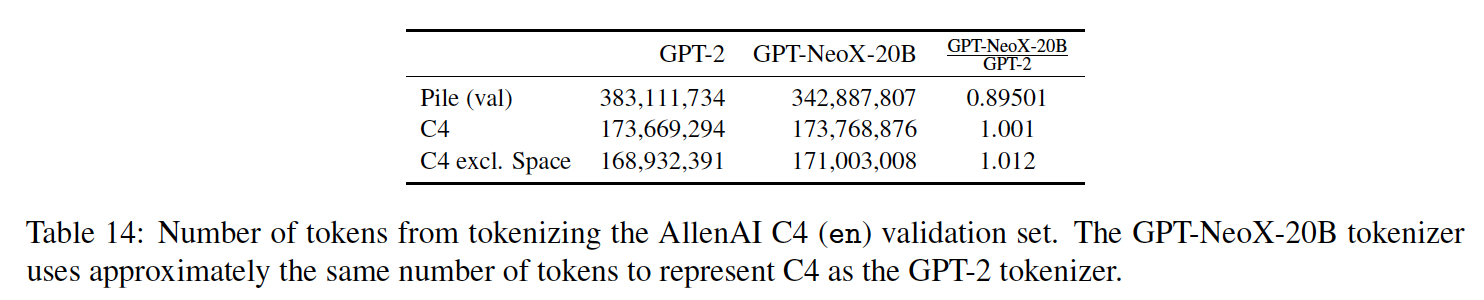
tokenization对比的例子(全部的示例参考论文附录):

数据重复:在过去的两年里,训练自回归语言模型时的标准做法是只训练一个
epoch。最近的研究声称,看到了更进一步地对训练数据去重的好处。特别是,除了GPT-3和Jurassic-1之外,每个公开的大型语言模型要么使用某种形式的数据去重,要么没有足够详细地讨论训练数据被做了什么处理。当
Pile最初被制作时,唯一存在的比GPT-NeoX-20B更大的语言模型是GPT-3,它对其训练数据的高质量子集进行了升采样。随后Pile被发布,由于缺乏大规模消融实验的资源、并且在较小的数据规模上缺乏明显的影响,我们选择按原样使用Pile。如下图所示,即使在20B的参数规模下,我们也没有看到跨越一个epoch边界后,测试损失和验证损失出现恶化。不幸的是,那些声称从数据去重中看到改进的论文,没有一篇论文发布了证明这一点的
trained models,这使得复现和确认他们的结果很困难。《Deduplicating training data makes language models better》发布了他们使用的数据去重的代码,我们打算在未来用它来更详细地探索这个问题。值得注意的是,即使在
loss或task evaluation方面没有改善,但仍有令人信服的理由为任何投入生产的模型对训练数据去重。具体而言,系统分析表明,在减少训练数据的泄漏方面有很大的好处。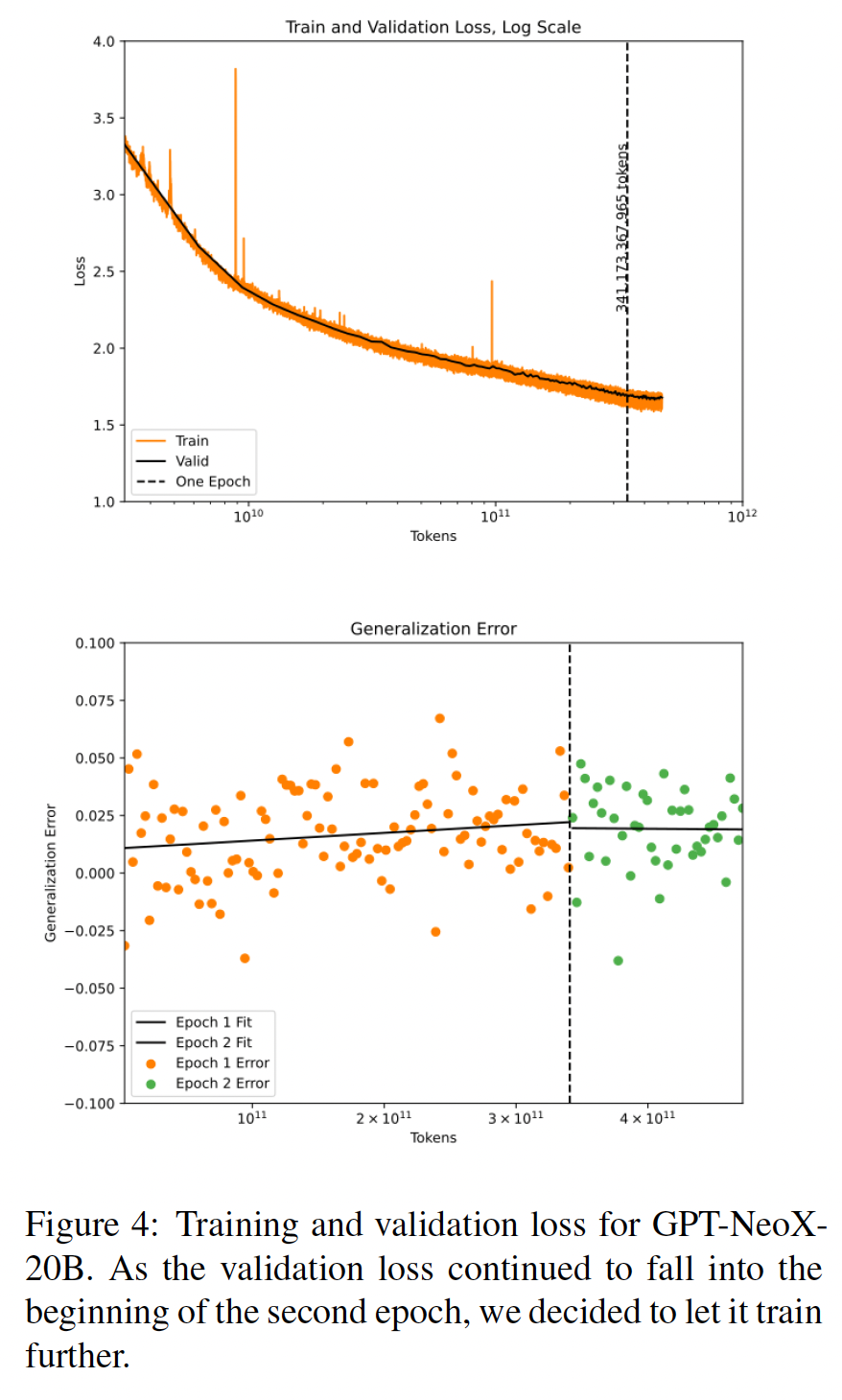
48.3 实验
为了评估我们的模型,我们使用
EleutherAI Language Model Evaluation Harness(《A framework for few-shot language model evaluation》),这是一个用于语言模型评估的开源代码库,支持许多模型的API。由于我们的目标是使一个强大的模型可以公开访问,我们与至少有10B个参数可以公开访问的英语语言模型进行比较。我们与OpenAI API上的GPT-3模型、开源的FairSeq稠密模型、以及GPT-J-6B进行比较。我们不与T5或其衍生模型进行比较,因为我们的评估方法假定这些模型是自回归的。虽然有一个已经公开发布的Megatron-11B checkpoint,但发布的代码是不能用的,我们也没能让模型运行起来。我们没有与任何mixture-of-experts: MOE模型进行比较,因为没有任何公开的MoE模型能达到与10B参数的稠密模型相当的性能。GPT-3 API模型的规模没有得到官方确认,但我们遵循《A framework for few-shot language model evaluation》,认为GPT-3模型的规模为350M (Ada)、1.3B (Babbage)、6.7B (Curie)和175B (Da Vinci)。我们将GPT-J-6B和GPT-NeoX-20B都归入GPT-NeoX模型的范畴,因为这两个模型都是用相同的架构训练的,并且是在同一个数据集上训练的。然而,我们用虚线将它们连接起来,以反映这两个模型不是像FairSeq和GPT-3模型那样在两个不同的尺度上训练的同一模型,它们是用不同的代码库、不同的tokenizer、以及不同数量的token来训练的。我们报告了两个
baseline:人类水平性能、随机性能。所有的图表都包含代表两个标准差的error bar,表明每个点周围的95%的置信区间。对于一些图,标准差非常小,以至于区间不明显。我们在一组不同的
standard language model evaluation dataset上评估我们的模型。我们将评估数据集为三个主要类别:自然语言任务、基于知识的高级任务、以及数学任务。我们对GPT-J-6B、GPT-NeoX-20B和FairSeq模型进行了zero-shot和five-shot评估,但由于资金限制,只对GPT-3模型进行了zero-shot评估。由于篇幅限制,这里只展示了一个有代表性的结果子集,其余的在原始论文的附录中。自然语言任务:我们在一系列不同的
standard language model evaluation dataset上评估我们的模型:ANLI、ARC、HeadQA (English)、HellaSwag、LAMBDADA、LogiQA、OpenBookQA、PiQA、PROST、QA4MRE、SciQ、TriviaQA、Winogrande、以及Winograd Schemas Challenge (WSC)的SuperGlue版。数学任务:解决数学问题是一个在人工智能研究中有着悠久历史的领域,尽管大型语言模型在算术任务、以及用自然语言表述的数学问题上往往表现得相当糟糕。我们对
MATH测试数据集以及GPT-3介绍的数字算术问题进行评估。请注意,MATH测试数据集通常都会进行微调,但由于计算上的限制,我们在这里只对模型进行zero-shot和five-shot评估。基于知识的高级任务:我们还对我们的模型回答事实问题(
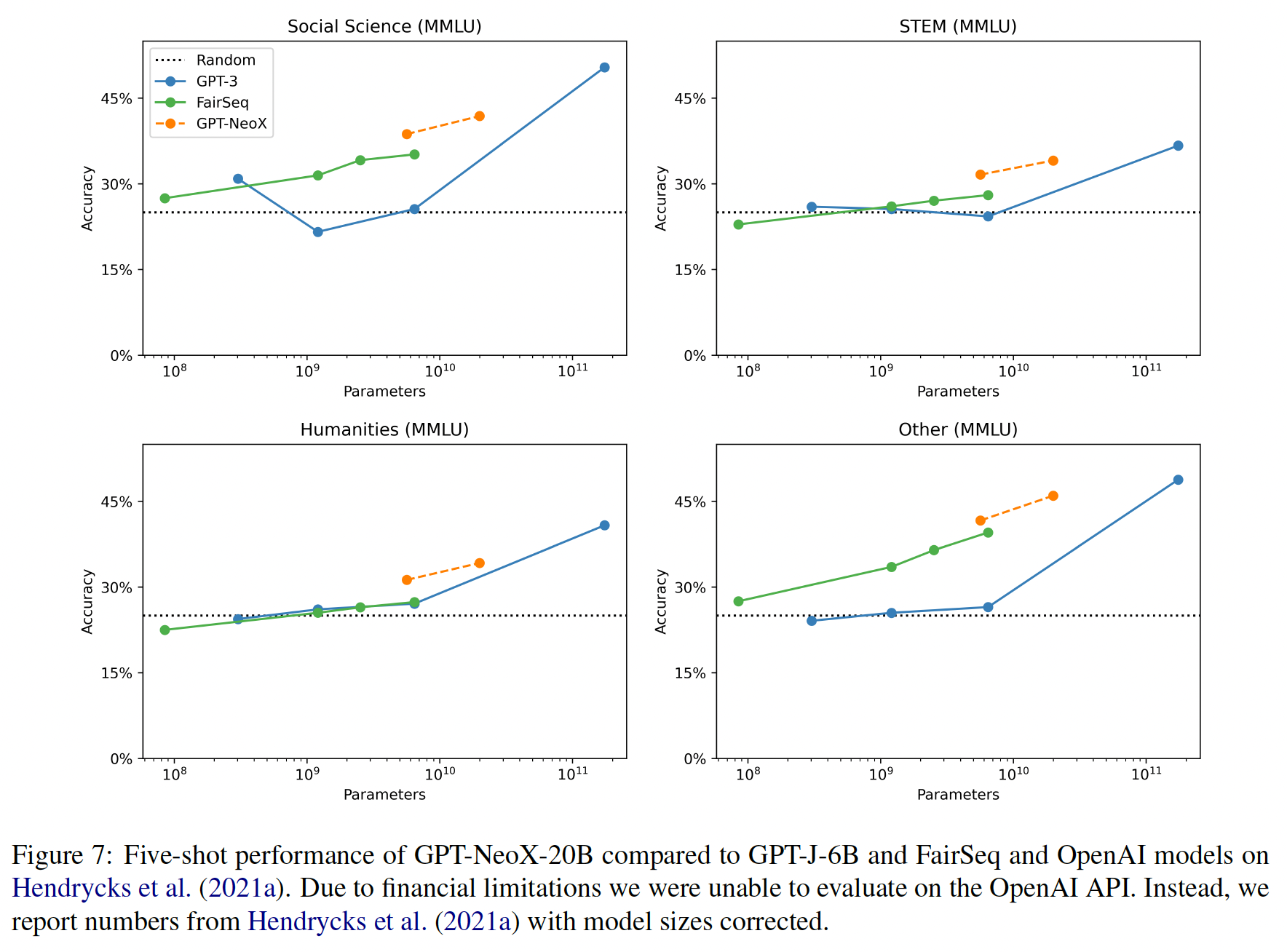
factual question)的能力感兴趣,这种事实问题需要高级知识。为了做到这一点,我们使用了《Measuring massive multitask language understanding》开发的各种不同领域的选择题数据集。按照这个数据集的通常做法,我们聚焦于按学科领域聚合的结果: 如下图所示,包括人文、社会科学、STEM和杂项。我们从《Measuring massive multitask language understanding》的five-shot GPT-3结果出发,报告了five-shot的性能,以便与以前的工作相比较。
自然语言任务的结果:虽然
GPT-NeoX-20B在某些任务(如ARC、LAMBADA、PIQA、PROST)上优于FairSeq 13B,但在其他任务(如HellaSwag、LogiQA的zero-shot)上表现不佳。总的来说,在我们所做的32项评估中,我们在22项任务中表现优异,在4项任务中表现不佳,在6项任务中处于误差范围之内。到目前为止,我们最弱的表现是在
HellaSwag上,在zero-shot和five-shot的评估中,我们的得分都比FairSeq 13B低四个标准差。同样,GPT-J在HellaSwag上的表现在zero-shot中比FairSeq 6.7B低三个标准差,在five-shot中低六个标准差。我们发现这种巨大的性能损失在很大程度上是无法解释的;虽然我们最初认为Pile中大量的非散文的数据子集是罪魁祸首,但我们注意到GPT-J和GPT-NeoX在非常相似的Lambada任务上比FairSeq模型的性能要好得多,而且差距大致相同。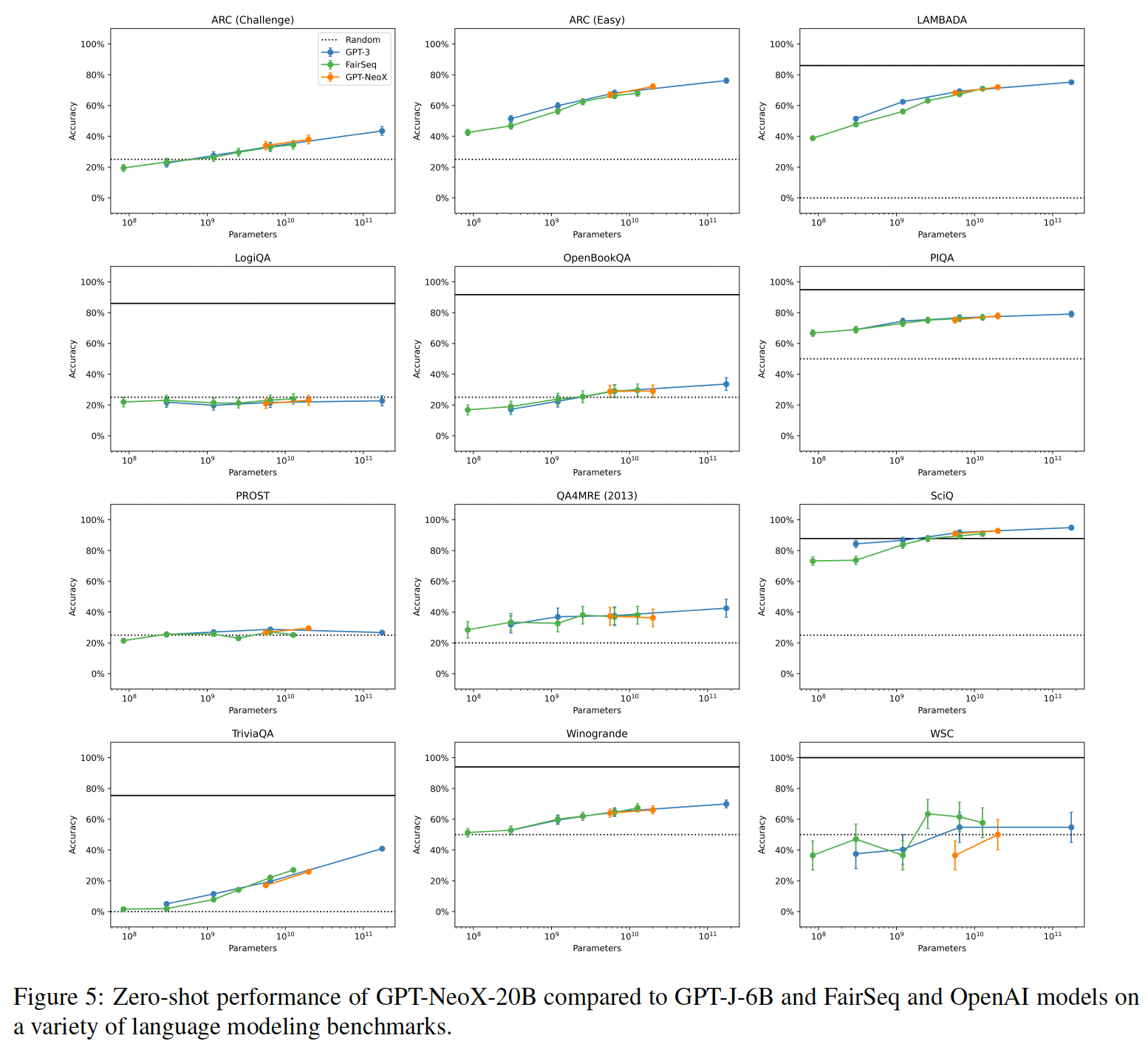
数学:虽然
GPT-3和FairSeq模型在算术任务上的表现通常相当接近,但它们的表现一直被GPT-J和GPT-NeoX所超越。我们猜测,这可以追溯到训练数据中普遍存在的数学方程,但我们警告说,人们不应该认为这意味着在Pile上训练会产生更好的out-of-distribution的算术推理。《Impact of pretraining term frequencies on few-shot reasoning》表明,Pile中的数学方程的频率与GPT-J在该方程上的表现有很强的相关性,我们认为这在GPT-NeoX 20B、FairSeq和GPT-3中没有理由不存在。遗憾的是,我们无法研究FairSeq和GPT-3模型中的这种效应,因为作者没有公布他们的训练数据。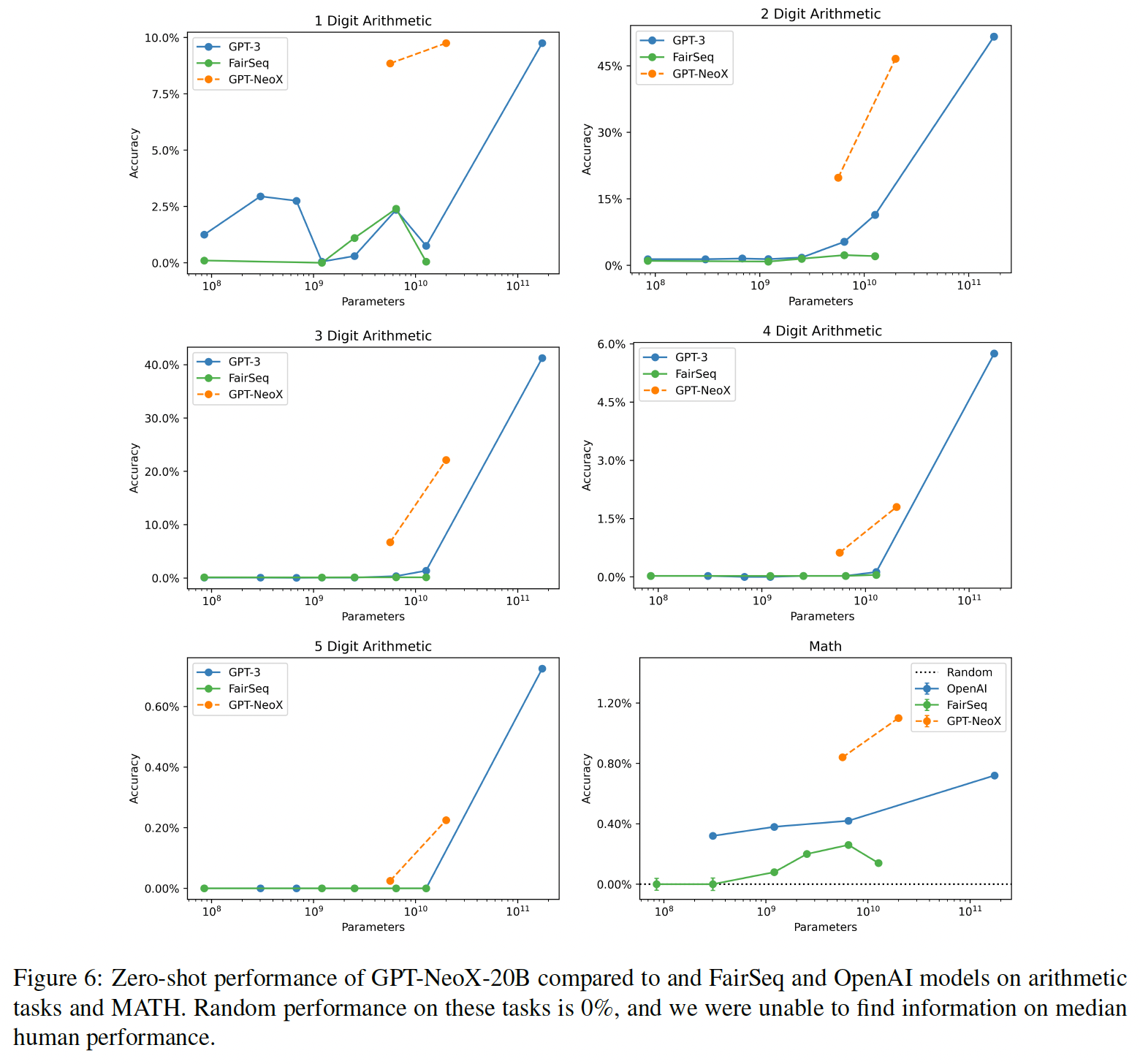
基于知识的高级任务:虽然
GPT-NeoX和FairSeq模型在five-shot的情况下,与GPT-3相比,在MMLU上都表现出优势的性能(Figure 7),但在zero-shot的情况下,它们的性能要接近很多( 原始论文附录中的Table 10 ~ 13)。《Measuring mathematical problem solving with the MATH dataset》声称发现,相对于zero-shot,few-shot并不能提高性能,但他们只研究了GPT-3。相比之下,我们发现GPT-NeoX和FairSeq模型在只有5个样本的情况下确实有很大的改善。我们认为这是一个警告,不要只根据一个模型得出关于评价指标的强烈结论,并鼓励研究人员开发新的evaluation benchmark从而利用多个不同类别的模型,以避免将他们的结论过度适用于一个特定的模型。强大的
Few-Shot Learning:我们的实验表明,GPT-J-6B和GPT-NeoX-20B从fews-hot评估中获得的好处大大超过FairSeq模型。当从0-shot评估到5-shot评估时,GPT-J-6B提高了0.0526,GPT-NeoX-20B提高了0.0598,而FairSeq 6.7B和13B模型分别提高了0.0051和0.0183。这一结果在统计学上是显著的,并且对prompting的扰动是鲁棒的。虽然我们目前对此没有特别的解释,但我们认为这是对我们模型的强烈推荐。虽然由于资金限制,我们没有对GPT-3进行系统的five-shot评估,但Table 10 ~ 13(参考原始论文中的附录)和Figure 7中显示的性能变化进一步支持了GPT-J-6B和GPT-NeoX-20B能够从five-shot examples中获得明显的收益的说法。
48.4 讨论
局限性:
训练的最佳超参数:超参数调优是一个昂贵的过程,对于几十亿参数的模型来说,全面进行调优往往是不可行的。由于上述局限性,我们选择了根据较小规模的实验、以及根据以前发表的工作(
GPT-3)的超参数的插值(针对我们的模型规模),从而选择超参数。然而,我们的模型架构和training setup的几个方面(包括数据和tokenizer),都与GPT-3有很大分歧。因此,几乎可以肯定的是,我们的模型所使用的超参数不再是最佳的,而且有可能从来都不是最佳的。缺乏
Coding Evaluation:在这个模型的开发过程中,我们做出的许多设计选择都是为了提高coding task的性能。然而,我们低估了现有coding benchmark(《Evaluating large language models trained on code》)的难度和成本,因此无法在该领域评估模型。我们希望在未来能做到这一点。Data Duplication:最后,缺乏数据去重也可能对下游性能产生影响。最近的工作表明,训练数据的去重会对困惑度产生很大影响(《Deduplicating training data makes language models better》)。虽然我们的实验没有显示出这种迹象,但由于有很多研究者发现了相反的结果,所以很难否定数据去重。
发布一个
20B参数的LLM:目前的研究现状是,大型语言模型只是人们训练和发表文章的东西,但并没有实际发布。据我们所知,GPT-NeoX-20B是有史以来公开发布的最大、性能最强的稠密语言模型。各个团体对不发布大型语言模型提出了各种理由,但最主要的理由是:宣称公众对LLM的访问会造成伤害。发布这个模型是我们让研究人员广泛使用
GPT-NeoX-20B的工作的开始,而不是结束。由于模型的大小,在两个RTX 3090Ti或单个A6000 GPU上进行推理是最经济的,而微调需要明显更多的计算。真正促进LLM的广泛使用意味着除了模型本身之外,还要促进computing infrastructure的广泛使用。我们计划通过继续努力降低我们模型的推理成本,以及与研究人员合作,提供他们在我们的模型上进行实验所需的computing infrastructure,从而在这个问题上取得进展。我们强烈鼓励那些对研究GPT-NeoX-20B感兴趣、但缺乏必要的infrastructure的研究人员主动与我们联系,讨论我们如何为你助力。
四十九、Bloom[2022]
pretrained language model已经成为现代自然语言处理pipeline的基石,因为它们经常从较小数量的标记数据中产生更好的性能。ELMo、ULMFiT、GPT、以及BERT的发展导致了pretrained model的广泛使用,并且作为初始化从而用于下游任务的微调。随后发现,pretrained language model可以在没有任何额外训练的情况下执行有用的任务,这进一步证明了pretrained language model的效用。此外,根据经验观察,语言模型的性能往往随着模型的变大而增加(有时是可预测的、有时是突然的),这导致了scaling的增加趋势。除了环境问题,训练大型语言模型(large language model: LLM)的成本只有资源丰富的组织才能承受。此外,直到最近,大多数LLM都没有公开发布。因此,学术界的大多数人都被排除在LLM的发展之外。这种排斥产生了具体的后果;例如,大多数LLM主要是在英文文本上进行训练。为了解决这些问题,论文
《BLOOM: A 176B-Parameter Open-Access Multilingual Language Model》提出了BigScience Large Open-science Open-access Multilingual Language Model: BLOOM。BLOOM是一个在46种自然语言和13种编程语言上训练的176B参数的语言模型,是由数百名研究人员合作开发并发布的。训练BLOOM的算力是通过法国GENCI和IDRIS的公共拨款提供的,利用IDRIS的Jean Zay超级计算机。为了建立BLOOM,论文对它的每个组成部分都进行了彻底的设计,包括训练数据集、模型结构和训练目标、以及分布式学习的工程策略。论文还对该模型的能力进行了分析。论文的总体目标不仅是公开发布一个大规模的多语种语言模型,其性能可与最近开发的系统相媲美,而且还记录了其开发过程中的协调过程(coordinated process)。本文的目的是对这些设计步骤提供一个high-level的概述,同时参考作者在开发BLOOM的过程中产生的个别报告。
49.1 背景
语言建模:语言建模指的是对文本中的
token序列的概率进行建模的任务,其中token是文本的一个单位(如单词、子词、字符或字节等)。在这项工作中(以及目前大多数语言建模的应用中),我们对文本中的token的联合概率建模为:其中:
token的序列,token,token序列。这种方法被称为自回归语言建模,可以被看作是反复预测
next token的概率。早期的语言模型:语言模型在
NLP中的应用有很长的历史。早期的语言模型主要是n-gram模型,它根据一个长度为token序列在训练语料库中出现的次数来估计该序列的概率。在实践中,n-gram模型面临两个主要问题:首先,随着
其次,对于未出现在训练数据中的
token序列,模型没有直接的方法来计算该序列的概率。
在这些问题上的进展使得
n-gram模型在NLP的大多数领域得到了广泛的应用。神经语言模型:神经语言模型是
n-gram模型的替代,最早由《Natural language processing with modular pdp networks and distributed lexicon》以及《Sequential neural text compression》提出,后来由《A neural probabilistic language model》推广。神经语言模型使用一个神经网络来估计在给定prior tokens的条件下预测next token的概率。虽然早期的工作使用了具有固定长度历史窗口的前馈神经网络,但
《Recurrent neural network based language model》、《Generating text with recurrent neural networks》、《Generating sequences with recurrent neural networks》提议使用递归神经网络,并发现这大大改善了性能。最近,基于
Transformer架构的语言模型(《Attention is all you need》)被证明比递归神经网络更有效。因此,Transformer已经成为语言模型的事实选择。
迁移学习:随着使用神经网络的语言建模的进展,
NLP pipeline已经越来越多地采用迁移学习的框架。在迁移学习中,一个模型的参数首先在一个数据丰富的任务上进行预训练,然后再在一个下游任务上进行微调。历史上常见的获得
pretrained参数的方法是词向量(《Distributed representations of words and phrases and their compositionality》),通过训练使共同出现的单词之间的词向量的内积很大。然而,
《Deep contextualized word representations》、《Universal language model fine-tuning for text classification》、《Improving language understanding by generative pre-training》、《BERT: Pre-training of deep bidirectional transformers for language understanding》的后续工作表明,《Natural language processing (almost) from scratch》的框架,即整个模型在被微调之前进行预训练,可以达到更强的性能。具体而言,
GPT、BERT展示了使用pretrained Transformer语言模型的强大结果,促使人们在逐步完善的模型上开展工作(RoBERTa, XLNet, BART, T5, ERNIE等等)。
Few-Shot/Zero-Shot Learning:虽然对pretrained模型进行微调仍然是在有限的标记数据下获得高性能的有效方法,但并行推进的工作表明,pretrained语言模型可以被诱导执行任务,而不需要任何后续的训练。在
《A neural conversational model》在一个神经对话模型中观察到有限的task-performing行为后,GPT-2后来证明,基于Transformer的语言模型在从网络上爬取的文本上进行训练,可以在不同程度上执行各种任务。值得注意的是,
GPT-2发现,性能随着模型规模的扩大而提高,从而激发了描述(《Scaling laws for neural language models》、《Training compute-optimal large language models》)和利用scale的效益的工作(Megatron-LM、GPT-3、Megatron-Turing、Palm、Gopher、Ernie 3.0 Titan、PanGu-alpha、OPT)。这种方法成功的一个主要因素是task-specific样本在馈入模型时的格式化方式。GPT-3推广了设计prompt的想法,即提供任务的自然语言描述,同时允许输入一些input-output behavior的demo。
LLM发展的社会局限性:虽然大型语言模型的大小持续地增加,使其在广泛的任务中得到改善,但也加剧了其开发和使用的问题(《On the dangers of stochastic parrots: Can language models be too big?》)。大型模型的计算费用也使学术界的大多数人无法参与其开发、评估和常规使用。
此外,计算成本也导致了对大型语言模型的训练和使用所产生的碳足迹(
carbon footprint)的担忧,现有的碳足迹研究可能低估了排放。促进全球碳足迹的增加会加剧气候变化,对已经被边缘化的社群产生最严重的影响。此外,资源集中在少数(通常是工业)机构(主要是技术专家),阻碍了对该技术的包容性、协作性和可靠性的管理:
首先,由行业从业人员推动的关于技术的公共叙事会导致对其使用的适宜性产生夸大的期望,导致研究和政策优先级的错位,并可能在例如医疗应用中造成可怕的后果。
其次,在一个以技术为媒介的世界里,技术发展的各个阶段的选择最终都会影响人们的生活,其影响方式最接近于法规的影响,尽管在这个过程中没有同样明确的利益相关者。当开发工作以优先考虑内部定义的性能,而不是对社会的影响为指导时,开发者的价值就会被强调,而不是直接用户和间接用户的价值。尽管让这种技术由企业单方面开发会带来巨大的社会危险,但
EleutherAI是中国以外唯一一个在BigScience Workshop召开之前就在开发大型语言模型的非企业实体。
BigScience:参与者:
BLOOM的发展是由BigScience协调的。BigScience是一个开放的研究协同,其目标是公开发布一个LLM。该项目是在获得GENCI在其IDRIS/CNRS的Jean Zay超级计算机上的算力资助后开始的。它最初是围绕着Hugging Face和法国NLP社区(创始成员)的共同努力而建立的,并迅速开放,发展成为一个更广泛的国际合作,以支持其语言的、地理的、以及科学的多样性的目标。最终,超过1200人注册成为BigScience的参与者,并被允许进入其交流群。他们不仅有机器学习和计算机科学的背景,也有语言学、统计学、社会文化人类学、哲学、法律和其他领域的背景。在这些人中,有数百人直接为该项目发布的工件(artifact)之一做出了贡献。虽然最多的参与者最终来自于美国,但也有38个国家的代表。组织:
BigScience所解决的一系列相关研究问题,反映在项目的工作小组组织中。每个工作小组由不同程度的参与者组成,包括主席(主席的作用是围绕整个项目的特定方面进行自我组织)。重要的是,我们鼓励参与者加入一个以上的工作小组,以分享经验和信息,这就形成了下图中的30个工作小组。大多数工作组的工作重点是与BLOOM的开发直接相关的任务。此外,有几个小组专注于对LLM的评估和特定领域的数据集开发,如生物医学文本、历史文本。《BigScience: A case study in the social construction of a multilingual large language model》对这一倡议背后的动机、其历史和一些经验教训进行了更大的概述。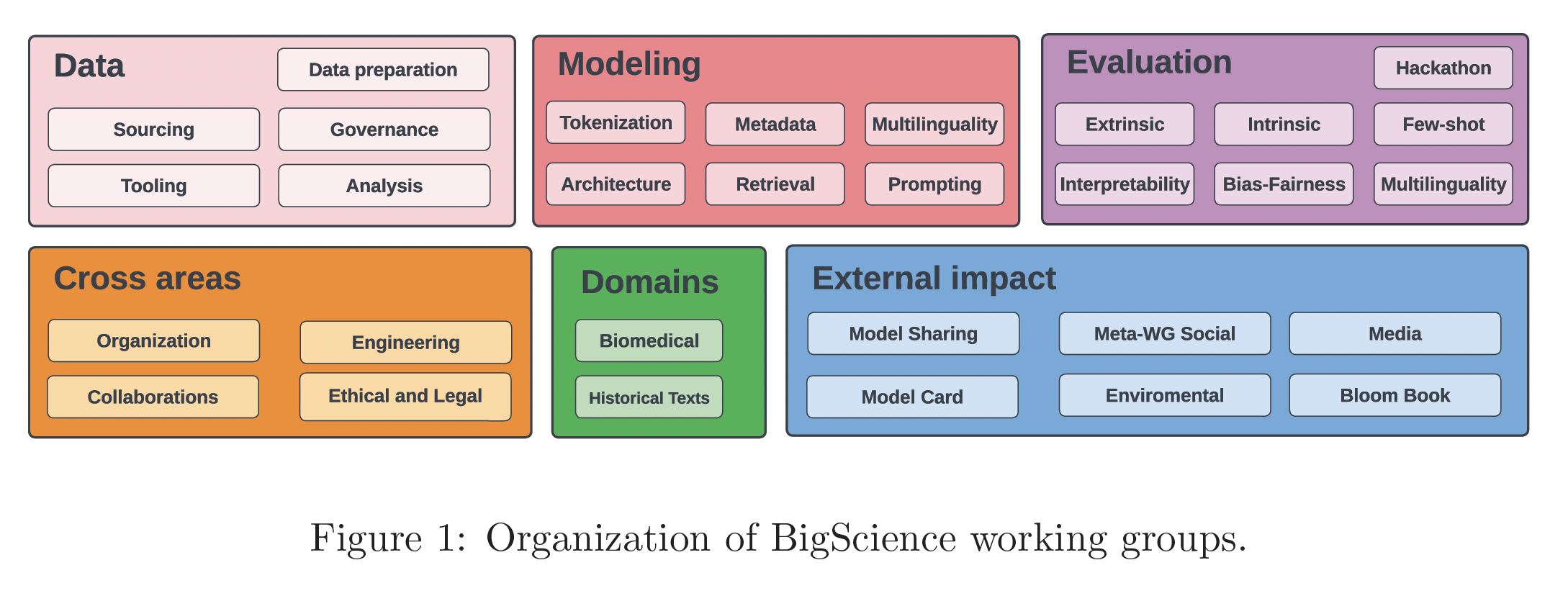
BigScience中的伦理考虑:为了承认并开始解决BigScience中LLM的社会局限性,研讨会依靠合作设计的道德宪章(Ethical Charter)和对美国以外的司法管辖区的适用法规的原始研究来指导整个项目的选择。具体而言,宪章强调了包容性和多样性、开放性和可复制性、以及组织的各方面的责任等价值观。在项目的数据集整理、建模、工程、评估、以及其他社会影响(贯穿始终)方面,这些价值观都以不同的方式展示出来。
49.2 模型
49.2.1 训练数据集
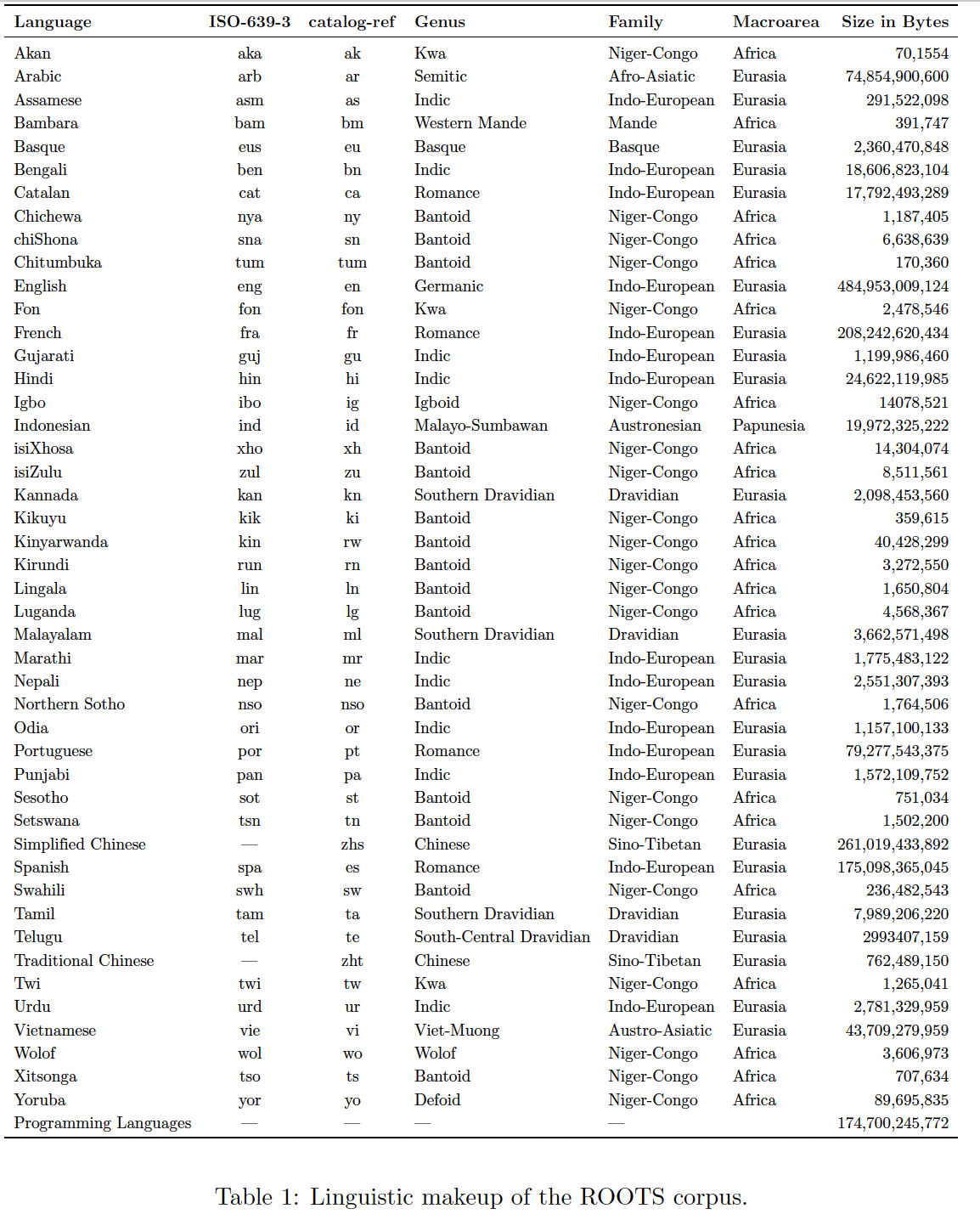
BLOOM在ROOTS语料库上进行了训练,该语料库是498个Hugging Face datasets的综合体,大约1.61 T的文本,涵盖了46种自然语言和13种编程语言。该数据集的high-level概览可见于Figure 3,而每一种语言及其linguistic genus、族、以及宏观领域的详细列表则见于Table 1。除了语料库本身,这个过程还导致了一些组织工具和技术工具的开发和发布,包括Figure 2中所示的工具。本节的其余部分将通过提供编制语料库所采取的步骤的简要总结,从而说明这些努力的背景。更详细的关于整个数据集策划过程及其结果,我们请读者参考《The BigScience ROOTS corpus:A 1.6TB composite multilingual dataset》。Figure 3:左图中,每个方框代表一种语言,方块大小代表语言规模的占比(字节数);右图中,在大约三万个文件中,十三种编程语言的文件数量占比。
动机:背景知识中提到的开发者和技术的使用者(自愿的或非自愿的)之间的脱节,在数据集的策划工作中尤为明显。这些数据集支持最近的大型机器学习项目。而在这些项目中,有意(
intentional)的数据工作通常被低估。在LLM的背景下,这种趋势体现在一系列基于启发式的过滤方法上,这些方法优先考虑以尽可能少的成本获得尽可能多的高质量数据,而不是考虑数据主体(data subject)的需求和权利,其中质量通常被定义为在下游任务中最大化性能,同时偶尔删除开发人员认为冒犯性的内容。虽然这些方法确实以相对较少的人力产生了
TB级的数据,但将源材料(如CommonCrawl dumps)的bias与过滤方法的bias相结合,往往会导致边缘化人群(marginalized population)的负面结果。在一个案例中,使用
block list来删除色情文本被证明也抑制了语料库中的LGBTQ+和非裔美国人英语(African American English: AAE)文本(《Documenting large webtext corpora: Acase study on the colossal clean crawled corpus》)。在另一个项目中,使用
Reddit的外链作为种子语料库的质量指标(GPT-2),导致trained model在其输出中隐含地优先考虑以美国为中心的观点(《The ghost in the machine has an american accent: value conflict in gpt-3》)。在另一个项目中,一个依靠机器学习的
image-text alignment model的过滤方法,被证明在创建的多模态数据集中加剧了其偏见(《Multimodal datasets: misogyny, pornography, and malignant stereotypes》)。
此外,这种抽象的数据策划方法导致了难以有意义地归档、以及事后治理的语料库,因为个别
item的出处和authorship通常会在这个过程中丢失。尽管像《The pile: An 800gb dataset of diverse text for language modeling》这样的工作将先前记录的individual sources的compilations置于被抓取的数据之上,为解决这些问题迈出了一步(《Datasheet for the pile》)。在
BigScience workshop的背景下,根据其道德宪章,我们的目标是在数据策划和归档过程中优先考虑人类的参与、当地的专业知识、以及语言知识,如以下各节所述。数据治理:大型文本语料库包括关于人的文本和由人创造的文本,人是数据主体。不同的人和机构可能在法律上拥有这些数据,使他们成为数据权利人(
rights-holder)。随着机器学习开发者将这些数据收集并整理成越来越大的数据集从而支持训练更大的模型,开发新的方法来考虑所有相关方的利益变得越来越重要,这些相关方包括开发者、数据主体、以及数据权利人。BigScience的努力旨在通过一个结合技术、法律和社会学专业知识的多学科视角来满足这些需求。该小组在两个不同的时间范围内专注于两个相互关联的主要目标:设计一个结构用于长期的国际数据治理(该数据治理有限考虑数据权利人的代理权)。
具体建议用于处理直接用于
BigScience项目的数据。
《Data governance in the age of large-scale data-driven language technology》的工作中介绍了第一个目标的进展,该工作进一步激发了数据治理的需求和要求,并概述了数据保管人(custodian)、权利人和其他各方之间的network所需的结构,以适当地治理共享数据。这些行为者之间的互动旨在考虑数据和算法主体的隐私、知识产权和用户权利,其方式旨在优先考虑当地的知识、以及指导价值的expression。特别是,这种方法依赖于数据提供者和data host之间的结构化协议,这些协议规定了数据可用于什么。虽然我们没能在项目启动和模型训练之间的相对较短的时间内完全建立起一个国际组织,但我们主要通过以下方式努力整合这方面的经验教训(反过来说,也是为了适应我们遇到的实际问题):
首先,只要有可能,我们就从特定的提供者那里寻求明确的许可来使用
BigScience背景下的数据(例如《S2ORC: The semantic scholar open research corpus》的S2ORC语料库,或者法国《世界报》的文章)。其次,在预处理的最后阶段之前,我们将各个数据源分开,以保持可追溯性,并根据其特定上下文的需要处理每一个数据源。
再次,我们对构成整个语料库的各种数据源采取
composite release的方式,以促进可重复性和后续研究,同时尊重这些source-dependent的需求。
可视化和访问
ROOTS语料库的资源可以在Hugging Face Hub的BigScience Data组织上找到。该组织拥有几个demo(或Space),可以用来深入了解整个语料库,以及直接访问(498个中的)223个components。考虑到它们的许可状态、隐私风险以及与原始保管人的协议,我们能够分发这些components。最后,由于我们知道未来对
BLOOM模型的调研可能需要对整个语料库的完全访问,我们也邀请有相关研究项目的研究人员通过注册表格加入正在进行的数据分析工作。数据源:给定数据治理的策略,下一步是确定训练语料库的构成。这个阶段是由几个目标驱动的,这些目标有时会有内在的竞争。其中一些竞争包括:建立一个世界上尽可能多的人可以使用的语言模型,同时只包括一些语言(在这些语言上,我们足够专业从而策划一个与以前数据集规模相当的数据集),同时提高文档的标准并尊重数据主体和算法主体的权利。
语言的选择:这些考虑导致我们采用了一个渐进的过程来选择哪些语言将被纳入语料库。我们首先列出了世界上使用人数最多的八种语言,在项目的早期阶段,我们对这些语言进行了积极的宣传,邀请流利地使用该语言的人加入数据工作。然后,根据语言社区的建议(
《Participatory research for low-resourced machine translation: A case study inafrican languages》),我们将最初选择的斯瓦希里语(Swahili)扩大到尼日尔-刚果语(Niger-Congo)语言类别,将印地语(Hindi)和乌尔都语(Urdu)扩大到印度语系(Indic)语言。最后,我们提议,对于另一些语言,如果任何由3名或更多精通该语言的参与者组成的小组,如果他们愿意承诺选择数据源并指导处理过程,就可以将该语言添加到支持的列表中,以避免通过自动语言识别选择的语料库在没有特定语言专业知识的情况下出现常见问题(《Quality at a glance: An audit of web-crawled multilingual datasets》)。数据源选择:语料库的最大部分是由研讨会的参与者和研究集体策划的,他们共同编制了
BigScience Catalogue目录:一个涵盖各种语言的processed和non-processed的数据源的大清单。这采取了由Machine Learning Tokyo、Masakhane和LatinX in AI等社区共同组织的hackathons的形式。作为对这些努力的补充,其他工作组的参与者编制了language-specific resource,如专注于阿拉伯语的Masader repository。通过这种自下而上的方法,总共确定了252个数据源,每个语言类别至少有21个数据源。此外,为了增加我们的西班牙文、中文、法文和英文等数据源的geographic coverage,参与者通过pseudocrawl(一种从通用Common Crawl快照中获取这些网站的方法)确定了他们语言中的本地相关网站,以添加到语料库中。GitHub Code:该目录进一步补充了从谷歌BigQuery上的GitHub数据集合中收集到的编程语言数据集,然后对exact matches的数据进行了去重。对语言的选择反映了《Competition-level code generation with AlphaCode》为训练AlphaCode模型所做的设计选择。OSCAR: 为了不偏离使用互联网作为预训练数据来源的标准研究实践(GPT-1、T5),同时也为了满足我们在BLOOM大小下的计算预算的数据量需求,我们进一步从OSCAR 21.09版本中获取数据,对应于2021年2月的Common Crawl快照,最终占到语料库的38%。
数据预处理:在确定
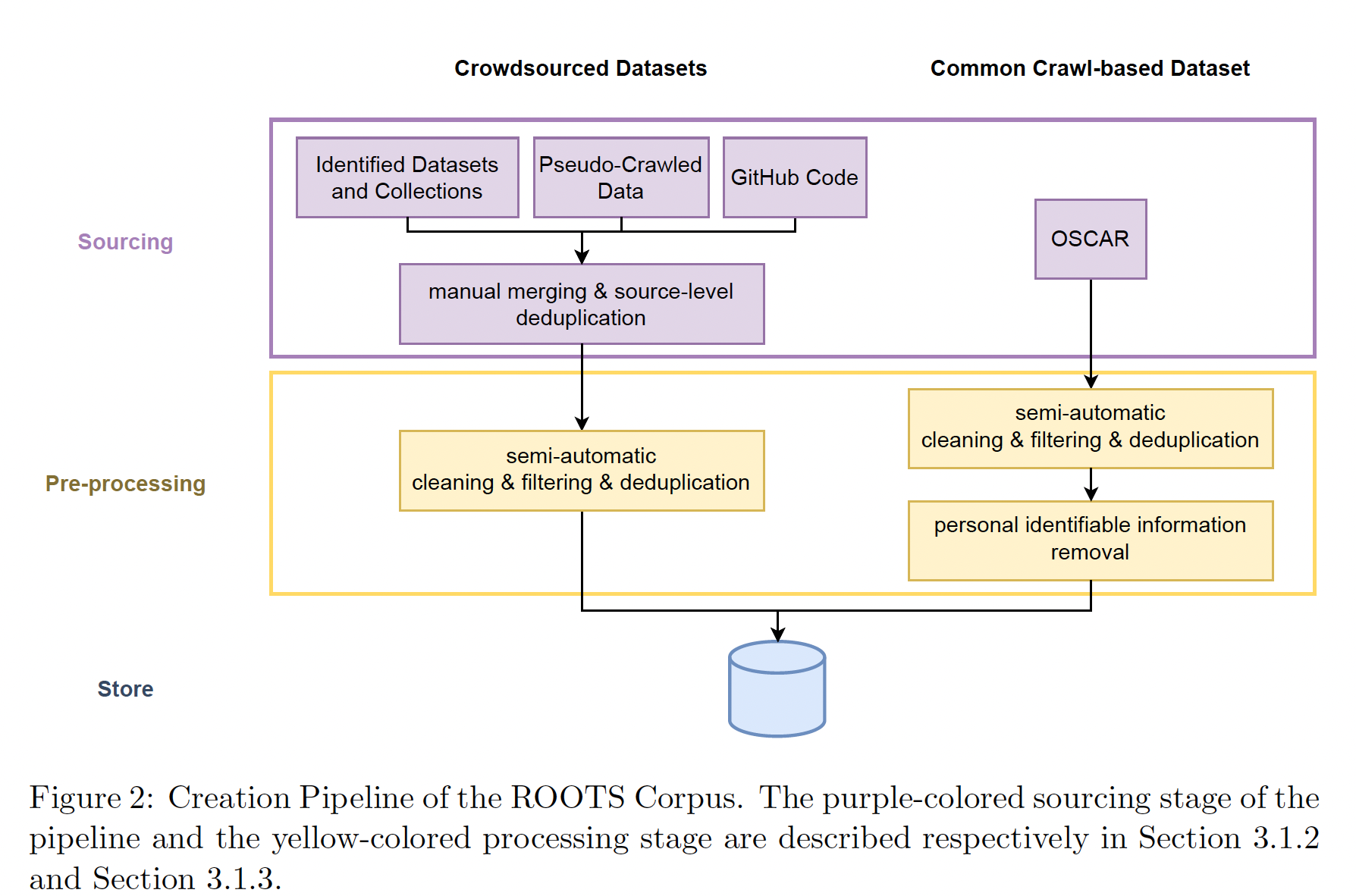
source后,数据处理过程涉及几个步骤来处理data curation的多个方面。下图中可以看到构建ROOTS的总体视图和processing pipeline。这个过程中开发的所有工具都可以在GitHub上找到。获取源数据:第一步是获取前面所确定的所有文本数据源的数据,这包括从各种格式的
NLP数据集中下载和提取文本字段(包括如问答数据集、摘要数据集、或对话数据集),从压缩文件(如法国的科学文章repository)爬取和处理大量的PDF文件,以及大量网站中提取和预处理文本(这些网站包括:从目录中的192个网站、数据工作组成员选择的另一批地域多样化的456个网站的集合)。 后者需要开发新的工具,从Common Crawl WARC文件中的HTML中提取文本,我们在main data preparation repository中提供了这些文件。 我们能够从539个网站的所有URL中找到并提取可用的文本数据。192 + 456 = 548,这里的539说明作者对所有的网站进行了一些过滤处理。质量过滤:在获得文本后,我们发现大多数数据源包含一些非自然语言的文本,例如
preprocessing error、SEO页面、或垃圾邮件(包括色情垃圾邮件)。为了过滤非自然语言,我们定义了一套质量指标,其中高质量的文本被定义为由人类为人类所写(written by humans for humans),没有内容的区别(因为我们希望内容选择完全是由更负责任的human source selection的领域)或先验的语法判断。完整的指标列表见《The BigScience ROOTS corpus:A 1.6TB composite multilingual dataset》。重要的是,这些指标主要以两种方式适应每个数据源的需要。首先,他们的参数,如阈值和支持的
term list,是由fluent speakers为每种语言单独选择的。其次,我们手动检查了每个数据源,以确定哪些指标最有可能识别非自然语言。
这两个过程都得到了工具的支持,以使其影响可视化。
数据去重和隐私再加工:最后,我们通过两个重复去重步骤删除了近乎重复的文件,并编辑了我们可以从语料库的
OSCAR版本中识别的个人身份信息(如social security number: SSN),因为它被认为是呈现最高隐私风险的来源,这促使我们应用regrex-based的再加工,即使在正则表达式有一些假阳性的情况下。
Prompted Dataset:multitask prompted finetuning(也被称为instruction tuning)涉及在training mixture上微调pretrained language model,其中这个training mixture由自然语言prompts指定的一组大的不同的任务所组成。T0(作为BigScience的一部分开发)表明,在prompted datasets的multitask mixture上进行微调的语言模型具有很强的zero-shot task generalization能力。此外,T0被证明优于那些大一个数量级但没有经过这种微调的语言模型。在这些结果的激励下,我们探索了使用现有的自然语言数据集来进行multitask prompted finetuning。T0是在Public Pool of Prompts: P3的一个子集上训练的,P3是各种现有的和开源的英语自然语言数据集的prompts的集合。这个prompts集合是通过一系列涉及BigScience collaborators的hackathons活动创建的,hackathons参与者为170多个数据集编写了总共2000多个prompts。P3中的数据集涵盖了各种自然语言任务,包括情感分析、问答、以及自然语言推理,不包括有害内容或非自然语言(如编程语言)。PromptSource是一个开源工具包(也作为BigScience的一部分开发),为创建、共享、以及使用自然语言prompts提供了便利。收集过程的全部细节在(《Multitask prompted training enables zero-shot task generalization》、《PromptSource: An integrated development environment and repository for natural language prompts》)中给出。在对
BLOOM进行预训练后,我们应用同样的大规模多任务微调配方(recipe),使BLOOM具备多语言zero-shot task generalization能力。我们将得到的模型称为BLOOMZ。为了训练BLOOMZ,我们对P3进行了扩展,以包括除英语以外的新语言数据集和新任务,如翻译。这就产生了xP3,一个涵盖46种语言和16项任务的83个数据集的prompts集合。如下图所示,xP3反映了ROOTS的语言分布。xP3中的任务既有跨语言的(如翻译),也有单语言的(如摘要、问答)。我们使用PromptSource来收集这些prompts,为prompts添加额外的metadata,如input language和target language。为了研究多语言prompts的重要性,我们还将xP3中的English prompts用机器翻译成相应的语言,以产生一个名为xP3mt的集合。关于xP3和xP3mt的prompt collection的进一步细节,见《Crosslingual generalization through multitask finetuning》。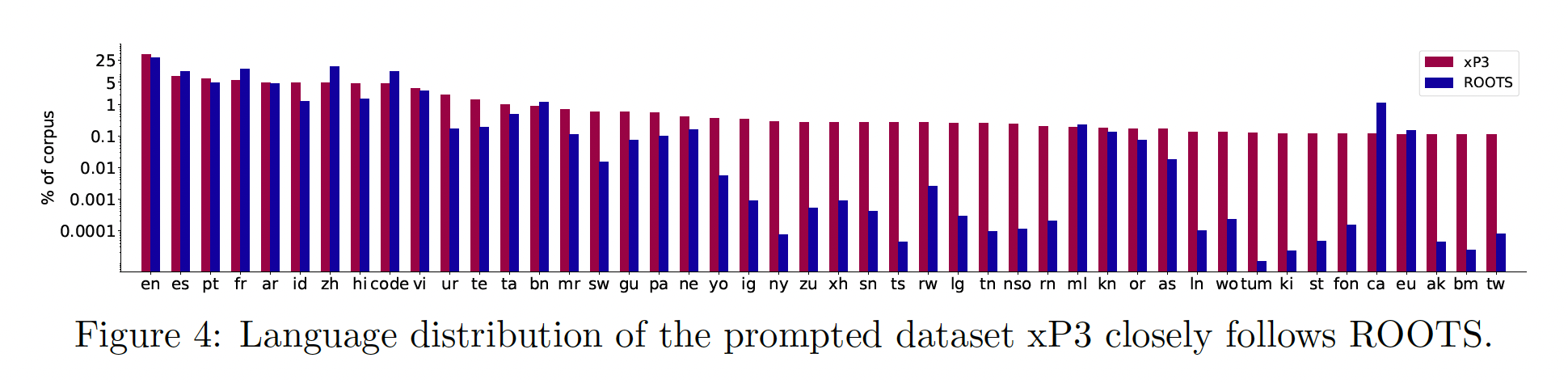
49.2.2 模型架构
这里讨论了我们的设计方法和
BLOOM模型的架构。深入的研究和实验可以在《What language model to train if you have one million GPU hours?》和《What language model architecture and pretraining objective works best for zero-shot generalization?》找到。我们首先回顾了我们的设计方法,然后激励我们选择训练一个causal decoder-only的模型。最后,我们论证了我们的模型结构偏离标准做法的方式。设计方法:所有可能的架构的设计空间是巨大的,使详尽的探索成为不可能。一种选择是完全复制现有大型语言模型的架构。另一方面,大量关于改进现有架构的工作相对来说很少被采用(
《Do transformer modifications transfer across implementations and applications?》);采用其中的一些推荐做法可以产生一个明显更好的模型。我们采取中间立场,关注如下的模型系列:已经被证明scale well,并且在公开可用的工具和代码库中有合理支持。我们对模型的组件和超参数进行消融分析,以寻求对我们的final compute budget的最佳利用。消融分析的实验设计:
LLM的主要吸引力之一是它们以zero-shot/few-shot的方式执行任务的能力:足够大的模型可以简单地从上下文指令和例子中执行新的任务(GPT-2),而不需要在监督样本上进行专门的训练。因此,由于对100B+的模型进行微调是不容易的,我们把对架构决策的评估集中在zero-shot generalization上,而不考虑迁移学习。具体来说,我们在不同的任务集合上测量了
zero-shot性能:来自EleutherAI语言模型评估工具(EAI-Eval)的29个任务、以及来自T0评估集(T0-Eval)的9个任务。两者之间有很大的重叠:只有T0-Eval的一个任务(StoryCloze)不在EAI-Eval中,尽管两者之间的所有prompts都不一样。有关任务和baseline的详细清单,请参见《What language model to train if you have one million GPU hours?》。我们还注意到,我们的任务集合共享了GPT-3 evaluation的31个任务中的17个。我们使用较小的模型进行消融实验。我们使用
6.7B的参数规模进行pretraining objective的消融分析,用1.3B的参数规模进行剩余的消融实验(包括position embedding、activation和layer normalization)。最近,《LLM.int8(): 8-bit matrix multiplication for transformers at scale》确定了大于6.7B的模型的phase transition,其中观察到outliers features的出现。这就提出了疑问:是否应该假定在13B规模下获得的结果可以推断到我们最终的模型规模?范围之外的架构:我们没有考虑
mixture-of-expert: MoE,因为缺乏关于MoE的广泛使用的、能大规模训练MoE的GPU-based代码库。同样地,我们也没有考虑
state-space模型。在设计BLOOM的时候,它们在自然语言任务中一直表现不佳。这两种方法都很有前途:现在已经在MoE的large scale上表现出有竞争力的结果,在较小的scale上state-space模型与H3也表现出有竞争力的结果。
架构和
pretraining objective:尽管大多数现代语言模型都是基于Transformer架构的,但架构实现之间存在着重大的deviation。值得注意的是,虽然最初的Transformer是基于encoder-decoder架构的,但许多流行的模型都选择了encoder-only(如BERT)或decoder-only(如GPT)方法。目前,所有超过100B参数的SOTA语言模型都是causal decoder-only模型。这与T5的研究结果相反,在T5的研究结果中,对于迁移学习,encoder-decoder模型的表现明显优于decoder-only模型。在我们的工作之前,文献中缺乏对不同架构和
pretraining objective的zero-shot generalization能力的系统评估。我们在《What language model architecture and pretraining objective works best for zero-shot generalization?》中探讨了这个问题,其中我们评估了encoder-decoder架构和decoder-only架构,以及它们与causal、prefix、以及masked language的modeling pretraining objective的交互。我们的结果显示,在紧接着预训练后,causal decoder-only模型表现最好,验证了SOTA的LLM的选择。此外,causal decoder-only模型可以在预训练后更有效地适应non-causal的架构和objective,这种方法已经被《Transcending scaling laws with 0.1% extra compute》进一步探索和证实。建模细节:除了选择架构和
pretraining objective外,人们还提出了对原始Transformer架构的一些改变。例如,替代的positional embedding方案(RoFormer、ALiBi)、或新的激活函数(《GLU variants improve transformer》)。因此,我们进行了一系列的实验,以评估《What language model to train if you have one million GPU hours?》中的causal decoder-only模型的每一个修改的好处。我们在BLOOM中采用了两种架构的修改:ALiBi Positional Embedding:ALiBi没有向embedding layer添加位置信息,而是直接根据按key和query的距离来减弱注意力分数(《Train short, test long: Attention with linear biases enables input length extrapolation》)。虽然ALiBi最初的动机是它能够推断出更长的序列,但我们发现它也导致了更平滑的训练和更好的下游性能,甚至在原始序列的长度上超过了learned embedding和rotary embedding。Embedding LayerNorm:在训练104B参数模型的初步实验中,我们按照bitsandbytes库的StableEmbedding layer所推荐的,在embedding layer之后立即添加了一个additional layer normalization。我们发现这大大改善了训练的稳定性。尽管我们也发现它惩罚了zero-shot generalization(《What language model to train if you have one million GPU hours?》),但我们在训练BLOOM时在第一个embedding layer之后增加了additional layer normalization从而避免训练不稳定。注意初步的104B实验是在float16中进行的,而最终的训练是在bfloat16中进行的。因为从那时起,float16被认为是造成训练LLM中许多观察到的不稳定性的原因(《OPT: Open pre-trained transformer language models》、《Glm-130b: An open bilingual pre-trained model》)。可能是bfloat16减轻了对embedding LayerNorm的需要。注意:虽然
embedding layer之后添加一个layer norm会有助于训练的稳定性,但是它降低了模型的性能。
我们在下图中展示了
BLOOM的完整架构,供参考。BLOOM采用的是Pre-LN的方案(原始Transformer用的是Post-LN的方案),即:Layer Norm在残差块中、在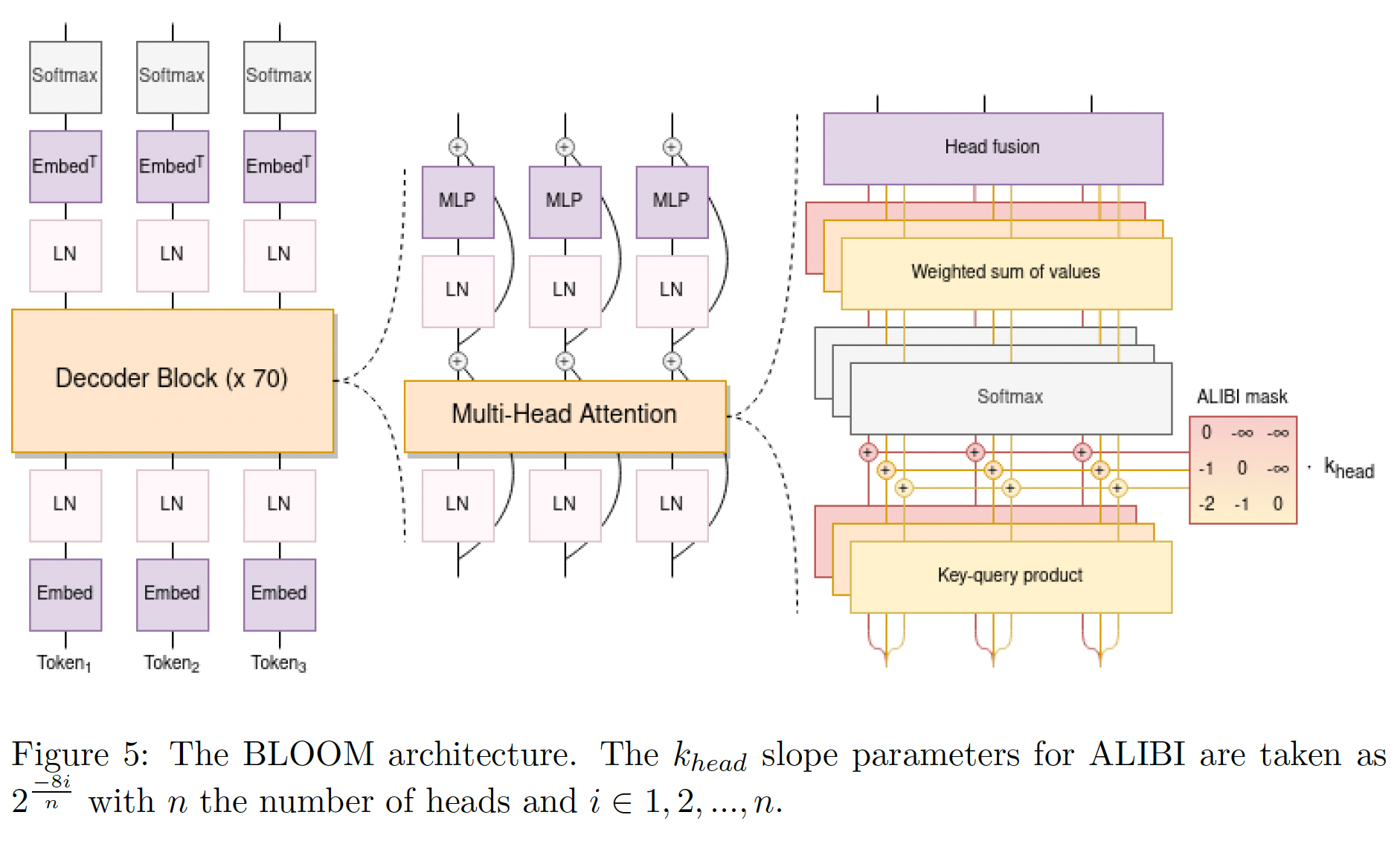
49.2.3 Tokenization
训练
tokenizer的设计决策往往被忽视,而采用默认配置(《Between words and characters: A brief history of open-vocabulary modeling and tokenization in nlp》) 。例如,OPT和GPT-3都使用GPT-2的tokenizer,这个tokenizer是为英语而训练的。这可以说是合理的,因为评估tokenizer的特定选择对模型下游性能的影响,这受到了巨大的训练成本的限制。然而,BLOOM训练数据的多样的特性,需要谨慎的设计选择,以确保tokenizer以无损的方式对句子进行编码。Validation:与现有的monolingual tokenizer相比,我们使用我们的tokenizer的fertility(《Exploring bert's vocabulary》)作为健全性检查(sanity check)的一个指标。fertility被定义为tokenizer为每个单词或每个数据集创建的subwords的数量。我们使用Universal Dependencies 2.9和OSCAR中我们感兴趣的语言的子集来衡量fertility指标。与monolingual tokenizer相比,一种语言的fertility非常高,可能表明该模型的下游多语性能下降(《How good is your tokenizer? on the monolingual performance of multilingual language models》)。我们的目标是,当我们的multilingual tokenizer与相应语言的monolingual tokenizer进行比较时,每种语言的fertility不能降低超过10个百分点。在所有的实验中,Hugging Face Tokenizers库被用来设计和训练tested tokenizers。
Tokenizer Training Data:我们最初使用的是ROOTS的非去重子集。然而,对tokenizer的词表(vocabulary)的定性研究显示了其训练数据的问题。例如,在tokenizer的早期版本中,我们发现整个URL被存储为tokens,这是由几个包含大量重复内容的文件造成的。这些问题促使我们在tokenizer的训练数据中删除重复的行。然后,我们对每种语言采用与training data相同的采样比例。词汇量:大的词汇量(
vocabulary size)可以减少对某些句子过度分割的风险,特别是对低资源语言(low-resource language)。我们使用150k和250k的词汇量进行了验证实验,以便于与现有的多语言建模文献进行比较(《Unsupervised cross-lingual representation learning at scale》、《mT5: A massively multilingual pre-trained text-to-text transformer》)。与monolingual tokenizer相比,我们最终确定了250k的词汇量来达到我们的initial fertility objective。由于词汇量决定了embedding矩阵的大小,出于GPU效率的考虑,它也必须能被128整除;它也能被4整除,以便使用张量并行。我们使用了250,680个词表条目的最终规模,并为未来可能的应用保留了200个token,例如使用placeholder tokens来移除私人信息。Byte-level BPE:该tokenizer是一个learned subword tokenizer,使用《A new algorithm for data compression》介绍的Byte Pair Encoding: BPE算法训练。为了在tokenization过程中不丢失信息,tokenizer从字节而不是字符作为最小的单位开始创建merges(GPT-2)。这样一来,tokenization永远不会导致unknown tokens,因为所有256个字节都可以包含在tokenizer的词表中。此外,Byte-level BPE最大限度地实现了语言之间的vocabulary sharing(《Neural machine translation with byte-level subwords》)。Normalization:在BPE tokenization算法的上游,没有对文本进行normalization,以便拥有尽可能通用的模型。在所有情况下,我们观察到,在所有考虑到的语言中,添加NFKC等unicode normalization并没有将fertility降低0.8%以上,但其代价是使模型的通用性降低;例如,导致Pre-tokenization:我们的pre-tokenization有两个目标:产生文本的第一次分割(通常使用空白符号和标点符号)。
限制
token序列的最大长度,其中token由BPE算法来产生。
所使用的
pre-tokenization规则是以下的正则表达式:"?[^(\S|[.,!...。,、~“])]+",它将单词分割开来,同时保留所有的字符,特别是对编程语言至关重要的空格和换行序列。我们不使用其他tokenizer中常见的以英语为中心的拆分(例如围绕'nt或'll的拆分)。我们也没有在numbers和digits上使用拆分(如果这么拆分,会在阿拉伯语和code中造成问题)。数字
112要不要拆分成1 1 2三个数字?LLaMA进行了这种拆分,而BLOOM, GLM-130B没有进行这种拆分。
49.2.4 工程
硬件:该模型在
Jean Zay上进行训练,这是一台法国政府资助的超级计算机,由GENCI拥有,在法国国家科学研究中心(French National Center for Scientific Research: CNRS)的国家计算中心IDRIS运行。训练BLOOM花了大约3.5个月时间,消耗了1,082,990个计算小时。训练在48个节点上进行,每个节点有8个NVIDIA A100 80GB GPU(总共384个GPU)。由于训练期间可能出现硬件故障,我们还保留了4个备用节点。这些节点配备了2x AMD EPYC 7543 32-Core CPU和512GB内存,而存储则由全闪存和硬盘驱动器混合处理,使用SpectrumScale(GPFS)并行文件系统,在超级计算机的所有节点和用户之间共享。每个节点有4个NVLink GPU-to-GPU的互连,实现了节点内的通信;而每个节点有4个Omni-Path 100 Gbps链接,以enhanced的超立方体8D全局拓扑结构排列,用于节点间的通信。框架:
BLOOM是用Megatron-DeepSpeed(《Using DeepSpeed and Megatron to train Megatron-Turing NLG 530B, a large-scale generative language model》)训练的,这是一个大规模分布式训练的框架。它由两部分组成:Megatron-LM提供了Transformer实现、张量并行、以及数据加载原语。DeepSpeed提供了ZeRO optimizer、模型流水线、以及通用分布式训练组件。
这个框架允许我们用
3D并行(如下图所示)有效地训练,这是分布式深度学习的三种互补的方法的融合。这些方法描述如下:数据并行(
Data parallelism: DP):拷贝模型多次,每个副本放在不同的设备上,并馈入数据的一个分片。处理是并行进行的,所有的模型副本在每个training step结束时都被同步。张量并行(
Tensor parallelism: TP):将模型的各个layer以层为单位,拆分到多个设备上。这样,我们不是让整个activation张量或梯度张量驻留在单个GPU上,而是将该张量的分片(以层为单位)放在不同的GPU上。这种技术有时被称为水平并行、或层内模型并行。流水线并行(
Pipeline parallelism: PP):将模型的每一层分割到多个GPU上,因此每个GPU上只放置模型的某些层的一部分。这有时被称为垂直并行。
最后,
Zero Redundancy Optimizer(《ZeRO: Memory optimizations toward training trillion parameter models》)允许不同的进程只持有一个training step所需的一部分数据(parameters、梯度、以及optimizer states)。我们使用了ZeRO stage 1,也就是说,只有optimizer states是以这种方式分片的。上述四个组件组合在一起,可以扩展到数百个
GPU,并具有极高的GPU利用率。在我们使用A100 GPU的fastest配置中,我们能够实现156 TFLOPs,达到了目标:理论峰值性能312 TFLOPs(float32或bfloat16)的一半。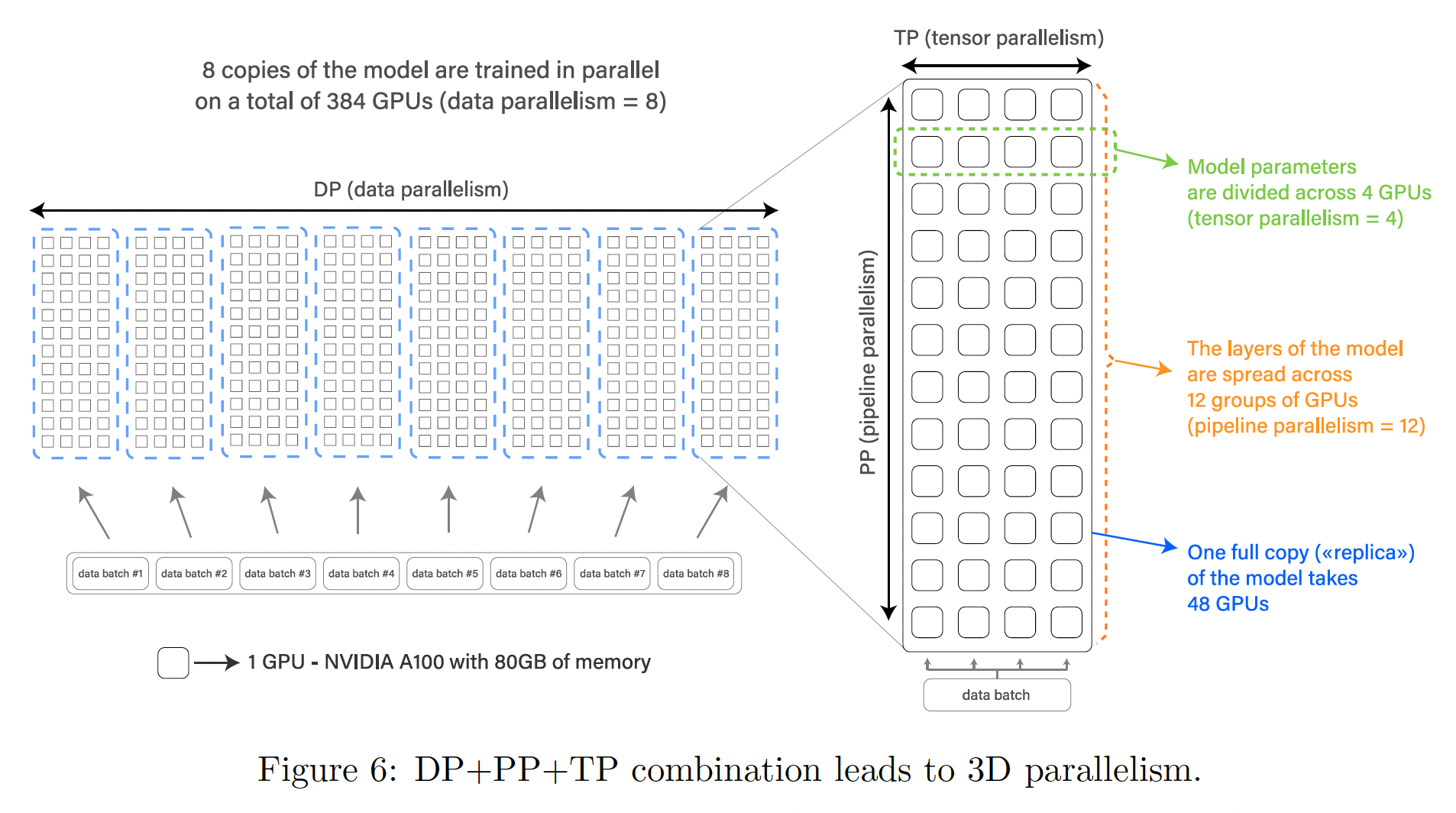
浮点格式:在
NVIDIA V100 GPU上早期的的104B参数模型实验中,我们观察到了数值不稳定性,导致了不可逆的训练发散。我们假设,这些不稳定性源于我们最初使用的IEEE float16,这是一种动态范围非常有限的16位浮点格式,可能会导致溢出。我们最终获得的NVIDIA A100 GPU支持bfloat16格式,其动态范围与float32相同。另一方面,bfloat16的精度仍然低得多,这促使我们使用混合精度训练(《Mixed precision training》)。这种技术以float32的精度执行某些精度敏感的操作,如gradient accumulation和softmax,其余操作则以较低的精度执行,使我们能够实现高性能和训练稳定性的平衡。最终,我们在bfloat16混合精度下进行了最终训练,这被证明解决了不稳定问题(与《Using DeepSpeed and Megatron to train Megatron-Turing NLG 530B, a large-scale generative language model》之前的观察一致)。融合的
CUDA kernels:一般来说,GPU不能在检索数据(为了进行计算)的同时进行这些计算。此外,现代GPU的计算性能远远高于每个操作(在GPU编程中通常称为kernel)所需的内存传输速度。Kernel fusion(《Optimizing data warehousing applications for GPUs using kernel fusion/fission》)是一种优化GPU-based的计算的方法,只在一个kernel call中执行几个连续的操作。这种方法提供了一种最小化数据传输的方法:中间结果留在GPU寄存器中,而不是被复制到VRAM中,从而节省了开销。我们使用了由
Megatron-LM提供的几个自定义的fused CUDA kernels。首先,我们使用一个
optimized kernel来执行LayerNorm,以及融合了各种操作(如scaling, masking, softmax等等)的组合的kernel。此外,还使用
PyTorch的JIT功能将bias项的加法与GeLU activation融合。作为使用fused kernel的一个例子,在GeLU操作中增加bias项不会增加额外的时间,因为该操作是memory-bound的:与GPU VRAM和寄存器之间的数据传输相比,额外的计算可以忽略不计,因此融合这两个操作基本上可以将其运行时间减半。
额外的变化:扩展到
384个GPU需要两个final changes:禁用异步的CUDA kernel launches(为了便于调试和防止死锁)、将parameter groups拆分成更小的subgroups(以避免过度的CPU内存分配)。在训练期间,我们面临着硬件故障的问题:平均每周有
1 ~ 2个GPU发生故障。由于有备份节点并自动使用,而且每三个小时保存一次checkpoint,这并没有对训练的吞吐量产生很大影响。data loader中的PyTorch死锁错误、以及磁盘空间问题导致了5 ~ 10小时的停机时间。鉴于工程问题相对稀少,而且只有一个loss spike,模型很快就恢复了,因此与同类项目(《OPT: Open pre-trained transformer language models》)相比,人工干预的必要性较小。我们训练BLOOM的经验的全部细节、以及我们面临的所有问题,这些详细报告都是公开的。
49.2.5 训练
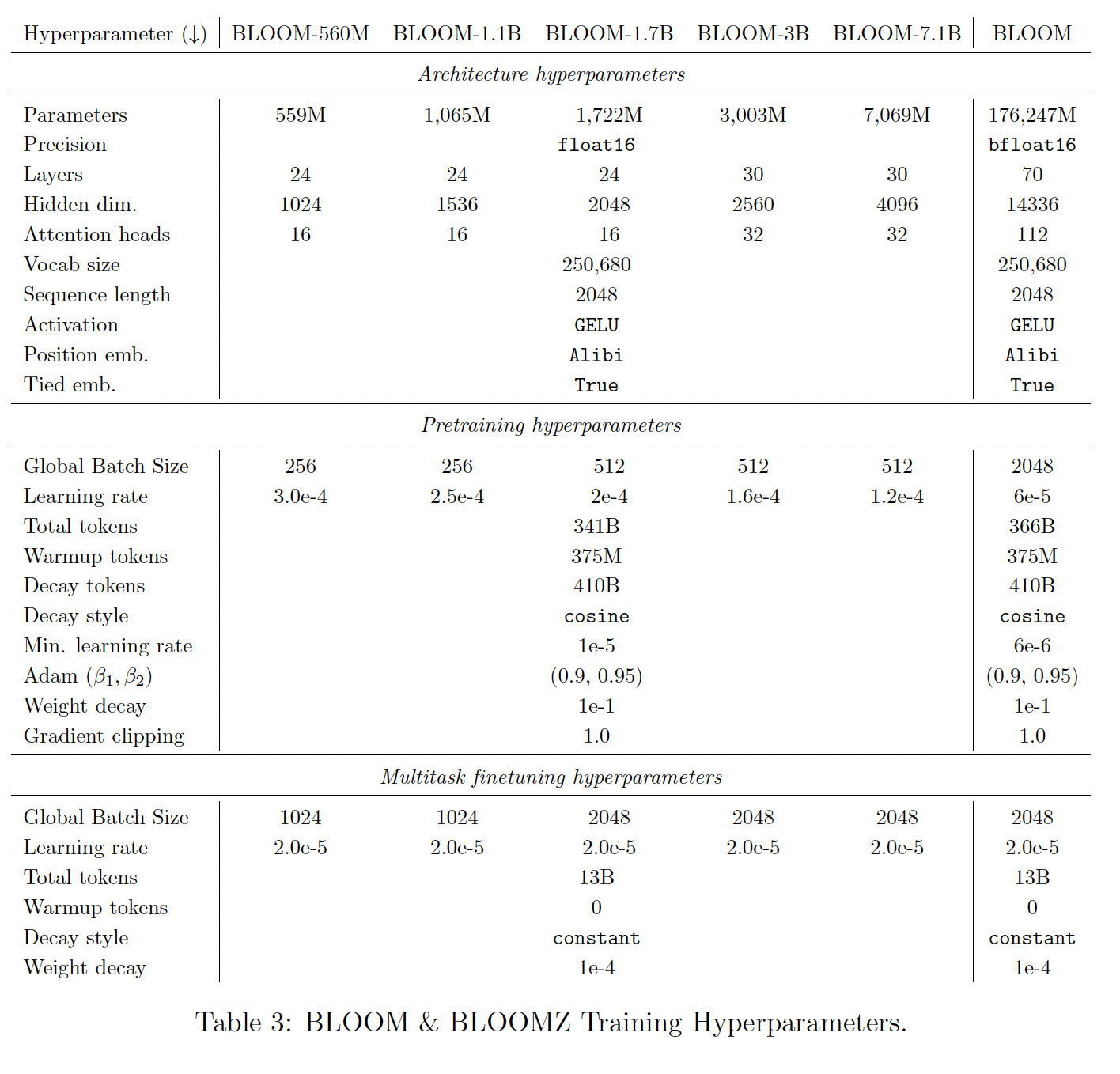
Pretrained Model:我们用下表中详列的相应的超参数来训练BLOOM的六种尺寸变体。架构和训练超参数来自于我们的实验结果(《What language model to train if you have one million GPU hours?》)和之前训练大型语言模型的工作(GPT-3、《Scaling laws for neural language models》)。non-176B模型的模型深度和宽度大致遵循以前的文献(GPT-3、OPT),对3B和7.1B的模型有所偏离,只是为了在我们的训练设置上更容易适应这些模型。由于多语言词汇量较大,BLOOM的embedding参数规模也较大,但scaling文献对embedding操作进行了折扣(《Scaling laws for neural language models》)。在
104B参数规模的开发过程中,我们试验了不同的Adam参数值、权重衰减值和梯度剪裁值,以达到稳定的目的,但没有发现有什么帮助。对于所有的模型,我们使用
cosine learning rate decay schedule,超过410B tokens(即,cosine length的长度) ,训练的序列长度选择计算允许条件时的上限,并在前375M tokens进行预热。我们使用权重衰减、梯度剪裁、以及no dropout。ROOTS数据集包含大约341B个文本token,所以我们的目标是对所有模型进行等量token的训练。然而,考虑到训练期间公布的revised scaling laws(《Training compute-optimal large language models》),我们决定在重复数据上对大型模型进行额外的25B tokens的训练。由于warmup tokens + decay tokens大于tokens总数,因此从未达到learning rate decay的终点。余弦学习率调度的周期为
410B tokens,它是数据集规模341B的1.20倍。这是《Training Compute-Optimal Large Language Models》论文得出的经验结果。
多任务微调:
finetuned BLOOMZ模型(《Crosslingual generalization through multitask finetuning》)保持与BLOOM模型相同的架构超参数。微调超参数粗略地基于T0(《Multitask prompted training enables zero-shot task generalization》)和FLAN(《Finetuned language models are zero-shot learners》)。学习率是由各自pretrained model的最小学习率的两倍决定的,然后进行四舍五入。对于小型变体,global batch size乘以4,以增加吞吐量。虽然模型被微调了13B tokens,但best checkpoint是根据一个单独的验证集选择的。我们发现在经过1B ~ 6B tokens的微调后,性能趋于稳定。Contrastive Finetuning:我们还使用SGPT Bi-Encoder配方(《SGPT: GPT sentence embeddings for semantic search》)对1.3B和7.1B参数的BLOOM模型进行了对比性微调,以训练产生高质量text embedding的模型。我们创建了面向多语言信息检索的SGPT-BLOOM-7.1Bmsmarco、以及面向多语言语义文本相似性(semantic textual similarity: STS)的SGPT-BLOOM-1.7B-nli。然而,最近的基准测试发现,这些模型也推广到其他各种embedding任务,如bitext mining、reranking、或用于下游分类任务的特征提取(《MTEB: Massive text embedding benchmark》)。碳足迹(
Carbon Footprint):虽然大多数估算语言模型碳足迹的尝试都揭示了由于模型训练过程中消耗的能源而产生的排放,但其他排放源也是需要考虑的。在估算BLOOM的碳排放时,我们受到生命周期评估(Life Cycle Assessment: LCA)方法的启发,旨在考虑设备制造、中间模型训练、以及部署等方面的排放。根据我们的估计,BLOOM training的碳排放加起来约为81吨CO2eq,其中14%是由设备制造过程产生的(11吨)、30%是训练期间消耗的能源(25吨)、55%是用于训练的设备和计算集群的闲置消耗(45吨)。将
BLOOM训练的碳排放与其他类似模型进行比较(见下表),发现虽然BLOOM的能耗(433 Mwh)略高于OPT(324 Mwh),但其排放量却减少了约2/3(25吨对比70吨)。这要归功于用于训练BLOOM的能源网(energy grid) 的低碳强度,其排放量为57 gCO2eq/kWh,而用于OPT训练的能源网为231 gCO2eq/kWh。具体来说,法国的国家能源网(Jean Zay所使用的)主要由核能驱动,与由煤炭和天然气等能源驱动的电网相比,核能是低碳的。虽然对核能的可持续性存在争议,但它是目前碳密集度最低的能源之一。BLOOM和OPT比GPT-3的碳排放量要少得多(《Carbon emissions and large neural network training》),这可以归因于几个因素,包括更有效的硬件、以及碳密集度较低的能源。我们还进一步探讨了:在
Big Science研讨会范围内在Jean Zay上进行的计算,以及实时运行BLOOM模型API的碳足迹。就整个计算的碳足迹而言,我们估计最终的BLOOM训练约占总排放量的37%,其他过程如中间的training run和模型评估加起来占其他的63%。这略低于OPT论文作者的估计,他们说由于实验、baseline、以及消融分析,其模型的总碳足迹大约高2倍。我们正在对BLOOM API的碳排放进行探索,估计模型在具有16个GPU的GCP instance上的实时部署,在us-central地区运行,每天的部署会排放大约20公斤的CO2eq(或0.83 kg/hour)。这个数字并不代表所有的部署用例,而且会因使用的硬件以及模型实施的具体情况(如是否使用batching)和模型收到的请求数量而有所不同。关于BLOOM的碳足迹的更多信息可以在《Estimating the Carbon Footprint of BLOOM, a 176B Parameter Language Model》中找到。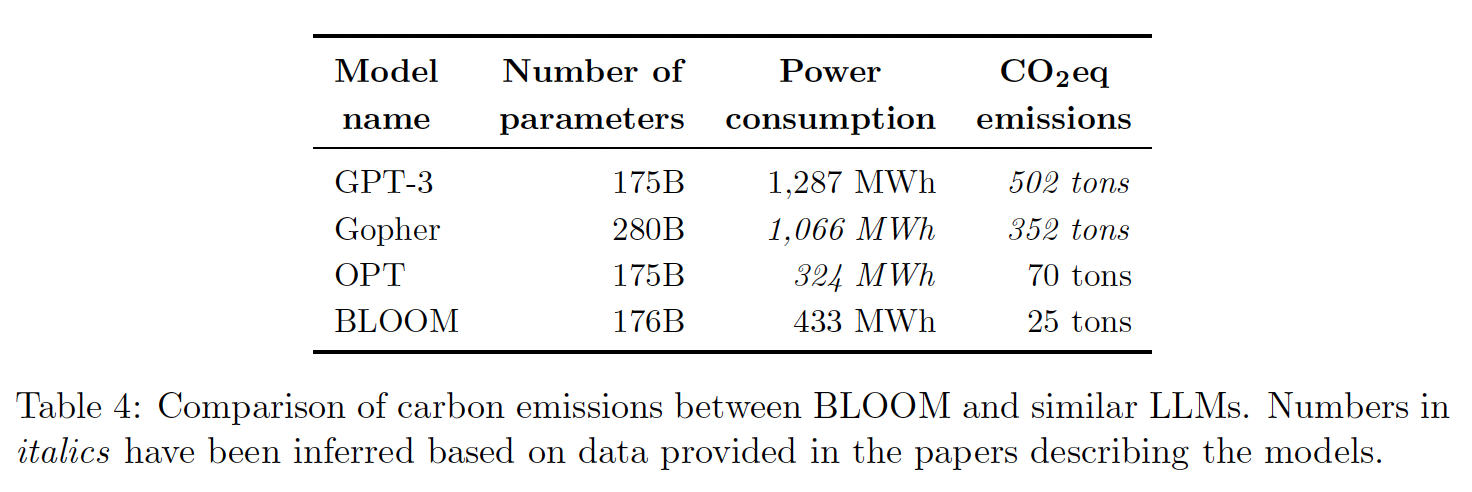
49.2.6 发布
开放性一直是
BLOOM发展的核心,我们希望确保它能被社区轻松使用。因此,我们致力于将文档制作成Model Card、以及致力于一个新的license用于解决项目的具体目标。Model Card:按照发布机器学习模型的最佳实践,BLOOM模型已经与详细的Model Card一起发布,描述了其技术规范、训练细节、预期用途、范围外用途、以及模型的局限性。各工作小组的参与者共同制作了最终的Model Card、以及每个checkpoint的类似的Model Card。这项工作是协作性的,主要是通过思考和讨论每一个部分,然后根据参与者在讨论过程中自然形成的分类和区别,进一步划分为子部分。Licensing:考虑到BLOOM可能带来的潜在有害的使用情况,我们选择在无限制的开放使用、以及负责任的使用之间取得平衡,包括行为使用条款(《Behavioral use licensing for responsible ai》),以限制该模型在潜在有害使用情况下的应用。这类条款通常包括在越来越多的负责任的人工智能许可证(Responsible AI Licenses: RAIL) 中,社区在发布他们的模型时一直在采用这类许可证。为BLOOM开发的RAIL license的一个突出方面是,它将源代码license和模型license分开,其中模型指的是trained parameters。它还包括对模型的使用和衍生作品的详细定义,以确保通过prompting、finetuning、distillation、使用logits和概率分布等预期的下游使用被明确地确定。license包含13个行为使用限制,这些限制是根据BLOOM模型卡中描述的预期用途和局限性,以及BigScience的道德宪章确定的。license免费提供该模型,用户只要遵守条款(包括使用限制),就可以自由使用该模型。BLOOM的源代码已在Apache 2.0 open source license下提供。
49.3 评估
我们的评估集中在
zero-shot/few-shot setting上。我们的目标是准确描述:在最真实地反映模型在实践中可能被使用的方式的setting中,BLOOM与现有的LLM相比如何。由于这些模型的规模,prompt-based adaptation和few-shot in-context learning目前比微调更常见。因此,我们报告了在zero-shot/one-shot的prompt-based setting中,以及在多任务微调之后,一系列任务和语言的结果。为了与其他模型进行比较,我们首先报告了在zero-shot setting设置下的标准基准任务的性能。然后,我们使用多语言摘要、以及机器翻译来比较不同语言的性能。我们还从multilingual probing的角度来解释BLOOM的泛化能力。
49.3.1 实验设计
prompts:基于最近关于prompting对语言模型性能的影响的研究,我们决定建立一个语言模型评估套件,允许我们改变基本的任务数据以及用于contextualize任务的prompting。我们的prompts是在BLOOM发布之前开发的,并没有使用模型进行任何先验的完善。也就是说,我们在评估中使用的prompts是人类认为从语言模型中获取所需task behavior的合理方式。我们以这种方式设计prompts的目的是为了模拟一个新用户可以从BLOOM中期待的真实的zero-shot/one-shot的结果。这与呈现最佳性能的prompt design形成对比,其中结果来自于多轮trial-and-error。我们选择报告前者是因为后者更难系统性地复现,可以说是对模型在一般情况下如何工作的一种不太有代表性的描述,不能代表真正的zero-shot learning(zero-shot learning没有任何标记数据,而trial-and-error事实上存在一些标记数据)。我们使用
promptsource为每个任务生成多个prompts。我们遵循《Multitask prompted training enables zero-shot task generalization》使用的程序,其中prompt generation是众包的,因此我们看到整个prompts的长度和风格有很大的不同。为了提高质量和清晰度,我们对每个prompt进行了多次同行评议,以确保artifacts和一致性。下表显示了用于
WMT'14任务的prompts的例子。我们还为许多任务生成了prompts,但由于资源限制,这些prompts没有包括在本文的页面中。我们对所有任务(包括本文分析的任务和尚未分析的任务)的所有prompts都是公开的。
基础设施:我们的框架扩展了
EleutherAI的语言模型评估工具(《A frameworkfor few-shot language model evaluation》),将其与前面 ”训练数据集“ 章节中描述的promptsource library整合。我们将我们的Prompted Language Model Evaluation Harness作为一个开放源码库发布给人们使用。我们使用这个框架来运行实验和汇总结果。数据集:
SuperGLUE:我们使用SuperGLUE评估套件的分类任务子集,具体而言是:Ax-b, Ax-g, BoolQ, CB, WiC, WSC,RTE任务。我们排除了其余的任务,因为它们需要的计算量比我们考虑的所有这些任务的总和还要多一个数量级。这些任务是纯英语的,因此它们被包含在以前的工作中从而便于比较,而以前的工作主要集中在纯英语的模型上。我们还注意到,这些任务的性能还没有使用zero-shot/one-shot prompt-based setting来广泛报道过。T0是第一个例外,但该模型是instruction-tuned的,因此不能与BLOOM和OPT等模型直接比较。对于每个任务,我们从
promptsource中随机选择五个prompts样本,在这组prompts上评估所有模型。与Evaluation Harness(《A framework for few-shot language model evaluation》)中的其他prompting task一样,一个模型对给定prompt的预测是这样得到的:使用与prompt相关的、指定的一组候选label string,然后选择这些label string中对数似然最大的那个。机器翻译(
Machine Translation: MT):我们在三个数据集(使用ISO-639-2 code来指代语言)上评估BLOOM:WMT14 eng <-> fre and eng <-> hin、Flores-101和DiaBLa。我们使用BLEU的sacrebleu实现进行评估,对WMT和DiaBLa使用默认的tokenization,对Flores使用spm-flores-101。我们使用贪婪解码,生成预测直到EOS token,或者另外对1-shot的情况使用\n###\n。每个数据集的最大生成长度被设定为与文献中通常使用的长度一致;具体来说,WikiLingua和WMT14为64 tokens,Flores-101和DiaBla为512 tokens。具体任务的实验设计细节参考后文。摘要:我们对
WikiLingua数据集的摘要进行评估。WikiLingua是一个多语言摘要数据集,包括WikiHow文章、以及step-by-step summary的pair对。pair对在多种语言之间进行对齐,source和摘要的翻译由一个国际翻译团队进一步审核。one-shot条件自然语言生成通常未被规模与BLOOM相当的模型所报道。PaLM是第一个例外,它在WikiLingua上报告了分数;但是,只考察了该模型在英语中的摘要能力。相比之下,我们选择通过评估源语言的抽象摘要能力来测试BLOOM固有的多语言能力。我们专注于九种语言(阿拉伯语、英语、西班牙语、法语、印地语、印度尼西亚语、葡萄牙语、越南语、汉语),这些语言是BigScience工作的目标之一。自然语言生成是众所周知的对于评估是一个挑战,而多语言生成由于缺乏指标支持而使这一挑战更加复杂。根据
《Repairing the cracked foundation: A survey of obstacles in evaluation practices for generated text》的建议,我们报告了ROUGE-2、ROUGE-L和Levenshtein距离。对ROUGE的一个重要修改是使用从Flores-101数据集建立的SentencePiece tokenizer。一个朴素的方法会使用基于英语的tokenizer,但使用多语言tokenizer可以提高能力来衡量多语言生成的fidelity。为了尽量减少模型的inference时间,我们使用了更新后的GEM基准的子样本(3000个均匀采样的测试集的样本)。作者指出,在比较测试集子样本和完整测试集之间的模型性能时,差异很小。对于解码和生成,我们使用与上述机器翻译相同的程序。
baseline模型:我们在适当的时候(如,它们支持evaluation数据集的语言的情况下)使用以下baseline模型:mGPT:在Wikipedia和Common Crawl的60种语言上训练的GPT-style模型。GPT-Neo, GPT-J-6B, GPTNeoX:在Pile上训练的一系列GPT-style模型。T0:T5的一个变体,在P3的数据集上进行了multitask prompted finetuning。OPT:一系列的GPT-style模型,在混合数据集上训练,其中训练集包括RoBERTa和Pile。XGLM:一个在CC100数据集的变体上训练的GPT-style多语言模型。M2M:一个大型多语言模型,它被训练从而用于在100种语言之间进行翻译。AlexaTM:一个encoder-decoder模型,它在Wikipedia和mC4数据集上训练,混合了masked language modeling和causal language modeling的objective。mTk-Instruct:T5的一个变体,在来自Super-NaturalInstructions的数据集上进行了multitask prompted finetuning。Codex:在GitHub的代码上微调的一系列GPT模型。GPT-fr:一个在法语文本上训练的GPT-style模型。
49.3.2 Zero-Shot 性能
在整个自然语言理解任务、和自然语言生成任务中,我们发现
pretrained模型的zero-shot性能接近随机。下图显示了模型在一系列SuperGLUE基准任务的一组prompts中的平均zero-shot表现。Table 6和Table 7显示了多个模型和数据集在English-French和English-Hindi上的zero-shot机器翻译结果。我们没有报告zero-shot在文本摘要方面的表现,因为文本生成实验的运行成本很高,而且根据这里报告的结果、以及在zero-shot文本摘要上的的初始实验,很明显文本摘要方面的表现会很差。在所有的情况下,在标准语言模型上训练的模型的zero-shot性能都接近于随机。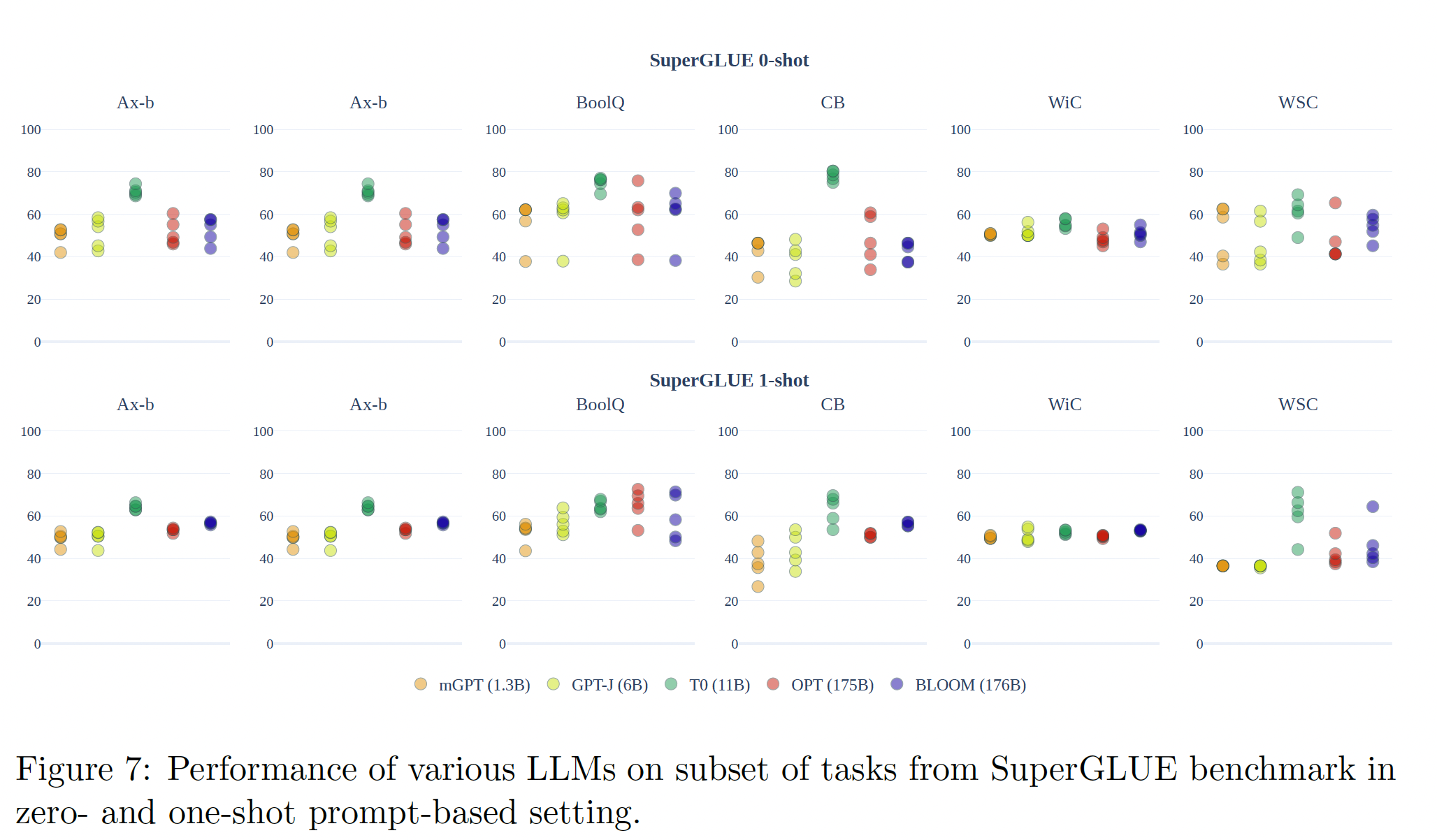
SuperGLUE:在SuperGLUE上,虽然某些prompts显示出性能的提高,幅度高达10个点的准确率,但各prompts的平均性能总是在随机值附近徘徊,这表明单个prompts的成功主要是统计上的方差。T0模型是个例外,它显示了强大的性能。然而,这个模型在多任务设置中进行了微调(类似于BLOOMZ),以提高在zero-shot prompting setting中的性能,因此与这里显示的其他模型没有直接可比性。翻译:在
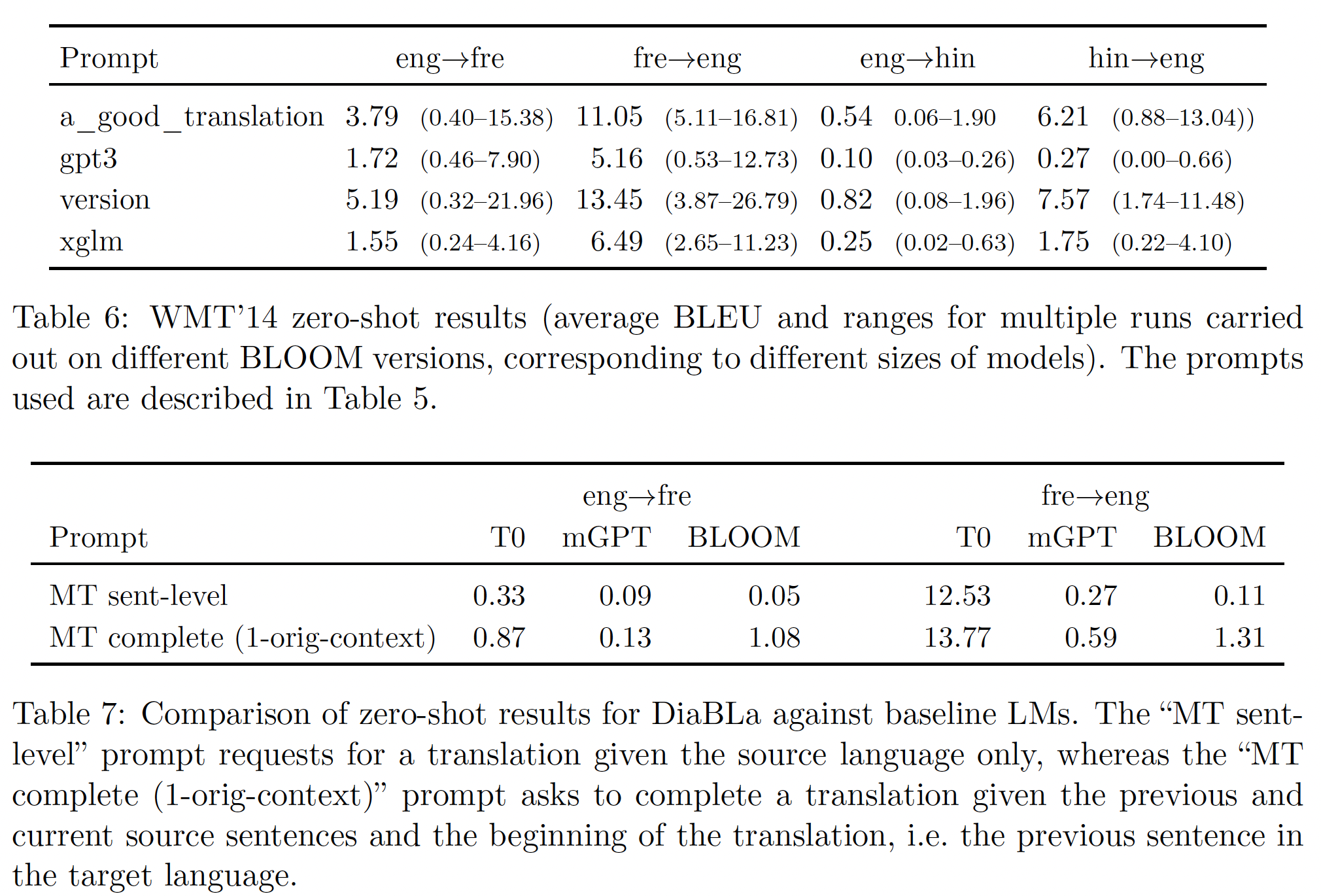
zero-shot setting中,翻译的结果通常很差,如Table 6所示,该表给出了不同prompts和多次运行的平均分数。多次运行是在不同的BLOOM版本(不同规模)中进行的。不同的run的得分不同(例如,"version" prompt的得分是0.32 ~ 21.96),有点令人惊讶的是,最好的prompts往往是比较啰嗦的prompts("version"和"a_good_translation"的prompts)。一个直觉是:啰嗦的
prompts提供了更多的信息。观察到的两个主要问题是:
over-generation、没有产生正确的语言(一个好的翻译的明显前提条件)。这些问题在其他语言模型中也可以看到,从Table 7中显示的DiaBla数据集上的普遍不良结果就可以看出。尽管不是一个多语言模型,T0有时可以进行英语翻译(12.53和13.77的BLEU分),尽管它是一个基于英语的模型这一事实可能解释了为什么它表现得更好。对于BLOOM来说,通过使用以目标语言结尾的prompts(而不是以要翻译的源文本结尾,其中gpt3风格的prompts是以源文本结尾),在into-English的方向上,错误语言的问题得到了部分缓解,这可能是因为用相同的语言生成prompt的continuation更容易。
49.3.3 One-Shot 性能
在
one-shot evaluation中,模型被给定一个in-context training example,我们发现,生成任务(机器翻译和文本摘要)的性能普遍提高,但SuperGLUE的分类任务却没有。SuperGLUE:Figure 7显示了one-shot的性能和zero-shot的结果。与zero-shot性能相比,在所有的prompts和模型中,对SuperGLUE的one-shot性能变化都有所降低。总的来说,one-shot setting没有明显的改善:模型的平均准确率仍然几乎总是处于随机状态(T0除外)。我们进行了一项额外的分析,比较了不同模型规模的
BLOOM模型。作为baseline,我们还测量了类似规模的OPT模型(350M参数到175B参数)的平均one-shot准确率。Figure 8显示了不同模型规模下每个prompt在每个任务上的准确率。OPT模型系列和BLOOM模型系列都随着规模的扩大而略有改善,在所有任务中,模型族之间没有一致的差异。BLOOM-176B在Ax-b、CB和WiC上领先于OPT-175B。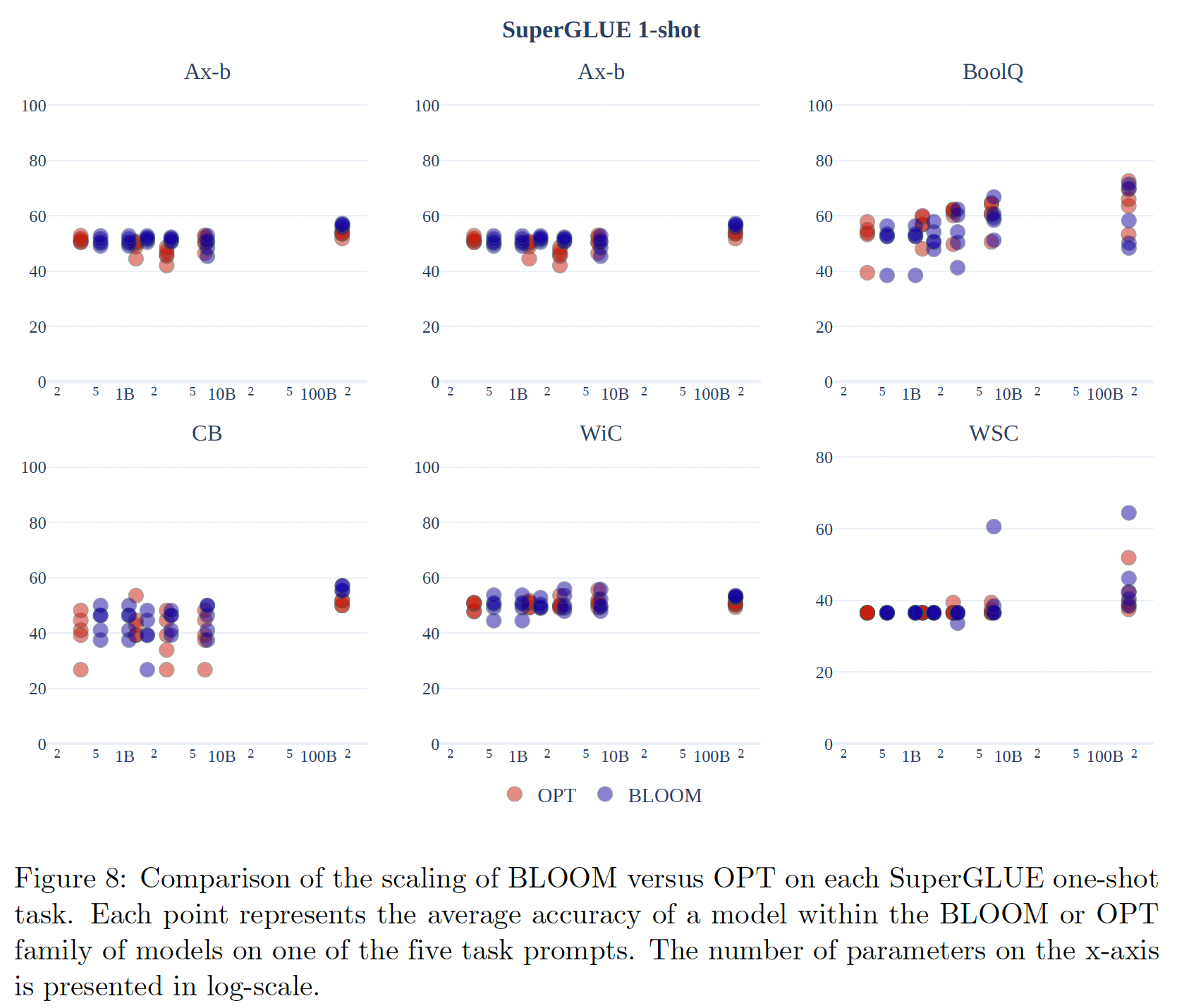
机器翻译:在
1-shot setting中,我们使用XGLM prompt测试了Flores-101的dev-test数据集中的几个语言方向。我们从同一数据集中随机选择1-shot example,这可能与过去的工作不同。我们将high-resource language pairs(Table 8(c))、high-to-mid-resource language pair(Table 8(d))、low-resource language pair(Table 8(a))以及Romance语系相关语言之间(Table 8(b))的结果分开。语言被分为低资源、中资源、以及高资源,取决于它们在
ROOTS中的表现。对于high-resource pair和mid-to-high-resource pair,我们与有615M参数的M2M-124模型的监督结果进行比较,《The Flores-101 evaluation benchmark for low-resource and multilingual machine translation》计算了该模型的分数。此外,我们还与XGLM(7.5B)的1-shot结果(《Few-shot learning with multilingual language models》)和32-shot AlexaTM结果(《Few-shot learning using a large-scale multilingual seq2seq model》)进行比较。无论是高资源语言之间的翻译、还是从高资源语言到中等资源语言的翻译,结果都很好,这表明
BLOOM具有良好的多语言能力,甚至可以跨文字(这里是拉丁文或扩展拉丁文、中文、阿拉伯文和梵文之间)。与有监督的M2M模型相比,在这种1-shot setting下,结果往往是相当的、有时甚至更好,而且在许多情况下,结果与AlexaTM的结果相当。许多低资源语言的翻译质量很好,与有监督的
M2M模型相当,甚至略好。然而,斯瓦希里语(Swahili)和约鲁巴语(Yoruba)之间的结果非常差,这两种语言在BLOOM的训练数据中存在但代表性不足(每种语言<50k tokens)。这与Romance(因此也是相关语言)之间的翻译结果形成鲜明对比,后者的翻译结果全面良好,包括从Galician: glg的翻译(这种语言没有包括在训练数据中,但与其他罗曼语有许多相似之处,特别是与葡萄牙语(Portuguese: por))。然而,这确实对BLOOM在训练中所包含的那些代表性不足的低资源语言上的质量提出了质疑。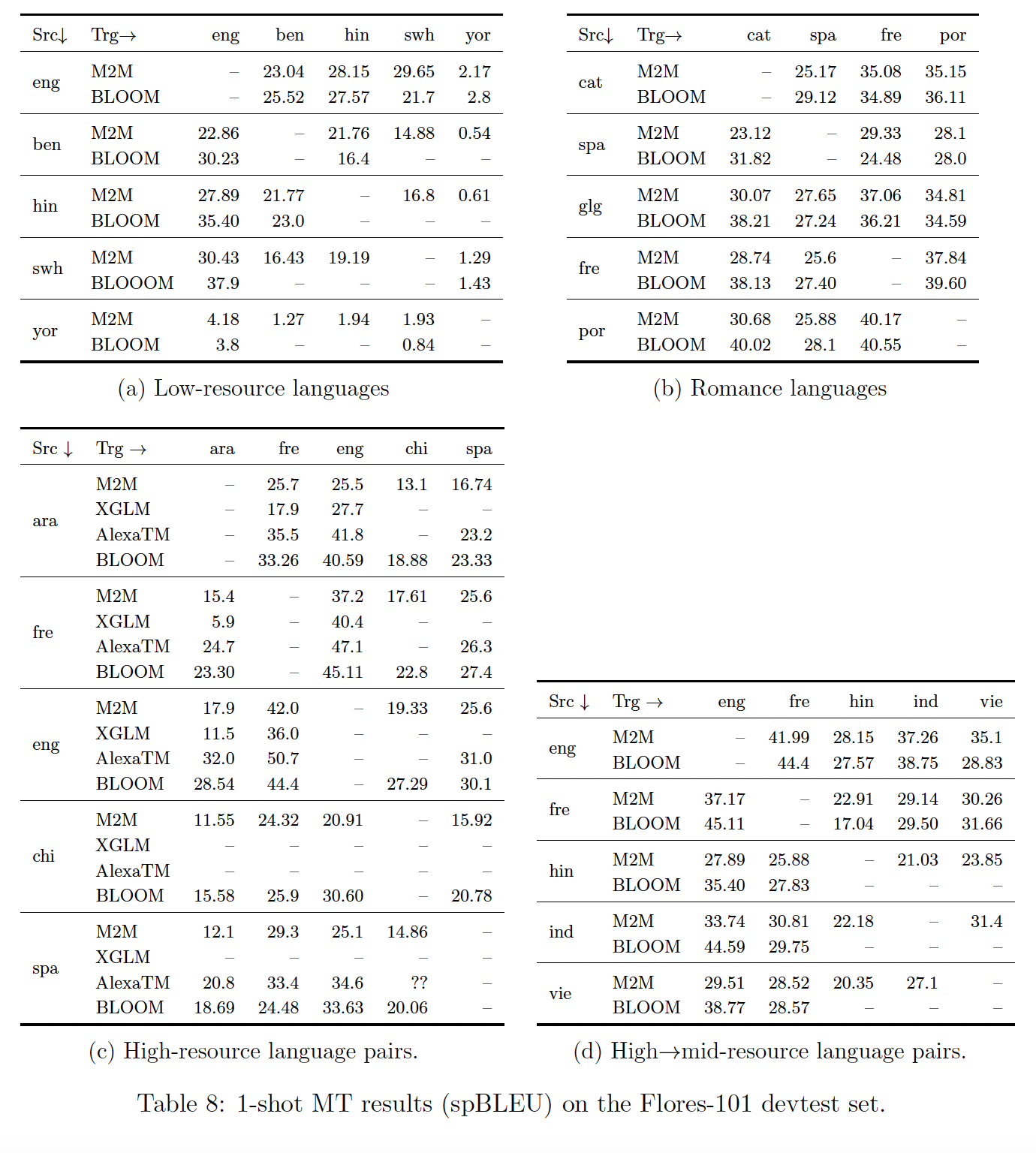
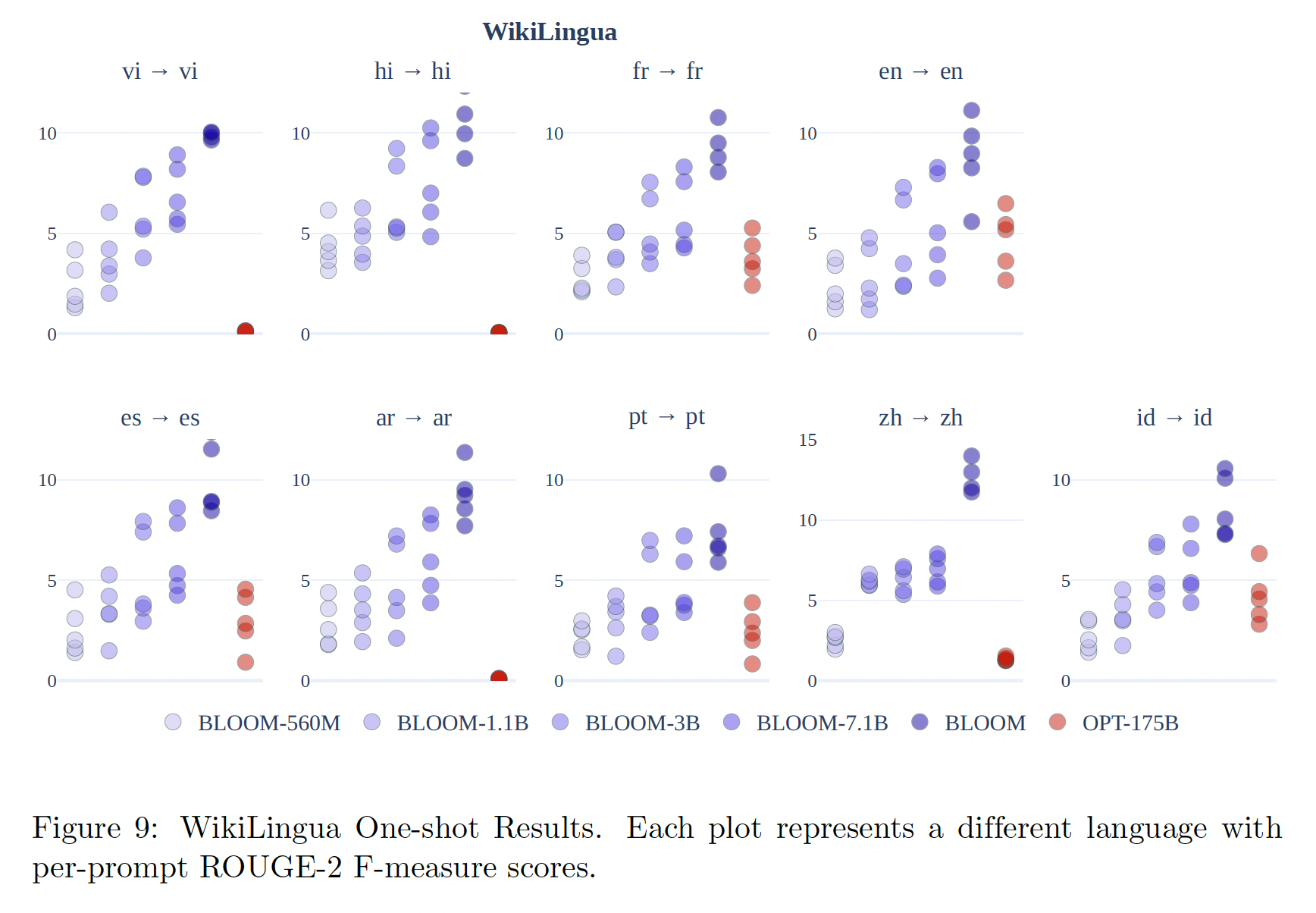
文本摘要:下图显示了
OPT-175B和BLOOM模型的one-shot结果。每点代表per-prompt score。关键的启示是,BLOOM在多语言文本摘要方面取得了比OPT更高的性能,而且性能随着模型的参数数的增加而增加。我们怀疑这是由于BLOOM的多语言训练的结果。正如在 ”实验设计“ 章节所讨论的,我们报告
ROUGE-2的分数是为了与以前的工作进行比较,也是因为缺乏替代的generation evaluation。然而,我们从质量上观察到,在许多情况下,ROUGE-2得分低估了系统所生成的摘要的质量。这里没有画出横坐标。读者猜测横坐标是模型大小。
49.3.4 多任务微调
在最近关于多任务微调的工作基础上(
《Multitask prompted training enables zero-shot task generalization》、《Finetuned language models are zero-shot learners》、《What language model architecture and pretraining objective works best for zero-shot generalization?》),我们探索使用多语言多任务微调来提高BLOOM模型的zero-shot性能。我们使用 ”训练数据集“ 章节所述的
xP3语料库对BLOOM模型进行了多语言多任务微调。我们发现,zero-shot的性能明显增加。在下图中,我们比较了pretrained BLOOM和pretrained XGLM模型与多任务微调的BLOOMZ、T0、以及mTk-Instruct的zero-shot性能。BLOOM和XGLM的表现接近random baseline,对于NLI (XNLI)为33%、对于共指解析(XWinograd)和句子补全(XCOPA和XStoryCloze)为50%。在经历了多语言多任务微调之后(
BLOOMZ),在所描述的保留任务上,zero-shot性能有了明显的改善。尽管也经过了多任务微调,但由于T0是一个单语的英语模型,它在所展示的多语言数据集上的表现很差。然而,《Crosslingual generalization through multitask finetuning》提供的其他结果显示,在控制模型规模和架构时,在xP3上进行微调的模型在英语数据集上的表现也优于T0。这可能是由于T0的微调数据集(P3)包含的数据集和prompts的多样性不如xP3。多任务微调性能已被证明与数据集和prompts的数量相关(《Scaling instruction-finetuned language models》)。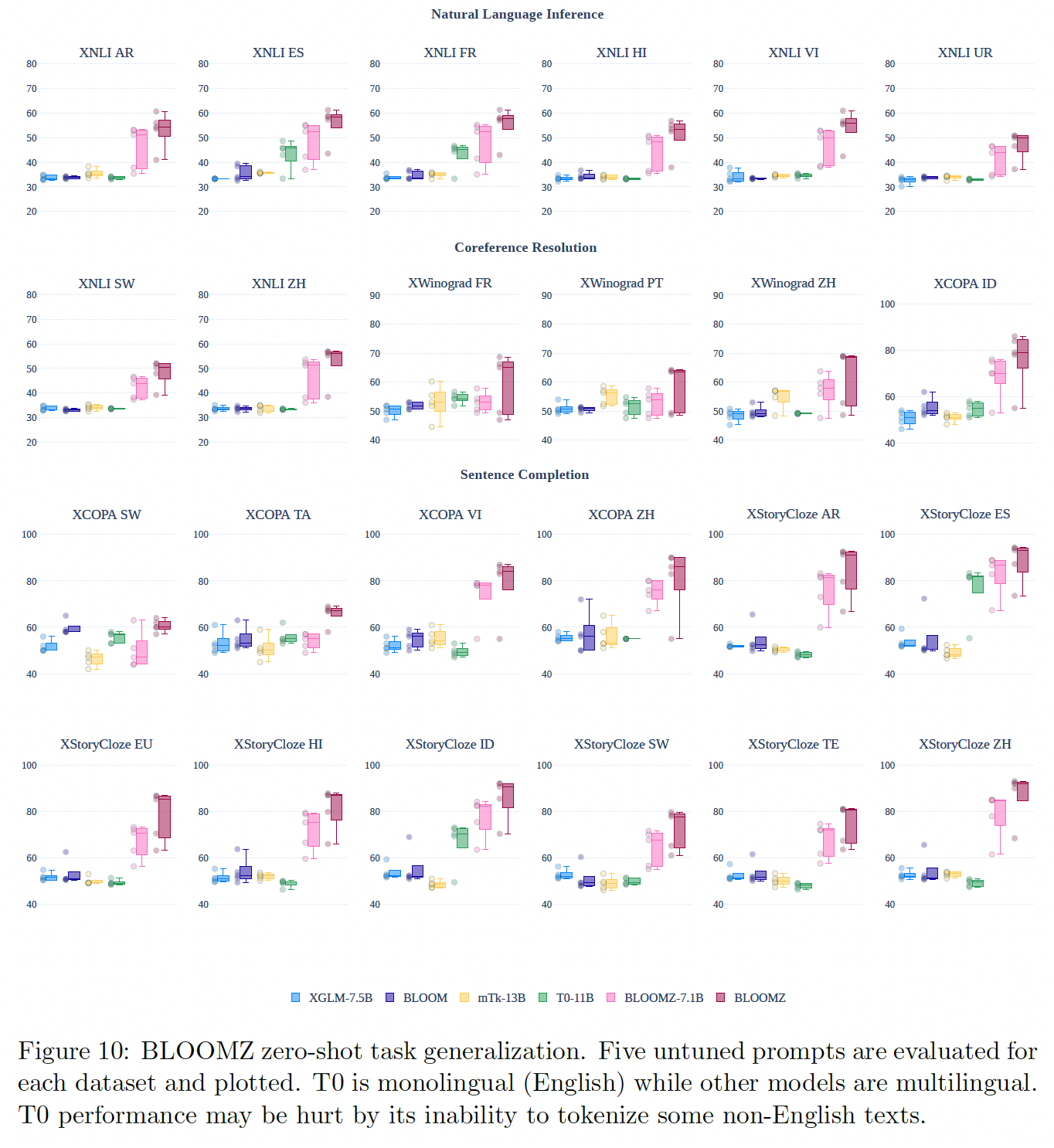
49.3.5 Code 生成
BLOOM的预训练语料库ROOTS包括大约11%的代码。在下表中,我们报告了BLOOM在HumanEval(《Evaluating large language models trained on code》)的基准测试结果。我们发现pretrained BLOOM模型的性能与在Pile上训练的类似规模的GPT模型相似。Pile包含英文数据和大约13%的代码(GitHub + StackExchange),这与ROOTS中的代码数据来源和代码数据比例相似。仅仅对代码数据进行了微调的
Codex模型明显强于其他模型。多任务微调的BLOOMZ模型并没有比BLOOM模型有明显的改善。我们假设这是由于微调数据集xP3不包含大量的pure code completion。相反,xP3包含与代码相关的任务,如估计一个给定的Python代码片段的时间复杂性。《Crosslingual generalization through multitask finetuning》提供了额外的分析。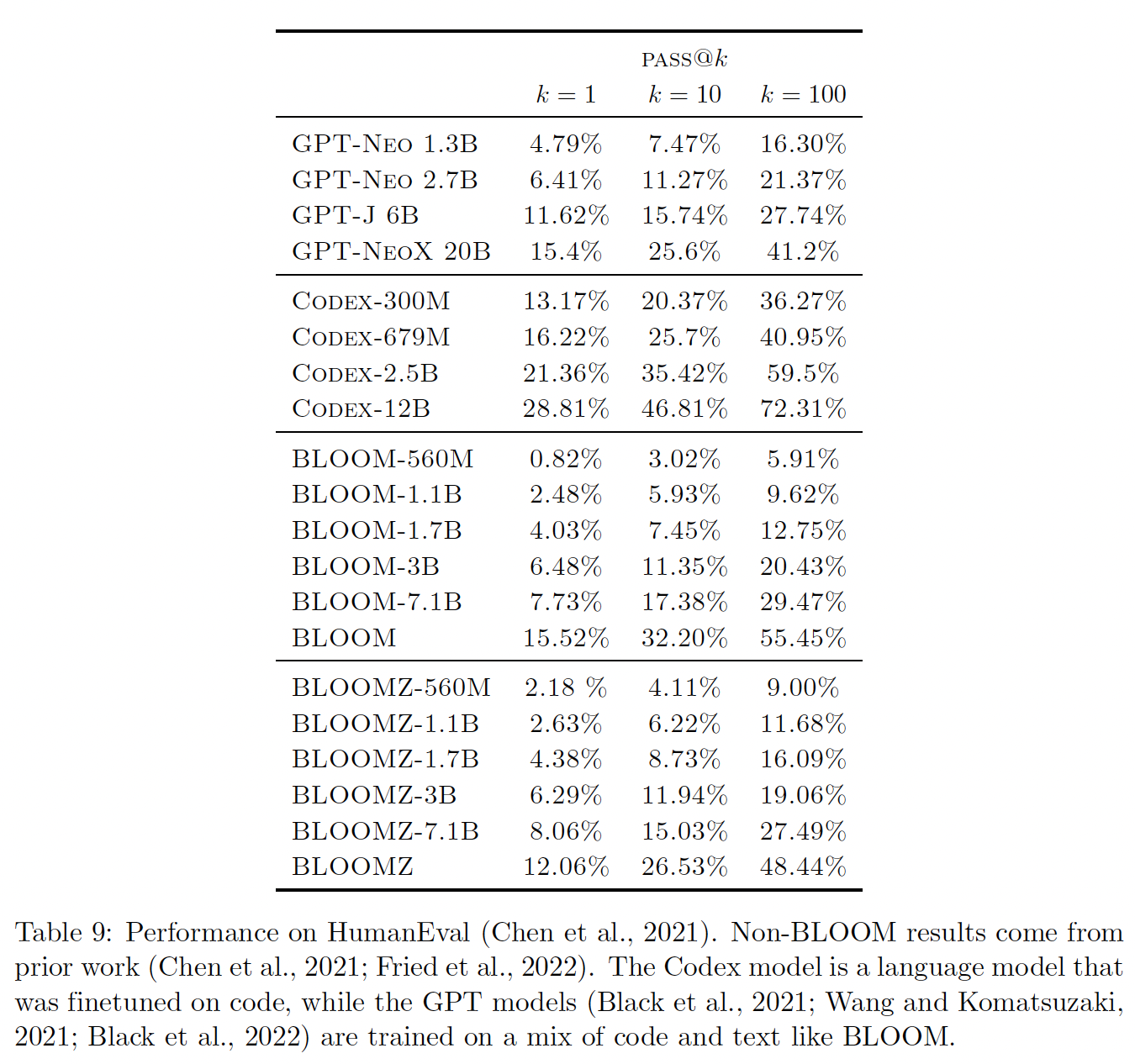
49.3.6 Embedding
在 ”训练“ 章节中,我们概述了
contrastive finetuning procedure用于创建SGPTBLOOM text embedding模型。在下表中,我们报告了来自Massive Text Embedding Benchmark: MTEB的两个多语言数据集的基准测试结果。我们发现:SGPT-BLOOM-7.1B-msmarco在几个分类任务和语义文本相似性任务上提供了SOTA性能。然而,它有7.1B参数,比多语言MiniLM和MPNet等模型大一个数量级。SGPT-BLOOM-1.7B-nli的表现明显较差,可能是由于参数较少,其微调时间较短(NNI是一个比MS-MARCO小得多的数据集)。除了
BLOOM模型之外,ST5-XL是最大的模型,有1.2B参数。然而,作为一个纯英语的模型,它在非英语语言上的表现很差。
下表中的语言是
BLOOM预训练语料库的一部分。更多语言和数据集的性能可以在MTEB排行榜上查看。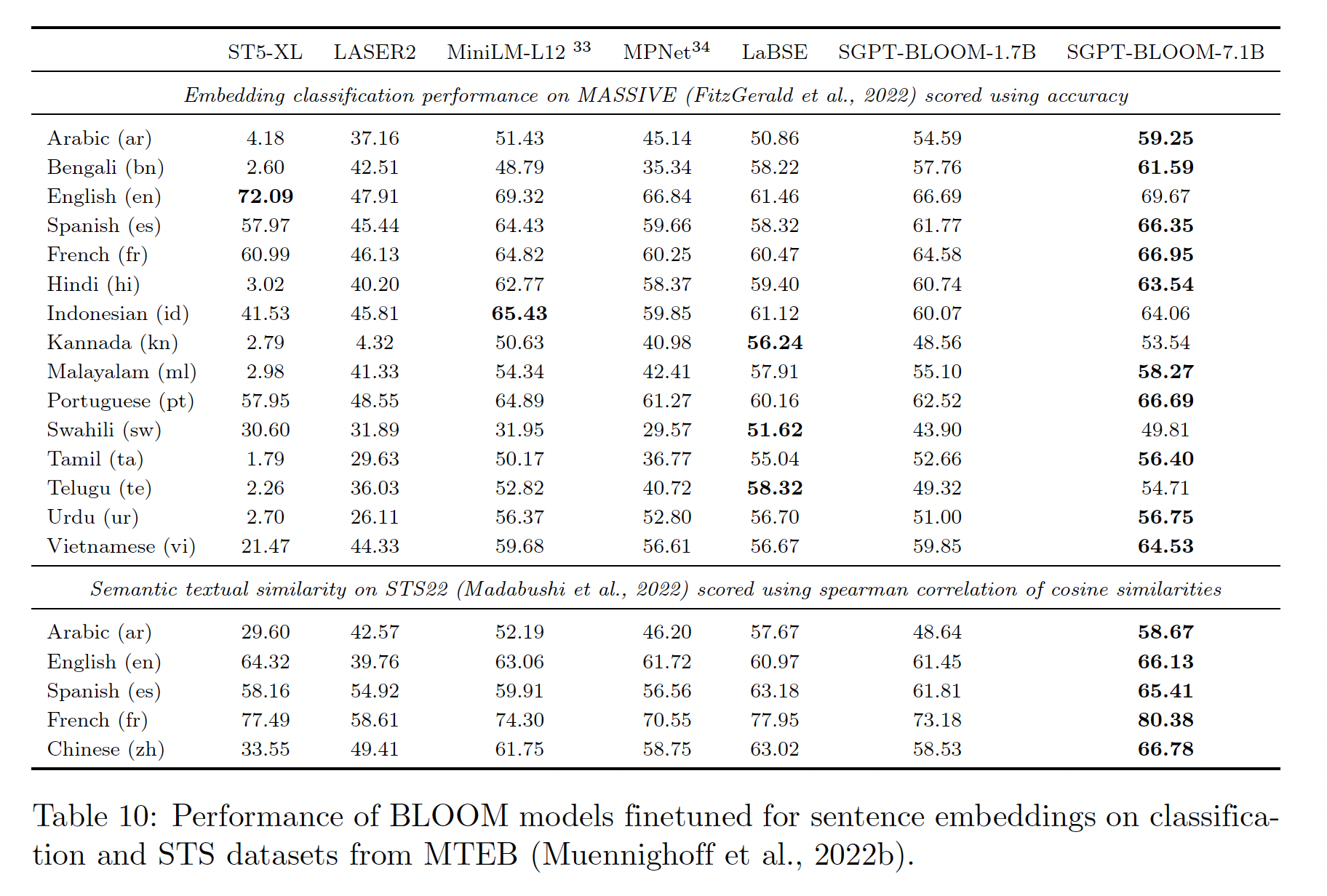
49.3.7 Multilingual Probing
probing已经成为分析和解释LLM内部运作的重要评价范式,尽管它带有某些不足(《Probing classifiers: Promises, shortcomings, and advances》)。除了training objective loss或下游任务评估外,对LLM embedding的考察有助于阐明模型的泛化能力,这对考察缺乏标记数据集或benchmark的语言尤其有利。方法:为了解释
BLOOM的多语言泛化能力,我们利用Universal Probing框架对104种语言和80种形态句法特征进行系统性的probing analysis(《Universal and independent: Multilingual probing framework for exhaustive model interpretation and evaluation》)。该框架针对Universal Dependencies:UD中的每种语言提供了SentEval-style(《What you can cram into a single vector: Probing sentence embeddings for linguistic properties》)的probing steup和数据集。我们考虑了BLOOM的预训练语料库、以及UD treebanks中存在的7个语系的以下17种语言:Arabic (Afro-Asiatic), Bambara (Mande), Basque (language isolate), Bengali, Catalan, English, French,Hindi, Marathi, Portuguese, Spanish, Urdu (Indo-European), Chinese (Sino-Tibetan), Indonesian(Austronesian), Tamil (Dravidian), Wolof, Yoruba (Niger-Congo)。我们的设置总共涵盖了38个形态句法特征,这些特征代表了特定语言的语言学信息。我们在下表中提供了一个数据集样本(标签为单数Single/复数Plural)。probing程序的进行情况如下:首先,我们在
1.7B参数的BLOOM变体(BLOOM 1B7)和BLOOM(有176B参数)的每一层计算输入句子的<s>-pooled representation。其次,我们训练一个二元逻辑回归分类器,以预测句子中是否存在形态句法特征。选择逻辑回归是因为它相对于非线性
probing分类器有更高的selectivity。我们在这里使用原始的UD training/validation/test splits。第三,由于大多数
probing任务的target class不平衡,probing性能是通过F1加权得分来评估的。结果是不同随机种子的三次运行的平均值。

baseline:我们将probing性能与随机猜测、基于以下TF-IDF特征训练的逻辑回归分类器进行比较:word unigrams, character N-grams, BPE42 token N-grams, SentencePiece token N-grams。我们使用N-gram范围为[1,2,3,4],并将TF-IDF词表限制在top-250k个特征。相关性:我们进行统计测试,从而分析
probing性能与语言学、数据集和模型配置准则之间的相关性:language script:结果按language script,拉丁文和其他文字(Devanagari, Tamil, and Arabic),分为两组。在这里,我们使用non-parametric Mann-Whitney U test。语系:结果按语系分为
7组。我们应用方差分析法(ANOVA)来分析各组之间的差异。probing和预训练数据集大小:我们运行Pearson correlation coefficient test来计算probing性能和这些data configuration criteria之间的相关性。模型大小的影响:按
BLOOM版本将结果分为两组。在这里,我们使用Mann-Whitney U test检验,看看参数数量和probing结果之间是否存在相关性。
Probing结果:下表列出了probing实验的结果,是每种语言内probing task和实验运行的平均数。总的情况是,BLOOM-1B7的表现与BLOOM相当或更好,而两种LLM的表现都超过了基于计数的baseline。具体而言,
LLM在Arabic, Basque, and Indo-European languages (e.g., Catalan, French, Hindi, Portuguese, Spanish, and Urdu)上的表现更为强劲,而Bengali, Wolof, and Yoruba的得分最低。我们把这种行为归因于为迁移能力:BLOOM对于构成大量数据集的密切相关的语言,能更好地推断其语言属性。例如,在任何Romance上的表现都比英语好,而印度语的结果与高资源语言的结果接近。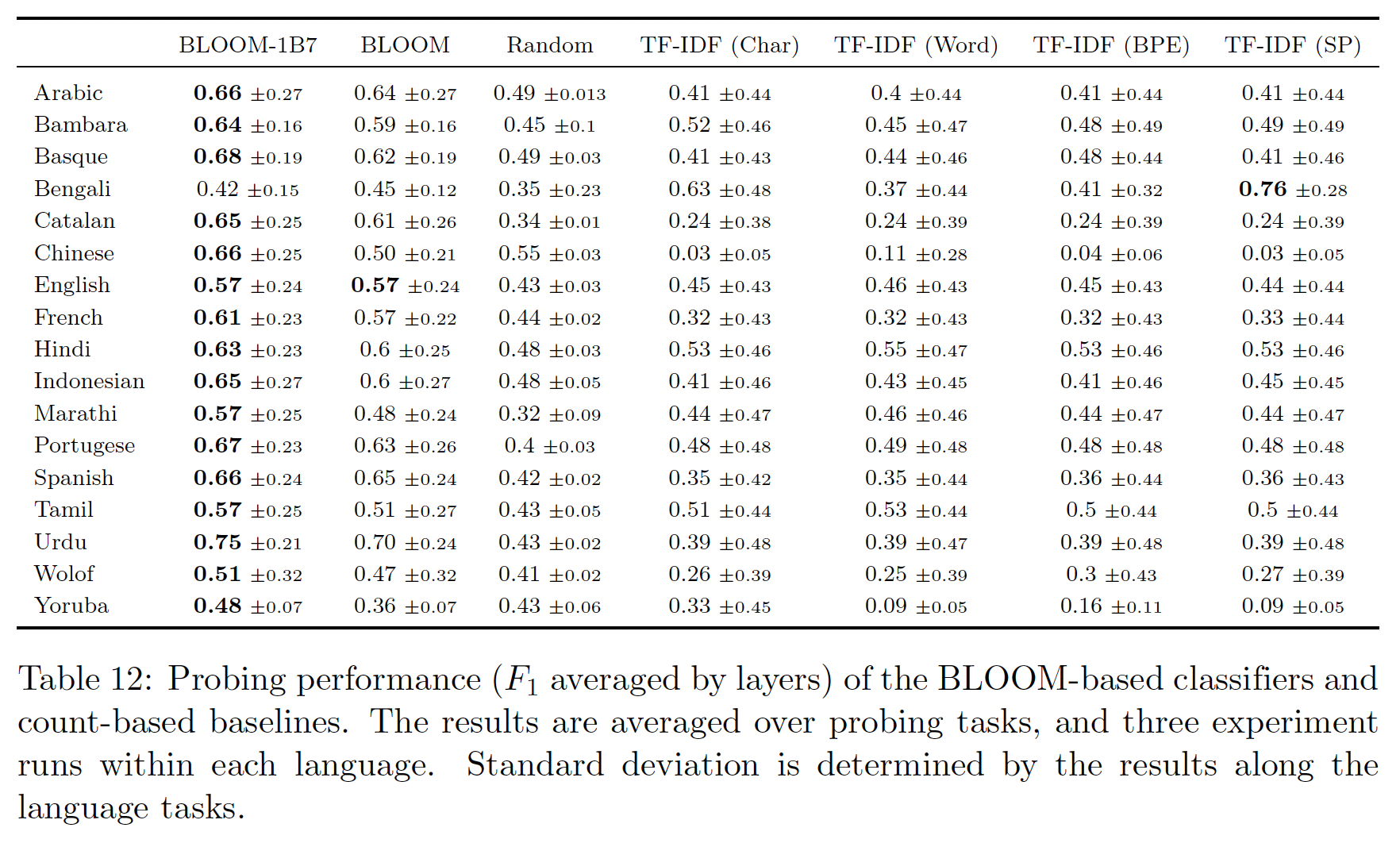
下图显示了至少在
5种语言中的形态句法特征的language-wise probing性能结果。尽管规模不同,但两种LLM的probing性能是相似的。我们发现,在不考虑语言的情况下,LLM可以很好地推断出情绪(Mood)和人称(Person)。数字、NumType(数字类型)和声音在大多数语言中的推断效果一般。这些模型在其他类别中普遍表现出较差的质量,表明它们没有编码这种形态学信息。对这种性能差异的可能解释可能是这些类别的可能值的多样性。例如,情绪和人称在所提交的语言中具有相似的值,而Case值的集合则高度依赖于语言。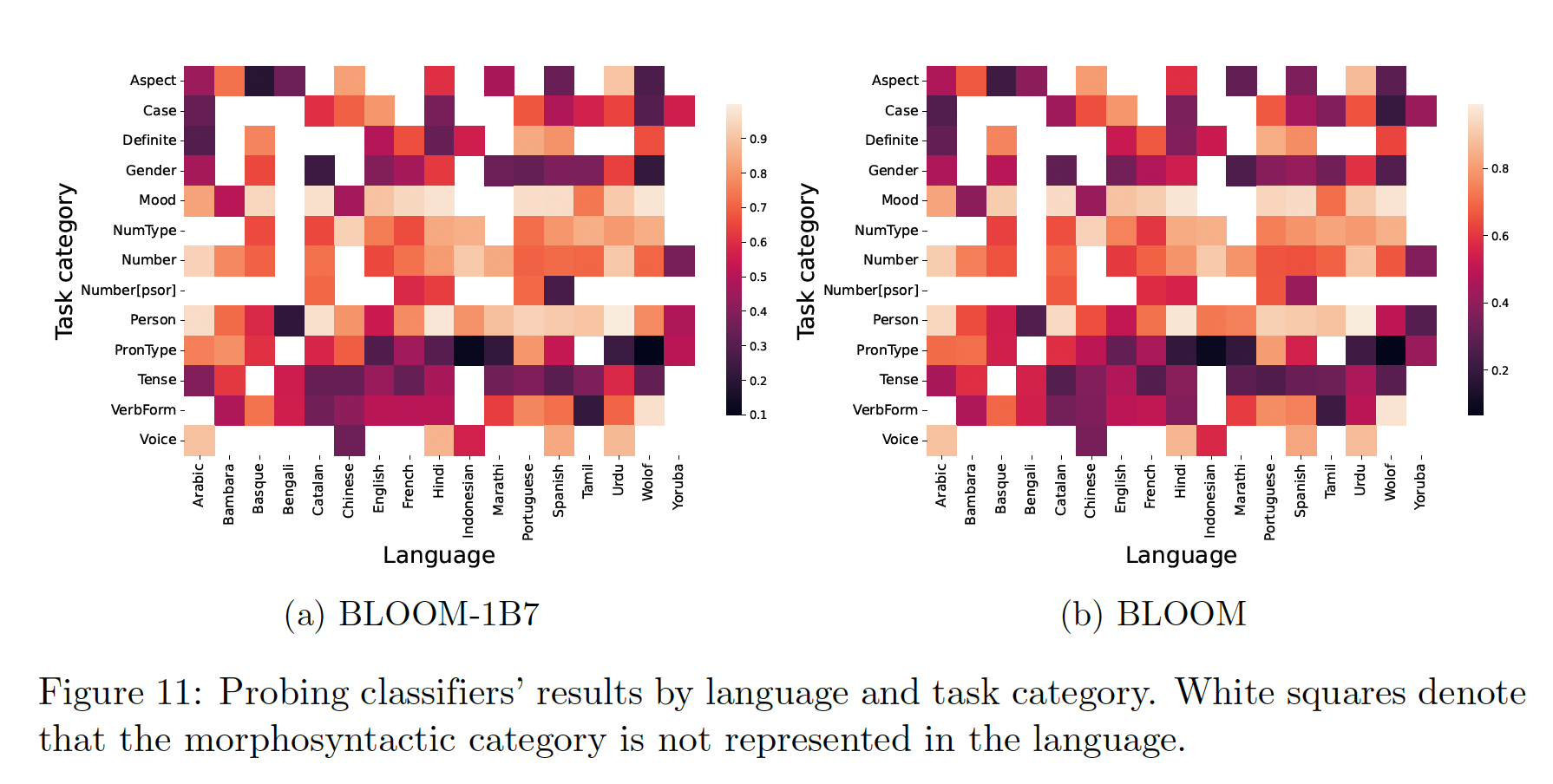
相关性结果:相关性分析结果支持关于
probing性能的结论,并揭示了贡献因子(如下表所示)。两种模型在具有不同
language script的语言上显示出类似的结果。BLOOM-1B7的结果与语系、probing dataset size、和预训练数据集大小高度相关。根据
Mann-Whithey U test的结果,BLOOM-1B7的结果明显优于BLOOM(P < 0.01)。然而,BLOOM在不同的语言上表现出更稳定的性能,尽管它在预训练期间看到了大量的数据。这可能表明有更多参数的模型具有更好的泛化能力。
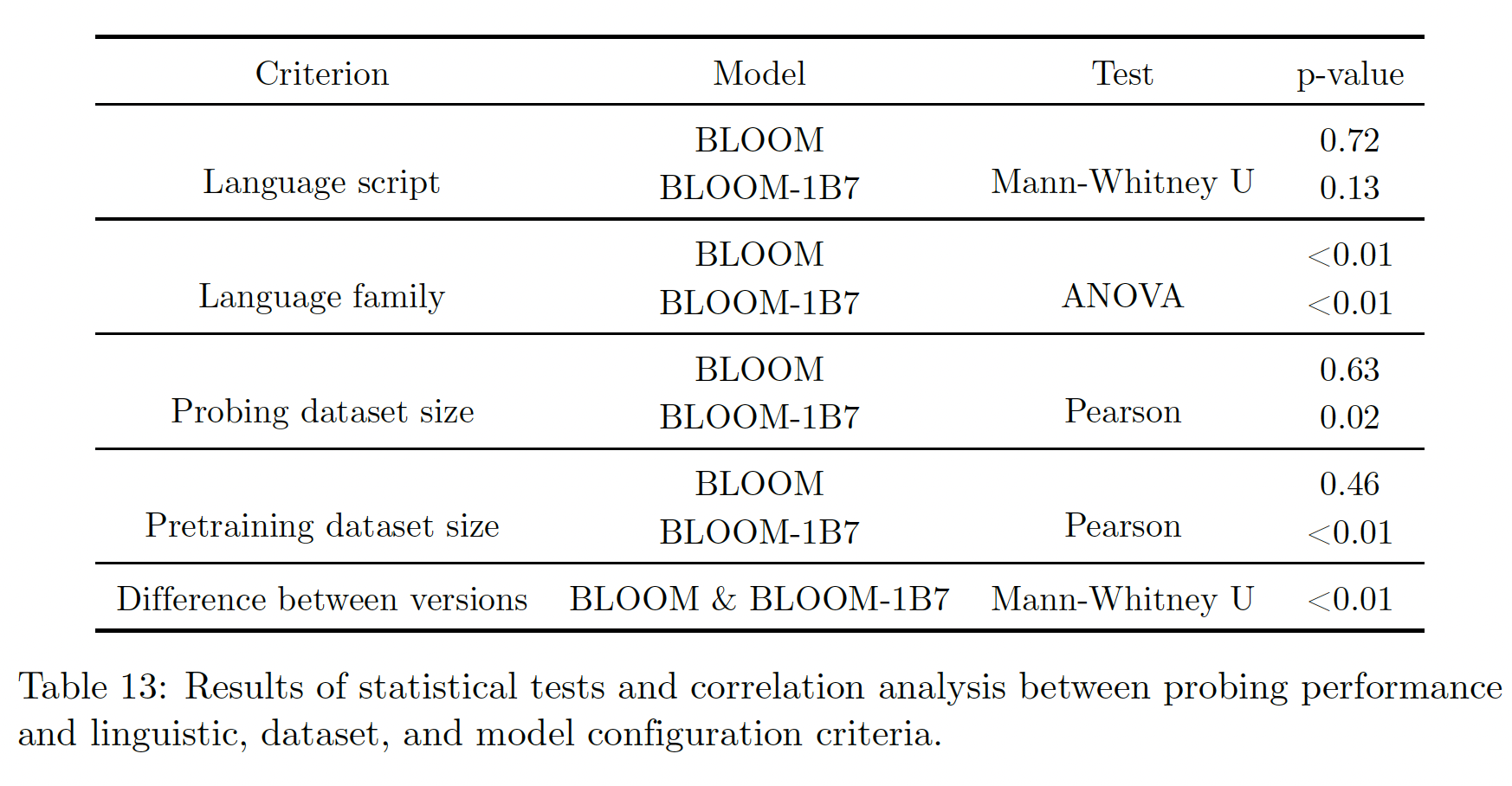
49.3.8 Bias
作为对
BLOOM学到的bias的初步研究,我们提出了对多语言CrowS-Pairs数据集的评估,该数据集结合了《CrowS-pairs:A challenge dataset for measuring social biases in masked language models》开发的CrowS-Pairs数据集的修订版和《French CrowS-pairs: Extending a challenge dataset for measuring social bias in masked language models to a language other than English》引入的法语版CrowS-Pairs。这项评估的一个挑战是如何将原本用于
masked language model的数据集适应于autoregressive language model(如BLOOM)。CrowS-Pairs依靠minimal pairs来比较一个刻板印象的语句、以及一个非刻板印象的语句(例如,"Women can't drive."是一个性别刻板印象,而"Men can't drive."则不是)。这两种陈述的不同之处在于刻板印象所针对的social category,而且该social category在刻板印象陈述(stereotyped statement)中存在而在非刻板印象陈述(non-stereotyped statement)中不存在。评价的目的是评估模型对刻板印象陈述的系统偏好。最初的metric score比较了一对句子的pseudo-loglikelihood,以确定哪个句子从masked language model中获得了更高的分数。prompts被设计成要求模型根据所描述情况的可能性和现实性来选择其中一个语句。下图显示,
BLOOM的overall prompt accuracy接近0.50,这表明总体上没有偏差。我们注意到,英语和法语的得分非常接近,这表明模型在这两种语言上的整体行为相似。我们还展示了英语和法语的mono-lingual autoregressive model的结果,包括GPT-Neo和GPT-FR。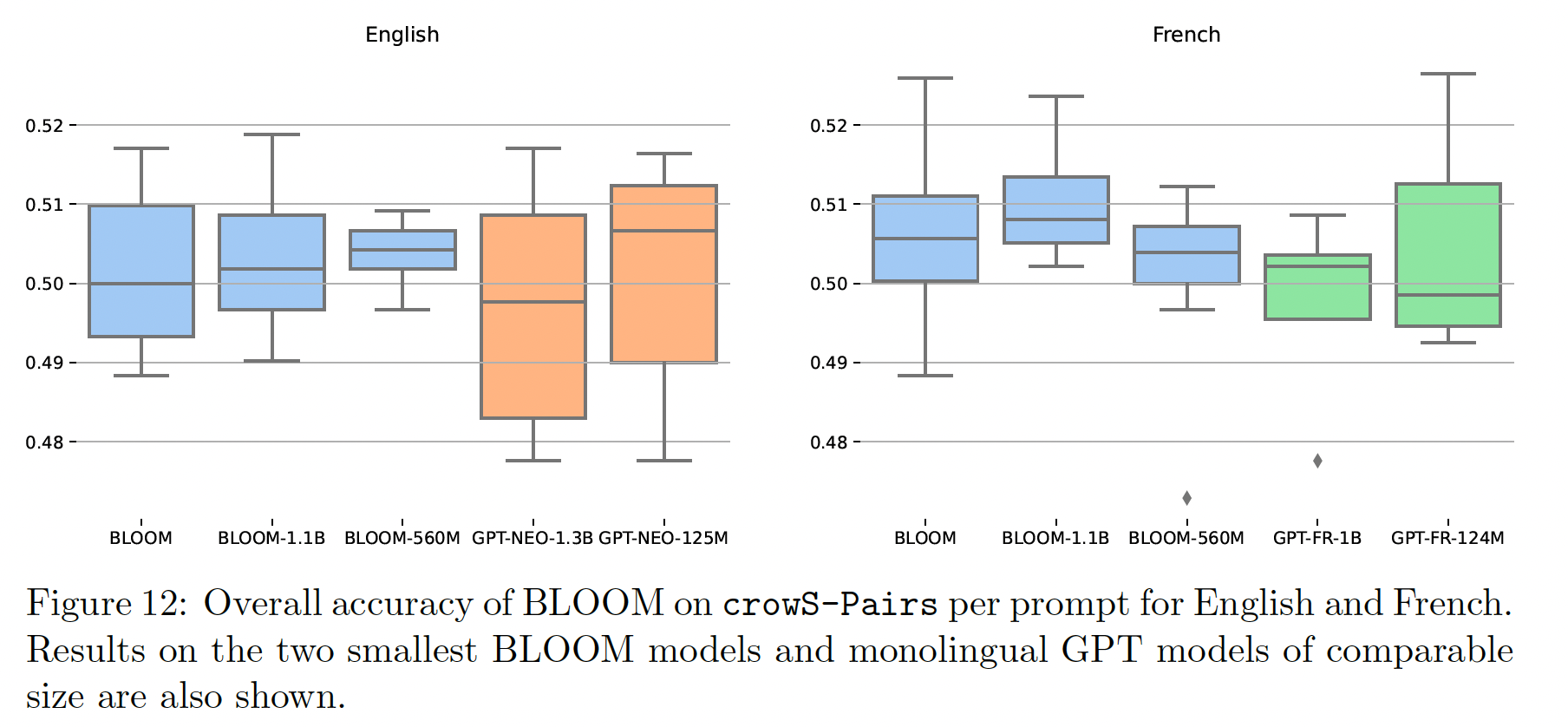
下表列出了
CrowS-Pairs数据集中每个bias类型的结果。结果在各个类别上是相当均匀的,这与以前关于masked language model的研究形成了鲜明的对比(这些研究表明模型在特定的类别中容易出现bias)。尽管如此,两种语言的准确率总体上与50有明显的差异(T-test, p < .05),以及一些偏见的类别,如表中的星号所示。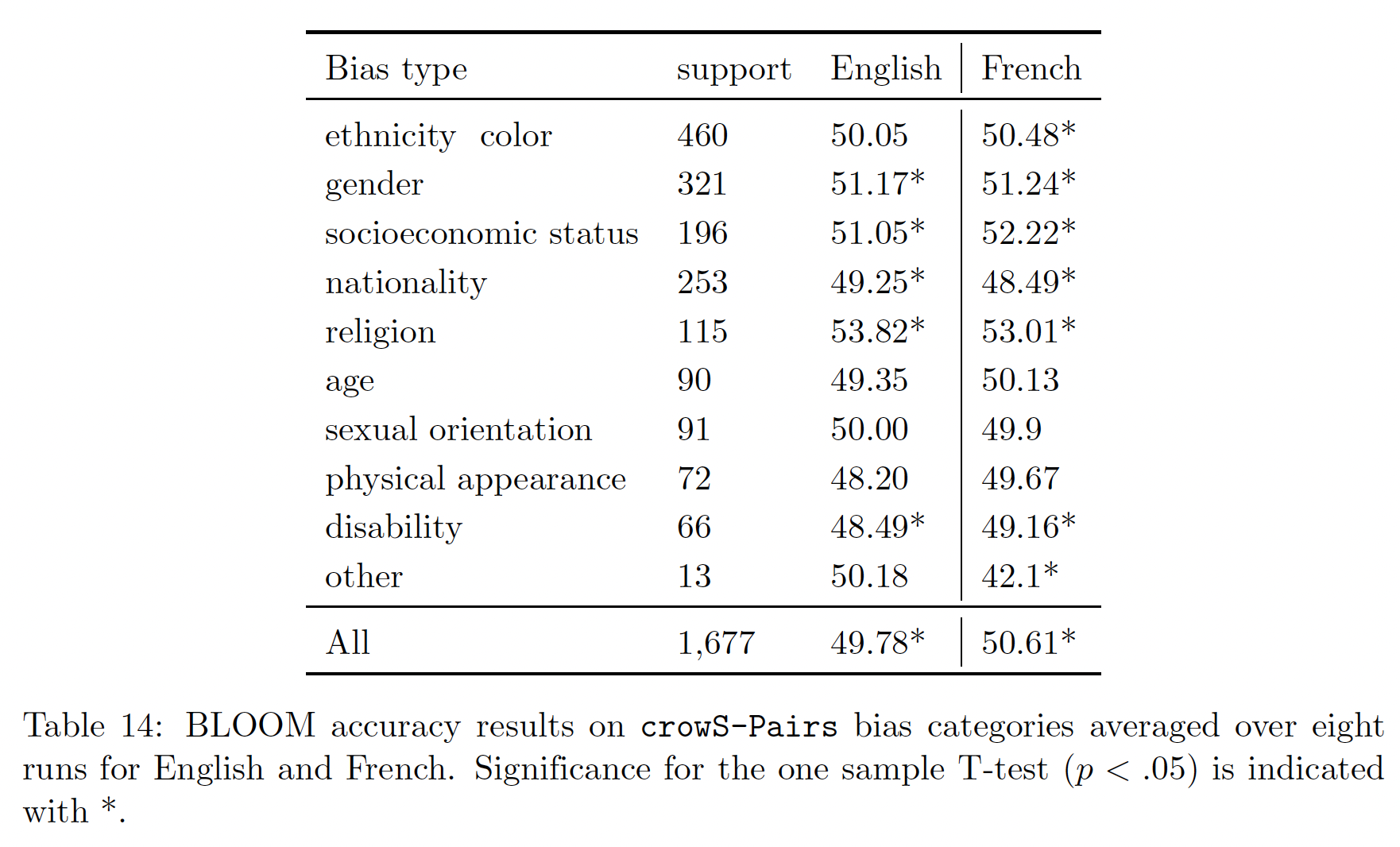
局限性:
《Stereotyping Norwegian salmon: An inventory of pitfalls in fairness benchmark datasets》讨论了原始CrowS-Pairs语料库的有效性问题。这里使用的CrowS-Pairs版本与原始版本不同,它解决了论文指出的一些问题,并根据从法语使用者那里收集的可变印象构建了200个额外的句子对。在最近对英语和法语的masked language model的bias评估中,在修订后的数据集上获得的结果与在原始数据集上获得的结果没有明显的区别(《French CrowS-pairs:Extending a challenge dataset for measuring social bias in masked language models to a language other than English》)。然而,它的原始validation在这里并不自然适用,与其他CrowS-Pairs结果的比较也更加困难。为了更有力地评估偏差,用CrowS-Pairs得到的结果应该与其他的measures of bias进行比较,同时对模型中的所有语言进行评估。然而,正如《You reap what you sow: On the challenges of bias evaluation under multilingual settings》所指出的,可用于多语言bias评估的材料(语料、measures)非常少。尽管我们的检查表明模型中存在着有限的偏见,但它们不能涵盖可能的使用场景的广度。模型可能产生较大影响的一种情况是语言多样性(
linguistic diversity)和语言变体(language variation)。由于BLOOM的训练资源是精心策划的,它们也可能比其他模型更大程度地捕捉到一些语言变体。这也影响了trained model公平地代表不同的语言变体的能力。这种差异可能有助于某些语言变体比其他语言变体的传播和合法化。我们对模型中的偏差的评估进一步限制在多语言CrowS-Pairs所涵盖的场景、语言、以及语言变体上。因此,我们期望在我们使用CrowS-Pair的结果和更广泛的模型使用之间有一个区别(关于这种差异的更详细的探索,见《Ai and the everything in the whole wide world benchmark》)。语言变体:比如中国国内的各种方言。