四十六、EDCN[2021]
《Enhancing Explicit and Implicit Feature Interactions via Information Sharing for Parallel Deep CTR Models》
有效地建模
feature interactions对于工业推荐系统中的CTR预测至关重要。具有并行结构的SOTA的deep CTR模型(例如DCN)通过独立的并行网络学习显式的和隐式的feature interactions。然而,这些模型存在简单共享(trivial sharing)的问题,即hidden layers的共享不足、以及network input的共享过度,限制了模型的表达能力和有效性。因此,为了增强显式的和隐式的
feature interactions之间的信息共享,我们提出了一种新颖的deep CTR模型EDCN。EDCN引入了两个高级模块,即桥接模块(bridge module)和调制模块(regulation module)。对于并行网络的每一个hidden layer,这两个模块协同工作以捕获layer-wise的交互信号并学习差异性的特征分布(discriminative feature distributions)。此外,两个模块是轻量级的、以及模型无关的,可以很好地推广到主流的并行deep CTR模型。我们进行了大量的实验和研究,以证明EDCN在两个公共数据集和一个工业数据集上的有效性。此外,还验证了两个模块与各种并行结构的模型的兼容性,并已部署到华为在线广告平台上;经过一个月的A/B test,与并行结构的base模型相比,CTR和eCPM分别提高了7.30%和4.85%。近年来,基于深度学习的
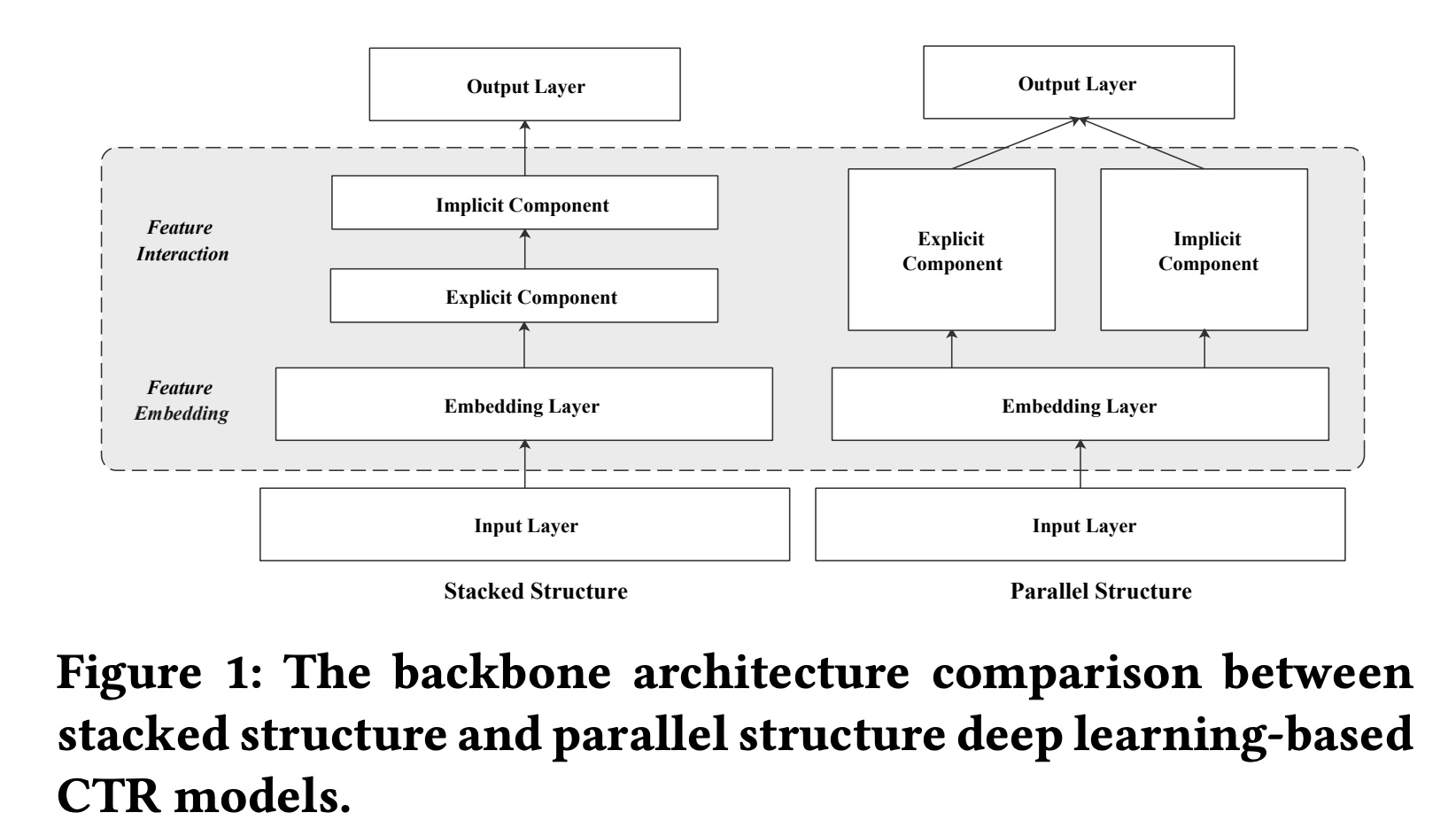
CTR模型迅速兴起,具有以端到端方式来捕获informative feature interactions的能力,摆脱了手动特征工程和pre-defined formula的阻碍。代表性模型,如Wide & Deep、DeepFM、DCN、PIN、DIN和DIEN,联合学习显式的和隐式的feature interactions并实现显著的性能提升。这些deep CTR模型可以根据所用于建模显式的和隐式的feature interactions的网络的组合方式分为两类,即并行结构(parallel structure)和堆叠结构(stacked structure),如Figure 1所示。具有堆叠结构的模型将两个网络以串行的方式组合在一起,其中一个网络用于显式的有界阶次的
feature interactions,另一个网络用于隐式的feature interactions,例如PIN、DIN和DIEN。另一方面,具有并行结构的模型以并行的方式联合训练两个网络,例如
DeepFM、DCN和xDeepFM,如Figure 2所示。
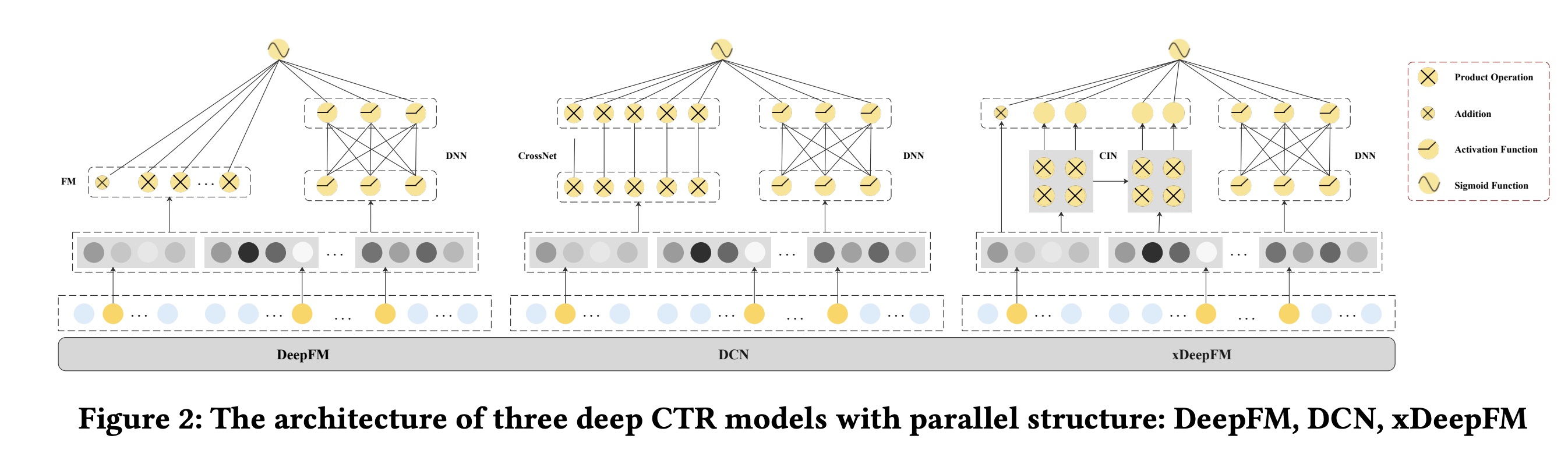
在本文中,我们专注于通过信息共享(
information sharing)来增强显式的和隐式的feature interactions从而来优化具有并行结构的模型。为了使我们的演示简单明了,我们以Deep & Cross Network: DCN为例,这是一个具有代表性的并行结构的模型,在模型性能和效率之间取得了良好的平衡。然而,两个并行网络之间执行的简单共享策略限制了其表达能力和有效性,详述如下。hidden layers的共享不足(insufficient sharing):DCN并行且独立地执行交叉网络(显式交互)和深度网络(隐式交互),并且学到的latent representations直到最后一层才融合。我们将这种融合模式称为late fusion。在late fusion中,显式的和隐式的feature interaction networks不会在intermediate hidden layers共享信息,这会削弱彼此之间的interactive signals,并且可能在反向传播过程中容易导致梯度倾斜(《 Dense multimodal fusion for hierarchically joint representation》)。总而言之,这种hidden layers的共享不足的策略,阻碍了这些并行结构模型中effective feature interactions的学习过程。network input的过度共享(excessive sharing)。DCN中的交叉网络(cross network)和深度网络(deep network)共享相同的embedding layer作为输入,这意味着所有input features都被无差别地输入到并行网络中。然而,正如《AutoFeature: Searching for Feature Interactions and Their Architectures for Click-through Rate Prediction》所指出的,不同的特征适用于不同的interaction函数。因此,network inputs的过度共享,以及将所有特征无差别地输入到所有并行网络中,可能不是一个合理的选择,会导致性能不佳。
为了解决上述各种并行结构的模型中普遍存在的
sharing问题,我们提出了一种基于DCN的新型deep CTR模型,即Enhanced Deep & Cross Network: EDCN。具体来说,我们引入了两个新模块,即bridge module和regulation module,分别解决hidden layers的insufficient sharing、以及network input的excessive sharing的问题。一方面,
bridge module通过在交叉网络和深度网络之间建立连接进行dense fusion,从而捕获并行网络之间的layer-wise interactive signals,并增强feature interactions。另一方面,
regulation module旨在通过soft selection方式通过field-wise gating network学习不同子网络的差异化的特征分布(discriminative feature distributions)。此外,regulation module还能够与bridge module协同工作,进一步学习每个hidden layer的合理输入,使两个并行网络协同学习显式的和隐式的feature interactions。
这两个模块轻量级且与模型无关,可以很好地推广到各种并行结构的
deep CTR模型,以显著提高性能,同时降低时间复杂度和空间复杂度。不一定能降低时间复杂度和空间复杂度,事实上这两个模块会增加复杂度。
贡献:
我们分析了并行结构模型中存在的
sharing的问题,即hidden layers的insufficient sharing、以及network input的excessive sharing,并提出了一种新颖的deep CTR模型EDCN,以增强显式的和隐式的feature interactions之间的信息共享。在
EDCN中,我们提出bridge module从而捕获并行网络之间的layer-wise interactive signals,提出regulation module来学习两个网络的每个hidden layer的差异化的特征分布。我们提出的
bridge module and regulation module是轻量级的和与模型无关的,可以很好地推广到主流的并行deep CTR模型以提高性能。在两个公共数据集和一个工业数据集上进行了大量的实验,以证明
EDCN优于SOTA baseline。此外,还验证了bridge module and regulation module与各种并行结构的CTR模型的兼容性。在华为广告平台进行的为期一个月的online A/B test显示,两个模块在CTR和eCPM方面分别比base模型提升了7.30%和4.85%。
46.1 基础概念
给定数据集
multi-fields的数据记录。CTR预估任务是对每个输入为了更好地预测在现实的复杂环境下的用户行为,互联网规模的工业推荐系统收集了大量的特征,包括用户画像(性别、年龄)、
item属性(名称、类目)、以及上下文信息(例如workday、位置)来构建训练数据集。对于数值特征(例如
bidding price、使用次数),常用的方法是离散化,包括:soft discretization:如AutoDis。hard discretization:通过将numerical features变换为categorical features,例如对数离散化(logarithm discretization)、和基于树的离散化。
然后,可以通过
field-aware one-hot encoding将multi-field categorical record转换为高维稀疏特征。例如,一个实例(Gender=Male, Age=18, Category=Electronics, ..., Weekday=Monday)可以被表示为:对于遵循
feature embedding & feature interaction范式的基于深度学习的CTR模型,它应用embedding layer将每个稀疏向量转换为低维稠密向量,这通常称为feature embedding。对于第categorical field,可以通过embedding look-up操作获得feature embedding:其中:
embedding矩阵,vocabulary规模,embedding size。one-hot向量。
因此,
embedding layer的结果表示为:其中
field数量,然后,
feature embedding被馈入到堆叠结构或并行结构的模型中,从而捕获explicit/implicit feature interactions。接着通过判别函数CTR得分。DCN:DCN是一个典型的并行结构的CTR模型,它将embeddingfeature interaction。具体而言,这两个网络中的cross layers和deep layers分别表示为:其中:
cross layer的输出,cross layer的权重参数和偏置参数。deep layer的输出,deep layer的权重参数和偏置参数。
注意,交叉网络和深度网络的输入是相同的,即
最后,交叉网络和深度网络的结果在最后一层(第
其中:
sigmoid函数。
然而,简单的共享策略限制了
DCN的表达能力和有效性。一方面,交叉网络和深度网络是独立的,学到的
representations直到最后一层才融合。另一方面,交叉网络和深度网络都以相同的
embeddingfeature selection的重视。
这两个缺陷阻碍了
DCN中effective feature interactions的学习过程,导致性能不佳。为了克服这些问题,我们提出了一种Enhanced Deep & Cross Network: EDCN,它有两个模块,即bridge module和regulation module,将在下一节中介绍。
46.2 EDCN
EDCN的架构如Figure 4所示,与原始DCN相比,它包括两个核心模块,即bridge module和regulation module。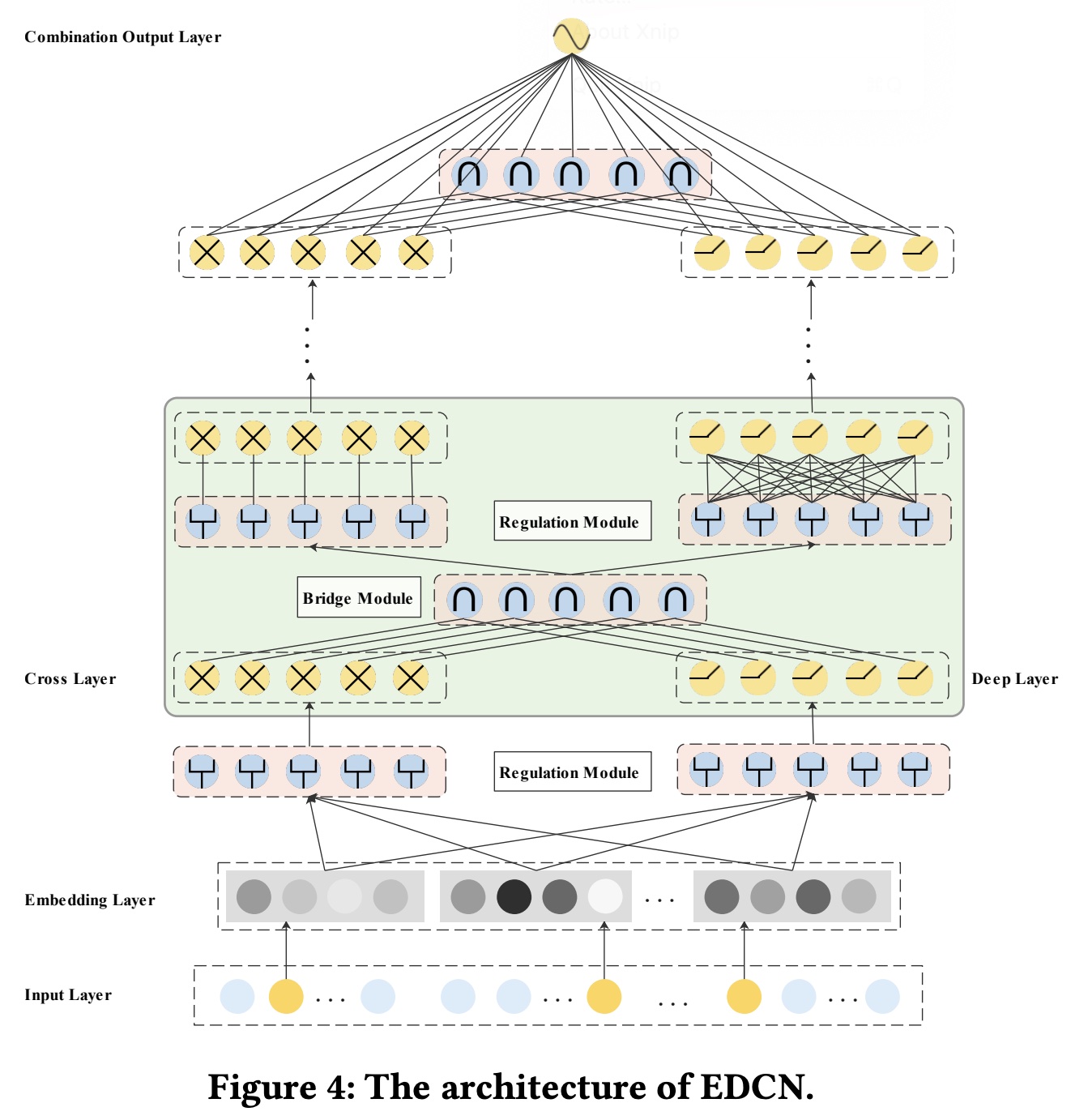
46.2.1 Bridge Module
现有的并行的
deep CTR模型分别通过两个并行子网络学习显式的和隐式的feature interactions,例如DeepFM、DCN、xDeepFM和AutoInt。两个子网络分开独立运行,这意味着直到最后一层才进行信息融合,这称为后期融合(late fusion)。后期融合策略无法捕获在中间层(intermediate layers)中两个并行网络之间的相关性,从而削弱了explicit and implicit feature interaction之间的交互信号。此外,每个子网络中冗长的updating progress可能导致反向传播过程中梯度倾斜(《 Dense multimodal fusion for hierarchically joint representation》),从而阻碍两个网络的学习过程。为了克服这一限制,我们引入了一种
dense fusion策略,该策略由我们提出的bridge module实现,以捕获两个并行网络之间的layer-wise交互信号。与仅在子网络的最后一层执行信息共享的late fusion不同,dense fusion在每一层共享中间信息(intermediate information),利用multi-level交互信号,并缓解梯度问题。Figure 3展示了late fusion和dense fusion之间的比较。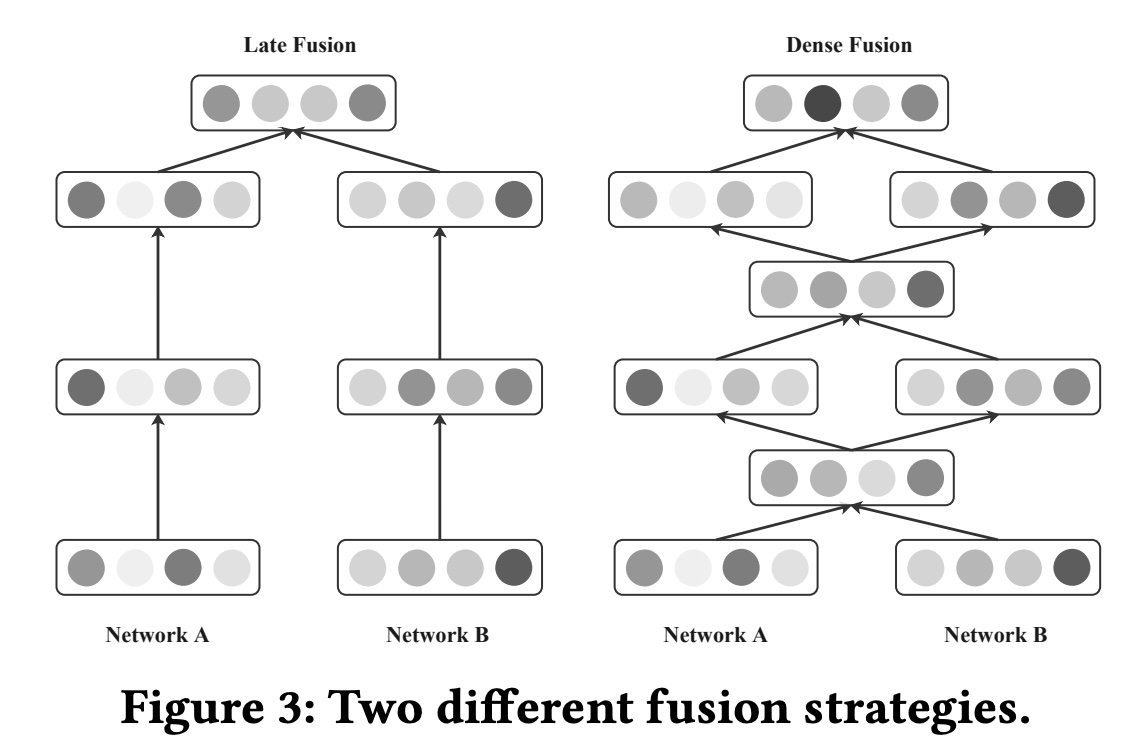
更具体地说,在
EDCN中,在每对cross layer and deep layer之后插入一个bridge module,从而捕获有效的layer-wise交互。正式地,假设第cross layer和第deep layer的输出记作bridge module可以表示为Pointwise Addition:逐元素地计算输入向量的element-wise sum。它没有parameters,公式为Hadamard Product:逐元素地计算输入向量的element-wise乘积 。它也没有parameters,公式为Concatenation:将输入向量拼接起来,并传递到具有ReLU激活函数的feed-forward layer,以保持输出向量的维度为bridge module第Attention Pooling:利用self-attention network来衡量两个输入向量的重要性,并相应地执行attentive pooling。该交互函数记作:bridge module第attention weights。
其中,
bridge module第transform weight parameter。这两个子网络共享相同的
attention参数。总而言之,
bridge module充当连接explicit and implicit modeling networks的桥梁,加强了网络之间的交互信号,避免了反向传播过程中的倾斜梯度。我们在消融研究中对上述四个函数进行了实证比较。
46.2.2 Regulation Module
具有并行结构的
deep CTR模型基于shared embeddings来同时利用显式的和隐式的特征。显式的feature interactions通常使用预定义的交互函数来建模,以有效探索bounded-degree interaction(例如,DCN中的cross network);而隐式的feature interactions主要通过全连接层来学习。直观地讲,不同的特征适合不同的交互函数,如AutoFeature论文中所观察到的。因此,需要仔细为两个并行网络选择不同的特征,而不是像DCN那样将所有特征平等地馈入这两个网络。受
MMoE中使用的门控机制的启发,我们提出了一个regulation module,由field-wise gating network实现,为每个并行网络soft-select差异化的特征分布。具体而言,假设有field-wise门控单元为:其中:实数
field的门控权重(gating weight)。注意:这里的门控单元是
free-parameter,而不是由input来决定的(有一种做法是将input馈入一个子网络从而得到门控单元)。论文的实验部分表明,这种方法的效果反而更好。读者猜测这是因为:可以视为对所有样本都相同的全局门控参数,与样本无关,因此训练更加稳定。为了获得差异化的特征分布,对
Softmax激活函数,得到:其中:
field的gating score。因此,网络regulated representation除了
shared embedding layer之外,我们还将regulation module与每个bridge module一起执行,如Figure 4所示。请注意,
DCN中的交叉网络实际上是xDeepFM论文中所示。换句话说,field信息仍然存在于bridge module的fused representation中。因此,bridge module之后的regulation module的工作原理,与shared embedding layer的regulation module相同。这段话是解释:为什么在
bridge module的output representation上应用regulation module。
46.2.3 Combination Output Layer
堆叠
logits layer进行预测。假设第cross layer, deep layer and bridge module的输出分别为EDCN的结果表示为:其中,
有没有必要将
bridge module的输出拼接进来?读者认为,这样就相当于三个子网络,而不是原始DCN的两个子网络,因此比DCN更强是可以预期的(表达能力更强)。损失函数是广泛使用的带有正则化项的
LogLoss,如下所示:其中:
L2正则化权重,
46.2.4 讨论
复杂度分析:这里分析
bridge module and regulation module的时间复杂度和空间复杂度。将
embedding size记作Hadamard Product作为bridge module中的交互函数,因为它在实验中实现了最佳性能。由于无参数的逐元素乘积,单个
bridge module的时间复杂度和空间复杂度分别为此外,由于计算
regulation module的时间复杂度也为field-wise的,其空间复杂度为
上述分析表明这两个模块是轻量级的,关于模型效率的实证研究将在实验部分详细阐述。
兼容性分析:
EDCN提出了两个核心模块,即bridge module and regulation module,可以无缝应用于主流的并行结构的模型,如DeepFM、DCN、xDeepFM、AutoInt等。bridge module捕获不同并行网络之间的layer-wise interaction,增强跨网络的交互信号。而
regulation module可以为不同的并行网络来区分特征分布。
这两个模块可以很好地推广到并行结构的模型,这由实验部分中阐述的兼容性研究所证明。具体而言,为了应对隐式网络和显式网络具有不同层的情况,我们利用层数较少的子网络的最后一层输出与另一个子网络重复执行桥接操作。
46.3 实验
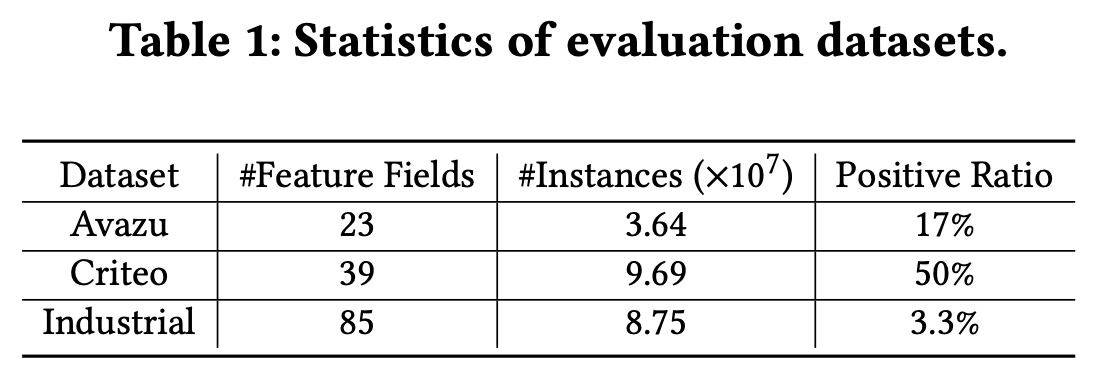
数据集:两个流行的
benchmarks(即Avazu、Criteo)和一个工业数据集。Table 1总结了所有三个数据集的统计数据。Avazu数据集包含23个fields,涵盖从user/device特征到广告属性。我们以8:1:1的比例将数据集随机分为训练集、验证集和测试集。Criteo数据集包含26个categorical fields和13个numerical fields,其中第1-7天用于训练,第8天和第9天分别用于验证和测试。我们遵循PNN中的相同数据处理程序,通过执行negative down-sampling以保持positive ratio接近50%,并将数值特征转换为categorical特征。工业数据集包含从华为广告平台采样的连续
9天的点击日志。该数据集的feature set由44个categorical特征和41个numerical特征组成,它们通过各种混杂的、手动设计的规则进行离散化。我们将第1-7天设置为训练集,第8天设置为验证集,第9天设置为测试集。
评估指标:
AUC, LogLoss。所有实验重复5次以获得平均性能。进行two-tailed unpaired t-test以检测EDCN与best baseline之间的显著差异。baseline与实现细节:为了证明
EDCN的有效性,我们将它与代表性的deep CTR模型进行了比较,包括FNN、Wide & Deep、DeepFM、DCN、DCN-V2、xDeepFM、AutoInt和PNN。所有模型均在
TensorFlow上实现,我们使用mini-batch Adam对所有模型进行优化,其中学习率从batch size固定为2000。此外,embedding size设置为40。deep network的隐层默认固定为400-400-400,并应用Batch Normalization。L2正则化的权重从dropout rate从具体来说,
DCN、DCN-V2和xDeepFM中用于建模显式的feature interactions的网络结构(即CrossNet和CIN)均设置为3层。AutoInt中multi-head attention的head设为12、attention factor设为20。默认情况下,bridge module中的交互函数选择Hadamard Product。regulation module中的1.0,以确保开始时每个field的权重相等。
46.3.1 性能比较
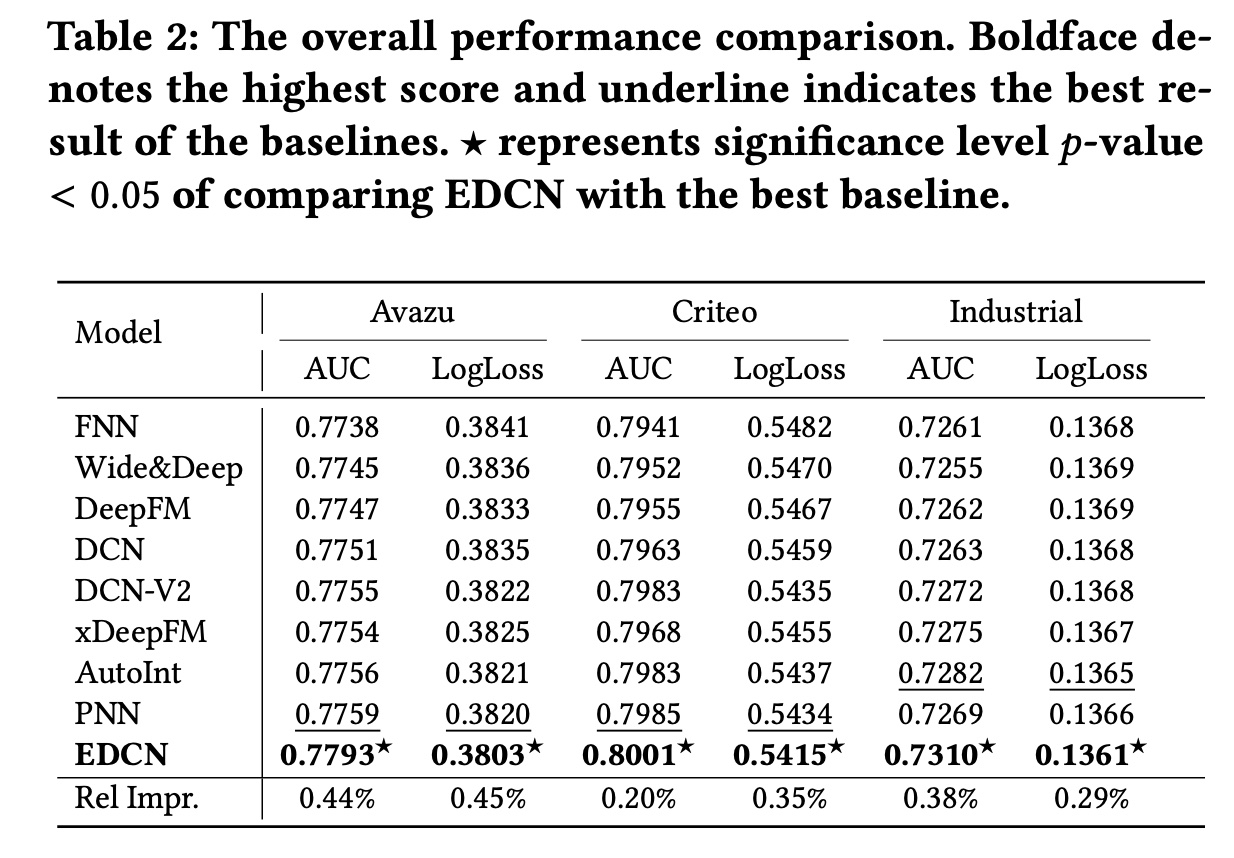
Table 2展示了模型在这三个数据集上的表现,从中我们得到以下观察结果:在三个数据集上,
EDCN在AUC和LogLoss方面的表现都远远优于所有SOTA baselines,这证明了EDCN在CTR预测任务中的卓越性能。在三个数据集上,与原始
DCN模型相比,EDCN的AUC分别提高了0.54%、0.48%和0.65%。我们认为这一显著改进归因于以下原因:(1):基于dense fusion策略的bridge module有助于加强并行网络之间的layer-wise interaction and supervision。虽然deep layers的网络宽度被扩展为与embedding layer相同,但性能的提高并不是通过额外的hidden neurons来实现的(因为在三个数据集上extended-width DCN实现的平均AUC仅提高了不到0.03%)。(2):regulation module调制了shared embeddings和fused information,将差异化的特征分布传递到不同的子网络中,这帮助子网络soft-select合适的特征。
46.3.2 与不同模型的兼容性分析
Bridge Module的兼容性分析:为了证明我们提出的bridge module的兼容性,我们在三种流行的deep parallel CTR模型(即xDeepFM、DCN和DCN-V2)中为每个hidden layer引入了bridge module。配备bridge module的模型从
Table 3中,我们可以观察到bridge module一致性地提高了deep parallel CTR模型的性能。AUC指标的平均改进分别为xDeepFM上改进0.13%、DCN上改进0.42%和DCN-V2上改进0.20%,这证明了bridge module的有效性。原因在于layer-wise bridge module利用dense fusion策略来捕获interactive correlation signals,并随后为explicit and implicit feature modeling带来好处。此外,由于引入了不同子网络之间的multi-paths,反向传播时梯度更新更加均衡,从而可以很好地缓解梯度倾斜问题。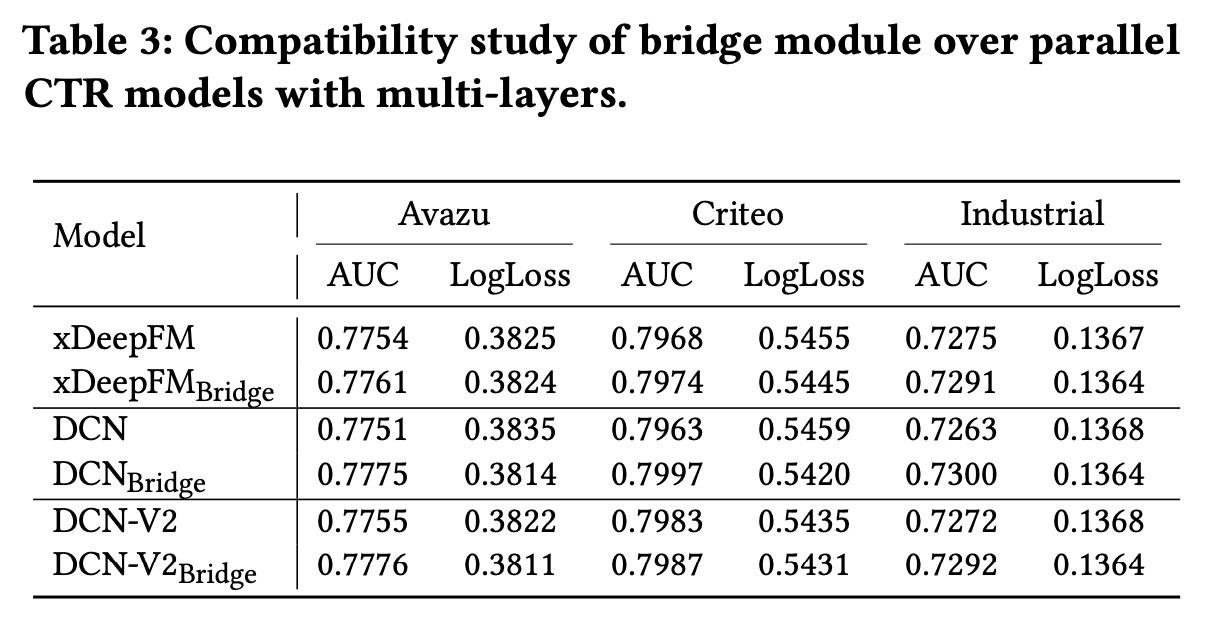
Regulation Module的兼容性分析:我们提出的regulation module也是与模型无关的。在本节中,我们进行了广泛的实验来证明其兼容性,方法是将regulation module应用于五种SOTA的并行CTR模型:DeepFM、xDeepFM、AutoInt、DCN、DCN-V2以及late fusion策略,因此我们仅在embedding layer上执行regulation module。配备regulation module的模型EDCN。从Table 4中可以观察到一致的改进。如前所述,
regulation module差异化特征分布并将它们传递到不同的子网络中,在这些子网络中将分别利用不同的feature collections。从反向传播的角度来看,由于并行结构的模型中的shared embeddings,来自多个子网络的梯度可能会在一定程度上相互冲突。通过regulation module,在反向传播到embedding layer之前对梯度进行调制,从而缓解梯度冲突。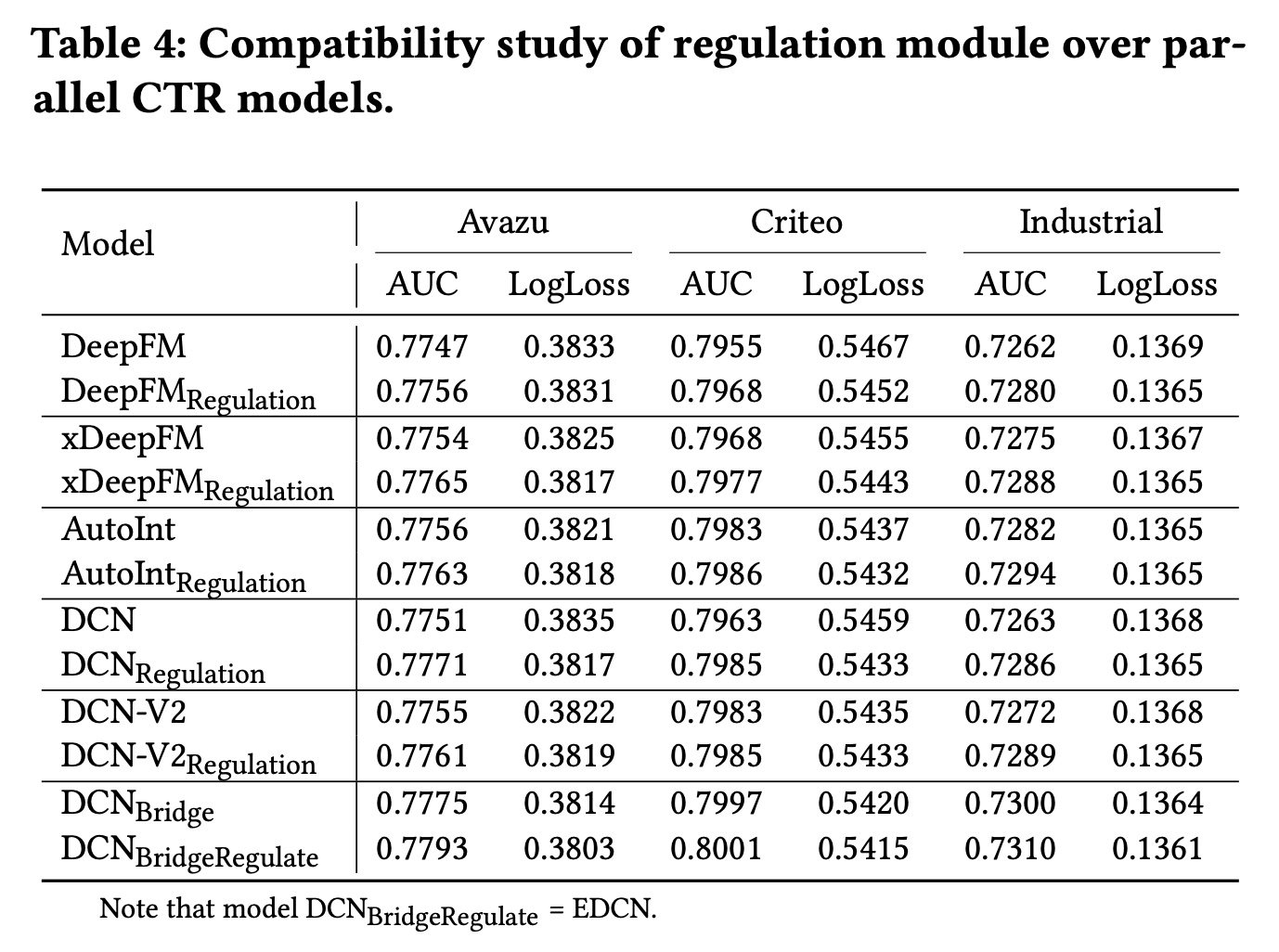
46.3.3 Regulation Module 的分析
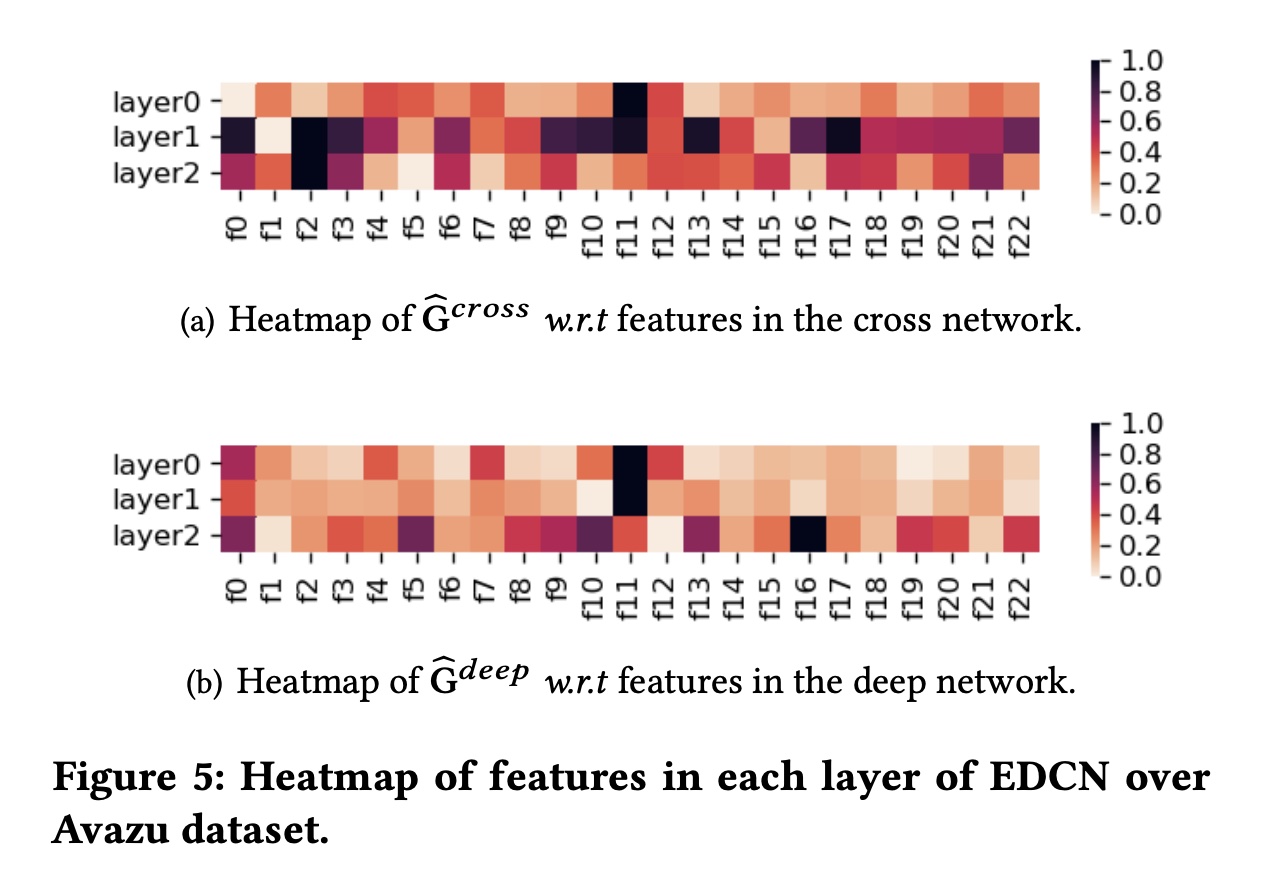
为了生动地说明
regulation module的feature regulation结果,我们将EDCN中并行网络的每个hidden layer的权重分布min-max归一化将每个元素[0,1]之间以直观呈现)。Avazu数据集上的结果如Figure 5所示。请注意,颜色越深,表示该field越倾向于相应的特征交互方式(即EDCN中的交叉网络和深度网络)。注意,图中的
从热力图中我们可以观察到特征分布在不同
layers和不同feature interaction方式之间有所不同。具体而言:对于交叉网络和深度网络,
f11在layer0和layer1中具有较大的权重。f2在交叉网络的layer2更具差异性,而f16在深度网络的layer2更具差异性。此外,交叉网络中的热力图更加多样化,表明某些
fields在bounded-degree explicit feature interaction中比其他fields发挥更重要的作用。相反,大多数fields对implicit feature interactions的贡献相对地相似。另一个观察结果是,随着层数的增加,不同子网络的偏好更加明显。特征分布在
layer0相对接近,而在layer 2则明显不同。因此,EDCN利用regulation module来soft-select差异化的特征分布,从而充分利用不同的特征。
47.3.4 消融研究
Bridge Module:为了比较bridge module中不同交互函数的性能,我们探索了四个交互函数EDCN-ADD)、hadamard product(EDCN-PROD)、拼接(EDCN-CON)、以及attention pooling(EDCN-ATT)。从
Figure 6可以看出,hadamard product的表现明显优于其他函数,这可能是由于以下原因。一方面,
hadamard product是无参数的,因此不涉及任何额外的learnable parameters,比有参数的方法(例如拼接和attention pooling)更容易稳定地训练。另一方面,与逐点加法相比,乘积操作是推荐模型中更好的
interaction modeling操作,如DeepFM, PNN, FM所示。
下图应该是
(a) Avazu,(b) Criteo。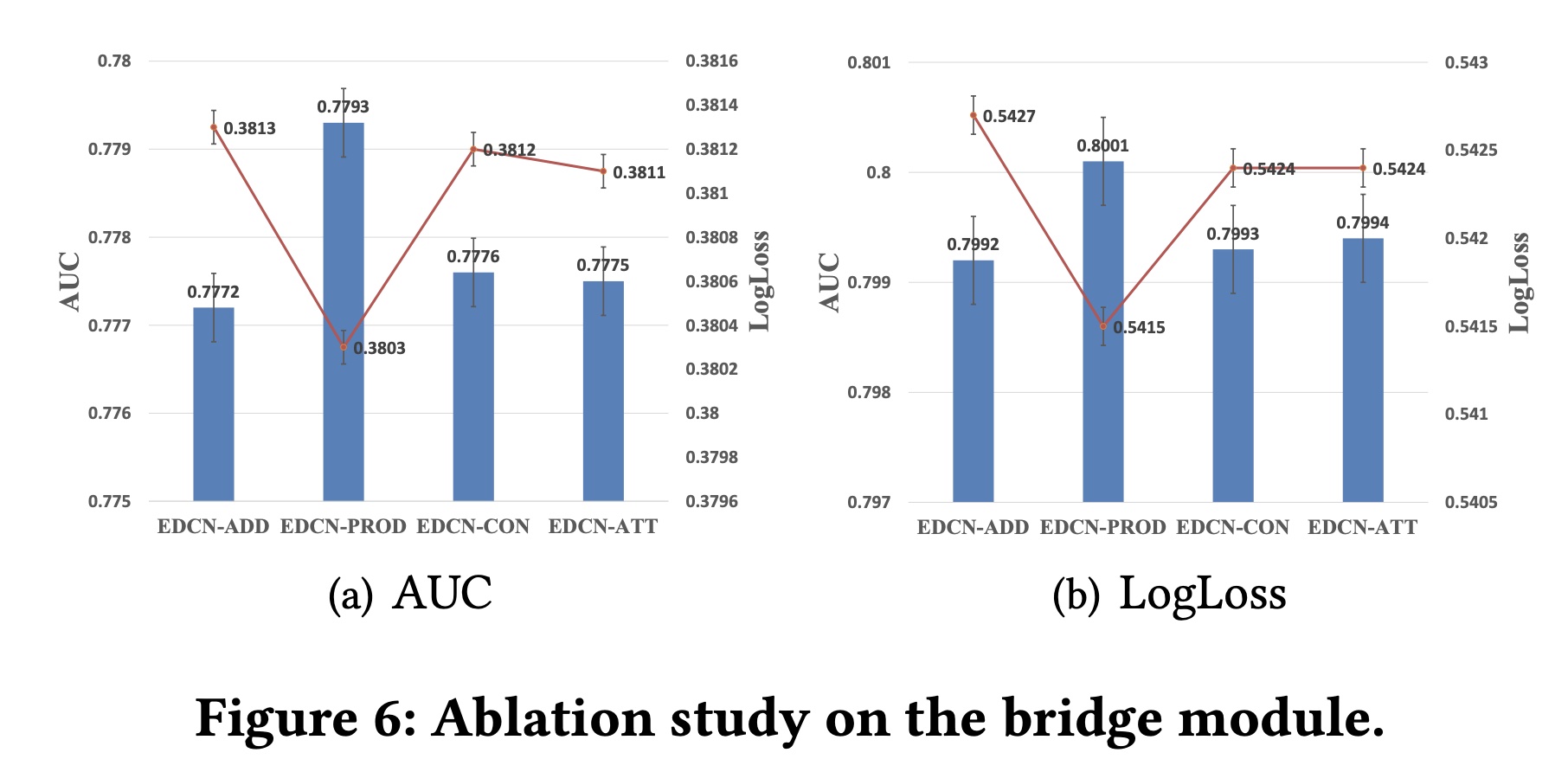
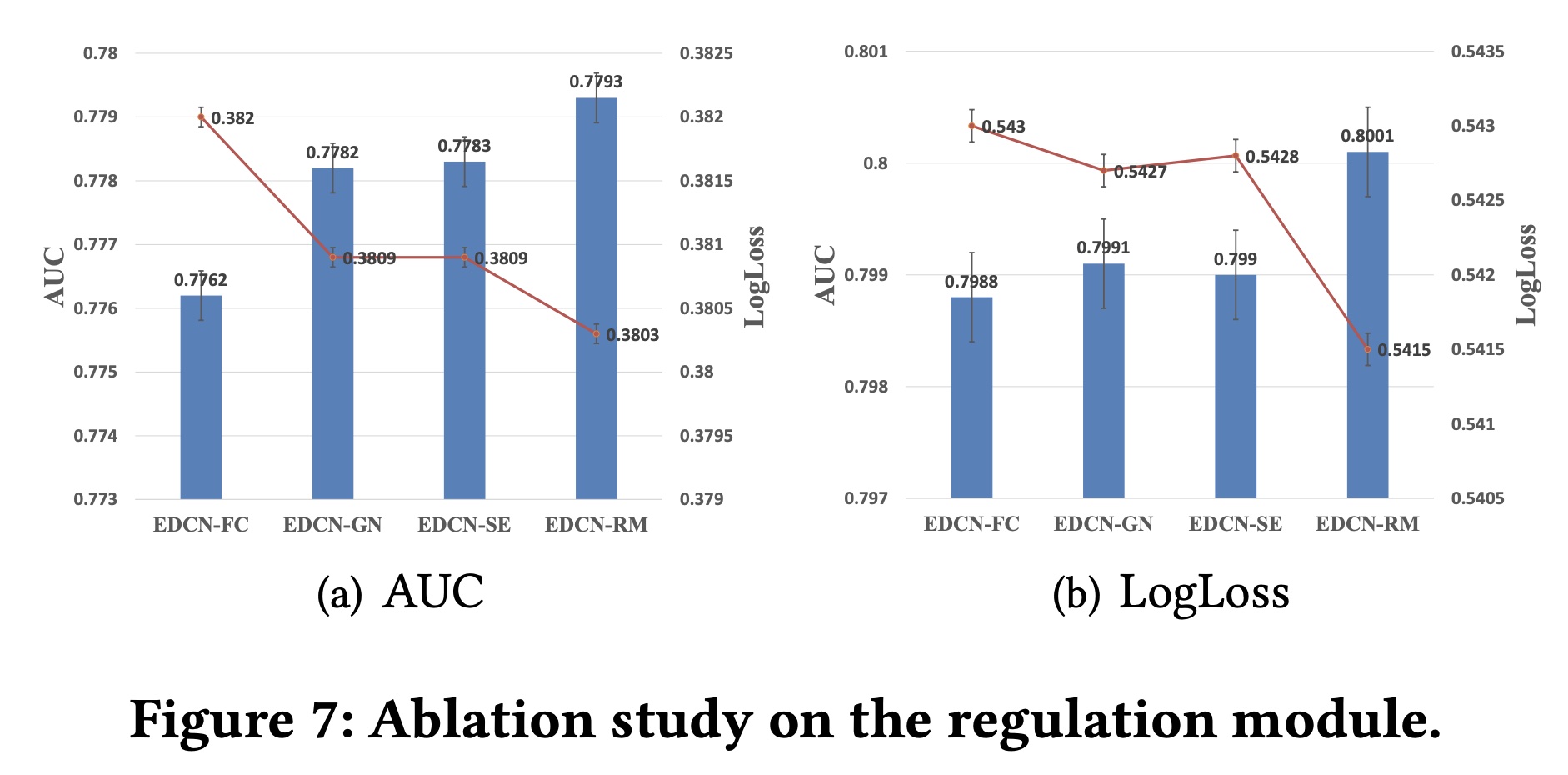
Regulation Module:为了证明我们提出的regulation module的有效性,我们进行了实验,用三种方法替换了regulation module (RM)。Fully connection (FC):全连接是一种常用的变换方法,从前一层提取representation。Squeeze-and-Excitation (SE):Squeeze-and-Excitation Networ执行Squeeze, Excitation and Re-Weight步骤,从而使用informative features来re-scale representation。GateNet (GN):GateNet提出feature embedding gate来从feature-level选择显著的信息(salient information)。
Figure 7显示了这些方法之间的比较。我们可以观察到:简单的
FC获得最差的结果。此外,与
nonregulation(即GN和SE方法在Avazu上取得了改进,而在Criteo上略有下降。RM始终比其他竞争对手取得显著改进,证明了我们提出的regulation module的有效性。
46.3.5 模型复杂度
为了定量分析我们提出的
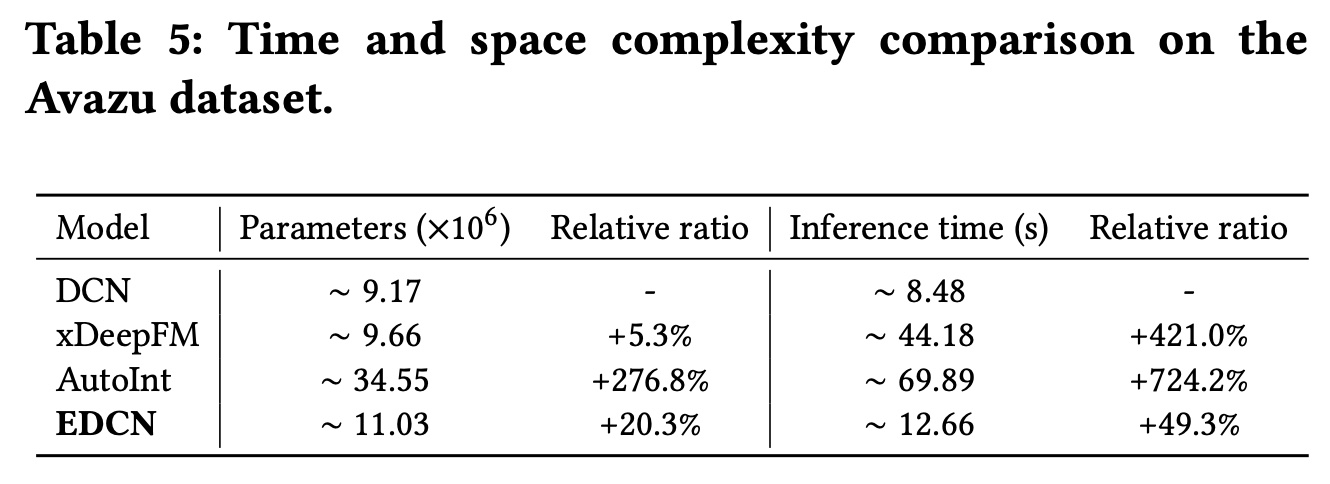
EDCN的空间复杂度和时间复杂度,我们比较了三个具有并行结构的代表性的deep CTR模型的模型参数和推理时间(在整个测试集上)。所有实验均在具有16G内存的NVIDIA Tesla P100-PCIE GPU上进行。Table 5报告了Avazu数据集上的比较结果。我们可以观察到:
与
DCN相比,EDCN增加的模型参数和推理时间是可以接受的,表明EDCN引入的两个模块在实际工业应用中是轻量级的和可行的。此外,
xDeepFM的推理时间比EDCN长得多,而EDCN增加的模型参数比AutoInt小得多。
46.3.6 Online A/B Test
online A/B test从3月10日到4月10日进行了一个月。比较的基线表示为bridge module和regulation module,命名为CTR和eCPM。连续
30天的在线结果表明,我们提出的模块比基线Table 6所示。我们可以观察到:在
Instant Access(Video Page)场景中,7.30%(2.42%)和4.85%(1.71%)的CTR和eCPM改进。此外,增加的
serving latency在工业界中也是可以接受的。
结果表明,
bridge module and regulation module在用户体验和平台收入方面带来了显著的性能改进,同时只有轻微的latency overload。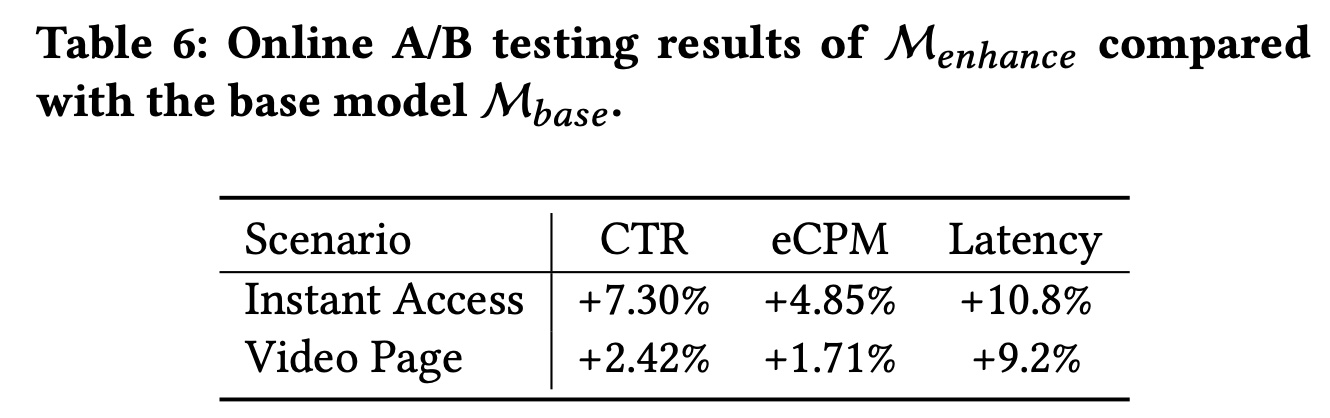
四十七、GDCN[2023]
《Towards Deeper, Lighter and Interpretable Cross Network for CTR Prediction》
有效地建模
feature interactions对于提高CTR模型的预测性能至关重要。然而,现有的方法面临三个重大挑战:首先,虽然大多数方法可以自动捕获高阶
feature interactions,但随着feature interactions的阶次增加,它们的性能往往会下降。其次,现有方法缺乏能力对预测结果提供令人信服的解释,特别是对于高阶
feature interactions,这限制了其预测的可信度。第三,许多方法都存在冗余参数,特别是在
embedding layer中。
本文提出了一种称为
Gated Deep Cross Network (GDCN)的新方法,以及一种Field-level Dimension Optimization (FDO)方法来应对这些挑战。作为GDCN的核心结构,Gated Cross Network (GCN)捕获显式的高阶feature interactions,并在每个阶次中使用information gate来动态地过滤important interactions。此外,我们使用FDO方法,根据每个field的重要性来学习condensed dimensions。在五个数据集上进行的综合实验证明了GDCN的有效性、优越性和可解释性。此外,我们验证了FDO在learning various dimensions和reducing model parameters方面的有效性。大多数
CTR建模方法通常由三种layer组成:feature embedding, feature interaction, and prediction。为了提高CTR预测的准确性,人们已经提出了许多专注于设计有效feature interaction架构的方法。然而,以前的工作,如Logistic Regression (LR)和FM-based的方法,只能建模低阶feature interactions或固定阶次的feature interactions。随着互联网规模的推荐系统变得越来越复杂,对捕获高阶feature interactions的方法的需求日益增长。因此,一些最新的方法能够对显式的和隐式的高阶feature interactions进行联合建模,并实现显著的性能改进。虽然这些方法取得了很大进展,但它们仍然有三个主要局限性:首先,随着
feature interactions阶次的增加,这些方法的有效性趋于下降。一般来说,所能够捕获的交互的最大阶次由feature interactions的depth决定。随着interaction layers的加深,interactions的数量呈指数增长,这使得模型能够生成更多的高阶交互。然而,并不是所有的交互都是有帮助的,这也带来了许多不必要的交互,导致性能下降和计算复杂度增加。许多现有的SOTA工作已经通过hyper-parameter analysis证实,当交互阶次超过一定深度(通常是三阶)时,它们的性能会下降。因此,至关重要的是进行改进从而确保高阶交互具有positive影响,而不是引入更多噪音并导致次优性能。其次,现有方法缺乏可解释性,限制了其
predictions and recommendations的可信度。大多数方法由于隐式的feature interactions(通过DNN)、或为所有feature interactions分配相等的权重,从而导致可解释性较低。尽管一些方法(《DCAP: Deep Cross Attentional Product Network for User Response Prediction》、《Interpretable click-through rate prediction through hierarchical attention》、《Autoint: Automatic feature interaction learning via selfattentive neural networks》)试图通过self-attention机制学到的attention scores来提供解释,但这种方法倾向于融合(fuse)所有features information,因此很难区分哪些交互是必不可少的,尤其是对于高阶的crosses。因此,开发方法能够从模型的和实例的角度来提供有说服力的解释,至关重要,从而实现更可靠的、更可信的结果。第三,大多数现有模型包含大量冗余参数,尤其是在
embedding layer中。许多方法依赖于feature-wise的交互结构,这些结构假设所有fields的embedding dimensions是相等的。然而,考虑到fields的信息容量,有些fields只需要相对较短的维度。因此,这些模型在embedding layer产生大量冗余参数。但直接降低embedding维度会导致模型性能下降。同时,大多数方法仅侧重于减少non-embedding参数,与减少embedding参数相比,对整体参数减少的影响并不显著。尽管DCN和DCN-V2使用经验公式为每个field分配不同的维度,该公式仅基于feature numbers来计算维度,但它们忽略了每个field的重要性,并且经常无法减少模型参数。因此,我们的目标是为每个field分配field-specific and condensed dimensions,考虑其固有的重要性,并有效减少embedding参数。
本文提出了一种称为
Gated Deep Cross Network (GDCN)的模型、以及一种称为Field-level Dimension Optimization (FDO)的方法来解决上述限制。在DCN-V2优雅而高效的设计的基础上,GDCN进一步提高了低阶交互和高阶交互的性能,并且在模型的和实例的视角下都表现出了很好的可解释性。GDCN通过提出的Gated Cross Network (GCN)对explicit feature interactions进行建模,然后与DNN集成以学习implicit feature interactions。GCN由两个核心组件组成:feature crossing和information gate。feature crossing组件在bounded degree内捕获显式的交互,而information gate则在每个cross order上选择性地放大重要性高的important cross features并减轻不重要特征的影响。此外,考虑到field各自的重要性,FDO方法可以为每个field分配压缩的和独立的维度。贡献:
我们引入了一种新方法
GDCN,通过GCN和DNN学习显式的和隐式的feature interactions。GCN设计了一个information gate来动态地过滤next-order cross features并有效地控制信息流。与现有方法相比,GDCN在捕获更深层次的高阶交互方面表现出更高的性能和稳定性。我们开发了
FDO方法,为每个field分配压缩的维度,考虑到每个field固有的重要性。通过使用FDO,GCN仅以原始模型参数的23%实现了可比性能,并且以更小的模型大小、以及更快的训练速度超越了现有的SOTA模型。综合实验表明
GDCN在五个数据集上具有很高的有效性和泛化能力。此外,我们的方法在model level和instance level提供了出色的可解释性,增强了我们对模型预测的理解。
论文其实创新点不多也不大,更多的是工程上的工作。而且创新点之间(
GCN和FDO)没啥关系,强行拼凑一起得到一篇论文。
47.1 GDCN
受
DCN-V2的启发,我们开发了GDCN,它由embedding layer、gated cross network (GCN)和deep network (DNN)组成。embedding layer将高维稀疏的输入转换为低维稠密的representations。GCN旨在捕获显式的feature interactions,并使用information gate来识别重要的交叉特征。然后,
DNN被集成进来从而建模隐式的feature crosses。
本质上,
GDCN是DCN-V2的泛化,继承了DCN-V2出色的表达能力,并具有简单而优雅的公式,易于部署。然而,GDCN通过采用information gates从而引入了一个关键的区别,它在每个阶次中自适应地过滤交叉特征,而不是统一聚合所有特征。这使GDCN能够真正利用deeper的高阶cross-information,而不会出现性能下降,并为GDCN赋予了针对每个实例的动态可解释性。GDCN的架构如Figure 1所示,展示了结合GCN和DNN网络的两种结构:(a) GDCN-S and (b) GDCN-P。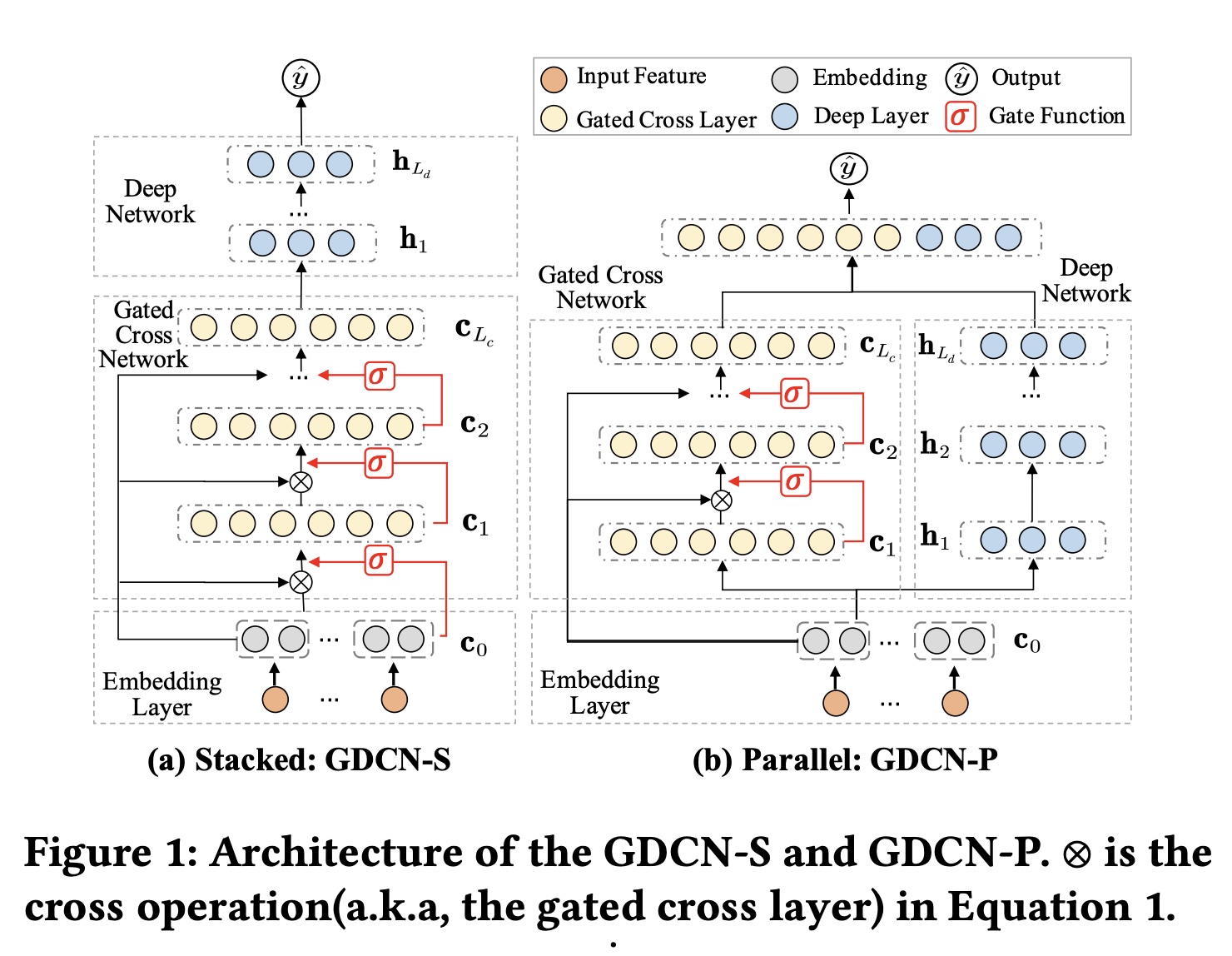
Embedding Layer:输入实例通常是multi-field tabular data records,其中包含fields和field-aware one-hot vector来表示。embedding layer将稀疏的高维特征转换为稠密的低维embedding matrixCTR模型要求embedding维度相同,从而匹配特定的interaction操作。然而,GDCN允许任意embedding维度,并且embedding layer的输出以向量拼接来表示:Gated Cross Network (GCN):作为GDCN的核心结构,GCN旨在通过information gate来建模显式的有界的feature crosses。GCN的第gated cross layer表示为:其中:
embedding layer的base input,其中包含一阶特征。gated cross layer(即,第gated cross layer)的输出特征,用作当前第gated cross layer的输入。gated cross layer的输出。sigmoid函数,
Figure 2可视化了gated cross layer的过程。下图中的
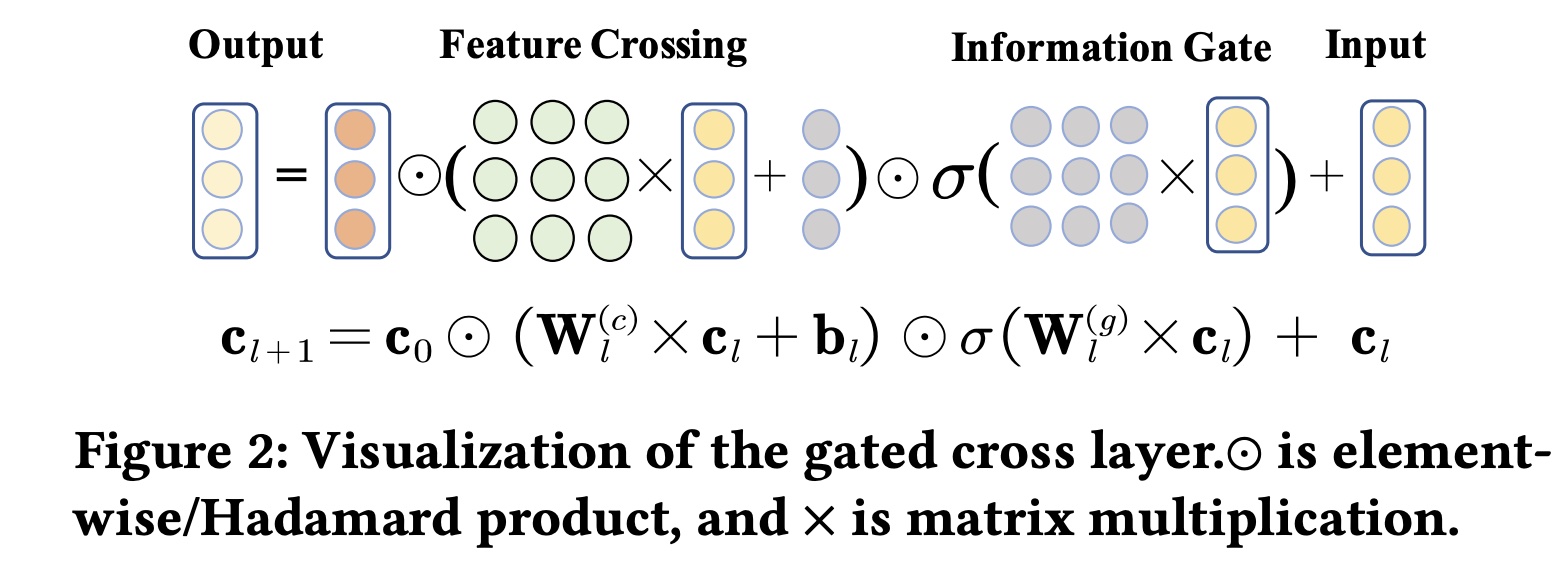
在每个
gated cross layer中,都有两个核心组件:feature crossing和information gate,如公式和Figure 2所示。feature crossing组件以bit-level计算一阶特征cross matrix),表示第field之间的固有重要性。但是,并非所有的
positive影响。随着cross depth的增加,交叉特征呈现指数级增长,这会引入交叉噪声并可能导致性能不佳。为了解决这个问题,我们引入了
information gate组件。作为soft gate,它自适应地学习第sigmoid函数gate values。然后将它们逐元素乘以feature crossing的结果。此过程放大了重要特征,并减轻了不重要特征的影响。随着cross layers数量的增加,每个cross layer的information gate都会过滤下一阶次的交叉特征并有效控制信息流。
最后,通过将输入
feature crossing and information gate的结果相加,生成最终的output cross vector0阶到第事实上,
GCN是DCN的变体,区别在与GCN多了一个Information Gate而已。那么,是否有更好的Information Gate?比如,直接用information gate的输入?Deep Neural Network (DNN):DNN的目标是建模隐式feature interactions。DNN的每个deep layer表示为:其中:
deep layer中可学习的权重矩阵和偏置向量。deep layer的input和output,ReLU。
整合
GCN和DNN:现有的研究主要采用两种结构来整合显式的和隐式的交互信息:堆叠和并行。因此,我们也以两种方式将GCN和DNN结合起来,得到了两个版本的GDCN。Figure 1(a)展示了堆叠结构:GDCN-S。embedding向量GCN并输出然后
DNN从而生成最终的交叉向量
gated cross layer and deep network的深度。Figure 1(b)展示了并行结构:GDCN-P。embedding向量GCN和DNN中。GCN和DNN的输出(即
训练和预测:最后,我们通过标准的逻辑回归函数计算预测点击率:
其中:
sigmoid函数。
损失函数是广泛使用的二元交叉熵损失(又名
LogLoss):其中:
与
DCN-V2的关系:GDCN是DCN-V2的推广。当省略information gate或所有gate values都设置为1时,GDCN会退回到DCN-V2。在DCN-V2中,cross layer(即CN-V2)平等对待所有交叉特征并直接将它们聚合到下一个阶次,而未考虑不同交叉特征的不同重要性。然而,GDCN引入了GCN,在每个gated cross layer中都包含一个information gate。这个information gate自适应地学习所有交叉特征的bit-wise gate values,从而实现对每个交叉特征的重要性的细粒度控制。值得注意的是,GDCN和DCN-V2都能够建模bit-wise and vector-wise特征交叉,如DCN-V2中所示。虽然
GDCN和DCN-V2都使用了门控机制,但它们的目的和设计原理不同。DCN-V2引入了MMoE的思想,将cross matrix分解为多个较小的子空间或“专家”。然后,门控函数将这些专家组合在一起。这种方法主要减少了cross matrices中的non-embedding参数,同时保持了性能。不同的是,
GDCN利用门控机制自适应地选择重要的交叉特征,真正利用deeper的交叉特征,而不会降低性能。它提供了动态的instance-based的可解释性,可以更好地理解和分析模型的决策过程。
为了进一步提高
GDCN的cost-efficiency,接下来提出了一种field-level维度优化方法,以直接减少embedding参数。
47.2 FDO
embedding维度通常决定了编码信息的能力。然而,为所有field分配相同的维度会忽略不同field的信息容量。例如,“性别” 和“item id” 等field中的特征的数量范围从DCN-V2和DCN采用经验公式根据每个field的特征的数量,为每个field分配独立的维度,即field的真正重要性。 受FmFM的启发,我们使用后验的Field-level Dimension Optimization (FDO)方法,该方法根据每个field在特定数据集中的固有重要性来学习其独立的维度。首先,我们训练一个完整模型,采用固定的
field维度为16,正如先前的研究所建议的那样。此过程使我们能够为每个field生成一个informative embedding table。接下来,我们使用
PCA为每个field的embedding table计算一组奇异值,按奇异值的幅值(magnitude)降序排列。通过评估信息利用率(即information ratio),我们可以通过识别对整体information summation贡献最大的field选择合适的压缩维度。最后,我们使用上一步中学到的
field维度训练一个新模型。
实际上,我们只需要基于
full model学习一次一组field dimensions,然后在后续模型refresh时重复使用它。Table 1列出了具有80%和95%的information ratio时,每个field的优化后的维度。当保留
95%比率时,field维度范围为2到15。降低
information ratio会导致每个field的维度减少。具有大量特征的
field有时需要更高的维度,如在fields {#23, #24}中观察到的那样。然而,情况并非总是如此;例如,fields {#16, #25}表现出更小的维度。在实验部分中,我们提供了实验证据,表明field的维度与其在预测过程中的重要性密切相关,而不是其特征数量此外,通过保留超过
80%的information ratio,我们可以获得更轻的GCN模型,其性能略优于具有完整embedding维度的GCN模型,并超过其他SOTA模型。
我们还对
FDO进行了更全面的分析,以了解field维度与其固有重要性之间的联系。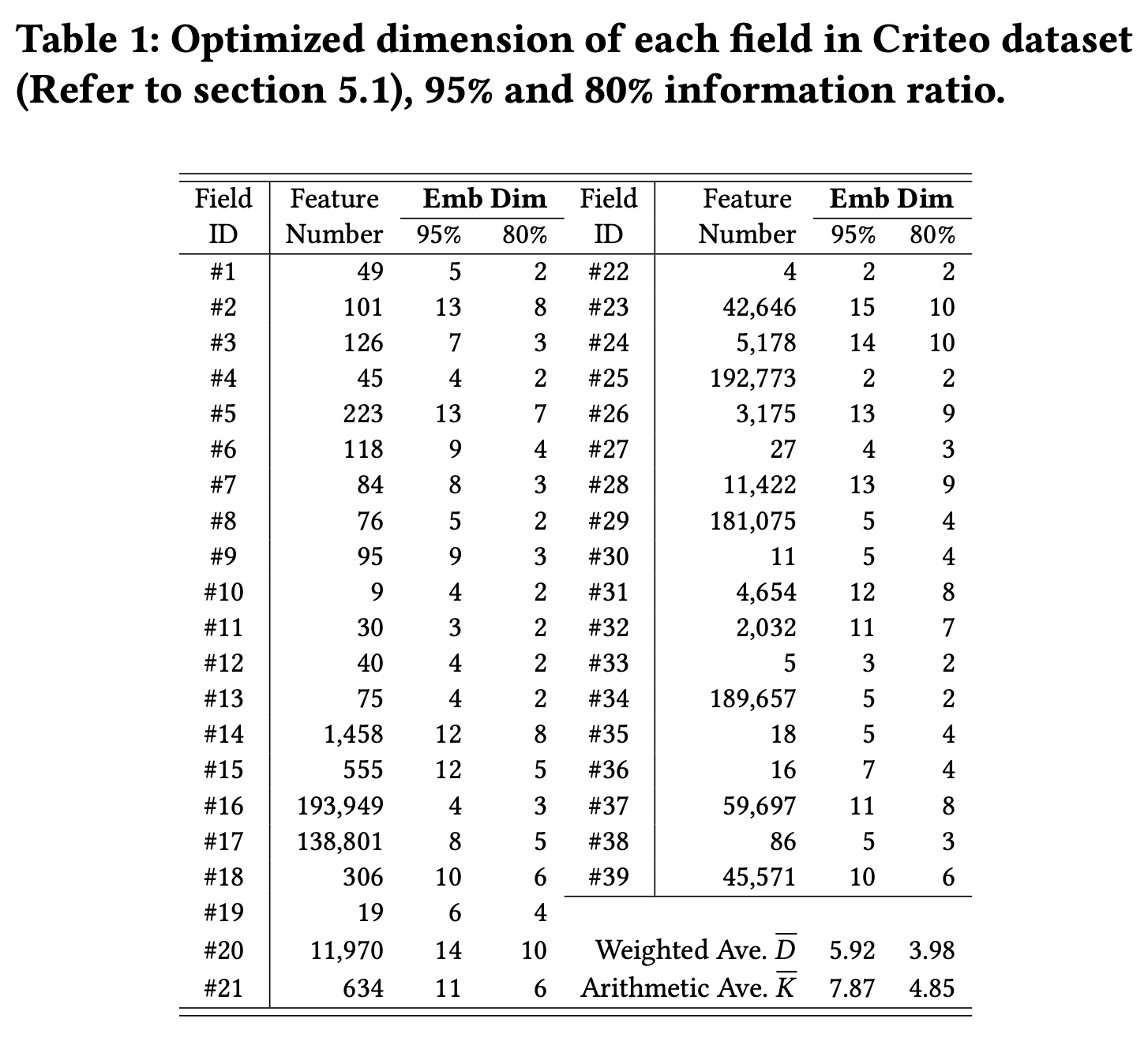
参数分析:定义:
embedding;feature representations子集,对应于第field,第
field中的特征的数量记作类似地,令
field的embedding维度,其中field的embedding维度。
对于一个输入的实例,算数平均的维度为
embedding layer的输出维度为embedding参数的总量为Criteo数据集中,原始特征数量超过30M,稀疏度超过99.99%,embedding参数占据了模型参数的绝大部分。因此,embedding参数的数量,而non-embedding参数的数量,例如DCN-V2和GCN中的cross matrix时间复杂度主要与
通过采用
FDO方法,我们可以通过缩小某些field的不必要维度来refine特征维度,以减少冗余的embedding参数。当使用固定维度
16时,embedding参数为然而,在
95% information ratio的FDO之后,embedding参数减少到embedding参数的37%。如果我们根据公式(即
field维度,加权平均维度18.66,导致emebdding参数为field分配了更大的维度,忽略了每个field的特定重要性。相比之下,FDO是一种后验方法,它基于从训练好的embedding table中提取的特定信息来学习field-level维度。
随着
field维度的降低,算术平均维度16降至7.87)。这样,GCN网络中的non-embedding参数,即cross matrixgate matrix
47.3 实验
数据集:
Criteo、Avazu、Malware、Frappe、ML-tag。这些数据集的统计数据如Table 2所示,详细描述可在给定的参考文献中找到。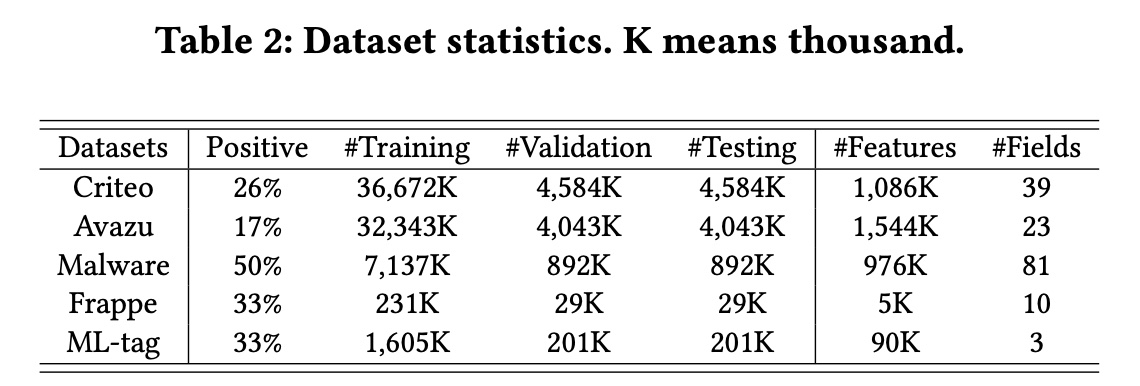
数据预处理:
首先,我们将每个数据集随机分成训练集(
80%)、验证集(10%)和测试集(10%)。其次,在
Criteo和Avazu中,我们删除某个field中出现次数少于阈值的低频特征,并将其视为dummy feature "<unkonwn>"。Criteo和Avazu的阈值分别设置为{10, 5}。最后,在
Criteo数据集中,我们通过将实数值1。这是Criteo竞赛的获胜者所采用的。
评估指标:
AUC、Logloss。baseline方法:我们与四类代表性的方法进行了比较。一阶方法,例如
LR。建模二阶交叉特征的基于
FM的方法,包括FM、FwFM、DIFM和FmFM。捕获高阶交叉特征的方法,包括
CrossNet(CN)、CIN、AutoInt、AFN、CN-V2、IPNN、OPNN、FINT、FiBiNET和SerMaskNet。代表性的集成/并行方法,包括
WDL、DeepFM、DCN、xDeepFM、AutoInt+、AFN+、DCN-V2、NON、FED和ParaMaskNet。
我们没有展示某些方法的结果,例如
CCPM、GBDT、FFM、HoFM、AFM、NFM,因为许多模型已经超越了它们。实现细节:
我们使用
Pytorch实现所有模型,并参考现有工作。我们使用
Adam优化器优化所有模型,默认学习率为0.001。我们在训练过程中使用Reduce-LR-On-Plateau scheduler,当性能在连续3 epochs停止改善时,将学习率降低10倍。我们在验证集上应用
patience = 5的早停(early stopping),以避免过拟合。batch size设置为4096。所有数据集的embedding维度均为16。根据先前的研究,我们对涉及
DNN的模型采用相同的结构(即3层,400-400-400),以便进行公平比较。除非另有说明,所有激活函数均为ReLU,dropout rate = 0.5。对于我们提出的
GCN、GDCN-S和GDCN-P,除非另有说明,默认的gated cross layer数量为3。对于其他
baseline,我们参考了两个benchmark工作(即BARS和FuxiCTR)及其原始文献来微调它们的超参数。
显著性检验:为了确保公平比较,我们在单个
GPU(NVIDIA TITAN V)上使用随机种子运行每种方法10次,并报告平均的测试性能。我们执行双尾t-test来检测我们的方法与最佳baseline方法之间的统计显着性。在所有实验中,与最佳baseline相比的改进具有统计学意义(Table 3和Table 4中用 ★ 表示。
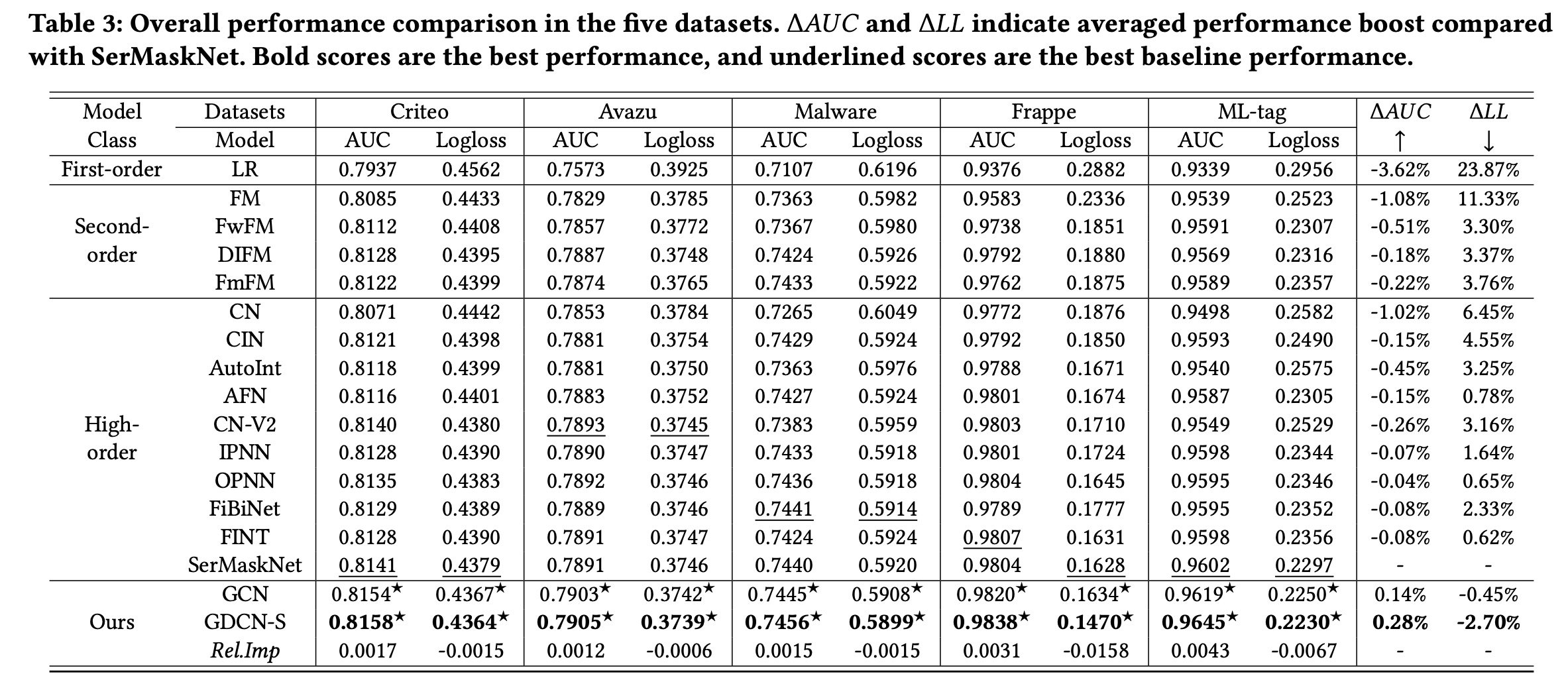
47.3.1 整体性能
注意,这里的结果是在没有应用
FDO的情况下得出的。
与堆叠式模型的比较:我们将
GCN和GDCN-S与stacked baseline模型进行比较,包括一阶、二阶和高阶模型。整体性能总结在Table 3中。我们有以下观察结果:首先,在大多数情况下,高阶模型优于一阶模型和二阶模型,证明了学习复杂的高阶
feature interactions的有效性。值得注意的是,OPNN、FiBiNet、FINT和SerMaskNet等模型表现更佳,它们使用一个stacked DNN同时捕获显式的和隐式的特征交叉。这证实了对显式的和隐式的高阶feature interactions进行建模背后的原理。其次,
GCN通过仅考虑显式的多项式feature interactions,始终优于所有堆叠的baseline模型。GCN是CN-V2的泛化,增加了一个information gate来识别有意义的交叉特征。GCN的性能验证了并非所有交叉特征都对最终预测有益,大量不相关的交互会引入不必要的噪音。通过自适应地re-weighting每个阶次中的交叉特征,GCN比CN-V2实现了显著的性能提升。此外,它优于SerMaskNet,平均0.14%,平均0.45%。第三,
GDCN-S超越了所有堆叠的baseline并实现最佳性能。在GDCN-S中,stacked DNN进一步学习GCN结构之上的隐式交互信息。因此,与其他堆叠式模型(例如OPNN、FINT和SerMaskNet)相比,GDCN-S优于GCN并实现更高的预测准确率。具体来说,与SerMaskNet相比,GDCN-S实现了平均0.28%(2.70%(
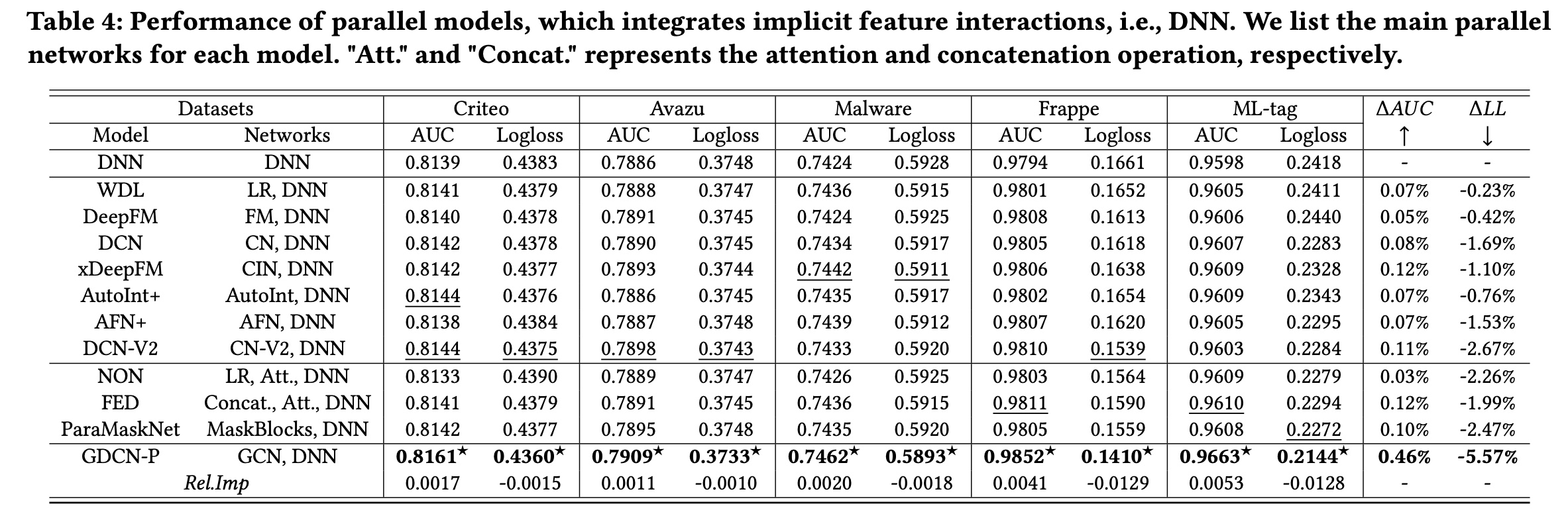
与并行式模型的比较:
Table 4展示了SOTA的ensemble/parallel模型的性能。每种方法都包含并行网络,例如DeepFM中的FM和DNN,以及DCN-V2中的CN-V2和DNN。此外,我们将这些模型与常规的DNN模型进行比较,并在此基础上计算首先,整合隐式的和显式的
feature interactions可以增强预测能力。DNN仅建模隐式的feature interactions,而将DNN与捕获显式feature interactions的其他网络相结合得到的并行模型优于单个网络。值得注意的是,GCN显示出最显著的平均性能改进,从0.46%和5.57%可以看出。这凸显了GCN与其他basic operation网络相比的卓越能力。其次,
GDCN-P的表现优于所有并行式模型和堆叠式模型。与Table 4中的并行式模型相比,GDCN-P实现了卓越的性能,超越了所有最佳baseline。此外,当考虑堆叠式模型并使用Table 3中的SerMaskNet作为benchmark时,GDCN-P实现了0.38%(4.26%(
47.3.2 Deeper 高阶特征交叉
通过改变
cross depth将GCN与其他模型进行比较:我们将GCN与五个可以捕获高阶交互的代表性模型进行比较,即AFN、FINT、CN-V2、DNN和IPNN。Figure 3说明了在Criteo数据集上随着cross depth的增加而出现的测试AUC和Logloss。随着交叉层的增加,五个被比较的模型的性能得到改善。然而,当
cross depth变得更深(例如,超过2、3或4个交叉层)时,它们的性能会显著下降。这些模型可以在功能上捕获更深的高阶显式和隐式的feature interactions,但高阶的交叉特征也会引入不必要的噪声,这可能会导致过拟合并导致结果下降。在许多SOTA工作中进行的cross depth超参数分析中也观察到了这个问题。相反,随着交叉层数从
1增加到8,GCN的性能不断提高。具体来说,与CN-V2模型相比,GCN包含了一个information gate。该information gate使GCN能够对每个阶次识别有用的交叉特征,并仅积累最终预测所需的信息。因此,即使cross depth变得更深,GCN的表现始终优于CN-V2和其他模型,验证了information gate设计的合理性。
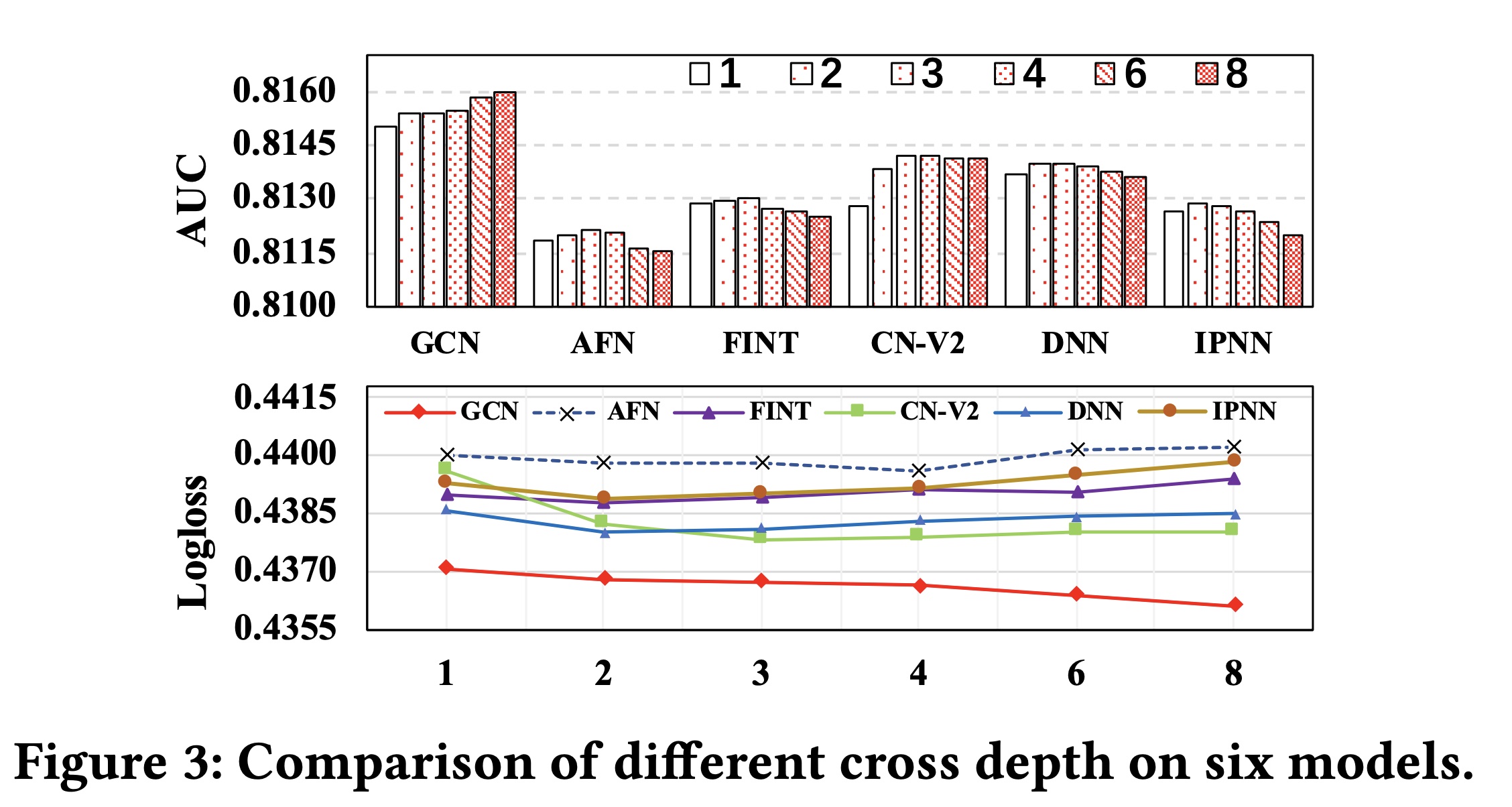
具有更深
gated cross layers的GCN和GDCN-P的性能:在Criteo和Malware数据集上,我们进一步将GCN和GDCN-P的cross depth从1增加到16。值得注意的是,我们将GDCN-P中的DNN深度固定在3,以防止DNN导致的过拟合。Figure 4展示了实验结果。随着
cross depth的增加,GCN和GDCN-P的性能都得到了改善,在GDCN-P中观察到的趋势与GCN的趋势一致。在加入
DNN组件后,GDCN-P的表现始终优于GCN,这凸显了使用DNN捕获隐式feature interactions的重要性。此外,
DNN使GDCN-P能够更早地获得最佳结果。具体来说,当深度超过8或10时,GCN的性能会达到稳定状态,而GDCN-P的阈值为4或6。尽管
GCN和GDCN-P可以选择有价值的交叉特征,但随着cross depth的增加,高阶交叉特征的有用性会急剧下降。这种现象符合人们的普遍直觉,即个人在做出决策(例如点击或购买item)时通常不会同时受到太多特征的影响。值得注意的是,在
cross depth超过稳定阈值后,我们的模型的性能保持稳定,而不是下降。
47.3.3 GCN 的可解释性
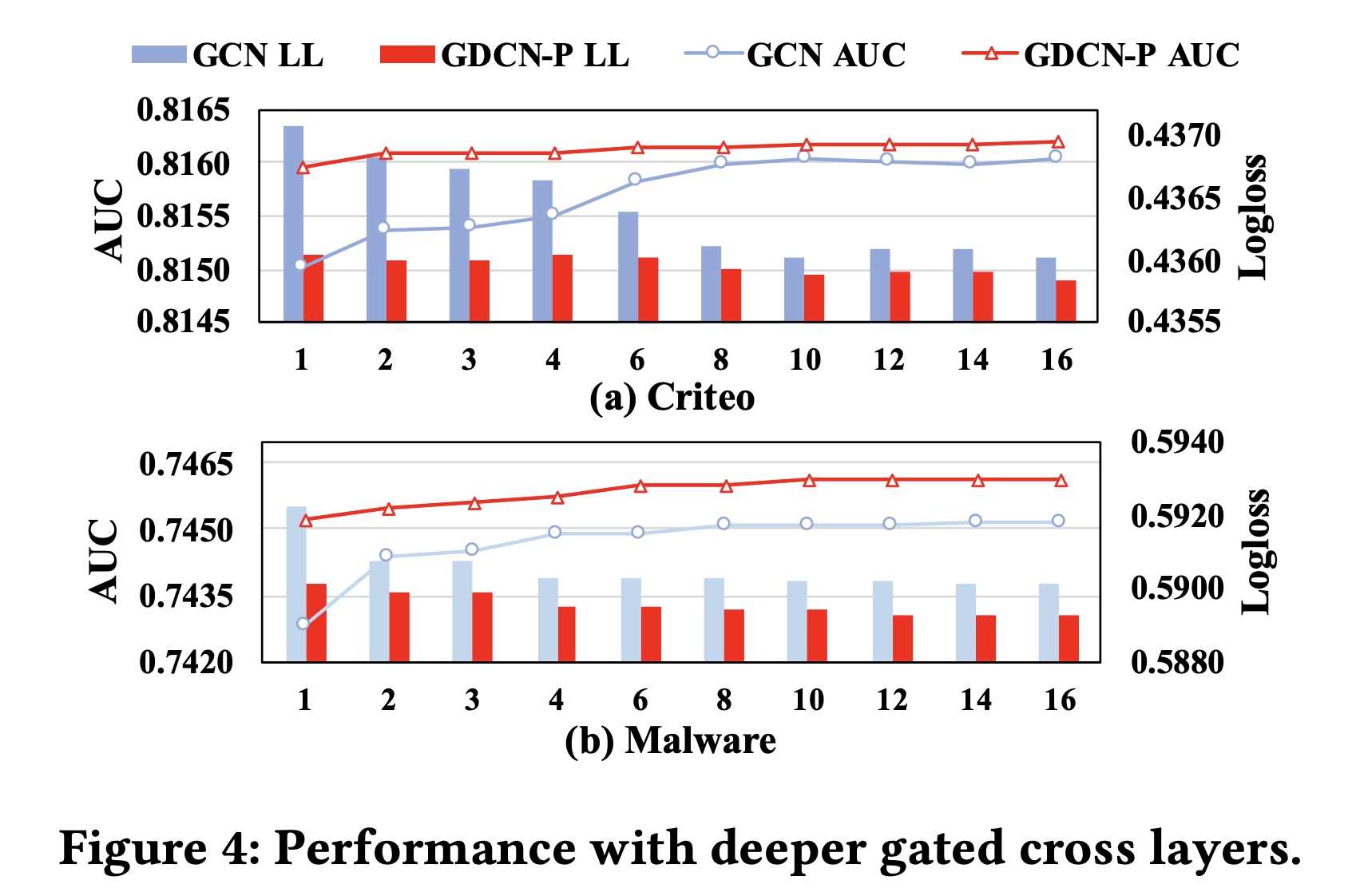
可解释性对于理解
specific predictions背后的原因、以及增强对预测结果的信心至关重要。GCN从模型的和实例的角度提供静态的和动态的解释,有助于全面理解模型的决策过程。静态的
model interpretability:在GCN中,交叉矩阵fields之间交互的相对重要性的指标。如果每个实例由F个fields组成,每个field具有相同的field sizebit-wise和block-wise的方式来表示:其中,每个分块矩阵
field和第field之间一阶交叉的重要性。当应用FDO学习各个field维度时,分块矩阵field和第field的不同维度。field与第field之间的一阶交叉的重要性。此外,随着交叉层的增加,相应的交叉矩阵可以进一步表明多个
field之间的固有的relation importance。Figure 5(a)展示了GCN在Criteo数据集上学到的第一阶交叉层的分块交叉矩阵DCN-V2类似,每个color box代表相应分块矩阵Frobenius范数,表示field cross的重要性。红色越深,表示学到的交叉越强,例如<#3, #2>和<#9, #6>。将
FDO方法应用于GCN时,GCN-FDO仍然能够捕获相似的交叉重要性,如Figure 5(b)所示。两个矩阵之间的余弦相似度为0.89,表明在应用FDO之前和之后,在捕获固有field cross重要性方面具有很强的一致性。
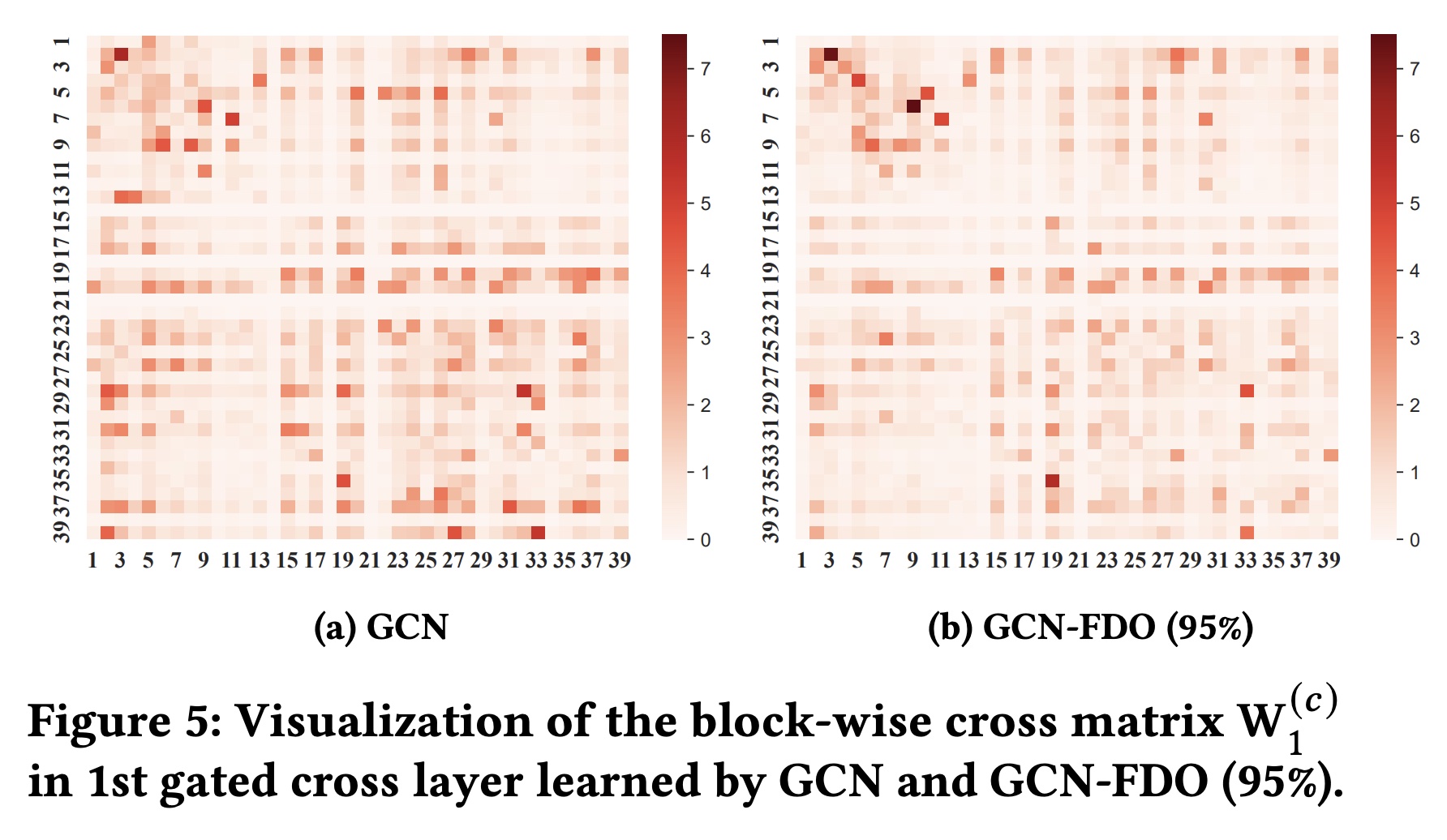
动态的
instance interpretability:基于模型的可解释性可以捕获不同field之间的静态关系,但由于模型训练完成后交叉矩阵保持不变,因此存在局限性。然而,GCN还通过information gate学到的gate weights提供动态可解释性,为每个input instance提供bit-wise的和field-wise的解释。我们从
Criteo数据集中随机选择两个实例来可视化学到的gate weights,并检查从第一个到第三个gated cross layer的gate values。Figure 6(a)展示了bit-wise gate weight vectors,每层的维度为bit-wise cross的重要性。使用bit-wise gate vector,我们通过对每个field对应的16-bit values取平均值来导出field-wise gate vectors。Figure 6(b)显示了field-wise gate weight vectors(specific feature的重要性。由于gated cross layer中的gate weights是使用sigmoid函数计算的,因此red blocks(大于0.5)表示重要特征,而blue blocks(小于0.5)表示不重要特征。
Figure 6(a)和Figure 6(b)揭示了bit-level和field-level的交叉特征的重要性,以及它们在每个实例的不同cross layers中是如何变化的。通常,低阶特征交叉包含更重要的特征,而高阶特征交叉包含不太重要的特征。在第一层中,许多特征交叉被标识为重要的(红色块),而在第二和第三交叉层中,大多数交叉是中性的(白色块)或不重要的(蓝色块),尤其是在第三层。这符合我们的直觉:随着交叉层的增加,重要的交叉特征的数量显著减少,因此我们设计了
information gate来自适应地选择重要特征。相反,大多数模型在建模高阶交叉时无法选择有用的特征交叉,导致性能下降,如《Deeper 高阶特征交叉》章节所证实的。此外,从
Figure 6(b)中,我们可以识别出重要的或不重要的特定特征,例如特征{#20, #23, #28}很重要,而特征{#6, #11, #30}不重要。我们还可以从input instance中引用这些specific important features的名称。一旦我们知道哪些特征有影响,我们就可以解释甚至干预有助于用户点击率的相关特征。
最后,在
Figure 7中,我们记录并平均了M个实例的field-level gate vectors,表明每个field的平均重要性,特别是在第一层。例如,field {#20, #23, #24}非常重要,而field {#11, #27, #30}相对较不重要。此外,Figure 7从统计角度进一步验证了随着交叉层的增加,重要交叉特征的数量显著减少。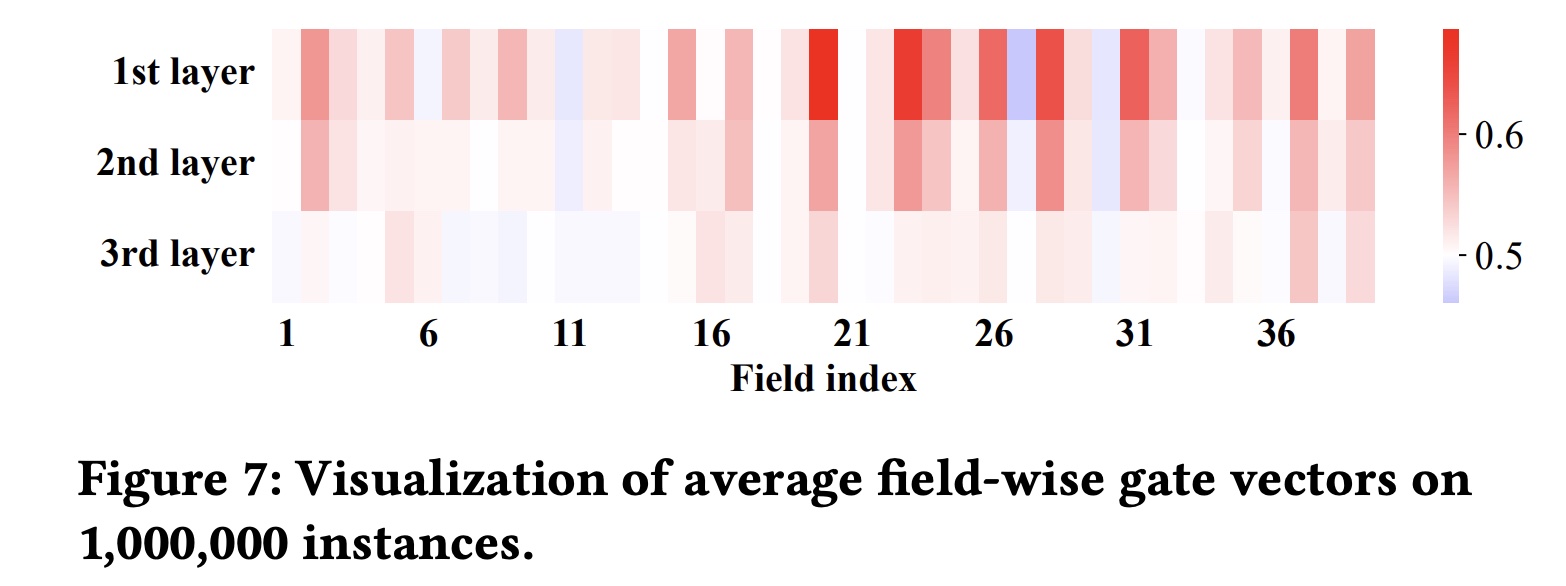
47.3.4 FDO 的综合分析
效果分析:我们将
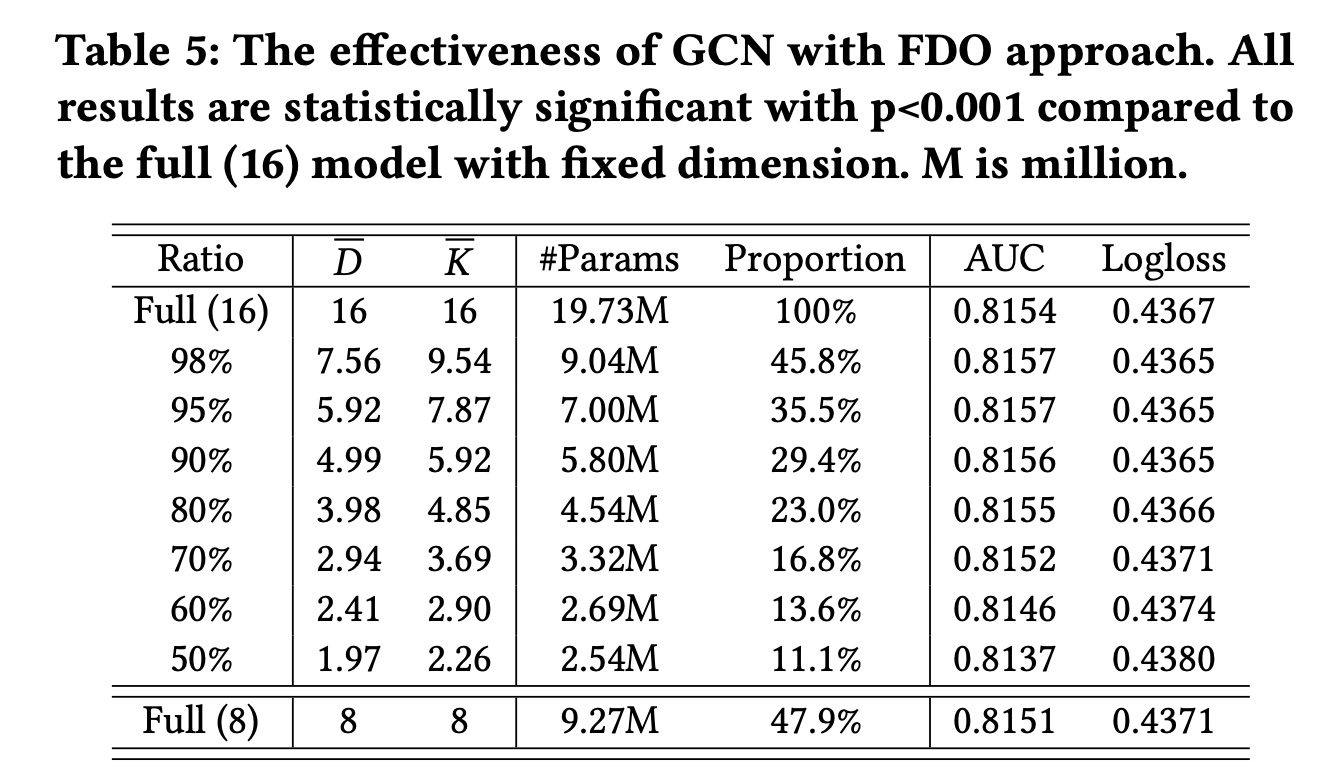
FDO方法应用于GCN,并通过保持information ratio从50%到98%来评估其性能。Table 5显示了结果,包括权重平均维度#Params)。当保持
80%的information ratio时,我们只需要23%的参数,而模型的性能与完整模型相当。此外,当
information ratio在80%到98%之间时,模型性能甚至比完整模型更好。这是因为FDOrefine了每个field的特征维度,消除了非必要的维度信息并减少了交叉过程中的冗余。然而,当
information ratio较低(即低于80%)时,较短的维度无法充分表示相应field的特征,导致预测性能显著下降。最后,我们将整个模型的维度从
16减少到8,大约相当于95%比率下的加权平均维度(7.56)。虽然它直接减少了模型的参数,但也导致了性能的下降。其他研究同样证实了减少embedding大小的负面影响。相比之下,FDO方法可以更直接地减少参数数量,同时实现相媲美的性能。
内存和效率比较:在
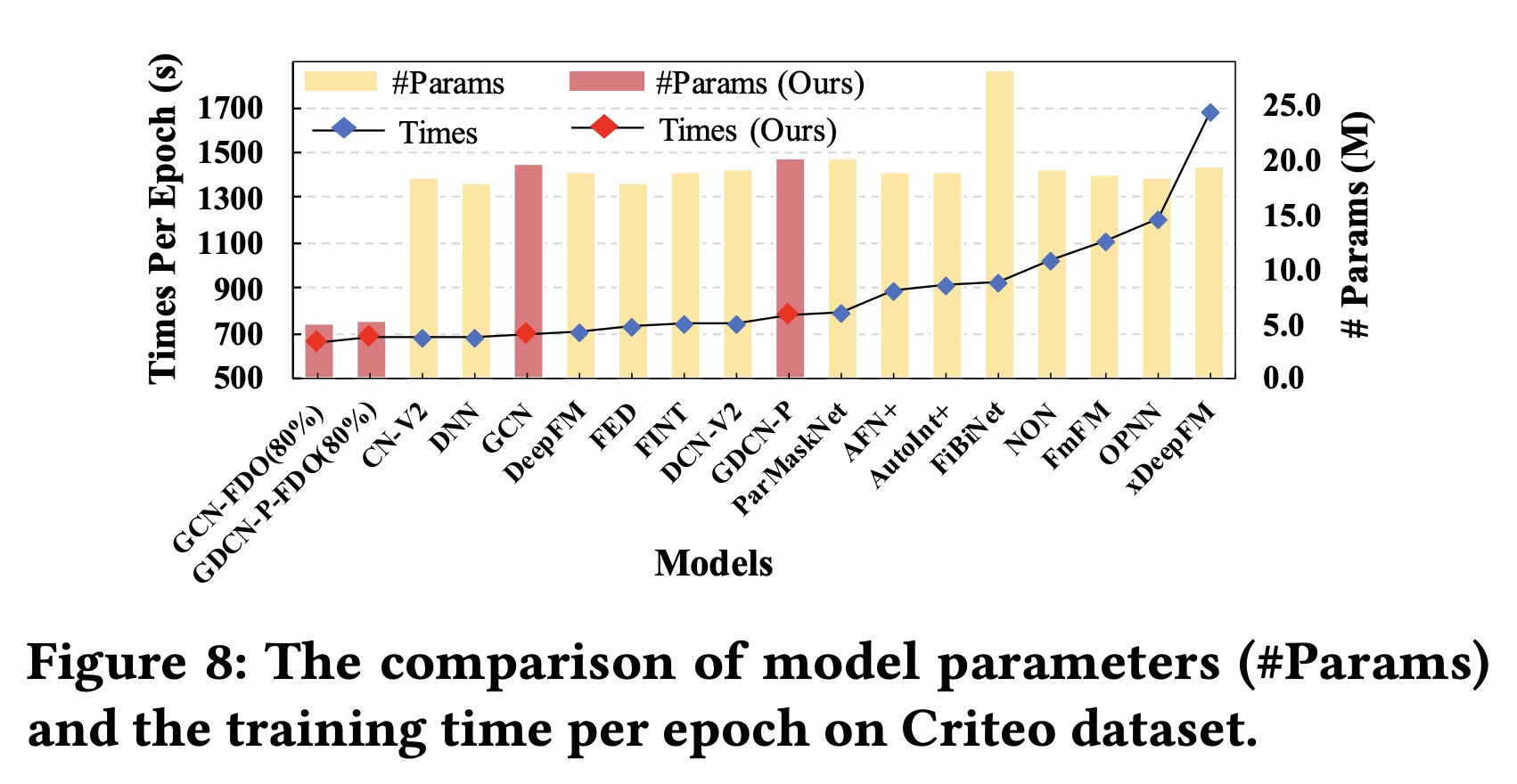
Criteo数据集上,我们在删除低频特征后总共有1.086M个特征。当使用固定维度(embedding参数约为17.4M。如Figure 8所示:大多数现有模型的参数范围从
18M到20M,主要是由于embedding参数。通过应用
FDO,我们可以直接减少embedding参数。同时,GCN-FDO和GDCN-PFDO仅使用约5M模型参数就实现了相媲美的准确率
我们进一步比较了现有
SOTA模型的训练时间:未经维度优化的
GCN和GDCN的训练时间与DNN和DCN-V2相当。应用
FDO后,GCN-FDO和GDCN-P-FDO以更少的参数和更快的训练速度超越了所有的SOTA模型。
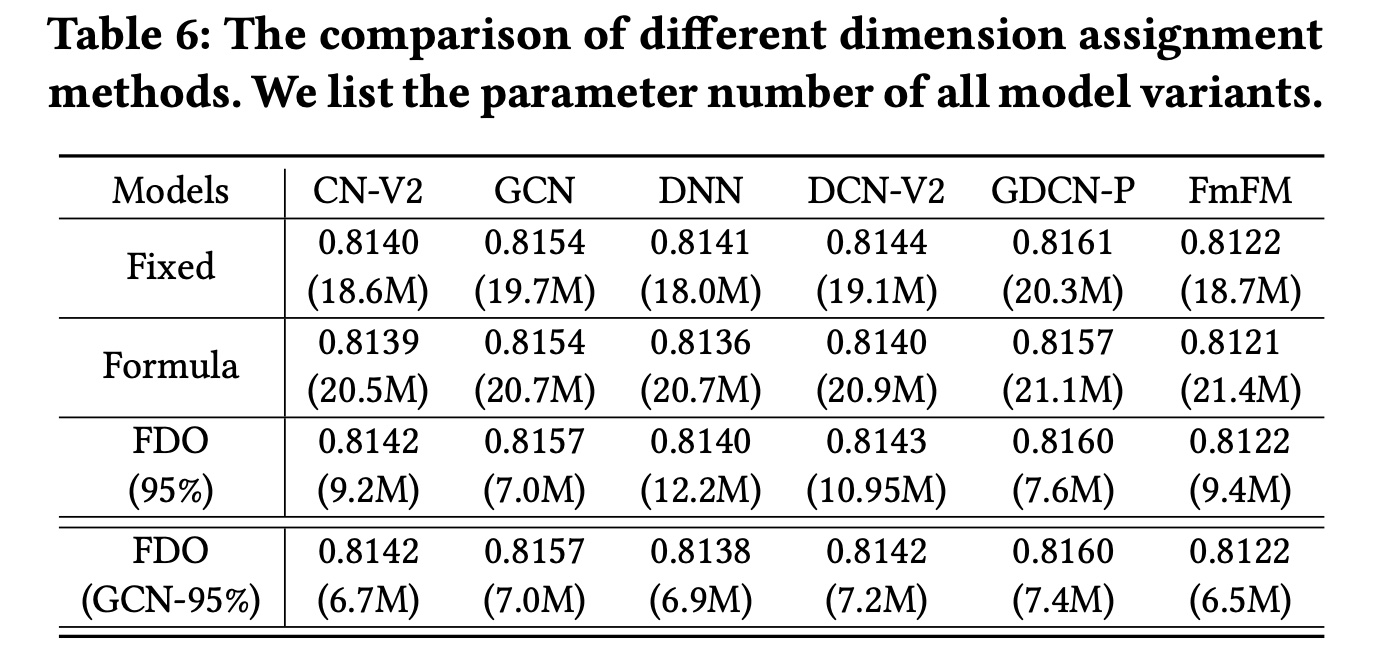
兼容性分析:我们进一步将
FDO应用于DNN、CNV2、DCN-V2和FmFM,它们不需要相同的field维度。此外,我们将FDO与分配固定维度、以及FDO章节中提到的分配不同维度的Formula method进行了比较。Table 6显示了结果。首先,
Formula method增加了模型参数并降低了其性能,因为它只考虑每个field中的特征数量,而忽略了field在训练过程中的重要性。相反,FDO是一种后验方法,它通过在trained embedding table中合并重要信息来学习field维度。其次,将
FDO应用于CN-V2和GCN比base模型获得了更好的性能。由于CN-V2和GCN主要关注显式的bit-level特征交叉,FDO通过删除不必要的embedding信息来refinefield维度。然而,将FDO应用于包含DNN网络的DNN、DCN-V2和GDCN-P会导致性能略有下降。最后,这些结果表明,我们可以使用
FDO基于SOTA模型获取group field dimensions,并将其复用为其他模型的默认维度。在Table 6的最后一行,我们基于GCN学习了具有95% information ratio的group field dimensions,并将其应用于其他五个模型。与使用模型本身学到维度相比,这种方法实现了相媲美的性能,并且进一步减少了参数数量。可以只需要训练一次,就可以将
group field dimension应用到多个模型,这降低了获取group field dimension的成本。
对
condensed field dimensions的理解:通过FDO学到的field维度表明了相应field的重要性。如
Figure 7所示,我们可以确定每个field的平均重要性,例如field {#20, #23, #24}很重要,而field {#11, #27, #30}则不重要。参考
Table 1,在应用95% information ratio的FDO后,field {#20, #23, #24}确实具有更长的维度。相反,field {#11, #27, #30}的维度较短。
为了进一步验证这一观察结果,我们计算了第一层中
averaged field importance与95% ratio的optimization field dimensions之间的皮尔逊相关系数。相关系数为0.82,p-value小于field维度与其各自重要性之间存在显著相关性。因此,我们可以直接从FDO学到的field维度粗略地识别哪些field是重要的。请注意,
field维度并不总是与field中的特征数量相关。例如,field {#16, #25}具有最大的特征数量,但它们的field维度很短,其重要性也不大。如果使用Formula method分配field维度,则field {#16, #25}将具有最长的维度。这种比较进一步凸显了所引入的FDO方法的合理性和优越性。
四十八、DCN V3[2024]
《DCNv3: Towards Next Generation Deep Cross Network for Click-Through Rate Prediction》
Deep & Cross Network及其衍生模型面临四个主要限制:现有的显式
feature interaction方法的性能通常弱于隐式的deep neural network: DNN,从而削弱了它们的必要性。许多模型在增加
feature interactions的阶数时无法自适应地过滤噪声。大多数模型的
fusion方法无法为其不同子网络提供合适的监督信号。虽然大多数模型声称可以捕获高阶
feature interactions,但它们通常通过DNN以隐式的和不可解释的方式进行,这限制了模型预测的可信度。
为了解决已发现的局限性,本文提出了下一代深度交叉网络:
Deep Cross Network v3: DCNv3,以及它的两个子网络:Linear Cross Network: LCN和Exponential Cross Network: ECN用于CTR预测。DCNv3在feature interaction modeling中可解释性的同时,线性地和指数地增加feature interaction的阶数,实现真正的Deep Crossing,而不仅仅是Deep & Cross。此外,我们采用Self-Mask操作来过滤噪声,并将Cross Network中的参数数量减少一半。在fusion layer,我们使用一种简单但有效的multi-loss trade-off and calculation方法Tri-BCE,来提供适当的监督信号。在六个数据集上的全面实验证明了DCNv3的有效性、效率和可解释性。大多数
interaction-based的CTR预测模型都遵循DCN提出的范式,该范式旨在构建显式的和隐式的feature interactions,并融合不同interaction information的predictions以增强可解释性和准确性。尽管当前的CTR范式非常有效,但仍存在一些需要克服的局限性:explicit interactions的必要性有限:如Figure 1所示,大多数仅使用显式feature interactions的模型(例如CIN)的AUC性能低于81.3,而deep neural network: DNN的AUC性能更好,为81.4。这表明大多数explicit modeling方法的性能弱于implicit DNN,这无疑削弱了集成显式feature interactions的必要性。然而,一些工作也强调了DNN在捕获multiplicative feature interactions方面的局限性。因此,有必要探索一种更有效的方法用于显式feature interactions。噪声过滤能力低下:许多研究指出
CTR模型包含大量冗余feature interactions和噪声,尤其是在高阶feature interactions中。因此,大多数CTR模型仅使用两到三个网络层来构建,放弃了对有效高阶feature interaction信息的explicit capture。同时,为模型过滤噪声通常会产生额外的计算成本,从而导致更长的训练时间和推理时间,可能会抵消提高模型准确率所带来的好处。监督信号不足且没有区分性:大多数同时使用显式和隐式
feature interaction方法的模型都需要一个fusion layer来获得最终预测。然而,它们只使用final prediction来计算损失,而不是为不同方法本身提供适当的监督信号。这削弱了监督信号的有效性。此外,一些研究,例如Figure 1中的CL4CTR,试图引入辅助损失来提供额外的监督信号。然而,这通常会引入额外的计算成本和loss trade-off超参数,增加了超参数调优的难度。因此,一种简单、高效、有效的计算监督信号的方法至关重要。缺乏可解释性:如
Figure 1所示,大多数模型集成DNN来建模隐式高阶feature interactions,并实现81.3到81.5之间的AUC性能。这证明了隐式feature interactions的有效性。然而,隐式feature interactions缺乏可解释性,这降低了CTR模型预测的可信度。
为了解决这些局限性,本文提出了下一代
deep cross network:Deep Cross Network v3: DCNv3,以及它的两个子网络:Linear Cross Network: LCN和Exponential Cross Network: ECN。DCNv3集成了低阶的和高阶的feature interactions,同时通过避免使用DNN进行隐式高阶feature interaction modeling来确保模型的可解释性。具体而言,我们引入了一种新的指数增长的Deep Crossing方法来显式地建模高阶feature interactions,并将以前的交叉方法归类为Shallow Crossing。同时,我们设计了一个Self-Mask操作来过滤噪声并将Cross Network中的参数数量减少一半。在fusion layer,我们提出了一种简单而有效的multi-loss计算方法,称为Tri-BCE,为不同的子网络提供合适的监督信号。本文贡献:
据我们所知,这是第一篇仅使用显式
feature interaction modeling而不集成DNN就实现令人惊讶的性能的作品,这可能与过去CTR prediction文献中的流行范式形成鲜明对比。因此,这项工作可能会激发对feature interaction modeling的进一步回顾和创新。我们引入了一种新颖的
feature interaction modeling方法,称为Deep Crossing,它随着层数的增加而呈指数增长,从而实现真正的deep cross network。该方法显式地捕获feature interaction信息,同时使用Self-Mask操作将参数数量减少一半并过滤噪声。我们提出了一种新颖的
CTR模型,称为DCNv3,它通过两个子网络LCN和ECN显式地捕获低阶和高阶feature interactions。此外,我们引入了一种简单而有效的multi-loss trade-off and calculation方法,称为Tri-BCE,以确保不同的子网络接收适当的监督信号。在六个数据集上进行的全面实验证明了
DCNv3的有效性、效率和可解释性。根据我们的实验结果,我们的模型在多个CTR预测benchmarks上取得了第一名的排名。
论文核心思想还可以,就是效果可能没有达到预期,导致作者搞了一些
tricky的操作(比如所谓的self-mask)来提升性能,导致实验的对比结果不太可信。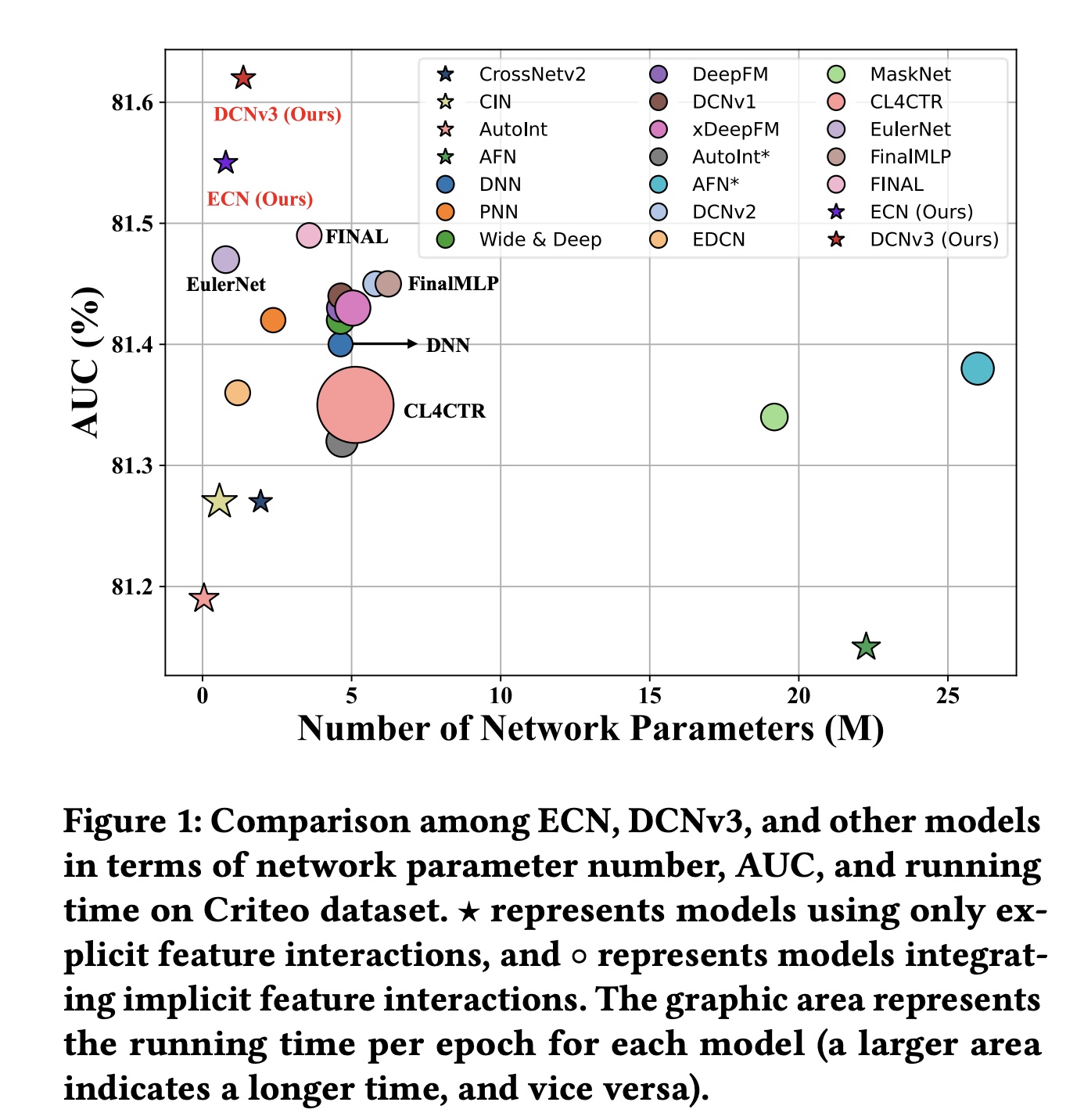
Feature Interaction:隐式
feature interaction旨在使用DNN自动学习复杂的non-manually defined的数据模式和高阶feature interactions。它效率高,表现良好,但缺乏可解释性。显式
feature interaction旨在通过预定义的函数直接建模输入特征之间的组合和关系,从而提高模型的可解释性。
线性增加显式
feature interaction的一种流行方法是Hadamard Product将特征feature interaction的方法是所谓 “更有效地生成高阶特征” 指的是用更少的层数获得更高阶的特征。
48.1 模型
模型架构如下图所示。
ECN和LCN的主要区别在与左侧的输入。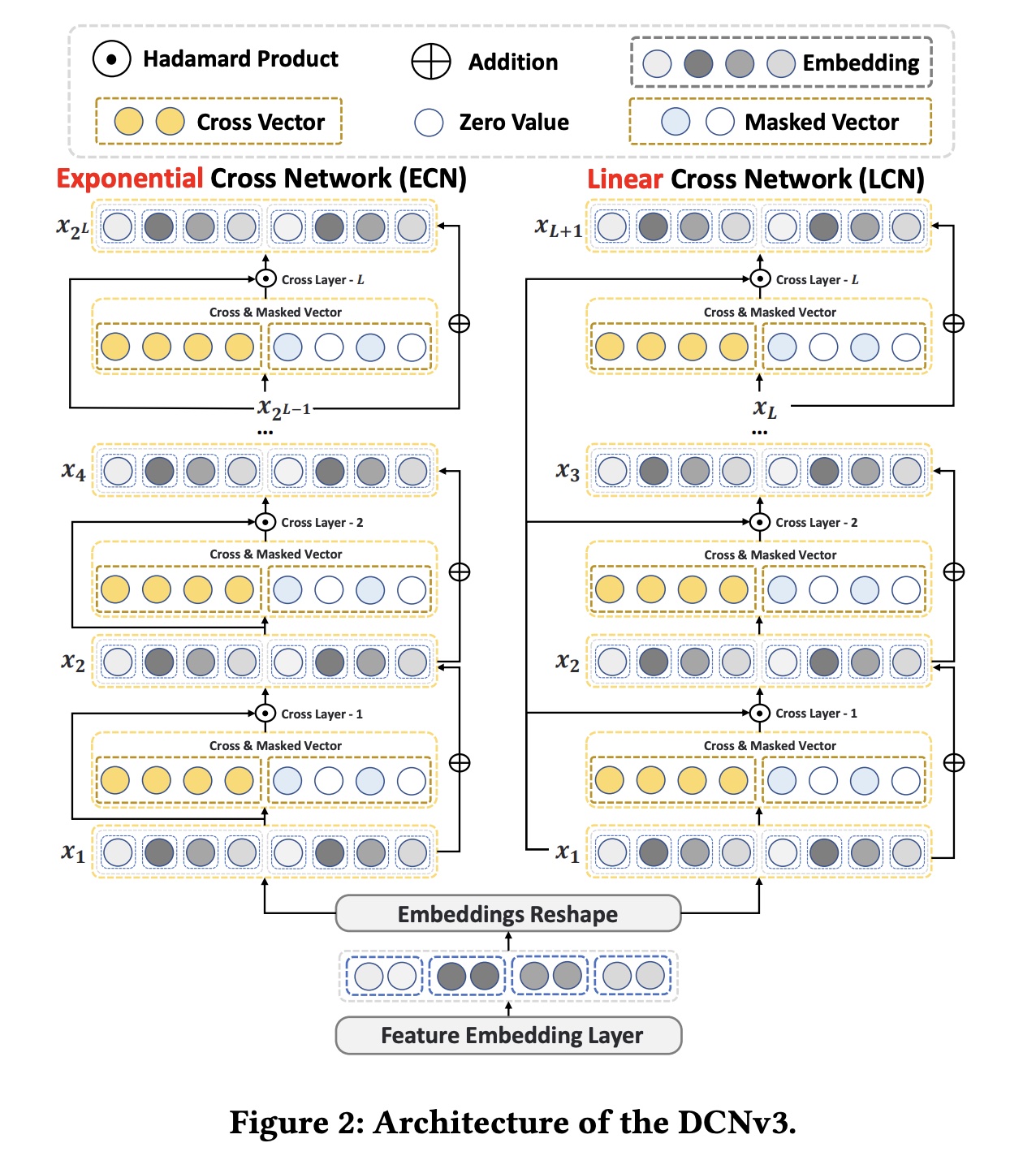
48.1.1 Embedding & Reshape Layer
CTR prediction任务的输入multi-field categorical data,使用one-hot encoding来表示。大多数CTR预测模型利用embedding layer将它们转换为低维稠密向量:
其中:embedding matrix ,embeddin 维度,field 的vocabulary size 。
在我们的模型中,为了使网络能够从
multi-views中获得更丰富的信息,我们使用分块操作来reshape the embeddings,将它们分成两个不同的视图:其中:
original view,another view。进一步,我们可以得到
reshaping后的resulting embedding:其中:
fields数量,embedding维度,LCN和ECN的输入。chunk()函数是什么?作者讲的不明不白。读者猜测是:将每个field的embedding向量一分为二;左半边拼接起来,构成original view;右半边拼接起来,构成anoher view。这么做的目的是为了下游的
Self-Mask操作而准备的。但是,为什么不用FFM来做投影呢?
48.1.2 Deep Cross Network v3
LCN:用于具有线性增长的低阶(浅)的explicit feature interaction。其递归公式如下:其中:
original view)的Cross Vector。feature interaction。Mask表示Self-Mask(在another view),稍后将详细介绍。为什么将
Mask拼接上来而不是与
由于线性增长的
feature interaction方法难以在有限的层数内捕获高阶交互,因此我们引入ECN来实现真正的、高效的deep cross network。ECN:作为DCNv3的核心结构,用于指数级增长的高阶(深度)explicit feature interaction。其递归公式为:其中:
feature interaction。从
Figure 3可以看出,原始的Cross Network v2本质上是一种shallow crossing方法,通过层的堆叠实现feature interactions阶次的线性增长。实验表明,DCNv2中交叉层的最佳数量为2或3,其大部分性能来自负责隐式交互的DNN。相比之下,ECN将feature interactions阶次的指数级增长,从而在有限的层数内实现特征的Deep Crossing,显式地捕获高阶feature interactions。
Self-Mask:Figure 3可视化了不同crossing方法的计算过程。Cross Vectorbit-level建模特征之间的交互,而权重矩阵feature fields的固有重要性。然而,正如一些论文指出的那样,并非所有feature interactions都对CTR任务中的最终预测有益。因此,我们在another view中引入了Self-Mask操作来过滤掉feature interactions中的噪声信息(对应于original view的交互信息的完整性(对应于Self-Mask操作如下:其中
LN表示LayerNorm:增益向量
这里也可以使用其他
mask机制,例如基于伯努利分布的random Mask、基于Top-K选择的learnable Mask等。为了确保我们提出的模型简单而有效,我们使用LayerNorm对50%的零值,以滤掉噪声并提高计算效率。Fusion:大多数先前的CTR模型试图建模显式和隐式feature interactions,这本质上意味着同时捕获低阶和高阶feature interactions。我们的DCNv3通过整合LCN和ECN来实现这一点,避免使用可解释性较差的DNN:其中:
Mean表示均值运算,last number。ECN、LCN和DCNv3的预测结果。
48.1.3 Tri-BCE Los
Tri-BCE loss calculation and trade-off方法如Figure 4所示。我们使用广泛采用的二元交叉熵损失(即Logloss)作为DCNv3的primary and auxiliary loss:其中:
ground-truth,batch size。primary loss,ECN和LCN预测结果的auxiliary losses。
为了给每个子网络提供合适的监督信号,我们为它们分配了自适应权重:
并联合训练它们以实现
Tri-BCE loss:注意,
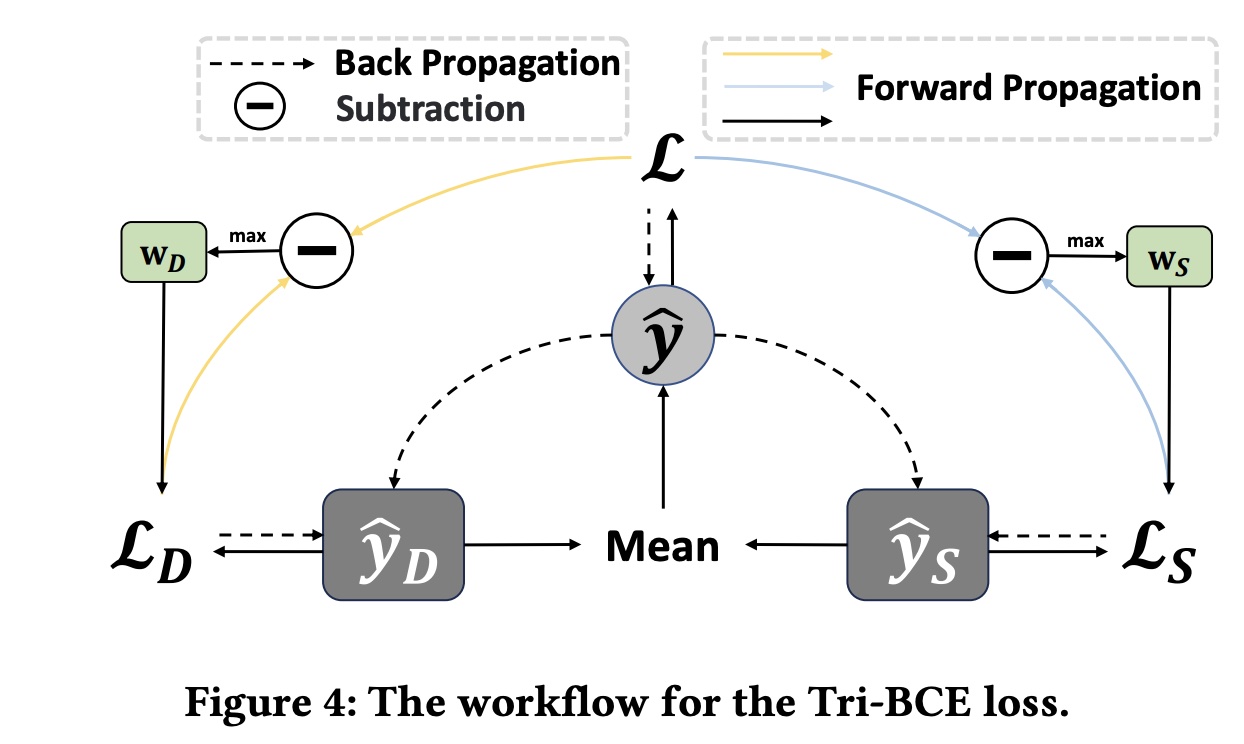
如
《TF4CTR:Twin Focus Framework for CTR Prediction via Adaptive Sample Differentiation》所示,向子网络提供单一监督信号通常不是最优的。我们提出的Tri-BCE loss通过提供自适应权重(该权重在整个学习过程中变化)来帮助子网络学习更好的参数。理论上,我们可以推导出由其中:
类似地,
可以观察到,对于
Tri-BCE loss还提供了基于ground-truth labelprimary and auxiliary loss之间的差异自适应地调整其权重。因此,Tri-BCE loss为子网络提供了更合适的监督信号。
48.1.4 复杂度分析
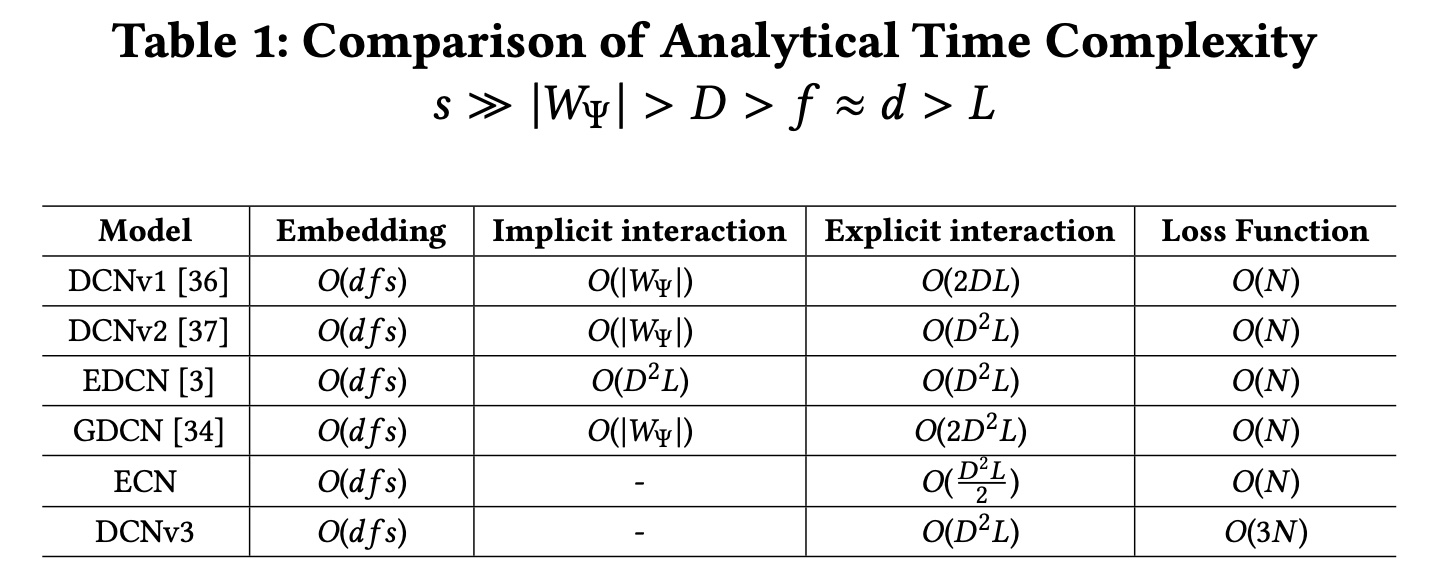
为了进一步比较
DCN系列模型的效率,我们讨论并分析了不同模型的时间复杂度。令DNN中预定义的参数数量。其他变量的定义可以在前面的部分中找到。为了清楚起见,我们在Table 1中进一步提供了不同变量大小的比较。我们可以得出:所有模型对于
embedding的时间复杂度相同。因此,我们仅在实验部分可视化non-embedding参数。除了我们提出的
ECN和DCNv3之外,所有其他模型都包含隐式交互以增强预测性能,这会产生额外的计算成本。在显式交互方面,
ECN仅具有比DCNv1更高的时间复杂度,而GDCN的时间复杂度是ECN的四倍。由于我们的
DCNv3使用Tri-BCE loss,因此DCNv3的loss计算时间复杂度是其他模型的三倍。但这并不影响模型的推理速度。
时间复杂度只看
48.2 实验
四个研究问题(
research question: RQ):RQ1:DCNv3在性能方面是否优于其他CTR模型?它们在大规模的和高度稀疏的数据集上表现良好吗?RQ2:DCNv3与其他CTR模型相比是否更有效率?RQ3:DCNv3是否具有可解释性和过滤噪音的能力?RQ4:不同的配置如何影响模型?
数据集:
Avazu, Criteo, ML-1M, KDD12, iPinYou, and KKBox。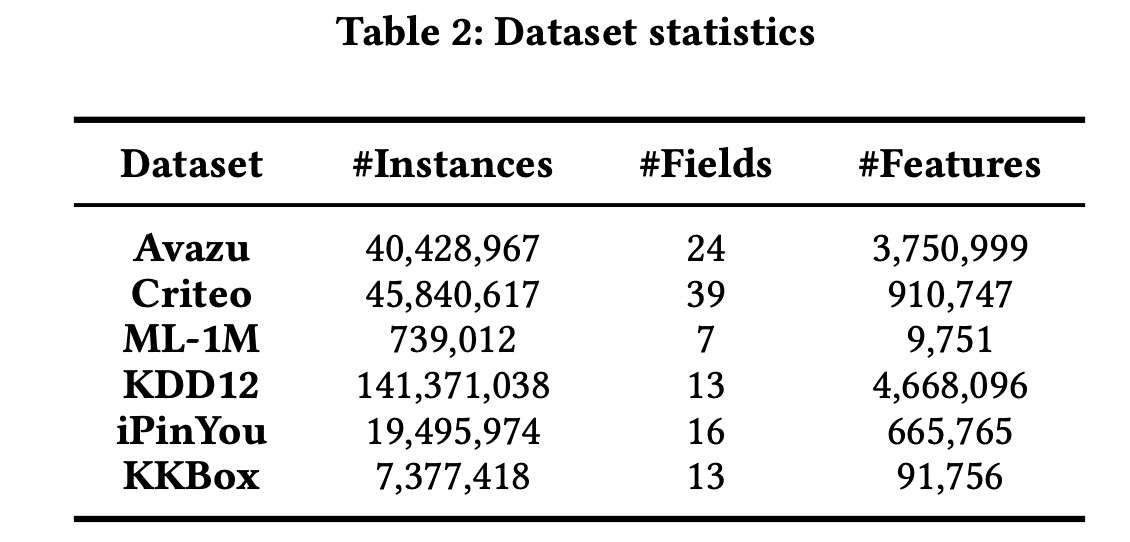
数据集预处理:我们遵循
《Open benchmarking for click-through rate prediction》中概述的方法。对于
Avazu数据集,我们将其包含的时间戳字段转换为三个新的feature fields:hour, weekday, and weekend。对于
Criteo和KDD12数据集,我们通过将每个numeric valuenumerical feature fields离散化:我们设置了一个阈值,用默认的
"OOV" token替换低频的categorical features。我们将Criteo、KKBox和KDD12的阈值设置为10,将Avazu和iPinYou的阈值设置为2,将小数据集ML-1M的阈值设置为1。
更具体的数据处理过程和结果可以在我们的开源运行日志和配置文件中找到,我们在此不再详述。
评估指标:
Logloss, AUC。这里
Logloss是baseline方法:我们将DCNv3与一些SOTA模型进行了比较 (*表示将原始模型与DNN网络集成):(1):由于ECN是一个执行显式feature interactions的独立网络,在两个大规模数据集上,我们将其与几个也执行显式feature interactions的模型进行了比较。例如:LR实现了一阶feature interactions。FM及其衍生模型FM、FwFM、AFM、FmFM实现了二阶特征交互。CrossNetv1、CrossNetv2、CIN、AutoInt、AFN、FiGNN实现了高阶feature interactions。
(2):为了验证DCNv3相对于包含隐式feature interactions的模型的优越性,我们进一步选择了几个高性能的代表性的baseline,例如PNN和Wide & Deep;DeepFM和DCNv1;xDeepFM;AutoInt*;AFN*;DCNv2和EDCN、MaskNet;CL4CTR、EulerNet、FinalMLP和FINAL。
实现细节:我们使用
PyTorch实现所有模型,并参考现有作品 。我们使用Adam optimizer优化所有模型,默认学习率设置为0.001。为了公平比较,我们将KKBox的embedding维度设置为128,将其他数据集的embedding维度设置为16。Criteo、ML-1M和iPinYou数据集的batch size设置为4,096,其他数据集的batch size设置为10,000。为了防止过拟合,我们采用patience = 2的早停。baseline模型的超参数是根据 (《An open-source CTR prediction library》、《Open benchmarking for click-through-rate prediction》)及其原始论文中提供的最佳值进行配置和微调的。 有关模型超参数和数据集配置的更多详细信息,请参阅我们简单易懂的运行日志,此处不再赘述。
48.2.1 RQ1 整体性能
与仅使用显式
feature interactions的模型进行比较:由于ECN模型显式地以feature interactions为特征,我们选择了11个代表性的模型进行比较,分为一阶、二阶和高阶等等。我们用粗体表示性能最好的,用下划线表示得分次好的。实验结果如Table 3所示,我们可以得出以下结论:通过比较
Table 3和Table 4,我们发现大多数仅仅使用显式feature interactions的模型通常比集成隐式feature interactions的模型表现更差,甚至比简单的DNN更差。这无疑削弱了显式feature interactions的必要性。总体而言,捕获高阶
feature interactions通常可以提高模型性能。例如:FM在两个大规模数据集Avazu和Criteo上的表现优于LR。而
CrossNetv2在Avazu上的表现优于除FwFM之外的所有一阶和二阶feature interaction模型。
这证明了高阶
feature interactions的有效性。更复杂的模型结构不一定会带来性能提升。与
FM相比,AFM引入了更复杂的注意力机制,但并没有取得更好的性能,这一点在《Open benchmarking for click-through rate prediction》中也有所报道。但是,与CrossNetv1相比,CrossNetv2扩展了权重矩阵的规模,从而带来了一定程度的性能提升。因此,我们应该仔细设计模型架构。FiGNN在显式feature interaction模型中取得了最佳的baseline性能。然而,与FiGNN相比,我们的ECN在Avazu数据集上仍然实现了Logloss下降0.4%、AUC增加0.54%,在Criteo数据集上实现了Logloss下降0.18%、AUC增加0.17%,均在统计显著水平上超过0.001。这证明了ECN的优越性。

与集成隐式
feature interactions的模型的比较:为了进一步全面研究DCNv3在各种CTR数据集(例如,大规模稀疏数据集)上的性能优势和泛化能力,我们选择了15个有代表性的baseline模型和6个基准数据集。我们用粗体突出显示ECN和DCNv3的性能,并用下划线突出最佳baseline性能。Table 4展示了实验结果,从中我们可以得出以下观察结果:总体而言,
DCNv3在所有六个数据集上都取得了最佳性能,与最强的baseline模型相比,平均AUC提高了0.21%,平均Logloss降低了0.11%,均超过了0.1%的统计显著阈值。这证明了DCNv3的有效性。FinalMLP模型在Avazu和Criteo数据集上取得了良好的性能,超越了大多数结合显式和隐式feature interactions的CTR模型。这证明了隐式feature interactions的有效性。因此,大多数CTR模型试图将DNN集成到显式feature interaction模型中以提高性能。然而,DCNv3仅使用显式feature interactions就实现了SOTA性能,表明仅使用显式feature interaction进行建模的有效性和潜力。DCNv3在所有六个数据集上都实现了优于ECN的性能,证明了LCN在捕获低阶feature interactions和Tri-BCE loss方面的有效性。值得注意的是,在iPinYou数据集上,我们观察到所有模型的Logloss值都在0.0055水平左右。这是由于数据集中正样本和负样本之间的不平衡,其他工作也报告了类似的结果。ECN在AUC方面优于所有baseline模型,唯一的例外是KKBox数据集上的Logloss optimization,ECN比DCNv1弱。这进一步证明了ECN的有效性,因为它通过指数级增长的feature interactions和噪声过滤机制捕获高质量的feature interaction信息。

48.2.2 深入研究 DCNv3
效率比较(
RQ2):为了验证DCNv3的效率,我们为25个baseline模型固定了最优超参数,并比较了它们的参数数量(四舍五入到小数点后两位)和运行时间(五次运行的平均值)。实验结果如Figure 5所示。我们可以得出:显式
CTR模型通常使用较少的参数。例如,LR, FM, FwFM, and AFM的non-embedding参数几乎为零,而FmFM, CrossNet, CIN, and AutoInt都需要少于1M的参数。值得注意的是,参数数量并不总是与时间复杂度相关。虽然CIN仅使用0.57M个参数,但其每个epoch的训练时间最多达到606秒,因此不适合实际生产环境。FiGNN和AutoInt面临同样的问题。在所有模型中,
LR模型的运行时间最短,为150秒。CrossNetv1和CrossNetv2紧随其后,在提升性能的同时,时间几乎不增加。这证明了CrossNet及其系列模型的效率。作为deep CTR模型的基本组成部分,DNN仅需156秒。由于CTR并行结构的parallel-friendly特性,一些精心设计的deep CTR模型(如DCNv2、FinalMLP和FINAL)在运行时间没有大幅增加的情况下显著提高了预测准确率。我们提出的
ECN和DCNv3是DCN系列中参数效率最高的模型,分别仅需0.78M和1.37M个参数即可实现SOTA性能。同时,在运行时间方面,DCNv3始终优于FinalMLP, FINAL, DCNv2, and DCNv1等强大的baseline模型。这证明了DCNv3的时间效率。尽管由于使用了Tri-BCE loss,DCNv3比ECN多需要20秒,但它仍然与DCNv2相当。值得注意的是,loss的额外计算成本仅在训练期间产生,不会影响实际应用中的推理速度。这进一步证明了ECN和DCNv3的效率。

DCNv3的可解释性和噪声过滤能力(RQ3):可解释性在CTR预测任务中至关重要,因为它可以帮助研究人员理解预测并增加对结果的信心。在本节中,我们研究动态的Cross & Masked Vector和静态的Figure 6所示(Value表示每个feature field的Frobenius范数),我们可以得出以下观察结果:从
Figure 6 (a∼d)中,我们观察到UserID在LCN和ECN的第一层都具有很高的重要性,但随着层数的增加而降低。同时,
UserID的
feature field变得重要时,其在UserID, Occupation, Age fields)。这证明了我们引入的Self-Mask操作的有效性,该操作通过更积极地为某些feature fields分配零值来进一步过滤掉噪音。从
Figure 6 (e, f)中,我们观察到LCN和ECN在同一层捕获不同的feature interaction信息。在
LCN中,3阶特征的重要性从而生成4阶feature interactions。相反,在
ECN中,feature interactions。
因此,对于
UserID × Genres,与LCN相比,ECN展示了更低的重要性。这进一步证明了DCNv3的有效性。总体而言,我们观察到高阶
feature interactions的重要性低于低阶feature interactions,这在一些工作中也有类似的报道。例如,在Figure 6中,(f)与(e)相比,鲜红色块较少;并且(a)中的蓝色块随着层数的增加逐渐变暗,(b)中的情况类似。

消融研究(
RQ4):为了研究DCNv3各组件对其性能的影响,我们对DCNv3的几种变体进行了实验:w/o TB:使用BCE代替Tri-BCE的DCNv3。w/o LN:没有LayerNorm的Self-Mask。
消融实验结果如
Table 5所示。可以看到:ECN和LCN与DCNv3相比都表现出一定的性能损失,这表明有必要同时捕获高阶和低阶feature interactions。与
ECN相比,LCN的表现始终不佳,证明了指数级feature interaction方法的优越性。同时,
w/o TB的变体也导致一定程度的性能下降,在KKBox上尤为明显。LayerNorm的目的是保证Self-Mask保持0.5左右的masking rate,因此删除它会导致masking rate不稳定,从而导致一些性能损失。
这些证明了
DCNv3中每个组件的必要性和有效性。为什么没有移除
Self-Mask的对比实验?
网络深度的影响(
RQ4):为了进一步研究不同神经网络深度对ECN性能的影响,我们在两个大规模CTR数据集Criteo和KDD12上进行了实验。Figure 7显示了ECN在测试集上的AUC和Logloss性能。从
Figure 7中我们观察到:在
Criteo数据集上,该模型在4层的深度下实现了最佳性能,这表明ECN最多可以捕获feature interactions。在
KDD12数据集上,ECN在6层的深度下实现了最佳性能,这意味着它捕获了feature interactions。
相比之下,在线性增长的
CrossNetv2中实现相同阶次的feature interactions分别需要ECN凭借其指数级增长的feature interaction机制轻松实现了这一点。这进一步证明了ECN的有效性。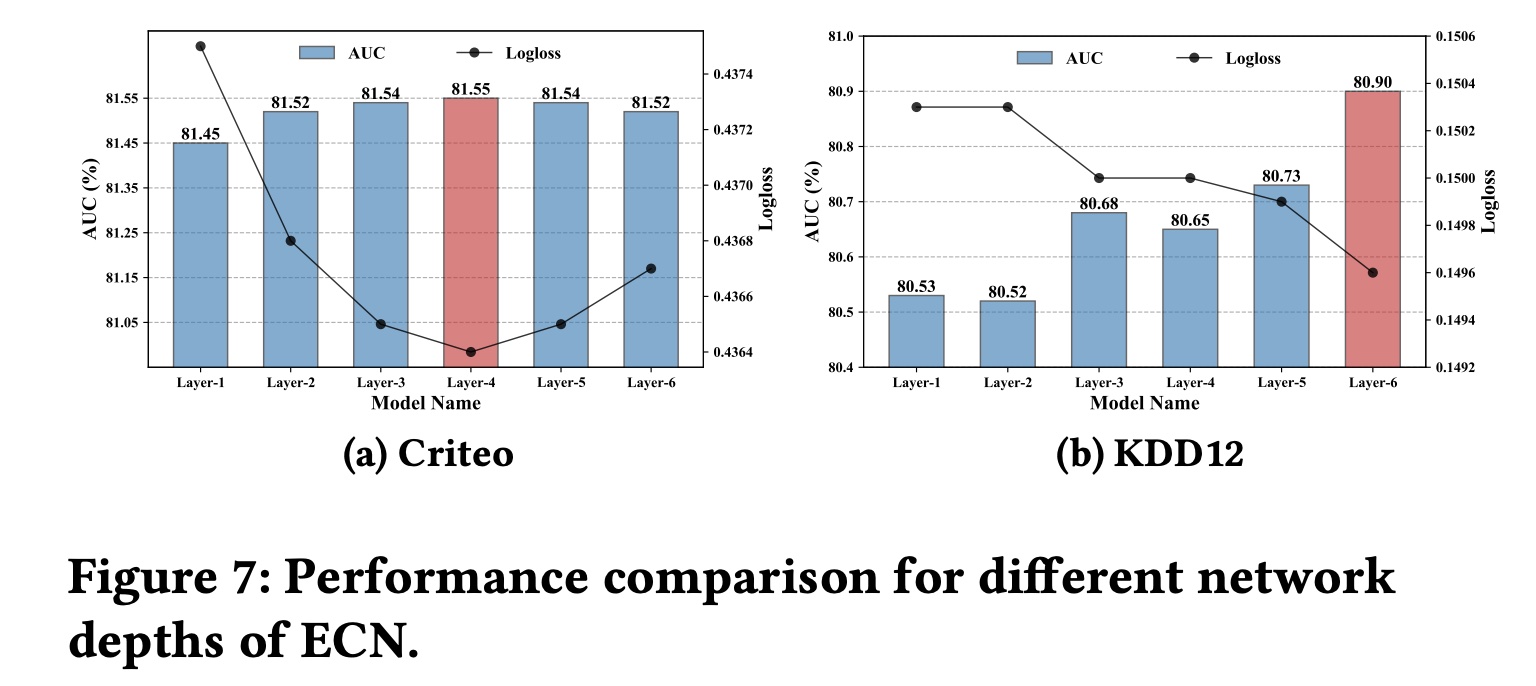
四十九、FINAL[2023]
《FINAL: Factorized Interaction Layer for CTR Prediction》
普通的
multi-layer perceptron: MLP网络在学习multiplicative feature interactions方面效率低下,因此feature interaction learning成为CTR预测的重要主题。现有的feature interaction网络可以有效地补充MLP的学习,但单独使用时,它们的性能往往不如MLP。因此,将它们与MLP网络集成对于提高性能是必要的。这种情况促使我们探索一种更好的MLP backbone替代方案,以取代MLP。 受factorization machines的启发,在本文中,我们提出了FINAL,这是一种factorized interaction layer,它扩展了广泛使用的线性层,并且能够学习二阶feature interactions。与MLP类似,多个FINAL layers可以堆叠成一个FINAL block,从而产生具有指数级增长的feature interactions。我们将feature interactions和MLP统一到单个FINAL block中,并通过经验证明其作为MLP block替代品的有效性。此外,我们探索了两个FINAL blocks的ensemble作为增强型双流CTR模型(enhanced two-stream CTR model),在开放benchmark数据集上创造了新的SOTA。FINAL可以轻松用作building block,并且已在华为的多个应用程序中实现了业务指标增益。我们的源代码将在MindSpore/models和FuxiCTR/model_zoo上提供。CTR预测任务通常被表述为二分类问题,其中包含丰富但异构的特征,例如user profiles, item attributes, and session contexts。因此,feature interaction learning成为CTR预测的重要研究课题。现有方法通常遵循两个方向来建模feature interactions。第一个是使用
multi-layer perceptrons: MLP隐式地学习特征之间的隐藏关系。虽然已经证明MLP理论上可以近似任何有界的连续函数,但在实践中,在给定有限网络大小的情况下,它们在建模combinatorial feature interactions方面很弱 。第二种方法是使用特征之间的
multiplicative operations来显式地建模它们的交互。例如,DCN,FM,xDeepFM,这些方法中的feature combination degree通常与堆叠层数成线性比例,因此需要相当深的架构才能全面覆盖有用的特征组合。然而,由于许多广泛记载的问题,例如gradient explosion/vanishmen(《Which neural net architectures give rise to exploding and vanishing gradients?》)和rank collapse(《Attention is not all you need: Pure attention loses rank doubly exponentially with depth》、《Rank diminishing in deep neural network》),很难优化非常深的模型。
因此,现有方法很难有效地建模高阶
feature interactions。在本文中,我们提出了一个
Factorized Interaction Layer: FINAL来显式地学习multiplicative feature interactions,它可以实现非常高的combination orders而无需繁琐的层堆叠(Figure 1)。受fast exponentiation算法的启发,FINAL采用hierarchical的方式以指数级速度提高feature interaction阶次。在每个hierarchy中,input representations与一系列连续的non-linear layers的representations output相乘,从而逐步增加feature interaction阶次。通过用多个hierarchies处理feature representations,feature interactions的阶次进一步呈指数级增加。基于提出的FINAL模块,我们设计了一个统一的框架,该框架结合了多个FINAL blocks从而在不同视图中学习feature interactions,并且我们通过使用它们的预测作为common teachers来交换它们所编码的互补知识来进行自蒸馏(self-distillation)。我们在四个公共数据集上进行了广泛的实验,结果验证了FINAL的优越性。它还在我们企业举办的多个商业场景的在线实验中取得了显著的成功。FINAL为编写CTR预测模型提供了一种全新而简单的选项,有望为各种推荐场景提供支持。论文创新性一般。
DCN V3也是类似的思路:Exponential Cross Network、以及self-distillation。但是DCN V3采用的是1, 2, 4, 8, 16,...这样的指数,而这里用的1, 3, 9, 27, ...这样的指数。另外,这里的FINAL Block仅仅得到最高指数,而没有使用残差连接,因此往往需要多个不同层的FINAL Block并行拼接。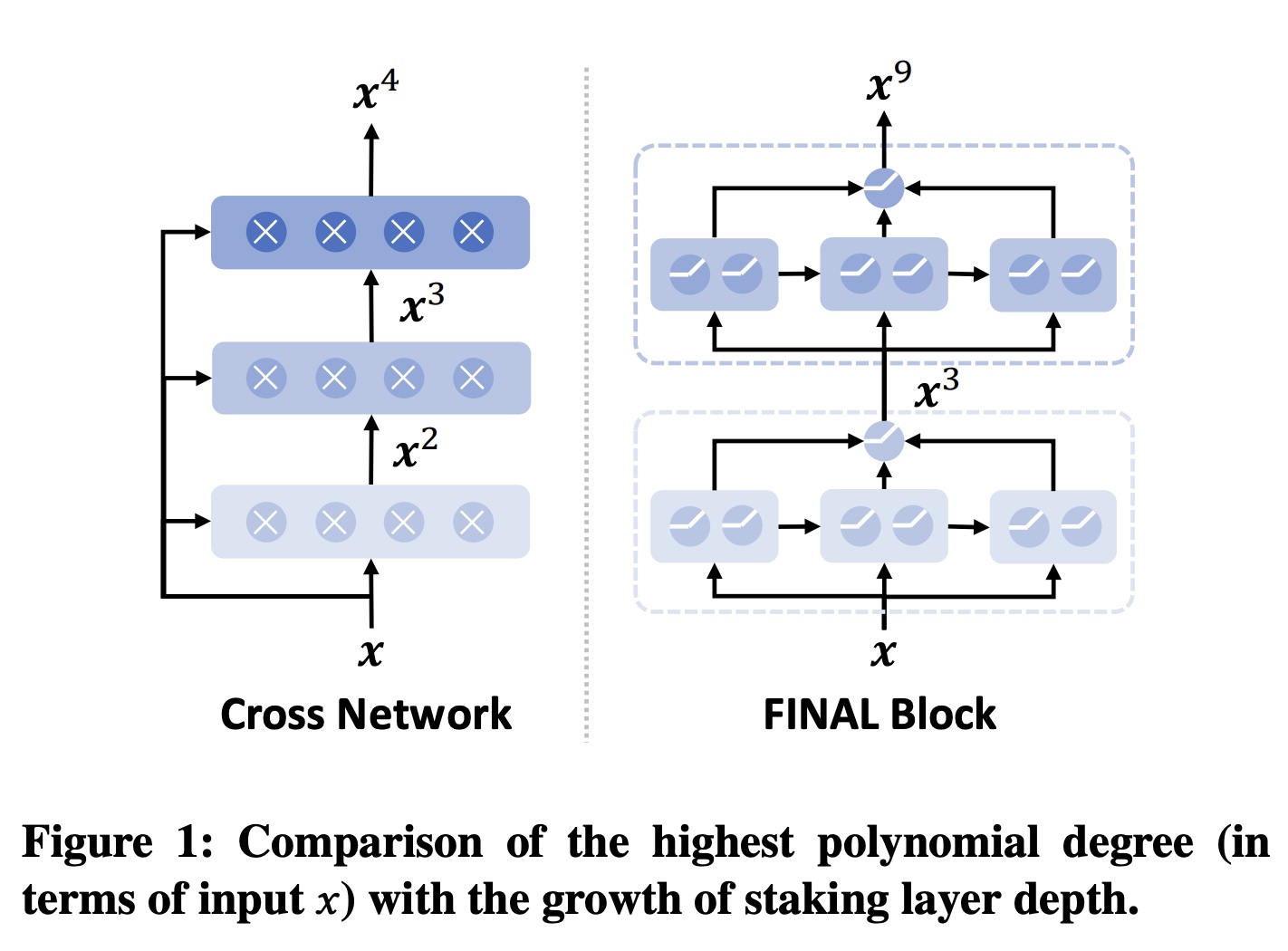
49.1 模型
FINAL总体框架如Figure 2所示。它主要由多个并行的FINAL blocks组成,旨在建模不同的feature interaction模式。每个FINAL block包含几个factorized interaction layers,其中feature interactions的最大阶次随模型深度呈指数级增长。来自不同blocks的预测分数被组合成一个统一的预测分数作为final prediction,它也充当virtual teacher从而self-teach这些blocks以交换和fuse它们的隐藏知识。通过这种方式,可以有效、全面地捕捉复杂的feature interactions。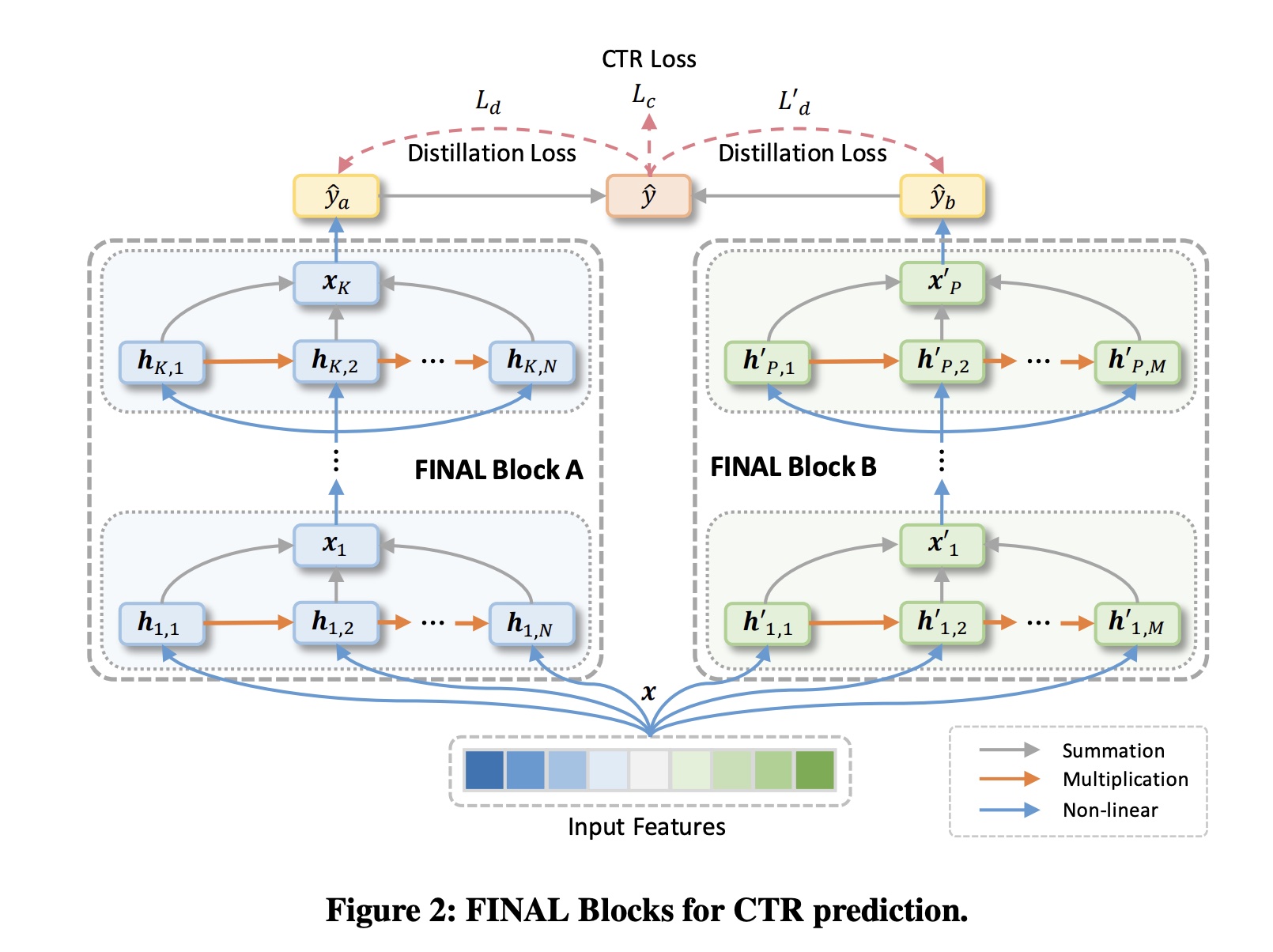
FINAL Block:我们方法的基本单元是FINAL block。它接收一个flattened feature vectorfield,例如one-hot features, embedded categorical features, and numerical features。由于工业场景中精心设计的特征的多样性、复杂性和异质性,特征之间的交互通常可能是很复杂的且隐式的。因此,建模高阶交互对于有效利用特征至关重要。在实践中,如何以最小的model depths实现足够高的交互阶次,对性能和效率都很重要。受
fast exponentiation算法思想的启发,我们设计了一种hierarchical的feature interaction机制来实现指数级的阶次增长。在每个hierarchy中,使用factorized interaction layer通过几个multiplicative operations来提高feature interaction阶次。令factorized interaction layer的输入。它使用以下公式进行转换:其中:
layer output。operation的权重参数和偏置向量,multiplicative interaction的数量。
直观地讲,
feature interaction阶次与multiplicative operations的数量成正比。通过聚合每个step中的中间结果,每个层的输出可以包含multi-granularity的feature interactions。在FINAL block中,我们堆叠多个factorized interaction layers,以便每个层的initial feature interaction degree都成指数级放大。这样,multiplicative operations的FINAL block的最高多项式阶次(就Cross-block Knowledge Transfer:在我们的方法中,我们倾向于使用多个FINAL blocks来从不同视图来学习feature interactions。我们首先使用不同的线性投影层(
linear projection layers)将hidden representations转换为output logits。这些
logits按均值聚合为统一的logit,然后通过sigmoid函数进一步对其进行归一化以进行模型训练(记作
我们使用二元交叉熵损失来计算
CTR prediction loss,如下所示:其中:
label和预测分数,为了促进不同
FINAL block之间的knowledge sharing,我们执行self-knowledge distillation,以赋予它们inter-block knowledge。具体来说,我们使用聚合后的分数block从这个synthesized prediction中学习。以dual-block网络为例(Figure 2),我们用block的normalized prediction scores。它们对应的知识蒸馏损失(knowledge distillation losses)如下:其中:
block-specific predictions。为什么不用
ground-truthteacher?我们使用
task loss和knowledge transfer regularizations来优化模型,模型训练的整体损失函数为:这样,每个
block都知道任务监督信号和cross-block知识,因此可以更好地应对复杂的feature interactions。knowledge transfer regularizations本质上是迫使每个子网的输出都接近模型的整体输出。讨论:最后,我们简要讨论了模型复杂度和兼容性。假设
parallel blocks的数量和隐层维度是常数,那么我们框架的理论复杂度为feature interaction阶次,普通的layer-stacking方法所需的计算复杂度通常为feature interactions时可能具有显著的效率优势。此外,FINAL block是一个即插即用的模块,可以直接插入到现有架构、或替换现有架构的MLP-based的feature interaction模块。因此,FINAL与各种CTR预测方法兼容,并且可以轻松地为它们提供支持。
49.2 实验
数据集:
Criteo, Avazu, MovieLens, and Frappe。为了公平比较,我们重用了
《Adaptive factorization network: Learning adaptive-order feature interactions》发布的预处理数据集,并遵循相同的splitting和预处理程序。评估指标:
AUC。baselines:我们将其与四类现有模型进行比较,按feature interactions阶次分类:一阶(仅使用单个特征):
Logistic Regression: LR。二阶(建模
pair-wise feature interactions):Factorized Machine (FM) and AFM。三阶(建模
triple-wise feature interactions):CrossNet(两层)、CrossNetV2(两层)和CIN(两层)。高阶:
DCN、DCNV2、DeepFM、AutoInt、xDeepFM和SAM。
实现细节:我们基于开源
CTR prediction library,即FuxiCTR, 实现了所有研究的模型。为了进行公平比较,我们遵循《Adaptive factorization network: Learning adaptive-order feature interactions》中的相同实验设置。所有
baseline均使用Adam optimizer进行训练,其中学习率为0.001,batch size为4096,embedding维度为10,MLP隐单元的数量为[400, 400, 400]。我们采用两个
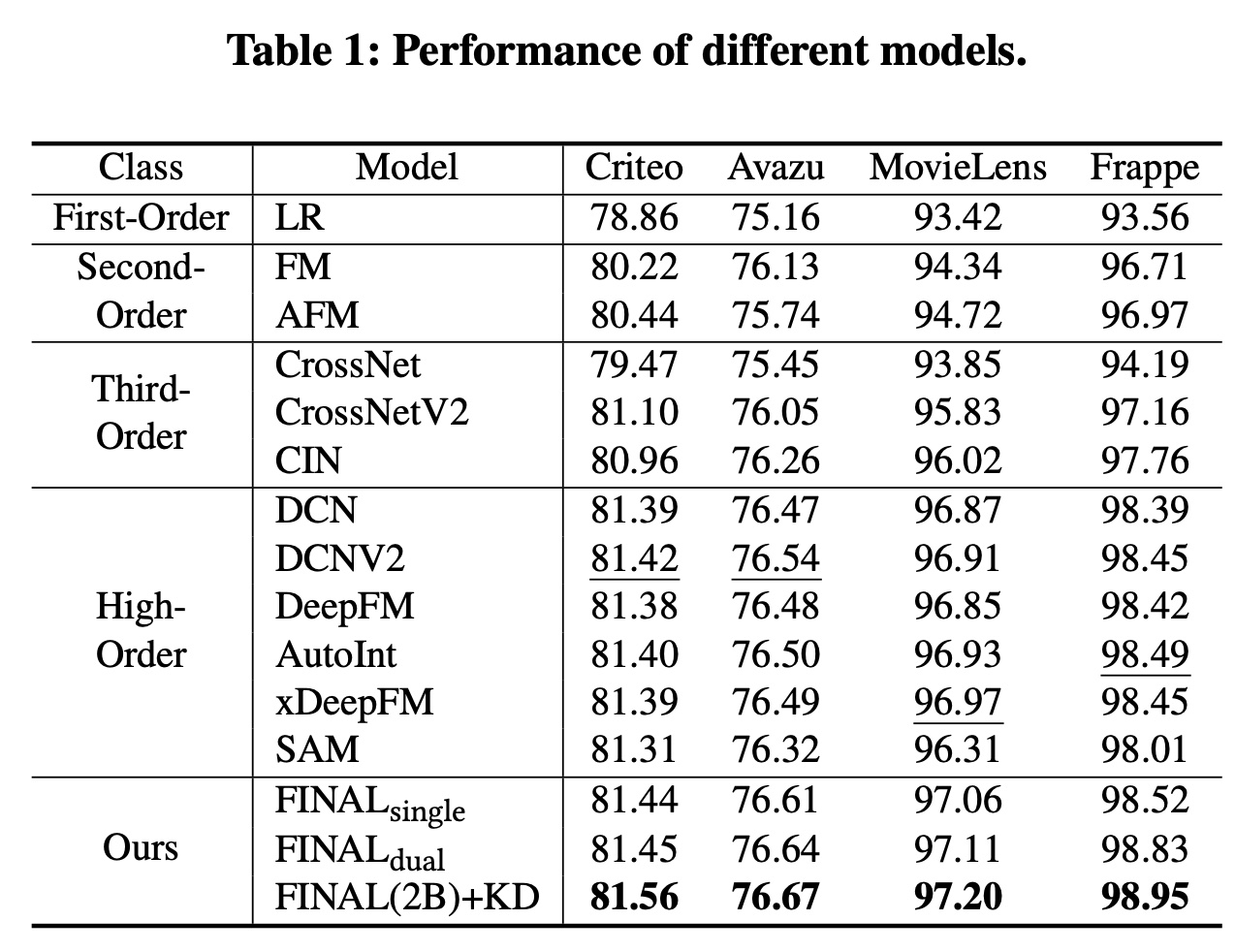
FINAL blocks和两个factorized interaction layers(Table 1展示了在四个数据集上的评估结果,从中我们得到以下发现:首先,
LR在所有数据集上的表现最差,这表明feature interaction modeling在CTR预测中的必要性。其次,能够建模高阶
feature interactions的方法往往会获得更好的性能,这是直观的,因为可以考虑更复杂的feature relatedness。由于FINAL在建模高阶feature interactions方面特别强大,因此它在所有数据集上都获得了最佳性能,并且其优势非常显著(t-test中FINAL在捕获复杂特征关系方面的有效性。第三,
dual-block FINAL model略优于single-block模型。这可能是因为使用多个blocks有助于学习具有不同结构和初始化参数的diverse feature interaction信息。第四,
self-knowledge distillation可以进一步提高multi-block FINAL model的性能。这进一步表明了不同blocks中编码的知识具有互补性,使用知识蒸馏(knowledge distillation)将它们融合可以更好地指导FINAL block learning。
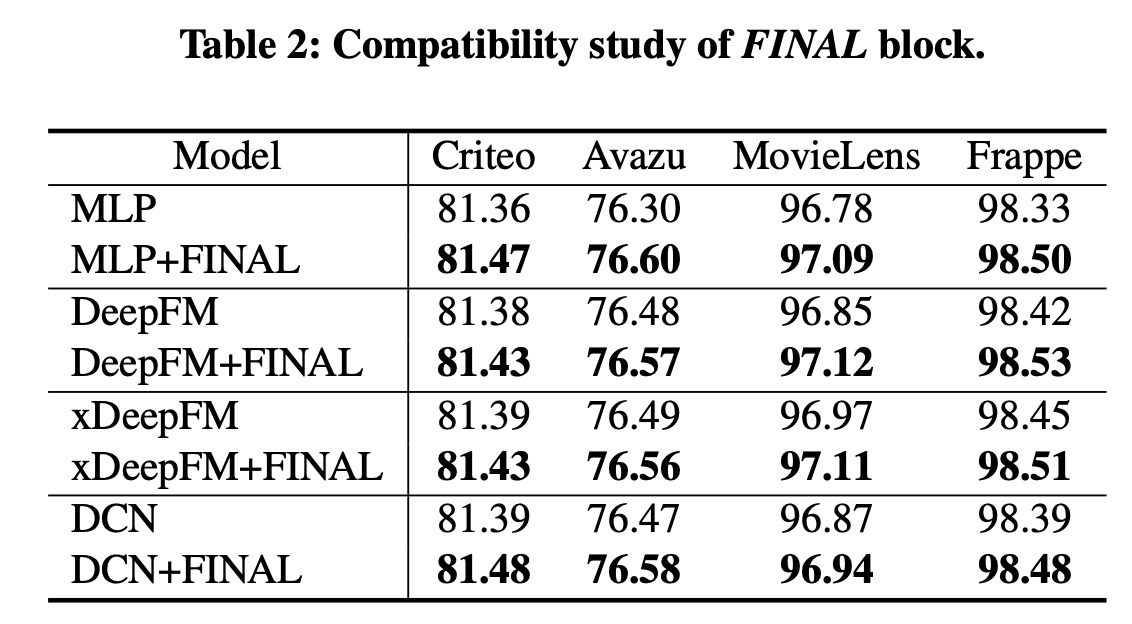
我们的
FINAL block是一个即插即用模块,可以提升各种deep CTR模型的性能。为了证明FINAL block的兼容性,我们将其作为MLP block的替代品引入了四种流行的deep CTR模型(即MLP, DeepFM, xDeepFM, and DCN),结果如Table 2所示。我们观察到
FINAL block一致地改进了流行的deep CTR模型。这验证了FINAL确实捕获了这些模型忽略的有用线索。由于FINAL独立于backbone架构,因此它是一个灵活的组件,可用于为实际系统中的各种CTR预测模型提供支持。这本质上是模型的集成,因此效果比原始模型更好是可以预期的。
在线评估:由于其显著的性能提升和低延迟,我们在企业的多个商业场景中部署了
FINAL。在本节中,我们选取两个代表性场景来展示其优越性。News Feed推荐:我们在商业新闻推荐场景中进行在线评估,其中数百万日活用户消费数字新闻文章。在线A/B test持续一个月,从2022年9月25日到10月25日。对于online serving,我们将整个流量的5%作为实验组,其中包括超过300k活跃用户。 我们将我们的方法与精心设计的baseline模型进行了比较。Figure 3总结了连续30天的在线结果。我们的模型在评估期间显示出一致性的在线点击率改进,平均点击率提高了3.17%。additional online inference latency增加了22.22%,这在我们的系统中是可以接受的。实验结果证明了FINAL在feed recommendation中的有效性。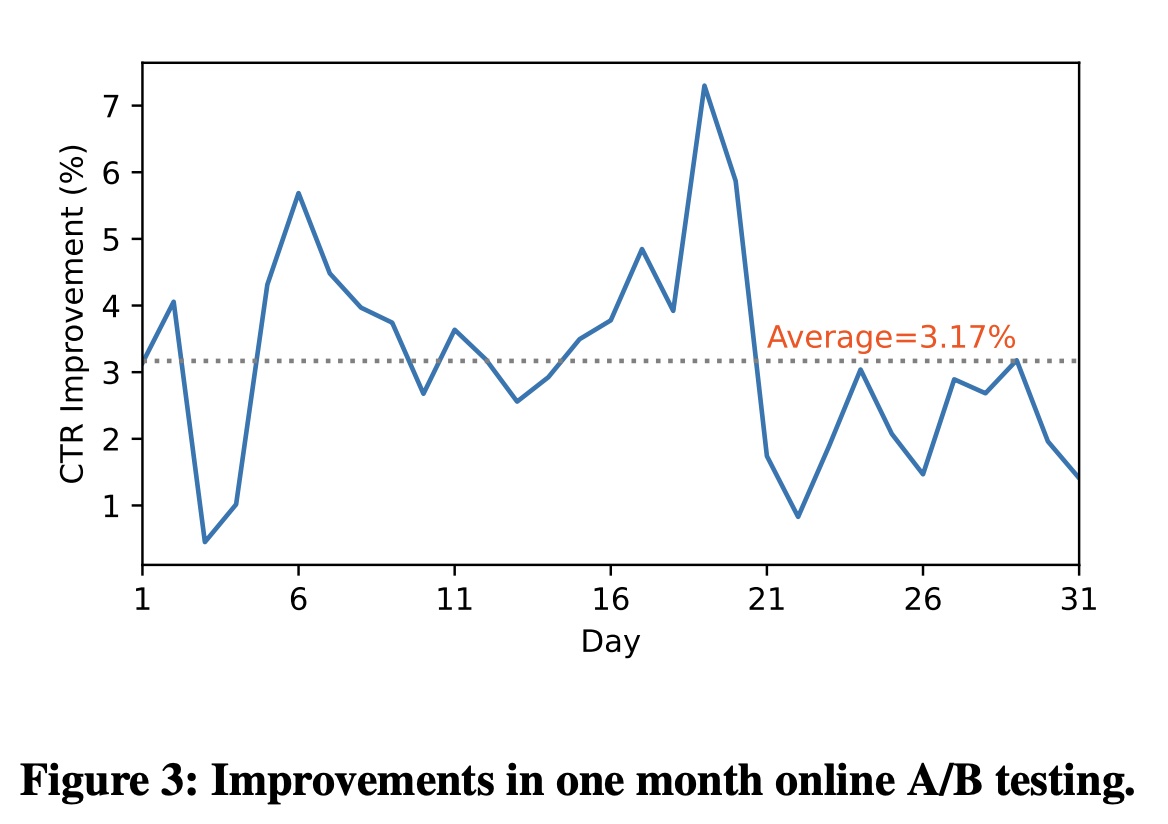
Online advertisement display:在线广告需要同时预测点击率和Post-click conversion rate: CVR。在我们的广告展示场景中,转化对应于安装应用程序、提交注册信息、用户留存(user retention)等事件。多任务学习(
multi-task learning: MTL)是联合CTR and CVR estimation的常用解决方案。一般来说,MTL采用具有shared-bottom结构的模型,其中bottom embedding layers的参数在任务之间共享。然后,应用MLP模块从shared bottom来学习feature interactions并对特定任务进行预测。我们使用FINAL block替此MTL框架中的MLP进行比较。对于online serving,我们随机选择5%的用户作为实验组,通过FINAL-enhanced model提供广告推荐。对照组为另外5%的用户,采用baseline MTL model。连续7天的在线A/B test结果显示,整体CVR增益为5.52%。结果验证了FINAL对于在线广告的有效性。
五十、FinalMLP[2023]
《FinalMLP: An Enhanced Two-Stream MLP Model for CTR Prediction》
虽然多层感知机 (
multi-layer perceptron: MLP)是许多deep CTR预测模型的核心组件,但人们普遍认为,单独应用简单的MLP网络在学习乘性特征交互(multiplicative feature interactions)方面效率低下。因此,许多双流交互(two-stream interaction)模型(例如DeepFM和DCN)已通过将MLP网络与另一个专用网络(dedicated network)集成从而来增强CTR预测。由于MLP stream隐式学习特征交互(feature interactions),现有研究主要侧重于提升complementary stream中的显式特征交互(explicit feature interactions)。相比之下,我们的实证研究表明,只需结合两个
MLP即可获得令人惊讶的良好性能,这是现有工作从未报道过的。基于这一观察,我们进一步提出了可以轻松插入的feature gating layers和interaction aggregation layers,从而得到enhanced two-stream MLP model。这样,它不仅可以实现差异化的feature inputs,还可以有效地融合两个streams之间的stream-level interactions。我们在四个开放benchmark datasets上的评估结果,以及我们工业系统中的online A/B test表明,FinalMLP比许多复杂的two-stream CTR模型取得了更好的性能。CTR预测的关键挑战之一是学习特征之间的复杂关系,使得模型能够在罕见的feature interactions情况下仍能很好地泛化。多层感知机作为深度学习中强大而通用的组件,已成为各种
CTR预测模型的核心构建块(building block)。尽管MLP在理论上被认为是一种通用近似器,但人们普遍认识到,在实践中,应用简单的MLP网络学习multiplicative feature interactions(例如,点乘dot)效率低下。为了提升学习
explicit feature interactions(二阶或三阶特征)的能力,人们已经提出了各种feature interaction网络。典型的例子包括factorization machines: FM、cross network、compressed interaction network: CIN、self-attention based interaction、adaptive factorization network: AFN等。这些网络引入了
inductive bias来有效地学习feature interactions,但失去了MLP的expressiveness,如Table 3中的实验所示。因此,双流(two-stream)CTR预测模型得到了广泛应用,例如DeepFM、DCN、xDeepFM和AutoInt+,它们将MLP网络和专用的feature interaction网络集成在一起,以提升CTR预测。具体来说,MLP stream隐式地学习feature interactions,而另一个stream以互补的方式提升explicit feature interactions。由于其有效性,双流模型已成为工业部署的热门选择。尽管许多现有研究已经验证了双流模型相对于单个
MLP模型的有效性,但没有一项研究报告了双流模型与简单地并行组合两个MLP网络的双流MLP模型(记作DualMLP)的性能比较。因此,我们的工作首次尝试描述DualMLP的性能。我们在开放benchmark datasets上进行的经验研究表明,尽管DualMLP很简单,但可以实现令人惊讶的良好性能,与许多精心设计的双流模型相当甚至更好(参见我们的实验)。这一观察促使我们研究这种双流MLP模型的潜力,并进一步扩展它以构建一个简单但强大的CTR预测模型。
双流模型实际上可以看作是两个并行网络的
ensemble。这些双流模型的一个优点是每个流都可以从不同的角度学习feature interactions,从而互补以实现更好的性能。例如:Wide&Deep和DeepFM提出使用一个流来捕获低阶feature interactions,另一个流来学习高阶feature interactions。DCN和AutoInt+提倡分别在两个流中学习explicit feature interactions和implicit feature interactions。xDeepFM从vector-wise和bit-wise的角度进一步提升了feature interaction learning。
这些先前的结果验证了两个
network streams的差异化(或多样性)对双流模型的有效性有很大影响。与现有的通过设计不同的网络结构(例如,
CrossNet、CIN)来实现stream differentiation的双流模型相比,DualMLP的局限性在于两个流都只是MLP网络。我们的初步实验还表明,当针对两个MLP使用不同的网络大小(如,不同的层数、不同的units数量)来调优DualMLP时,可以获得更好的性能。这一结果促使我们进一步探索如何扩大两个流的差异化,以改进DualMLP作为base model。此外,现有的双流模型通常通过
summation或concatenation来组合两个流,这可能会浪费对高阶(即stream-level) 的feature interactions进行建模的机会。如何更好地融合stream outputs成为另一个值得进一步探索的研究问题。为了解决这些问题,本文构建了一个增强型双流
MLP模型,即FinalMLP,它在两个MLP module networks之上集成了feature gating层和interaction aggregation。更具体地说,我们提出了一个
stream-specific的feature gating layer,它允许获得gating-based的feature importance weights从而用于soft feature selection。也就是说,可以通过以learnable parameters、用户特征、或item特征为条件,从不同角度计算feature gating,从而分别产生全局的、user-specific、或item-specific的feature importance weights。通过灵活地选择不同的gating-condition features,我们能够为每个流得出stream-specific features,从而增强feature inputs的差异化,以实现两个流的complementary feature interaction learning。为了将
stream outputs以stream-level feature interaction来融合,我们提出了一个基于二阶双线性融合(second-order bilinear fusion)的interaction aggregation层 。为了降低计算复杂度,我们进一步将计算分解为sub-groups,从而实现高效的multi-head bilinear fusion。
feature gating层和interaction aggregation层都可以轻松插入现有的双流模型中。我们在四个开放benchmark datasets上的实验结果表明,FinalMLP优于现有的双流模型,并达到了新的SOTA。此外,我们通过离线评估和在线A/B testing验证了其在工业环境中的有效性,其中FinalMLP还显示出比所部署的baseline显著的性能提升。我们设想,简单而有效的FinalMLP模型可以作为未来开发双流CTR模型的新的强大baseline。本文的主要贡献总结如下:
据我们所知,这是第一项通过实证证明双流
MLP模型令人惊讶的有效性的研究,这可能与文献中的普遍看法相反。我们提出了
FinalMLP,这是一种增强型双流MLP模型,具有pluggable feature gating and interaction aggregation layers。我们在
benchmark datasets上进行了离线实验,并在生产系统中进行了online A/B test,以验证FinalMLP的有效性。
50.1 模型
双流
MLP模型:尽管双流MLP模型很简单,但据我们所知,之前的研究尚未报道过这种模型。因此,我们首次尝试研究这种用于CTR预测的模型,称为DualMLP,它简单地将两个独立的MLP网络组合成两个流。具体而言,双流MLP模型可以表述如下:其中:
MLP网络。两个MLP的规模(即,层数、隐层大小)可以根据数据进行不同的设置。feature inputs,而output representations。
在大多数以前的工作中,
feature inputsfeature embeddings的拼接(可能包含一些池化操作)stream outputs通常通过简单的操作进行融合,例如summation和concatenation,忽略stream-level interactions。接下来,我们介绍两个可以分别被插入到inputs中和outputs中的模块,以提升双流MLP模型。
50.1.1 Stream-Specific Feature Selection
许多现有研究强调了结合两种不同的
feature interaction网络(例如,implicit vs. explicit、low-order vs. high-order,、bit-wise vs. vector-wise)以有效地实现准确的CTR预测。我们的工作不是设计专用的网络结构,而是旨在通过stream-specific的feature selection来扩大两个流之间的差异,从而产生差异化的feature inputs。 受MMOE中使用的门控机制的启发,我们提出了一个stream-specific的feature gating模块来soft-select stream-specific features,即为每个流不同地重新加权feature inputs。在MMOE中,gating weights以task-specific features为条件,从而重新加权expert outputs。同样地,我们通过以learnable parameters, user features, or item features为条件,从不同角度执行feature gating,从而分别产生global, user-specific, or item-specific feature importance weights。具体来说,我们通过
context-aware feature gating layer进行stream-specific feature selection,如下所示:其中:
MLP的门控网络,它以stream-specific conditional featureselement-wise gating weightsuser/item的一组特征中选择learnable parameters。feature importance weights是通过使用sigmoid函数2将其转换为[0, 2]的范围从而获得的,使得权重的平均值为1。给定
concatenated feature embeddingsfeature outputs
我们的
feature gating模块允许通过从不同角度设置conditional featuresfeature inputs。例如,Figure 1(a)演示了user-specific和item-specific的feature gating的案例,它分别从用户的角度和item的角度来调制(modulate)每个流。这减少了两个相似的MLP streams之间的“homogeneous”学习,并能够实现feature interactions的更多的complementary learning。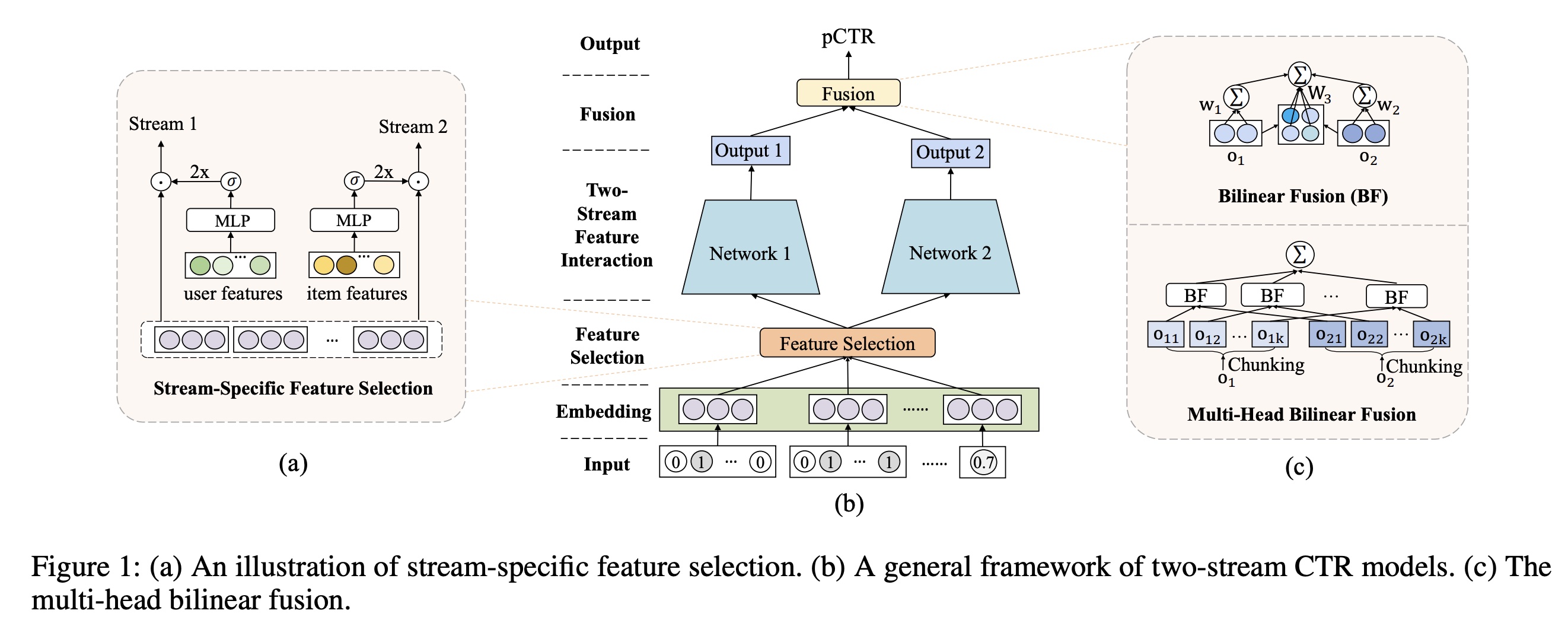
50.1.2 Stream-Level Interaction Aggregation
Bilinear Fusion:如前所述,现有工作大多采用summation或concatenation作为融合层(fusion layer),但这些操作无法捕stream-level feature interactions。受到CV领域中广泛研究的双线性池化(bilinear pooling)的启发,我们提出了一个双线性交互聚合层(bilinear interaction aggregation layer),通过用stream-level feature interaction来融合stream outputs。如Figure 1(c)所示,所预测的点击率公式如下:其中:
双线性项
当
当
concatenation fusion,即
有趣的是,
bilinear fusion也与常用的FM模型有联系。具体来说,FM通过以下公式来建模one-hot/multi-hot feature encoding和concatenation来获得)之间的二阶特征交互,从而进行CTR预测:其中:
embedding矩阵。可以看出,当
FM是bilinear fusion的一种特殊形式。然而,当
1000维输出,1M参数,计算成本高昂。为了降低计算复杂度,我们在下面介绍了扩展的多头双线性融合(multi-head bilinear fusion)。通常
embedding维度相等,都是选择较小的维度,如128。很少选择非常大的维度。Multi-Head Bilinear Fusion:multi-head attention之所以具有吸引力,是因为它能够将来自不同representation subspaces并使用相同attention pooling的知识结合起来。在最近成功的Transformer模型中,它减少了计算量,并一致性地提高了性能。受Transformer成功的启发,我们将bilinear fusion扩展为多头的版本。具体来说,我们不是直接计算其中:
sub-space representation,multi-head attention类似,我们在每个子空间中执行bilinear fusion,将sum pooling聚合subspace computation,以得到最终的预测的点击率:其中:
sigmoid激活函数的bilinear fusion。通过与
multi-head attention类似的subspace computation,理论上我们可以将bilinear fusion的参数数量和计算复杂度减少element-wise product fusion。如果multi-head learning,从而使模型获得更好的性能。实际上,multi-head fusions在GPU中并行计算,从而进一步提高效率。最后,我们的
stream-specific feature gating模块和stream-level interaction aggregation模块可以被插入到模型中,从而生成增强型的双流MLP模型,即FinalMLP。
50.1.3 模型训练
为了训练
FinalMLP,我们应用了广泛使用的二元交叉熵损失:
50.2 实验
数据集:
Criteo, Avazu, MovieLens, and Frappe。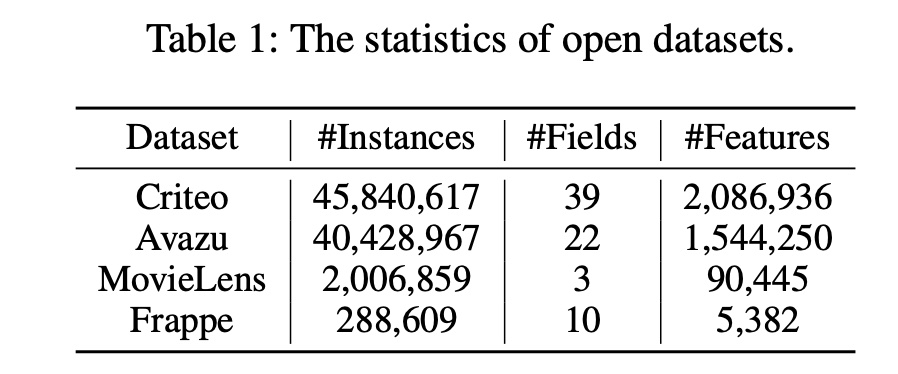
评估指标:
AUC。此外,AUC增加0.1被认为是CTR预测的显著改善。baseline:single-stream的显式的feature interaction网络:一阶:
Logistic Regression (LR)。二阶:
FM、AFM、FFM、FwFM、FmFM。三阶:
HOFM(3rd)、CrossNet(2L)、CrossNetV2(2L)和CIN(2L)。我们特意将最大阶次设置为“3rd”、或将交互层数设置为“2L”,从而获得三阶特征交互。高阶:
CrossNet、CrossNetV2、CIN、AutoInt、FiGNN、AFN和SAM,可自动学习高阶feature interaction。
双流
CTR模型:相关工作中所介绍的。
实现:
重用
baseline模型。基于
FuxiCTR实现我们的模型。我们的评估遵循与
AFN相同的实验设置,将embedding维度设置为10,将batch size设置为4096,将默认MLP大小设置为[400, 400, 400]。对于DualMLP和FinalMLP,我们调优在1∼3层中的两个MLP以增强stream diversity。 我们将学习率设置为1e−3或5e−4。我们通过广泛的网格搜索(平均每个模型约30次运行)调优所有研究模型的所有其他超参数(例如,embedding regularization和dropout rate)。我们注意到,通过优化后的FuxiCTR实现和足够的超参数调优,我们获得的模型性能比AFT原始论文中报告的要好得多。因此,我们报告自己的实验结果,而不是重复使用他们的实验结果来进行公平的比较。为了促进可重复的研究,我们开源了FinalMLP的代码和running logs以及所有使用的baseline。
50.2.1 MLP vs. Explicit Feature Interaction
这里我们将
MLP与精心设计的feature interaction网络进行比较,如下表所示。令人惊讶的是,我们观察到MLP的表现可以与精心设计的显式feature interaction网络不相上下,甚至超越它们。这一观察结果也与DCN-V2论文中报告的结果一致,其中表明经过良好调优的MLP模型(即DNN)可获得与许多现有模型相当的性能。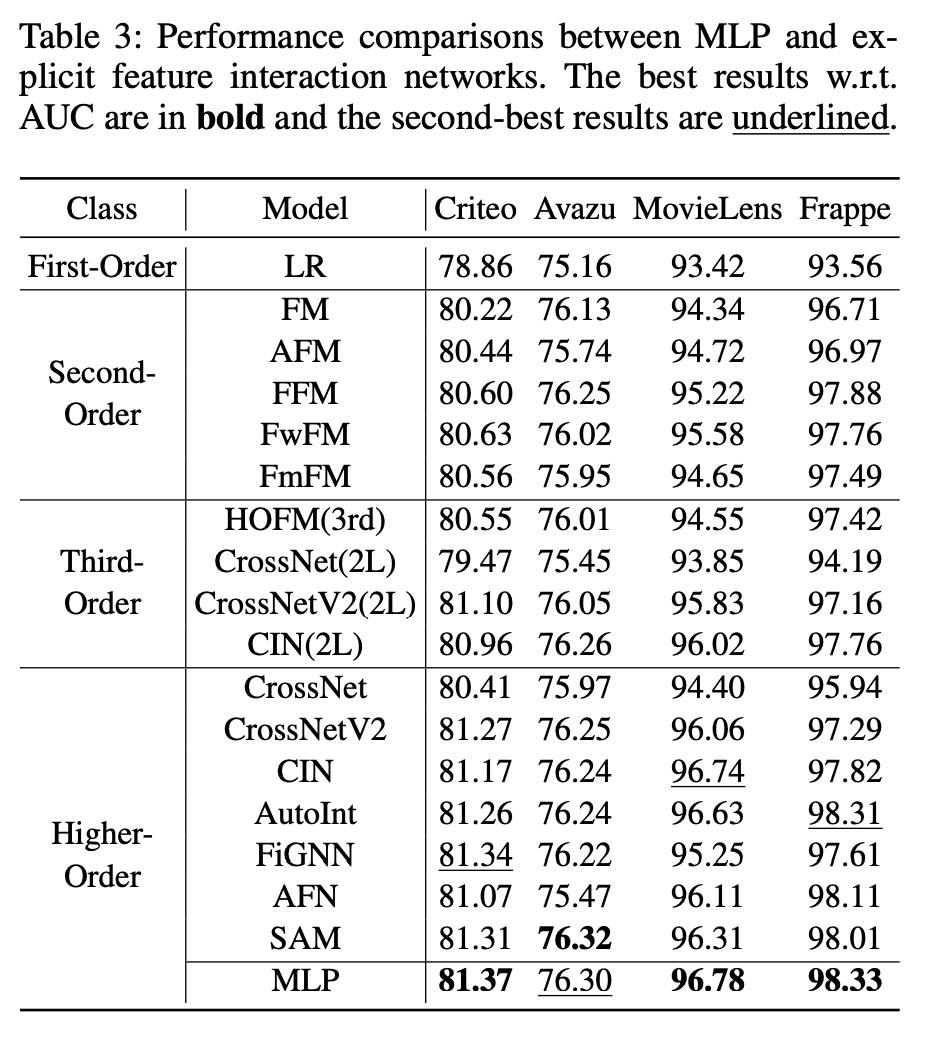
总体而言,
MLP取得的出色表现表明,尽管其结构简单且在学习multiplicative features方面较弱,但MLP在以隐式方式学习feature interactions方面非常具有表达能力。这也部分解释了为什么现有研究双流模型,其中双流模型将显式feature interaction网络与MLP结合起来作为CTR预测。不幸的是,MLP的优势从未在任何现有工作中得到明确揭示。受上述观察的启发,我们更进一步研究一种未经探索的模型结构的潜力,该模型结构简单地将两个MLP作为双流MLP模型。
50.2.2 DualMLP and FinalMLP vs. Two-Stream Baselines
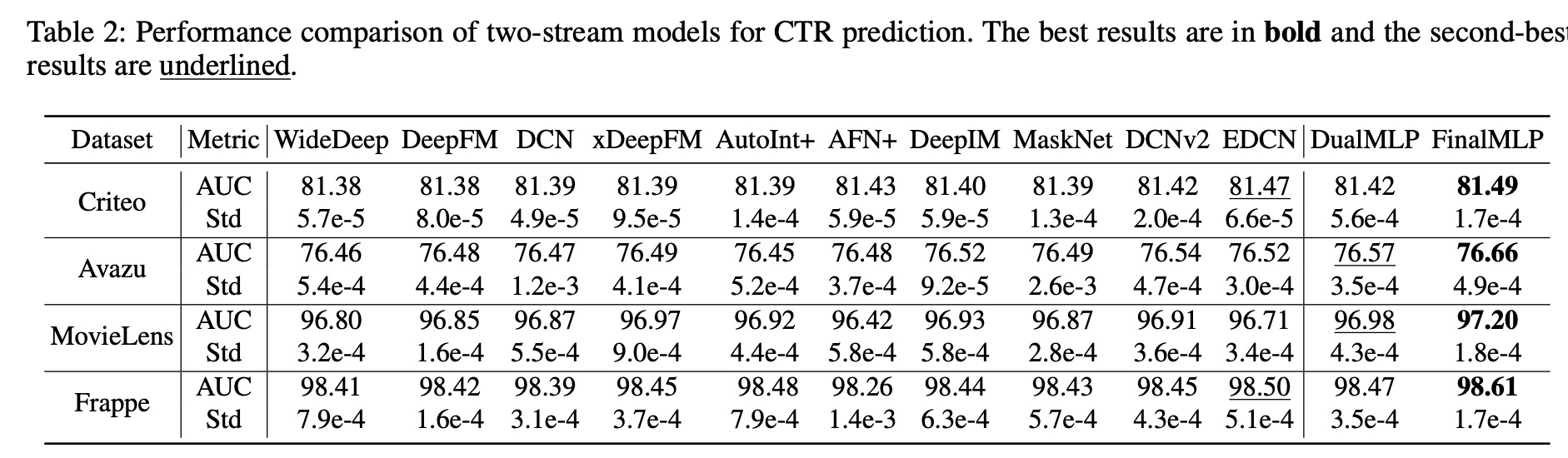
我们对下表中所示的代表性的双流模型进行了全面比较。从结果中,我们得出以下观察结果:
首先,我们可以看到双流模型通常优于
Table 3中报告的单流模型,尤其是单个MLP模型。这符合现有工作,表明双流模型可以学习互补的特征,从而能够更好地建模CTR prediction。其次,简单的双流模型
DualMLP表现得出奇地好。通过仔细调优两个流的MLP layers,DualMLP可以实现与其他复杂的双流baseline相当甚至更好的性能。据我们所知,DualMLP的强大性能从未在文献中报道过。在我们的实验中,我们发现通过在两个流中设置不同的MLP size来增加stream network的多样性可以提高DualMLP的性能。这促使我们进一步开发增强的双流MLP模型,即FinalMLP。/第三,通过我们在
feature gating和fusion方面的可插入式扩展,FinalMLP在四个开放数据集上的表现始终优于DualMLP以及所有其他的双流基线。这证明了我们的FinalMLP的有效性。截至撰写本文时,FinalMLP在Criteo上的PapersWithCode和BARS的CTR prediction排行榜上排名第一。
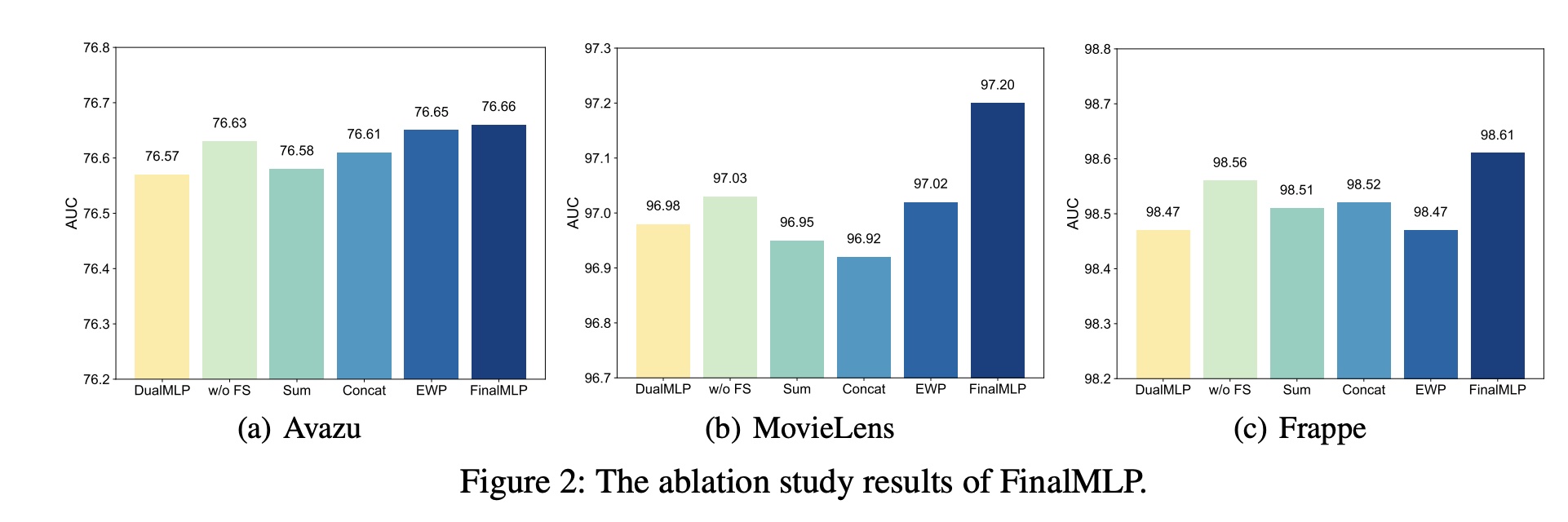
50.2.3 消融研究
Feature Selection and Bilinear Fusion的效果:具体来说,我们将FinalMLP与以下变体进行比较:DualMLP:简单的双流MLP模型,仅将两个MLP作为两个流。w/o FS:缺乏通过context-aware feature gating实现stream-specific的特征选择模块的FinalMLP。Sum:在FinalMLP中使用summation融合。Concat:在FinalMLP中使用concatenation融合。EWP:在FinalMLP中使用Element-Wise Product(即Hadamard乘积)融合。
消融研究结果如
Figure 2所示。我们可以看到:当删除
feature selection模块、或用其他常用融合操作替换bilinear fusion时,性能会下降。这验证了我们的feature selection模块和bilinear fusion模块的有效性。此外,我们观察到
bilinear fusion比feature selection起着更重要的作用,因为替换前者会导致更多的性能下降。
Multi-Head Bilinear Fusion的效果:我们研究了subspace grouping技术对bilinear fusion的影响。下表显示了通过改变子空间数量(即heads数量bilinear fusion时FinalMLP的性能。OOM表示在设置中发生Out-Of-Memory错误。我们发现使用更多参数(即较小的
stream-level特征交互,同时减少冗余的特征交互,类似于multi-head attention。在实践中,可以通过调优effectiveness和efficiency之间的良好平衡。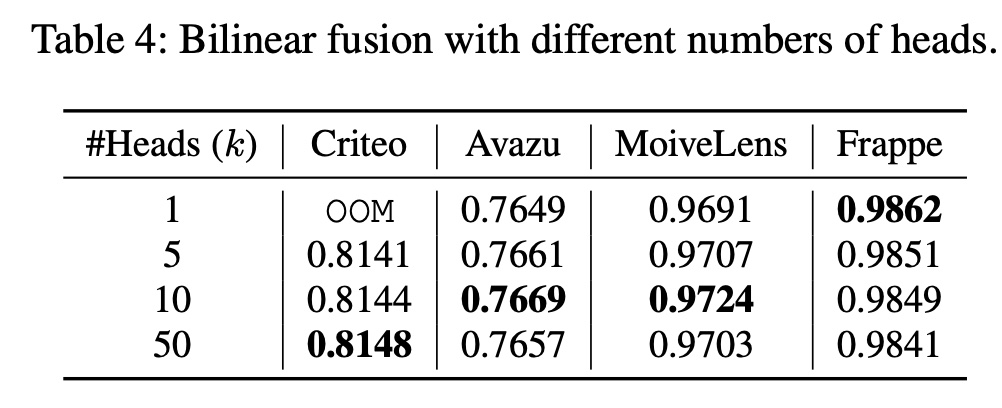
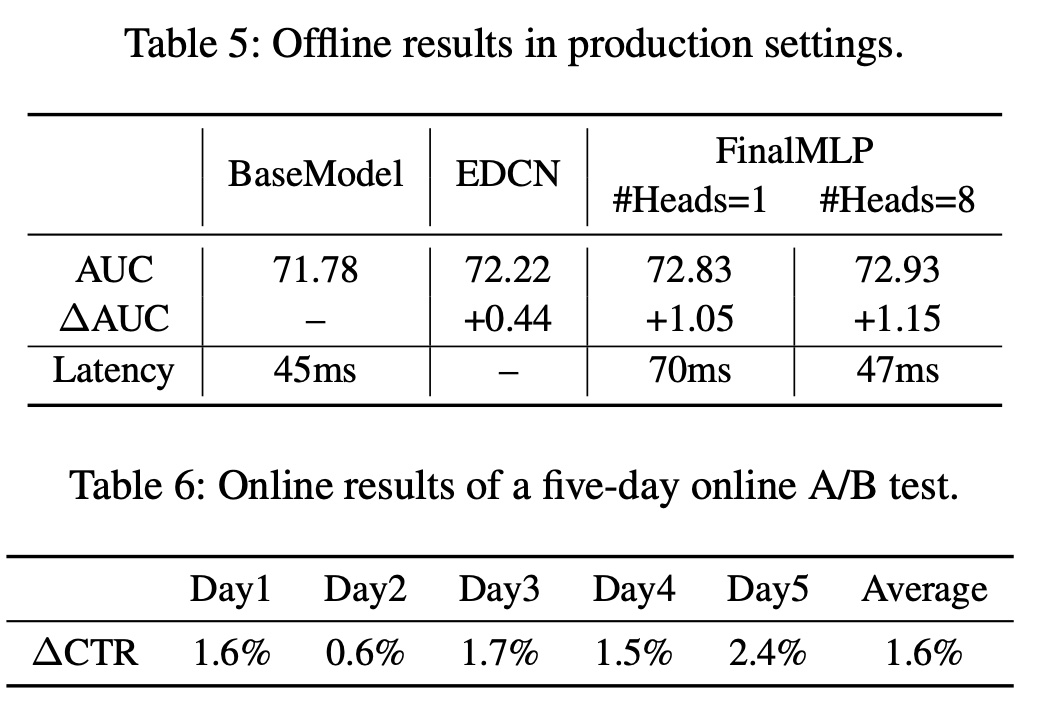
Industrial Evaluation:我们进一步在新闻推荐生产系统中评估FinalMLP,该系统每天为数百万用户提供服务。我们首先使用来自3天的用户点击日志(包含1.2B个样本)的训练数据进行离线评估。AUC结果如Table 5所示。与在线部署的
deep BaseModel相比,FinalMLP在AUC上获得了超过一个点的改进。我们还将其与
EDCN进行了比较,这是一项最近的工作,它通过双流网络之间的交互增强了DCN。FinalMLP在AUC上比EDCN获得了额外的0.44个点的改进。
此外,我们测试了接收用户请求和返回预测结果之间的端到端的推理延迟(
inference latency)。我们可以看到,通过应用我们的multi-head bilinear fusion,延迟可以从70毫秒(使用1 head)减少到47毫秒(使用8 heads),与在线部署的BaseModel(45毫秒)达到相同的延迟水平。此外,通过选择适当的head num,AUC结果也会略有改善。我们最终报告了
7月18日至22日进行的在线A/B test的结果,结果显示在Table 6中。FinalMLP平均实现了1.6%的CTR改进。这样的改进对我们的生产系统意义重大。