三十九、AutoDis[2021]
如下图所示,大多数现有的深度
CTR模型遵循Embedding & Feature Interaction (FI)的范式。由于特征交互在CTR预测中的重要性,大多数工作集中在设计FI模块的网络架构从而更好地捕获显式特征交互或隐式特征交互。虽然在文献中没有很好的研究,但embedding模块也是深度CTR模型的一个关键因素,原因有二:embedding模块是后续FI模块的基石,直接影响FI模块的效果。- 深度
CTR模型中的参数数量大量集中在embedding模块,自然地对预测性能有很高的影响。
然而,
embedding模块被研究界所忽视,这促使《An Embedding Learning Framework for Numerical Features in CTR Prediction》进行深入研究。embedding模块通常以look-up table的方式工作,将输入数据的每个categorical field特征映射到具有可学习参数的潜在embedding空间。不幸的是,这种categorization策略不能用于处理数值特征,因为在一个numerical field(如身高)可能有无限多的特征取值。在实践中,现有的数值特征的
representation方法可以归纳为三类(如下图的红色虚线框):No Embedding:直接使用原始特征取值或转换,而不学习embedding。Field Embedding:为每个numerical field学习单个field embedding。Discretization:通过各种启发式离散化策略将数值特征转换为categorical feature,并分配embedding。
然而,前两类可能会由于
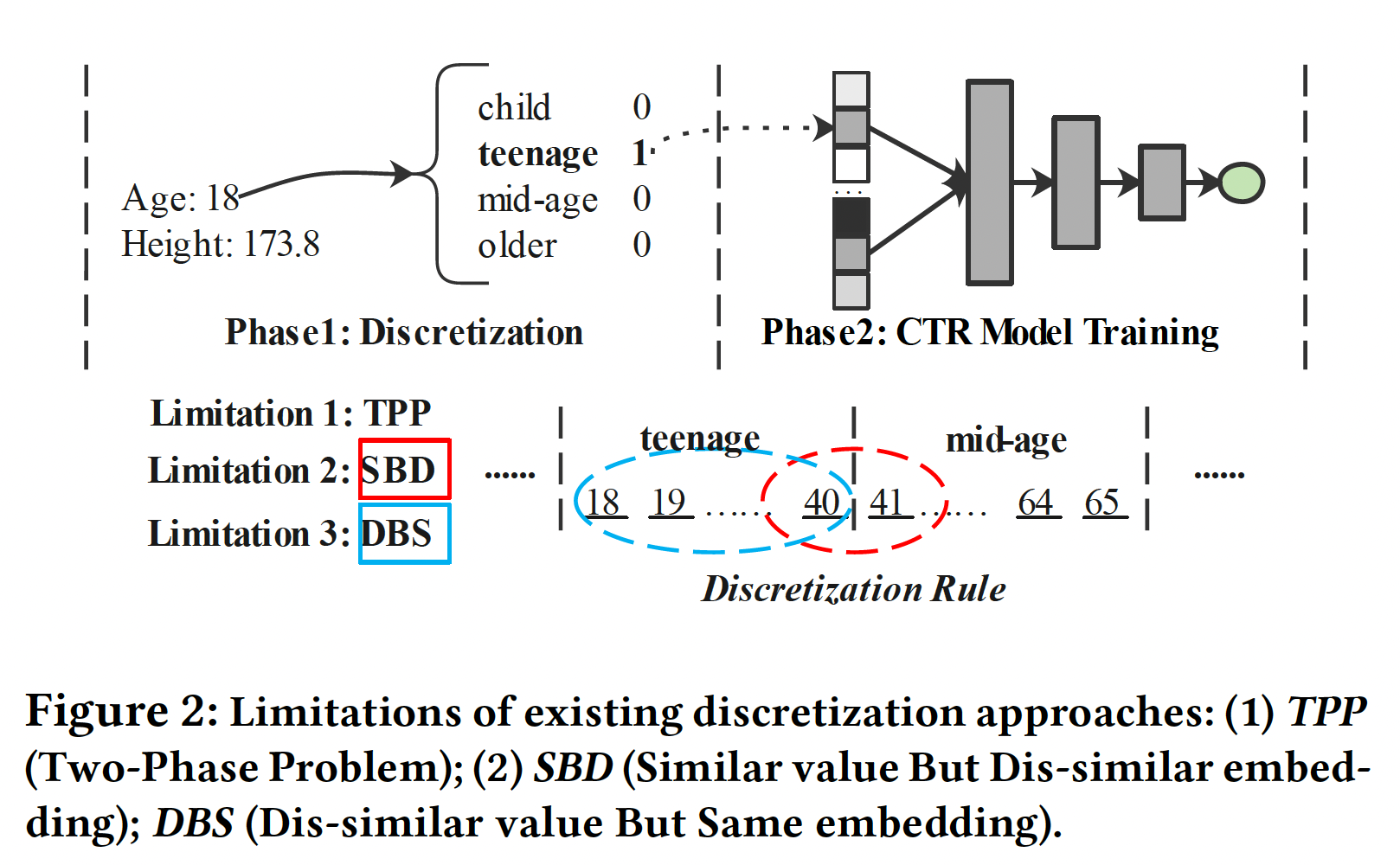
representation的低容量而导致性能不佳。最后一类也是次优的,因为这种基于启发式的离散化规则不是以CTR模型的最终目标进行优化的。此外,hard discretization-based的方法受到Similar value But Dis-similar embedding: SBD和Dis-similar value But Same embedding: DBS问题的影响,其细节将在后面讨论。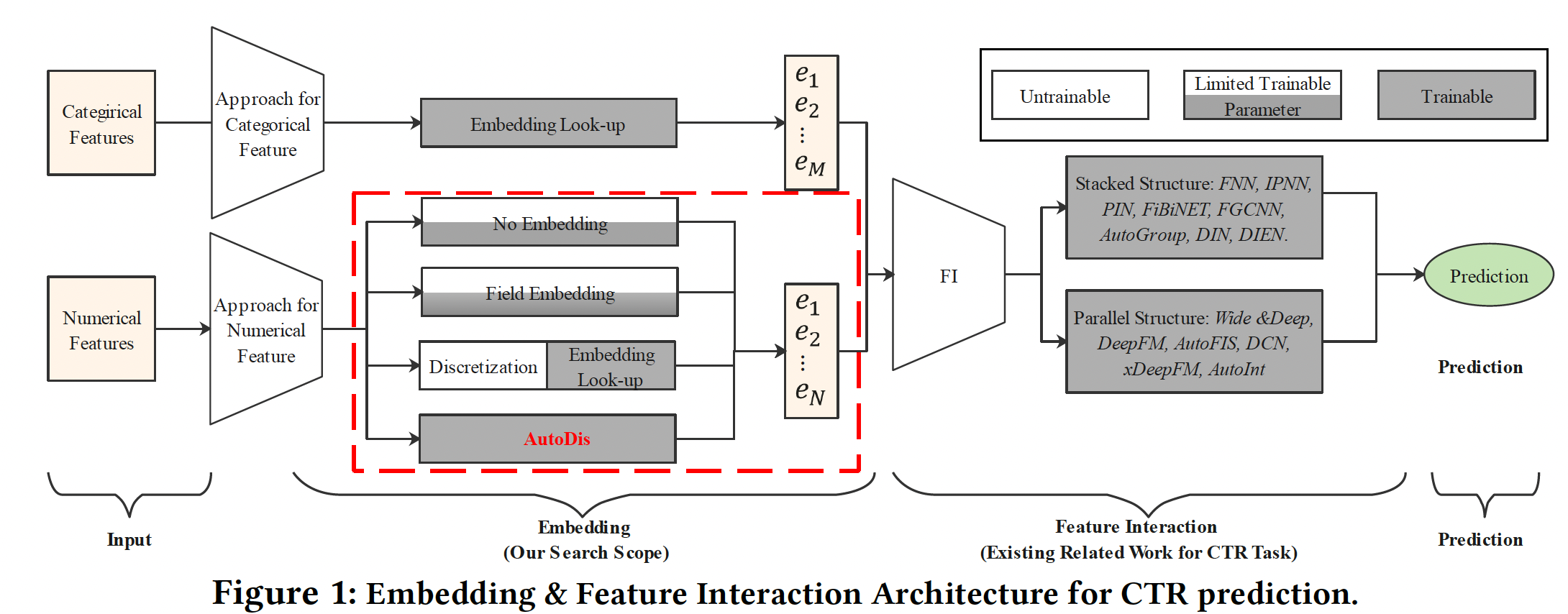
为了解决现有方法的局限性,论文
《An Embedding Learning Framework for Numerical Features in CTR Prediction》提出了一个基于soft discretization的数值特征的automatic end-to-end embedding learning framework,即AutoDis。AutoDis由三个核心模块组成:meta-embedding、automatic discretization和aggregation,从而实现高的模型容量、端到端的训练、以及unique representation等特性。具体而言:- 首先,论文为每个
numerical field精心设计了一组meta-embedding,这些meta-embedding在该field内的所有特征取值之间是共享的,并从field的角度学习全局知识,其中embedding参数的数量是可控的。 - 然后,利用可微的
automatic discretization模块进行soft discretization,并且捕获每个数值特征和field-specific meta-embedding之间的相关性。 - 最后,利用一个
aggregation函数从而学习unique Continuous-But-Different representation。
据作者所知,
AutoDis是第一个用于numerical feature embedding的端到端soft discretization框架,可以与深度CTR模型的最终目标共同优化。论文主要贡献:
- 论文提出了
AutoDis,一个可插拔的用于numerical feature的embedding learning框架,它具有很高的模型容量,能够以端到端的方式生成unique representation并且具有可管理的参数数量。 - 在
AutoDis中,论文为每个numerical field设计了meta-embedding从而学习全局的共享知识。此外,一个可微的automatic discretization被用来捕获数值特征和meta-embedding之间的相关性,而一个aggregation过程被用来为每个特征学习一个unique Continuous-But-Different representation。 - 在两个公共数据集和一个工业数据集上进行了综合实验,证明了
AutoDis比现有的数值特征的representation方法更有优势。此外,AutoDis与各种流行的深度CTR模型兼容,大大改善了它们的推荐性能。在一个主流广告平台的online A/B test表明,AutoDis在CTR和eCPM方面比商业baseline提高了2.1%和2.7%。
相关工作:
Embedding:作为深度CTR模型的基石,embedding模块对模型的性能有重大影响,因为它占用了大部分的模型参数。我们在此简单介绍推荐领域中基于embedding look-up的研究。现有的研究主要集中在设计
adaptable的embedding算法,通过为不同的特征分配可变长度的embedding或multi-embeddings,如Mixed-dimension(《Mixed dimension embeddings with application to memory-efficient recommendation systems》),NIS(《Neural Input Search for Large Scale Recommendation Models》)和AutoEmb(《AutoEmb: Automated Embedding Dimensionality Search in Streaming Recommendations》)。另一条研究方向深入研究了
embedding compression,从而减少web-scale数据集的内存占用。然而,这些方法只能以
look-up table的方式应用于categorical feature、或离散化后的数值特征。很少有研究关注数值特征的embedding learning,这在工业的深度CTR模型中是至关重要的。Feature Interaction:根据显式特征交互和隐式特征交互的不同组合,现有的CTR模型可以分为两类:堆叠结构、并行结构。堆叠结构:首先对
embeddings进行建模显示特征交互,然后堆叠DNN来抽取high-level的隐式特征交互。代表性的模型包括FNN、IPNN、PIN、FiBiNET、FGCNN、AutoGroup、DIN和DIEN。并行结构:利用两个并行网络分别捕捉显式特征交互信号和隐式特征交互信号,并在输出层融合信息。代表性的模型包括
Wide & Deep、DeepFM、AutoFIS、DCN、xDeepFM和AutoInt。在这些模型中,隐式特征交互是通过
DNN模型提取的。而对于显式特征交互,Wide & Deep采用手工制作的交叉特征,DeepFM和AutoFIS采用FM结构,DCN采用cross network,xDeepFM采用Compressed Interaction Network: CIN,AutoInt利用多头自注意力网络。
39.1 模型
39.1.1 基础概念
假设用于训练
CTR模型的数据集由categorical fields和numerical fields的multi-field数据记录:其中:
numerical field的标量值;categorical field的特征取值的one-hot vector。对于第
categorical field,可以通过embedding look-up操作获得feature embedding:其中:
categorical field的embedding matrix,embedding size,categorical field的词表规模。因此,
categorical field的representation为:对于
numerical field,现有的representation方法可以总结为三类:No Embedding、Field Embedding、Discretization。No Embedding:这种方式直接使用原始值或原始值的变换,而不学习embedding。例如,Google Play的Wide & Deep和JD.com的DMT分别使用原始数值特征和归一化的数值特征。此外,YouTube DNN利用了归一化特征取值在
Facebook的DLRM中,他们使用了一个多层感知机来建模所有的数值特征:其中
DNN的结构为512-256-d,直观而言,这些
No Embedding方法由于容量太小,很难捕获到numerical field的informative知识。Field Embedding:学术界常用的方法是Field Embedding,即同一个field内的的所有数值特征共享一个uniform field embedding,然后将这个field embedding与它们的特征取值相乘:其中:
numerical field的uniform embedding vector。然而,由于单个共享的
field-specific embedding、以及field内不同特征之间的线性缩放关系,Field Embedding的representation容量是有限的。例如,收入
Field Embedding的做法:即,收入分别为
1和10000的两个用户,其相似度大于收入分别为1和1的两个用户。这在实际场景中是不恰当的。Discretization:在工业推荐系统中,处理数值特征的一个流行方法是Discretization,即把数值特征转化为categorical feature。对于第numerical field的特征feature embeddingdiscretization和embedding look-up:其中:
numerical field的embedding matrix;numerical field人工设计的离散化函数,它将该特征内的每个特征取值映射到具体来说,有三种广泛使用的离散化函数:
Equal Distance/Frequency Discretization: EDD/EFD:EDD将特征取值划分到numerical field的特征取值范围为interval width定义为EDD离散化函数类似地,
EFD将范围Logarithm Discretization: LD:Kaggle比赛中Criteo advertiser prediction的冠军利用对数和floor操作将数值特征转化为categorical形式。离散化后的结果LD离散化函数Tree-based Discretization: TD:除了深度学习模型外,tree-based模型(如GBDT)在推荐中被广泛使用,因为它们能够有效地处理数值特征。因此,许多tree-based方法被用来离散化数值特征。
虽然
Discretization在工业界被广泛使用,但它们仍然有三个限制(如下图所示):Two-Phase Problem: TPP:离散化过程是由启发式规则或其他模型决定的,因此它不能与CTR预测任务的最终目标一起优化,导致次优性能。Similar value But Dis-similar embedding: SBD:这些离散化策略可能将类似的特征(边界值)分离到两个不同的桶中,因此它们之后的embedding明显不同。例如,
Age field常用的离散化是将[18,40]确定为青少年、[41,65]确定为中年,这导致数值40和41的embedding明显不同。Dis-similar value But Same embedding: DBS:现有的离散化策略可能将明显不同的元素分组同一个桶中,导致无法区分的embedding。使用同一个例子(Age field),18和40之间的数值在同一个桶里,因此被分配了相同的embedding。然而,18岁和40岁的人可能具有非常不同的特征。基于离散化的策略不能有效地描述数值特征变化的连续性。
综上所述,下表中列出了
AutoDis与现有representation方法的三方面比较。我们可以观察到,这些方法要么因为容量小而难以捕获informative知识、要么需要专业的特征工程,这些可能会降低整体性能。因此,我们提出了AutoDis框架。据我们所知,它是第一个具有高模型容量、端到端训练、以及保留unique representation特性的numerical features embedding learning框架。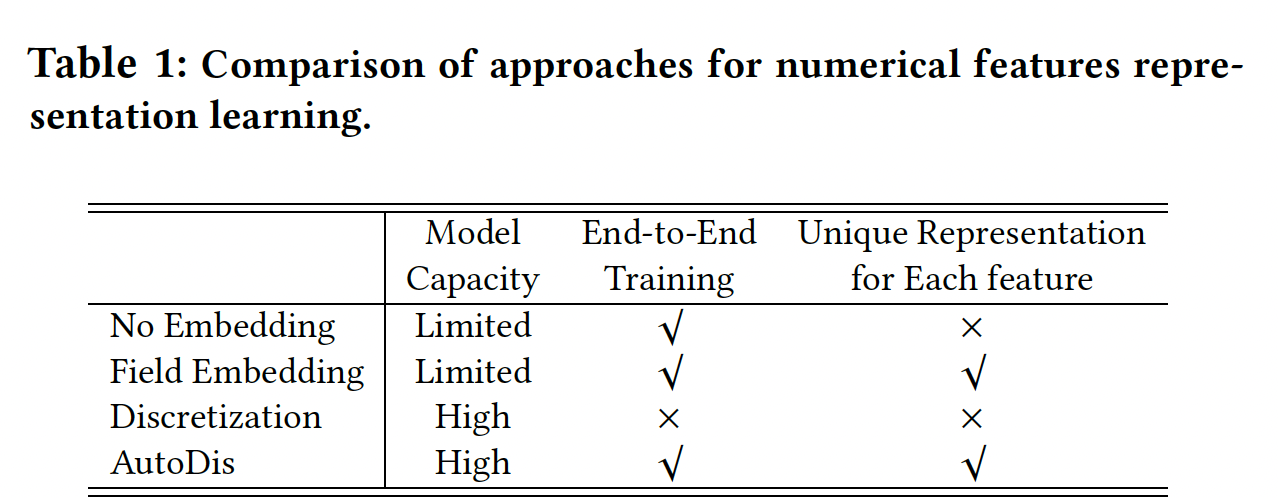
39.1.2 AutoDis
AutoDis框架如Figure 3所示,它可以作为针对数值特征的可插拔的embedding framework,与现有的深度CTR模型兼容。AutoDis包含三个核心模块:meta-embedding、automatic discretization、aggregation。代码实现比较简单直观: 数值特征
DNN网络(隐层维度为softmax激活函数) -> 单层DNN网络(隐层维度为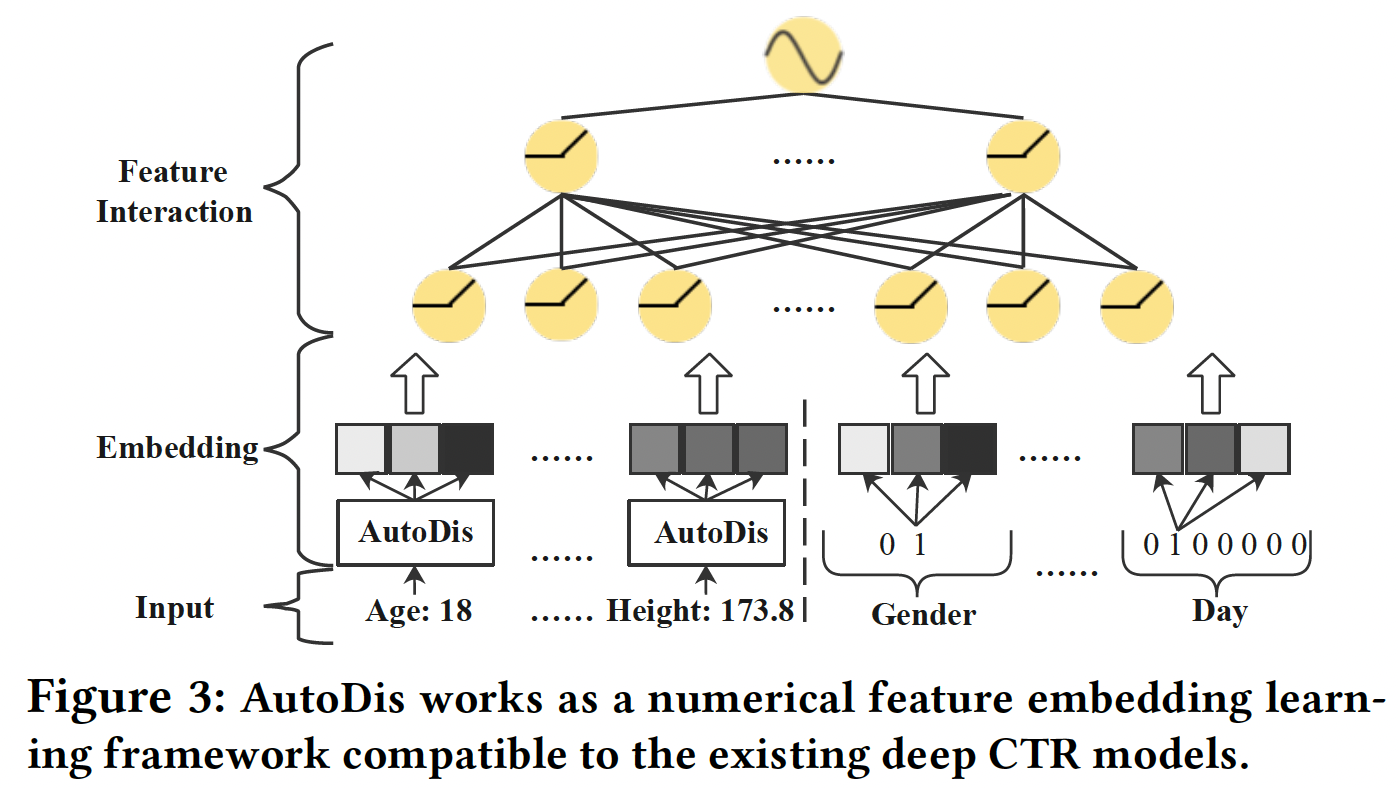
对于第
numerical field,AutoDis可以通过如下方式为每个数值特征unique representation(如Figure 4所示):其中:
numerical field的meta-embedding matrix。numerical field的automatic discretization函数。所有
numerical field都使用相同的聚合函数。
最后,
categorical特征和数值特征的embedding被拼接起来,并馈入一个深度CTR模型进行预测: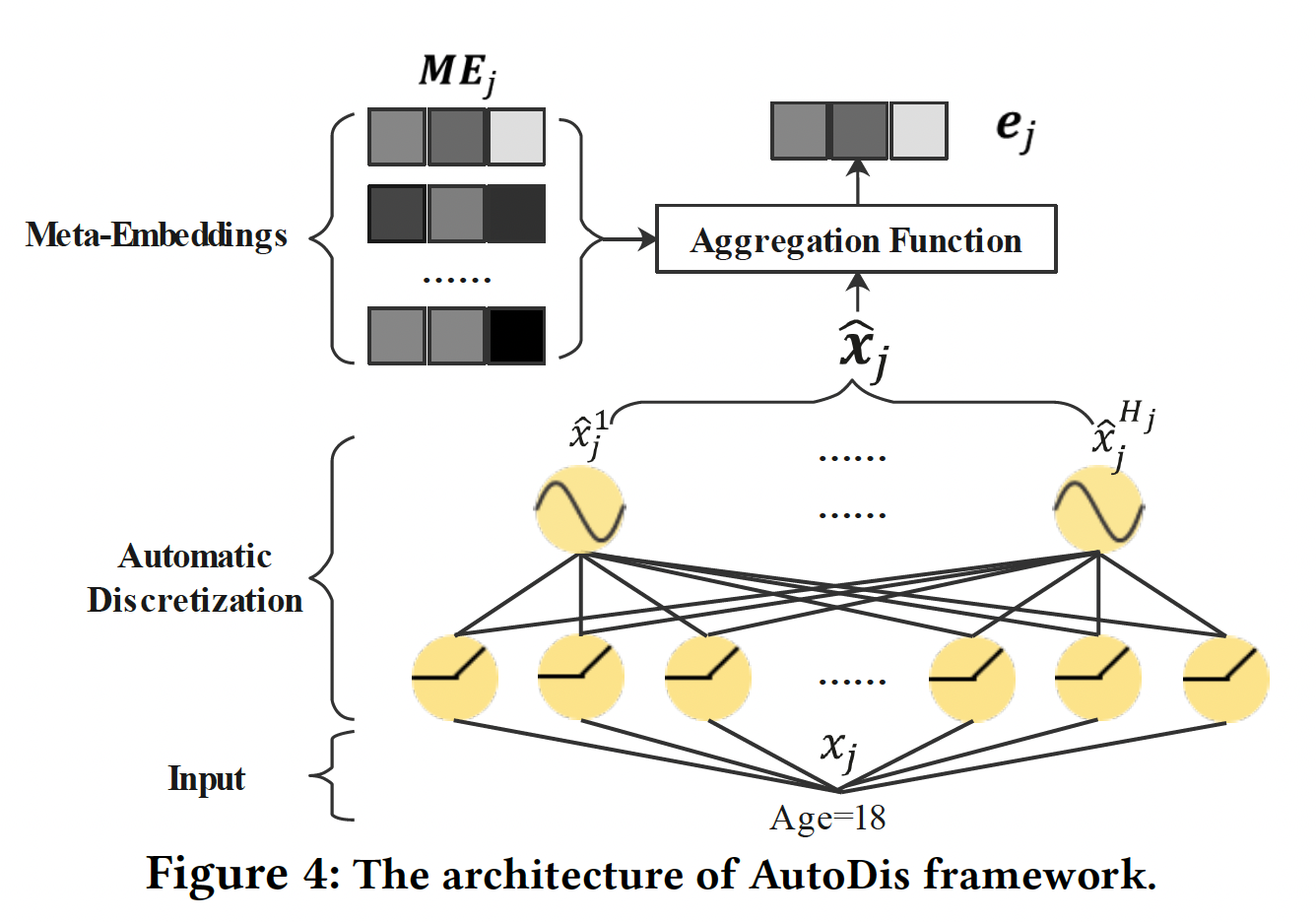
Meta-Embeddings: 为了平衡模型的容量和复杂性,对于第numerical field,我们设计了一组meta-embeddingsfield内的特征所共享,meta-embedding的数量。 每个meta-embedding可以被看作是潜在空间中的一个子空间,用于提高表达能力和容量。通过结合这些meta-embedding,学习到的embedding比Field Embedding方法更informative,因此可以很好地保留高的模型容量。此外,所需参数的数量由scalable。对于不同的
fieldfield,field,Automatic Discretization:为了捕获数值特征的值和所设计的meta-embeddings之间的复杂关联,我们提出了一个可微的automatic discretization模块numerical field的每个数值特征被离散化到bucket embedding对应于上面提到的meta-embedding。具体而言,利用一个带有
skip-connection的两层神经网络,将numerical field特征取值其中:
automatic discretization network在第numerical feature field上的可学习参数。Leaky-ReLU为激活函数,skip-connection的控制因子control factor。
投影结果为:
numerical field特征取值Softmax函数将numerical field特征取值meta-embedding其中:
discretization分布。因此,通过automatic discretization函数numerical field特征取值numerical field特征取值meta-embedding(即bucket embedding)之间的相关性。这种离散化方法可以理解为soft discretization。与前面提到的hard discretization相比,soft discretization没有将特征取值离散化到一个确定的桶中,这样就可以很好地解决SBD和DBS问题。此外,可微的soft discretization使我们的AutoDis能够实现端到端的训练,并以最终目标进行优化。值得注意的是:当温度系数
discretization分布趋于均匀分布;当discretization分布趋于one-hot分布。因此,温度系数automatic discretization distribution中起着重要作用。此外,不同field的特征分布是不同的,因此对不同的features学习不同的temperature coefficient adaptive network(双层网络),它同时考虑了global field statistics feature和local input feature,公式如下:其中:
numerical field特征的全局统计特征向量,包括:采样的累积分布函数Cumulative Distribution Function: CDF、均值。local input feature。
为了指导模型训练,
rescale为这个温度系数自适应网络的设计不太简洁,工程实现也更复杂。根据实验部分的结论,这里完全可以微调
global温度来实现。Aggregation Function:在得到feature value和meta-embeddings之间的相关性后,可以通过对meta-embeddings进行聚合操作embedding。我们考虑了以下聚合函数Max-Pooling:选择最相关的meta-embedding(具有最高概率其中:
meta-embedding的索引,meta-embedding。然而,这种
hard selection策略使AutoDis退化为一种hard discretization方法,从而导致上述的SBD问题和DBS问题。Top-K-Sum:将具有最高相关性top-K个meta-embedding相加:其中
meta-embedding的索引,meta-embedding。然而,
Top-K-Sum方法有两个局限性:- 尽管与
Max-Pooling相比,可能生成的embedding数量从DBS问题。 - 学习到的
embedding
- 尽管与
Weighted- Average:充分地利用整个meta-embeddings集合、以及meta-embedding与特征取值的相关性:通过这种加权聚合策略,相关的元嵌入对提供一个信息丰富的嵌入有更大的贡献,而不相关的元嵌入则在很大程度上被忽略了。此外,这种策略保证了每个特征都能学到
unique representation,同时,学到的embedding是Continuous-But-Different,即,特征取值越接近则embedding就越相似。
训练:
AutoDis是以端到端的方式与具体的深度CTR模型的最终目标共同训练的。损失函数是广泛使用的带有正则化项的LogLoss:其中:
ground truth label和预测结果;L2正则化系数;categorical field的feature embedding参数、meta-embedding和automatic discretization参数、以及深度CTR模型的参数。为了稳定训练过程,我们在数据预处理阶段采用了特征归一化技术,将数值特征取值缩放到
[0, 1]。第numerical field的取值
39.2 实验
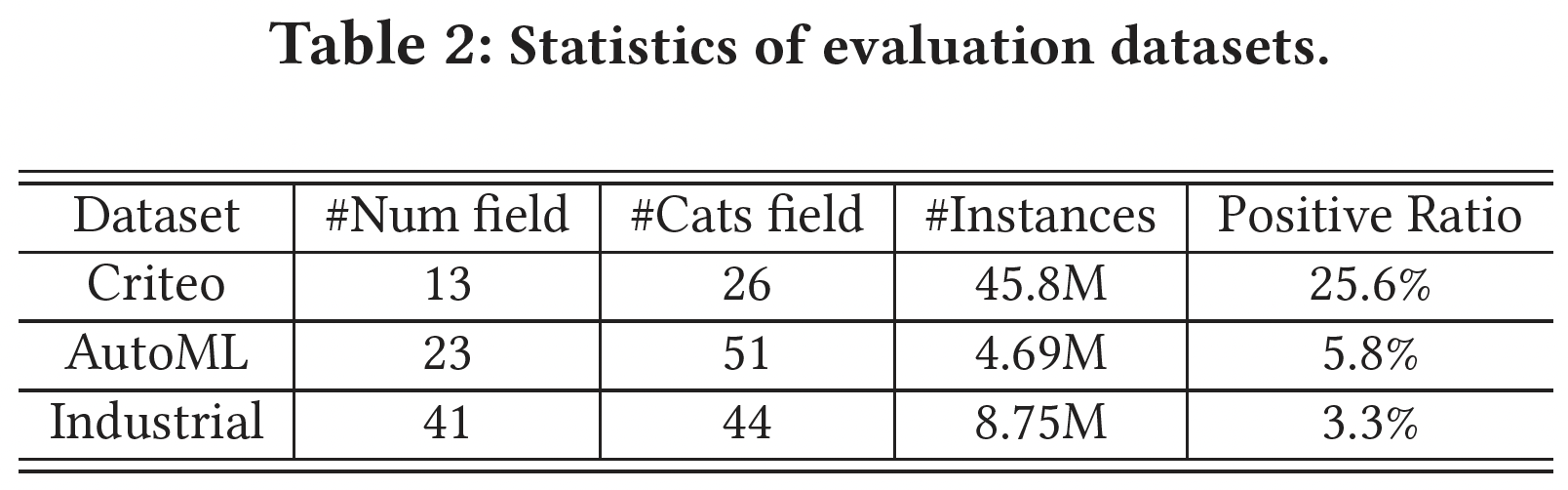
数据集:
Criteo:Criteo Display Advertising Challenge 2013发布的,包含13个numerical feature field。AutoML:AutoML for Lifelong Machine Learning Challenge in NeurIPS 2018发布的,包含23个numerical feature field。- 工业数据集:从一个主流的在线广告平台上采样收集的,有
41个numerical feature field。
数据集的统计数据如下表所示。
评估指标:
AUC, LogLoss。所有的实验都通过改变随机数种子重复
5次。采用two-tailed unpaired t-test来检测AutoDis和最佳baseline之间的显著差异。baseline方法:为了证明所提出的AutoDis的有效性,我们将AutoDis与数值特征的三类representation learning方法进行了比较:No Embedding(YouTube, DLRM)、Field Embedding: FE(DeepFM)、Discretization(EDD,如IPNN;LD以及TD,如DeepGBM)。此外,为了验证
AutoDis框架与embedding-based的深度CTR模型的兼容性,我们将AutoDis应用于六个代表性模型:FNN、Wide & Deep、DeepFM、DCN、IPNN、xDeepFM。实现:
- 我们用
mini-batch Adam优化所有的模型,其中学习率的搜索空间为{10e-6, 5e-5, ... , 10e-2}。 - 此外,在
Criteo和AutoML数据集中,embedding size分别被设置为80和70。 - 深度
CTR模型中的隐层默认固定为1024-512-256-128,DCN和xDeepFM中的显式特征交互(即CrossNet和CIN)被设置为3层。 L2正则化系数的搜索空间为{10e-6, 5e-5, ... , 10e-3}。- 对于
AutoDis,每个numerical field的meta-embedding数量为:Criteo数据集为20个,AutoML数据集为40个。 skip-connection控制因子的搜索空间为{0, 0.1, ... , 1},temperature coefficient adaptive network的神经元数量设置为64
- 我们用
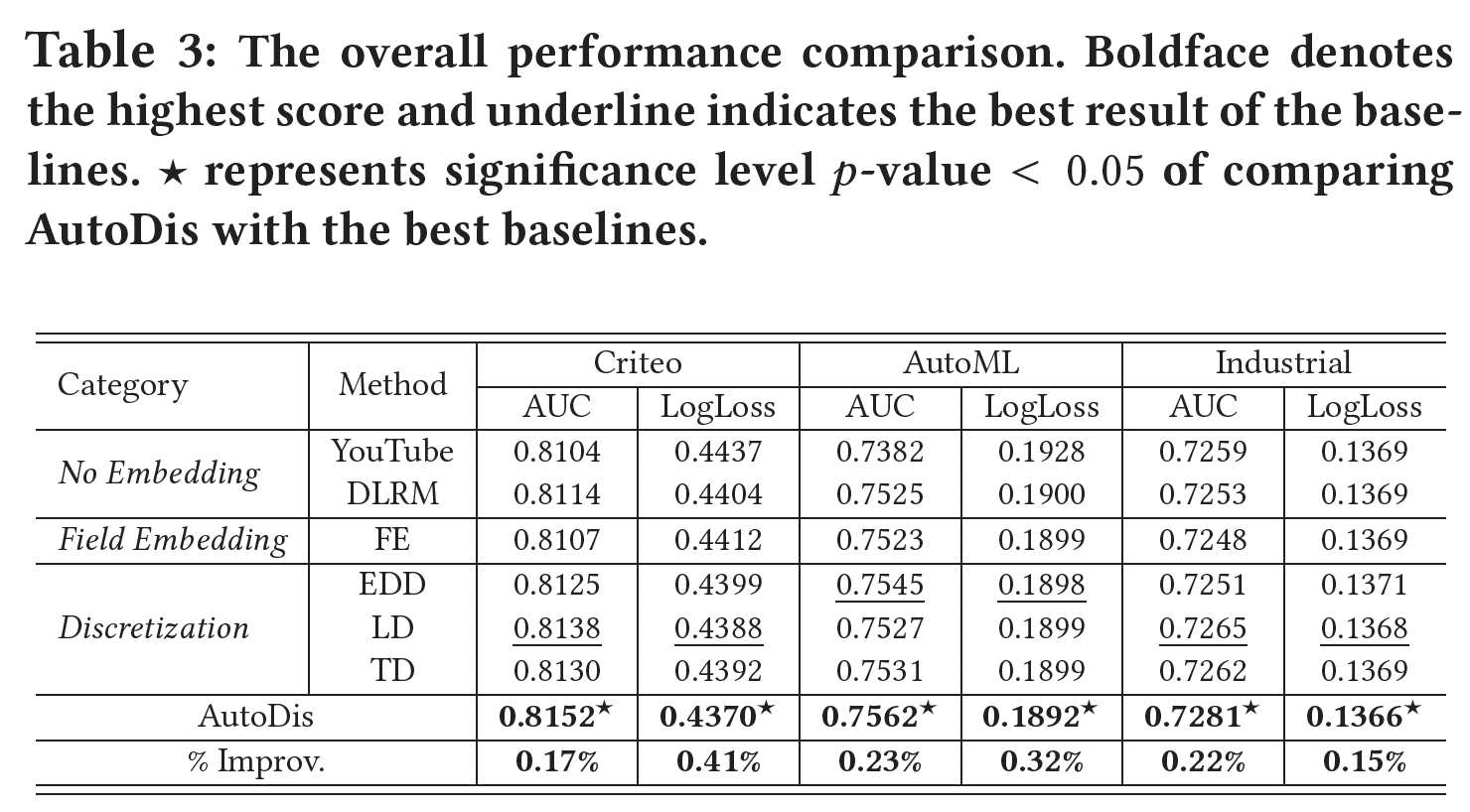
和其它
Representation Learning方法的比较:我们在三个数据集上执行不同的numerical feature representation learning方法,并选择DeepFM作为深度CTR模型。结果如下表所示。可以看到:AutoDis在所有数据集上的表现都远远超过了所有的baseline,显示了其对不同数值特征的优越性和鲁棒性。No Embedding和Field Embedding方法的表现比Discretization和AutoDis更差。No Embedding和Field Embedding这两类方法存在容量低和表达能力有限的问题。No Embedding, Field Embedding二者之间的差距不大,基本上在0.1%以内。与现有的三种将数值特征转化为
categorical形式的Discretization方法相比,AutoDis的AUC比最佳baseline分别提高了0.17%、0.23%、以及0.22%。
不用
CTR模型的比较:AutoDis是一个通用框架,可以被视为改善各种深度CTR模型性能的插件。为了证明其兼容性,这里我们通过在一系列流行的模型上应用AutoDis进行了广泛的实验,结果如下表所示。可以看到:与Field Embedding representation方法相比,AutoDis框架显著提高了这些模型的预测性能。numerical feature discretization和embedding learning过程的优化是以这些CTR模型为最终目标的,因此可以得到informative representation,性能也可以得到提高。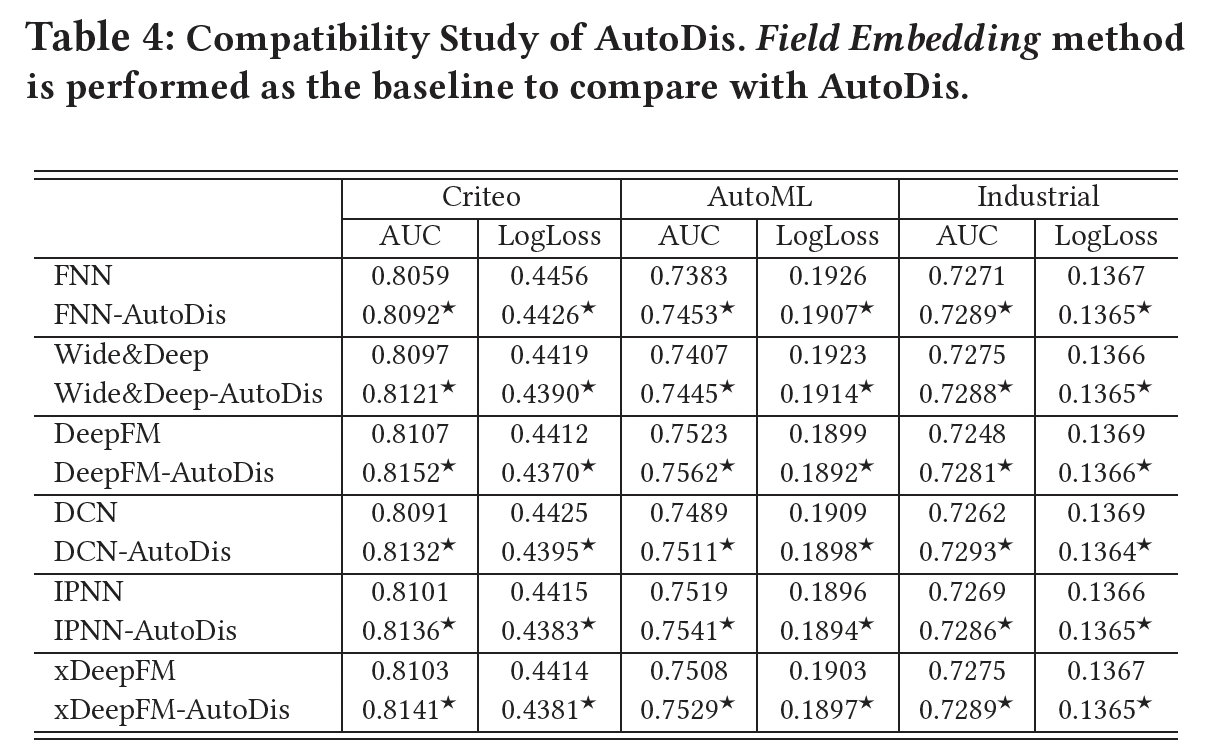
Online A/B Testing:我们在一个主流广告平台上进行在线实验从而验证AutoDis的优越性能,该平台每天有数百万活跃用户与广告互动,并产生数千万的用户日志事件。对于控制组,数值特征通过hybrid manually-designed rules(如EDD、TD等)进行离散化。实验组则选择AutoDis对所有数值特征进行离散化和自动学习embedding。将AutoDis部署到现有的CTR模型中很方便,几乎不需要online serving系统的工程工作。AutoDis实现了0.2%的离线AUC的提升。此外,相对于对照组,实验组在线CTR和eCPM分别提升了2.1%和2.7%(统计学意义),这带来了巨大的商业利润。此外,随着
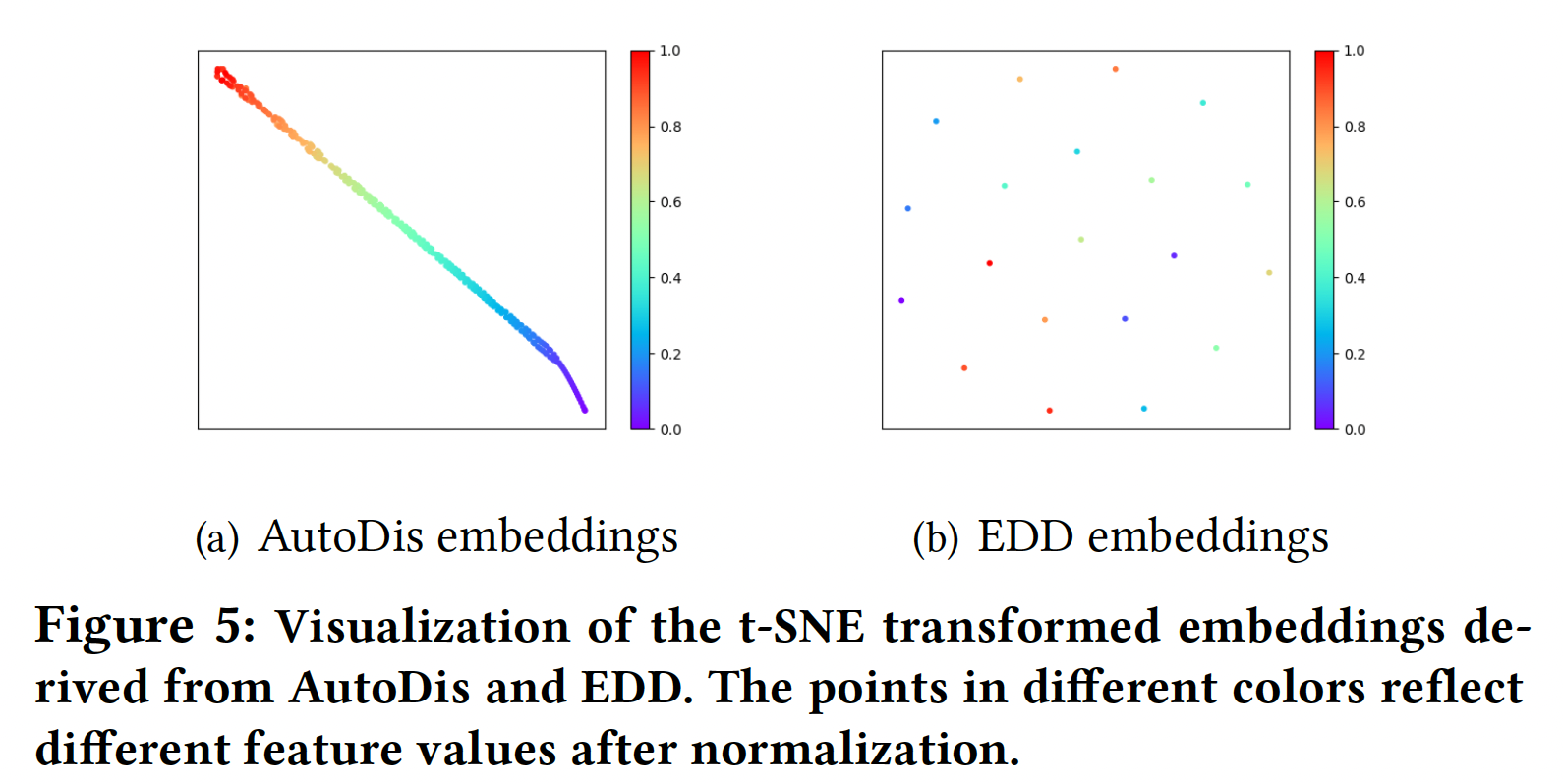
AutoDis的融合,现有的数值特征不再需要任何离散化规则。此外,在未来引入更多的数值特征将更加有效,而不需要探索任何人工制作的规则。Embedding Analysis:为了更深入地理解通过AutoDis学到的Continuous-But-Different embedding,我们分别在embeddings的宏观分析、以及soft discretization的微观分析中做了进一步的调研。Embeddings的宏观分析:下图提供了DeepFM-AutoDis和DeepFM-EDD在Criteo数据集的第3个numerical field中得出的embedding的可视化。我们随机选择250个embedding,并使用t-SNE将它们投影到一个二维空间。具有相似颜色的节点具有相似的值。可以看到:AutoDis为每个特征学习了一个unique embedding。此外,相似的数值特征(具有相似的颜色)由密切相关的embeddings(在二维空间中具有相似的位置)来表示,这阐述了embedding的Continuous-But-Different的特性。- 然而,
EDD为一个桶中的所有特征学习相同的embedding、而在不同的桶中学习完全不同的embedding,这导致了to step-wise "unsmooth" embedding,从而导致了较差的任务表现。
Soft Discretization的微观分析:我们通过调查DeepFM-AutoDis的soft discretization过程中的Softmax分布进行一些微观分析。我们从Criteo数据集的第8个numerical field中选择一个相邻的feature-pair(特征取值为1和2)、以及一个相距较远的feature-pair(特征取值为1和10),然后在下图中可视化它们的discretization distribution。可以看到:相邻的feature-pair具有相似的Softmax分布,而相距较远的feature-pair具有不同的分布。这一特点有利于保证相似的特征取值能够通过
AutoDis学习相似的embedding,从而保持embedding的连续性。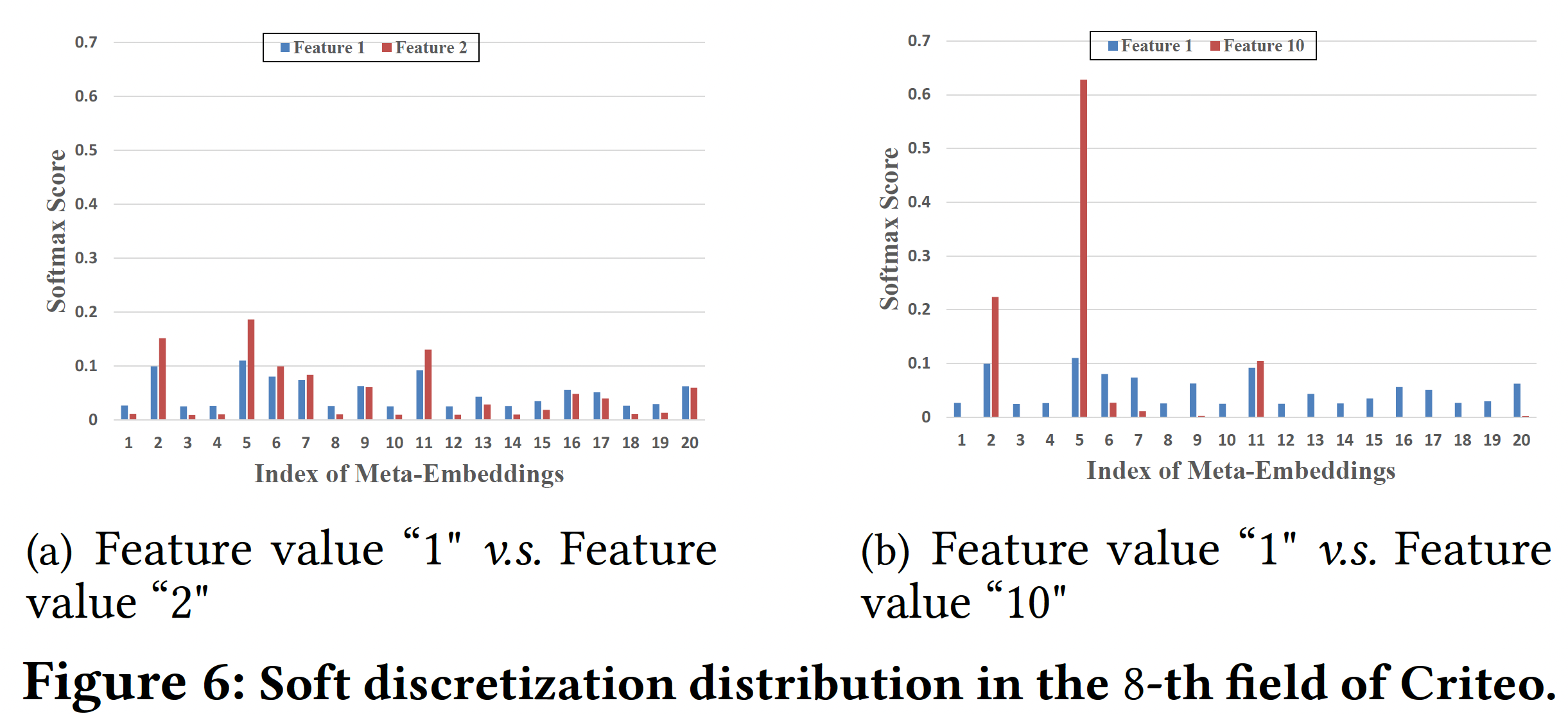
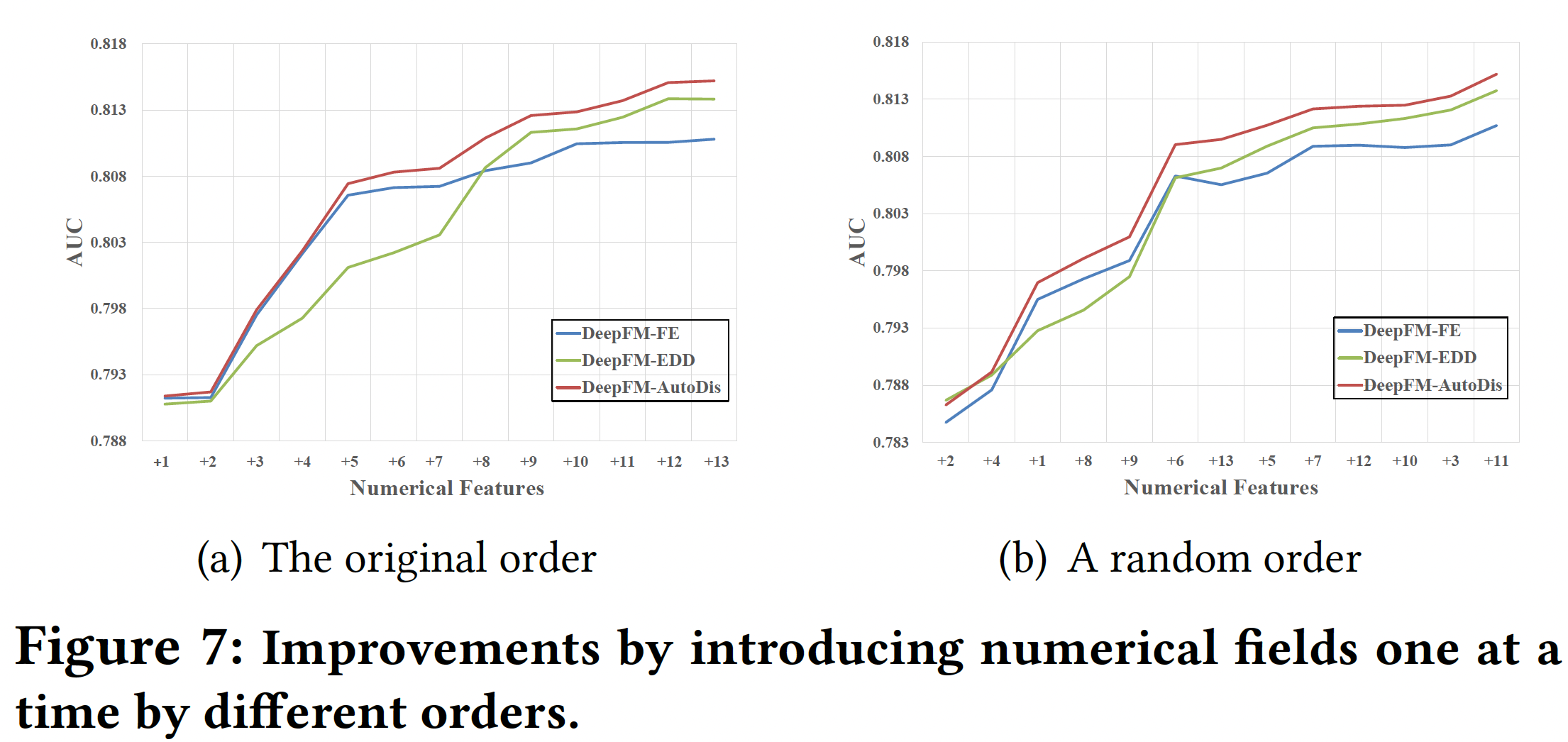
Numerical Fields Analysis:为了评估DeepFM-AutoDis对每个numerical field的影响,在Criteo数据集中,我们选择了所有26个categorical fields作为基础特征,并每次累积添加13个numerical fields中的一个。下图展示了根据数据集的原始顺序和随机顺序添加numerical fields的预测性能。可以看到:- 即使只有一个
numerical field,AutoDis也能提高性能。 AutoDis对多个numerical fields具有cumulative improvement。- 与现有方法相比,
AutoDis取得的性能改善更加显著和稳定。
- 即使只有一个
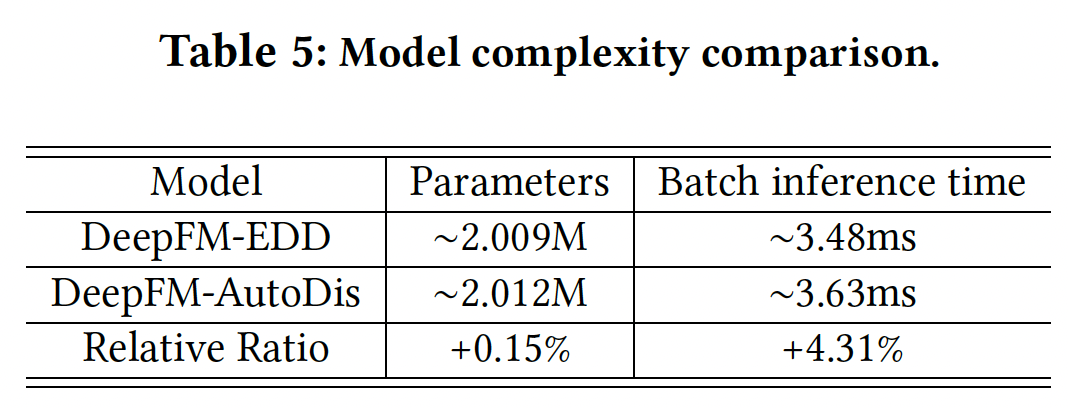
Model Complexity:为了定量分析我们提出的AutoDis的空间复杂度和时间复杂度,我们比较了DeepFM上的EDD离散化方法的模型参数、以及batch inference time,结果如下表所示。可以看到:- 与
EDD相比,AutoDis增加的模型参数量可以忽略不计。 - 此外,
AutoDis的计算效率也是可比的。
- 与
消融研究和超参数敏感性:
聚合策略:下图总结了
DeepFM-AutoDis采用Max-Pooling、Top-K-Sum、Weighted-Average等聚合策略的预测性能。可以看到:Weighted-Average策略实现了最好的性能。原因是:与其他策略相比,Weighted-Average策略充分利用了meta-embeddings及其相应的关联性,完全克服了DBS和SBD问题。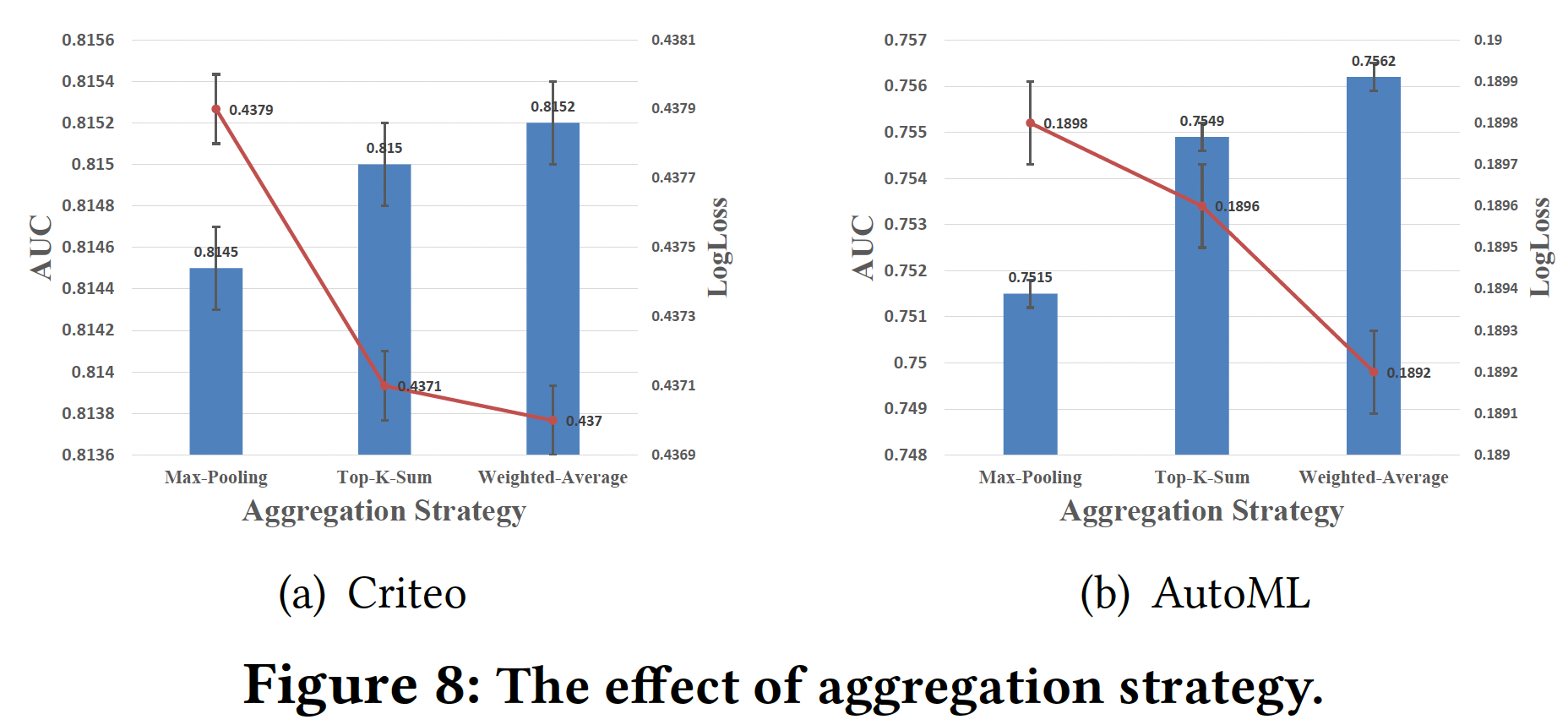
温度系数:为了证明
temperature coefficient adaptive network在生成feature-specific- 在
Criteo和AutoML数据集上,最佳全局温度分别为1e-5和4e-3左右。 - 然而,我们的
temperature coefficient adaptive network取得了最好的结果(红色虚线),因为它可以根据global field statistics feature和local input feature,针对不同的特征自适应地调整温度系数,获得更合适的discretization distribution。
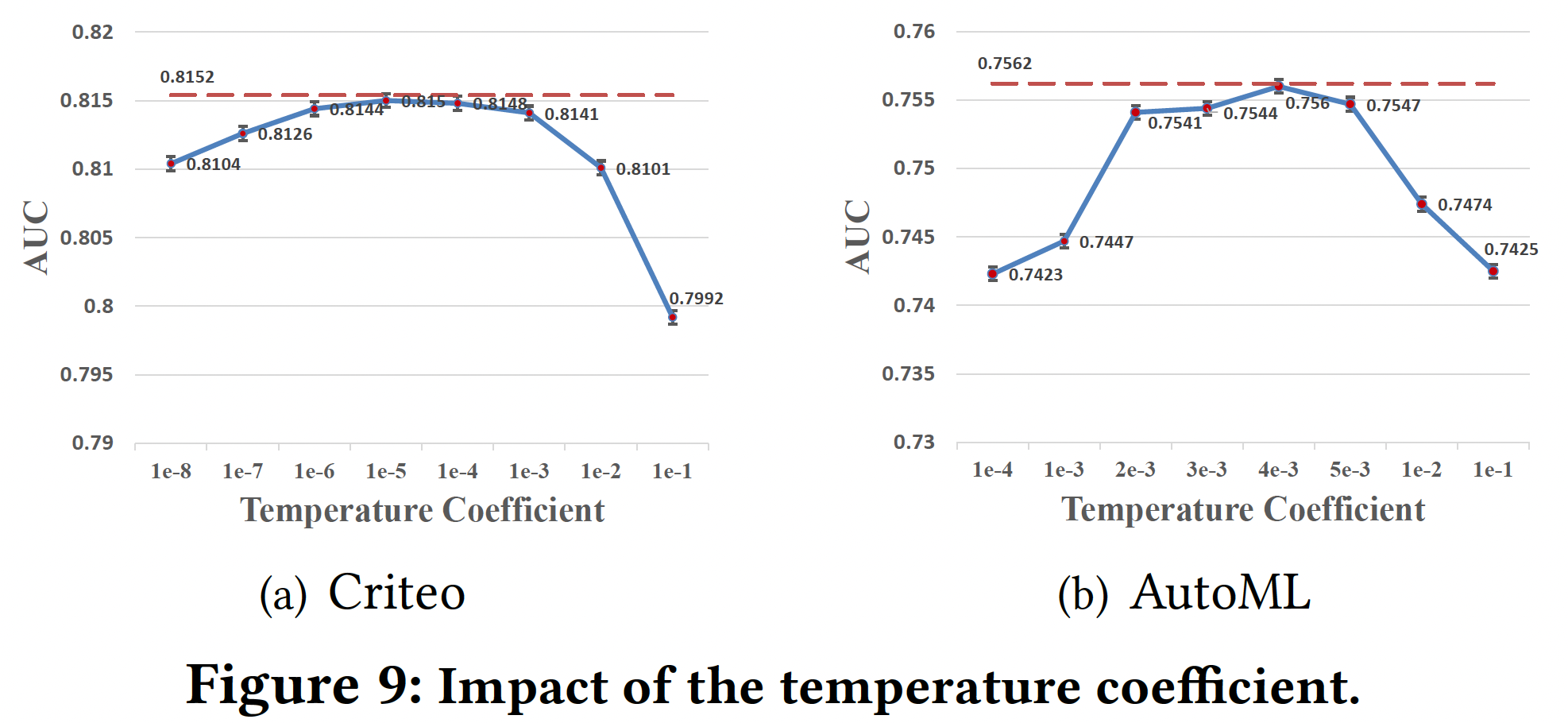
- 在
Meta-Embeddings的数量:实验结果如下图所示。可以看到:Meta-Embeddings数量的增加有助于在开始时大幅提高性能,因为meta-embeddings中涉及更丰富的信息。- 然而,使用过多的
meta-embeddings不仅会增加计算负担,而且会使性能受挫。
考虑到预测效果和训练效率,我们将
Criteo和AutoML数据集的数量分别设定为20和40。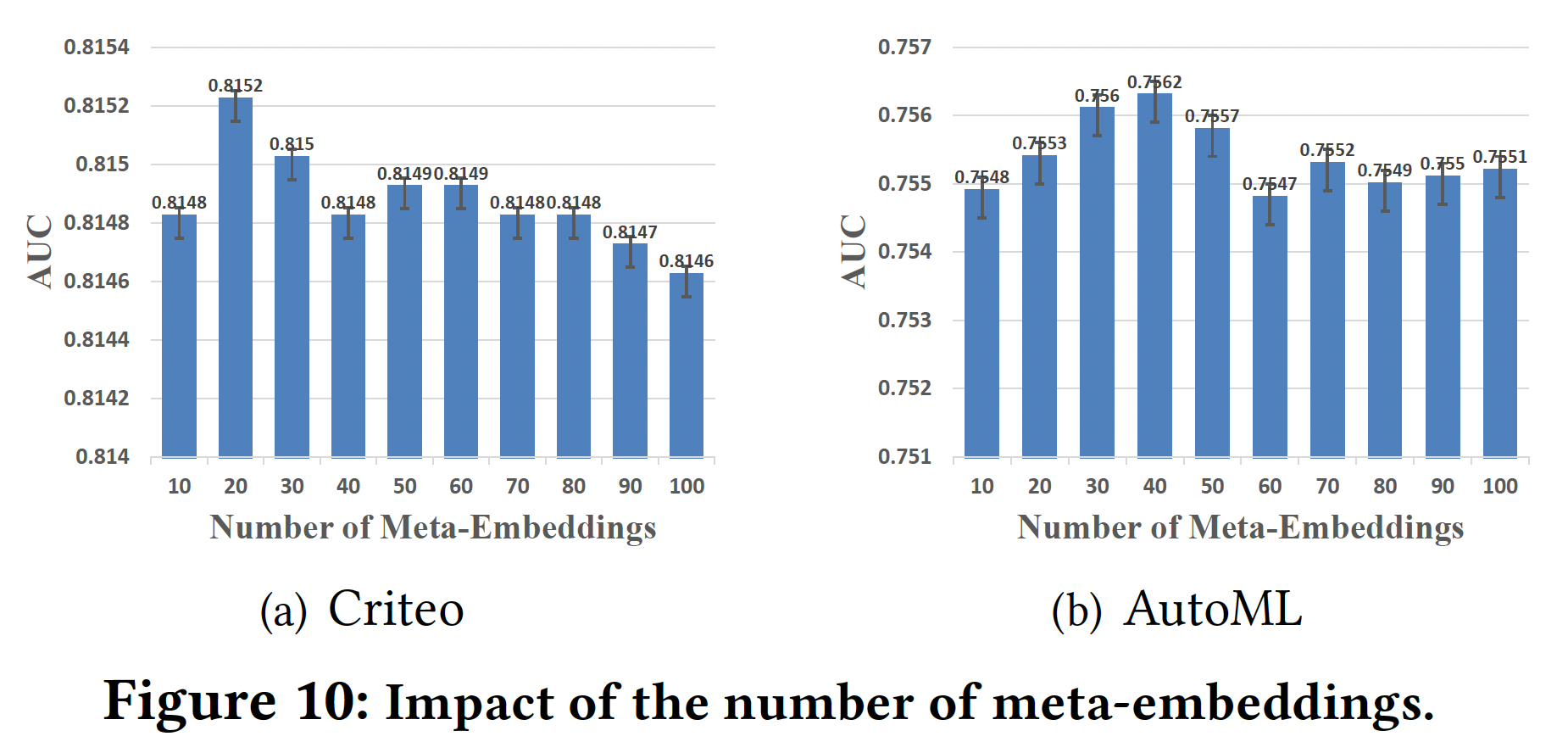
四十、MDE[2020]
标准的
embedding做法是:将objects以固定的统一纬度uniform dimension: UD当
embedding维度当
embedding维度objects数量很大时,内存消耗就成为一个问题。例如,在推荐模型中,embedding layer可以占到存储模型所需内存的99.9%以上,而在large-scale setting中,它可能会消耗数百GB甚至数百TB。不仅内存消耗是一个瓶颈,模型太大也容易过拟合。
因此,寻找新颖
embedding representation是一个重要的挑战,其中该embedding representation使用更少的参数,同时保留下游模型的预测性能。在现实世界的
applications中,object的频率往往是严重倾斜的。例如:- 对于
full MovieLens数据集,top 10%的用户收到的query数量和剩余90%的用户一样多、top 1%的item收到的query数量和剩余99%的item一样多。 - 此外,在
Criteo Kaggle数据集上,top 0:0003%的indices收到的query数量与剩余3200万个indices一样多。
为了在推荐中利用
heterogeneous object popularity,论文《Mixed Dimension Embeddings with Application to Memory-Efficient Recommendation Systems》提出了mixed dimension(MD) embedding layer,其中一个specific-object的embedding维度随着该object的popularity而变化,而不是保持全局统一。论文的案例研究和理论分析表明:MD embedding的效果很好,因为它们不会在rare embedding上浪费参数,同时也不会欠拟合popular embedding。此外,在测试期间,MD embedding通过有效地分配参数从而最小化popularity-weighted loss。论文贡献:
- 论文提出了一种用于推荐系统的
mixed dimension embedding layer,并提供了一种新颖的数学方法来确定具有可变popularity的特征的尺寸。这种方法训练速度快、易于调优、并且在实验中表现良好。 - 通过矩阵补全
matrix completion和factorization model,论文证明了在有足够的popularity倾斜的情况下,mixed dimension embedding在内存有限的情况下会产生较低的失真,在数据有限的情况下会有更好的泛化效果。 - 对于内存有限的领域,论文推导出最佳特征维度。这个维度只取决于特征的
popularity、参数预算、以及pairwise交互的奇异值谱。
40.1 背景
与典型的协同过滤
collaborative filtering: CF相比,CTR预测任务包括额外的上下文。这些上下文特征通过索引集合(categorical)和浮点数(continuous)来表达。这些特征可以代表关于点击事件或个性化事件的上下文的任意细节。第categorical特征可以用一个索引categorical特征,我们还有one-hot向量。我们使用
SOTA的deep learning recommendation model: DLRM作为一个现成的深度模型。各种深度CTR预测模型都是由内存密集型的embedding layer驱动的。embedding layer的大小和预测性能之间的权衡似乎是一个不可避免的权衡。对于一个给定的模型embedding layercategorical特征。通常,每个categorical特征都有自己的独立的embedding matrix:embedding layer,categorical的embedding matrix。相关工作:最近的工作提出了类似、但实质上不同的
non-uniform embedding架构的技术,尤其是针对自然语言处理领域(《Groupreduce: Block-wise low-rank approximation for neural language model shrinking》、《Adaptive input representations for neural language modeling》)。这些方法都不适合用于CTR预测,因为它们忽略了CTR中固有的feature-level结构。还有一些方法是为
RecSys embedding layer提出神经架构搜索neural architecture search : NAS(《Neural input search for large scale recommendation models》),其中使用强化学习算法来构建embedding layer。与计算昂贵的NAS相比,我们表明non-uniform embedding layer的架构搜索可以简化为调优一个超参数,而不需要NAS。由于我们的理论框架,模型搜索的这种简化是可能的。此外,与以前所有的non-uniform embedding的工作相比,我们从理论上分析了我们的方法。此外,过去的工作并没有从经验上验证他们的方法所推测的工作机制。从
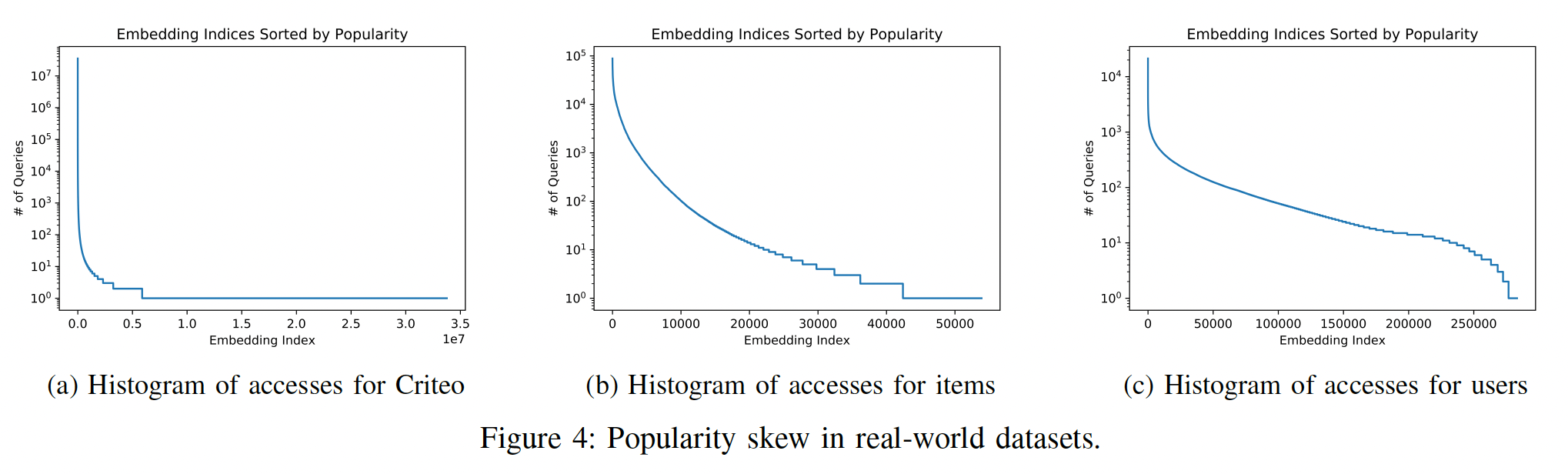
popularity倾斜的角度来看,embedding normalization实际上隐含了对rare embeddings的惩罚,而不是对popular embeddings的惩罚。这是因为更大一部分的training updates仅包含rare embeddings的norm penalty signal(而很少包含rare出现的事件)。如下图所示,图
(a)表示Criteo Kaggle数据集中所有特征的access的直方图;图(b), (c)分别为MovieLens数据集的user feature, item feature的access的直方图。这些图都是典型的长尾分布。
40.2 模型
MD embedding layer架构block组成,每个block对应一个categorical field。这些block定义为block的矩阵;categorical特征的embeding size;categorical特征的词表大小;categorical特征共享的base dimension,且满足MD embedding,然后
一个关键问题是如何确定
embedding sizePower-law Sizing Scheme:我们定义block-level概率block中的embedding的平均查询概率。当block与特征一一对应(我们这里的情况),那么假设
categorical feature都是单值(而不是多值的),那么对于词表大小为categorical feature,每个取值出现的平均概率为更一般的情况下,
block-wise伯努利采样矩阵。那么Popularity-Based Dimension Sizing为:其中:无穷范数是元素绝对值中的最大值;
embedding size都等于embedding size与它们的popularity成正比。理论分析见原始论文。
注意:这里仅考虑
field-level的popularity,而没有考虑value-level的popularity。例如,“学历” 这个field中,低学历的value占比更大,需要更高的维度。论文中的这种维度分配方式,使得词表越大的
field,其维度越小;词表越小的field,其维度越大。例如,“性别” 只有两个取值,该field被分配的embedding维度最大。论文中的这种维度分配是启发式的规则,并不是从数据中学到的。
40.3 实验
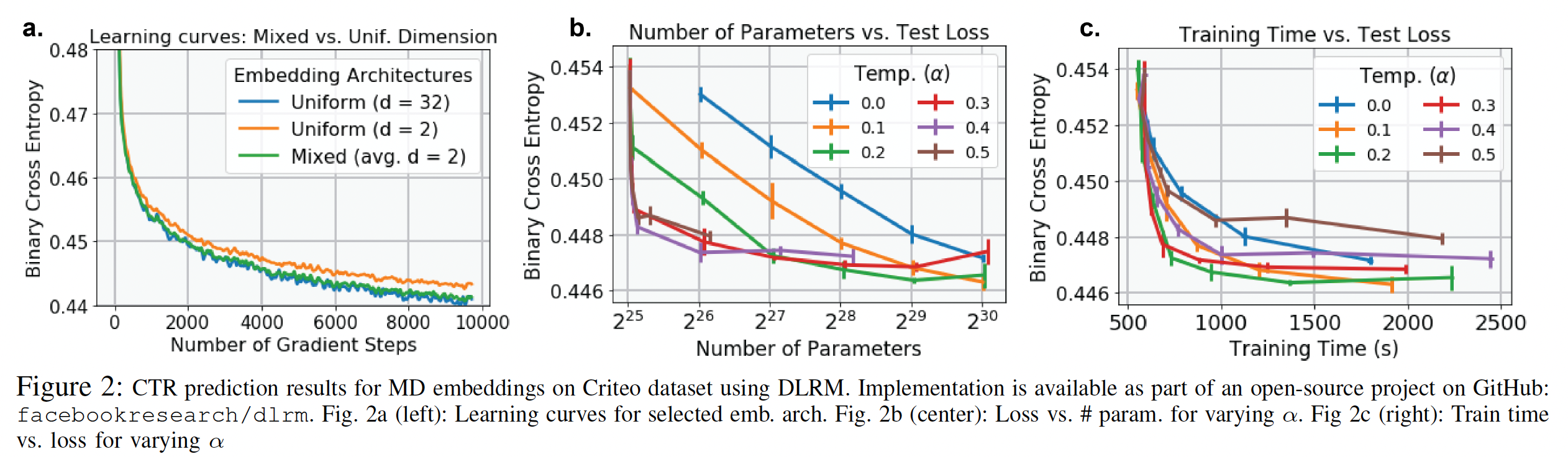
baseline方法:统一的DLRM。实验结果:
MD embedding产生的learning curve与UD embedding相当(下图(a)),但是参数规模减少了16倍。MD embedding layer改善了每种parameter budget下的memory-performance(下图(b))。- 最佳温度
parameter budget,对于较小的预算,较高的温度会导致更低的loss。 embedding获得的性能以0.1%的准确性优势略微优于UD embedding,但是参数规模约为UD embedding的一半。MD embedding的训练速度比UD embedding快两倍(下图(c))。
四十一、NIS[2020]
大多数现代神经网络模型可以被认为是由两个组件组成的:
- 一个是将原始(可能是
categorical的)输入数据转换为浮点值的输入组件。 - 另一个是将输入组件的输出结合起来并计算出模型的最终输出的
representation learning组件。
自
《Neural Architecture Search with Reinforcement Learning》发表以来,以自动化的、数据驱动的方式设计神经网络架构(AutoML)最近吸引了很多研究兴趣。然而,该领域以前的研究主要集中在representation learning组件的自动化设计上,而对输入组件的关注很少。这是因为大多数研究都是在图像理解问题上进行的,其中representation learning组件对模型性能非常重要,而输入组件是微不足道的,因为图像像素已经是浮点形式。对于工业界经常遇到的大规模推荐问题,情况则完全不同。虽然
representation learning组件很重要,但输入组件在模型中起着更关键的作用。这是因为许多推荐问题涉及到具有大cardinality的categorical特征,而输入组件为这些离散特征的每一项分配embedding向量。这就导致了输入组件中有大量的embedding参数,这些参数在模型大小和模型归纳偏置inductive bias上都占主导地位。例如,
YouTube视频推荐模型使用了一个规模为1M的video ID vocabulary,每个video ID有256维的embedding向量。这意味着仅video ID特征就使用了256M个参数,而且随着更多离散特征的加入,这个数字还会迅速增长。 相比之下,representation learning组件只包括三个全连接层。因此,模型参数的数量主要集中在输入组件,这自然对模型性能有很高的影响。在实践中,尽管categorical特征的vocabulary size和embedding size很重要,但它们往往是通过尝试一些具有不同手工制作的配置的模型从而以启发式的方式选择的。由于这些模型通常体积大,训练成本高,这种方法计算量大,可能会导致次优的结果。在论文
《Neural Input Search for Large Scale Recommendation Models》中,作者提出了Neural Input Search: NIS,这是一种新颖的方法,为模型输入组件的每个离散特征自动寻找embedding size和vocabulary size。NIS创建了一个由Embedding Blocks集合组成的搜索空间,其中blocks的每个组合代表不同的vocabulary and embedding配置。最佳配置是通过像ENAS这样的强化学习算法在单个training run中搜索而来。此外,作者提出一种新的
embedding类型,称之为Multi-size Embedding : ME。ME允许将较大尺寸(即,维度)的embedding向量分配给更常见的、或更predictive的feature item,而将较小尺寸的embedding向量分配给不常见的、或没有predictive的feature item。这与通常采用的方法相反,即在词表的所有item中使用同样维度的embedding,这称之为Single-size Embedding: SE。作者认为,SE是对模型容量和训练数据的低效利用。这是因为:- 对于频繁出现的、或高
predictive的item,我们需要一个大的embedding维度来编码它们与其他item的细微关系nuanced relation。 - 但对于长尾
item,由于它们在训练集中的稀有性rarity,训练相同维度的good embedding可能需要太多的epoch。并且当训练数据有限时,对于rare item采用大维度的embedding可能会过拟合。
有了
ME,在相同的模型容量下,我们可以覆盖词表中更多的item,同时减少所需的训练数据规模和计算成本从而为长尾item训练良好的embedding。下图概览了基于
Embedding Blocks的搜索空间、以及强化学习控制器如何对候选SE和ME进行采样。图
(a):Single-size Embedding,其中仅保留top 2M个item,embedding维度192。图
(b):Multi-size Embedding,其中top 2M个item的embedding维度为192、剩余7M个item的embedding维度为64。注意:这要求词表中的
id是根据频次来降序排列。这对于频次分布的波动较大的field而言,需要经常重新编码id和重新训练。embedding table包含两个超参数:emebdding size、以及词表大小(即,保留高频的多少个item)。这篇论文保留了所有的item,并针对性地优化embedding size。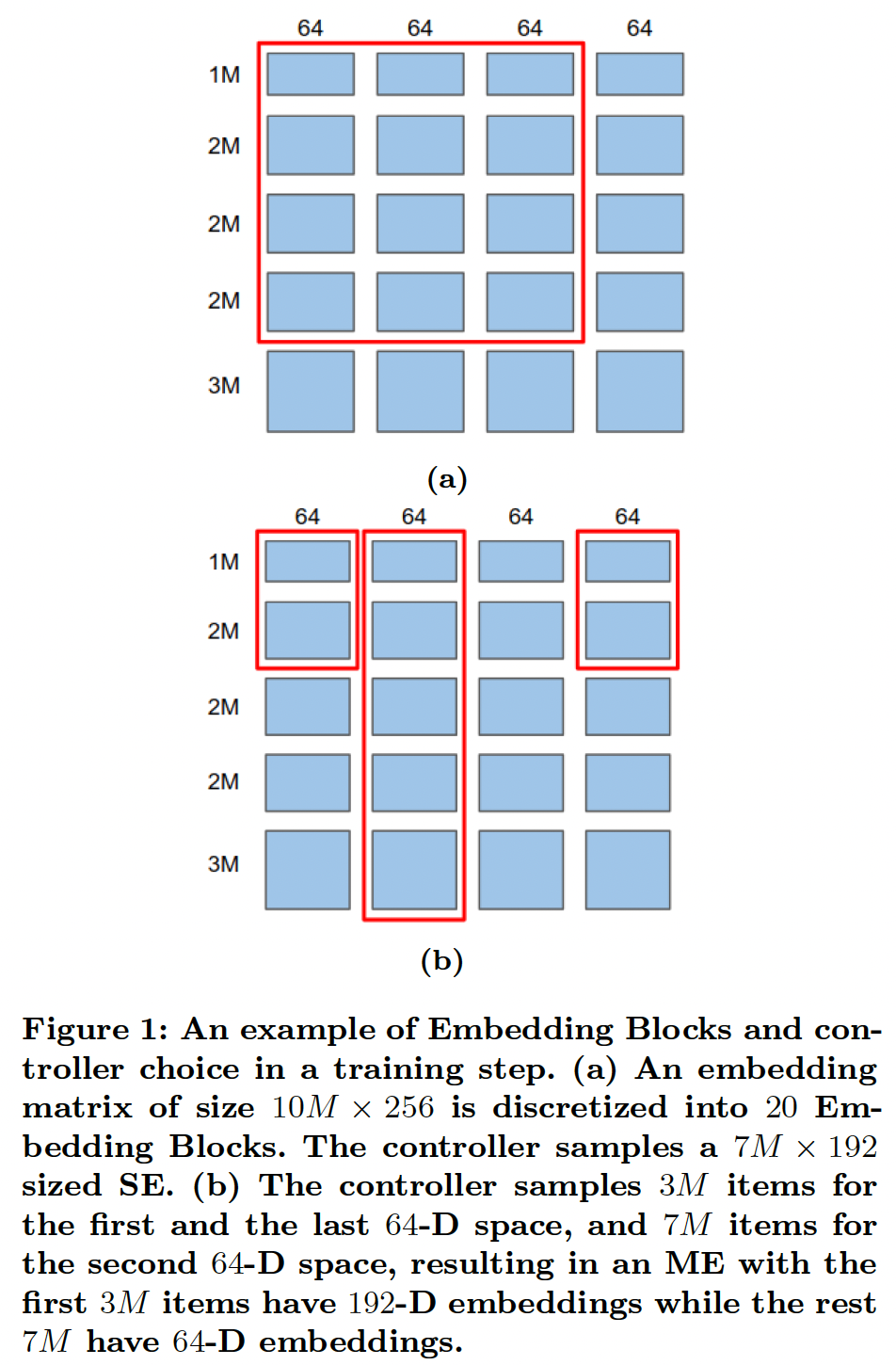
作者通过在两个广泛研究的推荐问题的公共数据集上的实验,证明了
NIS在为SE和ME寻找良好的vocabulary size和embedding size配置方面的有效性。给定baseline推荐模型,NIS能够显著提高它们的性能,同时在所有实验中显著减少embedding参数的数量(从而减少模型的规模)。此外,作者将NIS应用于Google App store中的一个真实世界的大规模App ranking模型,并进行了离线实验和在线A/B test,结果是+1.02%的App Install,而模型大小减少了30%。这个新的NIS App ranking模型已经部署在生产中。- 一个是将原始(可能是
相关工作:几乎所有以前的
NAS研究工作都集中在为图像/视频理解问题寻找最佳的representation learning组件。对于大规模的推荐问题,通过利用先进的representation learning组件(如CNN, RNN等)也取得了很大的成果。然而,尽管输入组件由于embedding从而包含了很大一部分模型参数,但它在整个工业界中经常被启发式地设计,如YouTube, Google Play, Netflix等。据我们所知,我们的工作首次将自动化的神经网络设计引入输入组件从而用于大规模推荐问题。
41.1 模型
- 假设模型的输入由一组
categorical特征vocabulary。 - 一个
embedding变量vocabulary size,embedding维度。对于任何item的embedding向量。 - 令
"memory budget",它指的是模型的embedding矩阵使用的浮点数的总数。对于一个embedding矩阵,它的浮点数总数为
41.1.1 Neural Input Search Problems
Single-size Embedding: SE:single-size embedding是一个形状为embedding矩阵,其中词表中的每一个item(共计item)都表示为一个embedding向量。以前的工作大多使用SE来表示离散的特征,每个特征的下面我们提出一个
Neural Input Search问题从而自动寻找每个特征的最佳SE,即NIS-SE。解决这个问题的方法将在后面介绍。Problem NIS-SE:为每个vocabulary sizeembedding dimension该问题涉及两个
trade-off:特征之间的
memory budget:更有用的特征应该得到更多的预算。每个特征内部的
vocabulary size和embedding dimension之间的memory budget。- 大的
vocabulary size给了我们更高的覆盖率,让我们包括尾部item作为输入信号。 - 大的
embedding dimension可以提高我们对头部item的预测,因为头部item有更多的训练数据。此外,大的embedding dimension可以编码更细微的信息。
- 大的
在
memory budget内,SE使得我们很难同时获得高覆盖率和高质量embedding。为了克服这一困难,我们引入了一种新的embedding类型,即Multi-size Embedding。Multi-size Embedding: ME:Multi-size Embedding允许词表中的不同item有不同维度的embedding。它让我们对头部item使用大维度的embedding、对尾部item使用小维度的embedding。对尾部item使用较少的参数是有意义的,因为它们的训练数据较少。现在,一个
embedding变量(对应于一个特征)的vocabulary size和embedding size是由Multisize Embedding Spec: MES给出的。MES是pair的列表:pair的vocabulary size,满足categorical feature的总的vocabulary size。这相当于将单个词表划分为
pair的embedding size,满足
这可以解释为:最开始的
item有embedding维度item有embedding维度ME就等价于SE。我们对于每个
embedding矩阵SE中那样只有一个embedding矩阵embedding投影到reduction操作在同一个embedding矩阵的累计vocabulary size,则词表中第item的ME定义为:其中:
item在第block内的相对编号。通过对每个特征的适当的
MES,ME能够同时实现对尾部item的高覆盖率、以及头部item的高质量representation。然而,为所有特征手动寻找最佳MSE是非常困难的,因此需要一个自动方法来搜索合适的MES。下面我们介绍Multi-size Embedding的Neural Input Search问题,即NIS-ME。解决这个问题的方法将在后面介绍。NIS-ME:为每个MES在任何使用
embedding的模型中,ME都可以用来直接替代SE。通常,给定一组vocabulary IDSE,然后对这些SE进行一个或多个reduce操作。例如,一个常用的reduce操作是bag-of-words: BOW,即对embedding进行求和或求平均。为了了解在这种情况下ME是如何直接替代SE的,即BOW的ME版本(我们称之为MBOW),由以下公式给出:其中
ME是相加的。这在下图中得到了说明。请注意,对于那些embedding进行求和是更高效的。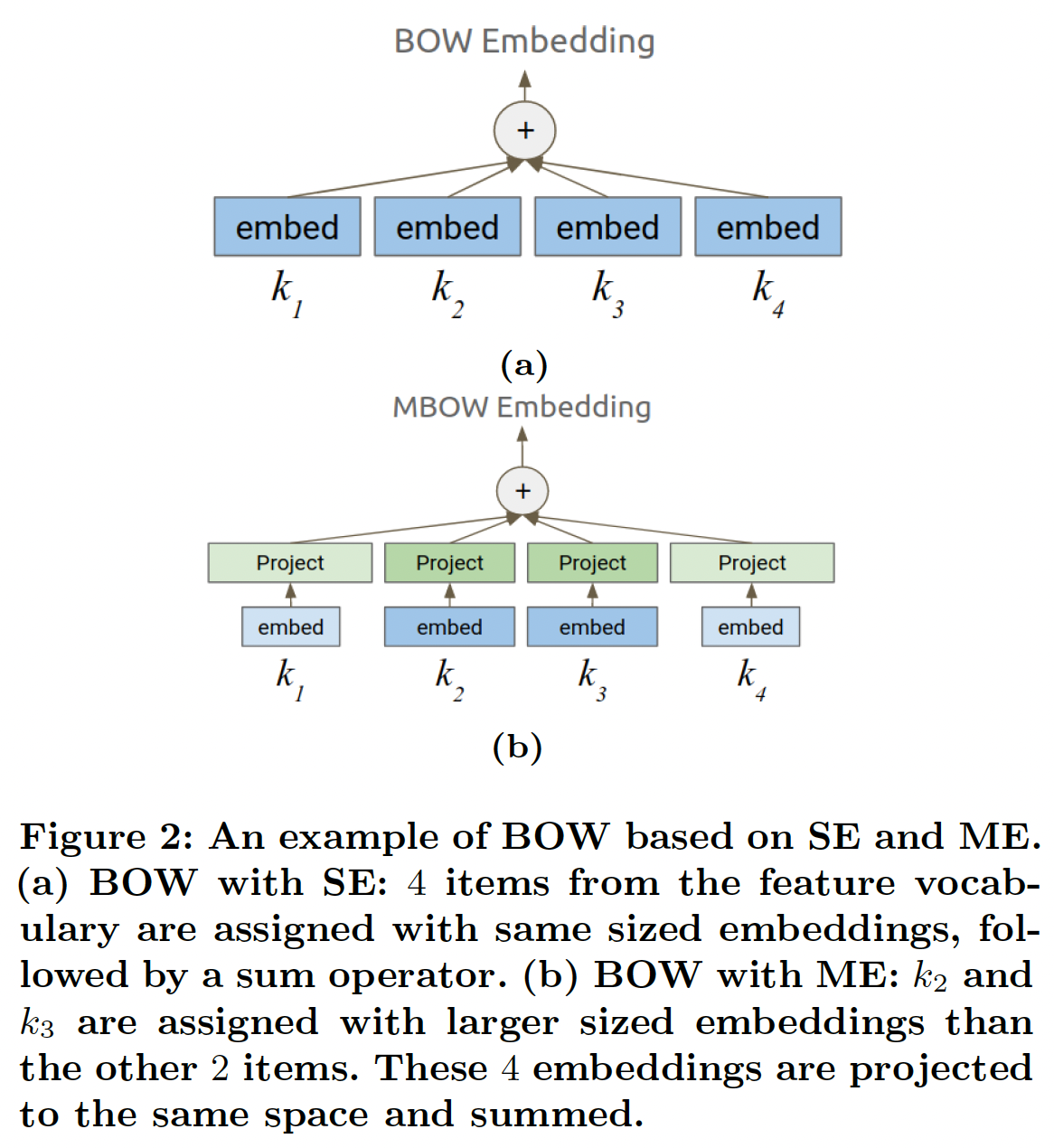
41.1.2 Neural Input Search Approach
我们在模型的输入组件开发了一个新的搜索空间,它包含了我们想要搜索的
SE或ME。我们使用一个独立的controller,从而在每一个step中为每个离散特征挑选一个SE或ME。这些选中的SE或ME与主模型的其他部分(不包括控制器)一起被训练。此外,我们使用主模型的前向传播来计算控制器的选择的奖励(是准确率和内存成本的组合),并使用A3C策略梯度方法将奖励用于训练控制器变量。正如论文在实验部分所述,
NIS方法对具有大vocabulary size的categorical特征的影响更大。至于像性别、学历这种词典规模较小的categorical特征,则NIS方法的价值不大。搜索空间:
Embedding Blocks:对于vocabulary size为vocabulary中的item允许的最大embedding size。 我们称这些矩阵为Embedding Blocks。这可以看作是将一个大小为embedding矩阵离散化为例如,假设
v=10M(M代表一百万),[1M, 2M, 2M, 2M, 3M];可以把列离散成四块:[64, 64, 64, 64]。这样就有20个Embedding Blocks,如Figure 1所示。此外,对于每个
embedding映射到一个共同的reduction操作。 显然,对于所有的embedding中的参数数量相比,投影矩阵中的参数数量是可以忽略的。Embedding Blocks是搜索空间的构建块,允许控制器在每个training step中采样不同的SE或ME。Controller Choices:controller是一个神经网络,从softmax概率中采样不同的SE或ME。它的确切行为取决于我们是对SE还是ME进行优化。下面我们将描述控制器在一个特征SE:为了对SE进行优化,在每个training step中,控制器集合pairEmbedding Blockstraining step。因此,控制器有效地挑选了一个SE,如Figure 1(a)中的红色矩形内的SE,它代表了一个大小为SE。在这一步中,词表中第item中的embedding为:其中:
vocabulary size。
定义
embedding size,显然,embedding表示第item,然后将其投影到一个vocabulary ID为item都被认为是out-of-vocabulary,要特别处理,通常采用的方法是使用零向量作为它们的embedding。因此,这种SE的选择带来的内存成本(参数数量)为:如果在
training step中选择了(0, 0),就相当于从模型中去除该特征。因此,在这个training step中,zero embedding被用于这个特征的所有item,相应的存储成本为0。随着控制器探索不同的SE,它根据每个choice引起的奖励进行训练,并最终收敛到最佳选择。如果它收敛到(0, 0),意味着这个特征应该被删除。显然,对于一个给定的特征,搜索空间的大小是ME:当对ME进行优化时,控制器不是做出单个选择,而是做出一连串的- 如果
Embedding Blockstraining step。 - 如果
item,整个embedding都将被移除。
因此,控制器选择了一个自定义的
Embedding Blocks子集(而不仅仅是一个网格),它组成了一个MES。如Figure 1(b)所示:- 第一个
64-D embedding被开头的3M个item所使用。 - 第二个
64-D embedding被所有10M个item所利用。 - 第三个
64-D embedding不被任何item所使用。 - 最后一个
64-D embedding被开头的3M个item所使用。
因此,词表中开头的
3M个item被分配了192维的embedding,而最后7M个item只被分配了64维的embedding。换句话说,在这个training step中实现了MES [(3M, 192), (7M, 64)]。数学上,令
item在当前training step的embedding为:如果
SE的emebdding公式为:SE相比,ME公式中的sum不是从ME的内存成本为:- 如果
奖励:由于主模型是通过控制器对
SE或ME的选择来训练的,控制器是通过主模型对验证集样本的前向传播计算出来的奖励来训练的。我们将奖励定义为:其中:
embedding配置,质量奖励:一类常见的推荐问题是检索问题,其目的是给定模型的输入从而在一个可能非常大的
vocabularyitem。这类问题的objective通常是实现high recall,因此我们可以直接让Recall@N(Recall@N变得太昂贵,我们可以通过采样一个小的negative set(即,负采样),使用Sampled Recall@N作为代理。另一类常见的问题是排序
ranking问题。ranking模型的质量通常由ROC-AUC来衡量,他可以作为质量奖励。同样,对于回归问题,质量奖励可以设置为
prediction和label之间的L2-loss的负值。内存成本:我们定义内存成本为:
注意:
embedding参数的代价所对应的质量奖励的增量。例如,如果质量奖励是ROC-AUC,embedding参数,如果它能使ROC-AUC增加0.1。这是因为额外的
41.1.3 Training the Neural Input Search Model
Warm up阶段:如前所述,训练NIS模型涉及到主模型和控制器之间consecutive steps的交替训练。如果我们从第0步开始训练控制器,我们会得到一个恶性循环:没有被控制器选中的Embedding Blocks没有得到充分的训练,因此给出了不好的奖励,导致它们在未来被选中的机会更少。为了防止这种情况,前几个
training steps包括一个warm up阶段,我们训练所有的Embedding Blocks,并固定控制器参数。warm up阶段确保所有Embedding Blocks得到一些训练。在warm up阶段之后,我们转向使用A3C交替训练主模型和控制器。在预热阶段,控制器被固定为选择所有的
Embedding Blocks。Baseline Network:作为A3C算法的一部分,我们使用一个baseline网络来预测每个控制器(使用已经做出的选择)的期望奖励。baseline网络的结构与控制器网络相同,但有自己的变量,这些变量与控制器变量一起使用验证集进行训练。然后,我们从每个step的奖励中减去baseline,计算出advantage从而用于训练控制器。baseline网络是主模型的拷贝,但是采用了不同的变量。每次更新主模型之后,就将主模型的参数拷贝给baseline。总体训练流程为:
warm up:通过训练集来更新主模型,此时选择所有的Embedding Blocks。迭代:
- 在验证集上评估主模型的奖励,并通过奖励最大化来更新控制器参数。
- 通过新的控制器参数,在训练集上更新主模型。
41.2 实验
41.2.1 公共数据集
数据集:
MovieLens-1M:包含了由6千多个用户创建的1M条电影评分记录。我们通过遵循一个广泛采用的实验设置来制定一个电影推荐问题。用户的评分被视为隐性反馈,也就是说,只要用户给电影打了分,就被认为是对该电影感兴趣。此外,对于每个用户,从电影词表中均匀地采样4部随机电影作为用户的负样本(负采样策略,而不是在训练之前提前准备并固定了负样本)。意外的命中会被删除,即:负样本集合中包含了正样本,则把正样本从负样本集合中剔除。由于每条评分记录都有一个时间戳,我们把每个用户的最近一个评分记录拿出来进行测试。在测试阶段,对于每个正样本,我们随机采样
99部电影作为负样本来计算评价指标。测试期间的采样策略与训练期间相同。KKBox:来自WSDM KKBox音乐推荐挑战赛,任务是预测用户在一个时间窗口内第一次可观察到的听歌事件后是否会重复听歌。数据集同时包含了正样本和负样本:正样本表示用户重复听了这首歌,负样本表示用户没有再听这首歌。因此,与MovieLens-1M数据集不同的是,我们没有通过随机采样来手动构造负样本,而是使用数据集提供的负样本。由于该数据集没有与每条记录相关的时间戳,我们随机采样
80%的记录用于训练、20%的记录用于测试。
对于这两个数据集,我们进一步从训练集中随机采样
10%的样本用于训练控制器的验证集。下表给出了我们应用
NIS的特征的vocabulary size(即,feature的unique item数量)。注意,原始的KKBox数据集有更多的特征,这些特征要么是浮点特征(如 "歌曲长度")、要么是小vocabulary size的categorical特征(如 "流派")。由于NIS对具有大vocabulary size的categorical特征的影响更大,在我们的实验中,为了简单起见,我们只使用下表中列出的特征。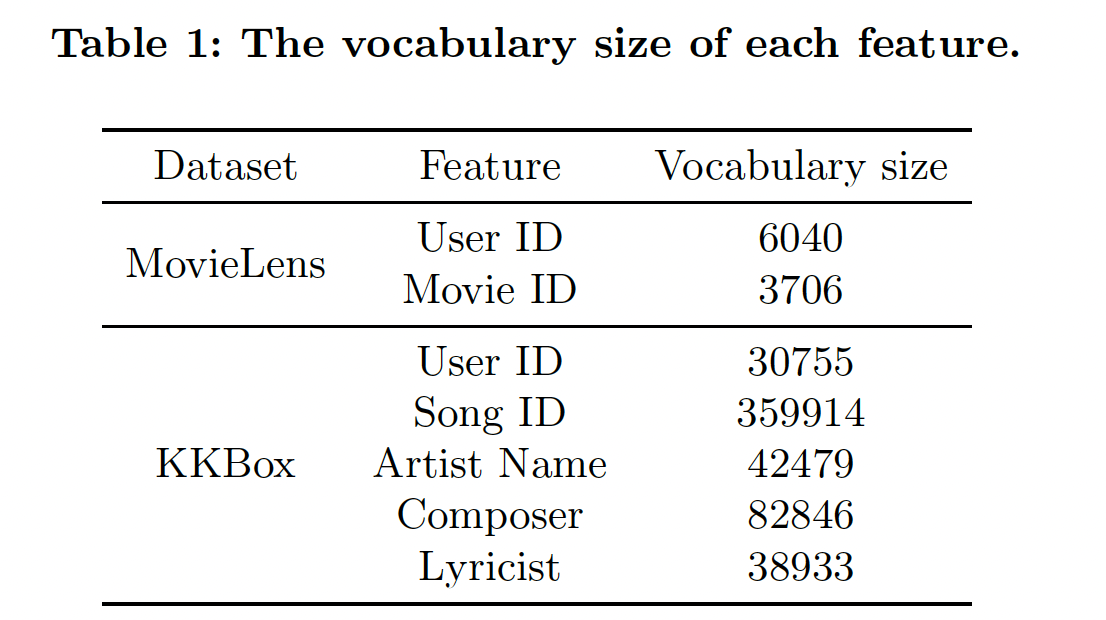
vocabulary构建细节:以MovieLens-1M为例,遍历每个user-movie评分记录,并计算每个用户在整个数据集中出现的记录数量,根据计数结果给每个用户分配vocabulary ID:最高频的用户分配ID 0、最低频的用户分配最大的ID。其它特征、其它数据集也以类似的方式构建vocabulary。在生产环境中,特征的频次分布有变化,如何处理?如何处理新出现的
ID,如新广告的ID?这些论文都没有提到。读者猜测,NIS仅适用于ID分布变化不大的场景。对于新闻、广告等等ID不断生成、消亡的领域,NIS可能需要进行适配。实验配置:
NIS方法实际上是模型结构无关的,可以应用于各种类型的模型。这里我们采用Neural Collaborative Filtering: NCF模型。NCF模型包括两个组件:Matrix Factorization: MF组件、多层感知器MLP组件,如下图所示。MF组件中的user embedding和item embedding是MF embedding。MLP组件中的user embedding和item embedding是MLP layer(ReLU激活函数),其大小分别为top MLP layer的输出被称作MLP embedding。我们没有使用任何规范化技术,如
BatchNorm、LayerNorm等。这意味着
MLP组件和MF组件并没有共享embedding,因此每个id都有两套embedding。
MF embedding和MLP embedding拼接起来,然后被用于计算logit(通过一个所有权重(包括隐层权重和
embedding矩阵)使用高斯分布随机初始化,高斯分布的均值为零、标准差为embedding的维度。任何权重都没有使用正则化或dropout。当一个特征有多个取值时(如,一首歌有多个作曲家),这些特征的取值的embedding是均值池化。当某些训练样本中存在缺失的特征值时,使用全零的embedding。对于
MovieLens-1M数据集,item embedding是简单的movie embedding。于KKBox数据集,由于每个item(即歌曲)有多个特征,即song ID、艺术家姓名、作曲家、作词人,item embedding的计算方法如下:- 对于
MF组件,四个特征中的每一个都表示为一个embedding,然后将它们拼接起来并通过一个MF组件中的item embedding。 - 对于
MLP组件,四个特征中的每一个都表示为一个embedding,然后将它们拼接起来并通过一个MLP组件中的item embedding。
给出一个预先选择的
embedding参数的模型,我们首先将其作为baseline,不应用NIS。然后,我们将每个特征的embedding size增加一倍,从而产生embedding参数,并应用NIS的内存预算baseline模型相同)。我们预期NIS通过更好地分配baseline更好。我们进一步用NIS的极限,看看它是否还能比baseline模型表现更好。我们为
baseline模型实验了NIS模型将有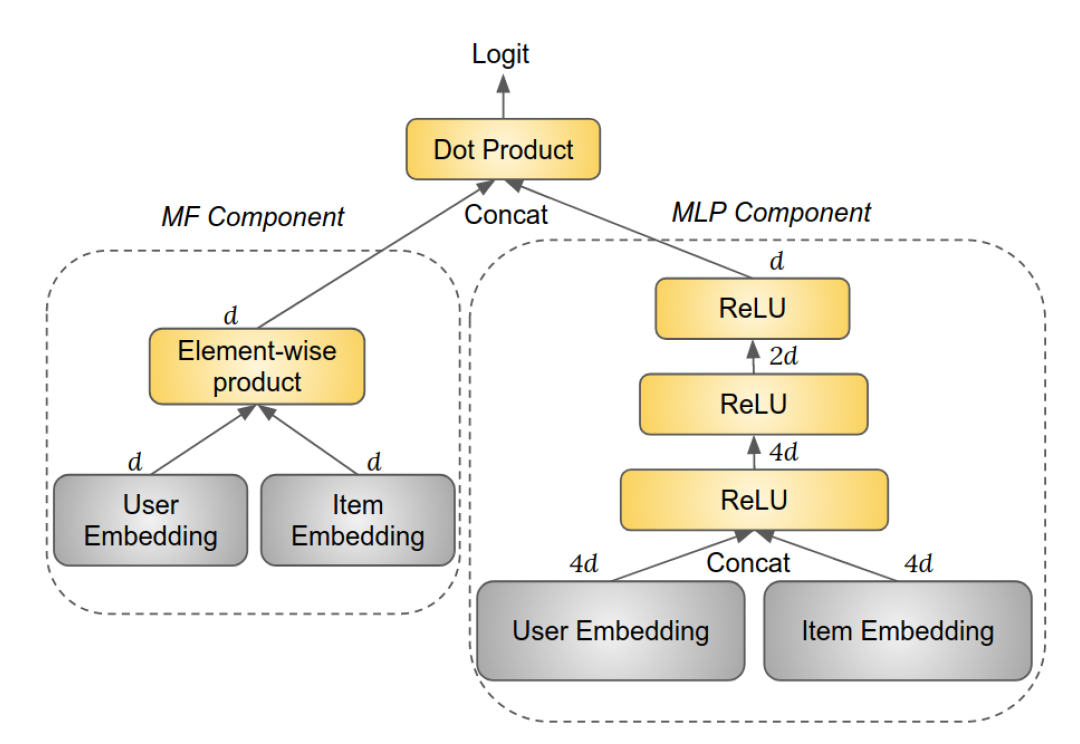
控制器:控制器用于在所有候选的
choice上产生一个概率分布。我们在所有的实验中使用了一个简单的控制器:对于
SE settting,控制器为每个特征分配一个logit。该向量被初始化为零向量。控制器从这个多样式分布中采样不同的
SE。注意:每个特征的搜索空间大小为SE是独立采样的。我们没有使用更复杂的控制器结构,如
RNN,因为不清楚对一个特征做出的决策是否会影响其他特征,以及应该按照何种顺序做出决策。对于
SE setting,控制器为每个特征从对于
ME setting,控制器为每个特征分配对于
ME setting,控制器为每个特征从
每个特征构建了
20个Embedding Blocks,其中:total vocabulary size。在实践中,我们发现这种配置在细粒度和搜索空间大小之间取得了良好的平衡。如前所述,控制器使用验证集进行训练。对于
MovieLens-1M数据集,我们使用Recall@1(也称作HitRate@1)作为质量奖励Recall, MRR, NDCG。对于KKBox数据集,我们使用ROC-AUC作为质量奖励 ,并报告测试集上的ROC-AUC。在所有的实验中,我们设定训练细节:
- 主模型:
batch size = 256,应用梯度裁剪(梯度范数阈值为1.0),学习率为0.1,使用Adagrad优化器。在开始A3C算法之前,进行了100K步的预热阶段。 - 控制器:使用
Adagrad优化器,学习率为0.1,不使用梯度裁剪(因为一个低概率但高回报的行动应该得到一个非常高的梯度,以显著提高其概率)。每个控制器的决策都由验证集的64个样本所共享,从中计算出一个奖励值。
在预热阶段结束后,控制器和主模型每隔一个
mini-batch step进行交替训练。在所有的实验中,我们在主模型和控制器都收敛后停止训练(而不是仅有一个收敛)。我们使用了分布式训练,其中
5个worker独立地进行并行训练。- 主模型:
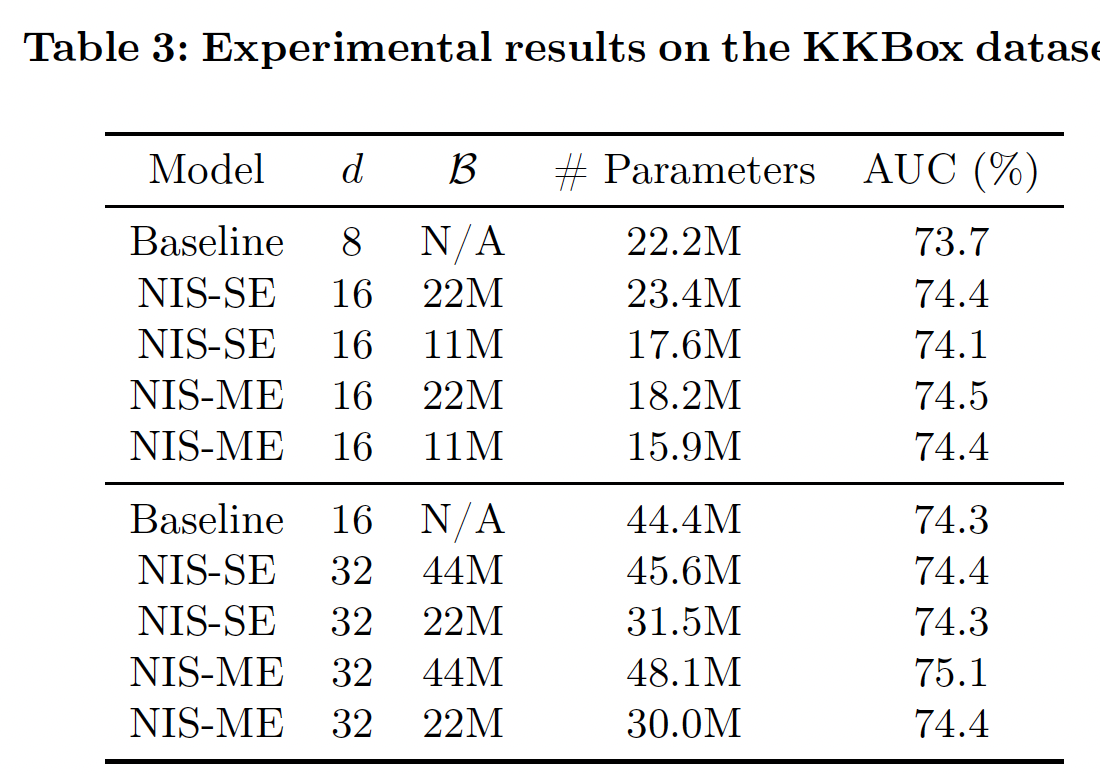
Table 2和Table 3分别报告了MovieLens-1M数据集和KKBox数据集的实验结果。注意,NIS模型的内存预算。可以看到:NIS能够持续取得比baseline模型更好的性能,很多时候参数明显减少,证明了我们方法的有效性。- 在相同的条件下,
NIS-ME模型总是优于NIS-SE,而且通常参数比NIS-SE更少。 - 即使
baseline模型大小的一半,NIS模型也几乎总是优于baseline。这不仅证明了我们方法的有效性,而且还表明在重度约束条件下有可能实现卓越的性能。 - 一些
NIS模型通过超出内存预算获得了卓越的性能。这种模型质量和模型规模之间的tradeoff反映在奖励函数的设计中。当内存预算只是一个指导方针而不严格时,这一点特别有用。
41.2.2 真实世界大型数据集
这里我们描述如何将
NIS应用到Google Play App store的ranking model。该模型的目标是:根据App被安装的可能性对一组App进行排序。数据集由(Context, App, Label)组成,其中Label=0表示App未被安装、Label=1表示App被安装。总共有20个离散特征被用来表示Context和App,如App ID、Developer ID、App Title等。离散特征的vocabulary size从数百到数百万不等。每个特征的embedding维度和vocabulary size经过几年的手工优化。实验配置:对于
Embedding Blocks,我们设置vocabulary size。需要注意的是,对于每个特征,我们没有平均分割vocabulary,而是给top-10%的item分配了一个Embedding Block,因为数据集中的高频特征都是最重要的,也就是说,top-10%的item通常出现在大多数训练样本中。这进一步证明了Multi-size Embedding在实践中的必要性。此外,我们设置
production model的embedding size(在不同特征上取值为8 ~ 32)。在将embedding size增加到三倍从而允许更高的模型容量的同时,我们设置内存预算production model的embedding参数的总数。显然,这里的目标是提高模型的预测能力,同时减少模型的大小。我们使用
ROC-AUC作为质量奖励,并设置0.001的ROC-AUC增长从而允许离线实验:离线
ROC-AUC指标如下表所示。可以看到:- 在
SE setting和ME setting中,NIS能够以较少的参数数量改善production model的ROC-AUC性能。 NIS-ME模型在参数数量更少的情况下也能取得比NIS-SE更好的性能,因为Multi-size Embedding可以通过给head items更多的参数、给tail items更少的参数来更好地利用内存预算。与production model相比,NIS-ME在ROC-AUC上得到了0.4%的改进,而模型大小减少了30%。
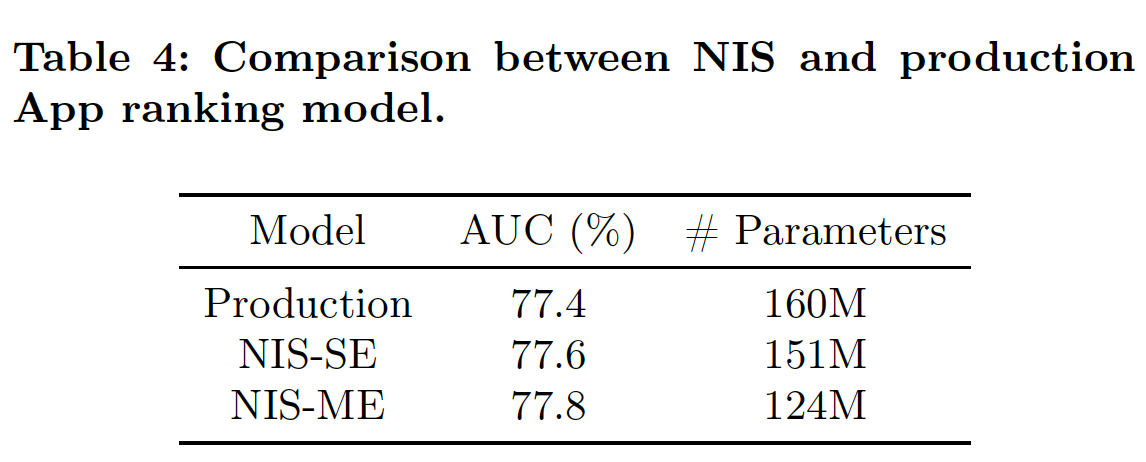
- 在
在线
A/B test:我们进一步用实时流量进行了A/B test的在线实验。由于NIS-ME模型优于NIS-SE模型,A/B test只在NIS-ME模型上进行。我们监测了App Install指标,并得出结论:NIS-ME模型能够将App Install增加1.02%。NIS-ME模型目前部署在100%的流量上,取代了本实验中使用的production baseline model。稳定性:当部署在生产中时,
NIS-ME模型需要每天进行重新训练和刷新。了解模型的性能可以维持多久是很重要的。这是因为每个特征的数据分布可能会随着时间的推移而发生重大变化,所以MES可能不再是最优的,在这种情况下,我们需要重新运行NIS,找到更适合新数据分布的MES。因为
NIS的词表构建依赖于ID频次分布,而在生产环境中,ID频次分布可能随时间发生变化。我们进行了为期
2个月的研究,监测原始production model和NIS-ME模型的ROC-AUC,如下图所示。显然,NIS-ME模型相对于production model的优势在2个月的时间里非常稳定,说明没有必要经常重新运行NIS。在实践中,我们只在模型结构发生变化或要增加新特征时才运行NIS。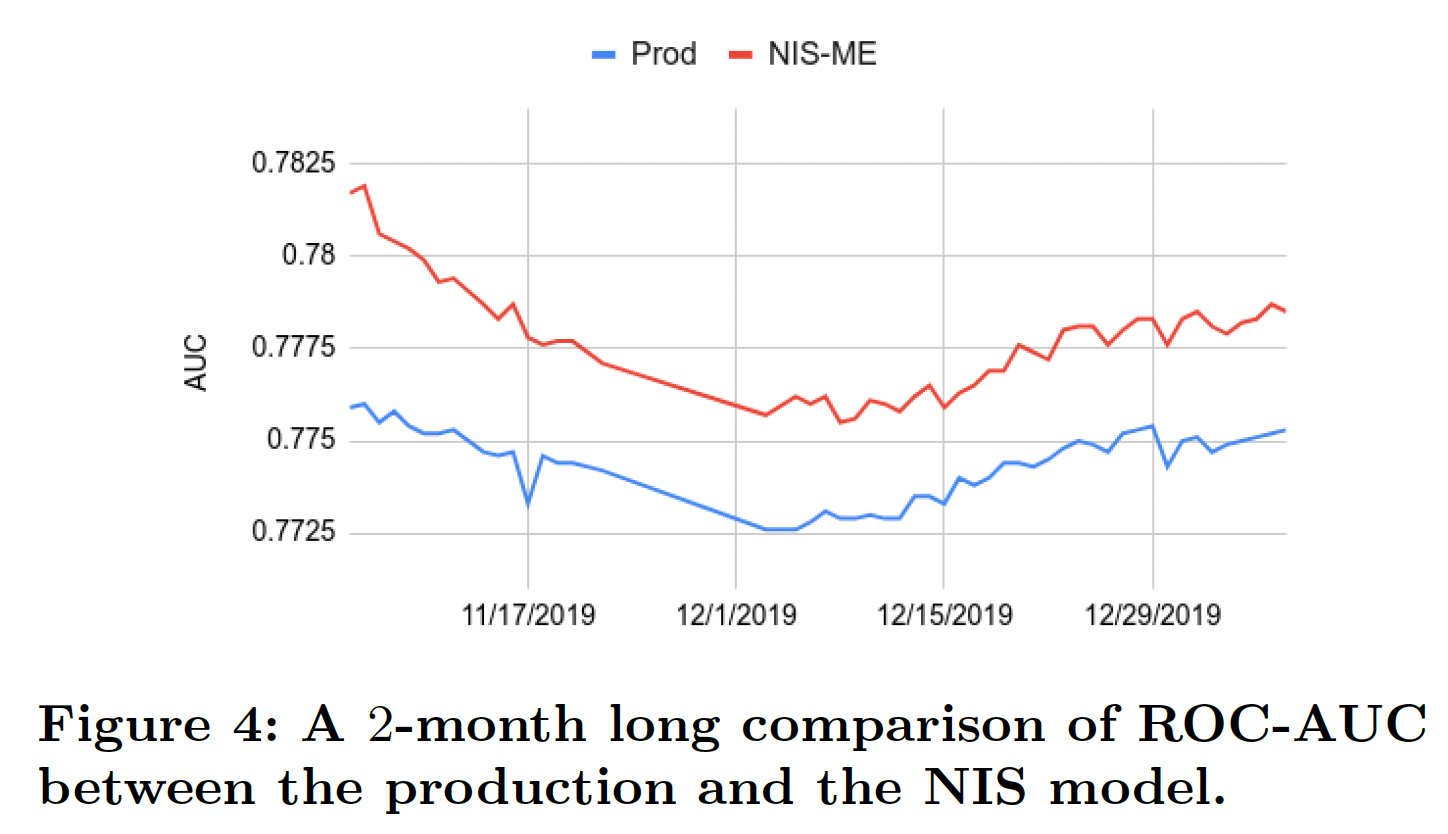
四十二、AutoEmb[2020]
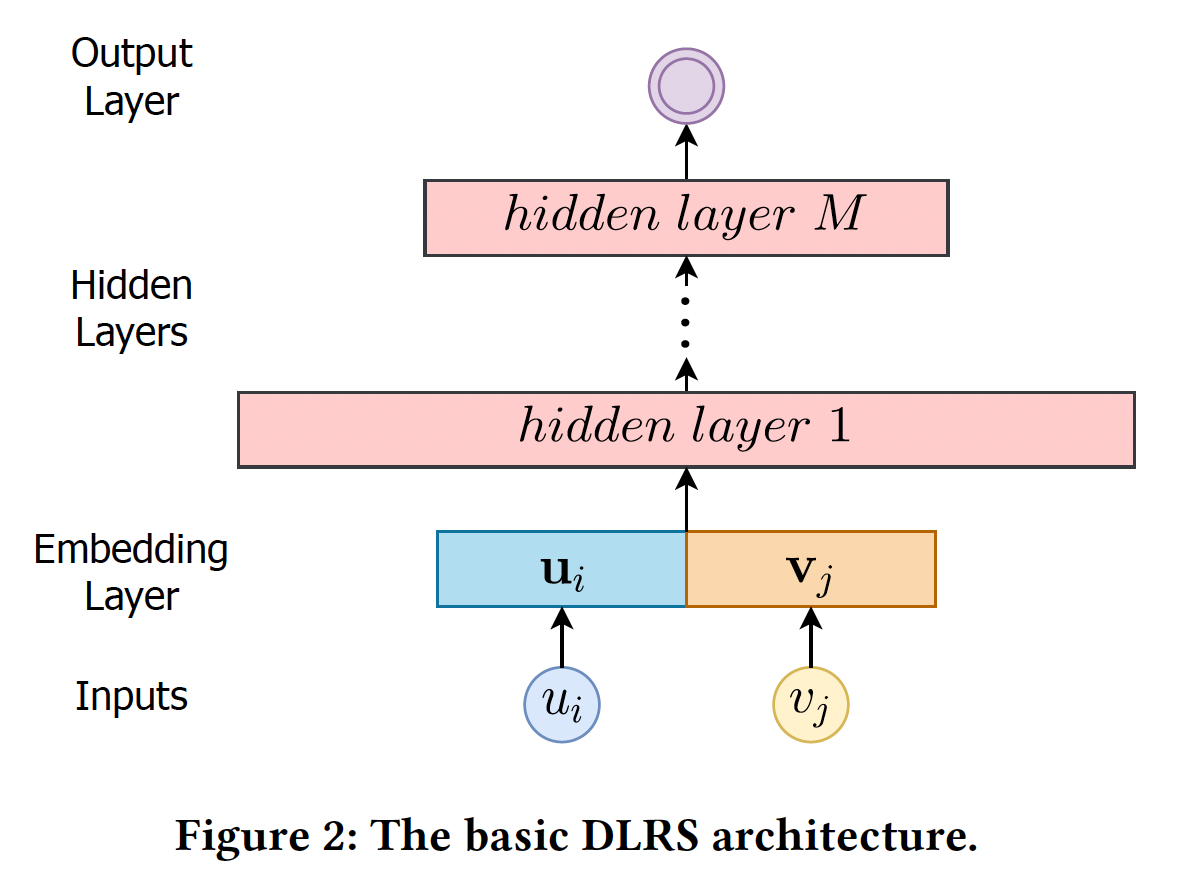
deep learning based recommender systems: DLRSs的架构通常主要由三个关键部分组成:embedding layer:将高维空间中的原始的user/item特征映射到低维embedding空间中的稠密向量。hidden layer:进行非线性变换以转换输入特征。output layer:根据hidden layer的representation对特定的推荐任务进行预测。
大多数现有的研究都聚焦在为
hidden layer和output layer设计复杂的神经网络架构,而embedding layer并没有获得太多的关注。然而,在拥有海量user和item的大规模真实世界推荐系统中,embedding layer在准确推荐中发挥着巨大的关键作用。embedding最典型的用途是将一个ID(即user ID或item ID)转换成一个实值向量。每个embedding都可以被认为是一个latent representation。与手工制作的特征相比,经过良好学习的embedding已经被证明可以显著提高推荐性能。这是因为embedding可以降低categorical变量的维度(如one-hot id),并有意义地在潜空间中代表user/item。大多数现有的
DLRSs在其embedding layer中往往采用统一的固定维度。换句话说,所有的user(或item)共享相同的、固定的embedding size。这自然引起了一个问题:我们是否需要为不同的user/item采用不同的embedding size?为了研究这个问题,论文
《AutoEmb: Automated Embedding Dimensionality Search in Streaming Recommendations》对movielens-20m数据集进行了初步研究。对于每个用户,作者首先选择该用户的固定比例的评分作为测试集,然后选择embedding维度为2/16/128的DLRS的推荐性能在mean-squared-error: MSE和准确率方面的变化。更低的MSE(或更高的准确率)意味着更好的性能。注意,作者在这项工作中把user/item的交互次数称为popularity。从图中可以看到:随着popularity- 不同
embedding size的模型的性能增加,但较大的embedding size获益更多。 - 较小的
embedding size首先工作得更好,然后被较大的embedding size所超越。
这些观察结果是非常符合预期,因为
embedding size通常决定了待学习的模型参数的数量、以及由embedding所编码信息的容量。- 一方面,较小的
embedding size往往意味着较少的模型参数和较低的容量。因此,当popularity小的时候,它们可以很好地工作。然而,当随着popularity的增加,embedding需要编码更多的信息,较低的容量会而限制其性能。 - 另一方面,更大的
embedding size通常表示更多的模型参数和更高的容量。它们通常需要足够的数据从而被良好地训练。因此,当popularity小的时候,它们不能很好地工作;但随着popularity的增加,它们有可能捕获更多的信息。
鉴于
user/item在推荐系统中具有非常不同的popularity,DLRSs应该允许不同的embedding size。这一特性在实践中是非常需要的,因为现实世界的推荐系统是popularity高度动态的streaming。例如,新的交互会迅速发生,新的用user/item会不断增加。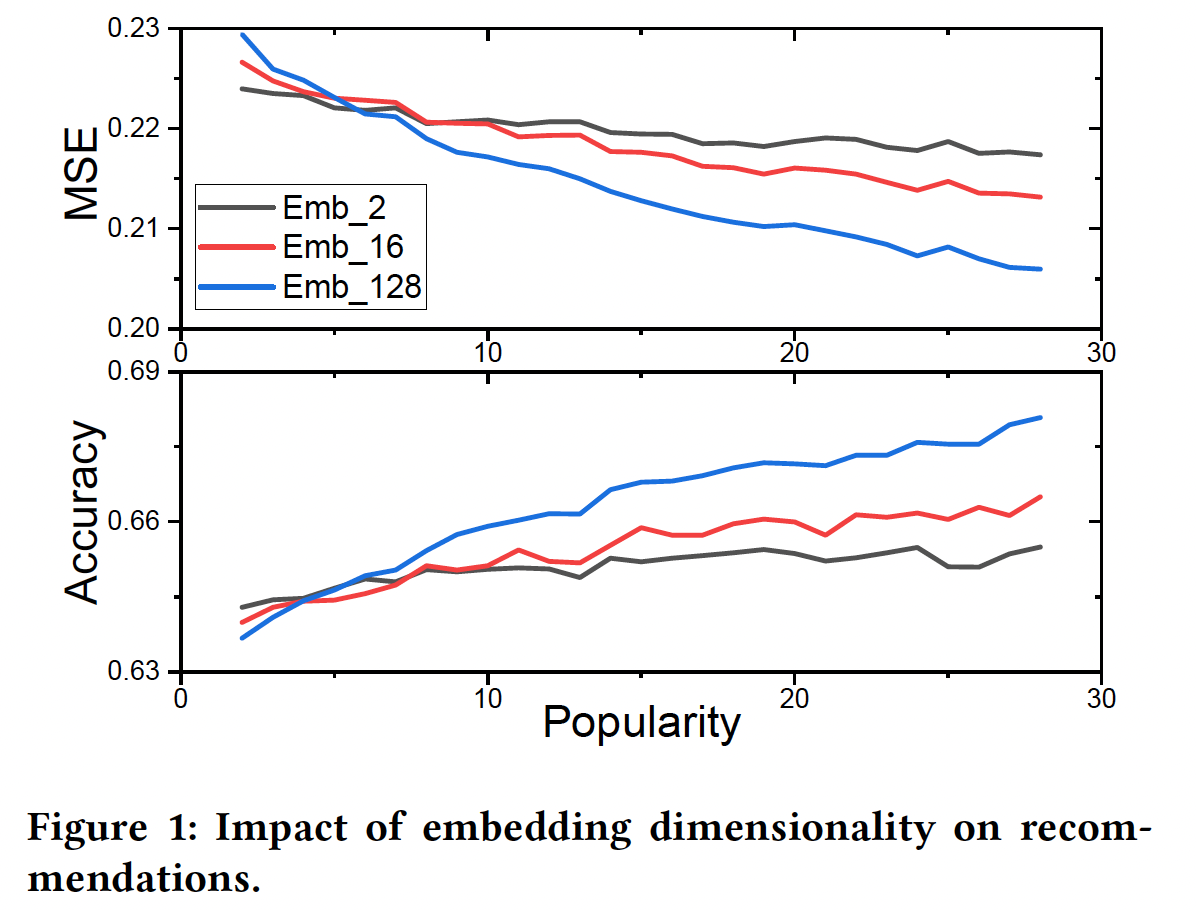
在论文
《AutoEmb: Automated Embedding Dimensionality Search in Streaming Recommendations》中,作者的目标是在streaming setting下,在embedding layer为不同的user/item实现不同的embedding size。这里面临着巨大的挑战:- 首先,现实世界的推荐系统中的
user/item的数量非常大,而且popularity是高度动态的,很难为不同的user/item手动选择不同的embedding size。 - 其次,在现有的
DLRSs中,first hidden layer的输入维度通常是统一的和固定的,它们很难接受来自embedding layer的不同维度。
作者试图解决这些挑战,从而建立了一个基于端到端的可微的
AutoML框架(即,AutoEmb),它可以通过自动的、动态的方式利用各种embedding size。论文通过现实世界的电商数据中的实验来证明了所提出的框架的有效性。相关工作:
deep learning based recommender system:近年来,一系列基于深度学习技术的神经推荐模型被提出,性能提升明显(如,NCF, DeepFM, DSPR, MV-DNN, AutoRec, GRU4Rec)。然而,这些工作大多集中在设计复杂的神经网络架构上,而对embedding layer没有给予过多关注。AutoML for Neural Architecture Search:《Neural input search for large scale recommendation models》首次将NAS用于大规模的推荐模型,并提出了一种新型的embedding方式,即Multi-size Embedding: ME。然而,它不能应用于streaming recommendation setting,其中popularity不是预先知道的而是高度动态的。
42.1 模型
Basic DLRS架构:我们在下图中阐述了一个basic的DLRS架构,它包含三个部分:embedding layer:将user ID/item IDembedding向量hidden layer:是全连接层,将embedding向量hierarchical feature representation。output layer:生成prediction从而用于推荐。
给定一个
user-item的交互,DLRS首先根据user ID和item ID进行embedding-lookup过程,并将两个embedding拼接起来;然后DLRS将拼接后的embedding馈入hidden layer并进行预测。 然而,它有固定的神经网络架构,不能处理不同的embedding size。接下来,我们将加强这个basic的DLRS架构,以实现各种embedding size。AutoEmb仅聚焦于user id和item id的embedding size优化,而没有考虑其他的categorical feature。并且论文描述的算法仅应用streaming recommendation setting。论文的思想比较简单:为每个
id分配embedding size,然后用强化学习进行择优。难以落地,因为最终得到的模型,参数规模几乎增长到换一个思路:给定一个
baseline model,我们可以将baseline model的embedding size划分为NIS),然后由控制器来选择需要横跨几个子维度。这种方法和NIS的区别在于:NIS的控制器是独立的自由变量,每个变量代表对应的概率。虽然控制器没有包含item的popularity信息,可以自由变量的update次数就代表了item出现的频次,因此隐式地包含了popularity信息。- 而这个思路里,控制器的输入包含了
item的popularity信息,可以给予控制器一定的指导。
Enhanced DLRS架构:正如前面所讨论的,当popularity较低时,具有较少模型参数的shorter embedding可以产生更好的推荐;而随着popularity的增加,具有更多模型参数和更高容量的longer embedding可以获得更好的推荐性能。在这个观察的激励下,为具有不同popularity的user/item分配不同的embedding size是非常理想的。然而,basic DLRS架构由于其固定的神经网络架构而无法处理各种embedding size。解决这一挑战的基本思路是将各种
embedding size转换为同一维度,这样DLRS就可以根据当前user/item的popularity选择其中一个transformed embedding。下图说明了embedding的转换和选择过程。假设我们有embedding空间embedding维度(即,embedding size)分别为embedding空间的embedding集合为embedding向量其中:
bias向量。经过线性变换,我们将原始
embedding向量embeddingmagnitude变化很大,这使得它们变得magnitude-incomparable。为了解决这一难题,我们对转换后的embeddingBatch- Norm与Tanh激活:其中:
mini-batch的均值,mini-batch的方差,Tanh激活函数将embedding归一化到0~1之间。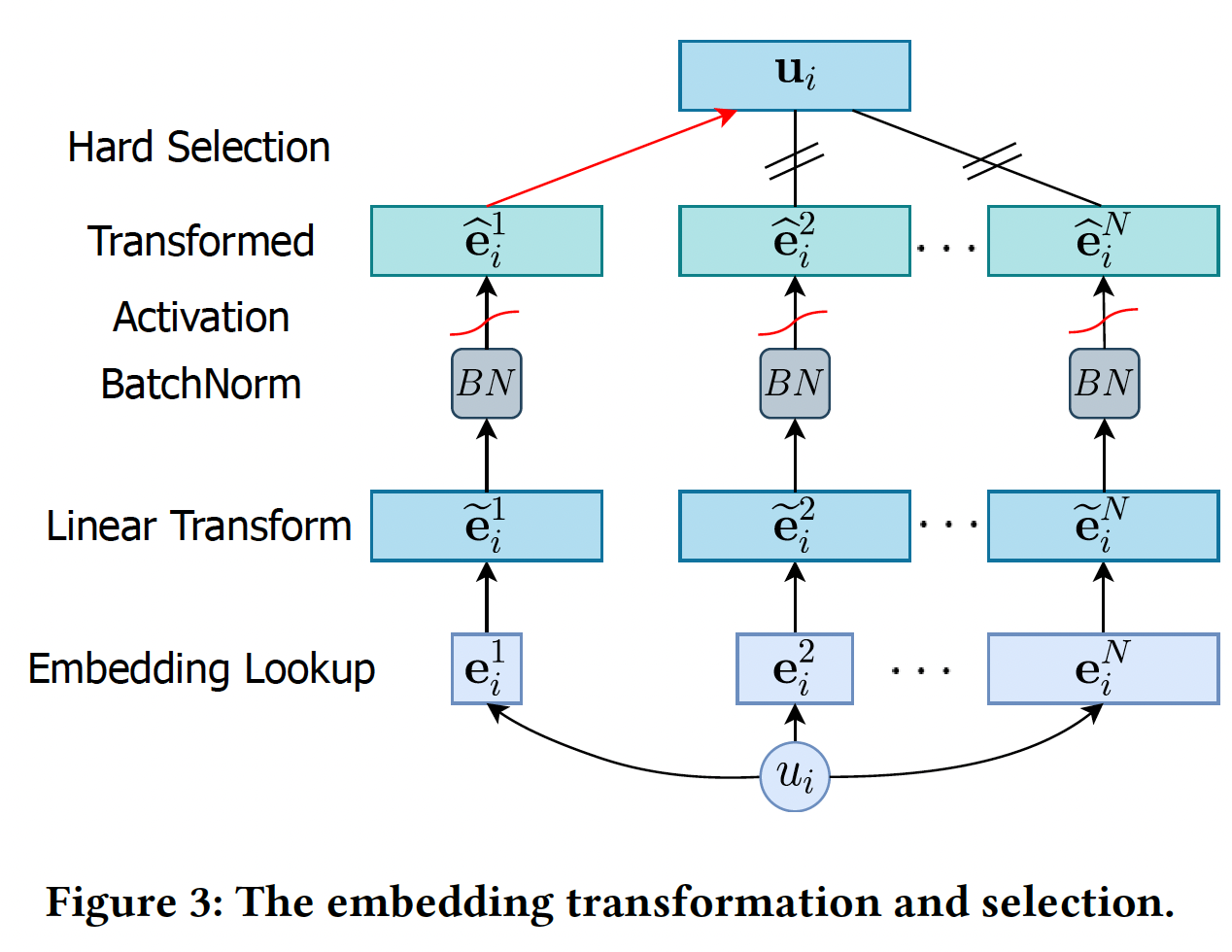
给定一个
itemembedding集合magnitude-comparable的转换后的embedding根据
popularity,DLRS将选择一对转换后的embeddinguseritemrepresentation:embedding size是由一个控制器controller选择的,将在后面详细介绍。然后,我们将user representation和item representation拼接起来,即output layer从而生成useritem为了获得理想的效果,
embedding table占据了模型的绝大部分参数,因此embedding table使得模型的规模几乎翻了Controller:我们提出了一种基于AutoML的方法来自动确定embedding size。具体而言,我们设计了两个控制器网络,分别决定user embedding size和item embedding size,如下图所示。对于一个特定的
user/item,控制器的输入由两部分组成:user/item的当前popularity、上下文信息(如previous超参数和loss)。上下文信息可以被看作是衡量previously分配给user/item的超参数是否运作良好的信号。换句话说,如果previous超参数工作得很好,那么这次生成的新的超参数应该有些类似。controller的输入特征具体都是什么?论文并未说明。也不必深究,因为论文的应用价值不高。该控制器接收上述输入,通过几层全连接网络进行转换,然后生成
hierarchical feature representation。output layer是具有Softmax layer。在这项工作中,我们用user controller的item controller的embedding空间的概率。controller自动选择最大概率的空间作为final embedding空间,即:有了控制器,
embedding size搜索的任务就简化为优化控制器的参数,从而根据user/item的popularity自动生成合适的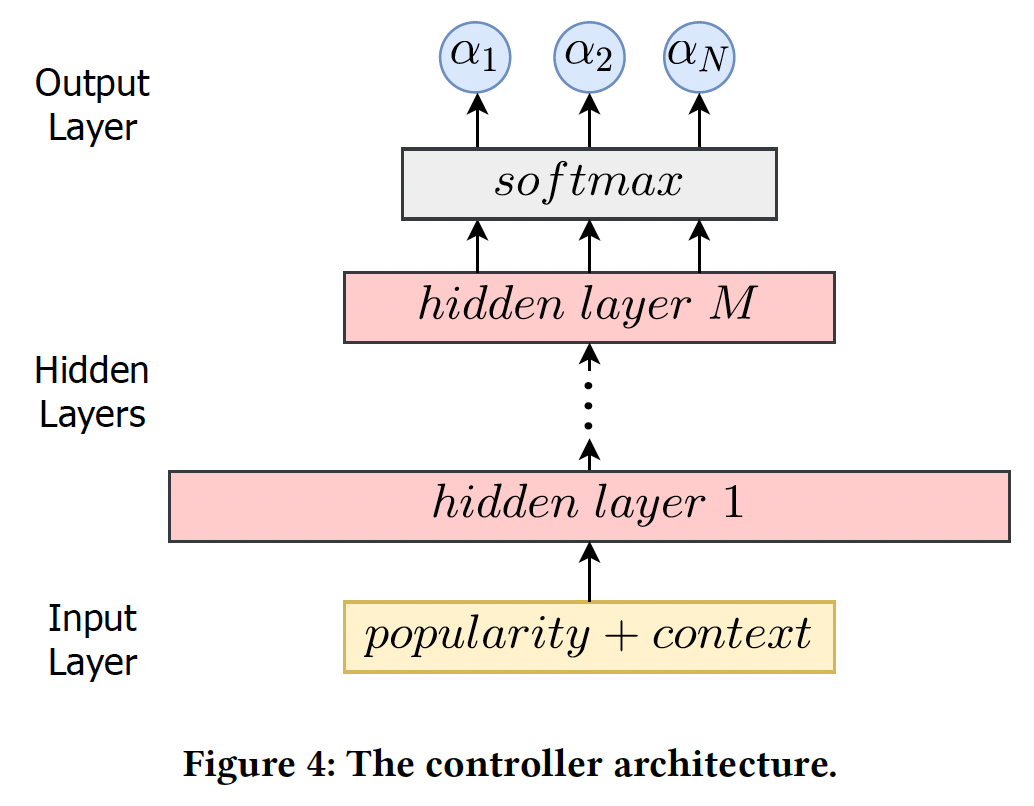
Soft Selection:上面的控制器对embedding空间进行了hard selection,即:每次我们只从控制器中选择一个具有最大概率的embedding空间。这种hard selection使得整个框架不是端到端的可微的。为此,我们选择了一种soft selection:有了
soft selection,enhanced DLRS是端到端的可微的。新的结构如下图所示,我们增加了transformed embedding layer,它对embedding空间进行soft selection,选择过程由两个控制器(分别用于user和item)来决定。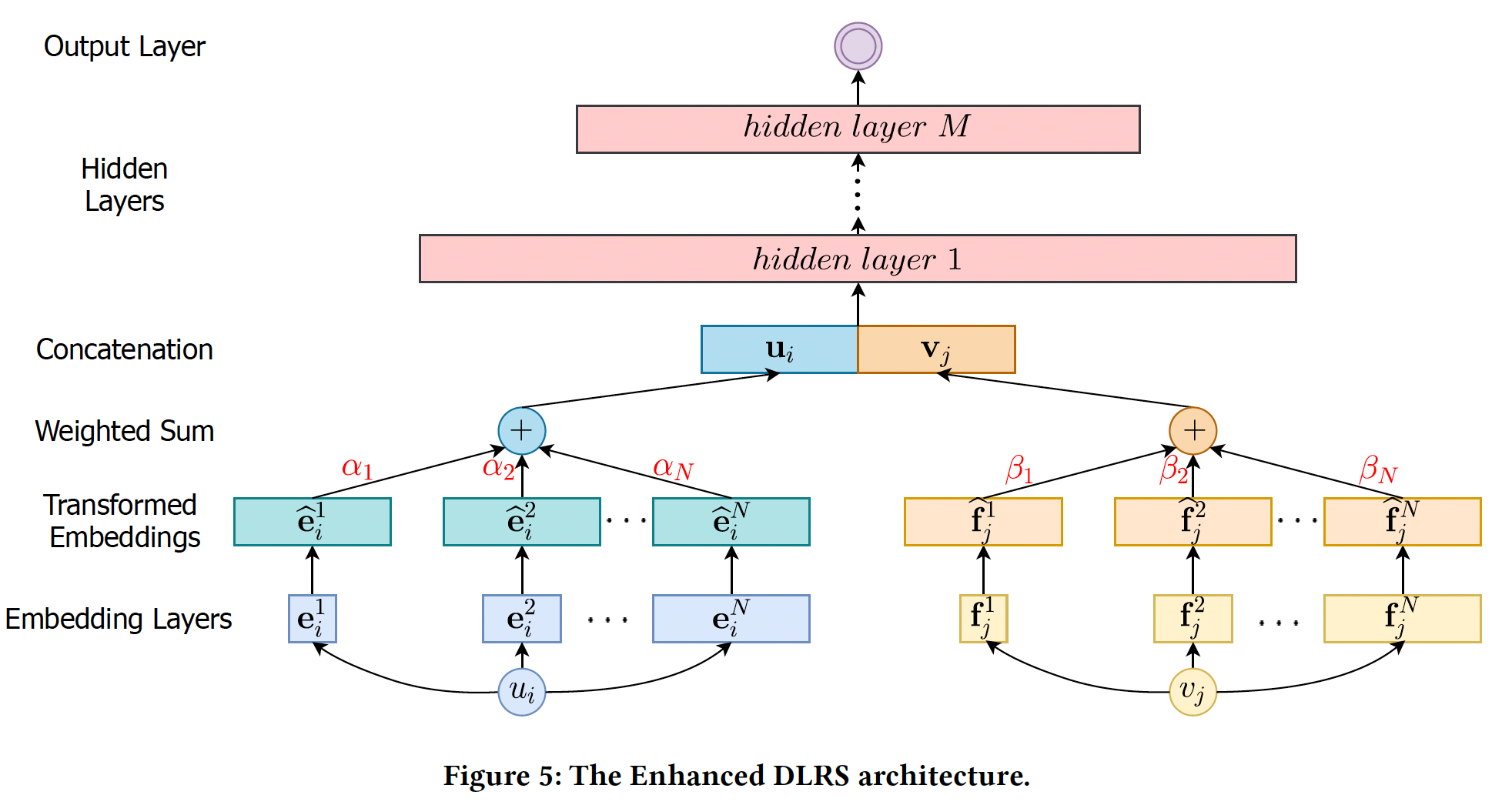
优化方法:优化任务是联合优化
DLRS的参数(如differentiable architecture search: DARTS)技术概念的启发,我们为AutoEmb框架采用了基于DARTS的优化,通过梯度下降分别优化训练损失DLRS的参数embedding dimensionality search的目标是找到使验证损失DLRS的参数bilevel优化问题,其中因为优化内层的
DARTS的近似方案:其中
training step来估计值得注意的是,与计算机视觉任务上的
DARTS不同,我们没有推导离散架构的阶段(即,DARTS根据softmax概率选择最可能的操作来生成离散的神经网络架构)。这是因为随着新的user-item交互的发生,user/item的popularity是高度动态的,这使我们无法为user/item选择一个特定的embedding size。DARTS based Optimization for AutoEmb算法:输入:
user-item交互、以及ground-truth标签输出:训练好的
DLRS参数算法步骤:
迭代直到收敛,迭代步骤:
从
previous的user-item交互中随机采样一个mini-batch的验证数据。基于梯度下降来更新
其中
first-order approximation。收集一个
mini-batch的训练数据。基于当前参数
基于当前参数
DLRS的prediction。评估
prediction的效果并记录下来。通过梯度下降来更新
值得注意的是,在
batch-based streaming recommendation setting中,优化过程遵循"evaluate, train, evaluate, train..."的方式。 换句话说,我们总是不断地收集新的user-item交互数据。当我们有一个完整的mini-batch的样本时,我们首先根据我们的AutoEmb框架的当前参数进行预测,评估预测的性能并记录下来;然后我们通过最小化prediction和ground truth label之间的损失来更新AutoEmb的参数。接下来我们收集另一个mini-batch的user-item交互,执行同样的过程。因此,不存在预先拆分的验证集和测试集。换句话讲:为了计算
previous的user-item交互中采样一个mini-batch,作为验证集。没有独立的测试阶段,即没有预先拆分的测试集。
遵循
《Streaming recommender systems》中的streaming recommendation setting,我们也有离线参数估计阶段和在线推理阶段:- 在离线参数估计阶段,我们使用历史上的
user-item交互来预先训练AutoEmb的参数。 - 然后我们在线启动
AutoEmb,在在线推理阶段持续更新AutoEmb参数。
- 在离线参数估计阶段,我们使用历史上的
42.2 实验
数据集:
Movielens-20m, Movielens-latest, Netflix Prize data。统计数据如下表所示。对于每个数据集,我们使用
70%的user-item交互进行离线参数估计,其他30%用于在线学习。为了证明我们的框架在embedding selection任务中的有效性,我们消除了其他的上下文特征(如,用户的年龄、item的category)从而排除其他特征的影响。但为了更好地推荐,将这些上下文特征纳入框架是很简单的。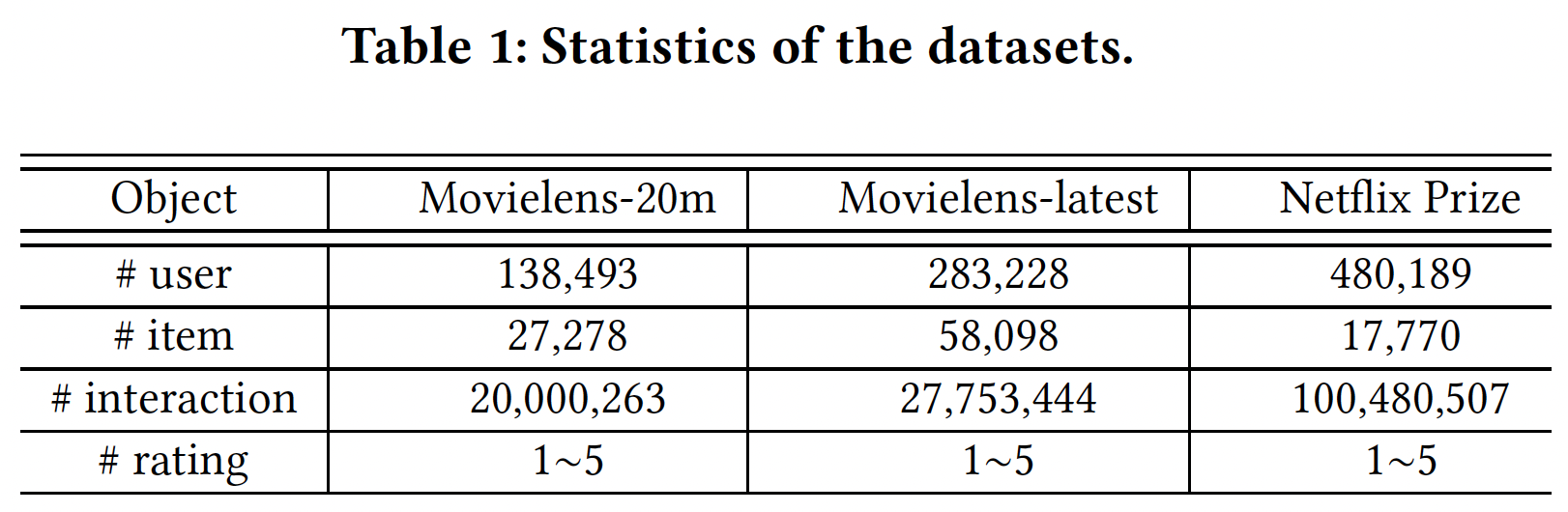
实现细节:
对于
DLRS:embedding layer:选择embedding sizeembedding维度为128。我们将每个user/item的三个embedding拼接起来,这大大改善了embedding的lookup速度。hidden layer:我们有两个隐层,大小为256*512和512*512。output layer:我们做两类任务:- 对于
rating regression任务,输出层为512*1。 - 对于
rating classification任务,输出层为512*5,采用Softmax激活,因为有5类评级。
- 对于
对于控制器:
input layer:输入特征维度为38。hidden layer:我们有两个隐层,大小为38*512和512*512。output layer:形状为512*3,采用Softmax激活函数,并输出
batch-size = 500,DLRS和控制器的学习率分别为0.01和0.001。AutoEmb框架的所有超参数都通过交叉验证来调优。相应地,我们也对baseline进行了超参数调优,以进行公平的比较。
评估指标:
对于回归任务,我们首先将评分二元化为
{0, 1},然后通过最小化mean-squared-error: MSE损失来训练框架。性能可以通过MSE损失和准确率来评估(我们使用0.5作为阈值来分配标签)。如何二元化,作者并未说明。读者猜测是用当前评分除以最大评分(如,
5分)从而得到0 ~ 1之间的浮点数。对于分类任务,评分
1~5被视为5个类,框架通过最小化交叉熵损失(CE loss)进行训练。性能由交叉熵和准确率来衡量。
baseline方法:Fixed-size Embedding:为所有的user/item分配了一个固定的embedding size。为了公平比较,我们将embedding size设定为146 = 2 + 16 + 128。换句话说,它占用的内存与AutoEmb相同。Supervised Attention Model: SAM:它具有与AutoEmb完全相同的架构,同时我们通过端到端的监督学习的方式,在同一个batch的训练数据上同时更新DLRS的参数和控制器的参数。Differentiable architecture search: DARTS:它是标准的DARTS方法,为三种类型的embedding维度训练
值得注意的是,
Neural Input Search model和Mixed Dimension Embedding model不能应用于streaming recommendation setting,因为它们假设user/item的popularity是预先知道的和固定的,然后用大的embedding size来分配高popularity的user/item。然而,在现实世界的streaming recommender system中,popularity不是预先知道的,而是高度动态的。在线阶段的比较结果如下表所示。可以看到:
SAM的表现比FSE好,因为SAM根据popularity在不同维度的embedding上分配注意力权重,而FSE对所有user/item都有一个固定的embedding维度。这些结果表明,推荐质量确实与user/item的popularity有关,而引入不同的embedding维度并根据popularity调整embedding上的权重可以提高推荐性能。DARTS优于SAM,因为像DARTS这样的AutoML模型在验证集上更新控制器的参数,可以提高泛化能力,而像SAM这样的端到端模型在同一个batch训练数据上同时更新DLRS和控制器的参数,可能导致过拟合。这些结果验证了AutoML技术比传统的监督学习在推荐中的有效性。我们提出的模型
AutoEmb比标准DARTS模型有更好的性能。DARTS在三种embedding维度上为每个user/item分别训练了user/item的这些权重可能不会被很好地训练,因为这个user/item的交互有限。AutoEmb的控制器可以纳入大量的user/item交互,并从中捕获到重要的特征。另外,控制器有一个显式的
popularity输入,这可能有助于控制器学习popularity和embedding维度之间的依赖关系,而DARTS则不能。这些结果证明了开发一个控制器而不仅仅是实值权重的必要性。在离线参数估计阶段之后,在线阶段的大多数
user/item已经变得非常popular。换句话说,AutoEmb对热门user/item有稳定的改进。
综上所述,所提出的框架在不同的数据集和不同的指标上都优于
baseline。这些结果证明了AutoEmb框架的有效性。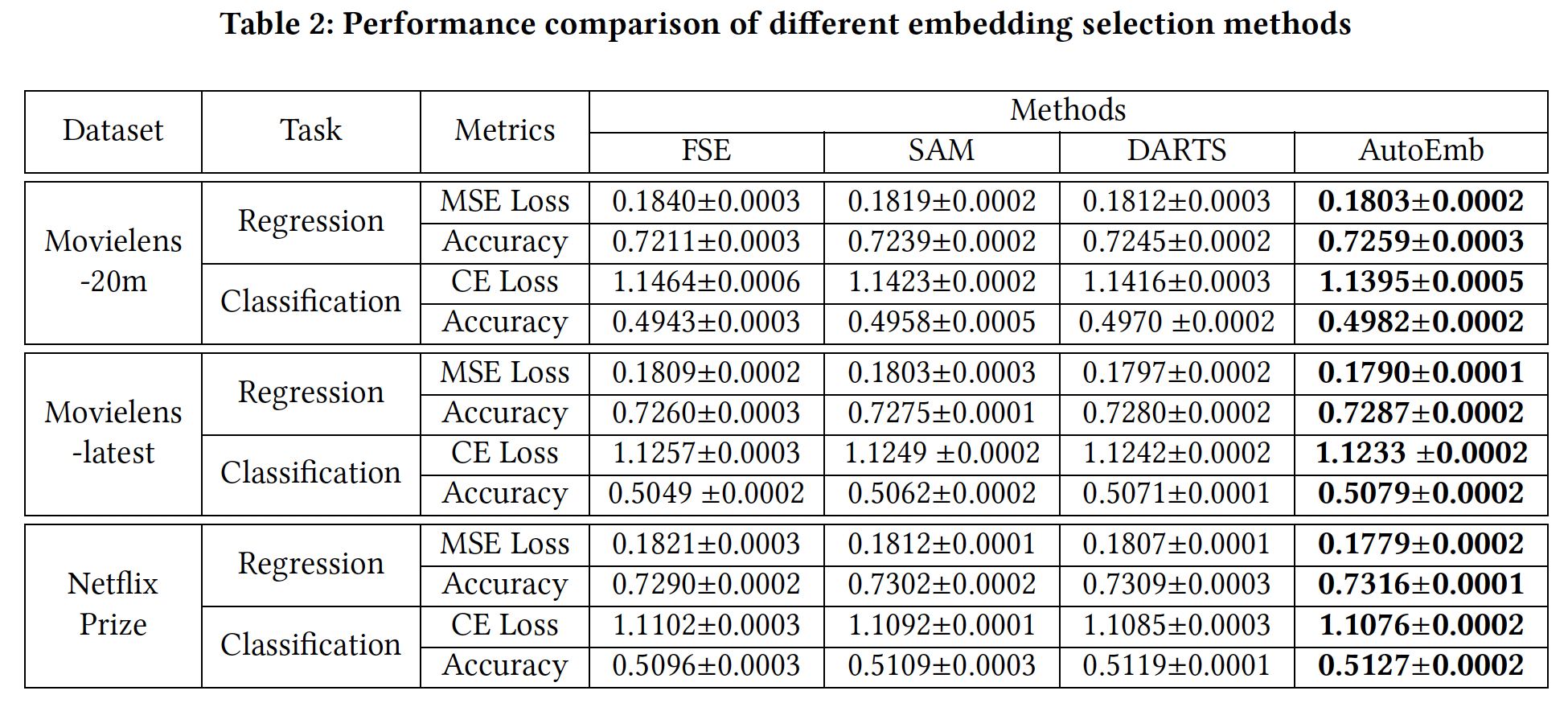
我们将调查所提出的控制器是否能根据各种
popularity产生适当的权重。因此,我们比较了没有控制器的FSE、有监督注意力控制器的SAM、以及有基于AutoML的控制器的AutoEmb。Figure 6显示了Movielens-20m数据集的结果,其中x轴是popularity,y轴对应的是性能。由于篇幅有限,我们省略了其他数据集的类似结果。可以看到:当
popularity较小时,FSE的表现比SAM和AutoEmb差。这是因为较大维度的embedding需要足够的数据才能很好地学习。参数较少的小型embedding可以快速捕捉一些high-level的特性,这可以帮助冷启动预测。随着
popularity的提高,FSE的表现超过了SAM。这个结果很有趣,但也很有启发性,原因可能是,SAM的控制器过拟合少量的训练样本,这导致了次优的性能。相反,
AutoEmb的控制器是在验证集上训练的,这提高了它的泛化能力。这个原因也将在下面的小节中得到验证。AutoEmb总是优于FSE和SAM,这意味着所提出的框架能够根据popularity自动地、动态地调整不同维度的embedding的权重。为了进一步探究
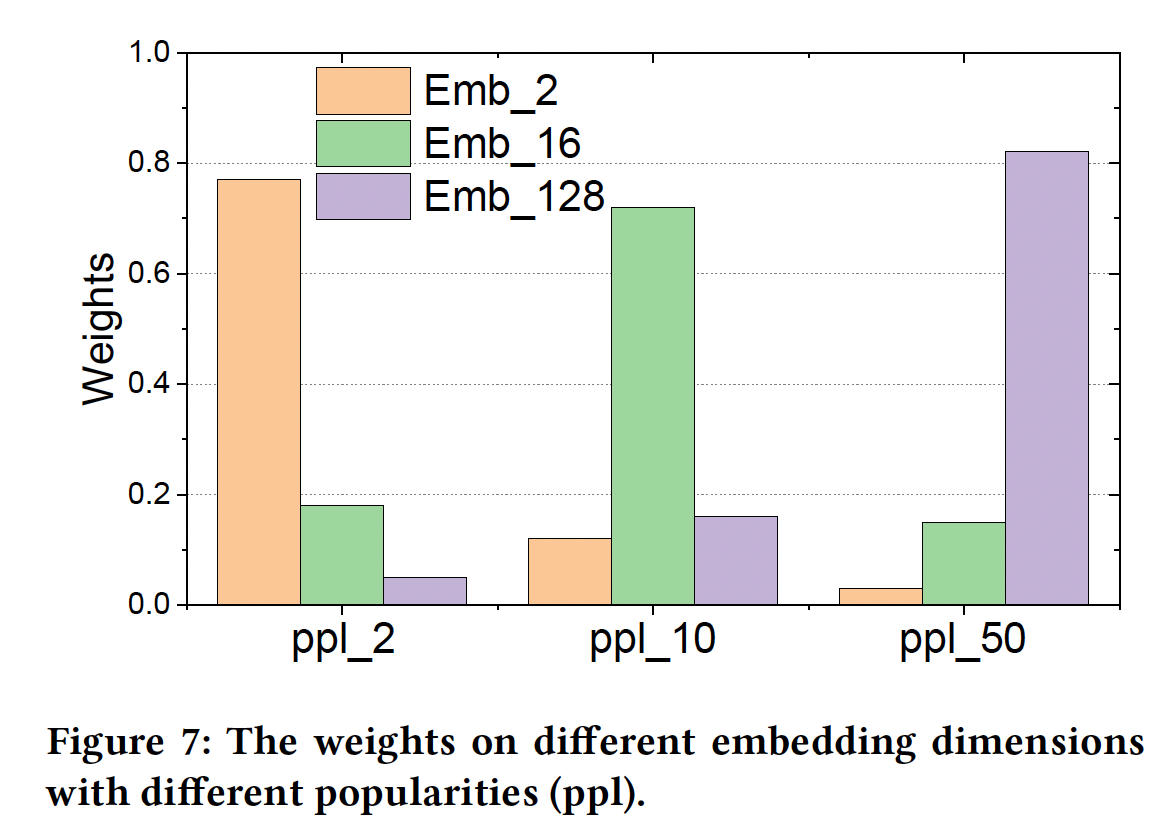
AutoEmb的控制器根据popularity产生的权重,我们在Figure 7中画出了不同popularity的权重分布。我们可以观察到:在小的popularity下,分布倾向于小维度的embedding;而随着popularity的增加,分布倾向于大维度的embedding。这一观察验证了我们的上述分析。
综上所述,
AutoEmb的控制器可以通过自动的、动态的方式为不同的popularity产生合理的权重。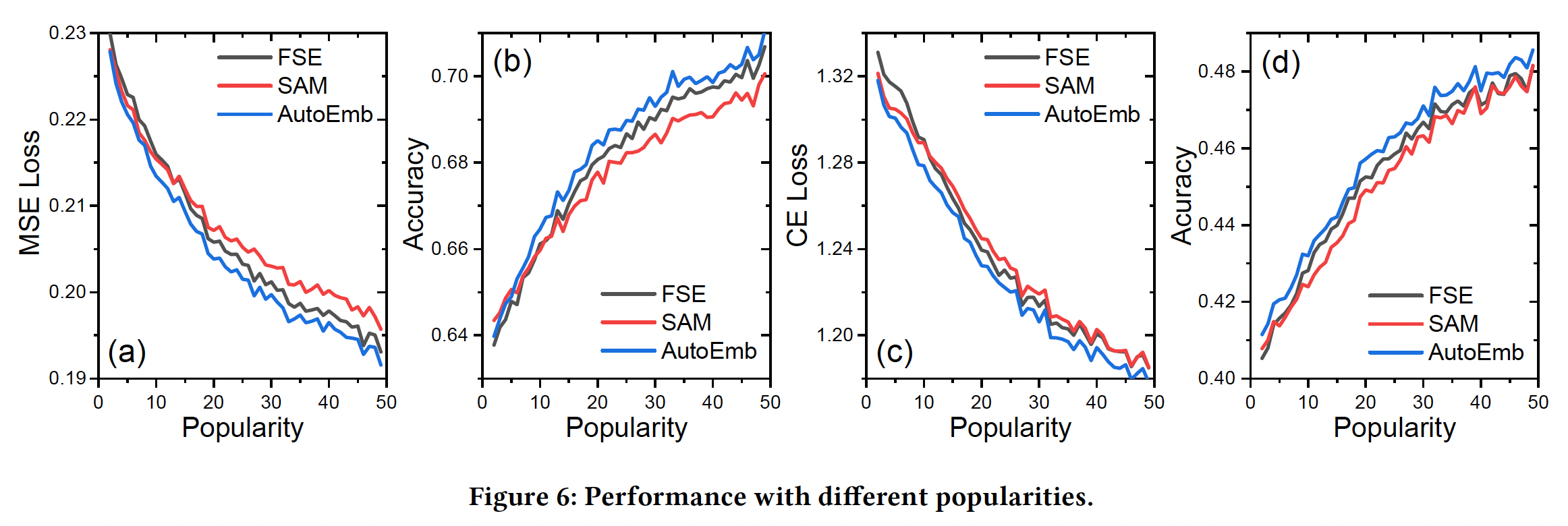
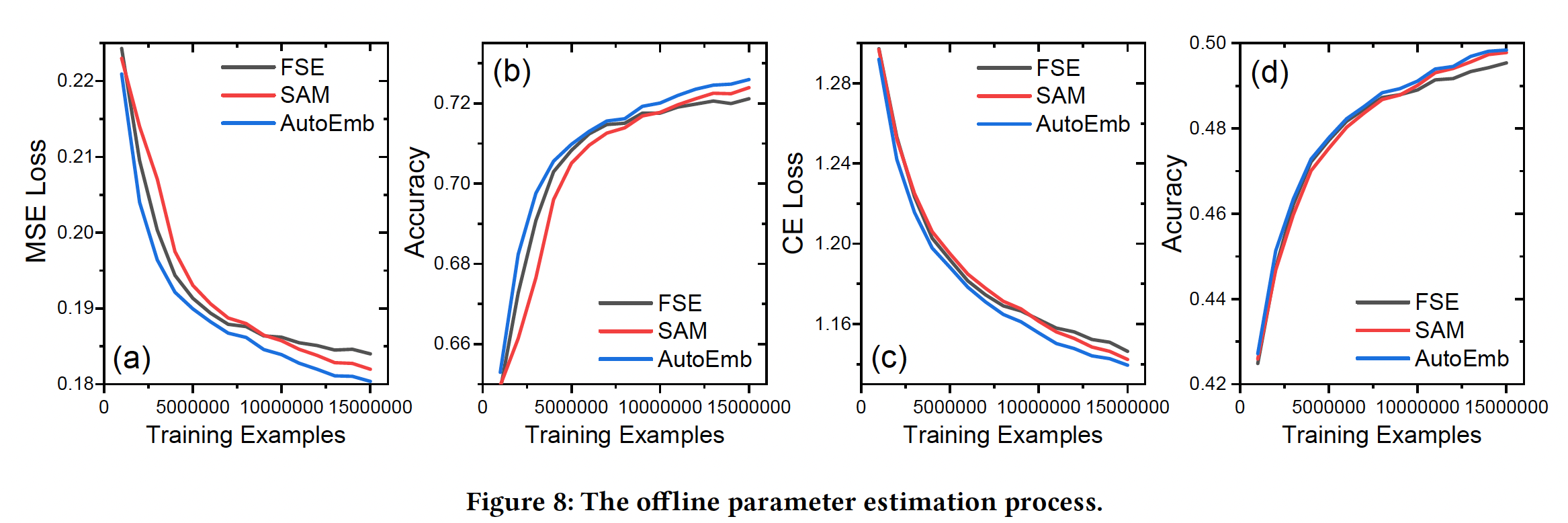
不同数据规模下的性能:训练基于深度学习的推荐系统通常需要大量的
user-item交互数据。我们提出的AutoEmb框架在DLRS中引入了一个额外的控制器网络、以及一些额外的参数,这可能使它难以被很好地训练。我们在下图中展示了优化过程,其中x轴是训练样本的数量,y轴对应的是性能。可以看到:- 在早期训练阶段,
SAM的表现最差,因为它的控制器对少量的训练样本过拟合。 - 随着数据的增加,
SAM的过拟合问题逐渐得到缓解,SAM的表现优于FSE,这验证了在不同embedding维度上加权的必要性。 AutoML在整个训练过程中优于SAM和FSE。尤其是在训练样本不足的早期训练阶段,它能明显提高训练效果。
- 在早期训练阶段,
四十三、AutoDim[2021]
大多数现有的推荐系统为所有的
feature field指定了固定的、统一的embedding维度,这可能会导致内存效率的降低。- 首先,
embedding维度往往决定了编码信息的能力。因此,为所有的feature field分配相同的维度可能会失去highly predictive特征的信息,而将内存浪费在non-predictive特征上。因此,我们应该给highly informative和highly predictive的特征分配一个大的维度,例如,location-based的推荐系统中的"location"特征。 - 其次,不同的
feature field有不同的cardinality(即unique value的数量)。例如,性别特征只有两个(即male和female),而itemID特征通常涉及数百万个unique value。直观而言,我们应该为具有较大cardinality的feature field分配较大的维度从而编码它们与其他特征的复杂关系,并为具有较小cardinality的feature field分配较小的维度从而避免由于过度参数化而产生的过拟合问题。
根据上述原因,我们非常希望能以一种
memory-efficient的方式为不同的feature field分配不同的embedding维度。在论文
《AutoDim: Field-aware Embedding Dimension Search in Recommender Systems》中,作者的目标是为不同的feature field提供不同的embedding维度从而用于推荐。但是这里面临着几个巨大的挑战:- 首先,
embedding维度、特征分布、以及神经网络架构之间的关系是非常复杂的,这使得我们很难为每个feature field手动分配embedding维度。 - 其次,现实世界的推荐系统往往涉及成百上千的
feature field。由于难以置信的巨大搜索空间(feature field的候选维数,feature field的数量)带来的昂贵的计算成本,很难为所有feature field人为地选择不同的维度。
作者试图解决这些挑战,从而得到一个端到端的可微的
AutoML-based框架(AutoDim),它可以通过自动化的、数据驱动的方式有效地分配embedding维度给不同的feature field。论文主要贡献:
- 作者发现了将
various的embedding维度分配给不同的feature field可以提高推荐性能的现象。 - 作者提出了一个
AutoML-based的端到端框架AutoDim,它可以自动选择各种embedding维度到不同的feature field。 - 作者在真实世界的
benchmark数据集上证明了所提框架的有效性。
- 首先,
43.1 模型
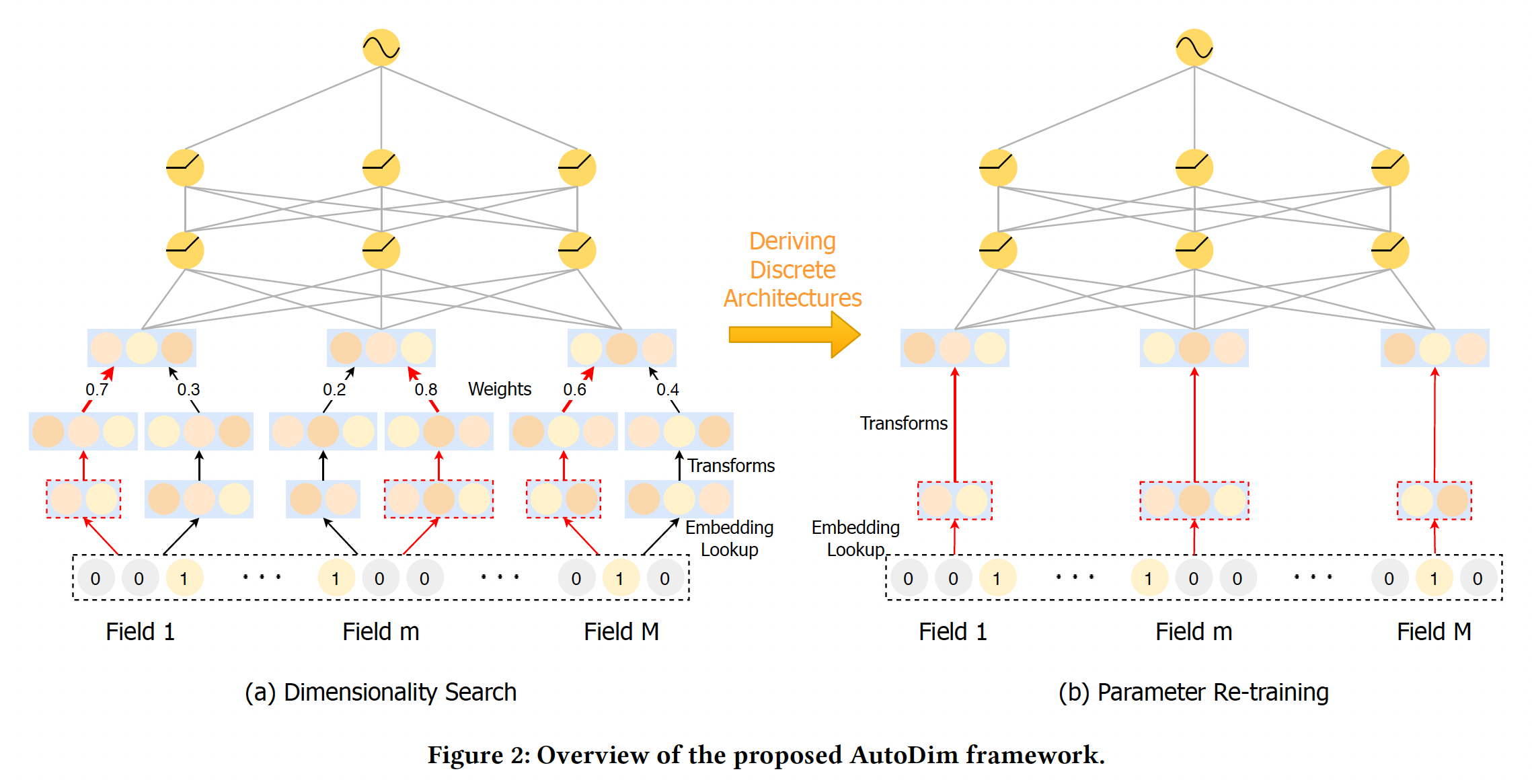
AutoDim是一个AutoML-based框架,它可以为不同feature field自动分配不同的embedding维度。框架如下图所示,其中包括维度搜索阶段、参数重训练阶段。AutoDim的思想和AutoEmb类似,也是为每个id分配embedding size,然后用强化学习进行择优。但是,AutoDim相对容易落地,因为AutoDim本质上是寻找每个词表的最佳维度,是一个超参数调优工具,找到最佳维度之后应用到目标模型中。二者不同的地方:AutoEmb使用popularity信息作为特征来获得筛选概率,而AutoDim仅依靠特征本身的embedding来获得筛选概率。AutoDim有一个重训练阶段。实际上也可以在AutoEmb中引入重训练。
43.1.1 Dimensionality Search
Embedding Lookup:对于每个user-item交互样本,我们有feature field,如性别、年龄等等。对于第feature field,我们分配了emebdding空间embedding空间的维度分别为embedding空间的cardinality是该feature field中unique feature value的数量。相应地,我们定义
embedding空间的候选embedding的集合,如下图所示。因此,分配给特征feature field分配相同的候选维度集合,但引入不同的候选集合是很直接的。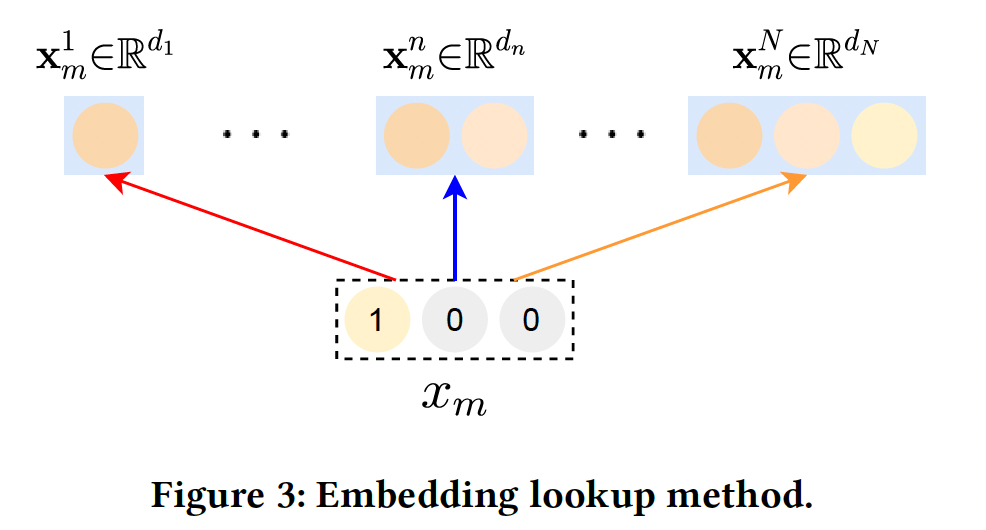
统一各种维度:由于现有的
DLRS中第一层MLP的输入维度通常是固定的,所以它们很难处理各种候选维度。因此,我们需要将embedding向量embedding向量其中:
bias向量。对于不同的feature field,所有具有相同维度的候选embedding都共享相同的权重矩阵和bias向量,这可以减少模型参数的数量。过线性变换,我们将原始
embedding向量embeddingmagnitude方差很大,这使得它们变得不可比incomparable。为了解决这一难题,我们对转换后的嵌入进行BatchNorm:其中:
mini-batch的均值,mini-batch的方差,Dimension Selection:我们通过引入Gumbel-softmax操作,对不同维度的hard selection进行了近似处理(因为hard selection是不可微的)。具体而言,假设权重Gumbel-max技巧得到一个hard selection其中:
0-1之间的均匀分布,gumbel噪声(用于扰动argmax操作等价于通过然而,由于
argmax操作,这个技巧是不可的。为了解决这个问题,我们使用softmax函数作为argmax操作的连续的、可微的近似,即gumbel-softmax:其中:
gumbel-softmax操作的输出的平滑度。当gumbel-softmax的输出就会变得更接近于ont-hot向量。embedding维度的概率。
为什么要用
gumble-softmax操作?直接用softmax操作如何?作者并未说明原因。embedding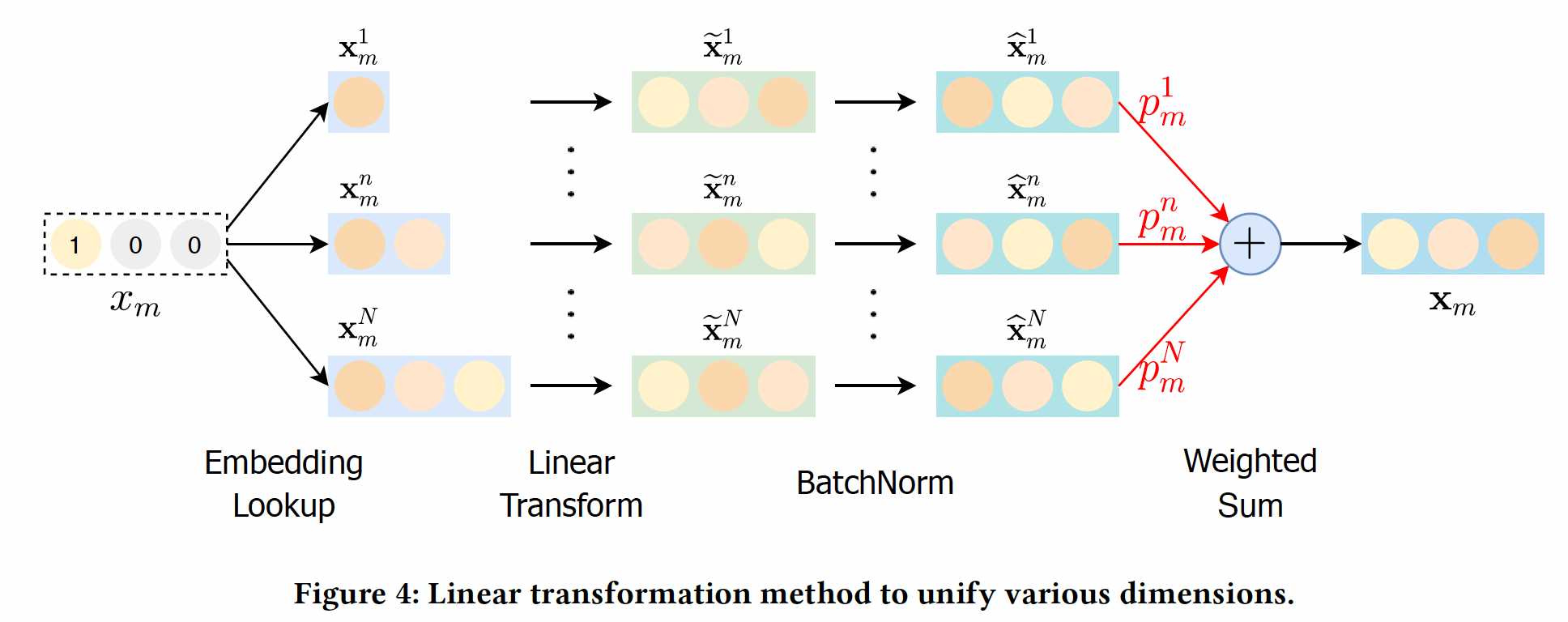
然后我们拼接所有特征的
embedding,即其中:
bias,感知机的输出馈入
output layer,得到最终预测:其中:
output layer的权重和bias,目标函数为负的对数似然:
其中:
ground-truth。
43.1.2 优化
AutoDim中需要优化的参数有两个方面:DLRS的参数,包括embedding部分和MLP部分。embedding维度的权重。
DLRS参数受可微分架构搜索(
differentiable architecture search: DARTS)技术的启发,这种优化形成了一个
bilevel的优化问题,其中权重DLRS参数DARTS的近似方案:其中:
在近似方案中,当更新
优化方法与
AutoEmb完全相同。AutoDim中DARTS based优化算法:输入:特征
ground-truth label输出:训练好的
DLRS参数算法步骤:
迭代直到收敛,迭代步骤为:
- 从验证数据集中采样一个
mini-batch的数据。 - 通过
- 收集一个
mini-batch的训练数据。 - 基于当前的
- 通过
- 从验证数据集中采样一个
43.1.3 参数重训练
由于
dimensionality search阶段的次优embedding维度也会影响模型的训练,所以希望有一个重训练阶段,只用最优维度训练模型,消除这些次优的影响。Deriving Discrete Dimensions:在重训练过程中,每个feature field的最佳embedding空间(维度)被选择为与最大权重相对应的维度:Figure 2(a)给出了一个示例,红色箭头表示所选中的embedding维度。Model Re-training:给定所选的embedding空间,我们可以为特征unique的embedding向量embedding拼接起来再馈入隐层。最后,DLRS的所有参数,包括embedding和MLP,将通过反向传播使监督损失函数注意:
- 现有的大多数深度推荐算法都是通过交互操作(如内积)来捕获
feature field之间的交互。这些交互操作要求所有field的embedding向量具有相同的尺寸。因此,被选中的embedding仍然被映射到相同的维度。 - 在重训练阶段,不再使用
Batch-Norm操作,因为每个field的候选embedding之间没有竞争。
- 现有的大多数深度推荐算法都是通过交互操作(如内积)来捕获
DLRS重训练阶段的优化过程:输入:特征
ground-truth label输出:训练好的
DLRS参数算法步骤:
迭代直到收敛,迭代步骤为:
- 采样一个
mini-batch的训练数据。 - 基于当前的
- 通过
- 采样一个
43.2 实验
数据集:
Criteo。每个样本包含13个数值feature field、26个categorical feature field。我们按照
Criteo竞赛获胜者的建议,将数值特征归一化:然后将数值特征进行分桶从而转换为
categorical feature。我们使用
90%的数据作为训练集/验证集(8:1),其余10%作为测试集。实现细节:
DLRS:embedding组件:在我们的GPU内存限制下,我们将最大的embedding维度设置为32。对于每个feature field,我们从embedding维度{2, 8, 16, 24, 32}中选择。MLP组件:我们有两个隐层,形状分别为Criteo数据集的feature field数量。我们对两个隐层使用batch normalization、dropout(dropout rate = 0.2)和ReLU激活。输出层为Sigmoid激活函数。
feature field的softmax激活来产生的。对于Gumbel-Softmax,我们使用退火温度training step。
更新
DLRS和0.001和0.001,batch size = 2000。我们的模型可以应用于任何具有embedding layer的深度推荐系统。在本文中,我们展示了在著名的FM、W&D、以及DeepFM上应用AutoDim的性能。评估指标:
AUC, Logloss, Params。Params指标是该模型的embedding参数数量。我们省略了MLP参数的数量,因为MLP参数仅占模型总参数的一小部分。baseline方法:Full Dimension Embedding: FDE:所有的feature field分配了最大的候选维度,即32。Mixed Dimension Embedding: MDE:参考论文《Mixed Dimension Embeddings with Application to Memory-Efficient Recommendation Systems》。Differentiable Product Quantization: DPQ:参考《Differentiable product quantization for end-to-end embedding compression》。Neural Input Search: NIS:参考《Neural input search for large scale recommendation models》。Multi-granular quantized embeddings: MGQE:参考《Learning Multi-granular Quantized Embeddingsfor Large-Vocab Categorical Features in Recommender Systems》。Automated Embedding Dimensionality Search: AEmb:参考《AutoEmb: Automated Embedding Dimensionality Search in Streaming Recommendations》。Random Search: RaS:随机搜索是神经网络搜索的强大baseline。我们应用相同的候选embedding维度,在每个实验时间随机分配维度到feature field,并报告最佳性能。AD-s:它与AutoDim共享相同的架构,同时我们在同一training batch上以端到端反向传播的方式同时更新DLRS参数和AutoDim。
实验结果如下表所示,可以看到:
FDE实现了最差的推荐性能和最大的Params,其中FDE对所有feature field分配了最大的embedding维度32。这一结果表明,为所有feature field分配相同的维度,不仅内存效率低下,而且会在模型中引入许多噪音。RaS, AD-s, AutoDim比MDE, DPQ, NIS, MGQE, AEmb表现得更好,这两组方法的主要区别在于:- 第一组方法旨在为不同的
feature field分配不同的embedding维度,而相同feature field中的embedding共享同一维度。 - 第二组方法试图为同一
feature field中的不同特征取值分配不同的embedding维度,分配方式基于特征取值的popularity。
第二组方法具有几个方面的挑战:
- 每个
feature field都有许多unique值。例如,在Criteo数据集中,每个feature field平均有unique值。这导致每个feature field的搜索空间非常大(即使在分桶之后),这就很难找到最优解。而在AutoDim中,每个feature field的搜索空间为 - 仅根据
popularity(即一个特征取值在训练集中出现的次数)来分配维度可能会失去该特征的其他重要特性。 - 在实时推荐系统中,特征取值的
popularity通常是动态的,预先未知。例如,冷启动的user/item。
- 第一组方法旨在为不同的
AutoDim优于RaS和AD-s。AutoDim在验证集的mini-batch上更新AD-s在同一训练集mini-batch上同时更新DLRS,可能导致过拟合。RaS随机搜索维度,其中搜索空间很大。
AD-s的Params比AutoDim大得多,这说明更大的维度能更有效地减少训练损失。因为
AD-s是监督学习训练的,目标是最小化训练损失,最终筛选到的维度更大。而AutoDim是强化学习训练的,奖励是最小化验证损失,最终筛选到的维度更小。
综上所述,与有代表性的
baseline相比,AutoDim取得了明显更好的推荐性能,并节省了70%∼80%的embedding参数。这些结果证明了AutoDim框架的有效性。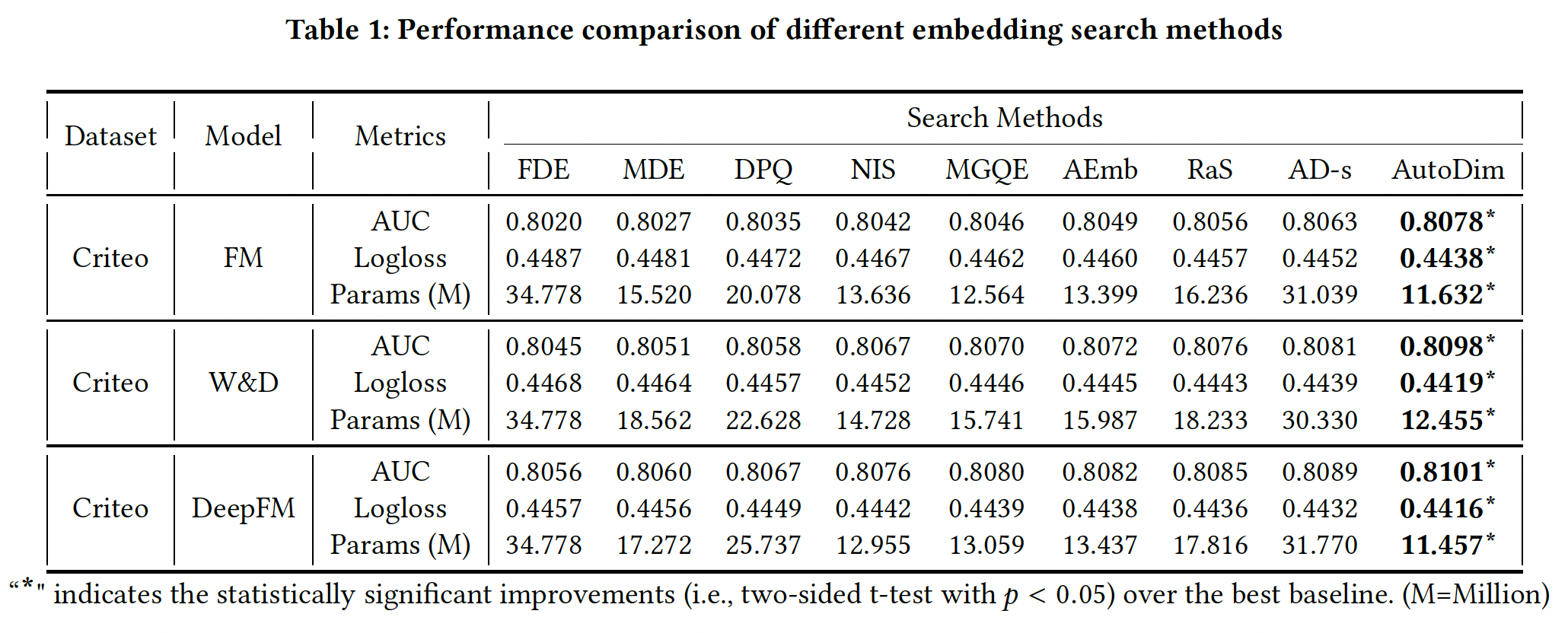
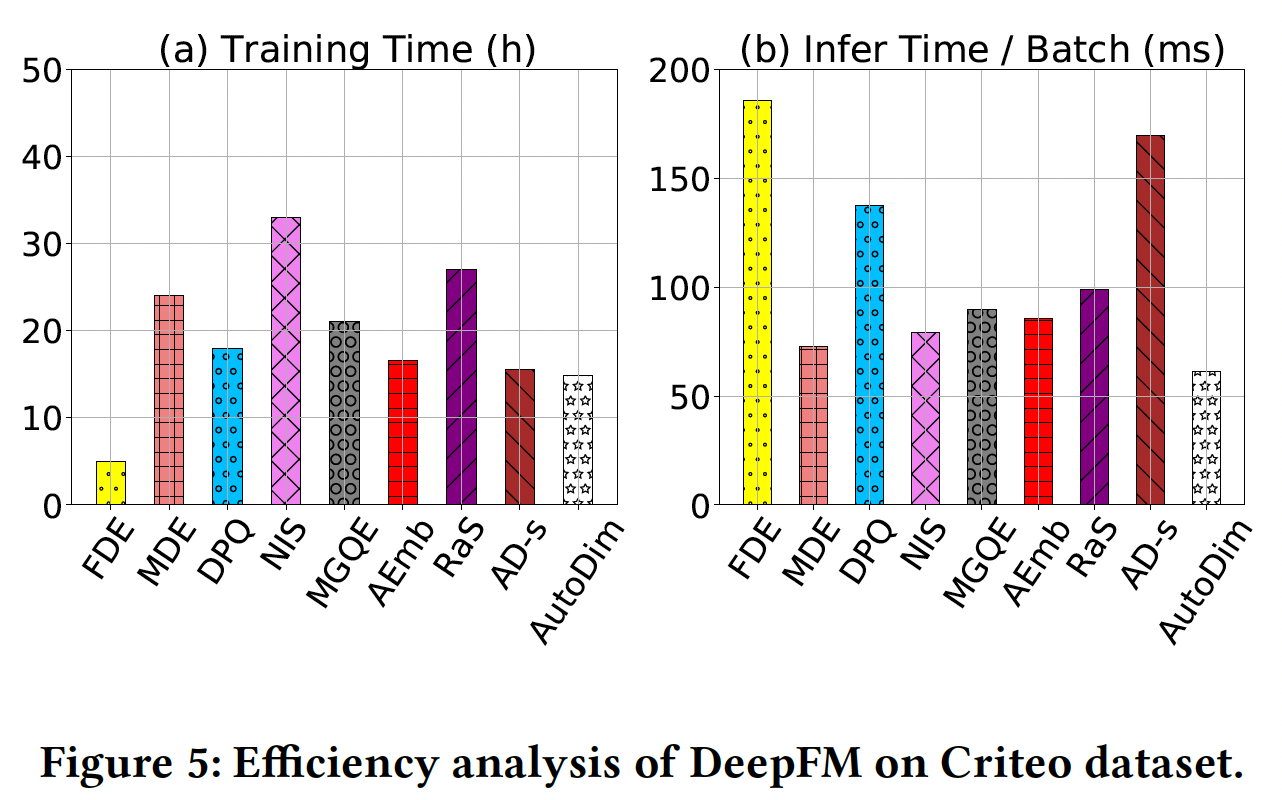
效率分析:本节研究了在
Criteo数据集上对DeepFM应用搜索方法的效率(在一个Tesla K80 GPU上),如下图所示。可以看到:对于训练时间(图
(a)):AutoDim和AD-s具有很快的训练速度,原因是它们的搜索空间比其他baseline小。FDE的训练速度最快,因为我们直接把它的embedding维度设置为32,即没有搜索阶段。然而它的推荐效果是所有方法中最差的。
对于推理时间(图
(b)):AutoDim实现了最少的推理时间,因为AutoDim最终选择的推荐模型的embedding参数最少(即Params指标)。
超参数研究:除了深度推荐系统常见的超参数(如隐层的数量,由于篇幅有限,我们省略这种常规超参数的分析),我们的模型有一个特殊的超参数,即更新
AutoDim优化过程中,我们交替地在训练数据上更新DLRS的参数、在验证数据上更新DLRS的参数,这显然减少了大量的计算,也提高了性能。为了研究
AutoDim的DeepFM在Criteo数据集上的表现如何。结果如下表所示,x轴上,DLRS参数。从图
(a), (b)可以看到,当AutoDim达到了最佳AUC/Logloss。换句话说,更新从图
(d)可以看到,与设置50%∼的训练时间。从图
(c)可以看到,较低的Params,反之亦然。原因是AutoDim通过最小化验证损失来更新- 当频繁更新
AutoDim倾向于选择较小的embedding size,具有更好的泛化能力,同时可能存在欠拟合问题。 - 而当不频繁地更新
AutoDim倾向于选择较大的embedding size,在训练集上表现更好,但可能导致过拟合问题。
- 当频繁更新
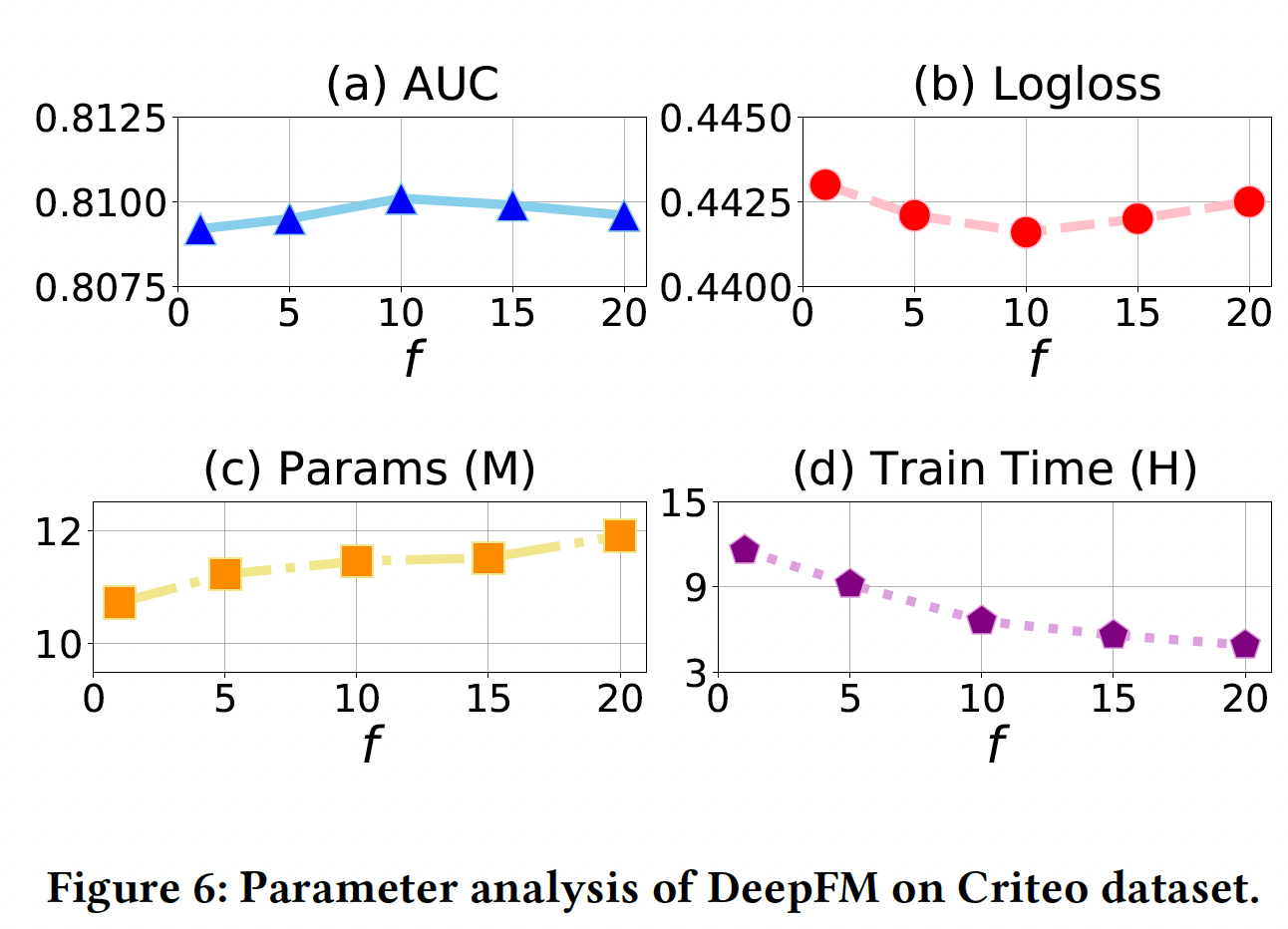
案例研究:这里我们研究
AutoDim是否可以为更重要的特征分配更大的embedding维度。由于Criteo的feature field是匿名的,我们在MovieLens-1m数据集上应用具有AutoDim的W&D。MovieLens-1m数据集有categorical feature field:movieId, year, genres, userId, gender, age, occupation, zip。由于MovieLens-1m比Criteo小得多,我们将候选embedding维度设定为{2, 4, 8, 16}。为了衡量一个
feature field对最终预测的贡献,我们只用这个field建立一个W&D模型,训练这个模型并在测试集上评估。较高的AUC和较低的Logloss意味着该feature field更有predictive。然后,我们建立一个包含所有
feature field的、全面的W&D模型,并应用AutoDim来选择维度。结果如下表所示:- 没有一个
feature field被分配到16维的embedding空间,这意味着候选embedding维度{2, 4, 8, 16}足以覆盖所有可能的选择。 - 对比每个
feature field的W&D的AUC/Logloss,我们可以发现,AutoDim为重要的(高预测性的)feature field分配了较大的embedding维度,如movieId和userId,反之亦然。 - 我们建立了一个
full dimension embedding: FDE版本的W&D,其中所有的feature field都被分配为最大维度16。其表现为AUC=0.8077, Logloss=0.5383,而带有AutoDim的W&D的表现为AUC=0.8113, Logloss=0.5242,并且后者节省了57%的embedding参数。
总之,上述观察结果验证了
AutoDim可以将更大的embedding维度分配给更predictive的feature field。
- 没有一个
四十四、PEP[2021]
基于深度学习的推荐模型利用
embedding技术将这些稀疏的categorical feature映射为实值的稠密向量,以抽取用户偏好和item特性。embedding table可能包含大量的参数,并花费巨大的内存,因为总是有大量的原始特征。因此,embedding table的存储成本最高。一个很好的例子是
YouTube Recommendation Systems。它需要数以千万计的参数用于YouTube video ID的embedding。考虑到当今服务提供商对即时推荐的需求不断增加,embedding table的规模成为深度学习推荐模型的效率瓶颈。另一方面,具有uniform emebdding size的特征可能难以处理不同特征之间的异质性。例如,有些特征比较稀疏,分配太大的embeddding size很可能导致过拟合问题。因此,当所有特征的embedding size是uniform时,推荐模型往往是次优的。现有的关于这个问题的工作可以分为两类:
- 一些工作(
《Model size reduction using frequency based double hashing for recommender systems》、《Compositional embedding susing complementary partitions for memory-efficient recommendation systems》、《Learning multi-granular quantized embeddings for large-vocab categorical features in recommender systems》)提出,一些密切相关的特征可以共享部分embedding,从而减少整个成本。 - 另一些工作提出依靠人类设计的规则(
《Mixed dimension embeddings with application to memory-efficient recommendation systems》)或神经结构搜索(《Neural input search for large scale recommendation models》、《Automated embedding dimensionality search in streaming recommendations》、《Differentiable neural input search for recommender systems》)为不同特征分配size灵活的embedding。
尽管得到了
embedding size减小的embedding table,但这些方法在推荐性能和计算成本这两个最受关注的方面仍然不能有好的表现。具体来说,这些方法要么获得较差的推荐性能、要么花费大量的时间和精力来获得合适的embedding size。在论文
《Learnable embedding sizes for recommender systems》中,为了解决现有工作的局限性,作者提出了一个简单而有效的pruning-based框架,名为Plug-in Embedding Pruning: PEP,它可以插入各种embedding-based的推荐模型中。论文的方法采用了一种直接的方式:一次性裁剪那些不必要的embedding参数来减少参数数量。具体而言,
PEP引入了可学习的阈值,可以通过梯度下降与emebdding参数共同训练。请注意,阈值被用来自动确定每个参数的重要性。然后,embedding向量中小于阈值的元素将被裁剪掉。然后,整个embedding table被裁剪,从而确保每个特征有一个合适的embedding size。也就是说,embedding size是灵活的。在得到裁剪后的embedding table后,作者在彩票假说(Lottery Ticket Hypothesis: LTH)的启发下重新训练模型。彩票假说表明,与原始网络相比,子网络可以达到更高的准确性。基于灵活的embedding size和LTH,PEP可以降低embedding参数,同时保持甚至提高模型的推荐性能。最后,虽然推荐性能和参数数量之间总是存在
tradeoff,但PEP只需运行一次就可以获得多个裁剪后的embedding table。换句话说,PEP可以一次性生成多个memory-efficient的embedding矩阵,这可以很好地处理现实世界应用中对性能或内存效率的各种需求。PEP至少训练两遍:第一遍用于裁剪、第二遍用于重训练。论文在三个公共基准数据集(
Criteo, Avazu, MovieLens-1M)上进行了广泛的实验。结果表明,与SOTA的baseline相比,PEP不仅可以达到最好的性能,而且可以减少97% ~ 99%的参数。进一步的研究表明,PEP在计算上是相当高效的,只需要一些额外的时间进行embedding size的学习。此外,对所学到embedding的可视化和可解释性分析证实,PEP可以捕获到特征的固有属性,这为未来的研究提供了启示。- 一些工作(
相关工作:
Embedding参数共享:这些方法的核心思想是使不同的特征通过参数共享来复用embedding。《Learning multi-granular quantized embeddings for large-vocab categorical features in recommender systems》提出了MGQE,从共享的small size的centroid embeddings中检索embedding fragments,然后通过拼接这些fragments生成final embedding。《Model size reduction using frequency based double hashing for recommender systems》使用双哈希技巧double-hash trick,使低频特征共享一个小的embedding-table,同时减少哈希碰撞的可能性。即,对低频特征的
embedding space分解为两个更小的embedding space从而缓解过拟合、降低模型规模。《Compositional embeddings using complementary partitions for memory-efficient recommendation systems》试图通过组合多个较小的embedding(称为embedding fragments),从一个小的embedding table中为每个feature category产生一个unique embedding vector。这种组合通常是通过embedding fragments之间的拼接、相加、或element-wise相乘来实现的。
然而,这些方法有两个限制:
- 首先,工程师需要精心设计参数共享比例,以平衡准确性和内存成本。
- 其次,这些粗略的
embedding共享策略不能找到embedding table中的冗余部分,因此它总是导致推荐性能的下降。
在这项工作中,我们的方法通过从数据中学习,自动选择合适的
emebdding用量。因此,工程师们可以不必为设计共享策略付出巨大努力,并且通过去除冗余参数和缓解过拟合问题来提高模型性能。Embedding Size Selection:最近,一些方法提出了一种新的混合维度的embedding table的范式。具体来说,不同于给所有特征分配统一的embedding size,不同的特征可以有不同的embedding size。MDE(《Mixed dimension embeddings with application to memory-efficient recommendation systems》)提出了一个人为定义的规则,即一个特征的embedding size与它的popularity成正比。然而,这种基于规则的方法过于粗糙,无法处理那些低频但是重要的特征。此外,MDE中存在大量的超参数,需要大量的超参数调优工作。其他一些工作依靠神经架构搜索
Neural Architecture Search: NAS为不同的特征分配了自适应的embedding size。NIS(《Neural input search for large scale recommendation models》) 使用了一种基于强化学习的算法,从人类专家预先定义的候选集中搜索embedding size。NIS采用一个控制器来为不同的embedding size生成概率分布。NIS的控制器被DartsEmb(《Autoemb: Automated embedding dimensionality search in streaming recommendations》)进一步扩展,将强化学习搜索算法替换为可微的搜索。AutoDim(《Memory-efficient embedding for recommendations》)以与DartsEmb相同的方式为不同的feature field分配不同的embedding size,而不是单个特征。DNIS(《Differentiable neural input search for recommender systems》)使候选embedding size是连续的,没有预定义的候选尺寸。
然而,所有这些基于
NAS的方法在搜索过程中需要极高的计算成本。即使是采用微分架构搜索算法的方法,其搜索成本仍然是无法承受的。此外,这些方法还需要在设计适当的搜索空间方面做出巨大努力。与这些工作不同的是,我们的
pruning-based方法可以相当有效地进行训练,并且在确定embedding size的候选集时不需要任何人工努力。
44.1 模型
一般来说,深度学习推荐模型将各种原始特征(包括用户画像和
item属性)作为输入,预测用户喜欢某个item的概率。具体而言,模型将用户画像和item属性的组合(用field的拼接:其中:
feature field数量;feature representation(通常为one-hot向量);;为向量拼接。对于
embedding-based推荐模型为它生成对应的embedding向量:其中:
feature field的embedding矩阵,feature field的unique取值数量,embedding size。模型针对所有
feature field的embedding矩阵为:模型的预测得分为:
其中:
prediction model(如FM),embedding矩阵以外的参数。为了学习模型的参数(包括
embedding矩阵),我们需要优化如下的训练损失:其中:
ground-truth label,通常而言,推荐任务中采用
logloss损失函数:其中:
通过裁剪实现可学习的
embedding size:如前所述,针对memory-efficient embedding learning的可行方案是为不同的特征embeddingembedding sizecolumn-wise sparsity,这等于是缩小了embedding size。如下图所示,
embeddingembedding size。此外,一些不重要的feature embedding,如embedding参数。请注意,稀疏矩阵存储技术可以帮助我们大大节省内存用量。如果某一列被裁剪为零,则意味着该维度不重要;如果某一行被裁剪为零,则意味着该
feature value不重要。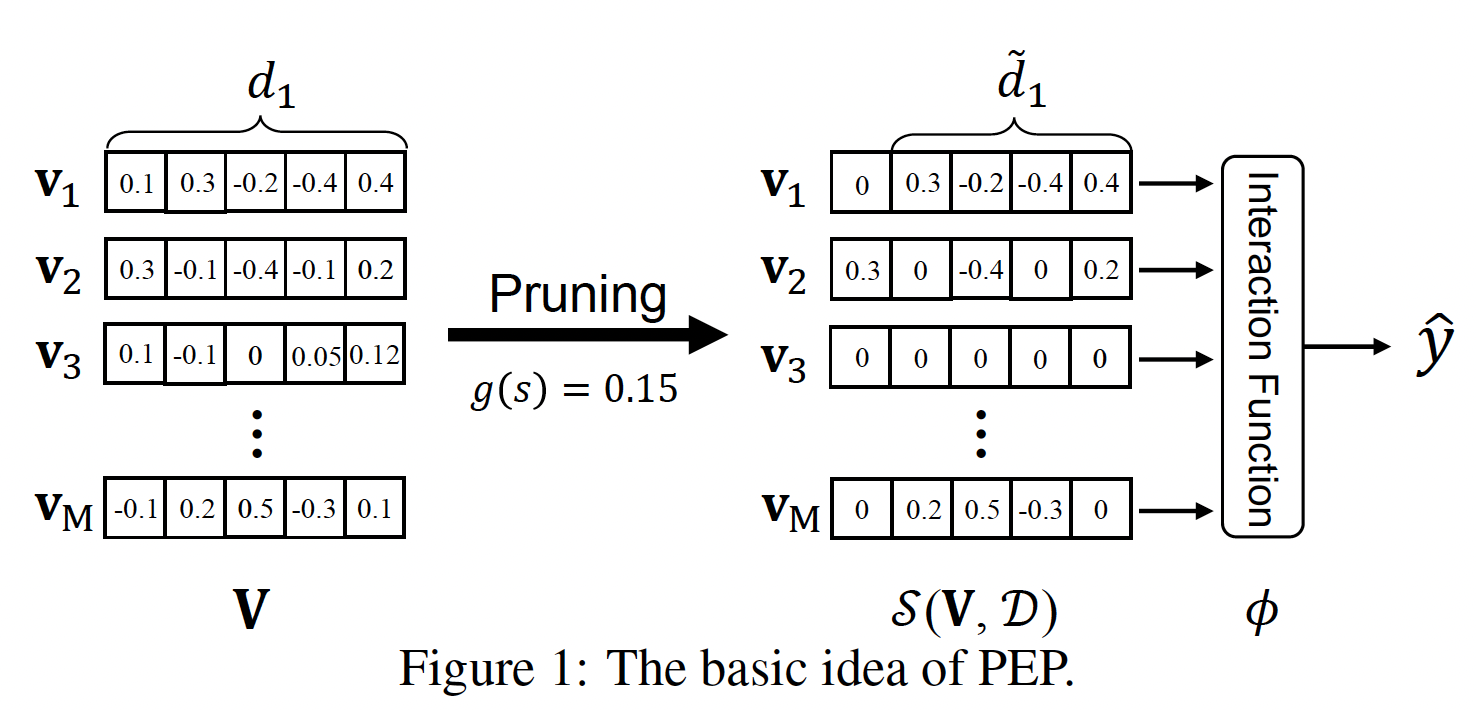
在这种情况下,我们将
embedding size的选择问题转换为学习embedding矩阵column-wise sparsity。为了达到这个目的,我们对其中:
L0范数(即,非零元素的数量);parameter budget,它是对embedding参数总数的约束。这里其实是
global sparsity,而不仅仅是column-wise sparsity。然而,由于
L0范数约束的非凸性,上式的直接优化是NP-hard的。为了解决这个问题,人们研究了L0范数的凸松弛,即L1范数。尽管如此,这类凸松弛方法仍然面临着两个主要问题:- 首先,计算成本太高,尤其是当推荐模型有数百万个参数时。
- 其次,参数预算
为了解决这两个问题,受软阈值重参数化的启发(
《Soft threshold weight reparameterization for learnable sparsity》),我们直接优化其中:
embedding矩阵。element-wise的,定义为:裁剪函数的物理意义为:
- 如果
- 如果
其中:
pruning parameter。函数
sigmoid函数。根据《Soft threshold weight reparameterization for learnable sparsity》,其中对于
unstructured sparsity,sigmoid函数;对于structured sparsity,1、将负数转换为-1、零保持不变。
- 如果
采用
然后,可训练的裁剪参数
其中:
Hadamard积。为了解决
sub-gradient来重新表述更新方程如下:其中:
true时返回1、否则返回0。然后,只要我们选择一个连续的函数
sub-gradient也可以用于裁剪阈值
embedding矩阵中的参数用量。然而,为什么我们的PEP可以通过训练数据学习合适的PEP试图在优化过程中更新如下图所示,我们在
MovieLens-1M和Criteo数据集上绘制了with/without PEP的FM的训练曲线,以证实我们的假设。可以看到:我们的PEP可以实现更低的训练损失。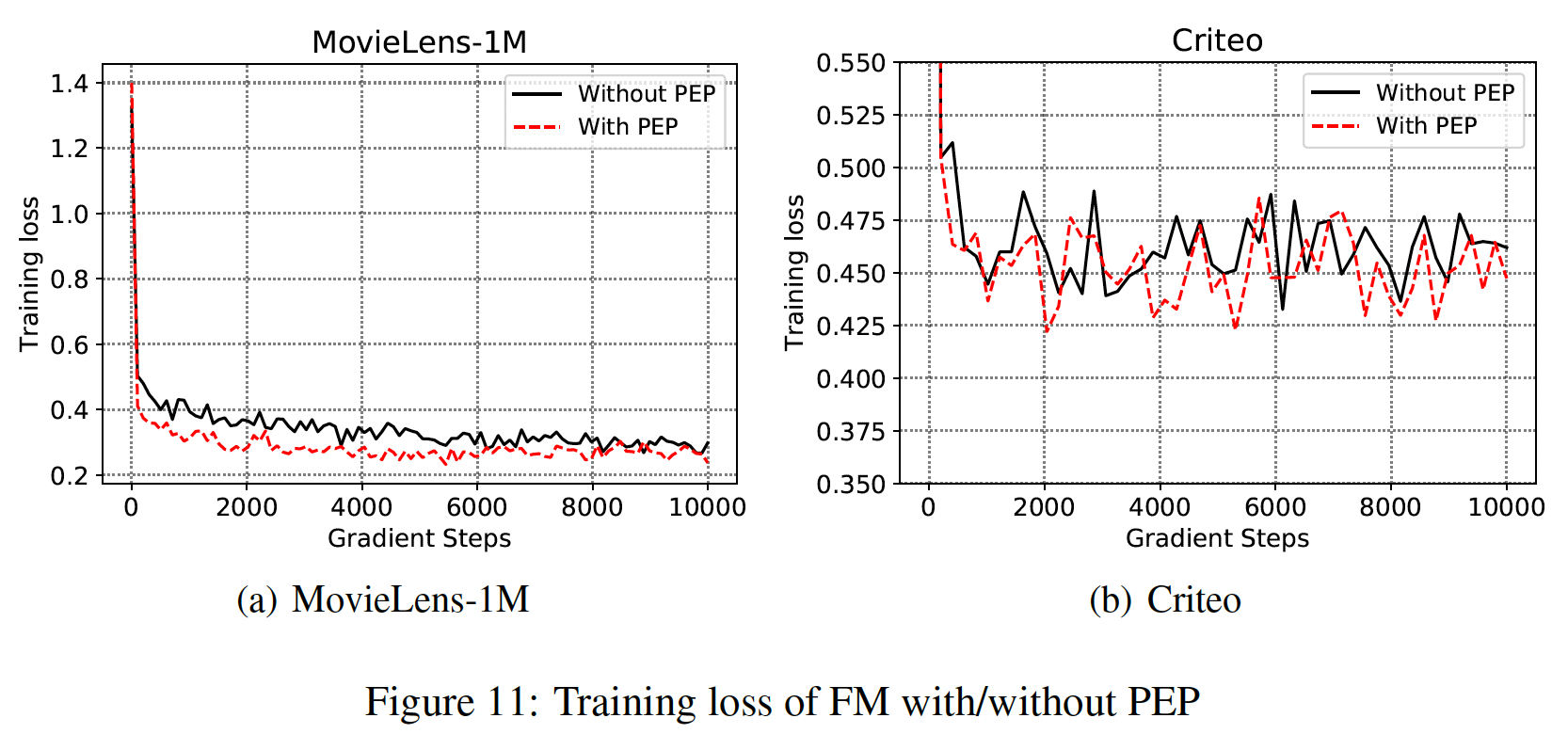
用彩票假说重新训练:在将
embedding矩阵embedding参数应该保留或放弃。然后我们用裁剪后的embedding table重新训练模型。彩票假说
Lottery Ticket Hypothesis(《The lottery ticket hypothesis: Finding sparse, trainable neural networks》)说明:随机初始化的稠密网络中的一个子网络可以与原始网络相匹配,当以相同的迭代次数进行隔离训练时。这个子网络被称为中奖票winning ticket。因此,我们不是随机地重新初始化权重,而是重新训练基础模型,同时将权重重新初始化为原来(但是被掩码后的)的权重注意,重训练阶段有三种初始化方式:
- 与第一轮训练独立的随机初始化。
- 把第一轮训练采用的随机初始化共享到重训练阶段。
- 把第一轮训练得到的训练好的权重作为重训练阶段的初始化。
LTH和本文采用的是第二种方式。注意,重训练阶段需要把被
masked的embedding element固定为零,且在更新过程中不要更新梯度。为了验证重训练的有效性,我们对比了四种操作:
Without pruning:base model。Without retrain:经过裁剪之后的模型,但是没有重训练。Winning ticket(random reinit):经过裁剪以及重训练之后的模型,但是重训练时采用与第一轮训练所独立的随机初始化。Winning ticket(original init):经过裁剪以及重训练之后的模型,并且共享第一轮训练的初始化权重来随机初始化重训练,即我们的PEP。
可以看到:
- 在重训练时,与
random reinit相比,original init的winning ticket可以使训练过程更快,并获得更高的推荐准确性。这证明了我们设计的再训练的有效性。 random reinit的winning ticket仍然优于未裁剪的模型。通过减少不太重要的特征的embedding参数,模型的性能可以从对那些过度参数化的embedding的降噪中受益。这可以解释为,当embedding size统一时,它很可能会对那些过度参数化的embedding进行过拟合。without retrain的PEP的性能会有一点下降,但它仍然优于原始模型。without retrain和原始模型之间的gap,要比with retrain和without retrain之间的gap更大。这些结果表明,PEP主要受益于合适的embedding size选择。
我们猜测重训练的好处:在搜索阶段,
embedding矩阵中不太重要的元素被逐渐裁剪,直到训练过程达到收敛。然而,在早期的训练阶段,当这些元素没有被裁剪时,它们可能对那些重要元素的梯度更新产生负面影响。这可能使这些重要元素的学习变得次优。因此,重训练步骤可以消除这种影响并提高性能。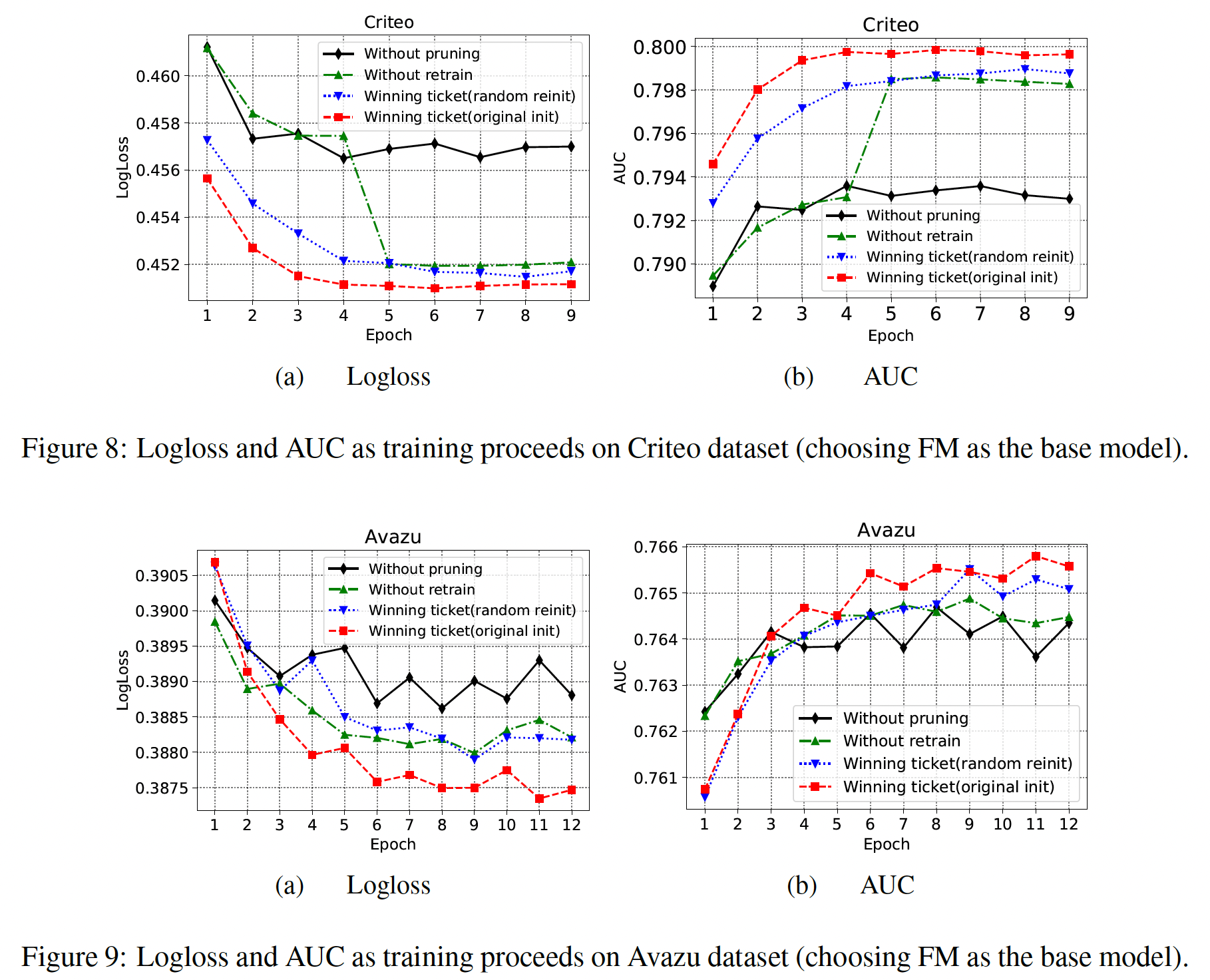
细粒度裁剪:上述方程中的阈值参数
global-wise pruning。然而,embedding向量field的特征也可能有不同的重要性。因此,embedding矩阵中的值需要不同的稀疏性预算,用全局阈值的裁剪可能不是最佳的。为了更好地处理Dimension-Wise:阈值参数embedding中的每个值都将被独立地裁剪,不同field的embedding共享相同的Feature-Wise:阈值参数embedding中的所有值采用相同的标量阈值,不同field的embedding采用不同的标量阈值。Feature-Dimension-Wise:阈值参数
注意,这里的阈值参数并不是人工调优的超参数,而是从数据中学习的可训练参数。
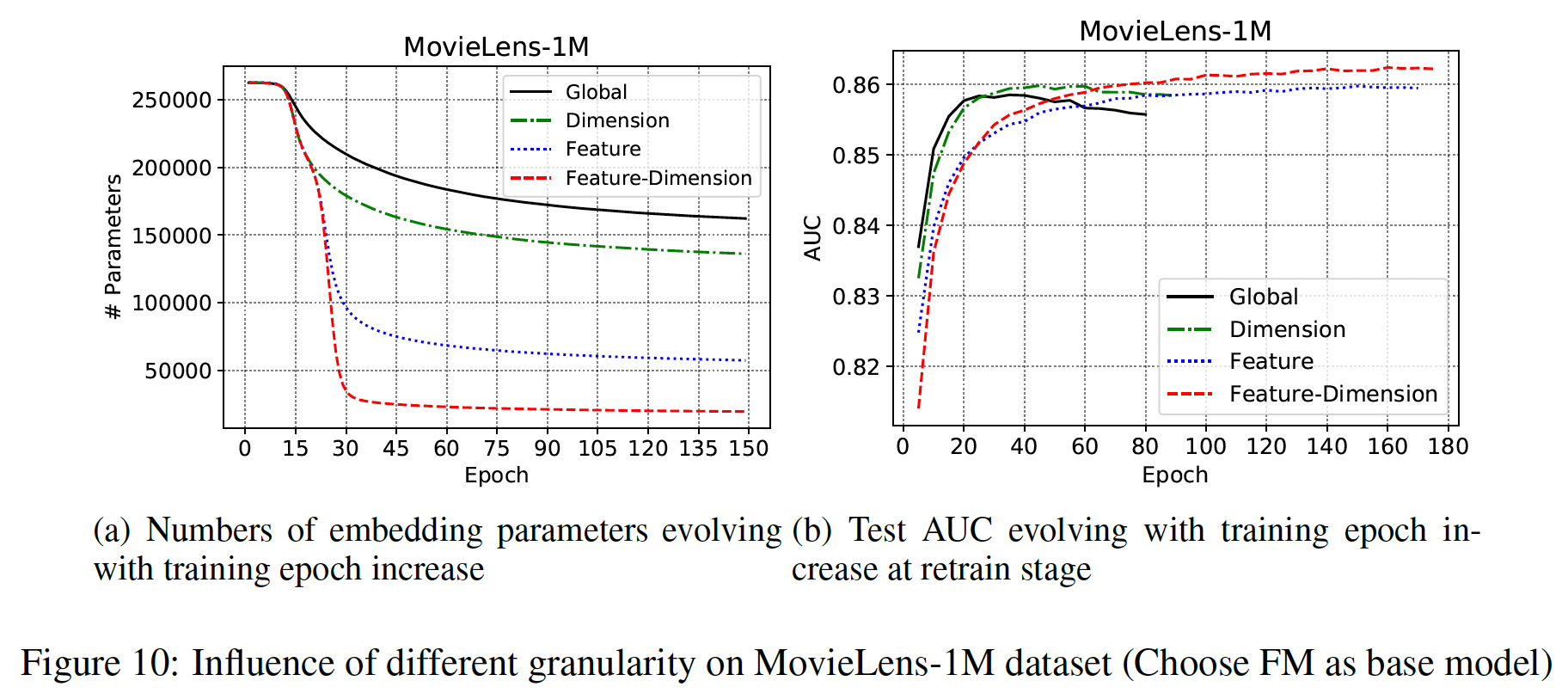
如下图所示:
Feature-Dimension粒度可以比其它粒度的embedding参数减少得更多,并且在retrain阶段获得了最好的性能。Dimension粒度的裁剪可以在较少的训练周期内达到可比的AUC。
PEP算法:输入:初始
embeddingbase modeltarget parameter规模输出:训练好的稀疏
embedding算法步骤:
迭代,直到满足
通过
获取二元
pruning mask将裁剪后的
embedding parameter设置为初始值重训练从而最小化
44.2 实验
数据集:
MovieLens-1M, Criteo, Avazu。MovieLens-1M:遵从AutoInt,我们将评分在1 or 2的样本作为负样本、评分在4 or 5的样本作为正样本。评分为3的样本视为中性样本从而被移除。Criteo:对于数值特征,我们使用log变换从而进行归一化:Creteo/Avazu:频次低于10的特征被认为是'unknown'。所有样本被随机拆分为训练集、验证集、测试集,比例为
80%/10%/10%。
评估指标:
AUC, Logloss。baseline:Uniform Embedding: UE:uniform embedding size。MGQE:从共享的small size的centroid embeddings中检索embedding fragments,然后通过拼接这些fragments生成final embedding。MGQE为不同item学习不同容量的embedding。该方法是embedding-parameter-sharing方法中的最强baseline。Mixed Dimension Embedding: MDE:基于人工定义的规则,即一个特征的embedding size与它的popularity成正比。该方法是SOTA的human-rule-based方法。DartsEmb:SOTA的NAS-based方法,它允许特征自动在一个给定的搜索空间中搜索embedding size。
我们没有比较
NIS,因为它没有开放源代码,并且它的基于深度学习的搜索方法在速度方面太慢。我们将
baseline方法和我们的PEP应用到三种feature-based推荐模型上:FM, DeepFM, AutoInt。实现细节:
在
pruning和re-training阶段,遵从AutoInt和DeepFM,我们采用学习率为0.001的Adam优化器。对于
MovieLens-1M, Criteo, Avazu数据集分别将-15/-150/-150。PEP的粒度设置为:在
Criteo, Avazu数据集上设置为Dimension-wise从而用于PEP-2, PEP-3, PEP-4。PEP-0, PEP-1, PEP-2, PEP-3, PEP-4分别代表不同的稀疏度配置,根据PEP算法中不同的0.05, 0.1, 0.2, 0.3, 0.4这五个稀疏率。其它数据集上设置为
Feature Dimension-wise。
在裁剪之前,所有模型的
base embedding dimension64。在重训练阶段,我们根据训练期间验证集的损失,利用了早停技术。
我们使用
PyTorch来实现我们的方法,并在单块12G内存的TITAN V GPU上以mini-batch size = 1024进行训练。baseline方法的配置:对于
Uniform Embedding,我们的embedding size搜索空间为:MovieLens-1M数据集为[8, 16, 32,64]、Criteo和Avazu数据集为[4, 8, 16],因为当对于其他
baseline,我们首先调优超参数使得模型具有最高的推荐性能、或最高的参数缩减率。然后我们调优这些模型从而达到性能和参数缩减率之间的tradeoff。MDE的搜索空间:维度[4, 8, 16, 32]中搜索,blocks数量[8, 16]中搜索,[0.1, 0.2, 0.3]中搜索。MGQE的搜索空间:维度[8, 16, 32]中搜索,子空间数量[4, 8, 16]中搜索,中心点数量[64, 128, 256, 512]中搜索。DartsEmb搜索空间:三组候选的embedding空间:{1, 2, 8}、{2, 4, 16}、{4, 8, 32}。
我们在
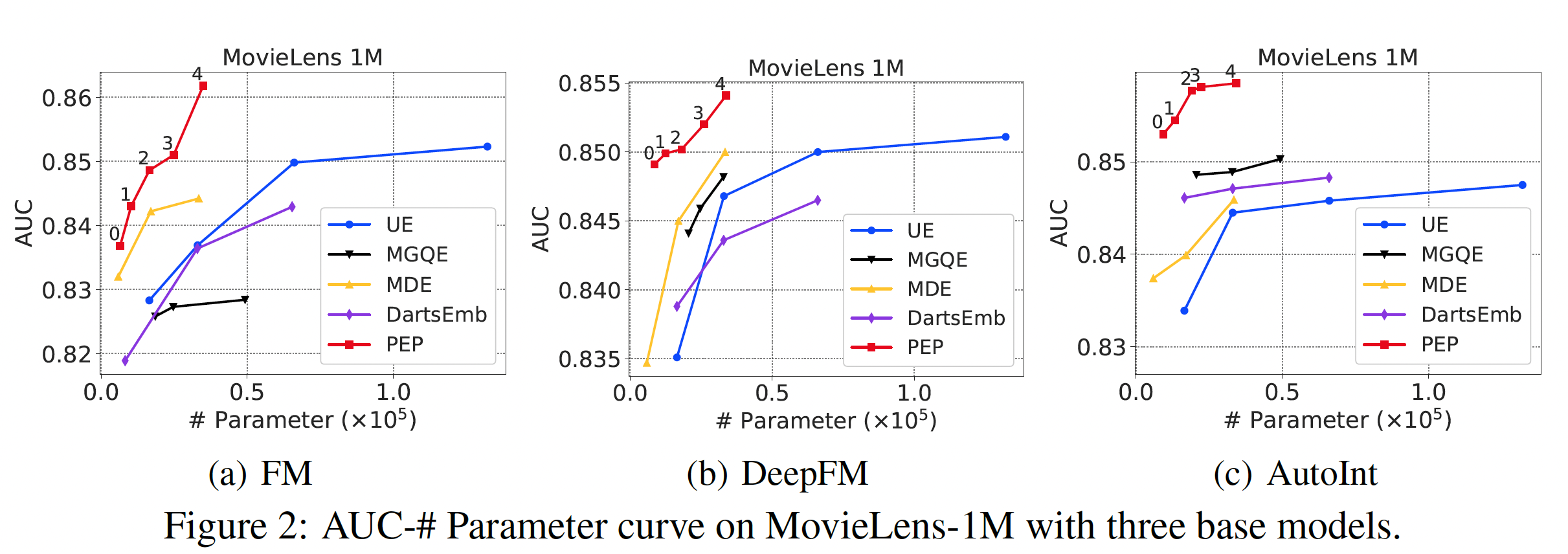
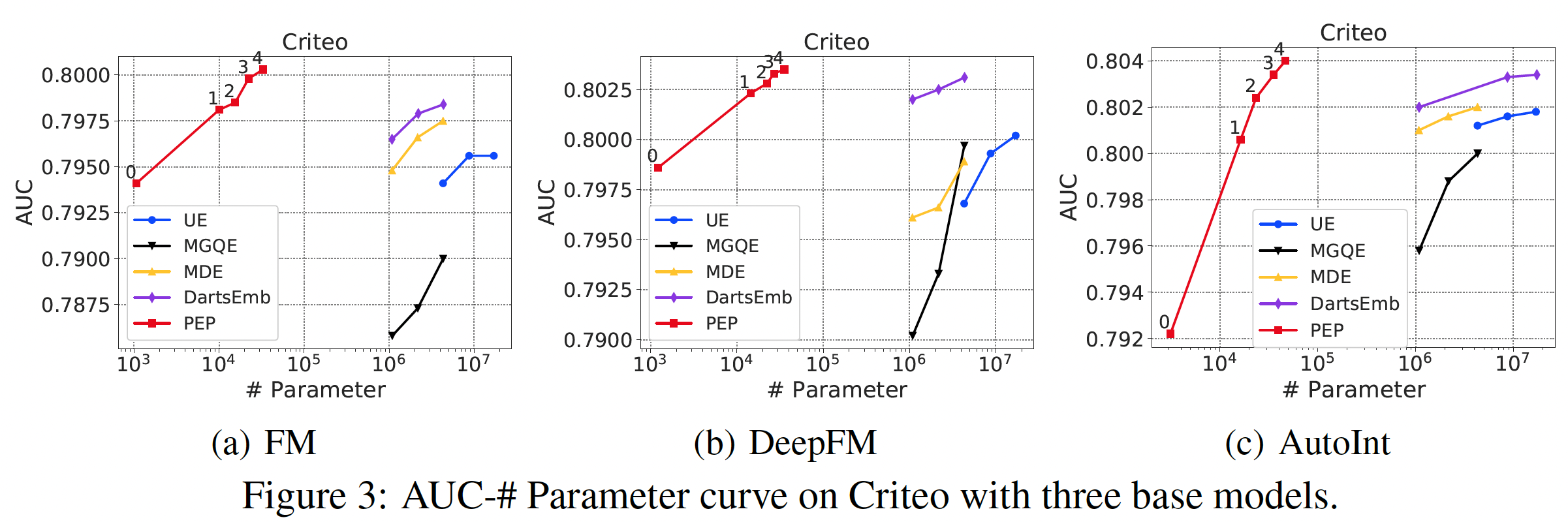
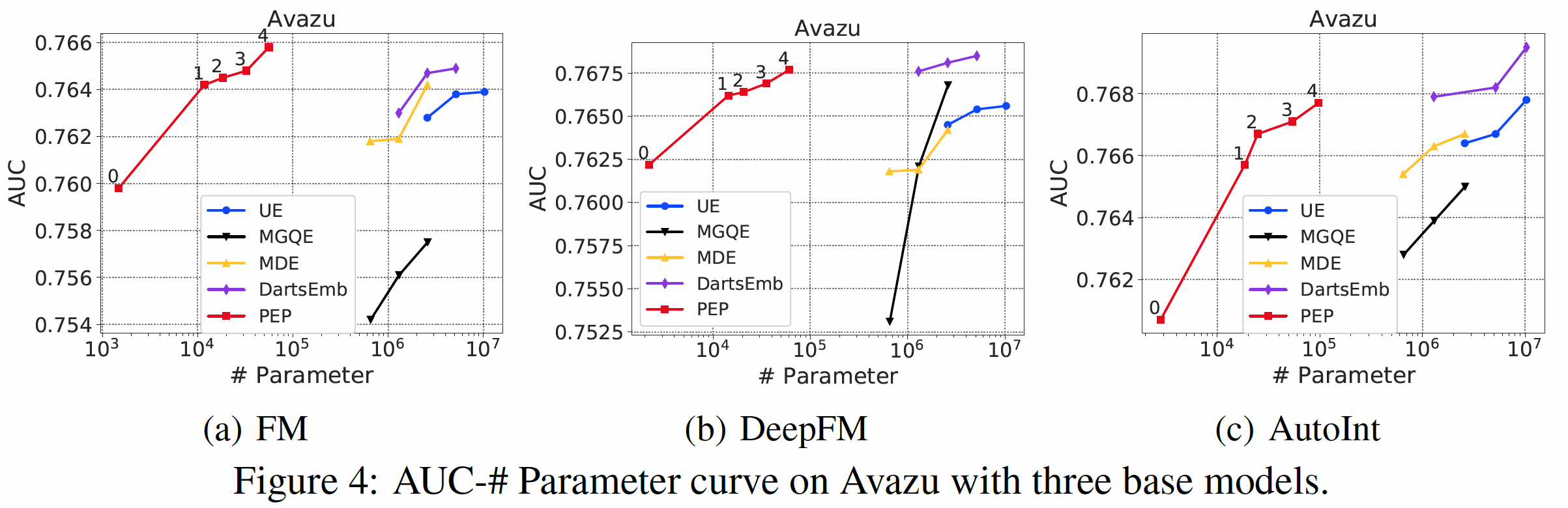
Figure 2, 3, 4中展示了推荐性能和参数数量的曲线。由于推荐性能和参数数量之间存在tradeoff,曲线是由具有不同稀疏性要求的点组成的。可以看到:我们的方法大大减少了参数的数量。在所有的实验中,我们的
PEP实现了最高的参数缩减率 ,特别是在相对较大的数据集(Criteo和Avazu)中。具体而言,在Criteo和Avazu数据集中,与最佳baseline相比,我们的PEP-0可以减少99.90%的参数用量(量级从embedding矩阵的参数使用率如此之低,意味着只有数百个embedding是非零的。通过将不太重要的特征的embedding设置为零,我们的PEP可以打破现有方法中最小embedding size为1的限制(我们的方法可以实现embedding size = 0)。我们后续对MovieLens数据集进行了更多的分析,以帮助我们理解为什么我们的方法可以实现如此有效的参数缩减。我们的方法实现了强大的推荐性能。我们的方法一直优于基于
uniform embedding的模型,并在大多数情况下取得了比其他方法更好的准确性。具体而言,对于Criteo数据集上的FM模型,在AUC方面,PEP比UE相对提高了0.59%、比DartsEmb相对提高了0.24%。从其他数据集和其他推荐模型的实验中也可以看到类似的改进。值得注意的是,我们的方法可以在极端的稀疏范围内保持强大的
AUC性能。例如,当参数数量只有PEP推荐性能仍然明显优于线性回归模型。
PEP的效率分析:PEP将导致额外的时间成本从而为不同的特征找到合适的size。这里我们研究了计算成本,并比较了PEP和DartsEmb在Criteo数据集上的每个训练epoch的运行时间。我们以相同的batch size实现这两个模型,并在同一平台上测试它们。这里的比较很有误导性。因为
PEP需要重训练,也就是training epoch数量要翻倍。而这里仅仅比较单个epoch的训练时间,这是不公平的比较。下表中给出了三种不同模型的每个
epoch的训练时间。可以看到:- 我们的
PEP的额外计算成本只有20% ~ 30%,与基础模型相比,这是可以接受的。 DartsEmb在其bi-level优化过程中需要将近两倍的计算时间来搜索一个好的embedding size。- 此外,
DartsEmb需要多次搜索以适应不同的内存预算,因为每次搜索都需要完全重新运行。与DartsEmb不同的是,我们的PEP只需一次运行就可以获得多个embedding方案,这些方案可以应用于不同的应用场景。因此,在现实世界的系统中,我们的PEP在embedding size搜索方面的时间成本可以进一步降低。

- 我们的
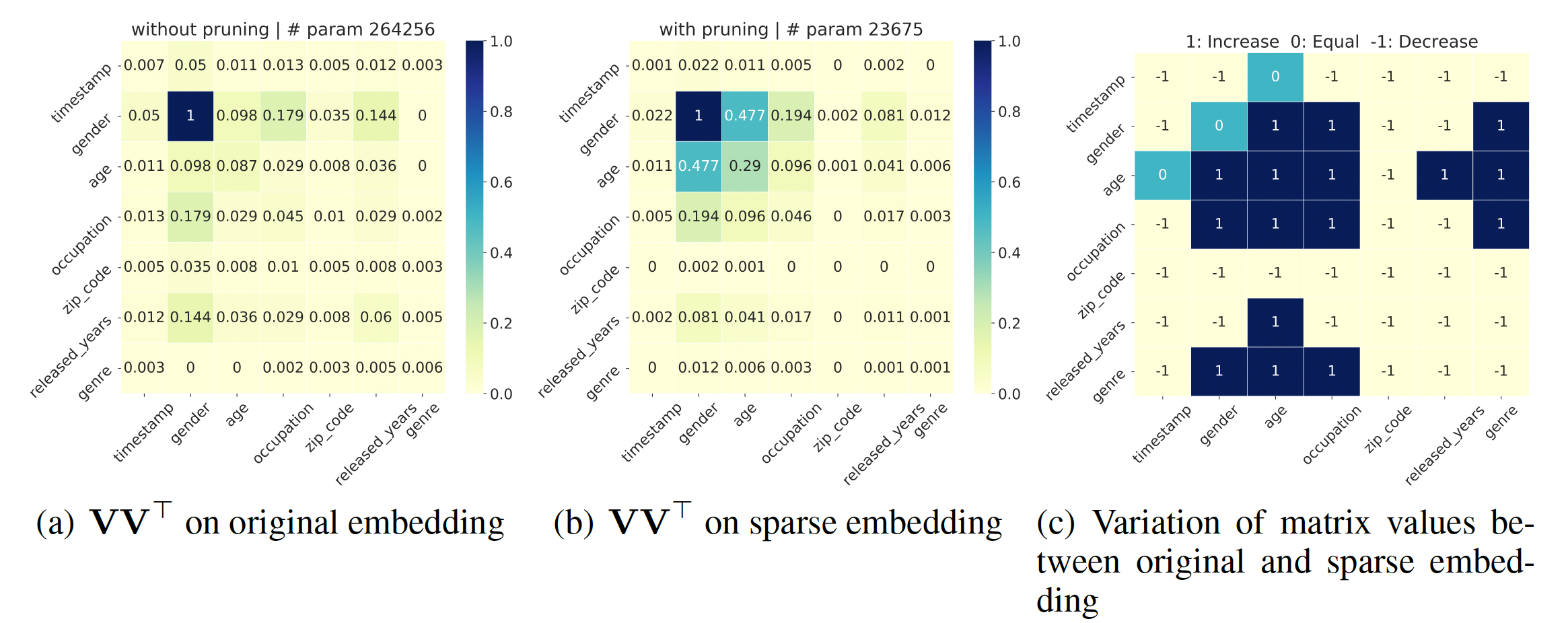
对裁剪后的
embedding进行可解释的分析:在这一节中,我们通过可视化的特征交互矩阵进行可解释的分析,该矩阵由field feature点积结果的绝对值的归一化平均值,其中越高表示这两个field有更强的相关性。可以看到:我们的PEP可以减少不重要的特征交互之间的参数数量,同时保持那些有意义的特征交互的重要性。通过对那些不太重要的特征交互进行降噪,PEP可以减少embedding参数,同时保持或提高准确性。归一化怎么做的?
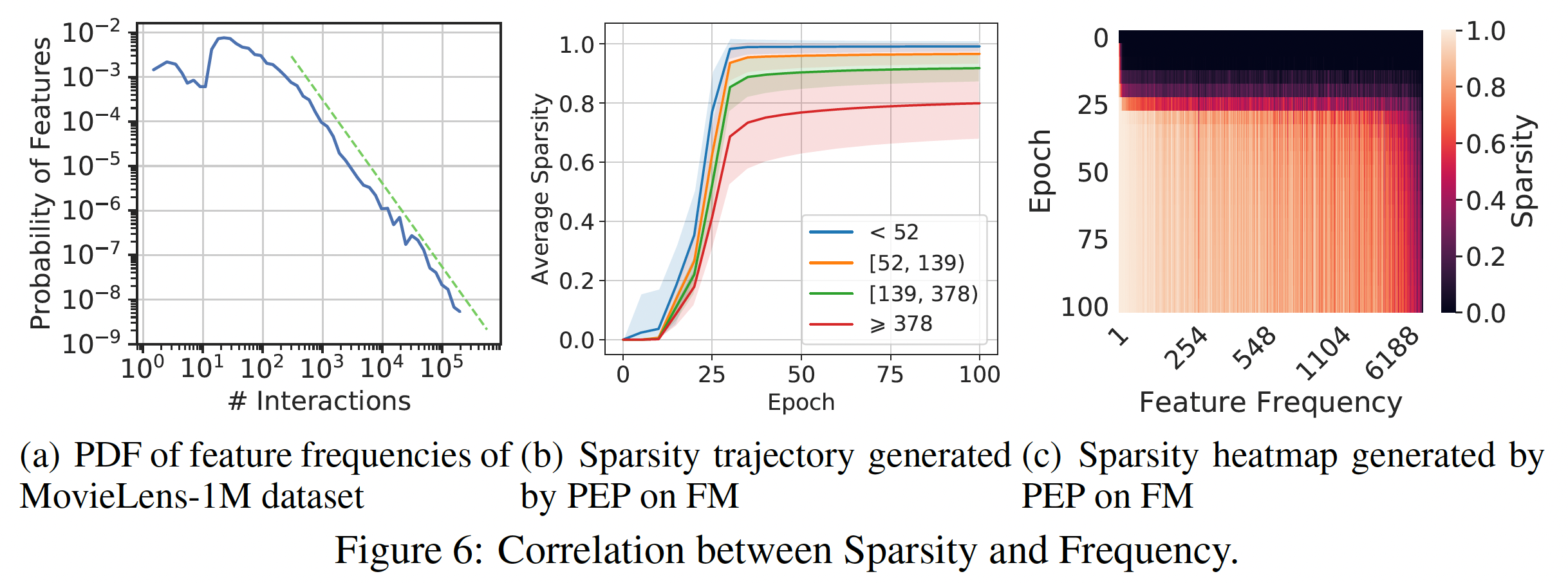
稀疏性和频次之间的相关性:如下图所示,不同特征之间的特征频次是高度多样化的。因此,使用统一的
embedding size可能无法处理它们的异质性,这一特性在embedding size的选择上起着重要作用。因此,最近的一些工作显式利用特征频次。与他们不同的是,我们的PEP以端到端的自动方式缩减参数,从而规避了复杂的人工操作。然而,特征频次是决定一个特征是否重要的因素之一。因此,我们研究我们的方法是否能检测到频次的影响,以及学习到的embedding size是否与频次有关。我们首先分析训练期间的稀疏度轨迹,如下图
(b)所示,不同的颜色表示根据popularity划分的不同的feature group。对于每一组,我们首先计算每个特征的稀疏度,然后计算所有特征上的平均值。图片中的阴影代表一个组内的方差。我们可以看到:PEP倾向于给高频特征分配更大的embedding size,从而确保有足够的表达能力。而对于低频特征,其趋势则相反。这些结果符合这样的假设:高频特征应该有更多的
embedding参数;而对于低频特征的embedding,几个参数就足够了。然后,我们探究了裁剪后的
embedding的稀疏度和每个特征的频次之间的关系,如下图(c)所示。可以看到:大多数
relationship与上述分析一致。一些低频特征被分配了较大的
embedding size,而一些具有较大popularity的特征被分配了较小的embedding size。这说明:像以前的大多数工作那样简单地给高频特征分配更多的参数,并不能处理特征和它们的popularity之间的复杂联系。我们的方法是基于数据进行裁剪,这可以反映出特征的固有属性,从而可以以一种更优雅和有效的方式缩减参数。
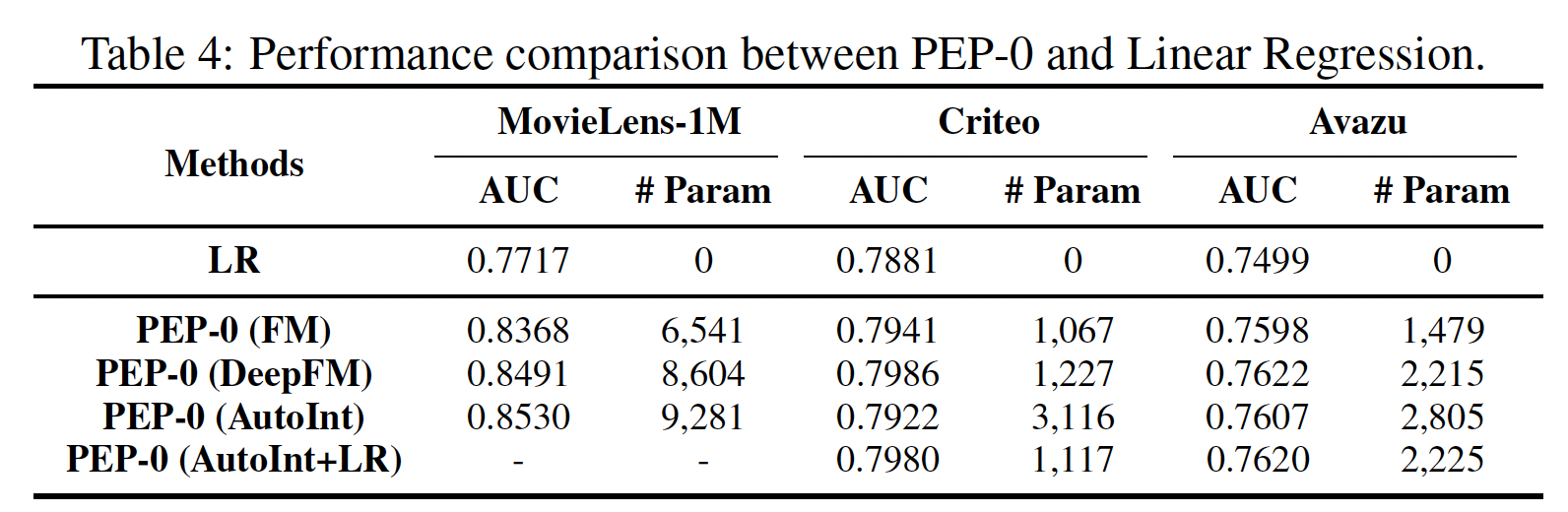
线性回归(
Linear Regression: LR)模型是一个无embedding的模型,只根据原始特征的线性组合进行预测。因此,值得将我们在极稀疏水平上的方法(PEP-0)与LR进行比较,如下表所示。可以看到:- 我们的
PEP-0在所有情况下都明显优于LR。这一结果证明,我们的PEP-0并不依赖FM和DeepFM中的LR部分来保持强大的推荐性能。因此,即使在极其稀疏的情况下,我们的PEP在现实世界的场景中仍然具有很高的应用价值。 - 值得注意的是,
AutoInt模型不包含LR组件,所以在Criteo和Avazu数据集上AutoInt的PEP-0导致了性能的大幅下降。我们尝试在AutoInt的PEP-0中包含LR,并测试其性能。我们可以看到,在Criteo和Avazu上的准确率超过了没有LR的AutoInt。这可以解释为LR帮助我们的PEP-0获得更稳定的性能。
- 我们的
四十五、DeepLight[2021]
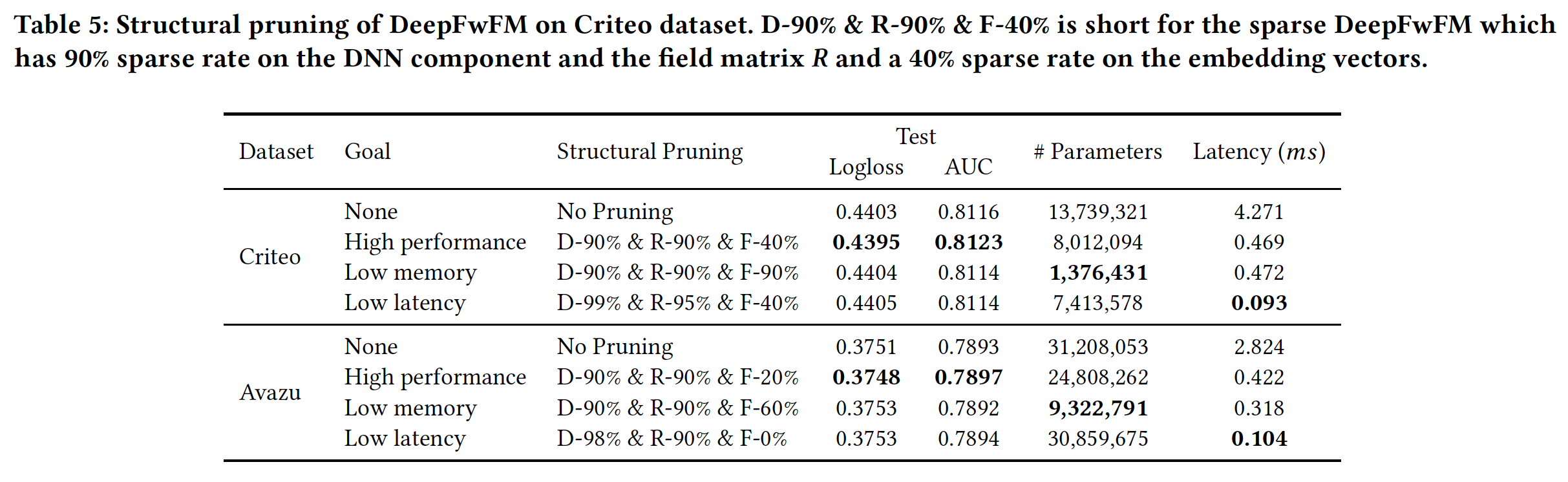
在
CTR预测任务上,广义线性模型和factorization machine : FM取得了巨大的成功。然而,由于缺乏学习更深层次特征交互的机制,它们的预测能力有限。为了解决这个问题,基于embedding的神经网络提出同时包含浅层组件(来学习低阶特征交互)、DNN组件(来学习高阶特征交互),如Wide&Deep, DeepFM, NFM, DCN, xDeepFM, AutoInt, AutoFIS。尽管这些新颖的模型有所改进,但与诸如LR或FM的简单模型相比,预测速度慢了数百倍。随之而来的一个问题是:我们是否能够为高质量的深度模型提供令人满意的模型延迟和资源消耗,从而用于广告服务中的实时响应?为实现这一目标,实际解决方案需要应对以下挑战:
(C1)高质量:用于服务的“瘦身”模型预期与原始的“臃肿”模型一样准确。(c2)低延迟:服务延迟应该非常低,以保持高Query per second: QPS、以及很少的超时。(C3)低消耗:在在线广告服务中,pull模型的checkpoint并将其存储在内存中的内存成本应该很低。
然而,所有现有的基于
embedding的神经网络,如DeepFM, NFM, xDeepFM, AutoInt,仍然专注于增加模型复杂度以实现(C1),同时牺牲(C2)和(C3)。虽然人们提出了一些方法,如AutoCross来提高模型效率,但它们没有采用DNN框架,未能达到SOTA。为了共同解决这些挑战,论文《DeepLight: Deep Lightweight Feature Interactions for Accelerating CTR Predictions in Ad Serving》提出了一种有效的模型,即所谓的field-weighted embedding-based neural network: DeepFwFM,通过field pair importance matrix来改进FM模块。DeepFwFM在经验上与xDeepFM一样强大,但效率更高。如下图所示,DeepFwFM的每个组件都有一个approximately sparse structure,这意味着结构剪枝的优势并可能导致更紧凑的结构。通过裁剪DeepFwFM的DNN组件并进一步压缩浅层组件,得到的深度轻量化结构(即,DeepLight)大大减少了推理时间,仍然保持了模型性能。
据作者所知,这是第一篇研究裁剪
embedding based的DNN模型以加速广告服务中的CTR预测的论文。总之,所提出的DeepFwFM在快速的、准确的推断方面具有巨大潜力。与现有的基于embedding的神经网络相比,该模型具有以下优点:为了解决
(C1)高质量的挑战,DeepFwFM利用FwFM中的field pair importance的思想,以提高对低阶特征交互的理解,而不是探索高阶特征交互。值得注意的是,与SOTA的xDepFM模型相比,这种改进以非常低的复杂性达到了SOTA,并且在深度模型加速方面仍然显示出巨大的潜力。(C1)高质量的挑战并不是由DeepLight解决的,而是由基础模型FwFM解决的。为了解决
(C2)低延迟的挑战,可以对模型进行裁剪以进一步加速:- 裁剪深度组件中的冗余参数以获得最大的加速。
- 移除
FwFM中的week field pair以获得额外的显著加速。
由此产生的轻量化结构最终几乎达到一百倍的加速。
为了解决
(C3)低消耗的挑战,可以促进embedding向量的稀疏性,并保留最多的discriminant signal,这会产生巨大的参数压缩。
通过克服这些挑战(
C1-C3),由此产生的稀疏DeepFwFM(即所谓的DeepLight),最终不仅在预测方面,而且在深度模型加速方面取得了显著的性能。它在Criteo数据集上实现了46倍的速度提升,在Avazu数据集上达到了27倍的速度,而不损失AUC。源代码参考https://github.com/WayneDW/sDeepFwFM。
45.1 模型
注:这篇论文的核心是如何对
DeepFwFM进行压缩,而不是提出DeepFwFM。事实上,DeepFwFM就是DNN作为deep组件、FwFM作为wide组件的神经网络,毫无新意 。此外,
DeepLight的剪枝方法也是工程上的应用(把训练好的模型中的接近于零的权重裁剪掉),而没有多少创新点。实验部分提示了基于剪枝的模型设计方案:首先设计较大容量的模型从而提升模型的表达能力,然后执行剪枝从而降低
latency、减少过拟合。这种方案的一个潜在缺点是:训练资源消耗更大。
45.1.1 DeepFwFM
给定数据集
label,二阶多项式模型
其中:
FM模型其中:
embedding向量的集合;embedding向量;embedding向量的维度。可以看到,
FM模型将参数规模从Deep & Cross通过一系列的cross操作来建模高阶交互:其中:
通过进一步组合
DNN组件,我们可以获得xDeepFM,这是CTR预测中的SOTA模型。尽管xDeepFM在建模特征交互方面具有强大的性能,但众所周知,它比DeepFM的成本要高得多,并增加了速度较慢。因此我们考虑FwFM模型,并提出了Deep Field-weighted Factorization Machine: DeepFwFM:其中:
FwFM模型,用于建模二阶特征交互。DNN的参数(包括权重矩阵和bias向量)。field的embedding向量,fieldembedding向量。这就是
FwFM原始论文中 的FwFM_FiLV,用embedding向量,field pair重要性矩阵,它建模field pair的交互强度。field。
DeepFwFM有两个创新:DeepFwFM比xDeepFM快得多,因为我们不试图通过浅层组件来建模高阶(三阶甚至或更高)的特征交互。尽管xDeepFM包含强大的compressed interaction network: CIN来逼近任意固定阶次的多项式,但主要缺点是CIN的时间复杂度甚至高于xDeepFM中的DNN组件,导致了昂贵的计算。DeepFwFM比DeepFM更准确,因为它克服了矩阵分解中的稳定性问题,并通过考虑field pair importance导致更准确的预测。
如下图所示,
DeepFM通过FM组件中每个hidden node与输出节点之间的weight-1 connection(即,feature embedding之间内积的权重为1)来建模低阶特征交互,然而,这无法适应局部几何结构,并牺牲了鲁棒性。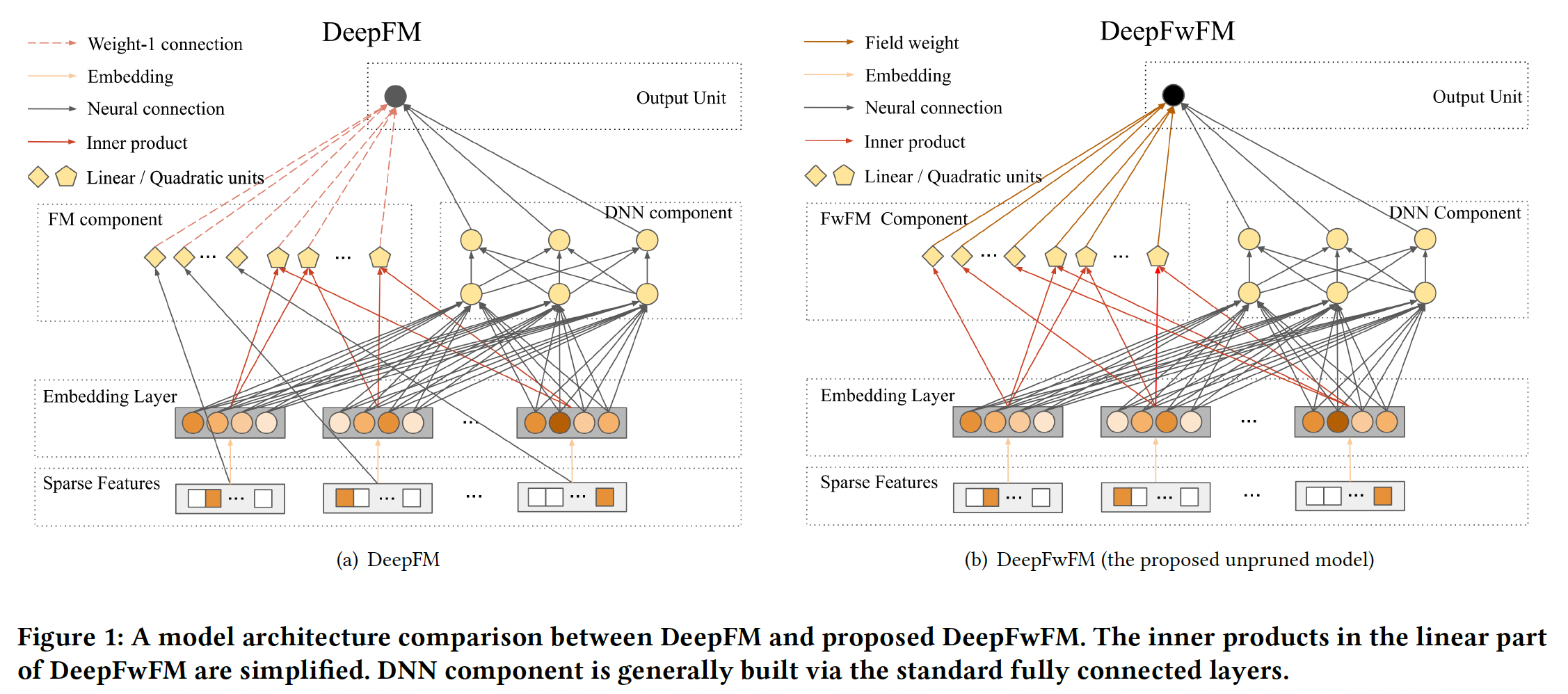
为了证明我们模型的优势,我们对
DeepFwFM的计算复杂性进行了定量分析。给定embedding sizeembedding layer只有lookup(即field数量 为DNN组件的floating point operations: FLOPs为FwFM组件的FLOPs为类似地,我们可以得到
DeepFM和xDeepFM的计算复杂度,如下表所示。可以看到:xDeepFM的CIN层需要DNN组件的操作数量。FM组件和FwFM组件比DNN组件快得多。
尽管
DeepFwFM的计算复杂度较好,但是它仍然未能将延迟降低到一个良好的水平。事实上,由于包含DNN组件,DeepFwFM可能会慢数百倍,这会显著降低在线CTR预测的速度。
45.1.2 DeepLight
DNN组件无疑是导致高延迟问题并且无法满足在线要求的主要原因。因此,需要一种适当的加速方法来加速预测。为什么采用结构剪枝:深度模型加速三种主要方法组成:结构剪枝
structural pruning、知识蒸馏knowledge distillation、量化quantization,其中结构剪枝方法因其显著的性能而受到广泛关注。此外,DeepFwFM的每个组件,如DNN组件、field pair interaction matrixembedding向量,都具有高度稀疏的结构,如Figure 2所示。这促使我们考虑结构剪枝以加速浅层组件和DNN组件。对于其他选择:
量化在推断期间采用了定点精度。然而,它没有充分利用
DeepFwFM每个组件的稀疏结构,甚至对模型性能有损。知识蒸馏技术通过训练小网络(即
student model)以模仿大网络(即teacher model),但它存在以下问题:- 学生模型从教师模型学习的能力有限。
- 如果性能恶化,很难清楚这是由于教师模型导致、还是由于教学过程导致。
这就是我们在这项工作中采用结构剪枝的原因。
如何进行结构剪枝:
设计:我们建议裁剪以下三个组件(在
DeepFwFM模型的背景下),而不是简单地以统一的稀疏率应用剪枝技术。这三个组件专门设计用于广告预测任务:剪枝
DNN组件的权重(不包括bias)从而移除神经元连接。剪枝
field pair interaction matrixfield interaction。注意:移除冗余的
field interaction,意味着建模时无需考虑对应field之间的内积计算。剪枝
embedding向量中的元素,从而导致稀疏的embedding向量。
结合以上努力,我们获得了所需的
DeepLight模型,如下图所示。DeepLight是一种稀疏的DeepFwFM,它提供了一种整体方法,通过在推理期间修改训练好的架构来加速推理。注意,
DeepLight是用于训练好的模型,是一种剪枝算法,而不是一种训练算法。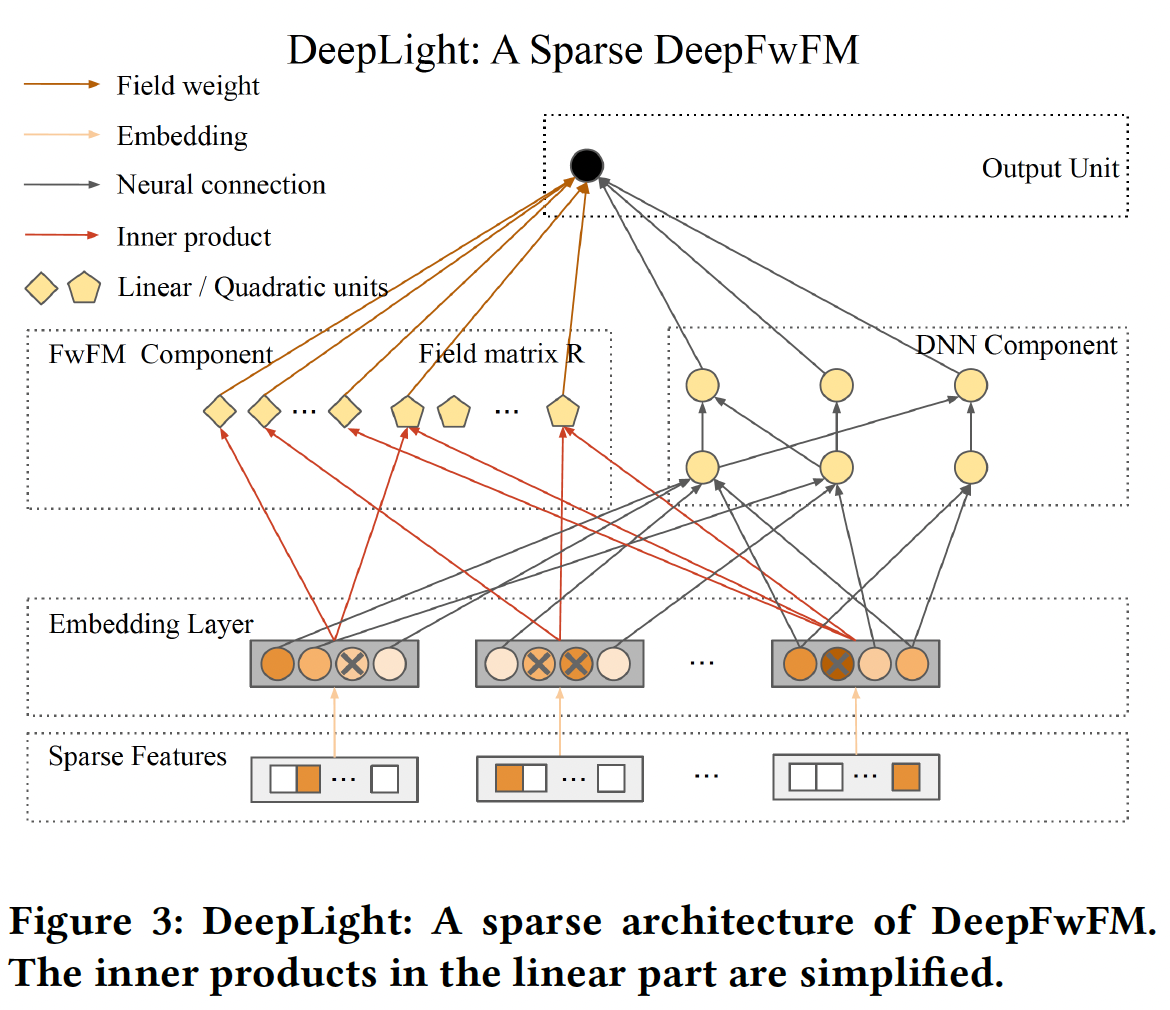
优点:通过实验表明:
- 与原始
DNN组件相比,稀疏的DNN组件的计算复杂度要低得多。它导致最大的计算加速。 sparse field pair interaction matrixFwFM组件的显著加速。此外,裁剪field pair selection。一旦裁剪了field pairfeature pair都将被丢弃。AutoFIS也实现了类似类型的field pair selection。sparse embedding大大减少了内存使用,因为feature embedding主导了CTR预测深度学习模型中的参数数量。
- 与原始
实现:从过度参数化的模型中选择一个良好的稀疏网络是
NP难的,并且无法保证最优算法能够解决它。在结构剪枝领域有大量的经验研究,包括权重剪枝、神经元剪枝、以及其他单元剪枝。考虑到我们的模型只包含一个标准的FwFM组件和一个普通的DNN组件,我们进行了权重剪枝,并寻求在不调用专用库的情况下实现高稀疏性和加速。定义稀疏率
99%的权重都被裁剪。结构剪枝算法:
输入:
- 训练好的
target model - 目标稀疏率
- 阻尼因子
- 训练好的
输出:剪枝后的模型
算法步骤:
剪枝:对于
训练网络一个
iteration。这是为了在每次裁剪之后,重新训练模型从而进行微调,以便错误修剪的权重有可能再次变得活跃。
对模型的每个组件
更新组件当前轮次的裁剪比例
这是设置自适应的裁剪比例,使得在早期剪枝的很快(裁剪比例较大)、在后期剪枝很慢(裁剪比例较小)。
注意:这种裁剪方式无法确保最终模型能够得到
根据权重的
magnitude,裁剪最小的
降低计算复杂度:
DNN组件是导致高推断时间的瓶颈。在DNN组件的剪枝之后,FwFM组件成为限制,这需要对field matrixembedding层的剪枝对计算没有显著的加速。在对
DNN组件的权重设置一个中等大小的bias)的情况下,相应的加速可以接近理想的95%时,我们可能无法达到理想的加速比,因为bias的计算和稀疏结构(如compressed row storage: CRS)的开销。关于field matrixDNN组件中的目标稀疏率降低空间复杂度:在
embedding layer中进行剪枝也显著减少了DeepFwFM中的参数数量,因此节省了大量内存。在embedding layer中,至于
DNN组件,权重参数的数量(不包括bias)可以从field matrix由于
DeepFwFM中的总参数由embedding向量参数所主导 ,embedding向量上的
4.2 实验
数据集:
Criteo, Avazu。对于
Criteo数据集,我们采用由Criteo竞赛获胜者提出的对数转换来归一化数值特征:此外,我们还将所有频次低于
8的特征视为"unknown"。我们将数据集随机分成两部分:90%用于训练、剩下的10%用于测试。对于
Avazu数据集,我们使用10天的点击记录,并随机拆分80%的样本用于训练、剩下的20%用于测试。我们还将所有频次低于5的特征视为"unknown"。
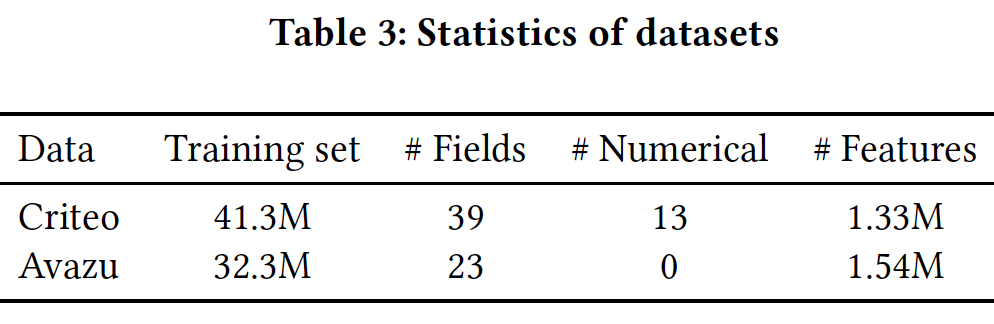
数据集的统计信息如下表所示。
评估指标:
LogLoss, AUC。baseline方法:在emebdding-based神经网络模型中,我们选择DeepFM, NFM, xDeepFM作为baseline,因为它们具有与DeepFwFM相似的架构,也是CTR预测的SOTA模型。最终,六个baseline模型为:LR, FM, FwFM, DeepFM, NFM, xDeepFM。实现细节:我们使用
PyTorch训练模型。Criteo数据集:为了对
Criteo数据集进行公平比较,我们遵循DeepFM和xDeepFM原始论文中的参数设置,并将学习率设置为0.001。embedding size设为10。DeepFM, NFM, xDeepFM的DNN组件默认设置为:- 网络架构为
400 x 400 x 400。 drooout rate为0.5。
此外,我们也将裁剪后的
DeepFwFM与更小尺寸的DeepFwFM进行比较。对于这些更小尺寸的DeepFwFM,它们的DNN组件分别为:25 x 25 x 25(记做N-25)、15 x 15 x 15(记做N-25)。原始尺寸的未裁剪DeepFwFM记做N-400。- 网络架构为
对于
xDeepFM,CIN的架构为100 x 100 x 50。我们微调了
L2惩罚,并将其设置为3e-7。我们在所有实验中使用
Adam优化器,batch size = 2048。
Avazu数据集:保持了与Criteo数据集相同的设置,除了embedding size设为20、L2惩罚为6e-7、DNN网络结构为300 x 300 x 300。
关于实践中的训练时间(而不是推理时间),所有模型之间没有太大的差异。
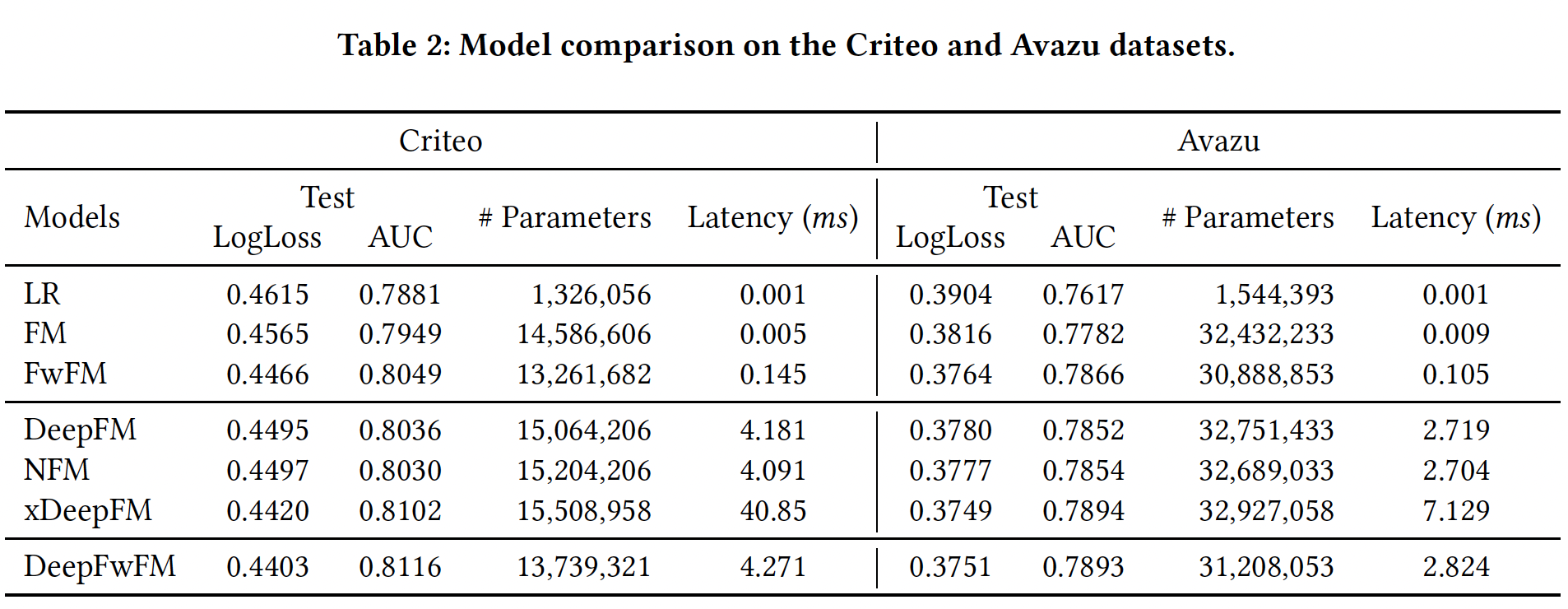
FwFM和DeepFwFM的速度略快于DeepFM和xDeepFM,这是由于FwFM与DeepFwFM在线性项上的创新(用内积代替线性项)。DeepFwFM和其它稠密模型的比较:对没有剪枝的密集模型的评估显示了过度参数化模型所表现出的最大潜力,如下表所示。可以看到:LR在所有数据集上的表现都比其他模型都要差,这表明特征交互对于提高CTR预测至关重要。- 大多数
embedding-based神经网络的表现优于低阶方法(如LR和FM),这意味着建模高阶特征互动的重要性。 - 低阶的
FwFM仍然胜过NFM和DeepFM,显示了field matrix NFM利用黑盒DNN隐式地学习低阶特征交互和高阶特征交互,由于缺乏显式识别低阶特征交互的机制,可能会过拟合数据集。- 在所有
embedding-based神经网络方法中,xDeepFM和DeepFwFM在所有数据集上效果最好。然而,xDeepFM的推理时间远远超过DeepFwFM。
稀疏化模型
DeepLight:我们选择阻尼因子2个epoch,然后训练8个epoch用于剪枝。我们每隔10个iteration剪枝一次从而降低计算代价。即:前
2个epoch训练好模型;后面的8个epoch执行剪枝。DNN剪枝加速:仅裁剪DNN组件的权重,DNN的bias、field matrixembedding layer的参数照常处理。我们尝试不同的剪枝率,并将不同稀疏率的网络与较小结构的网络进行比较。结果如Table 4所示。可以看到:- 具有稀疏
DNN组件的DeepFwFM优于稠密DeepFwFM,即使在Criteo数据集上稀疏率高达95%。在我们将Criteo数据集上的稀疏率提高到99%之前,这一现象保持不变。 - 相比之下,具有类似参数规模的相应小型网络,如
N-25和N-15,获得的结果比原始的N-400要差得多,显示了裁剪过度参数化的网络相比从较小的网络训练更强大。
在
Avazu数据集上,我们得到同样的结论。稀疏模型在90%的稀疏率下获得了最好的预测性能,只有当稀疏率大于99.5%时才会变差。关于模型加速,从下图中可以看到:较大的稀疏率总是带来较低的延迟。因此在这两个数据集上,稀疏模型在性能超越原始稠密模型的基础上,都实现了高达
16倍的推理速度提升。这里获得的好处主要是更低的延迟。虽然模型性能略有提升,但是低于
0.1%,因此效果不显著。但是,和
N-25, N-15这两个更小的网络相比,DeepLight的性能提升比较显著。然而DeepLight的训练时间也更长。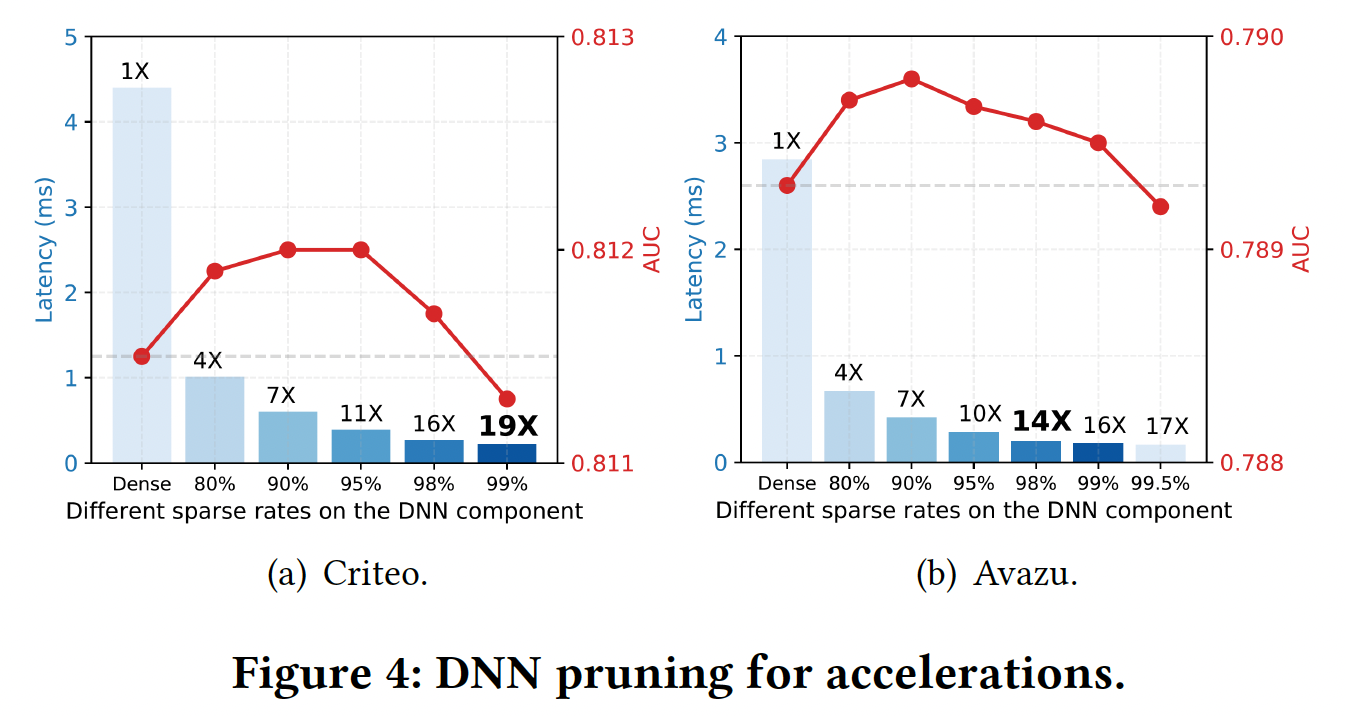
- 具有稀疏
Field MatrixDNN组件进行高稀疏度化之后,我们已经获得了显著的加速,接近20倍。为了进一步提高速度,增加DNN组件的稀疏率可能会有降低性能的风险,并且由于矩阵计算的开销,不会产生明显的加速。从Figure 2可以看出,field matrixfield matrix我们根据
field matrixDNN组件已经被剪枝的基础上),如下图所示。可以看到:我们可以在不牺牲性能的情况下对field matrix95%的稀疏率,此外推断速度可以进一步加快2到3倍。因此,我们最终可以在不牺牲性能的情况下获得46倍和27倍的速度提升。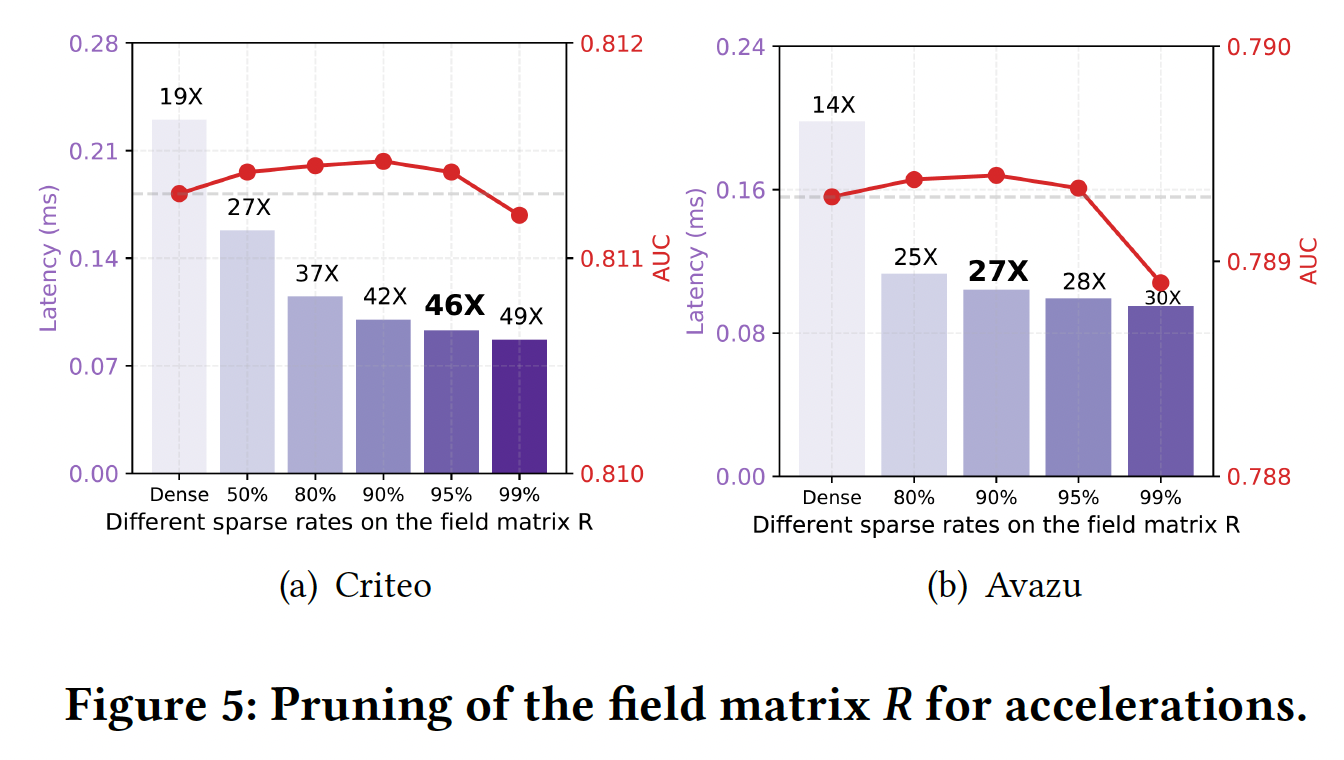
Embedding Vector剪枝用于节省内存:关于embedding的剪枝,我们发现为所有field的embedding设置一个全局阈值,比为每个field的embedding向量设置单独的阈值获得略好的性能。因此,我们在全局阈值的基础上进行了实验。如下图所示:
Criteo数据集上可以采用较高的稀疏率,如80%,并保持几乎相同的性能。- 相比之下,在
Avazu数据集上比较敏感,当采用60%的稀疏率时,性能开始低于稠密模型。
从下表可以看到,大多数模型优于较小的
embedding size的baseline模型(称为E-X),这说明了使用大的embedding size,然后在过度参数化的网络上应用剪枝技术以避免过拟合。剪枝
embedding似乎并没有带来多少AUC提升(0.03%左右,非常微小)。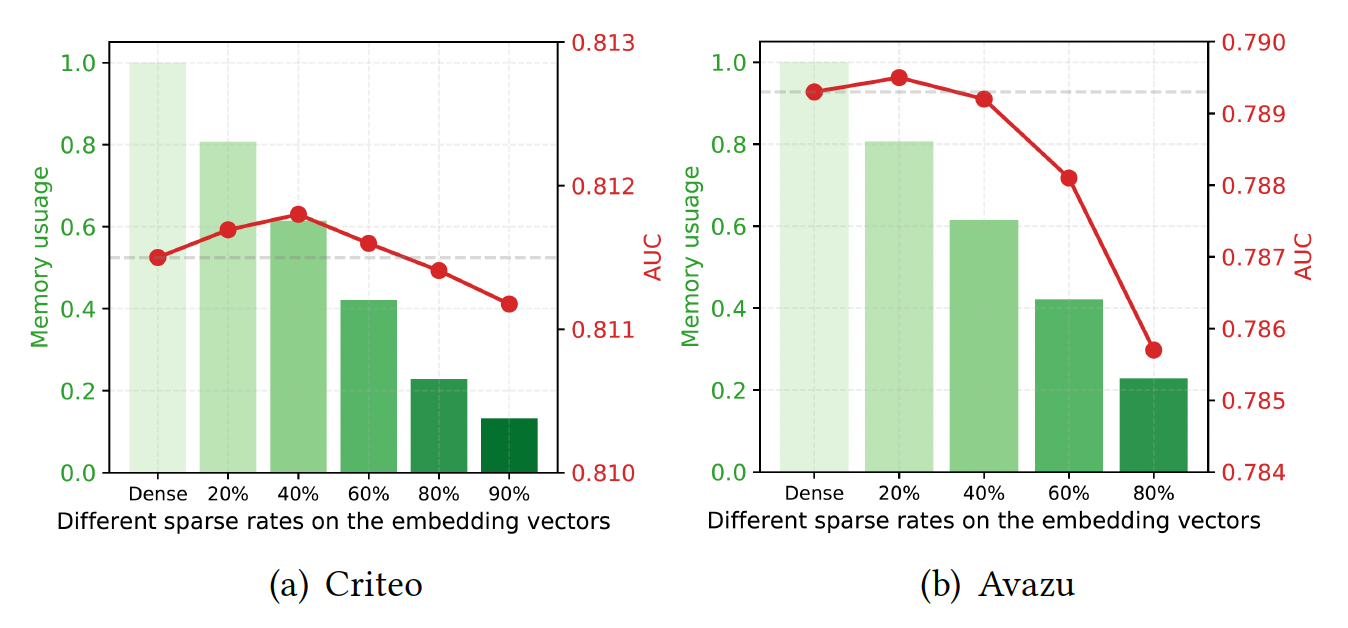
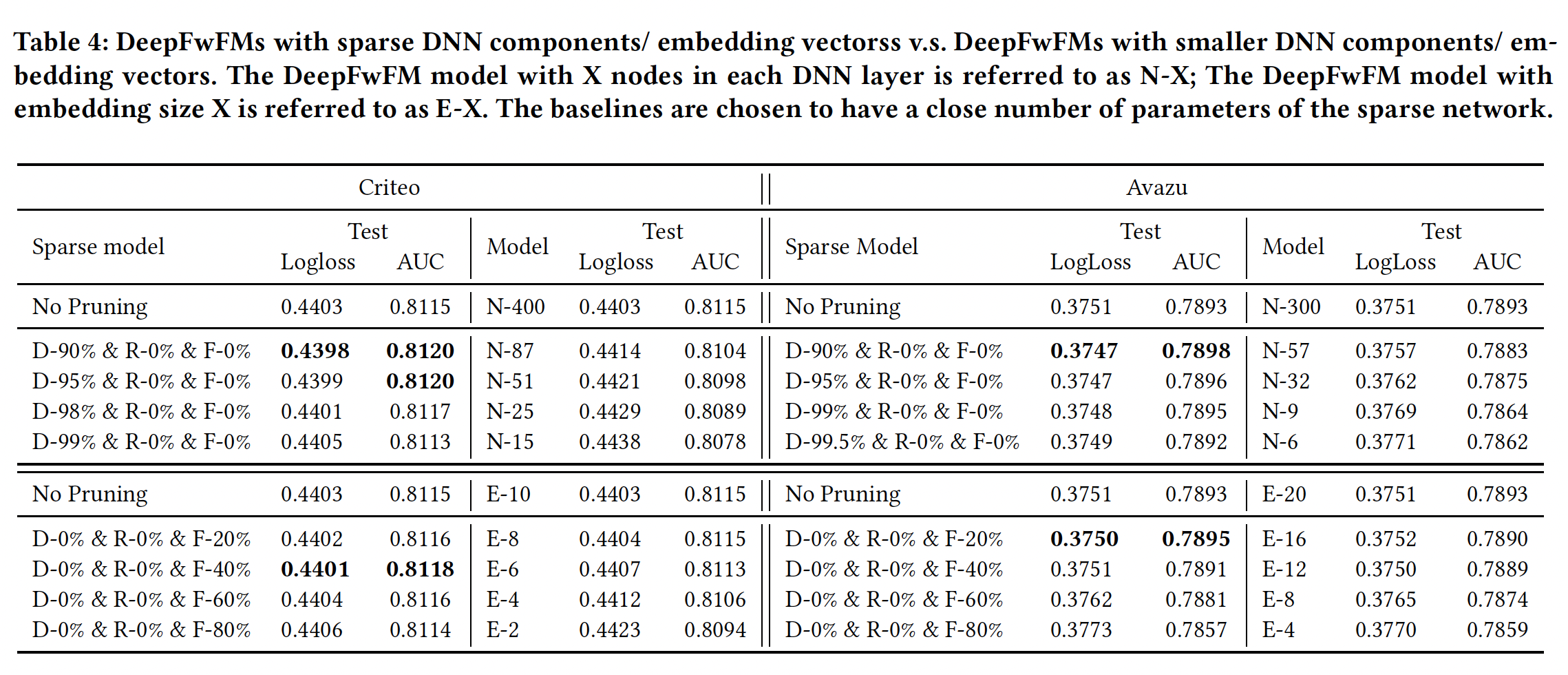
DeepFwFM的结构剪枝:从上述实验中,我们看到DNN组件和field matrix对于性能驱动的任务:
- 在
Criteo数据集上,我们可以通过sparse DeepFwFM将SOTA AUC从0.8116提高到0.8223,其中DNN组件和field matrix90%、embedding向量中的剪枝率为40%。该模型被称为D-90% & R-90% & F-40%。 - 在
Avazu数据集上,我们可以通过sparse DeepFwFM将SOTA AUC从0.7893提高到0.7897,其中DNN组件和field matrix90%、embedding向量中的剪枝率为20%。该模型被称为D-90% & R-90% & F-20%。
这里的剪枝对于性能提升非常微小,几乎可以忽略。因为太小的提升可能由于超参数配置、随机因素等等的影响,而观察不到。
- 在
对于内存驱动的任务:在
Criteo数据集和Avazu数据集上的内存节省分别高达10倍和2.5倍。对于延迟驱动的任务:我们使用结构为
D-99% & R-95% & F-40%的DeepLight在Criteo数据集上实现了46倍的速度提升,使用结构为D-98% & R-90% & F-0%的DeepLight在Avazu数据集上实现了27倍的速度提升,而且没有损失准确性。
DeepLight和其它稀疏模型的比较:对于其他模型,我们也尝试了在不牺牲性能的情况下加速预测的最佳结构。关于xDeepFM中的CIN组件,我们用C-99%表示CIN组件的99%的稀疏率。结果如下表所示。可以看到:- 所有
embedding-based的神经网络都采用高稀疏率来保持性能。 - 此外,
DeepLight在预测时间上与sparse DeepFM和sparse NFM相当,但在Criteo数据集上的AUC至少提高了0.8%,在Avazu数据集上提高了0.4%。 DeepLight获得了与xDeepFM相似的预测性能,但其速度几乎是10倍。
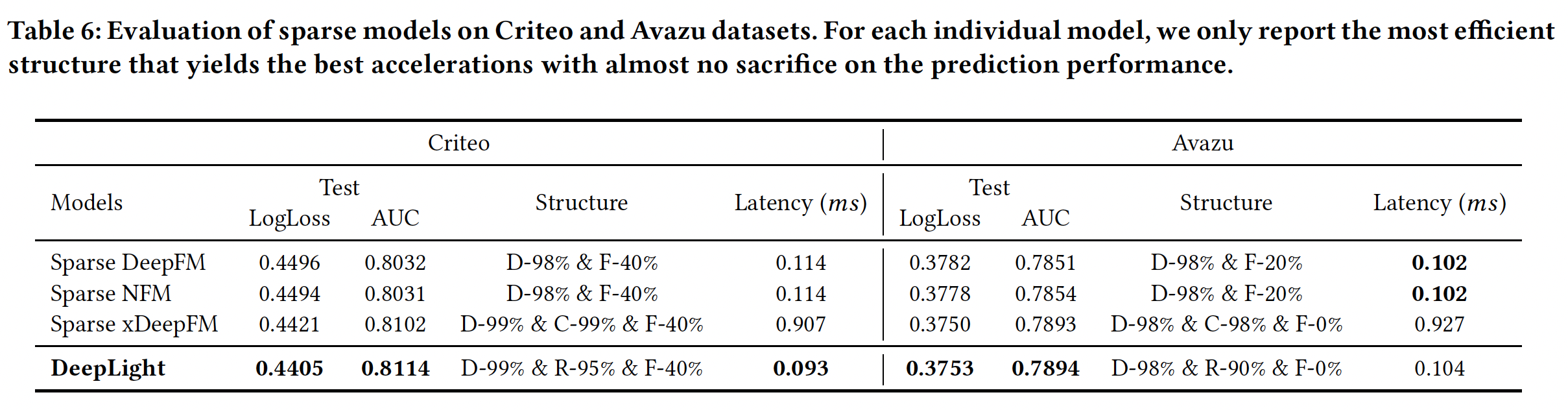
- 所有