边际概率推断
基于概率图模型定义的联合概率分布,能够对目标变量的边际分布进行推断。概率图模型的推断方法可以分为两大类:
- 精确推断方法。该方法的缺点:通常情况下此类方法的计算复杂度随着极大团规模的增长呈现指数级增长,因此适用范围有限。
- 近似推断方法。此类方法在实际任务中更常用。
一、精确推断
- 精确推断的实质是一类动态规划算法。它利用图模型所描述的条件独立性来降低计算量。
1.1 变量消去法
变量消去法是最直观的精确推断算法。
以下图为例来介绍变量消去法的工作流程。假设推断目标是计算边际概率
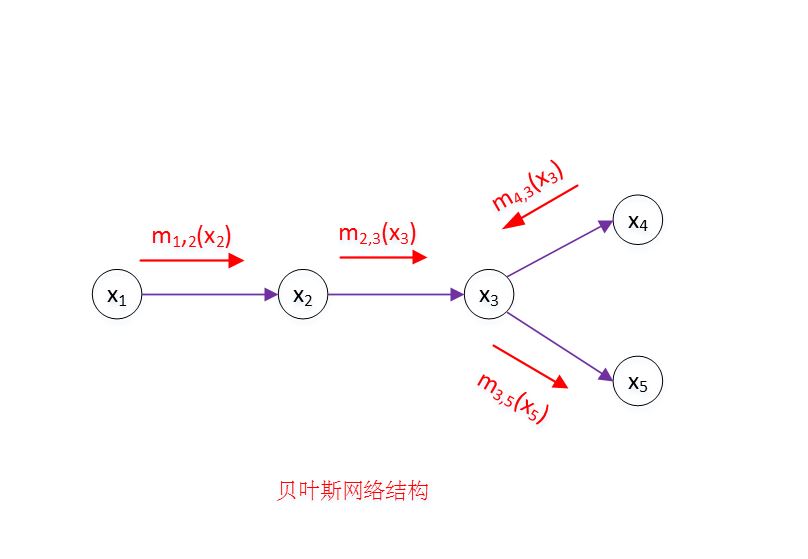
为了计算 ,只需要通过加法消去变量 即可。
其中联合概率分布 是已知的。
根据条件独立性有: 。
代入上式并重新安排 的位置有:
定义:
其中: 仅仅是 的函数; 仅仅是 的函数; 仅仅是 的函数。
于是有:
实际上图中有 ,最终
如果是无向图模型,上述方法同样适用。
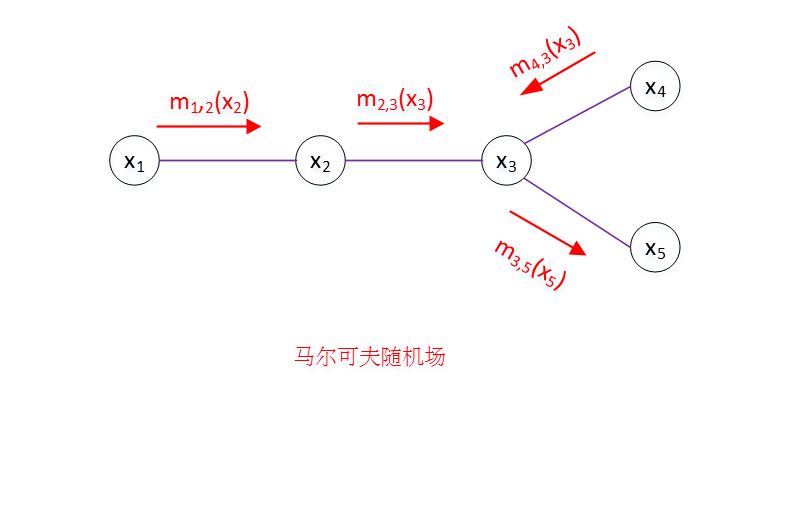
根据马尔可夫随机场的联合概率分布有:
边际分布:
定义:
其中: 仅仅是 的函数; 仅仅是 的函数; 仅仅是 的函数。
于是有:
- 其中的 为归一化常量,使得 满足概率的定义。
- 这里 ,这就是无向概率图模型和有向概率图模型的一个重要区别。
变量消去法通过利用乘法对加法的分配律,将多个变量的积的求和转化为对部分变量交替进行求积与求和的问题。
优点:这种转化使得每次的求和与求积运算限制在局部,仅与部分变量有关,从而简化了计算。
缺点:若需要计算多个边际分布,重复使用变量消去法将会造成大量的冗余计算。
如:如果要同时计算 ,则变量消去法会重复计算 。
1.2 信念传播
信念传播
Belief Propagation算法将变量消去法中的求和操作看作一个消息传递过程,解决了求解多个边际分布时的重复计算问题。在变量消去法中,求和操作为: 。其中 表示结点 的相邻结点的下标集合。
在信念传播算法中,这个操作被看作从 向 传递了一个消息 。这样,变量消去的过程就可以描述为消息传递过程。
每次消息传递操作仅与 及其邻接结点直接相关,消息传递相关的计算被限制在图的局部进行。
在信念传播算法中:
- 一个结点仅在接收到来自其他所有结点的消息后才能向另一个结点发送消息。
- 结点的边际分布正比于它所接收的消息的乘积: 。
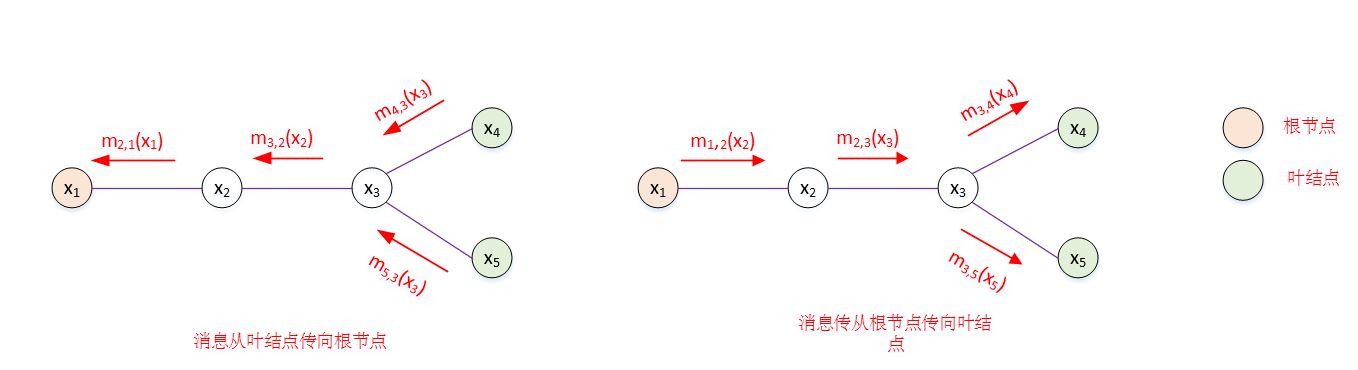
如果图结构中没有环,则信念传播算法经过两个步骤即可完成所有消息传递,进而计算所有变量上的边际分布:
- 指定一个根节点,从所有叶结点开始向根节点传递消息,直到根节点收到所有邻接结点的消息。
- 从根节点开始向叶结点传递消息,直到所有叶结点均收到消息。
此时每条边上都有方向不同的两条消息
二、近似推断
精确推断方法通常需要很大的计算开销,因此在现实应用中近似推断方法更为常用。
近似推断方法可以分作两类:
- 采样
sampling。通过使用随机化方法完成近似。 - 使用确定性近似完成近似推断,典型代表为变分推断
variantional inference。
- 采样
2.1 MCMC 采样
MCMC采样是一种常见的采样方法,可以用于概率图模型的近似推断。其原理部分参考数学基础部分的蒙特卡洛方法与 MCMC 采样。
2.2 变分推断
变分推断通过使用已知简单分布来逼近需要推断的复杂分布,并通过限制近似分布的类型,从而得到一种局部最优、但具有确定解的近似后验分布。
给定多维随机变量 ,其中每个分量都依赖于随机变量 。假定 是观测变量, 是隐含变量。
推断任务是:由观察到的随机变量 来估计隐变量 和分布参数变量 , 即求解 和 。
的估计可以使用
EM算法:(设数据集 )在
E步:根据 时刻的参数 ,计算 函数:在
M步:基于E步的结果进行最大化寻优: 。
根据
EM算法的原理知道, 是隐变量 的一个近似后验分布。事实上我们可以人工构造一个概率分布 来近似后验分布 ,其中 为参数。
如:,其中 为参数, 表示正态分布。
这样构造的 与 的作用相同,它们都是对 的一个近似。
但是选择构造 的优势是:可以选择一些性质较好的分布。
根据后验概率的定义,对于每个 都需要构造对应的 。
根据 ,两边同时取对数有:
同时对两边对分布 求期望,由于 与 无关,因此有:
其中 为
KL散度(Kullback-Leibler divergence),其定义为:我们的目标是使得 尽可能靠近 ,即: 。
考虑到 与 无关,因此上述目标等价于:
称 为
ELBO:Evidence Lower Bound。是观测变量的概率,一般被称作
evidence。因为 ,所以有:。因此它被称作
Evidence Lower Bound。考虑
ELBO:- 第一项称作能量函数。为了使得
ELBO最大,则它倾向于在 较大的地方 也较大。 - 第二项为 分布的熵。为了使得
ELBO最大,则它倾向于 为均匀分布。
- 第一项称作能量函数。为了使得
假设 可以拆解为一系列相互独立的子变量 ,则有: 。这被称作平均场
mean field approximation。此时
ELBO为:定义 ,它就是 中去掉 的剩余部分。定义 为 中去掉 的剩余部分。
考虑第一项:
考虑到括号内的内容为:
因此第一项为: 。
考虑第二项:
由于 构成了一个分布函数,因此 :
则有:
即:
定义一个概率分布 ,其中 是与 有关、与 无关的常数项。
则有:
其中 ,因此有:
为求解 ,则可以看到当 时, 取最大值。 因此得到 的更新规则:
根据 可知:在对 进行更新时,融合了 之外的其他 的信息。
在实际应用变分法时,最重要的是考虑如何对隐变量 进行拆解,以及假设各种变量子集服从何种分布。
如果隐变量 的拆解或者变量子集的分布假设不当,则会导致变分法效率低、效果差。