Sentence Embedding
一、Paragraph Vector[2014]
文本分类和文本聚类在许多应用中发挥着重要作用,例如,文档检索、
web搜索、垃圾邮件过滤。这些应用的核心是机器学习算法,如逻辑回归或Kmeans。这些算法通常需要将text input表示为一个固定长度的向量。对于文本,最常见的固定长度的vector representation是bag-of-words: BOW或bag-of-n-grams: BONG,因为它简单、高效,而且通常具有令人惊讶的准确性。然而,
BOW有很多缺点:单词的顺序丢失了,因此只要使用相同的单词,不同的句子可以有完全相同的
representation。即使
bag-of-n-grams考虑了short context中的单词顺序,它也受到了数据稀疏和高维度的影响。bag-of-words和bag-of-n-grams对单词的语义(正式地说,是单词与单词之间的距离)没有什么感觉。这意味着"powerful"、"strong"和"Paris"等单词的距离相同,尽管从语义上来说,"powerful"应该更接近"strong",而不是更接近"Paris"。
在论文
《Distributed Representations of Sentences and Documents》中,作者提出了Paragraph Vector,这是一个无监督的框架,可以为文本段学习连续分布式向量表示continuous distributed vector representation。这些文本可以是句子、段落、或者文档。Paragraph Vector这个名字是为了强调这个方法可以应用于不同长度的文本段,从一个短语或句子到一个大文档。在作者的模型中,
vector representation被训练成有助于预测段落中的单词。更确切地说,作者将当前段落的paragraph vector与当前段落中的一些word vector拼接起来,并预测给定context中的following word。word vector和paragraph vector都是通过随机梯度下降和反向传播来训练的。paragraph vector在段落之间是唯一的,而word vector在段落之间是共享的。在预测时,paragraph vector是通过固定word vector并训练新的paragraph vector(直到收敛)来推断的。论文的技术受到最近使用神经网络学习
word vector的工作的启发。在word vector的工作中,每个单词由一个向量表示,该向量与context中的其他word vector拼接或取平均,结果向量用于预测context中的其他单词。其结果是,在模型被训练后,word vector被映射到一个向量空间中,从而使语义相似的单词具有相似的vector representation(例如,"strong"与"powerful"相近)。在这些成功的技术之后,研究人员试图将模型扩展到
word-level之外,实现phrase-level或sentence-level的representation。例如,一个简单的方法是使用文档中所有单词的word vector的加权平均值。一个更复杂的方法是使用matrix-vector操作,将word vector按照一个句子的解析树给出的顺序进行组合。这两种方法都有不足之处:第一种方法,即
word vector的加权平均法,与标准的BOW模型一样,失去了单词的顺序。第二种方法,使用解析树来组合
word vector,已经被证明只对句子有效,因为它依赖于解析。
Paragraph Vector能够构建长度可变的输入序列的representation。与之前的一些方法不同,它是通用的,适用于任何长度的文本:句子、段落和文档。它不需要对word weighting函数进行task-specific调优,也不依赖于解析树。在论文中,作者将进一步介绍在几个基准数据集上的实验,以证明Paragraph Vector的优势。例如:在情感分析任务中,
Paragraph Vector取得了新的SOTA,比复杂的方法更好,在错误率方面有超过16%的相对改善。在文本分类任务中,
Paragraph Vector击败了BOW模型,产生了约30%的相对改进。
相关工作:略。(技术过于古老,不用花时间研究相关工作)。
1.1 模型
我们首先讨论了以前的学习
word vector的方法。这些方法是我们Paragraph Vector方法的灵感来源。
1.1.1 学习 Word Vector
一个众所周知的学习
word vector的框架如下图所示。其任务是根据上下文中的其他单词来预测一个单词。在这个框架中,每个单词都被映射成一个unique vector,用矩阵emebdding size,vocabulary。vocabulary中的位置为索引的。然后,上下文中所有单词的word vector的拼接或sum,用于预测句子中下一个词。正式而言,给定单词序列
word vector model的objective是最大化平均对数概率:其中:
预测任务通常是通过
multiclass分类器(如softmax)来完成的:其中:
其中:
softmax参数;word vector的拼接或均值池化来构建的。在实践中,可以使用
hierarchical softmax用于加速训练。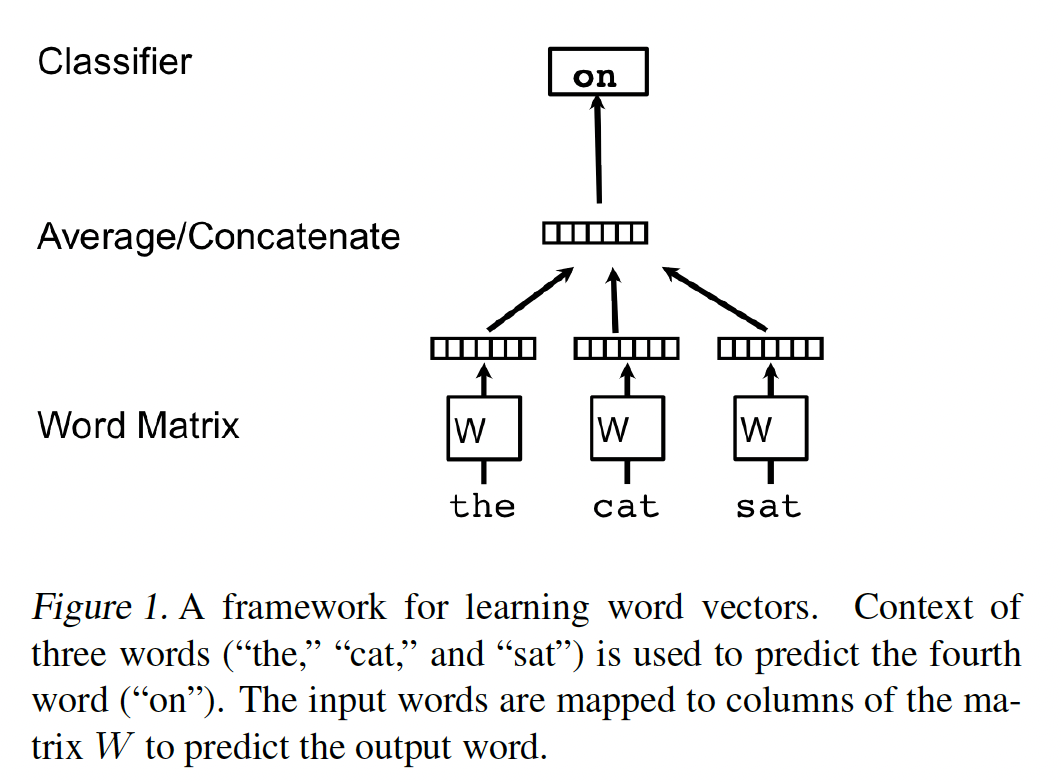
基于神经网络的
word vector通常使用随机梯度下降进行训练,梯度是通过反向传播获得的。这种类型的模型通常被称为neural language model。 在code.google.com/p/word2vec/上有一个基于神经网络的训练word vector算法的具体实现。 训练收敛后,具有相似含义的单词被映射到向量空间中的相似位置。例如,"powerful"和"strong"彼此接近,而"powerful"和"Paris"则比较遥远。word vector之间的差值也具有意义。例如,word vector可以用简单的向量代数来回答类比问题:"King" - "man" + "woman" = "Queen"。
1.1.2 PV-DM
我们学习
paragraph vector的方法受到学习word vector方法的启发。其灵感在于,word vector被用于预测句子中的下一个单词。我们的paragraph vector的思想也是类似的:paragraph vector被用于预测句子中的下一个单词。如下图所示,在我们的
Paragraph Vector framework中,每个paragraph被映射到一个unique vector(由矩阵unique vector(由矩阵embedding维度,paragraph集合,vocabulary。在实验中,我们拼接这些向量。paragraph vector类似于BERT中的CLS token。但是在BERT中,CLS token是全局共享的;而在paragraph vector中,每个句子都有自己的CLS token。那么,是否可以有折中的方案:同一篇文档的
CLS token共享、不同文档的CLS token不共享,这样CLS token捕获到整篇文档的语义。同一个段落的
CLS token共享、不同段落的CLS token不共享,这样CLS token捕获到了该段落的语义。
即,
global CLS token、language id(捕获不同语言的信息)、domain id(捕获不同领域的信息)、document id(捕获不同文章的信息)、paragraph id(捕获不同段落的信息)、sentence id(捕获不同句子的信息)。此外,
BERT中通过多层的Transformer Layer,可以使得CLS token能够捕获到整个序列的语义。而paragraph vector是一个浅层的网络,paragram id没有信息融合使得无法捕获整个序列的意义。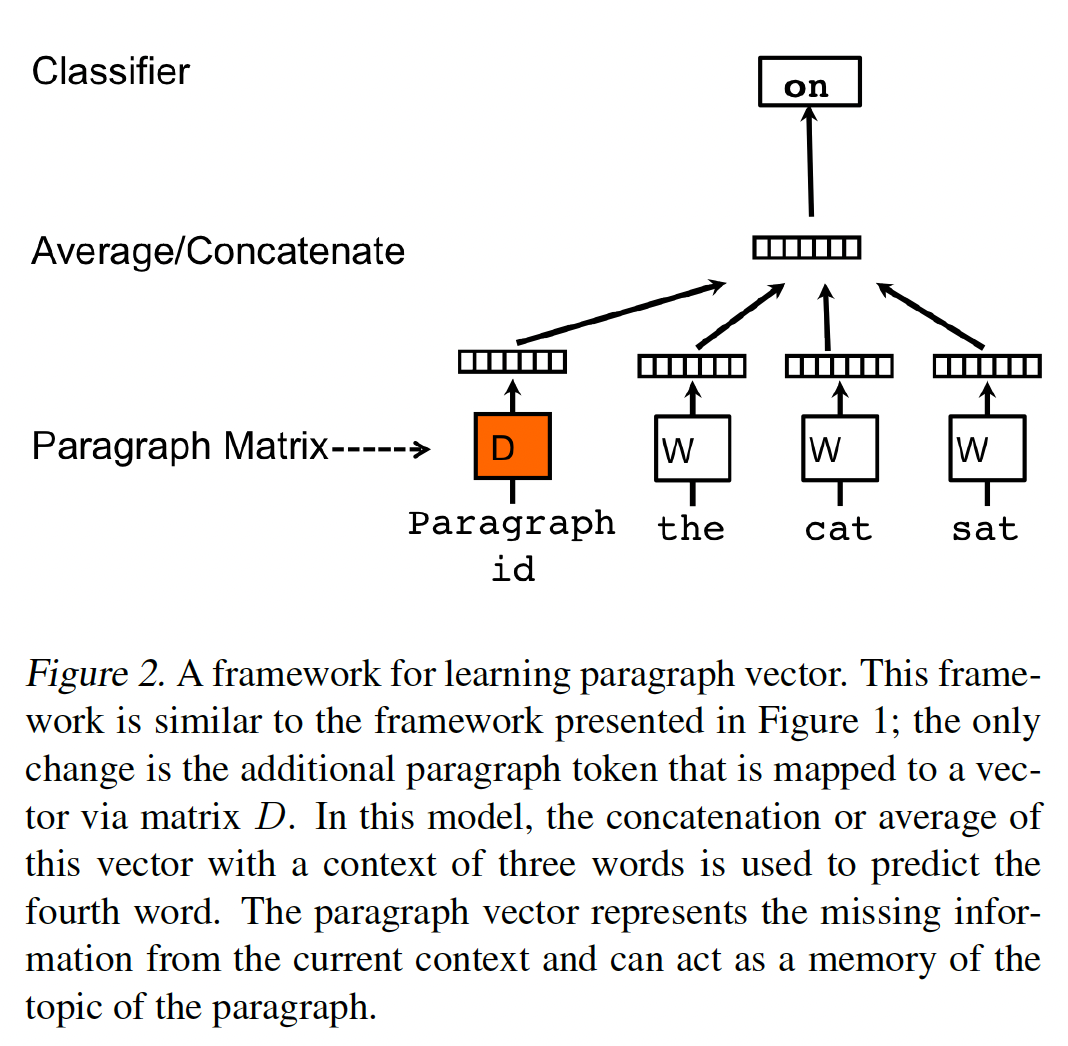
更正式地,与
word vector framework相比,这个模型的唯一变化是通过paragraph token可以被认为是另一个单词。它就像一个memory,可以记住当前context中缺少的东西,或者说记住段落的主题。由于这个原因,我们通常把这个模型称为Distributed Memory Model of Paragraph Vector: PV-DM。context是固定长度的,它是利用滑动窗口在段落上采样而得到的。paragraph vector在同一段落产生的所有context中共享,但没有在不同段落中共享。然而,word vector矩阵"powerful"的vector representation在所有段落中是相同的。paragraph vector和word vector是用随机梯度下降训练的,梯度是通过反向传播获得的。在预测时,人们需要执行一个推理步骤来计算一个新段落的paragraph vector。这也是通过梯度下降得到的。在这个步骤中,模型其他部分的参数,即word vectorsoftmax参数经过训练后,
paragraph vector可以作为段落的特征。我们可以将这些特征直接馈入传统的机器学习技术,如逻辑回归、支持向量机或K-means。总之,该算法本身有两个关键阶段:
在训练数据集上训练
word vectorsoftmax权重softmax biasparagraph vector在推断时,通过在
paragraph vector。
推断时还需要重新训练,成本太高了。
paragraph vector的优势:paragraph vector的一个重要优点是它们是从未标记的数据中学习的,因此可以很好地用于没有足够标记数据的任务。paragraph vector也解决了BOW模型的一些关键弱点:首先,
paragraph vector继承了word vector的一个重要属性:单词的语义。在语义空间,"powerful"比"Paris"更接近于"strong"。其次,
paragraph vector考虑到了单词顺序,至少在small context中是这样的,就像具有较大n值的n-gram模型。paragraph vector仅考虑部分的单词顺序(通过上下文窗口)而没有像GPT那样完全地考虑单词顺序。
1.1.3 PV-DBOW
上述方法考虑了
paragraph vector与word vector的拼接来预测文本窗口中的下一个单词。另一种方法是忽略输入中的context word,但强迫模型预测从段落中随机抽取的单词,如下图所示。我们把这个版本命名为Distributed Bag of Words version of Paragraph Vector: PV-DBOW,与上一节的Distributed Memory version of Paragraph Vector: PV-DM相对应。除了概念上的简单外,这个模型需要存储更少的数据。我们只需要存储
softmax参数softmax参数和word vector。这个模型也类似于word vector中的Skip-gram模型。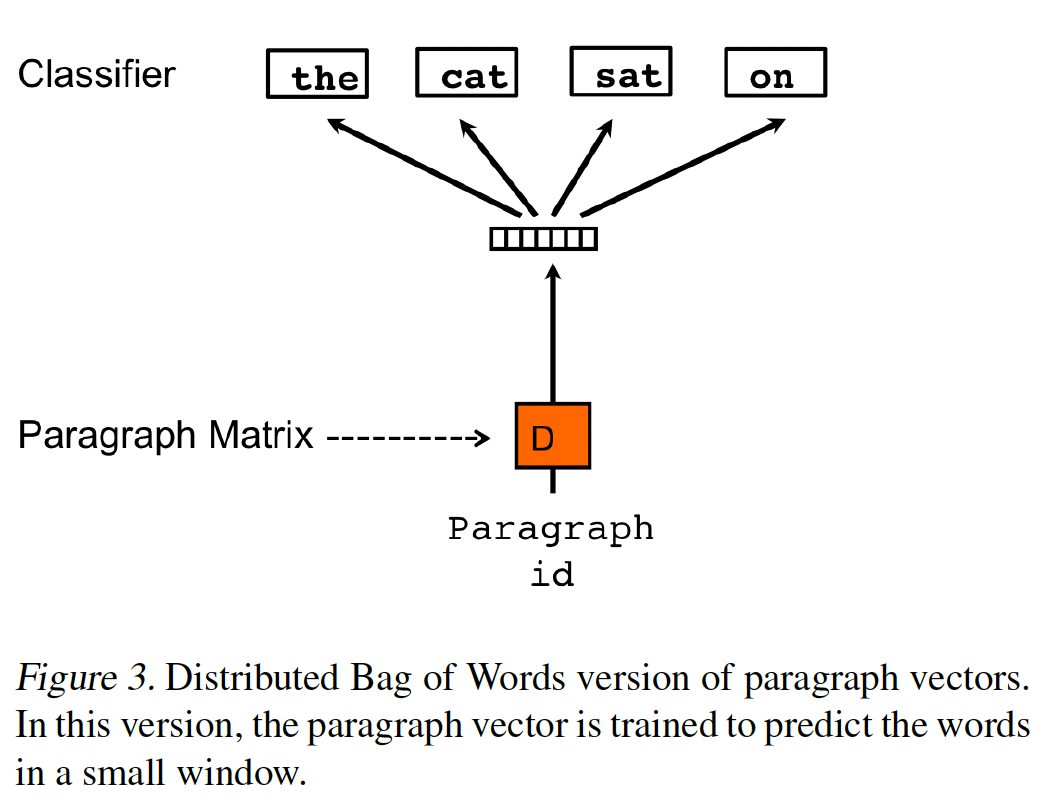
在我们的实验中,每个
paragraph vector是两个向量的组合:一个是由PV-DM学习的、另一个是由PV-DBOW学习的。单独的PV-DM通常对大多数任务都很有效,但它与PV-DBOW的组合通常在我们尝试的许多任务中更加一致的改善,因此强烈推荐。
1.2 实验
略。(技术过于古老,不用花时间研究实验细节)。
二、Skip-Thought Vectors[2015]
近年来,已经开发了几种方法来学习将
word vector映射到sentence vector,包括RNN、CNN等。所有这些方法产生的sentence representation都被传递给一个有监督的任务,并依赖于一个类别标签。因此,这些方法学习高质量的sentence representation,但只针对各自的任务进行调优。paragraph vector是上述模型的一个替代方案,因为它可以通过引入distributed sentence indicator作为神经语言模型的一部分来学习无监督的sentence representation。缺点是在测试时,需要进行推理来计算一个新的paragraph vector。在论文
《Skip-Thought Vectors》中,作者抛弃了composition method,并考虑一个替代的损失函数。论文考虑以下问题:是否存在一个任务和相应的损失函数,使我们能够学习高度通用的sentence representation?论文通过提出一个学习高质量sentence vector的模型来证明这一点,而没有考虑到特定的监督任务。以word vector学习为灵感,作者提出了一个目标函数,将《Efficient estimation of word representations in vector space》的skip-gram模型抽象到sentence level。也就是说,不是用一个单词来预测它的surrounding context,而是对一个句子进行编码来预测它的surrounding sentence。 因此,任何composition operator都可以被替换为sentence encoder,只需要修改目标函数。模型如下图所示。论文称这个模型为skip-thoughts,而模型得到的向量被称为skip-thought vector。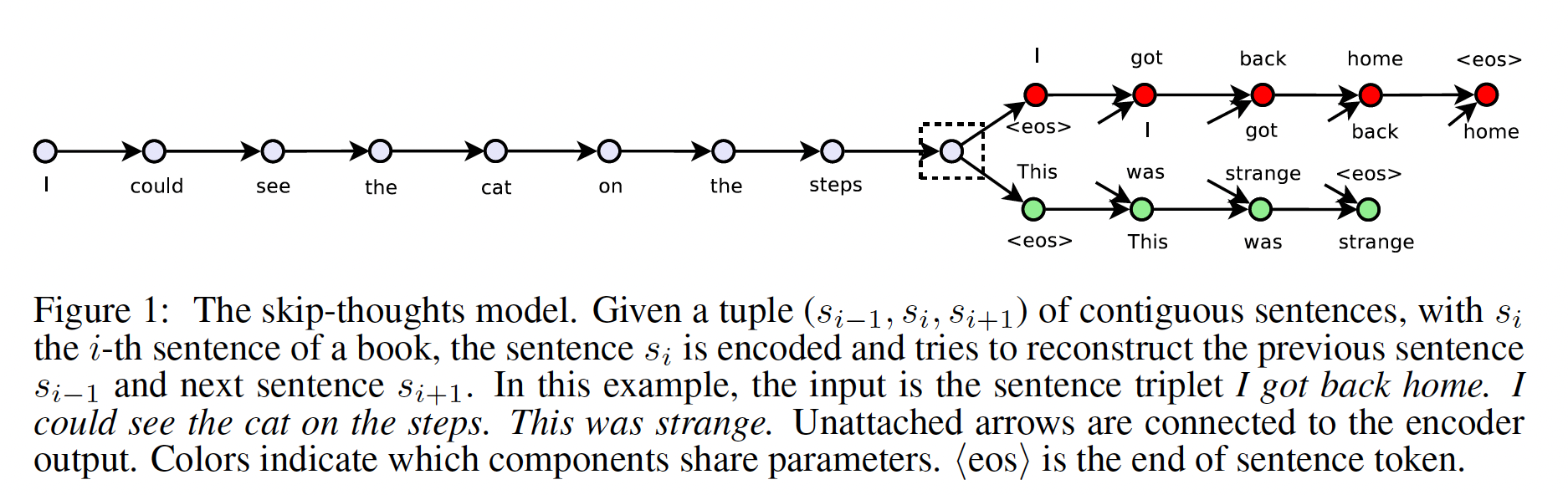
模型依赖于连续文本的训练语料库。论文选择使用一个大型的小说集合,即
BookCorpus数据集来训练模型。这些是由尚未出版的作者写的免费书籍。该数据集有16种不同类型的书籍,例如,浪漫类(2865本)、幻想类(1479本)、科幻类(786本)、青少年类(430本),等等。下表给出了BookCorpus的汇总统计。
除了记叙文之外,
BookCorpus还包含对话、情感、以及人物之间的广泛互动。此外,有了足够大的集合,训练集就不会偏向于任何特定的领域或应用。下表显示了在BookCorpus数据集上训练的模型的句子的最近邻。这些结果表明,skip-thought vector学会了准确捕获它们所编码的句子的语义和句法。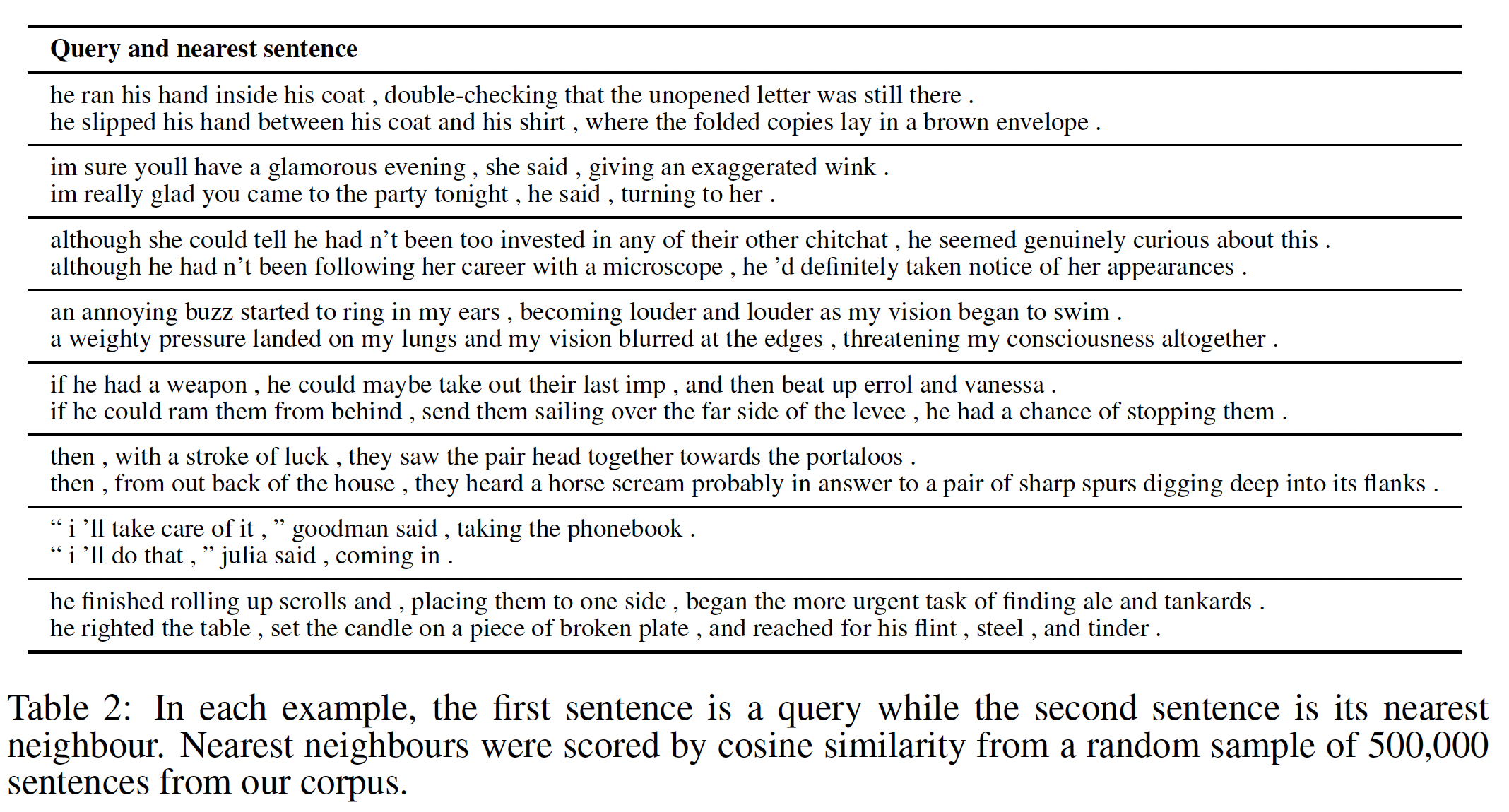
作者在一个新提出的
setting中评估了skip-thought vector:在学习了skip-thoughts之后,冻结模型并将编码器作为一个通用的特征提取器用于任意的任务。在论文的实验中,作者考虑了8个任务:语义相关性、转述检测paraphrase detection、image-sentence ranking、以及5个标准的classification benchmark。在这些实验中,论文抽取skip-thought vector并训练线性模型来直接评估这些representation,而不需要任何额外的微调。事实证明,skip-thoughts产生了通用的representation,在所有考虑的任务中都表现得很鲁棒。这样的实验设置导致的一个困难是:难以构建一个足够大的
word vocabulary来编码任意的句子。例如,Wikipedia文章中的一个句子可能包含一些极不可能出现在book vocabulary中的名词。作者通过学习一种映射来解决这个问题,该映射将word representation从一个模型迁移到另一个模型。利用word2vec representation,作者学习从word2vec空间到编码器空间的线性映射。经过训练,任何出现在word2vec中的单词都可以在编码器的word embedding空间中得到一个向量。
2.1 模型
我们利用
encoder-decoder框架来实现skip-thoughts:一个编码器将句子映射到一个
sentence vector。一个解码器根据
sentence vector来生成周围的句子。
人们已经探索了一些
encoder-decoder,如ConvNet-RNN、RNN-RNN、LSTM-LSTM。在我们的模型中,我们使用一个带有GRU的RNN encoder和一个带有conditional GRU的RNN decoder。这种模型组合几乎与神经机器翻译中使用的RNN encoder-decoder相同。GRU已经被证明在序列建模任务上与LSTM表现得一样好,而在概念上却更简单。2023年最热门的、用于NLP的encoder-decoder框架是Transformer。给定关于句子的一个三元组
word embedding。我们的模型包含三个部分:编码器、解码器、目标函数。Encoder:令句子time step,编码器产生一个隐状态representation。因此,隐状态representation。为了编码一个句子,我们递归地执行如下方程(去掉下标
其中:
proposed state update;update gate;reset gate;sigmoid函数;Decoder:解码器是一个神经语言模型,它以编码器的输出vocabulary matrix其中:
representation。给定句子
representation其中:
output word embedding,它对应于前一个句子
Objective:给定三元组
这种方法是
Transformer-based中典型的encoder-decoder方法,并非常类似于GPT预训练的思想。Skip-Thoughts无法区分前一个句子、后一个句子。在Transformer-based方法中也仅仅考虑next sentence generation。可以通过编码器中添加一个
indicator token来指示:是生成前一个句子还是后一个句子。使用时联合考虑这两种情况(考虑前一个句子和后一个句子)下的representation。GPT预训练是根据文本顺序来依次预测,而并没有考虑逆序预测(即这里的vocabulary expansion:我们现在描述一下如何将我们编码器的vocabulary扩展到它在训练期间没有见过的单词。假设我们有一个word vector模型,如word2vec。令word representation的word embedding space。令RNN word embedding space。我们假设vocabulary要远远大于vocabulary。我们的目标是构建一个映射我们学习
2.2 实验
略。(技术过于古老,不用花时间研究实验细节)。
三、FastSent[2016]
distributed representation在当今的NLP研究中无处不在。对于单词或word-like entity,人们已经提出方法从自然发生的(未标记的)训练数据中获得这种representation,这些方法基于相对而言task-agnostic objective(如预测相邻的单词)。相比之下,学习短语或句子的distributed representation的最佳方法还没有定论。 随着更先进的语言处理技术的出现,将短语或句子表示为连续值向量的模型比较常见。 虽然人们已经非正式地观察到这种模型的内部sentence representation可以反映语义直觉,但不知道哪些架构或目标可以产生 “最佳” 的或最有用的representation。解决这个问题最终会对语言处理系统产生重大影响。事实上,正是短语和句子,而不是单个的单词,编码了human-like的通用世界知识(或 "常识common sense"),这是目前大多数语言理解系统的一个关键缺失部分。论文
《Learning Distributed Representations of Sentences from Unlabelled Data》通过对学习句子distributed representation的前沿方法的系统性比较来解决这个问题。论文将比较的范围限制在不需要为训练模型而收集标记数据的方法上,因为这种方法更具有成本效益,而且适用于各种语言和领域。作者还提出了两个新的短语或句子的representation learning objective:Sequential Denoising Autoencoder: SDAE、FastSent(一个sentence-level log-linear bag-of-words model)。作者在在两种类型的任务(监督评估和非监督评估)上比较了所有的方法。在监督评估任务上,
representation被用于分类器或回归模型。在非监督评估任务上,
representation用于余弦距离从而进行查询。
作者观察到,根据评估指标的性质,不同方法存在明显的差异。具体而言,更深或更复杂的模型(需要更多的时间和资源来训练)通常在监督任务中表现最好,而浅层对数线性
log-linear模型在无监督的benchmark上效果最好。具体而言:SkipThought Vectors在大多数监督评估任务中表现最好,但SDAE在转述识别paraphrase identification任务中表现最好。相反,在(无监督的)
SICK句子关联性基准上,FastSent,一个简单的SkipThought objective的对数线性变体,比所有其他模型表现得更好。有趣的是,在有监督基准和无监督基准中表现出最强性能的方法是一个
bag-of-word模型,该模型被训练从而组合word embedding(即,学习word emebdding的线性组合)。
3.1 模型
为了限制分析,我们比较了从无标签的、自然产生的数据中计算
sentence representation的神经语言模型,就像word representation的主要方法一样。同样,我们也不关注"bottom up"的模型,其中phrase representation或sentence representation是由单词(这些单词组成了短语或句子)的word vector上的固定数学运算建立的,尽管我们确实考虑了一个典型的案例,如CBOW。文本上的现有方法:
SkipThought Vectors:对于文档中的连续句子SkipThought模型被训练为,给定source sentence的条件下,预测target sentencesequence-to-sequence模型一样,在训练中,source sentence被一个具有GRU单元的RNN网络所 “编码”,然后依次 “解码” 到两个target sentence中。重要的是,由于RNN在每个time-step采用了一组update weights,编码器和解码器都对source sentence中的单词顺序很敏感。对于
target sentence中的每个位置,解码器计算vocabulary的softmax分布。训练目标是target sentencecorrect word的负对数似然之和。当训练之后,编码器可以将单词序列映射到单个向量。Paragraph Vector:《Distributed representations of sentences and documents》提出了两个关于sentence representation的对数线性模型:DBOW模型为训练语料库中的每个句子word embeddingsoftmax分布,该分布被优化以预测给定句子word embedding在
DM模型中,连续单词的k-gramword embedding与
我们使用了
Gensim的实现,按照作者的建议,将训练数据中的每个句子视为一个"paragraph"。在训练过程中,DM和DBOW模型都为训练语料库中的每一个句子(以及单词)存储representation。因此,即使在大型服务器上,也只能训练representation size = 200的模型,以及combination操作为均值池化(而不是拼接)的DM模型。Bottom-Up Method:我们在Books语料库上训练CBOW word embedding和Skip-Gram word embedding,并执行sum池化从而得到sentence representation。我们还与
CPHRASE进行了比较,后者是利用基于句法解析的(监督)解析器来推断分布式semantic representation。C-PHRASE在本文中使用的几个evaluation中取得了distributed representation的SOTA。Non-Distributed Baseline:我们实现了一个TFIDF BOW model,在这个模型中,句子representation编码了一组feature-word在TFIDF来加权。这些feature-word是20万个单词。
在结构化资源上训练的模型:下面的模型依赖于更加结构化的数据(相比较于
raw text而言):DictRep:训练神经网络模型从而将dictionary definition映射到单词的pre-trained word embedding,这些单词都是由dictionary definition所定义的。他们试验了BOW和RNN(带LSTM单元)编码架构和变体,其中input word embedding是学到的或pre-trained的(+embs)从而匹配target word embedding。我们使用现有的代码和训练数据实现他们的模型。CaptionRep:使用与DictRep相同的整体架构,我们训练了(BOW和RNN)模型,将COCO数据集中的caption映射到图片的pre-trained vector representation上。image representation由深度卷积网络编码,该网络是在ILSVRC 2014年的object recognition任务中训练的。NMT:我们考虑由神经机器翻译模型学到的sentence representation。这些模型具有与SkipThought相同的架构,但在sentence-aligned translated text上进行训练。我们在2015 WMT的所有可用的En-Fr和En-De数据上使用标准架构。
新的
test-based模型:我们引入两种新的方法来解决现有方法的某些不足:Sequential (Denoising) Autoencoder:SkipThought objective需要具有连贯的句子间叙述coherent inter-sentence narrative的训练文本,这使得它在移植到社交网络、或由符号知识产生的人工语言等领域方面存在问题。 为了避免这一限制,我们试验了一种基于denoising autoencoder: DAE的representation-learning objective。在DAE中,高维输入数据根据一些噪声函数被破坏,模型被训练为从corrupted version中恢复原始数据。作为这个过程的结果,DAE学会通过解释其variation的重要因子的特征来表达数据。将数据转化为DAE representation(作为"pre-training"或初始化步骤)可以在深度前馈网络中获得更强大的(监督)分类性能。最初的
DAE是前馈神经网络,应用于固定尺寸的(图像)数据。在这里,我们通过噪声函数首先,对于
然后,对于
non-overlapping bigram然后,我们训练与
NMT相同的LSTM-based encoder-decoder架构,但使用denoising objective从而在给定corrupted version
训练好的模型可以将新的单词序列编码为
distributed representation。我们称这个模型为Sequential Denoising Autoencoder: SDAE。注意,与SkipThought不同,SDAE可以在任意顺序的句子集上训练。我们给没有噪音的情况(即
Sequential Autoencoder: SAE。这种setting对应了《Semi-supervised sequence learning》应用于文本分类任务的方法。当
word dropout,它在有监督的语言任务中也被用作深度网络的正则化器。对于较大的
objective类似于word-level debagging。
对于
SDAE,我们在验证集上调优了+embs),其中单词由(固定的)pre-trained embedding来表示。SDAE类似于BERT或BART等预训练方法。FastSent:SkipThought的表现表明,丰富的句子语义可以从相邻句子的内容中推断出来。该模型可以说是利用了一种sentence-level Distributional Hypothesis。尽管如此,像许多深度神经语言模型一样,SkipThought的训练速度非常慢。FastSent是一个简单的additive (log-linear) sentence model,旨在利用相同的信号,但计算成本要低得多。给定某个句子在上下文中的
BOW representation,该模型只需预测相邻的句子(也表示为BOW)。更正式地说,FastSent为vocabulary中的每个单词source embeddingtarget embeddingembedding为构成它的单词的所有source embedding之和:损失函数为:
其中:
softmax函数。与
SkipThoughts相比,FastSent用均值池化代替了编码器,同时剔除了解码器。FastSent类似于CBOW,只是FastSent用整个句子作为上下文,而不是固定长度的上下文窗口。我们还试验了一个变体(
+AE),在这个变体中,除了相邻的句子作为目标之外,encoded (source) representationFastSent+AE的损失函数为:在测试期间,训练好的模型(非常快速地)将
unseen单词序列编码到distributed representation:
模型训练和调优:除非另有说明,否则所有模型都是在
Toronto Books Corpus上训练的,该语料库具有SkipThought和FastSent所需的语义连贯性。该语料库由7000多本书中的70M个有序句子组成。log-linear model(SkipGram, CBOW, ParagraphVec, FastSent)在一个CPU core上训练了一个epoch。这些模型的representation维度GPU上训练。S(D)AE也训练了一个epoch(8天)。SkipThought模型训练了两个星期,覆盖了不到一个epoch。对于
CaptionRep和DictRep来说,性能是在held-out training data上监测的,并且在损失函数达到一个plateau(大约24个小时)后停止训练。NMT模型的训练时间为72小时。
3.2 实验
略。(技术过于古老,不用花时间研究实验细节)。
3.3 讨论
不同的
objective产生不同的representation:这似乎是显而易见的,但是结果证实了应该对不同的application采用不同的学习方法。例如:SkipThought在TREC上表现最好也许并不奇怪,因为这个数据集的标签是由紧随question之后的语言(即answer)所决定的。另一方面,完全聚焦于句子内容的模型,如
SDAE,可能更有利于转述检测paraphrase detection。
有监督的性能和无监督的性能之间的差异:许多在监督评估中表现最好的模型在无监督的环境中表现不佳。在
SkipThought、S(D)AE和NMT模型中,损失函数的计算是基于内部sentence representation的非线性解码,因此,representation space的几何信息可能不会反映在一个简单的余弦距离中。log-linear model在这种无监督的情况下通常表现更好。资源需求的差异:不同的模型需要不同的资源来训练和使用,这可能会限制它们的应用。
单词顺序的作用尚不清楚:
在监督评估中,对词序敏感的模型(
76.3)和不敏感的模型(76.6)的平均得分大致相同。然而,在无监督评估中,
BOW模型的平均得分是0.55,而基于RNN的模型(顺序敏感)的平均得分是0.42。
这似乎与广泛持有的观点不一致,即单词顺序在决定英语句子的意义方面起着重要作用。
一种可能的原因是:大多数句子都可以被一个概念语义(可以在
distributed lexical representation中进行编码)所区分,而这个概念语义与单词顺序无关。另一个可能的原因是:目前的评价标准没有充分反映order-dependent。在
2023年,随着Large Language Model的兴起,单词顺序被证明是非常重要的。评估结果的局限性:所有评价结果的内部一致性
internal consistency为0.81(略高于"acceptable")。当分别考虑监督任务(或无监督任务)时,一致性指标要高得多。这表明,就sentence representation的共同特性而言,有监督的基准和无监督的基准确实优先考虑了不同的属性。
四、InferSent[2017]
单词的
distributed representation(或word embedding)已被证明可以为自然语言处理和计算机视觉中的各种任务提供有用的特征。虽然关于word embedding的有用性、以及如何学习word embedding似乎已经达成了共识,但对于承载完整句子意义的representation来说,这一点还不清楚。也就是说,如何在单个向量中捕获多个单词和短语之间的关系仍然是一个有待解决的问题。在论文
《Supervised Learning of Universal Sentence Representations from Natural Language Inference Data》中,作者研究了学习句子的universal representation,即在大型语料库中训练得到的sentence encoder模型,并随后迁移到其他任务中。为了建立这样一个编码器,有两个问题需要解决,即:最好的神经网络结构是什么、如何以及在什么任务上训练这样一个网络。遵从现有的学习
word embedding的工作,目前的大多数方法考虑以无监督的方式学习sentence encoder,如SkipThought或FastSent。 在这里,作者研究是否可以利用监督学习来代替无监督学习,这是受到计算机视觉的结果的启发。在计算机视觉中,许多模型在ImageNet上进行预训练,然后迁移到下游任务。作者比较了在各种监督任务上训练的sentence embedding,并表明从自然语言推理(natural language inference: NLI)任务上训练的模型所产生的sentence embedding在迁移准确性transfer accuracy方面达到了最佳结果。作者假设,自然语言推理作为一项训练任务的适宜性是由以下事实造成的,即它是一项涉及推理句子内部语义关系的high-level的理解任务。与计算机视觉中卷积神经网络占主导地位不同,使用神经网络对一个句子进行编码有多种方式。因此,作者研究了
sentence encoding架构对representational transferability的影响,并比较了卷积的、递归的、以及更简单的word composition的方案。论文的实验表明,在
Stanford Natural Language Inference: SNLI数据集上训练的基于双向LSTM架构的编码器,与SkipThought或FastSent等所有现有的无监督方法相比,产生了SOTA的sentence embedding,同时训练速度更快。作者在一组广泛且多样的迁移任务上证实了这一发现,这些任务衡量了sentence representation捕获通用的、有用的信息的能力。相关工作:略。(技术过于古老,不用花时间研究相关工作)。
4.1 模型
这项工作结合了两个研究方向:
如何使用
NLI任务来训练通用的sentence encoding模型。sentence encoder的架构。具体来说,我们研究了标准的RNN模型,如LSTM和GRU。对于这些模型,我们研究了hidden representation的均值池化和最大池化。我们还研究了一个自注意力网络,包含了对句子的不同视图;以及一个分层卷积网络,可以看作是一种基于树的方法,融合了不同层次的抽象。
自然语言推理
Natural Language Inference: NLI任务:SNLI数据集由570k个人类标注的英语sentence pair组成,人工标记为三个类别之一:蕴含entailment、矛盾contradiction、中性neutral。SNLI捕获了自然语言推理,也被称为Recognizing Textual Entailment: RTE,并构成了显式构建的最大的高质量的带标记的资源之一,从而要求理解句子语义。我们假设,NLI的语义性质使其成为以监督方式学习universal sentence embedding的良好候选。也就是说,我们的目标是证明在自然语言推理上训练的sentence encoder能够学习sentence representation,该sentence representation捕获了通用的、有用的特征。模型可以通过两种不同的方式在
SNLI上进行训练:基于
sentence encoding的模型,显式地将各个句子的编码分开。即,
encoder的输入是单个句子。联合方法,允许同时使用两个句子的
encoding(从而使用交叉特征、或跨句子的注意力)。即,
encoder的输入是sentence pair。
由于我们的目标是训练一个通用的
sentence encoder,我们采用第一种设置。如下图所示,这种典型的结构使用一个共享的sentence encoder,输出premisehypothesisrepresentation(分别记做sentence vector被生成之后,应用3种matching方法来抽取注意,这里应用了人工的特征工程来进行特征交叉。
得到的向量捕获了来自
premise和hypothesis的信息,并被馈入到一个由多层全连接层组成的3类分类器中,最终形成一个softmax layer。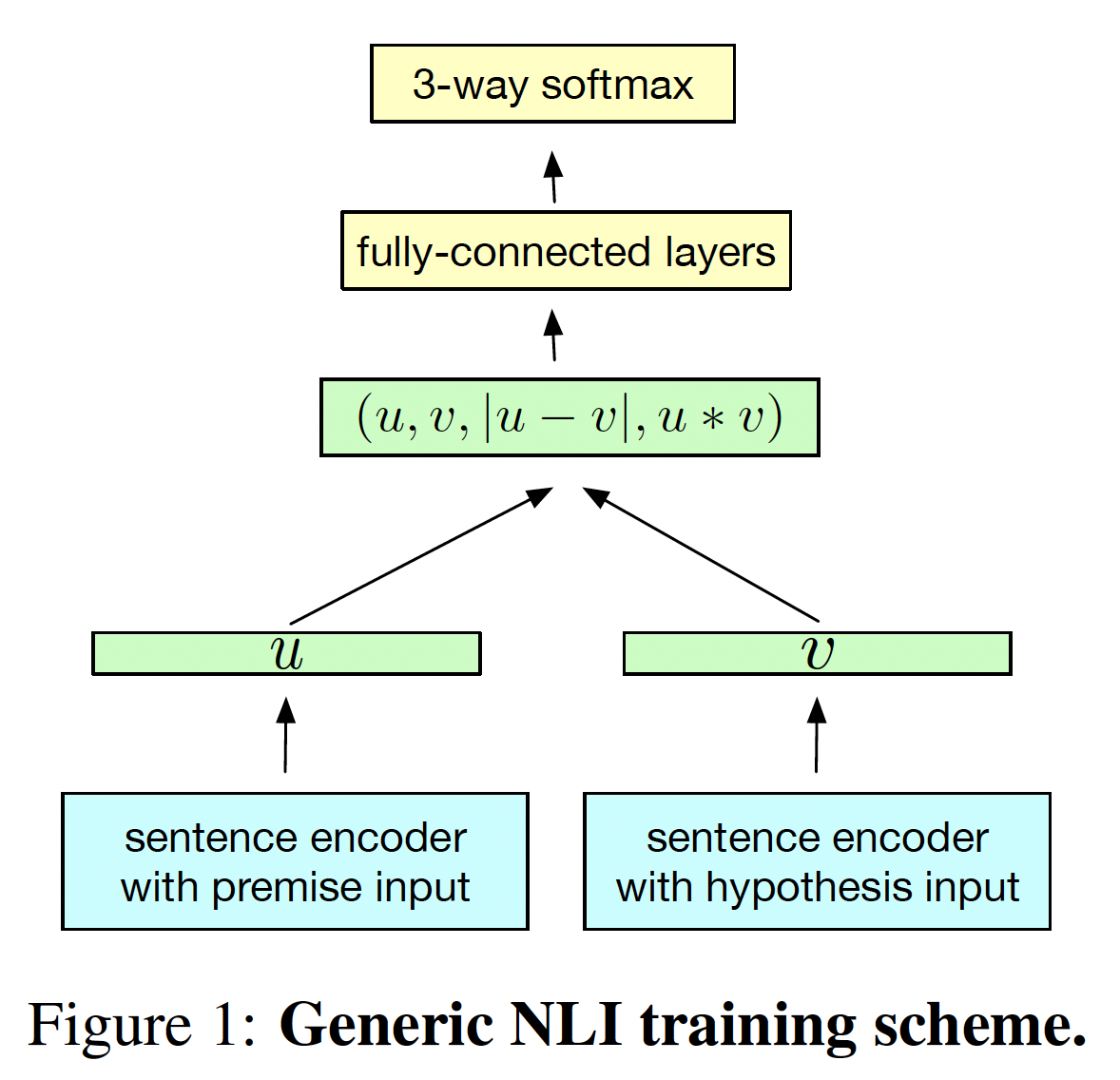
sentence encoder架构:目前存在多种将句子编码为固定尺寸的representation的神经网络,目前还不清楚哪种网络能最好地捕获通用的、有用的信息。我们比较了7种不同的架构:带有LSTM或GRU的标准recurrent encoder、拼接从左到右GRU和从右到左GRU的last hidden state、带有均值池化或最大池化的BiLSTM、自注意力网络、分层卷积网络。LSTM和GRU:我们的第一个,也是最简单的编码器应用了LSTM或GRU模块的RNN。给定包含hidden representationGRU)。句子通过最后一个hidden vectorGRU,而GRU。我们还考虑了一个
BiGRU-last模型,它将从左到右GRU的最后一个hidden state和从右到左GRU的最后一个hidden state拼接起来。带均值池化/最大池化的
BiLSTM:给定包含BiLSTM计算hidden representation我们尝试用均值池化、或最大池化将
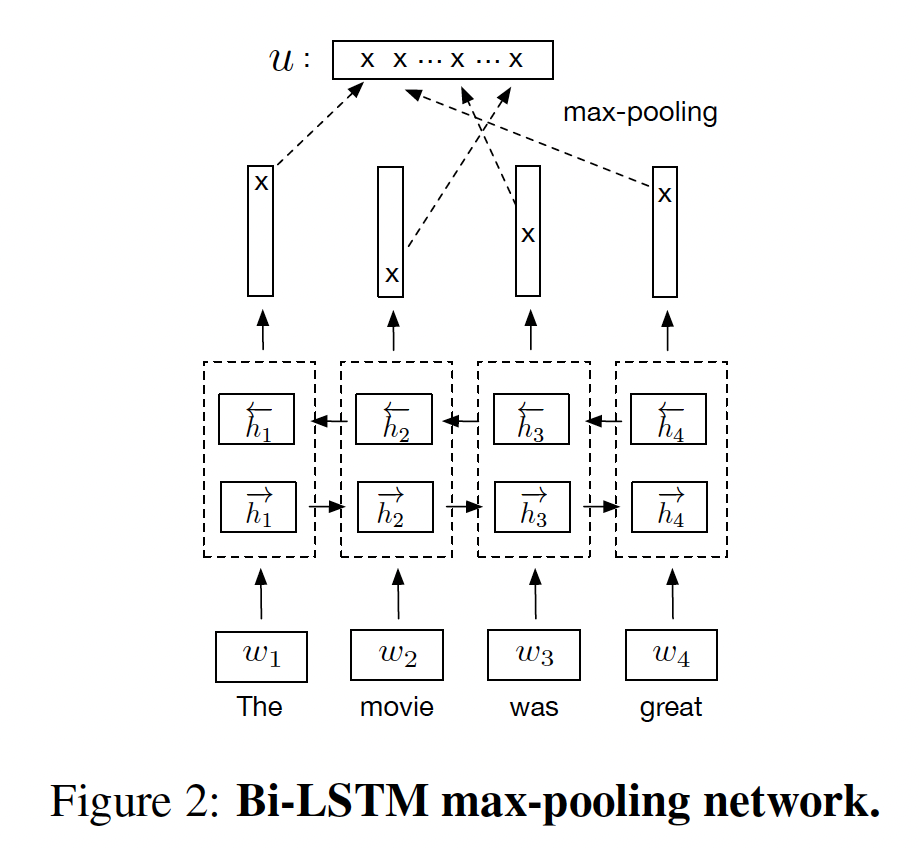
自注意力网络:
self-attentive sentence encoder在BiLSTM的hidden states上使用注意力机制来生成input sentence的representation其中:
BiLSTM的output hidden vector,context query vector。
遵从
《A structured self-attentive sentence embedding》,我们使用一个注意力网络,该网络对于输入的句子具有多个视图,使得模型能够学到句子的哪一部分对于给定的任务是重要的。具体而言,我们有四个context vectorrepresentation。然后这四个representation拼接起来得到sentence representation如下图所示,给出了自注意力网络的架构(只有一个视图)。
注意,这里只有一个
BiLSTM,BiLSTM的output hidden states经过四个context vector的注意力,从而得到四个不同的sentence representation。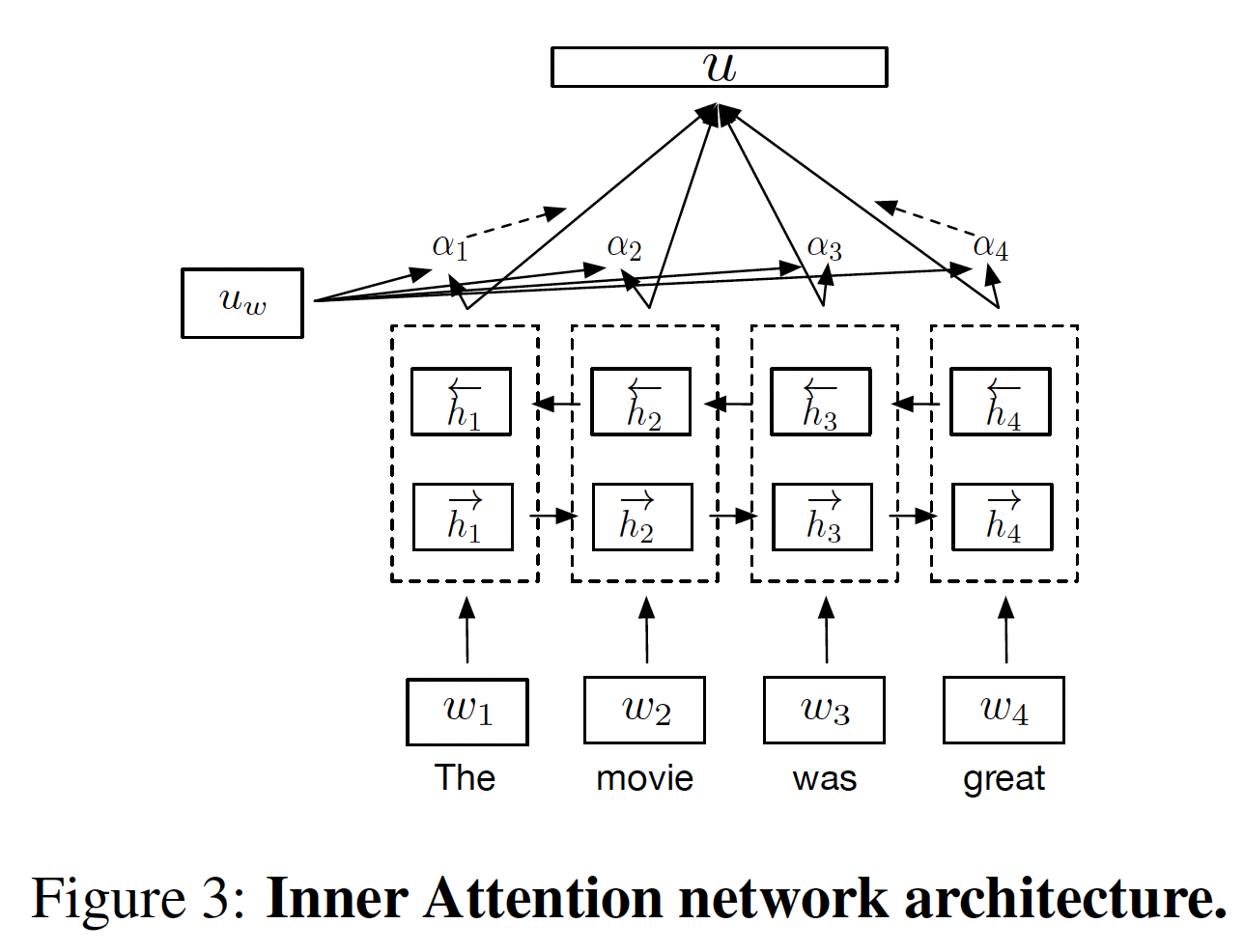
分层卷积网络:目前在分类任务上表现最好的模型之一是被称为
AdaSent的卷积架构,它在不同的抽象层次上拼接了不同的sentence representation。受这个架构的启发,我们引入了一个由4层卷积层组成的更快的版本。在每一层,通过对feature map执行最大池化从而计算出一个representationfinal representationlevel的representation拼接起来。因此,该模型在一个固定尺寸的representation中捕获到了输入句子的hierarchical abstraction。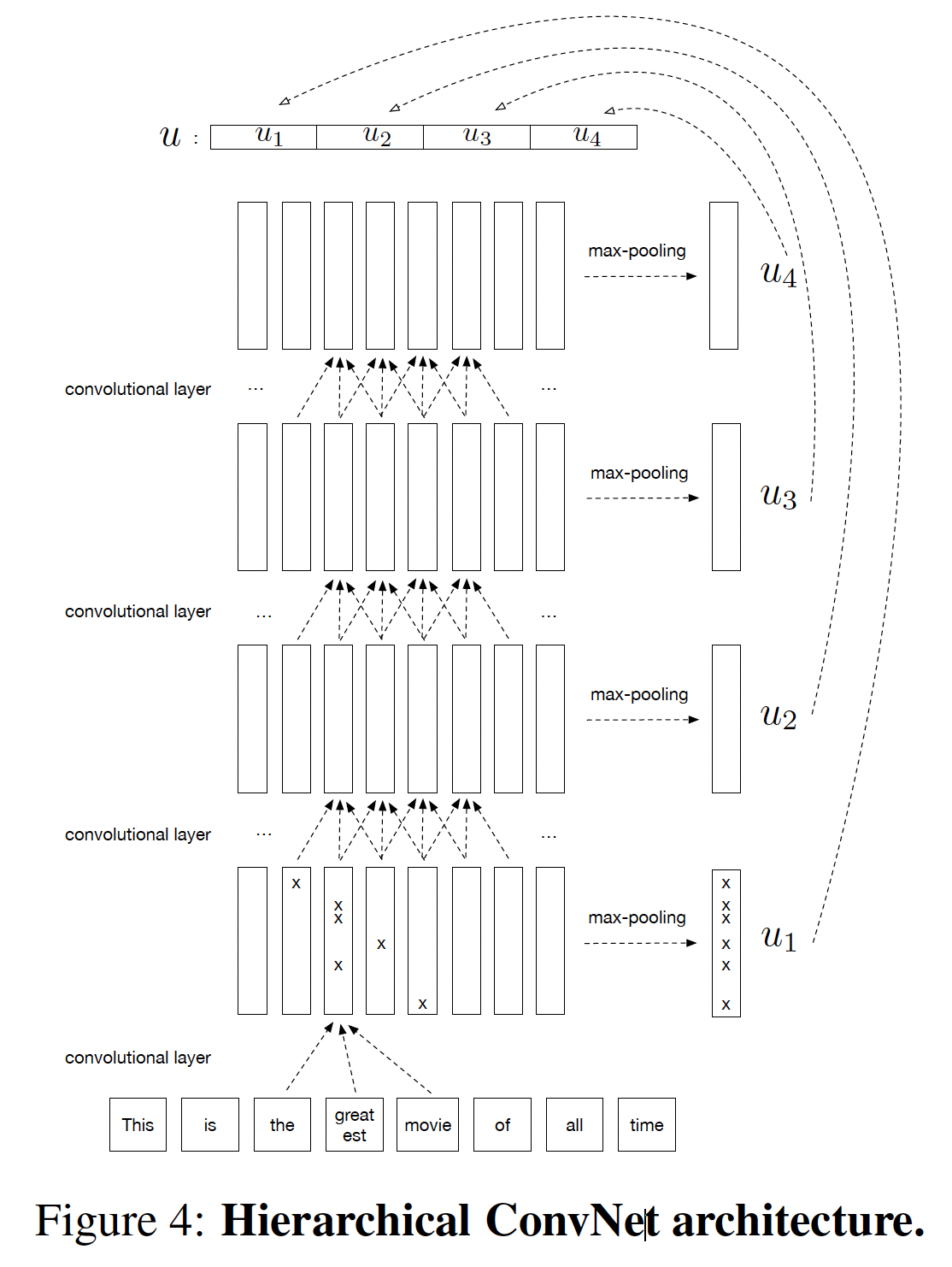
训练细节:
对于我们在
SNLI上训练的所有模型,我们使用SGD,学习率为0.1,权重衰减为0.99。在每个epoch中,如果验证集准确率下降,我们将学习率除以5。当学习率低于10-5的阈值时,训练就停止。我们使用batch size = 64。对于分类器,我们使用了一个多层感知器,其中隐层数量为
1,隐层维度为512。我们使用在
Common Crawl 840B上训练的具有300维的开源GloVe向量作为fixed word embedding。这是早期的
pre-training方法的应用:利用pretrained word embedding。
4.2 实验
略。(技术过于古老,不用花时间研究实验细节)。
五、Simple-But-Tough-To-Beat Baseline For Sentence Embedding [2017]
word embedding是自然语言处理和信息检索的基本构建模块。最近的工作试图计算能够捕获单词序列(短语、句子和段落)语义的embedding,其方法从简单的word vectors的组合,到复杂的架构(如CNN, RNN)。最近,《Towards universal paraphrastic sentence embeddings》通过从标准的word embedding开始,并根据来自Paraphrase pairs dataset: PPDB的监督对其进行修改,通过训练一个简单的word averaging model来构建sentence embedding,从而学习了通用的、paraphrastic的sentence embedding。这种简单的方法在文本相似性任务上比各种方法有更好的表现,可以作为文本分类任务的良好初始化。然而,来自paraphrase dataset的监督似乎很关键,因为他们报告说,initial word embedding的简单地取均值的效果并不理想。论文
《A Simple but Tough-to-Beat Baseline for Sentence Embeddings》给出了一种新的sentence embedding方法:只需计算句子中word vectors的加权平均,然后把加权平均向量在句子的word vectors的第一个奇异向量上的投影移除("common component removal")。这里,单词word frequency。这个权重被称作smooth inverse frequency: SIF。该方法在各种文本相似性任务上取得了明显优于unweighted average的性能,在其中大多数任务上甚至击败了《Towards universal paraphrastic sentence embeddings》中测试的一些复杂的监督方法,包括一些RNN和LSTM模型。该方法非常适用于domain adaptation setting,即把从不同语料库上训练好的word vector来计算不同任务的sentence embedding。它对加权方案也相当鲁棒:使用从不同语料库中估计的词频不会损害性能。
参数
这里的核心在于移除第一个奇异向量上的投影,因为这会改善
word embedding的各向异性问题。相关工作:略。(技术过于古老,不用花时间研究相关工作)。
5.1 模型
我们简单回顾一下
《A latent variable model approach to PMI-based word embeddings》中的用于文本的latent variable generative model。该模型将语料库的生成视为一个动态过程,第discourse vectorvocabulary中的每个单词emebdding向量embedding向量就是模型的latent variable。discourse vector代表了 “正在谈论的东西”。discourse vectorword embedding向量discourse和单词之间的相关性。在时刻log-linear word production model决定:discourse vectorsimilar discourse下产生的。在《A latent variable model approach to PMI-based word embeddings》中显示,在一些合理的假设下,这个模型产生的行为(即,在word-word共现概率方面)符合word2vec和Glove等经验性工作。random walk model可以被relaxed,即允许jump。因为一个简单的计算表明,它们对单词的共现概率的影响可以忽略不计。实验报告表明,用这个模型计算出来的
word vector与Glove和word2vec(CBOW)计算得到的word vector相似。我们改进的
RandomWalk模型:显然,很容易将sentence embedding定义为:给定一个句子discourse vector做一个MAP估计。我们注意到,我们假设discourse vectoremitted时不会有太大的变化,因此为了简单起见,我们可以用一个discourse vectordiscourse vector《A latent variable model approach to PMI-based word embeddings》中,MAP估计值是句子中所有单词的embedding的均值(最多可乘以标量)。在本文中,为了更
realistic的建模,我们对模型做了如下改变。该模型有两种类型的 “平滑项”,它们是为了说明这样的事实:有些单词是脱离上下文出现的、以及有些高频词(例如"the"、"and "等)在任何discourse中都经常出现。首先,我们在对数线性模型中引入一个附加项
unigram概率(在整个语料库中),word vector其次,我们引入了一个
common discourse vectormost frequent discourse的修正项,其中most frequent discourse通常与句法有关。
具体而言,给定
discourse vector其中:
我们看到,该模型允许一个与
discoursecommon discourse vector上式的物理意义:单词的词频越大,则被观察到的概率越大(由
discourse vector越相关,则则被观察到的概率越大(由注意,由于
计算
sentence embedding:sentence embedding被定义为case中,MLE与MAP相同,因为先验分布是均匀的。) 我们借用《A latent variable model approach to PMI-based word embeddings》的关键建模假设,即单词令:
根据泰勒展开公式:
因此在单位球上,
也就是说,
MLE近似于句子中单词的向量的加权平均。注意,对于词频较高的单词在实际应用中,
为了估计
first principal component来估计方向final sentence embedding是通过对Sentence Embedding算法:输入:
word embedding输出:
sentence embedding算法步骤:
对于
将
first singular vector(是一个单位向量)。对于
因为
5.2 实验
略。(技术过于古老,不用花时间研究实验细节)。
六、QuickThoughts[2018]
在语言领域,
distributional hypothesis在获得单词的semantic vector representations的学习方法的发展中是不可或缺的。这个hypothesis是说:一个单词的意义是由它出现的word-context所决定的。基于这个hypothesis的神经网络方法已经成功地从大型文本语料库中学习了高质量的representation。最近的方法将类似的思想用于学习
sentence representation。 这些方法是encoder-decoder模型,学习预测/重构给定句子的context sentence。尽管它们很成功,但这些方法中存在几个建模问题:用句子的形式来表达一个概念有很多方式。理想的
semantic representation对表达意义的形式不敏感。现有的模型被训练来重建一个句子的表面形式,这就迫使模型不仅要预测其语义,还要预测与句子的语义无关的方面。与这些模型相关的另一个问题是计算成本。这些方法有一个
word level reconstruction objective,涉及到对目标句子的单词进行顺序地解码。在整个vocabulary上用output softmax layer进行训练是训练速度慢的一个重要原因。这进一步限制了vocabulary和模型的大小。
论文
《An efficient framework for learning sentence representations》通过提出一个直接在sentence embedding space运行的objective来规避这些问题。generation objective被一个discriminative approximation所取代。在这个discriminative approximation中,模型试图在一组候选句子中识别出一个正确的目标句子。在这个背景下,我们将句子的 "意义" 解释为句子中的信息,这些信息允许它从上下文句子的信息中预测和被预测。作者将该方法命名为quick thoughts: QT,以表示对thought vectors的有效学习。论文贡献:
提出了一个简单而通用的框架来有效地学习
sentence representation。 论文训练了广泛使用的编码器架构,比以前的方法快一个数量级,同时取得更好的性能。在涉及理解句子语义的几个下游任务中建立了一个新的
unsupervised sentence representation learning的SOTA。
相关工作:略。(技术过于古老,不用花时间研究相关工作)。
6.1 模型
先前的工作以不同的方式实现了
distributional hypothesis。下图(a)展示了一种常见的方法,即encoding函数计算输入句子的vector representation,然后decoding函数试图生成以该representation为条件的目标句子的单词。在
skip-thought model中,目标句子是那些出现在输入句子附近的句子。解码器也有一些变体,比如预测
input sentence而不是邻近句子的自编码器模型(FastSent)、以及预测input sentence中的一个窗口的单词(Paragraph Vector)。
我们没有训练一个模型来重建输入句子或其邻居的表面形式,而是采取了以下方法:使用当前句子的含义来预测相邻句子的含义,其中含义由
encoding函数计算出的sentence embedding来表示。尽管这种建模方法很简单,但我们表明,它有利于学习丰富的representation。 我们的方法如下图(b)所示。给定一个输入的句子,它像以前一样用一些函数进行编码。但模型不是生成目标句子,而是从一组候选句子中选择正确的目标句子。将generation视为从所有可能的句子中选择一个句子,这可以被看作是对generation problem的一种discriminative approximation。这两种方法的一个关键区别是:在图(b)中,模型可以选择忽略句子中与构建semantic embedding space无关的方面。图
(a)是生成式,图(b)是判别式。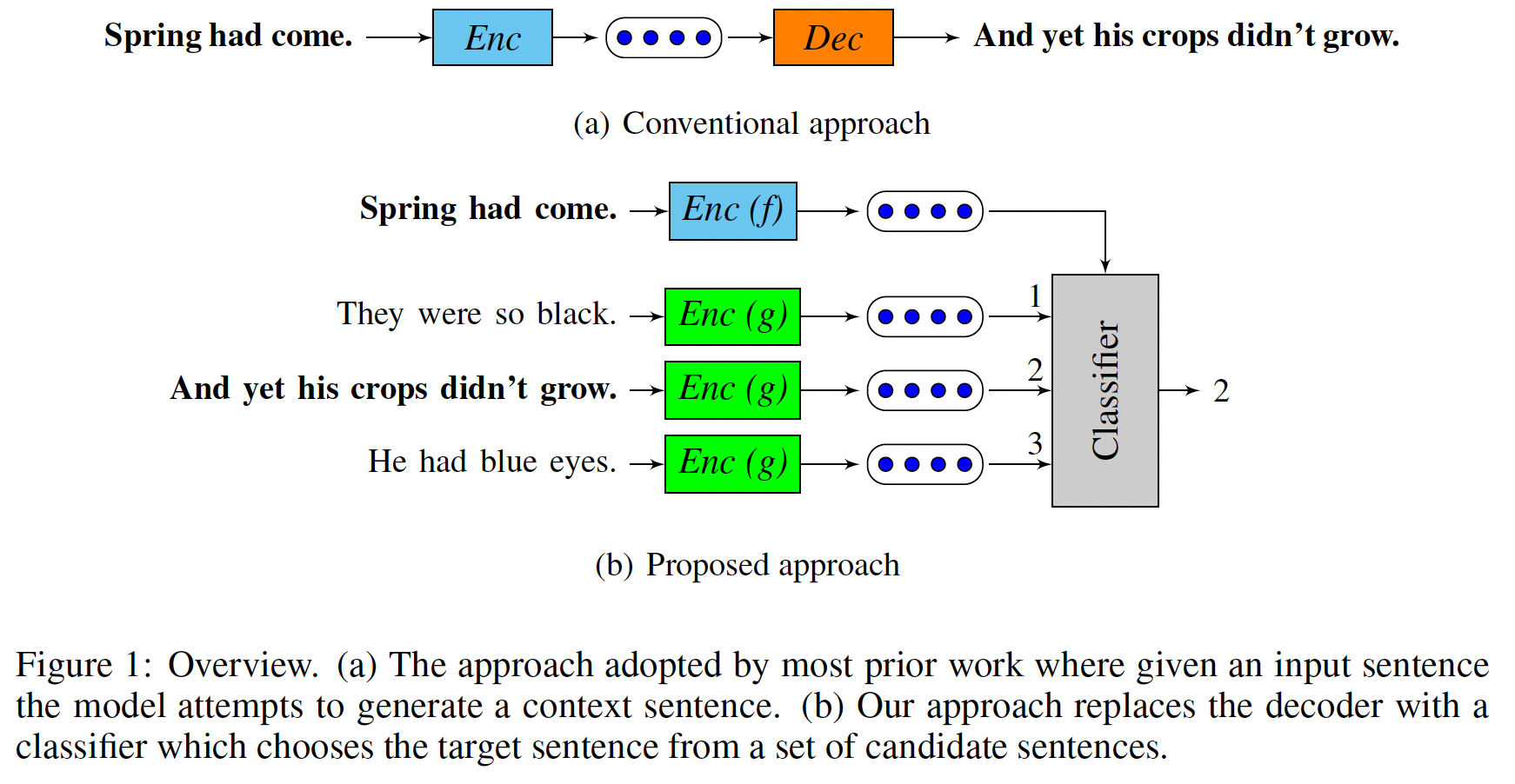
正式地,令
context size)。令ground truth)和许多其他非上下文句子从而用于分类。对于
sentence position(如,next sentence),一个候选句子其中:
training objective是使训练数据该建模方法类似于
SkipGram方法,区别在于在SkipGram方法中word扮演了sentence的角色。在SkipGram中,encoding函数是简单的lookup table,training objective是在给定一组负样本的情况下,最大化source word与target word(位于source word上下文中)之间的相似度。我们选择同一个
mini-batch中的所有sentence作为另一种候选的
training objective为:类似于SkipGram的负采样方法,我们使用二分类器的形式,将一组句子作为输入,并将它们分类为可信的和不可信的。然而我们发现前者的objective效果更好,可能是由于它施加了宽松的约束:它不要求将上下文句子分为正/负两类,而只要求ground-truth context比contrastive context更可信。根据经验,前者的objective也比最大边际损失表现得更好。在我们的实验中,
sentence encoder和优秀的分类器(从而弥补编码器)。这是不可取的,因为分类器将被丢弃,只有句子编码器将被用来为下游任务提取特征。尽量减少分类器中的参数数量,鼓励编码器学习有用的representation。我们考虑
input parameter和output parameter来学习word representation。由于这些模型是在大型语料库中训练的,因此参数共享不是一个重要的问题。在测试期间,对于一个给定的句子representation是两个编码器的输出的拼接我们的框架允许使用灵活的编码函数。我们使用
RNN作为sentence representation learning方法中被广泛使用。句子的单词被依次馈入到RNN,最后的hidden state被解释为句子的representation。我们使用GRU作为RNN单元。
6.2 实验
略。(技术过于古老,不用花时间研究实验细节)。