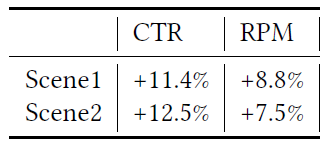
十六、DeepMCP[2019]
点击率
click-through rate: CTR预估是预测用户点击某个item的概率。它在在线广告系统中扮演着重要的角色。例如,广告排序策略通常取决于CTR x bid,其中bid为广告的点击出价。此外,根据常见的cost-per-click: CPC扣费模式,广告主仅在用户点击广告之后才扣费。因此,为了最大限度地提高收入并保持理想的用户体验,准确预估广告的CTR至关重要。CTR预估引起了学术界和工业界的广泛关注。例如:逻辑回归
Logistic Regression: LR模型考虑了线性的特征重要性,并将预测的CTR建模为:sigmoid函数,bias,分解机
Factorization Machine: FM模型进一步对pairwise特征交互interaction进行建模。它将预估的CTR建模为:embedding向量,近年来,深度神经网络
Deep Neural Network: DNN被广泛用于CTR预估和item推荐,从而自动学习特征representation和高阶特征交互。为了同时利用浅层模型和深层模型,人们还提出了混合模型。例如:
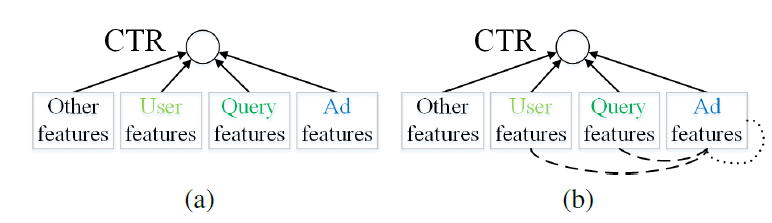
Wide & Deep结合了LR和DNN,从而提高模型的memorization和generalization能力。DeepFM结合了FM和DNN,从而进一步提高了学习特征交互的模型能力。Neural Factorization Machine: NFM结合了FM的线性和DNN的非线性。 尽管如此,这些模型仅考虑了feature-CTR关系,并且存在数据稀疏问题。论文《Representation Learning-Assisted Click-Through Rate Prediction》提出的DeepMCP模型额外考虑了feature-feature关系,例如如user-ad关系、ad-ad关系,从而学习更多信息丰富的、统计可靠的特征representation,最终提高CTR预估的性能。下图说明了DeepMCP(图(b)) 和其它方法图(a))的主要区别:
(a):经典的CTR预估方法建模feature-CTR关系。(b):DeepMCP进一步对feautre-feature关系进行建模,诸如user-ad关系(虚实线)、ad-ad关系(点线)。
注意:
FM模型中的特征交互仍然是建模feature-CTR关系。可以将其视为tow_features-CTR关系,因为它建模了特征交互CTRrepresentationlatent embedding向量,更具体而言,论文提出的
DeepMCP模型包含三个部分:一个matching subnet、一个correlation subnet、一个prediction subnet,这也是DeepMCP模型名称的由来。这三个部分共享相同的embedding矩阵。matching subnet对user-ad的关系(即,广告是否匹配用户的兴趣)进行建模,并旨在学习有用的用户representation和有用的广告representation。correlation subnet对ad-ad的关系(即,哪些广告位于用户点击序列的时间窗口内)进行建模,并旨在学习有用的广告representation。prediction subnet对feature-CTR关系进行建模,并旨在预测在给定所有特征的条件下的CTR。
当这些
subnet在目标label的监督下联合优化时,学到的特征representation既具有良好的预测能力、又具有良好的表达能力。此外,由于同一个特征以不同的方式出现在不同的subnet中,因此学到的representation在统计上更加可靠。总之,论文的主要贡献是:
论文提出了一种用于
CTR预估的新模型DeepMCP。与主要考虑feature-CTR关系的经典CTR预估模型不同,DeepMCP进一步考虑了user-ad关系和ad-ad关系。论文对两个大规模数据集进行了大量实验,从而比较了
DeepMCP和其它几个state-of-the-art模型的性能。论文还公开了DeepMCP的实现代码。
相关工作:
CTR预估:CTR预估引起了学术界和工业界的广泛关注。广义线性模型,如逻辑回归
Logistic Regression: LR和Follow-The-Regularized-Leader: FTRL在实践中表现出不错的性能。然而,线性模型缺乏学习复杂特征交互的能力。分解机
Factorization Machine: FM以被涉及特征的潜在向量latent vector的形式对pairwise特征交互建模。Field-aware FM和Field-weighted FM进一步考虑了特征所属field的影响,从而提高FM的性能。
近年来,深度神经网络
Deep Neural Network被广泛用于CTR预估和item推荐,以自动学习特征representation和高阶特征交互。Factorization-machine supported Neural Network: FNN在应用DNN之前预训练FM。Product-based Neural Network: PNN在embedding layer和全连接层之间引入了product layer。Wide & Deep结合了LR和DNN,从而提高模型的memorization和generalization能力。DeepFM像FM一样对低阶特征交互进行建模,并像DNN一样对高阶特征交互进行建模。Neural Factorization Machine: NFM结合了FM的线性和神经网络的非线性。
尽管如此,这些方法主要是对
feature-CTR关系进行建模。我们提出的DeepMCP模型进一步考虑了user-ad和ad-ad的关系。Multi-modal / Multi-task Learning:我们的工作也与多模态/多任务学习密切相关,其中引入了多种信息或辅助任务来帮助提高main task的性能。《Collaborative knowledge base embedding for recommender systems》利用知识库knowledge base中的异质信息heterogeneous information(如结构化内容、文本内容、视觉内容)来提高推荐系统的质量。《Recommendation with multisource heterogeneous information》除了利用经典的item结构信息之外,还利用文本内容和社交tag信息来改进推荐。《Improving entity recommendation with search log and multi-task learning》引入上下文感知排序context-aware ranking作为辅助任务,以便更好地对实体推荐中的query语义进行建模。《Deep cascade multi-task learning for slot filling in online shopping assistant》提出了一种多任务模型,该模型额外学习了segment tagging和named entity tagging,从而用于在线购物助手中的槽位slot填充。
在我们的工作中,我们解决了一个不同的问题。我们引入了两个辅助的、但是相关的任务(即共享了
embedding的matching subnet和correlation subnet)来提高CTR预估的性能。
16.1 模型
在线广告中点击率预估任务是估计用户点击特定广告的概率。下表展示了一些样本实例,每一行都是
CTR预估的一个样本。其中第一列是label(点击是1、未点击是0)。每个样本可以用多个field来描述,例如用户信息field(用户ID、城市等)和广告信息field(创意ID、标题等)。field的实例化对应了一个特征。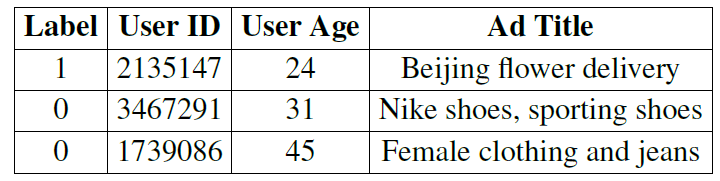
与大多数主要考虑
feature-CTR关系的现有CTR预估模型不同,我们提出的DeepMCP模型额外考虑了user-ad和ad-ad关系。DeepMCP包含三个部分:一个matching subnet、一个correlation subnet、一个prediction subnet,如下图(a)所示。当这些subnet在目标label的监督下联合优化时,学到的特征representation既具有良好的预测能力、又具有良好的表达能力。DeepMCP的另一个特点是:尽管在训练过程中所有subnet都处于活跃状态,但是在测试过程中只有prediction subnet处于活跃状态,如下图(b)所示。这使得测试阶段变得相当简单和高效。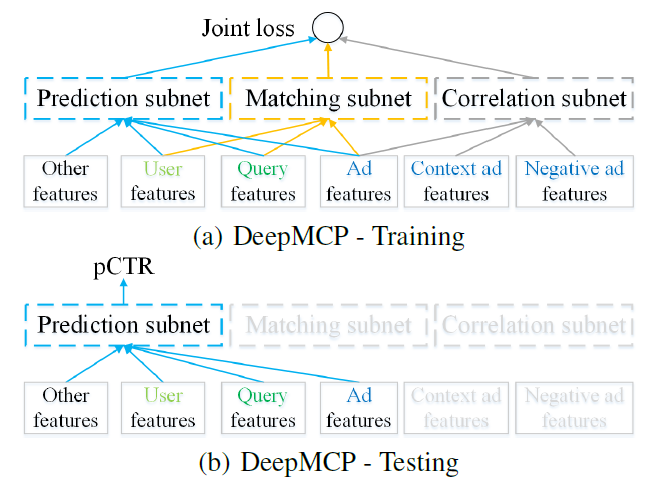
我们将特征分为四组:用户特征(如用户
ID、年龄)、query特征(如query、query category)、广告特征(如创意ID、广告标题)、其它特征(如一天中的小时、星期)。每个subnet使用不同的特征集合。具体而言:prediction subnet使用所有四组特征,matching subnet使用user, query, ad三组特征,correlation subnet仅使用ad特征。所有subnet共享相同的embedding矩阵。注意:
Context ad features和Negative ad features是correlation subnet中,位于用户点击序列的时间窗口内上下文广告、以及窗口外的负采样广告。它们仅用于correlation subnet。DeepMCP的整体结构如下图所示,所有的subnet共享相同的embedding矩阵。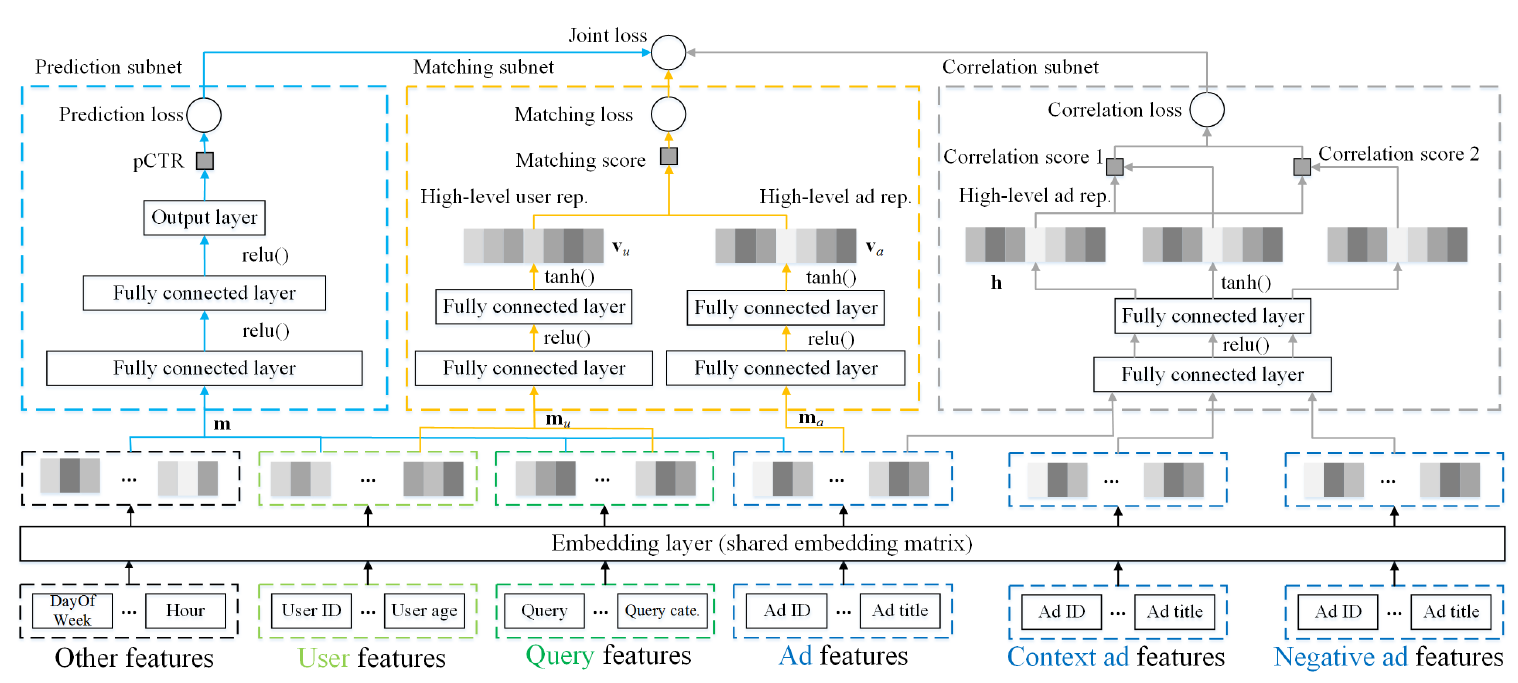
16.1.1 Prediction Subnet
prediction subnet这里是一个典型的DNN模型,它对feature-CTR关系进行建模(其中显式地或隐式地对特征交互进行建模)。它旨在在目标label的监督下,根据所有特征预估点击率。尽管如此,DeepMCP模型非常灵活,可以使用任何其它CTR预估模型来代替prediction subnet,如Wide & Deep、DeepFM等。prediction subnet的整体结构为:首先,单个特征
ID)通过一个embedding层,然后映射到对应的embedding向量embedding向量维度,假设特征
embedding的集合构成一个embedding矩阵注意:
这里假设所有特征都是离散的。如果存在连续值的特征,则需要首先对其进行离散化。
对于多类别的离散特征(如广告标题中的
bi-gram,一个广告标题可能包含多个bi-gram),我们首先将每个bi-gram映射到一个embedding向量,然后再执行一个sum pooling从而得到广告标题的、聚合后的embedding向量。
接着,我们将样本的所有特征的
embedding向量拼接为一个长的向量fully connected:FC层(带有ReLU非线性激活函数),从而学到高阶的非线性特征交互。最后,最后一层
FC层的输出sigmoid函数从而得到预估的CTR:其中
为缓解过拟合,我们在每个
FC层之后都应用了dropout。prediction subnet的损失函数为训练集的交叉熵:其中:
label;CTR。
16.1.2 Matching Subnet
matching subnet对user-ad的关系(即,广告是否匹配用户的兴趣)进行建模,并旨在学习有用的用户representation和有用的广告representation。它的灵感来自于网络搜索的语义匹配模型semantic matching model。在推荐系统的经典矩阵分解中,
rating score近似为用户ID潜在向量和item ID潜在向量的内积。在我们的问题中,我们没有直接match用户ID和广告ID,而是在更高级别上进行了match,并结合了关于用户的所有特征、关于广告的所有特征。当用户点击广告时,我们假设所点击的广告至少部分和用户需求相关(考虑到用户提交的
query,如果有的话)。因此,我们希望用户特征(和query特征)的representation和广告特征的representation相匹配。具体而言,
matching subnet包含两个部分:用户部分
user part:用户部分的输入是用户特征(如用户ID、年龄)和query特征(如query、query category)。像在
prediction subnet中一样,单个特征embedding层,然后映射为对应的embedding向量embedding拼接为长向量然后向量
fully connected:FC层(带有ReLU非线性激活函数),从而学到高阶的非线性特征交互。对于最后一个FC层,我们使用tanh非线性激活函数(而不是ReLU),我们后面解释这么做的原因。用户部分的输出是一个
high-level的用户representation向量广告部分
ad part:广告部分的输入是广告特征(如广告ID、广告标题)。同样,我们首先将每个广告特征映射到对应的
embedding向量,然后将单个广告embedding拼接为长向量然后向量
fully connected:FC层(带有ReLU非线性激活函数),从而得到一个high-level的广告representation向量FC层,我们使用tanh非线性激活函数(而不是ReLU)。
注意:通常用户部分、广告部分的输入具有不同的特征维度,即
matching subnet之后,然后我们通过下式计算
matching score我们并没有使用
ReLU作为最后一个FC层的激活函数,因为ReLU之后的输出将包含很多零,这使得注意:前面
prediction subnet最后一个FC层仍然采用ReLU,因为其输出为至少有两种选择来建模
matching score:point-wise模型:当用户pair-wise模型:如果用户margin超参数。
这里我们选择
point-wise模型,因为它可以直接将训练数据集重新用于prediction subnet。我们将matching subnet的损失函数定义为:其中:
matching subnet也是采用是否点击作为label,这和prediction subnet完全相同。二者不同的地方在于:matching subnet是uv粒度,而prediction subnet是pv粒度。matching subnet通过representation向量的内积来建模用户和广告的相关性,用户信息和广告信息只有在进行内积的时候才产生融合。而prediction subnet直接建模点击率,用户信息和广告信息在embedding layer之后就产生融合。
16.1.3 Correlation Subnet
correlation subnet对ad-ad的关系(即,哪些广告位于用户点击序列的时间窗口内)进行建模,并旨在学习有用的广告representation。在我们的问题中,由于用户的点击广告构成了随时间推移的、具有一定相关性的序列,因此我们使用skip-gram模型来学习有用的广告representation。给定单个用户点击广告的广告序列
其中:
概率
softmax、层次softmax、负采样。由于负采样的效率高,我们选择负采样技术将其中:
sigmoid函数。high-level representation,它涉及广告FC层。
correlation subnet的损失函数为负的对数似然:考虑所有用户的
correlation subnet总的损失。
16.1.4 其它
离线训练过程:
DeepMCP的最终联合损失函数为:其中
subnet的重要性。DeepMCP通过在训练集上最小化联合损失函数来训练。由于我们的目标是最大化CTR预估性能,因此训练过程中我们在独立的验证集上评估模型,并记录验证AUC。最佳模型参数在最高的验证AUC处获得。在线预测过程:
DeepMCP模型仅需要计算预估的点击率pCTR,因此只有prediction subnet处于活跃状态。这使得DeepMCP的在线预测阶段相当简单和高效。
16.2 实验
数据集:我们使用两个大型数据集:
Avito广告数据集:数据集包含来自俄罗斯最大的通用分类网站avito.ru的广告日志的随机样本。我们将2015-04-28 ~ 2015-05-18的广告日志用于训练、2015-05-19的广告日志用于验证、2015-05-20的广告日志用于测试。在
CTR预估中,测试通常是第二天的预测,这里测试集包含ID、IP ID、用户浏览器、用户设备)、query特征(如query、query category、query参数)、广告特征(如广告ID、广告标题、广告cateogry)、其它特征(如hour of day、day of week)。Company广告数据集:数据集包含来自阿里巴巴商业广告系统的广告曝光日志和点击日志的随机样本。我们使用2018年八月到九月连续30天的日志用于训练,下一天的日志用于验证、下下一天的日志用于测试。测试集包含
query特征、广告特征、其它特征。
baseline方法:我们使用以下CTR预估的baseline方法:LR:逻辑回归方法。它是线性模型,建模了特征重要性。FM:因子分解机。它同时对一阶特征重要性和二阶特征交互进行建模。DNN:深度神经网络,它包含一个embedding层、几个FC层、一个输出层。Wide & Deep:它同时结合了LR(wide部分)、DNN(deep部分)。PNN:product-based神经网络,它在DNN的embedding层和FC层之间引入了一个乘积层production layer。DeepFM:它结合了FM(wide部分)、DNN(deep部分)。DeepCP:DeepMCP模型的一种变体,仅包含correlation subnet和prediction subnet。它等价于在联合损失函数中设置DeepMP:DeepMCP模型的一种变体,仅包含matching subnet和prediction subnet。它等价于在联合损失函数中设置
实验配置:
考虑到每个特征的取值范围很广,因此我们设置每个特征的维度
embedding矩阵规模太大。对于基于神经网络的模型,我们设置全连接层的层数为
2、维度分别为512和256。我们设置
batch size=28,上下文窗口大小dropout rate=0.5。所有这些方法都在
tensorflow中实现,并通过Adagrad算法进行优化。
评估指标:测试
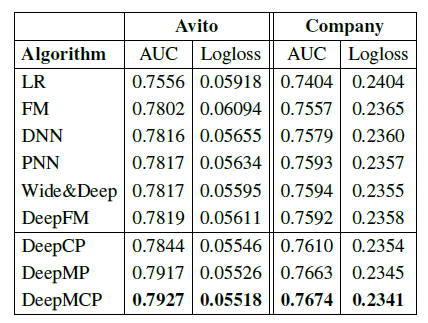
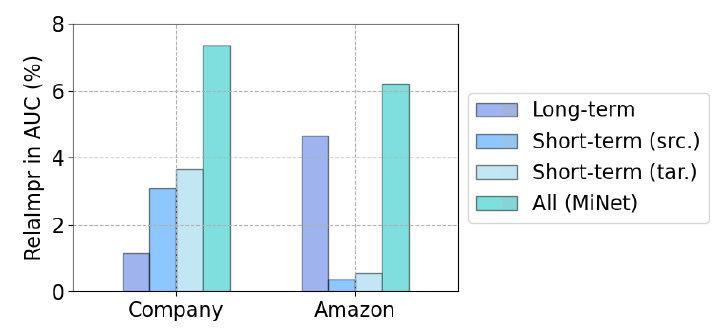
AUC(越大越好)、测试logloss(越小越好)。实验结果如下表所示,可以看到:
FM性能要比LR好得多,这是因为FM建模了二阶特征交互,而LR仅建模一阶的特征重要性。DNN性能进一步优于FM,因为它可以学习高阶非线性特征交互。PNN优于DNN,因为它进一步引入了production layer。Wide & Deep进一步优于PNN,因为它结合了LR和DNN,从而提高了模型的记忆memorization能力和泛化generalization能力。DeepFM结合了FM和DNN,它在Avito数据集上优于Wide & Deep,但是在Company数据集上性能稍差。DeepCP和DeepMP在两个数据集上都超越了表现最好的baseline。由于
baseline方法仅考虑单个CTR预估任务,因此这些观察结果表明:考虑额外的representation learning任务可以帮助更好地执行CTR预估。还可以观察到
DeepMP的性能比DeepCP更好,这表明:matching subnet要比correlation subnet带来更多的好处。这是可以理解的,因为
matching subnet同时考虑了用户和广告,而correlation subnet仅考虑了广告。DeepMCP在这两个数据集上均表现最佳,这些证明了DeepMCP的有效性。
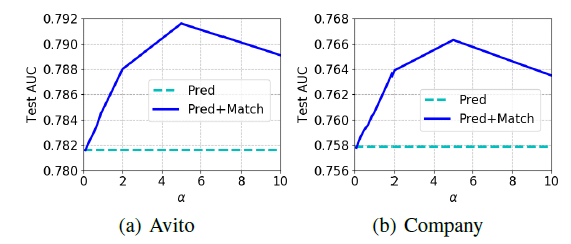
超参数
DeepMCP测试AUC的影响,其中Pred表示DNN、Pred+Corr表示DeepCP、Pred+Match表示DeepMP。可以看到:当超参数
AUC开始提升;当AUC开始下降。在
Company数据集上,较大的DNN更差。总体而言,
matching subnet比correlation subnet带来更大的测试AUC提升。
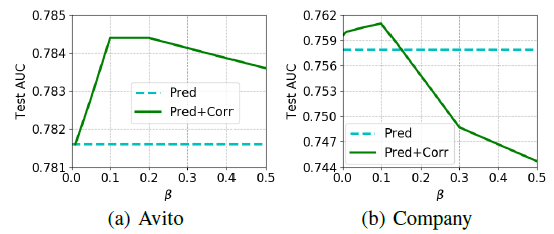
隐层维度的影响:下图给出了两层隐层的模型中,测试
AUC和隐层维度的关系。为了方便阅读,我们仅展示了DNN, Wide & Deep, DeepMCP的结果。我们使用收缩结构,其中第二层维度为第一层维度的一半。第一层维度选择从128增加到512。可以看到:当隐层维度增加时,测试
AUC通常会提升;但是当维度进一步增加时,测试AUC可能会下降。这可能是因为训练更复杂的模型更加困难。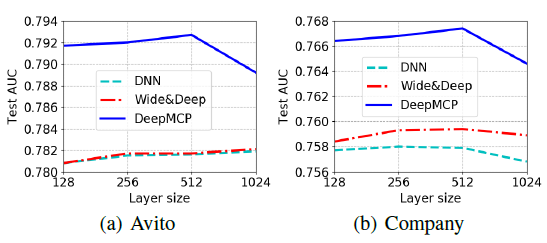
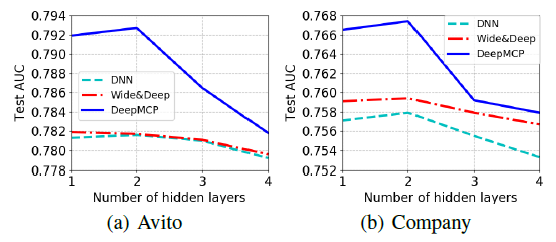
隐层数量的影响:我们对比了不同深度的模型的效果。为了方便阅读,我们仅展示了
DNN, Wide & Deep, DeepMCP的结果。我们分别使用一层([256])、两层([512, 256])、三层([1024, 512, 256])、四层([2048, 1024, 512, 256])。可以看到:
当隐层数量从
1层增加到2层时,模型性能通常会提高。这是因为更多的隐层具有更好的表达能力。但是当隐层数量进一步增加时,性能就会下降。这是因为训练更深的神经网络更加困难。
十七、DMR[2020]
Matching和Ranking是推荐系统中信息检索的两个经典阶段。matching阶段(又称作候选生成candidate generation)通过将user和item进行matching,从而从整个item集合中检索一小部分候选对象candidate。基于协同过滤的方法被广泛用于计算
user-to-item的相关性,并选择最相关的item。ranking阶段通过ranking模型为不同matching方法生成的候选者打分,并将top-N打分的item呈现给最终用户。
用户点击是推荐系统中非常重要的评估指标,它是所有后续转化行为的基础。
click-through rate: CTR的预估已经引起了学术界和工业界的广泛关注。个性化
personalization是提高CTR预估性能和提升用户体验的关键。已经提出了很多基于深度学习的方法来进行CTR预估,这些方法可以学习隐式特征交互并提升模型容量capability。这些方法大多数都关注于设计自动特征交互的网络结构。最近,有人提出了几种模型来从点击、购买之类的用户行为数据中提取用户兴趣,这对于用户没有明确显示其兴趣的推荐配置
setting而言非常重要。为了表示用户的兴趣,这些模型考虑了用户交互的item和目标item之间的item-to-item相关性。但是,这些模型主要聚焦于用户
representation,而忽略了表达user-to-item相关性。user-to-item相关性直接衡量了用户对目标item的个性化偏好,并在基于协同过滤的matching方法中精心建模。基于这些观察,论文
《Deep Match to Rank Model for Personalized Click-Through Rate Prediction》提出了一种新的模型,称作Deep Match to Rank: DMR。该模型将协同过滤的思想和matching思想相结合,用于CTR预估的ranking任务,从而提高了CTR预估的性能。DMR包含User-to-Item Network和Item-to-Item Network这两个子网来代表user-to-item的相关性。在
User-to-Item Network,论文通过embedding空间中user embedding和item embedding的内积来表达用户和item之间的相关性。其中user embedding是从用户行为中抽取而来。考虑到最近的行为可以更好地反映用户的时间的兴趣
temporal interest,论文应用注意力机制来自适应地学习每种行为在行为序列中的权重,并考虑行为在序列中的位置position。同时,论文提出一个辅助的
match网络auxiliary match network来推动更大larger的内积从而代表更高的相关性,并帮助更好地拟合User-to-Item Network。辅助
match网络可以视为一种match方法,其任务是根据用户的历史行为来预测下一个要点击的item,然后论文在DMR中共同训练matching模型和ranking模型。据作者所知,DMR是第一个在CTR预估任务中联合训练matching和ranking的模型。在
Item-to-Item Network,论文首先计算用户交互item和目标item之间的item-to-item相似度,其中采用考虑了位置信息position information的注意力机制。然后论文将item-to-item相似性相加,从而获得了另一种形式的user-to-item相关性。注意,一般而言在
matching阶段,候选者通常是通过多种matching方法生成的,以满足用户需求的多样性,并且不同方法之间的user-to-item相关性得分是不可比的not comparable。但是在DMR中,可以以统一的方式将相关性强度进行比较。
论文的主要贡献:
论文指出捕获用户和
item之间相关性的重要性,这可以使CTR预估模型更加个性化和有效。受此启发,论文提出了一种称作DMR的新模型,该模型在mathcing方法中应用协同过滤的思想,通过User-to-Item和Item-to-Item Network来表示相关性。论文设计了辅助
match网络,可以将其视为mathcing模型,从而帮助更好地训练User-to-Item Network。据作者所知,DMR是第一个在CTR预估模型中联合训练matching和ranking的模型。考虑到最近的行为对用户的动态兴趣贡献更大
temporal interest,论文在注意力机制中引入positional encoding来自适应地学习每个行为的权重。论文在公共数据集和工业数据集上进行了广泛的实验,证明了所提出的
DMR比state-of-the-art的模型有着显著提升。
相关工作:
特征交互:最近,基于深度学习的
CTR预估模型备受关注并取得了显著的效果。与传统的线性模型相比,基于深度学习的方法可以增强模型容量capability,并且通过非线性变换学习隐式特征交互。通过从高维稀疏特征中学习低维representation,深度模型对罕见的特征组合有更好的估计estimation。然而,实际应用中高维稀疏特征带来了很大的挑战:深度模型可能会过拟合
overfit。基于此,人们提出了不同的模型,以便更好地对特征交互进行建模,提高CTR预估的性能。Wide & Deep通过联合训练线性模型和非线性深度模型,从而结合了二者的优势。Deep Crossing应用深度残差网络来学习交叉特征。PNN在embedding layer和全连接层之间引入一个product layer,从而探索高阶特征交互。AFM基于对二阶特征交互建模的分解机factorization-machine: FM,通过注意力机制来学习加权的特征交互。DeepFM和NFM通过将FM与深度网络相结合,从而结合了低阶特征交互和高阶特征交互。DCN引入了cross network来学习某种有界阶次bounded-degree特征交互。
在
DMR模型中,user-to-item相关性的representation可以视为用户和item之间的一种特征交互。用户行为特征:和搜索排序
search ranking不同,在推荐系统和许多其他application中,用户并没有清楚地表明他们的意图。因此,从用户行为中捕获用户兴趣对于CTR预估至关重要,而上述模型对此关注较少。可变长度的用户行为特征通常通过简单的均值池化转变为固定长度的向量,这意味着所有行为都同等重要。
DIN通过加权sum池化来表示用户兴趣,其中每个用户行为相对于目标item的权重通过注意力机制自适应学习。DIEN不仅提取用户兴趣,而且建模兴趣的动态演变temporal evolution。DSIN利用行为序列中的会话信息来建模兴趣演变。
在
DMR模型中,受Transformer的启发,论文将positional encoding引入注意力机制从而捕获用户的动态兴趣temporal interest。user-to-item相关性:尽管取得了很大进展,但是这些方法侧重于用户representation,而忽略了user-to-item相关性的表达,而后者直接衡量了用户对目标item的偏好强度。在提出的DMR中,论文关注表达user-to-item的相关性,从而提高个性化CTR模型的性能。基于协同过滤
collaborative filtering: CF的方法在构建推荐系统的matching阶段非常成功。在这些方法中,item-to-item CF因其在实时个性化方面的可解释性和效率而被广泛应用于工业推荐setting。通过预先计算好item-to-item的相似度矩阵,系统可以向用户推荐与该用户历史点击item相似的item。为了计算
item-to-item相似度,早期的工作侧重于统计量,例如余弦相似度和Pearson系数。基于深度学习的方法NAIS采用带注意力机制的item-to-item CF,从而区分用户不同行为的重要性,这与DIN有相似的想法。item-to-item CF可以视为获取user-to-item相关性的间接方法。和
item-to-item CF不同,基于矩阵分解的CF方法通过在低维空间中计算user representation和item representation的内积来直接计算user和item相关性。以类似的基于内积的形式,人们提出了基于深度学习的方法来从用户的历史行为中学习user representation,这可以看作是矩阵分解技术的非线性泛化。《Deep neural networks for youtube recommendations》将matching视为极端多分类问题,其中点击预估问题变成了根据用户的历史行为准确地分类用户接下来将要点击的item。《Session-based recommendations with recurrent neural networks》将GRU应用到基于会话的推荐任务。TDM使用tree-based方法来超越基于内积的方法。
在
DMR模型中,一方面论文使用user representation和item representation之间的内积来获得一种user-to-item的相关性;另一方面论文应用注意力机制来表示item-to-item的相似性,并进一步基于这种相似性来获得另一种user-to-item的相关性。
17.1 模型
这里我们详细介绍
Deep Match to Rank:DMR模型的设计。首先我们从两个方面概述了基于深度学习的
CTR模型的基本结构:特征表示feature representation、多层感知机multiple layer perceptron: MLP。然后我们介绍建模
user-to-item相关性的、带有两个子网的DMR的总体结构。
17.1.1 Feature Rpresentation
我们的推荐系统中包含四类特征:
用户画像
User Profile:包含用户ID、消费水平等等。Target Item特征:包括item ID、category ID等等。用户行为
User Behavior:是用户交互的item形成的item序列。上下文
Context:包含时间、matching方法、以及对应的matching score等。
大多数特征都是离散型特征,可以将其转换为高维的
one-hot向量。在基于深度学习的模型中,one-hot向量通过embedding layer转换为低维稠密特征。例如,
item ID的embedding矩阵可以表示为:item集合的大小,embedding向量维度,item的embedding向量。无需在
one-hot向量和embedding矩阵之间进行复杂的矩阵乘法,embedding layer通过查表look up table就可以获取embedding向量。我们将离散特征
embedding和normalized的连续特征拼接起来,其中:用户画像User Profile的拼接特征为User Behavior的拼接特征为Target Item的拼接特征为Context的拼接特征为注意,用户行为序列包含很多个
item,因此用User Behavior的特征是由这些item的特征向量列表拼接而成||表示向量拼接。
User Behavior特征和Target Item特征位于相同的特征空间,并共享相同的embedding矩阵以降低内存需求。注意:
item的representation。它和item ID的embedding向量,而item ID和cate ID等embedding向量的拼接。
17.1.2 MLP
所有特征向量拼接起来构成样本的完整
representation之后,将representation灌入MLP。MLP隐层的激活函数为PRelu,最终输出层采用sigmoid激活函数从而用于二分类任务。MLP输入的长度需要固定,因此需要将User Behavior特征向量交叉熵损失函数通常和
sigmoid函数一起使用,其对数函数可以抵消sigmoid函数中指数的副作用。给定样本其中
MLP的预测输出的点击概率。
17.1.3 DMR
基于深度学习
CTR模型的basic结构很难通过隐式特征交互来捕获用户和item的相关性。在DMR中,我们提出了两个子网,即User-to-Item Network、Item-to-Item Network,从而建模user-to-item相关性,进而可以提高个性化CTR模型的性能。DMR结构如下图所示:输入特征向量是嵌入
embedded的离散特征、和正则化normalized的连续特征的拼接。DMR使用两个子网(User-to-Item Network、Item-to-Item Network)以两种形式来建模user-to-item相关性。两种形式的
user-to-item相关性、用户的动态兴趣temporal interest的representation、以及其它所有特征向量拼接起来,然后馈入到MLP中。
最终损失由
MLP的target loss和辅助的match network loss组成。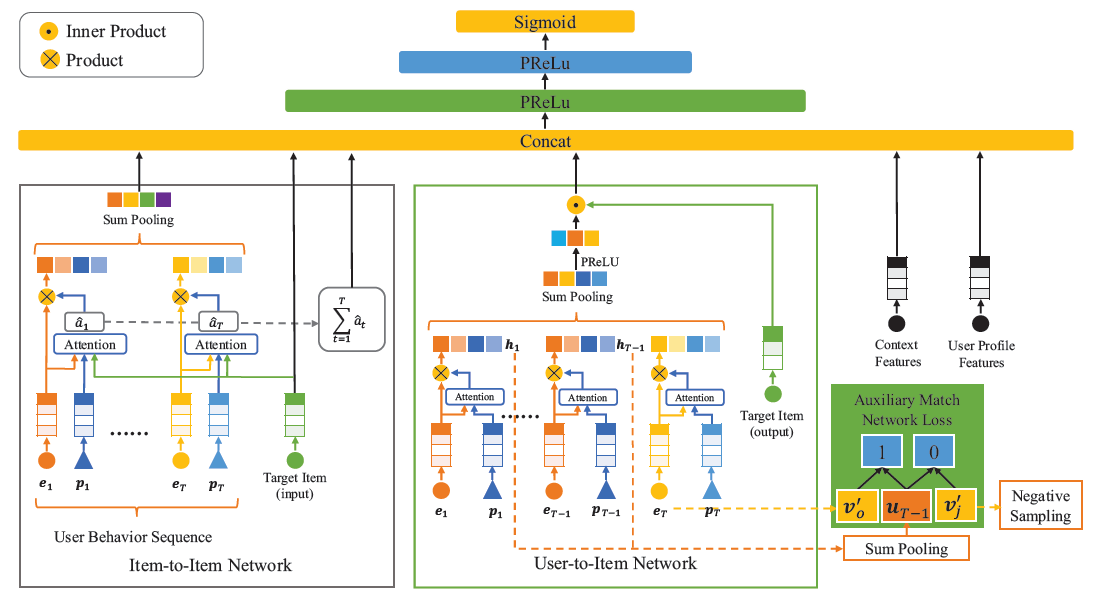
a. User-to-Item Network
遵循基于矩阵分解的
matching方法中的representation形式,User-to-Item Network通过user representation和item representation的内积来建模用户和目标item之间的相关性,这可以视作用户和item之间的一种特征交互。为获得
user representation,我们求助于User Behavior特征。用户不会在推荐场景中明确展现其兴趣,而用户行为则隐式地反映了用户兴趣。表达用户兴趣的一种朴素方法是:对用户行为特征使用均值池化。这种方法认为每种行为对于最终用户兴趣做出同等贡献。
但是,用户的兴趣可能会随着时间而变化。在这种情况下,最近的行为可能会更好地反映用户的时间
temporal兴趣。根据发生的时刻为每个行为分配权重可以缓解该问题,但是也很难找到最佳权重。在
User-to-Item Network中,我们使用位置编码作为query的注意力机制来自适应地学习每个行为的权重,其中用户行为的位置position是行为序列中按发生时间排序的序列编号。数学描述为:其中:
embedding。
通过加权的
sum池化,我们将User Behavior特征向量item representation的维度最终用户的
representation其中:
这里的
attention计算的是基于positional embedding计算不同位置的、归一化的重要性。这里没有考虑target item的重要性,因为计算user representation时不会融合item representation信息。这里的
attention网络有三个细节,为简化起见我们忽略了它们:首先,可以添加更多的隐层从而具有更好的
representation。其次,除了位置编码之外,还可以将更多的、反映用户兴趣强度的上下文特征添加到
attention网络中,例如行为类型(如点击、购买、收藏)、停留时长等。在这些特征中,位置在我们的应用中影响力最大。第三,以行为发生时间的倒序对位置进行编码,从而确保最近的行为获得第一个位置。
尽管
RNN擅长处理序列数据,尤其是在NLP任务中,但是它不适合建模用户行为序列。和严格遵循某些规则的文本不同,用户行为序列是不确定的uncertain,并且可能会受到呈现给用户的内容的影响。如果没有特殊设计的结构,那么RNN很难提高预测效果。此外,串行计算的
RNN给在线serving系统带来了挑战。目标
item的representationembedding矩阵look up。其中target item的一个独立的embedding矩阵,它不是和embedding矩阵为区分这两个
embedding矩阵,我们称Target Item的input representation、称Target Item的output representation。尽管这种方式增加了存储空间,但是与embedding大小增加了一倍,而模型具有更强的表达能力。我们将在实验部分验证该结论。得到用户
representationitem的representationitem的相关性:我们预期更大的
但是,从反向传播的角度来看,仅通过点击标签的监督来确保这一点并不容易。此外,
embedding矩阵relevance unitmatch网络,该网络从用户行为中引入label,从而监督User-to-Item Network。辅助
match网络的任务是基于之前的extreme的多分类任务。遵从前文中用户
representationrepresentation,记作item其中
item的output representation。因此,针对target item的output representationsoftmax layer的参数。通过使用交叉熵损失函数,则我们得到辅助
match网络的损失为:其中:
match网络的样本数量,item数量。match网络的样本target item是否为第item。item为itemmatch网络的样本target item为第item的预测概率。
然而上式中的
item总数match网络损失函数定义为:其中:
sigmoid函数;最终的损失函数为:
其中
通过从
User Behavior中引入标签,辅助match网络可以推动更大的embedding矩阵理解
User-to-Item Network的另一种方法是:在统一模型中共同训练ranking模型和matching模型,其中matching模型是辅助match网络。在
matching阶段,候选者是通过多路match来生成,其中每一路match之间的分数不可比not comparable,每个候选者仅具有对应matching方法的相关性得分。和仅将
matching score作为特征馈入MLP不同,User-to-Item Network能够在给定任务Target Item的情况下获得user-to-item相关性得分,并且相关性以统一的方式可比comparable。
b. Item-to-Item Network
除了直接计算
user-to-item相关性之外,我们还提出了Item-to-Item Network以间接方式来表达相关性。首先我们建模用户交互的
item和target item之间的相似性similarity,然后对这些相似性相加从而得到另一种形式的user-to-item相关性relevance。为了使得相关性的
representation更具有表达性,我们使用attention机制(而不是User-to-Item Network中的内积)来建模item-to-item相似性。给定用户交互的
item、target item、位置编码作为输入,item-to-item相似性的公式为:其中:
target item的特征向量,embedding,
用户行为和
target item之间的item-to-item相似性之和构成了另一种类型的user-to-item相关性:通过加权的
sum池化,UserBehavior特征其中
注意:计算
1.0。和用户
representationrepresentationtarget item有所不同。通过注意力机制的局部激活能力,和目标item相关的行为的权重更高,并且主导了目标相关的用户representation两种类型的
user-to-item相关性MLP。MLP的最终输入为:
注,
DMR模型相当于对模型空间新增了约束:对于正样本,不仅点击率预估为1.0,还需要user representation和item representation之间相关性很高。负样本也是类似。
17.2 实验
数据集:
Alimama Dataset(公共数据集):包含从Taobao连续8天中随机采样的曝光和点击日志。前
7天的日志用于训练,最后1天的日志用于测试。数据集包含2600万条日志,一共有114万用户、84万item。工业数据集:数据集包含从阿里巴巴在线推荐系统收集的曝光和点击日志。
我们将前
14天的日志用于训练、第15天的日志用于测试。数据集包含11.8亿条日志,一共有1090万用户、4860万item。
baseline方法:LR:逻辑回归方法。它是一种经典的线性模型,可以看作是浅层神经网络。线性模型通常需要手动特征工程才能表现良好,这里我们添加了User Behavior和Target Item的叉积cross-product。Wide&Deep:它具有一个wide部分和一个deep部分,因此同时结合了线性模型和非线性深度模型的优势。在我们的实现中,wide部分和上述LR模型完全相同。PNN:它引入了product层以及全连接层,从而探索高阶特征交互。DIN:它通过自适应地学习注意力权重从而表示用户对目标item的兴趣。注意:如果没有两种
user-to-item相关性、如果没有使用positional encoding,那么我们的DMR退化为DIN模型。DIEN:DIEN通过两层GRU建模了用户对目标item的兴趣演化。
实验配置:
在公共数据集上:我们将学习率设为
0.001,batch size = 256,item embedding维度为32,用户行为序列的最大长度为50,MLP中的隐层维度分别为512,256,128。此外,辅助
match网络中的负样本数设为2000,辅助损失的权重0.1。在工业数据集上:除了将
item embedding维度设为64,其它超参数和公共数据集相同。
下表给出了实验结果。我们使用
AUC作为评估指标,所有实验重复5次并报告平均结果。Relative Improvement: RI表示基于LR的相对提升。可以看到:
LR的表现明显比Wide&Deep和其它基于深度学习的模型更差,这证明了深度神经网络中非线性变换和高阶特征交互的有效性。PNN受益于product layer,从而相比Wide&Deep实现了更好的特征交互从而性能更好。在用户没有显式表现其兴趣的推荐场景中,捕获用户的兴趣至关重要。
在基于深度学习的模型中,
Wide&Deep和PNN表现最差,尤其是在工业数据集上,这证明了从用户行为中抽取用户兴趣的重要性。DIN代表了用户对目标item的兴趣,但是忽略了用户行为中的顺序信息。DIEN的性能优于DIN,这主要归因于捕获了用户兴趣演变的两层GRU结构。基于用户兴趣
representation,DRM进一步通过User-to-Item Network和Item-to-Item Network来分别捕获两种形式的user-to-item相关性。通过相关性的
representation,DRM充分考虑了用户对目标item的个性化偏好,并且大幅度击败了所有baseline方法,包括LR、Wide&Deep、PNN、DIN、DIEN。
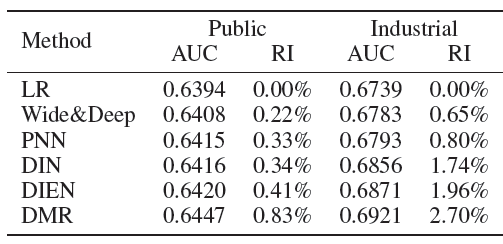
下表给出了公共数据集和工业数据集上具有不同组成部分的
DMR的比较结果,Relative Improvement: RI表示基于DMR的相对提升。其中:DMR I2I表示仅有Item-to-Item Network。DMR U2I表示仅有User-to-Item Network。DMR-No-AM表示没有辅助match网络。DMR-NO-PE表示User-to-Item Network中没有位置编码。DMR-Double表示embedding(即item embedding。
可以看到:
user-to-item相关性的representation的有效性:为了获得更具表达能力的representation,我们应用了不同的操作来建模user-to-item相关性。User-to-Item Network使用基于内积的操作来计算相关性,Item-to-Item Network使用attention网络来计算相关性。可以看到,这两个子网的组合要比单独使用时表现更好,这说明两种不同类型的user-to-item相关性是有效的,并且两种形式的user-to-item相关性是互补的,不是冗余的。辅助
match网络的有效性:和没有辅助match网络的DMR相比,完整DMR获得了更好的性能。辅助
match网络从用户行为中引入标签来监督训练,并在用户representation和item representation之间推入更大的内积从而表示更高的相关性。额外
embedding矩阵User-to-Item Network使用额外的embedding矩阵match网络的softmax layer中的参数。我们尝试将
item embedding的尺寸翻倍,并且共享embedding从而得到DMR-Double,其参数数量和 原始DMR相同。可以看到原始DMR的性能优于DMR-Double。这证明了单独的embedding矩阵位置编码的有效性:可以看到,在
User-to-Item Network中没有位置编码的DMR要差于完整的DMR。通过位置编码,
DMR会考虑用户行为序列中的顺序信息,并提取用户的动态兴趣。在工业数据集上,User-to-Item Network没有位置编码的DMR甚至要比没有整个User-to-Item Network的DMR(即DMR I2I)表现更差,这意味着没有位置编码的User-to-Item Network很难拟合。
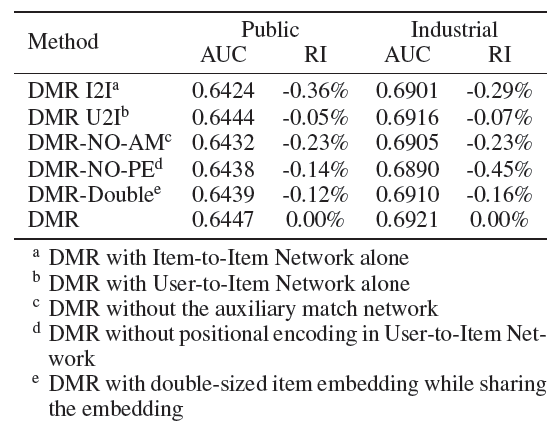
user-to-item相关性的representation的有效性:我们在公共数据集和工业数据集上探索了两个user-to-item相关性的值,如下图所示。这些值分别在正样本和负样本中取平均。不出所料,正样本的
user-to-item相关性高于负样本,这意味着我们的user-to-item相关性模型是合理的。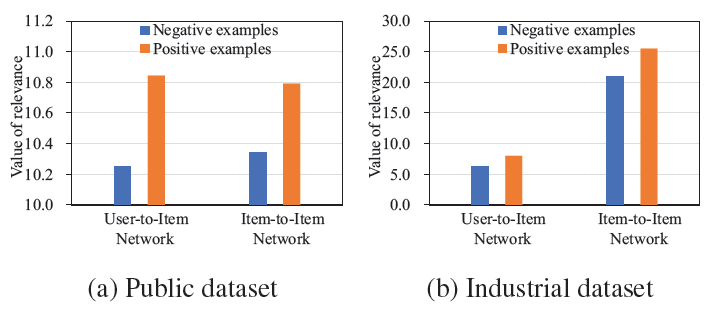
辅助
match网络的有效性:下图显式了DMR在公共数据集和工业数据集上的学习曲线learning curve。可以看到目标损失matching和ranking联合训练是有效的。其中
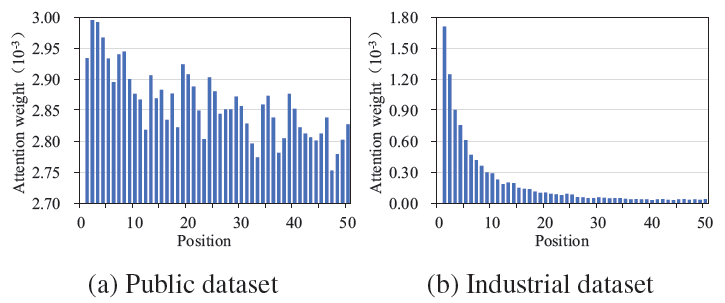
位置编码的有效性:我们探索用户行为序列中不同位置的注意力权重。下图给出了公共数据集和工业数据集上
Item-to-Item Network中的平均权重,其中距离当前时间越近的行为具有越小的位置编号。尽管注意力权重受到多个因素的影响,但是总体趋势是:如预期所示,最近的行为获得更高的注意力权重,尤其是在工业数据集上。
在线
A/B测试:我们在阿里巴巴的推荐系统中进行在线A/B测试。和我们系统中最新版本的CTR模型DIN相比,DMR的CTR提升了5.5%,click per user提升了12.8%。由于提升如此之大,DMR已经部署到线上从而提供推荐服务。
十八、MiNet[2020]
点击率
click-through rate: CTR预估是在线广告系统中的一项关键任务,它旨在预估用户点击目标广告的概率。预估的CTR会影响广告ranking策略和广告收费模型。因此为了维持理想的用户体验并使收入最大化,准确预估广告的CTR至关重要。CTR预估引起了学术界和工业界的广泛关注。例如:因子分解机
Factorization Machine: FM用于建模pairwise特征交互。深度神经网络
Deep Neural Network用于CTR预估和item推荐,从而自动学习feature representation和高阶特征交互。Wide & Deep(结合了逻辑回归和DNN)之类的混合模型还同时利用了浅层模型和深层模型。此外,深度兴趣网络
Deep Interest Network: DIN基于历史行为对动态的用户兴趣进行建模。深度时空网络
eep Spatio-Temporal Network: DSTN联合利用上下文广告、点击广告、未点击广告进行CTR预估。
可以看到,目前现有工作主要针对单域
CTR预估single-domain CTR prediction,即它们仅将广告数据用于CTR预估,并且对诸如特征交互、用户历史行为、上下文信息等方面建模。不过,广告通常会以原生内容natural content进行展示,这为跨域CTR预估cross-domain CTR prediction提供了机会。论文
《MiNet: Mixed Interest Network for Cross-Domain Click-Through Rate Prediction》解决了这个问题,并利用来自源域source domain的辅助数据来提高目标域target domain的CTR预估性能。论文的研究基于UC头条 (一个集成在UC浏览器APP中的新闻feed服务,每天为数亿用户提供服务),其中源域是新闻(news domain)、目标域是广告(ad domain)。跨域
CTR预估的一个主要优势在于:通过跨域的丰富数据可以缓解目标域中的数据稀疏性和冷启动问题,从而提高CTR预估性能。为了有效利用跨域数据,论文考虑以下三种类型的用户兴趣:跨域的长期兴趣:每个用户都有自己的画像特征,例如用户
ID、年龄段、性别、城市。这些用户画像特征反映了用户的长期内在兴趣。基于跨域数据(即用户和他/她互动的所有新闻、广告),我们能够学习语义上更丰富、统计上更可靠的用户特征embedding。源域的短期兴趣:对于要预估
CTR的每个目标广告,在源域中都有相应的短期用户行为(如,用户刚刚查看的新闻)。尽管新闻的内容可能和目标广告的内容完全不同,但是它们之间可能存在一定的相关性。例如,用户在查看一些娱乐新闻之后很可能会点击游戏广告。基于这种关系,我们可以将有用的知识从源域迁移transfer到目标域。目标域的短期兴趣:对于要预估
CTR的每个目标广告,在目标域中还存在相应的短期用户行为。用户最近点击过的广告可能会对用户在不久的将来点击哪些广告有很大的影响。
尽管上述想法看起来很有希望,但是它面临着一些挑战:
首先,并非所有点击的新闻对于目标广告的
CTR有指示作用indicative。同样地,并非所有点击的广告都能提供关于目标广告
CTR的有用信息。第三,模型必须能够将知识从新闻域迁移到广告域。
第四,针对不同的目标广告,三种类型的用户兴趣的相对重要性可能会有所不同。例如:
如果目标广告和最近点击的广告相似,那么目标域的短期兴趣应该更为重要。
如果目标广告和最近点击的新闻、广告都不相关,那么长期兴趣应该更为重要。
最后,目标广告的
representation和三种类型用户兴趣的representation具有不同的维数(由于特征数量不同)。维数的差异discrepancy自然地强化或削弱某些representation的影响,这是不希望的。
为解决这些挑战,论文提出了混合兴趣网络
Mixed Interest Network: MiNet。在MiNet中:长期兴趣是通过拼接用户画像特征
embeddingembedding是基于跨域数据共同学习,从而实现知识迁移的。源域的短期兴趣是通过向量
目标域的短期兴趣是通过向量
另外,
MiNet包含item-level和interest-level两个level的注意力。item-level注意力同时应用于源域和目标域,它们可以自适应地从最近点击的新闻/广告中提取有用的信息(从而应对挑战1和2)。我们还引入了一个迁移矩阵
transfer matrix,从而将知识从新闻迁移到广告(从而应对挑战3)。此外,长期兴趣基于跨域数据来学习,这也可以进行知识迁移(从而应对挑战3)。interest-level注意力动态调整针对不同目标广告时,三种类型用户兴趣的重要性(从而应对挑战4),从而自适应地融合不同的兴趣representation。此外,具有适当激活函数的
interest-level注意力也可以处理维度差异问题(从而应对挑战5)。
离线和在线实验结果都证明了
MiNet在CTR预估方面的有效性。MiNet的效果优于几种state-of-the-art的CTR预估方法。作者已经在UC头条中部署了MiNet,A/B测试结果也表明在线CTR也有了很大提升。目前MiNet已经服务于UC头条的主要广告流量。论文的主要贡献:
论文提出在跨域
CTR预估中联合考虑三种类型的用户兴趣:跨域的长期兴趣、源域的短期兴趣、目标域的短期兴趣。论文提出了
MiNet模型来实现上述目标。MiNet模型包含两个level的注意力,其中:item-level注意力可以自适应地从点击的新闻/点击的广告中提取有用的信息。interest-level注意力可以自适应地融合不同的兴趣representation。
论文进行了大量的离线实验来验证
MiNet以及几种state-of-the-art的CTR预估模型的性能。论文还进行了消融研究,从而提供模型背后的进一步的洞察。
相关工作:
CTR预估:现有工作主要解决单域single-domainCTR预估问题,他们对以下方面进行建模:特征交互(如FM, DeepFM)、feature embedding(如DeepMP)、用户历史行为(如DIN,DSTN)、上下文信息(如DSTN)。特征交互:
由于诸如逻辑回归
Logistic Regression: LR和Follow-The-Regularized-Leader: FTRL等广义线性模型缺乏学习复杂特征交互的能力,因此人们提出了因子分解机Factorization Machine: FM来解决这个限制。Field-aware FM: FFM和Field-weighted FM通过考虑特征所属的field的影响来进一步改进FM。近年来,人们提出了深度神经网络
DNN和Product-based Neural Network: PNN等神经网络模型来自动学习特征representation和高阶特征交互。Wide & Deep、DeepFM、Neural Factorization Machine: NFM等一些模型结合了浅层模型和深层模型来同时捕获低阶特征交互和高阶特征交互。feature embedding:Deep Matching and Prediction: DeepMP模型结合了两个subnet来学习更具有表达能力的feature embedding从而用于CTR预估。用户历史行为:
Deep Interest Network: DIN和Deep Interest Evolution Network: DIEN基于历史点击行为对用户兴趣建模。上下文信息:
《Relational click prediction for sponsored search》和《Exploiting contextual factors for click modeling in sponsored search》考虑各种上下文因子,例如广告交互、广告深度ad depth、query多样性等。Deep Spatio-Temporal Network: DSTN联合利用了上下文广告、点击广告、未点击广告进行CTR预估。
跨域推荐:跨域推荐旨在通过从源域
source domain迁移知识来提高目标域target domain的推荐性能。这些方法大致可以分为三类:协同的collaborative、基于内容的content-based、混合的hybrid。协同方法利用跨域的交互数据(如评级
rating)。《Relational learning via collective matrix factorization》提出了协同矩阵分解Collective Matrix Factorization: CMF,它假设一个通用的全局用户因子矩阵global user factor matrix并同时分解来自多个域的矩阵。《Cross-domain Recommendation Without Sharing User-relevant Data》提出了用于跨域推荐的神经注意力迁移推荐Neural Attentive Transfer Recommendation: NATR,而无需共享用户相关的数据。《Conet: Collaborative cross networks for cross-domain recommendation》提出了协同交叉网络Collaborative cross Network,它通过交叉连接cross connection实现跨域的双重知识迁移dual knowledge transfer。基于内容的方法利用了用户或
item的属性。《A multi-view deep learning approach for cross domain user modeling in recommendation systems》将用户画像和item属性转换为稠密向量,并且在潜在空间中match它们。《Collaborative knowledge base embedding for recommender systems》利用item的文本知识、结构知识、视觉知识作为辅助信息来帮助学习item embedding。混合方法结合了交互数据和属性数据。
《CCCFNet: a content-boosted collaborative filtering neural network for cross domain recommender systems》在一个统一的框架中结合了协同过滤和基于内容的过滤。
不同的是,在本文中,作者解决了跨域
CTR预估问题。论文对三种类型的用户兴趣进行建模,并在神经网络框架中自适应地融合它们。
18.1 模型
在线广告中的
CTR预估任务是建立一个预估模型来预测用户点击特定广告的可能性。每个样本可以由多个field描述,如用户信息(用户ID、城市、年龄等)、广告信息(素材ID、Campaign ID、广告标题等)。每个field的实例代表一个特征,如用户ID字段可能包含诸如2135147或3467291。下表为
CTR预估任务样本的示例,其中Label表示用户是否点击这个广告。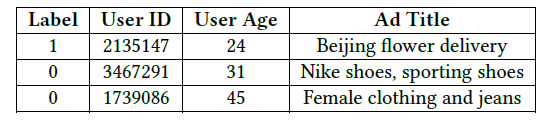
我们定义跨域
CTR预估问题为:利用一个源域(或多个源域)中的数据来提高目标域中CTR预估性能。在新闻
feeds流广告中(如下图所示的UC头条 ),源域就是原生natural的新闻feeds流、目标域是广告。这种情况下,源域和目标域共享同一组用户,但是没有重叠的item。
为了有效利用跨域数据,我们提出了混合兴趣网络
Mixed Interest Network: MiNet,如下图所示。该模型对三种类型的用户兴趣进行了建模:跨域的长期兴趣是通过拼接用户画像特征
embeddingembedding是基于跨域数据共同学习,从而实现知识迁移的。源域的短期兴趣是通过向量
目标域的短期兴趣是通过向量
在
MiNet中,我们还应用了两种level的注意力:item-level注意力、interest-level注意力。item-level注意力的目的是从最近点击的新闻/广告中提取有用的信息(和待预估CTR的目标广告相关),并抑制噪声。interest-level注意力的目的是自适应地调整三种类型的用户兴趣(即
接下来我们详细描述各个组件。
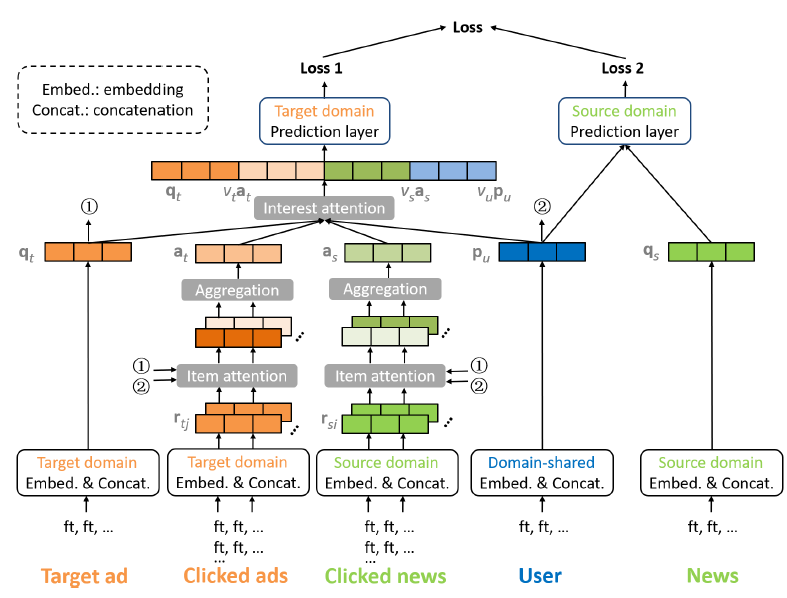
18.1.1 Feature Embedding
我们首先将特征编码为
one-hot encoding。对于某个离散型特征,假设其unique取值数量为unique集合选取的是在两个域中的unique取值集合的交集,即:该unique值在两个域中都出现过。对于该特征的第
one-hot encoding记作:其中
1、其它项全部为零。然后我们将稀疏的高维
one-hot encoding映射到适合神经网络的稠密的低维embedding向量。具体而言,我们定义一个embedding矩阵embedding维度且满足那么该特征的第
embedding向量
18.1.2 跨域的长期兴趣
对于每个广告样本,我们将其特征拆分为用户特征、广告特征。
我们获取所有广告特征,并拼接对应的
embedding向量,从而获取目标域中的广告的representation向量同样地,我们可以在源域中获得新闻
representation向量对于用户,我们通过相应的用户特征
embedding向量进行拼接,从而获得长期兴趣representation向量例如,如果用户
UID = u123, City = BJ, Gender = male, OS = ios,则我们有:其中
||表示向量拼接。长期兴趣
representation向量
这里
representation向量维度、新闻representation向量维度、用户representation向量维度。
18.1.3 源域目标的短期兴趣
给定一个用户,对于目标域中的每个目标广告,用户通常会在源域中查看新闻。尽管新闻的内容可能和目标广告的内容完全不同,但是它们之间可能存在一定的相关性。例如,用户在查看一些娱乐新闻之后很可能点击游戏广告。基于这种关系,我们可以将有用的知识从源域迁移到目标域。
令最近点击的新闻的
representation向量的集合为具体而言,聚合的
representation其中
聚合的
representation剩下的问题是如何计算权重
一种简单的方法是选择
另一种方式是基于注意力机制,
其中
上式仅单独考虑每条被点击的新闻
此外,上式也未考虑目标用户。例如,无论目标广告是关于咖啡还是衣服,无论目标用户是
我们提出
item-level注意力,其中:
attention隐向量维度;上式考虑了以下方面:
源域中点击的新闻
目标域中的目标广告
目标用户
点击新闻和目标广告之间的迁移交互
transferred interaction其中
transfer matrix,它将源域的
通过这种方式,计算出的
aware、以及目标用户感知的aware。另外,它还考虑了点击新闻和跨域目标广告之间的交互interaction。如果采用两层
DNN来计算attention,是否可以移除迁移交互项?
复杂度缩减:
item-level注意力中,迁移矩阵为降低计算复杂度,我们将
18.1.4 目标域的短期兴趣
给定用户,对于每个目标广告,该用户在目标域中也具有近期行为。用户最近点击的广告对用户不久将来点击的广告有很大的影响。
令最近点击的广告的
representation向量集合为representation其中:
attention隐向量维度;聚合的
representation上式考虑了以下方面:
目标域中点击的广告
目标域中的目标广告
目标用户
点击的广告和目标广告之间的交互
interaction
类似地,计算出的
aware、以及目标用户感知的aware。
18.1.5 Interest-Level Attention
在获得三种类型的用户兴趣
CTR。尽管
aspect,并且具有不同的维度。因此,我们不能使用加权和的方式来融合它们。一种可能的解决方案是将所有可用信息拼接起来作为一个长的输入向量:
但是,这样的解决方案找不到针对目标广告
因此,我们没有使用
其中
其中:
intrinsic重要性,而不管该兴趣的实际取值。
可以看到,这些权重是根据所有可用信息来计算的,以便在给定其它类型的用户兴趣的条件下考虑特定类型用户兴趣对于目标广告的贡献。
item-level attention采用了加权sum池化,而interest-level attention采用了加权拼接。事实上向量拼接(相比较于池化操作)可以保留尽可能多的信息。由于历史行为序列的长度不固定,因此为了得到固定长度的向量所以选择了加权池化。
由于兴趣
embedding数量是固定的3个,因此可以进行向量拼接从而得到固定长度的向量。
我们使用
1.0。这是我们想要的效果,因为这些权重可以补偿维度差异问题dimension discrepancy problem。例如,当
如果我们用
sigmoid函数代替exp函数,使得分配给0.0 ~ 1.0之间,那么也无法解决这个问题。而如果分配给
1.0,那么可以很好地缓解这种维度差异效应。
而且,这些权重是自动学习的,因此在必要时也会小于
1.0。这里并没有对重要性进行归一化,因此得到的是 “绝对相关性”。归一化之后代表的是“相对相关性”。另外为了使得绝对相关性非负,这里使用指数函数
exp。具体效果可以做实验来对比。
18.1.6 模型和部署
在目标域,我们让输入向量
ReLU激活函数的几个全连接层FC layer,从而利用高阶特征交互以及非线性变换。具体而言:
其中:
最后,向量
sigmoid输出层得到目标广告的预估CTR:其中
为了便于长期兴趣
embedding向量的拼接。同样地,我们让
FC层和一个sigmoid输出层(这些层都具有自己的参数)。最后,我们获得了目标新闻的预估CTRrepresentation向量的集合我们使用交叉熵作为损失函数。在目标域中,训练集上的损失函数为:
其中:
label,CTR,label集合。类似地,我们得到源域中的损失函数
其中
注意:
我们在
UC头条部署了MiNet,其广告投放系统架构如下图所示。在2019年12月到2020年1月的两周内,我们在A/B test框架中进行了在线实验,其中的basic模型为DSTN,评估指标为实际CTR。在线
A/B test表明,和DSTN相比,MiNet使得在线CTR提升了4.12%。该结果证明了MiNet在实际CTR预估任务中的有效性。经过A/B test之后,MiNet服务于UC头条的主要流量。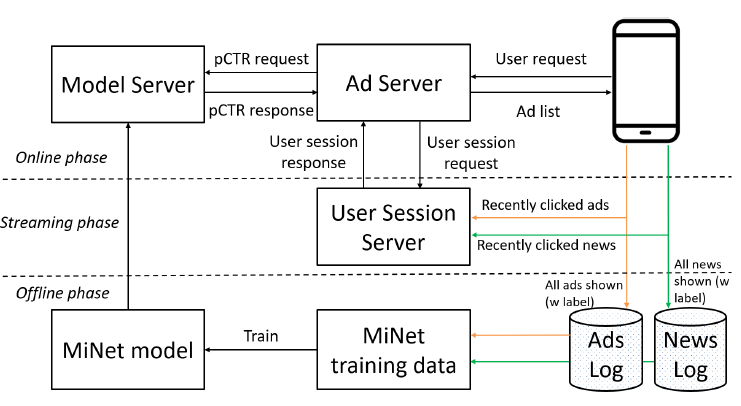
18.2 实验
数据集:
Company News-Ads数据集:该数据集包含UC头条中从新闻系统和广告系统中随机抽取的新闻、广告的曝光和点击日志。源域是新闻,目标域是广告。我们将
2019年的连续6天的日志用于初始训练,随后一天的日志用于验证,再之后一天的日志用于测试。在验证集上找到最佳超参数之后,我们将初始训练集和验证集合并为最终训练集,并使用最佳超参数重新训练。使用的特征包括:用户特征(如用户
ID、agent、城市)、新闻特征(如新闻标题、新闻category、新闻tag)、广告特征(如广告标题、广告ID、广告category)。Amazon Books-Movies数据集:Amazon数据集已被广泛用于评估推荐系统的性能。我们选择两个最大的类别来用于跨域CTR预估任务,即图书Books、影视Movies&TV。源域是图书,目标域是影视。我们在每个域中只保留至少有5次评分的用户。我们将评级为4,5分的评分转换为label 1,其它的评分都视为label 0。为了模拟
CTR预估的行业惯例(即,预估未来的CTR而不是过去的CTR),我们按照时间顺序对用户日志进行排序,然后将每个用户的最后一个评分构成测试集、倒数第二个评分构成验证集、其它评分构成初始训练集。在验证集上找到最佳超参数之后,我们将初始训练集和验证集合并为最终训练集,并使用最佳超参数重新训练。使用的特征包括:用户特征(用户
ID)、图书/影视特征(item ID、品牌、标题、主类目category和子类目)。
这些数据集的统计信息如下表所示。
fts.表示特征features,ini.表示初始的initial,insts.表示实例instances,val.表示验证validation,avg.表示均值average。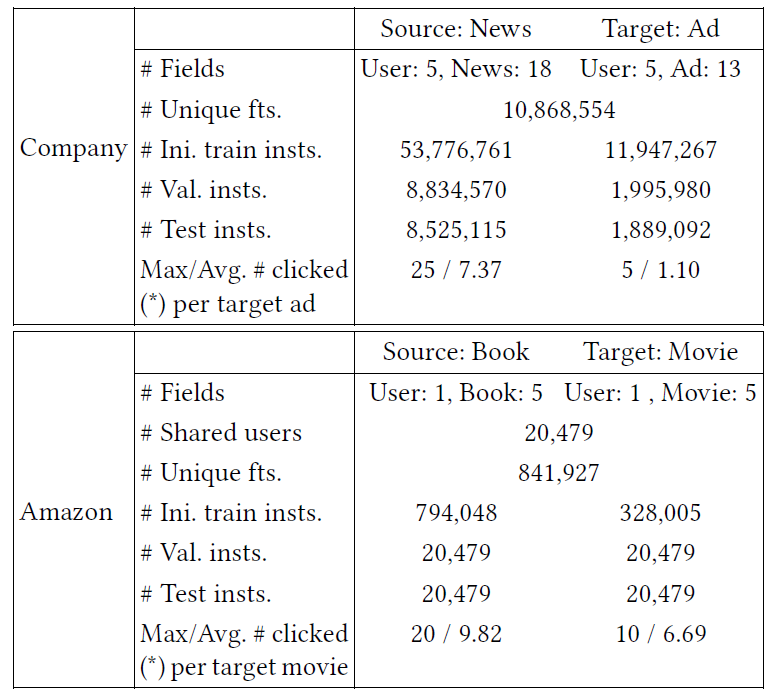
baseline方法:我们比较了单域方法和跨域方法。现有的跨域方法主要是为跨域推荐而提出的,必要时我们将其扩展用于跨域CTR预估(如,包含属性特征而不是仅包含ID特征,并且调整损失函数)。单域方法:
LR:逻辑回归。它是一个广义的线性模型。FM:因子分解机。它同时对一阶特征重要性和二阶特征交互进行建模。DNN:深度神经网络。它包含一个embedding层、几个FC层、以及一个输出层。Wide & Deep:经典的Wide & Deep模型。它结合了逻辑回归(wide部分)和DNN(deep部分)。DeepFM:DeepFM模型。它结合了FM(wide部分)和DNN(deep部分)。DeepMP:Deep Matching and Prediction模型(即DeepMCP)。它学习了用于CTR预估的、更有表达能力的feature embedding。DIN:Deep Interest Network模型。它基于历史行为对动态用户兴趣进行建模,从而进行CTR预估。DSTN:Deep Spatio-Temporal Network模型。它利用时空辅助信息(即,上下文信息,点击的广告,未点击的广告)进行CTR预估。
跨域方法:
CCCFNet:Cross-domain Content-boosted Collaborative Filtering Network。它将协同过滤和content-based filtering结合起来的因子分解框架。它与神经网络有关,因为CF中的潜在因子等价于神经网络中的embedding向量。MV-DNN:Multi-View DNN模型。它扩展了Deep Structured Semantic Model: DSSM,并具有multi-tower的matching结构。MLP++:MLP++模型。它利用了两个MLP,并且跨域共享的用户embedding。CoNet:Collaborative cross Network模型。它在MLP++上添加交叉连接单元cross connection unit,从而实现双重dual知识迁移。
模型配置:
每个特征的
embedding向量维度设置为10维。item-level注意力中,迁移矩阵Company数据集:基于神经网络模型中的
FC层数量设为[512, 256]。attention隐向量维度batch size为512,目标域batch size为128。
Amazon数据集:基于神经网络模型中的
FC层数量设为[256, 128]。attention隐向量维度batch size为64,目标域batch size为32。
所有方法都基于
Tensorflow实现,并使用Adagrad算法。每个方法运行5次,并报告平均结果。评估指标:
AUC, RelaImpr, Logloss。AUC反映了对于随机选择的正样本和负样本,模型将正样本排序rank在负样本之上的概率。对于完全随机的模型,AUC = 0.5。AUC越大越好。AUC的一个很小的改进可能会导致在线CTR的显著提升。RelaImpr衡量指定模型相对于基础模型的相对提升。由于随机模型的AUC为0.5,因此RelaImpr定义为:Logloss:测试集(目标域)的对数损失,即
实验结果如下表所示。
*表示和最佳的baseline相比,基于成对t-test检验的、可以看到:
就
AUC而言,诸如LR和FM之类的浅层模型的表现要比深度模型更差。FM的性能优于LR,因为它可以进一步建模二阶特征交互。与
LR和DNN相比,Wide & Deep获得了更高的AUC,表明结合LR和DNN可以提高预估性能。在单域方法中,
DSTN表现最佳。因为DSTN共同考虑了可能影响目标广告CTR的各种时空因素。在跨域方法中,
CCCFNet优于LR和FM,这表明使用跨域数据可以提高性能。CCCFNet性能比其它跨域方法更差,因为它压缩了所有属性特征。MV-DNN的性能和MLP++相近,它们都通过embedding共享来实现知识迁移。CoNet在MLP++上引入了交叉连接单元,从而实现跨域的双重知识迁移。然而,这也引入了更高的复杂度和随机噪声。
CCCFNet,MV-DNN,MLP++,CoNet主要考虑长期的用户兴趣。相反,我们提出的MiNet不仅考虑了长期用户兴趣,还考了了这两个域的短期兴趣。通过适当地结合这些不同的兴趣信号,MiNet显著地超越了这些baseline方法。
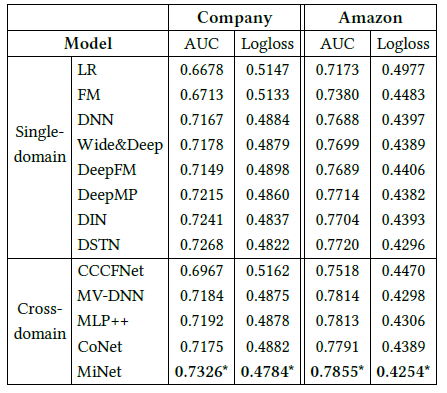
level of attention:这里我们考察注意力level的影响。我们采用以下配置:没有
attention机制、仅item-level attention、仅interest-level attention(并且使用文中提出的指数激活函数)、仅interest-level attention(但是用sigmoid代替exp函数)、同时采用两种attention机制。实验结果如下图所示(
Base model:DNN),可以看到:没有
attention的表现最差,这是因为如果没有注意力机制来提取,那么有用的信号很容易被噪音淹没。item-level attention或者interest-level attention都可以提升AUC,同时使用二者可以获得最高的AUC。interest-level attention(sigmoid)效果比interest-level attention(exp)更差。这是因为不合适的激活函数无法有效解决维度差异问题。
这些结果证明了我们提出的分层注意力机制的有效性。
item-level attention:这里我们考察MiNet中item-level注意力权重,并检查它们是否可以捕获有信息的信号。下面给出
Company数据集中随机选择的一个活跃用户(因此具有相同的点击广告集合、点击新闻集合),对于不同目标广告的注意力权重。由于隐私问题,我们仅按照类目粒度展示广告和新闻。由于广告位于同一个域中,因此比较容易判断点击广告和目标广告之间的相关性。而广告和新闻位于不同的域中,因此很难判断它们之间的相关性。因此我们根据用户的行为日志来计算概率
可以看到:
当目标广告为时尚媒体
Publishing & Media:P&M时,P&M类目的点击广告权重最高,而娱乐Entertainment类目的点击新闻权重最高。当目标广告为游戏
Game时,游戏类目的点击广告权重最高,而体育新闻类目的点击新闻权重最高。
以上结果表明,
item-level注意力确实可以动态捕获针对不同目标广告的更重要的信息。我们还观察到,该模型可以学到点击新闻和目标广告之间的某种相关性。具有较高
理论上
top 3重要性的历史点击广告和历史点击新闻?
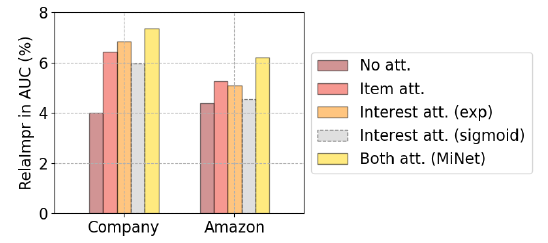
interest-level attention:这里我们研究MiNet中不同类型的用户兴趣建模的效果。我们观察到两个数据集上完全不同的现象,如下图所示(
Base model:DNN)。src.表示源域source domain、tar.表示目标域target domain。在
Company数据集上,和建模长期兴趣相比,建模短期兴趣可以实现更高的AUC。这表明短期行为非常有帮助。在
Amazon数据集上,建模长期兴趣会产生更高的AUC。这是因为Amazon数据集是电商数据集而不是广告,并且评分的性质和点击的性质不同。MiNet综合考虑所有类型的用户兴趣时,获得了最高的AUC。这表明不同类型的用户兴趣可以相互补充,联合建模可以带来最好的效果。
十九、DSTN[2019]
点击率
Click-Through Rate: CTR预估是用于预测用户点击某个item的可能性。它在在线广告系统中起着重要作用。例如,广告ranking策略通常取决于CTR x bid,其中bid是点击广告后系统获得的收益。另外,根据常见的cost-per-click: CPC计费模式,只有在用户点击广告之后才会对广告主收费。因此,为了最大化程度地增加收入并保持理想的用户体验,准确地预估广告的CTR至关重要。CTR预估引起了学术界和工业界的广泛关注。一系列研究方向是利用机器学习方法独立预估每个广告的CTR。例如,因子分解机Factorization Machine: FM根据所涉及特征对应的潜在向量来建模pairwise特征交互。近年来,深度神经网络DNN被用于CTR预估和item推荐,以自动学习feature representation和高阶特征交互。为了同时利用浅层模型和深层模型,人们还提出了混合模型hybrid model。例如,Wide & Deep将逻辑回归Logistic Regression: LR和DNN结合起来,从而提高模型的memorization和generalization能力。DeepFM将FM和DNN相结合,进一步提高了模型学习特征交互的能力。这一系列方法独立地考虑每个目标广告,但是忽略了可能影响目标广告
CTR的其它广告。在本文中,我们从两个角度探讨辅助广告auxiliary ad。空域
spatial domain角度:我们考虑在同一个页面上出现的、目标广告上方展示的上下文广告contextual ad。背后的直觉是:共同展示的广告可能会争夺用户的注意力。
时域
temporal domain角度:我们考虑用户的历史点击和历史未点击广告。背后的直觉是:历史点击广告可以反映用户的偏好,历史未点击广告可能一定程度上表明用户的不喜欢。
这两个角度包含了三种类型的辅助数据
auxiliary data(如下图所示):同一个页面上出现的、目标广告上方展示的上下文广告contextual ad;用户的历史点击广告clicked ad;用户的历史未点击广告unclicked ad。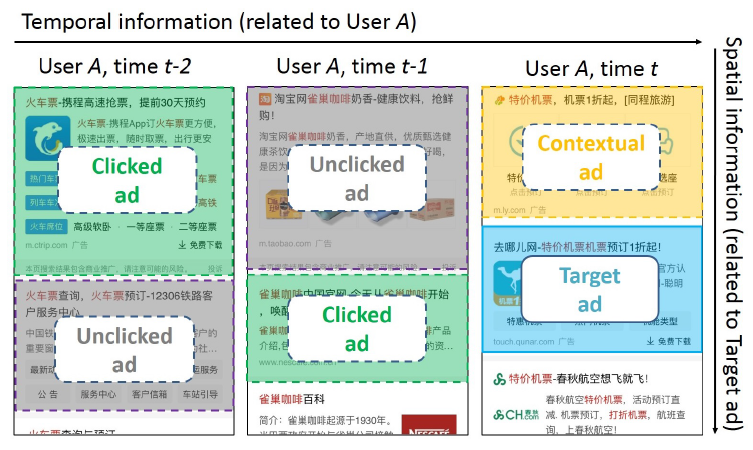
为有效利用这些辅助数据,我们必须解决以下问题:
由于每种类型辅助广告的数量可能会有所不同,因此模型必须能够适应所有可能的情况。
例如,可能有
1个上下文广告、2个历史点击广告、4个历史未点击广告,也可能是0个上下文广告、3个历史点击广告、2个历史未点击广告。由于辅助广告不一定和目标广告相关,因此模型应该能够提取有用的信息并抑制辅助数据中的噪声。
例如,如果历史点击广告集合是关于咖啡、衣服、汽车的广告,而目标广告是咖啡广告,那么模型能够学到哪个历史点击广告对目标广告的
CTR预估更有用。每种类型辅助广告的影响程度可能会有所不同,并且模型应该能够区分它们的贡献。
例如,应该区别对待上下文广告和历史点击广告的重要性。
模型应该能够融合所有可用的信息。
为了解决这些问题,论文
《Deep Spatio-Temporal Neural Networks for Click-Through Rate Prediction》提出了用于CTR预估的深度时空神经网络Deep SpatioTemporal neural Network: DSTN的三种变体。这些变体包括:池化pooling模型、自注意力self-attention模型、交互式注意力interactive attention模型。其中,交互式注意力模型完全解决了上述问题。在一个公共数据集和两个工业数据集上的离线实验表明:
DSTN的效果优于几种state-of-the-art的CTR预估方法。作者在中国第二大搜索引擎 “神马搜索” 中部署了DSTN模型。在线A/B test表明:和线上最新的serving模型相比,DSTN模型的在线CTR得到显著提升。论文主要贡献:
论文探索了三种类型的辅助数据,从而提高目标广告的
CTR预估。这些辅助数据包括:展示在同一个页面上的、目标广告上方的上下文广告,用户历史点击广告,用户历史未点击广告。论文提出了有效融合这些辅助数据来预测目标广告
CTR的DSTN模型。DSTN模型能够学习辅助数据和目标广告之间的交互,并强调更重要的hidden information。论文对来自真实广告系统的三个大规模数据集进行了广泛的离线实验,从而测试
DSTN和几种state-of-the-art方法的性能。论文还进行了案例研究,从而提供模型背后的进一步洞察。论文在中国第二大搜索引擎神马搜索中部署了性能最好的
DSTN。论文还进行了在线A/B test,从而评估DSTN在实际CTR预估任务中的性能。
相关工作:
CTR预估:学习特征交互效应effect of feature interaction似乎对于准确的CTR预估至关重要。广义线性模型,如逻辑回归
Logistic Regression: LR和Follow-The-Regularized-Leader: FTRL在实践中表现出不错的性能。然而,线性模型缺乏学习复杂特征交互的能力。因子分解机
Factorization Machine: FM根据所涉及特征的潜在向量对pairwise特征交互进行建模。Field-aware FM: FFM和Field-weighted FM通过考虑特征所属的field的影响来进一步改进FM。
近年来,深度神经网络
DNN显示出强大的自动学习有信息量informative的feature representation的能力。因此,DNN也被用于CTR预估和item推荐,以自动学习feature representation和高阶特征交互。FNN在应用DNN之前预训练FM。PNN在embedding layer和全连接层之间引入了一个product layer。Wide & Deep模型结合了LR和DNN来同时捕获低阶特征交互和高阶特征交互。这种结构还同时提高了模型的memorization和generalization能力。DeepFM像FM一样对低阶特征交互建模、像DNN一样对高阶特征交互建模。NFM结合了FM的线性和神经网络的非线性。
利用辅助数据进行
CTR预估:另外有一系列研究利用辅助数据来提高CTR预估性能。RNN-based模型:《Sequential Click Prediction for Sponsored Search with Recurrent Neural Networks》考虑用户的历史行为(例如,该用户点击了哪些广告)。论文使用RNN来建模用户行为序列的依赖性。《Improved recurrent neural networks for session-based recommendations》为session-based推荐提出了改进的RNN。
基于
RNN的模型的一个主要问题是:模型生成一个行为序列的整体embedding向量,该向量只能保留用户非常有限的信息。即使使用LSTM和GRU等高级记忆单元结构,长期依赖性仍然难以保留。此外,由于其递归结构,RNN的离线训练过程和在线预测过程都很耗时。CRF-based模型:《Relational click prediction for sponsored search》考虑了同一页面上显示的广告之间的pairwise关系,并提出了一种基于条件随机场Conditional Random Field: CRF的CTR预估模型。《Exploiting contextual factors for click modeling in sponsored search》在建模CTR时考虑了各种上下文因子,例如广告深度ad depth、query多样性、广告交互。
这些模型的一个主要问题是:需要根据数据分析手动定义顶点特征函数
vertex feature function和边特征函数edge feature function,并且难以将模型推广到其它类型的数据。差异:本文提出的
DSTN和先前工作的不同之处在于:DSTN将异质辅助数据heterogeneous auxiliary data(即上下文、点击广告、未点击广告)集成在一个统一的框架中,而RNN-based模型无法利用上下文广告和未点击广告,而CRF-based模型无法结合点击广告和未点击广告。DSTN不是RNN based,因此更容易实现,并且训练和在线评估都更快。
19.1 模型
这里我们首先介绍
CTR预估问题,然后介绍DSTN模型的三种变体。CTR预估问题:在线广告中的CTR预估任务是建立一个预估模型来估计用户点击特定广告的概率。每个样本都可以由多个字段
field来描述,例如用户信息(用户ID、用户城市、用户年龄等等),以及广告信息(广告创意ID、广告计划ID、广告标题等等)。我们将每个样本称作ad instance,它不仅包含广告信息,也包括用户信息、上下文信息等。字段的实例
instance是一个特征。例如,用户ID字段可能包含诸如2135147或3467291的特征。下表给出了一些例子,其中:第一列是标签列,1表示发生点击行为,0表示未发生点击行为;其它各列均为一个字段。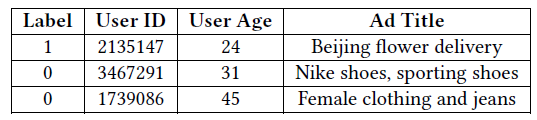
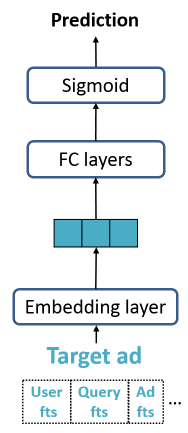
诸如
FM, DNN, Wide & Deep之类的经典CTR预估模型主要考虑目标广告(如下图所示,target ad表示目标广告对应的样本),它们聚焦于如何表示样本特征,以及如何学习特征交互。与这些方法不同,我们探索了辅助数据(即辅助广告)来提升
CTR预估。我们必须解决以下问题:如何适应每种类型辅助广告的不同数量的各种情况。
如何从辅助广告中提取有用的信息并抑制噪音。
如何区分每种类型辅助广告的贡献。
如何融合所有可用信息。
19.1.1 Embedding
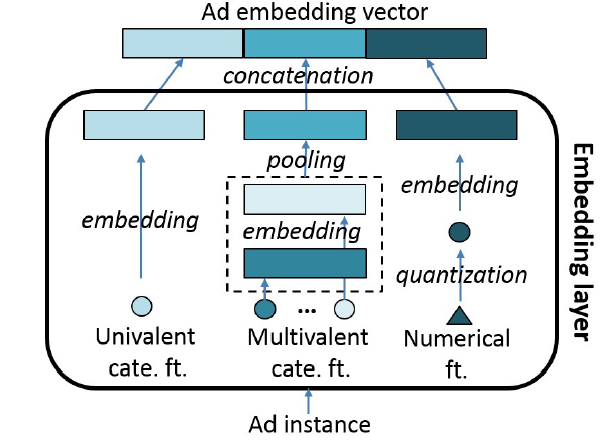
在介绍模型之前,我们首先介绍所有模型中常见的
embedding过程。embedding过程是先将每个特征映射到一个embedding向量,然后将每个样本表示为相应特征embedding向量的拼接concatenation。假设某个特征有
unique值。我们创建一个embedding矩阵embedding向量。这个embedding矩阵我们将特征分为三种类型并进行不同的处理,如下图所示。
cate.表示categorical,ft.表示feature。ad instance表示样本,ad embedding vector表示样本embedding向量。单值
univalent的离散特征:这类特征仅包含单个值。例如用户
ID就是这类特征的代表,每个用户ID特征只有一个用户ID值。如果我们使用one-hot特征表示,则由于unique用户ID数量可能高达embedding向量从而适用于神经网络。和
one-hot representation相比,这些embedding向量包含更丰富的信息。多值
multivalent的离散特征:这类特征包含一组值。例如广告标题就是这类特征的代表。假设广告标题为
ABCD,那么它的bi-gram表示为:AB, BC, CD。由于这类特征包含取值的数量不是固定的,因此我们首先将每个值映射到embedding向量,然后执行池化来生成固定长度的聚合向量。数值特征:用户年龄是数值特征的典型例子。每个数值特征首先被离散化为离散的桶,然后表示为桶
ID,最后将每个桶ID映射到embedding向量。
经过
embedding过程之后,样本的representationembedding向量的拼接,每个emebdding向量对应于一个field。在
embedding之后:每个目标广告
target ad获得了一个embedding向量embedding维度。上下文广告集合获得了
embedding向量embedding维度。历史点击广告集合获得了
embedding向量embedding维度。历史未点击广告集合获得了
embedding向量embedding维度。
注意:
embedding、广告embedding、上下文embedding(如query)。embedding、上下文embedding,而不包含用户embedding。因为历史点击广告、历史未点击广告和目标广告都是同一个用户,没必要提供冗余的、重复的用户信息。
embedding,而不包含用户embedding、广告embedding。因为上下文广告和目标广告都是同一个用户、同一个上下文(如
query)。
19.1.2 DSTN
a. DSTN-Pooling
由于不同用户的辅助广告数量
auxiliary instance处理未固定长度的向量。在DSTN-Pooling模型中,我们使用sum池化来实现该目标,模型结构如下图所示。representation向量representation向量representation向量如果某种类型的辅助广告完全缺失(例如,根本没有上下文广告)则我们将全零向量作为其聚合
representation向量。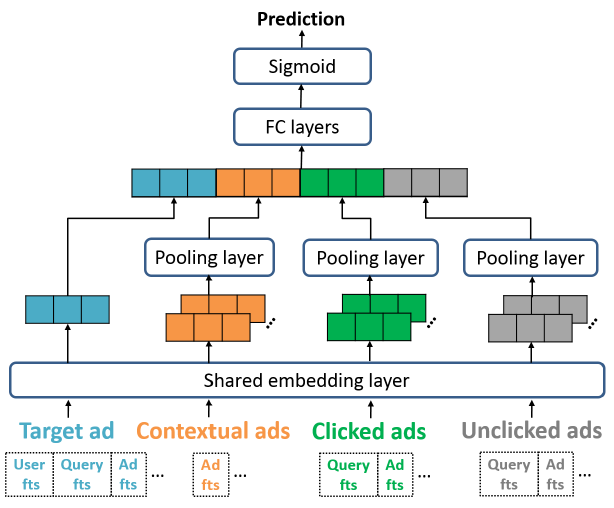
现在我们有了目标广告的
representationrepresentationrepresentation中包含的信息。具体而言,我们生成融合的
representation其中:
representation映射到相同的语义空间。bias向量。
可以看到,我们实际上使用不同的权重来融合来自不同类型数据的输入。这是因为不同类型的辅助数据对于目标广告的影响程度可能不同,因此我们需要区分这些差异。
此外,融合的
representationrepresentation如果我们将目标广告的
representationrepresentation其中:
bias向量。这种方式大大简化了模型。因此,
DSTN-Pooling模型最终的设计为:首先拼接各个
representation从而获得临时representaion然后将
ReLU激活函数的全连接层FC layer,从而利用高阶特征交互以及非线性变换。文献表明:ReLU激活函数在收敛速度和模型效果方面比tanh激活函数具有明显的优势。其中:
全连接层输出向量
sigmoid函数来生成目标广告的预估CTR:其中
此外,为了避免模拟过拟合,我们在每个全连接层之后应用 dropout 。
所有的模型参数通过最小化交叉熵损失函数来学习,其中损失函数定义为:
其中:
label;CTR;label的集合。可以看到:在
DSTN-Pooling模型中,当给定用户在给定位置展示不同的目标广告时只有representationrepresentation仅用作静态基础信息。而且,由于
sum池化生成的,因此有用的信息很容易被淹没在噪声中。例如,如果目标广告是关于咖啡的,但是大多数历史点击广告是关于衣服的、少部分历史点击广告是关于咖啡的。那么,虽然关于衣服的这些历史点击广告对于目标广告的贡献很小,但是sum的结果显然是由这些关于衣服的历史点击广告所主导。
b. DSTN-Self Attention
DSTN-Self Attention模型:鉴于DSTN-Pooling的上述限制,我们考虑采用自注意力机制,即DSTN-Self Attention模型。在我们的
DSTN-Self Attention模型中,我们在每种类型的辅助数据上应用自注意力从而强调更重要的信息。以上下文辅助广告为例,其聚合representation向量建模为:其中
representation的注意力系数,它计算为:其中
representation向量Multilayer Perceptron: MLP。自注意力机制的优点在于:可以根据
self-attention来加权不同的辅助广告权重
归一化的注意力系数
每种类型辅助广告的绝对数量也很重要,但是归一化并未捕获这种效果。例如,假设每个上下文辅助广告的重要性都相同,则采用归一化的注意力系数完全无法区分是
1个上下文辅助广告、还是100个上下文辅助广告。
c. DSTN-Interactive Attention
DSTN-Interactive Attention:鉴于DSTN-Self Attention的上述限制,我们考虑引入每种类型辅助广告和目标广告之间的显式交互,即DSTN-Interactive Attention模型,如下图所示。以上下文辅助广告为例,其聚合
representation向量建模为:其中:
和
DSTN-Self Attention相比,这里的此外,
类似地,我们为历史点击辅助广告生成
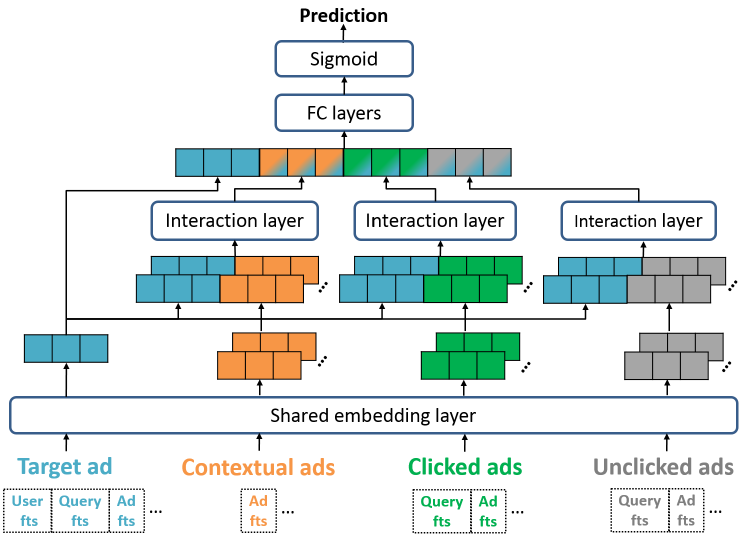
DSTN-Interactive Attention模型最终得到融合的representation为:和
DSTN-Pooling相比,可以看到:辅助
representation例如,假设历史点击广告和咖啡、衣服、汽车相关。
当目标广告
当目标广告
此外,模型仍然保留了使用不同的权重来融合不同类型辅助数据输入的特点。
最后,模型中的权重
最后我们给出
DNN, DSTN-Pooling, DSTN-Interactive Attention等模型的结构对比,如下图所示。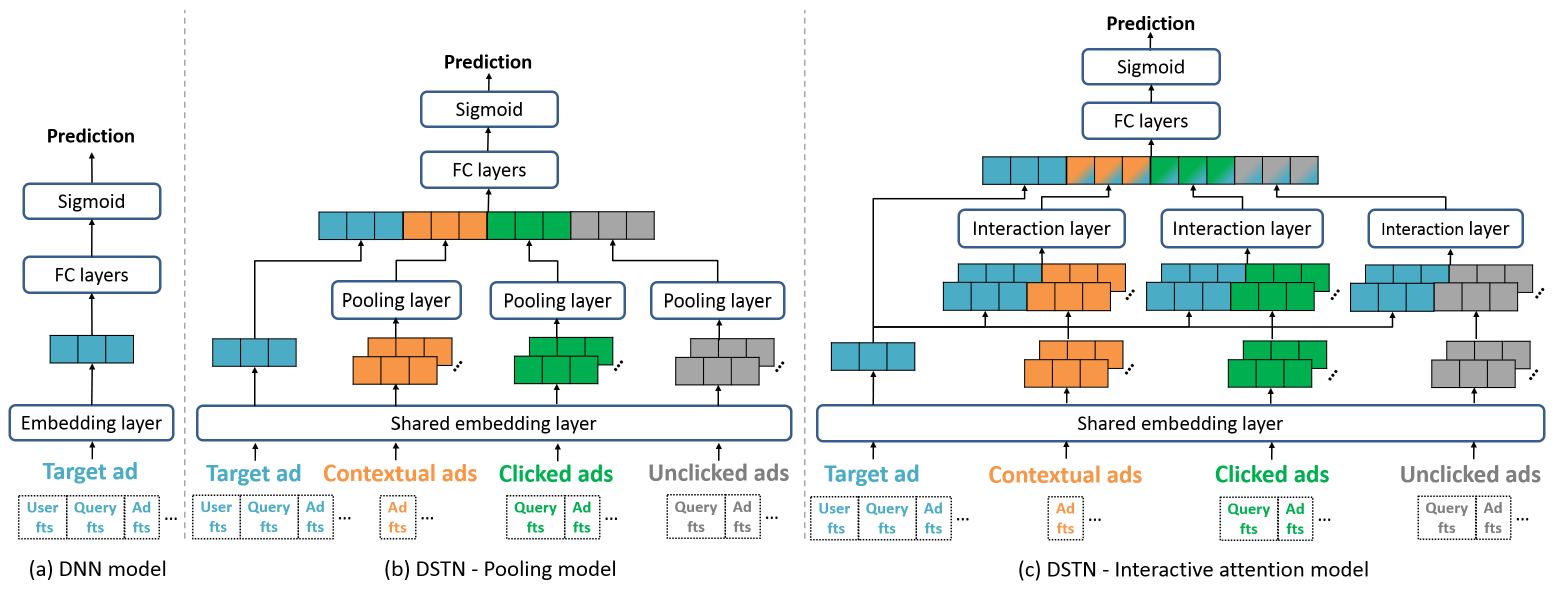
19.1.3 部署
我们在中国第二大搜索引擎 “神马搜索” 中部署了
DSTN-I(简称DSTN)。下图给出了系统的体系架构,其中包括离线阶段、流式streaming阶段、在线阶段。离线阶段:在线用户行为(广告曝光/点击)不断地记录到离线用户日志数据库中。系统从日志数据库中提取训练数据,并训练
DSTN模型。离线训练首先以
batch方式执行,然后周期性地使用最新的日志数据对训练好的模型进行增量更新。streaming阶段:在线用户行为也会被发送到用户会话服务器User Session Server(延迟不超过10s),该服务器上维护并更新了每个用户历史记录的hashmap。为了减少内存需求和在线计算量,
hashmap保持了每个用户最近3天内的最多5个历史点击广告和5个历史未点击广告。如果超过5个,则仅保留最新的5个。在线阶段:收到用户请求之后,
Ad Server首先从User Session Server检索用户历史记录数据。然后Ad Server向Model Server请求一组候选广告的pCTR。
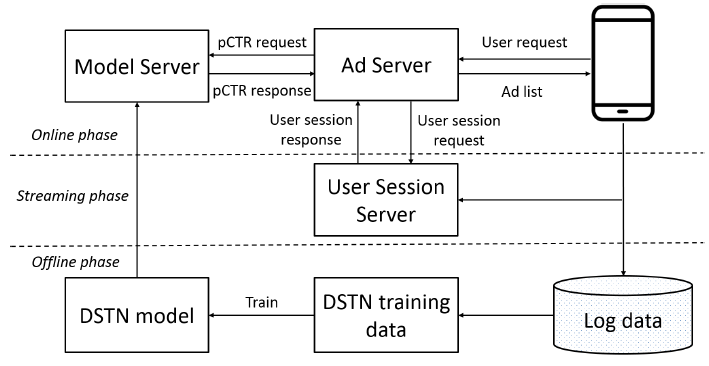
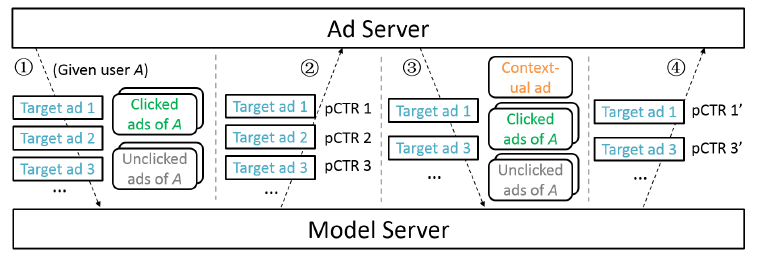
在线阶段的
pCTR请求是分为几个步骤来完成的。这是因为神马搜索现在每个app页面拥有3-4个广告位,因此需要为用户返回3-4个广告。而且,前面的广告是后面广告的上下文。①:
Ad Server将候选目标广告集合以及历史点击广告、历史未点击广告一起发送给Model Server。此时没有上下文广告集合。②:
Model Server返回这些候选目标广告的pCTR。③:
Ad Server根据某些排序策略(依赖于pCTR)选择top候选目标广告。假设该top候选目标广告是广告2,然后广告2将成为其它目标广告的上下文广告。Ad Server将剩余的候选目标广告集合以及上下文广告(广告2)、历史点击广告、历史未点击广告一起发送给Model Server。④:
Model Server将返回剩余候选目标广告的pCTR。
理论上讲我们需要多次执行步骤 ③和④,从而依次挑选目标广告并更新上下文广告集合。但是考虑到预测准确率和服务延迟之间的折衷,我们仅执行步骤③和④一次,并在步骤④之后
Ad Server选择2-3个得分最高的剩余候选目标广告,并将最终广告列表发送给用户。本质是,在线预估的时候上下文广告集合是不确定的,依赖于在线策略的选择。
19.2 实验
这里我们对三个大型数据集进行实验,从而评估所提出的
DSTN以及几种state-of-the-art的CTR预估方法的效果数据集:
Avito广告数据集:该数据集包含来自俄罗斯最大的通用分类网站avito.ru的广告日志随机采样的样本。我们将2015-04-28 ~ 2015-05-18的广告日志用于训练,将2015-05-19的广告日志用于验证,将2015-05-20的广告日志用于测试。我们使用的特征包括:
广告特征,如广告
ID、广告标题、广告类别、广告的父类别parent category(类别的上一级类别)。用户特征,如用户
ID、IP ID、用户agent、用户agent OS、用户设备。query特征,如搜索query、搜索位置location、搜索类别cateogry、搜索参数parameter。
Search广告数据集:该数据集包含来自阿里巴巴商业搜索广告系统的广告曝光和点击日志随机采样的样本。我们将2018年6月连续7天的广告日志用于训练,将下一天的广告日志用于验证,将下下一天的广告日志用于测试。我们使用的特征包括:
广告特征,如广告
ID、广告标题、广告行业。用户特征,如用户
ID、IP ID、用户agent。query特征,如搜索query、搜索位置location。
News feed广告数据集:该数据集来自阿里巴巴商业新闻feed广告系统的广告曝光和点击日志随机采样的样本。我们将2018年7月连续7天的广告日志用于训练,将下一天的广告日志用于验证,将下下一天的广告日志用于测试。我们使用的特征包括:
广告特征,如广告
ID、广告标题、广告行业。用户特征,如用户
ID、召回的广告主题matched ad topic的数量。交叉特征,如
AdType-AdResource。
该数据集中的辅助数据不包含上下文广告。这是因为在我们的新闻
feed广告系统中,页面上仅显示一个广告。
数据集的统计信息如下表所示,其中
avg表示average、ctxt表示contextual、pta表示per target ad。可以看到distinct特征数量可以高达4600万。
baseline方法:LR:逻辑回归模型Logistic Regression。它是一个广义线性模型,建模了一阶特征重要性。FM:因子分解机模型Factorization Machine。它同时对一阶特征重要性和二阶特征交互进行建模。DNN:深度神经网络Deep Neural Network。每个样本首先经过一个embedding层,然后经过几个全连接层。最后输出层利用sigmoid函数来预估CTR。Wide&Deep:Wide&Deep模型。它结合了LR模型(wide部分)和DNN模型(deep部分)。DeepFM:DeepFM模型。它结合了FM模型(wide部分)和DNN模型(deep部分),并且在wide部分和deep部分之间共享相同的输入和embedding向量。事实证明,DeepFM的性能优于Wide&Deep, FNN, PNN等模型。CRF:条件随机场Conditional Random Field方法。它同时考虑了广告的特征、以及该广告和周围广告surrounding ad的相似性。CTR预估的对数几率通过manually defined。CRF在某种程度上是不切实际的,因为在商业广告系统中,无法预先知道目标广告下面的广告。因此,我们仅将上下文广告(即目标广告上方的广告)用作周围的广告。GRU:Gated Recurrent Unit,最先进的RNN网络之一。它利用了用户的历史点击广告序列。DSTN-P:DSTN-Pooling模型。它使用sum池化来聚合辅助数据。DSTN-S:DSTN-Self Attention模型。它使用self attention来聚合辅助数据。DSTN-I:DSTN-Interactive Attention模型。它引入了辅助数据和目标广告之间的显式交互。
在所有这些方法中,
CRF, GRU, DSTN均考虑辅助广告,而所有其它方法都聚焦于目标广告上。具体而言:CRF考虑了上下文广告,GRU考虑了历史点击广告,DSTN考虑了上下文广告、历史点击广告、历史未点击广告。配置:
每个特征的
embedding向量维度设为10。因为distinct特征数量太高,如果embedding维度太大则参数规模异常巨大。DNN, Wide&Deep, DeepFM, GRU, DSTN中全连接层的层数设为2,每层的维度分别为512,256。dropout rate设为0.5。GRU的隐层维度设置为128。DSTN-S中的MLP,隐层维度为128。DSTN-I中的128。所有方法都在
Tensorflow中实现,并通过Adagrad算法进行优化。batch size设为128。我们使用用户最近
3天的历史行为。为了降低内存需求,我们进一步限制5个,则我们全部使用;如果超过5个,则我们使用最新的5个。
评估指标:测试集上的
AUC, logloss。AUC反映了对于随机选择的一个正样本和一个负样本,模型对正样本的rank高于负样本的概率。下表给出了实验结果。可以看到:
Wide&Deep比LR, DNN获得了更高的AUC;同样地,DeepFM比FM, DNN获得了更高的AUC。这些结果表明:将
wide部分和deep部分组合在一起可以提高整体的预测能力。CRF的效果比LR好得多,因为CRF可以通过一个系数来校正LR的预测,该系数summarize了当前广告和上下文广告的相似性。但是,这种相似性是基于原始字符串人工定义的,因此遇到了语义
gap的困扰。GRU在两个数据集上(除了Search数据集)的表现优于LR, FM, DNN, Wide&Deep, DeepFM,因为GRU还利用了历史点击广告。GRU的改善在News Feed广告数据集上最为明显。这是因为用户没有在News Feed广告中提交query,因此历史行为非常有信息量informative。DSTN-P优于GRU。原因有两个:首先,用户行为序列中的连续行为可能没有很好的相关性。例如,某个用户最近点击了零食和咖啡的广告。下一次点击的广告可能是关于牙膏的,而不是关于食品的。这仅仅取决于用户的需要,而不是与之前点击广告的相关性。因此,考虑用户行为序列可能不一定有助于提高预测性能。
其次,
DSTN-P可以利用上下文广告、历史未点击广告中的信息。
当我们比较
DSTN的不同变体时,可以观察到:DSTN-S的性能优于DSTN-P,而DSTN-I的性能进一步优于DSTN-P。这些结果表明:和简单的
sum池化相比,self attention机制可以更好地强调有用的信息。而interactive attention机制显式地引入了目标广告和辅助广告之间的互动,因此可以自适应地抽取比self attention更多的相关信息。我们还观察到,
logloss不一定与AUC相关。即AUC更大的模型,其logloss不一定更小。尽管如此,DSTN-I在所有数据集上的AUC最大、logloss也最小,这显示了模型的有效性。
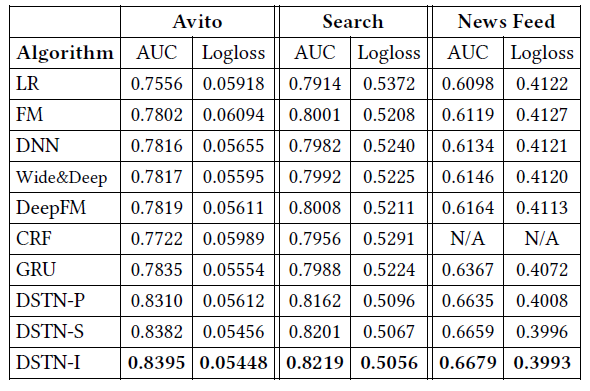
为了检查不同类型辅助数据的影响,我们在
DSTN-I模型中分别仅提供上下文广告、仅提供历史点击广告、仅提供历史未点击广告。为了衡量效果,我们定义并计算以下两个指标:绝对
AUC提升absolute AUC improvement: AbsImp:其中
ctxt是上下文的缩写。标准化的
AUC提升normalized AUC improvemen: NlzImp:这里我们针对平均辅助数据的规模进行归一化。
AbsImp考虑AUC的整体提升,而NlzImp将AUC提升效果针对单个辅助广告进行标准化。通常我们关注AUC的绝对提升而不是相对提升,因为在工业实践中AUC的绝对提升更具有意义和指导性。实验结果如下图所示。
从
(a)中可以看到:不同类型辅助数据的效果在不同数据集上有所不同。上下文广告在Avito数据集上的AbsImp最高,而历史未点击广告在Search数据集上的AbsImp最高。从
(b)中可以看到:有意思的是,一旦标准化之后,上下文广告、历史点击广告的作用就比历史未点击广告高得多。这符合直觉,因为上下文广告可能会分散用户的注意力,而历史点击广告通常会反映出用户的兴趣。相反,历史未点击广告可能会产生很大的噪音:历史未点击可能表明用户对广告不感兴趣,或者用户根本没有查看广告。
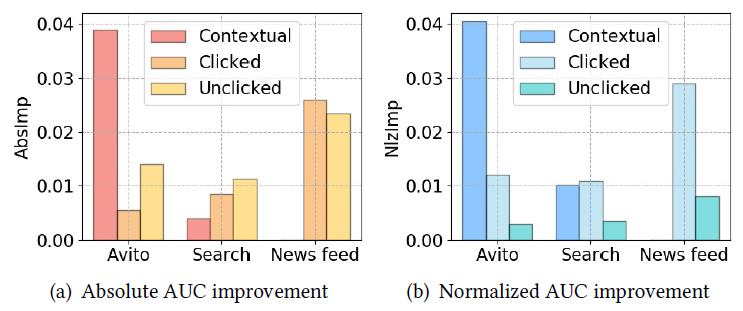
为了检查全连接层深度的影响,我们在
DSTN-I模型中分别选择了三种不同配置的全连接层:单层256维、两层512-256维、三层1024-512-256维。实验结果如下图所示。可以看到:
增加全连接层的数量可以在一开始改善
AUC,但是随后添加更多层时,提升的幅度会降低。最后,添加更多的层甚至可能导致轻微的性能降级
degradation。这可能是由于更多的模型参数导致过拟合,以及更深的模型导致训练难度增加而导致的。
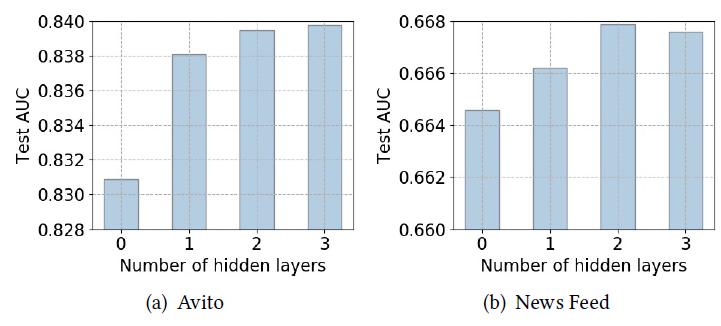
下图分别给出了
NN和DSTN-I学到的ad-embedding的可视化(基于t-SNE),不同颜色代表不同的子类目。这些广告是基于5个主类目(电子、服装、家具、计算机、个人护理)下的20个子类目。我们在每个子类目中随机选择100个广告。注意:这里可视化的是
target ad embedding,而这里的的ad embedding只有广告信息,不包含query信息和用户信息。可以看到:
两种方法学到的
embedding均显示了清晰的簇结构,每个簇代表一组相似的广告。尽管如此,
DNN还是将iPhone和 “三星手机” 混在一起,将 “床” 和 “橱柜” 混在一起,将 “礼服” 和 “鞋子” 混在一起。相比之下,DSTN-I学习到了更清晰的簇,并清楚地区分了不同的子类目。
这些结果表明,
DSTN-I可以借助辅助广告来学习更具代表性的embedding。
现在我们通过对
Avito数据集的一些案例研究来检查DSTN-I辅助广告的注意力权重。我们很难分别检查每种类型的辅助广告,因为很难找到包含足够数量的、所有辅助类型广告的案例。上下文广告:下图给出了关于
YotaPhone的目标广告。我们显示了三个上下文广告,分别是手机镜头、三星手机、HTC手机。我们给出了上下文广告的注意力权重可以看到:两个手机广告的权重相差不大(约
0.6),但是手机镜头广告(最不相似)的权重却要高得多(约0.8)。这样的观察结果符合
《Relational click prediction for sponsored search》中的分析,作者发现:周围的广告和目标广告越相似,目标广告的点击率就越低。这是因为相似的广告可以分散用户的注意力,因为所有这些广告都提供相似的产品或服务。相反,相异的广告可以帮助目标广告更加引人注目,因此
DSTN-I将手机镜头广告给予较大的权重。因此对于上下文广告,和目标广告越相似,注意力权重越低。

历史点击广告:目标广告是关于自拍杆。我们给出了历史点击广告的注意力权重
第一个历史点击广告是关于婴儿安全座椅,这显然与目标广告无关,其注意力权重为
0.5223。第二个历史点击广告是关于闪光灯,闪光灯是用于摄影的数码相机的附件,其注意力权重(
0.7057)要比婴儿安全座椅高得多。第三个历史点击广告是关于三脚架,三脚架和自拍杆更为相似,因此注意力权重更高(
0.8449)。第四个历史点击广告也是关于自拍杆,其注意力权重最高(
0.9776)。
这些观察结果表明:历史点击广告和目标广告越相似,注意力权重越高。这是因为:如果用户曾经点击了和目标广告类似的广告,则用户也可能会点击目标广告。

历史未点击广告:目标广告是关于
Sony相机套装的。四个历史未点击广告分别与自行车、自拍杆、相机镜头、相机套装有关。我们给出了历史未点击广告的注意力权重这些广告和目标广告的相似性依次递增,因此相应的注意力权重也在增加。
这些观察结果表明:历史未点击广告和目标广告越相似,注意力权重越高。这是因为:如果用户过去没有点击和目标广告类似的广告,那么用户很可能也不会点击目标广告。
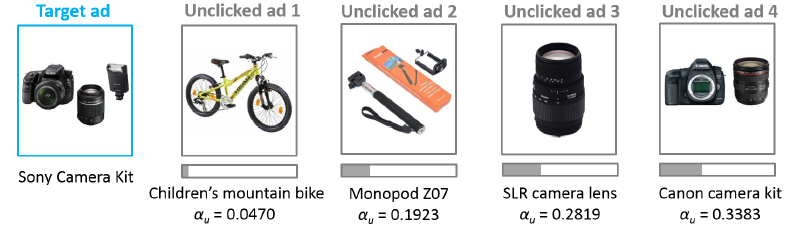
将历史点击广告和历史未点击广告的注意力权重进行比较,我们发现一个有趣的现象:即使历史未点击广告和目标广告非常相似,历史未点击广告的平均权重也要比历史点击广告的平均权重小得多。这是因为历史点击广告会反映出可能的用户偏好,而历史未点击广告则更加模棱两可
ambiguous。我们于
2019年1月进行了为期两周的在线A/B test实现。基准模型是Wide&Deep,这是我们最新的在线serving模型。我们的在线评估指标是CTR。在线实验结果表明:
DSTN的效果始终优于Wide&Deep,两周的平均CTR提升在6.92%。这证明了DSTN在实际点击率预估任务中的有效性。目前我们已经在神马搜索中部署了DSTN。
二十、BST[2019]
在过去的十年中,推荐系统已经成为业界最流行的应用
application。并且在过去的五年中,基于深度学习的方法已经广泛应用于工业推荐系统中。在中国最大的电商平台阿里巴巴上,推荐系统一直是Gross Merchandise Volume: GMV和收入的主要引擎,并且在丰富的电商场景中已经部署了各种基于深度学习的推荐方法。阿里巴巴的推荐系统分为两个阶段:
match和rank。在
match阶段,根据和用户交互的item选择一组相似的item。然后在
rank阶段,我们学习一个经过微调fine-tuned的预测模型,从而预测用户点击给定候选item集合的可能性。
在论文
《Behavior Sequence Transformer for E-commerce Recommendation in Alibaba》中,我们重点关注阿里巴巴旗下淘宝(中国最大的Consumer-to-Consumer: C2C平台)的rank阶段。在这个阶段,我们有数百万的候选item,并且需要在给定用户历史行为的情况下预测用户点击候选item的概率。在深度学习时代,
embedding和MLP已经成为工业推荐系统的标准范式:大量原始特征作为向量被嵌入到低维空间中,然后馈入称作多层感知机multi layer perceptron: MLP的全连接层中,从而预测用户是否会点击某个item。代表作是谷歌的wide and deep learning: WDL,以及阿里巴巴的Deep Interest networks: DIN。在淘宝,我们在
WDL的基础上构建了rank模型,在Embedding&MLP范式中使用了各种特征。例如,item类目category、品牌brand,item的统计数字,用户画像特征等等。尽管该框架取得了成功,但是它本身远远不能令人满意,因为它实际上忽略了一种非常重要的信号:用户行为序列(即用户按顺序点击的item)背后的序列信号sequential signal。例如,用户在淘宝上购买了
iphone之后倾向于点击手机保护套,或者在购买一条裤子之后试图找到合适的鞋子。从这个意义上讲,在淘宝的rank阶段部署预测模型时,不考虑这一因素是有问题的。在
WDL中,模型只是简单地拼接所有特征,而没有捕获用户行为序列中的顺序信息order information。在
DIN中,模型使用注意力机制来捕获候选item和用户历史点击item之间的相似性,也没有考虑用户行为序列背后的序列性质sequential nature。
因此,在这项工作中,为解决
WDL和DIN面临的上述问题,我们尝试将用户行为序列的序列信号融合到淘宝的推荐系统中。受到
natural language processing: NLP中机器翻译任务的Transformer的巨大成功的启发,我们采用self-attention机制,通过考虑embedding阶段的序列信息来学习用户行为序列中每个item的更好的representation。然后将这些item representation馈入到MLP中来预测用户对候选item的响应。Transformer的主要优势在于,它可以通过self-attention机制更好地捕获句子中单词之间的依赖关系。从直觉上讲,用户行为序列中item之间的'dependency'也可以通过Transformer来提取。因此,我们在淘宝上提出了用于电商推荐的user behavior sequence transformer: BST。离线实验和在线
A/B test显示了BST与现有方法相比的优越性。BST已经部署在淘宝推荐的rank阶段,每天为数亿消费者提供推荐服务。相关工作:自从
WDL提出以来,人们已经提出了一系列基于深度学习的方法来提高CTR预估的工作,如DeepFM、XDeepFM、Deep and Cross等。然而,所有这些先前的工作都集中在神经网络的特征组合或不同架构上,而忽略了现实世界推荐场景中用户行为序列的顺序特性sequential nature。最近,
DIN通过注意力机制来处理用户的行为序列。我们的模型和DIN之间的主要区别在于,我们提出使用Transformer来学习用户行为序列中每个item的更deeper的representation,而DIN试图捕获历史点击item和目标item的相似性。换句话讲,我们的transformer模型更适合捕获序列信号。在
《Self-attentive sequential recommendation》和《BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer》中,他们使用Transformer模型来以sequence-to-sequence的方式解决序列推荐问题,而我们的CTR预估模型与他们的架构不同。
20.1 模型
在
rank阶段,我们将推荐任务建模为点击率Click-Through Rate: CTR预估问题,其定义如下:给定用户item构成的用户行为序列itemitem) 的概率。我们在
WDL的基础上构建了BST,整体架构如下图所示。从图中可以看到BST遵循流行的Embedding&MLP范式,其中历史点击item和相关的特征首先被嵌入到低维向量中,然后被馈送到MLP。具体而言,
BST将用户行为序列(包括target item和其它特征Other Features)作为输入。其中Other Features包括:用户画像特征、上下文特征、item特征、以及交叉特征。首先,这些输入特征被嵌入为低维向量。为了更好地捕获行为序列中
item之间的关系,可以使用transformer layer来学习序列中每个item的更深层representation。然后,通过将
Other Features的embedding和transformer layer的输出进行拼接,并使用三层MLP来学习hidden features的交互作用。最后,使用
sigmoid函数生成最终输出。
注意:
Positional Features被合并到Sequence Item Features中。BST和WDL之间的主要区别在于:BST添加了transformer layer,从而通过捕获底层的序列信号来学到用户点击item的更好的representation。接下来的内容我们将以自下而上的方式介绍
BST的关键组件:embedding layer、transformer layer、MLP。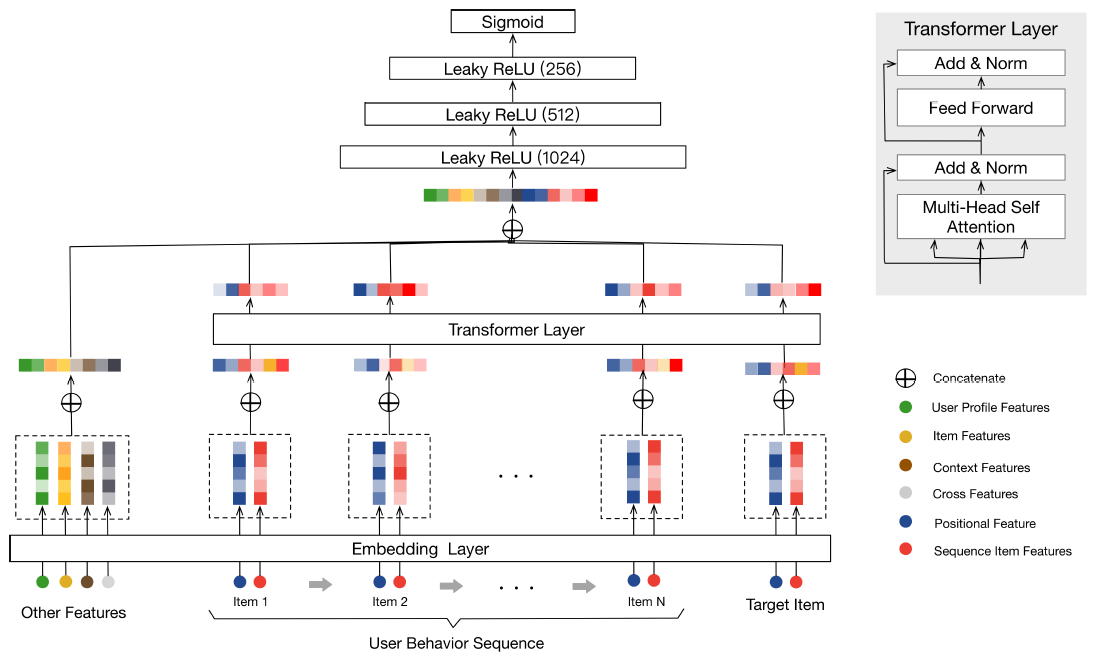
20.1.1 Embedding Layer
第一个组件是
embedding layer,它将所有输入特征嵌入到一个固定大小的低维向量中。在我们的场景中有各种特征,如用户画像特征、
item特征、上下文特征、以及不同特征的组合(即交叉特征)。由于我们的工作聚焦于使用transformer对用户行为序列进行建模,因此为简单起见我们将所有这些特征都表示为Other Features,并在下表中给出了一些示例。我们将
Other Features拼接起来,将它们嵌入到低维向量中。对于这些特征,我们创建一个embedding矩阵embedding向量的维度,uniqe特征数量。
此外,我们还获得了用户行为序列中每个
item(包括目标item)的embedding。我们使用两种类型的特征来表示一个item:Sequence Item Features(红色)、Positional Features(深蓝色)。Sequence Item Features包括item id和category id。注意,一个
item往往具有数百个特征,而在用户行为序列中选择item的所有这些特征代价太大。正如我们先前的工作《Billion-scale commodity embedding for e-commerce recommendation in alibaba》所述,item id和category id足以满足性能要求。因此我们选择这两个稀疏特征来表示嵌入用户行为序列中的每个item。Positional Features对应于下面的positional embedding。
对于每个
item,我们将Sequence Item Features和Positional Features拼接起来,并创建一个embedding矩阵embedding向量的维度,item数量。我们使用item的embedding。
positional embedding:在《Attention is all you need》中,作者提出了一种positional embedding来捕获句子中的顺序信息order information。同样地,顺序order也存在于用户行为序列中。因此,我们添加position作为bottom layer每个item的输入特征,然后将其投影为低维向量。注意,
itemposition value计算为:其中:
target item,item。recommending time,而item
我们采用这种方法,因为在我们的场景中,它的性能优于
《Attention is all you need》中的sin和cos函数。
20.1.2 Transformer Layer
这一部分,我们介绍了
Transformer layer,它通过捕获行为序列中每个item与其它item的关系来学习item的更深deeper的representation。self-attention layer:缩放的内积注意力scaled dot-product attention定义为:其中:
query,key,value。在我们的场景中,
self-attention操作将item的embedding作为输入,通过线性映射将其转换为三个矩阵,并将其馈入attention layer。遵从
《Attention is all you need》,我们使用multi-head attention:其中:
item的embedding矩阵。head数量。
Point-wise Feed-Forward Network:遵从《Attention is all you need》,我们添加一个point-wise Feed-Forward Network:FFN来进一步提升模型的非线性,它定义为:为避免过拟合并且学习层次的有意义的特征,我们同时在
self-attention和FFN中使用dropout和LeakyReLU。然后self-attention layer和FFN layer的总输出为:其中:
normalization layer。
Stacking the self-attention blocks:在第一个self-attention block之后,它会聚合所有历史item的embedding。为了进一步建模底层item序列的复杂关系。我们堆叠了self-attention building block,其中第block定义为:实践中我们观察到
20.1.3 MLP Layer & Loss Function
我们将
Other Features的embedding和应用于target item的Transformer layer的输出进行拼接,然后使用三个全连接层来进一步学习这些dense features之间的交互。这是工业推荐系统的标准做法。为了预测用户是否点击
target itemsigmoid函数作为输出单元。为了训练模型,我们使用交叉熵损失函数:
其中:
label。sigmoid单元之后的输出,代表样本
20.3 实验
数据集:数据集是根据
Taobao App的日志来构建的。我们根据用户在八天内的行为来构建离线数据集,其中前七天用于训练集、第八天用于测试集。数据集的统计信息如下表所示,可以看到该数据集非常大并且非常稀疏。

baseline:为了显示BST的有效性,我们将它和其它两个模型进行比较:WDL和DIN。此外,我们通过将序列信息合并到
WDL(称作WDL(+Seq))中来创建baseline方法,该方法将历史点击item的embedding进行均值聚合。我们的框架是在
WDL的基础上通过使用Transformer添加序列建模而构建的,而DIN是通过注意力机制来捕获目标item和历史点击item之间的相似性。评估指标:
对于离线结果,我们使用
AUC得分来评估不同模型的性能。对于在线
A/B test,我们使用CTR和平均RT来评估所有模型。RT是响应时间response time: RT的缩写,它是给定query(即淘宝上来自用户的一个请求)生成推荐结果的时间成本。我们使用平均RT来衡量在线生产环境中各种效率的指标。
配置:我们的模型是使用
Python2.7和Tensorflow 1.4实现的,并且选择了Adagrad作为优化器。此外,我们在下表中给出了模型参数的详细信息。

实验结果如下表所示,其中
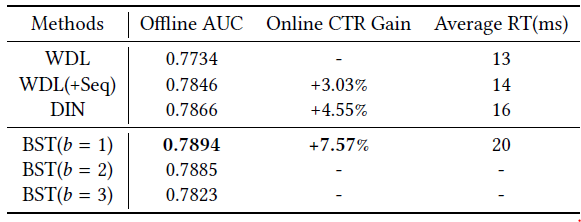
Online CTR Grain是相对于控制组control group(即WDL)。从结果中我们可以看到BST相比于baseline的优越性。具体而言:离线
AUC从0.7734(WDL)和0.7866(DIN) 提高到0.7894(BST)。比较
WDL和WDL(+Seq)时,我们可以看到以简单的平均方式结合序列信息的有效性。这意味着BST在self-attention的帮助下,具有强大的能力来捕获底层用户行为序列的序列信号。注意:根据我们的实际经验,即使离线
AUC的收益很小,也可以带来在线CTR的巨大收益。Google的研究人员在WDL中报道了类似的现象。此外,就效率而言,
BST的平均RT接近WDL和DIN的平均RT,这保证了在现实世界的大型推荐系统中部署诸如Transformer之类的复杂模型的可行性。最后,我们还展示了堆叠
self-attention layer的影响。可以看到AUC。这可能是由于以下事实:用户行为序列中的序列依赖性并不像机器翻译任务中的句子那样复杂。因此,较少的
block数量就足以获得良好的性能。在《Self-attentive sequential recommendation》中报道了类似的观察结果。因此,我们选择BST,并且仅在下表中报告CTR增益。
二十一、ESM2[2019]
从互联网上大量可用的
options中为用户发现有价值的产品或服务已经成为现代在线application(如电商、社交网络、广告等等)的基本功能fundamental functionality。推荐系统Recommender System可以起到这个作用,为用户提供准确accurate、及时timely和个性化personalized的服务。下图显示了电商平台中在线推荐的架构。它包含两个基础部分fundamental component,即系统推荐system recommendation和用户反馈user feedback。在分析了用户的长期行为
long-term behavior和短期行为short-term behavior之后,推荐系统首先召回了大量相关related的item。然后,根据几种排序指标ranking metrics(例如点击率Click-Through Rate: CTR、转化率Conversion Rate: CVR等等)对召回的item进行排序并向用户展示。接下来,当浏览推荐的
item时,用户可能会点击并最终购买感兴趣的item。这就是电商交易中的典型的用户行为序列路径user sequential behavior path“曝光impression--> 点击click--> 购买purchase”。
推荐系统收集了用户的这些反馈,并将其用于估计更准确的排序指标,这对于下一轮生成高质量的推荐确实非常关键。这里,本文重点关注后点击
post-click的CVR估计estimation任务。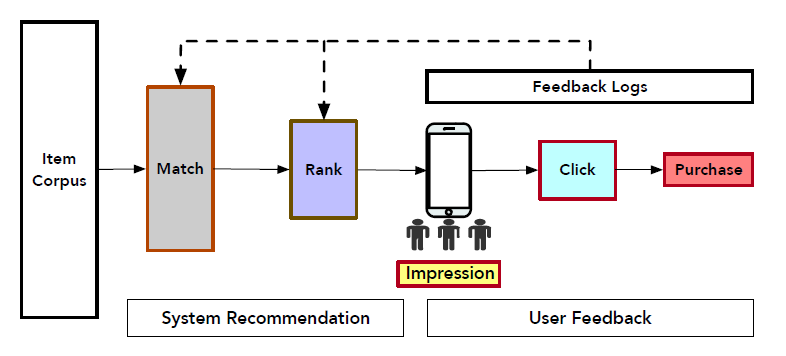
但是,
CVR估计中的两个关键问题使得该任务相当具有挑战性,即样本选择偏差sample Selection Bias: SSB和数据稀疏性Data Sparsity: DS。SSB指的是训练空间和推断空间之间数据分布的系统性差异systematic difference。即:常规的CVR模型仅在点击的样本上进行训练,但是在所有曝光样本上进行推断inference。直觉地,点击样本仅仅是曝光样本的一小部分,并且受到用户
self-selection(如用户点击)的偏见biased。因此,当CVR模型在线serving时,SSB问题将降低其性能。此外,由于和曝光样本相比,点击样本相对更少。因此来自行为序列路径 “点击 --> 购买” 的训练样本数量不足以拟合
CVR任务的大的参数空间,从而导致DS问题。
如下图所示说明了传统
CVR预估中样本选择偏差问题,其中训练空间仅由点击样本组成,而推断空间是所有曝光样本的整个空间。另外,从曝光到购买,数据量是逐渐减少。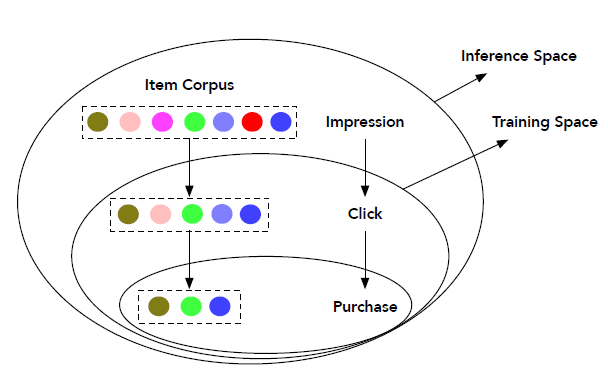
如何处理
SSB和DS问题对于开发高效的工业级推荐系统至关重要。已经有一些研究来应对这些挑战。例如,Entire Space Multi-Task Model: ESMM模型通过多任务学习框架在用户行为序列路径 “曝光--> 点击 --> 购买” 上定义了CVR任务。它使用整个空间上的所有曝光样本进行训练,以完成两个辅助任务
auxiliary task(即post-view CTR和post-view CTCVR)。因此,当在线推断时,从CTR和CTCVR导出的CVR也适用于相同的整个空间,从而有效地解决了SSB问题。此外,
CVR网络和具有丰富标记样本的辅助CTR网络共享相同的特征representation,这有助于缓解DS问题。
尽管
ESSM通过同时处理SSB和DS问题从而获得了比传统方法更好的性能,但是由于购买行为的训练样本很少(根据来自淘宝电商平台的大规模真实交易日志,不到0.1%的曝光行为转化为购买),它仍然难以缓解DS问题。在对日志进行详细分析之后,论文
《Entire Space Multi-Task Modeling via Post-Click Behavior Decomposition for Conversion Rate Prediction》发现用户总是在点击之后采取了一些和购买相关的动作purchase-related action。例如,由于某些原因(如等待折扣),用户可以将青睐的item添加到购物车(或者wish list)中,而不是立即购买。此外,这些行为确实比购物行为更加丰富。有鉴于此,该论文提出了后点击行为分解post-click behavior decomposition的新思想。具体而言,在点击和购买之间并行
parallel地插入不相交的购买相关purchase-related的决定性动作Deterministic Action: DAction、以及购买无关的其它动作Other Action: OAction,形成一个新颖的 “曝光 --> 点击 -->D(O)Action--> 购买” 的用户行为序列图user sequential behavior graph。其中任务关系由条件概率明确地定义。此外,在这个图上定义模型能够利用整个空间上的所有曝光样本以及来自后点击行为post-click behavior的额外的丰富abundant的监督信号supervisory signal,这将有效地共同解决SSB和DS问题。在论文
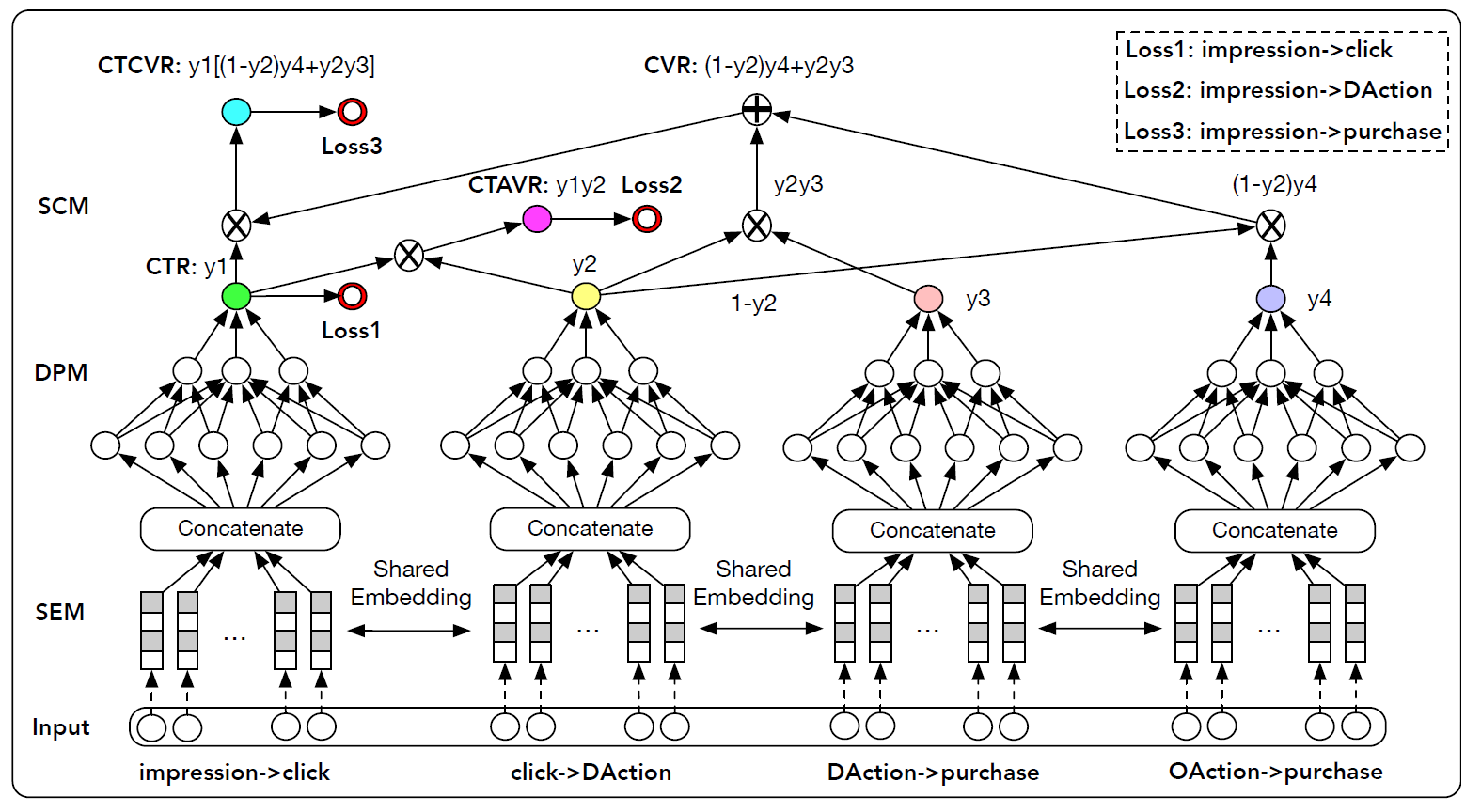
《Entire Space Multi-Task Modeling via Post-Click Behavior Decomposition for Conversion Rate Prediction》中,作者借助深度神经网络来体现上述思想。具体而言,论文提出了一种新颖的深度神经网络推荐模型,称作Elaborated Entire Space Supervised Multi-task Model: ESM2。ESM2包含三个模块:共享embedding模块shared embedding module: SEM、分解预估模块decomposed prediction module: DPM、序列合成模块sequential composition module: SCM。首先,
SEM通过线性的全连接层将ID类型的one-hot特征向量嵌入到dense representation中。然后,这些
embedding被馈入到后续的DPM中。在该DPM中,各个预测子网通过在整个空间上对所有曝光样本进行多任务学习来并行parallel预估分解的子目标decomposed sub-target的概率。最后,
SCM根据图上定义的条件概率规则conditional probability rule defined,依次合成compose最终的CVR和一些辅助概率。在图的某些子路径sub-path上定义的multiple losses用于监督ESM2的训练。
本文的主要贡献:
据我们所知,我们是第一个引入后点击行为分解
post-click behavior decomposition的思想来在整个空间内对CVR建模的。显式分解explicit decomposition产生了一个新的用户行为序列图 “曝光 --> 点击 -->D(O)Action--> 购买 ”。我们提出了一种名为
ESM2的新颖的神经推荐方法,该方法根据用户行为图user behavior graph上定义的条件概率规则,在多任务学习框架中同时对CVR预估任务prediction task和辅助任务auxiliary task进行建模。通过收集大量带标签的的后点击行为数据
post-click action data,ESM2可以有效解决SSB和DS问题。我们的模型在现实世界的离线数据集上比典型的
state-of-the-art方法获得了更好的性能。我们还将其部署在我们的在线推荐系统中,并取得了显著的提升,证明了其在工业应用中的价值。
相关工作:我们提出的方法通过在整个空间上采用多任务学习框架来专门解决
CVR预估问题。因此,我们从以下两个方面简要回顾了最相关的工作:CVR预估、多任务学习。CVR预估:CVR预估是许多在线应用的关键组成部分,例如搜索引擎search engines、推荐系统recommender systems、在线广告online advertising。然而,尽管最近CTR方法得到了蓬勃发展,很少提出针对CVR任务的文献。事实上,CVR建模是非常具有挑战性的,因为转化行为是极为罕见的事件,只有极少量的曝光item最终被点击和购买。近年来,由于深度神经网络在特征
representation和端到端建模end-to-end modeling方面的卓越能力,因此在包括推荐系统在内的许多领域都取得了重大进展。在本文中,我们也采用了深度神经网络对CVR预估任务prediction task进行了建模。与上述方法相比,我们基于一种新颖的后点击行为分解post-click behavior decomposition思想,提出了一个新颖的用户行为序列图 “曝光 --> 点击 -->D(O)Action--> 购买 ” 。根据图中定义的条件概率规则,我们的网络结构经过专门设计,可以并行预测parallel几个分解的子目标decomposed sub-target,并依次合成从而形成最终的CVR。多任务学习:由于用户的购买行为在时间上具有多阶段性
multi-stage nature,如曝光、点击、购买,先前的工作试图通过多任务框架来形式化CVR预估任务。例如:《multi-task learning for recommender systems》通过同时对ranking任务和rating prediction任务建模,提出了一个基于多任务学习的推荐系统。《Modeling task relationships in multi-task learning with multi-gate mixture-of-experts》提出了一种多任务学习方法,称作multi-gate mixture-of-experts: MMOE, 以从数据中明确学习任务关系。《Neural Multi-Task Recommendation from Multi-Behavior Data》提出一种神经多任务推荐模型neural multi-task recommendation model来学习不同类型行为之间的级联关系cascading relationship。相反,我们通过关联
associating用户的序列行为图来同时建模CTR和CVR任务,其中任务关系由条件概率明确定义。《Perceive your users in depth: Learning universal user representations from multiple e-commerce tasks》提出学习跨多个任务的通用用户representation,以实现更有效的个性化。我们也通过跨不同任务共享
embedded特征来探索这种思想。最近,
《Entire space multi-task model: An effective approach for estimating post-click conversion rate》提出了用于CVR预估的entire space multi-task model: ESMM模型。它将CTR任务和CTCVR任务作为辅助任务添加到主CVR任务中。我们的方法受到
ESMM的启发,但有以下显著的不同:我们提出了一个新颖的后点击行为分解post-click behavior decomposition的思想来重构一个新的用户行为序列图 “曝光 --> 点击 -->D(O)Action--> 购买”。通过在这个图上定义模型,可以同时形式化最终的CVR任务以及辅助任务auxiliary tasks。我们的方法可以利用整个空间的所有曝光样本以及来自用户后点击行为
post-click behaviors的丰富的监督信号,这些监督信号和购买行为高度相关,因此可以同时解决SSB和DS问题。
21.1 模型
在实践中,一个
item从曝光到购买,这之间可能存在多种类型的序列动作sequential action。例如,在点击一个感兴趣的item之后,用户可以毫不犹豫的直接购买它,或者将其添加到购物车中然后最终进行购买。这些行为路径如下图(a)所示。图(a)为区分从曝光到购买的、包含后点击行为的多条路径multiple path,例如 “曝光 --> 点击 --> 添加到购物车 --> 购买” 。我们可以根据几个预定义的、特定的和购买相关
purchase-related的后点击动作post-click action来简化和分组这些路径,即添加到购物车Shopping Cart: SCart、添加到愿望清单Wish list: Wish,如下图(b)所示。图(b)为描述简化的购买过程的有向图,其中边上的数字表示不同路径的稀疏性。根据我们对真实世界在线日志的数据分析,我们发现只有
1%的点击行为最终会转化为购买行为,这表明购买训练样本很少。然而,SCart和Wish这样的一些后点击动作的数据量远大于购买量。如,10%的点击会转化为加购物车。此外,这些后点击动作与最终购买行为高度相关。例如,12%的加购物车行为会转化为购买行为、31%的加愿望清单行为会转化为购买行为。考虑到后点击行为
post-click behaviors和购买行为高度相关,我们如何以某种方式利用大量的后点击行为从而使得CVR预估收益?直观地讲,一种解决方案是将购买相关的后点击动作与购买行为一起建模到多任务预测框架multi-task prediction framework中。关键是如何恰当地形式化它们,因为它们具有明确的序列相关性sequential correlation。例如,购买行为可能是以SCart或Wish行为为条件的。为此,我们定义了一个名为Deterministic Action: DAction的单个节点node来合并这些预定义的、特定的与购买相关的后点击动作,例如SCart和Wish,如下图(c)所示。DAction有两个性质:与购买行为高度相关、具有来自用户反馈的丰富的确定性deterministic的监督信号。例如,1表示执行某些特定操作(即在点击之后添加到购物车中、或者点击之后添加到愿望清单中),0表示未执行这些操作。我们还在点击和购买之间添加了一个名为
Other Action: OAction的节点,以处理DAction以外的其它后点击行为。借此方式,传统的行为路径 “曝光 --> 点击 --> 购买” 就变为新颖novel的、精巧elaborated的用户行为序列图 “曝光 --> 点击 -->D(O)Action--> 购买”,如下图(c)所示。通过在该图上定义模型,可以利用整个空间上的所有曝光样本以及来自
D(O)Action的额外的丰富的监督信号,这可以有效地避免SSB和DS问题。我们称这种新颖的想法为后点击行为分解post-click behavior decomposition。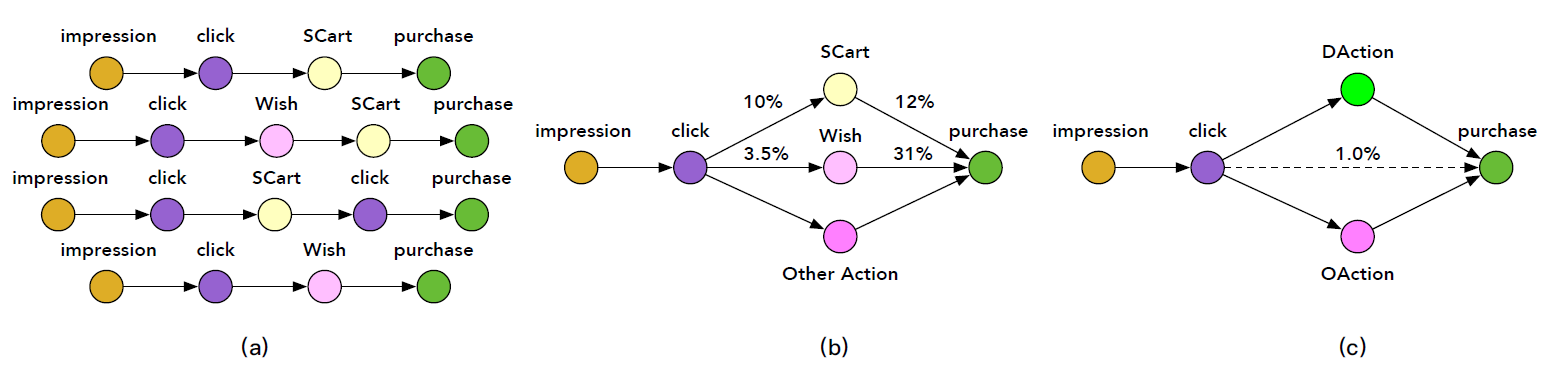
21.1.1 条件概率分解
这里我们根据上图
(c)中定义的有向图来介绍CVR的条件概率分解conditional probability decomposition,以及相关的辅助任务auxiliary tasks。定义
itempost view ctritem其中:
itemitem
定义
itemclick-through DAction CVRitemDAction动作的条件概率。这由有向图中的路径 “曝光 --> 点击 -->DAction” 来描述。从数学上讲,这可以写成:其中:
itemDAction动作。这里假设:如果用户未点击
itemDAction动作。即:DAction” 。考虑到点击(
定义
itemCVRitemitemD(O)Action--> 购买” 来描述。从数学上讲,这可以写成:其中:
itemDAction-> 购买” 。这里我们假设DAction(OAction-> 购买” 。这里我们假设OAction(
定义
itemclick-through CVR为itemD(O)Action--> 购买” 来描述。从数学上讲,这可以写成:考虑到如果没有点击就没有任何购买,即:
则上式简化为:
因此,上式可以通过将有向图 “曝光 --> 点击 -->
D(O)Action--> 购买” 分解为 “曝光 --> 点击”、以及 “点击 -->D(O)Action--> 购买”,并根据链式法则chain rule整合之前所有的公式(即
21.1.2 ESM2 模型
从前面推导可以看到:
hidden probability variablesub-path上的条件概率,其中:DAction“ 的条件概率。DAction-> 购买” 的条件概率。OAction-> 购买” 的条件概率。
此外,这四个子目标
sub-target在整个空间中定义,并且可以使用所有曝光样本进行预测。以SSB问题。 实际上根据前面的推导,intermediate variable。由于SSB。另一方面, 给定用户的日志,
ground truth label是可用的,这些label可用于监督这些子目标。因此,一种直观的方法是通过多任务学习框架同时对它们进行建模。为此,我们提出了一种新颖的深度神经推荐模型
neural recommendation model,称作Elaborated Entire Space Supervised Multi-task Mode: ESM2,用于CVR预估。ESM2之所以取这个名字是因为:首先,
其次,派生的
ESM2由三个关键模块组成:一个共享的
embedding模块Shared Embedding Module: SEM。SEM将稀疏特征嵌入到稠密的representation中。一个分解
decomposed的预估模块Decomposed Prediction Module: DPM。DPM可以预估分解目标的概率。一个顺序
sequential的合成composition模块Sequential Composition Module: SCM。SCM将预估分解目标的概率按顺序合成在一起,以计算最终的CVR以及其它相关的辅助任务(即CTR、CTAVR、CTCVR)。
整体模型如下图所示。
共享的
embedding模块:首先我们设计一个共享的embedding模块,从而嵌入来自user field、item field、user-item cross field的所有稀疏ID特征和稠密数值特征。用户特征包括
user ID、年龄、性别、购买力等等。item特征包括item ID、价格、历史日志统计的历史累计CTR和历史累计CVR等等。user-item特征包括用户对item的历史偏好分historical preference score等等。稠密特征首先基于它们的边界
boundary来离散化,然后将其表示为one-hot向量。
令第
one-hot之后为one-hot特征为:其中
由于
one-hot编码的稀疏性,我们使用线性的全连接层将它们嵌入到dense representation中。令第embedding矩阵为embedding为:第
embedding特征为:分解预估模块 :然后一旦获得了所有的特征
embedding,就将这些embedding拼接到一起,馈入几个分解的预估模块,并由每个模型共享。DPM中的每个预估网络分别在 “曝光 --> 点击”、“点击 -->DAction”、“DAction--> 购买”、“OAction--> 购买” 等路径上预估分解的target的概率。在本文中,我们采用多层感知机
Multi-Layer Perception: MLP作为预估网络。除了输出层之外,所有非线性激活函数均为ReLU。对于输出层,我们使用Sigmoid函数将输出映射为0.0 ~ 1.0之间的概率值。从数学上讲,这可以写成:其中:
sigmoid函数。MLP学到的映射函数,
例如,上图中的第一个
MLP输出了估计的概率estimated probabilitypost-view CTR。顺序合成模块:最后我们设计了一个顺序合成模块,根据前面描述的公式合成上述预估概率,从而计算转化率
auxiliary target(包括post-view CTRclick-through DAction CVRclick-through CVR如上图的顶部所示,顺序合成模块是一个无参的前馈神经网络,它表示购买决策有向图
purchasing decision digraph所定义的条件概率。注意:
所有任务共享相同的
embedding,使这些任务使用所有曝光样本进行训练。即在整个空间上对这些任务进行建模,从而在推断阶段不会出现SSB问题。轻量级的分解预估模块由共享的
embedding模块严格正则化,其中共享的embedding模块包含了大部分的训练参数。我们的模型提出了一种高效的网络设计,其中共享的
embedding模块可以并行运行,因此在在线部署时可以有较低的latency。
训练目标:令
ground truth label(是否点击、是否发生deterministic action、是否发生购买行为)。然后我们定义所有训练样本的联合post-view pCTR为:其中
label空间使用负的对数函数进行变换之后,我们得到
logloss:类似地,我们得到
其中:
DAction label空间label空间最终的训练目标函数为:
其中:
ESM2模型中的所有参数。1.0。
需要强调的是:
添加中间损失
intermediate loss来监督分解后的子任务,可以有效地利用后点击行为中丰富的标记数据,从而缓解模型受到DS的影响。所有损失都是从整个空间建模的角度来计算的,这有效解决了
SSB的问题。
21.2 实验
为了评估
ESM2模型的有效性,我们针对从现实世界电商场景中收集的离线数据集和在线部署进行了广泛的实验。我们将ESM2和一些代表性的state-of-the-art方法进行比较,包括GBDT、DNN、使用过采样over-sampling思想的DNN、ESMM等。首先我们介绍评估设置
setting,包括数据集准备、评估指标、对比的SOTA方法的简要说明、以及模型实现细节。然后我们给出比较结果并进行分析。接着我们介绍消融研究。最后我们对不同的后点击行为进行效果分析。数据集:我们通过从我们的在线电商平台(世界上最大的第三方零售平台之一)收集用户的行为序列和反馈日志来制作离线数据集。
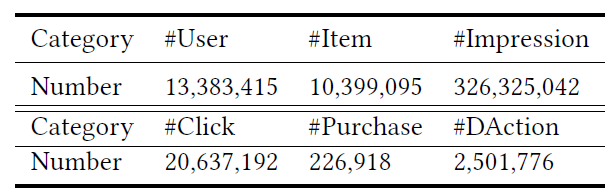
我们得到超过
3亿个样本,其中包含用户特征、item特征、user-item交叉特征以及序列的反馈标签sequential feedback label(如,是否点击、是否DAction、是否购买)。下表给出了离线数据集的统计信息。我们将离线数据集进一步划分为不相交的训练集、验证集、测试集。
评估指标:为了全面评估
ESM2模型的有效性,并将其和SOTA方法进行比较,我们使用三种广泛采纳的指标:AUC、GAUC、F1 score。AUC刻画了模型的排序能力ranking ability:其中:
GAUC首先根据每个用户ID从而将数据划分为不同的组,然后在每个组中计算AUC,最后对每个组的AUC加权平均。即:其中:
1。AUC。
F1 score定义为:其中
precision、recall。
baseline方法:GBDT:梯度提升决策树gradient boosting decision tree: GBDT。它遵循gradient boosting machine: GBM的思想,能够为回归任务和分类任务提供有竞争力的、高度健壮robust的、可解释性的方法。本文中,我们将其作为non-deep learning-based方法的典型代表。DNN:我们还实现了一个深度神经网络baseline模型,该模型具有和ESM2中单个分支相同的结构和超参数。和ESM2不同,它是用 “点击 --> 购买” 或者 “曝光 --> 点击” 路径上的样本进行训练,从而分别预估转化率DNN-OS:由于 “曝光 --> 购买” 和 “点击 --> 购买” 路径上的数据稀疏性,很难训练具有良好泛化能力的深度神经网络。为了解决该问题,我们训练一个叫做DNN-OS的深度模型,它在训练期间利用了过采样over-sampling策略来增加正样本。它具有与上述DNN模型相同的结构和超参数。ESMM:为了公平地进行比较,我们为ESMM使用与上述深度模型相同的主干结构backbone structure。ESMM直接在用户序列路径 “曝光 --> 点击 --> 购买” 上对转化率进行建模,而没有考虑和购买相关的后点击行为post-click behavior。
简而言之:
前三种方法分别从 “曝光 --> 点击”、“点击 --> 购买” 路径上的样本来学习预估
而对于
ESMM和我们的ESM2,则是通过在整个空间上直接建模预估
实验配置:
对于
GBDT模型,以下超参数是根据验证集AUC来选择的:树的数量为
150。树的深度为
8。拆分一个顶点的最小样本量为
20。每次迭代的样本采样率
0.6。每次迭代的特征采样率为
0.6。损失函数为
logistic loss。
对基于深度神经网络的模型,它们基于
TensorFlow实现,并使用Adam优化器。学习率为
0.0005,mini-batch size = 1000。在所有模型中,使用
logistic loss。MLP有5层,每层的尺寸分别为512, 256, 128, 32, 2。dropout设置为dropout ratio = 0.5。
这些配置(基于深度神经网络的模型)如下表所示。
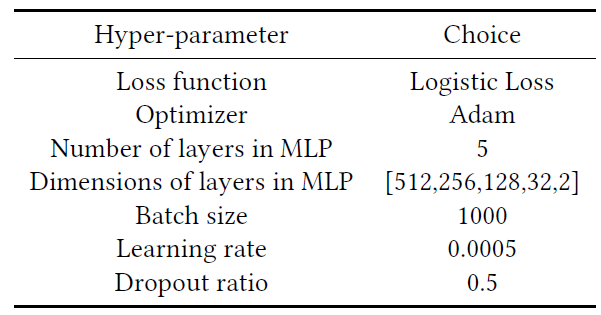
离线数据集的评估结果如下表所示。可以看到:
DNN方法相比较GBDT模型在CVR AUC、CTCVR AUC、CTCVR GAUC上分别获得了0.0242、0.0102、0.0117的增益。这证明了深度神经网络的强大representation能力。和普通的
DNN不同,DNN-OS使用过采样策略来解决DS问题,从而获得比DNN更好的性能。对于
ESMM,它针对 “曝光 --> 点击 --> 购买” 路径来建模,从而试图同时解决SSB和DS问题。得益于对整个空间的建模以及丰富的训练样本,它的性能优于DNN-OS。尽管如此,
ESMM忽略了后点击行为的影响,仍然受到购买训练样本稀疏的困扰,因此仍然难以解决DS问题。我们提出的
ESM2进一步利用了这些后点击行为。在多任务学习框架下并行预测一些分解的子目标之后,ESM2依次合成这些预测从而形成最终的CVR。可以看到,我们的
ESM2超越了所有的其它方法。例如,ESM2相较于ESMM模型在CVR AUC、CTCVR AUC、CTCVR GAUC上分别获得了0.0088、0.0101、0.0145的增益。值得一提的是,离线AUC增加0.01总是意味着在线推荐系统收入的显著增加。
对于
F1 score,我们分别通过为CVR和CTCVR设置不同的阈值来报告几个结果。首先,我们根据预估的
CVR或CTCVR分数对所有样本进行降序排序。然后,由于
CVR任务的稀疏性(大约1%的预估样本为正样本),我们选择三个阈值:top @ 0.1%、top @ 0.6%、top @ 1%,从而将样本划分为positive group和negative group。最后,我们计算在这些不同阈值下,预估结果的
precision, recall, F1 score。
评估结果在下表中给出。可以观察到和
AUC/GAUC类似的趋势。同样地,我们的ESM2方法在不同的配置下也达到了最佳性能。
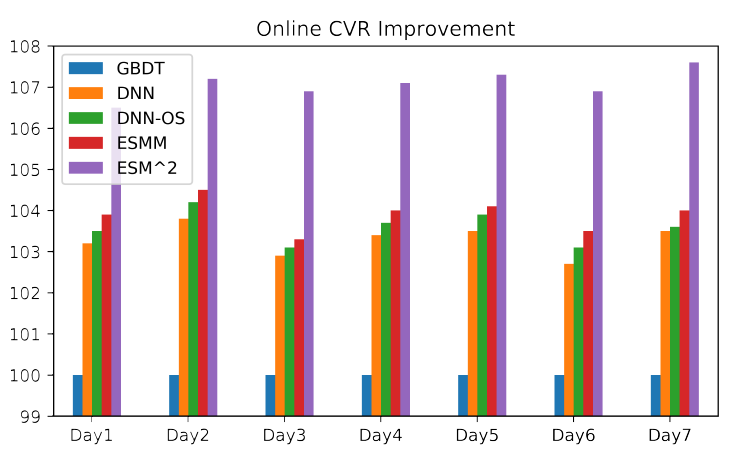
在线性能:在我们的推荐系统中部署深度网络模型并不是一件容易的事情,因为推荐系统每天服务于数亿用户。例如,在流量高峰时每秒超过
1亿用户。因此,需要一个实用的模型来进行高吞吐量、低延迟的实时CVR预估。例如,在我们的系统中,应该在不到100毫秒的时间内为每个访客预测数百个推荐的item。得益于并行的网络结构,我们的模型计算效率高,可以在20毫秒内响应每个在线请求。为了使在线评估公平
fair、置信confident、可比较comparable,A/B test的每种部署的方法都包含相同数量的用户(例如数百万用户)。在线评估结果如下图所示,其中我们使用GBDT模型作为baseline。可以看到:DNN, DNN-OS, ESMM的性能相当,明显优于baseline模型,并且ESMM的性能稍好。我们提出的
ESM2显著优于所有的其它方法,这证明了它的优越性。此外,
ESM2相比ESMM在CVR上提升了3%,这对于电商平台具有显著的商业价值。
以上结果说明了:
深度神经网络比
tree-based的GBDT具有更强的representation能力。在整个样本空间中的多任务学习框架可以作为解决
SSB和DS问题的有效工具。基于后点击行为分解
post-click behaviors decomposition的思想,ESM2通过在整个空间上对CVR建模并利用deterministic行为中大量的监督信号来有效解决SSB和DS问题,并获得最佳性能。
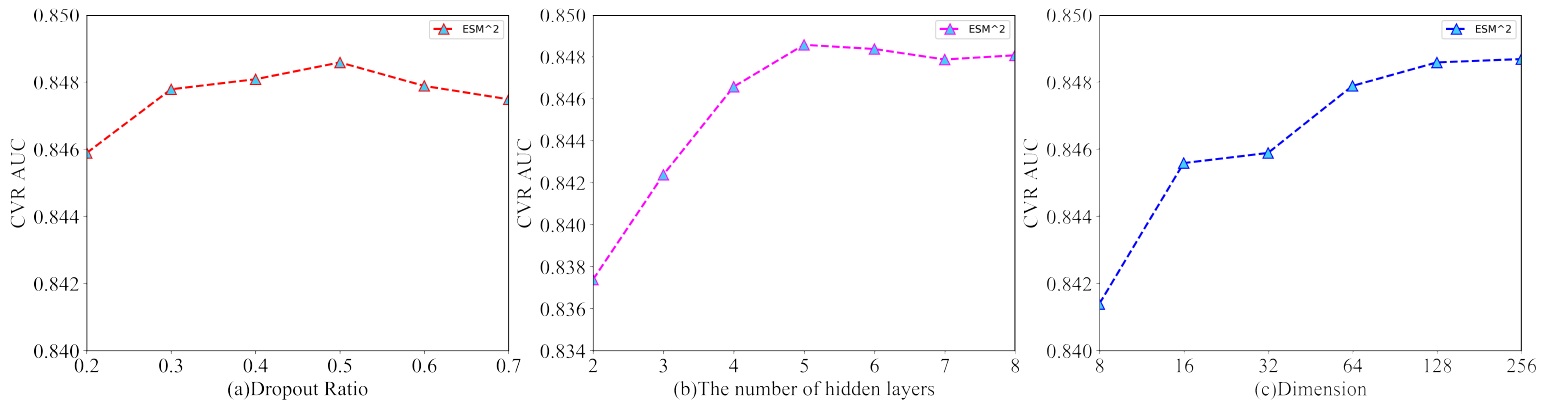
消融研究:这里我们介绍详细的消融研究,包括深度神经网络的超参数设置、嵌入稠密数值特征
embedding dense numerical features的有效性、以及分解的后点击行为的选择。深度神经网络的超参数:这里我们以三个关键的超参数(
dropout rate、隐层的层数、item特征的embedding维度)为例,从而说明了我们的ESM2模型中的超参数选择过程。dropout rate指的是通过在训练过程中随机停止deactivating一些神经单元的正则化技术。通过引入随机性,可以增强神经网络的泛化能力。我们在模型中尝试了不同的
dropout rate,从0.2到0.7。如图(a)所示,dropout rate = 0.5时性能最佳。因此,如果没有特别指出,那么实验中我们默认将dropout rate设为0.5。增加网络的深度可以提高模型容量,但是也可能导致过拟合。因此,我们根据验证集的
AUC仔细设置了这个超参数。从图
(b)可以看到:在开始阶段(即从两层增加到五层),增加隐层的数量会不断提高模型的性能。但是,模型在五层达到饱和,后续增加更多的层甚至会略微降低验证AUC,这表明模型可能对训练集过拟合。因此,如果没有特别指出,那么实验中我们默认使用五层的隐层。item特征embedding的维度是一个关键的超参数。高维特征可以保留更多信息,但是也可能包含噪声并导致模型复杂度更高。我们尝试了不同的超参数设置,并在图
(c)中给出结果。可以看到:增加维度通常会提高性能,但是在维度为128时性能达到饱和。而继续增加维度没有更多收益。因此,为了在模型容量和模型复杂度之间的trade-off,如果没有特别指出,那么实验中我们默认将item特征embedding的维度设为128。
嵌入稠密数值特征的有效性:在我们的任务中有几个数值特征。
一种常见的做法是首先将它们离散为
one-hot向量,然后将它们与ID特征拼接在一起,然后再通过线性投影层将它们嵌入到稠密特征。但是,我们认为对数值特征的离散化one-hot向量表示可能会损失一定的信息。另一种方案将数值特征归一化,然后使用
tanh激活函数来嵌入它们,即:其中:
(-1,+1)之间。然后我们将归一化的数值特征和嵌入的
ID特征拼接在一起,作为ESM2模型的输入。和基于离散化的方案相比,归一化的方案获得了
0.004的AUC增益。因此,如果没有特别指出,那么实验中我们默认对稠密的数值特征使用基于归一化的方案。
分解的后点击行为的有效性:当分解后点击行为时,我们可以将不同的行为聚合到
DAction节点中。例如only SCart、only Wish、SCart and Wish。这里我们评估不同选择的有效性,结果如下表所示。可以看到:
SCart and Wish的组合达到了最佳的AUC。这是合理的,因为和其它两种情况相比,SCart and Wish有更多的购买相关的标记数据来解决DS问题。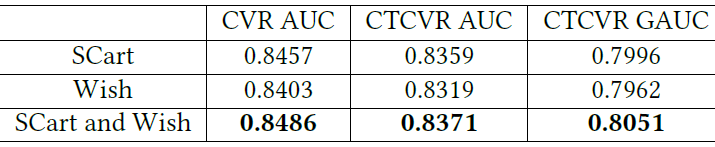
用户行为的性能分析:为了了解
ESM2的性能以及和ESMM的区别,我们根据用户购买行为的次数将测试集分为四组:[0,10]、[11,20]、[21,50]、[51, +)。我们报告了每组中两种方法的CVR AUC和CTCVR AUC,结果如下图所示。可以看到:两种方法的
CVR AUC(CTCVR AUC) 都随着购买行为次数的增加而降低。但是我们观察到,每组中
ESM2相对于ESMM的相对增益在增加,即0.72%、0.81%、1.13%、1.30%。
通常,具有更多购买行为的用户总是具有更活跃的后点击行为,例如
SCart和Wish。我们的ESM2模型通过添加DAction节点来处理此类后点击行为,该节点由来自用户反馈的deterministic信号来监督学习。因此,它在这些样本上比ESMM具有更好的表示能力,并在具有高频购买行为的用户上获得了更好的性能。论文没有分析为什么模型在更多购买行为的用户的
AUC上下降。这表明模型在这些高购买行为的用户上学习不充分,是否可以将他们作为hard样本?或者把购买次数作为特征从而让模型知道这个信息?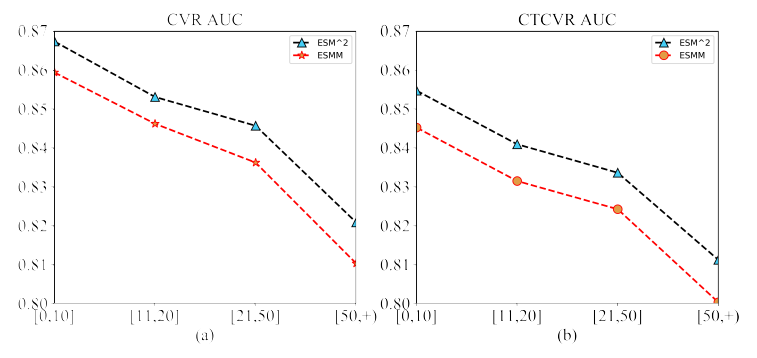
二十二、MV-DNN[2015]
推荐系统和内容个性化
content personalization在web服务中扮演着越来越重要的角色。最近的很多web服务都致力于寻找与用户最相关relevant的内容,以最大限度地提高网站的互动engagement、并最大限度地降低寻找相关内容relevant content的时间。完成该任务的主要方法称作协同过滤
Collaborative Filtering: CF,它使用用户在网站上的历史交互interaction来预测最相关的内容从而进行推荐。另一种常见的方法是基于内容的推荐content-based recommendation,它使用有关item特征或/和用户特征来基于特征之间的相似性similarity从而向用户推荐新的item。虽然这两种方法在许多实际应用中运行良好,但是它们通常都面临一定的限制limitations和挑战challenges,尤其是在个性化需求日益增加以及考虑推荐质量recommendation quality的情况下。具体而言:CF在提供高质量推荐之前需要大量的网站交互interaction的历史记录。这个问题被称作用户冷启动问题user cold start problem。在一个新建的在线服务中,由于用户与网站的历史交互很少或者没有历史交互,因此问题变得更加严重。因此,传统的CF方法通常无法为新用户提供高质量的推荐。另一方面,
content-based推荐方法从每个用户或/和item中提取特征,并使用这些特征进行推荐。例如,如果两个新闻Newstopic,并且用户喜欢新闻similarity(如地理位置location相似、年龄相似、性别相同),则系统可以向用户item。在实践中,研究表明:
content-based方法可以很好地处理新item的冷启动问题。然而,当应用于对新用户的推荐时,其有效性是有问题的。因为user-level特征通常更难获取,并且user-level特征通常是是从用户在线个人画像user online profiles中的有限信息生成的,而这些信息无法准确地捕获实际的用户兴趣。即:精准画像难以获取,而且画像相似不代表兴趣相似。
为解决这些限制,论文
《 Multi-View Deep Learning Approach for Cross Domain User Modeling in Recommendation Systems》提出了一个利用用户特征和item特征的推荐系统。和许多基于用户画像user profile-based的方法不同,为了构建用户特征,论文提出从用户的浏览和搜索历史中提取丰富的特征来建模用户的兴趣。潜在的假设是:用户的历史在线活动historical online activities反映了用户的背景background和偏好preference,因此提供了关于用户可能感兴趣的item和主题topic的精确洞察precise insight。例如,具有很多与婴儿相关query和相关网站访问的用户可能暗示着这个用户是一个新生儿的妈妈。通过这些丰富的用户在线活动user online activities,可以更有效地实现对相关relevant的item的推荐。在论文中,作者提出了一种新颖的深度学习方法,该方法从深度结构语义模型
Deep Structured Semantic Model: DSSM扩展而来,将用户和item映射到共享的语义空间,并推荐与用户在语义空间中相似性最大的item。为此,论文的模型通过非线性转换层将用户和item(均由丰富的特征集合来表示)投影到紧凑的共享潜在语义空间compact shared latent semantic space中。在这个语义空间中,用户的语义表示和用户喜欢的item的语义表示之间的相似性similarity被最大化。这使得该模型能够学到兴趣的映射interesting mapping。例如,访问过fifa.com的用户喜欢阅读有关世界杯的新闻,并在PC或者Xbox玩足球游戏。用户侧
user side的丰富特征可以对用户的行为进行建模,从而克服了content-based推荐中的诸多限制。用
user的行为来代替用户画像,可以解决用户画像不准或者不全的问题。该模型还有效地解决了用户冷启动问题,因为该模型允许我们从
query中捕获用户兴趣并推荐相关的item(例如音乐),即使用户没有使用音乐服务的任何历史记录。该模型有一个
ranking-based目标,旨在将正样本(用户喜欢的item)排名高于负样本。这种ranking-based目标已经被证明对推荐系统更有利。
此外,作者扩展了原始的
DSSM模型(在本文中称之为single-view DNN,因为DSSM学习来自单个领域domain的用户特征和item特征),从而联合学习来自不同领域的item的特征。作者将新模型命名为Multi-View Deep Neural Network: MV-DNN。在文献中,多视图学习
multi-view learning是一个经过充分研究的领域,它从非共享公共特征空间not share common feature space的数据中学习。作者认为MV-DNN是多视图学习配置setup中一种通用的深度学习方法。具体而言,在包含新闻News、Apps、Movie/TV日志的数据集中,作者不是为每个领域建立独立的模型来简单地将用户特征映射到领域内的item特征,而是建立新的多视图模型来发现潜在空间中用户特征的单个映射,从而与来自所有领域的item特征共同进行了优化。MV-DNN使得我们能够学到更好的用户representation,它利用更多的跨域数据,并利用来自所有领域的用户偏好数据从而解决数据稀疏性问题。论文在实验中表明:这种多视图扩展同时提高了所有领域的推荐质量。此外,值得一提的是,深度学习模型中的非线性映射使得我们能够在潜在空间中找到用户的紧凑表示
compact representation,这使得存储学到的用户映射user mapping以及在不同任务之间共享信息变得更加容易。使用深度学习来建模丰富的用户特征的另一个挑战是特征空间的高维
high dimension,这使得学习效率低下并可能影响模型的泛化能力。作者提出了几种有效effective且可扩展scalable的降维技术,这些技术在不损失大量信息的情况下可以将维度降低到合理的大小。论文的主要贡献:
使用丰富的用户特征来构建通用的推荐系统。
为
content-based推荐系统提出深度学习方法,并研究不同的技术以扩展该系统。引入新颖的多视图深度学习模型,通过组合来自多个领域的数据集来构建推荐系统。
通过利用从
multi-view DNN model中学到的语义特征映射semantic feature mapping来解决文献中未充分研究的用户冷启动问题。使用四个真实世界的大型数据集进行严格的实验,并证明论文提出的方法相对于
state-of-the-art方法有着显著的优势。
相关工作:已有大量文献对推荐系统进行广泛的研究。这里我们旨在回顾一组与论文提出的方法最相关的代表性方法。通常推荐系统可以分为协同推荐
collaborative recommendation和基于内容的推荐content-based recommendation。协同推荐系统
Collaborative Recommendation Systems向用户推荐一个item,如果相似的用户喜欢这个item。该技术的例子包括:最近邻模型
nearest neighbor modeling、矩阵补全Matrix Completion、受限玻尔兹曼机Restricted Boltzmann machine、贝叶斯矩阵分解Bayesian matrix factorization等等。本质上,这些方法都是用户协同过滤user collaborative filtering、item协同过滤item collaborative filtering、或者同时item和用户的协同过滤。在
user-based协同过滤中,基于用户喜欢的item来计算用户之间的相似度similarity。然后,通过组合相似用户在目标item上的score来计算当前用户对目标item的user-item pair的score。在
item-based协同过滤中,基于喜欢这两个item的用户来计算item之间的相似度similarity。然后向用户推荐该用户曾经喜欢的item所相似的item。在
user-item based协同过滤中,基于user-item矩阵为user和item找到公共空间common space,并结合item representation和用户representation来找到推荐。几乎所有矩阵分解方法都是这种技术的例子。
collaborative filtering: CF可以扩展到大规模设置large-scale setup,但是它无法处理新用户和新item。这一问题通常被称作冷启动问题cold-start issue。content-based推荐从item和/或用户的画像中提取特征,并根据这些特征向用户推荐item。背后的假设是:相似的用户倾向于喜欢他们以前喜欢的item所相似的item。在
《Amazon.com recommendations: Item-to-item collaborative filtering》中,作者提出了一种方法来构建具有用户历史喜欢的item的一些特征的搜索query,从而寻找其它相关的item来推荐。在
《Personalized news recommendation based on click behavior》中,作者给出了另一个例子,其中每个用户都是由新闻主题topics上的分布建模的。其中这个主题分布是根据用户喜欢的文章来构建的,并且使用和用户相同地理位置location的所有其它用户的主题分布偏好preference作为先验分布prior distribution。这种方法可以处理新
item(新的新闻),但是对于新用户,系统仅使用地理位置特征,这意味着新用户预期看到该用户当地最热门的主题topics的新闻。这可能是推荐新闻的很好的特性,但是在其他领域(如Apps推荐)中,仅使用地理位置信息location information可能无法得到用户偏好的一个很好的先验prior。
最近,研究人员开发了将协同推荐和
content-based推荐结合在一起的方法。在
《Content-boosted collaborative filtering for improved recommendations》中,作者在使用协同过滤之前使用item特征来平滑用户数据。在
《Tied boltzmann machines for cold start recommendations》中,作者使用受限玻尔兹曼机来学习item之间的相似性,然后将其与协同过滤相结合。在
《Collaborative topic modeling for recommending scientific articles》中开发从一种贝叶斯方法来共同学习item(在他们的场景中item是研究论文research paper) 在不同主题topics上的分布、以及评分矩阵的因子分解。
在推荐系统中处理冷启动问题主要针对新
item(没有任何用户评分的item)进行研究。如前所述,所有content-based filtering都可以处理item的冷启动,并且有一些方法是专门针对冷启动问题开发和评估的。《Learning preferences of new users in recommender systems: an information theoretic approach》中的工作研究了如何通过推荐能够提供用户最多偏好信息的item、同时最小化推荐不相关内容irrelevant content的概率,从而为新用户逐步地学习用户偏好。近年来,通过丰富的特征进行用户建模的研究很多。例如,已经表明用户的搜索
query可以用于发现用户之间的相似性。用户搜索历史中的丰富特征也被用于个性化的web搜索。对于推荐系统,《Scalable hierarchical multitask learning algorithms for conversion optimization in display advertising》中的作者利用用户的历史搜索query来构建推荐广告的个性化分类personalized taxonomy。另一方面,研究人员发现,用户的社交行为也可以用于建立用户画像。在
《Twitter-based user modeling for news recommendations》中,作者使用Twitter数据中的用户推文tweets来推荐新闻文章。大多数传统的推荐系统的研究都几种在单个领域
domain内的数据。最近人们对跨域推荐cross domain recommendation越来越感兴趣。有不同的方法来处理跨域推荐。一种方法是假设不同的领域共享相似的用户集合,但是不共享
item集合。如《Cross-domain collaborative recommendation in a cold-start context: The impact of user profile size on the quality of recommendation》所示。在他们的工作中,作者从电影评分数据集和书籍评分数据集抽取公共用户并增强数据,然后将增强的数据集用于执行协同过滤。他们表明:这种方法尤其有助于那些在某个领域中几乎没有用户画像的用户(冷启动用户)。另一种方法处理的场景是:同样的
item集合在不同领域中共享不同类型的反馈(如用户点击、用户显式评分等等)。在
《Transfer learning in collaborative filtering for sparsity reduction》中,作者介绍了一种用于跨域矩阵分解的坐标系转换方法coordinate system transfer method。在
《Transfer learning for collaborative filtering via a rating-matrix generative model》中,作者研究了在领域之间不存在共享用户或共享item的情况下的跨域推荐。他们开发了一个生成模型来发现不同领域之间的公共簇common clusters。但是,由于计算成本问题,他们的方法无法扩展到中等规模数据集之外。在
《Cross-domain collaboration recommendation》中介绍了一种不同的author collaboration推荐方法,其中他们建立了一个主题模型来推荐来自不同研究领域的author collaboration。
对于推荐系统中的很多方法,目标函数是最小化
user-item矩阵重构reconstruction的均方误差。最近,ranking-based目标函数已经显示出在给出更好的推荐方面更有效。深度学习最近被提出从而用于为协同过滤和
content-based方法建立推荐系统。在
《Restricted boltzmann machines for collaborative filtering》中,受限玻尔兹曼机模型被用于协同过滤。在
《Cross-domain collaborative recommendation in a cold-start context: The impact of user profile size on the quality of recommendation》中,深度学习用于content-based推荐,其中深度学习用于学习音乐特征的embedding。然后使用这个embedding在协同过滤中对矩阵分解进行正则化。
22.1 模型
22.1.1 数据集
这里首先介绍数据集。我们描述了每个数据集的数据收集过程和特征表示
feature representation,以及数据集的一些基本统计信息。这里使用的四个数据集是从微软的几款产品的用户日志中收集的,包括:Bing Web vertical的搜索引擎日志、Bing News vertical的新闻浏览历史记录、Windows AppStore的App下载日志、Xbox的Movie/TV观看日志。所有日志都是在2013-12 ~ 2014-06期间收集的,并且重点关注美国、加拿大、英国等英语市场English-speaking markets。用户特征:我们从
Bing收集了用户的搜索query和他们点击的URL,从而形成用户特征。首先对
query进行规范化normalized、词干化stemmed,然后将其拆分为unigram特征。然后,我们使用
TF-IDF得分来保留最热门popular和最重要non-trivial的特征。对于
URL,我们压缩到仅保留domain-level(如www.linkedin.com) 。
通过对
query和URL的这些操作我们降低了特征的维度。总体而言,我们选择了
300万个uni-gram特征和50万个域名特征,最终得到的用户特征向量user feature vector为350万维。query特征向量为300万维,分量大小为对应uni-gram term的TF-IDF得分。域名特征向量为
50万维,为域名的one-hot向量。
新闻特征:我们从
Bing News vertical收集了点击的新闻News。每个新闻item由三部分的特征来表示:第一部分是使用字母三元组表示
letter tri-gram representation编码的标题特征。第二部分是每篇新闻的
top-level类目category(如娱乐Entertainment) 编码的二元特征。第三部分是在每篇新闻中,通过内部专有的
NLP parser抽取的命名实体Named Entities,这些命名实体也是通过letter tri-gram representation来编码。
这三部分得到的新闻特征向量为
10万维。App特征:我们从Windows AppStore日志中收集用户历史下载的App。每个App item由两部分的特征来表示:第一部分是使用
letter tri-gram representation编码的App标题特征。第二部分是每个
App的类目category(如游戏Game) 编码的二元特征。
考虑到
App描述信息descriptions不断的变化,我们决定不将它纳入特征空间中。最终得到的App特征向量为5万维。Movie/TV特征:我们从XBox日志中收集了每个XBox用户观看的历史Movie/TV。每个item由两部分的特征来表示:第一部分是
item标题和描述信息description合并为文本特征text features,然后使用letter tri-gram来编码。第二部分是每个
item的流派genre编码的二元特征。
最终得到的
Movie/TV特征向量为5万维。在我们的神经网络框架中,用户特征被映射到用户视图
user view,其它特征被映射到不同的item视图item view。出于训练的目的,每个用户视图都与一个包含相应用户集合的item视图相匹配。为实现这一点,我们根据用户ID(每个用户都有一个唯一的、匿名的、哈希的Microsoft User ID)来执行inner join,从而得到user-item view pair。这导致每个user-item view pair中包含的用户数量不同。下表描述了本文所使用的数据的一些基本统计信息。
Joint Users列给出了item view和user view之间公共用户common users的数量。读者注:为什么用搜索数据作为
User View?因为搜索数据的规模最大、用户行为最丰富、暴露用户的主动意图,从而能够更好地刻画用户兴趣。
22.1.2 DSSM
在论文
《Learning deep structured semantic models for web search using click-through data》中引入了深度结构化语义模型deep structured semantic model: DSSM,从而增强web搜索上下文中的query document匹配。考虑到DSSM和我们提出的MV-DNN模型密切相关,因此这里我们简要回顾一下DSSM。DSSM的典型体系结构如下图所示。DNN的输入(原始文本特征)是一个高维的term vector,例如query或document中term的未归一化的原始计数raw count。然后
DSSM通过两个神经网络传递其输入,每个神经网络对应不同的输入(如query和document),并将每个输入映射到共享语义空间shared semantic space中的语义向量semantic vector。对于
web document ranking,DSSM将query和document之间的相关度得分relevance score计算为它们对应的语义向量之间的余弦相似度cosine similarity,并通过document和query的相似度得分对document进行排序rank。
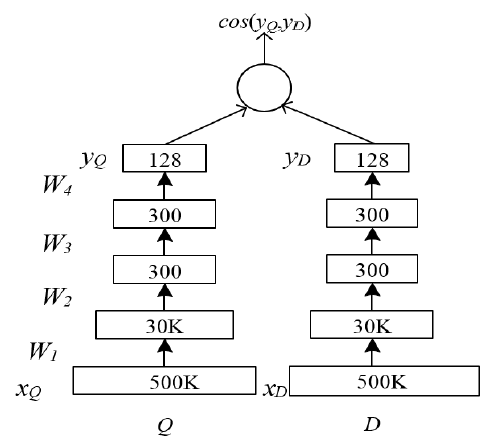
正式而言,对于
DSSM中的单个神经网络,如果我们将term vector,将hidden vector。令其中
tanh函数:然后,
querydocumentsemantic relevance score为:其中
query语义向量和document语义向量。在
web搜索中,给定query条件下,document按照它和query之间的语义相关性得分semantic relevance score进行排序。传统上,每个单词
word由一个one-hot word vector来表示,其中向量的维度是词表vocabulary的大小。然而,在现实世界的web搜索任务中词表通常非常大,因此one-hot向量的word representation使得模型的学习代价太大。因此,DSSM使用一个word hashing layer来用一个letter tri-gram vector来表示一个单词。例如,给定一个单词(如
web),在添加了单词边界符号(如#web#)之后,单词被分割为一系列的letter n-grams。然后,单词表示为letter tri-grams的count vector。例如,web这个单词的letter tri-gram representation为:#-w-e, w-e-b, e-b-#。在
DSSM中,第一层layer的权重矩阵term-vector映射到letter tri-gram count vector的letter tri-gram映射矩阵,这不需要学习。尽管英语单词的总量可能非常庞大,但是英语(或者其它类似语言)中不同的
letter tri-grams总量通常是有限的。因此,这种做法可以泛化到没有在训练集中出现的新单词。在训练中,假设
query和针对该query点击的document相关,我们利用这一信号来训练DSSM的参数,即权重矩阵首先,给定
query的条件下,一个document被点击的概率是通过softmax函数从它们之间的语义相关性得分来估计:其中:
softmax函数中的平滑因子smoothing factor,并且通常是根据实验中的验证集来设定的。document的集合。理想情况下document。实际上对于每个
(query, clicked-document)的pair对,记作query、document,我们使用document来近似
然后,我们通过最大化在整个训练集上的、给定
query条件下点击document的likelihood来估计模型参数:其中
注意,虽然目标函数
22.1.3 MV-DNN
DSSM可以视作一个多学习框架multi-learning framework,它将数据的两个不同的视图映射到一个共享视图shared view。从这个意义上讲,可以从更一般地角度来学习两个不同视图之间的共享映射shared mapping。在这项工作中我们提出了
DSSM的扩展,其中包含有两个以上的数据视图,我们称之为多视图DNN模型Multi-view DNN: MV-DNN。在这种配置setting下我们有pivot view称作auxiliary views记作每个
domain input每个视图
shared semantic space
MV-DNN的体系架构如下图所示。在我们的推荐系统设置setup中,我们将中心视图item创建辅助视图。下图中,
MV-DNN将高维稀疏特征(如用户、新闻、App中的原始特征)映射为联合语义空间joint semantic space中的低维稠密特征。DNN第一个隐层(具有5万个单元)完成单词哈希word hashing。然后将word-hashed特征通过多个非线性层来投影,其中最后一层的激活值构成了语义空间中的特征。注意:该图中的输入的特征维度(
5M和3M)是假设的,因为实际上每个视图可以具有任意数量的特征。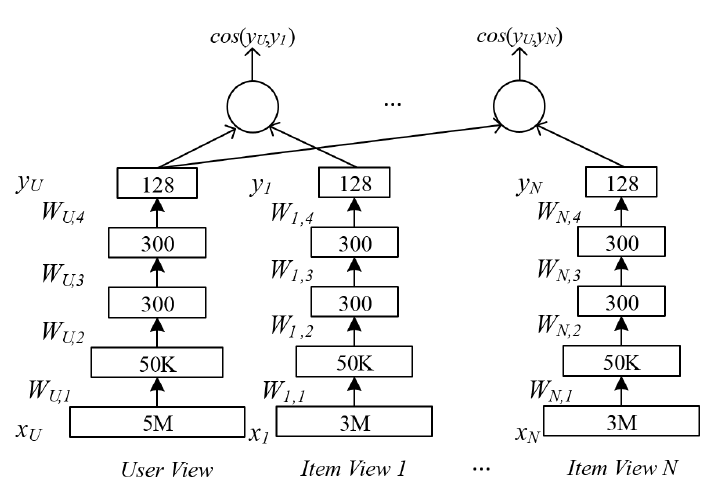
给定训练的一组
user-item view pair,假设第MV-DNN的目标函数是为每个视图找到一个非线性映射,使得在语义空间中,中心视图的映射其中:
item数量,该目标函数就是将各辅助视图的目标函数相加。
具有该目标函数的直觉是:试图为用户特征找到单个映射
single mapping,该映射可以将用户特征转换到一个匹配不同视图/领域中用户喜欢的所有item的空间中。这种共享参数的方式允许没有足够信息的领域通过具有更多数据的其它领域来学习良好的映射。例如,如果我们假设具有相似新闻
News偏好的用户在其他领域中也具有相似的偏好,那么这意味着其它领域也可以从新闻领域学到的用户映射中受益,那么这种方式应该会很好地工作。如果该假设成立,那么来自任何领域的样本都将有助于所有领域中更准确
accurately地对相似用户进行分组。实验结果表明,该假设在我们实验的领域是合理的,我们将在实验部分进一步阐述。DSSM和MV-DNN的目标函数评估的是:最大化正样本和负样本之间的相对序关系。这和CTR预估任务中的logloss目标函数不同,后者的目标是准确预估样本的点击率。因此DSSM和MV-DNN无法直接应用与CTR预估任务,而只能用于推荐任务。MV-DNN训练:可以使用随机梯度下降Stochastic Gradient Decent: SGD来训练MV-DNN。实际上每个训练样本都包含一对
a pair输入,一个用于用户视图user view、一个用于数据视图data view。因此,尽管在我们的模型中仅有一个用户视图,但是使用user feature files会更方便,每个文件对应于一个item特征文件item feature file。MV-DNN的优势:尽管MV-DNN是原始DSSM框架的扩展,但是MV-DNN具有几个独特的特点使得它优于DSSM。首先,原始的
DSSM模型对query视图和document视图使用相同的特征维度,并使用相同的representation(例如letter tri-gram)进行预处理。这在特征构建步骤feature composition step中产生了巨大的限制。原始的
DSSM使用相同的塔结构来处理query视图和doc视图,因此特征维度和预处理方法都一样。由于推荐系统的异质性
heterogeneity,用户视图和item视图很可能具有不同的输入特征。此外,很多类型的特征不能用
letter tri-gram来最佳地表示。例如,
URL域名特征通常包含前缀和后缀,如www、com、org。如果采用letter tri-gram,那么这些前缀、后缀将映射到相同的letter tri-gram。在实践中我们发现,在输入的原始文本很短的情况下(如原始
DSSM模型中的query文本和document标题),letter tri-gram的representation工作得很理想。但是不适合为通常包含大量query和URL域名的user-level特征来建模。
通过消除这些约束,新的
MV-DNN模型可以融合类别特征categorical feature(如电影题材、app类目)、地理位置特征(如国家、地区)、以及来自用户输入的uni-gram或bi-gram表示的原始文本特征。其次,
MV-DNN有能力扩展到很多不同的领域,而这是原始DSSM框架无法做到的。通过在每个
user-item view pair之间执行pair-wise训练,我们的模型能够轻松地采用新的view pair。这些新的view pair可能包含完全独立的用户集合和item集合。例如,可以添加从Xbox games收集的新的数据集。通过在每次训练迭代中交替
user-view pair,我们的模型最终可以收敛到最优的用户视图embedding。这个用户视图embedding通过所有item视图来训练。注意,虽然理论上我们可以在不同的
item视图中使用不同的用户集合,但是在我们的实验中我们选择在所有视图中保持相同的用户集合。这是为了同时考虑便利性convenience和更容易特征归一化feature normalization。
22.1.4 降维和数据缩减
在实践中,
MV-DNN通常需要在高维特征空间中为用户视图处理大量的训练样本。为了系统的可扩展性,我们提出了几种降维技术来减少用户视图中的特征数量。然后,我们提出了一种压缩
compact和摘要summarize用户训练样本的思想,从而将训练数据的数量缩减reduce到用户数量的线性关系。用户特征降维技术(仅用于用户视图):
top特征:一种简单的用户特征降维方法是选择top-K的最高频most frequent特征。我们选择特征出现频率
>= 0.001的用户特征。 主要的基本假设是:可以使用一组相对较小的、解释用户常见在线行为common online behavior的常用特征frequent feature来很好地描述用户。注意,用户的原始特征使用
TF-IDF得分进行预处理,以便我们选择的top特征不再包含搜索query中的常见停用词。最终用户特征的维度为8.3万。K-means:K-means是一种众所周知的聚类技术,旨在创建多个聚类使得每个点与其最近的聚类之间的距离之和最小化。这里的基本思想是:将相似的特征分组到同一个簇中。
给定输入
point然后对这
然后我们统计这些簇中分别有多少个点。假设簇
这相当于将
然后我们归一化
实际上可以不用归一化。可以通过实验对比归一化和未归一化的效果。
对于用户特征向量
为了能够使用
K-means提取合理数量的特征,我们需要有相对较大的簇数量。因为考虑到用户特征的维度为350万,较少的簇(比如100)将导致大块large chunk特征在同一个簇中。因此,这将产生难以学到有用模式的特征。为了缓解这个问题,我们将簇数量设置为10k。这意味着平均每个簇有350个用户特征。大规模的簇和大规模的原始特征使得运行
K-means的计算量很大。在我们的实验中,我们使用了一个基于云计算的Map-Reduce实现来运行K-means。LSH:局部敏感哈希Local Sensitive Hashing: LSH的工作原理是使用随机投影矩阵random projection matrix将数据投影到一个低得多的低维空间,使得原始空间中的pair-wise余弦距离cosine distance仍然在新空间中保留preserved。LSH需要一个变换矩阵LSH的输出向量具体而言,为了计算每个
两个输入向量
LSH输出向量accuracy保持余弦相似度,我们需要提高投影数量k-Means聚类的簇数量相同。LSH可以独立地应用于每个特征向量,并且可以独立地计算所有投影,因此使得该算法在Map-Reduce框架内高度可分布distributable。但是,LSH算法需要生成变换矩阵case中该矩阵包含从标准正态分布300GB的存储空间。此外,在计算LSH向量的时候,必须将LSH在Map-Reduce框架中代价太大。人们已经提出了很多方案来解决这个问题,其中大多数方案都是基于生成稀疏矩阵
《Online generation of locality sensitive hash signatures》中介绍的池化技巧pooling trick。 基本思想是:保留一个由size为size。为了获得元素consistent hash function来获得10000倍,并且可以在Map-Reduce期间仅使用10M的存储空间轻松地存储在每个节点上。
减少训练样本的数量:每个视图的训练数据包含
pair对item,这可能使得训练数据非常大。例如,在我们的新闻News推荐数据集中,pair对的数量远远超过10亿。即使使用优化的GPU实现optimized GPU implementation,训练也会非常慢。为了缓解这个问题,我们压缩了训练数据,使得每个视图中每个用户都包含一个训练样本。具体而言,压缩的训练样本使用了用户在该视图中喜欢的所有
item的特征的均值(即对item特征进行均值池化)。这样可以将每个视图的训练样本数量降低为用户数量,从而大大减少了训练数据的大小。注意,这种技术的一个问题是:目标函数现在变成了最大化用户特征和用户喜欢的
item的平均特征之间的相似性。在评估的时候有细微的差异,因为在测试期间每个用户只能提供一个item。但是,这种逼近approximation是必要的,使得系统有很好的可扩展性。此外,实验结果表明:这种逼近在实践中仍然会产生非常有前景的结果。
22.2 实验
这里我们将解释我们的实验研究过程,并简要回顾了我们作为
baseline的几种推荐算法。数据集:对于每个数据集,我们旨在评估已经在该领域中具有历史交互的用户(老用户)、以及在该领域中没有任何历史交互但是在用户视图中具有历史搜索和浏览行为的用户(新用户)。为了进行评估,我们根据以下标准将数据集划分为训练集和测试集:
首先,以
0.9 : 0.1的比例为每个用户随机分配一个train或者test的标记。然后,对于每个带
test标记的用户,我们以0.8 : 0.2的比例将其进一步随机分配一个old或者new标记。接着,对于每个带
old标记的用户,他们的50%的item用于训练、剩余的用于测试。于每个带
new标记的用户,他们的所有item都用于测试,从而确保这批用户的user-item的pair永远不会出现在训练过程中。通过这种方式,这批用户都成为系统的全新用户。
数据集的详细划分信息在下表所示。

性能评估:对于训练数据集中的每个
pair对,我们随机选择其它的9个item9个测试的pair对评估指标是:衡量系统对用户
pair对pair对平均倒数排名
Mean Reciprocal Rank: MRR:计算所有item中正确item的排名的倒数,然后对整个测试数据集的得分进行平均。Precision@1: P@1:计算系统将正确item排名为top 1 item的次数占比。
注意:这种随机抽取
item为负样本的方式有可能导致负样本太简单。可以考虑同类目或者同主题下抽取负样本,从而得到hard负样本来评估。baseline方法:标准的
SVD矩阵分解:在这个baseline中,我们构建user-item矩阵,并使用SVD执行矩阵分解。这是协同过滤技术的标准baseline。实际上,该
baseline仅在相对较小的数据集(在我们的case中为Apps数据)上在计算上是可行的。此外,该方法不能为新用户提供推荐,因为他们没有出现在user-item矩阵中。最热门
item:由于SVD无法处理新用户的推荐,因此我们使用最热门item作为新用户的简单baseline。它的工作原理是首先计算训练集中每个
item的频次frequency,然后针对每个测试样本pair对item的频次来排序。Canonical Correlation Analysis: CCA:CCA是一种传统的多视图学习技术,旨在找到两对two pair线性变换,每个输入视图一对,使得变换后transformed的数据之间的相关性最大化。CCA和DSSM相似,但是有两个主要区别:尽管
CCA的kernel版存在非线性变换,但是CCA经常使用线性变换,因为kernel版在大规模数据中计算量是不可行的。CCA在某种固定方差certain fixed variance约束下最大化相关性,而DSSM最大化correct pair的排序rank。排序目标函数ranking objective已经被证明是一个更好的推荐系统目标函数。
在我们针对
CCA的实验中,我们仅使用top-k的用户特征,因为其它两种降维技术(K-means和LSH)产生了一个非常稀疏的特征向量,这会使得相关性矩阵correlation matrix过于稠密dense从而无法有效地计算。协同主题回归
Collaborative Topic Regression: CTR:CTR是最近提出的推荐系统,它结合了贝叶斯矩阵分解Bayesian matrix factorization和item特征来创建item推荐。它在学术论文推荐academic paper recommendation方面已被证明是成功的。在
CTR模型中有两个输入:协同矩阵collaborative matrix、item特征(以bag-of-words来表示)。该模型通过最大化协同矩阵的重构误差reconstruction error并将item特征作为额外信号extra signal从而匹配用户和item。这有助于对训练数据中没有出现过的新item进行建模。对于我们场景中的新用户推荐,我们将协同矩阵item特征。single-view DNN:对于Apps和News数据集,我们运行三组实验来训练单视图DNN模型,每组实验对应于一种降维方法(SV-TopK、SV-Kmeans、SV-LSH)。MV-DNN:我们针对MV-DNN进行了另外三组实验。前两个使用
TopK或Kmeans降维的用户特征(MV-TopK、MV-Kmeans)来联合训练Apps和News数据。第三组实验使用
TopK用户特征(MV-TopK w/Xbox)来联合训练Apps、News、Movie/TV数据。
我们评估了
App数据集(第一张表)和News数据集(第二张表)中的不同方法获得的结果,如下表所示。我们将算法分为三类:第一类是baseline方法,第二类是我们的单视图模型,第三类是MV-DNN模型。可以看到:第一类方法:
朴素的最热门
item的baseline表现很差,这证明了对新用户的简单解决方案在我们的场景下不会很好地工作。即使对于在协同过滤矩阵中存在的老用户,标准的
SVD矩阵分解方法在该任务中也不够好。出乎意料的是,
CCA模型的表现并不比对Apps数据的随机猜测更好。这表明在DSSM中使用非线性映射以及基于排序的目标函数ranking-based objective对于系统很重要。CTR模型对于老用户而言表现不错,但是对于新用户却表现不佳。
第二类方法:对于单视图
DNN,结果表明性能取决于所使用的的降维方法。对于
Apps和News数据而言,最好的降维方法是top-K特征降维方法,该方法的性能远远优于其它两种方法。这可以被视为对以下假设的证实:用户可以使用相对较少的、有信息量
informative的特征的集合来建模。这也表明K-means和LSH在正确捕获用户行为语义方面不太有效。作为单视图
DNN和传统推荐方法的直接比较,我们的最佳模型 (SV-TopK) 的性能优于最佳的baseline方法(CTR,它也利用了item特征来进行推荐),其中在所有用户上提升了11%(MRR得分为0.497 vs 0.448) 、在新用户上提升了36.7%(MRR得分为0.436 vs 0.319)。在
P@1指标上,我们看到了更大的提升:在所有用户上提升13%、在新用户上提升88.7%。这表明我们的系统在推荐top-rated item方面的有效性。
第三类方法:对于
MV-DNN,结果表明添加更多领域确实有助于同时改善所有领域。具体而言:通过将
News视图和Apps视图进行联合训练,我们发现News和Apps数据集在这两个指标中都有显著提升。具体而言,在
App数据中,和最佳单视图模型相比,所有用户的MRR得分从0.497提升到0.517,相对提升4%。更重要的是,我们看到新用户有大幅提升,这表明一个视图中缺少新用户的数据可以通过其它视图该用户的数据来弥补。这可以从App数据集中新用户的相对提升来说明,其中新用户的MRR指标提升了7%(0.436 vs 0.466)、P@1指标提升11%(0.268 vs 0.297)。因此,我们迫切地想知道:我们能否安全地得出结论,即更多的视图确实有助于提升系统的性能?为了回答这个问题,我们进一步将
Xbox数据添加到框架中,并使用三个user-item view pair来训练了一个MV-DNN模型。结果令人振奋: 在
Apps数据中所有用户的MRR得分进一步提升了6%、新用户的MRR得分进一步提升了8%。另一方面,通过和
state-of-the-art算法进行比较,我们具有top-K特征的MV-DNN with Xbox view的方法相比CTR模型在所有用户上的P@1指标提升25.2%(0.277 vs 0.347)、在新用户上的P@1指标提升115%(0.142 vs 0.306)。
News数据集也可以观察到类似的结果:相对于CTR模型,MV-DNN在所有用户上的P@1指标提升49%、在新用户上的P@1指标提升101%。注意,在该数据集中缺少CCA和SVD的结果。由于包含150万用户和超过10亿条数据,这两种传统算法无法处理如此大规模的数据。很明显,我们基于DNN的方法可以很轻松地扩展到数十亿条数据,同时产生出色的推荐结果。下表为
App数据集的结果: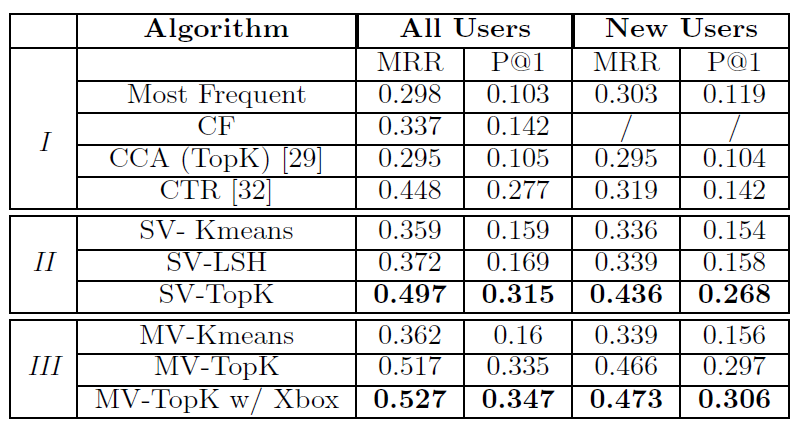
下表为
News数据集的结果: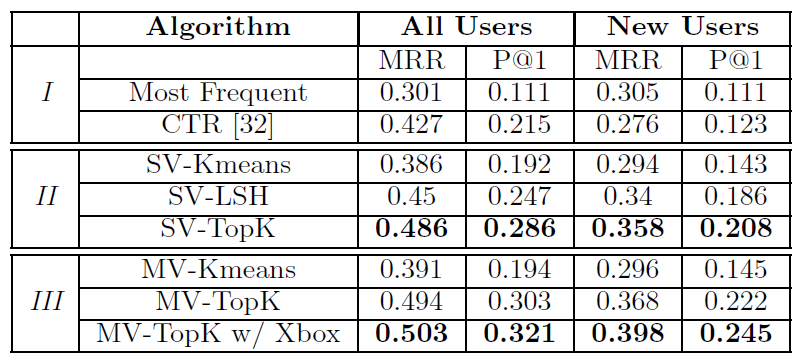
为了探索从系统中学到的模型的有效性,我们执行以下实验来测试单特征输入
single-feature input的推荐性能。具体而言,我们采用了性能最佳的系统(带top-k特征的MV-DNN),并构建了仅开启URL域名特征的用户特征user feature。由此产生的用户特征只有一个值,即域名ID。然后,我们针对其它视图运行我们的预测模型,以便在所有现有item中找到最匹配的News和Apps。下表显示了其中的一些结果。可以看到,学到的推荐系统确实非常有效。在第一个示例中,我们假设用户仅访问了
brackobama.com。匹配度最高的新闻显示了和奥巴马总统Obama以及Obamacare health的所有相关信息,这些信息都和该网站有关。另一方面,这个示例中最匹配的Apps也和健康有关。在第二个例子中,我们有一个用户访问了
www.spiegel.de,这是一个主要的在线的德国新闻网站,除了用户会阅读德语之外,它没有告诉关于用户的更多信息。该系统为用户匹配了2014年FIFA世界杯的文章,这似乎是德国人在这段时间内的共同兴趣。在最后一个例子中,用户似乎对婴儿相关的信息感兴趣,最匹配的
News和Apps都和婴儿、怀孕等相关。
注意:在这个实验中我们仅使用域名
ID,域名的名字domain name对于目标任务而言是未知的。
公共数据集:为进一步展示我们的方法在跨域用户建模方面的优势,我们对公共数据集进行了一系列实验。
数据集包含来自五个领域(数据挖掘、理论等等)的
33739位作者,其中每条数据包含研究领域的name、论文的标题和摘要、论文的作者列表、论文的发表年份。目标是推荐来自另一个领域的作者进行跨领域合作cross-domain collaboration。我们使用
single-view DNN来建模这种跨领域协作(如数据挖掘和理论研究学者之间的协作)。在这种情况下,用户视图和item视图都共享相同的特征表示。具体而言,我们使用作者在训练期间(1990~2001年)发表的论文的标题和摘要中的uni-gram单词作为特征,从而得到31932维的特征向量。我们随机选择训练期间已经有跨域协作、并且在测试期间至少由五个跨域协作的作者作为我们的测试集。对于不同领域之间的每个协作集合,我们将迭代100次来训练一个single-view DNN。注:这里仅评估了single-view DNN(即DSSM)。结果如下表所示。总体而言,除了
P@20指标之外,我们的方法在所有四个跨域数据集中的性能均明显优于CTL方法。特别是,我们在P@100时实现了更高的召回率,这对于DM to theory提升了96%的推荐性能。结果表明,将丰富的用户特征和非线性深度神经模型结合使用,确实可以捕获更多语义,而这些语义无法使用传统的
word-based共享模型(例如生成式的主题模型topic model)准确地建模。我们相信,使用多视图DNN模型可以进一步提高性能。但是我们将其留待将来研究。在效率方面,作者报告了整个数据集的
CTL方法的训练时间为12~15小时。而我们的算法运行速度非常快,每个模型仅用5~7分钟就可以在GPU机器上以相同数量的数据完成100次迭代。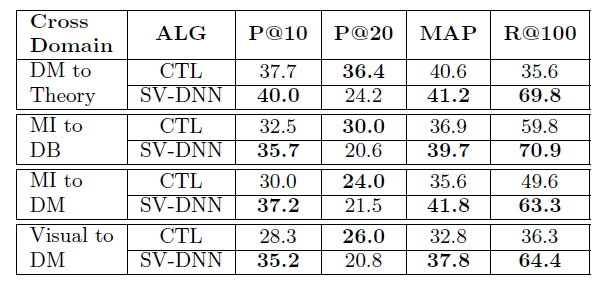
可扩展性:这里我们根据训练时间来比较各种算法的性能。我们的方法使用
SGD进行训练,因此可以使用分布式训练来处理大量数据。下表给出了不同方法的性能的详细信息。可以看到:
对于较小的
Apps数据集,SVD和CCA训练完成时间相对较快(大约四个小时),但是推荐性能却很差。single-view DNN模型(SV-TopK)在33小时内完成了100次训练迭代。content-based CTR模型需要花费很长的时间进行训练,原因是CTR需要使用LDA模型训练的主题比例 (然后
CTR获取了这些文件,并优化了用户特征和item特征之间的关联。因此,对于这两个数据集,训练CTR比我们的深度学习模型更昂贵。另一方面,我们看到
SV-TopK和MV-TopK都表现出对数据大小的 (亚)线性训练时间。因为当更多的数据可用时,SGD通常会花费更少的时间来收敛。
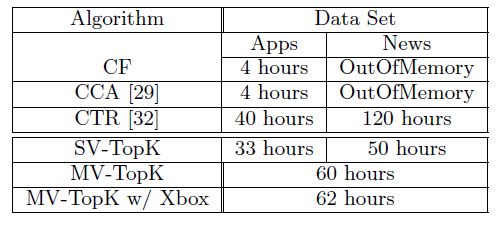
另外,下图显示了
News和Apps视图在MV-TopK模型的每次迭代期间的训练误差。在我们的实验中,我们手动将训练迭代次数设置为100次。有两个原因:一个原因是,尽管随着时间的推移效果提升越来越小,但是我们仍然能够看到所有视图的性能都有所提升。
另一个原因是,我们发现在实践中,某些视图的收敛速度比其他视图更快。例如,对于下图中的特定模型,
News视图在20次迭代后迅速收敛,而Apps视图大约花费了70次迭代才能达到收敛。由于训练期间交替使用
user-item view pair的过程以及不同视图的收敛速度不同,因此使用早停以进一步提高模型的可扩展性成为未来的关键工作。
二十三、CAN[2020]
随着机器学习模型,尤其是推荐系统模型的日益复杂,如何有效地处理丰富的输入特征成为一个关键问题。对于工业环境中的在线推荐器
recommender,模型通常使用one-hot编码的十亿级二元稀疏特征进行训练。每个特征也可以视为一个unique ID:它首先被映射到一个低维的embedding,然后被输入到模型中。处理大规模输入的一种简单方法是考虑特征之间相互独立。在这种假设下,特征之间没有联系,因此可以直接训练广义线性模型,从而基于特征的组合来估计点击率
CTR。然而,推荐系统中的target item和 “用户历史点击” 等特征是高度相关的,即存在对最终预测目标(如点击率)的特征协作效应feature collective effect,称作feature co-action。例如,点击历史中有 “泳衣” 的一名女性用户,由于 “泳衣” 和 “泳镜” 的co-action,很可能会点击推荐的 “泳镜”。feature co-action可以被认为是对一组原始特征的子图进行建模。如果子图仅包含两个特征,那么建模feature co-action相当于对两个ID之间的边进行建模。co-action effect解释了一组特征如何与优化目标相关联。如下图所示,feature co-action显式地将特征pair对[A, B]连接到target label。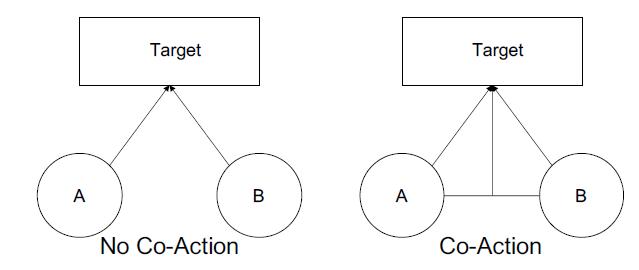
近年来,已有一些工作致力于建模
feature co-action,这些方法可以分为三类:基于聚合
aggregation的方法聚焦于学习如何聚合用户的历史行为序列,从而获得CTR预估的有区分性discriminative的representation。这些方法利用feature co-action对历史行为序列中的每个user action的权重进行建模,然后对加权的用户行为序列进行sum池化从而表示用户兴趣。基于图的方法将特征视为节点,这些节点被连接成有向图或无向图。在这种情况下,
feature co-action作为信息沿着边传播的edge weight。和基于聚合的方法、基于图的方法不同(这两种方法将
feature co-action建模为权重),组合嵌入combinatorial embedding方法通过显式组合特征embedding来对feature co-action进行建模。
尽管这些方法以不同的方式导致
CTR预估的提升,但是它们仍然存在一些缺点:基于聚合的方法和基于图的方法仅通过
edge weight对feature co-action进行建模,但是edge仅用于信息聚合information aggregation而不是用于信息增强information augmentation。combinatorial embedding方法将两个特征的embedding相结合,从而对feature co-action进行建模。 例如,PNN执行两个特征的内积或外积以增强augment输入。combinatorial embedding方法的一个主要缺点是:embedding同时承担了representation learning和co-action modeling的责任。representation learning任务和co-action modeling可能会相互冲突,从而限制了性能。
在论文
《 CAN: Revisiting Feature Co-Action for Click-Through Rate Prediction》中,论文强调了feature co-action建模的重要性,并认为state-of-the-art方法严重低估了co-action的重要性。由于表达能力有限,这些方法无法捕获到feature co-action。捕获feature co-action以增强输入的重要性在于它可以降低模型学习和捕获co-action的难度。假设存在一个最优函数co-action,通过在输入阶段显式提供为了验证论文的假设,即当前的方法无法完全捕获
feature co-action,论文回顾了state-of-the-art的方法和设计实验,从而表明探索feature co-action潜力的简单方法可以提高性能。例如,如果选择了特征co-occurrence将被视为一个新特征并馈入到模型中。作者将这个baseline称作笛卡尔积cartesian product模型。虽然笛卡尔积是co-action modeling的直接方法,但是它存在一些严重的缺陷,如参数量太大、特征完全独立的embedding learning。然而令人惊讶的是,根据论文的一些初步实验,作者发现大多数state-of-the-art的combinatorial embedding方法完全被笛卡尔积击败。作者推测这种情况可能是因为这些方法的表达能力差,并且无法学到平衡representation和co-action modeling的embedding。为此,作者提出了
feature co-action网络Co-Action Network: CAN,它可以在输入阶段捕获feature co-action,并有效利用不同特征pair对的互信息mutual information和公共信息common information。CAN不是直接参数化parameterize笛卡尔积embedding,而是参数化embedding生成网络generation network。这种参数化将追加参数的规模从embedding维度,具体而言,
CAN区分了用于representation learning和co-action modeling的embedding空间,其中embedding生成网络派生自co-action modeling空间。通过这种方式,CAN丰富了它的表达能力,缓解了representation learning和co-action learning的之间的冲突。与笛卡尔积模型相比,CAN由于提高了参数的利用率,因此显著降低了存储成本和计算成本。本文主要贡献:
作者强调了
feature co-action建模的重要性,而state-of-the-art方法严重低估了这一点。具体而言,论文重新回顾了现有的建模feature co-action的方法。实验结果表明:这些方法无法捕获笛卡尔积baseline的性能。这表明当前的CTR模型没有充分探索原始feature co-action的潜力。受观察的启发,作者提出了一个轻量级模型
Co-Action Network: CAN,从而建模原始特征之间的co-action。CAN可以有效地捕获feature co-action,在降低存储代价和计算代价的同时提高模型性能。论文对公共数据集和工业数据集进行了广泛的实验,一致的优势验证了
CAN的有效性。到目前为止,CAN已经部署在阿里巴巴的展示广告系统中,带来了平均12%的点击率提升、平均8%的RPM提升。论文介绍了在工业环境中部署
CAN的技术。CAN利用feature co-action的思想和作者学到的经验教训可以泛化到其它的setup,因此受到研究人员和业界从业者的关注。
相关工作::一些研究工作致力于
CTR预估中建模feature co-action。这些方法可以分为三类:aggregation-based方法、graph-based方法、combinatorial embedding方法。aggregation-based方法:深度CTR预估模型通常遵循embedding & MLP的范式。在这些方法中,大规模稀疏输入特征(即ID特征)首先映射到低维向量,然后以group-wise的方式聚合为固定长度的向量。最终拼接好的向量馈入多层感知机MLP。一系列工作聚焦于学习如何聚合特征以获得
CTR预估的、有区分性discriminative的representation。CNN、RNN、Transformer、Capsule等不同的神经架构被用于聚合特征。DIN是采用注意力机制进行特征聚合的代表性工作之一。它使用注意力来激活关于给定target item的局部历史行为,并成功地捕获到用户兴趣的多样性特点diversity characteristic。DIEN进一步提出了一种辅助损失来从历史行为中捕获潜在的兴趣。此外,DIEN将注意力机制和GRU相结合,对用户兴趣的动态演化进行建模从而进行特征聚合。MIND认为单个向量可能不足以捕获用户和item中的复杂模式。MIND引入了胶囊网络和动态路由机制来学习多个representation来聚合原始特征。受到
self-attention架构在seq-to-seq learning任务中取得成功的启发,DSIN引入了Transformer以进行特征聚合。MIMN提出了一种memory-based的架构来聚合特征并解决长期long-term用户兴趣建模的挑战。
graph-based方法:图包含节点和边,其中ID特征可以由节点embedding表示,feature co-action可以沿着边建模。基于图的方法(如Graph Neural Network: GNN)对每个节点进行特征传播,并在传播过程中聚合了邻域信息。feature co-action被建模为边权重,用于特征传播从而沿着边局部平滑节点embedding。《Spectral Networks and Locally Connected Networks on Graphs》首先提出了一种基于谱图spectral graph的卷积网络扩展,从而用于特征传播。GCN进一步简化了图卷积层。在GCN中,边是预定义的,边的权重是一维实数。边的权重用于聚合邻域信息以建模feature co-action。GAT学习每个中间层intermediate layer分配不同的边权重。GAT也通过边权重对feature co-action进行建模,但是由于注意力机制,GAT中的权重是节点的函数。因此注意力机制使得GAT更有效地对feature co-action进行建模。还有一些工作利用不同节点之间的
meta-path进行embedding learning。
尽管基于图的方法在图结构化数据中取得了巨大的成功,但是
feature co-action仅由表示连接强度的一维权重来建模。这种表达能力可能不足以建模feature co-action。combinatorial embedding方法:组合embedding方法根据组合embedding来度量feature co-action。FM是浅层模型时代的代表性方法。在FM中,feature co-action被建模为特征的latent vector的内积。然而,FM在不同类型的inter-field相互作用中使用相同的latent vector,这可能会导致耦合梯度coupled gradient问题并降低模型容量。假设有三个特征:性别、地点、星期。某个样本的特征为:“男性”、“上海”、“周日”。因此有:
因此有梯度:
假设性别和星期是独立的,那么理想情况下
inter-field相互作用中使用相同的latent vector引起的。此外,
FM的表达能力也受到浅层的限制。受到深度学习成功的启发,最近的
CTR预估模型也已经从传统的浅层方法过度到现代的深度方法。DNN在bit-wise level建模非线性交互的能力非常强大,但是feature co-action是隐式学习的。许多工作已经表明: 通过组合特征embedding来显式建模feature co-action有利于CTR预估。Wide&Deep手动设计的笛卡尔积作为wide模块的输入,其中wide模块是一个广义的线性模型。wide模块结合深度神经网络来预估CTR。DeepFM在Wide&Deep中将wide部分替换为FM模块,从而无需手动构建笛卡尔积。Productbased Neural Network: PNN引入一个product layer来捕获inter-field category之间的feature co-action。product layer的输出馈入到后续的DNN来执行最终的预测。Deep & Cross Network: DCN在每一层应用特征交叉。
尽管和普通
DNN相比,这些方法取得了显著的性能提升,但是它们仍然存在一些局限性。具体而言,每个ID embedding同时承担representation learning和co-action modeling的责任。representation learning和co-action modeling之间的相互干扰可能会损害性能。因此,combinatorial embedding的限制没有充分利用feature co-action的能力。
23.1 模型
feature co-action回顾:这里我们首先简要介绍一下CTR预估中的feature co-action,然后我们回顾建模feature co-action的state-of-the-art方法。在广告系统中,用户
其中:
embedding函数,它将稀疏的ID特征映射到可学习的、稠密的embedding向量。其中embedding维度。
除了这些一元特征,一些工作将特征交互建模为
DNN的附加输入:其中
特征交互的融合改善了预测结果,这表明来自不同
group的特征组合提供了额外的信息。直观的原因是:在CTR预估任务中,某些特征组合与label的关系,比单独isolated的特征本身与label的关系更强。以用户点击行为为例,由于用户兴趣的存在,用户点击历史与用户可能点击的target item之间存在很强的关联。因此,用户点击历史和target item的组合是CTR预估的有效共现co-occurrence特征。我们将这种与label关系密切的特征交互称作特征协同feature co-action。仔细回顾以前的
DNN-based方法,可以发现一些深度神经网络即使不使用组合特征作为输入,也可以捕获特定特征之间的交互。例如,DIN和DIEN使用注意力机制来捕获用户行为特征和item之间的交互。然而,这些方法的弱点在于它们仅局限于用户兴趣序列的特征交互,并且都是处理特征的embedding向量。而低维空间中的embedding向量往往会丢失很多原始信息。最直接的实现方法是为每个组合特征学习一个
embedding向量,即笛卡尔积cartesian product。然而,这也存在一些严重的缺陷:第一个问题是参数爆炸问题。例如,取值空间大小为
此外,包含相同特征的两个组合之间没有信息共享,这也限制了笛卡尔积的表达能力。
另外,笛卡尔积的方式也无法泛化到训练期间
unseen的特征组合。
一些工作尝试使用特殊的网络结构来建模
feature co-action。然而,大多数这种相互交互的结构,与特征组feature groups的representation之间没有任何区别。为了不受笛卡尔积和其它先前工作缺陷的情况下利用
feature co-action,我们提出了一个Co-Action Network: CAN模型来有效地捕获inter-field交互。根据以上分析,以往的工作并没有充分挖掘feature co-action的潜力。受笛卡尔积中特征组合独立编码的启发,CAN引入了一个可插拔pluggable模块:协同单元co-action unit。co-action unit聚焦于扩展参数空间parameter space,并有效地应用参数来建模feature co-action。具体而言,co-action unit充分利用一侧(例如用户侧)的参数来构建应用于另一侧(例如广告侧)的多层感知机MLP。这种特征交叉范式给模型带来了更大的灵活性。一方面,增加参数维度意味着扩展
MLP参数和层数。另一方面,和在具有相同特征的不同组合之间不共享信息的笛卡尔积相比,
co-action unit提高了参数利用率,因为MLP直接使用feature embedding。此外,为了在模型中融入高阶信息,我们引入了多阶增强
multi orders enhancement,它显式地为co-action unit构建了一个多项式输入。多阶信息促进了模型的非线性,有助于更好的feature co-action。
此外,我们提出了包括
embedding独立性、组合独立性、阶次独立性的multi-level independence,并通过拓宽broadening参数空间来保证co-action learning的独立性。CAN的整体架构如下图所示。用户特征和target item特征以两种方式输入到CAN中。在第一种方式中,所有的用户特征
target item特征embedding layer编码为稠密向量,然后分别拼接为在第二种方式中,来自
co-action unit的co-action modeling。co-action unit的算子operator定义为:它扮演
MLP的角色,它的参数来自于co-action unit的细节后面详述。
CAN的最终架构形式化为:其中:
co-action unit的lookup table的参数,DNN的参数。ground truth记作其中
feature embedding的参数(用于计算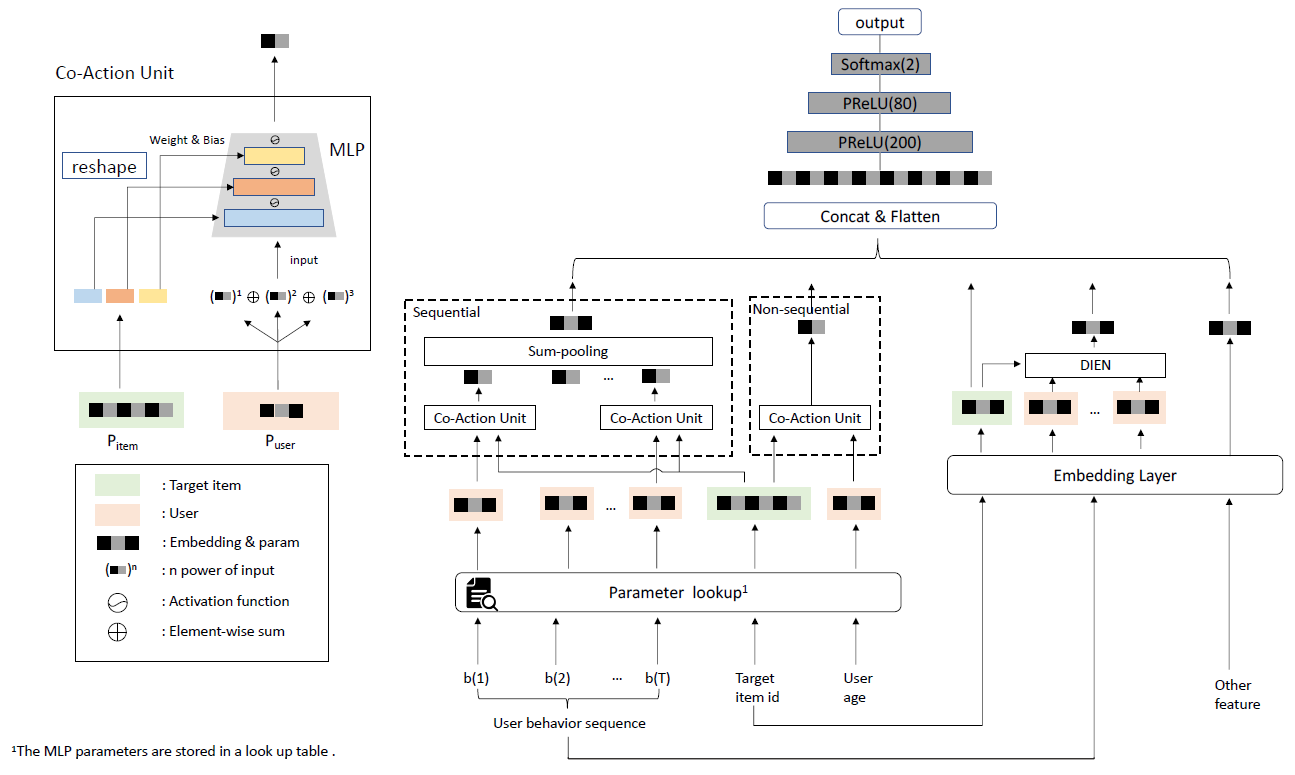
co-action unit:co-action unit的详细结构如上图左侧部分所示。每个item特征通过MLP table lookup从而对应一个多层感知机MLP的输入。 输出的feature co-action和common feature embeddings一起用于最终的CTR预估。注意:上图中
Parameter lookup独立于Embedding Layer,这使得representation learning和co-action modeling是独立的。weight和bias,co-action输出unique ID数量,事实上
item是所有item中的一小部分,因此其数量小于用户点击历史中的item数量。因此,我们选择reshape为MLP的权重矩阵和bias向量。
给定某个
item ID特征的参数user ID特征的参数reshape为bias向量,即:其中
然后
feature co-action计算为:其中:
feature co-action。读者注:本质上是将向量内积这种线性交互形式替换为
MLP这种非线性交互形式。在MLP中,输入为用户侧embedding、权重为广告侧embedding的respahe。对于像用户点击历史这样的序列特征,
co-action unit应用于每个历史点击item,然后对序列进行sum池化;对于用户画像这样的非序列特征,co-action unit并未进行池化。和其它方法相比,我们提出的
co-action unit至少有三个优势:和以往在不同类型的
inter-field相互作用中使用相同的latent向量不同,co-action unit利用DNN的计算能力,通过动态参数和输入而不是固定模型来耦合两个分特征component feature,从而提供更大容量来保证两个field特征的更新并且避免耦合梯度。其次,可学习参数的规模较小。
co-action learning的最终目标是学习每个co-action feature的良好的representation向量。但是,直接学习分特征component feature的笛卡尔积的embedding需要学习相当大规模的参数。例如,考虑两个具有ID数量的特征。如果我们通过学习笛卡尔积的embedding来学习co-action representation,则参数的规模应该是embedding维度。但是,通过使用co-action unit,这个规模可以降低到co-action unit的维度。更少的参数不仅有利于学习,还可以有效减轻在线系统的负担。第三,和之前的其他工作相比,
co-action unit对新的特征组合具有更好的泛化能力。给定一个新的特征组合,只要之前训练过两侧的embedding,co-action unit仍然可以工作。
读者注:为简化讨论,假设
co-action unit没有非线性激活函数、也没有bias。假设
co-action unit只有一层,用户侧的embeddingitem侧的embedding可以拆分为embedding
因此特征组合得到新的交叉特征为
如果 co-action unit 为 item 侧的 embedding 可以拆分为:
得到的交叉特征为:
因此 item 侧的 embedding 可以视为高阶的(multi-head (第 head 数量为 embedding 。如果muti-head 退化为 single-head、并且不同阶次的 item embedding 共享,则 co-action unit 退化回 Deep Cross Network 。
一方面,
co-action unit类似于DIN,它们都是仅考虑和target item的交互。但是它们交互的方式(即交互函数)不同。另一方面,
co-action unit类似于xDeepFM,它们都是显式建模特征交互,但是xDeepFM考虑了field-level的特征交互。
因此这篇论文创新点存疑,并且 co-action unit 是否能够捕获feature co-action 也是存疑的。
此外,CAN 用了两套 embedding:一套用于建模 feature co-action、另一套建模 feature representation,这大大增加了模型的参数(几乎翻倍)。
多阶加强
Multi-order Enhancement:前面提到的feature co-action基本上是基于一阶特征形成的,也可以在高阶上估计特征交互。虽然co-action unit可以利用深层MLP隐式地学习高阶特征交互,但是学习过程被认为很漫长。为此,我们在co-action unit中显式引入多阶信息从而获得多项式输入。这是通过将其中
这里的近似是假设不同阶次之间的权重是共享的。
注意:当
SeLU作为激活函数;当tanh激活函数,从而避免由于高阶项引起的数值问题。多阶增强
multi-order enhancement有效地提升了模型对co-action modeling的非线性拟合能力,而不会带来额外的计算和存储成本。多
level独立性Multi-level Independence:learning independence是co-action modeling的主要关注点之一。为了确保学习的独立性,我们根据重要性从不同方面提出了三个level的策略:level 1:参数独立性,这是必须的。如前所述,我们的方法区分了representation learning和co-action modeling的参数。参数独立性是我们CAN的基础。level 2:组合独立性,这是推荐的。随着特征组合数量的增加,feature co-action线性增长。根据经验,target item特征像item_id, category_id被选为权重侧embedding,而用户特征则用于输入侧embedding。由于权重侧embedding可以和多个输入侧embedding组合,反之亦然,因此我们的方法以指数方式扩大了它们的维度。假设有embedding和embedding,那么我们将权重侧embedding的维度扩大embedding的维度扩大其中
在前向传播中,这些
embedding被分为几个部分来完成MLP操作。level 3:阶次独立性,这是可选的。为了进一步提高多阶输入中co-action modeling的灵活性,我们的方法对不同的阶次使用了不同的权重侧embedding。权重侧embedding的维度也相应增加了orders倍。注意,此时由于
协作独立性
co-action independence有助于co-action modeling,但是同时也带来了额外的内存访问和计算成本。在独立性level和部署成本之间存在tradeoff。从经验上来讲,模型使用的独立性level越高,模型需要的训练数据就越多。在我们的广告系统中,我们使用了 三个level的独立性。但是由于缺乏训练样本,我们在公共数据集中仅使用了embedding独立性。
23.2 实验
数据集:我们使用三个公开可访问的数据集进行
CTR预估任务的实验:Amazon数据集:包含来自Amazon的产品评论和元数据。在24个产品类目中,我们选择Books子集,其中包含75053个用户、358367个item、1583个类目。由于
Amazon数据集最初不是CTR预估数据集,因此未提供负样本。遵从前人的工作,我们随机选择未被特定用户评论的item作为该用户的负样本,并创建相应的用户行为序列(点击和未点击)。最大序列长度限制为100。Taobao数据集:来自淘宝推荐系统中用户行为的集合。数据集包含大约100万用户,用户行为包括点击、购买、加购物车、收藏。我们获取每个用户的点击行为,并根据时间戳进行排序从而构建用户行为序列。最大序列长度限制为200。Avazu数据集:是Avazu提供的移动广告数据,包含11天的真实工业数据,前10天用于训练、第11天用于测试。对于
Amazon数据集和Taobao数据集,我们根据用户行为序列对feature co-action进行建模。相反,对于Avazu数据集,我们使用离散特征对feature co-action进行建模,因为Avazu数据集包含各种数据字段,适合验证序列/非序列对feature co-action建模的影响。在训练期间,第
10天被视为验证集。
数据集的统计信息如下表所示。
baseline方法:在本文中,我们使用DIEN作为CAN的base model。请注意,由于co-action unit是可插拔模块,因此允许使用其它任何模型。为了验证我们方法的有效性,我们将
CAN和当前聚焦于特征交互的方法进行了比较。为了公平比较,DIEN被用作这些方法的basis。DIEN:它设计了一个兴趣抽取层来从用户行为序列中捕获用户兴趣。兴趣演化层进一步用于对兴趣演化过程进行建模。笛卡尔积
Cartesian Product:它是将两个集合相乘从而形成所有有序pair对的集合。有序pair对的第一个元素属于第一组集合、第二个元素属于第二组集合。PNN:它使用product layer和全连接层来探索高阶特征交互。NCF:它提出了一种神经网络架构来学习user和item的潜在特征,这些特征用于使用神经网络对协同过滤进行建模。DeepFM:它是一种新的神经网络架构,它结合了FM和深度学习的能力。
实现:我们使用
Tensorflow实现了CAN。对于
MLP,权重维度为4 x 4,这导致(4 x 4 + 4) x 8 = 160(包括bias)。我们使用多阶加强,其中
2。模型从头开始训练,模型参数初始化为高斯分布(均值为
0、标准差为0.01)。优化器为Adam,batch size = 128,学习率为0.001。我们使用三层
MLP来预测最终的CTR,隐层维度为200 x 100 x 2。
模型的评估指标为
AUC。下表给出了
Amazon数据集和Taobao数据集上的实验结果。可以看到:CAN在两个数据集上都优于其它state-of-the-art的方法。和
base模型DIEN相比,CAN分别将AUC提高了1.7%和2.1%。同时CAN在很大程度上优于其它co-action方法,这证明了我们的方法在co-action modeling上的有效性。值得注意的是,作为纯粹的
representation learning方法,笛卡尔积方法和其它组合embedding方法(如PNN、NCF、DeepFM)相比,可以获得更好的性能。这表明虽然这些组合embedding方法可以抽取一些co-action特征,但是笛卡尔积确实可以学习具有良好representation和co-action的embedding。相比之下,
CAN取得了比笛卡尔积和组合embedding方法更好的结果,这意味着基于网络机制的CAN可以同时学习representation和co-action。
消融研究:为了研究每个组件的影响,我们进行了几项消融研究,如下表所示。
多阶
multi order:首先我们评估多阶的影响。在从一阶到二阶,
AUC提升了很多。之后随着阶次的增加,差距开始缩小甚至造成负向影响。
多阶对于性能增益的影响很小,因此在实践中我们使用
2阶或者3阶是合适的。MLP深度:其次,我们展示了co-action modeling的影响。具体而言,我们分别训练了具有不同MLP层数的模型,分别为1/2/4/8。MLP层的输入和输出维度不变。可以看到:
一般而言,更深的
MLP会带来更高的性能。但是当层数超过
4时,没有明显的AUC增益,即8层MLP相比较4层MLP仅增加了0.02%的AUC。主要原因是训练样本对于如此深的架构来说是不够的。
激活函数:最后,我们比较了不同激活函数的影响。可以看到:
非线性使得
AUC提高了0.03% ~ 0.41%。在阶次为
2的情况下,Tanh相比SeLU表现出更显著的性能,因为Tanh起到了normalizer的作用,从而避免高阶次的数值稳定性问题。
模型通用性
universality和泛化generalization:为了验证CAN的特征通用性和泛化能力,我们从两个方面对CAN和其它方法进行比较:验证具有非序列的co-action特征,并预测训练期间未见过的co-action特征的样本。通用性:虽然
CAN主要针对包含大量行为序列的真实工业数据而设计,但是它仍然能够处理非序列输入。Avazu数据集包含24个数据字段,我们从中选择9个字段构建16种特征组合。实验结果如下表所示。可以看到:CAN优于大多数方法并且和笛卡尔积相当。DNN作为basic模型,没有包含任何序列特征。因此除了DNN之外,其它方法都包含了16种组合特征。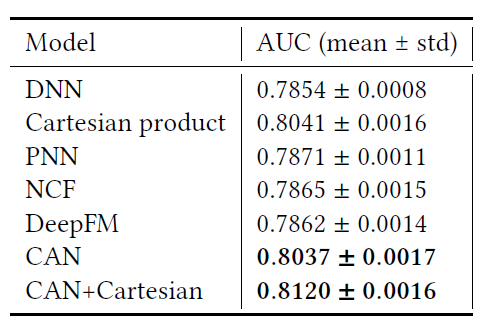
泛化能力:在真实的商业场景中,每天都会出现无数的特征组合,这就需要
CTR模型的快速响应。泛化能力对于实际应用非常重要。为此,我们从
Amazon测试集中删除了包含现有特征组合的样本。通过这种方式,我们获得了一个新的测试集,其特征组合对于训练好的模型而言是全新的。注意:我们仅要求特征组合为zero shot,而不是所有特征都是zero shot。实验结果如下表所示可以看到:
笛卡尔积在这种场景下是无效的(
DIEN+Cartesian相比于DIEN几乎没有提升),因为它依赖于训练好的co-action embedding,但是测试集中这种co-action embedding不可用。相反,
CAN仍然运行良好。与其它方法相比,CAN显示出对新特征组合的出色泛化能力。
在真实的工业环境中,特征组合非常稀疏,只要
CAN处理新的特征组合就容易的多。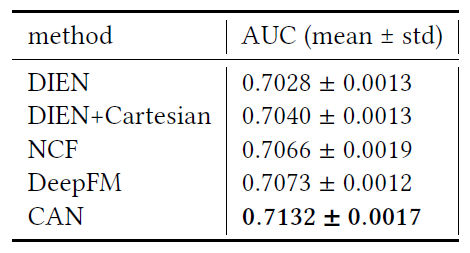
工业数据集上的结果:
在线
Serving和挑战:一开始我们在我们的系统上部署了笛卡尔积模型,这造成了很多麻烦。一方面,即使使用
ID低频过滤,模型大小也以极大的速度扩大。另一方面,额外的
ID也带来了无法接受的embedding look up操作的数量以及系统响应延迟。
相比之下,
CAN在这方面要有好的多。为了在我们的广告系统上部署CAN,我们选择了21个特征,包括6个广告特征、15个用户特征来生成特征组合,以便由于co-action独立性而分配了额外的21个embedding空间。显著增加的
embedding空间仍然导致在线serving的巨大压力。由于用户特征大多数为长度超过100的行为序列,因此需要额外的内存访问,导致响应延迟上升。此外,feature co-action的计算成本根据特征组合的数量线性增加,这也给我们的系统带来了相当大的响应延迟。解决方案:为了解决这些问题,我们付出了很多努力来减少响应延迟。我们从三个方面简化模型:
序列截断:
16个用户特征的长度从50到500不等。为了降低内存访问成本,我们简单地对我们的用户特征应用序列截断。例如,长度为200的所有用户行为序列都截断到50。最近的用户行为被保留。序列截断将
Query Per Second: QPS提高20%,但是导致AUC降低0.1%,这是可以接受的。组合缩减:
6个广告特征和15个用户特征最多可以获得90个特征组合,这是一个沉重的负担。经验上,同一类型的广告特征和用户特征的组合可以更好地对特征共现co-occurrence进行建模。根据这个原则,我们保留item_id、item_click_history、category_id、category_click_history等组合,并删除一些不相关的组合。这样,组合的数量从90减少到48个,QPS提高了30%。计算
kernel优化:co-action计算涉及到[batch_size, K, dim_in, dim_out]和[batch_size, K, seq_len, dim_in]。其中K, seq_len, dim_in, dim_out分别指的是co-action特征数量、用户行为序列长度、MLP输入维度、MLP输出维度。在我们的场景中,
dim_in和dim_out不是常用的形状,因此这种矩阵没有被Basic Linear Algebra Subprograms:BLAS很好地优化。为了解决这个问题,我们重写了内部计算逻辑,带来了60%的QPS提升。此外,由于该矩阵乘法之后是
seq_len维度上的sum池化,我们进一步在矩阵乘法和sum池化之间进行了kernel fusion。通过这种方式,避免了矩阵乘法输出的中间结果写入GPU内存,这又带来了47%的QPS提升。
通过这一系列的优化,使得
CAN能够在主流量main traffic中稳定地在线serving。在我们的系统中,每个GPU可以处理将近1K QPS。下表给出了我们的在线A/B test中CAN对CTR和RPM:Revenue Per Mille的提升。